+  +
+  +
+
ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation
+
+[](https://paperswithcode.com/sota/pose-estimation-on-coco-test-dev?p=vitpose-simple-vision-transformer-baselines)
+[](https://paperswithcode.com/sota/pose-estimation-on-aic?p=vitpose-simple-vision-transformer-baselines)
+[](https://paperswithcode.com/sota/pose-estimation-on-crowdpose?p=vitpose-simple-vision-transformer-baselines)
+[](https://paperswithcode.com/sota/pose-estimation-on-ochuman?p=vitpose-simple-vision-transformer-baselines)
+
++ Results | + Updates | + Usage | + Todo | + Acknowledge +
+ +
+
 +
+
+
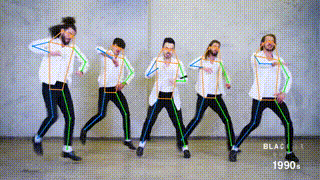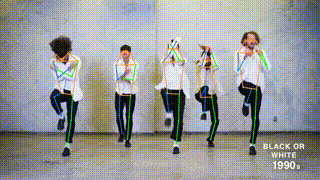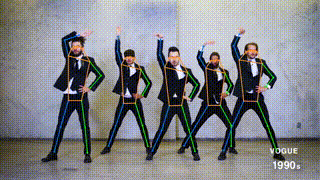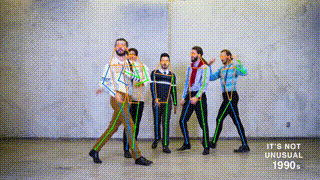 +
+
 +
+## Web Demo
+
+- Integrated into [Huggingface Spaces 🤗](https://huggingface.co/spaces) using [Gradio](https://github.com/gradio-app/gradio). Try out the Web Demo for video: [](https://huggingface.co/spaces/hysts/ViTPose_video) and images [](https://huggingface.co/spaces/Gradio-Blocks/ViTPose)
+
+## MAE Pre-trained model
+
+- The small size MAE pre-trained model can be found in [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccZeiFjh4DJ7gjYyg?e=iTMdMq).
+- The base, large, and huge pre-trained models using MAE can be found in the [MAE official repo](https://github.com/facebookresearch/mae).
+
+## Results from this repo on MS COCO val set (single-task training)
+
+Using detection results from a detector that obtains 56 mAP on person. The configs here are for both training and test.
+
+> With classic decoder
+
+| Model | Pretrain | Resolution | AP | AR | config | log | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: | :----: | :----: |
+| ViTPose-S | MAE | 256x192 | 73.8 | 79.2 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_small_coco_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgcchdNXBAh7ClS14pA?e=dKXmJ6) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccifT1XlGRatxg3vw?e=9wz7BY) |
+| ViTPose-B | MAE | 256x192 | 75.8 | 81.1 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_base_coco_256x192.py) | [log](logs/vitpose-b.log.json) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSMjp1_NrV3VRSmK?e=Q1uZKs) |
+| ViTPose-L | MAE | 256x192 | 78.3 | 83.5 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_large_coco_256x192.py) | [log](logs/vitpose-l.log.json) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSd9k_kuktPtiP4F?e=K7DGYT) |
+| ViTPose-H | MAE | 256x192 | 79.1 | 84.1 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_huge_coco_256x192.py) | [log](logs/vitpose-h.log.json) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgShLMI-kkmvNfF_h?e=dEhGHe) |
+
+> With simple decoder
+
+| Model | Pretrain | Resolution | AP | AR | config | log | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: | :----: | :----: |
+| ViTPose-S | MAE | 256x192 | 73.5 | 78.9 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_small_simple_coco_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccfkqELJqE67kpRtw?e=InSjJP) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccgb_50jIgiYkHvdw?e=D7RbH2) |
+| ViTPose-B | MAE | 256x192 | 75.5 | 80.9 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_base_simple_coco_256x192.py) | [log](logs/vitpose-b-simple.log.json) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSRPKrD5PmDRiv0R?e=jifvOe) |
+| ViTPose-L | MAE | 256x192 | 78.2 | 83.4 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_large_simple_coco_256x192.py) | [log](logs/vitpose-l-simple.log.json) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSVS6DP2LmKwZ3sm?e=MmCvDT) |
+| ViTPose-H | MAE | 256x192 | 78.9 | 84.0 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_huge_simple_coco_256x192.py) | [log](logs/vitpose-h-simple.log.json) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSbHyN2mjh2n2LyG?e=y0FgMK) |
+
+
+## Results with multi-task training
+
+**Note** \* There may exist duplicate images in the crowdpose training set and the validation images in other datasets, as discussed in [issue #24](https://github.com/ViTAE-Transformer/ViTPose/issues/24). Please be careful when using these models for evaluation. We provide the results without the crowpose dataset for reference.
+
+### Human datasets (MS COCO, AIC, MPII, CrowdPose)
+> Results on MS COCO val set
+
+Using detection results from a detector that obtains 56 mAP on person. Note the configs here are only for evaluation.
+
+| Model | Dataset | Resolution | AP | AR | config | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: | :----: |
+| ViTPose-B | COCO+AIC+MPII | 256x192 | 77.1 | 82.2 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_base_coco_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcccwaTZ8xCFFM3Sjg?e=chmiK5) |
+| ViTPose-L | COCO+AIC+MPII | 256x192 | 78.7 | 83.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_large_coco_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccdOLQqSo6E87GfMw?e=TEurgW) |
+| ViTPose-H | COCO+AIC+MPII | 256x192 | 79.5 | 84.5 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_huge_coco_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccmHofkmfJDQDukVw?e=gRK224) |
+| ViTPose-G | COCO+AIC+MPII | 576x432 | 81.0 | 85.6 | | |
+| ViTPose-B* | COCO+AIC+MPII+CrowdPose | 256x192 | 77.5 | 82.6 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_base_coco_256x192.py) |[Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSrlMB093JzJtqq-?e=Jr5S3R) |
+| ViTPose-L* | COCO+AIC+MPII+CrowdPose | 256x192 | 79.1 | 84.1 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_large_coco_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgTBm3dCVmBUbHYT6?e=fHUrTq) |
+| ViTPose-H* | COCO+AIC+MPII+CrowdPose | 256x192 | 79.8 | 84.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_huge_coco_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgS5rLeRAJiWobCdh?e=41GsDd) |
+| **ViTPose+-S** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 75.8 | 82.6 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vitPose+_small_coco+aic+mpii+ap10k+apt36k+wholebody_256x192_udp.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccqO1JBHtBjNaeCbQ?e=ZN5NSz) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccrwORr61gT9E4n8g?e=kz9sz5) |
+| **ViTPose+-B** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 77.0 | 82.6 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vitPose+_base_coco+aic+mpii+ap10k+apt36k+wholebody_256x192_udp.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccjj9lgPTlkGT1HTw?e=OlS5zv) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcckRZk1bIAuRa_E1w?e=ylDB2G) |
+| **ViTPose+-L** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 78.6 | 84.1 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vitPose+_large_coco+aic+mpii+ap10k+apt36k+wholebody_256x192_udp.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccp7HJf4QMeQQpeyA?e=JagPNt) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccs1SNFUGSTsmRJ8w?e=a9zKwZ) |
+| **ViTPose+-H** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 79.4 | 84.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vitPose+_huge_coco+aic+mpii+ap10k+apt36k+wholebody_256x192_udp.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgcclxZOlwRJdqpIIjA?e=nFQgVC) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccoXv8rCUgVe7oD9Q?e=ZBw6gR) |
+
+
+> Results on OCHuman test set
+
+Using groundtruth bounding boxes. Note the configs here are only for evaluation.
+
+| Model | Dataset | Resolution | AP | AR | config | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: | :----: |
+| ViTPose-B | COCO+AIC+MPII | 256x192 | 88.0 | 89.6 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_base_ochuman_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcccwaTZ8xCFFM3Sjg?e=chmiK5) |
+| ViTPose-L | COCO+AIC+MPII | 256x192 | 90.9 | 92.2 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_large_ochuman_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccdOLQqSo6E87GfMw?e=TEurgW) |
+| ViTPose-H | COCO+AIC+MPII | 256x192 | 90.9 | 92.3 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_huge_ochuman_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccmHofkmfJDQDukVw?e=gRK224) |
+| ViTPose-G | COCO+AIC+MPII | 576x432 | 93.3 | 94.3 | | |
+| ViTPose-B* | COCO+AIC+MPII+CrowdPose | 256x192 | 88.2 | 90.0 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_base_ochuman_256x192.py) |[Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSrlMB093JzJtqq-?e=Jr5S3R) |
+| ViTPose-L* | COCO+AIC+MPII+CrowdPose | 256x192 | 91.5 | 92.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_large_ochuman_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgTBm3dCVmBUbHYT6?e=fHUrTq) |
+| ViTPose-H* | COCO+AIC+MPII+CrowdPose | 256x192 | 91.6 | 92.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_huge_ochuman_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgS5rLeRAJiWobCdh?e=41GsDd) |
+| **ViTPose+-S** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 78.4 | 80.6 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_small_ochuman_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccqO1JBHtBjNaeCbQ?e=ZN5NSz) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccrwORr61gT9E4n8g?e=kz9sz5) |
+| **ViTPose+-B** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 82.6 | 84.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_base_ochuman_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccjj9lgPTlkGT1HTw?e=OlS5zv) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcckRZk1bIAuRa_E1w?e=ylDB2G) |
+| **ViTPose+-L** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 85.7 | 87.5 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_large_ochuman_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccp7HJf4QMeQQpeyA?e=JagPNt) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccs1SNFUGSTsmRJ8w?e=a9zKwZ) |
+| **ViTPose+-H** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 85.7 | 87.4 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_huge_ochuman_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgcclxZOlwRJdqpIIjA?e=nFQgVC) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccoXv8rCUgVe7oD9Q?e=ZBw6gR) |
+
+> Results on MPII val set
+
+Using groundtruth bounding boxes. Note the configs here are only for evaluation. The metric is PCKh.
+
+| Model | Dataset | Resolution | Mean | config | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: |
+| ViTPose-B | COCO+AIC+MPII | 256x192 | 93.3 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_base_mpii_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcccwaTZ8xCFFM3Sjg?e=chmiK5) |
+| ViTPose-L | COCO+AIC+MPII | 256x192 | 94.0 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_large_mpii_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccdOLQqSo6E87GfMw?e=TEurgW) |
+| ViTPose-H | COCO+AIC+MPII | 256x192 | 94.1 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_huge_mpii_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccmHofkmfJDQDukVw?e=gRK224) |
+| ViTPose-G | COCO+AIC+MPII | 576x432 | 94.3 | | |
+| ViTPose-B* | COCO+AIC+MPII+CrowdPose | 256x192 | 93.4 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_base_mpii_256x192.py) |[Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSy_OSEm906wd2LB?e=GOSg14) |
+| ViTPose-L* | COCO+AIC+MPII+CrowdPose | 256x192 | 93.9 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_large_mpii_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgTM32I6Kpjr-esl6?e=qvh0Yl) |
+| ViTPose-H* | COCO+AIC+MPII+CrowdPose | 256x192 | 94.1 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_huge_mpii_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgTT90XEQBKy-scIH?e=D2WhTS) |
+| **ViTPose+-S** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 92.7 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_small_mpii_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccqO1JBHtBjNaeCbQ?e=ZN5NSz) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccrwORr61gT9E4n8g?e=kz9sz5) |
+| **ViTPose+-B** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 92.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_base_mpii_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccjj9lgPTlkGT1HTw?e=OlS5zv) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcckRZk1bIAuRa_E1w?e=ylDB2G) |
+| **ViTPose+-L** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 94.0 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_large_mpii_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccp7HJf4QMeQQpeyA?e=JagPNt) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccs1SNFUGSTsmRJ8w?e=a9zKwZ) |
+| **ViTPose+-H** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 94.2 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_huge_mpii_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgcclxZOlwRJdqpIIjA?e=nFQgVC) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccoXv8rCUgVe7oD9Q?e=ZBw6gR) |
+
+
+> Results on AI Challenger test set
+
+Using groundtruth bounding boxes. Note the configs here are only for evaluation.
+
+| Model | Dataset | Resolution | AP | AR | config | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: | :----: |
+| ViTPose-B | COCO+AIC+MPII | 256x192 | 32.0 | 36.3 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_base_aic_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcccwaTZ8xCFFM3Sjg?e=chmiK5) |
+| ViTPose-L | COCO+AIC+MPII | 256x192 | 34.5 | 39.0 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_large_aic_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccdOLQqSo6E87GfMw?e=TEurgW) |
+| ViTPose-H | COCO+AIC+MPII | 256x192 | 35.4 | 39.9 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_huge_aic_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccmHofkmfJDQDukVw?e=gRK224) |
+| ViTPose-G | COCO+AIC+MPII | 576x432 | 43.2 | 47.1 | | |
+| ViTPose-B* | COCO+AIC+MPII+CrowdPose | 256x192 | 31.9 | 36.3 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_base_aic_256x192.py) |[Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSlvdVaXTC92SHYH?e=j7iqcp) |
+| ViTPose-L* | COCO+AIC+MPII+CrowdPose | 256x192 | 34.6 | 39.0 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_large_aic_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgTF06FX3FSAm0MOH?e=rYts9F) |
+| ViTPose-H* | COCO+AIC+MPII+CrowdPose | 256x192 | 35.3 | 39.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_huge_aic_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgS1MRmb2mcow_K04?e=q9jPab) |
+| **ViTPose+-S** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 29.7 | 34.3 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_small_ochuman_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccqO1JBHtBjNaeCbQ?e=ZN5NSz) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccrwORr61gT9E4n8g?e=kz9sz5) |
+| **ViTPose+-B** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 31.8 | 36.3 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_base_ochuman_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccjj9lgPTlkGT1HTw?e=OlS5zv) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcckRZk1bIAuRa_E1w?e=ylDB2G) |
+| **ViTPose+-L** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 34.3 | 38.9 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_large_ochuman_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccp7HJf4QMeQQpeyA?e=JagPNt) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccs1SNFUGSTsmRJ8w?e=a9zKwZ) |
+| **ViTPose+-H** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 34.8 | 39.1 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_huge_ochuman_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgcclxZOlwRJdqpIIjA?e=nFQgVC) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccoXv8rCUgVe7oD9Q?e=ZBw6gR) |
+
+> Results on CrowdPose test set
+
+Using YOLOv3 human detector. Note the configs here are only for evaluation.
+
+| Model | Dataset | Resolution | AP | AP(H) | config | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: | :----: |
+| ViTPose-B* | COCO+AIC+MPII+CrowdPose | 256x192 | 74.7 | 63.3 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/ViTPose_base_crowdpose_256x192.py) |[Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgStrrCb91cPlaxJx?e=6Xobo6) |
+| ViTPose-L* | COCO+AIC+MPII+CrowdPose | 256x192 | 76.6 | 65.9 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/ViTPose_large_crowdpose_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgTK3dug-r7c6GFyu?e=1ZBpEG) |
+| ViTPose-H* | COCO+AIC+MPII+CrowdPose | 256x192 | 76.3 | 65.6 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/ViTPose_huge_crowdpose_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgS-oAvEV4MTD--Xr?e=EeW2Fu) |
+
+### Animal datasets (AP10K, APT36K)
+
+> Results on AP-10K test set
+
+| Model | Dataset | Resolution | AP | config | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: |
+| **ViTPose+-S** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 71.4 | [config](configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/ViTPose_small_ap10k_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccqO1JBHtBjNaeCbQ?e=ZN5NSz) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccrwORr61gT9E4n8g?e=kz9sz5) |
+| **ViTPose+-B** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 74.5 | [config](configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/ViTPose_base_ap10k_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccjj9lgPTlkGT1HTw?e=OlS5zv) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcckRZk1bIAuRa_E1w?e=ylDB2G) |
+| **ViTPose+-L** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 80.4 | [config](configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/ViTPose_large_ap10k_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccp7HJf4QMeQQpeyA?e=JagPNt) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccs1SNFUGSTsmRJ8w?e=a9zKwZ) |
+| **ViTPose+-H** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 82.4 | [config](configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/ViTPose_huge_ap10k_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgcclxZOlwRJdqpIIjA?e=nFQgVC) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccoXv8rCUgVe7oD9Q?e=ZBw6gR) |
+
+> Results on APT-36K val set
+
+| Model | Dataset | Resolution | AP | config | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: |
+| **ViTPose+-S** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 74.2 | [config](configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/apt36k/ViTPose_small_apt36k_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccqO1JBHtBjNaeCbQ?e=ZN5NSz) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccrwORr61gT9E4n8g?e=kz9sz5) |
+| **ViTPose+-B** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 75.9 | [config](configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/apt36k/ViTPose_base_apt36k_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccjj9lgPTlkGT1HTw?e=OlS5zv) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcckRZk1bIAuRa_E1w?e=ylDB2G) |
+| **ViTPose+-L** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 80.8 | [config](configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/apt36k/ViTPose_large_apt36k_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccp7HJf4QMeQQpeyA?e=JagPNt) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccs1SNFUGSTsmRJ8w?e=a9zKwZ) |
+| **ViTPose+-H** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 82.3 | [config](configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/apt36k/ViTPose_huge_apt36k_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgcclxZOlwRJdqpIIjA?e=nFQgVC) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccoXv8rCUgVe7oD9Q?e=ZBw6gR) |
+
+### WholeBody dataset
+
+| Model | Dataset | Resolution | AP | config | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: |
+| **ViTPose+-S** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 54.4 | [config](configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/ViTPose_small_wholebody_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccqO1JBHtBjNaeCbQ?e=ZN5NSz) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccrwORr61gT9E4n8g?e=kz9sz5) |
+| **ViTPose+-B** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 57.4 | [config](cconfigs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/ViTPose_base_wholebody_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccjj9lgPTlkGT1HTw?e=OlS5zv) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcckRZk1bIAuRa_E1w?e=ylDB2G) |
+| **ViTPose+-L** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 60.6 | [config](configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/ViTPose_large_wholebody_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccp7HJf4QMeQQpeyA?e=JagPNt) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccs1SNFUGSTsmRJ8w?e=a9zKwZ) |
+| **ViTPose+-H** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 61.2 | [config](configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/ViTPose_huge_wholebody_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgcclxZOlwRJdqpIIjA?e=nFQgVC) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccoXv8rCUgVe7oD9Q?e=ZBw6gR) |
+
+### Transfer results on the hand dataset (InterHand2.6M)
+
+| Model | Dataset | Resolution | AUC | config | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: |
+| **ViTPose+-S** | COCO+AIC+MPII+WholeBody | 256x192 | 86.5 | [config](configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/ViTPose_small_interhand2d_all_256x192.py) | Coming Soon |
+| **ViTPose+-B** | COCO+AIC+MPII+WholeBody | 256x192 | 87.0 | [config](configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/ViTPose_base_interhand2d_all_256x192.py) | Coming Soon |
+| **ViTPose+-L** | COCO+AIC+MPII+WholeBody | 256x192 | 87.5 | [config](configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/ViTPose_large_interhand2d_all_256x192.py) | Coming Soon |
+| **ViTPose+-H** | COCO+AIC+MPII+WholeBody | 256x192 | 87.6 | [config](configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/ViTPose_huge_interhand2d_all_256x192.py) | Coming Soon |
+
+## Updates
+
+> [2023-01-10] Update ViTPose+! It uses MoE strategies to jointly deal with human, animal, and wholebody pose estimation tasks.
+
+> [2022-05-24] Upload the single-task training code, single-task pre-trained models, and multi-task pretrained models.
+
+> [2022-05-06] Upload the logs for the base, large, and huge models!
+
+> [2022-04-27] Our ViTPose with ViTAE-G obtains 81.1 AP on COCO test-dev set!
+
+> Applications of ViTAE Transformer include: [image classification](https://github.com/ViTAE-Transformer/ViTAE-Transformer/tree/main/Image-Classification) | [object detection](https://github.com/ViTAE-Transformer/ViTAE-Transformer/tree/main/Object-Detection) | [semantic segmentation](https://github.com/ViTAE-Transformer/ViTAE-Transformer/tree/main/Semantic-Segmentation) | [animal pose segmentation](https://github.com/ViTAE-Transformer/ViTAE-Transformer/tree/main/Animal-Pose-Estimation) | [remote sensing](https://github.com/ViTAE-Transformer/ViTAE-Transformer-Remote-Sensing) | [matting](https://github.com/ViTAE-Transformer/ViTAE-Transformer-Matting) | [VSA](https://github.com/ViTAE-Transformer/ViTAE-VSA) | [ViTDet](https://github.com/ViTAE-Transformer/ViTDet)
+
+## Usage
+
+We use PyTorch 1.9.0 or NGC docker 21.06, and mmcv 1.3.9 for the experiments.
+```bash
+git clone https://github.com/open-mmlab/mmcv.git
+cd mmcv
+git checkout v1.3.9
+MMCV_WITH_OPS=1 pip install -e .
+cd ..
+git clone https://github.com/ViTAE-Transformer/ViTPose.git
+cd ViTPose
+pip install -v -e .
+```
+
+After install the two repos, install timm and einops, i.e.,
+```bash
+pip install timm==0.4.9 einops
+```
+
+After downloading the pretrained models, please conduct the experiments by running
+
+```bash
+# for single machine
+bash tools/dist_train.sh
+
+## Web Demo
+
+- Integrated into [Huggingface Spaces 🤗](https://huggingface.co/spaces) using [Gradio](https://github.com/gradio-app/gradio). Try out the Web Demo for video: [](https://huggingface.co/spaces/hysts/ViTPose_video) and images [](https://huggingface.co/spaces/Gradio-Blocks/ViTPose)
+
+## MAE Pre-trained model
+
+- The small size MAE pre-trained model can be found in [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccZeiFjh4DJ7gjYyg?e=iTMdMq).
+- The base, large, and huge pre-trained models using MAE can be found in the [MAE official repo](https://github.com/facebookresearch/mae).
+
+## Results from this repo on MS COCO val set (single-task training)
+
+Using detection results from a detector that obtains 56 mAP on person. The configs here are for both training and test.
+
+> With classic decoder
+
+| Model | Pretrain | Resolution | AP | AR | config | log | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: | :----: | :----: |
+| ViTPose-S | MAE | 256x192 | 73.8 | 79.2 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_small_coco_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgcchdNXBAh7ClS14pA?e=dKXmJ6) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccifT1XlGRatxg3vw?e=9wz7BY) |
+| ViTPose-B | MAE | 256x192 | 75.8 | 81.1 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_base_coco_256x192.py) | [log](logs/vitpose-b.log.json) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSMjp1_NrV3VRSmK?e=Q1uZKs) |
+| ViTPose-L | MAE | 256x192 | 78.3 | 83.5 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_large_coco_256x192.py) | [log](logs/vitpose-l.log.json) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSd9k_kuktPtiP4F?e=K7DGYT) |
+| ViTPose-H | MAE | 256x192 | 79.1 | 84.1 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_huge_coco_256x192.py) | [log](logs/vitpose-h.log.json) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgShLMI-kkmvNfF_h?e=dEhGHe) |
+
+> With simple decoder
+
+| Model | Pretrain | Resolution | AP | AR | config | log | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: | :----: | :----: |
+| ViTPose-S | MAE | 256x192 | 73.5 | 78.9 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_small_simple_coco_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccfkqELJqE67kpRtw?e=InSjJP) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccgb_50jIgiYkHvdw?e=D7RbH2) |
+| ViTPose-B | MAE | 256x192 | 75.5 | 80.9 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_base_simple_coco_256x192.py) | [log](logs/vitpose-b-simple.log.json) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSRPKrD5PmDRiv0R?e=jifvOe) |
+| ViTPose-L | MAE | 256x192 | 78.2 | 83.4 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_large_simple_coco_256x192.py) | [log](logs/vitpose-l-simple.log.json) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSVS6DP2LmKwZ3sm?e=MmCvDT) |
+| ViTPose-H | MAE | 256x192 | 78.9 | 84.0 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_huge_simple_coco_256x192.py) | [log](logs/vitpose-h-simple.log.json) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSbHyN2mjh2n2LyG?e=y0FgMK) |
+
+
+## Results with multi-task training
+
+**Note** \* There may exist duplicate images in the crowdpose training set and the validation images in other datasets, as discussed in [issue #24](https://github.com/ViTAE-Transformer/ViTPose/issues/24). Please be careful when using these models for evaluation. We provide the results without the crowpose dataset for reference.
+
+### Human datasets (MS COCO, AIC, MPII, CrowdPose)
+> Results on MS COCO val set
+
+Using detection results from a detector that obtains 56 mAP on person. Note the configs here are only for evaluation.
+
+| Model | Dataset | Resolution | AP | AR | config | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: | :----: |
+| ViTPose-B | COCO+AIC+MPII | 256x192 | 77.1 | 82.2 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_base_coco_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcccwaTZ8xCFFM3Sjg?e=chmiK5) |
+| ViTPose-L | COCO+AIC+MPII | 256x192 | 78.7 | 83.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_large_coco_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccdOLQqSo6E87GfMw?e=TEurgW) |
+| ViTPose-H | COCO+AIC+MPII | 256x192 | 79.5 | 84.5 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_huge_coco_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccmHofkmfJDQDukVw?e=gRK224) |
+| ViTPose-G | COCO+AIC+MPII | 576x432 | 81.0 | 85.6 | | |
+| ViTPose-B* | COCO+AIC+MPII+CrowdPose | 256x192 | 77.5 | 82.6 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_base_coco_256x192.py) |[Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSrlMB093JzJtqq-?e=Jr5S3R) |
+| ViTPose-L* | COCO+AIC+MPII+CrowdPose | 256x192 | 79.1 | 84.1 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_large_coco_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgTBm3dCVmBUbHYT6?e=fHUrTq) |
+| ViTPose-H* | COCO+AIC+MPII+CrowdPose | 256x192 | 79.8 | 84.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_huge_coco_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgS5rLeRAJiWobCdh?e=41GsDd) |
+| **ViTPose+-S** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 75.8 | 82.6 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vitPose+_small_coco+aic+mpii+ap10k+apt36k+wholebody_256x192_udp.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccqO1JBHtBjNaeCbQ?e=ZN5NSz) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccrwORr61gT9E4n8g?e=kz9sz5) |
+| **ViTPose+-B** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 77.0 | 82.6 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vitPose+_base_coco+aic+mpii+ap10k+apt36k+wholebody_256x192_udp.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccjj9lgPTlkGT1HTw?e=OlS5zv) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcckRZk1bIAuRa_E1w?e=ylDB2G) |
+| **ViTPose+-L** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 78.6 | 84.1 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vitPose+_large_coco+aic+mpii+ap10k+apt36k+wholebody_256x192_udp.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccp7HJf4QMeQQpeyA?e=JagPNt) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccs1SNFUGSTsmRJ8w?e=a9zKwZ) |
+| **ViTPose+-H** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 79.4 | 84.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vitPose+_huge_coco+aic+mpii+ap10k+apt36k+wholebody_256x192_udp.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgcclxZOlwRJdqpIIjA?e=nFQgVC) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccoXv8rCUgVe7oD9Q?e=ZBw6gR) |
+
+
+> Results on OCHuman test set
+
+Using groundtruth bounding boxes. Note the configs here are only for evaluation.
+
+| Model | Dataset | Resolution | AP | AR | config | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: | :----: |
+| ViTPose-B | COCO+AIC+MPII | 256x192 | 88.0 | 89.6 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_base_ochuman_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcccwaTZ8xCFFM3Sjg?e=chmiK5) |
+| ViTPose-L | COCO+AIC+MPII | 256x192 | 90.9 | 92.2 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_large_ochuman_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccdOLQqSo6E87GfMw?e=TEurgW) |
+| ViTPose-H | COCO+AIC+MPII | 256x192 | 90.9 | 92.3 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_huge_ochuman_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccmHofkmfJDQDukVw?e=gRK224) |
+| ViTPose-G | COCO+AIC+MPII | 576x432 | 93.3 | 94.3 | | |
+| ViTPose-B* | COCO+AIC+MPII+CrowdPose | 256x192 | 88.2 | 90.0 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_base_ochuman_256x192.py) |[Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSrlMB093JzJtqq-?e=Jr5S3R) |
+| ViTPose-L* | COCO+AIC+MPII+CrowdPose | 256x192 | 91.5 | 92.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_large_ochuman_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgTBm3dCVmBUbHYT6?e=fHUrTq) |
+| ViTPose-H* | COCO+AIC+MPII+CrowdPose | 256x192 | 91.6 | 92.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_huge_ochuman_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgS5rLeRAJiWobCdh?e=41GsDd) |
+| **ViTPose+-S** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 78.4 | 80.6 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_small_ochuman_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccqO1JBHtBjNaeCbQ?e=ZN5NSz) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccrwORr61gT9E4n8g?e=kz9sz5) |
+| **ViTPose+-B** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 82.6 | 84.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_base_ochuman_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccjj9lgPTlkGT1HTw?e=OlS5zv) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcckRZk1bIAuRa_E1w?e=ylDB2G) |
+| **ViTPose+-L** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 85.7 | 87.5 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_large_ochuman_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccp7HJf4QMeQQpeyA?e=JagPNt) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccs1SNFUGSTsmRJ8w?e=a9zKwZ) |
+| **ViTPose+-H** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 85.7 | 87.4 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_huge_ochuman_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgcclxZOlwRJdqpIIjA?e=nFQgVC) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccoXv8rCUgVe7oD9Q?e=ZBw6gR) |
+
+> Results on MPII val set
+
+Using groundtruth bounding boxes. Note the configs here are only for evaluation. The metric is PCKh.
+
+| Model | Dataset | Resolution | Mean | config | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: |
+| ViTPose-B | COCO+AIC+MPII | 256x192 | 93.3 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_base_mpii_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcccwaTZ8xCFFM3Sjg?e=chmiK5) |
+| ViTPose-L | COCO+AIC+MPII | 256x192 | 94.0 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_large_mpii_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccdOLQqSo6E87GfMw?e=TEurgW) |
+| ViTPose-H | COCO+AIC+MPII | 256x192 | 94.1 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_huge_mpii_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccmHofkmfJDQDukVw?e=gRK224) |
+| ViTPose-G | COCO+AIC+MPII | 576x432 | 94.3 | | |
+| ViTPose-B* | COCO+AIC+MPII+CrowdPose | 256x192 | 93.4 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_base_mpii_256x192.py) |[Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSy_OSEm906wd2LB?e=GOSg14) |
+| ViTPose-L* | COCO+AIC+MPII+CrowdPose | 256x192 | 93.9 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_large_mpii_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgTM32I6Kpjr-esl6?e=qvh0Yl) |
+| ViTPose-H* | COCO+AIC+MPII+CrowdPose | 256x192 | 94.1 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_huge_mpii_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgTT90XEQBKy-scIH?e=D2WhTS) |
+| **ViTPose+-S** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 92.7 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_small_mpii_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccqO1JBHtBjNaeCbQ?e=ZN5NSz) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccrwORr61gT9E4n8g?e=kz9sz5) |
+| **ViTPose+-B** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 92.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_base_mpii_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccjj9lgPTlkGT1HTw?e=OlS5zv) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcckRZk1bIAuRa_E1w?e=ylDB2G) |
+| **ViTPose+-L** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 94.0 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_large_mpii_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccp7HJf4QMeQQpeyA?e=JagPNt) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccs1SNFUGSTsmRJ8w?e=a9zKwZ) |
+| **ViTPose+-H** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 94.2 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_huge_mpii_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgcclxZOlwRJdqpIIjA?e=nFQgVC) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccoXv8rCUgVe7oD9Q?e=ZBw6gR) |
+
+
+> Results on AI Challenger test set
+
+Using groundtruth bounding boxes. Note the configs here are only for evaluation.
+
+| Model | Dataset | Resolution | AP | AR | config | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: | :----: |
+| ViTPose-B | COCO+AIC+MPII | 256x192 | 32.0 | 36.3 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_base_aic_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcccwaTZ8xCFFM3Sjg?e=chmiK5) |
+| ViTPose-L | COCO+AIC+MPII | 256x192 | 34.5 | 39.0 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_large_aic_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccdOLQqSo6E87GfMw?e=TEurgW) |
+| ViTPose-H | COCO+AIC+MPII | 256x192 | 35.4 | 39.9 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_huge_aic_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccmHofkmfJDQDukVw?e=gRK224) |
+| ViTPose-G | COCO+AIC+MPII | 576x432 | 43.2 | 47.1 | | |
+| ViTPose-B* | COCO+AIC+MPII+CrowdPose | 256x192 | 31.9 | 36.3 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_base_aic_256x192.py) |[Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSlvdVaXTC92SHYH?e=j7iqcp) |
+| ViTPose-L* | COCO+AIC+MPII+CrowdPose | 256x192 | 34.6 | 39.0 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_large_aic_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgTF06FX3FSAm0MOH?e=rYts9F) |
+| ViTPose-H* | COCO+AIC+MPII+CrowdPose | 256x192 | 35.3 | 39.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_huge_aic_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgS1MRmb2mcow_K04?e=q9jPab) |
+| **ViTPose+-S** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 29.7 | 34.3 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_small_ochuman_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccqO1JBHtBjNaeCbQ?e=ZN5NSz) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccrwORr61gT9E4n8g?e=kz9sz5) |
+| **ViTPose+-B** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 31.8 | 36.3 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_base_ochuman_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccjj9lgPTlkGT1HTw?e=OlS5zv) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcckRZk1bIAuRa_E1w?e=ylDB2G) |
+| **ViTPose+-L** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 34.3 | 38.9 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_large_ochuman_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccp7HJf4QMeQQpeyA?e=JagPNt) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccs1SNFUGSTsmRJ8w?e=a9zKwZ) |
+| **ViTPose+-H** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 34.8 | 39.1 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_huge_ochuman_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgcclxZOlwRJdqpIIjA?e=nFQgVC) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccoXv8rCUgVe7oD9Q?e=ZBw6gR) |
+
+> Results on CrowdPose test set
+
+Using YOLOv3 human detector. Note the configs here are only for evaluation.
+
+| Model | Dataset | Resolution | AP | AP(H) | config | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: | :----: |
+| ViTPose-B* | COCO+AIC+MPII+CrowdPose | 256x192 | 74.7 | 63.3 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/ViTPose_base_crowdpose_256x192.py) |[Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgStrrCb91cPlaxJx?e=6Xobo6) |
+| ViTPose-L* | COCO+AIC+MPII+CrowdPose | 256x192 | 76.6 | 65.9 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/ViTPose_large_crowdpose_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgTK3dug-r7c6GFyu?e=1ZBpEG) |
+| ViTPose-H* | COCO+AIC+MPII+CrowdPose | 256x192 | 76.3 | 65.6 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/ViTPose_huge_crowdpose_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgS-oAvEV4MTD--Xr?e=EeW2Fu) |
+
+### Animal datasets (AP10K, APT36K)
+
+> Results on AP-10K test set
+
+| Model | Dataset | Resolution | AP | config | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: |
+| **ViTPose+-S** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 71.4 | [config](configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/ViTPose_small_ap10k_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccqO1JBHtBjNaeCbQ?e=ZN5NSz) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccrwORr61gT9E4n8g?e=kz9sz5) |
+| **ViTPose+-B** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 74.5 | [config](configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/ViTPose_base_ap10k_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccjj9lgPTlkGT1HTw?e=OlS5zv) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcckRZk1bIAuRa_E1w?e=ylDB2G) |
+| **ViTPose+-L** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 80.4 | [config](configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/ViTPose_large_ap10k_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccp7HJf4QMeQQpeyA?e=JagPNt) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccs1SNFUGSTsmRJ8w?e=a9zKwZ) |
+| **ViTPose+-H** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 82.4 | [config](configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/ViTPose_huge_ap10k_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgcclxZOlwRJdqpIIjA?e=nFQgVC) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccoXv8rCUgVe7oD9Q?e=ZBw6gR) |
+
+> Results on APT-36K val set
+
+| Model | Dataset | Resolution | AP | config | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: |
+| **ViTPose+-S** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 74.2 | [config](configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/apt36k/ViTPose_small_apt36k_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccqO1JBHtBjNaeCbQ?e=ZN5NSz) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccrwORr61gT9E4n8g?e=kz9sz5) |
+| **ViTPose+-B** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 75.9 | [config](configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/apt36k/ViTPose_base_apt36k_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccjj9lgPTlkGT1HTw?e=OlS5zv) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcckRZk1bIAuRa_E1w?e=ylDB2G) |
+| **ViTPose+-L** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 80.8 | [config](configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/apt36k/ViTPose_large_apt36k_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccp7HJf4QMeQQpeyA?e=JagPNt) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccs1SNFUGSTsmRJ8w?e=a9zKwZ) |
+| **ViTPose+-H** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 82.3 | [config](configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/apt36k/ViTPose_huge_apt36k_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgcclxZOlwRJdqpIIjA?e=nFQgVC) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccoXv8rCUgVe7oD9Q?e=ZBw6gR) |
+
+### WholeBody dataset
+
+| Model | Dataset | Resolution | AP | config | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: |
+| **ViTPose+-S** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 54.4 | [config](configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/ViTPose_small_wholebody_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccqO1JBHtBjNaeCbQ?e=ZN5NSz) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccrwORr61gT9E4n8g?e=kz9sz5) |
+| **ViTPose+-B** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 57.4 | [config](cconfigs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/ViTPose_base_wholebody_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccjj9lgPTlkGT1HTw?e=OlS5zv) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgcckRZk1bIAuRa_E1w?e=ylDB2G) |
+| **ViTPose+-L** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 60.6 | [config](configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/ViTPose_large_wholebody_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgccp7HJf4QMeQQpeyA?e=JagPNt) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccs1SNFUGSTsmRJ8w?e=a9zKwZ) |
+| **ViTPose+-H** | COCO+AIC+MPII+AP10K+APT36K+WholeBody | 256x192 | 61.2 | [config](configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/ViTPose_huge_wholebody_256x192.py) | [log](https://1drv.ms/u/s!AimBgYV7JjTlgcclxZOlwRJdqpIIjA?e=nFQgVC) \| [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgccoXv8rCUgVe7oD9Q?e=ZBw6gR) |
+
+### Transfer results on the hand dataset (InterHand2.6M)
+
+| Model | Dataset | Resolution | AUC | config | weight |
+| :----: | :----: | :----: | :----: | :----: | :----: |
+| **ViTPose+-S** | COCO+AIC+MPII+WholeBody | 256x192 | 86.5 | [config](configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/ViTPose_small_interhand2d_all_256x192.py) | Coming Soon |
+| **ViTPose+-B** | COCO+AIC+MPII+WholeBody | 256x192 | 87.0 | [config](configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/ViTPose_base_interhand2d_all_256x192.py) | Coming Soon |
+| **ViTPose+-L** | COCO+AIC+MPII+WholeBody | 256x192 | 87.5 | [config](configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/ViTPose_large_interhand2d_all_256x192.py) | Coming Soon |
+| **ViTPose+-H** | COCO+AIC+MPII+WholeBody | 256x192 | 87.6 | [config](configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/ViTPose_huge_interhand2d_all_256x192.py) | Coming Soon |
+
+## Updates
+
+> [2023-01-10] Update ViTPose+! It uses MoE strategies to jointly deal with human, animal, and wholebody pose estimation tasks.
+
+> [2022-05-24] Upload the single-task training code, single-task pre-trained models, and multi-task pretrained models.
+
+> [2022-05-06] Upload the logs for the base, large, and huge models!
+
+> [2022-04-27] Our ViTPose with ViTAE-G obtains 81.1 AP on COCO test-dev set!
+
+> Applications of ViTAE Transformer include: [image classification](https://github.com/ViTAE-Transformer/ViTAE-Transformer/tree/main/Image-Classification) | [object detection](https://github.com/ViTAE-Transformer/ViTAE-Transformer/tree/main/Object-Detection) | [semantic segmentation](https://github.com/ViTAE-Transformer/ViTAE-Transformer/tree/main/Semantic-Segmentation) | [animal pose segmentation](https://github.com/ViTAE-Transformer/ViTAE-Transformer/tree/main/Animal-Pose-Estimation) | [remote sensing](https://github.com/ViTAE-Transformer/ViTAE-Transformer-Remote-Sensing) | [matting](https://github.com/ViTAE-Transformer/ViTAE-Transformer-Matting) | [VSA](https://github.com/ViTAE-Transformer/ViTAE-VSA) | [ViTDet](https://github.com/ViTAE-Transformer/ViTDet)
+
+## Usage
+
+We use PyTorch 1.9.0 or NGC docker 21.06, and mmcv 1.3.9 for the experiments.
+```bash
+git clone https://github.com/open-mmlab/mmcv.git
+cd mmcv
+git checkout v1.3.9
+MMCV_WITH_OPS=1 pip install -e .
+cd ..
+git clone https://github.com/ViTAE-Transformer/ViTPose.git
+cd ViTPose
+pip install -v -e .
+```
+
+After install the two repos, install timm and einops, i.e.,
+```bash
+pip install timm==0.4.9 einops
+```
+
+After downloading the pretrained models, please conduct the experiments by running
+
+```bash
+# for single machine
+bash tools/dist_train.sh 
+ +

+ +

diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/README.md b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/README.md new file mode 100644 index 0000000000000000000000000000000000000000..c62b4eecc9f8f1442dfd48ba57ef4734950e4225 --- /dev/null +++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/README.md @@ -0,0 +1,7 @@ +# Top-down heatmap-based pose estimation + +Top-down methods divide the task into two stages: object detection and pose estimation. + +They perform object detection first, followed by single-object pose estimation given object bounding boxes. +Instead of estimating keypoint coordinates directly, the pose estimator will produce heatmaps which represent the +likelihood of being a keypoint. diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/hrnet_animalpose.md b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/hrnet_animalpose.md new file mode 100644 index 0000000000000000000000000000000000000000..6241351c401c3732b2c9d06e78b27133cdabdc0f --- /dev/null +++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/hrnet_animalpose.md @@ -0,0 +1,40 @@ + + +
+
+
+
+
+HRNet (CVPR'2019)
+ +```bibtex +@inproceedings{sun2019deep, + title={Deep high-resolution representation learning for human pose estimation}, + author={Sun, Ke and Xiao, Bin and Liu, Dong and Wang, Jingdong}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={5693--5703}, + year={2019} +} +``` + +
+
+
+Results on AnimalPose validation set (1117 instances)
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :-------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_hrnet_w32](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/hrnet_w32_animalpose_256x256.py) | 256x256 | 0.736 | 0.959 | 0.832 | 0.775 | 0.966 | [ckpt](https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_animalpose_256x256-1aa7f075_20210426.pth) | [log](https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_animalpose_256x256_20210426.log.json) |
+| [pose_hrnet_w48](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/hrnet_w48_animalpose_256x256.py) | 256x256 | 0.737 | 0.959 | 0.823 | 0.778 | 0.962 | [ckpt](https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w48_animalpose_256x256-34644726_20210426.pth) | [log](https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w48_animalpose_256x256_20210426.log.json) |
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/hrnet_animalpose.yml b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/hrnet_animalpose.yml
new file mode 100644
index 0000000000000000000000000000000000000000..b1c84e242bd428d39e5d5062ce02ea71c2c318c6
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/hrnet_animalpose.yml
@@ -0,0 +1,40 @@
+Collections:
+- Name: HRNet
+ Paper:
+ Title: Deep high-resolution representation learning for human pose estimation
+ URL: http://openaccess.thecvf.com/content_CVPR_2019/html/Sun_Deep_High-Resolution_Representation_Learning_for_Human_Pose_Estimation_CVPR_2019_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/hrnet.md
+Models:
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/hrnet_w32_animalpose_256x256.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: &id001
+ - HRNet
+ Training Data: Animal-Pose
+ Name: topdown_heatmap_hrnet_w32_animalpose_256x256
+ Results:
+ - Dataset: Animal-Pose
+ Metrics:
+ AP: 0.736
+ AP@0.5: 0.959
+ AP@0.75: 0.832
+ AR: 0.775
+ AR@0.5: 0.966
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_animalpose_256x256-1aa7f075_20210426.pth
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/hrnet_w48_animalpose_256x256.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: Animal-Pose
+ Name: topdown_heatmap_hrnet_w48_animalpose_256x256
+ Results:
+ - Dataset: Animal-Pose
+ Metrics:
+ AP: 0.737
+ AP@0.5: 0.959
+ AP@0.75: 0.823
+ AR: 0.778
+ AR@0.5: 0.962
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w48_animalpose_256x256-34644726_20210426.pth
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/hrnet_w32_animalpose_256x256.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/hrnet_w32_animalpose_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..c83979f37f12475f0621e787c319ffb182fae5d3
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/hrnet_w32_animalpose_256x256.py
@@ -0,0 +1,172 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/animalpose.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=20,
+ dataset_joints=20,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/animalpose'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalPoseDataset',
+ ann_file=f'{data_root}/annotations/animalpose_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalPoseDataset',
+ ann_file=f'{data_root}/annotations/animalpose_val.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalPoseDataset',
+ ann_file=f'{data_root}/annotations/animalpose_val.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/hrnet_w48_animalpose_256x256.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/hrnet_w48_animalpose_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..7db4f23561c59aa3675fce79396a109d9099538a
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/hrnet_w48_animalpose_256x256.py
@@ -0,0 +1,172 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/animalpose.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=20,
+ dataset_joints=20,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/animalpose'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalPoseDataset',
+ ann_file=f'{data_root}/annotations/animalpose_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalPoseDataset',
+ ann_file=f'{data_root}/annotations/animalpose_val.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalPoseDataset',
+ ann_file=f'{data_root}/annotations/animalpose_val.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/res101_animalpose_256x256.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/res101_animalpose_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..0df1a2806a760ffdcf901549e3162e5b3a80a100
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/res101_animalpose_256x256.py
@@ -0,0 +1,141 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/animalpose.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=20,
+ dataset_joints=20,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet101',
+ backbone=dict(type='ResNet', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/animalpose'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalPoseDataset',
+ ann_file=f'{data_root}/annotations/animalpose_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalPoseDataset',
+ ann_file=f'{data_root}/annotations/animalpose_val.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalPoseDataset',
+ ann_file=f'{data_root}/annotations/animalpose_val.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/res152_animalpose_256x256.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/res152_animalpose_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..e362e53bd92c587febb17d7f4c3b4cd2db4bac5f
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/res152_animalpose_256x256.py
@@ -0,0 +1,141 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/animalpose.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=20,
+ dataset_joints=20,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet152',
+ backbone=dict(type='ResNet', depth=152),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/animalpose'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalPoseDataset',
+ ann_file=f'{data_root}/annotations/animalpose_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalPoseDataset',
+ ann_file=f'{data_root}/annotations/animalpose_val.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalPoseDataset',
+ ann_file=f'{data_root}/annotations/animalpose_val.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/res50_animalpose_256x256.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/res50_animalpose_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..fbd663dc59e6dda7f491efb0f8c2c4b3b0f5719f
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/res50_animalpose_256x256.py
@@ -0,0 +1,141 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/animalpose.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=20,
+ dataset_joints=20,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/animalpose'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalPoseDataset',
+ ann_file=f'{data_root}/annotations/animalpose_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalPoseDataset',
+ ann_file=f'{data_root}/annotations/animalpose_val.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalPoseDataset',
+ ann_file=f'{data_root}/annotations/animalpose_val.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/resnet_animalpose.md b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/resnet_animalpose.md
new file mode 100644
index 0000000000000000000000000000000000000000..6fe6f771d273ee4def4729739dd9c3b13dca47f8
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/resnet_animalpose.md
@@ -0,0 +1,41 @@
+
+
+Animal-Pose (ICCV'2019)
+ +```bibtex +@InProceedings{Cao_2019_ICCV, + author = {Cao, Jinkun and Tang, Hongyang and Fang, Hao-Shu and Shen, Xiaoyong and Lu, Cewu and Tai, Yu-Wing}, + title = {Cross-Domain Adaptation for Animal Pose Estimation}, + booktitle = {The IEEE International Conference on Computer Vision (ICCV)}, + month = {October}, + year = {2019} +} +``` + +
+
+
+
+
+SimpleBaseline2D (ECCV'2018)
+ +```bibtex +@inproceedings{xiao2018simple, + title={Simple baselines for human pose estimation and tracking}, + author={Xiao, Bin and Wu, Haiping and Wei, Yichen}, + booktitle={Proceedings of the European conference on computer vision (ECCV)}, + pages={466--481}, + year={2018} +} +``` + +
+
+
+Results on AnimalPose validation set (1117 instances)
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :-------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_resnet_50](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/res50_animalpose_256x256.py) | 256x256 | 0.688 | 0.945 | 0.772 | 0.733 | 0.952 | [ckpt](https://download.openmmlab.com/mmpose/animal/resnet/res50_animalpose_256x256-e1f30bff_20210426.pth) | [log](https://download.openmmlab.com/mmpose/animal/resnet/res50_animalpose_256x256_20210426.log.json) |
+| [pose_resnet_101](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/res101_animalpose_256x256.py) | 256x256 | 0.696 | 0.948 | 0.785 | 0.737 | 0.954 | [ckpt](https://download.openmmlab.com/mmpose/animal/resnet/res101_animalpose_256x256-85563f4a_20210426.pth) | [log](https://download.openmmlab.com/mmpose/animal/resnet/res101_animalpose_256x256_20210426.log.json) |
+| [pose_resnet_152](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/res152_animalpose_256x256.py) | 256x256 | 0.709 | 0.948 | 0.797 | 0.749 | 0.951 | [ckpt](https://download.openmmlab.com/mmpose/animal/resnet/res152_animalpose_256x256-a0a7506c_20210426.pth) | [log](https://download.openmmlab.com/mmpose/animal/resnet/res152_animalpose_256x256_20210426.log.json) |
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/resnet_animalpose.yml b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/resnet_animalpose.yml
new file mode 100644
index 0000000000000000000000000000000000000000..6900f8a5ccb625926872ea145e1f6919afa93d99
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/resnet_animalpose.yml
@@ -0,0 +1,56 @@
+Collections:
+- Name: SimpleBaseline2D
+ Paper:
+ Title: Simple baselines for human pose estimation and tracking
+ URL: http://openaccess.thecvf.com/content_ECCV_2018/html/Bin_Xiao_Simple_Baselines_for_ECCV_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/simplebaseline2d.md
+Models:
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/res50_animalpose_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: &id001
+ - SimpleBaseline2D
+ Training Data: Animal-Pose
+ Name: topdown_heatmap_res50_animalpose_256x256
+ Results:
+ - Dataset: Animal-Pose
+ Metrics:
+ AP: 0.688
+ AP@0.5: 0.945
+ AP@0.75: 0.772
+ AR: 0.733
+ AR@0.5: 0.952
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/resnet/res50_animalpose_256x256-e1f30bff_20210426.pth
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/res101_animalpose_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: Animal-Pose
+ Name: topdown_heatmap_res101_animalpose_256x256
+ Results:
+ - Dataset: Animal-Pose
+ Metrics:
+ AP: 0.696
+ AP@0.5: 0.948
+ AP@0.75: 0.785
+ AR: 0.737
+ AR@0.5: 0.954
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/resnet/res101_animalpose_256x256-85563f4a_20210426.pth
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/res152_animalpose_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: Animal-Pose
+ Name: topdown_heatmap_res152_animalpose_256x256
+ Results:
+ - Dataset: Animal-Pose
+ Metrics:
+ AP: 0.709
+ AP@0.5: 0.948
+ AP@0.75: 0.797
+ AR: 0.749
+ AR@0.5: 0.951
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/resnet/res152_animalpose_256x256-a0a7506c_20210426.pth
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/ViTPose_base_ap10k_256x192.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/ViTPose_base_ap10k_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..bd5daf5e746ce0a116c3fa7bc98231eaa305ed51
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/ViTPose_base_ap10k_256x192.py
@@ -0,0 +1,157 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/ap10k.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='ViT',
+ img_size=(256, 192),
+ patch_size=16,
+ embed_dim=768,
+ depth=12,
+ num_heads=12,
+ ratio=1,
+ use_checkpoint=False,
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_path_rate=0.3,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=768,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/apt36k'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=4,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{data_root}/annotations/train_annotations_1.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{data_root}/annotations/val_annotations_1.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{data_root}/annotations/val_annotations_1.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/ViTPose_huge_ap10k_256x192.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/ViTPose_huge_ap10k_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..1d2f8ab0630bb0f997b529303179b0e425c553ac
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/ViTPose_huge_ap10k_256x192.py
@@ -0,0 +1,157 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/ap10k.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='ViT',
+ img_size=(256, 192),
+ patch_size=16,
+ embed_dim=1280,
+ depth=32,
+ num_heads=16,
+ ratio=1,
+ use_checkpoint=False,
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_path_rate=0.3,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1280,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/ap10k'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=4,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{data_root}/annotations/ap10k-train-split1.json',
+ img_prefix=f'{data_root}/data/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{data_root}/annotations/ap10k-val-split1.json',
+ img_prefix=f'{data_root}/data/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{data_root}/annotations/ap10k-test-split1.json',
+ img_prefix=f'{data_root}/data/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/ViTPose_large_ap10k_256x192.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/ViTPose_large_ap10k_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..6e44c27b3088a3a670ba03e7961a3df6dd3706c2
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/ViTPose_large_ap10k_256x192.py
@@ -0,0 +1,157 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/ap10k.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='ViT',
+ img_size=(256, 192),
+ patch_size=16,
+ embed_dim=1024,
+ depth=24,
+ num_heads=16,
+ ratio=1,
+ use_checkpoint=False,
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_path_rate=0.3,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1024,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/ap10k'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=4,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{data_root}/annotations/ap10k-train-split1.json',
+ img_prefix=f'{data_root}/data/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{data_root}/annotations/ap10k-val-split1.json',
+ img_prefix=f'{data_root}/data/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{data_root}/annotations/ap10k-test-split1.json',
+ img_prefix=f'{data_root}/data/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/ViTPose_small_ap10k_256x192.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/ViTPose_small_ap10k_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..3c3f2b97905ba47318cde61f4eec35b4624bc554
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/ViTPose_small_ap10k_256x192.py
@@ -0,0 +1,157 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/ap10k.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='ViT',
+ img_size=(256, 192),
+ patch_size=16,
+ embed_dim=384,
+ depth=12,
+ num_heads=12,
+ ratio=1,
+ use_checkpoint=False,
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_path_rate=0.3,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=384,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/ap10k'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=4,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{data_root}/annotations/ap10k-train-split1.json',
+ img_prefix=f'{data_root}/data/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{data_root}/annotations/ap10k-val-split1.json',
+ img_prefix=f'{data_root}/data/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{data_root}/annotations/ap10k-test-split1.json',
+ img_prefix=f'{data_root}/data/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/hrnet_ap10k.md b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/hrnet_ap10k.md
new file mode 100644
index 0000000000000000000000000000000000000000..b9db08981c729c2fc63aafc4cf92b1bb86271f63
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/hrnet_ap10k.md
@@ -0,0 +1,41 @@
+
+
+Animal-Pose (ICCV'2019)
+ +```bibtex +@InProceedings{Cao_2019_ICCV, + author = {Cao, Jinkun and Tang, Hongyang and Fang, Hao-Shu and Shen, Xiaoyong and Lu, Cewu and Tai, Yu-Wing}, + title = {Cross-Domain Adaptation for Animal Pose Estimation}, + booktitle = {The IEEE International Conference on Computer Vision (ICCV)}, + month = {October}, + year = {2019} +} +``` + +
+
+
+
+
+HRNet (CVPR'2019)
+ +```bibtex +@inproceedings{sun2019deep, + title={Deep high-resolution representation learning for human pose estimation}, + author={Sun, Ke and Xiao, Bin and Liu, Dong and Wang, Jingdong}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={5693--5703}, + year={2019} +} +``` + +
+
+
+Results on AP-10K validation set
+
+| Arch | Input Size | AP | AP50 | AP75 | APM | APL | ckpt | log |
+| :-------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_hrnet_w32](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/hrnet_w32_ap10k_256x256.py) | 256x256 | 0.738 | 0.958 | 0.808 | 0.592 | 0.743 | [ckpt](https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_ap10k_256x256-18aac840_20211029.pth) | [log](https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_ap10k_256x256-18aac840_20211029.log.json) |
+| [pose_hrnet_w48](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/hrnet_w48_ap10k_256x256.py) | 256x256 | 0.744 | 0.959 | 0.807 | 0.589 | 0.748 | [ckpt](https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w48_ap10k_256x256-d95ab412_20211029.pth) | [log](https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w48_ap10k_256x256-d95ab412_20211029.log.json) |
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/hrnet_ap10k.yml b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/hrnet_ap10k.yml
new file mode 100644
index 0000000000000000000000000000000000000000..8cf0ced8b3401de47703881b7c4dd8137852d931
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/hrnet_ap10k.yml
@@ -0,0 +1,40 @@
+Collections:
+- Name: HRNet
+ Paper:
+ Title: Deep high-resolution representation learning for human pose estimation
+ URL: http://openaccess.thecvf.com/content_CVPR_2019/html/Sun_Deep_High-Resolution_Representation_Learning_for_Human_Pose_Estimation_CVPR_2019_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/hrnet.md
+Models:
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/hrnet_w32_ap10k_256x256.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: &id001
+ - HRNet
+ Training Data: AP-10K
+ Name: topdown_heatmap_hrnet_w32_ap10k_256x256
+ Results:
+ - Dataset: AP-10K
+ Metrics:
+ AP: 0.738
+ AP@0.5: 0.958
+ AP@0.75: 0.808
+ APL: 0.743
+ APM: 0.592
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_ap10k_256x256-18aac840_20211029.pth
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/hrnet_w48_ap10k_256x256.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: AP-10K
+ Name: topdown_heatmap_hrnet_w48_ap10k_256x256
+ Results:
+ - Dataset: AP-10K
+ Metrics:
+ AP: 0.744
+ AP@0.5: 0.959
+ AP@0.75: 0.807
+ APL: 0.748
+ APM: 0.589
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w48_ap10k_256x256-d95ab412_20211029.pth
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/hrnet_w32_ap10k_256x256.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/hrnet_w32_ap10k_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..da3900c03b1ddc8c2706383c3de97127363533d3
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/hrnet_w32_ap10k_256x256.py
@@ -0,0 +1,172 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/ap10k.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/ap10k'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=4,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{data_root}/annotations/ap10k-train-split1.json',
+ img_prefix=f'{data_root}/data/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{data_root}/annotations/ap10k-val-split1.json',
+ img_prefix=f'{data_root}/data/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{data_root}/annotations/ap10k-test-split1.json',
+ img_prefix=f'{data_root}/data/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/hrnet_w48_ap10k_256x256.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/hrnet_w48_ap10k_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..a2012ec8ee0ab65ce761368083e21ae082b2ead2
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/hrnet_w48_ap10k_256x256.py
@@ -0,0 +1,172 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/ap10k.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/ap10k'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=4,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{data_root}/annotations/ap10k-train-split1.json',
+ img_prefix=f'{data_root}/data/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{data_root}/annotations/ap10k-val-split1.json',
+ img_prefix=f'{data_root}/data/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{data_root}/annotations/ap10k-test-split1.json',
+ img_prefix=f'{data_root}/data/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/res101_ap10k_256x256.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/res101_ap10k_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..8496a3cc6960f9b8f7c29266912b4b20427669fb
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/res101_ap10k_256x256.py
@@ -0,0 +1,141 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/ap10k.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet101',
+ backbone=dict(type='ResNet', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/ap10k'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=4,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{data_root}/annotations/ap10k-train-split1.json',
+ img_prefix=f'{data_root}/data/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{data_root}/annotations/ap10k-val-split1.json',
+ img_prefix=f'{data_root}/data/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{data_root}/annotations/ap10k-test-split1.json',
+ img_prefix=f'{data_root}/data/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/res50_ap10k_256x256.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/res50_ap10k_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..1c5699cdb9da9884301d0c402437c936d9c2f608
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/res50_ap10k_256x256.py
@@ -0,0 +1,141 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/ap10k.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/ap10k'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=4,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{data_root}/annotations/ap10k-train-split1.json',
+ img_prefix=f'{data_root}/data/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{data_root}/annotations/ap10k-val-split1.json',
+ img_prefix=f'{data_root}/data/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{data_root}/annotations/ap10k-test-split1.json',
+ img_prefix=f'{data_root}/data/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/resnet_ap10k.md b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/resnet_ap10k.md
new file mode 100644
index 0000000000000000000000000000000000000000..3e1be927e51fe495c1f18026533017020fa03072
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/resnet_ap10k.md
@@ -0,0 +1,41 @@
+
+
+AP-10K (NeurIPS'2021)
+ +```bibtex +@misc{yu2021ap10k, + title={AP-10K: A Benchmark for Animal Pose Estimation in the Wild}, + author={Hang Yu and Yufei Xu and Jing Zhang and Wei Zhao and Ziyu Guan and Dacheng Tao}, + year={2021}, + eprint={2108.12617}, + archivePrefix={arXiv}, + primaryClass={cs.CV} +} +``` + +
+
+
+
+
+SimpleBaseline2D (ECCV'2018)
+ +```bibtex +@inproceedings{xiao2018simple, + title={Simple baselines for human pose estimation and tracking}, + author={Xiao, Bin and Wu, Haiping and Wei, Yichen}, + booktitle={Proceedings of the European conference on computer vision (ECCV)}, + pages={466--481}, + year={2018} +} +``` + +
+
+
+Results on AP-10K validation set
+
+| Arch | Input Size | AP | AP50 | AP75 | APM | APL | ckpt | log |
+| :-------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_resnet_50](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/res50_ap10k_256x256.py) | 256x256 | 0.699 | 0.940 | 0.760 | 0.570 | 0.703 | [ckpt](https://download.openmmlab.com/mmpose/animal/resnet/res50_ap10k_256x256-35760eb8_20211029.pth) | [log](https://download.openmmlab.com/mmpose/animal/resnet/res50_ap10k_256x256-35760eb8_20211029.log.json) |
+| [pose_resnet_101](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/res101_ap10k_256x256.py) | 256x256 | 0.698 | 0.943 | 0.754 | 0.543 | 0.702 | [ckpt](https://download.openmmlab.com/mmpose/animal/resnet/res101_ap10k_256x256-9edfafb9_20211029.pth) | [log](https://download.openmmlab.com/mmpose/animal/resnet/res101_ap10k_256x256-9edfafb9_20211029.log.json) |
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/resnet_ap10k.yml b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/resnet_ap10k.yml
new file mode 100644
index 0000000000000000000000000000000000000000..48b039fce89bb6fb6b1cd3d7b6c6e32fd7f5d2d5
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/resnet_ap10k.yml
@@ -0,0 +1,40 @@
+Collections:
+- Name: SimpleBaseline2D
+ Paper:
+ Title: Simple baselines for human pose estimation and tracking
+ URL: http://openaccess.thecvf.com/content_ECCV_2018/html/Bin_Xiao_Simple_Baselines_for_ECCV_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/simplebaseline2d.md
+Models:
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/res50_ap10k_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: &id001
+ - SimpleBaseline2D
+ Training Data: AP-10K
+ Name: topdown_heatmap_res50_ap10k_256x256
+ Results:
+ - Dataset: AP-10K
+ Metrics:
+ AP: 0.699
+ AP@0.5: 0.94
+ AP@0.75: 0.76
+ APL: 0.703
+ APM: 0.57
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/resnet/res50_ap10k_256x256-35760eb8_20211029.pth
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/res101_ap10k_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: AP-10K
+ Name: topdown_heatmap_res101_ap10k_256x256
+ Results:
+ - Dataset: AP-10K
+ Metrics:
+ AP: 0.698
+ AP@0.5: 0.943
+ AP@0.75: 0.754
+ APL: 0.702
+ APM: 0.543
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/resnet/res101_ap10k_256x256-9edfafb9_20211029.pth
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/apt36k/ViTPose_base_apt36k_256x192.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/apt36k/ViTPose_base_apt36k_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..e3aa5d40ecf8fea1212e8b641fe7e14321fff618
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/apt36k/ViTPose_base_apt36k_256x192.py
@@ -0,0 +1,157 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/ap10k.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='ViT',
+ img_size=(256, 192),
+ patch_size=16,
+ embed_dim=768,
+ depth=12,
+ num_heads=12,
+ ratio=1,
+ use_checkpoint=False,
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_path_rate=0.3,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=768,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/ap10k'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=4,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{data_root}/annotations/ap10k-train-split1.json',
+ img_prefix=f'{data_root}/data/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{data_root}/annotations/ap10k-val-split1.json',
+ img_prefix=f'{data_root}/data/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{data_root}/annotations/ap10k-test-split1.json',
+ img_prefix=f'{data_root}/data/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/apt36k/ViTPose_huge_apt36k_256x192.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/apt36k/ViTPose_huge_apt36k_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..0562e79a286b58f19db3b911aa8c6864f8209458
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/apt36k/ViTPose_huge_apt36k_256x192.py
@@ -0,0 +1,157 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/ap10k.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='ViT',
+ img_size=(256, 192),
+ patch_size=16,
+ embed_dim=1280,
+ depth=32,
+ num_heads=16,
+ ratio=1,
+ use_checkpoint=False,
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_path_rate=0.3,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1280,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/apt36k'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=4,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{data_root}/annotations/train_annotations_1.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{data_root}/annotations/val_annotations_1.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{data_root}/annotations/val_annotations_1.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/apt36k/ViTPose_large_apt36k_256x192.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/apt36k/ViTPose_large_apt36k_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..d4ae268d4c68f35ac2d757c15406706f90483d4e
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/apt36k/ViTPose_large_apt36k_256x192.py
@@ -0,0 +1,157 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/ap10k.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='ViT',
+ img_size=(256, 192),
+ patch_size=16,
+ embed_dim=1024,
+ depth=24,
+ num_heads=16,
+ ratio=1,
+ use_checkpoint=False,
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_path_rate=0.3,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1024,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/apt36k'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=4,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{data_root}/annotations/train_annotations_1.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{data_root}/annotations/val_annotations_1.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{data_root}/annotations/val_annotations_1.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/apt36k/ViTPose_small_apt36k_256x192.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/apt36k/ViTPose_small_apt36k_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..691d373b5ce391a41c997a300aaea7ccb0d63d7e
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/apt36k/ViTPose_small_apt36k_256x192.py
@@ -0,0 +1,157 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/ap10k.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='ViT',
+ img_size=(256, 192),
+ patch_size=16,
+ embed_dim=384,
+ depth=12,
+ num_heads=12,
+ ratio=1,
+ use_checkpoint=False,
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_path_rate=0.3,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=384,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/apt36k'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=4,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{data_root}/annotations/train_annotations_1.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{data_root}/annotations/val_annotations_1.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{data_root}/annotations/val_annotations_1.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
\ No newline at end of file
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/hrnet_atrw.md b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/hrnet_atrw.md
new file mode 100644
index 0000000000000000000000000000000000000000..097c2f6554d19af4b87ffd32a2c26b68d0031184
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/hrnet_atrw.md
@@ -0,0 +1,40 @@
+
+
+AP-10K (NeurIPS'2021)
+ +```bibtex +@misc{yu2021ap10k, + title={AP-10K: A Benchmark for Animal Pose Estimation in the Wild}, + author={Hang Yu and Yufei Xu and Jing Zhang and Wei Zhao and Ziyu Guan and Dacheng Tao}, + year={2021}, + eprint={2108.12617}, + archivePrefix={arXiv}, + primaryClass={cs.CV} +} +``` + +
+
+
+
+
+HRNet (CVPR'2019)
+ +```bibtex +@inproceedings{sun2019deep, + title={Deep high-resolution representation learning for human pose estimation}, + author={Sun, Ke and Xiao, Bin and Liu, Dong and Wang, Jingdong}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={5693--5703}, + year={2019} +} +``` + +
+
+
+Results on ATRW validation set
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :-------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_hrnet_w32](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/hrnet_w32_atrw_256x256.py) | 256x256 | 0.912 | 0.973 | 0.959 | 0.938 | 0.985 | [ckpt](https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_atrw_256x256-f027f09a_20210414.pth) | [log](https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_atrw_256x256_20210414.log.json) |
+| [pose_hrnet_w48](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/hrnet_w48_atrw_256x256.py) | 256x256 | 0.911 | 0.972 | 0.946 | 0.937 | 0.985 | [ckpt](https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w48_atrw_256x256-ac088892_20210414.pth) | [log](https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w48_atrw_256x256_20210414.log.json) |
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/hrnet_atrw.yml b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/hrnet_atrw.yml
new file mode 100644
index 0000000000000000000000000000000000000000..c33437024ca9231d2acfb0d001d33c2540b0f793
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/hrnet_atrw.yml
@@ -0,0 +1,40 @@
+Collections:
+- Name: HRNet
+ Paper:
+ Title: Deep high-resolution representation learning for human pose estimation
+ URL: http://openaccess.thecvf.com/content_CVPR_2019/html/Sun_Deep_High-Resolution_Representation_Learning_for_Human_Pose_Estimation_CVPR_2019_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/hrnet.md
+Models:
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/hrnet_w32_atrw_256x256.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: &id001
+ - HRNet
+ Training Data: ATRW
+ Name: topdown_heatmap_hrnet_w32_atrw_256x256
+ Results:
+ - Dataset: ATRW
+ Metrics:
+ AP: 0.912
+ AP@0.5: 0.973
+ AP@0.75: 0.959
+ AR: 0.938
+ AR@0.5: 0.985
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_atrw_256x256-f027f09a_20210414.pth
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/hrnet_w48_atrw_256x256.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: ATRW
+ Name: topdown_heatmap_hrnet_w48_atrw_256x256
+ Results:
+ - Dataset: ATRW
+ Metrics:
+ AP: 0.911
+ AP@0.5: 0.972
+ AP@0.75: 0.946
+ AR: 0.937
+ AR@0.5: 0.985
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w48_atrw_256x256-ac088892_20210414.pth
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/hrnet_w32_atrw_256x256.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/hrnet_w32_atrw_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..ef080ea929c2c612ea2182fafe544b7018423a92
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/hrnet_w32_atrw_256x256.py
@@ -0,0 +1,170 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/atrw.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=15,
+ dataset_joints=15,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/atrw'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalATRWDataset',
+ ann_file=f'{data_root}/annotations/keypoint_train.json',
+ img_prefix=f'{data_root}/images/train/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalATRWDataset',
+ ann_file=f'{data_root}/annotations/keypoint_val.json',
+ img_prefix=f'{data_root}/images/val/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalATRWDataset',
+ ann_file=f'{data_root}/annotations/keypoint_val.json',
+ img_prefix=f'{data_root}/images/val/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/hrnet_w48_atrw_256x256.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/hrnet_w48_atrw_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..86e647784e6c2236ed80ac30fb359622d1b17064
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/hrnet_w48_atrw_256x256.py
@@ -0,0 +1,170 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/atrw.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=15,
+ dataset_joints=15,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/atrw'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalATRWDataset',
+ ann_file=f'{data_root}/annotations/keypoint_train.json',
+ img_prefix=f'{data_root}/images/train/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalATRWDataset',
+ ann_file=f'{data_root}/annotations/keypoint_val.json',
+ img_prefix=f'{data_root}/images/val/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalATRWDataset',
+ ann_file=f'{data_root}/annotations/keypoint_val.json',
+ img_prefix=f'{data_root}/images/val/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/res101_atrw_256x256.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/res101_atrw_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..342e02711c119e1915433076508d10735ff088fa
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/res101_atrw_256x256.py
@@ -0,0 +1,139 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/atrw.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=15,
+ dataset_joints=15,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet101',
+ backbone=dict(type='ResNet', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/atrw'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalATRWDataset',
+ ann_file=f'{data_root}/annotations/keypoint_train.json',
+ img_prefix=f'{data_root}/images/train/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalATRWDataset',
+ ann_file=f'{data_root}/annotations/keypoint_val.json',
+ img_prefix=f'{data_root}/images/val/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalATRWDataset',
+ ann_file=f'{data_root}/annotations/keypoint_val.json',
+ img_prefix=f'{data_root}/images/val/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/res152_atrw_256x256.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/res152_atrw_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..1ed68cc0622bb3b5cc8f43718e340fe7312ca8dc
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/res152_atrw_256x256.py
@@ -0,0 +1,139 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/atrw.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=15,
+ dataset_joints=15,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet152',
+ backbone=dict(type='ResNet', depth=152),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/atrw'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalATRWDataset',
+ ann_file=f'{data_root}/annotations/keypoint_train.json',
+ img_prefix=f'{data_root}/images/train/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalATRWDataset',
+ ann_file=f'{data_root}/annotations/keypoint_val.json',
+ img_prefix=f'{data_root}/images/val/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalATRWDataset',
+ ann_file=f'{data_root}/annotations/keypoint_val.json',
+ img_prefix=f'{data_root}/images/val/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/res50_atrw_256x256.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/res50_atrw_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..28998435a06824d322f4035f33e82e3fd8351c1e
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/res50_atrw_256x256.py
@@ -0,0 +1,139 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/atrw.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=15,
+ dataset_joints=15,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/atrw'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalATRWDataset',
+ ann_file=f'{data_root}/annotations/keypoint_train.json',
+ img_prefix=f'{data_root}/images/train/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalATRWDataset',
+ ann_file=f'{data_root}/annotations/keypoint_val.json',
+ img_prefix=f'{data_root}/images/val/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalATRWDataset',
+ ann_file=f'{data_root}/annotations/keypoint_val.json',
+ img_prefix=f'{data_root}/images/val/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/resnet_atrw.md b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/resnet_atrw.md
new file mode 100644
index 0000000000000000000000000000000000000000..6e75463e57ee26d9e7da6abde9c815ecfb24c323
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/resnet_atrw.md
@@ -0,0 +1,41 @@
+
+
+ATRW (ACM MM'2020)
+ +```bibtex +@inproceedings{li2020atrw, + title={ATRW: A Benchmark for Amur Tiger Re-identification in the Wild}, + author={Li, Shuyuan and Li, Jianguo and Tang, Hanlin and Qian, Rui and Lin, Weiyao}, + booktitle={Proceedings of the 28th ACM International Conference on Multimedia}, + pages={2590--2598}, + year={2020} +} +``` + +
+
+
+
+
+SimpleBaseline2D (ECCV'2018)
+ +```bibtex +@inproceedings{xiao2018simple, + title={Simple baselines for human pose estimation and tracking}, + author={Xiao, Bin and Wu, Haiping and Wei, Yichen}, + booktitle={Proceedings of the European conference on computer vision (ECCV)}, + pages={466--481}, + year={2018} +} +``` + +
+
+
+Results on ATRW validation set
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :-------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_resnet_50](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/res50_atrw_256x256.py) | 256x256 | 0.900 | 0.973 | 0.932 | 0.929 | 0.985 | [ckpt](https://download.openmmlab.com/mmpose/animal/resnet/res50_atrw_256x256-546c4594_20210414.pth) | [log](https://download.openmmlab.com/mmpose/animal/resnet/res50_atrw_256x256_20210414.log.json) |
+| [pose_resnet_101](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/res101_atrw_256x256.py) | 256x256 | 0.898 | 0.973 | 0.936 | 0.927 | 0.985 | [ckpt](https://download.openmmlab.com/mmpose/animal/resnet/res101_atrw_256x256-da93f371_20210414.pth) | [log](https://download.openmmlab.com/mmpose/animal/resnet/res101_atrw_256x256_20210414.log.json) |
+| [pose_resnet_152](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/res152_atrw_256x256.py) | 256x256 | 0.896 | 0.973 | 0.931 | 0.927 | 0.985 | [ckpt](https://download.openmmlab.com/mmpose/animal/resnet/res152_atrw_256x256-2bb8e162_20210414.pth) | [log](https://download.openmmlab.com/mmpose/animal/resnet/res152_atrw_256x256_20210414.log.json) |
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/resnet_atrw.yml b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/resnet_atrw.yml
new file mode 100644
index 0000000000000000000000000000000000000000..d448cfcbf6f1fcaa30a579d5a7bd9c6959c437a3
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/resnet_atrw.yml
@@ -0,0 +1,56 @@
+Collections:
+- Name: SimpleBaseline2D
+ Paper:
+ Title: Simple baselines for human pose estimation and tracking
+ URL: http://openaccess.thecvf.com/content_ECCV_2018/html/Bin_Xiao_Simple_Baselines_for_ECCV_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/simplebaseline2d.md
+Models:
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/res50_atrw_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: &id001
+ - SimpleBaseline2D
+ Training Data: ATRW
+ Name: topdown_heatmap_res50_atrw_256x256
+ Results:
+ - Dataset: ATRW
+ Metrics:
+ AP: 0.9
+ AP@0.5: 0.973
+ AP@0.75: 0.932
+ AR: 0.929
+ AR@0.5: 0.985
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/resnet/res50_atrw_256x256-546c4594_20210414.pth
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/res101_atrw_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: ATRW
+ Name: topdown_heatmap_res101_atrw_256x256
+ Results:
+ - Dataset: ATRW
+ Metrics:
+ AP: 0.898
+ AP@0.5: 0.973
+ AP@0.75: 0.936
+ AR: 0.927
+ AR@0.5: 0.985
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/resnet/res101_atrw_256x256-da93f371_20210414.pth
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/res152_atrw_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: ATRW
+ Name: topdown_heatmap_res152_atrw_256x256
+ Results:
+ - Dataset: ATRW
+ Metrics:
+ AP: 0.896
+ AP@0.5: 0.973
+ AP@0.75: 0.931
+ AR: 0.927
+ AR@0.5: 0.985
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/resnet/res152_atrw_256x256-2bb8e162_20210414.pth
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/fly/res101_fly_192x192.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/fly/res101_fly_192x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..334300d9a6827d4eb6faeb42e08ba0ec0740ab16
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/fly/res101_fly_192x192.py
@@ -0,0 +1,130 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/fly.py'
+]
+evaluation = dict(interval=10, metric=['PCK', 'AUC', 'EPE'], save_best='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=32,
+ dataset_joints=32,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet101',
+ backbone=dict(type='ResNet', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 192],
+ heatmap_size=[48, 48],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/fly'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalFlyDataset',
+ ann_file=f'{data_root}/annotations/fly_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalFlyDataset',
+ ann_file=f'{data_root}/annotations/fly_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalFlyDataset',
+ ann_file=f'{data_root}/annotations/fly_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/fly/res152_fly_192x192.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/fly/res152_fly_192x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..90737b88886face476b0b3755c7690c64ebf485f
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/fly/res152_fly_192x192.py
@@ -0,0 +1,130 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/fly.py'
+]
+evaluation = dict(interval=10, metric=['PCK', 'AUC', 'EPE'], save_best='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=32,
+ dataset_joints=32,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet152',
+ backbone=dict(type='ResNet', depth=152),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 192],
+ heatmap_size=[48, 48],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/fly'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalFlyDataset',
+ ann_file=f'{data_root}/annotations/fly_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalFlyDataset',
+ ann_file=f'{data_root}/annotations/fly_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalFlyDataset',
+ ann_file=f'{data_root}/annotations/fly_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/fly/res50_fly_192x192.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/fly/res50_fly_192x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..20b29b5eb78a1b96702ef3c1d516019261659854
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/fly/res50_fly_192x192.py
@@ -0,0 +1,130 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/fly.py'
+]
+evaluation = dict(interval=10, metric=['PCK', 'AUC', 'EPE'], save_best='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=32,
+ dataset_joints=32,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 192],
+ heatmap_size=[48, 48],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/fly'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalFlyDataset',
+ ann_file=f'{data_root}/annotations/fly_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalFlyDataset',
+ ann_file=f'{data_root}/annotations/fly_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalFlyDataset',
+ ann_file=f'{data_root}/annotations/fly_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/fly/resnet_fly.md b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/fly/resnet_fly.md
new file mode 100644
index 0000000000000000000000000000000000000000..24060e422b28e1ac4284b699bf6fe3e8c6378a08
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/fly/resnet_fly.md
@@ -0,0 +1,44 @@
+
+
+ATRW (ACM MM'2020)
+ +```bibtex +@inproceedings{li2020atrw, + title={ATRW: A Benchmark for Amur Tiger Re-identification in the Wild}, + author={Li, Shuyuan and Li, Jianguo and Tang, Hanlin and Qian, Rui and Lin, Weiyao}, + booktitle={Proceedings of the 28th ACM International Conference on Multimedia}, + pages={2590--2598}, + year={2020} +} +``` + +
+
+
+
+
+SimpleBaseline2D (ECCV'2018)
+ +```bibtex +@inproceedings{xiao2018simple, + title={Simple baselines for human pose estimation and tracking}, + author={Xiao, Bin and Wu, Haiping and Wei, Yichen}, + booktitle={Proceedings of the European conference on computer vision (ECCV)}, + pages={466--481}, + year={2018} +} +``` + +
+
+
+Results on Vinegar Fly test set
+
+| Arch | Input Size | PCK@0.2 | AUC | EPE | ckpt | log |
+| :-------- | :--------: | :------: | :------: | :------: |:------: |:------: |
+|[pose_resnet_50](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/fly/res50_fly_192x192.py) | 192x192 | 0.996 | 0.910 | 2.00 | [ckpt](https://download.openmmlab.com/mmpose/animal/resnet/res50_fly_192x192-5d0ee2d9_20210407.pth) | [log](https://download.openmmlab.com/mmpose/animal/resnet/res50_fly_192x192_20210407.log.json) |
+|[pose_resnet_101](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/fly/res101_fly_192x192.py) | 192x192 | 0.996 | 0.912 | 1.95 | [ckpt](https://download.openmmlab.com/mmpose/animal/resnet/res101_fly_192x192-41a7a6cc_20210407.pth) | [log](https://download.openmmlab.com/mmpose/animal/resnet/res101_fly_192x192_20210407.log.json) |
+|[pose_resnet_152](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/fly/res152_fly_192x192.py) | 192x192 | 0.997 | 0.917 | 1.78 | [ckpt](https://download.openmmlab.com/mmpose/animal/resnet/res152_fly_192x192-fcafbd5a_20210407.pth) | [log](https://download.openmmlab.com/mmpose/animal/resnet/res152_fly_192x192_20210407.log.json) |
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/fly/resnet_fly.yml b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/fly/resnet_fly.yml
new file mode 100644
index 0000000000000000000000000000000000000000..c6475883418a1dbfdfbd4634477a14aa35459bef
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/fly/resnet_fly.yml
@@ -0,0 +1,50 @@
+Collections:
+- Name: SimpleBaseline2D
+ Paper:
+ Title: Simple baselines for human pose estimation and tracking
+ URL: http://openaccess.thecvf.com/content_ECCV_2018/html/Bin_Xiao_Simple_Baselines_for_ECCV_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/simplebaseline2d.md
+Models:
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/fly/res50_fly_192x192.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: &id001
+ - SimpleBaseline2D
+ Training Data: Vinegar Fly
+ Name: topdown_heatmap_res50_fly_192x192
+ Results:
+ - Dataset: Vinegar Fly
+ Metrics:
+ AUC: 0.91
+ EPE: 2.0
+ PCK@0.2: 0.996
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/resnet/res50_fly_192x192-5d0ee2d9_20210407.pth
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/fly/res101_fly_192x192.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: Vinegar Fly
+ Name: topdown_heatmap_res101_fly_192x192
+ Results:
+ - Dataset: Vinegar Fly
+ Metrics:
+ AUC: 0.912
+ EPE: 1.95
+ PCK@0.2: 0.996
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/resnet/res101_fly_192x192-41a7a6cc_20210407.pth
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/fly/res152_fly_192x192.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: Vinegar Fly
+ Name: topdown_heatmap_res152_fly_192x192
+ Results:
+ - Dataset: Vinegar Fly
+ Metrics:
+ AUC: 0.917
+ EPE: 1.78
+ PCK@0.2: 0.997
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/resnet/res152_fly_192x192-fcafbd5a_20210407.pth
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/hrnet_horse10.md b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/hrnet_horse10.md
new file mode 100644
index 0000000000000000000000000000000000000000..9fad3944eba7d330a4a395c5171c8fd7efce38de
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/hrnet_horse10.md
@@ -0,0 +1,44 @@
+
+
+Vinegar Fly (Nature Methods'2019)
+ +```bibtex +@article{pereira2019fast, + title={Fast animal pose estimation using deep neural networks}, + author={Pereira, Talmo D and Aldarondo, Diego E and Willmore, Lindsay and Kislin, Mikhail and Wang, Samuel S-H and Murthy, Mala and Shaevitz, Joshua W}, + journal={Nature methods}, + volume={16}, + number={1}, + pages={117--125}, + year={2019}, + publisher={Nature Publishing Group} +} +``` + +
+
+
+
+
+HRNet (CVPR'2019)
+ +```bibtex +@inproceedings{sun2019deep, + title={Deep high-resolution representation learning for human pose estimation}, + author={Sun, Ke and Xiao, Bin and Liu, Dong and Wang, Jingdong}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={5693--5703}, + year={2019} +} +``` + +
+
+
+Results on Horse-10 test set
+
+|Set | Arch | Input Size | PCK@0.3 | NME | ckpt | log |
+| :--- | :---: | :--------: | :------: | :------: |:------: |:------: |
+|split1| [pose_hrnet_w32](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/hrnet_w32_horse10_256x256-split1.py) | 256x256 | 0.951 | 0.122 | [ckpt](https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_horse10_256x256_split1-401d901a_20210405.pth) | [log](https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_horse10_256x256_split1_20210405.log.json) |
+|split2| [pose_hrnet_w32](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/hrnet_w32_horse10_256x256-split2.py) | 256x256 | 0.949 | 0.116 | [ckpt](https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_horse10_256x256_split2-04840523_20210405.pth) | [log](https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_horse10_256x256_split2_20210405.log.json) |
+|split3| [pose_hrnet_w32](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/hrnet_w32_horse10_256x256-split3.py) | 256x256 | 0.939 | 0.153 | [ckpt](https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_horse10_256x256_split3-4db47400_20210405.pth) | [log](https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_horse10_256x256_split3_20210405.log.json) |
+|split1| [pose_hrnet_w48](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/hrnet_w48_horse10_256x256-split1.py) | 256x256 | 0.973 | 0.095 | [ckpt](https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w48_horse10_256x256_split1-3c950d3b_20210405.pth) | [log](https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w48_horse10_256x256_split1_20210405.log.json) |
+|split2| [pose_hrnet_w48](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/hrnet_w48_horse10_256x256-split2.py) | 256x256 | 0.969 | 0.101 | [ckpt](https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w48_horse10_256x256_split2-8ef72b5d_20210405.pth) | [log](https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w48_horse10_256x256_split2_20210405.log.json) |
+|split3| [pose_hrnet_w48](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/hrnet_w48_horse10_256x256-split3.py) | 256x256 | 0.961 | 0.128 | [ckpt](https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w48_horse10_256x256_split3-0232ec47_20210405.pth) | [log](https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w48_horse10_256x256_split3_20210405.log.json) |
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/hrnet_horse10.yml b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/hrnet_horse10.yml
new file mode 100644
index 0000000000000000000000000000000000000000..16504855b154d17608dbf3c65442b920b21f425e
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/hrnet_horse10.yml
@@ -0,0 +1,86 @@
+Collections:
+- Name: HRNet
+ Paper:
+ Title: Deep high-resolution representation learning for human pose estimation
+ URL: http://openaccess.thecvf.com/content_CVPR_2019/html/Sun_Deep_High-Resolution_Representation_Learning_for_Human_Pose_Estimation_CVPR_2019_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/hrnet.md
+Models:
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/hrnet_w32_horse10_256x256-split1.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: &id001
+ - HRNet
+ Training Data: Horse-10
+ Name: topdown_heatmap_hrnet_w32_horse10_256x256-split1
+ Results:
+ - Dataset: Horse-10
+ Metrics:
+ NME: 0.122
+ PCK@0.3: 0.951
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_horse10_256x256_split1-401d901a_20210405.pth
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/hrnet_w32_horse10_256x256-split2.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: Horse-10
+ Name: topdown_heatmap_hrnet_w32_horse10_256x256-split2
+ Results:
+ - Dataset: Horse-10
+ Metrics:
+ NME: 0.116
+ PCK@0.3: 0.949
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_horse10_256x256_split2-04840523_20210405.pth
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/hrnet_w32_horse10_256x256-split3.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: Horse-10
+ Name: topdown_heatmap_hrnet_w32_horse10_256x256-split3
+ Results:
+ - Dataset: Horse-10
+ Metrics:
+ NME: 0.153
+ PCK@0.3: 0.939
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_horse10_256x256_split3-4db47400_20210405.pth
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/hrnet_w48_horse10_256x256-split1.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: Horse-10
+ Name: topdown_heatmap_hrnet_w48_horse10_256x256-split1
+ Results:
+ - Dataset: Horse-10
+ Metrics:
+ NME: 0.095
+ PCK@0.3: 0.973
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w48_horse10_256x256_split1-3c950d3b_20210405.pth
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/hrnet_w48_horse10_256x256-split2.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: Horse-10
+ Name: topdown_heatmap_hrnet_w48_horse10_256x256-split2
+ Results:
+ - Dataset: Horse-10
+ Metrics:
+ NME: 0.101
+ PCK@0.3: 0.969
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w48_horse10_256x256_split2-8ef72b5d_20210405.pth
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/hrnet_w48_horse10_256x256-split3.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: Horse-10
+ Name: topdown_heatmap_hrnet_w48_horse10_256x256-split3
+ Results:
+ - Dataset: Horse-10
+ Metrics:
+ NME: 0.128
+ PCK@0.3: 0.961
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w48_horse10_256x256_split3-0232ec47_20210405.pth
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/hrnet_w32_horse10_256x256-split1.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/hrnet_w32_horse10_256x256-split1.py
new file mode 100644
index 0000000000000000000000000000000000000000..76d2f1c812f1b3f71c7d7dca3f2133baabf29753
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/hrnet_w32_horse10_256x256-split1.py
@@ -0,0 +1,164 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/horse10.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=22,
+ dataset_joints=22,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 21
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 21
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/horse10'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-train-split1.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-test-split1.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-test-split1.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/hrnet_w32_horse10_256x256-split2.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/hrnet_w32_horse10_256x256-split2.py
new file mode 100644
index 0000000000000000000000000000000000000000..a4f2bb278c4110b1a8b9826c54cd07606664179c
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/hrnet_w32_horse10_256x256-split2.py
@@ -0,0 +1,164 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/horse10.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=22,
+ dataset_joints=22,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 21
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 21
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/horse10'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-train-split2.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-test-split2.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-test-split2.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/hrnet_w32_horse10_256x256-split3.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/hrnet_w32_horse10_256x256-split3.py
new file mode 100644
index 0000000000000000000000000000000000000000..38c2f82f9e97883264472fec7e9fa6128fcec1d1
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/hrnet_w32_horse10_256x256-split3.py
@@ -0,0 +1,164 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/horse10.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=22,
+ dataset_joints=22,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 21
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 21
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/horse10'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-train-split3.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-test-split3.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-test-split3.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/hrnet_w48_horse10_256x256-split1.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/hrnet_w48_horse10_256x256-split1.py
new file mode 100644
index 0000000000000000000000000000000000000000..0fea30d63a2c52ed8b1d2ccc9b525355a7ca56ad
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/hrnet_w48_horse10_256x256-split1.py
@@ -0,0 +1,164 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/horse10.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=22,
+ dataset_joints=22,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 21
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 21
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/horse10'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-train-split1.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-test-split1.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-test-split1.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/hrnet_w48_horse10_256x256-split2.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/hrnet_w48_horse10_256x256-split2.py
new file mode 100644
index 0000000000000000000000000000000000000000..49f0920e5759ddc2f14e4a9cee94fa9354b0cd86
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/hrnet_w48_horse10_256x256-split2.py
@@ -0,0 +1,164 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/horse10.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=22,
+ dataset_joints=22,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 21
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 21
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/horse10'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-train-split2.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-test-split2.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-test-split2.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/hrnet_w48_horse10_256x256-split3.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/hrnet_w48_horse10_256x256-split3.py
new file mode 100644
index 0000000000000000000000000000000000000000..1e0a4991f18cd89b0eb24cc0e2a8c881ef566bef
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/hrnet_w48_horse10_256x256-split3.py
@@ -0,0 +1,164 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/horse10.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=22,
+ dataset_joints=22,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 21
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 21
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/horse10'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-train-split3.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-test-split3.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-test-split3.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res101_horse10_256x256-split1.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res101_horse10_256x256-split1.py
new file mode 100644
index 0000000000000000000000000000000000000000..f67903582115f40086ebccccfeb272d0bb072189
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res101_horse10_256x256-split1.py
@@ -0,0 +1,133 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/horse10.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=22,
+ dataset_joints=22,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 21
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 21
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet101',
+ backbone=dict(type='ResNet', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/horse10'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-train-split1.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-test-split1.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-test-split1.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res101_horse10_256x256-split2.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res101_horse10_256x256-split2.py
new file mode 100644
index 0000000000000000000000000000000000000000..d5203d2c92f11920d6417073617e5b6f0434c66e
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res101_horse10_256x256-split2.py
@@ -0,0 +1,133 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/horse10.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=22,
+ dataset_joints=22,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 21
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 21
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet101',
+ backbone=dict(type='ResNet', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/horse10'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-train-split2.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-test-split2.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-test-split2.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res101_horse10_256x256-split3.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res101_horse10_256x256-split3.py
new file mode 100644
index 0000000000000000000000000000000000000000..c371bf0ae7c9493c0a28653bce758d7f5748be1e
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res101_horse10_256x256-split3.py
@@ -0,0 +1,133 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/horse10.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=22,
+ dataset_joints=22,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 21
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 21
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet101',
+ backbone=dict(type='ResNet', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/horse10'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-train-split3.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-test-split3.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-test-split3.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res152_horse10_256x256-split1.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res152_horse10_256x256-split1.py
new file mode 100644
index 0000000000000000000000000000000000000000..b119c4808fc845b49e2c2452c45bd2756162bf6f
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res152_horse10_256x256-split1.py
@@ -0,0 +1,133 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/horse10.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=22,
+ dataset_joints=22,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 21
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 21
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet152',
+ backbone=dict(type='ResNet', depth=152),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/horse10'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-train-split1.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-test-split1.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-test-split1.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res152_horse10_256x256-split2.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res152_horse10_256x256-split2.py
new file mode 100644
index 0000000000000000000000000000000000000000..68fefa69b65cde7302d29f1b44ce7deda4c2a9d1
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res152_horse10_256x256-split2.py
@@ -0,0 +1,133 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/horse10.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=22,
+ dataset_joints=22,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 21
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 21
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet152',
+ backbone=dict(type='ResNet', depth=152),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/horse10'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-train-split2.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-test-split2.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-test-split2.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res152_horse10_256x256-split3.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res152_horse10_256x256-split3.py
new file mode 100644
index 0000000000000000000000000000000000000000..6a5673f77f996ef3e94de7e4d673c9a063935102
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res152_horse10_256x256-split3.py
@@ -0,0 +1,133 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/horse10.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=22,
+ dataset_joints=22,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 21
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 21
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet152',
+ backbone=dict(type='ResNet', depth=152),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/horse10'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-train-split3.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-test-split3.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-test-split3.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res50_horse10_256x256-split1.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res50_horse10_256x256-split1.py
new file mode 100644
index 0000000000000000000000000000000000000000..2a14e16b9920476fec9a290cc12a60fdfa2b25b1
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res50_horse10_256x256-split1.py
@@ -0,0 +1,133 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/horse10.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=22,
+ dataset_joints=22,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 21
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 21
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/horse10'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-train-split1.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-test-split1.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-test-split1.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res50_horse10_256x256-split2.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res50_horse10_256x256-split2.py
new file mode 100644
index 0000000000000000000000000000000000000000..c9463010e5133b327ad94fe90e581280f0e11856
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res50_horse10_256x256-split2.py
@@ -0,0 +1,133 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/horse10.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=22,
+ dataset_joints=22,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 21
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 21
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/horse10'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-train-split2.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-test-split2.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-test-split2.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res50_horse10_256x256-split3.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res50_horse10_256x256-split3.py
new file mode 100644
index 0000000000000000000000000000000000000000..7612dd829a20ba4d754822a5da5bb59b564200af
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res50_horse10_256x256-split3.py
@@ -0,0 +1,133 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/horse10.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=22,
+ dataset_joints=22,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 21
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 21
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/horse10'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-train-split3.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-test-split3.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalHorse10Dataset',
+ ann_file=f'{data_root}/annotations/horse10-test-split3.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/resnet_horse10.md b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/resnet_horse10.md
new file mode 100644
index 0000000000000000000000000000000000000000..0b7797e103f0e952dde801be09087e0ab2351b98
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/resnet_horse10.md
@@ -0,0 +1,47 @@
+
+
+Horse-10 (WACV'2021)
+ +```bibtex +@inproceedings{mathis2021pretraining, + title={Pretraining boosts out-of-domain robustness for pose estimation}, + author={Mathis, Alexander and Biasi, Thomas and Schneider, Steffen and Yuksekgonul, Mert and Rogers, Byron and Bethge, Matthias and Mathis, Mackenzie W}, + booktitle={Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision}, + pages={1859--1868}, + year={2021} +} +``` + +
+
+
+
+
+SimpleBaseline2D (ECCV'2018)
+ +```bibtex +@inproceedings{xiao2018simple, + title={Simple baselines for human pose estimation and tracking}, + author={Xiao, Bin and Wu, Haiping and Wei, Yichen}, + booktitle={Proceedings of the European conference on computer vision (ECCV)}, + pages={466--481}, + year={2018} +} +``` + +
+
+
+Results on Horse-10 test set
+
+|Set | Arch | Input Size | PCK@0.3 | NME | ckpt | log |
+| :--- | :---: | :--------: | :------: | :------: |:------: |:------: |
+|split1| [pose_resnet_50](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res50_horse10_256x256-split1.py) | 256x256 | 0.956 | 0.113 | [ckpt](https://download.openmmlab.com/mmpose/animal/resnet/res50_horse10_256x256_split1-3a3dc37e_20210405.pth) | [log](https://download.openmmlab.com/mmpose/animal/resnet/res50_horse10_256x256_split1_20210405.log.json) |
+|split2| [pose_resnet_50](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res50_horse10_256x256-split2.py) | 256x256 | 0.954 | 0.111 | [ckpt](https://download.openmmlab.com/mmpose/animal/resnet/res50_horse10_256x256_split2-65e2a508_20210405.pth) | [log](https://download.openmmlab.com/mmpose/animal/resnet/res50_horse10_256x256_split2_20210405.log.json) |
+|split3| [pose_resnet_50](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res50_horse10_256x256-split3.py) | 256x256 | 0.946 | 0.129 | [ckpt](https://download.openmmlab.com/mmpose/animal/resnet/res50_horse10_256x256_split3-9637d4eb_20210405.pth) | [log](https://download.openmmlab.com/mmpose/animal/resnet/res50_horse10_256x256_split3_20210405.log.json) |
+|split1| [pose_resnet_101](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res101_horse10_256x256-split1.py) | 256x256 | 0.958 | 0.115 | [ckpt](https://download.openmmlab.com/mmpose/animal/resnet/res101_horse10_256x256_split1-1b7c259c_20210405.pth) | [log](https://download.openmmlab.com/mmpose/animal/resnet/res101_horse10_256x256_split1_20210405.log.json) |
+|split2| [pose_resnet_101](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res101_horse10_256x256-split2.py) | 256x256 | 0.955 | 0.115 | [ckpt](https://download.openmmlab.com/mmpose/animal/resnet/res101_horse10_256x256_split2-30e2fa87_20210405.pth) | [log](https://download.openmmlab.com/mmpose/animal/resnet/res101_horse10_256x256_split2_20210405.log.json) |
+|split3| [pose_resnet_101](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res101_horse10_256x256-split3.py) | 256x256 | 0.946 | 0.126 | [ckpt](https://download.openmmlab.com/mmpose/animal/resnet/res101_horse10_256x256_split3-2eea5bb1_20210405.pth) | [log](https://download.openmmlab.com/mmpose/animal/resnet/res101_horse10_256x256_split3_20210405.log.json) |
+|split1| [pose_resnet_152](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res152_horse10_256x256-split1.py) | 256x256 | 0.969 | 0.105 | [ckpt](https://download.openmmlab.com/mmpose/animal/resnet/res152_horse10_256x256_split1-7e81fe2d_20210405.pth) | [log](https://download.openmmlab.com/mmpose/animal/resnet/res152_horse10_256x256_split1_20210405.log.json) |
+|split2| [pose_resnet_152](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res152_horse10_256x256-split2.py) | 256x256 | 0.970 | 0.103 | [ckpt](https://download.openmmlab.com/mmpose/animal/resnet/res152_horse10_256x256_split2-3b3404a3_20210405.pth) | [log](https://download.openmmlab.com/mmpose/animal/resnet/res152_horse10_256x256_split2_20210405.log.json) |
+|split3| [pose_resnet_152](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res152_horse10_256x256-split3.py) | 256x256 | 0.957 | 0.131 | [ckpt](https://download.openmmlab.com/mmpose/animal/resnet/res152_horse10_256x256_split3-c957dac5_20210405.pth) | [log](https://download.openmmlab.com/mmpose/animal/resnet/res152_horse10_256x256_split3_20210405.log.json) |
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/resnet_horse10.yml b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/resnet_horse10.yml
new file mode 100644
index 0000000000000000000000000000000000000000..d1b39195422f059946f0eef1e6924b1599f91ee8
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/resnet_horse10.yml
@@ -0,0 +1,125 @@
+Collections:
+- Name: SimpleBaseline2D
+ Paper:
+ Title: Simple baselines for human pose estimation and tracking
+ URL: http://openaccess.thecvf.com/content_ECCV_2018/html/Bin_Xiao_Simple_Baselines_for_ECCV_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/simplebaseline2d.md
+Models:
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res50_horse10_256x256-split1.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: &id001
+ - SimpleBaseline2D
+ Training Data: Horse-10
+ Name: topdown_heatmap_res50_horse10_256x256-split1
+ Results:
+ - Dataset: Horse-10
+ Metrics:
+ NME: 0.113
+ PCK@0.3: 0.956
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/resnet/res50_horse10_256x256_split1-3a3dc37e_20210405.pth
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res50_horse10_256x256-split2.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: Horse-10
+ Name: topdown_heatmap_res50_horse10_256x256-split2
+ Results:
+ - Dataset: Horse-10
+ Metrics:
+ NME: 0.111
+ PCK@0.3: 0.954
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/resnet/res50_horse10_256x256_split2-65e2a508_20210405.pth
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res50_horse10_256x256-split3.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: Horse-10
+ Name: topdown_heatmap_res50_horse10_256x256-split3
+ Results:
+ - Dataset: Horse-10
+ Metrics:
+ NME: 0.129
+ PCK@0.3: 0.946
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/resnet/res50_horse10_256x256_split3-9637d4eb_20210405.pth
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res101_horse10_256x256-split1.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: Horse-10
+ Name: topdown_heatmap_res101_horse10_256x256-split1
+ Results:
+ - Dataset: Horse-10
+ Metrics:
+ NME: 0.115
+ PCK@0.3: 0.958
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/resnet/res101_horse10_256x256_split1-1b7c259c_20210405.pth
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res101_horse10_256x256-split2.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: Horse-10
+ Name: topdown_heatmap_res101_horse10_256x256-split2
+ Results:
+ - Dataset: Horse-10
+ Metrics:
+ NME: 0.115
+ PCK@0.3: 0.955
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/resnet/res101_horse10_256x256_split2-30e2fa87_20210405.pth
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res101_horse10_256x256-split3.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: Horse-10
+ Name: topdown_heatmap_res101_horse10_256x256-split3
+ Results:
+ - Dataset: Horse-10
+ Metrics:
+ NME: 0.126
+ PCK@0.3: 0.946
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/resnet/res101_horse10_256x256_split3-2eea5bb1_20210405.pth
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res152_horse10_256x256-split1.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: Horse-10
+ Name: topdown_heatmap_res152_horse10_256x256-split1
+ Results:
+ - Dataset: Horse-10
+ Metrics:
+ NME: 0.105
+ PCK@0.3: 0.969
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/resnet/res152_horse10_256x256_split1-7e81fe2d_20210405.pth
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res152_horse10_256x256-split2.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: Horse-10
+ Name: topdown_heatmap_res152_horse10_256x256-split2
+ Results:
+ - Dataset: Horse-10
+ Metrics:
+ NME: 0.103
+ PCK@0.3: 0.97
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/resnet/res152_horse10_256x256_split2-3b3404a3_20210405.pth
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res152_horse10_256x256-split3.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: Horse-10
+ Name: topdown_heatmap_res152_horse10_256x256-split3
+ Results:
+ - Dataset: Horse-10
+ Metrics:
+ NME: 0.131
+ PCK@0.3: 0.957
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/resnet/res152_horse10_256x256_split3-c957dac5_20210405.pth
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/locust/res101_locust_160x160.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/locust/res101_locust_160x160.py
new file mode 100644
index 0000000000000000000000000000000000000000..18ba8ace4ed0b867112e275c9499a308bfa09d4c
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/locust/res101_locust_160x160.py
@@ -0,0 +1,130 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/locust.py'
+]
+evaluation = dict(interval=10, metric=['PCK', 'AUC', 'EPE'], save_best='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=35,
+ dataset_joints=35,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet101',
+ backbone=dict(type='ResNet', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[160, 160],
+ heatmap_size=[40, 40],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/locust'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalLocustDataset',
+ ann_file=f'{data_root}/annotations/locust_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalLocustDataset',
+ ann_file=f'{data_root}/annotations/locust_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalLocustDataset',
+ ann_file=f'{data_root}/annotations/locust_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/locust/res152_locust_160x160.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/locust/res152_locust_160x160.py
new file mode 100644
index 0000000000000000000000000000000000000000..3966ef2e5c26da9661bda9fdbc0e0d88b77928d7
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/locust/res152_locust_160x160.py
@@ -0,0 +1,130 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/locust.py'
+]
+evaluation = dict(interval=10, metric=['PCK', 'AUC', 'EPE'], save_best='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=35,
+ dataset_joints=35,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet152',
+ backbone=dict(type='ResNet', depth=152),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[160, 160],
+ heatmap_size=[40, 40],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/locust'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalLocustDataset',
+ ann_file=f'{data_root}/annotations/locust_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalLocustDataset',
+ ann_file=f'{data_root}/annotations/locust_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalLocustDataset',
+ ann_file=f'{data_root}/annotations/locust_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/locust/res50_locust_160x160.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/locust/res50_locust_160x160.py
new file mode 100644
index 0000000000000000000000000000000000000000..0850fc27818a1378c16b7f4c922f5a51e5de15f6
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/locust/res50_locust_160x160.py
@@ -0,0 +1,130 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/locust.py'
+]
+evaluation = dict(interval=10, metric=['PCK', 'AUC', 'EPE'], save_best='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=35,
+ dataset_joints=35,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[160, 160],
+ heatmap_size=[40, 40],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/locust'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalLocustDataset',
+ ann_file=f'{data_root}/annotations/locust_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalLocustDataset',
+ ann_file=f'{data_root}/annotations/locust_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalLocustDataset',
+ ann_file=f'{data_root}/annotations/locust_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/locust/resnet_locust.md b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/locust/resnet_locust.md
new file mode 100644
index 0000000000000000000000000000000000000000..20958ffb9c165e1041b1ef102237132005e87036
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/locust/resnet_locust.md
@@ -0,0 +1,43 @@
+
+
+Horse-10 (WACV'2021)
+ +```bibtex +@inproceedings{mathis2021pretraining, + title={Pretraining boosts out-of-domain robustness for pose estimation}, + author={Mathis, Alexander and Biasi, Thomas and Schneider, Steffen and Yuksekgonul, Mert and Rogers, Byron and Bethge, Matthias and Mathis, Mackenzie W}, + booktitle={Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision}, + pages={1859--1868}, + year={2021} +} +``` + +
+
+
+
+
+SimpleBaseline2D (ECCV'2018)
+ +```bibtex +@inproceedings{xiao2018simple, + title={Simple baselines for human pose estimation and tracking}, + author={Xiao, Bin and Wu, Haiping and Wei, Yichen}, + booktitle={Proceedings of the European conference on computer vision (ECCV)}, + pages={466--481}, + year={2018} +} +``` + +
+
+
+Results on Desert Locust test set
+
+| Arch | Input Size | PCK@0.2 | AUC | EPE | ckpt | log |
+| :-------- | :--------: | :------: | :------: | :------: |:------: |:------: |
+|[pose_resnet_50](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/locust/res50_locust_160x160.py) | 160x160 | 0.999 | 0.899 | 2.27 | [ckpt](https://download.openmmlab.com/mmpose/animal/resnet/res50_locust_160x160-9efca22b_20210407.pth) | [log](https://download.openmmlab.com/mmpose/animal/resnet/res50_locust_160x160_20210407.log.json) |
+|[pose_resnet_101](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/locust/res101_locust_160x160.py) | 160x160 | 0.999 | 0.907 | 2.03 | [ckpt](https://download.openmmlab.com/mmpose/animal/resnet/res101_locust_160x160-d77986b3_20210407.pth) | [log](https://download.openmmlab.com/mmpose/animal/resnet/res101_locust_160x160_20210407.log.json) |
+|[pose_resnet_152](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/locust/res152_locust_160x160.py) | 160x160 | 1.000 | 0.926 | 1.48 | [ckpt](https://download.openmmlab.com/mmpose/animal/resnet/res152_locust_160x160-4ea9b372_20210407.pth) | [log](https://download.openmmlab.com/mmpose/animal/resnet/res152_locust_160x160_20210407.log.json) |
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/locust/resnet_locust.yml b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/locust/resnet_locust.yml
new file mode 100644
index 0000000000000000000000000000000000000000..c01a219745866c79cb6656ffcb0aabffc81a47ac
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/locust/resnet_locust.yml
@@ -0,0 +1,50 @@
+Collections:
+- Name: SimpleBaseline2D
+ Paper:
+ Title: Simple baselines for human pose estimation and tracking
+ URL: http://openaccess.thecvf.com/content_ECCV_2018/html/Bin_Xiao_Simple_Baselines_for_ECCV_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/simplebaseline2d.md
+Models:
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/locust/res50_locust_160x160.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: &id001
+ - SimpleBaseline2D
+ Training Data: Desert Locust
+ Name: topdown_heatmap_res50_locust_160x160
+ Results:
+ - Dataset: Desert Locust
+ Metrics:
+ AUC: 0.899
+ EPE: 2.27
+ PCK@0.2: 0.999
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/resnet/res50_locust_160x160-9efca22b_20210407.pth
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/locust/res101_locust_160x160.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: Desert Locust
+ Name: topdown_heatmap_res101_locust_160x160
+ Results:
+ - Dataset: Desert Locust
+ Metrics:
+ AUC: 0.907
+ EPE: 2.03
+ PCK@0.2: 0.999
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/resnet/res101_locust_160x160-d77986b3_20210407.pth
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/locust/res152_locust_160x160.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: Desert Locust
+ Name: topdown_heatmap_res152_locust_160x160
+ Results:
+ - Dataset: Desert Locust
+ Metrics:
+ AUC: 0.926
+ EPE: 1.48
+ PCK@0.2: 1.0
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/resnet/res152_locust_160x160-4ea9b372_20210407.pth
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/hrnet_macaque.md b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/hrnet_macaque.md
new file mode 100644
index 0000000000000000000000000000000000000000..abcffa04a1395a3978a1be5effc19317d56b975a
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/hrnet_macaque.md
@@ -0,0 +1,40 @@
+
+
+Desert Locust (Elife'2019)
+ +```bibtex +@article{graving2019deepposekit, + title={DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning}, + author={Graving, Jacob M and Chae, Daniel and Naik, Hemal and Li, Liang and Koger, Benjamin and Costelloe, Blair R and Couzin, Iain D}, + journal={Elife}, + volume={8}, + pages={e47994}, + year={2019}, + publisher={eLife Sciences Publications Limited} +} +``` + +
+
+
+
+
+HRNet (CVPR'2019)
+ +```bibtex +@inproceedings{sun2019deep, + title={Deep high-resolution representation learning for human pose estimation}, + author={Sun, Ke and Xiao, Bin and Liu, Dong and Wang, Jingdong}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={5693--5703}, + year={2019} +} +``` + +
+
+
+Results on MacaquePose with ground-truth detection bounding boxes
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :-------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_hrnet_w32](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/hrnet_w32_macaque_256x192.py) | 256x192 | 0.814 | 0.953 | 0.918 | 0.851 | 0.969 | [ckpt](https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_macaque_256x192-f7e9e04f_20210407.pth) | [log](https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_macaque_256x192_20210407.log.json) |
+| [pose_hrnet_w48](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/hrnet_w48_macaque_256x192.py) | 256x192 | 0.818 | 0.963 | 0.917 | 0.855 | 0.971 | [ckpt](https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w48_macaque_256x192-9b34b02a_20210407.pth) | [log](https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w48_macaque_256x192_20210407.log.json) |
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/hrnet_macaque.yml b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/hrnet_macaque.yml
new file mode 100644
index 0000000000000000000000000000000000000000..d02d1f8c42d3ad581021cf16757da9fdbee7dd53
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/hrnet_macaque.yml
@@ -0,0 +1,40 @@
+Collections:
+- Name: HRNet
+ Paper:
+ Title: Deep high-resolution representation learning for human pose estimation
+ URL: http://openaccess.thecvf.com/content_CVPR_2019/html/Sun_Deep_High-Resolution_Representation_Learning_for_Human_Pose_Estimation_CVPR_2019_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/hrnet.md
+Models:
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/hrnet_w32_macaque_256x192.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: &id001
+ - HRNet
+ Training Data: MacaquePose
+ Name: topdown_heatmap_hrnet_w32_macaque_256x192
+ Results:
+ - Dataset: MacaquePose
+ Metrics:
+ AP: 0.814
+ AP@0.5: 0.953
+ AP@0.75: 0.918
+ AR: 0.851
+ AR@0.5: 0.969
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w32_macaque_256x192-f7e9e04f_20210407.pth
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/hrnet_w48_macaque_256x192.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: MacaquePose
+ Name: topdown_heatmap_hrnet_w48_macaque_256x192
+ Results:
+ - Dataset: MacaquePose
+ Metrics:
+ AP: 0.818
+ AP@0.5: 0.963
+ AP@0.75: 0.917
+ AR: 0.855
+ AR@0.5: 0.971
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/hrnet/hrnet_w48_macaque_256x192-9b34b02a_20210407.pth
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/hrnet_w32_macaque_256x192.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/hrnet_w32_macaque_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..a5085dccdc9c12b030b57f132737f28fc13d6283
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/hrnet_w32_macaque_256x192.py
@@ -0,0 +1,172 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/macaque.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/macaque'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalMacaqueDataset',
+ ann_file=f'{data_root}/annotations/macaque_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalMacaqueDataset',
+ ann_file=f'{data_root}/annotations/macaque_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalMacaqueDataset',
+ ann_file=f'{data_root}/annotations/macaque_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/hrnet_w48_macaque_256x192.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/hrnet_w48_macaque_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..bae72c8c71f1b9b66e35bb26e3c22eb850b44554
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/hrnet_w48_macaque_256x192.py
@@ -0,0 +1,172 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/macaque.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/macaque'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalMacaqueDataset',
+ ann_file=f'{data_root}/annotations/macaque_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalMacaqueDataset',
+ ann_file=f'{data_root}/annotations/macaque_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalMacaqueDataset',
+ ann_file=f'{data_root}/annotations/macaque_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/res101_macaque_256x192.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/res101_macaque_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..3656eb68544bf335e8768e3c67dd95b53ec723e2
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/res101_macaque_256x192.py
@@ -0,0 +1,141 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/macaque.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet101',
+ backbone=dict(type='ResNet', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/macaque'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalMacaqueDataset',
+ ann_file=f'{data_root}/annotations/macaque_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalMacaqueDataset',
+ ann_file=f'{data_root}/annotations/macaque_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalMacaqueDataset',
+ ann_file=f'{data_root}/annotations/macaque_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/res152_macaque_256x192.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/res152_macaque_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..2267b27a0314e5dc86fa62f179cfefa898ff6494
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/res152_macaque_256x192.py
@@ -0,0 +1,141 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/macaque.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet152',
+ backbone=dict(type='ResNet', depth=152),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/macaque'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalMacaqueDataset',
+ ann_file=f'{data_root}/annotations/macaque_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalMacaqueDataset',
+ ann_file=f'{data_root}/annotations/macaque_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalMacaqueDataset',
+ ann_file=f'{data_root}/annotations/macaque_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/res50_macaque_256x192.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/res50_macaque_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..3c51c96518d9e61346035a7dbc663ac9462ce7a1
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/res50_macaque_256x192.py
@@ -0,0 +1,141 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/macaque.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/macaque'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalMacaqueDataset',
+ ann_file=f'{data_root}/annotations/macaque_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalMacaqueDataset',
+ ann_file=f'{data_root}/annotations/macaque_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalMacaqueDataset',
+ ann_file=f'{data_root}/annotations/macaque_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/resnet_macaque.md b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/resnet_macaque.md
new file mode 100644
index 0000000000000000000000000000000000000000..f6c7f6bd53d191df630e114123e08461c580799b
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/resnet_macaque.md
@@ -0,0 +1,41 @@
+
+
+MacaquePose (bioRxiv'2020)
+ +```bibtex +@article{labuguen2020macaquepose, + title={MacaquePose: A novel ‘in the wild’macaque monkey pose dataset for markerless motion capture}, + author={Labuguen, Rollyn and Matsumoto, Jumpei and Negrete, Salvador and Nishimaru, Hiroshi and Nishijo, Hisao and Takada, Masahiko and Go, Yasuhiro and Inoue, Ken-ichi and Shibata, Tomohiro}, + journal={bioRxiv}, + year={2020}, + publisher={Cold Spring Harbor Laboratory} +} +``` + +
+
+
+
+
+SimpleBaseline2D (ECCV'2018)
+ +```bibtex +@inproceedings{xiao2018simple, + title={Simple baselines for human pose estimation and tracking}, + author={Xiao, Bin and Wu, Haiping and Wei, Yichen}, + booktitle={Proceedings of the European conference on computer vision (ECCV)}, + pages={466--481}, + year={2018} +} +``` + +
+
+
+Results on MacaquePose with ground-truth detection bounding boxes
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :-------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_resnet_50](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/res50_macaque_256x192.py) | 256x192 | 0.799 | 0.952 | 0.919 | 0.837 | 0.964 | [ckpt](https://download.openmmlab.com/mmpose/animal/resnet/res50_macaque_256x192-98f1dd3a_20210407.pth) | [log](https://download.openmmlab.com/mmpose/animal/resnet/res50_macaque_256x192_20210407.log.json) |
+| [pose_resnet_101](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/res101_macaque_256x192.py) | 256x192 | 0.790 | 0.953 | 0.908 | 0.828 | 0.967 | [ckpt](https://download.openmmlab.com/mmpose/animal/resnet/res101_macaque_256x192-e3b9c6bb_20210407.pth) | [log](https://download.openmmlab.com/mmpose/animal/resnet/res101_macaque_256x192_20210407.log.json) |
+| [pose_resnet_152](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/res152_macaque_256x192.py) | 256x192 | 0.794 | 0.951 | 0.915 | 0.834 | 0.968 | [ckpt](https://download.openmmlab.com/mmpose/animal/resnet/res152_macaque_256x192-c42abc02_20210407.pth) | [log](https://download.openmmlab.com/mmpose/animal/resnet/res152_macaque_256x192_20210407.log.json) |
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/resnet_macaque.yml b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/resnet_macaque.yml
new file mode 100644
index 0000000000000000000000000000000000000000..31aa7566008d55d4b7b03f8d091e465032411d86
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/resnet_macaque.yml
@@ -0,0 +1,56 @@
+Collections:
+- Name: SimpleBaseline2D
+ Paper:
+ Title: Simple baselines for human pose estimation and tracking
+ URL: http://openaccess.thecvf.com/content_ECCV_2018/html/Bin_Xiao_Simple_Baselines_for_ECCV_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/simplebaseline2d.md
+Models:
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/res50_macaque_256x192.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: &id001
+ - SimpleBaseline2D
+ Training Data: MacaquePose
+ Name: topdown_heatmap_res50_macaque_256x192
+ Results:
+ - Dataset: MacaquePose
+ Metrics:
+ AP: 0.799
+ AP@0.5: 0.952
+ AP@0.75: 0.919
+ AR: 0.837
+ AR@0.5: 0.964
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/resnet/res50_macaque_256x192-98f1dd3a_20210407.pth
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/res101_macaque_256x192.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: MacaquePose
+ Name: topdown_heatmap_res101_macaque_256x192
+ Results:
+ - Dataset: MacaquePose
+ Metrics:
+ AP: 0.79
+ AP@0.5: 0.953
+ AP@0.75: 0.908
+ AR: 0.828
+ AR@0.5: 0.967
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/resnet/res101_macaque_256x192-e3b9c6bb_20210407.pth
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/res152_macaque_256x192.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: MacaquePose
+ Name: topdown_heatmap_res152_macaque_256x192
+ Results:
+ - Dataset: MacaquePose
+ Metrics:
+ AP: 0.794
+ AP@0.5: 0.951
+ AP@0.75: 0.915
+ AR: 0.834
+ AR@0.5: 0.968
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/resnet/res152_macaque_256x192-c42abc02_20210407.pth
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/zebra/res101_zebra_160x160.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/zebra/res101_zebra_160x160.py
new file mode 100644
index 0000000000000000000000000000000000000000..693867c5263f84a182a1d7742ffc996eacb42fd7
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/zebra/res101_zebra_160x160.py
@@ -0,0 +1,124 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/zebra.py'
+]
+evaluation = dict(interval=10, metric=['PCK', 'AUC', 'EPE'], save_best='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=9,
+ dataset_joints=9,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet101',
+ backbone=dict(type='ResNet', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[160, 160],
+ heatmap_size=[40, 40],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/zebra'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalZebraDataset',
+ ann_file=f'{data_root}/annotations/zebra_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalZebraDataset',
+ ann_file=f'{data_root}/annotations/zebra_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalZebraDataset',
+ ann_file=f'{data_root}/annotations/zebra_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/zebra/res152_zebra_160x160.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/zebra/res152_zebra_160x160.py
new file mode 100644
index 0000000000000000000000000000000000000000..edc07d3f9721d165aee3c3bf82f030aee9833653
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/zebra/res152_zebra_160x160.py
@@ -0,0 +1,124 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/zebra.py'
+]
+evaluation = dict(interval=10, metric=['PCK', 'AUC', 'EPE'], save_best='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=9,
+ dataset_joints=9,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet152',
+ backbone=dict(type='ResNet', depth=152),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[160, 160],
+ heatmap_size=[40, 40],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/zebra'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalZebraDataset',
+ ann_file=f'{data_root}/annotations/zebra_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalZebraDataset',
+ ann_file=f'{data_root}/annotations/zebra_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalZebraDataset',
+ ann_file=f'{data_root}/annotations/zebra_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/zebra/res50_zebra_160x160.py b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/zebra/res50_zebra_160x160.py
new file mode 100644
index 0000000000000000000000000000000000000000..3120b473f8abd6073b4a06a99c89b23e98137145
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/zebra/res50_zebra_160x160.py
@@ -0,0 +1,124 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/zebra.py'
+]
+evaluation = dict(interval=10, metric=['PCK', 'AUC', 'EPE'], save_best='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=1,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=9,
+ dataset_joints=9,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[160, 160],
+ heatmap_size=[40, 40],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/zebra'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='AnimalZebraDataset',
+ ann_file=f'{data_root}/annotations/zebra_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='AnimalZebraDataset',
+ ann_file=f'{data_root}/annotations/zebra_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='AnimalZebraDataset',
+ ann_file=f'{data_root}/annotations/zebra_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/zebra/resnet_zebra.md b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/zebra/resnet_zebra.md
new file mode 100644
index 0000000000000000000000000000000000000000..3d34d598ac1f2a19cea7d7d92304c6fd79daed51
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/zebra/resnet_zebra.md
@@ -0,0 +1,43 @@
+
+
+MacaquePose (bioRxiv'2020)
+ +```bibtex +@article{labuguen2020macaquepose, + title={MacaquePose: A novel ‘in the wild’macaque monkey pose dataset for markerless motion capture}, + author={Labuguen, Rollyn and Matsumoto, Jumpei and Negrete, Salvador and Nishimaru, Hiroshi and Nishijo, Hisao and Takada, Masahiko and Go, Yasuhiro and Inoue, Ken-ichi and Shibata, Tomohiro}, + journal={bioRxiv}, + year={2020}, + publisher={Cold Spring Harbor Laboratory} +} +``` + +
+
+
+
+
+SimpleBaseline2D (ECCV'2018)
+ +```bibtex +@inproceedings{xiao2018simple, + title={Simple baselines for human pose estimation and tracking}, + author={Xiao, Bin and Wu, Haiping and Wei, Yichen}, + booktitle={Proceedings of the European conference on computer vision (ECCV)}, + pages={466--481}, + year={2018} +} +``` + +
+
+
+Results on Grévy’s Zebra test set
+
+| Arch | Input Size | PCK@0.2 | AUC | EPE | ckpt | log |
+| :-------- | :--------: | :------: | :------: | :------: |:------: |:------: |
+|[pose_resnet_50](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/zebra/res50_zebra_160x160.py) | 160x160 | 1.000 | 0.914 | 1.86 | [ckpt](https://download.openmmlab.com/mmpose/animal/resnet/res50_zebra_160x160-5a104833_20210407.pth) | [log](https://download.openmmlab.com/mmpose/animal/resnet/res50_zebra_160x160_20210407.log.json) |
+|[pose_resnet_101](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/zebra/res101_zebra_160x160.py) | 160x160 | 1.000 | 0.916 | 1.82 | [ckpt](https://download.openmmlab.com/mmpose/animal/resnet/res101_zebra_160x160-e8cb2010_20210407.pth) | [log](https://download.openmmlab.com/mmpose/animal/resnet/res101_zebra_160x160_20210407.log.json) |
+|[pose_resnet_152](/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/zebra/res152_zebra_160x160.py) | 160x160 | 1.000 | 0.921 | 1.66 | [ckpt](https://download.openmmlab.com/mmpose/animal/resnet/res152_zebra_160x160-05de71dd_20210407.pth) | [log](https://download.openmmlab.com/mmpose/animal/resnet/res152_zebra_160x160_20210407.log.json) |
diff --git a/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/zebra/resnet_zebra.yml b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/zebra/resnet_zebra.yml
new file mode 100644
index 0000000000000000000000000000000000000000..54912ba569e3b545e04587bbd1ffa2191d6f16da
--- /dev/null
+++ b/vendor/ViTPose/configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/zebra/resnet_zebra.yml
@@ -0,0 +1,50 @@
+Collections:
+- Name: SimpleBaseline2D
+ Paper:
+ Title: Simple baselines for human pose estimation and tracking
+ URL: http://openaccess.thecvf.com/content_ECCV_2018/html/Bin_Xiao_Simple_Baselines_for_ECCV_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/simplebaseline2d.md
+Models:
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/zebra/res50_zebra_160x160.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: &id001
+ - SimpleBaseline2D
+ Training Data: "Gr\xE9vy\u2019s Zebra"
+ Name: topdown_heatmap_res50_zebra_160x160
+ Results:
+ - Dataset: "Gr\xE9vy\u2019s Zebra"
+ Metrics:
+ AUC: 0.914
+ EPE: 1.86
+ PCK@0.2: 1.0
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/resnet/res50_zebra_160x160-5a104833_20210407.pth
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/zebra/res101_zebra_160x160.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: "Gr\xE9vy\u2019s Zebra"
+ Name: topdown_heatmap_res101_zebra_160x160
+ Results:
+ - Dataset: "Gr\xE9vy\u2019s Zebra"
+ Metrics:
+ AUC: 0.916
+ EPE: 1.82
+ PCK@0.2: 1.0
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/resnet/res101_zebra_160x160-e8cb2010_20210407.pth
+- Config: configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/zebra/res152_zebra_160x160.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: "Gr\xE9vy\u2019s Zebra"
+ Name: topdown_heatmap_res152_zebra_160x160
+ Results:
+ - Dataset: "Gr\xE9vy\u2019s Zebra"
+ Metrics:
+ AUC: 0.921
+ EPE: 1.66
+ PCK@0.2: 1.0
+ Task: Animal 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/animal/resnet/res152_zebra_160x160-05de71dd_20210407.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/README.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..02682f406b67ad8e5884e0c5d1a25e7bd1a67f3c
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/README.md
@@ -0,0 +1,19 @@
+# Image-based Human Body 2D Pose Estimation
+
+Multi-person human pose estimation is defined as the task of detecting the poses (or keypoints) of all people from an input image.
+
+Existing approaches can be categorized into top-down and bottom-up approaches.
+
+Top-down methods (e.g. deeppose) divide the task into two stages: human detection and pose estimation. They perform human detection first, followed by single-person pose estimation given human bounding boxes.
+
+Bottom-up approaches (e.g. AE) first detect all the keypoints and then group/associate them into person instances.
+
+## Data preparation
+
+Please follow [DATA Preparation](/docs/en/tasks/2d_body_keypoint.md) to prepare data.
+
+## Demo
+
+Please follow [Demo](/demo/docs/2d_human_pose_demo.md#2d-human-pose-demo) to run demos.
+
+Grévy’s Zebra (Elife'2019)
+ +```bibtex +@article{graving2019deepposekit, + title={DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning}, + author={Graving, Jacob M and Chae, Daniel and Naik, Hemal and Li, Liang and Koger, Benjamin and Costelloe, Blair R and Couzin, Iain D}, + journal={Elife}, + volume={8}, + pages={e47994}, + year={2019}, + publisher={eLife Sciences Publications Limited} +} +``` + + diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/README.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..2048f2182b77605924ec48913c3203e3bc0a61be
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/README.md
@@ -0,0 +1,25 @@
+# Associative embedding: End-to-end learning for joint detection and grouping (AE)
+
+
+
+
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/README.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..2048f2182b77605924ec48913c3203e3bc0a61be
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/README.md
@@ -0,0 +1,25 @@
+# Associative embedding: End-to-end learning for joint detection and grouping (AE)
+
+
+
+
+
+
+AE is one of the most popular 2D bottom-up pose estimation approaches, that first detect all the keypoints and
+then group/associate them into person instances.
+
+In order to group all the predicted keypoints to individuals, a tag is also predicted for each detected keypoint.
+Tags of the same person are similar, while tags of different people are different. Thus the keypoints can be grouped
+according to the tags.
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/aic/higherhrnet_aic.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/aic/higherhrnet_aic.md
new file mode 100644
index 0000000000000000000000000000000000000000..e4737739ccafdce31982effd05e0a1b44a20d789
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/aic/higherhrnet_aic.md
@@ -0,0 +1,61 @@
+
+
+Associative Embedding (NIPS'2017)
+ +```bibtex +@inproceedings{newell2017associative, + title={Associative embedding: End-to-end learning for joint detection and grouping}, + author={Newell, Alejandro and Huang, Zhiao and Deng, Jia}, + booktitle={Advances in neural information processing systems}, + pages={2277--2287}, + year={2017} +} +``` + +
+
+
+
+
+Associative Embedding (NIPS'2017)
+ +```bibtex +@inproceedings{newell2017associative, + title={Associative embedding: End-to-end learning for joint detection and grouping}, + author={Newell, Alejandro and Huang, Zhiao and Deng, Jia}, + booktitle={Advances in neural information processing systems}, + pages={2277--2287}, + year={2017} +} +``` + +
+
+
+
+
+HigherHRNet (CVPR'2020)
+ +```bibtex +@inproceedings{cheng2020higherhrnet, + title={HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation}, + author={Cheng, Bowen and Xiao, Bin and Wang, Jingdong and Shi, Honghui and Huang, Thomas S and Zhang, Lei}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + pages={5386--5395}, + year={2020} +} +``` + +
+
+
+Results on AIC validation set without multi-scale test
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :----------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [HigherHRNet-w32](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/aic/higherhrnet_w32_aic_512x512.py) | 512x512 | 0.315 | 0.710 | 0.243 | 0.379 | 0.757 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet32_aic_512x512-9a674c33_20210130.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet32_aic_512x512_20210130.log.json) |
+
+Results on AIC validation set with multi-scale test. 3 default scales (\[2, 1, 0.5\]) are used
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :----------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [HigherHRNet-w32](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/aic/higherhrnet_w32_aic_512x512.py) | 512x512 | 0.323 | 0.718 | 0.254 | 0.379 | 0.758 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet32_aic_512x512-9a674c33_20210130.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet32_aic_512x512_20210130.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/aic/higherhrnet_aic.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/aic/higherhrnet_aic.yml
new file mode 100644
index 0000000000000000000000000000000000000000..37d24a423192e918733801aa44970fb3f30b838d
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/aic/higherhrnet_aic.yml
@@ -0,0 +1,42 @@
+Collections:
+- Name: HigherHRNet
+ Paper:
+ Title: 'HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose
+ Estimation'
+ URL: http://openaccess.thecvf.com/content_CVPR_2020/html/Cheng_HigherHRNet_Scale-Aware_Representation_Learning_for_Bottom-Up_Human_Pose_Estimation_CVPR_2020_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/higherhrnet.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/associative_embedding/aic/higherhrnet_w32_aic_512x512.py
+ In Collection: HigherHRNet
+ Metadata:
+ Architecture: &id001
+ - Associative Embedding
+ - HigherHRNet
+ Training Data: AI Challenger
+ Name: associative_embedding_higherhrnet_w32_aic_512x512
+ Results:
+ - Dataset: AI Challenger
+ Metrics:
+ AP: 0.315
+ AP@0.5: 0.71
+ AP@0.75: 0.243
+ AR: 0.379
+ AR@0.5: 0.757
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet32_aic_512x512-9a674c33_20210130.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/associative_embedding/aic/higherhrnet_w32_aic_512x512.py
+ In Collection: HigherHRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: AI Challenger
+ Name: associative_embedding_higherhrnet_w32_aic_512x512
+ Results:
+ - Dataset: AI Challenger
+ Metrics:
+ AP: 0.323
+ AP@0.5: 0.718
+ AP@0.75: 0.254
+ AR: 0.379
+ AR@0.5: 0.758
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet32_aic_512x512-9a674c33_20210130.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/aic/higherhrnet_w32_aic_512x512.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/aic/higherhrnet_w32_aic_512x512.py
new file mode 100644
index 0000000000000000000000000000000000000000..67602935cc952381b8081b993f220ad3a86c90d8
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/aic/higherhrnet_w32_aic_512x512.py
@@ -0,0 +1,195 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/aic.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+data_cfg = dict(
+ image_size=512,
+ base_size=256,
+ base_sigma=2,
+ heatmap_size=[128, 256],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=2,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='AEHigherResolutionHead',
+ in_channels=32,
+ num_joints=14,
+ tag_per_joint=True,
+ extra=dict(final_conv_kernel=1, ),
+ num_deconv_layers=1,
+ num_deconv_filters=[32],
+ num_deconv_kernels=[4],
+ num_basic_blocks=4,
+ cat_output=[True],
+ with_ae_loss=[True, False],
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=14,
+ num_stages=2,
+ ae_loss_type='exp',
+ with_ae_loss=[True, False],
+ push_loss_factor=[0.01, 0.01],
+ pull_loss_factor=[0.001, 0.001],
+ with_heatmaps_loss=[True, True],
+ heatmaps_loss_factor=[1.0, 1.0])),
+ train_cfg=dict(),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True, True],
+ with_ae=[True, False],
+ project2image=True,
+ align_corners=False,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1]),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ ]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/aic'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=24),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpAicDataset',
+ ann_file=f'{data_root}/annotations/aic_train.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_train_20170902/'
+ 'keypoint_train_images_20170902/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpAicDataset',
+ ann_file=f'{data_root}/annotations/aic_val.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_validation_20170911/'
+ 'keypoint_validation_images_20170911/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpAicDataset',
+ ann_file=f'{data_root}/annotations/aic_val.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_validation_20170911/'
+ 'keypoint_validation_images_20170911/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/aic/higherhrnet_w32_aic_512x512_udp.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/aic/higherhrnet_w32_aic_512x512_udp.py
new file mode 100644
index 0000000000000000000000000000000000000000..bf5fef221acb115d43fbf567ce3603d724921a33
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/aic/higherhrnet_w32_aic_512x512_udp.py
@@ -0,0 +1,198 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/aic.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+data_cfg = dict(
+ image_size=512,
+ base_size=256,
+ base_sigma=2,
+ heatmap_size=[128, 256],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=2,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='AEHigherResolutionHead',
+ in_channels=32,
+ num_joints=14,
+ tag_per_joint=True,
+ extra=dict(final_conv_kernel=1, ),
+ num_deconv_layers=1,
+ num_deconv_filters=[32],
+ num_deconv_kernels=[4],
+ num_basic_blocks=4,
+ cat_output=[True],
+ with_ae_loss=[True, False],
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=14,
+ num_stages=2,
+ ae_loss_type='exp',
+ with_ae_loss=[True, False],
+ push_loss_factor=[0.01, 0.01],
+ pull_loss_factor=[0.001, 0.001],
+ with_heatmaps_loss=[True, True],
+ heatmaps_loss_factor=[1.0, 1.0])),
+ train_cfg=dict(),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True, True],
+ with_ae=[True, False],
+ project2image=False,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True,
+ use_udp=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40,
+ use_udp=True),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ use_udp=True,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1], use_udp=True),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225])
+ ],
+ use_udp=True),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/aic'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=24),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpAicDataset',
+ ann_file=f'{data_root}/annotations/aic_train.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_train_20170902/'
+ 'keypoint_train_images_20170902/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpAicDataset',
+ ann_file=f'{data_root}/annotations/aic_val.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_validation_20170911/'
+ 'keypoint_validation_images_20170911/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpAicDataset',
+ ann_file=f'{data_root}/annotations/aic_val.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_validation_20170911/'
+ 'keypoint_validation_images_20170911/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/aic/hrnet_aic.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/aic/hrnet_aic.md
new file mode 100644
index 0000000000000000000000000000000000000000..89b6b18ef6229c2a1c78d0d6248f6489f3cb3e14
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/aic/hrnet_aic.md
@@ -0,0 +1,61 @@
+
+
+AI Challenger (ArXiv'2017)
+ +```bibtex +@article{wu2017ai, + title={Ai challenger: A large-scale dataset for going deeper in image understanding}, + author={Wu, Jiahong and Zheng, He and Zhao, Bo and Li, Yixin and Yan, Baoming and Liang, Rui and Wang, Wenjia and Zhou, Shipei and Lin, Guosen and Fu, Yanwei and others}, + journal={arXiv preprint arXiv:1711.06475}, + year={2017} +} +``` + +
+
+
+
+
+Associative Embedding (NIPS'2017)
+ +```bibtex +@inproceedings{newell2017associative, + title={Associative embedding: End-to-end learning for joint detection and grouping}, + author={Newell, Alejandro and Huang, Zhiao and Deng, Jia}, + booktitle={Advances in neural information processing systems}, + pages={2277--2287}, + year={2017} +} +``` + +
+
+
+
+
+HRNet (CVPR'2019)
+ +```bibtex +@inproceedings{sun2019deep, + title={Deep high-resolution representation learning for human pose estimation}, + author={Sun, Ke and Xiao, Bin and Liu, Dong and Wang, Jingdong}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={5693--5703}, + year={2019} +} +``` + +
+
+
+Results on AIC validation set without multi-scale test
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :----------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [HRNet-w32](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/aic/hrnet_w32_aic_512x512.py) | 512x512 | 0.303 | 0.697 | 0.225 | 0.373 | 0.755 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/hrnet_w32_aic_512x512-77e2a98a_20210131.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/hrnet_w32_aic_512x512_20210131.log.json) |
+
+Results on AIC validation set with multi-scale test. 3 default scales (\[2, 1, 0.5\]) are used
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :----------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [HRNet-w32](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/aic/hrnet_w32_aic_512x512.py) | 512x512 | 0.318 | 0.717 | 0.246 | 0.379 | 0.764 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/hrnet_w32_aic_512x512-77e2a98a_20210131.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/hrnet_w32_aic_512x512_20210131.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/aic/hrnet_aic.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/aic/hrnet_aic.yml
new file mode 100644
index 0000000000000000000000000000000000000000..3be9548fb8529e1deda50ef2b0b9ed5968d9848d
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/aic/hrnet_aic.yml
@@ -0,0 +1,41 @@
+Collections:
+- Name: HRNet
+ Paper:
+ Title: Deep high-resolution representation learning for human pose estimation
+ URL: http://openaccess.thecvf.com/content_CVPR_2019/html/Sun_Deep_High-Resolution_Representation_Learning_for_Human_Pose_Estimation_CVPR_2019_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/hrnet.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/associative_embedding/aic/hrnet_w32_aic_512x512.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: &id001
+ - Associative Embedding
+ - HRNet
+ Training Data: AI Challenger
+ Name: associative_embedding_hrnet_w32_aic_512x512
+ Results:
+ - Dataset: AI Challenger
+ Metrics:
+ AP: 0.303
+ AP@0.5: 0.697
+ AP@0.75: 0.225
+ AR: 0.373
+ AR@0.5: 0.755
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/hrnet_w32_aic_512x512-77e2a98a_20210131.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/associative_embedding/aic/hrnet_w32_aic_512x512.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: AI Challenger
+ Name: associative_embedding_hrnet_w32_aic_512x512
+ Results:
+ - Dataset: AI Challenger
+ Metrics:
+ AP: 0.318
+ AP@0.5: 0.717
+ AP@0.75: 0.246
+ AR: 0.379
+ AR@0.5: 0.764
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/hrnet_w32_aic_512x512-77e2a98a_20210131.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/aic/hrnet_w32_aic_512x512.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/aic/hrnet_w32_aic_512x512.py
new file mode 100644
index 0000000000000000000000000000000000000000..6e4b8363336397e703985c71fd62092d83176018
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/aic/hrnet_w32_aic_512x512.py
@@ -0,0 +1,191 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/aic.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+data_cfg = dict(
+ image_size=512,
+ base_size=256,
+ base_sigma=2,
+ heatmap_size=[128],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=1,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='AESimpleHead',
+ in_channels=32,
+ num_joints=14,
+ num_deconv_layers=0,
+ tag_per_joint=True,
+ with_ae_loss=[True],
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=14,
+ num_stages=1,
+ ae_loss_type='exp',
+ with_ae_loss=[True],
+ push_loss_factor=[0.01],
+ pull_loss_factor=[0.001],
+ with_heatmaps_loss=[True],
+ heatmaps_loss_factor=[1.0])),
+ train_cfg=dict(),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True],
+ with_ae=[True],
+ project2image=True,
+ align_corners=False,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1]),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ ]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/aic'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=24),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpAicDataset',
+ ann_file=f'{data_root}/annotations/aic_train.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_train_20170902/'
+ 'keypoint_train_images_20170902/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpAicDataset',
+ ann_file=f'{data_root}/annotations/aic_val.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_validation_20170911/'
+ 'keypoint_validation_images_20170911/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpAicDataset',
+ ann_file=f'{data_root}/annotations/aic_val.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_validation_20170911/'
+ 'keypoint_validation_images_20170911/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_coco.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_coco.md
new file mode 100644
index 0000000000000000000000000000000000000000..676e1708bf55edafd005c1f89f3319609a74ee8c
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_coco.md
@@ -0,0 +1,67 @@
+
+
+AI Challenger (ArXiv'2017)
+ +```bibtex +@article{wu2017ai, + title={Ai challenger: A large-scale dataset for going deeper in image understanding}, + author={Wu, Jiahong and Zheng, He and Zhao, Bo and Li, Yixin and Yan, Baoming and Liang, Rui and Wang, Wenjia and Zhou, Shipei and Lin, Guosen and Fu, Yanwei and others}, + journal={arXiv preprint arXiv:1711.06475}, + year={2017} +} +``` + +
+
+
+
+
+Associative Embedding (NIPS'2017)
+ +```bibtex +@inproceedings{newell2017associative, + title={Associative embedding: End-to-end learning for joint detection and grouping}, + author={Newell, Alejandro and Huang, Zhiao and Deng, Jia}, + booktitle={Advances in neural information processing systems}, + pages={2277--2287}, + year={2017} +} +``` + +
+
+
+
+
+HigherHRNet (CVPR'2020)
+ +```bibtex +@inproceedings{cheng2020higherhrnet, + title={HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation}, + author={Cheng, Bowen and Xiao, Bin and Wang, Jingdong and Shi, Honghui and Huang, Thomas S and Zhang, Lei}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + pages={5386--5395}, + year={2020} +} +``` + +
+
+
+Results on COCO val2017 without multi-scale test
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :----------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [HigherHRNet-w32](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w32_coco_512x512.py) | 512x512 | 0.677 | 0.870 | 0.738 | 0.723 | 0.890 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet32_coco_512x512-8ae85183_20200713.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet32_coco_512x512_20200713.log.json) |
+| [HigherHRNet-w32](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w32_coco_640x640.py) | 640x640 | 0.686 | 0.871 | 0.747 | 0.733 | 0.898 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet32_coco_640x640-a22fe938_20200712.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet32_coco_640x640_20200712.log.json) |
+| [HigherHRNet-w48](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w48_coco_512x512.py) | 512x512 | 0.686 | 0.873 | 0.741 | 0.731 | 0.892 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet48_coco_512x512-60fedcbc_20200712.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet48_coco_512x512_20200712.log.json) |
+
+Results on COCO val2017 with multi-scale test. 3 default scales (\[2, 1, 0.5\]) are used
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :----------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [HigherHRNet-w32](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w32_coco_512x512.py) | 512x512 | 0.706 | 0.881 | 0.771 | 0.747 | 0.901 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet32_coco_512x512-8ae85183_20200713.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet32_coco_512x512_20200713.log.json) |
+| [HigherHRNet-w32](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w32_coco_640x640.py) | 640x640 | 0.706 | 0.880 | 0.770 | 0.749 | 0.902 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet32_coco_640x640-a22fe938_20200712.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet32_coco_640x640_20200712.log.json) |
+| [HigherHRNet-w48](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w48_coco_512x512.py) | 512x512 | 0.716 | 0.884 | 0.775 | 0.755 | 0.901 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet48_coco_512x512-60fedcbc_20200712.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet48_coco_512x512_20200712.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_coco.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_coco.yml
new file mode 100644
index 0000000000000000000000000000000000000000..5302efe00f9e31682b6498d526963dc2b50db89b
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_coco.yml
@@ -0,0 +1,106 @@
+Collections:
+- Name: HigherHRNet
+ Paper:
+ Title: 'HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose
+ Estimation'
+ URL: http://openaccess.thecvf.com/content_CVPR_2020/html/Cheng_HigherHRNet_Scale-Aware_Representation_Learning_for_Bottom-Up_Human_Pose_Estimation_CVPR_2020_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/higherhrnet.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w32_coco_512x512.py
+ In Collection: HigherHRNet
+ Metadata:
+ Architecture: &id001
+ - Associative Embedding
+ - HigherHRNet
+ Training Data: COCO
+ Name: associative_embedding_higherhrnet_w32_coco_512x512
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.677
+ AP@0.5: 0.87
+ AP@0.75: 0.738
+ AR: 0.723
+ AR@0.5: 0.89
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet32_coco_512x512-8ae85183_20200713.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w32_coco_640x640.py
+ In Collection: HigherHRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: associative_embedding_higherhrnet_w32_coco_640x640
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.686
+ AP@0.5: 0.871
+ AP@0.75: 0.747
+ AR: 0.733
+ AR@0.5: 0.898
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet32_coco_640x640-a22fe938_20200712.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w48_coco_512x512.py
+ In Collection: HigherHRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: associative_embedding_higherhrnet_w48_coco_512x512
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.686
+ AP@0.5: 0.873
+ AP@0.75: 0.741
+ AR: 0.731
+ AR@0.5: 0.892
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet48_coco_512x512-60fedcbc_20200712.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w32_coco_512x512.py
+ In Collection: HigherHRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: associative_embedding_higherhrnet_w32_coco_512x512
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.706
+ AP@0.5: 0.881
+ AP@0.75: 0.771
+ AR: 0.747
+ AR@0.5: 0.901
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet32_coco_512x512-8ae85183_20200713.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w32_coco_640x640.py
+ In Collection: HigherHRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: associative_embedding_higherhrnet_w32_coco_640x640
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.706
+ AP@0.5: 0.88
+ AP@0.75: 0.77
+ AR: 0.749
+ AR@0.5: 0.902
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet32_coco_640x640-a22fe938_20200712.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w48_coco_512x512.py
+ In Collection: HigherHRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: associative_embedding_higherhrnet_w48_coco_512x512
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.716
+ AP@0.5: 0.884
+ AP@0.75: 0.775
+ AR: 0.755
+ AR@0.5: 0.901
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet48_coco_512x512-60fedcbc_20200712.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_udp_coco.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_udp_coco.md
new file mode 100644
index 0000000000000000000000000000000000000000..36ba0c8550af2c802a236cde54791494b2c34733
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_udp_coco.md
@@ -0,0 +1,75 @@
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+
+
+Associative Embedding (NIPS'2017)
+ +```bibtex +@inproceedings{newell2017associative, + title={Associative embedding: End-to-end learning for joint detection and grouping}, + author={Newell, Alejandro and Huang, Zhiao and Deng, Jia}, + booktitle={Advances in neural information processing systems}, + pages={2277--2287}, + year={2017} +} +``` + +
+
+
+
+
+HigherHRNet (CVPR'2020)
+ +```bibtex +@inproceedings{cheng2020higherhrnet, + title={HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation}, + author={Cheng, Bowen and Xiao, Bin and Wang, Jingdong and Shi, Honghui and Huang, Thomas S and Zhang, Lei}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + pages={5386--5395}, + year={2020} +} +``` + +
+
+
+
+
+UDP (CVPR'2020)
+ +```bibtex +@InProceedings{Huang_2020_CVPR, + author = {Huang, Junjie and Zhu, Zheng and Guo, Feng and Huang, Guan}, + title = {The Devil Is in the Details: Delving Into Unbiased Data Processing for Human Pose Estimation}, + booktitle = {The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, + month = {June}, + year = {2020} +} +``` + +
+
+
+Results on COCO val2017 without multi-scale test
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :----------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [HigherHRNet-w32_udp](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w32_coco_512x512_udp.py) | 512x512 | 0.678 | 0.862 | 0.736 | 0.724 | 0.890 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet32_coco_512x512_udp-8cc64794_20210222.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet32_coco_512x512_udp_20210222.log.json) |
+| [HigherHRNet-w48_udp](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w48_coco_512x512_udp.py) | 512x512 | 0.690 | 0.872 | 0.750 | 0.734 | 0.891 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet48_coco_512x512_udp-7cad61ef_20210222.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet48_coco_512x512_udp_20210222.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_udp_coco.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_udp_coco.yml
new file mode 100644
index 0000000000000000000000000000000000000000..1a04988d251b7f7c42639fccb160291614432c35
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_udp_coco.yml
@@ -0,0 +1,43 @@
+Collections:
+- Name: HigherHRNet
+ Paper:
+ Title: 'HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose
+ Estimation'
+ URL: http://openaccess.thecvf.com/content_CVPR_2020/html/Cheng_HigherHRNet_Scale-Aware_Representation_Learning_for_Bottom-Up_Human_Pose_Estimation_CVPR_2020_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/higherhrnet.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w32_coco_512x512_udp.py
+ In Collection: HigherHRNet
+ Metadata:
+ Architecture: &id001
+ - Associative Embedding
+ - HigherHRNet
+ - UDP
+ Training Data: COCO
+ Name: associative_embedding_higherhrnet_w32_coco_512x512_udp
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.678
+ AP@0.5: 0.862
+ AP@0.75: 0.736
+ AR: 0.724
+ AR@0.5: 0.89
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet32_coco_512x512_udp-8cc64794_20210222.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w48_coco_512x512_udp.py
+ In Collection: HigherHRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: associative_embedding_higherhrnet_w48_coco_512x512_udp
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.69
+ AP@0.5: 0.872
+ AP@0.75: 0.75
+ AR: 0.734
+ AR@0.5: 0.891
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet48_coco_512x512_udp-7cad61ef_20210222.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w32_coco_512x512.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w32_coco_512x512.py
new file mode 100644
index 0000000000000000000000000000000000000000..b6f549bad31b8cc18e47fd4c47cd3246540840e3
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w32_coco_512x512.py
@@ -0,0 +1,193 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+data_cfg = dict(
+ image_size=512,
+ base_size=256,
+ base_sigma=2,
+ heatmap_size=[128, 256],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=2,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='AEHigherResolutionHead',
+ in_channels=32,
+ num_joints=17,
+ tag_per_joint=True,
+ extra=dict(final_conv_kernel=1, ),
+ num_deconv_layers=1,
+ num_deconv_filters=[32],
+ num_deconv_kernels=[4],
+ num_basic_blocks=4,
+ cat_output=[True],
+ with_ae_loss=[True, False],
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=17,
+ num_stages=2,
+ ae_loss_type='exp',
+ with_ae_loss=[True, False],
+ push_loss_factor=[0.001, 0.001],
+ pull_loss_factor=[0.001, 0.001],
+ with_heatmaps_loss=[True, True],
+ heatmaps_loss_factor=[1.0, 1.0])),
+ train_cfg=dict(),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True, True],
+ with_ae=[True, False],
+ project2image=True,
+ align_corners=False,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1]),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ ]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=24),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w32_coco_512x512_udp.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w32_coco_512x512_udp.py
new file mode 100644
index 0000000000000000000000000000000000000000..6109c2e61c916cf0e6075d3929150c466d2f482c
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w32_coco_512x512_udp.py
@@ -0,0 +1,197 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+data_cfg = dict(
+ image_size=512,
+ base_size=256,
+ base_sigma=2,
+ heatmap_size=[128, 256],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=2,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='AEHigherResolutionHead',
+ in_channels=32,
+ num_joints=17,
+ tag_per_joint=True,
+ extra=dict(final_conv_kernel=1, ),
+ num_deconv_layers=1,
+ num_deconv_filters=[32],
+ num_deconv_kernels=[4],
+ num_basic_blocks=4,
+ cat_output=[True],
+ with_ae_loss=[True, False],
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=17,
+ num_stages=2,
+ ae_loss_type='exp',
+ with_ae_loss=[True, False],
+ push_loss_factor=[0.001, 0.001],
+ pull_loss_factor=[0.001, 0.001],
+ with_heatmaps_loss=[True, True],
+ heatmaps_loss_factor=[1.0, 1.0])),
+ train_cfg=dict(),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True, True],
+ with_ae=[True, False],
+ project2image=False,
+ align_corners=True,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True,
+ use_udp=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40,
+ use_udp=True),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ use_udp=True,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1], use_udp=True),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225])
+ ],
+ use_udp=True),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=24),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w32_coco_640x640.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w32_coco_640x640.py
new file mode 100644
index 0000000000000000000000000000000000000000..2daf4840bdbe946179fcc380844fe2226654fb05
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w32_coco_640x640.py
@@ -0,0 +1,193 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+data_cfg = dict(
+ image_size=640,
+ base_size=320,
+ base_sigma=2,
+ heatmap_size=[160, 320],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=2,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='AEHigherResolutionHead',
+ in_channels=32,
+ num_joints=17,
+ tag_per_joint=True,
+ extra=dict(final_conv_kernel=1, ),
+ num_deconv_layers=1,
+ num_deconv_filters=[32],
+ num_deconv_kernels=[4],
+ num_basic_blocks=4,
+ cat_output=[True],
+ with_ae_loss=[True, False],
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=17,
+ num_stages=2,
+ ae_loss_type='exp',
+ with_ae_loss=[True, False],
+ push_loss_factor=[0.001, 0.001],
+ pull_loss_factor=[0.001, 0.001],
+ with_heatmaps_loss=[True, True],
+ heatmaps_loss_factor=[1.0, 1.0])),
+ train_cfg=dict(),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True, True],
+ with_ae=[True, False],
+ project2image=True,
+ align_corners=False,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1]),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ ]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=16),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w32_coco_640x640_udp.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w32_coco_640x640_udp.py
new file mode 100644
index 0000000000000000000000000000000000000000..1b92efc4ffc8e7cde69abe5c5b68d743e06cef72
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w32_coco_640x640_udp.py
@@ -0,0 +1,197 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+data_cfg = dict(
+ image_size=640,
+ base_size=320,
+ base_sigma=2,
+ heatmap_size=[160, 320],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=2,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='AEHigherResolutionHead',
+ in_channels=32,
+ num_joints=17,
+ tag_per_joint=True,
+ extra=dict(final_conv_kernel=1, ),
+ num_deconv_layers=1,
+ num_deconv_filters=[32],
+ num_deconv_kernels=[4],
+ num_basic_blocks=4,
+ cat_output=[True],
+ with_ae_loss=[True, False],
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=17,
+ num_stages=2,
+ ae_loss_type='exp',
+ with_ae_loss=[True, False],
+ push_loss_factor=[0.001, 0.001],
+ pull_loss_factor=[0.001, 0.001],
+ with_heatmaps_loss=[True, True],
+ heatmaps_loss_factor=[1.0, 1.0])),
+ train_cfg=dict(),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True, True],
+ with_ae=[True, False],
+ project2image=False,
+ align_corners=True,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True,
+ use_udp=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40,
+ use_udp=True),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ use_udp=True,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1], use_udp=True),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225])
+ ],
+ use_udp=True),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=16),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w48_coco_512x512.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w48_coco_512x512.py
new file mode 100644
index 0000000000000000000000000000000000000000..031e6fc286923f2c2215ebf8233cbb6217600741
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w48_coco_512x512.py
@@ -0,0 +1,193 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+data_cfg = dict(
+ image_size=512,
+ base_size=256,
+ base_sigma=2,
+ heatmap_size=[128, 256],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=2,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='AEHigherResolutionHead',
+ in_channels=48,
+ num_joints=17,
+ tag_per_joint=True,
+ extra=dict(final_conv_kernel=1, ),
+ num_deconv_layers=1,
+ num_deconv_filters=[48],
+ num_deconv_kernels=[4],
+ num_basic_blocks=4,
+ cat_output=[True],
+ with_ae_loss=[True, False],
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=17,
+ num_stages=2,
+ ae_loss_type='exp',
+ with_ae_loss=[True, False],
+ push_loss_factor=[0.001, 0.001],
+ pull_loss_factor=[0.001, 0.001],
+ with_heatmaps_loss=[True, True],
+ heatmaps_loss_factor=[1.0, 1.0])),
+ train_cfg=dict(),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True, True],
+ with_ae=[True, False],
+ project2image=True,
+ align_corners=False,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1]),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ ]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=16),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w48_coco_512x512_udp.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w48_coco_512x512_udp.py
new file mode 100644
index 0000000000000000000000000000000000000000..ff298aece7fb69b56c4b37c19d17ac412864efc4
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w48_coco_512x512_udp.py
@@ -0,0 +1,197 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+data_cfg = dict(
+ image_size=512,
+ base_size=256,
+ base_sigma=2,
+ heatmap_size=[128, 256],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=2,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='AEHigherResolutionHead',
+ in_channels=48,
+ num_joints=17,
+ tag_per_joint=True,
+ extra=dict(final_conv_kernel=1, ),
+ num_deconv_layers=1,
+ num_deconv_filters=[48],
+ num_deconv_kernels=[4],
+ num_basic_blocks=4,
+ cat_output=[True],
+ with_ae_loss=[True, False],
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=17,
+ num_stages=2,
+ ae_loss_type='exp',
+ with_ae_loss=[True, False],
+ push_loss_factor=[0.001, 0.001],
+ pull_loss_factor=[0.001, 0.001],
+ with_heatmaps_loss=[True, True],
+ heatmaps_loss_factor=[1.0, 1.0])),
+ train_cfg=dict(),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True, True],
+ with_ae=[True, False],
+ project2image=False,
+ align_corners=True,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True,
+ use_udp=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40,
+ use_udp=True),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ use_udp=True,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1], use_udp=True),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225])
+ ],
+ use_udp=True),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=16),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hourglass_ae_coco.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hourglass_ae_coco.md
new file mode 100644
index 0000000000000000000000000000000000000000..b72e57023bf48443b5b0a2f65b9dcca1ef0c541a
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hourglass_ae_coco.md
@@ -0,0 +1,63 @@
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+
+
+Associative Embedding (NIPS'2017)
+ +```bibtex +@inproceedings{newell2017associative, + title={Associative embedding: End-to-end learning for joint detection and grouping}, + author={Newell, Alejandro and Huang, Zhiao and Deng, Jia}, + booktitle={Advances in neural information processing systems}, + pages={2277--2287}, + year={2017} +} +``` + +
+
+
+
+
+HourglassAENet (NIPS'2017)
+ +```bibtex +@inproceedings{newell2017associative, + title={Associative embedding: End-to-end learning for joint detection and grouping}, + author={Newell, Alejandro and Huang, Zhiao and Deng, Jia}, + booktitle={Advances in neural information processing systems}, + pages={2277--2287}, + year={2017} +} +``` + +
+
+
+Results on COCO val2017 without multi-scale test
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :----------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_hourglass_ae](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hourglass_ae_coco_512x512.py) | 512x512 | 0.613 | 0.833 | 0.667 | 0.659 | 0.850 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/hourglass_ae/hourglass_ae_coco_512x512-90af499f_20210920.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/hourglass_ae/hourglass_ae_coco_512x512_20210920.log.json) |
+
+Results on COCO val2017 with multi-scale test. 3 default scales (\[2, 1, 0.5\]) are used
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :----------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_hourglass_ae](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hourglass_ae_coco_512x512.py) | 512x512 | 0.667 | 0.855 | 0.723 | 0.707 | 0.877 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/hourglass_ae/hourglass_ae_coco_512x512-90af499f_20210920.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/hourglass_ae/hourglass_ae_coco_512x512_20210920.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hourglass_ae_coco.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hourglass_ae_coco.yml
new file mode 100644
index 0000000000000000000000000000000000000000..5b7d5e88f952e6f8fa0ea425496e736c47155e19
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hourglass_ae_coco.yml
@@ -0,0 +1,41 @@
+Collections:
+- Name: Associative Embedding
+ Paper:
+ Title: 'Associative embedding: End-to-end learning for joint detection and grouping'
+ URL: https://arxiv.org/abs/1611.05424
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/associative_embedding.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hourglass_ae_coco_512x512.py
+ In Collection: Associative Embedding
+ Metadata:
+ Architecture: &id001
+ - Associative Embedding
+ - HourglassAENet
+ Training Data: COCO
+ Name: associative_embedding_hourglass_ae_coco_512x512
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.613
+ AP@0.5: 0.833
+ AP@0.75: 0.667
+ AR: 0.659
+ AR@0.5: 0.85
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/hourglass_ae/hourglass_ae_coco_512x512-90af499f_20210920.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hourglass_ae_coco_512x512.py
+ In Collection: Associative Embedding
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: associative_embedding_hourglass_ae_coco_512x512
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.667
+ AP@0.5: 0.855
+ AP@0.75: 0.723
+ AR: 0.707
+ AR@0.5: 0.877
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/hourglass_ae/hourglass_ae_coco_512x512-90af499f_20210920.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hourglass_ae_coco_512x512.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hourglass_ae_coco_512x512.py
new file mode 100644
index 0000000000000000000000000000000000000000..351308a2dfdb28a694b91fa1100fd71690331b90
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hourglass_ae_coco_512x512.py
@@ -0,0 +1,167 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+data_cfg = dict(
+ image_size=512,
+ base_size=256,
+ base_sigma=2,
+ heatmap_size=[128],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=1,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained=None,
+ backbone=dict(
+ type='HourglassAENet',
+ num_stacks=4,
+ out_channels=34,
+ ),
+ keypoint_head=dict(
+ type='AEMultiStageHead',
+ in_channels=34,
+ out_channels=34,
+ num_stages=4,
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=0),
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=17,
+ num_stages=4,
+ ae_loss_type='exp',
+ with_heatmaps_loss=[True, True, True, True],
+ with_ae_loss=[True, True, True, True],
+ push_loss_factor=[0.001, 0.001, 0.001, 0.001],
+ pull_loss_factor=[0.001, 0.001, 0.001, 0.001],
+ heatmaps_loss_factor=[1.0, 1.0, 1.0, 1.0])),
+ train_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ img_size=data_cfg['image_size']),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True, True, True, True],
+ with_ae=[True, True, True, True],
+ select_output_index=[3],
+ project2image=True,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='MultitaskGatherTarget',
+ pipeline_list=[
+ [dict(type='BottomUpGenerateTarget', sigma=2, max_num_people=30)],
+ ],
+ pipeline_indices=[0] * 4,
+ keys=['targets', 'masks', 'joints']),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1]),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ ]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=6),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_coco.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_coco.md
new file mode 100644
index 0000000000000000000000000000000000000000..39f3e3b8e80ee070d0881e16058b93e6dcdb5576
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_coco.md
@@ -0,0 +1,65 @@
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+
+
+Associative Embedding (NIPS'2017)
+ +```bibtex +@inproceedings{newell2017associative, + title={Associative embedding: End-to-end learning for joint detection and grouping}, + author={Newell, Alejandro and Huang, Zhiao and Deng, Jia}, + booktitle={Advances in neural information processing systems}, + pages={2277--2287}, + year={2017} +} +``` + +
+
+
+
+
+HRNet (CVPR'2019)
+ +```bibtex +@inproceedings{sun2019deep, + title={Deep high-resolution representation learning for human pose estimation}, + author={Sun, Ke and Xiao, Bin and Liu, Dong and Wang, Jingdong}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={5693--5703}, + year={2019} +} +``` + +
+
+
+Results on COCO val2017 without multi-scale test
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :----------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [HRNet-w32](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w32_coco_512x512.py) | 512x512 | 0.654 | 0.863 | 0.720 | 0.710 | 0.892 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/hrnet_w32_coco_512x512-bcb8c247_20200816.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/hrnet_w32_coco_512x512_20200816.log.json) |
+| [HRNet-w48](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w48_coco_512x512.py) | 512x512 | 0.665 | 0.860 | 0.727 | 0.716 | 0.889 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/hrnet_w48_coco_512x512-cf72fcdf_20200816.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/hrnet_w48_coco_512x512_20200816.log.json) |
+
+Results on COCO val2017 with multi-scale test. 3 default scales (\[2, 1, 0.5\]) are used
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :----------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [HRNet-w32](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w32_coco_512x512.py) | 512x512 | 0.698 | 0.877 | 0.760 | 0.748 | 0.907 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/hrnet_w32_coco_512x512-bcb8c247_20200816.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/hrnet_w32_coco_512x512_20200816.log.json) |
+| [HRNet-w48](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w48_coco_512x512.py) | 512x512 | 0.712 | 0.880 | 0.771 | 0.757 | 0.909 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/hrnet_w48_coco_512x512-cf72fcdf_20200816.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/hrnet_w48_coco_512x512_20200816.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_coco.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_coco.yml
new file mode 100644
index 0000000000000000000000000000000000000000..2838b4a70bc3556ea971aa2f37bcf54ef1310009
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_coco.yml
@@ -0,0 +1,73 @@
+Collections:
+- Name: HRNet
+ Paper:
+ Title: Deep high-resolution representation learning for human pose estimation
+ URL: http://openaccess.thecvf.com/content_CVPR_2019/html/Sun_Deep_High-Resolution_Representation_Learning_for_Human_Pose_Estimation_CVPR_2019_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/hrnet.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w32_coco_512x512.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: &id001
+ - Associative Embedding
+ - HRNet
+ Training Data: COCO
+ Name: associative_embedding_hrnet_w32_coco_512x512
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.654
+ AP@0.5: 0.863
+ AP@0.75: 0.72
+ AR: 0.71
+ AR@0.5: 0.892
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/hrnet_w32_coco_512x512-bcb8c247_20200816.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w48_coco_512x512.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: associative_embedding_hrnet_w48_coco_512x512
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.665
+ AP@0.5: 0.86
+ AP@0.75: 0.727
+ AR: 0.716
+ AR@0.5: 0.889
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/hrnet_w48_coco_512x512-cf72fcdf_20200816.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w32_coco_512x512.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: associative_embedding_hrnet_w32_coco_512x512
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.698
+ AP@0.5: 0.877
+ AP@0.75: 0.76
+ AR: 0.748
+ AR@0.5: 0.907
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/hrnet_w32_coco_512x512-bcb8c247_20200816.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w48_coco_512x512.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: associative_embedding_hrnet_w48_coco_512x512
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.712
+ AP@0.5: 0.88
+ AP@0.75: 0.771
+ AR: 0.757
+ AR@0.5: 0.909
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/hrnet_w48_coco_512x512-cf72fcdf_20200816.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_udp_coco.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_udp_coco.md
new file mode 100644
index 0000000000000000000000000000000000000000..2388e5670e5577715799b85e98d02513518d6611
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_udp_coco.md
@@ -0,0 +1,75 @@
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+
+
+Associative Embedding (NIPS'2017)
+ +```bibtex +@inproceedings{newell2017associative, + title={Associative embedding: End-to-end learning for joint detection and grouping}, + author={Newell, Alejandro and Huang, Zhiao and Deng, Jia}, + booktitle={Advances in neural information processing systems}, + pages={2277--2287}, + year={2017} +} +``` + +
+
+
+
+
+HRNet (CVPR'2019)
+ +```bibtex +@inproceedings{sun2019deep, + title={Deep high-resolution representation learning for human pose estimation}, + author={Sun, Ke and Xiao, Bin and Liu, Dong and Wang, Jingdong}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={5693--5703}, + year={2019} +} +``` + +
+
+
+
+
+UDP (CVPR'2020)
+ +```bibtex +@InProceedings{Huang_2020_CVPR, + author = {Huang, Junjie and Zhu, Zheng and Guo, Feng and Huang, Guan}, + title = {The Devil Is in the Details: Delving Into Unbiased Data Processing for Human Pose Estimation}, + booktitle = {The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, + month = {June}, + year = {2020} +} +``` + +
+
+
+Results on COCO val2017 without multi-scale test
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :----------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [HRNet-w32_udp](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w32_coco_512x512_udp.py) | 512x512 | 0.671 | 0.863 | 0.729 | 0.717 | 0.889 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/hrnet_w32_coco_512x512_udp-91663bf9_20210220.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/hrnet_w32_coco_512x512_udp_20210220.log.json) |
+| [HRNet-w48_udp](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w48_coco_512x512_udp.py) | 512x512 | 0.681 | 0.872 | 0.741 | 0.725 | 0.892 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/hrnet_w48_coco_512x512_udp-de08fd8c_20210222.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/hrnet_w48_coco_512x512_udp_20210222.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_udp_coco.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_udp_coco.yml
new file mode 100644
index 0000000000000000000000000000000000000000..adc8d8dbc5f3ce13709935fe5412f611bf908f0c
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_udp_coco.yml
@@ -0,0 +1,43 @@
+Collections:
+- Name: UDP
+ Paper:
+ Title: 'The Devil Is in the Details: Delving Into Unbiased Data Processing for
+ Human Pose Estimation'
+ URL: http://openaccess.thecvf.com/content_CVPR_2020/html/Huang_The_Devil_Is_in_the_Details_Delving_Into_Unbiased_Data_CVPR_2020_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/techniques/udp.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w32_coco_512x512_udp.py
+ In Collection: UDP
+ Metadata:
+ Architecture: &id001
+ - Associative Embedding
+ - HRNet
+ - UDP
+ Training Data: COCO
+ Name: associative_embedding_hrnet_w32_coco_512x512_udp
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.671
+ AP@0.5: 0.863
+ AP@0.75: 0.729
+ AR: 0.717
+ AR@0.5: 0.889
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/hrnet_w32_coco_512x512_udp-91663bf9_20210220.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w48_coco_512x512_udp.py
+ In Collection: UDP
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: associative_embedding_hrnet_w48_coco_512x512_udp
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.681
+ AP@0.5: 0.872
+ AP@0.75: 0.741
+ AR: 0.725
+ AR@0.5: 0.892
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/hrnet_w48_coco_512x512_udp-de08fd8c_20210222.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w32_coco_512x512.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w32_coco_512x512.py
new file mode 100644
index 0000000000000000000000000000000000000000..11c63d587178fbbbf8b6825c54c55cdb9f884ff6
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w32_coco_512x512.py
@@ -0,0 +1,189 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+data_cfg = dict(
+ image_size=512,
+ base_size=256,
+ base_sigma=2,
+ heatmap_size=[128],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=1,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='AESimpleHead',
+ in_channels=32,
+ num_joints=17,
+ num_deconv_layers=0,
+ tag_per_joint=True,
+ with_ae_loss=[True],
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=17,
+ num_stages=1,
+ ae_loss_type='exp',
+ with_ae_loss=[True],
+ push_loss_factor=[0.001],
+ pull_loss_factor=[0.001],
+ with_heatmaps_loss=[True],
+ heatmaps_loss_factor=[1.0])),
+ train_cfg=dict(),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True],
+ with_ae=[True],
+ project2image=True,
+ align_corners=False,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1]),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ ]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=24),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w32_coco_512x512_udp.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w32_coco_512x512_udp.py
new file mode 100644
index 0000000000000000000000000000000000000000..bb0ef809615b236645139e09cb28cffac35d2360
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w32_coco_512x512_udp.py
@@ -0,0 +1,193 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+data_cfg = dict(
+ image_size=512,
+ base_size=256,
+ base_sigma=2,
+ heatmap_size=[128],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=1,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='AESimpleHead',
+ in_channels=32,
+ num_joints=17,
+ num_deconv_layers=0,
+ tag_per_joint=True,
+ with_ae_loss=[True],
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=17,
+ num_stages=1,
+ ae_loss_type='exp',
+ with_ae_loss=[True],
+ push_loss_factor=[0.001],
+ pull_loss_factor=[0.001],
+ with_heatmaps_loss=[True],
+ heatmaps_loss_factor=[1.0])),
+ train_cfg=dict(),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True],
+ with_ae=[True],
+ project2image=False,
+ align_corners=True,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True,
+ use_udp=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40,
+ use_udp=True),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ use_udp=True,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1], use_udp=True),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225])
+ ],
+ use_udp=True),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=24),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w32_coco_640x640.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w32_coco_640x640.py
new file mode 100644
index 0000000000000000000000000000000000000000..67629a1fd2014724e76a2802f04fee0c9cfc09a2
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w32_coco_640x640.py
@@ -0,0 +1,189 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+data_cfg = dict(
+ image_size=640,
+ base_size=320,
+ base_sigma=2,
+ heatmap_size=[160],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=1,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='AESimpleHead',
+ in_channels=32,
+ num_joints=17,
+ num_deconv_layers=0,
+ tag_per_joint=True,
+ with_ae_loss=[True],
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=17,
+ num_stages=1,
+ ae_loss_type='exp',
+ with_ae_loss=[True],
+ push_loss_factor=[0.001],
+ pull_loss_factor=[0.001],
+ with_heatmaps_loss=[True],
+ heatmaps_loss_factor=[1.0])),
+ train_cfg=dict(),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True],
+ with_ae=[True],
+ project2image=True,
+ align_corners=False,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1]),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ ]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=16),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w32_coco_640x640_udp.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w32_coco_640x640_udp.py
new file mode 100644
index 0000000000000000000000000000000000000000..44c2cecddcbb5d295009d64b2e3e5f17fc4d8cd3
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w32_coco_640x640_udp.py
@@ -0,0 +1,193 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+data_cfg = dict(
+ image_size=640,
+ base_size=320,
+ base_sigma=2,
+ heatmap_size=[160],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=1,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='AESimpleHead',
+ in_channels=32,
+ num_joints=17,
+ num_deconv_layers=0,
+ tag_per_joint=True,
+ with_ae_loss=[True],
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=17,
+ num_stages=1,
+ ae_loss_type='exp',
+ with_ae_loss=[True],
+ push_loss_factor=[0.001],
+ pull_loss_factor=[0.001],
+ with_heatmaps_loss=[True],
+ heatmaps_loss_factor=[1.0])),
+ train_cfg=dict(),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True],
+ with_ae=[True],
+ project2image=False,
+ align_corners=True,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True,
+ use_udp=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40,
+ use_udp=True),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ use_udp=True,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1], use_udp=True),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225])
+ ],
+ use_udp=True),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=16),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w48_coco_512x512.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w48_coco_512x512.py
new file mode 100644
index 0000000000000000000000000000000000000000..c385bb4f066c8ee5f0795bcb04db5c6722bcb10d
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w48_coco_512x512.py
@@ -0,0 +1,189 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+data_cfg = dict(
+ image_size=512,
+ base_size=256,
+ base_sigma=2,
+ heatmap_size=[128],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=1,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='AESimpleHead',
+ in_channels=48,
+ num_joints=17,
+ num_deconv_layers=0,
+ tag_per_joint=True,
+ with_ae_loss=[True],
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=17,
+ num_stages=1,
+ ae_loss_type='exp',
+ with_ae_loss=[True],
+ push_loss_factor=[0.001],
+ pull_loss_factor=[0.001],
+ with_heatmaps_loss=[True],
+ heatmaps_loss_factor=[1.0])),
+ train_cfg=dict(),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True],
+ with_ae=[True],
+ project2image=True,
+ align_corners=False,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1]),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ ]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=16),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w48_coco_512x512_udp.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w48_coco_512x512_udp.py
new file mode 100644
index 0000000000000000000000000000000000000000..b86aba82760e4174397c8af5997aa4a9062e7190
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w48_coco_512x512_udp.py
@@ -0,0 +1,193 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+data_cfg = dict(
+ image_size=512,
+ base_size=256,
+ base_sigma=2,
+ heatmap_size=[128],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=1,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='AESimpleHead',
+ in_channels=48,
+ num_joints=17,
+ num_deconv_layers=0,
+ tag_per_joint=True,
+ with_ae_loss=[True],
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=17,
+ num_stages=1,
+ ae_loss_type='exp',
+ with_ae_loss=[True],
+ push_loss_factor=[0.001],
+ pull_loss_factor=[0.001],
+ with_heatmaps_loss=[True],
+ heatmaps_loss_factor=[1.0])),
+ train_cfg=dict(),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True],
+ with_ae=[True],
+ project2image=False,
+ align_corners=True,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True,
+ use_udp=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40,
+ use_udp=True),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ use_udp=True,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1], use_udp=True),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225])
+ ],
+ use_udp=True),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=16),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w48_coco_640x640.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w48_coco_640x640.py
new file mode 100644
index 0000000000000000000000000000000000000000..711506240b798b549eb005a4debd333e2b61f43d
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w48_coco_640x640.py
@@ -0,0 +1,189 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+data_cfg = dict(
+ image_size=640,
+ base_size=320,
+ base_sigma=2,
+ heatmap_size=[160],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=1,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='AESimpleHead',
+ in_channels=48,
+ num_joints=17,
+ num_deconv_layers=0,
+ tag_per_joint=True,
+ with_ae_loss=[True],
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=17,
+ num_stages=1,
+ ae_loss_type='exp',
+ with_ae_loss=[True],
+ push_loss_factor=[0.001],
+ pull_loss_factor=[0.001],
+ with_heatmaps_loss=[True],
+ heatmaps_loss_factor=[1.0])),
+ train_cfg=dict(),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True],
+ with_ae=[True],
+ project2image=True,
+ align_corners=False,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1]),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ ]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=8),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w48_coco_640x640_udp.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w48_coco_640x640_udp.py
new file mode 100644
index 0000000000000000000000000000000000000000..e8ca32df54c8454e3640518d580dea87586ae663
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w48_coco_640x640_udp.py
@@ -0,0 +1,193 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+data_cfg = dict(
+ image_size=640,
+ base_size=320,
+ base_sigma=2,
+ heatmap_size=[160],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=1,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='AESimpleHead',
+ in_channels=48,
+ num_joints=17,
+ num_deconv_layers=0,
+ tag_per_joint=True,
+ with_ae_loss=[True],
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=17,
+ num_stages=1,
+ ae_loss_type='exp',
+ with_ae_loss=[True],
+ push_loss_factor=[0.001],
+ pull_loss_factor=[0.001],
+ with_heatmaps_loss=[True],
+ heatmaps_loss_factor=[1.0])),
+ train_cfg=dict(),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True],
+ with_ae=[True],
+ project2image=False,
+ align_corners=True,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True,
+ use_udp=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40,
+ use_udp=True),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ use_udp=True,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1], use_udp=True),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225])
+ ],
+ use_udp=True),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=8),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/mobilenetv2_coco.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/mobilenetv2_coco.md
new file mode 100644
index 0000000000000000000000000000000000000000..a9b222551d153f3734074a1b5c4d34d570381e9a
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/mobilenetv2_coco.md
@@ -0,0 +1,63 @@
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+
+
+Associative Embedding (NIPS'2017)
+ +```bibtex +@inproceedings{newell2017associative, + title={Associative embedding: End-to-end learning for joint detection and grouping}, + author={Newell, Alejandro and Huang, Zhiao and Deng, Jia}, + booktitle={Advances in neural information processing systems}, + pages={2277--2287}, + year={2017} +} +``` + +
+
+
+
+
+MobilenetV2 (CVPR'2018)
+ +```bibtex +@inproceedings{sandler2018mobilenetv2, + title={Mobilenetv2: Inverted residuals and linear bottlenecks}, + author={Sandler, Mark and Howard, Andrew and Zhu, Menglong and Zhmoginov, Andrey and Chen, Liang-Chieh}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={4510--4520}, + year={2018} +} +``` + +
+
+
+Results on COCO val2017 without multi-scale test
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :----------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_mobilenetv2](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/mobilenetv2_coco_512x512.py) | 512x512 | 0.380 | 0.671 | 0.368 | 0.473 | 0.741 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/mobilenetv2_coco_512x512-4d96e309_20200816.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/mobilenetv2_coco_512x512_20200816.log.json) |
+
+Results on COCO val2017 with multi-scale test. 3 default scales (\[2, 1, 0.5\]) are used
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :----------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_mobilenetv2](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/mobilenetv2_coco_512x512.py) | 512x512 | 0.442 | 0.696 | 0.422 | 0.517 | 0.766 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/mobilenetv2_coco_512x512-4d96e309_20200816.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/mobilenetv2_coco_512x512_20200816.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/mobilenetv2_coco.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/mobilenetv2_coco.yml
new file mode 100644
index 0000000000000000000000000000000000000000..95538eba854d71b46feb38e0db2d6069719f2947
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/mobilenetv2_coco.yml
@@ -0,0 +1,41 @@
+Collections:
+- Name: MobilenetV2
+ Paper:
+ Title: 'Mobilenetv2: Inverted residuals and linear bottlenecks'
+ URL: http://openaccess.thecvf.com/content_cvpr_2018/html/Sandler_MobileNetV2_Inverted_Residuals_CVPR_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/mobilenetv2.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/mobilenetv2_coco_512x512.py
+ In Collection: MobilenetV2
+ Metadata:
+ Architecture: &id001
+ - Associative Embedding
+ - MobilenetV2
+ Training Data: COCO
+ Name: associative_embedding_mobilenetv2_coco_512x512
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.38
+ AP@0.5: 0.671
+ AP@0.75: 0.368
+ AR: 0.473
+ AR@0.5: 0.741
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/mobilenetv2_coco_512x512-4d96e309_20200816.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/mobilenetv2_coco_512x512.py
+ In Collection: MobilenetV2
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: associative_embedding_mobilenetv2_coco_512x512
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.442
+ AP@0.5: 0.696
+ AP@0.75: 0.422
+ AR: 0.517
+ AR@0.5: 0.766
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/mobilenetv2_coco_512x512-4d96e309_20200816.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/mobilenetv2_coco_512x512.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/mobilenetv2_coco_512x512.py
new file mode 100644
index 0000000000000000000000000000000000000000..6b0d818707fa875cdc028e45233ad1b0684c0fdf
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/mobilenetv2_coco_512x512.py
@@ -0,0 +1,158 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+data_cfg = dict(
+ image_size=512,
+ base_size=256,
+ base_sigma=2,
+ heatmap_size=[128],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=1,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='mmcls://mobilenet_v2',
+ backbone=dict(type='MobileNetV2', widen_factor=1., out_indices=(7, )),
+ keypoint_head=dict(
+ type='AESimpleHead',
+ in_channels=1280,
+ num_joints=17,
+ tag_per_joint=True,
+ with_ae_loss=[True],
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=17,
+ num_stages=1,
+ ae_loss_type='exp',
+ with_ae_loss=[True],
+ push_loss_factor=[0.001],
+ pull_loss_factor=[0.001],
+ with_heatmaps_loss=[True],
+ heatmaps_loss_factor=[1.0])),
+ train_cfg=dict(),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True],
+ with_ae=[True],
+ project2image=True,
+ align_corners=False,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1]),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ ]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ workers_per_gpu=1,
+ train_dataloader=dict(samples_per_gpu=24),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res101_coco_512x512.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res101_coco_512x512.py
new file mode 100644
index 0000000000000000000000000000000000000000..d68700d118145cb881ecafce156a790ec45f6b0c
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res101_coco_512x512.py
@@ -0,0 +1,158 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+data_cfg = dict(
+ image_size=512,
+ base_size=256,
+ base_sigma=2,
+ heatmap_size=[128],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=1,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='torchvision://resnet101',
+ backbone=dict(type='ResNet', depth=101),
+ keypoint_head=dict(
+ type='AESimpleHead',
+ in_channels=2048,
+ num_joints=17,
+ tag_per_joint=True,
+ with_ae_loss=[True],
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=17,
+ num_stages=1,
+ ae_loss_type='exp',
+ with_ae_loss=[True],
+ push_loss_factor=[0.001],
+ pull_loss_factor=[0.001],
+ with_heatmaps_loss=[True],
+ heatmaps_loss_factor=[1.0])),
+ train_cfg=dict(),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True],
+ with_ae=[True],
+ project2image=True,
+ align_corners=False,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1]),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ ]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=16),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res101_coco_640x640.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res101_coco_640x640.py
new file mode 100644
index 0000000000000000000000000000000000000000..ff87ac8a51ddab62b7afd4fb0599da5db7ea1d70
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res101_coco_640x640.py
@@ -0,0 +1,158 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+data_cfg = dict(
+ image_size=640,
+ base_size=320,
+ base_sigma=2,
+ heatmap_size=[160],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=1,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='torchvision://resnet101',
+ backbone=dict(type='ResNet', depth=101),
+ keypoint_head=dict(
+ type='AESimpleHead',
+ in_channels=2048,
+ num_joints=17,
+ tag_per_joint=True,
+ with_ae_loss=[True],
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=17,
+ num_stages=1,
+ ae_loss_type='exp',
+ with_ae_loss=[True],
+ push_loss_factor=[0.001],
+ pull_loss_factor=[0.001],
+ with_heatmaps_loss=[True],
+ heatmaps_loss_factor=[1.0])),
+ train_cfg=dict(),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True],
+ with_ae=[True],
+ project2image=True,
+ align_corners=False,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1]),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ ]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=16),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res152_coco_512x512.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res152_coco_512x512.py
new file mode 100644
index 0000000000000000000000000000000000000000..b9ed79cc2eb52303b2a1a6e0d440ee519dcc9ebe
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res152_coco_512x512.py
@@ -0,0 +1,158 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+data_cfg = dict(
+ image_size=512,
+ base_size=256,
+ base_sigma=2,
+ heatmap_size=[128],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=1,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='torchvision://resnet152',
+ backbone=dict(type='ResNet', depth=152),
+ keypoint_head=dict(
+ type='AESimpleHead',
+ in_channels=2048,
+ num_joints=17,
+ tag_per_joint=True,
+ with_ae_loss=[True],
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=17,
+ num_stages=1,
+ ae_loss_type='exp',
+ with_ae_loss=[True],
+ push_loss_factor=[0.001],
+ pull_loss_factor=[0.001],
+ with_heatmaps_loss=[True],
+ heatmaps_loss_factor=[1.0])),
+ train_cfg=dict(),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True],
+ with_ae=[True],
+ project2image=True,
+ align_corners=False,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1]),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ ]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=16),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res152_coco_640x640.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res152_coco_640x640.py
new file mode 100644
index 0000000000000000000000000000000000000000..e473a83298e05719be75679320cf8299fd3d48cd
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res152_coco_640x640.py
@@ -0,0 +1,158 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+data_cfg = dict(
+ image_size=640,
+ base_size=320,
+ base_sigma=2,
+ heatmap_size=[160],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=1,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='torchvision://resnet152',
+ backbone=dict(type='ResNet', depth=152),
+ keypoint_head=dict(
+ type='AESimpleHead',
+ in_channels=2048,
+ num_joints=17,
+ tag_per_joint=True,
+ with_ae_loss=[True],
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=17,
+ num_stages=1,
+ ae_loss_type='exp',
+ with_ae_loss=[True],
+ push_loss_factor=[0.001],
+ pull_loss_factor=[0.001],
+ with_heatmaps_loss=[True],
+ heatmaps_loss_factor=[1.0])),
+ train_cfg=dict(),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True],
+ with_ae=[True],
+ project2image=True,
+ align_corners=False,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1]),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ ]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=16),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res50_coco_512x512.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res50_coco_512x512.py
new file mode 100644
index 0000000000000000000000000000000000000000..5022546c74185b8b60e075b32b289c1870f3e111
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res50_coco_512x512.py
@@ -0,0 +1,159 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+data_cfg = dict(
+ image_size=512,
+ base_size=256,
+ base_sigma=2,
+ heatmap_size=[128],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=1,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='AESimpleHead',
+ in_channels=2048,
+ num_joints=17,
+ tag_per_joint=True,
+ with_ae_loss=[True],
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=17,
+ num_stages=1,
+ ae_loss_type='exp',
+ with_ae_loss=[True],
+ push_loss_factor=[0.001],
+ pull_loss_factor=[0.001],
+ with_heatmaps_loss=[True],
+ heatmaps_loss_factor=[1.0],
+ )),
+ train_cfg=dict(),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True],
+ with_ae=[True],
+ project2image=True,
+ align_corners=False,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1]),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ ]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ workers_per_gpu=1,
+ train_dataloader=dict(samples_per_gpu=24),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res50_coco_640x640.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res50_coco_640x640.py
new file mode 100644
index 0000000000000000000000000000000000000000..8643525dd322aeed0b75dce3b17a706a9c9ff90b
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res50_coco_640x640.py
@@ -0,0 +1,158 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+data_cfg = dict(
+ image_size=640,
+ base_size=320,
+ base_sigma=2,
+ heatmap_size=[160],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=1,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='AESimpleHead',
+ in_channels=2048,
+ num_joints=17,
+ tag_per_joint=True,
+ with_ae_loss=[True],
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=17,
+ num_stages=1,
+ ae_loss_type='exp',
+ with_ae_loss=[True],
+ push_loss_factor=[0.001],
+ pull_loss_factor=[0.001],
+ with_heatmaps_loss=[True],
+ heatmaps_loss_factor=[1.0])),
+ train_cfg=dict(),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True],
+ with_ae=[True],
+ project2image=True,
+ align_corners=False,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1]),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ ]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ workers_per_gpu=1,
+ train_dataloader=dict(samples_per_gpu=24),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/resnet_coco.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/resnet_coco.md
new file mode 100644
index 0000000000000000000000000000000000000000..04b8505ddf2a7833ff8851f26ce660d752bd752c
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/resnet_coco.md
@@ -0,0 +1,69 @@
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+
+
+Associative Embedding (NIPS'2017)
+ +```bibtex +@inproceedings{newell2017associative, + title={Associative embedding: End-to-end learning for joint detection and grouping}, + author={Newell, Alejandro and Huang, Zhiao and Deng, Jia}, + booktitle={Advances in neural information processing systems}, + pages={2277--2287}, + year={2017} +} +``` + +
+
+
+
+
+ResNet (CVPR'2016)
+ +```bibtex +@inproceedings{he2016deep, + title={Deep residual learning for image recognition}, + author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={770--778}, + year={2016} +} +``` + +
+
+
+Results on COCO val2017 without multi-scale test
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :----------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_resnet_50](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res50_coco_512x512.py) | 512x512 | 0.466 | 0.742 | 0.479 | 0.552 | 0.797 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/res50_coco_512x512-5521bead_20200816.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/res50_coco_512x512_20200816.log.json) |
+| [pose_resnet_50](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res50_coco_640x640.py) | 640x640 | 0.479 | 0.757 | 0.487 | 0.566 | 0.810 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/res50_coco_640x640-2046f9cb_20200822.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/res50_coco_640x640_20200822.log.json) |
+| [pose_resnet_101](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res101_coco_512x512.py) | 512x512 | 0.554 | 0.807 | 0.599 | 0.622 | 0.841 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/res101_coco_512x512-e0c95157_20200816.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/res101_coco_512x512_20200816.log.json) |
+| [pose_resnet_152](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res152_coco_512x512.py) | 512x512 | 0.595 | 0.829 | 0.648 | 0.651 | 0.856 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/res152_coco_512x512-364eb38d_20200822.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/res152_coco_512x512_20200822.log.json) |
+
+Results on COCO val2017 with multi-scale test. 3 default scales (\[2, 1, 0.5\]) are used
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :----------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_resnet_50](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res50_coco_512x512.py) | 512x512 | 0.503 | 0.765 | 0.521 | 0.591 | 0.821 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/res50_coco_512x512-5521bead_20200816.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/res50_coco_512x512_20200816.log.json) |
+| [pose_resnet_50](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res50_coco_640x640.py) | 640x640 | 0.525 | 0.784 | 0.542 | 0.610 | 0.832 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/res50_coco_640x640-2046f9cb_20200822.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/res50_coco_640x640_20200822.log.json) |
+| [pose_resnet_101](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res101_coco_512x512.py) | 512x512 | 0.603 | 0.831 | 0.641 | 0.668 | 0.870 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/res101_coco_512x512-e0c95157_20200816.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/res101_coco_512x512_20200816.log.json) |
+| [pose_resnet_152](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res152_coco_512x512.py) | 512x512 | 0.660 | 0.860 | 0.713 | 0.709 | 0.889 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/res152_coco_512x512-364eb38d_20200822.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/res152_coco_512x512_20200822.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/resnet_coco.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/resnet_coco.yml
new file mode 100644
index 0000000000000000000000000000000000000000..45c49b8ecb72e9f1172091b8e2a7ddd2720498c5
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/resnet_coco.yml
@@ -0,0 +1,137 @@
+Collections:
+- Name: Associative Embedding
+ Paper:
+ Title: 'Associative embedding: End-to-end learning for joint detection and grouping'
+ URL: https://arxiv.org/abs/1611.05424
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/associative_embedding.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res50_coco_512x512.py
+ In Collection: Associative Embedding
+ Metadata:
+ Architecture: &id001
+ - Associative Embedding
+ - ResNet
+ Training Data: COCO
+ Name: associative_embedding_res50_coco_512x512
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.466
+ AP@0.5: 0.742
+ AP@0.75: 0.479
+ AR: 0.552
+ AR@0.5: 0.797
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/res50_coco_512x512-5521bead_20200816.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res50_coco_640x640.py
+ In Collection: Associative Embedding
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: associative_embedding_res50_coco_640x640
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.479
+ AP@0.5: 0.757
+ AP@0.75: 0.487
+ AR: 0.566
+ AR@0.5: 0.81
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/res50_coco_640x640-2046f9cb_20200822.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res101_coco_512x512.py
+ In Collection: Associative Embedding
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: associative_embedding_res101_coco_512x512
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.554
+ AP@0.5: 0.807
+ AP@0.75: 0.599
+ AR: 0.622
+ AR@0.5: 0.841
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/res101_coco_512x512-e0c95157_20200816.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res152_coco_512x512.py
+ In Collection: Associative Embedding
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: associative_embedding_res152_coco_512x512
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.595
+ AP@0.5: 0.829
+ AP@0.75: 0.648
+ AR: 0.651
+ AR@0.5: 0.856
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/res152_coco_512x512-364eb38d_20200822.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res50_coco_512x512.py
+ In Collection: Associative Embedding
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: associative_embedding_res50_coco_512x512
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.503
+ AP@0.5: 0.765
+ AP@0.75: 0.521
+ AR: 0.591
+ AR@0.5: 0.821
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/res50_coco_512x512-5521bead_20200816.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res50_coco_640x640.py
+ In Collection: Associative Embedding
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: associative_embedding_res50_coco_640x640
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.525
+ AP@0.5: 0.784
+ AP@0.75: 0.542
+ AR: 0.61
+ AR@0.5: 0.832
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/res50_coco_640x640-2046f9cb_20200822.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res101_coco_512x512.py
+ In Collection: Associative Embedding
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: associative_embedding_res101_coco_512x512
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.603
+ AP@0.5: 0.831
+ AP@0.75: 0.641
+ AR: 0.668
+ AR@0.5: 0.87
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/res101_coco_512x512-e0c95157_20200816.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res152_coco_512x512.py
+ In Collection: Associative Embedding
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: associative_embedding_res152_coco_512x512
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.66
+ AP@0.5: 0.86
+ AP@0.75: 0.713
+ AR: 0.709
+ AR@0.5: 0.889
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/res152_coco_512x512-364eb38d_20200822.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/higherhrnet_crowdpose.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/higherhrnet_crowdpose.md
new file mode 100644
index 0000000000000000000000000000000000000000..44451f645a291469141a97aacf41a3fac6926964
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/higherhrnet_crowdpose.md
@@ -0,0 +1,61 @@
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+
+
+Associative Embedding (NIPS'2017)
+ +```bibtex +@inproceedings{newell2017associative, + title={Associative embedding: End-to-end learning for joint detection and grouping}, + author={Newell, Alejandro and Huang, Zhiao and Deng, Jia}, + booktitle={Advances in neural information processing systems}, + pages={2277--2287}, + year={2017} +} +``` + +
+
+
+
+
+HigherHRNet (CVPR'2020)
+ +```bibtex +@inproceedings{cheng2020higherhrnet, + title={HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation}, + author={Cheng, Bowen and Xiao, Bin and Wang, Jingdong and Shi, Honghui and Huang, Thomas S and Zhang, Lei}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + pages={5386--5395}, + year={2020} +} +``` + +
+
+
+Results on CrowdPose test without multi-scale test
+
+| Arch | Input Size | AP | AP50 | AP75 | AP (E) | AP (M) | AP (H) | ckpt | log |
+| :----------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: | :------: |
+| [HigherHRNet-w32](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/higherhrnet_w32_crowdpose_512x512.py) | 512x512 | 0.655 | 0.859 | 0.705 | 0.728 | 0.660 | 0.577 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet32_crowdpose_512x512-1aa4a132_20201017.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet32_crowdpose_512x512_20201017.log.json) |
+
+Results on CrowdPose test with multi-scale test. 2 scales (\[2, 1\]) are used
+
+| Arch | Input Size | AP | AP50 | AP75 | AP (E) | AP (M) | AP (H) | ckpt | log |
+| :----------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: | :------: |
+| [HigherHRNet-w32](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/higherhrnet_w32_crowdpose_512x512.py) | 512x512 | 0.661 | 0.864 | 0.710 | 0.742 | 0.670 | 0.566 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet32_crowdpose_512x512-1aa4a132_20201017.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet32_crowdpose_512x512_20201017.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/higherhrnet_crowdpose.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/higherhrnet_crowdpose.yml
new file mode 100644
index 0000000000000000000000000000000000000000..b8a2980665d032846c32796196cc22a8be26f29e
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/higherhrnet_crowdpose.yml
@@ -0,0 +1,44 @@
+Collections:
+- Name: HigherHRNet
+ Paper:
+ Title: 'HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose
+ Estimation'
+ URL: http://openaccess.thecvf.com/content_CVPR_2020/html/Cheng_HigherHRNet_Scale-Aware_Representation_Learning_for_Bottom-Up_Human_Pose_Estimation_CVPR_2020_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/higherhrnet.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/higherhrnet_w32_crowdpose_512x512.py
+ In Collection: HigherHRNet
+ Metadata:
+ Architecture: &id001
+ - Associative Embedding
+ - HigherHRNet
+ Training Data: CrowdPose
+ Name: associative_embedding_higherhrnet_w32_crowdpose_512x512
+ Results:
+ - Dataset: CrowdPose
+ Metrics:
+ AP: 0.655
+ AP (E): 0.728
+ AP (H): 0.577
+ AP (M): 0.66
+ AP@0.5: 0.859
+ AP@0.75: 0.705
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet32_crowdpose_512x512-1aa4a132_20201017.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/higherhrnet_w32_crowdpose_512x512.py
+ In Collection: HigherHRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: CrowdPose
+ Name: associative_embedding_higherhrnet_w32_crowdpose_512x512
+ Results:
+ - Dataset: CrowdPose
+ Metrics:
+ AP: 0.661
+ AP (E): 0.742
+ AP (H): 0.566
+ AP (M): 0.67
+ AP@0.5: 0.864
+ AP@0.75: 0.71
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet32_crowdpose_512x512-1aa4a132_20201017.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/higherhrnet_w32_crowdpose_512x512.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/higherhrnet_w32_crowdpose_512x512.py
new file mode 100644
index 0000000000000000000000000000000000000000..18739b8b79109cd9db6f69c23423c6884892e93e
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/higherhrnet_w32_crowdpose_512x512.py
@@ -0,0 +1,192 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/crowdpose.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+data_cfg = dict(
+ image_size=512,
+ base_size=256,
+ base_sigma=2,
+ heatmap_size=[128, 256],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=2,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='AEHigherResolutionHead',
+ in_channels=32,
+ num_joints=14,
+ tag_per_joint=True,
+ extra=dict(final_conv_kernel=1, ),
+ num_deconv_layers=1,
+ num_deconv_filters=[32],
+ num_deconv_kernels=[4],
+ num_basic_blocks=4,
+ cat_output=[True],
+ with_ae_loss=[True, False],
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=14,
+ num_stages=2,
+ ae_loss_type='exp',
+ with_ae_loss=[True, False],
+ push_loss_factor=[0.001, 0.001],
+ pull_loss_factor=[0.001, 0.001],
+ with_heatmaps_loss=[True, True],
+ heatmaps_loss_factor=[1.0, 1.0])),
+ train_cfg=dict(),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True, True],
+ with_ae=[True, False],
+ project2image=True,
+ align_corners=False,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1]),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ ]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/crowdpose'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=24),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_trainval.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/higherhrnet_w32_crowdpose_512x512_udp.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/higherhrnet_w32_crowdpose_512x512_udp.py
new file mode 100644
index 0000000000000000000000000000000000000000..a853c3f57feaa0454226eb6c0ad5c05a381e2f73
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/higherhrnet_w32_crowdpose_512x512_udp.py
@@ -0,0 +1,196 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/crowdpose.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+data_cfg = dict(
+ image_size=512,
+ base_size=256,
+ base_sigma=2,
+ heatmap_size=[128, 256],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=2,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='AEHigherResolutionHead',
+ in_channels=32,
+ num_joints=14,
+ tag_per_joint=True,
+ extra=dict(final_conv_kernel=1, ),
+ num_deconv_layers=1,
+ num_deconv_filters=[32],
+ num_deconv_kernels=[4],
+ num_basic_blocks=4,
+ cat_output=[True],
+ with_ae_loss=[True, False],
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=14,
+ num_stages=2,
+ ae_loss_type='exp',
+ with_ae_loss=[True, False],
+ push_loss_factor=[0.001, 0.001],
+ pull_loss_factor=[0.001, 0.001],
+ with_heatmaps_loss=[True, True],
+ heatmaps_loss_factor=[1.0, 1.0])),
+ train_cfg=dict(),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True, True],
+ with_ae=[True, False],
+ project2image=False,
+ align_corners=True,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True,
+ use_udp=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40,
+ use_udp=True),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ use_udp=True,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1], use_udp=True),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225])
+ ],
+ use_udp=True),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/crowdpose'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=24),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_trainval.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/higherhrnet_w32_crowdpose_640x640.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/higherhrnet_w32_crowdpose_640x640.py
new file mode 100644
index 0000000000000000000000000000000000000000..7ce567b9b27ca8144ea6a31fb95e55c278db59d3
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/higherhrnet_w32_crowdpose_640x640.py
@@ -0,0 +1,192 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/crowdpose.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+data_cfg = dict(
+ image_size=640,
+ base_size=320,
+ base_sigma=2,
+ heatmap_size=[160, 320],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=2,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='AEHigherResolutionHead',
+ in_channels=32,
+ num_joints=14,
+ tag_per_joint=True,
+ extra=dict(final_conv_kernel=1, ),
+ num_deconv_layers=1,
+ num_deconv_filters=[32],
+ num_deconv_kernels=[4],
+ num_basic_blocks=4,
+ cat_output=[True],
+ with_ae_loss=[True, False],
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=14,
+ num_stages=2,
+ ae_loss_type='exp',
+ with_ae_loss=[True, False],
+ push_loss_factor=[0.001, 0.001],
+ pull_loss_factor=[0.001, 0.001],
+ with_heatmaps_loss=[True, True],
+ heatmaps_loss_factor=[1.0, 1.0])),
+ train_cfg=dict(),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True, True],
+ with_ae=[True, False],
+ project2image=True,
+ align_corners=False,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1]),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ ]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/crowdpose'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=16),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_trainval.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/higherhrnet_w32_crowdpose_640x640_udp.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/higherhrnet_w32_crowdpose_640x640_udp.py
new file mode 100644
index 0000000000000000000000000000000000000000..b9bf0e33420bf7479e94ea30af847c1d84cefd02
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/higherhrnet_w32_crowdpose_640x640_udp.py
@@ -0,0 +1,196 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/crowdpose.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+data_cfg = dict(
+ image_size=640,
+ base_size=320,
+ base_sigma=2,
+ heatmap_size=[160, 320],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=2,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='AEHigherResolutionHead',
+ in_channels=32,
+ num_joints=14,
+ tag_per_joint=True,
+ extra=dict(final_conv_kernel=1, ),
+ num_deconv_layers=1,
+ num_deconv_filters=[32],
+ num_deconv_kernels=[4],
+ num_basic_blocks=4,
+ cat_output=[True],
+ with_ae_loss=[True, False],
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=14,
+ num_stages=2,
+ ae_loss_type='exp',
+ with_ae_loss=[True, False],
+ push_loss_factor=[0.001, 0.001],
+ pull_loss_factor=[0.001, 0.001],
+ with_heatmaps_loss=[True, True],
+ heatmaps_loss_factor=[1.0, 1.0])),
+ train_cfg=dict(),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True, True],
+ with_ae=[True, False],
+ project2image=False,
+ align_corners=True,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True,
+ use_udp=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40,
+ use_udp=True),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ use_udp=True,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1], use_udp=True),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ ],
+ use_udp=True),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/crowdpose'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=16),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_trainval.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/higherhrnet_w48_crowdpose_512x512.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/higherhrnet_w48_crowdpose_512x512.py
new file mode 100644
index 0000000000000000000000000000000000000000..f82792de8cf49e926e4360a4641f3346f886c4e5
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/higherhrnet_w48_crowdpose_512x512.py
@@ -0,0 +1,192 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/crowdpose.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+data_cfg = dict(
+ image_size=512,
+ base_size=256,
+ base_sigma=2,
+ heatmap_size=[128, 256],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=2,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='AEHigherResolutionHead',
+ in_channels=48,
+ num_joints=14,
+ tag_per_joint=True,
+ extra=dict(final_conv_kernel=1, ),
+ num_deconv_layers=1,
+ num_deconv_filters=[48],
+ num_deconv_kernels=[4],
+ num_basic_blocks=4,
+ cat_output=[True],
+ with_ae_loss=[True, False],
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=14,
+ num_stages=2,
+ ae_loss_type='exp',
+ with_ae_loss=[True, False],
+ push_loss_factor=[0.001, 0.001],
+ pull_loss_factor=[0.001, 0.001],
+ with_heatmaps_loss=[True, True],
+ heatmaps_loss_factor=[1.0, 1.0])),
+ train_cfg=dict(),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True, True],
+ with_ae=[True, False],
+ project2image=True,
+ align_corners=False,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1]),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ ]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/crowdpose'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=16),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_trainval.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/higherhrnet_w48_crowdpose_512x512_udp.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/higherhrnet_w48_crowdpose_512x512_udp.py
new file mode 100644
index 0000000000000000000000000000000000000000..f7f2c89c8abe50aefb9f09ce1b84c84e60526c98
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/higherhrnet_w48_crowdpose_512x512_udp.py
@@ -0,0 +1,196 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/crowdpose.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+data_cfg = dict(
+ image_size=512,
+ base_size=256,
+ base_sigma=2,
+ heatmap_size=[128, 256],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=2,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='AEHigherResolutionHead',
+ in_channels=48,
+ num_joints=14,
+ tag_per_joint=True,
+ extra=dict(final_conv_kernel=1, ),
+ num_deconv_layers=1,
+ num_deconv_filters=[48],
+ num_deconv_kernels=[4],
+ num_basic_blocks=4,
+ cat_output=[True],
+ with_ae_loss=[True, False],
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=14,
+ num_stages=2,
+ ae_loss_type='exp',
+ with_ae_loss=[True, False],
+ push_loss_factor=[0.001, 0.001],
+ pull_loss_factor=[0.001, 0.001],
+ with_heatmaps_loss=[True, True],
+ heatmaps_loss_factor=[1.0, 1.0])),
+ train_cfg=dict(),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True, True],
+ with_ae=[True, False],
+ project2image=False,
+ align_corners=True,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True,
+ use_udp=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40,
+ use_udp=True),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ use_udp=True,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1], use_udp=True),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225])
+ ],
+ use_udp=True),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/crowdpose'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=16),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_trainval.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/mobilenetv2_crowdpose_512x512.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/mobilenetv2_crowdpose_512x512.py
new file mode 100644
index 0000000000000000000000000000000000000000..1e1cb8b735fcc88f7305ba32b42c0e1fa55dfb29
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/mobilenetv2_crowdpose_512x512.py
@@ -0,0 +1,157 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/crowdpose.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+data_cfg = dict(
+ image_size=512,
+ base_size=256,
+ base_sigma=2,
+ heatmap_size=[128],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=1,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='mmcls://mobilenet_v2',
+ backbone=dict(type='MobileNetV2', widen_factor=1., out_indices=(7, )),
+ keypoint_head=dict(
+ type='AESimpleHead',
+ in_channels=1280,
+ num_joints=14,
+ tag_per_joint=True,
+ with_ae_loss=[True],
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=14,
+ num_stages=1,
+ ae_loss_type='exp',
+ with_ae_loss=[True],
+ push_loss_factor=[0.001],
+ pull_loss_factor=[0.001],
+ with_heatmaps_loss=[True],
+ heatmaps_loss_factor=[1.0])),
+ train_cfg=dict(),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True],
+ with_ae=[True],
+ project2image=True,
+ align_corners=False,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1]),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ ]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/crowdpose'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=24),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_trainval.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/res101_crowdpose_512x512.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/res101_crowdpose_512x512.py
new file mode 100644
index 0000000000000000000000000000000000000000..5e3ca353bf26ca718a9af0085706e88b14c3ee87
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/res101_crowdpose_512x512.py
@@ -0,0 +1,157 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/crowdpose.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+data_cfg = dict(
+ image_size=512,
+ base_size=256,
+ base_sigma=2,
+ heatmap_size=[128],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=1,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='torchvision://resnet101',
+ backbone=dict(type='ResNet', depth=101),
+ keypoint_head=dict(
+ type='AESimpleHead',
+ in_channels=2048,
+ num_joints=14,
+ tag_per_joint=True,
+ with_ae_loss=[True],
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=14,
+ num_stages=1,
+ ae_loss_type='exp',
+ with_ae_loss=[True],
+ push_loss_factor=[0.001],
+ pull_loss_factor=[0.001],
+ with_heatmaps_loss=[True],
+ heatmaps_loss_factor=[1.0])),
+ train_cfg=dict(),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True],
+ with_ae=[True],
+ project2image=True,
+ align_corners=False,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1]),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ ]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/crowdpose'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=16),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_trainval.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/res152_crowdpose_512x512.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/res152_crowdpose_512x512.py
new file mode 100644
index 0000000000000000000000000000000000000000..c31129e69e5b1cbc17016bd8dd0524ae8c15e2d1
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/res152_crowdpose_512x512.py
@@ -0,0 +1,157 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/crowdpose.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+data_cfg = dict(
+ image_size=512,
+ base_size=256,
+ base_sigma=2,
+ heatmap_size=[128],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=1,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='torchvision://resnet152',
+ backbone=dict(type='ResNet', depth=152),
+ keypoint_head=dict(
+ type='AESimpleHead',
+ in_channels=2048,
+ num_joints=14,
+ tag_per_joint=True,
+ with_ae_loss=[True],
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=14,
+ num_stages=1,
+ ae_loss_type='exp',
+ with_ae_loss=[True],
+ push_loss_factor=[0.001],
+ pull_loss_factor=[0.001],
+ with_heatmaps_loss=[True],
+ heatmaps_loss_factor=[1.0])),
+ train_cfg=dict(),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True],
+ with_ae=[True],
+ project2image=True,
+ align_corners=False,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1]),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ ]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/crowdpose'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=16),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_trainval.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/res50_crowdpose_512x512.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/res50_crowdpose_512x512.py
new file mode 100644
index 0000000000000000000000000000000000000000..350f7fda2664f6b468fc6ea5857ade39ce97fd2f
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/res50_crowdpose_512x512.py
@@ -0,0 +1,158 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/crowdpose.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+data_cfg = dict(
+ image_size=512,
+ base_size=256,
+ base_sigma=2,
+ heatmap_size=[128],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=1,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='AESimpleHead',
+ in_channels=2048,
+ num_joints=14,
+ tag_per_joint=True,
+ with_ae_loss=[True],
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=14,
+ num_stages=1,
+ ae_loss_type='exp',
+ with_ae_loss=[True],
+ push_loss_factor=[0.001],
+ pull_loss_factor=[0.001],
+ with_heatmaps_loss=[True],
+ heatmaps_loss_factor=[1.0],
+ )),
+ train_cfg=dict(),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True],
+ with_ae=[True],
+ project2image=True,
+ align_corners=False,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1]),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ ]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/crowdpose'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=24),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_trainval.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/mhp/hrnet_mhp.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/mhp/hrnet_mhp.md
new file mode 100644
index 0000000000000000000000000000000000000000..dc15eb19bddc839c8f780c0d867f6d5611dea796
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/mhp/hrnet_mhp.md
@@ -0,0 +1,62 @@
+
+
+CrowdPose (CVPR'2019)
+ +```bibtex +@article{li2018crowdpose, + title={CrowdPose: Efficient Crowded Scenes Pose Estimation and A New Benchmark}, + author={Li, Jiefeng and Wang, Can and Zhu, Hao and Mao, Yihuan and Fang, Hao-Shu and Lu, Cewu}, + journal={arXiv preprint arXiv:1812.00324}, + year={2018} +} +``` + +
+
+
+
+
+Associative Embedding (NIPS'2017)
+ +```bibtex +@inproceedings{newell2017associative, + title={Associative embedding: End-to-end learning for joint detection and grouping}, + author={Newell, Alejandro and Huang, Zhiao and Deng, Jia}, + booktitle={Advances in neural information processing systems}, + pages={2277--2287}, + year={2017} +} +``` + +
+
+
+
+
+HRNet (CVPR'2019)
+ +```bibtex +@inproceedings{sun2019deep, + title={Deep high-resolution representation learning for human pose estimation}, + author={Sun, Ke and Xiao, Bin and Liu, Dong and Wang, Jingdong}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={5693--5703}, + year={2019} +} +``` + +
+
+
+Results on MHP v2.0 validation set without multi-scale test
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :----------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [HRNet-w48](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w48_mhp_512x512.py) | 512x512 | 0.583 | 0.895 | 0.666 | 0.656 | 0.931 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/hrnet_w48_mhp_512x512-85a6ab6f_20201229.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/hrnet_w48_mhp_512x512_20201229.log.json) |
+
+Results on MHP v2.0 validation set with multi-scale test. 3 default scales (\[2, 1, 0.5\]) are used
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :----------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [HRNet-w48](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w48_mhp_512x512.py) | 512x512 | 0.592 | 0.898 | 0.673 | 0.664 | 0.932 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/hrnet_w48_mhp_512x512-85a6ab6f_20201229.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/hrnet_w48_mhp_512x512_20201229.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/mhp/hrnet_mhp.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/mhp/hrnet_mhp.yml
new file mode 100644
index 0000000000000000000000000000000000000000..8eda9252d16dc61e309f5d9e97c950468f51effd
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/mhp/hrnet_mhp.yml
@@ -0,0 +1,41 @@
+Collections:
+- Name: HRNet
+ Paper:
+ Title: Deep high-resolution representation learning for human pose estimation
+ URL: http://openaccess.thecvf.com/content_CVPR_2019/html/Sun_Deep_High-Resolution_Representation_Learning_for_Human_Pose_Estimation_CVPR_2019_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/hrnet.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w48_mhp_512x512.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: &id001
+ - Associative Embedding
+ - HRNet
+ Training Data: MHP
+ Name: associative_embedding_hrnet_w48_mhp_512x512
+ Results:
+ - Dataset: MHP
+ Metrics:
+ AP: 0.583
+ AP@0.5: 0.895
+ AP@0.75: 0.666
+ AR: 0.656
+ AR@0.5: 0.931
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/hrnet_w48_mhp_512x512-85a6ab6f_20201229.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w48_mhp_512x512.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: MHP
+ Name: associative_embedding_hrnet_w48_mhp_512x512
+ Results:
+ - Dataset: MHP
+ Metrics:
+ AP: 0.592
+ AP@0.5: 0.898
+ AP@0.75: 0.673
+ AR: 0.664
+ AR@0.5: 0.932
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/hrnet_w48_mhp_512x512-85a6ab6f_20201229.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/mhp/hrnet_w48_mhp_512x512.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/mhp/hrnet_w48_mhp_512x512.py
new file mode 100644
index 0000000000000000000000000000000000000000..2c5b4dfc9fd28783ef2c7cd1abd4035939e73721
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/associative_embedding/mhp/hrnet_w48_mhp_512x512.py
@@ -0,0 +1,187 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mhp.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.005,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[400, 550])
+total_epochs = 600
+channel_cfg = dict(
+ dataset_joints=16,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15])
+
+data_cfg = dict(
+ image_size=512,
+ base_size=256,
+ base_sigma=2,
+ heatmap_size=[128],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=1,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='AESimpleHead',
+ in_channels=48,
+ num_joints=16,
+ num_deconv_layers=0,
+ tag_per_joint=True,
+ with_ae_loss=[True],
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=16,
+ num_stages=1,
+ ae_loss_type='exp',
+ with_ae_loss=[True],
+ push_loss_factor=[0.01],
+ pull_loss_factor=[0.01],
+ with_heatmaps_loss=[True],
+ heatmaps_loss_factor=[1.0])),
+ train_cfg=dict(),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True],
+ with_ae=[True],
+ project2image=True,
+ align_corners=False,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1]),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ ]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mhp'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=16),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpMhpDataset',
+ ann_file=f'{data_root}/annotations/mhp_train.json',
+ img_prefix=f'{data_root}/train/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpMhpDataset',
+ ann_file=f'{data_root}/annotations/mhp_val.json',
+ img_prefix=f'{data_root}/val/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpMhpDataset',
+ ann_file=f'{data_root}/annotations/mhp_val.json',
+ img_prefix=f'{data_root}/val/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/deeppose/README.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/deeppose/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..47346a72e44ee340239c18a7ba7c7dd9aba91bb2
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/deeppose/README.md
@@ -0,0 +1,24 @@
+# DeepPose: Human pose estimation via deep neural networks
+
+## Introduction
+
+
+
+MHP (ACM MM'2018)
+ +```bibtex +@inproceedings{zhao2018understanding, + title={Understanding humans in crowded scenes: Deep nested adversarial learning and a new benchmark for multi-human parsing}, + author={Zhao, Jian and Li, Jianshu and Cheng, Yu and Sim, Terence and Yan, Shuicheng and Feng, Jiashi}, + booktitle={Proceedings of the 26th ACM international conference on Multimedia}, + pages={792--800}, + year={2018} +} +``` + +
+
+
+DeepPose first proposes using deep neural networks (DNNs) to tackle the problem of human pose estimation.
+It follows the top-down paradigm, that first detects human bounding boxes and then estimates poses.
+It learns to directly regress the human body keypoint coordinates.
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/deeppose/coco/res101_coco_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/deeppose/coco/res101_coco_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..b46b8f50144d4805f224efad9c4b90510ff567ee
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/deeppose/coco/res101_coco_256x192.py
@@ -0,0 +1,132 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet101',
+ backbone=dict(type='ResNet', depth=101, num_stages=4, out_indices=(3, )),
+ neck=dict(type='GlobalAveragePooling'),
+ keypoint_head=dict(
+ type='DeepposeRegressionHead',
+ in_channels=2048,
+ num_joints=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='SmoothL1Loss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(flip_test=True))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTargetRegression'),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/deeppose/coco/res152_coco_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/deeppose/coco/res152_coco_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..580b9b0ae67894c9dede5513f6137a69f4ecb513
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/deeppose/coco/res152_coco_256x192.py
@@ -0,0 +1,132 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet152',
+ backbone=dict(type='ResNet', depth=152, num_stages=4, out_indices=(3, )),
+ neck=dict(type='GlobalAveragePooling'),
+ keypoint_head=dict(
+ type='DeepposeRegressionHead',
+ in_channels=2048,
+ num_joints=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='SmoothL1Loss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(flip_test=True))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTargetRegression'),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/deeppose/coco/res50_coco_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/deeppose/coco/res50_coco_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..c978eeb3b15b24c62ee9c81d6142c4e6fd69d9be
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/deeppose/coco/res50_coco_256x192.py
@@ -0,0 +1,132 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50, num_stages=4, out_indices=(3, )),
+ neck=dict(type='GlobalAveragePooling'),
+ keypoint_head=dict(
+ type='DeepposeRegressionHead',
+ in_channels=2048,
+ num_joints=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='SmoothL1Loss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(flip_test=True))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTargetRegression'),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/deeppose/coco/resnet_coco.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/deeppose/coco/resnet_coco.md
new file mode 100644
index 0000000000000000000000000000000000000000..5aaea7d1e132884c118ce907f93e7199ab7200b1
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/deeppose/coco/resnet_coco.md
@@ -0,0 +1,59 @@
+
+
+DeepPose (CVPR'2014)
+ +```bibtex +@inproceedings{toshev2014deeppose, + title={Deeppose: Human pose estimation via deep neural networks}, + author={Toshev, Alexander and Szegedy, Christian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={1653--1660}, + year={2014} +} +``` + +
+
+
+
+
+DeepPose (CVPR'2014)
+ +```bibtex +@inproceedings{toshev2014deeppose, + title={Deeppose: Human pose estimation via deep neural networks}, + author={Toshev, Alexander and Szegedy, Christian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={1653--1660}, + year={2014} +} +``` + +
+
+
+
+
+ResNet (CVPR'2016)
+ +```bibtex +@inproceedings{he2016deep, + title={Deep residual learning for image recognition}, + author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={770--778}, + year={2016} +} +``` + +
+
+
+Results on COCO val2017 with detector having human AP of 56.4 on COCO val2017 dataset
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :-------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [deeppose_resnet_50](/configs/body/2d_kpt_sview_rgb_img/deeppose/coco/res50_coco_256x192.py) | 256x192 | 0.526 | 0.816 | 0.586 | 0.638 | 0.887 | [ckpt](https://download.openmmlab.com/mmpose/top_down/deeppose/deeppose_res50_coco_256x192-f6de6c0e_20210205.pth) | [log](https://download.openmmlab.com/mmpose/top_down/deeppose/deeppose_res50_coco_256x192_20210205.log.json) |
+| [deeppose_resnet_101](/configs/body/2d_kpt_sview_rgb_img/deeppose/coco/res101_coco_256x192.py) | 256x192 | 0.560 | 0.832 | 0.628 | 0.668 | 0.900 | [ckpt](https://download.openmmlab.com/mmpose/top_down/deeppose/deeppose_res101_coco_256x192-2f247111_20210205.pth) | [log](https://download.openmmlab.com/mmpose/top_down/deeppose/deeppose_res101_coco_256x192_20210205.log.json) |
+| [deeppose_resnet_152](/configs/body/2d_kpt_sview_rgb_img/deeppose/coco/res152_coco_256x192.py) | 256x192 | 0.583 | 0.843 | 0.659 | 0.686 | 0.907 | [ckpt](https://download.openmmlab.com/mmpose/top_down/deeppose/deeppose_res152_coco_256x192-7df89a88_20210205.pth) | [log](https://download.openmmlab.com/mmpose/top_down/deeppose/deeppose_res152_coco_256x192_20210205.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/deeppose/coco/resnet_coco.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/deeppose/coco/resnet_coco.yml
new file mode 100644
index 0000000000000000000000000000000000000000..21cc7ee3b52efb92207838eda66d8a9b78714bbb
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/deeppose/coco/resnet_coco.yml
@@ -0,0 +1,57 @@
+Collections:
+- Name: ResNet
+ Paper:
+ Title: Deep residual learning for image recognition
+ URL: http://openaccess.thecvf.com/content_cvpr_2016/html/He_Deep_Residual_Learning_CVPR_2016_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/resnet.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/deeppose/coco/res50_coco_256x192.py
+ In Collection: ResNet
+ Metadata:
+ Architecture: &id001
+ - DeepPose
+ - ResNet
+ Training Data: COCO
+ Name: deeppose_res50_coco_256x192
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.526
+ AP@0.5: 0.816
+ AP@0.75: 0.586
+ AR: 0.638
+ AR@0.5: 0.887
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/deeppose/deeppose_res50_coco_256x192-f6de6c0e_20210205.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/deeppose/coco/res101_coco_256x192.py
+ In Collection: ResNet
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: deeppose_res101_coco_256x192
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.56
+ AP@0.5: 0.832
+ AP@0.75: 0.628
+ AR: 0.668
+ AR@0.5: 0.9
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/deeppose/deeppose_res101_coco_256x192-2f247111_20210205.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/deeppose/coco/res152_coco_256x192.py
+ In Collection: ResNet
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: deeppose_res152_coco_256x192
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.583
+ AP@0.5: 0.843
+ AP@0.75: 0.659
+ AR: 0.686
+ AR@0.5: 0.907
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/deeppose/deeppose_res152_coco_256x192-7df89a88_20210205.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/deeppose/mpii/res101_mpii_256x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/deeppose/mpii/res101_mpii_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..948975600e9d4d2c824295d85f3f7d0a07d3461e
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/deeppose/mpii/res101_mpii_256x256.py
@@ -0,0 +1,120 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii.py'
+]
+evaluation = dict(interval=10, metric='PCKh', save_best='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=list(range(16)),
+ inference_channel=list(range(16)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet101',
+ backbone=dict(type='ResNet', depth=101, num_stages=4, out_indices=(3, )),
+ neck=dict(type='GlobalAveragePooling'),
+ keypoint_head=dict(
+ type='DeepposeRegressionHead',
+ in_channels=2048,
+ num_joints=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='SmoothL1Loss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(flip_test=True))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTargetRegression'),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/deeppose/mpii/res152_mpii_256x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/deeppose/mpii/res152_mpii_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..8e8ce0ea91172e4b8f9a059b6eb6451af2bca852
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/deeppose/mpii/res152_mpii_256x256.py
@@ -0,0 +1,120 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii.py'
+]
+evaluation = dict(interval=10, metric='PCKh', save_best='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=list(range(16)),
+ inference_channel=list(range(16)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet152',
+ backbone=dict(type='ResNet', depth=152, num_stages=4, out_indices=(3, )),
+ neck=dict(type='GlobalAveragePooling'),
+ keypoint_head=dict(
+ type='DeepposeRegressionHead',
+ in_channels=2048,
+ num_joints=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='SmoothL1Loss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(flip_test=True))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTargetRegression'),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/deeppose/mpii/res50_mpii_256x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/deeppose/mpii/res50_mpii_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..314a21aea21092ac43695448506636840ce45f66
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/deeppose/mpii/res50_mpii_256x256.py
@@ -0,0 +1,120 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii.py'
+]
+evaluation = dict(interval=10, metric='PCKh', save_best='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=list(range(16)),
+ inference_channel=list(range(16)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50, num_stages=4, out_indices=(3, )),
+ neck=dict(type='GlobalAveragePooling'),
+ keypoint_head=dict(
+ type='DeepposeRegressionHead',
+ in_channels=2048,
+ num_joints=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='SmoothL1Loss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(flip_test=True))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTargetRegression'),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/deeppose/mpii/resnet_mpii.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/deeppose/mpii/resnet_mpii.md
new file mode 100644
index 0000000000000000000000000000000000000000..b6eb8e5859d0f783579f7feb9f45af4da89192b1
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/deeppose/mpii/resnet_mpii.md
@@ -0,0 +1,58 @@
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+
+
+DeepPose (CVPR'2014)
+ +```bibtex +@inproceedings{toshev2014deeppose, + title={Deeppose: Human pose estimation via deep neural networks}, + author={Toshev, Alexander and Szegedy, Christian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={1653--1660}, + year={2014} +} +``` + +
+
+
+
+
+ResNet (CVPR'2016)
+ +```bibtex +@inproceedings{he2016deep, + title={Deep residual learning for image recognition}, + author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={770--778}, + year={2016} +} +``` + +
+
+
+Results on MPII val set
+
+| Arch | Input Size | Mean | Mean@0.1 | ckpt | log |
+| :--- | :--------: | :------: | :------: |:------: |:------: |
+| [deeppose_resnet_50](/configs/body/2d_kpt_sview_rgb_img/deeppose/mpii/res50_mpii_256x256.py) | 256x256 | 0.825 | 0.174 | [ckpt](https://download.openmmlab.com/mmpose/top_down/deeppose/deeppose_res50_mpii_256x256-c63cd0b6_20210203.pth) | [log](https://download.openmmlab.com/mmpose/top_down/deeppose/deeppose_res50_mpii_256x256_20210203.log.json) |
+| [deeppose_resnet_101](/configs/body/2d_kpt_sview_rgb_img/deeppose/mpii/res101_mpii_256x256.py) | 256x256 | 0.841 | 0.193 | [ckpt](https://download.openmmlab.com/mmpose/top_down/deeppose/deeppose_res101_mpii_256x256-87516a90_20210205.pth) | [log](https://download.openmmlab.com/mmpose/top_down/deeppose/deeppose_res101_mpii_256x256_20210205.log.json) |
+| [deeppose_resnet_152](/configs/body/2d_kpt_sview_rgb_img/deeppose/mpii/res152_mpii_256x256.py) | 256x256 | 0.850 | 0.198 | [ckpt](https://download.openmmlab.com/mmpose/top_down/deeppose/deeppose_res152_mpii_256x256-15f5e6f9_20210205.pth) | [log](https://download.openmmlab.com/mmpose/top_down/deeppose/deeppose_res152_mpii_256x256_20210205.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/deeppose/mpii/resnet_mpii.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/deeppose/mpii/resnet_mpii.yml
new file mode 100644
index 0000000000000000000000000000000000000000..1685083653287bbee7fbf04474334a4acfb8d0c3
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/deeppose/mpii/resnet_mpii.yml
@@ -0,0 +1,48 @@
+Collections:
+- Name: ResNet
+ Paper:
+ Title: Deep residual learning for image recognition
+ URL: http://openaccess.thecvf.com/content_cvpr_2016/html/He_Deep_Residual_Learning_CVPR_2016_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/resnet.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/deeppose/mpii/res50_mpii_256x256.py
+ In Collection: ResNet
+ Metadata:
+ Architecture: &id001
+ - DeepPose
+ - ResNet
+ Training Data: MPII
+ Name: deeppose_res50_mpii_256x256
+ Results:
+ - Dataset: MPII
+ Metrics:
+ Mean: 0.825
+ Mean@0.1: 0.174
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/deeppose/deeppose_res50_mpii_256x256-c63cd0b6_20210203.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/deeppose/mpii/res101_mpii_256x256.py
+ In Collection: ResNet
+ Metadata:
+ Architecture: *id001
+ Training Data: MPII
+ Name: deeppose_res101_mpii_256x256
+ Results:
+ - Dataset: MPII
+ Metrics:
+ Mean: 0.841
+ Mean@0.1: 0.193
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/deeppose/deeppose_res101_mpii_256x256-87516a90_20210205.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/deeppose/mpii/res152_mpii_256x256.py
+ In Collection: ResNet
+ Metadata:
+ Architecture: *id001
+ Training Data: MPII
+ Name: deeppose_res152_mpii_256x256
+ Results:
+ - Dataset: MPII
+ Metrics:
+ Mean: 0.85
+ Mean@0.1: 0.198
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/deeppose/deeppose_res152_mpii_256x256-15f5e6f9_20210205.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/README.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..c6fef1486076e21762b23ea55f5d856fc36ce68b
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/README.md
@@ -0,0 +1,10 @@
+# Top-down heatmap-based pose estimation
+
+Top-down methods divide the task into two stages: human detection and pose estimation.
+
+They perform human detection first, followed by single-person pose estimation given human bounding boxes.
+Instead of estimating keypoint coordinates directly, the pose estimator will produce heatmaps which represent the
+likelihood of being a keypoint.
+
+Various neural network models have been proposed for better performance.
+The popular ones include stacked hourglass networks, and HRNet.
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_base_aic_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_base_aic_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..58f4567b60438e407baa26cb71502a32360b23d2
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_base_aic_256x192.py
@@ -0,0 +1,151 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/aic.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='ViT',
+ img_size=(256, 192),
+ patch_size=16,
+ embed_dim=768,
+ depth=12,
+ num_heads=12,
+ ratio=1,
+ use_checkpoint=False,
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_path_rate=0.3,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=768,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/aic'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_train.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_train_20170902/'
+ 'keypoint_train_images_20170902/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_val.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_validation_20170911/'
+ 'keypoint_validation_images_20170911/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_val.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_validation_20170911/'
+ 'keypoint_validation_images_20170911/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}))
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_huge_aic_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_huge_aic_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..277123bf26fd137af306114989127622ab2870e2
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_huge_aic_256x192.py
@@ -0,0 +1,151 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/aic.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='ViT',
+ img_size=(256, 192),
+ patch_size=16,
+ embed_dim=1280,
+ depth=32,
+ num_heads=16,
+ ratio=1,
+ use_checkpoint=False,
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_path_rate=0.55,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1280,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/aic'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_train.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_train_20170902/'
+ 'keypoint_train_images_20170902/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_val.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_validation_20170911/'
+ 'keypoint_validation_images_20170911/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_val.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_validation_20170911/'
+ 'keypoint_validation_images_20170911/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}))
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_large_aic_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_large_aic_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..2c64241adf07acab214545f8ccb5ad59772dd60b
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_large_aic_256x192.py
@@ -0,0 +1,151 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/aic.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='ViT',
+ img_size=(256, 192),
+ patch_size=16,
+ embed_dim=1024,
+ depth=24,
+ num_heads=16,
+ ratio=1,
+ use_checkpoint=False,
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_path_rate=0.55,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1024,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/aic'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_train.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_train_20170902/'
+ 'keypoint_train_images_20170902/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_val.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_validation_20170911/'
+ 'keypoint_validation_images_20170911/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_val.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_validation_20170911/'
+ 'keypoint_validation_images_20170911/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}))
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_small_aic_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_small_aic_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..af66009deac70a9f01c702516853da9a7fd27546
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_small_aic_256x192.py
@@ -0,0 +1,151 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/aic.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='ViT',
+ img_size=(256, 192),
+ patch_size=16,
+ embed_dim=384,
+ depth=12,
+ num_heads=12,
+ ratio=1,
+ use_checkpoint=False,
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_path_rate=0.3,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=384,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/aic'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_train.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_train_20170902/'
+ 'keypoint_train_images_20170902/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_val.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_validation_20170911/'
+ 'keypoint_validation_images_20170911/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_val.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_validation_20170911/'
+ 'keypoint_validation_images_20170911/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}))
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/hrnet_aic.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/hrnet_aic.md
new file mode 100644
index 0000000000000000000000000000000000000000..5331aba3379f908914ac487c48619d2f8767038e
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/hrnet_aic.md
@@ -0,0 +1,39 @@
+
+
+
+MPII (CVPR'2014)
+ +```bibtex +@inproceedings{andriluka14cvpr, + author = {Mykhaylo Andriluka and Leonid Pishchulin and Peter Gehler and Schiele, Bernt}, + title = {2D Human Pose Estimation: New Benchmark and State of the Art Analysis}, + booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, + year = {2014}, + month = {June} +} +``` + +
+
+
+
+
+HRNet (CVPR'2019)
+ +```bibtex +@inproceedings{sun2019deep, + title={Deep high-resolution representation learning for human pose estimation}, + author={Sun, Ke and Xiao, Bin and Liu, Dong and Wang, Jingdong}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={5693--5703}, + year={2019} +} +``` + +
+
+
+Results on AIC val set with ground-truth bounding boxes
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :-------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_hrnet_w32](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/hrnet_w32_aic_256x192.py) | 256x192 | 0.323 | 0.762 | 0.219 | 0.366 | 0.789 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_aic_256x192-30a4e465_20200826.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_aic_256x192_20200826.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/hrnet_aic.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/hrnet_aic.yml
new file mode 100644
index 0000000000000000000000000000000000000000..d80203665815204aaa190f7789871422f060d031
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/hrnet_aic.yml
@@ -0,0 +1,24 @@
+Collections:
+- Name: HRNet
+ Paper:
+ Title: Deep high-resolution representation learning for human pose estimation
+ URL: http://openaccess.thecvf.com/content_CVPR_2019/html/Sun_Deep_High-Resolution_Representation_Learning_for_Human_Pose_Estimation_CVPR_2019_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/hrnet.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/hrnet_w32_aic_256x192.py
+ In Collection: HRNet
+ Metadata:
+ Architecture:
+ - HRNet
+ Training Data: AI Challenger
+ Name: topdown_heatmap_hrnet_w32_aic_256x192
+ Results:
+ - Dataset: AI Challenger
+ Metrics:
+ AP: 0.323
+ AP@0.5: 0.762
+ AP@0.75: 0.219
+ AR: 0.366
+ AR@0.5: 0.789
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_aic_256x192-30a4e465_20200826.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/hrnet_w32_aic_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/hrnet_w32_aic_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..407782cc1fe99a1b4710300764ea8804fad81ebd
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/hrnet_w32_aic_256x192.py
@@ -0,0 +1,166 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/aic.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/aic'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_train.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_train_20170902/'
+ 'keypoint_train_images_20170902/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_val.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_validation_20170911/'
+ 'keypoint_validation_images_20170911/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_val.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_validation_20170911/'
+ 'keypoint_validation_images_20170911/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}))
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/hrnet_w32_aic_384x288.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/hrnet_w32_aic_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..772e6a23d19fb0ad833a3f8a8670fadd3bbac45b
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/hrnet_w32_aic_384x288.py
@@ -0,0 +1,166 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/aic.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='data/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/aic'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_train.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_train_20170902/'
+ 'keypoint_train_images_20170902/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_val.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_validation_20170911/'
+ 'keypoint_validation_images_20170911/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_val.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_validation_20170911/'
+ 'keypoint_validation_images_20170911/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}))
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/hrnet_w48_aic_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/hrnet_w48_aic_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..62c98ba67ea818b34d0ae7de47bab548aee939dc
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/hrnet_w48_aic_256x192.py
@@ -0,0 +1,166 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/aic.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='data/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/aic'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_train.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_train_20170902/'
+ 'keypoint_train_images_20170902/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_val.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_validation_20170911/'
+ 'keypoint_validation_images_20170911/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_val.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_validation_20170911/'
+ 'keypoint_validation_images_20170911/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}))
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/hrnet_w48_aic_384x288.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/hrnet_w48_aic_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..ef063eb2e817151773546ab39bb24127579fd6e3
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/hrnet_w48_aic_384x288.py
@@ -0,0 +1,167 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/aic.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup=None,
+ # warmup='linear',
+ # warmup_iters=500,
+ # warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='data/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/aic'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_train.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_train_20170902/'
+ 'keypoint_train_images_20170902/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_val.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_validation_20170911/'
+ 'keypoint_validation_images_20170911/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_val.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_validation_20170911/'
+ 'keypoint_validation_images_20170911/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}))
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/res101_aic_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/res101_aic_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..8dd2143d66b8940e09430a10a683190c8674a901
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/res101_aic_256x192.py
@@ -0,0 +1,135 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/aic.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet101',
+ backbone=dict(type='ResNet', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='data/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/aic'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_train.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_train_20170902/'
+ 'keypoint_train_images_20170902/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_val.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_validation_20170911/'
+ 'keypoint_validation_images_20170911/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_val.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_validation_20170911/'
+ 'keypoint_validation_images_20170911/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}))
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/res101_aic_384x288.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/res101_aic_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..0c1b750ab22130bdd42a2486b971b07a1c65cdb1
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/res101_aic_384x288.py
@@ -0,0 +1,135 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/aic.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet101',
+ backbone=dict(type='ResNet', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='data/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/aic'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_train.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_train_20170902/'
+ 'keypoint_train_images_20170902/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_val.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_validation_20170911/'
+ 'keypoint_validation_images_20170911/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_val.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_validation_20170911/'
+ 'keypoint_validation_images_20170911/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}))
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/res152_aic_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/res152_aic_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..9d4b64ddd742d926c8c8f9cbdbf1c3db00e9744c
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/res152_aic_256x192.py
@@ -0,0 +1,135 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/aic.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet152',
+ backbone=dict(type='ResNet', depth=152),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='data/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/aic'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_train.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_train_20170902/'
+ 'keypoint_train_images_20170902/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_val.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_validation_20170911/'
+ 'keypoint_validation_images_20170911/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_val.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_validation_20170911/'
+ 'keypoint_validation_images_20170911/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}))
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/res152_aic_384x288.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/res152_aic_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..b4d2276205c67a48b01eec1be2790b9dc7c8ea35
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/res152_aic_384x288.py
@@ -0,0 +1,135 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/aic.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet152',
+ backbone=dict(type='ResNet', depth=152),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='data/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/aic'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_train.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_train_20170902/'
+ 'keypoint_train_images_20170902/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_val.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_validation_20170911/'
+ 'keypoint_validation_images_20170911/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_val.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_validation_20170911/'
+ 'keypoint_validation_images_20170911/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}))
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/res50_aic_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/res50_aic_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..a937af4e9053c5bd2911a3d560181e9bce151c26
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/res50_aic_256x192.py
@@ -0,0 +1,134 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/aic.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/aic'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_train.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_train_20170902/'
+ 'keypoint_train_images_20170902/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_val.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_validation_20170911/'
+ 'keypoint_validation_images_20170911/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_val.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_validation_20170911/'
+ 'keypoint_validation_images_20170911/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}))
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/res50_aic_384x288.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/res50_aic_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..556cda077a103d7a826a70457d91958c1ddfd80e
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/res50_aic_384x288.py
@@ -0,0 +1,135 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/aic.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='data/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/aic'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_train.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_train_20170902/'
+ 'keypoint_train_images_20170902/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_val.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_validation_20170911/'
+ 'keypoint_validation_images_20170911/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownAicDataset',
+ ann_file=f'{data_root}/annotations/aic_val.json',
+ img_prefix=f'{data_root}/ai_challenger_keypoint_validation_20170911/'
+ 'keypoint_validation_images_20170911/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}))
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/resnet_aic.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/resnet_aic.md
new file mode 100644
index 0000000000000000000000000000000000000000..e733aba36d3905f626febfff9027658d433c50c7
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/resnet_aic.md
@@ -0,0 +1,55 @@
+
+
+AI Challenger (ArXiv'2017)
+ +```bibtex +@article{wu2017ai, + title={Ai challenger: A large-scale dataset for going deeper in image understanding}, + author={Wu, Jiahong and Zheng, He and Zhao, Bo and Li, Yixin and Yan, Baoming and Liang, Rui and Wang, Wenjia and Zhou, Shipei and Lin, Guosen and Fu, Yanwei and others}, + journal={arXiv preprint arXiv:1711.06475}, + year={2017} +} +``` + +
+
+
+
+
+SimpleBaseline2D (ECCV'2018)
+ +```bibtex +@inproceedings{xiao2018simple, + title={Simple baselines for human pose estimation and tracking}, + author={Xiao, Bin and Wu, Haiping and Wei, Yichen}, + booktitle={Proceedings of the European conference on computer vision (ECCV)}, + pages={466--481}, + year={2018} +} +``` + +
+
+
+
+
+ResNet (CVPR'2016)
+ +```bibtex +@inproceedings{he2016deep, + title={Deep residual learning for image recognition}, + author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={770--778}, + year={2016} +} +``` + +
+
+
+Results on AIC val set with ground-truth bounding boxes
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :-------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_resnet_101](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/res101_aic_256x192.py) | 256x192 | 0.294 | 0.736 | 0.174 | 0.337 | 0.763 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res101_aic_256x192-79b35445_20200826.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res101_aic_256x192_20200826.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/resnet_aic.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/resnet_aic.yml
new file mode 100644
index 0000000000000000000000000000000000000000..7fb30979bfcacfbd46f3886aa223510a6eaf7492
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/resnet_aic.yml
@@ -0,0 +1,25 @@
+Collections:
+- Name: SimpleBaseline2D
+ Paper:
+ Title: Simple baselines for human pose estimation and tracking
+ URL: http://openaccess.thecvf.com/content_ECCV_2018/html/Bin_Xiao_Simple_Baselines_for_ECCV_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/simplebaseline2d.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/res101_aic_256x192.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture:
+ - SimpleBaseline2D
+ - ResNet
+ Training Data: AI Challenger
+ Name: topdown_heatmap_res101_aic_256x192
+ Results:
+ - Dataset: AI Challenger
+ Metrics:
+ AP: 0.294
+ AP@0.5: 0.736
+ AP@0.75: 0.174
+ AR: 0.337
+ AR@0.5: 0.763
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res101_aic_256x192-79b35445_20200826.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/2xmspn50_coco_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/2xmspn50_coco_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..8e11fe346b32b552eb95a19b41a3225af7e260ba
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/2xmspn50_coco_256x192.py
@@ -0,0 +1,165 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-3,
+)
+
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(
+ type='MSPN',
+ unit_channels=256,
+ num_stages=2,
+ num_units=4,
+ num_blocks=[3, 4, 6, 3],
+ norm_cfg=dict(type='BN')),
+ keypoint_head=dict(
+ type='TopdownHeatmapMSMUHead',
+ out_shape=(64, 48),
+ unit_channels=256,
+ out_channels=channel_cfg['num_output_channels'],
+ num_stages=2,
+ num_units=4,
+ use_prm=False,
+ norm_cfg=dict(type='BN'),
+ loss_keypoint=([
+ dict(
+ type='JointsMSELoss', use_target_weight=True, loss_weight=0.25)
+ ] * 3 + [
+ dict(
+ type='JointsOHKMMSELoss',
+ use_target_weight=True,
+ loss_weight=1.)
+ ]) * 2),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='megvii',
+ shift_heatmap=False,
+ modulate_kernel=5))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ use_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='TopDownGenerateTarget',
+ kernel=[(15, 15), (11, 11), (9, 9), (7, 7)] + [(11, 11), (9, 9),
+ (7, 7), (5, 5)],
+ encoding='Megvii'),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=[
+ 'img',
+ ],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=4,
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/3xmspn50_coco_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/3xmspn50_coco_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..564a73fb5c16bae1ac7f7f8b61ae4cb4ec286c68
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/3xmspn50_coco_256x192.py
@@ -0,0 +1,165 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-3,
+)
+
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(
+ type='MSPN',
+ unit_channels=256,
+ num_stages=3,
+ num_units=4,
+ num_blocks=[3, 4, 6, 3],
+ norm_cfg=dict(type='BN')),
+ keypoint_head=dict(
+ type='TopdownHeatmapMSMUHead',
+ out_shape=(64, 48),
+ unit_channels=256,
+ out_channels=channel_cfg['num_output_channels'],
+ num_stages=3,
+ num_units=4,
+ use_prm=False,
+ norm_cfg=dict(type='BN'),
+ loss_keypoint=([
+ dict(
+ type='JointsMSELoss', use_target_weight=True, loss_weight=0.25)
+ ] * 3 + [
+ dict(
+ type='JointsOHKMMSELoss',
+ use_target_weight=True,
+ loss_weight=1.)
+ ]) * 3),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='megvii',
+ shift_heatmap=False,
+ modulate_kernel=5))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ use_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='TopDownGenerateTarget',
+ kernel=[(15, 15), (11, 11), (9, 9), (7, 7)] * 2 + [(11, 11), (9, 9),
+ (7, 7), (5, 5)],
+ encoding='Megvii'),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=[
+ 'img',
+ ],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=4,
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/3xrsn50_coco_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/3xrsn50_coco_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..86c1a742a43eea2dbe613b68770e747988d92f96
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/3xrsn50_coco_256x192.py
@@ -0,0 +1,165 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-3,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='RSN',
+ unit_channels=256,
+ num_stages=3,
+ num_units=4,
+ num_blocks=[3, 4, 6, 3],
+ num_steps=4,
+ norm_cfg=dict(type='BN')),
+ keypoint_head=dict(
+ type='TopdownHeatmapMSMUHead',
+ out_shape=(64, 48),
+ unit_channels=256,
+ out_channels=channel_cfg['num_output_channels'],
+ num_stages=3,
+ num_units=4,
+ use_prm=False,
+ norm_cfg=dict(type='BN'),
+ loss_keypoint=([
+ dict(
+ type='JointsMSELoss', use_target_weight=True, loss_weight=0.25)
+ ] * 3 + [
+ dict(
+ type='JointsOHKMMSELoss',
+ use_target_weight=True,
+ loss_weight=1.)
+ ]) * 3),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='megvii',
+ shift_heatmap=False,
+ modulate_kernel=5))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ use_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='TopDownGenerateTarget',
+ kernel=[(15, 15), (11, 11), (9, 9), (7, 7)] * 2 + [(11, 11), (9, 9),
+ (7, 7), (5, 5)],
+ encoding='Megvii'),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=[
+ 'img',
+ ],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=4,
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/4xmspn50_coco_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/4xmspn50_coco_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..0144234cbdf364efe28f65f1218249f156e82d91
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/4xmspn50_coco_256x192.py
@@ -0,0 +1,165 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-3,
+)
+
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(
+ type='MSPN',
+ unit_channels=256,
+ num_stages=4,
+ num_units=4,
+ num_blocks=[3, 4, 6, 3],
+ norm_cfg=dict(type='BN')),
+ keypoint_head=dict(
+ type='TopdownHeatmapMSMUHead',
+ out_shape=(64, 48),
+ unit_channels=256,
+ out_channels=channel_cfg['num_output_channels'],
+ num_stages=4,
+ num_units=4,
+ use_prm=False,
+ norm_cfg=dict(type='BN'),
+ loss_keypoint=([
+ dict(
+ type='JointsMSELoss', use_target_weight=True, loss_weight=0.25)
+ ] * 3 + [
+ dict(
+ type='JointsOHKMMSELoss',
+ use_target_weight=True,
+ loss_weight=1.)
+ ]) * 4),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='megvii',
+ shift_heatmap=False,
+ modulate_kernel=5))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ use_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='TopDownGenerateTarget',
+ kernel=[(15, 15), (11, 11), (9, 9), (7, 7)] * 3 + [(11, 11), (9, 9),
+ (7, 7), (5, 5)],
+ encoding='Megvii'),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=[
+ 'img',
+ ],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=4,
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_base_coco_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_base_coco_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..f639173081be86d3e54ae586c5a7a569779cb8d1
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_base_coco_256x192.py
@@ -0,0 +1,170 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(type='AdamW', lr=5e-4, betas=(0.9, 0.999), weight_decay=0.1,
+ constructor='LayerDecayOptimizerConstructor',
+ paramwise_cfg=dict(
+ num_layers=12,
+ layer_decay_rate=0.75,
+ custom_keys={
+ 'bias': dict(decay_multi=0.),
+ 'pos_embed': dict(decay_mult=0.),
+ 'relative_position_bias_table': dict(decay_mult=0.),
+ 'norm': dict(decay_mult=0.)
+ }
+ )
+ )
+
+optimizer_config = dict(grad_clip=dict(max_norm=1., norm_type=2))
+
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+target_type = 'GaussianHeatmap'
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='ViT',
+ img_size=(256, 192),
+ patch_size=16,
+ embed_dim=768,
+ depth=12,
+ num_heads=12,
+ ratio=1,
+ use_checkpoint=False,
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_path_rate=0.3,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=768,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=False,
+ target_type=target_type,
+ modulate_kernel=11,
+ use_udp=True))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='TopDownGenerateTarget',
+ sigma=2,
+ encoding='UDP',
+ target_type=target_type),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=4,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
+
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_base_simple_coco_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_base_simple_coco_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..d410a1534f35d0bcd1f9d01f408748081576a2b5
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_base_simple_coco_256x192.py
@@ -0,0 +1,171 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(type='AdamW', lr=5e-4, betas=(0.9, 0.999), weight_decay=0.1,
+ constructor='LayerDecayOptimizerConstructor',
+ paramwise_cfg=dict(
+ num_layers=12,
+ layer_decay_rate=0.75,
+ custom_keys={
+ 'bias': dict(decay_multi=0.),
+ 'pos_embed': dict(decay_mult=0.),
+ 'relative_position_bias_table': dict(decay_mult=0.),
+ 'norm': dict(decay_mult=0.)
+ }
+ )
+ )
+
+optimizer_config = dict(grad_clip=dict(max_norm=1., norm_type=2))
+
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+target_type = 'GaussianHeatmap'
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='ViT',
+ img_size=(256, 192),
+ patch_size=16,
+ embed_dim=768,
+ depth=12,
+ num_heads=12,
+ ratio=1,
+ use_checkpoint=False,
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_path_rate=0.3,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=768,
+ num_deconv_layers=0,
+ num_deconv_filters=[],
+ num_deconv_kernels=[],
+ upsample=4,
+ extra=dict(final_conv_kernel=3, ),
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=False,
+ target_type=target_type,
+ modulate_kernel=11,
+ use_udp=True))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='TopDownGenerateTarget',
+ sigma=2,
+ encoding='UDP',
+ target_type=target_type),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=4,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
+
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_huge_coco_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_huge_coco_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..298b2b59ef8310c73d481e95eb9fa39a8d0a7fef
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_huge_coco_256x192.py
@@ -0,0 +1,170 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(type='AdamW', lr=5e-4, betas=(0.9, 0.999), weight_decay=0.1,
+ constructor='LayerDecayOptimizerConstructor',
+ paramwise_cfg=dict(
+ num_layers=32,
+ layer_decay_rate=0.85,
+ custom_keys={
+ 'bias': dict(decay_multi=0.),
+ 'pos_embed': dict(decay_mult=0.),
+ 'relative_position_bias_table': dict(decay_mult=0.),
+ 'norm': dict(decay_mult=0.)
+ }
+ )
+ )
+
+optimizer_config = dict(grad_clip=dict(max_norm=1., norm_type=2))
+
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+target_type = 'GaussianHeatmap'
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='ViT',
+ img_size=(256, 192),
+ patch_size=16,
+ embed_dim=1280,
+ depth=32,
+ num_heads=16,
+ ratio=1,
+ use_checkpoint=False,
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_path_rate=0.55,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1280,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=False,
+ target_type=target_type,
+ modulate_kernel=11,
+ use_udp=True))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='TopDownGenerateTarget',
+ sigma=2,
+ encoding='UDP',
+ target_type=target_type),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=4,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
+
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_small_simple_coco_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_small_simple_coco_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..42ac25cf1f8556a5ee0e29b9fa3834fa9a1fff37
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_small_simple_coco_256x192.py
@@ -0,0 +1,170 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(type='AdamW', lr=5e-4, betas=(0.9, 0.999), weight_decay=0.1,
+ constructor='LayerDecayOptimizerConstructor',
+ paramwise_cfg=dict(
+ num_layers=12,
+ layer_decay_rate=0.8,
+ custom_keys={
+ 'bias': dict(decay_multi=0.),
+ 'pos_embed': dict(decay_mult=0.),
+ 'relative_position_bias_table': dict(decay_mult=0.),
+ 'norm': dict(decay_mult=0.)
+ }
+ )
+ )
+
+optimizer_config = dict(grad_clip=dict(max_norm=1., norm_type=2))
+
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+target_type = 'GaussianHeatmap'
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='ViT',
+ img_size=(256, 192),
+ patch_size=16,
+ embed_dim=384,
+ depth=12,
+ num_heads=12,
+ ratio=1,
+ use_checkpoint=False,
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_path_rate=0.1,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=384,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=False,
+ target_type=target_type,
+ modulate_kernel=11,
+ use_udp=True))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='TopDownGenerateTarget',
+ sigma=2,
+ encoding='UDP',
+ target_type=target_type),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=4,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
+
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/alexnet_coco_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/alexnet_coco_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..5704614306e57c17c5dc1f4df2cc8383f186cacc
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/alexnet_coco_256x192.py
@@ -0,0 +1,135 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(type='AlexNet', num_classes=-1),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=256,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[40, 56],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/cpm_coco.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/cpm_coco.md
new file mode 100644
index 0000000000000000000000000000000000000000..f159517386f9a70e5ca6800e842f166a734cf608
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/cpm_coco.md
@@ -0,0 +1,41 @@
+
+
+AI Challenger (ArXiv'2017)
+ +```bibtex +@article{wu2017ai, + title={Ai challenger: A large-scale dataset for going deeper in image understanding}, + author={Wu, Jiahong and Zheng, He and Zhao, Bo and Li, Yixin and Yan, Baoming and Liang, Rui and Wang, Wenjia and Zhou, Shipei and Lin, Guosen and Fu, Yanwei and others}, + journal={arXiv preprint arXiv:1711.06475}, + year={2017} +} +``` + +
+
+
+
+
+CPM (CVPR'2016)
+ +```bibtex +@inproceedings{wei2016convolutional, + title={Convolutional pose machines}, + author={Wei, Shih-En and Ramakrishna, Varun and Kanade, Takeo and Sheikh, Yaser}, + booktitle={Proceedings of the IEEE conference on Computer Vision and Pattern Recognition}, + pages={4724--4732}, + year={2016} +} +``` + +
+
+
+Results on COCO val2017 with detector having human AP of 56.4 on COCO val2017 dataset
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :----------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [cpm](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/cpm_coco_256x192.py) | 256x192 | 0.623 | 0.859 | 0.704 | 0.686 | 0.903 | [ckpt](https://download.openmmlab.com/mmpose/top_down/cpm/cpm_coco_256x192-aa4ba095_20200817.pth) | [log](https://download.openmmlab.com/mmpose/top_down/cpm/cpm_coco_256x192_20200817.log.json) |
+| [cpm](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/cpm_coco_384x288.py) | 384x288 | 0.650 | 0.864 | 0.725 | 0.708 | 0.905 | [ckpt](https://download.openmmlab.com/mmpose/top_down/cpm/cpm_coco_384x288-80feb4bc_20200821.pth) | [log](https://download.openmmlab.com/mmpose/top_down/cpm/cpm_coco_384x288_20200821.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/cpm_coco.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/cpm_coco.yml
new file mode 100644
index 0000000000000000000000000000000000000000..f3b3c4d15622680518ba0762c168cc8361b676c3
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/cpm_coco.yml
@@ -0,0 +1,40 @@
+Collections:
+- Name: CPM
+ Paper:
+ Title: Convolutional pose machines
+ URL: http://openaccess.thecvf.com/content_cvpr_2016/html/Wei_Convolutional_Pose_Machines_CVPR_2016_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/cpm.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/cpm_coco_256x192.py
+ In Collection: CPM
+ Metadata:
+ Architecture: &id001
+ - CPM
+ Training Data: COCO
+ Name: topdown_heatmap_cpm_coco_256x192
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.623
+ AP@0.5: 0.859
+ AP@0.75: 0.704
+ AR: 0.686
+ AR@0.5: 0.903
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/cpm/cpm_coco_256x192-aa4ba095_20200817.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/cpm_coco_384x288.py
+ In Collection: CPM
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: topdown_heatmap_cpm_coco_384x288
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.65
+ AP@0.5: 0.864
+ AP@0.75: 0.725
+ AR: 0.708
+ AR@0.5: 0.905
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/cpm/cpm_coco_384x288-80feb4bc_20200821.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/cpm_coco_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/cpm_coco_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..c9d118b62842ceb4d37be55f2072917fc377a835
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/cpm_coco_256x192.py
@@ -0,0 +1,143 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='CPM',
+ in_channels=3,
+ out_channels=channel_cfg['num_output_channels'],
+ feat_channels=128,
+ num_stages=6),
+ keypoint_head=dict(
+ type='TopdownHeatmapMultiStageHead',
+ in_channels=channel_cfg['num_output_channels'],
+ out_channels=channel_cfg['num_output_channels'],
+ num_stages=6,
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=0, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[24, 32],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/cpm_coco_384x288.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/cpm_coco_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..7e3ae32c397e3730325fbe65c6ef8b2880473654
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/cpm_coco_384x288.py
@@ -0,0 +1,143 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='CPM',
+ in_channels=3,
+ out_channels=channel_cfg['num_output_channels'],
+ feat_channels=128,
+ num_stages=6),
+ keypoint_head=dict(
+ type='TopdownHeatmapMultiStageHead',
+ in_channels=channel_cfg['num_output_channels'],
+ out_channels=channel_cfg['num_output_channels'],
+ num_stages=6,
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=0, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[36, 48],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hourglass52_coco_256x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hourglass52_coco_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..7ab6b159827c948494e87fbd74191cc5e95a80dc
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hourglass52_coco_256x256.py
@@ -0,0 +1,141 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='HourglassNet',
+ num_stacks=1,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapMultiStageHead',
+ in_channels=256,
+ out_channels=channel_cfg['num_output_channels'],
+ num_stages=1,
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hourglass_coco.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hourglass_coco.md
new file mode 100644
index 0000000000000000000000000000000000000000..a99fe7b0b8ddbbcc6993b2e76a0c1fbe49b4614e
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hourglass_coco.md
@@ -0,0 +1,42 @@
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+
+
+Hourglass (ECCV'2016)
+ +```bibtex +@inproceedings{newell2016stacked, + title={Stacked hourglass networks for human pose estimation}, + author={Newell, Alejandro and Yang, Kaiyu and Deng, Jia}, + booktitle={European conference on computer vision}, + pages={483--499}, + year={2016}, + organization={Springer} +} +``` + +
+
+
+Results on COCO val2017 with detector having human AP of 56.4 on COCO val2017 dataset
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :----------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_hourglass_52](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hourglass52_coco_256x256.py) | 256x256 | 0.726 | 0.896 | 0.799 | 0.780 | 0.934 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hourglass/hourglass52_coco_256x256-4ec713ba_20200709.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hourglass/hourglass52_coco_256x256_20200709.log.json) |
+| [pose_hourglass_52](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hourglass52_coco_384x384.py) | 384x384 | 0.746 | 0.900 | 0.813 | 0.797 | 0.939 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hourglass/hourglass52_coco_384x384-be91ba2b_20200812.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hourglass/hourglass52_coco_384x384_20200812.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hourglass_coco.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hourglass_coco.yml
new file mode 100644
index 0000000000000000000000000000000000000000..28f09df2afdcfbfdbbcfb0a27f52291038691c5f
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hourglass_coco.yml
@@ -0,0 +1,40 @@
+Collections:
+- Name: Hourglass
+ Paper:
+ Title: Stacked hourglass networks for human pose estimation
+ URL: https://link.springer.com/chapter/10.1007/978-3-319-46484-8_29
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/hourglass.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hourglass52_coco_256x256.py
+ In Collection: Hourglass
+ Metadata:
+ Architecture: &id001
+ - Hourglass
+ Training Data: COCO
+ Name: topdown_heatmap_hourglass52_coco_256x256
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.726
+ AP@0.5: 0.896
+ AP@0.75: 0.799
+ AR: 0.78
+ AR@0.5: 0.934
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/hourglass/hourglass52_coco_256x256-4ec713ba_20200709.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hourglass52_coco_384x384.py
+ In Collection: Hourglass
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: topdown_heatmap_hourglass52_coco_384x384
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.746
+ AP@0.5: 0.9
+ AP@0.75: 0.813
+ AR: 0.797
+ AR@0.5: 0.939
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/hourglass/hourglass52_coco_384x384-be91ba2b_20200812.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrformer_coco.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrformer_coco.md
new file mode 100644
index 0000000000000000000000000000000000000000..10c0ca5c0e1526515e491adbafc10d80ad8ddbf1
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrformer_coco.md
@@ -0,0 +1,42 @@
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+
+
+HRFormer (NIPS'2021)
+ +```bibtex +@article{yuan2021hrformer, + title={HRFormer: High-Resolution Vision Transformer for Dense Predict}, + author={Yuan, Yuhui and Fu, Rao and Huang, Lang and Lin, Weihong and Zhang, Chao and Chen, Xilin and Wang, Jingdong}, + journal={Advances in Neural Information Processing Systems}, + volume={34}, + year={2021} +} +``` + +
+
+
+Results on COCO val2017 with detector having human AP of 56.4 on COCO val2017 dataset
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :----------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_hrformer_small](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrformer_small_coco_256x192.py) | 256x192 | 0.737 | 0.899 | 0.810 | 0.792 | 0.938 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrformer/hrformer_small_coco_256x192-b657896f_20220226.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrformer/hrformer_small_coco_256x192_20220226.log.json) |
+| [pose_hrformer_small](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrformer_small_coco_384x288.py) | 384x288 | 0.755 | 0.906 | 0.822 | 0.805 | 0.941 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrformer/hrformer_small_coco_384x288-4b52b078_20220226.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrformer/hrformer_small_coco_384x288_20220226.log.json) |
+| [pose_hrformer_base](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrformer_base_coco_256x192.py) | 256x192 | 0.753 | 0.907 | 0.821 | 0.806 | 0.943 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrformer/hrformer_base_coco_256x192-66cee214_20220226.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrformer/hrformer_base_coco_256x192_20220226.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrformer_small_coco_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrformer_small_coco_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..edb658b28445a615fe61a06c2f4de609dc3a8400
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrformer_small_coco_256x192.py
@@ -0,0 +1,192 @@
+_base_ = ['../../../../_base_/datasets/coco.py']
+log_level = 'INFO'
+load_from = None
+resume_from = None
+dist_params = dict(backend='nccl')
+workflow = [('train', 1)]
+checkpoint_config = dict(interval=5, create_symlink=False)
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='AdamW',
+ lr=5e-4,
+ betas=(0.9, 0.999),
+ weight_decay=0.01,
+ paramwise_cfg=dict(
+ custom_keys={'relative_position_bias_table': dict(decay_mult=0.)}))
+
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrformer_small-09516375_20220226.pth',
+ backbone=dict(
+ type='HRFormer',
+ in_channels=3,
+ norm_cfg=norm_cfg,
+ extra=dict(
+ drop_path_rate=0.1,
+ with_rpe=False,
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(2, ),
+ num_channels=(64, ),
+ num_heads=[2],
+ num_mlp_ratios=[4]),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='HRFORMERBLOCK',
+ num_blocks=(2, 2),
+ num_channels=(32, 64),
+ num_heads=[1, 2],
+ mlp_ratios=[4, 4],
+ window_sizes=[7, 7]),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='HRFORMERBLOCK',
+ num_blocks=(2, 2, 2),
+ num_channels=(32, 64, 128),
+ num_heads=[1, 2, 4],
+ mlp_ratios=[4, 4, 4],
+ window_sizes=[7, 7, 7]),
+ stage4=dict(
+ num_modules=2,
+ num_branches=4,
+ block='HRFORMERBLOCK',
+ num_blocks=(2, 2, 2, 2),
+ num_channels=(32, 64, 128, 256),
+ num_heads=[1, 2, 4, 8],
+ mlp_ratios=[4, 4, 4, 4],
+ window_sizes=[7, 7, 7, 7]))),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_root = 'data/coco'
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file=f'{data_root}/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=64),
+ test_dataloader=dict(samples_per_gpu=64),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline),
+)
+
+# fp16 settings
+fp16 = dict(loss_scale='dynamic')
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrformer_small_coco_384x288.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrformer_small_coco_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..cc9b62e2aecf50f4ccb694d2882a41a76ad5d53c
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrformer_small_coco_384x288.py
@@ -0,0 +1,192 @@
+log_level = 'INFO'
+load_from = None
+resume_from = None
+dist_params = dict(backend='nccl')
+workflow = [('train', 1)]
+checkpoint_config = dict(interval=5, create_symlink=False)
+evaluation = dict(interval=10, metric='mAP', key_indicator='AP')
+
+optimizer = dict(
+ type='AdamW',
+ lr=5e-4,
+ betas=(0.9, 0.999),
+ weight_decay=0.01,
+ paramwise_cfg=dict(
+ custom_keys={'relative_position_bias_table': dict(decay_mult=0.)}))
+
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrformer_small-09516375_20220226.pth',
+ backbone=dict(
+ type='HRFormer',
+ in_channels=3,
+ norm_cfg=norm_cfg,
+ extra=dict(
+ drop_path_rate=0.1,
+ with_rpe=False,
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(2, ),
+ num_channels=(64, ),
+ num_heads=[2],
+ num_mlp_ratios=[4]),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='HRFORMERBLOCK',
+ num_blocks=(2, 2),
+ num_channels=(32, 64),
+ num_heads=[1, 2],
+ mlp_ratios=[4, 4],
+ window_sizes=[7, 7]),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='HRFORMERBLOCK',
+ num_blocks=(2, 2, 2),
+ num_channels=(32, 64, 128),
+ num_heads=[1, 2, 4],
+ mlp_ratios=[4, 4, 4],
+ window_sizes=[7, 7, 7]),
+ stage4=dict(
+ num_modules=2,
+ num_branches=4,
+ block='HRFORMERBLOCK',
+ num_blocks=(2, 2, 2, 2),
+ num_channels=(32, 64, 128, 256),
+ num_heads=[1, 2, 4, 8],
+ mlp_ratios=[4, 4, 4, 4],
+ window_sizes=[7, 7, 7, 7]))),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_root = 'data/coco'
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file=f'{data_root}/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=256),
+ test_dataloader=dict(samples_per_gpu=256),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline),
+)
+
+# fp16 settings
+fp16 = dict(loss_scale='dynamic')
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_augmentation_coco.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_augmentation_coco.md
new file mode 100644
index 0000000000000000000000000000000000000000..533a974cd46303d8cc1249b8be2c494f95f62278
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_augmentation_coco.md
@@ -0,0 +1,62 @@
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+
+
+HRNet (CVPR'2019)
+ +```bibtex +@inproceedings{sun2019deep, + title={Deep high-resolution representation learning for human pose estimation}, + author={Sun, Ke and Xiao, Bin and Liu, Dong and Wang, Jingdong}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={5693--5703}, + year={2019} +} +``` + +
+
+
+
+
+Albumentations (Information'2020)
+ +```bibtex +@article{buslaev2020albumentations, + title={Albumentations: fast and flexible image augmentations}, + author={Buslaev, Alexander and Iglovikov, Vladimir I and Khvedchenya, Eugene and Parinov, Alex and Druzhinin, Mikhail and Kalinin, Alexandr A}, + journal={Information}, + volume={11}, + number={2}, + pages={125}, + year={2020}, + publisher={Multidisciplinary Digital Publishing Institute} +} +``` + +
+
+
+Results on COCO val2017 with detector having human AP of 56.4 on COCO val2017 dataset
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :----------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [coarsedropout](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_256x192_coarsedropout.py) | 256x192 | 0.753 | 0.908 | 0.822 | 0.806 | 0.946 | [ckpt](https://download.openmmlab.com/mmpose/top_down/augmentation/hrnet_w32_coco_256x192_coarsedropout-0f16a0ce_20210320.pth) | [log](https://download.openmmlab.com/mmpose/top_down/augmentation/hrnet_w32_coco_256x192_coarsedropout_20210320.log.json) |
+| [gridmask](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_256x192_gridmask.py) | 256x192 | 0.752 | 0.906 | 0.825 | 0.804 | 0.943 | [ckpt](https://download.openmmlab.com/mmpose/top_down/augmentation/hrnet_w32_coco_256x192_gridmask-868180df_20210320.pth) | [log](https://download.openmmlab.com/mmpose/top_down/augmentation/hrnet_w32_coco_256x192_gridmask_20210320.log.json) |
+| [photometric](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_256x192_photometric.py) | 256x192 | 0.753 | 0.909 | 0.825 | 0.805 | 0.943 | [ckpt](https://download.openmmlab.com/mmpose/top_down/augmentation/hrnet_w32_coco_256x192_photometric-308cf591_20210320.pth) | [log](https://download.openmmlab.com/mmpose/top_down/augmentation/hrnet_w32_coco_256x192_photometric_20210320.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_augmentation_coco.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_augmentation_coco.yml
new file mode 100644
index 0000000000000000000000000000000000000000..58b7304e2944fb111d61e41ee5a18573ca7d8490
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_augmentation_coco.yml
@@ -0,0 +1,56 @@
+Collections:
+- Name: Albumentations
+ Paper:
+ Title: 'Albumentations: fast and flexible image augmentations'
+ URL: https://www.mdpi.com/649002
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/techniques/albumentations.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_256x192_coarsedropout.py
+ In Collection: Albumentations
+ Metadata:
+ Architecture: &id001
+ - HRNet
+ Training Data: COCO
+ Name: topdown_heatmap_hrnet_w32_coco_256x192_coarsedropout
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.753
+ AP@0.5: 0.908
+ AP@0.75: 0.822
+ AR: 0.806
+ AR@0.5: 0.946
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/augmentation/hrnet_w32_coco_256x192_coarsedropout-0f16a0ce_20210320.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_256x192_gridmask.py
+ In Collection: Albumentations
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: topdown_heatmap_hrnet_w32_coco_256x192_gridmask
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.752
+ AP@0.5: 0.906
+ AP@0.75: 0.825
+ AR: 0.804
+ AR@0.5: 0.943
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/augmentation/hrnet_w32_coco_256x192_gridmask-868180df_20210320.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_256x192_photometric.py
+ In Collection: Albumentations
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: topdown_heatmap_hrnet_w32_coco_256x192_photometric
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.753
+ AP@0.5: 0.909
+ AP@0.75: 0.825
+ AR: 0.805
+ AR@0.5: 0.943
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/augmentation/hrnet_w32_coco_256x192_photometric-308cf591_20210320.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_dark_coco.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_dark_coco.md
new file mode 100644
index 0000000000000000000000000000000000000000..794a08419aab4609bba8d9a05db6510800ff1851
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_dark_coco.md
@@ -0,0 +1,60 @@
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+
+
+HRNet (CVPR'2019)
+ +```bibtex +@inproceedings{sun2019deep, + title={Deep high-resolution representation learning for human pose estimation}, + author={Sun, Ke and Xiao, Bin and Liu, Dong and Wang, Jingdong}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={5693--5703}, + year={2019} +} +``` + +
+
+
+
+
+DarkPose (CVPR'2020)
+ +```bibtex +@inproceedings{zhang2020distribution, + title={Distribution-aware coordinate representation for human pose estimation}, + author={Zhang, Feng and Zhu, Xiatian and Dai, Hanbin and Ye, Mao and Zhu, Ce}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + pages={7093--7102}, + year={2020} +} +``` + +
+
+
+Results on COCO val2017 with detector having human AP of 56.4 on COCO val2017 dataset
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :----------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_hrnet_w32_dark](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_256x192_dark.py) | 256x192 | 0.757 | 0.907 | 0.823 | 0.808 | 0.943 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_coco_256x192_dark-07f147eb_20200812.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_coco_256x192_dark_20200812.log.json) |
+| [pose_hrnet_w32_dark](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_384x288_dark.py) | 384x288 | 0.766 | 0.907 | 0.831 | 0.815 | 0.943 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_coco_384x288_dark-307dafc2_20210203.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_coco_384x288_dark_20210203.log.json) |
+| [pose_hrnet_w48_dark](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_256x192_dark.py) | 256x192 | 0.764 | 0.907 | 0.830 | 0.814 | 0.943 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_256x192_dark-8cba3197_20200812.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_256x192_dark_20200812.log.json) |
+| [pose_hrnet_w48_dark](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_384x288_dark.py) | 384x288 | 0.772 | 0.910 | 0.836 | 0.820 | 0.946 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_384x288_dark-e881a4b6_20210203.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_384x288_dark_20210203.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_dark_coco.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_dark_coco.yml
new file mode 100644
index 0000000000000000000000000000000000000000..49c2e863bb85b76d4f853948f9f1c77ebdbe13a6
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_dark_coco.yml
@@ -0,0 +1,73 @@
+Collections:
+- Name: DarkPose
+ Paper:
+ Title: Distribution-aware coordinate representation for human pose estimation
+ URL: http://openaccess.thecvf.com/content_CVPR_2020/html/Zhang_Distribution-Aware_Coordinate_Representation_for_Human_Pose_Estimation_CVPR_2020_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/techniques/dark.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_256x192_dark.py
+ In Collection: DarkPose
+ Metadata:
+ Architecture: &id001
+ - HRNet
+ - DarkPose
+ Training Data: COCO
+ Name: topdown_heatmap_hrnet_w32_coco_256x192_dark
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.757
+ AP@0.5: 0.907
+ AP@0.75: 0.823
+ AR: 0.808
+ AR@0.5: 0.943
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_coco_256x192_dark-07f147eb_20200812.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_384x288_dark.py
+ In Collection: DarkPose
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: topdown_heatmap_hrnet_w32_coco_384x288_dark
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.766
+ AP@0.5: 0.907
+ AP@0.75: 0.831
+ AR: 0.815
+ AR@0.5: 0.943
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_coco_384x288_dark-307dafc2_20210203.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_256x192_dark.py
+ In Collection: DarkPose
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: topdown_heatmap_hrnet_w48_coco_256x192_dark
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.764
+ AP@0.5: 0.907
+ AP@0.75: 0.83
+ AR: 0.814
+ AR@0.5: 0.943
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_256x192_dark-8cba3197_20200812.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_384x288_dark.py
+ In Collection: DarkPose
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: topdown_heatmap_hrnet_w48_coco_384x288_dark
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.772
+ AP@0.5: 0.91
+ AP@0.75: 0.836
+ AR: 0.82
+ AR@0.5: 0.946
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_384x288_dark-e881a4b6_20210203.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_fp16_coco.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_fp16_coco.md
new file mode 100644
index 0000000000000000000000000000000000000000..c2e4b70494428786d83b747a4c494f5a9876268b
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_fp16_coco.md
@@ -0,0 +1,56 @@
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+
+
+HRNet (CVPR'2019)
+ +```bibtex +@inproceedings{sun2019deep, + title={Deep high-resolution representation learning for human pose estimation}, + author={Sun, Ke and Xiao, Bin and Liu, Dong and Wang, Jingdong}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={5693--5703}, + year={2019} +} +``` + +
+
+
+
+
+FP16 (ArXiv'2017)
+ +```bibtex +@article{micikevicius2017mixed, + title={Mixed precision training}, + author={Micikevicius, Paulius and Narang, Sharan and Alben, Jonah and Diamos, Gregory and Elsen, Erich and Garcia, David and Ginsburg, Boris and Houston, Michael and Kuchaiev, Oleksii and Venkatesh, Ganesh and others}, + journal={arXiv preprint arXiv:1710.03740}, + year={2017} +} +``` + +
+
+
+Results on COCO val2017 with detector having human AP of 56.4 on COCO val2017 dataset
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :----------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_hrnet_w32_fp16](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_256x192_fp16_dynamic.py) | 256x192 | 0.746 | 0.905 | 0.88 | 0.800 | 0.943 | [ckpt](hrnet_w32_coco_256x192_fp16_dynamic-290efc2e_20210430.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_coco_256x192_fp16_dynamic_20210430.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_fp16_coco.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_fp16_coco.yml
new file mode 100644
index 0000000000000000000000000000000000000000..47f39f4eb9e592b233f22a66aa8d8908a46b7201
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_fp16_coco.yml
@@ -0,0 +1,24 @@
+Collections:
+- Name: HRNet
+ Paper:
+ Title: Deep high-resolution representation learning for human pose estimation
+ URL: http://openaccess.thecvf.com/content_CVPR_2019/html/Sun_Deep_High-Resolution_Representation_Learning_for_Human_Pose_Estimation_CVPR_2019_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/hrnet.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_256x192_fp16_dynamic.py
+ In Collection: HRNet
+ Metadata:
+ Architecture:
+ - HRNet
+ Training Data: COCO
+ Name: topdown_heatmap_hrnet_w32_coco_256x192_fp16_dynamic
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.746
+ AP@0.5: 0.905
+ AP@0.75: 0.88
+ AR: 0.8
+ AR@0.5: 0.943
+ Task: Body 2D Keypoint
+ Weights: hrnet_w32_coco_256x192_fp16_dynamic-290efc2e_20210430.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_udp_coco.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_udp_coco.md
new file mode 100644
index 0000000000000000000000000000000000000000..acc7207a7b5710832e3f8a53a734ac8d2c7e08b9
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_udp_coco.md
@@ -0,0 +1,63 @@
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+
+
+HRNet (CVPR'2019)
+ +```bibtex +@inproceedings{sun2019deep, + title={Deep high-resolution representation learning for human pose estimation}, + author={Sun, Ke and Xiao, Bin and Liu, Dong and Wang, Jingdong}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={5693--5703}, + year={2019} +} +``` + +
+
+
+
+
+UDP (CVPR'2020)
+ +```bibtex +@InProceedings{Huang_2020_CVPR, + author = {Huang, Junjie and Zhu, Zheng and Guo, Feng and Huang, Guan}, + title = {The Devil Is in the Details: Delving Into Unbiased Data Processing for Human Pose Estimation}, + booktitle = {The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, + month = {June}, + year = {2020} +} +``` + +
+
+
+Results on COCO val2017 with detector having human AP of 56.4 on COCO val2017 dataset
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :----------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_hrnet_w32_udp](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_256x192_udp.py) | 256x192 | 0.760 | 0.907 | 0.827 | 0.811 | 0.945 | [ckpt](https://download.openmmlab.com/mmpose/top_down/udp/hrnet_w32_coco_256x192_udp-aba0be42_20210220.pth) | [log](https://download.openmmlab.com/mmpose/top_down/udp/hrnet_w32_coco_256x192_udp_20210220.log.json) |
+| [pose_hrnet_w32_udp](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_384x288_udp.py) | 384x288 | 0.769 | 0.908 | 0.833 | 0.817 | 0.944 | [ckpt](https://download.openmmlab.com/mmpose/top_down/udp/hrnet_w32_coco_384x288_udp-e97c1a0f_20210223.pth) | [log](https://download.openmmlab.com/mmpose/top_down/udp/hrnet_w32_coco_384x288_udp_20210223.log.json) |
+| [pose_hrnet_w48_udp](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_256x192_udp.py) | 256x192 | 0.767 | 0.906 | 0.834 | 0.817 | 0.945 | [ckpt](https://download.openmmlab.com/mmpose/top_down/udp/hrnet_w48_coco_256x192_udp-2554c524_20210223.pth) | [log](https://download.openmmlab.com/mmpose/top_down/udp/hrnet_w48_coco_256x192_udp_20210223.log.json) |
+| [pose_hrnet_w48_udp](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_384x288_udp.py) | 384x288 | 0.772 | 0.910 | 0.835 | 0.820 | 0.945 | [ckpt](https://download.openmmlab.com/mmpose/top_down/udp/hrnet_w48_coco_384x288_udp-0f89c63e_20210223.pth) | [log](https://download.openmmlab.com/mmpose/top_down/udp/hrnet_w48_coco_384x288_udp_20210223.log.json) |
+| [pose_hrnet_w32_udp_regress](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_256x192_udp_regress.py) | 256x192 | 0.758 | 0.908 | 0.823 | 0.812 | 0.943 | [ckpt](https://download.openmmlab.com/mmpose/top_down/udp/hrnet_w32_coco_256x192_udp_regress-be2dbba4_20210222.pth) | [log](https://download.openmmlab.com/mmpose/top_down/udp/hrnet_w32_coco_256x192_udp_regress_20210222.log.json) |
+
+Note that, UDP also adopts the unbiased encoding/decoding algorithm of [DARK](https://mmpose.readthedocs.io/en/latest/papers/techniques.html#div-align-center-darkpose-cvpr-2020-div).
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..8f3f45e3a9cdb8051e803e7ab4ffc4b09bc55409
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_256x192.py
@@ -0,0 +1,166 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_256x192_coarsedropout.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_256x192_coarsedropout.py
new file mode 100644
index 0000000000000000000000000000000000000000..9306e5cc701bf40157ca82aa168ec6935cfed8da
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_256x192_coarsedropout.py
@@ -0,0 +1,179 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/top_down/hrnet/'
+ 'hrnet_w32_coco_256x192-c78dce93_20200708.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(
+ type='CoarseDropout',
+ max_holes=8,
+ max_height=40,
+ max_width=40,
+ min_holes=1,
+ min_height=10,
+ min_width=10,
+ p=0.5),
+ ]),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_256x192_dark.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_256x192_dark.py
new file mode 100644
index 0000000000000000000000000000000000000000..6a04bd43156a1936fc71890e93929f659ade64e7
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_256x192_dark.py
@@ -0,0 +1,166 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='unbiased',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2, unbiased_encoding=True),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_256x192_fp16_dynamic.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_256x192_fp16_dynamic.py
new file mode 100644
index 0000000000000000000000000000000000000000..234d58a2626fa1d17a204884772870dbd66f46e3
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_256x192_fp16_dynamic.py
@@ -0,0 +1,4 @@
+_base_ = ['./hrnet_w32_coco_256x192.py']
+
+# fp16 settings
+fp16 = dict(loss_scale='dynamic')
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_256x192_udp.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_256x192_udp.py
new file mode 100644
index 0000000000000000000000000000000000000000..5512c3c5b96f100eee0be4934388aba0443ce6fc
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_256x192_udp.py
@@ -0,0 +1,173 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+target_type = 'GaussianHeatmap'
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=False,
+ target_type=target_type,
+ modulate_kernel=11,
+ use_udp=True))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='TopDownGenerateTarget',
+ sigma=2,
+ encoding='UDP',
+ target_type=target_type),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_256x192_udp_regress.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_256x192_udp_regress.py
new file mode 100644
index 0000000000000000000000000000000000000000..940ad911d2afb6abc507ebcdb802ce842fc1e3fd
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_256x192_udp_regress.py
@@ -0,0 +1,171 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+target_type = 'CombinedTarget'
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=3 * channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(
+ type='CombinedTargetMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=False,
+ target_type=target_type,
+ modulate_kernel=11,
+ use_udp=True))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='TopDownGenerateTarget', encoding='UDP', target_type=target_type),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_384x288.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..a1b8eb20f74c942c72aa373e7c5bd7a08ba89082
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_384x288.py
@@ -0,0 +1,166 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_384x288_udp.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_384x288_udp.py
new file mode 100644
index 0000000000000000000000000000000000000000..e8e7b5282f7e914080840afdf9e7c99d0204e408
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_384x288_udp.py
@@ -0,0 +1,173 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+target_type = 'GaussianHeatmap'
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=False,
+ target_type=target_type,
+ modulate_kernel=17,
+ use_udp=True))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='TopDownGenerateTarget',
+ sigma=3,
+ encoding='UDP',
+ target_type=target_type),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..305d680f227d29e39df621c9a6b81b5fae9bc8d7
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_256x192.py
@@ -0,0 +1,166 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_384x288.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..1776926bf139097d857c20a3d5350301e61a5d17
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_384x288.py
@@ -0,0 +1,166 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_384x288_dark.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_384x288_dark.py
new file mode 100644
index 0000000000000000000000000000000000000000..82a8009d02f103956bbb5b8bdd1b108805dc0441
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_384x288_dark.py
@@ -0,0 +1,166 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='unbiased',
+ shift_heatmap=True,
+ modulate_kernel=17))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3, unbiased_encoding=True),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_384x288_udp.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_384x288_udp.py
new file mode 100644
index 0000000000000000000000000000000000000000..8fa81909af3732e3b25b89b4f897598f8407c425
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_384x288_udp.py
@@ -0,0 +1,173 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+target_type = 'GaussianHeatmap'
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=False,
+ target_type=target_type,
+ modulate_kernel=17,
+ use_udp=True))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='TopDownGenerateTarget',
+ sigma=3,
+ encoding='UDP',
+ target_type=target_type),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/litehrnet_18_coco_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/litehrnet_18_coco_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..593bf2208534c306d2d59b1a93f46b7b60091fe3
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/litehrnet_18_coco_256x192.py
@@ -0,0 +1,157 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', key_indicator='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='LiteHRNet',
+ in_channels=3,
+ extra=dict(
+ stem=dict(stem_channels=32, out_channels=32, expand_ratio=1),
+ num_stages=3,
+ stages_spec=dict(
+ num_modules=(2, 4, 2),
+ num_branches=(2, 3, 4),
+ num_blocks=(2, 2, 2),
+ module_type=('LITE', 'LITE', 'LITE'),
+ with_fuse=(True, True, True),
+ reduce_ratios=(8, 8, 8),
+ num_channels=(
+ (40, 80),
+ (40, 80, 160),
+ (40, 80, 160, 320),
+ )),
+ with_head=True,
+ )),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=40,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/litehrnet_18_coco_384x288.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/litehrnet_18_coco_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..fdf41d5fbf3c53d913591d704d3ab122ed4017a9
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/litehrnet_18_coco_384x288.py
@@ -0,0 +1,157 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', key_indicator='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='LiteHRNet',
+ in_channels=3,
+ extra=dict(
+ stem=dict(stem_channels=32, out_channels=32, expand_ratio=1),
+ num_stages=3,
+ stages_spec=dict(
+ num_modules=(2, 4, 2),
+ num_branches=(2, 3, 4),
+ num_blocks=(2, 2, 2),
+ module_type=('LITE', 'LITE', 'LITE'),
+ with_fuse=(True, True, True),
+ reduce_ratios=(8, 8, 8),
+ num_channels=(
+ (40, 80),
+ (40, 80, 160),
+ (40, 80, 160, 320),
+ )),
+ with_head=True,
+ )),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=40,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/litehrnet_coco.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/litehrnet_coco.md
new file mode 100644
index 0000000000000000000000000000000000000000..7ce55162b9b7f9c706e95eace342326b978f4013
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/litehrnet_coco.md
@@ -0,0 +1,42 @@
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+
+
+LiteHRNet (CVPR'2021)
+ +```bibtex +@inproceedings{Yulitehrnet21, + title={Lite-HRNet: A Lightweight High-Resolution Network}, + author={Yu, Changqian and Xiao, Bin and Gao, Changxin and Yuan, Lu and Zhang, Lei and Sang, Nong and Wang, Jingdong}, + booktitle={CVPR}, + year={2021} +} +``` + +
+
+
+Results on COCO val2017 with detector having human AP of 56.4 on COCO val2017 dataset
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :----------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [LiteHRNet-18](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/litehrnet_18_coco_256x192.py) | 256x192 | 0.643 | 0.868 | 0.720 | 0.706 | 0.912 | [ckpt](https://download.openmmlab.com/mmpose/top_down/litehrnet/litehrnet18_coco_256x192-6bace359_20211230.pth) | [log](https://download.openmmlab.com/mmpose/top_down/litehrnet/litehrnet18_coco_256x192_20211230.log.json) |
+| [LiteHRNet-18](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/litehrnet_18_coco_384x288.py) | 384x288 | 0.677 | 0.878 | 0.746 | 0.735 | 0.920 | [ckpt](https://download.openmmlab.com/mmpose/top_down/litehrnet/litehrnet18_coco_384x288-8d4dac48_20211230.pth) | [log](https://download.openmmlab.com/mmpose/top_down/litehrnet/litehrnet18_coco_384x288_20211230.log.json) |
+| [LiteHRNet-30](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/litehrnet_30_coco_256x192.py) | 256x192 | 0.675 | 0.881 | 0.754 | 0.736 | 0.924 | [ckpt](https://download.openmmlab.com/mmpose/top_down/litehrnet/litehrnet30_coco_256x192-4176555b_20210626.pth) | [log](https://download.openmmlab.com/mmpose/top_down/litehrnet/litehrnet30_coco_256x192_20210626.log.json) |
+| [LiteHRNet-30](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/litehrnet_30_coco_384x288.py) | 384x288 | 0.700 | 0.884 | 0.776 | 0.758 | 0.928 | [ckpt](https://download.openmmlab.com/mmpose/top_down/litehrnet/litehrnet30_coco_384x288-a3aef5c4_20210626.pth) | [log](https://download.openmmlab.com/mmpose/top_down/litehrnet/litehrnet30_coco_384x288_20210626.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/litehrnet_coco.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/litehrnet_coco.yml
new file mode 100644
index 0000000000000000000000000000000000000000..1ba22c59364a6960cf8619fc69b98f10d4f5b1ff
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/litehrnet_coco.yml
@@ -0,0 +1,72 @@
+Collections:
+- Name: LiteHRNet
+ Paper:
+ Title: 'Lite-HRNet: A Lightweight High-Resolution Network'
+ URL: https://arxiv.org/abs/2104.06403
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/litehrnet.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/litehrnet_18_coco_256x192.py
+ In Collection: LiteHRNet
+ Metadata:
+ Architecture: &id001
+ - LiteHRNet
+ Training Data: COCO
+ Name: topdown_heatmap_litehrnet_18_coco_256x192
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.643
+ AP@0.5: 0.868
+ AP@0.75: 0.72
+ AR: 0.706
+ AR@0.5: 0.912
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/litehrnet/litehrnet18_coco_256x192-6bace359_20211230.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/litehrnet_18_coco_384x288.py
+ In Collection: LiteHRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: topdown_heatmap_litehrnet_18_coco_384x288
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.677
+ AP@0.5: 0.878
+ AP@0.75: 0.746
+ AR: 0.735
+ AR@0.5: 0.92
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/litehrnet/litehrnet18_coco_384x288-8d4dac48_20211230.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/litehrnet_30_coco_256x192.py
+ In Collection: LiteHRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: topdown_heatmap_litehrnet_30_coco_256x192
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.675
+ AP@0.5: 0.881
+ AP@0.75: 0.754
+ AR: 0.736
+ AR@0.5: 0.924
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/litehrnet/litehrnet30_coco_256x192-4176555b_20210626.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/litehrnet_30_coco_384x288.py
+ In Collection: LiteHRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: topdown_heatmap_litehrnet_30_coco_384x288
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.7
+ AP@0.5: 0.884
+ AP@0.75: 0.776
+ AR: 0.758
+ AR@0.5: 0.928
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/litehrnet/litehrnet30_coco_384x288-a3aef5c4_20210626.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/mobilenetv2_coco.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/mobilenetv2_coco.yml
new file mode 100644
index 0000000000000000000000000000000000000000..cf19575fae9d0949bf50c577d92ab253fc21318b
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/mobilenetv2_coco.yml
@@ -0,0 +1,40 @@
+Collections:
+- Name: MobilenetV2
+ Paper:
+ Title: 'Mobilenetv2: Inverted residuals and linear bottlenecks'
+ URL: http://openaccess.thecvf.com/content_cvpr_2018/html/Sandler_MobileNetV2_Inverted_Residuals_CVPR_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/mobilenetv2.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/mobilenetv2_coco_256x192.py
+ In Collection: MobilenetV2
+ Metadata:
+ Architecture: &id001
+ - MobilenetV2
+ Training Data: COCO
+ Name: topdown_heatmap_mobilenetv2_coco_256x192
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.646
+ AP@0.5: 0.874
+ AP@0.75: 0.723
+ AR: 0.707
+ AR@0.5: 0.917
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/mobilenetv2/mobilenetv2_coco_256x192-d1e58e7b_20200727.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/mobilenetv2_coco_384x288.py
+ In Collection: MobilenetV2
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: topdown_heatmap_mobilenetv2_coco_384x288
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.673
+ AP@0.5: 0.879
+ AP@0.75: 0.743
+ AR: 0.729
+ AR@0.5: 0.916
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/mobilenetv2/mobilenetv2_coco_384x288-26be4816_20200727.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/mobilenetv2_coco_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/mobilenetv2_coco_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..8e613b6e0daa5dc901594333604f76159ff9eb12
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/mobilenetv2_coco_256x192.py
@@ -0,0 +1,135 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='mmcls://mobilenet_v2',
+ backbone=dict(type='MobileNetV2', widen_factor=1., out_indices=(7, )),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1280,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/mspn50_coco_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/mspn50_coco_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..9e0c0171dec1c2f059483409b6ba2325498c31e2
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/mspn50_coco_256x192.py
@@ -0,0 +1,164 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-3,
+)
+
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(
+ type='MSPN',
+ unit_channels=256,
+ num_stages=1,
+ num_units=4,
+ num_blocks=[3, 4, 6, 3],
+ norm_cfg=dict(type='BN')),
+ keypoint_head=dict(
+ type='TopdownHeatmapMSMUHead',
+ out_shape=(64, 48),
+ unit_channels=256,
+ out_channels=channel_cfg['num_output_channels'],
+ num_stages=1,
+ num_units=4,
+ use_prm=False,
+ norm_cfg=dict(type='BN'),
+ loss_keypoint=[
+ dict(
+ type='JointsMSELoss', use_target_weight=True, loss_weight=0.25)
+ ] * 3 + [
+ dict(
+ type='JointsOHKMMSELoss',
+ use_target_weight=True,
+ loss_weight=1.)
+ ]),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='megvii',
+ shift_heatmap=False,
+ modulate_kernel=5))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ use_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='TopDownGenerateTarget',
+ kernel=[(11, 11), (9, 9), (7, 7), (5, 5)],
+ encoding='Megvii'),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=[
+ 'img',
+ ],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=4,
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/mspn_coco.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/mspn_coco.md
new file mode 100644
index 0000000000000000000000000000000000000000..22a3f9b1e16d3bc0018774492ce61f21edf817bf
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/mspn_coco.md
@@ -0,0 +1,42 @@
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+
+
+MSPN (ArXiv'2019)
+ +```bibtex +@article{li2019rethinking, + title={Rethinking on Multi-Stage Networks for Human Pose Estimation}, + author={Li, Wenbo and Wang, Zhicheng and Yin, Binyi and Peng, Qixiang and Du, Yuming and Xiao, Tianzi and Yu, Gang and Lu, Hongtao and Wei, Yichen and Sun, Jian}, + journal={arXiv preprint arXiv:1901.00148}, + year={2019} +} +``` + +
+
+
+Results on COCO val2017 with detector having human AP of 56.4 on COCO val2017 dataset
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :-------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [mspn_50](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/mspn50_coco_256x192.py) | 256x192 | 0.723 | 0.895 | 0.794 | 0.788 | 0.933 | [ckpt](https://download.openmmlab.com/mmpose/top_down/mspn/mspn50_coco_256x192-8fbfb5d0_20201123.pth) | [log](https://download.openmmlab.com/mmpose/top_down/mspn/mspn50_coco_256x192_20201123.log.json) |
+| [2xmspn_50](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/2xmspn50_coco_256x192.py) | 256x192 | 0.754 | 0.903 | 0.825 | 0.815 | 0.941 | [ckpt](https://download.openmmlab.com/mmpose/top_down/mspn/2xmspn50_coco_256x192-c8765a5c_20201123.pth) | [log](https://download.openmmlab.com/mmpose/top_down/mspn/2xmspn50_coco_256x192_20201123.log.json) |
+| [3xmspn_50](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/3xmspn50_coco_256x192.py) | 256x192 | 0.758 | 0.904 | 0.830 | 0.821 | 0.943 | [ckpt](https://download.openmmlab.com/mmpose/top_down/mspn/3xmspn50_coco_256x192-e348f18e_20201123.pth) | [log](https://download.openmmlab.com/mmpose/top_down/mspn/3xmspn50_coco_256x192_20201123.log.json) |
+| [4xmspn_50](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/4xmspn50_coco_256x192.py) | 256x192 | 0.764 | 0.906 | 0.835 | 0.826 | 0.944 | [ckpt](https://download.openmmlab.com/mmpose/top_down/mspn/4xmspn50_coco_256x192-7b837afb_20201123.pth) | [log](https://download.openmmlab.com/mmpose/top_down/mspn/4xmspn50_coco_256x192_20201123.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res101_coco_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res101_coco_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..b0963b44abfbe4f4f369b38040315171faf00b5c
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res101_coco_256x192.py
@@ -0,0 +1,135 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet101',
+ backbone=dict(type='ResNet', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res101_coco_256x192_dark.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res101_coco_256x192_dark.py
new file mode 100644
index 0000000000000000000000000000000000000000..465c00f22815f7119ebaaaeb522c14a82e0d6897
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res101_coco_256x192_dark.py
@@ -0,0 +1,135 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet101',
+ backbone=dict(type='ResNet', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='unbiased',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2, unbiased_encoding=True),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res101_coco_384x288.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res101_coco_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..037811ad84ffb047b337677a1fcbcbe61d6682ce
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res101_coco_384x288.py
@@ -0,0 +1,135 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet101',
+ backbone=dict(type='ResNet', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res101_coco_384x288_dark.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res101_coco_384x288_dark.py
new file mode 100644
index 0000000000000000000000000000000000000000..3a413c9c3f834fd6aae069557c580bfca814b494
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res101_coco_384x288_dark.py
@@ -0,0 +1,135 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet101',
+ backbone=dict(type='ResNet', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='unbiased',
+ shift_heatmap=True,
+ modulate_kernel=17))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3, unbiased_encoding=True),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res152_coco_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res152_coco_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..24537ccecec040f40efad011d5c0529d6f4cb74d
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res152_coco_256x192.py
@@ -0,0 +1,135 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet152',
+ backbone=dict(type='ResNet', depth=152),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res152_coco_384x288_dark.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res152_coco_384x288_dark.py
new file mode 100644
index 0000000000000000000000000000000000000000..88f192f7c77630d83ea443f5d2d547e0515a33f9
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res152_coco_384x288_dark.py
@@ -0,0 +1,135 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet152',
+ backbone=dict(type='ResNet', depth=152),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='unbiased',
+ shift_heatmap=True,
+ modulate_kernel=17))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3, unbiased_encoding=True),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..f64aad0be882d74efb591688e3a357a36453d9a5
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_256x192.py
@@ -0,0 +1,135 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_256x192_dark.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_256x192_dark.py
new file mode 100644
index 0000000000000000000000000000000000000000..5121bb08b196fc255ba3d9ab408de791ddd4e7d4
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_256x192_dark.py
@@ -0,0 +1,135 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='unbiased',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2, unbiased_encoding=True),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_384x288.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..7bd86690d2c4237b812aff4076458d5bacd8b98d
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_384x288.py
@@ -0,0 +1,135 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest101_coco_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest101_coco_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..e737b6ae44126b811cff84954712143fcb2b2281
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest101_coco_256x192.py
@@ -0,0 +1,135 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='mmcls://resnest101',
+ backbone=dict(type='ResNeSt', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest101_coco_384x288.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest101_coco_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..7fb13b1954e019805a231ce427deb41b0e0db7bf
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest101_coco_384x288.py
@@ -0,0 +1,135 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='mmcls://resnest101',
+ backbone=dict(type='ResNeSt', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest200_coco_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest200_coco_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..399a4d3c983c5a763446ae70b274f265559a5039
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest200_coco_256x192.py
@@ -0,0 +1,135 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', key_indicator='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='mmcls://resnest200',
+ backbone=dict(type='ResNeSt', depth=200),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest200_coco_384x288.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest200_coco_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..7a16cd378117d04cd5cb481f6593a1e88ccdba44
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest200_coco_384x288.py
@@ -0,0 +1,135 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', key_indicator='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='mmcls://resnest200',
+ backbone=dict(type='ResNeSt', depth=200),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=16,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=16),
+ test_dataloader=dict(samples_per_gpu=16),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest_coco.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest_coco.md
new file mode 100644
index 0000000000000000000000000000000000000000..4bb1ab04b32ac81aa9e3424d391de658659d257c
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest_coco.md
@@ -0,0 +1,46 @@
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+
+
+ResNeSt (ArXiv'2020)
+ +```bibtex +@article{zhang2020resnest, + title={ResNeSt: Split-Attention Networks}, + author={Zhang, Hang and Wu, Chongruo and Zhang, Zhongyue and Zhu, Yi and Zhang, Zhi and Lin, Haibin and Sun, Yue and He, Tong and Muller, Jonas and Manmatha, R. and Li, Mu and Smola, Alexander}, + journal={arXiv preprint arXiv:2004.08955}, + year={2020} +} +``` + +
+
+
+Results on COCO val2017 with detector having human AP of 56.4 on COCO val2017 dataset
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :-------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_resnest_50](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest50_coco_256x192.py) | 256x192 | 0.721 | 0.899 | 0.802 | 0.776 | 0.938 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnest/resnest50_coco_256x192-6e65eece_20210320.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnest/resnest50_coco_256x192_20210320.log.json) |
+| [pose_resnest_50](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest50_coco_384x288.py) | 384x288 | 0.737 | 0.900 | 0.811 | 0.789 | 0.938 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnest/resnest50_coco_384x288-dcd20436_20210320.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnest/resnest50_coco_384x288_20210320.log.json) |
+| [pose_resnest_101](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest101_coco_256x192.py) | 256x192 | 0.725 | 0.899 | 0.807 | 0.781 | 0.939 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnest/resnest101_coco_256x192-2ffcdc9d_20210320.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnest/resnest101_coco_256x192_20210320.log.json) |
+| [pose_resnest_101](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest101_coco_384x288.py) | 384x288 | 0.746 | 0.906 | 0.820 | 0.798 | 0.943 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnest/resnest101_coco_384x288-80660658_20210320.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnest/resnest101_coco_384x288_20210320.log.json) |
+| [pose_resnest_200](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest200_coco_256x192.py) | 256x192 | 0.732 | 0.905 | 0.812 | 0.787 | 0.942 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnest/resnest200_coco_256x192-db007a48_20210517.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnest/resnest200_coco_256x192_20210517.log.json) |
+| [pose_resnest_200](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest200_coco_384x288.py) | 384x288 | 0.754 | 0.908 | 0.827 | 0.807 | 0.945 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnest/resnest200_coco_384x288-b5bb76cb_20210517.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnest/resnest200_coco_384x288_20210517.log.json) |
+| [pose_resnest_269](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest269_coco_256x192.py) | 256x192 | 0.738 | 0.907 | 0.819 | 0.793 | 0.945 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnest/resnest269_coco_256x192-2a7882ac_20210517.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnest/resnest269_coco_256x192_20210517.log.json) |
+| [pose_resnest_269](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest269_coco_384x288.py) | 384x288 | 0.755 | 0.908 | 0.828 | 0.806 | 0.943 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnest/resnest269_coco_384x288-b142b9fb_20210517.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnest/resnest269_coco_384x288_20210517.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnet_coco.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnet_coco.md
new file mode 100644
index 0000000000000000000000000000000000000000..b66b95420d2edd5ca82fdc7a1ac4ec4c658ce6f8
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnet_coco.md
@@ -0,0 +1,62 @@
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+
+
+SimpleBaseline2D (ECCV'2018)
+ +```bibtex +@inproceedings{xiao2018simple, + title={Simple baselines for human pose estimation and tracking}, + author={Xiao, Bin and Wu, Haiping and Wei, Yichen}, + booktitle={Proceedings of the European conference on computer vision (ECCV)}, + pages={466--481}, + year={2018} +} +``` + +
+
+
+
+
+ResNet (CVPR'2016)
+ +```bibtex +@inproceedings{he2016deep, + title={Deep residual learning for image recognition}, + author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={770--778}, + year={2016} +} +``` + +
+
+
+Results on COCO val2017 with detector having human AP of 56.4 on COCO val2017 dataset
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :-------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_resnet_50](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_256x192.py) | 256x192 | 0.718 | 0.898 | 0.795 | 0.773 | 0.937 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res50_coco_256x192-ec54d7f3_20200709.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res50_coco_256x192_20200709.log.json) |
+| [pose_resnet_50](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_384x288.py) | 384x288 | 0.731 | 0.900 | 0.799 | 0.783 | 0.931 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res50_coco_384x288-e6f795e9_20200709.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res50_coco_384x288_20200709.log.json) |
+| [pose_resnet_101](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res101_coco_256x192.py) | 256x192 | 0.726 | 0.899 | 0.806 | 0.781 | 0.939 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res101_coco_256x192-6e6babf0_20200708.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res101_coco_256x192_20200708.log.json) |
+| [pose_resnet_101](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res101_coco_384x288.py) | 384x288 | 0.748 | 0.905 | 0.817 | 0.798 | 0.940 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res101_coco_384x288-8c71bdc9_20200709.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res101_coco_384x288_20200709.log.json) |
+| [pose_resnet_152](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res152_coco_256x192.py) | 256x192 | 0.735 | 0.905 | 0.812 | 0.790 | 0.943 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res152_coco_256x192-f6e307c2_20200709.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res152_coco_256x192_20200709.log.json) |
+| [pose_resnet_152](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res152_coco_384x288.py) | 384x288 | 0.750 | 0.908 | 0.821 | 0.800 | 0.942 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res152_coco_384x288-3860d4c9_20200709.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res152_coco_384x288_20200709.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnet_coco.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnet_coco.yml
new file mode 100644
index 0000000000000000000000000000000000000000..3ba17ab7ed939c255389e47851575e98c375b053
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnet_coco.yml
@@ -0,0 +1,105 @@
+Collections:
+- Name: SimpleBaseline2D
+ Paper:
+ Title: Simple baselines for human pose estimation and tracking
+ URL: http://openaccess.thecvf.com/content_ECCV_2018/html/Bin_Xiao_Simple_Baselines_for_ECCV_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/simplebaseline2d.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_256x192.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: &id001
+ - SimpleBaseline2D
+ - ResNet
+ Training Data: COCO
+ Name: topdown_heatmap_res50_coco_256x192
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.718
+ AP@0.5: 0.898
+ AP@0.75: 0.795
+ AR: 0.773
+ AR@0.5: 0.937
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res50_coco_256x192-ec54d7f3_20200709.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_384x288.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: topdown_heatmap_res50_coco_384x288
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.731
+ AP@0.5: 0.9
+ AP@0.75: 0.799
+ AR: 0.783
+ AR@0.5: 0.931
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res50_coco_384x288-e6f795e9_20200709.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res101_coco_256x192.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: topdown_heatmap_res101_coco_256x192
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.726
+ AP@0.5: 0.899
+ AP@0.75: 0.806
+ AR: 0.781
+ AR@0.5: 0.939
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res101_coco_256x192-6e6babf0_20200708.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res101_coco_384x288.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: topdown_heatmap_res101_coco_384x288
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.748
+ AP@0.5: 0.905
+ AP@0.75: 0.817
+ AR: 0.798
+ AR@0.5: 0.94
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res101_coco_384x288-8c71bdc9_20200709.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res152_coco_256x192.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: topdown_heatmap_res152_coco_256x192
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.735
+ AP@0.5: 0.905
+ AP@0.75: 0.812
+ AR: 0.79
+ AR@0.5: 0.943
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res152_coco_256x192-f6e307c2_20200709.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res152_coco_384x288.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: topdown_heatmap_res152_coco_384x288
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.75
+ AP@0.5: 0.908
+ AP@0.75: 0.821
+ AR: 0.8
+ AR@0.5: 0.942
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res152_coco_384x288-3860d4c9_20200709.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnet_dark_coco.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnet_dark_coco.yml
new file mode 100644
index 0000000000000000000000000000000000000000..7a4c79e6d45de4c7c30631b54b826e15804bf6d9
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnet_dark_coco.yml
@@ -0,0 +1,106 @@
+Collections:
+- Name: DarkPose
+ Paper:
+ Title: Distribution-aware coordinate representation for human pose estimation
+ URL: http://openaccess.thecvf.com/content_CVPR_2020/html/Zhang_Distribution-Aware_Coordinate_Representation_for_Human_Pose_Estimation_CVPR_2020_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/techniques/dark.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_256x192_dark.py
+ In Collection: DarkPose
+ Metadata:
+ Architecture: &id001
+ - SimpleBaseline2D
+ - ResNet
+ - DarkPose
+ Training Data: COCO
+ Name: topdown_heatmap_res50_coco_256x192_dark
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.724
+ AP@0.5: 0.898
+ AP@0.75: 0.8
+ AR: 0.777
+ AR@0.5: 0.936
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res50_coco_256x192_dark-43379d20_20200709.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_384x288_dark.py
+ In Collection: DarkPose
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: topdown_heatmap_res50_coco_384x288_dark
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.735
+ AP@0.5: 0.9
+ AP@0.75: 0.801
+ AR: 0.785
+ AR@0.5: 0.937
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res50_coco_384x288_dark-33d3e5e5_20210203.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res101_coco_256x192_dark.py
+ In Collection: DarkPose
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: topdown_heatmap_res101_coco_256x192_dark
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.732
+ AP@0.5: 0.899
+ AP@0.75: 0.808
+ AR: 0.786
+ AR@0.5: 0.938
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res101_coco_256x192_dark-64d433e6_20200812.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res101_coco_384x288_dark.py
+ In Collection: DarkPose
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: topdown_heatmap_res101_coco_384x288_dark
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.749
+ AP@0.5: 0.902
+ AP@0.75: 0.816
+ AR: 0.799
+ AR@0.5: 0.939
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res101_coco_384x288_dark-cb45c88d_20210203.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res152_coco_256x192_dark.py
+ In Collection: DarkPose
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: topdown_heatmap_res152_coco_256x192_dark
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.745
+ AP@0.5: 0.905
+ AP@0.75: 0.821
+ AR: 0.797
+ AR@0.5: 0.942
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res152_coco_256x192_dark-ab4840d5_20200812.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res152_coco_384x288_dark.py
+ In Collection: DarkPose
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: topdown_heatmap_res152_coco_384x288_dark
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.757
+ AP@0.5: 0.909
+ AP@0.75: 0.826
+ AR: 0.806
+ AR@0.5: 0.943
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res152_coco_384x288_dark-d3b8ebd7_20210203.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnet_fp16_coco.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnet_fp16_coco.md
new file mode 100644
index 0000000000000000000000000000000000000000..5b147298be2648a24178af5c2b78a8d9a2b9003f
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnet_fp16_coco.md
@@ -0,0 +1,73 @@
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+
+
+SimpleBaseline2D (ECCV'2018)
+ +```bibtex +@inproceedings{xiao2018simple, + title={Simple baselines for human pose estimation and tracking}, + author={Xiao, Bin and Wu, Haiping and Wei, Yichen}, + booktitle={Proceedings of the European conference on computer vision (ECCV)}, + pages={466--481}, + year={2018} +} +``` + +
+
+
+
+
+ResNet (CVPR'2016)
+ +```bibtex +@inproceedings{he2016deep, + title={Deep residual learning for image recognition}, + author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={770--778}, + year={2016} +} +``` + +
+
+
+
+
+FP16 (ArXiv'2017)
+ +```bibtex +@article{micikevicius2017mixed, + title={Mixed precision training}, + author={Micikevicius, Paulius and Narang, Sharan and Alben, Jonah and Diamos, Gregory and Elsen, Erich and Garcia, David and Ginsburg, Boris and Houston, Michael and Kuchaiev, Oleksii and Venkatesh, Ganesh and others}, + journal={arXiv preprint arXiv:1710.03740}, + year={2017} +} +``` + +
+
+
+Results on COCO val2017 with detector having human AP of 56.4 on COCO val2017 dataset
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :-------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_resnet_50_fp16](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_256x192_fp16_dynamic.py) | 256x192 | 0.717 | 0.898 | 0.793 | 0.772 | 0.936 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res50_coco_256x192_fp16_dynamic-6edb79f3_20210430.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res50_coco_256x192_fp16_dynamic_20210430.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnet_fp16_coco.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnet_fp16_coco.yml
new file mode 100644
index 0000000000000000000000000000000000000000..8c7da122c2d29456c72c0f6e24d0eac5e4dee5b4
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnet_fp16_coco.yml
@@ -0,0 +1,25 @@
+Collections:
+- Name: SimpleBaseline2D
+ Paper:
+ Title: Simple baselines for human pose estimation and tracking
+ URL: http://openaccess.thecvf.com/content_ECCV_2018/html/Bin_Xiao_Simple_Baselines_for_ECCV_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/simplebaseline2d.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_256x192_fp16_dynamic.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture:
+ - SimpleBaseline2D
+ - ResNet
+ Training Data: COCO
+ Name: topdown_heatmap_res50_coco_256x192_fp16_dynamic
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.717
+ AP@0.5: 0.898
+ AP@0.75: 0.793
+ AR: 0.772
+ AR@0.5: 0.936
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res50_coco_256x192_fp16_dynamic-6edb79f3_20210430.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d101_coco_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d101_coco_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..fc5a5765426d7ebd76570da476fb9b59000cc765
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d101_coco_256x192.py
@@ -0,0 +1,135 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='mmcls://resnet101_v1d',
+ backbone=dict(type='ResNetV1d', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d101_coco_384x288.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d101_coco_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..8c3bcaa1ed4ed8f0c05de0909a7c2a44912b904e
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d101_coco_384x288.py
@@ -0,0 +1,135 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='mmcls://resnet101_v1d',
+ backbone=dict(type='ResNetV1d', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d152_coco_384x288.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d152_coco_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..b9397f6291c7db63ac39a56ae76bc164fdce27ba
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d152_coco_384x288.py
@@ -0,0 +1,135 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='mmcls://resnet152_v1d',
+ backbone=dict(type='ResNetV1d', depth=152),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=48,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d50_coco_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d50_coco_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..d54416419c6d87ab22523dea41fe4fc6398cbf74
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d50_coco_256x192.py
@@ -0,0 +1,135 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='mmcls://resnet50_v1d',
+ backbone=dict(type='ResNetV1d', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d50_coco_384x288.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d50_coco_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..8435abd01b5b48c5bb85abd9567849cc720cc871
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d50_coco_384x288.py
@@ -0,0 +1,135 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='mmcls://resnet50_v1d',
+ backbone=dict(type='ResNetV1d', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d_coco.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d_coco.md
new file mode 100644
index 0000000000000000000000000000000000000000..a879858488bdd1afccb7f31b489d79b3c77cf858
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d_coco.md
@@ -0,0 +1,45 @@
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+
+
+ResNetV1D (CVPR'2019)
+ +```bibtex +@inproceedings{he2019bag, + title={Bag of tricks for image classification with convolutional neural networks}, + author={He, Tong and Zhang, Zhi and Zhang, Hang and Zhang, Zhongyue and Xie, Junyuan and Li, Mu}, + booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition}, + pages={558--567}, + year={2019} +} +``` + +
+
+
+Results on COCO val2017 with detector having human AP of 56.4 on COCO val2017 dataset
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :----------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_resnetv1d_50](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d50_coco_256x192.py) | 256x192 | 0.722 | 0.897 | 0.799 | 0.777 | 0.933 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnetv1d/resnetv1d50_coco_256x192-a243b840_20200727.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnetv1d/resnetv1d50_coco_256x192_20200727.log.json) |
+| [pose_resnetv1d_50](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d50_coco_384x288.py) | 384x288 | 0.730 | 0.900 | 0.799 | 0.780 | 0.934 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnetv1d/resnetv1d50_coco_384x288-01f3fbb9_20200727.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnetv1d/resnetv1d50_coco_384x288_20200727.log.json) |
+| [pose_resnetv1d_101](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d101_coco_256x192.py) | 256x192 | 0.731 | 0.899 | 0.809 | 0.786 | 0.938 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnetv1d/resnetv1d101_coco_256x192-5bd08cab_20200727.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnetv1d/resnetv1d101_coco_256x192_20200727.log.json) |
+| [pose_resnetv1d_101](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d101_coco_384x288.py) | 384x288 | 0.748 | 0.902 | 0.816 | 0.799 | 0.939 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnetv1d/resnetv1d101_coco_384x288-5f9e421d_20200730.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnetv1d/resnetv1d101_coco_384x288-20200730.log.json) |
+| [pose_resnetv1d_152](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d152_coco_256x192.py) | 256x192 | 0.737 | 0.902 | 0.812 | 0.791 | 0.940 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnetv1d/resnetv1d152_coco_256x192-c4df51dc_20200727.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnetv1d/resnetv1d152_coco_256x192_20200727.log.json) |
+| [pose_resnetv1d_152](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d152_coco_384x288.py) | 384x288 | 0.752 | 0.909 | 0.821 | 0.802 | 0.944 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnetv1d/resnetv1d152_coco_384x288-626c622d_20200730.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnetv1d/resnetv1d152_coco_384x288-20200730.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d_coco.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d_coco.yml
new file mode 100644
index 0000000000000000000000000000000000000000..f7e9a1bd6616dfbc31bff374f0fa7950be6fc47b
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d_coco.yml
@@ -0,0 +1,104 @@
+Collections:
+- Name: ResNetV1D
+ Paper:
+ Title: Bag of tricks for image classification with convolutional neural networks
+ URL: http://openaccess.thecvf.com/content_CVPR_2019/html/He_Bag_of_Tricks_for_Image_Classification_with_Convolutional_Neural_Networks_CVPR_2019_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/resnetv1d.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d50_coco_256x192.py
+ In Collection: ResNetV1D
+ Metadata:
+ Architecture: &id001
+ - ResNetV1D
+ Training Data: COCO
+ Name: topdown_heatmap_resnetv1d50_coco_256x192
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.722
+ AP@0.5: 0.897
+ AP@0.75: 0.799
+ AR: 0.777
+ AR@0.5: 0.933
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnetv1d/resnetv1d50_coco_256x192-a243b840_20200727.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d50_coco_384x288.py
+ In Collection: ResNetV1D
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: topdown_heatmap_resnetv1d50_coco_384x288
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.73
+ AP@0.5: 0.9
+ AP@0.75: 0.799
+ AR: 0.78
+ AR@0.5: 0.934
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnetv1d/resnetv1d50_coco_384x288-01f3fbb9_20200727.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d101_coco_256x192.py
+ In Collection: ResNetV1D
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: topdown_heatmap_resnetv1d101_coco_256x192
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.731
+ AP@0.5: 0.899
+ AP@0.75: 0.809
+ AR: 0.786
+ AR@0.5: 0.938
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnetv1d/resnetv1d101_coco_256x192-5bd08cab_20200727.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d101_coco_384x288.py
+ In Collection: ResNetV1D
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: topdown_heatmap_resnetv1d101_coco_384x288
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.748
+ AP@0.5: 0.902
+ AP@0.75: 0.816
+ AR: 0.799
+ AR@0.5: 0.939
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnetv1d/resnetv1d101_coco_384x288-5f9e421d_20200730.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d152_coco_256x192.py
+ In Collection: ResNetV1D
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: topdown_heatmap_resnetv1d152_coco_256x192
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.737
+ AP@0.5: 0.902
+ AP@0.75: 0.812
+ AR: 0.791
+ AR@0.5: 0.94
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnetv1d/resnetv1d152_coco_256x192-c4df51dc_20200727.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d152_coco_384x288.py
+ In Collection: ResNetV1D
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: topdown_heatmap_resnetv1d152_coco_384x288
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.752
+ AP@0.5: 0.909
+ AP@0.75: 0.821
+ AR: 0.802
+ AR@0.5: 0.944
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnetv1d/resnetv1d152_coco_384x288-626c622d_20200730.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnext101_coco_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnext101_coco_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..082ccdda8b11db85016ddc3d4fdcf4abae665dc8
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnext101_coco_256x192.py
@@ -0,0 +1,135 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='mmcls://resnext101_32x4d',
+ backbone=dict(type='ResNeXt', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnext101_coco_384x288.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnext101_coco_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..bc548a682c8dbd8414c700c59025b024224e9226
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnext101_coco_384x288.py
@@ -0,0 +1,135 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='mmcls://resnext101_32x4d',
+ backbone=dict(type='ResNeXt', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnext50_coco_384x288.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnext50_coco_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..61645dec70964fa8db13d0b58e0871973c568239
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnext50_coco_384x288.py
@@ -0,0 +1,135 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='mmcls://resnext50_32x4d',
+ backbone=dict(type='ResNeXt', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnext_coco.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnext_coco.md
new file mode 100644
index 0000000000000000000000000000000000000000..8f241f03a418e2c1a0802d8bfaa506b9578acccb
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnext_coco.md
@@ -0,0 +1,45 @@
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+
+
+ResNext (CVPR'2017)
+ +```bibtex +@inproceedings{xie2017aggregated, + title={Aggregated residual transformations for deep neural networks}, + author={Xie, Saining and Girshick, Ross and Doll{\'a}r, Piotr and Tu, Zhuowen and He, Kaiming}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={1492--1500}, + year={2017} +} +``` + +
+
+
+Results on COCO val2017 with detector having human AP of 56.4 on COCO val2017 dataset
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :----------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_resnext_50](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnext50_coco_256x192.py) | 256x192 | 0.714 | 0.898 | 0.789 | 0.771 | 0.937 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnext/resnext50_coco_256x192-dcff15f6_20200727.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnext/resnext50_coco_256x192_20200727.log.json) |
+| [pose_resnext_50](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnext50_coco_384x288.py) | 384x288 | 0.724 | 0.899 | 0.794 | 0.777 | 0.935 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnext/resnext50_coco_384x288-412c848f_20200727.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnext/resnext50_coco_384x288_20200727.log.json) |
+| [pose_resnext_101](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnext101_coco_256x192.py) | 256x192 | 0.726 | 0.900 | 0.801 | 0.782 | 0.940 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnext/resnext101_coco_256x192-c7eba365_20200727.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnext/resnext101_coco_256x192_20200727.log.json) |
+| [pose_resnext_101](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnext101_coco_384x288.py) | 384x288 | 0.743 | 0.903 | 0.815 | 0.795 | 0.939 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnext/resnext101_coco_384x288-f5eabcd6_20200727.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnext/resnext101_coco_384x288_20200727.log.json) |
+| [pose_resnext_152](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnext152_coco_256x192.py) | 256x192 | 0.730 | 0.904 | 0.808 | 0.786 | 0.940 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnext/resnext152_coco_256x192-102449aa_20200727.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnext/resnext152_coco_256x192_20200727.log.json) |
+| [pose_resnext_152](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnext152_coco_384x288.py) | 384x288 | 0.742 | 0.902 | 0.810 | 0.794 | 0.939 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnext/resnext152_coco_384x288-806176df_20200727.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnext/resnext152_coco_384x288_20200727.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/rsn18_coco_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/rsn18_coco_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..3176d00b502132aa3409a421bd39b663c7cd100e
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/rsn18_coco_256x192.py
@@ -0,0 +1,164 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=2e-2,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 190, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='RSN',
+ unit_channels=256,
+ num_stages=1,
+ num_units=4,
+ num_blocks=[2, 2, 2, 2],
+ num_steps=4,
+ norm_cfg=dict(type='BN')),
+ keypoint_head=dict(
+ type='TopdownHeatmapMSMUHead',
+ out_shape=(64, 48),
+ unit_channels=256,
+ out_channels=channel_cfg['num_output_channels'],
+ num_stages=1,
+ num_units=4,
+ use_prm=False,
+ norm_cfg=dict(type='BN'),
+ loss_keypoint=[
+ dict(
+ type='JointsMSELoss', use_target_weight=True, loss_weight=0.25)
+ ] * 3 + [
+ dict(
+ type='JointsOHKMMSELoss',
+ use_target_weight=True,
+ loss_weight=1.)
+ ]),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='megvii',
+ shift_heatmap=False,
+ modulate_kernel=5))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ use_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='TopDownGenerateTarget',
+ kernel=[(11, 11), (9, 9), (7, 7), (5, 5)],
+ encoding='Megvii'),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=[
+ 'img',
+ ],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=4,
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/rsn50_coco_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/rsn50_coco_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..65bf136ebb9760fe4395906cce44385904e40dd7
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/rsn50_coco_256x192.py
@@ -0,0 +1,164 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-3,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='RSN',
+ unit_channels=256,
+ num_stages=1,
+ num_units=4,
+ num_blocks=[3, 4, 6, 3],
+ num_steps=4,
+ norm_cfg=dict(type='BN')),
+ keypoint_head=dict(
+ type='TopdownHeatmapMSMUHead',
+ out_shape=(64, 48),
+ unit_channels=256,
+ out_channels=channel_cfg['num_output_channels'],
+ num_stages=1,
+ num_units=4,
+ use_prm=False,
+ norm_cfg=dict(type='BN'),
+ loss_keypoint=[
+ dict(
+ type='JointsMSELoss', use_target_weight=True, loss_weight=0.25)
+ ] * 3 + [
+ dict(
+ type='JointsOHKMMSELoss',
+ use_target_weight=True,
+ loss_weight=1.)
+ ]),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='megvii',
+ shift_heatmap=False,
+ modulate_kernel=5))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ use_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='TopDownGenerateTarget',
+ kernel=[(11, 11), (9, 9), (7, 7), (5, 5)],
+ encoding='Megvii'),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=[
+ 'img',
+ ],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=4,
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/rsn_coco.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/rsn_coco.md
new file mode 100644
index 0000000000000000000000000000000000000000..7cbb691e7ac8f1f73842e371dce2da6c943ce85d
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/rsn_coco.md
@@ -0,0 +1,44 @@
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+
+
+RSN (ECCV'2020)
+ +```bibtex +@misc{cai2020learning, + title={Learning Delicate Local Representations for Multi-Person Pose Estimation}, + author={Yuanhao Cai and Zhicheng Wang and Zhengxiong Luo and Binyi Yin and Angang Du and Haoqian Wang and Xinyu Zhou and Erjin Zhou and Xiangyu Zhang and Jian Sun}, + year={2020}, + eprint={2003.04030}, + archivePrefix={arXiv}, + primaryClass={cs.CV} +} +``` + +
+
+
+Results on COCO val2017 with detector having human AP of 56.4 on COCO val2017 dataset
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :-------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [rsn_18](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/rsn18_coco_256x192.py) | 256x192 | 0.704 | 0.887 | 0.779 | 0.771 | 0.926 | [ckpt](https://download.openmmlab.com/mmpose/top_down/rsn/rsn18_coco_256x192-72f4b4a7_20201127.pth) | [log](https://download.openmmlab.com/mmpose/top_down/rsn/rsn18_coco_256x192_20201127.log.json) |
+| [rsn_50](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/rsn50_coco_256x192.py) | 256x192 | 0.723 | 0.896 | 0.800 | 0.788 | 0.934 | [ckpt](https://download.openmmlab.com/mmpose/top_down/rsn/rsn50_coco_256x192-72ffe709_20201127.pth) | [log](https://download.openmmlab.com/mmpose/top_down/rsn/rsn50_coco_256x192_20201127.log.json) |
+| [2xrsn_50](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/2xrsn50_coco_256x192.py) | 256x192 | 0.745 | 0.899 | 0.818 | 0.809 | 0.939 | [ckpt](https://download.openmmlab.com/mmpose/top_down/rsn/2xrsn50_coco_256x192-50648f0e_20201127.pth) | [log](https://download.openmmlab.com/mmpose/top_down/rsn/2xrsn50_coco_256x192_20201127.log.json) |
+| [3xrsn_50](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/3xrsn50_coco_256x192.py) | 256x192 | 0.750 | 0.900 | 0.823 | 0.813 | 0.940 | [ckpt](https://download.openmmlab.com/mmpose/top_down/rsn/3xrsn50_coco_256x192-58f57a68_20201127.pth) | [log](https://download.openmmlab.com/mmpose/top_down/rsn/3xrsn50_coco_256x192_20201127.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/scnet101_coco_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/scnet101_coco_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..0b4c33b6168b3da4ac7bfcce3d736c85ef2a6b10
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/scnet101_coco_256x192.py
@@ -0,0 +1,134 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/scnet101-94250a77.pth',
+ backbone=dict(type='SCNet', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=1,
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/scnet50_coco_384x288.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/scnet50_coco_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..2909f7872788cdb89d8e9d1ef24363fc3357ae01
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/scnet50_coco_384x288.py
@@ -0,0 +1,134 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/scnet50-7ef0a199.pth',
+ backbone=dict(type='SCNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=1,
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/scnet_coco.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/scnet_coco.md
new file mode 100644
index 0000000000000000000000000000000000000000..38754c0c2c26aca8553bee16f9cc6ff0f77c35db
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/scnet_coco.md
@@ -0,0 +1,43 @@
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+
+
+SCNet (CVPR'2020)
+ +```bibtex +@inproceedings{liu2020improving, + title={Improving Convolutional Networks with Self-Calibrated Convolutions}, + author={Liu, Jiang-Jiang and Hou, Qibin and Cheng, Ming-Ming and Wang, Changhu and Feng, Jiashi}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + pages={10096--10105}, + year={2020} +} +``` + +
+
+
+Results on COCO val2017 with detector having human AP of 56.4 on COCO val2017 dataset
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :----------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_scnet_50](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/scnet50_coco_256x192.py) | 256x192 | 0.728 | 0.899 | 0.807 | 0.784 | 0.938 | [ckpt](https://download.openmmlab.com/mmpose/top_down/scnet/scnet50_coco_256x192-6920f829_20200709.pth) | [log](https://download.openmmlab.com/mmpose/top_down/scnet/scnet50_coco_256x192_20200709.log.json) |
+| [pose_scnet_50](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/scnet50_coco_384x288.py) | 384x288 | 0.751 | 0.906 | 0.818 | 0.802 | 0.943 | [ckpt](https://download.openmmlab.com/mmpose/top_down/scnet/scnet50_coco_384x288-9cacd0ea_20200709.pth) | [log](https://download.openmmlab.com/mmpose/top_down/scnet/scnet50_coco_384x288_20200709.log.json) |
+| [pose_scnet_101](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/scnet101_coco_256x192.py) | 256x192 | 0.733 | 0.903 | 0.813 | 0.790 | 0.941 | [ckpt](https://download.openmmlab.com/mmpose/top_down/scnet/scnet101_coco_256x192-6d348ef9_20200709.pth) | [log](https://download.openmmlab.com/mmpose/top_down/scnet/scnet101_coco_256x192_20200709.log.json) |
+| [pose_scnet_101](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/scnet101_coco_384x288.py) | 384x288 | 0.752 | 0.906 | 0.823 | 0.804 | 0.943 | [ckpt](https://download.openmmlab.com/mmpose/top_down/scnet/scnet101_coco_384x288-0b6e631b_20200709.pth) | [log](https://download.openmmlab.com/mmpose/top_down/scnet/scnet101_coco_384x288_20200709.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/seresnet101_coco_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/seresnet101_coco_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..1942597ead9d51a576bfe8da48f9cbb2e80bd61b
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/seresnet101_coco_256x192.py
@@ -0,0 +1,135 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='mmcls://se-resnet101',
+ backbone=dict(type='SEResNet', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/seresnet101_coco_384x288.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/seresnet101_coco_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..412f79dcd2b4c8280330d5a9aa92a6370457f3ea
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/seresnet101_coco_384x288.py
@@ -0,0 +1,135 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='mmcls://se-resnet101',
+ backbone=dict(type='SEResNet', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/seresnet152_coco_384x288.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/seresnet152_coco_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..83734d70a0f1a452303fdb99bbadedcac0e22f2c
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/seresnet152_coco_384x288.py
@@ -0,0 +1,135 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(type='SEResNet', depth=152),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=48,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/seresnet50_coco_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/seresnet50_coco_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..f499c61904007f2a7edbfe31f199d3f0465989a3
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/seresnet50_coco_256x192.py
@@ -0,0 +1,135 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='mmcls://se-resnet50',
+ backbone=dict(type='SEResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/seresnet50_coco_384x288.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/seresnet50_coco_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..87cddbfc3aae50b14f2a05e1499bc4781b2d1cbc
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/seresnet50_coco_384x288.py
@@ -0,0 +1,135 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='mmcls://se-resnet50',
+ backbone=dict(type='SEResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/seresnet_coco.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/seresnet_coco.yml
new file mode 100644
index 0000000000000000000000000000000000000000..75d1b9ceaa7f68496afda063c5fc1e3e25d65590
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/seresnet_coco.yml
@@ -0,0 +1,104 @@
+Collections:
+- Name: SEResNet
+ Paper:
+ Title: Squeeze-and-excitation networks
+ URL: http://openaccess.thecvf.com/content_cvpr_2018/html/Hu_Squeeze-and-Excitation_Networks_CVPR_2018_paper
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/seresnet.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/seresnet50_coco_256x192.py
+ In Collection: SEResNet
+ Metadata:
+ Architecture: &id001
+ - SEResNet
+ Training Data: COCO
+ Name: topdown_heatmap_seresnet50_coco_256x192
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.728
+ AP@0.5: 0.9
+ AP@0.75: 0.809
+ AR: 0.784
+ AR@0.5: 0.94
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/seresnet/seresnet50_coco_256x192-25058b66_20200727.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/seresnet50_coco_384x288.py
+ In Collection: SEResNet
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: topdown_heatmap_seresnet50_coco_384x288
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.748
+ AP@0.5: 0.905
+ AP@0.75: 0.819
+ AR: 0.799
+ AR@0.5: 0.941
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/seresnet/seresnet50_coco_384x288-bc0b7680_20200727.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/seresnet101_coco_256x192.py
+ In Collection: SEResNet
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: topdown_heatmap_seresnet101_coco_256x192
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.734
+ AP@0.5: 0.904
+ AP@0.75: 0.815
+ AR: 0.79
+ AR@0.5: 0.942
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/seresnet/seresnet101_coco_256x192-83f29c4d_20200727.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/seresnet101_coco_384x288.py
+ In Collection: SEResNet
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: topdown_heatmap_seresnet101_coco_384x288
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.753
+ AP@0.5: 0.907
+ AP@0.75: 0.823
+ AR: 0.805
+ AR@0.5: 0.943
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/seresnet/seresnet101_coco_384x288-48de1709_20200727.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/seresnet152_coco_256x192.py
+ In Collection: SEResNet
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: topdown_heatmap_seresnet152_coco_256x192
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.73
+ AP@0.5: 0.899
+ AP@0.75: 0.81
+ AR: 0.786
+ AR@0.5: 0.94
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/seresnet/seresnet152_coco_256x192-1c628d79_20200727.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/seresnet152_coco_384x288.py
+ In Collection: SEResNet
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: topdown_heatmap_seresnet152_coco_384x288
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.753
+ AP@0.5: 0.906
+ AP@0.75: 0.823
+ AR: 0.806
+ AR@0.5: 0.945
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/seresnet/seresnet152_coco_384x288-58b23ee8_20200727.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/shufflenetv1_coco.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/shufflenetv1_coco.md
new file mode 100644
index 0000000000000000000000000000000000000000..59592e13147ab66bb5048e2f547468c409552440
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/shufflenetv1_coco.md
@@ -0,0 +1,41 @@
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+
+
+ShufflenetV1 (CVPR'2018)
+ +```bibtex +@inproceedings{zhang2018shufflenet, + title={Shufflenet: An extremely efficient convolutional neural network for mobile devices}, + author={Zhang, Xiangyu and Zhou, Xinyu and Lin, Mengxiao and Sun, Jian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={6848--6856}, + year={2018} +} +``` + +
+
+
+Results on COCO val2017 with detector having human AP of 56.4 on COCO val2017 dataset
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :----------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_shufflenetv1](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/shufflenetv1_coco_256x192.py) | 256x192 | 0.585 | 0.845 | 0.650 | 0.651 | 0.894 | [ckpt](https://download.openmmlab.com/mmpose/top_down/shufflenetv1/shufflenetv1_coco_256x192-353bc02c_20200727.pth) | [log](https://download.openmmlab.com/mmpose/top_down/shufflenetv1/shufflenetv1_coco_256x192_20200727.log.json) |
+| [pose_shufflenetv1](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/shufflenetv1_coco_384x288.py) | 384x288 | 0.622 | 0.859 | 0.685 | 0.684 | 0.901 | [ckpt](https://download.openmmlab.com/mmpose/top_down/shufflenetv1/shufflenetv1_coco_384x288-b2930b24_20200804.pth) | [log](https://download.openmmlab.com/mmpose/top_down/shufflenetv1/shufflenetv1_coco_384x288_20200804.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/shufflenetv1_coco.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/shufflenetv1_coco.yml
new file mode 100644
index 0000000000000000000000000000000000000000..29947512c319b99576c526ed60c83e74ee3acc6a
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/shufflenetv1_coco.yml
@@ -0,0 +1,41 @@
+Collections:
+- Name: ShufflenetV1
+ Paper:
+ Title: 'Shufflenet: An extremely efficient convolutional neural network for mobile
+ devices'
+ URL: http://openaccess.thecvf.com/content_cvpr_2018/html/Zhang_ShuffleNet_An_Extremely_CVPR_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/shufflenetv1.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/shufflenetv1_coco_256x192.py
+ In Collection: ShufflenetV1
+ Metadata:
+ Architecture: &id001
+ - ShufflenetV1
+ Training Data: COCO
+ Name: topdown_heatmap_shufflenetv1_coco_256x192
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.585
+ AP@0.5: 0.845
+ AP@0.75: 0.65
+ AR: 0.651
+ AR@0.5: 0.894
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/shufflenetv1/shufflenetv1_coco_256x192-353bc02c_20200727.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/shufflenetv1_coco_384x288.py
+ In Collection: ShufflenetV1
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: topdown_heatmap_shufflenetv1_coco_384x288
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.622
+ AP@0.5: 0.859
+ AP@0.75: 0.685
+ AR: 0.684
+ AR@0.5: 0.901
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/shufflenetv1/shufflenetv1_coco_384x288-b2930b24_20200804.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/shufflenetv2_coco.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/shufflenetv2_coco.md
new file mode 100644
index 0000000000000000000000000000000000000000..7c88ba017408204c1605a13d51a9935db5c01484
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/shufflenetv2_coco.md
@@ -0,0 +1,41 @@
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+
+
+ShufflenetV2 (ECCV'2018)
+ +```bibtex +@inproceedings{ma2018shufflenet, + title={Shufflenet v2: Practical guidelines for efficient cnn architecture design}, + author={Ma, Ningning and Zhang, Xiangyu and Zheng, Hai-Tao and Sun, Jian}, + booktitle={Proceedings of the European conference on computer vision (ECCV)}, + pages={116--131}, + year={2018} +} +``` + +
+
+
+Results on COCO val2017 with detector having human AP of 56.4 on COCO val2017 dataset
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :----------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_shufflenetv2](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/shufflenetv2_coco_256x192.py) | 256x192 | 0.599 | 0.854 | 0.663 | 0.664 | 0.899 | [ckpt](https://download.openmmlab.com/mmpose/top_down/shufflenetv2/shufflenetv2_coco_256x192-0aba71c7_20200921.pth) | [log](https://download.openmmlab.com/mmpose/top_down/shufflenetv2/shufflenetv2_coco_256x192_20200921.log.json) |
+| [pose_shufflenetv2](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/shufflenetv2_coco_384x288.py) | 384x288 | 0.636 | 0.865 | 0.705 | 0.697 | 0.909 | [ckpt](https://download.openmmlab.com/mmpose/top_down/shufflenetv2/shufflenetv2_coco_384x288-fb38ac3a_20200921.pth) | [log](https://download.openmmlab.com/mmpose/top_down/shufflenetv2/shufflenetv2_coco_384x288_20200921.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/shufflenetv2_coco_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/shufflenetv2_coco_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..44745a67781c2b1e9d79f9ee1841c32bde53d16a
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/shufflenetv2_coco_256x192.py
@@ -0,0 +1,135 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='mmcls://shufflenet_v2',
+ backbone=dict(type='ShuffleNetV2', widen_factor=1.0),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1024,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/shufflenetv2_coco_384x288.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/shufflenetv2_coco_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..ebff9346c548cb2bc657202d0dfa457aa24b18f8
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/shufflenetv2_coco_384x288.py
@@ -0,0 +1,135 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='mmcls://shufflenet_v2',
+ backbone=dict(type='ShuffleNetV2', widen_factor=1.0),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1024,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vgg_coco.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vgg_coco.md
new file mode 100644
index 0000000000000000000000000000000000000000..4cc6f6f5dd7c41c212c81865b6dbbe26ac0b2a3b
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vgg_coco.md
@@ -0,0 +1,39 @@
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+
+
+VGG (ICLR'2015)
+ +```bibtex +@article{simonyan2014very, + title={Very deep convolutional networks for large-scale image recognition}, + author={Simonyan, Karen and Zisserman, Andrew}, + journal={arXiv preprint arXiv:1409.1556}, + year={2014} +} +``` + +
+
+
+Results on COCO val2017 with detector having human AP of 56.4 on COCO val2017 dataset
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :----------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [vgg](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vgg16_bn_coco_256x192.py) | 256x192 | 0.698 | 0.890 | 0.768 | 0.754 | 0.929 | [ckpt](https://download.openmmlab.com/mmpose/top_down/vgg/vgg16_bn_coco_256x192-7e7c58d6_20210517.pth) | [log](https://download.openmmlab.com/mmpose/top_down/vgg/vgg16_bn_coco_256x192_20210517.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vipnas_coco.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vipnas_coco.md
new file mode 100644
index 0000000000000000000000000000000000000000..c86943c5224543e632a100bf18d83f44f3691d4b
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vipnas_coco.md
@@ -0,0 +1,40 @@
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+
+
+ViPNAS (CVPR'2021)
+ +```bibtex +@article{xu2021vipnas, + title={ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search}, + author={Xu, Lumin and Guan, Yingda and Jin, Sheng and Liu, Wentao and Qian, Chen and Luo, Ping and Ouyang, Wanli and Wang, Xiaogang}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + year={2021} +} +``` + +
+
+
+Results on COCO val2017 with detector having human AP of 56.4 on COCO val2017 dataset
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :-------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [S-ViPNAS-MobileNetV3](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vipnas_mbv3_coco_256x192.py) | 256x192 | 0.700 | 0.887 | 0.778 | 0.757 | 0.929 | [ckpt](https://download.openmmlab.com/mmpose/top_down/vipnas/vipnas_mbv3_coco_256x192-7018731a_20211122.pth) | [log](https://download.openmmlab.com/mmpose/top_down/vipnas/vipnas_mbv3_coco_256x192_20211122.log.json) |
+| [S-ViPNAS-Res50](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vipnas_res50_coco_256x192.py) | 256x192 | 0.711 | 0.893 | 0.789 | 0.769 | 0.934 | [ckpt](https://download.openmmlab.com/mmpose/top_down/vipnas/vipnas_res50_coco_256x192-cc43b466_20210624.pth) | [log](https://download.openmmlab.com/mmpose/top_down/vipnas/vipnas_res50_coco_256x192_20210624.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vipnas_coco.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vipnas_coco.yml
new file mode 100644
index 0000000000000000000000000000000000000000..e476d28d12d5ae3679865034213443c389767d02
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vipnas_coco.yml
@@ -0,0 +1,40 @@
+Collections:
+- Name: ViPNAS
+ Paper:
+ Title: 'ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search'
+ URL: https://arxiv.org/abs/2105.10154
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/vipnas.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vipnas_mbv3_coco_256x192.py
+ In Collection: ViPNAS
+ Metadata:
+ Architecture: &id001
+ - ViPNAS
+ Training Data: COCO
+ Name: topdown_heatmap_vipnas_mbv3_coco_256x192
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.7
+ AP@0.5: 0.887
+ AP@0.75: 0.778
+ AR: 0.757
+ AR@0.5: 0.929
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/vipnas/vipnas_mbv3_coco_256x192-7018731a_20211122.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vipnas_res50_coco_256x192.py
+ In Collection: ViPNAS
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: topdown_heatmap_vipnas_res50_coco_256x192
+ Results:
+ - Dataset: COCO
+ Metrics:
+ AP: 0.711
+ AP@0.5: 0.893
+ AP@0.75: 0.789
+ AR: 0.769
+ AR@0.5: 0.934
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/vipnas/vipnas_res50_coco_256x192-cc43b466_20210624.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vipnas_mbv3_coco_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vipnas_mbv3_coco_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..96420528833e9fcc8849444db3d4a03307e295cc
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vipnas_mbv3_coco_256x192.py
@@ -0,0 +1,138 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', key_indicator='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(type='ViPNAS_MobileNetV3'),
+ keypoint_head=dict(
+ type='ViPNASHeatmapSimpleHead',
+ in_channels=160,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_filters=(160, 160, 160),
+ num_deconv_groups=(160, 160, 160),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vipnas_res50_coco_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vipnas_res50_coco_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..3409caee7837407748e928de81612072161f6801
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vipnas_res50_coco_256x192.py
@@ -0,0 +1,136 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py'
+]
+evaluation = dict(interval=10, metric='mAP', key_indicator='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(type='ViPNAS_ResNet', depth=50),
+ keypoint_head=dict(
+ type='ViPNASHeatmapSimpleHead',
+ in_channels=608,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vitPose+_huge_coco+aic+mpii+ap10k+apt36k+wholebody_256x192_udp.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vitPose+_huge_coco+aic+mpii+ap10k+apt36k+wholebody_256x192_udp.py
new file mode 100644
index 0000000000000000000000000000000000000000..612aaf0b32688fdf874c30eefe6bbb3ab0fb9767
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vitPose+_huge_coco+aic+mpii+ap10k+apt36k+wholebody_256x192_udp.py
@@ -0,0 +1,491 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py',
+ '../../../../_base_/datasets/aic_info.py',
+ '../../../../_base_/datasets/mpii_info.py',
+ '../../../../_base_/datasets/ap10k_info.py',
+ '../../../../_base_/datasets/coco_wholebody_info.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(type='AdamW', lr=1e-3, betas=(0.9, 0.999), weight_decay=0.1,
+ constructor='LayerDecayOptimizerConstructor',
+ paramwise_cfg=dict(
+ num_layers=32,
+ layer_decay_rate=0.8,
+ custom_keys={
+ 'bias': dict(decay_multi=0.),
+ 'pos_embed': dict(decay_mult=0.),
+ 'relative_position_bias_table': dict(decay_mult=0.),
+ 'norm': dict(decay_mult=0.)
+ }
+ )
+ )
+
+optimizer_config = dict(grad_clip=dict(max_norm=1., norm_type=2))
+
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+target_type = 'GaussianHeatmap'
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+aic_channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+mpii_channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=list(range(16)),
+ inference_channel=list(range(16)))
+crowdpose_channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+ap10k_channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+cocowholebody_channel_cfg = dict(
+ num_output_channels=133,
+ dataset_joints=133,
+ dataset_channel=[
+ list(range(133)),
+ ],
+ inference_channel=list(range(133)))
+
+
+# model settings
+model = dict(
+ type='TopDownMoE',
+ pretrained=None,
+ backbone=dict(
+ type='ViTMoE',
+ img_size=(256, 192),
+ patch_size=16,
+ embed_dim=1280,
+ depth=32,
+ num_heads=16,
+ ratio=1,
+ use_checkpoint=False,
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_path_rate=0.55,
+ num_expert=6,
+ part_features=320
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1280,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ associate_keypoint_head=[
+ dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1280,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=aic_channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1280,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=mpii_channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1280,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=ap10k_channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1280,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=ap10k_channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1280,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=cocowholebody_channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ ],
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=False,
+ target_type=target_type,
+ modulate_kernel=11,
+ use_udp=True))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+ max_num_joints=133,
+ dataset_idx=0,
+)
+
+aic_data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=aic_channel_cfg['num_output_channels'],
+ num_joints=aic_channel_cfg['dataset_joints'],
+ dataset_channel=aic_channel_cfg['dataset_channel'],
+ inference_channel=aic_channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+ max_num_joints=133,
+ dataset_idx=1,
+)
+
+mpii_data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=mpii_channel_cfg['num_output_channels'],
+ num_joints=mpii_channel_cfg['dataset_joints'],
+ dataset_channel=mpii_channel_cfg['dataset_channel'],
+ inference_channel=mpii_channel_cfg['inference_channel'],
+ max_num_joints=133,
+ dataset_idx=2,
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+ap10k_data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+ max_num_joints=133,
+ dataset_idx=3,
+)
+
+ap36k_data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+ max_num_joints=133,
+ dataset_idx=4,
+)
+
+cocowholebody_data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=cocowholebody_channel_cfg['num_output_channels'],
+ num_joints=cocowholebody_channel_cfg['dataset_joints'],
+ dataset_channel=cocowholebody_channel_cfg['dataset_channel'],
+ inference_channel=cocowholebody_channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+ dataset_idx=5,
+ max_num_joints=133,
+)
+
+cocowholebody_train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs', 'dataset_idx'
+ ]),
+]
+
+ap10k_train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs', 'dataset_idx'
+ ]),
+]
+
+aic_train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs', 'dataset_idx'
+ ]),
+]
+
+mpii_train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='TopDownGenerateTarget',
+ sigma=2,
+ encoding='UDP',
+ target_type=target_type),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs', 'dataset_idx'
+ ]),
+]
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='TopDownGenerateTarget',
+ sigma=2,
+ encoding='UDP',
+ target_type=target_type),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs', 'dataset_idx'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs', 'dataset_idx'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+aic_data_root = 'data/aic'
+mpii_data_root = 'data/mpii'
+ap10k_data_root = 'data/ap10k'
+ap36k_data_root = 'data/ap36k'
+
+data = dict(
+ samples_per_gpu=128,
+ workers_per_gpu=8,
+ val_dataloader=dict(samples_per_gpu=64),
+ test_dataloader=dict(samples_per_gpu=64),
+ train=[
+ dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ dict(
+ type='TopDownAicDataset',
+ ann_file=f'{aic_data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{aic_data_root}/ai_challenger_keypoint_train_20170909/'
+ 'keypoint_train_images_20170902/',
+ data_cfg=aic_data_cfg,
+ pipeline=aic_train_pipeline,
+ dataset_info={{_base_.aic_info}}),
+ dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{mpii_data_root}/annotations/mpii_train.json',
+ img_prefix=f'{mpii_data_root}/images/',
+ data_cfg=mpii_data_cfg,
+ pipeline=mpii_train_pipeline,
+ dataset_info={{_base_.mpii_info}}),
+ dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{ap10k_data_root}/annotations/ap10k-train-split1.json',
+ img_prefix=f'{ap10k_data_root}/data/',
+ data_cfg=ap10k_data_cfg,
+ pipeline=ap10k_train_pipeline,
+ dataset_info={{_base_.ap10k_info}}),
+ dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{ap36k_data_root}/annotations/train_annotations_1.json',
+ img_prefix=f'{ap36k_data_root}/',
+ data_cfg=ap36k_data_cfg,
+ pipeline=ap10k_train_pipeline,
+ dataset_info={{_base_.ap10k_info}}),
+ dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=cocowholebody_data_cfg,
+ pipeline=cocowholebody_train_pipeline,
+ dataset_info={{_base_.cocowholebody_info}}),
+ ],
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
+
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vitPose+_large_coco+aic+mpii+ap10k+apt36k+wholebody_256x192_udp.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vitPose+_large_coco+aic+mpii+ap10k+apt36k+wholebody_256x192_udp.py
new file mode 100644
index 0000000000000000000000000000000000000000..0936de449b9a2bb74510b51e1d4e81f2c11eb8ac
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vitPose+_large_coco+aic+mpii+ap10k+apt36k+wholebody_256x192_udp.py
@@ -0,0 +1,491 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco.py',
+ '../../../../_base_/datasets/aic_info.py',
+ '../../../../_base_/datasets/mpii_info.py',
+ '../../../../_base_/datasets/ap10k_info.py',
+ '../../../../_base_/datasets/coco_wholebody_info.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(type='AdamW', lr=1e-3, betas=(0.9, 0.999), weight_decay=0.1,
+ constructor='LayerDecayOptimizerConstructor',
+ paramwise_cfg=dict(
+ num_layers=24,
+ layer_decay_rate=0.8,
+ custom_keys={
+ 'bias': dict(decay_multi=0.),
+ 'pos_embed': dict(decay_mult=0.),
+ 'relative_position_bias_table': dict(decay_mult=0.),
+ 'norm': dict(decay_mult=0.)
+ }
+ )
+ )
+
+optimizer_config = dict(grad_clip=dict(max_norm=1., norm_type=2))
+
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+target_type = 'GaussianHeatmap'
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+aic_channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+mpii_channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=list(range(16)),
+ inference_channel=list(range(16)))
+crowdpose_channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+ap10k_channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+cocowholebody_channel_cfg = dict(
+ num_output_channels=133,
+ dataset_joints=133,
+ dataset_channel=[
+ list(range(133)),
+ ],
+ inference_channel=list(range(133)))
+
+
+# model settings
+model = dict(
+ type='TopDownMoE',
+ pretrained=None,
+ backbone=dict(
+ type='ViTMoE',
+ img_size=(256, 192),
+ patch_size=16,
+ embed_dim=1024,
+ depth=24,
+ num_heads=16,
+ ratio=1,
+ use_checkpoint=False,
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_path_rate=0.5,
+ num_expert=6,
+ part_features=256
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1024,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ associate_keypoint_head=[
+ dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1024,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=aic_channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1024,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=mpii_channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1024,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=ap10k_channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1024,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=ap10k_channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1024,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=cocowholebody_channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ ],
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=False,
+ target_type=target_type,
+ modulate_kernel=11,
+ use_udp=True))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+ max_num_joints=133,
+ dataset_idx=0,
+)
+
+aic_data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=aic_channel_cfg['num_output_channels'],
+ num_joints=aic_channel_cfg['dataset_joints'],
+ dataset_channel=aic_channel_cfg['dataset_channel'],
+ inference_channel=aic_channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+ max_num_joints=133,
+ dataset_idx=1,
+)
+
+mpii_data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=mpii_channel_cfg['num_output_channels'],
+ num_joints=mpii_channel_cfg['dataset_joints'],
+ dataset_channel=mpii_channel_cfg['dataset_channel'],
+ inference_channel=mpii_channel_cfg['inference_channel'],
+ max_num_joints=133,
+ dataset_idx=2,
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+ap10k_data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+ max_num_joints=133,
+ dataset_idx=3,
+)
+
+ap36k_data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+ max_num_joints=133,
+ dataset_idx=4,
+)
+
+cocowholebody_data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=cocowholebody_channel_cfg['num_output_channels'],
+ num_joints=cocowholebody_channel_cfg['dataset_joints'],
+ dataset_channel=cocowholebody_channel_cfg['dataset_channel'],
+ inference_channel=cocowholebody_channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+ dataset_idx=5,
+ max_num_joints=133,
+)
+
+cocowholebody_train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs', 'dataset_idx'
+ ]),
+]
+
+ap10k_train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs', 'dataset_idx'
+ ]),
+]
+
+aic_train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs', 'dataset_idx'
+ ]),
+]
+
+mpii_train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='TopDownGenerateTarget',
+ sigma=2,
+ encoding='UDP',
+ target_type=target_type),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs', 'dataset_idx'
+ ]),
+]
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='TopDownGenerateTarget',
+ sigma=2,
+ encoding='UDP',
+ target_type=target_type),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs', 'dataset_idx'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs', 'dataset_idx'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+aic_data_root = 'data/aic'
+mpii_data_root = 'data/mpii'
+ap10k_data_root = 'data/ap10k'
+ap36k_data_root = 'data/ap36k'
+
+data = dict(
+ samples_per_gpu=128,
+ workers_per_gpu=8,
+ val_dataloader=dict(samples_per_gpu=64),
+ test_dataloader=dict(samples_per_gpu=64),
+ train=[
+ dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ dict(
+ type='TopDownAicDataset',
+ ann_file=f'{aic_data_root}/annotations/person_keypoints_train2017.json',
+ img_prefix=f'{aic_data_root}/ai_challenger_keypoint_train_20170909/'
+ 'keypoint_train_images_20170902/',
+ data_cfg=aic_data_cfg,
+ pipeline=aic_train_pipeline,
+ dataset_info={{_base_.aic_info}}),
+ dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{mpii_data_root}/annotations/mpii_train.json',
+ img_prefix=f'{mpii_data_root}/images/',
+ data_cfg=mpii_data_cfg,
+ pipeline=mpii_train_pipeline,
+ dataset_info={{_base_.mpii_info}}),
+ dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{ap10k_data_root}/annotations/ap10k-train-split1.json',
+ img_prefix=f'{ap10k_data_root}/data/',
+ data_cfg=ap10k_data_cfg,
+ pipeline=ap10k_train_pipeline,
+ dataset_info={{_base_.ap10k_info}}),
+ dict(
+ type='AnimalAP10KDataset',
+ ann_file=f'{ap36k_data_root}/annotations/train_annotations_1.json',
+ img_prefix=f'{ap36k_data_root}/',
+ data_cfg=ap36k_data_cfg,
+ pipeline=ap10k_train_pipeline,
+ dataset_info={{_base_.ap10k_info}}),
+ dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=cocowholebody_data_cfg,
+ pipeline=cocowholebody_train_pipeline,
+ dataset_info={{_base_.cocowholebody_info}}),
+ ],
+ val=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoDataset',
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
+
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/ViTPose_base_crowdpose_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/ViTPose_base_crowdpose_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..ad98bc24d78b89e19db7f142aefce74d892ecd81
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/ViTPose_base_crowdpose_256x192.py
@@ -0,0 +1,149 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/crowdpose.py'
+]
+evaluation = dict(interval=10, metric='mAP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='ViT',
+ img_size=(256, 192),
+ patch_size=16,
+ embed_dim=768,
+ depth=12,
+ num_heads=12,
+ ratio=1,
+ use_checkpoint=False,
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_path_rate=0.3,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=768,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ crowd_matching=False,
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/crowdpose/annotations/'
+ 'det_for_crowd_test_0.1_0.5.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=6,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/crowdpose'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_trainval.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}))
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/ViTPose_huge_crowdpose_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/ViTPose_huge_crowdpose_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..3ddd2885a1457afa74344e8ced59299053af40a5
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/ViTPose_huge_crowdpose_256x192.py
@@ -0,0 +1,149 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/crowdpose.py'
+]
+evaluation = dict(interval=10, metric='mAP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='ViT',
+ img_size=(256, 192),
+ patch_size=16,
+ embed_dim=1280,
+ depth=32,
+ num_heads=16,
+ ratio=1,
+ use_checkpoint=False,
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_path_rate=0.3,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1280,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ crowd_matching=False,
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/crowdpose/annotations/'
+ 'det_for_crowd_test_0.1_0.5.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=6,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/crowdpose'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_trainval.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}))
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/ViTPose_large_crowdpose_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/ViTPose_large_crowdpose_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..9d6fd54f8211d2b3d451dc9b5c3331ba85583b0d
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/ViTPose_large_crowdpose_256x192.py
@@ -0,0 +1,149 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/crowdpose.py'
+]
+evaluation = dict(interval=10, metric='mAP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='ViT',
+ img_size=(256, 192),
+ patch_size=16,
+ embed_dim=1024,
+ depth=24,
+ num_heads=16,
+ ratio=1,
+ use_checkpoint=False,
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_path_rate=0.3,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1024,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ crowd_matching=False,
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/crowdpose/annotations/'
+ 'det_for_crowd_test_0.1_0.5.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=6,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/crowdpose'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_trainval.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}))
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/hrnet_crowdpose.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/hrnet_crowdpose.md
new file mode 100644
index 0000000000000000000000000000000000000000..6d3e2473c30fecf4c7f49b262b4ea2a8cefac992
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/hrnet_crowdpose.md
@@ -0,0 +1,39 @@
+
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+
+
+HRNet (CVPR'2019)
+ +```bibtex +@inproceedings{sun2019deep, + title={Deep high-resolution representation learning for human pose estimation}, + author={Sun, Ke and Xiao, Bin and Liu, Dong and Wang, Jingdong}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={5693--5703}, + year={2019} +} +``` + +
+
+
+Results on CrowdPose test with [YOLOv3](https://github.com/eriklindernoren/PyTorch-YOLOv3) human detector
+
+| Arch | Input Size | AP | AP50 | AP75 | AP (E) | AP (M) | AP (H) | ckpt | log |
+| :----------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: | :------: |
+| [pose_hrnet_w32](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/hrnet_w32_crowdpose_256x192.py) | 256x192 | 0.675 | 0.825 | 0.729 | 0.770 | 0.687 | 0.553 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_crowdpose_256x192-960be101_20201227.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_crowdpose_256x192_20201227.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/hrnet_crowdpose.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/hrnet_crowdpose.yml
new file mode 100644
index 0000000000000000000000000000000000000000..cf1f8b7a2d6aadb6d52f1a7f35e5a70db276ce7d
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/hrnet_crowdpose.yml
@@ -0,0 +1,25 @@
+Collections:
+- Name: HRNet
+ Paper:
+ Title: Deep high-resolution representation learning for human pose estimation
+ URL: http://openaccess.thecvf.com/content_CVPR_2019/html/Sun_Deep_High-Resolution_Representation_Learning_for_Human_Pose_Estimation_CVPR_2019_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/hrnet.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/hrnet_w32_crowdpose_256x192.py
+ In Collection: HRNet
+ Metadata:
+ Architecture:
+ - HRNet
+ Training Data: CrowdPose
+ Name: topdown_heatmap_hrnet_w32_crowdpose_256x192
+ Results:
+ - Dataset: CrowdPose
+ Metrics:
+ AP: 0.675
+ AP (E): 0.77
+ AP (H): 0.553
+ AP (M): 0.687
+ AP@0.5: 0.825
+ AP@0.75: 0.729
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_crowdpose_256x192-960be101_20201227.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/hrnet_w32_crowdpose_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/hrnet_w32_crowdpose_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..b8fc5f47d5dbc16ae36b83f0df53955670509bb1
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/hrnet_w32_crowdpose_256x192.py
@@ -0,0 +1,164 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/crowdpose.py'
+]
+evaluation = dict(interval=10, metric='mAP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ crowd_matching=False,
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/crowdpose/annotations/'
+ 'det_for_crowd_test_0.1_0.5.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=6,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/crowdpose'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_trainval.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}))
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/hrnet_w32_crowdpose_384x288.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/hrnet_w32_crowdpose_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..f94fda4a1980fec4b5859f1139b479a764e1f8e6
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/hrnet_w32_crowdpose_384x288.py
@@ -0,0 +1,164 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/crowdpose.py'
+]
+evaluation = dict(interval=10, metric='mAP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ crowd_matching=False,
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/crowdpose/annotations/'
+ 'det_for_crowd_test_0.1_0.5.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=6,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/crowdpose'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_trainval.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}))
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/hrnet_w48_crowdpose_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/hrnet_w48_crowdpose_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..fccc213e67adf0086a544be68f0dd1cadc8e7746
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/hrnet_w48_crowdpose_256x192.py
@@ -0,0 +1,164 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/crowdpose.py'
+]
+evaluation = dict(interval=10, metric='mAP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ crowd_matching=False,
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/crowdpose/annotations/'
+ 'det_for_crowd_test_0.1_0.5.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=6,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/crowdpose'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_trainval.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}))
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/hrnet_w48_crowdpose_384x288.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/hrnet_w48_crowdpose_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..e8373648aeb83f1e176222de63c185f2b1a36dfc
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/hrnet_w48_crowdpose_384x288.py
@@ -0,0 +1,164 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/crowdpose.py'
+]
+evaluation = dict(interval=10, metric='mAP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ crowd_matching=False,
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/crowdpose/annotations/'
+ 'det_for_crowd_test_0.1_0.5.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=6,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/crowdpose'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_trainval.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}))
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/res101_crowdpose_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/res101_crowdpose_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..b425b0c886b4365209ae4d879e91b6dd1458d87a
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/res101_crowdpose_256x192.py
@@ -0,0 +1,133 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/crowdpose.py'
+]
+evaluation = dict(interval=10, metric='mAP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet101',
+ backbone=dict(type='ResNet', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ crowd_matching=False,
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/crowdpose/annotations/'
+ 'det_for_crowd_test_0.1_0.5.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=6,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/crowdpose'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_trainval.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}))
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/res101_crowdpose_320x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/res101_crowdpose_320x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..5a0fecb24259bfa796c45c69104678903f502552
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/res101_crowdpose_320x256.py
@@ -0,0 +1,133 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/crowdpose.py'
+]
+evaluation = dict(interval=10, metric='mAP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet101',
+ backbone=dict(type='ResNet', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 320],
+ heatmap_size=[64, 80],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ crowd_matching=False,
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/crowdpose/annotations/'
+ 'det_for_crowd_test_0.1_0.5.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=6,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/crowdpose'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_trainval.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}))
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/res101_crowdpose_384x288.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/res101_crowdpose_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..0be685a06b510cb94274d02b592e890d5831ec3c
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/res101_crowdpose_384x288.py
@@ -0,0 +1,133 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/crowdpose.py'
+]
+evaluation = dict(interval=10, metric='mAP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet101',
+ backbone=dict(type='ResNet', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ crowd_matching=False,
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/crowdpose/annotations/'
+ 'det_for_crowd_test_0.1_0.5.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=6,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/crowdpose'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_trainval.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}))
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/res152_crowdpose_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/res152_crowdpose_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..ab4b2512b4759642cbf4758f77c4f15df71d2164
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/res152_crowdpose_256x192.py
@@ -0,0 +1,133 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/crowdpose.py'
+]
+evaluation = dict(interval=10, metric='mAP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet152',
+ backbone=dict(type='ResNet', depth=152),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ crowd_matching=False,
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/crowdpose/annotations/'
+ 'det_for_crowd_test_0.1_0.5.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=6,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/crowdpose'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_trainval.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}))
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/res152_crowdpose_384x288.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/res152_crowdpose_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..f54e428c87e3da15ac5eefd8a61d4ab33f275a94
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/res152_crowdpose_384x288.py
@@ -0,0 +1,133 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/crowdpose.py'
+]
+evaluation = dict(interval=10, metric='mAP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet152',
+ backbone=dict(type='ResNet', depth=152),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ crowd_matching=False,
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/crowdpose/annotations/'
+ 'det_for_crowd_test_0.1_0.5.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=6,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/crowdpose'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_trainval.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}))
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/res50_crowdpose_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/res50_crowdpose_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..22f765f1fc497217fe958a0b0a7ed34a628a6243
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/res50_crowdpose_256x192.py
@@ -0,0 +1,133 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/crowdpose.py'
+]
+evaluation = dict(interval=10, metric='mAP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ crowd_matching=False,
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/crowdpose/annotations/'
+ 'det_for_crowd_test_0.1_0.5.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=6,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/crowdpose'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_trainval.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}))
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/res50_crowdpose_384x288.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/res50_crowdpose_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..ea49a82987522d5978536efa2b5dacffe8be4185
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/res50_crowdpose_384x288.py
@@ -0,0 +1,133 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/crowdpose.py'
+]
+evaluation = dict(interval=10, metric='mAP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=14,
+ dataset_joints=14,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ crowd_matching=False,
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/crowdpose/annotations/'
+ 'det_for_crowd_test_0.1_0.5.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=6,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/crowdpose'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_trainval.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCrowdPoseDataset',
+ ann_file=f'{data_root}/annotations/mmpose_crowdpose_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}))
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/resnet_crowdpose.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/resnet_crowdpose.md
new file mode 100644
index 0000000000000000000000000000000000000000..81f9ee0522ee69cb12cc5c0139900fa350423158
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/resnet_crowdpose.md
@@ -0,0 +1,58 @@
+
+
+CrowdPose (CVPR'2019)
+ +```bibtex +@article{li2018crowdpose, + title={CrowdPose: Efficient Crowded Scenes Pose Estimation and A New Benchmark}, + author={Li, Jiefeng and Wang, Can and Zhu, Hao and Mao, Yihuan and Fang, Hao-Shu and Lu, Cewu}, + journal={arXiv preprint arXiv:1812.00324}, + year={2018} +} +``` + +
+
+
+
+
+SimpleBaseline2D (ECCV'2018)
+ +```bibtex +@inproceedings{xiao2018simple, + title={Simple baselines for human pose estimation and tracking}, + author={Xiao, Bin and Wu, Haiping and Wei, Yichen}, + booktitle={Proceedings of the European conference on computer vision (ECCV)}, + pages={466--481}, + year={2018} +} +``` + +
+
+
+
+
+ResNet (CVPR'2016)
+ +```bibtex +@inproceedings{he2016deep, + title={Deep residual learning for image recognition}, + author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={770--778}, + year={2016} +} +``` + +
+
+
+Results on CrowdPose test with [YOLOv3](https://github.com/eriklindernoren/PyTorch-YOLOv3) human detector
+
+| Arch | Input Size | AP | AP50 | AP75 | AP (E) | AP (M) | AP (H) | ckpt | log |
+| :----------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: | :------: |
+| [pose_resnet_50](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/res50_crowdpose_256x192.py) | 256x192 | 0.637 | 0.808 | 0.692 | 0.739 | 0.650 | 0.506 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res50_crowdpose_256x192-c6a526b6_20201227.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res50_crowdpose_256x192_20201227.log.json) |
+| [pose_resnet_101](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/res101_crowdpose_256x192.py) | 256x192 | 0.647 | 0.810 | 0.703 | 0.744 | 0.658 | 0.522 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res101_crowdpose_256x192-8f5870f4_20201227.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res101_crowdpose_256x192_20201227.log.json) |
+| [pose_resnet_101](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/res101_crowdpose_320x256.py) | 320x256 | 0.661 | 0.821 | 0.714 | 0.759 | 0.671 | 0.536 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res101_crowdpose_320x256-c88c512a_20201227.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res101_crowdpose_320x256_20201227.log.json) |
+| [pose_resnet_152](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/res152_crowdpose_256x192.py) | 256x192 | 0.656 | 0.818 | 0.712 | 0.754 | 0.666 | 0.532 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res152_crowdpose_256x192-dbd49aba_20201227.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res152_crowdpose_256x192_20201227.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/resnet_crowdpose.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/resnet_crowdpose.yml
new file mode 100644
index 0000000000000000000000000000000000000000..44b9c8e1d27e2812e1c05182bfe7219cc8ddc30e
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/resnet_crowdpose.yml
@@ -0,0 +1,77 @@
+Collections:
+- Name: SimpleBaseline2D
+ Paper:
+ Title: Simple baselines for human pose estimation and tracking
+ URL: http://openaccess.thecvf.com/content_ECCV_2018/html/Bin_Xiao_Simple_Baselines_for_ECCV_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/simplebaseline2d.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/res50_crowdpose_256x192.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: &id001
+ - SimpleBaseline2D
+ - ResNet
+ Training Data: CrowdPose
+ Name: topdown_heatmap_res50_crowdpose_256x192
+ Results:
+ - Dataset: CrowdPose
+ Metrics:
+ AP: 0.637
+ AP (E): 0.739
+ AP (H): 0.506
+ AP (M): 0.65
+ AP@0.5: 0.808
+ AP@0.75: 0.692
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res50_crowdpose_256x192-c6a526b6_20201227.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/res101_crowdpose_256x192.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: CrowdPose
+ Name: topdown_heatmap_res101_crowdpose_256x192
+ Results:
+ - Dataset: CrowdPose
+ Metrics:
+ AP: 0.647
+ AP (E): 0.744
+ AP (H): 0.522
+ AP (M): 0.658
+ AP@0.5: 0.81
+ AP@0.75: 0.703
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res101_crowdpose_256x192-8f5870f4_20201227.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/res101_crowdpose_320x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: CrowdPose
+ Name: topdown_heatmap_res101_crowdpose_320x256
+ Results:
+ - Dataset: CrowdPose
+ Metrics:
+ AP: 0.661
+ AP (E): 0.759
+ AP (H): 0.536
+ AP (M): 0.671
+ AP@0.5: 0.821
+ AP@0.75: 0.714
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res101_crowdpose_320x256-c88c512a_20201227.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/res152_crowdpose_256x192.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: CrowdPose
+ Name: topdown_heatmap_res152_crowdpose_256x192
+ Results:
+ - Dataset: CrowdPose
+ Metrics:
+ AP: 0.656
+ AP (E): 0.754
+ AP (H): 0.532
+ AP (M): 0.666
+ AP@0.5: 0.818
+ AP@0.75: 0.712
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res152_crowdpose_256x192-dbd49aba_20201227.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/h36m/hrnet_h36m.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/h36m/hrnet_h36m.md
new file mode 100644
index 0000000000000000000000000000000000000000..c658cba54d9f5baaa26f85bf7c49bbe9bb52d03a
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/h36m/hrnet_h36m.md
@@ -0,0 +1,44 @@
+
+
+CrowdPose (CVPR'2019)
+ +```bibtex +@article{li2018crowdpose, + title={CrowdPose: Efficient Crowded Scenes Pose Estimation and A New Benchmark}, + author={Li, Jiefeng and Wang, Can and Zhu, Hao and Mao, Yihuan and Fang, Hao-Shu and Lu, Cewu}, + journal={arXiv preprint arXiv:1812.00324}, + year={2018} +} +``` + +
+
+
+
+
+HRNet (CVPR'2019)
+ +```bibtex +@inproceedings{sun2019deep, + title={Deep high-resolution representation learning for human pose estimation}, + author={Sun, Ke and Xiao, Bin and Liu, Dong and Wang, Jingdong}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={5693--5703}, + year={2019} +} +``` + +
+
+
+Results on Human3.6M test set with ground truth 2D detections
+
+| Arch | Input Size | EPE | PCK | ckpt | log |
+| :--- | :-----------: | :---: | :---: | :----: | :---: |
+| [pose_hrnet_w32](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/h36m/hrnet_w32_h36m_256x256.py) | 256x256 | 9.43 | 0.911 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_h36m_256x256-d3206675_20210621.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_h36m_256x256_20210621.log.json) |
+| [pose_hrnet_w48](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/h36m/hrnet_w48_h36m_256x256.py) | 256x256 | 7.36 | 0.932 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_h36m_256x256-78e88d08_20210621.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_h36m_256x256_20210621.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/h36m/hrnet_h36m.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/h36m/hrnet_h36m.yml
new file mode 100644
index 0000000000000000000000000000000000000000..ac738b22d879f6d4084a975d40d6688a07376cdb
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/h36m/hrnet_h36m.yml
@@ -0,0 +1,34 @@
+Collections:
+- Name: HRNet
+ Paper:
+ Title: Deep high-resolution representation learning for human pose estimation
+ URL: http://openaccess.thecvf.com/content_CVPR_2019/html/Sun_Deep_High-Resolution_Representation_Learning_for_Human_Pose_Estimation_CVPR_2019_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/hrnet.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/h36m/hrnet_w32_h36m_256x256.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: &id001
+ - HRNet
+ Training Data: Human3.6M
+ Name: topdown_heatmap_hrnet_w32_h36m_256x256
+ Results:
+ - Dataset: Human3.6M
+ Metrics:
+ EPE: 9.43
+ PCK: 0.911
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_h36m_256x256-d3206675_20210621.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/h36m/hrnet_w48_h36m_256x256.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: Human3.6M
+ Name: topdown_heatmap_hrnet_w48_h36m_256x256
+ Results:
+ - Dataset: Human3.6M
+ Metrics:
+ EPE: 7.36
+ PCK: 0.932
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_h36m_256x256-78e88d08_20210621.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/h36m/hrnet_w32_h36m_256x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/h36m/hrnet_w32_h36m_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..94a59be92cfcf692a22a7ad35e6d205ad1871b62
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/h36m/hrnet_w32_h36m_256x256.py
@@ -0,0 +1,157 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/h36m.py'
+]
+evaluation = dict(interval=10, metric=['PCK', 'EPE'], key_indicator='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/h36m'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownH36MDataset',
+ ann_file=f'{data_root}/annotation_body2d/h36m_coco_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownH36MDataset',
+ ann_file=f'{data_root}/annotation_body2d/h36m_coco_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownH36MDataset',
+ ann_file=f'{data_root}/annotation_body2d/h36m_coco_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/h36m/hrnet_w48_h36m_256x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/h36m/hrnet_w48_h36m_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..03e1e50849ddf6f3528cac5c3fe526176bb16989
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/h36m/hrnet_w48_h36m_256x256.py
@@ -0,0 +1,157 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/h36m.py'
+]
+evaluation = dict(interval=10, metric=['PCK', 'EPE'], key_indicator='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/h36m'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownH36MDataset',
+ ann_file=f'{data_root}/annotation_body2d/h36m_coco_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownH36MDataset',
+ ann_file=f'{data_root}/annotation_body2d/h36m_coco_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownH36MDataset',
+ ann_file=f'{data_root}/annotation_body2d/h36m_coco_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/cpm_jhmdb.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/cpm_jhmdb.md
new file mode 100644
index 0000000000000000000000000000000000000000..a122e8aa24c7b834d8a6b4cb35e372309d30f50f
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/cpm_jhmdb.md
@@ -0,0 +1,56 @@
+
+
+Human3.6M (TPAMI'2014)
+ +```bibtex +@article{h36m_pami, + author = {Ionescu, Catalin and Papava, Dragos and Olaru, Vlad and Sminchisescu, Cristian}, + title = {Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments}, + journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence}, + publisher = {IEEE Computer Society}, + volume = {36}, + number = {7}, + pages = {1325-1339}, + month = {jul}, + year = {2014} +} +``` + +
+
+
+
+
+CPM (CVPR'2016)
+ +```bibtex +@inproceedings{wei2016convolutional, + title={Convolutional pose machines}, + author={Wei, Shih-En and Ramakrishna, Varun and Kanade, Takeo and Sheikh, Yaser}, + booktitle={Proceedings of the IEEE conference on Computer Vision and Pattern Recognition}, + pages={4724--4732}, + year={2016} +} +``` + +
+
+
+Results on Sub-JHMDB dataset
+
+The models are pre-trained on MPII dataset only. NO test-time augmentation (multi-scale /rotation testing) is used.
+
+- Normalized by Person Size
+
+| Split| Arch | Input Size | Head | Sho | Elb | Wri | Hip | Knee | Ank | Mean | ckpt | log |
+| :--- | :--------: | :--------: | :---: | :---: |:---: |:---: |:---: |:---: |:---: | :---: | :-----: |:------: |
+| Sub1 | [cpm](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/cpm_jhmdb_sub1_368x368.py) | 368x368 | 96.1 | 91.9 | 81.0 | 78.9 | 96.6 | 90.8| 87.3 | 89.5 | [ckpt](https://download.openmmlab.com/mmpose/top_down/cpm/cpm_jhmdb_sub1_368x368-2d2585c9_20201122.pth) | [log](https://download.openmmlab.com/mmpose/top_down/cpm/cpm_jhmdb_sub1_368x368_20201122.log.json) |
+| Sub2 | [cpm](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/cpm_jhmdb_sub2_368x368.py) | 368x368 | 98.1 | 93.6 | 77.1 | 70.9 | 94.0 | 89.1| 84.7 | 87.4 | [ckpt](https://download.openmmlab.com/mmpose/top_down/cpm/cpm_jhmdb_sub2_368x368-fc742f1f_20201122.pth) | [log](https://download.openmmlab.com/mmpose/top_down/cpm/cpm_jhmdb_sub2_368x368_20201122.log.json) |
+| Sub3 | [cpm](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/cpm_jhmdb_sub3_368x368.py) | 368x368 | 97.9 | 94.9 | 87.3 | 84.0 | 98.6 | 94.4| 86.2 | 92.4 | [ckpt](https://download.openmmlab.com/mmpose/top_down/cpm/cpm_jhmdb_sub3_368x368-49337155_20201122.pth) | [log](https://download.openmmlab.com/mmpose/top_down/cpm/cpm_jhmdb_sub3_368x368_20201122.log.json) |
+| Average | cpm | 368x368 | 97.4 | 93.5 | 81.5 | 77.9 | 96.4 | 91.4| 86.1 | 89.8 | - | - |
+
+- Normalized by Torso Size
+
+| Split| Arch | Input Size | Head | Sho | Elb | Wri | Hip | Knee | Ank | Mean | ckpt | log |
+| :--- | :--------: | :--------: | :---: | :---: |:---: |:---: |:---: |:---: |:---: | :---: | :-----: |:------: |
+| Sub1 | [cpm](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/cpm_jhmdb_sub1_368x368.py) | 368x368 | 89.0 | 63.0 | 54.0 | 54.9 | 68.2 | 63.1 | 61.2 | 66.0 | [ckpt](https://download.openmmlab.com/mmpose/top_down/cpm/cpm_jhmdb_sub1_368x368-2d2585c9_20201122.pth) | [log](https://download.openmmlab.com/mmpose/top_down/cpm/cpm_jhmdb_sub1_368x368_20201122.log.json) |
+| Sub2 | [cpm](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/cpm_jhmdb_sub2_368x368.py) | 368x368 | 90.3 | 57.9 | 46.8 | 44.3 | 60.8 | 58.2 | 62.4 | 61.1 | [ckpt](https://download.openmmlab.com/mmpose/top_down/cpm/cpm_jhmdb_sub2_368x368-fc742f1f_20201122.pth) | [log](https://download.openmmlab.com/mmpose/top_down/cpm/cpm_jhmdb_sub2_368x368_20201122.log.json) |
+| Sub3 | [cpm](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/cpm_jhmdb_sub3_368x368.py) | 368x368 | 91.0 | 72.6 | 59.9 | 54.0 | 73.2 | 68.5 | 65.8 | 70.3 | [ckpt](https://download.openmmlab.com/mmpose/top_down/cpm/cpm_jhmdb_sub3_368x368-49337155_20201122.pth) | [log](https://download.openmmlab.com/mmpose/top_down/cpm/cpm_jhmdb_sub3_368x368_20201122.log.json) |
+| Average | cpm | 368x368 | 90.1 | 64.5 | 53.6 | 51.1 | 67.4 | 63.3 | 63.1 | 65.7 | - | - |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/cpm_jhmdb.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/cpm_jhmdb.yml
new file mode 100644
index 0000000000000000000000000000000000000000..eda79a04c24cef7837deb17ee3da44bd3e415310
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/cpm_jhmdb.yml
@@ -0,0 +1,122 @@
+Collections:
+- Name: CPM
+ Paper:
+ Title: Convolutional pose machines
+ URL: http://openaccess.thecvf.com/content_cvpr_2016/html/Wei_Convolutional_Pose_Machines_CVPR_2016_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/cpm.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/cpm_jhmdb_sub1_368x368.py
+ In Collection: CPM
+ Metadata:
+ Architecture: &id001
+ - CPM
+ Training Data: JHMDB
+ Name: topdown_heatmap_cpm_jhmdb_sub1_368x368
+ Results:
+ - Dataset: JHMDB
+ Metrics:
+ Ank: 87.3
+ Elb: 81.0
+ Head: 96.1
+ Hip: 96.6
+ Knee: 90.8
+ Mean: 89.5
+ Sho: 91.9
+ Wri: 78.9
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/cpm/cpm_jhmdb_sub1_368x368-2d2585c9_20201122.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/cpm_jhmdb_sub2_368x368.py
+ In Collection: CPM
+ Metadata:
+ Architecture: *id001
+ Training Data: JHMDB
+ Name: topdown_heatmap_cpm_jhmdb_sub2_368x368
+ Results:
+ - Dataset: JHMDB
+ Metrics:
+ Ank: 84.7
+ Elb: 77.1
+ Head: 98.1
+ Hip: 94.0
+ Knee: 89.1
+ Mean: 87.4
+ Sho: 93.6
+ Wri: 70.9
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/cpm/cpm_jhmdb_sub2_368x368-fc742f1f_20201122.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/cpm_jhmdb_sub3_368x368.py
+ In Collection: CPM
+ Metadata:
+ Architecture: *id001
+ Training Data: JHMDB
+ Name: topdown_heatmap_cpm_jhmdb_sub3_368x368
+ Results:
+ - Dataset: JHMDB
+ Metrics:
+ Ank: 86.2
+ Elb: 87.3
+ Head: 97.9
+ Hip: 98.6
+ Knee: 94.4
+ Mean: 92.4
+ Sho: 94.9
+ Wri: 84.0
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/cpm/cpm_jhmdb_sub3_368x368-49337155_20201122.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/cpm_jhmdb_sub1_368x368.py
+ In Collection: CPM
+ Metadata:
+ Architecture: *id001
+ Training Data: JHMDB
+ Name: topdown_heatmap_cpm_jhmdb_sub1_368x368
+ Results:
+ - Dataset: JHMDB
+ Metrics:
+ Ank: 61.2
+ Elb: 54.0
+ Head: 89.0
+ Hip: 68.2
+ Knee: 63.1
+ Mean: 66.0
+ Sho: 63.0
+ Wri: 54.9
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/cpm/cpm_jhmdb_sub1_368x368-2d2585c9_20201122.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/cpm_jhmdb_sub2_368x368.py
+ In Collection: CPM
+ Metadata:
+ Architecture: *id001
+ Training Data: JHMDB
+ Name: topdown_heatmap_cpm_jhmdb_sub2_368x368
+ Results:
+ - Dataset: JHMDB
+ Metrics:
+ Ank: 62.4
+ Elb: 46.8
+ Head: 90.3
+ Hip: 60.8
+ Knee: 58.2
+ Mean: 61.1
+ Sho: 57.9
+ Wri: 44.3
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/cpm/cpm_jhmdb_sub2_368x368-fc742f1f_20201122.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/cpm_jhmdb_sub3_368x368.py
+ In Collection: CPM
+ Metadata:
+ Architecture: *id001
+ Training Data: JHMDB
+ Name: topdown_heatmap_cpm_jhmdb_sub3_368x368
+ Results:
+ - Dataset: JHMDB
+ Metrics:
+ Ank: 65.8
+ Elb: 59.9
+ Head: 91.0
+ Hip: 73.2
+ Knee: 68.5
+ Mean: 70.3
+ Sho: 72.6
+ Wri: 54.0
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/cpm/cpm_jhmdb_sub3_368x368-49337155_20201122.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/cpm_jhmdb_sub1_368x368.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/cpm_jhmdb_sub1_368x368.py
new file mode 100644
index 0000000000000000000000000000000000000000..15ae4a0f2059d59d766520635687a481b4f64366
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/cpm_jhmdb_sub1_368x368.py
@@ -0,0 +1,141 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/jhmdb.py'
+]
+load_from = 'https://download.openmmlab.com/mmpose/top_down/cpm/cpm_mpii_368x368-116e62b8_20200822.pth' # noqa: E501
+checkpoint_config = dict(interval=1)
+evaluation = dict(interval=1, metric=['PCK', 'tPCK'], save_best='Mean PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[20, 30])
+total_epochs = 40
+channel_cfg = dict(
+ num_output_channels=15,
+ dataset_joints=15,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='CPM',
+ in_channels=3,
+ out_channels=channel_cfg['num_output_channels'],
+ feat_channels=128,
+ num_stages=6),
+ keypoint_head=dict(
+ type='TopdownHeatmapMultiStageHead',
+ in_channels=channel_cfg['num_output_channels'],
+ out_channels=channel_cfg['num_output_channels'],
+ num_stages=6,
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=0, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[368, 368],
+ heatmap_size=[46, 46],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=[
+ 'img',
+ ],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/jhmdb'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownJhmdbDataset',
+ ann_file=f'{data_root}/annotations/Sub1_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownJhmdbDataset',
+ ann_file=f'{data_root}/annotations/Sub1_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownJhmdbDataset',
+ ann_file=f'{data_root}/annotations/Sub1_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/cpm_jhmdb_sub2_368x368.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/cpm_jhmdb_sub2_368x368.py
new file mode 100644
index 0000000000000000000000000000000000000000..1f885f541701295eeab24c6dbebccc4911035b54
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/cpm_jhmdb_sub2_368x368.py
@@ -0,0 +1,141 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/jhmdb.py'
+]
+load_from = 'https://download.openmmlab.com/mmpose/top_down/cpm/cpm_mpii_368x368-116e62b8_20200822.pth' # noqa: E501
+checkpoint_config = dict(interval=1)
+evaluation = dict(interval=1, metric=['PCK', 'tPCK'], save_best='Mean PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[20, 30])
+total_epochs = 40
+channel_cfg = dict(
+ num_output_channels=15,
+ dataset_joints=15,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='CPM',
+ in_channels=3,
+ out_channels=channel_cfg['num_output_channels'],
+ feat_channels=128,
+ num_stages=6),
+ keypoint_head=dict(
+ type='TopdownHeatmapMultiStageHead',
+ in_channels=channel_cfg['num_output_channels'],
+ out_channels=channel_cfg['num_output_channels'],
+ num_stages=6,
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=0, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[368, 368],
+ heatmap_size=[46, 46],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=[
+ 'img',
+ ],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/jhmdb'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownJhmdbDataset',
+ ann_file=f'{data_root}/annotations/Sub2_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownJhmdbDataset',
+ ann_file=f'{data_root}/annotations/Sub2_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownJhmdbDataset',
+ ann_file=f'{data_root}/annotations/Sub2_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/cpm_jhmdb_sub3_368x368.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/cpm_jhmdb_sub3_368x368.py
new file mode 100644
index 0000000000000000000000000000000000000000..69706a76c207b38a122c0b3fe0f7711a41598cb7
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/cpm_jhmdb_sub3_368x368.py
@@ -0,0 +1,141 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/jhmdb.py'
+]
+load_from = 'https://download.openmmlab.com/mmpose/top_down/cpm/cpm_mpii_368x368-116e62b8_20200822.pth' # noqa: E501
+checkpoint_config = dict(interval=1)
+evaluation = dict(interval=1, metric=['PCK', 'tPCK'], save_best='Mean PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[20, 30])
+total_epochs = 40
+channel_cfg = dict(
+ num_output_channels=15,
+ dataset_joints=15,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='CPM',
+ in_channels=3,
+ out_channels=channel_cfg['num_output_channels'],
+ feat_channels=128,
+ num_stages=6),
+ keypoint_head=dict(
+ type='TopdownHeatmapMultiStageHead',
+ in_channels=channel_cfg['num_output_channels'],
+ out_channels=channel_cfg['num_output_channels'],
+ num_stages=6,
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=0, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[368, 368],
+ heatmap_size=[46, 46],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=[
+ 'img',
+ ],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/jhmdb'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownJhmdbDataset',
+ ann_file=f'{data_root}/annotations/Sub3_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownJhmdbDataset',
+ ann_file=f'{data_root}/annotations/Sub3_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownJhmdbDataset',
+ ann_file=f'{data_root}/annotations/Sub3_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_2deconv_jhmdb_sub1_256x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_2deconv_jhmdb_sub1_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..0870a6cbd306e8fab3e1b342d97ea0f23b3bb7e9
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_2deconv_jhmdb_sub1_256x256.py
@@ -0,0 +1,136 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/jhmdb.py'
+]
+load_from = 'https://download.openmmlab.com/mmpose/top_down/resnet/res50_mpii_256x256-418ffc88_20200812.pth' # noqa: E501
+checkpoint_config = dict(interval=1)
+evaluation = dict(interval=1, metric=['PCK', 'tPCK'], save_best='Mean PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[20, 30])
+total_epochs = 40
+channel_cfg = dict(
+ num_output_channels=15,
+ dataset_joints=15,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[32, 32],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=[
+ 'img',
+ ],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/jhmdb'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownJhmdbDataset',
+ ann_file=f'{data_root}/annotations/Sub1_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownJhmdbDataset',
+ ann_file=f'{data_root}/annotations/Sub1_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownJhmdbDataset',
+ ann_file=f'{data_root}/annotations/Sub1_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_2deconv_jhmdb_sub2_256x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_2deconv_jhmdb_sub2_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..51f27b7e60236991bdc68efaaa3357f298927c0a
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_2deconv_jhmdb_sub2_256x256.py
@@ -0,0 +1,136 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/jhmdb.py'
+]
+load_from = 'https://download.openmmlab.com/mmpose/top_down/resnet/res50_mpii_256x256-418ffc88_20200812.pth' # noqa: E501
+checkpoint_config = dict(interval=1)
+evaluation = dict(interval=1, metric=['PCK', 'tPCK'], save_best='Mean PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[20, 30])
+total_epochs = 40
+channel_cfg = dict(
+ num_output_channels=15,
+ dataset_joints=15,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[32, 32],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=[
+ 'img',
+ ],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/jhmdb'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownJhmdbDataset',
+ ann_file=f'{data_root}/annotations/Sub2_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownJhmdbDataset',
+ ann_file=f'{data_root}/annotations/Sub2_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownJhmdbDataset',
+ ann_file=f'{data_root}/annotations/Sub2_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_2deconv_jhmdb_sub3_256x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_2deconv_jhmdb_sub3_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..db0026693a29acf55e61d6353618364c3626edc6
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_2deconv_jhmdb_sub3_256x256.py
@@ -0,0 +1,136 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/jhmdb.py'
+]
+load_from = 'https://download.openmmlab.com/mmpose/top_down/resnet/res50_mpii_256x256-418ffc88_20200812.pth' # noqa: E501
+checkpoint_config = dict(interval=1)
+evaluation = dict(interval=1, metric=['PCK', 'tPCK'], save_best='Mean PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[20, 30])
+total_epochs = 40
+channel_cfg = dict(
+ num_output_channels=15,
+ dataset_joints=15,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[32, 32],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=[
+ 'img',
+ ],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/jhmdb'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownJhmdbDataset',
+ ann_file=f'{data_root}/annotations/Sub3_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownJhmdbDataset',
+ ann_file=f'{data_root}/annotations/Sub3_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownJhmdbDataset',
+ ann_file=f'{data_root}/annotations/Sub3_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_jhmdb_sub1_256x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_jhmdb_sub1_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..857854161247694ab57f1efdb019c3a4da427374
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_jhmdb_sub1_256x256.py
@@ -0,0 +1,133 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/jhmdb.py'
+]
+load_from = 'https://download.openmmlab.com/mmpose/top_down/resnet/res50_mpii_256x256-418ffc88_20200812.pth' # noqa: E501
+checkpoint_config = dict(interval=1)
+evaluation = dict(interval=1, metric=['PCK', 'tPCK'], save_best='Mean PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[8, 15])
+total_epochs = 20
+channel_cfg = dict(
+ num_output_channels=15,
+ dataset_joints=15,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=[
+ 'img',
+ ],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/jhmdb'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownJhmdbDataset',
+ ann_file=f'{data_root}/annotations/Sub1_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownJhmdbDataset',
+ ann_file=f'{data_root}/annotations/Sub1_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownJhmdbDataset',
+ ann_file=f'{data_root}/annotations/Sub1_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_jhmdb_sub2_256x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_jhmdb_sub2_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..d52be3d11e265d515c51263727892f3787f5809d
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_jhmdb_sub2_256x256.py
@@ -0,0 +1,133 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/jhmdb.py'
+]
+load_from = 'https://download.openmmlab.com/mmpose/top_down/resnet/res50_mpii_256x256-418ffc88_20200812.pth' # noqa: E501
+checkpoint_config = dict(interval=1)
+evaluation = dict(interval=1, metric=['PCK', 'tPCK'], save_best='Mean PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[8, 15])
+total_epochs = 20
+channel_cfg = dict(
+ num_output_channels=15,
+ dataset_joints=15,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=[
+ 'img',
+ ],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/jhmdb'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownJhmdbDataset',
+ ann_file=f'{data_root}/annotations/Sub2_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownJhmdbDataset',
+ ann_file=f'{data_root}/annotations/Sub2_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownJhmdbDataset',
+ ann_file=f'{data_root}/annotations/Sub2_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_jhmdb_sub3_256x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_jhmdb_sub3_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..cf9ab7fb8755e0e8c729a317c13f852f7404c453
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_jhmdb_sub3_256x256.py
@@ -0,0 +1,133 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/jhmdb.py'
+]
+load_from = 'https://download.openmmlab.com/mmpose/top_down/resnet/res50_mpii_256x256-418ffc88_20200812.pth' # noqa: E501
+checkpoint_config = dict(interval=1)
+evaluation = dict(interval=1, metric=['PCK', 'tPCK'], save_best='Mean PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[8, 15])
+total_epochs = 20
+channel_cfg = dict(
+ num_output_channels=15,
+ dataset_joints=15,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=[
+ 'img',
+ ],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/jhmdb'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownJhmdbDataset',
+ ann_file=f'{data_root}/annotations/Sub3_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownJhmdbDataset',
+ ann_file=f'{data_root}/annotations/Sub3_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownJhmdbDataset',
+ ann_file=f'{data_root}/annotations/Sub3_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/resnet_jhmdb.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/resnet_jhmdb.md
new file mode 100644
index 0000000000000000000000000000000000000000..fa2b969180f24aeac67741f1cb31d377a3afc8db
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/resnet_jhmdb.md
@@ -0,0 +1,81 @@
+
+
+JHMDB (ICCV'2013)
+ +```bibtex +@inproceedings{Jhuang:ICCV:2013, + title = {Towards understanding action recognition}, + author = {H. Jhuang and J. Gall and S. Zuffi and C. Schmid and M. J. Black}, + booktitle = {International Conf. on Computer Vision (ICCV)}, + month = Dec, + pages = {3192-3199}, + year = {2013} +} +``` + +
+
+
+
+
+SimpleBaseline2D (ECCV'2018)
+ +```bibtex +@inproceedings{xiao2018simple, + title={Simple baselines for human pose estimation and tracking}, + author={Xiao, Bin and Wu, Haiping and Wei, Yichen}, + booktitle={Proceedings of the European conference on computer vision (ECCV)}, + pages={466--481}, + year={2018} +} +``` + +
+
+
+
+
+ResNet (CVPR'2016)
+ +```bibtex +@inproceedings{he2016deep, + title={Deep residual learning for image recognition}, + author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={770--778}, + year={2016} +} +``` + +
+
+
+Results on Sub-JHMDB dataset
+
+The models are pre-trained on MPII dataset only. *NO* test-time augmentation (multi-scale /rotation testing) is used.
+
+- Normalized by Person Size
+
+| Split| Arch | Input Size | Head | Sho | Elb | Wri | Hip | Knee | Ank | Mean | ckpt | log |
+| :--- | :--------: | :--------: | :---: | :---: |:---: |:---: |:---: |:---: |:---: | :---: | :-----: |:------: |
+| Sub1 | [pose_resnet_50](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_jhmdb_sub1_256x256.py) | 256x256 | 99.1 | 98.0 | 93.8 | 91.3 | 99.4 | 96.5| 92.8 | 96.1 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res50_jhmdb_sub1_256x256-932cb3b4_20201122.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res50_jhmdb_sub1_256x256_20201122.log.json) |
+| Sub2 | [pose_resnet_50](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_jhmdb_sub2_256x256.py) | 256x256 | 99.3 | 97.1 | 90.6 | 87.0 | 98.9 | 96.3| 94.1 | 95.0 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res50_jhmdb_sub2_256x256-83d606f7_20201122.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res50_jhmdb_sub2_256x256_20201122.log.json) |
+| Sub3 | [pose_resnet_50](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_jhmdb_sub3_256x256.py) | 256x256 | 99.0 | 97.9 | 94.0 | 91.6 | 99.7 | 98.0| 94.7 | 96.7 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res50_jhmdb_sub3_256x256-c4ec1a0b_20201122.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res50_jhmdb_sub3_256x256_20201122.log.json) |
+| Average | pose_resnet_50 | 256x256 | 99.2 | 97.7 | 92.8 | 90.0 | 99.3 | 96.9| 93.9 | 96.0 | - | - |
+| Sub1 | [pose_resnet_50 (2 Deconv.)](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_2deconv_jhmdb_sub1_256x256.py) | 256x256 | 99.1 | 98.5 | 94.6 | 92.0 | 99.4 | 94.6| 92.5 | 96.1 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res50_2deconv_jhmdb_sub1_256x256-f0574a52_20201122.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res50_2deconv_jhmdb_sub1_256x256_20201122.log.json) |
+| Sub2 | [pose_resnet_50 (2 Deconv.)](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_2deconv_jhmdb_sub2_256x256.py) | 256x256 | 99.3 | 97.8 | 91.0 | 87.0 | 99.1 | 96.5| 93.8 | 95.2 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res50_2deconv_jhmdb_sub2_256x256-f63af0ff_20201122.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res50_2deconv_jhmdb_sub2_256x256_20201122.log.json) |
+| Sub3 | [pose_resnet_50 (2 Deconv.)](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_2deconv_jhmdb_sub3_256x256.py) | 256x256 | 98.8 | 98.4 | 94.3 | 92.1 | 99.8 | 97.5| 93.8 | 96.7 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res50_2deconv_jhmdb_sub3_256x256-c4bc2ddb_20201122.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res50_2deconv_jhmdb_sub3_256x256_20201122.log.json) |
+| Average | pose_resnet_50 (2 Deconv.) | 256x256 | 99.1 | 98.2 | 93.3 | 90.4 | 99.4 | 96.2| 93.4 | 96.0 | - | - |
+
+- Normalized by Torso Size
+
+| Split| Arch | Input Size | Head | Sho | Elb | Wri | Hip | Knee | Ank | Mean | ckpt | log |
+| :--- | :--------: | :--------: | :---: | :---: |:---: |:---: |:---: |:---: |:---: | :---: | :-----: |:------: |
+| Sub1 | [pose_resnet_50](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_jhmdb_sub1_256x256.py) | 256x256 | 93.3 | 83.2 | 74.4 | 72.7 | 85.0 | 81.2 | 78.9 | 81.9 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res50_jhmdb_sub1_256x256-932cb3b4_20201122.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res50_jhmdb_sub1_256x256_20201122.log.json) |
+| Sub2 | [pose_resnet_50](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_jhmdb_sub2_256x256.py) | 256x256 | 94.1 | 74.9 | 64.5 | 62.5 | 77.9 | 71.9 | 78.6 | 75.5 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res50_jhmdb_sub2_256x256-83d606f7_20201122.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res50_jhmdb_sub2_256x256_20201122.log.json) |
+| Sub3 | [pose_resnet_50](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_jhmdb_sub3_256x256.py) | 256x256 | 97.0 | 82.2 | 74.9 | 70.7 | 84.7 | 83.7 | 84.2 | 82.9 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res50_jhmdb_sub3_256x256-c4ec1a0b_20201122.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res50_jhmdb_sub3_256x256_20201122.log.json) |
+| Average | pose_resnet_50 | 256x256 | 94.8 | 80.1 | 71.3 | 68.6 | 82.5 | 78.9 | 80.6 | 80.1 | - | - |
+| Sub1 | [pose_resnet_50 (2 Deconv.)](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_2deconv_jhmdb_sub1_256x256.py) | 256x256 | 92.4 | 80.6 | 73.2 | 70.5 | 82.3 | 75.4| 75.0 | 79.2 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res50_2deconv_jhmdb_sub1_256x256-f0574a52_20201122.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res50_2deconv_jhmdb_sub1_256x256_20201122.log.json) |
+| Sub2 | [pose_resnet_50 (2 Deconv.)](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_2deconv_jhmdb_sub2_256x256.py) | 256x256 | 93.4 | 73.6 | 63.8 | 60.5 | 75.1 | 68.4| 75.5 | 73.7 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res50_2deconv_jhmdb_sub2_256x256-f63af0ff_20201122.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res50_2deconv_jhmdb_sub2_256x256_20201122.log.json) |
+| Sub3 | [pose_resnet_50 (2 Deconv.)](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_2deconv_jhmdb_sub3_256x256.py) | 256x256 | 96.1 | 81.2 | 72.6 | 67.9 | 83.6 | 80.9| 81.5 | 81.2 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res50_2deconv_jhmdb_sub3_256x256-c4bc2ddb_20201122.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res50_2deconv_jhmdb_sub3_256x256_20201122.log.json) |
+| Average | pose_resnet_50 (2 Deconv.) | 256x256 | 94.0 | 78.5 | 69.9 | 66.3 | 80.3 | 74.9| 77.3 | 78.0 | - | - |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/resnet_jhmdb.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/resnet_jhmdb.yml
new file mode 100644
index 0000000000000000000000000000000000000000..0116ecac101574b050030a4157e0b66abd7e5a46
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/resnet_jhmdb.yml
@@ -0,0 +1,237 @@
+Collections:
+- Name: SimpleBaseline2D
+ Paper:
+ Title: Simple baselines for human pose estimation and tracking
+ URL: http://openaccess.thecvf.com/content_ECCV_2018/html/Bin_Xiao_Simple_Baselines_for_ECCV_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/simplebaseline2d.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_jhmdb_sub1_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: &id001
+ - SimpleBaseline2D
+ - ResNet
+ Training Data: JHMDB
+ Name: topdown_heatmap_res50_jhmdb_sub1_256x256
+ Results:
+ - Dataset: JHMDB
+ Metrics:
+ Ank: 92.8
+ Elb: 93.8
+ Head: 99.1
+ Hip: 99.4
+ Knee: 96.5
+ Mean: 96.1
+ Sho: 98.0
+ Wri: 91.3
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res50_jhmdb_sub1_256x256-932cb3b4_20201122.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_jhmdb_sub2_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: JHMDB
+ Name: topdown_heatmap_res50_jhmdb_sub2_256x256
+ Results:
+ - Dataset: JHMDB
+ Metrics:
+ Ank: 94.1
+ Elb: 90.6
+ Head: 99.3
+ Hip: 98.9
+ Knee: 96.3
+ Mean: 95.0
+ Sho: 97.1
+ Wri: 87.0
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res50_jhmdb_sub2_256x256-83d606f7_20201122.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_jhmdb_sub3_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: JHMDB
+ Name: topdown_heatmap_res50_jhmdb_sub3_256x256
+ Results:
+ - Dataset: JHMDB
+ Metrics:
+ Ank: 94.7
+ Elb: 94.0
+ Head: 99.0
+ Hip: 99.7
+ Knee: 98.0
+ Mean: 96.7
+ Sho: 97.9
+ Wri: 91.6
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res50_jhmdb_sub3_256x256-c4ec1a0b_20201122.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_2deconv_jhmdb_sub1_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: JHMDB
+ Name: topdown_heatmap_res50_2deconv_jhmdb_sub1_256x256
+ Results:
+ - Dataset: JHMDB
+ Metrics:
+ Ank: 92.5
+ Elb: 94.6
+ Head: 99.1
+ Hip: 99.4
+ Knee: 94.6
+ Mean: 96.1
+ Sho: 98.5
+ Wri: 92.0
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res50_2deconv_jhmdb_sub1_256x256-f0574a52_20201122.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_2deconv_jhmdb_sub2_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: JHMDB
+ Name: topdown_heatmap_res50_2deconv_jhmdb_sub2_256x256
+ Results:
+ - Dataset: JHMDB
+ Metrics:
+ Ank: 93.8
+ Elb: 91.0
+ Head: 99.3
+ Hip: 99.1
+ Knee: 96.5
+ Mean: 95.2
+ Sho: 97.8
+ Wri: 87.0
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res50_2deconv_jhmdb_sub2_256x256-f63af0ff_20201122.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_2deconv_jhmdb_sub3_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: JHMDB
+ Name: topdown_heatmap_res50_2deconv_jhmdb_sub3_256x256
+ Results:
+ - Dataset: JHMDB
+ Metrics:
+ Ank: 93.8
+ Elb: 94.3
+ Head: 98.8
+ Hip: 99.8
+ Knee: 97.5
+ Mean: 96.7
+ Sho: 98.4
+ Wri: 92.1
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res50_2deconv_jhmdb_sub3_256x256-c4bc2ddb_20201122.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_jhmdb_sub1_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: JHMDB
+ Name: topdown_heatmap_res50_jhmdb_sub1_256x256
+ Results:
+ - Dataset: JHMDB
+ Metrics:
+ Ank: 78.9
+ Elb: 74.4
+ Head: 93.3
+ Hip: 85.0
+ Knee: 81.2
+ Mean: 81.9
+ Sho: 83.2
+ Wri: 72.7
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res50_jhmdb_sub1_256x256-932cb3b4_20201122.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_jhmdb_sub2_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: JHMDB
+ Name: topdown_heatmap_res50_jhmdb_sub2_256x256
+ Results:
+ - Dataset: JHMDB
+ Metrics:
+ Ank: 78.6
+ Elb: 64.5
+ Head: 94.1
+ Hip: 77.9
+ Knee: 71.9
+ Mean: 75.5
+ Sho: 74.9
+ Wri: 62.5
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res50_jhmdb_sub2_256x256-83d606f7_20201122.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_jhmdb_sub3_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: JHMDB
+ Name: topdown_heatmap_res50_jhmdb_sub3_256x256
+ Results:
+ - Dataset: JHMDB
+ Metrics:
+ Ank: 84.2
+ Elb: 74.9
+ Head: 97.0
+ Hip: 84.7
+ Knee: 83.7
+ Mean: 82.9
+ Sho: 82.2
+ Wri: 70.7
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res50_jhmdb_sub3_256x256-c4ec1a0b_20201122.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_2deconv_jhmdb_sub1_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: JHMDB
+ Name: topdown_heatmap_res50_2deconv_jhmdb_sub1_256x256
+ Results:
+ - Dataset: JHMDB
+ Metrics:
+ Ank: 75.0
+ Elb: 73.2
+ Head: 92.4
+ Hip: 82.3
+ Knee: 75.4
+ Mean: 79.2
+ Sho: 80.6
+ Wri: 70.5
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res50_2deconv_jhmdb_sub1_256x256-f0574a52_20201122.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_2deconv_jhmdb_sub2_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: JHMDB
+ Name: topdown_heatmap_res50_2deconv_jhmdb_sub2_256x256
+ Results:
+ - Dataset: JHMDB
+ Metrics:
+ Ank: 75.5
+ Elb: 63.8
+ Head: 93.4
+ Hip: 75.1
+ Knee: 68.4
+ Mean: 73.7
+ Sho: 73.6
+ Wri: 60.5
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res50_2deconv_jhmdb_sub2_256x256-f63af0ff_20201122.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/res50_2deconv_jhmdb_sub3_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: JHMDB
+ Name: topdown_heatmap_res50_2deconv_jhmdb_sub3_256x256
+ Results:
+ - Dataset: JHMDB
+ Metrics:
+ Ank: 81.5
+ Elb: 72.6
+ Head: 96.1
+ Hip: 83.6
+ Knee: 80.9
+ Mean: 81.2
+ Sho: 81.2
+ Wri: 67.9
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res50_2deconv_jhmdb_sub3_256x256-c4bc2ddb_20201122.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mhp/res50_mhp_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mhp/res50_mhp_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..8b0a322040a5bafd5de7505b34f72ffe91117ed9
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mhp/res50_mhp_256x192.py
@@ -0,0 +1,133 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mhp.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ bbox_thr=1.0,
+ use_gt_bbox=True,
+ image_thr=0.0,
+ bbox_file='',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mhp'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMhpDataset',
+ ann_file=f'{data_root}/annotations/mhp_train.json',
+ img_prefix=f'{data_root}/train/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMhpDataset',
+ ann_file=f'{data_root}/annotations/mhp_val.json',
+ img_prefix=f'{data_root}/val/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMhpDataset',
+ ann_file=f'{data_root}/annotations/mhp_val.json',
+ img_prefix=f'{data_root}/val/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mhp/resnet_mhp.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mhp/resnet_mhp.md
new file mode 100644
index 0000000000000000000000000000000000000000..befa17ea9548975429e917385bdf45a2a9b7c723
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mhp/resnet_mhp.md
@@ -0,0 +1,59 @@
+
+
+JHMDB (ICCV'2013)
+ +```bibtex +@inproceedings{Jhuang:ICCV:2013, + title = {Towards understanding action recognition}, + author = {H. Jhuang and J. Gall and S. Zuffi and C. Schmid and M. J. Black}, + booktitle = {International Conf. on Computer Vision (ICCV)}, + month = Dec, + pages = {3192-3199}, + year = {2013} +} +``` + +
+
+
+
+
+SimpleBaseline2D (ECCV'2018)
+ +```bibtex +@inproceedings{xiao2018simple, + title={Simple baselines for human pose estimation and tracking}, + author={Xiao, Bin and Wu, Haiping and Wei, Yichen}, + booktitle={Proceedings of the European conference on computer vision (ECCV)}, + pages={466--481}, + year={2018} +} +``` + +
+
+
+
+
+ResNet (CVPR'2016)
+ +```bibtex +@inproceedings{he2016deep, + title={Deep residual learning for image recognition}, + author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={770--778}, + year={2016} +} +``` + +
+
+
+Results on MHP v2.0 val set
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :-------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_resnet_101](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mhp/res50_mhp_256x192.py) | 256x192 | 0.583 | 0.897 | 0.669 | 0.636 | 0.918 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res50_mhp_256x192-28c5b818_20201229.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res50_mhp_256x192_20201229.log.json) |
+
+Note that, the evaluation metric used here is mAP (adapted from COCO), which may be different from the official evaluation [codes](https://github.com/ZhaoJ9014/Multi-Human-Parsing/tree/master/Evaluation/Multi-Human-Pose).
+Please be cautious if you use the results in papers.
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mhp/resnet_mhp.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mhp/resnet_mhp.yml
new file mode 100644
index 0000000000000000000000000000000000000000..777b1dbb5f5d2fd03bbe56214785a8ce675f0a1c
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mhp/resnet_mhp.yml
@@ -0,0 +1,25 @@
+Collections:
+- Name: SimpleBaseline2D
+ Paper:
+ Title: Simple baselines for human pose estimation and tracking
+ URL: http://openaccess.thecvf.com/content_ECCV_2018/html/Bin_Xiao_Simple_Baselines_for_ECCV_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/simplebaseline2d.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mhp/res50_mhp_256x192.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture:
+ - SimpleBaseline2D
+ - ResNet
+ Training Data: MHP
+ Name: topdown_heatmap_res50_mhp_256x192
+ Results:
+ - Dataset: MHP
+ Metrics:
+ AP: 0.583
+ AP@0.5: 0.897
+ AP@0.75: 0.669
+ AR: 0.636
+ AR@0.5: 0.918
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res50_mhp_256x192-28c5b818_20201229.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_base_mpii_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_base_mpii_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..fbd0eef61be608bc5e151b48f55786691546d922
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_base_mpii_256x192.py
@@ -0,0 +1,146 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii.py'
+]
+evaluation = dict(interval=10, metric='PCKh', save_best='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+target_type = 'GaussianHeatmap'
+channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=list(range(16)),
+ inference_channel=list(range(16)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='ViT',
+ img_size=(256, 192),
+ patch_size=16,
+ embed_dim=768,
+ depth=12,
+ num_heads=12,
+ ratio=1,
+ use_checkpoint=False,
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_path_rate=0.3,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=768,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=False,
+ target_type=target_type,
+ modulate_kernel=11,
+ use_udp=True))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='TopDownGenerateTarget',
+ sigma=2,
+ encoding='UDP',
+ target_type=target_type),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_huge_mpii_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_huge_mpii_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..0cc680aee55c86336f29824e3f8986a282f2056c
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_huge_mpii_256x192.py
@@ -0,0 +1,146 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii.py'
+]
+evaluation = dict(interval=10, metric='PCKh', save_best='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+target_type = 'GaussianHeatmap'
+channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=list(range(16)),
+ inference_channel=list(range(16)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='ViT',
+ img_size=(256, 192),
+ patch_size=16,
+ embed_dim=1280,
+ depth=32,
+ num_heads=16,
+ ratio=1,
+ use_checkpoint=False,
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_path_rate=0.3,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1280,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=False,
+ target_type=target_type,
+ modulate_kernel=11,
+ use_udp=True))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='TopDownGenerateTarget',
+ sigma=2,
+ encoding='UDP',
+ target_type=target_type),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_large_mpii_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_large_mpii_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..7105e38a0561723017fef2c0d8479b609239c641
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_large_mpii_256x192.py
@@ -0,0 +1,146 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii.py'
+]
+evaluation = dict(interval=10, metric='PCKh', save_best='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+target_type = 'GaussianHeatmap'
+channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=list(range(16)),
+ inference_channel=list(range(16)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='ViT',
+ img_size=(256, 192),
+ patch_size=16,
+ embed_dim=1024,
+ depth=24,
+ num_heads=16,
+ ratio=1,
+ use_checkpoint=False,
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_path_rate=0.3,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1024,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=False,
+ target_type=target_type,
+ modulate_kernel=11,
+ use_udp=True))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='TopDownGenerateTarget',
+ sigma=2,
+ encoding='UDP',
+ target_type=target_type),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_small_mpii_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_small_mpii_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..f80f5228ab683eef03921d855e9c8b8f93620549
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_small_mpii_256x192.py
@@ -0,0 +1,146 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii.py'
+]
+evaluation = dict(interval=10, metric='PCKh', save_best='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+target_type = 'GaussianHeatmap'
+channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=list(range(16)),
+ inference_channel=list(range(16)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='ViT',
+ img_size=(256, 192),
+ patch_size=16,
+ embed_dim=384,
+ depth=12,
+ num_heads=12,
+ ratio=1,
+ use_checkpoint=False,
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_path_rate=0.3,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=384,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=False,
+ target_type=target_type,
+ modulate_kernel=11,
+ use_udp=True))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='TopDownGenerateTarget',
+ sigma=2,
+ encoding='UDP',
+ target_type=target_type),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/cpm_mpii.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/cpm_mpii.md
new file mode 100644
index 0000000000000000000000000000000000000000..5e9012f672f17a455a3637fd49da69f533d01bb0
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/cpm_mpii.md
@@ -0,0 +1,39 @@
+
+
+MHP (ACM MM'2018)
+ +```bibtex +@inproceedings{zhao2018understanding, + title={Understanding humans in crowded scenes: Deep nested adversarial learning and a new benchmark for multi-human parsing}, + author={Zhao, Jian and Li, Jianshu and Cheng, Yu and Sim, Terence and Yan, Shuicheng and Feng, Jiashi}, + booktitle={Proceedings of the 26th ACM international conference on Multimedia}, + pages={792--800}, + year={2018} +} +``` + +
+
+
+
+
+CPM (CVPR'2016)
+ +```bibtex +@inproceedings{wei2016convolutional, + title={Convolutional pose machines}, + author={Wei, Shih-En and Ramakrishna, Varun and Kanade, Takeo and Sheikh, Yaser}, + booktitle={Proceedings of the IEEE conference on Computer Vision and Pattern Recognition}, + pages={4724--4732}, + year={2016} +} +``` + +
+
+
+Results on MPII val set
+
+| Arch | Input Size | Mean | Mean@0.1 | ckpt | log |
+| :--- | :--------: | :------: | :------: |:------: |:------: |
+| [cpm](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/cpm_mpii_368x368.py) | 368x368 | 0.876 | 0.285 | [ckpt](https://download.openmmlab.com/mmpose/top_down/cpm/cpm_mpii_368x368-116e62b8_20200822.pth) | [log](https://download.openmmlab.com/mmpose/top_down/cpm/cpm_mpii_368x368_20200822.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/cpm_mpii.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/cpm_mpii.yml
new file mode 100644
index 0000000000000000000000000000000000000000..c62a93f069002b55bf2e3d3a716e0826fbae56d7
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/cpm_mpii.yml
@@ -0,0 +1,21 @@
+Collections:
+- Name: CPM
+ Paper:
+ Title: Convolutional pose machines
+ URL: http://openaccess.thecvf.com/content_cvpr_2016/html/Wei_Convolutional_Pose_Machines_CVPR_2016_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/cpm.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/cpm_mpii_368x368.py
+ In Collection: CPM
+ Metadata:
+ Architecture:
+ - CPM
+ Training Data: MPII
+ Name: topdown_heatmap_cpm_mpii_368x368
+ Results:
+ - Dataset: MPII
+ Metrics:
+ Mean: 0.876
+ Mean@0.1: 0.285
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/cpm/cpm_mpii_368x368-116e62b8_20200822.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/cpm_mpii_368x368.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/cpm_mpii_368x368.py
new file mode 100644
index 0000000000000000000000000000000000000000..62b81a5c79299c6633de519ae0cf99d02031b4cf
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/cpm_mpii_368x368.py
@@ -0,0 +1,132 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii.py'
+]
+evaluation = dict(interval=10, metric='PCKh', save_best='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=list(range(16)),
+ inference_channel=list(range(16)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='CPM',
+ in_channels=3,
+ out_channels=channel_cfg['num_output_channels'],
+ feat_channels=128,
+ num_stages=6),
+ keypoint_head=dict(
+ type='TopdownHeatmapMultiStageHead',
+ in_channels=channel_cfg['num_output_channels'],
+ out_channels=channel_cfg['num_output_channels'],
+ num_stages=6,
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=0, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[368, 368],
+ heatmap_size=[46, 46],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hourglass52_mpii_256x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hourglass52_mpii_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..5b96027fe54821bbac819d374c42e5bfa30cabb2
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hourglass52_mpii_256x256.py
@@ -0,0 +1,129 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii.py'
+]
+evaluation = dict(interval=10, metric='PCKh', save_best='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=list(range(16)),
+ inference_channel=list(range(16)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='HourglassNet',
+ num_stacks=1,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapMultiStageHead',
+ in_channels=256,
+ out_channels=channel_cfg['num_output_channels'],
+ num_stages=1,
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hourglass52_mpii_384x384.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hourglass52_mpii_384x384.py
new file mode 100644
index 0000000000000000000000000000000000000000..30f2ec04ee60e38e4c9ee16327252d45f3748e9b
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hourglass52_mpii_384x384.py
@@ -0,0 +1,129 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii.py'
+]
+evaluation = dict(interval=10, metric='PCKh', save_best='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=list(range(16)),
+ inference_channel=list(range(16)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='HourglassNet',
+ num_stacks=1,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapMultiStageHead',
+ in_channels=256,
+ out_channels=channel_cfg['num_output_channels'],
+ num_stages=1,
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[384, 384],
+ heatmap_size=[96, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hourglass_mpii.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hourglass_mpii.md
new file mode 100644
index 0000000000000000000000000000000000000000..d429415acfae5d43924653e30fbf76eb09de52ba
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hourglass_mpii.md
@@ -0,0 +1,41 @@
+
+
+MPII (CVPR'2014)
+ +```bibtex +@inproceedings{andriluka14cvpr, + author = {Mykhaylo Andriluka and Leonid Pishchulin and Peter Gehler and Schiele, Bernt}, + title = {2D Human Pose Estimation: New Benchmark and State of the Art Analysis}, + booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, + year = {2014}, + month = {June} +} +``` + +
+
+
+
+
+Hourglass (ECCV'2016)
+ +```bibtex +@inproceedings{newell2016stacked, + title={Stacked hourglass networks for human pose estimation}, + author={Newell, Alejandro and Yang, Kaiyu and Deng, Jia}, + booktitle={European conference on computer vision}, + pages={483--499}, + year={2016}, + organization={Springer} +} +``` + +
+
+
+Results on MPII val set
+
+| Arch | Input Size | Mean | Mean@0.1 | ckpt | log |
+| :--- | :--------: | :------: | :------: |:------: |:------: |
+| [pose_hourglass_52](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hourglass52_mpii_256x256.py) | 256x256 | 0.889 | 0.317 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hourglass/hourglass52_mpii_256x256-ae358435_20200812.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hourglass/hourglass52_mpii_256x256_20200812.log.json) |
+| [pose_hourglass_52](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hourglass52_mpii_384x384.py) | 384x384 | 0.894 | 0.366 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hourglass/hourglass52_mpii_384x384-04090bc3_20200812.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hourglass/hourglass52_mpii_384x384_20200812.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hourglass_mpii.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hourglass_mpii.yml
new file mode 100644
index 0000000000000000000000000000000000000000..ecd47008a220dc6a296c49b35cc12456599b490b
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hourglass_mpii.yml
@@ -0,0 +1,34 @@
+Collections:
+- Name: Hourglass
+ Paper:
+ Title: Stacked hourglass networks for human pose estimation
+ URL: https://link.springer.com/chapter/10.1007/978-3-319-46484-8_29
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/hourglass.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hourglass52_mpii_256x256.py
+ In Collection: Hourglass
+ Metadata:
+ Architecture: &id001
+ - Hourglass
+ Training Data: MPII
+ Name: topdown_heatmap_hourglass52_mpii_256x256
+ Results:
+ - Dataset: MPII
+ Metrics:
+ Mean: 0.889
+ Mean@0.1: 0.317
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/hourglass/hourglass52_mpii_256x256-ae358435_20200812.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hourglass52_mpii_384x384.py
+ In Collection: Hourglass
+ Metadata:
+ Architecture: *id001
+ Training Data: MPII
+ Name: topdown_heatmap_hourglass52_mpii_384x384
+ Results:
+ - Dataset: MPII
+ Metrics:
+ Mean: 0.894
+ Mean@0.1: 0.366
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/hourglass/hourglass52_mpii_384x384-04090bc3_20200812.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_dark_mpii.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_dark_mpii.md
new file mode 100644
index 0000000000000000000000000000000000000000..b7100183eae55d59ba2d1afe459c85a94df0acf0
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_dark_mpii.md
@@ -0,0 +1,57 @@
+
+
+MPII (CVPR'2014)
+ +```bibtex +@inproceedings{andriluka14cvpr, + author = {Mykhaylo Andriluka and Leonid Pishchulin and Peter Gehler and Schiele, Bernt}, + title = {2D Human Pose Estimation: New Benchmark and State of the Art Analysis}, + booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, + year = {2014}, + month = {June} +} +``` + +
+
+
+
+
+HRNet (CVPR'2019)
+ +```bibtex +@inproceedings{sun2019deep, + title={Deep high-resolution representation learning for human pose estimation}, + author={Sun, Ke and Xiao, Bin and Liu, Dong and Wang, Jingdong}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={5693--5703}, + year={2019} +} +``` + +
+
+
+
+
+DarkPose (CVPR'2020)
+ +```bibtex +@inproceedings{zhang2020distribution, + title={Distribution-aware coordinate representation for human pose estimation}, + author={Zhang, Feng and Zhu, Xiatian and Dai, Hanbin and Ye, Mao and Zhu, Ce}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + pages={7093--7102}, + year={2020} +} +``` + +
+
+
+Results on MPII val set
+
+| Arch | Input Size | Mean | Mean@0.1 | ckpt | log |
+| :--- | :--------: | :------: | :------: |:------: |:------: |
+| [pose_hrnet_w32_dark](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_w32_mpii_256x256_dark.py) | 256x256 | 0.904 | 0.354 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_mpii_256x256_dark-f1601c5b_20200927.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_mpii_256x256_dark_20200927.log.json) |
+| [pose_hrnet_w48_dark](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_w48_mpii_256x256_dark.py) | 256x256 | 0.905 | 0.360 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_mpii_256x256_dark-0decd39f_20200927.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_mpii_256x256_dark_20200927.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_dark_mpii.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_dark_mpii.yml
new file mode 100644
index 0000000000000000000000000000000000000000..795e135a923be338965e750a28160033bedd2f5d
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_dark_mpii.yml
@@ -0,0 +1,35 @@
+Collections:
+- Name: DarkPose
+ Paper:
+ Title: Distribution-aware coordinate representation for human pose estimation
+ URL: http://openaccess.thecvf.com/content_CVPR_2020/html/Zhang_Distribution-Aware_Coordinate_Representation_for_Human_Pose_Estimation_CVPR_2020_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/techniques/dark.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_w32_mpii_256x256_dark.py
+ In Collection: DarkPose
+ Metadata:
+ Architecture: &id001
+ - HRNet
+ - DarkPose
+ Training Data: MPII
+ Name: topdown_heatmap_hrnet_w32_mpii_256x256_dark
+ Results:
+ - Dataset: MPII
+ Metrics:
+ Mean: 0.904
+ Mean@0.1: 0.354
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_mpii_256x256_dark-f1601c5b_20200927.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_w48_mpii_256x256_dark.py
+ In Collection: DarkPose
+ Metadata:
+ Architecture: *id001
+ Training Data: MPII
+ Name: topdown_heatmap_hrnet_w48_mpii_256x256_dark
+ Results:
+ - Dataset: MPII
+ Metrics:
+ Mean: 0.905
+ Mean@0.1: 0.36
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_mpii_256x256_dark-0decd39f_20200927.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_mpii.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_mpii.md
new file mode 100644
index 0000000000000000000000000000000000000000..d4c205ca64c8537cf6189e4d206711f31b24edfe
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_mpii.md
@@ -0,0 +1,41 @@
+
+
+
+MPII (CVPR'2014)
+ +```bibtex +@inproceedings{andriluka14cvpr, + author = {Mykhaylo Andriluka and Leonid Pishchulin and Peter Gehler and Schiele, Bernt}, + title = {2D Human Pose Estimation: New Benchmark and State of the Art Analysis}, + booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, + year = {2014}, + month = {June} +} +``` + +
+
+
+
+
+HRNet (CVPR'2019)
+ +```bibtex +@inproceedings{sun2019deep, + title={Deep high-resolution representation learning for human pose estimation}, + author={Sun, Ke and Xiao, Bin and Liu, Dong and Wang, Jingdong}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={5693--5703}, + year={2019} +} +``` + +
+
+
+Results on MPII val set
+
+| Arch | Input Size | Mean | Mean@0.1 | ckpt | log |
+| :--- | :--------: | :------: | :------: |:------: |:------: |
+| [pose_hrnet_w32](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_w32_mpii_256x256.py) | 256x256 | 0.900 | 0.334 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_mpii_256x256-6c4f923f_20200812.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_mpii_256x256_20200812.log.json) |
+| [pose_hrnet_w48](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_w48_mpii_256x256.py) | 256x256 | 0.901 | 0.337 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_mpii_256x256-92cab7bd_20200812.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_mpii_256x256_20200812.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_mpii.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_mpii.yml
new file mode 100644
index 0000000000000000000000000000000000000000..94607111ef62935b44fb072f87efbdf42796ed5a
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_mpii.yml
@@ -0,0 +1,34 @@
+Collections:
+- Name: HRNet
+ Paper:
+ Title: Deep high-resolution representation learning for human pose estimation
+ URL: http://openaccess.thecvf.com/content_CVPR_2019/html/Sun_Deep_High-Resolution_Representation_Learning_for_Human_Pose_Estimation_CVPR_2019_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/hrnet.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_w32_mpii_256x256.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: &id001
+ - HRNet
+ Training Data: MPII
+ Name: topdown_heatmap_hrnet_w32_mpii_256x256
+ Results:
+ - Dataset: MPII
+ Metrics:
+ Mean: 0.9
+ Mean@0.1: 0.334
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_mpii_256x256-6c4f923f_20200812.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_w48_mpii_256x256.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: MPII
+ Name: topdown_heatmap_hrnet_w48_mpii_256x256
+ Results:
+ - Dataset: MPII
+ Metrics:
+ Mean: 0.901
+ Mean@0.1: 0.337
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_mpii_256x256-92cab7bd_20200812.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_w32_mpii_256x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_w32_mpii_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..1ef7e84d708f8426ab5aaa0502c15c82de4e81a6
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_w32_mpii_256x256.py
@@ -0,0 +1,154 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii.py'
+]
+evaluation = dict(interval=10, metric='PCKh', save_best='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=list(range(16)),
+ inference_channel=list(range(16)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_w32_mpii_256x256_dark.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_w32_mpii_256x256_dark.py
new file mode 100644
index 0000000000000000000000000000000000000000..503920eb1c50271b7f6615081464bf13265f97b9
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_w32_mpii_256x256_dark.py
@@ -0,0 +1,154 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii.py'
+]
+evaluation = dict(interval=10, metric='PCKh', save_best='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=list(range(16)),
+ inference_channel=list(range(16)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='unbiased',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2, unbiased_encoding=True),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_w32_mpii_256x256_udp.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_w32_mpii_256x256_udp.py
new file mode 100644
index 0000000000000000000000000000000000000000..d31a172fbf2a022a815ac65554afeb829e70ab8e
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_w32_mpii_256x256_udp.py
@@ -0,0 +1,161 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii.py'
+]
+evaluation = dict(interval=10, metric='PCKh', save_best='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+target_type = 'GaussianHeatmap'
+channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=list(range(16)),
+ inference_channel=list(range(16)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=False,
+ target_type=target_type,
+ modulate_kernel=11,
+ use_udp=True))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='TopDownGenerateTarget',
+ sigma=2,
+ encoding='UDP',
+ target_type=target_type),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_w48_mpii_256x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_w48_mpii_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..99a4ef131ea479c18cd754256bc73d221e7ff348
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_w48_mpii_256x256.py
@@ -0,0 +1,154 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii.py'
+]
+evaluation = dict(interval=10, metric='PCKh', save_best='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=list(range(16)),
+ inference_channel=list(range(16)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_w48_mpii_256x256_dark.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_w48_mpii_256x256_dark.py
new file mode 100644
index 0000000000000000000000000000000000000000..4531f0f99617711548bd2374f9095b049726580b
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_w48_mpii_256x256_dark.py
@@ -0,0 +1,154 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii.py'
+]
+evaluation = dict(interval=10, metric='PCKh', save_best='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=list(range(16)),
+ inference_channel=list(range(16)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='unbiased',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2, unbiased_encoding=True),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_w48_mpii_256x256_udp.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_w48_mpii_256x256_udp.py
new file mode 100644
index 0000000000000000000000000000000000000000..d373d830d9e1242248f2fef534a903916b851cfe
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_w48_mpii_256x256_udp.py
@@ -0,0 +1,161 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii.py'
+]
+evaluation = dict(interval=10, metric='PCKh', save_best='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+target_type = 'GaussianHeatmap'
+channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=list(range(16)),
+ inference_channel=list(range(16)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=False,
+ target_type=target_type,
+ modulate_kernel=11,
+ use_udp=True))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='TopDownGenerateTarget',
+ sigma=2,
+ encoding='UDP',
+ target_type=target_type),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/litehrnet_18_mpii_256x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/litehrnet_18_mpii_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..a2a31e2c266d999af8b9532aefb97ae22779896f
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/litehrnet_18_mpii_256x256.py
@@ -0,0 +1,145 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii.py'
+]
+evaluation = dict(interval=10, metric='PCKh', key_indicator='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=list(range(16)),
+ inference_channel=list(range(16)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='LiteHRNet',
+ in_channels=3,
+ extra=dict(
+ stem=dict(stem_channels=32, out_channels=32, expand_ratio=1),
+ num_stages=3,
+ stages_spec=dict(
+ num_modules=(2, 4, 2),
+ num_branches=(2, 3, 4),
+ num_blocks=(2, 2, 2),
+ module_type=('LITE', 'LITE', 'LITE'),
+ with_fuse=(True, True, True),
+ reduce_ratios=(8, 8, 8),
+ num_channels=(
+ (40, 80),
+ (40, 80, 160),
+ (40, 80, 160, 320),
+ )),
+ with_head=True,
+ )),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=40,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/litehrnet_30_mpii_256x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/litehrnet_30_mpii_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..3b56ac9325df90ba3d13e1190d9db63bdc93f678
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/litehrnet_30_mpii_256x256.py
@@ -0,0 +1,145 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii.py'
+]
+evaluation = dict(interval=10, metric='PCKh', key_indicator='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=list(range(16)),
+ inference_channel=list(range(16)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='LiteHRNet',
+ in_channels=3,
+ extra=dict(
+ stem=dict(stem_channels=32, out_channels=32, expand_ratio=1),
+ num_stages=3,
+ stages_spec=dict(
+ num_modules=(3, 8, 3),
+ num_branches=(2, 3, 4),
+ num_blocks=(2, 2, 2),
+ module_type=('LITE', 'LITE', 'LITE'),
+ with_fuse=(True, True, True),
+ reduce_ratios=(8, 8, 8),
+ num_channels=(
+ (40, 80),
+ (40, 80, 160),
+ (40, 80, 160, 320),
+ )),
+ with_head=True,
+ )),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=40,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/litehrnet_mpii.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/litehrnet_mpii.md
new file mode 100644
index 0000000000000000000000000000000000000000..d77a3bae6155f25180c12e541111529ab80d9594
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/litehrnet_mpii.md
@@ -0,0 +1,39 @@
+
+
+MPII (CVPR'2014)
+ +```bibtex +@inproceedings{andriluka14cvpr, + author = {Mykhaylo Andriluka and Leonid Pishchulin and Peter Gehler and Schiele, Bernt}, + title = {2D Human Pose Estimation: New Benchmark and State of the Art Analysis}, + booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, + year = {2014}, + month = {June} +} +``` + +
+
+
+
+
+LiteHRNet (CVPR'2021)
+ +```bibtex +@inproceedings{Yulitehrnet21, + title={Lite-HRNet: A Lightweight High-Resolution Network}, + author={Yu, Changqian and Xiao, Bin and Gao, Changxin and Yuan, Lu and Zhang, Lei and Sang, Nong and Wang, Jingdong}, + booktitle={CVPR}, + year={2021} +} +``` + +
+
+
+Results on MPII val set
+
+| Arch | Input Size | Mean | Mean@0.1 | ckpt | log |
+| :--- | :--------: | :------: | :------: |:------: |:------: |
+| [LiteHRNet-18](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/litehrnet_18_mpii_256x256.py) | 256x256 | 0.859 | 0.260 | [ckpt](https://download.openmmlab.com/mmpose/top_down/litehrnet/litehrnet18_mpii_256x256-cabd7984_20210623.pth) | [log](https://download.openmmlab.com/mmpose/top_down/litehrnet/litehrnet18_mpii_256x256_20210623.log.json) |
+| [LiteHRNet-30](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/litehrnet_30_mpii_256x256.py) | 256x256 | 0.869 | 0.271 | [ckpt](https://download.openmmlab.com/mmpose/top_down/litehrnet/litehrnet30_mpii_256x256-faae8bd8_20210622.pth) | [log](https://download.openmmlab.com/mmpose/top_down/litehrnet/litehrnet30_mpii_256x256_20210622.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/litehrnet_mpii.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/litehrnet_mpii.yml
new file mode 100644
index 0000000000000000000000000000000000000000..ae20a7352692714813ee839c62100a9b0f8c6250
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/litehrnet_mpii.yml
@@ -0,0 +1,34 @@
+Collections:
+- Name: LiteHRNet
+ Paper:
+ Title: 'Lite-HRNet: A Lightweight High-Resolution Network'
+ URL: https://arxiv.org/abs/2104.06403
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/litehrnet.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/litehrnet_18_mpii_256x256.py
+ In Collection: LiteHRNet
+ Metadata:
+ Architecture: &id001
+ - LiteHRNet
+ Training Data: MPII
+ Name: topdown_heatmap_litehrnet_18_mpii_256x256
+ Results:
+ - Dataset: MPII
+ Metrics:
+ Mean: 0.859
+ Mean@0.1: 0.26
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/litehrnet/litehrnet18_mpii_256x256-cabd7984_20210623.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/litehrnet_30_mpii_256x256.py
+ In Collection: LiteHRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: MPII
+ Name: topdown_heatmap_litehrnet_30_mpii_256x256
+ Results:
+ - Dataset: MPII
+ Metrics:
+ Mean: 0.869
+ Mean@0.1: 0.271
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/litehrnet/litehrnet30_mpii_256x256-faae8bd8_20210622.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/mobilenetv2_mpii.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/mobilenetv2_mpii.md
new file mode 100644
index 0000000000000000000000000000000000000000..f811d33041b8af9cfe226c9391228721b3a4ba98
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/mobilenetv2_mpii.md
@@ -0,0 +1,39 @@
+
+
+MPII (CVPR'2014)
+ +```bibtex +@inproceedings{andriluka14cvpr, + author = {Mykhaylo Andriluka and Leonid Pishchulin and Peter Gehler and Schiele, Bernt}, + title = {2D Human Pose Estimation: New Benchmark and State of the Art Analysis}, + booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, + year = {2014}, + month = {June} +} +``` + +
+
+
+
+
+MobilenetV2 (CVPR'2018)
+ +```bibtex +@inproceedings{sandler2018mobilenetv2, + title={Mobilenetv2: Inverted residuals and linear bottlenecks}, + author={Sandler, Mark and Howard, Andrew and Zhu, Menglong and Zhmoginov, Andrey and Chen, Liang-Chieh}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={4510--4520}, + year={2018} +} +``` + +
+
+
+Results on MPII val set
+
+| Arch | Input Size | Mean | Mean@0.1 | ckpt | log |
+| :--- | :--------: | :------: | :------: |:------: |:------: |
+| [pose_mobilenetv2](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mobilenet_v2/mpii/mobilenet_v2_mpii_256x256.py) | 256x256 | 0.854 | 0.235 | [ckpt](https://download.openmmlab.com/mmpose/top_down/mobilenetv2/mobilenetv2_mpii_256x256-e068afa7_20200812.pth) | [log](https://download.openmmlab.com/mmpose/top_down/mobilenetv2/mobilenetv2_mpii_256x256_20200812.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/mobilenetv2_mpii.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/mobilenetv2_mpii.yml
new file mode 100644
index 0000000000000000000000000000000000000000..87a4912b4ae4842480bf0642bac2d214fa65a4c5
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/mobilenetv2_mpii.yml
@@ -0,0 +1,21 @@
+Collections:
+- Name: MobilenetV2
+ Paper:
+ Title: 'Mobilenetv2: Inverted residuals and linear bottlenecks'
+ URL: http://openaccess.thecvf.com/content_cvpr_2018/html/Sandler_MobileNetV2_Inverted_Residuals_CVPR_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/mobilenetv2.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mobilenet_v2/mpii/mobilenet_v2_mpii_256x256.py
+ In Collection: MobilenetV2
+ Metadata:
+ Architecture:
+ - MobilenetV2
+ Training Data: MPII
+ Name: topdown_heatmap_mpii
+ Results:
+ - Dataset: MPII
+ Metrics:
+ Mean: 0.854
+ Mean@0.1: 0.235
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/mobilenetv2/mobilenetv2_mpii_256x256-e068afa7_20200812.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/mobilenetv2_mpii_256x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/mobilenetv2_mpii_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..b13feaf1fc77695d59fcc334e687909b72147aa2
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/mobilenetv2_mpii_256x256.py
@@ -0,0 +1,123 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii.py'
+]
+evaluation = dict(interval=10, metric='PCKh', save_best='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=list(range(16)),
+ inference_channel=list(range(16)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='mmcls://mobilenet_v2',
+ backbone=dict(type='MobileNetV2', widen_factor=1., out_indices=(7, )),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1280,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/res101_mpii_256x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/res101_mpii_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..6e09b84e98e02e044b4b7c7d967041582fd28502
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/res101_mpii_256x256.py
@@ -0,0 +1,123 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii.py'
+]
+evaluation = dict(interval=10, metric='PCKh', save_best='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=list(range(16)),
+ inference_channel=list(range(16)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet101',
+ backbone=dict(type='ResNet', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/res152_mpii_256x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/res152_mpii_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..9c5456e0041c8aeff08f8ce975206c3cdf2156f0
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/res152_mpii_256x256.py
@@ -0,0 +1,123 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii.py'
+]
+evaluation = dict(interval=10, metric='PCKh', save_best='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=list(range(16)),
+ inference_channel=list(range(16)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet152',
+ backbone=dict(type='ResNet', depth=152),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/res50_mpii_256x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/res50_mpii_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..c4c9898e43e2ed7ce0b2306d0b4f14b312d82bff
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/res50_mpii_256x256.py
@@ -0,0 +1,123 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii.py'
+]
+evaluation = dict(interval=10, metric='PCKh', save_best='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=list(range(16)),
+ inference_channel=list(range(16)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnet_mpii.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnet_mpii.md
new file mode 100644
index 0000000000000000000000000000000000000000..64a5337b5005144483a6c500237019d71bae9cad
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnet_mpii.md
@@ -0,0 +1,58 @@
+
+
+MPII (CVPR'2014)
+ +```bibtex +@inproceedings{andriluka14cvpr, + author = {Mykhaylo Andriluka and Leonid Pishchulin and Peter Gehler and Schiele, Bernt}, + title = {2D Human Pose Estimation: New Benchmark and State of the Art Analysis}, + booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, + year = {2014}, + month = {June} +} +``` + +
+
+
+
+
+SimpleBaseline2D (ECCV'2018)
+ +```bibtex +@inproceedings{xiao2018simple, + title={Simple baselines for human pose estimation and tracking}, + author={Xiao, Bin and Wu, Haiping and Wei, Yichen}, + booktitle={Proceedings of the European conference on computer vision (ECCV)}, + pages={466--481}, + year={2018} +} +``` + +
+
+
+
+
+ResNet (CVPR'2016)
+ +```bibtex +@inproceedings{he2016deep, + title={Deep residual learning for image recognition}, + author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={770--778}, + year={2016} +} +``` + +
+
+
+Results on MPII val set
+
+| Arch | Input Size | Mean | Mean@0.1 | ckpt | log |
+| :--- | :--------: | :------: | :------: |:------: |:------: |
+| [pose_resnet_50](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/res50_mpii_256x256.py) | 256x256 | 0.882 | 0.286 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res50_mpii_256x256-418ffc88_20200812.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res50_mpii_256x256_20200812.log.json) |
+| [pose_resnet_101](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/res101_mpii_256x256.py) | 256x256 | 0.888 | 0.290 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res101_mpii_256x256-416f5d71_20200812.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res101_mpii_256x256_20200812.log.json) |
+| [pose_resnet_152](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/res152_mpii_256x256.py) | 256x256 | 0.889 | 0.303 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res152_mpii_256x256-3ecba29d_20200812.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res152_mpii_256x256_20200812.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnet_mpii.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnet_mpii.yml
new file mode 100644
index 0000000000000000000000000000000000000000..227eb34c59cd05c9ff0d654a5fb27552af12aab7
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnet_mpii.yml
@@ -0,0 +1,48 @@
+Collections:
+- Name: SimpleBaseline2D
+ Paper:
+ Title: Simple baselines for human pose estimation and tracking
+ URL: http://openaccess.thecvf.com/content_ECCV_2018/html/Bin_Xiao_Simple_Baselines_for_ECCV_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/simplebaseline2d.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/res50_mpii_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: &id001
+ - SimpleBaseline2D
+ - ResNet
+ Training Data: MPII
+ Name: topdown_heatmap_res50_mpii_256x256
+ Results:
+ - Dataset: MPII
+ Metrics:
+ Mean: 0.882
+ Mean@0.1: 0.286
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res50_mpii_256x256-418ffc88_20200812.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/res101_mpii_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: MPII
+ Name: topdown_heatmap_res101_mpii_256x256
+ Results:
+ - Dataset: MPII
+ Metrics:
+ Mean: 0.888
+ Mean@0.1: 0.29
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res101_mpii_256x256-416f5d71_20200812.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/res152_mpii_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: MPII
+ Name: topdown_heatmap_res152_mpii_256x256
+ Results:
+ - Dataset: MPII
+ Metrics:
+ Mean: 0.889
+ Mean@0.1: 0.303
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res152_mpii_256x256-3ecba29d_20200812.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnetv1d101_mpii_256x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnetv1d101_mpii_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..d35b83a44ec1d555b6896c1ce8699802901faf29
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnetv1d101_mpii_256x256.py
@@ -0,0 +1,123 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii.py'
+]
+evaluation = dict(interval=10, metric='PCKh', save_best='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=list(range(16)),
+ inference_channel=list(range(16)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='mmcls://resnet101_v1d',
+ backbone=dict(type='ResNetV1d', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnetv1d152_mpii_256x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnetv1d152_mpii_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..f6e26ca93989ec7549dd7179a0f99e984b5505f4
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnetv1d152_mpii_256x256.py
@@ -0,0 +1,123 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii.py'
+]
+evaluation = dict(interval=10, metric='PCKh', save_best='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=list(range(16)),
+ inference_channel=list(range(16)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='mmcls://resnet152_v1d',
+ backbone=dict(type='ResNetV1d', depth=152),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnetv1d50_mpii_256x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnetv1d50_mpii_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..e10ad9ed76a7626451e764835ba26805de65a086
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnetv1d50_mpii_256x256.py
@@ -0,0 +1,123 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii.py'
+]
+evaluation = dict(interval=10, metric='PCKh', save_best='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=list(range(16)),
+ inference_channel=list(range(16)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='mmcls://resnet50_v1d',
+ backbone=dict(type='ResNetV1d', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnetv1d_mpii.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnetv1d_mpii.md
new file mode 100644
index 0000000000000000000000000000000000000000..27a655eedd1be7a8a7b11728e78ab6b88b16808a
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnetv1d_mpii.md
@@ -0,0 +1,41 @@
+
+
+MPII (CVPR'2014)
+ +```bibtex +@inproceedings{andriluka14cvpr, + author = {Mykhaylo Andriluka and Leonid Pishchulin and Peter Gehler and Schiele, Bernt}, + title = {2D Human Pose Estimation: New Benchmark and State of the Art Analysis}, + booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, + year = {2014}, + month = {June} +} +``` + +
+
+
+
+
+ResNetV1D (CVPR'2019)
+ +```bibtex +@inproceedings{he2019bag, + title={Bag of tricks for image classification with convolutional neural networks}, + author={He, Tong and Zhang, Zhi and Zhang, Hang and Zhang, Zhongyue and Xie, Junyuan and Li, Mu}, + booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition}, + pages={558--567}, + year={2019} +} +``` + +
+
+
+Results on MPII val set
+
+| Arch | Input Size | Mean | Mean@0.1 | ckpt | log |
+| :--- | :--------: | :------: | :------: |:------: |:------: |
+| [pose_resnetv1d_50](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnetv1d50_mpii_256x256.py) | 256x256 | 0.881 | 0.290 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnetv1d/resnetv1d50_mpii_256x256-2337a92e_20200812.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnetv1d/resnetv1d50_mpii_256x256_20200812.log.json) |
+| [pose_resnetv1d_101](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnetv1d101_mpii_256x256.py) | 256x256 | 0.883 | 0.295 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnetv1d/resnetv1d101_mpii_256x256-2851d710_20200812.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnetv1d/resnetv1d101_mpii_256x256_20200812.log.json) |
+| [pose_resnetv1d_152](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnetv1d152_mpii_256x256.py) | 256x256 | 0.888 | 0.300 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnetv1d/resnetv1d152_mpii_256x256-8b10a87c_20200812.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnetv1d/resnetv1d152_mpii_256x256_20200812.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnetv1d_mpii.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnetv1d_mpii.yml
new file mode 100644
index 0000000000000000000000000000000000000000..b02c3d44f17436c9ee248a3271651a85fef98555
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnetv1d_mpii.yml
@@ -0,0 +1,47 @@
+Collections:
+- Name: ResNetV1D
+ Paper:
+ Title: Bag of tricks for image classification with convolutional neural networks
+ URL: http://openaccess.thecvf.com/content_CVPR_2019/html/He_Bag_of_Tricks_for_Image_Classification_with_Convolutional_Neural_Networks_CVPR_2019_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/resnetv1d.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnetv1d50_mpii_256x256.py
+ In Collection: ResNetV1D
+ Metadata:
+ Architecture: &id001
+ - ResNetV1D
+ Training Data: MPII
+ Name: topdown_heatmap_resnetv1d50_mpii_256x256
+ Results:
+ - Dataset: MPII
+ Metrics:
+ Mean: 0.881
+ Mean@0.1: 0.29
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnetv1d/resnetv1d50_mpii_256x256-2337a92e_20200812.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnetv1d101_mpii_256x256.py
+ In Collection: ResNetV1D
+ Metadata:
+ Architecture: *id001
+ Training Data: MPII
+ Name: topdown_heatmap_resnetv1d101_mpii_256x256
+ Results:
+ - Dataset: MPII
+ Metrics:
+ Mean: 0.883
+ Mean@0.1: 0.295
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnetv1d/resnetv1d101_mpii_256x256-2851d710_20200812.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnetv1d152_mpii_256x256.py
+ In Collection: ResNetV1D
+ Metadata:
+ Architecture: *id001
+ Training Data: MPII
+ Name: topdown_heatmap_resnetv1d152_mpii_256x256
+ Results:
+ - Dataset: MPII
+ Metrics:
+ Mean: 0.888
+ Mean@0.1: 0.3
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnetv1d/resnetv1d152_mpii_256x256-8b10a87c_20200812.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnext101_mpii_256x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnext101_mpii_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..d01af2be2e1dd85b90245443dddb1a706938b159
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnext101_mpii_256x256.py
@@ -0,0 +1,123 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii.py'
+]
+evaluation = dict(interval=10, metric='PCKh', save_best='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=list(range(16)),
+ inference_channel=list(range(16)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='mmcls://resnext101_32x4d',
+ backbone=dict(type='ResNeXt', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnext152_mpii_256x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnext152_mpii_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..2d730b49a1196d90767f04fb595891fe01b4c76f
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnext152_mpii_256x256.py
@@ -0,0 +1,123 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii.py'
+]
+evaluation = dict(interval=10, metric='PCKh', save_best='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=list(range(16)),
+ inference_channel=list(range(16)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='mmcls://resnext152_32x4d',
+ backbone=dict(type='ResNeXt', depth=152),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnext50_mpii_256x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnext50_mpii_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..22d97420bba76867dca4325da7c928b6d157d78f
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnext50_mpii_256x256.py
@@ -0,0 +1,123 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii.py'
+]
+evaluation = dict(interval=10, metric='PCKh', save_best='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=list(range(16)),
+ inference_channel=list(range(16)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='mmcls://resnext50_32x4d',
+ backbone=dict(type='ResNeXt', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnext_mpii.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnext_mpii.md
new file mode 100644
index 0000000000000000000000000000000000000000..b118ca4fd0999e83daa64c6f2ee1f4b764dc2c12
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnext_mpii.md
@@ -0,0 +1,39 @@
+
+
+MPII (CVPR'2014)
+ +```bibtex +@inproceedings{andriluka14cvpr, + author = {Mykhaylo Andriluka and Leonid Pishchulin and Peter Gehler and Schiele, Bernt}, + title = {2D Human Pose Estimation: New Benchmark and State of the Art Analysis}, + booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, + year = {2014}, + month = {June} +} +``` + +
+
+
+
+
+ResNext (CVPR'2017)
+ +```bibtex +@inproceedings{xie2017aggregated, + title={Aggregated residual transformations for deep neural networks}, + author={Xie, Saining and Girshick, Ross and Doll{\'a}r, Piotr and Tu, Zhuowen and He, Kaiming}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={1492--1500}, + year={2017} +} +``` + +
+
+
+Results on MPII val set
+
+| Arch | Input Size | Mean | Mean@0.1 | ckpt | log |
+| :--- | :--------: | :------: | :------: |:------: |:------: |
+| [pose_resnext_152](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnext152_mpii_256x256.py) | 256x256 | 0.887 | 0.294 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnext/resnext152_mpii_256x256-df302719_20200927.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnext/resnext152_mpii_256x256_20200927.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnext_mpii.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnext_mpii.yml
new file mode 100644
index 0000000000000000000000000000000000000000..c3ce9cd12126bd92da34ff99f889e6c96faaf77d
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnext_mpii.yml
@@ -0,0 +1,21 @@
+Collections:
+- Name: ResNext
+ Paper:
+ Title: Aggregated residual transformations for deep neural networks
+ URL: http://openaccess.thecvf.com/content_cvpr_2017/html/Xie_Aggregated_Residual_Transformations_CVPR_2017_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/resnext.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnext152_mpii_256x256.py
+ In Collection: ResNext
+ Metadata:
+ Architecture:
+ - ResNext
+ Training Data: MPII
+ Name: topdown_heatmap_resnext152_mpii_256x256
+ Results:
+ - Dataset: MPII
+ Metrics:
+ Mean: 0.887
+ Mean@0.1: 0.294
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnext/resnext152_mpii_256x256-df302719_20200927.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/scnet101_mpii_256x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/scnet101_mpii_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..a4f746671f00fb12b9a511cd643b04b10530e268
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/scnet101_mpii_256x256.py
@@ -0,0 +1,124 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii.py'
+]
+evaluation = dict(interval=10, metric='PCKh', save_best='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=list(range(16)),
+ inference_channel=list(range(16)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/scnet101-94250a77.pth',
+ backbone=dict(type='SCNet', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/scnet50_mpii_256x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/scnet50_mpii_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..6a4011f3419ac1272f03be3f13d89d1021cac94b
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/scnet50_mpii_256x256.py
@@ -0,0 +1,124 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii.py'
+]
+evaluation = dict(interval=10, metric='PCKh', save_best='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=list(range(16)),
+ inference_channel=list(range(16)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/scnet50-7ef0a199.pth',
+ backbone=dict(type='SCNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/scnet_mpii.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/scnet_mpii.md
new file mode 100644
index 0000000000000000000000000000000000000000..0a282b77f9a1d09842e738f67cb5d4c13bb342e8
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/scnet_mpii.md
@@ -0,0 +1,40 @@
+
+
+MPII (CVPR'2014)
+ +```bibtex +@inproceedings{andriluka14cvpr, + author = {Mykhaylo Andriluka and Leonid Pishchulin and Peter Gehler and Schiele, Bernt}, + title = {2D Human Pose Estimation: New Benchmark and State of the Art Analysis}, + booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, + year = {2014}, + month = {June} +} +``` + +
+
+
+
+
+SCNet (CVPR'2020)
+ +```bibtex +@inproceedings{liu2020improving, + title={Improving Convolutional Networks with Self-Calibrated Convolutions}, + author={Liu, Jiang-Jiang and Hou, Qibin and Cheng, Ming-Ming and Wang, Changhu and Feng, Jiashi}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + pages={10096--10105}, + year={2020} +} +``` + +
+
+
+Results on MPII val set
+
+| Arch | Input Size | Mean | Mean@0.1 | ckpt | log |
+| :--- | :--------: | :------: | :------: |:------: |:------: |
+| [pose_scnet_50](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/scnet50_mpii_256x256.py) | 256x256 | 0.888 | 0.290 | [ckpt](https://download.openmmlab.com/mmpose/top_down/scnet/scnet50_mpii_256x256-a54b6af5_20200812.pth) | [log](https://download.openmmlab.com/mmpose/top_down/scnet/scnet50_mpii_256x256_20200812.log.json) |
+| [pose_scnet_101](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/scnet101_mpii_256x256.py) | 256x256 | 0.886 | 0.293 | [ckpt](https://download.openmmlab.com/mmpose/top_down/scnet/scnet101_mpii_256x256-b4c2d184_20200812.pth) | [log](https://download.openmmlab.com/mmpose/top_down/scnet/scnet101_mpii_256x256_20200812.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/scnet_mpii.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/scnet_mpii.yml
new file mode 100644
index 0000000000000000000000000000000000000000..681c59b39967bfd5ada38cdda4cf3dd8cf2969ae
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/scnet_mpii.yml
@@ -0,0 +1,34 @@
+Collections:
+- Name: SCNet
+ Paper:
+ Title: Improving Convolutional Networks with Self-Calibrated Convolutions
+ URL: http://openaccess.thecvf.com/content_CVPR_2020/html/Liu_Improving_Convolutional_Networks_With_Self-Calibrated_Convolutions_CVPR_2020_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/scnet.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/scnet50_mpii_256x256.py
+ In Collection: SCNet
+ Metadata:
+ Architecture: &id001
+ - SCNet
+ Training Data: MPII
+ Name: topdown_heatmap_scnet50_mpii_256x256
+ Results:
+ - Dataset: MPII
+ Metrics:
+ Mean: 0.888
+ Mean@0.1: 0.29
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/scnet/scnet50_mpii_256x256-a54b6af5_20200812.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/scnet101_mpii_256x256.py
+ In Collection: SCNet
+ Metadata:
+ Architecture: *id001
+ Training Data: MPII
+ Name: topdown_heatmap_scnet101_mpii_256x256
+ Results:
+ - Dataset: MPII
+ Metrics:
+ Mean: 0.886
+ Mean@0.1: 0.293
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/scnet/scnet101_mpii_256x256-b4c2d184_20200812.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/seresnet101_mpii_256x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/seresnet101_mpii_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..ffe3cfe2c536ff48e5ed9d1edf59cb94af38c1be
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/seresnet101_mpii_256x256.py
@@ -0,0 +1,123 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii.py'
+]
+evaluation = dict(interval=10, metric='PCKh', save_best='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=list(range(16)),
+ inference_channel=list(range(16)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='mmcls://se-resnet101',
+ backbone=dict(type='SEResNet', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/seresnet152_mpii_256x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/seresnet152_mpii_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..fa12a8d03ed75d8f656662f85ccac2a0e6d4130a
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/seresnet152_mpii_256x256.py
@@ -0,0 +1,123 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii.py'
+]
+evaluation = dict(interval=10, metric='PCKh', save_best='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=list(range(16)),
+ inference_channel=list(range(16)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(type='SEResNet', depth=152),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/seresnet50_mpii_256x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/seresnet50_mpii_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..a3382e19cc9f3d018eadca99f512bc4cf21c221c
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/seresnet50_mpii_256x256.py
@@ -0,0 +1,123 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii.py'
+]
+evaluation = dict(interval=10, metric='PCKh', save_best='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=list(range(16)),
+ inference_channel=list(range(16)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='mmcls://se-resnet50',
+ backbone=dict(type='SEResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/seresnet_mpii.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/seresnet_mpii.md
new file mode 100644
index 0000000000000000000000000000000000000000..fe25c1cab35cafdf3a487580dd840dcca174bb06
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/seresnet_mpii.md
@@ -0,0 +1,43 @@
+
+
+MPII (CVPR'2014)
+ +```bibtex +@inproceedings{andriluka14cvpr, + author = {Mykhaylo Andriluka and Leonid Pishchulin and Peter Gehler and Schiele, Bernt}, + title = {2D Human Pose Estimation: New Benchmark and State of the Art Analysis}, + booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, + year = {2014}, + month = {June} +} +``` + +
+
+
+
+
+SEResNet (CVPR'2018)
+ +```bibtex +@inproceedings{hu2018squeeze, + title={Squeeze-and-excitation networks}, + author={Hu, Jie and Shen, Li and Sun, Gang}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={7132--7141}, + year={2018} +} +``` + +
+
+
+Results on MPII val set
+
+| Arch | Input Size | Mean | Mean@0.1 | ckpt | log |
+| :--- | :--------: | :------: | :------: |:------: |:------: |
+| [pose_seresnet_50](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/seresnet50_mpii_256x256.py) | 256x256 | 0.884 | 0.292 | [ckpt](https://download.openmmlab.com/mmpose/top_down/seresnet/seresnet50_mpii_256x256-1bb21f79_20200927.pth) | [log](https://download.openmmlab.com/mmpose/top_down/seresnet/seresnet50_mpii_256x256_20200927.log.json) |
+| [pose_seresnet_101](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/seresnet101_mpii_256x256.py) | 256x256 | 0.884 | 0.295 | [ckpt](https://download.openmmlab.com/mmpose/top_down/seresnet/seresnet101_mpii_256x256-0ba14ff5_20200927.pth) | [log](https://download.openmmlab.com/mmpose/top_down/seresnet/seresnet101_mpii_256x256_20200927.log.json) |
+| [pose_seresnet_152\*](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/seresnet152_mpii_256x256.py) | 256x256 | 0.884 | 0.287 | [ckpt](https://download.openmmlab.com/mmpose/top_down/seresnet/seresnet152_mpii_256x256-6ea1e774_20200927.pth) | [log](https://download.openmmlab.com/mmpose/top_down/seresnet/seresnet152_mpii_256x256_20200927.log.json) |
+
+Note that \* means without imagenet pre-training.
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/seresnet_mpii.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/seresnet_mpii.yml
new file mode 100644
index 0000000000000000000000000000000000000000..86e79d30db3a21b09628c1d542aa835969fb880b
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/seresnet_mpii.yml
@@ -0,0 +1,47 @@
+Collections:
+- Name: SEResNet
+ Paper:
+ Title: Squeeze-and-excitation networks
+ URL: http://openaccess.thecvf.com/content_cvpr_2018/html/Hu_Squeeze-and-Excitation_Networks_CVPR_2018_paper
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/seresnet.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/seresnet50_mpii_256x256.py
+ In Collection: SEResNet
+ Metadata:
+ Architecture: &id001
+ - SEResNet
+ Training Data: MPII
+ Name: topdown_heatmap_seresnet50_mpii_256x256
+ Results:
+ - Dataset: MPII
+ Metrics:
+ Mean: 0.884
+ Mean@0.1: 0.292
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/seresnet/seresnet50_mpii_256x256-1bb21f79_20200927.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/seresnet101_mpii_256x256.py
+ In Collection: SEResNet
+ Metadata:
+ Architecture: *id001
+ Training Data: MPII
+ Name: topdown_heatmap_seresnet101_mpii_256x256
+ Results:
+ - Dataset: MPII
+ Metrics:
+ Mean: 0.884
+ Mean@0.1: 0.295
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/seresnet/seresnet101_mpii_256x256-0ba14ff5_20200927.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/seresnet152_mpii_256x256.py
+ In Collection: SEResNet
+ Metadata:
+ Architecture: *id001
+ Training Data: MPII
+ Name: topdown_heatmap_seresnet152_mpii_256x256
+ Results:
+ - Dataset: MPII
+ Metrics:
+ Mean: 0.884
+ Mean@0.1: 0.287
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/seresnet/seresnet152_mpii_256x256-6ea1e774_20200927.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/shufflenetv1_mpii.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/shufflenetv1_mpii.md
new file mode 100644
index 0000000000000000000000000000000000000000..fb165265725276c48cc893655ca025faaf7be3b0
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/shufflenetv1_mpii.md
@@ -0,0 +1,39 @@
+
+
+MPII (CVPR'2014)
+ +```bibtex +@inproceedings{andriluka14cvpr, + author = {Mykhaylo Andriluka and Leonid Pishchulin and Peter Gehler and Schiele, Bernt}, + title = {2D Human Pose Estimation: New Benchmark and State of the Art Analysis}, + booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, + year = {2014}, + month = {June} +} +``` + +
+
+
+
+
+ShufflenetV1 (CVPR'2018)
+ +```bibtex +@inproceedings{zhang2018shufflenet, + title={Shufflenet: An extremely efficient convolutional neural network for mobile devices}, + author={Zhang, Xiangyu and Zhou, Xinyu and Lin, Mengxiao and Sun, Jian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={6848--6856}, + year={2018} +} +``` + +
+
+
+Results on MPII val set
+
+| Arch | Input Size | Mean | Mean@0.1 | ckpt | log |
+| :--- | :--------: | :------: | :------: |:------: |:------: |
+| [pose_shufflenetv1](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/shufflenetv1_mpii_256x256.py) | 256x256 | 0.823 | 0.195 | [ckpt](https://download.openmmlab.com/mmpose/top_down/shufflenetv1/shufflenetv1_mpii_256x256-dcc1c896_20200925.pth) | [log](https://download.openmmlab.com/mmpose/top_down/shufflenetv1/shufflenetv1_mpii_256x256_20200925.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/shufflenetv1_mpii.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/shufflenetv1_mpii.yml
new file mode 100644
index 0000000000000000000000000000000000000000..f707dcfbb4c2be55a7cde70958a1ddac407fe508
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/shufflenetv1_mpii.yml
@@ -0,0 +1,22 @@
+Collections:
+- Name: ShufflenetV1
+ Paper:
+ Title: 'Shufflenet: An extremely efficient convolutional neural network for mobile
+ devices'
+ URL: http://openaccess.thecvf.com/content_cvpr_2018/html/Zhang_ShuffleNet_An_Extremely_CVPR_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/shufflenetv1.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/shufflenetv1_mpii_256x256.py
+ In Collection: ShufflenetV1
+ Metadata:
+ Architecture:
+ - ShufflenetV1
+ Training Data: MPII
+ Name: topdown_heatmap_shufflenetv1_mpii_256x256
+ Results:
+ - Dataset: MPII
+ Metrics:
+ Mean: 0.823
+ Mean@0.1: 0.195
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/shufflenetv1/shufflenetv1_mpii_256x256-dcc1c896_20200925.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/shufflenetv1_mpii_256x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/shufflenetv1_mpii_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..5a665ba0727d444b2bf1762e83e65fdc881792cd
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/shufflenetv1_mpii_256x256.py
@@ -0,0 +1,123 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii.py'
+]
+evaluation = dict(interval=10, metric='PCKh', save_best='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=list(range(16)),
+ inference_channel=list(range(16)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='mmcls://shufflenet_v1',
+ backbone=dict(type='ShuffleNetV1', groups=3),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=960,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/shufflenetv2_mpii.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/shufflenetv2_mpii.md
new file mode 100644
index 0000000000000000000000000000000000000000..9990df0c9daf23ca5d3389c7ef2b0862fac50d4a
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/shufflenetv2_mpii.md
@@ -0,0 +1,39 @@
+
+
+MPII (CVPR'2014)
+ +```bibtex +@inproceedings{andriluka14cvpr, + author = {Mykhaylo Andriluka and Leonid Pishchulin and Peter Gehler and Schiele, Bernt}, + title = {2D Human Pose Estimation: New Benchmark and State of the Art Analysis}, + booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, + year = {2014}, + month = {June} +} +``` + +
+
+
+
+
+ShufflenetV2 (ECCV'2018)
+ +```bibtex +@inproceedings{ma2018shufflenet, + title={Shufflenet v2: Practical guidelines for efficient cnn architecture design}, + author={Ma, Ningning and Zhang, Xiangyu and Zheng, Hai-Tao and Sun, Jian}, + booktitle={Proceedings of the European conference on computer vision (ECCV)}, + pages={116--131}, + year={2018} +} +``` + +
+
+
+Results on MPII val set
+
+| Arch | Input Size | Mean | Mean@0.1 | ckpt | log |
+| :--- | :--------: | :------: | :------: |:------: |:------: |
+| [pose_shufflenetv2](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/shufflenetv2_mpii_256x256.py) | 256x256 | 0.828 | 0.205 | [ckpt](https://download.openmmlab.com/mmpose/top_down/shufflenetv2/shufflenetv2_mpii_256x256-4fb9df2d_20200925.pth) | [log](https://download.openmmlab.com/mmpose/top_down/shufflenetv2/shufflenetv2_mpii_256x256_20200925.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/shufflenetv2_mpii.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/shufflenetv2_mpii.yml
new file mode 100644
index 0000000000000000000000000000000000000000..58a4724215f6004f7ffb8bced17ce9e228a44998
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/shufflenetv2_mpii.yml
@@ -0,0 +1,21 @@
+Collections:
+- Name: ShufflenetV2
+ Paper:
+ Title: 'Shufflenet v2: Practical guidelines for efficient cnn architecture design'
+ URL: http://openaccess.thecvf.com/content_ECCV_2018/html/Ningning_Light-weight_CNN_Architecture_ECCV_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/shufflenetv2.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/shufflenetv2_mpii_256x256.py
+ In Collection: ShufflenetV2
+ Metadata:
+ Architecture:
+ - ShufflenetV2
+ Training Data: MPII
+ Name: topdown_heatmap_shufflenetv2_mpii_256x256
+ Results:
+ - Dataset: MPII
+ Metrics:
+ Mean: 0.828
+ Mean@0.1: 0.205
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/shufflenetv2/shufflenetv2_mpii_256x256-4fb9df2d_20200925.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/shufflenetv2_mpii_256x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/shufflenetv2_mpii_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..25937d116bd16523ed5624a0dff76e3abdf9fc42
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/shufflenetv2_mpii_256x256.py
@@ -0,0 +1,123 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii.py'
+]
+evaluation = dict(interval=10, metric='PCKh', save_best='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=16,
+ dataset_joints=16,
+ dataset_channel=list(range(16)),
+ inference_channel=list(range(16)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='mmcls://shufflenet_v2',
+ backbone=dict(type='ShuffleNetV2', widen_factor=1.0),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1024,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiDataset',
+ ann_file=f'{data_root}/annotations/mpii_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii_trb/res101_mpii_trb_256x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii_trb/res101_mpii_trb_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..64e841a09a3bd02709f2b857ea5a10efc3a657ff
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii_trb/res101_mpii_trb_256x256.py
@@ -0,0 +1,122 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii_trb.py'
+]
+evaluation = dict(interval=10, metric='PCKh', save_best='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=40,
+ dataset_joints=40,
+ dataset_channel=list(range(40)),
+ inference_channel=list(range(40)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet101',
+ backbone=dict(type='ResNet', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiTrbDataset',
+ ann_file=f'{data_root}/annotations/mpii_trb_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiTrbDataset',
+ ann_file=f'{data_root}/annotations/mpii_trb_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiTrbDataset',
+ ann_file=f'{data_root}/annotations/mpii_trb_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}))
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii_trb/res152_mpii_trb_256x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii_trb/res152_mpii_trb_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..b9862fc8f0160cd4c1b6d9c89a7b3cd1b88346aa
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii_trb/res152_mpii_trb_256x256.py
@@ -0,0 +1,122 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii_trb.py'
+]
+evaluation = dict(interval=10, metric='PCKh', save_best='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=40,
+ dataset_joints=40,
+ dataset_channel=list(range(40)),
+ inference_channel=list(range(40)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet152',
+ backbone=dict(type='ResNet', depth=152),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiTrbDataset',
+ ann_file=f'{data_root}/annotations/mpii_trb_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiTrbDataset',
+ ann_file=f'{data_root}/annotations/mpii_trb_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiTrbDataset',
+ ann_file=f'{data_root}/annotations/mpii_trb_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}))
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii_trb/res50_mpii_trb_256x256.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii_trb/res50_mpii_trb_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..cdc24472abab2f77919352ebabdd3e2e138e8a09
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii_trb/res50_mpii_trb_256x256.py
@@ -0,0 +1,122 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpii_trb.py'
+]
+evaluation = dict(interval=10, metric='PCKh', save_best='PCKh')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+channel_cfg = dict(
+ num_output_channels=40,
+ dataset_joints=40,
+ dataset_channel=list(range(40)),
+ inference_channel=list(range(40)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_gt_bbox=True,
+ bbox_file=None,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/mpii'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownMpiiTrbDataset',
+ ann_file=f'{data_root}/annotations/mpii_trb_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownMpiiTrbDataset',
+ ann_file=f'{data_root}/annotations/mpii_trb_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownMpiiTrbDataset',
+ ann_file=f'{data_root}/annotations/mpii_trb_val.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}))
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii_trb/resnet_mpii_trb.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii_trb/resnet_mpii_trb.md
new file mode 100644
index 0000000000000000000000000000000000000000..10e2b9f8c1c488981ad7c34a7599215b3d55cf8a
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii_trb/resnet_mpii_trb.md
@@ -0,0 +1,58 @@
+
+
+MPII (CVPR'2014)
+ +```bibtex +@inproceedings{andriluka14cvpr, + author = {Mykhaylo Andriluka and Leonid Pishchulin and Peter Gehler and Schiele, Bernt}, + title = {2D Human Pose Estimation: New Benchmark and State of the Art Analysis}, + booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, + year = {2014}, + month = {June} +} +``` + +
+
+
+
+
+SimpleBaseline2D (ECCV'2018)
+ +```bibtex +@inproceedings{xiao2018simple, + title={Simple baselines for human pose estimation and tracking}, + author={Xiao, Bin and Wu, Haiping and Wei, Yichen}, + booktitle={Proceedings of the European conference on computer vision (ECCV)}, + pages={466--481}, + year={2018} +} +``` + +
+
+
+
+
+ResNet (CVPR'2016)
+ +```bibtex +@inproceedings{he2016deep, + title={Deep residual learning for image recognition}, + author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={770--778}, + year={2016} +} +``` + +
+
+
+Results on MPII-TRB val set
+
+| Arch | Input Size | Skeleton Acc | Contour Acc | Mean Acc | ckpt | log |
+| :--- | :--------: | :------: | :------: |:------: |:------: |:------: |
+| [pose_resnet_50](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii_trb/res50_mpii_trb_256x256.py) | 256x256 | 0.887 | 0.858 | 0.868 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res50_mpii_trb_256x256-896036b8_20200812.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res50_mpii_trb_256x256_20200812.log.json) |
+| [pose_resnet_101](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii_trb/res101_mpii_trb_256x256.py) | 256x256 | 0.890 | 0.863 | 0.873 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res101_mpii_trb_256x256-cfad2f05_20200812.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res101_mpii_trb_256x256_20200812.log.json) |
+| [pose_resnet_152](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii_trb/res152_mpii_trb_256x256.py) | 256x256 | 0.897 | 0.868 | 0.879 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res152_mpii_trb_256x256-dd369ce6_20200812.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res152_mpii_trb_256x256_20200812.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii_trb/resnet_mpii_trb.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii_trb/resnet_mpii_trb.yml
new file mode 100644
index 0000000000000000000000000000000000000000..0f7f7458137ee0fa5eed1853aad25e3a30318eee
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii_trb/resnet_mpii_trb.yml
@@ -0,0 +1,51 @@
+Collections:
+- Name: SimpleBaseline2D
+ Paper:
+ Title: Simple baselines for human pose estimation and tracking
+ URL: http://openaccess.thecvf.com/content_ECCV_2018/html/Bin_Xiao_Simple_Baselines_for_ECCV_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/simplebaseline2d.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii_trb/res50_mpii_trb_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: &id001
+ - SimpleBaseline2D
+ - ResNet
+ Training Data: MPII-TRB
+ Name: topdown_heatmap_res50_mpii_trb_256x256
+ Results:
+ - Dataset: MPII-TRB
+ Metrics:
+ Contour Acc: 0.858
+ Mean Acc: 0.868
+ Skeleton Acc: 0.887
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res50_mpii_trb_256x256-896036b8_20200812.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii_trb/res101_mpii_trb_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: MPII-TRB
+ Name: topdown_heatmap_res101_mpii_trb_256x256
+ Results:
+ - Dataset: MPII-TRB
+ Metrics:
+ Contour Acc: 0.863
+ Mean Acc: 0.873
+ Skeleton Acc: 0.89
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res101_mpii_trb_256x256-cfad2f05_20200812.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii_trb/res152_mpii_trb_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: MPII-TRB
+ Name: topdown_heatmap_res152_mpii_trb_256x256
+ Results:
+ - Dataset: MPII-TRB
+ Metrics:
+ Contour Acc: 0.868
+ Mean Acc: 0.879
+ Skeleton Acc: 0.897
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res152_mpii_trb_256x256-dd369ce6_20200812.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_base_ochuman_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_base_ochuman_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..84dbfacbb8abb61ac1e7bb5e2eea528d06bb4d13
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_base_ochuman_256x192.py
@@ -0,0 +1,153 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/ochuman.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='ViT',
+ img_size=(256, 192),
+ patch_size=16,
+ embed_dim=768,
+ depth=12,
+ num_heads=12,
+ ratio=1,
+ use_checkpoint=False,
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_path_rate=0.3,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=768,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/ochuman'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file='data/coco/annotations/person_keypoints_train2017.json',
+ img_prefix='data/coco//train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownOCHumanDataset',
+ ann_file=f'{data_root}/annotations/'
+ 'ochuman_coco_format_val_range_0.00_1.00.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownOCHumanDataset',
+ ann_file=f'{data_root}/annotations/'
+ 'ochuman_coco_format_test_range_0.00_1.00.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_huge_ochuman_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_huge_ochuman_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..130fca6264d2e1b6f949787cac23b8a857e22870
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_huge_ochuman_256x192.py
@@ -0,0 +1,153 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/ochuman.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='ViT',
+ img_size=(256, 192),
+ patch_size=16,
+ embed_dim=1280,
+ depth=32,
+ num_heads=16,
+ ratio=1,
+ use_checkpoint=False,
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_path_rate=0.3,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1280,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/ochuman'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file='data/coco/annotations/person_keypoints_train2017.json',
+ img_prefix='data/coco//train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownOCHumanDataset',
+ ann_file=f'{data_root}/annotations/'
+ 'ochuman_coco_format_val_range_0.00_1.00.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownOCHumanDataset',
+ ann_file=f'{data_root}/annotations/'
+ 'ochuman_coco_format_test_range_0.00_1.00.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_large_ochuman_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_large_ochuman_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..af7f5d1e3de14e2ecef1dc8b61aee2d7e50e8f45
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_large_ochuman_256x192.py
@@ -0,0 +1,153 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/ochuman.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='ViT',
+ img_size=(256, 192),
+ patch_size=16,
+ embed_dim=1024,
+ depth=24,
+ num_heads=16,
+ ratio=1,
+ use_checkpoint=False,
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_path_rate=0.3,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1024,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/ochuman'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file='data/coco/annotations/person_keypoints_train2017.json',
+ img_prefix='data/coco//train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownOCHumanDataset',
+ ann_file=f'{data_root}/annotations/'
+ 'ochuman_coco_format_val_range_0.00_1.00.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownOCHumanDataset',
+ ann_file=f'{data_root}/annotations/'
+ 'ochuman_coco_format_test_range_0.00_1.00.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_small_ochuman_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_small_ochuman_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..58bd1caba5bd07a4bef73e7131a995ee678043a4
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_small_ochuman_256x192.py
@@ -0,0 +1,153 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/ochuman.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='ViT',
+ img_size=(256, 192),
+ patch_size=16,
+ embed_dim=384,
+ depth=12,
+ num_heads=12,
+ ratio=1,
+ use_checkpoint=False,
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_path_rate=0.3,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=384,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/ochuman'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file='data/coco/annotations/person_keypoints_train2017.json',
+ img_prefix='data/coco//train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownOCHumanDataset',
+ ann_file=f'{data_root}/annotations/'
+ 'ochuman_coco_format_val_range_0.00_1.00.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownOCHumanDataset',
+ ann_file=f'{data_root}/annotations/'
+ 'ochuman_coco_format_test_range_0.00_1.00.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/hrnet_ochuman.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/hrnet_ochuman.md
new file mode 100644
index 0000000000000000000000000000000000000000..e844b067adb2d8cf59fcd8fe63a6b1e8d5f9825b
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/hrnet_ochuman.md
@@ -0,0 +1,44 @@
+
+
+MPII-TRB (ICCV'2019)
+ +```bibtex +@inproceedings{duan2019trb, + title={TRB: A Novel Triplet Representation for Understanding 2D Human Body}, + author={Duan, Haodong and Lin, Kwan-Yee and Jin, Sheng and Liu, Wentao and Qian, Chen and Ouyang, Wanli}, + booktitle={Proceedings of the IEEE International Conference on Computer Vision}, + pages={9479--9488}, + year={2019} +} +``` + +
+
+
+
+
+HRNet (CVPR'2019)
+ +```bibtex +@inproceedings{sun2019deep, + title={Deep high-resolution representation learning for human pose estimation}, + author={Sun, Ke and Xiao, Bin and Liu, Dong and Wang, Jingdong}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={5693--5703}, + year={2019} +} +``` + +
+
+
+Results on OCHuman test dataset with ground-truth bounding boxes
+
+Following the common setting, the models are trained on COCO train dataset, and evaluate on OCHuman dataset.
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :-------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_hrnet_w32](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/hrnet_w32_ochuman_256x192.py) | 256x192 | 0.591 | 0.748 | 0.641 | 0.631 | 0.775 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_coco_256x192-c78dce93_20200708.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_coco_256x192_20200708.log.json) |
+| [pose_hrnet_w32](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/hrnet_w32_ochuman_384x288.py) | 384x288 | 0.606 | 0.748 | 0.650 | 0.647 | 0.776 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_coco_384x288-d9f0d786_20200708.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_coco_384x288_20200708.log.json) |
+| [pose_hrnet_w48](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/hrnet_w48_ochuman_256x192.py) | 256x192 | 0.611 | 0.752 | 0.663 | 0.648 | 0.778 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_256x192_20200708.log.json) |
+| [pose_hrnet_w48](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/hrnet_w48_ochuman_384x288.py) | 384x288 | 0.616 | 0.749 | 0.663 | 0.653 | 0.773 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_384x288-314c8528_20200708.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_384x288_20200708.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/hrnet_ochuman.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/hrnet_ochuman.yml
new file mode 100644
index 0000000000000000000000000000000000000000..0b3b625af0baa50746f5f82a88d92a7d171e1392
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/hrnet_ochuman.yml
@@ -0,0 +1,72 @@
+Collections:
+- Name: HRNet
+ Paper:
+ Title: Deep high-resolution representation learning for human pose estimation
+ URL: http://openaccess.thecvf.com/content_CVPR_2019/html/Sun_Deep_High-Resolution_Representation_Learning_for_Human_Pose_Estimation_CVPR_2019_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/hrnet.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/hrnet_w32_ochuman_256x192.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: &id001
+ - HRNet
+ Training Data: OCHuman
+ Name: topdown_heatmap_hrnet_w32_ochuman_256x192
+ Results:
+ - Dataset: OCHuman
+ Metrics:
+ AP: 0.591
+ AP@0.5: 0.748
+ AP@0.75: 0.641
+ AR: 0.631
+ AR@0.5: 0.775
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_coco_256x192-c78dce93_20200708.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/hrnet_w32_ochuman_384x288.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: OCHuman
+ Name: topdown_heatmap_hrnet_w32_ochuman_384x288
+ Results:
+ - Dataset: OCHuman
+ Metrics:
+ AP: 0.606
+ AP@0.5: 0.748
+ AP@0.75: 0.65
+ AR: 0.647
+ AR@0.5: 0.776
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_coco_384x288-d9f0d786_20200708.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/hrnet_w48_ochuman_256x192.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: OCHuman
+ Name: topdown_heatmap_hrnet_w48_ochuman_256x192
+ Results:
+ - Dataset: OCHuman
+ Metrics:
+ AP: 0.611
+ AP@0.5: 0.752
+ AP@0.75: 0.663
+ AR: 0.648
+ AR@0.5: 0.778
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/hrnet_w48_ochuman_384x288.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: OCHuman
+ Name: topdown_heatmap_hrnet_w48_ochuman_384x288
+ Results:
+ - Dataset: OCHuman
+ Metrics:
+ AP: 0.616
+ AP@0.5: 0.749
+ AP@0.75: 0.663
+ AR: 0.653
+ AR@0.5: 0.773
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_384x288-314c8528_20200708.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/hrnet_w32_ochuman_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/hrnet_w32_ochuman_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..2ea620501b3522c1e5f91350cf33ce4443624643
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/hrnet_w32_ochuman_256x192.py
@@ -0,0 +1,168 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/ochuman.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/ochuman'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file='data/coco/annotations/person_keypoints_train2017.json',
+ img_prefix='data/coco//train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownOCHumanDataset',
+ ann_file=f'{data_root}/annotations/'
+ 'ochuman_coco_format_val_range_0.00_1.00.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownOCHumanDataset',
+ ann_file=f'{data_root}/annotations/'
+ 'ochuman_coco_format_test_range_0.00_1.00.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/hrnet_w32_ochuman_384x288.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/hrnet_w32_ochuman_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..3612849918fdfe18d9f9a0fd031b49e6928e6d6c
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/hrnet_w32_ochuman_384x288.py
@@ -0,0 +1,168 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/ochuman.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/ochuman'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file='data/coco/annotations/person_keypoints_train2017.json',
+ img_prefix='data/coco//train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownOCHumanDataset',
+ ann_file=f'{data_root}/annotations/'
+ 'ochuman_coco_format_val_range_0.00_1.00.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownOCHumanDataset',
+ ann_file=f'{data_root}/annotations/'
+ 'ochuman_coco_format_test_range_0.00_1.00.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/hrnet_w48_ochuman_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/hrnet_w48_ochuman_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..d26bd814ca4182542c9f78076672f32cb51acc7f
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/hrnet_w48_ochuman_256x192.py
@@ -0,0 +1,168 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/ochuman.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/ochuman'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file='data/coco/annotations/person_keypoints_train2017.json',
+ img_prefix='data/coco//train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownOCHumanDataset',
+ ann_file=f'{data_root}/annotations/'
+ 'ochuman_coco_format_val_range_0.00_1.00.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownOCHumanDataset',
+ ann_file=f'{data_root}/annotations/'
+ 'ochuman_coco_format_test_range_0.00_1.00.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/hrnet_w48_ochuman_384x288.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/hrnet_w48_ochuman_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..246adaf687bf3f69edcd1ab82e4c027e30511d37
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/hrnet_w48_ochuman_384x288.py
@@ -0,0 +1,168 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/ochuman.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/ochuman'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file='data/coco/annotations/person_keypoints_train2017.json',
+ img_prefix='data/coco//train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownOCHumanDataset',
+ ann_file=f'{data_root}/annotations/'
+ 'ochuman_coco_format_val_range_0.00_1.00.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownOCHumanDataset',
+ ann_file=f'{data_root}/annotations/'
+ 'ochuman_coco_format_test_range_0.00_1.00.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/res101_ochuman_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/res101_ochuman_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..c50002c895d3878b6986a36906f65e62b523515e
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/res101_ochuman_256x192.py
@@ -0,0 +1,137 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/ochuman.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet101',
+ backbone=dict(type='ResNet', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/ochuman'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file='data/coco/annotations/person_keypoints_train2017.json',
+ img_prefix='data/coco//train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownOCHumanDataset',
+ ann_file=f'{data_root}/annotations/'
+ 'ochuman_coco_format_val_range_0.00_1.00.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownOCHumanDataset',
+ ann_file=f'{data_root}/annotations/'
+ 'ochuman_coco_format_test_range_0.00_1.00.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/res101_ochuman_384x288.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/res101_ochuman_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..84e3842b7ff04055fa5e6f4f7f88e5190af85edc
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/res101_ochuman_384x288.py
@@ -0,0 +1,137 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/ochuman.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet101',
+ backbone=dict(type='ResNet', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/ochuman'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file='data/coco/annotations/person_keypoints_train2017.json',
+ img_prefix='data/coco//train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownOCHumanDataset',
+ ann_file=f'{data_root}/annotations/'
+ 'ochuman_coco_format_val_range_0.00_1.00.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownOCHumanDataset',
+ ann_file=f'{data_root}/annotations/'
+ 'ochuman_coco_format_test_range_0.00_1.00.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/res152_ochuman_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/res152_ochuman_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..b71fb679b851e9280810df589d46269420834989
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/res152_ochuman_256x192.py
@@ -0,0 +1,137 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/ochuman.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet152',
+ backbone=dict(type='ResNet', depth=152),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/ochuman'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file='data/coco/annotations/person_keypoints_train2017.json',
+ img_prefix='data/coco//train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownOCHumanDataset',
+ ann_file=f'{data_root}/annotations/'
+ 'ochuman_coco_format_val_range_0.00_1.00.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownOCHumanDataset',
+ ann_file=f'{data_root}/annotations/'
+ 'ochuman_coco_format_test_range_0.00_1.00.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/res152_ochuman_384x288.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/res152_ochuman_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..c6d95e1fcd780d9305b77595ce670122f56eee53
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/res152_ochuman_384x288.py
@@ -0,0 +1,137 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/ochuman.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet152',
+ backbone=dict(type='ResNet', depth=152),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/ochuman'
+data = dict(
+ samples_per_gpu=48,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file='data/coco/annotations/person_keypoints_train2017.json',
+ img_prefix='data/coco//train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownOCHumanDataset',
+ ann_file=f'{data_root}/annotations/'
+ 'ochuman_coco_format_val_range_0.00_1.00.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownOCHumanDataset',
+ ann_file=f'{data_root}/annotations/'
+ 'ochuman_coco_format_test_range_0.00_1.00.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/res50_ochuman_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/res50_ochuman_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..0649558c4a16eadfe7c6241657ace7c5e57872b1
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/res50_ochuman_256x192.py
@@ -0,0 +1,137 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/ochuman.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/ochuman'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file='data/coco/annotations/person_keypoints_train2017.json',
+ img_prefix='data/coco//train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownOCHumanDataset',
+ ann_file=f'{data_root}/annotations/'
+ 'ochuman_coco_format_val_range_0.00_1.00.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownOCHumanDataset',
+ ann_file=f'{data_root}/annotations/'
+ 'ochuman_coco_format_test_range_0.00_1.00.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/res50_ochuman_384x288.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/res50_ochuman_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..7b7f957c91b7acc9718c4c5d4bb215f5d50537bb
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/res50_ochuman_384x288.py
@@ -0,0 +1,137 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/ochuman.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/ochuman'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoDataset',
+ ann_file='data/coco/annotations/person_keypoints_train2017.json',
+ img_prefix='data/coco//train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownOCHumanDataset',
+ ann_file=f'{data_root}/annotations/'
+ 'ochuman_coco_format_val_range_0.00_1.00.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownOCHumanDataset',
+ ann_file=f'{data_root}/annotations/'
+ 'ochuman_coco_format_test_range_0.00_1.00.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/resnet_ochuman.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/resnet_ochuman.md
new file mode 100644
index 0000000000000000000000000000000000000000..5b948f811821edcfc007d5ec85663319ebeacd87
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/resnet_ochuman.md
@@ -0,0 +1,63 @@
+
+
+OCHuman (CVPR'2019)
+ +```bibtex +@inproceedings{zhang2019pose2seg, + title={Pose2seg: Detection free human instance segmentation}, + author={Zhang, Song-Hai and Li, Ruilong and Dong, Xin and Rosin, Paul and Cai, Zixi and Han, Xi and Yang, Dingcheng and Huang, Haozhi and Hu, Shi-Min}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={889--898}, + year={2019} +} +``` + +
+
+
+
+
+SimpleBaseline2D (ECCV'2018)
+ +```bibtex +@inproceedings{xiao2018simple, + title={Simple baselines for human pose estimation and tracking}, + author={Xiao, Bin and Wu, Haiping and Wei, Yichen}, + booktitle={Proceedings of the European conference on computer vision (ECCV)}, + pages={466--481}, + year={2018} +} +``` + +
+
+
+
+
+ResNet (CVPR'2016)
+ +```bibtex +@inproceedings{he2016deep, + title={Deep residual learning for image recognition}, + author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={770--778}, + year={2016} +} +``` + +
+
+
+Results on OCHuman test dataset with ground-truth bounding boxes
+
+Following the common setting, the models are trained on COCO train dataset, and evaluate on OCHuman dataset.
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | ckpt | log |
+| :-------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_resnet_50](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_256x192.py) | 256x192 | 0.546 | 0.726 | 0.593 | 0.592 | 0.755 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res50_coco_256x192-ec54d7f3_20200709.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res50_coco_256x192_20200709.log.json) |
+| [pose_resnet_50](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_384x288.py) | 384x288 | 0.539 | 0.723 | 0.574 | 0.588 | 0.756 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res50_coco_384x288-e6f795e9_20200709.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res50_coco_384x288_20200709.log.json) |
+| [pose_resnet_101](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res101_coco_256x192.py) | 256x192 | 0.559 | 0.724 | 0.606 | 0.605 | 0.751 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res101_coco_256x192-6e6babf0_20200708.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res101_coco_256x192_20200708.log.json) |
+| [pose_resnet_101](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res101_coco_384x288.py) | 384x288 | 0.571 | 0.715 | 0.615 | 0.615 | 0.748 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res101_coco_384x288-8c71bdc9_20200709.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res101_coco_384x288_20200709.log.json) |
+| [pose_resnet_152](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res152_coco_256x192.py) | 256x192 | 0.570 | 0.725 | 0.617 | 0.616 | 0.754 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res152_coco_256x192-f6e307c2_20200709.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res152_coco_256x192_20200709.log.json) |
+| [pose_resnet_152](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res152_coco_384x288.py) | 384x288 | 0.582 | 0.723 | 0.627 | 0.627 | 0.752 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res152_coco_384x288-3860d4c9_20200709.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res152_coco_384x288_20200709.log.json) |
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/resnet_ochuman.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/resnet_ochuman.yml
new file mode 100644
index 0000000000000000000000000000000000000000..7757701c2597f853ccf45a8ad593f297958e75b7
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/resnet_ochuman.yml
@@ -0,0 +1,105 @@
+Collections:
+- Name: SimpleBaseline2D
+ Paper:
+ Title: Simple baselines for human pose estimation and tracking
+ URL: http://openaccess.thecvf.com/content_ECCV_2018/html/Bin_Xiao_Simple_Baselines_for_ECCV_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/simplebaseline2d.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_256x192.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: &id001
+ - SimpleBaseline2D
+ - ResNet
+ Training Data: OCHuman
+ Name: topdown_heatmap_res50_coco_256x192
+ Results:
+ - Dataset: OCHuman
+ Metrics:
+ AP: 0.546
+ AP@0.5: 0.726
+ AP@0.75: 0.593
+ AR: 0.592
+ AR@0.5: 0.755
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res50_coco_256x192-ec54d7f3_20200709.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_384x288.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: OCHuman
+ Name: topdown_heatmap_res50_coco_384x288
+ Results:
+ - Dataset: OCHuman
+ Metrics:
+ AP: 0.539
+ AP@0.5: 0.723
+ AP@0.75: 0.574
+ AR: 0.588
+ AR@0.5: 0.756
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res50_coco_384x288-e6f795e9_20200709.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res101_coco_256x192.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: OCHuman
+ Name: topdown_heatmap_res101_coco_256x192
+ Results:
+ - Dataset: OCHuman
+ Metrics:
+ AP: 0.559
+ AP@0.5: 0.724
+ AP@0.75: 0.606
+ AR: 0.605
+ AR@0.5: 0.751
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res101_coco_256x192-6e6babf0_20200708.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res101_coco_384x288.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: OCHuman
+ Name: topdown_heatmap_res101_coco_384x288
+ Results:
+ - Dataset: OCHuman
+ Metrics:
+ AP: 0.571
+ AP@0.5: 0.715
+ AP@0.75: 0.615
+ AR: 0.615
+ AR@0.5: 0.748
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res101_coco_384x288-8c71bdc9_20200709.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res152_coco_256x192.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: OCHuman
+ Name: topdown_heatmap_res152_coco_256x192
+ Results:
+ - Dataset: OCHuman
+ Metrics:
+ AP: 0.57
+ AP@0.5: 0.725
+ AP@0.75: 0.617
+ AR: 0.616
+ AR@0.5: 0.754
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res152_coco_256x192-f6e307c2_20200709.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res152_coco_384x288.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: OCHuman
+ Name: topdown_heatmap_res152_coco_384x288
+ Results:
+ - Dataset: OCHuman
+ Metrics:
+ AP: 0.582
+ AP@0.5: 0.723
+ AP@0.75: 0.627
+ AR: 0.627
+ AR@0.5: 0.752
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res152_coco_384x288-3860d4c9_20200709.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/hrnet_posetrack18.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/hrnet_posetrack18.md
new file mode 100644
index 0000000000000000000000000000000000000000..9c8117b48b04ecc15a4daefa38738d34171e3318
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/hrnet_posetrack18.md
@@ -0,0 +1,56 @@
+
+
+
+OCHuman (CVPR'2019)
+ +```bibtex +@inproceedings{zhang2019pose2seg, + title={Pose2seg: Detection free human instance segmentation}, + author={Zhang, Song-Hai and Li, Ruilong and Dong, Xin and Rosin, Paul and Cai, Zixi and Han, Xi and Yang, Dingcheng and Huang, Haozhi and Hu, Shi-Min}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={889--898}, + year={2019} +} +``` + +
+
+
+
+
+HRNet (CVPR'2019)
+ +```bibtex +@inproceedings{sun2019deep, + title={Deep high-resolution representation learning for human pose estimation}, + author={Sun, Ke and Xiao, Bin and Liu, Dong and Wang, Jingdong}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={5693--5703}, + year={2019} +} +``` + +
+
+
+Results on PoseTrack2018 val with ground-truth bounding boxes
+
+| Arch | Input Size | Head | Shou | Elb | Wri | Hip | Knee | Ankl | Total | ckpt | log |
+| :--- | :--------: | :------: |:------: |:------: |:------: |:------: |:------: | :------: | :------: |:------: |:------: |
+| [pose_hrnet_w32](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/hrnet_w32_posetrack18_256x192.py) | 256x192 | 87.4 | 88.6 | 84.3 | 78.5 | 79.7 | 81.8 | 78.8 | 83.0 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_posetrack18_256x192-1ee951c4_20201028.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_posetrack18_256x192_20201028.log.json) |
+| [pose_hrnet_w32](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/hrnet_w32_posetrack18_384x288.py) | 384x288 | 87.0 | 88.8 | 85.0 | 80.1 | 80.5 | 82.6 | 79.4 | 83.6 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_posetrack18_384x288-806f00a3_20211130.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_posetrack18_384x288_20211130.log.json) |
+| [pose_hrnet_w48](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/hrnet_w48_posetrack18_256x192.py) | 256x192 | 88.2 | 90.1 | 85.8 | 80.8 | 80.7 | 83.3 | 80.3 | 84.4 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_posetrack18_256x192-b5d9b3f1_20211130.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_posetrack18_256x192_20211130.log.json) |
+| [pose_hrnet_w48](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/hrnet_w48_posetrack18_384x288.py) | 384x288 | 87.8 | 90.0 | 85.9 | 81.3 | 81.1 | 83.3 | 80.9 | 84.5 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_posetrack18_384x288-5fd6d3ff_20211130.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_posetrack18_384x288_20211130.log.json) |
+
+The models are first pre-trained on COCO dataset, and then fine-tuned on PoseTrack18.
+
+Results on PoseTrack2018 val with [MMDetection](https://github.com/open-mmlab/mmdetection) pre-trained [Cascade R-CNN](https://download.openmmlab.com/mmdetection/v2.0/cascade_rcnn/cascade_rcnn_x101_64x4d_fpn_20e_coco/cascade_rcnn_x101_64x4d_fpn_20e_coco_20200509_224357-051557b1.pth) (X-101-64x4d-FPN) human detector
+
+| Arch | Input Size | Head | Shou | Elb | Wri | Hip | Knee | Ankl | Total | ckpt | log |
+| :--- | :--------: | :------: |:------: |:------: |:------: |:------: |:------: | :------: | :------: |:------: |:------: |
+| [pose_hrnet_w32](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/hrnet_w32_posetrack18_256x192.py) | 256x192 | 78.0 | 82.9 | 79.5 | 73.8 | 76.9 | 76.6 | 70.2 | 76.9 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_posetrack18_256x192-1ee951c4_20201028.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_posetrack18_256x192_20201028.log.json) |
+| [pose_hrnet_w32](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/hrnet_w32_posetrack18_384x288.py) | 384x288 | 79.9 | 83.6 | 80.4 | 74.5 | 74.8 | 76.1 | 70.5 | 77.3 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_posetrack18_384x288-806f00a3_20211130.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_posetrack18_384x288_20211130.log.json) |
+| [pose_hrnet_w48](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/hrnet_w48_posetrack18_256x192.py) | 256x192 | 80.1 | 83.4 | 80.6 | 74.8 | 74.3 | 76.8 | 70.4 | 77.4 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_posetrack18_256x192-b5d9b3f1_20211130.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_posetrack18_256x192_20211130.log.json) |
+| [pose_hrnet_w48](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/hrnet_w48_posetrack18_384x288.py) | 384x288 | 80.2 | 83.8 | 80.9 | 75.2 | 74.7 | 76.7 | 71.7 | 77.8 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_posetrack18_384x288-5fd6d3ff_20211130.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_posetrack18_384x288_20211130.log.json) |
+
+The models are first pre-trained on COCO dataset, and then fine-tuned on PoseTrack18.
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/hrnet_posetrack18.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/hrnet_posetrack18.yml
new file mode 100644
index 0000000000000000000000000000000000000000..349daa295a1006a3c9ea424b5c709d47b6196a91
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/hrnet_posetrack18.yml
@@ -0,0 +1,160 @@
+Collections:
+- Name: HRNet
+ Paper:
+ Title: Deep high-resolution representation learning for human pose estimation
+ URL: http://openaccess.thecvf.com/content_CVPR_2019/html/Sun_Deep_High-Resolution_Representation_Learning_for_Human_Pose_Estimation_CVPR_2019_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/hrnet.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/hrnet_w32_posetrack18_256x192.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: &id001
+ - HRNet
+ Training Data: PoseTrack18
+ Name: topdown_heatmap_hrnet_w32_posetrack18_256x192
+ Results:
+ - Dataset: PoseTrack18
+ Metrics:
+ Ankl: 78.8
+ Elb: 84.3
+ Head: 87.4
+ Hip: 79.7
+ Knee: 81.8
+ Shou: 88.6
+ Total: 83.0
+ Wri: 78.5
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_posetrack18_256x192-1ee951c4_20201028.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/hrnet_w32_posetrack18_384x288.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: PoseTrack18
+ Name: topdown_heatmap_hrnet_w32_posetrack18_384x288
+ Results:
+ - Dataset: PoseTrack18
+ Metrics:
+ Ankl: 79.4
+ Elb: 85.0
+ Head: 87.0
+ Hip: 80.5
+ Knee: 82.6
+ Shou: 88.8
+ Total: 83.6
+ Wri: 80.1
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_posetrack18_384x288-806f00a3_20211130.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/hrnet_w48_posetrack18_256x192.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: PoseTrack18
+ Name: topdown_heatmap_hrnet_w48_posetrack18_256x192
+ Results:
+ - Dataset: PoseTrack18
+ Metrics:
+ Ankl: 80.3
+ Elb: 85.8
+ Head: 88.2
+ Hip: 80.7
+ Knee: 83.3
+ Shou: 90.1
+ Total: 84.4
+ Wri: 80.8
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_posetrack18_256x192-b5d9b3f1_20211130.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/hrnet_w48_posetrack18_384x288.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: PoseTrack18
+ Name: topdown_heatmap_hrnet_w48_posetrack18_384x288
+ Results:
+ - Dataset: PoseTrack18
+ Metrics:
+ Ankl: 80.9
+ Elb: 85.9
+ Head: 87.8
+ Hip: 81.1
+ Knee: 83.3
+ Shou: 90.0
+ Total: 84.5
+ Wri: 81.3
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_posetrack18_384x288-5fd6d3ff_20211130.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/hrnet_w32_posetrack18_256x192.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: PoseTrack18
+ Name: topdown_heatmap_hrnet_w32_posetrack18_256x192
+ Results:
+ - Dataset: PoseTrack18
+ Metrics:
+ Ankl: 70.2
+ Elb: 79.5
+ Head: 78.0
+ Hip: 76.9
+ Knee: 76.6
+ Shou: 82.9
+ Total: 76.9
+ Wri: 73.8
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_posetrack18_256x192-1ee951c4_20201028.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/hrnet_w32_posetrack18_384x288.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: PoseTrack18
+ Name: topdown_heatmap_hrnet_w32_posetrack18_384x288
+ Results:
+ - Dataset: PoseTrack18
+ Metrics:
+ Ankl: 70.5
+ Elb: 80.4
+ Head: 79.9
+ Hip: 74.8
+ Knee: 76.1
+ Shou: 83.6
+ Total: 77.3
+ Wri: 74.5
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_posetrack18_384x288-806f00a3_20211130.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/hrnet_w48_posetrack18_256x192.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: PoseTrack18
+ Name: topdown_heatmap_hrnet_w48_posetrack18_256x192
+ Results:
+ - Dataset: PoseTrack18
+ Metrics:
+ Ankl: 70.4
+ Elb: 80.6
+ Head: 80.1
+ Hip: 74.3
+ Knee: 76.8
+ Shou: 83.4
+ Total: 77.4
+ Wri: 74.8
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_posetrack18_256x192-b5d9b3f1_20211130.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/hrnet_w48_posetrack18_384x288.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: PoseTrack18
+ Name: topdown_heatmap_hrnet_w48_posetrack18_384x288
+ Results:
+ - Dataset: PoseTrack18
+ Metrics:
+ Ankl: 71.7
+ Elb: 80.9
+ Head: 80.2
+ Hip: 74.7
+ Knee: 76.7
+ Shou: 83.8
+ Total: 77.8
+ Wri: 75.2
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_posetrack18_384x288-5fd6d3ff_20211130.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/hrnet_w32_posetrack18_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/hrnet_w32_posetrack18_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..6e0bab25d081111c9eb2b6f30a2e733f10ca48fa
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/hrnet_w32_posetrack18_256x192.py
@@ -0,0 +1,169 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/posetrack18.py'
+]
+load_from = 'https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_coco_256x192-c78dce93_20200708.pth' # noqa: E501
+checkpoint_config = dict(interval=1)
+evaluation = dict(interval=1, metric='mAP', save_best='Total AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[10, 15])
+total_epochs = 20
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.4,
+ bbox_file='data/posetrack18/annotations/'
+ 'posetrack18_val_human_detections.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=[
+ 'img',
+ ],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/posetrack18'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownPoseTrack18Dataset',
+ ann_file=f'{data_root}/annotations/posetrack18_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownPoseTrack18Dataset',
+ ann_file=f'{data_root}/annotations/posetrack18_val.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownPoseTrack18Dataset',
+ ann_file=f'{data_root}/annotations/posetrack18_val.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/hrnet_w32_posetrack18_384x288.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/hrnet_w32_posetrack18_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..4cb933fbaf4f69bb517f1ccbe157ace5afce2d36
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/hrnet_w32_posetrack18_384x288.py
@@ -0,0 +1,169 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/posetrack18.py'
+]
+load_from = 'https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_coco_384x288-d9f0d786_20200708.pth' # noqa: E501
+checkpoint_config = dict(interval=1)
+evaluation = dict(interval=1, metric='mAP', save_best='Total AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[10, 15])
+total_epochs = 20
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.4,
+ bbox_file='data/posetrack18/annotations/'
+ 'posetrack18_val_human_detections.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=[
+ 'img',
+ ],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/posetrack18'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownPoseTrack18Dataset',
+ ann_file=f'{data_root}/annotations/posetrack18_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownPoseTrack18Dataset',
+ ann_file=f'{data_root}/annotations/posetrack18_val.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownPoseTrack18Dataset',
+ ann_file=f'{data_root}/annotations/posetrack18_val.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/hrnet_w48_posetrack18_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/hrnet_w48_posetrack18_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..dcfb6214c4ace61db2f72f54d3cf40c8f8033296
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/hrnet_w48_posetrack18_256x192.py
@@ -0,0 +1,169 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/posetrack18.py'
+]
+load_from = 'https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth' # noqa: E501
+checkpoint_config = dict(interval=1)
+evaluation = dict(interval=1, metric='mAP', save_best='Total AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[10, 15])
+total_epochs = 20
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.4,
+ bbox_file='data/posetrack18/annotations/'
+ 'posetrack18_val_human_detections.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=[
+ 'img',
+ ],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/posetrack18'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownPoseTrack18Dataset',
+ ann_file=f'{data_root}/annotations/posetrack18_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownPoseTrack18Dataset',
+ ann_file=f'{data_root}/annotations/posetrack18_val.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownPoseTrack18Dataset',
+ ann_file=f'{data_root}/annotations/posetrack18_val.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/hrnet_w48_posetrack18_384x288.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/hrnet_w48_posetrack18_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..78edf760140cd4d6041ae3304d5c14b660857840
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/hrnet_w48_posetrack18_384x288.py
@@ -0,0 +1,169 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/posetrack18.py'
+]
+load_from = 'https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_384x288-314c8528_20200708.pth' # noqa: E501
+checkpoint_config = dict(interval=1)
+evaluation = dict(interval=1, metric='mAP', save_best='Total AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[10, 15])
+total_epochs = 20
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.4,
+ bbox_file='data/posetrack18/annotations/'
+ 'posetrack18_val_human_detections.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=[
+ 'img',
+ ],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/posetrack18'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownPoseTrack18Dataset',
+ ann_file=f'{data_root}/annotations/posetrack18_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownPoseTrack18Dataset',
+ ann_file=f'{data_root}/annotations/posetrack18_val.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownPoseTrack18Dataset',
+ ann_file=f'{data_root}/annotations/posetrack18_val.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/res50_posetrack18_256x192.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/res50_posetrack18_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..341fa1b13c0b35c726e9f863be55856df774bcab
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/res50_posetrack18_256x192.py
@@ -0,0 +1,139 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/posetrack18.py'
+]
+load_from = 'https://download.openmmlab.com/mmpose/top_down/resnet/res50_coco_256x192-ec54d7f3_20200709.pth' # noqa: E501
+checkpoint_config = dict(interval=1)
+evaluation = dict(interval=1, metric='mAP', save_best='Total AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[10, 15])
+total_epochs = 20
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.4,
+ bbox_file='data/posetrack18/annotations/'
+ 'posetrack18_val_human_detections.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=[
+ 'img',
+ ],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/posetrack18'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownPoseTrack18Dataset',
+ ann_file=f'{data_root}/annotations/posetrack18_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownPoseTrack18Dataset',
+ ann_file=f'{data_root}/annotations/posetrack18_val.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownPoseTrack18Dataset',
+ ann_file=f'{data_root}/annotations/posetrack18_val.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/resnet_posetrack18.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/resnet_posetrack18.md
new file mode 100644
index 0000000000000000000000000000000000000000..26aee7ba51a4acc1ee549a1292f96f9dea710b4f
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/resnet_posetrack18.md
@@ -0,0 +1,66 @@
+
+
+PoseTrack18 (CVPR'2018)
+ +```bibtex +@inproceedings{andriluka2018posetrack, + title={Posetrack: A benchmark for human pose estimation and tracking}, + author={Andriluka, Mykhaylo and Iqbal, Umar and Insafutdinov, Eldar and Pishchulin, Leonid and Milan, Anton and Gall, Juergen and Schiele, Bernt}, + booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition}, + pages={5167--5176}, + year={2018} +} +``` + +
+
+
+
+
+SimpleBaseline2D (ECCV'2018)
+ +```bibtex +@inproceedings{xiao2018simple, + title={Simple baselines for human pose estimation and tracking}, + author={Xiao, Bin and Wu, Haiping and Wei, Yichen}, + booktitle={Proceedings of the European conference on computer vision (ECCV)}, + pages={466--481}, + year={2018} +} +``` + +
+
+
+
+
+ResNet (CVPR'2016)
+ +```bibtex +@inproceedings{he2016deep, + title={Deep residual learning for image recognition}, + author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={770--778}, + year={2016} +} +``` + +
+
+
+Results on PoseTrack2018 val with ground-truth bounding boxes
+
+| Arch | Input Size | Head | Shou | Elb | Wri | Hip | Knee | Ankl | Total | ckpt | log |
+| :--- | :--------: | :------: |:------: |:------: |:------: |:------: |:------: | :------: | :------: |:------: |:------: |
+| [pose_resnet_50](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/res50_posetrack18_256x192.py) | 256x192 | 86.5 | 87.5 | 82.3 | 75.6 | 79.9 | 78.6 | 74.0 | 81.0 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res50_posetrack18_256x192-a62807c7_20201028.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res50_posetrack18_256x192_20201028.log.json) |
+
+The models are first pre-trained on COCO dataset, and then fine-tuned on PoseTrack18.
+
+Results on PoseTrack2018 val with [MMDetection](https://github.com/open-mmlab/mmdetection) pre-trained [Cascade R-CNN](https://download.openmmlab.com/mmdetection/v2.0/cascade_rcnn/cascade_rcnn_x101_64x4d_fpn_20e_coco/cascade_rcnn_x101_64x4d_fpn_20e_coco_20200509_224357-051557b1.pth) (X-101-64x4d-FPN) human detector
+
+| Arch | Input Size | Head | Shou | Elb | Wri | Hip | Knee | Ankl | Total | ckpt | log |
+| :--- | :--------: | :------: |:------: |:------: |:------: |:------: |:------: | :------: | :------: |:------: |:------: |
+| [pose_resnet_50](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/res50_posetrack18_256x192.py) | 256x192 | 78.9 | 81.9 | 77.8 | 70.8 | 75.3 | 73.2 | 66.4 | 75.2 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res50_posetrack18_256x192-a62807c7_20201028.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res50_posetrack18_256x192_20201028.log.json) |
+
+The models are first pre-trained on COCO dataset, and then fine-tuned on PoseTrack18.
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/resnet_posetrack18.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/resnet_posetrack18.yml
new file mode 100644
index 0000000000000000000000000000000000000000..f85bc4b64834862f166ed6ba118337dcf1d12fe0
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/resnet_posetrack18.yml
@@ -0,0 +1,47 @@
+Collections:
+- Name: SimpleBaseline2D
+ Paper:
+ Title: Simple baselines for human pose estimation and tracking
+ URL: http://openaccess.thecvf.com/content_ECCV_2018/html/Bin_Xiao_Simple_Baselines_for_ECCV_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/simplebaseline2d.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/res50_posetrack18_256x192.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: &id001
+ - SimpleBaseline2D
+ - ResNet
+ Training Data: PoseTrack18
+ Name: topdown_heatmap_res50_posetrack18_256x192
+ Results:
+ - Dataset: PoseTrack18
+ Metrics:
+ Ankl: 74.0
+ Elb: 82.3
+ Head: 86.5
+ Hip: 79.9
+ Knee: 78.6
+ Shou: 87.5
+ Total: 81.0
+ Wri: 75.6
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res50_posetrack18_256x192-a62807c7_20201028.pth
+- Config: configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/res50_posetrack18_256x192.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: PoseTrack18
+ Name: topdown_heatmap_res50_posetrack18_256x192
+ Results:
+ - Dataset: PoseTrack18
+ Metrics:
+ Ankl: 66.4
+ Elb: 77.8
+ Head: 78.9
+ Hip: 75.3
+ Knee: 73.2
+ Shou: 81.9
+ Total: 75.2
+ Wri: 70.8
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res50_posetrack18_256x192-a62807c7_20201028.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_vid/README.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_vid/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..c638432b501656801367f035e70c4ac888130d14
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_vid/README.md
@@ -0,0 +1,9 @@
+# Video-based Single-view 2D Human Body Pose Estimation
+
+Multi-person 2D human pose estimation in video is defined as the task of detecting the poses (or keypoints) of all people from an input video.
+
+For this task, we currently support [PoseWarper](/configs/body/2d_kpt_sview_rgb_vid/posewarper).
+
+## Data preparation
+
+Please follow [DATA Preparation](/docs/en/tasks/2d_body_keypoint.md) to prepare data.
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_vid/posewarper/README.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_vid/posewarper/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..425d116704cc5ca1a9257ffc7575550fabf77981
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_vid/posewarper/README.md
@@ -0,0 +1,25 @@
+# Learning Temporal Pose Estimation from Sparsely-Labeled Videos
+
+
+
+PoseTrack18 (CVPR'2018)
+ +```bibtex +@inproceedings{andriluka2018posetrack, + title={Posetrack: A benchmark for human pose estimation and tracking}, + author={Andriluka, Mykhaylo and Iqbal, Umar and Insafutdinov, Eldar and Pishchulin, Leonid and Milan, Anton and Gall, Juergen and Schiele, Bernt}, + booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition}, + pages={5167--5176}, + year={2018} +} +``` + +
+
+
+PoseWarper proposes a network that leverages training videos with sparse annotations (every k frames) to learn to perform dense temporal pose propagation and estimation. Given a pair of video frames, a labeled Frame A and an unlabeled Frame B, the model is trained to predict human pose in Frame A using the features from Frame B by means of deformable convolutions to implicitly learn the pose warping between A and B.
+
+The training of PoseWarper can be split into two stages.
+
+The first-stage is trained with the pre-trained model and the main backbone is fine-tuned in a single-frame setting.
+
+The second-stage is trained with the model from the first stage, and the warping offsets are learned in a multi-frame setting while the backbone is frozen.
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_vid/posewarper/posetrack18/hrnet_posetrack18_posewarper.md b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_vid/posewarper/posetrack18/hrnet_posetrack18_posewarper.md
new file mode 100644
index 0000000000000000000000000000000000000000..0fd0a7f5af070590052cbd4cae6338f10402550e
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_vid/posewarper/posetrack18/hrnet_posetrack18_posewarper.md
@@ -0,0 +1,88 @@
+
+
+
+PoseWarper (NeurIPS'2019)
+ +```bibtex +@inproceedings{NIPS2019_gberta, +title = {Learning Temporal Pose Estimation from Sparsely Labeled Videos}, +author = {Bertasius, Gedas and Feichtenhofer, Christoph, and Tran, Du and Shi, Jianbo, and Torresani, Lorenzo}, +booktitle = {Advances in Neural Information Processing Systems 33}, +year = {2019}, +} +``` + +
+
+
+
+
+PoseWarper (NeurIPS'2019)
+ +```bibtex +@inproceedings{NIPS2019_gberta, +title = {Learning Temporal Pose Estimation from Sparsely Labeled Videos}, +author = {Bertasius, Gedas and Feichtenhofer, Christoph, and Tran, Du and Shi, Jianbo, and Torresani, Lorenzo}, +booktitle = {Advances in Neural Information Processing Systems 33}, +year = {2019}, +} +``` + +
+
+
+
+
+HRNet (CVPR'2019)
+ +```bibtex +@inproceedings{sun2019deep, + title={Deep high-resolution representation learning for human pose estimation}, + author={Sun, Ke and Xiao, Bin and Liu, Dong and Wang, Jingdong}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={5693--5703}, + year={2019} +} +``` + +
+
+
+
+
+PoseTrack18 (CVPR'2018)
+ +```bibtex +@inproceedings{andriluka2018posetrack, + title={Posetrack: A benchmark for human pose estimation and tracking}, + author={Andriluka, Mykhaylo and Iqbal, Umar and Insafutdinov, Eldar and Pishchulin, Leonid and Milan, Anton and Gall, Juergen and Schiele, Bernt}, + booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition}, + pages={5167--5176}, + year={2018} +} +``` + +
+
+
+Note that the training of PoseWarper can be split into two stages.
+
+The first-stage is trained with the pre-trained [checkpoint](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_384x288-314c8528_20200708.pth) on COCO dataset, and the main backbone is fine-tuned on PoseTrack18 in a single-frame setting.
+
+The second-stage is trained with the last [checkpoint](https://download.openmmlab.com/mmpose/top_down/posewarper/hrnet_w48_posetrack18_384x288_posewarper_stage1-08b632aa_20211130.pth) from the first stage, and the warping offsets are learned in a multi-frame setting while the backbone is frozen.
+
+Results on PoseTrack2018 val with ground-truth bounding boxes
+
+| Arch | Input Size | Head | Shou | Elb | Wri | Hip | Knee | Ankl | Total | ckpt | log |
+| :--- | :--------: | :------: |:------: |:------: |:------: |:------: |:------: | :------: | :------: |:------: |:------: |
+| [pose_hrnet_w48](/configs/body/2d_kpt_sview_rgb_vid/posewarper/posetrack18/hrnet_w48_posetrack18_384x288_posewarper_stage2.py) | 384x288 | 88.2 | 90.3 | 86.1 | 81.6 | 81.8 | 83.8 | 81.5 | 85.0 | [ckpt](https://download.openmmlab.com/mmpose/top_down/posewarper/hrnet_w48_posetrack18_384x288_posewarper_stage2-4abf88db_20211130.pth) | [log](https://download.openmmlab.com/mmpose/top_down/posewarper/hrnet_w48_posetrack18_384x288_posewarper_stage2_20211130.log.json) |
+
+Results on PoseTrack2018 val with precomputed human bounding boxes from PoseWarper supplementary data files from [this link](https://www.dropbox.com/s/ygfy6r8nitoggfq/PoseWarper_supp_files.zip?dl=0)1.
+
+| Arch | Input Size | Head | Shou | Elb | Wri | Hip | Knee | Ankl | Total | ckpt | log |
+| :--- | :--------: | :------: |:------: |:------: |:------: |:------: |:------: | :------: | :------: |:------: |:------: |
+| [pose_hrnet_w48](/configs/body/2d_kpt_sview_rgb_vid/posewarper/posetrack18/hrnet_w48_posetrack18_384x288_posewarper_stage2.py) | 384x288 | 81.8 | 85.6 | 82.7 | 77.2 | 76.8 | 79.0 | 74.4 | 79.8 | [ckpt](https://download.openmmlab.com/mmpose/top_down/posewarper/hrnet_w48_posetrack18_384x288_posewarper_stage2-4abf88db_20211130.pth) | [log](https://download.openmmlab.com/mmpose/top_down/posewarper/hrnet_w48_posetrack18_384x288_posewarper_stage2_20211130.log.json) |
+
+1 Please download the precomputed human bounding boxes on PoseTrack2018 val from `$PoseWarper_supp_files/posetrack18_precomputed_boxes/val_boxes.json` and place it here: `$mmpose/data/posetrack18/posetrack18_precomputed_boxes/val_boxes.json` to be consistent with the [config](/configs/body/2d_kpt_sview_rgb_vid/posewarper/posetrack18/hrnet_w48_posetrack18_384x288_posewarper_stage2.py). Please refer to [DATA Preparation](/docs/en/tasks/2d_body_keypoint.md) for more detail about data preparation.
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_vid/posewarper/posetrack18/hrnet_posetrack18_posewarper.yml b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_vid/posewarper/posetrack18/hrnet_posetrack18_posewarper.yml
new file mode 100644
index 0000000000000000000000000000000000000000..3d260312f085a95bcc5fbfe5c2d78f76a20ec4e9
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_vid/posewarper/posetrack18/hrnet_posetrack18_posewarper.yml
@@ -0,0 +1,47 @@
+Collections:
+- Name: PoseWarper
+ Paper:
+ Title: Learning Temporal Pose Estimation from Sparsely Labeled Videos
+ URL: https://arxiv.org/abs/1906.04016
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/posewarper.md
+Models:
+- Config: configs/body/2d_kpt_sview_rgb_vid/posewarper/posetrack18/hrnet_w48_posetrack18_384x288_posewarper_stage2.py
+ In Collection: PoseWarper
+ Metadata:
+ Architecture: &id001
+ - PoseWarper
+ - HRNet
+ Training Data: COCO
+ Name: posewarper_hrnet_w48_posetrack18_384x288_posewarper_stage2
+ Results:
+ - Dataset: COCO
+ Metrics:
+ Ankl: 81.5
+ Elb: 86.1
+ Head: 88.2
+ Hip: 81.8
+ Knee: 83.8
+ Shou: 90.3
+ Total: 85.0
+ Wri: 81.6
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/posewarper/hrnet_w48_posetrack18_384x288_posewarper_stage2-4abf88db_20211130.pth
+- Config: configs/body/2d_kpt_sview_rgb_vid/posewarper/posetrack18/hrnet_w48_posetrack18_384x288_posewarper_stage2.py
+ In Collection: PoseWarper
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO
+ Name: posewarper_hrnet_w48_posetrack18_384x288_posewarper_stage2
+ Results:
+ - Dataset: COCO
+ Metrics:
+ Ankl: 74.4
+ Elb: 82.7
+ Head: 81.8
+ Hip: 76.8
+ Knee: 79.0
+ Shou: 85.6
+ Total: 79.8
+ Wri: 77.2
+ Task: Body 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/posewarper/hrnet_w48_posetrack18_384x288_posewarper_stage2-4abf88db_20211130.pth
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_vid/posewarper/posetrack18/hrnet_w48_posetrack18_384x288_posewarper_stage1.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_vid/posewarper/posetrack18/hrnet_w48_posetrack18_384x288_posewarper_stage1.py
new file mode 100644
index 0000000000000000000000000000000000000000..f6ab2d8f76830eb56ca1bc03bd11e0522cdc256d
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_vid/posewarper/posetrack18/hrnet_w48_posetrack18_384x288_posewarper_stage1.py
@@ -0,0 +1,166 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/posetrack18.py'
+]
+load_from = 'https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_384x288-314c8528_20200708.pth' # noqa: E501
+cudnn_benchmark = True
+checkpoint_config = dict(interval=1)
+evaluation = dict(interval=1, metric='mAP', save_best='Total AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0001,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(policy='step', step=[5, 7])
+total_epochs = 10
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=True,
+ det_bbox_thr=0.2,
+ bbox_file='data/posetrack18/annotations/'
+ 'posetrack18_val_human_detections.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=45,
+ scale_factor=0.35),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=[
+ 'img',
+ ],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/posetrack18'
+data = dict(
+ samples_per_gpu=16,
+ workers_per_gpu=3,
+ val_dataloader=dict(samples_per_gpu=16),
+ test_dataloader=dict(samples_per_gpu=16),
+ train=dict(
+ type='TopDownPoseTrack18Dataset',
+ ann_file=f'{data_root}/annotations/posetrack18_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownPoseTrack18Dataset',
+ ann_file=f'{data_root}/annotations/posetrack18_val.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownPoseTrack18Dataset',
+ ann_file=f'{data_root}/annotations/posetrack18_val.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_vid/posewarper/posetrack18/hrnet_w48_posetrack18_384x288_posewarper_stage2.py b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_vid/posewarper/posetrack18/hrnet_w48_posetrack18_384x288_posewarper_stage2.py
new file mode 100644
index 0000000000000000000000000000000000000000..8eb5de9d3541e2dd1b1416ccd7a224ca1079593b
--- /dev/null
+++ b/vendor/ViTPose/configs/body/2d_kpt_sview_rgb_vid/posewarper/posetrack18/hrnet_w48_posetrack18_384x288_posewarper_stage2.py
@@ -0,0 +1,204 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/posetrack18.py'
+]
+load_from = 'https://download.openmmlab.com/mmpose/top_down/posewarper/hrnet_w48_posetrack18_384x288_posewarper_stage1-08b632aa_20211130.pth' # noqa: E501
+cudnn_benchmark = True
+checkpoint_config = dict(interval=1)
+evaluation = dict(interval=1, metric='mAP', save_best='Total AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0001,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(policy='step', step=[10, 15])
+total_epochs = 20
+log_config = dict(
+ interval=100,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='PoseWarper',
+ pretrained=None,
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ frozen_stages=4,
+ ),
+ concat_tensors=True,
+ neck=dict(
+ type='PoseWarperNeck',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'],
+ inner_channels=128,
+ deform_groups=channel_cfg['num_output_channels'],
+ dilations=(3, 6, 12, 18, 24),
+ trans_conv_kernel=1,
+ res_blocks_cfg=dict(block='BASIC', num_blocks=20),
+ offsets_kernel=3,
+ deform_conv_kernel=3,
+ freeze_trans_layer=True,
+ im2col_step=80),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=channel_cfg['num_output_channels'],
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=0, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=False,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ use_nms=True,
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.2,
+ bbox_file='data/posetrack18/posetrack18_precomputed_boxes/'
+ 'val_boxes.json',
+ # frame_indices_train=[-1, 0],
+ frame_index_rand=True,
+ frame_index_range=[-2, 2],
+ num_adj_frames=1,
+ frame_indices_test=[-2, -1, 0, 1, 2],
+ # the first weight is the current frame,
+ # then on ascending order of frame indices
+ frame_weight_train=(0.0, 1.0),
+ frame_weight_test=(0.3, 0.1, 0.25, 0.25, 0.1),
+)
+
+# take care of orders of the transforms
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=45,
+ scale_factor=0.35),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs', 'frame_weight'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=[
+ 'img',
+ ],
+ meta_keys=[
+ 'image_file',
+ 'center',
+ 'scale',
+ 'rotation',
+ 'bbox_score',
+ 'flip_pairs',
+ 'frame_weight',
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/posetrack18'
+data = dict(
+ samples_per_gpu=8,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=4),
+ test_dataloader=dict(samples_per_gpu=4),
+ train=dict(
+ type='TopDownPoseTrack18VideoDataset',
+ ann_file=f'{data_root}/annotations/posetrack18_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownPoseTrack18VideoDataset',
+ ann_file=f'{data_root}/annotations/posetrack18_val.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownPoseTrack18VideoDataset',
+ ann_file=f'{data_root}/annotations/posetrack18_val.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/3d_kpt_mview_rgb_img/README.md b/vendor/ViTPose/configs/body/3d_kpt_mview_rgb_img/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..7ac9137ba963b22de68156cc4512484bdd918f8e
--- /dev/null
+++ b/vendor/ViTPose/configs/body/3d_kpt_mview_rgb_img/README.md
@@ -0,0 +1,8 @@
+# Multi-view 3D Human Body Pose Estimation
+
+Multi-view 3D human body pose estimation targets at predicting the X, Y, Z coordinates of human body joints from multi-view RGB images.
+For this task, we currently support [VoxelPose](/configs/body/3d_kpt_mview_rgb_img/voxelpose).
+
+## Data preparation
+
+Please follow [DATA Preparation](/docs/en/tasks/3d_body_keypoint.md) to prepare data.
diff --git a/vendor/ViTPose/configs/body/3d_kpt_mview_rgb_img/voxelpose/README.md b/vendor/ViTPose/configs/body/3d_kpt_mview_rgb_img/voxelpose/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..f3160f5b92bf8065cb5823081ccabe3d8d513b09
--- /dev/null
+++ b/vendor/ViTPose/configs/body/3d_kpt_mview_rgb_img/voxelpose/README.md
@@ -0,0 +1,23 @@
+# VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Environment
+
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+VoxelPose proposes to break down the task of 3d human pose estimation into 2 stages: (1) Human center detection by Cuboid Proposal Network
+(2) Human pose regression by Pose Regression Network.
+
+The networks in the two stages are all based on 3D convolution. And the input feature volumes are generated by projecting each voxel to
+multi-view images and sampling at the projected location on the 2D heatmaps.
diff --git a/vendor/ViTPose/configs/body/3d_kpt_mview_rgb_img/voxelpose/panoptic/voxelpose_prn64x64x64_cpn80x80x20_panoptic_cam5.md b/vendor/ViTPose/configs/body/3d_kpt_mview_rgb_img/voxelpose/panoptic/voxelpose_prn64x64x64_cpn80x80x20_panoptic_cam5.md
new file mode 100644
index 0000000000000000000000000000000000000000..a71ad8e6a0916d14c55782b4677f30d0c43c432f
--- /dev/null
+++ b/vendor/ViTPose/configs/body/3d_kpt_mview_rgb_img/voxelpose/panoptic/voxelpose_prn64x64x64_cpn80x80x20_panoptic_cam5.md
@@ -0,0 +1,37 @@
+
+
+VoxelPose (ECCV'2020)
+ +```bibtex +@inproceedings{tumultipose, + title={VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Environment}, + author={Tu, Hanyue and Wang, Chunyu and Zeng, Wenjun}, + booktitle={ECCV}, + year={2020} +} +``` + +
+
+
+
+
+VoxelPose (ECCV'2020)
+ +```bibtex +@inproceedings{tumultipose, + title={VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Environment}, + author={Tu, Hanyue and Wang, Chunyu and Zeng, Wenjun}, + booktitle={ECCV}, + year={2020} +} +``` + +
+
+
+Results on CMU Panoptic dataset.
+
+| Arch | mAP | mAR | MPJPE | Recall@500mm| ckpt | log |
+| :--- | :---: | :---: | :---: | :---: | :---: | :---: |
+| [prn64_cpn80_res50](/configs/body/3d_kpt_mview_rgb_img/voxelpose/panoptic/voxelpose_prn64x64x64_cpn80x80x20_panoptic_cam5.py) | 97.31 | 97.99 | 17.57| 99.85| [ckpt](https://download.openmmlab.com/mmpose/body3d/voxelpose/voxelpose_prn64x64x64_cpn80x80x20_panoptic_cam5-545c150e_20211103.pth) | [log](https://download.openmmlab.com/mmpose/body3d/voxelpose/voxelpose_prn64x64x64_cpn80x80x20_panoptic_cam5_20211103.log.json) |
diff --git a/vendor/ViTPose/configs/body/3d_kpt_mview_rgb_img/voxelpose/panoptic/voxelpose_prn64x64x64_cpn80x80x20_panoptic_cam5.py b/vendor/ViTPose/configs/body/3d_kpt_mview_rgb_img/voxelpose/panoptic/voxelpose_prn64x64x64_cpn80x80x20_panoptic_cam5.py
new file mode 100644
index 0000000000000000000000000000000000000000..90996e1eeff112eec680c710a51722b6ba46ead5
--- /dev/null
+++ b/vendor/ViTPose/configs/body/3d_kpt_mview_rgb_img/voxelpose/panoptic/voxelpose_prn64x64x64_cpn80x80x20_panoptic_cam5.py
@@ -0,0 +1,226 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/panoptic_body3d.py'
+]
+checkpoint_config = dict(interval=1)
+evaluation = dict(interval=1, metric='mAP', save_best='mAP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0001,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[8, 9])
+total_epochs = 15
+log_config = dict(
+ interval=50, hooks=[
+ dict(type='TextLoggerHook'),
+ ])
+
+space_size = [8000, 8000, 2000]
+space_center = [0, -500, 800]
+cube_size = [80, 80, 20]
+sub_space_size = [2000, 2000, 2000]
+sub_cube_size = [64, 64, 64]
+image_size = [960, 512]
+heatmap_size = [240, 128]
+num_joints = 15
+
+train_data_cfg = dict(
+ image_size=image_size,
+ heatmap_size=[heatmap_size],
+ num_joints=num_joints,
+ seq_list=[
+ '160422_ultimatum1', '160224_haggling1', '160226_haggling1',
+ '161202_haggling1', '160906_ian1', '160906_ian2', '160906_ian3',
+ '160906_band1', '160906_band2'
+ ],
+ cam_list=[(0, 12), (0, 6), (0, 23), (0, 13), (0, 3)],
+ num_cameras=5,
+ seq_frame_interval=3,
+ subset='train',
+ root_id=2,
+ max_num=10,
+ space_size=space_size,
+ space_center=space_center,
+ cube_size=cube_size,
+)
+
+test_data_cfg = train_data_cfg.copy()
+test_data_cfg.update(
+ dict(
+ seq_list=[
+ '160906_pizza1',
+ '160422_haggling1',
+ '160906_ian5',
+ '160906_band4',
+ ],
+ seq_frame_interval=12,
+ subset='validation'))
+
+# model settings
+backbone = dict(
+ type='AssociativeEmbedding',
+ pretrained=None,
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='DeconvHead',
+ in_channels=2048,
+ out_channels=num_joints,
+ num_deconv_layers=3,
+ num_deconv_filters=(256, 256, 256),
+ num_deconv_kernels=(4, 4, 4),
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=15,
+ num_stages=1,
+ ae_loss_type='exp',
+ with_ae_loss=[False],
+ push_loss_factor=[0.001],
+ pull_loss_factor=[0.001],
+ with_heatmaps_loss=[True],
+ heatmaps_loss_factor=[1.0],
+ )),
+ train_cfg=dict(),
+ test_cfg=dict(
+ num_joints=num_joints,
+ nms_kernel=None,
+ nms_padding=None,
+ tag_per_joint=None,
+ max_num_people=None,
+ detection_threshold=None,
+ tag_threshold=None,
+ use_detection_val=None,
+ ignore_too_much=None,
+ ))
+
+model = dict(
+ type='DetectAndRegress',
+ backbone=backbone,
+ pretrained='checkpoints/resnet_50_deconv.pth.tar',
+ human_detector=dict(
+ type='VoxelCenterDetector',
+ image_size=image_size,
+ heatmap_size=heatmap_size,
+ space_size=space_size,
+ cube_size=cube_size,
+ space_center=space_center,
+ center_net=dict(type='V2VNet', input_channels=15, output_channels=1),
+ center_head=dict(
+ type='CuboidCenterHead',
+ space_size=space_size,
+ space_center=space_center,
+ cube_size=cube_size,
+ max_num=10,
+ max_pool_kernel=3),
+ train_cfg=dict(dist_threshold=500.0),
+ test_cfg=dict(center_threshold=0.3),
+ ),
+ pose_regressor=dict(
+ type='VoxelSinglePose',
+ image_size=image_size,
+ heatmap_size=heatmap_size,
+ sub_space_size=sub_space_size,
+ sub_cube_size=sub_cube_size,
+ num_joints=15,
+ pose_net=dict(type='V2VNet', input_channels=15, output_channels=15),
+ pose_head=dict(type='CuboidPoseHead', beta=100.0)))
+
+train_pipeline = [
+ dict(
+ type='MultiItemProcess',
+ pipeline=[
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=0,
+ scale_factor=[1.0, 1.0],
+ scale_type='long',
+ trans_factor=0),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ ]),
+ dict(
+ type='DiscardDuplicatedItems',
+ keys_list=[
+ 'joints_3d', 'joints_3d_visible', 'ann_info', 'roots_3d',
+ 'num_persons', 'sample_id'
+ ]),
+ dict(type='GenerateVoxel3DHeatmapTarget', sigma=200.0, joint_indices=[2]),
+ dict(
+ type='Collect',
+ keys=['img', 'targets_3d'],
+ meta_keys=[
+ 'num_persons', 'joints_3d', 'camera', 'center', 'scale',
+ 'joints_3d_visible', 'roots_3d'
+ ]),
+]
+
+val_pipeline = [
+ dict(
+ type='MultiItemProcess',
+ pipeline=[
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=0,
+ scale_factor=[1.0, 1.0],
+ scale_type='long',
+ trans_factor=0),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ ]),
+ dict(
+ type='DiscardDuplicatedItems',
+ keys_list=[
+ 'joints_3d', 'joints_3d_visible', 'ann_info', 'roots_3d',
+ 'num_persons', 'sample_id'
+ ]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['sample_id', 'camera', 'center', 'scale']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/panoptic/'
+data = dict(
+ samples_per_gpu=1,
+ workers_per_gpu=4,
+ val_dataloader=dict(samples_per_gpu=2),
+ test_dataloader=dict(samples_per_gpu=2),
+ train=dict(
+ type='Body3DMviewDirectPanopticDataset',
+ ann_file=None,
+ img_prefix=data_root,
+ data_cfg=train_data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='Body3DMviewDirectPanopticDataset',
+ ann_file=None,
+ img_prefix=data_root,
+ data_cfg=test_data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='Body3DMviewDirectPanopticDataset',
+ ann_file=None,
+ img_prefix=data_root,
+ data_cfg=test_data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/3d_kpt_mview_rgb_img/voxelpose/panoptic/voxelpose_prn64x64x64_cpn80x80x20_panoptic_cam5.yml b/vendor/ViTPose/configs/body/3d_kpt_mview_rgb_img/voxelpose/panoptic/voxelpose_prn64x64x64_cpn80x80x20_panoptic_cam5.yml
new file mode 100644
index 0000000000000000000000000000000000000000..8b5e57897fa76a36ea601598baa991fbe94e934f
--- /dev/null
+++ b/vendor/ViTPose/configs/body/3d_kpt_mview_rgb_img/voxelpose/panoptic/voxelpose_prn64x64x64_cpn80x80x20_panoptic_cam5.yml
@@ -0,0 +1,22 @@
+Collections:
+- Name: VoxelPose
+ Paper:
+ Title: 'VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Environment'
+ URL: https://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123460188.pdf
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/voxelpose.md
+Models:
+- Config: configs/body/3d_kpt_mview_rgb_img/voxelpose/panoptic/voxelpose_prn64x64x64_cpn80x80x20_panoptic_cam5.py
+ In Collection: VoxelPose
+ Metadata:
+ Architecture:
+ - VoxelPose
+ Training Data: CMU Panoptic
+ Name: voxelpose_voxelpose_prn64x64x64_cpn80x80x20_panoptic_cam5
+ Results:
+ - Dataset: CMU Panoptic
+ Metrics:
+ MPJPE: 17.57
+ mAP: 97.31
+ mAR: 97.99
+ Task: Body 3D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/body3d/voxelpose/voxelpose_prn64x64x64_cpn80x80x20_panoptic_cam5-545c150e_20211103.pth
diff --git a/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_img/README.md b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_img/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..30b2bd310cfbabb7911b46c154a8793aa41ebd60
--- /dev/null
+++ b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_img/README.md
@@ -0,0 +1,17 @@
+# Single-view 3D Human Body Pose Estimation
+
+3D pose estimation is the detection and analysis of X, Y, Z coordinates of human body joints from an RGB image.
+For single-person 3D pose estimation from a monocular camera, existing works can be classified into three categories:
+(1) from 2D poses to 3D poses (2D-to-3D pose lifting)
+(2) jointly learning 2D and 3D poses, and
+(3) directly regressing 3D poses from images.
+
+## Data preparation
+
+Please follow [DATA Preparation](/docs/en/tasks/3d_body_keypoint.md) to prepare data.
+
+## Demo
+
+Please follow [Demo](/demo/docs/3d_human_pose_demo.md) to run demos.
+
+CMU Panoptic (ICCV'2015)
+ +```bibtex +@Article = {joo_iccv_2015, +author = {Hanbyul Joo, Hao Liu, Lei Tan, Lin Gui, Bart Nabbe, Iain Matthews, Takeo Kanade, Shohei Nobuhara, and Yaser Sheikh}, +title = {Panoptic Studio: A Massively Multiview System for Social Motion Capture}, +booktitle = {ICCV}, +year = {2015} +} +``` + +
diff --git a/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_img/pose_lift/README.md b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_img/pose_lift/README.md new file mode 100644 index 0000000000000000000000000000000000000000..297c88896088a17041bc92f0cfba1550e9dabaa2 --- /dev/null +++ b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_img/pose_lift/README.md @@ -0,0 +1,23 @@ +# A simple yet effective baseline for 3d human pose estimation + + + +
+
+
+Simple 3D baseline proposes to break down the task of 3d human pose estimation into 2 stages: (1) Image → 2D pose
+(2) 2D pose → 3D pose.
+
+The authors find that “lifting” ground truth 2D joint locations to 3D space is a task that can be solved with a low error rate.
+Based on the success of 2d human pose estimation, it directly "lifts" 2d joint locations to 3d space.
diff --git a/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_img/pose_lift/h36m/simplebaseline3d_h36m.md b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_img/pose_lift/h36m/simplebaseline3d_h36m.md
new file mode 100644
index 0000000000000000000000000000000000000000..0aac3fdd451ac810bafdf19323dd5f0b7c302542
--- /dev/null
+++ b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_img/pose_lift/h36m/simplebaseline3d_h36m.md
@@ -0,0 +1,44 @@
+
+
+SimpleBaseline3D (ICCV'2017)
+ +```bibtex +@inproceedings{martinez_2017_3dbaseline, + title={A simple yet effective baseline for 3d human pose estimation}, + author={Martinez, Julieta and Hossain, Rayat and Romero, Javier and Little, James J.}, + booktitle={ICCV}, + year={2017} +} +``` + +
+
+
+
+
+SimpleBaseline3D (ICCV'2017)
+ +```bibtex +@inproceedings{martinez_2017_3dbaseline, + title={A simple yet effective baseline for 3d human pose estimation}, + author={Martinez, Julieta and Hossain, Rayat and Romero, Javier and Little, James J.}, + booktitle={ICCV}, + year={2017} +} +``` + +
+
+
+Results on Human3.6M dataset with ground truth 2D detections
+
+| Arch | MPJPE | P-MPJPE | ckpt | log |
+| :--- | :---: | :---: | :---: | :---: |
+| [simple_baseline_3d_tcn1](/configs/body/3d_kpt_sview_rgb_img/pose_lift/h36m/simplebaseline3d_h36m.py) | 43.4 | 34.3 | [ckpt](https://download.openmmlab.com/mmpose/body3d/simple_baseline/simple3Dbaseline_h36m-f0ad73a4_20210419.pth) | [log](https://download.openmmlab.com/mmpose/body3d/simple_baseline/20210415_065056.log.json) |
+
+1 Differing from the original paper, we didn't apply the `max-norm constraint` because we found this led to a better convergence and performance.
diff --git a/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_img/pose_lift/h36m/simplebaseline3d_h36m.py b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_img/pose_lift/h36m/simplebaseline3d_h36m.py
new file mode 100644
index 0000000000000000000000000000000000000000..2ec29530a51a7db9593fa15c40c8a846ecda06d9
--- /dev/null
+++ b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_img/pose_lift/h36m/simplebaseline3d_h36m.py
@@ -0,0 +1,180 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/h36m.py'
+]
+evaluation = dict(interval=10, metric=['mpjpe', 'p-mpjpe'], save_best='MPJPE')
+
+# optimizer settings
+optimizer = dict(
+ type='Adam',
+ lr=1e-3,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ by_epoch=False,
+ step=100000,
+ gamma=0.96,
+)
+
+total_epochs = 200
+
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='PoseLifter',
+ pretrained=None,
+ backbone=dict(
+ type='TCN',
+ in_channels=2 * 17,
+ stem_channels=1024,
+ num_blocks=2,
+ kernel_sizes=(1, 1, 1),
+ dropout=0.5),
+ keypoint_head=dict(
+ type='TemporalRegressionHead',
+ in_channels=1024,
+ num_joints=16, # do not predict root joint
+ loss_keypoint=dict(type='MSELoss')),
+ train_cfg=dict(),
+ test_cfg=dict(restore_global_position=True))
+
+# data settings
+data_root = 'data/h36m'
+data_cfg = dict(
+ num_joints=17,
+ seq_len=1,
+ seq_frame_interval=1,
+ causal=True,
+ joint_2d_src='gt',
+ need_camera_param=False,
+ camera_param_file=f'{data_root}/annotation_body3d/cameras.pkl',
+)
+
+# 3D joint normalization parameters
+# From file: '{data_root}/annotation_body3d/fps50/joint3d_rel_stats.pkl'
+joint_3d_normalize_param = dict(
+ mean=[[-2.55652589e-04, -7.11960570e-03, -9.81433052e-04],
+ [-5.65463051e-03, 3.19636009e-01, 7.19329269e-02],
+ [-1.01705840e-02, 6.91147892e-01, 1.55352986e-01],
+ [2.55651315e-04, 7.11954606e-03, 9.81423866e-04],
+ [-5.09729780e-03, 3.27040413e-01, 7.22258095e-02],
+ [-9.99656606e-03, 7.08277383e-01, 1.58016408e-01],
+ [2.90583676e-03, -2.11363307e-01, -4.74210915e-02],
+ [5.67537804e-03, -4.35088906e-01, -9.76974016e-02],
+ [5.93884964e-03, -4.91891970e-01, -1.10666618e-01],
+ [7.37352083e-03, -5.83948619e-01, -1.31171400e-01],
+ [5.41920653e-03, -3.83931702e-01, -8.68145417e-02],
+ [2.95964662e-03, -1.87567488e-01, -4.34536934e-02],
+ [1.26585822e-03, -1.20170579e-01, -2.82526049e-02],
+ [4.67186639e-03, -3.83644089e-01, -8.55125784e-02],
+ [1.67648571e-03, -1.97007177e-01, -4.31368364e-02],
+ [8.70569015e-04, -1.68664569e-01, -3.73902498e-02]],
+ std=[[0.11072244, 0.02238818, 0.07246294],
+ [0.15856311, 0.18933832, 0.20880479],
+ [0.19179935, 0.24320062, 0.24756193],
+ [0.11072181, 0.02238805, 0.07246253],
+ [0.15880454, 0.19977188, 0.2147063],
+ [0.18001944, 0.25052739, 0.24853247],
+ [0.05210694, 0.05211406, 0.06908241],
+ [0.09515367, 0.10133032, 0.12899733],
+ [0.11742458, 0.12648469, 0.16465091],
+ [0.12360297, 0.13085539, 0.16433336],
+ [0.14602232, 0.09707956, 0.13952731],
+ [0.24347532, 0.12982249, 0.20230181],
+ [0.2446877, 0.21501816, 0.23938235],
+ [0.13876084, 0.1008926, 0.1424411],
+ [0.23687529, 0.14491219, 0.20980829],
+ [0.24400695, 0.23975028, 0.25520584]])
+
+# 2D joint normalization parameters
+# From file: '{data_root}/annotation_body3d/fps50/joint2d_stats.pkl'
+joint_2d_normalize_param = dict(
+ mean=[[532.08351635, 419.74137558], [531.80953144, 418.2607141],
+ [530.68456967, 493.54259285], [529.36968722, 575.96448516],
+ [532.29767646, 421.28483336], [531.93946631, 494.72186795],
+ [529.71984447, 578.96110365], [532.93699382, 370.65225054],
+ [534.1101856, 317.90342311], [534.55416813, 304.24143901],
+ [534.86955004, 282.31030885], [534.11308566, 330.11296796],
+ [533.53637525, 376.2742511], [533.49380107, 391.72324565],
+ [533.52579142, 330.09494668], [532.50804964, 374.190479],
+ [532.72786934, 380.61615716]],
+ std=[[107.73640054, 63.35908715], [119.00836213, 64.1215443],
+ [119.12412107, 50.53806215], [120.61688045, 56.38444891],
+ [101.95735275, 62.89636486], [106.24832897, 48.41178119],
+ [108.46734966, 54.58177071], [109.07369806, 68.70443672],
+ [111.20130351, 74.87287863], [111.63203838, 77.80542514],
+ [113.22330788, 79.90670556], [105.7145833, 73.27049436],
+ [107.05804267, 73.93175781], [107.97449418, 83.30391802],
+ [121.60675105, 74.25691526], [134.34378973, 77.48125087],
+ [131.79990652, 89.86721124]])
+
+train_pipeline = [
+ dict(
+ type='GetRootCenteredPose',
+ item='target',
+ visible_item='target_visible',
+ root_index=0,
+ root_name='root_position',
+ remove_root=True),
+ dict(
+ type='NormalizeJointCoordinate',
+ item='target',
+ mean=joint_3d_normalize_param['mean'],
+ std=joint_3d_normalize_param['std']),
+ dict(
+ type='NormalizeJointCoordinate',
+ item='input_2d',
+ mean=joint_2d_normalize_param['mean'],
+ std=joint_2d_normalize_param['std']),
+ dict(type='PoseSequenceToTensor', item='input_2d'),
+ dict(
+ type='Collect',
+ keys=[('input_2d', 'input'), 'target'],
+ meta_name='metas',
+ meta_keys=[
+ 'target_image_path', 'flip_pairs', 'root_position',
+ 'root_position_index', 'target_mean', 'target_std'
+ ])
+]
+
+val_pipeline = train_pipeline
+test_pipeline = val_pipeline
+
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=64),
+ test_dataloader=dict(samples_per_gpu=64),
+ train=dict(
+ type='Body3DH36MDataset',
+ ann_file=f'{data_root}/annotation_body3d/fps50/h36m_train.npz',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='Body3DH36MDataset',
+ ann_file=f'{data_root}/annotation_body3d/fps50/h36m_test.npz',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='Body3DH36MDataset',
+ ann_file=f'{data_root}/annotation_body3d/fps50/h36m_test.npz',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_img/pose_lift/h36m/simplebaseline3d_h36m.yml b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_img/pose_lift/h36m/simplebaseline3d_h36m.yml
new file mode 100644
index 0000000000000000000000000000000000000000..b6de86b8f2a860e1a9440c1ee2057490b559308d
--- /dev/null
+++ b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_img/pose_lift/h36m/simplebaseline3d_h36m.yml
@@ -0,0 +1,21 @@
+Collections:
+- Name: SimpleBaseline3D
+ Paper:
+ Title: A simple yet effective baseline for 3d human pose estimation
+ URL: http://openaccess.thecvf.com/content_iccv_2017/html/Martinez_A_Simple_yet_ICCV_2017_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/simplebaseline3d.md
+Models:
+- Config: configs/body/3d_kpt_sview_rgb_img/pose_lift/h36m/simplebaseline3d_h36m.py
+ In Collection: SimpleBaseline3D
+ Metadata:
+ Architecture:
+ - SimpleBaseline3D
+ Training Data: Human3.6M
+ Name: pose_lift_simplebaseline3d_h36m
+ Results:
+ - Dataset: Human3.6M
+ Metrics:
+ MPJPE: 43.4
+ P-MPJPE: 34.3
+ Task: Body 3D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/body3d/simple_baseline/simple3Dbaseline_h36m-f0ad73a4_20210419.pth
diff --git a/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_img/pose_lift/mpi_inf_3dhp/simplebaseline3d_mpi-inf-3dhp.md b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_img/pose_lift/mpi_inf_3dhp/simplebaseline3d_mpi-inf-3dhp.md
new file mode 100644
index 0000000000000000000000000000000000000000..7e91fabccfae7d07184caf2039d15ace051ee3b5
--- /dev/null
+++ b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_img/pose_lift/mpi_inf_3dhp/simplebaseline3d_mpi-inf-3dhp.md
@@ -0,0 +1,42 @@
+
+
+Human3.6M (TPAMI'2014)
+ +```bibtex +@article{h36m_pami, + author = {Ionescu, Catalin and Papava, Dragos and Olaru, Vlad and Sminchisescu, Cristian}, + title = {Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments}, + journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence}, + publisher = {IEEE Computer Society}, + volume = {36}, + number = {7}, + pages = {1325-1339}, + month = {jul}, + year = {2014} +} +``` + +
+
+
+
+
+SimpleBaseline3D (ICCV'2017)
+ +```bibtex +@inproceedings{martinez_2017_3dbaseline, + title={A simple yet effective baseline for 3d human pose estimation}, + author={Martinez, Julieta and Hossain, Rayat and Romero, Javier and Little, James J.}, + booktitle={ICCV}, + year={2017} +} +``` + +
+
+
+Results on MPI-INF-3DHP dataset with ground truth 2D detections
+
+| Arch | MPJPE | P-MPJPE | 3DPCK | 3DAUC | ckpt | log |
+| :--- | :---: | :---: | :---: | :---: | :---: | :---: |
+| [simple_baseline_3d_tcn1](configs/body/3d_kpt_sview_rgb_img/pose_lift/mpi_inf_3dhp/simplebaseline3d_mpi-inf-3dhp.py) | 84.3 | 53.2 | 85.0 | 52.0 | [ckpt](https://download.openmmlab.com/mmpose/body3d/simplebaseline3d/simplebaseline3d_mpi-inf-3dhp-b75546f6_20210603.pth) | [log](https://download.openmmlab.com/mmpose/body3d/simplebaseline3d/simplebaseline3d_mpi-inf-3dhp_20210603.log.json) |
+
+1 Differing from the original paper, we didn't apply the `max-norm constraint` because we found this led to a better convergence and performance.
diff --git a/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_img/pose_lift/mpi_inf_3dhp/simplebaseline3d_mpi-inf-3dhp.py b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_img/pose_lift/mpi_inf_3dhp/simplebaseline3d_mpi-inf-3dhp.py
new file mode 100644
index 0000000000000000000000000000000000000000..fbe23db0f73fc260af1998fc7461b8b40eeb5144
--- /dev/null
+++ b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_img/pose_lift/mpi_inf_3dhp/simplebaseline3d_mpi-inf-3dhp.py
@@ -0,0 +1,192 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpi_inf_3dhp.py'
+]
+evaluation = dict(
+ interval=10,
+ metric=['mpjpe', 'p-mpjpe', '3dpck', '3dauc'],
+ key_indicator='MPJPE')
+
+# optimizer settings
+optimizer = dict(
+ type='Adam',
+ lr=1e-3,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ by_epoch=False,
+ step=100000,
+ gamma=0.96,
+)
+
+total_epochs = 200
+
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='PoseLifter',
+ pretrained=None,
+ backbone=dict(
+ type='TCN',
+ in_channels=2 * 17,
+ stem_channels=1024,
+ num_blocks=2,
+ kernel_sizes=(1, 1, 1),
+ dropout=0.5),
+ keypoint_head=dict(
+ type='TemporalRegressionHead',
+ in_channels=1024,
+ num_joints=16, # do not predict root joint
+ loss_keypoint=dict(type='MSELoss')),
+ train_cfg=dict(),
+ test_cfg=dict(restore_global_position=True))
+
+# data settings
+data_root = 'data/mpi_inf_3dhp'
+train_data_cfg = dict(
+ num_joints=17,
+ seq_len=1,
+ seq_frame_interval=1,
+ causal=True,
+ joint_2d_src='gt',
+ need_camera_param=False,
+ camera_param_file=f'{data_root}/annotations/cameras_train.pkl',
+)
+test_data_cfg = dict(
+ num_joints=17,
+ seq_len=1,
+ seq_frame_interval=1,
+ causal=True,
+ joint_2d_src='gt',
+ need_camera_param=False,
+ camera_param_file=f'{data_root}/annotations/cameras_test.pkl',
+)
+
+# 3D joint normalization parameters
+# From file: '{data_root}/annotations/joint3d_rel_stats.pkl'
+joint_3d_normalize_param = dict(
+ mean=[[1.29798757e-02, -6.14242101e-01, -8.27376088e-02],
+ [8.76858608e-03, -3.99992424e-01, -5.62749816e-02],
+ [1.96335208e-02, -3.64617227e-01, -4.88267063e-02],
+ [2.75206678e-02, -1.95085890e-01, -2.01508894e-02],
+ [2.22896982e-02, -1.37878727e-01, -5.51315396e-03],
+ [-4.16641282e-03, -3.65152343e-01, -5.43331534e-02],
+ [-1.83806493e-02, -1.88053038e-01, -2.78737492e-02],
+ [-1.81491930e-02, -1.22997985e-01, -1.15657333e-02],
+ [1.02960759e-02, -3.93481284e-03, 2.56594686e-03],
+ [-9.82312721e-04, 3.03909927e-01, 6.40930378e-02],
+ [-7.40153218e-03, 6.03930248e-01, 1.01704308e-01],
+ [-1.02960759e-02, 3.93481284e-03, -2.56594686e-03],
+ [-2.65585735e-02, 3.10685217e-01, 5.90257974e-02],
+ [-2.97909979e-02, 6.09658773e-01, 9.83101419e-02],
+ [5.27935016e-03, -1.95547908e-01, -3.06803451e-02],
+ [9.67095383e-03, -4.67827216e-01, -6.31183199e-02]],
+ std=[[0.22265961, 0.19394593, 0.24823498],
+ [0.14710804, 0.13572695, 0.16518279],
+ [0.16562233, 0.12820609, 0.1770134],
+ [0.25062919, 0.1896429, 0.24869254],
+ [0.29278334, 0.29575863, 0.28972444],
+ [0.16916984, 0.13424898, 0.17943313],
+ [0.24760463, 0.18768265, 0.24697394],
+ [0.28709979, 0.28541425, 0.29065647],
+ [0.08867271, 0.02868353, 0.08192097],
+ [0.21473598, 0.23872363, 0.22448061],
+ [0.26021136, 0.3188117, 0.29020494],
+ [0.08867271, 0.02868353, 0.08192097],
+ [0.20729183, 0.2332424, 0.22969608],
+ [0.26214967, 0.3125435, 0.29601641],
+ [0.07129179, 0.06720073, 0.0811808],
+ [0.17489889, 0.15827879, 0.19465977]])
+
+# 2D joint normalization parameters
+# From file: '{data_root}/annotations/joint2d_stats.pkl'
+joint_2d_normalize_param = dict(
+ mean=[[991.90641651, 862.69810047], [1012.08511619, 957.61720198],
+ [1014.49360896, 974.59889655], [1015.67993223, 1055.61969227],
+ [1012.53566238, 1082.80581721], [1009.22188073, 973.93984209],
+ [1005.0694331, 1058.35166276], [1003.49327495, 1089.75631017],
+ [1010.54615457, 1141.46165082], [1003.63254875, 1283.37687485],
+ [1001.97780897, 1418.03079034], [1006.61419313, 1145.20131053],
+ [999.60794074, 1287.13556333], [998.33830821, 1422.30463081],
+ [1008.58017385, 1143.33148068], [1010.97561846, 1053.38953748],
+ [1012.06704779, 925.75338048]],
+ std=[[23374.39708662, 7213.93351296], [533.82975336, 219.70387631],
+ [539.03326985, 218.9370412], [566.57219249, 233.32613405],
+ [590.4265317, 269.2245025], [539.92993936, 218.53166338],
+ [546.30605944, 228.43631598], [564.88616584, 267.85235566],
+ [515.76216052, 206.72322146], [500.6260933, 223.24233285],
+ [505.35940904, 268.4394148], [512.43406541, 202.93095363],
+ [502.41443672, 218.70111819], [509.76363747, 267.67317375],
+ [511.65693552, 204.13307947], [521.66823785, 205.96774166],
+ [541.47940161, 226.01738951]])
+
+train_pipeline = [
+ dict(
+ type='GetRootCenteredPose',
+ item='target',
+ visible_item='target_visible',
+ root_index=14,
+ root_name='root_position',
+ remove_root=True),
+ dict(
+ type='NormalizeJointCoordinate',
+ item='target',
+ mean=joint_3d_normalize_param['mean'],
+ std=joint_3d_normalize_param['std']),
+ dict(
+ type='NormalizeJointCoordinate',
+ item='input_2d',
+ mean=joint_2d_normalize_param['mean'],
+ std=joint_2d_normalize_param['std']),
+ dict(type='PoseSequenceToTensor', item='input_2d'),
+ dict(
+ type='Collect',
+ keys=[('input_2d', 'input'), 'target'],
+ meta_name='metas',
+ meta_keys=[
+ 'target_image_path', 'flip_pairs', 'root_position',
+ 'root_position_index', 'target_mean', 'target_std'
+ ])
+]
+
+val_pipeline = train_pipeline
+test_pipeline = val_pipeline
+
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=64),
+ test_dataloader=dict(samples_per_gpu=64),
+ train=dict(
+ type='Body3DMpiInf3dhpDataset',
+ ann_file=f'{data_root}/annotations/mpi_inf_3dhp_train.npz',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=train_data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='Body3DMpiInf3dhpDataset',
+ ann_file=f'{data_root}/annotations/mpi_inf_3dhp_test_valid.npz',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=test_data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='Body3DMpiInf3dhpDataset',
+ ann_file=f'{data_root}/annotations/mpi_inf_3dhp_test_valid.npz',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=test_data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_img/pose_lift/mpi_inf_3dhp/simplebaseline3d_mpi-inf-3dhp.yml b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_img/pose_lift/mpi_inf_3dhp/simplebaseline3d_mpi-inf-3dhp.yml
new file mode 100644
index 0000000000000000000000000000000000000000..bca7b505281160a3cce7dee6fe9dba95059f3331
--- /dev/null
+++ b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_img/pose_lift/mpi_inf_3dhp/simplebaseline3d_mpi-inf-3dhp.yml
@@ -0,0 +1,23 @@
+Collections:
+- Name: SimpleBaseline3D
+ Paper:
+ Title: A simple yet effective baseline for 3d human pose estimation
+ URL: http://openaccess.thecvf.com/content_iccv_2017/html/Martinez_A_Simple_yet_ICCV_2017_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/simplebaseline3d.md
+Models:
+- Config: configs/body/3d_kpt_sview_rgb_img/pose_lift/mpi_inf_3dhp/simplebaseline3d_mpi-inf-3dhp.py
+ In Collection: SimpleBaseline3D
+ Metadata:
+ Architecture:
+ - SimpleBaseline3D
+ Training Data: MPI-INF-3DHP
+ Name: pose_lift_simplebaseline3d_mpi-inf-3dhp
+ Results:
+ - Dataset: MPI-INF-3DHP
+ Metrics:
+ 3DAUC: 52.0
+ 3DPCK: 85.0
+ MPJPE: 84.3
+ P-MPJPE: 53.2
+ Task: Body 3D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/body3d/simplebaseline3d/simplebaseline3d_mpi-inf-3dhp-b75546f6_20210603.pth
diff --git a/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/README.md b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..8473efc0745516c0c2f751fc7f20c76565263166
--- /dev/null
+++ b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/README.md
@@ -0,0 +1,11 @@
+# Video-based Single-view 3D Human Body Pose Estimation
+
+Video-based 3D pose estimation is the detection and analysis of X, Y, Z coordinates of human body joints from a sequence of RGB images.
+For single-person 3D pose estimation from a monocular camera, existing works can be classified into three categories:
+(1) from 2D poses to 3D poses (2D-to-3D pose lifting)
+(2) jointly learning 2D and 3D poses, and
+(3) directly regressing 3D poses from images.
+
+## Data preparation
+
+Please follow [DATA Preparation](/docs/en/tasks/3d_body_keypoint.md) to prepare data.
diff --git a/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/README.md b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..c820a2f089cf7ca9810931a153915e4aa5e93fab
--- /dev/null
+++ b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/README.md
@@ -0,0 +1,22 @@
+# 3D human pose estimation in video with temporal convolutions and semi-supervised training
+
+## Introduction
+
+
+
+MPI-INF-3DHP (3DV'2017)
+ +```bibtex +@inproceedings{mono-3dhp2017, + author = {Mehta, Dushyant and Rhodin, Helge and Casas, Dan and Fua, Pascal and Sotnychenko, Oleksandr and Xu, Weipeng and Theobalt, Christian}, + title = {Monocular 3D Human Pose Estimation In The Wild Using Improved CNN Supervision}, + booktitle = {3D Vision (3DV), 2017 Fifth International Conference on}, + url = {http://gvv.mpi-inf.mpg.de/3dhp_dataset}, + year = {2017}, + organization={IEEE}, + doi={10.1109/3dv.2017.00064}, +} +``` + +
+
+
+Based on the success of 2d human pose estimation, it directly "lifts" a sequence of 2d keypoints to 3d keypoints.
diff --git a/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m.md b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m.md
new file mode 100644
index 0000000000000000000000000000000000000000..cad6bd5051eabe9bc5aa77ca849943fd20614ca1
--- /dev/null
+++ b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m.md
@@ -0,0 +1,66 @@
+
+
+VideoPose3D (CVPR'2019)
+ +```bibtex +@inproceedings{pavllo20193d, + title={3d human pose estimation in video with temporal convolutions and semi-supervised training}, + author={Pavllo, Dario and Feichtenhofer, Christoph and Grangier, David and Auli, Michael}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + pages={7753--7762}, + year={2019} +} +``` + +
+
+
+
+
+VideoPose3D (CVPR'2019)
+ +```bibtex +@inproceedings{pavllo20193d, + title={3d human pose estimation in video with temporal convolutions and semi-supervised training}, + author={Pavllo, Dario and Feichtenhofer, Christoph and Grangier, David and Auli, Michael}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + pages={7753--7762}, + year={2019} +} +``` + +
+
+
+Results on Human3.6M dataset with ground truth 2D detections, supervised training
+
+| Arch | Receptive Field | MPJPE | P-MPJPE | ckpt | log |
+| :--- | :---: | :---: | :---: | :---: | :---: |
+| [VideoPose3D](/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m_27frames_fullconv_supervised.py) | 27 | 40.0 | 30.1 | [ckpt](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_27frames_fullconv_supervised-fe8fbba9_20210527.pth) | [log](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_27frames_fullconv_supervised_20210527.log.json) |
+| [VideoPose3D](/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m_81frames_fullconv_supervised.py) | 81 | 38.9 | 29.2 | [ckpt](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_81frames_fullconv_supervised-1f2d1104_20210527.pth) | [log](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_81frames_fullconv_supervised_20210527.log.json) |
+| [VideoPose3D](/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m_243frames_fullconv_supervised.py) | 243 | 37.6 | 28.3 | [ckpt](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_243frames_fullconv_supervised-880bea25_20210527.pth) | [log](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_243frames_fullconv_supervised_20210527.log.json) |
+
+Results on Human3.6M dataset with CPN 2D detections1, supervised training
+
+| Arch | Receptive Field | MPJPE | P-MPJPE | ckpt | log |
+| :--- | :---: | :---: | :---: | :---: | :---: |
+| [VideoPose3D](/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m_1frame_fullconv_supervised_cpn_ft.py) | 1 | 52.9 | 41.3 | [ckpt](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_1frame_fullconv_supervised_cpn_ft-5c3afaed_20210527.pth) | [log](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_1frame_fullconv_supervised_cpn_ft_20210527.log.json) |
+| [VideoPose3D](/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m_243frames_fullconv_supervised_cpn_ft.py) | 243 | 47.9 | 38.0 | [ckpt](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_243frames_fullconv_supervised_cpn_ft-88f5abbb_20210527.pth) | [log](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_243frames_fullconv_supervised_cpn_ft_20210527.log.json) |
+
+Results on Human3.6M dataset with ground truth 2D detections, semi-supervised training
+
+| Training Data | Arch | Receptive Field | MPJPE | P-MPJPE | N-MPJPE | ckpt | log |
+| :--- | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
+| 10% S1 | [VideoPose3D](/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m_27frames_fullconv_semi-supervised.py) | 27 | 58.1 | 42.8 | 54.7 | [ckpt](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_27frames_fullconv_semi-supervised-54aef83b_20210527.pth) | [log](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_27frames_fullconv_semi-supervised_20210527.log.json) |
+
+Results on Human3.6M dataset with CPN 2D detections1, semi-supervised training
+
+| Training Data | Arch | Receptive Field | MPJPE | P-MPJPE | N-MPJPE | ckpt | log |
+| :--- | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
+| 10% S1 | [VideoPose3D](/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m_27frames_fullconv_semi-supervised_cpn_ft.py) | 27 | 67.4 | 50.1 | 63.2 | [ckpt](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_27frames_fullconv_semi-supervised_cpn_ft-71be9cde_20210527.pth) | [log](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_27frames_fullconv_semi-supervised_cpn_ft_20210527.log.json) |
+
+1 CPN 2D detections are provided by [official repo](https://github.com/facebookresearch/VideoPose3D/blob/master/DATASETS.md). The reformatted version used in this repository can be downloaded from [train_detection](https://download.openmmlab.com/mmpose/body3d/videopose/cpn_ft_h36m_dbb_train.npy) and [test_detection](https://download.openmmlab.com/mmpose/body3d/videopose/cpn_ft_h36m_dbb_test.npy).
diff --git a/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m.yml b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m.yml
new file mode 100644
index 0000000000000000000000000000000000000000..392c494ace4de30d1c7576ac9392ecfc6270751e
--- /dev/null
+++ b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m.yml
@@ -0,0 +1,102 @@
+Collections:
+- Name: VideoPose3D
+ Paper:
+ Title: 3d human pose estimation in video with temporal convolutions and semi-supervised
+ training
+ URL: http://openaccess.thecvf.com/content_CVPR_2019/html/Pavllo_3D_Human_Pose_Estimation_in_Video_With_Temporal_Convolutions_and_CVPR_2019_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/videopose3d.md
+Models:
+- Config: configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m_27frames_fullconv_supervised.py
+ In Collection: VideoPose3D
+ Metadata:
+ Architecture: &id001
+ - VideoPose3D
+ Training Data: Human3.6M
+ Name: video_pose_lift_videopose3d_h36m_27frames_fullconv_supervised
+ Results:
+ - Dataset: Human3.6M
+ Metrics:
+ MPJPE: 40.0
+ P-MPJPE: 30.1
+ Task: Body 3D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_27frames_fullconv_supervised-fe8fbba9_20210527.pth
+- Config: configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m_81frames_fullconv_supervised.py
+ In Collection: VideoPose3D
+ Metadata:
+ Architecture: *id001
+ Training Data: Human3.6M
+ Name: video_pose_lift_videopose3d_h36m_81frames_fullconv_supervised
+ Results:
+ - Dataset: Human3.6M
+ Metrics:
+ MPJPE: 38.9
+ P-MPJPE: 29.2
+ Task: Body 3D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_81frames_fullconv_supervised-1f2d1104_20210527.pth
+- Config: configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m_243frames_fullconv_supervised.py
+ In Collection: VideoPose3D
+ Metadata:
+ Architecture: *id001
+ Training Data: Human3.6M
+ Name: video_pose_lift_videopose3d_h36m_243frames_fullconv_supervised
+ Results:
+ - Dataset: Human3.6M
+ Metrics:
+ MPJPE: 37.6
+ P-MPJPE: 28.3
+ Task: Body 3D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_243frames_fullconv_supervised-880bea25_20210527.pth
+- Config: configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m_1frame_fullconv_supervised_cpn_ft.py
+ In Collection: VideoPose3D
+ Metadata:
+ Architecture: *id001
+ Training Data: Human3.6M
+ Name: video_pose_lift_videopose3d_h36m_1frame_fullconv_supervised_cpn_ft
+ Results:
+ - Dataset: Human3.6M
+ Metrics:
+ MPJPE: 52.9
+ P-MPJPE: 41.3
+ Task: Body 3D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_1frame_fullconv_supervised_cpn_ft-5c3afaed_20210527.pth
+- Config: configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m_243frames_fullconv_supervised_cpn_ft.py
+ In Collection: VideoPose3D
+ Metadata:
+ Architecture: *id001
+ Training Data: Human3.6M
+ Name: video_pose_lift_videopose3d_h36m_243frames_fullconv_supervised_cpn_ft
+ Results:
+ - Dataset: Human3.6M
+ Metrics:
+ MPJPE: 47.9
+ P-MPJPE: 38.0
+ Task: Body 3D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_243frames_fullconv_supervised_cpn_ft-88f5abbb_20210527.pth
+- Config: configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m_27frames_fullconv_semi-supervised.py
+ In Collection: VideoPose3D
+ Metadata:
+ Architecture: *id001
+ Training Data: Human3.6M
+ Name: video_pose_lift_videopose3d_h36m_27frames_fullconv_semi-supervised
+ Results:
+ - Dataset: Human3.6M
+ Metrics:
+ MPJPE: 58.1
+ N-MPJPE: 54.7
+ P-MPJPE: 42.8
+ Task: Body 3D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_27frames_fullconv_semi-supervised-54aef83b_20210527.pth
+- Config: configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m_27frames_fullconv_semi-supervised_cpn_ft.py
+ In Collection: VideoPose3D
+ Metadata:
+ Architecture: *id001
+ Training Data: Human3.6M
+ Name: video_pose_lift_videopose3d_h36m_27frames_fullconv_semi-supervised_cpn_ft
+ Results:
+ - Dataset: Human3.6M
+ Metrics:
+ MPJPE: 67.4
+ N-MPJPE: 63.2
+ P-MPJPE: 50.1
+ Task: Body 3D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_27frames_fullconv_semi-supervised_cpn_ft-71be9cde_20210527.pth
diff --git a/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m_1frame_fullconv_supervised_cpn_ft.py b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m_1frame_fullconv_supervised_cpn_ft.py
new file mode 100644
index 0000000000000000000000000000000000000000..2de3c3bbcd2ede1dd7031398c865296596d8f4c7
--- /dev/null
+++ b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m_1frame_fullconv_supervised_cpn_ft.py
@@ -0,0 +1,158 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/h36m.py'
+]
+evaluation = dict(
+ interval=10, metric=['mpjpe', 'p-mpjpe'], key_indicator='MPJPE')
+
+# optimizer settings
+optimizer = dict(
+ type='Adam',
+ lr=1e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='exp',
+ by_epoch=True,
+ gamma=0.98,
+)
+
+total_epochs = 160
+
+log_config = dict(
+ interval=20,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='PoseLifter',
+ pretrained=None,
+ backbone=dict(
+ type='TCN',
+ in_channels=2 * 17,
+ stem_channels=1024,
+ num_blocks=4,
+ kernel_sizes=(1, 1, 1, 1, 1),
+ dropout=0.25,
+ use_stride_conv=True),
+ keypoint_head=dict(
+ type='TemporalRegressionHead',
+ in_channels=1024,
+ num_joints=17,
+ loss_keypoint=dict(type='MPJPELoss')),
+ train_cfg=dict(),
+ test_cfg=dict(restore_global_position=True))
+
+# data settings
+data_root = 'data/h36m'
+train_data_cfg = dict(
+ num_joints=17,
+ seq_len=1,
+ seq_frame_interval=1,
+ causal=False,
+ temporal_padding=False,
+ joint_2d_src='detection',
+ joint_2d_det_file=f'{data_root}/joint_2d_det_files/' +
+ 'cpn_ft_h36m_dbb_train.npy',
+ need_camera_param=True,
+ camera_param_file=f'{data_root}/annotation_body3d/cameras.pkl',
+)
+test_data_cfg = dict(
+ num_joints=17,
+ seq_len=1,
+ seq_frame_interval=1,
+ causal=False,
+ temporal_padding=False,
+ joint_2d_src='detection',
+ joint_2d_det_file=f'{data_root}/joint_2d_det_files/' +
+ 'cpn_ft_h36m_dbb_test.npy',
+ need_camera_param=True,
+ camera_param_file=f'{data_root}/annotation_body3d/cameras.pkl',
+)
+
+train_pipeline = [
+ dict(
+ type='GetRootCenteredPose',
+ item='target',
+ visible_item='target_visible',
+ root_index=0,
+ root_name='root_position',
+ remove_root=False),
+ dict(type='ImageCoordinateNormalization', item='input_2d'),
+ dict(
+ type='RelativeJointRandomFlip',
+ item=['input_2d', 'target'],
+ flip_cfg=[
+ dict(center_mode='static', center_x=0.),
+ dict(center_mode='root', center_index=0)
+ ],
+ visible_item=['input_2d_visible', 'target_visible'],
+ flip_prob=0.5),
+ dict(type='PoseSequenceToTensor', item='input_2d'),
+ dict(
+ type='Collect',
+ keys=[('input_2d', 'input'), 'target'],
+ meta_name='metas',
+ meta_keys=['target_image_path', 'flip_pairs', 'root_position'])
+]
+
+val_pipeline = [
+ dict(
+ type='GetRootCenteredPose',
+ item='target',
+ visible_item='target_visible',
+ root_index=0,
+ root_name='root_position',
+ remove_root=False),
+ dict(type='ImageCoordinateNormalization', item='input_2d'),
+ dict(type='PoseSequenceToTensor', item='input_2d'),
+ dict(
+ type='Collect',
+ keys=[('input_2d', 'input'), 'target'],
+ meta_name='metas',
+ meta_keys=['target_image_path', 'flip_pairs', 'root_position'])
+]
+
+test_pipeline = val_pipeline
+
+data = dict(
+ samples_per_gpu=128,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=128),
+ test_dataloader=dict(samples_per_gpu=128),
+ train=dict(
+ type='Body3DH36MDataset',
+ ann_file=f'{data_root}/annotation_body3d/fps50/h36m_train.npz',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=train_data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='Body3DH36MDataset',
+ ann_file=f'{data_root}/annotation_body3d/fps50/h36m_test.npz',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=test_data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='Body3DH36MDataset',
+ ann_file=f'{data_root}/annotation_body3d/fps50/h36m_test.npz',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=test_data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m_243frames_fullconv_supervised.py b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m_243frames_fullconv_supervised.py
new file mode 100644
index 0000000000000000000000000000000000000000..23b23fede0bc7840859b997b44f070b9019367d3
--- /dev/null
+++ b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m_243frames_fullconv_supervised.py
@@ -0,0 +1,144 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/h36m.py'
+]
+evaluation = dict(
+ interval=10, metric=['mpjpe', 'p-mpjpe'], key_indicator='MPJPE')
+
+# optimizer settings
+optimizer = dict(
+ type='Adam',
+ lr=1e-3,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='exp',
+ by_epoch=True,
+ gamma=0.975,
+)
+
+total_epochs = 160
+
+log_config = dict(
+ interval=20,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='PoseLifter',
+ pretrained=None,
+ backbone=dict(
+ type='TCN',
+ in_channels=2 * 17,
+ stem_channels=1024,
+ num_blocks=4,
+ kernel_sizes=(3, 3, 3, 3, 3),
+ dropout=0.25,
+ use_stride_conv=True),
+ keypoint_head=dict(
+ type='TemporalRegressionHead',
+ in_channels=1024,
+ num_joints=17,
+ loss_keypoint=dict(type='MPJPELoss')),
+ train_cfg=dict(),
+ test_cfg=dict(restore_global_position=True))
+
+# data settings
+data_root = 'data/h36m'
+data_cfg = dict(
+ num_joints=17,
+ seq_len=243,
+ seq_frame_interval=1,
+ causal=False,
+ temporal_padding=True,
+ joint_2d_src='gt',
+ need_camera_param=True,
+ camera_param_file=f'{data_root}/annotation_body3d/cameras.pkl',
+)
+
+train_pipeline = [
+ dict(
+ type='GetRootCenteredPose',
+ item='target',
+ visible_item='target_visible',
+ root_index=0,
+ root_name='root_position',
+ remove_root=False),
+ dict(type='ImageCoordinateNormalization', item='input_2d'),
+ dict(
+ type='RelativeJointRandomFlip',
+ item=['input_2d', 'target'],
+ flip_cfg=[
+ dict(center_mode='static', center_x=0.),
+ dict(center_mode='root', center_index=0)
+ ],
+ visible_item=['input_2d_visible', 'target_visible'],
+ flip_prob=0.5),
+ dict(type='PoseSequenceToTensor', item='input_2d'),
+ dict(
+ type='Collect',
+ keys=[('input_2d', 'input'), 'target'],
+ meta_name='metas',
+ meta_keys=['target_image_path', 'flip_pairs', 'root_position'])
+]
+
+val_pipeline = [
+ dict(
+ type='GetRootCenteredPose',
+ item='target',
+ visible_item='target_visible',
+ root_index=0,
+ root_name='root_position',
+ remove_root=False),
+ dict(type='ImageCoordinateNormalization', item='input_2d'),
+ dict(type='PoseSequenceToTensor', item='input_2d'),
+ dict(
+ type='Collect',
+ keys=[('input_2d', 'input'), 'target'],
+ meta_name='metas',
+ meta_keys=['target_image_path', 'flip_pairs', 'root_position'])
+]
+
+test_pipeline = val_pipeline
+
+data = dict(
+ samples_per_gpu=128,
+ workers_per_gpu=0,
+ val_dataloader=dict(samples_per_gpu=128),
+ test_dataloader=dict(samples_per_gpu=128),
+ train=dict(
+ type='Body3DH36MDataset',
+ ann_file=f'{data_root}/annotation_body3d/fps50/h36m_train.npz',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='Body3DH36MDataset',
+ ann_file=f'{data_root}/annotation_body3d/fps50/h36m_test.npz',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='Body3DH36MDataset',
+ ann_file=f'{data_root}/annotation_body3d/fps50/h36m_test.npz',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m_243frames_fullconv_supervised_cpn_ft.py b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m_243frames_fullconv_supervised_cpn_ft.py
new file mode 100644
index 0000000000000000000000000000000000000000..65d7b49053800b6ecdc6a153a3f4349a90974bc0
--- /dev/null
+++ b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m_243frames_fullconv_supervised_cpn_ft.py
@@ -0,0 +1,158 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/h36m.py'
+]
+evaluation = dict(
+ interval=10, metric=['mpjpe', 'p-mpjpe'], key_indicator='MPJPE')
+
+# optimizer settings
+optimizer = dict(
+ type='Adam',
+ lr=1e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='exp',
+ by_epoch=True,
+ gamma=0.98,
+)
+
+total_epochs = 200
+
+log_config = dict(
+ interval=20,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='PoseLifter',
+ pretrained=None,
+ backbone=dict(
+ type='TCN',
+ in_channels=2 * 17,
+ stem_channels=1024,
+ num_blocks=4,
+ kernel_sizes=(3, 3, 3, 3, 3),
+ dropout=0.25,
+ use_stride_conv=True),
+ keypoint_head=dict(
+ type='TemporalRegressionHead',
+ in_channels=1024,
+ num_joints=17,
+ loss_keypoint=dict(type='MPJPELoss')),
+ train_cfg=dict(),
+ test_cfg=dict(restore_global_position=True))
+
+# data settings
+data_root = 'data/h36m'
+train_data_cfg = dict(
+ num_joints=17,
+ seq_len=243,
+ seq_frame_interval=1,
+ causal=False,
+ temporal_padding=True,
+ joint_2d_src='detection',
+ joint_2d_det_file=f'{data_root}/joint_2d_det_files/' +
+ 'cpn_ft_h36m_dbb_train.npy',
+ need_camera_param=True,
+ camera_param_file=f'{data_root}/annotation_body3d/cameras.pkl',
+)
+test_data_cfg = dict(
+ num_joints=17,
+ seq_len=243,
+ seq_frame_interval=1,
+ causal=False,
+ temporal_padding=True,
+ joint_2d_src='detection',
+ joint_2d_det_file=f'{data_root}/joint_2d_det_files/' +
+ 'cpn_ft_h36m_dbb_test.npy',
+ need_camera_param=True,
+ camera_param_file=f'{data_root}/annotation_body3d/cameras.pkl',
+)
+
+train_pipeline = [
+ dict(
+ type='GetRootCenteredPose',
+ item='target',
+ visible_item='target_visible',
+ root_index=0,
+ root_name='root_position',
+ remove_root=False),
+ dict(type='ImageCoordinateNormalization', item='input_2d'),
+ dict(
+ type='RelativeJointRandomFlip',
+ item=['input_2d', 'target'],
+ flip_cfg=[
+ dict(center_mode='static', center_x=0.),
+ dict(center_mode='root', center_index=0)
+ ],
+ visible_item=['input_2d_visible', 'target_visible'],
+ flip_prob=0.5),
+ dict(type='PoseSequenceToTensor', item='input_2d'),
+ dict(
+ type='Collect',
+ keys=[('input_2d', 'input'), 'target'],
+ meta_name='metas',
+ meta_keys=['target_image_path', 'flip_pairs', 'root_position'])
+]
+
+val_pipeline = [
+ dict(
+ type='GetRootCenteredPose',
+ item='target',
+ visible_item='target_visible',
+ root_index=0,
+ root_name='root_position',
+ remove_root=False),
+ dict(type='ImageCoordinateNormalization', item='input_2d'),
+ dict(type='PoseSequenceToTensor', item='input_2d'),
+ dict(
+ type='Collect',
+ keys=[('input_2d', 'input'), 'target'],
+ meta_name='metas',
+ meta_keys=['target_image_path', 'flip_pairs', 'root_position'])
+]
+
+test_pipeline = val_pipeline
+
+data = dict(
+ samples_per_gpu=128,
+ workers_per_gpu=0,
+ val_dataloader=dict(samples_per_gpu=128),
+ test_dataloader=dict(samples_per_gpu=128),
+ train=dict(
+ type='Body3DH36MDataset',
+ ann_file=f'{data_root}/annotation_body3d/fps50/h36m_train.npz',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=train_data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='Body3DH36MDataset',
+ ann_file=f'{data_root}/annotation_body3d/fps50/h36m_test.npz',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=test_data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='Body3DH36MDataset',
+ ann_file=f'{data_root}/annotation_body3d/fps50/h36m_test.npz',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=test_data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m_27frames_fullconv_semi-supervised.py b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m_27frames_fullconv_semi-supervised.py
new file mode 100644
index 0000000000000000000000000000000000000000..70404c9fcede383f32e3c6cb2a77f9924d804b78
--- /dev/null
+++ b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m_27frames_fullconv_semi-supervised.py
@@ -0,0 +1,222 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/h36m.py'
+]
+checkpoint_config = dict(interval=20)
+evaluation = dict(
+ interval=10, metric=['mpjpe', 'p-mpjpe', 'n-mpjpe'], key_indicator='MPJPE')
+
+# optimizer settings
+optimizer = dict(
+ type='Adam',
+ lr=1e-3,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='exp',
+ by_epoch=True,
+ gamma=0.98,
+)
+
+total_epochs = 200
+
+log_config = dict(
+ interval=20,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='PoseLifter',
+ pretrained=None,
+ backbone=dict(
+ type='TCN',
+ in_channels=2 * 17,
+ stem_channels=1024,
+ num_blocks=2,
+ kernel_sizes=(3, 3, 3),
+ dropout=0.25,
+ use_stride_conv=True),
+ keypoint_head=dict(
+ type='TemporalRegressionHead',
+ in_channels=1024,
+ num_joints=17,
+ loss_keypoint=dict(type='MPJPELoss')),
+ traj_backbone=dict(
+ type='TCN',
+ in_channels=2 * 17,
+ stem_channels=1024,
+ num_blocks=2,
+ kernel_sizes=(3, 3, 3),
+ dropout=0.25,
+ use_stride_conv=True),
+ traj_head=dict(
+ type='TemporalRegressionHead',
+ in_channels=1024,
+ num_joints=1,
+ loss_keypoint=dict(type='MPJPELoss', use_target_weight=True),
+ is_trajectory=True),
+ loss_semi=dict(
+ type='SemiSupervisionLoss',
+ joint_parents=[0, 0, 1, 2, 0, 4, 5, 0, 7, 8, 9, 8, 11, 12, 8, 14, 15],
+ warmup_iterations=1311376 // 64 // 8 *
+ 5), # dataset_size // samples_per_gpu // gpu_num * warmup_epochs
+ train_cfg=dict(),
+ test_cfg=dict(restore_global_position=True))
+
+# data settings
+data_root = 'data/h36m'
+labeled_data_cfg = dict(
+ num_joints=17,
+ seq_len=27,
+ seq_frame_interval=1,
+ causal=False,
+ temporal_padding=True,
+ joint_2d_src='gt',
+ subset=0.1,
+ subjects=['S1'],
+ need_camera_param=True,
+ camera_param_file=f'{data_root}/annotation_body3d/cameras.pkl',
+)
+unlabeled_data_cfg = dict(
+ num_joints=17,
+ seq_len=27,
+ seq_frame_interval=1,
+ causal=False,
+ temporal_padding=True,
+ joint_2d_src='gt',
+ subjects=['S5', 'S6', 'S7', 'S8'],
+ need_camera_param=True,
+ camera_param_file=f'{data_root}/annotation_body3d/cameras.pkl',
+ need_2d_label=True)
+val_data_cfg = dict(
+ num_joints=17,
+ seq_len=27,
+ seq_frame_interval=1,
+ causal=False,
+ temporal_padding=True,
+ joint_2d_src='gt',
+ need_camera_param=True,
+ camera_param_file=f'{data_root}/annotation_body3d/cameras.pkl')
+test_data_cfg = val_data_cfg
+
+train_labeled_pipeline = [
+ dict(
+ type='GetRootCenteredPose',
+ item='target',
+ visible_item='target_visible',
+ root_index=0,
+ root_name='root_position',
+ remove_root=False),
+ dict(type='ImageCoordinateNormalization', item='input_2d'),
+ dict(
+ type='RelativeJointRandomFlip',
+ item=['input_2d', 'target'],
+ flip_cfg=[
+ dict(center_mode='static', center_x=0.),
+ dict(center_mode='root', center_index=0)
+ ],
+ visible_item=['input_2d_visible', 'target_visible'],
+ flip_prob=0.5),
+ dict(type='PoseSequenceToTensor', item='input_2d'),
+ dict(
+ type='Collect',
+ keys=[('input_2d', 'input'), 'target',
+ ('root_position', 'traj_target')],
+ meta_name='metas',
+ meta_keys=['target_image_path', 'flip_pairs', 'root_position'])
+]
+
+train_unlabeled_pipeline = [
+ dict(
+ type='ImageCoordinateNormalization',
+ item=['input_2d', 'target_2d'],
+ norm_camera=True),
+ dict(
+ type='RelativeJointRandomFlip',
+ item=['input_2d', 'target_2d'],
+ flip_cfg=[
+ dict(center_mode='static', center_x=0.),
+ dict(center_mode='static', center_x=0.)
+ ],
+ visible_item='input_2d_visible',
+ flip_prob=0.5,
+ flip_camera=True),
+ dict(type='PoseSequenceToTensor', item='input_2d'),
+ dict(type='CollectCameraIntrinsics'),
+ dict(
+ type='Collect',
+ keys=[('input_2d', 'unlabeled_input'),
+ ('target_2d', 'unlabeled_target_2d'), 'intrinsics'],
+ meta_name='unlabeled_metas',
+ meta_keys=['target_image_path', 'flip_pairs'])
+]
+
+val_pipeline = [
+ dict(
+ type='GetRootCenteredPose',
+ item='target',
+ visible_item='target_visible',
+ root_index=0,
+ root_name='root_position',
+ remove_root=False),
+ dict(type='ImageCoordinateNormalization', item='input_2d'),
+ dict(type='PoseSequenceToTensor', item='input_2d'),
+ dict(
+ type='Collect',
+ keys=[('input_2d', 'input'), 'target'],
+ meta_name='metas',
+ meta_keys=['target_image_path', 'flip_pairs', 'root_position'])
+]
+
+test_pipeline = val_pipeline
+
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=64),
+ test_dataloader=dict(samples_per_gpu=64),
+ train=dict(
+ type='Body3DSemiSupervisionDataset',
+ labeled_dataset=dict(
+ type='Body3DH36MDataset',
+ ann_file=f'{data_root}/annotation_body3d/fps50/h36m_train.npz',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=labeled_data_cfg,
+ pipeline=train_labeled_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ unlabeled_dataset=dict(
+ type='Body3DH36MDataset',
+ ann_file=f'{data_root}/annotation_body3d/fps50/h36m_train.npz',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=unlabeled_data_cfg,
+ pipeline=train_unlabeled_pipeline,
+ dataset_info={{_base_.dataset_info}})),
+ val=dict(
+ type='Body3DH36MDataset',
+ ann_file=f'{data_root}/annotation_body3d/fps50/h36m_test.npz',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=val_data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='Body3DH36MDataset',
+ ann_file=f'{data_root}/annotation_body3d/fps50/h36m_test.npz',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=test_data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m_27frames_fullconv_semi-supervised_cpn_ft.py b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m_27frames_fullconv_semi-supervised_cpn_ft.py
new file mode 100644
index 0000000000000000000000000000000000000000..7b0d9fe5205e44b9062fdc60a7d51f8671e556b4
--- /dev/null
+++ b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m_27frames_fullconv_semi-supervised_cpn_ft.py
@@ -0,0 +1,228 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/h36m.py'
+]
+checkpoint_config = dict(interval=20)
+evaluation = dict(
+ interval=10, metric=['mpjpe', 'p-mpjpe', 'n-mpjpe'], key_indicator='MPJPE')
+
+# optimizer settings
+optimizer = dict(
+ type='Adam',
+ lr=1e-3,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='exp',
+ by_epoch=True,
+ gamma=0.98,
+)
+
+total_epochs = 200
+
+log_config = dict(
+ interval=20,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='PoseLifter',
+ pretrained=None,
+ backbone=dict(
+ type='TCN',
+ in_channels=2 * 17,
+ stem_channels=1024,
+ num_blocks=2,
+ kernel_sizes=(3, 3, 3),
+ dropout=0.25,
+ use_stride_conv=True),
+ keypoint_head=dict(
+ type='TemporalRegressionHead',
+ in_channels=1024,
+ num_joints=17,
+ loss_keypoint=dict(type='MPJPELoss')),
+ traj_backbone=dict(
+ type='TCN',
+ in_channels=2 * 17,
+ stem_channels=1024,
+ num_blocks=2,
+ kernel_sizes=(3, 3, 3),
+ dropout=0.25,
+ use_stride_conv=True),
+ traj_head=dict(
+ type='TemporalRegressionHead',
+ in_channels=1024,
+ num_joints=1,
+ loss_keypoint=dict(type='MPJPELoss', use_target_weight=True),
+ is_trajectory=True),
+ loss_semi=dict(
+ type='SemiSupervisionLoss',
+ joint_parents=[0, 0, 1, 2, 0, 4, 5, 0, 7, 8, 9, 8, 11, 12, 8, 14, 15],
+ warmup_iterations=1311376 // 64 // 8 *
+ 5), # dataset_size // samples_per_gpu // gpu_num * warmup_epochs
+ train_cfg=dict(),
+ test_cfg=dict(restore_global_position=True))
+
+# data settings
+data_root = 'data/h36m'
+labeled_data_cfg = dict(
+ num_joints=17,
+ seq_len=27,
+ seq_frame_interval=1,
+ causal=False,
+ temporal_padding=True,
+ joint_2d_src='detection',
+ joint_2d_det_file=f'{data_root}/joint_2d_det_files/' +
+ 'cpn_ft_h36m_dbb_train.npy',
+ subset=0.1,
+ subjects=['S1'],
+ need_camera_param=True,
+ camera_param_file=f'{data_root}/annotation_body3d/cameras.pkl',
+)
+unlabeled_data_cfg = dict(
+ num_joints=17,
+ seq_len=27,
+ seq_frame_interval=1,
+ causal=False,
+ temporal_padding=True,
+ joint_2d_src='detection',
+ joint_2d_det_file=f'{data_root}/joint_2d_det_files/' +
+ 'cpn_ft_h36m_dbb_train.npy',
+ subjects=['S5', 'S6', 'S7', 'S8'],
+ need_camera_param=True,
+ camera_param_file=f'{data_root}/annotation_body3d/cameras.pkl',
+ need_2d_label=True)
+val_data_cfg = dict(
+ num_joints=17,
+ seq_len=27,
+ seq_frame_interval=1,
+ causal=False,
+ temporal_padding=True,
+ joint_2d_src='detection',
+ joint_2d_det_file=f'{data_root}/joint_2d_det_files/' +
+ 'cpn_ft_h36m_dbb_test.npy',
+ need_camera_param=True,
+ camera_param_file=f'{data_root}/annotation_body3d/cameras.pkl')
+test_data_cfg = val_data_cfg
+
+train_labeled_pipeline = [
+ dict(
+ type='GetRootCenteredPose',
+ item='target',
+ visible_item='target_visible',
+ root_index=0,
+ root_name='root_position',
+ remove_root=False),
+ dict(type='ImageCoordinateNormalization', item='input_2d'),
+ dict(
+ type='RelativeJointRandomFlip',
+ item=['input_2d', 'target'],
+ flip_cfg=[
+ dict(center_mode='static', center_x=0.),
+ dict(center_mode='root', center_index=0)
+ ],
+ visible_item=['input_2d_visible', 'target_visible'],
+ flip_prob=0.5),
+ dict(type='PoseSequenceToTensor', item='input_2d'),
+ dict(
+ type='Collect',
+ keys=[('input_2d', 'input'), 'target',
+ ('root_position', 'traj_target')],
+ meta_name='metas',
+ meta_keys=['target_image_path', 'flip_pairs', 'root_position'])
+]
+
+train_unlabeled_pipeline = [
+ dict(
+ type='ImageCoordinateNormalization',
+ item=['input_2d', 'target_2d'],
+ norm_camera=True),
+ dict(
+ type='RelativeJointRandomFlip',
+ item=['input_2d', 'target_2d'],
+ flip_cfg=[
+ dict(center_mode='static', center_x=0.),
+ dict(center_mode='static', center_x=0.)
+ ],
+ visible_item='input_2d_visible',
+ flip_prob=0.5,
+ flip_camera=True),
+ dict(type='PoseSequenceToTensor', item='input_2d'),
+ dict(type='CollectCameraIntrinsics'),
+ dict(
+ type='Collect',
+ keys=[('input_2d', 'unlabeled_input'),
+ ('target_2d', 'unlabeled_target_2d'), 'intrinsics'],
+ meta_name='unlabeled_metas',
+ meta_keys=['target_image_path', 'flip_pairs'])
+]
+
+val_pipeline = [
+ dict(
+ type='GetRootCenteredPose',
+ item='target',
+ visible_item='target_visible',
+ root_index=0,
+ root_name='root_position',
+ remove_root=False),
+ dict(type='ImageCoordinateNormalization', item='input_2d'),
+ dict(type='PoseSequenceToTensor', item='input_2d'),
+ dict(
+ type='Collect',
+ keys=[('input_2d', 'input'), 'target'],
+ meta_name='metas',
+ meta_keys=['target_image_path', 'flip_pairs', 'root_position'])
+]
+
+test_pipeline = val_pipeline
+
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=0,
+ val_dataloader=dict(samples_per_gpu=64),
+ test_dataloader=dict(samples_per_gpu=64),
+ train=dict(
+ type='Body3DSemiSupervisionDataset',
+ labeled_dataset=dict(
+ type='Body3DH36MDataset',
+ ann_file=f'{data_root}/annotation_body3d/fps50/h36m_train.npz',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=labeled_data_cfg,
+ pipeline=train_labeled_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ unlabeled_dataset=dict(
+ type='Body3DH36MDataset',
+ ann_file=f'{data_root}/annotation_body3d/fps50/h36m_train.npz',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=unlabeled_data_cfg,
+ pipeline=train_unlabeled_pipeline,
+ dataset_info={{_base_.dataset_info}})),
+ val=dict(
+ type='Body3DH36MDataset',
+ ann_file=f'{data_root}/annotation_body3d/fps50/h36m_test.npz',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=val_data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='Body3DH36MDataset',
+ ann_file=f'{data_root}/annotation_body3d/fps50/h36m_test.npz',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=test_data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m_27frames_fullconv_supervised.py b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m_27frames_fullconv_supervised.py
new file mode 100644
index 0000000000000000000000000000000000000000..5f28a59b4c273d5dabd043d957b95e6c1286ce6a
--- /dev/null
+++ b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m_27frames_fullconv_supervised.py
@@ -0,0 +1,144 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/h36m.py'
+]
+evaluation = dict(
+ interval=10, metric=['mpjpe', 'p-mpjpe'], key_indicator='MPJPE')
+
+# optimizer settings
+optimizer = dict(
+ type='Adam',
+ lr=1e-3,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='exp',
+ by_epoch=True,
+ gamma=0.975,
+)
+
+total_epochs = 160
+
+log_config = dict(
+ interval=20,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='PoseLifter',
+ pretrained=None,
+ backbone=dict(
+ type='TCN',
+ in_channels=2 * 17,
+ stem_channels=1024,
+ num_blocks=2,
+ kernel_sizes=(3, 3, 3),
+ dropout=0.25,
+ use_stride_conv=True),
+ keypoint_head=dict(
+ type='TemporalRegressionHead',
+ in_channels=1024,
+ num_joints=17,
+ loss_keypoint=dict(type='MPJPELoss')),
+ train_cfg=dict(),
+ test_cfg=dict(restore_global_position=True))
+
+# data settings
+data_root = 'data/h36m'
+data_cfg = dict(
+ num_joints=17,
+ seq_len=27,
+ seq_frame_interval=1,
+ causal=False,
+ temporal_padding=True,
+ joint_2d_src='gt',
+ need_camera_param=True,
+ camera_param_file=f'{data_root}/annotation_body3d/cameras.pkl',
+)
+
+train_pipeline = [
+ dict(
+ type='GetRootCenteredPose',
+ item='target',
+ visible_item='target_visible',
+ root_index=0,
+ root_name='root_position',
+ remove_root=False),
+ dict(type='ImageCoordinateNormalization', item='input_2d'),
+ dict(
+ type='RelativeJointRandomFlip',
+ item=['input_2d', 'target'],
+ flip_cfg=[
+ dict(center_mode='static', center_x=0.),
+ dict(center_mode='root', center_index=0)
+ ],
+ visible_item=['input_2d_visible', 'target_visible'],
+ flip_prob=0.5),
+ dict(type='PoseSequenceToTensor', item='input_2d'),
+ dict(
+ type='Collect',
+ keys=[('input_2d', 'input'), 'target'],
+ meta_name='metas',
+ meta_keys=['target_image_path', 'flip_pairs', 'root_position'])
+]
+
+val_pipeline = [
+ dict(
+ type='GetRootCenteredPose',
+ item='target',
+ visible_item='target_visible',
+ root_index=0,
+ root_name='root_position',
+ remove_root=False),
+ dict(type='ImageCoordinateNormalization', item='input_2d'),
+ dict(type='PoseSequenceToTensor', item='input_2d'),
+ dict(
+ type='Collect',
+ keys=[('input_2d', 'input'), 'target'],
+ meta_name='metas',
+ meta_keys=['target_image_path', 'flip_pairs', 'root_position'])
+]
+
+test_pipeline = val_pipeline
+
+data = dict(
+ samples_per_gpu=128,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=128),
+ test_dataloader=dict(samples_per_gpu=128),
+ train=dict(
+ type='Body3DH36MDataset',
+ ann_file=f'{data_root}/annotation_body3d/fps50/h36m_train.npz',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='Body3DH36MDataset',
+ ann_file=f'{data_root}/annotation_body3d/fps50/h36m_test.npz',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='Body3DH36MDataset',
+ ann_file=f'{data_root}/annotation_body3d/fps50/h36m_test.npz',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m_81frames_fullconv_supervised.py b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m_81frames_fullconv_supervised.py
new file mode 100644
index 0000000000000000000000000000000000000000..507a9f42c6cd6abdfa949b310a51ce10ad55c0e4
--- /dev/null
+++ b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m_81frames_fullconv_supervised.py
@@ -0,0 +1,144 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/h36m.py'
+]
+evaluation = dict(
+ interval=10, metric=['mpjpe', 'p-mpjpe'], key_indicator='MPJPE')
+
+# optimizer settings
+optimizer = dict(
+ type='Adam',
+ lr=1e-3,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='exp',
+ by_epoch=True,
+ gamma=0.975,
+)
+
+total_epochs = 160
+
+log_config = dict(
+ interval=20,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='PoseLifter',
+ pretrained=None,
+ backbone=dict(
+ type='TCN',
+ in_channels=2 * 17,
+ stem_channels=1024,
+ num_blocks=3,
+ kernel_sizes=(3, 3, 3, 3),
+ dropout=0.25,
+ use_stride_conv=True),
+ keypoint_head=dict(
+ type='TemporalRegressionHead',
+ in_channels=1024,
+ num_joints=17,
+ loss_keypoint=dict(type='MPJPELoss')),
+ train_cfg=dict(),
+ test_cfg=dict(restore_global_position=True))
+
+# data settings
+data_root = 'data/h36m'
+data_cfg = dict(
+ num_joints=17,
+ seq_len=81,
+ seq_frame_interval=1,
+ causal=False,
+ temporal_padding=True,
+ joint_2d_src='gt',
+ need_camera_param=True,
+ camera_param_file=f'{data_root}/annotation_body3d/cameras.pkl',
+)
+
+train_pipeline = [
+ dict(
+ type='GetRootCenteredPose',
+ item='target',
+ visible_item='target_visible',
+ root_index=0,
+ root_name='root_position',
+ remove_root=False),
+ dict(type='ImageCoordinateNormalization', item='input_2d'),
+ dict(
+ type='RelativeJointRandomFlip',
+ item=['input_2d', 'target'],
+ flip_cfg=[
+ dict(center_mode='static', center_x=0.),
+ dict(center_mode='root', center_index=0)
+ ],
+ visible_item=['input_2d_visible', 'target_visible'],
+ flip_prob=0.5),
+ dict(type='PoseSequenceToTensor', item='input_2d'),
+ dict(
+ type='Collect',
+ keys=[('input_2d', 'input'), 'target'],
+ meta_name='metas',
+ meta_keys=['target_image_path', 'flip_pairs', 'root_position'])
+]
+
+val_pipeline = [
+ dict(
+ type='GetRootCenteredPose',
+ item='target',
+ visible_item='target_visible',
+ root_index=0,
+ root_name='root_position',
+ remove_root=False),
+ dict(type='ImageCoordinateNormalization', item='input_2d'),
+ dict(type='PoseSequenceToTensor', item='input_2d'),
+ dict(
+ type='Collect',
+ keys=[('input_2d', 'input'), 'target'],
+ meta_name='metas',
+ meta_keys=['target_image_path', 'flip_pairs', 'root_position'])
+]
+
+test_pipeline = val_pipeline
+
+data = dict(
+ samples_per_gpu=128,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=128),
+ test_dataloader=dict(samples_per_gpu=128),
+ train=dict(
+ type='Body3DH36MDataset',
+ ann_file=f'{data_root}/annotation_body3d/fps50/h36m_train.npz',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='Body3DH36MDataset',
+ ann_file=f'{data_root}/annotation_body3d/fps50/h36m_test.npz',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='Body3DH36MDataset',
+ ann_file=f'{data_root}/annotation_body3d/fps50/h36m_test.npz',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/mpi_inf_3dhp/videopose3d_mpi-inf-3dhp.md b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/mpi_inf_3dhp/videopose3d_mpi-inf-3dhp.md
new file mode 100644
index 0000000000000000000000000000000000000000..d85edc57b44368c86783c35adf3d320674e68819
--- /dev/null
+++ b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/mpi_inf_3dhp/videopose3d_mpi-inf-3dhp.md
@@ -0,0 +1,41 @@
+
+
+Human3.6M (TPAMI'2014)
+ +```bibtex +@article{h36m_pami, + author = {Ionescu, Catalin and Papava, Dragos and Olaru, Vlad and Sminchisescu, Cristian}, + title = {Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments}, + journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence}, + publisher = {IEEE Computer Society}, + volume = {36}, + number = {7}, + pages = {1325-1339}, + month = {jul}, + year = {2014} +} +``` + +
+
+
+
+
+VideoPose3D (CVPR'2019)
+ +```bibtex +@inproceedings{pavllo20193d, + title={3d human pose estimation in video with temporal convolutions and semi-supervised training}, + author={Pavllo, Dario and Feichtenhofer, Christoph and Grangier, David and Auli, Michael}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + pages={7753--7762}, + year={2019} +} +``` + +
+
+
+Results on MPI-INF-3DHP dataset with ground truth 2D detections, supervised training
+
+| Arch | Receptive Field | MPJPE | P-MPJPE | 3DPCK | 3DAUC | ckpt | log |
+| :--- | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
+| [VideoPose3D](configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/mpi_inf_3dhp/videopose3d_mpi-inf-3dhp_1frame_fullconv_supervised_gt.py) | 1 | 58.3 | 40.6 | 94.1 | 63.1 | [ckpt](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_mpi-inf-3dhp_1frame_fullconv_supervised_gt-d6ed21ef_20210603.pth) | [log](https://download.openmmlab.com/mmpose/body3d/videopose/videopose_mpi-inf-3dhp_1frame_fullconv_supervised_gt_20210603.log.json) |
diff --git a/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/mpi_inf_3dhp/videopose3d_mpi-inf-3dhp.yml b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/mpi_inf_3dhp/videopose3d_mpi-inf-3dhp.yml
new file mode 100644
index 0000000000000000000000000000000000000000..70c073a8d9fb69765e32feae242d122b2bd2567a
--- /dev/null
+++ b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/mpi_inf_3dhp/videopose3d_mpi-inf-3dhp.yml
@@ -0,0 +1,24 @@
+Collections:
+- Name: VideoPose3D
+ Paper:
+ Title: 3d human pose estimation in video with temporal convolutions and semi-supervised
+ training
+ URL: http://openaccess.thecvf.com/content_CVPR_2019/html/Pavllo_3D_Human_Pose_Estimation_in_Video_With_Temporal_Convolutions_and_CVPR_2019_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/videopose3d.md
+Models:
+- Config: configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/mpi_inf_3dhp/videopose3d_mpi-inf-3dhp_1frame_fullconv_supervised_gt.py
+ In Collection: VideoPose3D
+ Metadata:
+ Architecture:
+ - VideoPose3D
+ Training Data: MPI-INF-3DHP
+ Name: video_pose_lift_videopose3d_mpi-inf-3dhp_1frame_fullconv_supervised_gt
+ Results:
+ - Dataset: MPI-INF-3DHP
+ Metrics:
+ 3DAUC: 63.1
+ 3DPCK: 94.1
+ MPJPE: 58.3
+ P-MPJPE: 40.6
+ Task: Body 3D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/body3d/videopose/videopose_mpi-inf-3dhp_1frame_fullconv_supervised_gt-d6ed21ef_20210603.pth
diff --git a/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/mpi_inf_3dhp/videopose3d_mpi-inf-3dhp_1frame_fullconv_supervised_gt.py b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/mpi_inf_3dhp/videopose3d_mpi-inf-3dhp_1frame_fullconv_supervised_gt.py
new file mode 100644
index 0000000000000000000000000000000000000000..dac308a60a11af88932c6c406ef465dcc9862396
--- /dev/null
+++ b/vendor/ViTPose/configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/mpi_inf_3dhp/videopose3d_mpi-inf-3dhp_1frame_fullconv_supervised_gt.py
@@ -0,0 +1,156 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/mpi_inf_3dhp.py'
+]
+evaluation = dict(
+ interval=10,
+ metric=['mpjpe', 'p-mpjpe', '3dpck', '3dauc'],
+ key_indicator='MPJPE')
+
+# optimizer settings
+optimizer = dict(
+ type='Adam',
+ lr=1e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='exp',
+ by_epoch=True,
+ gamma=0.98,
+)
+
+total_epochs = 160
+
+log_config = dict(
+ interval=20,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=17,
+ dataset_joints=17,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+# model settings
+model = dict(
+ type='PoseLifter',
+ pretrained=None,
+ backbone=dict(
+ type='TCN',
+ in_channels=2 * 17,
+ stem_channels=1024,
+ num_blocks=4,
+ kernel_sizes=(1, 1, 1, 1, 1),
+ dropout=0.25,
+ use_stride_conv=True),
+ keypoint_head=dict(
+ type='TemporalRegressionHead',
+ in_channels=1024,
+ num_joints=17,
+ loss_keypoint=dict(type='MPJPELoss')),
+ train_cfg=dict(),
+ test_cfg=dict(restore_global_position=True))
+
+# data settings
+data_root = 'data/mpi_inf_3dhp'
+train_data_cfg = dict(
+ num_joints=17,
+ seq_len=1,
+ seq_frame_interval=1,
+ causal=False,
+ temporal_padding=False,
+ joint_2d_src='gt',
+ need_camera_param=True,
+ camera_param_file=f'{data_root}/annotations/cameras_train.pkl',
+)
+test_data_cfg = dict(
+ num_joints=17,
+ seq_len=1,
+ seq_frame_interval=1,
+ causal=False,
+ temporal_padding=False,
+ joint_2d_src='gt',
+ need_camera_param=True,
+ camera_param_file=f'{data_root}/annotations/cameras_test.pkl',
+)
+
+train_pipeline = [
+ dict(
+ type='GetRootCenteredPose',
+ item='target',
+ visible_item='target_visible',
+ root_index=14,
+ root_name='root_position',
+ remove_root=False),
+ dict(type='ImageCoordinateNormalization', item='input_2d'),
+ dict(
+ type='RelativeJointRandomFlip',
+ item=['input_2d', 'target'],
+ flip_cfg=[
+ dict(center_mode='static', center_x=0.),
+ dict(center_mode='root', center_index=14)
+ ],
+ visible_item=['input_2d_visible', 'target_visible'],
+ flip_prob=0.5),
+ dict(type='PoseSequenceToTensor', item='input_2d'),
+ dict(
+ type='Collect',
+ keys=[('input_2d', 'input'), 'target'],
+ meta_name='metas',
+ meta_keys=['target_image_path', 'flip_pairs', 'root_position'])
+]
+
+val_pipeline = [
+ dict(
+ type='GetRootCenteredPose',
+ item='target',
+ visible_item='target_visible',
+ root_index=14,
+ root_name='root_position',
+ remove_root=False),
+ dict(type='ImageCoordinateNormalization', item='input_2d'),
+ dict(type='PoseSequenceToTensor', item='input_2d'),
+ dict(
+ type='Collect',
+ keys=[('input_2d', 'input'), 'target'],
+ meta_name='metas',
+ meta_keys=['target_image_path', 'flip_pairs', 'root_position'])
+]
+
+test_pipeline = val_pipeline
+
+data = dict(
+ samples_per_gpu=128,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=128),
+ test_dataloader=dict(samples_per_gpu=128),
+ train=dict(
+ type='Body3DMpiInf3dhpDataset',
+ ann_file=f'{data_root}/annotations/mpi_inf_3dhp_train.npz',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=train_data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='Body3DMpiInf3dhpDataset',
+ ann_file=f'{data_root}/annotations/mpi_inf_3dhp_test_valid.npz',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=test_data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='Body3DMpiInf3dhpDataset',
+ ann_file=f'{data_root}/annotations/mpi_inf_3dhp_test_valid.npz',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=test_data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/body/3d_mesh_sview_rgb_img/README.md b/vendor/ViTPose/configs/body/3d_mesh_sview_rgb_img/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..a0c7817f40f334ddbc79b3e3c2b5f27e9cfff076
--- /dev/null
+++ b/vendor/ViTPose/configs/body/3d_mesh_sview_rgb_img/README.md
@@ -0,0 +1,120 @@
+# Human Body 3D Mesh Recovery
+
+This task aims at recovering the full 3D mesh representation (parameterized by shape and 3D joint angles) of a
+human body from a single RGB image.
+
+## Data preparation
+
+The preparation for human mesh recovery mainly includes:
+
+- Datasets
+- Annotations
+- SMPL Model
+
+Please follow [DATA Preparation](/docs/en/tasks/3d_body_mesh.md) to prepare them.
+
+## Prepare Pretrained Models
+
+Please download the pretrained HMR model from
+[here](https://download.openmmlab.com/mmpose/mesh/hmr/hmr_mesh_224x224-c21e8229_20201015.pth),
+and make it looks like this:
+
+```text
+mmpose
+`-- models
+ `-- pytorch
+ `-- hmr
+ |-- hmr_mesh_224x224-c21e8229_20201015.pth
+```
+
+## Inference with pretrained models
+
+### Test a Dataset
+
+You can use the following commands to test the pretrained model on Human3.6M test set and
+evaluate the joint error.
+
+```shell
+# single-gpu testing
+python tools/test.py configs/mesh/hmr/hmr_resnet_50.py \
+models/pytorch/hmr/hmr_mesh_224x224-c21e8229_20201015.pth --eval=joint_error
+
+# multiple-gpu testing
+./tools/dist_test.sh configs/mesh/hmr/hmr_resnet_50.py \
+models/pytorch/hmr/hmr_mesh_224x224-c21e8229_20201015.pth 8 --eval=joint_error
+```
+
+## Train the model
+
+In order to train the model, please download the
+[zip file](https://drive.google.com/file/d/1JrwfHYIFdQPO7VeBEG9Kk3xsZMVJmhtv/view?usp=sharing)
+of the sampled train images of Human3.6M dataset.
+Extract the images and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── h36m_train
+ ├── S1
+ │ ├── S1_Directions_1.54138969
+ │ │ ├── S1_Directions_1.54138969_000001.jpg
+ │ │ ├── S1_Directions_1.54138969_000006.jpg
+ │ │ └── ...
+ │ ├── S1_Directions_1.55011271
+ │ └── ...
+ ├── S11
+ │ ├── S11_Directions_1.54138969
+ │ ├── S11_Directions_1.55011271
+ │ └── ...
+ ├── S5
+ │ ├── S5_Directions_1.54138969
+ │ ├── S5_Directions_1.55011271
+ │ └── S5_WalkTogether.60457274
+ ├── S6
+ │ ├── S6_Directions_1.54138969
+ │ ├── S6_Directions_1.55011271
+ │ └── S6_WalkTogether.60457274
+ ├── S7
+ │ ├── S7_Directions_1.54138969
+ │ ├── S7_Directions_1.55011271
+ │ └── S7_WalkTogether.60457274
+ ├── S8
+ │ ├── S8_Directions_1.54138969
+ │ ├── S8_Directions_1.55011271
+ │ └── S8_WalkTogether_2.60457274
+ └── S9
+ ├── S9_Directions_1.54138969
+ ├── S9_Directions_1.55011271
+ └── S9_WalkTogether.60457274
+
+```
+
+Please also download the preprocessed annotation file for Human3.6M train set from
+[here](https://drive.google.com/file/d/1NveJQGS4IYaASaJbLHT_zOGqm6Lo_gh5/view?usp=sharing)
+under `$MMPOSE/data/mesh_annotation_files`, and make it like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── mesh_annotation_files
+ ├── h36m_train.npz
+ └── ...
+```
+
+### Train with multiple GPUs
+
+Here is the code of using 8 GPUs to train HMR net:
+
+```shell
+./tools/dist_train.sh configs/mesh/hmr/hmr_resnet_50.py 8 --work-dir work_dirs/hmr --no-validate
+```
diff --git a/vendor/ViTPose/configs/body/3d_mesh_sview_rgb_img/hmr/README.md b/vendor/ViTPose/configs/body/3d_mesh_sview_rgb_img/hmr/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..b970e4970531b78773681c893c7950831824cd10
--- /dev/null
+++ b/vendor/ViTPose/configs/body/3d_mesh_sview_rgb_img/hmr/README.md
@@ -0,0 +1,24 @@
+# End-to-end Recovery of Human Shape and Pose
+
+## Introduction
+
+
+
+MPI-INF-3DHP (3DV'2017)
+ +```bibtex +@inproceedings{mono-3dhp2017, + author = {Mehta, Dushyant and Rhodin, Helge and Casas, Dan and Fua, Pascal and Sotnychenko, Oleksandr and Xu, Weipeng and Theobalt, Christian}, + title = {Monocular 3D Human Pose Estimation In The Wild Using Improved CNN Supervision}, + booktitle = {3D Vision (3DV), 2017 Fifth International Conference on}, + url = {http://gvv.mpi-inf.mpg.de/3dhp_dataset}, + year = {2017}, + organization={IEEE}, + doi={10.1109/3dv.2017.00064}, +} +``` + +
+
+
+HMR is an end-to-end framework for reconstructing a full 3D mesh of a human body from a single RGB image.
diff --git a/vendor/ViTPose/configs/body/3d_mesh_sview_rgb_img/hmr/mixed/res50_mixed_224x224.py b/vendor/ViTPose/configs/body/3d_mesh_sview_rgb_img/hmr/mixed/res50_mixed_224x224.py
new file mode 100644
index 0000000000000000000000000000000000000000..669cba07d996ddbdb3948861b2c379865429879e
--- /dev/null
+++ b/vendor/ViTPose/configs/body/3d_mesh_sview_rgb_img/hmr/mixed/res50_mixed_224x224.py
@@ -0,0 +1,149 @@
+_base_ = ['../../../../_base_/default_runtime.py']
+use_adversarial_train = True
+
+optimizer = dict(
+ generator=dict(type='Adam', lr=2.5e-4),
+ discriminator=dict(type='Adam', lr=1e-4))
+
+optimizer_config = None
+
+lr_config = dict(policy='Fixed', by_epoch=False)
+
+total_epochs = 100
+img_res = 224
+
+# model settings
+model = dict(
+ type='ParametricMesh',
+ pretrained=None,
+ backbone=dict(type='ResNet', depth=50),
+ mesh_head=dict(
+ type='HMRMeshHead',
+ in_channels=2048,
+ smpl_mean_params='models/smpl/smpl_mean_params.npz',
+ ),
+ disc=dict(),
+ smpl=dict(
+ type='SMPL',
+ smpl_path='models/smpl',
+ joints_regressor='models/smpl/joints_regressor_cmr.npy'),
+ train_cfg=dict(disc_step=1),
+ test_cfg=dict(),
+ loss_mesh=dict(
+ type='MeshLoss',
+ joints_2d_loss_weight=100,
+ joints_3d_loss_weight=1000,
+ vertex_loss_weight=20,
+ smpl_pose_loss_weight=30,
+ smpl_beta_loss_weight=0.2,
+ focal_length=5000,
+ img_res=img_res),
+ loss_gan=dict(
+ type='GANLoss',
+ gan_type='lsgan',
+ real_label_val=1.0,
+ fake_label_val=0.0,
+ loss_weight=1))
+
+data_cfg = dict(
+ image_size=[img_res, img_res],
+ iuv_size=[img_res // 4, img_res // 4],
+ num_joints=24,
+ use_IUV=False,
+ uv_type='BF')
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='MeshRandomChannelNoise', noise_factor=0.4),
+ dict(type='MeshRandomFlip', flip_prob=0.5),
+ dict(type='MeshGetRandomScaleRotation', rot_factor=30, scale_factor=0.25),
+ dict(type='MeshAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=[
+ 'img', 'joints_2d', 'joints_2d_visible', 'joints_3d',
+ 'joints_3d_visible', 'pose', 'beta', 'has_smpl'
+ ],
+ meta_keys=['image_file', 'center', 'scale', 'rotation']),
+]
+
+train_adv_pipeline = [dict(type='Collect', keys=['mosh_theta'], meta_keys=[])]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='MeshAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=[
+ 'img',
+ ],
+ meta_keys=['image_file', 'center', 'scale', 'rotation']),
+]
+
+test_pipeline = val_pipeline
+
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ train=dict(
+ type='MeshAdversarialDataset',
+ train_dataset=dict(
+ type='MeshMixDataset',
+ configs=[
+ dict(
+ ann_file='data/mesh_annotation_files/h36m_train.npz',
+ img_prefix='data/h36m_train',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline),
+ dict(
+ ann_file='data/mesh_annotation_files/'
+ 'mpi_inf_3dhp_train.npz',
+ img_prefix='data/mpi_inf_3dhp',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline),
+ dict(
+ ann_file='data/mesh_annotation_files/'
+ 'lsp_dataset_original_train.npz',
+ img_prefix='data/lsp_dataset_original',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline),
+ dict(
+ ann_file='data/mesh_annotation_files/hr-lspet_train.npz',
+ img_prefix='data/hr-lspet',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline),
+ dict(
+ ann_file='data/mesh_annotation_files/mpii_train.npz',
+ img_prefix='data/mpii',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline),
+ dict(
+ ann_file='data/mesh_annotation_files/coco_2014_train.npz',
+ img_prefix='data/coco',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline)
+ ],
+ partition=[0.35, 0.15, 0.1, 0.10, 0.10, 0.2]),
+ adversarial_dataset=dict(
+ type='MoshDataset',
+ ann_file='data/mesh_annotation_files/CMU_mosh.npz',
+ pipeline=train_adv_pipeline),
+ ),
+ test=dict(
+ type='MeshH36MDataset',
+ ann_file='data/mesh_annotation_files/h36m_valid_protocol2.npz',
+ img_prefix='data/Human3.6M',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ ),
+)
diff --git a/vendor/ViTPose/configs/body/3d_mesh_sview_rgb_img/hmr/mixed/resnet_mixed.md b/vendor/ViTPose/configs/body/3d_mesh_sview_rgb_img/hmr/mixed/resnet_mixed.md
new file mode 100644
index 0000000000000000000000000000000000000000..e76d54e6013315b4091880eee279537004407df1
--- /dev/null
+++ b/vendor/ViTPose/configs/body/3d_mesh_sview_rgb_img/hmr/mixed/resnet_mixed.md
@@ -0,0 +1,62 @@
+
+
+HMR (CVPR'2018)
+ +```bibtex +@inProceedings{kanazawaHMR18, + title={End-to-end Recovery of Human Shape and Pose}, + author = {Angjoo Kanazawa + and Michael J. Black + and David W. Jacobs + and Jitendra Malik}, + booktitle={Computer Vision and Pattern Recognition (CVPR)}, + year={2018} +} +``` + +
+
+
+
+
+HMR (CVPR'2018)
+ +```bibtex +@inProceedings{kanazawaHMR18, + title={End-to-end Recovery of Human Shape and Pose}, + author = {Angjoo Kanazawa + and Michael J. Black + and David W. Jacobs + and Jitendra Malik}, + booktitle={Computer Vision and Pattern Recognition (CVPR)}, + year={2018} +} +``` + +
+
+
+
+
+ResNet (CVPR'2016)
+ +```bibtex +@inproceedings{he2016deep, + title={Deep residual learning for image recognition}, + author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={770--778}, + year={2016} +} +``` + +
+
+
+Results on Human3.6M with ground-truth bounding box having MPJPE-PA of 52.60 mm on Protocol2
+
+| Arch | Input Size | MPJPE (P1)| MPJPE-PA (P1) | MPJPE (P2) | MPJPE-PA (P2) | ckpt | log |
+| :-------------- | :-----------: | :------: | :------: | :------: | :------: | :------: |:------: |
+| [hmr_resnet_50](/configs/body/3d_mesh_sview_rgb_img/hmr/mixed/res50_mixed_224x224.py) | 224x224 | 80.75 | 55.08 | 80.35 | 52.60 | [ckpt](https://download.openmmlab.com/mmpose/mesh/hmr/hmr_mesh_224x224-c21e8229_20201015.pth) | [log](https://download.openmmlab.com/mmpose/mesh/hmr/hmr_mesh_224x224_20201015.log.json) |
diff --git a/vendor/ViTPose/configs/body/3d_mesh_sview_rgb_img/hmr/mixed/resnet_mixed.yml b/vendor/ViTPose/configs/body/3d_mesh_sview_rgb_img/hmr/mixed/resnet_mixed.yml
new file mode 100644
index 0000000000000000000000000000000000000000..b5307dd052795c58740d1845f913852fa0d4b164
--- /dev/null
+++ b/vendor/ViTPose/configs/body/3d_mesh_sview_rgb_img/hmr/mixed/resnet_mixed.yml
@@ -0,0 +1,24 @@
+Collections:
+- Name: HMR
+ Paper:
+ Title: End-to-end Recovery of Human Shape and Pose
+ URL: http://openaccess.thecvf.com/content_cvpr_2018/html/Kanazawa_End-to-End_Recovery_of_CVPR_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/hmr.md
+Models:
+- Config: configs/body/3d_mesh_sview_rgb_img/hmr/mixed/res50_mixed_224x224.py
+ In Collection: HMR
+ Metadata:
+ Architecture:
+ - HMR
+ - ResNet
+ Training Data: Human3.6M
+ Name: hmr_res50_mixed_224x224
+ Results:
+ - Dataset: Human3.6M
+ Metrics:
+ MPJPE (P1): 80.75
+ MPJPE (P2): 80.35
+ MPJPE-PA (P1): 55.08
+ MPJPE-PA (P2): 52.6
+ Task: Body 3D Mesh
+ Weights: https://download.openmmlab.com/mmpose/mesh/hmr/hmr_mesh_224x224-c21e8229_20201015.pth
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/README.md b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..65a4c3dec855ddea53d6d89f9ee3d6e76263a5b1
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/README.md
@@ -0,0 +1,16 @@
+# 2D Face Landmark Detection
+
+2D face landmark detection (also referred to as face alignment) is defined as the task of detecting the face keypoints from an input image.
+
+Normally, the input images are cropped face images, where the face locates at the center;
+or the rough location (or the bounding box) of the hand is provided.
+
+## Data preparation
+
+Please follow [DATA Preparation](/docs/en/tasks/2d_face_keypoint.md) to prepare data.
+
+## Demo
+
+Please follow [Demo](/demo/docs/2d_face_demo.md) to run demos.
+
+Human3.6M (TPAMI'2014)
+ +```bibtex +@article{h36m_pami, + author = {Ionescu, Catalin and Papava, Dragos and Olaru, Vlad and Sminchisescu, Cristian}, + title = {Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments}, + journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence}, + publisher = {IEEE Computer Society}, + volume = {36}, + number = {7}, + pages = {1325-1339}, + month = {jul}, + year = {2014} +} +``` + +
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/deeppose/README.md b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/deeppose/README.md new file mode 100644 index 0000000000000000000000000000000000000000..155c92ac183305d8d159a001f215d44d4566b866 --- /dev/null +++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/deeppose/README.md @@ -0,0 +1,24 @@ +# DeepPose: Human pose estimation via deep neural networks + +## Introduction + + + +
+
+
+DeepPose first proposes using deep neural networks (DNNs) to tackle the problem of pose estimation.
+It follows the top-down paradigm, that first detects the bounding boxes and then estimates poses.
+It learns to directly regress the face keypoint coordinates.
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/deeppose/wflw/res50_wflw_256x256.py b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/deeppose/wflw/res50_wflw_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..4c32cf765d386f02e73b1e5276acfd3de1ebd9db
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/deeppose/wflw/res50_wflw_256x256.py
@@ -0,0 +1,122 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/wflw.py'
+]
+evaluation = dict(interval=1, metric=['NME'], save_best='NME')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=5,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=98,
+ dataset_joints=98,
+ dataset_channel=[
+ list(range(98)),
+ ],
+ inference_channel=list(range(98)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50, num_stages=4, out_indices=(3, )),
+ neck=dict(type='GlobalAveragePooling'),
+ keypoint_head=dict(
+ type='DeepposeRegressionHead',
+ in_channels=2048,
+ num_joints=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='SmoothL1Loss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(flip_test=True))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTargetRegression'),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/wflw'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='FaceWFLWDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_wflw_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='FaceWFLWDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_wflw_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='FaceWFLWDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_wflw_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/deeppose/wflw/res50_wflw_256x256_softwingloss.py b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/deeppose/wflw/res50_wflw_256x256_softwingloss.py
new file mode 100644
index 0000000000000000000000000000000000000000..b3ebd31d1c5ceb0706597e739c6e7560832b1791
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/deeppose/wflw/res50_wflw_256x256_softwingloss.py
@@ -0,0 +1,122 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/wflw.py'
+]
+evaluation = dict(interval=1, metric=['NME'], save_best='NME')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=5,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=98,
+ dataset_joints=98,
+ dataset_channel=[
+ list(range(98)),
+ ],
+ inference_channel=list(range(98)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50, num_stages=4, out_indices=(3, )),
+ neck=dict(type='GlobalAveragePooling'),
+ keypoint_head=dict(
+ type='DeepposeRegressionHead',
+ in_channels=2048,
+ num_joints=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='SoftWingLoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(flip_test=True))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTargetRegression'),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/wflw'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='FaceWFLWDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_wflw_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='FaceWFLWDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_wflw_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='FaceWFLWDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_wflw_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/deeppose/wflw/res50_wflw_256x256_wingloss.py b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/deeppose/wflw/res50_wflw_256x256_wingloss.py
new file mode 100644
index 0000000000000000000000000000000000000000..5578c81d697713c16eb227c6e5d956ab544c5b79
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/deeppose/wflw/res50_wflw_256x256_wingloss.py
@@ -0,0 +1,122 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/wflw.py'
+]
+evaluation = dict(interval=1, metric=['NME'], save_best='NME')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=5,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=98,
+ dataset_joints=98,
+ dataset_channel=[
+ list(range(98)),
+ ],
+ inference_channel=list(range(98)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50, num_stages=4, out_indices=(3, )),
+ neck=dict(type='GlobalAveragePooling'),
+ keypoint_head=dict(
+ type='DeepposeRegressionHead',
+ in_channels=2048,
+ num_joints=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='WingLoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(flip_test=True))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTargetRegression'),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/wflw'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='FaceWFLWDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_wflw_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='FaceWFLWDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_wflw_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='FaceWFLWDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_wflw_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/deeppose/wflw/resnet_softwingloss_wflw.md b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/deeppose/wflw/resnet_softwingloss_wflw.md
new file mode 100644
index 0000000000000000000000000000000000000000..e7bad5704326465af9b1d16ff94bc33d16f9e070
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/deeppose/wflw/resnet_softwingloss_wflw.md
@@ -0,0 +1,75 @@
+
+
+DeepPose (CVPR'2014)
+ +```bibtex +@inproceedings{toshev2014deeppose, + title={Deeppose: Human pose estimation via deep neural networks}, + author={Toshev, Alexander and Szegedy, Christian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={1653--1660}, + year={2014} +} +``` + +
+
+
+
+
+DeepPose (CVPR'2014)
+ +```bibtex +@inproceedings{toshev2014deeppose, + title={Deeppose: Human pose estimation via deep neural networks}, + author={Toshev, Alexander and Szegedy, Christian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={1653--1660}, + year={2014} +} +``` + +
+
+
+
+
+ResNet (CVPR'2016)
+ +```bibtex +@inproceedings{he2016deep, + title={Deep residual learning for image recognition}, + author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={770--778}, + year={2016} +} +``` + +
+
+
+
+
+SoftWingloss (TIP'2021)
+ +```bibtex +@article{lin2021structure, + title={Structure-Coherent Deep Feature Learning for Robust Face Alignment}, + author={Lin, Chunze and Zhu, Beier and Wang, Quan and Liao, Renjie and Qian, Chen and Lu, Jiwen and Zhou, Jie}, + journal={IEEE Transactions on Image Processing}, + year={2021}, + publisher={IEEE} +} +``` + +
+
+
+Results on WFLW dataset
+
+The model is trained on WFLW train.
+
+| Arch | Input Size | NME*test* | NME*pose* | NME*illumination* | NME*occlusion* | NME*blur* | NME*makeup* | NME*expression* | ckpt | log |
+| :-----| :--------: | :------------------: | :------------------: |:---------------------------: |:------------------------: | :------------------: | :--------------: |:-------------------------: |:---: | :---: |
+| [deeppose_res50_softwingloss](/configs/face/2d_kpt_sview_rgb_img/deeppose/wflw/res50_wflw_256x256_softwingloss.py) | 256x256 | 4.41 | 7.77 | 4.37 | 5.27 | 5.01 | 4.36 | 4.70 | [ckpt](https://download.openmmlab.com/mmpose/face/deeppose/deeppose_res50_wflw_256x256_softwingloss-4d34f22a_20211212.pth) | [log](https://download.openmmlab.com/mmpose/face/deeppose/deeppose_res50_wflw_256x256_softwingloss_20211212.log.json) |
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/deeppose/wflw/resnet_softwingloss_wflw.yml b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/deeppose/wflw/resnet_softwingloss_wflw.yml
new file mode 100644
index 0000000000000000000000000000000000000000..ffd81c0534cd9c48548461145dbdf5640a492b17
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/deeppose/wflw/resnet_softwingloss_wflw.yml
@@ -0,0 +1,28 @@
+Collections:
+- Name: SoftWingloss
+ Paper:
+ Title: Structure-Coherent Deep Feature Learning for Robust Face Alignment
+ URL: https://ieeexplore.ieee.org/document/9442331/
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/techniques/softwingloss.md
+Models:
+- Config: configs/face/2d_kpt_sview_rgb_img/deeppose/wflw/res50_wflw_256x256_softwingloss.py
+ In Collection: SoftWingloss
+ Metadata:
+ Architecture:
+ - DeepPose
+ - ResNet
+ - SoftWingloss
+ Training Data: WFLW
+ Name: deeppose_res50_wflw_256x256_softwingloss
+ Results:
+ - Dataset: WFLW
+ Metrics:
+ NME blur: 5.01
+ NME expression: 4.7
+ NME illumination: 4.37
+ NME makeup: 4.36
+ NME occlusion: 5.27
+ NME pose: 7.77
+ NME test: 4.41
+ Task: Face 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/face/deeppose/deeppose_res50_wflw_256x256_softwingloss-4d34f22a_20211212.pth
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/deeppose/wflw/resnet_wflw.md b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/deeppose/wflw/resnet_wflw.md
new file mode 100644
index 0000000000000000000000000000000000000000..f27f74a4548dfc4f8fb033eb1c9c29d04ffd74a1
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/deeppose/wflw/resnet_wflw.md
@@ -0,0 +1,58 @@
+
+
+WFLW (CVPR'2018)
+ +```bibtex +@inproceedings{wu2018look, + title={Look at boundary: A boundary-aware face alignment algorithm}, + author={Wu, Wayne and Qian, Chen and Yang, Shuo and Wang, Quan and Cai, Yici and Zhou, Qiang}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={2129--2138}, + year={2018} +} +``` + +
+
+
+
+
+DeepPose (CVPR'2014)
+ +```bibtex +@inproceedings{toshev2014deeppose, + title={Deeppose: Human pose estimation via deep neural networks}, + author={Toshev, Alexander and Szegedy, Christian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={1653--1660}, + year={2014} +} +``` + +
+
+
+
+
+ResNet (CVPR'2016)
+ +```bibtex +@inproceedings{he2016deep, + title={Deep residual learning for image recognition}, + author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={770--778}, + year={2016} +} +``` + +
+
+
+Results on WFLW dataset
+
+The model is trained on WFLW train.
+
+| Arch | Input Size | NME*test* | NME*pose* | NME*illumination* | NME*occlusion* | NME*blur* | NME*makeup* | NME*expression* | ckpt | log |
+| :-----| :--------: | :------------------: | :------------------: |:---------------------------: |:------------------------: | :------------------: | :--------------: |:-------------------------: |:---: | :---: |
+| [deeppose_res50](/configs/face/2d_kpt_sview_rgb_img/deeppose/wflw/res50_wflw_256x256.py) | 256x256 | 4.85 | 8.50 | 4.81 | 5.69 | 5.45 | 4.82 | 5.20 | [ckpt](https://download.openmmlab.com/mmpose/face/deeppose/deeppose_res50_wflw_256x256-92d0ba7f_20210303.pth) | [log](https://download.openmmlab.com/mmpose/face/deeppose/deeppose_res50_wflw_256x256_20210303.log.json) |
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/deeppose/wflw/resnet_wflw.yml b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/deeppose/wflw/resnet_wflw.yml
new file mode 100644
index 0000000000000000000000000000000000000000..03df2a716ef81252348f1c6713ffe7166892f3aa
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/deeppose/wflw/resnet_wflw.yml
@@ -0,0 +1,27 @@
+Collections:
+- Name: ResNet
+ Paper:
+ Title: Deep residual learning for image recognition
+ URL: http://openaccess.thecvf.com/content_cvpr_2016/html/He_Deep_Residual_Learning_CVPR_2016_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/resnet.md
+Models:
+- Config: configs/face/2d_kpt_sview_rgb_img/deeppose/wflw/res50_wflw_256x256.py
+ In Collection: ResNet
+ Metadata:
+ Architecture:
+ - DeepPose
+ - ResNet
+ Training Data: WFLW
+ Name: deeppose_res50_wflw_256x256
+ Results:
+ - Dataset: WFLW
+ Metrics:
+ NME blur: 5.45
+ NME expression: 5.2
+ NME illumination: 4.81
+ NME makeup: 4.82
+ NME occlusion: 5.69
+ NME pose: 8.5
+ NME test: 4.85
+ Task: Face 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/face/deeppose/deeppose_res50_wflw_256x256-92d0ba7f_20210303.pth
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/deeppose/wflw/resnet_wingloss_wflw.md b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/deeppose/wflw/resnet_wingloss_wflw.md
new file mode 100644
index 0000000000000000000000000000000000000000..eb5fd1929e6ecc3fecf205b60d472bb04ada2cb8
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/deeppose/wflw/resnet_wingloss_wflw.md
@@ -0,0 +1,76 @@
+
+
+WFLW (CVPR'2018)
+ +```bibtex +@inproceedings{wu2018look, + title={Look at boundary: A boundary-aware face alignment algorithm}, + author={Wu, Wayne and Qian, Chen and Yang, Shuo and Wang, Quan and Cai, Yici and Zhou, Qiang}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={2129--2138}, + year={2018} +} +``` + +
+
+
+
+
+DeepPose (CVPR'2014)
+ +```bibtex +@inproceedings{toshev2014deeppose, + title={Deeppose: Human pose estimation via deep neural networks}, + author={Toshev, Alexander and Szegedy, Christian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={1653--1660}, + year={2014} +} +``` + +
+
+
+
+
+ResNet (CVPR'2016)
+ +```bibtex +@inproceedings{he2016deep, + title={Deep residual learning for image recognition}, + author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={770--778}, + year={2016} +} +``` + +
+
+
+
+
+Wingloss (CVPR'2018)
+ +```bibtex +@inproceedings{feng2018wing, + title={Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks}, + author={Feng, Zhen-Hua and Kittler, Josef and Awais, Muhammad and Huber, Patrik and Wu, Xiao-Jun}, + booktitle={Computer Vision and Pattern Recognition (CVPR), 2018 IEEE Conference on}, + year={2018}, + pages ={2235-2245}, + organization={IEEE} +} +``` + +
+
+
+Results on WFLW dataset
+
+The model is trained on WFLW train.
+
+| Arch | Input Size | NME*test* | NME*pose* | NME*illumination* | NME*occlusion* | NME*blur* | NME*makeup* | NME*expression* | ckpt | log |
+| :-----| :--------: | :------------------: | :------------------: |:---------------------------: |:------------------------: | :------------------: | :--------------: |:-------------------------: |:---: | :---: |
+| [deeppose_res50_wingloss](/configs/face/2d_kpt_sview_rgb_img/deeppose/wflw/res50_wflw_256x256_wingloss.py) | 256x256 | 4.64 | 8.25 | 4.59 | 5.56 | 5.26 | 4.59 | 5.07 | [ckpt](https://download.openmmlab.com/mmpose/face/deeppose/deeppose_res50_wflw_256x256_wingloss-f82a5e53_20210303.pth) | [log](https://download.openmmlab.com/mmpose/face/deeppose/deeppose_res50_wflw_256x256_wingloss_20210303.log.json) |
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/deeppose/wflw/resnet_wingloss_wflw.yml b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/deeppose/wflw/resnet_wingloss_wflw.yml
new file mode 100644
index 0000000000000000000000000000000000000000..494258b4ec06a8ef81b097d173911f6c58941cb2
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/deeppose/wflw/resnet_wingloss_wflw.yml
@@ -0,0 +1,29 @@
+Collections:
+- Name: Wingloss
+ Paper:
+ Title: Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural
+ Networks
+ URL: http://openaccess.thecvf.com/content_cvpr_2018/html/Feng_Wing_Loss_for_CVPR_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/techniques/wingloss.md
+Models:
+- Config: configs/face/2d_kpt_sview_rgb_img/deeppose/wflw/res50_wflw_256x256_wingloss.py
+ In Collection: Wingloss
+ Metadata:
+ Architecture:
+ - DeepPose
+ - ResNet
+ - Wingloss
+ Training Data: WFLW
+ Name: deeppose_res50_wflw_256x256_wingloss
+ Results:
+ - Dataset: WFLW
+ Metrics:
+ NME blur: 5.26
+ NME expression: 5.07
+ NME illumination: 4.59
+ NME makeup: 4.59
+ NME occlusion: 5.56
+ NME pose: 8.25
+ NME test: 4.64
+ Task: Face 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/face/deeppose/deeppose_res50_wflw_256x256_wingloss-f82a5e53_20210303.pth
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/300w/hrnetv2_300w.md b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/300w/hrnetv2_300w.md
new file mode 100644
index 0000000000000000000000000000000000000000..aae3b73ffe9a99b76fb815fac3029153b85594c6
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/300w/hrnetv2_300w.md
@@ -0,0 +1,44 @@
+
+
+WFLW (CVPR'2018)
+ +```bibtex +@inproceedings{wu2018look, + title={Look at boundary: A boundary-aware face alignment algorithm}, + author={Wu, Wayne and Qian, Chen and Yang, Shuo and Wang, Quan and Cai, Yici and Zhou, Qiang}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={2129--2138}, + year={2018} +} +``` + +
+
+
+
+
+HRNetv2 (TPAMI'2019)
+ +```bibtex +@article{WangSCJDZLMTWLX19, + title={Deep High-Resolution Representation Learning for Visual Recognition}, + author={Jingdong Wang and Ke Sun and Tianheng Cheng and + Borui Jiang and Chaorui Deng and Yang Zhao and Dong Liu and Yadong Mu and + Mingkui Tan and Xinggang Wang and Wenyu Liu and Bin Xiao}, + journal={TPAMI}, + year={2019} +} +``` + +
+
+
+Results on 300W dataset
+
+The model is trained on 300W train.
+
+| Arch | Input Size | NME*common* | NME*challenge* | NME*full* | NME*test* | ckpt | log |
+| :-----| :--------: | :------------------: | :------------------: | :--------------: |:-------------------------: |:---: | :---: |
+| [pose_hrnetv2_w18](/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/300w/hrnetv2_w18_300w_256x256.py) | 256x256 | 2.86 | 5.45 | 3.37 | 3.97 | [ckpt](https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_300w_256x256-eea53406_20211019.pth) | [log](https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_300w_256x256_20211019.log.json) |
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/300w/hrnetv2_300w.yml b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/300w/hrnetv2_300w.yml
new file mode 100644
index 0000000000000000000000000000000000000000..3d03f9e716ff41ebf9faada16bf1864809e5ad7f
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/300w/hrnetv2_300w.yml
@@ -0,0 +1,23 @@
+Collections:
+- Name: HRNetv2
+ Paper:
+ Title: Deep High-Resolution Representation Learning for Visual Recognition
+ URL: https://ieeexplore.ieee.org/abstract/document/9052469/
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/hrnetv2.md
+Models:
+- Config: configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/300w/hrnetv2_w18_300w_256x256.py
+ In Collection: HRNetv2
+ Metadata:
+ Architecture:
+ - HRNetv2
+ Training Data: 300W
+ Name: topdown_heatmap_hrnetv2_w18_300w_256x256
+ Results:
+ - Dataset: 300W
+ Metrics:
+ NME challenge: 5.45
+ NME common: 2.86
+ NME full: 3.37
+ NME test: 3.97
+ Task: Face 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_300w_256x256-eea53406_20211019.pth
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/300w/hrnetv2_w18_300w_256x256.py b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/300w/hrnetv2_w18_300w_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..88c9bdf91a97676814e01b6902ab0492b2148c49
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/300w/hrnetv2_w18_300w_256x256.py
@@ -0,0 +1,160 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/300w.py'
+]
+checkpoint_config = dict(interval=1)
+evaluation = dict(interval=1, metric=['NME'], save_best='NME')
+
+optimizer = dict(
+ type='Adam',
+ lr=2e-3,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[40, 55])
+total_epochs = 60
+log_config = dict(
+ interval=5,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=68,
+ dataset_joints=68,
+ dataset_channel=[
+ list(range(68)),
+ ],
+ inference_channel=list(range(68)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='open-mmlab://msra/hrnetv2_w18',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(18, 36)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(18, 36, 72)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(18, 36, 72, 144),
+ multiscale_output=True),
+ upsample=dict(mode='bilinear', align_corners=False))),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=[18, 36, 72, 144],
+ in_index=(0, 1, 2, 3),
+ input_transform='resize_concat',
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(
+ final_conv_kernel=1, num_conv_layers=1, num_conv_kernels=(1, )),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=1.5),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/300w'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='Face300WDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_300w_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='Face300WDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_300w_valid.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='Face300WDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_300w_valid.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/300w/hrnetv2_w18_300w_256x256_dark.py b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/300w/hrnetv2_w18_300w_256x256_dark.py
new file mode 100644
index 0000000000000000000000000000000000000000..6275f6fa41367602f2633fd0e9dd91587c6129ba
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/300w/hrnetv2_w18_300w_256x256_dark.py
@@ -0,0 +1,160 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/300w.py'
+]
+checkpoint_config = dict(interval=1)
+evaluation = dict(interval=1, metric=['NME'], save_best='NME')
+
+optimizer = dict(
+ type='Adam',
+ lr=2e-3,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[40, 55])
+total_epochs = 60
+log_config = dict(
+ interval=5,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=68,
+ dataset_joints=68,
+ dataset_channel=[
+ list(range(68)),
+ ],
+ inference_channel=list(range(68)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='open-mmlab://msra/hrnetv2_w18',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(18, 36)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(18, 36, 72)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(18, 36, 72, 144),
+ multiscale_output=True),
+ upsample=dict(mode='bilinear', align_corners=False))),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=[18, 36, 72, 144],
+ in_index=(0, 1, 2, 3),
+ input_transform='resize_concat',
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(
+ final_conv_kernel=1, num_conv_layers=1, num_conv_kernels=(1, )),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='unbiased',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2, unbiased_encoding=True),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/300w'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='Face300WDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_300w_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='Face300WDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_300w_valid.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='Face300WDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_300w_valid.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/300w/res50_300w_256x256.py b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/300w/res50_300w_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..9194cfb2f8305fbd08dd946406551c8a0a82eac1
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/300w/res50_300w_256x256.py
@@ -0,0 +1,126 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/300w.py'
+]
+checkpoint_config = dict(interval=1)
+evaluation = dict(interval=1, metric=['NME'], save_best='NME')
+
+optimizer = dict(
+ type='Adam',
+ lr=2e-3,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[40, 55])
+total_epochs = 60
+log_config = dict(
+ interval=5,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=68,
+ dataset_joints=68,
+ dataset_channel=[
+ list(range(68)),
+ ],
+ inference_channel=list(range(68)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/300w'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='Face300WDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_300w_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='Face300WDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_300w_valid.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='Face300WDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_300w_valid.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/README.md b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..4ed6f5b02c8502ef0f23f699ec81554fc88ff36f
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/README.md
@@ -0,0 +1,10 @@
+# Top-down heatmap-based face keypoint estimation
+
+Top-down methods divide the task into two stages: face detection and face keypoint estimation.
+
+They perform face detection first, followed by face keypoint estimation given face bounding boxes.
+Instead of estimating keypoint coordinates directly, the pose estimator will produce heatmaps which represent the
+likelihood of being a keypoint.
+
+Various neural network models have been proposed for better performance.
+The popular ones include HRNetv2.
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/aflw/hrnetv2_aflw.md b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/aflw/hrnetv2_aflw.md
new file mode 100644
index 0000000000000000000000000000000000000000..52907485c31fead106dcc94908bfaee10e3fa1e0
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/aflw/hrnetv2_aflw.md
@@ -0,0 +1,43 @@
+
+
+300W (IMAVIS'2016)
+ +```bibtex +@article{sagonas2016300, + title={300 faces in-the-wild challenge: Database and results}, + author={Sagonas, Christos and Antonakos, Epameinondas and Tzimiropoulos, Georgios and Zafeiriou, Stefanos and Pantic, Maja}, + journal={Image and vision computing}, + volume={47}, + pages={3--18}, + year={2016}, + publisher={Elsevier} +} +``` + +
+
+
+
+
+HRNetv2 (TPAMI'2019)
+ +```bibtex +@article{WangSCJDZLMTWLX19, + title={Deep High-Resolution Representation Learning for Visual Recognition}, + author={Jingdong Wang and Ke Sun and Tianheng Cheng and + Borui Jiang and Chaorui Deng and Yang Zhao and Dong Liu and Yadong Mu and + Mingkui Tan and Xinggang Wang and Wenyu Liu and Bin Xiao}, + journal={TPAMI}, + year={2019} +} +``` + +
+
+
+Results on AFLW dataset
+
+The model is trained on AFLW train and evaluated on AFLW full and frontal.
+
+| Arch | Input Size | NME*full* | NME*frontal* | ckpt | log |
+| :-------------- | :-----------: | :------: | :------: |:------: |:------: |
+| [pose_hrnetv2_w18](/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/aflw/hrnetv2_w18_aflw_256x256.py) | 256x256 | 1.41 | 1.27 | [ckpt](https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_aflw_256x256-f2bbc62b_20210125.pth) | [log](https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_aflw_256x256_20210125.log.json) |
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/aflw/hrnetv2_aflw.yml b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/aflw/hrnetv2_aflw.yml
new file mode 100644
index 0000000000000000000000000000000000000000..1ee61e35afef3372541a0603f687e7af57b59c2b
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/aflw/hrnetv2_aflw.yml
@@ -0,0 +1,21 @@
+Collections:
+- Name: HRNetv2
+ Paper:
+ Title: Deep High-Resolution Representation Learning for Visual Recognition
+ URL: https://ieeexplore.ieee.org/abstract/document/9052469/
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/hrnetv2.md
+Models:
+- Config: configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/aflw/hrnetv2_w18_aflw_256x256.py
+ In Collection: HRNetv2
+ Metadata:
+ Architecture:
+ - HRNetv2
+ Training Data: AFLW
+ Name: topdown_heatmap_hrnetv2_w18_aflw_256x256
+ Results:
+ - Dataset: AFLW
+ Metrics:
+ NME frontal: 1.27
+ NME full: 1.41
+ Task: Face 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_aflw_256x256-f2bbc62b_20210125.pth
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/aflw/hrnetv2_dark_aflw.md b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/aflw/hrnetv2_dark_aflw.md
new file mode 100644
index 0000000000000000000000000000000000000000..19161ec6b308ca6af9a166536c209431b749438f
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/aflw/hrnetv2_dark_aflw.md
@@ -0,0 +1,60 @@
+
+
+AFLW (ICCVW'2011)
+ +```bibtex +@inproceedings{koestinger2011annotated, + title={Annotated facial landmarks in the wild: A large-scale, real-world database for facial landmark localization}, + author={Koestinger, Martin and Wohlhart, Paul and Roth, Peter M and Bischof, Horst}, + booktitle={2011 IEEE international conference on computer vision workshops (ICCV workshops)}, + pages={2144--2151}, + year={2011}, + organization={IEEE} +} +``` + +
+
+
+
+
+HRNetv2 (TPAMI'2019)
+ +```bibtex +@article{WangSCJDZLMTWLX19, + title={Deep High-Resolution Representation Learning for Visual Recognition}, + author={Jingdong Wang and Ke Sun and Tianheng Cheng and + Borui Jiang and Chaorui Deng and Yang Zhao and Dong Liu and Yadong Mu and + Mingkui Tan and Xinggang Wang and Wenyu Liu and Bin Xiao}, + journal={TPAMI}, + year={2019} +} +``` + +
+
+
+
+
+DarkPose (CVPR'2020)
+ +```bibtex +@inproceedings{zhang2020distribution, + title={Distribution-aware coordinate representation for human pose estimation}, + author={Zhang, Feng and Zhu, Xiatian and Dai, Hanbin and Ye, Mao and Zhu, Ce}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + pages={7093--7102}, + year={2020} +} +``` + +
+
+
+Results on AFLW dataset
+
+The model is trained on AFLW train and evaluated on AFLW full and frontal.
+
+| Arch | Input Size | NME*full* | NME*frontal* | ckpt | log |
+| :-------------- | :-----------: | :------: | :------: |:------: |:------: |
+| [pose_hrnetv2_w18_dark](/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/aflw/hrnetv2_w18_aflw_256x256_dark.py) | 256x256 | 1.34 | 1.20 | [ckpt](https://download.openmmlab.com/mmpose/face/darkpose/hrnetv2_w18_aflw_256x256_dark-219606c0_20210125.pth) | [log](https://download.openmmlab.com/mmpose/face/darkpose/hrnetv2_w18_aflw_256x256_dark_20210125.log.json) |
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/aflw/hrnetv2_dark_aflw.yml b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/aflw/hrnetv2_dark_aflw.yml
new file mode 100644
index 0000000000000000000000000000000000000000..ab60120930746f6ab4e6bbee6203c08dec14b482
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/aflw/hrnetv2_dark_aflw.yml
@@ -0,0 +1,22 @@
+Collections:
+- Name: DarkPose
+ Paper:
+ Title: Distribution-aware coordinate representation for human pose estimation
+ URL: http://openaccess.thecvf.com/content_CVPR_2020/html/Zhang_Distribution-Aware_Coordinate_Representation_for_Human_Pose_Estimation_CVPR_2020_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/techniques/dark.md
+Models:
+- Config: configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/aflw/hrnetv2_w18_aflw_256x256_dark.py
+ In Collection: DarkPose
+ Metadata:
+ Architecture:
+ - HRNetv2
+ - DarkPose
+ Training Data: AFLW
+ Name: topdown_heatmap_hrnetv2_w18_aflw_256x256_dark
+ Results:
+ - Dataset: AFLW
+ Metrics:
+ NME frontal: 1.2
+ NME full: 1.34
+ Task: Face 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/face/darkpose/hrnetv2_w18_aflw_256x256_dark-219606c0_20210125.pth
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/aflw/hrnetv2_w18_aflw_256x256.py b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/aflw/hrnetv2_w18_aflw_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..b139c2323dbfb0addb3baf3a6c348962e232331f
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/aflw/hrnetv2_w18_aflw_256x256.py
@@ -0,0 +1,160 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/aflw.py'
+]
+checkpoint_config = dict(interval=1)
+evaluation = dict(interval=1, metric=['NME'], save_best='NME')
+
+optimizer = dict(
+ type='Adam',
+ lr=2e-3,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[40, 55])
+total_epochs = 60
+log_config = dict(
+ interval=5,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=19,
+ dataset_joints=19,
+ dataset_channel=[
+ list(range(19)),
+ ],
+ inference_channel=list(range(19)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='open-mmlab://msra/hrnetv2_w18',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(18, 36)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(18, 36, 72)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(18, 36, 72, 144),
+ multiscale_output=True),
+ upsample=dict(mode='bilinear', align_corners=False))),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=[18, 36, 72, 144],
+ in_index=(0, 1, 2, 3),
+ input_transform='resize_concat',
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(
+ final_conv_kernel=1, num_conv_layers=1, num_conv_kernels=(1, )),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/aflw'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='FaceAFLWDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_aflw_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='FaceAFLWDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_aflw_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='FaceAFLWDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_aflw_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/aflw/hrnetv2_w18_aflw_256x256_dark.py b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/aflw/hrnetv2_w18_aflw_256x256_dark.py
new file mode 100644
index 0000000000000000000000000000000000000000..d7ab367de704b615b6fa3caf2cce97b60d4e7c91
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/aflw/hrnetv2_w18_aflw_256x256_dark.py
@@ -0,0 +1,160 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/aflw.py'
+]
+checkpoint_config = dict(interval=1)
+evaluation = dict(interval=1, metric=['NME'], save_best='NME')
+
+optimizer = dict(
+ type='Adam',
+ lr=2e-3,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[40, 55])
+total_epochs = 60
+log_config = dict(
+ interval=5,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=19,
+ dataset_joints=19,
+ dataset_channel=[
+ list(range(19)),
+ ],
+ inference_channel=list(range(19)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='open-mmlab://msra/hrnetv2_w18',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(18, 36)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(18, 36, 72)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(18, 36, 72, 144),
+ multiscale_output=True),
+ upsample=dict(mode='bilinear', align_corners=False))),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=[18, 36, 72, 144],
+ in_index=(0, 1, 2, 3),
+ input_transform='resize_concat',
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(
+ final_conv_kernel=1, num_conv_layers=1, num_conv_kernels=(1, )),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='unbiased',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2, unbiased_encoding=True),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/aflw'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='FaceAFLWDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_aflw_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='FaceAFLWDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_aflw_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='FaceAFLWDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_aflw_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/aflw/res50_aflw_256x256.py b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/aflw/res50_aflw_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..3e216574600978f3ca55af0cfb9f97b233ffe313
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/aflw/res50_aflw_256x256.py
@@ -0,0 +1,126 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/aflw.py'
+]
+checkpoint_config = dict(interval=1)
+evaluation = dict(interval=1, metric=['NME'], save_best='NME')
+
+optimizer = dict(
+ type='Adam',
+ lr=2e-3,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[40, 55])
+total_epochs = 60
+log_config = dict(
+ interval=5,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=19,
+ dataset_joints=19,
+ dataset_channel=[
+ list(range(19)),
+ ],
+ inference_channel=list(range(19)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/aflw'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='FaceAFLWDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_aflw_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='FaceAFLWDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_aflw_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='FaceAFLWDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_aflw_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/hourglass52_coco_wholebody_face_256x256.py b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/hourglass52_coco_wholebody_face_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..b7989b49808187dbd3158070e47fcfa54247853d
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/hourglass52_coco_wholebody_face_256x256.py
@@ -0,0 +1,132 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody_face.py'
+]
+checkpoint_config = dict(interval=1)
+evaluation = dict(interval=1, metric=['NME'], key_indicator='NME')
+
+optimizer = dict(
+ type='Adam',
+ lr=2e-3,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[40, 55])
+total_epochs = 60
+log_config = dict(
+ interval=5,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=68,
+ dataset_joints=68,
+ dataset_channel=[
+ list(range(68)),
+ ],
+ inference_channel=list(range(68)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='HourglassNet',
+ num_stacks=1,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapMultiStageHead',
+ in_channels=256,
+ out_channels=channel_cfg['num_output_channels'],
+ num_stages=1,
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='FaceCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='FaceCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='FaceCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/hourglass_coco_wholebody_face.md b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/hourglass_coco_wholebody_face.md
new file mode 100644
index 0000000000000000000000000000000000000000..9cc9af478dc6d89a2d8ea4de23d7f3a6d082b827
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/hourglass_coco_wholebody_face.md
@@ -0,0 +1,39 @@
+
+
+AFLW (ICCVW'2011)
+ +```bibtex +@inproceedings{koestinger2011annotated, + title={Annotated facial landmarks in the wild: A large-scale, real-world database for facial landmark localization}, + author={Koestinger, Martin and Wohlhart, Paul and Roth, Peter M and Bischof, Horst}, + booktitle={2011 IEEE international conference on computer vision workshops (ICCV workshops)}, + pages={2144--2151}, + year={2011}, + organization={IEEE} +} +``` + +
+
+
+
+
+Hourglass (ECCV'2016)
+ +```bibtex +@inproceedings{newell2016stacked, + title={Stacked hourglass networks for human pose estimation}, + author={Newell, Alejandro and Yang, Kaiyu and Deng, Jia}, + booktitle={European conference on computer vision}, + pages={483--499}, + year={2016}, + organization={Springer} +} +``` + +
+
+
+Results on COCO-WholeBody-Face val set
+
+| Arch | Input Size | NME | ckpt | log |
+| :-------------- | :-----------: | :------: |:------: |:------: |
+| [pose_hourglass_52](/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/hourglass52_coco_wholebody_face_256x256.py) | 256x256 | 0.0586 | [ckpt](https://download.openmmlab.com/mmpose/face/hourglass/hourglass52_coco_wholebody_face_256x256-6994cf2e_20210909.pth) | [log](https://download.openmmlab.com/mmpose/face/hourglass/hourglass52_coco_wholebody_face_256x256_20210909.log.json) |
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/hourglass_coco_wholebody_face.yml b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/hourglass_coco_wholebody_face.yml
new file mode 100644
index 0000000000000000000000000000000000000000..03761d866e573566090f40f7fb0d917126dd0f41
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/hourglass_coco_wholebody_face.yml
@@ -0,0 +1,20 @@
+Collections:
+- Name: Hourglass
+ Paper:
+ Title: Stacked hourglass networks for human pose estimation
+ URL: https://link.springer.com/chapter/10.1007/978-3-319-46484-8_29
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/hourglass.md
+Models:
+- Config: configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/hourglass52_coco_wholebody_face_256x256.py
+ In Collection: Hourglass
+ Metadata:
+ Architecture:
+ - Hourglass
+ Training Data: COCO-WholeBody-Face
+ Name: topdown_heatmap_hourglass52_coco_wholebody_face_256x256
+ Results:
+ - Dataset: COCO-WholeBody-Face
+ Metrics:
+ NME: 0.0586
+ Task: Face 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/face/hourglass/hourglass52_coco_wholebody_face_256x256-6994cf2e_20210909.pth
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/hrnetv2_coco_wholebody_face.md b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/hrnetv2_coco_wholebody_face.md
new file mode 100644
index 0000000000000000000000000000000000000000..f1d4fb8d329059ffe1821d3c18fa4b9c2ba17947
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/hrnetv2_coco_wholebody_face.md
@@ -0,0 +1,39 @@
+
+
+COCO-WholeBody-Face (ECCV'2020)
+ +```bibtex +@inproceedings{jin2020whole, + title={Whole-Body Human Pose Estimation in the Wild}, + author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping}, + booktitle={Proceedings of the European Conference on Computer Vision (ECCV)}, + year={2020} +} +``` + +
+
+
+
+
+HRNetv2 (TPAMI'2019)
+ +```bibtex +@article{WangSCJDZLMTWLX19, + title={Deep High-Resolution Representation Learning for Visual Recognition}, + author={Jingdong Wang and Ke Sun and Tianheng Cheng and + Borui Jiang and Chaorui Deng and Yang Zhao and Dong Liu and Yadong Mu and + Mingkui Tan and Xinggang Wang and Wenyu Liu and Bin Xiao}, + journal={TPAMI}, + year={2019} +} +``` + +
+
+
+Results on COCO-WholeBody-Face val set
+
+| Arch | Input Size | NME | ckpt | log |
+| :-------------- | :-----------: | :------: |:------: |:------: |
+| [pose_hrnetv2_w18](/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/hrnetv2_w18_coco_wholebody_face_256x256.py) | 256x256 | 0.0569 | [ckpt](https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_coco_wholebody_face_256x256-c1ca469b_20210909.pth) | [log](https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_coco_wholebody_face_256x256_20210909.log.json) |
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/hrnetv2_coco_wholebody_face.yml b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/hrnetv2_coco_wholebody_face.yml
new file mode 100644
index 0000000000000000000000000000000000000000..754598e49a7460596b8e393806a69d4bbe9985b8
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/hrnetv2_coco_wholebody_face.yml
@@ -0,0 +1,20 @@
+Collections:
+- Name: HRNetv2
+ Paper:
+ Title: Deep High-Resolution Representation Learning for Visual Recognition
+ URL: https://ieeexplore.ieee.org/abstract/document/9052469/
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/hrnetv2.md
+Models:
+- Config: configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/hrnetv2_w18_coco_wholebody_face_256x256.py
+ In Collection: HRNetv2
+ Metadata:
+ Architecture:
+ - HRNetv2
+ Training Data: COCO-WholeBody-Face
+ Name: topdown_heatmap_hrnetv2_w18_coco_wholebody_face_256x256
+ Results:
+ - Dataset: COCO-WholeBody-Face
+ Metrics:
+ NME: 0.0569
+ Task: Face 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_coco_wholebody_face_256x256-c1ca469b_20210909.pth
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/hrnetv2_dark_coco_wholebody_face.md b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/hrnetv2_dark_coco_wholebody_face.md
new file mode 100644
index 0000000000000000000000000000000000000000..4de0db0cd0cb0e3da7bdcf7aebad9c3101519ff5
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/hrnetv2_dark_coco_wholebody_face.md
@@ -0,0 +1,56 @@
+
+
+COCO-WholeBody-Face (ECCV'2020)
+ +```bibtex +@inproceedings{jin2020whole, + title={Whole-Body Human Pose Estimation in the Wild}, + author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping}, + booktitle={Proceedings of the European Conference on Computer Vision (ECCV)}, + year={2020} +} +``` + +
+
+
+
+
+HRNetv2 (TPAMI'2019)
+ +```bibtex +@article{WangSCJDZLMTWLX19, + title={Deep High-Resolution Representation Learning for Visual Recognition}, + author={Jingdong Wang and Ke Sun and Tianheng Cheng and + Borui Jiang and Chaorui Deng and Yang Zhao and Dong Liu and Yadong Mu and + Mingkui Tan and Xinggang Wang and Wenyu Liu and Bin Xiao}, + journal={TPAMI}, + year={2019} +} +``` + +
+
+
+
+
+DarkPose (CVPR'2020)
+ +```bibtex +@inproceedings{zhang2020distribution, + title={Distribution-aware coordinate representation for human pose estimation}, + author={Zhang, Feng and Zhu, Xiatian and Dai, Hanbin and Ye, Mao and Zhu, Ce}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + pages={7093--7102}, + year={2020} +} +``` + +
+
+
+Results on COCO-WholeBody-Face val set
+
+| Arch | Input Size | NME | ckpt | log |
+| :-------------- | :-----------: | :------: |:------: |:------: |
+| [pose_hrnetv2_w18_dark](/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/hrnetv2_w18_coco_wholebody_face_256x256_dark.py) | 256x256 | 0.0513 | [ckpt](https://download.openmmlab.com/mmpose/face/darkpose/hrnetv2_w18_coco_wholebody_face_256x256_dark-3d9a334e_20210909.pth) | [log](https://download.openmmlab.com/mmpose/face/darkpose/hrnetv2_w18_coco_wholebody_face_256x256_dark_20210909.log.json) |
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/hrnetv2_dark_coco_wholebody_face.yml b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/hrnetv2_dark_coco_wholebody_face.yml
new file mode 100644
index 0000000000000000000000000000000000000000..e8b9e895744e742aa5d9ebc2ca9d3a7d28617fe2
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/hrnetv2_dark_coco_wholebody_face.yml
@@ -0,0 +1,21 @@
+Collections:
+- Name: DarkPose
+ Paper:
+ Title: Distribution-aware coordinate representation for human pose estimation
+ URL: http://openaccess.thecvf.com/content_CVPR_2020/html/Zhang_Distribution-Aware_Coordinate_Representation_for_Human_Pose_Estimation_CVPR_2020_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/techniques/dark.md
+Models:
+- Config: configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/hrnetv2_w18_coco_wholebody_face_256x256_dark.py
+ In Collection: DarkPose
+ Metadata:
+ Architecture:
+ - HRNetv2
+ - DarkPose
+ Training Data: COCO-WholeBody-Face
+ Name: topdown_heatmap_hrnetv2_w18_coco_wholebody_face_256x256_dark
+ Results:
+ - Dataset: COCO-WholeBody-Face
+ Metrics:
+ NME: 0.0513
+ Task: Face 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/face/darkpose/hrnetv2_w18_coco_wholebody_face_256x256_dark-3d9a334e_20210909.pth
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/hrnetv2_w18_coco_wholebody_face_256x256.py b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/hrnetv2_w18_coco_wholebody_face_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..88722deaaa1075ea55aa104a3bbe7bd9832c70eb
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/hrnetv2_w18_coco_wholebody_face_256x256.py
@@ -0,0 +1,160 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody_face.py'
+]
+checkpoint_config = dict(interval=1)
+evaluation = dict(interval=1, metric=['NME'], key_indicator='NME')
+
+optimizer = dict(
+ type='Adam',
+ lr=2e-3,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[40, 55])
+total_epochs = 60
+log_config = dict(
+ interval=5,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=68,
+ dataset_joints=68,
+ dataset_channel=[
+ list(range(68)),
+ ],
+ inference_channel=list(range(68)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='open-mmlab://msra/hrnetv2_w18',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(18, 36)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(18, 36, 72)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(18, 36, 72, 144),
+ multiscale_output=True),
+ upsample=dict(mode='bilinear', align_corners=False))),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=[18, 36, 72, 144],
+ in_index=(0, 1, 2, 3),
+ input_transform='resize_concat',
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(
+ final_conv_kernel=1, num_conv_layers=1, num_conv_kernels=(1, )),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='FaceCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='FaceCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='FaceCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/hrnetv2_w18_coco_wholebody_face_256x256_dark.py b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/hrnetv2_w18_coco_wholebody_face_256x256_dark.py
new file mode 100644
index 0000000000000000000000000000000000000000..e3998c3bde899e16fdd629f4450c55244f223765
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/hrnetv2_w18_coco_wholebody_face_256x256_dark.py
@@ -0,0 +1,160 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody_face.py'
+]
+checkpoint_config = dict(interval=1)
+evaluation = dict(interval=1, metric=['NME'], key_indicator='NME')
+
+optimizer = dict(
+ type='Adam',
+ lr=2e-3,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[40, 55])
+total_epochs = 60
+log_config = dict(
+ interval=5,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=68,
+ dataset_joints=68,
+ dataset_channel=[
+ list(range(68)),
+ ],
+ inference_channel=list(range(68)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='open-mmlab://msra/hrnetv2_w18',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(18, 36)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(18, 36, 72)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(18, 36, 72, 144),
+ multiscale_output=True),
+ upsample=dict(mode='bilinear', align_corners=False))),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=[18, 36, 72, 144],
+ in_index=(0, 1, 2, 3),
+ input_transform='resize_concat',
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(
+ final_conv_kernel=1, num_conv_layers=1, num_conv_kernels=(1, )),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='unbiased',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2, unbiased_encoding=True),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='FaceCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='FaceCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='FaceCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/mobilenetv2_coco_wholebody_face.md b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/mobilenetv2_coco_wholebody_face.md
new file mode 100644
index 0000000000000000000000000000000000000000..3db8e5f4e651ebd3b945851eefe6c40e725ef87a
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/mobilenetv2_coco_wholebody_face.md
@@ -0,0 +1,38 @@
+
+
+COCO-WholeBody-Face (ECCV'2020)
+ +```bibtex +@inproceedings{jin2020whole, + title={Whole-Body Human Pose Estimation in the Wild}, + author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping}, + booktitle={Proceedings of the European Conference on Computer Vision (ECCV)}, + year={2020} +} +``` + +
+
+
+
+
+MobilenetV2 (CVPR'2018)
+ +```bibtex +@inproceedings{sandler2018mobilenetv2, + title={Mobilenetv2: Inverted residuals and linear bottlenecks}, + author={Sandler, Mark and Howard, Andrew and Zhu, Menglong and Zhmoginov, Andrey and Chen, Liang-Chieh}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={4510--4520}, + year={2018} +} +``` + +
+
+
+Results on COCO-WholeBody-Face val set
+
+| Arch | Input Size | NME | ckpt | log |
+| :-------------- | :-----------: | :------: |:------: |:------: |
+| [pose_mobilenetv2](/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/mobilenetv2_coco_wholebody_face_256x256.py) | 256x256 | 0.0612 | [ckpt](https://download.openmmlab.com/mmpose/face/mobilenetv2/mobilenetv2_coco_wholebody_face_256x256-4a3f096e_20210909.pth) | [log](https://download.openmmlab.com/mmpose/face/mobilenetv2/mobilenetv2_coco_wholebody_face_256x256_20210909.log.json) |
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/mobilenetv2_coco_wholebody_face.yml b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/mobilenetv2_coco_wholebody_face.yml
new file mode 100644
index 0000000000000000000000000000000000000000..f1e23e7deea45c7c6df91f3f77fdf400968d288f
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/mobilenetv2_coco_wholebody_face.yml
@@ -0,0 +1,20 @@
+Collections:
+- Name: MobilenetV2
+ Paper:
+ Title: 'Mobilenetv2: Inverted residuals and linear bottlenecks'
+ URL: http://openaccess.thecvf.com/content_cvpr_2018/html/Sandler_MobileNetV2_Inverted_Residuals_CVPR_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/mobilenetv2.md
+Models:
+- Config: configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/mobilenetv2_coco_wholebody_face_256x256.py
+ In Collection: MobilenetV2
+ Metadata:
+ Architecture:
+ - MobilenetV2
+ Training Data: COCO-WholeBody-Face
+ Name: topdown_heatmap_mobilenetv2_coco_wholebody_face_256x256
+ Results:
+ - Dataset: COCO-WholeBody-Face
+ Metrics:
+ NME: 0.0612
+ Task: Face 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/face/mobilenetv2/mobilenetv2_coco_wholebody_face_256x256-4a3f096e_20210909.pth
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/mobilenetv2_coco_wholebody_face_256x256.py b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/mobilenetv2_coco_wholebody_face_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..a1b54e0ca939fc395c9669b1f438f612ea28c221
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/mobilenetv2_coco_wholebody_face_256x256.py
@@ -0,0 +1,126 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody_face.py'
+]
+checkpoint_config = dict(interval=1)
+evaluation = dict(interval=1, metric=['NME'], key_indicator='NME')
+
+optimizer = dict(
+ type='Adam',
+ lr=2e-3,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[40, 55])
+total_epochs = 60
+log_config = dict(
+ interval=5,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=68,
+ dataset_joints=68,
+ dataset_channel=[
+ list(range(68)),
+ ],
+ inference_channel=list(range(68)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='mmcls://mobilenet_v2',
+ backbone=dict(type='MobileNetV2', widen_factor=1., out_indices=(7, )),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1280,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='FaceCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='FaceCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='FaceCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/res50_coco_wholebody_face_256x256.py b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/res50_coco_wholebody_face_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..3c636a329e16715f291eac591d85fb528d7fc6c2
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/res50_coco_wholebody_face_256x256.py
@@ -0,0 +1,126 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody_face.py'
+]
+checkpoint_config = dict(interval=1)
+evaluation = dict(interval=1, metric=['NME'], key_indicator='NME')
+
+optimizer = dict(
+ type='Adam',
+ lr=2e-3,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[40, 55])
+total_epochs = 60
+log_config = dict(
+ interval=5,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=68,
+ dataset_joints=68,
+ dataset_channel=[
+ list(range(68)),
+ ],
+ inference_channel=list(range(68)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='FaceCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='FaceCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='FaceCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/resnet_coco_wholebody_face.md b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/resnet_coco_wholebody_face.md
new file mode 100644
index 0000000000000000000000000000000000000000..b63a74e442d5733ea3ce5bbbd906055acf569119
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/resnet_coco_wholebody_face.md
@@ -0,0 +1,55 @@
+
+
+COCO-WholeBody-Face (ECCV'2020)
+ +```bibtex +@inproceedings{jin2020whole, + title={Whole-Body Human Pose Estimation in the Wild}, + author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping}, + booktitle={Proceedings of the European Conference on Computer Vision (ECCV)}, + year={2020} +} +``` + +
+
+
+
+
+SimpleBaseline2D (ECCV'2018)
+ +```bibtex +@inproceedings{xiao2018simple, + title={Simple baselines for human pose estimation and tracking}, + author={Xiao, Bin and Wu, Haiping and Wei, Yichen}, + booktitle={Proceedings of the European conference on computer vision (ECCV)}, + pages={466--481}, + year={2018} +} +``` + +
+
+
+
+
+ResNet (CVPR'2016)
+ +```bibtex +@inproceedings{he2016deep, + title={Deep residual learning for image recognition}, + author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={770--778}, + year={2016} +} +``` + +
+
+
+Results on COCO-WholeBody-Face val set
+
+| Arch | Input Size | NME | ckpt | log |
+| :-------------- | :-----------: | :------: |:------: |:------: |
+| [pose_res50](/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/res50_coco_wholebody_face_256x256.py) | 256x256 | 0.0566 | [ckpt](https://download.openmmlab.com/mmpose/face/resnet/res50_coco_wholebody_face_256x256-5128edf5_20210909.pth) | [log](https://download.openmmlab.com/mmpose/face/resnet/res50_coco_wholebody_face_256x256_20210909.log.json) |
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/resnet_coco_wholebody_face.yml b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/resnet_coco_wholebody_face.yml
new file mode 100644
index 0000000000000000000000000000000000000000..9e25ebc72f5e22c859781486c194c7ff2249f064
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/resnet_coco_wholebody_face.yml
@@ -0,0 +1,21 @@
+Collections:
+- Name: SimpleBaseline2D
+ Paper:
+ Title: Simple baselines for human pose estimation and tracking
+ URL: http://openaccess.thecvf.com/content_ECCV_2018/html/Bin_Xiao_Simple_Baselines_for_ECCV_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/simplebaseline2d.md
+Models:
+- Config: configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/res50_coco_wholebody_face_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture:
+ - SimpleBaseline2D
+ - ResNet
+ Training Data: COCO-WholeBody-Face
+ Name: topdown_heatmap_res50_coco_wholebody_face_256x256
+ Results:
+ - Dataset: COCO-WholeBody-Face
+ Metrics:
+ NME: 0.0566
+ Task: Face 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/face/resnet/res50_coco_wholebody_face_256x256-5128edf5_20210909.pth
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/scnet50_coco_wholebody_face_256x256.py b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/scnet50_coco_wholebody_face_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..b02d71149ec54e6673e1f201c5fc5a0aed47c6d8
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/scnet50_coco_wholebody_face_256x256.py
@@ -0,0 +1,127 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody_face.py'
+]
+checkpoint_config = dict(interval=1)
+evaluation = dict(interval=1, metric=['NME'], key_indicator='NME')
+
+optimizer = dict(
+ type='Adam',
+ lr=2e-3,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[40, 55])
+total_epochs = 60
+log_config = dict(
+ interval=5,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=68,
+ dataset_joints=68,
+ dataset_channel=[
+ list(range(68)),
+ ],
+ inference_channel=list(range(68)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/scnet50-7ef0a199.pth',
+ backbone=dict(type='SCNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='FaceCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='FaceCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='FaceCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/scnet_coco_wholebody_face.md b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/scnet_coco_wholebody_face.md
new file mode 100644
index 0000000000000000000000000000000000000000..48029a01caf018a5f190f98e2428b2b329056cad
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/scnet_coco_wholebody_face.md
@@ -0,0 +1,38 @@
+
+
+COCO-WholeBody-Face (ECCV'2020)
+ +```bibtex +@inproceedings{jin2020whole, + title={Whole-Body Human Pose Estimation in the Wild}, + author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping}, + booktitle={Proceedings of the European Conference on Computer Vision (ECCV)}, + year={2020} +} +``` + +
+
+
+
+
+SCNet (CVPR'2020)
+ +```bibtex +@inproceedings{liu2020improving, + title={Improving Convolutional Networks with Self-Calibrated Convolutions}, + author={Liu, Jiang-Jiang and Hou, Qibin and Cheng, Ming-Ming and Wang, Changhu and Feng, Jiashi}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + pages={10096--10105}, + year={2020} +} +``` + +
+
+
+Results on COCO-WholeBody-Face val set
+
+| Arch | Input Size | NME | ckpt | log |
+| :-------------- | :-----------: | :------: |:------: |:------: |
+| [pose_scnet_50](/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/scnet50_coco_wholebody_face_256x256.py) | 256x256 | 0.0565 | [ckpt](https://download.openmmlab.com/mmpose/face/scnet/scnet50_coco_wholebody_face_256x256-a0183f5f_20210909.pth) | [log](https://download.openmmlab.com/mmpose/face/scnet/scnet50_coco_wholebody_face_256x256_20210909.log.json) |
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/scnet_coco_wholebody_face.yml b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/scnet_coco_wholebody_face.yml
new file mode 100644
index 0000000000000000000000000000000000000000..7be429196f67ee588962ce17746659d22b7789d4
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/scnet_coco_wholebody_face.yml
@@ -0,0 +1,20 @@
+Collections:
+- Name: SCNet
+ Paper:
+ Title: Improving Convolutional Networks with Self-Calibrated Convolutions
+ URL: http://openaccess.thecvf.com/content_CVPR_2020/html/Liu_Improving_Convolutional_Networks_With_Self-Calibrated_Convolutions_CVPR_2020_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/scnet.md
+Models:
+- Config: configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/scnet50_coco_wholebody_face_256x256.py
+ In Collection: SCNet
+ Metadata:
+ Architecture:
+ - SCNet
+ Training Data: COCO-WholeBody-Face
+ Name: topdown_heatmap_scnet50_coco_wholebody_face_256x256
+ Results:
+ - Dataset: COCO-WholeBody-Face
+ Metrics:
+ NME: 0.0565
+ Task: Face 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/face/scnet/scnet50_coco_wholebody_face_256x256-a0183f5f_20210909.pth
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/cofw/hrnetv2_cofw.md b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/cofw/hrnetv2_cofw.md
new file mode 100644
index 0000000000000000000000000000000000000000..051fced17c500d5106b48962235b6a65f369bce1
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/cofw/hrnetv2_cofw.md
@@ -0,0 +1,42 @@
+
+
+COCO-WholeBody-Face (ECCV'2020)
+ +```bibtex +@inproceedings{jin2020whole, + title={Whole-Body Human Pose Estimation in the Wild}, + author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping}, + booktitle={Proceedings of the European Conference on Computer Vision (ECCV)}, + year={2020} +} +``` + +
+
+
+
+
+HRNetv2 (TPAMI'2019)
+ +```bibtex +@article{WangSCJDZLMTWLX19, + title={Deep High-Resolution Representation Learning for Visual Recognition}, + author={Jingdong Wang and Ke Sun and Tianheng Cheng and + Borui Jiang and Chaorui Deng and Yang Zhao and Dong Liu and Yadong Mu and + Mingkui Tan and Xinggang Wang and Wenyu Liu and Bin Xiao}, + journal={TPAMI}, + year={2019} +} +``` + +
+
+
+Results on COFW dataset
+
+The model is trained on COFW train.
+
+| Arch | Input Size | NME | ckpt | log |
+| :-----| :--------: | :----: |:---: | :---: |
+| [pose_hrnetv2_w18](/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/cofw/hrnetv2_w18_cofw_256x256.py) | 256x256 | 3.40 | [ckpt](https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_cofw_256x256-49243ab8_20211019.pth) | [log](https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_cofw_256x256_20211019.log.json) |
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/cofw/hrnetv2_cofw.yml b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/cofw/hrnetv2_cofw.yml
new file mode 100644
index 0000000000000000000000000000000000000000..abeb759662cd4826599940eea04474e2e59a8375
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/cofw/hrnetv2_cofw.yml
@@ -0,0 +1,20 @@
+Collections:
+- Name: HRNetv2
+ Paper:
+ Title: Deep High-Resolution Representation Learning for Visual Recognition
+ URL: https://ieeexplore.ieee.org/abstract/document/9052469/
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/hrnetv2.md
+Models:
+- Config: configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/cofw/hrnetv2_w18_cofw_256x256.py
+ In Collection: HRNetv2
+ Metadata:
+ Architecture:
+ - HRNetv2
+ Training Data: COFW
+ Name: topdown_heatmap_hrnetv2_w18_cofw_256x256
+ Results:
+ - Dataset: COFW
+ Metrics:
+ NME: 3.4
+ Task: Face 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_cofw_256x256-49243ab8_20211019.pth
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/cofw/hrnetv2_w18_cofw_256x256.py b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/cofw/hrnetv2_w18_cofw_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..cf316bcff72edaff2de157458cc14dde019262ac
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/cofw/hrnetv2_w18_cofw_256x256.py
@@ -0,0 +1,160 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/cofw.py'
+]
+checkpoint_config = dict(interval=1)
+evaluation = dict(interval=1, metric=['NME'], save_best='NME')
+
+optimizer = dict(
+ type='Adam',
+ lr=2e-3,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[40, 55])
+total_epochs = 60
+log_config = dict(
+ interval=5,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=29,
+ dataset_joints=29,
+ dataset_channel=[
+ list(range(29)),
+ ],
+ inference_channel=list(range(29)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='open-mmlab://msra/hrnetv2_w18',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(18, 36)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(18, 36, 72)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(18, 36, 72, 144),
+ multiscale_output=True),
+ upsample=dict(mode='bilinear', align_corners=False))),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=[18, 36, 72, 144],
+ in_index=(0, 1, 2, 3),
+ input_transform='resize_concat',
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(
+ final_conv_kernel=1, num_conv_layers=1, num_conv_kernels=(1, )),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=1.5),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/cofw'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='FaceCOFWDataset',
+ ann_file=f'{data_root}/annotations/cofw_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='FaceCOFWDataset',
+ ann_file=f'{data_root}/annotations/cofw_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='FaceCOFWDataset',
+ ann_file=f'{data_root}/annotations/cofw_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/cofw/hrnetv2_w18_cofw_256x256_dark.py b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/cofw/hrnetv2_w18_cofw_256x256_dark.py
new file mode 100644
index 0000000000000000000000000000000000000000..e8eb6e27d5522cc9c9883be09a5f3a5e8cb612f2
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/cofw/hrnetv2_w18_cofw_256x256_dark.py
@@ -0,0 +1,160 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/cofw.py'
+]
+checkpoint_config = dict(interval=1)
+evaluation = dict(interval=1, metric=['NME'], save_best='NME')
+
+optimizer = dict(
+ type='Adam',
+ lr=2e-3,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[40, 55])
+total_epochs = 60
+log_config = dict(
+ interval=5,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=29,
+ dataset_joints=29,
+ dataset_channel=[
+ list(range(29)),
+ ],
+ inference_channel=list(range(29)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='open-mmlab://msra/hrnetv2_w18',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(18, 36)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(18, 36, 72)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(18, 36, 72, 144),
+ multiscale_output=True),
+ upsample=dict(mode='bilinear', align_corners=False))),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=[18, 36, 72, 144],
+ in_index=(0, 1, 2, 3),
+ input_transform='resize_concat',
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(
+ final_conv_kernel=1, num_conv_layers=1, num_conv_kernels=(1, )),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='unbiased',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2, unbiased_encoding=True),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/cofw'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='FaceCOFWDataset',
+ ann_file=f'{data_root}/annotations/cofw_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='FaceCOFWDataset',
+ ann_file=f'{data_root}/annotations/cofw_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='FaceCOFWDataset',
+ ann_file=f'{data_root}/annotations/cofw_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/cofw/res50_cofw_256x256.py b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/cofw/res50_cofw_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..13b37c1d4f2b626dd87e194258a1e9297de34158
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/cofw/res50_cofw_256x256.py
@@ -0,0 +1,126 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/cofw.py'
+]
+checkpoint_config = dict(interval=1)
+evaluation = dict(interval=1, metric=['NME'], save_best='NME')
+
+optimizer = dict(
+ type='Adam',
+ lr=2e-3,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[40, 55])
+total_epochs = 60
+log_config = dict(
+ interval=5,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=29,
+ dataset_joints=29,
+ dataset_channel=[
+ list(range(29)),
+ ],
+ inference_channel=list(range(29)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/cofw'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='FaceCOFWDataset',
+ ann_file=f'{data_root}/annotations/cofw_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='FaceCOFWDataset',
+ ann_file=f'{data_root}/annotations/cofw_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='FaceCOFWDataset',
+ ann_file=f'{data_root}/annotations/cofw_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/hrnetv2_awing_wflw.md b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/hrnetv2_awing_wflw.md
new file mode 100644
index 0000000000000000000000000000000000000000..193029918241ace3b208d865513d06583b9f52d3
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/hrnetv2_awing_wflw.md
@@ -0,0 +1,59 @@
+
+
+COFW (ICCV'2013)
+ +```bibtex +@inproceedings{burgos2013robust, + title={Robust face landmark estimation under occlusion}, + author={Burgos-Artizzu, Xavier P and Perona, Pietro and Doll{\'a}r, Piotr}, + booktitle={Proceedings of the IEEE international conference on computer vision}, + pages={1513--1520}, + year={2013} +} +``` + +
+
+
+
+
+HRNetv2 (TPAMI'2019)
+ +```bibtex +@article{WangSCJDZLMTWLX19, + title={Deep High-Resolution Representation Learning for Visual Recognition}, + author={Jingdong Wang and Ke Sun and Tianheng Cheng and + Borui Jiang and Chaorui Deng and Yang Zhao and Dong Liu and Yadong Mu and + Mingkui Tan and Xinggang Wang and Wenyu Liu and Bin Xiao}, + journal={TPAMI}, + year={2019} +} +``` + +
+
+
+
+
+AdaptiveWingloss (ICCV'2019)
+ +```bibtex +@inproceedings{wang2019adaptive, + title={Adaptive wing loss for robust face alignment via heatmap regression}, + author={Wang, Xinyao and Bo, Liefeng and Fuxin, Li}, + booktitle={Proceedings of the IEEE/CVF international conference on computer vision}, + pages={6971--6981}, + year={2019} +} +``` + +
+
+
+Results on WFLW dataset
+
+The model is trained on WFLW train.
+
+| Arch | Input Size | NME*test* | NME*pose* | NME*illumination* | NME*occlusion* | NME*blur* | NME*makeup* | NME*expression* | ckpt | log |
+| :-----| :--------: | :------------------: | :------------------: |:---------------------------: |:------------------------: | :------------------: | :--------------: |:-------------------------: |:---: | :---: |
+| [pose_hrnetv2_w18_awing](/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/hrnetv2_w18_wflw_256x256_awing.py) | 256x256 | 4.02 | 6.94 | 3.96 | 4.78 | 4.59 | 3.85 | 4.28 | [ckpt](https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_wflw_256x256_awing-5af5055c_20211212.pth) | [log](https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_wflw_256x256_awing_20211212.log.json) |
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/hrnetv2_awing_wflw.yml b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/hrnetv2_awing_wflw.yml
new file mode 100644
index 0000000000000000000000000000000000000000..af61d3013a1692df5268468dde5396144a0db2f1
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/hrnetv2_awing_wflw.yml
@@ -0,0 +1,27 @@
+Collections:
+- Name: HRNetv2
+ Paper:
+ Title: Deep High-Resolution Representation Learning for Visual Recognition
+ URL: https://ieeexplore.ieee.org/abstract/document/9052469/
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/hrnetv2.md
+Models:
+- Config: configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/hrnetv2_w18_wflw_256x256_awing.py
+ In Collection: HRNetv2
+ Metadata:
+ Architecture:
+ - HRNetv2
+ - AdaptiveWingloss
+ Training Data: WFLW
+ Name: topdown_heatmap_hrnetv2_w18_wflw_256x256_awing
+ Results:
+ - Dataset: WFLW
+ Metrics:
+ NME blur: 4.59
+ NME expression: 4.28
+ NME illumination: 3.96
+ NME makeup: 3.85
+ NME occlusion: 4.78
+ NME pose: 6.94
+ NME test: 4.02
+ Task: Face 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_wflw_256x256_awing-5af5055c_20211212.pth
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/hrnetv2_dark_wflw.md b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/hrnetv2_dark_wflw.md
new file mode 100644
index 0000000000000000000000000000000000000000..8e22009a71aca41fbf354942eb730b9128f7a0df
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/hrnetv2_dark_wflw.md
@@ -0,0 +1,59 @@
+
+
+WFLW (CVPR'2018)
+ +```bibtex +@inproceedings{wu2018look, + title={Look at boundary: A boundary-aware face alignment algorithm}, + author={Wu, Wayne and Qian, Chen and Yang, Shuo and Wang, Quan and Cai, Yici and Zhou, Qiang}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={2129--2138}, + year={2018} +} +``` + +
+
+
+
+
+HRNetv2 (TPAMI'2019)
+ +```bibtex +@article{WangSCJDZLMTWLX19, + title={Deep High-Resolution Representation Learning for Visual Recognition}, + author={Jingdong Wang and Ke Sun and Tianheng Cheng and + Borui Jiang and Chaorui Deng and Yang Zhao and Dong Liu and Yadong Mu and + Mingkui Tan and Xinggang Wang and Wenyu Liu and Bin Xiao}, + journal={TPAMI}, + year={2019} +} +``` + +
+
+
+
+
+DarkPose (CVPR'2020)
+ +```bibtex +@inproceedings{zhang2020distribution, + title={Distribution-aware coordinate representation for human pose estimation}, + author={Zhang, Feng and Zhu, Xiatian and Dai, Hanbin and Ye, Mao and Zhu, Ce}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + pages={7093--7102}, + year={2020} +} +``` + +
+
+
+Results on WFLW dataset
+
+The model is trained on WFLW train.
+
+| Arch | Input Size | NME*test* | NME*pose* | NME*illumination* | NME*occlusion* | NME*blur* | NME*makeup* | NME*expression* | ckpt | log |
+| :-----| :--------: | :------------------: | :------------------: |:---------------------------: |:------------------------: | :------------------: | :--------------: |:-------------------------: |:---: | :---: |
+| [pose_hrnetv2_w18_dark](/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/hrnetv2_w18_wflw_256x256_dark.py) | 256x256 | 3.98 | 6.99 | 3.96 | 4.78 | 4.57 | 3.87 | 4.30 | [ckpt](https://download.openmmlab.com/mmpose/face/darkpose/hrnetv2_w18_wflw_256x256_dark-3f8e0c2c_20210125.pth) | [log](https://download.openmmlab.com/mmpose/face/darkpose/hrnetv2_w18_wflw_256x256_dark_20210125.log.json) |
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/hrnetv2_dark_wflw.yml b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/hrnetv2_dark_wflw.yml
new file mode 100644
index 0000000000000000000000000000000000000000..f5133d9627cf72043725b9669bf75fed60d3934f
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/hrnetv2_dark_wflw.yml
@@ -0,0 +1,27 @@
+Collections:
+- Name: DarkPose
+ Paper:
+ Title: Distribution-aware coordinate representation for human pose estimation
+ URL: http://openaccess.thecvf.com/content_CVPR_2020/html/Zhang_Distribution-Aware_Coordinate_Representation_for_Human_Pose_Estimation_CVPR_2020_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/techniques/dark.md
+Models:
+- Config: configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/hrnetv2_w18_wflw_256x256_dark.py
+ In Collection: DarkPose
+ Metadata:
+ Architecture:
+ - HRNetv2
+ - DarkPose
+ Training Data: WFLW
+ Name: topdown_heatmap_hrnetv2_w18_wflw_256x256_dark
+ Results:
+ - Dataset: WFLW
+ Metrics:
+ NME blur: 4.57
+ NME expression: 4.3
+ NME illumination: 3.96
+ NME makeup: 3.87
+ NME occlusion: 4.78
+ NME pose: 6.99
+ NME test: 3.98
+ Task: Face 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/face/darkpose/hrnetv2_w18_wflw_256x256_dark-3f8e0c2c_20210125.pth
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/hrnetv2_w18_wflw_256x256.py b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/hrnetv2_w18_wflw_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..d89b32a6330384102da83f804a6d5cfa5f030f8a
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/hrnetv2_w18_wflw_256x256.py
@@ -0,0 +1,160 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/wflw.py'
+]
+checkpoint_config = dict(interval=1)
+evaluation = dict(interval=1, metric=['NME'], save_best='NME')
+
+optimizer = dict(
+ type='Adam',
+ lr=2e-3,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[40, 55])
+total_epochs = 60
+log_config = dict(
+ interval=5,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=98,
+ dataset_joints=98,
+ dataset_channel=[
+ list(range(98)),
+ ],
+ inference_channel=list(range(98)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='open-mmlab://msra/hrnetv2_w18',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(18, 36)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(18, 36, 72)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(18, 36, 72, 144),
+ multiscale_output=True),
+ upsample=dict(mode='bilinear', align_corners=False))),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=[18, 36, 72, 144],
+ in_index=(0, 1, 2, 3),
+ input_transform='resize_concat',
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(
+ final_conv_kernel=1, num_conv_layers=1, num_conv_kernels=(1, )),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/wflw'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='FaceWFLWDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_wflw_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='FaceWFLWDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_wflw_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='FaceWFLWDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_wflw_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/hrnetv2_w18_wflw_256x256_awing.py b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/hrnetv2_w18_wflw_256x256_awing.py
new file mode 100644
index 0000000000000000000000000000000000000000..db83c19a5eb30679413ae9c472849c3825e278dc
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/hrnetv2_w18_wflw_256x256_awing.py
@@ -0,0 +1,160 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/wflw.py'
+]
+checkpoint_config = dict(interval=1)
+evaluation = dict(interval=1, metric=['NME'], save_best='NME')
+
+optimizer = dict(
+ type='Adam',
+ lr=2e-3,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[40, 55])
+total_epochs = 60
+log_config = dict(
+ interval=5,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=98,
+ dataset_joints=98,
+ dataset_channel=[
+ list(range(98)),
+ ],
+ inference_channel=list(range(98)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='open-mmlab://msra/hrnetv2_w18',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(18, 36)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(18, 36, 72)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(18, 36, 72, 144),
+ multiscale_output=True),
+ upsample=dict(mode='bilinear', align_corners=False))),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=[18, 36, 72, 144],
+ in_index=(0, 1, 2, 3),
+ input_transform='resize_concat',
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(
+ final_conv_kernel=1, num_conv_layers=1, num_conv_kernels=(1, )),
+ loss_keypoint=dict(type='AdaptiveWingLoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/wflw'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='FaceWFLWDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_wflw_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='FaceWFLWDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_wflw_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='FaceWFLWDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_wflw_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/hrnetv2_w18_wflw_256x256_dark.py b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/hrnetv2_w18_wflw_256x256_dark.py
new file mode 100644
index 0000000000000000000000000000000000000000..0c28f56f47256f521cc09c1bcd9623959ae44861
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/hrnetv2_w18_wflw_256x256_dark.py
@@ -0,0 +1,160 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/wflw.py'
+]
+checkpoint_config = dict(interval=1)
+evaluation = dict(interval=1, metric=['NME'], save_best='NME')
+
+optimizer = dict(
+ type='Adam',
+ lr=2e-3,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[40, 55])
+total_epochs = 60
+log_config = dict(
+ interval=5,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=98,
+ dataset_joints=98,
+ dataset_channel=[
+ list(range(98)),
+ ],
+ inference_channel=list(range(98)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='open-mmlab://msra/hrnetv2_w18',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(18, 36)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(18, 36, 72)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(18, 36, 72, 144),
+ multiscale_output=True),
+ upsample=dict(mode='bilinear', align_corners=False))),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=[18, 36, 72, 144],
+ in_index=(0, 1, 2, 3),
+ input_transform='resize_concat',
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(
+ final_conv_kernel=1, num_conv_layers=1, num_conv_kernels=(1, )),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='unbiased',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2, unbiased_encoding=True),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/wflw'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='FaceWFLWDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_wflw_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='FaceWFLWDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_wflw_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='FaceWFLWDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_wflw_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/hrnetv2_wflw.md b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/hrnetv2_wflw.md
new file mode 100644
index 0000000000000000000000000000000000000000..70ca3ad5e9a053ec183c01bb31b19f6f02a76ca6
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/hrnetv2_wflw.md
@@ -0,0 +1,42 @@
+
+
+WFLW (CVPR'2018)
+ +```bibtex +@inproceedings{wu2018look, + title={Look at boundary: A boundary-aware face alignment algorithm}, + author={Wu, Wayne and Qian, Chen and Yang, Shuo and Wang, Quan and Cai, Yici and Zhou, Qiang}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={2129--2138}, + year={2018} +} +``` + +
+
+
+
+
+HRNetv2 (TPAMI'2019)
+ +```bibtex +@article{WangSCJDZLMTWLX19, + title={Deep High-Resolution Representation Learning for Visual Recognition}, + author={Jingdong Wang and Ke Sun and Tianheng Cheng and + Borui Jiang and Chaorui Deng and Yang Zhao and Dong Liu and Yadong Mu and + Mingkui Tan and Xinggang Wang and Wenyu Liu and Bin Xiao}, + journal={TPAMI}, + year={2019} +} +``` + +
+
+
+Results on WFLW dataset
+
+The model is trained on WFLW train.
+
+| Arch | Input Size | NME*test* | NME*pose* | NME*illumination* | NME*occlusion* | NME*blur* | NME*makeup* | NME*expression* | ckpt | log |
+| :-----| :--------: | :------------------: | :------------------: |:---------------------------: |:------------------------: | :------------------: | :--------------: |:-------------------------: |:---: | :---: |
+| [pose_hrnetv2_w18](/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/hrnetv2_w18_wflw_256x256.py) | 256x256 | 4.06 | 6.98 | 3.99 | 4.83 | 4.59 | 3.92 | 4.33 | [ckpt](https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_wflw_256x256-2bf032a6_20210125.pth) | [log](https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_wflw_256x256_20210125.log.json) |
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/hrnetv2_wflw.yml b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/hrnetv2_wflw.yml
new file mode 100644
index 0000000000000000000000000000000000000000..517aa89aebfceb51e44e9b23ceb0a6084644f6ad
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/hrnetv2_wflw.yml
@@ -0,0 +1,26 @@
+Collections:
+- Name: HRNetv2
+ Paper:
+ Title: Deep High-Resolution Representation Learning for Visual Recognition
+ URL: https://ieeexplore.ieee.org/abstract/document/9052469/
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/hrnetv2.md
+Models:
+- Config: configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/hrnetv2_w18_wflw_256x256.py
+ In Collection: HRNetv2
+ Metadata:
+ Architecture:
+ - HRNetv2
+ Training Data: WFLW
+ Name: topdown_heatmap_hrnetv2_w18_wflw_256x256
+ Results:
+ - Dataset: WFLW
+ Metrics:
+ NME blur: 4.59
+ NME expression: 4.33
+ NME illumination: 3.99
+ NME makeup: 3.92
+ NME occlusion: 4.83
+ NME pose: 6.98
+ NME test: 4.06
+ Task: Face 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_wflw_256x256-2bf032a6_20210125.pth
diff --git a/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/res50_wflw_256x256.py b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/res50_wflw_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..d2f5d3443a20e987c96a454c46a188fc0ff9c1db
--- /dev/null
+++ b/vendor/ViTPose/configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/res50_wflw_256x256.py
@@ -0,0 +1,126 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/wflw.py'
+]
+checkpoint_config = dict(interval=1)
+evaluation = dict(interval=1, metric=['NME'], save_best='NME')
+
+optimizer = dict(
+ type='Adam',
+ lr=2e-3,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[40, 55])
+total_epochs = 60
+log_config = dict(
+ interval=5,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=98,
+ dataset_joints=98,
+ dataset_channel=[
+ list(range(98)),
+ ],
+ inference_channel=list(range(98)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/wflw'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='FaceWFLWDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_wflw_train.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='FaceWFLWDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_wflw_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='FaceWFLWDataset',
+ ann_file=f'{data_root}/annotations/face_landmarks_wflw_test.json',
+ img_prefix=f'{data_root}/images/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/README.md b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..6818d3dc1d7f9a25bea8ecc73f1c9b0b563ba21b
--- /dev/null
+++ b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/README.md
@@ -0,0 +1,7 @@
+# 2D Fashion Landmark Detection
+
+2D fashion landmark detection (also referred to as fashion alignment) aims to detect the key-point located at the functional region of clothes, for example the neckline and the cuff.
+
+## Data preparation
+
+Please follow [DATA Preparation](/docs/en/tasks/2d_fashion_landmark.md) to prepare data.
diff --git a/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/deeppose/README.md b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/deeppose/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..2dacfddfd451a49d3044936fdee995d6dfd29ac4
--- /dev/null
+++ b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/deeppose/README.md
@@ -0,0 +1,24 @@
+# Deeppose: Human pose estimation via deep neural networks
+
+## Introduction
+
+
+
+WFLW (CVPR'2018)
+ +```bibtex +@inproceedings{wu2018look, + title={Look at boundary: A boundary-aware face alignment algorithm}, + author={Wu, Wayne and Qian, Chen and Yang, Shuo and Wang, Quan and Cai, Yici and Zhou, Qiang}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={2129--2138}, + year={2018} +} +``` + +
+
+
+DeepPose first proposes using deep neural networks (DNNs) to tackle the problem of keypoint detection.
+It follows the top-down paradigm, that first detects the bounding boxes and then estimates poses.
+It learns to directly regress the fashion keypoint coordinates.
diff --git a/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/res101_deepfashion_full_256x192.py b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/res101_deepfashion_full_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..a59b0a9a7e34ee2d65da5b2a257b8723dda1f5d5
--- /dev/null
+++ b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/res101_deepfashion_full_256x192.py
@@ -0,0 +1,136 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/deepfashion_full.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=8,
+ dataset_joints=8,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet101',
+ backbone=dict(type='ResNet', depth=101, num_stages=4, out_indices=(3, )),
+ neck=dict(type='GlobalAveragePooling'),
+ keypoint_head=dict(
+ type='DeepposeRegressionHead',
+ in_channels=2048,
+ num_joints=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='SmoothL1Loss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(flip_test=True))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTargetRegression'),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/fld'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_full_train.json',
+ img_prefix=f'{data_root}/img/',
+ subset='full',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_full_val.json',
+ img_prefix=f'{data_root}/img/',
+ subset='full',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_full_test.json',
+ img_prefix=f'{data_root}/img/',
+ subset='full',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/res101_deepfashion_lower_256x192.py b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/res101_deepfashion_lower_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..0c6af600fd01277781feca695caec496a96ea8db
--- /dev/null
+++ b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/res101_deepfashion_lower_256x192.py
@@ -0,0 +1,136 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/deepfashion_lower.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=4,
+ dataset_joints=4,
+ dataset_channel=[
+ [0, 1, 2, 3],
+ ],
+ inference_channel=[0, 1, 2, 3])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet101',
+ backbone=dict(type='ResNet', depth=101, num_stages=4, out_indices=(3, )),
+ neck=dict(type='GlobalAveragePooling'),
+ keypoint_head=dict(
+ type='DeepposeRegressionHead',
+ in_channels=2048,
+ num_joints=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='SmoothL1Loss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(flip_test=True))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTargetRegression'),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/fld'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_lower_train.json',
+ img_prefix=f'{data_root}/img/',
+ subset='lower',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_lower_val.json',
+ img_prefix=f'{data_root}/img/',
+ subset='lower',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_lower_test.json',
+ img_prefix=f'{data_root}/img/',
+ subset='lower',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/res101_deepfashion_upper_256x192.py b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/res101_deepfashion_upper_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..77826c51249d196e739712ddf4d94f75d8218668
--- /dev/null
+++ b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/res101_deepfashion_upper_256x192.py
@@ -0,0 +1,136 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/deepfashion_upper.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=6,
+ dataset_joints=6,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet101',
+ backbone=dict(type='ResNet', depth=101, num_stages=4, out_indices=(3, )),
+ neck=dict(type='GlobalAveragePooling'),
+ keypoint_head=dict(
+ type='DeepposeRegressionHead',
+ in_channels=2048,
+ num_joints=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='SmoothL1Loss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(flip_test=True))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTargetRegression'),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/fld'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_upper_train.json',
+ img_prefix=f'{data_root}/img/',
+ subset='upper',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_upper_val.json',
+ img_prefix=f'{data_root}/img/',
+ subset='upper',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_upper_test.json',
+ img_prefix=f'{data_root}/img/',
+ subset='upper',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/res152_deepfashion_full_256x192.py b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/res152_deepfashion_full_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..9d587c77d356cf75f786d81e197ee42d321f8f4c
--- /dev/null
+++ b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/res152_deepfashion_full_256x192.py
@@ -0,0 +1,136 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/deepfashion_full.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=8,
+ dataset_joints=8,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet152',
+ backbone=dict(type='ResNet', depth=152, num_stages=4, out_indices=(3, )),
+ neck=dict(type='GlobalAveragePooling'),
+ keypoint_head=dict(
+ type='DeepposeRegressionHead',
+ in_channels=2048,
+ num_joints=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='SmoothL1Loss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(flip_test=True))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTargetRegression'),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/fld'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_full_train.json',
+ img_prefix=f'{data_root}/img/',
+ subset='full',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_full_val.json',
+ img_prefix=f'{data_root}/img/',
+ subset='full',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_full_test.json',
+ img_prefix=f'{data_root}/img/',
+ subset='full',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/res152_deepfashion_lower_256x192.py b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/res152_deepfashion_lower_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..9a08301516aca6e89002000d89cd8c112c7483ec
--- /dev/null
+++ b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/res152_deepfashion_lower_256x192.py
@@ -0,0 +1,136 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/deepfashion_lower.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=4,
+ dataset_joints=4,
+ dataset_channel=[
+ [0, 1, 2, 3],
+ ],
+ inference_channel=[0, 1, 2, 3])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet152',
+ backbone=dict(type='ResNet', depth=152, num_stages=4, out_indices=(3, )),
+ neck=dict(type='GlobalAveragePooling'),
+ keypoint_head=dict(
+ type='DeepposeRegressionHead',
+ in_channels=2048,
+ num_joints=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='SmoothL1Loss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(flip_test=True))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTargetRegression'),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/fld'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_lower_train.json',
+ img_prefix=f'{data_root}/img/',
+ subset='lower',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_lower_val.json',
+ img_prefix=f'{data_root}/img/',
+ subset='lower',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_lower_test.json',
+ img_prefix=f'{data_root}/img/',
+ subset='lower',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/res152_deepfashion_upper_256x192.py b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/res152_deepfashion_upper_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..8c89056e2602d72935adef047a873654fbf586fc
--- /dev/null
+++ b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/res152_deepfashion_upper_256x192.py
@@ -0,0 +1,136 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/deepfashion_upper.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=6,
+ dataset_joints=6,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet152',
+ backbone=dict(type='ResNet', depth=152, num_stages=4, out_indices=(3, )),
+ neck=dict(type='GlobalAveragePooling'),
+ keypoint_head=dict(
+ type='DeepposeRegressionHead',
+ in_channels=2048,
+ num_joints=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='SmoothL1Loss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(flip_test=True))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTargetRegression'),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/fld'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_upper_train.json',
+ img_prefix=f'{data_root}/img/',
+ subset='upper',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_upper_val.json',
+ img_prefix=f'{data_root}/img/',
+ subset='upper',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_upper_test.json',
+ img_prefix=f'{data_root}/img/',
+ subset='upper',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/res50_deepfashion_full_256x192.py b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/res50_deepfashion_full_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..27bb30f2a1090a4a8d481f63a6c8dc984b7502c3
--- /dev/null
+++ b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/res50_deepfashion_full_256x192.py
@@ -0,0 +1,140 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/deepfashion_full.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=8,
+ dataset_joints=8,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50, num_stages=4, out_indices=(3, )),
+ neck=dict(type='GlobalAveragePooling'),
+ keypoint_head=dict(
+ type='DeepposeRegressionHead',
+ in_channels=2048,
+ num_joints=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='SmoothL1Loss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTargetRegression'),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/fld'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_full_train.json',
+ img_prefix=f'{data_root}/img/',
+ subset='full',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_full_val.json',
+ img_prefix=f'{data_root}/img/',
+ subset='full',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_full_test.json',
+ img_prefix=f'{data_root}/img/',
+ subset='full',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/res50_deepfashion_lower_256x192.py b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/res50_deepfashion_lower_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..c0bb9686100a2ddad266f75e82aaa6b0b42b5017
--- /dev/null
+++ b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/res50_deepfashion_lower_256x192.py
@@ -0,0 +1,140 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/deepfashion_lower.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=4,
+ dataset_joints=4,
+ dataset_channel=[
+ [0, 1, 2, 3],
+ ],
+ inference_channel=[0, 1, 2, 3])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50, num_stages=4, out_indices=(3, )),
+ neck=dict(type='GlobalAveragePooling'),
+ keypoint_head=dict(
+ type='DeepposeRegressionHead',
+ in_channels=2048,
+ num_joints=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='SmoothL1Loss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTargetRegression'),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/fld'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_lower_train.json',
+ img_prefix=f'{data_root}/img/',
+ subset='lower',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_lower_val.json',
+ img_prefix=f'{data_root}/img/',
+ subset='lower',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_lower_test.json',
+ img_prefix=f'{data_root}/img/',
+ subset='lower',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/res50_deepfashion_upper_256x192.py b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/res50_deepfashion_upper_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..e5ca1b245053fb3b8d1c23288155e630dc8d4735
--- /dev/null
+++ b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/res50_deepfashion_upper_256x192.py
@@ -0,0 +1,140 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/deepfashion_upper.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=6,
+ dataset_joints=6,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50, num_stages=4, out_indices=(3, )),
+ neck=dict(type='GlobalAveragePooling'),
+ keypoint_head=dict(
+ type='DeepposeRegressionHead',
+ in_channels=2048,
+ num_joints=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='SmoothL1Loss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTargetRegression'),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/fld'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_upper_train.json',
+ img_prefix=f'{data_root}/img/',
+ subset='upper',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_upper_val.json',
+ img_prefix=f'{data_root}/img/',
+ subset='upper',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_upper_test.json',
+ img_prefix=f'{data_root}/img/',
+ subset='upper',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/resnet_deepfashion.md b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/resnet_deepfashion.md
new file mode 100644
index 0000000000000000000000000000000000000000..d0f3f2a8d8e6a0139d7ecb5c8d9766c1b709a577
--- /dev/null
+++ b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/resnet_deepfashion.md
@@ -0,0 +1,75 @@
+
+
+DeepPose (CVPR'2014)
+ +```bibtex +@inproceedings{toshev2014deeppose, + title={Deeppose: Human pose estimation via deep neural networks}, + author={Toshev, Alexander and Szegedy, Christian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={1653--1660}, + year={2014} +} +``` + +
+
+
+
+
+DeepPose (CVPR'2014)
+ +```bibtex +@inproceedings{toshev2014deeppose, + title={Deeppose: Human pose estimation via deep neural networks}, + author={Toshev, Alexander and Szegedy, Christian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={1653--1660}, + year={2014} +} +``` + +
+
+
+
+
+ResNet (CVPR'2016)
+ +```bibtex +@inproceedings{he2016deep, + title={Deep residual learning for image recognition}, + author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={770--778}, + year={2016} +} +``` + +
+
+
+
+
+DeepFashion (CVPR'2016)
+ +```bibtex +@inproceedings{liuLQWTcvpr16DeepFashion, + author = {Liu, Ziwei and Luo, Ping and Qiu, Shi and Wang, Xiaogang and Tang, Xiaoou}, + title = {DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations}, + booktitle = {Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, + month = {June}, + year = {2016} +} +``` + +
+
+
+Results on DeepFashion val set
+
+|Set | Arch | Input Size | PCK@0.2 | AUC | EPE | ckpt | log |
+| :--- | :---: | :--------: | :------: | :------: | :------: |:------: |:------: |
+|upper | [deeppose_resnet_50](/configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/res50_deepfashion_upper_256x192.py) | 256x256 | 0.965 | 0.535 | 17.2 | [ckpt](https://download.openmmlab.com/mmpose/fashion/deeppose/deeppose_res50_deepfashion_upper_256x192-497799fb_20210309.pth) | [log](https://download.openmmlab.com/mmpose/fashion/deeppose/deeppose_res50_deepfashion_upper_256x192_20210309.log.json) |
+|lower | [deeppose_resnet_50](/configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/res50_deepfashion_lower_256x192.py) | 256x256 | 0.971 | 0.678 | 11.8 | [ckpt](https://download.openmmlab.com/mmpose/fashion/deeppose/deeppose_res50_deepfashion_lower_256x192-94e0e653_20210309.pth) | [log](https://download.openmmlab.com/mmpose/fashion/deeppose/deeppose_res50_deepfashion_lower_256x192_20210309.log.json) |
+|full | [deeppose_resnet_50](/configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/res50_deepfashion_full_256x192.py) | 256x256 | 0.983 | 0.602 | 14.0 | [ckpt](https://download.openmmlab.com/mmpose/fashion/deeppose/deeppose_res50_deepfashion_full_256x192-4e0273e2_20210309.pth) | [log](https://download.openmmlab.com/mmpose/fashion/deeppose/deeppose_res50_deepfashion_full_256x192_20210309.log.json) |
diff --git a/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/resnet_deepfashion.yml b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/resnet_deepfashion.yml
new file mode 100644
index 0000000000000000000000000000000000000000..392ac02117ca9849f94e28ad868ea78366fd4404
--- /dev/null
+++ b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/resnet_deepfashion.yml
@@ -0,0 +1,51 @@
+Collections:
+- Name: ResNet
+ Paper:
+ Title: Deep residual learning for image recognition
+ URL: http://openaccess.thecvf.com/content_cvpr_2016/html/He_Deep_Residual_Learning_CVPR_2016_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/resnet.md
+Models:
+- Config: configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/res50_deepfashion_upper_256x192.py
+ In Collection: ResNet
+ Metadata:
+ Architecture: &id001
+ - DeepPose
+ - ResNet
+ Training Data: DeepFashion
+ Name: deeppose_res50_deepfashion_upper_256x192
+ Results:
+ - Dataset: DeepFashion
+ Metrics:
+ AUC: 0.535
+ EPE: 17.2
+ PCK@0.2: 0.965
+ Task: Fashion 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/fashion/deeppose/deeppose_res50_deepfashion_upper_256x192-497799fb_20210309.pth
+- Config: configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/res50_deepfashion_lower_256x192.py
+ In Collection: ResNet
+ Metadata:
+ Architecture: *id001
+ Training Data: DeepFashion
+ Name: deeppose_res50_deepfashion_lower_256x192
+ Results:
+ - Dataset: DeepFashion
+ Metrics:
+ AUC: 0.678
+ EPE: 11.8
+ PCK@0.2: 0.971
+ Task: Fashion 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/fashion/deeppose/deeppose_res50_deepfashion_lower_256x192-94e0e653_20210309.pth
+- Config: configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/res50_deepfashion_full_256x192.py
+ In Collection: ResNet
+ Metadata:
+ Architecture: *id001
+ Training Data: DeepFashion
+ Name: deeppose_res50_deepfashion_full_256x192
+ Results:
+ - Dataset: DeepFashion
+ Metrics:
+ AUC: 0.602
+ EPE: 14.0
+ PCK@0.2: 0.983
+ Task: Fashion 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/fashion/deeppose/deeppose_res50_deepfashion_full_256x192-4e0273e2_20210309.pth
diff --git a/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/README.md b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..7eaa145f56aa800ccd4449bf2a7d293587c92e2a
--- /dev/null
+++ b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/README.md
@@ -0,0 +1,9 @@
+# Top-down heatmap-based fashion keypoint estimation
+
+Top-down methods divide the task into two stages: clothes detection and fashion keypoint estimation.
+
+They perform clothes detection first, followed by fashion keypoint estimation given fashion bounding boxes.
+Instead of estimating keypoint coordinates directly, the pose estimator will produce heatmaps which represent the
+likelihood of being a keypoint.
+
+Various neural network models have been proposed for better performance.
diff --git a/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/hrnet_w32_deepfashion_full_256x192.py b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/hrnet_w32_deepfashion_full_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..d70d51ee061295b8219e1f09a09437fcceb70110
--- /dev/null
+++ b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/hrnet_w32_deepfashion_full_256x192.py
@@ -0,0 +1,170 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/deepfashion_full.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=8,
+ dataset_joints=8,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/fld'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_full_train.json',
+ img_prefix=f'{data_root}/img/',
+ subset='full',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_full_val.json',
+ img_prefix=f'{data_root}/img/',
+ subset='full',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_full_test.json',
+ img_prefix=f'{data_root}/img/',
+ subset='full',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/hrnet_w32_deepfashion_full_256x192_udp.py b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/hrnet_w32_deepfashion_full_256x192_udp.py
new file mode 100644
index 0000000000000000000000000000000000000000..3a885d3099e5e52bde40c84d24ad2327981e598c
--- /dev/null
+++ b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/hrnet_w32_deepfashion_full_256x192_udp.py
@@ -0,0 +1,177 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/deepfashion_full.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+target_type = 'GaussianHeatmap'
+channel_cfg = dict(
+ num_output_channels=8,
+ dataset_joints=8,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=False,
+ target_type=target_type,
+ modulate_kernel=11,
+ use_udp=True))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='TopDownGenerateTarget',
+ sigma=2,
+ encoding='UDP',
+ target_type=target_type),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/fld'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_full_train.json',
+ img_prefix=f'{data_root}/img/',
+ subset='full',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_full_val.json',
+ img_prefix=f'{data_root}/img/',
+ subset='full',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_full_test.json',
+ img_prefix=f'{data_root}/img/',
+ subset='full',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/hrnet_w32_deepfashion_lower_256x192.py b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/hrnet_w32_deepfashion_lower_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..2a81cfc1bd4d14e3b33e54ab2ad35b7364ccbc82
--- /dev/null
+++ b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/hrnet_w32_deepfashion_lower_256x192.py
@@ -0,0 +1,169 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/deepfashion_lower.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=4,
+ dataset_joints=4,
+ dataset_channel=[
+ [0, 1, 2, 3],
+ ],
+ inference_channel=[0, 1, 2, 3])
+
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/fld'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_lower_train.json',
+ img_prefix=f'{data_root}/img/',
+ subset='lower',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_lower_val.json',
+ img_prefix=f'{data_root}/img/',
+ subset='lower',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_lower_test.json',
+ img_prefix=f'{data_root}/img/',
+ subset='lower',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/hrnet_w32_deepfashion_lower_256x192_udp.py b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/hrnet_w32_deepfashion_lower_256x192_udp.py
new file mode 100644
index 0000000000000000000000000000000000000000..49d7b7d887a05b63c3ee1abd738d8d16d56d7697
--- /dev/null
+++ b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/hrnet_w32_deepfashion_lower_256x192_udp.py
@@ -0,0 +1,176 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/deepfashion_lower.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+target_type = 'GaussianHeatmap'
+channel_cfg = dict(
+ num_output_channels=4,
+ dataset_joints=4,
+ dataset_channel=[
+ [0, 1, 2, 3],
+ ],
+ inference_channel=[0, 1, 2, 3])
+
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=False,
+ target_type=target_type,
+ modulate_kernel=11,
+ use_udp=True))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='TopDownGenerateTarget',
+ sigma=2,
+ encoding='UDP',
+ target_type=target_type),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/fld'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_lower_train.json',
+ img_prefix=f'{data_root}/img/',
+ subset='lower',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_lower_val.json',
+ img_prefix=f'{data_root}/img/',
+ subset='lower',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_lower_test.json',
+ img_prefix=f'{data_root}/img/',
+ subset='lower',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/hrnet_w32_deepfashion_upper_256x192.py b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/hrnet_w32_deepfashion_upper_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..e8bf5bcae11e6bd2afc46b4e2e7a6bd85ea1e7a2
--- /dev/null
+++ b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/hrnet_w32_deepfashion_upper_256x192.py
@@ -0,0 +1,170 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/deepfashion_upper.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=6,
+ dataset_joints=6,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/fld'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_upper_train.json',
+ img_prefix=f'{data_root}/img/',
+ subset='upper',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_upper_val.json',
+ img_prefix=f'{data_root}/img/',
+ subset='upper',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_upper_test.json',
+ img_prefix=f'{data_root}/img/',
+ subset='upper',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/hrnet_w32_deepfashion_upper_256x192_udp.py b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/hrnet_w32_deepfashion_upper_256x192_udp.py
new file mode 100644
index 0000000000000000000000000000000000000000..b5b3bbfc39ab9004b9a65e1ddd3767b117ca11af
--- /dev/null
+++ b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/hrnet_w32_deepfashion_upper_256x192_udp.py
@@ -0,0 +1,177 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/deepfashion_upper.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+target_type = 'GaussianHeatmap'
+channel_cfg = dict(
+ num_output_channels=6,
+ dataset_joints=6,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=False,
+ target_type=target_type,
+ modulate_kernel=11,
+ use_udp=True))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='TopDownGenerateTarget',
+ sigma=2,
+ encoding='UDP',
+ target_type=target_type),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/fld'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_upper_train.json',
+ img_prefix=f'{data_root}/img/',
+ subset='upper',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_upper_val.json',
+ img_prefix=f'{data_root}/img/',
+ subset='upper',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_upper_test.json',
+ img_prefix=f'{data_root}/img/',
+ subset='upper',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/hrnet_w48_deepfashion_full_256x192.py b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/hrnet_w48_deepfashion_full_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..5e61e6a3975770c1d7230a9a13096928dd1b3286
--- /dev/null
+++ b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/hrnet_w48_deepfashion_full_256x192.py
@@ -0,0 +1,170 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/deepfashion_full.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=8,
+ dataset_joints=8,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/fld'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_full_train.json',
+ img_prefix=f'{data_root}/img/',
+ subset='full',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_full_val.json',
+ img_prefix=f'{data_root}/img/',
+ subset='full',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_full_test.json',
+ img_prefix=f'{data_root}/img/',
+ subset='full',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/hrnet_w48_deepfashion_full_256x192_udp.py b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/hrnet_w48_deepfashion_full_256x192_udp.py
new file mode 100644
index 0000000000000000000000000000000000000000..43e039db6c9234cc6eb7e288c641cf72e50392be
--- /dev/null
+++ b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/hrnet_w48_deepfashion_full_256x192_udp.py
@@ -0,0 +1,177 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/deepfashion_full.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+target_type = 'GaussianHeatmap'
+channel_cfg = dict(
+ num_output_channels=8,
+ dataset_joints=8,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=False,
+ target_type=target_type,
+ modulate_kernel=11,
+ use_udp=True))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='TopDownGenerateTarget',
+ sigma=2,
+ encoding='UDP',
+ target_type=target_type),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/fld'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_full_train.json',
+ img_prefix=f'{data_root}/img/',
+ subset='full',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_full_val.json',
+ img_prefix=f'{data_root}/img/',
+ subset='full',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_full_test.json',
+ img_prefix=f'{data_root}/img/',
+ subset='full',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/hrnet_w48_deepfashion_lower_256x192.py b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/hrnet_w48_deepfashion_lower_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..b03d6801265c24a364686bda8a6aa55ea7867e61
--- /dev/null
+++ b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/hrnet_w48_deepfashion_lower_256x192.py
@@ -0,0 +1,170 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/deepfashion_lower.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=4,
+ dataset_joints=4,
+ dataset_channel=[
+ [0, 1, 2, 3],
+ ],
+ inference_channel=[0, 1, 2, 3])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/fld'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_lower_train.json',
+ img_prefix=f'{data_root}/img/',
+ subset='lower',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_lower_val.json',
+ img_prefix=f'{data_root}/img/',
+ subset='lower',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_lower_test.json',
+ img_prefix=f'{data_root}/img/',
+ subset='lower',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/hrnet_w48_deepfashion_lower_256x192_udp.py b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/hrnet_w48_deepfashion_lower_256x192_udp.py
new file mode 100644
index 0000000000000000000000000000000000000000..c42bb4aa15c86d72107fe8cf3616bc74ba370efa
--- /dev/null
+++ b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/hrnet_w48_deepfashion_lower_256x192_udp.py
@@ -0,0 +1,177 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/deepfashion_lower.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+target_type = 'GaussianHeatmap'
+channel_cfg = dict(
+ num_output_channels=4,
+ dataset_joints=4,
+ dataset_channel=[
+ [0, 1, 2, 3],
+ ],
+ inference_channel=[0, 1, 2, 3])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=False,
+ target_type=target_type,
+ modulate_kernel=11,
+ use_udp=True))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='TopDownGenerateTarget',
+ sigma=2,
+ encoding='UDP',
+ target_type=target_type),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/fld'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_lower_train.json',
+ img_prefix=f'{data_root}/img/',
+ subset='lower',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_lower_val.json',
+ img_prefix=f'{data_root}/img/',
+ subset='lower',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_lower_test.json',
+ img_prefix=f'{data_root}/img/',
+ subset='lower',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/hrnet_w48_deepfashion_upper_256x192.py b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/hrnet_w48_deepfashion_upper_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..aa14b3c2bb524adc15247e2b7632cec3c726b45d
--- /dev/null
+++ b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/hrnet_w48_deepfashion_upper_256x192.py
@@ -0,0 +1,170 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/deepfashion_upper.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=6,
+ dataset_joints=6,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/fld'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_upper_train.json',
+ img_prefix=f'{data_root}/img/',
+ subset='upper',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_upper_val.json',
+ img_prefix=f'{data_root}/img/',
+ subset='upper',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_upper_test.json',
+ img_prefix=f'{data_root}/img/',
+ subset='upper',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/hrnet_w48_deepfashion_upper_256x192_udp.py b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/hrnet_w48_deepfashion_upper_256x192_udp.py
new file mode 100644
index 0000000000000000000000000000000000000000..9f01adb699a1ce9c48281e1f78a6b51f1de7b476
--- /dev/null
+++ b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/hrnet_w48_deepfashion_upper_256x192_udp.py
@@ -0,0 +1,177 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/deepfashion_upper.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+target_type = 'GaussianHeatmap'
+channel_cfg = dict(
+ num_output_channels=6,
+ dataset_joints=6,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=False,
+ target_type=target_type,
+ modulate_kernel=11,
+ use_udp=True))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='TopDownGenerateTarget',
+ sigma=2,
+ encoding='UDP',
+ target_type=target_type),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/fld'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_upper_train.json',
+ img_prefix=f'{data_root}/img/',
+ subset='upper',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_upper_val.json',
+ img_prefix=f'{data_root}/img/',
+ subset='upper',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_upper_test.json',
+ img_prefix=f'{data_root}/img/',
+ subset='upper',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/res101_deepfashion_full_256x192.py b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/res101_deepfashion_full_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..038111db308e57fcc53f69c0de2b8ed99c4c872e
--- /dev/null
+++ b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/res101_deepfashion_full_256x192.py
@@ -0,0 +1,139 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/deepfashion_full.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=8,
+ dataset_joints=8,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet101',
+ backbone=dict(type='ResNet', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/fld'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_full_train.json',
+ img_prefix=f'{data_root}/img/',
+ subset='full',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_full_val.json',
+ img_prefix=f'{data_root}/img/',
+ subset='full',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_full_test.json',
+ img_prefix=f'{data_root}/img/',
+ subset='full',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/res101_deepfashion_lower_256x192.py b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/res101_deepfashion_lower_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..530161a5813c090968b954df4cb2f8a495656377
--- /dev/null
+++ b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/res101_deepfashion_lower_256x192.py
@@ -0,0 +1,139 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/deepfashion_lower.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=4,
+ dataset_joints=4,
+ dataset_channel=[
+ [0, 1, 2, 3],
+ ],
+ inference_channel=[0, 1, 2, 3])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet101',
+ backbone=dict(type='ResNet', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/fld'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_lower_train.json',
+ img_prefix=f'{data_root}/img/',
+ subset='lower',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_lower_val.json',
+ img_prefix=f'{data_root}/img/',
+ subset='lower',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_lower_test.json',
+ img_prefix=f'{data_root}/img/',
+ subset='lower',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/res101_deepfashion_upper_256x192.py b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/res101_deepfashion_upper_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..bf3b7d2e0bfa1e31cd437f28ade2b8244495b1f3
--- /dev/null
+++ b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/res101_deepfashion_upper_256x192.py
@@ -0,0 +1,139 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/deepfashion_upper.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=6,
+ dataset_joints=6,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet101',
+ backbone=dict(type='ResNet', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/fld'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_upper_train.json',
+ img_prefix=f'{data_root}/img/',
+ subset='upper',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_upper_val.json',
+ img_prefix=f'{data_root}/img/',
+ subset='upper',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_upper_test.json',
+ img_prefix=f'{data_root}/img/',
+ subset='upper',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/res152_deepfashion_full_256x192.py b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/res152_deepfashion_full_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..da19ce28ad2f3b0408dc1802e586727272103b02
--- /dev/null
+++ b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/res152_deepfashion_full_256x192.py
@@ -0,0 +1,139 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/deepfashion_full.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=8,
+ dataset_joints=8,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet152',
+ backbone=dict(type='ResNet', depth=152),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/fld'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_full_train.json',
+ img_prefix=f'{data_root}/img/',
+ subset='full',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_full_val.json',
+ img_prefix=f'{data_root}/img/',
+ subset='full',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_full_test.json',
+ img_prefix=f'{data_root}/img/',
+ subset='full',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/res152_deepfashion_lower_256x192.py b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/res152_deepfashion_lower_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..dfe78cf8a29ee60371755995a52dfce4e7eeec26
--- /dev/null
+++ b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/res152_deepfashion_lower_256x192.py
@@ -0,0 +1,139 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/deepfashion_lower.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=4,
+ dataset_joints=4,
+ dataset_channel=[
+ [0, 1, 2, 3],
+ ],
+ inference_channel=[0, 1, 2, 3])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet152',
+ backbone=dict(type='ResNet', depth=152),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/fld'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_lower_train.json',
+ img_prefix=f'{data_root}/img/',
+ subset='lower',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_lower_val.json',
+ img_prefix=f'{data_root}/img/',
+ subset='lower',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_lower_test.json',
+ img_prefix=f'{data_root}/img/',
+ subset='lower',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/res152_deepfashion_upper_256x192.py b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/res152_deepfashion_upper_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..93d0ef51654f6473728ba725d1e0acfffd078711
--- /dev/null
+++ b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/res152_deepfashion_upper_256x192.py
@@ -0,0 +1,139 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/deepfashion_upper.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=6,
+ dataset_joints=6,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet152',
+ backbone=dict(type='ResNet', depth=152),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/fld'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_upper_train.json',
+ img_prefix=f'{data_root}/img/',
+ subset='upper',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_upper_val.json',
+ img_prefix=f'{data_root}/img/',
+ subset='upper',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_upper_test.json',
+ img_prefix=f'{data_root}/img/',
+ subset='upper',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/res50_deepfashion_full_256x192.py b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/res50_deepfashion_full_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..559cb3a2298be62bc06a47b2561c1ceda55247a3
--- /dev/null
+++ b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/res50_deepfashion_full_256x192.py
@@ -0,0 +1,139 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/deepfashion_full.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=8,
+ dataset_joints=8,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5, 6, 7],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5, 6, 7])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/fld'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_full_train.json',
+ img_prefix=f'{data_root}/img/',
+ subset='full',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_full_val.json',
+ img_prefix=f'{data_root}/img/',
+ subset='full',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_full_test.json',
+ img_prefix=f'{data_root}/img/',
+ subset='full',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/res50_deepfashion_lower_256x192.py b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/res50_deepfashion_lower_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..6be9538ccf0b62a8a6e3501a429633c0a9dc74ec
--- /dev/null
+++ b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/res50_deepfashion_lower_256x192.py
@@ -0,0 +1,139 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/deepfashion_lower.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=4,
+ dataset_joints=4,
+ dataset_channel=[
+ [0, 1, 2, 3],
+ ],
+ inference_channel=[0, 1, 2, 3])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/fld'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_lower_train.json',
+ img_prefix=f'{data_root}/img/',
+ subset='lower',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_lower_val.json',
+ img_prefix=f'{data_root}/img/',
+ subset='lower',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_lower_test.json',
+ img_prefix=f'{data_root}/img/',
+ subset='lower',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/res50_deepfashion_upper_256x192.py b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/res50_deepfashion_upper_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..6e45afeccb104c505b492d2d94620f903138b75e
--- /dev/null
+++ b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/res50_deepfashion_upper_256x192.py
@@ -0,0 +1,139 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/deepfashion_upper.py'
+]
+evaluation = dict(interval=10, metric='PCK', save_best='PCK')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=6,
+ dataset_joints=6,
+ dataset_channel=[
+ [0, 1, 2, 3, 4, 5],
+ ],
+ inference_channel=[0, 1, 2, 3, 4, 5])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/fld'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_upper_train.json',
+ img_prefix=f'{data_root}/img/',
+ subset='upper',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_upper_val.json',
+ img_prefix=f'{data_root}/img/',
+ subset='upper',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='DeepFashionDataset',
+ ann_file=f'{data_root}/annotations/fld_upper_test.json',
+ img_prefix=f'{data_root}/img/',
+ subset='upper',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/resnet_deepfashion.md b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/resnet_deepfashion.md
new file mode 100644
index 0000000000000000000000000000000000000000..ca23c8d1e0abe08f0482e81f32869c0fb7778161
--- /dev/null
+++ b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/resnet_deepfashion.md
@@ -0,0 +1,75 @@
+
+
+DeepFashion (ECCV'2016)
+ +```bibtex +@inproceedings{liuYLWTeccv16FashionLandmark, + author = {Liu, Ziwei and Yan, Sijie and Luo, Ping and Wang, Xiaogang and Tang, Xiaoou}, + title = {Fashion Landmark Detection in the Wild}, + booktitle = {European Conference on Computer Vision (ECCV)}, + month = {October}, + year = {2016} + } +``` + +
+
+
+
+
+SimpleBaseline2D (ECCV'2018)
+ +```bibtex +@inproceedings{xiao2018simple, + title={Simple baselines for human pose estimation and tracking}, + author={Xiao, Bin and Wu, Haiping and Wei, Yichen}, + booktitle={Proceedings of the European conference on computer vision (ECCV)}, + pages={466--481}, + year={2018} +} +``` + +
+
+
+
+
+ResNet (CVPR'2016)
+ +```bibtex +@inproceedings{he2016deep, + title={Deep residual learning for image recognition}, + author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={770--778}, + year={2016} +} +``` + +
+
+
+
+
+DeepFashion (CVPR'2016)
+ +```bibtex +@inproceedings{liuLQWTcvpr16DeepFashion, + author = {Liu, Ziwei and Luo, Ping and Qiu, Shi and Wang, Xiaogang and Tang, Xiaoou}, + title = {DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations}, + booktitle = {Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, + month = {June}, + year = {2016} +} +``` + +
+
+
+Results on DeepFashion val set
+
+|Set | Arch | Input Size | PCK@0.2 | AUC | EPE | ckpt | log |
+| :--- | :---: | :--------: | :------: | :------: | :------: |:------: |:------: |
+|upper | [pose_resnet_50](/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/res50_deepfashion_upper_256x192.py) | 256x256 | 0.954 | 0.578 | 16.8 | [ckpt](https://download.openmmlab.com/mmpose/fashion/resnet/res50_deepfashion_upper_256x192-41794f03_20210124.pth) | [log](https://download.openmmlab.com/mmpose/fashion/resnet/res50_deepfashion_upper_256x192_20210124.log.json) |
+|lower | [pose_resnet_50](/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/res50_deepfashion_lower_256x192.py) | 256x256 | 0.965 | 0.744 | 10.5 | [ckpt](https://download.openmmlab.com/mmpose/fashion/resnet/res50_deepfashion_lower_256x192-1292a839_20210124.pth) | [log](https://download.openmmlab.com/mmpose/fashion/resnet/res50_deepfashion_lower_256x192_20210124.log.json) |
+|full | [pose_resnet_50](/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/res50_deepfashion_full_256x192.py) | 256x256 | 0.977 | 0.664 | 12.7 | [ckpt](https://download.openmmlab.com/mmpose/fashion/resnet/res50_deepfashion_full_256x192-0dbd6e42_20210124.pth) | [log](https://download.openmmlab.com/mmpose/fashion/resnet/res50_deepfashion_full_256x192_20210124.log.json) |
diff --git a/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/resnet_deepfashion.yml b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/resnet_deepfashion.yml
new file mode 100644
index 0000000000000000000000000000000000000000..bd871418d2bc6bb1ca532f51bc7464b215af4dea
--- /dev/null
+++ b/vendor/ViTPose/configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/resnet_deepfashion.yml
@@ -0,0 +1,51 @@
+Collections:
+- Name: SimpleBaseline2D
+ Paper:
+ Title: Simple baselines for human pose estimation and tracking
+ URL: http://openaccess.thecvf.com/content_ECCV_2018/html/Bin_Xiao_Simple_Baselines_for_ECCV_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/simplebaseline2d.md
+Models:
+- Config: configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/res50_deepfashion_upper_256x192.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: &id001
+ - SimpleBaseline2D
+ - ResNet
+ Training Data: DeepFashion
+ Name: topdown_heatmap_res50_deepfashion_upper_256x192
+ Results:
+ - Dataset: DeepFashion
+ Metrics:
+ AUC: 0.578
+ EPE: 16.8
+ PCK@0.2: 0.954
+ Task: Fashion 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/fashion/resnet/res50_deepfashion_upper_256x192-41794f03_20210124.pth
+- Config: configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/res50_deepfashion_lower_256x192.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: DeepFashion
+ Name: topdown_heatmap_res50_deepfashion_lower_256x192
+ Results:
+ - Dataset: DeepFashion
+ Metrics:
+ AUC: 0.744
+ EPE: 10.5
+ PCK@0.2: 0.965
+ Task: Fashion 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/fashion/resnet/res50_deepfashion_lower_256x192-1292a839_20210124.pth
+- Config: configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/res50_deepfashion_full_256x192.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: DeepFashion
+ Name: topdown_heatmap_res50_deepfashion_full_256x192
+ Results:
+ - Dataset: DeepFashion
+ Metrics:
+ AUC: 0.664
+ EPE: 12.7
+ PCK@0.2: 0.977
+ Task: Fashion 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/fashion/resnet/res50_deepfashion_full_256x192-0dbd6e42_20210124.pth
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/README.md b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..b8047eafa65f864d8797ab6faf834f3fbf5176a3
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/README.md
@@ -0,0 +1,16 @@
+# 2D Hand Pose Estimation
+
+2D hand pose estimation is defined as the task of detecting the poses (or keypoints) of the hand from an input image.
+
+Normally, the input images are cropped hand images, where the hand locates at the center;
+or the rough location (or the bounding box) of the hand is provided.
+
+## Data preparation
+
+Please follow [DATA Preparation](/docs/en/tasks/2d_hand_keypoint.md) to prepare data.
+
+## Demo
+
+Please follow [Demo](/demo/docs/2d_hand_demo.md) to run demos.
+
+DeepFashion (ECCV'2016)
+ +```bibtex +@inproceedings{liuYLWTeccv16FashionLandmark, + author = {Liu, Ziwei and Yan, Sijie and Luo, Ping and Wang, Xiaogang and Tang, Xiaoou}, + title = {Fashion Landmark Detection in the Wild}, + booktitle = {European Conference on Computer Vision (ECCV)}, + month = {October}, + year = {2016} + } +``` + +
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/deeppose/README.md b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/deeppose/README.md new file mode 100644 index 0000000000000000000000000000000000000000..846d120515552a9ced401bb0bee64dbe3b76a74e --- /dev/null +++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/deeppose/README.md @@ -0,0 +1,24 @@ +# Deeppose: Human pose estimation via deep neural networks + +## Introduction + + + +
+
+
+DeepPose first proposes using deep neural networks (DNNs) to tackle the problem of keypoint detection.
+It follows the top-down paradigm, that first detects the bounding boxes and then estimates poses.
+It learns to directly regress the hand keypoint coordinates.
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/deeppose/onehand10k/res50_onehand10k_256x256.py b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/deeppose/onehand10k/res50_onehand10k_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..3fdde7549739c6a2adfffbbdddf77a8c2def4f6c
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/deeppose/onehand10k/res50_onehand10k_256x256.py
@@ -0,0 +1,131 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/onehand10k.py'
+]
+evaluation = dict(interval=10, metric=['PCK', 'AUC', 'EPE'], save_best='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=21,
+ dataset_joints=21,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50, num_stages=4, out_indices=(3, )),
+ neck=dict(type='GlobalAveragePooling'),
+ keypoint_head=dict(
+ type='DeepposeRegressionHead',
+ in_channels=2048,
+ num_joints=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='SmoothL1Loss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTargetRegression'),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/onehand10k'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='OneHand10KDataset',
+ ann_file=f'{data_root}/annotations/onehand10k_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='OneHand10KDataset',
+ ann_file=f'{data_root}/annotations/onehand10k_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='OneHand10KDataset',
+ ann_file=f'{data_root}/annotations/onehand10k_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/deeppose/onehand10k/resnet_onehand10k.md b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/deeppose/onehand10k/resnet_onehand10k.md
new file mode 100644
index 0000000000000000000000000000000000000000..42b2a01652d81cb09801e9cf96f3453d184a6b95
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/deeppose/onehand10k/resnet_onehand10k.md
@@ -0,0 +1,59 @@
+
+
+DeepPose (CVPR'2014)
+ +```bibtex +@inproceedings{toshev2014deeppose, + title={Deeppose: Human pose estimation via deep neural networks}, + author={Toshev, Alexander and Szegedy, Christian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={1653--1660}, + year={2014} +} +``` + +
+
+
+
+
+DeepPose (CVPR'2014)
+ +```bibtex +@inproceedings{toshev2014deeppose, + title={Deeppose: Human pose estimation via deep neural networks}, + author={Toshev, Alexander and Szegedy, Christian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={1653--1660}, + year={2014} +} +``` + +
+
+
+
+
+ResNet (CVPR'2016)
+ +```bibtex +@inproceedings{he2016deep, + title={Deep residual learning for image recognition}, + author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={770--778}, + year={2016} +} +``` + +
+
+
+Results on OneHand10K val set
+
+| Arch | Input Size | PCK@0.2 | AUC | EPE | ckpt | log |
+| :--- | :--------: | :------: | :------: | :------: |:------: |:------: |
+| [deeppose_resnet_50](/configs/hand/2d_kpt_sview_rgb_img/deeppose/onehand10k/res50_onehand10k_256x256.py) | 256x256 | 0.990 | 0.486 | 34.28 | [ckpt](https://download.openmmlab.com/mmpose/hand/deeppose/deeppose_res50_onehand10k_256x256-cbddf43a_20210330.pth) | [log](https://download.openmmlab.com/mmpose/hand/deeppose/deeppose_res50_onehand10k_256x256_20210330.log.json) |
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/deeppose/onehand10k/resnet_onehand10k.yml b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/deeppose/onehand10k/resnet_onehand10k.yml
new file mode 100644
index 0000000000000000000000000000000000000000..994a32a658dbd49b775b943331eef01ac099a798
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/deeppose/onehand10k/resnet_onehand10k.yml
@@ -0,0 +1,23 @@
+Collections:
+- Name: ResNet
+ Paper:
+ Title: Deep residual learning for image recognition
+ URL: http://openaccess.thecvf.com/content_cvpr_2016/html/He_Deep_Residual_Learning_CVPR_2016_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/resnet.md
+Models:
+- Config: configs/hand/2d_kpt_sview_rgb_img/deeppose/onehand10k/res50_onehand10k_256x256.py
+ In Collection: ResNet
+ Metadata:
+ Architecture:
+ - DeepPose
+ - ResNet
+ Training Data: OneHand10K
+ Name: deeppose_res50_onehand10k_256x256
+ Results:
+ - Dataset: OneHand10K
+ Metrics:
+ AUC: 0.486
+ EPE: 34.28
+ PCK@0.2: 0.99
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/deeppose/deeppose_res50_onehand10k_256x256-cbddf43a_20210330.pth
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/deeppose/panoptic2d/res50_panoptic2d_256x256.py b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/deeppose/panoptic2d/res50_panoptic2d_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..c0fd4d3738ecc2d43797da61ec2c4cb6465e7a12
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/deeppose/panoptic2d/res50_panoptic2d_256x256.py
@@ -0,0 +1,131 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/panoptic_hand2d.py'
+]
+evaluation = dict(interval=10, metric=['PCKh', 'AUC', 'EPE'], save_best='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=21,
+ dataset_joints=21,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50, num_stages=4, out_indices=(3, )),
+ neck=dict(type='GlobalAveragePooling'),
+ keypoint_head=dict(
+ type='DeepposeRegressionHead',
+ in_channels=2048,
+ num_joints=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='SmoothL1Loss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTargetRegression'),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/panoptic'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='PanopticDataset',
+ ann_file=f'{data_root}/annotations/panoptic_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='PanopticDataset',
+ ann_file=f'{data_root}/annotations/panoptic_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='PanopticDataset',
+ ann_file=f'{data_root}/annotations/panoptic_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/deeppose/panoptic2d/resnet_panoptic2d.md b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/deeppose/panoptic2d/resnet_panoptic2d.md
new file mode 100644
index 0000000000000000000000000000000000000000..b5082315a9d7be26bdc4aca87324a32f996e76ae
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/deeppose/panoptic2d/resnet_panoptic2d.md
@@ -0,0 +1,56 @@
+
+
+OneHand10K (TCSVT'2019)
+ +```bibtex +@article{wang2018mask, + title={Mask-pose cascaded cnn for 2d hand pose estimation from single color image}, + author={Wang, Yangang and Peng, Cong and Liu, Yebin}, + journal={IEEE Transactions on Circuits and Systems for Video Technology}, + volume={29}, + number={11}, + pages={3258--3268}, + year={2018}, + publisher={IEEE} +} +``` + +
+
+
+
+
+DeepPose (CVPR'2014)
+ +```bibtex +@inproceedings{toshev2014deeppose, + title={Deeppose: Human pose estimation via deep neural networks}, + author={Toshev, Alexander and Szegedy, Christian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={1653--1660}, + year={2014} +} +``` + +
+
+
+
+
+ResNet (CVPR'2016)
+ +```bibtex +@inproceedings{he2016deep, + title={Deep residual learning for image recognition}, + author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={770--778}, + year={2016} +} +``` + +
+
+
+Results on CMU Panoptic (MPII+NZSL val set)
+
+| Arch | Input Size | PCKh@0.7 | AUC | EPE | ckpt | log |
+| :--- | :--------: | :------: | :------: | :------: |:------: |:------: |
+| [deeppose_resnet_50](/configs/hand/2d_kpt_sview_rgb_img/deeppose/panoptic2d/res50_panoptic2d_256x256.py) | 256x256 | 0.999 | 0.686 | 9.36 | [ckpt](https://download.openmmlab.com/mmpose/hand/deeppose/deeppose_res50_panoptic_256x256-8a745183_20210330.pth) | [log](https://download.openmmlab.com/mmpose/hand/deeppose/deeppose_res50_panoptic_256x256_20210330.log.json) |
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/deeppose/panoptic2d/resnet_panoptic2d.yml b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/deeppose/panoptic2d/resnet_panoptic2d.yml
new file mode 100644
index 0000000000000000000000000000000000000000..1cf7747b501fcf6cbdfc41b90e2978136d94e405
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/deeppose/panoptic2d/resnet_panoptic2d.yml
@@ -0,0 +1,23 @@
+Collections:
+- Name: ResNet
+ Paper:
+ Title: Deep residual learning for image recognition
+ URL: http://openaccess.thecvf.com/content_cvpr_2016/html/He_Deep_Residual_Learning_CVPR_2016_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/resnet.md
+Models:
+- Config: configs/hand/2d_kpt_sview_rgb_img/deeppose/panoptic2d/res50_panoptic2d_256x256.py
+ In Collection: ResNet
+ Metadata:
+ Architecture:
+ - DeepPose
+ - ResNet
+ Training Data: CMU Panoptic HandDB
+ Name: deeppose_res50_panoptic2d_256x256
+ Results:
+ - Dataset: CMU Panoptic HandDB
+ Metrics:
+ AUC: 0.686
+ EPE: 9.36
+ PCKh@0.7: 0.999
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/deeppose/deeppose_res50_panoptic_256x256-8a745183_20210330.pth
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/deeppose/rhd2d/res50_rhd2d_256x256.py b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/deeppose/rhd2d/res50_rhd2d_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..fdcfb45cabe874c9518bead088e685730f1c4afb
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/deeppose/rhd2d/res50_rhd2d_256x256.py
@@ -0,0 +1,131 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/rhd2d.py'
+]
+evaluation = dict(interval=10, metric=['PCK', 'AUC', 'EPE'], save_best='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=21,
+ dataset_joints=21,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50, num_stages=4, out_indices=(3, )),
+ neck=dict(type='GlobalAveragePooling'),
+ keypoint_head=dict(
+ type='DeepposeRegressionHead',
+ in_channels=2048,
+ num_joints=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='SmoothL1Loss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTargetRegression'),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/rhd'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='Rhd2DDataset',
+ ann_file=f'{data_root}/annotations/rhd_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='Rhd2DDataset',
+ ann_file=f'{data_root}/annotations/rhd_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='Rhd2DDataset',
+ ann_file=f'{data_root}/annotations/rhd_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/deeppose/rhd2d/resnet_rhd2d.md b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/deeppose/rhd2d/resnet_rhd2d.md
new file mode 100644
index 0000000000000000000000000000000000000000..292552054428493f0b4b8941d8928fa089b77cd9
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/deeppose/rhd2d/resnet_rhd2d.md
@@ -0,0 +1,57 @@
+
+
+CMU Panoptic HandDB (CVPR'2017)
+ +```bibtex +@inproceedings{simon2017hand, + title={Hand keypoint detection in single images using multiview bootstrapping}, + author={Simon, Tomas and Joo, Hanbyul and Matthews, Iain and Sheikh, Yaser}, + booktitle={Proceedings of the IEEE conference on Computer Vision and Pattern Recognition}, + pages={1145--1153}, + year={2017} +} +``` + +
+
+
+
+
+DeepPose (CVPR'2014)
+ +```bibtex +@inproceedings{toshev2014deeppose, + title={Deeppose: Human pose estimation via deep neural networks}, + author={Toshev, Alexander and Szegedy, Christian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={1653--1660}, + year={2014} +} +``` + +
+
+
+
+
+ResNet (CVPR'2016)
+ +```bibtex +@inproceedings{he2016deep, + title={Deep residual learning for image recognition}, + author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={770--778}, + year={2016} +} +``` + +
+
+
+Results on RHD test set
+
+| Arch | Input Size | PCK@0.2 | AUC | EPE | ckpt | log |
+| :--- | :--------: | :------: | :------: | :------: |:------: |:------: |
+| [deeppose_resnet_50](/configs/hand/2d_kpt_sview_rgb_img/deeppose/rhd2d/res50_rhd2d_256x256.py) | 256x256 | 0.988 | 0.865 | 3.29 | [ckpt](https://download.openmmlab.com/mmpose/hand/deeppose/deeppose_res50_rhd2d_256x256-37f1c4d3_20210330.pth) | [log](https://download.openmmlab.com/mmpose/hand/deeppose/deeppose_res50_rhd2d_256x256_20210330.log.json) |
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/deeppose/rhd2d/resnet_rhd2d.yml b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/deeppose/rhd2d/resnet_rhd2d.yml
new file mode 100644
index 0000000000000000000000000000000000000000..5ba15ad3c865e0792a9a42f1b3325a49263e7361
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/deeppose/rhd2d/resnet_rhd2d.yml
@@ -0,0 +1,23 @@
+Collections:
+- Name: ResNet
+ Paper:
+ Title: Deep residual learning for image recognition
+ URL: http://openaccess.thecvf.com/content_cvpr_2016/html/He_Deep_Residual_Learning_CVPR_2016_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/resnet.md
+Models:
+- Config: configs/hand/2d_kpt_sview_rgb_img/deeppose/rhd2d/res50_rhd2d_256x256.py
+ In Collection: ResNet
+ Metadata:
+ Architecture:
+ - DeepPose
+ - ResNet
+ Training Data: RHD
+ Name: deeppose_res50_rhd2d_256x256
+ Results:
+ - Dataset: RHD
+ Metrics:
+ AUC: 0.865
+ EPE: 3.29
+ PCK@0.2: 0.988
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/deeppose/deeppose_res50_rhd2d_256x256-37f1c4d3_20210330.pth
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/README.md b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..82d150bd1f9479c8a9794f2d137f0ddcdb862279
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/README.md
@@ -0,0 +1,9 @@
+# Top-down heatmap-based hand keypoint estimation
+
+Top-down methods divide the task into two stages: hand detection and hand keypoint estimation.
+
+They perform hand detection first, followed by hand keypoint estimation given hand bounding boxes.
+Instead of estimating keypoint coordinates directly, the pose estimator will produce heatmaps which represent the
+likelihood of being a keypoint.
+
+Various neural network models have been proposed for better performance.
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/hourglass52_coco_wholebody_hand_256x256.py b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/hourglass52_coco_wholebody_hand_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..3e79ae581970c2c83dec872da365f3b1b8d016b5
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/hourglass52_coco_wholebody_hand_256x256.py
@@ -0,0 +1,137 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody_hand.py'
+]
+evaluation = dict(
+ interval=10, metric=['PCK', 'AUC', 'EPE'], key_indicator='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=21,
+ dataset_joints=21,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='HourglassNet',
+ num_stacks=1,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapMultiStageHead',
+ in_channels=256,
+ out_channels=channel_cfg['num_output_channels'],
+ num_stages=1,
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='HandCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='HandCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='HandCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/hourglass_coco_wholebody_hand.md b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/hourglass_coco_wholebody_hand.md
new file mode 100644
index 0000000000000000000000000000000000000000..72438883fa6eeb95fb413c8963dc4155743a75dd
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/hourglass_coco_wholebody_hand.md
@@ -0,0 +1,39 @@
+
+
+RHD (ICCV'2017)
+ +```bibtex +@TechReport{zb2017hand, + author={Christian Zimmermann and Thomas Brox}, + title={Learning to Estimate 3D Hand Pose from Single RGB Images}, + institution={arXiv:1705.01389}, + year={2017}, + note="https://arxiv.org/abs/1705.01389", + url="https://lmb.informatik.uni-freiburg.de/projects/hand3d/" +} +``` + +
+
+
+
+
+Hourglass (ECCV'2016)
+ +```bibtex +@inproceedings{newell2016stacked, + title={Stacked hourglass networks for human pose estimation}, + author={Newell, Alejandro and Yang, Kaiyu and Deng, Jia}, + booktitle={European conference on computer vision}, + pages={483--499}, + year={2016}, + organization={Springer} +} +``` + +
+
+
+Results on COCO-WholeBody-Hand val set
+
+| Arch | Input Size | PCK@0.2 | AUC | EPE | ckpt | log |
+| :--- | :--------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_hourglass_52](/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/hourglass52_coco_wholebody_hand_256x256.py) | 256x256 | 0.804 | 0.835 | 4.54 | [ckpt](https://download.openmmlab.com/mmpose/hand/hourglass/hourglass52_coco_wholebody_hand_256x256-7b05c6db_20210909.pth) | [log](https://download.openmmlab.com/mmpose/hand/hourglass/hourglass52_coco_wholebody_hand_256x256_20210909.log.json) |
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/hourglass_coco_wholebody_hand.yml b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/hourglass_coco_wholebody_hand.yml
new file mode 100644
index 0000000000000000000000000000000000000000..426952c6f4f658b6b332a3b78e369f955952baf9
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/hourglass_coco_wholebody_hand.yml
@@ -0,0 +1,22 @@
+Collections:
+- Name: Hourglass
+ Paper:
+ Title: Stacked hourglass networks for human pose estimation
+ URL: https://link.springer.com/chapter/10.1007/978-3-319-46484-8_29
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/hourglass.md
+Models:
+- Config: configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/hourglass52_coco_wholebody_hand_256x256.py
+ In Collection: Hourglass
+ Metadata:
+ Architecture:
+ - Hourglass
+ Training Data: COCO-WholeBody-Hand
+ Name: topdown_heatmap_hourglass52_coco_wholebody_hand_256x256
+ Results:
+ - Dataset: COCO-WholeBody-Hand
+ Metrics:
+ AUC: 0.835
+ EPE: 4.54
+ PCK@0.2: 0.804
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/hourglass/hourglass52_coco_wholebody_hand_256x256-7b05c6db_20210909.pth
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/hrnetv2_coco_wholebody_hand.md b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/hrnetv2_coco_wholebody_hand.md
new file mode 100644
index 0000000000000000000000000000000000000000..15f08e168e484e2775f7f35dd02c832bc6f0393f
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/hrnetv2_coco_wholebody_hand.md
@@ -0,0 +1,39 @@
+
+
+COCO-WholeBody-Hand (ECCV'2020)
+ +```bibtex +@inproceedings{jin2020whole, + title={Whole-Body Human Pose Estimation in the Wild}, + author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping}, + booktitle={Proceedings of the European Conference on Computer Vision (ECCV)}, + year={2020} +} +``` + +
+
+
+
+
+HRNetv2 (TPAMI'2019)
+ +```bibtex +@article{WangSCJDZLMTWLX19, + title={Deep High-Resolution Representation Learning for Visual Recognition}, + author={Jingdong Wang and Ke Sun and Tianheng Cheng and + Borui Jiang and Chaorui Deng and Yang Zhao and Dong Liu and Yadong Mu and + Mingkui Tan and Xinggang Wang and Wenyu Liu and Bin Xiao}, + journal={TPAMI}, + year={2019} +} +``` + +
+
+
+Results on COCO-WholeBody-Hand val set
+
+| Arch | Input Size | PCK@0.2 | AUC | EPE | ckpt | log |
+| :--- | :--------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_hrnetv2_w18](/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/hrnetv2_w18_coco_wholebody_hand_256x256.py) | 256x256 | 0.813 | 0.840 | 4.39 | [ckpt](https://download.openmmlab.com/mmpose/hand/hrnetv2/hrnetv2_w18_coco_wholebody_hand_256x256-1c028db7_20210908.pth) | [log](https://download.openmmlab.com/mmpose/hand/hrnetv2/hrnetv2_w18_coco_wholebody_hand_256x256_20210908.log.json) |
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/hrnetv2_coco_wholebody_hand.yml b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/hrnetv2_coco_wholebody_hand.yml
new file mode 100644
index 0000000000000000000000000000000000000000..1a4b4445d9985fbb1d4e18174127f95ded5269ce
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/hrnetv2_coco_wholebody_hand.yml
@@ -0,0 +1,22 @@
+Collections:
+- Name: HRNetv2
+ Paper:
+ Title: Deep High-Resolution Representation Learning for Visual Recognition
+ URL: https://ieeexplore.ieee.org/abstract/document/9052469/
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/hrnetv2.md
+Models:
+- Config: configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/hrnetv2_w18_coco_wholebody_hand_256x256.py
+ In Collection: HRNetv2
+ Metadata:
+ Architecture:
+ - HRNetv2
+ Training Data: COCO-WholeBody-Hand
+ Name: topdown_heatmap_hrnetv2_w18_coco_wholebody_hand_256x256
+ Results:
+ - Dataset: COCO-WholeBody-Hand
+ Metrics:
+ AUC: 0.84
+ EPE: 4.39
+ PCK@0.2: 0.813
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/hrnetv2/hrnetv2_w18_coco_wholebody_hand_256x256-1c028db7_20210908.pth
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/hrnetv2_dark_coco_wholebody_hand.md b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/hrnetv2_dark_coco_wholebody_hand.md
new file mode 100644
index 0000000000000000000000000000000000000000..e3af94b65c39dca554958c64fadcb7966a6f8407
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/hrnetv2_dark_coco_wholebody_hand.md
@@ -0,0 +1,56 @@
+
+
+COCO-WholeBody-Hand (ECCV'2020)
+ +```bibtex +@inproceedings{jin2020whole, + title={Whole-Body Human Pose Estimation in the Wild}, + author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping}, + booktitle={Proceedings of the European Conference on Computer Vision (ECCV)}, + year={2020} +} +``` + +
+
+
+
+
+HRNetv2 (TPAMI'2019)
+ +```bibtex +@article{WangSCJDZLMTWLX19, + title={Deep High-Resolution Representation Learning for Visual Recognition}, + author={Jingdong Wang and Ke Sun and Tianheng Cheng and + Borui Jiang and Chaorui Deng and Yang Zhao and Dong Liu and Yadong Mu and + Mingkui Tan and Xinggang Wang and Wenyu Liu and Bin Xiao}, + journal={TPAMI}, + year={2019} +} +``` + +
+
+
+
+
+DarkPose (CVPR'2020)
+ +```bibtex +@inproceedings{zhang2020distribution, + title={Distribution-aware coordinate representation for human pose estimation}, + author={Zhang, Feng and Zhu, Xiatian and Dai, Hanbin and Ye, Mao and Zhu, Ce}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + pages={7093--7102}, + year={2020} +} +``` + +
+
+
+Results on COCO-WholeBody-Hand val set
+
+| Arch | Input Size | PCK@0.2 | AUC | EPE | ckpt | log |
+| :--- | :--------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_hrnetv2_w18_dark](/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/hrnetv2_w18_coco_wholebody_hand_256x256_dark.py) | 256x256 | 0.814 | 0.840 | 4.37 | [ckpt](https://download.openmmlab.com/mmpose/hand/dark/hrnetv2_w18_coco_wholebody_hand_256x256_dark-a9228c9c_20210908.pth) | [log](https://download.openmmlab.com/mmpose/hand/dark/hrnetv2_w18_coco_wholebody_hand_256x256_dark_20210908.log.json) |
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/hrnetv2_dark_coco_wholebody_hand.yml b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/hrnetv2_dark_coco_wholebody_hand.yml
new file mode 100644
index 0000000000000000000000000000000000000000..31d0a38ab797914e38704c49c85fd0f84ab5f392
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/hrnetv2_dark_coco_wholebody_hand.yml
@@ -0,0 +1,23 @@
+Collections:
+- Name: DarkPose
+ Paper:
+ Title: Distribution-aware coordinate representation for human pose estimation
+ URL: http://openaccess.thecvf.com/content_CVPR_2020/html/Zhang_Distribution-Aware_Coordinate_Representation_for_Human_Pose_Estimation_CVPR_2020_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/techniques/dark.md
+Models:
+- Config: configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/hrnetv2_w18_coco_wholebody_hand_256x256_dark.py
+ In Collection: DarkPose
+ Metadata:
+ Architecture:
+ - HRNetv2
+ - DarkPose
+ Training Data: COCO-WholeBody-Hand
+ Name: topdown_heatmap_hrnetv2_w18_coco_wholebody_hand_256x256_dark
+ Results:
+ - Dataset: COCO-WholeBody-Hand
+ Metrics:
+ AUC: 0.84
+ EPE: 4.37
+ PCK@0.2: 0.814
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/dark/hrnetv2_w18_coco_wholebody_hand_256x256_dark-a9228c9c_20210908.pth
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/hrnetv2_w18_coco_wholebody_hand_256x256.py b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/hrnetv2_w18_coco_wholebody_hand_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..7679379361e187d0e79bace42ecb81ede8f7d593
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/hrnetv2_w18_coco_wholebody_hand_256x256.py
@@ -0,0 +1,165 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody_hand.py'
+]
+evaluation = dict(
+ interval=10, metric=['PCK', 'AUC', 'EPE'], key_indicator='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=21,
+ dataset_joints=21,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='open-mmlab://msra/hrnetv2_w18',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(18, 36)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(18, 36, 72)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(18, 36, 72, 144),
+ multiscale_output=True),
+ upsample=dict(mode='bilinear', align_corners=False))),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=[18, 36, 72, 144],
+ in_index=(0, 1, 2, 3),
+ input_transform='resize_concat',
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(
+ final_conv_kernel=1, num_conv_layers=1, num_conv_kernels=(1, )),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='HandCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='HandCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='HandCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/hrnetv2_w18_coco_wholebody_hand_256x256_dark.py b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/hrnetv2_w18_coco_wholebody_hand_256x256_dark.py
new file mode 100644
index 0000000000000000000000000000000000000000..4cc62f77e4e28ada6ec44e4504e8aad6cdddd34f
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/hrnetv2_w18_coco_wholebody_hand_256x256_dark.py
@@ -0,0 +1,165 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody_hand.py'
+]
+evaluation = dict(
+ interval=10, metric=['PCK', 'AUC', 'EPE'], key_indicator='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=21,
+ dataset_joints=21,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='open-mmlab://msra/hrnetv2_w18',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(18, 36)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(18, 36, 72)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(18, 36, 72, 144),
+ multiscale_output=True),
+ upsample=dict(mode='bilinear', align_corners=False))),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=[18, 36, 72, 144],
+ in_index=(0, 1, 2, 3),
+ input_transform='resize_concat',
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(
+ final_conv_kernel=1, num_conv_layers=1, num_conv_kernels=(1, )),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='unbiased',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2, unbiased_encoding=True),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='HandCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='HandCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='HandCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/litehrnet_coco_wholebody_hand.md b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/litehrnet_coco_wholebody_hand.md
new file mode 100644
index 0000000000000000000000000000000000000000..51a9d78e0a358ba91cb7ae76d27750ce54b7a9ec
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/litehrnet_coco_wholebody_hand.md
@@ -0,0 +1,37 @@
+
+
+COCO-WholeBody-Hand (ECCV'2020)
+ +```bibtex +@inproceedings{jin2020whole, + title={Whole-Body Human Pose Estimation in the Wild}, + author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping}, + booktitle={Proceedings of the European Conference on Computer Vision (ECCV)}, + year={2020} +} +``` + +
+
+
+
+
+LiteHRNet (CVPR'2021)
+ +```bibtex +@inproceedings{Yulitehrnet21, + title={Lite-HRNet: A Lightweight High-Resolution Network}, + author={Yu, Changqian and Xiao, Bin and Gao, Changxin and Yuan, Lu and Zhang, Lei and Sang, Nong and Wang, Jingdong}, + booktitle={CVPR}, + year={2021} +} +``` + +
+
+
+Results on COCO-WholeBody-Hand val set
+
+| Arch | Input Size | PCK@0.2 | AUC | EPE | ckpt | log |
+| :--- | :--------: | :------: | :------: | :------: |:------: |:------: |
+| [LiteHRNet-18](/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/litehrnet_w18_coco_wholebody_hand_256x256.py) | 256x256 | 0.795 | 0.830 | 4.77 | [ckpt](https://download.openmmlab.com/mmpose/hand/litehrnet/litehrnet_w18_coco_wholebody_hand_256x256-d6945e6a_20210908.pth) | [log](https://download.openmmlab.com/mmpose/hand/litehrnet/litehrnet_w18_coco_wholebody_hand_256x256_20210908.log.json) |
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/litehrnet_coco_wholebody_hand.yml b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/litehrnet_coco_wholebody_hand.yml
new file mode 100644
index 0000000000000000000000000000000000000000..d7751dcb179cc4a0cfa01e07e2be863059f43e99
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/litehrnet_coco_wholebody_hand.yml
@@ -0,0 +1,22 @@
+Collections:
+- Name: LiteHRNet
+ Paper:
+ Title: 'Lite-HRNet: A Lightweight High-Resolution Network'
+ URL: https://arxiv.org/abs/2104.06403
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/litehrnet.md
+Models:
+- Config: configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/litehrnet_w18_coco_wholebody_hand_256x256.py
+ In Collection: LiteHRNet
+ Metadata:
+ Architecture:
+ - LiteHRNet
+ Training Data: COCO-WholeBody-Hand
+ Name: topdown_heatmap_litehrnet_w18_coco_wholebody_hand_256x256
+ Results:
+ - Dataset: COCO-WholeBody-Hand
+ Metrics:
+ AUC: 0.83
+ EPE: 4.77
+ PCK@0.2: 0.795
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/litehrnet/litehrnet_w18_coco_wholebody_hand_256x256-d6945e6a_20210908.pth
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/litehrnet_w18_coco_wholebody_hand_256x256.py b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/litehrnet_w18_coco_wholebody_hand_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..04c526d860eb42b05a316b700fb99a9cad492edf
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/litehrnet_w18_coco_wholebody_hand_256x256.py
@@ -0,0 +1,152 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody_hand.py'
+]
+evaluation = dict(
+ interval=10, metric=['PCK', 'AUC', 'EPE'], key_indicator='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=21,
+ dataset_joints=21,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='LiteHRNet',
+ in_channels=3,
+ extra=dict(
+ stem=dict(stem_channels=32, out_channels=32, expand_ratio=1),
+ num_stages=3,
+ stages_spec=dict(
+ num_modules=(2, 4, 2),
+ num_branches=(2, 3, 4),
+ num_blocks=(2, 2, 2),
+ module_type=('LITE', 'LITE', 'LITE'),
+ with_fuse=(True, True, True),
+ reduce_ratios=(8, 8, 8),
+ num_channels=(
+ (40, 80),
+ (40, 80, 160),
+ (40, 80, 160, 320),
+ )),
+ with_head=True,
+ )),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=40,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='HandCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='HandCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='HandCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/mobilenetv2_coco_wholebody_hand.md b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/mobilenetv2_coco_wholebody_hand.md
new file mode 100644
index 0000000000000000000000000000000000000000..7fa4afc8b4656d10e10d5a5fc3b11c0379fd896e
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/mobilenetv2_coco_wholebody_hand.md
@@ -0,0 +1,38 @@
+
+
+COCO-WholeBody-Hand (ECCV'2020)
+ +```bibtex +@inproceedings{jin2020whole, + title={Whole-Body Human Pose Estimation in the Wild}, + author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping}, + booktitle={Proceedings of the European Conference on Computer Vision (ECCV)}, + year={2020} +} +``` + +
+
+
+
+
+MobilenetV2 (CVPR'2018)
+ +```bibtex +@inproceedings{sandler2018mobilenetv2, + title={Mobilenetv2: Inverted residuals and linear bottlenecks}, + author={Sandler, Mark and Howard, Andrew and Zhu, Menglong and Zhmoginov, Andrey and Chen, Liang-Chieh}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={4510--4520}, + year={2018} +} +``` + +
+
+
+Results on COCO-WholeBody-Hand val set
+
+| Arch | Input Size | PCK@0.2 | AUC | EPE | ckpt | log |
+| :--------: | :--------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_mobilenetv2](/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/mobilenetv2_coco_wholebody_hand_256x256.py) | 256x256 | 0.795 | 0.829 | 4.77 | [ckpt](https://download.openmmlab.com/mmpose/hand/mobilenetv2/mobilenetv2_coco_wholebody_hand_256x256-06b8c877_20210909.pth) | [log](https://download.openmmlab.com/mmpose/hand/mobilenetv2/mobilenetv2_coco_wholebody_hand_256x256_20210909.log.json) |
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/mobilenetv2_coco_wholebody_hand.yml b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/mobilenetv2_coco_wholebody_hand.yml
new file mode 100644
index 0000000000000000000000000000000000000000..aa0df1bf7ce36469e4b07496205c3b195e30b66b
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/mobilenetv2_coco_wholebody_hand.yml
@@ -0,0 +1,22 @@
+Collections:
+- Name: MobilenetV2
+ Paper:
+ Title: 'Mobilenetv2: Inverted residuals and linear bottlenecks'
+ URL: http://openaccess.thecvf.com/content_cvpr_2018/html/Sandler_MobileNetV2_Inverted_Residuals_CVPR_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/mobilenetv2.md
+Models:
+- Config: configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/mobilenetv2_coco_wholebody_hand_256x256.py
+ In Collection: MobilenetV2
+ Metadata:
+ Architecture:
+ - MobilenetV2
+ Training Data: COCO-WholeBody-Hand
+ Name: topdown_heatmap_mobilenetv2_coco_wholebody_hand_256x256
+ Results:
+ - Dataset: COCO-WholeBody-Hand
+ Metrics:
+ AUC: 0.829
+ EPE: 4.77
+ PCK@0.2: 0.795
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/mobilenetv2/mobilenetv2_coco_wholebody_hand_256x256-06b8c877_20210909.pth
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/mobilenetv2_coco_wholebody_hand_256x256.py b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/mobilenetv2_coco_wholebody_hand_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..7bd8af1d2c3989faffd246875d89a07ee1de4298
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/mobilenetv2_coco_wholebody_hand_256x256.py
@@ -0,0 +1,131 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody_hand.py'
+]
+evaluation = dict(
+ interval=10, metric=['PCK', 'AUC', 'EPE'], key_indicator='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=21,
+ dataset_joints=21,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='mmcls://mobilenet_v2',
+ backbone=dict(type='MobileNetV2', widen_factor=1., out_indices=(7, )),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1280,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='HandCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='HandCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='HandCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/res50_coco_wholebody_hand_256x256.py b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/res50_coco_wholebody_hand_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..8693eb219243bcc844fe4e7a41f8d05daa2732a3
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/res50_coco_wholebody_hand_256x256.py
@@ -0,0 +1,131 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody_hand.py'
+]
+evaluation = dict(
+ interval=10, metric=['PCK', 'AUC', 'EPE'], key_indicator='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=21,
+ dataset_joints=21,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='HandCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='HandCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='HandCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/resnet_coco_wholebody_hand.md b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/resnet_coco_wholebody_hand.md
new file mode 100644
index 0000000000000000000000000000000000000000..0d2781ba7e79c6e0272acec96bf1d8e29b5ff9fa
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/resnet_coco_wholebody_hand.md
@@ -0,0 +1,55 @@
+
+
+COCO-WholeBody-Hand (ECCV'2020)
+ +```bibtex +@inproceedings{jin2020whole, + title={Whole-Body Human Pose Estimation in the Wild}, + author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping}, + booktitle={Proceedings of the European Conference on Computer Vision (ECCV)}, + year={2020} +} +``` + +
+
+
+
+
+SimpleBaseline2D (ECCV'2018)
+ +```bibtex +@inproceedings{xiao2018simple, + title={Simple baselines for human pose estimation and tracking}, + author={Xiao, Bin and Wu, Haiping and Wei, Yichen}, + booktitle={Proceedings of the European conference on computer vision (ECCV)}, + pages={466--481}, + year={2018} +} +``` + +
+
+
+
+
+ResNet (CVPR'2016)
+ +```bibtex +@inproceedings{he2016deep, + title={Deep residual learning for image recognition}, + author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={770--778}, + year={2016} +} +``` + +
+
+
+Results on COCO-WholeBody-Hand val set
+
+| Arch | Input Size | PCK@0.2 | AUC | EPE | ckpt | log |
+| :--------: | :--------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_resnet_50](/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/res50_coco_wholebody_hand_256x256.py) | 256x256 | 0.800 | 0.833 | 4.64 | [ckpt](https://download.openmmlab.com/mmpose/hand/resnet/res50_coco_wholebody_hand_256x256-8dbc750c_20210908.pth) | [log](https://download.openmmlab.com/mmpose/hand/resnet/res50_coco_wholebody_hand_256x256_20210908.log.json) |
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/resnet_coco_wholebody_hand.yml b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/resnet_coco_wholebody_hand.yml
new file mode 100644
index 0000000000000000000000000000000000000000..d1e22ea7ad4946d196f59e76c31f83e1aea3d89b
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/resnet_coco_wholebody_hand.yml
@@ -0,0 +1,23 @@
+Collections:
+- Name: SimpleBaseline2D
+ Paper:
+ Title: Simple baselines for human pose estimation and tracking
+ URL: http://openaccess.thecvf.com/content_ECCV_2018/html/Bin_Xiao_Simple_Baselines_for_ECCV_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/simplebaseline2d.md
+Models:
+- Config: configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/res50_coco_wholebody_hand_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture:
+ - SimpleBaseline2D
+ - ResNet
+ Training Data: COCO-WholeBody-Hand
+ Name: topdown_heatmap_res50_coco_wholebody_hand_256x256
+ Results:
+ - Dataset: COCO-WholeBody-Hand
+ Metrics:
+ AUC: 0.833
+ EPE: 4.64
+ PCK@0.2: 0.8
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/resnet/res50_coco_wholebody_hand_256x256-8dbc750c_20210908.pth
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/scnet50_coco_wholebody_hand_256x256.py b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/scnet50_coco_wholebody_hand_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..aa9f9e41c74061e862bb211a9f6a57132dc7aa1f
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/scnet50_coco_wholebody_hand_256x256.py
@@ -0,0 +1,132 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody_hand.py'
+]
+evaluation = dict(
+ interval=10, metric=['PCK', 'AUC', 'EPE'], key_indicator='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=21,
+ dataset_joints=21,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/scnet50-7ef0a199.pth',
+ backbone=dict(type='SCNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='HandCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='HandCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='HandCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/scnet_coco_wholebody_hand.md b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/scnet_coco_wholebody_hand.md
new file mode 100644
index 0000000000000000000000000000000000000000..5a7304e4db04f0779f43d53c8c293b6ee1bfc81a
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/scnet_coco_wholebody_hand.md
@@ -0,0 +1,38 @@
+
+
+COCO-WholeBody-Hand (ECCV'2020)
+ +```bibtex +@inproceedings{jin2020whole, + title={Whole-Body Human Pose Estimation in the Wild}, + author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping}, + booktitle={Proceedings of the European Conference on Computer Vision (ECCV)}, + year={2020} +} +``` + +
+
+
+
+
+SCNet (CVPR'2020)
+ +```bibtex +@inproceedings{liu2020improving, + title={Improving Convolutional Networks with Self-Calibrated Convolutions}, + author={Liu, Jiang-Jiang and Hou, Qibin and Cheng, Ming-Ming and Wang, Changhu and Feng, Jiashi}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + pages={10096--10105}, + year={2020} +} +``` + +
+
+
+Results on COCO-WholeBody-Hand val set
+
+| Arch | Input Size | PCK@0.2 | AUC | EPE | ckpt | log |
+| :--------: | :--------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_scnet_50](/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/scnet50_coco_wholebody_hand_256x256.py) | 256x256 | 0.803 | 0.834 | 4.55 | [ckpt](https://download.openmmlab.com/mmpose/hand/scnet/scnet50_coco_wholebody_hand_256x256-e73414c7_20210909.pth) | [log](https://download.openmmlab.com/mmpose/hand/scnet/scnet50_coco_wholebody_hand_256x256_20210909.log.json) |
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/scnet_coco_wholebody_hand.yml b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/scnet_coco_wholebody_hand.yml
new file mode 100644
index 0000000000000000000000000000000000000000..241ba81139273842bfbc699d96dac64e572bfd4f
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/scnet_coco_wholebody_hand.yml
@@ -0,0 +1,22 @@
+Collections:
+- Name: SCNet
+ Paper:
+ Title: Improving Convolutional Networks with Self-Calibrated Convolutions
+ URL: http://openaccess.thecvf.com/content_CVPR_2020/html/Liu_Improving_Convolutional_Networks_With_Self-Calibrated_Convolutions_CVPR_2020_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/scnet.md
+Models:
+- Config: configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/scnet50_coco_wholebody_hand_256x256.py
+ In Collection: SCNet
+ Metadata:
+ Architecture:
+ - SCNet
+ Training Data: COCO-WholeBody-Hand
+ Name: topdown_heatmap_scnet50_coco_wholebody_hand_256x256
+ Results:
+ - Dataset: COCO-WholeBody-Hand
+ Metrics:
+ AUC: 0.834
+ EPE: 4.55
+ PCK@0.2: 0.803
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/scnet/scnet50_coco_wholebody_hand_256x256-e73414c7_20210909.pth
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/freihand2d/hrnetv2_w18_freihand2d_256x256.py b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/freihand2d/hrnetv2_w18_freihand2d_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..f9fc516480933a0302a36d844071714edd68dc4a
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/freihand2d/hrnetv2_w18_freihand2d_256x256.py
@@ -0,0 +1,165 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/freihand2d.py'
+]
+evaluation = dict(
+ interval=10, metric=['PCK', 'AUC', 'EPE'], key_indicator='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=21,
+ dataset_joints=21,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='open-mmlab://msra/hrnetv2_w18',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(18, 36)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(18, 36, 72)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(18, 36, 72, 144),
+ multiscale_output=True),
+ upsample=dict(mode='bilinear', align_corners=False))),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=[18, 36, 72, 144],
+ in_index=(0, 1, 2, 3),
+ input_transform='resize_concat',
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(
+ final_conv_kernel=1, num_conv_layers=1, num_conv_kernels=(1, )),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/freihand'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='FreiHandDataset',
+ ann_file=f'{data_root}/annotations/freihand_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='FreiHandDataset',
+ ann_file=f'{data_root}/annotations/freihand_val.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='FreiHandDataset',
+ ann_file=f'{data_root}/annotations/freihand_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/freihand2d/res50_freihand2d_224x224.py b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/freihand2d/res50_freihand2d_224x224.py
new file mode 100644
index 0000000000000000000000000000000000000000..d7d774bb35554e62a6f3aa9e3a1bef8cc4bf6a49
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/freihand2d/res50_freihand2d_224x224.py
@@ -0,0 +1,131 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/freihand2d.py'
+]
+checkpoint_config = dict(interval=1)
+evaluation = dict(interval=1, metric=['PCK', 'AUC', 'EPE'], save_best='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[50, 70])
+total_epochs = 100
+log_config = dict(
+ interval=20,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=21,
+ dataset_joints=21,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[224, 224],
+ heatmap_size=[56, 56],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/freihand'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='FreiHandDataset',
+ ann_file=f'{data_root}/annotations/freihand_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='FreiHandDataset',
+ ann_file=f'{data_root}/annotations/freihand_val.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='FreiHandDataset',
+ ann_file=f'{data_root}/annotations/freihand_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/freihand2d/resnet_freihand2d.md b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/freihand2d/resnet_freihand2d.md
new file mode 100644
index 0000000000000000000000000000000000000000..55629b23ea2e462db7b998ca785a8778b34d88c1
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/freihand2d/resnet_freihand2d.md
@@ -0,0 +1,57 @@
+
+
+COCO-WholeBody-Hand (ECCV'2020)
+ +```bibtex +@inproceedings{jin2020whole, + title={Whole-Body Human Pose Estimation in the Wild}, + author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping}, + booktitle={Proceedings of the European Conference on Computer Vision (ECCV)}, + year={2020} +} +``` + +
+
+
+
+
+SimpleBaseline2D (ECCV'2018)
+ +```bibtex +@inproceedings{xiao2018simple, + title={Simple baselines for human pose estimation and tracking}, + author={Xiao, Bin and Wu, Haiping and Wei, Yichen}, + booktitle={Proceedings of the European conference on computer vision (ECCV)}, + pages={466--481}, + year={2018} +} +``` + +
+
+
+
+
+ResNet (CVPR'2016)
+ +```bibtex +@inproceedings{he2016deep, + title={Deep residual learning for image recognition}, + author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={770--778}, + year={2016} +} +``` + +
+
+
+Results on FreiHand val & test set
+
+| Set | Arch | Input Size | PCK@0.2 | AUC | EPE | ckpt | log |
+| :--- | :--------: | :--------: | :------: | :------: | :------: |:------: |:------: |
+|val| [pose_resnet_50](/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/freihand2d/res50_freihand_224x224.py) | 224x224 | 0.993 | 0.868 | 3.25 | [ckpt](https://download.openmmlab.com/mmpose/hand/resnet/res50_freihand_224x224-ff0799bc_20200914.pth) | [log](https://download.openmmlab.com/mmpose/hand/resnet/res50_freihand_224x224_20200914.log.json) |
+|test| [pose_resnet_50](/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/freihand2d/res50_freihand_224x224.py) | 224x224 | 0.992 | 0.868 | 3.27 | [ckpt](https://download.openmmlab.com/mmpose/hand/resnet/res50_freihand_224x224-ff0799bc_20200914.pth) | [log](https://download.openmmlab.com/mmpose/hand/resnet/res50_freihand_224x224_20200914.log.json) |
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/freihand2d/resnet_freihand2d.yml b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/freihand2d/resnet_freihand2d.yml
new file mode 100644
index 0000000000000000000000000000000000000000..f83395f97263db320f26e629cbbd62ba8368842b
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/freihand2d/resnet_freihand2d.yml
@@ -0,0 +1,37 @@
+Collections:
+- Name: SimpleBaseline2D
+ Paper:
+ Title: Simple baselines for human pose estimation and tracking
+ URL: http://openaccess.thecvf.com/content_ECCV_2018/html/Bin_Xiao_Simple_Baselines_for_ECCV_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/simplebaseline2d.md
+Models:
+- Config: configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/freihand2d/res50_freihand_224x224.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: &id001
+ - SimpleBaseline2D
+ - ResNet
+ Training Data: FreiHand
+ Name: topdown_heatmap_res50_freihand_224x224
+ Results:
+ - Dataset: FreiHand
+ Metrics:
+ AUC: 0.868
+ EPE: 3.25
+ PCK@0.2: 0.993
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/resnet/res50_freihand_224x224-ff0799bc_20200914.pth
+- Config: configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/freihand2d/res50_freihand_224x224.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: FreiHand
+ Name: topdown_heatmap_res50_freihand_224x224
+ Results:
+ - Dataset: FreiHand
+ Metrics:
+ AUC: 0.868
+ EPE: 3.27
+ PCK@0.2: 0.992
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/resnet/res50_freihand_224x224-ff0799bc_20200914.pth
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/ViTPose_base_interhand2d_all_256x192.py b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/ViTPose_base_interhand2d_all_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..275b3a3a0b72d3333077dbcba548ede0ada43de0
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/ViTPose_base_interhand2d_all_256x192.py
@@ -0,0 +1,162 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/interhand2d.py'
+]
+checkpoint_config = dict(interval=5)
+evaluation = dict(interval=5, metric=['PCK', 'AUC', 'EPE'], save_best='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[40, 50])
+total_epochs = 60
+log_config = dict(
+ interval=20,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=21,
+ dataset_joints=21,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='ViT',
+ img_size=(256, 192),
+ patch_size=16,
+ embed_dim=768,
+ depth=12,
+ num_heads=12,
+ ratio=1,
+ use_checkpoint=False,
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_path_rate=0.3,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=768,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/interhand2.6m'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='InterHand2DDataset',
+ ann_file=f'{data_root}/annotations/all/'
+ 'InterHand2.6M_train_data.json',
+ camera_file=f'{data_root}/annotations/all/'
+ 'InterHand2.6M_train_camera.json',
+ joint_file=f'{data_root}/annotations/all/'
+ 'InterHand2.6M_train_joint_3d.json',
+ img_prefix=f'{data_root}/images/train/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='InterHand2DDataset',
+ ann_file=f'{data_root}/annotations/machine_annot/'
+ 'InterHand2.6M_val_data.json',
+ camera_file=f'{data_root}/annotations/machine_annot/'
+ 'InterHand2.6M_val_camera.json',
+ joint_file=f'{data_root}/annotations/machine_annot/'
+ 'InterHand2.6M_val_joint_3d.json',
+ img_prefix=f'{data_root}/images/val/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='InterHand2DDataset',
+ ann_file=f'{data_root}/annotations/all/'
+ 'InterHand2.6M_test_data.json',
+ camera_file=f'{data_root}/annotations/all/'
+ 'InterHand2.6M_test_camera.json',
+ joint_file=f'{data_root}/annotations/all/'
+ 'InterHand2.6M_test_joint_3d.json',
+ img_prefix=f'{data_root}/images/test/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/ViTPose_huge_interhand2d_all_256x192.py b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/ViTPose_huge_interhand2d_all_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..2af0f77d17f2153f8454b2e25c59e83239890144
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/ViTPose_huge_interhand2d_all_256x192.py
@@ -0,0 +1,162 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/interhand2d.py'
+]
+checkpoint_config = dict(interval=5)
+evaluation = dict(interval=5, metric=['PCK', 'AUC', 'EPE'], save_best='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[40, 50])
+total_epochs = 60
+log_config = dict(
+ interval=20,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=21,
+ dataset_joints=21,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='ViT',
+ img_size=(256, 192),
+ patch_size=16,
+ embed_dim=1280,
+ depth=32,
+ num_heads=16,
+ ratio=1,
+ use_checkpoint=False,
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_path_rate=0.3,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1280,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/interhand2.6m'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='InterHand2DDataset',
+ ann_file=f'{data_root}/annotations/all/'
+ 'InterHand2.6M_train_data.json',
+ camera_file=f'{data_root}/annotations/all/'
+ 'InterHand2.6M_train_camera.json',
+ joint_file=f'{data_root}/annotations/all/'
+ 'InterHand2.6M_train_joint_3d.json',
+ img_prefix=f'{data_root}/images/train/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='InterHand2DDataset',
+ ann_file=f'{data_root}/annotations/machine_annot/'
+ 'InterHand2.6M_val_data.json',
+ camera_file=f'{data_root}/annotations/machine_annot/'
+ 'InterHand2.6M_val_camera.json',
+ joint_file=f'{data_root}/annotations/machine_annot/'
+ 'InterHand2.6M_val_joint_3d.json',
+ img_prefix=f'{data_root}/images/val/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='InterHand2DDataset',
+ ann_file=f'{data_root}/annotations/all/'
+ 'InterHand2.6M_test_data.json',
+ camera_file=f'{data_root}/annotations/all/'
+ 'InterHand2.6M_test_camera.json',
+ joint_file=f'{data_root}/annotations/all/'
+ 'InterHand2.6M_test_joint_3d.json',
+ img_prefix=f'{data_root}/images/test/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/ViTPose_large_interhand2d_all_256x192.py b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/ViTPose_large_interhand2d_all_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..72c33a72f4d596479ff54c71bebbf66242e0c29d
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/ViTPose_large_interhand2d_all_256x192.py
@@ -0,0 +1,162 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/interhand2d.py'
+]
+checkpoint_config = dict(interval=5)
+evaluation = dict(interval=5, metric=['PCK', 'AUC', 'EPE'], save_best='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[40, 50])
+total_epochs = 60
+log_config = dict(
+ interval=20,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=21,
+ dataset_joints=21,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='ViT',
+ img_size=(256, 192),
+ patch_size=16,
+ embed_dim=1024,
+ depth=24,
+ num_heads=16,
+ ratio=1,
+ use_checkpoint=False,
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_path_rate=0.3,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1024,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/interhand2.6m'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='InterHand2DDataset',
+ ann_file=f'{data_root}/annotations/all/'
+ 'InterHand2.6M_train_data.json',
+ camera_file=f'{data_root}/annotations/all/'
+ 'InterHand2.6M_train_camera.json',
+ joint_file=f'{data_root}/annotations/all/'
+ 'InterHand2.6M_train_joint_3d.json',
+ img_prefix=f'{data_root}/images/train/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='InterHand2DDataset',
+ ann_file=f'{data_root}/annotations/machine_annot/'
+ 'InterHand2.6M_val_data.json',
+ camera_file=f'{data_root}/annotations/machine_annot/'
+ 'InterHand2.6M_val_camera.json',
+ joint_file=f'{data_root}/annotations/machine_annot/'
+ 'InterHand2.6M_val_joint_3d.json',
+ img_prefix=f'{data_root}/images/val/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='InterHand2DDataset',
+ ann_file=f'{data_root}/annotations/all/'
+ 'InterHand2.6M_test_data.json',
+ camera_file=f'{data_root}/annotations/all/'
+ 'InterHand2.6M_test_camera.json',
+ joint_file=f'{data_root}/annotations/all/'
+ 'InterHand2.6M_test_joint_3d.json',
+ img_prefix=f'{data_root}/images/test/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/ViTPose_small_interhand2d_all_256x192.py b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/ViTPose_small_interhand2d_all_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..d344dcaa937768f822dacfe6baf6d9c5c4efea0c
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/ViTPose_small_interhand2d_all_256x192.py
@@ -0,0 +1,162 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/interhand2d.py'
+]
+checkpoint_config = dict(interval=5)
+evaluation = dict(interval=5, metric=['PCK', 'AUC', 'EPE'], save_best='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[40, 50])
+total_epochs = 60
+log_config = dict(
+ interval=20,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=21,
+ dataset_joints=21,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='ViT',
+ img_size=(256, 192),
+ patch_size=16,
+ embed_dim=384,
+ depth=12,
+ num_heads=12,
+ ratio=1,
+ use_checkpoint=False,
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_path_rate=0.3,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=384,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/interhand2.6m'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='InterHand2DDataset',
+ ann_file=f'{data_root}/annotations/all/'
+ 'InterHand2.6M_train_data.json',
+ camera_file=f'{data_root}/annotations/all/'
+ 'InterHand2.6M_train_camera.json',
+ joint_file=f'{data_root}/annotations/all/'
+ 'InterHand2.6M_train_joint_3d.json',
+ img_prefix=f'{data_root}/images/train/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='InterHand2DDataset',
+ ann_file=f'{data_root}/annotations/machine_annot/'
+ 'InterHand2.6M_val_data.json',
+ camera_file=f'{data_root}/annotations/machine_annot/'
+ 'InterHand2.6M_val_camera.json',
+ joint_file=f'{data_root}/annotations/machine_annot/'
+ 'InterHand2.6M_val_joint_3d.json',
+ img_prefix=f'{data_root}/images/val/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='InterHand2DDataset',
+ ann_file=f'{data_root}/annotations/all/'
+ 'InterHand2.6M_test_data.json',
+ camera_file=f'{data_root}/annotations/all/'
+ 'InterHand2.6M_test_camera.json',
+ joint_file=f'{data_root}/annotations/all/'
+ 'InterHand2.6M_test_joint_3d.json',
+ img_prefix=f'{data_root}/images/test/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/res50_interhand2d_all_256x256.py b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/res50_interhand2d_all_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..f5d4eac8170c2e1826c242caa4e5a179f8f5dc77
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/res50_interhand2d_all_256x256.py
@@ -0,0 +1,146 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/interhand2d.py'
+]
+checkpoint_config = dict(interval=5)
+evaluation = dict(interval=5, metric=['PCK', 'AUC', 'EPE'], save_best='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[40, 50])
+total_epochs = 60
+log_config = dict(
+ interval=20,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=21,
+ dataset_joints=21,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/interhand2.6m'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='InterHand2DDataset',
+ ann_file=f'{data_root}/annotations/all/'
+ 'InterHand2.6M_train_data.json',
+ camera_file=f'{data_root}/annotations/all/'
+ 'InterHand2.6M_train_camera.json',
+ joint_file=f'{data_root}/annotations/all/'
+ 'InterHand2.6M_train_joint_3d.json',
+ img_prefix=f'{data_root}/images/train/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='InterHand2DDataset',
+ ann_file=f'{data_root}/annotations/machine_annot/'
+ 'InterHand2.6M_val_data.json',
+ camera_file=f'{data_root}/annotations/machine_annot/'
+ 'InterHand2.6M_val_camera.json',
+ joint_file=f'{data_root}/annotations/machine_annot/'
+ 'InterHand2.6M_val_joint_3d.json',
+ img_prefix=f'{data_root}/images/val/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='InterHand2DDataset',
+ ann_file=f'{data_root}/annotations/all/'
+ 'InterHand2.6M_test_data.json',
+ camera_file=f'{data_root}/annotations/all/'
+ 'InterHand2.6M_test_camera.json',
+ joint_file=f'{data_root}/annotations/all/'
+ 'InterHand2.6M_test_joint_3d.json',
+ img_prefix=f'{data_root}/images/test/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/res50_interhand2d_human_256x256.py b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/res50_interhand2d_human_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..7b0fc2b1382ceff02bf4d0aa4514b4bbded9751e
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/res50_interhand2d_human_256x256.py
@@ -0,0 +1,146 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/interhand2d.py'
+]
+checkpoint_config = dict(interval=5)
+evaluation = dict(interval=5, metric=['PCK', 'AUC', 'EPE'], save_best='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[40, 50])
+total_epochs = 60
+log_config = dict(
+ interval=20,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=21,
+ dataset_joints=21,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/interhand2.6m'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='InterHand2DDataset',
+ ann_file=f'{data_root}/annotations/human_annot/'
+ 'InterHand2.6M_train_data.json',
+ camera_file=f'{data_root}/annotations/human_annot/'
+ 'InterHand2.6M_train_camera.json',
+ joint_file=f'{data_root}/annotations/human_annot/'
+ 'InterHand2.6M_train_joint_3d.json',
+ img_prefix=f'{data_root}/images/train/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='InterHand2DDataset',
+ ann_file=f'{data_root}/annotations/machine_annot/'
+ 'InterHand2.6M_val_data.json',
+ camera_file=f'{data_root}/annotations/machine_annot/'
+ 'InterHand2.6M_val_camera.json',
+ joint_file=f'{data_root}/annotations/machine_annot/'
+ 'InterHand2.6M_val_joint_3d.json',
+ img_prefix=f'{data_root}/images/val/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='InterHand2DDataset',
+ ann_file=f'{data_root}/annotations/human_annot/'
+ 'InterHand2.6M_test_data.json',
+ camera_file=f'{data_root}/annotations/human_annot/'
+ 'InterHand2.6M_test_camera.json',
+ joint_file=f'{data_root}/annotations/human_annot/'
+ 'InterHand2.6M_test_joint_3d.json',
+ img_prefix=f'{data_root}/images/test/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/res50_interhand2d_machine_256x256.py b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/res50_interhand2d_machine_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..5b0cff66bc8a98de7a39581b048e01240db11dae
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/res50_interhand2d_machine_256x256.py
@@ -0,0 +1,146 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/interhand2d.py'
+]
+checkpoint_config = dict(interval=5)
+evaluation = dict(interval=5, metric=['PCK', 'AUC', 'EPE'], save_best='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[40, 50])
+total_epochs = 60
+log_config = dict(
+ interval=20,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=21,
+ dataset_joints=21,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/interhand2.6m'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='InterHand2DDataset',
+ ann_file=f'{data_root}/annotations/machine_annot/'
+ 'InterHand2.6M_train_data.json',
+ camera_file=f'{data_root}/annotations/machine_annot/'
+ 'InterHand2.6M_train_camera.json',
+ joint_file=f'{data_root}/annotations/machine_annot/'
+ 'InterHand2.6M_train_joint_3d.json',
+ img_prefix=f'{data_root}/images/train/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='InterHand2DDataset',
+ ann_file=f'{data_root}/annotations/machine_annot/'
+ 'InterHand2.6M_val_data.json',
+ camera_file=f'{data_root}/annotations/machine_annot/'
+ 'InterHand2.6M_val_camera.json',
+ joint_file=f'{data_root}/annotations/machine_annot/'
+ 'InterHand2.6M_val_joint_3d.json',
+ img_prefix=f'{data_root}/images/val/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='InterHand2DDataset',
+ ann_file=f'{data_root}/annotations/machine_annot/'
+ 'InterHand2.6M_test_data.json',
+ camera_file=f'{data_root}/annotations/machine_annot/'
+ 'InterHand2.6M_test_camera.json',
+ joint_file=f'{data_root}/annotations/machine_annot/'
+ 'InterHand2.6M_test_joint_3d.json',
+ img_prefix=f'{data_root}/images/test/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/resnet_interhand2d.md b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/resnet_interhand2d.md
new file mode 100644
index 0000000000000000000000000000000000000000..197e53d44cbda53397a2b57f0a61cca10378d1c0
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/resnet_interhand2d.md
@@ -0,0 +1,66 @@
+
+
+FreiHand (ICCV'2019)
+ +```bibtex +@inproceedings{zimmermann2019freihand, + title={Freihand: A dataset for markerless capture of hand pose and shape from single rgb images}, + author={Zimmermann, Christian and Ceylan, Duygu and Yang, Jimei and Russell, Bryan and Argus, Max and Brox, Thomas}, + booktitle={Proceedings of the IEEE International Conference on Computer Vision}, + pages={813--822}, + year={2019} +} +``` + +
+
+
+
+
+SimpleBaseline2D (ECCV'2018)
+ +```bibtex +@inproceedings{xiao2018simple, + title={Simple baselines for human pose estimation and tracking}, + author={Xiao, Bin and Wu, Haiping and Wei, Yichen}, + booktitle={Proceedings of the European conference on computer vision (ECCV)}, + pages={466--481}, + year={2018} +} +``` + +
+
+
+
+
+ResNet (CVPR'2016)
+ +```bibtex +@inproceedings{he2016deep, + title={Deep residual learning for image recognition}, + author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={770--778}, + year={2016} +} +``` + +
+
+
+Results on InterHand2.6M val & test set
+
+|Train Set| Set | Arch | Input Size | PCK@0.2 | AUC | EPE | ckpt | log |
+| :--- | :--- | :--------: | :--------: | :------: | :------: | :------: |:------: |:------: |
+|Human_annot|val(M)| [pose_resnet_50](/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/res50_interhand2d_human_256x256.py) | 256x256 | 0.973 | 0.828 | 5.15 | [ckpt](https://download.openmmlab.com/mmpose/hand/resnet/res50_interhand2d_256x256_human-77b27d1a_20201029.pth) | [log](https://download.openmmlab.com/mmpose/hand/resnet/res50_interhand2d_256x256_human_20201029.log.json) |
+|Human_annot|test(H)| [pose_resnet_50](/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/res50_interhand2d_human_256x256.py) | 256x256 | 0.973 | 0.826 | 5.27 | [ckpt](https://download.openmmlab.com/mmpose/hand/resnet/res50_interhand2d_256x256_human-77b27d1a_20201029.pth) | [log](https://download.openmmlab.com/mmpose/hand/resnet/res50_interhand2d_256x256_human_20201029.log.json) |
+|Human_annot|test(M)| [pose_resnet_50](/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/res50_interhand2d_human_256x256.py) | 256x256 | 0.975 | 0.841 | 4.90 | [ckpt](https://download.openmmlab.com/mmpose/hand/resnet/res50_interhand2d_256x256_human-77b27d1a_20201029.pth) | [log](https://download.openmmlab.com/mmpose/hand/resnet/res50_interhand2d_256x256_human_20201029.log.json) |
+|Human_annot|test(H+M)| [pose_resnet_50](/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/res50_interhand2d_human_256x256.py) | 256x256 | 0.975 | 0.839 | 4.97 | [ckpt](https://download.openmmlab.com/mmpose/hand/resnet/res50_interhand2d_256x256_human-77b27d1a_20201029.pth) | [log](https://download.openmmlab.com/mmpose/hand/resnet/res50_interhand2d_256x256_human_20201029.log.json) |
+|Machine_annot|val(M)| [pose_resnet_50](/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/res50_interhand2d_machine_256x256.py) | 256x256 | 0.970 | 0.824 | 5.39 | [ckpt](https://download.openmmlab.com/mmpose/hand/resnet/res50_interhand2d_256x256_machine-8f3efe9a_20201102.pth) | [log](https://download.openmmlab.com/mmpose/hand/resnet/res50_interhand2d_256x256_machine_20201102.log.json) |
+|Machine_annot|test(H)| [pose_resnet_50](/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/res50_interhand2d_machine_256x256.py) | 256x256 | 0.969 | 0.821 | 5.52 | [ckpt](https://download.openmmlab.com/mmpose/hand/resnet/res50_interhand2d_256x256_machine-8f3efe9a_20201102.pth) | [log](https://download.openmmlab.com/mmpose/hand/resnet/res50_interhand2d_256x256_machine_20201102.log.json) |
+|Machine_annot|test(M)| [pose_resnet_50](/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/res50_interhand2d_machine_256x256.py) | 256x256 | 0.972 | 0.838 | 5.03 | [ckpt](https://download.openmmlab.com/mmpose/hand/resnet/res50_interhand2d_256x256_machine-8f3efe9a_20201102.pth) | [log](https://download.openmmlab.com/mmpose/hand/resnet/res50_interhand2d_256x256_machine_20201102.log.json) |
+|Machine_annot|test(H+M)| [pose_resnet_50](/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/res50_interhand2d_machine_256x256.py) | 256x256 | 0.972 | 0.837 | 5.11 | [ckpt](https://download.openmmlab.com/mmpose/hand/resnet/res50_interhand2d_256x256_machine-8f3efe9a_20201102.pth) | [log](https://download.openmmlab.com/mmpose/hand/resnet/res50_interhand2d_256x256_machine_20201102.log.json) |
+|All|val(M)| [pose_resnet_50](/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/res50_interhand2d_all_256x256.py) | 256x256 | 0.977 | 0.840 | 4.66 | [ckpt](https://download.openmmlab.com/mmpose/hand/resnet/res50_interhand2d_256x256_all-78cc95d4_20201102.pth) | [log](https://download.openmmlab.com/mmpose/hand/resnet/res50_interhand2d_256x256_all_20201102.log.json) |
+|All|test(H)| [pose_resnet_50](/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/res50_interhand2d_all_256x256.py) | 256x256 | 0.979 | 0.839 | 4.65 | [ckpt](https://download.openmmlab.com/mmpose/hand/resnet/res50_interhand2d_256x256_all-78cc95d4_20201102.pth) | [log](https://download.openmmlab.com/mmpose/hand/resnet/res50_interhand2d_256x256_all_20201102.log.json) |
+|All|test(M)| [pose_resnet_50](/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/res50_interhand2d_all_256x256.py) | 256x256 | 0.979 | 0.838 | 4.42 | [ckpt](https://download.openmmlab.com/mmpose/hand/resnet/res50_interhand2d_256x256_all-78cc95d4_20201102.pth) | [log](https://download.openmmlab.com/mmpose/hand/resnet/res50_interhand2d_256x256_all_20201102.log.json) |
+|All|test(H+M)| [pose_resnet_50](/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/res50_interhand2d_all_256x256.py) | 256x256 | 0.979 | 0.851 | 4.46 | [ckpt](https://download.openmmlab.com/mmpose/hand/resnet/res50_interhand2d_256x256_all-78cc95d4_20201102.pth) | [log](https://download.openmmlab.com/mmpose/hand/resnet/res50_interhand2d_256x256_all_20201102.log.json) |
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/resnet_interhand2d.yml b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/resnet_interhand2d.yml
new file mode 100644
index 0000000000000000000000000000000000000000..ff9ca057a76e998db1da1871c8376f81f320a199
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/resnet_interhand2d.yml
@@ -0,0 +1,177 @@
+Collections:
+- Name: SimpleBaseline2D
+ Paper:
+ Title: Simple baselines for human pose estimation and tracking
+ URL: http://openaccess.thecvf.com/content_ECCV_2018/html/Bin_Xiao_Simple_Baselines_for_ECCV_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/simplebaseline2d.md
+Models:
+- Config: configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/res50_interhand2d_human_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: &id001
+ - SimpleBaseline2D
+ - ResNet
+ Training Data: InterHand2.6M
+ Name: topdown_heatmap_res50_interhand2d_human_256x256
+ Results:
+ - Dataset: InterHand2.6M
+ Metrics:
+ AUC: 0.828
+ EPE: 5.15
+ PCK@0.2: 0.973
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/resnet/res50_interhand2d_256x256_human-77b27d1a_20201029.pth
+- Config: configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/res50_interhand2d_human_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: InterHand2.6M
+ Name: topdown_heatmap_res50_interhand2d_human_256x256
+ Results:
+ - Dataset: InterHand2.6M
+ Metrics:
+ AUC: 0.826
+ EPE: 5.27
+ PCK@0.2: 0.973
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/resnet/res50_interhand2d_256x256_human-77b27d1a_20201029.pth
+- Config: configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/res50_interhand2d_human_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: InterHand2.6M
+ Name: topdown_heatmap_res50_interhand2d_human_256x256
+ Results:
+ - Dataset: InterHand2.6M
+ Metrics:
+ AUC: 0.841
+ EPE: 4.9
+ PCK@0.2: 0.975
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/resnet/res50_interhand2d_256x256_human-77b27d1a_20201029.pth
+- Config: configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/res50_interhand2d_human_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: InterHand2.6M
+ Name: topdown_heatmap_res50_interhand2d_human_256x256
+ Results:
+ - Dataset: InterHand2.6M
+ Metrics:
+ AUC: 0.839
+ EPE: 4.97
+ PCK@0.2: 0.975
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/resnet/res50_interhand2d_256x256_human-77b27d1a_20201029.pth
+- Config: configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/res50_interhand2d_machine_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: InterHand2.6M
+ Name: topdown_heatmap_res50_interhand2d_machine_256x256
+ Results:
+ - Dataset: InterHand2.6M
+ Metrics:
+ AUC: 0.824
+ EPE: 5.39
+ PCK@0.2: 0.97
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/resnet/res50_interhand2d_256x256_machine-8f3efe9a_20201102.pth
+- Config: configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/res50_interhand2d_machine_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: InterHand2.6M
+ Name: topdown_heatmap_res50_interhand2d_machine_256x256
+ Results:
+ - Dataset: InterHand2.6M
+ Metrics:
+ AUC: 0.821
+ EPE: 5.52
+ PCK@0.2: 0.969
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/resnet/res50_interhand2d_256x256_machine-8f3efe9a_20201102.pth
+- Config: configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/res50_interhand2d_machine_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: InterHand2.6M
+ Name: topdown_heatmap_res50_interhand2d_machine_256x256
+ Results:
+ - Dataset: InterHand2.6M
+ Metrics:
+ AUC: 0.838
+ EPE: 5.03
+ PCK@0.2: 0.972
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/resnet/res50_interhand2d_256x256_machine-8f3efe9a_20201102.pth
+- Config: configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/res50_interhand2d_machine_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: InterHand2.6M
+ Name: topdown_heatmap_res50_interhand2d_machine_256x256
+ Results:
+ - Dataset: InterHand2.6M
+ Metrics:
+ AUC: 0.837
+ EPE: 5.11
+ PCK@0.2: 0.972
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/resnet/res50_interhand2d_256x256_machine-8f3efe9a_20201102.pth
+- Config: configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/res50_interhand2d_all_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: InterHand2.6M
+ Name: topdown_heatmap_res50_interhand2d_all_256x256
+ Results:
+ - Dataset: InterHand2.6M
+ Metrics:
+ AUC: 0.84
+ EPE: 4.66
+ PCK@0.2: 0.977
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/resnet/res50_interhand2d_256x256_all-78cc95d4_20201102.pth
+- Config: configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/res50_interhand2d_all_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: InterHand2.6M
+ Name: topdown_heatmap_res50_interhand2d_all_256x256
+ Results:
+ - Dataset: InterHand2.6M
+ Metrics:
+ AUC: 0.839
+ EPE: 4.65
+ PCK@0.2: 0.979
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/resnet/res50_interhand2d_256x256_all-78cc95d4_20201102.pth
+- Config: configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/res50_interhand2d_all_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: InterHand2.6M
+ Name: topdown_heatmap_res50_interhand2d_all_256x256
+ Results:
+ - Dataset: InterHand2.6M
+ Metrics:
+ AUC: 0.838
+ EPE: 4.42
+ PCK@0.2: 0.979
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/resnet/res50_interhand2d_256x256_all-78cc95d4_20201102.pth
+- Config: configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/res50_interhand2d_all_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: InterHand2.6M
+ Name: topdown_heatmap_res50_interhand2d_all_256x256
+ Results:
+ - Dataset: InterHand2.6M
+ Metrics:
+ AUC: 0.851
+ EPE: 4.46
+ PCK@0.2: 0.979
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/resnet/res50_interhand2d_256x256_all-78cc95d4_20201102.pth
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/hrnetv2_dark_onehand10k.md b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/hrnetv2_dark_onehand10k.md
new file mode 100644
index 0000000000000000000000000000000000000000..b6d40948042926792cabb2d4ce649458db06700b
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/hrnetv2_dark_onehand10k.md
@@ -0,0 +1,60 @@
+
+
+InterHand2.6M (ECCV'2020)
+ +```bibtex +@InProceedings{Moon_2020_ECCV_InterHand2.6M, +author = {Moon, Gyeongsik and Yu, Shoou-I and Wen, He and Shiratori, Takaaki and Lee, Kyoung Mu}, +title = {InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image}, +booktitle = {European Conference on Computer Vision (ECCV)}, +year = {2020} +} +``` + +
+
+
+
+
+HRNetv2 (TPAMI'2019)
+ +```bibtex +@article{WangSCJDZLMTWLX19, + title={Deep High-Resolution Representation Learning for Visual Recognition}, + author={Jingdong Wang and Ke Sun and Tianheng Cheng and + Borui Jiang and Chaorui Deng and Yang Zhao and Dong Liu and Yadong Mu and + Mingkui Tan and Xinggang Wang and Wenyu Liu and Bin Xiao}, + journal={TPAMI}, + year={2019} +} +``` + +
+
+
+
+
+DarkPose (CVPR'2020)
+ +```bibtex +@inproceedings{zhang2020distribution, + title={Distribution-aware coordinate representation for human pose estimation}, + author={Zhang, Feng and Zhu, Xiatian and Dai, Hanbin and Ye, Mao and Zhu, Ce}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + pages={7093--7102}, + year={2020} +} +``` + +
+
+
+Results on OneHand10K val set
+
+| Arch | Input Size | PCK@0.2 | AUC | EPE | ckpt | log |
+| :--- | :--------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_hrnetv2_w18_dark](/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/hrnetv2_w18_onehand10k_256x256_dark.py) | 256x256 | 0.990 | 0.573 | 23.84 | [ckpt](https://download.openmmlab.com/mmpose/hand/dark/hrnetv2_w18_onehand10k_256x256_dark-a2f80c64_20210330.pth) | [log](https://download.openmmlab.com/mmpose/hand/dark/hrnetv2_w18_onehand10k_256x256_dark_20210330.log.json) |
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/hrnetv2_dark_onehand10k.yml b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/hrnetv2_dark_onehand10k.yml
new file mode 100644
index 0000000000000000000000000000000000000000..17b2901b36f1c2f232283183bb07aea48e2c8d86
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/hrnetv2_dark_onehand10k.yml
@@ -0,0 +1,23 @@
+Collections:
+- Name: DarkPose
+ Paper:
+ Title: Distribution-aware coordinate representation for human pose estimation
+ URL: http://openaccess.thecvf.com/content_CVPR_2020/html/Zhang_Distribution-Aware_Coordinate_Representation_for_Human_Pose_Estimation_CVPR_2020_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/techniques/dark.md
+Models:
+- Config: configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/hrnetv2_w18_onehand10k_256x256_dark.py
+ In Collection: DarkPose
+ Metadata:
+ Architecture:
+ - HRNetv2
+ - DarkPose
+ Training Data: OneHand10K
+ Name: topdown_heatmap_hrnetv2_w18_onehand10k_256x256_dark
+ Results:
+ - Dataset: OneHand10K
+ Metrics:
+ AUC: 0.573
+ EPE: 23.84
+ PCK@0.2: 0.99
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/dark/hrnetv2_w18_onehand10k_256x256_dark-a2f80c64_20210330.pth
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/hrnetv2_onehand10k.md b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/hrnetv2_onehand10k.md
new file mode 100644
index 0000000000000000000000000000000000000000..464e16a4c24e4eed7962ece0032a28796f0af877
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/hrnetv2_onehand10k.md
@@ -0,0 +1,43 @@
+
+
+OneHand10K (TCSVT'2019)
+ +```bibtex +@article{wang2018mask, + title={Mask-pose cascaded cnn for 2d hand pose estimation from single color image}, + author={Wang, Yangang and Peng, Cong and Liu, Yebin}, + journal={IEEE Transactions on Circuits and Systems for Video Technology}, + volume={29}, + number={11}, + pages={3258--3268}, + year={2018}, + publisher={IEEE} +} +``` + +
+
+
+
+
+HRNetv2 (TPAMI'2019)
+ +```bibtex +@article{WangSCJDZLMTWLX19, + title={Deep High-Resolution Representation Learning for Visual Recognition}, + author={Jingdong Wang and Ke Sun and Tianheng Cheng and + Borui Jiang and Chaorui Deng and Yang Zhao and Dong Liu and Yadong Mu and + Mingkui Tan and Xinggang Wang and Wenyu Liu and Bin Xiao}, + journal={TPAMI}, + year={2019} +} +``` + +
+
+
+Results on OneHand10K val set
+
+| Arch | Input Size | PCK@0.2 | AUC | EPE | ckpt | log |
+| :--- | :--------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_hrnetv2_w18](/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/hrnetv2_w18_onehand10k_256x256.py) | 256x256 | 0.990 | 0.568 | 24.16 | [ckpt](https://download.openmmlab.com/mmpose/hand/hrnetv2/hrnetv2_w18_onehand10k_256x256-30bc9c6b_20210330.pth) | [log](https://download.openmmlab.com/mmpose/hand/hrnetv2/hrnetv2_w18_onehand10k_256x256_20210330.log.json) |
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/hrnetv2_onehand10k.yml b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/hrnetv2_onehand10k.yml
new file mode 100644
index 0000000000000000000000000000000000000000..6b104bd7cb417114cc58e98aa333c204e49dc4a8
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/hrnetv2_onehand10k.yml
@@ -0,0 +1,22 @@
+Collections:
+- Name: HRNetv2
+ Paper:
+ Title: Deep High-Resolution Representation Learning for Visual Recognition
+ URL: https://ieeexplore.ieee.org/abstract/document/9052469/
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/hrnetv2.md
+Models:
+- Config: configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/hrnetv2_w18_onehand10k_256x256.py
+ In Collection: HRNetv2
+ Metadata:
+ Architecture:
+ - HRNetv2
+ Training Data: OneHand10K
+ Name: topdown_heatmap_hrnetv2_w18_onehand10k_256x256
+ Results:
+ - Dataset: OneHand10K
+ Metrics:
+ AUC: 0.568
+ EPE: 24.16
+ PCK@0.2: 0.99
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/hrnetv2/hrnetv2_w18_onehand10k_256x256-30bc9c6b_20210330.pth
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/hrnetv2_udp_onehand10k.md b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/hrnetv2_udp_onehand10k.md
new file mode 100644
index 0000000000000000000000000000000000000000..8247cd08105e23a430eb7ff3da2662476147d582
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/hrnetv2_udp_onehand10k.md
@@ -0,0 +1,60 @@
+
+
+OneHand10K (TCSVT'2019)
+ +```bibtex +@article{wang2018mask, + title={Mask-pose cascaded cnn for 2d hand pose estimation from single color image}, + author={Wang, Yangang and Peng, Cong and Liu, Yebin}, + journal={IEEE Transactions on Circuits and Systems for Video Technology}, + volume={29}, + number={11}, + pages={3258--3268}, + year={2018}, + publisher={IEEE} +} +``` + +
+
+
+
+
+HRNetv2 (TPAMI'2019)
+ +```bibtex +@article{WangSCJDZLMTWLX19, + title={Deep High-Resolution Representation Learning for Visual Recognition}, + author={Jingdong Wang and Ke Sun and Tianheng Cheng and + Borui Jiang and Chaorui Deng and Yang Zhao and Dong Liu and Yadong Mu and + Mingkui Tan and Xinggang Wang and Wenyu Liu and Bin Xiao}, + journal={TPAMI}, + year={2019} +} +``` + +
+
+
+
+
+UDP (CVPR'2020)
+ +```bibtex +@InProceedings{Huang_2020_CVPR, + author = {Huang, Junjie and Zhu, Zheng and Guo, Feng and Huang, Guan}, + title = {The Devil Is in the Details: Delving Into Unbiased Data Processing for Human Pose Estimation}, + booktitle = {The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, + month = {June}, + year = {2020} +} +``` + +
+
+
+Results on OneHand10K val set
+
+| Arch | Input Size | PCK@0.2 | AUC | EPE | ckpt | log |
+| :--- | :--------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_hrnetv2_w18_udp](/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/hrnetv2_w18_onehand10k_256x256_udp.py) | 256x256 | 0.990 | 0.572 | 23.87 | [ckpt](https://download.openmmlab.com/mmpose/hand/udp/hrnetv2_w18_onehand10k_256x256_udp-0d1b515d_20210330.pth) | [log](https://download.openmmlab.com/mmpose/hand/udp/hrnetv2_w18_onehand10k_256x256_udp_20210330.log.json) |
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/hrnetv2_udp_onehand10k.yml b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/hrnetv2_udp_onehand10k.yml
new file mode 100644
index 0000000000000000000000000000000000000000..7251110179d3a88f3e3dbfc98be990231e8a345f
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/hrnetv2_udp_onehand10k.yml
@@ -0,0 +1,24 @@
+Collections:
+- Name: UDP
+ Paper:
+ Title: 'The Devil Is in the Details: Delving Into Unbiased Data Processing for
+ Human Pose Estimation'
+ URL: http://openaccess.thecvf.com/content_CVPR_2020/html/Huang_The_Devil_Is_in_the_Details_Delving_Into_Unbiased_Data_CVPR_2020_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/techniques/udp.md
+Models:
+- Config: configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/hrnetv2_w18_onehand10k_256x256_udp.py
+ In Collection: UDP
+ Metadata:
+ Architecture:
+ - HRNetv2
+ - UDP
+ Training Data: OneHand10K
+ Name: topdown_heatmap_hrnetv2_w18_onehand10k_256x256_udp
+ Results:
+ - Dataset: OneHand10K
+ Metrics:
+ AUC: 0.572
+ EPE: 23.87
+ PCK@0.2: 0.99
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/udp/hrnetv2_w18_onehand10k_256x256_udp-0d1b515d_20210330.pth
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/hrnetv2_w18_onehand10k_256x256.py b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/hrnetv2_w18_onehand10k_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..36e930631b0bae66f263f7b05afd3e447af66d70
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/hrnetv2_w18_onehand10k_256x256.py
@@ -0,0 +1,164 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/onehand10k.py'
+]
+evaluation = dict(interval=10, metric=['PCK', 'AUC', 'EPE'], save_best='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=21,
+ dataset_joints=21,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='open-mmlab://msra/hrnetv2_w18',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(18, 36)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(18, 36, 72)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(18, 36, 72, 144),
+ multiscale_output=True),
+ upsample=dict(mode='bilinear', align_corners=False))),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=[18, 36, 72, 144],
+ in_index=(0, 1, 2, 3),
+ input_transform='resize_concat',
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(
+ final_conv_kernel=1, num_conv_layers=1, num_conv_kernels=(1, )),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/onehand10k'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='OneHand10KDataset',
+ ann_file=f'{data_root}/annotations/onehand10k_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='OneHand10KDataset',
+ ann_file=f'{data_root}/annotations/onehand10k_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='OneHand10KDataset',
+ ann_file=f'{data_root}/annotations/onehand10k_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/hrnetv2_w18_onehand10k_256x256_dark.py b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/hrnetv2_w18_onehand10k_256x256_dark.py
new file mode 100644
index 0000000000000000000000000000000000000000..3b1e8a7c93569fd20c461ccb1b6fee562e6657db
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/hrnetv2_w18_onehand10k_256x256_dark.py
@@ -0,0 +1,164 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/onehand10k.py'
+]
+evaluation = dict(interval=10, metric=['PCK', 'AUC', 'EPE'], save_best='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=21,
+ dataset_joints=21,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='open-mmlab://msra/hrnetv2_w18',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(18, 36)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(18, 36, 72)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(18, 36, 72, 144),
+ multiscale_output=True),
+ upsample=dict(mode='bilinear', align_corners=False))),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=[18, 36, 72, 144],
+ in_index=(0, 1, 2, 3),
+ input_transform='resize_concat',
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(
+ final_conv_kernel=1, num_conv_layers=1, num_conv_kernels=(1, )),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='unbiased',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2, unbiased_encoding=True),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/onehand10k'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='OneHand10KDataset',
+ ann_file=f'{data_root}/annotations/onehand10k_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='OneHand10KDataset',
+ ann_file=f'{data_root}/annotations/onehand10k_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='OneHand10KDataset',
+ ann_file=f'{data_root}/annotations/onehand10k_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/hrnetv2_w18_onehand10k_256x256_udp.py b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/hrnetv2_w18_onehand10k_256x256_udp.py
new file mode 100644
index 0000000000000000000000000000000000000000..3694a3cdaf3d4142b4bfc73ec11984302a0b29fd
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/hrnetv2_w18_onehand10k_256x256_udp.py
@@ -0,0 +1,171 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/onehand10k.py'
+]
+evaluation = dict(interval=10, metric=['PCK', 'AUC', 'EPE'], save_best='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+target_type = 'GaussianHeatmap'
+channel_cfg = dict(
+ num_output_channels=21,
+ dataset_joints=21,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='open-mmlab://msra/hrnetv2_w18',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(18, 36)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(18, 36, 72)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(18, 36, 72, 144),
+ multiscale_output=True),
+ upsample=dict(mode='bilinear', align_corners=False))),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=[18, 36, 72, 144],
+ in_index=(0, 1, 2, 3),
+ input_transform='resize_concat',
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(
+ final_conv_kernel=1, num_conv_layers=1, num_conv_kernels=(1, )),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=False,
+ target_type=target_type,
+ modulate_kernel=11,
+ use_udp=True))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='TopDownGenerateTarget',
+ sigma=2,
+ encoding='UDP',
+ target_type=target_type),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/onehand10k'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='OneHand10KDataset',
+ ann_file=f'{data_root}/annotations/onehand10k_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='OneHand10KDataset',
+ ann_file=f'{data_root}/annotations/onehand10k_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='OneHand10KDataset',
+ ann_file=f'{data_root}/annotations/onehand10k_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/mobilenetv2_onehand10k.md b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/mobilenetv2_onehand10k.md
new file mode 100644
index 0000000000000000000000000000000000000000..6e45d76b517355272151fc977886bf4f583591f8
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/mobilenetv2_onehand10k.md
@@ -0,0 +1,42 @@
+
+
+OneHand10K (TCSVT'2019)
+ +```bibtex +@article{wang2018mask, + title={Mask-pose cascaded cnn for 2d hand pose estimation from single color image}, + author={Wang, Yangang and Peng, Cong and Liu, Yebin}, + journal={IEEE Transactions on Circuits and Systems for Video Technology}, + volume={29}, + number={11}, + pages={3258--3268}, + year={2018}, + publisher={IEEE} +} +``` + +
+
+
+
+
+MobilenetV2 (CVPR'2018)
+ +```bibtex +@inproceedings{sandler2018mobilenetv2, + title={Mobilenetv2: Inverted residuals and linear bottlenecks}, + author={Sandler, Mark and Howard, Andrew and Zhu, Menglong and Zhmoginov, Andrey and Chen, Liang-Chieh}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={4510--4520}, + year={2018} +} +``` + +
+
+
+Results on OneHand10K val set
+
+| Arch | Input Size | PCK@0.2 | AUC | EPE | ckpt | log |
+| :--- | :--------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_mobilenet_v2](/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/mobilenetv2_onehand10k_256x256.py) | 256x256 | 0.986 | 0.537 | 28.60 | [ckpt](https://download.openmmlab.com/mmpose/hand/mobilenetv2/mobilenetv2_onehand10k_256x256-f3a3d90e_20210330.pth) | [log](https://download.openmmlab.com/mmpose/hand/mobilenetv2/mobilenetv2_onehand10k_256x256_20210330.log.json) |
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/mobilenetv2_onehand10k.yml b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/mobilenetv2_onehand10k.yml
new file mode 100644
index 0000000000000000000000000000000000000000..c4f81d6f4e18d139912e350887ab56e03eab4592
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/mobilenetv2_onehand10k.yml
@@ -0,0 +1,22 @@
+Collections:
+- Name: MobilenetV2
+ Paper:
+ Title: 'Mobilenetv2: Inverted residuals and linear bottlenecks'
+ URL: http://openaccess.thecvf.com/content_cvpr_2018/html/Sandler_MobileNetV2_Inverted_Residuals_CVPR_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/mobilenetv2.md
+Models:
+- Config: configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/mobilenetv2_onehand10k_256x256.py
+ In Collection: MobilenetV2
+ Metadata:
+ Architecture:
+ - MobilenetV2
+ Training Data: OneHand10K
+ Name: topdown_heatmap_mobilenetv2_onehand10k_256x256
+ Results:
+ - Dataset: OneHand10K
+ Metrics:
+ AUC: 0.537
+ EPE: 28.6
+ PCK@0.2: 0.986
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/mobilenetv2/mobilenetv2_onehand10k_256x256-f3a3d90e_20210330.pth
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/mobilenetv2_onehand10k_256x256.py b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/mobilenetv2_onehand10k_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..9cb41c397ce2b1ade1321d75e178e33a9fe37f7d
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/mobilenetv2_onehand10k_256x256.py
@@ -0,0 +1,131 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/onehand10k.py'
+]
+evaluation = dict(interval=10, metric=['PCK', 'AUC', 'EPE'], save_best='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=21,
+ dataset_joints=21,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='mmcls://mobilenet_v2',
+ backbone=dict(type='MobileNetV2', widen_factor=1., out_indices=(7, )),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1280,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/onehand10k'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='OneHand10KDataset',
+ ann_file=f'{data_root}/annotations/onehand10k_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='OneHand10KDataset',
+ ann_file=f'{data_root}/annotations/onehand10k_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='OneHand10KDataset',
+ ann_file=f'{data_root}/annotations/onehand10k_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/res50_onehand10k_256x256.py b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/res50_onehand10k_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..e5bd56682c532be7a5c46963e2662012e040825f
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/res50_onehand10k_256x256.py
@@ -0,0 +1,130 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/onehand10k.py'
+]
+evaluation = dict(interval=10, metric=['PCK', 'AUC', 'EPE'], save_best='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=20,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=21,
+ dataset_joints=21,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/onehand10k'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='OneHand10KDataset',
+ ann_file=f'{data_root}/annotations/onehand10k_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='OneHand10KDataset',
+ ann_file=f'{data_root}/annotations/onehand10k_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='OneHand10KDataset',
+ ann_file=f'{data_root}/annotations/onehand10k_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/resnet_onehand10k.md b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/resnet_onehand10k.md
new file mode 100644
index 0000000000000000000000000000000000000000..1d190760318d2de5c390791a1ff293fb78c08ddd
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/resnet_onehand10k.md
@@ -0,0 +1,59 @@
+
+
+OneHand10K (TCSVT'2019)
+ +```bibtex +@article{wang2018mask, + title={Mask-pose cascaded cnn for 2d hand pose estimation from single color image}, + author={Wang, Yangang and Peng, Cong and Liu, Yebin}, + journal={IEEE Transactions on Circuits and Systems for Video Technology}, + volume={29}, + number={11}, + pages={3258--3268}, + year={2018}, + publisher={IEEE} +} +``` + +
+
+
+
+
+SimpleBaseline2D (ECCV'2018)
+ +```bibtex +@inproceedings{xiao2018simple, + title={Simple baselines for human pose estimation and tracking}, + author={Xiao, Bin and Wu, Haiping and Wei, Yichen}, + booktitle={Proceedings of the European conference on computer vision (ECCV)}, + pages={466--481}, + year={2018} +} +``` + +
+
+
+
+
+ResNet (CVPR'2016)
+ +```bibtex +@inproceedings{he2016deep, + title={Deep residual learning for image recognition}, + author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={770--778}, + year={2016} +} +``` + +
+
+
+Results on OneHand10K val set
+
+| Arch | Input Size | PCK@0.2 | AUC | EPE | ckpt | log |
+| :--- | :--------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_resnet_50](/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/res50_onehand10k_256x256.py) | 256x256 | 0.989 | 0.555 | 25.19 | [ckpt](https://download.openmmlab.com/mmpose/hand/resnet/res50_onehand10k_256x256-739c8639_20210330.pth) | [log](https://download.openmmlab.com/mmpose/hand/resnet/res50_onehand10k_256x256_20210330.log.json) |
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/resnet_onehand10k.yml b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/resnet_onehand10k.yml
new file mode 100644
index 0000000000000000000000000000000000000000..065f99d667b0d62f7c0080ed24c9469c5cd8a82b
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/resnet_onehand10k.yml
@@ -0,0 +1,23 @@
+Collections:
+- Name: SimpleBaseline2D
+ Paper:
+ Title: Simple baselines for human pose estimation and tracking
+ URL: http://openaccess.thecvf.com/content_ECCV_2018/html/Bin_Xiao_Simple_Baselines_for_ECCV_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/simplebaseline2d.md
+Models:
+- Config: configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/res50_onehand10k_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture:
+ - SimpleBaseline2D
+ - ResNet
+ Training Data: OneHand10K
+ Name: topdown_heatmap_res50_onehand10k_256x256
+ Results:
+ - Dataset: OneHand10K
+ Metrics:
+ AUC: 0.555
+ EPE: 25.19
+ PCK@0.2: 0.989
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/resnet/res50_onehand10k_256x256-739c8639_20210330.pth
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/hrnetv2_dark_panoptic2d.md b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/hrnetv2_dark_panoptic2d.md
new file mode 100644
index 0000000000000000000000000000000000000000..6ac86361123f7e1e163a2057dd98a5c51032df63
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/hrnetv2_dark_panoptic2d.md
@@ -0,0 +1,57 @@
+
+
+OneHand10K (TCSVT'2019)
+ +```bibtex +@article{wang2018mask, + title={Mask-pose cascaded cnn for 2d hand pose estimation from single color image}, + author={Wang, Yangang and Peng, Cong and Liu, Yebin}, + journal={IEEE Transactions on Circuits and Systems for Video Technology}, + volume={29}, + number={11}, + pages={3258--3268}, + year={2018}, + publisher={IEEE} +} +``` + +
+
+
+
+
+HRNetv2 (TPAMI'2019)
+ +```bibtex +@article{WangSCJDZLMTWLX19, + title={Deep High-Resolution Representation Learning for Visual Recognition}, + author={Jingdong Wang and Ke Sun and Tianheng Cheng and + Borui Jiang and Chaorui Deng and Yang Zhao and Dong Liu and Yadong Mu and + Mingkui Tan and Xinggang Wang and Wenyu Liu and Bin Xiao}, + journal={TPAMI}, + year={2019} +} +``` + +
+
+
+
+
+DarkPose (CVPR'2020)
+ +```bibtex +@inproceedings{zhang2020distribution, + title={Distribution-aware coordinate representation for human pose estimation}, + author={Zhang, Feng and Zhu, Xiatian and Dai, Hanbin and Ye, Mao and Zhu, Ce}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + pages={7093--7102}, + year={2020} +} +``` + +
+
+
+Results on CMU Panoptic (MPII+NZSL val set)
+
+| Arch | Input Size | PCKh@0.7 | AUC | EPE | ckpt | log |
+| :--- | :--------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_hrnetv2_w18_dark](/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/hrnetv2_w18_panoptic_256x256_dark.py) | 256x256 | 0.999 | 0.745 | 7.77 | [ckpt](https://download.openmmlab.com/mmpose/hand/dark/hrnetv2_w18_panoptic_256x256_dark-1f1e4b74_20210330.pth) | [log](https://download.openmmlab.com/mmpose/hand/dark/hrnetv2_w18_panoptic_256x256_dark_20210330.log.json) |
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/hrnetv2_dark_panoptic2d.yml b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/hrnetv2_dark_panoptic2d.yml
new file mode 100644
index 0000000000000000000000000000000000000000..33f7f7d25c382f7bc878b52d7d39fc3952c375fb
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/hrnetv2_dark_panoptic2d.yml
@@ -0,0 +1,23 @@
+Collections:
+- Name: DarkPose
+ Paper:
+ Title: Distribution-aware coordinate representation for human pose estimation
+ URL: http://openaccess.thecvf.com/content_CVPR_2020/html/Zhang_Distribution-Aware_Coordinate_Representation_for_Human_Pose_Estimation_CVPR_2020_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/techniques/dark.md
+Models:
+- Config: configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/hrnetv2_w18_panoptic_256x256_dark.py
+ In Collection: DarkPose
+ Metadata:
+ Architecture:
+ - HRNetv2
+ - DarkPose
+ Training Data: CMU Panoptic HandDB
+ Name: topdown_heatmap_hrnetv2_w18_panoptic_256x256_dark
+ Results:
+ - Dataset: CMU Panoptic HandDB
+ Metrics:
+ AUC: 0.745
+ EPE: 7.77
+ PCKh@0.7: 0.999
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/dark/hrnetv2_w18_panoptic_256x256_dark-1f1e4b74_20210330.pth
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/hrnetv2_panoptic2d.md b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/hrnetv2_panoptic2d.md
new file mode 100644
index 0000000000000000000000000000000000000000..8b4cf1f80c71596e2c049b580e246a589d9987f2
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/hrnetv2_panoptic2d.md
@@ -0,0 +1,40 @@
+
+
+CMU Panoptic HandDB (CVPR'2017)
+ +```bibtex +@inproceedings{simon2017hand, + title={Hand keypoint detection in single images using multiview bootstrapping}, + author={Simon, Tomas and Joo, Hanbyul and Matthews, Iain and Sheikh, Yaser}, + booktitle={Proceedings of the IEEE conference on Computer Vision and Pattern Recognition}, + pages={1145--1153}, + year={2017} +} +``` + +
+
+
+
+
+HRNetv2 (TPAMI'2019)
+ +```bibtex +@article{WangSCJDZLMTWLX19, + title={Deep High-Resolution Representation Learning for Visual Recognition}, + author={Jingdong Wang and Ke Sun and Tianheng Cheng and + Borui Jiang and Chaorui Deng and Yang Zhao and Dong Liu and Yadong Mu and + Mingkui Tan and Xinggang Wang and Wenyu Liu and Bin Xiao}, + journal={TPAMI}, + year={2019} +} +``` + +
+
+
+Results on CMU Panoptic (MPII+NZSL val set)
+
+| Arch | Input Size | PCKh@0.7 | AUC | EPE | ckpt | log |
+| :--- | :--------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_hrnetv2_w18](/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/hrnetv2_w18_panoptic_256x256.py) | 256x256 | 0.999 | 0.744 | 7.79 | [ckpt](https://download.openmmlab.com/mmpose/hand/hrnetv2/hrnetv2_w18_panoptic_256x256-53b12345_20210330.pth) | [log](https://download.openmmlab.com/mmpose/hand/hrnetv2/hrnetv2_w18_panoptic_256x256_20210330.log.json) |
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/hrnetv2_panoptic2d.yml b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/hrnetv2_panoptic2d.yml
new file mode 100644
index 0000000000000000000000000000000000000000..06f7bd1a20a40055256c2e49c4b844a71f0a118b
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/hrnetv2_panoptic2d.yml
@@ -0,0 +1,22 @@
+Collections:
+- Name: HRNetv2
+ Paper:
+ Title: Deep High-Resolution Representation Learning for Visual Recognition
+ URL: https://ieeexplore.ieee.org/abstract/document/9052469/
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/hrnetv2.md
+Models:
+- Config: configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/hrnetv2_w18_panoptic_256x256.py
+ In Collection: HRNetv2
+ Metadata:
+ Architecture:
+ - HRNetv2
+ Training Data: CMU Panoptic HandDB
+ Name: topdown_heatmap_hrnetv2_w18_panoptic_256x256
+ Results:
+ - Dataset: CMU Panoptic HandDB
+ Metrics:
+ AUC: 0.744
+ EPE: 7.79
+ PCKh@0.7: 0.999
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/hrnetv2/hrnetv2_w18_panoptic_256x256-53b12345_20210330.pth
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/hrnetv2_udp_panoptic2d.md b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/hrnetv2_udp_panoptic2d.md
new file mode 100644
index 0000000000000000000000000000000000000000..fe1ea73624c9fafa782452b59ee5cd671945360e
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/hrnetv2_udp_panoptic2d.md
@@ -0,0 +1,57 @@
+
+
+CMU Panoptic HandDB (CVPR'2017)
+ +```bibtex +@inproceedings{simon2017hand, + title={Hand keypoint detection in single images using multiview bootstrapping}, + author={Simon, Tomas and Joo, Hanbyul and Matthews, Iain and Sheikh, Yaser}, + booktitle={Proceedings of the IEEE conference on Computer Vision and Pattern Recognition}, + pages={1145--1153}, + year={2017} +} +``` + +
+
+
+
+
+HRNetv2 (TPAMI'2019)
+ +```bibtex +@article{WangSCJDZLMTWLX19, + title={Deep High-Resolution Representation Learning for Visual Recognition}, + author={Jingdong Wang and Ke Sun and Tianheng Cheng and + Borui Jiang and Chaorui Deng and Yang Zhao and Dong Liu and Yadong Mu and + Mingkui Tan and Xinggang Wang and Wenyu Liu and Bin Xiao}, + journal={TPAMI}, + year={2019} +} +``` + +
+
+
+
+
+UDP (CVPR'2020)
+ +```bibtex +@InProceedings{Huang_2020_CVPR, + author = {Huang, Junjie and Zhu, Zheng and Guo, Feng and Huang, Guan}, + title = {The Devil Is in the Details: Delving Into Unbiased Data Processing for Human Pose Estimation}, + booktitle = {The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, + month = {June}, + year = {2020} +} +``` + +
+
+
+Results on CMU Panoptic (MPII+NZSL val set)
+
+| Arch | Input Size | PCKh@0.7 | AUC | EPE | ckpt | log |
+| :--- | :--------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_hrnetv2_w18_udp](/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/hrnetv2_w18_panoptic_256x256_udp.py) | 256x256 | 0.998 | 0.742 | 7.84 | [ckpt](https://download.openmmlab.com/mmpose/hand/udp/hrnetv2_w18_panoptic_256x256_udp-f9e15948_20210330.pth) | [log](https://download.openmmlab.com/mmpose/hand/udp/hrnetv2_w18_panoptic_256x256_udp_20210330.log.json) |
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/hrnetv2_udp_panoptic2d.yml b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/hrnetv2_udp_panoptic2d.yml
new file mode 100644
index 0000000000000000000000000000000000000000..cd1e91e2dbe0d77e6f3a8398589ea8480874b985
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/hrnetv2_udp_panoptic2d.yml
@@ -0,0 +1,24 @@
+Collections:
+- Name: UDP
+ Paper:
+ Title: 'The Devil Is in the Details: Delving Into Unbiased Data Processing for
+ Human Pose Estimation'
+ URL: http://openaccess.thecvf.com/content_CVPR_2020/html/Huang_The_Devil_Is_in_the_Details_Delving_Into_Unbiased_Data_CVPR_2020_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/techniques/udp.md
+Models:
+- Config: configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/hrnetv2_w18_panoptic_256x256_udp.py
+ In Collection: UDP
+ Metadata:
+ Architecture:
+ - HRNetv2
+ - UDP
+ Training Data: CMU Panoptic HandDB
+ Name: topdown_heatmap_hrnetv2_w18_panoptic_256x256_udp
+ Results:
+ - Dataset: CMU Panoptic HandDB
+ Metrics:
+ AUC: 0.742
+ EPE: 7.84
+ PCKh@0.7: 0.998
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/udp/hrnetv2_w18_panoptic_256x256_udp-f9e15948_20210330.pth
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/hrnetv2_w18_panoptic2d_256x256.py b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/hrnetv2_w18_panoptic2d_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..148ba027ecca2e95e6b078ed2371959a72d90f5c
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/hrnetv2_w18_panoptic2d_256x256.py
@@ -0,0 +1,164 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/panoptic_hand2d.py'
+]
+evaluation = dict(interval=10, metric=['PCKh', 'AUC', 'EPE'], save_best='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=21,
+ dataset_joints=21,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='open-mmlab://msra/hrnetv2_w18',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(18, 36)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(18, 36, 72)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(18, 36, 72, 144),
+ multiscale_output=True),
+ upsample=dict(mode='bilinear', align_corners=False))),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=[18, 36, 72, 144],
+ in_index=(0, 1, 2, 3),
+ input_transform='resize_concat',
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(
+ final_conv_kernel=1, num_conv_layers=1, num_conv_kernels=(1, )),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/panoptic'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='PanopticDataset',
+ ann_file=f'{data_root}/annotations/panoptic_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='PanopticDataset',
+ ann_file=f'{data_root}/annotations/panoptic_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='PanopticDataset',
+ ann_file=f'{data_root}/annotations/panoptic_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/hrnetv2_w18_panoptic2d_256x256_dark.py b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/hrnetv2_w18_panoptic2d_256x256_dark.py
new file mode 100644
index 0000000000000000000000000000000000000000..94c2ab06be0d571ee00e1bc52ff55332f5ca0643
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/hrnetv2_w18_panoptic2d_256x256_dark.py
@@ -0,0 +1,164 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/panoptic_hand2d.py'
+]
+evaluation = dict(interval=10, metric=['PCKh', 'AUC', 'EPE'], save_best='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=21,
+ dataset_joints=21,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='open-mmlab://msra/hrnetv2_w18',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(18, 36)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(18, 36, 72)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(18, 36, 72, 144),
+ multiscale_output=True),
+ upsample=dict(mode='bilinear', align_corners=False))),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=[18, 36, 72, 144],
+ in_index=(0, 1, 2, 3),
+ input_transform='resize_concat',
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(
+ final_conv_kernel=1, num_conv_layers=1, num_conv_kernels=(1, )),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='unbiased',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2, unbiased_encoding=True),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/panoptic'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='PanopticDataset',
+ ann_file=f'{data_root}/annotations/panoptic_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='PanopticDataset',
+ ann_file=f'{data_root}/annotations/panoptic_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='PanopticDataset',
+ ann_file=f'{data_root}/annotations/panoptic_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/hrnetv2_w18_panoptic2d_256x256_udp.py b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/hrnetv2_w18_panoptic2d_256x256_udp.py
new file mode 100644
index 0000000000000000000000000000000000000000..bfb89a6adac93bcc2a294559348617fc6e99d451
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/hrnetv2_w18_panoptic2d_256x256_udp.py
@@ -0,0 +1,171 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/panoptic_hand2d.py'
+]
+evaluation = dict(interval=10, metric=['PCKh', 'AUC', 'EPE'], save_best='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+target_type = 'GaussianHeatmap'
+channel_cfg = dict(
+ num_output_channels=21,
+ dataset_joints=21,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='open-mmlab://msra/hrnetv2_w18',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(18, 36)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(18, 36, 72)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(18, 36, 72, 144),
+ multiscale_output=True),
+ upsample=dict(mode='bilinear', align_corners=False))),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=[18, 36, 72, 144],
+ in_index=(0, 1, 2, 3),
+ input_transform='resize_concat',
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(
+ final_conv_kernel=1, num_conv_layers=1, num_conv_kernels=(1, )),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=False,
+ target_type=target_type,
+ modulate_kernel=11,
+ use_udp=True))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='TopDownGenerateTarget',
+ sigma=2,
+ encoding='UDP',
+ target_type=target_type),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/panoptic'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='PanopticDataset',
+ ann_file=f'{data_root}/annotations/panoptic_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='PanopticDataset',
+ ann_file=f'{data_root}/annotations/panoptic_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='PanopticDataset',
+ ann_file=f'{data_root}/annotations/panoptic_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/mobilenetv2_panoptic2d.md b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/mobilenetv2_panoptic2d.md
new file mode 100644
index 0000000000000000000000000000000000000000..def2133ca8a77d92b7d74e0ea73f73d1dc1e4183
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/mobilenetv2_panoptic2d.md
@@ -0,0 +1,39 @@
+
+
+CMU Panoptic HandDB (CVPR'2017)
+ +```bibtex +@inproceedings{simon2017hand, + title={Hand keypoint detection in single images using multiview bootstrapping}, + author={Simon, Tomas and Joo, Hanbyul and Matthews, Iain and Sheikh, Yaser}, + booktitle={Proceedings of the IEEE conference on Computer Vision and Pattern Recognition}, + pages={1145--1153}, + year={2017} +} +``` + +
+
+
+
+
+MobilenetV2 (CVPR'2018)
+ +```bibtex +@inproceedings{sandler2018mobilenetv2, + title={Mobilenetv2: Inverted residuals and linear bottlenecks}, + author={Sandler, Mark and Howard, Andrew and Zhu, Menglong and Zhmoginov, Andrey and Chen, Liang-Chieh}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={4510--4520}, + year={2018} +} +``` + +
+
+
+Results on CMU Panoptic (MPII+NZSL val set)
+
+| Arch | Input Size | PCKh@0.7 | AUC | EPE | ckpt | log |
+| :--- | :--------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_mobilenet_v2](/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/mobilenetv2_panoptic_256x256.py) | 256x256 | 0.998 | 0.694 | 9.70 | [ckpt](https://download.openmmlab.com/mmpose/hand/mobilenetv2/mobilenetv2_panoptic_256x256-b733d98c_20210330.pth) | [log](https://download.openmmlab.com/mmpose/hand/mobilenetv2/mobilenetv2_panoptic_256x256_20210330.log.json) |
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/mobilenetv2_panoptic2d.yml b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/mobilenetv2_panoptic2d.yml
new file mode 100644
index 0000000000000000000000000000000000000000..1339b1e944c7ee93585546e1fa0a853455fa12c7
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/mobilenetv2_panoptic2d.yml
@@ -0,0 +1,22 @@
+Collections:
+- Name: MobilenetV2
+ Paper:
+ Title: 'Mobilenetv2: Inverted residuals and linear bottlenecks'
+ URL: http://openaccess.thecvf.com/content_cvpr_2018/html/Sandler_MobileNetV2_Inverted_Residuals_CVPR_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/mobilenetv2.md
+Models:
+- Config: configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/mobilenetv2_panoptic_256x256.py
+ In Collection: MobilenetV2
+ Metadata:
+ Architecture:
+ - MobilenetV2
+ Training Data: CMU Panoptic HandDB
+ Name: topdown_heatmap_mobilenetv2_panoptic_256x256
+ Results:
+ - Dataset: CMU Panoptic HandDB
+ Metrics:
+ AUC: 0.694
+ EPE: 9.7
+ PCKh@0.7: 0.998
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/mobilenetv2/mobilenetv2_panoptic_256x256-b733d98c_20210330.pth
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/mobilenetv2_panoptic2d_256x256.py b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/mobilenetv2_panoptic2d_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..a164074edc4fc866d22482e91d41730de2d3788f
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/mobilenetv2_panoptic2d_256x256.py
@@ -0,0 +1,130 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/panoptic_hand2d.py'
+]
+evaluation = dict(interval=10, metric=['PCKh', 'AUC', 'EPE'], save_best='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=21,
+ dataset_joints=21,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='mmcls://mobilenet_v2',
+ backbone=dict(type='MobileNetV2', widen_factor=1., out_indices=(7, )),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1280,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/panoptic'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='PanopticDataset',
+ ann_file=f'{data_root}/annotations/panoptic_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='PanopticDataset',
+ ann_file=f'{data_root}/annotations/panoptic_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='PanopticDataset',
+ ann_file=f'{data_root}/annotations/panoptic_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/res50_panoptic2d_256x256.py b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/res50_panoptic2d_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..774711b19f68b0b335010df04acd456b385eb956
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/res50_panoptic2d_256x256.py
@@ -0,0 +1,130 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/panoptic_hand2d.py'
+]
+evaluation = dict(interval=10, metric=['PCKh', 'AUC', 'EPE'], save_best='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=21,
+ dataset_joints=21,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/panoptic'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='PanopticDataset',
+ ann_file=f'{data_root}/annotations/panoptic_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='PanopticDataset',
+ ann_file=f'{data_root}/annotations/panoptic_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='PanopticDataset',
+ ann_file=f'{data_root}/annotations/panoptic_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/resnet_panoptic2d.md b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/resnet_panoptic2d.md
new file mode 100644
index 0000000000000000000000000000000000000000..f92f22bc561afdb93c16cc278e53c7ec842d2f5c
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/resnet_panoptic2d.md
@@ -0,0 +1,56 @@
+
+
+CMU Panoptic HandDB (CVPR'2017)
+ +```bibtex +@inproceedings{simon2017hand, + title={Hand keypoint detection in single images using multiview bootstrapping}, + author={Simon, Tomas and Joo, Hanbyul and Matthews, Iain and Sheikh, Yaser}, + booktitle={Proceedings of the IEEE conference on Computer Vision and Pattern Recognition}, + pages={1145--1153}, + year={2017} +} +``` + +
+
+
+
+
+SimpleBaseline2D (ECCV'2018)
+ +```bibtex +@inproceedings{xiao2018simple, + title={Simple baselines for human pose estimation and tracking}, + author={Xiao, Bin and Wu, Haiping and Wei, Yichen}, + booktitle={Proceedings of the European conference on computer vision (ECCV)}, + pages={466--481}, + year={2018} +} +``` + +
+
+
+
+
+ResNet (CVPR'2016)
+ +```bibtex +@inproceedings{he2016deep, + title={Deep residual learning for image recognition}, + author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={770--778}, + year={2016} +} +``` + +
+
+
+Results on CMU Panoptic (MPII+NZSL val set)
+
+| Arch | Input Size | PCKh@0.7 | AUC | EPE | ckpt | log |
+| :--- | :--------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_resnet_50](/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/res50_panoptic_256x256.py) | 256x256 | 0.999 | 0.713 | 9.00 | [ckpt](https://download.openmmlab.com/mmpose/hand/resnet/res50_panoptic_256x256-4eafc561_20210330.pth) | [log](https://download.openmmlab.com/mmpose/hand/resnet/res50_panoptic_256x256_20210330.log.json) |
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/resnet_panoptic2d.yml b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/resnet_panoptic2d.yml
new file mode 100644
index 0000000000000000000000000000000000000000..79dd55598d5452168d31312b46f7a6ebe71861cb
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/resnet_panoptic2d.yml
@@ -0,0 +1,23 @@
+Collections:
+- Name: SimpleBaseline2D
+ Paper:
+ Title: Simple baselines for human pose estimation and tracking
+ URL: http://openaccess.thecvf.com/content_ECCV_2018/html/Bin_Xiao_Simple_Baselines_for_ECCV_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/simplebaseline2d.md
+Models:
+- Config: configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/res50_panoptic_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture:
+ - SimpleBaseline2D
+ - ResNet
+ Training Data: CMU Panoptic HandDB
+ Name: topdown_heatmap_res50_panoptic_256x256
+ Results:
+ - Dataset: CMU Panoptic HandDB
+ Metrics:
+ AUC: 0.713
+ EPE: 9.0
+ PCKh@0.7: 0.999
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/resnet/res50_panoptic_256x256-4eafc561_20210330.pth
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/hrnetv2_dark_rhd2d.md b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/hrnetv2_dark_rhd2d.md
new file mode 100644
index 0000000000000000000000000000000000000000..15bc4d5f75d31d0e804402c94f200f9314873361
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/hrnetv2_dark_rhd2d.md
@@ -0,0 +1,58 @@
+
+
+CMU Panoptic HandDB (CVPR'2017)
+ +```bibtex +@inproceedings{simon2017hand, + title={Hand keypoint detection in single images using multiview bootstrapping}, + author={Simon, Tomas and Joo, Hanbyul and Matthews, Iain and Sheikh, Yaser}, + booktitle={Proceedings of the IEEE conference on Computer Vision and Pattern Recognition}, + pages={1145--1153}, + year={2017} +} +``` + +
+
+
+
+
+HRNetv2 (TPAMI'2019)
+ +```bibtex +@article{WangSCJDZLMTWLX19, + title={Deep High-Resolution Representation Learning for Visual Recognition}, + author={Jingdong Wang and Ke Sun and Tianheng Cheng and + Borui Jiang and Chaorui Deng and Yang Zhao and Dong Liu and Yadong Mu and + Mingkui Tan and Xinggang Wang and Wenyu Liu and Bin Xiao}, + journal={TPAMI}, + year={2019} +} +``` + +
+
+
+
+
+DarkPose (CVPR'2020)
+ +```bibtex +@inproceedings{zhang2020distribution, + title={Distribution-aware coordinate representation for human pose estimation}, + author={Zhang, Feng and Zhu, Xiatian and Dai, Hanbin and Ye, Mao and Zhu, Ce}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + pages={7093--7102}, + year={2020} +} +``` + +
+
+
+Results on RHD test set
+
+| Arch | Input Size | PCK@0.2 | AUC | EPE | ckpt | log |
+| :--- | :--------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_hrnetv2_w18_dark](/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/hrnetv2_w18_rhd2d_256x256_dark.py) | 256x256 | 0.992 | 0.903 | 2.17 | [ckpt](https://download.openmmlab.com/mmpose/hand/dark/hrnetv2_w18_rhd2d_256x256_dark-4df3a347_20210330.pth) | [log](https://download.openmmlab.com/mmpose/hand/dark/hrnetv2_w18_rhd2d_256x256_dark_20210330.log.json) |
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/hrnetv2_dark_rhd2d.yml b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/hrnetv2_dark_rhd2d.yml
new file mode 100644
index 0000000000000000000000000000000000000000..6083f92e6b93058ede4d8ed1fce6b057f4e3be55
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/hrnetv2_dark_rhd2d.yml
@@ -0,0 +1,23 @@
+Collections:
+- Name: DarkPose
+ Paper:
+ Title: Distribution-aware coordinate representation for human pose estimation
+ URL: http://openaccess.thecvf.com/content_CVPR_2020/html/Zhang_Distribution-Aware_Coordinate_Representation_for_Human_Pose_Estimation_CVPR_2020_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/techniques/dark.md
+Models:
+- Config: configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/hrnetv2_w18_rhd2d_256x256_dark.py
+ In Collection: DarkPose
+ Metadata:
+ Architecture:
+ - HRNetv2
+ - DarkPose
+ Training Data: RHD
+ Name: topdown_heatmap_hrnetv2_w18_rhd2d_256x256_dark
+ Results:
+ - Dataset: RHD
+ Metrics:
+ AUC: 0.903
+ EPE: 2.17
+ PCK@0.2: 0.992
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/dark/hrnetv2_w18_rhd2d_256x256_dark-4df3a347_20210330.pth
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/hrnetv2_rhd2d.md b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/hrnetv2_rhd2d.md
new file mode 100644
index 0000000000000000000000000000000000000000..bb1b0ed6d18916b5e20588d91e3e915c4d23ccda
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/hrnetv2_rhd2d.md
@@ -0,0 +1,41 @@
+
+
+RHD (ICCV'2017)
+ +```bibtex +@TechReport{zb2017hand, + author={Christian Zimmermann and Thomas Brox}, + title={Learning to Estimate 3D Hand Pose from Single RGB Images}, + institution={arXiv:1705.01389}, + year={2017}, + note="https://arxiv.org/abs/1705.01389", + url="https://lmb.informatik.uni-freiburg.de/projects/hand3d/" +} +``` + +
+
+
+
+
+HRNetv2 (TPAMI'2019)
+ +```bibtex +@article{WangSCJDZLMTWLX19, + title={Deep High-Resolution Representation Learning for Visual Recognition}, + author={Jingdong Wang and Ke Sun and Tianheng Cheng and + Borui Jiang and Chaorui Deng and Yang Zhao and Dong Liu and Yadong Mu and + Mingkui Tan and Xinggang Wang and Wenyu Liu and Bin Xiao}, + journal={TPAMI}, + year={2019} +} +``` + +
+
+
+Results on RHD test set
+
+| Arch | Input Size | PCK@0.2 | AUC | EPE | ckpt | log |
+| :--- | :--------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_hrnetv2_w18](/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/hrnetv2_w18_rhd2d_256x256.py) | 256x256 | 0.992 | 0.902 | 2.21 | [ckpt](https://download.openmmlab.com/mmpose/hand/hrnetv2/hrnetv2_w18_rhd2d_256x256-95b20dd8_20210330.pth) | [log](https://download.openmmlab.com/mmpose/hand/hrnetv2/hrnetv2_w18_rhd2d_256x256_20210330.log.json) |
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/hrnetv2_rhd2d.yml b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/hrnetv2_rhd2d.yml
new file mode 100644
index 0000000000000000000000000000000000000000..6fbc9848896bf8a9b2a416c7bd95a932e6a39b73
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/hrnetv2_rhd2d.yml
@@ -0,0 +1,22 @@
+Collections:
+- Name: HRNetv2
+ Paper:
+ Title: Deep High-Resolution Representation Learning for Visual Recognition
+ URL: https://ieeexplore.ieee.org/abstract/document/9052469/
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/hrnetv2.md
+Models:
+- Config: configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/hrnetv2_w18_rhd2d_256x256.py
+ In Collection: HRNetv2
+ Metadata:
+ Architecture:
+ - HRNetv2
+ Training Data: RHD
+ Name: topdown_heatmap_hrnetv2_w18_rhd2d_256x256
+ Results:
+ - Dataset: RHD
+ Metrics:
+ AUC: 0.902
+ EPE: 2.21
+ PCK@0.2: 0.992
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/hrnetv2/hrnetv2_w18_rhd2d_256x256-95b20dd8_20210330.pth
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/hrnetv2_udp_rhd2d.md b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/hrnetv2_udp_rhd2d.md
new file mode 100644
index 0000000000000000000000000000000000000000..e18b661b5e8283740f362a365b7fc3cf42ecddd2
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/hrnetv2_udp_rhd2d.md
@@ -0,0 +1,58 @@
+
+
+RHD (ICCV'2017)
+ +```bibtex +@TechReport{zb2017hand, + author={Christian Zimmermann and Thomas Brox}, + title={Learning to Estimate 3D Hand Pose from Single RGB Images}, + institution={arXiv:1705.01389}, + year={2017}, + note="https://arxiv.org/abs/1705.01389", + url="https://lmb.informatik.uni-freiburg.de/projects/hand3d/" +} +``` + +
+
+
+
+
+HRNetv2 (TPAMI'2019)
+ +```bibtex +@article{WangSCJDZLMTWLX19, + title={Deep High-Resolution Representation Learning for Visual Recognition}, + author={Jingdong Wang and Ke Sun and Tianheng Cheng and + Borui Jiang and Chaorui Deng and Yang Zhao and Dong Liu and Yadong Mu and + Mingkui Tan and Xinggang Wang and Wenyu Liu and Bin Xiao}, + journal={TPAMI}, + year={2019} +} +``` + +
+
+
+
+
+UDP (CVPR'2020)
+ +```bibtex +@InProceedings{Huang_2020_CVPR, + author = {Huang, Junjie and Zhu, Zheng and Guo, Feng and Huang, Guan}, + title = {The Devil Is in the Details: Delving Into Unbiased Data Processing for Human Pose Estimation}, + booktitle = {The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, + month = {June}, + year = {2020} +} +``` + +
+
+
+Results on CMU Panoptic (MPII+NZSL val set)
+
+| Arch | Input Size | PCKh@0.7 | AUC | EPE | ckpt | log |
+| :--- | :--------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_hrnetv2_w18_udp](/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/hrnetv2_w18_rhd2d_256x256_udp.py) | 256x256 | 0.998 | 0.742 | 7.84 | [ckpt](https://download.openmmlab.com/mmpose/hand/udp/hrnetv2_w18_rhd2d_256x256_udp-63ba6007_20210330.pth) | [log](https://download.openmmlab.com/mmpose/hand/udp/hrnetv2_w18_rhd2d_256x256_udp_20210330.log.json) |
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/hrnetv2_udp_rhd2d.yml b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/hrnetv2_udp_rhd2d.yml
new file mode 100644
index 0000000000000000000000000000000000000000..40a19b4e2c741b79de9cb23ffdbd5375f1ede6ae
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/hrnetv2_udp_rhd2d.yml
@@ -0,0 +1,24 @@
+Collections:
+- Name: UDP
+ Paper:
+ Title: 'The Devil Is in the Details: Delving Into Unbiased Data Processing for
+ Human Pose Estimation'
+ URL: http://openaccess.thecvf.com/content_CVPR_2020/html/Huang_The_Devil_Is_in_the_Details_Delving_Into_Unbiased_Data_CVPR_2020_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/techniques/udp.md
+Models:
+- Config: configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/hrnetv2_w18_rhd2d_256x256_udp.py
+ In Collection: UDP
+ Metadata:
+ Architecture:
+ - HRNetv2
+ - UDP
+ Training Data: RHD
+ Name: topdown_heatmap_hrnetv2_w18_rhd2d_256x256_udp
+ Results:
+ - Dataset: RHD
+ Metrics:
+ AUC: 0.742
+ EPE: 7.84
+ PCKh@0.7: 0.998
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/udp/hrnetv2_w18_rhd2d_256x256_udp-63ba6007_20210330.pth
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/hrnetv2_w18_rhd2d_256x256.py b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/hrnetv2_w18_rhd2d_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..4989023f0161c68a32a8ad3c1e6f22d5b36372f0
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/hrnetv2_w18_rhd2d_256x256.py
@@ -0,0 +1,164 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/rhd2d.py'
+]
+evaluation = dict(interval=10, metric=['PCK', 'AUC', 'EPE'], save_best='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=21,
+ dataset_joints=21,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='open-mmlab://msra/hrnetv2_w18',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(18, 36)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(18, 36, 72)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(18, 36, 72, 144),
+ multiscale_output=True),
+ upsample=dict(mode='bilinear', align_corners=False))),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=[18, 36, 72, 144],
+ in_index=(0, 1, 2, 3),
+ input_transform='resize_concat',
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(
+ final_conv_kernel=1, num_conv_layers=1, num_conv_kernels=(1, )),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/rhd'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='Rhd2DDataset',
+ ann_file=f'{data_root}/annotations/rhd_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='Rhd2DDataset',
+ ann_file=f'{data_root}/annotations/rhd_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='Rhd2DDataset',
+ ann_file=f'{data_root}/annotations/rhd_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/hrnetv2_w18_rhd2d_256x256_dark.py b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/hrnetv2_w18_rhd2d_256x256_dark.py
new file mode 100644
index 0000000000000000000000000000000000000000..2645755550aee2aed054b621229e0aae29e955f3
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/hrnetv2_w18_rhd2d_256x256_dark.py
@@ -0,0 +1,164 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/rhd2d.py'
+]
+evaluation = dict(interval=10, metric=['PCK', 'AUC', 'EPE'], save_best='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=21,
+ dataset_joints=21,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='open-mmlab://msra/hrnetv2_w18',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(18, 36)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(18, 36, 72)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(18, 36, 72, 144),
+ multiscale_output=True),
+ upsample=dict(mode='bilinear', align_corners=False))),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=[18, 36, 72, 144],
+ in_index=(0, 1, 2, 3),
+ input_transform='resize_concat',
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(
+ final_conv_kernel=1, num_conv_layers=1, num_conv_kernels=(1, )),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='unbiased',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2, unbiased_encoding=True),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/rhd'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='Rhd2DDataset',
+ ann_file=f'{data_root}/annotations/rhd_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='Rhd2DDataset',
+ ann_file=f'{data_root}/annotations/rhd_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='Rhd2DDataset',
+ ann_file=f'{data_root}/annotations/rhd_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/hrnetv2_w18_rhd2d_256x256_udp.py b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/hrnetv2_w18_rhd2d_256x256_udp.py
new file mode 100644
index 0000000000000000000000000000000000000000..bf3acf46eea463dff5d5cde9b151729fe6e727b2
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/hrnetv2_w18_rhd2d_256x256_udp.py
@@ -0,0 +1,171 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/rhd2d.py'
+]
+evaluation = dict(interval=10, metric=['PCK', 'AUC', 'EPE'], save_best='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+target_type = 'GaussianHeatmap'
+channel_cfg = dict(
+ num_output_channels=21,
+ dataset_joints=21,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='open-mmlab://msra/hrnetv2_w18',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(18, 36)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(18, 36, 72)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(18, 36, 72, 144),
+ multiscale_output=True),
+ upsample=dict(mode='bilinear', align_corners=False))),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=[18, 36, 72, 144],
+ in_index=(0, 1, 2, 3),
+ input_transform='resize_concat',
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(
+ final_conv_kernel=1, num_conv_layers=1, num_conv_kernels=(1, )),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=False,
+ target_type=target_type,
+ modulate_kernel=11,
+ use_udp=True))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='TopDownGenerateTarget',
+ sigma=2,
+ encoding='UDP',
+ target_type=target_type),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine', use_udp=True),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/rhd'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='Rhd2DDataset',
+ ann_file=f'{data_root}/annotations/rhd_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='Rhd2DDataset',
+ ann_file=f'{data_root}/annotations/rhd_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='Rhd2DDataset',
+ ann_file=f'{data_root}/annotations/rhd_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/mobilenetv2_rhd2d.md b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/mobilenetv2_rhd2d.md
new file mode 100644
index 0000000000000000000000000000000000000000..448ed41f3c5dc4059238d86d53baf38be9b2277f
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/mobilenetv2_rhd2d.md
@@ -0,0 +1,40 @@
+
+
+RHD (ICCV'2017)
+ +```bibtex +@TechReport{zb2017hand, + author={Christian Zimmermann and Thomas Brox}, + title={Learning to Estimate 3D Hand Pose from Single RGB Images}, + institution={arXiv:1705.01389}, + year={2017}, + note="https://arxiv.org/abs/1705.01389", + url="https://lmb.informatik.uni-freiburg.de/projects/hand3d/" +} +``` + +
+
+
+
+
+MobilenetV2 (CVPR'2018)
+ +```bibtex +@inproceedings{sandler2018mobilenetv2, + title={Mobilenetv2: Inverted residuals and linear bottlenecks}, + author={Sandler, Mark and Howard, Andrew and Zhu, Menglong and Zhmoginov, Andrey and Chen, Liang-Chieh}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={4510--4520}, + year={2018} +} +``` + +
+
+
+Results on RHD test set
+
+| Arch | Input Size | PCK@0.2 | AUC | EPE | ckpt | log |
+| :--- | :--------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_mobilenet_v2](/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/mobilenetv2_rhd2d_256x256.py) | 256x256 | 0.985 | 0.883 | 2.80 | [ckpt](https://download.openmmlab.com/mmpose/hand/mobilenetv2/mobilenetv2_rhd2d_256x256-85fa02db_20210330.pth) | [log](https://download.openmmlab.com/mmpose/hand/mobilenetv2/mobilenetv2_rhd2d_256x256_20210330.log.json) |
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/mobilenetv2_rhd2d.yml b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/mobilenetv2_rhd2d.yml
new file mode 100644
index 0000000000000000000000000000000000000000..bd448d4a59d83e3d747d68e0567b541d36808a7f
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/mobilenetv2_rhd2d.yml
@@ -0,0 +1,22 @@
+Collections:
+- Name: MobilenetV2
+ Paper:
+ Title: 'Mobilenetv2: Inverted residuals and linear bottlenecks'
+ URL: http://openaccess.thecvf.com/content_cvpr_2018/html/Sandler_MobileNetV2_Inverted_Residuals_CVPR_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/mobilenetv2.md
+Models:
+- Config: configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/mobilenetv2_rhd2d_256x256.py
+ In Collection: MobilenetV2
+ Metadata:
+ Architecture:
+ - MobilenetV2
+ Training Data: RHD
+ Name: topdown_heatmap_mobilenetv2_rhd2d_256x256
+ Results:
+ - Dataset: RHD
+ Metrics:
+ AUC: 0.883
+ EPE: 2.8
+ PCK@0.2: 0.985
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/mobilenetv2/mobilenetv2_rhd2d_256x256-85fa02db_20210330.pth
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/mobilenetv2_rhd2d_256x256.py b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/mobilenetv2_rhd2d_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..44c94c1852500bf32390faba97b9a60b5357f191
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/mobilenetv2_rhd2d_256x256.py
@@ -0,0 +1,130 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/rhd2d.py'
+]
+evaluation = dict(interval=10, metric=['PCK', 'AUC', 'EPE'], save_best='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=10,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=21,
+ dataset_joints=21,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='mmcls://mobilenet_v2',
+ backbone=dict(type='MobileNetV2', widen_factor=1., out_indices=(7, )),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1280,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/rhd'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='Rhd2DDataset',
+ ann_file=f'{data_root}/annotations/rhd_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='Rhd2DDataset',
+ ann_file=f'{data_root}/annotations/rhd_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='Rhd2DDataset',
+ ann_file=f'{data_root}/annotations/rhd_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/res50_rhd2d_224x224.py b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/res50_rhd2d_224x224.py
new file mode 100644
index 0000000000000000000000000000000000000000..c1505698db92a5fb17347d180c69046636e98788
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/res50_rhd2d_224x224.py
@@ -0,0 +1,130 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/rhd2d.py'
+]
+evaluation = dict(interval=10, metric=['PCK', 'AUC', 'EPE'], save_best='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=20,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=21,
+ dataset_joints=21,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[224, 224],
+ heatmap_size=[56, 56],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/rhd'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='Rhd2DDataset',
+ ann_file=f'{data_root}/annotations/rhd_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='Rhd2DDataset',
+ ann_file=f'{data_root}/annotations/rhd_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='Rhd2DDataset',
+ ann_file=f'{data_root}/annotations/rhd_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/res50_rhd2d_256x256.py b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/res50_rhd2d_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..c987d338fc9580e62dbebe4c005f4355dba39334
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/res50_rhd2d_256x256.py
@@ -0,0 +1,130 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/rhd2d.py'
+]
+evaluation = dict(interval=10, metric=['PCK', 'AUC', 'EPE'], save_best='AUC')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+log_config = dict(
+ interval=20,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=21,
+ dataset_joints=21,
+ dataset_channel=[
+ [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20
+ ],
+ ],
+ inference_channel=[
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
+ 20
+ ])
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=90, scale_factor=0.3),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=['image_file', 'center', 'scale', 'rotation', 'flip_pairs']),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/rhd'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='Rhd2DDataset',
+ ann_file=f'{data_root}/annotations/rhd_train.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='Rhd2DDataset',
+ ann_file=f'{data_root}/annotations/rhd_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='Rhd2DDataset',
+ ann_file=f'{data_root}/annotations/rhd_test.json',
+ img_prefix=f'{data_root}/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/resnet_rhd2d.md b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/resnet_rhd2d.md
new file mode 100644
index 0000000000000000000000000000000000000000..78dee7b93bda9073ad6afb019d9205c405d2614d
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/resnet_rhd2d.md
@@ -0,0 +1,57 @@
+
+
+RHD (ICCV'2017)
+ +```bibtex +@TechReport{zb2017hand, + author={Christian Zimmermann and Thomas Brox}, + title={Learning to Estimate 3D Hand Pose from Single RGB Images}, + institution={arXiv:1705.01389}, + year={2017}, + note="https://arxiv.org/abs/1705.01389", + url="https://lmb.informatik.uni-freiburg.de/projects/hand3d/" +} +``` + +
+
+
+
+
+SimpleBaseline2D (ECCV'2018)
+ +```bibtex +@inproceedings{xiao2018simple, + title={Simple baselines for human pose estimation and tracking}, + author={Xiao, Bin and Wu, Haiping and Wei, Yichen}, + booktitle={Proceedings of the European conference on computer vision (ECCV)}, + pages={466--481}, + year={2018} +} +``` + +
+
+
+
+
+ResNet (CVPR'2016)
+ +```bibtex +@inproceedings{he2016deep, + title={Deep residual learning for image recognition}, + author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={770--778}, + year={2016} +} +``` + +
+
+
+Results on RHD test set
+
+| Arch | Input Size | PCK@0.2 | AUC | EPE | ckpt | log |
+| :--- | :--------: | :------: | :------: | :------: |:------: |:------: |
+| [pose_resnet50](/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/res50_rhd2d_256x256.py) | 256x256 | 0.991 | 0.898 | 2.33 | [ckpt](https://download.openmmlab.com/mmpose/hand/resnet/res50_rhd2d_256x256-5dc7e4cc_20210330.pth) | [log](https://download.openmmlab.com/mmpose/hand/resnet/res50_rhd2d_256x256_20210330.log.json) |
diff --git a/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/resnet_rhd2d.yml b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/resnet_rhd2d.yml
new file mode 100644
index 0000000000000000000000000000000000000000..457ace5fc2186f17b2ff73d0d5f532d090b6da41
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/resnet_rhd2d.yml
@@ -0,0 +1,23 @@
+Collections:
+- Name: SimpleBaseline2D
+ Paper:
+ Title: Simple baselines for human pose estimation and tracking
+ URL: http://openaccess.thecvf.com/content_ECCV_2018/html/Bin_Xiao_Simple_Baselines_for_ECCV_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/simplebaseline2d.md
+Models:
+- Config: configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/res50_rhd2d_256x256.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture:
+ - SimpleBaseline2D
+ - ResNet
+ Training Data: RHD
+ Name: topdown_heatmap_res50_rhd2d_256x256
+ Results:
+ - Dataset: RHD
+ Metrics:
+ AUC: 0.898
+ EPE: 2.33
+ PCK@0.2: 0.991
+ Task: Hand 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand/resnet/res50_rhd2d_256x256-5dc7e4cc_20210330.pth
diff --git a/vendor/ViTPose/configs/hand/3d_kpt_sview_rgb_img/README.md b/vendor/ViTPose/configs/hand/3d_kpt_sview_rgb_img/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..c058280df2ded5486bf04dcb92731ac6c6a93b0a
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/3d_kpt_sview_rgb_img/README.md
@@ -0,0 +1,7 @@
+# 3D Hand Pose Estimation
+
+3D hand pose estimation is defined as the task of detecting the poses (or keypoints) of the hand from an input image.
+
+## Data preparation
+
+Please follow [DATA Preparation](/docs/en/tasks/3d_hand_keypoint.md) to prepare data.
diff --git a/vendor/ViTPose/configs/hand/3d_kpt_sview_rgb_img/internet/README.md b/vendor/ViTPose/configs/hand/3d_kpt_sview_rgb_img/internet/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..f7d2a8ccffc8cc6f2249d98e045a82d25f810199
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/3d_kpt_sview_rgb_img/internet/README.md
@@ -0,0 +1,19 @@
+# InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image
+
+## Introduction
+
+
+
+RHD (ICCV'2017)
+ +```bibtex +@TechReport{zb2017hand, + author={Christian Zimmermann and Thomas Brox}, + title={Learning to Estimate 3D Hand Pose from Single RGB Images}, + institution={arXiv:1705.01389}, + year={2017}, + note="https://arxiv.org/abs/1705.01389", + url="https://lmb.informatik.uni-freiburg.de/projects/hand3d/" +} +``` + +
+
diff --git a/vendor/ViTPose/configs/hand/3d_kpt_sview_rgb_img/internet/interhand3d/internet_interhand3d.md b/vendor/ViTPose/configs/hand/3d_kpt_sview_rgb_img/internet/interhand3d/internet_interhand3d.md
new file mode 100644
index 0000000000000000000000000000000000000000..2c141628483305df44bc186fd4caa958f473599e
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/3d_kpt_sview_rgb_img/internet/interhand3d/internet_interhand3d.md
@@ -0,0 +1,55 @@
+
+
+InterNet (ECCV'2020)
+ +```bibtex +@InProceedings{Moon_2020_ECCV_InterHand2.6M, +author = {Moon, Gyeongsik and Yu, Shoou-I and Wen, He and Shiratori, Takaaki and Lee, Kyoung Mu}, +title = {InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image}, +booktitle = {European Conference on Computer Vision (ECCV)}, +year = {2020} +} +``` + +
+
+
+
+
+InterNet (ECCV'2020)
+ +```bibtex +@InProceedings{Moon_2020_ECCV_InterHand2.6M, +author = {Moon, Gyeongsik and Yu, Shoou-I and Wen, He and Shiratori, Takaaki and Lee, Kyoung Mu}, +title = {InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image}, +booktitle = {European Conference on Computer Vision (ECCV)}, +year = {2020} +} +``` + +
+
+
+
+
+ResNet (CVPR'2016)
+ +```bibtex +@inproceedings{he2016deep, + title={Deep residual learning for image recognition}, + author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={770--778}, + year={2016} +} +``` + +
+
+
+Results on InterHand2.6M val & test set
+
+|Train Set| Set | Arch | Input Size | MPJPE-single | MPJPE-interacting | MPJPE-all | MRRPE | APh | ckpt | log |
+| :--- | :--- | :--------: | :--------: | :------: | :------: | :------: |:------: |:------: |:------: |:------: |
+| All | test(H+M) | [InterNet_resnet_50](/configs/hand/3d_kpt_sview_rgb_img/internet/interhand3d/res50_interhand3d_all_256x256.py) | 256x256 | 9.47 | 13.40 | 11.59 | 29.28 | 0.99 | [ckpt](https://download.openmmlab.com/mmpose/hand3d/internet/res50_intehand3dv1.0_all_256x256-42b7f2ac_20210702.pth) | [log](https://download.openmmlab.com/mmpose/hand3d/internet/res50_intehand3dv1.0_all_256x256_20210702.log.json) |
+| All | val(M) | [InterNet_resnet_50](/configs/hand/3d_kpt_sview_rgb_img/internet/interhand3d/res50_interhand3d_all_256x256.py) | 256x256 | 11.22 | 15.23 | 13.16 | 31.73 | 0.98 | [ckpt](https://download.openmmlab.com/mmpose/hand3d/internet/res50_intehand3dv1.0_all_256x256-42b7f2ac_20210702.pth) | [log](https://download.openmmlab.com/mmpose/hand3d/internet/res50_intehand3dv1.0_all_256x256_20210702.log.json) |
diff --git a/vendor/ViTPose/configs/hand/3d_kpt_sview_rgb_img/internet/interhand3d/internet_interhand3d.yml b/vendor/ViTPose/configs/hand/3d_kpt_sview_rgb_img/internet/interhand3d/internet_interhand3d.yml
new file mode 100644
index 0000000000000000000000000000000000000000..34749b20c39124a1e9d5aaac91ebd25c45235c69
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/3d_kpt_sview_rgb_img/internet/interhand3d/internet_interhand3d.yml
@@ -0,0 +1,40 @@
+Collections:
+- Name: InterNet
+ Paper:
+ Title: 'InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation
+ from a Single RGB Image'
+ URL: https://link.springer.com/content/pdf/10.1007/978-3-030-58565-5_33.pdf
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/internet.md
+Models:
+- Config: configs/hand/3d_kpt_sview_rgb_img/internet/interhand3d/res50_interhand3d_all_256x256.py
+ In Collection: InterNet
+ Metadata:
+ Architecture: &id001
+ - InterNet
+ - ResNet
+ Training Data: InterHand2.6M
+ Name: internet_res50_interhand3d_all_256x256
+ Results:
+ - Dataset: InterHand2.6M
+ Metrics:
+ APh: 0.99
+ MPJPE-all: 11.59
+ MPJPE-interacting: 13.4
+ MPJPE-single: 9.47
+ Task: Hand 3D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand3d/internet/res50_intehand3dv1.0_all_256x256-42b7f2ac_20210702.pth
+- Config: configs/hand/3d_kpt_sview_rgb_img/internet/interhand3d/res50_interhand3d_all_256x256.py
+ In Collection: InterNet
+ Metadata:
+ Architecture: *id001
+ Training Data: InterHand2.6M
+ Name: internet_res50_interhand3d_all_256x256
+ Results:
+ - Dataset: InterHand2.6M
+ Metrics:
+ APh: 0.98
+ MPJPE-all: 13.16
+ MPJPE-interacting: 15.23
+ MPJPE-single: 11.22
+ Task: Hand 3D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/hand3d/internet/res50_intehand3dv1.0_all_256x256-42b7f2ac_20210702.pth
diff --git a/vendor/ViTPose/configs/hand/3d_kpt_sview_rgb_img/internet/interhand3d/res50_interhand3d_all_256x256.py b/vendor/ViTPose/configs/hand/3d_kpt_sview_rgb_img/internet/interhand3d/res50_interhand3d_all_256x256.py
new file mode 100644
index 0000000000000000000000000000000000000000..6acb9180e996ef5f50c17633b13207048cf30420
--- /dev/null
+++ b/vendor/ViTPose/configs/hand/3d_kpt_sview_rgb_img/internet/interhand3d/res50_interhand3d_all_256x256.py
@@ -0,0 +1,181 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/interhand3d.py'
+]
+checkpoint_config = dict(interval=1)
+evaluation = dict(
+ interval=1,
+ metric=['MRRPE', 'MPJPE', 'Handedness_acc'],
+ save_best='MPJPE_all')
+
+optimizer = dict(
+ type='Adam',
+ lr=2e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(policy='step', step=[15, 17])
+total_epochs = 20
+log_config = dict(
+ interval=20,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+channel_cfg = dict(
+ num_output_channels=42,
+ dataset_joints=42,
+ dataset_channel=[list(range(42))],
+ inference_channel=list(range(42)))
+
+# model settings
+model = dict(
+ type='Interhand3D',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='Interhand3DHead',
+ keypoint_head_cfg=dict(
+ in_channels=2048,
+ out_channels=21 * 64,
+ depth_size=64,
+ num_deconv_layers=3,
+ num_deconv_filters=(256, 256, 256),
+ num_deconv_kernels=(4, 4, 4),
+ ),
+ root_head_cfg=dict(
+ in_channels=2048,
+ heatmap_size=64,
+ hidden_dims=(512, ),
+ ),
+ hand_type_head_cfg=dict(
+ in_channels=2048,
+ num_labels=2,
+ hidden_dims=(512, ),
+ ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True),
+ loss_root_depth=dict(type='L1Loss', use_target_weight=True),
+ loss_hand_type=dict(type='BCELoss', use_target_weight=True),
+ ),
+ train_cfg={},
+ test_cfg=dict(flip_test=False))
+
+data_cfg = dict(
+ image_size=[256, 256],
+ heatmap_size=[64, 64, 64],
+ heatmap3d_depth_bound=400.0,
+ heatmap_size_root=64,
+ root_depth_bound=400.0,
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'])
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='HandRandomFlip', flip_prob=0.5),
+ dict(type='TopDownRandomTranslation', trans_factor=0.15),
+ dict(
+ type='TopDownGetRandomScaleRotation',
+ rot_factor=45,
+ scale_factor=0.25,
+ rot_prob=0.6),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='MultitaskGatherTarget',
+ pipeline_list=[
+ [dict(
+ type='Generate3DHeatmapTarget',
+ sigma=2.5,
+ max_bound=255,
+ )], [dict(type='HandGenerateRelDepthTarget')],
+ [
+ dict(
+ type='RenameKeys',
+ key_pairs=[('hand_type', 'target'),
+ ('hand_type_valid', 'target_weight')])
+ ]
+ ],
+ pipeline_indices=[0, 1, 2],
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'flip_pairs',
+ 'heatmap3d_depth_bound', 'root_depth_bound'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/interhand2.6m'
+data = dict(
+ samples_per_gpu=16,
+ workers_per_gpu=1,
+ train=dict(
+ type='InterHand3DDataset',
+ ann_file=f'{data_root}/annotations/all/'
+ 'InterHand2.6M_train_data.json',
+ camera_file=f'{data_root}/annotations/all/'
+ 'InterHand2.6M_train_camera.json',
+ joint_file=f'{data_root}/annotations/all/'
+ 'InterHand2.6M_train_joint_3d.json',
+ img_prefix=f'{data_root}/images/train/',
+ data_cfg=data_cfg,
+ use_gt_root_depth=True,
+ rootnet_result_file=None,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='InterHand3DDataset',
+ ann_file=f'{data_root}/annotations/machine_annot/'
+ 'InterHand2.6M_val_data.json',
+ camera_file=f'{data_root}/annotations/machine_annot/'
+ 'InterHand2.6M_val_camera.json',
+ joint_file=f'{data_root}/annotations/machine_annot/'
+ 'InterHand2.6M_val_joint_3d.json',
+ img_prefix=f'{data_root}/images/val/',
+ data_cfg=data_cfg,
+ use_gt_root_depth=True,
+ rootnet_result_file=None,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='InterHand3DDataset',
+ ann_file=f'{data_root}/annotations/all/'
+ 'InterHand2.6M_test_data.json',
+ camera_file=f'{data_root}/annotations/all/'
+ 'InterHand2.6M_test_camera.json',
+ joint_file=f'{data_root}/annotations/all/'
+ 'InterHand2.6M_test_joint_3d.json',
+ img_prefix=f'{data_root}/images/test/',
+ data_cfg=data_cfg,
+ use_gt_root_depth=True,
+ rootnet_result_file=None,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/README.md b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..904a391e7dd3ad45fa6b90a7ac0b9763f2ec2596
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/README.md
@@ -0,0 +1,19 @@
+# 2D Human Whole-Body Pose Estimation
+
+2D human whole-body pose estimation aims to localize dense landmarks on the entire human body including face, hands, body, and feet.
+
+Existing approaches can be categorized into top-down and bottom-up approaches.
+
+Top-down methods divide the task into two stages: human detection and whole-body pose estimation. They perform human detection first, followed by single-person whole-body pose estimation given human bounding boxes.
+
+Bottom-up approaches (e.g. AE) first detect all the whole-body keypoints and then group/associate them into person instances.
+
+## Data preparation
+
+Please follow [DATA Preparation](/docs/en/tasks/2d_wholebody_keypoint.md) to prepare data.
+
+## Demo
+
+Please follow [Demo](/demo/docs/2d_wholebody_pose_demo.md) to run demos.
+
+InterHand2.6M (ECCV'2020)
+ +```bibtex +@InProceedings{Moon_2020_ECCV_InterHand2.6M, +author = {Moon, Gyeongsik and Yu, Shoou-I and Wen, He and Shiratori, Takaaki and Lee, Kyoung Mu}, +title = {InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image}, +booktitle = {European Conference on Computer Vision (ECCV)}, +year = {2020} +} +``` + +
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/README.md b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/README.md new file mode 100644 index 0000000000000000000000000000000000000000..2048f2182b77605924ec48913c3203e3bc0a61be --- /dev/null +++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/README.md @@ -0,0 +1,25 @@ +# Associative embedding: End-to-end learning for joint detection and grouping (AE) + + + +
+
+
+AE is one of the most popular 2D bottom-up pose estimation approaches, that first detect all the keypoints and
+then group/associate them into person instances.
+
+In order to group all the predicted keypoints to individuals, a tag is also predicted for each detected keypoint.
+Tags of the same person are similar, while tags of different people are different. Thus the keypoints can be grouped
+according to the tags.
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/higherhrnet_coco-wholebody.md b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/higherhrnet_coco-wholebody.md
new file mode 100644
index 0000000000000000000000000000000000000000..6496280d669e277e4490b86e52ed70ec24622e59
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/higherhrnet_coco-wholebody.md
@@ -0,0 +1,58 @@
+
+
+Associative Embedding (NIPS'2017)
+ +```bibtex +@inproceedings{newell2017associative, + title={Associative embedding: End-to-end learning for joint detection and grouping}, + author={Newell, Alejandro and Huang, Zhiao and Deng, Jia}, + booktitle={Advances in neural information processing systems}, + pages={2277--2287}, + year={2017} +} +``` + +
+
+
+
+
+Associative Embedding (NIPS'2017)
+ +```bibtex +@inproceedings{newell2017associative, + title={Associative embedding: End-to-end learning for joint detection and grouping}, + author={Newell, Alejandro and Huang, Zhiao and Deng, Jia}, + booktitle={Advances in neural information processing systems}, + pages={2277--2287}, + year={2017} +} +``` + +
+
+
+
+
+HigherHRNet (CVPR'2020)
+ +```bibtex +@inproceedings{cheng2020higherhrnet, + title={HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation}, + author={Cheng, Bowen and Xiao, Bin and Wang, Jingdong and Shi, Honghui and Huang, Thomas S and Zhang, Lei}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + pages={5386--5395}, + year={2020} +} +``` + +
+
+
+Results on COCO-WholeBody v1.0 val without multi-scale test
+
+| Arch | Input Size | Body AP | Body AR | Foot AP | Foot AR | Face AP | Face AR | Hand AP | Hand AR | Whole AP | Whole AR | ckpt | log |
+| :---- | :--------: | :-----: | :-----: | :-----: | :-----: | :-----: | :------: | :-----: | :-----: | :------: |:-------: |:------: | :------: |
+| [HigherHRNet-w32+](/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/higherhrnet_w32_coco_wholebody_512x512.py) | 512x512 | 0.590 | 0.672 | 0.185 | 0.335 | 0.676 | 0.721 | 0.212 | 0.298 | 0.401 | 0.493 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet32_coco_wholebody_512x512_plus-2fa137ab_20210517.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet32_coco_wholebody_512x512_plus_20210517.log.json) |
+| [HigherHRNet-w48+](/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/higherhrnet_w48_coco_wholebody_512x512.py) | 512x512 | 0.630 | 0.706 | 0.440 | 0.573 | 0.730 | 0.777 | 0.389 | 0.477 | 0.487 | 0.574 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet48_coco_wholebody_512x512_plus-934f08aa_20210517.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet48_coco_wholebody_512x512_plus_20210517.log.json) |
+
+Note: `+` means the model is first pre-trained on original COCO dataset, and then fine-tuned on COCO-WholeBody dataset. We find this will lead to better performance.
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/higherhrnet_coco-wholebody.yml b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/higherhrnet_coco-wholebody.yml
new file mode 100644
index 0000000000000000000000000000000000000000..8f7b133be9eab240a9c5a2c67a923e7950450d4d
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/higherhrnet_coco-wholebody.yml
@@ -0,0 +1,52 @@
+Collections:
+- Name: HigherHRNet
+ Paper:
+ Title: 'HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose
+ Estimation'
+ URL: http://openaccess.thecvf.com/content_CVPR_2020/html/Cheng_HigherHRNet_Scale-Aware_Representation_Learning_for_Bottom-Up_Human_Pose_Estimation_CVPR_2020_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/higherhrnet.md
+Models:
+- Config: configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/higherhrnet_w32_coco_wholebody_512x512.py
+ In Collection: HigherHRNet
+ Metadata:
+ Architecture: &id001
+ - Associative Embedding
+ - HigherHRNet
+ Training Data: COCO-WholeBody
+ Name: associative_embedding_higherhrnet_w32_coco_wholebody_512x512
+ Results:
+ - Dataset: COCO-WholeBody
+ Metrics:
+ Body AP: 0.59
+ Body AR: 0.672
+ Face AP: 0.676
+ Face AR: 0.721
+ Foot AP: 0.185
+ Foot AR: 0.335
+ Hand AP: 0.212
+ Hand AR: 0.298
+ Whole AP: 0.401
+ Whole AR: 0.493
+ Task: Wholebody 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet32_coco_wholebody_512x512_plus-2fa137ab_20210517.pth
+- Config: configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/higherhrnet_w48_coco_wholebody_512x512.py
+ In Collection: HigherHRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO-WholeBody
+ Name: associative_embedding_higherhrnet_w48_coco_wholebody_512x512
+ Results:
+ - Dataset: COCO-WholeBody
+ Metrics:
+ Body AP: 0.63
+ Body AR: 0.706
+ Face AP: 0.73
+ Face AR: 0.777
+ Foot AP: 0.44
+ Foot AR: 0.573
+ Hand AP: 0.389
+ Hand AR: 0.477
+ Whole AP: 0.487
+ Whole AR: 0.574
+ Task: Wholebody 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/higher_hrnet48_coco_wholebody_512x512_plus-934f08aa_20210517.pth
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/higherhrnet_w32_coco_wholebody_512x512.py b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/higherhrnet_w32_coco_wholebody_512x512.py
new file mode 100644
index 0000000000000000000000000000000000000000..05574f975347eb26e8503058546e43fcc1c3c527
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/higherhrnet_w32_coco_wholebody_512x512.py
@@ -0,0 +1,195 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', key_indicator='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ num_output_channels=133,
+ dataset_joints=133,
+ dataset_channel=[
+ list(range(133)),
+ ],
+ inference_channel=list(range(133)))
+
+data_cfg = dict(
+ image_size=512,
+ base_size=256,
+ base_sigma=2,
+ heatmap_size=[128, 256],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=2,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='AEHigherResolutionHead',
+ in_channels=32,
+ num_joints=133,
+ tag_per_joint=True,
+ extra=dict(final_conv_kernel=1, ),
+ num_deconv_layers=1,
+ num_deconv_filters=[32],
+ num_deconv_kernels=[4],
+ num_basic_blocks=4,
+ cat_output=[True],
+ with_ae_loss=[True, False],
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=133,
+ num_stages=2,
+ ae_loss_type='exp',
+ with_ae_loss=[True, False],
+ push_loss_factor=[0.001, 0.001],
+ pull_loss_factor=[0.001, 0.001],
+ with_heatmaps_loss=[True, True],
+ heatmaps_loss_factor=[1.0, 1.0],
+ supervise_empty=False)),
+ train_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ img_size=data_cfg['image_size']),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True, True],
+ with_ae=[True, False],
+ project2image=True,
+ align_corners=False,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1]),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ ]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=24),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/higherhrnet_w32_coco_wholebody_640x640.py b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/higherhrnet_w32_coco_wholebody_640x640.py
new file mode 100644
index 0000000000000000000000000000000000000000..ee9edc893edfb38c816ca83238fe63c2aabf8872
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/higherhrnet_w32_coco_wholebody_640x640.py
@@ -0,0 +1,195 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', key_indicator='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ num_output_channels=133,
+ dataset_joints=133,
+ dataset_channel=[
+ list(range(133)),
+ ],
+ inference_channel=list(range(133)))
+
+data_cfg = dict(
+ image_size=640,
+ base_size=320,
+ base_sigma=2,
+ heatmap_size=[160, 320],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=2,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='AEHigherResolutionHead',
+ in_channels=32,
+ num_joints=133,
+ tag_per_joint=True,
+ extra=dict(final_conv_kernel=1, ),
+ num_deconv_layers=1,
+ num_deconv_filters=[32],
+ num_deconv_kernels=[4],
+ num_basic_blocks=4,
+ cat_output=[True],
+ with_ae_loss=[True, False],
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=133,
+ num_stages=2,
+ ae_loss_type='exp',
+ with_ae_loss=[True, False],
+ push_loss_factor=[0.001, 0.001],
+ pull_loss_factor=[0.001, 0.001],
+ with_heatmaps_loss=[True, True],
+ heatmaps_loss_factor=[1.0, 1.0],
+ supervise_empty=False)),
+ train_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ img_size=data_cfg['image_size']),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True, True],
+ with_ae=[True, False],
+ project2image=True,
+ align_corners=False,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1]),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ ]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=16),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/higherhrnet_w48_coco_wholebody_512x512.py b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/higherhrnet_w48_coco_wholebody_512x512.py
new file mode 100644
index 0000000000000000000000000000000000000000..d84143b8d2805f8650432147ab6f32b9922b215f
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/higherhrnet_w48_coco_wholebody_512x512.py
@@ -0,0 +1,195 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', key_indicator='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ num_output_channels=133,
+ dataset_joints=133,
+ dataset_channel=[
+ list(range(133)),
+ ],
+ inference_channel=list(range(133)))
+
+data_cfg = dict(
+ image_size=512,
+ base_size=256,
+ base_sigma=2,
+ heatmap_size=[128, 256],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=2,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='AEHigherResolutionHead',
+ in_channels=48,
+ num_joints=133,
+ tag_per_joint=True,
+ extra=dict(final_conv_kernel=1, ),
+ num_deconv_layers=1,
+ num_deconv_filters=[48],
+ num_deconv_kernels=[4],
+ num_basic_blocks=4,
+ cat_output=[True],
+ with_ae_loss=[True, False],
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=133,
+ num_stages=2,
+ ae_loss_type='exp',
+ with_ae_loss=[True, False],
+ push_loss_factor=[0.001, 0.001],
+ pull_loss_factor=[0.001, 0.001],
+ with_heatmaps_loss=[True, True],
+ heatmaps_loss_factor=[1.0, 1.0],
+ supervise_empty=False)),
+ train_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ img_size=data_cfg['image_size']),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True, True],
+ with_ae=[True, False],
+ project2image=True,
+ align_corners=False,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1]),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ ]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=16),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/higherhrnet_w48_coco_wholebody_640x640.py b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/higherhrnet_w48_coco_wholebody_640x640.py
new file mode 100644
index 0000000000000000000000000000000000000000..2c33e80df931f6a18f05ee1ebbb95998f7517600
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/higherhrnet_w48_coco_wholebody_640x640.py
@@ -0,0 +1,195 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', key_indicator='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ num_output_channels=133,
+ dataset_joints=133,
+ dataset_channel=[
+ list(range(133)),
+ ],
+ inference_channel=list(range(133)))
+
+data_cfg = dict(
+ image_size=640,
+ base_size=320,
+ base_sigma=2,
+ heatmap_size=[160, 320],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=2,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='AEHigherResolutionHead',
+ in_channels=48,
+ num_joints=133,
+ tag_per_joint=True,
+ extra=dict(final_conv_kernel=1, ),
+ num_deconv_layers=1,
+ num_deconv_filters=[48],
+ num_deconv_kernels=[4],
+ num_basic_blocks=4,
+ cat_output=[True],
+ with_ae_loss=[True, False],
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=133,
+ num_stages=2,
+ ae_loss_type='exp',
+ with_ae_loss=[True, False],
+ push_loss_factor=[0.001, 0.001],
+ pull_loss_factor=[0.001, 0.001],
+ with_heatmaps_loss=[True, True],
+ heatmaps_loss_factor=[1.0, 1.0],
+ supervise_empty=False)),
+ train_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ img_size=data_cfg['image_size']),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True, True],
+ with_ae=[True, False],
+ project2image=True,
+ align_corners=False,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1]),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ ]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=8),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/hrnet_coco-wholebody.md b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/hrnet_coco-wholebody.md
new file mode 100644
index 0000000000000000000000000000000000000000..4bc12c1946ccc3186370f85e0c0472dcd2d6e108
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/hrnet_coco-wholebody.md
@@ -0,0 +1,58 @@
+
+
+COCO-WholeBody (ECCV'2020)
+ +```bibtex +@inproceedings{jin2020whole, + title={Whole-Body Human Pose Estimation in the Wild}, + author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping}, + booktitle={Proceedings of the European Conference on Computer Vision (ECCV)}, + year={2020} +} +``` + +
+
+
+
+
+Associative Embedding (NIPS'2017)
+ +```bibtex +@inproceedings{newell2017associative, + title={Associative embedding: End-to-end learning for joint detection and grouping}, + author={Newell, Alejandro and Huang, Zhiao and Deng, Jia}, + booktitle={Advances in neural information processing systems}, + pages={2277--2287}, + year={2017} +} +``` + +
+
+
+
+
+HRNet (CVPR'2019)
+ +```bibtex +@inproceedings{sun2019deep, + title={Deep high-resolution representation learning for human pose estimation}, + author={Sun, Ke and Xiao, Bin and Liu, Dong and Wang, Jingdong}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={5693--5703}, + year={2019} +} +``` + +
+
+
+Results on COCO-WholeBody v1.0 val without multi-scale test
+
+| Arch | Input Size | Body AP | Body AR | Foot AP | Foot AR | Face AP | Face AR | Hand AP | Hand AR | Whole AP | Whole AR | ckpt | log |
+| :---- | :--------: | :-----: | :-----: | :-----: | :-----: | :-----: | :------: | :-----: | :-----: | :------: |:-------: |:------: | :------: |
+| [HRNet-w32+](/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/hrnet_w32_coco_wholebody_512x512.py) | 512x512 | 0.551 | 0.650 | 0.271 | 0.451 | 0.564 | 0.618 | 0.159 | 0.238 | 0.342 | 0.453 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/hrnet_w32_coco_wholebody_512x512_plus-f1f1185c_20210517.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/hrnet_w32_coco_wholebody_512x512_plus_20210517.log.json) |
+| [HRNet-w48+](/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/hrnet_w48_coco_wholebody_512x512.py) | 512x512 | 0.592 | 0.686 | 0.443 | 0.595 | 0.619 | 0.674 | 0.347 | 0.438 | 0.422 | 0.532 | [ckpt](https://download.openmmlab.com/mmpose/bottom_up/hrnet_w48_coco_wholebody_512x512_plus-4de8a695_20210517.pth) | [log](https://download.openmmlab.com/mmpose/bottom_up/hrnet_w48_coco_wholebody_512x512_plus_20210517.log.json) |
+
+Note: `+` means the model is first pre-trained on original COCO dataset, and then fine-tuned on COCO-WholeBody dataset. We find this will lead to better performance.
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/hrnet_coco-wholebody.yml b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/hrnet_coco-wholebody.yml
new file mode 100644
index 0000000000000000000000000000000000000000..69c1eded0903017450898fd4dc1e72fa5a3af505
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/hrnet_coco-wholebody.yml
@@ -0,0 +1,51 @@
+Collections:
+- Name: HRNet
+ Paper:
+ Title: Deep high-resolution representation learning for human pose estimation
+ URL: http://openaccess.thecvf.com/content_CVPR_2019/html/Sun_Deep_High-Resolution_Representation_Learning_for_Human_Pose_Estimation_CVPR_2019_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/hrnet.md
+Models:
+- Config: configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/hrnet_w32_coco_wholebody_512x512.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: &id001
+ - Associative Embedding
+ - HRNet
+ Training Data: COCO-WholeBody
+ Name: associative_embedding_hrnet_w32_coco_wholebody_512x512
+ Results:
+ - Dataset: COCO-WholeBody
+ Metrics:
+ Body AP: 0.551
+ Body AR: 0.65
+ Face AP: 0.564
+ Face AR: 0.618
+ Foot AP: 0.271
+ Foot AR: 0.451
+ Hand AP: 0.159
+ Hand AR: 0.238
+ Whole AP: 0.342
+ Whole AR: 0.453
+ Task: Wholebody 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/hrnet_w32_coco_wholebody_512x512_plus-f1f1185c_20210517.pth
+- Config: configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/hrnet_w48_coco_wholebody_512x512.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO-WholeBody
+ Name: associative_embedding_hrnet_w48_coco_wholebody_512x512
+ Results:
+ - Dataset: COCO-WholeBody
+ Metrics:
+ Body AP: 0.592
+ Body AR: 0.686
+ Face AP: 0.619
+ Face AR: 0.674
+ Foot AP: 0.443
+ Foot AR: 0.595
+ Hand AP: 0.347
+ Hand AR: 0.438
+ Whole AP: 0.422
+ Whole AR: 0.532
+ Task: Wholebody 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/bottom_up/hrnet_w48_coco_wholebody_512x512_plus-4de8a695_20210517.pth
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/hrnet_w32_coco_wholebody_512x512.py b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/hrnet_w32_coco_wholebody_512x512.py
new file mode 100644
index 0000000000000000000000000000000000000000..5f48f8710cb31a3838d2dd93b52b101ebb246ae2
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/hrnet_w32_coco_wholebody_512x512.py
@@ -0,0 +1,191 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', key_indicator='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ num_output_channels=133,
+ dataset_joints=133,
+ dataset_channel=[
+ list(range(133)),
+ ],
+ inference_channel=list(range(133)))
+
+data_cfg = dict(
+ image_size=512,
+ base_size=256,
+ base_sigma=2,
+ heatmap_size=[128],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=1,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='AESimpleHead',
+ in_channels=32,
+ num_joints=133,
+ num_deconv_layers=0,
+ tag_per_joint=True,
+ with_ae_loss=[True],
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=133,
+ num_stages=1,
+ ae_loss_type='exp',
+ with_ae_loss=[True],
+ push_loss_factor=[0.001],
+ pull_loss_factor=[0.001],
+ with_heatmaps_loss=[True],
+ heatmaps_loss_factor=[1.0],
+ supervise_empty=False)),
+ train_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ img_size=data_cfg['image_size']),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True],
+ with_ae=[True],
+ project2image=True,
+ align_corners=False,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1]),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ ]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=24),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/hrnet_w32_coco_wholebody_640x640.py b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/hrnet_w32_coco_wholebody_640x640.py
new file mode 100644
index 0000000000000000000000000000000000000000..006dea83217a96bd623266b90a1528a6b491fe62
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/hrnet_w32_coco_wholebody_640x640.py
@@ -0,0 +1,191 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', key_indicator='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ num_output_channels=133,
+ dataset_joints=133,
+ dataset_channel=[
+ list(range(133)),
+ ],
+ inference_channel=list(range(133)))
+
+data_cfg = dict(
+ image_size=640,
+ base_size=320,
+ base_sigma=2,
+ heatmap_size=[160],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=1,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='AESimpleHead',
+ in_channels=32,
+ num_joints=133,
+ num_deconv_layers=0,
+ tag_per_joint=True,
+ with_ae_loss=[True],
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=133,
+ num_stages=1,
+ ae_loss_type='exp',
+ with_ae_loss=[True],
+ push_loss_factor=[0.001],
+ pull_loss_factor=[0.001],
+ with_heatmaps_loss=[True],
+ heatmaps_loss_factor=[1.0],
+ supervise_empty=False)),
+ train_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ img_size=data_cfg['image_size']),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True],
+ with_ae=[True],
+ project2image=True,
+ align_corners=False,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1]),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ ]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=16),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/hrnet_w48_coco_wholebody_512x512.py b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/hrnet_w48_coco_wholebody_512x512.py
new file mode 100644
index 0000000000000000000000000000000000000000..ed3aeca41ae0f70f9e90b66fe4896062dbaf90d1
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/hrnet_w48_coco_wholebody_512x512.py
@@ -0,0 +1,191 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', key_indicator='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ num_output_channels=133,
+ dataset_joints=133,
+ dataset_channel=[
+ list(range(133)),
+ ],
+ inference_channel=list(range(133)))
+
+data_cfg = dict(
+ image_size=512,
+ base_size=256,
+ base_sigma=2,
+ heatmap_size=[128],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=1,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='AESimpleHead',
+ in_channels=48,
+ num_joints=133,
+ num_deconv_layers=0,
+ tag_per_joint=True,
+ with_ae_loss=[True],
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=133,
+ num_stages=1,
+ ae_loss_type='exp',
+ with_ae_loss=[True],
+ push_loss_factor=[0.001],
+ pull_loss_factor=[0.001],
+ with_heatmaps_loss=[True],
+ heatmaps_loss_factor=[1.0],
+ supervise_empty=False)),
+ train_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ img_size=data_cfg['image_size']),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True],
+ with_ae=[True],
+ project2image=True,
+ align_corners=False,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1]),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ ]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=16),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/hrnet_w48_coco_wholebody_640x640.py b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/hrnet_w48_coco_wholebody_640x640.py
new file mode 100644
index 0000000000000000000000000000000000000000..f75d2ab17636349cef45076eeea61a350d539237
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/hrnet_w48_coco_wholebody_640x640.py
@@ -0,0 +1,191 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody.py'
+]
+checkpoint_config = dict(interval=50)
+evaluation = dict(interval=50, metric='mAP', key_indicator='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=0.0015,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[200, 260])
+total_epochs = 300
+channel_cfg = dict(
+ num_output_channels=133,
+ dataset_joints=133,
+ dataset_channel=[
+ list(range(133)),
+ ],
+ inference_channel=list(range(133)))
+
+data_cfg = dict(
+ image_size=640,
+ base_size=320,
+ base_sigma=2,
+ heatmap_size=[160],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ num_scales=1,
+ scale_aware_sigma=False,
+)
+
+# model settings
+model = dict(
+ type='AssociativeEmbedding',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='AESimpleHead',
+ in_channels=48,
+ num_joints=133,
+ num_deconv_layers=0,
+ tag_per_joint=True,
+ with_ae_loss=[True],
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(
+ type='MultiLossFactory',
+ num_joints=133,
+ num_stages=1,
+ ae_loss_type='exp',
+ with_ae_loss=[True],
+ push_loss_factor=[0.001],
+ pull_loss_factor=[0.001],
+ with_heatmaps_loss=[True],
+ heatmaps_loss_factor=[1.0],
+ supervise_empty=False)),
+ train_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ img_size=data_cfg['image_size']),
+ test_cfg=dict(
+ num_joints=channel_cfg['dataset_joints'],
+ max_num_people=30,
+ scale_factor=[1],
+ with_heatmaps=[True],
+ with_ae=[True],
+ project2image=True,
+ align_corners=False,
+ nms_kernel=5,
+ nms_padding=2,
+ tag_per_joint=True,
+ detection_threshold=0.1,
+ tag_threshold=1,
+ use_detection_val=True,
+ ignore_too_much=False,
+ adjust=True,
+ refine=True,
+ flip_test=True))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='BottomUpRandomAffine',
+ rot_factor=30,
+ scale_factor=[0.75, 1.5],
+ scale_type='short',
+ trans_factor=40),
+ dict(type='BottomUpRandomFlip', flip_prob=0.5),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='BottomUpGenerateTarget',
+ sigma=2,
+ max_num_people=30,
+ ),
+ dict(
+ type='Collect',
+ keys=['img', 'joints', 'targets', 'masks'],
+ meta_keys=[]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='BottomUpGetImgSize', test_scale_factor=[1]),
+ dict(
+ type='BottomUpResizeAlign',
+ transforms=[
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ ]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'aug_data', 'test_scale_factor', 'base_size',
+ 'center', 'scale', 'flip_index'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ workers_per_gpu=2,
+ train_dataloader=dict(samples_per_gpu=8),
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='BottomUpCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='BottomUpCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='BottomUpCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/deeppose/coco-wholebody/res50_coco_wholebody_256x192.py b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/deeppose/coco-wholebody/res50_coco_wholebody_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..e24b56fb95f45a8d1e8f9928cb49f88591e7486f
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/deeppose/coco-wholebody/res50_coco_wholebody_256x192.py
@@ -0,0 +1,130 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=133,
+ dataset_joints=133,
+ dataset_channel=[
+ list(range(133)),
+ ],
+ inference_channel=list(range(133)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50, num_stages=4, out_indices=(3, )),
+ neck=dict(type='GlobalAveragePooling'),
+ keypoint_head=dict(
+ type='DeepposeRegressionHead',
+ in_channels=2048,
+ num_joints=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='SmoothL1Loss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(flip_test=True))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTargetRegression'),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/README.md b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..d95e939ce35225e614245eeb43d2f1ff589afe97
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/README.md
@@ -0,0 +1,10 @@
+# Top-down heatmap-based whole-body pose estimation
+
+Top-down methods divide the task into two stages: human detection and whole-body pose estimation.
+
+They perform human detection first, followed by single-person whole-body pose estimation given human bounding boxes.
+Instead of estimating keypoint coordinates directly, the pose estimator will produce heatmaps which represent the
+likelihood of being a keypoint.
+
+Various neural network models have been proposed for better performance.
+The popular ones include stacked hourglass networks, and HRNet.
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/ViTPose_base_wholebody_256x192.py b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/ViTPose_base_wholebody_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..02db322650b1f58655998dcab20c0ef23fb8ec33
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/ViTPose_base_wholebody_256x192.py
@@ -0,0 +1,149 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=133,
+ dataset_joints=133,
+ dataset_channel=[
+ list(range(133)),
+ ],
+ inference_channel=list(range(133)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='ViT',
+ img_size=(256, 192),
+ patch_size=16,
+ embed_dim=768,
+ depth=12,
+ num_heads=12,
+ ratio=1,
+ use_checkpoint=False,
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_path_rate=0.3,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=768,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/ViTPose_huge_wholebody_256x192.py b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/ViTPose_huge_wholebody_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..ccd8fd29afd372198cd4e89189c3f2186f96b810
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/ViTPose_huge_wholebody_256x192.py
@@ -0,0 +1,149 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=133,
+ dataset_joints=133,
+ dataset_channel=[
+ list(range(133)),
+ ],
+ inference_channel=list(range(133)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='ViT',
+ img_size=(256, 192),
+ patch_size=16,
+ embed_dim=1280,
+ depth=32,
+ num_heads=16,
+ ratio=1,
+ use_checkpoint=False,
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_path_rate=0.3,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1280,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/ViTPose_large_wholebody_256x192.py b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/ViTPose_large_wholebody_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..df96867906844766bfdf8cf12ce5246b4d9d73a8
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/ViTPose_large_wholebody_256x192.py
@@ -0,0 +1,149 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=133,
+ dataset_joints=133,
+ dataset_channel=[
+ list(range(133)),
+ ],
+ inference_channel=list(range(133)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='ViT',
+ img_size=(256, 192),
+ patch_size=16,
+ embed_dim=1024,
+ depth=24,
+ num_heads=16,
+ ratio=1,
+ use_checkpoint=False,
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_path_rate=0.3,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=1024,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/ViTPose_small_wholebody_256x192.py b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/ViTPose_small_wholebody_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..d1d4b054dcea5ff46c0723d13e445546dc307440
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/ViTPose_small_wholebody_256x192.py
@@ -0,0 +1,149 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=133,
+ dataset_joints=133,
+ dataset_channel=[
+ list(range(133)),
+ ],
+ inference_channel=list(range(133)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='ViT',
+ img_size=(256, 192),
+ patch_size=16,
+ embed_dim=384,
+ depth=12,
+ num_heads=12,
+ ratio=1,
+ use_checkpoint=False,
+ mlp_ratio=4,
+ qkv_bias=True,
+ drop_path_rate=0.3,
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=384,
+ num_deconv_layers=2,
+ num_deconv_filters=(256, 256),
+ num_deconv_kernels=(4, 4),
+ extra=dict(final_conv_kernel=1, ),
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_coco-wholebody.md b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_coco-wholebody.md
new file mode 100644
index 0000000000000000000000000000000000000000..d486926d2c473af7f78dae746f469ee39f920472
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_coco-wholebody.md
@@ -0,0 +1,41 @@
+
+
+COCO-WholeBody (ECCV'2020)
+ +```bibtex +@inproceedings{jin2020whole, + title={Whole-Body Human Pose Estimation in the Wild}, + author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping}, + booktitle={Proceedings of the European Conference on Computer Vision (ECCV)}, + year={2020} +} +``` + +
+
+
+
+
+HRNet (CVPR'2019)
+ +```bibtex +@inproceedings{sun2019deep, + title={Deep high-resolution representation learning for human pose estimation}, + author={Sun, Ke and Xiao, Bin and Liu, Dong and Wang, Jingdong}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={5693--5703}, + year={2019} +} +``` + +
+
+
+Results on COCO-WholeBody v1.0 val with detector having human AP of 56.4 on COCO val2017 dataset
+
+| Arch | Input Size | Body AP | Body AR | Foot AP | Foot AR | Face AP | Face AR | Hand AP | Hand AR | Whole AP | Whole AR | ckpt | log |
+| :---- | :--------: | :-----: | :-----: | :-----: | :-----: | :-----: | :------: | :-----: | :-----: | :------: |:-------: |:------: | :------: |
+| [pose_hrnet_w32](/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w32_coco_wholebody_256x192.py) | 256x192 | 0.700 | 0.746 | 0.567 | 0.645 | 0.637 | 0.688 | 0.473 | 0.546 | 0.553 | 0.626 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_coco_wholebody_256x192-853765cd_20200918.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_coco_wholebody_256x192_20200918.log.json) |
+| [pose_hrnet_w32](/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w32_coco_wholebody_384x288.py) | 384x288 | 0.701 | 0.773 | 0.586 | 0.692 | 0.727 | 0.783 | 0.516 | 0.604 | 0.586 | 0.674 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_coco_wholebody_384x288-78cacac3_20200922.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_coco_wholebody_384x288_20200922.log.json) |
+| [pose_hrnet_w48](/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w48_coco_wholebody_256x192.py) | 256x192 | 0.700 | 0.776 | 0.672 | 0.785 | 0.656 | 0.743 | 0.534 | 0.639 | 0.579 | 0.681 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_wholebody_256x192-643e18cb_20200922.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_wholebody_256x192_20200922.log.json) |
+| [pose_hrnet_w48](/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w48_coco_wholebody_384x288.py) | 384x288 | 0.722 | 0.790 | 0.694 | 0.799 | 0.777 | 0.834 | 0.587 | 0.679 | 0.631 | 0.716 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_wholebody_384x288-6e061c6a_20200922.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_wholebody_384x288_20200922.log.json) |
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_coco-wholebody.yml b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_coco-wholebody.yml
new file mode 100644
index 0000000000000000000000000000000000000000..707b893b6aa26d86ec4440de8b2264d71cfd9f7e
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_coco-wholebody.yml
@@ -0,0 +1,92 @@
+Collections:
+- Name: HRNet
+ Paper:
+ Title: Deep high-resolution representation learning for human pose estimation
+ URL: http://openaccess.thecvf.com/content_CVPR_2019/html/Sun_Deep_High-Resolution_Representation_Learning_for_Human_Pose_Estimation_CVPR_2019_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/hrnet.md
+Models:
+- Config: configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w32_coco_wholebody_256x192.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: &id001
+ - HRNet
+ Training Data: COCO-WholeBody
+ Name: topdown_heatmap_hrnet_w32_coco_wholebody_256x192
+ Results:
+ - Dataset: COCO-WholeBody
+ Metrics:
+ Body AP: 0.7
+ Body AR: 0.746
+ Face AP: 0.637
+ Face AR: 0.688
+ Foot AP: 0.567
+ Foot AR: 0.645
+ Hand AP: 0.473
+ Hand AR: 0.546
+ Whole AP: 0.553
+ Whole AR: 0.626
+ Task: Wholebody 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_coco_wholebody_256x192-853765cd_20200918.pth
+- Config: configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w32_coco_wholebody_384x288.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO-WholeBody
+ Name: topdown_heatmap_hrnet_w32_coco_wholebody_384x288
+ Results:
+ - Dataset: COCO-WholeBody
+ Metrics:
+ Body AP: 0.701
+ Body AR: 0.773
+ Face AP: 0.727
+ Face AR: 0.783
+ Foot AP: 0.586
+ Foot AR: 0.692
+ Hand AP: 0.516
+ Hand AR: 0.604
+ Whole AP: 0.586
+ Whole AR: 0.674
+ Task: Wholebody 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_coco_wholebody_384x288-78cacac3_20200922.pth
+- Config: configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w48_coco_wholebody_256x192.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO-WholeBody
+ Name: topdown_heatmap_hrnet_w48_coco_wholebody_256x192
+ Results:
+ - Dataset: COCO-WholeBody
+ Metrics:
+ Body AP: 0.7
+ Body AR: 0.776
+ Face AP: 0.656
+ Face AR: 0.743
+ Foot AP: 0.672
+ Foot AR: 0.785
+ Hand AP: 0.534
+ Hand AR: 0.639
+ Whole AP: 0.579
+ Whole AR: 0.681
+ Task: Wholebody 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_wholebody_256x192-643e18cb_20200922.pth
+- Config: configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w48_coco_wholebody_384x288.py
+ In Collection: HRNet
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO-WholeBody
+ Name: topdown_heatmap_hrnet_w48_coco_wholebody_384x288
+ Results:
+ - Dataset: COCO-WholeBody
+ Metrics:
+ Body AP: 0.722
+ Body AR: 0.79
+ Face AP: 0.777
+ Face AR: 0.834
+ Foot AP: 0.694
+ Foot AR: 0.799
+ Hand AP: 0.587
+ Hand AR: 0.679
+ Whole AP: 0.631
+ Whole AR: 0.716
+ Task: Wholebody 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_wholebody_384x288-6e061c6a_20200922.pth
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_dark_coco-wholebody.md b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_dark_coco-wholebody.md
new file mode 100644
index 0000000000000000000000000000000000000000..3edd51bffb2cfaedfcf1e5c86170146993c2be01
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_dark_coco-wholebody.md
@@ -0,0 +1,58 @@
+
+
+COCO-WholeBody (ECCV'2020)
+ +```bibtex +@inproceedings{jin2020whole, + title={Whole-Body Human Pose Estimation in the Wild}, + author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping}, + booktitle={Proceedings of the European Conference on Computer Vision (ECCV)}, + year={2020} +} +``` + +
+
+
+
+
+HRNet (CVPR'2019)
+ +```bibtex +@inproceedings{sun2019deep, + title={Deep high-resolution representation learning for human pose estimation}, + author={Sun, Ke and Xiao, Bin and Liu, Dong and Wang, Jingdong}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={5693--5703}, + year={2019} +} +``` + +
+
+
+
+
+DarkPose (CVPR'2020)
+ +```bibtex +@inproceedings{zhang2020distribution, + title={Distribution-aware coordinate representation for human pose estimation}, + author={Zhang, Feng and Zhu, Xiatian and Dai, Hanbin and Ye, Mao and Zhu, Ce}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + pages={7093--7102}, + year={2020} +} +``` + +
+
+
+Results on COCO-WholeBody v1.0 val with detector having human AP of 56.4 on COCO val2017 dataset
+
+| Arch | Input Size | Body AP | Body AR | Foot AP | Foot AR | Face AP | Face AR | Hand AP | Hand AR | Whole AP | Whole AR | ckpt | log |
+| :---- | :--------: | :-----: | :-----: | :-----: | :-----: | :-----: | :------: | :-----: | :-----: | :------: |:-------: |:------: | :------: |
+| [pose_hrnet_w32_dark](/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w32_coco_wholebody_256x192_dark.py) | 256x192 | 0.694 | 0.764 | 0.565 | 0.674 | 0.736 | 0.808 | 0.503 | 0.602 | 0.582 | 0.671 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_coco_wholebody_256x192_dark-469327ef_20200922.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_coco_wholebody_256x192_dark_20200922.log.json) |
+| [pose_hrnet_w48_dark+](/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w48_coco_wholebody_384x288_dark_plus.py) | 384x288 | 0.742 | 0.807 | 0.705 | 0.804 | 0.840 | 0.892 | 0.602 | 0.694 | 0.661 | 0.743 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_wholebody_384x288_dark-f5726563_20200918.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_wholebody_384x288_dark_20200918.log.json) |
+
+Note: `+` means the model is first pre-trained on original COCO dataset, and then fine-tuned on COCO-WholeBody dataset. We find this will lead to better performance.
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_dark_coco-wholebody.yml b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_dark_coco-wholebody.yml
new file mode 100644
index 0000000000000000000000000000000000000000..c15c6beda09a2586e135e184074501144ef018ae
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_dark_coco-wholebody.yml
@@ -0,0 +1,51 @@
+Collections:
+- Name: DarkPose
+ Paper:
+ Title: Distribution-aware coordinate representation for human pose estimation
+ URL: http://openaccess.thecvf.com/content_CVPR_2020/html/Zhang_Distribution-Aware_Coordinate_Representation_for_Human_Pose_Estimation_CVPR_2020_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/techniques/dark.md
+Models:
+- Config: configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w32_coco_wholebody_256x192_dark.py
+ In Collection: DarkPose
+ Metadata:
+ Architecture: &id001
+ - HRNet
+ - DarkPose
+ Training Data: COCO-WholeBody
+ Name: topdown_heatmap_hrnet_w32_coco_wholebody_256x192_dark
+ Results:
+ - Dataset: COCO-WholeBody
+ Metrics:
+ Body AP: 0.694
+ Body AR: 0.764
+ Face AP: 0.736
+ Face AR: 0.808
+ Foot AP: 0.565
+ Foot AR: 0.674
+ Hand AP: 0.503
+ Hand AR: 0.602
+ Whole AP: 0.582
+ Whole AR: 0.671
+ Task: Wholebody 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_coco_wholebody_256x192_dark-469327ef_20200922.pth
+- Config: configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w48_coco_wholebody_384x288_dark_plus.py
+ In Collection: DarkPose
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO-WholeBody
+ Name: topdown_heatmap_hrnet_w48_coco_wholebody_384x288_dark_plus
+ Results:
+ - Dataset: COCO-WholeBody
+ Metrics:
+ Body AP: 0.742
+ Body AR: 0.807
+ Face AP: 0.84
+ Face AR: 0.892
+ Foot AP: 0.705
+ Foot AR: 0.804
+ Hand AP: 0.602
+ Hand AR: 0.694
+ Whole AP: 0.661
+ Whole AR: 0.743
+ Task: Wholebody 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_wholebody_384x288_dark-f5726563_20200918.pth
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w32_coco_wholebody_256x192.py b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w32_coco_wholebody_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..a9c12160f1cd41ce3461b15cc747a0683e5b0e97
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w32_coco_wholebody_256x192.py
@@ -0,0 +1,164 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=133,
+ dataset_joints=133,
+ dataset_channel=[
+ list(range(133)),
+ ],
+ inference_channel=list(range(133)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w32_coco_wholebody_256x192_dark.py b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w32_coco_wholebody_256x192_dark.py
new file mode 100644
index 0000000000000000000000000000000000000000..2b0745fa5dde9241c939e6a6c4fcd5a5b222252c
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w32_coco_wholebody_256x192_dark.py
@@ -0,0 +1,164 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=133,
+ dataset_joints=133,
+ dataset_channel=[
+ list(range(133)),
+ ],
+ inference_channel=list(range(133)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='unbiased',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2, unbiased_encoding=True),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w32_coco_wholebody_384x288.py b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w32_coco_wholebody_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..1e867fa57b62bdb36f6919850566b90a78a27865
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w32_coco_wholebody_384x288.py
@@ -0,0 +1,164 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=133,
+ dataset_joints=133,
+ dataset_channel=[
+ list(range(133)),
+ ],
+ inference_channel=list(range(133)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w32_coco_wholebody_384x288_dark.py b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w32_coco_wholebody_384x288_dark.py
new file mode 100644
index 0000000000000000000000000000000000000000..97b7679cf0fa38d81fee10cff5edac97107838ad
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w32_coco_wholebody_384x288_dark.py
@@ -0,0 +1,164 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=133,
+ dataset_joints=133,
+ dataset_channel=[
+ list(range(133)),
+ ],
+ inference_channel=list(range(133)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='unbiased',
+ shift_heatmap=True,
+ modulate_kernel=17))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3, unbiased_encoding=True),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w48_coco_wholebody_256x192.py b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w48_coco_wholebody_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..039610e0ce2c4134485ac770f252d7574c0e94fd
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w48_coco_wholebody_256x192.py
@@ -0,0 +1,164 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=133,
+ dataset_joints=133,
+ dataset_channel=[
+ list(range(133)),
+ ],
+ inference_channel=list(range(133)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w48_coco_wholebody_256x192_dark.py b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w48_coco_wholebody_256x192_dark.py
new file mode 100644
index 0000000000000000000000000000000000000000..e19f03feaa3ec8f07b061d1ad095c05b95fd3157
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w48_coco_wholebody_256x192_dark.py
@@ -0,0 +1,164 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=133,
+ dataset_joints=133,
+ dataset_channel=[
+ list(range(133)),
+ ],
+ inference_channel=list(range(133)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='unbiased',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2, unbiased_encoding=True),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w48_coco_wholebody_384x288.py b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w48_coco_wholebody_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..0be7d03e942d8d22543baa23d69fdec790ae50f4
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w48_coco_wholebody_384x288.py
@@ -0,0 +1,165 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup=None,
+ # warmup='linear',
+ # warmup_iters=500,
+ # warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=133,
+ dataset_joints=133,
+ dataset_channel=[
+ list(range(133)),
+ ],
+ inference_channel=list(range(133)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w48_coco_wholebody_384x288_dark.py b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w48_coco_wholebody_384x288_dark.py
new file mode 100644
index 0000000000000000000000000000000000000000..5239244b78e371e4603ca16bc40096d397e82567
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w48_coco_wholebody_384x288_dark.py
@@ -0,0 +1,164 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=133,
+ dataset_joints=133,
+ dataset_channel=[
+ list(range(133)),
+ ],
+ inference_channel=list(range(133)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='unbiased',
+ shift_heatmap=True,
+ modulate_kernel=17))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3, unbiased_encoding=True),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w48_coco_wholebody_384x288_dark_plus.py b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w48_coco_wholebody_384x288_dark_plus.py
new file mode 100644
index 0000000000000000000000000000000000000000..a8a9856a6ac8c188b61cc87bb76d0649e187ea2f
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w48_coco_wholebody_384x288_dark_plus.py
@@ -0,0 +1,164 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody.py'
+]
+load_from = 'https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_384x288_dark-741844ba_20200812.pth' # noqa: E501
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=133,
+ dataset_joints=133,
+ dataset_channel=[
+ list(range(133)),
+ ],
+ inference_channel=list(range(133)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='unbiased',
+ shift_heatmap=True,
+ modulate_kernel=17))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3, unbiased_encoding=True),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/res101_coco_wholebody_256x192.py b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/res101_coco_wholebody_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..917396a4bc403d52aa0ba8216d909bf431b71c0d
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/res101_coco_wholebody_256x192.py
@@ -0,0 +1,133 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=133,
+ dataset_joints=133,
+ dataset_channel=[
+ list(range(133)),
+ ],
+ inference_channel=list(range(133)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet101',
+ backbone=dict(type='ResNet', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/res101_coco_wholebody_384x288.py b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/res101_coco_wholebody_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..fd2422e4334b5297a02ffd99c66830a279277448
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/res101_coco_wholebody_384x288.py
@@ -0,0 +1,133 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=133,
+ dataset_joints=133,
+ dataset_channel=[
+ list(range(133)),
+ ],
+ inference_channel=list(range(133)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet101',
+ backbone=dict(type='ResNet', depth=101),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/res152_coco_wholebody_256x192.py b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/res152_coco_wholebody_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..a59d1dcb9692b5cfe7456a988b394edb1221a03f
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/res152_coco_wholebody_256x192.py
@@ -0,0 +1,133 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=133,
+ dataset_joints=133,
+ dataset_channel=[
+ list(range(133)),
+ ],
+ inference_channel=list(range(133)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet152',
+ backbone=dict(type='ResNet', depth=152),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/res152_coco_wholebody_384x288.py b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/res152_coco_wholebody_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..fe03a6c88805c69d2b0e51ace69b0a6e4066274a
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/res152_coco_wholebody_384x288.py
@@ -0,0 +1,133 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=133,
+ dataset_joints=133,
+ dataset_channel=[
+ list(range(133)),
+ ],
+ inference_channel=list(range(133)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet152',
+ backbone=dict(type='ResNet', depth=152),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/res50_coco_wholebody_256x192.py b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/res50_coco_wholebody_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..5e39682b52a7b8e2a7798454a88193c610c5bae2
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/res50_coco_wholebody_256x192.py
@@ -0,0 +1,133 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=133,
+ dataset_joints=133,
+ dataset_channel=[
+ list(range(133)),
+ ],
+ inference_channel=list(range(133)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/res50_coco_wholebody_384x288.py b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/res50_coco_wholebody_384x288.py
new file mode 100644
index 0000000000000000000000000000000000000000..3d9de5d128cb432b26498259fbb8f7b0c269132b
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/res50_coco_wholebody_384x288.py
@@ -0,0 +1,133 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=133,
+ dataset_joints=133,
+ dataset_channel=[
+ list(range(133)),
+ ],
+ inference_channel=list(range(133)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='torchvision://resnet50',
+ backbone=dict(type='ResNet', depth=50),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=2048,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/resnet_coco-wholebody.md b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/resnet_coco-wholebody.md
new file mode 100644
index 0000000000000000000000000000000000000000..143c33f2e19bedca856178ba5de3e7c7521b7d8b
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/resnet_coco-wholebody.md
@@ -0,0 +1,43 @@
+
+
+COCO-WholeBody (ECCV'2020)
+ +```bibtex +@inproceedings{jin2020whole, + title={Whole-Body Human Pose Estimation in the Wild}, + author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping}, + booktitle={Proceedings of the European Conference on Computer Vision (ECCV)}, + year={2020} +} +``` + +
+
+
+
+
+SimpleBaseline2D (ECCV'2018)
+ +```bibtex +@inproceedings{xiao2018simple, + title={Simple baselines for human pose estimation and tracking}, + author={Xiao, Bin and Wu, Haiping and Wei, Yichen}, + booktitle={Proceedings of the European conference on computer vision (ECCV)}, + pages={466--481}, + year={2018} +} +``` + +
+
+
+Results on COCO-WholeBody v1.0 val with detector having human AP of 56.4 on COCO val2017 dataset
+
+| Arch | Input Size | Body AP | Body AR | Foot AP | Foot AR | Face AP | Face AR | Hand AP | Hand AR | Whole AP | Whole AR | ckpt | log |
+| :---- | :--------: | :-----: | :-----: | :-----: | :-----: | :-----: | :------: | :-----: | :-----: | :------: |:-------: |:------: | :------: |
+| [pose_resnet_50](/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/res50_coco_wholebody_256x192.py) | 256x192 | 0.652 | 0.739 | 0.614 | 0.746 | 0.608 | 0.716 | 0.460 | 0.584 | 0.520 | 0.633 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res50_coco_wholebody_256x192-9e37ed88_20201004.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res50_coco_wholebody_256x192_20201004.log.json) |
+| [pose_resnet_50](/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/res50_coco_wholebody_384x288.py) | 384x288 | 0.666 | 0.747 | 0.635 | 0.763 | 0.732 | 0.812 | 0.537 | 0.647 | 0.573 | 0.671 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res50_coco_wholebody_384x288-ce11e294_20201004.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res50_coco_wholebody_384x288_20201004.log.json) |
+| [pose_resnet_101](/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/res101_coco_wholebody_256x192.py) | 256x192 | 0.670 | 0.754 | 0.640 | 0.767 | 0.611 | 0.723 | 0.463 | 0.589 | 0.533 | 0.647 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res101_coco_wholebody_256x192-7325f982_20201004.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res101_coco_wholebody_256x192_20201004.log.json) |
+| [pose_resnet_101](/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/res101_coco_wholebody_384x288.py) | 384x288 | 0.692 | 0.770 | 0.680 | 0.798 | 0.747 | 0.822 | 0.549 | 0.658 | 0.597 | 0.692 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res101_coco_wholebody_384x288-6c137b9a_20201004.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res101_coco_wholebody_384x288_20201004.log.json) |
+| [pose_resnet_152](/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/res152_coco_wholebody_256x192.py) | 256x192 | 0.682 | 0.764 | 0.662 | 0.788 | 0.624 | 0.728 | 0.482 | 0.606 | 0.548 | 0.661 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res152_coco_wholebody_256x192-5de8ae23_20201004.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res152_coco_wholebody_256x192_20201004.log.json) |
+| [pose_resnet_152](/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/res152_coco_wholebody_384x288.py) | 384x288 | 0.703 | 0.780 | 0.693 | 0.813 | 0.751 | 0.825 | 0.559 | 0.667 | 0.610 | 0.705 | [ckpt](https://download.openmmlab.com/mmpose/top_down/resnet/res152_coco_wholebody_384x288-eab8caa8_20201004.pth) | [log](https://download.openmmlab.com/mmpose/top_down/resnet/res152_coco_wholebody_384x288_20201004.log.json) |
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/resnet_coco-wholebody.yml b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/resnet_coco-wholebody.yml
new file mode 100644
index 0000000000000000000000000000000000000000..84fea0885a4105e4a83f50868db5a0aaa9263e7e
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/resnet_coco-wholebody.yml
@@ -0,0 +1,134 @@
+Collections:
+- Name: SimpleBaseline2D
+ Paper:
+ Title: Simple baselines for human pose estimation and tracking
+ URL: http://openaccess.thecvf.com/content_ECCV_2018/html/Bin_Xiao_Simple_Baselines_for_ECCV_2018_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/algorithms/simplebaseline2d.md
+Models:
+- Config: configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/res50_coco_wholebody_256x192.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: &id001
+ - SimpleBaseline2D
+ Training Data: COCO-WholeBody
+ Name: topdown_heatmap_res50_coco_wholebody_256x192
+ Results:
+ - Dataset: COCO-WholeBody
+ Metrics:
+ Body AP: 0.652
+ Body AR: 0.739
+ Face AP: 0.608
+ Face AR: 0.716
+ Foot AP: 0.614
+ Foot AR: 0.746
+ Hand AP: 0.46
+ Hand AR: 0.584
+ Whole AP: 0.52
+ Whole AR: 0.633
+ Task: Wholebody 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res50_coco_wholebody_256x192-9e37ed88_20201004.pth
+- Config: configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/res50_coco_wholebody_384x288.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO-WholeBody
+ Name: topdown_heatmap_res50_coco_wholebody_384x288
+ Results:
+ - Dataset: COCO-WholeBody
+ Metrics:
+ Body AP: 0.666
+ Body AR: 0.747
+ Face AP: 0.732
+ Face AR: 0.812
+ Foot AP: 0.635
+ Foot AR: 0.763
+ Hand AP: 0.537
+ Hand AR: 0.647
+ Whole AP: 0.573
+ Whole AR: 0.671
+ Task: Wholebody 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res50_coco_wholebody_384x288-ce11e294_20201004.pth
+- Config: configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/res101_coco_wholebody_256x192.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO-WholeBody
+ Name: topdown_heatmap_res101_coco_wholebody_256x192
+ Results:
+ - Dataset: COCO-WholeBody
+ Metrics:
+ Body AP: 0.67
+ Body AR: 0.754
+ Face AP: 0.611
+ Face AR: 0.723
+ Foot AP: 0.64
+ Foot AR: 0.767
+ Hand AP: 0.463
+ Hand AR: 0.589
+ Whole AP: 0.533
+ Whole AR: 0.647
+ Task: Wholebody 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res101_coco_wholebody_256x192-7325f982_20201004.pth
+- Config: configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/res101_coco_wholebody_384x288.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO-WholeBody
+ Name: topdown_heatmap_res101_coco_wholebody_384x288
+ Results:
+ - Dataset: COCO-WholeBody
+ Metrics:
+ Body AP: 0.692
+ Body AR: 0.77
+ Face AP: 0.747
+ Face AR: 0.822
+ Foot AP: 0.68
+ Foot AR: 0.798
+ Hand AP: 0.549
+ Hand AR: 0.658
+ Whole AP: 0.597
+ Whole AR: 0.692
+ Task: Wholebody 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res101_coco_wholebody_384x288-6c137b9a_20201004.pth
+- Config: configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/res152_coco_wholebody_256x192.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO-WholeBody
+ Name: topdown_heatmap_res152_coco_wholebody_256x192
+ Results:
+ - Dataset: COCO-WholeBody
+ Metrics:
+ Body AP: 0.682
+ Body AR: 0.764
+ Face AP: 0.624
+ Face AR: 0.728
+ Foot AP: 0.662
+ Foot AR: 0.788
+ Hand AP: 0.482
+ Hand AR: 0.606
+ Whole AP: 0.548
+ Whole AR: 0.661
+ Task: Wholebody 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res152_coco_wholebody_256x192-5de8ae23_20201004.pth
+- Config: configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/res152_coco_wholebody_384x288.py
+ In Collection: SimpleBaseline2D
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO-WholeBody
+ Name: topdown_heatmap_res152_coco_wholebody_384x288
+ Results:
+ - Dataset: COCO-WholeBody
+ Metrics:
+ Body AP: 0.703
+ Body AR: 0.78
+ Face AP: 0.751
+ Face AR: 0.825
+ Foot AP: 0.693
+ Foot AR: 0.813
+ Hand AP: 0.559
+ Hand AR: 0.667
+ Whole AP: 0.61
+ Whole AR: 0.705
+ Task: Wholebody 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/resnet/res152_coco_wholebody_384x288-eab8caa8_20201004.pth
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/vipnas_coco-wholebody.md b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/vipnas_coco-wholebody.md
new file mode 100644
index 0000000000000000000000000000000000000000..b7ec8b96608f7cfc1a067703763b34ef76a276ad
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/vipnas_coco-wholebody.md
@@ -0,0 +1,38 @@
+
+
+COCO-WholeBody (ECCV'2020)
+ +```bibtex +@inproceedings{jin2020whole, + title={Whole-Body Human Pose Estimation in the Wild}, + author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping}, + booktitle={Proceedings of the European Conference on Computer Vision (ECCV)}, + year={2020} +} +``` + +
+
+
+
+
+ViPNAS (CVPR'2021)
+ +```bibtex +@article{xu2021vipnas, + title={ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search}, + author={Xu, Lumin and Guan, Yingda and Jin, Sheng and Liu, Wentao and Qian, Chen and Luo, Ping and Ouyang, Wanli and Wang, Xiaogang}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + year={2021} +} +``` + +
+
+
+Results on COCO-WholeBody v1.0 val with detector having human AP of 56.4 on COCO val2017 dataset
+
+| Arch | Input Size | Body AP | Body AR | Foot AP | Foot AR | Face AP | Face AR | Hand AP | Hand AR | Whole AP | Whole AR | ckpt | log |
+| :---- | :--------: | :-----: | :-----: | :-----: | :-----: | :-----: | :------: | :-----: | :-----: | :------: |:-------: |:------: | :------: |
+| [S-ViPNAS-MobileNetV3](/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/vipnas_mbv3_coco_wholebody_256x192.py) | 256x192 | 0.619 | 0.700 | 0.477 | 0.608 | 0.585 | 0.689 | 0.386 | 0.505 | 0.473 | 0.578 | [ckpt](https://download.openmmlab.com/mmpose/top_down/vipnas/vipnas_mbv3_coco_wholebody_256x192-0fee581a_20211205.pth) | [log](https://download.openmmlab.com/mmpose/top_down/vipnas/vipnas_mbv3_coco_wholebody_256x192_20211205.log.json) |
+| [S-ViPNAS-Res50](/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/vipnas_res50_coco_wholebody_256x192.py) | 256x192 | 0.643 | 0.726 | 0.553 | 0.694 | 0.587 | 0.698 | 0.410 | 0.529 | 0.495 | 0.607 | [ckpt](https://download.openmmlab.com/mmpose/top_down/vipnas/vipnas_res50_wholebody_256x192-49e1c3a4_20211112.pth) | [log](https://download.openmmlab.com/mmpose/top_down/vipnas/vipnas_res50_wholebody_256x192_20211112.log.json) |
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/vipnas_coco-wholebody.yml b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/vipnas_coco-wholebody.yml
new file mode 100644
index 0000000000000000000000000000000000000000..f52ddcdfa4075aaa194679c7fd6a4cbd5fcb6af4
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/vipnas_coco-wholebody.yml
@@ -0,0 +1,50 @@
+Collections:
+- Name: ViPNAS
+ Paper:
+ Title: 'ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search'
+ URL: https://arxiv.org/abs/2105.10154
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/vipnas.md
+Models:
+- Config: configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/vipnas_mbv3_coco_wholebody_256x192.py
+ In Collection: ViPNAS
+ Metadata:
+ Architecture: &id001
+ - ViPNAS
+ Training Data: COCO-WholeBody
+ Name: topdown_heatmap_vipnas_mbv3_coco_wholebody_256x192
+ Results:
+ - Dataset: COCO-WholeBody
+ Metrics:
+ Body AP: 0.619
+ Body AR: 0.7
+ Face AP: 0.585
+ Face AR: 0.689
+ Foot AP: 0.477
+ Foot AR: 0.608
+ Hand AP: 0.386
+ Hand AR: 0.505
+ Whole AP: 0.473
+ Whole AR: 0.578
+ Task: Wholebody 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/vipnas/vipnas_mbv3_coco_wholebody_256x192-0fee581a_20211205.pth
+- Config: configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/vipnas_res50_coco_wholebody_256x192.py
+ In Collection: ViPNAS
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO-WholeBody
+ Name: topdown_heatmap_vipnas_res50_coco_wholebody_256x192
+ Results:
+ - Dataset: COCO-WholeBody
+ Metrics:
+ Body AP: 0.643
+ Body AR: 0.726
+ Face AP: 0.587
+ Face AR: 0.698
+ Foot AP: 0.553
+ Foot AR: 0.694
+ Hand AP: 0.41
+ Hand AR: 0.529
+ Whole AP: 0.495
+ Whole AR: 0.607
+ Task: Wholebody 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/vipnas/vipnas_res50_wholebody_256x192-49e1c3a4_20211112.pth
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/vipnas_dark_coco-wholebody.md b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/vipnas_dark_coco-wholebody.md
new file mode 100644
index 0000000000000000000000000000000000000000..ea7a9e9035ca9fbad53e7d9fa5c58437faf847a9
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/vipnas_dark_coco-wholebody.md
@@ -0,0 +1,55 @@
+
+
+COCO-WholeBody (ECCV'2020)
+ +```bibtex +@inproceedings{jin2020whole, + title={Whole-Body Human Pose Estimation in the Wild}, + author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping}, + booktitle={Proceedings of the European Conference on Computer Vision (ECCV)}, + year={2020} +} +``` + +
+
+
+
+
+ViPNAS (CVPR'2021)
+ +```bibtex +@article{xu2021vipnas, + title={ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search}, + author={Xu, Lumin and Guan, Yingda and Jin, Sheng and Liu, Wentao and Qian, Chen and Luo, Ping and Ouyang, Wanli and Wang, Xiaogang}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + year={2021} +} +``` + +
+
+
+
+
+DarkPose (CVPR'2020)
+ +```bibtex +@inproceedings{zhang2020distribution, + title={Distribution-aware coordinate representation for human pose estimation}, + author={Zhang, Feng and Zhu, Xiatian and Dai, Hanbin and Ye, Mao and Zhu, Ce}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + pages={7093--7102}, + year={2020} +} +``` + +
+
+
+Results on COCO-WholeBody v1.0 val with detector having human AP of 56.4 on COCO val2017 dataset
+
+| Arch | Input Size | Body AP | Body AR | Foot AP | Foot AR | Face AP | Face AR | Hand AP | Hand AR | Whole AP | Whole AR | ckpt | log |
+| :---- | :--------: | :-----: | :-----: | :-----: | :-----: | :-----: | :------: | :-----: | :-----: | :------: |:-------: |:------: | :------: |
+| [S-ViPNAS-MobileNetV3_dark](/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/vipnas_mbv3_coco_wholebody_256x192_dark.py) | 256x192 | 0.632 | 0.710 | 0.530 | 0.660 | 0.672 | 0.771 | 0.404 | 0.519 | 0.508 | 0.607 | [ckpt](https://download.openmmlab.com/mmpose/top_down/vipnas/vipnas_mbv3_coco_wholebody_256x192_dark-e2158108_20211205.pth) | [log](https://download.openmmlab.com/mmpose/top_down/vipnas/vipnas_mbv3_coco_wholebody_256x192_dark_20211205.log.json) |
+| [S-ViPNAS-Res50_dark](/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/vipnas_res50_coco_wholebody_256x192_dark.py) | 256x192 | 0.650 | 0.732 | 0.550 | 0.686 | 0.684 | 0.784 | 0.437 | 0.554 | 0.528 | 0.632 | [ckpt](https://download.openmmlab.com/mmpose/top_down/vipnas/vipnas_res50_wholebody_256x192_dark-67c0ce35_20211112.pth) | [log](https://download.openmmlab.com/mmpose/top_down/vipnas/vipnas_res50_wholebody_256x192_dark_20211112.log.json) |
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/vipnas_dark_coco-wholebody.yml b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/vipnas_dark_coco-wholebody.yml
new file mode 100644
index 0000000000000000000000000000000000000000..ec948af798aea584577bf4aca6f5cf6c1085ef56
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/vipnas_dark_coco-wholebody.yml
@@ -0,0 +1,51 @@
+Collections:
+- Name: ViPNAS
+ Paper:
+ Title: 'ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search'
+ URL: https://arxiv.org/abs/2105.10154
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/backbones/vipnas.md
+Models:
+- Config: configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/vipnas_mbv3_coco_wholebody_256x192_dark.py
+ In Collection: ViPNAS
+ Metadata:
+ Architecture: &id001
+ - ViPNAS
+ - DarkPose
+ Training Data: COCO-WholeBody
+ Name: topdown_heatmap_vipnas_mbv3_coco_wholebody_256x192_dark
+ Results:
+ - Dataset: COCO-WholeBody
+ Metrics:
+ Body AP: 0.632
+ Body AR: 0.71
+ Face AP: 0.672
+ Face AR: 0.771
+ Foot AP: 0.53
+ Foot AR: 0.66
+ Hand AP: 0.404
+ Hand AR: 0.519
+ Whole AP: 0.508
+ Whole AR: 0.607
+ Task: Wholebody 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/vipnas/vipnas_mbv3_coco_wholebody_256x192_dark-e2158108_20211205.pth
+- Config: configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/vipnas_res50_coco_wholebody_256x192_dark.py
+ In Collection: ViPNAS
+ Metadata:
+ Architecture: *id001
+ Training Data: COCO-WholeBody
+ Name: topdown_heatmap_vipnas_res50_coco_wholebody_256x192_dark
+ Results:
+ - Dataset: COCO-WholeBody
+ Metrics:
+ Body AP: 0.65
+ Body AR: 0.732
+ Face AP: 0.684
+ Face AR: 0.784
+ Foot AP: 0.55
+ Foot AR: 0.686
+ Hand AP: 0.437
+ Hand AR: 0.554
+ Whole AP: 0.528
+ Whole AR: 0.632
+ Task: Wholebody 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/vipnas/vipnas_res50_wholebody_256x192_dark-67c0ce35_20211112.pth
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/vipnas_mbv3_coco_wholebody_256x192.py b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/vipnas_mbv3_coco_wholebody_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..2c36894785f2098f814704299e6837880e7b5694
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/vipnas_mbv3_coco_wholebody_256x192.py
@@ -0,0 +1,136 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=133,
+ dataset_joints=133,
+ dataset_channel=[
+ list(range(133)),
+ ],
+ inference_channel=list(range(133)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(type='ViPNAS_MobileNetV3'),
+ keypoint_head=dict(
+ type='ViPNASHeatmapSimpleHead',
+ in_channels=160,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_filters=(160, 160, 160),
+ num_deconv_groups=(160, 160, 160),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/vipnas_mbv3_coco_wholebody_256x192_dark.py b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/vipnas_mbv3_coco_wholebody_256x192_dark.py
new file mode 100644
index 0000000000000000000000000000000000000000..c9b825ef7531b20e39e895a743b1c358d0fab652
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/vipnas_mbv3_coco_wholebody_256x192_dark.py
@@ -0,0 +1,136 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=133,
+ dataset_joints=133,
+ dataset_channel=[
+ list(range(133)),
+ ],
+ inference_channel=list(range(133)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(type='ViPNAS_MobileNetV3'),
+ keypoint_head=dict(
+ type='ViPNASHeatmapSimpleHead',
+ in_channels=160,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_filters=(160, 160, 160),
+ num_deconv_groups=(160, 160, 160),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='unbiased',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2, unbiased_encoding=True),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/vipnas_res50_coco_wholebody_256x192.py b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/vipnas_res50_coco_wholebody_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..2c64edb5fc403abf3c58a0b101b58dca8ee933a1
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/vipnas_res50_coco_wholebody_256x192.py
@@ -0,0 +1,134 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=133,
+ dataset_joints=133,
+ dataset_channel=[
+ list(range(133)),
+ ],
+ inference_channel=list(range(133)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(type='ViPNAS_ResNet', depth=50),
+ keypoint_head=dict(
+ type='ViPNASHeatmapSimpleHead',
+ in_channels=608,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/vipnas_res50_coco_wholebody_256x192_dark.py b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/vipnas_res50_coco_wholebody_256x192_dark.py
new file mode 100644
index 0000000000000000000000000000000000000000..12a00d54aee342623c33c050e183a36031be2865
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/vipnas_res50_coco_wholebody_256x192_dark.py
@@ -0,0 +1,134 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/coco_wholebody.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=133,
+ dataset_joints=133,
+ dataset_channel=[
+ list(range(133)),
+ ],
+ inference_channel=list(range(133)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(type='ViPNAS_ResNet', depth=50),
+ keypoint_head=dict(
+ type='ViPNASHeatmapSimpleHead',
+ in_channels=608,
+ out_channels=channel_cfg['num_output_channels'],
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='unbiased',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=30,
+ scale_factor=0.25),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2, unbiased_encoding=True),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json',
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownCocoWholeBodyDataset',
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=test_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/halpe/hrnet_dark_halpe.md b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/halpe/hrnet_dark_halpe.md
new file mode 100644
index 0000000000000000000000000000000000000000..1b22b4b53da6d8acb06464342495822068870441
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/halpe/hrnet_dark_halpe.md
@@ -0,0 +1,57 @@
+
+
+COCO-WholeBody (ECCV'2020)
+ +```bibtex +@inproceedings{jin2020whole, + title={Whole-Body Human Pose Estimation in the Wild}, + author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping}, + booktitle={Proceedings of the European Conference on Computer Vision (ECCV)}, + year={2020} +} +``` + +
+
+
+
+
+HRNet (CVPR'2019)
+ +```bibtex +@inproceedings{sun2019deep, + title={Deep high-resolution representation learning for human pose estimation}, + author={Sun, Ke and Xiao, Bin and Liu, Dong and Wang, Jingdong}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={5693--5703}, + year={2019} +} +``` + +
+
+
+
+
+DarkPose (CVPR'2020)
+ +```bibtex +@inproceedings{zhang2020distribution, + title={Distribution-aware coordinate representation for human pose estimation}, + author={Zhang, Feng and Zhu, Xiatian and Dai, Hanbin and Ye, Mao and Zhu, Ce}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + pages={7093--7102}, + year={2020} +} +``` + +
+
+
+Results on Halpe v1.0 val with detector having human AP of 56.4 on COCO val2017 dataset
+
+| Arch | Input Size | Whole AP | Whole AR | ckpt | log |
+| :---- | :--------: | :------: |:-------: |:------: | :------: |
+| [pose_hrnet_w48_dark+](/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/halpe/hrnet_w48_halpe_384x288_dark_plus.py) | 384x288 | 0.531 | 0.642 | [ckpt](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_halpe_384x288_dark_plus-d13c2588_20211021.pth) | [log](https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_halpe_384x288_dark_plus_20211021.log.json) |
+
+Note: `+` means the model is first pre-trained on original COCO dataset, and then fine-tuned on Halpe dataset. We find this will lead to better performance.
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/halpe/hrnet_dark_halpe.yml b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/halpe/hrnet_dark_halpe.yml
new file mode 100644
index 0000000000000000000000000000000000000000..9c7b419fa43dbbe203cbd14fb09cd22cdf74350c
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/halpe/hrnet_dark_halpe.yml
@@ -0,0 +1,22 @@
+Collections:
+- Name: DarkPose
+ Paper:
+ Title: Distribution-aware coordinate representation for human pose estimation
+ URL: http://openaccess.thecvf.com/content_CVPR_2020/html/Zhang_Distribution-Aware_Coordinate_Representation_for_Human_Pose_Estimation_CVPR_2020_paper.html
+ README: https://github.com/open-mmlab/mmpose/blob/master/docs/en/papers/techniques/dark.md
+Models:
+- Config: configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/halpe/hrnet_w48_halpe_384x288_dark_plus.py
+ In Collection: DarkPose
+ Metadata:
+ Architecture:
+ - HRNet
+ - DarkPose
+ Training Data: Halpe
+ Name: topdown_heatmap_hrnet_w48_halpe_384x288_dark_plus
+ Results:
+ - Dataset: Halpe
+ Metrics:
+ Whole AP: 0.531
+ Whole AR: 0.642
+ Task: Wholebody 2D Keypoint
+ Weights: https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_halpe_384x288_dark_plus-d13c2588_20211021.pth
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/halpe/hrnet_w32_halpe_256x192.py b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/halpe/hrnet_w32_halpe_256x192.py
new file mode 100644
index 0000000000000000000000000000000000000000..9d6a2825f3375879af3bfe74967c27268848e0e2
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/halpe/hrnet_w32_halpe_256x192.py
@@ -0,0 +1,164 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/halpe.py'
+]
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=136,
+ dataset_joints=136,
+ dataset_channel=[
+ list(range(136)),
+ ],
+ inference_channel=list(range(136)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w32-36af842e.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=32,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='default',
+ shift_heatmap=True,
+ modulate_kernel=11))
+
+data_cfg = dict(
+ image_size=[192, 256],
+ heatmap_size=[48, 64],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/halpe'
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownHalpeDataset',
+ ann_file=f'{data_root}/annotations/halpe_train_v1.json',
+ img_prefix=f'{data_root}/hico_20160224_det/images/train2015/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownHalpeDataset',
+ ann_file=f'{data_root}/annotations/halpe_val_v1.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownHalpeDataset',
+ ann_file=f'{data_root}/annotations/halpe_val_v1.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/halpe/hrnet_w48_halpe_384x288_dark_plus.py b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/halpe/hrnet_w48_halpe_384x288_dark_plus.py
new file mode 100644
index 0000000000000000000000000000000000000000..b62947864f357c4aef49bc23063df452ccf6b0ee
--- /dev/null
+++ b/vendor/ViTPose/configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/halpe/hrnet_w48_halpe_384x288_dark_plus.py
@@ -0,0 +1,164 @@
+_base_ = [
+ '../../../../_base_/default_runtime.py',
+ '../../../../_base_/datasets/halpe.py'
+]
+load_from = 'https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_384x288_dark-741844ba_20200812.pth' # noqa: E501
+evaluation = dict(interval=10, metric='mAP', save_best='AP')
+
+optimizer = dict(
+ type='Adam',
+ lr=5e-4,
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200])
+total_epochs = 210
+channel_cfg = dict(
+ num_output_channels=136,
+ dataset_joints=136,
+ dataset_channel=[
+ list(range(136)),
+ ],
+ inference_channel=list(range(136)))
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained=None,
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'],
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='unbiased',
+ shift_heatmap=True,
+ modulate_kernel=17))
+
+data_cfg = dict(
+ image_size=[288, 384],
+ heatmap_size=[72, 96],
+ num_output_channels=channel_cfg['num_output_channels'],
+ num_joints=channel_cfg['dataset_joints'],
+ dataset_channel=channel_cfg['dataset_channel'],
+ inference_channel=channel_cfg['inference_channel'],
+ soft_nms=False,
+ nms_thr=1.0,
+ oks_thr=0.9,
+ vis_thr=0.2,
+ use_gt_bbox=False,
+ det_bbox_thr=0.0,
+ bbox_file='data/coco/person_detection_results/'
+ 'COCO_val2017_detections_AP_H_56_person.json',
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(
+ type='TopDownHalfBodyTransform',
+ num_joints_half_body=8,
+ prob_half_body=0.3),
+ dict(
+ type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=3, unbiased_encoding=True),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+
+test_pipeline = val_pipeline
+
+data_root = 'data/halpe'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownHalpeDataset',
+ ann_file=f'{data_root}/annotations/halpe_train_v1.json',
+ img_prefix=f'{data_root}/hico_20160224_det/images/train2015/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ val=dict(
+ type='TopDownHalpeDataset',
+ ann_file=f'{data_root}/annotations/halpe_val_v1.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+ test=dict(
+ type='TopDownHalpeDataset',
+ ann_file=f'{data_root}/annotations/halpe_val_v1.json',
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline,
+ dataset_info={{_base_.dataset_info}}),
+)
diff --git a/vendor/ViTPose/demo/MMPose_Tutorial.ipynb b/vendor/ViTPose/demo/MMPose_Tutorial.ipynb
new file mode 100644
index 0000000000000000000000000000000000000000..b5f08bd39551cc10d4176e2eb852e6cf84c8147e
--- /dev/null
+++ b/vendor/ViTPose/demo/MMPose_Tutorial.ipynb
@@ -0,0 +1,3181 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "F77yOqgkX8p4"
+ },
+ "source": [
+ "Halpe (CVPR'2020)
+ +```bibtex +@inproceedings{li2020pastanet, + title={PaStaNet: Toward Human Activity Knowledge Engine}, + author={Li, Yong-Lu and Xu, Liang and Liu, Xinpeng and Huang, Xijie and Xu, Yue and Wang, Shiyi and Fang, Hao-Shu and Ma, Ze and Chen, Mingyang and Lu, Cewu}, + booktitle={CVPR}, + year={2020} +} +``` + ++ +
+ 
+ +[2D human pose demo](docs/2d_human_pose_demo.md) +
+
++ +[2D human pose demo](docs/2d_human_pose_demo.md) +
+ +
+
+ +[2D human whole-body pose demo](docs/2d_wholebody_pose_demo.md) +
+
++ +[2D human whole-body pose demo](docs/2d_wholebody_pose_demo.md) +
+ +
+
+ +[2D hand pose demo](docs/2d_hand_demo.md) +
+
++ +[2D hand pose demo](docs/2d_hand_demo.md) +
+ +
+
+ +[2D face keypoint demo](docs/2d_face_demo.md) +
+
++ +[2D face keypoint demo](docs/2d_face_demo.md) +
+ +
+
+ +[3D human pose demo](docs/3d_human_pose_demo.md) +
+
++ +[3D human pose demo](docs/3d_human_pose_demo.md) +
+ +
+ 
+ +[2D pose tracking demo](docs/2d_pose_tracking_demo.md) +
+
++ +[2D pose tracking demo](docs/2d_pose_tracking_demo.md) +
+ +
+
+ +[2D animal_pose demo](docs/2d_animal_demo.md) +
+
++ +[2D animal_pose demo](docs/2d_animal_demo.md) +
+ +
+ 
+ +[3D hand_pose demo](docs/3d_hand_demo.md) +
+
++ +[3D hand_pose demo](docs/3d_hand_demo.md) +
+ +
+ 
+ +[Webcam demo](docs/webcam_demo.md) +
diff --git a/vendor/ViTPose/demo/body3d_two_stage_img_demo.py b/vendor/ViTPose/demo/body3d_two_stage_img_demo.py
new file mode 100644
index 0000000000000000000000000000000000000000..3cc6b0d8923cb8130b61a1b10b61179b79d01424
--- /dev/null
+++ b/vendor/ViTPose/demo/body3d_two_stage_img_demo.py
@@ -0,0 +1,296 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import os.path as osp
+import warnings
+from argparse import ArgumentParser
+
+import mmcv
+import numpy as np
+from xtcocotools.coco import COCO
+
+from mmpose.apis import (inference_pose_lifter_model,
+ inference_top_down_pose_model, vis_3d_pose_result)
+from mmpose.apis.inference import init_pose_model
+from mmpose.core import SimpleCamera
+from mmpose.datasets import DatasetInfo
+
+
+def _keypoint_camera_to_world(keypoints,
+ camera_params,
+ image_name=None,
+ dataset='Body3DH36MDataset'):
+ """Project 3D keypoints from the camera space to the world space.
+
+ Args:
+ keypoints (np.ndarray): 3D keypoints in shape [..., 3]
+ camera_params (dict): Parameters for all cameras.
+ image_name (str): The image name to specify the camera.
+ dataset (str): The dataset type, e.g. Body3DH36MDataset.
+ """
+ cam_key = None
+ if dataset == 'Body3DH36MDataset':
+ subj, rest = osp.basename(image_name).split('_', 1)
+ _, rest = rest.split('.', 1)
+ camera, rest = rest.split('_', 1)
+ cam_key = (subj, camera)
+ else:
+ raise NotImplementedError
+
+ camera = SimpleCamera(camera_params[cam_key])
+ keypoints_world = keypoints.copy()
+ keypoints_world[..., :3] = camera.camera_to_world(keypoints[..., :3])
+
+ return keypoints_world
+
+
+def main():
+ parser = ArgumentParser()
+ parser.add_argument(
+ 'pose_lifter_config',
+ help='Config file for the 2nd stage pose lifter model')
+ parser.add_argument(
+ 'pose_lifter_checkpoint',
+ help='Checkpoint file for the 2nd stage pose lifter model')
+ parser.add_argument(
+ '--pose-detector-config',
+ type=str,
+ default=None,
+ help='Config file for the 1st stage 2D pose detector')
+ parser.add_argument(
+ '--pose-detector-checkpoint',
+ type=str,
+ default=None,
+ help='Checkpoint file for the 1st stage 2D pose detector')
+ parser.add_argument('--img-root', type=str, default='', help='Image root')
+ parser.add_argument(
+ '--json-file',
+ type=str,
+ default=None,
+ help='Json file containing image and bbox information. Optionally,'
+ 'The Json file can also contain 2D pose information. See'
+ '"only-second-stage"')
+ parser.add_argument(
+ '--camera-param-file',
+ type=str,
+ default=None,
+ help='Camera parameter file for converting 3D pose predictions from '
+ ' the camera space to to world space. If None, no conversion will be '
+ 'applied.')
+ parser.add_argument(
+ '--only-second-stage',
+ action='store_true',
+ help='If true, load 2D pose detection result from the Json file and '
+ 'skip the 1st stage. The pose detection model will be ignored.')
+ parser.add_argument(
+ '--rebase-keypoint-height',
+ action='store_true',
+ help='Rebase the predicted 3D pose so its lowest keypoint has a '
+ 'height of 0 (landing on the ground). This is useful for '
+ 'visualization when the model do not predict the global position '
+ 'of the 3D pose.')
+ parser.add_argument(
+ '--show-ground-truth',
+ action='store_true',
+ help='If True, show ground truth if it is available. The ground truth '
+ 'should be contained in the annotations in the Json file with the key '
+ '"keypoints_3d" for each instance.')
+ parser.add_argument(
+ '--show',
+ action='store_true',
+ default=False,
+ help='whether to show img')
+ parser.add_argument(
+ '--out-img-root',
+ type=str,
+ default=None,
+ help='Root of the output visualization images. '
+ 'Default not saving the visualization images.')
+ parser.add_argument(
+ '--device', default='cuda:0', help='Device for inference')
+ parser.add_argument('--kpt-thr', type=float, default=0.3)
+ parser.add_argument(
+ '--radius',
+ type=int,
+ default=4,
+ help='Keypoint radius for visualization')
+ parser.add_argument(
+ '--thickness',
+ type=int,
+ default=1,
+ help='Link thickness for visualization')
+
+ args = parser.parse_args()
+ assert args.show or (args.out_img_root != '')
+
+ coco = COCO(args.json_file)
+
+ # First stage: 2D pose detection
+ pose_det_results_list = []
+ if args.only_second_stage:
+ from mmpose.apis.inference import _xywh2xyxy
+
+ print('Stage 1: load 2D pose results from Json file.')
+ for image_id, image in coco.imgs.items():
+ image_name = osp.join(args.img_root, image['file_name'])
+ ann_ids = coco.getAnnIds(image_id)
+ pose_det_results = []
+ for ann_id in ann_ids:
+ ann = coco.anns[ann_id]
+ keypoints = np.array(ann['keypoints']).reshape(-1, 3)
+ keypoints[..., 2] = keypoints[..., 2] >= 1
+ keypoints_3d = np.array(ann['keypoints_3d']).reshape(-1, 4)
+ keypoints_3d[..., 3] = keypoints_3d[..., 3] >= 1
+ bbox = np.array(ann['bbox']).reshape(1, -1)
+
+ pose_det_result = {
+ 'image_name': image_name,
+ 'bbox': _xywh2xyxy(bbox),
+ 'keypoints': keypoints,
+ 'keypoints_3d': keypoints_3d
+ }
+ pose_det_results.append(pose_det_result)
+ pose_det_results_list.append(pose_det_results)
+
+ else:
+ print('Stage 1: 2D pose detection.')
+
+ pose_det_model = init_pose_model(
+ args.pose_detector_config,
+ args.pose_detector_checkpoint,
+ device=args.device.lower())
+
+ assert pose_det_model.cfg.model.type == 'TopDown', 'Only "TopDown"' \
+ 'model is supported for the 1st stage (2D pose detection)'
+
+ dataset = pose_det_model.cfg.data['test']['type']
+ dataset_info = pose_det_model.cfg.data['test'].get(
+ 'dataset_info', None)
+ if dataset_info is None:
+ warnings.warn(
+ 'Please set `dataset_info` in the config.'
+ 'Check https://github.com/open-mmlab/mmpose/pull/663 '
+ 'for details.', DeprecationWarning)
+ else:
+ dataset_info = DatasetInfo(dataset_info)
+
+ img_keys = list(coco.imgs.keys())
+
+ for i in mmcv.track_iter_progress(range(len(img_keys))):
+ # get bounding box annotations
+ image_id = img_keys[i]
+ image = coco.loadImgs(image_id)[0]
+ image_name = osp.join(args.img_root, image['file_name'])
+ ann_ids = coco.getAnnIds(image_id)
+
+ # make person results for single image
+ person_results = []
+ for ann_id in ann_ids:
+ person = {}
+ ann = coco.anns[ann_id]
+ person['bbox'] = ann['bbox']
+ person_results.append(person)
+
+ pose_det_results, _ = inference_top_down_pose_model(
+ pose_det_model,
+ image_name,
+ person_results,
+ bbox_thr=None,
+ format='xywh',
+ dataset=dataset,
+ dataset_info=dataset_info,
+ return_heatmap=False,
+ outputs=None)
+
+ for res in pose_det_results:
+ res['image_name'] = image_name
+ pose_det_results_list.append(pose_det_results)
+
+ # Second stage: Pose lifting
+ print('Stage 2: 2D-to-3D pose lifting.')
+
+ pose_lift_model = init_pose_model(
+ args.pose_lifter_config,
+ args.pose_lifter_checkpoint,
+ device=args.device.lower())
+
+ assert pose_lift_model.cfg.model.type == 'PoseLifter', 'Only' \
+ '"PoseLifter" model is supported for the 2nd stage ' \
+ '(2D-to-3D lifting)'
+ dataset = pose_lift_model.cfg.data['test']['type']
+ dataset_info = pose_lift_model.cfg.data['test'].get('dataset_info', None)
+ if dataset_info is None:
+ warnings.warn(
+ 'Please set `dataset_info` in the config.'
+ 'Check https://github.com/open-mmlab/mmpose/pull/663 for details.',
+ DeprecationWarning)
+ else:
+ dataset_info = DatasetInfo(dataset_info)
+
+ camera_params = None
+ if args.camera_param_file is not None:
+ camera_params = mmcv.load(args.camera_param_file)
+
+ for i, pose_det_results in enumerate(
+ mmcv.track_iter_progress(pose_det_results_list)):
+ # 2D-to-3D pose lifting
+ # Note that the pose_det_results are regarded as a single-frame pose
+ # sequence
+ pose_lift_results = inference_pose_lifter_model(
+ pose_lift_model,
+ pose_results_2d=[pose_det_results],
+ dataset=dataset,
+ dataset_info=dataset_info,
+ with_track_id=False)
+
+ image_name = pose_det_results[0]['image_name']
+
+ # Pose processing
+ pose_lift_results_vis = []
+ for idx, res in enumerate(pose_lift_results):
+ keypoints_3d = res['keypoints_3d']
+ # project to world space
+ if camera_params is not None:
+ keypoints_3d = _keypoint_camera_to_world(
+ keypoints_3d,
+ camera_params=camera_params,
+ image_name=image_name,
+ dataset=dataset)
+ # rebase height (z-axis)
+ if args.rebase_keypoint_height:
+ keypoints_3d[..., 2] -= np.min(
+ keypoints_3d[..., 2], axis=-1, keepdims=True)
+ res['keypoints_3d'] = keypoints_3d
+ # Add title
+ det_res = pose_det_results[idx]
+ instance_id = det_res.get('track_id', idx)
+ res['title'] = f'Prediction ({instance_id})'
+ pose_lift_results_vis.append(res)
+ # Add ground truth
+ if args.show_ground_truth:
+ if 'keypoints_3d' not in det_res:
+ print('Fail to show ground truth. Please make sure that'
+ ' the instance annotations from the Json file'
+ ' contain "keypoints_3d".')
+ else:
+ gt = res.copy()
+ gt['keypoints_3d'] = det_res['keypoints_3d']
+ gt['title'] = f'Ground truth ({instance_id})'
+ pose_lift_results_vis.append(gt)
+
+ # Visualization
+ if args.out_img_root is None:
+ out_file = None
+ else:
+ os.makedirs(args.out_img_root, exist_ok=True)
+ out_file = osp.join(args.out_img_root, f'vis_{i}.jpg')
+
+ vis_3d_pose_result(
+ pose_lift_model,
+ result=pose_lift_results_vis,
+ img=image_name,
+ dataset_info=dataset_info,
+ out_file=out_file)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/vendor/ViTPose/demo/body3d_two_stage_video_demo.py b/vendor/ViTPose/demo/body3d_two_stage_video_demo.py
new file mode 100644
index 0000000000000000000000000000000000000000..5f47f62aeb8f4b65f340c46f6b9580e773f9100f
--- /dev/null
+++ b/vendor/ViTPose/demo/body3d_two_stage_video_demo.py
@@ -0,0 +1,307 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import os
+import os.path as osp
+from argparse import ArgumentParser
+
+import cv2
+import mmcv
+import numpy as np
+
+from mmpose.apis import (extract_pose_sequence, get_track_id,
+ inference_pose_lifter_model,
+ inference_top_down_pose_model, init_pose_model,
+ process_mmdet_results, vis_3d_pose_result)
+
+try:
+ from mmdet.apis import inference_detector, init_detector
+
+ has_mmdet = True
+except (ImportError, ModuleNotFoundError):
+ has_mmdet = False
+
+
+def covert_keypoint_definition(keypoints, pose_det_dataset, pose_lift_dataset):
+ """Convert pose det dataset keypoints definition to pose lifter dataset
+ keypoints definition.
+
+ Args:
+ keypoints (ndarray[K, 2 or 3]): 2D keypoints to be transformed.
+ pose_det_dataset, (str): Name of the dataset for 2D pose detector.
+ pose_lift_dataset (str): Name of the dataset for pose lifter model.
+ """
+ if pose_det_dataset == 'TopDownH36MDataset' and \
+ pose_lift_dataset == 'Body3DH36MDataset':
+ return keypoints
+ elif pose_det_dataset == 'TopDownCocoDataset' and \
+ pose_lift_dataset == 'Body3DH36MDataset':
+ keypoints_new = np.zeros((17, keypoints.shape[1]))
+ # pelvis is in the middle of l_hip and r_hip
+ keypoints_new[0] = (keypoints[11] + keypoints[12]) / 2
+ # thorax is in the middle of l_shoulder and r_shoulder
+ keypoints_new[8] = (keypoints[5] + keypoints[6]) / 2
+ # head is in the middle of l_eye and r_eye
+ keypoints_new[10] = (keypoints[1] + keypoints[2]) / 2
+ # spine is in the middle of thorax and pelvis
+ keypoints_new[7] = (keypoints_new[0] + keypoints_new[8]) / 2
+ # rearrange other keypoints
+ keypoints_new[[1, 2, 3, 4, 5, 6, 9, 11, 12, 13, 14, 15, 16]] = \
+ keypoints[[12, 14, 16, 11, 13, 15, 0, 5, 7, 9, 6, 8, 10]]
+ return keypoints_new
+ else:
+ raise NotImplementedError
+
+
+def main():
+ parser = ArgumentParser()
+ parser.add_argument('det_config', help='Config file for detection')
+ parser.add_argument('det_checkpoint', help='Checkpoint file for detection')
+ parser.add_argument(
+ 'pose_detector_config',
+ type=str,
+ default=None,
+ help='Config file for the 1st stage 2D pose detector')
+ parser.add_argument(
+ 'pose_detector_checkpoint',
+ type=str,
+ default=None,
+ help='Checkpoint file for the 1st stage 2D pose detector')
+ parser.add_argument(
+ 'pose_lifter_config',
+ help='Config file for the 2nd stage pose lifter model')
+ parser.add_argument(
+ 'pose_lifter_checkpoint',
+ help='Checkpoint file for the 2nd stage pose lifter model')
+ parser.add_argument(
+ '--video-path', type=str, default='', help='Video path')
+ parser.add_argument(
+ '--rebase-keypoint-height',
+ action='store_true',
+ help='Rebase the predicted 3D pose so its lowest keypoint has a '
+ 'height of 0 (landing on the ground). This is useful for '
+ 'visualization when the model do not predict the global position '
+ 'of the 3D pose.')
+ parser.add_argument(
+ '--norm-pose-2d',
+ action='store_true',
+ help='Scale the bbox (along with the 2D pose) to the average bbox '
+ 'scale of the dataset, and move the bbox (along with the 2D pose) to '
+ 'the average bbox center of the dataset. This is useful when bbox '
+ 'is small, especially in multi-person scenarios.')
+ parser.add_argument(
+ '--num-instances',
+ type=int,
+ default=-1,
+ help='The number of 3D poses to be visualized in every frame. If '
+ 'less than 0, it will be set to the number of pose results in the '
+ 'first frame.')
+ parser.add_argument(
+ '--show',
+ action='store_true',
+ default=False,
+ help='whether to show visualizations.')
+ parser.add_argument(
+ '--out-video-root',
+ type=str,
+ default=None,
+ help='Root of the output video file. '
+ 'Default not saving the visualization video.')
+ parser.add_argument(
+ '--device', default='cuda:0', help='Device for inference')
+ parser.add_argument(
+ '--det-cat-id',
+ type=int,
+ default=1,
+ help='Category id for bounding box detection model')
+ parser.add_argument(
+ '--bbox-thr',
+ type=float,
+ default=0.9,
+ help='Bounding box score threshold')
+ parser.add_argument('--kpt-thr', type=float, default=0.3)
+ parser.add_argument(
+ '--use-oks-tracking', action='store_true', help='Using OKS tracking')
+ parser.add_argument(
+ '--tracking-thr', type=float, default=0.3, help='Tracking threshold')
+ parser.add_argument(
+ '--euro',
+ action='store_true',
+ help='Using One_Euro_Filter for smoothing')
+ parser.add_argument(
+ '--radius',
+ type=int,
+ default=8,
+ help='Keypoint radius for visualization')
+ parser.add_argument(
+ '--thickness',
+ type=int,
+ default=2,
+ help='Link thickness for visualization')
+
+ assert has_mmdet, 'Please install mmdet to run the demo.'
+
+ args = parser.parse_args()
+ assert args.show or (args.out_video_root != '')
+ assert args.det_config is not None
+ assert args.det_checkpoint is not None
+
+ video = mmcv.VideoReader(args.video_path)
+ assert video.opened, f'Failed to load video file {args.video_path}'
+
+ # First stage: 2D pose detection
+ print('Stage 1: 2D pose detection.')
+
+ person_det_model = init_detector(
+ args.det_config, args.det_checkpoint, device=args.device.lower())
+
+ pose_det_model = init_pose_model(
+ args.pose_detector_config,
+ args.pose_detector_checkpoint,
+ device=args.device.lower())
+
+ assert pose_det_model.cfg.model.type == 'TopDown', 'Only "TopDown"' \
+ 'model is supported for the 1st stage (2D pose detection)'
+
+ pose_det_dataset = pose_det_model.cfg.data['test']['type']
+
+ pose_det_results_list = []
+ next_id = 0
+ pose_det_results = []
+ for frame in video:
+ pose_det_results_last = pose_det_results
+
+ # test a single image, the resulting box is (x1, y1, x2, y2)
+ mmdet_results = inference_detector(person_det_model, frame)
+
+ # keep the person class bounding boxes.
+ person_det_results = process_mmdet_results(mmdet_results,
+ args.det_cat_id)
+
+ # make person results for single image
+ pose_det_results, _ = inference_top_down_pose_model(
+ pose_det_model,
+ frame,
+ person_det_results,
+ bbox_thr=args.bbox_thr,
+ format='xyxy',
+ dataset=pose_det_dataset,
+ return_heatmap=False,
+ outputs=None)
+
+ # get track id for each person instance
+ pose_det_results, next_id = get_track_id(
+ pose_det_results,
+ pose_det_results_last,
+ next_id,
+ use_oks=args.use_oks_tracking,
+ tracking_thr=args.tracking_thr,
+ use_one_euro=args.euro,
+ fps=video.fps)
+
+ pose_det_results_list.append(copy.deepcopy(pose_det_results))
+
+ # Second stage: Pose lifting
+ print('Stage 2: 2D-to-3D pose lifting.')
+
+ pose_lift_model = init_pose_model(
+ args.pose_lifter_config,
+ args.pose_lifter_checkpoint,
+ device=args.device.lower())
+
+ assert pose_lift_model.cfg.model.type == 'PoseLifter', \
+ 'Only "PoseLifter" model is supported for the 2nd stage ' \
+ '(2D-to-3D lifting)'
+ pose_lift_dataset = pose_lift_model.cfg.data['test']['type']
+
+ if args.out_video_root == '':
+ save_out_video = False
+ else:
+ os.makedirs(args.out_video_root, exist_ok=True)
+ save_out_video = True
+
+ if save_out_video:
+ fourcc = cv2.VideoWriter_fourcc(*'mp4v')
+ fps = video.fps
+ writer = None
+
+ # convert keypoint definition
+ for pose_det_results in pose_det_results_list:
+ for res in pose_det_results:
+ keypoints = res['keypoints']
+ res['keypoints'] = covert_keypoint_definition(
+ keypoints, pose_det_dataset, pose_lift_dataset)
+
+ # load temporal padding config from model.data_cfg
+ if hasattr(pose_lift_model.cfg, 'test_data_cfg'):
+ data_cfg = pose_lift_model.cfg.test_data_cfg
+ else:
+ data_cfg = pose_lift_model.cfg.data_cfg
+
+ num_instances = args.num_instances
+ for i, pose_det_results in enumerate(
+ mmcv.track_iter_progress(pose_det_results_list)):
+ # extract and pad input pose2d sequence
+ pose_results_2d = extract_pose_sequence(
+ pose_det_results_list,
+ frame_idx=i,
+ causal=data_cfg.causal,
+ seq_len=data_cfg.seq_len,
+ step=data_cfg.seq_frame_interval)
+ # 2D-to-3D pose lifting
+ pose_lift_results = inference_pose_lifter_model(
+ pose_lift_model,
+ pose_results_2d=pose_results_2d,
+ dataset=pose_lift_dataset,
+ with_track_id=True,
+ image_size=video.resolution,
+ norm_pose_2d=args.norm_pose_2d)
+
+ # Pose processing
+ pose_lift_results_vis = []
+ for idx, res in enumerate(pose_lift_results):
+ keypoints_3d = res['keypoints_3d']
+ # exchange y,z-axis, and then reverse the direction of x,z-axis
+ keypoints_3d = keypoints_3d[..., [0, 2, 1]]
+ keypoints_3d[..., 0] = -keypoints_3d[..., 0]
+ keypoints_3d[..., 2] = -keypoints_3d[..., 2]
+ # rebase height (z-axis)
+ if args.rebase_keypoint_height:
+ keypoints_3d[..., 2] -= np.min(
+ keypoints_3d[..., 2], axis=-1, keepdims=True)
+ res['keypoints_3d'] = keypoints_3d
+ # add title
+ det_res = pose_det_results[idx]
+ instance_id = det_res['track_id']
+ res['title'] = f'Prediction ({instance_id})'
+ # only visualize the target frame
+ res['keypoints'] = det_res['keypoints']
+ res['bbox'] = det_res['bbox']
+ res['track_id'] = instance_id
+ pose_lift_results_vis.append(res)
+
+ # Visualization
+ if num_instances < 0:
+ num_instances = len(pose_lift_results_vis)
+ img_vis = vis_3d_pose_result(
+ pose_lift_model,
+ result=pose_lift_results_vis,
+ img=video[i],
+ out_file=None,
+ radius=args.radius,
+ thickness=args.thickness,
+ num_instances=num_instances)
+
+ if save_out_video:
+ if writer is None:
+ writer = cv2.VideoWriter(
+ osp.join(args.out_video_root,
+ f'vis_{osp.basename(args.video_path)}'), fourcc,
+ fps, (img_vis.shape[1], img_vis.shape[0]))
+ writer.write(img_vis)
+
+ if save_out_video:
+ writer.release()
+
+
+if __name__ == '__main__':
+ main()
diff --git a/vendor/ViTPose/demo/bottom_up_img_demo.py b/vendor/ViTPose/demo/bottom_up_img_demo.py
new file mode 100644
index 0000000000000000000000000000000000000000..ae343acd69458925f160937dd805a87e50d9d25b
--- /dev/null
+++ b/vendor/ViTPose/demo/bottom_up_img_demo.py
@@ -0,0 +1,127 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import os.path as osp
+import warnings
+from argparse import ArgumentParser
+
+import mmcv
+
+from mmpose.apis import (inference_bottom_up_pose_model, init_pose_model,
+ vis_pose_result)
+from mmpose.datasets import DatasetInfo
+
+
+def main():
+ """Visualize the demo images."""
+ parser = ArgumentParser()
+ parser.add_argument('pose_config', help='Config file for detection')
+ parser.add_argument('pose_checkpoint', help='Checkpoint file')
+ parser.add_argument(
+ '--img-path',
+ type=str,
+ help='Path to an image file or a image folder.')
+ parser.add_argument(
+ '--show',
+ action='store_true',
+ default=False,
+ help='whether to show img')
+ parser.add_argument(
+ '--out-img-root',
+ type=str,
+ default='',
+ help='Root of the output img file. '
+ 'Default not saving the visualization images.')
+ parser.add_argument(
+ '--device', default='cuda:0', help='Device used for inference')
+ parser.add_argument(
+ '--kpt-thr', type=float, default=0.3, help='Keypoint score threshold')
+ parser.add_argument(
+ '--pose-nms-thr',
+ type=float,
+ default=0.9,
+ help='OKS threshold for pose NMS')
+ parser.add_argument(
+ '--radius',
+ type=int,
+ default=4,
+ help='Keypoint radius for visualization')
+ parser.add_argument(
+ '--thickness',
+ type=int,
+ default=1,
+ help='Link thickness for visualization')
+
+ args = parser.parse_args()
+
+ assert args.show or (args.out_img_root != '')
+
+ # prepare image list
+ if osp.isfile(args.img_path):
+ image_list = [args.img_path]
+ elif osp.isdir(args.img_path):
+ image_list = [
+ osp.join(args.img_path, fn) for fn in os.listdir(args.img_path)
+ if fn.lower().endswith(('.png', '.jpg', '.jpeg', '.tiff', '.bmp'))
+ ]
+ else:
+ raise ValueError('Image path should be an image or image folder.'
+ f'Got invalid image path: {args.img_path}')
+
+ # build the pose model from a config file and a checkpoint file
+ pose_model = init_pose_model(
+ args.pose_config, args.pose_checkpoint, device=args.device.lower())
+
+ dataset = pose_model.cfg.data['test']['type']
+ dataset_info = pose_model.cfg.data['test'].get('dataset_info', None)
+ if dataset_info is None:
+ warnings.warn(
+ 'Please set `dataset_info` in the config.'
+ 'Check https://github.com/open-mmlab/mmpose/pull/663 for details.',
+ DeprecationWarning)
+ assert (dataset == 'BottomUpCocoDataset')
+ else:
+ dataset_info = DatasetInfo(dataset_info)
+
+ # optional
+ return_heatmap = False
+
+ # e.g. use ('backbone', ) to return backbone feature
+ output_layer_names = None
+
+ # process each image
+ for image_name in mmcv.track_iter_progress(image_list):
+
+ # test a single image, with a list of bboxes.
+ pose_results, returned_outputs = inference_bottom_up_pose_model(
+ pose_model,
+ image_name,
+ dataset=dataset,
+ dataset_info=dataset_info,
+ pose_nms_thr=args.pose_nms_thr,
+ return_heatmap=return_heatmap,
+ outputs=output_layer_names)
+
+ if args.out_img_root == '':
+ out_file = None
+ else:
+ os.makedirs(args.out_img_root, exist_ok=True)
+ out_file = os.path.join(
+ args.out_img_root,
+ f'vis_{osp.splitext(osp.basename(image_name))[0]}.jpg')
+
+ # show the results
+ vis_pose_result(
+ pose_model,
+ image_name,
+ pose_results,
+ radius=args.radius,
+ thickness=args.thickness,
+ dataset=dataset,
+ dataset_info=dataset_info,
+ kpt_score_thr=args.kpt_thr,
+ show=args.show,
+ out_file=out_file)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/vendor/ViTPose/demo/bottom_up_pose_tracking_demo.py b/vendor/ViTPose/demo/bottom_up_pose_tracking_demo.py
new file mode 100644
index 0000000000000000000000000000000000000000..b79e1f40de85995815048123c452a022e676d0e6
--- /dev/null
+++ b/vendor/ViTPose/demo/bottom_up_pose_tracking_demo.py
@@ -0,0 +1,158 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import warnings
+from argparse import ArgumentParser
+
+import cv2
+
+from mmpose.apis import (get_track_id, inference_bottom_up_pose_model,
+ init_pose_model, vis_pose_tracking_result)
+from mmpose.datasets import DatasetInfo
+
+
+def main():
+ """Visualize the demo images."""
+ parser = ArgumentParser()
+ parser.add_argument('pose_config', help='Config file for pose')
+ parser.add_argument('pose_checkpoint', help='Checkpoint file for pose')
+ parser.add_argument('--video-path', type=str, help='Video path')
+ parser.add_argument(
+ '--show',
+ action='store_true',
+ default=False,
+ help='whether to show visualizations.')
+ parser.add_argument(
+ '--out-video-root',
+ default='',
+ help='Root of the output video file. '
+ 'Default not saving the visualization video.')
+ parser.add_argument(
+ '--device', default='cuda:0', help='Device used for inference')
+ parser.add_argument(
+ '--kpt-thr', type=float, default=0.5, help='Keypoint score threshold')
+ parser.add_argument(
+ '--pose-nms-thr',
+ type=float,
+ default=0.9,
+ help='OKS threshold for pose NMS')
+ parser.add_argument(
+ '--use-oks-tracking', action='store_true', help='Using OKS tracking')
+ parser.add_argument(
+ '--tracking-thr', type=float, default=0.3, help='Tracking threshold')
+ parser.add_argument(
+ '--euro',
+ action='store_true',
+ help='Using One_Euro_Filter for smoothing')
+ parser.add_argument(
+ '--radius',
+ type=int,
+ default=4,
+ help='Keypoint radius for visualization')
+ parser.add_argument(
+ '--thickness',
+ type=int,
+ default=1,
+ help='Link thickness for visualization')
+
+ args = parser.parse_args()
+
+ assert args.show or (args.out_video_root != '')
+
+ # build the pose model from a config file and a checkpoint file
+ pose_model = init_pose_model(
+ args.pose_config, args.pose_checkpoint, device=args.device.lower())
+
+ dataset = pose_model.cfg.data['test']['type']
+ dataset_info = pose_model.cfg.data['test'].get('dataset_info', None)
+ if dataset_info is None:
+ warnings.warn(
+ 'Please set `dataset_info` in the config.'
+ 'Check https://github.com/open-mmlab/mmpose/pull/663 for details.',
+ DeprecationWarning)
+ assert (dataset == 'BottomUpCocoDataset')
+ else:
+ dataset_info = DatasetInfo(dataset_info)
+
+ cap = cv2.VideoCapture(args.video_path)
+ fps = None
+
+ assert cap.isOpened(), f'Faild to load video file {args.video_path}'
+
+ if args.out_video_root == '':
+ save_out_video = False
+ else:
+ os.makedirs(args.out_video_root, exist_ok=True)
+ save_out_video = True
+
+ if save_out_video:
+ fps = cap.get(cv2.CAP_PROP_FPS)
+ size = (int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)),
+ int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
+ fourcc = cv2.VideoWriter_fourcc(*'mp4v')
+ videoWriter = cv2.VideoWriter(
+ os.path.join(args.out_video_root,
+ f'vis_{os.path.basename(args.video_path)}'), fourcc,
+ fps, size)
+
+ # optional
+ return_heatmap = False
+
+ # e.g. use ('backbone', ) to return backbone feature
+ output_layer_names = None
+ next_id = 0
+ pose_results = []
+ while (cap.isOpened()):
+ flag, img = cap.read()
+ if not flag:
+ break
+ pose_results_last = pose_results
+
+ pose_results, returned_outputs = inference_bottom_up_pose_model(
+ pose_model,
+ img,
+ dataset=dataset,
+ dataset_info=dataset_info,
+ pose_nms_thr=args.pose_nms_thr,
+ return_heatmap=return_heatmap,
+ outputs=output_layer_names)
+
+ # get track id for each person instance
+ pose_results, next_id = get_track_id(
+ pose_results,
+ pose_results_last,
+ next_id,
+ use_oks=args.use_oks_tracking,
+ tracking_thr=args.tracking_thr,
+ use_one_euro=args.euro,
+ fps=fps)
+
+ # show the results
+ vis_img = vis_pose_tracking_result(
+ pose_model,
+ img,
+ pose_results,
+ radius=args.radius,
+ thickness=args.thickness,
+ dataset=dataset,
+ dataset_info=dataset_info,
+ kpt_score_thr=args.kpt_thr,
+ show=False)
+
+ if args.show:
+ cv2.imshow('Image', vis_img)
+
+ if save_out_video:
+ videoWriter.write(vis_img)
+
+ if args.show and cv2.waitKey(1) & 0xFF == ord('q'):
+ break
+
+ cap.release()
+ if save_out_video:
+ videoWriter.release()
+ if args.show:
+ cv2.destroyAllWindows()
+
+
+if __name__ == '__main__':
+ main()
diff --git a/vendor/ViTPose/demo/bottom_up_video_demo.py b/vendor/ViTPose/demo/bottom_up_video_demo.py
new file mode 100644
index 0000000000000000000000000000000000000000..14785a0c031412f96fd09027e5a995d297c31e2e
--- /dev/null
+++ b/vendor/ViTPose/demo/bottom_up_video_demo.py
@@ -0,0 +1,135 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import warnings
+from argparse import ArgumentParser
+
+import cv2
+
+from mmpose.apis import (inference_bottom_up_pose_model, init_pose_model,
+ vis_pose_result)
+from mmpose.datasets import DatasetInfo
+
+
+def main():
+ """Visualize the demo images."""
+ parser = ArgumentParser()
+ parser.add_argument('pose_config', help='Config file for pose')
+ parser.add_argument('pose_checkpoint', help='Checkpoint file for pose')
+ parser.add_argument('--video-path', type=str, help='Video path')
+ parser.add_argument(
+ '--show',
+ action='store_true',
+ default=False,
+ help='whether to show visualizations.')
+ parser.add_argument(
+ '--out-video-root',
+ default='',
+ help='Root of the output video file. '
+ 'Default not saving the visualization video.')
+ parser.add_argument(
+ '--device', default='cuda:0', help='Device used for inference')
+ parser.add_argument(
+ '--kpt-thr', type=float, default=0.3, help='Keypoint score threshold')
+ parser.add_argument(
+ '--pose-nms-thr',
+ type=float,
+ default=0.9,
+ help='OKS threshold for pose NMS')
+ parser.add_argument(
+ '--radius',
+ type=int,
+ default=4,
+ help='Keypoint radius for visualization')
+ parser.add_argument(
+ '--thickness',
+ type=int,
+ default=1,
+ help='Link thickness for visualization')
+
+ args = parser.parse_args()
+
+ assert args.show or (args.out_video_root != '')
+
+ # build the pose model from a config file and a checkpoint file
+ pose_model = init_pose_model(
+ args.pose_config, args.pose_checkpoint, device=args.device.lower())
+
+ dataset = pose_model.cfg.data['test']['type']
+ dataset_info = pose_model.cfg.data['test'].get('dataset_info', None)
+ if dataset_info is None:
+ warnings.warn(
+ 'Please set `dataset_info` in the config.'
+ 'Check https://github.com/open-mmlab/mmpose/pull/663 for details.',
+ DeprecationWarning)
+ assert (dataset == 'BottomUpCocoDataset')
+ else:
+ dataset_info = DatasetInfo(dataset_info)
+
+ cap = cv2.VideoCapture(args.video_path)
+
+ if args.out_video_root == '':
+ save_out_video = False
+ else:
+ os.makedirs(args.out_video_root, exist_ok=True)
+ save_out_video = True
+
+ if save_out_video:
+ fps = cap.get(cv2.CAP_PROP_FPS)
+ size = (int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)),
+ int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
+ fourcc = cv2.VideoWriter_fourcc(*'mp4v')
+ videoWriter = cv2.VideoWriter(
+ os.path.join(args.out_video_root,
+ f'vis_{os.path.basename(args.video_path)}'), fourcc,
+ fps, size)
+
+ # optional
+ return_heatmap = False
+
+ # e.g. use ('backbone', ) to return backbone feature
+ output_layer_names = None
+
+ while (cap.isOpened()):
+ flag, img = cap.read()
+ if not flag:
+ break
+
+ pose_results, returned_outputs = inference_bottom_up_pose_model(
+ pose_model,
+ img,
+ dataset=dataset,
+ dataset_info=dataset_info,
+ pose_nms_thr=args.pose_nms_thr,
+ return_heatmap=return_heatmap,
+ outputs=output_layer_names)
+
+ # show the results
+ vis_img = vis_pose_result(
+ pose_model,
+ img,
+ pose_results,
+ radius=args.radius,
+ thickness=args.thickness,
+ dataset=dataset,
+ dataset_info=dataset_info,
+ kpt_score_thr=args.kpt_thr,
+ show=False)
+
+ if args.show:
+ cv2.imshow('Image', vis_img)
+
+ if save_out_video:
+ videoWriter.write(vis_img)
+
+ if args.show and cv2.waitKey(1) & 0xFF == ord('q'):
+ break
+
+ cap.release()
+ if save_out_video:
+ videoWriter.release()
+ if args.show:
+ cv2.destroyAllWindows()
+
+
+if __name__ == '__main__':
+ main()
diff --git a/vendor/ViTPose/demo/docs/2d_animal_demo.md b/vendor/ViTPose/demo/docs/2d_animal_demo.md
new file mode 100644
index 0000000000000000000000000000000000000000..bb994e8b49f650e608672c306950a18c799f02f0
--- /dev/null
+++ b/vendor/ViTPose/demo/docs/2d_animal_demo.md
@@ -0,0 +1,148 @@
+## 2D Animal Pose Demo
+
+### 2D Animal Pose Image Demo
+
+#### Using gt hand bounding boxes as input
+
+We provide a demo script to test a single image, given gt json file.
+
+*Pose Model Preparation:*
+The pre-trained pose estimation model can be downloaded from [model zoo](https://mmpose.readthedocs.io/en/latest/topics/animal.html).
+Take [macaque model](https://download.openmmlab.com/mmpose/animal/resnet/res50_macaque_256x192-98f1dd3a_20210407.pth) as an example:
+
+```shell
+python demo/top_down_img_demo.py \
+ ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \
+ --img-root ${IMG_ROOT} --json-file ${JSON_FILE} \
+ --out-img-root ${OUTPUT_DIR} \
+ [--show --device ${GPU_ID or CPU}] \
+ [--kpt-thr ${KPT_SCORE_THR}]
+```
+
+Examples:
+
+```shell
+python demo/top_down_img_demo.py \
+ configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/res50_macaque_256x192.py \
+ https://download.openmmlab.com/mmpose/animal/resnet/res50_macaque_256x192-98f1dd3a_20210407.pth \
+ --img-root tests/data/macaque/ --json-file tests/data/macaque/test_macaque.json \
+ --out-img-root vis_results
+```
+
+To run demos on CPU:
+
+```shell
+python demo/top_down_img_demo.py \
+ configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/res50_macaque_256x192.py \
+ https://download.openmmlab.com/mmpose/animal/resnet/res50_macaque_256x192-98f1dd3a_20210407.pth \
+ --img-root tests/data/macaque/ --json-file tests/data/macaque/test_macaque.json \
+ --out-img-root vis_results \
+ --device=cpu
+```
+
+### 2D Animal Pose Video Demo
+
+We also provide video demos to illustrate the results.
+
+#### Using the full image as input
+
+If the video is cropped with the object centered in the screen, we can simply use the full image as the model input (without object detection).
+
+```shell
+python demo/top_down_video_demo_full_frame_without_det.py \
+ ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \
+ --video-path ${VIDEO_FILE} \
+ --out-video-root ${OUTPUT_VIDEO_ROOT} \
+ [--show --device ${GPU_ID or CPU}] \
+ [--kpt-thr ${KPT_SCORE_THR}]
+```
+
+Examples:
+
+```shell
+python demo/top_down_video_demo_full_frame_without_det.py \
+ configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/fly/res152_fly_192x192.py \
+ https://download.openmmlab.com/mmpose/animal/resnet/res152_fly_192x192-fcafbd5a_20210407.pth \
+ --video-path demo/resources/+ +[Webcam demo](docs/webcam_demo.md) +
+ +#### Using MMDetection to detect animals + +Assume that you have already installed [mmdet](https://github.com/open-mmlab/mmdetection). + +**COCO-animals** + +In COCO dataset, there are 80 object categories, including 10 common `animal` categories (15: 'bird', 16: 'cat', 17: 'dog', 18: 'horse', 19: 'sheep', 20: 'cow', 21: 'elephant', 22: 'bear', 23: 'zebra', 24: 'giraffe') +For these COCO-animals, please download the COCO pre-trained detection model from [MMDetection Model Zoo](https://mmdetection.readthedocs.io/en/latest/model_zoo.html). + +```shell +python demo/top_down_video_demo_with_mmdet.py \ + ${MMDET_CONFIG_FILE} ${MMDET_CHECKPOINT_FILE} \ + ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \ + --video-path ${VIDEO_FILE} \ + --out-video-root ${OUTPUT_VIDEO_ROOT} \ + --det-cat-id ${CATEGORY_ID} + [--show --device ${GPU_ID or CPU}] \ + [--bbox-thr ${BBOX_SCORE_THR} --kpt-thr ${KPT_SCORE_THR}] +``` + +Examples: + +```shell +python demo/top_down_video_demo_with_mmdet.py \ + demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \ + https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_2x_coco/faster_rcnn_r50_fpn_2x_coco_bbox_mAP-0.384_20200504_210434-a5d8aa15.pth \ + configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/res50_horse10_256x256-split1.py \ + https://download.openmmlab.com/mmpose/animal/resnet/res50_horse10_256x256_split1-3a3dc37e_20210405.pth \ + --video-path demo/resources/
+ +**Other Animals** + +For other animals, we have also provided some pre-trained animal detection models (1-class models). Supported models can be found in [det model zoo](/demo/docs/mmdet_modelzoo.md). +The pre-trained animal pose estimation model can be found in [pose model zoo](https://mmpose.readthedocs.io/en/latest/topics/animal.html). + +```shell +python demo/top_down_video_demo_with_mmdet.py \ + ${MMDET_CONFIG_FILE} ${MMDET_CHECKPOINT_FILE} \ + ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \ + --video-path ${VIDEO_FILE} \ + --out-video-root ${OUTPUT_VIDEO_ROOT} \ + [--det-cat-id ${CATEGORY_ID}] + [--show --device ${GPU_ID or CPU}] \ + [--bbox-thr ${BBOX_SCORE_THR} --kpt-thr ${KPT_SCORE_THR}] +``` + +Examples: + +```shell +python demo/top_down_video_demo_with_mmdet.py \ + demo/mmdetection_cfg/cascade_rcnn_x101_64x4d_fpn_1class.py \ + https://openmmlab.oss-cn-hangzhou.aliyuncs.com/mmpose/mmdet_pretrained/cascade_rcnn_x101_64x4d_fpn_20e_macaque-e45e36f5_20210409.pth \ + configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/res152_macaque_256x192.py \ + https://download.openmmlab.com/mmpose/animal/resnet/res152_macaque_256x192-c42abc02_20210407.pth \ + --video-path demo/resources/
+ +### Speed Up Inference + +Some tips to speed up MMPose inference: + +For 2D animal pose estimation models, try to edit the config file. For example, + +1. set `flip_test=False` in [macaque-res50](https://github.com/open-mmlab/mmpose/tree/e1ec589884235bee875c89102170439a991f8450/configs/animal/resnet/macaque/res50_macaque_256x192.py#L51). +1. set `post_process='default'` in [macaque-res50](https://github.com/open-mmlab/mmpose/tree/e1ec589884235bee875c89102170439a991f8450/configs/animal/resnet/macaque/res50_macaque_256x192.py#L52). diff --git a/vendor/ViTPose/demo/docs/2d_face_demo.md b/vendor/ViTPose/demo/docs/2d_face_demo.md new file mode 100644 index 0000000000000000000000000000000000000000..a3b0f8397ce1d185e20b9bac9dc19f719e266411 --- /dev/null +++ b/vendor/ViTPose/demo/docs/2d_face_demo.md @@ -0,0 +1,103 @@ +## 2D Face Keypoint Demo + +
+ +### 2D Face Image Demo + +#### Using gt face bounding boxes as input + +We provide a demo script to test a single image, given gt json file. + +*Face Keypoint Model Preparation:* +The pre-trained face keypoint estimation model can be found from [model zoo](https://mmpose.readthedocs.io/en/latest/topics/face.html). +Take [aflw model](https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_aflw_256x256-f2bbc62b_20210125.pth) as an example: + +```shell +python demo/top_down_img_demo.py \ + ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \ + --img-root ${IMG_ROOT} --json-file ${JSON_FILE} \ + --out-img-root ${OUTPUT_DIR} \ + [--show --device ${GPU_ID or CPU}] \ + [--kpt-thr ${KPT_SCORE_THR}] +``` + +Examples: + +```shell +python demo/top_down_img_demo.py \ + configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/aflw/hrnetv2_w18_aflw_256x256.py \ + https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_aflw_256x256-f2bbc62b_20210125.pth \ + --img-root tests/data/aflw/ --json-file tests/data/aflw/test_aflw.json \ + --out-img-root vis_results +``` + +To run demos on CPU: + +```shell +python demo/top_down_img_demo.py \ + configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/aflw/hrnetv2_w18_aflw_256x256.py \ + https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_aflw_256x256-f2bbc62b_20210125.pth \ + --img-root tests/data/aflw/ --json-file tests/data/aflw/test_aflw.json \ + --out-img-root vis_results \ + --device=cpu +``` + +#### Using face bounding box detectors + +We provide a demo script to run face detection and face keypoint estimation. + +Please install `face_recognition` before running the demo, by `pip install face_recognition`. +For more details, please refer to https://github.com/ageitgey/face_recognition. + +```shell +python demo/face_img_demo.py \ + ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \ + --img-root ${IMG_ROOT} --img ${IMG_FILE} \ + --out-img-root ${OUTPUT_DIR} \ + [--show --device ${GPU_ID or CPU}] \ + [--kpt-thr ${KPT_SCORE_THR}] +``` + +```shell +python demo/face_img_demo.py \ + configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/aflw/hrnetv2_w18_aflw_256x256.py \ + https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_aflw_256x256-f2bbc62b_20210125.pth \ + --img-root tests/data/aflw/ \ + --img image04476.jpg \ + --out-img-root vis_results +``` + +### 2D Face Video Demo + +We also provide a video demo to illustrate the results. + +Please install `face_recognition` before running the demo, by `pip install face_recognition`. +For more details, please refer to https://github.com/ageitgey/face_recognition. + +```shell +python demo/face_video_demo.py \ + ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \ + --video-path ${VIDEO_FILE} \ + --out-video-root ${OUTPUT_VIDEO_ROOT} \ + [--show --device ${GPU_ID or CPU}] \ + [--kpt-thr ${KPT_SCORE_THR}] +``` + +Examples: + +```shell +python demo/face_video_demo.py \ + configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/aflw/hrnetv2_w18_aflw_256x256.py \ + https://download.openmmlab.com/mmpose/face/hrnetv2/hrnetv2_w18_aflw_256x256-f2bbc62b_20210125.pth \ + --video-path https://user-images.githubusercontent.com/87690686/137441355-ec4da09c-3a8f-421b-bee9-b8b26f8c2dd0.mp4 \ + --out-video-root vis_results +``` + +### Speed Up Inference + +Some tips to speed up MMPose inference: + +For 2D face keypoint estimation models, try to edit the config file. For example, + +1. set `flip_test=False` in [face-hrnetv2_w18](https://github.com/open-mmlab/mmpose/tree/e1ec589884235bee875c89102170439a991f8450/configs/face/hrnetv2/aflw/hrnetv2_w18_aflw_256x256.py#L83). +1. set `post_process='default'` in [face-hrnetv2_w18](https://github.com/open-mmlab/mmpose/tree/e1ec589884235bee875c89102170439a991f8450/configs/face/hrnetv2/aflw/hrnetv2_w18_aflw_256x256.py#L84). diff --git a/vendor/ViTPose/demo/docs/2d_hand_demo.md b/vendor/ViTPose/demo/docs/2d_hand_demo.md new file mode 100644 index 0000000000000000000000000000000000000000..14b30f749a1818a5b85309e3c1818a7b44d89aa3 --- /dev/null +++ b/vendor/ViTPose/demo/docs/2d_hand_demo.md @@ -0,0 +1,113 @@ +## 2D Hand Keypoint Demo + +
+ +### 2D Hand Image Demo + +#### Using gt hand bounding boxes as input + +We provide a demo script to test a single image, given gt json file. + +*Hand Pose Model Preparation:* +The pre-trained hand pose estimation model can be downloaded from [model zoo](https://mmpose.readthedocs.io/en/latest/topics/hand%282d%29.html). +Take [onehand10k model](https://download.openmmlab.com/mmpose/top_down/resnet/res50_onehand10k_256x256-e67998f6_20200813.pth) as an example: + +```shell +python demo/top_down_img_demo.py \ + ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \ + --img-root ${IMG_ROOT} --json-file ${JSON_FILE} \ + --out-img-root ${OUTPUT_DIR} \ + [--show --device ${GPU_ID or CPU}] \ + [--kpt-thr ${KPT_SCORE_THR}] +``` + +Examples: + +```shell +python demo/top_down_img_demo.py \ + configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/res50_onehand10k_256x256.py \ + https://download.openmmlab.com/mmpose/top_down/resnet/res50_onehand10k_256x256-e67998f6_20200813.pth \ + --img-root tests/data/onehand10k/ --json-file tests/data/onehand10k/test_onehand10k.json \ + --out-img-root vis_results +``` + +To run demos on CPU: + +```shell +python demo/top_down_img_demo.py \ + configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/res50_onehand10k_256x256.py \ + https://download.openmmlab.com/mmpose/top_down/resnet/res50_onehand10k_256x256-e67998f6_20200813.pth \ + --img-root tests/data/onehand10k/ --json-file tests/data/onehand10k/test_onehand10k.json \ + --out-img-root vis_results \ + --device=cpu +``` + +#### Using mmdet for hand bounding box detection + +We provide a demo script to run mmdet for hand detection, and mmpose for hand pose estimation. + +Assume that you have already installed [mmdet](https://github.com/open-mmlab/mmdetection). + +*Hand Box Model Preparation:* The pre-trained hand box estimation model can be found in [det model zoo](/demo/docs/mmdet_modelzoo.md). + +*Hand Pose Model Preparation:* The pre-trained hand pose estimation model can be downloaded from [pose model zoo](https://mmpose.readthedocs.io/en/latest/topics/hand%282d%29.html). + +```shell +python demo/top_down_img_demo_with_mmdet.py \ + ${MMDET_CONFIG_FILE} ${MMDET_CHECKPOINT_FILE} \ + ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \ + --img-root ${IMG_ROOT} --img ${IMG_FILE} \ + --out-img-root ${OUTPUT_DIR} \ + [--show --device ${GPU_ID or CPU}] \ + [--bbox-thr ${BBOX_SCORE_THR} --kpt-thr ${KPT_SCORE_THR}] +``` + +```shell +python demo/top_down_img_demo_with_mmdet.py demo/mmdetection_cfg/cascade_rcnn_x101_64x4d_fpn_1class.py \ + https://download.openmmlab.com/mmpose/mmdet_pretrained/cascade_rcnn_x101_64x4d_fpn_20e_onehand10k-dac19597_20201030.pth \ + configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/res50_onehand10k_256x256.py \ + https://download.openmmlab.com/mmpose/top_down/resnet/res50_onehand10k_256x256-e67998f6_20200813.pth \ + --img-root tests/data/onehand10k/ \ + --img 9.jpg \ + --out-img-root vis_results +``` + +### 2D Hand Video Demo + +We also provide a video demo to illustrate the results. + +Assume that you have already installed [mmdet](https://github.com/open-mmlab/mmdetection). + +*Hand Box Model Preparation:* The pre-trained hand box estimation model can be found in [det model zoo](/demo/docs/mmdet_modelzoo.md). + +*Hand Pose Model Preparation:* The pre-trained hand pose estimation model can be found in [pose model zoo](https://mmpose.readthedocs.io/en/latest/topics/hand%282d%29.html). + +```shell +python demo/top_down_video_demo_with_mmdet.py \ + ${MMDET_CONFIG_FILE} ${MMDET_CHECKPOINT_FILE} \ + ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \ + --video-path ${VIDEO_FILE} \ + --out-video-root ${OUTPUT_VIDEO_ROOT} \ + [--show --device ${GPU_ID or CPU}] \ + [--bbox-thr ${BBOX_SCORE_THR} --kpt-thr ${KPT_SCORE_THR}] +``` + +Examples: + +```shell +python demo/top_down_video_demo_with_mmdet.py demo/mmdetection_cfg/cascade_rcnn_x101_64x4d_fpn_1class.py \ + https://download.openmmlab.com/mmpose/mmdet_pretrained/cascade_rcnn_x101_64x4d_fpn_20e_onehand10k-dac19597_20201030.pth \ + configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/res50_onehand10k_256x256.py \ + https://download.openmmlab.com/mmpose/top_down/resnet/res50_onehand10k_256x256-e67998f6_20200813.pth \ + --video-path https://user-images.githubusercontent.com/87690686/137441388-3ea93d26-5445-4184-829e-bf7011def9e4.mp4 \ + --out-video-root vis_results +``` + +### Speed Up Inference + +Some tips to speed up MMPose inference: + +For 2D hand pose estimation models, try to edit the config file. For example, + +1. set `flip_test=False` in [hand-res50](https://github.com/open-mmlab/mmpose/tree/e1ec589884235bee875c89102170439a991f8450/configs/hand/resnet/onehand10k/res50_onehand10k_256x256.py#L56). +1. set `post_process='default'` in [hand-res50](https://github.com/open-mmlab/mmpose/tree/e1ec589884235bee875c89102170439a991f8450/configs/hand/resnet/onehand10k/res50_onehand10k_256x256.py#L57). diff --git a/vendor/ViTPose/demo/docs/2d_human_pose_demo.md b/vendor/ViTPose/demo/docs/2d_human_pose_demo.md new file mode 100644 index 0000000000000000000000000000000000000000..fc264a34da3e5917a33b5282e35fd2c7aaa5066d --- /dev/null +++ b/vendor/ViTPose/demo/docs/2d_human_pose_demo.md @@ -0,0 +1,159 @@ +## 2D Human Pose Demo + +

+ +### 2D Human Pose Top-Down Image Demo + +#### Using gt human bounding boxes as input + +We provide a demo script to test a single image, given gt json file. + +```shell +python demo/top_down_img_demo.py \ + ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \ + --img-root ${IMG_ROOT} --json-file ${JSON_FILE} \ + --out-img-root ${OUTPUT_DIR} \ + [--show --device ${GPU_ID or CPU}] \ + [--kpt-thr ${KPT_SCORE_THR}] +``` + +Examples: + +```shell +python demo/top_down_img_demo.py \ + configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_256x192.py \ + https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth \ + --img-root tests/data/coco/ --json-file tests/data/coco/test_coco.json \ + --out-img-root vis_results +``` + +To run demos on CPU: + +```shell +python demo/top_down_img_demo.py \ + configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_256x192.py \ + https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth \ + --img-root tests/data/coco/ --json-file tests/data/coco/test_coco.json \ + --out-img-root vis_results \ + --device=cpu +``` + +#### Using mmdet for human bounding box detection + +We provide a demo script to run mmdet for human detection, and mmpose for pose estimation. + +Assume that you have already installed [mmdet](https://github.com/open-mmlab/mmdetection). + +```shell +python demo/top_down_img_demo_with_mmdet.py \ + ${MMDET_CONFIG_FILE} ${MMDET_CHECKPOINT_FILE} \ + ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \ + --img-root ${IMG_ROOT} --img ${IMG_FILE} \ + --out-img-root ${OUTPUT_DIR} \ + [--show --device ${GPU_ID or CPU}] \ + [--bbox-thr ${BBOX_SCORE_THR} --kpt-thr ${KPT_SCORE_THR}] +``` + +Examples: + +```shell +python demo/top_down_img_demo_with_mmdet.py \ + demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \ + https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \ + configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_256x192.py \ + https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth \ + --img-root tests/data/coco/ \ + --img 000000196141.jpg \ + --out-img-root vis_results +``` + +### 2D Human Pose Top-Down Video Demo + +We also provide a video demo to illustrate the results. + +Assume that you have already installed [mmdet](https://github.com/open-mmlab/mmdetection). + +```shell +python demo/top_down_video_demo_with_mmdet.py \ + ${MMDET_CONFIG_FILE} ${MMDET_CHECKPOINT_FILE} \ + ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \ + --video-path ${VIDEO_FILE} \ + --out-video-root ${OUTPUT_VIDEO_ROOT} \ + [--show --device ${GPU_ID or CPU}] \ + [--bbox-thr ${BBOX_SCORE_THR} --kpt-thr ${KPT_SCORE_THR}] +``` + +Examples: + +```shell +python demo/top_down_video_demo_with_mmdet.py \ + demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \ + https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \ + configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_256x192.py \ + https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth \ + --video-path demo/resources/demo.mp4 \ + --out-video-root vis_results +``` + +### 2D Human Pose Bottom-Up Image Demo + +We provide a demo script to test a single image. + +```shell +python demo/bottom_up_img_demo.py \ + ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \ + --img-path ${IMG_PATH}\ + --out-img-root ${OUTPUT_DIR} \ + [--show --device ${GPU_ID or CPU}] \ + [--kpt-thr ${KPT_SCORE_THR} --pose-nms-thr ${POSE_NMS_THR}] +``` + +Examples: + +```shell +python demo/bottom_up_img_demo.py \ + configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w32_coco_512x512.py \ + https://download.openmmlab.com/mmpose/bottom_up/hrnet_w32_coco_512x512-bcb8c247_20200816.pth \ + --img-path tests/data/coco/ \ + --out-img-root vis_results +``` + +### 2D Human Pose Bottom-Up Video Demo + +We also provide a video demo to illustrate the results. + +```shell +python demo/bottom_up_video_demo.py \ + ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \ + --video-path ${VIDEO_FILE} \ + --out-video-root ${OUTPUT_VIDEO_ROOT} \ + [--show --device ${GPU_ID or CPU}] \ + [--kpt-thr ${KPT_SCORE_THR} --pose-nms-thr ${POSE_NMS_THR}] +``` + +Examples: + +```shell +python demo/bottom_up_video_demo.py \ + configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w32_coco_512x512.py \ + https://download.openmmlab.com/mmpose/bottom_up/hrnet_w32_coco_512x512-bcb8c247_20200816.pth \ + --video-path demo/resources/demo.mp4 \ + --out-video-root vis_results +``` + +### Speed Up Inference + +Some tips to speed up MMPose inference: + +For top-down models, try to edit the config file. For example, + +1. set `flip_test=False` in [topdown-res50](https://github.com/open-mmlab/mmpose/tree/e1ec589884235bee875c89102170439a991f8450/configs/top_down/resnet/coco/res50_coco_256x192.py#L51). +1. set `post_process='default'` in [topdown-res50](https://github.com/open-mmlab/mmpose/tree/e1ec589884235bee875c89102170439a991f8450/configs/top_down/resnet/coco/res50_coco_256x192.py#L52). +1. use faster human bounding box detector, see [MMDetection](https://mmdetection.readthedocs.io/en/latest/model_zoo.html). + +For bottom-up models, try to edit the config file. For example, + +1. set `flip_test=False` in [AE-res50](https://github.com/open-mmlab/mmpose/tree/e1ec589884235bee875c89102170439a991f8450/configs/bottom_up/resnet/coco/res50_coco_512x512.py#L80). +1. set `adjust=False` in [AE-res50](https://github.com/open-mmlab/mmpose/tree/e1ec589884235bee875c89102170439a991f8450/configs/bottom_up/resnet/coco/res50_coco_512x512.py#L78). +1. set `refine=False` in [AE-res50](https://github.com/open-mmlab/mmpose/tree/e1ec589884235bee875c89102170439a991f8450/configs/bottom_up/resnet/coco/res50_coco_512x512.py#L79). +1. use smaller input image size in [AE-res50](https://github.com/open-mmlab/mmpose/tree/e1ec589884235bee875c89102170439a991f8450/configs/bottom_up/resnet/coco/res50_coco_512x512.py#L39). diff --git a/vendor/ViTPose/demo/docs/2d_pose_tracking_demo.md b/vendor/ViTPose/demo/docs/2d_pose_tracking_demo.md new file mode 100644 index 0000000000000000000000000000000000000000..9b299413b2dfebde22c0d7024b32e8c0b880ba8d --- /dev/null +++ b/vendor/ViTPose/demo/docs/2d_pose_tracking_demo.md @@ -0,0 +1,101 @@ +## 2D Pose Tracking Demo + +
+ +### 2D Top-Down Video Human Pose Tracking Demo + +We provide a video demo to illustrate the pose tracking results. + +Assume that you have already installed [mmdet](https://github.com/open-mmlab/mmdetection). + +```shell +python demo/top_down_pose_tracking_demo_with_mmdet.py \ + ${MMDET_CONFIG_FILE} ${MMDET_CHECKPOINT_FILE} \ + ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \ + --video-path ${VIDEO_FILE} \ + --out-video-root ${OUTPUT_VIDEO_ROOT} \ + [--show --device ${GPU_ID or CPU}] \ + [--bbox-thr ${BBOX_SCORE_THR} --kpt-thr ${KPT_SCORE_THR}] + [--use-oks-tracking --tracking-thr ${TRACKING_THR} --euro] +``` + +Examples: + +```shell +python demo/top_down_pose_tracking_demo_with_mmdet.py \ + demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \ + https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \ + configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_256x192.py \ + https://download.openmmlab.com/mmpose/top_down/resnet/res50_coco_256x192-ec54d7f3_20200709.pth \ + --video-path demo/resources/demo.mp4 \ + --out-video-root vis_results +``` + +### 2D Top-Down Video Human Pose Tracking Demo with MMTracking + +MMTracking is an open source video perception toolbox based on PyTorch for tracking related tasks. +Here we show how to utilize MMTracking and MMPose to achieve human pose tracking. + +Assume that you have already installed [mmtracking](https://github.com/open-mmlab/mmtracking). + +```shell +python demo/top_down_video_demo_with_mmtracking.py \ + ${MMTRACKING_CONFIG_FILE} \ + ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \ + --video-path ${VIDEO_FILE} \ + --out-video-root ${OUTPUT_VIDEO_ROOT} \ + [--show --device ${GPU_ID or CPU}] \ + [--bbox-thr ${BBOX_SCORE_THR} --kpt-thr ${KPT_SCORE_THR}] +``` + +Examples: + +```shell +python demo/top_down_pose_tracking_demo_with_mmtracking.py \ + demo/mmtracking_cfg/tracktor_faster-rcnn_r50_fpn_4e_mot17-private.py \ + configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_256x192.py \ + https://download.openmmlab.com/mmpose/top_down/resnet/res50_coco_256x192-ec54d7f3_20200709.pth \ + --video-path demo/resources/demo.mp4 \ + --out-video-root vis_results +``` + +### 2D Bottom-Up Video Human Pose Tracking Demo + +We also provide a pose tracking demo with bottom-up pose estimation methods. + +```shell +python demo/bottom_up_pose_tracking_demo.py \ + ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \ + --video-path ${VIDEO_FILE} \ + --out-video-root ${OUTPUT_VIDEO_ROOT} \ + [--show --device ${GPU_ID or CPU}] \ + [--kpt-thr ${KPT_SCORE_THR} --pose-nms-thr ${POSE_NMS_THR}] + [--use-oks-tracking --tracking-thr ${TRACKING_THR} --euro] +``` + +Examples: + +```shell +python demo/bottom_up_pose_tracking_demo.py \ + configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w32_coco_512x512.py \ + https://download.openmmlab.com/mmpose/bottom_up/hrnet_w32_coco_512x512-bcb8c247_20200816.pth \ + --video-path demo/resources/demo.mp4 \ + --out-video-root vis_results +``` + +### Speed Up Inference + +Some tips to speed up MMPose inference: + +For top-down models, try to edit the config file. For example, + +1. set `flip_test=False` in [topdown-res50](https://github.com/open-mmlab/mmpose/tree/e1ec589884235bee875c89102170439a991f8450/configs/top_down/resnet/coco/res50_coco_256x192.py#L51). +1. set `post_process='default'` in [topdown-res50](https://github.com/open-mmlab/mmpose/tree/e1ec589884235bee875c89102170439a991f8450/configs/top_down/resnet/coco/res50_coco_256x192.py#L52). +1. use faster human detector or human tracker, see [MMDetection](https://mmdetection.readthedocs.io/en/latest/model_zoo.html) or [MMTracking](https://mmtracking.readthedocs.io/en/latest/model_zoo.html). + +For bottom-up models, try to edit the config file. For example, + +1. set `flip_test=False` in [AE-res50](https://github.com/open-mmlab/mmpose/tree/e1ec589884235bee875c89102170439a991f8450/configs/bottom_up/resnet/coco/res50_coco_512x512.py#L80). +1. set `adjust=False` in [AE-res50](https://github.com/open-mmlab/mmpose/tree/e1ec589884235bee875c89102170439a991f8450/configs/bottom_up/resnet/coco/res50_coco_512x512.py#L78). +1. set `refine=False` in [AE-res50](https://github.com/open-mmlab/mmpose/tree/e1ec589884235bee875c89102170439a991f8450/configs/bottom_up/resnet/coco/res50_coco_512x512.py#L79). +1. use smaller input image size in [AE-res50](https://github.com/open-mmlab/mmpose/tree/e1ec589884235bee875c89102170439a991f8450/configs/bottom_up/resnet/coco/res50_coco_512x512.py#L39). diff --git a/vendor/ViTPose/demo/docs/2d_wholebody_pose_demo.md b/vendor/ViTPose/demo/docs/2d_wholebody_pose_demo.md new file mode 100644 index 0000000000000000000000000000000000000000..a2050eae1d6a1cbb4870292563239369922df629 --- /dev/null +++ b/vendor/ViTPose/demo/docs/2d_wholebody_pose_demo.md @@ -0,0 +1,106 @@ +## 2D Human Whole-Body Pose Demo + +
+ +### 2D Human Whole-Body Pose Top-Down Image Demo + +#### Using gt human bounding boxes as input + +We provide a demo script to test a single image, given gt json file. + +```shell +python demo/top_down_img_demo.py \ + ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \ + --img-root ${IMG_ROOT} --json-file ${JSON_FILE} \ + --out-img-root ${OUTPUT_DIR} \ + [--show --device ${GPU_ID or CPU}] \ + [--kpt-thr ${KPT_SCORE_THR}] +``` + +Examples: + +```shell +python demo/top_down_img_demo.py \ + configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w48_coco_wholebody_384x288_dark_plus.py \ + https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_wholebody_384x288_dark-f5726563_20200918.pth \ + --img-root tests/data/coco/ --json-file tests/data/coco/test_coco.json \ + --out-img-root vis_results +``` + +To run demos on CPU: + +```shell +python demo/top_down_img_demo.py \ + configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w48_coco_wholebody_384x288_dark_plus.py \ + https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_wholebody_384x288_dark-f5726563_20200918.pth \ + --img-root tests/data/coco/ --json-file tests/data/coco/test_coco.json \ + --out-img-root vis_results \ + --device=cpu +``` + +#### Using mmdet for human bounding box detection + +We provide a demo script to run mmdet for human detection, and mmpose for pose estimation. + +Assume that you have already installed [mmdet](https://github.com/open-mmlab/mmdetection). + +```shell +python demo/top_down_img_demo_with_mmdet.py \ + ${MMDET_CONFIG_FILE} ${MMDET_CHECKPOINT_FILE} \ + ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \ + --img-root ${IMG_ROOT} --img ${IMG_FILE} \ + --out-img-root ${OUTPUT_DIR} \ + [--show --device ${GPU_ID or CPU}] \ + [--bbox-thr ${BBOX_SCORE_THR} --kpt-thr ${KPT_SCORE_THR}] +``` + +Examples: + +```shell +python demo/top_down_img_demo_with_mmdet.py \ + demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \ + https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \ + configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w48_coco_wholebody_384x288_dark_plus.py \ + https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_wholebody_384x288_dark-f5726563_20200918.pth \ + --img-root tests/data/coco/ \ + --img 000000196141.jpg \ + --out-img-root vis_results +``` + +### 2D Human Whole-Body Pose Top-Down Video Demo + +We also provide a video demo to illustrate the results. + +Assume that you have already installed [mmdet](https://github.com/open-mmlab/mmdetection). + +```shell +python demo/top_down_video_demo_with_mmdet.py \ + ${MMDET_CONFIG_FILE} ${MMDET_CHECKPOINT_FILE} \ + ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \ + --video-path ${VIDEO_FILE} \ + --out-video-root ${OUTPUT_VIDEO_ROOT} \ + [--show --device ${GPU_ID or CPU}] \ + [--bbox-thr ${BBOX_SCORE_THR} --kpt-thr ${KPT_SCORE_THR}] +``` + +Examples: + +```shell +python demo/top_down_video_demo_with_mmdet.py \ + demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \ + https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \ + configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_w48_coco_wholebody_384x288_dark_plus.py \ + https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_wholebody_384x288_dark-f5726563_20200918.pth \ + --video-path https://user-images.githubusercontent.com/87690686/137440639-fb08603d-9a35-474e-b65f-46b5c06b68d6.mp4 \ + --out-video-root vis_results +``` + +### Speed Up Inference + +Some tips to speed up MMPose inference: + +For top-down models, try to edit the config file. For example, + +1. set `flip_test=False` in [pose_hrnet_w48_dark+](https://github.com/open-mmlab/mmpose/tree/e1ec589884235bee875c89102170439a991f8450/configs/wholebody/darkpose/coco-wholebody/hrnet_w48_coco_wholebody_384x288_dark_plus.py#L80). +1. set `post_process='default'` in [pose_hrnet_w48_dark+](https://github.com/open-mmlab/mmpose/tree/e1ec589884235bee875c89102170439a991f8450/configs/wholebody/darkpose/coco-wholebody/hrnet_w48_coco_wholebody_384x288_dark_plus.py#L81). +1. use faster human bounding box detector, see [MMDetection](https://mmdetection.readthedocs.io/en/latest/model_zoo.html). diff --git a/vendor/ViTPose/demo/docs/3d_body_mesh_demo.md b/vendor/ViTPose/demo/docs/3d_body_mesh_demo.md new file mode 100644 index 0000000000000000000000000000000000000000..b1e93db7791ebdaf8fced2ef6637740f76bdccd7 --- /dev/null +++ b/vendor/ViTPose/demo/docs/3d_body_mesh_demo.md @@ -0,0 +1,28 @@ +## 3D Mesh Demo + +

+ +### 3D Mesh Recovery Demo + +We provide a demo script to recover human 3D mesh from a single image. + +```shell +python demo/mesh_img_demo.py \ + ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \ + --json-file ${JSON_FILE} \ + --img-root ${IMG_ROOT} \ + [--show] \ + [--device ${GPU_ID or CPU}] \ + [--out-img-root ${OUTPUT_DIR}] +``` + +Example: + +```shell +python demo/mesh_img_demo.py \ + configs/body/3d_mesh_sview_rgb_img/hmr/mixed/res50_mixed_224x224.py \ + https://download.openmmlab.com/mmpose/mesh/hmr/hmr_mesh_224x224-c21e8229_20201015.pth \ + --json-file tests/data/h36m/h36m_coco.json \ + --img-root tests/data/h36m \ + --out-img-root vis_results +``` diff --git a/vendor/ViTPose/demo/docs/3d_hand_demo.md b/vendor/ViTPose/demo/docs/3d_hand_demo.md new file mode 100644 index 0000000000000000000000000000000000000000..a3204b7d54d50df4c0f447f074784342787bdef2 --- /dev/null +++ b/vendor/ViTPose/demo/docs/3d_hand_demo.md @@ -0,0 +1,50 @@ +## 3D Hand Demo + +
+ +### 3D Hand Estimation Image Demo + +#### Using gt hand bounding boxes as input + +We provide a demo script to test a single image, given gt json file. + +```shell +python demo/interhand3d_img_demo.py \ + ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \ + --json-file ${JSON_FILE} \ + --img-root ${IMG_ROOT} \ + [--camera-param-file ${CAMERA_PARAM_FILE}] \ + [--gt-joints-file ${GT_JOINTS_FILE}]\ + [--show] \ + [--device ${GPU_ID or CPU}] \ + [--out-img-root ${OUTPUT_DIR}] \ + [--rebase-keypoint-height] \ + [--show-ground-truth] +``` + +Example with gt keypoints and camera parameters: + +```shell +python demo/interhand3d_img_demo.py \ + configs/hand/3d_kpt_sview_rgb_img/internet/interhand3d/res50_interhand3d_all_256x256.py \ + https://download.openmmlab.com/mmpose/hand3d/internet/res50_intehand3d_all_256x256-b9c1cf4c_20210506.pth \ + --json-file tests/data/interhand2.6m/test_interhand2.6m_data.json \ + --img-root tests/data/interhand2.6m \ + --camera-param-file tests/data/interhand2.6m/test_interhand2.6m_camera.json \ + --gt-joints-file tests/data/interhand2.6m/test_interhand2.6m_joint_3d.json \ + --out-img-root vis_results \ + --rebase-keypoint-height \ + --show-ground-truth +``` + +Example without gt keypoints and camera parameters: + +```shell +python demo/interhand3d_img_demo.py \ + configs/hand/3d_kpt_sview_rgb_img/internet/interhand3d/res50_interhand3d_all_256x256.py \ + https://download.openmmlab.com/mmpose/hand3d/internet/res50_intehand3d_all_256x256-b9c1cf4c_20210506.pth \ + --json-file tests/data/interhand2.6m/test_interhand2.6m_data.json \ + --img-root tests/data/interhand2.6m \ + --out-img-root vis_results \ + --rebase-keypoint-height +``` diff --git a/vendor/ViTPose/demo/docs/3d_human_pose_demo.md b/vendor/ViTPose/demo/docs/3d_human_pose_demo.md new file mode 100644 index 0000000000000000000000000000000000000000..4771c691e62567ec3c5214f38932e020ef6b4213 --- /dev/null +++ b/vendor/ViTPose/demo/docs/3d_human_pose_demo.md @@ -0,0 +1,84 @@ +## 3D Human Pose Demo + +
+ +### 3D Human Pose Two-stage Estimation Image Demo + +#### Using ground truth 2D poses as the 1st stage (pose detection) result, and inference the 2nd stage (2D-to-3D lifting) + +We provide a demo script to test on single images with a given ground-truth Json file. + +```shell +python demo/body3d_two_stage_img_demo.py \ + ${MMPOSE_CONFIG_FILE_3D} \ + ${MMPOSE_CHECKPOINT_FILE_3D} \ + --json-file ${JSON_FILE} \ + --img-root ${IMG_ROOT} \ + --only-second-stage \ + [--show] \ + [--device ${GPU_ID or CPU}] \ + [--out-img-root ${OUTPUT_DIR}] \ + [--rebase-keypoint-height] \ + [--show-ground-truth] +``` + +Example: + +```shell +python demo/body3d_two_stage_img_demo.py \ + configs/body/3d_kpt_sview_rgb_img/pose_lift/h36m/simplebaseline3d_h36m.py \ + https://download.openmmlab.com/mmpose/body3d/simple_baseline/simple3Dbaseline_h36m-f0ad73a4_20210419.pth \ + --json-file tests/data/h36m/h36m_coco.json \ + --img-root tests/data/h36m \ + --camera-param-file tests/data/h36m/cameras.pkl \ + --only-second-stage \ + --out-img-root vis_results \ + --rebase-keypoint-height \ + --show-ground-truth +``` + +### 3D Human Pose Two-stage Estimation Video Demo + +#### Using mmdet for human bounding box detection and top-down model for the 1st stage (2D pose detection), and inference the 2nd stage (2D-to-3D lifting) + +Assume that you have already installed [mmdet](https://github.com/open-mmlab/mmdetection). + +```shell +python demo/body3d_two_stage_video_demo.py \ + ${MMDET_CONFIG_FILE} \ + ${MMDET_CHECKPOINT_FILE} \ + ${MMPOSE_CONFIG_FILE_2D} \ + ${MMPOSE_CHECKPOINT_FILE_2D} \ + ${MMPOSE_CONFIG_FILE_3D} \ + ${MMPOSE_CHECKPOINT_FILE_3D} \ + --video-path ${VIDEO_PATH} \ + [--rebase-keypoint-height] \ + [--norm-pose-2d] \ + [--num-poses-vis NUM_POSES_VIS] \ + [--show] \ + [--out-video-root ${OUT_VIDEO_ROOT}] \ + [--device ${GPU_ID or CPU}] \ + [--det-cat-id DET_CAT_ID] \ + [--bbox-thr BBOX_THR] \ + [--kpt-thr KPT_THR] \ + [--use-oks-tracking] \ + [--tracking-thr TRACKING_THR] \ + [--euro] \ + [--radius RADIUS] \ + [--thickness THICKNESS] +``` + +Example: + +```shell +python demo/body3d_two_stage_video_demo.py \ + demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \ + https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \ + configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_256x192.py \ + https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth \ + configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m_243frames_fullconv_supervised_cpn_ft.py \ + https://download.openmmlab.com/mmpose/body3d/videopose/videopose_h36m_243frames_fullconv_supervised_cpn_ft-88f5abbb_20210527.pth \ + --video-path demo/resources/
+
+
+
+### Usage Tips
+
+- **Which model is used in the demo tool?**
+
+ Please check the following default arguments in the script. You can also choose other models from the [MMDetection Model Zoo](https://github.com/open-mmlab/mmdetection/blob/master/docs/model_zoo.md) and [MMPose Model Zoo](https://mmpose.readthedocs.io/en/latest/modelzoo.html#) or use your own models.
+
+ | Model | Arguments |
+ | :--: | :-- |
+ | Detection | `--det-config`, `--det-checkpoint` |
+ | Human Pose | `--human-pose-config`, `--human-pose-checkpoint` |
+ | Animal Pose | `--animal-pose-config`, `--animal-pose-checkpoint` |
+
+- **Can this tool run without GPU?**
+
+ Yes, you can set `--device=cpu` and the model inference will be performed on CPU. Of course, this may cause a low inference FPS compared to using GPU devices.
+
+- **Why there is time delay between the pose visualization and the video?**
+
+ The video I/O and model inference are running asynchronously and the latter usually takes more time for a single frame. To allevidate the time delay, you can:
+
+ 1. set `--display-delay=MILLISECONDS` to defer the video stream, according to the inference delay shown at the top left corner. Or,
+
+ 2. set `--synchronous-mode` to force video stream being aligned with inference results. This may reduce the video display FPS.
+
+- **Can this tool process video files?**
+
+ Yes. You can set `--cam-id=VIDEO_FILE_PATH` to run the demo tool in offline mode on a video file. Note that `--synchronous-mode` should be set in this case.
+
+- **How to enable/disable the special effects?**
+
+ The special effects can be enabled/disabled at launch time by setting arguments like `--bugeye`, `--sunglasses`, *etc*. You can also toggle the effects by keyboard shortcuts like `b`, `s` when the tool starts.
+
+- **What if my computer doesn't have a camera?**
+
+ You can use a smart phone as a webcam with apps like [Camo](https://reincubate.com/camo/) or [DroidCam](https://www.dev47apps.com/).
diff --git a/vendor/ViTPose/demo/face_img_demo.py b/vendor/ViTPose/demo/face_img_demo.py
new file mode 100644
index 0000000000000000000000000000000000000000..e94eb08cdbba139b1104b5fe16b4648b1d03b8c4
--- /dev/null
+++ b/vendor/ViTPose/demo/face_img_demo.py
@@ -0,0 +1,140 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import warnings
+from argparse import ArgumentParser
+
+from mmpose.apis import (inference_top_down_pose_model, init_pose_model,
+ vis_pose_result)
+from mmpose.datasets import DatasetInfo
+
+try:
+ import face_recognition
+ has_face_det = True
+except (ImportError, ModuleNotFoundError):
+ has_face_det = False
+
+
+def process_face_det_results(face_det_results):
+ """Process det results, and return a list of bboxes.
+
+ :param face_det_results: (top, right, bottom and left)
+ :return: a list of detected bounding boxes (x,y,x,y)-format
+ """
+
+ person_results = []
+ for bbox in face_det_results:
+ person = {}
+ # left, top, right, bottom
+ person['bbox'] = [bbox[3], bbox[0], bbox[1], bbox[2]]
+ person_results.append(person)
+
+ return person_results
+
+
+def main():
+ """Visualize the demo images.
+
+ Using mmdet to detect the human.
+ """
+ parser = ArgumentParser()
+ parser.add_argument('pose_config', help='Config file for pose')
+ parser.add_argument('pose_checkpoint', help='Checkpoint file for pose')
+ parser.add_argument('--img-root', type=str, default='', help='Image root')
+ parser.add_argument('--img', type=str, default='', help='Image file')
+ parser.add_argument(
+ '--show',
+ action='store_true',
+ default=False,
+ help='whether to show img')
+ parser.add_argument(
+ '--out-img-root',
+ type=str,
+ default='',
+ help='root of the output img file. '
+ 'Default not saving the visualization images.')
+ parser.add_argument(
+ '--device', default='cuda:0', help='Device used for inference')
+ parser.add_argument(
+ '--kpt-thr', type=float, default=0.3, help='Keypoint score threshold')
+ parser.add_argument(
+ '--radius',
+ type=int,
+ default=4,
+ help='Keypoint radius for visualization')
+ parser.add_argument(
+ '--thickness',
+ type=int,
+ default=1,
+ help='Link thickness for visualization')
+
+ assert has_face_det, 'Please install face_recognition to run the demo. ' \
+ '"pip install face_recognition", For more details, ' \
+ 'see https://github.com/ageitgey/face_recognition'
+
+ args = parser.parse_args()
+
+ assert args.show or (args.out_img_root != '')
+ assert args.img != ''
+
+ # build the pose model from a config file and a checkpoint file
+ pose_model = init_pose_model(
+ args.pose_config, args.pose_checkpoint, device=args.device.lower())
+
+ dataset = pose_model.cfg.data['test']['type']
+ dataset_info = pose_model.cfg.data['test'].get('dataset_info', None)
+ if dataset_info is None:
+ warnings.warn(
+ 'Please set `dataset_info` in the config.'
+ 'Check https://github.com/open-mmlab/mmpose/pull/663 for details.',
+ DeprecationWarning)
+ else:
+ dataset_info = DatasetInfo(dataset_info)
+
+ image_name = os.path.join(args.img_root, args.img)
+
+ # test a single image, the resulting box is (top, right, bottom and left)
+ image = face_recognition.load_image_file(image_name)
+ face_det_results = face_recognition.face_locations(image)
+
+ # keep the person class bounding boxes.
+ face_results = process_face_det_results(face_det_results)
+
+ # optional
+ return_heatmap = False
+
+ # e.g. use ('backbone', ) to return backbone feature
+ output_layer_names = None
+
+ pose_results, returned_outputs = inference_top_down_pose_model(
+ pose_model,
+ image_name,
+ face_results,
+ bbox_thr=None,
+ format='xyxy',
+ dataset=dataset,
+ dataset_info=dataset_info,
+ return_heatmap=return_heatmap,
+ outputs=output_layer_names)
+
+ if args.out_img_root == '':
+ out_file = None
+ else:
+ os.makedirs(args.out_img_root, exist_ok=True)
+ out_file = os.path.join(args.out_img_root, f'vis_{args.img}')
+
+ # show the results
+ vis_pose_result(
+ pose_model,
+ image_name,
+ pose_results,
+ radius=args.radius,
+ thickness=args.thickness,
+ dataset=dataset,
+ dataset_info=dataset_info,
+ kpt_score_thr=args.kpt_thr,
+ show=args.show,
+ out_file=out_file)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/vendor/ViTPose/demo/face_video_demo.py b/vendor/ViTPose/demo/face_video_demo.py
new file mode 100644
index 0000000000000000000000000000000000000000..cebe262eb61b5ade18ff065eddbcc2415b7c137c
--- /dev/null
+++ b/vendor/ViTPose/demo/face_video_demo.py
@@ -0,0 +1,167 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import warnings
+from argparse import ArgumentParser
+
+import cv2
+
+from mmpose.apis import (inference_top_down_pose_model, init_pose_model,
+ vis_pose_result)
+from mmpose.datasets import DatasetInfo
+
+try:
+ import face_recognition
+ has_face_det = True
+except (ImportError, ModuleNotFoundError):
+ has_face_det = False
+
+
+def process_face_det_results(face_det_results):
+ """Process det results, and return a list of bboxes.
+
+ :param face_det_results: (top, right, bottom and left)
+ :return: a list of detected bounding boxes (x,y,x,y)-format
+ """
+
+ person_results = []
+ for bbox in face_det_results:
+ person = {}
+ # left, top, right, bottom
+ person['bbox'] = [bbox[3], bbox[0], bbox[1], bbox[2]]
+ person_results.append(person)
+
+ return person_results
+
+
+def main():
+ """Visualize the demo images.
+
+ Using mmdet to detect the human.
+ """
+ parser = ArgumentParser()
+ parser.add_argument('pose_config', help='Config file for pose')
+ parser.add_argument('pose_checkpoint', help='Checkpoint file for pose')
+ parser.add_argument('--video-path', type=str, help='Video path')
+ parser.add_argument(
+ '--show',
+ action='store_true',
+ default=False,
+ help='whether to show visualizations.')
+ parser.add_argument(
+ '--out-video-root',
+ default='',
+ help='Root of the output video file. '
+ 'Default not saving the visualization video.')
+ parser.add_argument(
+ '--device', default='cuda:0', help='Device used for inference')
+ parser.add_argument(
+ '--kpt-thr', type=float, default=0.3, help='Keypoint score threshold')
+ parser.add_argument(
+ '--radius',
+ type=int,
+ default=4,
+ help='Keypoint radius for visualization')
+ parser.add_argument(
+ '--thickness',
+ type=int,
+ default=1,
+ help='Link thickness for visualization')
+
+ assert has_face_det, 'Please install face_recognition to run the demo. '\
+ '"pip install face_recognition", For more details, '\
+ 'see https://github.com/ageitgey/face_recognition'
+
+ args = parser.parse_args()
+
+ assert args.show or (args.out_video_root != '')
+
+ # build the pose model from a config file and a checkpoint file
+ pose_model = init_pose_model(
+ args.pose_config, args.pose_checkpoint, device=args.device.lower())
+
+ dataset = pose_model.cfg.data['test']['type']
+ dataset_info = pose_model.cfg.data['test'].get('dataset_info', None)
+ if dataset_info is None:
+ warnings.warn(
+ 'Please set `dataset_info` in the config.'
+ 'Check https://github.com/open-mmlab/mmpose/pull/663 for details.',
+ DeprecationWarning)
+ else:
+ dataset_info = DatasetInfo(dataset_info)
+
+ cap = cv2.VideoCapture(args.video_path)
+ assert cap.isOpened(), f'Faild to load video file {args.video_path}'
+
+ if args.out_video_root == '':
+ save_out_video = False
+ else:
+ os.makedirs(args.out_video_root, exist_ok=True)
+ save_out_video = True
+
+ if save_out_video:
+ fps = cap.get(cv2.CAP_PROP_FPS)
+ size = (int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)),
+ int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
+ fourcc = cv2.VideoWriter_fourcc(*'mp4v')
+ videoWriter = cv2.VideoWriter(
+ os.path.join(args.out_video_root,
+ f'vis_{os.path.basename(args.video_path)}'), fourcc,
+ fps, size)
+
+ # optional
+ return_heatmap = False
+
+ # e.g. use ('backbone', ) to return backbone feature
+ output_layer_names = None
+
+ while (cap.isOpened()):
+ flag, img = cap.read()
+ if not flag:
+ break
+
+ face_det_results = face_recognition.face_locations(
+ cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
+ face_results = process_face_det_results(face_det_results)
+
+ # test a single image, with a list of bboxes.
+ pose_results, returned_outputs = inference_top_down_pose_model(
+ pose_model,
+ img,
+ face_results,
+ bbox_thr=None,
+ format='xyxy',
+ dataset=dataset,
+ dataset_info=dataset_info,
+ return_heatmap=return_heatmap,
+ outputs=output_layer_names)
+
+ # show the results
+ vis_img = vis_pose_result(
+ pose_model,
+ img,
+ pose_results,
+ radius=args.radius,
+ thickness=args.thickness,
+ dataset=dataset,
+ dataset_info=dataset_info,
+ kpt_score_thr=args.kpt_thr,
+ show=False)
+
+ if args.show:
+ cv2.imshow('Image', vis_img)
+
+ if save_out_video:
+ videoWriter.write(vis_img)
+
+ if args.show and cv2.waitKey(1) & 0xFF == ord('q'):
+ break
+
+ cap.release()
+ if save_out_video:
+ videoWriter.release()
+ if args.show:
+ cv2.destroyAllWindows()
+
+
+if __name__ == '__main__':
+ main()
diff --git a/vendor/ViTPose/demo/interhand3d_img_demo.py b/vendor/ViTPose/demo/interhand3d_img_demo.py
new file mode 100644
index 0000000000000000000000000000000000000000..a6dbeff3b9cba6eb95b8ec0ce98d4ac8ae48cb0a
--- /dev/null
+++ b/vendor/ViTPose/demo/interhand3d_img_demo.py
@@ -0,0 +1,258 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import os.path as osp
+from argparse import ArgumentParser
+
+import mmcv
+import numpy as np
+from xtcocotools.coco import COCO
+
+from mmpose.apis import inference_interhand_3d_model, vis_3d_pose_result
+from mmpose.apis.inference import init_pose_model
+from mmpose.core import SimpleCamera
+
+
+def _transform_interhand_camera_param(interhand_camera_param):
+ """Transform the camera parameters in interhand2.6m dataset to the format
+ of SimpleCamera.
+
+ Args:
+ interhand_camera_param (dict): camera parameters including:
+ - camrot: 3x3, camera rotation matrix (world-to-camera)
+ - campos: 3x1, camera location in world space
+ - focal: 2x1, camera focal length
+ - princpt: 2x1, camera center
+
+ Returns:
+ param (dict): camera parameters including:
+ - R: 3x3, camera rotation matrix (camera-to-world)
+ - T: 3x1, camera translation (camera-to-world)
+ - f: 2x1, camera focal length
+ - c: 2x1, camera center
+ """
+ camera_param = {}
+ camera_param['R'] = np.array(interhand_camera_param['camrot']).T
+ camera_param['T'] = np.array(interhand_camera_param['campos'])[:, None]
+ camera_param['f'] = np.array(interhand_camera_param['focal'])[:, None]
+ camera_param['c'] = np.array(interhand_camera_param['princpt'])[:, None]
+ return camera_param
+
+
+def main():
+ parser = ArgumentParser()
+ parser.add_argument('pose_config', help='Config file for pose network')
+ parser.add_argument('pose_checkpoint', help='Checkpoint file')
+ parser.add_argument('--img-root', type=str, default='', help='Image root')
+ parser.add_argument(
+ '--json-file',
+ type=str,
+ default='',
+ help='Json file containing image info.')
+ parser.add_argument(
+ '--camera-param-file',
+ type=str,
+ default=None,
+ help='Camera parameter file for converting 3D pose predictions from '
+ ' the pixel space to camera space. If None, keypoints in pixel space'
+ 'will be visualized')
+ parser.add_argument(
+ '--gt-joints-file',
+ type=str,
+ default=None,
+ help='Optional argument. Ground truth 3D keypoint parameter file. '
+ 'If None, gt keypoints will not be shown and keypoints in pixel '
+ 'space will be visualized.')
+ parser.add_argument(
+ '--rebase-keypoint-height',
+ action='store_true',
+ help='Rebase the predicted 3D pose so its lowest keypoint has a '
+ 'height of 0 (landing on the ground). This is useful for '
+ 'visualization when the model do not predict the global position '
+ 'of the 3D pose.')
+ parser.add_argument(
+ '--show-ground-truth',
+ action='store_true',
+ help='If True, show ground truth keypoint if it is available.')
+ parser.add_argument(
+ '--show',
+ action='store_true',
+ default=False,
+ help='whether to show img')
+ parser.add_argument(
+ '--out-img-root',
+ type=str,
+ default=None,
+ help='Root of the output visualization images. '
+ 'Default not saving the visualization images.')
+ parser.add_argument(
+ '--device', default='cuda:0', help='Device for inference')
+ parser.add_argument(
+ '--kpt-thr', type=float, default=0.3, help='Keypoint score threshold')
+ parser.add_argument(
+ '--radius',
+ type=int,
+ default=4,
+ help='Keypoint radius for visualization')
+ parser.add_argument(
+ '--thickness',
+ type=int,
+ default=1,
+ help='Link thickness for visualization')
+
+ args = parser.parse_args()
+ assert args.show or (args.out_img_root != '')
+
+ coco = COCO(args.json_file)
+
+ # build the pose model from a config file and a checkpoint file
+ pose_model = init_pose_model(
+ args.pose_config, args.pose_checkpoint, device=args.device.lower())
+ dataset = pose_model.cfg.data['test']['type']
+
+ # load camera parameters
+ camera_params = None
+ if args.camera_param_file is not None:
+ camera_params = mmcv.load(args.camera_param_file)
+ # load ground truth joints parameters
+ gt_joint_params = None
+ if args.gt_joints_file is not None:
+ gt_joint_params = mmcv.load(args.gt_joints_file)
+
+ # load hand bounding boxes
+ det_results_list = []
+ for image_id, image in coco.imgs.items():
+ image_name = osp.join(args.img_root, image['file_name'])
+
+ ann_ids = coco.getAnnIds(image_id)
+ det_results = []
+
+ capture_key = str(image['capture'])
+ camera_key = image['camera']
+ frame_idx = image['frame_idx']
+
+ for ann_id in ann_ids:
+ ann = coco.anns[ann_id]
+ if camera_params is not None:
+ camera_param = {
+ key: camera_params[capture_key][key][camera_key]
+ for key in camera_params[capture_key].keys()
+ }
+ camera_param = _transform_interhand_camera_param(camera_param)
+ else:
+ camera_param = None
+ if gt_joint_params is not None:
+ joint_param = gt_joint_params[capture_key][str(frame_idx)]
+ gt_joint = np.concatenate([
+ np.array(joint_param['world_coord']),
+ np.array(joint_param['joint_valid'])
+ ],
+ axis=-1)
+ else:
+ gt_joint = None
+
+ det_result = {
+ 'image_name': image_name,
+ 'bbox': ann['bbox'], # bbox format is 'xywh'
+ 'camera_param': camera_param,
+ 'keypoints_3d_gt': gt_joint
+ }
+ det_results.append(det_result)
+ det_results_list.append(det_results)
+
+ for i, det_results in enumerate(
+ mmcv.track_iter_progress(det_results_list)):
+
+ image_name = det_results[0]['image_name']
+
+ pose_results = inference_interhand_3d_model(
+ pose_model, image_name, det_results, dataset=dataset)
+
+ # Post processing
+ pose_results_vis = []
+ for idx, res in enumerate(pose_results):
+ keypoints_3d = res['keypoints_3d']
+ # normalize kpt score
+ if keypoints_3d[:, 3].max() > 1:
+ keypoints_3d[:, 3] /= 255
+ # get 2D keypoints in pixel space
+ res['keypoints'] = keypoints_3d[:, [0, 1, 3]]
+
+ # For model-predicted keypoints, channel 0 and 1 are coordinates
+ # in pixel space, and channel 2 is the depth (in mm) relative
+ # to root joints.
+ # If both camera parameter and absolute depth of root joints are
+ # provided, we can transform keypoint to camera space for better
+ # visualization.
+ camera_param = res['camera_param']
+ keypoints_3d_gt = res['keypoints_3d_gt']
+ if camera_param is not None and keypoints_3d_gt is not None:
+ # build camera model
+ camera = SimpleCamera(camera_param)
+ # transform gt joints from world space to camera space
+ keypoints_3d_gt[:, :3] = camera.world_to_camera(
+ keypoints_3d_gt[:, :3])
+
+ # transform relative depth to absolute depth
+ keypoints_3d[:21, 2] += keypoints_3d_gt[20, 2]
+ keypoints_3d[21:, 2] += keypoints_3d_gt[41, 2]
+
+ # transform keypoints from pixel space to camera space
+ keypoints_3d[:, :3] = camera.pixel_to_camera(
+ keypoints_3d[:, :3])
+
+ # rotate the keypoint to make z-axis correspondent to height
+ # for better visualization
+ vis_R = np.array([[1, 0, 0], [0, 0, -1], [0, 1, 0]])
+ keypoints_3d[:, :3] = keypoints_3d[:, :3] @ vis_R
+ if keypoints_3d_gt is not None:
+ keypoints_3d_gt[:, :3] = keypoints_3d_gt[:, :3] @ vis_R
+
+ # rebase height (z-axis)
+ if args.rebase_keypoint_height:
+ valid = keypoints_3d[..., 3] > 0
+ keypoints_3d[..., 2] -= np.min(
+ keypoints_3d[valid, 2], axis=-1, keepdims=True)
+ res['keypoints_3d'] = keypoints_3d
+ res['keypoints_3d_gt'] = keypoints_3d_gt
+
+ # Add title
+ instance_id = res.get('track_id', idx)
+ res['title'] = f'Prediction ({instance_id})'
+ pose_results_vis.append(res)
+ # Add ground truth
+ if args.show_ground_truth:
+ if keypoints_3d_gt is None:
+ print('Fail to show ground truth. Please make sure that'
+ ' gt-joints-file is provided.')
+ else:
+ gt = res.copy()
+ if args.rebase_keypoint_height:
+ valid = keypoints_3d_gt[..., 3] > 0
+ keypoints_3d_gt[..., 2] -= np.min(
+ keypoints_3d_gt[valid, 2], axis=-1, keepdims=True)
+ gt['keypoints_3d'] = keypoints_3d_gt
+ gt['title'] = f'Ground truth ({instance_id})'
+ pose_results_vis.append(gt)
+
+ # Visualization
+ if args.out_img_root is None:
+ out_file = None
+ else:
+ os.makedirs(args.out_img_root, exist_ok=True)
+ out_file = osp.join(args.out_img_root, f'vis_{i}.jpg')
+
+ vis_3d_pose_result(
+ pose_model,
+ result=pose_results_vis,
+ img=det_results[0]['image_name'],
+ out_file=out_file,
+ dataset=dataset,
+ show=args.show,
+ kpt_score_thr=args.kpt_thr,
+ radius=args.radius,
+ thickness=args.thickness,
+ )
+
+
+if __name__ == '__main__':
+ main()
diff --git a/vendor/ViTPose/demo/mesh_img_demo.py b/vendor/ViTPose/demo/mesh_img_demo.py
new file mode 100644
index 0000000000000000000000000000000000000000..127ebad3b79c19d8dffae0afd489bcc0212cba8f
--- /dev/null
+++ b/vendor/ViTPose/demo/mesh_img_demo.py
@@ -0,0 +1,93 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+from argparse import ArgumentParser
+
+from xtcocotools.coco import COCO
+
+from mmpose.apis import (inference_mesh_model, init_pose_model,
+ vis_3d_mesh_result)
+
+
+def main():
+ """Visualize the demo images.
+
+ Require the json_file containing boxes.
+ """
+ parser = ArgumentParser()
+ parser.add_argument('pose_config', help='Config file for detection')
+ parser.add_argument('pose_checkpoint', help='Checkpoint file')
+ parser.add_argument('--img-root', type=str, default='', help='Image root')
+ parser.add_argument(
+ '--json-file',
+ type=str,
+ default='',
+ help='Json file containing image info.')
+ parser.add_argument(
+ '--show',
+ action='store_true',
+ default=False,
+ help='whether to show img')
+ parser.add_argument(
+ '--out-img-root',
+ type=str,
+ default='',
+ help='Root of the output img file. '
+ 'Default not saving the visualization images.')
+ parser.add_argument(
+ '--device', default='cuda:0', help='Device used for inference')
+
+ args = parser.parse_args()
+
+ assert args.show or (args.out_img_root != '')
+
+ coco = COCO(args.json_file)
+ # build the pose model from a config file and a checkpoint file
+ pose_model = init_pose_model(
+ args.pose_config, args.pose_checkpoint, device=args.device.lower())
+
+ dataset = pose_model.cfg.data['test']['type']
+
+ img_keys = list(coco.imgs.keys())
+
+ # process each image
+ for i in range(len(img_keys)):
+ # get bounding box annotations
+ image_id = img_keys[i]
+ image = coco.loadImgs(image_id)[0]
+ image_name = os.path.join(args.img_root, image['file_name'])
+ ann_ids = coco.getAnnIds(image_id)
+
+ # make person bounding boxes
+ person_results = []
+ for ann_id in ann_ids:
+ person = {}
+ ann = coco.anns[ann_id]
+ # bbox format is 'xywh'
+ person['bbox'] = ann['bbox']
+ person_results.append(person)
+
+ # test a single image, with a list of bboxes
+ pose_results = inference_mesh_model(
+ pose_model,
+ image_name,
+ person_results,
+ bbox_thr=None,
+ format='xywh',
+ dataset=dataset)
+
+ if args.out_img_root == '':
+ out_file = None
+ else:
+ os.makedirs(args.out_img_root, exist_ok=True)
+ out_file = os.path.join(args.out_img_root, f'vis_{i}.jpg')
+
+ vis_3d_mesh_result(
+ pose_model,
+ pose_results,
+ image_name,
+ show=args.show,
+ out_file=out_file)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/vendor/ViTPose/demo/mmdetection_cfg/cascade_rcnn_x101_64x4d_fpn_1class.py b/vendor/ViTPose/demo/mmdetection_cfg/cascade_rcnn_x101_64x4d_fpn_1class.py
new file mode 100644
index 0000000000000000000000000000000000000000..4e60b6b73971d598e40efdcc408d9385b3140b71
--- /dev/null
+++ b/vendor/ViTPose/demo/mmdetection_cfg/cascade_rcnn_x101_64x4d_fpn_1class.py
@@ -0,0 +1,255 @@
+checkpoint_config = dict(interval=1)
+# yapf:disable
+log_config = dict(
+ interval=50,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+# yapf:enable
+dist_params = dict(backend='nccl')
+log_level = 'INFO'
+load_from = None
+resume_from = None
+workflow = [('train', 1)]
+
+# optimizer
+optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[16, 19])
+total_epochs = 20
+# model settings
+model = dict(
+ type='CascadeRCNN',
+ pretrained='open-mmlab://resnext101_64x4d',
+ backbone=dict(
+ type='ResNeXt',
+ depth=101,
+ groups=64,
+ base_width=4,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ frozen_stages=1,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ style='pytorch'),
+ neck=dict(
+ type='FPN',
+ in_channels=[256, 512, 1024, 2048],
+ out_channels=256,
+ num_outs=5),
+ rpn_head=dict(
+ type='RPNHead',
+ in_channels=256,
+ feat_channels=256,
+ anchor_generator=dict(
+ type='AnchorGenerator',
+ scales=[8],
+ ratios=[0.5, 1.0, 2.0],
+ strides=[4, 8, 16, 32, 64]),
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[.0, .0, .0, .0],
+ target_stds=[1.0, 1.0, 1.0, 1.0]),
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
+ loss_bbox=dict(type='SmoothL1Loss', beta=1.0 / 9.0, loss_weight=1.0)),
+ roi_head=dict(
+ type='CascadeRoIHead',
+ num_stages=3,
+ stage_loss_weights=[1, 0.5, 0.25],
+ bbox_roi_extractor=dict(
+ type='SingleRoIExtractor',
+ roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
+ out_channels=256,
+ featmap_strides=[4, 8, 16, 32]),
+ bbox_head=[
+ dict(
+ type='Shared2FCBBoxHead',
+ in_channels=256,
+ fc_out_channels=1024,
+ roi_feat_size=7,
+ num_classes=1,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.1, 0.1, 0.2, 0.2]),
+ reg_class_agnostic=True,
+ loss_cls=dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=1.0),
+ loss_bbox=dict(type='SmoothL1Loss', beta=1.0,
+ loss_weight=1.0)),
+ dict(
+ type='Shared2FCBBoxHead',
+ in_channels=256,
+ fc_out_channels=1024,
+ roi_feat_size=7,
+ num_classes=1,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.05, 0.05, 0.1, 0.1]),
+ reg_class_agnostic=True,
+ loss_cls=dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=1.0),
+ loss_bbox=dict(type='SmoothL1Loss', beta=1.0,
+ loss_weight=1.0)),
+ dict(
+ type='Shared2FCBBoxHead',
+ in_channels=256,
+ fc_out_channels=1024,
+ roi_feat_size=7,
+ num_classes=1,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.033, 0.033, 0.067, 0.067]),
+ reg_class_agnostic=True,
+ loss_cls=dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=1.0),
+ loss_bbox=dict(type='SmoothL1Loss', beta=1.0, loss_weight=1.0))
+ ]),
+ # model training and testing settings
+ train_cfg=dict(
+ rpn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.7,
+ neg_iou_thr=0.3,
+ min_pos_iou=0.3,
+ match_low_quality=True,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=256,
+ pos_fraction=0.5,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=False),
+ allowed_border=0,
+ pos_weight=-1,
+ debug=False),
+ rpn_proposal=dict(
+ nms_pre=2000,
+ max_per_img=2000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=[
+ dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.5,
+ neg_iou_thr=0.5,
+ min_pos_iou=0.5,
+ match_low_quality=False,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=512,
+ pos_fraction=0.25,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=True),
+ pos_weight=-1,
+ debug=False),
+ dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.6,
+ neg_iou_thr=0.6,
+ min_pos_iou=0.6,
+ match_low_quality=False,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=512,
+ pos_fraction=0.25,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=True),
+ pos_weight=-1,
+ debug=False),
+ dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.7,
+ neg_iou_thr=0.7,
+ min_pos_iou=0.7,
+ match_low_quality=False,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=512,
+ pos_fraction=0.25,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=True),
+ pos_weight=-1,
+ debug=False)
+ ]),
+ test_cfg=dict(
+ rpn=dict(
+ nms_pre=1000,
+ max_per_img=1000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=dict(
+ score_thr=0.05,
+ nms=dict(type='nms', iou_threshold=0.5),
+ max_per_img=100)))
+
+dataset_type = 'CocoDataset'
+data_root = 'data/coco'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(1333, 800),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+data = dict(
+ samples_per_gpu=2,
+ workers_per_gpu=2,
+ train=dict(
+ type=dataset_type,
+ ann_file=f'{data_root}/annotations/instances_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ pipeline=train_pipeline),
+ val=dict(
+ type=dataset_type,
+ ann_file=f'{data_root}/annotations/instances_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ pipeline=test_pipeline),
+ test=dict(
+ type=dataset_type,
+ ann_file=f'{data_root}/annotations/instances_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ pipeline=test_pipeline))
+evaluation = dict(interval=1, metric='bbox')
diff --git a/vendor/ViTPose/demo/mmdetection_cfg/cascade_rcnn_x101_64x4d_fpn_coco.py b/vendor/ViTPose/demo/mmdetection_cfg/cascade_rcnn_x101_64x4d_fpn_coco.py
new file mode 100644
index 0000000000000000000000000000000000000000..f91bd0d105b9394c514ffb82d54117dba347680a
--- /dev/null
+++ b/vendor/ViTPose/demo/mmdetection_cfg/cascade_rcnn_x101_64x4d_fpn_coco.py
@@ -0,0 +1,256 @@
+checkpoint_config = dict(interval=1)
+# yapf:disable
+log_config = dict(
+ interval=50,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+# yapf:enable
+dist_params = dict(backend='nccl')
+log_level = 'INFO'
+load_from = None
+resume_from = None
+workflow = [('train', 1)]
+
+# optimizer
+optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[16, 19])
+total_epochs = 20
+
+# model settings
+model = dict(
+ type='CascadeRCNN',
+ pretrained='open-mmlab://resnext101_64x4d',
+ backbone=dict(
+ type='ResNeXt',
+ depth=101,
+ groups=64,
+ base_width=4,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ frozen_stages=1,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ style='pytorch'),
+ neck=dict(
+ type='FPN',
+ in_channels=[256, 512, 1024, 2048],
+ out_channels=256,
+ num_outs=5),
+ rpn_head=dict(
+ type='RPNHead',
+ in_channels=256,
+ feat_channels=256,
+ anchor_generator=dict(
+ type='AnchorGenerator',
+ scales=[8],
+ ratios=[0.5, 1.0, 2.0],
+ strides=[4, 8, 16, 32, 64]),
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[.0, .0, .0, .0],
+ target_stds=[1.0, 1.0, 1.0, 1.0]),
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
+ loss_bbox=dict(type='SmoothL1Loss', beta=1.0 / 9.0, loss_weight=1.0)),
+ roi_head=dict(
+ type='CascadeRoIHead',
+ num_stages=3,
+ stage_loss_weights=[1, 0.5, 0.25],
+ bbox_roi_extractor=dict(
+ type='SingleRoIExtractor',
+ roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
+ out_channels=256,
+ featmap_strides=[4, 8, 16, 32]),
+ bbox_head=[
+ dict(
+ type='Shared2FCBBoxHead',
+ in_channels=256,
+ fc_out_channels=1024,
+ roi_feat_size=7,
+ num_classes=80,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.1, 0.1, 0.2, 0.2]),
+ reg_class_agnostic=True,
+ loss_cls=dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=1.0),
+ loss_bbox=dict(type='SmoothL1Loss', beta=1.0,
+ loss_weight=1.0)),
+ dict(
+ type='Shared2FCBBoxHead',
+ in_channels=256,
+ fc_out_channels=1024,
+ roi_feat_size=7,
+ num_classes=80,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.05, 0.05, 0.1, 0.1]),
+ reg_class_agnostic=True,
+ loss_cls=dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=1.0),
+ loss_bbox=dict(type='SmoothL1Loss', beta=1.0,
+ loss_weight=1.0)),
+ dict(
+ type='Shared2FCBBoxHead',
+ in_channels=256,
+ fc_out_channels=1024,
+ roi_feat_size=7,
+ num_classes=80,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.033, 0.033, 0.067, 0.067]),
+ reg_class_agnostic=True,
+ loss_cls=dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=1.0),
+ loss_bbox=dict(type='SmoothL1Loss', beta=1.0, loss_weight=1.0))
+ ]),
+ # model training and testing settings
+ train_cfg=dict(
+ rpn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.7,
+ neg_iou_thr=0.3,
+ min_pos_iou=0.3,
+ match_low_quality=True,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=256,
+ pos_fraction=0.5,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=False),
+ allowed_border=0,
+ pos_weight=-1,
+ debug=False),
+ rpn_proposal=dict(
+ nms_pre=2000,
+ max_per_img=2000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=[
+ dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.5,
+ neg_iou_thr=0.5,
+ min_pos_iou=0.5,
+ match_low_quality=False,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=512,
+ pos_fraction=0.25,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=True),
+ pos_weight=-1,
+ debug=False),
+ dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.6,
+ neg_iou_thr=0.6,
+ min_pos_iou=0.6,
+ match_low_quality=False,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=512,
+ pos_fraction=0.25,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=True),
+ pos_weight=-1,
+ debug=False),
+ dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.7,
+ neg_iou_thr=0.7,
+ min_pos_iou=0.7,
+ match_low_quality=False,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=512,
+ pos_fraction=0.25,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=True),
+ pos_weight=-1,
+ debug=False)
+ ]),
+ test_cfg=dict(
+ rpn=dict(
+ nms_pre=1000,
+ max_per_img=1000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=dict(
+ score_thr=0.05,
+ nms=dict(type='nms', iou_threshold=0.5),
+ max_per_img=100)))
+
+dataset_type = 'CocoDataset'
+data_root = 'data/coco'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(1333, 800),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+data = dict(
+ samples_per_gpu=2,
+ workers_per_gpu=2,
+ train=dict(
+ type=dataset_type,
+ ann_file=f'{data_root}/annotations/instances_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ pipeline=train_pipeline),
+ val=dict(
+ type=dataset_type,
+ ann_file=f'{data_root}/annotations/instances_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ pipeline=test_pipeline),
+ test=dict(
+ type=dataset_type,
+ ann_file=f'{data_root}/annotations/instances_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ pipeline=test_pipeline))
+evaluation = dict(interval=1, metric='bbox')
diff --git a/vendor/ViTPose/demo/mmdetection_cfg/faster_rcnn_r50_fpn_1class.py b/vendor/ViTPose/demo/mmdetection_cfg/faster_rcnn_r50_fpn_1class.py
new file mode 100644
index 0000000000000000000000000000000000000000..ee54f5b66bd216c485db0a56a68bf2793428d123
--- /dev/null
+++ b/vendor/ViTPose/demo/mmdetection_cfg/faster_rcnn_r50_fpn_1class.py
@@ -0,0 +1,182 @@
+checkpoint_config = dict(interval=1)
+# yapf:disable
+log_config = dict(
+ interval=50,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+# yapf:enable
+dist_params = dict(backend='nccl')
+log_level = 'INFO'
+load_from = None
+resume_from = None
+workflow = [('train', 1)]
+# optimizer
+optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[8, 11])
+total_epochs = 12
+
+model = dict(
+ type='FasterRCNN',
+ pretrained='torchvision://resnet50',
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ frozen_stages=1,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=True,
+ style='pytorch'),
+ neck=dict(
+ type='FPN',
+ in_channels=[256, 512, 1024, 2048],
+ out_channels=256,
+ num_outs=5),
+ rpn_head=dict(
+ type='RPNHead',
+ in_channels=256,
+ feat_channels=256,
+ anchor_generator=dict(
+ type='AnchorGenerator',
+ scales=[8],
+ ratios=[0.5, 1.0, 2.0],
+ strides=[4, 8, 16, 32, 64]),
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[.0, .0, .0, .0],
+ target_stds=[1.0, 1.0, 1.0, 1.0]),
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
+ loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
+ roi_head=dict(
+ type='StandardRoIHead',
+ bbox_roi_extractor=dict(
+ type='SingleRoIExtractor',
+ roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
+ out_channels=256,
+ featmap_strides=[4, 8, 16, 32]),
+ bbox_head=dict(
+ type='Shared2FCBBoxHead',
+ in_channels=256,
+ fc_out_channels=1024,
+ roi_feat_size=7,
+ num_classes=1,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.1, 0.1, 0.2, 0.2]),
+ reg_class_agnostic=False,
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
+ loss_bbox=dict(type='L1Loss', loss_weight=1.0))),
+ # model training and testing settings
+ train_cfg=dict(
+ rpn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.7,
+ neg_iou_thr=0.3,
+ min_pos_iou=0.3,
+ match_low_quality=True,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=256,
+ pos_fraction=0.5,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=False),
+ allowed_border=-1,
+ pos_weight=-1,
+ debug=False),
+ rpn_proposal=dict(
+ nms_pre=2000,
+ max_per_img=1000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.5,
+ neg_iou_thr=0.5,
+ min_pos_iou=0.5,
+ match_low_quality=False,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=512,
+ pos_fraction=0.25,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=True),
+ pos_weight=-1,
+ debug=False)),
+ test_cfg=dict(
+ rpn=dict(
+ nms_pre=1000,
+ max_per_img=1000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=dict(
+ score_thr=0.05,
+ nms=dict(type='nms', iou_threshold=0.5),
+ max_per_img=100)
+ # soft-nms is also supported for rcnn testing
+ # e.g., nms=dict(type='soft_nms', iou_threshold=0.5, min_score=0.05)
+ ))
+
+dataset_type = 'CocoDataset'
+data_root = 'data/coco'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(1333, 800),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+data = dict(
+ samples_per_gpu=2,
+ workers_per_gpu=2,
+ train=dict(
+ type=dataset_type,
+ ann_file=f'{data_root}/annotations/instances_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ pipeline=train_pipeline),
+ val=dict(
+ type=dataset_type,
+ ann_file=f'{data_root}/annotations/instances_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ pipeline=test_pipeline),
+ test=dict(
+ type=dataset_type,
+ ann_file=f'{data_root}/annotations/instances_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ pipeline=test_pipeline))
+evaluation = dict(interval=1, metric='bbox')
diff --git a/vendor/ViTPose/demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py b/vendor/ViTPose/demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py
new file mode 100644
index 0000000000000000000000000000000000000000..a9ad9528b22163ae7ce1390375b69227fd6eafd9
--- /dev/null
+++ b/vendor/ViTPose/demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py
@@ -0,0 +1,182 @@
+checkpoint_config = dict(interval=1)
+# yapf:disable
+log_config = dict(
+ interval=50,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+# yapf:enable
+dist_params = dict(backend='nccl')
+log_level = 'INFO'
+load_from = None
+resume_from = None
+workflow = [('train', 1)]
+# optimizer
+optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[8, 11])
+total_epochs = 12
+
+model = dict(
+ type='FasterRCNN',
+ pretrained='torchvision://resnet50',
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ frozen_stages=1,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=True,
+ style='pytorch'),
+ neck=dict(
+ type='FPN',
+ in_channels=[256, 512, 1024, 2048],
+ out_channels=256,
+ num_outs=5),
+ rpn_head=dict(
+ type='RPNHead',
+ in_channels=256,
+ feat_channels=256,
+ anchor_generator=dict(
+ type='AnchorGenerator',
+ scales=[8],
+ ratios=[0.5, 1.0, 2.0],
+ strides=[4, 8, 16, 32, 64]),
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[.0, .0, .0, .0],
+ target_stds=[1.0, 1.0, 1.0, 1.0]),
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
+ loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
+ roi_head=dict(
+ type='StandardRoIHead',
+ bbox_roi_extractor=dict(
+ type='SingleRoIExtractor',
+ roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
+ out_channels=256,
+ featmap_strides=[4, 8, 16, 32]),
+ bbox_head=dict(
+ type='Shared2FCBBoxHead',
+ in_channels=256,
+ fc_out_channels=1024,
+ roi_feat_size=7,
+ num_classes=80,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.1, 0.1, 0.2, 0.2]),
+ reg_class_agnostic=False,
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
+ loss_bbox=dict(type='L1Loss', loss_weight=1.0))),
+ # model training and testing settings
+ train_cfg=dict(
+ rpn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.7,
+ neg_iou_thr=0.3,
+ min_pos_iou=0.3,
+ match_low_quality=True,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=256,
+ pos_fraction=0.5,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=False),
+ allowed_border=-1,
+ pos_weight=-1,
+ debug=False),
+ rpn_proposal=dict(
+ nms_pre=2000,
+ max_per_img=1000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.5,
+ neg_iou_thr=0.5,
+ min_pos_iou=0.5,
+ match_low_quality=False,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=512,
+ pos_fraction=0.25,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=True),
+ pos_weight=-1,
+ debug=False)),
+ test_cfg=dict(
+ rpn=dict(
+ nms_pre=1000,
+ max_per_img=1000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=dict(
+ score_thr=0.05,
+ nms=dict(type='nms', iou_threshold=0.5),
+ max_per_img=100)
+ # soft-nms is also supported for rcnn testing
+ # e.g., nms=dict(type='soft_nms', iou_threshold=0.5, min_score=0.05)
+ ))
+
+dataset_type = 'CocoDataset'
+data_root = 'data/coco'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(1333, 800),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+data = dict(
+ samples_per_gpu=2,
+ workers_per_gpu=2,
+ train=dict(
+ type=dataset_type,
+ ann_file=f'{data_root}/annotations/instances_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ pipeline=train_pipeline),
+ val=dict(
+ type=dataset_type,
+ ann_file=f'{data_root}/annotations/instances_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ pipeline=test_pipeline),
+ test=dict(
+ type=dataset_type,
+ ann_file=f'{data_root}/annotations/instances_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ pipeline=test_pipeline))
+evaluation = dict(interval=1, metric='bbox')
diff --git a/vendor/ViTPose/demo/mmdetection_cfg/mask_rcnn_r50_fpn_2x_coco.py b/vendor/ViTPose/demo/mmdetection_cfg/mask_rcnn_r50_fpn_2x_coco.py
new file mode 100644
index 0000000000000000000000000000000000000000..05d39fa9a87a0200f9b9d29cd19acd28c155d126
--- /dev/null
+++ b/vendor/ViTPose/demo/mmdetection_cfg/mask_rcnn_r50_fpn_2x_coco.py
@@ -0,0 +1,242 @@
+model = dict(
+ type='MaskRCNN',
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ frozen_stages=1,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=True,
+ style='pytorch',
+ init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
+ neck=dict(
+ type='FPN',
+ in_channels=[256, 512, 1024, 2048],
+ out_channels=256,
+ num_outs=5),
+ rpn_head=dict(
+ type='RPNHead',
+ in_channels=256,
+ feat_channels=256,
+ anchor_generator=dict(
+ type='AnchorGenerator',
+ scales=[8],
+ ratios=[0.5, 1.0, 2.0],
+ strides=[4, 8, 16, 32, 64]),
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0.0, 0.0, 0.0, 0.0],
+ target_stds=[1.0, 1.0, 1.0, 1.0]),
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
+ loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
+ roi_head=dict(
+ type='StandardRoIHead',
+ bbox_roi_extractor=dict(
+ type='SingleRoIExtractor',
+ roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
+ out_channels=256,
+ featmap_strides=[4, 8, 16, 32]),
+ bbox_head=dict(
+ type='Shared2FCBBoxHead',
+ in_channels=256,
+ fc_out_channels=1024,
+ roi_feat_size=7,
+ num_classes=80,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0.0, 0.0, 0.0, 0.0],
+ target_stds=[0.1, 0.1, 0.2, 0.2]),
+ reg_class_agnostic=False,
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
+ loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
+ mask_roi_extractor=dict(
+ type='SingleRoIExtractor',
+ roi_layer=dict(type='RoIAlign', output_size=14, sampling_ratio=0),
+ out_channels=256,
+ featmap_strides=[4, 8, 16, 32]),
+ mask_head=dict(
+ type='FCNMaskHead',
+ num_convs=4,
+ in_channels=256,
+ conv_out_channels=256,
+ num_classes=80,
+ loss_mask=dict(
+ type='CrossEntropyLoss', use_mask=True, loss_weight=1.0))),
+ train_cfg=dict(
+ rpn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.7,
+ neg_iou_thr=0.3,
+ min_pos_iou=0.3,
+ match_low_quality=True,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=256,
+ pos_fraction=0.5,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=False),
+ allowed_border=-1,
+ pos_weight=-1,
+ debug=False),
+ rpn_proposal=dict(
+ nms_pre=2000,
+ max_per_img=1000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.5,
+ neg_iou_thr=0.5,
+ min_pos_iou=0.5,
+ match_low_quality=True,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=512,
+ pos_fraction=0.25,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=True),
+ mask_size=28,
+ pos_weight=-1,
+ debug=False)),
+ test_cfg=dict(
+ rpn=dict(
+ nms_pre=1000,
+ max_per_img=1000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=dict(
+ score_thr=0.05,
+ nms=dict(type='nms', iou_threshold=0.5),
+ max_per_img=100,
+ mask_thr_binary=0.5)))
+dataset_type = 'CocoDataset'
+data_root = 'data/coco/'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
+ dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(
+ type='Normalize',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True),
+ dict(type='Pad', size_divisor=32),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels', 'gt_masks'])
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(1333, 800),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(
+ type='Normalize',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True),
+ dict(type='Pad', size_divisor=32),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img'])
+ ])
+]
+data = dict(
+ samples_per_gpu=2,
+ workers_per_gpu=2,
+ train=dict(
+ type='CocoDataset',
+ ann_file='data/coco/annotations/instances_train2017.json',
+ img_prefix='data/coco/train2017/',
+ pipeline=[
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
+ dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(
+ type='Normalize',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True),
+ dict(type='Pad', size_divisor=32),
+ dict(type='DefaultFormatBundle'),
+ dict(
+ type='Collect',
+ keys=['img', 'gt_bboxes', 'gt_labels', 'gt_masks'])
+ ]),
+ val=dict(
+ type='CocoDataset',
+ ann_file='data/coco/annotations/instances_val2017.json',
+ img_prefix='data/coco/val2017/',
+ pipeline=[
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(1333, 800),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(
+ type='Normalize',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True),
+ dict(type='Pad', size_divisor=32),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img'])
+ ])
+ ]),
+ test=dict(
+ type='CocoDataset',
+ ann_file='data/coco/annotations/instances_val2017.json',
+ img_prefix='data/coco/val2017/',
+ pipeline=[
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(1333, 800),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(
+ type='Normalize',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True),
+ dict(type='Pad', size_divisor=32),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img'])
+ ])
+ ]))
+evaluation = dict(metric=['bbox', 'segm'])
+optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
+optimizer_config = dict(grad_clip=None)
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[16, 22])
+runner = dict(type='EpochBasedRunner', max_epochs=24)
+checkpoint_config = dict(interval=1)
+log_config = dict(interval=50, hooks=[dict(type='TextLoggerHook')])
+custom_hooks = [dict(type='NumClassCheckHook')]
+dist_params = dict(backend='nccl')
+log_level = 'INFO'
+load_from = None
+resume_from = None
+workflow = [('train', 1)]
diff --git a/vendor/ViTPose/demo/mmdetection_cfg/ssdlite_mobilenetv2_scratch_600e_coco.py b/vendor/ViTPose/demo/mmdetection_cfg/ssdlite_mobilenetv2_scratch_600e_coco.py
new file mode 100644
index 0000000000000000000000000000000000000000..91b9e593817cdb25899fdd664fadc10f3c0060d0
--- /dev/null
+++ b/vendor/ViTPose/demo/mmdetection_cfg/ssdlite_mobilenetv2_scratch_600e_coco.py
@@ -0,0 +1,216 @@
+# =========================================================
+# from 'mmdetection/configs/_base_/default_runtime.py'
+# =========================================================
+checkpoint_config = dict(interval=1)
+# yapf:disable
+log_config = dict(
+ interval=50,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+# yapf:enable
+custom_hooks = [dict(type='NumClassCheckHook')]
+# =========================================================
+
+# =========================================================
+# from 'mmdetection/configs/_base_/datasets/coco_detection.py'
+# =========================================================
+# dataset settings
+dataset_type = 'CocoDataset'
+data_root = 'data/coco/'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(1333, 800),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+data = dict(
+ samples_per_gpu=2,
+ workers_per_gpu=2,
+ train=dict(
+ type=dataset_type,
+ ann_file=data_root + 'annotations/instances_train2017.json',
+ img_prefix=data_root + 'train2017/',
+ pipeline=train_pipeline),
+ val=dict(
+ type=dataset_type,
+ ann_file=data_root + 'annotations/instances_val2017.json',
+ img_prefix=data_root + 'val2017/',
+ pipeline=test_pipeline),
+ test=dict(
+ type=dataset_type,
+ ann_file=data_root + 'annotations/instances_val2017.json',
+ img_prefix=data_root + 'val2017/',
+ pipeline=test_pipeline))
+evaluation = dict(interval=1, metric='bbox')
+# =========================================================
+
+dist_params = dict(backend='nccl')
+log_level = 'INFO'
+load_from = None
+resume_from = None
+workflow = [('train', 1)]
+
+model = dict(
+ type='SingleStageDetector',
+ backbone=dict(
+ type='MobileNetV2',
+ out_indices=(4, 7),
+ norm_cfg=dict(type='BN', eps=0.001, momentum=0.03),
+ init_cfg=dict(type='TruncNormal', layer='Conv2d', std=0.03)),
+ neck=dict(
+ type='SSDNeck',
+ in_channels=(96, 1280),
+ out_channels=(96, 1280, 512, 256, 256, 128),
+ level_strides=(2, 2, 2, 2),
+ level_paddings=(1, 1, 1, 1),
+ l2_norm_scale=None,
+ use_depthwise=True,
+ norm_cfg=dict(type='BN', eps=0.001, momentum=0.03),
+ act_cfg=dict(type='ReLU6'),
+ init_cfg=dict(type='TruncNormal', layer='Conv2d', std=0.03)),
+ bbox_head=dict(
+ type='SSDHead',
+ in_channels=(96, 1280, 512, 256, 256, 128),
+ num_classes=80,
+ use_depthwise=True,
+ norm_cfg=dict(type='BN', eps=0.001, momentum=0.03),
+ act_cfg=dict(type='ReLU6'),
+ init_cfg=dict(type='Normal', layer='Conv2d', std=0.001),
+
+ # set anchor size manually instead of using the predefined
+ # SSD300 setting.
+ anchor_generator=dict(
+ type='SSDAnchorGenerator',
+ scale_major=False,
+ strides=[16, 32, 64, 107, 160, 320],
+ ratios=[[2, 3], [2, 3], [2, 3], [2, 3], [2, 3], [2, 3]],
+ min_sizes=[48, 100, 150, 202, 253, 304],
+ max_sizes=[100, 150, 202, 253, 304, 320]),
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[.0, .0, .0, .0],
+ target_stds=[0.1, 0.1, 0.2, 0.2])),
+ # model training and testing settings
+ train_cfg=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.5,
+ neg_iou_thr=0.5,
+ min_pos_iou=0.,
+ ignore_iof_thr=-1,
+ gt_max_assign_all=False),
+ smoothl1_beta=1.,
+ allowed_border=-1,
+ pos_weight=-1,
+ neg_pos_ratio=3,
+ debug=False),
+ test_cfg=dict(
+ nms_pre=1000,
+ nms=dict(type='nms', iou_threshold=0.45),
+ min_bbox_size=0,
+ score_thr=0.02,
+ max_per_img=200))
+cudnn_benchmark = True
+
+# dataset settings
+dataset_type = 'CocoDataset'
+data_root = 'data/coco/'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+train_pipeline = [
+ dict(type='LoadImageFromFile', to_float32=True),
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(
+ type='PhotoMetricDistortion',
+ brightness_delta=32,
+ contrast_range=(0.5, 1.5),
+ saturation_range=(0.5, 1.5),
+ hue_delta=18),
+ dict(
+ type='Expand',
+ mean=img_norm_cfg['mean'],
+ to_rgb=img_norm_cfg['to_rgb'],
+ ratio_range=(1, 4)),
+ dict(
+ type='MinIoURandomCrop',
+ min_ious=(0.1, 0.3, 0.5, 0.7, 0.9),
+ min_crop_size=0.3),
+ dict(type='Resize', img_scale=(320, 320), keep_ratio=False),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='Pad', size_divisor=320),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(320, 320),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=False),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=320),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+data = dict(
+ samples_per_gpu=24,
+ workers_per_gpu=4,
+ train=dict(
+ _delete_=True,
+ type='RepeatDataset', # use RepeatDataset to speed up training
+ times=5,
+ dataset=dict(
+ type=dataset_type,
+ ann_file=data_root + 'annotations/instances_train2017.json',
+ img_prefix=data_root + 'train2017/',
+ pipeline=train_pipeline)),
+ val=dict(pipeline=test_pipeline),
+ test=dict(pipeline=test_pipeline))
+
+# optimizer
+optimizer = dict(type='SGD', lr=0.015, momentum=0.9, weight_decay=4.0e-5)
+optimizer_config = dict(grad_clip=None)
+
+# learning policy
+lr_config = dict(
+ policy='CosineAnnealing',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ min_lr=0)
+runner = dict(type='EpochBasedRunner', max_epochs=120)
+
+# Avoid evaluation and saving weights too frequently
+evaluation = dict(interval=5, metric='bbox')
+checkpoint_config = dict(interval=5)
+custom_hooks = [
+ dict(type='NumClassCheckHook'),
+ dict(type='CheckInvalidLossHook', interval=50, priority='VERY_LOW')
+]
diff --git a/vendor/ViTPose/demo/mmdetection_cfg/yolov3_d53_320_273e_coco.py b/vendor/ViTPose/demo/mmdetection_cfg/yolov3_d53_320_273e_coco.py
new file mode 100644
index 0000000000000000000000000000000000000000..d7e9cca1eb34f9935a9eaf74b4cae18d1efaa248
--- /dev/null
+++ b/vendor/ViTPose/demo/mmdetection_cfg/yolov3_d53_320_273e_coco.py
@@ -0,0 +1,140 @@
+# model settings
+model = dict(
+ type='YOLOV3',
+ pretrained='open-mmlab://darknet53',
+ backbone=dict(type='Darknet', depth=53, out_indices=(3, 4, 5)),
+ neck=dict(
+ type='YOLOV3Neck',
+ num_scales=3,
+ in_channels=[1024, 512, 256],
+ out_channels=[512, 256, 128]),
+ bbox_head=dict(
+ type='YOLOV3Head',
+ num_classes=80,
+ in_channels=[512, 256, 128],
+ out_channels=[1024, 512, 256],
+ anchor_generator=dict(
+ type='YOLOAnchorGenerator',
+ base_sizes=[[(116, 90), (156, 198), (373, 326)],
+ [(30, 61), (62, 45), (59, 119)],
+ [(10, 13), (16, 30), (33, 23)]],
+ strides=[32, 16, 8]),
+ bbox_coder=dict(type='YOLOBBoxCoder'),
+ featmap_strides=[32, 16, 8],
+ loss_cls=dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=True,
+ loss_weight=1.0,
+ reduction='sum'),
+ loss_conf=dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=True,
+ loss_weight=1.0,
+ reduction='sum'),
+ loss_xy=dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=True,
+ loss_weight=2.0,
+ reduction='sum'),
+ loss_wh=dict(type='MSELoss', loss_weight=2.0, reduction='sum')),
+ # training and testing settings
+ train_cfg=dict(
+ assigner=dict(
+ type='GridAssigner',
+ pos_iou_thr=0.5,
+ neg_iou_thr=0.5,
+ min_pos_iou=0)),
+ test_cfg=dict(
+ nms_pre=1000,
+ min_bbox_size=0,
+ score_thr=0.05,
+ conf_thr=0.005,
+ nms=dict(type='nms', iou_threshold=0.45),
+ max_per_img=100))
+# dataset settings
+dataset_type = 'CocoDataset'
+data_root = 'data/coco'
+img_norm_cfg = dict(mean=[0, 0, 0], std=[255., 255., 255.], to_rgb=True)
+train_pipeline = [
+ dict(type='LoadImageFromFile', to_float32=True),
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(type='PhotoMetricDistortion'),
+ dict(
+ type='Expand',
+ mean=img_norm_cfg['mean'],
+ to_rgb=img_norm_cfg['to_rgb'],
+ ratio_range=(1, 2)),
+ dict(
+ type='MinIoURandomCrop',
+ min_ious=(0.4, 0.5, 0.6, 0.7, 0.8, 0.9),
+ min_crop_size=0.3),
+ dict(type='Resize', img_scale=(320, 320), keep_ratio=True),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels'])
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(320, 320),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img'])
+ ])
+]
+data = dict(
+ samples_per_gpu=8,
+ workers_per_gpu=4,
+ train=dict(
+ type=dataset_type,
+ ann_file=f'{data_root}/annotations/instances_train2017.json',
+ img_prefix=f'{data_root}/train2017/',
+ pipeline=train_pipeline),
+ val=dict(
+ type=dataset_type,
+ ann_file=f'{data_root}/annotations/instances_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ pipeline=test_pipeline),
+ test=dict(
+ type=dataset_type,
+ ann_file=f'{data_root}/annotations/instances_val2017.json',
+ img_prefix=f'{data_root}/val2017/',
+ pipeline=test_pipeline))
+# optimizer
+optimizer = dict(type='SGD', lr=0.001, momentum=0.9, weight_decay=0.0005)
+optimizer_config = dict(grad_clip=dict(max_norm=35, norm_type=2))
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=2000, # same as burn-in in darknet
+ warmup_ratio=0.1,
+ step=[218, 246])
+# runtime settings
+runner = dict(type='EpochBasedRunner', max_epochs=273)
+evaluation = dict(interval=1, metric=['bbox'])
+
+checkpoint_config = dict(interval=1)
+# yapf:disable
+log_config = dict(
+ interval=50,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+# yapf:enable
+custom_hooks = [dict(type='NumClassCheckHook')]
+
+dist_params = dict(backend='nccl')
+log_level = 'INFO'
+load_from = None
+resume_from = None
+workflow = [('train', 1)]
diff --git a/vendor/ViTPose/demo/mmtracking_cfg/deepsort_faster-rcnn_fpn_4e_mot17-private-half.py b/vendor/ViTPose/demo/mmtracking_cfg/deepsort_faster-rcnn_fpn_4e_mot17-private-half.py
new file mode 100644
index 0000000000000000000000000000000000000000..1d7fccf0cbe9929618274218274726eb28577273
--- /dev/null
+++ b/vendor/ViTPose/demo/mmtracking_cfg/deepsort_faster-rcnn_fpn_4e_mot17-private-half.py
@@ -0,0 +1,321 @@
+model = dict(
+ detector=dict(
+ type='FasterRCNN',
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ frozen_stages=1,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=True,
+ style='pytorch',
+ init_cfg=dict(
+ type='Pretrained', checkpoint='torchvision://resnet50')),
+ neck=dict(
+ type='FPN',
+ in_channels=[256, 512, 1024, 2048],
+ out_channels=256,
+ num_outs=5),
+ rpn_head=dict(
+ type='RPNHead',
+ in_channels=256,
+ feat_channels=256,
+ anchor_generator=dict(
+ type='AnchorGenerator',
+ scales=[8],
+ ratios=[0.5, 1.0, 2.0],
+ strides=[4, 8, 16, 32, 64]),
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0.0, 0.0, 0.0, 0.0],
+ target_stds=[1.0, 1.0, 1.0, 1.0],
+ clip_border=False),
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
+ loss_bbox=dict(
+ type='SmoothL1Loss', beta=0.1111111111111111,
+ loss_weight=1.0)),
+ roi_head=dict(
+ type='StandardRoIHead',
+ bbox_roi_extractor=dict(
+ type='SingleRoIExtractor',
+ roi_layer=dict(
+ type='RoIAlign', output_size=7, sampling_ratio=0),
+ out_channels=256,
+ featmap_strides=[4, 8, 16, 32]),
+ bbox_head=dict(
+ type='Shared2FCBBoxHead',
+ in_channels=256,
+ fc_out_channels=1024,
+ roi_feat_size=7,
+ num_classes=1,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0.0, 0.0, 0.0, 0.0],
+ target_stds=[0.1, 0.1, 0.2, 0.2],
+ clip_border=False),
+ reg_class_agnostic=False,
+ loss_cls=dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=1.0),
+ loss_bbox=dict(type='SmoothL1Loss', loss_weight=1.0))),
+ train_cfg=dict(
+ rpn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.7,
+ neg_iou_thr=0.3,
+ min_pos_iou=0.3,
+ match_low_quality=True,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=256,
+ pos_fraction=0.5,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=False),
+ allowed_border=-1,
+ pos_weight=-1,
+ debug=False),
+ rpn_proposal=dict(
+ nms_pre=2000,
+ max_per_img=1000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.5,
+ neg_iou_thr=0.5,
+ min_pos_iou=0.5,
+ match_low_quality=False,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=512,
+ pos_fraction=0.25,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=True),
+ pos_weight=-1,
+ debug=False)),
+ test_cfg=dict(
+ rpn=dict(
+ nms_pre=1000,
+ max_per_img=1000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=dict(
+ score_thr=0.05,
+ nms=dict(type='nms', iou_threshold=0.5),
+ max_per_img=100)),
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint='https://download.openmmlab.com/mmtracking/'
+ 'mot/faster_rcnn/faster-rcnn_r50_fpn_4e_mot17-half-64ee2ed4.pth')),
+ type='DeepSORT',
+ motion=dict(type='KalmanFilter', center_only=False),
+ reid=dict(
+ type='BaseReID',
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ num_stages=4,
+ out_indices=(3, ),
+ style='pytorch'),
+ neck=dict(type='GlobalAveragePooling', kernel_size=(8, 4), stride=1),
+ head=dict(
+ type='LinearReIDHead',
+ num_fcs=1,
+ in_channels=2048,
+ fc_channels=1024,
+ out_channels=128,
+ num_classes=380,
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ loss_pairwise=dict(
+ type='TripletLoss', margin=0.3, loss_weight=1.0),
+ norm_cfg=dict(type='BN1d'),
+ act_cfg=dict(type='ReLU')),
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint='https://download.openmmlab.com/mmtracking/'
+ 'mot/reid/tracktor_reid_r50_iter25245-a452f51f.pth')),
+ tracker=dict(
+ type='SortTracker',
+ obj_score_thr=0.5,
+ reid=dict(
+ num_samples=10,
+ img_scale=(256, 128),
+ img_norm_cfg=None,
+ match_score_thr=2.0),
+ match_iou_thr=0.5,
+ momentums=None,
+ num_tentatives=2,
+ num_frames_retain=100))
+dataset_type = 'MOTChallengeDataset'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+train_pipeline = [
+ dict(type='LoadMultiImagesFromFile', to_float32=True),
+ dict(type='SeqLoadAnnotations', with_bbox=True, with_track=True),
+ dict(
+ type='SeqResize',
+ img_scale=(1088, 1088),
+ share_params=True,
+ ratio_range=(0.8, 1.2),
+ keep_ratio=True,
+ bbox_clip_border=False),
+ dict(type='SeqPhotoMetricDistortion', share_params=True),
+ dict(
+ type='SeqRandomCrop',
+ share_params=False,
+ crop_size=(1088, 1088),
+ bbox_clip_border=False),
+ dict(type='SeqRandomFlip', share_params=True, flip_ratio=0.5),
+ dict(
+ type='SeqNormalize',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True),
+ dict(type='SeqPad', size_divisor=32),
+ dict(type='MatchInstances', skip_nomatch=True),
+ dict(
+ type='VideoCollect',
+ keys=[
+ 'img', 'gt_bboxes', 'gt_labels', 'gt_match_indices',
+ 'gt_instance_ids'
+ ]),
+ dict(type='SeqDefaultFormatBundle', ref_prefix='ref')
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(1088, 1088),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(
+ type='Normalize',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True),
+ dict(type='Pad', size_divisor=32),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='VideoCollect', keys=['img'])
+ ])
+]
+data_root = 'data/MOT17/'
+data = dict(
+ samples_per_gpu=2,
+ workers_per_gpu=2,
+ train=dict(
+ type='MOTChallengeDataset',
+ visibility_thr=-1,
+ ann_file='data/MOT17/annotations/half-train_cocoformat.json',
+ img_prefix='data/MOT17/train',
+ ref_img_sampler=dict(
+ num_ref_imgs=1,
+ frame_range=10,
+ filter_key_img=True,
+ method='uniform'),
+ pipeline=[
+ dict(type='LoadMultiImagesFromFile', to_float32=True),
+ dict(type='SeqLoadAnnotations', with_bbox=True, with_track=True),
+ dict(
+ type='SeqResize',
+ img_scale=(1088, 1088),
+ share_params=True,
+ ratio_range=(0.8, 1.2),
+ keep_ratio=True,
+ bbox_clip_border=False),
+ dict(type='SeqPhotoMetricDistortion', share_params=True),
+ dict(
+ type='SeqRandomCrop',
+ share_params=False,
+ crop_size=(1088, 1088),
+ bbox_clip_border=False),
+ dict(type='SeqRandomFlip', share_params=True, flip_ratio=0.5),
+ dict(
+ type='SeqNormalize',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True),
+ dict(type='SeqPad', size_divisor=32),
+ dict(type='MatchInstances', skip_nomatch=True),
+ dict(
+ type='VideoCollect',
+ keys=[
+ 'img', 'gt_bboxes', 'gt_labels', 'gt_match_indices',
+ 'gt_instance_ids'
+ ]),
+ dict(type='SeqDefaultFormatBundle', ref_prefix='ref')
+ ]),
+ val=dict(
+ type='MOTChallengeDataset',
+ ann_file='data/MOT17/annotations/half-val_cocoformat.json',
+ img_prefix='data/MOT17/train',
+ ref_img_sampler=None,
+ pipeline=[
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(1088, 1088),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(
+ type='Normalize',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True),
+ dict(type='Pad', size_divisor=32),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='VideoCollect', keys=['img'])
+ ])
+ ]),
+ test=dict(
+ type='MOTChallengeDataset',
+ ann_file='data/MOT17/annotations/half-val_cocoformat.json',
+ img_prefix='data/MOT17/train',
+ ref_img_sampler=None,
+ pipeline=[
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(1088, 1088),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(
+ type='Normalize',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True),
+ dict(type='Pad', size_divisor=32),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='VideoCollect', keys=['img'])
+ ])
+ ]))
+optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
+optimizer_config = dict(grad_clip=None)
+checkpoint_config = dict(interval=1)
+log_config = dict(interval=50, hooks=[dict(type='TextLoggerHook')])
+dist_params = dict(backend='nccl')
+log_level = 'INFO'
+load_from = None
+resume_from = None
+workflow = [('train', 1)]
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=100,
+ warmup_ratio=0.01,
+ step=[3])
+total_epochs = 4
+evaluation = dict(metric=['bbox', 'track'], interval=1)
+search_metrics = ['MOTA', 'IDF1', 'FN', 'FP', 'IDs', 'MT', 'ML']
diff --git a/vendor/ViTPose/demo/mmtracking_cfg/tracktor_faster-rcnn_r50_fpn_4e_mot17-private.py b/vendor/ViTPose/demo/mmtracking_cfg/tracktor_faster-rcnn_r50_fpn_4e_mot17-private.py
new file mode 100644
index 0000000000000000000000000000000000000000..9736269bd9ca1f950eadaa7a4933656db3130ca8
--- /dev/null
+++ b/vendor/ViTPose/demo/mmtracking_cfg/tracktor_faster-rcnn_r50_fpn_4e_mot17-private.py
@@ -0,0 +1,325 @@
+model = dict(
+ detector=dict(
+ type='FasterRCNN',
+ pretrained='torchvision://resnet50',
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ frozen_stages=1,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=True,
+ style='pytorch'),
+ neck=dict(
+ type='FPN',
+ in_channels=[256, 512, 1024, 2048],
+ out_channels=256,
+ num_outs=5),
+ rpn_head=dict(
+ type='RPNHead',
+ in_channels=256,
+ feat_channels=256,
+ anchor_generator=dict(
+ type='AnchorGenerator',
+ scales=[8],
+ ratios=[0.5, 1.0, 2.0],
+ strides=[4, 8, 16, 32, 64]),
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0.0, 0.0, 0.0, 0.0],
+ target_stds=[1.0, 1.0, 1.0, 1.0],
+ clip_border=False),
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
+ loss_bbox=dict(
+ type='SmoothL1Loss', beta=0.1111111111111111,
+ loss_weight=1.0)),
+ roi_head=dict(
+ type='StandardRoIHead',
+ bbox_roi_extractor=dict(
+ type='SingleRoIExtractor',
+ roi_layer=dict(
+ type='RoIAlign', output_size=7, sampling_ratio=0),
+ out_channels=256,
+ featmap_strides=[4, 8, 16, 32]),
+ bbox_head=dict(
+ type='Shared2FCBBoxHead',
+ in_channels=256,
+ fc_out_channels=1024,
+ roi_feat_size=7,
+ num_classes=1,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0.0, 0.0, 0.0, 0.0],
+ target_stds=[0.1, 0.1, 0.2, 0.2],
+ clip_border=False),
+ reg_class_agnostic=False,
+ loss_cls=dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=1.0),
+ loss_bbox=dict(type='SmoothL1Loss', loss_weight=1.0))),
+ train_cfg=dict(
+ rpn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.7,
+ neg_iou_thr=0.3,
+ min_pos_iou=0.3,
+ match_low_quality=True,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=256,
+ pos_fraction=0.5,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=False),
+ allowed_border=-1,
+ pos_weight=-1,
+ debug=False),
+ rpn_proposal=dict(
+ nms_pre=2000,
+ max_per_img=1000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.5,
+ neg_iou_thr=0.5,
+ min_pos_iou=0.5,
+ match_low_quality=False,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=512,
+ pos_fraction=0.25,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=True),
+ pos_weight=-1,
+ debug=False)),
+ test_cfg=dict(
+ rpn=dict(
+ nms_pre=1000,
+ max_per_img=1000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=dict(
+ score_thr=0.05,
+ nms=dict(type='nms', iou_threshold=0.5),
+ max_per_img=100))),
+ type='Tracktor',
+ pretrains=dict(
+ detector='https://download.openmmlab.com/mmtracking/'
+ 'mot/faster_rcnn/faster-rcnn_r50_fpn_4e_mot17-ffa52ae7.pth',
+ reid='https://download.openmmlab.com/mmtracking/mot/'
+ 'reid/reid_r50_6e_mot17-4bf6b63d.pth'),
+ reid=dict(
+ type='BaseReID',
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ num_stages=4,
+ out_indices=(3, ),
+ style='pytorch'),
+ neck=dict(type='GlobalAveragePooling', kernel_size=(8, 4), stride=1),
+ head=dict(
+ type='LinearReIDHead',
+ num_fcs=1,
+ in_channels=2048,
+ fc_channels=1024,
+ out_channels=128,
+ num_classes=378,
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ loss_pairwise=dict(
+ type='TripletLoss', margin=0.3, loss_weight=1.0),
+ norm_cfg=dict(type='BN1d'),
+ act_cfg=dict(type='ReLU'))),
+ motion=dict(
+ type='CameraMotionCompensation',
+ warp_mode='cv2.MOTION_EUCLIDEAN',
+ num_iters=100,
+ stop_eps=1e-05),
+ tracker=dict(
+ type='TracktorTracker',
+ obj_score_thr=0.5,
+ regression=dict(
+ obj_score_thr=0.5,
+ nms=dict(type='nms', iou_threshold=0.6),
+ match_iou_thr=0.3),
+ reid=dict(
+ num_samples=10,
+ img_scale=(256, 128),
+ img_norm_cfg=None,
+ match_score_thr=2.0,
+ match_iou_thr=0.2),
+ momentums=None,
+ num_frames_retain=10))
+dataset_type = 'MOTChallengeDataset'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+train_pipeline = [
+ dict(type='LoadMultiImagesFromFile', to_float32=True),
+ dict(type='SeqLoadAnnotations', with_bbox=True, with_track=True),
+ dict(
+ type='SeqResize',
+ img_scale=(1088, 1088),
+ share_params=True,
+ ratio_range=(0.8, 1.2),
+ keep_ratio=True,
+ bbox_clip_border=False),
+ dict(type='SeqPhotoMetricDistortion', share_params=True),
+ dict(
+ type='SeqRandomCrop',
+ share_params=False,
+ crop_size=(1088, 1088),
+ bbox_clip_border=False),
+ dict(type='SeqRandomFlip', share_params=True, flip_ratio=0.5),
+ dict(
+ type='SeqNormalize',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True),
+ dict(type='SeqPad', size_divisor=32),
+ dict(type='MatchInstances', skip_nomatch=True),
+ dict(
+ type='VideoCollect',
+ keys=[
+ 'img', 'gt_bboxes', 'gt_labels', 'gt_match_indices',
+ 'gt_instance_ids'
+ ]),
+ dict(type='SeqDefaultFormatBundle', ref_prefix='ref')
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(1088, 1088),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(
+ type='Normalize',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True),
+ dict(type='Pad', size_divisor=32),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='VideoCollect', keys=['img'])
+ ])
+]
+data_root = 'data/MOT17/'
+data = dict(
+ samples_per_gpu=2,
+ workers_per_gpu=2,
+ train=dict(
+ type='MOTChallengeDataset',
+ visibility_thr=-1,
+ ann_file='data/MOT17/annotations/train_cocoformat.json',
+ img_prefix='data/MOT17/train',
+ ref_img_sampler=dict(
+ num_ref_imgs=1,
+ frame_range=10,
+ filter_key_img=True,
+ method='uniform'),
+ pipeline=[
+ dict(type='LoadMultiImagesFromFile', to_float32=True),
+ dict(type='SeqLoadAnnotations', with_bbox=True, with_track=True),
+ dict(
+ type='SeqResize',
+ img_scale=(1088, 1088),
+ share_params=True,
+ ratio_range=(0.8, 1.2),
+ keep_ratio=True,
+ bbox_clip_border=False),
+ dict(type='SeqPhotoMetricDistortion', share_params=True),
+ dict(
+ type='SeqRandomCrop',
+ share_params=False,
+ crop_size=(1088, 1088),
+ bbox_clip_border=False),
+ dict(type='SeqRandomFlip', share_params=True, flip_ratio=0.5),
+ dict(
+ type='SeqNormalize',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True),
+ dict(type='SeqPad', size_divisor=32),
+ dict(type='MatchInstances', skip_nomatch=True),
+ dict(
+ type='VideoCollect',
+ keys=[
+ 'img', 'gt_bboxes', 'gt_labels', 'gt_match_indices',
+ 'gt_instance_ids'
+ ]),
+ dict(type='SeqDefaultFormatBundle', ref_prefix='ref')
+ ]),
+ val=dict(
+ type='MOTChallengeDataset',
+ ann_file='data/MOT17/annotations/train_cocoformat.json',
+ img_prefix='data/MOT17/train',
+ ref_img_sampler=None,
+ pipeline=[
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(1088, 1088),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(
+ type='Normalize',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True),
+ dict(type='Pad', size_divisor=32),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='VideoCollect', keys=['img'])
+ ])
+ ]),
+ test=dict(
+ type='MOTChallengeDataset',
+ ann_file='data/MOT17/annotations/train_cocoformat.json',
+ img_prefix='data/MOT17/train',
+ ref_img_sampler=None,
+ pipeline=[
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(1088, 1088),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(
+ type='Normalize',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True),
+ dict(type='Pad', size_divisor=32),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='VideoCollect', keys=['img'])
+ ])
+ ]))
+optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
+optimizer_config = dict(grad_clip=None)
+checkpoint_config = dict(interval=1)
+log_config = dict(interval=50, hooks=[dict(type='TextLoggerHook')])
+dist_params = dict(backend='nccl')
+log_level = 'INFO'
+load_from = None
+resume_from = None
+workflow = [('train', 1)]
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=100,
+ warmup_ratio=0.01,
+ step=[3])
+total_epochs = 4
+evaluation = dict(metric=['bbox', 'track'], interval=1)
+search_metrics = ['MOTA', 'IDF1', 'FN', 'FP', 'IDs', 'MT', 'ML']
+test_set = 'train'
diff --git a/vendor/ViTPose/demo/resources/demo.mp4 b/vendor/ViTPose/demo/resources/demo.mp4
new file mode 100644
index 0000000000000000000000000000000000000000..2ba10c2a68726ccb398163e4505cfd190ec4dba1
Binary files /dev/null and b/vendor/ViTPose/demo/resources/demo.mp4 differ
diff --git a/vendor/ViTPose/demo/resources/sunglasses.jpg b/vendor/ViTPose/demo/resources/sunglasses.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..5d3cee870232cb35415e3ae71ea07e9fbb45dfdf
Binary files /dev/null and b/vendor/ViTPose/demo/resources/sunglasses.jpg differ
diff --git a/vendor/ViTPose/demo/top_down_img_demo.py b/vendor/ViTPose/demo/top_down_img_demo.py
new file mode 100644
index 0000000000000000000000000000000000000000..da1697814f02708475b6ee83fae8ea81360d9c4b
--- /dev/null
+++ b/vendor/ViTPose/demo/top_down_img_demo.py
@@ -0,0 +1,129 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import warnings
+from argparse import ArgumentParser
+
+from xtcocotools.coco import COCO
+
+from mmpose.apis import (inference_top_down_pose_model, init_pose_model,
+ vis_pose_result)
+from mmpose.datasets import DatasetInfo
+
+
+def main():
+ """Visualize the demo images.
+
+ Require the json_file containing boxes.
+ """
+ parser = ArgumentParser()
+ parser.add_argument('pose_config', help='Config file for detection')
+ parser.add_argument('pose_checkpoint', help='Checkpoint file')
+ parser.add_argument('--img-root', type=str, default='', help='Image root')
+ parser.add_argument(
+ '--json-file',
+ type=str,
+ default='',
+ help='Json file containing image info.')
+ parser.add_argument(
+ '--show',
+ action='store_true',
+ default=False,
+ help='whether to show img')
+ parser.add_argument(
+ '--out-img-root',
+ type=str,
+ default='',
+ help='Root of the output img file. '
+ 'Default not saving the visualization images.')
+ parser.add_argument(
+ '--device', default='cuda:0', help='Device used for inference')
+ parser.add_argument(
+ '--kpt-thr', type=float, default=0.3, help='Keypoint score threshold')
+ parser.add_argument(
+ '--radius',
+ type=int,
+ default=4,
+ help='Keypoint radius for visualization')
+ parser.add_argument(
+ '--thickness',
+ type=int,
+ default=1,
+ help='Link thickness for visualization')
+
+ args = parser.parse_args()
+
+ assert args.show or (args.out_img_root != '')
+
+ coco = COCO(args.json_file)
+ # build the pose model from a config file and a checkpoint file
+ pose_model = init_pose_model(
+ args.pose_config, args.pose_checkpoint, device=args.device.lower())
+
+ dataset = pose_model.cfg.data['test']['type']
+ dataset_info = pose_model.cfg.data['test'].get('dataset_info', None)
+ if dataset_info is None:
+ warnings.warn(
+ 'Please set `dataset_info` in the config.'
+ 'Check https://github.com/open-mmlab/mmpose/pull/663 for details.',
+ DeprecationWarning)
+ else:
+ dataset_info = DatasetInfo(dataset_info)
+
+ img_keys = list(coco.imgs.keys())
+
+ # optional
+ return_heatmap = False
+
+ # e.g. use ('backbone', ) to return backbone feature
+ output_layer_names = None
+
+ # process each image
+ for i in range(len(img_keys)):
+ # get bounding box annotations
+ image_id = img_keys[i]
+ image = coco.loadImgs(image_id)[0]
+ image_name = os.path.join(args.img_root, image['file_name'])
+ ann_ids = coco.getAnnIds(image_id)
+
+ # make person bounding boxes
+ person_results = []
+ for ann_id in ann_ids:
+ person = {}
+ ann = coco.anns[ann_id]
+ # bbox format is 'xywh'
+ person['bbox'] = ann['bbox']
+ person_results.append(person)
+
+ # test a single image, with a list of bboxes
+ pose_results, returned_outputs = inference_top_down_pose_model(
+ pose_model,
+ image_name,
+ person_results,
+ bbox_thr=None,
+ format='xywh',
+ dataset=dataset,
+ dataset_info=dataset_info,
+ return_heatmap=return_heatmap,
+ outputs=output_layer_names)
+
+ if args.out_img_root == '':
+ out_file = None
+ else:
+ os.makedirs(args.out_img_root, exist_ok=True)
+ out_file = os.path.join(args.out_img_root, f'vis_{i}.jpg')
+
+ vis_pose_result(
+ pose_model,
+ image_name,
+ pose_results,
+ dataset=dataset,
+ dataset_info=dataset_info,
+ kpt_score_thr=args.kpt_thr,
+ radius=args.radius,
+ thickness=args.thickness,
+ show=args.show,
+ out_file=out_file)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/vendor/ViTPose/demo/top_down_img_demo_with_mmdet.py b/vendor/ViTPose/demo/top_down_img_demo_with_mmdet.py
new file mode 100644
index 0000000000000000000000000000000000000000..227f44b2cfdcaa66e60ed2e1a13074bc292a1893
--- /dev/null
+++ b/vendor/ViTPose/demo/top_down_img_demo_with_mmdet.py
@@ -0,0 +1,138 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import warnings
+from argparse import ArgumentParser
+
+from mmpose.apis import (inference_top_down_pose_model, init_pose_model,
+ process_mmdet_results, vis_pose_result)
+from mmpose.datasets import DatasetInfo
+
+try:
+ from mmdet.apis import inference_detector, init_detector
+ has_mmdet = True
+except (ImportError, ModuleNotFoundError):
+ has_mmdet = False
+
+
+def main():
+ """Visualize the demo images.
+
+ Using mmdet to detect the human.
+ """
+ parser = ArgumentParser()
+ parser.add_argument('det_config', help='Config file for detection')
+ parser.add_argument('det_checkpoint', help='Checkpoint file for detection')
+ parser.add_argument('pose_config', help='Config file for pose')
+ parser.add_argument('pose_checkpoint', help='Checkpoint file for pose')
+ parser.add_argument('--img-root', type=str, default='', help='Image root')
+ parser.add_argument('--img', type=str, default='', help='Image file')
+ parser.add_argument(
+ '--show',
+ action='store_true',
+ default=False,
+ help='whether to show img')
+ parser.add_argument(
+ '--out-img-root',
+ type=str,
+ default='',
+ help='root of the output img file. '
+ 'Default not saving the visualization images.')
+ parser.add_argument(
+ '--device', default='cuda:0', help='Device used for inference')
+ parser.add_argument(
+ '--det-cat-id',
+ type=int,
+ default=1,
+ help='Category id for bounding box detection model')
+ parser.add_argument(
+ '--bbox-thr',
+ type=float,
+ default=0.3,
+ help='Bounding box score threshold')
+ parser.add_argument(
+ '--kpt-thr', type=float, default=0.3, help='Keypoint score threshold')
+ parser.add_argument(
+ '--radius',
+ type=int,
+ default=4,
+ help='Keypoint radius for visualization')
+ parser.add_argument(
+ '--thickness',
+ type=int,
+ default=1,
+ help='Link thickness for visualization')
+
+ assert has_mmdet, 'Please install mmdet to run the demo.'
+
+ args = parser.parse_args()
+
+ assert args.show or (args.out_img_root != '')
+ assert args.img != ''
+ assert args.det_config is not None
+ assert args.det_checkpoint is not None
+
+ det_model = init_detector(
+ args.det_config, args.det_checkpoint, device=args.device.lower())
+ # build the pose model from a config file and a checkpoint file
+ pose_model = init_pose_model(
+ args.pose_config, args.pose_checkpoint, device=args.device.lower())
+
+ dataset = pose_model.cfg.data['test']['type']
+ dataset_info = pose_model.cfg.data['test'].get('dataset_info', None)
+ if dataset_info is None:
+ warnings.warn(
+ 'Please set `dataset_info` in the config.'
+ 'Check https://github.com/open-mmlab/mmpose/pull/663 for details.',
+ DeprecationWarning)
+ else:
+ dataset_info = DatasetInfo(dataset_info)
+
+ image_name = os.path.join(args.img_root, args.img)
+
+ # test a single image, the resulting box is (x1, y1, x2, y2)
+ mmdet_results = inference_detector(det_model, image_name)
+
+ # keep the person class bounding boxes.
+ person_results = process_mmdet_results(mmdet_results, args.det_cat_id)
+
+ # test a single image, with a list of bboxes.
+
+ # optional
+ return_heatmap = False
+
+ # e.g. use ('backbone', ) to return backbone feature
+ output_layer_names = None
+
+ pose_results, returned_outputs = inference_top_down_pose_model(
+ pose_model,
+ image_name,
+ person_results,
+ bbox_thr=args.bbox_thr,
+ format='xyxy',
+ dataset=dataset,
+ dataset_info=dataset_info,
+ return_heatmap=return_heatmap,
+ outputs=output_layer_names)
+
+ if args.out_img_root == '':
+ out_file = None
+ else:
+ os.makedirs(args.out_img_root, exist_ok=True)
+ out_file = os.path.join(args.out_img_root, f'vis_{args.img}')
+
+ # show the results
+ vis_pose_result(
+ pose_model,
+ image_name,
+ pose_results,
+ dataset=dataset,
+ dataset_info=dataset_info,
+ kpt_score_thr=args.kpt_thr,
+ radius=args.radius,
+ thickness=args.thickness,
+ show=args.show,
+ out_file=out_file)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/vendor/ViTPose/demo/top_down_pose_tracking_demo_with_mmdet.py b/vendor/ViTPose/demo/top_down_pose_tracking_demo_with_mmdet.py
new file mode 100644
index 0000000000000000000000000000000000000000..5ddcd934ee3cc28d627d7620186512175391a96f
--- /dev/null
+++ b/vendor/ViTPose/demo/top_down_pose_tracking_demo_with_mmdet.py
@@ -0,0 +1,190 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import warnings
+from argparse import ArgumentParser
+
+import cv2
+
+from mmpose.apis import (get_track_id, inference_top_down_pose_model,
+ init_pose_model, process_mmdet_results,
+ vis_pose_tracking_result)
+from mmpose.datasets import DatasetInfo
+
+try:
+ from mmdet.apis import inference_detector, init_detector
+ has_mmdet = True
+except (ImportError, ModuleNotFoundError):
+ has_mmdet = False
+
+
+def main():
+ """Visualize the demo images.
+
+ Using mmdet to detect the human.
+ """
+ parser = ArgumentParser()
+ parser.add_argument('det_config', help='Config file for detection')
+ parser.add_argument('det_checkpoint', help='Checkpoint file for detection')
+ parser.add_argument('pose_config', help='Config file for pose')
+ parser.add_argument('pose_checkpoint', help='Checkpoint file for pose')
+ parser.add_argument('--video-path', type=str, help='Video path')
+ parser.add_argument(
+ '--show',
+ action='store_true',
+ default=False,
+ help='whether to show visualizations.')
+ parser.add_argument(
+ '--out-video-root',
+ default='',
+ help='Root of the output video file. '
+ 'Default not saving the visualization video.')
+ parser.add_argument(
+ '--device', default='cuda:0', help='Device used for inference')
+ parser.add_argument(
+ '--det-cat-id',
+ type=int,
+ default=1,
+ help='Category id for bounding box detection model')
+ parser.add_argument(
+ '--bbox-thr',
+ type=float,
+ default=0.3,
+ help='Bounding box score threshold')
+ parser.add_argument(
+ '--kpt-thr', type=float, default=0.3, help='Keypoint score threshold')
+ parser.add_argument(
+ '--use-oks-tracking', action='store_true', help='Using OKS tracking')
+ parser.add_argument(
+ '--tracking-thr', type=float, default=0.3, help='Tracking threshold')
+ parser.add_argument(
+ '--euro',
+ action='store_true',
+ help='Using One_Euro_Filter for smoothing')
+ parser.add_argument(
+ '--radius',
+ type=int,
+ default=4,
+ help='Keypoint radius for visualization')
+ parser.add_argument(
+ '--thickness',
+ type=int,
+ default=1,
+ help='Link thickness for visualization')
+
+ assert has_mmdet, 'Please install mmdet to run the demo.'
+
+ args = parser.parse_args()
+
+ assert args.show or (args.out_video_root != '')
+ assert args.det_config is not None
+ assert args.det_checkpoint is not None
+
+ det_model = init_detector(
+ args.det_config, args.det_checkpoint, device=args.device.lower())
+ # build the pose model from a config file and a checkpoint file
+ pose_model = init_pose_model(
+ args.pose_config, args.pose_checkpoint, device=args.device.lower())
+
+ dataset = pose_model.cfg.data['test']['type']
+ dataset_info = pose_model.cfg.data['test'].get('dataset_info', None)
+ if dataset_info is None:
+ warnings.warn(
+ 'Please set `dataset_info` in the config.'
+ 'Check https://github.com/open-mmlab/mmpose/pull/663 for details.',
+ DeprecationWarning)
+ else:
+ dataset_info = DatasetInfo(dataset_info)
+
+ cap = cv2.VideoCapture(args.video_path)
+ fps = None
+
+ assert cap.isOpened(), f'Faild to load video file {args.video_path}'
+
+ if args.out_video_root == '':
+ save_out_video = False
+ else:
+ os.makedirs(args.out_video_root, exist_ok=True)
+ save_out_video = True
+
+ if save_out_video:
+ fps = cap.get(cv2.CAP_PROP_FPS)
+ size = (int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)),
+ int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
+ fourcc = cv2.VideoWriter_fourcc(*'mp4v')
+ videoWriter = cv2.VideoWriter(
+ os.path.join(args.out_video_root,
+ f'vis_{os.path.basename(args.video_path)}'), fourcc,
+ fps, size)
+
+ # optional
+ return_heatmap = False
+
+ # e.g. use ('backbone', ) to return backbone feature
+ output_layer_names = None
+
+ next_id = 0
+ pose_results = []
+ while (cap.isOpened()):
+ pose_results_last = pose_results
+
+ flag, img = cap.read()
+ if not flag:
+ break
+ # test a single image, the resulting box is (x1, y1, x2, y2)
+ mmdet_results = inference_detector(det_model, img)
+
+ # keep the person class bounding boxes.
+ person_results = process_mmdet_results(mmdet_results, args.det_cat_id)
+
+ # test a single image, with a list of bboxes.
+ pose_results, returned_outputs = inference_top_down_pose_model(
+ pose_model,
+ img,
+ person_results,
+ bbox_thr=args.bbox_thr,
+ format='xyxy',
+ dataset=dataset,
+ dataset_info=dataset_info,
+ return_heatmap=return_heatmap,
+ outputs=output_layer_names)
+
+ # get track id for each person instance
+ pose_results, next_id = get_track_id(
+ pose_results,
+ pose_results_last,
+ next_id,
+ use_oks=args.use_oks_tracking,
+ tracking_thr=args.tracking_thr,
+ use_one_euro=args.euro,
+ fps=fps)
+
+ # show the results
+ vis_img = vis_pose_tracking_result(
+ pose_model,
+ img,
+ pose_results,
+ radius=args.radius,
+ thickness=args.thickness,
+ dataset=dataset,
+ dataset_info=dataset_info,
+ kpt_score_thr=args.kpt_thr,
+ show=False)
+
+ if args.show:
+ cv2.imshow('Image', vis_img)
+
+ if save_out_video:
+ videoWriter.write(vis_img)
+
+ if args.show and cv2.waitKey(1) & 0xFF == ord('q'):
+ break
+
+ cap.release()
+ if save_out_video:
+ videoWriter.release()
+ if args.show:
+ cv2.destroyAllWindows()
+
+
+if __name__ == '__main__':
+ main()
diff --git a/vendor/ViTPose/demo/top_down_pose_tracking_demo_with_mmtracking.py b/vendor/ViTPose/demo/top_down_pose_tracking_demo_with_mmtracking.py
new file mode 100644
index 0000000000000000000000000000000000000000..9902e0674ecd070ba96e86a6672420cfe8ebbedf
--- /dev/null
+++ b/vendor/ViTPose/demo/top_down_pose_tracking_demo_with_mmtracking.py
@@ -0,0 +1,185 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import warnings
+from argparse import ArgumentParser
+
+import cv2
+
+from mmpose.apis import (inference_top_down_pose_model, init_pose_model,
+ vis_pose_tracking_result)
+from mmpose.datasets import DatasetInfo
+
+try:
+ from mmtrack.apis import inference_mot
+ from mmtrack.apis import init_model as init_tracking_model
+ has_mmtrack = True
+except (ImportError, ModuleNotFoundError):
+ has_mmtrack = False
+
+
+def process_mmtracking_results(mmtracking_results):
+ """Process mmtracking results.
+
+ :param mmtracking_results:
+ :return: a list of tracked bounding boxes
+ """
+ person_results = []
+ # 'track_results' is changed to 'track_bboxes'
+ # in https://github.com/open-mmlab/mmtracking/pull/300
+ if 'track_bboxes' in mmtracking_results:
+ tracking_results = mmtracking_results['track_bboxes'][0]
+ elif 'track_results' in mmtracking_results:
+ tracking_results = mmtracking_results['track_results'][0]
+
+ for track in tracking_results:
+ person = {}
+ person['track_id'] = int(track[0])
+ person['bbox'] = track[1:]
+ person_results.append(person)
+ return person_results
+
+
+def main():
+ """Visualize the demo images.
+
+ Using mmdet to detect the human.
+ """
+ parser = ArgumentParser()
+ parser.add_argument('tracking_config', help='Config file for tracking')
+ parser.add_argument('pose_config', help='Config file for pose')
+ parser.add_argument('pose_checkpoint', help='Checkpoint file for pose')
+ parser.add_argument('--video-path', type=str, help='Video path')
+ parser.add_argument(
+ '--show',
+ action='store_true',
+ default=False,
+ help='whether to show visualizations.')
+ parser.add_argument(
+ '--out-video-root',
+ default='',
+ help='Root of the output video file. '
+ 'Default not saving the visualization video.')
+ parser.add_argument(
+ '--device', default='cuda:0', help='Device used for inference')
+ parser.add_argument(
+ '--bbox-thr',
+ type=float,
+ default=0.3,
+ help='Bounding box score threshold')
+ parser.add_argument(
+ '--kpt-thr', type=float, default=0.3, help='Keypoint score threshold')
+ parser.add_argument(
+ '--radius',
+ type=int,
+ default=4,
+ help='Keypoint radius for visualization')
+ parser.add_argument(
+ '--thickness',
+ type=int,
+ default=1,
+ help='Link thickness for visualization')
+
+ assert has_mmtrack, 'Please install mmtrack to run the demo.'
+
+ args = parser.parse_args()
+
+ assert args.show or (args.out_video_root != '')
+ assert args.tracking_config is not None
+
+ tracking_model = init_tracking_model(
+ args.tracking_config, None, device=args.device.lower())
+ # build the pose model from a config file and a checkpoint file
+ pose_model = init_pose_model(
+ args.pose_config, args.pose_checkpoint, device=args.device.lower())
+
+ dataset = pose_model.cfg.data['test']['type']
+ dataset_info = pose_model.cfg.data['test'].get('dataset_info', None)
+ if dataset_info is None:
+ warnings.warn(
+ 'Please set `dataset_info` in the config.'
+ 'Check https://github.com/open-mmlab/mmpose/pull/663 for details.',
+ DeprecationWarning)
+ else:
+ dataset_info = DatasetInfo(dataset_info)
+
+ cap = cv2.VideoCapture(args.video_path)
+ assert cap.isOpened(), f'Faild to load video file {args.video_path}'
+
+ if args.out_video_root == '':
+ save_out_video = False
+ else:
+ os.makedirs(args.out_video_root, exist_ok=True)
+ save_out_video = True
+
+ if save_out_video:
+ fps = cap.get(cv2.CAP_PROP_FPS)
+ size = (int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)),
+ int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
+ fourcc = cv2.VideoWriter_fourcc(*'mp4v')
+ videoWriter = cv2.VideoWriter(
+ os.path.join(args.out_video_root,
+ f'vis_{os.path.basename(args.video_path)}'), fourcc,
+ fps, size)
+
+ # optional
+ return_heatmap = False
+
+ # e.g. use ('backbone', ) to return backbone feature
+ output_layer_names = None
+
+ frame_id = 0
+ while (cap.isOpened()):
+ flag, img = cap.read()
+ if not flag:
+ break
+
+ mmtracking_results = inference_mot(
+ tracking_model, img, frame_id=frame_id)
+
+ # keep the person class bounding boxes.
+ person_results = process_mmtracking_results(mmtracking_results)
+
+ # test a single image, with a list of bboxes.
+ pose_results, returned_outputs = inference_top_down_pose_model(
+ pose_model,
+ img,
+ person_results,
+ bbox_thr=args.bbox_thr,
+ format='xyxy',
+ dataset=dataset,
+ dataset_info=dataset_info,
+ return_heatmap=return_heatmap,
+ outputs=output_layer_names)
+
+ # show the results
+ vis_img = vis_pose_tracking_result(
+ pose_model,
+ img,
+ pose_results,
+ radius=args.radius,
+ thickness=args.thickness,
+ dataset=dataset,
+ dataset_info=dataset_info,
+ kpt_score_thr=args.kpt_thr,
+ show=False)
+
+ if args.show:
+ cv2.imshow('Image', vis_img)
+
+ if save_out_video:
+ videoWriter.write(vis_img)
+
+ if args.show and cv2.waitKey(1) & 0xFF == ord('q'):
+ break
+
+ frame_id += 1
+
+ cap.release()
+ if save_out_video:
+ videoWriter.release()
+ if args.show:
+ cv2.destroyAllWindows()
+
+
+if __name__ == '__main__':
+ main()
diff --git a/vendor/ViTPose/demo/top_down_video_demo_full_frame_without_det.py b/vendor/ViTPose/demo/top_down_video_demo_full_frame_without_det.py
new file mode 100644
index 0000000000000000000000000000000000000000..2d81810899578c504330c2bda6163cd4496e78b2
--- /dev/null
+++ b/vendor/ViTPose/demo/top_down_video_demo_full_frame_without_det.py
@@ -0,0 +1,139 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import warnings
+from argparse import ArgumentParser
+
+import cv2
+import numpy as np
+
+from mmpose.apis import (inference_top_down_pose_model, init_pose_model,
+ vis_pose_result)
+from mmpose.datasets import DatasetInfo
+
+
+def main():
+ """Visualize the demo images.
+
+ Using mmdet to detect the human.
+ """
+ parser = ArgumentParser()
+ parser.add_argument('pose_config', help='Config file for pose')
+ parser.add_argument('pose_checkpoint', help='Checkpoint file for pose')
+ parser.add_argument('--video-path', type=str, help='Video path')
+ parser.add_argument(
+ '--show',
+ action='store_true',
+ default=False,
+ help='whether to show visualizations.')
+ parser.add_argument(
+ '--out-video-root',
+ default='',
+ help='Root of the output video file. '
+ 'Default not saving the visualization video.')
+ parser.add_argument(
+ '--device', default='cuda:0', help='Device used for inference')
+ parser.add_argument(
+ '--kpt-thr', type=float, default=0.3, help='Keypoint score threshold')
+ parser.add_argument(
+ '--radius',
+ type=int,
+ default=4,
+ help='Keypoint radius for visualization')
+ parser.add_argument(
+ '--thickness',
+ type=int,
+ default=1,
+ help='Link thickness for visualization')
+
+ args = parser.parse_args()
+
+ assert args.show or (args.out_video_root != '')
+ # build the pose model from a config file and a checkpoint file
+ pose_model = init_pose_model(
+ args.pose_config, args.pose_checkpoint, device=args.device.lower())
+
+ dataset = pose_model.cfg.data['test']['type']
+ dataset_info = pose_model.cfg.data['test'].get('dataset_info', None)
+ if dataset_info is None:
+ warnings.warn(
+ 'Please set `dataset_info` in the config.'
+ 'Check https://github.com/open-mmlab/mmpose/pull/663 for details.',
+ DeprecationWarning)
+ else:
+ dataset_info = DatasetInfo(dataset_info)
+
+ cap = cv2.VideoCapture(args.video_path)
+ assert cap.isOpened(), f'Faild to load video file {args.video_path}'
+
+ fps = cap.get(cv2.CAP_PROP_FPS)
+ size = (int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)),
+ int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
+
+ if args.out_video_root == '':
+ save_out_video = False
+ else:
+ os.makedirs(args.out_video_root, exist_ok=True)
+ save_out_video = True
+
+ if save_out_video:
+ fourcc = cv2.VideoWriter_fourcc(*'mp4v')
+ videoWriter = cv2.VideoWriter(
+ os.path.join(args.out_video_root,
+ f'vis_{os.path.basename(args.video_path)}'), fourcc,
+ fps, size)
+
+ # optional
+ return_heatmap = False
+
+ # e.g. use ('backbone', ) to return backbone feature
+ output_layer_names = None
+
+ while (cap.isOpened()):
+ flag, img = cap.read()
+ if not flag:
+ break
+
+ # keep the person class bounding boxes.
+ person_results = [{'bbox': np.array([0, 0, size[0], size[1]])}]
+
+ # test a single image, with a list of bboxes.
+ pose_results, returned_outputs = inference_top_down_pose_model(
+ pose_model,
+ img,
+ person_results,
+ format='xyxy',
+ dataset=dataset,
+ dataset_info=dataset_info,
+ return_heatmap=return_heatmap,
+ outputs=output_layer_names)
+
+ # show the results
+ vis_img = vis_pose_result(
+ pose_model,
+ img,
+ pose_results,
+ radius=args.radius,
+ thickness=args.thickness,
+ dataset=dataset,
+ dataset_info=dataset_info,
+ kpt_score_thr=args.kpt_thr,
+ show=False)
+
+ if args.show:
+ cv2.imshow('Image', vis_img)
+
+ if save_out_video:
+ videoWriter.write(vis_img)
+
+ if args.show and cv2.waitKey(1) & 0xFF == ord('q'):
+ break
+
+ cap.release()
+ if save_out_video:
+ videoWriter.release()
+ if args.show:
+ cv2.destroyAllWindows()
+
+
+if __name__ == '__main__':
+ main()
diff --git a/vendor/ViTPose/demo/top_down_video_demo_with_mmdet.py b/vendor/ViTPose/demo/top_down_video_demo_with_mmdet.py
new file mode 100644
index 0000000000000000000000000000000000000000..8ba32322cd7941ef21b14545656fc72a077b5e71
--- /dev/null
+++ b/vendor/ViTPose/demo/top_down_video_demo_with_mmdet.py
@@ -0,0 +1,165 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import warnings
+from argparse import ArgumentParser
+
+import cv2
+
+from mmpose.apis import (inference_top_down_pose_model, init_pose_model,
+ process_mmdet_results, vis_pose_result)
+from mmpose.datasets import DatasetInfo
+
+try:
+ from mmdet.apis import inference_detector, init_detector
+ has_mmdet = True
+except (ImportError, ModuleNotFoundError):
+ has_mmdet = False
+
+
+def main():
+ """Visualize the demo images.
+
+ Using mmdet to detect the human.
+ """
+ parser = ArgumentParser()
+ parser.add_argument('det_config', help='Config file for detection')
+ parser.add_argument('det_checkpoint', help='Checkpoint file for detection')
+ parser.add_argument('pose_config', help='Config file for pose')
+ parser.add_argument('pose_checkpoint', help='Checkpoint file for pose')
+ parser.add_argument('--video-path', type=str, help='Video path')
+ parser.add_argument(
+ '--show',
+ action='store_true',
+ default=False,
+ help='whether to show visualizations.')
+ parser.add_argument(
+ '--out-video-root',
+ default='',
+ help='Root of the output video file. '
+ 'Default not saving the visualization video.')
+ parser.add_argument(
+ '--device', default='cuda:0', help='Device used for inference')
+ parser.add_argument(
+ '--det-cat-id',
+ type=int,
+ default=1,
+ help='Category id for bounding box detection model')
+ parser.add_argument(
+ '--bbox-thr',
+ type=float,
+ default=0.3,
+ help='Bounding box score threshold')
+ parser.add_argument(
+ '--kpt-thr', type=float, default=0.3, help='Keypoint score threshold')
+ parser.add_argument(
+ '--radius',
+ type=int,
+ default=4,
+ help='Keypoint radius for visualization')
+ parser.add_argument(
+ '--thickness',
+ type=int,
+ default=1,
+ help='Link thickness for visualization')
+
+ assert has_mmdet, 'Please install mmdet to run the demo.'
+
+ args = parser.parse_args()
+
+ assert args.show or (args.out_video_root != '')
+ assert args.det_config is not None
+ assert args.det_checkpoint is not None
+
+ det_model = init_detector(
+ args.det_config, args.det_checkpoint, device=args.device.lower())
+ # build the pose model from a config file and a checkpoint file
+ pose_model = init_pose_model(
+ args.pose_config, args.pose_checkpoint, device=args.device.lower())
+
+ dataset = pose_model.cfg.data['test']['type']
+ dataset_info = pose_model.cfg.data['test'].get('dataset_info', None)
+ if dataset_info is None:
+ warnings.warn(
+ 'Please set `dataset_info` in the config.'
+ 'Check https://github.com/open-mmlab/mmpose/pull/663 for details.',
+ DeprecationWarning)
+ else:
+ dataset_info = DatasetInfo(dataset_info)
+
+ cap = cv2.VideoCapture(args.video_path)
+ assert cap.isOpened(), f'Faild to load video file {args.video_path}'
+
+ if args.out_video_root == '':
+ save_out_video = False
+ else:
+ os.makedirs(args.out_video_root, exist_ok=True)
+ save_out_video = True
+
+ if save_out_video:
+ fps = cap.get(cv2.CAP_PROP_FPS)
+ size = (int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)),
+ int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
+ fourcc = cv2.VideoWriter_fourcc(*'mp4v')
+ videoWriter = cv2.VideoWriter(
+ os.path.join(args.out_video_root,
+ f'vis_{os.path.basename(args.video_path)}'), fourcc,
+ fps, size)
+
+ # optional
+ return_heatmap = False
+
+ # e.g. use ('backbone', ) to return backbone feature
+ output_layer_names = None
+
+ while (cap.isOpened()):
+ flag, img = cap.read()
+ if not flag:
+ break
+ # test a single image, the resulting box is (x1, y1, x2, y2)
+ mmdet_results = inference_detector(det_model, img)
+
+ # keep the person class bounding boxes.
+ person_results = process_mmdet_results(mmdet_results, args.det_cat_id)
+
+ # test a single image, with a list of bboxes.
+ pose_results, returned_outputs = inference_top_down_pose_model(
+ pose_model,
+ img,
+ person_results,
+ bbox_thr=args.bbox_thr,
+ format='xyxy',
+ dataset=dataset,
+ dataset_info=dataset_info,
+ return_heatmap=return_heatmap,
+ outputs=output_layer_names)
+
+ # show the results
+ vis_img = vis_pose_result(
+ pose_model,
+ img,
+ pose_results,
+ dataset=dataset,
+ dataset_info=dataset_info,
+ kpt_score_thr=args.kpt_thr,
+ radius=args.radius,
+ thickness=args.thickness,
+ show=False)
+
+ if args.show:
+ cv2.imshow('Image', vis_img)
+
+ if save_out_video:
+ videoWriter.write(vis_img)
+
+ if args.show and cv2.waitKey(1) & 0xFF == ord('q'):
+ break
+
+ cap.release()
+ if save_out_video:
+ videoWriter.release()
+ if args.show:
+ cv2.destroyAllWindows()
+
+
+if __name__ == '__main__':
+ main()
diff --git a/vendor/ViTPose/demo/webcam_demo.py b/vendor/ViTPose/demo/webcam_demo.py
new file mode 100644
index 0000000000000000000000000000000000000000..bff300121d8d3e5d1cbfaa445dbb6dbd50ad1c20
--- /dev/null
+++ b/vendor/ViTPose/demo/webcam_demo.py
@@ -0,0 +1,585 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import time
+from collections import deque
+from queue import Queue
+from threading import Event, Lock, Thread
+
+import cv2
+import numpy as np
+
+from mmpose.apis import (get_track_id, inference_top_down_pose_model,
+ init_pose_model, vis_pose_result)
+from mmpose.core import apply_bugeye_effect, apply_sunglasses_effect
+from mmpose.utils import StopWatch
+
+try:
+ from mmdet.apis import inference_detector, init_detector
+ has_mmdet = True
+except (ImportError, ModuleNotFoundError):
+ has_mmdet = False
+
+try:
+ import psutil
+ psutil_proc = psutil.Process()
+except (ImportError, ModuleNotFoundError):
+ psutil_proc = None
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--cam-id', type=str, default='0')
+ parser.add_argument(
+ '--det-config',
+ type=str,
+ default='demo/mmdetection_cfg/'
+ 'ssdlite_mobilenetv2_scratch_600e_coco.py',
+ help='Config file for detection')
+ parser.add_argument(
+ '--det-checkpoint',
+ type=str,
+ default='https://download.openmmlab.com/mmdetection/v2.0/ssd/'
+ 'ssdlite_mobilenetv2_scratch_600e_coco/ssdlite_mobilenetv2_'
+ 'scratch_600e_coco_20210629_110627-974d9307.pth',
+ help='Checkpoint file for detection')
+ parser.add_argument(
+ '--enable-human-pose',
+ type=int,
+ default=1,
+ help='Enable human pose estimation')
+ parser.add_argument(
+ '--enable-animal-pose',
+ type=int,
+ default=0,
+ help='Enable animal pose estimation')
+ parser.add_argument(
+ '--human-pose-config',
+ type=str,
+ default='configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/'
+ 'coco-wholebody/vipnas_res50_coco_wholebody_256x192_dark.py',
+ help='Config file for human pose')
+ parser.add_argument(
+ '--human-pose-checkpoint',
+ type=str,
+ default='https://download.openmmlab.com/'
+ 'mmpose/top_down/vipnas/'
+ 'vipnas_res50_wholebody_256x192_dark-67c0ce35_20211112.pth',
+ help='Checkpoint file for human pose')
+ parser.add_argument(
+ '--human-det-ids',
+ type=int,
+ default=[1],
+ nargs='+',
+ help='Object category label of human in detection results.'
+ 'Default is [1(person)], following COCO definition.')
+ parser.add_argument(
+ '--animal-pose-config',
+ type=str,
+ default='configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/'
+ 'animalpose/hrnet_w32_animalpose_256x256.py',
+ help='Config file for animal pose')
+ parser.add_argument(
+ '--animal-pose-checkpoint',
+ type=str,
+ default='https://download.openmmlab.com/mmpose/animal/hrnet/'
+ 'hrnet_w32_animalpose_256x256-1aa7f075_20210426.pth',
+ help='Checkpoint file for animal pose')
+ parser.add_argument(
+ '--animal-det-ids',
+ type=int,
+ default=[16, 17, 18, 19, 20],
+ nargs='+',
+ help='Object category label of animals in detection results'
+ 'Default is [16(cat), 17(dog), 18(horse), 19(sheep), 20(cow)], '
+ 'following COCO definition.')
+ parser.add_argument(
+ '--device', default='cuda:0', help='Device used for inference')
+ parser.add_argument(
+ '--det-score-thr',
+ type=float,
+ default=0.5,
+ help='bbox score threshold')
+ parser.add_argument(
+ '--kpt-thr', type=float, default=0.3, help='bbox score threshold')
+ parser.add_argument(
+ '--vis-mode',
+ type=int,
+ default=2,
+ help='0-none. 1-detection only. 2-detection and pose.')
+ parser.add_argument(
+ '--sunglasses', action='store_true', help='Apply `sunglasses` effect.')
+ parser.add_argument(
+ '--bugeye', action='store_true', help='Apply `bug-eye` effect.')
+
+ parser.add_argument(
+ '--out-video-file',
+ type=str,
+ default=None,
+ help='Record the video into a file. This may reduce the frame rate')
+
+ parser.add_argument(
+ '--out-video-fps',
+ type=int,
+ default=20,
+ help='Set the FPS of the output video file.')
+
+ parser.add_argument(
+ '--buffer-size',
+ type=int,
+ default=-1,
+ help='Frame buffer size. If set -1, the buffer size will be '
+ 'automatically inferred from the display delay time. Default: -1')
+
+ parser.add_argument(
+ '--inference-fps',
+ type=int,
+ default=10,
+ help='Maximum inference FPS. This is to limit the resource consuming '
+ 'especially when the detection and pose model are lightweight and '
+ 'very fast. Default: 10.')
+
+ parser.add_argument(
+ '--display-delay',
+ type=int,
+ default=0,
+ help='Delay the output video in milliseconds. This can be used to '
+ 'align the output video and inference results. The delay can be '
+ 'disabled by setting a non-positive delay time. Default: 0')
+
+ parser.add_argument(
+ '--synchronous-mode',
+ action='store_true',
+ help='Enable synchronous mode that video I/O and inference will be '
+ 'temporally aligned. Note that this will reduce the display FPS.')
+
+ return parser.parse_args()
+
+
+def process_mmdet_results(mmdet_results, class_names=None, cat_ids=1):
+ """Process mmdet results to mmpose input format.
+
+ Args:
+ mmdet_results: raw output of mmdet model
+ class_names: class names of mmdet model
+ cat_ids (int or List[int]): category id list that will be preserved
+ Returns:
+ List[Dict]: detection results for mmpose input
+ """
+ if isinstance(mmdet_results, tuple):
+ mmdet_results = mmdet_results[0]
+
+ if not isinstance(cat_ids, (list, tuple)):
+ cat_ids = [cat_ids]
+
+ # only keep bboxes of interested classes
+ bbox_results = [mmdet_results[i - 1] for i in cat_ids]
+ bboxes = np.vstack(bbox_results)
+
+ # get textual labels of classes
+ labels = np.concatenate([
+ np.full(bbox.shape[0], i - 1, dtype=np.int32)
+ for i, bbox in zip(cat_ids, bbox_results)
+ ])
+ if class_names is None:
+ labels = [f'class: {i}' for i in labels]
+ else:
+ labels = [class_names[i] for i in labels]
+
+ det_results = []
+ for bbox, label in zip(bboxes, labels):
+ det_result = dict(bbox=bbox, label=label)
+ det_results.append(det_result)
+ return det_results
+
+
+def read_camera():
+ # init video reader
+ print('Thread "input" started')
+ cam_id = args.cam_id
+ if cam_id.isdigit():
+ cam_id = int(cam_id)
+ vid_cap = cv2.VideoCapture(cam_id)
+ if not vid_cap.isOpened():
+ print(f'Cannot open camera (ID={cam_id})')
+ exit()
+
+ while not event_exit.is_set():
+ # capture a camera frame
+ ret_val, frame = vid_cap.read()
+ if ret_val:
+ ts_input = time.time()
+
+ event_inference_done.clear()
+ with input_queue_mutex:
+ input_queue.append((ts_input, frame))
+
+ if args.synchronous_mode:
+ event_inference_done.wait()
+
+ frame_buffer.put((ts_input, frame))
+ else:
+ # input ending signal
+ frame_buffer.put((None, None))
+ break
+
+ vid_cap.release()
+
+
+def inference_detection():
+ print('Thread "det" started')
+ stop_watch = StopWatch(window=10)
+ min_interval = 1.0 / args.inference_fps
+ _ts_last = None # timestamp when last inference was done
+
+ while True:
+ while len(input_queue) < 1:
+ time.sleep(0.001)
+ with input_queue_mutex:
+ ts_input, frame = input_queue.popleft()
+ # inference detection
+ with stop_watch.timeit('Det'):
+ mmdet_results = inference_detector(det_model, frame)
+
+ t_info = stop_watch.report_strings()
+ with det_result_queue_mutex:
+ det_result_queue.append((ts_input, frame, t_info, mmdet_results))
+
+ # limit the inference FPS
+ _ts = time.time()
+ if _ts_last is not None and _ts - _ts_last < min_interval:
+ time.sleep(min_interval - _ts + _ts_last)
+ _ts_last = time.time()
+
+
+def inference_pose():
+ print('Thread "pose" started')
+ stop_watch = StopWatch(window=10)
+
+ while True:
+ while len(det_result_queue) < 1:
+ time.sleep(0.001)
+ with det_result_queue_mutex:
+ ts_input, frame, t_info, mmdet_results = det_result_queue.popleft()
+
+ pose_results_list = []
+ for model_info, pose_history in zip(pose_model_list,
+ pose_history_list):
+ model_name = model_info['name']
+ pose_model = model_info['model']
+ cat_ids = model_info['cat_ids']
+ pose_results_last = pose_history['pose_results_last']
+ next_id = pose_history['next_id']
+
+ with stop_watch.timeit(model_name):
+ # process mmdet results
+ det_results = process_mmdet_results(
+ mmdet_results,
+ class_names=det_model.CLASSES,
+ cat_ids=cat_ids)
+
+ # inference pose model
+ dataset_name = pose_model.cfg.data['test']['type']
+ pose_results, _ = inference_top_down_pose_model(
+ pose_model,
+ frame,
+ det_results,
+ bbox_thr=args.det_score_thr,
+ format='xyxy',
+ dataset=dataset_name)
+
+ pose_results, next_id = get_track_id(
+ pose_results,
+ pose_results_last,
+ next_id,
+ use_oks=False,
+ tracking_thr=0.3,
+ use_one_euro=True,
+ fps=None)
+
+ pose_results_list.append(pose_results)
+
+ # update pose history
+ pose_history['pose_results_last'] = pose_results
+ pose_history['next_id'] = next_id
+
+ t_info += stop_watch.report_strings()
+ with pose_result_queue_mutex:
+ pose_result_queue.append((ts_input, t_info, pose_results_list))
+
+ event_inference_done.set()
+
+
+def display():
+ print('Thread "display" started')
+ stop_watch = StopWatch(window=10)
+
+ # initialize result status
+ ts_inference = None # timestamp of the latest inference result
+ fps_inference = 0. # infenrece FPS
+ t_delay_inference = 0. # inference result time delay
+ pose_results_list = None # latest inference result
+ t_info = [] # upstream time information (list[str])
+
+ # initialize visualization and output
+ sunglasses_img = None # resource image for sunglasses effect
+ text_color = (228, 183, 61) # text color to show time/system information
+ vid_out = None # video writer
+
+ # show instructions
+ print('Keyboard shortcuts: ')
+ print('"v": Toggle the visualization of bounding boxes and poses.')
+ print('"s": Toggle the sunglasses effect.')
+ print('"b": Toggle the bug-eye effect.')
+ print('"Q", "q" or Esc: Exit.')
+
+ while True:
+ with stop_watch.timeit('_FPS_'):
+ # acquire a frame from buffer
+ ts_input, frame = frame_buffer.get()
+ # input ending signal
+ if ts_input is None:
+ break
+
+ img = frame
+
+ # get pose estimation results
+ if len(pose_result_queue) > 0:
+ with pose_result_queue_mutex:
+ _result = pose_result_queue.popleft()
+ _ts_input, t_info, pose_results_list = _result
+
+ _ts = time.time()
+ if ts_inference is not None:
+ fps_inference = 1.0 / (_ts - ts_inference)
+ ts_inference = _ts
+ t_delay_inference = (_ts - _ts_input) * 1000
+
+ # visualize detection and pose results
+ if pose_results_list is not None:
+ for model_info, pose_results in zip(pose_model_list,
+ pose_results_list):
+ pose_model = model_info['model']
+ bbox_color = model_info['bbox_color']
+
+ dataset_name = pose_model.cfg.data['test']['type']
+
+ # show pose results
+ if args.vis_mode == 1:
+ img = vis_pose_result(
+ pose_model,
+ img,
+ pose_results,
+ radius=4,
+ thickness=2,
+ dataset=dataset_name,
+ kpt_score_thr=1e7,
+ bbox_color=bbox_color)
+ elif args.vis_mode == 2:
+ img = vis_pose_result(
+ pose_model,
+ img,
+ pose_results,
+ radius=4,
+ thickness=2,
+ dataset=dataset_name,
+ kpt_score_thr=args.kpt_thr,
+ bbox_color=bbox_color)
+
+ # sunglasses effect
+ if args.sunglasses:
+ if dataset_name in {
+ 'TopDownCocoDataset',
+ 'TopDownCocoWholeBodyDataset'
+ }:
+ left_eye_idx = 1
+ right_eye_idx = 2
+ elif dataset_name == 'AnimalPoseDataset':
+ left_eye_idx = 0
+ right_eye_idx = 1
+ else:
+ raise ValueError(
+ 'Sunglasses effect does not support'
+ f'{dataset_name}')
+ if sunglasses_img is None:
+ # The image attributes to:
+ # https://www.vecteezy.com/free-vector/glass
+ # Glass Vectors by Vecteezy
+ sunglasses_img = cv2.imread(
+ 'demo/resources/sunglasses.jpg')
+ img = apply_sunglasses_effect(img, pose_results,
+ sunglasses_img,
+ left_eye_idx,
+ right_eye_idx)
+ # bug-eye effect
+ if args.bugeye:
+ if dataset_name in {
+ 'TopDownCocoDataset',
+ 'TopDownCocoWholeBodyDataset'
+ }:
+ left_eye_idx = 1
+ right_eye_idx = 2
+ elif dataset_name == 'AnimalPoseDataset':
+ left_eye_idx = 0
+ right_eye_idx = 1
+ else:
+ raise ValueError('Bug-eye effect does not support'
+ f'{dataset_name}')
+ img = apply_bugeye_effect(img, pose_results,
+ left_eye_idx, right_eye_idx)
+
+ # delay control
+ if args.display_delay > 0:
+ t_sleep = args.display_delay * 0.001 - (time.time() - ts_input)
+ if t_sleep > 0:
+ time.sleep(t_sleep)
+ t_delay = (time.time() - ts_input) * 1000
+
+ # show time information
+ t_info_display = stop_watch.report_strings() # display fps
+ t_info_display.append(f'Inference FPS: {fps_inference:>5.1f}')
+ t_info_display.append(f'Delay: {t_delay:>3.0f}')
+ t_info_display.append(
+ f'Inference Delay: {t_delay_inference:>3.0f}')
+ t_info_str = ' | '.join(t_info_display + t_info)
+ cv2.putText(img, t_info_str, (20, 20), cv2.FONT_HERSHEY_DUPLEX,
+ 0.3, text_color, 1)
+ # collect system information
+ sys_info = [
+ f'RES: {img.shape[1]}x{img.shape[0]}',
+ f'Buffer: {frame_buffer.qsize()}/{frame_buffer.maxsize}'
+ ]
+ if psutil_proc is not None:
+ sys_info += [
+ f'CPU: {psutil_proc.cpu_percent():.1f}%',
+ f'MEM: {psutil_proc.memory_percent():.1f}%'
+ ]
+ sys_info_str = ' | '.join(sys_info)
+ cv2.putText(img, sys_info_str, (20, 40), cv2.FONT_HERSHEY_DUPLEX,
+ 0.3, text_color, 1)
+
+ # save the output video frame
+ if args.out_video_file is not None:
+ if vid_out is None:
+ fourcc = cv2.VideoWriter_fourcc(*'mp4v')
+ fps = args.out_video_fps
+ frame_size = (img.shape[1], img.shape[0])
+ vid_out = cv2.VideoWriter(args.out_video_file, fourcc, fps,
+ frame_size)
+
+ vid_out.write(img)
+
+ # display
+ cv2.imshow('mmpose webcam demo', img)
+ keyboard_input = cv2.waitKey(1)
+ if keyboard_input in (27, ord('q'), ord('Q')):
+ break
+ elif keyboard_input == ord('s'):
+ args.sunglasses = not args.sunglasses
+ elif keyboard_input == ord('b'):
+ args.bugeye = not args.bugeye
+ elif keyboard_input == ord('v'):
+ args.vis_mode = (args.vis_mode + 1) % 3
+
+ cv2.destroyAllWindows()
+ if vid_out is not None:
+ vid_out.release()
+ event_exit.set()
+
+
+def main():
+ global args
+ global frame_buffer
+ global input_queue, input_queue_mutex
+ global det_result_queue, det_result_queue_mutex
+ global pose_result_queue, pose_result_queue_mutex
+ global det_model, pose_model_list, pose_history_list
+ global event_exit, event_inference_done
+
+ args = parse_args()
+
+ assert has_mmdet, 'Please install mmdet to run the demo.'
+ assert args.det_config is not None
+ assert args.det_checkpoint is not None
+
+ # build detection model
+ det_model = init_detector(
+ args.det_config, args.det_checkpoint, device=args.device.lower())
+
+ # build pose models
+ pose_model_list = []
+ if args.enable_human_pose:
+ pose_model = init_pose_model(
+ args.human_pose_config,
+ args.human_pose_checkpoint,
+ device=args.device.lower())
+ model_info = {
+ 'name': 'HumanPose',
+ 'model': pose_model,
+ 'cat_ids': args.human_det_ids,
+ 'bbox_color': (148, 139, 255),
+ }
+ pose_model_list.append(model_info)
+ if args.enable_animal_pose:
+ pose_model = init_pose_model(
+ args.animal_pose_config,
+ args.animal_pose_checkpoint,
+ device=args.device.lower())
+ model_info = {
+ 'name': 'AnimalPose',
+ 'model': pose_model,
+ 'cat_ids': args.animal_det_ids,
+ 'bbox_color': 'cyan',
+ }
+ pose_model_list.append(model_info)
+
+ # store pose history for pose tracking
+ pose_history_list = []
+ for _ in range(len(pose_model_list)):
+ pose_history_list.append({'pose_results_last': [], 'next_id': 0})
+
+ # frame buffer
+ if args.buffer_size > 0:
+ buffer_size = args.buffer_size
+ else:
+ # infer buffer size from the display delay time
+ # assume that the maximum video fps is 30
+ buffer_size = round(30 * (1 + max(args.display_delay, 0) / 1000.))
+ frame_buffer = Queue(maxsize=buffer_size)
+
+ # queue of input frames
+ # element: (timestamp, frame)
+ input_queue = deque(maxlen=1)
+ input_queue_mutex = Lock()
+
+ # queue of detection results
+ # element: tuple(timestamp, frame, time_info, det_results)
+ det_result_queue = deque(maxlen=1)
+ det_result_queue_mutex = Lock()
+
+ # queue of detection/pose results
+ # element: (timestamp, time_info, pose_results_list)
+ pose_result_queue = deque(maxlen=1)
+ pose_result_queue_mutex = Lock()
+
+ try:
+ event_exit = Event()
+ event_inference_done = Event()
+ t_input = Thread(target=read_camera, args=())
+ t_det = Thread(target=inference_detection, args=(), daemon=True)
+ t_pose = Thread(target=inference_pose, args=(), daemon=True)
+
+ t_input.start()
+ t_det.start()
+ t_pose.start()
+
+ # run display in the main thread
+ display()
+ # join the input thread (non-daemon)
+ t_input.join()
+
+ except KeyboardInterrupt:
+ pass
+
+
+if __name__ == '__main__':
+ main()
diff --git a/vendor/ViTPose/docker/Dockerfile b/vendor/ViTPose/docker/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..f7d6192910fa2401218c67a7e9e01634d83f364e
--- /dev/null
+++ b/vendor/ViTPose/docker/Dockerfile
@@ -0,0 +1,29 @@
+ARG PYTORCH="1.6.0"
+ARG CUDA="10.1"
+ARG CUDNN="7"
+
+FROM pytorch/pytorch:${PYTORCH}-cuda${CUDA}-cudnn${CUDNN}-devel
+
+ENV TORCH_CUDA_ARCH_LIST="6.0 6.1 7.0+PTX"
+ENV TORCH_NVCC_FLAGS="-Xfatbin -compress-all"
+ENV CMAKE_PREFIX_PATH="$(dirname $(which conda))/../"
+
+RUN apt-get update && apt-get install -y git ninja-build libglib2.0-0 libsm6 libxrender-dev libxext6 libgl1-mesa-glx\
+ && apt-get clean \
+ && rm -rf /var/lib/apt/lists/*
+
+# Install xtcocotools
+RUN pip install cython
+RUN pip install xtcocotools
+
+# Install MMCV
+RUN pip install mmcv-full==latest+torch1.6.0+cu101 -f https://download.openmmlab.com/mmcv/dist/index.html
+
+# Install MMPose
+RUN conda clean --all
+RUN git clone https://github.com/open-mmlab/mmpose.git /mmpose
+WORKDIR /mmpose
+RUN mkdir -p /mmpose/data
+ENV FORCE_CUDA="1"
+RUN pip install -r requirements/build.txt
+RUN pip install --no-cache-dir -e .
diff --git a/vendor/ViTPose/docker/serve/Dockerfile b/vendor/ViTPose/docker/serve/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..74a31044b09c0f50fdedeaf4c1ba6138f5c9823a
--- /dev/null
+++ b/vendor/ViTPose/docker/serve/Dockerfile
@@ -0,0 +1,47 @@
+ARG PYTORCH="1.6.0"
+ARG CUDA="10.1"
+ARG CUDNN="7"
+FROM pytorch/pytorch:${PYTORCH}-cuda${CUDA}-cudnn${CUDNN}-devel
+
+ENV PYTHONUNBUFFERED TRUE
+
+RUN apt-get update && \
+ DEBIAN_FRONTEND=noninteractive apt-get install --no-install-recommends -y \
+ ca-certificates \
+ g++ \
+ openjdk-11-jre-headless \
+ # MMDet Requirements
+ ffmpeg libsm6 libxext6 git ninja-build libglib2.0-0 libsm6 libxrender-dev libxext6 \
+ && rm -rf /var/lib/apt/lists/*
+
+ENV PATH="/opt/conda/bin:$PATH"
+RUN export FORCE_CUDA=1
+
+
+# MMLAB
+ARG PYTORCH
+ARG CUDA
+RUN ["/bin/bash", "-c", "pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu${CUDA//./}/torch${PYTORCH}/index.html"]
+RUN pip install mmpose
+
+# TORCHSEVER
+RUN pip install torchserve torch-model-archiver
+
+RUN useradd -m model-server \
+ && mkdir -p /home/model-server/tmp
+
+COPY entrypoint.sh /usr/local/bin/entrypoint.sh
+
+RUN chmod +x /usr/local/bin/entrypoint.sh \
+ && chown -R model-server /home/model-server
+
+COPY config.properties /home/model-server/config.properties
+RUN mkdir /home/model-server/model-store && chown -R model-server /home/model-server/model-store
+
+EXPOSE 8080 8081 8082
+
+USER model-server
+WORKDIR /home/model-server
+ENV TEMP=/home/model-server/tmp
+ENTRYPOINT ["/usr/local/bin/entrypoint.sh"]
+CMD ["serve"]
diff --git a/vendor/ViTPose/docker/serve/Dockerfile_mmcls b/vendor/ViTPose/docker/serve/Dockerfile_mmcls
new file mode 100644
index 0000000000000000000000000000000000000000..7f63170176b9e810f343197ad8cafd95dbda7752
--- /dev/null
+++ b/vendor/ViTPose/docker/serve/Dockerfile_mmcls
@@ -0,0 +1,49 @@
+ARG PYTORCH="1.6.0"
+ARG CUDA="10.1"
+ARG CUDNN="7"
+FROM pytorch/pytorch:${PYTORCH}-cuda${CUDA}-cudnn${CUDNN}-devel
+
+ARG MMCV="1.3.8"
+ARG MMCLS="0.16.0"
+
+ENV PYTHONUNBUFFERED TRUE
+
+RUN apt-get update && \
+ DEBIAN_FRONTEND=noninteractive apt-get install --no-install-recommends -y \
+ ca-certificates \
+ g++ \
+ openjdk-11-jre-headless \
+ # MMDet Requirements
+ ffmpeg libsm6 libxext6 git ninja-build libglib2.0-0 libsm6 libxrender-dev libxext6 \
+ && rm -rf /var/lib/apt/lists/*
+
+ENV PATH="/opt/conda/bin:$PATH"
+RUN export FORCE_CUDA=1
+
+# TORCHSEVER
+RUN pip install torchserve torch-model-archiver
+
+# MMLAB
+ARG PYTORCH
+ARG CUDA
+RUN ["/bin/bash", "-c", "pip install mmcv-full==${MMCV} -f https://download.openmmlab.com/mmcv/dist/cu${CUDA//./}/torch${PYTORCH}/index.html"]
+RUN pip install mmcls==${MMCLS}
+
+RUN useradd -m model-server \
+ && mkdir -p /home/model-server/tmp
+
+COPY entrypoint.sh /usr/local/bin/entrypoint.sh
+
+RUN chmod +x /usr/local/bin/entrypoint.sh \
+ && chown -R model-server /home/model-server
+
+COPY config.properties /home/model-server/config.properties
+RUN mkdir /home/model-server/model-store && chown -R model-server /home/model-server/model-store
+
+EXPOSE 8080 8081 8082
+
+USER model-server
+WORKDIR /home/model-server
+ENV TEMP=/home/model-server/tmp
+ENTRYPOINT ["/usr/local/bin/entrypoint.sh"]
+CMD ["serve"]
diff --git a/vendor/ViTPose/docker/serve/config.properties b/vendor/ViTPose/docker/serve/config.properties
new file mode 100644
index 0000000000000000000000000000000000000000..efb9c47e40ab550bac765611e6c6c6f2a7152f11
--- /dev/null
+++ b/vendor/ViTPose/docker/serve/config.properties
@@ -0,0 +1,5 @@
+inference_address=http://0.0.0.0:8080
+management_address=http://0.0.0.0:8081
+metrics_address=http://0.0.0.0:8082
+model_store=/home/model-server/model-store
+load_models=all
diff --git a/vendor/ViTPose/docker/serve/entrypoint.sh b/vendor/ViTPose/docker/serve/entrypoint.sh
new file mode 100644
index 0000000000000000000000000000000000000000..41ba00b048aed84b45c5a8015a016ff148e97d86
--- /dev/null
+++ b/vendor/ViTPose/docker/serve/entrypoint.sh
@@ -0,0 +1,12 @@
+#!/bin/bash
+set -e
+
+if [[ "$1" = "serve" ]]; then
+ shift 1
+ torchserve --start --ts-config /home/model-server/config.properties
+else
+ eval "$@"
+fi
+
+# prevent docker exit
+tail -f /dev/null
diff --git a/vendor/ViTPose/docs/en/Makefile b/vendor/ViTPose/docs/en/Makefile
new file mode 100644
index 0000000000000000000000000000000000000000..d4bb2cbb9eddb1bb1b4f366623044af8e4830919
--- /dev/null
+++ b/vendor/ViTPose/docs/en/Makefile
@@ -0,0 +1,20 @@
+# Minimal makefile for Sphinx documentation
+#
+
+# You can set these variables from the command line, and also
+# from the environment for the first two.
+SPHINXOPTS ?=
+SPHINXBUILD ?= sphinx-build
+SOURCEDIR = .
+BUILDDIR = _build
+
+# Put it first so that "make" without argument is like "make help".
+help:
+ @$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
+
+.PHONY: help Makefile
+
+# Catch-all target: route all unknown targets to Sphinx using the new
+# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
+%: Makefile
+ @$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
diff --git a/vendor/ViTPose/docs/en/_static/css/readthedocs.css b/vendor/ViTPose/docs/en/_static/css/readthedocs.css
new file mode 100644
index 0000000000000000000000000000000000000000..efc4b986a5348c645842a135883d4713986a7169
--- /dev/null
+++ b/vendor/ViTPose/docs/en/_static/css/readthedocs.css
@@ -0,0 +1,6 @@
+.header-logo {
+ background-image: url("../images/mmpose-logo.png");
+ background-size: 120px 50px;
+ height: 50px;
+ width: 120px;
+}
diff --git a/vendor/ViTPose/docs/en/_static/images/mmpose-logo.png b/vendor/ViTPose/docs/en/_static/images/mmpose-logo.png
new file mode 100644
index 0000000000000000000000000000000000000000..128e1714f0933d0dfe0ab82d6f8780c48e0edc21
Binary files /dev/null and b/vendor/ViTPose/docs/en/_static/images/mmpose-logo.png differ
diff --git a/vendor/ViTPose/docs/en/api.rst b/vendor/ViTPose/docs/en/api.rst
new file mode 100644
index 0000000000000000000000000000000000000000..af0ec96bb7104ef8829c657ee9f2fe032bad69a7
--- /dev/null
+++ b/vendor/ViTPose/docs/en/api.rst
@@ -0,0 +1,111 @@
+mmpose.apis
+-------------
+.. automodule:: mmpose.apis
+ :members:
+
+
+mmpose.core
+-------------
+evaluation
+^^^^^^^^^^^
+.. automodule:: mmpose.core.evaluation
+ :members:
+
+fp16
+^^^^^^^^^^^
+.. automodule:: mmpose.core.fp16
+ :members:
+
+
+utils
+^^^^^^^^^^^
+.. automodule:: mmpose.core.utils
+ :members:
+
+
+post_processing
+^^^^^^^^^^^^^^^^
+.. automodule:: mmpose.core.post_processing
+ :members:
+
+
+mmpose.models
+---------------
+backbones
+^^^^^^^^^^^
+.. automodule:: mmpose.models.backbones
+ :members:
+
+necks
+^^^^^^^^^^^
+.. automodule:: mmpose.models.necks
+ :members:
+
+detectors
+^^^^^^^^^^^
+.. automodule:: mmpose.models.detectors
+ :members:
+
+heads
+^^^^^^^^^^^^^^^
+.. automodule:: mmpose.models.heads
+ :members:
+
+losses
+^^^^^^^^^^^
+.. automodule:: mmpose.models.losses
+ :members:
+
+misc
+^^^^^^^^^^^
+.. automodule:: mmpose.models.misc
+ :members:
+
+mmpose.datasets
+-----------------
+.. automodule:: mmpose.datasets
+ :members:
+
+datasets
+^^^^^^^^^^^
+.. automodule:: mmpose.datasets.datasets.top_down
+ :members:
+ :noindex:
+
+.. automodule:: mmpose.datasets.datasets.bottom_up
+ :members:
+ :noindex:
+
+pipelines
+^^^^^^^^^^^
+.. automodule:: mmpose.datasets.pipelines
+ :members:
+
+.. automodule:: mmpose.datasets.pipelines.loading
+ :members:
+
+.. automodule:: mmpose.datasets.pipelines.shared_transform
+ :members:
+
+.. automodule:: mmpose.datasets.pipelines.top_down_transform
+ :members:
+
+.. automodule:: mmpose.datasets.pipelines.bottom_up_transform
+ :members:
+
+.. automodule:: mmpose.datasets.pipelines.mesh_transform
+ :members:
+
+.. automodule:: mmpose.datasets.pipelines.pose3d_transform
+ :members:
+
+samplers
+^^^^^^^^^^^
+.. automodule:: mmpose.datasets.samplers
+ :members:
+ :noindex:
+
+mmpose.utils
+---------------
+.. automodule:: mmpose.utils
+ :members:
diff --git a/vendor/ViTPose/docs/en/benchmark.md b/vendor/ViTPose/docs/en/benchmark.md
new file mode 100644
index 0000000000000000000000000000000000000000..7e9b56d6f38ffc8fe129428cee7659f55f5c5961
--- /dev/null
+++ b/vendor/ViTPose/docs/en/benchmark.md
@@ -0,0 +1,46 @@
+# Benchmark
+
+We compare our results with some popular frameworks and official releases in terms of speed and accuracy.
+
+## Comparison Rules
+
+Here we compare our MMPose repo with other pose estimation toolboxes in the same data and model settings.
+
+To ensure the fairness of the comparison, the comparison experiments were conducted under the same hardware environment and using the same dataset.
+For each model setting, we kept the same data pre-processing methods to make sure the same feature input.
+In addition, we also used Memcached, a distributed memory-caching system, to load the data in all the compared toolboxes.
+This minimizes the IO time during benchmark.
+
+The time we measured is the average training time for an iteration, including data processing and model training.
+The training speed is measure with s/iter. The lower, the better.
+
+### Results on COCO val2017 with detector having human AP of 56.4 on COCO val2017 dataset
+
+We demonstrate the superiority of our MMPose framework in terms of speed and accuracy on the standard COCO keypoint detection benchmark.
+The mAP (the mean average precision) is used as the evaluation metric.
+
+| Model | Input size| MMPose (s/iter) | HRNet (s/iter) | MMPose (mAP) | HRNet (mAP) |
+| :--- | :---------------: | :---------------: |:--------------------: | :----------------------------: | :-----------------: |
+| resnet_50 | 256x192 | **0.28** | 0.64 | **0.718** | 0.704 |
+| resnet_50 | 384x288 | **0.81** | 1.24 | **0.731** | 0.722 |
+| resnet_101 | 256x192 | **0.36** | 0.84 | **0.726** | 0.714 |
+| resnet_101 | 384x288 | **0.79** | 1.53 | **0.748** | 0.736 |
+| resnet_152 | 256x192 | **0.49** | 1.00 | **0.735** | 0.720 |
+| resnet_152 | 384x288 | **0.96** | 1.65 | **0.750** | 0.743 |
+| hrnet_w32 | 256x192 | **0.54** | 1.31 | **0.746** | 0.744 |
+| hrnet_w32 | 384x288 | **0.76** | 2.00 | **0.760** | 0.758 |
+| hrnet_w48 | 256x192 | **0.66** | 1.55 | **0.756** | 0.751 |
+| hrnet_w48 | 384x288 | **1.23** | 2.20 | **0.767** | 0.763 |
+
+## Hardware
+
+- 8 NVIDIA Tesla V100 (32G) GPUs
+- Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz
+
+## Software Environment
+
+- Python 3.7
+- PyTorch 1.4
+- CUDA 10.1
+- CUDNN 7.6.03
+- NCCL 2.4.08
diff --git a/vendor/ViTPose/docs/en/changelog.md b/vendor/ViTPose/docs/en/changelog.md
new file mode 100644
index 0000000000000000000000000000000000000000..37f6b3cce511c58be0be3f9d82a92944f5bf8631
--- /dev/null
+++ b/vendor/ViTPose/docs/en/changelog.md
@@ -0,0 +1,665 @@
+# Changelog
+
+## v0.24.0 (07/03/2022)
+
+**Highlights**
+
+- Support HRFormer ["HRFormer: High-Resolution Vision Transformer for Dense Predict"](https://proceedings.neurips.cc/paper/2021/hash/3bbfdde8842a5c44a0323518eec97cbe-Abstract.html), NeurIPS'2021 ([\#1203](https://github.com/open-mmlab/mmpose/pull/1203)) @zengwang430521
+- Support Windows installation with pip ([\#1213](https://github.com/open-mmlab/mmpose/pull/1213)) @jin-s13, @ly015
+- Add WebcamAPI documents ([\#1187](https://github.com/open-mmlab/mmpose/pull/1187)) @ly015
+
+**New Features**
+
+- Support HRFormer ["HRFormer: High-Resolution Vision Transformer for Dense Predict"](https://proceedings.neurips.cc/paper/2021/hash/3bbfdde8842a5c44a0323518eec97cbe-Abstract.html), NeurIPS'2021 ([\#1203](https://github.com/open-mmlab/mmpose/pull/1203)) @zengwang430521
+- Support Windows installation with pip ([\#1213](https://github.com/open-mmlab/mmpose/pull/1213)) @jin-s13, @ly015
+- Support CPU training with mmcv < v1.4.4 ([\#1161](https://github.com/open-mmlab/mmpose/pull/1161)) @EasonQYS, @ly015
+- Add "Valentine Magic" demo with WebcamAPI ([\#1189](https://github.com/open-mmlab/mmpose/pull/1189), [\#1191](https://github.com/open-mmlab/mmpose/pull/1191)) @liqikai9
+
+**Improvements**
+
+- Refactor multi-view 3D pose estimation framework towards better modularization and expansibility ([\#1196](https://github.com/open-mmlab/mmpose/pull/1196)) @wusize
+- Add WebcamAPI documents and tutorials ([\#1187](https://github.com/open-mmlab/mmpose/pull/1187)) @ly015
+- Refactor dataset evaluation interface to align with other OpenMMLab codebases ([\#1209](https://github.com/open-mmlab/mmpose/pull/1209)) @ly015
+- Add deprecation message for deploy tools since [MMDeploy](https://github.com/open-mmlab/mmdeploy) has supported MMPose ([\#1207](https://github.com/open-mmlab/mmpose/pull/1207)) @QwQ2000
+- Improve documentation quality ([\#1206](https://github.com/open-mmlab/mmpose/pull/1206), [\#1161](https://github.com/open-mmlab/mmpose/pull/1161)) @ly015
+- Switch to OpenMMLab official pre-commit-hook for copyright check ([\#1214](https://github.com/open-mmlab/mmpose/pull/1214)) @ly015
+
+**Bug Fixes**
+
+- Fix hard-coded data collating and scattering in inference ([\#1175](https://github.com/open-mmlab/mmpose/pull/1175)) @ly015
+- Fix model configs on JHMDB dataset ([\#1188](https://github.com/open-mmlab/mmpose/pull/1188)) @jin-s13
+- Fix area calculation in pose tracking inference ([\#1197](https://github.com/open-mmlab/mmpose/pull/1197)) @pallgeuer
+- Fix registry scope conflict of module wrapper ([\#1204](https://github.com/open-mmlab/mmpose/pull/1204)) @ly015
+- Update MMCV installation in CI and documents ([\#1205](https://github.com/open-mmlab/mmpose/pull/1205))
+- Fix incorrect color channel order in visualization functions ([\#1212](https://github.com/open-mmlab/mmpose/pull/1212)) @ly015
+
+## v0.23.0 (11/02/2022)
+
+**Highlights**
+
+- Add [MMPose Webcam API](https://github.com/open-mmlab/mmpose/tree/master/tools/webcam): A simple yet powerful tools to develop interactive webcam applications with MMPose functions. ([\#1178](https://github.com/open-mmlab/mmpose/pull/1178), [\#1173](https://github.com/open-mmlab/mmpose/pull/1173), [\#1173](https://github.com/open-mmlab/mmpose/pull/1173), [\#1143](https://github.com/open-mmlab/mmpose/pull/1143), [\#1094](https://github.com/open-mmlab/mmpose/pull/1094), [\#1133](https://github.com/open-mmlab/mmpose/pull/1133), [\#1098](https://github.com/open-mmlab/mmpose/pull/1098), [\#1160](https://github.com/open-mmlab/mmpose/pull/1160)) @ly015, @jin-s13, @liqikai9, @wusize, @luminxu, @zengwang430521 @mzr1996
+
+**New Features**
+
+- Add [MMPose Webcam API](https://github.com/open-mmlab/mmpose/tree/master/tools/webcam): A simple yet powerful tools to develop interactive webcam applications with MMPose functions. ([\#1178](https://github.com/open-mmlab/mmpose/pull/1178), [\#1173](https://github.com/open-mmlab/mmpose/pull/1173), [\#1173](https://github.com/open-mmlab/mmpose/pull/1173), [\#1143](https://github.com/open-mmlab/mmpose/pull/1143), [\#1094](https://github.com/open-mmlab/mmpose/pull/1094), [\#1133](https://github.com/open-mmlab/mmpose/pull/1133), [\#1098](https://github.com/open-mmlab/mmpose/pull/1098), [\#1160](https://github.com/open-mmlab/mmpose/pull/1160)) @ly015, @jin-s13, @liqikai9, @wusize, @luminxu, @zengwang430521 @mzr1996
+- Support ConcatDataset ([\#1139](https://github.com/open-mmlab/mmpose/pull/1139)) @Canwang-sjtu
+- Support CPU training and testing ([\#1157](https://github.com/open-mmlab/mmpose/pull/1157)) @ly015
+
+**Improvements**
+
+- Add multi-processing configurations to speed up distributed training and testing ([\#1146](https://github.com/open-mmlab/mmpose/pull/1146)) @ly015
+- Add default runtime config ([\#1145](https://github.com/open-mmlab/mmpose/pull/1145))
+
+- Upgrade isort in pre-commit hook ([\#1179](https://github.com/open-mmlab/mmpose/pull/1179)) @liqikai9
+- Update README and documents ([\#1171](https://github.com/open-mmlab/mmpose/pull/1171), [\#1167](https://github.com/open-mmlab/mmpose/pull/1167), [\#1153](https://github.com/open-mmlab/mmpose/pull/1153), [\#1149](https://github.com/open-mmlab/mmpose/pull/1149), [\#1148](https://github.com/open-mmlab/mmpose/pull/1148), [\#1147](https://github.com/open-mmlab/mmpose/pull/1147), [\#1140](https://github.com/open-mmlab/mmpose/pull/1140)) @jin-s13, @wusize, @TommyZihao, @ly015
+
+**Bug Fixes**
+
+- Fix undeterministic behavior in pre-commit hooks ([\#1136](https://github.com/open-mmlab/mmpose/pull/1136)) @jin-s13
+- Deprecate the support for "python setup.py test" ([\#1179](https://github.com/open-mmlab/mmpose/pull/1179)) @ly015
+- Fix incompatible settings with MMCV on HSigmoid default parameters ([\#1132](https://github.com/open-mmlab/mmpose/pull/1132)) @ly015
+- Fix albumentation installation ([\#1184](https://github.com/open-mmlab/mmpose/pull/1184)) @BIGWangYuDong
+
+## v0.22.0 (04/01/2022)
+
+**Highlights**
+
+- Support VoxelPose ["VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Environment"](https://arxiv.org/abs/2004.06239), ECCV'2020 ([\#1050](https://github.com/open-mmlab/mmpose/pull/1050)) @wusize
+- Support Soft Wing loss ["Structure-Coherent Deep Feature Learning for Robust Face Alignment"](https://linchunze.github.io/papers/TIP21_Structure_coherent_FA.pdf), TIP'2021 ([\#1077](https://github.com/open-mmlab/mmpose/pull/1077)) @jin-s13
+- Support Adaptive Wing loss ["Adaptive Wing Loss for Robust Face Alignment via Heatmap Regression"](https://arxiv.org/abs/1904.07399), ICCV'2019 ([\#1072](https://github.com/open-mmlab/mmpose/pull/1072)) @jin-s13
+
+**New Features**
+
+- Support VoxelPose ["VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Environment"](https://arxiv.org/abs/2004.06239), ECCV'2020 ([\#1050](https://github.com/open-mmlab/mmpose/pull/1050)) @wusize
+- Support Soft Wing loss ["Structure-Coherent Deep Feature Learning for Robust Face Alignment"](https://linchunze.github.io/papers/TIP21_Structure_coherent_FA.pdf), TIP'2021 ([\#1077](https://github.com/open-mmlab/mmpose/pull/1077)) @jin-s13
+- Support Adaptive Wing loss ["Adaptive Wing Loss for Robust Face Alignment via Heatmap Regression"](https://arxiv.org/abs/1904.07399), ICCV'2019 ([\#1072](https://github.com/open-mmlab/mmpose/pull/1072)) @jin-s13
+- Add LiteHRNet-18 Checkpoints trained on COCO. ([\#1120](https://github.com/open-mmlab/mmpose/pull/1120)) @jin-s13
+
+**Improvements**
+
+- Improve documentation quality ([\#1115](https://github.com/open-mmlab/mmpose/pull/1115), [\#1111](https://github.com/open-mmlab/mmpose/pull/1111), [\#1105](https://github.com/open-mmlab/mmpose/pull/1105), [\#1087](https://github.com/open-mmlab/mmpose/pull/1087), [\#1086](https://github.com/open-mmlab/mmpose/pull/1086), [\#1085](https://github.com/open-mmlab/mmpose/pull/1085), [\#1084](https://github.com/open-mmlab/mmpose/pull/1084), [\#1083](https://github.com/open-mmlab/mmpose/pull/1083), [\#1124](https://github.com/open-mmlab/mmpose/pull/1124), [\#1070](https://github.com/open-mmlab/mmpose/pull/1070), [\#1068](https://github.com/open-mmlab/mmpose/pull/1068)) @jin-s13, @liqikai9, @ly015
+- Support CircleCI ([\#1074](https://github.com/open-mmlab/mmpose/pull/1074)) @ly015
+- Skip unit tests in CI when only document files were changed ([\#1074](https://github.com/open-mmlab/mmpose/pull/1074), [\#1041](https://github.com/open-mmlab/mmpose/pull/1041)) @QwQ2000, @ly015
+- Support file_client_args in LoadImageFromFile ([\#1076](https://github.com/open-mmlab/mmpose/pull/1076)) @jin-s13
+
+**Bug Fixes**
+
+- Fix a bug in Dark UDP postprocessing that causes error when the channel number is large. ([\#1079](https://github.com/open-mmlab/mmpose/pull/1079), [\#1116](https://github.com/open-mmlab/mmpose/pull/1116)) @X00123, @jin-s13
+- Fix hard-coded `sigmas` in bottom-up image demo ([\#1107](https://github.com/open-mmlab/mmpose/pull/1107), [\#1101](https://github.com/open-mmlab/mmpose/pull/1101)) @chenxinfeng4, @liqikai9
+- Fix unstable checks in unit tests ([\#1112](https://github.com/open-mmlab/mmpose/pull/1112)) @ly015
+- Do not destroy NULL windows if `args.show==False` in demo scripts ([\#1104](https://github.com/open-mmlab/mmpose/pull/1104)) @bladrome
+
+## v0.21.0 (06/12/2021)
+
+**Highlights**
+
+- Support ["Learning Temporal Pose Estimation from Sparsely-Labeled Videos"](https://arxiv.org/abs/1906.04016), NeurIPS'2019 ([\#932](https://github.com/open-mmlab/mmpose/pull/932), [\#1006](https://github.com/open-mmlab/mmpose/pull/1006), [\#1036](https://github.com/open-mmlab/mmpose/pull/1036), [\#1060](https://github.com/open-mmlab/mmpose/pull/1060)) @liqikai9
+- Add ViPNAS-MobileNetV3 models ([\#1025](https://github.com/open-mmlab/mmpose/pull/1025)) @luminxu, @jin-s13
+- Add [inference speed benchmark](/docs/en/inference_speed_summary.md) ([\#1028](https://github.com/open-mmlab/mmpose/pull/1028), [\#1034](https://github.com/open-mmlab/mmpose/pull/1034), [\#1044](https://github.com/open-mmlab/mmpose/pull/1044)) @liqikai9
+
+**New Features**
+
+- Support ["Learning Temporal Pose Estimation from Sparsely-Labeled Videos"](https://arxiv.org/abs/1906.04016), NeurIPS'2019 ([\#932](https://github.com/open-mmlab/mmpose/pull/932), [\#1006](https://github.com/open-mmlab/mmpose/pull/1006), [\#1036](https://github.com/open-mmlab/mmpose/pull/1036)) @liqikai9
+- Add ViPNAS-MobileNetV3 models ([\#1025](https://github.com/open-mmlab/mmpose/pull/1025)) @luminxu, @jin-s13
+- Add light-weight top-down models for whole-body keypoint detection ([\#1009](https://github.com/open-mmlab/mmpose/pull/1009), [\#1020](https://github.com/open-mmlab/mmpose/pull/1020), [\#1055](https://github.com/open-mmlab/mmpose/pull/1055)) @luminxu, @ly015
+- Add HRNet checkpoints with various settings on PoseTrack18 ([\#1035](https://github.com/open-mmlab/mmpose/pull/1035)) @liqikai9
+
+**Improvements**
+
+- Add [inference speed benchmark](/docs/en/inference_speed_summary.md) ([\#1028](https://github.com/open-mmlab/mmpose/pull/1028), [\#1034](https://github.com/open-mmlab/mmpose/pull/1034), [\#1044](https://github.com/open-mmlab/mmpose/pull/1044)) @liqikai9
+- Update model metafile format ([\#1001](https://github.com/open-mmlab/mmpose/pull/1001)) @ly015
+- Support minus output feature index in mobilenet_v3 ([\#1005](https://github.com/open-mmlab/mmpose/pull/1005)) @luminxu
+- Improve documentation quality ([\#1018](https://github.com/open-mmlab/mmpose/pull/1018), [\#1026](https://github.com/open-mmlab/mmpose/pull/1026), [\#1027](https://github.com/open-mmlab/mmpose/pull/1027), [\#1031](https://github.com/open-mmlab/mmpose/pull/1031), [\#1038](https://github.com/open-mmlab/mmpose/pull/1038), [\#1046](https://github.com/open-mmlab/mmpose/pull/1046), [\#1056](https://github.com/open-mmlab/mmpose/pull/1056), [\#1057](https://github.com/open-mmlab/mmpose/pull/1057)) @edybk, @luminxu, @ly015, @jin-s13
+- Set default random seed in training initialization ([\#1030](https://github.com/open-mmlab/mmpose/pull/1030)) @ly015
+- Skip CI when only specific files changed ([\#1041](https://github.com/open-mmlab/mmpose/pull/1041), [\#1059](https://github.com/open-mmlab/mmpose/pull/1059)) @QwQ2000, @ly015
+- Automatically cancel uncompleted action runs when new commit arrives ([\#1053](https://github.com/open-mmlab/mmpose/pull/1053)) @ly015
+
+**Bug Fixes**
+
+- Update pose tracking demo to be compatible with latest mmtracking ([\#1014](https://github.com/open-mmlab/mmpose/pull/1014)) @jin-s13
+- Fix symlink creation failure when installed in Windows environments ([\#1039](https://github.com/open-mmlab/mmpose/pull/1039)) @QwQ2000
+- Fix AP-10K dataset sigmas ([\#1040](https://github.com/open-mmlab/mmpose/pull/1040)) @jin-s13
+
+## v0.20.0 (01/11/2021)
+
+**Highlights**
+
+- Add AP-10K dataset for animal pose estimation ([\#987](https://github.com/open-mmlab/mmpose/pull/987)) @Annbless, @AlexTheBad, @jin-s13, @ly015
+- Support TorchServe ([\#979](https://github.com/open-mmlab/mmpose/pull/979)) @ly015
+
+**New Features**
+
+- Add AP-10K dataset for animal pose estimation ([\#987](https://github.com/open-mmlab/mmpose/pull/987)) @Annbless, @AlexTheBad, @jin-s13, @ly015
+- Add HRNetv2 checkpoints on 300W and COFW datasets ([\#980](https://github.com/open-mmlab/mmpose/pull/980)) @jin-s13
+- Support TorchServe ([\#979](https://github.com/open-mmlab/mmpose/pull/979)) @ly015
+
+**Bug Fixes**
+
+- Fix some deprecated or risky settings in configs ([\#963](https://github.com/open-mmlab/mmpose/pull/963), [\#976](https://github.com/open-mmlab/mmpose/pull/976), [\#992](https://github.com/open-mmlab/mmpose/pull/992)) @jin-s13, @wusize
+- Fix issues of default arguments of training and testing scripts ([\#970](https://github.com/open-mmlab/mmpose/pull/970), [\#985](https://github.com/open-mmlab/mmpose/pull/985)) @liqikai9, @wusize
+- Fix heatmap and tag size mismatch in bottom-up with UDP ([\#994](https://github.com/open-mmlab/mmpose/pull/994)) @wusize
+- Fix python3.9 installation in CI ([\#983](https://github.com/open-mmlab/mmpose/pull/983)) @ly015
+- Fix model zoo document integrity issue ([\#990](https://github.com/open-mmlab/mmpose/pull/990)) @jin-s13
+
+**Improvements**
+
+- Support non-square input shape for bottom-up ([\#991](https://github.com/open-mmlab/mmpose/pull/991)) @wusize
+- Add image and video resources for demo ([\#971](https://github.com/open-mmlab/mmpose/pull/971)) @liqikai9
+- Use CUDA docker images to accelerate CI ([\#973](https://github.com/open-mmlab/mmpose/pull/973)) @ly015
+- Add codespell hook and fix detected typos ([\#977](https://github.com/open-mmlab/mmpose/pull/977)) @ly015
+
+## v0.19.0 (08/10/2021)
+
+**Highlights**
+
+- Add models for Associative Embedding with Hourglass network backbone ([\#906](https://github.com/open-mmlab/mmpose/pull/906), [\#955](https://github.com/open-mmlab/mmpose/pull/955)) @jin-s13, @luminxu
+- Support COCO-Wholebody-Face and COCO-Wholebody-Hand datasets ([\#813](https://github.com/open-mmlab/mmpose/pull/813)) @jin-s13, @innerlee, @luminxu
+- Upgrade dataset interface ([\#901](https://github.com/open-mmlab/mmpose/pull/901), [\#924](https://github.com/open-mmlab/mmpose/pull/924)) @jin-s13, @innerlee, @ly015, @liqikai9
+- New style of documentation ([\#945](https://github.com/open-mmlab/mmpose/pull/945)) @ly015
+
+**New Features**
+
+- Add models for Associative Embedding with Hourglass network backbone ([\#906](https://github.com/open-mmlab/mmpose/pull/906), [\#955](https://github.com/open-mmlab/mmpose/pull/955)) @jin-s13, @luminxu
+- Support COCO-Wholebody-Face and COCO-Wholebody-Hand datasets ([\#813](https://github.com/open-mmlab/mmpose/pull/813)) @jin-s13, @innerlee, @luminxu
+- Add pseudo-labeling tool to generate COCO style keypoint annotations with given bounding boxes ([\#928](https://github.com/open-mmlab/mmpose/pull/928)) @soltkreig
+- New style of documentation ([\#945](https://github.com/open-mmlab/mmpose/pull/945)) @ly015
+
+**Bug Fixes**
+
+- Fix segmentation parsing in Macaque dataset preprocessing ([\#948](https://github.com/open-mmlab/mmpose/pull/948)) @jin-s13
+- Fix dependencies that may lead to CI failure in downstream projects ([\#936](https://github.com/open-mmlab/mmpose/pull/936), [\#953](https://github.com/open-mmlab/mmpose/pull/953)) @RangiLyu, @ly015
+- Fix keypoint order in Human3.6M dataset ([\#940](https://github.com/open-mmlab/mmpose/pull/940)) @ttxskk
+- Fix unstable image loading for Interhand2.6M ([\#913](https://github.com/open-mmlab/mmpose/pull/913)) @zengwang430521
+
+**Improvements**
+
+- Upgrade dataset interface ([\#901](https://github.com/open-mmlab/mmpose/pull/901), [\#924](https://github.com/open-mmlab/mmpose/pull/924)) @jin-s13, @innerlee, @ly015, @liqikai9
+- Improve demo usability and stability ([\#908](https://github.com/open-mmlab/mmpose/pull/908), [\#934](https://github.com/open-mmlab/mmpose/pull/934)) @ly015
+- Standardize model metafile format ([\#941](https://github.com/open-mmlab/mmpose/pull/941)) @ly015
+- Support `persistent_worker` and several other arguments in configs ([\#946](https://github.com/open-mmlab/mmpose/pull/946)) @jin-s13
+- Use MMCV root model registry to enable cross-project module building ([\#935](https://github.com/open-mmlab/mmpose/pull/935)) @RangiLyu
+- Improve the document quality ([\#916](https://github.com/open-mmlab/mmpose/pull/916), [\#909](https://github.com/open-mmlab/mmpose/pull/909), [\#942](https://github.com/open-mmlab/mmpose/pull/942), [\#913](https://github.com/open-mmlab/mmpose/pull/913), [\#956](https://github.com/open-mmlab/mmpose/pull/956)) @jin-s13, @ly015, @bit-scientist, @zengwang430521
+- Improve pull request template ([\#952](https://github.com/open-mmlab/mmpose/pull/952), [\#954](https://github.com/open-mmlab/mmpose/pull/954)) @ly015
+
+**Breaking Changes**
+
+- Upgrade dataset interface ([\#901](https://github.com/open-mmlab/mmpose/pull/901)) @jin-s13, @innerlee, @ly015
+
+## v0.18.0 (01/09/2021)
+
+**Bug Fixes**
+
+- Fix redundant model weight loading in pytorch-to-onnx conversion ([\#850](https://github.com/open-mmlab/mmpose/pull/850)) @ly015
+- Fix a bug in update_model_index.py that may cause pre-commit hook failure([\#866](https://github.com/open-mmlab/mmpose/pull/866)) @ly015
+- Fix a bug in interhand_3d_head ([\#890](https://github.com/open-mmlab/mmpose/pull/890)) @zengwang430521
+- Fix pose tracking demo failure caused by out-of-date configs ([\#891](https://github.com/open-mmlab/mmpose/pull/891))
+
+**Improvements**
+
+- Add automatic benchmark regression tools ([\#849](https://github.com/open-mmlab/mmpose/pull/849), [\#880](https://github.com/open-mmlab/mmpose/pull/880), [\#885](https://github.com/open-mmlab/mmpose/pull/885)) @liqikai9, @ly015
+- Add copyright information and checking hook ([\#872](https://github.com/open-mmlab/mmpose/pull/872))
+- Add PR template ([\#875](https://github.com/open-mmlab/mmpose/pull/875)) @ly015
+- Add citation information ([\#876](https://github.com/open-mmlab/mmpose/pull/876)) @ly015
+- Add python3.9 in CI ([\#877](https://github.com/open-mmlab/mmpose/pull/877), [\#883](https://github.com/open-mmlab/mmpose/pull/883)) @ly015
+- Improve the quality of the documents ([\#845](https://github.com/open-mmlab/mmpose/pull/845), [\#845](https://github.com/open-mmlab/mmpose/pull/845), [\#848](https://github.com/open-mmlab/mmpose/pull/848), [\#867](https://github.com/open-mmlab/mmpose/pull/867), [\#870](https://github.com/open-mmlab/mmpose/pull/870), [\#873](https://github.com/open-mmlab/mmpose/pull/873), [\#896](https://github.com/open-mmlab/mmpose/pull/896)) @jin-s13, @ly015, @zhiqwang
+
+## v0.17.0 (06/08/2021)
+
+**Highlights**
+
+1. Support ["Lite-HRNet: A Lightweight High-Resolution Network"](https://arxiv.org/abs/2104.06403) CVPR'2021 ([\#733](https://github.com/open-mmlab/mmpose/pull/733),[\#800](https://github.com/open-mmlab/mmpose/pull/800)) @jin-s13
+2. Add 3d body mesh demo ([\#771](https://github.com/open-mmlab/mmpose/pull/771)) @zengwang430521
+3. Add Chinese documentation ([\#787](https://github.com/open-mmlab/mmpose/pull/787), [\#798](https://github.com/open-mmlab/mmpose/pull/798), [\#799](https://github.com/open-mmlab/mmpose/pull/799), [\#802](https://github.com/open-mmlab/mmpose/pull/802), [\#804](https://github.com/open-mmlab/mmpose/pull/804), [\#805](https://github.com/open-mmlab/mmpose/pull/805), [\#815](https://github.com/open-mmlab/mmpose/pull/815), [\#816](https://github.com/open-mmlab/mmpose/pull/816), [\#817](https://github.com/open-mmlab/mmpose/pull/817), [\#819](https://github.com/open-mmlab/mmpose/pull/819), [\#839](https://github.com/open-mmlab/mmpose/pull/839)) @ly015, @luminxu, @jin-s13, @liqikai9, @zengwang430521
+4. Add Colab Tutorial ([\#834](https://github.com/open-mmlab/mmpose/pull/834)) @ly015
+
+**New Features**
+
+- Support ["Lite-HRNet: A Lightweight High-Resolution Network"](https://arxiv.org/abs/2104.06403) CVPR'2021 ([\#733](https://github.com/open-mmlab/mmpose/pull/733),[\#800](https://github.com/open-mmlab/mmpose/pull/800)) @jin-s13
+- Add 3d body mesh demo ([\#771](https://github.com/open-mmlab/mmpose/pull/771)) @zengwang430521
+- Add Chinese documentation ([\#787](https://github.com/open-mmlab/mmpose/pull/787), [\#798](https://github.com/open-mmlab/mmpose/pull/798), [\#799](https://github.com/open-mmlab/mmpose/pull/799), [\#802](https://github.com/open-mmlab/mmpose/pull/802), [\#804](https://github.com/open-mmlab/mmpose/pull/804), [\#805](https://github.com/open-mmlab/mmpose/pull/805), [\#815](https://github.com/open-mmlab/mmpose/pull/815), [\#816](https://github.com/open-mmlab/mmpose/pull/816), [\#817](https://github.com/open-mmlab/mmpose/pull/817), [\#819](https://github.com/open-mmlab/mmpose/pull/819), [\#839](https://github.com/open-mmlab/mmpose/pull/839)) @ly015, @luminxu, @jin-s13, @liqikai9, @zengwang430521
+- Add Colab Tutorial ([\#834](https://github.com/open-mmlab/mmpose/pull/834)) @ly015
+- Support training for InterHand v1.0 dataset ([\#761](https://github.com/open-mmlab/mmpose/pull/761)) @zengwang430521
+
+**Bug Fixes**
+
+- Fix mpii pckh@0.1 index ([\#773](https://github.com/open-mmlab/mmpose/pull/773)) @jin-s13
+- Fix multi-node distributed test ([\#818](https://github.com/open-mmlab/mmpose/pull/818)) @ly015
+- Fix docstring and init_weights error of ShuffleNetV1 ([\#814](https://github.com/open-mmlab/mmpose/pull/814)) @Junjun2016
+- Fix imshow_bbox error when input bboxes is empty ([\#796](https://github.com/open-mmlab/mmpose/pull/796)) @ly015
+- Fix model zoo doc generation ([\#778](https://github.com/open-mmlab/mmpose/pull/778)) @ly015
+- Fix typo ([\#767](https://github.com/open-mmlab/mmpose/pull/767)), ([\#780](https://github.com/open-mmlab/mmpose/pull/780), [\#782](https://github.com/open-mmlab/mmpose/pull/782)) @ly015, @jin-s13
+
+**Breaking Changes**
+
+- Use MMCV EvalHook ([\#686](https://github.com/open-mmlab/mmpose/pull/686)) @ly015
+
+**Improvements**
+
+- Add pytest.ini and fix docstring ([\#812](https://github.com/open-mmlab/mmpose/pull/812)) @jin-s13
+- Update MSELoss ([\#829](https://github.com/open-mmlab/mmpose/pull/829)) @Ezra-Yu
+- Move process_mmdet_results into inference.py ([\#831](https://github.com/open-mmlab/mmpose/pull/831)) @ly015
+- Update resource limit ([\#783](https://github.com/open-mmlab/mmpose/pull/783)) @jin-s13
+- Use COCO 2D pose model in 3D demo examples ([\#785](https://github.com/open-mmlab/mmpose/pull/785)) @ly015
+- Change model zoo titles in the doc from center-aligned to left-aligned ([\#792](https://github.com/open-mmlab/mmpose/pull/792), [\#797](https://github.com/open-mmlab/mmpose/pull/797)) @ly015
+- Support MIM ([\#706](https://github.com/open-mmlab/mmpose/pull/706), [\#794](https://github.com/open-mmlab/mmpose/pull/794)) @ly015
+- Update out-of-date configs ([\#827](https://github.com/open-mmlab/mmpose/pull/827)) @jin-s13
+- Remove opencv-python-headless dependency by albumentations ([\#833](https://github.com/open-mmlab/mmpose/pull/833)) @ly015
+- Update QQ QR code in README_CN.md ([\#832](https://github.com/open-mmlab/mmpose/pull/832)) @ly015
+
+## v0.16.0 (02/07/2021)
+
+**Highlights**
+
+1. Support ["ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search"](https://arxiv.org/abs/2105.10154) CVPR'2021 ([\#742](https://github.com/open-mmlab/mmpose/pull/742),[\#755](https://github.com/open-mmlab/mmpose/pull/755)).
+1. Support MPI-INF-3DHP dataset ([\#683](https://github.com/open-mmlab/mmpose/pull/683),[\#746](https://github.com/open-mmlab/mmpose/pull/746),[\#751](https://github.com/open-mmlab/mmpose/pull/751)).
+1. Add webcam demo tool ([\#729](https://github.com/open-mmlab/mmpose/pull/729))
+1. Add 3d body and hand pose estimation demo ([\#704](https://github.com/open-mmlab/mmpose/pull/704), [\#727](https://github.com/open-mmlab/mmpose/pull/727)).
+
+**New Features**
+
+- Support ["ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search"](https://arxiv.org/abs/2105.10154) CVPR'2021 ([\#742](https://github.com/open-mmlab/mmpose/pull/742),[\#755](https://github.com/open-mmlab/mmpose/pull/755))
+- Support MPI-INF-3DHP dataset ([\#683](https://github.com/open-mmlab/mmpose/pull/683),[\#746](https://github.com/open-mmlab/mmpose/pull/746),[\#751](https://github.com/open-mmlab/mmpose/pull/751))
+- Support Webcam demo ([\#729](https://github.com/open-mmlab/mmpose/pull/729))
+- Support Interhand 3d demo ([\#704](https://github.com/open-mmlab/mmpose/pull/704))
+- Support 3d pose video demo ([\#727](https://github.com/open-mmlab/mmpose/pull/727))
+- Support H36m dataset for 2d pose estimation ([\#709](https://github.com/open-mmlab/mmpose/pull/709), [\#735](https://github.com/open-mmlab/mmpose/pull/735))
+- Add scripts to generate mim metafile ([\#749](https://github.com/open-mmlab/mmpose/pull/749))
+
+**Bug Fixes**
+
+- Fix typos ([\#692](https://github.com/open-mmlab/mmpose/pull/692),[\#696](https://github.com/open-mmlab/mmpose/pull/696),[\#697](https://github.com/open-mmlab/mmpose/pull/697),[\#698](https://github.com/open-mmlab/mmpose/pull/698),[\#712](https://github.com/open-mmlab/mmpose/pull/712),[\#718](https://github.com/open-mmlab/mmpose/pull/718),[\#728](https://github.com/open-mmlab/mmpose/pull/728))
+- Change model download links from `http` to `https` ([\#716](https://github.com/open-mmlab/mmpose/pull/716))
+
+**Breaking Changes**
+
+- Switch to MMCV MODEL_REGISTRY ([\#669](https://github.com/open-mmlab/mmpose/pull/669))
+
+**Improvements**
+
+- Refactor MeshMixDataset ([\#752](https://github.com/open-mmlab/mmpose/pull/752))
+- Rename 'GaussianHeatMap' to 'GaussianHeatmap' ([\#745](https://github.com/open-mmlab/mmpose/pull/745))
+- Update out-of-date configs ([\#734](https://github.com/open-mmlab/mmpose/pull/734))
+- Improve compatibility for breaking changes ([\#731](https://github.com/open-mmlab/mmpose/pull/731))
+- Enable to control radius and thickness in visualization ([\#722](https://github.com/open-mmlab/mmpose/pull/722))
+- Add regex dependency ([\#720](https://github.com/open-mmlab/mmpose/pull/720))
+
+## v0.15.0 (02/06/2021)
+
+**Highlights**
+
+1. Support 3d video pose estimation (VideoPose3D).
+1. Support 3d hand pose estimation (InterNet).
+1. Improve presentation of modelzoo.
+
+**New Features**
+
+- Support "InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image" (ECCV‘20) ([\#624](https://github.com/open-mmlab/mmpose/pull/624))
+- Support "3D human pose estimation in video with temporal convolutions and semi-supervised training" (CVPR'19) ([\#602](https://github.com/open-mmlab/mmpose/pull/602), [\#681](https://github.com/open-mmlab/mmpose/pull/681))
+- Support 3d pose estimation demo ([\#653](https://github.com/open-mmlab/mmpose/pull/653), [\#670](https://github.com/open-mmlab/mmpose/pull/670))
+- Support bottom-up whole-body pose estimation ([\#689](https://github.com/open-mmlab/mmpose/pull/689))
+- Support mmcli ([\#634](https://github.com/open-mmlab/mmpose/pull/634))
+
+**Bug Fixes**
+
+- Fix opencv compatibility ([\#635](https://github.com/open-mmlab/mmpose/pull/635))
+- Fix demo with UDP ([\#637](https://github.com/open-mmlab/mmpose/pull/637))
+- Fix bottom-up model onnx conversion ([\#680](https://github.com/open-mmlab/mmpose/pull/680))
+- Fix `GPU_IDS` in distributed training ([\#668](https://github.com/open-mmlab/mmpose/pull/668))
+- Fix MANIFEST.in ([\#641](https://github.com/open-mmlab/mmpose/pull/641), [\#657](https://github.com/open-mmlab/mmpose/pull/657))
+- Fix docs ([\#643](https://github.com/open-mmlab/mmpose/pull/643),[\#684](https://github.com/open-mmlab/mmpose/pull/684),[\#688](https://github.com/open-mmlab/mmpose/pull/688),[\#690](https://github.com/open-mmlab/mmpose/pull/690),[\#692](https://github.com/open-mmlab/mmpose/pull/692))
+
+**Breaking Changes**
+
+- Reorganize configs by tasks, algorithms, datasets, and techniques ([\#647](https://github.com/open-mmlab/mmpose/pull/647))
+- Rename heads and detectors ([\#667](https://github.com/open-mmlab/mmpose/pull/667))
+
+**Improvements**
+
+- Add `radius` and `thickness` parameters in visualization ([\#638](https://github.com/open-mmlab/mmpose/pull/638))
+- Add `trans_prob` parameter in `TopDownRandomTranslation` ([\#650](https://github.com/open-mmlab/mmpose/pull/650))
+- Switch to `MMCV MODEL_REGISTRY` ([\#669](https://github.com/open-mmlab/mmpose/pull/669))
+- Update dependencies ([\#674](https://github.com/open-mmlab/mmpose/pull/674), [\#676](https://github.com/open-mmlab/mmpose/pull/676))
+
+## v0.14.0 (06/05/2021)
+
+**Highlights**
+
+1. Support animal pose estimation with 7 popular datasets.
+1. Support "A simple yet effective baseline for 3d human pose estimation" (ICCV'17).
+
+**New Features**
+
+- Support "A simple yet effective baseline for 3d human pose estimation" (ICCV'17) ([\#554](https://github.com/open-mmlab/mmpose/pull/554),[\#558](https://github.com/open-mmlab/mmpose/pull/558),[\#566](https://github.com/open-mmlab/mmpose/pull/566),[\#570](https://github.com/open-mmlab/mmpose/pull/570),[\#589](https://github.com/open-mmlab/mmpose/pull/589))
+- Support animal pose estimation ([\#559](https://github.com/open-mmlab/mmpose/pull/559),[\#561](https://github.com/open-mmlab/mmpose/pull/561),[\#563](https://github.com/open-mmlab/mmpose/pull/563),[\#571](https://github.com/open-mmlab/mmpose/pull/571),[\#603](https://github.com/open-mmlab/mmpose/pull/603),[\#605](https://github.com/open-mmlab/mmpose/pull/605))
+- Support Horse-10 dataset ([\#561](https://github.com/open-mmlab/mmpose/pull/561)), MacaquePose dataset ([\#561](https://github.com/open-mmlab/mmpose/pull/561)), Vinegar Fly dataset ([\#561](https://github.com/open-mmlab/mmpose/pull/561)), Desert Locust dataset ([\#561](https://github.com/open-mmlab/mmpose/pull/561)), Grevy's Zebra dataset ([\#561](https://github.com/open-mmlab/mmpose/pull/561)), ATRW dataset ([\#571](https://github.com/open-mmlab/mmpose/pull/571)), and Animal-Pose dataset ([\#603](https://github.com/open-mmlab/mmpose/pull/603))
+- Support bottom-up pose tracking demo ([\#574](https://github.com/open-mmlab/mmpose/pull/574))
+- Support FP16 training ([\#584](https://github.com/open-mmlab/mmpose/pull/584),[\#616](https://github.com/open-mmlab/mmpose/pull/616),[\#626](https://github.com/open-mmlab/mmpose/pull/626))
+- Support NMS for bottom-up ([\#609](https://github.com/open-mmlab/mmpose/pull/609))
+
+**Bug Fixes**
+
+- Fix bugs in the top-down demo, when there are no people in the images ([\#569](https://github.com/open-mmlab/mmpose/pull/569)).
+- Fix the links in the doc ([\#612](https://github.com/open-mmlab/mmpose/pull/612))
+
+**Improvements**
+
+- Speed up top-down inference ([\#560](https://github.com/open-mmlab/mmpose/pull/560))
+- Update github CI ([\#562](https://github.com/open-mmlab/mmpose/pull/562), [\#564](https://github.com/open-mmlab/mmpose/pull/564))
+- Update Readme ([\#578](https://github.com/open-mmlab/mmpose/pull/578),[\#579](https://github.com/open-mmlab/mmpose/pull/579),[\#580](https://github.com/open-mmlab/mmpose/pull/580),[\#592](https://github.com/open-mmlab/mmpose/pull/592),[\#599](https://github.com/open-mmlab/mmpose/pull/599),[\#600](https://github.com/open-mmlab/mmpose/pull/600),[\#607](https://github.com/open-mmlab/mmpose/pull/607))
+- Update Faq ([\#587](https://github.com/open-mmlab/mmpose/pull/587), [\#610](https://github.com/open-mmlab/mmpose/pull/610))
+
+## v0.13.0 (31/03/2021)
+
+**Highlights**
+
+1. Support Wingloss.
+1. Support RHD hand dataset.
+
+**New Features**
+
+- Support Wingloss ([\#482](https://github.com/open-mmlab/mmpose/pull/482))
+- Support RHD hand dataset ([\#523](https://github.com/open-mmlab/mmpose/pull/523), [\#551](https://github.com/open-mmlab/mmpose/pull/551))
+- Support Human3.6m dataset for 3d keypoint detection ([\#518](https://github.com/open-mmlab/mmpose/pull/518), [\#527](https://github.com/open-mmlab/mmpose/pull/527))
+- Support TCN model for 3d keypoint detection ([\#521](https://github.com/open-mmlab/mmpose/pull/521), [\#522](https://github.com/open-mmlab/mmpose/pull/522))
+- Support Interhand3D model for 3d hand detection ([\#536](https://github.com/open-mmlab/mmpose/pull/536))
+- Support Multi-task detector ([\#480](https://github.com/open-mmlab/mmpose/pull/480))
+
+**Bug Fixes**
+
+- Fix PCKh@0.1 calculation ([\#516](https://github.com/open-mmlab/mmpose/pull/516))
+- Fix unittest ([\#529](https://github.com/open-mmlab/mmpose/pull/529))
+- Fix circular importing ([\#542](https://github.com/open-mmlab/mmpose/pull/542))
+- Fix bugs in bottom-up keypoint score ([\#548](https://github.com/open-mmlab/mmpose/pull/548))
+
+**Improvements**
+
+- Update config & checkpoints ([\#525](https://github.com/open-mmlab/mmpose/pull/525), [\#546](https://github.com/open-mmlab/mmpose/pull/546))
+- Fix typos ([\#514](https://github.com/open-mmlab/mmpose/pull/514), [\#519](https://github.com/open-mmlab/mmpose/pull/519), [\#532](https://github.com/open-mmlab/mmpose/pull/532), [\#537](https://github.com/open-mmlab/mmpose/pull/537), )
+- Speed up post processing ([\#535](https://github.com/open-mmlab/mmpose/pull/535))
+- Update mmcv version dependency ([\#544](https://github.com/open-mmlab/mmpose/pull/544))
+
+## v0.12.0 (28/02/2021)
+
+**Highlights**
+
+1. Support DeepPose algorithm.
+
+**New Features**
+
+- Support DeepPose algorithm ([\#446](https://github.com/open-mmlab/mmpose/pull/446), [\#461](https://github.com/open-mmlab/mmpose/pull/461))
+- Support interhand3d dataset ([\#468](https://github.com/open-mmlab/mmpose/pull/468))
+- Support Albumentation pipeline ([\#469](https://github.com/open-mmlab/mmpose/pull/469))
+- Support PhotometricDistortion pipeline ([\#485](https://github.com/open-mmlab/mmpose/pull/485))
+- Set seed option for training ([\#493](https://github.com/open-mmlab/mmpose/pull/493))
+- Add demos for face keypoint detection ([\#502](https://github.com/open-mmlab/mmpose/pull/502))
+
+**Bug Fixes**
+
+- Change channel order according to configs ([\#504](https://github.com/open-mmlab/mmpose/pull/504))
+- Fix `num_factors` in UDP encoding ([\#495](https://github.com/open-mmlab/mmpose/pull/495))
+- Fix configs ([\#456](https://github.com/open-mmlab/mmpose/pull/456))
+
+**Breaking Changes**
+
+- Refactor configs for wholebody pose estimation ([\#487](https://github.com/open-mmlab/mmpose/pull/487), [\#491](https://github.com/open-mmlab/mmpose/pull/491))
+- Rename `decode` function for heads ([\#481](https://github.com/open-mmlab/mmpose/pull/481))
+
+**Improvements**
+
+- Update config & checkpoints ([\#453](https://github.com/open-mmlab/mmpose/pull/453),[\#484](https://github.com/open-mmlab/mmpose/pull/484),[\#487](https://github.com/open-mmlab/mmpose/pull/487))
+- Add README in Chinese ([\#462](https://github.com/open-mmlab/mmpose/pull/462))
+- Add tutorials about configs ([\#465](https://github.com/open-mmlab/mmpose/pull/465))
+- Add demo videos for various tasks ([\#499](https://github.com/open-mmlab/mmpose/pull/499), [\#503](https://github.com/open-mmlab/mmpose/pull/503))
+- Update docs about MMPose installation ([\#467](https://github.com/open-mmlab/mmpose/pull/467), [\#505](https://github.com/open-mmlab/mmpose/pull/505))
+- Rename `stat.py` to `stats.py` ([\#483](https://github.com/open-mmlab/mmpose/pull/483))
+- Fix typos ([\#463](https://github.com/open-mmlab/mmpose/pull/463), [\#464](https://github.com/open-mmlab/mmpose/pull/464), [\#477](https://github.com/open-mmlab/mmpose/pull/477), [\#481](https://github.com/open-mmlab/mmpose/pull/481))
+- latex to bibtex ([\#471](https://github.com/open-mmlab/mmpose/pull/471))
+- Update FAQ ([\#466](https://github.com/open-mmlab/mmpose/pull/466))
+
+## v0.11.0 (31/01/2021)
+
+**Highlights**
+
+1. Support fashion landmark detection.
+1. Support face keypoint detection.
+1. Support pose tracking with MMTracking.
+
+**New Features**
+
+- Support fashion landmark detection (DeepFashion) ([\#413](https://github.com/open-mmlab/mmpose/pull/413))
+- Support face keypoint detection (300W, AFLW, COFW, WFLW) ([\#367](https://github.com/open-mmlab/mmpose/pull/367))
+- Support pose tracking demo with MMTracking ([\#427](https://github.com/open-mmlab/mmpose/pull/427))
+- Support face demo ([\#443](https://github.com/open-mmlab/mmpose/pull/443))
+- Support AIC dataset for bottom-up methods ([\#438](https://github.com/open-mmlab/mmpose/pull/438), [\#449](https://github.com/open-mmlab/mmpose/pull/449))
+
+**Bug Fixes**
+
+- Fix multi-batch training ([\#434](https://github.com/open-mmlab/mmpose/pull/434))
+- Fix sigmas in AIC dataset ([\#441](https://github.com/open-mmlab/mmpose/pull/441))
+- Fix config file ([\#420](https://github.com/open-mmlab/mmpose/pull/420))
+
+**Breaking Changes**
+
+- Refactor Heads ([\#382](https://github.com/open-mmlab/mmpose/pull/382))
+
+**Improvements**
+
+- Update readme ([\#409](https://github.com/open-mmlab/mmpose/pull/409), [\#412](https://github.com/open-mmlab/mmpose/pull/412), [\#415](https://github.com/open-mmlab/mmpose/pull/415), [\#416](https://github.com/open-mmlab/mmpose/pull/416), [\#419](https://github.com/open-mmlab/mmpose/pull/419), [\#421](https://github.com/open-mmlab/mmpose/pull/421), [\#422](https://github.com/open-mmlab/mmpose/pull/422), [\#424](https://github.com/open-mmlab/mmpose/pull/424), [\#425](https://github.com/open-mmlab/mmpose/pull/425), [\#435](https://github.com/open-mmlab/mmpose/pull/435), [\#436](https://github.com/open-mmlab/mmpose/pull/436), [\#437](https://github.com/open-mmlab/mmpose/pull/437), [\#444](https://github.com/open-mmlab/mmpose/pull/444), [\#445](https://github.com/open-mmlab/mmpose/pull/445))
+- Add GAP (global average pooling) neck ([\#414](https://github.com/open-mmlab/mmpose/pull/414))
+- Speed up ([\#411](https://github.com/open-mmlab/mmpose/pull/411), [\#423](https://github.com/open-mmlab/mmpose/pull/423))
+- Support COCO test-dev test ([\#433](https://github.com/open-mmlab/mmpose/pull/433))
+
+## v0.10.0 (31/12/2020)
+
+**Highlights**
+
+1. Support more human pose estimation methods.
+ - [UDP](https://arxiv.org/abs/1911.07524)
+1. Support pose tracking.
+1. Support multi-batch inference.
+1. Add some useful tools, including `analyze_logs`, `get_flops`, `print_config`.
+1. Support more backbone networks.
+ - [ResNest](https://arxiv.org/pdf/2004.08955.pdf)
+ - [VGG](https://arxiv.org/abs/1409.1556)
+
+**New Features**
+
+- Support UDP ([\#353](https://github.com/open-mmlab/mmpose/pull/353), [\#371](https://github.com/open-mmlab/mmpose/pull/371), [\#402](https://github.com/open-mmlab/mmpose/pull/402))
+- Support multi-batch inference ([\#390](https://github.com/open-mmlab/mmpose/pull/390))
+- Support MHP dataset ([\#386](https://github.com/open-mmlab/mmpose/pull/386))
+- Support pose tracking demo ([\#380](https://github.com/open-mmlab/mmpose/pull/380))
+- Support mpii-trb demo ([\#372](https://github.com/open-mmlab/mmpose/pull/372))
+- Support mobilenet for hand pose estimation ([\#377](https://github.com/open-mmlab/mmpose/pull/377))
+- Support ResNest backbone ([\#370](https://github.com/open-mmlab/mmpose/pull/370))
+- Support VGG backbone ([\#370](https://github.com/open-mmlab/mmpose/pull/370))
+- Add some useful tools, including `analyze_logs`, `get_flops`, `print_config` ([\#324](https://github.com/open-mmlab/mmpose/pull/324))
+
+**Bug Fixes**
+
+- Fix bugs in pck evaluation ([\#328](https://github.com/open-mmlab/mmpose/pull/328))
+- Fix model download links in README ([\#396](https://github.com/open-mmlab/mmpose/pull/396), [\#397](https://github.com/open-mmlab/mmpose/pull/397))
+- Fix CrowdPose annotations and update benchmarks ([\#384](https://github.com/open-mmlab/mmpose/pull/384))
+- Fix modelzoo stat ([\#354](https://github.com/open-mmlab/mmpose/pull/354), [\#360](https://github.com/open-mmlab/mmpose/pull/360), [\#362](https://github.com/open-mmlab/mmpose/pull/362))
+- Fix config files for aic datasets ([\#340](https://github.com/open-mmlab/mmpose/pull/340))
+
+**Breaking Changes**
+
+- Rename `image_thr` to `det_bbox_thr` for top-down methods.
+
+**Improvements**
+
+- Organize the readme files ([\#398](https://github.com/open-mmlab/mmpose/pull/398), [\#399](https://github.com/open-mmlab/mmpose/pull/399), [\#400](https://github.com/open-mmlab/mmpose/pull/400))
+- Check linting for markdown ([\#379](https://github.com/open-mmlab/mmpose/pull/379))
+- Add faq.md ([\#350](https://github.com/open-mmlab/mmpose/pull/350))
+- Remove PyTorch 1.4 in CI ([\#338](https://github.com/open-mmlab/mmpose/pull/338))
+- Add pypi badge in readme ([\#329](https://github.com/open-mmlab/mmpose/pull/329))
+
+## v0.9.0 (30/11/2020)
+
+**Highlights**
+
+1. Support more human pose estimation methods.
+ - [MSPN](https://arxiv.org/abs/1901.00148)
+ - [RSN](https://arxiv.org/abs/2003.04030)
+1. Support video pose estimation datasets.
+ - [sub-JHMDB](http://jhmdb.is.tue.mpg.de/dataset)
+1. Support Onnx model conversion.
+
+**New Features**
+
+- Support MSPN ([\#278](https://github.com/open-mmlab/mmpose/pull/278))
+- Support RSN ([\#221](https://github.com/open-mmlab/mmpose/pull/221), [\#318](https://github.com/open-mmlab/mmpose/pull/318))
+- Support new post-processing method for MSPN & RSN ([\#288](https://github.com/open-mmlab/mmpose/pull/288))
+- Support sub-JHMDB dataset ([\#292](https://github.com/open-mmlab/mmpose/pull/292))
+- Support urls for pre-trained models in config files ([\#232](https://github.com/open-mmlab/mmpose/pull/232))
+- Support Onnx ([\#305](https://github.com/open-mmlab/mmpose/pull/305))
+
+**Bug Fixes**
+
+- Fix model download links in README ([\#255](https://github.com/open-mmlab/mmpose/pull/255), [\#315](https://github.com/open-mmlab/mmpose/pull/315))
+
+**Breaking Changes**
+
+- `post_process=True|False` and `unbiased_decoding=True|False` are deprecated, use `post_process=None|default|unbiased` etc. instead ([\#288](https://github.com/open-mmlab/mmpose/pull/288))
+
+**Improvements**
+
+- Enrich the model zoo ([\#256](https://github.com/open-mmlab/mmpose/pull/256), [\#320](https://github.com/open-mmlab/mmpose/pull/320))
+- Set the default map_location as 'cpu' to reduce gpu memory cost ([\#227](https://github.com/open-mmlab/mmpose/pull/227))
+- Support return heatmaps and backbone features for bottom-up models ([\#229](https://github.com/open-mmlab/mmpose/pull/229))
+- Upgrade mmcv maximum & minimum version ([\#269](https://github.com/open-mmlab/mmpose/pull/269), [\#313](https://github.com/open-mmlab/mmpose/pull/313))
+- Automatically add modelzoo statistics to readthedocs ([\#252](https://github.com/open-mmlab/mmpose/pull/252))
+- Fix Pylint issues ([\#258](https://github.com/open-mmlab/mmpose/pull/258), [\#259](https://github.com/open-mmlab/mmpose/pull/259), [\#260](https://github.com/open-mmlab/mmpose/pull/260), [\#262](https://github.com/open-mmlab/mmpose/pull/262), [\#265](https://github.com/open-mmlab/mmpose/pull/265), [\#267](https://github.com/open-mmlab/mmpose/pull/267), [\#268](https://github.com/open-mmlab/mmpose/pull/268), [\#270](https://github.com/open-mmlab/mmpose/pull/270), [\#271](https://github.com/open-mmlab/mmpose/pull/271), [\#272](https://github.com/open-mmlab/mmpose/pull/272), [\#273](https://github.com/open-mmlab/mmpose/pull/273), [\#275](https://github.com/open-mmlab/mmpose/pull/275), [\#276](https://github.com/open-mmlab/mmpose/pull/276), [\#283](https://github.com/open-mmlab/mmpose/pull/283), [\#285](https://github.com/open-mmlab/mmpose/pull/285), [\#293](https://github.com/open-mmlab/mmpose/pull/293), [\#294](https://github.com/open-mmlab/mmpose/pull/294), [\#295](https://github.com/open-mmlab/mmpose/pull/295))
+- Improve README ([\#226](https://github.com/open-mmlab/mmpose/pull/226), [\#257](https://github.com/open-mmlab/mmpose/pull/257), [\#264](https://github.com/open-mmlab/mmpose/pull/264), [\#280](https://github.com/open-mmlab/mmpose/pull/280), [\#296](https://github.com/open-mmlab/mmpose/pull/296))
+- Support PyTorch 1.7 in CI ([\#274](https://github.com/open-mmlab/mmpose/pull/274))
+- Add docs/tutorials for running demos ([\#263](https://github.com/open-mmlab/mmpose/pull/263))
+
+## v0.8.0 (31/10/2020)
+
+**Highlights**
+
+1. Support more human pose estimation datasets.
+ - [CrowdPose](https://github.com/Jeff-sjtu/CrowdPose)
+ - [PoseTrack18](https://posetrack.net/)
+1. Support more 2D hand keypoint estimation datasets.
+ - [InterHand2.6](https://github.com/facebookresearch/InterHand2.6M)
+1. Support adversarial training for 3D human shape recovery.
+1. Support multi-stage losses.
+1. Support mpii demo.
+
+**New Features**
+
+- Support [CrowdPose](https://github.com/Jeff-sjtu/CrowdPose) dataset ([\#195](https://github.com/open-mmlab/mmpose/pull/195))
+- Support [PoseTrack18](https://posetrack.net/) dataset ([\#220](https://github.com/open-mmlab/mmpose/pull/220))
+- Support [InterHand2.6](https://github.com/facebookresearch/InterHand2.6M) dataset ([\#202](https://github.com/open-mmlab/mmpose/pull/202))
+- Support adversarial training for 3D human shape recovery ([\#192](https://github.com/open-mmlab/mmpose/pull/192))
+- Support multi-stage losses ([\#204](https://github.com/open-mmlab/mmpose/pull/204))
+
+**Bug Fixes**
+
+- Fix config files ([\#190](https://github.com/open-mmlab/mmpose/pull/190))
+
+**Improvements**
+
+- Add mpii demo ([\#216](https://github.com/open-mmlab/mmpose/pull/216))
+- Improve README ([\#181](https://github.com/open-mmlab/mmpose/pull/181), [\#183](https://github.com/open-mmlab/mmpose/pull/183), [\#208](https://github.com/open-mmlab/mmpose/pull/208))
+- Support return heatmaps and backbone features ([\#196](https://github.com/open-mmlab/mmpose/pull/196), [\#212](https://github.com/open-mmlab/mmpose/pull/212))
+- Support different return formats of mmdetection models ([\#217](https://github.com/open-mmlab/mmpose/pull/217))
+
+## v0.7.0 (30/9/2020)
+
+**Highlights**
+
+1. Support HMR for 3D human shape recovery.
+1. Support WholeBody human pose estimation.
+ - [COCO-WholeBody](https://github.com/jin-s13/COCO-WholeBody)
+1. Support more 2D hand keypoint estimation datasets.
+ - [Frei-hand](https://lmb.informatik.uni-freiburg.de/projects/freihand/)
+ - [CMU Panoptic HandDB](http://domedb.perception.cs.cmu.edu/handdb.html)
+1. Add more popular backbones & enrich the [modelzoo](https://mmpose.readthedocs.io/en/latest/model_zoo.html)
+ - ShuffleNetv2
+1. Support hand demo and whole-body demo.
+
+**New Features**
+
+- Support HMR for 3D human shape recovery ([\#157](https://github.com/open-mmlab/mmpose/pull/157), [\#160](https://github.com/open-mmlab/mmpose/pull/160), [\#161](https://github.com/open-mmlab/mmpose/pull/161), [\#162](https://github.com/open-mmlab/mmpose/pull/162))
+- Support [COCO-WholeBody](https://github.com/jin-s13/COCO-WholeBody) dataset ([\#133](https://github.com/open-mmlab/mmpose/pull/133))
+- Support [Frei-hand](https://lmb.informatik.uni-freiburg.de/projects/freihand/) dataset ([\#125](https://github.com/open-mmlab/mmpose/pull/125))
+- Support [CMU Panoptic HandDB](http://domedb.perception.cs.cmu.edu/handdb.html) dataset ([\#144](https://github.com/open-mmlab/mmpose/pull/144))
+- Support H36M dataset ([\#159](https://github.com/open-mmlab/mmpose/pull/159))
+- Support ShuffleNetv2 ([\#139](https://github.com/open-mmlab/mmpose/pull/139))
+- Support saving best models based on key indicator ([\#127](https://github.com/open-mmlab/mmpose/pull/127))
+
+**Bug Fixes**
+
+- Fix typos in docs ([\#121](https://github.com/open-mmlab/mmpose/pull/121))
+- Fix assertion ([\#142](https://github.com/open-mmlab/mmpose/pull/142))
+
+**Improvements**
+
+- Add tools to transform .mat format to .json format ([\#126](https://github.com/open-mmlab/mmpose/pull/126))
+- Add hand demo ([\#115](https://github.com/open-mmlab/mmpose/pull/115))
+- Add whole-body demo ([\#163](https://github.com/open-mmlab/mmpose/pull/163))
+- Reuse mmcv utility function and update version files ([\#135](https://github.com/open-mmlab/mmpose/pull/135), [\#137](https://github.com/open-mmlab/mmpose/pull/137))
+- Enrich the modelzoo ([\#147](https://github.com/open-mmlab/mmpose/pull/147), [\#169](https://github.com/open-mmlab/mmpose/pull/169))
+- Improve docs ([\#174](https://github.com/open-mmlab/mmpose/pull/174), [\#175](https://github.com/open-mmlab/mmpose/pull/175), [\#178](https://github.com/open-mmlab/mmpose/pull/178))
+- Improve README ([\#176](https://github.com/open-mmlab/mmpose/pull/176))
+- Improve version.py ([\#173](https://github.com/open-mmlab/mmpose/pull/173))
+
+## v0.6.0 (31/8/2020)
+
+**Highlights**
+
+1. Add more popular backbones & enrich the [modelzoo](https://mmpose.readthedocs.io/en/latest/model_zoo.html)
+ - ResNext
+ - SEResNet
+ - ResNetV1D
+ - MobileNetv2
+ - ShuffleNetv1
+ - CPM (Convolutional Pose Machine)
+1. Add more popular datasets:
+ - [AIChallenger](https://arxiv.org/abs/1711.06475?context=cs.CV)
+ - [MPII](http://human-pose.mpi-inf.mpg.de/)
+ - [MPII-TRB](https://github.com/kennymckormick/Triplet-Representation-of-human-Body)
+ - [OCHuman](http://www.liruilong.cn/projects/pose2seg/index.html)
+1. Support 2d hand keypoint estimation.
+ - [OneHand10K](https://www.yangangwang.com/papers/WANG-MCC-2018-10.html)
+1. Support bottom-up inference.
+
+**New Features**
+
+- Support [OneHand10K](https://www.yangangwang.com/papers/WANG-MCC-2018-10.html) dataset ([\#52](https://github.com/open-mmlab/mmpose/pull/52))
+- Support [MPII](http://human-pose.mpi-inf.mpg.de/) dataset ([\#55](https://github.com/open-mmlab/mmpose/pull/55))
+- Support [MPII-TRB](https://github.com/kennymckormick/Triplet-Representation-of-human-Body) dataset ([\#19](https://github.com/open-mmlab/mmpose/pull/19), [\#47](https://github.com/open-mmlab/mmpose/pull/47), [\#48](https://github.com/open-mmlab/mmpose/pull/48))
+- Support [OCHuman](http://www.liruilong.cn/projects/pose2seg/index.html) dataset ([\#70](https://github.com/open-mmlab/mmpose/pull/70))
+- Support [AIChallenger](https://arxiv.org/abs/1711.06475?context=cs.CV) dataset ([\#87](https://github.com/open-mmlab/mmpose/pull/87))
+- Support multiple backbones ([\#26](https://github.com/open-mmlab/mmpose/pull/26))
+- Support CPM model ([\#56](https://github.com/open-mmlab/mmpose/pull/56))
+
+**Bug Fixes**
+
+- Fix configs for MPII & MPII-TRB datasets ([\#93](https://github.com/open-mmlab/mmpose/pull/93))
+- Fix the bug of missing `test_pipeline` in configs ([\#14](https://github.com/open-mmlab/mmpose/pull/14))
+- Fix typos ([\#27](https://github.com/open-mmlab/mmpose/pull/27), [\#28](https://github.com/open-mmlab/mmpose/pull/28), [\#50](https://github.com/open-mmlab/mmpose/pull/50), [\#53](https://github.com/open-mmlab/mmpose/pull/53), [\#63](https://github.com/open-mmlab/mmpose/pull/63))
+
+**Improvements**
+
+- Update benchmark ([\#93](https://github.com/open-mmlab/mmpose/pull/93))
+- Add Dockerfile ([\#44](https://github.com/open-mmlab/mmpose/pull/44))
+- Improve unittest coverage and minor fix ([\#18](https://github.com/open-mmlab/mmpose/pull/18))
+- Support CPUs for train/val/demo ([\#34](https://github.com/open-mmlab/mmpose/pull/34))
+- Support bottom-up demo ([\#69](https://github.com/open-mmlab/mmpose/pull/69))
+- Add tools to publish model ([\#62](https://github.com/open-mmlab/mmpose/pull/62))
+- Enrich the modelzoo ([\#64](https://github.com/open-mmlab/mmpose/pull/64), [\#68](https://github.com/open-mmlab/mmpose/pull/68), [\#82](https://github.com/open-mmlab/mmpose/pull/82))
+
+## v0.5.0 (21/7/2020)
+
+**Highlights**
+
+- MMPose is released.
+
+**Main Features**
+
+- Support both top-down and bottom-up pose estimation approaches.
+- Achieve higher training efficiency and higher accuracy than other popular codebases (e.g. AlphaPose, HRNet)
+- Support various backbone models: ResNet, HRNet, SCNet, Houglass and HigherHRNet.
diff --git a/vendor/ViTPose/docs/en/collect.py b/vendor/ViTPose/docs/en/collect.py
new file mode 100644
index 0000000000000000000000000000000000000000..5f8aedee0616d0bcf61d325feeced3738d524218
--- /dev/null
+++ b/vendor/ViTPose/docs/en/collect.py
@@ -0,0 +1,101 @@
+#!/usr/bin/env python
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import re
+from glob import glob
+
+from titlecase import titlecase
+
+os.makedirs('topics', exist_ok=True)
+os.makedirs('papers', exist_ok=True)
+
+# Step 1: get subtopics: a mix of topic and task
+minisections = [
+ x.split('/')[-2:] for x in glob('../../configs/*/*') if '_base_' not in x
+]
+alltopics = sorted(list(set(x[0] for x in minisections)))
+subtopics = []
+for t in alltopics:
+ data = [x[1].split('_') for x in minisections if x[0] == t]
+ valid_ids = []
+ for i in range(len(data[0])):
+ if len(set(x[i] for x in data)) > 1:
+ valid_ids.append(i)
+ if len(valid_ids) > 0:
+ subtopics.extend([
+ f"{titlecase(t)}({','.join([d[i].title() for i in valid_ids])})",
+ t, '_'.join(d)
+ ] for d in data)
+ else:
+ subtopics.append([titlecase(t), t, '_'.join(data[0])])
+
+contents = {}
+for subtopic, topic, task in sorted(subtopics):
+ # Step 2: get all datasets
+ datasets = sorted(
+ list(
+ set(
+ x.split('/')[-2]
+ for x in glob(f'../../configs/{topic}/{task}/*/*/'))))
+ contents[subtopic] = {d: {} for d in datasets}
+ for dataset in datasets:
+ # Step 3: get all settings: algorithm + backbone + trick
+ for file in glob(f'../../configs/{topic}/{task}/*/{dataset}/*.md'):
+ keywords = (file.split('/')[-3],
+ *file.split('/')[-1].split('_')[:-1])
+ with open(file, 'r') as f:
+ contents[subtopic][dataset][keywords] = f.read()
+
+# Step 4: write files by topic
+for subtopic, datasets in contents.items():
+ lines = [f'# {subtopic}', '']
+ for dataset, keywords in datasets.items():
+ if len(keywords) == 0:
+ continue
+ lines += [
+ '+
', '
', '', f'## {titlecase(dataset)} Dataset', '' + ] + for keyword, info in keywords.items(): + keyword_strs = [titlecase(x.replace('_', ' ')) for x in keyword] + lines += [ + '
', '', + (f'### {" + ".join(keyword_strs)}' + f' on {titlecase(dataset)}'), '', info, '' + ] + + with open(f'topics/{subtopic.lower()}.md', 'w') as f: + f.write('\n'.join(lines)) + +# Step 5: write files by paper +allfiles = [x.split('/')[-2:] for x in glob('../en/papers/*/*.md')] +sections = sorted(list(set(x[0] for x in allfiles))) +for section in sections: + lines = [f'# {titlecase(section)}', ''] + files = [f for s, f in allfiles if s == section] + for file in files: + with open(f'../en/papers/{section}/{file}', 'r') as f: + keyline = [ + line for line in f.readlines() if line.startswith('
', '', + (f'### {" + ".join(keyword_strs)}' + f' on {titlecase(dataset)}'), '', info, '' + ] + if len(paperlines) > 0: + lines += ['
', '
', '', f'## {papername}', ''] + lines += paperlines + + with open(f'papers/{section}.md', 'w') as f: + f.write('\n'.join(lines)) diff --git a/vendor/ViTPose/docs/en/conf.py b/vendor/ViTPose/docs/en/conf.py new file mode 100644 index 0000000000000000000000000000000000000000..10efef64d6ae6818bc6a2b85715265fe5ad4a017 --- /dev/null +++ b/vendor/ViTPose/docs/en/conf.py @@ -0,0 +1,116 @@ +# Copyright (c) OpenMMLab. All rights reserved. +# Configuration file for the Sphinx documentation builder. +# +# This file only contains a selection of the most common options. For a full +# list see the documentation: +# https://www.sphinx-doc.org/en/master/usage/configuration.html + +# -- Path setup -------------------------------------------------------------- + +# If extensions (or modules to document with autodoc) are in another directory, +# add these directories to sys.path here. If the directory is relative to the +# documentation root, use os.path.abspath to make it absolute, like shown here. +# +import os +import subprocess +import sys + +import pytorch_sphinx_theme + +sys.path.insert(0, os.path.abspath('../..')) + +# -- Project information ----------------------------------------------------- + +project = 'MMPose' +copyright = '2020-2021, OpenMMLab' +author = 'MMPose Authors' + +# The full version, including alpha/beta/rc tags +version_file = '../../mmpose/version.py' + + +def get_version(): + with open(version_file, 'r') as f: + exec(compile(f.read(), version_file, 'exec')) + return locals()['__version__'] + + +release = get_version() + +# -- General configuration --------------------------------------------------- + +# Add any Sphinx extension module names here, as strings. They can be +# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom +# ones. +extensions = [ + 'sphinx.ext.autodoc', 'sphinx.ext.napoleon', 'sphinx.ext.viewcode', + 'sphinx_markdown_tables', 'sphinx_copybutton', 'myst_parser' +] + +autodoc_mock_imports = ['json_tricks', 'mmpose.version'] + +# Ignore >>> when copying code +copybutton_prompt_text = r'>>> |\.\.\. ' +copybutton_prompt_is_regexp = True + +# Add any paths that contain templates here, relative to this directory. +templates_path = ['_templates'] + +# List of patterns, relative to source directory, that match files and +# directories to ignore when looking for source files. +# This pattern also affects html_static_path and html_extra_path. +exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store'] + +# -- Options for HTML output ------------------------------------------------- +source_suffix = { + '.rst': 'restructuredtext', + '.md': 'markdown', +} + +# The theme to use for HTML and HTML Help pages. See the documentation for +# a list of builtin themes. +# +html_theme = 'pytorch_sphinx_theme' +html_theme_path = [pytorch_sphinx_theme.get_html_theme_path()] +html_theme_options = { + 'menu': [ + { + 'name': + 'Tutorial', + 'url': + 'https://colab.research.google.com/github/' + 'open-mmlab/mmpose/blob/master/demo/MMPose_Tutorial.ipynb' + }, + { + 'name': 'GitHub', + 'url': 'https://github.com/open-mmlab/mmpose' + }, + ], + # Specify the language of the shared menu + 'menu_lang': + 'en' +} + +# Add any paths that contain custom static files (such as style sheets) here, +# relative to this directory. They are copied after the builtin static files, +# so a file named "default.css" will overwrite the builtin "default.css". + +language = 'en' + +html_static_path = ['_static'] +html_css_files = ['css/readthedocs.css'] + +# Enable ::: for my_st +myst_enable_extensions = ['colon_fence'] + +master_doc = 'index' + + +def builder_inited_handler(app): + subprocess.run(['./collect.py']) + subprocess.run(['./merge_docs.sh']) + subprocess.run(['./stats.py']) + + +def setup(app): + app.connect('builder-inited', builder_inited_handler) diff --git a/vendor/ViTPose/docs/en/data_preparation.md b/vendor/ViTPose/docs/en/data_preparation.md new file mode 100644 index 0000000000000000000000000000000000000000..0c691f532d504eecb24f566feaf0a1eaeb7a9f24 --- /dev/null +++ b/vendor/ViTPose/docs/en/data_preparation.md @@ -0,0 +1,13 @@ +# Prepare Datasets + +MMPose supports multiple tasks. Please follow the corresponding guidelines for data preparation. + +- [2D Body Keypoint](tasks/2d_body_keypoint.md) +- [3D Body Keypoint](tasks/3d_body_keypoint.md) +- [3D Body Mesh Recovery](tasks/3d_body_mesh.md) +- [2D Hand Keypoint](tasks/2d_hand_keypoint.md) +- [3D Hand Keypoint](tasks/3d_hand_keypoint.md) +- [2D Face Keypoint](tasks/2d_face_keypoint.md) +- [2D WholeBody Keypoint](tasks/2d_wholebody_keypoint.md) +- [2D Fashion Landmark](tasks/2d_fashion_landmark.md) +- [2D Animal Keypoint](tasks/2d_animal_keypoint.md) diff --git a/vendor/ViTPose/docs/en/faq.md b/vendor/ViTPose/docs/en/faq.md new file mode 100644 index 0000000000000000000000000000000000000000..277885f3787b361c73980d23f71fe0436fee9834 --- /dev/null +++ b/vendor/ViTPose/docs/en/faq.md @@ -0,0 +1,135 @@ +# FAQ + +We list some common issues faced by many users and their corresponding solutions here. +Feel free to enrich the list if you find any frequent issues and have ways to help others to solve them. +If the contents here do not cover your issue, please create an issue using the [provided templates](/.github/ISSUE_TEMPLATE/error-report.md) and make sure you fill in all required information in the template. + +## Installation + +- **Unable to install xtcocotools** + + 1. Try to install it using pypi manually `pip install xtcocotools`. + 1. If step1 does not work. Try to install it from [source](https://github.com/jin-s13/xtcocoapi). + + ``` + git clone https://github.com/jin-s13/xtcocoapi + cd xtcocoapi + python setup.py install + ``` + +- **No matching distribution found for xtcocotools>=1.6** + + 1. Install cython by `pip install cython`. + 1. Install xtcocotools from [source](https://github.com/jin-s13/xtcocoapi). + + ``` + git clone https://github.com/jin-s13/xtcocoapi + cd xtcocoapi + python setup.py install + ``` + +- **"No module named 'mmcv.ops'"; "No module named 'mmcv._ext'"** + + 1. Uninstall existing mmcv in the environment using `pip uninstall mmcv`. + 1. Install mmcv-full following the [installation instruction](https://mmcv.readthedocs.io/en/latest/#installation). + +## Data + +- **How to convert my 2d keypoint dataset to coco-type?** + + You may refer to this conversion [tool](https://github.com/open-mmlab/mmpose/blob/master/tools/dataset/parse_macaquepose_dataset.py) to prepare your data. + Here is an [example](https://github.com/open-mmlab/mmpose/blob/master/tests/data/macaque/test_macaque.json) of the coco-type json. + In the coco-type json, we need "categories", "annotations" and "images". "categories" contain some basic information of the dataset, e.g. class name and keypoint names. + "images" contain image-level information. We need "id", "file_name", "height", "width". Others are optional. + Note: (1) It is okay that "id"s are not continuous or not sorted (e.g. 1000, 40, 352, 333 ...). + + "annotations" contain instance-level information. We need "image_id", "id", "keypoints", "num_keypoints", "bbox", "iscrowd", "area", "category_id". Others are optional. + Note: (1) "num_keypoints" means the number of visible keypoints. (2) By default, please set "iscrowd: 0". (3) "area" can be calculated using the bbox (area = w * h) (4) Simply set "category_id: 1". (5) The "image_id" in "annotations" should match the "id" in "images". + +- **What if my custom dataset does not have bounding box label?** + + We can estimate the bounding box of a person as the minimal box that tightly bounds all the keypoints. + +- **What if my custom dataset does not have segmentation label?** + + Just set the `area` of the person as the area of the bounding boxes. During evaluation, please set `use_area=False` as in this [example](https://github.com/open-mmlab/mmpose/blob/a82dd486853a8a471522ac06b8b9356db61f8547/mmpose/datasets/datasets/top_down/topdown_aic_dataset.py#L113). + +- **What is `COCO_val2017_detections_AP_H_56_person.json`? Can I train pose models without it?** + + "COCO_val2017_detections_AP_H_56_person.json" contains the "detected" human bounding boxes for COCO validation set, which are generated by FasterRCNN. + One can choose to use gt bounding boxes to evaluate models, by setting `use_gt_bbox=True` and `bbox_file=''`. Or one can use detected boxes to evaluate + the generalizability of models, by setting `use_gt_bbox=False` and `bbox_file='COCO_val2017_detections_AP_H_56_person.json'`. + +## Training + +- **RuntimeError: Address already in use** + + Set the environment variables `MASTER_PORT=XXX`. For example, + `MASTER_PORT=29517 GPUS=16 GPUS_PER_NODE=8 CPUS_PER_TASK=2 ./tools/slurm_train.sh Test res50 configs/body/2D_Kpt_SV_RGB_Img/topdown_hm/coco/res50_coco_256x192.py work_dirs/res50_coco_256x192` + +- **"Unexpected keys in source state dict" when loading pre-trained weights** + + It's normal that some layers in the pretrained model are not used in the pose model. ImageNet-pretrained classification network and the pose network may have different architectures (e.g. no classification head). So some unexpected keys in source state dict is actually expected. + +- **How to use trained models for backbone pre-training ?** + + Refer to [Use Pre-Trained Model](/docs/en/tutorials/1_finetune.md#use-pre-trained-model), + in order to use the pre-trained model for the whole network (backbone + head), the new config adds the link of pre-trained models in the `load_from`. + + And to use backbone for pre-training, you can change `pretrained` value in the backbone dict of config files to the checkpoint path / url. + When training, the unexpected keys will be ignored. + +- **How to visualize the training accuracy/loss curves in real-time ?** + + Use `TensorboardLoggerHook` in `log_config` like + + ```python + log_config=dict(interval=20, hooks=[dict(type='TensorboardLoggerHook')]) + ``` + + You can refer to [tutorials/6_customize_runtime.md](/tutorials/6_customize_runtime.md#log-config) and the example [config](https://github.com/open-mmlab/mmpose/tree/e1ec589884235bee875c89102170439a991f8450/configs/top_down/resnet/coco/res50_coco_256x192.py#L26). + +- **Log info is NOT printed** + + Use smaller log interval. For example, change `interval=50` to `interval=1` in the [config](https://github.com/open-mmlab/mmpose/tree/e1ec589884235bee875c89102170439a991f8450/configs/top_down/resnet/coco/res50_coco_256x192.py#L23). + +- **How to fix stages of backbone when finetuning a model ?** + + You can refer to [`def _freeze_stages()`](https://github.com/open-mmlab/mmpose/blob/d026725554f9dc08e8708bd9da8678f794a7c9a6/mmpose/models/backbones/resnet.py#L618) and [`frozen_stages`](https://github.com/open-mmlab/mmpose/blob/d026725554f9dc08e8708bd9da8678f794a7c9a6/mmpose/models/backbones/resnet.py#L498), + reminding to set `find_unused_parameters = True` in config files for distributed training or testing. + +## Evaluation + +- **How to evaluate on MPII test dataset?** + Since we do not have the ground-truth for test dataset, we cannot evaluate it 'locally'. + If you would like to evaluate the performance on test set, you have to upload the pred.mat (which is generated during testing) to the official server via email, according to [the MPII guideline](http://human-pose.mpi-inf.mpg.de/#evaluation). + +- **For top-down 2d pose estimation, why predicted joint coordinates can be out of the bounding box (bbox)?** + We do not directly use the bbox to crop the image. bbox will be first transformed to center & scale, and the scale will be multiplied by a factor (1.25) to include some context. If the ratio of width/height is different from that of model input (possibly 192/256), we will adjust the bbox. + +## Inference + +- **How to run mmpose on CPU?** + + Run demos with `--device=cpu`. + +- **How to speed up inference?** + + For top-down models, try to edit the config file. For example, + + 1. set `flip_test=False` in [topdown-res50](https://github.com/open-mmlab/mmpose/tree/e1ec589884235bee875c89102170439a991f8450/configs/top_down/resnet/coco/res50_coco_256x192.py#L51). + 1. set `post_process='default'` in [topdown-res50](https://github.com/open-mmlab/mmpose/tree/e1ec589884235bee875c89102170439a991f8450/configs/top_down/resnet/coco/res50_coco_256x192.py#L54). + 1. use faster human bounding box detector, see [MMDetection](https://mmdetection.readthedocs.io/en/latest/model_zoo.html). + + For bottom-up models, try to edit the config file. For example, + + 1. set `flip_test=False` in [AE-res50](https://github.com/open-mmlab/mmpose/tree/e1ec589884235bee875c89102170439a991f8450/configs/bottom_up/resnet/coco/res50_coco_512x512.py#L91). + 1. set `adjust=False` in [AE-res50](https://github.com/open-mmlab/mmpose/tree/e1ec589884235bee875c89102170439a991f8450/configs/bottom_up/resnet/coco/res50_coco_512x512.py#L89). + 1. set `refine=False` in [AE-res50](https://github.com/open-mmlab/mmpose/tree/e1ec589884235bee875c89102170439a991f8450/configs/bottom_up/resnet/coco/res50_coco_512x512.py#L90). + 1. use smaller input image size in [AE-res50](https://github.com/open-mmlab/mmpose/tree/e1ec589884235bee875c89102170439a991f8450/configs/bottom_up/resnet/coco/res50_coco_512x512.py#L39). + +## Deployment + +- **Why is the onnx model converted by mmpose throwing error when converting to other frameworks such as TensorRT?** + + For now, we can only make sure that models in mmpose are onnx-compatible. However, some operations in onnx may be unsupported by your target framework for deployment, e.g. TensorRT in [this issue](https://github.com/open-mmlab/mmaction2/issues/414). When such situation occurs, we suggest you raise an issue and ask the community to help as long as `pytorch2onnx.py` works well and is verified numerically. diff --git a/vendor/ViTPose/docs/en/getting_started.md b/vendor/ViTPose/docs/en/getting_started.md new file mode 100644 index 0000000000000000000000000000000000000000..d7cfea3d2745dbdf61e464673d5eaac4d8253385 --- /dev/null +++ b/vendor/ViTPose/docs/en/getting_started.md @@ -0,0 +1,283 @@ +# Getting Started + +This page provides basic tutorials about the usage of MMPose. +For installation instructions, please see [install.md](install.md). + + + +- [Prepare Datasets](#prepare-datasets) +- [Inference with Pre-Trained Models](#inference-with-pre-trained-models) + - [Test a dataset](#test-a-dataset) + - [Run demos](#run-demos) +- [Train a Model](#train-a-model) + - [Train with a single GPU](#train-with-a-single-gpu) + - [Train with CPU](#train-with-cpu) + - [Train with multiple GPUs](#train-with-multiple-gpus) + - [Train with multiple machines](#train-with-multiple-machines) + - [Launch multiple jobs on a single machine](#launch-multiple-jobs-on-a-single-machine) +- [Benchmark](#benchmark) +- [Tutorials](#tutorials) + + + +## Prepare Datasets + +MMPose supports multiple tasks. Please follow the corresponding guidelines for data preparation. + +- [2D Body Keypoint Detection](/docs/en/tasks/2d_body_keypoint.md) +- [3D Body Keypoint Detection](/docs/en/tasks/3d_body_keypoint.md) +- [3D Body Mesh Recovery](/docs/en/tasks/3d_body_mesh.md) +- [2D Hand Keypoint Detection](/docs/en/tasks/2d_hand_keypoint.md) +- [3D Hand Keypoint Detection](/docs/en/tasks/3d_hand_keypoint.md) +- [2D Face Keypoint Detection](/docs/en/tasks/2d_face_keypoint.md) +- [2D WholeBody Keypoint Detection](/docs/en/tasks/2d_wholebody_keypoint.md) +- [2D Fashion Landmark Detection](/docs/en/tasks/2d_fashion_landmark.md) +- [2D Animal Keypoint Detection](/docs/en/tasks/2d_animal_keypoint.md) + +## Inference with Pre-trained Models + +We provide testing scripts to evaluate a whole dataset (COCO, MPII etc.), +and provide some high-level apis for easier integration to other OpenMMLab projects. + +### Test a dataset + +- [x] single GPU +- [x] CPU +- [x] single node multiple GPUs +- [x] multiple node + +You can use the following commands to test a dataset. + +```shell +# single-gpu testing +python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [--out ${RESULT_FILE}] [--fuse-conv-bn] \ + [--eval ${EVAL_METRICS}] [--gpu_collect] [--tmpdir ${TMPDIR}] [--cfg-options ${CFG_OPTIONS}] \ + [--launcher ${JOB_LAUNCHER}] [--local_rank ${LOCAL_RANK}] + +# CPU: disable GPUs and run single-gpu testing script +export CUDA_VISIBLE_DEVICES=-1 +python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [--out ${RESULT_FILE}] \ + [--eval ${EVAL_METRICS}] + +# multi-gpu testing +./tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [--out ${RESULT_FILE}] [--fuse-conv-bn] \ + [--eval ${EVAL_METRIC}] [--gpu_collect] [--tmpdir ${TMPDIR}] [--cfg-options ${CFG_OPTIONS}] \ + [--launcher ${JOB_LAUNCHER}] [--local_rank ${LOCAL_RANK}] +``` + +Note that the provided `CHECKPOINT_FILE` is either the path to the model checkpoint file downloaded in advance, or the url link to the model checkpoint. + +Optional arguments: + +- `RESULT_FILE`: Filename of the output results. If not specified, the results will not be saved to a file. +- `--fuse-conv-bn`: Whether to fuse conv and bn, this will slightly increase the inference speed. +- `EVAL_METRICS`: Items to be evaluated on the results. Allowed values depend on the dataset. +- `--gpu_collect`: If specified, recognition results will be collected using gpu communication. Otherwise, it will save the results on different gpus to `TMPDIR` and collect them by the rank 0 worker. +- `TMPDIR`: Temporary directory used for collecting results from multiple workers, available when `--gpu_collect` is not specified. +- `CFG_OPTIONS`: Override some settings in the used config, the key-value pair in xxx=yyy format will be merged into config file. For example, '--cfg-options model.backbone.depth=18 model.backbone.with_cp=True'. +- `JOB_LAUNCHER`: Items for distributed job initialization launcher. Allowed choices are `none`, `pytorch`, `slurm`, `mpi`. Especially, if set to none, it will test in a non-distributed mode. +- `LOCAL_RANK`: ID for local rank. If not specified, it will be set to 0. + +Examples: + +Assume that you have already downloaded the checkpoints to the directory `checkpoints/`. + +1. Test ResNet50 on COCO (without saving the test results) and evaluate the mAP. + + ```shell + ./tools/dist_test.sh configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_256x192.py \ + checkpoints/SOME_CHECKPOINT.pth 1 \ + --eval mAP + ``` + +1. Test ResNet50 on COCO with 8 GPUS. Download the checkpoint via url, and evaluate the mAP. + + ```shell + ./tools/dist_test.sh configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_256x192.py \ + https://download.openmmlab.com/mmpose/top_down/resnet/res50_coco_256x192-ec54d7f3_20200709.pth 8 \ + --eval mAP + ``` + +1. Test ResNet50 on COCO in slurm environment and evaluate the mAP. + + ```shell + ./tools/slurm_test.sh slurm_partition test_job \ + configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_256x192.py \ + checkpoints/SOME_CHECKPOINT.pth \ + --eval mAP + ``` + +### Run demos + +We also provide scripts to run demos. +Here is an example of running top-down human pose demos using ground-truth bounding boxes. + +```shell +python demo/top_down_img_demo.py \ + ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \ + --img-root ${IMG_ROOT} --json-file ${JSON_FILE} \ + --out-img-root ${OUTPUT_DIR} \ + [--show --device ${GPU_ID}] \ + [--kpt-thr ${KPT_SCORE_THR}] +``` + +Examples: + +```shell +python demo/top_down_img_demo.py \ + configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_256x192.py \ + https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth \ + --img-root tests/data/coco/ --json-file tests/data/coco/test_coco.json \ + --out-img-root vis_results +``` + +More examples and details can be found in the [demo folder](/demo) and the [demo docs](https://mmpose.readthedocs.io/en/latest/demo.html). + +## Train a model + +MMPose implements distributed training and non-distributed training, +which uses `MMDistributedDataParallel` and `MMDataParallel` respectively. + +We adopt distributed training for both single machine and multiple machines. Supposing that the server has 8 GPUs, 8 processes will be started and each process runs on a single GPU. + +Each process keeps an isolated model, data loader, and optimizer. Model parameters are only synchronized once at the beginning. After a forward and backward pass, gradients will be allreduced among all GPUs, and the optimizer will update model parameters. Since the gradients are allreduced, the model parameter stays the same for all processes after the iteration. + +### Training setting + +All outputs (log files and checkpoints) will be saved to the working directory, +which is specified by `work_dir` in the config file. + +By default we evaluate the model on the validation set after each epoch, you can change the evaluation interval by modifying the interval argument in the training config + +```python +evaluation = dict(interval=5) # This evaluate the model per 5 epoch. +``` + +According to the [Linear Scaling Rule](https://arxiv.org/abs/1706.02677), you need to set the learning rate proportional to the batch size if you use different GPUs or videos per GPU, e.g., lr=0.01 for 4 GPUs x 2 video/gpu and lr=0.08 for 16 GPUs x 4 video/gpu. + +### Train with a single GPU + +```shell +python tools/train.py ${CONFIG_FILE} [optional arguments] +``` + +If you want to specify the working directory in the command, you can add an argument `--work-dir ${YOUR_WORK_DIR}`. + +### Train with CPU + +The process of training on the CPU is consistent with single GPU training. We just need to disable GPUs before the training process. + +```shell +export CUDA_VISIBLE_DEVICES=-1 +``` + +And then run the script [above](#training-on-a-single-GPU). + +**Note**: + +We do not recommend users to use CPU for training because it is too slow. We support this feature to allow users to debug on machines without GPU for convenience. + +### Train with multiple GPUs + +```shell +./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [optional arguments] +``` + +Optional arguments are: + +- `--work-dir ${WORK_DIR}`: Override the working directory specified in the config file. +- `--resume-from ${CHECKPOINT_FILE}`: Resume from a previous checkpoint file. +- `--no-validate`: Whether not to evaluate the checkpoint during training. +- `--gpus ${GPU_NUM}`: Number of gpus to use, which is only applicable to non-distributed training. +- `--gpu-ids ${GPU_IDS}`: IDs of gpus to use, which is only applicable to non-distributed training. +- `--seed ${SEED}`: Seed id for random state in python, numpy and pytorch to generate random numbers. +- `--deterministic`: If specified, it will set deterministic options for CUDNN backend. +- `--cfg-options CFG_OPTIONS`: Override some settings in the used config, the key-value pair in xxx=yyy format will be merged into config file. For example, '--cfg-options model.backbone.depth=18 model.backbone.with_cp=True'. +- `--launcher ${JOB_LAUNCHER}`: Items for distributed job initialization launcher. Allowed choices are `none`, `pytorch`, `slurm`, `mpi`. Especially, if set to none, it will test in a non-distributed mode. +- `--autoscale-lr`: If specified, it will automatically scale lr with the number of gpus by [Linear Scaling Rule](https://arxiv.org/abs/1706.02677). +- `LOCAL_RANK`: ID for local rank. If not specified, it will be set to 0. + +Difference between `resume-from` and `load-from`: +`resume-from` loads both the model weights and optimizer status, and the epoch is also inherited from the specified checkpoint. It is usually used for resuming the training process that is interrupted accidentally. +`load-from` only loads the model weights and the training epoch starts from 0. It is usually used for finetuning. + +Here is an example of using 8 GPUs to load ResNet50 checkpoint. + +```shell +./tools/dist_train.sh configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_256x192.py 8 --resume_from work_dirs/res50_coco_256x192/latest.pth +``` + +### Train with multiple machines + +If you can run MMPose on a cluster managed with [slurm](https://slurm.schedmd.com/), you can use the script `slurm_train.sh`. (This script also supports single machine training.) + +```shell +./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${WORK_DIR} +``` + +Here is an example of using 16 GPUs to train ResNet50 on the dev partition in a slurm cluster. +(Use `GPUS_PER_NODE=8` to specify a single slurm cluster node with 8 GPUs, `CPUS_PER_TASK=2` to use 2 cpus per task. +Assume that `Test` is a valid ${PARTITION} name.) + +```shell +GPUS=16 GPUS_PER_NODE=8 CPUS_PER_TASK=2 ./tools/slurm_train.sh Test res50 configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_256x192.py work_dirs/res50_coco_256x192 +``` + +You can check [slurm_train.sh](/tools/slurm_train.sh) for full arguments and environment variables. + +If you have just multiple machines connected with ethernet, you can refer to +pytorch [launch utility](https://pytorch.org/docs/en/stable/distributed_deprecated.html#launch-utility). +Usually it is slow if you do not have high speed networking like InfiniBand. + +### Launch multiple jobs on a single machine + +If you launch multiple jobs on a single machine, e.g., 2 jobs of 4-GPU training on a machine with 8 GPUs, +you need to specify different ports (29500 by default) for each job to avoid communication conflict. + +If you use `dist_train.sh` to launch training jobs, you can set the port in commands. + +```shell +CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 ./tools/dist_train.sh ${CONFIG_FILE} 4 +CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 ./tools/dist_train.sh ${CONFIG_FILE} 4 +``` + +If you use launch training jobs with slurm, you need to modify the config files (usually the 4th line in config files) to set different communication ports. + +In `config1.py`, + +```python +dist_params = dict(backend='nccl', port=29500) +``` + +In `config2.py`, + +```python +dist_params = dict(backend='nccl', port=29501) +``` + +Then you can launch two jobs with `config1.py` ang `config2.py`. + +```shell +CUDA_VISIBLE_DEVICES=0,1,2,3 ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config1.py ${WORK_DIR} 4 +CUDA_VISIBLE_DEVICES=4,5,6,7 ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config2.py ${WORK_DIR} 4 +``` + +## Benchmark + +You can get average inference speed using the following script. Note that it does not include the IO time and the pre-processing time. + +```shell +python tools/analysis/benchmark_inference.py ${MMPOSE_CONFIG_FILE} +``` + +## Tutorials + +We provide some tutorials for users: + +- [learn about configs](tutorials/0_config.md) +- [finetune model](tutorials/1_finetune.md) +- [add new dataset](tutorials/2_new_dataset.md) +- [customize data pipelines](tutorials/3_data_pipeline.md) +- [add new modules](tutorials/4_new_modules.md) +- [export a model to ONNX](tutorials/5_export_model.md) +- [customize runtime settings](tutorials/6_customize_runtime.md). diff --git a/vendor/ViTPose/docs/en/index.rst b/vendor/ViTPose/docs/en/index.rst new file mode 100644 index 0000000000000000000000000000000000000000..a56282236fecdc30f97add4a22d5b6b2537b64cd --- /dev/null +++ b/vendor/ViTPose/docs/en/index.rst @@ -0,0 +1,99 @@ +Welcome to MMPose's documentation! +================================== + +You can change the documentation language at the lower-left corner of the page. + +您可以在页面左下角切换文档语言。 + +.. toctree:: + :maxdepth: 2 + + install.md + getting_started.md + demo.md + benchmark.md + inference_speed_summary.md + +.. toctree:: + :maxdepth: 2 + :caption: Datasets + + datasets.md + tasks/2d_body_keypoint.md + tasks/2d_wholebody_keypoint.md + tasks/2d_face_keypoint.md + tasks/2d_hand_keypoint.md + tasks/2d_fashion_landmark.md + tasks/2d_animal_keypoint.md + tasks/3d_body_keypoint.md + tasks/3d_body_mesh.md + tasks/3d_hand_keypoint.md + +.. toctree:: + :maxdepth: 2 + :caption: Model Zoo + + modelzoo.md + topics/animal.md + topics/body(2d,kpt,sview,img).md + topics/body(2d,kpt,sview,vid).md + topics/body(3d,kpt,sview,img).md + topics/body(3d,kpt,sview,vid).md + topics/body(3d,kpt,mview,img).md + topics/body(3d,mesh,sview,img).md + topics/face.md + topics/fashion.md + topics/hand(2d).md + topics/hand(3d).md + topics/wholebody.md + +.. toctree:: + :maxdepth: 2 + :caption: Model Zoo (by paper) + + papers/algorithms.md + papers/backbones.md + papers/datasets.md + papers/techniques.md + +.. toctree:: + :maxdepth: 2 + :caption: Tutorials + + tutorials/0_config.md + tutorials/1_finetune.md + tutorials/2_new_dataset.md + tutorials/3_data_pipeline.md + tutorials/4_new_modules.md + tutorials/5_export_model.md + tutorials/6_customize_runtime.md + +.. toctree:: + :maxdepth: 2 + :caption: Useful Tools and Scripts + + useful_tools.md + +.. toctree:: + :maxdepth: 2 + :caption: Notes + + changelog.md + faq.md + +.. toctree:: + :caption: API Reference + + api.rst + +.. toctree:: + :caption: Languages + + language.md + + +Indices and tables +================== + +* :ref:`genindex` +* :ref:`search` diff --git a/vendor/ViTPose/docs/en/inference_speed_summary.md b/vendor/ViTPose/docs/en/inference_speed_summary.md new file mode 100644 index 0000000000000000000000000000000000000000..9d165ec2cccef81e3fe15690320ff40f12c27aca --- /dev/null +++ b/vendor/ViTPose/docs/en/inference_speed_summary.md @@ -0,0 +1,114 @@ +# Inference Speed + +We summarize the model complexity and inference speed of major models in MMPose, including FLOPs, parameter counts and inference speeds on both CPU and GPU devices with different batch sizes. We also compare the mAP of different models on COCO human keypoint dataset, showing the trade-off between model performance and model complexity. + +## Comparison Rules + +To ensure the fairness of the comparison, the comparison experiments are conducted under the same hardware and software environment using the same dataset. We also list the mAP (mean average precision) on COCO human keypoint dataset of the models along with the corresponding config files. + +For model complexity information measurement, we calculate the FLOPs and parameter counts of a model with corresponding input shape. Note that some layers or ops are currently not supported, for example, `DeformConv2d`, so you may need to check if all ops are supported and verify that the flops and parameter counts computation is correct. + +For inference speed, we omit the time for data pre-processing and only measure the time for model forwarding and data post-processing. For each model setting, we keep the same data pre-processing methods to make sure the same feature input. We measure the inference speed on both CPU and GPU devices. For topdown heatmap models, we also test the case when the batch size is larger, e.g., 10, to test model performance in crowded scenes. + +The inference speed is measured with frames per second (FPS), namely the average iterations per second, which can show how fast the model can handle an input. The higher, the faster, the better. + +### Hardware + +- GPU: GeForce GTX 1660 SUPER +- CPU: Intel(R) Core(TM) i7-8700 CPU @ 3.20GHz + +### Software Environment + +- Ubuntu 16.04 +- Python 3.8 +- PyTorch 1.10 +- CUDA 10.2 +- mmcv-full 1.3.17 +- mmpose 0.20.0 + +## Model complexity information and inference speed results of major models in MMPose + +| Algorithm | Model | config | Input size | mAP | Flops (GFLOPs) | Params (M) | GPU Inference Speed
(FPS)1 | GPU Inference Speed
(FPS, bs=10)2 | CPU Inference Speed
(FPS) | CPU Inference Speed
(FPS, bs=10) | +| :--- | :---------------: | :-----------------: |:--------------------: | :----------------------------: | :-----------------: | :---------------: |:--------------------: | :----------------------------: | :-----------------: | :-----------------: | +| topdown_heatmap | Alexnet | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/alexnet_coco_256x192.py) | (3, 192, 256) | 0.397 | 1.42 | 5.62 | 229.21 ± 16.91 | 33.52 ± 1.14 | 13.92 ± 0.60 | 1.38 ± 0.02 | +| topdown_heatmap | CPM | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/cpm_coco_256x192.py) | (3, 192, 256) | 0.623 | 63.81 | 31.3 | 11.35 ± 0.22 | 3.87 ± 0.07 | 0.31 ± 0.01 | 0.03 ± 0.00 | +| topdown_heatmap | CPM | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/cpm_coco_384x288.py) | (3, 288, 384) | 0.65 | 143.57 | 31.3 | 7.09 ± 0.14 | 2.10 ± 0.05 | 0.14 ± 0.00 | 0.01 ± 0.00 | +| topdown_heatmap | Hourglass-52 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hourglass52_coco_256x256.py) | (3, 256, 256) | 0.726 | 28.67 | 94.85 | 25.50 ± 1.68 | 3.99 ± 0.07 | 0.92 ± 0.03 | 0.09 ± 0.00 | +| topdown_heatmap | Hourglass-52 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hourglass52_coco_384x384.py) | (3, 384, 384) | 0.746 | 64.5 | 94.85 | 14.74 ± 0.8 | 1.86 ± 0.06 | 0.43 ± 0.03 | 0.04 ± 0.00 | +| topdown_heatmap | HRNet-W32 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_256x192.py) | (3, 192, 256) | 0.746 | 7.7 | 28.54 | 22.73 ± 1.12 | 6.60 ± 0.14 | 2.73 ± 0.11 | 0.32 ± 0.00 | +| topdown_heatmap | HRNet-W32 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_384x288.py) | (3, 288, 384) | 0.76 | 17.33 | 28.54 | 22.78 ± 1.21 | 3.28 ± 0.08 | 1.35 ± 0.05 | 0.14 ± 0.00 | +| topdown_heatmap | HRNet-W48 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_256x192.py) | (3, 192, 256) | 0.756 | 15.77 | 63.6 | 22.01 ± 1.10 | 3.74 ± 0.10 | 1.46 ± 0.05 | 0.16 ± 0.00 | +| topdown_heatmap | HRNet-W48 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_384x288.py) | (3, 288, 384) | 0.767 | 35.48 | 63.6 | 15.03 ± 1.03 | 1.80 ± 0.03 | 0.68 ± 0.02 | 0.07 ± 0.00 | +| topdown_heatmap | LiteHRNet-30 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/litehrnet_30_coco_256x192.py) | (3, 192, 256) | 0.675 | 0.42 | 1.76 | 11.86 ± 0.38 | 9.77 ± 0.23 | 5.84 ± 0.39 | 0.80 ± 0.00 | +| topdown_heatmap | LiteHRNet-30 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/litehrnet_30_coco_384x288.py) | (3, 288, 384) | 0.7 | 0.95 | 1.76 | 11.52 ± 0.39 | 5.18 ± 0.11 | 3.45 ± 0.22 | 0.37 ± 0.00 | +| topdown_heatmap | MobilenetV2 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/mobilenetv2_coco_256x192.py) | (3, 192, 256) | 0.646 | 1.59 | 9.57 | 91.82 ± 10.98 | 17.85 ± 0.32 | 10.44 ± 0.80 | 1.05 ± 0.01 | +| topdown_heatmap | MobilenetV2 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/mobilenetv2_coco_384x288.py) | (3, 288, 384) | 0.673 | 3.57 | 9.57 | 71.27 ± 6.82 | 8.00 ± 0.15 | 5.01 ± 0.32 | 0.46 ± 0.00 | +| topdown_heatmap | MSPN-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/mspn50_coco_256x192.py) | (3, 192, 256) | 0.723 | 5.11 | 25.11 | 59.65 ± 3.74 | 9.51 ± 0.15 | 3.98 ± 0.21 | 0.43 ± 0.00 | +| topdown_heatmap | 2xMSPN-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/2xmspn50_coco_256x192.py) | (3, 192, 256) | 0.754 | 11.35 | 56.8 | 30.64 ± 2.61 | 4.74 ± 0.12 | 1.85 ± 0.08 | 0.20 ± 0.00 | +| topdown_heatmap | 3xMSPN-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/3xmspn50_coco_256x192.py) | (3, 192, 256) | 0.758 | 17.59 | 88.49 | 20.90 ± 1.82 | 3.22 ± 0.08 | 1.23 ± 0.04 | 0.13 ± 0.00 | +| topdown_heatmap | 4xMSPN-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/4xmspn50_coco_256x192.py) | (3, 192, 256) | 0.764 | 23.82 | 120.18 | 15.79 ± 1.14 | 2.45 ± 0.05 | 0.90 ± 0.03 | 0.10 ± 0.00 | +| topdown_heatmap | ResNest-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest50_coco_256x192.py) | (3, 192, 256) | 0.721 | 6.73 | 35.93 | 48.36 ± 4.12 | 7.48 ± 0.13 | 3.00 ± 0.13 | 0.33 ± 0.00 | +| topdown_heatmap | ResNest-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest50_coco_384x288.py) | (3, 288, 384) | 0.737 | 15.14 | 35.93 | 30.30 ± 2.30 | 3.62 ± 0.09 | 1.43 ± 0.05 | 0.13 ± 0.00 | +| topdown_heatmap | ResNest-101 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest101_coco_256x192.py) | (3, 192, 256) | 0.725 | 10.38 | 56.61 | 29.21 ± 1.98 | 5.30 ± 0.12 | 2.01 ± 0.08 | 0.22 ± 0.00 | +| topdown_heatmap | ResNest-101 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest101_coco_384x288.py) | (3, 288, 384) | 0.746 | 23.36 | 56.61 | 19.02 ± 1.40 | 2.59 ± 0.05 | 0.97 ± 0.03 | 0.09 ± 0.00 | +| topdown_heatmap | ResNest-200 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest200_coco_256x192.py) | (3, 192, 256) | 0.732 | 17.5 | 78.54 | 16.11 ± 0.71 | 3.29 ± 0.07 | 1.33 ± 0.02 | 0.14 ± 0.00 | +| topdown_heatmap | ResNest-200 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest200_coco_384x288.py) | (3, 288, 384) | 0.754 | 39.37 | 78.54 | 11.48 ± 0.68 | 1.58 ± 0.02 | 0.63 ± 0.01 | 0.06 ± 0.00 | +| topdown_heatmap | ResNest-269 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest269_coco_256x192.py) | (3, 192, 256) | 0.738 | 22.45 | 119.27 | 12.02 ± 0.47 | 2.60 ± 0.05 | 1.03 ± 0.01 | 0.11 ± 0.00 | +| topdown_heatmap | ResNest-269 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest269_coco_384x288.py) | (3, 288, 384) | 0.755 | 50.5 | 119.27 | 8.82 ± 0.42 | 1.24 ± 0.02 | 0.49 ± 0.01 | 0.05 ± 0.00 | +| topdown_heatmap | ResNet-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_256x192.py) | (3, 192, 256) | 0.718 | 5.46 | 34 | 64.23 ± 6.05 | 9.33 ± 0.21 | 4.00 ± 0.10 | 0.41 ± 0.00 | +| topdown_heatmap | ResNet-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_384x288.py) | (3, 288, 384) | 0.731 | 12.29 | 34 | 36.78 ± 3.05 | 4.48 ± 0.12 | 1.92 ± 0.04 | 0.19 ± 0.00 | +| topdown_heatmap | ResNet-101 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res101_coco_256x192.py) | (3, 192, 256) | 0.726 | 9.11 | 52.99 | 43.35 ± 4.36 | 6.44 ± 0.14 | 2.57 ± 0.05 | 0.27 ± 0.00 | +| topdown_heatmap | ResNet-101 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res101_coco_384x288.py) | (3, 288, 384) | 0.748 | 20.5 | 52.99 | 23.29 ± 1.83 | 3.12 ± 0.09 | 1.23 ± 0.03 | 0.11 ± 0.00 | +| topdown_heatmap | ResNet-152 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res152_coco_256x192.py) | (3, 192, 256) | 0.735 | 12.77 | 68.64 | 32.31 ± 2.84 | 4.88 ± 0.17 | 1.89 ± 0.03 | 0.20 ± 0.00 | +| topdown_heatmap | ResNet-152 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res152_coco_384x288.py) | (3, 288, 384) | 0.75 | 28.73 | 68.64 | 17.32 ± 1.17 | 2.40 ± 0.04 | 0.91 ± 0.01 | 0.08 ± 0.00 | +| topdown_heatmap | ResNetV1d-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d50_coco_256x192.py) | (3, 192, 256) | 0.722 | 5.7 | 34.02 | 63.44 ± 6.09 | 9.09 ± 0.10 | 3.82 ± 0.10 | 0.39 ± 0.00 | +| topdown_heatmap | ResNetV1d-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d50_coco_384x288.py) | (3, 288, 384) | 0.73 | 12.82 | 34.02 | 36.21 ± 3.10 | 4.30 ± 0.12 | 1.82 ± 0.04 | 0.16 ± 0.00 | +| topdown_heatmap | ResNetV1d-101 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d101_coco_256x192.py) | (3, 192, 256) | 0.731 | 9.35 | 53.01 | 41.48 ± 3.76 | 6.33 ± 0.15 | 2.48 ± 0.05 | 0.26 ± 0.00 | +| topdown_heatmap | ResNetV1d-101 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d101_coco_384x288.py) | (3, 288, 384) | 0.748 | 21.04 | 53.01 | 23.49 ± 1.76 | 3.07 ± 0.07 | 1.19 ± 0.02 | 0.11 ± 0.00 | +| topdown_heatmap | ResNetV1d-152 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d152_coco_256x192.py) | (3, 192, 256) | 0.737 | 13.01 | 68.65 | 31.96 ± 2.87 | 4.69 ± 0.18 | 1.87 ± 0.02 | 0.19 ± 0.00 | +| topdown_heatmap | ResNetV1d-152 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d152_coco_384x288.py) | (3, 288, 384) | 0.752 | 29.26 | 68.65 | 17.31 ± 1.13 | 2.32 ± 0.04 | 0.88 ± 0.01 | 0.08 ± 0.00 | +| topdown_heatmap | ResNext-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnext50_coco_256x192.py) | (3, 192, 256) | 0.714 | 5.61 | 33.47 | 48.34 ± 3.85 | 7.66 ± 0.13 | 3.71 ± 0.10 | 0.37 ± 0.00 | +| topdown_heatmap | ResNext-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnext50_coco_384x288.py) | (3, 288, 384) | 0.724 | 12.62 | 33.47 | 30.66 ± 2.38 | 3.64 ± 0.11 | 1.73 ± 0.03 | 0.15 ± 0.00 | +| topdown_heatmap | ResNext-101 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnext101_coco_256x192.py) | (3, 192, 256) | 0.726 | 9.29 | 52.62 | 27.33 ± 2.35 | 5.09 ± 0.13 | 2.45 ± 0.04 | 0.25 ± 0.00 | +| topdown_heatmap | ResNext-101 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnext101_coco_384x288.py) | (3, 288, 384) | 0.743 | 20.91 | 52.62 | 18.19 ± 1.38 | 2.42 ± 0.04 | 1.15 ± 0.01 | 0.10 ± 0.00 | +| topdown_heatmap | ResNext-152 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnext152_coco_256x192.py) | (3, 192, 256) | 0.73 | 12.98 | 68.39 | 19.61 ± 1.61 | 3.80 ± 0.13 | 1.83 ± 0.02 | 0.18 ± 0.00 | +| topdown_heatmap | ResNext-152 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnext152_coco_384x288.py) | (3, 288, 384) | 0.742 | 29.21 | 68.39 | 13.14 ± 0.75 | 1.82 ± 0.03 | 0.85 ± 0.01 | 0.08 ± 0.00 | +| topdown_heatmap | RSN-18 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/rsn18_coco_256x192.py) | (3, 192, 256) | 0.704 | 2.27 | 9.14 | 47.80 ± 4.50 | 13.68 ± 0.25 | 6.70 ± 0.28 | 0.70 ± 0.00 | +| topdown_heatmap | RSN-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/rsn50_coco_256x192.py) | (3, 192, 256) | 0.723 | 4.11 | 19.33 | 27.22 ± 1.61 | 8.81 ± 0.13 | 3.98 ± 0.12 | 0.45 ± 0.00 | +| topdown_heatmap | 2xRSN-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/2xrsn50_coco_256x192.py) | (3, 192, 256) | 0.745 | 8.29 | 39.26 | 13.88 ± 0.64 | 4.78 ± 0.13 | 2.02 ± 0.04 | 0.23 ± 0.00 | +| topdown_heatmap | 3xRSN-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/3xrsn50_coco_256x192.py) | (3, 192, 256) | 0.75 | 12.47 | 59.2 | 9.40 ± 0.32 | 3.37 ± 0.09 | 1.34 ± 0.03 | 0.15 ± 0.00 | +| topdown_heatmap | SCNet-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/scnet50_coco_256x192.py) | (3, 192, 256) | 0.728 | 5.31 | 34.01 | 40.76 ± 3.08 | 8.35 ± 0.19 | 3.82 ± 0.08 | 0.40 ± 0.00 | +| topdown_heatmap | SCNet-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/scnet50_coco_384x288.py) | (3, 288, 384) | 0.751 | 11.94 | 34.01 | 32.61 ± 2.97 | 4.19 ± 0.10 | 1.85 ± 0.03 | 0.17 ± 0.00 | +| topdown_heatmap | SCNet-101 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/scnet101_coco_256x192.py) | (3, 192, 256) | 0.733 | 8.51 | 53.01 | 24.28 ± 1.19 | 5.80 ± 0.13 | 2.49 ± 0.05 | 0.27 ± 0.00 | +| topdown_heatmap | SCNet-101 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/scnet101_coco_384x288.py) | (3, 288, 384) | 0.752 | 19.14 | 53.01 | 20.43 ± 1.76 | 2.91 ± 0.06 | 1.23 ± 0.02 | 0.12 ± 0.00 | +| topdown_heatmap | SeresNet-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/seresnet50_coco_256x192.py) | (3, 192, 256) | 0.728 | 5.47 | 36.53 | 54.83 ± 4.94 | 8.80 ± 0.12 | 3.85 ± 0.10 | 0.40 ± 0.00 | +| topdown_heatmap | SeresNet-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/seresnet50_coco_384x288.py) | (3, 288, 384) | 0.748 | 12.3 | 36.53 | 33.00 ± 2.67 | 4.26 ± 0.12 | 1.86 ± 0.04 | 0.17 ± 0.00 | +| topdown_heatmap | SeresNet-101 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/seresnet101_coco_256x192.py) | (3, 192, 256) | 0.734 | 9.13 | 57.77 | 33.90 ± 2.65 | 6.01 ± 0.13 | 2.48 ± 0.05 | 0.26 ± 0.00 | +| topdown_heatmap | SeresNet-101 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/seresnet101_coco_384x288.py) | (3, 288, 384) | 0.753 | 20.53 | 57.77 | 20.57 ± 1.57 | 2.96 ± 0.07 | 1.20 ± 0.02 | 0.11 ± 0.00 | +| topdown_heatmap | SeresNet-152 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/seresnet152_coco_256x192.py) | (3, 192, 256) | 0.73 | 12.79 | 75.26 | 24.25 ± 1.95 | 4.45 ± 0.10 | 1.82 ± 0.02 | 0.19 ± 0.00 | +| topdown_heatmap | SeresNet-152 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/seresnet152_coco_384x288.py) | (3, 288, 384) | 0.753 | 28.76 | 75.26 | 15.11 ± 0.99 | 2.25 ± 0.04 | 0.88 ± 0.01 | 0.08 ± 0.00 | +| topdown_heatmap | ShuffleNetV1 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/shufflenetv1_coco_256x192.py) | (3, 192, 256) | 0.585 | 1.35 | 6.94 | 80.79 ± 8.95 | 21.91 ± 0.46 | 11.84 ± 0.59 | 1.25 ± 0.01 | +| topdown_heatmap | ShuffleNetV1 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/shufflenetv1_coco_384x288.py) | (3, 288, 384) | 0.622 | 3.05 | 6.94 | 63.45 ± 5.21 | 9.84 ± 0.10 | 6.01 ± 0.31 | 0.57 ± 0.00 | +| topdown_heatmap | ShuffleNetV2 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/shufflenetv2_coco_256x192.py) | (3, 192, 256) | 0.599 | 1.37 | 7.55 | 82.36 ± 7.30 | 22.68 ± 0.53 | 12.40 ± 0.66 | 1.34 ± 0.02 | +| topdown_heatmap | ShuffleNetV2 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/shufflenetv2_coco_384x288.py) | (3, 288, 384) | 0.636 | 3.08 | 7.55 | 63.63 ± 5.72 | 10.47 ± 0.16 | 6.32 ± 0.28 | 0.63 ± 0.01 | +| topdown_heatmap | VGG16 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vgg16_bn_coco_256x192.py) | (3, 192, 256) | 0.698 | 16.22 | 18.92 | 51.91 ± 2.98 | 6.18 ± 0.13 | 1.64 ± 0.03 | 0.15 ± 0.00 | +| topdown_heatmap | VIPNAS + ResNet-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vipnas_res50_coco_256x192.py) | (3, 192, 256) | 0.711 | 1.49 | 7.29 | 34.88 ± 2.45 | 10.29 ± 0.13 | 6.51 ± 0.17 | 0.65 ± 0.00 | +| topdown_heatmap | VIPNAS + MobileNetV3 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vipnas_mbv3_coco_256x192.py) | (3, 192, 256) | 0.7 | 0.76 | 5.9 | 53.62 ± 6.59 | 11.54 ± 0.18 | 1.26 ± 0.02 | 0.13 ± 0.00 | +| Associative Embedding | HigherHRNet-W32 | [config](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w32_coco_512x512.py) | (3, 512, 512) | 0.677 | 46.58 | 28.65 | 7.80 ± 0.67 | / | 0.28 ± 0.02 | / | +| Associative Embedding | HigherHRNet-W32 | [config](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w32_coco_640x640.py) | (3, 640, 640) | 0.686 | 72.77 | 28.65 | 5.30 ± 0.37 | / | 0.17 ± 0.01 | / | +| Associative Embedding | HigherHRNet-W48 | [config](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w48_coco_512x512.py) | (3, 512, 512) | 0.686 | 96.17 | 63.83 | 4.55 ± 0.35 | / | 0.15 ± 0.01 | / | +| Associative Embedding | Hourglass-AE | [config](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hourglass_ae_coco_512x512.py) | (3, 512, 512) | 0.613 | 221.58 | 138.86 | 3.55 ± 0.24 | / | 0.08 ± 0.00 | / | +| Associative Embedding | HRNet-W32 | [config](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w32_coco_512x512.py) | (3, 512, 512) | 0.654 | 41.1 | 28.54 | 8.93 ± 0.76 | / | 0.33 ± 0.02 | / | +| Associative Embedding | HRNet-W48 | [config](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w48_coco_512x512.py) | (3, 512, 512) | 0.665 | 84.12 | 63.6 | 5.27 ± 0.43 | / | 0.18 ± 0.01 | / | +| Associative Embedding | MobilenetV2 | [config](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/mobilenetv2_coco_512x512.py) | (3, 512, 512) | 0.38 | 8.54 | 9.57 | 21.24 ± 1.34 | / | 0.81 ± 0.06 | / | +| Associative Embedding | ResNet-50 | [config](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res50_coco_512x512.py) | (3, 512, 512) | 0.466 | 29.2 | 34 | 11.71 ± 0.97 | / | 0.41 ± 0.02 | / | +| Associative Embedding | ResNet-50 | [config](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res50_coco_640x640.py) | (3, 640, 640) | 0.479 | 45.62 | 34 | 8.20 ± 0.58 | / | 0.26 ± 0.02 | / | +| Associative Embedding | ResNet-101 | [config](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res101_coco_512x512.py) | (3, 512, 512) | 0.554 | 48.67 | 53 | 8.26 ± 0.68 | / | 0.28 ± 0.02 | / | +| Associative Embedding | ResNet-101 | [config](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res152_coco_512x512.py) | (3, 512, 512) | 0.595 | 68.17 | 68.64 | 6.25 ± 0.53 | / | 0.21 ± 0.01 | / | +| DeepPose | ResNet-50 | [config](/configs/body/2d_kpt_sview_rgb_img/deeppose/coco/res50_coco_256x192.py) | (3, 192, 256) | 0.526 | 4.04 | 23.58 | 82.20 ± 7.54 | / | 5.50 ± 0.18 | / | +| DeepPose | ResNet-101 | [config](/configs/body/2d_kpt_sview_rgb_img/deeppose/coco/res101_coco_256x192.py) | (3, 192, 256) | 0.56 | 7.69 | 42.57 | 48.93 ± 4.02 | / | 3.10 ± 0.07 | / | +| DeepPose | ResNet-152 | [config](/configs/body/2d_kpt_sview_rgb_img/deeppose/coco/res152_coco_256x192.py) | (3, 192, 256) | 0.583 | 11.34 | 58.21 | 35.06 ± 3.50 | / | 2.19 ± 0.04 | / | + +1 Note that we run multiple iterations and record the time of each iteration, and the mean and standard deviation value of FPS are both shown. + +2 The FPS is defined as the average iterations per second, regardless of the batch size in this iteration. diff --git a/vendor/ViTPose/docs/en/install.md b/vendor/ViTPose/docs/en/install.md new file mode 100644 index 0000000000000000000000000000000000000000..a668b232b063b7028d9d4bd7d5c5650f57b3c89a --- /dev/null +++ b/vendor/ViTPose/docs/en/install.md @@ -0,0 +1,202 @@ +# Installation + + + +- [Requirements](#requirements) +- [Prepare Environment](#prepare-environment) +- [Install MMPose](#install-mmpose) +- [Install with CPU only](#install-with-cpu-only) +- [A from-scratch setup script](#a-from-scratch-setup-script) +- [Another option: Docker Image](#another-option-docker-image) +- [Developing with multiple MMPose versions](#developing-with-multiple-mmpose-versions) + + + +## Requirements + +- Linux (Windows is not officially supported) +- Python 3.6+ +- PyTorch 1.3+ +- CUDA 9.2+ (If you build PyTorch from source, CUDA 9.0 is also compatible) +- GCC 5+ +- [mmcv](https://github.com/open-mmlab/mmcv) (Please install the latest version of mmcv-full) +- Numpy +- cv2 +- json_tricks +- [xtcocotools](https://github.com/jin-s13/xtcocoapi) + +Optional: + +- [mmdet](https://github.com/open-mmlab/mmdetection) (to run pose demos) +- [mmtrack](https://github.com/open-mmlab/mmtracking) (to run pose tracking demos) +- [pyrender](https://pyrender.readthedocs.io/en/latest/install/index.html) (to run 3d mesh demos) +- [smplx](https://github.com/vchoutas/smplx) (to run 3d mesh demos) + +## Prepare environment + +a. Create a conda virtual environment and activate it. + +```shell +conda create -n open-mmlab python=3.7 -y +conda activate open-mmlab +``` + +b. Install PyTorch and torchvision following the [official instructions](https://pytorch.org/), e.g., + +```shell +conda install pytorch torchvision -c pytorch +``` + +```{note} +Make sure that your compilation CUDA version and runtime CUDA version match. +``` + +You can check the supported CUDA version for precompiled packages on the [PyTorch website](https://pytorch.org/). + +`E.g.1` If you have CUDA 10.2 installed under `/usr/local/cuda` and would like to install PyTorch 1.8.0, +you need to install the prebuilt PyTorch with CUDA 10.2. + +```shell +conda install pytorch==1.8.0 torchvision==0.9.0 cudatoolkit=10.2 -c pytorch +``` + +`E.g.2` If you have CUDA 9.2 installed under `/usr/local/cuda` and would like to install PyTorch 1.7.0., +you need to install the prebuilt PyTorch with CUDA 9.2. + +```shell +conda install pytorch==1.7.0 torchvision==0.8.0 cudatoolkit=9.2 -c pytorch +``` + +If you build PyTorch from source instead of installing the pre-built package, you can use more CUDA versions such as 9.0. + +## Install MMPose + +a. Install mmcv, we recommend you to install the pre-built mmcv as below. + +```shell +# pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/{cu_version}/{torch_version}/index.html +pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu102/torch1.9.0/index.html +# We can ignore the micro version of PyTorch +pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu102/torch1.9/index.html +``` + +mmcv-full is only compiled on PyTorch 1.x.0 because the compatibility usually holds between 1.x.0 and 1.x.1. If your PyTorch version is 1.x.1, you can install mmcv-full compiled with PyTorch 1.x.0 and it usually works well. + +See [here](https://github.com/open-mmlab/mmcv#installation) for different versions of MMCV compatible to different PyTorch and CUDA versions. + +Optionally you can choose to compile mmcv from source by the following command + +```shell +git clone https://github.com/open-mmlab/mmcv.git +cd mmcv +MMCV_WITH_OPS=1 pip install -e . # package mmcv-full, which contains cuda ops, will be installed after this step +# OR pip install -e . # package mmcv, which contains no cuda ops, will be installed after this step +cd .. +``` + +**Important:** You need to run `pip uninstall mmcv` first if you have mmcv installed. If mmcv and mmcv-full are both installed, there will be `ModuleNotFoundError`. + +b. Clone the mmpose repository + +```shell +git clone git@github.com:open-mmlab/mmpose.git # or git clone https://github.com/open-mmlab/mmpose +cd mmpose +``` + +c. Install build requirements and then install mmpose + +```shell +pip install -r requirements.txt +pip install -v -e . # or "python setup.py develop" +``` + +If you build MMPose on macOS, replace the last command with + +```shell +CC=clang CXX=clang++ CFLAGS='-stdlib=libc++' pip install -e . +``` + +d. Install optional modules + +- [mmdet](https://github.com/open-mmlab/mmdetection) (to run pose demos) +- [mmtrack](https://github.com/open-mmlab/mmtracking) (to run pose tracking demos) +- [pyrender](https://pyrender.readthedocs.io/en/latest/install/index.html) (to run 3d mesh demos) +- [smplx](https://github.com/vchoutas/smplx) (to run 3d mesh demos) + +```{note} +1. The git commit id will be written to the version number with step c, e.g. 0.6.0+2e7045c. The version will also be saved in trained models. + It is recommended that you run step d each time you pull some updates from github. If C++/CUDA codes are modified, then this step is compulsory. + +1. Following the above instructions, mmpose is installed on `dev` mode, any local modifications made to the code will take effect without the need to reinstall it (unless you submit some commits and want to update the version number). + +1. If you would like to use `opencv-python-headless` instead of `opencv-python`, + you can install it before installing MMCV. + +1. If you have `mmcv` installed, you need to firstly uninstall `mmcv`, and then install `mmcv-full`. + +1. Some dependencies are optional. Running `python setup.py develop` will only install the minimum runtime requirements. + To use optional dependencies like `smplx`, either install them with `pip install -r requirements/optional.txt` + or specify desired extras when calling `pip` (e.g. `pip install -v -e .[optional]`, + valid keys for the `[optional]` field are `all`, `tests`, `build`, and `optional`) like `pip install -v -e .[tests,build]`. +``` + +## Install with CPU only + +The code can be built for CPU only environment (where CUDA isn't available). + +In CPU mode you can run the demo/demo.py for example. + +## A from-scratch setup script + +Here is a full script for setting up mmpose with conda and link the dataset path (supposing that your COCO dataset path is $COCO_ROOT). + +```shell +conda create -n open-mmlab python=3.7 -y +conda activate open-mmlab + +# install latest pytorch prebuilt with the default prebuilt CUDA version (usually the latest) +conda install -c pytorch pytorch torchvision -y + +# install the latest mmcv-full +# Please replace ``{cu_version}`` and ``{torch_version}`` in the url to your desired one. +# See [here](https://github.com/open-mmlab/mmcv#installation) for different versions of MMCV compatible to different PyTorch and CUDA versions. +pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/{cu_version}/{torch_version}/index.html + +# install mmpose +git clone https://github.com/open-mmlab/mmpose.git +cd mmpose +pip install -r requirements.txt +pip install -v -e . + +mkdir data +ln -s $COCO_ROOT data/coco +``` + +## Another option: Docker Image + +We provide a [Dockerfile](/docker/Dockerfile) to build an image. + +```shell +# build an image with PyTorch 1.6.0, CUDA 10.1, CUDNN 7. +docker build -f ./docker/Dockerfile --rm -t mmpose . +``` + +**Important:** Make sure you've installed the [nvidia-container-toolkit](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html#docker). + +Run the following cmd: + +```shell +docker run --gpus all\ + --shm-size=8g \ + -it -v {DATA_DIR}:/mmpose/data mmpose +``` + +## Developing with multiple MMPose versions + +The train and test scripts already modify the `PYTHONPATH` to ensure the script use the MMPose in the current directory. + +To use the default MMPose installed in the environment rather than that you are working with, you can remove the following line in those scripts. + +```shell +PYTHONPATH="$(dirname $0)/..":$PYTHONPATH +``` diff --git a/vendor/ViTPose/docs/en/language.md b/vendor/ViTPose/docs/en/language.md new file mode 100644 index 0000000000000000000000000000000000000000..a0a6259bee27121ca837c85141ebca0307d617b4 --- /dev/null +++ b/vendor/ViTPose/docs/en/language.md @@ -0,0 +1,3 @@ +## English + +## 简体中文 diff --git a/vendor/ViTPose/docs/en/make.bat b/vendor/ViTPose/docs/en/make.bat new file mode 100644 index 0000000000000000000000000000000000000000..922152e96a04a242e6fc40f124261d74890617d8 --- /dev/null +++ b/vendor/ViTPose/docs/en/make.bat @@ -0,0 +1,35 @@ +@ECHO OFF + +pushd %~dp0 + +REM Command file for Sphinx documentation + +if "%SPHINXBUILD%" == "" ( + set SPHINXBUILD=sphinx-build +) +set SOURCEDIR=. +set BUILDDIR=_build + +if "%1" == "" goto help + +%SPHINXBUILD% >NUL 2>NUL +if errorlevel 9009 ( + echo. + echo.The 'sphinx-build' command was not found. Make sure you have Sphinx + echo.installed, then set the SPHINXBUILD environment variable to point + echo.to the full path of the 'sphinx-build' executable. Alternatively you + echo.may add the Sphinx directory to PATH. + echo. + echo.If you don't have Sphinx installed, grab it from + echo.http://sphinx-doc.org/ + exit /b 1 +) + +%SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O% +goto end + +:help +%SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O% + +:end +popd diff --git a/vendor/ViTPose/docs/en/merge_docs.sh b/vendor/ViTPose/docs/en/merge_docs.sh new file mode 100644 index 0000000000000000000000000000000000000000..6484b78f4355558f546053fd2869898100178001 --- /dev/null +++ b/vendor/ViTPose/docs/en/merge_docs.sh @@ -0,0 +1,28 @@ +#!/usr/bin/env bash +# Copyright (c) OpenMMLab. All rights reserved. + +sed -i '$a\\n' ../../demo/docs/*_demo.md +cat ../../demo/docs/*_demo.md | sed "s/#/#&/" | sed "s/md###t/html#t/g" | sed '1i\# Demo' | sed 's=](/docs/en/=](/=g' | sed 's=](/=](https://github.com/open-mmlab/mmpose/tree/master/=g' >demo.md + + # remove /docs/ for link used in doc site +sed -i 's=](/docs/en/=](=g' ./tutorials/*.md +sed -i 's=](/docs/en/=](=g' ./tasks/*.md +sed -i 's=](/docs/en/=](=g' ./papers/*.md +sed -i 's=](/docs/en/=](=g' ./topics/*.md +sed -i 's=](/docs/en/=](=g' data_preparation.md +sed -i 's=](/docs/en/=](=g' getting_started.md +sed -i 's=](/docs/en/=](=g' install.md +sed -i 's=](/docs/en/=](=g' benchmark.md +sed -i 's=](/docs/en/=](=g' changelog.md +sed -i 's=](/docs/en/=](=g' faq.md + +sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/master/=g' ./tutorials/*.md +sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/master/=g' ./tasks/*.md +sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/master/=g' ./papers/*.md +sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/master/=g' ./topics/*.md +sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/master/=g' data_preparation.md +sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/master/=g' getting_started.md +sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/master/=g' install.md +sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/master/=g' benchmark.md +sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/master/=g' changelog.md +sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/master/=g' faq.md diff --git a/vendor/ViTPose/docs/en/papers/algorithms/associative_embedding.md b/vendor/ViTPose/docs/en/papers/algorithms/associative_embedding.md new file mode 100644 index 0000000000000000000000000000000000000000..3a27267ae9f822e0609bc8513835dbcef7ef343a --- /dev/null +++ b/vendor/ViTPose/docs/en/papers/algorithms/associative_embedding.md @@ -0,0 +1,30 @@ +# Associative embedding: End-to-end learning for joint detection and grouping (AE) + + + +
+
+
+## Abstract
+
+
+
+We introduce associative embedding, a novel method for supervising convolutional neural networks for the task of detection and grouping. A number of computer vision problems can be framed in this manner including multi-person pose estimation, instance segmentation, and multi-object tracking. Usually the grouping of detections is achieved with multi-stage pipelines, instead we propose an approach that teaches a network to simultaneously output detections and group assignments. This technique can be easily integrated into any state-of-the-art network architecture that produces pixel-wise predictions. We show how to apply this method to both multi-person pose estimation and instance segmentation and report state-of-the-art performance for multi-person pose on the MPII and MS-COCO datasets.
+
+
+
+Associative Embedding (NIPS'2017)
+ +```bibtex +@inproceedings{newell2017associative, + title={Associative embedding: End-to-end learning for joint detection and grouping}, + author={Newell, Alejandro and Huang, Zhiao and Deng, Jia}, + booktitle={Advances in neural information processing systems}, + pages={2277--2287}, + year={2017} +} +``` + +
+ +
+
diff --git a/vendor/ViTPose/docs/en/papers/algorithms/awingloss.md b/vendor/ViTPose/docs/en/papers/algorithms/awingloss.md
new file mode 100644
index 0000000000000000000000000000000000000000..4d4b93a87c622b6b965cab31ac402b8445934a9a
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/algorithms/awingloss.md
@@ -0,0 +1,31 @@
+# Adaptive Wing Loss for Robust Face Alignment via Heatmap Regression
+
+
+
+
+
+
+
+## Abstract
+
+
+
+Heatmap regression with a deep network has become one of the mainstream approaches to localize facial landmarks. However, the loss function for heatmap regression is rarely studied. In this paper, we analyze the ideal loss function properties for heatmap regression in face alignment problems. Then we propose a novel loss function, named Adaptive Wing loss, that is able to adapt its shape to different types of ground truth heatmap pixels. This adaptability penalizes loss more on foreground pixels while less on background pixels. To address the imbalance between foreground and background pixels, we also propose Weighted Loss Map, which assigns high weights on foreground and difficult background pixels to help training process focus more on pixels that are crucial to landmark localization. To further improve face alignment accuracy, we introduce boundary prediction and CoordConv with boundary coordinates. Extensive experiments on different benchmarks, including COFW, 300W and WFLW, show our approach outperforms the state-of-the-art by a significant margin on
+various evaluation metrics. Besides, the Adaptive Wing loss also helps other heatmap regression tasks.
+
+
+
+AdaptiveWingloss (ICCV'2019)
+ +```bibtex +@inproceedings{wang2019adaptive, + title={Adaptive wing loss for robust face alignment via heatmap regression}, + author={Wang, Xinyao and Bo, Liefeng and Fuxin, Li}, + booktitle={Proceedings of the IEEE/CVF international conference on computer vision}, + pages={6971--6981}, + year={2019} +} +``` + +
+ +
+
diff --git a/vendor/ViTPose/docs/en/papers/algorithms/cpm.md b/vendor/ViTPose/docs/en/papers/algorithms/cpm.md
new file mode 100644
index 0000000000000000000000000000000000000000..fb5dbfacec909f86b58d1ed4b24e75cad039c49e
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/algorithms/cpm.md
@@ -0,0 +1,30 @@
+# Convolutional pose machines
+
+
+
+
+
+
+
+## Abstract
+
+
+
+We introduce associative embedding, a novel method for supervising convolutional neural networks for the task of detection and grouping. A number of computer vision problems can be framed in this manner including multi-person pose estimation, instance segmentation, and multi-object tracking. Usually the grouping of detections is achieved with multi-stage pipelines, instead we propose an approach that teaches a network to simultaneously output detections and group assignments. This technique can be easily integrated into any state-of-the-art network architecture that produces pixel-wise predictions. We show how to apply this method to both multi-person pose estimation and instance segmentation and report state-of-the-art performance for multi-person pose on the MPII and MS-COCO datasets.
+
+
+
+CPM (CVPR'2016)
+ +```bibtex +@inproceedings{wei2016convolutional, + title={Convolutional pose machines}, + author={Wei, Shih-En and Ramakrishna, Varun and Kanade, Takeo and Sheikh, Yaser}, + booktitle={Proceedings of the IEEE conference on Computer Vision and Pattern Recognition}, + pages={4724--4732}, + year={2016} +} +``` + +
+ +
+
diff --git a/vendor/ViTPose/docs/en/papers/algorithms/dark.md b/vendor/ViTPose/docs/en/papers/algorithms/dark.md
new file mode 100644
index 0000000000000000000000000000000000000000..083b7596ab1e7aadb3f154eea58a170b7b22fb54
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/algorithms/dark.md
@@ -0,0 +1,30 @@
+# Distribution-aware coordinate representation for human pose estimation
+
+
+
+
+
+
+
+## Abstract
+
+
+
+While being the de facto standard coordinate representation for human pose estimation, heatmap has not been investigated in-depth. This work fills this gap. For the first time, we find that the process of decoding the predicted heatmaps into the final joint coordinates in the original image space is surprisingly significant for the performance. We further probe the design limitations of the standard coordinate decoding method, and propose a more principled distributionaware decoding method. Also, we improve the standard coordinate encoding process (i.e. transforming ground-truth coordinates to heatmaps) by generating unbiased/accurate heatmaps. Taking the two together, we formulate a novel Distribution-Aware coordinate Representation of Keypoints (DARK) method. Serving as a model-agnostic plug-in, DARK brings about significant performance boost to existing human pose estimation models. Extensive experiments show that DARK yields the best results on two common benchmarks, MPII and COCO. Besides, DARK achieves the 2nd place entry in the ICCV 2019 COCO Keypoints Challenge. The code is available online.
+
+
+
+DarkPose (CVPR'2020)
+ +```bibtex +@inproceedings{zhang2020distribution, + title={Distribution-aware coordinate representation for human pose estimation}, + author={Zhang, Feng and Zhu, Xiatian and Dai, Hanbin and Ye, Mao and Zhu, Ce}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + pages={7093--7102}, + year={2020} +} +``` + +
+ +
+
diff --git a/vendor/ViTPose/docs/en/papers/algorithms/deeppose.md b/vendor/ViTPose/docs/en/papers/algorithms/deeppose.md
new file mode 100644
index 0000000000000000000000000000000000000000..24778ba9db6ecfa35ea2dfabc68cadfeb3b24d7c
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/algorithms/deeppose.md
@@ -0,0 +1,30 @@
+# DeepPose: Human pose estimation via deep neural networks
+
+
+
+
+
+
+
+## Abstract
+
+
+
+We propose a method for human pose estimation based on Deep Neural Networks (DNNs). The pose estimation is formulated as a DNN-based regression problem towards body joints. We present a cascade of such DNN regressors which results in high precision pose estimates. The approach has the advantage of reasoning about pose in a holistic fashion and has a simple but yet powerful formulation which capitalizes on recent advances in Deep Learning. We present a detailed empirical analysis with state-of-art or better performance on four academic benchmarks of diverse real-world images.
+
+
+
+DeepPose (CVPR'2014)
+ +```bibtex +@inproceedings{toshev2014deeppose, + title={Deeppose: Human pose estimation via deep neural networks}, + author={Toshev, Alexander and Szegedy, Christian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={1653--1660}, + year={2014} +} +``` + +
+ +
+
diff --git a/vendor/ViTPose/docs/en/papers/algorithms/higherhrnet.md b/vendor/ViTPose/docs/en/papers/algorithms/higherhrnet.md
new file mode 100644
index 0000000000000000000000000000000000000000..c1d61c992a1f41e986d785560de0709407578dee
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/algorithms/higherhrnet.md
@@ -0,0 +1,30 @@
+# HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation
+
+
+
+
+
+
+
+## Abstract
+
+
+
+Bottom-up human pose estimation methods have difficulties in predicting the correct pose for small persons due to challenges in scale variation. In this paper, we present HigherHRNet: a novel bottom-up human pose estimation method for learning scale-aware representations using high-resolution feature pyramids. Equipped with multi-resolution supervision for training and multi-resolution aggregation for inference, the proposed approach is able to solve the scale variation challenge in bottom-up multi-person pose estimation and localize keypoints more precisely, especially for small person. The feature pyramid in HigherHRNet consists of feature map outputs from HRNet and upsampled higher-resolution outputs through a transposed convolution. HigherHRNet outperforms the previous best bottom-up method by 2.5% AP for medium person on COCO test-dev, showing its effectiveness in handling scale variation. Furthermore, HigherHRNet achieves new state-of-the-art result on COCO test-dev (70.5% AP) without using refinement or other post-processing techniques, surpassing all existing bottom-up methods. HigherHRNet even surpasses all top-down methods on CrowdPose test (67.6% AP), suggesting its robustness in crowded scene.
+
+
+
+HigherHRNet (CVPR'2020)
+ +```bibtex +@inproceedings{cheng2020higherhrnet, + title={HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation}, + author={Cheng, Bowen and Xiao, Bin and Wang, Jingdong and Shi, Honghui and Huang, Thomas S and Zhang, Lei}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + pages={5386--5395}, + year={2020} +} +``` + +
+ +
+
diff --git a/vendor/ViTPose/docs/en/papers/algorithms/hmr.md b/vendor/ViTPose/docs/en/papers/algorithms/hmr.md
new file mode 100644
index 0000000000000000000000000000000000000000..5c90aa45218fcab1cd1f03d22af5c3c802b26be5
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/algorithms/hmr.md
@@ -0,0 +1,32 @@
+# End-to-end Recovery of Human Shape and Pose
+
+
+
+
+
+
+
+## Abstract
+
+
+
+We describe Human Mesh Recovery (HMR), an end-to-end framework for reconstructing a full 3D mesh of a human body from a single RGB image. In contrast to most current methods that compute 2D or 3D joint locations, we produce a richer and more useful mesh representation that is parameterized by shape and 3D joint angles. The main objective is to minimize the reprojection loss of keypoints, which allows our model to be trained using in-the-wild images that only have ground truth 2D annotations. However, the reprojection loss alone is highly underconstrained. In this work we address this problem by introducing an adversary trained to tell whether human body shape and pose are real or not using a large database of 3D human meshes. We show that HMR can be trained with and without using any paired 2D-to-3D supervision. We do not rely on intermediate 2D keypoint detections and infer 3D pose and shape parameters directly from image pixels. Our model runs in real-time given a bounding box containing the person. We demonstrate our approach on various images in-the-wild and out-perform previous optimization-based methods that output 3D meshes and show competitive results on tasks such as 3D joint location estimation and part segmentation.
+
+
+
+HMR (CVPR'2018)
+ +```bibtex +@inProceedings{kanazawaHMR18, + title={End-to-end Recovery of Human Shape and Pose}, + author = {Angjoo Kanazawa + and Michael J. Black + and David W. Jacobs + and Jitendra Malik}, + booktitle={Computer Vision and Pattern Recognition (CVPR)}, + year={2018} +} +``` + +
+ +
+
diff --git a/vendor/ViTPose/docs/en/papers/algorithms/hourglass.md b/vendor/ViTPose/docs/en/papers/algorithms/hourglass.md
new file mode 100644
index 0000000000000000000000000000000000000000..7782484a31fc01d7daed19536328e653e317bda0
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/algorithms/hourglass.md
@@ -0,0 +1,31 @@
+# Stacked hourglass networks for human pose estimation
+
+
+
+
+
+
+
+## Abstract
+
+
+
+This work introduces a novel convolutional network architecture for the task of human pose estimation. Features are processed across all scales and consolidated to best capture the various spatial relationships associated with the body. We show how repeated bottom-up, top-down processing used in conjunction with intermediate supervision is critical to improving the performance of the network. We refer to the architecture as a “stacked hourglass” network based on the successive steps of pooling and upsampling that are done to produce a final set of predictions. State-of-the-art results are achieved on the FLIC and MPII benchmarks outcompeting all recent methods.
+
+
+
+Hourglass (ECCV'2016)
+ +```bibtex +@inproceedings{newell2016stacked, + title={Stacked hourglass networks for human pose estimation}, + author={Newell, Alejandro and Yang, Kaiyu and Deng, Jia}, + booktitle={European conference on computer vision}, + pages={483--499}, + year={2016}, + organization={Springer} +} +``` + +
+ +
+
diff --git a/vendor/ViTPose/docs/en/papers/algorithms/hrnet.md b/vendor/ViTPose/docs/en/papers/algorithms/hrnet.md
new file mode 100644
index 0000000000000000000000000000000000000000..05a46f543ef25de847c5fcb4704f56e5cea2bd42
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/algorithms/hrnet.md
@@ -0,0 +1,32 @@
+# Deep high-resolution representation learning for human pose estimation
+
+
+
+
+
+
+
+## Abstract
+
+
+
+In this paper, we are interested in the human pose estimation problem with a focus on learning reliable highresolution representations. Most existing methods recover high-resolution representations from low-resolution representations produced by a high-to-low resolution network. Instead, our proposed network maintains high-resolution representations through the whole process. We start from a high-resolution subnetwork as the first stage, gradually add high-to-low resolution subnetworks one by one to form more stages, and connect the mutliresolution subnetworks in parallel. We conduct repeated multi-scale fusions such that each of the high-to-low resolution representations receives information from other parallel representations over and over, leading to rich highresolution representations. As a result, the predicted keypoint heatmap is potentially more accurate and spatially more precise. We empirically demonstrate the effectiveness
+of our network through the superior pose estimation results over two benchmark datasets: the COCO keypoint detection
+dataset and the MPII Human Pose dataset. In addition, we show the superiority of our network in pose tracking on the PoseTrack dataset.
+
+
+
+HRNet (CVPR'2019)
+ +```bibtex +@inproceedings{sun2019deep, + title={Deep high-resolution representation learning for human pose estimation}, + author={Sun, Ke and Xiao, Bin and Liu, Dong and Wang, Jingdong}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={5693--5703}, + year={2019} +} +``` + +
+ +
+
diff --git a/vendor/ViTPose/docs/en/papers/algorithms/hrnetv2.md b/vendor/ViTPose/docs/en/papers/algorithms/hrnetv2.md
new file mode 100644
index 0000000000000000000000000000000000000000..f2ed2a9c0c8797a842e73c980e1868cdbfbf8cc8
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/algorithms/hrnetv2.md
@@ -0,0 +1,31 @@
+# Deep high-resolution representation learning for visual recognition
+
+
+
+
+
+
+
+## Abstract
+
+
+
+High-resolution representations are essential for position-sensitive vision problems, such as human pose estimation, semantic segmentation, and object detection. Existing state-of-the-art frameworks first encode the input image as a low-resolution representation through a subnetwork that is formed by connecting high-to-low resolution convolutions in series (e.g., ResNet, VGGNet), and then recover the high-resolution representation from the encoded low-resolution representation. Instead, our proposed network, named as High-Resolution Network (HRNet), maintains high-resolution representations through the whole process. There are two key characteristics: (i) Connect the high-to-low resolution convolution streams in parallel and (ii) repeatedly exchange the information across resolutions. The benefit is that the resulting representation is semantically richer and spatially more precise. We show the superiority of the proposed HRNet in a wide range of applications, including human pose estimation, semantic segmentation, and object detection, suggesting that the HRNet is a stronger backbone for computer vision problems.
+
+
+
+HRNetv2 (TPAMI'2019)
+ +```bibtex +@article{WangSCJDZLMTWLX19, + title={Deep High-Resolution Representation Learning for Visual Recognition}, + author={Jingdong Wang and Ke Sun and Tianheng Cheng and + Borui Jiang and Chaorui Deng and Yang Zhao and Dong Liu and Yadong Mu and + Mingkui Tan and Xinggang Wang and Wenyu Liu and Bin Xiao}, + journal={TPAMI}, + year={2019} +} +``` + +
+ +
+
diff --git a/vendor/ViTPose/docs/en/papers/algorithms/internet.md b/vendor/ViTPose/docs/en/papers/algorithms/internet.md
new file mode 100644
index 0000000000000000000000000000000000000000..e37ea72cea85da8b1fd6bf143b6958ff18972377
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/algorithms/internet.md
@@ -0,0 +1,29 @@
+# InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image
+
+
+
+
+
+
+
+## Abstract
+
+
+
+Analysis of hand-hand interactions is a crucial step towards better understanding human behavior. However, most researches in 3D hand pose estimation have focused on the isolated single hand case. Therefore, we firstly propose (1) a large-scale dataset, InterHand2.6M, and (2) a baseline network, InterNet, for 3D interacting hand pose estimation from a single RGB image. The proposed InterHand2.6M consists of 2.6 M labeled single and interacting hand frames under various poses from multiple subjects. Our InterNet simultaneously performs 3D single and interacting hand pose estimation. In our experiments, we demonstrate big gains in 3D interacting hand pose estimation accuracy when leveraging the interacting hand data in InterHand2.6M. We also report the accuracy of InterNet on InterHand2.6M, which serves as a strong baseline for this new dataset. Finally, we show 3D interacting hand pose estimation results from general images.
+
+
+
+InterNet (ECCV'2020)
+ +```bibtex +@InProceedings{Moon_2020_ECCV_InterHand2.6M, +author = {Moon, Gyeongsik and Yu, Shoou-I and Wen, He and Shiratori, Takaaki and Lee, Kyoung Mu}, +title = {InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image}, +booktitle = {European Conference on Computer Vision (ECCV)}, +year = {2020} +} +``` + +
+ +
+
diff --git a/vendor/ViTPose/docs/en/papers/algorithms/litehrnet.md b/vendor/ViTPose/docs/en/papers/algorithms/litehrnet.md
new file mode 100644
index 0000000000000000000000000000000000000000..f446062caf6b5a88d1206c1cb412bf74006da6f2
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/algorithms/litehrnet.md
@@ -0,0 +1,30 @@
+# Lite-HRNet: A Lightweight High-Resolution Network
+
+
+
+
+
+
+
+## Abstract
+
+
+
+We present an efficient high-resolution network, Lite-HRNet, for human pose estimation. We start by simply applying the efficient shuffle block in ShuffleNet to HRNet (high-resolution network), yielding stronger performance over popular lightweight networks, such as MobileNet, ShuffleNet, and Small HRNet.
+We find that the heavily-used pointwise (1x1) convolutions in shuffle blocks become the computational bottleneck. We introduce a lightweight unit, conditional channel weighting, to replace costly pointwise (1x1) convolutions in shuffle blocks. The complexity of channel weighting is linear w.r.t the number of channels and lower than the quadratic time complexity for pointwise convolutions. Our solution learns the weights from all the channels and over multiple resolutions that are readily available in the parallel branches in HRNet. It uses the weights as the bridge to exchange information across channels and resolutions, compensating the role played by the pointwise (1x1) convolution. Lite-HRNet demonstrates superior results on human pose estimation over popular lightweight networks. Moreover, Lite-HRNet can be easily applied to semantic segmentation task in the same lightweight manner.
+
+
+
+LiteHRNet (CVPR'2021)
+ +```bibtex +@inproceedings{Yulitehrnet21, + title={Lite-HRNet: A Lightweight High-Resolution Network}, + author={Yu, Changqian and Xiao, Bin and Gao, Changxin and Yuan, Lu and Zhang, Lei and Sang, Nong and Wang, Jingdong}, + booktitle={CVPR}, + year={2021} +} +``` + +
+ +
+
diff --git a/vendor/ViTPose/docs/en/papers/algorithms/mspn.md b/vendor/ViTPose/docs/en/papers/algorithms/mspn.md
new file mode 100644
index 0000000000000000000000000000000000000000..1915cd3915fe6d0457ce6f8c02dbe4b306a6941b
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/algorithms/mspn.md
@@ -0,0 +1,29 @@
+# Rethinking on multi-stage networks for human pose estimation
+
+
+
+
+
+
+
+## Abstract
+
+
+
+Existing pose estimation approaches fall into two categories: single-stage and multi-stage methods. While multi-stage methods are seemingly more suited for the task, their performance in current practice is not as good as single-stage methods. This work studies this issue. We argue that the current multi-stage methods' unsatisfactory performance comes from the insufficiency in various design choices. We propose several improvements, including the single-stage module design, cross stage feature aggregation, and coarse-to-fine supervision. The resulting method establishes the new state-of-the-art on both MS COCO and MPII Human Pose dataset, justifying the effectiveness of a multi-stage architecture. The source code is publicly available for further research.
+
+
+
+MSPN (ArXiv'2019)
+ +```bibtex +@article{li2019rethinking, + title={Rethinking on Multi-Stage Networks for Human Pose Estimation}, + author={Li, Wenbo and Wang, Zhicheng and Yin, Binyi and Peng, Qixiang and Du, Yuming and Xiao, Tianzi and Yu, Gang and Lu, Hongtao and Wei, Yichen and Sun, Jian}, + journal={arXiv preprint arXiv:1901.00148}, + year={2019} +} +``` + +
+ +
+
diff --git a/vendor/ViTPose/docs/en/papers/algorithms/posewarper.md b/vendor/ViTPose/docs/en/papers/algorithms/posewarper.md
new file mode 100644
index 0000000000000000000000000000000000000000..285a36c582bc831667216d24d5bc20480e66e933
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/algorithms/posewarper.md
@@ -0,0 +1,29 @@
+# Learning Temporal Pose Estimation from Sparsely-Labeled Videos
+
+
+
+
+
+
+
+## Abstract
+
+
+
+Modern approaches for multi-person pose estimation in video require large amounts of dense annotations. However, labeling every frame in a video is costly and labor intensive. To reduce the need for dense annotations, we propose a PoseWarper network that leverages training videos with sparse annotations (every k frames) to learn to perform dense temporal pose propagation and estimation. Given a pair of video frames---a labeled Frame A and an unlabeled Frame B---we train our model to predict human pose in Frame A using the features from Frame B by means of deformable convolutions to implicitly learn the pose warping between A and B. We demonstrate that we can leverage our trained PoseWarper for several applications. First, at inference time we can reverse the application direction of our network in order to propagate pose information from manually annotated frames to unlabeled frames. This makes it possible to generate pose annotations for the entire video given only a few manually-labeled frames. Compared to modern label propagation methods based on optical flow, our warping mechanism is much more compact (6M vs 39M parameters), and also more accurate (88.7% mAP vs 83.8% mAP). We also show that we can improve the accuracy of a pose estimator by training it on an augmented dataset obtained by adding our propagated poses to the original manual labels. Lastly, we can use our PoseWarper to aggregate temporal pose information from neighboring frames during inference. This allows our system to achieve state-of-the-art pose detection results on the PoseTrack2017 and PoseTrack2018 datasets.
+
+
+
+PoseWarper (NeurIPS'2019)
+ +```bibtex +@inproceedings{NIPS2019_gberta, +title = {Learning Temporal Pose Estimation from Sparsely Labeled Videos}, +author = {Bertasius, Gedas and Feichtenhofer, Christoph, and Tran, Du and Shi, Jianbo, and Torresani, Lorenzo}, +booktitle = {Advances in Neural Information Processing Systems 33}, +year = {2019}, +} +``` + +
+ +
+
diff --git a/vendor/ViTPose/docs/en/papers/algorithms/rsn.md b/vendor/ViTPose/docs/en/papers/algorithms/rsn.md
new file mode 100644
index 0000000000000000000000000000000000000000..b1fb1ea9131d0b55828123211a8f8625c377f085
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/algorithms/rsn.md
@@ -0,0 +1,31 @@
+# Learning delicate local representations for multi-person pose estimation
+
+
+
+
+
+
+
+## Abstract
+
+
+
+In this paper, we propose a novel method called Residual Steps Network (RSN). RSN aggregates features with the same spatial size (Intra-level features) efficiently to obtain delicate local representations, which retain rich low-level spatial information and result in precise keypoint localization. Additionally, we observe the output features contribute differently to final performance. To tackle this problem, we propose an efficient attention mechanism - Pose Refine Machine (PRM) to make a trade-off between local and global representations in output features and further refine the keypoint locations. Our approach won the 1st place of COCO Keypoint Challenge 2019 and achieves state-of-the-art results on both COCO and MPII benchmarks, without using extra training data and pretrained model. Our single model achieves 78.6 on COCO test-dev, 93.0 on MPII test dataset. Ensembled models achieve 79.2 on COCO test-dev, 77.1 on COCO test-challenge dataset.
+
+
+
+RSN (ECCV'2020)
+ +```bibtex +@misc{cai2020learning, + title={Learning Delicate Local Representations for Multi-Person Pose Estimation}, + author={Yuanhao Cai and Zhicheng Wang and Zhengxiong Luo and Binyi Yin and Angang Du and Haoqian Wang and Xinyu Zhou and Erjin Zhou and Xiangyu Zhang and Jian Sun}, + year={2020}, + eprint={2003.04030}, + archivePrefix={arXiv}, + primaryClass={cs.CV} +} +``` + +
+ +
+
diff --git a/vendor/ViTPose/docs/en/papers/algorithms/scnet.md b/vendor/ViTPose/docs/en/papers/algorithms/scnet.md
new file mode 100644
index 0000000000000000000000000000000000000000..043c144111789880f4f1d8b6ee5059518e185e8f
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/algorithms/scnet.md
@@ -0,0 +1,30 @@
+# Improving Convolutional Networks with Self-Calibrated Convolutions
+
+
+
+
+
+
+
+## Abstract
+
+
+
+Recent advances on CNNs are mostly devoted to designing more complex architectures to enhance their representation learning capacity. In this paper, we consider how to improve the basic convolutional feature transformation process of CNNs without tuning the model architectures. To this end, we present a novel self-calibrated convolutions that explicitly expand fields-of-view of each convolutional layers through internal communications and hence enrich the output features. In particular, unlike the standard convolutions that fuse spatial and channel-wise information using small kernels (e.g., 3x3), self-calibrated convolutions adaptively build long-range spatial and inter-channel dependencies around each spatial location through a novel self-calibration operation. Thus, it can help CNNs generate more discriminative representations by explicitly incorporating richer information. Our self-calibrated convolution design is simple and generic, and can be easily applied to augment standard convolutional layers without introducing extra parameters and complexity. Extensive experiments demonstrate that when applying self-calibrated convolutions into different backbones, our networks can significantly improve the baseline models in a variety of vision tasks, including image recognition, object detection, instance segmentation, and keypoint detection, with no need to change the network architectures. We hope this work could provide a promising way for future research in designing novel convolutional feature transformations for improving convolutional networks. Code is available on the project page.
+
+
+
+SCNet (CVPR'2020)
+ +```bibtex +@inproceedings{liu2020improving, + title={Improving Convolutional Networks with Self-Calibrated Convolutions}, + author={Liu, Jiang-Jiang and Hou, Qibin and Cheng, Ming-Ming and Wang, Changhu and Feng, Jiashi}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + pages={10096--10105}, + year={2020} +} +``` + +
+ +
+
diff --git a/vendor/ViTPose/docs/en/papers/algorithms/simplebaseline2d.md b/vendor/ViTPose/docs/en/papers/algorithms/simplebaseline2d.md
new file mode 100644
index 0000000000000000000000000000000000000000..026ef92afc5a89bdede8bbada21f56cbfc18fc32
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/algorithms/simplebaseline2d.md
@@ -0,0 +1,31 @@
+# Simple baselines for human pose estimation and tracking
+
+
+
+
+
+
+
+## Abstract
+
+
+
+There has been significant progress on pose estimation and increasing interests on pose tracking in recent years. At the same time, the overall algorithm and system complexity increases as well, making the algorithm analysis and comparison more difficult. This work provides simple and effective baseline methods. They are helpful for inspiring and
+evaluating new ideas for the field. State-of-the-art results are achieved on challenging benchmarks.
+
+
+
+SimpleBaseline2D (ECCV'2018)
+ +```bibtex +@inproceedings{xiao2018simple, + title={Simple baselines for human pose estimation and tracking}, + author={Xiao, Bin and Wu, Haiping and Wei, Yichen}, + booktitle={Proceedings of the European conference on computer vision (ECCV)}, + pages={466--481}, + year={2018} +} +``` + +
+ +
+
diff --git a/vendor/ViTPose/docs/en/papers/algorithms/simplebaseline3d.md b/vendor/ViTPose/docs/en/papers/algorithms/simplebaseline3d.md
new file mode 100644
index 0000000000000000000000000000000000000000..ee3c58368a5f71bda3199d385707336215086aaa
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/algorithms/simplebaseline3d.md
@@ -0,0 +1,29 @@
+# A simple yet effective baseline for 3d human pose estimation
+
+
+
+
+
+
+
+## Abstract
+
+
+
+Following the success of deep convolutional networks, state-of-the-art methods for 3d human pose estimation have focused on deep end-to-end systems that predict 3d joint locations given raw image pixels. Despite their excellent performance, it is often not easy to understand whether their remaining error stems from a limited 2d pose (visual) understanding, or from a failure to map 2d poses into 3-dimensional positions. With the goal of understanding these sources of error, we set out to build a system that given 2d joint locations predicts 3d positions. Much to our surprise, we have found that, with current technology, "lifting" ground truth 2d joint locations to 3d space is a task that can be solved with a remarkably low error rate: a relatively simple deep feed-forward network outperforms the best reported result by about 30% on Human3.6M, the largest publicly available 3d pose estimation benchmark. Furthermore, training our system on the output of an off-the-shelf state-of-the-art 2d detector (i.e., using images as input) yields state of the art results -- this includes an array of systems that have been trained end-to-end specifically for this task. Our results indicate that a large portion of the error of modern deep 3d pose estimation systems stems from their visual analysis, and suggests directions to further advance the state of the art in 3d human pose estimation.
+
+
+
+SimpleBaseline3D (ICCV'2017)
+ +```bibtex +@inproceedings{martinez_2017_3dbaseline, + title={A simple yet effective baseline for 3d human pose estimation}, + author={Martinez, Julieta and Hossain, Rayat and Romero, Javier and Little, James J.}, + booktitle={ICCV}, + year={2017} +} +``` + +
+ +
+
diff --git a/vendor/ViTPose/docs/en/papers/algorithms/softwingloss.md b/vendor/ViTPose/docs/en/papers/algorithms/softwingloss.md
new file mode 100644
index 0000000000000000000000000000000000000000..524a6089ffee69e109a0a721fa14b820df88ae8b
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/algorithms/softwingloss.md
@@ -0,0 +1,30 @@
+# Structure-Coherent Deep Feature Learning for Robust Face Alignment
+
+
+
+
+
+
+
+## Abstract
+
+
+
+In this paper, we propose a structure-coherent deep feature learning method for face alignment. Unlike most existing face alignment methods which overlook the facial structure cues, we explicitly exploit the relation among facial landmarks to make the detector robust to hard cases such as occlusion and large pose. Specifically, we leverage a landmark-graph relational network to enforce the structural relationships among landmarks. We consider the facial landmarks as structural graph nodes and carefully design the neighborhood to passing features among the most related nodes. Our method dynamically adapts the weights of node neighborhood to eliminate distracted information from noisy nodes, such as occluded landmark point. Moreover, different from most previous works which only tend to penalize the landmarks absolute position during the training, we propose a relative location loss to enhance the information of relative location of landmarks. This relative location supervision further regularizes the facial structure. Our approach considers the interactions among facial landmarks and can be easily implemented on top of any convolutional backbone to boost the performance. Extensive experiments on three popular benchmarks, including WFLW, COFW and 300W, demonstrate the effectiveness of the proposed method. In particular, due to explicit structure modeling, our approach is especially robust to challenging cases resulting in impressive low failure rate on COFW and WFLW datasets.
+
+
+
+SoftWingloss (TIP'2021)
+ +```bibtex +@article{lin2021structure, + title={Structure-Coherent Deep Feature Learning for Robust Face Alignment}, + author={Lin, Chunze and Zhu, Beier and Wang, Quan and Liao, Renjie and Qian, Chen and Lu, Jiwen and Zhou, Jie}, + journal={IEEE Transactions on Image Processing}, + year={2021}, + publisher={IEEE} +} +``` + +
+ +
+
diff --git a/vendor/ViTPose/docs/en/papers/algorithms/udp.md b/vendor/ViTPose/docs/en/papers/algorithms/udp.md
new file mode 100644
index 0000000000000000000000000000000000000000..bb4acebfbc9474312e992a67e2a19ef2df12be85
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/algorithms/udp.md
@@ -0,0 +1,30 @@
+# The Devil is in the Details: Delving into Unbiased Data Processing for Human Pose Estimation
+
+
+
+
+
+
+
+## Abstract
+
+
+
+Recently, the leading performance of human pose estimation is dominated by top-down methods. Being a fundamental component in training and inference, data processing has not been systematically considered in pose estimation community, to the best of our knowledge. In this paper, we focus on this problem and find that the devil of top-down pose estimator is in the biased data processing. Specifically, by investigating the standard data processing in state-of-the-art approaches mainly including data transformation and encoding-decoding, we find that the results obtained by common flipping strategy are unaligned with the original ones in inference. Moreover, there is statistical error in standard encoding-decoding during both training and inference. Two problems couple together and significantly degrade the pose estimation performance. Based on quantitative analyses, we then formulate a principled way to tackle this dilemma. Data is processed in continuous space based on unit length (the intervals between pixels) instead of in discrete space with pixel, and a combined classification and regression approach is adopted to perform encoding-decoding. The Unbiased Data Processing (UDP) for human pose estimation can be achieved by combining the two together. UDP not only boosts the performance of existing methods by a large margin but also plays a important role in result reproducing and future exploration. As a model-agnostic approach, UDP promotes SimpleBaseline-ResNet50-256x192 by 1.5 AP (70.2 to 71.7) and HRNet-W32-256x192 by 1.7 AP (73.5 to 75.2) on COCO test-dev set. The HRNet-W48-384x288 equipped with UDP achieves 76.5 AP and sets a new state-of-the-art for human pose estimation. The source code is publicly available for further research.
+
+
+
+UDP (CVPR'2020)
+ +```bibtex +@InProceedings{Huang_2020_CVPR, + author = {Huang, Junjie and Zhu, Zheng and Guo, Feng and Huang, Guan}, + title = {The Devil Is in the Details: Delving Into Unbiased Data Processing for Human Pose Estimation}, + booktitle = {The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, + month = {June}, + year = {2020} +} +``` + +
+ +
+
diff --git a/vendor/ViTPose/docs/en/papers/algorithms/videopose3d.md b/vendor/ViTPose/docs/en/papers/algorithms/videopose3d.md
new file mode 100644
index 0000000000000000000000000000000000000000..f8647e0ee8a67666f352454aa40c256f07bd4c30
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/algorithms/videopose3d.md
@@ -0,0 +1,30 @@
+# 3D human pose estimation in video with temporal convolutions and semi-supervised training
+
+
+
+
+
+
+
+## Abstract
+
+
+
+In this work, we demonstrate that 3D poses in video can be effectively estimated with a fully convolutional model based on dilated temporal convolutions over 2D keypoints. We also introduce back-projection, a simple and effective semi-supervised training method that leverages unlabeled video data. We start with predicted 2D keypoints for unlabeled video, then estimate 3D poses and finally back-project to the input 2D keypoints. In the supervised setting, our fully-convolutional model outperforms the previous best result from the literature by 6 mm mean per-joint position error on Human3.6M, corresponding to an error reduction of 11%, and the model also shows significant improvements on HumanEva-I. Moreover, experiments with back-projection show that it comfortably outperforms previous state-of-the-art results in semi-supervised settings where labeled data is scarce.
+
+
+
+VideoPose3D (CVPR'2019)
+ +```bibtex +@inproceedings{pavllo20193d, + title={3d human pose estimation in video with temporal convolutions and semi-supervised training}, + author={Pavllo, Dario and Feichtenhofer, Christoph and Grangier, David and Auli, Michael}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + pages={7753--7762}, + year={2019} +} +``` + +
+ +
+
diff --git a/vendor/ViTPose/docs/en/papers/algorithms/vipnas.md b/vendor/ViTPose/docs/en/papers/algorithms/vipnas.md
new file mode 100644
index 0000000000000000000000000000000000000000..5f52a8cac04cf48cb2e330afe176d835588034c6
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/algorithms/vipnas.md
@@ -0,0 +1,29 @@
+# ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search
+
+
+
+
+
+
+
+## Abstract
+
+
+
+Human pose estimation has achieved significant progress in recent years. However, most of the recent methods focus on improving accuracy using complicated models and ignoring real-time efficiency. To achieve a better trade-off between accuracy and efficiency, we propose a novel neural architecture search (NAS) method, termed ViPNAS, to search networks in both spatial and temporal levels for fast online video pose estimation. In the spatial level, we carefully design the search space with five different dimensions including network depth, width, kernel size, group number, and attentions. In the temporal level, we search from a series of temporal feature fusions to optimize the total accuracy and speed across multiple video frames. To the best of our knowledge, we are the first to search for the temporal feature fusion and automatic computation allocation in videos. Extensive experiments demonstrate the effectiveness of our approach on the challenging COCO2017 and PoseTrack2018 datasets. Our discovered model family, S-ViPNAS and T-ViPNAS, achieve significantly higher inference speed (CPU real-time) without sacrificing the accuracy compared to the previous state-of-the-art methods.
+
+
+
+ViPNAS (CVPR'2021)
+ +```bibtex +@article{xu2021vipnas, + title={ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search}, + author={Xu, Lumin and Guan, Yingda and Jin, Sheng and Liu, Wentao and Qian, Chen and Luo, Ping and Ouyang, Wanli and Wang, Xiaogang}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + year={2021} +} +``` + +
+ +
+
diff --git a/vendor/ViTPose/docs/en/papers/algorithms/voxelpose.md b/vendor/ViTPose/docs/en/papers/algorithms/voxelpose.md
new file mode 100644
index 0000000000000000000000000000000000000000..384f4ca1e57c1ad51ef79557f661b891f08173e7
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/algorithms/voxelpose.md
@@ -0,0 +1,29 @@
+# VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Environment
+
+
+
+
+
+
+
+## Abstract
+
+
+
+We present VoxelPose to estimate 3D poses of multiple people from multiple camera views. In contrast to the previous efforts which require to establish cross-view correspondence based on noisy and incomplete 2D pose estimates, VoxelPose directly operates in the 3D space therefore avoids making incorrect decisions in each camera view. To achieve this goal, features in all camera views are aggregated in the 3D voxel space and fed into Cuboid Proposal Network (CPN) to localize all people. Then we propose Pose Regression Network (PRN) to estimate a detailed 3D pose for each proposal. The approach is robust to occlusion which occurs frequently in practice. Without bells and whistles, it outperforms the previous methods on several public datasets.
+
+
+
+VoxelPose (ECCV'2020)
+ +```bibtex +@inproceedings{tumultipose, + title={VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Environment}, + author={Tu, Hanyue and Wang, Chunyu and Zeng, Wenjun}, + booktitle={ECCV}, + year={2020} +} +``` + +
+ +
+
diff --git a/vendor/ViTPose/docs/en/papers/algorithms/wingloss.md b/vendor/ViTPose/docs/en/papers/algorithms/wingloss.md
new file mode 100644
index 0000000000000000000000000000000000000000..2aaa05722eda24201cd35e1028349994d1f0fd6b
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/algorithms/wingloss.md
@@ -0,0 +1,31 @@
+# Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks
+
+
+
+
+
+
+
+## Abstract
+
+
+
+We present a new loss function, namely Wing loss, for robust facial landmark localisation with Convolutional Neural Networks (CNNs). We first compare and analyse different loss functions including L2, L1 and smooth L1. The analysis of these loss functions suggests that, for the training of a CNN-based localisation model, more attention should be paid to small and medium range errors. To this end, we design a piece-wise loss function. The new loss amplifies the impact of errors from the interval (-w, w) by switching from L1 loss to a modified logarithm function. To address the problem of under-representation of samples with large out-of-plane head rotations in the training set, we propose a simple but effective boosting strategy, referred to as pose-based data balancing. In particular, we deal with the data imbalance problem by duplicating the minority training samples and perturbing them by injecting random image rotation, bounding box translation and other data augmentation approaches. Last, the proposed approach is extended to create a two-stage framework for robust facial landmark localisation. The experimental results obtained on AFLW and 300W demonstrate the merits of the Wing loss function, and prove the superiority of the proposed method over the state-of-the-art approaches.
+
+
+
+Wingloss (CVPR'2018)
+ +```bibtex +@inproceedings{feng2018wing, + title={Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks}, + author={Feng, Zhen-Hua and Kittler, Josef and Awais, Muhammad and Huber, Patrik and Wu, Xiao-Jun}, + booktitle={Computer Vision and Pattern Recognition (CVPR), 2018 IEEE Conference on}, + year={2018}, + pages ={2235-2245}, + organization={IEEE} +} +``` + +
+ +
+
diff --git a/vendor/ViTPose/docs/en/papers/backbones/alexnet.md b/vendor/ViTPose/docs/en/papers/backbones/alexnet.md
new file mode 100644
index 0000000000000000000000000000000000000000..9a7d0bb87d25ff64384d674ff3a8fab88c3ce21f
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/backbones/alexnet.md
@@ -0,0 +1,30 @@
+# Imagenet classification with deep convolutional neural networks
+
+
+
+
+
+
+
+## Abstract
+
+
+
+We trained a large, deep convolutional neural network to classify the 1.2 million high-resolution images in the ImageNet LSVRC-2010 contest into the 1000 different classes. On the test data, we achieved top-1 and top-5 error rates of 37.5% and 17.0% which is considerably better than the previous state-of-the-art. The neural network, which has 60 million parameters and 650,000 neurons, consists of five convolutional layers, some of which are followed by max-pooling layers, and three fully-connected layers with a final 1000-way softmax. To make training faster, we used non-saturating neurons and a very efficient GPU implementation of the convolution operation. To reduce overfitting in the fully-connected layers we employed a recently-developed regularization method called “dropout” that proved to be very effective. We also entered a variant of this model in the ILSVRC-2012 competition and achieved a winning top-5 test error rate of 15.3%, compared to 26.2% achieved by the second-best entry
+
+
+
+AlexNet (NeurIPS'2012)
+ +```bibtex +@inproceedings{krizhevsky2012imagenet, + title={Imagenet classification with deep convolutional neural networks}, + author={Krizhevsky, Alex and Sutskever, Ilya and Hinton, Geoffrey E}, + booktitle={Advances in neural information processing systems}, + pages={1097--1105}, + year={2012} +} +``` + +
+ +
+
diff --git a/vendor/ViTPose/docs/en/papers/backbones/cpm.md b/vendor/ViTPose/docs/en/papers/backbones/cpm.md
new file mode 100644
index 0000000000000000000000000000000000000000..fb5dbfacec909f86b58d1ed4b24e75cad039c49e
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/backbones/cpm.md
@@ -0,0 +1,30 @@
+# Convolutional pose machines
+
+
+
+
+
+
+
+## Abstract
+
+
+
+We introduce associative embedding, a novel method for supervising convolutional neural networks for the task of detection and grouping. A number of computer vision problems can be framed in this manner including multi-person pose estimation, instance segmentation, and multi-object tracking. Usually the grouping of detections is achieved with multi-stage pipelines, instead we propose an approach that teaches a network to simultaneously output detections and group assignments. This technique can be easily integrated into any state-of-the-art network architecture that produces pixel-wise predictions. We show how to apply this method to both multi-person pose estimation and instance segmentation and report state-of-the-art performance for multi-person pose on the MPII and MS-COCO datasets.
+
+
+
+CPM (CVPR'2016)
+ +```bibtex +@inproceedings{wei2016convolutional, + title={Convolutional pose machines}, + author={Wei, Shih-En and Ramakrishna, Varun and Kanade, Takeo and Sheikh, Yaser}, + booktitle={Proceedings of the IEEE conference on Computer Vision and Pattern Recognition}, + pages={4724--4732}, + year={2016} +} +``` + +
+
+
diff --git a/vendor/ViTPose/docs/en/papers/backbones/higherhrnet.md b/vendor/ViTPose/docs/en/papers/backbones/higherhrnet.md
new file mode 100644
index 0000000000000000000000000000000000000000..c1d61c992a1f41e986d785560de0709407578dee
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/backbones/higherhrnet.md
@@ -0,0 +1,30 @@
+# HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation
+
+
+
+
+
+
+
+## Abstract
+
+
+
+Bottom-up human pose estimation methods have difficulties in predicting the correct pose for small persons due to challenges in scale variation. In this paper, we present HigherHRNet: a novel bottom-up human pose estimation method for learning scale-aware representations using high-resolution feature pyramids. Equipped with multi-resolution supervision for training and multi-resolution aggregation for inference, the proposed approach is able to solve the scale variation challenge in bottom-up multi-person pose estimation and localize keypoints more precisely, especially for small person. The feature pyramid in HigherHRNet consists of feature map outputs from HRNet and upsampled higher-resolution outputs through a transposed convolution. HigherHRNet outperforms the previous best bottom-up method by 2.5% AP for medium person on COCO test-dev, showing its effectiveness in handling scale variation. Furthermore, HigherHRNet achieves new state-of-the-art result on COCO test-dev (70.5% AP) without using refinement or other post-processing techniques, surpassing all existing bottom-up methods. HigherHRNet even surpasses all top-down methods on CrowdPose test (67.6% AP), suggesting its robustness in crowded scene.
+
+
+
+HigherHRNet (CVPR'2020)
+ +```bibtex +@inproceedings{cheng2020higherhrnet, + title={HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation}, + author={Cheng, Bowen and Xiao, Bin and Wang, Jingdong and Shi, Honghui and Huang, Thomas S and Zhang, Lei}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + pages={5386--5395}, + year={2020} +} +``` + +
+
+
diff --git a/vendor/ViTPose/docs/en/papers/backbones/hourglass.md b/vendor/ViTPose/docs/en/papers/backbones/hourglass.md
new file mode 100644
index 0000000000000000000000000000000000000000..7782484a31fc01d7daed19536328e653e317bda0
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/backbones/hourglass.md
@@ -0,0 +1,31 @@
+# Stacked hourglass networks for human pose estimation
+
+
+
+
+
+
+
+## Abstract
+
+
+
+This work introduces a novel convolutional network architecture for the task of human pose estimation. Features are processed across all scales and consolidated to best capture the various spatial relationships associated with the body. We show how repeated bottom-up, top-down processing used in conjunction with intermediate supervision is critical to improving the performance of the network. We refer to the architecture as a “stacked hourglass” network based on the successive steps of pooling and upsampling that are done to produce a final set of predictions. State-of-the-art results are achieved on the FLIC and MPII benchmarks outcompeting all recent methods.
+
+
+
+Hourglass (ECCV'2016)
+ +```bibtex +@inproceedings{newell2016stacked, + title={Stacked hourglass networks for human pose estimation}, + author={Newell, Alejandro and Yang, Kaiyu and Deng, Jia}, + booktitle={European conference on computer vision}, + pages={483--499}, + year={2016}, + organization={Springer} +} +``` + +
+
+
diff --git a/vendor/ViTPose/docs/en/papers/backbones/hrformer.md b/vendor/ViTPose/docs/en/papers/backbones/hrformer.md
new file mode 100644
index 0000000000000000000000000000000000000000..dfa7a13f6b368b64669eb6acfa0d6d637fcb3496
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/backbones/hrformer.md
@@ -0,0 +1,39 @@
+# HRFormer: High-Resolution Vision Transformer for Dense Predict
+
+
+
+
+
+
+
+## Abstract
+
+
+
+We present a High-Resolution Transformer (HRFormer) that learns high-resolution representations for dense
+prediction tasks, in contrast to the original Vision Transformer that produces low-resolution representations
+and has high memory and computational cost. We take advantage of the multi-resolution parallel design
+introduced in high-resolution convolutional networks (HRNet), along with local-window self-attention
+that performs self-attention over small non-overlapping image windows, for improving the memory and
+computation efficiency. In addition, we introduce a convolution into the FFN to exchange information
+across the disconnected image windows. We demonstrate the effectiveness of the HighResolution Transformer
+on both human pose estimation and semantic segmentation tasks, e.g., HRFormer outperforms Swin
+transformer by 1.3 AP on COCO pose estimation with 50% fewer parameters and 30% fewer FLOPs.
+Code is available at: https://github.com/HRNet/HRFormer
+
+
+
+HRFormer (NIPS'2021)
+ +```bibtex +@article{yuan2021hrformer, + title={HRFormer: High-Resolution Vision Transformer for Dense Predict}, + author={Yuan, Yuhui and Fu, Rao and Huang, Lang and Lin, Weihong and Zhang, Chao and Chen, Xilin and Wang, Jingdong}, + journal={Advances in Neural Information Processing Systems}, + volume={34}, + year={2021} +} +``` + +
+ +
+
diff --git a/vendor/ViTPose/docs/en/papers/backbones/hrnet.md b/vendor/ViTPose/docs/en/papers/backbones/hrnet.md
new file mode 100644
index 0000000000000000000000000000000000000000..05a46f543ef25de847c5fcb4704f56e5cea2bd42
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/backbones/hrnet.md
@@ -0,0 +1,32 @@
+# Deep high-resolution representation learning for human pose estimation
+
+
+
+
+
+
+
+## Abstract
+
+
+
+In this paper, we are interested in the human pose estimation problem with a focus on learning reliable highresolution representations. Most existing methods recover high-resolution representations from low-resolution representations produced by a high-to-low resolution network. Instead, our proposed network maintains high-resolution representations through the whole process. We start from a high-resolution subnetwork as the first stage, gradually add high-to-low resolution subnetworks one by one to form more stages, and connect the mutliresolution subnetworks in parallel. We conduct repeated multi-scale fusions such that each of the high-to-low resolution representations receives information from other parallel representations over and over, leading to rich highresolution representations. As a result, the predicted keypoint heatmap is potentially more accurate and spatially more precise. We empirically demonstrate the effectiveness
+of our network through the superior pose estimation results over two benchmark datasets: the COCO keypoint detection
+dataset and the MPII Human Pose dataset. In addition, we show the superiority of our network in pose tracking on the PoseTrack dataset.
+
+
+
+HRNet (CVPR'2019)
+ +```bibtex +@inproceedings{sun2019deep, + title={Deep high-resolution representation learning for human pose estimation}, + author={Sun, Ke and Xiao, Bin and Liu, Dong and Wang, Jingdong}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={5693--5703}, + year={2019} +} +``` + +
+
+
diff --git a/vendor/ViTPose/docs/en/papers/backbones/hrnetv2.md b/vendor/ViTPose/docs/en/papers/backbones/hrnetv2.md
new file mode 100644
index 0000000000000000000000000000000000000000..f2ed2a9c0c8797a842e73c980e1868cdbfbf8cc8
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/backbones/hrnetv2.md
@@ -0,0 +1,31 @@
+# Deep high-resolution representation learning for visual recognition
+
+
+
+
+
+
+
+## Abstract
+
+
+
+High-resolution representations are essential for position-sensitive vision problems, such as human pose estimation, semantic segmentation, and object detection. Existing state-of-the-art frameworks first encode the input image as a low-resolution representation through a subnetwork that is formed by connecting high-to-low resolution convolutions in series (e.g., ResNet, VGGNet), and then recover the high-resolution representation from the encoded low-resolution representation. Instead, our proposed network, named as High-Resolution Network (HRNet), maintains high-resolution representations through the whole process. There are two key characteristics: (i) Connect the high-to-low resolution convolution streams in parallel and (ii) repeatedly exchange the information across resolutions. The benefit is that the resulting representation is semantically richer and spatially more precise. We show the superiority of the proposed HRNet in a wide range of applications, including human pose estimation, semantic segmentation, and object detection, suggesting that the HRNet is a stronger backbone for computer vision problems.
+
+
+
+HRNetv2 (TPAMI'2019)
+ +```bibtex +@article{WangSCJDZLMTWLX19, + title={Deep High-Resolution Representation Learning for Visual Recognition}, + author={Jingdong Wang and Ke Sun and Tianheng Cheng and + Borui Jiang and Chaorui Deng and Yang Zhao and Dong Liu and Yadong Mu and + Mingkui Tan and Xinggang Wang and Wenyu Liu and Bin Xiao}, + journal={TPAMI}, + year={2019} +} +``` + +
+
+
diff --git a/vendor/ViTPose/docs/en/papers/backbones/litehrnet.md b/vendor/ViTPose/docs/en/papers/backbones/litehrnet.md
new file mode 100644
index 0000000000000000000000000000000000000000..f446062caf6b5a88d1206c1cb412bf74006da6f2
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/backbones/litehrnet.md
@@ -0,0 +1,30 @@
+# Lite-HRNet: A Lightweight High-Resolution Network
+
+
+
+
+
+
+
+## Abstract
+
+
+
+We present an efficient high-resolution network, Lite-HRNet, for human pose estimation. We start by simply applying the efficient shuffle block in ShuffleNet to HRNet (high-resolution network), yielding stronger performance over popular lightweight networks, such as MobileNet, ShuffleNet, and Small HRNet.
+We find that the heavily-used pointwise (1x1) convolutions in shuffle blocks become the computational bottleneck. We introduce a lightweight unit, conditional channel weighting, to replace costly pointwise (1x1) convolutions in shuffle blocks. The complexity of channel weighting is linear w.r.t the number of channels and lower than the quadratic time complexity for pointwise convolutions. Our solution learns the weights from all the channels and over multiple resolutions that are readily available in the parallel branches in HRNet. It uses the weights as the bridge to exchange information across channels and resolutions, compensating the role played by the pointwise (1x1) convolution. Lite-HRNet demonstrates superior results on human pose estimation over popular lightweight networks. Moreover, Lite-HRNet can be easily applied to semantic segmentation task in the same lightweight manner.
+
+
+
+LiteHRNet (CVPR'2021)
+ +```bibtex +@inproceedings{Yulitehrnet21, + title={Lite-HRNet: A Lightweight High-Resolution Network}, + author={Yu, Changqian and Xiao, Bin and Gao, Changxin and Yuan, Lu and Zhang, Lei and Sang, Nong and Wang, Jingdong}, + booktitle={CVPR}, + year={2021} +} +``` + +
+
+
diff --git a/vendor/ViTPose/docs/en/papers/backbones/mobilenetv2.md b/vendor/ViTPose/docs/en/papers/backbones/mobilenetv2.md
new file mode 100644
index 0000000000000000000000000000000000000000..9456520d46399060f00531a93e8612bff7625550
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/backbones/mobilenetv2.md
@@ -0,0 +1,30 @@
+# Mobilenetv2: Inverted residuals and linear bottlenecks
+
+
+
+
+
+
+
+## Abstract
+
+
+
+In this paper we describe a new mobile architecture, mbox{MobileNetV2}, that improves the state of the art performance of mobile models on multiple tasks and benchmarks as well as across a spectrum of different model sizes. We also describe efficient ways of applying these mobile models to object detection in a novel framework we call mbox{SSDLite}. Additionally, we demonstrate how to build mobile semantic segmentation models through a reduced form of mbox{DeepLabv3} which we call Mobile mbox{DeepLabv3}. is based on an inverted residual structure where the shortcut connections are between the thin bottleneck layers. The intermediate expansion layer uses lightweight depthwise convolutions to filter features as a source of non-linearity. Additionally, we find that it is important to remove non-linearities in the narrow layers in order to maintain representational power. We demonstrate that this improves performance and provide an intuition that led to this design. Finally, our approach allows decoupling of the input/output domains from the expressiveness of the transformation, which provides a convenient framework for further analysis. We measure our performance on mbox{ImageNet}~cite{Russakovsky:2015:ILS:2846547.2846559} classification, COCO object detection cite{COCO}, VOC image segmentation cite{PASCAL}. We evaluate the trade-offs between accuracy, and number of operations measured by multiply-adds (MAdd), as well as actual latency, and the number of parameters.
+
+
+
+MobilenetV2 (CVPR'2018)
+ +```bibtex +@inproceedings{sandler2018mobilenetv2, + title={Mobilenetv2: Inverted residuals and linear bottlenecks}, + author={Sandler, Mark and Howard, Andrew and Zhu, Menglong and Zhmoginov, Andrey and Chen, Liang-Chieh}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={4510--4520}, + year={2018} +} +``` + +
+ +
+
diff --git a/vendor/ViTPose/docs/en/papers/backbones/mspn.md b/vendor/ViTPose/docs/en/papers/backbones/mspn.md
new file mode 100644
index 0000000000000000000000000000000000000000..1915cd3915fe6d0457ce6f8c02dbe4b306a6941b
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/backbones/mspn.md
@@ -0,0 +1,29 @@
+# Rethinking on multi-stage networks for human pose estimation
+
+
+
+
+
+
+
+## Abstract
+
+
+
+Existing pose estimation approaches fall into two categories: single-stage and multi-stage methods. While multi-stage methods are seemingly more suited for the task, their performance in current practice is not as good as single-stage methods. This work studies this issue. We argue that the current multi-stage methods' unsatisfactory performance comes from the insufficiency in various design choices. We propose several improvements, including the single-stage module design, cross stage feature aggregation, and coarse-to-fine supervision. The resulting method establishes the new state-of-the-art on both MS COCO and MPII Human Pose dataset, justifying the effectiveness of a multi-stage architecture. The source code is publicly available for further research.
+
+
+
+MSPN (ArXiv'2019)
+ +```bibtex +@article{li2019rethinking, + title={Rethinking on Multi-Stage Networks for Human Pose Estimation}, + author={Li, Wenbo and Wang, Zhicheng and Yin, Binyi and Peng, Qixiang and Du, Yuming and Xiao, Tianzi and Yu, Gang and Lu, Hongtao and Wei, Yichen and Sun, Jian}, + journal={arXiv preprint arXiv:1901.00148}, + year={2019} +} +``` + +
+
+
diff --git a/vendor/ViTPose/docs/en/papers/backbones/resnest.md b/vendor/ViTPose/docs/en/papers/backbones/resnest.md
new file mode 100644
index 0000000000000000000000000000000000000000..748c94737a4ebc96ec50a5520e1fa5c547651d42
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/backbones/resnest.md
@@ -0,0 +1,29 @@
+# ResNeSt: Split-Attention Networks
+
+
+
+
+
+
+
+## Abstract
+
+
+
+It is well known that featuremap attention and multi-path representation are important for visual recognition. In this paper, we present a modularized architecture, which applies the channel-wise attention on different network branches to leverage their success in capturing cross-feature interactions and learning diverse representations. Our design results in a simple and unified computation block, which can be parameterized using only a few variables. Our model, named ResNeSt, outperforms EfficientNet in accuracy and latency trade-off on image classification. In addition, ResNeSt has achieved superior transfer learning results on several public benchmarks serving as the backbone, and has been adopted by the winning entries of COCO-LVIS challenge. The source code for complete system and pretrained models are publicly available.
+
+
+
+ResNeSt (ArXiv'2020)
+ +```bibtex +@article{zhang2020resnest, + title={ResNeSt: Split-Attention Networks}, + author={Zhang, Hang and Wu, Chongruo and Zhang, Zhongyue and Zhu, Yi and Zhang, Zhi and Lin, Haibin and Sun, Yue and He, Tong and Muller, Jonas and Manmatha, R. and Li, Mu and Smola, Alexander}, + journal={arXiv preprint arXiv:2004.08955}, + year={2020} +} +``` + +
+ +
+
diff --git a/vendor/ViTPose/docs/en/papers/backbones/resnet.md b/vendor/ViTPose/docs/en/papers/backbones/resnet.md
new file mode 100644
index 0000000000000000000000000000000000000000..86b91ffc38623af6f4fd8614371cb3f3db2d6fe2
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/backbones/resnet.md
@@ -0,0 +1,32 @@
+# Deep residual learning for image recognition
+
+
+
+
+
+
+
+## Abstract
+
+
+
+Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from
+considerably increased depth. On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers—8× deeper than VGG nets but still having lower complexity. An ensemble of these residual nets achieves 3.57% error on the ImageNet test set. This result won the 1st place on the ILSVRC 2015 classification task. We also present analysis on CIFAR-10 with 100 and 1000 layers. The depth of representations is of central importance for many visual recognition tasks. Solely due to our extremely deep representations, we obtain a 28% relative improvement on the COCO object detection dataset. Deep residual nets are foundations of our submissions to ILSVRC
+& COCO 2015 competitions1 , where we also won the 1st places on the tasks of ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation.
+
+
+
+ResNet (CVPR'2016)
+ +```bibtex +@inproceedings{he2016deep, + title={Deep residual learning for image recognition}, + author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={770--778}, + year={2016} +} +``` + +
+ +
+
diff --git a/vendor/ViTPose/docs/en/papers/backbones/resnetv1d.md b/vendor/ViTPose/docs/en/papers/backbones/resnetv1d.md
new file mode 100644
index 0000000000000000000000000000000000000000..ebde55454e4750dfce018e1f13cb7a464380b5ae
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/backbones/resnetv1d.md
@@ -0,0 +1,31 @@
+# Bag of tricks for image classification with convolutional neural networks
+
+
+
+
+
+
+
+## Abstract
+
+
+
+Much of the recent progress made in image classification research can be credited to training procedure refinements, such as changes in data augmentations and optimization methods. In the literature, however, most refinements are either briefly mentioned as implementation details or only visible in source code. In this paper, we will examine a collection of such refinements and empirically evaluate their impact on the final model accuracy through ablation study. We will show that, by combining these refinements together, we are able to improve various CNN models significantly. For example, we raise ResNet-50’s top-1 validation accuracy from 75.3% to 79.29% on ImageNet. We will also demonstrate that improvement on image classification accuracy leads to better transfer learning performance in other application domains such as object detection and semantic
+segmentation.
+
+
+
+ResNetV1D (CVPR'2019)
+ +```bibtex +@inproceedings{he2019bag, + title={Bag of tricks for image classification with convolutional neural networks}, + author={He, Tong and Zhang, Zhi and Zhang, Hang and Zhang, Zhongyue and Xie, Junyuan and Li, Mu}, + booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition}, + pages={558--567}, + year={2019} +} +``` + +
+ +
+
diff --git a/vendor/ViTPose/docs/en/papers/backbones/resnext.md b/vendor/ViTPose/docs/en/papers/backbones/resnext.md
new file mode 100644
index 0000000000000000000000000000000000000000..9803ee9bcd578c6a34369750a1b39e5ffa497797
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/backbones/resnext.md
@@ -0,0 +1,30 @@
+# Aggregated residual transformations for deep neural networks
+
+
+
+
+
+
+
+## Abstract
+
+
+
+We present a simple, highly modularized network architecture for image classification. Our network is constructed by repeating a building block that aggregates a set of transformations with the same topology. Our simple design results in a homogeneous, multi-branch architecture that has only a few hyper-parameters to set. This strategy exposes a new dimension, which we call "cardinality" (the size of the set of transformations), as an essential factor in addition to the dimensions of depth and width. On the ImageNet-1K dataset, we empirically show that even under the restricted condition of maintaining complexity, increasing cardinality is able to improve classification accuracy. Moreover, increasing cardinality is more effective than going deeper or wider when we increase the capacity. Our models, named ResNeXt, are the foundations of our entry to the ILSVRC 2016 classification task in which we secured 2nd place. We further investigate ResNeXt on an ImageNet-5K set and the COCO detection set, also showing better results than its ResNet counterpart. The code and models are publicly available online.
+
+
+
+ResNext (CVPR'2017)
+ +```bibtex +@inproceedings{xie2017aggregated, + title={Aggregated residual transformations for deep neural networks}, + author={Xie, Saining and Girshick, Ross and Doll{\'a}r, Piotr and Tu, Zhuowen and He, Kaiming}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={1492--1500}, + year={2017} +} +``` + +
+ +
+
diff --git a/vendor/ViTPose/docs/en/papers/backbones/rsn.md b/vendor/ViTPose/docs/en/papers/backbones/rsn.md
new file mode 100644
index 0000000000000000000000000000000000000000..b1fb1ea9131d0b55828123211a8f8625c377f085
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/backbones/rsn.md
@@ -0,0 +1,31 @@
+# Learning delicate local representations for multi-person pose estimation
+
+
+
+
+
+
+
+## Abstract
+
+
+
+In this paper, we propose a novel method called Residual Steps Network (RSN). RSN aggregates features with the same spatial size (Intra-level features) efficiently to obtain delicate local representations, which retain rich low-level spatial information and result in precise keypoint localization. Additionally, we observe the output features contribute differently to final performance. To tackle this problem, we propose an efficient attention mechanism - Pose Refine Machine (PRM) to make a trade-off between local and global representations in output features and further refine the keypoint locations. Our approach won the 1st place of COCO Keypoint Challenge 2019 and achieves state-of-the-art results on both COCO and MPII benchmarks, without using extra training data and pretrained model. Our single model achieves 78.6 on COCO test-dev, 93.0 on MPII test dataset. Ensembled models achieve 79.2 on COCO test-dev, 77.1 on COCO test-challenge dataset.
+
+
+
+RSN (ECCV'2020)
+ +```bibtex +@misc{cai2020learning, + title={Learning Delicate Local Representations for Multi-Person Pose Estimation}, + author={Yuanhao Cai and Zhicheng Wang and Zhengxiong Luo and Binyi Yin and Angang Du and Haoqian Wang and Xinyu Zhou and Erjin Zhou and Xiangyu Zhang and Jian Sun}, + year={2020}, + eprint={2003.04030}, + archivePrefix={arXiv}, + primaryClass={cs.CV} +} +``` + +
+
+
diff --git a/vendor/ViTPose/docs/en/papers/backbones/scnet.md b/vendor/ViTPose/docs/en/papers/backbones/scnet.md
new file mode 100644
index 0000000000000000000000000000000000000000..043c144111789880f4f1d8b6ee5059518e185e8f
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/backbones/scnet.md
@@ -0,0 +1,30 @@
+# Improving Convolutional Networks with Self-Calibrated Convolutions
+
+
+
+
+
+
+
+## Abstract
+
+
+
+Recent advances on CNNs are mostly devoted to designing more complex architectures to enhance their representation learning capacity. In this paper, we consider how to improve the basic convolutional feature transformation process of CNNs without tuning the model architectures. To this end, we present a novel self-calibrated convolutions that explicitly expand fields-of-view of each convolutional layers through internal communications and hence enrich the output features. In particular, unlike the standard convolutions that fuse spatial and channel-wise information using small kernels (e.g., 3x3), self-calibrated convolutions adaptively build long-range spatial and inter-channel dependencies around each spatial location through a novel self-calibration operation. Thus, it can help CNNs generate more discriminative representations by explicitly incorporating richer information. Our self-calibrated convolution design is simple and generic, and can be easily applied to augment standard convolutional layers without introducing extra parameters and complexity. Extensive experiments demonstrate that when applying self-calibrated convolutions into different backbones, our networks can significantly improve the baseline models in a variety of vision tasks, including image recognition, object detection, instance segmentation, and keypoint detection, with no need to change the network architectures. We hope this work could provide a promising way for future research in designing novel convolutional feature transformations for improving convolutional networks. Code is available on the project page.
+
+
+
+SCNet (CVPR'2020)
+ +```bibtex +@inproceedings{liu2020improving, + title={Improving Convolutional Networks with Self-Calibrated Convolutions}, + author={Liu, Jiang-Jiang and Hou, Qibin and Cheng, Ming-Ming and Wang, Changhu and Feng, Jiashi}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + pages={10096--10105}, + year={2020} +} +``` + +
+
+
diff --git a/vendor/ViTPose/docs/en/papers/backbones/seresnet.md b/vendor/ViTPose/docs/en/papers/backbones/seresnet.md
new file mode 100644
index 0000000000000000000000000000000000000000..52178e5cf0b68e9512888bcfaaeb3d0c2b7a81b5
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/backbones/seresnet.md
@@ -0,0 +1,30 @@
+# Squeeze-and-excitation networks
+
+
+
+
+
+
+
+## Abstract
+
+
+
+Convolutional neural networks are built upon the convolution operation, which extracts informative features by fusing spatial and channel-wise information together within local receptive fields. In order to boost the representational power of a network, several recent approaches have shown the benefit of enhancing spatial encoding. In this work, we focus on the channel relationship and propose a novel architectural unit, which we term the “Squeeze-and-Excitation” (SE) block, that adaptively recalibrates channel-wise feature responses by explicitly modelling interdependencies between channels. We demonstrate that by stacking these blocks together, we can construct SENet architectures that generalise extremely well across challenging datasets. Crucially, we find that SE blocks produce significant performance improvements for existing state-of-the-art deep architectures at minimal additional computational cost. SENets formed the foundation of our ILSVRC 2017 classification submission which won first place and significantly reduced the top-5 error to 2.251%, achieving a ∼25% relative improvement over the winning entry of 2016. Code and models are available at https: //github.com/hujie-frank/SENet.
+
+
+
+SEResNet (CVPR'2018)
+ +```bibtex +@inproceedings{hu2018squeeze, + title={Squeeze-and-excitation networks}, + author={Hu, Jie and Shen, Li and Sun, Gang}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={7132--7141}, + year={2018} +} +``` + +
+ +
+
diff --git a/vendor/ViTPose/docs/en/papers/backbones/shufflenetv1.md b/vendor/ViTPose/docs/en/papers/backbones/shufflenetv1.md
new file mode 100644
index 0000000000000000000000000000000000000000..a314c9b709ca8aaf6f7c47138fe3eee2aabd4bb9
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/backbones/shufflenetv1.md
@@ -0,0 +1,30 @@
+# Shufflenet: An extremely efficient convolutional neural network for mobile devices
+
+
+
+
+
+
+
+## Abstract
+
+
+
+We introduce an extremely computation-efficient CNN architecture named ShuffleNet, which is designed specially for mobile devices with very limited computing power (e.g., 10-150 MFLOPs). The new architecture utilizes two new operations, pointwise group convolution and channel shuffle, to greatly reduce computation cost while maintaining accuracy. Experiments on ImageNet classification and MS COCO object detection demonstrate the superior performance of ShuffleNet over other structures, e.g. lower top-1 error (absolute 7.8%) than recent MobileNet~cite{howard2017mobilenets} on ImageNet classification task, under the computation budget of 40 MFLOPs. On an ARM-based mobile device, ShuffleNet achieves $sim$13$ imes$ actual speedup over AlexNet while maintaining comparable accuracy.
+
+
+
+ShufflenetV1 (CVPR'2018)
+ +```bibtex +@inproceedings{zhang2018shufflenet, + title={Shufflenet: An extremely efficient convolutional neural network for mobile devices}, + author={Zhang, Xiangyu and Zhou, Xinyu and Lin, Mengxiao and Sun, Jian}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={6848--6856}, + year={2018} +} +``` + +
+ +
+
diff --git a/vendor/ViTPose/docs/en/papers/backbones/shufflenetv2.md b/vendor/ViTPose/docs/en/papers/backbones/shufflenetv2.md
new file mode 100644
index 0000000000000000000000000000000000000000..834ee38bc0deb814d7c3f911c919a8696764b415
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/backbones/shufflenetv2.md
@@ -0,0 +1,30 @@
+# Shufflenet v2: Practical guidelines for efficient cnn architecture design
+
+
+
+
+
+
+
+## Abstract
+
+
+
+Current network architecture design is mostly guided by the indirect metric of computation complexity, i.e., FLOPs. However, the direct metric, such as speed, also depends on the other factors such as memory access cost and platform characterics. Taking these factors into account, this work proposes practical guidelines for efficient network de- sign. Accordingly, a new architecture called ShuffleNet V2 is presented. Comprehensive experiments verify that it is the state-of-the-art in both speed and accuracy.
+
+
+
+ShufflenetV2 (ECCV'2018)
+ +```bibtex +@inproceedings{ma2018shufflenet, + title={Shufflenet v2: Practical guidelines for efficient cnn architecture design}, + author={Ma, Ningning and Zhang, Xiangyu and Zheng, Hai-Tao and Sun, Jian}, + booktitle={Proceedings of the European conference on computer vision (ECCV)}, + pages={116--131}, + year={2018} +} +``` + +
+ +
+
diff --git a/vendor/ViTPose/docs/en/papers/backbones/vgg.md b/vendor/ViTPose/docs/en/papers/backbones/vgg.md
new file mode 100644
index 0000000000000000000000000000000000000000..3a92a46b986a9a8907a74333bcee6acff6d01891
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/backbones/vgg.md
@@ -0,0 +1,29 @@
+# Very Deep Convolutional Networks for Large-Scale Image Recognition
+
+
+
+
+
+
+
+## Abstract
+
+
+
+In this work we investigate the effect of the convolutional network depth on its accuracy in the large-scale image recognition setting. Our main contribution is a thorough evaluation of networks of increasing depth using an architecture with very small (3x3) convolution filters, which shows that a significant improvement on the prior-art configurations can be achieved by pushing the depth to 16-19 weight layers. These findings were the basis of our ImageNet Challenge 2014 submission, where our team secured the first and the second places in the localisation and classification tracks respectively. We also show that our representations generalise well to other datasets, where they achieve state-of-the-art results. We have made our two best-performing ConvNet models publicly available to facilitate further research on the use of deep visual representations in computer vision.
+
+
+
+VGG (ICLR'2015)
+ +```bibtex +@article{simonyan2014very, + title={Very deep convolutional networks for large-scale image recognition}, + author={Simonyan, Karen and Zisserman, Andrew}, + journal={arXiv preprint arXiv:1409.1556}, + year={2014} +} +``` + +
+ +
+
diff --git a/vendor/ViTPose/docs/en/papers/backbones/vipnas.md b/vendor/ViTPose/docs/en/papers/backbones/vipnas.md
new file mode 100644
index 0000000000000000000000000000000000000000..5f52a8cac04cf48cb2e330afe176d835588034c6
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/backbones/vipnas.md
@@ -0,0 +1,29 @@
+# ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search
+
+
+
+
+
+
+
+## Abstract
+
+
+
+Human pose estimation has achieved significant progress in recent years. However, most of the recent methods focus on improving accuracy using complicated models and ignoring real-time efficiency. To achieve a better trade-off between accuracy and efficiency, we propose a novel neural architecture search (NAS) method, termed ViPNAS, to search networks in both spatial and temporal levels for fast online video pose estimation. In the spatial level, we carefully design the search space with five different dimensions including network depth, width, kernel size, group number, and attentions. In the temporal level, we search from a series of temporal feature fusions to optimize the total accuracy and speed across multiple video frames. To the best of our knowledge, we are the first to search for the temporal feature fusion and automatic computation allocation in videos. Extensive experiments demonstrate the effectiveness of our approach on the challenging COCO2017 and PoseTrack2018 datasets. Our discovered model family, S-ViPNAS and T-ViPNAS, achieve significantly higher inference speed (CPU real-time) without sacrificing the accuracy compared to the previous state-of-the-art methods.
+
+
+
+ViPNAS (CVPR'2021)
+ +```bibtex +@article{xu2021vipnas, + title={ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search}, + author={Xu, Lumin and Guan, Yingda and Jin, Sheng and Liu, Wentao and Qian, Chen and Luo, Ping and Ouyang, Wanli and Wang, Xiaogang}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + year={2021} +} +``` + +
+
+
diff --git a/vendor/ViTPose/docs/en/papers/datasets/300w.md b/vendor/ViTPose/docs/en/papers/datasets/300w.md
new file mode 100644
index 0000000000000000000000000000000000000000..7af778ee6d821ec5817ae55e1729ebef43867668
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/datasets/300w.md
@@ -0,0 +1,20 @@
+# 300 faces in-the-wild challenge: Database and results
+
+
+
+
+
+
diff --git a/vendor/ViTPose/docs/en/papers/datasets/aflw.md b/vendor/ViTPose/docs/en/papers/datasets/aflw.md
new file mode 100644
index 0000000000000000000000000000000000000000..f04f265c836a3fcccbd4869d22291db3235c672d
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/datasets/aflw.md
@@ -0,0 +1,19 @@
+# Annotated facial landmarks in the wild: A large-scale, real-world database for facial landmark localization
+
+
+
+300W (IMAVIS'2016)
+ +```bibtex +@article{sagonas2016300, + title={300 faces in-the-wild challenge: Database and results}, + author={Sagonas, Christos and Antonakos, Epameinondas and Tzimiropoulos, Georgios and Zafeiriou, Stefanos and Pantic, Maja}, + journal={Image and vision computing}, + volume={47}, + pages={3--18}, + year={2016}, + publisher={Elsevier} +} +``` + +
+
diff --git a/vendor/ViTPose/docs/en/papers/datasets/aic.md b/vendor/ViTPose/docs/en/papers/datasets/aic.md
new file mode 100644
index 0000000000000000000000000000000000000000..5054609a394ac3fe6f621caa86f60d7e0186c79c
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/datasets/aic.md
@@ -0,0 +1,17 @@
+# Ai challenger: A large-scale dataset for going deeper in image understanding
+
+
+
+AFLW (ICCVW'2011)
+ +```bibtex +@inproceedings{koestinger2011annotated, + title={Annotated facial landmarks in the wild: A large-scale, real-world database for facial landmark localization}, + author={Koestinger, Martin and Wohlhart, Paul and Roth, Peter M and Bischof, Horst}, + booktitle={2011 IEEE international conference on computer vision workshops (ICCV workshops)}, + pages={2144--2151}, + year={2011}, + organization={IEEE} +} +``` + +
+
diff --git a/vendor/ViTPose/docs/en/papers/datasets/animalpose.md b/vendor/ViTPose/docs/en/papers/datasets/animalpose.md
new file mode 100644
index 0000000000000000000000000000000000000000..58303b8ee27c58d3e262359f25578b10657a2729
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/datasets/animalpose.md
@@ -0,0 +1,18 @@
+# Cross-Domain Adaptation for Animal Pose Estimation
+
+
+
+AI Challenger (ArXiv'2017)
+ +```bibtex +@article{wu2017ai, + title={Ai challenger: A large-scale dataset for going deeper in image understanding}, + author={Wu, Jiahong and Zheng, He and Zhao, Bo and Li, Yixin and Yan, Baoming and Liang, Rui and Wang, Wenjia and Zhou, Shipei and Lin, Guosen and Fu, Yanwei and others}, + journal={arXiv preprint arXiv:1711.06475}, + year={2017} +} +``` + +
+
diff --git a/vendor/ViTPose/docs/en/papers/datasets/ap10k.md b/vendor/ViTPose/docs/en/papers/datasets/ap10k.md
new file mode 100644
index 0000000000000000000000000000000000000000..e36988d833ae41efafa7408830b19bbeb8494f2b
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/datasets/ap10k.md
@@ -0,0 +1,19 @@
+# AP-10K: A Benchmark for Animal Pose Estimation in the Wild
+
+
+
+Animal-Pose (ICCV'2019)
+ +```bibtex +@InProceedings{Cao_2019_ICCV, + author = {Cao, Jinkun and Tang, Hongyang and Fang, Hao-Shu and Shen, Xiaoyong and Lu, Cewu and Tai, Yu-Wing}, + title = {Cross-Domain Adaptation for Animal Pose Estimation}, + booktitle = {The IEEE International Conference on Computer Vision (ICCV)}, + month = {October}, + year = {2019} +} +``` + +
+
diff --git a/vendor/ViTPose/docs/en/papers/datasets/atrw.md b/vendor/ViTPose/docs/en/papers/datasets/atrw.md
new file mode 100644
index 0000000000000000000000000000000000000000..fe83ac0e94ab3c513c30d1b016ab4a87d200807b
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/datasets/atrw.md
@@ -0,0 +1,18 @@
+# ATRW: A Benchmark for Amur Tiger Re-identification in the Wild
+
+
+
+AP-10K (NeurIPS'2021)
+ +```bibtex +@misc{yu2021ap10k, + title={AP-10K: A Benchmark for Animal Pose Estimation in the Wild}, + author={Hang Yu and Yufei Xu and Jing Zhang and Wei Zhao and Ziyu Guan and Dacheng Tao}, + year={2021}, + eprint={2108.12617}, + archivePrefix={arXiv}, + primaryClass={cs.CV} +} +``` + +
+
diff --git a/vendor/ViTPose/docs/en/papers/datasets/coco.md b/vendor/ViTPose/docs/en/papers/datasets/coco.md
new file mode 100644
index 0000000000000000000000000000000000000000..8051dc756b0124816ed4db8e4cf5f31d363f6fa5
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/datasets/coco.md
@@ -0,0 +1,19 @@
+# Microsoft coco: Common objects in context
+
+
+
+ATRW (ACM MM'2020)
+ +```bibtex +@inproceedings{li2020atrw, + title={ATRW: A Benchmark for Amur Tiger Re-identification in the Wild}, + author={Li, Shuyuan and Li, Jianguo and Tang, Hanlin and Qian, Rui and Lin, Weiyao}, + booktitle={Proceedings of the 28th ACM International Conference on Multimedia}, + pages={2590--2598}, + year={2020} +} +``` + +
+
diff --git a/vendor/ViTPose/docs/en/papers/datasets/coco_wholebody.md b/vendor/ViTPose/docs/en/papers/datasets/coco_wholebody.md
new file mode 100644
index 0000000000000000000000000000000000000000..69cb2b98d14b9cf426775944607c8b6d08674736
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/datasets/coco_wholebody.md
@@ -0,0 +1,17 @@
+# Whole-Body Human Pose Estimation in the Wild
+
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
diff --git a/vendor/ViTPose/docs/en/papers/datasets/coco_wholebody_face.md b/vendor/ViTPose/docs/en/papers/datasets/coco_wholebody_face.md
new file mode 100644
index 0000000000000000000000000000000000000000..3e1d3d45011546273f93ba3a131824b7fb70994a
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/datasets/coco_wholebody_face.md
@@ -0,0 +1,17 @@
+# Whole-Body Human Pose Estimation in the Wild
+
+
+
+COCO-WholeBody (ECCV'2020)
+ +```bibtex +@inproceedings{jin2020whole, + title={Whole-Body Human Pose Estimation in the Wild}, + author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping}, + booktitle={Proceedings of the European Conference on Computer Vision (ECCV)}, + year={2020} +} +``` + +
+
diff --git a/vendor/ViTPose/docs/en/papers/datasets/coco_wholebody_hand.md b/vendor/ViTPose/docs/en/papers/datasets/coco_wholebody_hand.md
new file mode 100644
index 0000000000000000000000000000000000000000..51e21693639d21d8541a102fe9a4fd16ceb9adef
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/datasets/coco_wholebody_hand.md
@@ -0,0 +1,17 @@
+# Whole-Body Human Pose Estimation in the Wild
+
+
+
+COCO-WholeBody-Face (ECCV'2020)
+ +```bibtex +@inproceedings{jin2020whole, + title={Whole-Body Human Pose Estimation in the Wild}, + author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping}, + booktitle={Proceedings of the European Conference on Computer Vision (ECCV)}, + year={2020} +} +``` + +
+
diff --git a/vendor/ViTPose/docs/en/papers/datasets/cofw.md b/vendor/ViTPose/docs/en/papers/datasets/cofw.md
new file mode 100644
index 0000000000000000000000000000000000000000..20d29acdc704eed6c716eff9fcb4a347aa51c8a7
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/datasets/cofw.md
@@ -0,0 +1,18 @@
+# Robust face landmark estimation under occlusion
+
+
+
+COCO-WholeBody-Hand (ECCV'2020)
+ +```bibtex +@inproceedings{jin2020whole, + title={Whole-Body Human Pose Estimation in the Wild}, + author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping}, + booktitle={Proceedings of the European Conference on Computer Vision (ECCV)}, + year={2020} +} +``` + +
+
diff --git a/vendor/ViTPose/docs/en/papers/datasets/crowdpose.md b/vendor/ViTPose/docs/en/papers/datasets/crowdpose.md
new file mode 100644
index 0000000000000000000000000000000000000000..ee678aa74f90c5891846832a1343a6e685d37913
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/datasets/crowdpose.md
@@ -0,0 +1,17 @@
+# CrowdPose: Efficient Crowded Scenes Pose Estimation and A New Benchmark
+
+
+
+COFW (ICCV'2013)
+ +```bibtex +@inproceedings{burgos2013robust, + title={Robust face landmark estimation under occlusion}, + author={Burgos-Artizzu, Xavier P and Perona, Pietro and Doll{\'a}r, Piotr}, + booktitle={Proceedings of the IEEE international conference on computer vision}, + pages={1513--1520}, + year={2013} +} +``` + +
+
diff --git a/vendor/ViTPose/docs/en/papers/datasets/deepfashion.md b/vendor/ViTPose/docs/en/papers/datasets/deepfashion.md
new file mode 100644
index 0000000000000000000000000000000000000000..3955cf30923693f1faa6d7bc335fb7079a5f0dad
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/datasets/deepfashion.md
@@ -0,0 +1,35 @@
+# DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations
+
+
+
+CrowdPose (CVPR'2019)
+ +```bibtex +@article{li2018crowdpose, + title={CrowdPose: Efficient Crowded Scenes Pose Estimation and A New Benchmark}, + author={Li, Jiefeng and Wang, Can and Zhu, Hao and Mao, Yihuan and Fang, Hao-Shu and Lu, Cewu}, + journal={arXiv preprint arXiv:1812.00324}, + year={2018} +} +``` + +
+
+
+
+
+DeepFashion (CVPR'2016)
+ +```bibtex +@inproceedings{liuLQWTcvpr16DeepFashion, + author = {Liu, Ziwei and Luo, Ping and Qiu, Shi and Wang, Xiaogang and Tang, Xiaoou}, + title = {DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations}, + booktitle = {Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, + month = {June}, + year = {2016} +} +``` + +
+
diff --git a/vendor/ViTPose/docs/en/papers/datasets/fly.md b/vendor/ViTPose/docs/en/papers/datasets/fly.md
new file mode 100644
index 0000000000000000000000000000000000000000..ed1a9c148ec748d89cf18d26d7ea4a8021fc1b30
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/datasets/fly.md
@@ -0,0 +1,21 @@
+# Fast animal pose estimation using deep neural networks
+
+
+
+DeepFashion (ECCV'2016)
+ +```bibtex +@inproceedings{liuYLWTeccv16FashionLandmark, + author = {Liu, Ziwei and Yan, Sijie and Luo, Ping and Wang, Xiaogang and Tang, Xiaoou}, + title = {Fashion Landmark Detection in the Wild}, + booktitle = {European Conference on Computer Vision (ECCV)}, + month = {October}, + year = {2016} + } +``` + +
+
diff --git a/vendor/ViTPose/docs/en/papers/datasets/freihand.md b/vendor/ViTPose/docs/en/papers/datasets/freihand.md
new file mode 100644
index 0000000000000000000000000000000000000000..ee086020691f4f3c36d08759fa4b603209da2dd5
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/datasets/freihand.md
@@ -0,0 +1,18 @@
+# Freihand: A dataset for markerless capture of hand pose and shape from single rgb images
+
+
+
+Vinegar Fly (Nature Methods'2019)
+ +```bibtex +@article{pereira2019fast, + title={Fast animal pose estimation using deep neural networks}, + author={Pereira, Talmo D and Aldarondo, Diego E and Willmore, Lindsay and Kislin, Mikhail and Wang, Samuel S-H and Murthy, Mala and Shaevitz, Joshua W}, + journal={Nature methods}, + volume={16}, + number={1}, + pages={117--125}, + year={2019}, + publisher={Nature Publishing Group} +} +``` + +
+
diff --git a/vendor/ViTPose/docs/en/papers/datasets/h36m.md b/vendor/ViTPose/docs/en/papers/datasets/h36m.md
new file mode 100644
index 0000000000000000000000000000000000000000..143e15417cba0b6bce2d9454c8b15506326ed1ae
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/datasets/h36m.md
@@ -0,0 +1,22 @@
+# Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments
+
+
+
+FreiHand (ICCV'2019)
+ +```bibtex +@inproceedings{zimmermann2019freihand, + title={Freihand: A dataset for markerless capture of hand pose and shape from single rgb images}, + author={Zimmermann, Christian and Ceylan, Duygu and Yang, Jimei and Russell, Bryan and Argus, Max and Brox, Thomas}, + booktitle={Proceedings of the IEEE International Conference on Computer Vision}, + pages={813--822}, + year={2019} +} +``` + +
+
diff --git a/vendor/ViTPose/docs/en/papers/datasets/halpe.md b/vendor/ViTPose/docs/en/papers/datasets/halpe.md
new file mode 100644
index 0000000000000000000000000000000000000000..f71793fdbd5f1658a10f493eb1ff6fb598d4fb05
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/datasets/halpe.md
@@ -0,0 +1,17 @@
+# PaStaNet: Toward Human Activity Knowledge Engine
+
+
+
+Human3.6M (TPAMI'2014)
+ +```bibtex +@article{h36m_pami, + author = {Ionescu, Catalin and Papava, Dragos and Olaru, Vlad and Sminchisescu, Cristian}, + title = {Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments}, + journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence}, + publisher = {IEEE Computer Society}, + volume = {36}, + number = {7}, + pages = {1325-1339}, + month = {jul}, + year = {2014} +} +``` + +
+
diff --git a/vendor/ViTPose/docs/en/papers/datasets/horse10.md b/vendor/ViTPose/docs/en/papers/datasets/horse10.md
new file mode 100644
index 0000000000000000000000000000000000000000..94e559db5146dd932469ad35b16b8eb4a0f3d4e3
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/datasets/horse10.md
@@ -0,0 +1,18 @@
+# Pretraining boosts out-of-domain robustness for pose estimation
+
+
+
+Halpe (CVPR'2020)
+ +```bibtex +@inproceedings{li2020pastanet, + title={PaStaNet: Toward Human Activity Knowledge Engine}, + author={Li, Yong-Lu and Xu, Liang and Liu, Xinpeng and Huang, Xijie and Xu, Yue and Wang, Shiyi and Fang, Hao-Shu and Ma, Ze and Chen, Mingyang and Lu, Cewu}, + booktitle={CVPR}, + year={2020} +} +``` + +
+
diff --git a/vendor/ViTPose/docs/en/papers/datasets/interhand.md b/vendor/ViTPose/docs/en/papers/datasets/interhand.md
new file mode 100644
index 0000000000000000000000000000000000000000..6b4458a01e0ed1394b7258de15e10a56c5c63432
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/datasets/interhand.md
@@ -0,0 +1,18 @@
+# InterHand2.6M: A dataset and baseline for 3D interacting hand pose estimation from a single RGB image
+
+
+
+Horse-10 (WACV'2021)
+ +```bibtex +@inproceedings{mathis2021pretraining, + title={Pretraining boosts out-of-domain robustness for pose estimation}, + author={Mathis, Alexander and Biasi, Thomas and Schneider, Steffen and Yuksekgonul, Mert and Rogers, Byron and Bethge, Matthias and Mathis, Mackenzie W}, + booktitle={Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision}, + pages={1859--1868}, + year={2021} +} +``` + +
+
diff --git a/vendor/ViTPose/docs/en/papers/datasets/jhmdb.md b/vendor/ViTPose/docs/en/papers/datasets/jhmdb.md
new file mode 100644
index 0000000000000000000000000000000000000000..890d788ab2e2ef3e727d08aa897eff9a32b41926
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/datasets/jhmdb.md
@@ -0,0 +1,19 @@
+# Towards understanding action recognition
+
+
+
+InterHand2.6M (ECCV'2020)
+ +```bibtex +@article{moon2020interhand2, + title={InterHand2.6M: A dataset and baseline for 3D interacting hand pose estimation from a single RGB image}, + author={Moon, Gyeongsik and Yu, Shoou-I and Wen, He and Shiratori, Takaaki and Lee, Kyoung Mu}, + journal={arXiv preprint arXiv:2008.09309}, + year={2020}, + publisher={Springer} +} +``` + +
+
diff --git a/vendor/ViTPose/docs/en/papers/datasets/locust.md b/vendor/ViTPose/docs/en/papers/datasets/locust.md
new file mode 100644
index 0000000000000000000000000000000000000000..896ee03b8310543f1b336ed54419a6262a0d181c
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/datasets/locust.md
@@ -0,0 +1,20 @@
+# DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning
+
+
+
+JHMDB (ICCV'2013)
+ +```bibtex +@inproceedings{Jhuang:ICCV:2013, + title = {Towards understanding action recognition}, + author = {H. Jhuang and J. Gall and S. Zuffi and C. Schmid and M. J. Black}, + booktitle = {International Conf. on Computer Vision (ICCV)}, + month = Dec, + pages = {3192-3199}, + year = {2013} +} +``` + +
+
diff --git a/vendor/ViTPose/docs/en/papers/datasets/macaque.md b/vendor/ViTPose/docs/en/papers/datasets/macaque.md
new file mode 100644
index 0000000000000000000000000000000000000000..be4bec1131bc251d1c6983dd342d91769c09a467
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/datasets/macaque.md
@@ -0,0 +1,18 @@
+# MacaquePose: A novel ‘in the wild’macaque monkey pose dataset for markerless motion capture
+
+
+
+Desert Locust (Elife'2019)
+ +```bibtex +@article{graving2019deepposekit, + title={DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning}, + author={Graving, Jacob M and Chae, Daniel and Naik, Hemal and Li, Liang and Koger, Benjamin and Costelloe, Blair R and Couzin, Iain D}, + journal={Elife}, + volume={8}, + pages={e47994}, + year={2019}, + publisher={eLife Sciences Publications Limited} +} +``` + +
+
diff --git a/vendor/ViTPose/docs/en/papers/datasets/mhp.md b/vendor/ViTPose/docs/en/papers/datasets/mhp.md
new file mode 100644
index 0000000000000000000000000000000000000000..6dc5b17cccf192d0ec634b787bc38cdea911802c
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/datasets/mhp.md
@@ -0,0 +1,18 @@
+# Understanding humans in crowded scenes: Deep nested adversarial learning and a new benchmark for multi-human parsing
+
+
+
+MacaquePose (bioRxiv'2020)
+ +```bibtex +@article{labuguen2020macaquepose, + title={MacaquePose: A novel ‘in the wild’macaque monkey pose dataset for markerless motion capture}, + author={Labuguen, Rollyn and Matsumoto, Jumpei and Negrete, Salvador and Nishimaru, Hiroshi and Nishijo, Hisao and Takada, Masahiko and Go, Yasuhiro and Inoue, Ken-ichi and Shibata, Tomohiro}, + journal={bioRxiv}, + year={2020}, + publisher={Cold Spring Harbor Laboratory} +} +``` + +
+
diff --git a/vendor/ViTPose/docs/en/papers/datasets/mpi_inf_3dhp.md b/vendor/ViTPose/docs/en/papers/datasets/mpi_inf_3dhp.md
new file mode 100644
index 0000000000000000000000000000000000000000..3a26d49fd5bf532aa265ce159d4380e774be5a1e
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/datasets/mpi_inf_3dhp.md
@@ -0,0 +1,20 @@
+# Monocular 3D Human Pose Estimation In The Wild Using Improved CNN Supervision
+
+
+
+MHP (ACM MM'2018)
+ +```bibtex +@inproceedings{zhao2018understanding, + title={Understanding humans in crowded scenes: Deep nested adversarial learning and a new benchmark for multi-human parsing}, + author={Zhao, Jian and Li, Jianshu and Cheng, Yu and Sim, Terence and Yan, Shuicheng and Feng, Jiashi}, + booktitle={Proceedings of the 26th ACM international conference on Multimedia}, + pages={792--800}, + year={2018} +} +``` + +
+
diff --git a/vendor/ViTPose/docs/en/papers/datasets/mpii.md b/vendor/ViTPose/docs/en/papers/datasets/mpii.md
new file mode 100644
index 0000000000000000000000000000000000000000..e2df7cfd7d181f02802486667866cf663c442bc0
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/datasets/mpii.md
@@ -0,0 +1,18 @@
+# 2D Human Pose Estimation: New Benchmark and State of the Art Analysis
+
+
+
+MPI-INF-3DHP (3DV'2017)
+ +```bibtex +@inproceedings{mono-3dhp2017, + author = {Mehta, Dushyant and Rhodin, Helge and Casas, Dan and Fua, Pascal and Sotnychenko, Oleksandr and Xu, Weipeng and Theobalt, Christian}, + title = {Monocular 3D Human Pose Estimation In The Wild Using Improved CNN Supervision}, + booktitle = {3D Vision (3DV), 2017 Fifth International Conference on}, + url = {http://gvv.mpi-inf.mpg.de/3dhp_dataset}, + year = {2017}, + organization={IEEE}, + doi={10.1109/3dv.2017.00064}, +} +``` + +
+
diff --git a/vendor/ViTPose/docs/en/papers/datasets/mpii_trb.md b/vendor/ViTPose/docs/en/papers/datasets/mpii_trb.md
new file mode 100644
index 0000000000000000000000000000000000000000..b3e96a77d2522851c27ba1301c609ba794a522a4
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/datasets/mpii_trb.md
@@ -0,0 +1,18 @@
+# TRB: A Novel Triplet Representation for Understanding 2D Human Body
+
+
+
+MPII (CVPR'2014)
+ +```bibtex +@inproceedings{andriluka14cvpr, + author = {Mykhaylo Andriluka and Leonid Pishchulin and Peter Gehler and Schiele, Bernt}, + title = {2D Human Pose Estimation: New Benchmark and State of the Art Analysis}, + booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, + year = {2014}, + month = {June} +} +``` + +
+
diff --git a/vendor/ViTPose/docs/en/papers/datasets/ochuman.md b/vendor/ViTPose/docs/en/papers/datasets/ochuman.md
new file mode 100644
index 0000000000000000000000000000000000000000..5211c341e42937a2ca5a22dac2d62901390720c2
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/datasets/ochuman.md
@@ -0,0 +1,18 @@
+# Pose2seg: Detection free human instance segmentation
+
+
+
+MPII-TRB (ICCV'2019)
+ +```bibtex +@inproceedings{duan2019trb, + title={TRB: A Novel Triplet Representation for Understanding 2D Human Body}, + author={Duan, Haodong and Lin, Kwan-Yee and Jin, Sheng and Liu, Wentao and Qian, Chen and Ouyang, Wanli}, + booktitle={Proceedings of the IEEE International Conference on Computer Vision}, + pages={9479--9488}, + year={2019} +} +``` + +
+
diff --git a/vendor/ViTPose/docs/en/papers/datasets/onehand10k.md b/vendor/ViTPose/docs/en/papers/datasets/onehand10k.md
new file mode 100644
index 0000000000000000000000000000000000000000..5710fda4771e79182341b358a173d618f823c2e3
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/datasets/onehand10k.md
@@ -0,0 +1,21 @@
+# Mask-pose cascaded cnn for 2d hand pose estimation from single color image
+
+
+
+OCHuman (CVPR'2019)
+ +```bibtex +@inproceedings{zhang2019pose2seg, + title={Pose2seg: Detection free human instance segmentation}, + author={Zhang, Song-Hai and Li, Ruilong and Dong, Xin and Rosin, Paul and Cai, Zixi and Han, Xi and Yang, Dingcheng and Huang, Haozhi and Hu, Shi-Min}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={889--898}, + year={2019} +} +``` + +
+
diff --git a/vendor/ViTPose/docs/en/papers/datasets/panoptic.md b/vendor/ViTPose/docs/en/papers/datasets/panoptic.md
new file mode 100644
index 0000000000000000000000000000000000000000..60719c4df9df2e93756cf43c82cbf0edd8149f1f
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/datasets/panoptic.md
@@ -0,0 +1,18 @@
+# Hand keypoint detection in single images using multiview bootstrapping
+
+
+
+OneHand10K (TCSVT'2019)
+ +```bibtex +@article{wang2018mask, + title={Mask-pose cascaded cnn for 2d hand pose estimation from single color image}, + author={Wang, Yangang and Peng, Cong and Liu, Yebin}, + journal={IEEE Transactions on Circuits and Systems for Video Technology}, + volume={29}, + number={11}, + pages={3258--3268}, + year={2018}, + publisher={IEEE} +} +``` + +
+
diff --git a/vendor/ViTPose/docs/en/papers/datasets/panoptic_body3d.md b/vendor/ViTPose/docs/en/papers/datasets/panoptic_body3d.md
new file mode 100644
index 0000000000000000000000000000000000000000..b7f45c8beb9400101b16c956f26845a1f01c27d7
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/datasets/panoptic_body3d.md
@@ -0,0 +1,17 @@
+# Panoptic Studio: A Massively Multiview System for Social Motion Capture
+
+
+
+CMU Panoptic HandDB (CVPR'2017)
+ +```bibtex +@inproceedings{simon2017hand, + title={Hand keypoint detection in single images using multiview bootstrapping}, + author={Simon, Tomas and Joo, Hanbyul and Matthews, Iain and Sheikh, Yaser}, + booktitle={Proceedings of the IEEE conference on Computer Vision and Pattern Recognition}, + pages={1145--1153}, + year={2017} +} +``` + +
+
diff --git a/vendor/ViTPose/docs/en/papers/datasets/posetrack18.md b/vendor/ViTPose/docs/en/papers/datasets/posetrack18.md
new file mode 100644
index 0000000000000000000000000000000000000000..90cfcb54f82aab26851417b2e976da5bc3556c50
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/datasets/posetrack18.md
@@ -0,0 +1,18 @@
+# Posetrack: A benchmark for human pose estimation and tracking
+
+
+
+CMU Panoptic (ICCV'2015)
+ +```bibtex +@Article = {joo_iccv_2015, +author = {Hanbyul Joo, Hao Liu, Lei Tan, Lin Gui, Bart Nabbe, Iain Matthews, Takeo Kanade, Shohei Nobuhara, and Yaser Sheikh}, +title = {Panoptic Studio: A Massively Multiview System for Social Motion Capture}, +booktitle = {ICCV}, +year = {2015} +} +``` + +
+
diff --git a/vendor/ViTPose/docs/en/papers/datasets/rhd.md b/vendor/ViTPose/docs/en/papers/datasets/rhd.md
new file mode 100644
index 0000000000000000000000000000000000000000..1855037bdceb07024c192c40b19e8efb599b0cbf
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/datasets/rhd.md
@@ -0,0 +1,19 @@
+# Learning to Estimate 3D Hand Pose from Single RGB Images
+
+
+
+PoseTrack18 (CVPR'2018)
+ +```bibtex +@inproceedings{andriluka2018posetrack, + title={Posetrack: A benchmark for human pose estimation and tracking}, + author={Andriluka, Mykhaylo and Iqbal, Umar and Insafutdinov, Eldar and Pishchulin, Leonid and Milan, Anton and Gall, Juergen and Schiele, Bernt}, + booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition}, + pages={5167--5176}, + year={2018} +} +``` + +
+
diff --git a/vendor/ViTPose/docs/en/papers/datasets/wflw.md b/vendor/ViTPose/docs/en/papers/datasets/wflw.md
new file mode 100644
index 0000000000000000000000000000000000000000..08c3ccced32535c12ee487a3b3f99c6d3d696679
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/datasets/wflw.md
@@ -0,0 +1,18 @@
+# Look at boundary: A boundary-aware face alignment algorithm
+
+
+
+RHD (ICCV'2017)
+ +```bibtex +@TechReport{zb2017hand, + author={Christian Zimmermann and Thomas Brox}, + title={Learning to Estimate 3D Hand Pose from Single RGB Images}, + institution={arXiv:1705.01389}, + year={2017}, + note="https://arxiv.org/abs/1705.01389", + url="https://lmb.informatik.uni-freiburg.de/projects/hand3d/" +} +``` + +
+
diff --git a/vendor/ViTPose/docs/en/papers/datasets/zebra.md b/vendor/ViTPose/docs/en/papers/datasets/zebra.md
new file mode 100644
index 0000000000000000000000000000000000000000..2727e595fc1a037b84eecb7381d7a5f7de15e90c
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/datasets/zebra.md
@@ -0,0 +1,20 @@
+# DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning
+
+
+
+WFLW (CVPR'2018)
+ +```bibtex +@inproceedings{wu2018look, + title={Look at boundary: A boundary-aware face alignment algorithm}, + author={Wu, Wayne and Qian, Chen and Yang, Shuo and Wang, Quan and Cai, Yici and Zhou, Qiang}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={2129--2138}, + year={2018} +} +``` + +
+
diff --git a/vendor/ViTPose/docs/en/papers/techniques/albumentations.md b/vendor/ViTPose/docs/en/papers/techniques/albumentations.md
new file mode 100644
index 0000000000000000000000000000000000000000..9d09a7a3448cceca73c95003ee262bcea6473bcd
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/techniques/albumentations.md
@@ -0,0 +1,21 @@
+# Albumentations: fast and flexible image augmentations
+
+
+
+Grévy’s Zebra (Elife'2019)
+ +```bibtex +@article{graving2019deepposekit, + title={DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning}, + author={Graving, Jacob M and Chae, Daniel and Naik, Hemal and Li, Liang and Koger, Benjamin and Costelloe, Blair R and Couzin, Iain D}, + journal={Elife}, + volume={8}, + pages={e47994}, + year={2019}, + publisher={eLife Sciences Publications Limited} +} +``` + +
+
diff --git a/vendor/ViTPose/docs/en/papers/techniques/awingloss.md b/vendor/ViTPose/docs/en/papers/techniques/awingloss.md
new file mode 100644
index 0000000000000000000000000000000000000000..4d4b93a87c622b6b965cab31ac402b8445934a9a
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/techniques/awingloss.md
@@ -0,0 +1,31 @@
+# Adaptive Wing Loss for Robust Face Alignment via Heatmap Regression
+
+
+
+Albumentations (Information'2020)
+ +```bibtex +@article{buslaev2020albumentations, + title={Albumentations: fast and flexible image augmentations}, + author={Buslaev, Alexander and Iglovikov, Vladimir I and Khvedchenya, Eugene and Parinov, Alex and Druzhinin, Mikhail and Kalinin, Alexandr A}, + journal={Information}, + volume={11}, + number={2}, + pages={125}, + year={2020}, + publisher={Multidisciplinary Digital Publishing Institute} +} +``` + +
+
+
+## Abstract
+
+
+
+Heatmap regression with a deep network has become one of the mainstream approaches to localize facial landmarks. However, the loss function for heatmap regression is rarely studied. In this paper, we analyze the ideal loss function properties for heatmap regression in face alignment problems. Then we propose a novel loss function, named Adaptive Wing loss, that is able to adapt its shape to different types of ground truth heatmap pixels. This adaptability penalizes loss more on foreground pixels while less on background pixels. To address the imbalance between foreground and background pixels, we also propose Weighted Loss Map, which assigns high weights on foreground and difficult background pixels to help training process focus more on pixels that are crucial to landmark localization. To further improve face alignment accuracy, we introduce boundary prediction and CoordConv with boundary coordinates. Extensive experiments on different benchmarks, including COFW, 300W and WFLW, show our approach outperforms the state-of-the-art by a significant margin on
+various evaluation metrics. Besides, the Adaptive Wing loss also helps other heatmap regression tasks.
+
+
+
+AdaptiveWingloss (ICCV'2019)
+ +```bibtex +@inproceedings{wang2019adaptive, + title={Adaptive wing loss for robust face alignment via heatmap regression}, + author={Wang, Xinyao and Bo, Liefeng and Fuxin, Li}, + booktitle={Proceedings of the IEEE/CVF international conference on computer vision}, + pages={6971--6981}, + year={2019} +} +``` + +
+
+
diff --git a/vendor/ViTPose/docs/en/papers/techniques/dark.md b/vendor/ViTPose/docs/en/papers/techniques/dark.md
new file mode 100644
index 0000000000000000000000000000000000000000..083b7596ab1e7aadb3f154eea58a170b7b22fb54
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/techniques/dark.md
@@ -0,0 +1,30 @@
+# Distribution-aware coordinate representation for human pose estimation
+
+
+
+
+
+
+
+## Abstract
+
+
+
+While being the de facto standard coordinate representation for human pose estimation, heatmap has not been investigated in-depth. This work fills this gap. For the first time, we find that the process of decoding the predicted heatmaps into the final joint coordinates in the original image space is surprisingly significant for the performance. We further probe the design limitations of the standard coordinate decoding method, and propose a more principled distributionaware decoding method. Also, we improve the standard coordinate encoding process (i.e. transforming ground-truth coordinates to heatmaps) by generating unbiased/accurate heatmaps. Taking the two together, we formulate a novel Distribution-Aware coordinate Representation of Keypoints (DARK) method. Serving as a model-agnostic plug-in, DARK brings about significant performance boost to existing human pose estimation models. Extensive experiments show that DARK yields the best results on two common benchmarks, MPII and COCO. Besides, DARK achieves the 2nd place entry in the ICCV 2019 COCO Keypoints Challenge. The code is available online.
+
+
+
+DarkPose (CVPR'2020)
+ +```bibtex +@inproceedings{zhang2020distribution, + title={Distribution-aware coordinate representation for human pose estimation}, + author={Zhang, Feng and Zhu, Xiatian and Dai, Hanbin and Ye, Mao and Zhu, Ce}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, + pages={7093--7102}, + year={2020} +} +``` + +
+
+
diff --git a/vendor/ViTPose/docs/en/papers/techniques/fp16.md b/vendor/ViTPose/docs/en/papers/techniques/fp16.md
new file mode 100644
index 0000000000000000000000000000000000000000..7fd7ee0011a5946ed55119bac3d262b67b52d2d5
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/techniques/fp16.md
@@ -0,0 +1,17 @@
+# Mixed Precision Training
+
+
+
+
+
+
diff --git a/vendor/ViTPose/docs/en/papers/techniques/softwingloss.md b/vendor/ViTPose/docs/en/papers/techniques/softwingloss.md
new file mode 100644
index 0000000000000000000000000000000000000000..524a6089ffee69e109a0a721fa14b820df88ae8b
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/techniques/softwingloss.md
@@ -0,0 +1,30 @@
+# Structure-Coherent Deep Feature Learning for Robust Face Alignment
+
+
+
+FP16 (ArXiv'2017)
+ +```bibtex +@article{micikevicius2017mixed, + title={Mixed precision training}, + author={Micikevicius, Paulius and Narang, Sharan and Alben, Jonah and Diamos, Gregory and Elsen, Erich and Garcia, David and Ginsburg, Boris and Houston, Michael and Kuchaiev, Oleksii and Venkatesh, Ganesh and others}, + journal={arXiv preprint arXiv:1710.03740}, + year={2017} +} +``` + +
+
+
+## Abstract
+
+
+
+In this paper, we propose a structure-coherent deep feature learning method for face alignment. Unlike most existing face alignment methods which overlook the facial structure cues, we explicitly exploit the relation among facial landmarks to make the detector robust to hard cases such as occlusion and large pose. Specifically, we leverage a landmark-graph relational network to enforce the structural relationships among landmarks. We consider the facial landmarks as structural graph nodes and carefully design the neighborhood to passing features among the most related nodes. Our method dynamically adapts the weights of node neighborhood to eliminate distracted information from noisy nodes, such as occluded landmark point. Moreover, different from most previous works which only tend to penalize the landmarks absolute position during the training, we propose a relative location loss to enhance the information of relative location of landmarks. This relative location supervision further regularizes the facial structure. Our approach considers the interactions among facial landmarks and can be easily implemented on top of any convolutional backbone to boost the performance. Extensive experiments on three popular benchmarks, including WFLW, COFW and 300W, demonstrate the effectiveness of the proposed method. In particular, due to explicit structure modeling, our approach is especially robust to challenging cases resulting in impressive low failure rate on COFW and WFLW datasets.
+
+
+
+SoftWingloss (TIP'2021)
+ +```bibtex +@article{lin2021structure, + title={Structure-Coherent Deep Feature Learning for Robust Face Alignment}, + author={Lin, Chunze and Zhu, Beier and Wang, Quan and Liao, Renjie and Qian, Chen and Lu, Jiwen and Zhou, Jie}, + journal={IEEE Transactions on Image Processing}, + year={2021}, + publisher={IEEE} +} +``` + +
+
+
diff --git a/vendor/ViTPose/docs/en/papers/techniques/udp.md b/vendor/ViTPose/docs/en/papers/techniques/udp.md
new file mode 100644
index 0000000000000000000000000000000000000000..bb4acebfbc9474312e992a67e2a19ef2df12be85
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/techniques/udp.md
@@ -0,0 +1,30 @@
+# The Devil is in the Details: Delving into Unbiased Data Processing for Human Pose Estimation
+
+
+
+
+
+
+
+## Abstract
+
+
+
+Recently, the leading performance of human pose estimation is dominated by top-down methods. Being a fundamental component in training and inference, data processing has not been systematically considered in pose estimation community, to the best of our knowledge. In this paper, we focus on this problem and find that the devil of top-down pose estimator is in the biased data processing. Specifically, by investigating the standard data processing in state-of-the-art approaches mainly including data transformation and encoding-decoding, we find that the results obtained by common flipping strategy are unaligned with the original ones in inference. Moreover, there is statistical error in standard encoding-decoding during both training and inference. Two problems couple together and significantly degrade the pose estimation performance. Based on quantitative analyses, we then formulate a principled way to tackle this dilemma. Data is processed in continuous space based on unit length (the intervals between pixels) instead of in discrete space with pixel, and a combined classification and regression approach is adopted to perform encoding-decoding. The Unbiased Data Processing (UDP) for human pose estimation can be achieved by combining the two together. UDP not only boosts the performance of existing methods by a large margin but also plays a important role in result reproducing and future exploration. As a model-agnostic approach, UDP promotes SimpleBaseline-ResNet50-256x192 by 1.5 AP (70.2 to 71.7) and HRNet-W32-256x192 by 1.7 AP (73.5 to 75.2) on COCO test-dev set. The HRNet-W48-384x288 equipped with UDP achieves 76.5 AP and sets a new state-of-the-art for human pose estimation. The source code is publicly available for further research.
+
+
+
+UDP (CVPR'2020)
+ +```bibtex +@InProceedings{Huang_2020_CVPR, + author = {Huang, Junjie and Zhu, Zheng and Guo, Feng and Huang, Guan}, + title = {The Devil Is in the Details: Delving Into Unbiased Data Processing for Human Pose Estimation}, + booktitle = {The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, + month = {June}, + year = {2020} +} +``` + +
+
+
diff --git a/vendor/ViTPose/docs/en/papers/techniques/wingloss.md b/vendor/ViTPose/docs/en/papers/techniques/wingloss.md
new file mode 100644
index 0000000000000000000000000000000000000000..2aaa05722eda24201cd35e1028349994d1f0fd6b
--- /dev/null
+++ b/vendor/ViTPose/docs/en/papers/techniques/wingloss.md
@@ -0,0 +1,31 @@
+# Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks
+
+
+
+
+
+
+
+## Abstract
+
+
+
+We present a new loss function, namely Wing loss, for robust facial landmark localisation with Convolutional Neural Networks (CNNs). We first compare and analyse different loss functions including L2, L1 and smooth L1. The analysis of these loss functions suggests that, for the training of a CNN-based localisation model, more attention should be paid to small and medium range errors. To this end, we design a piece-wise loss function. The new loss amplifies the impact of errors from the interval (-w, w) by switching from L1 loss to a modified logarithm function. To address the problem of under-representation of samples with large out-of-plane head rotations in the training set, we propose a simple but effective boosting strategy, referred to as pose-based data balancing. In particular, we deal with the data imbalance problem by duplicating the minority training samples and perturbing them by injecting random image rotation, bounding box translation and other data augmentation approaches. Last, the proposed approach is extended to create a two-stage framework for robust facial landmark localisation. The experimental results obtained on AFLW and 300W demonstrate the merits of the Wing loss function, and prove the superiority of the proposed method over the state-of-the-art approaches.
+
+
+
+Wingloss (CVPR'2018)
+ +```bibtex +@inproceedings{feng2018wing, + title={Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks}, + author={Feng, Zhen-Hua and Kittler, Josef and Awais, Muhammad and Huber, Patrik and Wu, Xiao-Jun}, + booktitle={Computer Vision and Pattern Recognition (CVPR), 2018 IEEE Conference on}, + year={2018}, + pages ={2235-2245}, + organization={IEEE} +} +``` + +
+
+
diff --git a/vendor/ViTPose/docs/en/stats.py b/vendor/ViTPose/docs/en/stats.py
new file mode 100644
index 0000000000000000000000000000000000000000..10ce3ab40f45e07c5c38ee4d8f7225670dc75f04
--- /dev/null
+++ b/vendor/ViTPose/docs/en/stats.py
@@ -0,0 +1,176 @@
+#!/usr/bin/env python
+# Copyright (c) OpenMMLab. All rights reserved.
+import functools as func
+import glob
+import re
+from os.path import basename, splitext
+
+import numpy as np
+import titlecase
+
+
+def anchor(name):
+ return re.sub(r'-+', '-', re.sub(r'[^a-zA-Z0-9]', '-',
+ name.strip().lower())).strip('-')
+
+
+# Count algorithms
+
+files = sorted(glob.glob('topics/*.md'))
+
+stats = []
+
+for f in files:
+ with open(f, 'r') as content_file:
+ content = content_file.read()
+
+ # title
+ title = content.split('\n')[0].replace('#', '')
+
+ # count papers
+ papers = set(
+ (papertype, titlecase.titlecase(paper.lower().strip()))
+ for (papertype, paper) in re.findall(
+ r'\s*\n.*?\btitle\s*=\s*{(.*?)}',
+ content, re.DOTALL))
+ # paper links
+ revcontent = '\n'.join(list(reversed(content.splitlines())))
+ paperlinks = {}
+ for _, p in papers:
+ print(p)
+ paperlinks[p] = ', '.join(
+ ((f'[{paperlink} ⇨]'
+ f'(topics/{splitext(basename(f))[0]}.html#{anchor(paperlink)})')
+ for paperlink in re.findall(
+ rf'\btitle\s*=\s*{{\s*{p}\s*}}.*?\n### (.*?)\s*[,;]?\s*\n',
+ revcontent, re.DOTALL | re.IGNORECASE)))
+ print(' ', paperlinks[p])
+ paperlist = '\n'.join(
+ sorted(f' - [{t}] {x} ({paperlinks[x]})' for t, x in papers))
+ # count configs
+ configs = set(x.lower().strip()
+ for x in re.findall(r'.*configs/.*\.py', content))
+
+ # count ckpts
+ ckpts = set(x.lower().strip()
+ for x in re.findall(r'https://download.*\.pth', content)
+ if 'mmpose' in x)
+
+ statsmsg = f"""
+## [{title}]({f})
+
+* Number of checkpoints: {len(ckpts)}
+* Number of configs: {len(configs)}
+* Number of papers: {len(papers)}
+{paperlist}
+
+ """
+
+ stats.append((papers, configs, ckpts, statsmsg))
+
+allpapers = func.reduce(lambda a, b: a.union(b), [p for p, _, _, _ in stats])
+allconfigs = func.reduce(lambda a, b: a.union(b), [c for _, c, _, _ in stats])
+allckpts = func.reduce(lambda a, b: a.union(b), [c for _, _, c, _ in stats])
+
+# Summarize
+
+msglist = '\n'.join(x for _, _, _, x in stats)
+papertypes, papercounts = np.unique([t for t, _ in allpapers],
+ return_counts=True)
+countstr = '\n'.join(
+ [f' - {t}: {c}' for t, c in zip(papertypes, papercounts)])
+
+modelzoo = f"""
+# Overview
+
+* Number of checkpoints: {len(allckpts)}
+* Number of configs: {len(allconfigs)}
+* Number of papers: {len(allpapers)}
+{countstr}
+
+For supported datasets, see [datasets overview](datasets.md).
+
+{msglist}
+
+"""
+
+with open('modelzoo.md', 'w') as f:
+ f.write(modelzoo)
+
+# Count datasets
+
+files = sorted(glob.glob('tasks/*.md'))
+# files = sorted(glob.glob('docs/tasks/*.md'))
+
+datastats = []
+
+for f in files:
+ with open(f, 'r') as content_file:
+ content = content_file.read()
+
+ # title
+ title = content.split('\n')[0].replace('#', '')
+
+ # count papers
+ papers = set(
+ (papertype, titlecase.titlecase(paper.lower().strip()))
+ for (papertype, paper) in re.findall(
+ r'\s*\n.*?\btitle\s*=\s*{(.*?)}',
+ content, re.DOTALL))
+ # paper links
+ revcontent = '\n'.join(list(reversed(content.splitlines())))
+ paperlinks = {}
+ for _, p in papers:
+ print(p)
+ paperlinks[p] = ', '.join(
+ (f'[{p} ⇨](tasks/{splitext(basename(f))[0]}.html#{anchor(p)})'
+ for p in re.findall(
+ rf'\btitle\s*=\s*{{\s*{p}\s*}}.*?\n## (.*?)\s*[,;]?\s*\n',
+ revcontent, re.DOTALL | re.IGNORECASE)))
+ print(' ', paperlinks[p])
+ paperlist = '\n'.join(
+ sorted(f' - [{t}] {x} ({paperlinks[x]})' for t, x in papers))
+ # count configs
+ configs = set(x.lower().strip()
+ for x in re.findall(r'https.*configs/.*\.py', content))
+
+ # count ckpts
+ ckpts = set(x.lower().strip()
+ for x in re.findall(r'https://download.*\.pth', content)
+ if 'mmpose' in x)
+
+ statsmsg = f"""
+## [{title}]({f})
+
+* Number of papers: {len(papers)}
+{paperlist}
+
+ """
+
+ datastats.append((papers, configs, ckpts, statsmsg))
+
+alldatapapers = func.reduce(lambda a, b: a.union(b),
+ [p for p, _, _, _ in datastats])
+
+# Summarize
+
+msglist = '\n'.join(x for _, _, _, x in stats)
+datamsglist = '\n'.join(x for _, _, _, x in datastats)
+papertypes, papercounts = np.unique([t for t, _ in alldatapapers],
+ return_counts=True)
+countstr = '\n'.join(
+ [f' - {t}: {c}' for t, c in zip(papertypes, papercounts)])
+
+modelzoo = f"""
+# Overview
+
+* Number of papers: {len(alldatapapers)}
+{countstr}
+
+For supported pose algorithms, see [modelzoo overview](modelzoo.md).
+
+{datamsglist}
+"""
+
+with open('datasets.md', 'w') as f:
+ f.write(modelzoo)
diff --git a/vendor/ViTPose/docs/en/tasks/2d_animal_keypoint.md b/vendor/ViTPose/docs/en/tasks/2d_animal_keypoint.md
new file mode 100644
index 0000000000000000000000000000000000000000..c33ebb8074684a9997927a43d7accfc7ce9b1547
--- /dev/null
+++ b/vendor/ViTPose/docs/en/tasks/2d_animal_keypoint.md
@@ -0,0 +1,448 @@
+# 2D Animal Keypoint Dataset
+
+It is recommended to symlink the dataset root to `$MMPOSE/data`.
+If your folder structure is different, you may need to change the corresponding paths in config files.
+
+MMPose supported datasets:
+
+- [Animal-Pose](#animal-pose) \[ [Homepage](https://sites.google.com/view/animal-pose/) \]
+- [AP-10K](#ap-10k) \[ [Homepage](https://github.com/AlexTheBad/AP-10K/) \]
+- [Horse-10](#horse-10) \[ [Homepage](http://www.mackenziemathislab.org/horse10) \]
+- [MacaquePose](#macaquepose) \[ [Homepage](http://www.pri.kyoto-u.ac.jp/datasets/macaquepose/index.html) \]
+- [Vinegar Fly](#vinegar-fly) \[ [Homepage](https://github.com/jgraving/DeepPoseKit-Data) \]
+- [Desert Locust](#desert-locust) \[ [Homepage](https://github.com/jgraving/DeepPoseKit-Data) \]
+- [Grévy’s Zebra](#grvys-zebra) \[ [Homepage](https://github.com/jgraving/DeepPoseKit-Data) \]
+- [ATRW](#atrw) \[ [Homepage](https://cvwc2019.github.io/challenge.html) \]
+
+## Animal-Pose
+
+
+
+
+
+
+
+For [Animal-Pose](https://sites.google.com/view/animal-pose/) dataset, we prepare the dataset as follows:
+
+1. Download the images of [PASCAL2011](http://www.google.com/url?q=http%3A%2F%2Fhost.robots.ox.ac.uk%2Fpascal%2FVOC%2Fvoc2011%2Findex.html&sa=D&sntz=1&usg=AFQjCNGmiJGkhSSWtShDe7NwRPyyyBUYSQ), especially the five categories (dog, cat, sheep, cow, horse), which we use as trainval dataset.
+1. Download the [test-set](https://drive.google.com/drive/folders/1DwhQobZlGntOXxdm7vQsE4bqbFmN3b9y?usp=sharing) images with raw annotations (1000 images, 5 categories).
+1. We have pre-processed the annotations to make it compatible with MMPose. Please download the annotation files from [annotations](https://download.openmmlab.com/mmpose/datasets/animalpose_annotations.tar). If you would like to generate the annotations by yourself, please check our dataset parsing [codes](/tools/dataset/parse_animalpose_dataset.py).
+
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── animalpose
+ │
+ │-- VOC2011
+ │ │-- Annotations
+ │ │-- ImageSets
+ │ │-- JPEGImages
+ │ │-- SegmentationClass
+ │ │-- SegmentationObject
+ │
+ │-- animalpose_image_part2
+ │ │-- cat
+ │ │-- cow
+ │ │-- dog
+ │ │-- horse
+ │ │-- sheep
+ │
+ │-- annotations
+ │ │-- animalpose_train.json
+ │ |-- animalpose_val.json
+ │ |-- animalpose_trainval.json
+ │ │-- animalpose_test.json
+ │
+ │-- PASCAL2011_animal_annotation
+ │ │-- cat
+ │ │ |-- 2007_000528_1.xml
+ │ │ |-- 2007_000549_1.xml
+ │ │ │-- ...
+ │ │-- cow
+ │ │-- dog
+ │ │-- horse
+ │ │-- sheep
+ │
+ │-- annimalpose_anno2
+ │ │-- cat
+ │ │ |-- ca1.xml
+ │ │ |-- ca2.xml
+ │ │ │-- ...
+ │ │-- cow
+ │ │-- dog
+ │ │-- horse
+ │ │-- sheep
+
+```
+
+The official dataset does not provide the official train/val/test set split.
+We choose the images from PascalVOC for train & val. In total, we have 3608 images and 5117 annotations for train+val, where
+2798 images with 4000 annotations are used for training, and 810 images with 1117 annotations are used for validation.
+Those images from other sources (1000 images with 1000 annotations) are used for testing.
+
+## AP-10K
+
+
+
+Animal-Pose (ICCV'2019)
+ +```bibtex +@InProceedings{Cao_2019_ICCV, + author = {Cao, Jinkun and Tang, Hongyang and Fang, Hao-Shu and Shen, Xiaoyong and Lu, Cewu and Tai, Yu-Wing}, + title = {Cross-Domain Adaptation for Animal Pose Estimation}, + booktitle = {The IEEE International Conference on Computer Vision (ICCV)}, + month = {October}, + year = {2019} +} +``` + +
+
+
+For [AP-10K](https://github.com/AlexTheBad/AP-10K/) dataset, images and annotations can be downloaded from [download](https://drive.google.com/file/d/1-FNNGcdtAQRehYYkGY1y4wzFNg4iWNad/view?usp=sharing).
+Note, this data and annotation data is for non-commercial use only.
+
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── ap10k
+ │-- annotations
+ │ │-- ap10k-train-split1.json
+ │ |-- ap10k-train-split2.json
+ │ |-- ap10k-train-split3.json
+ │ │-- ap10k-val-split1.json
+ │ |-- ap10k-val-split2.json
+ │ |-- ap10k-val-split3.json
+ │ |-- ap10k-test-split1.json
+ │ |-- ap10k-test-split2.json
+ │ |-- ap10k-test-split3.json
+ │-- data
+ │ │-- 000000000001.jpg
+ │ │-- 000000000002.jpg
+ │ │-- ...
+
+```
+
+The annotation files in 'annotation' folder contains 50 labeled animal species. There are total 10,015 labeled images with 13,028 instances in the AP-10K dataset. We randonly split them into train, val, and test set following the ratio of 7:1:2.
+
+## Horse-10
+
+
+
+AP-10K (NeurIPS'2021)
+ +```bibtex +@misc{yu2021ap10k, + title={AP-10K: A Benchmark for Animal Pose Estimation in the Wild}, + author={Hang Yu and Yufei Xu and Jing Zhang and Wei Zhao and Ziyu Guan and Dacheng Tao}, + year={2021}, + eprint={2108.12617}, + archivePrefix={arXiv}, + primaryClass={cs.CV} +} +``` + +
+
+
+For [Horse-10](http://www.mackenziemathislab.org/horse10) dataset, images can be downloaded from [download](http://www.mackenziemathislab.org/horse10).
+Please download the annotation files from [horse10_annotations](https://download.openmmlab.com/mmpose/datasets/horse10_annotations.tar). Note, this data and annotation data is for non-commercial use only, per the authors (see http://horse10.deeplabcut.org for more information).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── horse10
+ │-- annotations
+ │ │-- horse10-train-split1.json
+ │ |-- horse10-train-split2.json
+ │ |-- horse10-train-split3.json
+ │ │-- horse10-test-split1.json
+ │ |-- horse10-test-split2.json
+ │ |-- horse10-test-split3.json
+ │-- labeled-data
+ │ │-- BrownHorseinShadow
+ │ │-- BrownHorseintoshadow
+ │ │-- ...
+
+```
+
+## MacaquePose
+
+
+
+Horse-10 (WACV'2021)
+ +```bibtex +@inproceedings{mathis2021pretraining, + title={Pretraining boosts out-of-domain robustness for pose estimation}, + author={Mathis, Alexander and Biasi, Thomas and Schneider, Steffen and Yuksekgonul, Mert and Rogers, Byron and Bethge, Matthias and Mathis, Mackenzie W}, + booktitle={Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision}, + pages={1859--1868}, + year={2021} +} +``` + +
+
+
+For [MacaquePose](http://www.pri.kyoto-u.ac.jp/datasets/macaquepose/index.html) dataset, images can be downloaded from [download](http://www.pri.kyoto-u.ac.jp/datasets/macaquepose/index.html).
+Please download the annotation files from [macaque_annotations](https://download.openmmlab.com/mmpose/datasets/macaque_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── macaque
+ │-- annotations
+ │ │-- macaque_train.json
+ │ |-- macaque_test.json
+ │-- images
+ │ │-- 01418849d54b3005.jpg
+ │ │-- 0142d1d1a6904a70.jpg
+ │ │-- 01ef2c4c260321b7.jpg
+ │ │-- 020a1c75c8c85238.jpg
+ │ │-- 020b1506eef2557d.jpg
+ │ │-- ...
+
+```
+
+Since the official dataset does not provide the test set, we randomly select 12500 images for training, and the rest for evaluation (see [code](/tools/dataset/parse_macaquepose_dataset.py)).
+
+## Vinegar Fly
+
+
+
+MacaquePose (bioRxiv'2020)
+ +```bibtex +@article{labuguen2020macaquepose, + title={MacaquePose: A novel ‘in the wild’macaque monkey pose dataset for markerless motion capture}, + author={Labuguen, Rollyn and Matsumoto, Jumpei and Negrete, Salvador and Nishimaru, Hiroshi and Nishijo, Hisao and Takada, Masahiko and Go, Yasuhiro and Inoue, Ken-ichi and Shibata, Tomohiro}, + journal={bioRxiv}, + year={2020}, + publisher={Cold Spring Harbor Laboratory} +} +``` + +
+
+
+For [Vinegar Fly](https://github.com/jgraving/DeepPoseKit-Data) dataset, images can be downloaded from [vinegar_fly_images](https://download.openmmlab.com/mmpose/datasets/vinegar_fly_images.tar).
+Please download the annotation files from [vinegar_fly_annotations](https://download.openmmlab.com/mmpose/datasets/vinegar_fly_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── fly
+ │-- annotations
+ │ │-- fly_train.json
+ │ |-- fly_test.json
+ │-- images
+ │ │-- 0.jpg
+ │ │-- 1.jpg
+ │ │-- 2.jpg
+ │ │-- 3.jpg
+ │ │-- ...
+
+```
+
+Since the official dataset does not provide the test set, we randomly select 90\% images for training, and the rest (10\%) for evaluation (see [code](/tools/dataset/parse_deepposekit_dataset.py)).
+
+## Desert Locust
+
+
+
+Vinegar Fly (Nature Methods'2019)
+ +```bibtex +@article{pereira2019fast, + title={Fast animal pose estimation using deep neural networks}, + author={Pereira, Talmo D and Aldarondo, Diego E and Willmore, Lindsay and Kislin, Mikhail and Wang, Samuel S-H and Murthy, Mala and Shaevitz, Joshua W}, + journal={Nature methods}, + volume={16}, + number={1}, + pages={117--125}, + year={2019}, + publisher={Nature Publishing Group} +} +``` + +
+
+
+For [Desert Locust](https://github.com/jgraving/DeepPoseKit-Data) dataset, images can be downloaded from [locust_images](https://download.openmmlab.com/mmpose/datasets/locust_images.tar).
+Please download the annotation files from [locust_annotations](https://download.openmmlab.com/mmpose/datasets/locust_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── locust
+ │-- annotations
+ │ │-- locust_train.json
+ │ |-- locust_test.json
+ │-- images
+ │ │-- 0.jpg
+ │ │-- 1.jpg
+ │ │-- 2.jpg
+ │ │-- 3.jpg
+ │ │-- ...
+
+```
+
+Since the official dataset does not provide the test set, we randomly select 90\% images for training, and the rest (10\%) for evaluation (see [code](/tools/dataset/parse_deepposekit_dataset.py)).
+
+## Grévy’s Zebra
+
+
+
+Desert Locust (Elife'2019)
+ +```bibtex +@article{graving2019deepposekit, + title={DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning}, + author={Graving, Jacob M and Chae, Daniel and Naik, Hemal and Li, Liang and Koger, Benjamin and Costelloe, Blair R and Couzin, Iain D}, + journal={Elife}, + volume={8}, + pages={e47994}, + year={2019}, + publisher={eLife Sciences Publications Limited} +} +``` + +
+
+
+For [Grévy’s Zebra](https://github.com/jgraving/DeepPoseKit-Data) dataset, images can be downloaded from [zebra_images](https://download.openmmlab.com/mmpose/datasets/zebra_images.tar).
+Please download the annotation files from [zebra_annotations](https://download.openmmlab.com/mmpose/datasets/zebra_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── zebra
+ │-- annotations
+ │ │-- zebra_train.json
+ │ |-- zebra_test.json
+ │-- images
+ │ │-- 0.jpg
+ │ │-- 1.jpg
+ │ │-- 2.jpg
+ │ │-- 3.jpg
+ │ │-- ...
+
+```
+
+Since the official dataset does not provide the test set, we randomly select 90\% images for training, and the rest (10\%) for evaluation (see [code](/tools/dataset/parse_deepposekit_dataset.py)).
+
+## ATRW
+
+
+
+Grévy’s Zebra (Elife'2019)
+ +```bibtex +@article{graving2019deepposekit, + title={DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning}, + author={Graving, Jacob M and Chae, Daniel and Naik, Hemal and Li, Liang and Koger, Benjamin and Costelloe, Blair R and Couzin, Iain D}, + journal={Elife}, + volume={8}, + pages={e47994}, + year={2019}, + publisher={eLife Sciences Publications Limited} +} +``` + +
+
+
+ATRW captures images of the Amur tiger (also known as Siberian tiger, Northeast-China tiger) in the wild.
+For [ATRW](https://cvwc2019.github.io/challenge.html) dataset, please download images from
+[Pose_train](https://lilablobssc.blob.core.windows.net/cvwc2019/train/atrw_pose_train.tar.gz),
+[Pose_val](https://lilablobssc.blob.core.windows.net/cvwc2019/train/atrw_pose_val.tar.gz), and
+[Pose_test](https://lilablobssc.blob.core.windows.net/cvwc2019/test/atrw_pose_test.tar.gz).
+Note that in the ATRW official annotation files, the key "file_name" is written as "filename". To make it compatible with
+other coco-type json files, we have modified this key.
+Please download the modified annotation files from [atrw_annotations](https://download.openmmlab.com/mmpose/datasets/atrw_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── atrw
+ │-- annotations
+ │ │-- keypoint_train.json
+ │ │-- keypoint_val.json
+ │ │-- keypoint_trainval.json
+ │-- images
+ │ │-- train
+ │ │ │-- 000002.jpg
+ │ │ │-- 000003.jpg
+ │ │ │-- ...
+ │ │-- val
+ │ │ │-- 000001.jpg
+ │ │ │-- 000013.jpg
+ │ │ │-- ...
+ │ │-- test
+ │ │ │-- 000000.jpg
+ │ │ │-- 000004.jpg
+ │ │ │-- ...
+
+```
diff --git a/vendor/ViTPose/docs/en/tasks/2d_body_keypoint.md b/vendor/ViTPose/docs/en/tasks/2d_body_keypoint.md
new file mode 100644
index 0000000000000000000000000000000000000000..625e4d57147c164f1495b8a4ac2c461075a467e7
--- /dev/null
+++ b/vendor/ViTPose/docs/en/tasks/2d_body_keypoint.md
@@ -0,0 +1,500 @@
+# 2D Body Keypoint Datasets
+
+It is recommended to symlink the dataset root to `$MMPOSE/data`.
+If your folder structure is different, you may need to change the corresponding paths in config files.
+
+MMPose supported datasets:
+
+- Images
+ - [COCO](#coco) \[ [Homepage](http://cocodataset.org/) \]
+ - [MPII](#mpii) \[ [Homepage](http://human-pose.mpi-inf.mpg.de/) \]
+ - [MPII-TRB](#mpii-trb) \[ [Homepage](https://github.com/kennymckormick/Triplet-Representation-of-human-Body) \]
+ - [AI Challenger](#aic) \[ [Homepage](https://github.com/AIChallenger/AI_Challenger_2017) \]
+ - [CrowdPose](#crowdpose) \[ [Homepage](https://github.com/Jeff-sjtu/CrowdPose) \]
+ - [OCHuman](#ochuman) \[ [Homepage](https://github.com/liruilong940607/OCHumanApi) \]
+ - [MHP](#mhp) \[ [Homepage](https://lv-mhp.github.io/dataset) \]
+- Videos
+ - [PoseTrack18](#posetrack18) \[ [Homepage](https://posetrack.net/users/download.php) \]
+ - [sub-JHMDB](#sub-jhmdb-dataset) \[ [Homepage](http://jhmdb.is.tue.mpg.de/dataset) \]
+
+## COCO
+
+
+
+ATRW (ACM MM'2020)
+ +```bibtex +@inproceedings{li2020atrw, + title={ATRW: A Benchmark for Amur Tiger Re-identification in the Wild}, + author={Li, Shuyuan and Li, Jianguo and Tang, Hanlin and Qian, Rui and Lin, Weiyao}, + booktitle={Proceedings of the 28th ACM International Conference on Multimedia}, + pages={2590--2598}, + year={2020} +} +``` + +
+
+
+For [COCO](http://cocodataset.org/) data, please download from [COCO download](http://cocodataset.org/#download), 2017 Train/Val is needed for COCO keypoints training and validation.
+[HRNet-Human-Pose-Estimation](https://github.com/HRNet/HRNet-Human-Pose-Estimation) provides person detection result of COCO val2017 to reproduce our multi-person pose estimation results.
+Please download from [OneDrive](https://1drv.ms/f/s!AhIXJn_J-blWzzDXoz5BeFl8sWM-) or [GoogleDrive](https://drive.google.com/drive/folders/1fRUDNUDxe9fjqcRZ2bnF_TKMlO0nB_dk?usp=sharing).
+Optionally, to evaluate on COCO'2017 test-dev, please download the [image-info](https://download.openmmlab.com/mmpose/datasets/person_keypoints_test-dev-2017.json).
+Download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── coco
+ │-- annotations
+ │ │-- person_keypoints_train2017.json
+ │ |-- person_keypoints_val2017.json
+ │ |-- person_keypoints_test-dev-2017.json
+ |-- person_detection_results
+ | |-- COCO_val2017_detections_AP_H_56_person.json
+ | |-- COCO_test-dev2017_detections_AP_H_609_person.json
+ │-- train2017
+ │ │-- 000000000009.jpg
+ │ │-- 000000000025.jpg
+ │ │-- 000000000030.jpg
+ │ │-- ...
+ `-- val2017
+ │-- 000000000139.jpg
+ │-- 000000000285.jpg
+ │-- 000000000632.jpg
+ │-- ...
+
+```
+
+## MPII
+
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+For [MPII](http://human-pose.mpi-inf.mpg.de/) data, please download from [MPII Human Pose Dataset](http://human-pose.mpi-inf.mpg.de/).
+We have converted the original annotation files into json format, please download them from [mpii_annotations](https://download.openmmlab.com/mmpose/datasets/mpii_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── mpii
+ |── annotations
+ | |── mpii_gt_val.mat
+ | |── mpii_test.json
+ | |── mpii_train.json
+ | |── mpii_trainval.json
+ | `── mpii_val.json
+ `── images
+ |── 000001163.jpg
+ |── 000003072.jpg
+
+```
+
+During training and inference, the prediction result will be saved as '.mat' format by default. We also provide a tool to convert this '.mat' to more readable '.json' format.
+
+```shell
+python tools/dataset/mat2json ${PRED_MAT_FILE} ${GT_JSON_FILE} ${OUTPUT_PRED_JSON_FILE}
+```
+
+For example,
+
+```shell
+python tools/dataset/mat2json work_dirs/res50_mpii_256x256/pred.mat data/mpii/annotations/mpii_val.json pred.json
+```
+
+## MPII-TRB
+
+
+
+MPII (CVPR'2014)
+ +```bibtex +@inproceedings{andriluka14cvpr, + author = {Mykhaylo Andriluka and Leonid Pishchulin and Peter Gehler and Schiele, Bernt}, + title = {2D Human Pose Estimation: New Benchmark and State of the Art Analysis}, + booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, + year = {2014}, + month = {June} +} +``` + +
+
+
+For [MPII-TRB](https://github.com/kennymckormick/Triplet-Representation-of-human-Body) data, please download from [MPII Human Pose Dataset](http://human-pose.mpi-inf.mpg.de/).
+Please download the annotation files from [mpii_trb_annotations](https://download.openmmlab.com/mmpose/datasets/mpii_trb_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── mpii
+ |── annotations
+ | |── mpii_trb_train.json
+ | |── mpii_trb_val.json
+ `── images
+ |── 000001163.jpg
+ |── 000003072.jpg
+
+```
+
+## AIC
+
+
+
+MPII-TRB (ICCV'2019)
+ +```bibtex +@inproceedings{duan2019trb, + title={TRB: A Novel Triplet Representation for Understanding 2D Human Body}, + author={Duan, Haodong and Lin, Kwan-Yee and Jin, Sheng and Liu, Wentao and Qian, Chen and Ouyang, Wanli}, + booktitle={Proceedings of the IEEE International Conference on Computer Vision}, + pages={9479--9488}, + year={2019} +} +``` + +
+
+
+For [AIC](https://github.com/AIChallenger/AI_Challenger_2017) data, please download from [AI Challenger 2017](https://github.com/AIChallenger/AI_Challenger_2017), 2017 Train/Val is needed for keypoints training and validation.
+Please download the annotation files from [aic_annotations](https://download.openmmlab.com/mmpose/datasets/aic_annotations.tar).
+Download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── aic
+ │-- annotations
+ │ │-- aic_train.json
+ │ |-- aic_val.json
+ │-- ai_challenger_keypoint_train_20170902
+ │ │-- keypoint_train_images_20170902
+ │ │ │-- 0000252aea98840a550dac9a78c476ecb9f47ffa.jpg
+ │ │ │-- 000050f770985ac9653198495ef9b5c82435d49c.jpg
+ │ │ │-- ...
+ `-- ai_challenger_keypoint_validation_20170911
+ │-- keypoint_validation_images_20170911
+ │-- 0002605c53fb92109a3f2de4fc3ce06425c3b61f.jpg
+ │-- 0003b55a2c991223e6d8b4b820045bd49507bf6d.jpg
+ │-- ...
+```
+
+## CrowdPose
+
+
+
+AI Challenger (ArXiv'2017)
+ +```bibtex +@article{wu2017ai, + title={Ai challenger: A large-scale dataset for going deeper in image understanding}, + author={Wu, Jiahong and Zheng, He and Zhao, Bo and Li, Yixin and Yan, Baoming and Liang, Rui and Wang, Wenjia and Zhou, Shipei and Lin, Guosen and Fu, Yanwei and others}, + journal={arXiv preprint arXiv:1711.06475}, + year={2017} +} +``` + +
+
+
+For [CrowdPose](https://github.com/Jeff-sjtu/CrowdPose) data, please download from [CrowdPose](https://github.com/Jeff-sjtu/CrowdPose).
+Please download the annotation files and human detection results from [crowdpose_annotations](https://download.openmmlab.com/mmpose/datasets/crowdpose_annotations.tar).
+For top-down approaches, we follow [CrowdPose](https://arxiv.org/abs/1812.00324) to use the [pre-trained weights](https://pjreddie.com/media/files/yolov3.weights) of [YOLOv3](https://github.com/eriklindernoren/PyTorch-YOLOv3) to generate the detected human bounding boxes.
+For model training, we follow [HigherHRNet](https://github.com/HRNet/HigherHRNet-Human-Pose-Estimation) to train models on CrowdPose train/val dataset, and evaluate models on CrowdPose test dataset.
+Download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── crowdpose
+ │-- annotations
+ │ │-- mmpose_crowdpose_train.json
+ │ │-- mmpose_crowdpose_val.json
+ │ │-- mmpose_crowdpose_trainval.json
+ │ │-- mmpose_crowdpose_test.json
+ │ │-- det_for_crowd_test_0.1_0.5.json
+ │-- images
+ │-- 100000.jpg
+ │-- 100001.jpg
+ │-- 100002.jpg
+ │-- ...
+```
+
+## OCHuman
+
+
+
+CrowdPose (CVPR'2019)
+ +```bibtex +@article{li2018crowdpose, + title={CrowdPose: Efficient Crowded Scenes Pose Estimation and A New Benchmark}, + author={Li, Jiefeng and Wang, Can and Zhu, Hao and Mao, Yihuan and Fang, Hao-Shu and Lu, Cewu}, + journal={arXiv preprint arXiv:1812.00324}, + year={2018} +} +``` + +
+
+
+For [OCHuman](https://github.com/liruilong940607/OCHumanApi) data, please download the images and annotations from [OCHuman](https://github.com/liruilong940607/OCHumanApi),
+Move them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── ochuman
+ │-- annotations
+ │ │-- ochuman_coco_format_val_range_0.00_1.00.json
+ │ |-- ochuman_coco_format_test_range_0.00_1.00.json
+ |-- images
+ │-- 000001.jpg
+ │-- 000002.jpg
+ │-- 000003.jpg
+ │-- ...
+
+```
+
+## MHP
+
+
+
+OCHuman (CVPR'2019)
+ +```bibtex +@inproceedings{zhang2019pose2seg, + title={Pose2seg: Detection free human instance segmentation}, + author={Zhang, Song-Hai and Li, Ruilong and Dong, Xin and Rosin, Paul and Cai, Zixi and Han, Xi and Yang, Dingcheng and Huang, Haozhi and Hu, Shi-Min}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={889--898}, + year={2019} +} +``` + +
+
+
+For [MHP](https://lv-mhp.github.io/dataset) data, please download from [MHP](https://lv-mhp.github.io/dataset).
+Please download the annotation files from [mhp_annotations](https://download.openmmlab.com/mmpose/datasets/mhp_annotations.tar.gz).
+Please download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── mhp
+ │-- annotations
+ │ │-- mhp_train.json
+ │ │-- mhp_val.json
+ │
+ `-- train
+ │ │-- images
+ │ │ │-- 1004.jpg
+ │ │ │-- 10050.jpg
+ │ │ │-- ...
+ │
+ `-- val
+ │ │-- images
+ │ │ │-- 10059.jpg
+ │ │ │-- 10068.jpg
+ │ │ │-- ...
+ │
+ `-- test
+ │ │-- images
+ │ │ │-- 1005.jpg
+ │ │ │-- 10052.jpg
+ │ │ │-- ...~~~~
+```
+
+## PoseTrack18
+
+
+
+MHP (ACM MM'2018)
+ +```bibtex +@inproceedings{zhao2018understanding, + title={Understanding humans in crowded scenes: Deep nested adversarial learning and a new benchmark for multi-human parsing}, + author={Zhao, Jian and Li, Jianshu and Cheng, Yu and Sim, Terence and Yan, Shuicheng and Feng, Jiashi}, + booktitle={Proceedings of the 26th ACM international conference on Multimedia}, + pages={792--800}, + year={2018} +} +``` + +
+
+
+For [PoseTrack18](https://posetrack.net/users/download.php) data, please download from [PoseTrack18](https://posetrack.net/users/download.php).
+Please download the annotation files from [posetrack18_annotations](https://download.openmmlab.com/mmpose/datasets/posetrack18_annotations.tar).
+We have merged the video-wise separated official annotation files into two json files (posetrack18_train & posetrack18_val.json). We also generate the [mask files](https://download.openmmlab.com/mmpose/datasets/posetrack18_mask.tar) to speed up training.
+For top-down approaches, we use [MMDetection](https://github.com/open-mmlab/mmdetection) pre-trained [Cascade R-CNN](https://download.openmmlab.com/mmdetection/v2.0/cascade_rcnn/cascade_rcnn_x101_64x4d_fpn_20e_coco/cascade_rcnn_x101_64x4d_fpn_20e_coco_20200509_224357-051557b1.pth) (X-101-64x4d-FPN) to generate the detected human bounding boxes.
+Please download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── posetrack18
+ │-- annotations
+ │ │-- posetrack18_train.json
+ │ │-- posetrack18_val.json
+ │ │-- posetrack18_val_human_detections.json
+ │ │-- train
+ │ │ │-- 000001_bonn_train.json
+ │ │ │-- 000002_bonn_train.json
+ │ │ │-- ...
+ │ │-- val
+ │ │ │-- 000342_mpii_test.json
+ │ │ │-- 000522_mpii_test.json
+ │ │ │-- ...
+ │ `-- test
+ │ │-- 000001_mpiinew_test.json
+ │ │-- 000002_mpiinew_test.json
+ │ │-- ...
+ │
+ `-- images
+ │ │-- train
+ │ │ │-- 000001_bonn_train
+ │ │ │ │-- 000000.jpg
+ │ │ │ │-- 000001.jpg
+ │ │ │ │-- ...
+ │ │ │-- ...
+ │ │-- val
+ │ │ │-- 000342_mpii_test
+ │ │ │ │-- 000000.jpg
+ │ │ │ │-- 000001.jpg
+ │ │ │ │-- ...
+ │ │ │-- ...
+ │ `-- test
+ │ │-- 000001_mpiinew_test
+ │ │ │-- 000000.jpg
+ │ │ │-- 000001.jpg
+ │ │ │-- ...
+ │ │-- ...
+ `-- mask
+ │-- train
+ │ │-- 000002_bonn_train
+ │ │ │-- 000000.jpg
+ │ │ │-- 000001.jpg
+ │ │ │-- ...
+ │ │-- ...
+ `-- val
+ │-- 000522_mpii_test
+ │ │-- 000000.jpg
+ │ │-- 000001.jpg
+ │ │-- ...
+ │-- ...
+```
+
+The official evaluation tool for PoseTrack should be installed from GitHub.
+
+```shell
+pip install git+https://github.com/svenkreiss/poseval.git
+```
+
+## sub-JHMDB dataset
+
+
+
+PoseTrack18 (CVPR'2018)
+ +```bibtex +@inproceedings{andriluka2018posetrack, + title={Posetrack: A benchmark for human pose estimation and tracking}, + author={Andriluka, Mykhaylo and Iqbal, Umar and Insafutdinov, Eldar and Pishchulin, Leonid and Milan, Anton and Gall, Juergen and Schiele, Bernt}, + booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition}, + pages={5167--5176}, + year={2018} +} +``` + +
+
+
+For [sub-JHMDB](http://jhmdb.is.tue.mpg.de/dataset) data, please download the [images](<(http://files.is.tue.mpg.de/jhmdb/Rename_Images.tar.gz)>) from [JHMDB](http://jhmdb.is.tue.mpg.de/dataset),
+Please download the annotation files from [jhmdb_annotations](https://download.openmmlab.com/mmpose/datasets/jhmdb_annotations.tar).
+Move them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── jhmdb
+ │-- annotations
+ │ │-- Sub1_train.json
+ │ |-- Sub1_test.json
+ │ │-- Sub2_train.json
+ │ |-- Sub2_test.json
+ │ │-- Sub3_train.json
+ │ |-- Sub3_test.json
+ |-- Rename_Images
+ │-- brush_hair
+ │ │--April_09_brush_hair_u_nm_np1_ba_goo_0
+ | │ │--00001.png
+ | │ │--00002.png
+ │-- catch
+ │-- ...
+
+```
diff --git a/vendor/ViTPose/docs/en/tasks/2d_face_keypoint.md b/vendor/ViTPose/docs/en/tasks/2d_face_keypoint.md
new file mode 100644
index 0000000000000000000000000000000000000000..fe715003b3458fb75cfc81b823415cc42d7904e3
--- /dev/null
+++ b/vendor/ViTPose/docs/en/tasks/2d_face_keypoint.md
@@ -0,0 +1,306 @@
+# 2D Face Keypoint Datasets
+
+It is recommended to symlink the dataset root to `$MMPOSE/data`.
+If your folder structure is different, you may need to change the corresponding paths in config files.
+
+MMPose supported datasets:
+
+- [300W](#300w-dataset) \[ [Homepage](https://ibug.doc.ic.ac.uk/resources/300-W/) \]
+- [WFLW](#wflw-dataset) \[ [Homepage](https://wywu.github.io/projects/LAB/WFLW.html) \]
+- [AFLW](#aflw-dataset) \[ [Homepage](https://www.tugraz.at/institute/icg/research/team-bischof/lrs/downloads/aflw/) \]
+- [COFW](#cofw-dataset) \[ [Homepage](http://www.vision.caltech.edu/xpburgos/ICCV13/) \]
+- [COCO-WholeBody-Face](#coco-wholebody-face) \[ [Homepage](https://github.com/jin-s13/COCO-WholeBody/) \]
+
+## 300W Dataset
+
+
+
+RSN (ECCV'2020)
+ +```bibtex +@misc{cai2020learning, + title={Learning Delicate Local Representations for Multi-Person Pose Estimation}, + author={Yuanhao Cai and Zhicheng Wang and Zhengxiong Luo and Binyi Yin and Angang Du and Haoqian Wang and Xinyu Zhou and Erjin Zhou and Xiangyu Zhang and Jian Sun}, + year={2020}, + eprint={2003.04030}, + archivePrefix={arXiv}, + primaryClass={cs.CV} +} +``` + +
+
+
+For 300W data, please download images from [300W Dataset](https://ibug.doc.ic.ac.uk/resources/300-W/).
+Please download the annotation files from [300w_annotations](https://download.openmmlab.com/mmpose/datasets/300w_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── 300w
+ |── annotations
+ | |── face_landmarks_300w_train.json
+ | |── face_landmarks_300w_valid.json
+ | |── face_landmarks_300w_valid_common.json
+ | |── face_landmarks_300w_valid_challenge.json
+ | |── face_landmarks_300w_test.json
+ `── images
+ |── afw
+ | |── 1051618982_1.jpg
+ | |── 111076519_1.jpg
+ | ...
+ |── helen
+ | |── trainset
+ | | |── 100032540_1.jpg
+ | | |── 100040721_1.jpg
+ | | ...
+ | |── testset
+ | | |── 296814969_3.jpg
+ | | |── 2968560214_1.jpg
+ | | ...
+ |── ibug
+ | |── image_003_1.jpg
+ | |── image_004_1.jpg
+ | ...
+ |── lfpw
+ | |── trainset
+ | | |── image_0001.png
+ | | |── image_0002.png
+ | | ...
+ | |── testset
+ | | |── image_0001.png
+ | | |── image_0002.png
+ | | ...
+ `── Test
+ |── 01_Indoor
+ | |── indoor_001.png
+ | |── indoor_002.png
+ | ...
+ `── 02_Outdoor
+ |── outdoor_001.png
+ |── outdoor_002.png
+ ...
+```
+
+## WFLW Dataset
+
+
+
+300W (IMAVIS'2016)
+ +```bibtex +@article{sagonas2016300, + title={300 faces in-the-wild challenge: Database and results}, + author={Sagonas, Christos and Antonakos, Epameinondas and Tzimiropoulos, Georgios and Zafeiriou, Stefanos and Pantic, Maja}, + journal={Image and vision computing}, + volume={47}, + pages={3--18}, + year={2016}, + publisher={Elsevier} +} +``` + +
+
+
+For WFLW data, please download images from [WFLW Dataset](https://wywu.github.io/projects/LAB/WFLW.html).
+Please download the annotation files from [wflw_annotations](https://download.openmmlab.com/mmpose/datasets/wflw_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── wflw
+ |── annotations
+ | |── face_landmarks_wflw_train.json
+ | |── face_landmarks_wflw_test.json
+ | |── face_landmarks_wflw_test_blur.json
+ | |── face_landmarks_wflw_test_occlusion.json
+ | |── face_landmarks_wflw_test_expression.json
+ | |── face_landmarks_wflw_test_largepose.json
+ | |── face_landmarks_wflw_test_illumination.json
+ | |── face_landmarks_wflw_test_makeup.json
+ |
+ `── images
+ |── 0--Parade
+ | |── 0_Parade_marchingband_1_1015.jpg
+ | |── 0_Parade_marchingband_1_1031.jpg
+ | ...
+ |── 1--Handshaking
+ | |── 1_Handshaking_Handshaking_1_105.jpg
+ | |── 1_Handshaking_Handshaking_1_107.jpg
+ | ...
+ ...
+```
+
+## AFLW Dataset
+
+
+
+WFLW (CVPR'2018)
+ +```bibtex +@inproceedings{wu2018look, + title={Look at boundary: A boundary-aware face alignment algorithm}, + author={Wu, Wayne and Qian, Chen and Yang, Shuo and Wang, Quan and Cai, Yici and Zhou, Qiang}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={2129--2138}, + year={2018} +} +``` + +
+
+
+For AFLW data, please download images from [AFLW Dataset](https://www.tugraz.at/institute/icg/research/team-bischof/lrs/downloads/aflw/).
+Please download the annotation files from [aflw_annotations](https://download.openmmlab.com/mmpose/datasets/aflw_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── aflw
+ |── annotations
+ | |── face_landmarks_aflw_train.json
+ | |── face_landmarks_aflw_test_frontal.json
+ | |── face_landmarks_aflw_test.json
+ `── images
+ |── flickr
+ |── 0
+ | |── image00002.jpg
+ | |── image00013.jpg
+ | ...
+ |── 2
+ | |── image00004.jpg
+ | |── image00006.jpg
+ | ...
+ `── 3
+ |── image00032.jpg
+ |── image00035.jpg
+ ...
+```
+
+## COFW Dataset
+
+
+
+AFLW (ICCVW'2011)
+ +```bibtex +@inproceedings{koestinger2011annotated, + title={Annotated facial landmarks in the wild: A large-scale, real-world database for facial landmark localization}, + author={Koestinger, Martin and Wohlhart, Paul and Roth, Peter M and Bischof, Horst}, + booktitle={2011 IEEE international conference on computer vision workshops (ICCV workshops)}, + pages={2144--2151}, + year={2011}, + organization={IEEE} +} +``` + +
+
+
+For COFW data, please download from [COFW Dataset (Color Images)](http://www.vision.caltech.edu/xpburgos/ICCV13/Data/COFW_color.zip).
+Move `COFW_train_color.mat` and `COFW_test_color.mat` to `data/cofw/` and make them look like:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── cofw
+ |── COFW_train_color.mat
+ |── COFW_test_color.mat
+```
+
+Run the following script under `{MMPose}/data`
+
+`python tools/dataset/parse_cofw_dataset.py`
+
+And you will get
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── cofw
+ |── COFW_train_color.mat
+ |── COFW_test_color.mat
+ |── annotations
+ | |── cofw_train.json
+ | |── cofw_test.json
+ |── images
+ |── 000001.jpg
+ |── 000002.jpg
+```
+
+## COCO-WholeBody (Face)
+
+[DATASET]
+
+```bibtex
+@inproceedings{jin2020whole,
+ title={Whole-Body Human Pose Estimation in the Wild},
+ author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping},
+ booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
+ year={2020}
+}
+```
+
+For [COCO-WholeBody](https://github.com/jin-s13/COCO-WholeBody/) dataset, images can be downloaded from [COCO download](http://cocodataset.org/#download), 2017 Train/Val is needed for COCO keypoints training and validation.
+Download COCO-WholeBody annotations for COCO-WholeBody annotations for [Train](https://drive.google.com/file/d/1thErEToRbmM9uLNi1JXXfOsaS5VK2FXf/view?usp=sharing) / [Validation](https://drive.google.com/file/d/1N6VgwKnj8DeyGXCvp1eYgNbRmw6jdfrb/view?usp=sharing) (Google Drive).
+Download person detection result of COCO val2017 from [OneDrive](https://1drv.ms/f/s!AhIXJn_J-blWzzDXoz5BeFl8sWM-) or [GoogleDrive](https://drive.google.com/drive/folders/1fRUDNUDxe9fjqcRZ2bnF_TKMlO0nB_dk?usp=sharing).
+Download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── coco
+ │-- annotations
+ │ │-- coco_wholebody_train_v1.0.json
+ │ |-- coco_wholebody_val_v1.0.json
+ |-- person_detection_results
+ | |-- COCO_val2017_detections_AP_H_56_person.json
+ │-- train2017
+ │ │-- 000000000009.jpg
+ │ │-- 000000000025.jpg
+ │ │-- 000000000030.jpg
+ │ │-- ...
+ `-- val2017
+ │-- 000000000139.jpg
+ │-- 000000000285.jpg
+ │-- 000000000632.jpg
+ │-- ...
+
+```
+
+Please also install the latest version of [Extended COCO API](https://github.com/jin-s13/xtcocoapi) to support COCO-WholeBody evaluation:
+
+`pip install xtcocotools`
diff --git a/vendor/ViTPose/docs/en/tasks/2d_fashion_landmark.md b/vendor/ViTPose/docs/en/tasks/2d_fashion_landmark.md
new file mode 100644
index 0000000000000000000000000000000000000000..c0eb2c8435b34d0df29070fdd4e09b643bc15efe
--- /dev/null
+++ b/vendor/ViTPose/docs/en/tasks/2d_fashion_landmark.md
@@ -0,0 +1,76 @@
+# 2D Fashion Landmark Dataset
+
+It is recommended to symlink the dataset root to `$MMPOSE/data`.
+If your folder structure is different, you may need to change the corresponding paths in config files.
+
+MMPose supported datasets:
+
+- [DeepFashion](#deepfashion) \[ [Homepage](http://mmlab.ie.cuhk.edu.hk/projects/DeepFashion/LandmarkDetection.html) \]
+
+## DeepFashion (Fashion Landmark Detection, FLD)
+
+
+
+COFW (ICCV'2013)
+ +```bibtex +@inproceedings{burgos2013robust, + title={Robust face landmark estimation under occlusion}, + author={Burgos-Artizzu, Xavier P and Perona, Pietro and Doll{\'a}r, Piotr}, + booktitle={Proceedings of the IEEE international conference on computer vision}, + pages={1513--1520}, + year={2013} +} +``` + +
+
+
+
+
+DeepFashion (CVPR'2016)
+ +```bibtex +@inproceedings{liuLQWTcvpr16DeepFashion, + author = {Liu, Ziwei and Luo, Ping and Qiu, Shi and Wang, Xiaogang and Tang, Xiaoou}, + title = {DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations}, + booktitle = {Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, + month = {June}, + year = {2016} +} +``` + +
+
+
+For [DeepFashion](http://mmlab.ie.cuhk.edu.hk/projects/DeepFashion/LandmarkDetection.html) dataset, images can be downloaded from [download](http://mmlab.ie.cuhk.edu.hk/projects/DeepFashion/LandmarkDetection.html).
+Please download the annotation files from [fld_annotations](https://download.openmmlab.com/mmpose/datasets/fld_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── fld
+ │-- annotations
+ │ │-- fld_upper_train.json
+ │ |-- fld_upper_val.json
+ │ |-- fld_upper_test.json
+ │ │-- fld_lower_train.json
+ │ |-- fld_lower_val.json
+ │ |-- fld_lower_test.json
+ │ │-- fld_full_train.json
+ │ |-- fld_full_val.json
+ │ |-- fld_full_test.json
+ │-- img
+ │ │-- img_00000001.jpg
+ │ │-- img_00000002.jpg
+ │ │-- img_00000003.jpg
+ │ │-- img_00000004.jpg
+ │ │-- img_00000005.jpg
+ │ │-- ...
+```
diff --git a/vendor/ViTPose/docs/en/tasks/2d_hand_keypoint.md b/vendor/ViTPose/docs/en/tasks/2d_hand_keypoint.md
new file mode 100644
index 0000000000000000000000000000000000000000..20f93d4c21c40697460ca91be7005eb087ffdd12
--- /dev/null
+++ b/vendor/ViTPose/docs/en/tasks/2d_hand_keypoint.md
@@ -0,0 +1,319 @@
+# 2D Hand Keypoint Datasets
+
+It is recommended to symlink the dataset root to `$MMPOSE/data`.
+If your folder structure is different, you may need to change the corresponding paths in config files.
+
+MMPose supported datasets:
+
+- [OneHand10K](#onehand10k) \[ [Homepage](https://www.yangangwang.com/papers/WANG-MCC-2018-10.html) \]
+- [FreiHand](#freihand-dataset) \[ [Homepage](https://lmb.informatik.uni-freiburg.de/projects/freihand/) \]
+- [CMU Panoptic HandDB](#cmu-panoptic-handdb) \[ [Homepage](http://domedb.perception.cs.cmu.edu/handdb.html) \]
+- [InterHand2.6M](#interhand26m) \[ [Homepage](https://mks0601.github.io/InterHand2.6M/) \]
+- [RHD](#rhd-dataset) \[ [Homepage](https://lmb.informatik.uni-freiburg.de/resources/datasets/RenderedHandposeDataset.en.html) \]
+- [COCO-WholeBody-Hand](#coco-wholebody-hand) \[ [Homepage](https://github.com/jin-s13/COCO-WholeBody/) \]
+
+## OneHand10K
+
+
+
+DeepFashion (ECCV'2016)
+ +```bibtex +@inproceedings{liuYLWTeccv16FashionLandmark, + author = {Liu, Ziwei and Yan, Sijie and Luo, Ping and Wang, Xiaogang and Tang, Xiaoou}, + title = {Fashion Landmark Detection in the Wild}, + booktitle = {European Conference on Computer Vision (ECCV)}, + month = {October}, + year = {2016} + } +``` + +
+
+
+For [OneHand10K](https://www.yangangwang.com/papers/WANG-MCC-2018-10.html) data, please download from [OneHand10K Dataset](https://www.yangangwang.com/papers/WANG-MCC-2018-10.html).
+Please download the annotation files from [onehand10k_annotations](https://download.openmmlab.com/mmpose/datasets/onehand10k_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── onehand10k
+ |── annotations
+ | |── onehand10k_train.json
+ | |── onehand10k_test.json
+ `── Train
+ | |── source
+ | |── 0.jpg
+ | |── 1.jpg
+ | ...
+ `── Test
+ |── source
+ |── 0.jpg
+ |── 1.jpg
+
+```
+
+## FreiHAND Dataset
+
+
+
+OneHand10K (TCSVT'2019)
+ +```bibtex +@article{wang2018mask, + title={Mask-pose cascaded cnn for 2d hand pose estimation from single color image}, + author={Wang, Yangang and Peng, Cong and Liu, Yebin}, + journal={IEEE Transactions on Circuits and Systems for Video Technology}, + volume={29}, + number={11}, + pages={3258--3268}, + year={2018}, + publisher={IEEE} +} +``` + +
+
+
+For [FreiHAND](https://lmb.informatik.uni-freiburg.de/projects/freihand/) data, please download from [FreiHand Dataset](https://lmb.informatik.uni-freiburg.de/resources/datasets/FreihandDataset.en.html).
+Since the official dataset does not provide validation set, we randomly split the training data into 8:1:1 for train/val/test.
+Please download the annotation files from [freihand_annotations](https://download.openmmlab.com/mmpose/datasets/frei_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── freihand
+ |── annotations
+ | |── freihand_train.json
+ | |── freihand_val.json
+ | |── freihand_test.json
+ `── training
+ |── rgb
+ | |── 00000000.jpg
+ | |── 00000001.jpg
+ | ...
+ |── mask
+ |── 00000000.jpg
+ |── 00000001.jpg
+ ...
+```
+
+## CMU Panoptic HandDB
+
+
+
+FreiHand (ICCV'2019)
+ +```bibtex +@inproceedings{zimmermann2019freihand, + title={Freihand: A dataset for markerless capture of hand pose and shape from single rgb images}, + author={Zimmermann, Christian and Ceylan, Duygu and Yang, Jimei and Russell, Bryan and Argus, Max and Brox, Thomas}, + booktitle={Proceedings of the IEEE International Conference on Computer Vision}, + pages={813--822}, + year={2019} +} +``` + +
+
+
+For [CMU Panoptic HandDB](http://domedb.perception.cs.cmu.edu/handdb.html), please download from [CMU Panoptic HandDB](http://domedb.perception.cs.cmu.edu/handdb.html).
+Following [Simon et al](https://arxiv.org/abs/1704.07809), panoptic images (hand143_panopticdb) and MPII & NZSL training sets (manual_train) are used for training, while MPII & NZSL test set (manual_test) for testing.
+Please download the annotation files from [panoptic_annotations](https://download.openmmlab.com/mmpose/datasets/panoptic_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── panoptic
+ |── annotations
+ | |── panoptic_train.json
+ | |── panoptic_test.json
+ |
+ `── hand143_panopticdb
+ | |── imgs
+ | | |── 00000000.jpg
+ | | |── 00000001.jpg
+ | | ...
+ |
+ `── hand_labels
+ |── manual_train
+ | |── 000015774_01_l.jpg
+ | |── 000015774_01_r.jpg
+ | ...
+ |
+ `── manual_test
+ |── 000648952_02_l.jpg
+ |── 000835470_01_l.jpg
+ ...
+```
+
+## InterHand2.6M
+
+
+
+CMU Panoptic HandDB (CVPR'2017)
+ +```bibtex +@inproceedings{simon2017hand, + title={Hand keypoint detection in single images using multiview bootstrapping}, + author={Simon, Tomas and Joo, Hanbyul and Matthews, Iain and Sheikh, Yaser}, + booktitle={Proceedings of the IEEE conference on Computer Vision and Pattern Recognition}, + pages={1145--1153}, + year={2017} +} +``` + +
+
+
+For [InterHand2.6M](https://mks0601.github.io/InterHand2.6M/), please download from [InterHand2.6M](https://mks0601.github.io/InterHand2.6M/).
+Please download the annotation files from [annotations](https://drive.google.com/drive/folders/1pWXhdfaka-J0fSAze0MsajN0VpZ8e8tO).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── interhand2.6m
+ |── annotations
+ | |── all
+ | |── human_annot
+ | |── machine_annot
+ | |── skeleton.txt
+ | |── subject.txt
+ |
+ `── images
+ | |── train
+ | | |-- Capture0 ~ Capture26
+ | |── val
+ | | |-- Capture0
+ | |── test
+ | | |-- Capture0 ~ Capture7
+```
+
+## RHD Dataset
+
+
+
+InterHand2.6M (ECCV'2020)
+ +```bibtex +@InProceedings{Moon_2020_ECCV_InterHand2.6M, +author = {Moon, Gyeongsik and Yu, Shoou-I and Wen, He and Shiratori, Takaaki and Lee, Kyoung Mu}, +title = {InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image}, +booktitle = {European Conference on Computer Vision (ECCV)}, +year = {2020} +} +``` + +
+
+
+For [RHD Dataset](https://lmb.informatik.uni-freiburg.de/resources/datasets/RenderedHandposeDataset.en.html), please download from [RHD Dataset](https://lmb.informatik.uni-freiburg.de/resources/datasets/RenderedHandposeDataset.en.html).
+Please download the annotation files from [rhd_annotations](https://download.openmmlab.com/mmpose/datasets/rhd_annotations.zip).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── rhd
+ |── annotations
+ | |── rhd_train.json
+ | |── rhd_test.json
+ `── training
+ | |── color
+ | | |── 00000.jpg
+ | | |── 00001.jpg
+ | |── depth
+ | | |── 00000.jpg
+ | | |── 00001.jpg
+ | |── mask
+ | | |── 00000.jpg
+ | | |── 00001.jpg
+ `── evaluation
+ | |── color
+ | | |── 00000.jpg
+ | | |── 00001.jpg
+ | |── depth
+ | | |── 00000.jpg
+ | | |── 00001.jpg
+ | |── mask
+ | | |── 00000.jpg
+ | | |── 00001.jpg
+```
+
+## COCO-WholeBody (Hand)
+
+[DATASET]
+
+```bibtex
+@inproceedings{jin2020whole,
+ title={Whole-Body Human Pose Estimation in the Wild},
+ author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping},
+ booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
+ year={2020}
+}
+```
+
+For [COCO-WholeBody](https://github.com/jin-s13/COCO-WholeBody/) dataset, images can be downloaded from [COCO download](http://cocodataset.org/#download), 2017 Train/Val is needed for COCO keypoints training and validation.
+Download COCO-WholeBody annotations for COCO-WholeBody annotations for [Train](https://drive.google.com/file/d/1thErEToRbmM9uLNi1JXXfOsaS5VK2FXf/view?usp=sharing) / [Validation](https://drive.google.com/file/d/1N6VgwKnj8DeyGXCvp1eYgNbRmw6jdfrb/view?usp=sharing) (Google Drive).
+Download person detection result of COCO val2017 from [OneDrive](https://1drv.ms/f/s!AhIXJn_J-blWzzDXoz5BeFl8sWM-) or [GoogleDrive](https://drive.google.com/drive/folders/1fRUDNUDxe9fjqcRZ2bnF_TKMlO0nB_dk?usp=sharing).
+Download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── coco
+ │-- annotations
+ │ │-- coco_wholebody_train_v1.0.json
+ │ |-- coco_wholebody_val_v1.0.json
+ |-- person_detection_results
+ | |-- COCO_val2017_detections_AP_H_56_person.json
+ │-- train2017
+ │ │-- 000000000009.jpg
+ │ │-- 000000000025.jpg
+ │ │-- 000000000030.jpg
+ │ │-- ...
+ `-- val2017
+ │-- 000000000139.jpg
+ │-- 000000000285.jpg
+ │-- 000000000632.jpg
+ │-- ...
+```
+
+Please also install the latest version of [Extended COCO API](https://github.com/jin-s13/xtcocoapi) to support COCO-WholeBody evaluation:
+
+`pip install xtcocotools`
diff --git a/vendor/ViTPose/docs/en/tasks/2d_wholebody_keypoint.md b/vendor/ViTPose/docs/en/tasks/2d_wholebody_keypoint.md
new file mode 100644
index 0000000000000000000000000000000000000000..e3d573ffbdd62302035ddbd1747e36dc1da8f4cd
--- /dev/null
+++ b/vendor/ViTPose/docs/en/tasks/2d_wholebody_keypoint.md
@@ -0,0 +1,125 @@
+# 2D Wholebody Keypoint Datasets
+
+It is recommended to symlink the dataset root to `$MMPOSE/data`.
+If your folder structure is different, you may need to change the corresponding paths in config files.
+
+MMPose supported datasets:
+
+- [COCO-WholeBody](#coco-wholebody) \[ [Homepage](https://github.com/jin-s13/COCO-WholeBody/) \]
+- [Halpe](#halpe) \[ [Homepage](https://github.com/Fang-Haoshu/Halpe-FullBody/) \]
+
+## COCO-WholeBody
+
+
+
+RHD (ICCV'2017)
+ +```bibtex +@TechReport{zb2017hand, + author={Christian Zimmermann and Thomas Brox}, + title={Learning to Estimate 3D Hand Pose from Single RGB Images}, + institution={arXiv:1705.01389}, + year={2017}, + note="https://arxiv.org/abs/1705.01389", + url="https://lmb.informatik.uni-freiburg.de/projects/hand3d/" +} +``` + +
+
+
+For [COCO-WholeBody](https://github.com/jin-s13/COCO-WholeBody/) dataset, images can be downloaded from [COCO download](http://cocodataset.org/#download), 2017 Train/Val is needed for COCO keypoints training and validation.
+Download COCO-WholeBody annotations for COCO-WholeBody annotations for [Train](https://drive.google.com/file/d/1thErEToRbmM9uLNi1JXXfOsaS5VK2FXf/view?usp=sharing) / [Validation](https://drive.google.com/file/d/1N6VgwKnj8DeyGXCvp1eYgNbRmw6jdfrb/view?usp=sharing) (Google Drive).
+Download person detection result of COCO val2017 from [OneDrive](https://1drv.ms/f/s!AhIXJn_J-blWzzDXoz5BeFl8sWM-) or [GoogleDrive](https://drive.google.com/drive/folders/1fRUDNUDxe9fjqcRZ2bnF_TKMlO0nB_dk?usp=sharing).
+Download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── coco
+ │-- annotations
+ │ │-- coco_wholebody_train_v1.0.json
+ │ |-- coco_wholebody_val_v1.0.json
+ |-- person_detection_results
+ | |-- COCO_val2017_detections_AP_H_56_person.json
+ │-- train2017
+ │ │-- 000000000009.jpg
+ │ │-- 000000000025.jpg
+ │ │-- 000000000030.jpg
+ │ │-- ...
+ `-- val2017
+ │-- 000000000139.jpg
+ │-- 000000000285.jpg
+ │-- 000000000632.jpg
+ │-- ...
+
+```
+
+Please also install the latest version of [Extended COCO API](https://github.com/jin-s13/xtcocoapi) (version>=1.5) to support COCO-WholeBody evaluation:
+
+`pip install xtcocotools`
+
+## Halpe
+
+
+
+COCO-WholeBody (ECCV'2020)
+ +```bibtex +@inproceedings{jin2020whole, + title={Whole-Body Human Pose Estimation in the Wild}, + author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping}, + booktitle={Proceedings of the European Conference on Computer Vision (ECCV)}, + year={2020} +} +``` + +
+
+
+For [Halpe](https://github.com/Fang-Haoshu/Halpe-FullBody/) dataset, please download images and annotations from [Halpe download](https://github.com/Fang-Haoshu/Halpe-FullBody).
+The images of the training set are from [HICO-Det](https://drive.google.com/open?id=1QZcJmGVlF9f4h-XLWe9Gkmnmj2z1gSnk) and those of the validation set are from [COCO](http://images.cocodataset.org/zips/val2017.zip).
+Download person detection result of COCO val2017 from [OneDrive](https://1drv.ms/f/s!AhIXJn_J-blWzzDXoz5BeFl8sWM-) or [GoogleDrive](https://drive.google.com/drive/folders/1fRUDNUDxe9fjqcRZ2bnF_TKMlO0nB_dk?usp=sharing).
+Download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── halpe
+ │-- annotations
+ │ │-- halpe_train_v1.json
+ │ |-- halpe_val_v1.json
+ |-- person_detection_results
+ | |-- COCO_val2017_detections_AP_H_56_person.json
+ │-- hico_20160224_det
+ │ │-- anno_bbox.mat
+ │ │-- anno.mat
+ │ │-- README
+ │ │-- images
+ │ │ │-- train2015
+ │ │ │ │-- HICO_train2015_00000001.jpg
+ │ │ │ │-- HICO_train2015_00000002.jpg
+ │ │ │ │-- HICO_train2015_00000003.jpg
+ │ │ │ │-- ...
+ │ │ │-- test2015
+ │ │-- tools
+ │ │-- ...
+ `-- val2017
+ │-- 000000000139.jpg
+ │-- 000000000285.jpg
+ │-- 000000000632.jpg
+ │-- ...
+
+```
+
+Please also install the latest version of [Extended COCO API](https://github.com/jin-s13/xtcocoapi) (version>=1.5) to support Halpe evaluation:
+
+`pip install xtcocotools`
diff --git a/vendor/ViTPose/docs/en/tasks/3d_body_keypoint.md b/vendor/ViTPose/docs/en/tasks/3d_body_keypoint.md
new file mode 100644
index 0000000000000000000000000000000000000000..c5ca2a1dba1a0d82730621a85cfa1eef164fbbea
--- /dev/null
+++ b/vendor/ViTPose/docs/en/tasks/3d_body_keypoint.md
@@ -0,0 +1,120 @@
+# 3D Body Keypoint Datasets
+
+It is recommended to symlink the dataset root to `$MMPOSE/data`.
+If your folder structure is different, you may need to change the corresponding paths in config files.
+
+MMPose supported datasets:
+
+- [Human3.6M](#human36m) \[ [Homepage](http://vision.imar.ro/human3.6m/description.php) \]
+- [CMU Panoptic](#cmu-panoptic) \[ [Homepage](http://domedb.perception.cs.cmu.edu/) \]
+
+## Human3.6M
+
+
+
+Halpe (CVPR'2020)
+ +```bibtex +@inproceedings{li2020pastanet, + title={PaStaNet: Toward Human Activity Knowledge Engine}, + author={Li, Yong-Lu and Xu, Liang and Liu, Xinpeng and Huang, Xijie and Xu, Yue and Wang, Shiyi and Fang, Hao-Shu and Ma, Ze and Chen, Mingyang and Lu, Cewu}, + booktitle={CVPR}, + year={2020} +} +``` + +
+
+
+For [Human3.6M](http://vision.imar.ro/human3.6m/description.php), please download from the official website and run the [preprocessing script](/tools/dataset/preprocess_h36m.py), which will extract camera parameters and pose annotations at full framerate (50 FPS) and downsampled framerate (10 FPS). The processed data should have the following structure:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ ├── h36m
+ ├── annotation_body3d
+ | ├── cameras.pkl
+ | ├── fps50
+ | | ├── h36m_test.npz
+ | | ├── h36m_train.npz
+ | | ├── joint2d_rel_stats.pkl
+ | | ├── joint2d_stats.pkl
+ | | ├── joint3d_rel_stats.pkl
+ | | `── joint3d_stats.pkl
+ | `── fps10
+ | ├── h36m_test.npz
+ | ├── h36m_train.npz
+ | ├── joint2d_rel_stats.pkl
+ | ├── joint2d_stats.pkl
+ | ├── joint3d_rel_stats.pkl
+ | `── joint3d_stats.pkl
+ `── images
+ ├── S1
+ | ├── S1_Directions_1.54138969
+ | | ├── S1_Directions_1.54138969_00001.jpg
+ | | ├── S1_Directions_1.54138969_00002.jpg
+ | | ├── ...
+ | ├── ...
+ ├── S5
+ ├── S6
+ ├── S7
+ ├── S8
+ ├── S9
+ `── S11
+```
+
+Please note that Human3.6M dataset is also used in the [3D_body_mesh](/docs/en/tasks/3d_body_mesh.md) task, where different schemes for data preprocessing and organizing are adopted.
+
+## CMU Panoptic
+
+Human3.6M (TPAMI'2014)
+ +```bibtex +@article{h36m_pami, + author = {Ionescu, Catalin and Papava, Dragos and Olaru, Vlad and Sminchisescu, Cristian}, + title = {Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments}, + journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence}, + publisher = {IEEE Computer Society}, + volume = {36}, + number = {7}, + pages = {1325-1339}, + month = {jul}, + year = {2014} +} +``` + +
+
+
+Please follow [voxelpose-pytorch](https://github.com/microsoft/voxelpose-pytorch) to prepare this dataset.
+
+1. Download the dataset by following the instructions in [panoptic-toolbox](https://github.com/CMU-Perceptual-Computing-Lab/panoptic-toolbox) and extract them under `$MMPOSE/data/panoptic`.
+
+2. Only download those sequences that are needed. You can also just download a subset of camera views by specifying the number of views (HD_Video_Number) and changing the camera order in `./scripts/getData.sh`. The used sequences and camera views can be found in [VoxelPose](https://arxiv.org/abs/2004.06239). Note that the sequence "160906_band3" might not be available due to errors on the server of CMU Panoptic.
+
+3. Note that we only use HD videos, calibration data, and 3D Body Keypoint in the codes. You can comment out other irrelevant codes such as downloading 3D Face data in `./scripts/getData.sh`.
+
+The directory tree should be like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ ├── panoptic
+ ├── 16060224_haggling1
+ | | ├── hdImgs
+ | | ├── hdvideos
+ | | ├── hdPose3d_stage1_coco19
+ | | ├── calibration_160224_haggling1.json
+ ├── 160226_haggling1
+ ├── ...
+```
diff --git a/vendor/ViTPose/docs/en/tasks/3d_body_mesh.md b/vendor/ViTPose/docs/en/tasks/3d_body_mesh.md
new file mode 100644
index 0000000000000000000000000000000000000000..aced63c802c20f0d7b07277393076f2e03f87afc
--- /dev/null
+++ b/vendor/ViTPose/docs/en/tasks/3d_body_mesh.md
@@ -0,0 +1,342 @@
+# 3D Body Mesh Recovery Datasets
+
+It is recommended to symlink the dataset root to `$MMPOSE/data`.
+If your folder structure is different, you may need to change the corresponding paths in config files.
+
+To achieve high-quality human mesh estimation, we use multiple datasets for training.
+The following items should be prepared for human mesh training:
+
+
+
+- [3D Body Mesh Recovery Datasets](#3d-body-mesh-recovery-datasets)
+ - [Notes](#notes)
+ - [Annotation Files for Human Mesh Estimation](#annotation-files-for-human-mesh-estimation)
+ - [SMPL Model](#smpl-model)
+ - [COCO](#coco)
+ - [Human3.6M](#human36m)
+ - [MPI-INF-3DHP](#mpi-inf-3dhp)
+ - [LSP](#lsp)
+ - [LSPET](#lspet)
+ - [CMU MoShed Data](#cmu-moshed-data)
+
+
+
+## Notes
+
+### Annotation Files for Human Mesh Estimation
+
+For human mesh estimation, we use multiple datasets for training.
+The annotation of different datasets are preprocessed to the same format. Please
+follow the [preprocess procedure](https://github.com/nkolot/SPIN/tree/master/datasets/preprocess)
+of SPIN to generate the annotation files or download the processed files from
+[here](https://download.openmmlab.com/mmpose/datasets/mesh_annotation_files.zip),
+and make it look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── mesh_annotation_files
+ ├── coco_2014_train.npz
+ ├── h36m_valid_protocol1.npz
+ ├── h36m_valid_protocol2.npz
+ ├── hr-lspet_train.npz
+ ├── lsp_dataset_original_train.npz
+ ├── mpi_inf_3dhp_train.npz
+ └── mpii_train.npz
+```
+
+### SMPL Model
+
+```bibtex
+@article{loper2015smpl,
+ title={SMPL: A skinned multi-person linear model},
+ author={Loper, Matthew and Mahmood, Naureen and Romero, Javier and Pons-Moll, Gerard and Black, Michael J},
+ journal={ACM transactions on graphics (TOG)},
+ volume={34},
+ number={6},
+ pages={1--16},
+ year={2015},
+ publisher={ACM New York, NY, USA}
+}
+```
+
+For human mesh estimation, SMPL model is used to generate the human mesh.
+Please download the [gender neutral SMPL model](http://smplify.is.tue.mpg.de/),
+[joints regressor](https://download.openmmlab.com/mmpose/datasets/joints_regressor_cmr.npy)
+and [mean parameters](https://download.openmmlab.com/mmpose/datasets/smpl_mean_params.npz)
+under `$MMPOSE/models/smpl`, and make it look like this:
+
+```text
+mmpose
+├── mmpose
+├── ...
+├── models
+ │── smpl
+ ├── joints_regressor_cmr.npy
+ ├── smpl_mean_params.npz
+ └── SMPL_NEUTRAL.pkl
+```
+
+## COCO
+
+
+
+CMU Panoptic (ICCV'2015)
+ +```bibtex +@Article = {joo_iccv_2015, +author = {Hanbyul Joo, Hao Liu, Lei Tan, Lin Gui, Bart Nabbe, Iain Matthews, Takeo Kanade, Shohei Nobuhara, and Yaser Sheikh}, +title = {Panoptic Studio: A Massively Multiview System for Social Motion Capture}, +booktitle = {ICCV}, +year = {2015} +} +``` + +
+
+
+For [COCO](http://cocodataset.org/) data, please download from [COCO download](http://cocodataset.org/#download). COCO'2014 Train is needed for human mesh estimation training.
+Download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── coco
+ │-- train2014
+ │ ├── COCO_train2014_000000000009.jpg
+ │ ├── COCO_train2014_000000000025.jpg
+ │ ├── COCO_train2014_000000000030.jpg
+ | │-- ...
+
+```
+
+## Human3.6M
+
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+For [Human3.6M](http://vision.imar.ro/human3.6m/description.php), we use the MoShed data provided in [HMR](https://github.com/akanazawa/hmr) for training.
+However, due to license limitations, we are not allowed to redistribute the MoShed data.
+
+For the evaluation on Human3.6M dataset, please follow the
+[preprocess procedure](https://github.com/nkolot/SPIN/tree/master/datasets/preprocess)
+of SPIN to extract test images from
+[Human3.6M](http://vision.imar.ro/human3.6m/description.php) original videos,
+and make it look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── Human3.6M
+ ├── images
+ ├── S11_Directions_1.54138969_000001.jpg
+ ├── S11_Directions_1.54138969_000006.jpg
+ ├── S11_Directions_1.54138969_000011.jpg
+ ├── ...
+```
+
+The download of Human3.6M dataset is quite difficult, you can also download the
+[zip file](https://drive.google.com/file/d/1WnRJD9FS3NUf7MllwgLRJJC-JgYFr8oi/view?usp=sharing)
+of the test images. However, due to the license limitations, we are not allowed to
+redistribute the images either. So the users need to download the original video and
+extract the images by themselves.
+
+## MPI-INF-3DHP
+
+
+
+```bibtex
+@inproceedings{mono-3dhp2017,
+ author = {Mehta, Dushyant and Rhodin, Helge and Casas, Dan and Fua, Pascal and Sotnychenko, Oleksandr and Xu, Weipeng and Theobalt, Christian},
+ title = {Monocular 3D Human Pose Estimation In The Wild Using Improved CNN Supervision},
+ booktitle = {3D Vision (3DV), 2017 Fifth International Conference on},
+ url = {http://gvv.mpi-inf.mpg.de/3dhp_dataset},
+ year = {2017},
+ organization={IEEE},
+ doi={10.1109/3dv.2017.00064},
+}
+```
+
+For [MPI-INF-3DHP](http://gvv.mpi-inf.mpg.de/3dhp-dataset/), please follow the
+[preprocess procedure](https://github.com/nkolot/SPIN/tree/master/datasets/preprocess)
+of SPIN to sample images, and make them like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ ├── mpi_inf_3dhp_test_set
+ │ ├── TS1
+ │ ├── TS2
+ │ ├── TS3
+ │ ├── TS4
+ │ ├── TS5
+ │ └── TS6
+ ├── S1
+ │ ├── Seq1
+ │ └── Seq2
+ ├── S2
+ │ ├── Seq1
+ │ └── Seq2
+ ├── S3
+ │ ├── Seq1
+ │ └── Seq2
+ ├── S4
+ │ ├── Seq1
+ │ └── Seq2
+ ├── S5
+ │ ├── Seq1
+ │ └── Seq2
+ ├── S6
+ │ ├── Seq1
+ │ └── Seq2
+ ├── S7
+ │ ├── Seq1
+ │ └── Seq2
+ └── S8
+ ├── Seq1
+ └── Seq2
+```
+
+## LSP
+
+
+
+```bibtex
+@inproceedings{johnson2010clustered,
+ title={Clustered Pose and Nonlinear Appearance Models for Human Pose Estimation.},
+ author={Johnson, Sam and Everingham, Mark},
+ booktitle={bmvc},
+ volume={2},
+ number={4},
+ pages={5},
+ year={2010},
+ organization={Citeseer}
+}
+```
+
+For [LSP](https://sam.johnson.io/research/lsp.html), please download the high resolution version
+[LSP dataset original](http://sam.johnson.io/research/lsp_dataset_original.zip).
+Extract them under `$MMPOSE/data`, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── lsp_dataset_original
+ ├── images
+ ├── im0001.jpg
+ ├── im0002.jpg
+ └── ...
+```
+
+## LSPET
+
+
+
+```bibtex
+@inproceedings{johnson2011learning,
+ title={Learning effective human pose estimation from inaccurate annotation},
+ author={Johnson, Sam and Everingham, Mark},
+ booktitle={CVPR 2011},
+ pages={1465--1472},
+ year={2011},
+ organization={IEEE}
+}
+```
+
+For [LSPET](https://sam.johnson.io/research/lspet.html), please download its high resolution form
+[HR-LSPET](http://datasets.d2.mpi-inf.mpg.de/hr-lspet/hr-lspet.zip).
+Extract them under `$MMPOSE/data`, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── lspet_dataset
+ ├── images
+ │ ├── im00001.jpg
+ │ ├── im00002.jpg
+ │ ├── im00003.jpg
+ │ └── ...
+ └── joints.mat
+```
+
+## CMU MoShed Data
+
+
+
+```bibtex
+@inproceedings{kanazawa2018end,
+ title={End-to-end recovery of human shape and pose},
+ author={Kanazawa, Angjoo and Black, Michael J and Jacobs, David W and Malik, Jitendra},
+ booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
+ pages={7122--7131},
+ year={2018}
+}
+```
+
+Real-world SMPL parameters are used for the adversarial training in human mesh estimation.
+The MoShed data provided in [HMR](https://github.com/akanazawa/hmr) is included in this
+[zip file](https://download.openmmlab.com/mmpose/datasets/mesh_annotation_files.zip).
+Please download and extract it under `$MMPOSE/data`, and make it look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── mesh_annotation_files
+ ├── CMU_mosh.npz
+ └── ...
+```
diff --git a/vendor/ViTPose/docs/en/tasks/3d_hand_keypoint.md b/vendor/ViTPose/docs/en/tasks/3d_hand_keypoint.md
new file mode 100644
index 0000000000000000000000000000000000000000..17537e44767a6af0ca3412054ea1b5c492a9bfff
--- /dev/null
+++ b/vendor/ViTPose/docs/en/tasks/3d_hand_keypoint.md
@@ -0,0 +1,55 @@
+# 3D Hand Keypoint Datasets
+
+It is recommended to symlink the dataset root to `$MMPOSE/data`.
+If your folder structure is different, you may need to change the corresponding paths in config files.
+
+MMPose supported datasets:
+
+- [InterHand2.6M](#interhand26m) \[ [Homepage](https://mks0601.github.io/InterHand2.6M/) \]
+
+## InterHand2.6M
+
+
+
+Human3.6M (TPAMI'2014)
+ +```bibtex +@article{h36m_pami, + author = {Ionescu, Catalin and Papava, Dragos and Olaru, Vlad and Sminchisescu, Cristian}, + title = {Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments}, + journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence}, + publisher = {IEEE Computer Society}, + volume = {36}, + number = {7}, + pages = {1325-1339}, + month = {jul}, + year = {2014} +} +``` + +
+
+
+For [InterHand2.6M](https://mks0601.github.io/InterHand2.6M/), please download from [InterHand2.6M](https://mks0601.github.io/InterHand2.6M/).
+Please download the annotation files from [annotations](https://drive.google.com/drive/folders/1pWXhdfaka-J0fSAze0MsajN0VpZ8e8tO).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── interhand2.6m
+ |── annotations
+ | |── all
+ | |── human_annot
+ | |── machine_annot
+ | |── skeleton.txt
+ | |── subject.txt
+ |
+ `── images
+ | |── train
+ | | |-- Capture0 ~ Capture26
+ | |── val
+ | | |-- Capture0
+ | |── test
+ | | |-- Capture0 ~ Capture7
+```
diff --git a/vendor/ViTPose/docs/en/tutorials/0_config.md b/vendor/ViTPose/docs/en/tutorials/0_config.md
new file mode 100644
index 0000000000000000000000000000000000000000..4ca07805a46fda3b6adc860da958eeb9f7c77cf1
--- /dev/null
+++ b/vendor/ViTPose/docs/en/tutorials/0_config.md
@@ -0,0 +1,235 @@
+# Tutorial 0: Learn about Configs
+
+We use python files as configs, incorporate modular and inheritance design into our config system, which is convenient to conduct various experiments.
+You can find all the provided configs under `$MMPose/configs`. If you wish to inspect the config file,
+you may run `python tools/analysis/print_config.py /PATH/TO/CONFIG` to see the complete config.
+
+
+
+- [Modify config through script arguments](#modify-config-through-script-arguments)
+- [Config File Naming Convention](#config-file-naming-convention)
+ - [Config System Example](#config-system-example)
+- [FAQ](#faq)
+ - [Use intermediate variables in configs](#use-intermediate-variables-in-configs)
+
+
+
+## Modify config through script arguments
+
+When submitting jobs using "tools/train.py" or "tools/test.py", you may specify `--cfg-options` to in-place modify the config.
+
+- Update config keys of dict chains.
+
+ The config options can be specified following the order of the dict keys in the original config.
+ For example, `--cfg-options model.backbone.norm_eval=False` changes the all BN modules in model backbones to `train` mode.
+
+- Update keys inside a list of configs.
+
+ Some config dicts are composed as a list in your config. For example, the training pipeline `data.train.pipeline` is normally a list
+ e.g. `[dict(type='LoadImageFromFile'), dict(type='TopDownRandomFlip', flip_prob=0.5), ...]`. If you want to change `'flip_prob=0.5'` to `'flip_prob=0.0'` in the pipeline,
+ you may specify `--cfg-options data.train.pipeline.1.flip_prob=0.0`.
+
+- Update values of list/tuples.
+
+ If the value to be updated is a list or a tuple. For example, the config file normally sets `workflow=[('train', 1)]`. If you want to
+ change this key, you may specify `--cfg-options workflow="[(train,1),(val,1)]"`. Note that the quotation mark \" is necessary to
+ support list/tuple data types, and that **NO** white space is allowed inside the quotation marks in the specified value.
+
+## Config File Naming Convention
+
+We follow the style below to name config files. Contributors are advised to follow the same style.
+
+```
+configs/{topic}/{task}/{algorithm}/{dataset}/{backbone}_[model_setting]_{dataset}_[input_size]_[technique].py
+```
+
+`{xxx}` is required field and `[yyy]` is optional.
+
+- `{topic}`: topic type, e.g. `body`, `face`, `hand`, `animal`, etc.
+- `{task}`: task type, `[2d | 3d]_[kpt | mesh]_[sview | mview]_[rgb | rgbd]_[img | vid]`. The task is categorized in 5: (1) 2D or 3D pose estimation, (2) representation type: keypoint (kpt), mesh, or DensePose (dense). (3) Single-view (sview) or multi-view (mview), (4) RGB or RGBD, and (5) Image (img) or Video (vid). e.g. `2d_kpt_sview_rgb_img`, `3d_kpt_sview_rgb_vid`, etc.
+- `{algorithm}`: algorithm type, e.g. `associative_embedding`, `deeppose`, etc.
+- `{dataset}`: dataset name, e.g. `coco`, etc.
+- `{backbone}`: backbone type, e.g. `res50` (ResNet-50), etc.
+- `[model setting]`: specific setting for some models.
+- `[input_size]`: input size of the model.
+- `[technique]`: some specific techniques, including losses, augmentation and tricks, e.g. `wingloss`, `udp`, `fp16`.
+
+### Config System
+
+- An Example of 2D Top-down Heatmap-based Human Pose Estimation
+
+ To help the users have a basic idea of a complete config structure and the modules in the config system,
+ we make brief comments on 'https://github.com/open-mmlab/mmpose/tree/e1ec589884235bee875c89102170439a991f8450/configs/top_down/resnet/coco/res50_coco_256x192.py' as the following.
+ For more detailed usage and alternative for per parameter in each module, please refer to the API documentation.
+
+ ```python
+ # runtime settings
+ log_level = 'INFO' # The level of logging
+ load_from = None # load models as a pre-trained model from a given path. This will not resume training
+ resume_from = None # Resume checkpoints from a given path, the training will be resumed from the epoch when the checkpoint's is saved
+ dist_params = dict(backend='nccl') # Parameters to setup distributed training, the port can also be set
+ workflow = [('train', 1)] # Workflow for runner. [('train', 1)] means there is only one workflow and the workflow named 'train' is executed once
+ checkpoint_config = dict( # Config to set the checkpoint hook, Refer to https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/checkpoint.py for implementation
+ interval=10) # Interval to save checkpoint
+ evaluation = dict( # Config of evaluation during training
+ interval=10, # Interval to perform evaluation
+ metric='mAP', # Metrics to be performed
+ save_best='AP') # set `AP` as key indicator to save best checkpoint
+ # optimizer
+ optimizer = dict(
+ # Config used to build optimizer, support (1). All the optimizers in PyTorch
+ # whose arguments are also the same as those in PyTorch. (2). Custom optimizers
+ # which are builed on `constructor`, referring to "tutorials/4_new_modules.md"
+ # for implementation.
+ type='Adam', # Type of optimizer, refer to https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/optimizer/default_constructor.py#L13 for more details
+ lr=5e-4, # Learning rate, see detail usages of the parameters in the documentation of PyTorch
+ )
+ optimizer_config = dict(grad_clip=None) # Do not use gradient clip
+ # learning policy
+ lr_config = dict( # Learning rate scheduler config used to register LrUpdater hook
+ policy='step', # Policy of scheduler, also support CosineAnnealing, Cyclic, etc. Refer to details of supported LrUpdater from https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/lr_updater.py#L9
+ warmup='linear', # Type of warmup used. It can be None(use no warmup), 'constant', 'linear' or 'exp'.
+ warmup_iters=500, # The number of iterations or epochs that warmup
+ warmup_ratio=0.001, # LR used at the beginning of warmup equals to warmup_ratio * initial_lr
+ step=[170, 200]) # Steps to decay the learning rate
+ total_epochs = 210 # Total epochs to train the model
+ log_config = dict( # Config to register logger hook
+ interval=50, # Interval to print the log
+ hooks=[
+ dict(type='TextLoggerHook'), # The logger used to record the training process
+ # dict(type='TensorboardLoggerHook') # The Tensorboard logger is also supported
+ ])
+
+ channel_cfg = dict(
+ num_output_channels=17, # The output channels of keypoint head
+ dataset_joints=17, # Number of joints in the dataset
+ dataset_channel=[ # Dataset supported channels
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[ # Channels to output
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+ # model settings
+ model = dict( # Config of the model
+ type='TopDown', # Type of the model
+ pretrained='torchvision://resnet50', # The url/site of the pretrained model
+ backbone=dict( # Dict for backbone
+ type='ResNet', # Name of the backbone
+ depth=50), # Depth of ResNet model
+ keypoint_head=dict( # Dict for keypoint head
+ type='TopdownHeatmapSimpleHead', # Name of keypoint head
+ in_channels=2048, # The input channels of keypoint head
+ out_channels=channel_cfg['num_output_channels'], # The output channels of keypoint head
+ loss_keypoint=dict( # Dict for keypoint loss
+ type='JointsMSELoss', # Name of keypoint loss
+ use_target_weight=True)), # Whether to consider target_weight during loss calculation
+ train_cfg=dict(), # Config of training hyper-parameters
+ test_cfg=dict( # Config of testing hyper-parameters
+ flip_test=True, # Whether to use flip-test during inference
+ post_process='default', # Use 'default' post-processing approach.
+ shift_heatmap=True, # Shift and align the flipped heatmap to achieve higher performance
+ modulate_kernel=11)) # Gaussian kernel size for modulation. Only used for "post_process='unbiased'"
+
+ data_cfg = dict(
+ image_size=[192, 256], # Size of model input resolution
+ heatmap_size=[48, 64], # Size of the output heatmap
+ num_output_channels=channel_cfg['num_output_channels'], # Number of output channels
+ num_joints=channel_cfg['dataset_joints'], # Number of joints
+ dataset_channel=channel_cfg['dataset_channel'], # Dataset supported channels
+ inference_channel=channel_cfg['inference_channel'], # Channels to output
+ soft_nms=False, # Whether to perform soft-nms during inference
+ nms_thr=1.0, # Threshold for non maximum suppression.
+ oks_thr=0.9, # Threshold of oks (object keypoint similarity) score during nms
+ vis_thr=0.2, # Threshold of keypoint visibility
+ use_gt_bbox=False, # Whether to use ground-truth bounding box during testing
+ det_bbox_thr=0.0, # Threshold of detected bounding box score. Used when 'use_gt_bbox=True'
+ bbox_file='data/coco/person_detection_results/' # Path to the bounding box detection file
+ 'COCO_val2017_detections_AP_H_56_person.json',
+ )
+
+ train_pipeline = [
+ dict(type='LoadImageFromFile'), # Loading image from file
+ dict(type='TopDownRandomFlip', # Perform random flip augmentation
+ flip_prob=0.5), # Probability of implementing flip
+ dict(
+ type='TopDownHalfBodyTransform', # Config of TopDownHalfBodyTransform data-augmentation
+ num_joints_half_body=8, # Threshold of performing half-body transform.
+ prob_half_body=0.3), # Probability of implementing half-body transform
+ dict(
+ type='TopDownGetRandomScaleRotation', # Config of TopDownGetRandomScaleRotation
+ rot_factor=40, # Rotating to ``[-2*rot_factor, 2*rot_factor]``.
+ scale_factor=0.5), # Scaling to ``[1-scale_factor, 1+scale_factor]``.
+ dict(type='TopDownAffine', # Affine transform the image to make input.
+ use_udp=False), # Do not use unbiased data processing.
+ dict(type='ToTensor'), # Convert other types to tensor type pipeline
+ dict(
+ type='NormalizeTensor', # Normalize input tensors
+ mean=[0.485, 0.456, 0.406], # Mean values of different channels to normalize
+ std=[0.229, 0.224, 0.225]), # Std values of different channels to normalize
+ dict(type='TopDownGenerateTarget', # Generate heatmap target. Different encoding types supported.
+ sigma=2), # Sigma of heatmap gaussian
+ dict(
+ type='Collect', # Collect pipeline that decides which keys in the data should be passed to the detector
+ keys=['img', 'target', 'target_weight'], # Keys of input
+ meta_keys=[ # Meta keys of input
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+ ]
+
+ val_pipeline = [
+ dict(type='LoadImageFromFile'), # Loading image from file
+ dict(type='TopDownAffine'), # Affine transform the image to make input.
+ dict(type='ToTensor'), # Config of ToTensor
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406], # Mean values of different channels to normalize
+ std=[0.229, 0.224, 0.225]), # Std values of different channels to normalize
+ dict(
+ type='Collect', # Collect pipeline that decides which keys in the data should be passed to the detector
+ keys=['img'], # Keys of input
+ meta_keys=[ # Meta keys of input
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+ ]
+
+ test_pipeline = val_pipeline
+
+ data_root = 'data/coco' # Root of the dataset
+ data = dict( # Config of data
+ samples_per_gpu=64, # Batch size of each single GPU during training
+ workers_per_gpu=2, # Workers to pre-fetch data for each single GPU
+ val_dataloader=dict(samples_per_gpu=32), # Batch size of each single GPU during validation
+ test_dataloader=dict(samples_per_gpu=32), # Batch size of each single GPU during testing
+ train=dict( # Training dataset config
+ type='TopDownCocoDataset', # Name of dataset
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json', # Path to annotation file
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline),
+ val=dict( # Validation dataset config
+ type='TopDownCocoDataset', # Name of dataset
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json', # Path to annotation file
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline),
+ test=dict( # Testing dataset config
+ type='TopDownCocoDataset', # Name of dataset
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json', # Path to annotation file
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline),
+ )
+
+ ```
+
+## FAQ
+
+### Use intermediate variables in configs
+
+Some intermediate variables are used in the config files, like `train_pipeline`/`val_pipeline`/`test_pipeline` etc.
+
+For Example, we would like to first define `train_pipeline`/`val_pipeline`/`test_pipeline` and pass them into `data`.
+Thus, `train_pipeline`/`val_pipeline`/`test_pipeline` are intermediate variable.
diff --git a/vendor/ViTPose/docs/en/tutorials/1_finetune.md b/vendor/ViTPose/docs/en/tutorials/1_finetune.md
new file mode 100644
index 0000000000000000000000000000000000000000..7f8ea097e16f58b261714e36829096848720d9b6
--- /dev/null
+++ b/vendor/ViTPose/docs/en/tutorials/1_finetune.md
@@ -0,0 +1,153 @@
+# Tutorial 1: Finetuning Models
+
+Detectors pre-trained on the COCO dataset can serve as a good pre-trained model for other datasets, e.g., COCO-WholeBody Dataset.
+This tutorial provides instruction for users to use the models provided in the [Model Zoo](https://mmpose.readthedocs.io/en/latest/modelzoo.html) for other datasets to obtain better performance.
+
+
+
+- [Outline](#outline)
+- [Modify Head](#modify-head)
+- [Modify Dataset](#modify-dataset)
+- [Modify Training Schedule](#modify-training-schedule)
+- [Use Pre-Trained Model](#use-pre-trained-model)
+
+
+
+## Outline
+
+There are two steps to finetune a model on a new dataset.
+
+- Add support for the new dataset following [Tutorial 2: Adding New Dataset](tutorials/../2_new_dataset.md).
+- Modify the configs as will be discussed in this tutorial.
+
+To finetune on the custom datasets, the users need to modify four parts in the config.
+
+## Modify Head
+
+Then the new config needs to modify the model according to the keypoint numbers of the new datasets. By only changing `out_channels` in the keypoint_head.
+For example, we have 133 keypoints for COCO-WholeBody, and we have 17 keypoints for COCO.
+
+```python
+channel_cfg = dict(
+ num_output_channels=133, # changing from 17 to 133
+ dataset_joints=133, # changing from 17 to 133
+ dataset_channel=[
+ list(range(133)), # changing from 17 to 133
+ ],
+ inference_channel=list(range(133))) # changing from 17 to 133
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'], # modify this
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='unbiased',
+ shift_heatmap=True,
+ modulate_kernel=17))
+```
+
+Note that the `pretrained='https://download.openmmlab.com/mmpose/pretrain_models/hrnet_w48-8ef0771d.pth'` setting is used for initializing backbone.
+If you are training a new model from ImageNet-pretrained weights, this is for you.
+However, this setting is not related to our task at hand. What we need is load_from, which will be discussed later.
+
+## Modify dataset
+
+The users may also need to prepare the dataset and write the configs about dataset.
+MMPose supports multiple (10+) dataset, including COCO, COCO-WholeBody and MPII-TRB.
+
+```python
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoWholeBodyDataset', # modify the name of the dataset
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json', # modify the path to the annotation file
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline),
+ val=dict(
+ type='TopDownCocoWholeBodyDataset', # modify the name of the dataset
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json', # modify the path to the annotation file
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline),
+ test=dict(
+ type='TopDownCocoWholeBodyDataset', # modify the name of the dataset
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json', # modify the path to the annotation file
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline)
+)
+```
+
+## Modify training schedule
+
+The finetuning hyperparameters vary from the default schedule. It usually requires smaller learning rate and less training epochs
+
+```python
+optimizer = dict(
+ type='Adam',
+ lr=5e-4, # reduce it
+)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200]) # reduce it
+total_epochs = 210 # reduce it
+```
+
+## Use pre-trained model
+
+Users can load a pre-trained model by setting the `load_from` field of the config to the model's path or link.
+The users might need to download the model weights before training to avoid the download time during training.
+
+```python
+# use the pre-trained model for the whole HRNet
+load_from = 'https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_384x288_dark-741844ba_20200812.pth' # model path can be found in model zoo
+```
diff --git a/vendor/ViTPose/docs/en/tutorials/2_new_dataset.md b/vendor/ViTPose/docs/en/tutorials/2_new_dataset.md
new file mode 100644
index 0000000000000000000000000000000000000000..de628b49e1fed5a3f8104563013433ab34ac6f4d
--- /dev/null
+++ b/vendor/ViTPose/docs/en/tutorials/2_new_dataset.md
@@ -0,0 +1,318 @@
+# Tutorial 2: Adding New Dataset
+
+## Customize datasets by reorganizing data to COCO format
+
+The simplest way to use the custom dataset is to convert your annotation format to COCO dataset format.
+
+The annotation json files in COCO format has the following necessary keys:
+
+```python
+'images': [
+ {
+ 'file_name': '000000001268.jpg',
+ 'height': 427,
+ 'width': 640,
+ 'id': 1268
+ },
+ ...
+],
+'annotations': [
+ {
+ 'segmentation': [[426.36,
+ ...
+ 424.34,
+ 223.3]],
+ 'keypoints': [0,0,0,
+ 0,0,0,
+ 0,0,0,
+ 427,220,2,
+ 443,222,2,
+ 414,228,2,
+ 449,232,2,
+ 408,248,1,
+ 454,261,2,
+ 0,0,0,
+ 0,0,0,
+ 411,287,2,
+ 431,287,2,
+ 0,0,0,
+ 458,265,2,
+ 0,0,0,
+ 466,300,1],
+ 'num_keypoints': 10,
+ 'area': 3894.5826,
+ 'iscrowd': 0,
+ 'image_id': 1268,
+ 'bbox': [402.34, 205.02, 65.26, 88.45],
+ 'category_id': 1,
+ 'id': 215218
+ },
+ ...
+],
+'categories': [
+ {'id': 1, 'name': 'person'},
+ ]
+```
+
+There are three necessary keys in the json file:
+
+- `images`: contains a list of images with their information like `file_name`, `height`, `width`, and `id`.
+- `annotations`: contains the list of instance annotations.
+- `categories`: contains the category name ('person') and its ID (1).
+
+## Create a custom dataset_info config file for the dataset
+
+Add a new dataset info config file.
+
+```
+configs/_base_/datasets/custom.py
+```
+
+An example of the dataset config is as follows.
+
+`keypoint_info` contains the information about each keypoint.
+
+1. `name`: the keypoint name. The keypoint name must be unique.
+2. `id`: the keypoint id.
+3. `color`: ([B, G, R]) is used for keypoint visualization.
+4. `type`: 'upper' or 'lower', will be used in data augmetation.
+5. `swap`: indicates the 'swap pair' (also known as 'flip pair'). When applying image horizontal flip, the left part will become the right part. We need to flip the keypoints accordingly.
+
+`skeleton_info` contains the information about the keypoint connectivity, which is used for visualization.
+
+`joint_weights` assigns different loss weights to different keypoints.
+
+`sigmas` is used to calculate the OKS score. Please read [keypoints-eval](https://cocodataset.org/#keypoints-eval) to learn more about it.
+
+```
+dataset_info = dict(
+ dataset_name='coco',
+ paper_info=dict(
+ author='Lin, Tsung-Yi and Maire, Michael and '
+ 'Belongie, Serge and Hays, James and '
+ 'Perona, Pietro and Ramanan, Deva and '
+ r'Doll{\'a}r, Piotr and Zitnick, C Lawrence',
+ title='Microsoft coco: Common objects in context',
+ container='European conference on computer vision',
+ year='2014',
+ homepage='http://cocodataset.org/',
+ ),
+ keypoint_info={
+ 0:
+ dict(name='nose', id=0, color=[51, 153, 255], type='upper', swap=''),
+ 1:
+ dict(
+ name='left_eye',
+ id=1,
+ color=[51, 153, 255],
+ type='upper',
+ swap='right_eye'),
+ 2:
+ dict(
+ name='right_eye',
+ id=2,
+ color=[51, 153, 255],
+ type='upper',
+ swap='left_eye'),
+ 3:
+ dict(
+ name='left_ear',
+ id=3,
+ color=[51, 153, 255],
+ type='upper',
+ swap='right_ear'),
+ 4:
+ dict(
+ name='right_ear',
+ id=4,
+ color=[51, 153, 255],
+ type='upper',
+ swap='left_ear'),
+ 5:
+ dict(
+ name='left_shoulder',
+ id=5,
+ color=[0, 255, 0],
+ type='upper',
+ swap='right_shoulder'),
+ 6:
+ dict(
+ name='right_shoulder',
+ id=6,
+ color=[255, 128, 0],
+ type='upper',
+ swap='left_shoulder'),
+ 7:
+ dict(
+ name='left_elbow',
+ id=7,
+ color=[0, 255, 0],
+ type='upper',
+ swap='right_elbow'),
+ 8:
+ dict(
+ name='right_elbow',
+ id=8,
+ color=[255, 128, 0],
+ type='upper',
+ swap='left_elbow'),
+ 9:
+ dict(
+ name='left_wrist',
+ id=9,
+ color=[0, 255, 0],
+ type='upper',
+ swap='right_wrist'),
+ 10:
+ dict(
+ name='right_wrist',
+ id=10,
+ color=[255, 128, 0],
+ type='upper',
+ swap='left_wrist'),
+ 11:
+ dict(
+ name='left_hip',
+ id=11,
+ color=[0, 255, 0],
+ type='lower',
+ swap='right_hip'),
+ 12:
+ dict(
+ name='right_hip',
+ id=12,
+ color=[255, 128, 0],
+ type='lower',
+ swap='left_hip'),
+ 13:
+ dict(
+ name='left_knee',
+ id=13,
+ color=[0, 255, 0],
+ type='lower',
+ swap='right_knee'),
+ 14:
+ dict(
+ name='right_knee',
+ id=14,
+ color=[255, 128, 0],
+ type='lower',
+ swap='left_knee'),
+ 15:
+ dict(
+ name='left_ankle',
+ id=15,
+ color=[0, 255, 0],
+ type='lower',
+ swap='right_ankle'),
+ 16:
+ dict(
+ name='right_ankle',
+ id=16,
+ color=[255, 128, 0],
+ type='lower',
+ swap='left_ankle')
+ },
+ skeleton_info={
+ 0:
+ dict(link=('left_ankle', 'left_knee'), id=0, color=[0, 255, 0]),
+ 1:
+ dict(link=('left_knee', 'left_hip'), id=1, color=[0, 255, 0]),
+ 2:
+ dict(link=('right_ankle', 'right_knee'), id=2, color=[255, 128, 0]),
+ 3:
+ dict(link=('right_knee', 'right_hip'), id=3, color=[255, 128, 0]),
+ 4:
+ dict(link=('left_hip', 'right_hip'), id=4, color=[51, 153, 255]),
+ 5:
+ dict(link=('left_shoulder', 'left_hip'), id=5, color=[51, 153, 255]),
+ 6:
+ dict(link=('right_shoulder', 'right_hip'), id=6, color=[51, 153, 255]),
+ 7:
+ dict(
+ link=('left_shoulder', 'right_shoulder'),
+ id=7,
+ color=[51, 153, 255]),
+ 8:
+ dict(link=('left_shoulder', 'left_elbow'), id=8, color=[0, 255, 0]),
+ 9:
+ dict(
+ link=('right_shoulder', 'right_elbow'), id=9, color=[255, 128, 0]),
+ 10:
+ dict(link=('left_elbow', 'left_wrist'), id=10, color=[0, 255, 0]),
+ 11:
+ dict(link=('right_elbow', 'right_wrist'), id=11, color=[255, 128, 0]),
+ 12:
+ dict(link=('left_eye', 'right_eye'), id=12, color=[51, 153, 255]),
+ 13:
+ dict(link=('nose', 'left_eye'), id=13, color=[51, 153, 255]),
+ 14:
+ dict(link=('nose', 'right_eye'), id=14, color=[51, 153, 255]),
+ 15:
+ dict(link=('left_eye', 'left_ear'), id=15, color=[51, 153, 255]),
+ 16:
+ dict(link=('right_eye', 'right_ear'), id=16, color=[51, 153, 255]),
+ 17:
+ dict(link=('left_ear', 'left_shoulder'), id=17, color=[51, 153, 255]),
+ 18:
+ dict(
+ link=('right_ear', 'right_shoulder'), id=18, color=[51, 153, 255])
+ },
+ joint_weights=[
+ 1., 1., 1., 1., 1., 1., 1., 1.2, 1.2, 1.5, 1.5, 1., 1., 1.2, 1.2, 1.5,
+ 1.5
+ ],
+ sigmas=[
+ 0.026, 0.025, 0.025, 0.035, 0.035, 0.079, 0.079, 0.072, 0.072, 0.062,
+ 0.062, 0.107, 0.107, 0.087, 0.087, 0.089, 0.089
+ ])
+```
+
+## Create a custom dataset class
+
+1. First create a package inside the mmpose/datasets/datasets folder.
+
+2. Create a class definition of your dataset in the package folder and register it in the registry with a name. Without a name, it will keep giving the error. `KeyError: 'XXXXX is not in the dataset registry'`
+
+ ```
+ @DATASETS.register_module(name='MyCustomDataset')
+ class MyCustomDataset(SomeOtherBaseClassAsPerYourNeed):
+ ```
+
+3. Make sure you have updated the `__init__.py` of your package folder
+
+4. Make sure you have updated the `__init__.py` of the dataset package folder.
+
+## Create a custom training config file
+
+Create a custom training config file as per your need and the model/architecture you want to use in the configs folder. You may modify an existing config file to use the new custom dataset.
+
+In `configs/my_custom_config.py`:
+
+```python
+...
+# dataset settings
+dataset_type = 'MyCustomDataset'
+...
+data = dict(
+ samples_per_gpu=2,
+ workers_per_gpu=2,
+ train=dict(
+ type=dataset_type,
+ ann_file='path/to/your/train/json',
+ img_prefix='path/to/your/train/img',
+ ...),
+ val=dict(
+ type=dataset_type,
+ ann_file='path/to/your/val/json',
+ img_prefix='path/to/your/val/img',
+ ...),
+ test=dict(
+ type=dataset_type,
+ ann_file='path/to/your/test/json',
+ img_prefix='path/to/your/test/img',
+ ...))
+...
+```
+
+Make sure you have provided all the paths correctly.
diff --git a/vendor/ViTPose/docs/en/tutorials/3_data_pipeline.md b/vendor/ViTPose/docs/en/tutorials/3_data_pipeline.md
new file mode 100644
index 0000000000000000000000000000000000000000..a637a8c113d4d9cb0285d88421311aba7c711e2d
--- /dev/null
+++ b/vendor/ViTPose/docs/en/tutorials/3_data_pipeline.md
@@ -0,0 +1,153 @@
+# Tutorial 3: Custom Data Pipelines
+
+## Design of Data pipelines
+
+Following typical conventions, we use `Dataset` and `DataLoader` for data loading
+with multiple workers. `Dataset` returns a dict of data items corresponding
+the arguments of models' forward method.
+Since the data in pose estimation may not be the same size (image size, gt bbox size, etc.),
+we introduce a new `DataContainer` type in MMCV to help collect and distribute
+data of different size.
+See [here](https://github.com/open-mmlab/mmcv/blob/master/mmcv/parallel/data_container.py) for more details.
+
+The data preparation pipeline and the dataset is decomposed. Usually a dataset
+defines how to process the annotations and a data pipeline defines all the steps to prepare a data dict.
+A pipeline consists of a sequence of operations. Each operation takes a dict as input and also output a dict for the next transform.
+
+The operations are categorized into data loading, pre-processing, formatting, label generating.
+
+Here is an pipeline example for Simple Baseline (ResNet50).
+
+```python
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(type='TopDownHalfBodyTransform', num_joints_half_body=8, prob_half_body=0.3),
+ dict(type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+```
+
+For each operation, we list the related dict fields that are added/updated/removed.
+
+### Data loading
+
+`LoadImageFromFile`
+
+- add: img, img_file
+
+### Pre-processing
+
+`TopDownRandomFlip`
+
+- update: img, joints_3d, joints_3d_visible, center
+
+`TopDownHalfBodyTransform`
+
+- update: center, scale
+
+`TopDownGetRandomScaleRotation`
+
+- update: scale, rotation
+
+`TopDownAffine`
+
+- update: img, joints_3d, joints_3d_visible
+
+`NormalizeTensor`
+
+- update: img
+
+### Generating labels
+
+`TopDownGenerateTarget`
+
+- add: target, target_weight
+
+### Formatting
+
+`ToTensor`
+
+- update: 'img'
+
+`Collect`
+
+- add: img_meta (the keys of img_meta is specified by `meta_keys`)
+- remove: all other keys except for those specified by `keys`
+
+## Extend and use custom pipelines
+
+1. Write a new pipeline in any file, e.g., `my_pipeline.py`. It takes a dict as input and return a dict.
+
+ ```python
+ from mmpose.datasets import PIPELINES
+
+ @PIPELINES.register_module()
+ class MyTransform:
+
+ def __call__(self, results):
+ results['dummy'] = True
+ return results
+ ```
+
+1. Import the new class.
+
+ ```python
+ from .my_pipeline import MyTransform
+ ```
+
+1. Use it in config files.
+
+ ```python
+ train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(type='TopDownHalfBodyTransform', num_joints_half_body=8, prob_half_body=0.3),
+ dict(type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='MyTransform'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+ ]
+ ```
diff --git a/vendor/ViTPose/docs/en/tutorials/4_new_modules.md b/vendor/ViTPose/docs/en/tutorials/4_new_modules.md
new file mode 100644
index 0000000000000000000000000000000000000000..e1864b21e1b93667c5c0aa6ae5c8f03dd69e94f7
--- /dev/null
+++ b/vendor/ViTPose/docs/en/tutorials/4_new_modules.md
@@ -0,0 +1,213 @@
+# Tutorial 4: Adding New Modules
+
+## Customize optimizer
+
+A customized optimizer could be defined as following.
+Assume you want to add a optimizer named as `MyOptimizer`, which has arguments `a`, `b`, and `c`.
+You need to first implement the new optimizer in a file, e.g., in `mmpose/core/optimizer/my_optimizer.py`:
+
+```python
+from mmcv.runner import OPTIMIZERS
+from torch.optim import Optimizer
+
+
+@OPTIMIZERS.register_module()
+class MyOptimizer(Optimizer):
+
+ def __init__(self, a, b, c)
+
+```
+
+Then add this module in `mmpose/core/optimizer/__init__.py` thus the registry will
+find the new module and add it:
+
+```python
+from .my_optimizer import MyOptimizer
+```
+
+Then you can use `MyOptimizer` in `optimizer` field of config files.
+In the configs, the optimizers are defined by the field `optimizer` like the following:
+
+```python
+optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
+```
+
+To use your own optimizer, the field can be changed as
+
+```python
+optimizer = dict(type='MyOptimizer', a=a_value, b=b_value, c=c_value)
+```
+
+We already support to use all the optimizers implemented by PyTorch, and the only modification is to change the `optimizer` field of config files.
+For example, if you want to use `ADAM`, though the performance will drop a lot, the modification could be as the following.
+
+```python
+optimizer = dict(type='Adam', lr=0.0003, weight_decay=0.0001)
+```
+
+The users can directly set arguments following the [API doc](https://pytorch.org/docs/stable/optim.html?highlight=optim#module-torch.optim) of PyTorch.
+
+## Customize optimizer constructor
+
+Some models may have some parameter-specific settings for optimization, e.g. weight decay for BatchNorm layers.
+The users can do those fine-grained parameter tuning through customizing optimizer constructor.
+
+```
+from mmcv.utils import build_from_cfg
+
+from mmcv.runner import OPTIMIZER_BUILDERS, OPTIMIZERS
+from mmpose.utils import get_root_logger
+from .cocktail_optimizer import CocktailOptimizer
+
+
+@OPTIMIZER_BUILDERS.register_module()
+class CocktailOptimizerConstructor:
+
+ def __init__(self, optimizer_cfg, paramwise_cfg=None):
+
+ def __call__(self, model):
+
+ return my_optimizer
+
+```
+
+### Develop new components
+
+We basically categorize model components into 3 types.
+
+- detectors: the whole pose detector model pipeline, usually contains a backbone and keypoint_head.
+- backbone: usually an FCN network to extract feature maps, e.g., ResNet, HRNet.
+- keypoint_head: the component for pose estimation task, usually contains some deconv layers.
+
+1. Create a new file `mmpose/models/backbones/my_model.py`.
+
+```python
+import torch.nn as nn
+
+from ..builder import BACKBONES
+
+@BACKBONES.register_module()
+class MyModel(nn.Module):
+
+ def __init__(self, arg1, arg2):
+ pass
+
+ def forward(self, x): # should return a tuple
+ pass
+
+ def init_weights(self, pretrained=None):
+ pass
+```
+
+2. Import the module in `mmpose/models/backbones/__init__.py`.
+
+```python
+from .my_model import MyModel
+```
+
+3. Create a new file `mmpose/models/keypoint_heads/my_head.py`.
+
+You can write a new keypoint head inherit from `nn.Module`,
+and overwrite `init_weights(self)` and `forward(self, x)` method.
+
+```python
+from ..builder import HEADS
+
+
+@HEADS.register_module()
+class MyHead(nn.Module):
+
+ def __init__(self, arg1, arg2):
+ pass
+
+ def forward(self, x):
+ pass
+
+ def init_weights(self):
+ pass
+```
+
+4. Import the module in `mmpose/models/keypoint_heads/__init__.py`
+
+```python
+from .my_head import MyHead
+```
+
+5. Use it in your config file.
+
+For the top-down 2D pose estimation model, we set the module type as `TopDown`.
+
+```python
+model = dict(
+ type='TopDown',
+ backbone=dict(
+ type='MyModel',
+ arg1=xxx,
+ arg2=xxx),
+ keypoint_head=dict(
+ type='MyHead',
+ arg1=xxx,
+ arg2=xxx))
+```
+
+### Add new loss
+
+Assume you want to add a new loss as `MyLoss`, for keypoints estimation.
+To add a new loss function, the users need implement it in `mmpose/models/losses/my_loss.py`.
+The decorator `weighted_loss` enable the loss to be weighted for each element.
+
+```python
+import torch
+import torch.nn as nn
+
+from mmpose.models import LOSSES
+
+def my_loss(pred, target):
+ assert pred.size() == target.size() and target.numel() > 0
+ loss = torch.abs(pred - target)
+ loss = torch.mean(loss)
+ return loss
+
+@LOSSES.register_module()
+class MyLoss(nn.Module):
+
+ def __init__(self, use_target_weight=False):
+ super(MyLoss, self).__init__()
+ self.criterion = my_loss()
+ self.use_target_weight = use_target_weight
+
+ def forward(self, output, target, target_weight):
+ batch_size = output.size(0)
+ num_joints = output.size(1)
+
+ heatmaps_pred = output.reshape(
+ (batch_size, num_joints, -1)).split(1, 1)
+ heatmaps_gt = target.reshape((batch_size, num_joints, -1)).split(1, 1)
+
+ loss = 0.
+
+ for idx in range(num_joints):
+ heatmap_pred = heatmaps_pred[idx].squeeze(1)
+ heatmap_gt = heatmaps_gt[idx].squeeze(1)
+ if self.use_target_weight:
+ loss += self.criterion(
+ heatmap_pred * target_weight[:, idx],
+ heatmap_gt * target_weight[:, idx])
+ else:
+ loss += self.criterion(heatmap_pred, heatmap_gt)
+
+ return loss / num_joints
+```
+
+Then the users need to add it in the `mmpose/models/losses/__init__.py`.
+
+```python
+from .my_loss import MyLoss, my_loss
+
+```
+
+To use it, modify the `loss_keypoint` field in the model.
+
+```python
+loss_keypoint=dict(type='MyLoss', use_target_weight=False)
+```
diff --git a/vendor/ViTPose/docs/en/tutorials/5_export_model.md b/vendor/ViTPose/docs/en/tutorials/5_export_model.md
new file mode 100644
index 0000000000000000000000000000000000000000..14d76100a4a3c17d9c82476c83279c2d02c958ce
--- /dev/null
+++ b/vendor/ViTPose/docs/en/tutorials/5_export_model.md
@@ -0,0 +1,48 @@
+# Tutorial 5: Exporting a model to ONNX
+
+Open Neural Network Exchange [(ONNX)](https://onnx.ai/) is an open ecosystem that empowers AI developers to choose the right tools as their project evolves.
+
+
+
+- [Supported Models](#supported-models)
+- [Usage](#usage)
+ - [Prerequisite](#prerequisite)
+
+
+
+## Supported Models
+
+So far, our codebase supports onnx exporting from pytorch models trained with MMPose. The supported models include:
+
+- ResNet
+- HRNet
+- HigherHRNet
+
+## Usage
+
+For simple exporting, you can use the [script](/tools/pytorch2onnx.py) here. Note that the package `onnx` and `onnxruntime` are required for verification after exporting.
+
+### Prerequisite
+
+First, install onnx.
+
+```shell
+pip install onnx onnxruntime
+```
+
+We provide a python script to export the pytorch model trained by MMPose to ONNX.
+
+```shell
+python tools/deployment/pytorch2onnx.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [--shape ${SHAPE}] \
+ [--verify] [--show] [--output-file ${OUTPUT_FILE}] [--opset-version ${VERSION}]
+```
+
+Optional arguments:
+
+- `--shape`: The shape of input tensor to the model. If not specified, it will be set to `1 3 256 192`.
+- `--verify`: Determines whether to verify the exported model, runnably and numerically. If not specified, it will be set to `False`.
+- `--show`: Determines whether to print the architecture of the exported model. If not specified, it will be set to `False`.
+- `--output-file`: The output onnx model name. If not specified, it will be set to `tmp.onnx`.
+- `--opset-version`: Determines the operation set version of onnx, we recommend you to use a higher version such as 11 for compatibility. If not specified, it will be set to `11`.
+
+Please fire an issue if you discover any checkpoints that are not perfectly exported or suffer some loss in accuracy.
diff --git a/vendor/ViTPose/docs/en/tutorials/6_customize_runtime.md b/vendor/ViTPose/docs/en/tutorials/6_customize_runtime.md
new file mode 100644
index 0000000000000000000000000000000000000000..2803cd5c70577875db80fc3c91426682d2429bf0
--- /dev/null
+++ b/vendor/ViTPose/docs/en/tutorials/6_customize_runtime.md
@@ -0,0 +1,352 @@
+# Tutorial 6: Customize Runtime Settings
+
+In this tutorial, we will introduce some methods about how to customize optimization methods, training schedules, workflow and hooks when running your own settings for the project.
+
+
+
+- [Customize Optimization Methods](#customize-optimization-methods)
+ - [Customize optimizer supported by PyTorch](#customize-optimizer-supported-by-pytorch)
+ - [Customize self-implemented optimizer](#customize-self-implemented-optimizer)
+ - [1. Define a new optimizer](#1-define-a-new-optimizer)
+ - [2. Add the optimizer to registry](#2-add-the-optimizer-to-registry)
+ - [3. Specify the optimizer in the config file](#3-specify-the-optimizer-in-the-config-file)
+ - [Customize optimizer constructor](#customize-optimizer-constructor)
+ - [Additional settings](#additional-settings)
+- [Customize Training Schedules](#customize-training-schedules)
+- [Customize Workflow](#customize-workflow)
+- [Customize Hooks](#customize-hooks)
+ - [Customize self-implemented hooks](#customize-self-implemented-hooks)
+ - [1. Implement a new hook](#1-implement-a-new-hook)
+ - [2. Register the new hook](#2-register-the-new-hook)
+ - [3. Modify the config](#3-modify-the-config)
+ - [Use hooks implemented in MMCV](#use-hooks-implemented-in-mmcv)
+ - [Modify default runtime hooks](#modify-default-runtime-hooks)
+ - [Checkpoint config](#checkpoint-config)
+ - [Log config](#log-config)
+ - [Evaluation config](#evaluation-config)
+
+
+
+## Customize Optimization Methods
+
+### Customize optimizer supported by PyTorch
+
+We already support to use all the optimizers implemented by PyTorch, and the only modification is to change the `optimizer` field of config files.
+For example, if you want to use `Adam`, the modification could be as the following.
+
+```python
+optimizer = dict(type='Adam', lr=0.0003, weight_decay=0.0001)
+```
+
+To modify the learning rate of the model, the users only need to modify the `lr` in the config of optimizer.
+The users can directly set arguments following the [API doc](https://pytorch.org/docs/stable/optim.html?highlight=optim#module-torch.optim) of PyTorch.
+
+For example, if you want to use `Adam` with the setting like `torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)` in PyTorch,
+the modification could be set as the following.
+
+```python
+optimizer = dict(type='Adam', lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)
+```
+
+### Customize self-implemented optimizer
+
+#### 1. Define a new optimizer
+
+A customized optimizer could be defined as following.
+
+Assume you want to add an optimizer named `MyOptimizer`, which has arguments `a`, `b`, and `c`.
+You need to create a new directory named `mmpose/core/optimizer`.
+And then implement the new optimizer in a file, e.g., in `mmpose/core/optimizer/my_optimizer.py`:
+
+```python
+from .builder import OPTIMIZERS
+from torch.optim import Optimizer
+
+
+@OPTIMIZERS.register_module()
+class MyOptimizer(Optimizer):
+
+ def __init__(self, a, b, c):
+
+```
+
+#### 2. Add the optimizer to registry
+
+To find the above module defined above, this module should be imported into the main namespace at first. There are two ways to achieve it.
+
+- Modify `mmpose/core/optimizer/__init__.py` to import it.
+
+ The newly defined module should be imported in `mmpose/core/optimizer/__init__.py` so that the registry will
+ find the new module and add it:
+
+```python
+from .my_optimizer import MyOptimizer
+```
+
+- Use `custom_imports` in the config to manually import it
+
+```python
+custom_imports = dict(imports=['mmpose.core.optimizer.my_optimizer'], allow_failed_imports=False)
+```
+
+The module `mmpose.core.optimizer.my_optimizer` will be imported at the beginning of the program and the class `MyOptimizer` is then automatically registered.
+Note that only the package containing the class `MyOptimizer` should be imported. `mmpose.core.optimizer.my_optimizer.MyOptimizer` **cannot** be imported directly.
+
+#### 3. Specify the optimizer in the config file
+
+Then you can use `MyOptimizer` in `optimizer` field of config files.
+In the configs, the optimizers are defined by the field `optimizer` like the following:
+
+```python
+optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
+```
+
+To use your own optimizer, the field can be changed to
+
+```python
+optimizer = dict(type='MyOptimizer', a=a_value, b=b_value, c=c_value)
+```
+
+### Customize optimizer constructor
+
+Some models may have some parameter-specific settings for optimization, e.g. weight decay for BatchNorm layers.
+The users can do those fine-grained parameter tuning through customizing optimizer constructor.
+
+```python
+from mmcv.utils import build_from_cfg
+
+from mmcv.runner.optimizer import OPTIMIZER_BUILDERS, OPTIMIZERS
+from mmpose.utils import get_root_logger
+from .my_optimizer import MyOptimizer
+
+
+@OPTIMIZER_BUILDERS.register_module()
+class MyOptimizerConstructor:
+
+ def __init__(self, optimizer_cfg, paramwise_cfg=None):
+ pass
+
+ def __call__(self, model):
+
+ return my_optimizer
+```
+
+The default optimizer constructor is implemented [here](https://github.com/open-mmlab/mmcv/blob/9ecd6b0d5ff9d2172c49a182eaa669e9f27bb8e7/mmcv/runner/optimizer/default_constructor.py#L11),
+which could also serve as a template for new optimizer constructor.
+
+### Additional settings
+
+Tricks not implemented by the optimizer should be implemented through optimizer constructor (e.g., set parameter-wise learning rates) or hooks.
+We list some common settings that could stabilize the training or accelerate the training. Feel free to create PR, issue for more settings.
+
+- __Use gradient clip to stabilize training__:
+ Some models need gradient clip to clip the gradients to stabilize the training process. An example is as below:
+
+ ```python
+ optimizer_config = dict(grad_clip=dict(max_norm=35, norm_type=2))
+ ```
+
+- __Use momentum schedule to accelerate model convergence__:
+ We support momentum scheduler to modify model's momentum according to learning rate, which could make the model converge in a faster way.
+ Momentum scheduler is usually used with LR scheduler, for example, the following config is used in 3D detection to accelerate convergence.
+ For more details, please refer to the implementation of [CyclicLrUpdater](https://github.com/open-mmlab/mmcv/blob/f48241a65aebfe07db122e9db320c31b685dc674/mmcv/runner/hooks/lr_updater.py#L327)
+ and [CyclicMomentumUpdater](https://github.com/open-mmlab/mmcv/blob/f48241a65aebfe07db122e9db320c31b685dc674/mmcv/runner/hooks/momentum_updater.py#L130).
+
+ ```python
+ lr_config = dict(
+ policy='cyclic',
+ target_ratio=(10, 1e-4),
+ cyclic_times=1,
+ step_ratio_up=0.4,
+ )
+ momentum_config = dict(
+ policy='cyclic',
+ target_ratio=(0.85 / 0.95, 1),
+ cyclic_times=1,
+ step_ratio_up=0.4,
+ )
+ ```
+
+## Customize Training Schedules
+
+we use step learning rate with default value in config files, this calls [`StepLRHook`](https://github.com/open-mmlab/mmcv/blob/f48241a65aebfe07db122e9db320c31b685dc674/mmcv/runner/hooks/lr_updater.py#L153) in MMCV.
+We support many other learning rate schedule [here](https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/lr_updater.py), such as `CosineAnnealing` and `Poly` schedule. Here are some examples
+
+- Poly schedule:
+
+ ```python
+ lr_config = dict(policy='poly', power=0.9, min_lr=1e-4, by_epoch=False)
+ ```
+
+- ConsineAnnealing schedule:
+
+ ```python
+ lr_config = dict(
+ policy='CosineAnnealing',
+ warmup='linear',
+ warmup_iters=1000,
+ warmup_ratio=1.0 / 10,
+ min_lr_ratio=1e-5)
+ ```
+
+## Customize Workflow
+
+By default, we recommend users to use `EpochEvalHook` to do evaluation after training epoch, but they can still use `val` workflow as an alternative.
+
+Workflow is a list of (phase, epochs) to specify the running order and epochs. By default it is set to be
+
+```python
+workflow = [('train', 1)]
+```
+
+which means running 1 epoch for training.
+Sometimes user may want to check some metrics (e.g. loss, accuracy) about the model on the validate set.
+In such case, we can set the workflow as
+
+```python
+[('train', 1), ('val', 1)]
+```
+
+so that 1 epoch for training and 1 epoch for validation will be run iteratively.
+
+```{note}
+1. The parameters of model will not be updated during val epoch.
+1. Keyword `total_epochs` in the config only controls the number of training epochs and will not affect the validation workflow.
+1. Workflows `[('train', 1), ('val', 1)]` and `[('train', 1)]` will not change the behavior of `EpochEvalHook` because `EpochEvalHook` is called by `after_train_epoch` and validation workflow only affect hooks that are called through `after_val_epoch`.
+ Therefore, the only difference between `[('train', 1), ('val', 1)]` and `[('train', 1)]` is that the runner will calculate losses on validation set after each training epoch.
+```
+
+## Customize Hooks
+
+### Customize self-implemented hooks
+
+#### 1. Implement a new hook
+
+Here we give an example of creating a new hook in MMPose and using it in training.
+
+```python
+from mmcv.runner import HOOKS, Hook
+
+
+@HOOKS.register_module()
+class MyHook(Hook):
+
+ def __init__(self, a, b):
+ pass
+
+ def before_run(self, runner):
+ pass
+
+ def after_run(self, runner):
+ pass
+
+ def before_epoch(self, runner):
+ pass
+
+ def after_epoch(self, runner):
+ pass
+
+ def before_iter(self, runner):
+ pass
+
+ def after_iter(self, runner):
+ pass
+```
+
+Depending on the functionality of the hook, the users need to specify what the hook will do at each stage of the training in `before_run`, `after_run`, `before_epoch`, `after_epoch`, `before_iter`, and `after_iter`.
+
+#### 2. Register the new hook
+
+Then we need to make `MyHook` imported. Assuming the file is in `mmpose/core/utils/my_hook.py` there are two ways to do that:
+
+- Modify `mmpose/core/utils/__init__.py` to import it.
+
+ The newly defined module should be imported in `mmpose/core/utils/__init__.py` so that the registry will
+ find the new module and add it:
+
+```python
+from .my_hook import MyHook
+```
+
+- Use `custom_imports` in the config to manually import it
+
+```python
+custom_imports = dict(imports=['mmpose.core.utils.my_hook'], allow_failed_imports=False)
+```
+
+#### 3. Modify the config
+
+```python
+custom_hooks = [
+ dict(type='MyHook', a=a_value, b=b_value)
+]
+```
+
+You can also set the priority of the hook by adding key `priority` to `'NORMAL'` or `'HIGHEST'` as below
+
+```python
+custom_hooks = [
+ dict(type='MyHook', a=a_value, b=b_value, priority='NORMAL')
+]
+```
+
+By default the hook's priority is set as `NORMAL` during registration.
+
+### Use hooks implemented in MMCV
+
+If the hook is already implemented in MMCV, you can directly modify the config to use the hook as below
+
+```python
+mmcv_hooks = [
+ dict(type='MMCVHook', a=a_value, b=b_value, priority='NORMAL')
+]
+```
+
+### Modify default runtime hooks
+
+There are some common hooks that are not registered through `custom_hooks` but has been registered by default when importing MMCV, they are
+
+- log_config
+- checkpoint_config
+- evaluation
+- lr_config
+- optimizer_config
+- momentum_config
+
+In those hooks, only the logger hook has the `VERY_LOW` priority, others' priority are `NORMAL`.
+The above-mentioned tutorials already cover how to modify `optimizer_config`, `momentum_config`, and `lr_config`.
+Here we reveals how what we can do with `log_config`, `checkpoint_config`, and `evaluation`.
+
+#### Checkpoint config
+
+The MMCV runner will use `checkpoint_config` to initialize [`CheckpointHook`](https://github.com/open-mmlab/mmcv/blob/9ecd6b0d5ff9d2172c49a182eaa669e9f27bb8e7/mmcv/runner/hooks/checkpoint.py#L9).
+
+```python
+checkpoint_config = dict(interval=1)
+```
+
+The users could set `max_keep_ckpts` to only save only small number of checkpoints or decide whether to store state dict of optimizer by `save_optimizer`.
+More details of the arguments are [here](https://mmcv.readthedocs.io/en/latest/api.html#mmcv.runner.CheckpointHook)
+
+#### Log config
+
+The `log_config` wraps multiple logger hooks and enables to set intervals. Now MMCV supports `WandbLoggerHook`, `MlflowLoggerHook`, and `TensorboardLoggerHook`.
+The detail usages can be found in the [doc](https://mmcv.readthedocs.io/en/latest/api.html#mmcv.runner.LoggerHook).
+
+```python
+log_config = dict(
+ interval=50,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ dict(type='TensorboardLoggerHook')
+ ])
+```
+
+#### Evaluation config
+
+The config of `evaluation` will be used to initialize the [`EvalHook`](https://github.com/open-mmlab/mmpose/blob/master/mmpose/core/evaluation/eval_hooks.py#L11).
+Except the key `interval`, other arguments such as `metric` will be passed to the `dataset.evaluate()`
+
+```python
+evaluation = dict(interval=1, metric='mAP')
+```
diff --git a/vendor/ViTPose/docs/en/useful_tools.md b/vendor/ViTPose/docs/en/useful_tools.md
new file mode 100644
index 0000000000000000000000000000000000000000..a9d246dfdec0318f437b7faf03cf26144f22bcba
--- /dev/null
+++ b/vendor/ViTPose/docs/en/useful_tools.md
@@ -0,0 +1,232 @@
+# Useful Tools
+
+Apart from training/testing scripts, We provide lots of useful tools under the `tools/` directory.
+
+
+
+- [Log Analysis](#log-analysis)
+- [Model Complexity (experimental)](#model-complexity-experimental)
+- [Model Conversion](#model-conversion)
+ - [MMPose model to ONNX (experimental)](#mmpose-model-to-onnx-experimental)
+ - [Prepare a model for publishing](#prepare-a-model-for-publishing)
+- [Model Serving](#model-serving)
+- [Miscellaneous](#miscellaneous)
+ - [Evaluating a metric](#evaluating-a-metric)
+ - [Print the entire config](#print-the-entire-config)
+
+
+
+## Log Analysis
+
+`tools/analysis/analyze_logs.py` plots loss/pose acc curves given a training log file. Run `pip install seaborn` first to install the dependency.
+
+
+
+```shell
+python tools/analysis/analyze_logs.py plot_curve ${JSON_LOGS} [--keys ${KEYS}] [--title ${TITLE}] [--legend ${LEGEND}] [--backend ${BACKEND}] [--style ${STYLE}] [--out ${OUT_FILE}]
+```
+
+Examples:
+
+- Plot the mse loss of some run.
+
+ ```shell
+ python tools/analysis/analyze_logs.py plot_curve log.json --keys loss --legend loss
+ ```
+
+- Plot the acc of some run, and save the figure to a pdf.
+
+ ```shell
+ python tools/analysis/analyze_logs.py plot_curve log.json --keys acc_pose --out results.pdf
+ ```
+
+- Compare the acc of two runs in the same figure.
+
+ ```shell
+ python tools/analysis/analyze_logs.py plot_curve log1.json log2.json --keys acc_pose --legend run1 run2
+ ```
+
+You can also compute the average training speed.
+
+```shell
+python tools/analysis/analyze_logs.py cal_train_time ${JSON_LOGS} [--include-outliers]
+```
+
+- Compute the average training speed for a config file
+
+ ```shell
+ python tools/analysis/analyze_logs.py cal_train_time log.json
+ ```
+
+ The output is expected to be like the following.
+
+ ```text
+ -----Analyze train time of log.json-----
+ slowest epoch 114, average time is 0.9662
+ fastest epoch 16, average time is 0.7532
+ time std over epochs is 0.0426
+ average iter time: 0.8406 s/iter
+ ```
+
+## Model Complexity (Experimental)
+
+`/tools/analysis/get_flops.py` is a script adapted from [flops-counter.pytorch](https://github.com/sovrasov/flops-counter.pytorch) to compute the FLOPs and params of a given model.
+
+```shell
+python tools/analysis/get_flops.py ${CONFIG_FILE} [--shape ${INPUT_SHAPE}]
+```
+
+We will get the result like this
+
+```text
+
+==============================
+Input shape: (1, 3, 256, 192)
+Flops: 8.9 GMac
+Params: 28.04 M
+==============================
+```
+
+```{note}
+This tool is still experimental and we do not guarantee that the number is absolutely correct.
+```
+
+You may use the result for simple comparisons, but double check it before you adopt it in technical reports or papers.
+
+(1) FLOPs are related to the input shape while parameters are not. The default input shape is (1, 3, 340, 256) for 2D recognizer, (1, 3, 32, 340, 256) for 3D recognizer.
+(2) Some operators are not counted into FLOPs like GN and custom operators. Refer to [`mmcv.cnn.get_model_complexity_info()`](https://github.com/open-mmlab/mmcv/blob/master/mmcv/cnn/utils/flops_counter.py) for details.
+
+## Model Conversion
+
+### MMPose model to ONNX (experimental)
+
+`/tools/deployment/pytorch2onnx.py` is a script to convert model to [ONNX](https://github.com/onnx/onnx) format.
+It also supports comparing the output results between Pytorch and ONNX model for verification.
+Run `pip install onnx onnxruntime` first to install the dependency.
+
+```shell
+python tools/deployment/pytorch2onnx.py $CONFIG_PATH $CHECKPOINT_PATH --shape $SHAPE --verify
+```
+
+### Prepare a model for publishing
+
+`tools/publish_model.py` helps users to prepare their model for publishing.
+
+Before you upload a model to AWS, you may want to:
+
+(1) convert model weights to CPU tensors.
+(2) delete the optimizer states.
+(3) compute the hash of the checkpoint file and append the hash id to the filename.
+
+```shell
+python tools/publish_model.py ${INPUT_FILENAME} ${OUTPUT_FILENAME}
+```
+
+E.g.,
+
+```shell
+python tools/publish_model.py work_dirs/hrnet_w32_coco_256x192/latest.pth hrnet_w32_coco_256x192
+```
+
+The final output filename will be `hrnet_w32_coco_256x192-{hash id}_{time_stamp}.pth`.
+
+## Model Serving
+
+MMPose supports model serving with [`TorchServe`](https://pytorch.org/serve/). You can serve an MMPose model via following steps:
+
+### 1. Install TorchServe
+
+Please follow the official installation guide of TorchServe: https://github.com/pytorch/serve#install-torchserve-and-torch-model-archiver
+
+### 2. Convert model from MMPose to TorchServe
+
+```shell
+python tools/deployment/mmpose2torchserve.py \
+ ${CONFIG_FILE} ${CHECKPOINT_FILE} \
+ --output-folder ${MODEL_STORE} \
+ --model-name ${MODEL_NAME}
+```
+
+**Note**: ${MODEL_STORE} needs to be an absolute path to a folder.
+
+A model file `${MODEL_NAME}.mar` will be generated and placed in the `${MODEL_STORE}` folder.
+
+### 3. Deploy model serving
+
+We introduce following 2 approaches to deploying the model serving.
+
+#### Use TorchServe API
+
+```shell
+torchserve --start \
+ --model-store ${MODEL_STORE} \
+ --models ${MODEL_PATH1} [${MODEL_NAME}=${MODEL_PATH2} ... ]
+```
+
+Example:
+
+```shell
+# serve one model
+torchserve --start --model-store /models --models hrnet=hrnet.mar
+
+# serve all models in model-store
+torchserve --start --model-store /models --models all
+```
+
+After executing the `torchserve` command above, TorchServe runse on your host, listening for inference requests. Check the [official docs](https://github.com/pytorch/serve/blob/master/docs/server.md) for more information.
+
+#### Use `mmpose-serve` docker image
+
+**Build `mmpose-serve` docker image:**
+
+```shell
+docker build -t mmpose-serve:latest docker/serve/
+```
+
+**Run `mmpose-serve`:**
+
+Check the official docs for [running TorchServe with docker](https://github.com/pytorch/serve/blob/master/docker/README.md#running-torchserve-in-a-production-docker-environment).
+
+In order to run in GPU, you need to install [nvidia-docker](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html). You can omit the `--gpus` argument in order to run in CPU.
+
+Example:
+
+```shell
+docker run --rm \
+--cpus 8 \
+--gpus device=0 \
+-p8080:8080 -p8081:8081 -p8082:8082 \
+--mount type=bind,source=$MODEL_STORE,target=/home/model-server/model-store \
+mmpose-serve:latest
+```
+
+[Read the docs](https://github.com/pytorch/serve/blob/072f5d088cce9bb64b2a18af065886c9b01b317b/docs/rest_api.md/) about the Inference (8080), Management (8081) and Metrics (8082) APis
+
+### 4. Test deployment
+
+You can use `tools/deployment/test_torchserver.py` to test the model serving. It will compare and visualize the result of torchserver and pytorch.
+
+```shell
+python tools/deployment/test_torchserver.py ${IMAGE_PAHT} ${CONFIG_PATH} ${CHECKPOINT_PATH} ${MODEL_NAME} --out-dir ${OUT_DIR}
+```
+
+Example:
+
+```shell
+python tools/deployment/test_torchserver.py \
+ ls tests/data/coco/000000000785.jpg \
+ configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_256x192.py \
+ https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth \
+ hrnet \
+ --out-dir vis_results
+```
+
+## Miscellaneous
+
+### Print the entire config
+
+`tools/analysis/print_config.py` prints the whole config verbatim, expanding all its imports.
+
+```shell
+python tools/print_config.py ${CONFIG} [-h] [--options ${OPTIONS [OPTIONS...]}]
+```
diff --git a/vendor/ViTPose/docs/zh_cn/Makefile b/vendor/ViTPose/docs/zh_cn/Makefile
new file mode 100644
index 0000000000000000000000000000000000000000..d4bb2cbb9eddb1bb1b4f366623044af8e4830919
--- /dev/null
+++ b/vendor/ViTPose/docs/zh_cn/Makefile
@@ -0,0 +1,20 @@
+# Minimal makefile for Sphinx documentation
+#
+
+# You can set these variables from the command line, and also
+# from the environment for the first two.
+SPHINXOPTS ?=
+SPHINXBUILD ?= sphinx-build
+SOURCEDIR = .
+BUILDDIR = _build
+
+# Put it first so that "make" without argument is like "make help".
+help:
+ @$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
+
+.PHONY: help Makefile
+
+# Catch-all target: route all unknown targets to Sphinx using the new
+# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
+%: Makefile
+ @$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
diff --git a/vendor/ViTPose/docs/zh_cn/_static/css/readthedocs.css b/vendor/ViTPose/docs/zh_cn/_static/css/readthedocs.css
new file mode 100644
index 0000000000000000000000000000000000000000..efc4b986a5348c645842a135883d4713986a7169
--- /dev/null
+++ b/vendor/ViTPose/docs/zh_cn/_static/css/readthedocs.css
@@ -0,0 +1,6 @@
+.header-logo {
+ background-image: url("../images/mmpose-logo.png");
+ background-size: 120px 50px;
+ height: 50px;
+ width: 120px;
+}
diff --git a/vendor/ViTPose/docs/zh_cn/_static/images/mmpose-logo.png b/vendor/ViTPose/docs/zh_cn/_static/images/mmpose-logo.png
new file mode 100644
index 0000000000000000000000000000000000000000..128e1714f0933d0dfe0ab82d6f8780c48e0edc21
Binary files /dev/null and b/vendor/ViTPose/docs/zh_cn/_static/images/mmpose-logo.png differ
diff --git a/vendor/ViTPose/docs/zh_cn/api.rst b/vendor/ViTPose/docs/zh_cn/api.rst
new file mode 100644
index 0000000000000000000000000000000000000000..2856891b9f115e076e76a48c03fafe787a8f0ec4
--- /dev/null
+++ b/vendor/ViTPose/docs/zh_cn/api.rst
@@ -0,0 +1,109 @@
+mmpose.apis
+-------------
+.. automodule:: mmpose.apis
+ :members:
+
+
+mmpose.core
+-------------
+evaluation
+^^^^^^^^^^^
+.. automodule:: mmpose.core.evaluation
+ :members:
+
+fp16
+^^^^^^^^^^^
+.. automodule:: mmpose.core.fp16
+ :members:
+
+
+utils
+^^^^^^^^^^^
+.. automodule:: mmpose.core.utils
+ :members:
+
+
+post_processing
+^^^^^^^^^^^^^^^^
+.. automodule:: mmpose.core.post_processing
+ :members:
+
+
+mmpose.models
+---------------
+backbones
+^^^^^^^^^^^
+.. automodule:: mmpose.models.backbones
+ :members:
+
+necks
+^^^^^^^^^^^
+.. automodule:: mmpose.models.necks
+ :members:
+
+detectors
+^^^^^^^^^^^
+.. automodule:: mmpose.models.detectors
+ :members:
+
+heads
+^^^^^^^^^^^^^^^
+.. automodule:: mmpose.models.heads
+ :members:
+
+losses
+^^^^^^^^^^^
+.. automodule:: mmpose.models.losses
+ :members:
+
+misc
+^^^^^^^^^^^
+.. automodule:: mmpose.models.misc
+ :members:
+
+mmpose.datasets
+-----------------
+.. automodule:: mmpose.datasets
+ :members:
+
+datasets
+^^^^^^^^^^^
+.. automodule:: mmpose.datasets.datasets.top_down
+ :members:
+
+.. automodule:: mmpose.datasets.datasets.bottom_up
+ :members:
+
+pipelines
+^^^^^^^^^^^
+.. automodule:: mmpose.datasets.pipelines
+ :members:
+
+.. automodule:: mmpose.datasets.pipelines.loading
+ :members:
+
+.. automodule:: mmpose.datasets.pipelines.shared_transform
+ :members:
+
+.. automodule:: mmpose.datasets.pipelines.top_down_transform
+ :members:
+
+.. automodule:: mmpose.datasets.pipelines.bottom_up_transform
+ :members:
+
+.. automodule:: mmpose.datasets.pipelines.mesh_transform
+ :members:
+
+.. automodule:: mmpose.datasets.pipelines.pose3d_transform
+ :members:
+
+samplers
+^^^^^^^^^^^
+.. automodule:: mmpose.datasets.samplers
+ :members:
+
+
+mmpose.utils
+---------------
+.. automodule:: mmpose.utils
+ :members:
diff --git a/vendor/ViTPose/docs/zh_cn/benchmark.md b/vendor/ViTPose/docs/zh_cn/benchmark.md
new file mode 100644
index 0000000000000000000000000000000000000000..0de8844a4aab8ea06ab353c3a8e7b40a6767d840
--- /dev/null
+++ b/vendor/ViTPose/docs/zh_cn/benchmark.md
@@ -0,0 +1,3 @@
+# 基准测试
+
+内容建设中……
diff --git a/vendor/ViTPose/docs/zh_cn/collect.py b/vendor/ViTPose/docs/zh_cn/collect.py
new file mode 100644
index 0000000000000000000000000000000000000000..5f8aedee0616d0bcf61d325feeced3738d524218
--- /dev/null
+++ b/vendor/ViTPose/docs/zh_cn/collect.py
@@ -0,0 +1,101 @@
+#!/usr/bin/env python
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import re
+from glob import glob
+
+from titlecase import titlecase
+
+os.makedirs('topics', exist_ok=True)
+os.makedirs('papers', exist_ok=True)
+
+# Step 1: get subtopics: a mix of topic and task
+minisections = [
+ x.split('/')[-2:] for x in glob('../../configs/*/*') if '_base_' not in x
+]
+alltopics = sorted(list(set(x[0] for x in minisections)))
+subtopics = []
+for t in alltopics:
+ data = [x[1].split('_') for x in minisections if x[0] == t]
+ valid_ids = []
+ for i in range(len(data[0])):
+ if len(set(x[i] for x in data)) > 1:
+ valid_ids.append(i)
+ if len(valid_ids) > 0:
+ subtopics.extend([
+ f"{titlecase(t)}({','.join([d[i].title() for i in valid_ids])})",
+ t, '_'.join(d)
+ ] for d in data)
+ else:
+ subtopics.append([titlecase(t), t, '_'.join(data[0])])
+
+contents = {}
+for subtopic, topic, task in sorted(subtopics):
+ # Step 2: get all datasets
+ datasets = sorted(
+ list(
+ set(
+ x.split('/')[-2]
+ for x in glob(f'../../configs/{topic}/{task}/*/*/'))))
+ contents[subtopic] = {d: {} for d in datasets}
+ for dataset in datasets:
+ # Step 3: get all settings: algorithm + backbone + trick
+ for file in glob(f'../../configs/{topic}/{task}/*/{dataset}/*.md'):
+ keywords = (file.split('/')[-3],
+ *file.split('/')[-1].split('_')[:-1])
+ with open(file, 'r') as f:
+ contents[subtopic][dataset][keywords] = f.read()
+
+# Step 4: write files by topic
+for subtopic, datasets in contents.items():
+ lines = [f'# {subtopic}', '']
+ for dataset, keywords in datasets.items():
+ if len(keywords) == 0:
+ continue
+ lines += [
+ 'InterHand2.6M (ECCV'2020)
+ +```bibtex +@InProceedings{Moon_2020_ECCV_InterHand2.6M, +author = {Moon, Gyeongsik and Yu, Shoou-I and Wen, He and Shiratori, Takaaki and Lee, Kyoung Mu}, +title = {InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image}, +booktitle = {European Conference on Computer Vision (ECCV)}, +year = {2020} +} +``` + +', '
', '', f'## {titlecase(dataset)} Dataset', '' + ] + for keyword, info in keywords.items(): + keyword_strs = [titlecase(x.replace('_', ' ')) for x in keyword] + lines += [ + '
', '', + (f'### {" + ".join(keyword_strs)}' + f' on {titlecase(dataset)}'), '', info, '' + ] + + with open(f'topics/{subtopic.lower()}.md', 'w') as f: + f.write('\n'.join(lines)) + +# Step 5: write files by paper +allfiles = [x.split('/')[-2:] for x in glob('../en/papers/*/*.md')] +sections = sorted(list(set(x[0] for x in allfiles))) +for section in sections: + lines = [f'# {titlecase(section)}', ''] + files = [f for s, f in allfiles if s == section] + for file in files: + with open(f'../en/papers/{section}/{file}', 'r') as f: + keyline = [ + line for line in f.readlines() if line.startswith('
', '', + (f'### {" + ".join(keyword_strs)}' + f' on {titlecase(dataset)}'), '', info, '' + ] + if len(paperlines) > 0: + lines += ['
', '
', '', f'## {papername}', ''] + lines += paperlines + + with open(f'papers/{section}.md', 'w') as f: + f.write('\n'.join(lines)) diff --git a/vendor/ViTPose/docs/zh_cn/conf.py b/vendor/ViTPose/docs/zh_cn/conf.py new file mode 100644 index 0000000000000000000000000000000000000000..991325547d5ddded70c65bca7fc00bd02ba3bcdb --- /dev/null +++ b/vendor/ViTPose/docs/zh_cn/conf.py @@ -0,0 +1,112 @@ +# Copyright (c) OpenMMLab. All rights reserved. +# Configuration file for the Sphinx documentation builder. +# +# This file only contains a selection of the most common options. For a full +# list see the documentation: +# https://www.sphinx-doc.org/en/master/usage/configuration.html + +# -- Path setup -------------------------------------------------------------- + +# If extensions (or modules to document with autodoc) are in another directory, +# add these directories to sys.path here. If the directory is relative to the +# documentation root, use os.path.abspath to make it absolute, like shown here. +# +import os +import subprocess +import sys + +import pytorch_sphinx_theme + +sys.path.insert(0, os.path.abspath('../..')) + +# -- Project information ----------------------------------------------------- + +project = 'MMPose' +copyright = '2020-2021, OpenMMLab' +author = 'MMPose Authors' + +# The full version, including alpha/beta/rc tags +version_file = '../../mmpose/version.py' + + +def get_version(): + with open(version_file, 'r') as f: + exec(compile(f.read(), version_file, 'exec')) + return locals()['__version__'] + + +release = get_version() + +# -- General configuration --------------------------------------------------- + +# Add any Sphinx extension module names here, as strings. They can be +# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom +# ones. +extensions = [ + 'sphinx.ext.autodoc', 'sphinx.ext.napoleon', 'sphinx.ext.viewcode', + 'sphinx_markdown_tables', 'sphinx_copybutton', 'myst_parser' +] + +autodoc_mock_imports = ['json_tricks', 'mmpose.version'] + +# Ignore >>> when copying code +copybutton_prompt_text = r'>>> |\.\.\. ' +copybutton_prompt_is_regexp = True + +# Add any paths that contain templates here, relative to this directory. +templates_path = ['_templates'] + +# List of patterns, relative to source directory, that match files and +# directories to ignore when looking for source files. +# This pattern also affects html_static_path and html_extra_path. +exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store'] + +# -- Options for HTML output ------------------------------------------------- +source_suffix = { + '.rst': 'restructuredtext', + '.md': 'markdown', +} + +# The theme to use for HTML and HTML Help pages. See the documentation for +# a list of builtin themes. +# +html_theme = 'pytorch_sphinx_theme' +html_theme_path = [pytorch_sphinx_theme.get_html_theme_path()] +html_theme_options = { + 'menu': [{ + 'name': + '教程', + 'url': + 'https://colab.research.google.com/github/' + 'open-mmlab/mmpose/blob/master/demo/MMPose_Tutorial.ipynb' + }, { + 'name': 'GitHub', + 'url': 'https://github.com/open-mmlab/mmpose' + }], + 'menu_lang': + 'cn' +} + +# Add any paths that contain custom static files (such as style sheets) here, +# relative to this directory. They are copied after the builtin static files, +# so a file named "default.css" will overwrite the builtin "default.css". + +language = 'zh_CN' + +html_static_path = ['_static'] +html_css_files = ['css/readthedocs.css'] + +# Enable ::: for my_st +myst_enable_extensions = ['colon_fence'] + +master_doc = 'index' + + +def builder_inited_handler(app): + subprocess.run(['./collect.py']) + subprocess.run(['./merge_docs.sh']) + subprocess.run(['./stats.py']) + + +def setup(app): + app.connect('builder-inited', builder_inited_handler) diff --git a/vendor/ViTPose/docs/zh_cn/data_preparation.md b/vendor/ViTPose/docs/zh_cn/data_preparation.md new file mode 100644 index 0000000000000000000000000000000000000000..ee91f6f1f596377c0a4fff7a00ffe3e0492c61b7 --- /dev/null +++ b/vendor/ViTPose/docs/zh_cn/data_preparation.md @@ -0,0 +1,13 @@ +# 准备数据集 + +MMPose支持多种姿态估计任务,对应的数据集准备方法请参考下列文档。 + +- [2D人体关键点](tasks/2d_body_keypoint.md) +- [3D人体关键点](tasks/3d_body_keypoint.md) +- [3D人体网格模型](tasks/3d_body_mesh.md) +- [2D手部关键点](tasks/2d_hand_keypoint.md) +- [3D手部关键点](tasks/3d_hand_keypoint.md) +- [2D人脸关键点](tasks/2d_face_keypoint.md) +- [2D全身人体关键点](tasks/2d_wholebody_keypoint.md) +- [2D服装关键点](tasks/2d_fashion_landmark.md) +- [2D动物关键点](tasks/2d_animal_keypoint.md) diff --git a/vendor/ViTPose/docs/zh_cn/faq.md b/vendor/ViTPose/docs/zh_cn/faq.md new file mode 100644 index 0000000000000000000000000000000000000000..0bb8e6cf161eed3f7e9d71cd301ee0d4a84114bc --- /dev/null +++ b/vendor/ViTPose/docs/zh_cn/faq.md @@ -0,0 +1,3 @@ +# 常见问题 + +内容建设中…… diff --git a/vendor/ViTPose/docs/zh_cn/getting_started.md b/vendor/ViTPose/docs/zh_cn/getting_started.md new file mode 100644 index 0000000000000000000000000000000000000000..c8b1b26050272b3faf7042dbaf2959bc09fb16e4 --- /dev/null +++ b/vendor/ViTPose/docs/zh_cn/getting_started.md @@ -0,0 +1,270 @@ +# 基础教程 + +本文档提供 MMPose 的基础使用教程。请先参阅 [安装指南](install.md),进行 MMPose 的安装。 + + + +- [准备数据集](#准备数据集) +- [使用预训练模型进行推理](#使用预训练模型进行推理) + - [测试某个数据集](#测试某个数据集) + - [运行演示](#运行演示) +- [如何训练模型](#如何训练模型) + - [使用单个 GPU 训练](#使用单个-GPU-训练) + - [使用 CPU 训练](#使用-CPU-训练) + - [使用多个 GPU 训练](#使用多个-GPU-训练) + - [使用多台机器训练](#使用多台机器训练) + - [使用单台机器启动多个任务](#使用单台机器启动多个任务) +- [基准测试](#基准测试) +- [进阶教程](#进阶教程) + + + +## 准备数据集 + +MMPose 支持各种不同的任务。请根据需要,查阅对应的数据集准备教程。 + +- [2D 人体关键点检测](/docs/zh_cn/tasks/2d_body_keypoint.md) +- [3D 人体关键点检测](/docs/zh_cn/tasks/3d_body_keypoint.md) +- [3D 人体形状恢复](/docs/zh_cn/tasks/3d_body_mesh.md) +- [2D 人手关键点检测](/docs/zh_cn/tasks/2d_hand_keypoint.md) +- [3D 人手关键点检测](/docs/zh_cn/tasks/3d_hand_keypoint.md) +- [2D 人脸关键点检测](/docs/zh_cn/tasks/2d_face_keypoint.md) +- [2D 全身人体关键点检测](/docs/zh_cn/tasks/2d_wholebody_keypoint.md) +- [2D 服饰关键点检测](/docs/zh_cn/tasks/2d_fashion_landmark.md) +- [2D 动物关键点检测](/docs/zh_cn/tasks/2d_animal_keypoint.md) + +## 使用预训练模型进行推理 + +MMPose 提供了一些测试脚本用于测试数据集上的指标(如 COCO, MPII 等), +并提供了一些高级 API,使您可以轻松使用 MMPose。 + +### 测试某个数据集 + +- [x] 单 GPU 测试 +- [x] CPU 测试 +- [x] 单节点多 GPU 测试 +- [x] 多节点测试 + +用户可使用以下命令测试数据集 + +```shell +# 单 GPU 测试 +python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [--out ${RESULT_FILE}] [--fuse-conv-bn] \ + [--eval ${EVAL_METRICS}] [--gpu_collect] [--tmpdir ${TMPDIR}] [--cfg-options ${CFG_OPTIONS}] \ + [--launcher ${JOB_LAUNCHER}] [--local_rank ${LOCAL_RANK}] + +# CPU 测试:禁用 GPU 并运行测试脚本 +export CUDA_VISIBLE_DEVICES=-1 +python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [--out ${RESULT_FILE}] \ + [--eval ${EVAL_METRICS}] + +# 多 GPU 测试 +./tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [--out ${RESULT_FILE}] [--eval ${EVAL_METRICS}] \ + [--gpu-collect] [--tmpdir ${TMPDIR}] [--options ${OPTIONS}] [--average-clips ${AVG_TYPE}] \ + [--launcher ${JOB_LAUNCHER}] [--local_rank ${LOCAL_RANK}] +``` + +此处的 `CHECKPOINT_FILE` 可以是本地的模型权重文件的路径,也可以是模型的下载链接。 + +可选参数: + +- `RESULT_FILE`:输出结果文件名。如果没有被指定,则不会保存测试结果。 +- `--fuse-conv-bn`: 是否融合 BN 和 Conv 层。该操作会略微提升模型推理速度。 +- `EVAL_METRICS`:测试指标。其可选值与对应数据集相关,如 `mAP`,适用于 COCO 等数据集,`PCK` `AUC` `EPE` 适用于 OneHand10K 等数据集等。 +- `--gpu-collect`:如果被指定,姿态估计结果将会通过 GPU 通信进行收集。否则,它将被存储到不同 GPU 上的 `TMPDIR` 文件夹中,并在 rank 0 的进程中被收集。 +- `TMPDIR`:用于存储不同进程收集的结果文件的临时文件夹。该变量仅当 `--gpu-collect` 没有被指定时有效。 +- `CFG_OPTIONS`:覆盖配置文件中的一些实验设置。比如,可以设置'--cfg-options model.backbone.depth=18 model.backbone.with_cp=True',在线修改配置文件内容。 +- `JOB_LAUNCHER`:分布式任务初始化启动器选项。可选值有 `none`,`pytorch`,`slurm`,`mpi`。特别地,如果被设置为 `none`, 则会以非分布式模式进行测试。 +- `LOCAL_RANK`:本地 rank 的 ID。如果没有被指定,则会被设置为 0。 + +例子: + +假定用户将下载的模型权重文件放置在 `checkpoints/` 目录下。 + +1. 在 COCO 数据集下测试 ResNet50(不存储测试结果为文件),并验证 `mAP` 指标 + + ```shell + ./tools/dist_test.sh configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_256x192.py \ + checkpoints/SOME_CHECKPOINT.pth 1 \ + --eval mAP + ``` + +1. 使用 8 块 GPU 在 COCO 数据集下测试 ResNet。在线下载模型权重,并验证 `mAP` 指标。 + + ```shell + ./tools/dist_test.sh configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_256x192.py \ + https://download.openmmlab.com/mmpose/top_down/resnet/res50_coco_256x192-ec54d7f3_20200709.pth 8 \ + --eval mAP + ``` + +1. 在 slurm 分布式环境中测试 ResNet50 在 COCO 数据集下的 `mAP` 指标 + + ```shell + ./tools/slurm_test.sh slurm_partition test_job \ + configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_256x192.py \ + checkpoints/SOME_CHECKPOINT.pth \ + --eval mAP + ``` + +### 运行演示 + +我们提供了丰富的脚本,方便大家快速运行演示。 +下面是 多人人体姿态估计 的演示示例,此处我们使用了人工标注的人体框作为输入。 + +```shell +python demo/top_down_img_demo.py \ + ${MMPOSE_CONFIG_FILE} ${MMPOSE_CHECKPOINT_FILE} \ + --img-root ${IMG_ROOT} --json-file ${JSON_FILE} \ + --out-img-root ${OUTPUT_DIR} \ + [--show --device ${GPU_ID}] \ + [--kpt-thr ${KPT_SCORE_THR}] +``` + +例子: + +```shell +python demo/top_down_img_demo.py \ + configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_256x192.py \ + https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth \ + --img-root tests/data/coco/ --json-file tests/data/coco/test_coco.json \ + --out-img-root vis_results +``` + +更多实例和细节可以查看 [demo文件夹](/demo) 和 [demo文档](https://mmpose.readthedocs.io/en/latest/demo.html)。 + +## 如何训练模型 + +MMPose 使用 `MMDistributedDataParallel` 进行分布式训练,使用 `MMDataParallel` 进行非分布式训练。 + +对于单机多卡与多台机器的情况,MMPose 使用分布式训练。假设服务器有 8 块 GPU,则会启动 8 个进程,并且每台 GPU 对应一个进程。 + +每个进程拥有一个独立的模型,以及对应的数据加载器和优化器。 +模型参数同步只发生于最开始。之后,每经过一次前向与后向计算,所有 GPU 中梯度都执行一次 allreduce 操作,而后优化器将更新模型参数。 +由于梯度执行了 allreduce 操作,因此不同 GPU 中模型参数将保持一致。 + +### 训练配置 + +所有的输出(日志文件和模型权重文件)会被将保存到工作目录下。工作目录通过配置文件中的参数 `work_dir` 指定。 + +默认情况下,MMPose 在每轮训练轮后会在验证集上评估模型,可以通过在训练配置中修改 `interval` 参数来更改评估间隔 + +```python +evaluation = dict(interval=5) # 每 5 轮训练进行一次模型评估 +``` + +根据 [Linear Scaling Rule](https://arxiv.org/abs/1706.02677),当 GPU 数量或每个 GPU 上的视频批大小改变时,用户可根据批大小按比例地调整学习率,如,当 4 GPUs x 2 video/gpu 时,lr=0.01;当 16 GPUs x 4 video/gpu 时,lr=0.08。 + +### 使用单个 GPU 训练 + +```shell +python tools/train.py ${CONFIG_FILE} [optional arguments] +``` + +如果用户想在命令中指定工作目录,则需要增加参数 `--work-dir ${YOUR_WORK_DIR}` + +### 使用 CPU 训练 + +使用 CPU 训练的流程和使用单 GPU 训练的流程一致,我们仅需要在训练流程开始前禁用 GPU。 + +```shell +export CUDA_VISIBLE_DEVICES=-1 +``` + +之后运行单 GPU 训练脚本即可。 + +**注意**: + +我们不推荐用户使用 CPU 进行训练,这太过缓慢。我们支持这个功能是为了方便用户在没有 GPU 的机器上进行调试。 + +### 使用多个 GPU 训练 + +```shell +./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [optional arguments] +``` + +可选参数为: + +- `--work-dir ${WORK_DIR}`:覆盖配置文件中指定的工作目录。 +- `--resume-from ${CHECKPOINT_FILE}`:从以前的模型权重文件恢复训练。 +- `--no-validate`: 在训练过程中,不进行验证。 +- `--gpus ${GPU_NUM}`:使用的 GPU 数量,仅适用于非分布式训练。 +- `--gpu-ids ${GPU_IDS}`:使用的 GPU ID,仅适用于非分布式训练。 +- `--seed ${SEED}`:设置 python,numpy 和 pytorch 里的种子 ID,已用于生成随机数。 +- `--deterministic`:如果被指定,程序将设置 CUDNN 后端的确定化选项。 +- `--cfg-options CFG_OPTIONS`:覆盖配置文件中的一些实验设置。比如,可以设置'--cfg-options model.backbone.depth=18 model.backbone.with_cp=True',在线修改配置文件内容。 +- `--launcher ${JOB_LAUNCHER}`:分布式任务初始化启动器选项。可选值有 `none`,`pytorch`,`slurm`,`mpi`。特别地,如果被设置为 `none`, 则会以非分布式模式进行测试。 +- `--autoscale-lr`:根据 [Linear Scaling Rule](https://arxiv.org/abs/1706.02677),当 GPU 数量或每个 GPU 上的视频批大小改变时,用户可根据批大小按比例地调整学习率。 +- `LOCAL_RANK`:本地 rank 的 ID。如果没有被指定,则会被设置为 0。 + +`resume-from` 和 `load-from` 的区别: +`resume-from` 加载模型参数和优化器状态,并且保留检查点所在的训练轮数,常被用于恢复意外被中断的训练。 +`load-from` 只加载模型参数,但训练轮数从 0 开始计数,常被用于微调模型。 + +这里提供一个使用 8 块 GPU 加载 ResNet50 模型权重文件的例子。 + +```shell +./tools/dist_train.sh configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_256x192.py 8 --resume_from work_dirs/res50_coco_256x192/latest.pth +``` + +### 使用多台机器训练 + +如果用户在 [slurm](https://slurm.schedmd.com/) 集群上运行 MMPose,可使用 `slurm_train.sh` 脚本。(该脚本也支持单台机器上训练) + +```shell +[GPUS=${GPUS}] ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} [--work-dir ${WORK_DIR}] +``` + +这里给出一个在 slurm 集群上的 dev 分区使用 16 块 GPU 训练 ResNet50 的例子。 +使用 `GPUS_PER_NODE=8` 参数来指定一个有 8 块 GPUS 的 slurm 集群节点,使用 `CPUS_PER_TASK=2` 来指定每个任务拥有2块cpu。 + +```shell +GPUS=16 GPUS_PER_NODE=8 CPUS_PER_TASK=2 ./tools/slurm_train.sh Test res50 configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_256x192.py work_dirs/res50_coco_256x192 +``` + +用户可以查看 [slurm_train.sh](/tools/slurm_train.sh) 文件来检查完整的参数和环境变量。 + +如果用户的多台机器通过 Ethernet 连接,则可以参考 pytorch [launch utility](https://pytorch.org/docs/en/stable/distributed.html#launch-utility)。如果用户没有高速网络,如 InfiniBand,速度将会非常慢。 + +### 使用单台机器启动多个任务 + +如果用使用单台机器启动多个任务,如在有 8 块 GPU 的单台机器上启动 2 个需要 4 块 GPU 的训练任务,则需要为每个任务指定不同端口,以避免通信冲突。 + +如果用户使用 `dist_train.sh` 脚本启动训练任务,则可以通过以下命令指定端口 + +```shell +CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 ./tools/dist_train.sh ${CONFIG_FILE} 4 +CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 ./tools/dist_train.sh ${CONFIG_FILE} 4 +``` + +如果用户在 slurm 集群下启动多个训练任务,则需要修改配置文件(通常是配置文件的第 4 行)中的 `dist_params` 变量,以设置不同的通信端口。 + +在 `config1.py` 中, + +```python +dist_params = dict(backend='nccl', port=29500) +``` + +在 `config2.py` 中, + +```python +dist_params = dict(backend='nccl', port=29501) +``` + +之后便可启动两个任务,分别对应 `config1.py` 和 `config2.py`。 + +```shell +CUDA_VISIBLE_DEVICES=0,1,2,3 GPUS=4 ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config1.py [--work-dir ${WORK_DIR}] +CUDA_VISIBLE_DEVICES=4,5,6,7 GPUS=4 ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config2.py [--work-dir ${WORK_DIR}] +``` + +## 进阶教程 + +目前, MMPose 提供了以下更详细的教程: + +- [如何编写配置文件](tutorials/0_config.md) +- [如何微调模型](tutorials/1_finetune.md) +- [如何增加新数据集](tutorials/2_new_dataset.md) +- [如何设计数据处理流程](tutorials/3_data_pipeline.md) +- [如何增加新模块](tutorials/4_new_modules.md) +- [如何导出模型为 onnx 格式](tutorials/5_export_model.md) +- [如何自定义模型运行参数](tutorials/6_customize_runtime.md) diff --git a/vendor/ViTPose/docs/zh_cn/index.rst b/vendor/ViTPose/docs/zh_cn/index.rst new file mode 100644 index 0000000000000000000000000000000000000000..e51f885cb7238f034c13c8da23c194e26a8a7263 --- /dev/null +++ b/vendor/ViTPose/docs/zh_cn/index.rst @@ -0,0 +1,97 @@ +欢迎来到 MMPose 中文文档! +================================== + +您可以在页面左下角切换文档语言。 + +You can change the documentation language at the lower-left corner of the page. + +.. toctree:: + :maxdepth: 2 + + install.md + getting_started.md + demo.md + benchmark.md + inference_speed_summary.md + +.. toctree:: + :maxdepth: 2 + :caption: 数据集 + + datasets.md + tasks/2d_body_keypoint.md + tasks/2d_wholebody_keypoint.md + tasks/2d_face_keypoint.md + tasks/2d_hand_keypoint.md + tasks/2d_fashion_landmark.md + tasks/2d_animal_keypoint.md + tasks/3d_body_keypoint.md + tasks/3d_body_mesh.md + tasks/3d_hand_keypoint.md + +.. toctree:: + :maxdepth: 2 + :caption: 模型池 + + modelzoo.md + topics/animal.md + topics/body(2d,kpt,sview,img).md + topics/body(2d,kpt,sview,vid).md + topics/body(3d,kpt,sview,img).md + topics/body(3d,kpt,sview,vid).md + topics/body(3d,kpt,mview,img).md + topics/body(3d,mesh,sview,img).md + topics/face.md + topics/fashion.md + topics/hand(2d).md + topics/hand(3d).md + topics/wholebody.md + +.. toctree:: + :maxdepth: 2 + :caption: 模型池(按论文整理) + + papers/algorithms.md + papers/backbones.md + papers/datasets.md + papers/techniques.md + +.. toctree:: + :maxdepth: 2 + :caption: 教程 + + tutorials/0_config.md + tutorials/1_finetune.md + tutorials/2_new_dataset.md + tutorials/3_data_pipeline.md + tutorials/4_new_modules.md + tutorials/5_export_model.md + tutorials/6_customize_runtime.md + +.. toctree:: + :maxdepth: 2 + :caption: 常用工具 + + useful_tools.md + +.. toctree:: + :maxdepth: 2 + :caption: Notes + + faq.md + +.. toctree:: + :caption: API文档 + + api.rst + +.. toctree:: + :caption: 语言 + + Language.md + +Indices and tables +================== + +* :ref:`genindex` +* :ref:`search` diff --git a/vendor/ViTPose/docs/zh_cn/inference_speed_summary.md b/vendor/ViTPose/docs/zh_cn/inference_speed_summary.md new file mode 100644 index 0000000000000000000000000000000000000000..f5a23fc6127c18e157374337612549f23ada592c --- /dev/null +++ b/vendor/ViTPose/docs/zh_cn/inference_speed_summary.md @@ -0,0 +1,114 @@ +# 推理速度总结 + +这里总结了 MMPose 中主要模型的复杂度信息和推理速度,包括模型的计算复杂度、参数数量,以及以不同的批处理大小在 CPU 和 GPU 上的推理速度。还比较了不同模型在 COCO 人体关键点数据集上的全类别平均正确率,展示了模型性能和模型复杂度之间的折中。 + +## 比较规则 + +为了保证比较的公平性,在相同的硬件和软件环境下使用相同的数据集进行了比较实验。还列出了模型在 COCO 人体关键点数据集上的全类别平均正确率以及相应的配置文件。 + +对于模型复杂度信息,计算具有相应输入形状的模型的浮点数运算次数和参数数量。请注意,当前某些网络层或算子还未支持,如 `DeformConv2d` ,因此您可能需要检查是否所有操作都已支持,并验证浮点数运算次数和参数数量的计算是否正确。 + +对于推理速度,忽略了数据预处理的时间,只测量模型前向计算和数据后处理的时间。对于每个模型设置,保持相同的数据预处理方法,以确保相同的特征输入。分别测量了在 CPU 和 GPU 设备上的推理速度。对于自上而下的热图模型,我们还测试了批处理量较大(例如,10)情况,以测试拥挤场景下的模型性能。 + +推断速度是用每秒处理的帧数 (FPS) 来衡量的,即每秒模型的平均迭代次数,它可以显示模型处理输入的速度。这个数值越高,表示推理速度越快,模型性能越好。 + +### 硬件 + +- GPU: GeForce GTX 1660 SUPER +- CPU: Intel(R) Core(TM) i7-8700 CPU @ 3.20GHz + +### 软件环境 + +- Ubuntu 16.04 +- Python 3.8 +- PyTorch 1.10 +- CUDA 10.2 +- mmcv-full 1.3.17 +- mmpose 0.20.0 + +## MMPose 中主要模型的复杂度信息和推理速度总结 + +| Algorithm | Model | config | Input size | mAP | Flops (GFLOPs) | Params (M) | GPU Inference Speed
(FPS)1 | GPU Inference Speed
(FPS, bs=10)2 | CPU Inference Speed
(FPS) | CPU Inference Speed
(FPS, bs=10) | +| :--- | :---------------: | :-----------------: |:--------------------: | :----------------------------: | :-----------------: | :---------------: |:--------------------: | :----------------------------: | :-----------------: | :-----------------: | +| topdown_heatmap | Alexnet | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/alexnet_coco_256x192.py) | (3, 192, 256) | 0.397 | 1.42 | 5.62 | 229.21 ± 16.91 | 33.52 ± 1.14 | 13.92 ± 0.60 | 1.38 ± 0.02 | +| topdown_heatmap | CPM | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/cpm_coco_256x192.py) | (3, 192, 256) | 0.623 | 63.81 | 31.3 | 11.35 ± 0.22 | 3.87 ± 0.07 | 0.31 ± 0.01 | 0.03 ± 0.00 | +| topdown_heatmap | CPM | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/cpm_coco_384x288.py) | (3, 288, 384) | 0.65 | 143.57 | 31.3 | 7.09 ± 0.14 | 2.10 ± 0.05 | 0.14 ± 0.00 | 0.01 ± 0.00 | +| topdown_heatmap | Hourglass-52 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hourglass52_coco_256x256.py) | (3, 256, 256) | 0.726 | 28.67 | 94.85 | 25.50 ± 1.68 | 3.99 ± 0.07 | 0.92 ± 0.03 | 0.09 ± 0.00 | +| topdown_heatmap | Hourglass-52 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hourglass52_coco_384x384.py) | (3, 384, 384) | 0.746 | 64.5 | 94.85 | 14.74 ± 0.8 | 1.86 ± 0.06 | 0.43 ± 0.03 | 0.04 ± 0.00 | +| topdown_heatmap | HRNet-W32 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_256x192.py) | (3, 192, 256) | 0.746 | 7.7 | 28.54 | 22.73 ± 1.12 | 6.60 ± 0.14 | 2.73 ± 0.11 | 0.32 ± 0.00 | +| topdown_heatmap | HRNet-W32 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_384x288.py) | (3, 288, 384) | 0.76 | 17.33 | 28.54 | 22.78 ± 1.21 | 3.28 ± 0.08 | 1.35 ± 0.05 | 0.14 ± 0.00 | +| topdown_heatmap | HRNet-W48 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_256x192.py) | (3, 192, 256) | 0.756 | 15.77 | 63.6 | 22.01 ± 1.10 | 3.74 ± 0.10 | 1.46 ± 0.05 | 0.16 ± 0.00 | +| topdown_heatmap | HRNet-W48 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_384x288.py) | (3, 288, 384) | 0.767 | 35.48 | 63.6 | 15.03 ± 1.03 | 1.80 ± 0.03 | 0.68 ± 0.02 | 0.07 ± 0.00 | +| topdown_heatmap | LiteHRNet-30 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/litehrnet_30_coco_256x192.py) | (3, 192, 256) | 0.675 | 0.42 | 1.76 | 11.86 ± 0.38 | 9.77 ± 0.23 | 5.84 ± 0.39 | 0.80 ± 0.00 | +| topdown_heatmap | LiteHRNet-30 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/litehrnet_30_coco_384x288.py) | (3, 288, 384) | 0.7 | 0.95 | 1.76 | 11.52 ± 0.39 | 5.18 ± 0.11 | 3.45 ± 0.22 | 0.37 ± 0.00 | +| topdown_heatmap | MobilenetV2 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/mobilenetv2_coco_256x192.py) | (3, 192, 256) | 0.646 | 1.59 | 9.57 | 91.82 ± 10.98 | 17.85 ± 0.32 | 10.44 ± 0.80 | 1.05 ± 0.01 | +| topdown_heatmap | MobilenetV2 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/mobilenetv2_coco_384x288.py) | (3, 288, 384) | 0.673 | 3.57 | 9.57 | 71.27 ± 6.82 | 8.00 ± 0.15 | 5.01 ± 0.32 | 0.46 ± 0.00 | +| topdown_heatmap | MSPN-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/mspn50_coco_256x192.py) | (3, 192, 256) | 0.723 | 5.11 | 25.11 | 59.65 ± 3.74 | 9.51 ± 0.15 | 3.98 ± 0.21 | 0.43 ± 0.00 | +| topdown_heatmap | 2xMSPN-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/2xmspn50_coco_256x192.py) | (3, 192, 256) | 0.754 | 11.35 | 56.8 | 30.64 ± 2.61 | 4.74 ± 0.12 | 1.85 ± 0.08 | 0.20 ± 0.00 | +| topdown_heatmap | 3xMSPN-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/3xmspn50_coco_256x192.py) | (3, 192, 256) | 0.758 | 17.59 | 88.49 | 20.90 ± 1.82 | 3.22 ± 0.08 | 1.23 ± 0.04 | 0.13 ± 0.00 | +| topdown_heatmap | 4xMSPN-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/4xmspn50_coco_256x192.py) | (3, 192, 256) | 0.764 | 23.82 | 120.18 | 15.79 ± 1.14 | 2.45 ± 0.05 | 0.90 ± 0.03 | 0.10 ± 0.00 | +| topdown_heatmap | ResNest-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest50_coco_256x192.py) | (3, 192, 256) | 0.721 | 6.73 | 35.93 | 48.36 ± 4.12 | 7.48 ± 0.13 | 3.00 ± 0.13 | 0.33 ± 0.00 | +| topdown_heatmap | ResNest-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest50_coco_384x288.py) | (3, 288, 384) | 0.737 | 15.14 | 35.93 | 30.30 ± 2.30 | 3.62 ± 0.09 | 1.43 ± 0.05 | 0.13 ± 0.00 | +| topdown_heatmap | ResNest-101 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest101_coco_256x192.py) | (3, 192, 256) | 0.725 | 10.38 | 56.61 | 29.21 ± 1.98 | 5.30 ± 0.12 | 2.01 ± 0.08 | 0.22 ± 0.00 | +| topdown_heatmap | ResNest-101 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest101_coco_384x288.py) | (3, 288, 384) | 0.746 | 23.36 | 56.61 | 19.02 ± 1.40 | 2.59 ± 0.05 | 0.97 ± 0.03 | 0.09 ± 0.00 | +| topdown_heatmap | ResNest-200 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest200_coco_256x192.py) | (3, 192, 256) | 0.732 | 17.5 | 78.54 | 16.11 ± 0.71 | 3.29 ± 0.07 | 1.33 ± 0.02 | 0.14 ± 0.00 | +| topdown_heatmap | ResNest-200 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest200_coco_384x288.py) | (3, 288, 384) | 0.754 | 39.37 | 78.54 | 11.48 ± 0.68 | 1.58 ± 0.02 | 0.63 ± 0.01 | 0.06 ± 0.00 | +| topdown_heatmap | ResNest-269 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest269_coco_256x192.py) | (3, 192, 256) | 0.738 | 22.45 | 119.27 | 12.02 ± 0.47 | 2.60 ± 0.05 | 1.03 ± 0.01 | 0.11 ± 0.00 | +| topdown_heatmap | ResNest-269 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest269_coco_384x288.py) | (3, 288, 384) | 0.755 | 50.5 | 119.27 | 8.82 ± 0.42 | 1.24 ± 0.02 | 0.49 ± 0.01 | 0.05 ± 0.00 | +| topdown_heatmap | ResNet-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_256x192.py) | (3, 192, 256) | 0.718 | 5.46 | 34 | 64.23 ± 6.05 | 9.33 ± 0.21 | 4.00 ± 0.10 | 0.41 ± 0.00 | +| topdown_heatmap | ResNet-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res50_coco_384x288.py) | (3, 288, 384) | 0.731 | 12.29 | 34 | 36.78 ± 3.05 | 4.48 ± 0.12 | 1.92 ± 0.04 | 0.19 ± 0.00 | +| topdown_heatmap | ResNet-101 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res101_coco_256x192.py) | (3, 192, 256) | 0.726 | 9.11 | 52.99 | 43.35 ± 4.36 | 6.44 ± 0.14 | 2.57 ± 0.05 | 0.27 ± 0.00 | +| topdown_heatmap | ResNet-101 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res101_coco_384x288.py) | (3, 288, 384) | 0.748 | 20.5 | 52.99 | 23.29 ± 1.83 | 3.12 ± 0.09 | 1.23 ± 0.03 | 0.11 ± 0.00 | +| topdown_heatmap | ResNet-152 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res152_coco_256x192.py) | (3, 192, 256) | 0.735 | 12.77 | 68.64 | 32.31 ± 2.84 | 4.88 ± 0.17 | 1.89 ± 0.03 | 0.20 ± 0.00 | +| topdown_heatmap | ResNet-152 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/res152_coco_384x288.py) | (3, 288, 384) | 0.75 | 28.73 | 68.64 | 17.32 ± 1.17 | 2.40 ± 0.04 | 0.91 ± 0.01 | 0.08 ± 0.00 | +| topdown_heatmap | ResNetV1d-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d50_coco_256x192.py) | (3, 192, 256) | 0.722 | 5.7 | 34.02 | 63.44 ± 6.09 | 9.09 ± 0.10 | 3.82 ± 0.10 | 0.39 ± 0.00 | +| topdown_heatmap | ResNetV1d-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d50_coco_384x288.py) | (3, 288, 384) | 0.73 | 12.82 | 34.02 | 36.21 ± 3.10 | 4.30 ± 0.12 | 1.82 ± 0.04 | 0.16 ± 0.00 | +| topdown_heatmap | ResNetV1d-101 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d101_coco_256x192.py) | (3, 192, 256) | 0.731 | 9.35 | 53.01 | 41.48 ± 3.76 | 6.33 ± 0.15 | 2.48 ± 0.05 | 0.26 ± 0.00 | +| topdown_heatmap | ResNetV1d-101 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d101_coco_384x288.py) | (3, 288, 384) | 0.748 | 21.04 | 53.01 | 23.49 ± 1.76 | 3.07 ± 0.07 | 1.19 ± 0.02 | 0.11 ± 0.00 | +| topdown_heatmap | ResNetV1d-152 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d152_coco_256x192.py) | (3, 192, 256) | 0.737 | 13.01 | 68.65 | 31.96 ± 2.87 | 4.69 ± 0.18 | 1.87 ± 0.02 | 0.19 ± 0.00 | +| topdown_heatmap | ResNetV1d-152 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d152_coco_384x288.py) | (3, 288, 384) | 0.752 | 29.26 | 68.65 | 17.31 ± 1.13 | 2.32 ± 0.04 | 0.88 ± 0.01 | 0.08 ± 0.00 | +| topdown_heatmap | ResNext-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnext50_coco_256x192.py) | (3, 192, 256) | 0.714 | 5.61 | 33.47 | 48.34 ± 3.85 | 7.66 ± 0.13 | 3.71 ± 0.10 | 0.37 ± 0.00 | +| topdown_heatmap | ResNext-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnext50_coco_384x288.py) | (3, 288, 384) | 0.724 | 12.62 | 33.47 | 30.66 ± 2.38 | 3.64 ± 0.11 | 1.73 ± 0.03 | 0.15 ± 0.00 | +| topdown_heatmap | ResNext-101 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnext101_coco_256x192.py) | (3, 192, 256) | 0.726 | 9.29 | 52.62 | 27.33 ± 2.35 | 5.09 ± 0.13 | 2.45 ± 0.04 | 0.25 ± 0.00 | +| topdown_heatmap | ResNext-101 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnext101_coco_384x288.py) | (3, 288, 384) | 0.743 | 20.91 | 52.62 | 18.19 ± 1.38 | 2.42 ± 0.04 | 1.15 ± 0.01 | 0.10 ± 0.00 | +| topdown_heatmap | ResNext-152 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnext152_coco_256x192.py) | (3, 192, 256) | 0.73 | 12.98 | 68.39 | 19.61 ± 1.61 | 3.80 ± 0.13 | 1.83 ± 0.02 | 0.18 ± 0.00 | +| topdown_heatmap | ResNext-152 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnext152_coco_384x288.py) | (3, 288, 384) | 0.742 | 29.21 | 68.39 | 13.14 ± 0.75 | 1.82 ± 0.03 | 0.85 ± 0.01 | 0.08 ± 0.00 | +| topdown_heatmap | RSN-18 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/rsn18_coco_256x192.py) | (3, 192, 256) | 0.704 | 2.27 | 9.14 | 47.80 ± 4.50 | 13.68 ± 0.25 | 6.70 ± 0.28 | 0.70 ± 0.00 | +| topdown_heatmap | RSN-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/rsn50_coco_256x192.py) | (3, 192, 256) | 0.723 | 4.11 | 19.33 | 27.22 ± 1.61 | 8.81 ± 0.13 | 3.98 ± 0.12 | 0.45 ± 0.00 | +| topdown_heatmap | 2xRSN-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/2xrsn50_coco_256x192.py) | (3, 192, 256) | 0.745 | 8.29 | 39.26 | 13.88 ± 0.64 | 4.78 ± 0.13 | 2.02 ± 0.04 | 0.23 ± 0.00 | +| topdown_heatmap | 3xRSN-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/3xrsn50_coco_256x192.py) | (3, 192, 256) | 0.75 | 12.47 | 59.2 | 9.40 ± 0.32 | 3.37 ± 0.09 | 1.34 ± 0.03 | 0.15 ± 0.00 | +| topdown_heatmap | SCNet-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/scnet50_coco_256x192.py) | (3, 192, 256) | 0.728 | 5.31 | 34.01 | 40.76 ± 3.08 | 8.35 ± 0.19 | 3.82 ± 0.08 | 0.40 ± 0.00 | +| topdown_heatmap | SCNet-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/scnet50_coco_384x288.py) | (3, 288, 384) | 0.751 | 11.94 | 34.01 | 32.61 ± 2.97 | 4.19 ± 0.10 | 1.85 ± 0.03 | 0.17 ± 0.00 | +| topdown_heatmap | SCNet-101 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/scnet101_coco_256x192.py) | (3, 192, 256) | 0.733 | 8.51 | 53.01 | 24.28 ± 1.19 | 5.80 ± 0.13 | 2.49 ± 0.05 | 0.27 ± 0.00 | +| topdown_heatmap | SCNet-101 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/scnet101_coco_384x288.py) | (3, 288, 384) | 0.752 | 19.14 | 53.01 | 20.43 ± 1.76 | 2.91 ± 0.06 | 1.23 ± 0.02 | 0.12 ± 0.00 | +| topdown_heatmap | SeresNet-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/seresnet50_coco_256x192.py) | (3, 192, 256) | 0.728 | 5.47 | 36.53 | 54.83 ± 4.94 | 8.80 ± 0.12 | 3.85 ± 0.10 | 0.40 ± 0.00 | +| topdown_heatmap | SeresNet-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/seresnet50_coco_384x288.py) | (3, 288, 384) | 0.748 | 12.3 | 36.53 | 33.00 ± 2.67 | 4.26 ± 0.12 | 1.86 ± 0.04 | 0.17 ± 0.00 | +| topdown_heatmap | SeresNet-101 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/seresnet101_coco_256x192.py) | (3, 192, 256) | 0.734 | 9.13 | 57.77 | 33.90 ± 2.65 | 6.01 ± 0.13 | 2.48 ± 0.05 | 0.26 ± 0.00 | +| topdown_heatmap | SeresNet-101 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/seresnet101_coco_384x288.py) | (3, 288, 384) | 0.753 | 20.53 | 57.77 | 20.57 ± 1.57 | 2.96 ± 0.07 | 1.20 ± 0.02 | 0.11 ± 0.00 | +| topdown_heatmap | SeresNet-152 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/seresnet152_coco_256x192.py) | (3, 192, 256) | 0.73 | 12.79 | 75.26 | 24.25 ± 1.95 | 4.45 ± 0.10 | 1.82 ± 0.02 | 0.19 ± 0.00 | +| topdown_heatmap | SeresNet-152 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/seresnet152_coco_384x288.py) | (3, 288, 384) | 0.753 | 28.76 | 75.26 | 15.11 ± 0.99 | 2.25 ± 0.04 | 0.88 ± 0.01 | 0.08 ± 0.00 | +| topdown_heatmap | ShuffleNetV1 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/shufflenetv1_coco_256x192.py) | (3, 192, 256) | 0.585 | 1.35 | 6.94 | 80.79 ± 8.95 | 21.91 ± 0.46 | 11.84 ± 0.59 | 1.25 ± 0.01 | +| topdown_heatmap | ShuffleNetV1 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/shufflenetv1_coco_384x288.py) | (3, 288, 384) | 0.622 | 3.05 | 6.94 | 63.45 ± 5.21 | 9.84 ± 0.10 | 6.01 ± 0.31 | 0.57 ± 0.00 | +| topdown_heatmap | ShuffleNetV2 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/shufflenetv2_coco_256x192.py) | (3, 192, 256) | 0.599 | 1.37 | 7.55 | 82.36 ± 7.30 | 22.68 ± 0.53 | 12.40 ± 0.66 | 1.34 ± 0.02 | +| topdown_heatmap | ShuffleNetV2 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/shufflenetv2_coco_384x288.py) | (3, 288, 384) | 0.636 | 3.08 | 7.55 | 63.63 ± 5.72 | 10.47 ± 0.16 | 6.32 ± 0.28 | 0.63 ± 0.01 | +| topdown_heatmap | VGG16 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vgg16_bn_coco_256x192.py) | (3, 192, 256) | 0.698 | 16.22 | 18.92 | 51.91 ± 2.98 | 6.18 ± 0.13 | 1.64 ± 0.03 | 0.15 ± 0.00 | +| topdown_heatmap | VIPNAS + ResNet-50 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vipnas_res50_coco_256x192.py) | (3, 192, 256) | 0.711 | 1.49 | 7.29 | 34.88 ± 2.45 | 10.29 ± 0.13 | 6.51 ± 0.17 | 0.65 ± 0.00 | +| topdown_heatmap | VIPNAS + MobileNetV3 | [config](/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vipnas_mbv3_coco_256x192.py) | (3, 192, 256) | 0.7 | 0.76 | 5.9 | 53.62 ± 6.59 | 11.54 ± 0.18 | 1.26 ± 0.02 | 0.13 ± 0.00 | +| Associative Embedding | HigherHRNet-W32 | [config](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w32_coco_512x512.py) | (3, 512, 512) | 0.677 | 46.58 | 28.65 | 7.80 ± 0.67 | / | 0.28 ± 0.02 | / | +| Associative Embedding | HigherHRNet-W32 | [config](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w32_coco_640x640.py) | (3, 640, 640) | 0.686 | 72.77 | 28.65 | 5.30 ± 0.37 | / | 0.17 ± 0.01 | / | +| Associative Embedding | HigherHRNet-W48 | [config](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_w48_coco_512x512.py) | (3, 512, 512) | 0.686 | 96.17 | 63.83 | 4.55 ± 0.35 | / | 0.15 ± 0.01 | / | +| Associative Embedding | Hourglass-AE | [config](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hourglass_ae_coco_512x512.py) | (3, 512, 512) | 0.613 | 221.58 | 138.86 | 3.55 ± 0.24 | / | 0.08 ± 0.00 | / | +| Associative Embedding | HRNet-W32 | [config](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w32_coco_512x512.py) | (3, 512, 512) | 0.654 | 41.1 | 28.54 | 8.93 ± 0.76 | / | 0.33 ± 0.02 | / | +| Associative Embedding | HRNet-W48 | [config](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_w48_coco_512x512.py) | (3, 512, 512) | 0.665 | 84.12 | 63.6 | 5.27 ± 0.43 | / | 0.18 ± 0.01 | / | +| Associative Embedding | MobilenetV2 | [config](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/mobilenetv2_coco_512x512.py) | (3, 512, 512) | 0.38 | 8.54 | 9.57 | 21.24 ± 1.34 | / | 0.81 ± 0.06 | / | +| Associative Embedding | ResNet-50 | [config](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res50_coco_512x512.py) | (3, 512, 512) | 0.466 | 29.2 | 34 | 11.71 ± 0.97 | / | 0.41 ± 0.02 | / | +| Associative Embedding | ResNet-50 | [config](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res50_coco_640x640.py) | (3, 640, 640) | 0.479 | 45.62 | 34 | 8.20 ± 0.58 | / | 0.26 ± 0.02 | / | +| Associative Embedding | ResNet-101 | [config](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res101_coco_512x512.py) | (3, 512, 512) | 0.554 | 48.67 | 53 | 8.26 ± 0.68 | / | 0.28 ± 0.02 | / | +| Associative Embedding | ResNet-101 | [config](/configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/res152_coco_512x512.py) | (3, 512, 512) | 0.595 | 68.17 | 68.64 | 6.25 ± 0.53 | / | 0.21 ± 0.01 | / | +| DeepPose | ResNet-50 | [config](/configs/body/2d_kpt_sview_rgb_img/deeppose/coco/res50_coco_256x192.py) | (3, 192, 256) | 0.526 | 4.04 | 23.58 | 82.20 ± 7.54 | / | 5.50 ± 0.18 | / | +| DeepPose | ResNet-101 | [config](/configs/body/2d_kpt_sview_rgb_img/deeppose/coco/res101_coco_256x192.py) | (3, 192, 256) | 0.56 | 7.69 | 42.57 | 48.93 ± 4.02 | / | 3.10 ± 0.07 | / | +| DeepPose | ResNet-152 | [config](/configs/body/2d_kpt_sview_rgb_img/deeppose/coco/res152_coco_256x192.py) | (3, 192, 256) | 0.583 | 11.34 | 58.21 | 35.06 ± 3.50 | / | 2.19 ± 0.04 | / | + +1 注意,这里运行迭代多次,并记录每次迭代的时间,同时展示了 FPS 数值的平均值和标准差。 + +2 FPS 定义为每秒的平均迭代次数,与此迭代中的批处理大小无关。 diff --git a/vendor/ViTPose/docs/zh_cn/install.md b/vendor/ViTPose/docs/zh_cn/install.md new file mode 100644 index 0000000000000000000000000000000000000000..c876ee5c2a043f44d7db0ed4ff75b2d75e531c9f --- /dev/null +++ b/vendor/ViTPose/docs/zh_cn/install.md @@ -0,0 +1,202 @@ +# 安装 + +本文档提供了安装 MMPose 的相关步骤。 + + + +- [安装依赖包](#安装依赖包) +- [准备环境](#准备环境) +- [MMPose 的安装步骤](#MMPose-的安装步骤) +- [CPU 环境下的安装步骤](#CPU-环境下的安装步骤) +- [利用 Docker 镜像安装 MMPose](#利用-Docker-镜像安装-MMPose) +- [源码安装 MMPose](#源码安装-MMPose) +- [在多个 MMPose 版本下进行开发](#在多个-MMPose-版本下进行开发) + + + +## 安装依赖包 + +- Linux (Windows 系统暂未有官方支持) +- Python 3.6+ +- PyTorch 1.3+ +- CUDA 9.2+ (如果从源码编译 PyTorch,则可以兼容 CUDA 9.0 版本) +- GCC 5+ +- [mmcv](https://github.com/open-mmlab/mmcv) 请安装最新版本的 mmcv-full +- Numpy +- cv2 +- json_tricks +- [xtcocotools](https://github.com/jin-s13/xtcocoapi) + +可选项: + +- [mmdet](https://github.com/open-mmlab/mmdetection) (用于“姿态估计”) +- [mmtrack](https://github.com/open-mmlab/mmtracking) (用于“姿态跟踪”) +- [pyrender](https://pyrender.readthedocs.io/en/latest/install/index.html) (用于“三维人体形状恢复”) +- [smplx](https://github.com/vchoutas/smplx) (用于“三维人体形状恢复”) + +## 准备环境 + +a. 创建并激活 conda 虚拟环境,如: + +```shell +conda create -n open-mmlab python=3.7 -y +conda activate open-mmlab +``` + +b. 参考 [官方文档](https://pytorch.org/) 安装 PyTorch 和 torchvision ,如: + +```shell +conda install pytorch torchvision -c pytorch +``` + +**注**:确保 CUDA 的编译版本和 CUDA 的运行版本相匹配。 +用户可以参照 [PyTorch 官网](https://pytorch.org/) 对预编译包所支持的 CUDA 版本进行核对。 + +`例 1`:如果用户的 `/usr/local/cuda` 文件夹下已安装 CUDA 10.2 版本,并且想要安装 PyTorch 1.8.0 版本, +则需要安装 CUDA 10.2 下预编译的 PyTorch。 + +```shell +conda install pytorch==1.8.0 torchvision==0.9.0 cudatoolkit=10.2 -c pytorch +``` + +`例 2`:如果用户的 `/usr/local/cuda` 文件夹下已安装 CUDA 9.2 版本,并且想要安装 PyTorch 1.7.0 版本, +则需要安装 CUDA 9.2 下预编译的 PyTorch。 + +```shell +conda install pytorch==1.7.0 torchvision==0.8.0 cudatoolkit=9.2 -c pytorch +``` + +如果 PyTorch 是由源码进行编译安装(而非直接下载预编译好的安装包),则可以使用更多的 CUDA 版本(如 9.0 版本)。 + +## MMPose 的安装步骤 + +a. 安装最新版本的 mmcv-full。MMPose 推荐用户使用如下的命令安装预编译好的 mmcv。 + +```shell +# pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/{cu_version}/{torch_version}/index.html +pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu102/torch1.9.0/index.html +# 我们可以忽略 PyTorch 的小版本号 +pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu102/torch1.9/index.html +``` + +PyTorch 在 1.x.0 和 1.x.1 之间通常是兼容的,故 mmcv-full 只提供 1.x.0 的编译包。如果你的 PyTorch 版本是 1.x.1,你可以放心地安装在 1.x.0 版本编译的 mmcv-full。 + +可查阅 [这里](https://github.com/open-mmlab/mmcv#installation) 以参考不同版本的 MMCV 所兼容的 PyTorch 和 CUDA 版本。 + +另外,用户也可以通过使用以下命令从源码进行编译: + +```shell +git clone https://github.com/open-mmlab/mmcv.git +cd mmcv +MMCV_WITH_OPS=1 pip install -e . # mmcv-full 包含一些 cuda 算子,执行该步骤会安装 mmcv-full(而非 mmcv) +# 或者使用 pip install -e . # 这个命令安装的 mmcv 将不包含 cuda ops,通常适配 CPU(无 GPU)环境 +cd .. +``` + +**注意**:如果之前安装过 mmcv,那么需要先使用 `pip uninstall mmcv` 命令进行卸载。如果 mmcv 和 mmcv-full 同时被安装, 会报 `ModuleNotFoundError` 的错误。 + +b. 克隆 MMPose 库。 + +```shell +git clone https://github.com/open-mmlab/mmpose.git +cd mmpose +``` + +c. 安装依赖包和 MMPose。 + +```shell +pip install -r requirements.txt +pip install -v -e . # or "python setup.py develop" +``` + +如果是在 macOS 环境安装 MMPose,则需使用如下命令: + +```shell +CC=clang CXX=clang++ CFLAGS='-stdlib=libc++' pip install -e . +``` + +d. 安装其他可选依赖。 + +如果用户不需要做相关任务,这部分步骤可以选择跳过。 + +可选项: + +- [mmdet](https://github.com/open-mmlab/mmdetection) (用于“姿态估计”) +- [mmtrack](https://github.com/open-mmlab/mmtracking) (用于“姿态跟踪”) +- [pyrender](https://pyrender.readthedocs.io/en/latest/install/index.html) (用于“三维人体形状恢复”) +- [smplx](https://github.com/vchoutas/smplx) (用于“三维人体形状恢复”) + +注意: + +1. 在步骤 c 中,git commit 的 id 将会被写到版本号中,如 0.6.0+2e7045c。这个版本号也会被保存到训练好的模型中。 + 这里推荐用户每次在步骤 b 中对本地代码和 github 上的源码进行同步。如果 C++/CUDA 代码被修改,就必须进行这一步骤。 + +1. 根据上述步骤,MMPose 就会以 `dev` 模式被安装,任何本地的代码修改都会立刻生效,不需要再重新安装一遍(除非用户提交了 commits,并且想更新版本号)。 + +1. 如果用户想使用 `opencv-python-headless` 而不是 `opencv-python`,可再安装 MMCV 前安装 `opencv-python-headless`。 + +1. 如果 mmcv 已经被安装,用户需要使用 `pip uninstall mmcv` 命令进行卸载。如果 mmcv 和 mmcv-full 同时被安装, 会报 `ModuleNotFoundError` 的错误。 + +1. 一些依赖包是可选的。运行 `python setup.py develop` 将只会安装运行代码所需的最小要求依赖包。 + 要想使用一些可选的依赖包,如 `smplx`,用户需要通过 `pip install -r requirements/optional.txt` 进行安装, + 或者通过调用 `pip`(如 `pip install -v -e .[optional]`,这里的 `[optional]` 可替换为 `all`,`tests`,`build` 或 `optional`) 指定安装对应的依赖包,如 `pip install -v -e .[tests,build]`。 + +## CPU 环境下的安装步骤 + +MMPose 可以在只有 CPU 的环境下安装(即无法使用 GPU 的环境)。 + +在 CPU 模式下,用户可以运行 `demo/demo.py` 的代码。 + +## 源码安装 MMPose + +这里提供了 conda 下安装 MMPose 并链接 COCO 数据集路径的完整脚本(假设 COCO 数据的路径在 $COCO_ROOT)。 + +```shell +conda create -n open-mmlab python=3.7 -y +conda activate open-mmlab + +# 安装最新的,使用默认版本的 CUDA 版本(一般为最新版本)预编译的 PyTorch 包 +conda install -c pytorch pytorch torchvision -y + +# 安装 mmcv-full。其中,命令里 url 的 ``{cu_version}`` 和 ``{torch_version}`` 变量需由用户进行指定。 +# 可查阅 [这里](https://github.com/open-mmlab/mmcv#installation) 以参考不同版本的 MMCV 所兼容的 PyTorch 和 CUDA 版本。 +pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/{cu_version}/{torch_version}/index.html + +# 安装 mmpose +git clone git@github.com:open-mmlab/mmpose.git +cd mmpose +pip install -r requirements.txt +python setup.py develop + +mkdir data +ln -s $COCO_ROOT data/coco +``` + +## 利用 Docker 镜像安装 MMPose + +MMPose 提供一个 [Dockerfile](/docker/Dockerfile) 用户创建 docker 镜像。 + +```shell +# 创建拥有 PyTorch 1.6.0, CUDA 10.1, CUDNN 7 配置的 docker 镜像. +docker build -f ./docker/Dockerfile --rm -t mmpose . +``` + +**注意**:用户需要确保已经安装了 [nvidia-container-toolkit](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html#docker)。 + +运行以下命令: + +```shell +docker run --gpus all\ + --shm-size=8g \ + -it -v {DATA_DIR}:/mmpose/data mmpose +``` + +## 在多个 MMPose 版本下进行开发 + +MMPose 的训练和测试脚本已经修改了 `PYTHONPATH` 变量,以确保其能够运行当前目录下的 MMPose。 + +如果想要运行环境下默认的 MMPose,用户需要在训练和测试脚本中去除这一行: + +```shell +PYTHONPATH="$(dirname $0)/..":$PYTHONPATH +``` diff --git a/vendor/ViTPose/docs/zh_cn/language.md b/vendor/ViTPose/docs/zh_cn/language.md new file mode 100644 index 0000000000000000000000000000000000000000..a0a6259bee27121ca837c85141ebca0307d617b4 --- /dev/null +++ b/vendor/ViTPose/docs/zh_cn/language.md @@ -0,0 +1,3 @@ +## English + +## 简体中文 diff --git a/vendor/ViTPose/docs/zh_cn/make.bat b/vendor/ViTPose/docs/zh_cn/make.bat new file mode 100644 index 0000000000000000000000000000000000000000..922152e96a04a242e6fc40f124261d74890617d8 --- /dev/null +++ b/vendor/ViTPose/docs/zh_cn/make.bat @@ -0,0 +1,35 @@ +@ECHO OFF + +pushd %~dp0 + +REM Command file for Sphinx documentation + +if "%SPHINXBUILD%" == "" ( + set SPHINXBUILD=sphinx-build +) +set SOURCEDIR=. +set BUILDDIR=_build + +if "%1" == "" goto help + +%SPHINXBUILD% >NUL 2>NUL +if errorlevel 9009 ( + echo. + echo.The 'sphinx-build' command was not found. Make sure you have Sphinx + echo.installed, then set the SPHINXBUILD environment variable to point + echo.to the full path of the 'sphinx-build' executable. Alternatively you + echo.may add the Sphinx directory to PATH. + echo. + echo.If you don't have Sphinx installed, grab it from + echo.http://sphinx-doc.org/ + exit /b 1 +) + +%SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O% +goto end + +:help +%SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O% + +:end +popd diff --git a/vendor/ViTPose/docs/zh_cn/merge_docs.sh b/vendor/ViTPose/docs/zh_cn/merge_docs.sh new file mode 100644 index 0000000000000000000000000000000000000000..51fc8bc84f250eb1ec7fac8379c2f6b0c845bfa0 --- /dev/null +++ b/vendor/ViTPose/docs/zh_cn/merge_docs.sh @@ -0,0 +1,28 @@ +#!/usr/bin/env bash +# Copyright (c) OpenMMLab. All rights reserved. + +sed -i '$a\\n' ../../demo/docs/*_demo.md +cat ../../demo/docs/*_demo.md | sed "s/#/#&/" | sed "s/md###t/html#t/g" | sed '1i\# 示例' | sed 's=](/docs/zh_cn/=](/=g' | sed 's=](/=](https://github.com/open-mmlab/mmpose/tree/master/=g' >demo.md + + # remove /docs_zh-CN/ for link used in doc site +sed -i 's=](/docs/zh_cn/=](=g' ./tutorials/*.md +sed -i 's=](/docs/zh_cn/=](=g' ./tasks/*.md +sed -i 's=](/docs/zh_cn/=](=g' ./papers/*.md +sed -i 's=](/docs/zh_cn/=](=g' ./topics/*.md +sed -i 's=](/docs/zh_cn/=](=g' data_preparation.md +sed -i 's=](/docs/zh_cn/=](=g' getting_started.md +sed -i 's=](/docs/zh_cn/=](=g' install.md +sed -i 's=](/docs/zh_cn/=](=g' benchmark.md +# sed -i 's=](/docs/zh_cn/=](=g' changelog.md +sed -i 's=](/docs/zh_cn/=](=g' faq.md + +sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/master/=g' ./tutorials/*.md +sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/master/=g' ./tasks/*.md +sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/master/=g' ./papers/*.md +sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/master/=g' ./topics/*.md +sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/master/=g' data_preparation.md +sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/master/=g' getting_started.md +sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/master/=g' install.md +sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/master/=g' benchmark.md +# sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/master/=g' changelog.md +sed -i 's=](/=](https://github.com/open-mmlab/mmpose/tree/master/=g' faq.md diff --git a/vendor/ViTPose/docs/zh_cn/stats.py b/vendor/ViTPose/docs/zh_cn/stats.py new file mode 100644 index 0000000000000000000000000000000000000000..d947ab10ba9beacf9da8ed208c3a1f78fa22f149 --- /dev/null +++ b/vendor/ViTPose/docs/zh_cn/stats.py @@ -0,0 +1,176 @@ +#!/usr/bin/env python +# Copyright (c) OpenMMLab. All rights reserved. +import functools as func +import glob +import re +from os.path import basename, splitext + +import numpy as np +import titlecase + + +def anchor(name): + return re.sub(r'-+', '-', re.sub(r'[^a-zA-Z0-9]', '-', + name.strip().lower())).strip('-') + + +# Count algorithms + +files = sorted(glob.glob('topics/*.md')) + +stats = [] + +for f in files: + with open(f, 'r') as content_file: + content = content_file.read() + + # title + title = content.split('\n')[0].replace('#', '') + + # count papers + papers = set( + (papertype, titlecase.titlecase(paper.lower().strip())) + for (papertype, paper) in re.findall( + r'\s*\n.*?\btitle\s*=\s*{(.*?)}', + content, re.DOTALL)) + # paper links + revcontent = '\n'.join(list(reversed(content.splitlines()))) + paperlinks = {} + for _, p in papers: + print(p) + paperlinks[p] = ', '.join( + ((f'[{paperlink} ⇨]' + f'(topics/{splitext(basename(f))[0]}.html#{anchor(paperlink)})') + for paperlink in re.findall( + rf'\btitle\s*=\s*{{\s*{p}\s*}}.*?\n### (.*?)\s*[,;]?\s*\n', + revcontent, re.DOTALL | re.IGNORECASE))) + print(' ', paperlinks[p]) + paperlist = '\n'.join( + sorted(f' - [{t}] {x} ({paperlinks[x]})' for t, x in papers)) + # count configs + configs = set(x.lower().strip() + for x in re.findall(r'.*configs/.*\.py', content)) + + # count ckpts + ckpts = set(x.lower().strip() + for x in re.findall(r'https://download.*\.pth', content) + if 'mmpose' in x) + + statsmsg = f""" +## [{title}]({f}) + +* 模型权重文件数量: {len(ckpts)} +* 配置文件数量: {len(configs)} +* 论文数量: {len(papers)} +{paperlist} + + """ + + stats.append((papers, configs, ckpts, statsmsg)) + +allpapers = func.reduce(lambda a, b: a.union(b), [p for p, _, _, _ in stats]) +allconfigs = func.reduce(lambda a, b: a.union(b), [c for _, c, _, _ in stats]) +allckpts = func.reduce(lambda a, b: a.union(b), [c for _, _, c, _ in stats]) + +# Summarize + +msglist = '\n'.join(x for _, _, _, x in stats) +papertypes, papercounts = np.unique([t for t, _ in allpapers], + return_counts=True) +countstr = '\n'.join( + [f' - {t}: {c}' for t, c in zip(papertypes, papercounts)]) + +modelzoo = f""" +# 概览 + +* 模型权重文件数量: {len(allckpts)} +* 配置文件数量: {len(allconfigs)} +* 论文数量: {len(allpapers)} +{countstr} + +已支持的数据集详细信息请见 [数据集](datasets.md). + +{msglist} + +""" + +with open('modelzoo.md', 'w') as f: + f.write(modelzoo) + +# Count datasets + +files = sorted(glob.glob('tasks/*.md')) +# files = sorted(glob.glob('docs/tasks/*.md')) + +datastats = [] + +for f in files: + with open(f, 'r') as content_file: + content = content_file.read() + + # title + title = content.split('\n')[0].replace('#', '') + + # count papers + papers = set( + (papertype, titlecase.titlecase(paper.lower().strip())) + for (papertype, paper) in re.findall( + r'\s*\n.*?\btitle\s*=\s*{(.*?)}', + content, re.DOTALL)) + # paper links + revcontent = '\n'.join(list(reversed(content.splitlines()))) + paperlinks = {} + for _, p in papers: + print(p) + paperlinks[p] = ', '.join( + (f'[{p} ⇨](tasks/{splitext(basename(f))[0]}.html#{anchor(p)})' + for p in re.findall( + rf'\btitle\s*=\s*{{\s*{p}\s*}}.*?\n## (.*?)\s*[,;]?\s*\n', + revcontent, re.DOTALL | re.IGNORECASE))) + print(' ', paperlinks[p]) + paperlist = '\n'.join( + sorted(f' - [{t}] {x} ({paperlinks[x]})' for t, x in papers)) + # count configs + configs = set(x.lower().strip() + for x in re.findall(r'https.*configs/.*\.py', content)) + + # count ckpts + ckpts = set(x.lower().strip() + for x in re.findall(r'https://download.*\.pth', content) + if 'mmpose' in x) + + statsmsg = f""" +## [{title}]({f}) + +* 论文数量: {len(papers)} +{paperlist} + + """ + + datastats.append((papers, configs, ckpts, statsmsg)) + +alldatapapers = func.reduce(lambda a, b: a.union(b), + [p for p, _, _, _ in datastats]) + +# Summarize + +msglist = '\n'.join(x for _, _, _, x in stats) +datamsglist = '\n'.join(x for _, _, _, x in datastats) +papertypes, papercounts = np.unique([t for t, _ in alldatapapers], + return_counts=True) +countstr = '\n'.join( + [f' - {t}: {c}' for t, c in zip(papertypes, papercounts)]) + +modelzoo = f""" +# 概览 + +* 论文数量: {len(alldatapapers)} +{countstr} + +已支持的算法详细信息请见 [模型池](modelzoo.md). + +{datamsglist} +""" + +with open('datasets.md', 'w') as f: + f.write(modelzoo) diff --git a/vendor/ViTPose/docs/zh_cn/tasks/2d_animal_keypoint.md b/vendor/ViTPose/docs/zh_cn/tasks/2d_animal_keypoint.md new file mode 100644 index 0000000000000000000000000000000000000000..3149533047b4457bf9b3088e14f0940db4bb743c --- /dev/null +++ b/vendor/ViTPose/docs/zh_cn/tasks/2d_animal_keypoint.md @@ -0,0 +1,3 @@ +# 2D动物关键点数据集 + +内容建设中…… diff --git a/vendor/ViTPose/docs/zh_cn/tasks/2d_body_keypoint.md b/vendor/ViTPose/docs/zh_cn/tasks/2d_body_keypoint.md new file mode 100644 index 0000000000000000000000000000000000000000..47a1c3e40a7d4f866f1f9128186d9ee2d2d75bd5 --- /dev/null +++ b/vendor/ViTPose/docs/zh_cn/tasks/2d_body_keypoint.md @@ -0,0 +1,496 @@ +# 2D 人体关键点数据集 + +我们建议您将数据集的根目录放置在 `$MMPOSE/data` 下。 +如果您的文件结构比较特别,您需要在配置文件中修改相应的路径。 + +MMPose 支持的数据集如下所示: + +- 图像 + - [COCO](#coco) \[ [主页](http://cocodataset.org/) \] + - [MPII](#mpii) \[ [主页](http://human-pose.mpi-inf.mpg.de/) \] + - [MPII-TRB](#mpii-trb) \[ [主页](https://github.com/kennymckormick/Triplet-Representation-of-human-Body) \] + - [AI Challenger](#aic) \[ [主页](https://github.com/AIChallenger/AI_Challenger_2017) \] + - [CrowdPose](#crowdpose) \[ [主页](https://github.com/Jeff-sjtu/CrowdPose) \] + - [OCHuman](#ochuman) \[ [主页](https://github.com/liruilong940607/OCHumanApi) \] + - [MHP](#mhp) \[ [主页](https://lv-mhp.github.io/dataset) \] +- 视频 + - [PoseTrack18](#posetrack18) \[ [主页](https://posetrack.net/users/download.php) \] + - [sub-JHMDB](#sub-jhmdb-dataset) \[ [主页](http://jhmdb.is.tue.mpg.de/dataset) \] + +## COCO + + + +
+
+
+请从此链接 [COCO download](http://cocodataset.org/#download) 下载数据集。请注意,2017 Train/Val 对于 COCO 关键点的训练和评估是非常必要的。
+[HRNet-Human-Pose-Estimation](https://github.com/HRNet/HRNet-Human-Pose-Estimation) 提供了 COCO val2017 的检测结果,可用于复现我们的多人姿态估计的结果。
+请从 [OneDrive](https://1drv.ms/f/s!AhIXJn_J-blWzzDXoz5BeFl8sWM-) 或 [GoogleDrive](https://drive.google.com/drive/folders/1fRUDNUDxe9fjqcRZ2bnF_TKMlO0nB_dk?usp=sharing)下载。
+可选地, 为了在 COCO'2017 test-dev 上评估, 请下载 [image-info](https://download.openmmlab.com/mmpose/datasets/person_keypoints_test-dev-2017.json)。
+请将数据置于 $MMPOSE/data 目录下,并整理成如下的格式:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── coco
+ │-- annotations
+ │ │-- person_keypoints_train2017.json
+ │ |-- person_keypoints_val2017.json
+ │ |-- person_keypoints_test-dev-2017.json
+ |-- person_detection_results
+ | |-- COCO_val2017_detections_AP_H_56_person.json
+ | |-- COCO_test-dev2017_detections_AP_H_609_person.json
+ │-- train2017
+ │ │-- 000000000009.jpg
+ │ │-- 000000000025.jpg
+ │ │-- 000000000030.jpg
+ │ │-- ...
+ `-- val2017
+ │-- 000000000139.jpg
+ │-- 000000000285.jpg
+ │-- 000000000632.jpg
+ │-- ...
+
+```
+
+## MPII
+
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+请从此链接 [MPII Human Pose Dataset](http://human-pose.mpi-inf.mpg.de/) 下载数据集。
+我们已经将原来的标注文件转成了 json 格式,请从此链接 [mpii_annotations](https://download.openmmlab.com/mmpose/datasets/mpii_annotations.tar) 下载。
+请将数据置于 $MMPOSE/data 目录下,并整理成如下的格式:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── mpii
+ |── annotations
+ | |── mpii_gt_val.mat
+ | |── mpii_test.json
+ | |── mpii_train.json
+ | |── mpii_trainval.json
+ | `── mpii_val.json
+ `── images
+ |── 000001163.jpg
+ |── 000003072.jpg
+
+```
+
+在训练和推理过程中,预测结果将会被默认保存为 '.mat' 的格式。我们提供了一个工具将这种 '.mat' 的格式转换成更加易读的 '.json' 格式。
+
+```shell
+python tools/dataset/mat2json ${PRED_MAT_FILE} ${GT_JSON_FILE} ${OUTPUT_PRED_JSON_FILE}
+```
+
+比如,
+
+```shell
+python tools/dataset/mat2json work_dirs/res50_mpii_256x256/pred.mat data/mpii/annotations/mpii_val.json pred.json
+```
+
+## MPII-TRB
+
+
+
+MPII (CVPR'2014)
+ +```bibtex +@inproceedings{andriluka14cvpr, + author = {Mykhaylo Andriluka and Leonid Pishchulin and Peter Gehler and Schiele, Bernt}, + title = {2D Human Pose Estimation: New Benchmark and State of the Art Analysis}, + booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, + year = {2014}, + month = {June} +} +``` + +
+
+
+请从此链接[MPII Human Pose Dataset](http://human-pose.mpi-inf.mpg.de/)下载数据集,并从此链接 [mpii_trb_annotations](https://download.openmmlab.com/mmpose/datasets/mpii_trb_annotations.tar) 下载标注文件。
+请将数据置于 $MMPOSE/data 目录下,并整理成如下的格式:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── mpii
+ |── annotations
+ | |── mpii_trb_train.json
+ | |── mpii_trb_val.json
+ `── images
+ |── 000001163.jpg
+ |── 000003072.jpg
+
+```
+
+## AIC
+
+
+
+MPII-TRB (ICCV'2019)
+ +```bibtex +@inproceedings{duan2019trb, + title={TRB: A Novel Triplet Representation for Understanding 2D Human Body}, + author={Duan, Haodong and Lin, Kwan-Yee and Jin, Sheng and Liu, Wentao and Qian, Chen and Ouyang, Wanli}, + booktitle={Proceedings of the IEEE International Conference on Computer Vision}, + pages={9479--9488}, + year={2019} +} +``` + +
+
+
+请从此链接 [AI Challenger 2017](https://github.com/AIChallenger/AI_Challenger_2017) 下载 [AIC](https://github.com/AIChallenger/AI_Challenger_2017) 数据集。请注意,2017 Train/Val 对于关键点的训练和评估是必要的。
+请从此链接 [aic_annotations](https://download.openmmlab.com/mmpose/datasets/aic_annotations.tar) 下载标注文件。
+请将数据置于 $MMPOSE/data 目录下,并整理成如下的格式:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── aic
+ │-- annotations
+ │ │-- aic_train.json
+ │ |-- aic_val.json
+ │-- ai_challenger_keypoint_train_20170902
+ │ │-- keypoint_train_images_20170902
+ │ │ │-- 0000252aea98840a550dac9a78c476ecb9f47ffa.jpg
+ │ │ │-- 000050f770985ac9653198495ef9b5c82435d49c.jpg
+ │ │ │-- ...
+ `-- ai_challenger_keypoint_validation_20170911
+ │-- keypoint_validation_images_20170911
+ │-- 0002605c53fb92109a3f2de4fc3ce06425c3b61f.jpg
+ │-- 0003b55a2c991223e6d8b4b820045bd49507bf6d.jpg
+ │-- ...
+```
+
+## CrowdPose
+
+
+
+AI Challenger (ArXiv'2017)
+ +```bibtex +@article{wu2017ai, + title={Ai challenger: A large-scale dataset for going deeper in image understanding}, + author={Wu, Jiahong and Zheng, He and Zhao, Bo and Li, Yixin and Yan, Baoming and Liang, Rui and Wang, Wenjia and Zhou, Shipei and Lin, Guosen and Fu, Yanwei and others}, + journal={arXiv preprint arXiv:1711.06475}, + year={2017} +} +``` + +
+
+
+请从此链接 [CrowdPose](https://github.com/Jeff-sjtu/CrowdPose) 下载数据集,并从此链接 [crowdpose_annotations](https://download.openmmlab.com/mmpose/datasets/crowdpose_annotations.tar) 下载标注文件和人体检测结果。
+对于 top-down 方法,我们仿照 [CrowdPose](https://arxiv.org/abs/1812.00324),使用 [YOLOv3](https://github.com/eriklindernoren/PyTorch-YOLOv3)的[预训练权重](https://pjreddie.com/media/files/yolov3.weights) 来产生人体的检测框。
+对于模型训练, 我们仿照 [HigherHRNet](https://github.com/HRNet/HigherHRNet-Human-Pose-Estimation),在 CrowdPose 训练/验证 数据集上训练模型, 并在 CrowdPose 测试集上评估模型。
+请将数据置于 $MMPOSE/data 目录下,并整理成如下的格式:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── crowdpose
+ │-- annotations
+ │ │-- mmpose_crowdpose_train.json
+ │ │-- mmpose_crowdpose_val.json
+ │ │-- mmpose_crowdpose_trainval.json
+ │ │-- mmpose_crowdpose_test.json
+ │ │-- det_for_crowd_test_0.1_0.5.json
+ │-- images
+ │-- 100000.jpg
+ │-- 100001.jpg
+ │-- 100002.jpg
+ │-- ...
+```
+
+## OCHuman
+
+
+
+CrowdPose (CVPR'2019)
+ +```bibtex +@article{li2018crowdpose, + title={CrowdPose: Efficient Crowded Scenes Pose Estimation and A New Benchmark}, + author={Li, Jiefeng and Wang, Can and Zhu, Hao and Mao, Yihuan and Fang, Hao-Shu and Lu, Cewu}, + journal={arXiv preprint arXiv:1812.00324}, + year={2018} +} +``` + +
+
+
+请从此链接 [OCHuman](https://github.com/liruilong940607/OCHumanApi) 下载数据集的图像和标注文件。
+请将数据置于 $MMPOSE/data 目录下,并整理成如下的格式:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── ochuman
+ │-- annotations
+ │ │-- ochuman_coco_format_val_range_0.00_1.00.json
+ │ |-- ochuman_coco_format_test_range_0.00_1.00.json
+ |-- images
+ │-- 000001.jpg
+ │-- 000002.jpg
+ │-- 000003.jpg
+ │-- ...
+
+```
+
+## MHP
+
+
+
+OCHuman (CVPR'2019)
+ +```bibtex +@inproceedings{zhang2019pose2seg, + title={Pose2seg: Detection free human instance segmentation}, + author={Zhang, Song-Hai and Li, Ruilong and Dong, Xin and Rosin, Paul and Cai, Zixi and Han, Xi and Yang, Dingcheng and Huang, Haozhi and Hu, Shi-Min}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={889--898}, + year={2019} +} +``` + +
+
+
+请从此链接 [MHP](https://lv-mhp.github.io/dataset)下载数据文件,并从此链接 [mhp_annotations](https://download.openmmlab.com/mmpose/datasets/mhp_annotations.tar.gz)下载标注文件。
+请将数据置于 $MMPOSE/data 目录下,并整理成如下的格式:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── mhp
+ │-- annotations
+ │ │-- mhp_train.json
+ │ │-- mhp_val.json
+ │
+ `-- train
+ │ │-- images
+ │ │ │-- 1004.jpg
+ │ │ │-- 10050.jpg
+ │ │ │-- ...
+ │
+ `-- val
+ │ │-- images
+ │ │ │-- 10059.jpg
+ │ │ │-- 10068.jpg
+ │ │ │-- ...
+ │
+ `-- test
+ │ │-- images
+ │ │ │-- 1005.jpg
+ │ │ │-- 10052.jpg
+ │ │ │-- ...~~~~
+```
+
+## PoseTrack18
+
+
+
+MHP (ACM MM'2018)
+ +```bibtex +@inproceedings{zhao2018understanding, + title={Understanding humans in crowded scenes: Deep nested adversarial learning and a new benchmark for multi-human parsing}, + author={Zhao, Jian and Li, Jianshu and Cheng, Yu and Sim, Terence and Yan, Shuicheng and Feng, Jiashi}, + booktitle={Proceedings of the 26th ACM international conference on Multimedia}, + pages={792--800}, + year={2018} +} +``` + +
+
+
+请从此链接 [PoseTrack18](https://posetrack.net/users/download.php)下载数据文件,并从此链接下载 [posetrack18_annotations](https://download.openmmlab.com/mmpose/datasets/posetrack18_annotations.tar)下载标注文件。
+我们已将官方提供的所有单视频标注文件合并为两个 json 文件 (posetrack18_train & posetrack18_val.json),并生成了 [mask files](https://download.openmmlab.com/mmpose/datasets/posetrack18_mask.tar) 来加速训练。
+对于 top-down 的方法, 我们使用 [MMDetection](https://github.com/open-mmlab/mmdetection) 的预训练 [Cascade R-CNN](https://download.openmmlab.com/mmdetection/v2.0/cascade_rcnn/cascade_rcnn_x101_64x4d_fpn_20e_coco/cascade_rcnn_x101_64x4d_fpn_20e_coco_20200509_224357-051557b1.pth) (X-101-64x4d-FPN) 来生成人体的检测框。
+请将数据置于 $MMPOSE/data 目录下,并整理成如下的格式:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── posetrack18
+ │-- annotations
+ │ │-- posetrack18_train.json
+ │ │-- posetrack18_val.json
+ │ │-- posetrack18_val_human_detections.json
+ │ │-- train
+ │ │ │-- 000001_bonn_train.json
+ │ │ │-- 000002_bonn_train.json
+ │ │ │-- ...
+ │ │-- val
+ │ │ │-- 000342_mpii_test.json
+ │ │ │-- 000522_mpii_test.json
+ │ │ │-- ...
+ │ `-- test
+ │ │-- 000001_mpiinew_test.json
+ │ │-- 000002_mpiinew_test.json
+ │ │-- ...
+ │
+ `-- images
+ │ │-- train
+ │ │ │-- 000001_bonn_train
+ │ │ │ │-- 000000.jpg
+ │ │ │ │-- 000001.jpg
+ │ │ │ │-- ...
+ │ │ │-- ...
+ │ │-- val
+ │ │ │-- 000342_mpii_test
+ │ │ │ │-- 000000.jpg
+ │ │ │ │-- 000001.jpg
+ │ │ │ │-- ...
+ │ │ │-- ...
+ │ `-- test
+ │ │-- 000001_mpiinew_test
+ │ │ │-- 000000.jpg
+ │ │ │-- 000001.jpg
+ │ │ │-- ...
+ │ │-- ...
+ `-- mask
+ │-- train
+ │ │-- 000002_bonn_train
+ │ │ │-- 000000.jpg
+ │ │ │-- 000001.jpg
+ │ │ │-- ...
+ │ │-- ...
+ `-- val
+ │-- 000522_mpii_test
+ │ │-- 000000.jpg
+ │ │-- 000001.jpg
+ │ │-- ...
+ │-- ...
+```
+
+请从 Github 上安装 PoseTrack 官方评估工具:
+
+```shell
+pip install git+https://github.com/svenkreiss/poseval.git
+```
+
+## sub-JHMDB dataset
+
+
+
+PoseTrack18 (CVPR'2018)
+ +```bibtex +@inproceedings{andriluka2018posetrack, + title={Posetrack: A benchmark for human pose estimation and tracking}, + author={Andriluka, Mykhaylo and Iqbal, Umar and Insafutdinov, Eldar and Pishchulin, Leonid and Milan, Anton and Gall, Juergen and Schiele, Bernt}, + booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition}, + pages={5167--5176}, + year={2018} +} +``` + +
+
+
+对于 [sub-JHMDB](http://jhmdb.is.tue.mpg.de/dataset) 数据集,请从此链接 [images](<(http://files.is.tue.mpg.de/jhmdb/Rename_Images.tar.gz)>) (来自 [JHMDB](http://jhmdb.is.tue.mpg.de/dataset))下载,
+请从此链接 [jhmdb_annotations](https://download.openmmlab.com/mmpose/datasets/jhmdb_annotations.tar)下载标注文件。
+将它们移至 $MMPOSE/data目录下, 使得文件呈如下的格式:
+
+```text
+mmpose
+├── mmpose
+├── docs
+├── tests
+├── tools
+├── configs
+`── data
+ │── jhmdb
+ │-- annotations
+ │ │-- Sub1_train.json
+ │ |-- Sub1_test.json
+ │ │-- Sub2_train.json
+ │ |-- Sub2_test.json
+ │ │-- Sub3_train.json
+ │ |-- Sub3_test.json
+ |-- Rename_Images
+ │-- brush_hair
+ │ │--April_09_brush_hair_u_nm_np1_ba_goo_0
+ | │ │--00001.png
+ | │ │--00002.png
+ │-- catch
+ │-- ...
+
+```
diff --git a/vendor/ViTPose/docs/zh_cn/tasks/2d_face_keypoint.md b/vendor/ViTPose/docs/zh_cn/tasks/2d_face_keypoint.md
new file mode 100644
index 0000000000000000000000000000000000000000..81655de425f2e309508a282b6fd2c56f7354c257
--- /dev/null
+++ b/vendor/ViTPose/docs/zh_cn/tasks/2d_face_keypoint.md
@@ -0,0 +1,3 @@
+# 2D人脸关键点数据集
+
+内容建设中……
diff --git a/vendor/ViTPose/docs/zh_cn/tasks/2d_fashion_landmark.md b/vendor/ViTPose/docs/zh_cn/tasks/2d_fashion_landmark.md
new file mode 100644
index 0000000000000000000000000000000000000000..25b7fd7c6484d8d1f876ecd13536dcc9764c7177
--- /dev/null
+++ b/vendor/ViTPose/docs/zh_cn/tasks/2d_fashion_landmark.md
@@ -0,0 +1,3 @@
+# 2D服装关键点数据集
+
+内容建设中……
diff --git a/vendor/ViTPose/docs/zh_cn/tasks/2d_hand_keypoint.md b/vendor/ViTPose/docs/zh_cn/tasks/2d_hand_keypoint.md
new file mode 100644
index 0000000000000000000000000000000000000000..61c3eb3fa4ab43b534dc75d26f128f14ced2588e
--- /dev/null
+++ b/vendor/ViTPose/docs/zh_cn/tasks/2d_hand_keypoint.md
@@ -0,0 +1,3 @@
+# 2D手部关键点数据集
+
+内容建设中……
diff --git a/vendor/ViTPose/docs/zh_cn/tasks/2d_wholebody_keypoint.md b/vendor/ViTPose/docs/zh_cn/tasks/2d_wholebody_keypoint.md
new file mode 100644
index 0000000000000000000000000000000000000000..23495ded145034e02420e8c564b4d90b10070c7a
--- /dev/null
+++ b/vendor/ViTPose/docs/zh_cn/tasks/2d_wholebody_keypoint.md
@@ -0,0 +1,3 @@
+# 2D全身人体关键点数据集
+
+内容建设中……
diff --git a/vendor/ViTPose/docs/zh_cn/tasks/3d_body_keypoint.md b/vendor/ViTPose/docs/zh_cn/tasks/3d_body_keypoint.md
new file mode 100644
index 0000000000000000000000000000000000000000..6ed59ffec74cdeac3561f35ab2d7c9f3181010a7
--- /dev/null
+++ b/vendor/ViTPose/docs/zh_cn/tasks/3d_body_keypoint.md
@@ -0,0 +1,3 @@
+# 3D人体关键点数据集
+
+内容建设中……
diff --git a/vendor/ViTPose/docs/zh_cn/tasks/3d_body_mesh.md b/vendor/ViTPose/docs/zh_cn/tasks/3d_body_mesh.md
new file mode 100644
index 0000000000000000000000000000000000000000..24d364803ef5dd08f6fad75aedf7b288ccb62080
--- /dev/null
+++ b/vendor/ViTPose/docs/zh_cn/tasks/3d_body_mesh.md
@@ -0,0 +1,3 @@
+# 3D人体网格模型数据集
+
+内容建设中……
diff --git a/vendor/ViTPose/docs/zh_cn/tasks/3d_hand_keypoint.md b/vendor/ViTPose/docs/zh_cn/tasks/3d_hand_keypoint.md
new file mode 100644
index 0000000000000000000000000000000000000000..b0843a9f8fb6b751d6d9735a9c3d3d91951d3624
--- /dev/null
+++ b/vendor/ViTPose/docs/zh_cn/tasks/3d_hand_keypoint.md
@@ -0,0 +1,3 @@
+# 3D手部关键点数据集
+
+内容建设中……
diff --git a/vendor/ViTPose/docs/zh_cn/tutorials/0_config.md b/vendor/ViTPose/docs/zh_cn/tutorials/0_config.md
new file mode 100644
index 0000000000000000000000000000000000000000..024f3c6d65ea31a57c37a0f6b3c0e17fa2625048
--- /dev/null
+++ b/vendor/ViTPose/docs/zh_cn/tutorials/0_config.md
@@ -0,0 +1,234 @@
+# 教程 0: 模型配置文件
+
+我们使用 python 文件作为配置文件,将模块化设计和继承设计结合到配置系统中,便于进行各种实验。
+您可以在 `$MMPose/configs` 下找到所有提供的配置。如果要检查配置文件,您可以运行
+`python tools/analysis/print_config.py /PATH/TO/CONFIG` 来查看完整的配置。
+
+
+
+- [通过脚本参数修改配置](#通过脚本参数修改配置)
+- [配置文件命名约定](#配置文件命名约定)
+ - [配置系统](#配置系统)
+- [常见问题](#常见问题)
+ - [在配置中使用中间变量](#在配置中使用中间变量)
+
+
+
+## 通过脚本参数修改配置
+
+当使用 "tools/train.py" 或 "tools/test.py" 提交作业时,您可以指定 `--cfg-options` 来修改配置。
+
+- 更新配置字典链的键值。
+
+ 可以按照原始配置文件中字典的键的顺序指定配置选项。
+ 例如,`--cfg-options model.backbone.norm_eval=False` 将主干网络中的所有 BN 模块更改为 `train` 模式。
+
+- 更新配置列表内部的键值。
+
+ 一些配置字典在配置文件中会形成一个列表。例如,训练流水线 `data.train.pipeline` 通常是一个列表。
+ 例如,`[dict(type='LoadImageFromFile'), dict(type='TopDownRandomFlip', flip_prob=0.5), ...]` 。如果要将流水线中的 `'flip_prob=0.5'` 更改为 `'flip_prob=0.0'`,您可以这样指定 `--cfg-options data.train.pipeline.1.flip_prob=0.0` 。
+
+- 更新列表 / 元组的值。
+
+ 如果要更新的值是列表或元组,例如,配置文件通常设置为 `workflow=[('train', 1)]` 。
+ 如果您想更改这个键,您可以这样指定 `--cfg-options workflow="[(train,1),(val,1)]"` 。
+ 请注意,引号 \" 是必要的,以支持列表 / 元组数据类型,并且指定值的引号内 **不允许** 有空格。
+
+## 配置文件命名约定
+
+我们按照下面的样式命名配置文件。建议贡献者也遵循同样的风格。
+
+```
+configs/{topic}/{task}/{algorithm}/{dataset}/{backbone}_[model_setting]_{dataset}_[input_size]_[technique].py
+```
+
+`{xxx}` 是必填字段,`[yyy]` 是可选字段.
+
+- `{topic}`: 主题类型,如 `body`, `face`, `hand`, `animal` 等。
+- `{task}`: 任务类型, `[2d | 3d]_[kpt | mesh]_[sview | mview]_[rgb | rgbd]_[img | vid]` 。任务类型从5个维度定义:(1)二维或三维姿态估计;(2)姿态表示形式:关键点 (kpt)、网格 (mesh) 或密集姿态 (dense); (3)单视图 (sview) 或多视图 (mview);(4)RGB 或 RGBD; 以及(5)图像 (img) 或视频 (vid)。例如, `2d_kpt_sview_rgb_img`, `3d_kpt_sview_rgb_vid`, 等等。
+- `{algorithm}`: 算法类型,例如,`associative_embedding`, `deeppose` 等。
+- `{dataset}`: 数据集名称,例如, `coco` 等。
+- `{backbone}`: 主干网络类型,例如,`res50` (ResNet-50) 等。
+- `[model setting]`: 对某些模型的特定设置。
+- `[input_size]`: 模型的输入大小。
+- `[technique]`: 一些特定的技术,包括损失函数,数据增强,训练技巧等,例如, `wingloss`, `udp`, `fp16` 等.
+
+### 配置系统
+
+- 基于热图的二维自顶向下的人体姿态估计实例
+
+ 为了帮助用户对完整的配置结构和配置系统中的模块有一个基本的了解,
+ 我们下面对配置文件 'https://github.com/open-mmlab/mmpose/tree/e1ec589884235bee875c89102170439a991f8450/configs/top_down/resnet/coco/res50_coco_256x192.py' 作简要的注释。
+ 有关每个模块中每个参数的更详细用法和替代方法,请参阅 API 文档。
+
+ ```python
+ # 运行设置
+ log_level = 'INFO' # 日志记录级别
+ load_from = None # 从给定路径加载预训练模型
+ resume_from = None # 从给定路径恢复模型权重文件,将从保存模型权重文件时的轮次开始继续训练
+ dist_params = dict(backend='nccl') # 设置分布式训练的参数,也可以设置端口
+ workflow = [('train', 1)] # 运行程序的工作流。[('train', 1)] 表示只有一个工作流,名为 'train' 的工作流执行一次
+ checkpoint_config = dict( # 设置模型权重文件钩子的配置,请参阅 https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/checkpoint.py 的实现
+ interval=10) # 保存模型权重文件的间隔
+ evaluation = dict( # 训练期间评估的配置
+ interval=10, # 执行评估的间隔
+ metric='mAP', # 采用的评价指标
+ key_indicator='AP') # 将 `AP` 设置为关键指标以保存最佳模型权重文件
+ # 优化器
+ optimizer = dict(
+ # 用于构建优化器的配置,支持 (1). PyTorch 中的所有优化器,
+ # 其参数也与 PyTorch 中的相同. (2). 自定义的优化器
+ # 它们通过 `constructor` 构建,可参阅 "tutorials/4_new_modules.md"
+ # 的实现。
+ type='Adam', # 优化器的类型, 可参阅 https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/optimizer/default_constructor.py#L13 获取更多细节
+ lr=5e-4, # 学习率, 参数的详细用法见 PyTorch 文档
+ )
+ optimizer_config = dict(grad_clip=None) # 不限制梯度的范围
+ # 学习率调整策略
+ lr_config = dict( # 用于注册 LrUpdater 钩子的学习率调度器的配置
+ policy='step', # 调整策略, 还支持 CosineAnnealing, Cyclic, 等等,请参阅 https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/lr_updater.py#L9 获取支持的 LrUpdater 细节
+ warmup='linear', # 使用的预热类型,它可以是 None (不使用预热), 'constant', 'linear' 或者 'exp'.
+ warmup_iters=500, # 预热的迭代次数或者轮数
+ warmup_ratio=0.001, # 预热开始时使用的学习率,等于预热比 (warmup_ratio) * 初始学习率
+ step=[170, 200]) # 降低学习率的步数
+ total_epochs = 210 # 训练模型的总轮数
+ log_config = dict( # 注册日志记录器钩子的配置
+ interval=50, # 打印日志的间隔
+ hooks=[
+ dict(type='TextLoggerHook'), # 用来记录训练过程的日志记录器
+ # dict(type='TensorboardLoggerHook') # 也支持 Tensorboard 日志记录器
+ ])
+
+ channel_cfg = dict(
+ num_output_channels=17, # 关键点头部的输出通道数
+ dataset_joints=17, # 数据集的关节数
+ dataset_channel=[ # 数据集支持的通道数
+ [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
+ ],
+ inference_channel=[ # 输出通道数
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
+ ])
+
+ # 模型设置
+ model = dict( # 模型的配置
+ type='TopDown', # 模型的类型
+ pretrained='torchvision://resnet50', # 预训练模型的 url / 网址
+ backbone=dict( # 主干网络的字典
+ type='ResNet', # 主干网络的名称
+ depth=50), # ResNet 模型的深度
+ keypoint_head=dict( # 关键点头部的字典
+ type='TopdownHeatmapSimpleHead', # 关键点头部的名称
+ in_channels=2048, # 关键点头部的输入通道数
+ out_channels=channel_cfg['num_output_channels'], # 关键点头部的输出通道数
+ loss_keypoint=dict( # 关键点损失函数的字典
+ type='JointsMSELoss', # 关键点损失函数的名称
+ use_target_weight=True)), # 在损失计算中是否考虑目标权重
+ train_cfg=dict(), # 训练超参数的配置
+ test_cfg=dict( # 测试超参数的配置
+ flip_test=True, # 推断时是否使用翻转测试
+ post_process='default', # 使用“默认” (default) 后处理方法。
+ shift_heatmap=True, # 移动并对齐翻转的热图以获得更高的性能
+ modulate_kernel=11)) # 用于调制的高斯核大小。仅用于 "post_process='unbiased'"
+
+ data_cfg = dict(
+ image_size=[192, 256], # 模型输入分辨率的大小
+ heatmap_size=[48, 64], # 输出热图的大小
+ num_output_channels=channel_cfg['num_output_channels'], # 输出通道数
+ num_joints=channel_cfg['dataset_joints'], # 关节点数量
+ dataset_channel=channel_cfg['dataset_channel'], # 数据集支持的通道数
+ inference_channel=channel_cfg['inference_channel'], # 输出通道数
+ soft_nms=False, # 推理过程中是否执行 soft_nms
+ nms_thr=1.0, # 非极大抑制阈值
+ oks_thr=0.9, # nms 期间 oks(对象关键点相似性)得分阈值
+ vis_thr=0.2, # 关键点可见性阈值
+ use_gt_bbox=False, # 测试时是否使用人工标注的边界框
+ det_bbox_thr=0.0, # 检测到的边界框分数的阈值。当 'use_gt_bbox=True' 时使用
+ bbox_file='data/coco/person_detection_results/' # 边界框检测文件的路径
+ 'COCO_val2017_detections_AP_H_56_person.json',
+ )
+
+ train_pipeline = [
+ dict(type='LoadImageFromFile'), # 从文件加载图像
+ dict(type='TopDownRandomFlip', # 执行随机翻转增强
+ flip_prob=0.5), # 执行翻转的概率
+ dict(
+ type='TopDownHalfBodyTransform', # TopDownHalfBodyTransform 数据增强的配置
+ num_joints_half_body=8, # 执行半身变换的阈值
+ prob_half_body=0.3), # 执行翻转的概率
+ dict(
+ type='TopDownGetRandomScaleRotation', # TopDownGetRandomScaleRotation 的配置
+ rot_factor=40, # 旋转到 ``[-2*rot_factor, 2*rot_factor]``.
+ scale_factor=0.5), # 缩放到 ``[1-scale_factor, 1+scale_factor]``.
+ dict(type='TopDownAffine', # 对图像进行仿射变换形成输入
+ use_udp=False), # 不使用无偏数据处理
+ dict(type='ToTensor'), # 将其他类型转换为张量类型流水线
+ dict(
+ type='NormalizeTensor', # 标准化输入张量
+ mean=[0.485, 0.456, 0.406], # 要标准化的不同通道的平均值
+ std=[0.229, 0.224, 0.225]), # 要标准化的不同通道的标准差
+ dict(type='TopDownGenerateTarget', # 生成热图目标。支持不同的编码类型
+ sigma=2), # 热图高斯的 Sigma
+ dict(
+ type='Collect', # 收集决定数据中哪些键应该传递到检测器的流水线
+ keys=['img', 'target', 'target_weight'], # 输入键
+ meta_keys=[ # 输入的元键
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+ ]
+
+ val_pipeline = [
+ dict(type='LoadImageFromFile'), # 从文件加载图像
+ dict(type='TopDownAffine'), # 对图像进行仿射变换形成输入
+ dict(type='ToTensor'), # ToTensor 的配置
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406], # 要标准化的不同通道的平均值
+ std=[0.229, 0.224, 0.225]), # 要标准化的不同通道的标准差
+ dict(
+ type='Collect', # 收集决定数据中哪些键应该传递到检测器的流水线
+ keys=['img'], # 输入键
+ meta_keys=[ # 输入的元键
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+ ]
+
+ test_pipeline = val_pipeline
+
+ data_root = 'data/coco' # 数据集的配置
+ data = dict(
+ samples_per_gpu=64, # 训练期间每个 GPU 的 Batch size
+ workers_per_gpu=2, # 每个 GPU 预取数据的 worker 个数
+ val_dataloader=dict(samples_per_gpu=32), # 验证期间每个 GPU 的 Batch size
+ test_dataloader=dict(samples_per_gpu=32), # 测试期间每个 GPU 的 Batch size
+ train=dict( # 训练数据集的配置
+ type='TopDownCocoDataset', # 数据集的名称
+ ann_file=f'{data_root}/annotations/person_keypoints_train2017.json', # 标注文件的路径
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline),
+ val=dict( # 验证数据集的配置
+ type='TopDownCocoDataset', # 数据集的名称
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json', # 标注文件的路径
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline),
+ test=dict( # 测试数据集的配置
+ type='TopDownCocoDataset', # 数据集的名称
+ ann_file=f'{data_root}/annotations/person_keypoints_val2017.json', # 标注文件的路径
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline),
+ )
+
+ ```
+
+## 常见问题
+
+### 在配置中使用中间变量
+
+配置文件中使用了一些中间变量,如 `train_pipeline`/`val_pipeline`/`test_pipeline` 等。
+
+例如,我们首先要定义 `train_pipeline`/`val_pipeline`/`test_pipeline`,然后将它们传递到 `data` 中。
+因此,`train_pipeline`/`val_pipeline`/`test_pipeline` 是中间变量。
diff --git a/vendor/ViTPose/docs/zh_cn/tutorials/1_finetune.md b/vendor/ViTPose/docs/zh_cn/tutorials/1_finetune.md
new file mode 100644
index 0000000000000000000000000000000000000000..55c2f55194acec73a88d3856ff40aaaec06e2b3c
--- /dev/null
+++ b/vendor/ViTPose/docs/zh_cn/tutorials/1_finetune.md
@@ -0,0 +1,153 @@
+# 教程 1:如何微调模型
+
+在 COCO 数据集上进行预训练,然后在其他数据集(如 COCO-WholeBody 数据集)上进行微调,往往可以提升模型的效果。
+本教程介绍如何使用[模型库](https://mmpose.readthedocs.io/en/latest/modelzoo.html)中的预训练模型,并在其他数据集上进行微调。
+
+
+
+- [概要](#概要)
+- [修改 Head](#修改网络头)
+- [修改数据集](#修改数据集)
+- [修改训练策略](#修改训练策略)
+- [使用预训练模型](#使用预训练模型)
+
+
+
+## 概要
+
+对新数据集上的模型微调需要两个步骤:
+
+1. 支持新数据集。详情参见 [教程 2:如何增加新数据集](2_new_dataset.md)
+2. 修改配置文件。这部分将在本教程中做具体讨论。
+
+例如,如果想要在自定义数据集上,微调 COCO 预训练的模型,则需要修改 [配置文件](0_config.md) 中 网络头、数据集、训练策略、预训练模型四个部分。
+
+## 修改网络头
+
+如果自定义数据集的关键点个数,与 COCO 不同,则需要相应修改 `keypoint_head` 中的 `out_channels` 参数。
+网络头(head)的最后一层的预训练参数不会被载入,而其他层的参数都会被正常载入。
+例如,COCO-WholeBody 拥有 133 个关键点,因此需要把 17 (COCO 数据集的关键点数目) 改为 133。
+
+```python
+channel_cfg = dict(
+ num_output_channels=133, # 从 17 改为 133
+ dataset_joints=133, # 从 17 改为 133
+ dataset_channel=[
+ list(range(133)), # 从 17 改为 133
+ ],
+ inference_channel=list(range(133))) # 从 17 改为 133
+
+# model settings
+model = dict(
+ type='TopDown',
+ pretrained='https://download.openmmlab.com/mmpose/'
+ 'pretrain_models/hrnet_w48-8ef0771d.pth',
+ backbone=dict(
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(48, 96)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(48, 96, 192)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(48, 96, 192, 384))),
+ ),
+ keypoint_head=dict(
+ type='TopdownHeatmapSimpleHead',
+ in_channels=48,
+ out_channels=channel_cfg['num_output_channels'], # 已对应修改
+ num_deconv_layers=0,
+ extra=dict(final_conv_kernel=1, ),
+ loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
+ train_cfg=dict(),
+ test_cfg=dict(
+ flip_test=True,
+ post_process='unbiased',
+ shift_heatmap=True,
+ modulate_kernel=17))
+```
+
+其中, `pretrained='https://download.openmmlab.com/mmpose/pretrain_models/hrnet_w48-8ef0771d.pth'` 表示采用 ImageNet 预训练的权重,初始化主干网络(backbone)。
+不过,`pretrained` 只会初始化主干网络(backbone),而不会初始化网络头(head)。因此,我们模型微调时的预训练权重一般通过 `load_from` 指定,而不是使用 `pretrained` 指定。
+
+## 支持自己的数据集
+
+MMPose 支持十余种不同的数据集,包括 COCO, COCO-WholeBody, MPII, MPII-TRB 等数据集。
+用户可将自定义数据集转换为已有数据集格式,并修改如下字段。
+
+```python
+data_root = 'data/coco'
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=32),
+ test_dataloader=dict(samples_per_gpu=32),
+ train=dict(
+ type='TopDownCocoWholeBodyDataset', # 对应修改数据集名称
+ ann_file=f'{data_root}/annotations/coco_wholebody_train_v1.0.json', # 修改数据集标签路径
+ img_prefix=f'{data_root}/train2017/',
+ data_cfg=data_cfg,
+ pipeline=train_pipeline),
+ val=dict(
+ type='TopDownCocoWholeBodyDataset', # 对应修改数据集名称
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json', # 修改数据集标签路径
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline),
+ test=dict(
+ type='TopDownCocoWholeBodyDataset', # 对应修改数据集名称
+ ann_file=f'{data_root}/annotations/coco_wholebody_val_v1.0.json', # 修改数据集标签路径
+ img_prefix=f'{data_root}/val2017/',
+ data_cfg=data_cfg,
+ pipeline=val_pipeline)
+)
+```
+
+## 修改训练策略
+
+通常情况下,微调模型时设置较小的学习率和训练轮数,即可取得较好效果。
+
+```python
+# 优化器
+optimizer = dict(
+ type='Adam',
+ lr=5e-4, # 可以适当减小
+)
+optimizer_config = dict(grad_clip=None)
+# 学习策略
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[170, 200]) # 可以适当减小
+total_epochs = 210 # 可以适当减小
+```
+
+## 使用预训练模型
+
+网络设置中的 `pretrained`,仅会在主干网络模型上加载预训练参数。若要载入整个网络的预训练参数,需要通过 `load_from` 指定模型文件路径或模型链接。
+
+```python
+# 将预训练模型用于整个 HRNet 网络
+load_from = 'https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_384x288_dark-741844ba_20200812.pth' # 模型路径可以在 model zoo 中找到
+```
diff --git a/vendor/ViTPose/docs/zh_cn/tutorials/2_new_dataset.md b/vendor/ViTPose/docs/zh_cn/tutorials/2_new_dataset.md
new file mode 100644
index 0000000000000000000000000000000000000000..53d43062d2f407fc7396bcba6821a60369df412f
--- /dev/null
+++ b/vendor/ViTPose/docs/zh_cn/tutorials/2_new_dataset.md
@@ -0,0 +1,316 @@
+# 教程 2: 增加新的数据集
+
+## 将数据集转化为COCO格式
+
+我们首先需要将自定义数据集,转换为COCO数据集格式。
+
+COCO数据集格式的json标注文件有以下关键字:
+
+```python
+'images': [
+ {
+ 'file_name': '000000001268.jpg',
+ 'height': 427,
+ 'width': 640,
+ 'id': 1268
+ },
+ ...
+],
+'annotations': [
+ {
+ 'segmentation': [[426.36,
+ ...
+ 424.34,
+ 223.3]],
+ 'keypoints': [0,0,0,
+ 0,0,0,
+ 0,0,0,
+ 427,220,2,
+ 443,222,2,
+ 414,228,2,
+ 449,232,2,
+ 408,248,1,
+ 454,261,2,
+ 0,0,0,
+ 0,0,0,
+ 411,287,2,
+ 431,287,2,
+ 0,0,0,
+ 458,265,2,
+ 0,0,0,
+ 466,300,1],
+ 'num_keypoints': 10,
+ 'area': 3894.5826,
+ 'iscrowd': 0,
+ 'image_id': 1268,
+ 'bbox': [402.34, 205.02, 65.26, 88.45],
+ 'category_id': 1,
+ 'id': 215218
+ },
+ ...
+],
+'categories': [
+ {'id': 1, 'name': 'person'},
+ ]
+```
+
+Json文件中必须包含以下三个关键字:
+
+- `images`: 包含图片信息的列表,提供图片的 `file_name`, `height`, `width` 和 `id` 等信息。
+- `annotations`: 包含实例标注的列表。
+- `categories`: 包含类别名称 ('person') 和对应的 ID (1)。
+
+## 为自定义数据集创建 dataset_info 数据集配置文件
+
+在如下位置,添加一个数据集配置文件。
+
+```
+configs/_base_/datasets/custom.py
+```
+
+数据集配置文件的样例如下:
+
+`keypoint_info` 包含每个关键点的信息,其中:
+
+1. `name`: 代表关键点的名称。一个数据集的每个关键点,名称必须唯一。
+2. `id`: 关键点的标识号。
+3. `color`: ([B, G, R]) 用于可视化关键点。
+4. `type`: 分为 'upper' 和 'lower' 两种,用于数据增强。
+5. `swap`: 表示与当前关键点,“镜像对称”的关键点名称。
+
+`skeleton_info` 包含关键点之间的连接关系,主要用于可视化。
+
+`joint_weights` 可以为不同的关键点设置不同的损失权重,用于训练。
+
+`sigmas` 用于计算 OKS 得分,具体内容请参考 [keypoints-eval](https://cocodataset.org/#keypoints-eval)。
+
+```
+dataset_info = dict(
+ dataset_name='coco',
+ paper_info=dict(
+ author='Lin, Tsung-Yi and Maire, Michael and '
+ 'Belongie, Serge and Hays, James and '
+ 'Perona, Pietro and Ramanan, Deva and '
+ r'Doll{\'a}r, Piotr and Zitnick, C Lawrence',
+ title='Microsoft coco: Common objects in context',
+ container='European conference on computer vision',
+ year='2014',
+ homepage='http://cocodataset.org/',
+ ),
+ keypoint_info={
+ 0:
+ dict(name='nose', id=0, color=[51, 153, 255], type='upper', swap=''),
+ 1:
+ dict(
+ name='left_eye',
+ id=1,
+ color=[51, 153, 255],
+ type='upper',
+ swap='right_eye'),
+ 2:
+ dict(
+ name='right_eye',
+ id=2,
+ color=[51, 153, 255],
+ type='upper',
+ swap='left_eye'),
+ 3:
+ dict(
+ name='left_ear',
+ id=3,
+ color=[51, 153, 255],
+ type='upper',
+ swap='right_ear'),
+ 4:
+ dict(
+ name='right_ear',
+ id=4,
+ color=[51, 153, 255],
+ type='upper',
+ swap='left_ear'),
+ 5:
+ dict(
+ name='left_shoulder',
+ id=5,
+ color=[0, 255, 0],
+ type='upper',
+ swap='right_shoulder'),
+ 6:
+ dict(
+ name='right_shoulder',
+ id=6,
+ color=[255, 128, 0],
+ type='upper',
+ swap='left_shoulder'),
+ 7:
+ dict(
+ name='left_elbow',
+ id=7,
+ color=[0, 255, 0],
+ type='upper',
+ swap='right_elbow'),
+ 8:
+ dict(
+ name='right_elbow',
+ id=8,
+ color=[255, 128, 0],
+ type='upper',
+ swap='left_elbow'),
+ 9:
+ dict(
+ name='left_wrist',
+ id=9,
+ color=[0, 255, 0],
+ type='upper',
+ swap='right_wrist'),
+ 10:
+ dict(
+ name='right_wrist',
+ id=10,
+ color=[255, 128, 0],
+ type='upper',
+ swap='left_wrist'),
+ 11:
+ dict(
+ name='left_hip',
+ id=11,
+ color=[0, 255, 0],
+ type='lower',
+ swap='right_hip'),
+ 12:
+ dict(
+ name='right_hip',
+ id=12,
+ color=[255, 128, 0],
+ type='lower',
+ swap='left_hip'),
+ 13:
+ dict(
+ name='left_knee',
+ id=13,
+ color=[0, 255, 0],
+ type='lower',
+ swap='right_knee'),
+ 14:
+ dict(
+ name='right_knee',
+ id=14,
+ color=[255, 128, 0],
+ type='lower',
+ swap='left_knee'),
+ 15:
+ dict(
+ name='left_ankle',
+ id=15,
+ color=[0, 255, 0],
+ type='lower',
+ swap='right_ankle'),
+ 16:
+ dict(
+ name='right_ankle',
+ id=16,
+ color=[255, 128, 0],
+ type='lower',
+ swap='left_ankle')
+ },
+ skeleton_info={
+ 0:
+ dict(link=('left_ankle', 'left_knee'), id=0, color=[0, 255, 0]),
+ 1:
+ dict(link=('left_knee', 'left_hip'), id=1, color=[0, 255, 0]),
+ 2:
+ dict(link=('right_ankle', 'right_knee'), id=2, color=[255, 128, 0]),
+ 3:
+ dict(link=('right_knee', 'right_hip'), id=3, color=[255, 128, 0]),
+ 4:
+ dict(link=('left_hip', 'right_hip'), id=4, color=[51, 153, 255]),
+ 5:
+ dict(link=('left_shoulder', 'left_hip'), id=5, color=[51, 153, 255]),
+ 6:
+ dict(link=('right_shoulder', 'right_hip'), id=6, color=[51, 153, 255]),
+ 7:
+ dict(
+ link=('left_shoulder', 'right_shoulder'),
+ id=7,
+ color=[51, 153, 255]),
+ 8:
+ dict(link=('left_shoulder', 'left_elbow'), id=8, color=[0, 255, 0]),
+ 9:
+ dict(
+ link=('right_shoulder', 'right_elbow'), id=9, color=[255, 128, 0]),
+ 10:
+ dict(link=('left_elbow', 'left_wrist'), id=10, color=[0, 255, 0]),
+ 11:
+ dict(link=('right_elbow', 'right_wrist'), id=11, color=[255, 128, 0]),
+ 12:
+ dict(link=('left_eye', 'right_eye'), id=12, color=[51, 153, 255]),
+ 13:
+ dict(link=('nose', 'left_eye'), id=13, color=[51, 153, 255]),
+ 14:
+ dict(link=('nose', 'right_eye'), id=14, color=[51, 153, 255]),
+ 15:
+ dict(link=('left_eye', 'left_ear'), id=15, color=[51, 153, 255]),
+ 16:
+ dict(link=('right_eye', 'right_ear'), id=16, color=[51, 153, 255]),
+ 17:
+ dict(link=('left_ear', 'left_shoulder'), id=17, color=[51, 153, 255]),
+ 18:
+ dict(
+ link=('right_ear', 'right_shoulder'), id=18, color=[51, 153, 255])
+ },
+ joint_weights=[
+ 1., 1., 1., 1., 1., 1., 1., 1.2, 1.2, 1.5, 1.5, 1., 1., 1.2, 1.2, 1.5,
+ 1.5
+ ],
+ sigmas=[
+ 0.026, 0.025, 0.025, 0.035, 0.035, 0.079, 0.079, 0.072, 0.072, 0.062,
+ 0.062, 0.107, 0.107, 0.087, 0.087, 0.089, 0.089
+ ])
+```
+
+## 创建自定义数据集类
+
+1. 首先在 mmpose/datasets/datasets 文件夹创建一个包,比如命名为 custom。
+
+2. 定义数据集类,并且注册这个类。
+
+ ```
+ @DATASETS.register_module(name='MyCustomDataset')
+ class MyCustomDataset(SomeOtherBaseClassAsPerYourNeed):
+ ```
+
+3. 为你的自定义类别创建 `mmpose/datasets/datasets/custom/__init__.py`
+
+4. 更新 `mmpose/datasets/__init__.py`
+
+## 创建和修改训练配置文件
+
+创建和修改训练配置文件,来使用你的自定义数据集。
+
+在 `configs/my_custom_config.py` 中,修改如下几行。
+
+```python
+...
+# dataset settings
+dataset_type = 'MyCustomDataset'
+...
+data = dict(
+ samples_per_gpu=2,
+ workers_per_gpu=2,
+ train=dict(
+ type=dataset_type,
+ ann_file='path/to/your/train/json',
+ img_prefix='path/to/your/train/img',
+ ...),
+ val=dict(
+ type=dataset_type,
+ ann_file='path/to/your/val/json',
+ img_prefix='path/to/your/val/img',
+ ...),
+ test=dict(
+ type=dataset_type,
+ ann_file='path/to/your/test/json',
+ img_prefix='path/to/your/test/img',
+ ...))
+...
+```
diff --git a/vendor/ViTPose/docs/zh_cn/tutorials/3_data_pipeline.md b/vendor/ViTPose/docs/zh_cn/tutorials/3_data_pipeline.md
new file mode 100644
index 0000000000000000000000000000000000000000..d2d48662ae53e7e3a7ba60f61f612ea1e227107d
--- /dev/null
+++ b/vendor/ViTPose/docs/zh_cn/tutorials/3_data_pipeline.md
@@ -0,0 +1,151 @@
+# 教程 3: 自定义数据前处理流水线
+
+## 设计数据前处理流水线
+
+参照惯例,MMPose 使用 `Dataset` 和 `DataLoader` 实现多进程数据加载。
+`Dataset` 返回一个字典,作为模型的输入。
+由于姿态估计任务的数据大小不一定相同(图片大小,边界框大小等),MMPose 使用 MMCV 中的 `DataContainer` 收集和分配不同大小的数据。
+详情可见[此处](https://github.com/open-mmlab/mmcv/blob/master/mmcv/parallel/data_container.py)。
+
+数据前处理流水线和数据集是相互独立的。
+通常,数据集定义如何处理标注文件,而数据前处理流水线将原始数据处理成网络输入。
+数据前处理流水线包含一系列操作。
+每个操作都输入一个字典(dict),新增/更新/删除相关字段,最终输出更新后的字典作为下一个操作的输入。
+
+数据前处理流水线的操作可以被分类为数据加载、预处理、格式化和生成监督等(后文将详细介绍)。
+
+这里以 Simple Baseline (ResNet50) 的数据前处理流水线为例:
+
+```python
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(type='TopDownHalfBodyTransform', num_joints_half_body=8, prob_half_body=0.3),
+ dict(type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+]
+
+val_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownAffine'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'image_file', 'center', 'scale', 'rotation', 'bbox_score',
+ 'flip_pairs'
+ ]),
+]
+```
+
+下面列出每个操作新增/更新/删除的相关字典字段。
+
+### 数据加载
+
+`LoadImageFromFile`
+
+- 新增: img, img_file
+
+### 预处理
+
+`TopDownRandomFlip`
+
+- 更新: img, joints_3d, joints_3d_visible, center
+
+`TopDownHalfBodyTransform`
+
+- 更新: center, scale
+
+`TopDownGetRandomScaleRotation`
+
+- 更新: scale, rotation
+
+`TopDownAffine`
+
+- 更新: img, joints_3d, joints_3d_visible
+
+`NormalizeTensor`
+
+- 更新: img
+
+### 生成监督
+
+`TopDownGenerateTarget`
+
+- 新增: target, target_weight
+
+### 格式化
+
+`ToTensor`
+
+- 更新: 'img'
+
+`Collect`
+
+- 新增: img_meta (其包含的字段由 `meta_keys` 指定)
+- 删除: 除了 `keys` 指定以外的所有字段
+
+## 扩展和使用自定义流水线
+
+1. 将一个新的处理流水线操作写入任一文件中,例如 `my_pipeline.py`。它以一个字典作为输入,并返回一个更新后的字典。
+
+ ```python
+ from mmpose.datasets import PIPELINES
+
+ @PIPELINES.register_module()
+ class MyTransform:
+
+ def __call__(self, results):
+ results['dummy'] = True
+ return results
+ ```
+
+1. 导入定义好的新类。
+
+ ```python
+ from .my_pipeline import MyTransform
+ ```
+
+1. 在配置文件中使用它。
+
+ ```python
+ train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='TopDownRandomFlip', flip_prob=0.5),
+ dict(type='TopDownHalfBodyTransform', num_joints_half_body=8, prob_half_body=0.3),
+ dict(type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
+ dict(type='TopDownAffine'),
+ dict(type='MyTransform'),
+ dict(type='ToTensor'),
+ dict(
+ type='NormalizeTensor',
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]),
+ dict(type='TopDownGenerateTarget', sigma=2),
+ dict(
+ type='Collect',
+ keys=['img', 'target', 'target_weight'],
+ meta_keys=[
+ 'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
+ 'rotation', 'bbox_score', 'flip_pairs'
+ ]),
+ ]
+ ```
diff --git a/vendor/ViTPose/docs/zh_cn/tutorials/4_new_modules.md b/vendor/ViTPose/docs/zh_cn/tutorials/4_new_modules.md
new file mode 100644
index 0000000000000000000000000000000000000000..4a8db97c4bc2fb943240535896b15d1784bd9314
--- /dev/null
+++ b/vendor/ViTPose/docs/zh_cn/tutorials/4_new_modules.md
@@ -0,0 +1,214 @@
+# 教程 4: 增加新的模块
+
+## 自定义优化器
+
+在本教程中,我们将介绍如何为项目定制优化器.
+假设想要添加一个名为 `MyOptimizer` 的优化器,它有 `a`,`b` 和 `c` 三个参数。
+那么首先需要在一个文件中实现该优化器,例如 `mmpose/core/optimizer/my_optimizer.py`:
+
+```python
+from mmcv.runner import OPTIMIZERS
+from torch.optim import Optimizer
+
+
+@OPTIMIZERS.register_module()
+class MyOptimizer(Optimizer):
+
+ def __init__(self, a, b, c)
+
+```
+
+然后需要将其添加到 `mmpose/core/optimizer/__init__.py` 中,从而让注册器可以找到这个新的优化器并添加它:
+
+```python
+from .my_optimizer import MyOptimizer
+```
+
+之后,可以在配置文件的 `optimizer` 字段中使用 `MyOptimizer`。
+在配置中,优化器由 `optimizer` 字段所定义,如下所示:
+
+```python
+optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
+```
+
+若要使用自己新定义的优化器,可以将字段修改为:
+
+```python
+optimizer = dict(type='MyOptimizer', a=a_value, b=b_value, c=c_value)
+```
+
+我们已经支持使用 PyTorch 实现的所有优化器,
+只需要更改配置文件的 `optimizer` 字段。
+例如:若用户想要使用`ADAM`优化器,只需要做出如下修改,虽然这会造成网络效果下降。
+
+```python
+optimizer = dict(type='Adam', lr=0.0003, weight_decay=0.0001)
+```
+
+用户可以直接根据 [PyTorch API 文档](https://pytorch.org/docs/stable/optim.html?highlight=optim#module-torch.optim)
+对参数进行设置。
+
+## 自定义优化器构造器
+
+某些模型可能对不同层的参数有特定的优化设置,例如 BatchNorm 层的权值衰减。
+用户可以通过自定义优化器构造函数来进行这些细粒度的参数调整。
+
+```python
+from mmcv.utils import build_from_cfg
+
+from mmcv.runner import OPTIMIZER_BUILDERS, OPTIMIZERS
+from mmpose.utils import get_root_logger
+from .cocktail_optimizer import CocktailOptimizer
+
+
+@OPTIMIZER_BUILDERS.register_module()
+class CocktailOptimizerConstructor:
+
+ def __init__(self, optimizer_cfg, paramwise_cfg=None):
+
+ def __call__(self, model):
+
+ return my_optimizer
+
+```
+
+## 开发新组件
+
+MMPose 将模型组件分为 3 种基础模型:
+
+- 检测器(detector):整个检测器模型流水线,通常包含一个主干网络(backbone)和关键点头(keypoint_head)。
+- 主干网络(backbone):通常为一个用于提取特征的 FCN 网络,例如 ResNet,HRNet。
+- 关键点头(keypoint_head):用于姿势估计的组件,通常包括一系列反卷积层。
+
+1. 创建一个新文件 `mmpose/models/backbones/my_model.py`.
+
+```python
+import torch.nn as nn
+
+from ..builder import BACKBONES
+
+@BACKBONES.register_module()
+class MyModel(nn.Module):
+
+ def __init__(self, arg1, arg2):
+ pass
+
+ def forward(self, x): # should return a tuple
+ pass
+
+ def init_weights(self, pretrained=None):
+ pass
+```
+
+2. 在 `mmpose/models/backbones/__init__.py` 中导入新的主干网络.
+
+```python
+from .my_model import MyModel
+```
+
+3. 创建一个新文件 `mmpose/models/keypoint_heads/my_head.py`.
+
+用户可以通过继承 `nn.Module` 编写一个新的关键点头,
+并重写 `init_weights(self)` 和 `forward(self, x)` 方法。
+
+```python
+from ..builder import HEADS
+
+
+@HEADS.register_module()
+class MyHead(nn.Module):
+
+ def __init__(self, arg1, arg2):
+ pass
+
+ def forward(self, x):
+ pass
+
+ def init_weights(self):
+ pass
+```
+
+4. 在 `mmpose/models/keypoint_heads/__init__.py` 中导入新的关键点头
+
+```python
+from .my_head import MyHead
+```
+
+5. 在配置文件中使用它。
+
+对于自顶向下的 2D 姿态估计模型,我们将模型类型设置为 `TopDown`。
+
+```python
+model = dict(
+ type='TopDown',
+ backbone=dict(
+ type='MyModel',
+ arg1=xxx,
+ arg2=xxx),
+ keypoint_head=dict(
+ type='MyHead',
+ arg1=xxx,
+ arg2=xxx))
+```
+
+### 添加新的损失函数
+
+假设用户想要为关键点估计添加一个名为 `MyLoss`的新损失函数。
+为了添加一个新的损失函数,用户需要在 `mmpose/models/losses/my_loss.py` 下实现该函数。
+其中,装饰器 `weighted_loss` 使损失函数能够为每个元素加权。
+
+```python
+import torch
+import torch.nn as nn
+
+from mmpose.models import LOSSES
+
+def my_loss(pred, target):
+ assert pred.size() == target.size() and target.numel() > 0
+ loss = torch.abs(pred - target)
+ loss = torch.mean(loss)
+ return loss
+
+@LOSSES.register_module()
+class MyLoss(nn.Module):
+
+ def __init__(self, use_target_weight=False):
+ super(MyLoss, self).__init__()
+ self.criterion = my_loss()
+ self.use_target_weight = use_target_weight
+
+ def forward(self, output, target, target_weight):
+ batch_size = output.size(0)
+ num_joints = output.size(1)
+
+ heatmaps_pred = output.reshape(
+ (batch_size, num_joints, -1)).split(1, 1)
+ heatmaps_gt = target.reshape((batch_size, num_joints, -1)).split(1, 1)
+
+ loss = 0.
+
+ for idx in range(num_joints):
+ heatmap_pred = heatmaps_pred[idx].squeeze(1)
+ heatmap_gt = heatmaps_gt[idx].squeeze(1)
+ if self.use_target_weight:
+ loss += self.criterion(
+ heatmap_pred * target_weight[:, idx],
+ heatmap_gt * target_weight[:, idx])
+ else:
+ loss += self.criterion(heatmap_pred, heatmap_gt)
+
+ return loss / num_joints
+```
+
+之后,用户需要把它添加进 `mmpose/models/losses/__init__.py`。
+
+```python
+from .my_loss import MyLoss, my_loss
+
+```
+
+若要使用新的损失函数,可以修改模型中的 `loss_keypoint` 字段。
+
+```python
+loss_keypoint=dict(type='MyLoss', use_target_weight=False)
+```
diff --git a/vendor/ViTPose/docs/zh_cn/tutorials/5_export_model.md b/vendor/ViTPose/docs/zh_cn/tutorials/5_export_model.md
new file mode 100644
index 0000000000000000000000000000000000000000..341d79acb4cb68cfc3ece54771d774c3eb7c1783
--- /dev/null
+++ b/vendor/ViTPose/docs/zh_cn/tutorials/5_export_model.md
@@ -0,0 +1,48 @@
+# 教程 5:如何导出模型为 onnx 格式
+
+开放式神经网络交换格式(Open Neural Network Exchange,即 [ONNX](https://onnx.ai/))是各种框架共用的一种模型交换格式,AI 开发人员可以方便将模型部署到所需的框架之中。
+
+
+
+- [支持的模型](#支持的模型)
+- [如何使用](#如何使用)
+ - [准备工作](#准备工作)
+
+
+
+## 支持的模型
+
+MMPose 支持将训练好的各种 Pytorch 模型导出为 ONNX 格式。支持的模型包括但不限于:
+
+- ResNet
+- HRNet
+- HigherHRNet
+
+## 如何使用
+
+用户可以使用这里的 [脚本](/tools/deployment/pytorch2onnx.py) 来导出 ONNX 格式。
+
+### 准备工作
+
+首先,安装 onnx
+
+```shell
+pip install onnx onnxruntime
+```
+
+MMPose 提供了一个 python 脚本,将 MMPose 训练的 pytorch 模型导出到 ONNX。
+
+```shell
+python tools/deployment/pytorch2onnx.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [--shape ${SHAPE}] \
+ [--verify] [--show] [--output-file ${OUTPUT_FILE}] [--is-localizer] [--opset-version ${VERSION}]
+```
+
+可选参数:
+
+- `--shape`: 模型输入张量的形状。对于 2D 关键点检测模型(如 HRNet),输入形状应当为 `$batch $channel $height $width` (例如,`1 3 256 192`);
+- `--verify`: 是否对导出模型进行验证,验证项包括是否可运行,数值是否正确等。如果没有手动指定,默认为 `False`。
+- `--show`: 是否打印导出模型的结构。如果没有手动指定,默认为 `False`。
+- `--output-file`: 导出的 onnx 模型名。如果没有手动指定,默认为 `tmp.onnx`。
+- `--opset-version`:决定 onnx 的执行版本,MMPose 推荐用户使用高版本(例如 11 版本)的 onnx 以确保稳定性。如果没有手动指定,默认为 `11`。
+
+如果发现提供的模型权重文件没有被成功导出,或者存在精度损失,可以在本 repo 下提出问题(issue)。
diff --git a/vendor/ViTPose/docs/zh_cn/tutorials/6_customize_runtime.md b/vendor/ViTPose/docs/zh_cn/tutorials/6_customize_runtime.md
new file mode 100644
index 0000000000000000000000000000000000000000..979ba8a95e975ea6362e9c7490c26e832787ebe8
--- /dev/null
+++ b/vendor/ViTPose/docs/zh_cn/tutorials/6_customize_runtime.md
@@ -0,0 +1,3 @@
+# 教程 6: 自定义运行时设置
+
+内容建设中……
diff --git a/vendor/ViTPose/docs/zh_cn/useful_tools.md b/vendor/ViTPose/docs/zh_cn/useful_tools.md
new file mode 100644
index 0000000000000000000000000000000000000000..a85f7a1e45571ca0d4e7cde5042b4ea93441ebf4
--- /dev/null
+++ b/vendor/ViTPose/docs/zh_cn/useful_tools.md
@@ -0,0 +1,3 @@
+# 常用工具
+
+内容建设中……
diff --git a/vendor/ViTPose/figures/Throughput.png b/vendor/ViTPose/figures/Throughput.png
new file mode 100644
index 0000000000000000000000000000000000000000..b13edca0906b38a3f16a7206db867b1b7d7591ef
Binary files /dev/null and b/vendor/ViTPose/figures/Throughput.png differ
diff --git a/vendor/ViTPose/logs/vitpose-b-simple.log.json b/vendor/ViTPose/logs/vitpose-b-simple.log.json
new file mode 100644
index 0000000000000000000000000000000000000000..03a8b909296919cee3308be3562de0edefbeb651
--- /dev/null
+++ b/vendor/ViTPose/logs/vitpose-b-simple.log.json
@@ -0,0 +1,1072 @@
+{"env_info": "sys.platform: linux\nPython: 3.8.10 | packaged by conda-forge | (default, May 11 2021, 07:01:05) [GCC 9.3.0]\nCUDA available: True\nGPU 0,1,2,3,4,5,6,7: A100-SXM4-40GB\nCUDA_HOME: /usr/local/cuda\nNVCC: Build cuda_11.3.r11.3/compiler.29920130_0\nGCC: gcc (Ubuntu 9.3.0-17ubuntu1~20.04) 9.3.0\nPyTorch: 1.9.0a0+c3d40fd\nPyTorch compiling details: PyTorch built with:\n - GCC 9.3\n - C++ Version: 201402\n - Intel(R) Math Kernel Library Version 2019.0.5 Product Build 20190808 for Intel(R) 64 architecture applications\n - Intel(R) MKL-DNN v2.1.2 (Git Hash N/A)\n - OpenMP 201511 (a.k.a. OpenMP 4.5)\n - NNPACK is enabled\n - CPU capability usage: AVX2\n - CUDA Runtime 11.3\n - NVCC architecture flags: -gencode;arch=compute_52,code=sm_52;-gencode;arch=compute_60,code=sm_60;-gencode;arch=compute_61,code=sm_61;-gencode;arch=compute_70,code=sm_70;-gencode;arch=compute_75,code=sm_75;-gencode;arch=compute_80,code=sm_80;-gencode;arch=compute_86,code=sm_86;-gencode;arch=compute_86,code=compute_86\n - CuDNN 8.2.1\n - Magma 2.5.2\n - Build settings: BLAS_INFO=mkl, BUILD_TYPE=Release, CUDA_VERSION=11.3, CUDNN_VERSION=8.2.1, CXX_COMPILER=/usr/bin/c++, CXX_FLAGS= -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_KINETO -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DUSE_XNNPACK -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -O2 -fPIC -Wno-narrowing -Wall -Wextra -Werror=return-type -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wno-sign-compare -Wno-unused-parameter -Wno-unused-variable -Wno-unused-function -Wno-unused-result -Wno-unused-local-typedefs -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-psabi -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Werror=cast-function-type -Wno-stringop-overflow, LAPACK_INFO=mkl, PERF_WITH_AVX=1, PERF_WITH_AVX2=1, PERF_WITH_AVX512=1, TORCH_VERSION=1.9.0, USE_CUDA=ON, USE_CUDNN=ON, USE_EXCEPTION_PTR=1, USE_GFLAGS=OFF, USE_GLOG=OFF, USE_MKL=ON, USE_MKLDNN=ON, USE_MPI=ON, USE_NCCL=ON, USE_NNPACK=ON, USE_OPENMP=ON, \n\nTorchVision: 0.10.0a0\nOpenCV: 4.5.5\nMMCV: 1.3.9\nMMCV Compiler: GCC 9.3\nMMCV CUDA Compiler: 11.3\nMMPose: 0.24.0+8c33819", "seed": 0, "hook_msgs": {}}
+{"mode": "train", "epoch": 1, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.06604, "heatmap_loss": 0.003, "acc_pose": 0.01043, "loss": 0.003, "grad_norm": 0.38666, "time": 0.39767}
+{"mode": "train", "epoch": 1, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00217, "acc_pose": 0.08058, "loss": 0.00217, "grad_norm": 0.06469, "time": 0.24281}
+{"mode": "train", "epoch": 1, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.00036, "heatmap_loss": 0.0021, "acc_pose": 0.15628, "loss": 0.0021, "grad_norm": 0.08979, "time": 0.2394}
+{"mode": "train", "epoch": 1, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00204, "acc_pose": 0.2118, "loss": 0.00204, "grad_norm": 0.14474, "time": 0.23907}
+{"mode": "train", "epoch": 1, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.0004, "heatmap_loss": 0.00187, "acc_pose": 0.28084, "loss": 0.00187, "grad_norm": 0.14126, "time": 0.23857}
+{"mode": "train", "epoch": 2, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05567, "heatmap_loss": 0.00168, "acc_pose": 0.37635, "loss": 0.00168, "grad_norm": 0.19422, "time": 0.29901}
+{"mode": "train", "epoch": 2, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00034, "heatmap_loss": 0.00158, "acc_pose": 0.42443, "loss": 0.00158, "grad_norm": 0.16822, "time": 0.24035}
+{"mode": "train", "epoch": 2, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00035, "heatmap_loss": 0.00151, "acc_pose": 0.44287, "loss": 0.00151, "grad_norm": 0.138, "time": 0.30115}
+{"mode": "train", "epoch": 2, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00155, "acc_pose": 0.45717, "loss": 0.00155, "grad_norm": 0.21266, "time": 0.23907}
+{"mode": "train", "epoch": 2, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00139, "acc_pose": 0.49205, "loss": 0.00139, "grad_norm": 0.12632, "time": 0.23874}
+{"mode": "train", "epoch": 3, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05619, "heatmap_loss": 0.00138, "acc_pose": 0.52319, "loss": 0.00138, "grad_norm": 0.15, "time": 0.29848}
+{"mode": "train", "epoch": 3, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00041, "heatmap_loss": 0.00129, "acc_pose": 0.53713, "loss": 0.00129, "grad_norm": 0.0895, "time": 0.2398}
+{"mode": "train", "epoch": 3, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00127, "acc_pose": 0.55022, "loss": 0.00127, "grad_norm": 0.09171, "time": 0.23905}
+{"mode": "train", "epoch": 3, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00126, "acc_pose": 0.55783, "loss": 0.00126, "grad_norm": 0.10844, "time": 0.23849}
+{"mode": "train", "epoch": 3, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00125, "acc_pose": 0.5577, "loss": 0.00125, "grad_norm": 0.12846, "time": 0.23861}
+{"mode": "train", "epoch": 4, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05603, "heatmap_loss": 0.0012, "acc_pose": 0.58006, "loss": 0.0012, "grad_norm": 0.10276, "time": 0.29732}
+{"mode": "train", "epoch": 4, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00118, "acc_pose": 0.58914, "loss": 0.00118, "grad_norm": 0.07626, "time": 0.23964}
+{"mode": "train", "epoch": 4, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00119, "acc_pose": 0.5981, "loss": 0.00119, "grad_norm": 0.13942, "time": 0.23998}
+{"mode": "train", "epoch": 4, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00049, "heatmap_loss": 0.00116, "acc_pose": 0.60457, "loss": 0.00116, "grad_norm": 0.09702, "time": 0.2392}
+{"mode": "train", "epoch": 4, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.0004, "heatmap_loss": 0.00115, "acc_pose": 0.60457, "loss": 0.00115, "grad_norm": 0.08902, "time": 0.23895}
+{"mode": "train", "epoch": 5, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05601, "heatmap_loss": 0.00114, "acc_pose": 0.61465, "loss": 0.00114, "grad_norm": 0.11699, "time": 0.29574}
+{"mode": "train", "epoch": 5, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00036, "heatmap_loss": 0.00113, "acc_pose": 0.60386, "loss": 0.00113, "grad_norm": 0.0915, "time": 0.23815}
+{"mode": "train", "epoch": 5, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00112, "acc_pose": 0.61607, "loss": 0.00112, "grad_norm": 0.10761, "time": 0.2381}
+{"mode": "train", "epoch": 5, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00111, "acc_pose": 0.62341, "loss": 0.00111, "grad_norm": 0.08451, "time": 0.23763}
+{"mode": "train", "epoch": 5, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00039, "heatmap_loss": 0.00109, "acc_pose": 0.62698, "loss": 0.00109, "grad_norm": 0.082, "time": 0.23786}
+{"mode": "train", "epoch": 6, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05525, "heatmap_loss": 0.00108, "acc_pose": 0.63422, "loss": 0.00108, "grad_norm": 0.08735, "time": 0.29806}
+{"mode": "train", "epoch": 6, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00109, "acc_pose": 0.62348, "loss": 0.00109, "grad_norm": 0.11136, "time": 0.23796}
+{"mode": "train", "epoch": 6, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00038, "heatmap_loss": 0.00108, "acc_pose": 0.62961, "loss": 0.00108, "grad_norm": 0.09459, "time": 0.23757}
+{"mode": "train", "epoch": 6, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00106, "acc_pose": 0.6341, "loss": 0.00106, "grad_norm": 0.06872, "time": 0.23733}
+{"mode": "train", "epoch": 6, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00106, "acc_pose": 0.64455, "loss": 0.00106, "grad_norm": 0.09621, "time": 0.23768}
+{"mode": "train", "epoch": 7, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05533, "heatmap_loss": 0.00105, "acc_pose": 0.64043, "loss": 0.00105, "grad_norm": 0.08922, "time": 0.29892}
+{"mode": "train", "epoch": 7, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00026, "heatmap_loss": 0.00103, "acc_pose": 0.64771, "loss": 0.00103, "grad_norm": 0.08456, "time": 0.23854}
+{"mode": "train", "epoch": 7, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00103, "acc_pose": 0.64946, "loss": 0.00103, "grad_norm": 0.07217, "time": 0.23784}
+{"mode": "train", "epoch": 7, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00103, "acc_pose": 0.65472, "loss": 0.00103, "grad_norm": 0.08321, "time": 0.23835}
+{"mode": "train", "epoch": 7, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00039, "heatmap_loss": 0.00103, "acc_pose": 0.65549, "loss": 0.00103, "grad_norm": 0.09728, "time": 0.23781}
+{"mode": "train", "epoch": 8, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05517, "heatmap_loss": 0.00104, "acc_pose": 0.65961, "loss": 0.00104, "grad_norm": 0.14034, "time": 0.29906}
+{"mode": "train", "epoch": 8, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.001, "acc_pose": 0.66192, "loss": 0.001, "grad_norm": 0.05771, "time": 0.23837}
+{"mode": "train", "epoch": 8, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.001, "acc_pose": 0.65668, "loss": 0.001, "grad_norm": 0.05233, "time": 0.23852}
+{"mode": "train", "epoch": 8, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.001, "acc_pose": 0.66936, "loss": 0.001, "grad_norm": 0.08233, "time": 0.23854}
+{"mode": "train", "epoch": 8, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00099, "acc_pose": 0.66416, "loss": 0.00099, "grad_norm": 0.05946, "time": 0.23728}
+{"mode": "train", "epoch": 9, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05542, "heatmap_loss": 0.001, "acc_pose": 0.66572, "loss": 0.001, "grad_norm": 0.10617, "time": 0.30054}
+{"mode": "train", "epoch": 9, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00026, "heatmap_loss": 0.00099, "acc_pose": 0.6701, "loss": 0.00099, "grad_norm": 0.08829, "time": 0.23842}
+{"mode": "train", "epoch": 9, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00034, "heatmap_loss": 0.00098, "acc_pose": 0.67829, "loss": 0.00098, "grad_norm": 0.05567, "time": 0.23885}
+{"mode": "train", "epoch": 9, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00098, "acc_pose": 0.67141, "loss": 0.00098, "grad_norm": 0.0712, "time": 0.23733}
+{"mode": "train", "epoch": 9, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00097, "acc_pose": 0.67683, "loss": 0.00097, "grad_norm": 0.0582, "time": 0.23804}
+{"mode": "train", "epoch": 10, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05555, "heatmap_loss": 0.00099, "acc_pose": 0.67833, "loss": 0.00099, "grad_norm": 0.09599, "time": 0.29633}
+{"mode": "train", "epoch": 10, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00026, "heatmap_loss": 0.00097, "acc_pose": 0.67067, "loss": 0.00097, "grad_norm": 0.07639, "time": 0.23825}
+{"mode": "train", "epoch": 10, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00095, "acc_pose": 0.68063, "loss": 0.00095, "grad_norm": 0.05137, "time": 0.23805}
+{"mode": "train", "epoch": 10, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00026, "heatmap_loss": 0.00094, "acc_pose": 0.6764, "loss": 0.00094, "grad_norm": 0.03778, "time": 0.23827}
+{"mode": "train", "epoch": 10, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00096, "acc_pose": 0.68385, "loss": 0.00096, "grad_norm": 0.06712, "time": 0.23759}
+{"mode": "val", "epoch": 10, "iter": 407, "lr": 1e-05, "AP": 0.63837, "AP .5": 0.86642, "AP .75": 0.70795, "AP (M)": 0.5647, "AP (L)": 0.66097, "AR": 0.70179, "AR .5": 0.91105, "AR .75": 0.76826, "AR (M)": 0.65744, "AR (L)": 0.7644}
+{"mode": "train", "epoch": 11, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05525, "heatmap_loss": 0.00096, "acc_pose": 0.67874, "loss": 0.00096, "grad_norm": 0.07083, "time": 0.29458}
+{"mode": "train", "epoch": 11, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00094, "acc_pose": 0.68238, "loss": 0.00094, "grad_norm": 0.04506, "time": 0.23757}
+{"mode": "train", "epoch": 11, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00043, "heatmap_loss": 0.00094, "acc_pose": 0.68553, "loss": 0.00094, "grad_norm": 0.0475, "time": 0.23761}
+{"mode": "train", "epoch": 11, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00096, "acc_pose": 0.68279, "loss": 0.00096, "grad_norm": 0.07904, "time": 0.23772}
+{"mode": "train", "epoch": 11, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00041, "heatmap_loss": 0.00093, "acc_pose": 0.69423, "loss": 0.00093, "grad_norm": 0.04556, "time": 0.23776}
+{"mode": "train", "epoch": 12, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05603, "heatmap_loss": 0.00093, "acc_pose": 0.6903, "loss": 0.00093, "grad_norm": 0.04698, "time": 0.29789}
+{"mode": "train", "epoch": 12, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00042, "heatmap_loss": 0.00092, "acc_pose": 0.69255, "loss": 0.00092, "grad_norm": 0.03949, "time": 0.23809}
+{"mode": "train", "epoch": 12, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00093, "acc_pose": 0.69281, "loss": 0.00093, "grad_norm": 0.05889, "time": 0.23721}
+{"mode": "train", "epoch": 12, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00039, "heatmap_loss": 0.00094, "acc_pose": 0.68719, "loss": 0.00094, "grad_norm": 0.08132, "time": 0.23735}
+{"mode": "train", "epoch": 12, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00093, "acc_pose": 0.68701, "loss": 0.00093, "grad_norm": 0.05247, "time": 0.23795}
+{"mode": "train", "epoch": 13, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05549, "heatmap_loss": 0.00091, "acc_pose": 0.69548, "loss": 0.00091, "grad_norm": 0.04458, "time": 0.29595}
+{"mode": "train", "epoch": 13, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00091, "acc_pose": 0.70027, "loss": 0.00091, "grad_norm": 0.03347, "time": 0.23765}
+{"mode": "train", "epoch": 13, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.0004, "heatmap_loss": 0.00092, "acc_pose": 0.69554, "loss": 0.00092, "grad_norm": 0.04732, "time": 0.23761}
+{"mode": "train", "epoch": 13, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00093, "acc_pose": 0.69756, "loss": 0.00093, "grad_norm": 0.06773, "time": 0.23723}
+{"mode": "train", "epoch": 13, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00034, "heatmap_loss": 0.00091, "acc_pose": 0.7035, "loss": 0.00091, "grad_norm": 0.04501, "time": 0.23708}
+{"mode": "train", "epoch": 14, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05581, "heatmap_loss": 0.00091, "acc_pose": 0.69652, "loss": 0.00091, "grad_norm": 0.04158, "time": 0.29602}
+{"mode": "train", "epoch": 14, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00091, "acc_pose": 0.70099, "loss": 0.00091, "grad_norm": 0.051, "time": 0.23796}
+{"mode": "train", "epoch": 14, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00038, "heatmap_loss": 0.0009, "acc_pose": 0.70055, "loss": 0.0009, "grad_norm": 0.03919, "time": 0.23848}
+{"mode": "train", "epoch": 14, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.0009, "acc_pose": 0.69891, "loss": 0.0009, "grad_norm": 0.03838, "time": 0.23745}
+{"mode": "train", "epoch": 14, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00089, "acc_pose": 0.71053, "loss": 0.00089, "grad_norm": 0.04312, "time": 0.23757}
+{"mode": "train", "epoch": 15, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.0546, "heatmap_loss": 0.00091, "acc_pose": 0.70013, "loss": 0.00091, "grad_norm": 0.06748, "time": 0.29568}
+{"mode": "train", "epoch": 15, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.0009, "acc_pose": 0.70443, "loss": 0.0009, "grad_norm": 0.04362, "time": 0.23768}
+{"mode": "train", "epoch": 15, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00039, "heatmap_loss": 0.00089, "acc_pose": 0.69834, "loss": 0.00089, "grad_norm": 0.03224, "time": 0.23757}
+{"mode": "train", "epoch": 15, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00091, "acc_pose": 0.71183, "loss": 0.00091, "grad_norm": 0.05983, "time": 0.23695}
+{"mode": "train", "epoch": 15, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00041, "heatmap_loss": 0.0009, "acc_pose": 0.70458, "loss": 0.0009, "grad_norm": 0.05525, "time": 0.23665}
+{"mode": "train", "epoch": 16, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05598, "heatmap_loss": 0.00088, "acc_pose": 0.71245, "loss": 0.00088, "grad_norm": 0.03527, "time": 0.29595}
+{"mode": "train", "epoch": 16, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00088, "acc_pose": 0.71503, "loss": 0.00088, "grad_norm": 0.04073, "time": 0.23798}
+{"mode": "train", "epoch": 16, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00087, "acc_pose": 0.71386, "loss": 0.00087, "grad_norm": 0.02801, "time": 0.23762}
+{"mode": "train", "epoch": 16, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00088, "acc_pose": 0.71223, "loss": 0.00088, "grad_norm": 0.02729, "time": 0.23706}
+{"mode": "train", "epoch": 16, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00088, "acc_pose": 0.70968, "loss": 0.00088, "grad_norm": 0.03779, "time": 0.23759}
+{"mode": "train", "epoch": 17, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.0551, "heatmap_loss": 0.00087, "acc_pose": 0.71041, "loss": 0.00087, "grad_norm": 0.03594, "time": 0.29539}
+{"mode": "train", "epoch": 17, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00038, "heatmap_loss": 0.00087, "acc_pose": 0.70648, "loss": 0.00087, "grad_norm": 0.0325, "time": 0.23827}
+{"mode": "train", "epoch": 17, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00087, "acc_pose": 0.71506, "loss": 0.00087, "grad_norm": 0.03089, "time": 0.23735}
+{"mode": "train", "epoch": 17, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00045, "heatmap_loss": 0.00087, "acc_pose": 0.71828, "loss": 0.00087, "grad_norm": 0.02832, "time": 0.23705}
+{"mode": "train", "epoch": 17, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00087, "acc_pose": 0.71975, "loss": 0.00087, "grad_norm": 0.0344, "time": 0.23709}
+{"mode": "train", "epoch": 18, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05602, "heatmap_loss": 0.00086, "acc_pose": 0.71735, "loss": 0.00086, "grad_norm": 0.03983, "time": 0.29506}
+{"mode": "train", "epoch": 18, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00086, "acc_pose": 0.72363, "loss": 0.00086, "grad_norm": 0.03434, "time": 0.23796}
+{"mode": "train", "epoch": 18, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00087, "acc_pose": 0.72045, "loss": 0.00087, "grad_norm": 0.0429, "time": 0.2375}
+{"mode": "train", "epoch": 18, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00049, "heatmap_loss": 0.00085, "acc_pose": 0.72336, "loss": 0.00085, "grad_norm": 0.02021, "time": 0.23736}
+{"mode": "train", "epoch": 18, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00085, "acc_pose": 0.7178, "loss": 0.00085, "grad_norm": 0.01832, "time": 0.23708}
+{"mode": "train", "epoch": 19, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05597, "heatmap_loss": 0.00086, "acc_pose": 0.71666, "loss": 0.00086, "grad_norm": 0.02529, "time": 0.29665}
+{"mode": "train", "epoch": 19, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00086, "acc_pose": 0.72188, "loss": 0.00086, "grad_norm": 0.0217, "time": 0.23762}
+{"mode": "train", "epoch": 19, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00042, "heatmap_loss": 0.00086, "acc_pose": 0.7079, "loss": 0.00086, "grad_norm": 0.0237, "time": 0.23737}
+{"mode": "train", "epoch": 19, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00085, "acc_pose": 0.71605, "loss": 0.00085, "grad_norm": 0.02618, "time": 0.23787}
+{"mode": "train", "epoch": 19, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00085, "acc_pose": 0.72437, "loss": 0.00085, "grad_norm": 0.02708, "time": 0.23762}
+{"mode": "train", "epoch": 20, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05609, "heatmap_loss": 0.00084, "acc_pose": 0.73148, "loss": 0.00084, "grad_norm": 0.02049, "time": 0.2974}
+{"mode": "train", "epoch": 20, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00085, "acc_pose": 0.72254, "loss": 0.00085, "grad_norm": 0.02335, "time": 0.23702}
+{"mode": "train", "epoch": 20, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00085, "acc_pose": 0.71958, "loss": 0.00085, "grad_norm": 0.02002, "time": 0.23759}
+{"mode": "train", "epoch": 20, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00085, "acc_pose": 0.72853, "loss": 0.00085, "grad_norm": 0.01957, "time": 0.23723}
+{"mode": "train", "epoch": 20, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00085, "acc_pose": 0.72391, "loss": 0.00085, "grad_norm": 0.01602, "time": 0.23665}
+{"mode": "val", "epoch": 20, "iter": 407, "lr": 1e-05, "AP": 0.67925, "AP .5": 0.8837, "AP .75": 0.75609, "AP (M)": 0.60565, "AP (L)": 0.70507, "AR": 0.73942, "AR .5": 0.92506, "AR .75": 0.80872, "AR (M)": 0.69574, "AR (L)": 0.80223}
+{"mode": "train", "epoch": 21, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05577, "heatmap_loss": 0.00084, "acc_pose": 0.72554, "loss": 0.00084, "grad_norm": 0.02352, "time": 0.29537}
+{"mode": "train", "epoch": 21, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00083, "acc_pose": 0.7328, "loss": 0.00083, "grad_norm": 0.01845, "time": 0.2377}
+{"mode": "train", "epoch": 21, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00084, "acc_pose": 0.72321, "loss": 0.00084, "grad_norm": 0.01548, "time": 0.23764}
+{"mode": "train", "epoch": 21, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00083, "acc_pose": 0.73154, "loss": 0.00083, "grad_norm": 0.01761, "time": 0.23741}
+{"mode": "train", "epoch": 21, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00048, "heatmap_loss": 0.00084, "acc_pose": 0.72735, "loss": 0.00084, "grad_norm": 0.01933, "time": 0.23793}
+{"mode": "train", "epoch": 22, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.0575, "heatmap_loss": 0.00084, "acc_pose": 0.73036, "loss": 0.00084, "grad_norm": 0.0149, "time": 0.29853}
+{"mode": "train", "epoch": 22, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00083, "acc_pose": 0.72176, "loss": 0.00083, "grad_norm": 0.01498, "time": 0.23759}
+{"mode": "train", "epoch": 22, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00033, "heatmap_loss": 0.00083, "acc_pose": 0.72366, "loss": 0.00083, "grad_norm": 0.0133, "time": 0.23688}
+{"mode": "train", "epoch": 22, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00083, "acc_pose": 0.73883, "loss": 0.00083, "grad_norm": 0.01589, "time": 0.23779}
+{"mode": "train", "epoch": 22, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00037, "heatmap_loss": 0.00083, "acc_pose": 0.73341, "loss": 0.00083, "grad_norm": 0.01457, "time": 0.23712}
+{"mode": "train", "epoch": 23, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05537, "heatmap_loss": 0.00083, "acc_pose": 0.73013, "loss": 0.00083, "grad_norm": 0.01788, "time": 0.29544}
+{"mode": "train", "epoch": 23, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00083, "acc_pose": 0.72666, "loss": 0.00083, "grad_norm": 0.01243, "time": 0.23884}
+{"mode": "train", "epoch": 23, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00082, "acc_pose": 0.72682, "loss": 0.00082, "grad_norm": 0.01182, "time": 0.23815}
+{"mode": "train", "epoch": 23, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00082, "acc_pose": 0.7358, "loss": 0.00082, "grad_norm": 0.01424, "time": 0.23766}
+{"mode": "train", "epoch": 23, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00044, "heatmap_loss": 0.00082, "acc_pose": 0.73676, "loss": 0.00082, "grad_norm": 0.01435, "time": 0.2375}
+{"mode": "train", "epoch": 24, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05792, "heatmap_loss": 0.00082, "acc_pose": 0.73306, "loss": 0.00082, "grad_norm": 0.01602, "time": 0.29919}
+{"mode": "train", "epoch": 24, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00082, "acc_pose": 0.74126, "loss": 0.00082, "grad_norm": 0.01145, "time": 0.23793}
+{"mode": "train", "epoch": 24, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00082, "acc_pose": 0.72971, "loss": 0.00082, "grad_norm": 0.01037, "time": 0.23748}
+{"mode": "train", "epoch": 24, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00082, "acc_pose": 0.7308, "loss": 0.00082, "grad_norm": 0.00989, "time": 0.23744}
+{"mode": "train", "epoch": 24, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00041, "heatmap_loss": 0.00082, "acc_pose": 0.73027, "loss": 0.00082, "grad_norm": 0.01138, "time": 0.23737}
+{"mode": "train", "epoch": 25, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05532, "heatmap_loss": 0.00081, "acc_pose": 0.74274, "loss": 0.00081, "grad_norm": 0.00933, "time": 0.29558}
+{"mode": "train", "epoch": 25, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00026, "heatmap_loss": 0.00081, "acc_pose": 0.73547, "loss": 0.00081, "grad_norm": 0.00834, "time": 0.23721}
+{"mode": "train", "epoch": 25, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00081, "acc_pose": 0.73283, "loss": 0.00081, "grad_norm": 0.01052, "time": 0.23754}
+{"mode": "train", "epoch": 25, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00082, "acc_pose": 0.73266, "loss": 0.00082, "grad_norm": 0.00814, "time": 0.23802}
+{"mode": "train", "epoch": 25, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00033, "heatmap_loss": 0.00081, "acc_pose": 0.73633, "loss": 0.00081, "grad_norm": 0.00717, "time": 0.23677}
+{"mode": "train", "epoch": 26, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05758, "heatmap_loss": 0.00081, "acc_pose": 0.73481, "loss": 0.00081, "grad_norm": 0.0082, "time": 0.29876}
+{"mode": "train", "epoch": 26, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00037, "heatmap_loss": 0.00081, "acc_pose": 0.73453, "loss": 0.00081, "grad_norm": 0.00675, "time": 0.23799}
+{"mode": "train", "epoch": 26, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00081, "acc_pose": 0.73398, "loss": 0.00081, "grad_norm": 0.00678, "time": 0.23788}
+{"mode": "train", "epoch": 26, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00081, "acc_pose": 0.74144, "loss": 0.00081, "grad_norm": 0.00706, "time": 0.23768}
+{"mode": "train", "epoch": 26, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00033, "heatmap_loss": 0.0008, "acc_pose": 0.74359, "loss": 0.0008, "grad_norm": 0.00706, "time": 0.2375}
+{"mode": "train", "epoch": 27, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.0553, "heatmap_loss": 0.0008, "acc_pose": 0.74146, "loss": 0.0008, "grad_norm": 0.00706, "time": 0.29532}
+{"mode": "train", "epoch": 27, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.0008, "acc_pose": 0.74841, "loss": 0.0008, "grad_norm": 0.00706, "time": 0.23735}
+{"mode": "train", "epoch": 27, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.0008, "acc_pose": 0.74248, "loss": 0.0008, "grad_norm": 0.00558, "time": 0.23758}
+{"mode": "train", "epoch": 27, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00035, "heatmap_loss": 0.0008, "acc_pose": 0.74657, "loss": 0.0008, "grad_norm": 0.00517, "time": 0.2368}
+{"mode": "train", "epoch": 27, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00035, "heatmap_loss": 0.0008, "acc_pose": 0.7365, "loss": 0.0008, "grad_norm": 0.00516, "time": 0.23699}
+{"mode": "train", "epoch": 28, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05584, "heatmap_loss": 0.0008, "acc_pose": 0.74584, "loss": 0.0008, "grad_norm": 0.00484, "time": 0.29809}
+{"mode": "train", "epoch": 28, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00044, "heatmap_loss": 0.00079, "acc_pose": 0.74047, "loss": 0.00079, "grad_norm": 0.00413, "time": 0.23805}
+{"mode": "train", "epoch": 28, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.0008, "acc_pose": 0.74093, "loss": 0.0008, "grad_norm": 0.00468, "time": 0.23732}
+{"mode": "train", "epoch": 28, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.0008, "acc_pose": 0.74111, "loss": 0.0008, "grad_norm": 0.00422, "time": 0.23708}
+{"mode": "train", "epoch": 28, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.0008, "acc_pose": 0.74444, "loss": 0.0008, "grad_norm": 0.00418, "time": 0.23777}
+{"mode": "train", "epoch": 29, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05527, "heatmap_loss": 0.0008, "acc_pose": 0.74997, "loss": 0.0008, "grad_norm": 0.00392, "time": 0.29555}
+{"mode": "train", "epoch": 29, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.0008, "acc_pose": 0.74134, "loss": 0.0008, "grad_norm": 0.00357, "time": 0.23782}
+{"mode": "train", "epoch": 29, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00079, "acc_pose": 0.73602, "loss": 0.00079, "grad_norm": 0.00353, "time": 0.23722}
+{"mode": "train", "epoch": 29, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00043, "heatmap_loss": 0.00079, "acc_pose": 0.74325, "loss": 0.00079, "grad_norm": 0.00342, "time": 0.23743}
+{"mode": "train", "epoch": 29, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00034, "heatmap_loss": 0.00079, "acc_pose": 0.74558, "loss": 0.00079, "grad_norm": 0.00282, "time": 0.23729}
+{"mode": "train", "epoch": 30, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05833, "heatmap_loss": 0.00079, "acc_pose": 0.73937, "loss": 0.00079, "grad_norm": 0.00273, "time": 0.29884}
+{"mode": "train", "epoch": 30, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00026, "heatmap_loss": 0.00079, "acc_pose": 0.74583, "loss": 0.00079, "grad_norm": 0.00268, "time": 0.2375}
+{"mode": "train", "epoch": 30, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00079, "acc_pose": 0.74417, "loss": 0.00079, "grad_norm": 0.00253, "time": 0.23741}
+{"mode": "train", "epoch": 30, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00041, "heatmap_loss": 0.00079, "acc_pose": 0.74494, "loss": 0.00079, "grad_norm": 0.00235, "time": 0.23757}
+{"mode": "train", "epoch": 30, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00079, "acc_pose": 0.74755, "loss": 0.00079, "grad_norm": 0.00245, "time": 0.23718}
+{"mode": "val", "epoch": 30, "iter": 407, "lr": 1e-05, "AP": 0.69612, "AP .5": 0.88545, "AP .75": 0.77546, "AP (M)": 0.62122, "AP (L)": 0.72185, "AR": 0.75605, "AR .5": 0.929, "AR .75": 0.82604, "AR (M)": 0.71073, "AR (L)": 0.82129}
+{"mode": "train", "epoch": 31, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05431, "heatmap_loss": 0.00079, "acc_pose": 0.74551, "loss": 0.00079, "grad_norm": 0.00201, "time": 0.29382}
+{"mode": "train", "epoch": 31, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00079, "acc_pose": 0.7465, "loss": 0.00079, "grad_norm": 0.00215, "time": 0.23806}
+{"mode": "train", "epoch": 31, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00037, "heatmap_loss": 0.00078, "acc_pose": 0.74335, "loss": 0.00078, "grad_norm": 0.00193, "time": 0.23755}
+{"mode": "train", "epoch": 31, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00041, "heatmap_loss": 0.00078, "acc_pose": 0.7551, "loss": 0.00078, "grad_norm": 0.00199, "time": 0.23765}
+{"mode": "train", "epoch": 31, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00078, "acc_pose": 0.75625, "loss": 0.00078, "grad_norm": 0.00175, "time": 0.23732}
+{"mode": "train", "epoch": 32, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05592, "heatmap_loss": 0.00078, "acc_pose": 0.75197, "loss": 0.00078, "grad_norm": 0.00165, "time": 0.29626}
+{"mode": "train", "epoch": 32, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00078, "acc_pose": 0.75534, "loss": 0.00078, "grad_norm": 0.00156, "time": 0.23794}
+{"mode": "train", "epoch": 32, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00038, "heatmap_loss": 0.00078, "acc_pose": 0.74844, "loss": 0.00078, "grad_norm": 0.00157, "time": 0.23804}
+{"mode": "train", "epoch": 32, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00078, "acc_pose": 0.75512, "loss": 0.00078, "grad_norm": 0.00146, "time": 0.23763}
+{"mode": "train", "epoch": 32, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00077, "acc_pose": 0.75512, "loss": 0.00077, "grad_norm": 0.00154, "time": 0.23715}
+{"mode": "train", "epoch": 33, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05625, "heatmap_loss": 0.00078, "acc_pose": 0.7558, "loss": 0.00078, "grad_norm": 0.00147, "time": 0.29699}
+{"mode": "train", "epoch": 33, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00033, "heatmap_loss": 0.00078, "acc_pose": 0.74875, "loss": 0.00078, "grad_norm": 0.00138, "time": 0.23794}
+{"mode": "train", "epoch": 33, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00026, "heatmap_loss": 0.00077, "acc_pose": 0.76127, "loss": 0.00077, "grad_norm": 0.00131, "time": 0.23772}
+{"mode": "train", "epoch": 33, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00079, "acc_pose": 0.74355, "loss": 0.00079, "grad_norm": 0.00145, "time": 0.23714}
+{"mode": "train", "epoch": 33, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00036, "heatmap_loss": 0.00078, "acc_pose": 0.76302, "loss": 0.00078, "grad_norm": 0.00134, "time": 0.23743}
+{"mode": "train", "epoch": 34, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05507, "heatmap_loss": 0.00077, "acc_pose": 0.75337, "loss": 0.00077, "grad_norm": 0.00133, "time": 0.29779}
+{"mode": "train", "epoch": 34, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00056, "heatmap_loss": 0.00078, "acc_pose": 0.751, "loss": 0.00078, "grad_norm": 0.00128, "time": 0.23805}
+{"mode": "train", "epoch": 34, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00037, "heatmap_loss": 0.00077, "acc_pose": 0.75355, "loss": 0.00077, "grad_norm": 0.00132, "time": 0.23758}
+{"mode": "train", "epoch": 34, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00041, "heatmap_loss": 0.00077, "acc_pose": 0.7545, "loss": 0.00077, "grad_norm": 0.00132, "time": 0.23678}
+{"mode": "train", "epoch": 34, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00039, "heatmap_loss": 0.00077, "acc_pose": 0.75408, "loss": 0.00077, "grad_norm": 0.00125, "time": 0.23786}
+{"mode": "train", "epoch": 35, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.0558, "heatmap_loss": 0.00077, "acc_pose": 0.75187, "loss": 0.00077, "grad_norm": 0.00123, "time": 0.29754}
+{"mode": "train", "epoch": 35, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00038, "heatmap_loss": 0.00077, "acc_pose": 0.75255, "loss": 0.00077, "grad_norm": 0.00129, "time": 0.23822}
+{"mode": "train", "epoch": 35, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00077, "acc_pose": 0.75309, "loss": 0.00077, "grad_norm": 0.00126, "time": 0.23692}
+{"mode": "train", "epoch": 35, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00077, "acc_pose": 0.76513, "loss": 0.00077, "grad_norm": 0.00122, "time": 0.23769}
+{"mode": "train", "epoch": 35, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00077, "acc_pose": 0.764, "loss": 0.00077, "grad_norm": 0.00122, "time": 0.23763}
+{"mode": "train", "epoch": 36, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.0549, "heatmap_loss": 0.00076, "acc_pose": 0.74888, "loss": 0.00076, "grad_norm": 0.00122, "time": 0.29763}
+{"mode": "train", "epoch": 36, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00077, "acc_pose": 0.75556, "loss": 0.00077, "grad_norm": 0.00126, "time": 0.23741}
+{"mode": "train", "epoch": 36, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00041, "heatmap_loss": 0.00076, "acc_pose": 0.75351, "loss": 0.00076, "grad_norm": 0.0012, "time": 0.23741}
+{"mode": "train", "epoch": 36, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00076, "acc_pose": 0.7582, "loss": 0.00076, "grad_norm": 0.00122, "time": 0.2376}
+{"mode": "train", "epoch": 36, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00077, "acc_pose": 0.75613, "loss": 0.00077, "grad_norm": 0.00122, "time": 0.23717}
+{"mode": "train", "epoch": 37, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05511, "heatmap_loss": 0.00076, "acc_pose": 0.75098, "loss": 0.00076, "grad_norm": 0.00126, "time": 0.29507}
+{"mode": "train", "epoch": 37, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00042, "heatmap_loss": 0.00077, "acc_pose": 0.75532, "loss": 0.00077, "grad_norm": 0.00124, "time": 0.23781}
+{"mode": "train", "epoch": 37, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00076, "acc_pose": 0.75451, "loss": 0.00076, "grad_norm": 0.00119, "time": 0.23774}
+{"mode": "train", "epoch": 37, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.0004, "heatmap_loss": 0.00076, "acc_pose": 0.76572, "loss": 0.00076, "grad_norm": 0.00119, "time": 0.23775}
+{"mode": "train", "epoch": 37, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00076, "acc_pose": 0.75317, "loss": 0.00076, "grad_norm": 0.00124, "time": 0.23689}
+{"mode": "train", "epoch": 38, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05538, "heatmap_loss": 0.00077, "acc_pose": 0.75943, "loss": 0.00077, "grad_norm": 0.00121, "time": 0.29579}
+{"mode": "train", "epoch": 38, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00025, "heatmap_loss": 0.00076, "acc_pose": 0.75805, "loss": 0.00076, "grad_norm": 0.00121, "time": 0.23787}
+{"mode": "train", "epoch": 38, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00076, "acc_pose": 0.75782, "loss": 0.00076, "grad_norm": 0.0012, "time": 0.23768}
+{"mode": "train", "epoch": 38, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00042, "heatmap_loss": 0.00076, "acc_pose": 0.75269, "loss": 0.00076, "grad_norm": 0.00124, "time": 0.23655}
+{"mode": "train", "epoch": 38, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00076, "acc_pose": 0.75364, "loss": 0.00076, "grad_norm": 0.00123, "time": 0.23675}
+{"mode": "train", "epoch": 39, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05571, "heatmap_loss": 0.00076, "acc_pose": 0.75459, "loss": 0.00076, "grad_norm": 0.00117, "time": 0.29669}
+{"mode": "train", "epoch": 39, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00075, "acc_pose": 0.75936, "loss": 0.00075, "grad_norm": 0.0012, "time": 0.23801}
+{"mode": "train", "epoch": 39, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00075, "acc_pose": 0.75447, "loss": 0.00075, "grad_norm": 0.00123, "time": 0.23776}
+{"mode": "train", "epoch": 39, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00035, "heatmap_loss": 0.00076, "acc_pose": 0.75363, "loss": 0.00076, "grad_norm": 0.00117, "time": 0.23766}
+{"mode": "train", "epoch": 39, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00038, "heatmap_loss": 0.00076, "acc_pose": 0.75584, "loss": 0.00076, "grad_norm": 0.00123, "time": 0.23711}
+{"mode": "train", "epoch": 40, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05517, "heatmap_loss": 0.00075, "acc_pose": 0.76049, "loss": 0.00075, "grad_norm": 0.00124, "time": 0.29723}
+{"mode": "train", "epoch": 40, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00075, "acc_pose": 0.75196, "loss": 0.00075, "grad_norm": 0.00124, "time": 0.23827}
+{"mode": "train", "epoch": 40, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00049, "heatmap_loss": 0.00076, "acc_pose": 0.76155, "loss": 0.00076, "grad_norm": 0.00119, "time": 0.23778}
+{"mode": "train", "epoch": 40, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00033, "heatmap_loss": 0.00075, "acc_pose": 0.75913, "loss": 0.00075, "grad_norm": 0.00119, "time": 0.23692}
+{"mode": "train", "epoch": 40, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00076, "acc_pose": 0.76202, "loss": 0.00076, "grad_norm": 0.00119, "time": 0.23766}
+{"mode": "val", "epoch": 40, "iter": 407, "lr": 1e-05, "AP": 0.7078, "AP .5": 0.89179, "AP .75": 0.78361, "AP (M)": 0.63486, "AP (L)": 0.73106, "AR": 0.76702, "AR .5": 0.93309, "AR .75": 0.83486, "AR (M)": 0.7236, "AR (L)": 0.82921}
+{"mode": "train", "epoch": 41, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05463, "heatmap_loss": 0.00075, "acc_pose": 0.76932, "loss": 0.00075, "grad_norm": 0.00116, "time": 0.29406}
+{"mode": "train", "epoch": 41, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00026, "heatmap_loss": 0.00075, "acc_pose": 0.761, "loss": 0.00075, "grad_norm": 0.00124, "time": 0.23743}
+{"mode": "train", "epoch": 41, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00026, "heatmap_loss": 0.00075, "acc_pose": 0.77072, "loss": 0.00075, "grad_norm": 0.00121, "time": 0.23693}
+{"mode": "train", "epoch": 41, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00075, "acc_pose": 0.76342, "loss": 0.00075, "grad_norm": 0.00119, "time": 0.23759}
+{"mode": "train", "epoch": 41, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00075, "acc_pose": 0.75184, "loss": 0.00075, "grad_norm": 0.00119, "time": 0.23744}
+{"mode": "train", "epoch": 42, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05555, "heatmap_loss": 0.00075, "acc_pose": 0.76218, "loss": 0.00075, "grad_norm": 0.00118, "time": 0.29607}
+{"mode": "train", "epoch": 42, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00044, "heatmap_loss": 0.00075, "acc_pose": 0.75349, "loss": 0.00075, "grad_norm": 0.00116, "time": 0.23787}
+{"mode": "train", "epoch": 42, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00075, "acc_pose": 0.75874, "loss": 0.00075, "grad_norm": 0.00116, "time": 0.23698}
+{"mode": "train", "epoch": 42, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.0004, "heatmap_loss": 0.00074, "acc_pose": 0.76176, "loss": 0.00074, "grad_norm": 0.00121, "time": 0.23781}
+{"mode": "train", "epoch": 42, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.0004, "heatmap_loss": 0.00075, "acc_pose": 0.7568, "loss": 0.00075, "grad_norm": 0.00123, "time": 0.23763}
+{"mode": "train", "epoch": 43, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05499, "heatmap_loss": 0.00075, "acc_pose": 0.76789, "loss": 0.00075, "grad_norm": 0.00117, "time": 0.29545}
+{"mode": "train", "epoch": 43, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00075, "acc_pose": 0.76216, "loss": 0.00075, "grad_norm": 0.00123, "time": 0.23737}
+{"mode": "train", "epoch": 43, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00074, "acc_pose": 0.76361, "loss": 0.00074, "grad_norm": 0.00123, "time": 0.23754}
+{"mode": "train", "epoch": 43, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.0004, "heatmap_loss": 0.00075, "acc_pose": 0.76122, "loss": 0.00075, "grad_norm": 0.00124, "time": 0.23759}
+{"mode": "train", "epoch": 43, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00075, "acc_pose": 0.77237, "loss": 0.00075, "grad_norm": 0.00119, "time": 0.23726}
+{"mode": "train", "epoch": 44, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05545, "heatmap_loss": 0.00074, "acc_pose": 0.76251, "loss": 0.00074, "grad_norm": 0.00115, "time": 0.29803}
+{"mode": "train", "epoch": 44, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00074, "acc_pose": 0.76543, "loss": 0.00074, "grad_norm": 0.0012, "time": 0.23825}
+{"mode": "train", "epoch": 44, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00074, "acc_pose": 0.76974, "loss": 0.00074, "grad_norm": 0.00118, "time": 0.23804}
+{"mode": "train", "epoch": 44, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00074, "acc_pose": 0.76495, "loss": 0.00074, "grad_norm": 0.00121, "time": 0.23733}
+{"mode": "train", "epoch": 44, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00039, "heatmap_loss": 0.00074, "acc_pose": 0.76377, "loss": 0.00074, "grad_norm": 0.00122, "time": 0.23729}
+{"mode": "train", "epoch": 45, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05605, "heatmap_loss": 0.00074, "acc_pose": 0.76621, "loss": 0.00074, "grad_norm": 0.00119, "time": 0.2961}
+{"mode": "train", "epoch": 45, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00074, "acc_pose": 0.76208, "loss": 0.00074, "grad_norm": 0.00117, "time": 0.23812}
+{"mode": "train", "epoch": 45, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.0004, "heatmap_loss": 0.00073, "acc_pose": 0.75759, "loss": 0.00073, "grad_norm": 0.00117, "time": 0.23803}
+{"mode": "train", "epoch": 45, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00042, "heatmap_loss": 0.00074, "acc_pose": 0.76632, "loss": 0.00074, "grad_norm": 0.00119, "time": 0.23699}
+{"mode": "train", "epoch": 45, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00074, "acc_pose": 0.76257, "loss": 0.00074, "grad_norm": 0.00118, "time": 0.23791}
+{"mode": "train", "epoch": 46, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05616, "heatmap_loss": 0.00074, "acc_pose": 0.76408, "loss": 0.00074, "grad_norm": 0.00126, "time": 0.29515}
+{"mode": "train", "epoch": 46, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00074, "acc_pose": 0.7732, "loss": 0.00074, "grad_norm": 0.00122, "time": 0.23835}
+{"mode": "train", "epoch": 46, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00074, "acc_pose": 0.76623, "loss": 0.00074, "grad_norm": 0.00117, "time": 0.23735}
+{"mode": "train", "epoch": 46, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00074, "acc_pose": 0.76587, "loss": 0.00074, "grad_norm": 0.00121, "time": 0.23721}
+{"mode": "train", "epoch": 46, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00074, "acc_pose": 0.77218, "loss": 0.00074, "grad_norm": 0.00116, "time": 0.2371}
+{"mode": "train", "epoch": 47, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05584, "heatmap_loss": 0.00074, "acc_pose": 0.76193, "loss": 0.00074, "grad_norm": 0.0012, "time": 0.29633}
+{"mode": "train", "epoch": 47, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00074, "acc_pose": 0.7727, "loss": 0.00074, "grad_norm": 0.00118, "time": 0.23771}
+{"mode": "train", "epoch": 47, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00074, "acc_pose": 0.76267, "loss": 0.00074, "grad_norm": 0.00122, "time": 0.23715}
+{"mode": "train", "epoch": 47, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00037, "heatmap_loss": 0.00073, "acc_pose": 0.76812, "loss": 0.00073, "grad_norm": 0.00123, "time": 0.23809}
+{"mode": "train", "epoch": 47, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00039, "heatmap_loss": 0.00073, "acc_pose": 0.77549, "loss": 0.00073, "grad_norm": 0.00123, "time": 0.23727}
+{"mode": "train", "epoch": 48, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05515, "heatmap_loss": 0.00073, "acc_pose": 0.76733, "loss": 0.00073, "grad_norm": 0.00119, "time": 0.2979}
+{"mode": "train", "epoch": 48, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00073, "acc_pose": 0.76378, "loss": 0.00073, "grad_norm": 0.0012, "time": 0.23745}
+{"mode": "train", "epoch": 48, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.0004, "heatmap_loss": 0.00073, "acc_pose": 0.77478, "loss": 0.00073, "grad_norm": 0.00117, "time": 0.2392}
+{"mode": "train", "epoch": 48, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00034, "heatmap_loss": 0.00074, "acc_pose": 0.7687, "loss": 0.00074, "grad_norm": 0.00121, "time": 0.23857}
+{"mode": "train", "epoch": 48, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00044, "heatmap_loss": 0.00073, "acc_pose": 0.77365, "loss": 0.00073, "grad_norm": 0.00118, "time": 0.23808}
+{"mode": "train", "epoch": 49, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05549, "heatmap_loss": 0.00073, "acc_pose": 0.76562, "loss": 0.00073, "grad_norm": 0.00118, "time": 0.29854}
+{"mode": "train", "epoch": 49, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00025, "heatmap_loss": 0.00074, "acc_pose": 0.76915, "loss": 0.00074, "grad_norm": 0.00118, "time": 0.23841}
+{"mode": "train", "epoch": 49, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00072, "acc_pose": 0.77123, "loss": 0.00072, "grad_norm": 0.0012, "time": 0.23822}
+{"mode": "train", "epoch": 49, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00073, "acc_pose": 0.76877, "loss": 0.00073, "grad_norm": 0.0012, "time": 0.23766}
+{"mode": "train", "epoch": 49, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00073, "acc_pose": 0.77245, "loss": 0.00073, "grad_norm": 0.00117, "time": 0.23789}
+{"mode": "train", "epoch": 50, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05526, "heatmap_loss": 0.00073, "acc_pose": 0.78114, "loss": 0.00073, "grad_norm": 0.00121, "time": 0.29767}
+{"mode": "train", "epoch": 50, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00073, "acc_pose": 0.77351, "loss": 0.00073, "grad_norm": 0.00115, "time": 0.23844}
+{"mode": "train", "epoch": 50, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00073, "acc_pose": 0.77405, "loss": 0.00073, "grad_norm": 0.00119, "time": 0.23858}
+{"mode": "train", "epoch": 50, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00037, "heatmap_loss": 0.00073, "acc_pose": 0.76802, "loss": 0.00073, "grad_norm": 0.00116, "time": 0.23742}
+{"mode": "train", "epoch": 50, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00073, "acc_pose": 0.76487, "loss": 0.00073, "grad_norm": 0.00121, "time": 0.23795}
+{"mode": "val", "epoch": 50, "iter": 407, "lr": 1e-05, "AP": 0.71611, "AP .5": 0.89335, "AP .75": 0.79372, "AP (M)": 0.64252, "AP (L)": 0.74068, "AR": 0.77377, "AR .5": 0.9353, "AR .75": 0.84288, "AR (M)": 0.73081, "AR (L)": 0.83605}
+{"mode": "train", "epoch": 51, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05597, "heatmap_loss": 0.00072, "acc_pose": 0.77757, "loss": 0.00072, "grad_norm": 0.00114, "time": 0.29634}
+{"mode": "train", "epoch": 51, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00073, "acc_pose": 0.76987, "loss": 0.00073, "grad_norm": 0.00122, "time": 0.23839}
+{"mode": "train", "epoch": 51, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00043, "heatmap_loss": 0.00073, "acc_pose": 0.76946, "loss": 0.00073, "grad_norm": 0.00118, "time": 0.23824}
+{"mode": "train", "epoch": 51, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00035, "heatmap_loss": 0.00072, "acc_pose": 0.77492, "loss": 0.00072, "grad_norm": 0.00123, "time": 0.23785}
+{"mode": "train", "epoch": 51, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00072, "acc_pose": 0.78261, "loss": 0.00072, "grad_norm": 0.00121, "time": 0.23758}
+{"mode": "train", "epoch": 52, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05507, "heatmap_loss": 0.00072, "acc_pose": 0.77043, "loss": 0.00072, "grad_norm": 0.0012, "time": 0.29954}
+{"mode": "train", "epoch": 52, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00073, "acc_pose": 0.77113, "loss": 0.00073, "grad_norm": 0.0012, "time": 0.23871}
+{"mode": "train", "epoch": 52, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00043, "heatmap_loss": 0.00072, "acc_pose": 0.77536, "loss": 0.00072, "grad_norm": 0.00123, "time": 0.23797}
+{"mode": "train", "epoch": 52, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00039, "heatmap_loss": 0.00071, "acc_pose": 0.77504, "loss": 0.00071, "grad_norm": 0.00113, "time": 0.23857}
+{"mode": "train", "epoch": 52, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00038, "heatmap_loss": 0.00073, "acc_pose": 0.76407, "loss": 0.00073, "grad_norm": 0.00122, "time": 0.23748}
+{"mode": "train", "epoch": 53, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05497, "heatmap_loss": 0.00072, "acc_pose": 0.77408, "loss": 0.00072, "grad_norm": 0.0012, "time": 0.2981}
+{"mode": "train", "epoch": 53, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00026, "heatmap_loss": 0.00072, "acc_pose": 0.76882, "loss": 0.00072, "grad_norm": 0.00114, "time": 0.23767}
+{"mode": "train", "epoch": 53, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00041, "heatmap_loss": 0.00072, "acc_pose": 0.77249, "loss": 0.00072, "grad_norm": 0.00129, "time": 0.23782}
+{"mode": "train", "epoch": 53, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00073, "acc_pose": 0.77442, "loss": 0.00073, "grad_norm": 0.00122, "time": 0.23726}
+{"mode": "train", "epoch": 53, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00054, "heatmap_loss": 0.00072, "acc_pose": 0.77078, "loss": 0.00072, "grad_norm": 0.00113, "time": 0.23684}
+{"mode": "train", "epoch": 54, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05762, "heatmap_loss": 0.00072, "acc_pose": 0.77605, "loss": 0.00072, "grad_norm": 0.00117, "time": 0.29907}
+{"mode": "train", "epoch": 54, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00072, "acc_pose": 0.76977, "loss": 0.00072, "grad_norm": 0.00119, "time": 0.23859}
+{"mode": "train", "epoch": 54, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00072, "acc_pose": 0.77894, "loss": 0.00072, "grad_norm": 0.00116, "time": 0.23837}
+{"mode": "train", "epoch": 54, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00026, "heatmap_loss": 0.00072, "acc_pose": 0.77221, "loss": 0.00072, "grad_norm": 0.00121, "time": 0.23811}
+{"mode": "train", "epoch": 54, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00026, "heatmap_loss": 0.00072, "acc_pose": 0.77577, "loss": 0.00072, "grad_norm": 0.00122, "time": 0.2379}
+{"mode": "train", "epoch": 55, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05551, "heatmap_loss": 0.00072, "acc_pose": 0.77832, "loss": 0.00072, "grad_norm": 0.0012, "time": 0.29758}
+{"mode": "train", "epoch": 55, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00072, "acc_pose": 0.76762, "loss": 0.00072, "grad_norm": 0.00121, "time": 0.23781}
+{"mode": "train", "epoch": 55, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00045, "heatmap_loss": 0.00072, "acc_pose": 0.7681, "loss": 0.00072, "grad_norm": 0.00113, "time": 0.2384}
+{"mode": "train", "epoch": 55, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00033, "heatmap_loss": 0.00072, "acc_pose": 0.77465, "loss": 0.00072, "grad_norm": 0.00121, "time": 0.23806}
+{"mode": "train", "epoch": 55, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00039, "heatmap_loss": 0.00072, "acc_pose": 0.77402, "loss": 0.00072, "grad_norm": 0.00126, "time": 0.23786}
+{"mode": "train", "epoch": 56, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05596, "heatmap_loss": 0.00073, "acc_pose": 0.77239, "loss": 0.00073, "grad_norm": 0.00115, "time": 0.29711}
+{"mode": "train", "epoch": 56, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00071, "acc_pose": 0.77973, "loss": 0.00071, "grad_norm": 0.00113, "time": 0.23836}
+{"mode": "train", "epoch": 56, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00036, "heatmap_loss": 0.00071, "acc_pose": 0.77293, "loss": 0.00071, "grad_norm": 0.0012, "time": 0.23848}
+{"mode": "train", "epoch": 56, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00071, "acc_pose": 0.76923, "loss": 0.00071, "grad_norm": 0.00115, "time": 0.23817}
+{"mode": "train", "epoch": 56, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00071, "acc_pose": 0.77468, "loss": 0.00071, "grad_norm": 0.00118, "time": 0.23762}
+{"mode": "train", "epoch": 57, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05614, "heatmap_loss": 0.00072, "acc_pose": 0.78341, "loss": 0.00072, "grad_norm": 0.00122, "time": 0.29814}
+{"mode": "train", "epoch": 57, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00071, "acc_pose": 0.7735, "loss": 0.00071, "grad_norm": 0.00119, "time": 0.2388}
+{"mode": "train", "epoch": 57, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.0004, "heatmap_loss": 0.00072, "acc_pose": 0.77503, "loss": 0.00072, "grad_norm": 0.00119, "time": 0.23777}
+{"mode": "train", "epoch": 57, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00072, "acc_pose": 0.78395, "loss": 0.00072, "grad_norm": 0.00116, "time": 0.23723}
+{"mode": "train", "epoch": 57, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00071, "acc_pose": 0.77884, "loss": 0.00071, "grad_norm": 0.00115, "time": 0.23741}
+{"mode": "train", "epoch": 58, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05507, "heatmap_loss": 0.00071, "acc_pose": 0.77971, "loss": 0.00071, "grad_norm": 0.00119, "time": 0.29773}
+{"mode": "train", "epoch": 58, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00071, "acc_pose": 0.77583, "loss": 0.00071, "grad_norm": 0.00115, "time": 0.23832}
+{"mode": "train", "epoch": 58, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00071, "acc_pose": 0.77109, "loss": 0.00071, "grad_norm": 0.00118, "time": 0.23743}
+{"mode": "train", "epoch": 58, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00052, "heatmap_loss": 0.00072, "acc_pose": 0.78119, "loss": 0.00072, "grad_norm": 0.00119, "time": 0.23797}
+{"mode": "train", "epoch": 58, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00071, "acc_pose": 0.77584, "loss": 0.00071, "grad_norm": 0.00115, "time": 0.237}
+{"mode": "train", "epoch": 59, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05556, "heatmap_loss": 0.00071, "acc_pose": 0.77753, "loss": 0.00071, "grad_norm": 0.00112, "time": 0.29693}
+{"mode": "train", "epoch": 59, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00071, "acc_pose": 0.7822, "loss": 0.00071, "grad_norm": 0.00117, "time": 0.23872}
+{"mode": "train", "epoch": 59, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00071, "acc_pose": 0.78044, "loss": 0.00071, "grad_norm": 0.00117, "time": 0.23855}
+{"mode": "train", "epoch": 59, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00042, "heatmap_loss": 0.00071, "acc_pose": 0.77846, "loss": 0.00071, "grad_norm": 0.00114, "time": 0.23821}
+{"mode": "train", "epoch": 59, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00071, "acc_pose": 0.78134, "loss": 0.00071, "grad_norm": 0.00117, "time": 0.23795}
+{"mode": "train", "epoch": 60, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05559, "heatmap_loss": 0.00071, "acc_pose": 0.77917, "loss": 0.00071, "grad_norm": 0.00117, "time": 0.29746}
+{"mode": "train", "epoch": 60, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.0007, "acc_pose": 0.77837, "loss": 0.0007, "grad_norm": 0.00114, "time": 0.2384}
+{"mode": "train", "epoch": 60, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00043, "heatmap_loss": 0.00071, "acc_pose": 0.77468, "loss": 0.00071, "grad_norm": 0.00117, "time": 0.23821}
+{"mode": "train", "epoch": 60, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00043, "heatmap_loss": 0.00071, "acc_pose": 0.78059, "loss": 0.00071, "grad_norm": 0.00114, "time": 0.23826}
+{"mode": "train", "epoch": 60, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00045, "heatmap_loss": 0.00071, "acc_pose": 0.768, "loss": 0.00071, "grad_norm": 0.00115, "time": 0.23808}
+{"mode": "val", "epoch": 60, "iter": 407, "lr": 1e-05, "AP": 0.72138, "AP .5": 0.89564, "AP .75": 0.7972, "AP (M)": 0.64857, "AP (L)": 0.74628, "AR": 0.77805, "AR .5": 0.93671, "AR .75": 0.84509, "AR (M)": 0.7363, "AR (L)": 0.83846}
+{"mode": "train", "epoch": 61, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.0554, "heatmap_loss": 0.0007, "acc_pose": 0.77166, "loss": 0.0007, "grad_norm": 0.00119, "time": 0.29563}
+{"mode": "train", "epoch": 61, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00026, "heatmap_loss": 0.00071, "acc_pose": 0.7693, "loss": 0.00071, "grad_norm": 0.00115, "time": 0.23903}
+{"mode": "train", "epoch": 61, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00071, "acc_pose": 0.77334, "loss": 0.00071, "grad_norm": 0.00116, "time": 0.23866}
+{"mode": "train", "epoch": 61, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00034, "heatmap_loss": 0.00071, "acc_pose": 0.77783, "loss": 0.00071, "grad_norm": 0.00112, "time": 0.23817}
+{"mode": "train", "epoch": 61, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00071, "acc_pose": 0.77896, "loss": 0.00071, "grad_norm": 0.00114, "time": 0.23786}
+{"mode": "train", "epoch": 62, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05553, "heatmap_loss": 0.0007, "acc_pose": 0.77425, "loss": 0.0007, "grad_norm": 0.00115, "time": 0.29672}
+{"mode": "train", "epoch": 62, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.0007, "acc_pose": 0.77808, "loss": 0.0007, "grad_norm": 0.00121, "time": 0.23911}
+{"mode": "train", "epoch": 62, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.0004, "heatmap_loss": 0.00071, "acc_pose": 0.77604, "loss": 0.00071, "grad_norm": 0.00115, "time": 0.23842}
+{"mode": "train", "epoch": 62, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00042, "heatmap_loss": 0.0007, "acc_pose": 0.78096, "loss": 0.0007, "grad_norm": 0.00118, "time": 0.23845}
+{"mode": "train", "epoch": 62, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00041, "heatmap_loss": 0.0007, "acc_pose": 0.78172, "loss": 0.0007, "grad_norm": 0.00114, "time": 0.23806}
+{"mode": "train", "epoch": 63, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05552, "heatmap_loss": 0.0007, "acc_pose": 0.78298, "loss": 0.0007, "grad_norm": 0.00117, "time": 0.29697}
+{"mode": "train", "epoch": 63, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.0007, "acc_pose": 0.7858, "loss": 0.0007, "grad_norm": 0.00116, "time": 0.23805}
+{"mode": "train", "epoch": 63, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.0007, "acc_pose": 0.78429, "loss": 0.0007, "grad_norm": 0.00119, "time": 0.23766}
+{"mode": "train", "epoch": 63, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00071, "acc_pose": 0.78255, "loss": 0.00071, "grad_norm": 0.00116, "time": 0.23813}
+{"mode": "train", "epoch": 63, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00071, "acc_pose": 0.77609, "loss": 0.00071, "grad_norm": 0.00118, "time": 0.23743}
+{"mode": "train", "epoch": 64, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05838, "heatmap_loss": 0.0007, "acc_pose": 0.77652, "loss": 0.0007, "grad_norm": 0.00116, "time": 0.30218}
+{"mode": "train", "epoch": 64, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00043, "heatmap_loss": 0.0007, "acc_pose": 0.77511, "loss": 0.0007, "grad_norm": 0.00115, "time": 0.23898}
+{"mode": "train", "epoch": 64, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00071, "acc_pose": 0.78095, "loss": 0.00071, "grad_norm": 0.00119, "time": 0.23865}
+{"mode": "train", "epoch": 64, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.0007, "acc_pose": 0.7802, "loss": 0.0007, "grad_norm": 0.00114, "time": 0.23772}
+{"mode": "train", "epoch": 64, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00042, "heatmap_loss": 0.0007, "acc_pose": 0.78143, "loss": 0.0007, "grad_norm": 0.00115, "time": 0.23793}
+{"mode": "train", "epoch": 65, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05579, "heatmap_loss": 0.0007, "acc_pose": 0.78406, "loss": 0.0007, "grad_norm": 0.00112, "time": 0.29678}
+{"mode": "train", "epoch": 65, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00033, "heatmap_loss": 0.00069, "acc_pose": 0.7834, "loss": 0.00069, "grad_norm": 0.00114, "time": 0.2387}
+{"mode": "train", "epoch": 65, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00035, "heatmap_loss": 0.0007, "acc_pose": 0.78294, "loss": 0.0007, "grad_norm": 0.00114, "time": 0.23829}
+{"mode": "train", "epoch": 65, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.0007, "acc_pose": 0.78132, "loss": 0.0007, "grad_norm": 0.00116, "time": 0.23749}
+{"mode": "train", "epoch": 65, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00043, "heatmap_loss": 0.0007, "acc_pose": 0.77918, "loss": 0.0007, "grad_norm": 0.00116, "time": 0.23706}
+{"mode": "train", "epoch": 66, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05545, "heatmap_loss": 0.00069, "acc_pose": 0.78726, "loss": 0.00069, "grad_norm": 0.00115, "time": 0.29681}
+{"mode": "train", "epoch": 66, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.0007, "acc_pose": 0.77942, "loss": 0.0007, "grad_norm": 0.00116, "time": 0.2385}
+{"mode": "train", "epoch": 66, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00026, "heatmap_loss": 0.0007, "acc_pose": 0.78373, "loss": 0.0007, "grad_norm": 0.00111, "time": 0.23823}
+{"mode": "train", "epoch": 66, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.0004, "heatmap_loss": 0.00069, "acc_pose": 0.78505, "loss": 0.00069, "grad_norm": 0.00109, "time": 0.23796}
+{"mode": "train", "epoch": 66, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.0007, "acc_pose": 0.78205, "loss": 0.0007, "grad_norm": 0.00113, "time": 0.23796}
+{"mode": "train", "epoch": 67, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05525, "heatmap_loss": 0.0007, "acc_pose": 0.78533, "loss": 0.0007, "grad_norm": 0.00115, "time": 0.29627}
+{"mode": "train", "epoch": 67, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00033, "heatmap_loss": 0.0007, "acc_pose": 0.77484, "loss": 0.0007, "grad_norm": 0.00111, "time": 0.23843}
+{"mode": "train", "epoch": 67, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.0007, "acc_pose": 0.78363, "loss": 0.0007, "grad_norm": 0.0011, "time": 0.23817}
+{"mode": "train", "epoch": 67, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00033, "heatmap_loss": 0.00069, "acc_pose": 0.78485, "loss": 0.00069, "grad_norm": 0.00119, "time": 0.23733}
+{"mode": "train", "epoch": 67, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00034, "heatmap_loss": 0.0007, "acc_pose": 0.78197, "loss": 0.0007, "grad_norm": 0.0011, "time": 0.23785}
+{"mode": "train", "epoch": 68, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05473, "heatmap_loss": 0.00069, "acc_pose": 0.77871, "loss": 0.00069, "grad_norm": 0.00118, "time": 0.29722}
+{"mode": "train", "epoch": 68, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00069, "acc_pose": 0.7817, "loss": 0.00069, "grad_norm": 0.00112, "time": 0.23827}
+{"mode": "train", "epoch": 68, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00069, "acc_pose": 0.78345, "loss": 0.00069, "grad_norm": 0.00117, "time": 0.23837}
+{"mode": "train", "epoch": 68, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.0007, "acc_pose": 0.78277, "loss": 0.0007, "grad_norm": 0.00117, "time": 0.23836}
+{"mode": "train", "epoch": 68, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00042, "heatmap_loss": 0.0007, "acc_pose": 0.77956, "loss": 0.0007, "grad_norm": 0.00115, "time": 0.23827}
+{"mode": "train", "epoch": 69, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05541, "heatmap_loss": 0.00069, "acc_pose": 0.78485, "loss": 0.00069, "grad_norm": 0.00111, "time": 0.29847}
+{"mode": "train", "epoch": 69, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00069, "acc_pose": 0.77935, "loss": 0.00069, "grad_norm": 0.00117, "time": 0.23853}
+{"mode": "train", "epoch": 69, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00042, "heatmap_loss": 0.00069, "acc_pose": 0.77785, "loss": 0.00069, "grad_norm": 0.00115, "time": 0.23831}
+{"mode": "train", "epoch": 69, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00039, "heatmap_loss": 0.00069, "acc_pose": 0.78656, "loss": 0.00069, "grad_norm": 0.00123, "time": 0.23762}
+{"mode": "train", "epoch": 69, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.0007, "acc_pose": 0.78485, "loss": 0.0007, "grad_norm": 0.00115, "time": 0.2377}
+{"mode": "train", "epoch": 70, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05501, "heatmap_loss": 0.0007, "acc_pose": 0.77889, "loss": 0.0007, "grad_norm": 0.00114, "time": 0.29669}
+{"mode": "train", "epoch": 70, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00069, "acc_pose": 0.78786, "loss": 0.00069, "grad_norm": 0.00112, "time": 0.23795}
+{"mode": "train", "epoch": 70, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00037, "heatmap_loss": 0.0007, "acc_pose": 0.77356, "loss": 0.0007, "grad_norm": 0.00112, "time": 0.23774}
+{"mode": "train", "epoch": 70, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00069, "acc_pose": 0.78678, "loss": 0.00069, "grad_norm": 0.00114, "time": 0.23789}
+{"mode": "train", "epoch": 70, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.0004, "heatmap_loss": 0.00069, "acc_pose": 0.77726, "loss": 0.00069, "grad_norm": 0.00113, "time": 0.23828}
+{"mode": "val", "epoch": 70, "iter": 407, "lr": 1e-05, "AP": 0.72817, "AP .5": 0.89885, "AP .75": 0.8047, "AP (M)": 0.65621, "AP (L)": 0.75381, "AR": 0.78438, "AR .5": 0.94065, "AR .75": 0.8528, "AR (M)": 0.74288, "AR (L)": 0.84452}
+{"mode": "train", "epoch": 71, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05504, "heatmap_loss": 0.00069, "acc_pose": 0.7847, "loss": 0.00069, "grad_norm": 0.00114, "time": 0.29496}
+{"mode": "train", "epoch": 71, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00039, "heatmap_loss": 0.00069, "acc_pose": 0.78253, "loss": 0.00069, "grad_norm": 0.00116, "time": 0.23797}
+{"mode": "train", "epoch": 71, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00025, "heatmap_loss": 0.00069, "acc_pose": 0.78197, "loss": 0.00069, "grad_norm": 0.00114, "time": 0.23813}
+{"mode": "train", "epoch": 71, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.0004, "heatmap_loss": 0.00069, "acc_pose": 0.78725, "loss": 0.00069, "grad_norm": 0.00113, "time": 0.23788}
+{"mode": "train", "epoch": 71, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00069, "acc_pose": 0.78549, "loss": 0.00069, "grad_norm": 0.00112, "time": 0.23844}
+{"mode": "train", "epoch": 72, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05576, "heatmap_loss": 0.00069, "acc_pose": 0.79079, "loss": 0.00069, "grad_norm": 0.00115, "time": 0.29724}
+{"mode": "train", "epoch": 72, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.0007, "acc_pose": 0.78246, "loss": 0.0007, "grad_norm": 0.00116, "time": 0.23785}
+{"mode": "train", "epoch": 72, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00036, "heatmap_loss": 0.00069, "acc_pose": 0.78044, "loss": 0.00069, "grad_norm": 0.0011, "time": 0.23782}
+{"mode": "train", "epoch": 72, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00069, "acc_pose": 0.78957, "loss": 0.00069, "grad_norm": 0.00115, "time": 0.23782}
+{"mode": "train", "epoch": 72, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00069, "acc_pose": 0.78198, "loss": 0.00069, "grad_norm": 0.00112, "time": 0.23742}
+{"mode": "train", "epoch": 73, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05532, "heatmap_loss": 0.00068, "acc_pose": 0.79024, "loss": 0.00068, "grad_norm": 0.00113, "time": 0.29759}
+{"mode": "train", "epoch": 73, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.0004, "heatmap_loss": 0.00069, "acc_pose": 0.7897, "loss": 0.00069, "grad_norm": 0.00115, "time": 0.23795}
+{"mode": "train", "epoch": 73, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00043, "heatmap_loss": 0.00069, "acc_pose": 0.77524, "loss": 0.00069, "grad_norm": 0.00116, "time": 0.23808}
+{"mode": "train", "epoch": 73, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00043, "heatmap_loss": 0.00069, "acc_pose": 0.78901, "loss": 0.00069, "grad_norm": 0.00114, "time": 0.23777}
+{"mode": "train", "epoch": 73, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00069, "acc_pose": 0.78808, "loss": 0.00069, "grad_norm": 0.00118, "time": 0.23807}
+{"mode": "train", "epoch": 74, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05561, "heatmap_loss": 0.00069, "acc_pose": 0.78406, "loss": 0.00069, "grad_norm": 0.0011, "time": 0.29627}
+{"mode": "train", "epoch": 74, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00068, "acc_pose": 0.78153, "loss": 0.00068, "grad_norm": 0.00112, "time": 0.23898}
+{"mode": "train", "epoch": 74, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00024, "heatmap_loss": 0.00069, "acc_pose": 0.77742, "loss": 0.00069, "grad_norm": 0.00115, "time": 0.23772}
+{"mode": "train", "epoch": 74, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00024, "heatmap_loss": 0.00069, "acc_pose": 0.78799, "loss": 0.00069, "grad_norm": 0.00114, "time": 0.2375}
+{"mode": "train", "epoch": 74, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00038, "heatmap_loss": 0.00069, "acc_pose": 0.78226, "loss": 0.00069, "grad_norm": 0.00114, "time": 0.23783}
+{"mode": "train", "epoch": 75, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05593, "heatmap_loss": 0.00068, "acc_pose": 0.78827, "loss": 0.00068, "grad_norm": 0.00112, "time": 0.29815}
+{"mode": "train", "epoch": 75, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00026, "heatmap_loss": 0.00068, "acc_pose": 0.78345, "loss": 0.00068, "grad_norm": 0.00115, "time": 0.23854}
+{"mode": "train", "epoch": 75, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00033, "heatmap_loss": 0.00068, "acc_pose": 0.7859, "loss": 0.00068, "grad_norm": 0.00114, "time": 0.23764}
+{"mode": "train", "epoch": 75, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00069, "acc_pose": 0.79172, "loss": 0.00069, "grad_norm": 0.00121, "time": 0.23726}
+{"mode": "train", "epoch": 75, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00068, "acc_pose": 0.78876, "loss": 0.00068, "grad_norm": 0.00116, "time": 0.23715}
+{"mode": "train", "epoch": 76, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05832, "heatmap_loss": 0.00068, "acc_pose": 0.78713, "loss": 0.00068, "grad_norm": 0.00112, "time": 0.30043}
+{"mode": "train", "epoch": 76, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00068, "acc_pose": 0.78441, "loss": 0.00068, "grad_norm": 0.00115, "time": 0.23851}
+{"mode": "train", "epoch": 76, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00068, "acc_pose": 0.79425, "loss": 0.00068, "grad_norm": 0.00108, "time": 0.23819}
+{"mode": "train", "epoch": 76, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00068, "acc_pose": 0.79158, "loss": 0.00068, "grad_norm": 0.00114, "time": 0.23762}
+{"mode": "train", "epoch": 76, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.0004, "heatmap_loss": 0.00068, "acc_pose": 0.79362, "loss": 0.00068, "grad_norm": 0.00116, "time": 0.23772}
+{"mode": "train", "epoch": 77, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.0559, "heatmap_loss": 0.00068, "acc_pose": 0.78506, "loss": 0.00068, "grad_norm": 0.00111, "time": 0.29759}
+{"mode": "train", "epoch": 77, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00069, "acc_pose": 0.78254, "loss": 0.00069, "grad_norm": 0.00116, "time": 0.23758}
+{"mode": "train", "epoch": 77, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00068, "acc_pose": 0.78978, "loss": 0.00068, "grad_norm": 0.0011, "time": 0.23799}
+{"mode": "train", "epoch": 77, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00068, "acc_pose": 0.78738, "loss": 0.00068, "grad_norm": 0.00115, "time": 0.23781}
+{"mode": "train", "epoch": 77, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00068, "acc_pose": 0.78962, "loss": 0.00068, "grad_norm": 0.00116, "time": 0.23718}
+{"mode": "train", "epoch": 78, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05549, "heatmap_loss": 0.00069, "acc_pose": 0.78945, "loss": 0.00069, "grad_norm": 0.00115, "time": 0.29783}
+{"mode": "train", "epoch": 78, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00068, "acc_pose": 0.79658, "loss": 0.00068, "grad_norm": 0.00117, "time": 0.23854}
+{"mode": "train", "epoch": 78, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00069, "acc_pose": 0.78481, "loss": 0.00069, "grad_norm": 0.00109, "time": 0.238}
+{"mode": "train", "epoch": 78, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00068, "acc_pose": 0.78425, "loss": 0.00068, "grad_norm": 0.00114, "time": 0.23777}
+{"mode": "train", "epoch": 78, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00042, "heatmap_loss": 0.00068, "acc_pose": 0.79208, "loss": 0.00068, "grad_norm": 0.00109, "time": 0.23753}
+{"mode": "train", "epoch": 79, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.0549, "heatmap_loss": 0.00068, "acc_pose": 0.78919, "loss": 0.00068, "grad_norm": 0.00114, "time": 0.29769}
+{"mode": "train", "epoch": 79, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00067, "acc_pose": 0.78084, "loss": 0.00067, "grad_norm": 0.00111, "time": 0.23828}
+{"mode": "train", "epoch": 79, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00068, "acc_pose": 0.77814, "loss": 0.00068, "grad_norm": 0.00114, "time": 0.23792}
+{"mode": "train", "epoch": 79, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00035, "heatmap_loss": 0.00068, "acc_pose": 0.7939, "loss": 0.00068, "grad_norm": 0.00111, "time": 0.23778}
+{"mode": "train", "epoch": 79, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00068, "acc_pose": 0.7905, "loss": 0.00068, "grad_norm": 0.00111, "time": 0.23813}
+{"mode": "train", "epoch": 80, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05532, "heatmap_loss": 0.00068, "acc_pose": 0.79143, "loss": 0.00068, "grad_norm": 0.00113, "time": 0.29733}
+{"mode": "train", "epoch": 80, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00068, "acc_pose": 0.79438, "loss": 0.00068, "grad_norm": 0.00114, "time": 0.23847}
+{"mode": "train", "epoch": 80, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00038, "heatmap_loss": 0.00068, "acc_pose": 0.77666, "loss": 0.00068, "grad_norm": 0.00113, "time": 0.23752}
+{"mode": "train", "epoch": 80, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00068, "acc_pose": 0.79314, "loss": 0.00068, "grad_norm": 0.00115, "time": 0.23835}
+{"mode": "train", "epoch": 80, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00068, "acc_pose": 0.78742, "loss": 0.00068, "grad_norm": 0.00115, "time": 0.23728}
+{"mode": "val", "epoch": 80, "iter": 407, "lr": 1e-05, "AP": 0.73203, "AP .5": 0.90021, "AP .75": 0.80724, "AP (M)": 0.66029, "AP (L)": 0.75704, "AR": 0.78775, "AR .5": 0.94002, "AR .75": 0.85422, "AR (M)": 0.74668, "AR (L)": 0.84731}
+{"mode": "train", "epoch": 81, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05484, "heatmap_loss": 0.00067, "acc_pose": 0.79104, "loss": 0.00067, "grad_norm": 0.00111, "time": 0.29466}
+{"mode": "train", "epoch": 81, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00068, "acc_pose": 0.7867, "loss": 0.00068, "grad_norm": 0.0011, "time": 0.23888}
+{"mode": "train", "epoch": 81, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00068, "acc_pose": 0.78561, "loss": 0.00068, "grad_norm": 0.00117, "time": 0.23747}
+{"mode": "train", "epoch": 81, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00068, "acc_pose": 0.79354, "loss": 0.00068, "grad_norm": 0.00111, "time": 0.23773}
+{"mode": "train", "epoch": 81, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00068, "acc_pose": 0.78947, "loss": 0.00068, "grad_norm": 0.00111, "time": 0.23741}
+{"mode": "train", "epoch": 82, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05524, "heatmap_loss": 0.00068, "acc_pose": 0.79379, "loss": 0.00068, "grad_norm": 0.00113, "time": 0.29637}
+{"mode": "train", "epoch": 82, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00068, "acc_pose": 0.79255, "loss": 0.00068, "grad_norm": 0.00113, "time": 0.2381}
+{"mode": "train", "epoch": 82, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00067, "acc_pose": 0.79487, "loss": 0.00067, "grad_norm": 0.00114, "time": 0.23845}
+{"mode": "train", "epoch": 82, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00044, "heatmap_loss": 0.00068, "acc_pose": 0.78844, "loss": 0.00068, "grad_norm": 0.00116, "time": 0.23821}
+{"mode": "train", "epoch": 82, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00043, "heatmap_loss": 0.00068, "acc_pose": 0.78995, "loss": 0.00068, "grad_norm": 0.00109, "time": 0.23824}
+{"mode": "train", "epoch": 83, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05494, "heatmap_loss": 0.00067, "acc_pose": 0.79323, "loss": 0.00067, "grad_norm": 0.00109, "time": 0.29728}
+{"mode": "train", "epoch": 83, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00039, "heatmap_loss": 0.00068, "acc_pose": 0.78942, "loss": 0.00068, "grad_norm": 0.00115, "time": 0.23784}
+{"mode": "train", "epoch": 83, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00043, "heatmap_loss": 0.00068, "acc_pose": 0.78551, "loss": 0.00068, "grad_norm": 0.00113, "time": 0.23912}
+{"mode": "train", "epoch": 83, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00068, "acc_pose": 0.78727, "loss": 0.00068, "grad_norm": 0.00119, "time": 0.2378}
+{"mode": "train", "epoch": 83, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00068, "acc_pose": 0.79298, "loss": 0.00068, "grad_norm": 0.00116, "time": 0.23835}
+{"mode": "train", "epoch": 84, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05549, "heatmap_loss": 0.00067, "acc_pose": 0.79055, "loss": 0.00067, "grad_norm": 0.00108, "time": 0.29685}
+{"mode": "train", "epoch": 84, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00067, "acc_pose": 0.78485, "loss": 0.00067, "grad_norm": 0.00117, "time": 0.23853}
+{"mode": "train", "epoch": 84, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00026, "heatmap_loss": 0.00068, "acc_pose": 0.78851, "loss": 0.00068, "grad_norm": 0.00111, "time": 0.23785}
+{"mode": "train", "epoch": 84, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00067, "acc_pose": 0.79638, "loss": 0.00067, "grad_norm": 0.00112, "time": 0.23763}
+{"mode": "train", "epoch": 84, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00068, "acc_pose": 0.78579, "loss": 0.00068, "grad_norm": 0.00114, "time": 0.23784}
+{"mode": "train", "epoch": 85, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05524, "heatmap_loss": 0.00067, "acc_pose": 0.78836, "loss": 0.00067, "grad_norm": 0.00108, "time": 0.29557}
+{"mode": "train", "epoch": 85, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00067, "acc_pose": 0.79896, "loss": 0.00067, "grad_norm": 0.00113, "time": 0.23807}
+{"mode": "train", "epoch": 85, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00067, "acc_pose": 0.78872, "loss": 0.00067, "grad_norm": 0.00113, "time": 0.23791}
+{"mode": "train", "epoch": 85, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00067, "acc_pose": 0.79805, "loss": 0.00067, "grad_norm": 0.00114, "time": 0.2379}
+{"mode": "train", "epoch": 85, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00033, "heatmap_loss": 0.00068, "acc_pose": 0.79708, "loss": 0.00068, "grad_norm": 0.00116, "time": 0.23778}
+{"mode": "train", "epoch": 86, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05512, "heatmap_loss": 0.00067, "acc_pose": 0.79813, "loss": 0.00067, "grad_norm": 0.00114, "time": 0.29762}
+{"mode": "train", "epoch": 86, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00067, "acc_pose": 0.78935, "loss": 0.00067, "grad_norm": 0.00112, "time": 0.23834}
+{"mode": "train", "epoch": 86, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00067, "acc_pose": 0.78874, "loss": 0.00067, "grad_norm": 0.00113, "time": 0.23803}
+{"mode": "train", "epoch": 86, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00067, "acc_pose": 0.7899, "loss": 0.00067, "grad_norm": 0.00109, "time": 0.2371}
+{"mode": "train", "epoch": 86, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.0004, "heatmap_loss": 0.00067, "acc_pose": 0.79064, "loss": 0.00067, "grad_norm": 0.00108, "time": 0.23755}
+{"mode": "train", "epoch": 87, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05535, "heatmap_loss": 0.00067, "acc_pose": 0.79587, "loss": 0.00067, "grad_norm": 0.00113, "time": 0.29624}
+{"mode": "train", "epoch": 87, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00067, "acc_pose": 0.79855, "loss": 0.00067, "grad_norm": 0.00112, "time": 0.23789}
+{"mode": "train", "epoch": 87, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00025, "heatmap_loss": 0.00067, "acc_pose": 0.79109, "loss": 0.00067, "grad_norm": 0.0011, "time": 0.23796}
+{"mode": "train", "epoch": 87, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00041, "heatmap_loss": 0.00067, "acc_pose": 0.79806, "loss": 0.00067, "grad_norm": 0.0011, "time": 0.23734}
+{"mode": "train", "epoch": 87, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00042, "heatmap_loss": 0.00067, "acc_pose": 0.79565, "loss": 0.00067, "grad_norm": 0.00111, "time": 0.23752}
+{"mode": "train", "epoch": 88, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05511, "heatmap_loss": 0.00066, "acc_pose": 0.79446, "loss": 0.00066, "grad_norm": 0.0011, "time": 0.29771}
+{"mode": "train", "epoch": 88, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00067, "acc_pose": 0.79298, "loss": 0.00067, "grad_norm": 0.00112, "time": 0.23818}
+{"mode": "train", "epoch": 88, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00033, "heatmap_loss": 0.00067, "acc_pose": 0.79468, "loss": 0.00067, "grad_norm": 0.00113, "time": 0.23857}
+{"mode": "train", "epoch": 88, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00033, "heatmap_loss": 0.00067, "acc_pose": 0.79632, "loss": 0.00067, "grad_norm": 0.00112, "time": 0.23838}
+{"mode": "train", "epoch": 88, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00067, "acc_pose": 0.79843, "loss": 0.00067, "grad_norm": 0.00114, "time": 0.23832}
+{"mode": "train", "epoch": 89, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.0556, "heatmap_loss": 0.00067, "acc_pose": 0.78548, "loss": 0.00067, "grad_norm": 0.00112, "time": 0.2981}
+{"mode": "train", "epoch": 89, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00025, "heatmap_loss": 0.00067, "acc_pose": 0.79223, "loss": 0.00067, "grad_norm": 0.00115, "time": 0.23838}
+{"mode": "train", "epoch": 89, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00067, "acc_pose": 0.78878, "loss": 0.00067, "grad_norm": 0.00121, "time": 0.23792}
+{"mode": "train", "epoch": 89, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00056, "heatmap_loss": 0.00067, "acc_pose": 0.79663, "loss": 0.00067, "grad_norm": 0.00111, "time": 0.2376}
+{"mode": "train", "epoch": 89, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00066, "acc_pose": 0.79829, "loss": 0.00066, "grad_norm": 0.0011, "time": 0.23762}
+{"mode": "train", "epoch": 90, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05498, "heatmap_loss": 0.00067, "acc_pose": 0.79504, "loss": 0.00067, "grad_norm": 0.00112, "time": 0.30106}
+{"mode": "train", "epoch": 90, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00067, "acc_pose": 0.79976, "loss": 0.00067, "grad_norm": 0.00112, "time": 0.23872}
+{"mode": "train", "epoch": 90, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00041, "heatmap_loss": 0.00067, "acc_pose": 0.78713, "loss": 0.00067, "grad_norm": 0.00108, "time": 0.23887}
+{"mode": "train", "epoch": 90, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00067, "acc_pose": 0.79488, "loss": 0.00067, "grad_norm": 0.00119, "time": 0.23823}
+{"mode": "train", "epoch": 90, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00039, "heatmap_loss": 0.00067, "acc_pose": 0.79608, "loss": 0.00067, "grad_norm": 0.00113, "time": 0.23769}
+{"mode": "val", "epoch": 90, "iter": 407, "lr": 1e-05, "AP": 0.73256, "AP .5": 0.89784, "AP .75": 0.80885, "AP (M)": 0.66064, "AP (L)": 0.75623, "AR": 0.78794, "AR .5": 0.93939, "AR .75": 0.85674, "AR (M)": 0.74542, "AR (L)": 0.84942}
+{"mode": "train", "epoch": 91, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05469, "heatmap_loss": 0.00066, "acc_pose": 0.80078, "loss": 0.00066, "grad_norm": 0.00115, "time": 0.295}
+{"mode": "train", "epoch": 91, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00066, "acc_pose": 0.80182, "loss": 0.00066, "grad_norm": 0.00114, "time": 0.23834}
+{"mode": "train", "epoch": 91, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00066, "acc_pose": 0.80168, "loss": 0.00066, "grad_norm": 0.0011, "time": 0.23828}
+{"mode": "train", "epoch": 91, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00054, "heatmap_loss": 0.00067, "acc_pose": 0.79537, "loss": 0.00067, "grad_norm": 0.00114, "time": 0.23833}
+{"mode": "train", "epoch": 91, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00067, "acc_pose": 0.79351, "loss": 0.00067, "grad_norm": 0.00113, "time": 0.23792}
+{"mode": "train", "epoch": 92, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05496, "heatmap_loss": 0.00066, "acc_pose": 0.79906, "loss": 0.00066, "grad_norm": 0.00107, "time": 0.29734}
+{"mode": "train", "epoch": 92, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00067, "acc_pose": 0.7911, "loss": 0.00067, "grad_norm": 0.00114, "time": 0.23897}
+{"mode": "train", "epoch": 92, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00026, "heatmap_loss": 0.00066, "acc_pose": 0.79368, "loss": 0.00066, "grad_norm": 0.0011, "time": 0.23776}
+{"mode": "train", "epoch": 92, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00067, "acc_pose": 0.79905, "loss": 0.00067, "grad_norm": 0.00111, "time": 0.23808}
+{"mode": "train", "epoch": 92, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00067, "acc_pose": 0.79408, "loss": 0.00067, "grad_norm": 0.00111, "time": 0.23817}
+{"mode": "train", "epoch": 93, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05519, "heatmap_loss": 0.00066, "acc_pose": 0.7947, "loss": 0.00066, "grad_norm": 0.00109, "time": 0.29795}
+{"mode": "train", "epoch": 93, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00026, "heatmap_loss": 0.00067, "acc_pose": 0.79181, "loss": 0.00067, "grad_norm": 0.00106, "time": 0.2383}
+{"mode": "train", "epoch": 93, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00067, "acc_pose": 0.79936, "loss": 0.00067, "grad_norm": 0.00115, "time": 0.23796}
+{"mode": "train", "epoch": 93, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00067, "acc_pose": 0.79944, "loss": 0.00067, "grad_norm": 0.00108, "time": 0.23834}
+{"mode": "train", "epoch": 93, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00066, "acc_pose": 0.80614, "loss": 0.00066, "grad_norm": 0.0011, "time": 0.2381}
+{"mode": "train", "epoch": 94, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05821, "heatmap_loss": 0.00066, "acc_pose": 0.79237, "loss": 0.00066, "grad_norm": 0.00111, "time": 0.30125}
+{"mode": "train", "epoch": 94, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00034, "heatmap_loss": 0.00067, "acc_pose": 0.8013, "loss": 0.00067, "grad_norm": 0.00112, "time": 0.23806}
+{"mode": "train", "epoch": 94, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00043, "heatmap_loss": 0.00066, "acc_pose": 0.79297, "loss": 0.00066, "grad_norm": 0.00109, "time": 0.23789}
+{"mode": "train", "epoch": 94, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00033, "heatmap_loss": 0.00066, "acc_pose": 0.79787, "loss": 0.00066, "grad_norm": 0.00111, "time": 0.23745}
+{"mode": "train", "epoch": 94, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00066, "acc_pose": 0.80462, "loss": 0.00066, "grad_norm": 0.00111, "time": 0.23762}
+{"mode": "train", "epoch": 95, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05598, "heatmap_loss": 0.00066, "acc_pose": 0.79554, "loss": 0.00066, "grad_norm": 0.00108, "time": 0.29566}
+{"mode": "train", "epoch": 95, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00038, "heatmap_loss": 0.00066, "acc_pose": 0.79217, "loss": 0.00066, "grad_norm": 0.00114, "time": 0.23807}
+{"mode": "train", "epoch": 95, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00067, "acc_pose": 0.78943, "loss": 0.00067, "grad_norm": 0.00109, "time": 0.2378}
+{"mode": "train", "epoch": 95, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00066, "acc_pose": 0.7973, "loss": 0.00066, "grad_norm": 0.0011, "time": 0.23837}
+{"mode": "train", "epoch": 95, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00066, "acc_pose": 0.79719, "loss": 0.00066, "grad_norm": 0.00113, "time": 0.23823}
+{"mode": "train", "epoch": 96, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.0586, "heatmap_loss": 0.00066, "acc_pose": 0.80401, "loss": 0.00066, "grad_norm": 0.00106, "time": 0.29923}
+{"mode": "train", "epoch": 96, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00066, "acc_pose": 0.79722, "loss": 0.00066, "grad_norm": 0.00112, "time": 0.23854}
+{"mode": "train", "epoch": 96, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00066, "acc_pose": 0.79589, "loss": 0.00066, "grad_norm": 0.00109, "time": 0.23805}
+{"mode": "train", "epoch": 96, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00067, "acc_pose": 0.79339, "loss": 0.00067, "grad_norm": 0.00116, "time": 0.23815}
+{"mode": "train", "epoch": 96, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00026, "heatmap_loss": 0.00067, "acc_pose": 0.80003, "loss": 0.00067, "grad_norm": 0.00112, "time": 0.23721}
+{"mode": "train", "epoch": 97, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05587, "heatmap_loss": 0.00066, "acc_pose": 0.79847, "loss": 0.00066, "grad_norm": 0.00108, "time": 0.29719}
+{"mode": "train", "epoch": 97, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00066, "acc_pose": 0.79531, "loss": 0.00066, "grad_norm": 0.00114, "time": 0.2384}
+{"mode": "train", "epoch": 97, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.0004, "heatmap_loss": 0.00066, "acc_pose": 0.80188, "loss": 0.00066, "grad_norm": 0.00112, "time": 0.23827}
+{"mode": "train", "epoch": 97, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.0004, "heatmap_loss": 0.00066, "acc_pose": 0.80344, "loss": 0.00066, "grad_norm": 0.00118, "time": 0.23803}
+{"mode": "train", "epoch": 97, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00035, "heatmap_loss": 0.00066, "acc_pose": 0.80074, "loss": 0.00066, "grad_norm": 0.00109, "time": 0.23765}
+{"mode": "train", "epoch": 98, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.0557, "heatmap_loss": 0.00066, "acc_pose": 0.79316, "loss": 0.00066, "grad_norm": 0.00107, "time": 0.29779}
+{"mode": "train", "epoch": 98, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00066, "acc_pose": 0.79537, "loss": 0.00066, "grad_norm": 0.00114, "time": 0.23837}
+{"mode": "train", "epoch": 98, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00039, "heatmap_loss": 0.00065, "acc_pose": 0.79733, "loss": 0.00065, "grad_norm": 0.00109, "time": 0.23859}
+{"mode": "train", "epoch": 98, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00066, "acc_pose": 0.80107, "loss": 0.00066, "grad_norm": 0.00107, "time": 0.2377}
+{"mode": "train", "epoch": 98, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00037, "heatmap_loss": 0.00066, "acc_pose": 0.79779, "loss": 0.00066, "grad_norm": 0.00113, "time": 0.23863}
+{"mode": "train", "epoch": 99, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05553, "heatmap_loss": 0.00066, "acc_pose": 0.80225, "loss": 0.00066, "grad_norm": 0.00108, "time": 0.29697}
+{"mode": "train", "epoch": 99, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00066, "acc_pose": 0.7962, "loss": 0.00066, "grad_norm": 0.00108, "time": 0.238}
+{"mode": "train", "epoch": 99, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00066, "acc_pose": 0.79832, "loss": 0.00066, "grad_norm": 0.00114, "time": 0.23849}
+{"mode": "train", "epoch": 99, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00039, "heatmap_loss": 0.00066, "acc_pose": 0.79392, "loss": 0.00066, "grad_norm": 0.00111, "time": 0.23786}
+{"mode": "train", "epoch": 99, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00066, "acc_pose": 0.80345, "loss": 0.00066, "grad_norm": 0.00112, "time": 0.23773}
+{"mode": "train", "epoch": 100, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05515, "heatmap_loss": 0.00065, "acc_pose": 0.80336, "loss": 0.00065, "grad_norm": 0.00107, "time": 0.29805}
+{"mode": "train", "epoch": 100, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00066, "acc_pose": 0.79345, "loss": 0.00066, "grad_norm": 0.00109, "time": 0.23869}
+{"mode": "train", "epoch": 100, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00066, "acc_pose": 0.79536, "loss": 0.00066, "grad_norm": 0.00113, "time": 0.23825}
+{"mode": "train", "epoch": 100, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00066, "acc_pose": 0.80095, "loss": 0.00066, "grad_norm": 0.0011, "time": 0.23795}
+{"mode": "train", "epoch": 100, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00066, "acc_pose": 0.79247, "loss": 0.00066, "grad_norm": 0.0011, "time": 0.23838}
+{"mode": "val", "epoch": 100, "iter": 407, "lr": 1e-05, "AP": 0.73578, "AP .5": 0.90219, "AP .75": 0.81051, "AP (M)": 0.66362, "AP (L)": 0.75984, "AR": 0.79126, "AR .5": 0.94112, "AR .75": 0.8569, "AR (M)": 0.74996, "AR (L)": 0.85076}
+{"mode": "train", "epoch": 101, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05464, "heatmap_loss": 0.00065, "acc_pose": 0.79855, "loss": 0.00065, "grad_norm": 0.00111, "time": 0.29408}
+{"mode": "train", "epoch": 101, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00035, "heatmap_loss": 0.00066, "acc_pose": 0.79295, "loss": 0.00066, "grad_norm": 0.00109, "time": 0.23875}
+{"mode": "train", "epoch": 101, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00066, "acc_pose": 0.80075, "loss": 0.00066, "grad_norm": 0.00113, "time": 0.23828}
+{"mode": "train", "epoch": 101, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00033, "heatmap_loss": 0.00066, "acc_pose": 0.79843, "loss": 0.00066, "grad_norm": 0.00112, "time": 0.23842}
+{"mode": "train", "epoch": 101, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00066, "acc_pose": 0.80004, "loss": 0.00066, "grad_norm": 0.00109, "time": 0.23826}
+{"mode": "train", "epoch": 102, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05548, "heatmap_loss": 0.00065, "acc_pose": 0.80593, "loss": 0.00065, "grad_norm": 0.00107, "time": 0.29694}
+{"mode": "train", "epoch": 102, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00065, "acc_pose": 0.79736, "loss": 0.00065, "grad_norm": 0.00107, "time": 0.23869}
+{"mode": "train", "epoch": 102, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00066, "acc_pose": 0.79286, "loss": 0.00066, "grad_norm": 0.00107, "time": 0.23757}
+{"mode": "train", "epoch": 102, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00044, "heatmap_loss": 0.00066, "acc_pose": 0.80762, "loss": 0.00066, "grad_norm": 0.00109, "time": 0.23835}
+{"mode": "train", "epoch": 102, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00033, "heatmap_loss": 0.00066, "acc_pose": 0.80393, "loss": 0.00066, "grad_norm": 0.00113, "time": 0.23718}
+{"mode": "train", "epoch": 103, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05525, "heatmap_loss": 0.00066, "acc_pose": 0.80247, "loss": 0.00066, "grad_norm": 0.00111, "time": 0.2975}
+{"mode": "train", "epoch": 103, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00066, "acc_pose": 0.7977, "loss": 0.00066, "grad_norm": 0.00112, "time": 0.23807}
+{"mode": "train", "epoch": 103, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00034, "heatmap_loss": 0.00066, "acc_pose": 0.8018, "loss": 0.00066, "grad_norm": 0.0011, "time": 0.23828}
+{"mode": "train", "epoch": 103, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00065, "acc_pose": 0.80236, "loss": 0.00065, "grad_norm": 0.00117, "time": 0.23824}
+{"mode": "train", "epoch": 103, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.0004, "heatmap_loss": 0.00066, "acc_pose": 0.79954, "loss": 0.00066, "grad_norm": 0.00111, "time": 0.23728}
+{"mode": "train", "epoch": 104, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05549, "heatmap_loss": 0.00065, "acc_pose": 0.79862, "loss": 0.00065, "grad_norm": 0.00112, "time": 0.29629}
+{"mode": "train", "epoch": 104, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00065, "acc_pose": 0.80127, "loss": 0.00065, "grad_norm": 0.00111, "time": 0.23833}
+{"mode": "train", "epoch": 104, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00065, "acc_pose": 0.79927, "loss": 0.00065, "grad_norm": 0.00115, "time": 0.23817}
+{"mode": "train", "epoch": 104, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00065, "acc_pose": 0.80439, "loss": 0.00065, "grad_norm": 0.0011, "time": 0.23776}
+{"mode": "train", "epoch": 104, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00066, "acc_pose": 0.79886, "loss": 0.00066, "grad_norm": 0.00117, "time": 0.23803}
+{"mode": "train", "epoch": 105, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05619, "heatmap_loss": 0.00065, "acc_pose": 0.80526, "loss": 0.00065, "grad_norm": 0.00109, "time": 0.29856}
+{"mode": "train", "epoch": 105, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00065, "acc_pose": 0.79418, "loss": 0.00065, "grad_norm": 0.00113, "time": 0.23834}
+{"mode": "train", "epoch": 105, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00065, "acc_pose": 0.7962, "loss": 0.00065, "grad_norm": 0.00112, "time": 0.23827}
+{"mode": "train", "epoch": 105, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00042, "heatmap_loss": 0.00065, "acc_pose": 0.80807, "loss": 0.00065, "grad_norm": 0.00109, "time": 0.23806}
+{"mode": "train", "epoch": 105, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00035, "heatmap_loss": 0.00066, "acc_pose": 0.79562, "loss": 0.00066, "grad_norm": 0.00115, "time": 0.23816}
+{"mode": "train", "epoch": 106, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05843, "heatmap_loss": 0.00065, "acc_pose": 0.79787, "loss": 0.00065, "grad_norm": 0.00111, "time": 0.30183}
+{"mode": "train", "epoch": 106, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00065, "acc_pose": 0.7975, "loss": 0.00065, "grad_norm": 0.00107, "time": 0.23822}
+{"mode": "train", "epoch": 106, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00065, "acc_pose": 0.79646, "loss": 0.00065, "grad_norm": 0.0011, "time": 0.2382}
+{"mode": "train", "epoch": 106, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00037, "heatmap_loss": 0.00065, "acc_pose": 0.8008, "loss": 0.00065, "grad_norm": 0.00115, "time": 0.23743}
+{"mode": "train", "epoch": 106, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00041, "heatmap_loss": 0.00065, "acc_pose": 0.80065, "loss": 0.00065, "grad_norm": 0.00107, "time": 0.23796}
+{"mode": "train", "epoch": 107, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05536, "heatmap_loss": 0.00065, "acc_pose": 0.80193, "loss": 0.00065, "grad_norm": 0.0011, "time": 0.29758}
+{"mode": "train", "epoch": 107, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00065, "acc_pose": 0.79633, "loss": 0.00065, "grad_norm": 0.00113, "time": 0.23925}
+{"mode": "train", "epoch": 107, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00065, "acc_pose": 0.80537, "loss": 0.00065, "grad_norm": 0.00107, "time": 0.23866}
+{"mode": "train", "epoch": 107, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00065, "acc_pose": 0.80169, "loss": 0.00065, "grad_norm": 0.00113, "time": 0.23821}
+{"mode": "train", "epoch": 107, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00041, "heatmap_loss": 0.00065, "acc_pose": 0.80186, "loss": 0.00065, "grad_norm": 0.00111, "time": 0.23794}
+{"mode": "train", "epoch": 108, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.0556, "heatmap_loss": 0.00065, "acc_pose": 0.80115, "loss": 0.00065, "grad_norm": 0.00109, "time": 0.29932}
+{"mode": "train", "epoch": 108, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00065, "acc_pose": 0.7986, "loss": 0.00065, "grad_norm": 0.0011, "time": 0.23893}
+{"mode": "train", "epoch": 108, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00065, "acc_pose": 0.79602, "loss": 0.00065, "grad_norm": 0.00114, "time": 0.2384}
+{"mode": "train", "epoch": 108, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00026, "heatmap_loss": 0.00065, "acc_pose": 0.8012, "loss": 0.00065, "grad_norm": 0.00106, "time": 0.23849}
+{"mode": "train", "epoch": 108, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00065, "acc_pose": 0.80378, "loss": 0.00065, "grad_norm": 0.00114, "time": 0.23821}
+{"mode": "train", "epoch": 109, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05604, "heatmap_loss": 0.00065, "acc_pose": 0.80553, "loss": 0.00065, "grad_norm": 0.00113, "time": 0.29756}
+{"mode": "train", "epoch": 109, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00065, "acc_pose": 0.79681, "loss": 0.00065, "grad_norm": 0.00113, "time": 0.23835}
+{"mode": "train", "epoch": 109, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00065, "acc_pose": 0.80413, "loss": 0.00065, "grad_norm": 0.00115, "time": 0.2385}
+{"mode": "train", "epoch": 109, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00065, "acc_pose": 0.80418, "loss": 0.00065, "grad_norm": 0.0011, "time": 0.23758}
+{"mode": "train", "epoch": 109, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00065, "acc_pose": 0.79996, "loss": 0.00065, "grad_norm": 0.00111, "time": 0.23828}
+{"mode": "train", "epoch": 110, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05511, "heatmap_loss": 0.00065, "acc_pose": 0.79632, "loss": 0.00065, "grad_norm": 0.00114, "time": 0.29953}
+{"mode": "train", "epoch": 110, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00026, "heatmap_loss": 0.00065, "acc_pose": 0.79784, "loss": 0.00065, "grad_norm": 0.00116, "time": 0.23828}
+{"mode": "train", "epoch": 110, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00046, "heatmap_loss": 0.00065, "acc_pose": 0.79869, "loss": 0.00065, "grad_norm": 0.00111, "time": 0.23829}
+{"mode": "train", "epoch": 110, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00064, "acc_pose": 0.81142, "loss": 0.00064, "grad_norm": 0.00109, "time": 0.2379}
+{"mode": "train", "epoch": 110, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.0004, "heatmap_loss": 0.00065, "acc_pose": 0.80731, "loss": 0.00065, "grad_norm": 0.00117, "time": 0.23825}
+{"mode": "val", "epoch": 110, "iter": 407, "lr": 1e-05, "AP": 0.74016, "AP .5": 0.90332, "AP .75": 0.81552, "AP (M)": 0.66892, "AP (L)": 0.76479, "AR": 0.79479, "AR .5": 0.9427, "AR .75": 0.86288, "AR (M)": 0.75373, "AR (L)": 0.85433}
+{"mode": "train", "epoch": 111, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05544, "heatmap_loss": 0.00064, "acc_pose": 0.80218, "loss": 0.00064, "grad_norm": 0.00113, "time": 0.29522}
+{"mode": "train", "epoch": 111, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00065, "acc_pose": 0.79976, "loss": 0.00065, "grad_norm": 0.00113, "time": 0.23883}
+{"mode": "train", "epoch": 111, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00065, "acc_pose": 0.79807, "loss": 0.00065, "grad_norm": 0.00112, "time": 0.23879}
+{"mode": "train", "epoch": 111, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00065, "acc_pose": 0.80151, "loss": 0.00065, "grad_norm": 0.00109, "time": 0.23842}
+{"mode": "train", "epoch": 111, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00045, "heatmap_loss": 0.00065, "acc_pose": 0.79999, "loss": 0.00065, "grad_norm": 0.00108, "time": 0.23829}
+{"mode": "train", "epoch": 112, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05798, "heatmap_loss": 0.00065, "acc_pose": 0.80438, "loss": 0.00065, "grad_norm": 0.00111, "time": 0.30022}
+{"mode": "train", "epoch": 112, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00065, "acc_pose": 0.79759, "loss": 0.00065, "grad_norm": 0.00108, "time": 0.23868}
+{"mode": "train", "epoch": 112, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.0005, "heatmap_loss": 0.00064, "acc_pose": 0.8071, "loss": 0.00064, "grad_norm": 0.00109, "time": 0.2376}
+{"mode": "train", "epoch": 112, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00064, "acc_pose": 0.81306, "loss": 0.00064, "grad_norm": 0.00109, "time": 0.23811}
+{"mode": "train", "epoch": 112, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00065, "acc_pose": 0.80903, "loss": 0.00065, "grad_norm": 0.00111, "time": 0.23828}
+{"mode": "train", "epoch": 113, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05516, "heatmap_loss": 0.00064, "acc_pose": 0.80779, "loss": 0.00064, "grad_norm": 0.0011, "time": 0.29703}
+{"mode": "train", "epoch": 113, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00045, "heatmap_loss": 0.00065, "acc_pose": 0.8044, "loss": 0.00065, "grad_norm": 0.00114, "time": 0.2387}
+{"mode": "train", "epoch": 113, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00065, "acc_pose": 0.80339, "loss": 0.00065, "grad_norm": 0.00113, "time": 0.23798}
+{"mode": "train", "epoch": 113, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00064, "acc_pose": 0.80959, "loss": 0.00064, "grad_norm": 0.0011, "time": 0.23753}
+{"mode": "train", "epoch": 113, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00065, "acc_pose": 0.80069, "loss": 0.00065, "grad_norm": 0.0011, "time": 0.23827}
+{"mode": "train", "epoch": 114, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05599, "heatmap_loss": 0.00064, "acc_pose": 0.80144, "loss": 0.00064, "grad_norm": 0.00113, "time": 0.29643}
+{"mode": "train", "epoch": 114, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00033, "heatmap_loss": 0.00064, "acc_pose": 0.80775, "loss": 0.00064, "grad_norm": 0.00111, "time": 0.2382}
+{"mode": "train", "epoch": 114, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00037, "heatmap_loss": 0.00065, "acc_pose": 0.79574, "loss": 0.00065, "grad_norm": 0.00111, "time": 0.23863}
+{"mode": "train", "epoch": 114, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00065, "acc_pose": 0.80961, "loss": 0.00065, "grad_norm": 0.00108, "time": 0.23758}
+{"mode": "train", "epoch": 114, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.0004, "heatmap_loss": 0.00064, "acc_pose": 0.8056, "loss": 0.00064, "grad_norm": 0.00111, "time": 0.2377}
+{"mode": "train", "epoch": 115, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05556, "heatmap_loss": 0.00064, "acc_pose": 0.80251, "loss": 0.00064, "grad_norm": 0.00112, "time": 0.29642}
+{"mode": "train", "epoch": 115, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00064, "acc_pose": 0.80277, "loss": 0.00064, "grad_norm": 0.00111, "time": 0.23823}
+{"mode": "train", "epoch": 115, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00033, "heatmap_loss": 0.00065, "acc_pose": 0.79817, "loss": 0.00065, "grad_norm": 0.00111, "time": 0.23798}
+{"mode": "train", "epoch": 115, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00064, "acc_pose": 0.8089, "loss": 0.00064, "grad_norm": 0.00108, "time": 0.23701}
+{"mode": "train", "epoch": 115, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00037, "heatmap_loss": 0.00065, "acc_pose": 0.80393, "loss": 0.00065, "grad_norm": 0.00111, "time": 0.23769}
+{"mode": "train", "epoch": 116, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05534, "heatmap_loss": 0.00065, "acc_pose": 0.81073, "loss": 0.00065, "grad_norm": 0.00115, "time": 0.29744}
+{"mode": "train", "epoch": 116, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00064, "acc_pose": 0.79862, "loss": 0.00064, "grad_norm": 0.00111, "time": 0.23888}
+{"mode": "train", "epoch": 116, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00037, "heatmap_loss": 0.00064, "acc_pose": 0.79645, "loss": 0.00064, "grad_norm": 0.00114, "time": 0.23811}
+{"mode": "train", "epoch": 116, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00043, "heatmap_loss": 0.00064, "acc_pose": 0.80408, "loss": 0.00064, "grad_norm": 0.00111, "time": 0.23733}
+{"mode": "train", "epoch": 116, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00041, "heatmap_loss": 0.00065, "acc_pose": 0.80349, "loss": 0.00065, "grad_norm": 0.00118, "time": 0.23764}
+{"mode": "train", "epoch": 117, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05576, "heatmap_loss": 0.00064, "acc_pose": 0.8015, "loss": 0.00064, "grad_norm": 0.00111, "time": 0.29767}
+{"mode": "train", "epoch": 117, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.0004, "heatmap_loss": 0.00064, "acc_pose": 0.80871, "loss": 0.00064, "grad_norm": 0.00115, "time": 0.23832}
+{"mode": "train", "epoch": 117, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00034, "heatmap_loss": 0.00064, "acc_pose": 0.80464, "loss": 0.00064, "grad_norm": 0.00111, "time": 0.23787}
+{"mode": "train", "epoch": 117, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00036, "heatmap_loss": 0.00064, "acc_pose": 0.80419, "loss": 0.00064, "grad_norm": 0.00107, "time": 0.23735}
+{"mode": "train", "epoch": 117, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00064, "acc_pose": 0.80763, "loss": 0.00064, "grad_norm": 0.0011, "time": 0.2374}
+{"mode": "train", "epoch": 118, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05527, "heatmap_loss": 0.00064, "acc_pose": 0.80362, "loss": 0.00064, "grad_norm": 0.00113, "time": 0.29782}
+{"mode": "train", "epoch": 118, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00064, "acc_pose": 0.80188, "loss": 0.00064, "grad_norm": 0.0011, "time": 0.23849}
+{"mode": "train", "epoch": 118, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00064, "acc_pose": 0.8045, "loss": 0.00064, "grad_norm": 0.00111, "time": 0.23862}
+{"mode": "train", "epoch": 118, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00064, "acc_pose": 0.80894, "loss": 0.00064, "grad_norm": 0.00107, "time": 0.23834}
+{"mode": "train", "epoch": 118, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00065, "acc_pose": 0.80581, "loss": 0.00065, "grad_norm": 0.00118, "time": 0.2378}
+{"mode": "train", "epoch": 119, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05556, "heatmap_loss": 0.00064, "acc_pose": 0.81368, "loss": 0.00064, "grad_norm": 0.0011, "time": 0.29909}
+{"mode": "train", "epoch": 119, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00064, "acc_pose": 0.81102, "loss": 0.00064, "grad_norm": 0.00114, "time": 0.23872}
+{"mode": "train", "epoch": 119, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00064, "acc_pose": 0.79795, "loss": 0.00064, "grad_norm": 0.00109, "time": 0.23833}
+{"mode": "train", "epoch": 119, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00064, "acc_pose": 0.80441, "loss": 0.00064, "grad_norm": 0.00112, "time": 0.23764}
+{"mode": "train", "epoch": 119, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.0004, "heatmap_loss": 0.00064, "acc_pose": 0.80503, "loss": 0.00064, "grad_norm": 0.00109, "time": 0.238}
+{"mode": "train", "epoch": 120, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05468, "heatmap_loss": 0.00064, "acc_pose": 0.81227, "loss": 0.00064, "grad_norm": 0.00111, "time": 0.29764}
+{"mode": "train", "epoch": 120, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00064, "acc_pose": 0.8068, "loss": 0.00064, "grad_norm": 0.00115, "time": 0.23849}
+{"mode": "train", "epoch": 120, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00064, "acc_pose": 0.80043, "loss": 0.00064, "grad_norm": 0.0011, "time": 0.23821}
+{"mode": "train", "epoch": 120, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00064, "acc_pose": 0.80377, "loss": 0.00064, "grad_norm": 0.00115, "time": 0.23827}
+{"mode": "train", "epoch": 120, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00064, "acc_pose": 0.80777, "loss": 0.00064, "grad_norm": 0.00109, "time": 0.23741}
+{"mode": "val", "epoch": 120, "iter": 407, "lr": 1e-05, "AP": 0.74112, "AP .5": 0.90327, "AP .75": 0.817, "AP (M)": 0.66913, "AP (L)": 0.76594, "AR": 0.79578, "AR .5": 0.94128, "AR .75": 0.86288, "AR (M)": 0.75458, "AR (L)": 0.85556}
+{"mode": "train", "epoch": 121, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05534, "heatmap_loss": 0.00064, "acc_pose": 0.80132, "loss": 0.00064, "grad_norm": 0.00109, "time": 0.29538}
+{"mode": "train", "epoch": 121, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00042, "heatmap_loss": 0.00064, "acc_pose": 0.81209, "loss": 0.00064, "grad_norm": 0.00109, "time": 0.23882}
+{"mode": "train", "epoch": 121, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00064, "acc_pose": 0.80901, "loss": 0.00064, "grad_norm": 0.00109, "time": 0.23841}
+{"mode": "train", "epoch": 121, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00064, "acc_pose": 0.80753, "loss": 0.00064, "grad_norm": 0.0011, "time": 0.23864}
+{"mode": "train", "epoch": 121, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.0004, "heatmap_loss": 0.00064, "acc_pose": 0.80783, "loss": 0.00064, "grad_norm": 0.0011, "time": 0.23802}
+{"mode": "train", "epoch": 122, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05573, "heatmap_loss": 0.00064, "acc_pose": 0.80505, "loss": 0.00064, "grad_norm": 0.00111, "time": 0.2989}
+{"mode": "train", "epoch": 122, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00064, "acc_pose": 0.80833, "loss": 0.00064, "grad_norm": 0.0011, "time": 0.23867}
+{"mode": "train", "epoch": 122, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00041, "heatmap_loss": 0.00064, "acc_pose": 0.80713, "loss": 0.00064, "grad_norm": 0.00115, "time": 0.23826}
+{"mode": "train", "epoch": 122, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00064, "acc_pose": 0.81057, "loss": 0.00064, "grad_norm": 0.00111, "time": 0.2381}
+{"mode": "train", "epoch": 122, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00064, "acc_pose": 0.80737, "loss": 0.00064, "grad_norm": 0.00108, "time": 0.23828}
+{"mode": "train", "epoch": 123, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05538, "heatmap_loss": 0.00064, "acc_pose": 0.81391, "loss": 0.00064, "grad_norm": 0.00111, "time": 0.29732}
+{"mode": "train", "epoch": 123, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00064, "acc_pose": 0.80893, "loss": 0.00064, "grad_norm": 0.00111, "time": 0.23857}
+{"mode": "train", "epoch": 123, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00042, "heatmap_loss": 0.00064, "acc_pose": 0.80662, "loss": 0.00064, "grad_norm": 0.00114, "time": 0.23854}
+{"mode": "train", "epoch": 123, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00038, "heatmap_loss": 0.00064, "acc_pose": 0.80559, "loss": 0.00064, "grad_norm": 0.00107, "time": 0.2387}
+{"mode": "train", "epoch": 123, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00063, "acc_pose": 0.81103, "loss": 0.00063, "grad_norm": 0.00108, "time": 0.23827}
+{"mode": "train", "epoch": 124, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05908, "heatmap_loss": 0.00064, "acc_pose": 0.80035, "loss": 0.00064, "grad_norm": 0.00109, "time": 0.30058}
+{"mode": "train", "epoch": 124, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00064, "acc_pose": 0.80458, "loss": 0.00064, "grad_norm": 0.00113, "time": 0.23849}
+{"mode": "train", "epoch": 124, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00064, "acc_pose": 0.80406, "loss": 0.00064, "grad_norm": 0.0011, "time": 0.23789}
+{"mode": "train", "epoch": 124, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00042, "heatmap_loss": 0.00064, "acc_pose": 0.80621, "loss": 0.00064, "grad_norm": 0.00109, "time": 0.23785}
+{"mode": "train", "epoch": 124, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00042, "heatmap_loss": 0.00064, "acc_pose": 0.8068, "loss": 0.00064, "grad_norm": 0.00108, "time": 0.2374}
+{"mode": "train", "epoch": 125, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05599, "heatmap_loss": 0.00064, "acc_pose": 0.80562, "loss": 0.00064, "grad_norm": 0.00109, "time": 0.2985}
+{"mode": "train", "epoch": 125, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00064, "acc_pose": 0.81197, "loss": 0.00064, "grad_norm": 0.00108, "time": 0.2381}
+{"mode": "train", "epoch": 125, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00063, "acc_pose": 0.80263, "loss": 0.00063, "grad_norm": 0.00106, "time": 0.23931}
+{"mode": "train", "epoch": 125, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00064, "acc_pose": 0.80346, "loss": 0.00064, "grad_norm": 0.00107, "time": 0.23752}
+{"mode": "train", "epoch": 125, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00064, "acc_pose": 0.80544, "loss": 0.00064, "grad_norm": 0.00111, "time": 0.2376}
+{"mode": "train", "epoch": 126, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05572, "heatmap_loss": 0.00063, "acc_pose": 0.80916, "loss": 0.00063, "grad_norm": 0.00107, "time": 0.29795}
+{"mode": "train", "epoch": 126, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00025, "heatmap_loss": 0.00064, "acc_pose": 0.80607, "loss": 0.00064, "grad_norm": 0.00117, "time": 0.23851}
+{"mode": "train", "epoch": 126, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00026, "heatmap_loss": 0.00064, "acc_pose": 0.80575, "loss": 0.00064, "grad_norm": 0.00113, "time": 0.23813}
+{"mode": "train", "epoch": 126, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00042, "heatmap_loss": 0.00064, "acc_pose": 0.81574, "loss": 0.00064, "grad_norm": 0.0011, "time": 0.23787}
+{"mode": "train", "epoch": 126, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00064, "acc_pose": 0.81082, "loss": 0.00064, "grad_norm": 0.00109, "time": 0.23789}
+{"mode": "train", "epoch": 127, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05554, "heatmap_loss": 0.00063, "acc_pose": 0.80856, "loss": 0.00063, "grad_norm": 0.00107, "time": 0.29717}
+{"mode": "train", "epoch": 127, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00035, "heatmap_loss": 0.00064, "acc_pose": 0.80298, "loss": 0.00064, "grad_norm": 0.00115, "time": 0.2391}
+{"mode": "train", "epoch": 127, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00043, "heatmap_loss": 0.00063, "acc_pose": 0.80384, "loss": 0.00063, "grad_norm": 0.00106, "time": 0.23855}
+{"mode": "train", "epoch": 127, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00064, "acc_pose": 0.80839, "loss": 0.00064, "grad_norm": 0.00112, "time": 0.23731}
+{"mode": "train", "epoch": 127, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00041, "heatmap_loss": 0.00064, "acc_pose": 0.81338, "loss": 0.00064, "grad_norm": 0.00112, "time": 0.23782}
+{"mode": "train", "epoch": 128, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05552, "heatmap_loss": 0.00064, "acc_pose": 0.80707, "loss": 0.00064, "grad_norm": 0.00114, "time": 0.29637}
+{"mode": "train", "epoch": 128, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00026, "heatmap_loss": 0.00063, "acc_pose": 0.80694, "loss": 0.00063, "grad_norm": 0.00109, "time": 0.23827}
+{"mode": "train", "epoch": 128, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00064, "acc_pose": 0.81061, "loss": 0.00064, "grad_norm": 0.00109, "time": 0.23744}
+{"mode": "train", "epoch": 128, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00063, "acc_pose": 0.79951, "loss": 0.00063, "grad_norm": 0.00113, "time": 0.23868}
+{"mode": "train", "epoch": 128, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00064, "acc_pose": 0.80615, "loss": 0.00064, "grad_norm": 0.0011, "time": 0.2379}
+{"mode": "train", "epoch": 129, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05623, "heatmap_loss": 0.00063, "acc_pose": 0.81046, "loss": 0.00063, "grad_norm": 0.00112, "time": 0.2978}
+{"mode": "train", "epoch": 129, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00063, "acc_pose": 0.81132, "loss": 0.00063, "grad_norm": 0.00109, "time": 0.23834}
+{"mode": "train", "epoch": 129, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00064, "acc_pose": 0.80199, "loss": 0.00064, "grad_norm": 0.00113, "time": 0.23825}
+{"mode": "train", "epoch": 129, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00063, "acc_pose": 0.80709, "loss": 0.00063, "grad_norm": 0.00107, "time": 0.23873}
+{"mode": "train", "epoch": 129, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00025, "heatmap_loss": 0.00064, "acc_pose": 0.8028, "loss": 0.00064, "grad_norm": 0.00106, "time": 0.23768}
+{"mode": "train", "epoch": 130, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.056, "heatmap_loss": 0.00063, "acc_pose": 0.80774, "loss": 0.00063, "grad_norm": 0.00111, "time": 0.29846}
+{"mode": "train", "epoch": 130, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00064, "acc_pose": 0.79642, "loss": 0.00064, "grad_norm": 0.00111, "time": 0.23818}
+{"mode": "train", "epoch": 130, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00045, "heatmap_loss": 0.00064, "acc_pose": 0.80553, "loss": 0.00064, "grad_norm": 0.00111, "time": 0.23782}
+{"mode": "train", "epoch": 130, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.0004, "heatmap_loss": 0.00063, "acc_pose": 0.8092, "loss": 0.00063, "grad_norm": 0.00111, "time": 0.2375}
+{"mode": "train", "epoch": 130, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00063, "acc_pose": 0.80885, "loss": 0.00063, "grad_norm": 0.00112, "time": 0.23767}
+{"mode": "val", "epoch": 130, "iter": 407, "lr": 1e-05, "AP": 0.74092, "AP .5": 0.90235, "AP .75": 0.81771, "AP (M)": 0.66984, "AP (L)": 0.76515, "AR": 0.79578, "AR .5": 0.94112, "AR .75": 0.86477, "AR (M)": 0.75354, "AR (L)": 0.85715}
+{"mode": "train", "epoch": 131, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05703, "heatmap_loss": 0.00063, "acc_pose": 0.81453, "loss": 0.00063, "grad_norm": 0.00107, "time": 0.29668}
+{"mode": "train", "epoch": 131, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00063, "acc_pose": 0.81044, "loss": 0.00063, "grad_norm": 0.00116, "time": 0.23853}
+{"mode": "train", "epoch": 131, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00064, "acc_pose": 0.80661, "loss": 0.00064, "grad_norm": 0.00112, "time": 0.2389}
+{"mode": "train", "epoch": 131, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00063, "acc_pose": 0.81361, "loss": 0.00063, "grad_norm": 0.00116, "time": 0.23858}
+{"mode": "train", "epoch": 131, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00064, "acc_pose": 0.81324, "loss": 0.00064, "grad_norm": 0.00109, "time": 0.23835}
+{"mode": "train", "epoch": 132, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05566, "heatmap_loss": 0.00063, "acc_pose": 0.80517, "loss": 0.00063, "grad_norm": 0.00109, "time": 0.29817}
+{"mode": "train", "epoch": 132, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00043, "heatmap_loss": 0.00064, "acc_pose": 0.81132, "loss": 0.00064, "grad_norm": 0.0011, "time": 0.23987}
+{"mode": "train", "epoch": 132, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00043, "heatmap_loss": 0.00063, "acc_pose": 0.81064, "loss": 0.00063, "grad_norm": 0.00106, "time": 0.23893}
+{"mode": "train", "epoch": 132, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00033, "heatmap_loss": 0.00063, "acc_pose": 0.80872, "loss": 0.00063, "grad_norm": 0.00111, "time": 0.23819}
+{"mode": "train", "epoch": 132, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00041, "heatmap_loss": 0.00063, "acc_pose": 0.81296, "loss": 0.00063, "grad_norm": 0.00105, "time": 0.23869}
+{"mode": "train", "epoch": 133, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05599, "heatmap_loss": 0.00063, "acc_pose": 0.80187, "loss": 0.00063, "grad_norm": 0.00117, "time": 0.29761}
+{"mode": "train", "epoch": 133, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00063, "acc_pose": 0.80975, "loss": 0.00063, "grad_norm": 0.00113, "time": 0.23974}
+{"mode": "train", "epoch": 133, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00064, "acc_pose": 0.8043, "loss": 0.00064, "grad_norm": 0.00111, "time": 0.23924}
+{"mode": "train", "epoch": 133, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00036, "heatmap_loss": 0.00063, "acc_pose": 0.80803, "loss": 0.00063, "grad_norm": 0.00108, "time": 0.23823}
+{"mode": "train", "epoch": 133, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00064, "acc_pose": 0.80206, "loss": 0.00064, "grad_norm": 0.00112, "time": 0.23853}
+{"mode": "train", "epoch": 134, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05548, "heatmap_loss": 0.00063, "acc_pose": 0.81253, "loss": 0.00063, "grad_norm": 0.00114, "time": 0.29777}
+{"mode": "train", "epoch": 134, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00063, "acc_pose": 0.80554, "loss": 0.00063, "grad_norm": 0.0011, "time": 0.23944}
+{"mode": "train", "epoch": 134, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00063, "acc_pose": 0.80795, "loss": 0.00063, "grad_norm": 0.00114, "time": 0.23798}
+{"mode": "train", "epoch": 134, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00063, "acc_pose": 0.81073, "loss": 0.00063, "grad_norm": 0.00112, "time": 0.23777}
+{"mode": "train", "epoch": 134, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00064, "acc_pose": 0.80147, "loss": 0.00064, "grad_norm": 0.00109, "time": 0.23794}
+{"mode": "train", "epoch": 135, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05547, "heatmap_loss": 0.00063, "acc_pose": 0.81048, "loss": 0.00063, "grad_norm": 0.00108, "time": 0.29855}
+{"mode": "train", "epoch": 135, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00063, "acc_pose": 0.80466, "loss": 0.00063, "grad_norm": 0.0011, "time": 0.23833}
+{"mode": "train", "epoch": 135, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00038, "heatmap_loss": 0.00063, "acc_pose": 0.80565, "loss": 0.00063, "grad_norm": 0.00107, "time": 0.23823}
+{"mode": "train", "epoch": 135, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00063, "acc_pose": 0.80749, "loss": 0.00063, "grad_norm": 0.00113, "time": 0.23837}
+{"mode": "train", "epoch": 135, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00063, "acc_pose": 0.81232, "loss": 0.00063, "grad_norm": 0.00106, "time": 0.23819}
+{"mode": "train", "epoch": 136, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05526, "heatmap_loss": 0.00063, "acc_pose": 0.81282, "loss": 0.00063, "grad_norm": 0.00106, "time": 0.29838}
+{"mode": "train", "epoch": 136, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00063, "acc_pose": 0.81474, "loss": 0.00063, "grad_norm": 0.00111, "time": 0.23822}
+{"mode": "train", "epoch": 136, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00062, "acc_pose": 0.806, "loss": 0.00062, "grad_norm": 0.00108, "time": 0.23769}
+{"mode": "train", "epoch": 136, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00044, "heatmap_loss": 0.00063, "acc_pose": 0.80255, "loss": 0.00063, "grad_norm": 0.00112, "time": 0.23762}
+{"mode": "train", "epoch": 136, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00062, "acc_pose": 0.81194, "loss": 0.00062, "grad_norm": 0.00108, "time": 0.23725}
+{"mode": "train", "epoch": 137, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05509, "heatmap_loss": 0.00063, "acc_pose": 0.81216, "loss": 0.00063, "grad_norm": 0.00111, "time": 0.29698}
+{"mode": "train", "epoch": 137, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00063, "acc_pose": 0.80442, "loss": 0.00063, "grad_norm": 0.0011, "time": 0.23829}
+{"mode": "train", "epoch": 137, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00063, "acc_pose": 0.80817, "loss": 0.00063, "grad_norm": 0.00109, "time": 0.23776}
+{"mode": "train", "epoch": 137, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00042, "heatmap_loss": 0.00063, "acc_pose": 0.81326, "loss": 0.00063, "grad_norm": 0.00113, "time": 0.23898}
+{"mode": "train", "epoch": 137, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00063, "acc_pose": 0.80965, "loss": 0.00063, "grad_norm": 0.00116, "time": 0.23813}
+{"mode": "train", "epoch": 138, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05543, "heatmap_loss": 0.00063, "acc_pose": 0.81263, "loss": 0.00063, "grad_norm": 0.00107, "time": 0.29697}
+{"mode": "train", "epoch": 138, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00062, "acc_pose": 0.81087, "loss": 0.00062, "grad_norm": 0.00108, "time": 0.23885}
+{"mode": "train", "epoch": 138, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00062, "acc_pose": 0.812, "loss": 0.00062, "grad_norm": 0.00109, "time": 0.23796}
+{"mode": "train", "epoch": 138, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00042, "heatmap_loss": 0.00063, "acc_pose": 0.81065, "loss": 0.00063, "grad_norm": 0.00107, "time": 0.23788}
+{"mode": "train", "epoch": 138, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00042, "heatmap_loss": 0.00063, "acc_pose": 0.81402, "loss": 0.00063, "grad_norm": 0.0011, "time": 0.23815}
+{"mode": "train", "epoch": 139, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05577, "heatmap_loss": 0.00062, "acc_pose": 0.81005, "loss": 0.00062, "grad_norm": 0.00109, "time": 0.29741}
+{"mode": "train", "epoch": 139, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00062, "acc_pose": 0.80965, "loss": 0.00062, "grad_norm": 0.00107, "time": 0.23866}
+{"mode": "train", "epoch": 139, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00063, "acc_pose": 0.81269, "loss": 0.00063, "grad_norm": 0.0011, "time": 0.2379}
+{"mode": "train", "epoch": 139, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00063, "acc_pose": 0.8078, "loss": 0.00063, "grad_norm": 0.00111, "time": 0.23838}
+{"mode": "train", "epoch": 139, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00063, "acc_pose": 0.80843, "loss": 0.00063, "grad_norm": 0.00111, "time": 0.2382}
+{"mode": "train", "epoch": 140, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05542, "heatmap_loss": 0.00063, "acc_pose": 0.81596, "loss": 0.00063, "grad_norm": 0.00115, "time": 0.29803}
+{"mode": "train", "epoch": 140, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00063, "acc_pose": 0.80831, "loss": 0.00063, "grad_norm": 0.00108, "time": 0.23804}
+{"mode": "train", "epoch": 140, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00041, "heatmap_loss": 0.00063, "acc_pose": 0.80667, "loss": 0.00063, "grad_norm": 0.00112, "time": 0.23796}
+{"mode": "train", "epoch": 140, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00064, "acc_pose": 0.81104, "loss": 0.00064, "grad_norm": 0.00113, "time": 0.23835}
+{"mode": "train", "epoch": 140, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00063, "acc_pose": 0.81019, "loss": 0.00063, "grad_norm": 0.00107, "time": 0.23784}
+{"mode": "val", "epoch": 140, "iter": 407, "lr": 1e-05, "AP": 0.74259, "AP .5": 0.90339, "AP .75": 0.81779, "AP (M)": 0.67053, "AP (L)": 0.76695, "AR": 0.79743, "AR .5": 0.94238, "AR .75": 0.86445, "AR (M)": 0.75649, "AR (L)": 0.85723}
+{"mode": "train", "epoch": 141, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05518, "heatmap_loss": 0.00063, "acc_pose": 0.81029, "loss": 0.00063, "grad_norm": 0.00106, "time": 0.2953}
+{"mode": "train", "epoch": 141, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00062, "acc_pose": 0.8157, "loss": 0.00062, "grad_norm": 0.00106, "time": 0.23859}
+{"mode": "train", "epoch": 141, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00038, "heatmap_loss": 0.00063, "acc_pose": 0.79984, "loss": 0.00063, "grad_norm": 0.00111, "time": 0.2379}
+{"mode": "train", "epoch": 141, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00063, "acc_pose": 0.81468, "loss": 0.00063, "grad_norm": 0.00111, "time": 0.23878}
+{"mode": "train", "epoch": 141, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00025, "heatmap_loss": 0.00063, "acc_pose": 0.811, "loss": 0.00063, "grad_norm": 0.00111, "time": 0.23803}
+{"mode": "train", "epoch": 142, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05481, "heatmap_loss": 0.00062, "acc_pose": 0.81336, "loss": 0.00062, "grad_norm": 0.00111, "time": 0.29792}
+{"mode": "train", "epoch": 142, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00063, "acc_pose": 0.80516, "loss": 0.00063, "grad_norm": 0.00106, "time": 0.23895}
+{"mode": "train", "epoch": 142, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00041, "heatmap_loss": 0.00063, "acc_pose": 0.81092, "loss": 0.00063, "grad_norm": 0.00111, "time": 0.23904}
+{"mode": "train", "epoch": 142, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00063, "acc_pose": 0.81346, "loss": 0.00063, "grad_norm": 0.00108, "time": 0.23777}
+{"mode": "train", "epoch": 142, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00062, "acc_pose": 0.81387, "loss": 0.00062, "grad_norm": 0.00111, "time": 0.23802}
+{"mode": "train", "epoch": 143, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.0553, "heatmap_loss": 0.00062, "acc_pose": 0.81821, "loss": 0.00062, "grad_norm": 0.00108, "time": 0.29676}
+{"mode": "train", "epoch": 143, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00063, "acc_pose": 0.81058, "loss": 0.00063, "grad_norm": 0.00112, "time": 0.23863}
+{"mode": "train", "epoch": 143, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00063, "acc_pose": 0.81227, "loss": 0.00063, "grad_norm": 0.00107, "time": 0.23806}
+{"mode": "train", "epoch": 143, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00062, "acc_pose": 0.81226, "loss": 0.00062, "grad_norm": 0.00108, "time": 0.23834}
+{"mode": "train", "epoch": 143, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00034, "heatmap_loss": 0.00063, "acc_pose": 0.81403, "loss": 0.00063, "grad_norm": 0.00108, "time": 0.23773}
+{"mode": "train", "epoch": 144, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05551, "heatmap_loss": 0.00062, "acc_pose": 0.80891, "loss": 0.00062, "grad_norm": 0.00108, "time": 0.29798}
+{"mode": "train", "epoch": 144, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00044, "heatmap_loss": 0.00062, "acc_pose": 0.80652, "loss": 0.00062, "grad_norm": 0.00112, "time": 0.23903}
+{"mode": "train", "epoch": 144, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00062, "acc_pose": 0.80218, "loss": 0.00062, "grad_norm": 0.00107, "time": 0.23891}
+{"mode": "train", "epoch": 144, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00044, "heatmap_loss": 0.00063, "acc_pose": 0.80633, "loss": 0.00063, "grad_norm": 0.0011, "time": 0.23805}
+{"mode": "train", "epoch": 144, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00062, "acc_pose": 0.81191, "loss": 0.00062, "grad_norm": 0.0011, "time": 0.23852}
+{"mode": "train", "epoch": 145, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05613, "heatmap_loss": 0.00062, "acc_pose": 0.81462, "loss": 0.00062, "grad_norm": 0.00104, "time": 0.29805}
+{"mode": "train", "epoch": 145, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00062, "acc_pose": 0.80996, "loss": 0.00062, "grad_norm": 0.00103, "time": 0.23841}
+{"mode": "train", "epoch": 145, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00062, "acc_pose": 0.81233, "loss": 0.00062, "grad_norm": 0.00105, "time": 0.238}
+{"mode": "train", "epoch": 145, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00062, "acc_pose": 0.80791, "loss": 0.00062, "grad_norm": 0.00112, "time": 0.23841}
+{"mode": "train", "epoch": 145, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00038, "heatmap_loss": 0.00062, "acc_pose": 0.82156, "loss": 0.00062, "grad_norm": 0.00107, "time": 0.23792}
+{"mode": "train", "epoch": 146, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05561, "heatmap_loss": 0.00062, "acc_pose": 0.80584, "loss": 0.00062, "grad_norm": 0.00112, "time": 0.29781}
+{"mode": "train", "epoch": 146, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00062, "acc_pose": 0.81173, "loss": 0.00062, "grad_norm": 0.00112, "time": 0.23936}
+{"mode": "train", "epoch": 146, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00042, "heatmap_loss": 0.00062, "acc_pose": 0.80634, "loss": 0.00062, "grad_norm": 0.00112, "time": 0.2392}
+{"mode": "train", "epoch": 146, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00033, "heatmap_loss": 0.00062, "acc_pose": 0.81288, "loss": 0.00062, "grad_norm": 0.0011, "time": 0.23893}
+{"mode": "train", "epoch": 146, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00033, "heatmap_loss": 0.00063, "acc_pose": 0.81138, "loss": 0.00063, "grad_norm": 0.00108, "time": 0.2387}
+{"mode": "train", "epoch": 147, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05562, "heatmap_loss": 0.00062, "acc_pose": 0.81915, "loss": 0.00062, "grad_norm": 0.00108, "time": 0.29724}
+{"mode": "train", "epoch": 147, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00062, "acc_pose": 0.80995, "loss": 0.00062, "grad_norm": 0.0011, "time": 0.23883}
+{"mode": "train", "epoch": 147, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00026, "heatmap_loss": 0.00063, "acc_pose": 0.80959, "loss": 0.00063, "grad_norm": 0.00109, "time": 0.23813}
+{"mode": "train", "epoch": 147, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00062, "acc_pose": 0.80883, "loss": 0.00062, "grad_norm": 0.00108, "time": 0.23833}
+{"mode": "train", "epoch": 147, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00034, "heatmap_loss": 0.00063, "acc_pose": 0.80725, "loss": 0.00063, "grad_norm": 0.00112, "time": 0.23815}
+{"mode": "train", "epoch": 148, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.055, "heatmap_loss": 0.00062, "acc_pose": 0.81123, "loss": 0.00062, "grad_norm": 0.00107, "time": 0.29747}
+{"mode": "train", "epoch": 148, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00062, "acc_pose": 0.81035, "loss": 0.00062, "grad_norm": 0.00113, "time": 0.2386}
+{"mode": "train", "epoch": 148, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00035, "heatmap_loss": 0.00062, "acc_pose": 0.81302, "loss": 0.00062, "grad_norm": 0.00112, "time": 0.23938}
+{"mode": "train", "epoch": 148, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00062, "acc_pose": 0.81062, "loss": 0.00062, "grad_norm": 0.0011, "time": 0.23821}
+{"mode": "train", "epoch": 148, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00026, "heatmap_loss": 0.00062, "acc_pose": 0.814, "loss": 0.00062, "grad_norm": 0.00109, "time": 0.23811}
+{"mode": "train", "epoch": 149, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05575, "heatmap_loss": 0.00062, "acc_pose": 0.80713, "loss": 0.00062, "grad_norm": 0.00108, "time": 0.29881}
+{"mode": "train", "epoch": 149, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00062, "acc_pose": 0.8189, "loss": 0.00062, "grad_norm": 0.00115, "time": 0.23866}
+{"mode": "train", "epoch": 149, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00037, "heatmap_loss": 0.00062, "acc_pose": 0.81984, "loss": 0.00062, "grad_norm": 0.00114, "time": 0.23863}
+{"mode": "train", "epoch": 149, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00062, "acc_pose": 0.81108, "loss": 0.00062, "grad_norm": 0.00109, "time": 0.23856}
+{"mode": "train", "epoch": 149, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00048, "heatmap_loss": 0.00062, "acc_pose": 0.8174, "loss": 0.00062, "grad_norm": 0.00109, "time": 0.2383}
+{"mode": "train", "epoch": 150, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05797, "heatmap_loss": 0.00062, "acc_pose": 0.81324, "loss": 0.00062, "grad_norm": 0.00111, "time": 0.30051}
+{"mode": "train", "epoch": 150, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00062, "acc_pose": 0.81773, "loss": 0.00062, "grad_norm": 0.00112, "time": 0.23906}
+{"mode": "train", "epoch": 150, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00062, "acc_pose": 0.81129, "loss": 0.00062, "grad_norm": 0.00108, "time": 0.23802}
+{"mode": "train", "epoch": 150, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00038, "heatmap_loss": 0.00062, "acc_pose": 0.82078, "loss": 0.00062, "grad_norm": 0.00111, "time": 0.23872}
+{"mode": "train", "epoch": 150, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00042, "heatmap_loss": 0.00062, "acc_pose": 0.81367, "loss": 0.00062, "grad_norm": 0.00109, "time": 0.2383}
+{"mode": "val", "epoch": 150, "iter": 407, "lr": 1e-05, "AP": 0.744, "AP .5": 0.90357, "AP .75": 0.81931, "AP (M)": 0.67174, "AP (L)": 0.76932, "AR": 0.79814, "AR .5": 0.94191, "AR .75": 0.86555, "AR (M)": 0.75561, "AR (L)": 0.85994}
+{"mode": "train", "epoch": 151, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05431, "heatmap_loss": 0.00062, "acc_pose": 0.8101, "loss": 0.00062, "grad_norm": 0.00106, "time": 0.29439}
+{"mode": "train", "epoch": 151, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00062, "acc_pose": 0.81982, "loss": 0.00062, "grad_norm": 0.00108, "time": 0.23883}
+{"mode": "train", "epoch": 151, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00062, "acc_pose": 0.81659, "loss": 0.00062, "grad_norm": 0.0011, "time": 0.23843}
+{"mode": "train", "epoch": 151, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00062, "acc_pose": 0.81179, "loss": 0.00062, "grad_norm": 0.00107, "time": 0.23876}
+{"mode": "train", "epoch": 151, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.0004, "heatmap_loss": 0.00062, "acc_pose": 0.8193, "loss": 0.00062, "grad_norm": 0.00109, "time": 0.23787}
+{"mode": "train", "epoch": 152, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05549, "heatmap_loss": 0.00061, "acc_pose": 0.81343, "loss": 0.00061, "grad_norm": 0.00113, "time": 0.29823}
+{"mode": "train", "epoch": 152, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00062, "acc_pose": 0.81664, "loss": 0.00062, "grad_norm": 0.00113, "time": 0.23825}
+{"mode": "train", "epoch": 152, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00035, "heatmap_loss": 0.00062, "acc_pose": 0.81455, "loss": 0.00062, "grad_norm": 0.00106, "time": 0.23864}
+{"mode": "train", "epoch": 152, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00062, "acc_pose": 0.81247, "loss": 0.00062, "grad_norm": 0.00111, "time": 0.23741}
+{"mode": "train", "epoch": 152, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.0004, "heatmap_loss": 0.00062, "acc_pose": 0.81909, "loss": 0.00062, "grad_norm": 0.0011, "time": 0.23788}
+{"mode": "train", "epoch": 153, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05529, "heatmap_loss": 0.00061, "acc_pose": 0.82056, "loss": 0.00061, "grad_norm": 0.00108, "time": 0.29737}
+{"mode": "train", "epoch": 153, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00062, "acc_pose": 0.82322, "loss": 0.00062, "grad_norm": 0.00109, "time": 0.23796}
+{"mode": "train", "epoch": 153, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00062, "acc_pose": 0.81923, "loss": 0.00062, "grad_norm": 0.00109, "time": 0.23817}
+{"mode": "train", "epoch": 153, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00062, "acc_pose": 0.81602, "loss": 0.00062, "grad_norm": 0.00111, "time": 0.2382}
+{"mode": "train", "epoch": 153, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00046, "heatmap_loss": 0.00061, "acc_pose": 0.81641, "loss": 0.00061, "grad_norm": 0.00111, "time": 0.23807}
+{"mode": "train", "epoch": 154, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05522, "heatmap_loss": 0.00062, "acc_pose": 0.81459, "loss": 0.00062, "grad_norm": 0.00108, "time": 0.2994}
+{"mode": "train", "epoch": 154, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00062, "acc_pose": 0.81521, "loss": 0.00062, "grad_norm": 0.00111, "time": 0.2401}
+{"mode": "train", "epoch": 154, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00054, "heatmap_loss": 0.00062, "acc_pose": 0.8041, "loss": 0.00062, "grad_norm": 0.00115, "time": 0.2382}
+{"mode": "train", "epoch": 154, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00036, "heatmap_loss": 0.00062, "acc_pose": 0.81312, "loss": 0.00062, "grad_norm": 0.00111, "time": 0.23858}
+{"mode": "train", "epoch": 154, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00033, "heatmap_loss": 0.00062, "acc_pose": 0.81178, "loss": 0.00062, "grad_norm": 0.00109, "time": 0.23912}
+{"mode": "train", "epoch": 155, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05575, "heatmap_loss": 0.00062, "acc_pose": 0.819, "loss": 0.00062, "grad_norm": 0.0011, "time": 0.29748}
+{"mode": "train", "epoch": 155, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00061, "acc_pose": 0.8142, "loss": 0.00061, "grad_norm": 0.00107, "time": 0.23845}
+{"mode": "train", "epoch": 155, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00062, "acc_pose": 0.81415, "loss": 0.00062, "grad_norm": 0.00106, "time": 0.23866}
+{"mode": "train", "epoch": 155, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00062, "acc_pose": 0.81364, "loss": 0.00062, "grad_norm": 0.00115, "time": 0.23759}
+{"mode": "train", "epoch": 155, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00033, "heatmap_loss": 0.00061, "acc_pose": 0.81613, "loss": 0.00061, "grad_norm": 0.00107, "time": 0.23763}
+{"mode": "train", "epoch": 156, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05872, "heatmap_loss": 0.00062, "acc_pose": 0.81084, "loss": 0.00062, "grad_norm": 0.00111, "time": 0.30124}
+{"mode": "train", "epoch": 156, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00062, "acc_pose": 0.81239, "loss": 0.00062, "grad_norm": 0.00105, "time": 0.23895}
+{"mode": "train", "epoch": 156, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.0004, "heatmap_loss": 0.00062, "acc_pose": 0.81087, "loss": 0.00062, "grad_norm": 0.0011, "time": 0.23911}
+{"mode": "train", "epoch": 156, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00026, "heatmap_loss": 0.00062, "acc_pose": 0.81356, "loss": 0.00062, "grad_norm": 0.00109, "time": 0.23894}
+{"mode": "train", "epoch": 156, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00062, "acc_pose": 0.81415, "loss": 0.00062, "grad_norm": 0.00105, "time": 0.23858}
+{"mode": "train", "epoch": 157, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05561, "heatmap_loss": 0.00061, "acc_pose": 0.82154, "loss": 0.00061, "grad_norm": 0.0011, "time": 0.29742}
+{"mode": "train", "epoch": 157, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00062, "acc_pose": 0.8191, "loss": 0.00062, "grad_norm": 0.00108, "time": 0.23874}
+{"mode": "train", "epoch": 157, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00062, "acc_pose": 0.81272, "loss": 0.00062, "grad_norm": 0.0011, "time": 0.23808}
+{"mode": "train", "epoch": 157, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00062, "acc_pose": 0.8213, "loss": 0.00062, "grad_norm": 0.00112, "time": 0.23898}
+{"mode": "train", "epoch": 157, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00026, "heatmap_loss": 0.00062, "acc_pose": 0.813, "loss": 0.00062, "grad_norm": 0.00112, "time": 0.23808}
+{"mode": "train", "epoch": 158, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05499, "heatmap_loss": 0.00062, "acc_pose": 0.81118, "loss": 0.00062, "grad_norm": 0.00124, "time": 0.29789}
+{"mode": "train", "epoch": 158, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00062, "acc_pose": 0.81534, "loss": 0.00062, "grad_norm": 0.00108, "time": 0.23825}
+{"mode": "train", "epoch": 158, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00061, "acc_pose": 0.80865, "loss": 0.00061, "grad_norm": 0.00107, "time": 0.23826}
+{"mode": "train", "epoch": 158, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00061, "acc_pose": 0.8184, "loss": 0.00061, "grad_norm": 0.00111, "time": 0.23839}
+{"mode": "train", "epoch": 158, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00054, "heatmap_loss": 0.00061, "acc_pose": 0.81523, "loss": 0.00061, "grad_norm": 0.00103, "time": 0.23777}
+{"mode": "train", "epoch": 159, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05505, "heatmap_loss": 0.00061, "acc_pose": 0.81211, "loss": 0.00061, "grad_norm": 0.00107, "time": 0.29912}
+{"mode": "train", "epoch": 159, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00026, "heatmap_loss": 0.00061, "acc_pose": 0.81116, "loss": 0.00061, "grad_norm": 0.00109, "time": 0.23895}
+{"mode": "train", "epoch": 159, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00041, "heatmap_loss": 0.00062, "acc_pose": 0.81083, "loss": 0.00062, "grad_norm": 0.00111, "time": 0.23893}
+{"mode": "train", "epoch": 159, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00042, "heatmap_loss": 0.00062, "acc_pose": 0.81392, "loss": 0.00062, "grad_norm": 0.00108, "time": 0.23828}
+{"mode": "train", "epoch": 159, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00062, "acc_pose": 0.81234, "loss": 0.00062, "grad_norm": 0.00114, "time": 0.23868}
+{"mode": "train", "epoch": 160, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05636, "heatmap_loss": 0.00061, "acc_pose": 0.81739, "loss": 0.00061, "grad_norm": 0.0011, "time": 0.29799}
+{"mode": "train", "epoch": 160, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00062, "acc_pose": 0.81562, "loss": 0.00062, "grad_norm": 0.00112, "time": 0.23939}
+{"mode": "train", "epoch": 160, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00061, "acc_pose": 0.81827, "loss": 0.00061, "grad_norm": 0.00113, "time": 0.23861}
+{"mode": "train", "epoch": 160, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00033, "heatmap_loss": 0.00061, "acc_pose": 0.81369, "loss": 0.00061, "grad_norm": 0.00106, "time": 0.23841}
+{"mode": "train", "epoch": 160, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.0005, "heatmap_loss": 0.00062, "acc_pose": 0.81201, "loss": 0.00062, "grad_norm": 0.00113, "time": 0.23883}
+{"mode": "val", "epoch": 160, "iter": 407, "lr": 1e-05, "AP": 0.74271, "AP .5": 0.90216, "AP .75": 0.81674, "AP (M)": 0.67082, "AP (L)": 0.76703, "AR": 0.79787, "AR .5": 0.94159, "AR .75": 0.86477, "AR (M)": 0.75545, "AR (L)": 0.85953}
+{"mode": "train", "epoch": 161, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05574, "heatmap_loss": 0.00062, "acc_pose": 0.81888, "loss": 0.00062, "grad_norm": 0.00105, "time": 0.2959}
+{"mode": "train", "epoch": 161, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00061, "acc_pose": 0.82173, "loss": 0.00061, "grad_norm": 0.00107, "time": 0.23988}
+{"mode": "train", "epoch": 161, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00061, "acc_pose": 0.81101, "loss": 0.00061, "grad_norm": 0.0011, "time": 0.23858}
+{"mode": "train", "epoch": 161, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00061, "acc_pose": 0.82391, "loss": 0.00061, "grad_norm": 0.00105, "time": 0.23893}
+{"mode": "train", "epoch": 161, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00038, "heatmap_loss": 0.00061, "acc_pose": 0.81525, "loss": 0.00061, "grad_norm": 0.00111, "time": 0.23852}
+{"mode": "train", "epoch": 162, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.055, "heatmap_loss": 0.00061, "acc_pose": 0.81708, "loss": 0.00061, "grad_norm": 0.00113, "time": 0.29881}
+{"mode": "train", "epoch": 162, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00061, "acc_pose": 0.81542, "loss": 0.00061, "grad_norm": 0.00112, "time": 0.23909}
+{"mode": "train", "epoch": 162, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00061, "acc_pose": 0.81549, "loss": 0.00061, "grad_norm": 0.00111, "time": 0.23839}
+{"mode": "train", "epoch": 162, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00061, "acc_pose": 0.81411, "loss": 0.00061, "grad_norm": 0.00107, "time": 0.23839}
+{"mode": "train", "epoch": 162, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00045, "heatmap_loss": 0.00062, "acc_pose": 0.81604, "loss": 0.00062, "grad_norm": 0.00109, "time": 0.23815}
+{"mode": "train", "epoch": 163, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05462, "heatmap_loss": 0.00061, "acc_pose": 0.81834, "loss": 0.00061, "grad_norm": 0.00117, "time": 0.29968}
+{"mode": "train", "epoch": 163, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00062, "acc_pose": 0.81281, "loss": 0.00062, "grad_norm": 0.00106, "time": 0.23847}
+{"mode": "train", "epoch": 163, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00062, "acc_pose": 0.80909, "loss": 0.00062, "grad_norm": 0.00109, "time": 0.23818}
+{"mode": "train", "epoch": 163, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00037, "heatmap_loss": 0.00061, "acc_pose": 0.81193, "loss": 0.00061, "grad_norm": 0.0011, "time": 0.23807}
+{"mode": "train", "epoch": 163, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00061, "acc_pose": 0.81536, "loss": 0.00061, "grad_norm": 0.00108, "time": 0.23766}
+{"mode": "train", "epoch": 164, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05533, "heatmap_loss": 0.00061, "acc_pose": 0.81475, "loss": 0.00061, "grad_norm": 0.00109, "time": 0.29788}
+{"mode": "train", "epoch": 164, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00061, "acc_pose": 0.81399, "loss": 0.00061, "grad_norm": 0.00108, "time": 0.23913}
+{"mode": "train", "epoch": 164, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00061, "acc_pose": 0.81158, "loss": 0.00061, "grad_norm": 0.00112, "time": 0.23883}
+{"mode": "train", "epoch": 164, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00043, "heatmap_loss": 0.00062, "acc_pose": 0.81409, "loss": 0.00062, "grad_norm": 0.00108, "time": 0.2382}
+{"mode": "train", "epoch": 164, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00061, "acc_pose": 0.82045, "loss": 0.00061, "grad_norm": 0.00114, "time": 0.23836}
+{"mode": "train", "epoch": 165, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05528, "heatmap_loss": 0.00061, "acc_pose": 0.81783, "loss": 0.00061, "grad_norm": 0.00107, "time": 0.29837}
+{"mode": "train", "epoch": 165, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00061, "acc_pose": 0.81787, "loss": 0.00061, "grad_norm": 0.00108, "time": 0.23798}
+{"mode": "train", "epoch": 165, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00061, "acc_pose": 0.82014, "loss": 0.00061, "grad_norm": 0.00105, "time": 0.23761}
+{"mode": "train", "epoch": 165, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00033, "heatmap_loss": 0.00061, "acc_pose": 0.81638, "loss": 0.00061, "grad_norm": 0.00109, "time": 0.23748}
+{"mode": "train", "epoch": 165, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00061, "acc_pose": 0.82416, "loss": 0.00061, "grad_norm": 0.00107, "time": 0.23703}
+{"mode": "train", "epoch": 166, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05594, "heatmap_loss": 0.00061, "acc_pose": 0.81982, "loss": 0.00061, "grad_norm": 0.00105, "time": 0.29848}
+{"mode": "train", "epoch": 166, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00061, "acc_pose": 0.81326, "loss": 0.00061, "grad_norm": 0.00111, "time": 0.23877}
+{"mode": "train", "epoch": 166, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00061, "acc_pose": 0.81214, "loss": 0.00061, "grad_norm": 0.00112, "time": 0.23858}
+{"mode": "train", "epoch": 166, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00061, "acc_pose": 0.81553, "loss": 0.00061, "grad_norm": 0.00108, "time": 0.23835}
+{"mode": "train", "epoch": 166, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00036, "heatmap_loss": 0.00061, "acc_pose": 0.81817, "loss": 0.00061, "grad_norm": 0.00109, "time": 0.23802}
+{"mode": "train", "epoch": 167, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05516, "heatmap_loss": 0.00062, "acc_pose": 0.82087, "loss": 0.00062, "grad_norm": 0.0011, "time": 0.29952}
+{"mode": "train", "epoch": 167, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00047, "heatmap_loss": 0.00061, "acc_pose": 0.81603, "loss": 0.00061, "grad_norm": 0.0011, "time": 0.23833}
+{"mode": "train", "epoch": 167, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00039, "heatmap_loss": 0.00061, "acc_pose": 0.8122, "loss": 0.00061, "grad_norm": 0.00109, "time": 0.23821}
+{"mode": "train", "epoch": 167, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00048, "heatmap_loss": 0.00061, "acc_pose": 0.82861, "loss": 0.00061, "grad_norm": 0.00106, "time": 0.23845}
+{"mode": "train", "epoch": 167, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00044, "heatmap_loss": 0.00061, "acc_pose": 0.81272, "loss": 0.00061, "grad_norm": 0.00107, "time": 0.23796}
+{"mode": "train", "epoch": 168, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05866, "heatmap_loss": 0.00061, "acc_pose": 0.82463, "loss": 0.00061, "grad_norm": 0.00114, "time": 0.30052}
+{"mode": "train", "epoch": 168, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00061, "acc_pose": 0.81608, "loss": 0.00061, "grad_norm": 0.0011, "time": 0.23862}
+{"mode": "train", "epoch": 168, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00061, "acc_pose": 0.81389, "loss": 0.00061, "grad_norm": 0.00111, "time": 0.23803}
+{"mode": "train", "epoch": 168, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00041, "heatmap_loss": 0.00061, "acc_pose": 0.81657, "loss": 0.00061, "grad_norm": 0.00106, "time": 0.23843}
+{"mode": "train", "epoch": 168, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00061, "acc_pose": 0.82185, "loss": 0.00061, "grad_norm": 0.00112, "time": 0.23801}
+{"mode": "train", "epoch": 169, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05524, "heatmap_loss": 0.00061, "acc_pose": 0.82481, "loss": 0.00061, "grad_norm": 0.00108, "time": 0.29809}
+{"mode": "train", "epoch": 169, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00026, "heatmap_loss": 0.00061, "acc_pose": 0.81147, "loss": 0.00061, "grad_norm": 0.00108, "time": 0.23833}
+{"mode": "train", "epoch": 169, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00061, "acc_pose": 0.81886, "loss": 0.00061, "grad_norm": 0.00115, "time": 0.23827}
+{"mode": "train", "epoch": 169, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00061, "acc_pose": 0.81814, "loss": 0.00061, "grad_norm": 0.00112, "time": 0.23739}
+{"mode": "train", "epoch": 169, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00038, "heatmap_loss": 0.00061, "acc_pose": 0.82153, "loss": 0.00061, "grad_norm": 0.00113, "time": 0.23778}
+{"mode": "train", "epoch": 170, "iter": 50, "lr": 1e-05, "memory": 14884, "data_time": 0.05571, "heatmap_loss": 0.00061, "acc_pose": 0.82154, "loss": 0.00061, "grad_norm": 0.00109, "time": 0.29784}
+{"mode": "train", "epoch": 170, "iter": 100, "lr": 1e-05, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.0006, "acc_pose": 0.81127, "loss": 0.0006, "grad_norm": 0.00109, "time": 0.23936}
+{"mode": "train", "epoch": 170, "iter": 150, "lr": 1e-05, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00061, "acc_pose": 0.80985, "loss": 0.00061, "grad_norm": 0.00108, "time": 0.23851}
+{"mode": "train", "epoch": 170, "iter": 200, "lr": 1e-05, "memory": 14884, "data_time": 0.00056, "heatmap_loss": 0.00061, "acc_pose": 0.81652, "loss": 0.00061, "grad_norm": 0.00116, "time": 0.23832}
+{"mode": "train", "epoch": 170, "iter": 250, "lr": 1e-05, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00061, "acc_pose": 0.81963, "loss": 0.00061, "grad_norm": 0.00106, "time": 0.23824}
+{"mode": "val", "epoch": 170, "iter": 407, "lr": 1e-05, "AP": 0.74564, "AP .5": 0.90364, "AP .75": 0.81755, "AP (M)": 0.6741, "AP (L)": 0.77142, "AR": 0.79937, "AR .5": 0.94222, "AR .75": 0.86398, "AR (M)": 0.75788, "AR (L)": 0.86009}
+{"mode": "train", "epoch": 171, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.05495, "heatmap_loss": 0.0006, "acc_pose": 0.82275, "loss": 0.0006, "grad_norm": 0.00104, "time": 0.29465}
+{"mode": "train", "epoch": 171, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.0006, "acc_pose": 0.82081, "loss": 0.0006, "grad_norm": 0.00108, "time": 0.23929}
+{"mode": "train", "epoch": 171, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.0004, "heatmap_loss": 0.00059, "acc_pose": 0.82772, "loss": 0.00059, "grad_norm": 0.00099, "time": 0.23895}
+{"mode": "train", "epoch": 171, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.0004, "heatmap_loss": 0.00059, "acc_pose": 0.82539, "loss": 0.00059, "grad_norm": 0.00103, "time": 0.23831}
+{"mode": "train", "epoch": 171, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.0004, "heatmap_loss": 0.00059, "acc_pose": 0.82168, "loss": 0.00059, "grad_norm": 0.00103, "time": 0.23779}
+{"mode": "train", "epoch": 172, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.05612, "heatmap_loss": 0.00059, "acc_pose": 0.8228, "loss": 0.00059, "grad_norm": 0.00101, "time": 0.29719}
+{"mode": "train", "epoch": 172, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.00026, "heatmap_loss": 0.00059, "acc_pose": 0.81677, "loss": 0.00059, "grad_norm": 0.00102, "time": 0.23828}
+{"mode": "train", "epoch": 172, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.00039, "heatmap_loss": 0.00059, "acc_pose": 0.82368, "loss": 0.00059, "grad_norm": 0.00102, "time": 0.23808}
+{"mode": "train", "epoch": 172, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00058, "acc_pose": 0.82832, "loss": 0.00058, "grad_norm": 0.0011, "time": 0.23833}
+{"mode": "train", "epoch": 172, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00058, "acc_pose": 0.83, "loss": 0.00058, "grad_norm": 0.00103, "time": 0.23762}
+{"mode": "train", "epoch": 173, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.05606, "heatmap_loss": 0.00059, "acc_pose": 0.82147, "loss": 0.00059, "grad_norm": 0.00103, "time": 0.29798}
+{"mode": "train", "epoch": 173, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.0004, "heatmap_loss": 0.00058, "acc_pose": 0.83014, "loss": 0.00058, "grad_norm": 0.00099, "time": 0.23782}
+{"mode": "train", "epoch": 173, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00058, "acc_pose": 0.82854, "loss": 0.00058, "grad_norm": 0.00106, "time": 0.23779}
+{"mode": "train", "epoch": 173, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00059, "acc_pose": 0.83193, "loss": 0.00059, "grad_norm": 0.00104, "time": 0.23822}
+{"mode": "train", "epoch": 173, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.00041, "heatmap_loss": 0.00059, "acc_pose": 0.83026, "loss": 0.00059, "grad_norm": 0.00103, "time": 0.23782}
+{"mode": "train", "epoch": 174, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.05533, "heatmap_loss": 0.00058, "acc_pose": 0.82887, "loss": 0.00058, "grad_norm": 0.00102, "time": 0.29848}
+{"mode": "train", "epoch": 174, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00059, "acc_pose": 0.82432, "loss": 0.00059, "grad_norm": 0.00104, "time": 0.23931}
+{"mode": "train", "epoch": 174, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00058, "acc_pose": 0.83, "loss": 0.00058, "grad_norm": 0.00096, "time": 0.23891}
+{"mode": "train", "epoch": 174, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.00045, "heatmap_loss": 0.00058, "acc_pose": 0.8326, "loss": 0.00058, "grad_norm": 0.001, "time": 0.23858}
+{"mode": "train", "epoch": 174, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00058, "acc_pose": 0.82293, "loss": 0.00058, "grad_norm": 0.00101, "time": 0.23862}
+{"mode": "train", "epoch": 175, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.05543, "heatmap_loss": 0.00058, "acc_pose": 0.83053, "loss": 0.00058, "grad_norm": 0.00098, "time": 0.29947}
+{"mode": "train", "epoch": 175, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00058, "acc_pose": 0.82883, "loss": 0.00058, "grad_norm": 0.00104, "time": 0.2384}
+{"mode": "train", "epoch": 175, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.00038, "heatmap_loss": 0.00058, "acc_pose": 0.82995, "loss": 0.00058, "grad_norm": 0.00098, "time": 0.23831}
+{"mode": "train", "epoch": 175, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00058, "acc_pose": 0.83118, "loss": 0.00058, "grad_norm": 0.00099, "time": 0.23774}
+{"mode": "train", "epoch": 175, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.00042, "heatmap_loss": 0.00058, "acc_pose": 0.83721, "loss": 0.00058, "grad_norm": 0.00098, "time": 0.23774}
+{"mode": "train", "epoch": 176, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.05886, "heatmap_loss": 0.00058, "acc_pose": 0.83028, "loss": 0.00058, "grad_norm": 0.00101, "time": 0.30043}
+{"mode": "train", "epoch": 176, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00058, "acc_pose": 0.82865, "loss": 0.00058, "grad_norm": 0.00105, "time": 0.23882}
+{"mode": "train", "epoch": 176, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.00041, "heatmap_loss": 0.00058, "acc_pose": 0.82407, "loss": 0.00058, "grad_norm": 0.00103, "time": 0.23866}
+{"mode": "train", "epoch": 176, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.00034, "heatmap_loss": 0.00058, "acc_pose": 0.82529, "loss": 0.00058, "grad_norm": 0.00103, "time": 0.23777}
+{"mode": "train", "epoch": 176, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00058, "acc_pose": 0.82751, "loss": 0.00058, "grad_norm": 0.00101, "time": 0.23796}
+{"mode": "train", "epoch": 177, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.05581, "heatmap_loss": 0.00057, "acc_pose": 0.831, "loss": 0.00057, "grad_norm": 0.00098, "time": 0.29822}
+{"mode": "train", "epoch": 177, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00058, "acc_pose": 0.82582, "loss": 0.00058, "grad_norm": 0.00097, "time": 0.23904}
+{"mode": "train", "epoch": 177, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00058, "acc_pose": 0.82504, "loss": 0.00058, "grad_norm": 0.001, "time": 0.23851}
+{"mode": "train", "epoch": 177, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00058, "acc_pose": 0.82893, "loss": 0.00058, "grad_norm": 0.00101, "time": 0.23813}
+{"mode": "train", "epoch": 177, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00057, "acc_pose": 0.83074, "loss": 0.00057, "grad_norm": 0.001, "time": 0.23816}
+{"mode": "train", "epoch": 178, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.05503, "heatmap_loss": 0.00058, "acc_pose": 0.83135, "loss": 0.00058, "grad_norm": 0.00103, "time": 0.29858}
+{"mode": "train", "epoch": 178, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00057, "acc_pose": 0.82851, "loss": 0.00057, "grad_norm": 0.00101, "time": 0.23851}
+{"mode": "train", "epoch": 178, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00057, "acc_pose": 0.83298, "loss": 0.00057, "grad_norm": 0.00097, "time": 0.23807}
+{"mode": "train", "epoch": 178, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.00041, "heatmap_loss": 0.00057, "acc_pose": 0.82771, "loss": 0.00057, "grad_norm": 0.00102, "time": 0.2385}
+{"mode": "train", "epoch": 178, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.00033, "heatmap_loss": 0.00057, "acc_pose": 0.83845, "loss": 0.00057, "grad_norm": 0.00096, "time": 0.23817}
+{"mode": "train", "epoch": 179, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.05503, "heatmap_loss": 0.00057, "acc_pose": 0.82537, "loss": 0.00057, "grad_norm": 0.00101, "time": 0.29775}
+{"mode": "train", "epoch": 179, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00058, "acc_pose": 0.82413, "loss": 0.00058, "grad_norm": 0.00106, "time": 0.23786}
+{"mode": "train", "epoch": 179, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00057, "acc_pose": 0.82898, "loss": 0.00057, "grad_norm": 0.00103, "time": 0.23837}
+{"mode": "train", "epoch": 179, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.00026, "heatmap_loss": 0.00057, "acc_pose": 0.83582, "loss": 0.00057, "grad_norm": 0.00097, "time": 0.2373}
+{"mode": "train", "epoch": 179, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.00038, "heatmap_loss": 0.00058, "acc_pose": 0.83443, "loss": 0.00058, "grad_norm": 0.001, "time": 0.23822}
+{"mode": "train", "epoch": 180, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.0549, "heatmap_loss": 0.00057, "acc_pose": 0.83147, "loss": 0.00057, "grad_norm": 0.00102, "time": 0.29853}
+{"mode": "train", "epoch": 180, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.00034, "heatmap_loss": 0.00058, "acc_pose": 0.8373, "loss": 0.00058, "grad_norm": 0.001, "time": 0.23883}
+{"mode": "train", "epoch": 180, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00058, "acc_pose": 0.8273, "loss": 0.00058, "grad_norm": 0.00106, "time": 0.23869}
+{"mode": "train", "epoch": 180, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00057, "acc_pose": 0.83483, "loss": 0.00057, "grad_norm": 0.00098, "time": 0.23851}
+{"mode": "train", "epoch": 180, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.00034, "heatmap_loss": 0.00058, "acc_pose": 0.83026, "loss": 0.00058, "grad_norm": 0.001, "time": 0.2385}
+{"mode": "val", "epoch": 180, "iter": 407, "lr": 0.0, "AP": 0.75254, "AP .5": 0.90662, "AP .75": 0.82583, "AP (M)": 0.68184, "AP (L)": 0.77785, "AR": 0.80674, "AR .5": 0.94506, "AR .75": 0.87217, "AR (M)": 0.76572, "AR (L)": 0.86641}
+{"mode": "train", "epoch": 181, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.05542, "heatmap_loss": 0.00058, "acc_pose": 0.83045, "loss": 0.00058, "grad_norm": 0.00103, "time": 0.29514}
+{"mode": "train", "epoch": 181, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.00039, "heatmap_loss": 0.00057, "acc_pose": 0.8327, "loss": 0.00057, "grad_norm": 0.001, "time": 0.23942}
+{"mode": "train", "epoch": 181, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.00035, "heatmap_loss": 0.00058, "acc_pose": 0.82877, "loss": 0.00058, "grad_norm": 0.00099, "time": 0.23873}
+{"mode": "train", "epoch": 181, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00057, "acc_pose": 0.832, "loss": 0.00057, "grad_norm": 0.00104, "time": 0.23859}
+{"mode": "train", "epoch": 181, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.00042, "heatmap_loss": 0.00057, "acc_pose": 0.83114, "loss": 0.00057, "grad_norm": 0.00103, "time": 0.2387}
+{"mode": "train", "epoch": 182, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.0561, "heatmap_loss": 0.00057, "acc_pose": 0.83273, "loss": 0.00057, "grad_norm": 0.00105, "time": 0.29583}
+{"mode": "train", "epoch": 182, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.00033, "heatmap_loss": 0.00057, "acc_pose": 0.83574, "loss": 0.00057, "grad_norm": 0.00094, "time": 0.23872}
+{"mode": "train", "epoch": 182, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00058, "acc_pose": 0.82801, "loss": 0.00058, "grad_norm": 0.00102, "time": 0.23745}
+{"mode": "train", "epoch": 182, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00057, "acc_pose": 0.83514, "loss": 0.00057, "grad_norm": 0.00102, "time": 0.23765}
+{"mode": "train", "epoch": 182, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.00045, "heatmap_loss": 0.00058, "acc_pose": 0.83457, "loss": 0.00058, "grad_norm": 0.00104, "time": 0.23785}
+{"mode": "train", "epoch": 183, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.0558, "heatmap_loss": 0.00057, "acc_pose": 0.82862, "loss": 0.00057, "grad_norm": 0.001, "time": 0.29887}
+{"mode": "train", "epoch": 183, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.00045, "heatmap_loss": 0.00057, "acc_pose": 0.83056, "loss": 0.00057, "grad_norm": 0.00098, "time": 0.23806}
+{"mode": "train", "epoch": 183, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.00026, "heatmap_loss": 0.00057, "acc_pose": 0.83264, "loss": 0.00057, "grad_norm": 0.00098, "time": 0.23803}
+{"mode": "train", "epoch": 183, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.00039, "heatmap_loss": 0.00057, "acc_pose": 0.83251, "loss": 0.00057, "grad_norm": 0.00104, "time": 0.23831}
+{"mode": "train", "epoch": 183, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00057, "acc_pose": 0.83265, "loss": 0.00057, "grad_norm": 0.00101, "time": 0.23766}
+{"mode": "train", "epoch": 184, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.05556, "heatmap_loss": 0.00058, "acc_pose": 0.82919, "loss": 0.00058, "grad_norm": 0.00107, "time": 0.29731}
+{"mode": "train", "epoch": 184, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00056, "acc_pose": 0.83391, "loss": 0.00056, "grad_norm": 0.00099, "time": 0.23878}
+{"mode": "train", "epoch": 184, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.00043, "heatmap_loss": 0.00057, "acc_pose": 0.83034, "loss": 0.00057, "grad_norm": 0.00098, "time": 0.23713}
+{"mode": "train", "epoch": 184, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.00042, "heatmap_loss": 0.00057, "acc_pose": 0.82259, "loss": 0.00057, "grad_norm": 0.00097, "time": 0.23859}
+{"mode": "train", "epoch": 184, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.0004, "heatmap_loss": 0.00057, "acc_pose": 0.83286, "loss": 0.00057, "grad_norm": 0.00102, "time": 0.23808}
+{"mode": "train", "epoch": 185, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.05591, "heatmap_loss": 0.00057, "acc_pose": 0.83669, "loss": 0.00057, "grad_norm": 0.001, "time": 0.29755}
+{"mode": "train", "epoch": 185, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.00038, "heatmap_loss": 0.00057, "acc_pose": 0.8316, "loss": 0.00057, "grad_norm": 0.00106, "time": 0.23844}
+{"mode": "train", "epoch": 185, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.00037, "heatmap_loss": 0.00057, "acc_pose": 0.83626, "loss": 0.00057, "grad_norm": 0.00099, "time": 0.238}
+{"mode": "train", "epoch": 185, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00057, "acc_pose": 0.83474, "loss": 0.00057, "grad_norm": 0.00102, "time": 0.23783}
+{"mode": "train", "epoch": 185, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.00043, "heatmap_loss": 0.00057, "acc_pose": 0.83135, "loss": 0.00057, "grad_norm": 0.00099, "time": 0.23748}
+{"mode": "train", "epoch": 186, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.05845, "heatmap_loss": 0.00057, "acc_pose": 0.82943, "loss": 0.00057, "grad_norm": 0.00103, "time": 0.30075}
+{"mode": "train", "epoch": 186, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00057, "acc_pose": 0.83015, "loss": 0.00057, "grad_norm": 0.00101, "time": 0.23814}
+{"mode": "train", "epoch": 186, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.00033, "heatmap_loss": 0.00057, "acc_pose": 0.83279, "loss": 0.00057, "grad_norm": 0.001, "time": 0.23798}
+{"mode": "train", "epoch": 186, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00057, "acc_pose": 0.83422, "loss": 0.00057, "grad_norm": 0.00105, "time": 0.23787}
+{"mode": "train", "epoch": 186, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00057, "acc_pose": 0.83223, "loss": 0.00057, "grad_norm": 0.00098, "time": 0.23715}
+{"mode": "train", "epoch": 187, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.05487, "heatmap_loss": 0.00057, "acc_pose": 0.83564, "loss": 0.00057, "grad_norm": 0.00101, "time": 0.29725}
+{"mode": "train", "epoch": 187, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.00041, "heatmap_loss": 0.00056, "acc_pose": 0.83331, "loss": 0.00056, "grad_norm": 0.00098, "time": 0.23854}
+{"mode": "train", "epoch": 187, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00057, "acc_pose": 0.82855, "loss": 0.00057, "grad_norm": 0.00103, "time": 0.23784}
+{"mode": "train", "epoch": 187, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00057, "acc_pose": 0.82935, "loss": 0.00057, "grad_norm": 0.001, "time": 0.2377}
+{"mode": "train", "epoch": 187, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.00034, "heatmap_loss": 0.00057, "acc_pose": 0.83291, "loss": 0.00057, "grad_norm": 0.00099, "time": 0.23778}
+{"mode": "train", "epoch": 188, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.05778, "heatmap_loss": 0.00057, "acc_pose": 0.83541, "loss": 0.00057, "grad_norm": 0.00103, "time": 0.29781}
+{"mode": "train", "epoch": 188, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00057, "acc_pose": 0.83522, "loss": 0.00057, "grad_norm": 0.00101, "time": 0.23886}
+{"mode": "train", "epoch": 188, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.00038, "heatmap_loss": 0.00057, "acc_pose": 0.83393, "loss": 0.00057, "grad_norm": 0.00099, "time": 0.23809}
+{"mode": "train", "epoch": 188, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00057, "acc_pose": 0.83419, "loss": 0.00057, "grad_norm": 0.00101, "time": 0.23823}
+{"mode": "train", "epoch": 188, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00056, "acc_pose": 0.83996, "loss": 0.00056, "grad_norm": 0.00097, "time": 0.23724}
+{"mode": "train", "epoch": 189, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.05594, "heatmap_loss": 0.00057, "acc_pose": 0.83497, "loss": 0.00057, "grad_norm": 0.00105, "time": 0.29797}
+{"mode": "train", "epoch": 189, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.00043, "heatmap_loss": 0.00056, "acc_pose": 0.83561, "loss": 0.00056, "grad_norm": 0.00097, "time": 0.23806}
+{"mode": "train", "epoch": 189, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.00042, "heatmap_loss": 0.00057, "acc_pose": 0.82915, "loss": 0.00057, "grad_norm": 0.00104, "time": 0.23772}
+{"mode": "train", "epoch": 189, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00057, "acc_pose": 0.82807, "loss": 0.00057, "grad_norm": 0.00104, "time": 0.23809}
+{"mode": "train", "epoch": 189, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.00044, "heatmap_loss": 0.00056, "acc_pose": 0.84192, "loss": 0.00056, "grad_norm": 0.00098, "time": 0.23803}
+{"mode": "train", "epoch": 190, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.05621, "heatmap_loss": 0.00057, "acc_pose": 0.83684, "loss": 0.00057, "grad_norm": 0.00099, "time": 0.29771}
+{"mode": "train", "epoch": 190, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.00033, "heatmap_loss": 0.00057, "acc_pose": 0.83388, "loss": 0.00057, "grad_norm": 0.00103, "time": 0.23862}
+{"mode": "train", "epoch": 190, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.00026, "heatmap_loss": 0.00056, "acc_pose": 0.83168, "loss": 0.00056, "grad_norm": 0.00102, "time": 0.2386}
+{"mode": "train", "epoch": 190, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00057, "acc_pose": 0.83736, "loss": 0.00057, "grad_norm": 0.00101, "time": 0.23805}
+{"mode": "train", "epoch": 190, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.00044, "heatmap_loss": 0.00057, "acc_pose": 0.83352, "loss": 0.00057, "grad_norm": 0.00098, "time": 0.23765}
+{"mode": "val", "epoch": 190, "iter": 407, "lr": 0.0, "AP": 0.75367, "AP .5": 0.9056, "AP .75": 0.82722, "AP (M)": 0.6829, "AP (L)": 0.77894, "AR": 0.80729, "AR .5": 0.94427, "AR .75": 0.87295, "AR (M)": 0.76602, "AR (L)": 0.86734}
+{"mode": "train", "epoch": 191, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.05447, "heatmap_loss": 0.00057, "acc_pose": 0.83621, "loss": 0.00057, "grad_norm": 0.00102, "time": 0.29555}
+{"mode": "train", "epoch": 191, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00057, "acc_pose": 0.83353, "loss": 0.00057, "grad_norm": 0.00101, "time": 0.23848}
+{"mode": "train", "epoch": 191, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00057, "acc_pose": 0.8351, "loss": 0.00057, "grad_norm": 0.00102, "time": 0.23832}
+{"mode": "train", "epoch": 191, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.00033, "heatmap_loss": 0.00057, "acc_pose": 0.83372, "loss": 0.00057, "grad_norm": 0.00099, "time": 0.23844}
+{"mode": "train", "epoch": 191, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.00033, "heatmap_loss": 0.00057, "acc_pose": 0.83136, "loss": 0.00057, "grad_norm": 0.00097, "time": 0.23819}
+{"mode": "train", "epoch": 192, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.056, "heatmap_loss": 0.00057, "acc_pose": 0.83077, "loss": 0.00057, "grad_norm": 0.00096, "time": 0.29858}
+{"mode": "train", "epoch": 192, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.00041, "heatmap_loss": 0.00056, "acc_pose": 0.83017, "loss": 0.00056, "grad_norm": 0.001, "time": 0.23917}
+{"mode": "train", "epoch": 192, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00057, "acc_pose": 0.83205, "loss": 0.00057, "grad_norm": 0.00104, "time": 0.2383}
+{"mode": "train", "epoch": 192, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00057, "acc_pose": 0.8345, "loss": 0.00057, "grad_norm": 0.00103, "time": 0.23777}
+{"mode": "train", "epoch": 192, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.00041, "heatmap_loss": 0.00057, "acc_pose": 0.84308, "loss": 0.00057, "grad_norm": 0.001, "time": 0.23852}
+{"mode": "train", "epoch": 193, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.0559, "heatmap_loss": 0.00057, "acc_pose": 0.8325, "loss": 0.00057, "grad_norm": 0.001, "time": 0.29809}
+{"mode": "train", "epoch": 193, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.00043, "heatmap_loss": 0.00056, "acc_pose": 0.83507, "loss": 0.00056, "grad_norm": 0.00102, "time": 0.23923}
+{"mode": "train", "epoch": 193, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00056, "acc_pose": 0.83941, "loss": 0.00056, "grad_norm": 0.001, "time": 0.23804}
+{"mode": "train", "epoch": 193, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00056, "acc_pose": 0.83103, "loss": 0.00056, "grad_norm": 0.00098, "time": 0.23827}
+{"mode": "train", "epoch": 193, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.00052, "heatmap_loss": 0.00057, "acc_pose": 0.83044, "loss": 0.00057, "grad_norm": 0.00103, "time": 0.23862}
+{"mode": "train", "epoch": 194, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.05568, "heatmap_loss": 0.00056, "acc_pose": 0.84037, "loss": 0.00056, "grad_norm": 0.00101, "time": 0.29786}
+{"mode": "train", "epoch": 194, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.00033, "heatmap_loss": 0.00057, "acc_pose": 0.82956, "loss": 0.00057, "grad_norm": 0.001, "time": 0.23902}
+{"mode": "train", "epoch": 194, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00056, "acc_pose": 0.83223, "loss": 0.00056, "grad_norm": 0.00103, "time": 0.23803}
+{"mode": "train", "epoch": 194, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00057, "acc_pose": 0.83441, "loss": 0.00057, "grad_norm": 0.00102, "time": 0.23826}
+{"mode": "train", "epoch": 194, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.00041, "heatmap_loss": 0.00056, "acc_pose": 0.83896, "loss": 0.00056, "grad_norm": 0.00099, "time": 0.23765}
+{"mode": "train", "epoch": 195, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.05538, "heatmap_loss": 0.00057, "acc_pose": 0.83412, "loss": 0.00057, "grad_norm": 0.00103, "time": 0.29745}
+{"mode": "train", "epoch": 195, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00057, "acc_pose": 0.82983, "loss": 0.00057, "grad_norm": 0.00105, "time": 0.23864}
+{"mode": "train", "epoch": 195, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00056, "acc_pose": 0.83915, "loss": 0.00056, "grad_norm": 0.00097, "time": 0.23811}
+{"mode": "train", "epoch": 195, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00056, "acc_pose": 0.83525, "loss": 0.00056, "grad_norm": 0.00099, "time": 0.23791}
+{"mode": "train", "epoch": 195, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.00036, "heatmap_loss": 0.00056, "acc_pose": 0.83659, "loss": 0.00056, "grad_norm": 0.00102, "time": 0.23735}
+{"mode": "train", "epoch": 196, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.05834, "heatmap_loss": 0.00056, "acc_pose": 0.83396, "loss": 0.00056, "grad_norm": 0.00103, "time": 0.30077}
+{"mode": "train", "epoch": 196, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00056, "acc_pose": 0.84077, "loss": 0.00056, "grad_norm": 0.00102, "time": 0.23818}
+{"mode": "train", "epoch": 196, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.00025, "heatmap_loss": 0.00057, "acc_pose": 0.82759, "loss": 0.00057, "grad_norm": 0.00102, "time": 0.23763}
+{"mode": "train", "epoch": 196, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00056, "acc_pose": 0.83884, "loss": 0.00056, "grad_norm": 0.00103, "time": 0.23749}
+{"mode": "train", "epoch": 196, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00057, "acc_pose": 0.83024, "loss": 0.00057, "grad_norm": 0.001, "time": 0.23792}
+{"mode": "train", "epoch": 197, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.05564, "heatmap_loss": 0.00057, "acc_pose": 0.83837, "loss": 0.00057, "grad_norm": 0.00104, "time": 0.29751}
+{"mode": "train", "epoch": 197, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00056, "acc_pose": 0.84034, "loss": 0.00056, "grad_norm": 0.00098, "time": 0.23823}
+{"mode": "train", "epoch": 197, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00056, "acc_pose": 0.8262, "loss": 0.00056, "grad_norm": 0.00103, "time": 0.23897}
+{"mode": "train", "epoch": 197, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00056, "acc_pose": 0.83061, "loss": 0.00056, "grad_norm": 0.00109, "time": 0.23806}
+{"mode": "train", "epoch": 197, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00056, "acc_pose": 0.8313, "loss": 0.00056, "grad_norm": 0.001, "time": 0.23761}
+{"mode": "train", "epoch": 198, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.05588, "heatmap_loss": 0.00056, "acc_pose": 0.83994, "loss": 0.00056, "grad_norm": 0.00099, "time": 0.29957}
+{"mode": "train", "epoch": 198, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00057, "acc_pose": 0.83524, "loss": 0.00057, "grad_norm": 0.00101, "time": 0.23886}
+{"mode": "train", "epoch": 198, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00056, "acc_pose": 0.83337, "loss": 0.00056, "grad_norm": 0.00106, "time": 0.2379}
+{"mode": "train", "epoch": 198, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00056, "acc_pose": 0.83189, "loss": 0.00056, "grad_norm": 0.00097, "time": 0.23816}
+{"mode": "train", "epoch": 198, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.00044, "heatmap_loss": 0.00056, "acc_pose": 0.83697, "loss": 0.00056, "grad_norm": 0.00101, "time": 0.23855}
+{"mode": "train", "epoch": 199, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.05551, "heatmap_loss": 0.00056, "acc_pose": 0.8352, "loss": 0.00056, "grad_norm": 0.00099, "time": 0.29993}
+{"mode": "train", "epoch": 199, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00056, "acc_pose": 0.83685, "loss": 0.00056, "grad_norm": 0.00097, "time": 0.23862}
+{"mode": "train", "epoch": 199, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.00042, "heatmap_loss": 0.00057, "acc_pose": 0.83016, "loss": 0.00057, "grad_norm": 0.001, "time": 0.2388}
+{"mode": "train", "epoch": 199, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.00042, "heatmap_loss": 0.00056, "acc_pose": 0.83094, "loss": 0.00056, "grad_norm": 0.001, "time": 0.23918}
+{"mode": "train", "epoch": 199, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00057, "acc_pose": 0.83679, "loss": 0.00057, "grad_norm": 0.00101, "time": 0.23822}
+{"mode": "train", "epoch": 200, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.05517, "heatmap_loss": 0.00056, "acc_pose": 0.83714, "loss": 0.00056, "grad_norm": 0.001, "time": 0.29909}
+{"mode": "train", "epoch": 200, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.00026, "heatmap_loss": 0.00056, "acc_pose": 0.83052, "loss": 0.00056, "grad_norm": 0.00104, "time": 0.23846}
+{"mode": "train", "epoch": 200, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00057, "acc_pose": 0.82843, "loss": 0.00057, "grad_norm": 0.00101, "time": 0.23816}
+{"mode": "train", "epoch": 200, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00056, "acc_pose": 0.8384, "loss": 0.00056, "grad_norm": 0.00101, "time": 0.2384}
+{"mode": "train", "epoch": 200, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00056, "acc_pose": 0.83475, "loss": 0.00056, "grad_norm": 0.00104, "time": 0.2376}
+{"mode": "val", "epoch": 200, "iter": 407, "lr": 0.0, "AP": 0.75469, "AP .5": 0.90635, "AP .75": 0.82768, "AP (M)": 0.68371, "AP (L)": 0.77982, "AR": 0.80889, "AR .5": 0.94521, "AR .75": 0.875, "AR (M)": 0.76793, "AR (L)": 0.86845}
+{"mode": "train", "epoch": 201, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.0555, "heatmap_loss": 0.00056, "acc_pose": 0.83538, "loss": 0.00056, "grad_norm": 0.00098, "time": 0.29443}
+{"mode": "train", "epoch": 201, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00056, "acc_pose": 0.83026, "loss": 0.00056, "grad_norm": 0.00102, "time": 0.23902}
+{"mode": "train", "epoch": 201, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00056, "acc_pose": 0.83277, "loss": 0.00056, "grad_norm": 0.00098, "time": 0.23876}
+{"mode": "train", "epoch": 201, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00056, "acc_pose": 0.84081, "loss": 0.00056, "grad_norm": 0.00098, "time": 0.23885}
+{"mode": "train", "epoch": 201, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00056, "acc_pose": 0.83308, "loss": 0.00056, "grad_norm": 0.00103, "time": 0.23832}
+{"mode": "train", "epoch": 202, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.05603, "heatmap_loss": 0.00056, "acc_pose": 0.83389, "loss": 0.00056, "grad_norm": 0.00098, "time": 0.29675}
+{"mode": "train", "epoch": 202, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.00025, "heatmap_loss": 0.00057, "acc_pose": 0.83877, "loss": 0.00057, "grad_norm": 0.001, "time": 0.23844}
+{"mode": "train", "epoch": 202, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00056, "acc_pose": 0.83628, "loss": 0.00056, "grad_norm": 0.00099, "time": 0.23773}
+{"mode": "train", "epoch": 202, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00056, "acc_pose": 0.83441, "loss": 0.00056, "grad_norm": 0.00105, "time": 0.23718}
+{"mode": "train", "epoch": 202, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00056, "acc_pose": 0.8441, "loss": 0.00056, "grad_norm": 0.00098, "time": 0.2374}
+{"mode": "train", "epoch": 203, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.05555, "heatmap_loss": 0.00056, "acc_pose": 0.83264, "loss": 0.00056, "grad_norm": 0.00101, "time": 0.2971}
+{"mode": "train", "epoch": 203, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.00028, "heatmap_loss": 0.00056, "acc_pose": 0.83781, "loss": 0.00056, "grad_norm": 0.00098, "time": 0.23913}
+{"mode": "train", "epoch": 203, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.00042, "heatmap_loss": 0.00056, "acc_pose": 0.83967, "loss": 0.00056, "grad_norm": 0.00102, "time": 0.23813}
+{"mode": "train", "epoch": 203, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.00041, "heatmap_loss": 0.00056, "acc_pose": 0.83274, "loss": 0.00056, "grad_norm": 0.00102, "time": 0.23805}
+{"mode": "train", "epoch": 203, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00056, "acc_pose": 0.83737, "loss": 0.00056, "grad_norm": 0.00101, "time": 0.23871}
+{"mode": "train", "epoch": 204, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.05594, "heatmap_loss": 0.00056, "acc_pose": 0.83507, "loss": 0.00056, "grad_norm": 0.00099, "time": 0.30297}
+{"mode": "train", "epoch": 204, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00057, "acc_pose": 0.83703, "loss": 0.00057, "grad_norm": 0.00101, "time": 0.23894}
+{"mode": "train", "epoch": 204, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.00026, "heatmap_loss": 0.00055, "acc_pose": 0.8351, "loss": 0.00055, "grad_norm": 0.00099, "time": 0.2387}
+{"mode": "train", "epoch": 204, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00056, "acc_pose": 0.83489, "loss": 0.00056, "grad_norm": 0.00102, "time": 0.23772}
+{"mode": "train", "epoch": 204, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00056, "acc_pose": 0.83477, "loss": 0.00056, "grad_norm": 0.00096, "time": 0.23852}
+{"mode": "train", "epoch": 205, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.05608, "heatmap_loss": 0.00056, "acc_pose": 0.83977, "loss": 0.00056, "grad_norm": 0.00099, "time": 0.29874}
+{"mode": "train", "epoch": 205, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00056, "acc_pose": 0.83482, "loss": 0.00056, "grad_norm": 0.001, "time": 0.23819}
+{"mode": "train", "epoch": 205, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00056, "acc_pose": 0.83623, "loss": 0.00056, "grad_norm": 0.00102, "time": 0.23787}
+{"mode": "train", "epoch": 205, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.00036, "heatmap_loss": 0.00056, "acc_pose": 0.84361, "loss": 0.00056, "grad_norm": 0.00102, "time": 0.23816}
+{"mode": "train", "epoch": 205, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00056, "acc_pose": 0.83904, "loss": 0.00056, "grad_norm": 0.00104, "time": 0.2374}
+{"mode": "train", "epoch": 206, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.05546, "heatmap_loss": 0.00056, "acc_pose": 0.8377, "loss": 0.00056, "grad_norm": 0.001, "time": 0.29717}
+{"mode": "train", "epoch": 206, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00056, "acc_pose": 0.8317, "loss": 0.00056, "grad_norm": 0.001, "time": 0.23868}
+{"mode": "train", "epoch": 206, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00056, "acc_pose": 0.83342, "loss": 0.00056, "grad_norm": 0.001, "time": 0.23807}
+{"mode": "train", "epoch": 206, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.0004, "heatmap_loss": 0.00056, "acc_pose": 0.83985, "loss": 0.00056, "grad_norm": 0.00108, "time": 0.23844}
+{"mode": "train", "epoch": 206, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.00029, "heatmap_loss": 0.00056, "acc_pose": 0.84122, "loss": 0.00056, "grad_norm": 0.00098, "time": 0.2372}
+{"mode": "train", "epoch": 207, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.05555, "heatmap_loss": 0.00056, "acc_pose": 0.83732, "loss": 0.00056, "grad_norm": 0.00102, "time": 0.29724}
+{"mode": "train", "epoch": 207, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00056, "acc_pose": 0.82959, "loss": 0.00056, "grad_norm": 0.00102, "time": 0.2386}
+{"mode": "train", "epoch": 207, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.00032, "heatmap_loss": 0.00056, "acc_pose": 0.8368, "loss": 0.00056, "grad_norm": 0.00098, "time": 0.23828}
+{"mode": "train", "epoch": 207, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00056, "acc_pose": 0.83661, "loss": 0.00056, "grad_norm": 0.00098, "time": 0.23839}
+{"mode": "train", "epoch": 207, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.00033, "heatmap_loss": 0.00056, "acc_pose": 0.84037, "loss": 0.00056, "grad_norm": 0.00096, "time": 0.23825}
+{"mode": "train", "epoch": 208, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.0562, "heatmap_loss": 0.00056, "acc_pose": 0.83729, "loss": 0.00056, "grad_norm": 0.00095, "time": 0.29709}
+{"mode": "train", "epoch": 208, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.0004, "heatmap_loss": 0.00056, "acc_pose": 0.83843, "loss": 0.00056, "grad_norm": 0.001, "time": 0.23967}
+{"mode": "train", "epoch": 208, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.00025, "heatmap_loss": 0.00056, "acc_pose": 0.83388, "loss": 0.00056, "grad_norm": 0.00104, "time": 0.23839}
+{"mode": "train", "epoch": 208, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.00042, "heatmap_loss": 0.00056, "acc_pose": 0.83803, "loss": 0.00056, "grad_norm": 0.00099, "time": 0.23805}
+{"mode": "train", "epoch": 208, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.00046, "heatmap_loss": 0.00056, "acc_pose": 0.83912, "loss": 0.00056, "grad_norm": 0.00101, "time": 0.23764}
+{"mode": "train", "epoch": 209, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.05597, "heatmap_loss": 0.00056, "acc_pose": 0.83608, "loss": 0.00056, "grad_norm": 0.001, "time": 0.29847}
+{"mode": "train", "epoch": 209, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00056, "acc_pose": 0.8376, "loss": 0.00056, "grad_norm": 0.00104, "time": 0.23899}
+{"mode": "train", "epoch": 209, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.0004, "heatmap_loss": 0.00056, "acc_pose": 0.83455, "loss": 0.00056, "grad_norm": 0.00102, "time": 0.23823}
+{"mode": "train", "epoch": 209, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.00042, "heatmap_loss": 0.00055, "acc_pose": 0.83978, "loss": 0.00055, "grad_norm": 0.001, "time": 0.23793}
+{"mode": "train", "epoch": 209, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.00031, "heatmap_loss": 0.00056, "acc_pose": 0.84095, "loss": 0.00056, "grad_norm": 0.00103, "time": 0.23811}
+{"mode": "train", "epoch": 210, "iter": 50, "lr": 0.0, "memory": 14884, "data_time": 0.05633, "heatmap_loss": 0.00056, "acc_pose": 0.83497, "loss": 0.00056, "grad_norm": 0.00101, "time": 0.29762}
+{"mode": "train", "epoch": 210, "iter": 100, "lr": 0.0, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00056, "acc_pose": 0.83635, "loss": 0.00056, "grad_norm": 0.00102, "time": 0.23953}
+{"mode": "train", "epoch": 210, "iter": 150, "lr": 0.0, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00056, "acc_pose": 0.83046, "loss": 0.00056, "grad_norm": 0.00102, "time": 0.2382}
+{"mode": "train", "epoch": 210, "iter": 200, "lr": 0.0, "memory": 14884, "data_time": 0.00027, "heatmap_loss": 0.00055, "acc_pose": 0.84158, "loss": 0.00055, "grad_norm": 0.00099, "time": 0.23867}
+{"mode": "train", "epoch": 210, "iter": 250, "lr": 0.0, "memory": 14884, "data_time": 0.0003, "heatmap_loss": 0.00056, "acc_pose": 0.83738, "loss": 0.00056, "grad_norm": 0.00097, "time": 0.23836}
+{"mode": "val", "epoch": 210, "iter": 407, "lr": 0.0, "AP": 0.75526, "AP .5": 0.90632, "AP .75": 0.82864, "AP (M)": 0.68432, "AP (L)": 0.78026, "AR": 0.80943, "AR .5": 0.94553, "AR .75": 0.87563, "AR (M)": 0.76826, "AR (L)": 0.86934}
diff --git a/vendor/ViTPose/logs/vitpose-b.log.json b/vendor/ViTPose/logs/vitpose-b.log.json
new file mode 100644
index 0000000000000000000000000000000000000000..7ef64c5af50d45df32675b26c6fc8de5ae87cb73
--- /dev/null
+++ b/vendor/ViTPose/logs/vitpose-b.log.json
@@ -0,0 +1,1072 @@
+{"env_info": "sys.platform: linux\nPython: 3.8.10 | packaged by conda-forge | (default, May 11 2021, 07:01:05) [GCC 9.3.0]\nCUDA available: True\nGPU 0,1,2,3,4,5,6,7: A100-SXM4-40GB\nCUDA_HOME: /usr/local/cuda\nNVCC: Build cuda_11.3.r11.3/compiler.29920130_0\nGCC: gcc (Ubuntu 9.3.0-17ubuntu1~20.04) 9.3.0\nPyTorch: 1.9.0a0+c3d40fd\nPyTorch compiling details: PyTorch built with:\n - GCC 9.3\n - C++ Version: 201402\n - Intel(R) Math Kernel Library Version 2019.0.5 Product Build 20190808 for Intel(R) 64 architecture applications\n - Intel(R) MKL-DNN v2.1.2 (Git Hash N/A)\n - OpenMP 201511 (a.k.a. OpenMP 4.5)\n - NNPACK is enabled\n - CPU capability usage: AVX2\n - CUDA Runtime 11.3\n - NVCC architecture flags: -gencode;arch=compute_52,code=sm_52;-gencode;arch=compute_60,code=sm_60;-gencode;arch=compute_61,code=sm_61;-gencode;arch=compute_70,code=sm_70;-gencode;arch=compute_75,code=sm_75;-gencode;arch=compute_80,code=sm_80;-gencode;arch=compute_86,code=sm_86;-gencode;arch=compute_86,code=compute_86\n - CuDNN 8.2.1\n - Magma 2.5.2\n - Build settings: BLAS_INFO=mkl, BUILD_TYPE=Release, CUDA_VERSION=11.3, CUDNN_VERSION=8.2.1, CXX_COMPILER=/usr/bin/c++, CXX_FLAGS= -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_KINETO -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DUSE_XNNPACK -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -O2 -fPIC -Wno-narrowing -Wall -Wextra -Werror=return-type -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wno-sign-compare -Wno-unused-parameter -Wno-unused-variable -Wno-unused-function -Wno-unused-result -Wno-unused-local-typedefs -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-psabi -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Werror=cast-function-type -Wno-stringop-overflow, LAPACK_INFO=mkl, PERF_WITH_AVX=1, PERF_WITH_AVX2=1, PERF_WITH_AVX512=1, TORCH_VERSION=1.9.0, USE_CUDA=ON, USE_CUDNN=ON, USE_EXCEPTION_PTR=1, USE_GFLAGS=OFF, USE_GLOG=OFF, USE_MKL=ON, USE_MKLDNN=ON, USE_MPI=ON, USE_NCCL=ON, USE_NNPACK=ON, USE_OPENMP=ON, \n\nTorchVision: 0.10.0a0\nOpenCV: 4.5.5\nMMCV: 1.3.9\nMMCV Compiler: GCC 9.3\nMMCV CUDA Compiler: 11.3\nMMPose: 0.24.0+5905982", "seed": 0, "hook_msgs": {}}
+{"mode": "train", "epoch": 1, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.06586, "heatmap_loss": 0.00214, "acc_pose": 0.06155, "loss": 0.00214, "time": 0.3532}
+{"mode": "train", "epoch": 1, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00046, "heatmap_loss": 0.00186, "acc_pose": 0.25887, "loss": 0.00186, "time": 0.19385}
+{"mode": "train", "epoch": 1, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00159, "acc_pose": 0.39629, "loss": 0.00159, "time": 0.19363}
+{"mode": "train", "epoch": 1, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00042, "heatmap_loss": 0.00145, "acc_pose": 0.46183, "loss": 0.00145, "time": 0.19371}
+{"mode": "train", "epoch": 1, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00135, "acc_pose": 0.50374, "loss": 0.00135, "time": 0.19344}
+{"mode": "train", "epoch": 2, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05537, "heatmap_loss": 0.00125, "acc_pose": 0.55242, "loss": 0.00125, "time": 0.25581}
+{"mode": "train", "epoch": 2, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00121, "acc_pose": 0.57423, "loss": 0.00121, "time": 0.19761}
+{"mode": "train", "epoch": 2, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00118, "acc_pose": 0.57644, "loss": 0.00118, "time": 0.19678}
+{"mode": "train", "epoch": 2, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00116, "acc_pose": 0.5839, "loss": 0.00116, "time": 0.19499}
+{"mode": "train", "epoch": 2, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00113, "acc_pose": 0.60309, "loss": 0.00113, "time": 0.19558}
+{"mode": "train", "epoch": 3, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05544, "heatmap_loss": 0.00109, "acc_pose": 0.62308, "loss": 0.00109, "time": 0.2537}
+{"mode": "train", "epoch": 3, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00107, "acc_pose": 0.62769, "loss": 0.00107, "time": 0.19374}
+{"mode": "train", "epoch": 3, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00106, "acc_pose": 0.62886, "loss": 0.00106, "time": 0.193}
+{"mode": "train", "epoch": 3, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00105, "acc_pose": 0.63644, "loss": 0.00105, "time": 0.19356}
+{"mode": "train", "epoch": 3, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00104, "acc_pose": 0.63998, "loss": 0.00104, "time": 0.19713}
+{"mode": "train", "epoch": 4, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05513, "heatmap_loss": 0.00102, "acc_pose": 0.65483, "loss": 0.00102, "time": 0.25179}
+{"mode": "train", "epoch": 4, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.001, "acc_pose": 0.6593, "loss": 0.001, "time": 0.19305}
+{"mode": "train", "epoch": 4, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00099, "acc_pose": 0.66863, "loss": 0.00099, "time": 0.1936}
+{"mode": "train", "epoch": 4, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00099, "acc_pose": 0.66848, "loss": 0.00099, "time": 0.19387}
+{"mode": "train", "epoch": 4, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00098, "acc_pose": 0.66785, "loss": 0.00098, "time": 0.19556}
+{"mode": "train", "epoch": 5, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05496, "heatmap_loss": 0.00097, "acc_pose": 0.6745, "loss": 0.00097, "time": 0.24984}
+{"mode": "train", "epoch": 5, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00097, "acc_pose": 0.66429, "loss": 0.00097, "time": 0.1925}
+{"mode": "train", "epoch": 5, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00095, "acc_pose": 0.67168, "loss": 0.00095, "time": 0.19244}
+{"mode": "train", "epoch": 5, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00095, "acc_pose": 0.67883, "loss": 0.00095, "time": 0.19243}
+{"mode": "train", "epoch": 5, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00094, "acc_pose": 0.67974, "loss": 0.00094, "time": 0.19273}
+{"mode": "train", "epoch": 6, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05462, "heatmap_loss": 0.00093, "acc_pose": 0.68822, "loss": 0.00093, "time": 0.25051}
+{"mode": "train", "epoch": 6, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00093, "acc_pose": 0.67627, "loss": 0.00093, "time": 0.19225}
+{"mode": "train", "epoch": 6, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00093, "acc_pose": 0.68534, "loss": 0.00093, "time": 0.19211}
+{"mode": "train", "epoch": 6, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00092, "acc_pose": 0.68586, "loss": 0.00092, "time": 0.193}
+{"mode": "train", "epoch": 6, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00041, "heatmap_loss": 0.00093, "acc_pose": 0.69321, "loss": 0.00093, "time": 0.19284}
+{"mode": "train", "epoch": 7, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.0553, "heatmap_loss": 0.00091, "acc_pose": 0.68836, "loss": 0.00091, "time": 0.25195}
+{"mode": "train", "epoch": 7, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.0009, "acc_pose": 0.69273, "loss": 0.0009, "time": 0.19219}
+{"mode": "train", "epoch": 7, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.0009, "acc_pose": 0.69318, "loss": 0.0009, "time": 0.19249}
+{"mode": "train", "epoch": 7, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00048, "heatmap_loss": 0.0009, "acc_pose": 0.69727, "loss": 0.0009, "time": 0.19333}
+{"mode": "train", "epoch": 7, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00048, "heatmap_loss": 0.0009, "acc_pose": 0.70019, "loss": 0.0009, "time": 0.19235}
+{"mode": "train", "epoch": 8, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05449, "heatmap_loss": 0.00089, "acc_pose": 0.69968, "loss": 0.00089, "time": 0.25249}
+{"mode": "train", "epoch": 8, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00089, "acc_pose": 0.70358, "loss": 0.00089, "time": 0.1928}
+{"mode": "train", "epoch": 8, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00089, "acc_pose": 0.6976, "loss": 0.00089, "time": 0.19226}
+{"mode": "train", "epoch": 8, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00043, "heatmap_loss": 0.00088, "acc_pose": 0.71078, "loss": 0.00088, "time": 0.19251}
+{"mode": "train", "epoch": 8, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00088, "acc_pose": 0.70111, "loss": 0.00088, "time": 0.19246}
+{"mode": "train", "epoch": 9, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05512, "heatmap_loss": 0.00087, "acc_pose": 0.70716, "loss": 0.00087, "time": 0.25195}
+{"mode": "train", "epoch": 9, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00047, "heatmap_loss": 0.00087, "acc_pose": 0.71206, "loss": 0.00087, "time": 0.19312}
+{"mode": "train", "epoch": 9, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00087, "acc_pose": 0.71496, "loss": 0.00087, "time": 0.19314}
+{"mode": "train", "epoch": 9, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00087, "acc_pose": 0.71324, "loss": 0.00087, "time": 0.1924}
+{"mode": "train", "epoch": 9, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00087, "acc_pose": 0.71267, "loss": 0.00087, "time": 0.19217}
+{"mode": "train", "epoch": 10, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05661, "heatmap_loss": 0.00087, "acc_pose": 0.71521, "loss": 0.00087, "time": 0.25368}
+{"mode": "train", "epoch": 10, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00086, "acc_pose": 0.70887, "loss": 0.00086, "time": 0.19235}
+{"mode": "train", "epoch": 10, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00085, "acc_pose": 0.71852, "loss": 0.00085, "time": 0.1927}
+{"mode": "train", "epoch": 10, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00085, "acc_pose": 0.71485, "loss": 0.00085, "time": 0.19248}
+{"mode": "train", "epoch": 10, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00086, "acc_pose": 0.71869, "loss": 0.00086, "time": 0.19279}
+{"mode": "val", "epoch": 10, "iter": 407, "lr": 1e-05, "AP": 0.67647, "AP .5": 0.87915, "AP .75": 0.75323, "AP (M)": 0.60167, "AP (L)": 0.70376, "AR": 0.73509, "AR .5": 0.92034, "AR .75": 0.80368, "AR (M)": 0.69085, "AR (L)": 0.79814}
+{"mode": "train", "epoch": 11, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.0548, "heatmap_loss": 0.00085, "acc_pose": 0.71744, "loss": 0.00085, "time": 0.24752}
+{"mode": "train", "epoch": 11, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00084, "acc_pose": 0.71827, "loss": 0.00084, "time": 0.19291}
+{"mode": "train", "epoch": 11, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00085, "acc_pose": 0.71782, "loss": 0.00085, "time": 0.19216}
+{"mode": "train", "epoch": 11, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00085, "acc_pose": 0.71726, "loss": 0.00085, "time": 0.19313}
+{"mode": "train", "epoch": 11, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00084, "acc_pose": 0.72753, "loss": 0.00084, "time": 0.19265}
+{"mode": "train", "epoch": 12, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05561, "heatmap_loss": 0.00084, "acc_pose": 0.72334, "loss": 0.00084, "time": 0.2506}
+{"mode": "train", "epoch": 12, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00083, "acc_pose": 0.7266, "loss": 0.00083, "time": 0.19257}
+{"mode": "train", "epoch": 12, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00084, "acc_pose": 0.72603, "loss": 0.00084, "time": 0.19243}
+{"mode": "train", "epoch": 12, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00083, "acc_pose": 0.71767, "loss": 0.00083, "time": 0.19218}
+{"mode": "train", "epoch": 12, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00083, "acc_pose": 0.72106, "loss": 0.00083, "time": 0.19258}
+{"mode": "train", "epoch": 13, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05507, "heatmap_loss": 0.00082, "acc_pose": 0.72823, "loss": 0.00082, "time": 0.25113}
+{"mode": "train", "epoch": 13, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00083, "acc_pose": 0.73015, "loss": 0.00083, "time": 0.19235}
+{"mode": "train", "epoch": 13, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00083, "acc_pose": 0.7245, "loss": 0.00083, "time": 0.19247}
+{"mode": "train", "epoch": 13, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00083, "acc_pose": 0.72801, "loss": 0.00083, "time": 0.19246}
+{"mode": "train", "epoch": 13, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00082, "acc_pose": 0.73468, "loss": 0.00082, "time": 0.19239}
+{"mode": "train", "epoch": 14, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05507, "heatmap_loss": 0.00082, "acc_pose": 0.72322, "loss": 0.00082, "time": 0.25141}
+{"mode": "train", "epoch": 14, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00082, "acc_pose": 0.7327, "loss": 0.00082, "time": 0.1921}
+{"mode": "train", "epoch": 14, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00082, "acc_pose": 0.7308, "loss": 0.00082, "time": 0.19211}
+{"mode": "train", "epoch": 14, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00042, "heatmap_loss": 0.00081, "acc_pose": 0.73022, "loss": 0.00081, "time": 0.19237}
+{"mode": "train", "epoch": 14, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00081, "acc_pose": 0.73573, "loss": 0.00081, "time": 0.19242}
+{"mode": "train", "epoch": 15, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05411, "heatmap_loss": 0.00082, "acc_pose": 0.72517, "loss": 0.00082, "time": 0.25139}
+{"mode": "train", "epoch": 15, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00081, "acc_pose": 0.73122, "loss": 0.00081, "time": 0.19184}
+{"mode": "train", "epoch": 15, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00042, "heatmap_loss": 0.00081, "acc_pose": 0.72444, "loss": 0.00081, "time": 0.19197}
+{"mode": "train", "epoch": 15, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00081, "acc_pose": 0.73929, "loss": 0.00081, "time": 0.19324}
+{"mode": "train", "epoch": 15, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00081, "acc_pose": 0.73636, "loss": 0.00081, "time": 0.19254}
+{"mode": "train", "epoch": 16, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05647, "heatmap_loss": 0.0008, "acc_pose": 0.73765, "loss": 0.0008, "time": 0.25156}
+{"mode": "train", "epoch": 16, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.0008, "acc_pose": 0.73862, "loss": 0.0008, "time": 0.19205}
+{"mode": "train", "epoch": 16, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.0008, "acc_pose": 0.73999, "loss": 0.0008, "time": 0.19259}
+{"mode": "train", "epoch": 16, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.0008, "acc_pose": 0.73841, "loss": 0.0008, "time": 0.19216}
+{"mode": "train", "epoch": 16, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.0008, "acc_pose": 0.74079, "loss": 0.0008, "time": 0.19225}
+{"mode": "train", "epoch": 17, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.0545, "heatmap_loss": 0.0008, "acc_pose": 0.73401, "loss": 0.0008, "time": 0.25128}
+{"mode": "train", "epoch": 17, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.0008, "acc_pose": 0.7345, "loss": 0.0008, "time": 0.19245}
+{"mode": "train", "epoch": 17, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00079, "acc_pose": 0.74211, "loss": 0.00079, "time": 0.19239}
+{"mode": "train", "epoch": 17, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.0008, "acc_pose": 0.7427, "loss": 0.0008, "time": 0.19418}
+{"mode": "train", "epoch": 17, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.0008, "acc_pose": 0.74482, "loss": 0.0008, "time": 0.19239}
+{"mode": "train", "epoch": 18, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05531, "heatmap_loss": 0.00079, "acc_pose": 0.739, "loss": 0.00079, "time": 0.25164}
+{"mode": "train", "epoch": 18, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00079, "acc_pose": 0.74628, "loss": 0.00079, "time": 0.19267}
+{"mode": "train", "epoch": 18, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00079, "acc_pose": 0.74222, "loss": 0.00079, "time": 0.19263}
+{"mode": "train", "epoch": 18, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00078, "acc_pose": 0.74936, "loss": 0.00078, "time": 0.19284}
+{"mode": "train", "epoch": 18, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00078, "acc_pose": 0.742, "loss": 0.00078, "time": 0.19224}
+{"mode": "train", "epoch": 19, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05511, "heatmap_loss": 0.00079, "acc_pose": 0.73899, "loss": 0.00079, "time": 0.25119}
+{"mode": "train", "epoch": 19, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00079, "acc_pose": 0.7438, "loss": 0.00079, "time": 0.19244}
+{"mode": "train", "epoch": 19, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00079, "acc_pose": 0.73262, "loss": 0.00079, "time": 0.19265}
+{"mode": "train", "epoch": 19, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00078, "acc_pose": 0.73536, "loss": 0.00078, "time": 0.19456}
+{"mode": "train", "epoch": 19, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00078, "acc_pose": 0.7495, "loss": 0.00078, "time": 0.19263}
+{"mode": "train", "epoch": 20, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05549, "heatmap_loss": 0.00077, "acc_pose": 0.75089, "loss": 0.00077, "time": 0.25155}
+{"mode": "train", "epoch": 20, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00078, "acc_pose": 0.75081, "loss": 0.00078, "time": 0.1922}
+{"mode": "train", "epoch": 20, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00078, "acc_pose": 0.74162, "loss": 0.00078, "time": 0.19299}
+{"mode": "train", "epoch": 20, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00078, "acc_pose": 0.74799, "loss": 0.00078, "time": 0.19342}
+{"mode": "train", "epoch": 20, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00078, "acc_pose": 0.74702, "loss": 0.00078, "time": 0.19327}
+{"mode": "val", "epoch": 20, "iter": 407, "lr": 1e-05, "AP": 0.70603, "AP .5": 0.89118, "AP .75": 0.78565, "AP (M)": 0.63397, "AP (L)": 0.73039, "AR": 0.76371, "AR .5": 0.93325, "AR .75": 0.83312, "AR (M)": 0.72131, "AR (L)": 0.82479}
+{"mode": "train", "epoch": 21, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05536, "heatmap_loss": 0.00078, "acc_pose": 0.7482, "loss": 0.00078, "time": 0.24936}
+{"mode": "train", "epoch": 21, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00077, "acc_pose": 0.75601, "loss": 0.00077, "time": 0.19306}
+{"mode": "train", "epoch": 21, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00077, "acc_pose": 0.74649, "loss": 0.00077, "time": 0.19248}
+{"mode": "train", "epoch": 21, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00077, "acc_pose": 0.75351, "loss": 0.00077, "time": 0.19257}
+{"mode": "train", "epoch": 21, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00078, "acc_pose": 0.74984, "loss": 0.00078, "time": 0.19268}
+{"mode": "train", "epoch": 22, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05546, "heatmap_loss": 0.00077, "acc_pose": 0.75352, "loss": 0.00077, "time": 0.25087}
+{"mode": "train", "epoch": 22, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00077, "acc_pose": 0.74849, "loss": 0.00077, "time": 0.19292}
+{"mode": "train", "epoch": 22, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00077, "acc_pose": 0.74769, "loss": 0.00077, "time": 0.19222}
+{"mode": "train", "epoch": 22, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00076, "acc_pose": 0.75639, "loss": 0.00076, "time": 0.19229}
+{"mode": "train", "epoch": 22, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.0003, "heatmap_loss": 0.00077, "acc_pose": 0.75617, "loss": 0.00077, "time": 0.19243}
+{"mode": "train", "epoch": 23, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05509, "heatmap_loss": 0.00077, "acc_pose": 0.75097, "loss": 0.00077, "time": 0.25071}
+{"mode": "train", "epoch": 23, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00076, "acc_pose": 0.75068, "loss": 0.00076, "time": 0.19198}
+{"mode": "train", "epoch": 23, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00044, "heatmap_loss": 0.00076, "acc_pose": 0.74992, "loss": 0.00076, "time": 0.19201}
+{"mode": "train", "epoch": 23, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00076, "acc_pose": 0.75933, "loss": 0.00076, "time": 0.19252}
+{"mode": "train", "epoch": 23, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00076, "acc_pose": 0.75636, "loss": 0.00076, "time": 0.19189}
+{"mode": "train", "epoch": 24, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05477, "heatmap_loss": 0.00076, "acc_pose": 0.75415, "loss": 0.00076, "time": 0.25066}
+{"mode": "train", "epoch": 24, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00056, "heatmap_loss": 0.00076, "acc_pose": 0.76588, "loss": 0.00076, "time": 0.19326}
+{"mode": "train", "epoch": 24, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00076, "acc_pose": 0.74952, "loss": 0.00076, "time": 0.19251}
+{"mode": "train", "epoch": 24, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00076, "acc_pose": 0.7519, "loss": 0.00076, "time": 0.19234}
+{"mode": "train", "epoch": 24, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00076, "acc_pose": 0.75092, "loss": 0.00076, "time": 0.19244}
+{"mode": "train", "epoch": 25, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05522, "heatmap_loss": 0.00075, "acc_pose": 0.76583, "loss": 0.00075, "time": 0.25092}
+{"mode": "train", "epoch": 25, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00075, "acc_pose": 0.75606, "loss": 0.00075, "time": 0.19216}
+{"mode": "train", "epoch": 25, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00075, "acc_pose": 0.7521, "loss": 0.00075, "time": 0.1922}
+{"mode": "train", "epoch": 25, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00076, "acc_pose": 0.75, "loss": 0.00076, "time": 0.19272}
+{"mode": "train", "epoch": 25, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00075, "acc_pose": 0.75397, "loss": 0.00075, "time": 0.19235}
+{"mode": "train", "epoch": 26, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05448, "heatmap_loss": 0.00075, "acc_pose": 0.75324, "loss": 0.00075, "time": 0.25065}
+{"mode": "train", "epoch": 26, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00075, "acc_pose": 0.75511, "loss": 0.00075, "time": 0.19286}
+{"mode": "train", "epoch": 26, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00075, "acc_pose": 0.75243, "loss": 0.00075, "time": 0.19261}
+{"mode": "train", "epoch": 26, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00075, "acc_pose": 0.7576, "loss": 0.00075, "time": 0.19276}
+{"mode": "train", "epoch": 26, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00075, "acc_pose": 0.76155, "loss": 0.00075, "time": 0.19273}
+{"mode": "train", "epoch": 27, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05497, "heatmap_loss": 0.00074, "acc_pose": 0.75893, "loss": 0.00074, "time": 0.25033}
+{"mode": "train", "epoch": 27, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00075, "acc_pose": 0.76467, "loss": 0.00075, "time": 0.19223}
+{"mode": "train", "epoch": 27, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00075, "acc_pose": 0.76127, "loss": 0.00075, "time": 0.19376}
+{"mode": "train", "epoch": 27, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00074, "acc_pose": 0.76668, "loss": 0.00074, "time": 0.19208}
+{"mode": "train", "epoch": 27, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00074, "acc_pose": 0.75405, "loss": 0.00074, "time": 0.19197}
+{"mode": "train", "epoch": 28, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05464, "heatmap_loss": 0.00074, "acc_pose": 0.76587, "loss": 0.00074, "time": 0.25071}
+{"mode": "train", "epoch": 28, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00034, "heatmap_loss": 0.00074, "acc_pose": 0.76107, "loss": 0.00074, "time": 0.19189}
+{"mode": "train", "epoch": 28, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00034, "heatmap_loss": 0.00074, "acc_pose": 0.75845, "loss": 0.00074, "time": 0.19204}
+{"mode": "train", "epoch": 28, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00075, "acc_pose": 0.76082, "loss": 0.00075, "time": 0.19233}
+{"mode": "train", "epoch": 28, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00045, "heatmap_loss": 0.00074, "acc_pose": 0.76397, "loss": 0.00074, "time": 0.19254}
+{"mode": "train", "epoch": 29, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05535, "heatmap_loss": 0.00074, "acc_pose": 0.76763, "loss": 0.00074, "time": 0.25172}
+{"mode": "train", "epoch": 29, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00047, "heatmap_loss": 0.00074, "acc_pose": 0.75546, "loss": 0.00074, "time": 0.1924}
+{"mode": "train", "epoch": 29, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00074, "acc_pose": 0.75609, "loss": 0.00074, "time": 0.19218}
+{"mode": "train", "epoch": 29, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00074, "acc_pose": 0.76331, "loss": 0.00074, "time": 0.19242}
+{"mode": "train", "epoch": 29, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00073, "acc_pose": 0.76193, "loss": 0.00073, "time": 0.19227}
+{"mode": "train", "epoch": 30, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05665, "heatmap_loss": 0.00074, "acc_pose": 0.75762, "loss": 0.00074, "time": 0.25177}
+{"mode": "train", "epoch": 30, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00074, "acc_pose": 0.76239, "loss": 0.00074, "time": 0.19266}
+{"mode": "train", "epoch": 30, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00074, "acc_pose": 0.76048, "loss": 0.00074, "time": 0.19228}
+{"mode": "train", "epoch": 30, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00073, "acc_pose": 0.76277, "loss": 0.00073, "time": 0.19233}
+{"mode": "train", "epoch": 30, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00073, "acc_pose": 0.76636, "loss": 0.00073, "time": 0.1922}
+{"mode": "val", "epoch": 30, "iter": 407, "lr": 1e-05, "AP": 0.71786, "AP .5": 0.89526, "AP .75": 0.79338, "AP (M)": 0.64611, "AP (L)": 0.74376, "AR": 0.77382, "AR .5": 0.93671, "AR .75": 0.84068, "AR (M)": 0.73111, "AR (L)": 0.83545}
+{"mode": "train", "epoch": 31, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.0541, "heatmap_loss": 0.00074, "acc_pose": 0.76361, "loss": 0.00074, "time": 0.2458}
+{"mode": "train", "epoch": 31, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00073, "acc_pose": 0.76492, "loss": 0.00073, "time": 0.19173}
+{"mode": "train", "epoch": 31, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00031, "heatmap_loss": 0.00073, "acc_pose": 0.76639, "loss": 0.00073, "time": 0.1918}
+{"mode": "train", "epoch": 31, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00073, "acc_pose": 0.77203, "loss": 0.00073, "time": 0.19183}
+{"mode": "train", "epoch": 31, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00073, "acc_pose": 0.77363, "loss": 0.00073, "time": 0.19296}
+{"mode": "train", "epoch": 32, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05523, "heatmap_loss": 0.00073, "acc_pose": 0.76809, "loss": 0.00073, "time": 0.25169}
+{"mode": "train", "epoch": 32, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00073, "acc_pose": 0.77178, "loss": 0.00073, "time": 0.19298}
+{"mode": "train", "epoch": 32, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00073, "acc_pose": 0.76417, "loss": 0.00073, "time": 0.19208}
+{"mode": "train", "epoch": 32, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00072, "acc_pose": 0.77183, "loss": 0.00072, "time": 0.19251}
+{"mode": "train", "epoch": 32, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00072, "acc_pose": 0.77596, "loss": 0.00072, "time": 0.19283}
+{"mode": "train", "epoch": 33, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.0552, "heatmap_loss": 0.00072, "acc_pose": 0.77209, "loss": 0.00072, "time": 0.24978}
+{"mode": "train", "epoch": 33, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00073, "acc_pose": 0.76675, "loss": 0.00073, "time": 0.19234}
+{"mode": "train", "epoch": 33, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00072, "acc_pose": 0.77506, "loss": 0.00072, "time": 0.19247}
+{"mode": "train", "epoch": 33, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00073, "acc_pose": 0.76651, "loss": 0.00073, "time": 0.19207}
+{"mode": "train", "epoch": 33, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00073, "acc_pose": 0.77826, "loss": 0.00073, "time": 0.19214}
+{"mode": "train", "epoch": 34, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05447, "heatmap_loss": 0.00072, "acc_pose": 0.76849, "loss": 0.00072, "time": 0.24981}
+{"mode": "train", "epoch": 34, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00073, "acc_pose": 0.76703, "loss": 0.00073, "time": 0.19198}
+{"mode": "train", "epoch": 34, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00072, "acc_pose": 0.76975, "loss": 0.00072, "time": 0.19295}
+{"mode": "train", "epoch": 34, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00072, "acc_pose": 0.77253, "loss": 0.00072, "time": 0.19283}
+{"mode": "train", "epoch": 34, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00072, "acc_pose": 0.77078, "loss": 0.00072, "time": 0.19223}
+{"mode": "train", "epoch": 35, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05555, "heatmap_loss": 0.00072, "acc_pose": 0.77102, "loss": 0.00072, "time": 0.25291}
+{"mode": "train", "epoch": 35, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00072, "acc_pose": 0.77044, "loss": 0.00072, "time": 0.1934}
+{"mode": "train", "epoch": 35, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00071, "acc_pose": 0.76908, "loss": 0.00071, "time": 0.19243}
+{"mode": "train", "epoch": 35, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00072, "acc_pose": 0.77703, "loss": 0.00072, "time": 0.19245}
+{"mode": "train", "epoch": 35, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00072, "acc_pose": 0.77626, "loss": 0.00072, "time": 0.1921}
+{"mode": "train", "epoch": 36, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05479, "heatmap_loss": 0.00071, "acc_pose": 0.76774, "loss": 0.00071, "time": 0.25197}
+{"mode": "train", "epoch": 36, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00072, "acc_pose": 0.77463, "loss": 0.00072, "time": 0.19206}
+{"mode": "train", "epoch": 36, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00072, "acc_pose": 0.77184, "loss": 0.00072, "time": 0.1921}
+{"mode": "train", "epoch": 36, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00071, "acc_pose": 0.77387, "loss": 0.00071, "time": 0.19195}
+{"mode": "train", "epoch": 36, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00072, "acc_pose": 0.77081, "loss": 0.00072, "time": 0.19231}
+{"mode": "train", "epoch": 37, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.0543, "heatmap_loss": 0.00071, "acc_pose": 0.77087, "loss": 0.00071, "time": 0.25135}
+{"mode": "train", "epoch": 37, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00072, "acc_pose": 0.77126, "loss": 0.00072, "time": 0.19271}
+{"mode": "train", "epoch": 37, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00071, "acc_pose": 0.77131, "loss": 0.00071, "time": 0.19198}
+{"mode": "train", "epoch": 37, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00071, "acc_pose": 0.78238, "loss": 0.00071, "time": 0.19235}
+{"mode": "train", "epoch": 37, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00071, "acc_pose": 0.76765, "loss": 0.00071, "time": 0.19294}
+{"mode": "train", "epoch": 38, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05483, "heatmap_loss": 0.00072, "acc_pose": 0.77779, "loss": 0.00072, "time": 0.25101}
+{"mode": "train", "epoch": 38, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00071, "acc_pose": 0.77601, "loss": 0.00071, "time": 0.19197}
+{"mode": "train", "epoch": 38, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00041, "heatmap_loss": 0.00071, "acc_pose": 0.77424, "loss": 0.00071, "time": 0.19173}
+{"mode": "train", "epoch": 38, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00043, "heatmap_loss": 0.00071, "acc_pose": 0.76905, "loss": 0.00071, "time": 0.19224}
+{"mode": "train", "epoch": 38, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00071, "acc_pose": 0.77167, "loss": 0.00071, "time": 0.19231}
+{"mode": "train", "epoch": 39, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05488, "heatmap_loss": 0.00071, "acc_pose": 0.77223, "loss": 0.00071, "time": 0.25027}
+{"mode": "train", "epoch": 39, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00044, "heatmap_loss": 0.0007, "acc_pose": 0.77558, "loss": 0.0007, "time": 0.19226}
+{"mode": "train", "epoch": 39, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00071, "acc_pose": 0.77093, "loss": 0.00071, "time": 0.19207}
+{"mode": "train", "epoch": 39, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00071, "acc_pose": 0.76871, "loss": 0.00071, "time": 0.19212}
+{"mode": "train", "epoch": 39, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00071, "acc_pose": 0.77157, "loss": 0.00071, "time": 0.19243}
+{"mode": "train", "epoch": 40, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.0557, "heatmap_loss": 0.0007, "acc_pose": 0.77453, "loss": 0.0007, "time": 0.25277}
+{"mode": "train", "epoch": 40, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00071, "acc_pose": 0.76985, "loss": 0.00071, "time": 0.19215}
+{"mode": "train", "epoch": 40, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00071, "acc_pose": 0.77671, "loss": 0.00071, "time": 0.19232}
+{"mode": "train", "epoch": 40, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00041, "heatmap_loss": 0.00071, "acc_pose": 0.77389, "loss": 0.00071, "time": 0.19209}
+{"mode": "train", "epoch": 40, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00071, "acc_pose": 0.77777, "loss": 0.00071, "time": 0.19181}
+{"mode": "val", "epoch": 40, "iter": 407, "lr": 1e-05, "AP": 0.72453, "AP .5": 0.89532, "AP .75": 0.79838, "AP (M)": 0.65275, "AP (L)": 0.74908, "AR": 0.78164, "AR .5": 0.93734, "AR .75": 0.84603, "AR (M)": 0.73983, "AR (L)": 0.84188}
+{"mode": "train", "epoch": 41, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05394, "heatmap_loss": 0.0007, "acc_pose": 0.78183, "loss": 0.0007, "time": 0.24558}
+{"mode": "train", "epoch": 41, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.0007, "acc_pose": 0.77461, "loss": 0.0007, "time": 0.19148}
+{"mode": "train", "epoch": 41, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.0007, "acc_pose": 0.78614, "loss": 0.0007, "time": 0.19225}
+{"mode": "train", "epoch": 41, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00071, "acc_pose": 0.77922, "loss": 0.00071, "time": 0.19207}
+{"mode": "train", "epoch": 41, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.0007, "acc_pose": 0.77005, "loss": 0.0007, "time": 0.19186}
+{"mode": "train", "epoch": 42, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05448, "heatmap_loss": 0.0007, "acc_pose": 0.77665, "loss": 0.0007, "time": 0.24936}
+{"mode": "train", "epoch": 42, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.0007, "acc_pose": 0.77607, "loss": 0.0007, "time": 0.19197}
+{"mode": "train", "epoch": 42, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.0007, "acc_pose": 0.77124, "loss": 0.0007, "time": 0.19287}
+{"mode": "train", "epoch": 42, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.0007, "acc_pose": 0.78102, "loss": 0.0007, "time": 0.19295}
+{"mode": "train", "epoch": 42, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.0007, "acc_pose": 0.77112, "loss": 0.0007, "time": 0.19253}
+{"mode": "train", "epoch": 43, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05526, "heatmap_loss": 0.0007, "acc_pose": 0.78248, "loss": 0.0007, "time": 0.25132}
+{"mode": "train", "epoch": 43, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.0007, "acc_pose": 0.77696, "loss": 0.0007, "time": 0.19219}
+{"mode": "train", "epoch": 43, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.0007, "acc_pose": 0.77936, "loss": 0.0007, "time": 0.19242}
+{"mode": "train", "epoch": 43, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.0007, "acc_pose": 0.77851, "loss": 0.0007, "time": 0.19315}
+{"mode": "train", "epoch": 43, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.0007, "acc_pose": 0.78764, "loss": 0.0007, "time": 0.19199}
+{"mode": "train", "epoch": 44, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05495, "heatmap_loss": 0.0007, "acc_pose": 0.77721, "loss": 0.0007, "time": 0.25107}
+{"mode": "train", "epoch": 44, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.0007, "acc_pose": 0.77977, "loss": 0.0007, "time": 0.19226}
+{"mode": "train", "epoch": 44, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00045, "heatmap_loss": 0.0007, "acc_pose": 0.78267, "loss": 0.0007, "time": 0.19199}
+{"mode": "train", "epoch": 44, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.0005, "heatmap_loss": 0.00069, "acc_pose": 0.78177, "loss": 0.00069, "time": 0.19237}
+{"mode": "train", "epoch": 44, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00069, "acc_pose": 0.78088, "loss": 0.00069, "time": 0.19254}
+{"mode": "train", "epoch": 45, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05639, "heatmap_loss": 0.00069, "acc_pose": 0.78068, "loss": 0.00069, "time": 0.25131}
+{"mode": "train", "epoch": 45, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00048, "heatmap_loss": 0.00069, "acc_pose": 0.7786, "loss": 0.00069, "time": 0.19231}
+{"mode": "train", "epoch": 45, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00069, "acc_pose": 0.77443, "loss": 0.00069, "time": 0.19236}
+{"mode": "train", "epoch": 45, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.0007, "acc_pose": 0.78213, "loss": 0.0007, "time": 0.19192}
+{"mode": "train", "epoch": 45, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.0007, "acc_pose": 0.78022, "loss": 0.0007, "time": 0.19207}
+{"mode": "train", "epoch": 46, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05545, "heatmap_loss": 0.00069, "acc_pose": 0.78274, "loss": 0.00069, "time": 0.25093}
+{"mode": "train", "epoch": 46, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00069, "acc_pose": 0.78374, "loss": 0.00069, "time": 0.19171}
+{"mode": "train", "epoch": 46, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00069, "acc_pose": 0.78126, "loss": 0.00069, "time": 0.19226}
+{"mode": "train", "epoch": 46, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00069, "acc_pose": 0.77904, "loss": 0.00069, "time": 0.19237}
+{"mode": "train", "epoch": 46, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00069, "acc_pose": 0.78787, "loss": 0.00069, "time": 0.19186}
+{"mode": "train", "epoch": 47, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05504, "heatmap_loss": 0.00069, "acc_pose": 0.7782, "loss": 0.00069, "time": 0.25105}
+{"mode": "train", "epoch": 47, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00069, "acc_pose": 0.78573, "loss": 0.00069, "time": 0.19187}
+{"mode": "train", "epoch": 47, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00069, "acc_pose": 0.77774, "loss": 0.00069, "time": 0.19222}
+{"mode": "train", "epoch": 47, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00069, "acc_pose": 0.78207, "loss": 0.00069, "time": 0.19199}
+{"mode": "train", "epoch": 47, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00069, "acc_pose": 0.78483, "loss": 0.00069, "time": 0.19205}
+{"mode": "train", "epoch": 48, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05514, "heatmap_loss": 0.00069, "acc_pose": 0.78327, "loss": 0.00069, "time": 0.25016}
+{"mode": "train", "epoch": 48, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00069, "acc_pose": 0.77421, "loss": 0.00069, "time": 0.1921}
+{"mode": "train", "epoch": 48, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00069, "acc_pose": 0.78616, "loss": 0.00069, "time": 0.19209}
+{"mode": "train", "epoch": 48, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00069, "acc_pose": 0.78081, "loss": 0.00069, "time": 0.19242}
+{"mode": "train", "epoch": 48, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00044, "heatmap_loss": 0.00069, "acc_pose": 0.7889, "loss": 0.00069, "time": 0.19229}
+{"mode": "train", "epoch": 49, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05447, "heatmap_loss": 0.00069, "acc_pose": 0.78302, "loss": 0.00069, "time": 0.25072}
+{"mode": "train", "epoch": 49, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00055, "heatmap_loss": 0.00069, "acc_pose": 0.78117, "loss": 0.00069, "time": 0.19206}
+{"mode": "train", "epoch": 49, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00068, "acc_pose": 0.78283, "loss": 0.00068, "time": 0.19178}
+{"mode": "train", "epoch": 49, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00041, "heatmap_loss": 0.00069, "acc_pose": 0.77924, "loss": 0.00069, "time": 0.19271}
+{"mode": "train", "epoch": 49, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00041, "heatmap_loss": 0.00069, "acc_pose": 0.78598, "loss": 0.00069, "time": 0.19216}
+{"mode": "train", "epoch": 50, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.0544, "heatmap_loss": 0.00068, "acc_pose": 0.79214, "loss": 0.00068, "time": 0.25106}
+{"mode": "train", "epoch": 50, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00068, "acc_pose": 0.78263, "loss": 0.00068, "time": 0.19243}
+{"mode": "train", "epoch": 50, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00068, "acc_pose": 0.78799, "loss": 0.00068, "time": 0.19176}
+{"mode": "train", "epoch": 50, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00068, "acc_pose": 0.78587, "loss": 0.00068, "time": 0.1919}
+{"mode": "train", "epoch": 50, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00068, "acc_pose": 0.78, "loss": 0.00068, "time": 0.19174}
+{"mode": "val", "epoch": 50, "iter": 407, "lr": 1e-05, "AP": 0.72904, "AP .5": 0.89718, "AP .75": 0.80435, "AP (M)": 0.65612, "AP (L)": 0.75492, "AR": 0.7858, "AR .5": 0.93986, "AR .75": 0.85123, "AR (M)": 0.74321, "AR (L)": 0.84738}
+{"mode": "train", "epoch": 51, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05473, "heatmap_loss": 0.00068, "acc_pose": 0.79149, "loss": 0.00068, "time": 0.24671}
+{"mode": "train", "epoch": 51, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00068, "acc_pose": 0.78256, "loss": 0.00068, "time": 0.19203}
+{"mode": "train", "epoch": 51, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00068, "acc_pose": 0.78395, "loss": 0.00068, "time": 0.1916}
+{"mode": "train", "epoch": 51, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00068, "acc_pose": 0.78794, "loss": 0.00068, "time": 0.19184}
+{"mode": "train", "epoch": 51, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00068, "acc_pose": 0.79344, "loss": 0.00068, "time": 0.19193}
+{"mode": "train", "epoch": 52, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05475, "heatmap_loss": 0.00068, "acc_pose": 0.78481, "loss": 0.00068, "time": 0.25102}
+{"mode": "train", "epoch": 52, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00032, "heatmap_loss": 0.00068, "acc_pose": 0.78579, "loss": 0.00068, "time": 0.19164}
+{"mode": "train", "epoch": 52, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00034, "heatmap_loss": 0.00068, "acc_pose": 0.79184, "loss": 0.00068, "time": 0.19205}
+{"mode": "train", "epoch": 52, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00067, "acc_pose": 0.78659, "loss": 0.00067, "time": 0.19191}
+{"mode": "train", "epoch": 52, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00069, "acc_pose": 0.77863, "loss": 0.00069, "time": 0.19222}
+{"mode": "train", "epoch": 53, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05435, "heatmap_loss": 0.00068, "acc_pose": 0.79202, "loss": 0.00068, "time": 0.25056}
+{"mode": "train", "epoch": 53, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00068, "acc_pose": 0.78314, "loss": 0.00068, "time": 0.19229}
+{"mode": "train", "epoch": 53, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00068, "acc_pose": 0.78853, "loss": 0.00068, "time": 0.19171}
+{"mode": "train", "epoch": 53, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00068, "acc_pose": 0.78848, "loss": 0.00068, "time": 0.19217}
+{"mode": "train", "epoch": 53, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00068, "acc_pose": 0.78373, "loss": 0.00068, "time": 0.19183}
+{"mode": "train", "epoch": 54, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05434, "heatmap_loss": 0.00068, "acc_pose": 0.79, "loss": 0.00068, "time": 0.25168}
+{"mode": "train", "epoch": 54, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00068, "acc_pose": 0.78208, "loss": 0.00068, "time": 0.1923}
+{"mode": "train", "epoch": 54, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00067, "acc_pose": 0.7913, "loss": 0.00067, "time": 0.19245}
+{"mode": "train", "epoch": 54, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00068, "acc_pose": 0.78945, "loss": 0.00068, "time": 0.19189}
+{"mode": "train", "epoch": 54, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00068, "acc_pose": 0.78786, "loss": 0.00068, "time": 0.19339}
+{"mode": "train", "epoch": 55, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05538, "heatmap_loss": 0.00068, "acc_pose": 0.79309, "loss": 0.00068, "time": 0.25186}
+{"mode": "train", "epoch": 55, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00067, "acc_pose": 0.78217, "loss": 0.00067, "time": 0.1919}
+{"mode": "train", "epoch": 55, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00068, "acc_pose": 0.78471, "loss": 0.00068, "time": 0.19294}
+{"mode": "train", "epoch": 55, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00067, "acc_pose": 0.78794, "loss": 0.00067, "time": 0.19258}
+{"mode": "train", "epoch": 55, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00068, "acc_pose": 0.78849, "loss": 0.00068, "time": 0.19291}
+{"mode": "train", "epoch": 56, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05496, "heatmap_loss": 0.00068, "acc_pose": 0.7894, "loss": 0.00068, "time": 0.25314}
+{"mode": "train", "epoch": 56, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00034, "heatmap_loss": 0.00067, "acc_pose": 0.78835, "loss": 0.00067, "time": 0.19329}
+{"mode": "train", "epoch": 56, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00067, "acc_pose": 0.78439, "loss": 0.00067, "time": 0.19274}
+{"mode": "train", "epoch": 56, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00067, "acc_pose": 0.78437, "loss": 0.00067, "time": 0.19252}
+{"mode": "train", "epoch": 56, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00067, "acc_pose": 0.78696, "loss": 0.00067, "time": 0.19317}
+{"mode": "train", "epoch": 57, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05546, "heatmap_loss": 0.00068, "acc_pose": 0.79492, "loss": 0.00068, "time": 0.25137}
+{"mode": "train", "epoch": 57, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00067, "acc_pose": 0.78607, "loss": 0.00067, "time": 0.19259}
+{"mode": "train", "epoch": 57, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00041, "heatmap_loss": 0.00067, "acc_pose": 0.78883, "loss": 0.00067, "time": 0.19413}
+{"mode": "train", "epoch": 57, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00067, "acc_pose": 0.79624, "loss": 0.00067, "time": 0.19218}
+{"mode": "train", "epoch": 57, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00067, "acc_pose": 0.79261, "loss": 0.00067, "time": 0.19216}
+{"mode": "train", "epoch": 58, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05489, "heatmap_loss": 0.00067, "acc_pose": 0.79323, "loss": 0.00067, "time": 0.2526}
+{"mode": "train", "epoch": 58, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00041, "heatmap_loss": 0.00067, "acc_pose": 0.78817, "loss": 0.00067, "time": 0.19202}
+{"mode": "train", "epoch": 58, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00047, "heatmap_loss": 0.00067, "acc_pose": 0.78635, "loss": 0.00067, "time": 0.19224}
+{"mode": "train", "epoch": 58, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00041, "heatmap_loss": 0.00067, "acc_pose": 0.79153, "loss": 0.00067, "time": 0.19215}
+{"mode": "train", "epoch": 58, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00044, "heatmap_loss": 0.00067, "acc_pose": 0.7901, "loss": 0.00067, "time": 0.19294}
+{"mode": "train", "epoch": 59, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.0557, "heatmap_loss": 0.00067, "acc_pose": 0.79163, "loss": 0.00067, "time": 0.25072}
+{"mode": "train", "epoch": 59, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00067, "acc_pose": 0.79631, "loss": 0.00067, "time": 0.19219}
+{"mode": "train", "epoch": 59, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00046, "heatmap_loss": 0.00067, "acc_pose": 0.79325, "loss": 0.00067, "time": 0.1922}
+{"mode": "train", "epoch": 59, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00067, "acc_pose": 0.79214, "loss": 0.00067, "time": 0.19225}
+{"mode": "train", "epoch": 59, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00067, "acc_pose": 0.79132, "loss": 0.00067, "time": 0.19245}
+{"mode": "train", "epoch": 60, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05641, "heatmap_loss": 0.00067, "acc_pose": 0.79097, "loss": 0.00067, "time": 0.25159}
+{"mode": "train", "epoch": 60, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00051, "heatmap_loss": 0.00066, "acc_pose": 0.7917, "loss": 0.00066, "time": 0.19219}
+{"mode": "train", "epoch": 60, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00067, "acc_pose": 0.78661, "loss": 0.00067, "time": 0.19198}
+{"mode": "train", "epoch": 60, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00041, "heatmap_loss": 0.00067, "acc_pose": 0.79153, "loss": 0.00067, "time": 0.19254}
+{"mode": "train", "epoch": 60, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00067, "acc_pose": 0.78208, "loss": 0.00067, "time": 0.19215}
+{"mode": "val", "epoch": 60, "iter": 407, "lr": 1e-05, "AP": 0.73611, "AP .5": 0.90005, "AP .75": 0.80881, "AP (M)": 0.66331, "AP (L)": 0.76088, "AR": 0.79137, "AR .5": 0.94002, "AR .75": 0.85784, "AR (M)": 0.7499, "AR (L)": 0.85154}
+{"mode": "train", "epoch": 61, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05447, "heatmap_loss": 0.00066, "acc_pose": 0.78464, "loss": 0.00066, "time": 0.24656}
+{"mode": "train", "epoch": 61, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00041, "heatmap_loss": 0.00067, "acc_pose": 0.78649, "loss": 0.00067, "time": 0.19152}
+{"mode": "train", "epoch": 61, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00067, "acc_pose": 0.78689, "loss": 0.00067, "time": 0.19177}
+{"mode": "train", "epoch": 61, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00066, "acc_pose": 0.79098, "loss": 0.00066, "time": 0.19191}
+{"mode": "train", "epoch": 61, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00066, "acc_pose": 0.79249, "loss": 0.00066, "time": 0.19209}
+{"mode": "train", "epoch": 62, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05525, "heatmap_loss": 0.00066, "acc_pose": 0.78429, "loss": 0.00066, "time": 0.25025}
+{"mode": "train", "epoch": 62, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00066, "acc_pose": 0.78807, "loss": 0.00066, "time": 0.19291}
+{"mode": "train", "epoch": 62, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00067, "acc_pose": 0.78893, "loss": 0.00067, "time": 0.19233}
+{"mode": "train", "epoch": 62, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00066, "acc_pose": 0.7921, "loss": 0.00066, "time": 0.19209}
+{"mode": "train", "epoch": 62, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00066, "acc_pose": 0.79448, "loss": 0.00066, "time": 0.19272}
+{"mode": "train", "epoch": 63, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05464, "heatmap_loss": 0.00066, "acc_pose": 0.79685, "loss": 0.00066, "time": 0.25186}
+{"mode": "train", "epoch": 63, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00066, "acc_pose": 0.7976, "loss": 0.00066, "time": 0.19232}
+{"mode": "train", "epoch": 63, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00066, "acc_pose": 0.79743, "loss": 0.00066, "time": 0.19191}
+{"mode": "train", "epoch": 63, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00067, "acc_pose": 0.79508, "loss": 0.00067, "time": 0.19311}
+{"mode": "train", "epoch": 63, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00044, "heatmap_loss": 0.00067, "acc_pose": 0.78809, "loss": 0.00067, "time": 0.19192}
+{"mode": "train", "epoch": 64, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05538, "heatmap_loss": 0.00066, "acc_pose": 0.7893, "loss": 0.00066, "time": 0.25187}
+{"mode": "train", "epoch": 64, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00066, "acc_pose": 0.78967, "loss": 0.00066, "time": 0.19232}
+{"mode": "train", "epoch": 64, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00067, "acc_pose": 0.79594, "loss": 0.00067, "time": 0.19242}
+{"mode": "train", "epoch": 64, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00032, "heatmap_loss": 0.00066, "acc_pose": 0.79249, "loss": 0.00066, "time": 0.19204}
+{"mode": "train", "epoch": 64, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00066, "acc_pose": 0.79078, "loss": 0.00066, "time": 0.19187}
+{"mode": "train", "epoch": 65, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.0565, "heatmap_loss": 0.00066, "acc_pose": 0.79394, "loss": 0.00066, "time": 0.25041}
+{"mode": "train", "epoch": 65, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00043, "heatmap_loss": 0.00065, "acc_pose": 0.79851, "loss": 0.00065, "time": 0.19284}
+{"mode": "train", "epoch": 65, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00067, "acc_pose": 0.7966, "loss": 0.00067, "time": 0.19206}
+{"mode": "train", "epoch": 65, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00066, "acc_pose": 0.7913, "loss": 0.00066, "time": 0.19196}
+{"mode": "train", "epoch": 65, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00066, "acc_pose": 0.79319, "loss": 0.00066, "time": 0.19176}
+{"mode": "train", "epoch": 66, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05571, "heatmap_loss": 0.00065, "acc_pose": 0.79889, "loss": 0.00065, "time": 0.25135}
+{"mode": "train", "epoch": 66, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00066, "acc_pose": 0.79215, "loss": 0.00066, "time": 0.19187}
+{"mode": "train", "epoch": 66, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00066, "acc_pose": 0.79463, "loss": 0.00066, "time": 0.19229}
+{"mode": "train", "epoch": 66, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00065, "acc_pose": 0.79849, "loss": 0.00065, "time": 0.19217}
+{"mode": "train", "epoch": 66, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00041, "heatmap_loss": 0.00066, "acc_pose": 0.79629, "loss": 0.00066, "time": 0.19225}
+{"mode": "train", "epoch": 67, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05533, "heatmap_loss": 0.00066, "acc_pose": 0.79648, "loss": 0.00066, "time": 0.25055}
+{"mode": "train", "epoch": 67, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00066, "acc_pose": 0.79117, "loss": 0.00066, "time": 0.19218}
+{"mode": "train", "epoch": 67, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00066, "acc_pose": 0.797, "loss": 0.00066, "time": 0.19224}
+{"mode": "train", "epoch": 67, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00065, "acc_pose": 0.7975, "loss": 0.00065, "time": 0.19195}
+{"mode": "train", "epoch": 67, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00066, "acc_pose": 0.79609, "loss": 0.00066, "time": 0.19285}
+{"mode": "train", "epoch": 68, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05442, "heatmap_loss": 0.00066, "acc_pose": 0.78921, "loss": 0.00066, "time": 0.25145}
+{"mode": "train", "epoch": 68, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00065, "acc_pose": 0.79322, "loss": 0.00065, "time": 0.19221}
+{"mode": "train", "epoch": 68, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00066, "acc_pose": 0.79577, "loss": 0.00066, "time": 0.19326}
+{"mode": "train", "epoch": 68, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00066, "acc_pose": 0.79547, "loss": 0.00066, "time": 0.192}
+{"mode": "train", "epoch": 68, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00066, "acc_pose": 0.79396, "loss": 0.00066, "time": 0.19198}
+{"mode": "train", "epoch": 69, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05496, "heatmap_loss": 0.00065, "acc_pose": 0.7979, "loss": 0.00065, "time": 0.25244}
+{"mode": "train", "epoch": 69, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00049, "heatmap_loss": 0.00065, "acc_pose": 0.7948, "loss": 0.00065, "time": 0.1933}
+{"mode": "train", "epoch": 69, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00065, "acc_pose": 0.79228, "loss": 0.00065, "time": 0.19254}
+{"mode": "train", "epoch": 69, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00066, "acc_pose": 0.79953, "loss": 0.00066, "time": 0.19247}
+{"mode": "train", "epoch": 69, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00066, "acc_pose": 0.79688, "loss": 0.00066, "time": 0.19245}
+{"mode": "train", "epoch": 70, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05464, "heatmap_loss": 0.00066, "acc_pose": 0.79411, "loss": 0.00066, "time": 0.25091}
+{"mode": "train", "epoch": 70, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00065, "acc_pose": 0.79673, "loss": 0.00065, "time": 0.19201}
+{"mode": "train", "epoch": 70, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00066, "acc_pose": 0.78696, "loss": 0.00066, "time": 0.19249}
+{"mode": "train", "epoch": 70, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00065, "acc_pose": 0.79823, "loss": 0.00065, "time": 0.19201}
+{"mode": "train", "epoch": 70, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00065, "acc_pose": 0.78989, "loss": 0.00065, "time": 0.19135}
+{"mode": "val", "epoch": 70, "iter": 407, "lr": 1e-05, "AP": 0.73885, "AP .5": 0.89861, "AP .75": 0.81704, "AP (M)": 0.66621, "AP (L)": 0.76477, "AR": 0.7938, "AR .5": 0.9397, "AR .75": 0.86351, "AR (M)": 0.75264, "AR (L)": 0.8534}
+{"mode": "train", "epoch": 71, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05608, "heatmap_loss": 0.00065, "acc_pose": 0.79897, "loss": 0.00065, "time": 0.24852}
+{"mode": "train", "epoch": 71, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00065, "acc_pose": 0.79596, "loss": 0.00065, "time": 0.19232}
+{"mode": "train", "epoch": 71, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00065, "acc_pose": 0.79493, "loss": 0.00065, "time": 0.19259}
+{"mode": "train", "epoch": 71, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00065, "acc_pose": 0.79969, "loss": 0.00065, "time": 0.19238}
+{"mode": "train", "epoch": 71, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00065, "acc_pose": 0.80418, "loss": 0.00065, "time": 0.19327}
+{"mode": "train", "epoch": 72, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05553, "heatmap_loss": 0.00065, "acc_pose": 0.80141, "loss": 0.00065, "time": 0.25123}
+{"mode": "train", "epoch": 72, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00066, "acc_pose": 0.79461, "loss": 0.00066, "time": 0.19232}
+{"mode": "train", "epoch": 72, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00065, "acc_pose": 0.79228, "loss": 0.00065, "time": 0.19204}
+{"mode": "train", "epoch": 72, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00065, "acc_pose": 0.80172, "loss": 0.00065, "time": 0.19286}
+{"mode": "train", "epoch": 72, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00065, "acc_pose": 0.79591, "loss": 0.00065, "time": 0.19365}
+{"mode": "train", "epoch": 73, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05505, "heatmap_loss": 0.00064, "acc_pose": 0.80155, "loss": 0.00064, "time": 0.25003}
+{"mode": "train", "epoch": 73, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00065, "acc_pose": 0.8018, "loss": 0.00065, "time": 0.19197}
+{"mode": "train", "epoch": 73, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00065, "acc_pose": 0.78611, "loss": 0.00065, "time": 0.19189}
+{"mode": "train", "epoch": 73, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00065, "acc_pose": 0.79986, "loss": 0.00065, "time": 0.19215}
+{"mode": "train", "epoch": 73, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00065, "acc_pose": 0.79967, "loss": 0.00065, "time": 0.19227}
+{"mode": "train", "epoch": 74, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05519, "heatmap_loss": 0.00065, "acc_pose": 0.79702, "loss": 0.00065, "time": 0.25121}
+{"mode": "train", "epoch": 74, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00065, "acc_pose": 0.79423, "loss": 0.00065, "time": 0.19208}
+{"mode": "train", "epoch": 74, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00065, "acc_pose": 0.78876, "loss": 0.00065, "time": 0.19238}
+{"mode": "train", "epoch": 74, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00065, "acc_pose": 0.80159, "loss": 0.00065, "time": 0.19206}
+{"mode": "train", "epoch": 74, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00065, "acc_pose": 0.79544, "loss": 0.00065, "time": 0.19198}
+{"mode": "train", "epoch": 75, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05561, "heatmap_loss": 0.00064, "acc_pose": 0.80118, "loss": 0.00064, "time": 0.25214}
+{"mode": "train", "epoch": 75, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00064, "acc_pose": 0.79685, "loss": 0.00064, "time": 0.19219}
+{"mode": "train", "epoch": 75, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00064, "acc_pose": 0.79865, "loss": 0.00064, "time": 0.19247}
+{"mode": "train", "epoch": 75, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00065, "acc_pose": 0.80118, "loss": 0.00065, "time": 0.19231}
+{"mode": "train", "epoch": 75, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00065, "acc_pose": 0.79748, "loss": 0.00065, "time": 0.19219}
+{"mode": "train", "epoch": 76, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05466, "heatmap_loss": 0.00065, "acc_pose": 0.80297, "loss": 0.00065, "time": 0.25148}
+{"mode": "train", "epoch": 76, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00064, "acc_pose": 0.79616, "loss": 0.00064, "time": 0.19236}
+{"mode": "train", "epoch": 76, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00064, "acc_pose": 0.80858, "loss": 0.00064, "time": 0.19186}
+{"mode": "train", "epoch": 76, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00065, "acc_pose": 0.80259, "loss": 0.00065, "time": 0.19215}
+{"mode": "train", "epoch": 76, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00047, "heatmap_loss": 0.00064, "acc_pose": 0.80446, "loss": 0.00064, "time": 0.19207}
+{"mode": "train", "epoch": 77, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05544, "heatmap_loss": 0.00064, "acc_pose": 0.79593, "loss": 0.00064, "time": 0.25126}
+{"mode": "train", "epoch": 77, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00065, "acc_pose": 0.79526, "loss": 0.00065, "time": 0.19174}
+{"mode": "train", "epoch": 77, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00048, "heatmap_loss": 0.00064, "acc_pose": 0.80325, "loss": 0.00064, "time": 0.19239}
+{"mode": "train", "epoch": 77, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00044, "heatmap_loss": 0.00064, "acc_pose": 0.79805, "loss": 0.00064, "time": 0.19235}
+{"mode": "train", "epoch": 77, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00064, "acc_pose": 0.8052, "loss": 0.00064, "time": 0.19221}
+{"mode": "train", "epoch": 78, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05637, "heatmap_loss": 0.00065, "acc_pose": 0.80693, "loss": 0.00065, "time": 0.252}
+{"mode": "train", "epoch": 78, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00044, "heatmap_loss": 0.00064, "acc_pose": 0.80859, "loss": 0.00064, "time": 0.19281}
+{"mode": "train", "epoch": 78, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00065, "acc_pose": 0.79971, "loss": 0.00065, "time": 0.19356}
+{"mode": "train", "epoch": 78, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00064, "acc_pose": 0.79723, "loss": 0.00064, "time": 0.19182}
+{"mode": "train", "epoch": 78, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00064, "acc_pose": 0.80167, "loss": 0.00064, "time": 0.19192}
+{"mode": "train", "epoch": 79, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05448, "heatmap_loss": 0.00064, "acc_pose": 0.79936, "loss": 0.00064, "time": 0.24966}
+{"mode": "train", "epoch": 79, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00064, "acc_pose": 0.79382, "loss": 0.00064, "time": 0.19209}
+{"mode": "train", "epoch": 79, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00064, "acc_pose": 0.79093, "loss": 0.00064, "time": 0.19219}
+{"mode": "train", "epoch": 79, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00064, "acc_pose": 0.80743, "loss": 0.00064, "time": 0.19223}
+{"mode": "train", "epoch": 79, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00064, "acc_pose": 0.80366, "loss": 0.00064, "time": 0.19195}
+{"mode": "train", "epoch": 80, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05484, "heatmap_loss": 0.00064, "acc_pose": 0.80389, "loss": 0.00064, "time": 0.25018}
+{"mode": "train", "epoch": 80, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00064, "acc_pose": 0.80386, "loss": 0.00064, "time": 0.1919}
+{"mode": "train", "epoch": 80, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00034, "heatmap_loss": 0.00064, "acc_pose": 0.79093, "loss": 0.00064, "time": 0.19272}
+{"mode": "train", "epoch": 80, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00043, "heatmap_loss": 0.00064, "acc_pose": 0.80277, "loss": 0.00064, "time": 0.19254}
+{"mode": "train", "epoch": 80, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00064, "acc_pose": 0.80215, "loss": 0.00064, "time": 0.19251}
+{"mode": "val", "epoch": 80, "iter": 407, "lr": 1e-05, "AP": 0.74116, "AP .5": 0.90293, "AP .75": 0.81726, "AP (M)": 0.66874, "AP (L)": 0.76787, "AR": 0.79606, "AR .5": 0.9427, "AR .75": 0.86398, "AR (M)": 0.75422, "AR (L)": 0.85678}
+{"mode": "train", "epoch": 81, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05453, "heatmap_loss": 0.00063, "acc_pose": 0.80361, "loss": 0.00063, "time": 0.24645}
+{"mode": "train", "epoch": 81, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00064, "acc_pose": 0.79771, "loss": 0.00064, "time": 0.19202}
+{"mode": "train", "epoch": 81, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00065, "acc_pose": 0.7966, "loss": 0.00065, "time": 0.19168}
+{"mode": "train", "epoch": 81, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00064, "acc_pose": 0.80434, "loss": 0.00064, "time": 0.19199}
+{"mode": "train", "epoch": 81, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00041, "heatmap_loss": 0.00064, "acc_pose": 0.80209, "loss": 0.00064, "time": 0.19159}
+{"mode": "train", "epoch": 82, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05478, "heatmap_loss": 0.00064, "acc_pose": 0.80272, "loss": 0.00064, "time": 0.25017}
+{"mode": "train", "epoch": 82, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00064, "acc_pose": 0.80388, "loss": 0.00064, "time": 0.19206}
+{"mode": "train", "epoch": 82, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00043, "heatmap_loss": 0.00064, "acc_pose": 0.80918, "loss": 0.00064, "time": 0.19207}
+{"mode": "train", "epoch": 82, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00048, "heatmap_loss": 0.00064, "acc_pose": 0.80201, "loss": 0.00064, "time": 0.19209}
+{"mode": "train", "epoch": 82, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00041, "heatmap_loss": 0.00064, "acc_pose": 0.80165, "loss": 0.00064, "time": 0.19214}
+{"mode": "train", "epoch": 83, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05483, "heatmap_loss": 0.00064, "acc_pose": 0.80791, "loss": 0.00064, "time": 0.25026}
+{"mode": "train", "epoch": 83, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00044, "heatmap_loss": 0.00064, "acc_pose": 0.80166, "loss": 0.00064, "time": 0.19168}
+{"mode": "train", "epoch": 83, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00064, "acc_pose": 0.80145, "loss": 0.00064, "time": 0.19237}
+{"mode": "train", "epoch": 83, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00064, "acc_pose": 0.79642, "loss": 0.00064, "time": 0.1923}
+{"mode": "train", "epoch": 83, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00064, "acc_pose": 0.80142, "loss": 0.00064, "time": 0.19182}
+{"mode": "train", "epoch": 84, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.0548, "heatmap_loss": 0.00063, "acc_pose": 0.80614, "loss": 0.00063, "time": 0.24973}
+{"mode": "train", "epoch": 84, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00063, "acc_pose": 0.79525, "loss": 0.00063, "time": 0.19159}
+{"mode": "train", "epoch": 84, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00064, "acc_pose": 0.8006, "loss": 0.00064, "time": 0.1935}
+{"mode": "train", "epoch": 84, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00041, "heatmap_loss": 0.00064, "acc_pose": 0.80601, "loss": 0.00064, "time": 0.19176}
+{"mode": "train", "epoch": 84, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00042, "heatmap_loss": 0.00064, "acc_pose": 0.79315, "loss": 0.00064, "time": 0.19226}
+{"mode": "train", "epoch": 85, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05508, "heatmap_loss": 0.00063, "acc_pose": 0.80192, "loss": 0.00063, "time": 0.25037}
+{"mode": "train", "epoch": 85, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00063, "acc_pose": 0.81023, "loss": 0.00063, "time": 0.19217}
+{"mode": "train", "epoch": 85, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00064, "acc_pose": 0.80009, "loss": 0.00064, "time": 0.19203}
+{"mode": "train", "epoch": 85, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00064, "acc_pose": 0.80771, "loss": 0.00064, "time": 0.19161}
+{"mode": "train", "epoch": 85, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00064, "acc_pose": 0.80864, "loss": 0.00064, "time": 0.19204}
+{"mode": "train", "epoch": 86, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05475, "heatmap_loss": 0.00064, "acc_pose": 0.80951, "loss": 0.00064, "time": 0.25199}
+{"mode": "train", "epoch": 86, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00064, "acc_pose": 0.80006, "loss": 0.00064, "time": 0.19216}
+{"mode": "train", "epoch": 86, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00064, "acc_pose": 0.79967, "loss": 0.00064, "time": 0.19189}
+{"mode": "train", "epoch": 86, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00063, "acc_pose": 0.80419, "loss": 0.00063, "time": 0.19219}
+{"mode": "train", "epoch": 86, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00063, "acc_pose": 0.80485, "loss": 0.00063, "time": 0.19289}
+{"mode": "train", "epoch": 87, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05525, "heatmap_loss": 0.00063, "acc_pose": 0.80828, "loss": 0.00063, "time": 0.25215}
+{"mode": "train", "epoch": 87, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00063, "acc_pose": 0.80988, "loss": 0.00063, "time": 0.19236}
+{"mode": "train", "epoch": 87, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00064, "acc_pose": 0.80108, "loss": 0.00064, "time": 0.19262}
+{"mode": "train", "epoch": 87, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00063, "acc_pose": 0.81004, "loss": 0.00063, "time": 0.19231}
+{"mode": "train", "epoch": 87, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00063, "acc_pose": 0.80742, "loss": 0.00063, "time": 0.19241}
+{"mode": "train", "epoch": 88, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05482, "heatmap_loss": 0.00063, "acc_pose": 0.80659, "loss": 0.00063, "time": 0.24915}
+{"mode": "train", "epoch": 88, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00063, "acc_pose": 0.8053, "loss": 0.00063, "time": 0.19199}
+{"mode": "train", "epoch": 88, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00063, "acc_pose": 0.80692, "loss": 0.00063, "time": 0.19236}
+{"mode": "train", "epoch": 88, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00063, "acc_pose": 0.80479, "loss": 0.00063, "time": 0.19246}
+{"mode": "train", "epoch": 88, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00041, "heatmap_loss": 0.00063, "acc_pose": 0.81144, "loss": 0.00063, "time": 0.19294}
+{"mode": "train", "epoch": 89, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05516, "heatmap_loss": 0.00063, "acc_pose": 0.79486, "loss": 0.00063, "time": 0.2506}
+{"mode": "train", "epoch": 89, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00063, "acc_pose": 0.80384, "loss": 0.00063, "time": 0.19254}
+{"mode": "train", "epoch": 89, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00064, "acc_pose": 0.79926, "loss": 0.00064, "time": 0.1916}
+{"mode": "train", "epoch": 89, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00046, "heatmap_loss": 0.00063, "acc_pose": 0.80609, "loss": 0.00063, "time": 0.19262}
+{"mode": "train", "epoch": 89, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00063, "acc_pose": 0.81015, "loss": 0.00063, "time": 0.19206}
+{"mode": "train", "epoch": 90, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05522, "heatmap_loss": 0.00063, "acc_pose": 0.80685, "loss": 0.00063, "time": 0.25041}
+{"mode": "train", "epoch": 90, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00063, "acc_pose": 0.80911, "loss": 0.00063, "time": 0.19226}
+{"mode": "train", "epoch": 90, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00063, "acc_pose": 0.799, "loss": 0.00063, "time": 0.19252}
+{"mode": "train", "epoch": 90, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00064, "acc_pose": 0.80475, "loss": 0.00064, "time": 0.19307}
+{"mode": "train", "epoch": 90, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00063, "acc_pose": 0.80843, "loss": 0.00063, "time": 0.19217}
+{"mode": "val", "epoch": 90, "iter": 407, "lr": 1e-05, "AP": 0.74286, "AP .5": 0.9013, "AP .75": 0.81831, "AP (M)": 0.67096, "AP (L)": 0.76935, "AR": 0.79646, "AR .5": 0.94049, "AR .75": 0.86429, "AR (M)": 0.75359, "AR (L)": 0.85819}
+{"mode": "train", "epoch": 91, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05503, "heatmap_loss": 0.00063, "acc_pose": 0.81116, "loss": 0.00063, "time": 0.24753}
+{"mode": "train", "epoch": 91, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00062, "acc_pose": 0.8159, "loss": 0.00062, "time": 0.19145}
+{"mode": "train", "epoch": 91, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00062, "acc_pose": 0.81161, "loss": 0.00062, "time": 0.19164}
+{"mode": "train", "epoch": 91, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00063, "acc_pose": 0.80523, "loss": 0.00063, "time": 0.19241}
+{"mode": "train", "epoch": 91, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00063, "acc_pose": 0.80871, "loss": 0.00063, "time": 0.19176}
+{"mode": "train", "epoch": 92, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05447, "heatmap_loss": 0.00063, "acc_pose": 0.81047, "loss": 0.00063, "time": 0.24996}
+{"mode": "train", "epoch": 92, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00063, "acc_pose": 0.80356, "loss": 0.00063, "time": 0.19211}
+{"mode": "train", "epoch": 92, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00062, "acc_pose": 0.80396, "loss": 0.00062, "time": 0.19197}
+{"mode": "train", "epoch": 92, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00063, "acc_pose": 0.80766, "loss": 0.00063, "time": 0.19189}
+{"mode": "train", "epoch": 92, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00064, "acc_pose": 0.8077, "loss": 0.00064, "time": 0.19237}
+{"mode": "train", "epoch": 93, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05454, "heatmap_loss": 0.00062, "acc_pose": 0.80546, "loss": 0.00062, "time": 0.252}
+{"mode": "train", "epoch": 93, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00063, "acc_pose": 0.80326, "loss": 0.00063, "time": 0.19201}
+{"mode": "train", "epoch": 93, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00063, "acc_pose": 0.81127, "loss": 0.00063, "time": 0.19257}
+{"mode": "train", "epoch": 93, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00063, "acc_pose": 0.8088, "loss": 0.00063, "time": 0.1926}
+{"mode": "train", "epoch": 93, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00062, "acc_pose": 0.81743, "loss": 0.00062, "time": 0.19256}
+{"mode": "train", "epoch": 94, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05461, "heatmap_loss": 0.00063, "acc_pose": 0.80452, "loss": 0.00063, "time": 0.2511}
+{"mode": "train", "epoch": 94, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00063, "acc_pose": 0.81313, "loss": 0.00063, "time": 0.192}
+{"mode": "train", "epoch": 94, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00063, "acc_pose": 0.80387, "loss": 0.00063, "time": 0.19229}
+{"mode": "train", "epoch": 94, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00046, "heatmap_loss": 0.00063, "acc_pose": 0.81286, "loss": 0.00063, "time": 0.19245}
+{"mode": "train", "epoch": 94, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.0003, "heatmap_loss": 0.00063, "acc_pose": 0.81364, "loss": 0.00063, "time": 0.19195}
+{"mode": "train", "epoch": 95, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05542, "heatmap_loss": 0.00063, "acc_pose": 0.80728, "loss": 0.00063, "time": 0.25103}
+{"mode": "train", "epoch": 95, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00062, "acc_pose": 0.80268, "loss": 0.00062, "time": 0.19213}
+{"mode": "train", "epoch": 95, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00044, "heatmap_loss": 0.00063, "acc_pose": 0.80206, "loss": 0.00063, "time": 0.19202}
+{"mode": "train", "epoch": 95, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00062, "acc_pose": 0.80861, "loss": 0.00062, "time": 0.19239}
+{"mode": "train", "epoch": 95, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00063, "acc_pose": 0.80633, "loss": 0.00063, "time": 0.19198}
+{"mode": "train", "epoch": 96, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05713, "heatmap_loss": 0.00062, "acc_pose": 0.81358, "loss": 0.00062, "time": 0.25202}
+{"mode": "train", "epoch": 96, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00063, "acc_pose": 0.81246, "loss": 0.00063, "time": 0.19227}
+{"mode": "train", "epoch": 96, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00062, "acc_pose": 0.80792, "loss": 0.00062, "time": 0.19154}
+{"mode": "train", "epoch": 96, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00063, "acc_pose": 0.80521, "loss": 0.00063, "time": 0.19348}
+{"mode": "train", "epoch": 96, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00043, "heatmap_loss": 0.00063, "acc_pose": 0.81268, "loss": 0.00063, "time": 0.19221}
+{"mode": "train", "epoch": 97, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05512, "heatmap_loss": 0.00062, "acc_pose": 0.81092, "loss": 0.00062, "time": 0.24973}
+{"mode": "train", "epoch": 97, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00063, "acc_pose": 0.80637, "loss": 0.00063, "time": 0.19213}
+{"mode": "train", "epoch": 97, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00062, "acc_pose": 0.81044, "loss": 0.00062, "time": 0.19168}
+{"mode": "train", "epoch": 97, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00062, "acc_pose": 0.81114, "loss": 0.00062, "time": 0.19412}
+{"mode": "train", "epoch": 97, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00062, "acc_pose": 0.80879, "loss": 0.00062, "time": 0.19252}
+{"mode": "train", "epoch": 98, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05495, "heatmap_loss": 0.00062, "acc_pose": 0.80414, "loss": 0.00062, "time": 0.25022}
+{"mode": "train", "epoch": 98, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00062, "acc_pose": 0.80786, "loss": 0.00062, "time": 0.19309}
+{"mode": "train", "epoch": 98, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00062, "acc_pose": 0.80986, "loss": 0.00062, "time": 0.19188}
+{"mode": "train", "epoch": 98, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00063, "acc_pose": 0.81335, "loss": 0.00063, "time": 0.19309}
+{"mode": "train", "epoch": 98, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00062, "acc_pose": 0.81094, "loss": 0.00062, "time": 0.19377}
+{"mode": "train", "epoch": 99, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05504, "heatmap_loss": 0.00062, "acc_pose": 0.81417, "loss": 0.00062, "time": 0.25037}
+{"mode": "train", "epoch": 99, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00062, "acc_pose": 0.80955, "loss": 0.00062, "time": 0.19293}
+{"mode": "train", "epoch": 99, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00062, "acc_pose": 0.81027, "loss": 0.00062, "time": 0.19271}
+{"mode": "train", "epoch": 99, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00062, "acc_pose": 0.80568, "loss": 0.00062, "time": 0.1921}
+{"mode": "train", "epoch": 99, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00062, "acc_pose": 0.81279, "loss": 0.00062, "time": 0.19152}
+{"mode": "train", "epoch": 100, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05586, "heatmap_loss": 0.00062, "acc_pose": 0.81099, "loss": 0.00062, "time": 0.25154}
+{"mode": "train", "epoch": 100, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00062, "acc_pose": 0.80873, "loss": 0.00062, "time": 0.19281}
+{"mode": "train", "epoch": 100, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00063, "acc_pose": 0.80616, "loss": 0.00063, "time": 0.19206}
+{"mode": "train", "epoch": 100, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00062, "acc_pose": 0.81351, "loss": 0.00062, "time": 0.19191}
+{"mode": "train", "epoch": 100, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00063, "acc_pose": 0.80599, "loss": 0.00063, "time": 0.19156}
+{"mode": "val", "epoch": 100, "iter": 407, "lr": 1e-05, "AP": 0.7467, "AP .5": 0.90302, "AP .75": 0.82033, "AP (M)": 0.67517, "AP (L)": 0.77231, "AR": 0.80083, "AR .5": 0.94159, "AR .75": 0.86713, "AR (M)": 0.75952, "AR (L)": 0.86094}
+{"mode": "train", "epoch": 101, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05444, "heatmap_loss": 0.00062, "acc_pose": 0.80548, "loss": 0.00062, "time": 0.24717}
+{"mode": "train", "epoch": 101, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00062, "acc_pose": 0.80486, "loss": 0.00062, "time": 0.19299}
+{"mode": "train", "epoch": 101, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00062, "acc_pose": 0.8118, "loss": 0.00062, "time": 0.19211}
+{"mode": "train", "epoch": 101, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00062, "acc_pose": 0.81092, "loss": 0.00062, "time": 0.1919}
+{"mode": "train", "epoch": 101, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00062, "acc_pose": 0.81148, "loss": 0.00062, "time": 0.19188}
+{"mode": "train", "epoch": 102, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05579, "heatmap_loss": 0.00061, "acc_pose": 0.81649, "loss": 0.00061, "time": 0.24961}
+{"mode": "train", "epoch": 102, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00062, "acc_pose": 0.80959, "loss": 0.00062, "time": 0.19136}
+{"mode": "train", "epoch": 102, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00062, "acc_pose": 0.80327, "loss": 0.00062, "time": 0.19238}
+{"mode": "train", "epoch": 102, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00062, "acc_pose": 0.81567, "loss": 0.00062, "time": 0.19295}
+{"mode": "train", "epoch": 102, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00041, "heatmap_loss": 0.00062, "acc_pose": 0.81356, "loss": 0.00062, "time": 0.19226}
+{"mode": "train", "epoch": 103, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05453, "heatmap_loss": 0.00062, "acc_pose": 0.81428, "loss": 0.00062, "time": 0.24998}
+{"mode": "train", "epoch": 103, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00062, "acc_pose": 0.81174, "loss": 0.00062, "time": 0.19193}
+{"mode": "train", "epoch": 103, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00062, "acc_pose": 0.81353, "loss": 0.00062, "time": 0.19219}
+{"mode": "train", "epoch": 103, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00061, "acc_pose": 0.81057, "loss": 0.00061, "time": 0.19246}
+{"mode": "train", "epoch": 103, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00062, "acc_pose": 0.81327, "loss": 0.00062, "time": 0.19187}
+{"mode": "train", "epoch": 104, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05473, "heatmap_loss": 0.00062, "acc_pose": 0.80931, "loss": 0.00062, "time": 0.25061}
+{"mode": "train", "epoch": 104, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00061, "acc_pose": 0.80997, "loss": 0.00061, "time": 0.19187}
+{"mode": "train", "epoch": 104, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00062, "acc_pose": 0.81138, "loss": 0.00062, "time": 0.19173}
+{"mode": "train", "epoch": 104, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00062, "acc_pose": 0.81623, "loss": 0.00062, "time": 0.19232}
+{"mode": "train", "epoch": 104, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00062, "acc_pose": 0.81245, "loss": 0.00062, "time": 0.19191}
+{"mode": "train", "epoch": 105, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05492, "heatmap_loss": 0.00062, "acc_pose": 0.81685, "loss": 0.00062, "time": 0.2503}
+{"mode": "train", "epoch": 105, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00062, "acc_pose": 0.80835, "loss": 0.00062, "time": 0.19204}
+{"mode": "train", "epoch": 105, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00062, "acc_pose": 0.80737, "loss": 0.00062, "time": 0.19147}
+{"mode": "train", "epoch": 105, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00061, "acc_pose": 0.81772, "loss": 0.00061, "time": 0.19153}
+{"mode": "train", "epoch": 105, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00062, "acc_pose": 0.81007, "loss": 0.00062, "time": 0.19228}
+{"mode": "train", "epoch": 106, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05502, "heatmap_loss": 0.00061, "acc_pose": 0.81111, "loss": 0.00061, "time": 0.25026}
+{"mode": "train", "epoch": 106, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00062, "acc_pose": 0.81189, "loss": 0.00062, "time": 0.19182}
+{"mode": "train", "epoch": 106, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00061, "acc_pose": 0.80567, "loss": 0.00061, "time": 0.19201}
+{"mode": "train", "epoch": 106, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00061, "acc_pose": 0.81659, "loss": 0.00061, "time": 0.19206}
+{"mode": "train", "epoch": 106, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00045, "heatmap_loss": 0.00062, "acc_pose": 0.81344, "loss": 0.00062, "time": 0.192}
+{"mode": "train", "epoch": 107, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05508, "heatmap_loss": 0.00061, "acc_pose": 0.81381, "loss": 0.00061, "time": 0.2501}
+{"mode": "train", "epoch": 107, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00061, "acc_pose": 0.80849, "loss": 0.00061, "time": 0.19163}
+{"mode": "train", "epoch": 107, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00043, "heatmap_loss": 0.00062, "acc_pose": 0.81678, "loss": 0.00062, "time": 0.19169}
+{"mode": "train", "epoch": 107, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00062, "acc_pose": 0.81517, "loss": 0.00062, "time": 0.19517}
+{"mode": "train", "epoch": 107, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00061, "acc_pose": 0.81179, "loss": 0.00061, "time": 0.19203}
+{"mode": "train", "epoch": 108, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05618, "heatmap_loss": 0.00061, "acc_pose": 0.815, "loss": 0.00061, "time": 0.25031}
+{"mode": "train", "epoch": 108, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00042, "heatmap_loss": 0.00061, "acc_pose": 0.80967, "loss": 0.00061, "time": 0.19267}
+{"mode": "train", "epoch": 108, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00062, "acc_pose": 0.80782, "loss": 0.00062, "time": 0.19188}
+{"mode": "train", "epoch": 108, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00061, "acc_pose": 0.81156, "loss": 0.00061, "time": 0.19225}
+{"mode": "train", "epoch": 108, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00061, "acc_pose": 0.8156, "loss": 0.00061, "time": 0.19235}
+{"mode": "train", "epoch": 109, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05567, "heatmap_loss": 0.00061, "acc_pose": 0.81956, "loss": 0.00061, "time": 0.24989}
+{"mode": "train", "epoch": 109, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00062, "acc_pose": 0.81434, "loss": 0.00062, "time": 0.19257}
+{"mode": "train", "epoch": 109, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00062, "acc_pose": 0.81774, "loss": 0.00062, "time": 0.19178}
+{"mode": "train", "epoch": 109, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00061, "acc_pose": 0.81452, "loss": 0.00061, "time": 0.19187}
+{"mode": "train", "epoch": 109, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00061, "acc_pose": 0.81425, "loss": 0.00061, "time": 0.19269}
+{"mode": "train", "epoch": 110, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05467, "heatmap_loss": 0.00061, "acc_pose": 0.81022, "loss": 0.00061, "time": 0.25053}
+{"mode": "train", "epoch": 110, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00061, "acc_pose": 0.81054, "loss": 0.00061, "time": 0.19269}
+{"mode": "train", "epoch": 110, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00062, "acc_pose": 0.80916, "loss": 0.00062, "time": 0.19261}
+{"mode": "train", "epoch": 110, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00061, "acc_pose": 0.82241, "loss": 0.00061, "time": 0.19204}
+{"mode": "train", "epoch": 110, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00061, "acc_pose": 0.81913, "loss": 0.00061, "time": 0.19199}
+{"mode": "val", "epoch": 110, "iter": 407, "lr": 1e-05, "AP": 0.74983, "AP .5": 0.90617, "AP .75": 0.82317, "AP (M)": 0.6781, "AP (L)": 0.77724, "AR": 0.8022, "AR .5": 0.94443, "AR .75": 0.8676, "AR (M)": 0.76113, "AR (L)": 0.86217}
+{"mode": "train", "epoch": 111, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05537, "heatmap_loss": 0.00061, "acc_pose": 0.81179, "loss": 0.00061, "time": 0.24751}
+{"mode": "train", "epoch": 111, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00061, "acc_pose": 0.81543, "loss": 0.00061, "time": 0.19101}
+{"mode": "train", "epoch": 111, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00061, "acc_pose": 0.8079, "loss": 0.00061, "time": 0.19101}
+{"mode": "train", "epoch": 111, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00061, "acc_pose": 0.81178, "loss": 0.00061, "time": 0.19306}
+{"mode": "train", "epoch": 111, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00053, "heatmap_loss": 0.00061, "acc_pose": 0.81227, "loss": 0.00061, "time": 0.19239}
+{"mode": "train", "epoch": 112, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05449, "heatmap_loss": 0.00061, "acc_pose": 0.81468, "loss": 0.00061, "time": 0.25152}
+{"mode": "train", "epoch": 112, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00061, "acc_pose": 0.81002, "loss": 0.00061, "time": 0.19205}
+{"mode": "train", "epoch": 112, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.0006, "acc_pose": 0.81938, "loss": 0.0006, "time": 0.19206}
+{"mode": "train", "epoch": 112, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00046, "heatmap_loss": 0.00061, "acc_pose": 0.82172, "loss": 0.00061, "time": 0.19226}
+{"mode": "train", "epoch": 112, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00061, "acc_pose": 0.81673, "loss": 0.00061, "time": 0.19187}
+{"mode": "train", "epoch": 113, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05558, "heatmap_loss": 0.00061, "acc_pose": 0.82035, "loss": 0.00061, "time": 0.25116}
+{"mode": "train", "epoch": 113, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00061, "acc_pose": 0.81598, "loss": 0.00061, "time": 0.19203}
+{"mode": "train", "epoch": 113, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00061, "acc_pose": 0.81924, "loss": 0.00061, "time": 0.19147}
+{"mode": "train", "epoch": 113, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.0006, "acc_pose": 0.82077, "loss": 0.0006, "time": 0.19247}
+{"mode": "train", "epoch": 113, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00061, "acc_pose": 0.81027, "loss": 0.00061, "time": 0.19164}
+{"mode": "train", "epoch": 114, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05508, "heatmap_loss": 0.00061, "acc_pose": 0.81236, "loss": 0.00061, "time": 0.25}
+{"mode": "train", "epoch": 114, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00061, "acc_pose": 0.81778, "loss": 0.00061, "time": 0.19147}
+{"mode": "train", "epoch": 114, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00061, "acc_pose": 0.80969, "loss": 0.00061, "time": 0.19371}
+{"mode": "train", "epoch": 114, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00061, "acc_pose": 0.82006, "loss": 0.00061, "time": 0.1921}
+{"mode": "train", "epoch": 114, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00061, "acc_pose": 0.81557, "loss": 0.00061, "time": 0.19229}
+{"mode": "train", "epoch": 115, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05501, "heatmap_loss": 0.00061, "acc_pose": 0.81472, "loss": 0.00061, "time": 0.24977}
+{"mode": "train", "epoch": 115, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.0006, "acc_pose": 0.81574, "loss": 0.0006, "time": 0.19268}
+{"mode": "train", "epoch": 115, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00061, "acc_pose": 0.81092, "loss": 0.00061, "time": 0.19161}
+{"mode": "train", "epoch": 115, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.0006, "acc_pose": 0.8189, "loss": 0.0006, "time": 0.19227}
+{"mode": "train", "epoch": 115, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00061, "acc_pose": 0.81757, "loss": 0.00061, "time": 0.19198}
+{"mode": "train", "epoch": 116, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05523, "heatmap_loss": 0.00061, "acc_pose": 0.82357, "loss": 0.00061, "time": 0.2508}
+{"mode": "train", "epoch": 116, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.0006, "acc_pose": 0.8122, "loss": 0.0006, "time": 0.19209}
+{"mode": "train", "epoch": 116, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00061, "acc_pose": 0.8094, "loss": 0.00061, "time": 0.19248}
+{"mode": "train", "epoch": 116, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00061, "acc_pose": 0.81742, "loss": 0.00061, "time": 0.19204}
+{"mode": "train", "epoch": 116, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00061, "acc_pose": 0.81641, "loss": 0.00061, "time": 0.19223}
+{"mode": "train", "epoch": 117, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05525, "heatmap_loss": 0.00061, "acc_pose": 0.80963, "loss": 0.00061, "time": 0.25207}
+{"mode": "train", "epoch": 117, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00061, "acc_pose": 0.81903, "loss": 0.00061, "time": 0.19274}
+{"mode": "train", "epoch": 117, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00061, "acc_pose": 0.81947, "loss": 0.00061, "time": 0.19175}
+{"mode": "train", "epoch": 117, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00061, "acc_pose": 0.8145, "loss": 0.00061, "time": 0.19219}
+{"mode": "train", "epoch": 117, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00061, "acc_pose": 0.82083, "loss": 0.00061, "time": 0.19235}
+{"mode": "train", "epoch": 118, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05452, "heatmap_loss": 0.00061, "acc_pose": 0.81477, "loss": 0.00061, "time": 0.25185}
+{"mode": "train", "epoch": 118, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.0006, "acc_pose": 0.81269, "loss": 0.0006, "time": 0.19326}
+{"mode": "train", "epoch": 118, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00034, "heatmap_loss": 0.00061, "acc_pose": 0.81516, "loss": 0.00061, "time": 0.19201}
+{"mode": "train", "epoch": 118, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00061, "acc_pose": 0.81906, "loss": 0.00061, "time": 0.19181}
+{"mode": "train", "epoch": 118, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00061, "acc_pose": 0.81847, "loss": 0.00061, "time": 0.19225}
+{"mode": "train", "epoch": 119, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05551, "heatmap_loss": 0.0006, "acc_pose": 0.82498, "loss": 0.0006, "time": 0.25093}
+{"mode": "train", "epoch": 119, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.0006, "acc_pose": 0.82093, "loss": 0.0006, "time": 0.19242}
+{"mode": "train", "epoch": 119, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00061, "acc_pose": 0.81044, "loss": 0.00061, "time": 0.19204}
+{"mode": "train", "epoch": 119, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00055, "heatmap_loss": 0.00061, "acc_pose": 0.81617, "loss": 0.00061, "time": 0.19207}
+{"mode": "train", "epoch": 119, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.0006, "acc_pose": 0.81784, "loss": 0.0006, "time": 0.19219}
+{"mode": "train", "epoch": 120, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05443, "heatmap_loss": 0.0006, "acc_pose": 0.82352, "loss": 0.0006, "time": 0.25154}
+{"mode": "train", "epoch": 120, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00057, "heatmap_loss": 0.00061, "acc_pose": 0.8182, "loss": 0.00061, "time": 0.19192}
+{"mode": "train", "epoch": 120, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00042, "heatmap_loss": 0.0006, "acc_pose": 0.81343, "loss": 0.0006, "time": 0.19103}
+{"mode": "train", "epoch": 120, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00061, "acc_pose": 0.81423, "loss": 0.00061, "time": 0.19133}
+{"mode": "train", "epoch": 120, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.0006, "acc_pose": 0.82044, "loss": 0.0006, "time": 0.19181}
+{"mode": "val", "epoch": 120, "iter": 407, "lr": 1e-05, "AP": 0.7498, "AP .5": 0.90547, "AP .75": 0.82554, "AP (M)": 0.67855, "AP (L)": 0.77477, "AR": 0.80337, "AR .5": 0.94458, "AR .75": 0.87075, "AR (M)": 0.7631, "AR (L)": 0.86221}
+{"mode": "train", "epoch": 121, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05492, "heatmap_loss": 0.0006, "acc_pose": 0.81164, "loss": 0.0006, "time": 0.24632}
+{"mode": "train", "epoch": 121, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.0006, "acc_pose": 0.82427, "loss": 0.0006, "time": 0.19166}
+{"mode": "train", "epoch": 121, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00061, "acc_pose": 0.82063, "loss": 0.00061, "time": 0.19171}
+{"mode": "train", "epoch": 121, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.0006, "acc_pose": 0.81664, "loss": 0.0006, "time": 0.19181}
+{"mode": "train", "epoch": 121, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.0006, "acc_pose": 0.82047, "loss": 0.0006, "time": 0.19218}
+{"mode": "train", "epoch": 122, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05619, "heatmap_loss": 0.0006, "acc_pose": 0.81626, "loss": 0.0006, "time": 0.25035}
+{"mode": "train", "epoch": 122, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.0006, "acc_pose": 0.81835, "loss": 0.0006, "time": 0.19156}
+{"mode": "train", "epoch": 122, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00061, "acc_pose": 0.82021, "loss": 0.00061, "time": 0.19176}
+{"mode": "train", "epoch": 122, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.0006, "acc_pose": 0.82212, "loss": 0.0006, "time": 0.19211}
+{"mode": "train", "epoch": 122, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00043, "heatmap_loss": 0.00061, "acc_pose": 0.81754, "loss": 0.00061, "time": 0.19151}
+{"mode": "train", "epoch": 123, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05495, "heatmap_loss": 0.0006, "acc_pose": 0.82216, "loss": 0.0006, "time": 0.252}
+{"mode": "train", "epoch": 123, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.0006, "acc_pose": 0.82143, "loss": 0.0006, "time": 0.19391}
+{"mode": "train", "epoch": 123, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.0006, "acc_pose": 0.82203, "loss": 0.0006, "time": 0.19214}
+{"mode": "train", "epoch": 123, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00041, "heatmap_loss": 0.00061, "acc_pose": 0.81943, "loss": 0.00061, "time": 0.19217}
+{"mode": "train", "epoch": 123, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.0006, "acc_pose": 0.82449, "loss": 0.0006, "time": 0.19199}
+{"mode": "train", "epoch": 124, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05588, "heatmap_loss": 0.0006, "acc_pose": 0.81102, "loss": 0.0006, "time": 0.25036}
+{"mode": "train", "epoch": 124, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00043, "heatmap_loss": 0.0006, "acc_pose": 0.81587, "loss": 0.0006, "time": 0.19155}
+{"mode": "train", "epoch": 124, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.0006, "acc_pose": 0.81816, "loss": 0.0006, "time": 0.19179}
+{"mode": "train", "epoch": 124, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.0006, "acc_pose": 0.81831, "loss": 0.0006, "time": 0.19254}
+{"mode": "train", "epoch": 124, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.0006, "acc_pose": 0.82083, "loss": 0.0006, "time": 0.19263}
+{"mode": "train", "epoch": 125, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05528, "heatmap_loss": 0.0006, "acc_pose": 0.81642, "loss": 0.0006, "time": 0.25005}
+{"mode": "train", "epoch": 125, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.0006, "acc_pose": 0.82335, "loss": 0.0006, "time": 0.19169}
+{"mode": "train", "epoch": 125, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.0006, "acc_pose": 0.81395, "loss": 0.0006, "time": 0.1921}
+{"mode": "train", "epoch": 125, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.0006, "acc_pose": 0.8148, "loss": 0.0006, "time": 0.19177}
+{"mode": "train", "epoch": 125, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.0006, "acc_pose": 0.81743, "loss": 0.0006, "time": 0.19241}
+{"mode": "train", "epoch": 126, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.0554, "heatmap_loss": 0.0006, "acc_pose": 0.82094, "loss": 0.0006, "time": 0.25023}
+{"mode": "train", "epoch": 126, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.0006, "acc_pose": 0.81538, "loss": 0.0006, "time": 0.19225}
+{"mode": "train", "epoch": 126, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.0006, "acc_pose": 0.82077, "loss": 0.0006, "time": 0.19268}
+{"mode": "train", "epoch": 126, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.0006, "acc_pose": 0.82534, "loss": 0.0006, "time": 0.19253}
+{"mode": "train", "epoch": 126, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.0006, "acc_pose": 0.82456, "loss": 0.0006, "time": 0.19184}
+{"mode": "train", "epoch": 127, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05487, "heatmap_loss": 0.0006, "acc_pose": 0.82089, "loss": 0.0006, "time": 0.25021}
+{"mode": "train", "epoch": 127, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.0006, "acc_pose": 0.81809, "loss": 0.0006, "time": 0.1916}
+{"mode": "train", "epoch": 127, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00059, "acc_pose": 0.81697, "loss": 0.00059, "time": 0.19177}
+{"mode": "train", "epoch": 127, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.0006, "acc_pose": 0.82091, "loss": 0.0006, "time": 0.19274}
+{"mode": "train", "epoch": 127, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.0006, "acc_pose": 0.82661, "loss": 0.0006, "time": 0.19184}
+{"mode": "train", "epoch": 128, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05634, "heatmap_loss": 0.0006, "acc_pose": 0.82038, "loss": 0.0006, "time": 0.25037}
+{"mode": "train", "epoch": 128, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.0006, "acc_pose": 0.81777, "loss": 0.0006, "time": 0.19205}
+{"mode": "train", "epoch": 128, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.0006, "acc_pose": 0.82411, "loss": 0.0006, "time": 0.1922}
+{"mode": "train", "epoch": 128, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.0006, "acc_pose": 0.81152, "loss": 0.0006, "time": 0.19187}
+{"mode": "train", "epoch": 128, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.0006, "acc_pose": 0.81675, "loss": 0.0006, "time": 0.19195}
+{"mode": "train", "epoch": 129, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05541, "heatmap_loss": 0.00059, "acc_pose": 0.8219, "loss": 0.00059, "time": 0.24903}
+{"mode": "train", "epoch": 129, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00059, "acc_pose": 0.82339, "loss": 0.00059, "time": 0.19213}
+{"mode": "train", "epoch": 129, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.0006, "acc_pose": 0.81459, "loss": 0.0006, "time": 0.19217}
+{"mode": "train", "epoch": 129, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00059, "acc_pose": 0.8209, "loss": 0.00059, "time": 0.19194}
+{"mode": "train", "epoch": 129, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.0006, "acc_pose": 0.81602, "loss": 0.0006, "time": 0.19188}
+{"mode": "train", "epoch": 130, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05521, "heatmap_loss": 0.0006, "acc_pose": 0.8188, "loss": 0.0006, "time": 0.25095}
+{"mode": "train", "epoch": 130, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.0006, "acc_pose": 0.80589, "loss": 0.0006, "time": 0.19196}
+{"mode": "train", "epoch": 130, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00044, "heatmap_loss": 0.0006, "acc_pose": 0.818, "loss": 0.0006, "time": 0.19146}
+{"mode": "train", "epoch": 130, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.0006, "acc_pose": 0.82281, "loss": 0.0006, "time": 0.19221}
+{"mode": "train", "epoch": 130, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00059, "acc_pose": 0.8201, "loss": 0.00059, "time": 0.19161}
+{"mode": "val", "epoch": 130, "iter": 407, "lr": 1e-05, "AP": 0.74963, "AP .5": 0.90487, "AP .75": 0.82631, "AP (M)": 0.67842, "AP (L)": 0.77457, "AR": 0.80252, "AR .5": 0.94254, "AR .75": 0.87012, "AR (M)": 0.76184, "AR (L)": 0.8618}
+{"mode": "train", "epoch": 131, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05452, "heatmap_loss": 0.0006, "acc_pose": 0.82752, "loss": 0.0006, "time": 0.24714}
+{"mode": "train", "epoch": 131, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00041, "heatmap_loss": 0.0006, "acc_pose": 0.82051, "loss": 0.0006, "time": 0.19152}
+{"mode": "train", "epoch": 131, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.0006, "acc_pose": 0.81651, "loss": 0.0006, "time": 0.19136}
+{"mode": "train", "epoch": 131, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00059, "acc_pose": 0.82415, "loss": 0.00059, "time": 0.19165}
+{"mode": "train", "epoch": 131, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.0006, "acc_pose": 0.82201, "loss": 0.0006, "time": 0.19189}
+{"mode": "train", "epoch": 132, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05525, "heatmap_loss": 0.00059, "acc_pose": 0.81879, "loss": 0.00059, "time": 0.25077}
+{"mode": "train", "epoch": 132, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.0006, "acc_pose": 0.82195, "loss": 0.0006, "time": 0.19215}
+{"mode": "train", "epoch": 132, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00059, "acc_pose": 0.82106, "loss": 0.00059, "time": 0.19208}
+{"mode": "train", "epoch": 132, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00059, "acc_pose": 0.82094, "loss": 0.00059, "time": 0.19212}
+{"mode": "train", "epoch": 132, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00055, "heatmap_loss": 0.0006, "acc_pose": 0.82537, "loss": 0.0006, "time": 0.19199}
+{"mode": "train", "epoch": 133, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05531, "heatmap_loss": 0.00059, "acc_pose": 0.81543, "loss": 0.00059, "time": 0.25017}
+{"mode": "train", "epoch": 133, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00059, "acc_pose": 0.82329, "loss": 0.00059, "time": 0.19385}
+{"mode": "train", "epoch": 133, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.0006, "acc_pose": 0.81867, "loss": 0.0006, "time": 0.19184}
+{"mode": "train", "epoch": 133, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00059, "acc_pose": 0.82061, "loss": 0.00059, "time": 0.19275}
+{"mode": "train", "epoch": 133, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.0006, "acc_pose": 0.81532, "loss": 0.0006, "time": 0.19232}
+{"mode": "train", "epoch": 134, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.0564, "heatmap_loss": 0.00059, "acc_pose": 0.82163, "loss": 0.00059, "time": 0.25219}
+{"mode": "train", "epoch": 134, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00044, "heatmap_loss": 0.00059, "acc_pose": 0.82044, "loss": 0.00059, "time": 0.1918}
+{"mode": "train", "epoch": 134, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00059, "acc_pose": 0.82087, "loss": 0.00059, "time": 0.19212}
+{"mode": "train", "epoch": 134, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00059, "acc_pose": 0.82624, "loss": 0.00059, "time": 0.19218}
+{"mode": "train", "epoch": 134, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.0006, "acc_pose": 0.81329, "loss": 0.0006, "time": 0.19392}
+{"mode": "train", "epoch": 135, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05517, "heatmap_loss": 0.00059, "acc_pose": 0.82422, "loss": 0.00059, "time": 0.25088}
+{"mode": "train", "epoch": 135, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00059, "acc_pose": 0.81927, "loss": 0.00059, "time": 0.19259}
+{"mode": "train", "epoch": 135, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.0006, "acc_pose": 0.81458, "loss": 0.0006, "time": 0.1914}
+{"mode": "train", "epoch": 135, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.0006, "acc_pose": 0.82048, "loss": 0.0006, "time": 0.19178}
+{"mode": "train", "epoch": 135, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00059, "acc_pose": 0.82168, "loss": 0.00059, "time": 0.19157}
+{"mode": "train", "epoch": 136, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05462, "heatmap_loss": 0.0006, "acc_pose": 0.82117, "loss": 0.0006, "time": 0.25159}
+{"mode": "train", "epoch": 136, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00059, "acc_pose": 0.82721, "loss": 0.00059, "time": 0.19242}
+{"mode": "train", "epoch": 136, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00059, "acc_pose": 0.81946, "loss": 0.00059, "time": 0.19176}
+{"mode": "train", "epoch": 136, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00059, "acc_pose": 0.8167, "loss": 0.00059, "time": 0.19167}
+{"mode": "train", "epoch": 136, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00045, "heatmap_loss": 0.00059, "acc_pose": 0.82652, "loss": 0.00059, "time": 0.19203}
+{"mode": "train", "epoch": 137, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05454, "heatmap_loss": 0.00059, "acc_pose": 0.82215, "loss": 0.00059, "time": 0.25023}
+{"mode": "train", "epoch": 137, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00059, "acc_pose": 0.81446, "loss": 0.00059, "time": 0.19344}
+{"mode": "train", "epoch": 137, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00059, "acc_pose": 0.81921, "loss": 0.00059, "time": 0.19353}
+{"mode": "train", "epoch": 137, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00059, "acc_pose": 0.82406, "loss": 0.00059, "time": 0.19354}
+{"mode": "train", "epoch": 137, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00059, "acc_pose": 0.82183, "loss": 0.00059, "time": 0.19217}
+{"mode": "train", "epoch": 138, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05472, "heatmap_loss": 0.00059, "acc_pose": 0.82144, "loss": 0.00059, "time": 0.2507}
+{"mode": "train", "epoch": 138, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00058, "acc_pose": 0.82454, "loss": 0.00058, "time": 0.19149}
+{"mode": "train", "epoch": 138, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00059, "acc_pose": 0.82263, "loss": 0.00059, "time": 0.19222}
+{"mode": "train", "epoch": 138, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00059, "acc_pose": 0.82331, "loss": 0.00059, "time": 0.1915}
+{"mode": "train", "epoch": 138, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00059, "acc_pose": 0.8272, "loss": 0.00059, "time": 0.19181}
+{"mode": "train", "epoch": 139, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05536, "heatmap_loss": 0.00059, "acc_pose": 0.82365, "loss": 0.00059, "time": 0.25096}
+{"mode": "train", "epoch": 139, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00059, "acc_pose": 0.82295, "loss": 0.00059, "time": 0.19119}
+{"mode": "train", "epoch": 139, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00059, "acc_pose": 0.82319, "loss": 0.00059, "time": 0.19313}
+{"mode": "train", "epoch": 139, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00059, "acc_pose": 0.81869, "loss": 0.00059, "time": 0.19293}
+{"mode": "train", "epoch": 139, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00047, "heatmap_loss": 0.00059, "acc_pose": 0.82135, "loss": 0.00059, "time": 0.19521}
+{"mode": "train", "epoch": 140, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05505, "heatmap_loss": 0.00059, "acc_pose": 0.82891, "loss": 0.00059, "time": 0.25031}
+{"mode": "train", "epoch": 140, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00059, "acc_pose": 0.82179, "loss": 0.00059, "time": 0.1922}
+{"mode": "train", "epoch": 140, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00059, "acc_pose": 0.81739, "loss": 0.00059, "time": 0.19234}
+{"mode": "train", "epoch": 140, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00047, "heatmap_loss": 0.0006, "acc_pose": 0.82255, "loss": 0.0006, "time": 0.19258}
+{"mode": "train", "epoch": 140, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00059, "acc_pose": 0.82323, "loss": 0.00059, "time": 0.19395}
+{"mode": "val", "epoch": 140, "iter": 407, "lr": 1e-05, "AP": 0.75261, "AP .5": 0.90621, "AP .75": 0.82417, "AP (M)": 0.68224, "AP (L)": 0.77726, "AR": 0.80601, "AR .5": 0.9449, "AR .75": 0.8698, "AR (M)": 0.76618, "AR (L)": 0.86451}
+{"mode": "train", "epoch": 141, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05549, "heatmap_loss": 0.00059, "acc_pose": 0.82214, "loss": 0.00059, "time": 0.24762}
+{"mode": "train", "epoch": 141, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00034, "heatmap_loss": 0.00058, "acc_pose": 0.82711, "loss": 0.00058, "time": 0.19284}
+{"mode": "train", "epoch": 141, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00059, "acc_pose": 0.81413, "loss": 0.00059, "time": 0.19171}
+{"mode": "train", "epoch": 141, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00059, "acc_pose": 0.82665, "loss": 0.00059, "time": 0.19169}
+{"mode": "train", "epoch": 141, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00059, "acc_pose": 0.82028, "loss": 0.00059, "time": 0.19201}
+{"mode": "train", "epoch": 142, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.0547, "heatmap_loss": 0.00058, "acc_pose": 0.82611, "loss": 0.00058, "time": 0.24992}
+{"mode": "train", "epoch": 142, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00059, "acc_pose": 0.81453, "loss": 0.00059, "time": 0.19264}
+{"mode": "train", "epoch": 142, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00059, "acc_pose": 0.82472, "loss": 0.00059, "time": 0.19199}
+{"mode": "train", "epoch": 142, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00059, "acc_pose": 0.82185, "loss": 0.00059, "time": 0.19244}
+{"mode": "train", "epoch": 142, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00058, "acc_pose": 0.82628, "loss": 0.00058, "time": 0.19159}
+{"mode": "train", "epoch": 143, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05484, "heatmap_loss": 0.00058, "acc_pose": 0.82915, "loss": 0.00058, "time": 0.24992}
+{"mode": "train", "epoch": 143, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00059, "acc_pose": 0.82372, "loss": 0.00059, "time": 0.19154}
+{"mode": "train", "epoch": 143, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00059, "acc_pose": 0.82387, "loss": 0.00059, "time": 0.1932}
+{"mode": "train", "epoch": 143, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00059, "acc_pose": 0.82538, "loss": 0.00059, "time": 0.19379}
+{"mode": "train", "epoch": 143, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00041, "heatmap_loss": 0.00059, "acc_pose": 0.82375, "loss": 0.00059, "time": 0.19272}
+{"mode": "train", "epoch": 144, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05493, "heatmap_loss": 0.00058, "acc_pose": 0.82198, "loss": 0.00058, "time": 0.24966}
+{"mode": "train", "epoch": 144, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00059, "acc_pose": 0.81837, "loss": 0.00059, "time": 0.19184}
+{"mode": "train", "epoch": 144, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00059, "acc_pose": 0.81692, "loss": 0.00059, "time": 0.19135}
+{"mode": "train", "epoch": 144, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00059, "acc_pose": 0.81968, "loss": 0.00059, "time": 0.19208}
+{"mode": "train", "epoch": 144, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00058, "acc_pose": 0.82419, "loss": 0.00058, "time": 0.19163}
+{"mode": "train", "epoch": 145, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05516, "heatmap_loss": 0.00059, "acc_pose": 0.82504, "loss": 0.00059, "time": 0.25048}
+{"mode": "train", "epoch": 145, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00058, "acc_pose": 0.8225, "loss": 0.00058, "time": 0.19288}
+{"mode": "train", "epoch": 145, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00059, "acc_pose": 0.82251, "loss": 0.00059, "time": 0.19267}
+{"mode": "train", "epoch": 145, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00059, "acc_pose": 0.82134, "loss": 0.00059, "time": 0.19238}
+{"mode": "train", "epoch": 145, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00031, "heatmap_loss": 0.00059, "acc_pose": 0.831, "loss": 0.00059, "time": 0.19193}
+{"mode": "train", "epoch": 146, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05544, "heatmap_loss": 0.00058, "acc_pose": 0.82208, "loss": 0.00058, "time": 0.2534}
+{"mode": "train", "epoch": 146, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00034, "heatmap_loss": 0.00058, "acc_pose": 0.82279, "loss": 0.00058, "time": 0.19204}
+{"mode": "train", "epoch": 146, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00042, "heatmap_loss": 0.00059, "acc_pose": 0.81746, "loss": 0.00059, "time": 0.19245}
+{"mode": "train", "epoch": 146, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00043, "heatmap_loss": 0.00059, "acc_pose": 0.82373, "loss": 0.00059, "time": 0.19291}
+{"mode": "train", "epoch": 146, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00059, "acc_pose": 0.82308, "loss": 0.00059, "time": 0.19255}
+{"mode": "train", "epoch": 147, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05503, "heatmap_loss": 0.00058, "acc_pose": 0.82892, "loss": 0.00058, "time": 0.25217}
+{"mode": "train", "epoch": 147, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00042, "heatmap_loss": 0.00058, "acc_pose": 0.82275, "loss": 0.00058, "time": 0.19268}
+{"mode": "train", "epoch": 147, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00059, "acc_pose": 0.82321, "loss": 0.00059, "time": 0.19182}
+{"mode": "train", "epoch": 147, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00059, "acc_pose": 0.82125, "loss": 0.00059, "time": 0.19208}
+{"mode": "train", "epoch": 147, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00059, "acc_pose": 0.81857, "loss": 0.00059, "time": 0.19179}
+{"mode": "train", "epoch": 148, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05525, "heatmap_loss": 0.00058, "acc_pose": 0.82104, "loss": 0.00058, "time": 0.25548}
+{"mode": "train", "epoch": 148, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00059, "acc_pose": 0.82385, "loss": 0.00059, "time": 0.19277}
+{"mode": "train", "epoch": 148, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00058, "acc_pose": 0.82472, "loss": 0.00058, "time": 0.19215}
+{"mode": "train", "epoch": 148, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00058, "acc_pose": 0.82551, "loss": 0.00058, "time": 0.19214}
+{"mode": "train", "epoch": 148, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00059, "acc_pose": 0.82771, "loss": 0.00059, "time": 0.19173}
+{"mode": "train", "epoch": 149, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.0548, "heatmap_loss": 0.00058, "acc_pose": 0.81944, "loss": 0.00058, "time": 0.25034}
+{"mode": "train", "epoch": 149, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00058, "acc_pose": 0.83109, "loss": 0.00058, "time": 0.19219}
+{"mode": "train", "epoch": 149, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00058, "acc_pose": 0.83027, "loss": 0.00058, "time": 0.1925}
+{"mode": "train", "epoch": 149, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00058, "acc_pose": 0.82611, "loss": 0.00058, "time": 0.1925}
+{"mode": "train", "epoch": 149, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00058, "acc_pose": 0.82879, "loss": 0.00058, "time": 0.19264}
+{"mode": "train", "epoch": 150, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05499, "heatmap_loss": 0.00058, "acc_pose": 0.8275, "loss": 0.00058, "time": 0.25061}
+{"mode": "train", "epoch": 150, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00058, "acc_pose": 0.82666, "loss": 0.00058, "time": 0.19225}
+{"mode": "train", "epoch": 150, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00059, "acc_pose": 0.82702, "loss": 0.00059, "time": 0.19196}
+{"mode": "train", "epoch": 150, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00058, "acc_pose": 0.83042, "loss": 0.00058, "time": 0.19169}
+{"mode": "train", "epoch": 150, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00058, "acc_pose": 0.82674, "loss": 0.00058, "time": 0.19322}
+{"mode": "val", "epoch": 150, "iter": 407, "lr": 1e-05, "AP": 0.75281, "AP .5": 0.90617, "AP .75": 0.82731, "AP (M)": 0.68037, "AP (L)": 0.77994, "AR": 0.8056, "AR .5": 0.94569, "AR .75": 0.87217, "AR (M)": 0.76394, "AR (L)": 0.86589}
+{"mode": "train", "epoch": 151, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05398, "heatmap_loss": 0.00058, "acc_pose": 0.82387, "loss": 0.00058, "time": 0.24667}
+{"mode": "train", "epoch": 151, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00058, "acc_pose": 0.83128, "loss": 0.00058, "time": 0.19228}
+{"mode": "train", "epoch": 151, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00058, "acc_pose": 0.82494, "loss": 0.00058, "time": 0.19149}
+{"mode": "train", "epoch": 151, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00027, "heatmap_loss": 0.00059, "acc_pose": 0.82431, "loss": 0.00059, "time": 0.19243}
+{"mode": "train", "epoch": 151, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00058, "acc_pose": 0.83391, "loss": 0.00058, "time": 0.19286}
+{"mode": "train", "epoch": 152, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05552, "heatmap_loss": 0.00058, "acc_pose": 0.82518, "loss": 0.00058, "time": 0.24988}
+{"mode": "train", "epoch": 152, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00048, "heatmap_loss": 0.00058, "acc_pose": 0.82858, "loss": 0.00058, "time": 0.19138}
+{"mode": "train", "epoch": 152, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00058, "acc_pose": 0.82808, "loss": 0.00058, "time": 0.19139}
+{"mode": "train", "epoch": 152, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00058, "acc_pose": 0.82286, "loss": 0.00058, "time": 0.19151}
+{"mode": "train", "epoch": 152, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00058, "acc_pose": 0.83341, "loss": 0.00058, "time": 0.19154}
+{"mode": "train", "epoch": 153, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05518, "heatmap_loss": 0.00058, "acc_pose": 0.83146, "loss": 0.00058, "time": 0.25071}
+{"mode": "train", "epoch": 153, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00058, "acc_pose": 0.83412, "loss": 0.00058, "time": 0.19291}
+{"mode": "train", "epoch": 153, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00058, "acc_pose": 0.82905, "loss": 0.00058, "time": 0.19336}
+{"mode": "train", "epoch": 153, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00058, "acc_pose": 0.82564, "loss": 0.00058, "time": 0.19272}
+{"mode": "train", "epoch": 153, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00041, "heatmap_loss": 0.00058, "acc_pose": 0.82935, "loss": 0.00058, "time": 0.19227}
+{"mode": "train", "epoch": 154, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05527, "heatmap_loss": 0.00058, "acc_pose": 0.8263, "loss": 0.00058, "time": 0.25089}
+{"mode": "train", "epoch": 154, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00058, "acc_pose": 0.82657, "loss": 0.00058, "time": 0.19177}
+{"mode": "train", "epoch": 154, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00058, "acc_pose": 0.81855, "loss": 0.00058, "time": 0.1917}
+{"mode": "train", "epoch": 154, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00058, "acc_pose": 0.82344, "loss": 0.00058, "time": 0.19289}
+{"mode": "train", "epoch": 154, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00058, "acc_pose": 0.82451, "loss": 0.00058, "time": 0.19189}
+{"mode": "train", "epoch": 155, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05507, "heatmap_loss": 0.00058, "acc_pose": 0.82992, "loss": 0.00058, "time": 0.25205}
+{"mode": "train", "epoch": 155, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00058, "acc_pose": 0.82861, "loss": 0.00058, "time": 0.19198}
+{"mode": "train", "epoch": 155, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00058, "acc_pose": 0.83292, "loss": 0.00058, "time": 0.19268}
+{"mode": "train", "epoch": 155, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00058, "acc_pose": 0.8262, "loss": 0.00058, "time": 0.19216}
+{"mode": "train", "epoch": 155, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00058, "acc_pose": 0.82733, "loss": 0.00058, "time": 0.19219}
+{"mode": "train", "epoch": 156, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05531, "heatmap_loss": 0.00058, "acc_pose": 0.82069, "loss": 0.00058, "time": 0.2516}
+{"mode": "train", "epoch": 156, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00058, "acc_pose": 0.82398, "loss": 0.00058, "time": 0.19197}
+{"mode": "train", "epoch": 156, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00058, "acc_pose": 0.81936, "loss": 0.00058, "time": 0.19169}
+{"mode": "train", "epoch": 156, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00058, "acc_pose": 0.82542, "loss": 0.00058, "time": 0.19264}
+{"mode": "train", "epoch": 156, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00058, "acc_pose": 0.82546, "loss": 0.00058, "time": 0.19197}
+{"mode": "train", "epoch": 157, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05563, "heatmap_loss": 0.00058, "acc_pose": 0.83582, "loss": 0.00058, "time": 0.2505}
+{"mode": "train", "epoch": 157, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00049, "heatmap_loss": 0.00058, "acc_pose": 0.83219, "loss": 0.00058, "time": 0.19197}
+{"mode": "train", "epoch": 157, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00058, "acc_pose": 0.82657, "loss": 0.00058, "time": 0.19174}
+{"mode": "train", "epoch": 157, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00058, "acc_pose": 0.83408, "loss": 0.00058, "time": 0.19202}
+{"mode": "train", "epoch": 157, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00058, "acc_pose": 0.82338, "loss": 0.00058, "time": 0.19263}
+{"mode": "train", "epoch": 158, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05457, "heatmap_loss": 0.00058, "acc_pose": 0.82197, "loss": 0.00058, "time": 0.25106}
+{"mode": "train", "epoch": 158, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00058, "acc_pose": 0.82714, "loss": 0.00058, "time": 0.1922}
+{"mode": "train", "epoch": 158, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00058, "acc_pose": 0.82272, "loss": 0.00058, "time": 0.19129}
+{"mode": "train", "epoch": 158, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00058, "acc_pose": 0.83326, "loss": 0.00058, "time": 0.19197}
+{"mode": "train", "epoch": 158, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00058, "acc_pose": 0.82628, "loss": 0.00058, "time": 0.1917}
+{"mode": "train", "epoch": 159, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05479, "heatmap_loss": 0.00057, "acc_pose": 0.8263, "loss": 0.00057, "time": 0.25114}
+{"mode": "train", "epoch": 159, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00047, "heatmap_loss": 0.00058, "acc_pose": 0.82326, "loss": 0.00058, "time": 0.19183}
+{"mode": "train", "epoch": 159, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00058, "acc_pose": 0.82222, "loss": 0.00058, "time": 0.19317}
+{"mode": "train", "epoch": 159, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00058, "acc_pose": 0.82751, "loss": 0.00058, "time": 0.19249}
+{"mode": "train", "epoch": 159, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00058, "acc_pose": 0.82732, "loss": 0.00058, "time": 0.19206}
+{"mode": "train", "epoch": 160, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05548, "heatmap_loss": 0.00058, "acc_pose": 0.82821, "loss": 0.00058, "time": 0.25355}
+{"mode": "train", "epoch": 160, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00058, "acc_pose": 0.82501, "loss": 0.00058, "time": 0.19187}
+{"mode": "train", "epoch": 160, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00058, "acc_pose": 0.82814, "loss": 0.00058, "time": 0.19187}
+{"mode": "train", "epoch": 160, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00057, "acc_pose": 0.82565, "loss": 0.00057, "time": 0.19203}
+{"mode": "train", "epoch": 160, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00058, "acc_pose": 0.82387, "loss": 0.00058, "time": 0.19166}
+{"mode": "val", "epoch": 160, "iter": 407, "lr": 1e-05, "AP": 0.75134, "AP .5": 0.90501, "AP .75": 0.82264, "AP (M)": 0.67996, "AP (L)": 0.77845, "AR": 0.80449, "AR .5": 0.9438, "AR .75": 0.86792, "AR (M)": 0.7634, "AR (L)": 0.86455}
+{"mode": "train", "epoch": 161, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05488, "heatmap_loss": 0.00058, "acc_pose": 0.83186, "loss": 0.00058, "time": 0.24761}
+{"mode": "train", "epoch": 161, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00058, "acc_pose": 0.83383, "loss": 0.00058, "time": 0.19295}
+{"mode": "train", "epoch": 161, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00041, "heatmap_loss": 0.00058, "acc_pose": 0.82452, "loss": 0.00058, "time": 0.19179}
+{"mode": "train", "epoch": 161, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00057, "acc_pose": 0.83441, "loss": 0.00057, "time": 0.19258}
+{"mode": "train", "epoch": 161, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00042, "heatmap_loss": 0.00057, "acc_pose": 0.82951, "loss": 0.00057, "time": 0.19259}
+{"mode": "train", "epoch": 162, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05476, "heatmap_loss": 0.00057, "acc_pose": 0.83003, "loss": 0.00057, "time": 0.25083}
+{"mode": "train", "epoch": 162, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00057, "acc_pose": 0.82521, "loss": 0.00057, "time": 0.19206}
+{"mode": "train", "epoch": 162, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00034, "heatmap_loss": 0.00057, "acc_pose": 0.83102, "loss": 0.00057, "time": 0.19244}
+{"mode": "train", "epoch": 162, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00057, "acc_pose": 0.82731, "loss": 0.00057, "time": 0.19203}
+{"mode": "train", "epoch": 162, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00058, "acc_pose": 0.82932, "loss": 0.00058, "time": 0.1916}
+{"mode": "train", "epoch": 163, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05594, "heatmap_loss": 0.00057, "acc_pose": 0.82989, "loss": 0.00057, "time": 0.25139}
+{"mode": "train", "epoch": 163, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00058, "acc_pose": 0.82605, "loss": 0.00058, "time": 0.1918}
+{"mode": "train", "epoch": 163, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00058, "acc_pose": 0.82663, "loss": 0.00058, "time": 0.19248}
+{"mode": "train", "epoch": 163, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00058, "acc_pose": 0.82289, "loss": 0.00058, "time": 0.19361}
+{"mode": "train", "epoch": 163, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00058, "acc_pose": 0.82748, "loss": 0.00058, "time": 0.19221}
+{"mode": "train", "epoch": 164, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05504, "heatmap_loss": 0.00057, "acc_pose": 0.82917, "loss": 0.00057, "time": 0.25205}
+{"mode": "train", "epoch": 164, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00058, "acc_pose": 0.8242, "loss": 0.00058, "time": 0.19225}
+{"mode": "train", "epoch": 164, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00058, "acc_pose": 0.82332, "loss": 0.00058, "time": 0.1916}
+{"mode": "train", "epoch": 164, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00058, "acc_pose": 0.82754, "loss": 0.00058, "time": 0.19178}
+{"mode": "train", "epoch": 164, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00058, "acc_pose": 0.83486, "loss": 0.00058, "time": 0.19193}
+{"mode": "train", "epoch": 165, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05501, "heatmap_loss": 0.00057, "acc_pose": 0.8288, "loss": 0.00057, "time": 0.25135}
+{"mode": "train", "epoch": 165, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00057, "acc_pose": 0.82906, "loss": 0.00057, "time": 0.19297}
+{"mode": "train", "epoch": 165, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00057, "acc_pose": 0.83139, "loss": 0.00057, "time": 0.19272}
+{"mode": "train", "epoch": 165, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00057, "acc_pose": 0.82862, "loss": 0.00057, "time": 0.19214}
+{"mode": "train", "epoch": 165, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00057, "acc_pose": 0.83616, "loss": 0.00057, "time": 0.1921}
+{"mode": "train", "epoch": 166, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05536, "heatmap_loss": 0.00058, "acc_pose": 0.82948, "loss": 0.00058, "time": 0.25108}
+{"mode": "train", "epoch": 166, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00057, "acc_pose": 0.82617, "loss": 0.00057, "time": 0.19216}
+{"mode": "train", "epoch": 166, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00057, "acc_pose": 0.82926, "loss": 0.00057, "time": 0.19289}
+{"mode": "train", "epoch": 166, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00057, "acc_pose": 0.82339, "loss": 0.00057, "time": 0.19259}
+{"mode": "train", "epoch": 166, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00057, "acc_pose": 0.8337, "loss": 0.00057, "time": 0.19221}
+{"mode": "train", "epoch": 167, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05503, "heatmap_loss": 0.00057, "acc_pose": 0.83072, "loss": 0.00057, "time": 0.25253}
+{"mode": "train", "epoch": 167, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00057, "acc_pose": 0.8275, "loss": 0.00057, "time": 0.19177}
+{"mode": "train", "epoch": 167, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00057, "acc_pose": 0.82792, "loss": 0.00057, "time": 0.1923}
+{"mode": "train", "epoch": 167, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00053, "heatmap_loss": 0.00057, "acc_pose": 0.83795, "loss": 0.00057, "time": 0.19257}
+{"mode": "train", "epoch": 167, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00057, "acc_pose": 0.82431, "loss": 0.00057, "time": 0.19176}
+{"mode": "train", "epoch": 168, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05552, "heatmap_loss": 0.00057, "acc_pose": 0.83464, "loss": 0.00057, "time": 0.25137}
+{"mode": "train", "epoch": 168, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00057, "acc_pose": 0.82931, "loss": 0.00057, "time": 0.19185}
+{"mode": "train", "epoch": 168, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00058, "acc_pose": 0.82353, "loss": 0.00058, "time": 0.19236}
+{"mode": "train", "epoch": 168, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00057, "acc_pose": 0.8298, "loss": 0.00057, "time": 0.19264}
+{"mode": "train", "epoch": 168, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00057, "acc_pose": 0.8333, "loss": 0.00057, "time": 0.1938}
+{"mode": "train", "epoch": 169, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05453, "heatmap_loss": 0.00057, "acc_pose": 0.83666, "loss": 0.00057, "time": 0.25086}
+{"mode": "train", "epoch": 169, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00057, "acc_pose": 0.8236, "loss": 0.00057, "time": 0.19201}
+{"mode": "train", "epoch": 169, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00057, "acc_pose": 0.83262, "loss": 0.00057, "time": 0.19211}
+{"mode": "train", "epoch": 169, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00057, "acc_pose": 0.82807, "loss": 0.00057, "time": 0.19165}
+{"mode": "train", "epoch": 169, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00043, "heatmap_loss": 0.00057, "acc_pose": 0.8341, "loss": 0.00057, "time": 0.19189}
+{"mode": "train", "epoch": 170, "iter": 50, "lr": 1e-05, "memory": 14090, "data_time": 0.05571, "heatmap_loss": 0.00057, "acc_pose": 0.83024, "loss": 0.00057, "time": 0.25108}
+{"mode": "train", "epoch": 170, "iter": 100, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00057, "acc_pose": 0.82416, "loss": 0.00057, "time": 0.19164}
+{"mode": "train", "epoch": 170, "iter": 150, "lr": 1e-05, "memory": 14090, "data_time": 0.00034, "heatmap_loss": 0.00057, "acc_pose": 0.82121, "loss": 0.00057, "time": 0.19149}
+{"mode": "train", "epoch": 170, "iter": 200, "lr": 1e-05, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00057, "acc_pose": 0.82803, "loss": 0.00057, "time": 0.19174}
+{"mode": "train", "epoch": 170, "iter": 250, "lr": 1e-05, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00057, "acc_pose": 0.83169, "loss": 0.00057, "time": 0.19257}
+{"mode": "val", "epoch": 170, "iter": 407, "lr": 1e-05, "AP": 0.7537, "AP .5": 0.90603, "AP .75": 0.83007, "AP (M)": 0.68317, "AP (L)": 0.78024, "AR": 0.80575, "AR .5": 0.94254, "AR .75": 0.87358, "AR (M)": 0.76452, "AR (L)": 0.86641}
+{"mode": "train", "epoch": 171, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.05487, "heatmap_loss": 0.00056, "acc_pose": 0.83586, "loss": 0.00056, "time": 0.24861}
+{"mode": "train", "epoch": 171, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00041, "heatmap_loss": 0.00056, "acc_pose": 0.8335, "loss": 0.00056, "time": 0.1925}
+{"mode": "train", "epoch": 171, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00042, "heatmap_loss": 0.00056, "acc_pose": 0.83515, "loss": 0.00056, "time": 0.1926}
+{"mode": "train", "epoch": 171, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00056, "acc_pose": 0.83831, "loss": 0.00056, "time": 0.19239}
+{"mode": "train", "epoch": 171, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00056, "acc_pose": 0.83195, "loss": 0.00056, "time": 0.19269}
+{"mode": "train", "epoch": 172, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.0573, "heatmap_loss": 0.00056, "acc_pose": 0.83641, "loss": 0.00056, "time": 0.25094}
+{"mode": "train", "epoch": 172, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00056, "acc_pose": 0.82807, "loss": 0.00056, "time": 0.193}
+{"mode": "train", "epoch": 172, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00056, "acc_pose": 0.83186, "loss": 0.00056, "time": 0.19177}
+{"mode": "train", "epoch": 172, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00055, "acc_pose": 0.83726, "loss": 0.00055, "time": 0.19226}
+{"mode": "train", "epoch": 172, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00056, "acc_pose": 0.83664, "loss": 0.00056, "time": 0.19215}
+{"mode": "train", "epoch": 173, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.05555, "heatmap_loss": 0.00056, "acc_pose": 0.83187, "loss": 0.00056, "time": 0.24988}
+{"mode": "train", "epoch": 173, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00055, "acc_pose": 0.83752, "loss": 0.00055, "time": 0.19189}
+{"mode": "train", "epoch": 173, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00055, "acc_pose": 0.83323, "loss": 0.00055, "time": 0.19257}
+{"mode": "train", "epoch": 173, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00056, "acc_pose": 0.83975, "loss": 0.00056, "time": 0.19207}
+{"mode": "train", "epoch": 173, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00056, "acc_pose": 0.83619, "loss": 0.00056, "time": 0.19221}
+{"mode": "train", "epoch": 174, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.05498, "heatmap_loss": 0.00056, "acc_pose": 0.83626, "loss": 0.00056, "time": 0.25149}
+{"mode": "train", "epoch": 174, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00056, "acc_pose": 0.83378, "loss": 0.00056, "time": 0.19227}
+{"mode": "train", "epoch": 174, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00055, "acc_pose": 0.83807, "loss": 0.00055, "time": 0.19233}
+{"mode": "train", "epoch": 174, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00055, "acc_pose": 0.84035, "loss": 0.00055, "time": 0.19199}
+{"mode": "train", "epoch": 174, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00055, "acc_pose": 0.82983, "loss": 0.00055, "time": 0.19239}
+{"mode": "train", "epoch": 175, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.05496, "heatmap_loss": 0.00055, "acc_pose": 0.83778, "loss": 0.00055, "time": 0.25102}
+{"mode": "train", "epoch": 175, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00055, "acc_pose": 0.83572, "loss": 0.00055, "time": 0.19156}
+{"mode": "train", "epoch": 175, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00056, "acc_pose": 0.83668, "loss": 0.00056, "time": 0.1926}
+{"mode": "train", "epoch": 175, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00055, "acc_pose": 0.83989, "loss": 0.00055, "time": 0.19205}
+{"mode": "train", "epoch": 175, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00055, "acc_pose": 0.84315, "loss": 0.00055, "time": 0.19183}
+{"mode": "train", "epoch": 176, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.05547, "heatmap_loss": 0.00055, "acc_pose": 0.8349, "loss": 0.00055, "time": 0.25204}
+{"mode": "train", "epoch": 176, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00055, "acc_pose": 0.83544, "loss": 0.00055, "time": 0.19244}
+{"mode": "train", "epoch": 176, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00056, "acc_pose": 0.83172, "loss": 0.00056, "time": 0.1926}
+{"mode": "train", "epoch": 176, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00055, "acc_pose": 0.83102, "loss": 0.00055, "time": 0.19291}
+{"mode": "train", "epoch": 176, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00055, "acc_pose": 0.83483, "loss": 0.00055, "time": 0.19186}
+{"mode": "train", "epoch": 177, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.05533, "heatmap_loss": 0.00055, "acc_pose": 0.83944, "loss": 0.00055, "time": 0.25214}
+{"mode": "train", "epoch": 177, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00055, "acc_pose": 0.83133, "loss": 0.00055, "time": 0.19252}
+{"mode": "train", "epoch": 177, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00056, "acc_pose": 0.83362, "loss": 0.00056, "time": 0.19231}
+{"mode": "train", "epoch": 177, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00055, "acc_pose": 0.83972, "loss": 0.00055, "time": 0.19191}
+{"mode": "train", "epoch": 177, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.00043, "heatmap_loss": 0.00055, "acc_pose": 0.83487, "loss": 0.00055, "time": 0.19314}
+{"mode": "train", "epoch": 178, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.05495, "heatmap_loss": 0.00055, "acc_pose": 0.84149, "loss": 0.00055, "time": 0.25159}
+{"mode": "train", "epoch": 178, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00055, "acc_pose": 0.83725, "loss": 0.00055, "time": 0.19263}
+{"mode": "train", "epoch": 178, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00055, "acc_pose": 0.84074, "loss": 0.00055, "time": 0.19187}
+{"mode": "train", "epoch": 178, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00042, "heatmap_loss": 0.00055, "acc_pose": 0.83352, "loss": 0.00055, "time": 0.19193}
+{"mode": "train", "epoch": 178, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00055, "acc_pose": 0.84432, "loss": 0.00055, "time": 0.19196}
+{"mode": "train", "epoch": 179, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.05538, "heatmap_loss": 0.00055, "acc_pose": 0.83752, "loss": 0.00055, "time": 0.25231}
+{"mode": "train", "epoch": 179, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00029, "heatmap_loss": 0.00056, "acc_pose": 0.83335, "loss": 0.00056, "time": 0.1913}
+{"mode": "train", "epoch": 179, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00055, "acc_pose": 0.83708, "loss": 0.00055, "time": 0.19205}
+{"mode": "train", "epoch": 179, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00055, "acc_pose": 0.84076, "loss": 0.00055, "time": 0.1926}
+{"mode": "train", "epoch": 179, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00055, "acc_pose": 0.8436, "loss": 0.00055, "time": 0.19284}
+{"mode": "train", "epoch": 180, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.05535, "heatmap_loss": 0.00055, "acc_pose": 0.84098, "loss": 0.00055, "time": 0.2521}
+{"mode": "train", "epoch": 180, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00055, "acc_pose": 0.84376, "loss": 0.00055, "time": 0.19207}
+{"mode": "train", "epoch": 180, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00055, "acc_pose": 0.83685, "loss": 0.00055, "time": 0.19195}
+{"mode": "train", "epoch": 180, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00055, "acc_pose": 0.84226, "loss": 0.00055, "time": 0.19252}
+{"mode": "train", "epoch": 180, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00055, "acc_pose": 0.83624, "loss": 0.00055, "time": 0.19212}
+{"mode": "val", "epoch": 180, "iter": 407, "lr": 0.0, "AP": 0.75758, "AP .5": 0.90726, "AP .75": 0.83111, "AP (M)": 0.68695, "AP (L)": 0.78294, "AR": 0.81066, "AR .5": 0.94553, "AR .75": 0.87579, "AR (M)": 0.76965, "AR (L)": 0.87064}
+{"mode": "train", "epoch": 181, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.05493, "heatmap_loss": 0.00055, "acc_pose": 0.83885, "loss": 0.00055, "time": 0.24778}
+{"mode": "train", "epoch": 181, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00055, "acc_pose": 0.83729, "loss": 0.00055, "time": 0.19264}
+{"mode": "train", "epoch": 181, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00055, "acc_pose": 0.83611, "loss": 0.00055, "time": 0.19216}
+{"mode": "train", "epoch": 181, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00055, "acc_pose": 0.83747, "loss": 0.00055, "time": 0.19216}
+{"mode": "train", "epoch": 181, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00055, "acc_pose": 0.83801, "loss": 0.00055, "time": 0.19206}
+{"mode": "train", "epoch": 182, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.05554, "heatmap_loss": 0.00055, "acc_pose": 0.8414, "loss": 0.00055, "time": 0.25046}
+{"mode": "train", "epoch": 182, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00055, "acc_pose": 0.83979, "loss": 0.00055, "time": 0.19208}
+{"mode": "train", "epoch": 182, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00055, "acc_pose": 0.83572, "loss": 0.00055, "time": 0.19325}
+{"mode": "train", "epoch": 182, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00055, "acc_pose": 0.84498, "loss": 0.00055, "time": 0.19228}
+{"mode": "train", "epoch": 182, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00055, "acc_pose": 0.8414, "loss": 0.00055, "time": 0.19235}
+{"mode": "train", "epoch": 183, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.05472, "heatmap_loss": 0.00055, "acc_pose": 0.83652, "loss": 0.00055, "time": 0.25158}
+{"mode": "train", "epoch": 183, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00055, "acc_pose": 0.83593, "loss": 0.00055, "time": 0.19173}
+{"mode": "train", "epoch": 183, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00055, "acc_pose": 0.83516, "loss": 0.00055, "time": 0.19241}
+{"mode": "train", "epoch": 183, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00055, "acc_pose": 0.8413, "loss": 0.00055, "time": 0.193}
+{"mode": "train", "epoch": 183, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.00046, "heatmap_loss": 0.00055, "acc_pose": 0.84172, "loss": 0.00055, "time": 0.19261}
+{"mode": "train", "epoch": 184, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.05505, "heatmap_loss": 0.00055, "acc_pose": 0.83701, "loss": 0.00055, "time": 0.25112}
+{"mode": "train", "epoch": 184, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00054, "acc_pose": 0.84295, "loss": 0.00054, "time": 0.19252}
+{"mode": "train", "epoch": 184, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00049, "heatmap_loss": 0.00054, "acc_pose": 0.83995, "loss": 0.00054, "time": 0.19189}
+{"mode": "train", "epoch": 184, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00055, "acc_pose": 0.83263, "loss": 0.00055, "time": 0.19337}
+{"mode": "train", "epoch": 184, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00055, "acc_pose": 0.84147, "loss": 0.00055, "time": 0.19272}
+{"mode": "train", "epoch": 185, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.05681, "heatmap_loss": 0.00054, "acc_pose": 0.84268, "loss": 0.00054, "time": 0.2535}
+{"mode": "train", "epoch": 185, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00055, "acc_pose": 0.8387, "loss": 0.00055, "time": 0.19158}
+{"mode": "train", "epoch": 185, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00055, "acc_pose": 0.84268, "loss": 0.00055, "time": 0.19202}
+{"mode": "train", "epoch": 185, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00055, "acc_pose": 0.84002, "loss": 0.00055, "time": 0.19314}
+{"mode": "train", "epoch": 185, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00055, "acc_pose": 0.83816, "loss": 0.00055, "time": 0.19262}
+{"mode": "train", "epoch": 186, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.05478, "heatmap_loss": 0.00055, "acc_pose": 0.83746, "loss": 0.00055, "time": 0.25255}
+{"mode": "train", "epoch": 186, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00055, "acc_pose": 0.83506, "loss": 0.00055, "time": 0.19225}
+{"mode": "train", "epoch": 186, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00055, "acc_pose": 0.83865, "loss": 0.00055, "time": 0.19235}
+{"mode": "train", "epoch": 186, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00055, "acc_pose": 0.83989, "loss": 0.00055, "time": 0.19164}
+{"mode": "train", "epoch": 186, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00054, "acc_pose": 0.84141, "loss": 0.00054, "time": 0.19264}
+{"mode": "train", "epoch": 187, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.05401, "heatmap_loss": 0.00055, "acc_pose": 0.84519, "loss": 0.00055, "time": 0.25138}
+{"mode": "train", "epoch": 187, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00054, "acc_pose": 0.84002, "loss": 0.00054, "time": 0.19334}
+{"mode": "train", "epoch": 187, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00055, "acc_pose": 0.8368, "loss": 0.00055, "time": 0.19262}
+{"mode": "train", "epoch": 187, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00055, "acc_pose": 0.83619, "loss": 0.00055, "time": 0.19211}
+{"mode": "train", "epoch": 187, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00055, "acc_pose": 0.84277, "loss": 0.00055, "time": 0.19247}
+{"mode": "train", "epoch": 188, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.0546, "heatmap_loss": 0.00054, "acc_pose": 0.84184, "loss": 0.00054, "time": 0.25051}
+{"mode": "train", "epoch": 188, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00054, "acc_pose": 0.84401, "loss": 0.00054, "time": 0.19243}
+{"mode": "train", "epoch": 188, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00055, "acc_pose": 0.84032, "loss": 0.00055, "time": 0.19284}
+{"mode": "train", "epoch": 188, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00055, "acc_pose": 0.83874, "loss": 0.00055, "time": 0.19487}
+{"mode": "train", "epoch": 188, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00054, "acc_pose": 0.84552, "loss": 0.00054, "time": 0.19293}
+{"mode": "train", "epoch": 189, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.05533, "heatmap_loss": 0.00055, "acc_pose": 0.84403, "loss": 0.00055, "time": 0.25171}
+{"mode": "train", "epoch": 189, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00054, "acc_pose": 0.84044, "loss": 0.00054, "time": 0.19225}
+{"mode": "train", "epoch": 189, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00055, "acc_pose": 0.84078, "loss": 0.00055, "time": 0.19167}
+{"mode": "train", "epoch": 189, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00055, "acc_pose": 0.83546, "loss": 0.00055, "time": 0.19196}
+{"mode": "train", "epoch": 189, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00054, "acc_pose": 0.84716, "loss": 0.00054, "time": 0.1933}
+{"mode": "train", "epoch": 190, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.05514, "heatmap_loss": 0.00055, "acc_pose": 0.84264, "loss": 0.00055, "time": 0.25016}
+{"mode": "train", "epoch": 190, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00055, "acc_pose": 0.84177, "loss": 0.00055, "time": 0.1921}
+{"mode": "train", "epoch": 190, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00054, "acc_pose": 0.84124, "loss": 0.00054, "time": 0.19178}
+{"mode": "train", "epoch": 190, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00054, "acc_pose": 0.84547, "loss": 0.00054, "time": 0.1927}
+{"mode": "train", "epoch": 190, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00055, "acc_pose": 0.84236, "loss": 0.00055, "time": 0.19218}
+{"mode": "val", "epoch": 190, "iter": 407, "lr": 0.0, "AP": 0.75787, "AP .5": 0.90716, "AP .75": 0.83162, "AP (M)": 0.68739, "AP (L)": 0.78369, "AR": 0.81, "AR .5": 0.94584, "AR .75": 0.87547, "AR (M)": 0.769, "AR (L)": 0.86968}
+{"mode": "train", "epoch": 191, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.05522, "heatmap_loss": 0.00054, "acc_pose": 0.8422, "loss": 0.00054, "time": 0.2481}
+{"mode": "train", "epoch": 191, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00055, "acc_pose": 0.84094, "loss": 0.00055, "time": 0.19158}
+{"mode": "train", "epoch": 191, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00054, "acc_pose": 0.84186, "loss": 0.00054, "time": 0.19232}
+{"mode": "train", "epoch": 191, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00054, "acc_pose": 0.84091, "loss": 0.00054, "time": 0.19136}
+{"mode": "train", "epoch": 191, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00054, "acc_pose": 0.83864, "loss": 0.00054, "time": 0.19157}
+{"mode": "train", "epoch": 192, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.05529, "heatmap_loss": 0.00055, "acc_pose": 0.83773, "loss": 0.00055, "time": 0.25}
+{"mode": "train", "epoch": 192, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00054, "acc_pose": 0.835, "loss": 0.00054, "time": 0.19243}
+{"mode": "train", "epoch": 192, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00054, "acc_pose": 0.84042, "loss": 0.00054, "time": 0.19309}
+{"mode": "train", "epoch": 192, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00054, "acc_pose": 0.84013, "loss": 0.00054, "time": 0.19314}
+{"mode": "train", "epoch": 192, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00054, "acc_pose": 0.84605, "loss": 0.00054, "time": 0.19255}
+{"mode": "train", "epoch": 193, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.05498, "heatmap_loss": 0.00055, "acc_pose": 0.84174, "loss": 0.00055, "time": 0.24998}
+{"mode": "train", "epoch": 193, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00054, "acc_pose": 0.84059, "loss": 0.00054, "time": 0.19211}
+{"mode": "train", "epoch": 193, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00054, "acc_pose": 0.84309, "loss": 0.00054, "time": 0.19311}
+{"mode": "train", "epoch": 193, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00054, "acc_pose": 0.83831, "loss": 0.00054, "time": 0.19315}
+{"mode": "train", "epoch": 193, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.00053, "heatmap_loss": 0.00054, "acc_pose": 0.83608, "loss": 0.00054, "time": 0.19314}
+{"mode": "train", "epoch": 194, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.05523, "heatmap_loss": 0.00054, "acc_pose": 0.8458, "loss": 0.00054, "time": 0.25094}
+{"mode": "train", "epoch": 194, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00055, "acc_pose": 0.83849, "loss": 0.00055, "time": 0.19248}
+{"mode": "train", "epoch": 194, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00054, "acc_pose": 0.84044, "loss": 0.00054, "time": 0.19252}
+{"mode": "train", "epoch": 194, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00054, "acc_pose": 0.83974, "loss": 0.00054, "time": 0.19176}
+{"mode": "train", "epoch": 194, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00054, "acc_pose": 0.84441, "loss": 0.00054, "time": 0.19311}
+{"mode": "train", "epoch": 195, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.0553, "heatmap_loss": 0.00054, "acc_pose": 0.84124, "loss": 0.00054, "time": 0.25226}
+{"mode": "train", "epoch": 195, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00034, "heatmap_loss": 0.00054, "acc_pose": 0.83477, "loss": 0.00054, "time": 0.19208}
+{"mode": "train", "epoch": 195, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00054, "acc_pose": 0.84552, "loss": 0.00054, "time": 0.19282}
+{"mode": "train", "epoch": 195, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00054, "acc_pose": 0.8402, "loss": 0.00054, "time": 0.19235}
+{"mode": "train", "epoch": 195, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00054, "acc_pose": 0.84204, "loss": 0.00054, "time": 0.19195}
+{"mode": "train", "epoch": 196, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.05563, "heatmap_loss": 0.00054, "acc_pose": 0.84103, "loss": 0.00054, "time": 0.25336}
+{"mode": "train", "epoch": 196, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00054, "acc_pose": 0.84822, "loss": 0.00054, "time": 0.19234}
+{"mode": "train", "epoch": 196, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00055, "acc_pose": 0.83332, "loss": 0.00055, "time": 0.19262}
+{"mode": "train", "epoch": 196, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00054, "acc_pose": 0.84668, "loss": 0.00054, "time": 0.19419}
+{"mode": "train", "epoch": 196, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00054, "acc_pose": 0.8371, "loss": 0.00054, "time": 0.19221}
+{"mode": "train", "epoch": 197, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.05533, "heatmap_loss": 0.00054, "acc_pose": 0.8437, "loss": 0.00054, "time": 0.24996}
+{"mode": "train", "epoch": 197, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00054, "acc_pose": 0.84633, "loss": 0.00054, "time": 0.19228}
+{"mode": "train", "epoch": 197, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00054, "acc_pose": 0.82946, "loss": 0.00054, "time": 0.19146}
+{"mode": "train", "epoch": 197, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00048, "heatmap_loss": 0.00054, "acc_pose": 0.83893, "loss": 0.00054, "time": 0.19192}
+{"mode": "train", "epoch": 197, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.00052, "heatmap_loss": 0.00054, "acc_pose": 0.84026, "loss": 0.00054, "time": 0.1921}
+{"mode": "train", "epoch": 198, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.05539, "heatmap_loss": 0.00054, "acc_pose": 0.8439, "loss": 0.00054, "time": 0.25053}
+{"mode": "train", "epoch": 198, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00055, "acc_pose": 0.84102, "loss": 0.00055, "time": 0.19229}
+{"mode": "train", "epoch": 198, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00054, "heatmap_loss": 0.00054, "acc_pose": 0.84033, "loss": 0.00054, "time": 0.19146}
+{"mode": "train", "epoch": 198, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00054, "acc_pose": 0.83822, "loss": 0.00054, "time": 0.192}
+{"mode": "train", "epoch": 198, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00054, "acc_pose": 0.84623, "loss": 0.00054, "time": 0.19201}
+{"mode": "train", "epoch": 199, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.05527, "heatmap_loss": 0.00054, "acc_pose": 0.84344, "loss": 0.00054, "time": 0.25363}
+{"mode": "train", "epoch": 199, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00054, "acc_pose": 0.84344, "loss": 0.00054, "time": 0.19245}
+{"mode": "train", "epoch": 199, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00055, "acc_pose": 0.83843, "loss": 0.00055, "time": 0.19248}
+{"mode": "train", "epoch": 199, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00054, "acc_pose": 0.83878, "loss": 0.00054, "time": 0.19266}
+{"mode": "train", "epoch": 199, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00055, "acc_pose": 0.84363, "loss": 0.00055, "time": 0.19198}
+{"mode": "train", "epoch": 200, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.05486, "heatmap_loss": 0.00054, "acc_pose": 0.84431, "loss": 0.00054, "time": 0.25024}
+{"mode": "train", "epoch": 200, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00054, "acc_pose": 0.83807, "loss": 0.00054, "time": 0.19269}
+{"mode": "train", "epoch": 200, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00054, "acc_pose": 0.83299, "loss": 0.00054, "time": 0.19169}
+{"mode": "train", "epoch": 200, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00054, "acc_pose": 0.84279, "loss": 0.00054, "time": 0.19193}
+{"mode": "train", "epoch": 200, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.00041, "heatmap_loss": 0.00054, "acc_pose": 0.83979, "loss": 0.00054, "time": 0.19181}
+{"mode": "val", "epoch": 200, "iter": 407, "lr": 0.0, "AP": 0.75755, "AP .5": 0.90679, "AP .75": 0.83125, "AP (M)": 0.6862, "AP (L)": 0.78449, "AR": 0.80956, "AR .5": 0.9449, "AR .75": 0.87531, "AR (M)": 0.76848, "AR (L)": 0.8699}
+{"mode": "train", "epoch": 201, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.0546, "heatmap_loss": 0.00054, "acc_pose": 0.83958, "loss": 0.00054, "time": 0.2469}
+{"mode": "train", "epoch": 201, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00054, "acc_pose": 0.8377, "loss": 0.00054, "time": 0.19233}
+{"mode": "train", "epoch": 201, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00054, "acc_pose": 0.8388, "loss": 0.00054, "time": 0.19249}
+{"mode": "train", "epoch": 201, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00054, "acc_pose": 0.84619, "loss": 0.00054, "time": 0.19361}
+{"mode": "train", "epoch": 201, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00054, "acc_pose": 0.83992, "loss": 0.00054, "time": 0.19324}
+{"mode": "train", "epoch": 202, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.05546, "heatmap_loss": 0.00054, "acc_pose": 0.84013, "loss": 0.00054, "time": 0.25025}
+{"mode": "train", "epoch": 202, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00055, "acc_pose": 0.84214, "loss": 0.00055, "time": 0.19265}
+{"mode": "train", "epoch": 202, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00054, "acc_pose": 0.84105, "loss": 0.00054, "time": 0.19196}
+{"mode": "train", "epoch": 202, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.0004, "heatmap_loss": 0.00054, "acc_pose": 0.84163, "loss": 0.00054, "time": 0.19168}
+{"mode": "train", "epoch": 202, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00054, "acc_pose": 0.84948, "loss": 0.00054, "time": 0.19196}
+{"mode": "train", "epoch": 203, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.0547, "heatmap_loss": 0.00054, "acc_pose": 0.83758, "loss": 0.00054, "time": 0.24917}
+{"mode": "train", "epoch": 203, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00054, "acc_pose": 0.84567, "loss": 0.00054, "time": 0.192}
+{"mode": "train", "epoch": 203, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00054, "acc_pose": 0.84453, "loss": 0.00054, "time": 0.19204}
+{"mode": "train", "epoch": 203, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00054, "acc_pose": 0.84029, "loss": 0.00054, "time": 0.19235}
+{"mode": "train", "epoch": 203, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00054, "acc_pose": 0.84212, "loss": 0.00054, "time": 0.1921}
+{"mode": "train", "epoch": 204, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.05564, "heatmap_loss": 0.00054, "acc_pose": 0.84082, "loss": 0.00054, "time": 0.25087}
+{"mode": "train", "epoch": 204, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00054, "acc_pose": 0.83945, "loss": 0.00054, "time": 0.19206}
+{"mode": "train", "epoch": 204, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00054, "acc_pose": 0.84128, "loss": 0.00054, "time": 0.19238}
+{"mode": "train", "epoch": 204, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00054, "acc_pose": 0.84176, "loss": 0.00054, "time": 0.19203}
+{"mode": "train", "epoch": 204, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00054, "acc_pose": 0.8399, "loss": 0.00054, "time": 0.19338}
+{"mode": "train", "epoch": 205, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.05522, "heatmap_loss": 0.00054, "acc_pose": 0.84643, "loss": 0.00054, "time": 0.25125}
+{"mode": "train", "epoch": 205, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00054, "acc_pose": 0.83879, "loss": 0.00054, "time": 0.19201}
+{"mode": "train", "epoch": 205, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00054, "acc_pose": 0.84232, "loss": 0.00054, "time": 0.19184}
+{"mode": "train", "epoch": 205, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00054, "acc_pose": 0.84765, "loss": 0.00054, "time": 0.19168}
+{"mode": "train", "epoch": 205, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00054, "acc_pose": 0.84443, "loss": 0.00054, "time": 0.19224}
+{"mode": "train", "epoch": 206, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.05471, "heatmap_loss": 0.00054, "acc_pose": 0.84274, "loss": 0.00054, "time": 0.25093}
+{"mode": "train", "epoch": 206, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00054, "acc_pose": 0.83922, "loss": 0.00054, "time": 0.19233}
+{"mode": "train", "epoch": 206, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00054, "acc_pose": 0.83649, "loss": 0.00054, "time": 0.19178}
+{"mode": "train", "epoch": 206, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00039, "heatmap_loss": 0.00054, "acc_pose": 0.84631, "loss": 0.00054, "time": 0.19277}
+{"mode": "train", "epoch": 206, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00054, "acc_pose": 0.84688, "loss": 0.00054, "time": 0.19176}
+{"mode": "train", "epoch": 207, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.05474, "heatmap_loss": 0.00054, "acc_pose": 0.84194, "loss": 0.00054, "time": 0.24985}
+{"mode": "train", "epoch": 207, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00054, "acc_pose": 0.83528, "loss": 0.00054, "time": 0.19236}
+{"mode": "train", "epoch": 207, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00054, "acc_pose": 0.84224, "loss": 0.00054, "time": 0.19215}
+{"mode": "train", "epoch": 207, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00036, "heatmap_loss": 0.00054, "acc_pose": 0.84453, "loss": 0.00054, "time": 0.19173}
+{"mode": "train", "epoch": 207, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.00044, "heatmap_loss": 0.00054, "acc_pose": 0.84403, "loss": 0.00054, "time": 0.19193}
+{"mode": "train", "epoch": 208, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.05579, "heatmap_loss": 0.00054, "acc_pose": 0.8411, "loss": 0.00054, "time": 0.25186}
+{"mode": "train", "epoch": 208, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00041, "heatmap_loss": 0.00054, "acc_pose": 0.84353, "loss": 0.00054, "time": 0.19204}
+{"mode": "train", "epoch": 208, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.0005, "heatmap_loss": 0.00054, "acc_pose": 0.84097, "loss": 0.00054, "time": 0.19191}
+{"mode": "train", "epoch": 208, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00043, "heatmap_loss": 0.00054, "acc_pose": 0.8434, "loss": 0.00054, "time": 0.19198}
+{"mode": "train", "epoch": 208, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.00043, "heatmap_loss": 0.00054, "acc_pose": 0.84669, "loss": 0.00054, "time": 0.19203}
+{"mode": "train", "epoch": 209, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.0567, "heatmap_loss": 0.00054, "acc_pose": 0.84273, "loss": 0.00054, "time": 0.25323}
+{"mode": "train", "epoch": 209, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00054, "acc_pose": 0.84593, "loss": 0.00054, "time": 0.19234}
+{"mode": "train", "epoch": 209, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00054, "acc_pose": 0.83997, "loss": 0.00054, "time": 0.19163}
+{"mode": "train", "epoch": 209, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00053, "acc_pose": 0.84397, "loss": 0.00053, "time": 0.19249}
+{"mode": "train", "epoch": 209, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.00038, "heatmap_loss": 0.00054, "acc_pose": 0.84646, "loss": 0.00054, "time": 0.19249}
+{"mode": "train", "epoch": 210, "iter": 50, "lr": 0.0, "memory": 14090, "data_time": 0.05512, "heatmap_loss": 0.00054, "acc_pose": 0.84194, "loss": 0.00054, "time": 0.25008}
+{"mode": "train", "epoch": 210, "iter": 100, "lr": 0.0, "memory": 14090, "data_time": 0.00035, "heatmap_loss": 0.00054, "acc_pose": 0.84276, "loss": 0.00054, "time": 0.1923}
+{"mode": "train", "epoch": 210, "iter": 150, "lr": 0.0, "memory": 14090, "data_time": 0.00034, "heatmap_loss": 0.00054, "acc_pose": 0.83771, "loss": 0.00054, "time": 0.19263}
+{"mode": "train", "epoch": 210, "iter": 200, "lr": 0.0, "memory": 14090, "data_time": 0.00034, "heatmap_loss": 0.00054, "acc_pose": 0.84572, "loss": 0.00054, "time": 0.194}
+{"mode": "train", "epoch": 210, "iter": 250, "lr": 0.0, "memory": 14090, "data_time": 0.00037, "heatmap_loss": 0.00054, "acc_pose": 0.84364, "loss": 0.00054, "time": 0.1921}
+{"mode": "val", "epoch": 210, "iter": 407, "lr": 0.0, "AP": 0.75797, "AP .5": 0.90664, "AP .75": 0.83177, "AP (M)": 0.68687, "AP (L)": 0.78389, "AR": 0.81072, "AR .5": 0.94553, "AR .75": 0.87657, "AR (M)": 0.77012, "AR (L)": 0.86983}
diff --git a/vendor/ViTPose/logs/vitpose-h-simple.log.json b/vendor/ViTPose/logs/vitpose-h-simple.log.json
new file mode 100644
index 0000000000000000000000000000000000000000..57a0502e96297e623bcba386b4687bb285cb3c0b
--- /dev/null
+++ b/vendor/ViTPose/logs/vitpose-h-simple.log.json
@@ -0,0 +1,1072 @@
+{"env_info": "sys.platform: linux\nPython: 3.8.10 | packaged by conda-forge | (default, May 11 2021, 07:01:05) [GCC 9.3.0]\nCUDA available: True\nGPU 0,1,2,3,4,5,6,7: A100-SXM4-40GB\nCUDA_HOME: /usr/local/cuda\nNVCC: Build cuda_11.3.r11.3/compiler.29920130_0\nGCC: gcc (Ubuntu 9.3.0-17ubuntu1~20.04) 9.3.0\nPyTorch: 1.9.0a0+c3d40fd\nPyTorch compiling details: PyTorch built with:\n - GCC 9.3\n - C++ Version: 201402\n - Intel(R) Math Kernel Library Version 2019.0.5 Product Build 20190808 for Intel(R) 64 architecture applications\n - Intel(R) MKL-DNN v2.1.2 (Git Hash N/A)\n - OpenMP 201511 (a.k.a. OpenMP 4.5)\n - NNPACK is enabled\n - CPU capability usage: AVX2\n - CUDA Runtime 11.3\n - NVCC architecture flags: -gencode;arch=compute_52,code=sm_52;-gencode;arch=compute_60,code=sm_60;-gencode;arch=compute_61,code=sm_61;-gencode;arch=compute_70,code=sm_70;-gencode;arch=compute_75,code=sm_75;-gencode;arch=compute_80,code=sm_80;-gencode;arch=compute_86,code=sm_86;-gencode;arch=compute_86,code=compute_86\n - CuDNN 8.2.1\n - Magma 2.5.2\n - Build settings: BLAS_INFO=mkl, BUILD_TYPE=Release, CUDA_VERSION=11.3, CUDNN_VERSION=8.2.1, CXX_COMPILER=/usr/bin/c++, CXX_FLAGS= -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_KINETO -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DUSE_XNNPACK -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -O2 -fPIC -Wno-narrowing -Wall -Wextra -Werror=return-type -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wno-sign-compare -Wno-unused-parameter -Wno-unused-variable -Wno-unused-function -Wno-unused-result -Wno-unused-local-typedefs -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-psabi -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Werror=cast-function-type -Wno-stringop-overflow, LAPACK_INFO=mkl, PERF_WITH_AVX=1, PERF_WITH_AVX2=1, PERF_WITH_AVX512=1, TORCH_VERSION=1.9.0, USE_CUDA=ON, USE_CUDNN=ON, USE_EXCEPTION_PTR=1, USE_GFLAGS=OFF, USE_GLOG=OFF, USE_MKL=ON, USE_MKLDNN=ON, USE_MPI=ON, USE_NCCL=ON, USE_NNPACK=ON, USE_OPENMP=ON, \n\nTorchVision: 0.10.0a0\nOpenCV: 4.5.5\nMMCV: 1.3.9\nMMCV Compiler: GCC 9.3\nMMCV CUDA Compiler: 11.3\nMMPose: 0.24.0+cb93b25", "seed": 0, "hook_msgs": {}}
+{"mode": "train", "epoch": 1, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.05293, "heatmap_loss": 0.00297, "acc_pose": 0.01131, "loss": 0.00297, "grad_norm": 0.19058, "time": 0.52151}
+{"mode": "train", "epoch": 1, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.0026, "acc_pose": 0.02932, "loss": 0.0026, "grad_norm": 0.18838, "time": 0.34167}
+{"mode": "train", "epoch": 1, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00054, "heatmap_loss": 0.00264, "acc_pose": 0.06887, "loss": 0.00264, "grad_norm": 0.19104, "time": 0.34008}
+{"mode": "train", "epoch": 1, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00276, "acc_pose": 0.08797, "loss": 0.00276, "grad_norm": 0.19039, "time": 0.34065}
+{"mode": "train", "epoch": 1, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00283, "acc_pose": 0.11359, "loss": 0.00283, "grad_norm": 0.16872, "time": 0.33942}
+{"mode": "train", "epoch": 2, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04677, "heatmap_loss": 0.00232, "acc_pose": 0.13551, "loss": 0.00232, "grad_norm": 0.06389, "time": 0.39018}
+{"mode": "train", "epoch": 2, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00214, "acc_pose": 0.17894, "loss": 0.00214, "grad_norm": 0.02635, "time": 0.34228}
+{"mode": "train", "epoch": 2, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00212, "acc_pose": 0.18381, "loss": 0.00212, "grad_norm": 0.02546, "time": 0.33966}
+{"mode": "train", "epoch": 2, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00212, "acc_pose": 0.18125, "loss": 0.00212, "grad_norm": 0.02535, "time": 0.34033}
+{"mode": "train", "epoch": 2, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00209, "acc_pose": 0.18781, "loss": 0.00209, "grad_norm": 0.01764, "time": 0.34053}
+{"mode": "train", "epoch": 3, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04671, "heatmap_loss": 0.00215, "acc_pose": 0.19025, "loss": 0.00215, "grad_norm": 0.02762, "time": 0.38975}
+{"mode": "train", "epoch": 3, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00206, "acc_pose": 0.20656, "loss": 0.00206, "grad_norm": 0.01532, "time": 0.34}
+{"mode": "train", "epoch": 3, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00203, "acc_pose": 0.19292, "loss": 0.00203, "grad_norm": 0.01494, "time": 0.33927}
+{"mode": "train", "epoch": 3, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00054, "heatmap_loss": 0.00201, "acc_pose": 0.21062, "loss": 0.00201, "grad_norm": 0.01142, "time": 0.33941}
+{"mode": "train", "epoch": 3, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00198, "acc_pose": 0.21841, "loss": 0.00198, "grad_norm": 0.0108, "time": 0.34021}
+{"mode": "train", "epoch": 4, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04666, "heatmap_loss": 0.00195, "acc_pose": 0.22025, "loss": 0.00195, "grad_norm": 0.01554, "time": 0.38756}
+{"mode": "train", "epoch": 4, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00206, "acc_pose": 0.2361, "loss": 0.00206, "grad_norm": 0.03529, "time": 0.33773}
+{"mode": "train", "epoch": 4, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00191, "acc_pose": 0.25507, "loss": 0.00191, "grad_norm": 0.02021, "time": 0.33854}
+{"mode": "train", "epoch": 4, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00188, "acc_pose": 0.27192, "loss": 0.00188, "grad_norm": 0.01774, "time": 0.3392}
+{"mode": "train", "epoch": 4, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00052, "heatmap_loss": 0.00178, "acc_pose": 0.30238, "loss": 0.00178, "grad_norm": 0.0109, "time": 0.33865}
+{"mode": "train", "epoch": 5, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04674, "heatmap_loss": 0.00165, "acc_pose": 0.37009, "loss": 0.00165, "grad_norm": 0.00831, "time": 0.38613}
+{"mode": "train", "epoch": 5, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00161, "acc_pose": 0.38802, "loss": 0.00161, "grad_norm": 0.01211, "time": 0.3344}
+{"mode": "train", "epoch": 5, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00052, "heatmap_loss": 0.00154, "acc_pose": 0.43671, "loss": 0.00154, "grad_norm": 0.0106, "time": 0.33466}
+{"mode": "train", "epoch": 5, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00152, "acc_pose": 0.431, "loss": 0.00152, "grad_norm": 0.0123, "time": 0.33503}
+{"mode": "train", "epoch": 5, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00149, "acc_pose": 0.44643, "loss": 0.00149, "grad_norm": 0.01491, "time": 0.3339}
+{"mode": "train", "epoch": 6, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04669, "heatmap_loss": 0.00137, "acc_pose": 0.49262, "loss": 0.00137, "grad_norm": 0.01059, "time": 0.38432}
+{"mode": "train", "epoch": 6, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00134, "acc_pose": 0.50653, "loss": 0.00134, "grad_norm": 0.00969, "time": 0.33462}
+{"mode": "train", "epoch": 6, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00131, "acc_pose": 0.54633, "loss": 0.00131, "grad_norm": 0.01392, "time": 0.33733}
+{"mode": "train", "epoch": 6, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00053, "heatmap_loss": 0.00139, "acc_pose": 0.52807, "loss": 0.00139, "grad_norm": 0.02206, "time": 0.33525}
+{"mode": "train", "epoch": 6, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00126, "acc_pose": 0.54308, "loss": 0.00126, "grad_norm": 0.00803, "time": 0.33717}
+{"mode": "train", "epoch": 7, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04684, "heatmap_loss": 0.00122, "acc_pose": 0.5614, "loss": 0.00122, "grad_norm": 0.00908, "time": 0.38928}
+{"mode": "train", "epoch": 7, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.0012, "acc_pose": 0.5816, "loss": 0.0012, "grad_norm": 0.00893, "time": 0.33679}
+{"mode": "train", "epoch": 7, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00126, "acc_pose": 0.57847, "loss": 0.00126, "grad_norm": 0.01545, "time": 0.33833}
+{"mode": "train", "epoch": 7, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00126, "acc_pose": 0.56575, "loss": 0.00126, "grad_norm": 0.01603, "time": 0.33832}
+{"mode": "train", "epoch": 7, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00115, "acc_pose": 0.60182, "loss": 0.00115, "grad_norm": 0.00492, "time": 0.33886}
+{"mode": "train", "epoch": 8, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.047, "heatmap_loss": 0.00111, "acc_pose": 0.60023, "loss": 0.00111, "grad_norm": 0.00606, "time": 0.38646}
+{"mode": "train", "epoch": 8, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00111, "acc_pose": 0.60057, "loss": 0.00111, "grad_norm": 0.00712, "time": 0.3384}
+{"mode": "train", "epoch": 8, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.0011, "acc_pose": 0.62444, "loss": 0.0011, "grad_norm": 0.00483, "time": 0.33978}
+{"mode": "train", "epoch": 8, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00108, "acc_pose": 0.61419, "loss": 0.00108, "grad_norm": 0.00424, "time": 0.33606}
+{"mode": "train", "epoch": 8, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00105, "acc_pose": 0.6378, "loss": 0.00105, "grad_norm": 0.00407, "time": 0.33708}
+{"mode": "train", "epoch": 9, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04672, "heatmap_loss": 0.00104, "acc_pose": 0.63702, "loss": 0.00104, "grad_norm": 0.00566, "time": 0.38555}
+{"mode": "train", "epoch": 9, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00104, "acc_pose": 0.6478, "loss": 0.00104, "grad_norm": 0.00667, "time": 0.3336}
+{"mode": "train", "epoch": 9, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00103, "acc_pose": 0.65266, "loss": 0.00103, "grad_norm": 0.00636, "time": 0.33507}
+{"mode": "train", "epoch": 9, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00102, "acc_pose": 0.63901, "loss": 0.00102, "grad_norm": 0.00689, "time": 0.33305}
+{"mode": "train", "epoch": 9, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00102, "acc_pose": 0.66026, "loss": 0.00102, "grad_norm": 0.00886, "time": 0.33449}
+{"mode": "train", "epoch": 10, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04667, "heatmap_loss": 0.00099, "acc_pose": 0.66112, "loss": 0.00099, "grad_norm": 0.00509, "time": 0.38456}
+{"mode": "train", "epoch": 10, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00098, "acc_pose": 0.6508, "loss": 0.00098, "grad_norm": 0.0045, "time": 0.33599}
+{"mode": "train", "epoch": 10, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00061, "heatmap_loss": 0.00099, "acc_pose": 0.65702, "loss": 0.00099, "grad_norm": 0.00503, "time": 0.33831}
+{"mode": "train", "epoch": 10, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00097, "acc_pose": 0.65133, "loss": 0.00097, "grad_norm": 0.00682, "time": 0.33685}
+{"mode": "train", "epoch": 10, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00097, "acc_pose": 0.64197, "loss": 0.00097, "grad_norm": 0.00532, "time": 0.33706}
+{"mode": "val", "epoch": 10, "iter": 204, "lr": 0.0, "AP": 0.67965, "AP .5": 0.88156, "AP .75": 0.75853, "AP (M)": 0.60239, "AP (L)": 0.70688, "AR": 0.74126, "AR .5": 0.92569, "AR .75": 0.81266, "AR (M)": 0.69325, "AR (L)": 0.80944}
+{"mode": "train", "epoch": 11, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04728, "heatmap_loss": 0.00097, "acc_pose": 0.67524, "loss": 0.00097, "grad_norm": 0.00782, "time": 0.38409}
+{"mode": "train", "epoch": 11, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00094, "acc_pose": 0.67478, "loss": 0.00094, "grad_norm": 0.00477, "time": 0.33797}
+{"mode": "train", "epoch": 11, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00094, "acc_pose": 0.66583, "loss": 0.00094, "grad_norm": 0.00515, "time": 0.33778}
+{"mode": "train", "epoch": 11, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00095, "acc_pose": 0.68735, "loss": 0.00095, "grad_norm": 0.00615, "time": 0.34056}
+{"mode": "train", "epoch": 11, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00093, "acc_pose": 0.68291, "loss": 0.00093, "grad_norm": 0.00471, "time": 0.34056}
+{"mode": "train", "epoch": 12, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.047, "heatmap_loss": 0.00093, "acc_pose": 0.67752, "loss": 0.00093, "grad_norm": 0.00733, "time": 0.38939}
+{"mode": "train", "epoch": 12, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00096, "acc_pose": 0.69269, "loss": 0.00096, "grad_norm": 0.00988, "time": 0.33734}
+{"mode": "train", "epoch": 12, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00095, "acc_pose": 0.68473, "loss": 0.00095, "grad_norm": 0.0072, "time": 0.33743}
+{"mode": "train", "epoch": 12, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00095, "acc_pose": 0.68487, "loss": 0.00095, "grad_norm": 0.00645, "time": 0.33615}
+{"mode": "train", "epoch": 12, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00091, "acc_pose": 0.68931, "loss": 0.00091, "grad_norm": 0.00318, "time": 0.33625}
+{"mode": "train", "epoch": 13, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04719, "heatmap_loss": 0.00092, "acc_pose": 0.68644, "loss": 0.00092, "grad_norm": 0.0051, "time": 0.38387}
+{"mode": "train", "epoch": 13, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.0009, "acc_pose": 0.70693, "loss": 0.0009, "grad_norm": 0.00332, "time": 0.33411}
+{"mode": "train", "epoch": 13, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.0009, "acc_pose": 0.6977, "loss": 0.0009, "grad_norm": 0.00403, "time": 0.33418}
+{"mode": "train", "epoch": 13, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00089, "acc_pose": 0.71661, "loss": 0.00089, "grad_norm": 0.00341, "time": 0.33429}
+{"mode": "train", "epoch": 13, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00089, "acc_pose": 0.69298, "loss": 0.00089, "grad_norm": 0.00415, "time": 0.33525}
+{"mode": "train", "epoch": 14, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04713, "heatmap_loss": 0.00089, "acc_pose": 0.69286, "loss": 0.00089, "grad_norm": 0.00417, "time": 0.38837}
+{"mode": "train", "epoch": 14, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00088, "acc_pose": 0.72214, "loss": 0.00088, "grad_norm": 0.00353, "time": 0.33828}
+{"mode": "train", "epoch": 14, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00053, "heatmap_loss": 0.00088, "acc_pose": 0.71615, "loss": 0.00088, "grad_norm": 0.00383, "time": 0.33746}
+{"mode": "train", "epoch": 14, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00088, "acc_pose": 0.70948, "loss": 0.00088, "grad_norm": 0.00385, "time": 0.33603}
+{"mode": "train", "epoch": 14, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00086, "acc_pose": 0.72187, "loss": 0.00086, "grad_norm": 0.0028, "time": 0.33876}
+{"mode": "train", "epoch": 15, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04682, "heatmap_loss": 0.00086, "acc_pose": 0.69541, "loss": 0.00086, "grad_norm": 0.003, "time": 0.38876}
+{"mode": "train", "epoch": 15, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00086, "acc_pose": 0.72578, "loss": 0.00086, "grad_norm": 0.00363, "time": 0.33775}
+{"mode": "train", "epoch": 15, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00086, "acc_pose": 0.69954, "loss": 0.00086, "grad_norm": 0.00268, "time": 0.3365}
+{"mode": "train", "epoch": 15, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00085, "acc_pose": 0.71021, "loss": 0.00085, "grad_norm": 0.00291, "time": 0.33587}
+{"mode": "train", "epoch": 15, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00085, "acc_pose": 0.69157, "loss": 0.00085, "grad_norm": 0.00304, "time": 0.33752}
+{"mode": "train", "epoch": 16, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04706, "heatmap_loss": 0.00084, "acc_pose": 0.73389, "loss": 0.00084, "grad_norm": 0.00281, "time": 0.38461}
+{"mode": "train", "epoch": 16, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00086, "acc_pose": 0.73023, "loss": 0.00086, "grad_norm": 0.00496, "time": 0.33403}
+{"mode": "train", "epoch": 16, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00086, "acc_pose": 0.71539, "loss": 0.00086, "grad_norm": 0.00453, "time": 0.33432}
+{"mode": "train", "epoch": 16, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00087, "acc_pose": 0.72183, "loss": 0.00087, "grad_norm": 0.00568, "time": 0.33329}
+{"mode": "train", "epoch": 16, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00084, "acc_pose": 0.72053, "loss": 0.00084, "grad_norm": 0.00318, "time": 0.33426}
+{"mode": "train", "epoch": 17, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04694, "heatmap_loss": 0.00084, "acc_pose": 0.73349, "loss": 0.00084, "grad_norm": 0.00263, "time": 0.38594}
+{"mode": "train", "epoch": 17, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00083, "acc_pose": 0.72952, "loss": 0.00083, "grad_norm": 0.00307, "time": 0.33608}
+{"mode": "train", "epoch": 17, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00083, "acc_pose": 0.7442, "loss": 0.00083, "grad_norm": 0.00347, "time": 0.33469}
+{"mode": "train", "epoch": 17, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00052, "heatmap_loss": 0.00082, "acc_pose": 0.72588, "loss": 0.00082, "grad_norm": 0.00206, "time": 0.33419}
+{"mode": "train", "epoch": 17, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00081, "acc_pose": 0.7362, "loss": 0.00081, "grad_norm": 0.00203, "time": 0.33487}
+{"mode": "train", "epoch": 18, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.0471, "heatmap_loss": 0.00082, "acc_pose": 0.72712, "loss": 0.00082, "grad_norm": 0.00278, "time": 0.38685}
+{"mode": "train", "epoch": 18, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00081, "acc_pose": 0.72257, "loss": 0.00081, "grad_norm": 0.00226, "time": 0.33612}
+{"mode": "train", "epoch": 18, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.0008, "acc_pose": 0.74582, "loss": 0.0008, "grad_norm": 0.00215, "time": 0.33885}
+{"mode": "train", "epoch": 18, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00081, "acc_pose": 0.72482, "loss": 0.00081, "grad_norm": 0.00261, "time": 0.337}
+{"mode": "train", "epoch": 18, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00081, "acc_pose": 0.7439, "loss": 0.00081, "grad_norm": 0.0027, "time": 0.33827}
+{"mode": "train", "epoch": 19, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04698, "heatmap_loss": 0.0008, "acc_pose": 0.73639, "loss": 0.0008, "grad_norm": 0.00199, "time": 0.38582}
+{"mode": "train", "epoch": 19, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.0008, "acc_pose": 0.75469, "loss": 0.0008, "grad_norm": 0.00232, "time": 0.33585}
+{"mode": "train", "epoch": 19, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00083, "acc_pose": 0.73045, "loss": 0.00083, "grad_norm": 0.00441, "time": 0.33611}
+{"mode": "train", "epoch": 19, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00088, "acc_pose": 0.73042, "loss": 0.00088, "grad_norm": 0.0042, "time": 0.33609}
+{"mode": "train", "epoch": 19, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00082, "acc_pose": 0.72058, "loss": 0.00082, "grad_norm": 0.00257, "time": 0.34133}
+{"mode": "train", "epoch": 20, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04692, "heatmap_loss": 0.00079, "acc_pose": 0.73707, "loss": 0.00079, "grad_norm": 0.00204, "time": 0.38993}
+{"mode": "train", "epoch": 20, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00054, "heatmap_loss": 0.00079, "acc_pose": 0.75538, "loss": 0.00079, "grad_norm": 0.00211, "time": 0.33839}
+{"mode": "train", "epoch": 20, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00079, "acc_pose": 0.74883, "loss": 0.00079, "grad_norm": 0.00188, "time": 0.3369}
+{"mode": "train", "epoch": 20, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00079, "acc_pose": 0.73459, "loss": 0.00079, "grad_norm": 0.00189, "time": 0.33622}
+{"mode": "train", "epoch": 20, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00079, "acc_pose": 0.73594, "loss": 0.00079, "grad_norm": 0.00184, "time": 0.33761}
+{"mode": "val", "epoch": 20, "iter": 204, "lr": 0.0, "AP": 0.73444, "AP .5": 0.89993, "AP .75": 0.81329, "AP (M)": 0.65545, "AP (L)": 0.76303, "AR": 0.79321, "AR .5": 0.94096, "AR .75": 0.86272, "AR (M)": 0.74728, "AR (L)": 0.85946}
+{"mode": "train", "epoch": 21, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04758, "heatmap_loss": 0.00078, "acc_pose": 0.73618, "loss": 0.00078, "grad_norm": 0.00192, "time": 0.38342}
+{"mode": "train", "epoch": 21, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00078, "acc_pose": 0.74914, "loss": 0.00078, "grad_norm": 0.00194, "time": 0.3369}
+{"mode": "train", "epoch": 21, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00078, "acc_pose": 0.75432, "loss": 0.00078, "grad_norm": 0.0019, "time": 0.33504}
+{"mode": "train", "epoch": 21, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00077, "acc_pose": 0.73291, "loss": 0.00077, "grad_norm": 0.00185, "time": 0.33576}
+{"mode": "train", "epoch": 21, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00078, "acc_pose": 0.74413, "loss": 0.00078, "grad_norm": 0.00258, "time": 0.33376}
+{"mode": "train", "epoch": 22, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04699, "heatmap_loss": 0.00078, "acc_pose": 0.74918, "loss": 0.00078, "grad_norm": 0.00243, "time": 0.38402}
+{"mode": "train", "epoch": 22, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00078, "acc_pose": 0.74641, "loss": 0.00078, "grad_norm": 0.0025, "time": 0.33569}
+{"mode": "train", "epoch": 22, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00077, "acc_pose": 0.7503, "loss": 0.00077, "grad_norm": 0.00241, "time": 0.33426}
+{"mode": "train", "epoch": 22, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00055, "heatmap_loss": 0.00078, "acc_pose": 0.75505, "loss": 0.00078, "grad_norm": 0.00265, "time": 0.33663}
+{"mode": "train", "epoch": 22, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00062, "heatmap_loss": 0.00076, "acc_pose": 0.76472, "loss": 0.00076, "grad_norm": 0.00183, "time": 0.336}
+{"mode": "train", "epoch": 23, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04689, "heatmap_loss": 0.00076, "acc_pose": 0.76097, "loss": 0.00076, "grad_norm": 0.00177, "time": 0.38724}
+{"mode": "train", "epoch": 23, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00077, "acc_pose": 0.75629, "loss": 0.00077, "grad_norm": 0.0024, "time": 0.3366}
+{"mode": "train", "epoch": 23, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00076, "acc_pose": 0.75633, "loss": 0.00076, "grad_norm": 0.00211, "time": 0.33368}
+{"mode": "train", "epoch": 23, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00076, "acc_pose": 0.7474, "loss": 0.00076, "grad_norm": 0.00189, "time": 0.33534}
+{"mode": "train", "epoch": 23, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00077, "acc_pose": 0.7524, "loss": 0.00077, "grad_norm": 0.00207, "time": 0.33498}
+{"mode": "train", "epoch": 24, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04687, "heatmap_loss": 0.00075, "acc_pose": 0.74043, "loss": 0.00075, "grad_norm": 0.0017, "time": 0.38812}
+{"mode": "train", "epoch": 24, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00057, "heatmap_loss": 0.00075, "acc_pose": 0.76057, "loss": 0.00075, "grad_norm": 0.00179, "time": 0.33768}
+{"mode": "train", "epoch": 24, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00053, "heatmap_loss": 0.00076, "acc_pose": 0.75992, "loss": 0.00076, "grad_norm": 0.00222, "time": 0.33684}
+{"mode": "train", "epoch": 24, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00052, "heatmap_loss": 0.0008, "acc_pose": 0.74762, "loss": 0.0008, "grad_norm": 0.0029, "time": 0.33481}
+{"mode": "train", "epoch": 24, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00076, "acc_pose": 0.75743, "loss": 0.00076, "grad_norm": 0.00187, "time": 0.33529}
+{"mode": "train", "epoch": 25, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04686, "heatmap_loss": 0.0008, "acc_pose": 0.74839, "loss": 0.0008, "grad_norm": 0.00255, "time": 0.38854}
+{"mode": "train", "epoch": 25, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00078, "acc_pose": 0.75396, "loss": 0.00078, "grad_norm": 0.00217, "time": 0.33724}
+{"mode": "train", "epoch": 25, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00076, "acc_pose": 0.76647, "loss": 0.00076, "grad_norm": 0.00187, "time": 0.33646}
+{"mode": "train", "epoch": 25, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00075, "acc_pose": 0.75792, "loss": 0.00075, "grad_norm": 0.00166, "time": 0.33582}
+{"mode": "train", "epoch": 25, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00074, "acc_pose": 0.75221, "loss": 0.00074, "grad_norm": 0.00179, "time": 0.33566}
+{"mode": "train", "epoch": 26, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04689, "heatmap_loss": 0.00074, "acc_pose": 0.76395, "loss": 0.00074, "grad_norm": 0.00159, "time": 0.38695}
+{"mode": "train", "epoch": 26, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00074, "acc_pose": 0.77739, "loss": 0.00074, "grad_norm": 0.00162, "time": 0.33516}
+{"mode": "train", "epoch": 26, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00073, "acc_pose": 0.75464, "loss": 0.00073, "grad_norm": 0.00169, "time": 0.33582}
+{"mode": "train", "epoch": 26, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00074, "acc_pose": 0.77193, "loss": 0.00074, "grad_norm": 0.00162, "time": 0.33465}
+{"mode": "train", "epoch": 26, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00073, "acc_pose": 0.75601, "loss": 0.00073, "grad_norm": 0.0017, "time": 0.33453}
+{"mode": "train", "epoch": 27, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04731, "heatmap_loss": 0.00074, "acc_pose": 0.7591, "loss": 0.00074, "grad_norm": 0.00166, "time": 0.38461}
+{"mode": "train", "epoch": 27, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00073, "acc_pose": 0.76521, "loss": 0.00073, "grad_norm": 0.00164, "time": 0.3341}
+{"mode": "train", "epoch": 27, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00073, "acc_pose": 0.77981, "loss": 0.00073, "grad_norm": 0.00182, "time": 0.33343}
+{"mode": "train", "epoch": 27, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00073, "acc_pose": 0.75147, "loss": 0.00073, "grad_norm": 0.00165, "time": 0.33274}
+{"mode": "train", "epoch": 27, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00072, "acc_pose": 0.75207, "loss": 0.00072, "grad_norm": 0.00168, "time": 0.33398}
+{"mode": "train", "epoch": 28, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04692, "heatmap_loss": 0.00072, "acc_pose": 0.7818, "loss": 0.00072, "grad_norm": 0.00172, "time": 0.38863}
+{"mode": "train", "epoch": 28, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00072, "acc_pose": 0.76466, "loss": 0.00072, "grad_norm": 0.00168, "time": 0.33695}
+{"mode": "train", "epoch": 28, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00073, "acc_pose": 0.76279, "loss": 0.00073, "grad_norm": 0.00175, "time": 0.33734}
+{"mode": "train", "epoch": 28, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00072, "acc_pose": 0.76678, "loss": 0.00072, "grad_norm": 0.00157, "time": 0.33717}
+{"mode": "train", "epoch": 28, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00072, "acc_pose": 0.75865, "loss": 0.00072, "grad_norm": 0.00182, "time": 0.33692}
+{"mode": "train", "epoch": 29, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04714, "heatmap_loss": 0.00072, "acc_pose": 0.75806, "loss": 0.00072, "grad_norm": 0.00186, "time": 0.38766}
+{"mode": "train", "epoch": 29, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00073, "acc_pose": 0.77253, "loss": 0.00073, "grad_norm": 0.00162, "time": 0.3343}
+{"mode": "train", "epoch": 29, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00072, "acc_pose": 0.77557, "loss": 0.00072, "grad_norm": 0.00167, "time": 0.33651}
+{"mode": "train", "epoch": 29, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00072, "acc_pose": 0.76979, "loss": 0.00072, "grad_norm": 0.00188, "time": 0.33741}
+{"mode": "train", "epoch": 29, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00072, "acc_pose": 0.76709, "loss": 0.00072, "grad_norm": 0.00167, "time": 0.33639}
+{"mode": "train", "epoch": 30, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04721, "heatmap_loss": 0.00072, "acc_pose": 0.76195, "loss": 0.00072, "grad_norm": 0.0017, "time": 0.38597}
+{"mode": "train", "epoch": 30, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00073, "acc_pose": 0.7692, "loss": 0.00073, "grad_norm": 0.00169, "time": 0.33692}
+{"mode": "train", "epoch": 30, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00072, "acc_pose": 0.77634, "loss": 0.00072, "grad_norm": 0.00171, "time": 0.33541}
+{"mode": "train", "epoch": 30, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00071, "acc_pose": 0.77697, "loss": 0.00071, "grad_norm": 0.00158, "time": 0.33744}
+{"mode": "train", "epoch": 30, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00054, "heatmap_loss": 0.00072, "acc_pose": 0.75441, "loss": 0.00072, "grad_norm": 0.00175, "time": 0.33718}
+{"mode": "val", "epoch": 30, "iter": 204, "lr": 0.0, "AP": 0.75264, "AP .5": 0.90546, "AP .75": 0.82769, "AP (M)": 0.67772, "AP (L)": 0.77964, "AR": 0.80932, "AR .5": 0.94742, "AR .75": 0.87547, "AR (M)": 0.76599, "AR (L)": 0.87161}
+{"mode": "train", "epoch": 31, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04772, "heatmap_loss": 0.00072, "acc_pose": 0.78441, "loss": 0.00072, "grad_norm": 0.0016, "time": 0.38064}
+{"mode": "train", "epoch": 31, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00071, "acc_pose": 0.78017, "loss": 0.00071, "grad_norm": 0.00158, "time": 0.33713}
+{"mode": "train", "epoch": 31, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00071, "acc_pose": 0.7625, "loss": 0.00071, "grad_norm": 0.00165, "time": 0.33729}
+{"mode": "train", "epoch": 31, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00071, "acc_pose": 0.77824, "loss": 0.00071, "grad_norm": 0.00168, "time": 0.34009}
+{"mode": "train", "epoch": 31, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.0007, "acc_pose": 0.77605, "loss": 0.0007, "grad_norm": 0.00159, "time": 0.33592}
+{"mode": "train", "epoch": 32, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04954, "heatmap_loss": 0.0007, "acc_pose": 0.77422, "loss": 0.0007, "grad_norm": 0.00153, "time": 0.38911}
+{"mode": "train", "epoch": 32, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00071, "acc_pose": 0.79526, "loss": 0.00071, "grad_norm": 0.00158, "time": 0.34117}
+{"mode": "train", "epoch": 32, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.0007, "acc_pose": 0.77912, "loss": 0.0007, "grad_norm": 0.00161, "time": 0.33969}
+{"mode": "train", "epoch": 32, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.0007, "acc_pose": 0.78037, "loss": 0.0007, "grad_norm": 0.00159, "time": 0.33931}
+{"mode": "train", "epoch": 32, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.0007, "acc_pose": 0.7759, "loss": 0.0007, "grad_norm": 0.00164, "time": 0.33966}
+{"mode": "train", "epoch": 33, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.047, "heatmap_loss": 0.0007, "acc_pose": 0.78046, "loss": 0.0007, "grad_norm": 0.00157, "time": 0.3874}
+{"mode": "train", "epoch": 33, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00062, "heatmap_loss": 0.00071, "acc_pose": 0.78073, "loss": 0.00071, "grad_norm": 0.00163, "time": 0.33505}
+{"mode": "train", "epoch": 33, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.0007, "acc_pose": 0.78105, "loss": 0.0007, "grad_norm": 0.00175, "time": 0.33515}
+{"mode": "train", "epoch": 33, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00053, "heatmap_loss": 0.0007, "acc_pose": 0.78112, "loss": 0.0007, "grad_norm": 0.0017, "time": 0.33414}
+{"mode": "train", "epoch": 33, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.0007, "acc_pose": 0.78013, "loss": 0.0007, "grad_norm": 0.00158, "time": 0.33492}
+{"mode": "train", "epoch": 34, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04717, "heatmap_loss": 0.0007, "acc_pose": 0.77626, "loss": 0.0007, "grad_norm": 0.00152, "time": 0.38795}
+{"mode": "train", "epoch": 34, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00074, "acc_pose": 0.75652, "loss": 0.00074, "grad_norm": 0.00198, "time": 0.33678}
+{"mode": "train", "epoch": 34, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00072, "acc_pose": 0.78386, "loss": 0.00072, "grad_norm": 0.00177, "time": 0.33887}
+{"mode": "train", "epoch": 34, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.0007, "acc_pose": 0.7807, "loss": 0.0007, "grad_norm": 0.00154, "time": 0.33665}
+{"mode": "train", "epoch": 34, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.0007, "acc_pose": 0.77928, "loss": 0.0007, "grad_norm": 0.00155, "time": 0.33513}
+{"mode": "train", "epoch": 35, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04699, "heatmap_loss": 0.0007, "acc_pose": 0.77964, "loss": 0.0007, "grad_norm": 0.00164, "time": 0.38551}
+{"mode": "train", "epoch": 35, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00069, "acc_pose": 0.78187, "loss": 0.00069, "grad_norm": 0.00161, "time": 0.33603}
+{"mode": "train", "epoch": 35, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00069, "acc_pose": 0.77757, "loss": 0.00069, "grad_norm": 0.00153, "time": 0.33614}
+{"mode": "train", "epoch": 35, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00054, "heatmap_loss": 0.00069, "acc_pose": 0.77432, "loss": 0.00069, "grad_norm": 0.00166, "time": 0.33445}
+{"mode": "train", "epoch": 35, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00055, "heatmap_loss": 0.00069, "acc_pose": 0.77995, "loss": 0.00069, "grad_norm": 0.0016, "time": 0.33804}
+{"mode": "train", "epoch": 36, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04718, "heatmap_loss": 0.00069, "acc_pose": 0.76456, "loss": 0.00069, "grad_norm": 0.00155, "time": 0.3866}
+{"mode": "train", "epoch": 36, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00069, "acc_pose": 0.7746, "loss": 0.00069, "grad_norm": 0.00153, "time": 0.33398}
+{"mode": "train", "epoch": 36, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00069, "acc_pose": 0.76628, "loss": 0.00069, "grad_norm": 0.00155, "time": 0.33506}
+{"mode": "train", "epoch": 36, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00068, "acc_pose": 0.77429, "loss": 0.00068, "grad_norm": 0.00154, "time": 0.33673}
+{"mode": "train", "epoch": 36, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00069, "acc_pose": 0.78511, "loss": 0.00069, "grad_norm": 0.0015, "time": 0.33873}
+{"mode": "train", "epoch": 37, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.047, "heatmap_loss": 0.00068, "acc_pose": 0.77047, "loss": 0.00068, "grad_norm": 0.00145, "time": 0.38832}
+{"mode": "train", "epoch": 37, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00054, "heatmap_loss": 0.00069, "acc_pose": 0.77379, "loss": 0.00069, "grad_norm": 0.00155, "time": 0.33481}
+{"mode": "train", "epoch": 37, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00068, "acc_pose": 0.7754, "loss": 0.00068, "grad_norm": 0.00146, "time": 0.33508}
+{"mode": "train", "epoch": 37, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00068, "acc_pose": 0.79712, "loss": 0.00068, "grad_norm": 0.00154, "time": 0.33642}
+{"mode": "train", "epoch": 37, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00054, "heatmap_loss": 0.00068, "acc_pose": 0.76381, "loss": 0.00068, "grad_norm": 0.00152, "time": 0.33721}
+{"mode": "train", "epoch": 38, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.0472, "heatmap_loss": 0.00068, "acc_pose": 0.78035, "loss": 0.00068, "grad_norm": 0.00156, "time": 0.38817}
+{"mode": "train", "epoch": 38, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00068, "acc_pose": 0.78901, "loss": 0.00068, "grad_norm": 0.00149, "time": 0.33891}
+{"mode": "train", "epoch": 38, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00069, "acc_pose": 0.80312, "loss": 0.00069, "grad_norm": 0.00153, "time": 0.33922}
+{"mode": "train", "epoch": 38, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00068, "acc_pose": 0.77435, "loss": 0.00068, "grad_norm": 0.00143, "time": 0.33857}
+{"mode": "train", "epoch": 38, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00069, "acc_pose": 0.79214, "loss": 0.00069, "grad_norm": 0.00161, "time": 0.33915}
+{"mode": "train", "epoch": 39, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04687, "heatmap_loss": 0.00068, "acc_pose": 0.79059, "loss": 0.00068, "grad_norm": 0.00155, "time": 0.38425}
+{"mode": "train", "epoch": 39, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00067, "acc_pose": 0.77419, "loss": 0.00067, "grad_norm": 0.00159, "time": 0.33603}
+{"mode": "train", "epoch": 39, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00072, "acc_pose": 0.79285, "loss": 0.00072, "grad_norm": 0.002, "time": 0.33776}
+{"mode": "train", "epoch": 39, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00072, "acc_pose": 0.76485, "loss": 0.00072, "grad_norm": 0.00154, "time": 0.33485}
+{"mode": "train", "epoch": 39, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00069, "acc_pose": 0.7805, "loss": 0.00069, "grad_norm": 0.00164, "time": 0.33488}
+{"mode": "train", "epoch": 40, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04698, "heatmap_loss": 0.00068, "acc_pose": 0.77962, "loss": 0.00068, "grad_norm": 0.00153, "time": 0.38415}
+{"mode": "train", "epoch": 40, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00068, "acc_pose": 0.78728, "loss": 0.00068, "grad_norm": 0.00157, "time": 0.3349}
+{"mode": "train", "epoch": 40, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00046, "heatmap_loss": 0.00068, "acc_pose": 0.78463, "loss": 0.00068, "grad_norm": 0.0015, "time": 0.33432}
+{"mode": "train", "epoch": 40, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00067, "acc_pose": 0.7979, "loss": 0.00067, "grad_norm": 0.00147, "time": 0.33532}
+{"mode": "train", "epoch": 40, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00067, "acc_pose": 0.77893, "loss": 0.00067, "grad_norm": 0.00145, "time": 0.33485}
+{"mode": "val", "epoch": 40, "iter": 204, "lr": 0.0, "AP": 0.76184, "AP .5": 0.90694, "AP .75": 0.83713, "AP (M)": 0.68769, "AP (L)": 0.7905, "AR": 0.81568, "AR .5": 0.94726, "AR .75": 0.88145, "AR (M)": 0.77225, "AR (L)": 0.87867}
+{"mode": "train", "epoch": 41, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04649, "heatmap_loss": 0.00067, "acc_pose": 0.78731, "loss": 0.00067, "grad_norm": 0.00146, "time": 0.38286}
+{"mode": "train", "epoch": 41, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00052, "heatmap_loss": 0.00067, "acc_pose": 0.78718, "loss": 0.00067, "grad_norm": 0.00159, "time": 0.33636}
+{"mode": "train", "epoch": 41, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00067, "acc_pose": 0.79362, "loss": 0.00067, "grad_norm": 0.00148, "time": 0.33439}
+{"mode": "train", "epoch": 41, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00067, "acc_pose": 0.77885, "loss": 0.00067, "grad_norm": 0.00149, "time": 0.33472}
+{"mode": "train", "epoch": 41, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00067, "acc_pose": 0.78137, "loss": 0.00067, "grad_norm": 0.0015, "time": 0.33538}
+{"mode": "train", "epoch": 42, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04667, "heatmap_loss": 0.00067, "acc_pose": 0.79283, "loss": 0.00067, "grad_norm": 0.00146, "time": 0.38602}
+{"mode": "train", "epoch": 42, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00067, "acc_pose": 0.78821, "loss": 0.00067, "grad_norm": 0.00149, "time": 0.33729}
+{"mode": "train", "epoch": 42, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00067, "acc_pose": 0.7928, "loss": 0.00067, "grad_norm": 0.0015, "time": 0.33597}
+{"mode": "train", "epoch": 42, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00066, "acc_pose": 0.80383, "loss": 0.00066, "grad_norm": 0.00153, "time": 0.33516}
+{"mode": "train", "epoch": 42, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00052, "heatmap_loss": 0.00067, "acc_pose": 0.78674, "loss": 0.00067, "grad_norm": 0.00148, "time": 0.33392}
+{"mode": "train", "epoch": 43, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04715, "heatmap_loss": 0.00067, "acc_pose": 0.78703, "loss": 0.00067, "grad_norm": 0.00159, "time": 0.38466}
+{"mode": "train", "epoch": 43, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00066, "acc_pose": 0.79378, "loss": 0.00066, "grad_norm": 0.0016, "time": 0.33314}
+{"mode": "train", "epoch": 43, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00052, "heatmap_loss": 0.00066, "acc_pose": 0.78707, "loss": 0.00066, "grad_norm": 0.00147, "time": 0.3343}
+{"mode": "train", "epoch": 43, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00066, "acc_pose": 0.79178, "loss": 0.00066, "grad_norm": 0.00141, "time": 0.3342}
+{"mode": "train", "epoch": 43, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00067, "acc_pose": 0.77378, "loss": 0.00067, "grad_norm": 0.00159, "time": 0.33665}
+{"mode": "train", "epoch": 44, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.0489, "heatmap_loss": 0.00066, "acc_pose": 0.78374, "loss": 0.00066, "grad_norm": 0.0015, "time": 0.38516}
+{"mode": "train", "epoch": 44, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00066, "acc_pose": 0.79839, "loss": 0.00066, "grad_norm": 0.00149, "time": 0.33426}
+{"mode": "train", "epoch": 44, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00066, "acc_pose": 0.79202, "loss": 0.00066, "grad_norm": 0.00143, "time": 0.33796}
+{"mode": "train", "epoch": 44, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00066, "acc_pose": 0.79628, "loss": 0.00066, "grad_norm": 0.0015, "time": 0.33842}
+{"mode": "train", "epoch": 44, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00066, "acc_pose": 0.78514, "loss": 0.00066, "grad_norm": 0.00148, "time": 0.33743}
+{"mode": "train", "epoch": 45, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.047, "heatmap_loss": 0.00067, "acc_pose": 0.79576, "loss": 0.00067, "grad_norm": 0.00149, "time": 0.38999}
+{"mode": "train", "epoch": 45, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00066, "acc_pose": 0.7971, "loss": 0.00066, "grad_norm": 0.00153, "time": 0.33598}
+{"mode": "train", "epoch": 45, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00066, "acc_pose": 0.78032, "loss": 0.00066, "grad_norm": 0.0015, "time": 0.33619}
+{"mode": "train", "epoch": 45, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00066, "acc_pose": 0.78611, "loss": 0.00066, "grad_norm": 0.00155, "time": 0.33448}
+{"mode": "train", "epoch": 45, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00066, "acc_pose": 0.80095, "loss": 0.00066, "grad_norm": 0.00144, "time": 0.33611}
+{"mode": "train", "epoch": 46, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04704, "heatmap_loss": 0.00065, "acc_pose": 0.78367, "loss": 0.00065, "grad_norm": 0.00149, "time": 0.3882}
+{"mode": "train", "epoch": 46, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00065, "acc_pose": 0.80015, "loss": 0.00065, "grad_norm": 0.00147, "time": 0.33629}
+{"mode": "train", "epoch": 46, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00066, "acc_pose": 0.78171, "loss": 0.00066, "grad_norm": 0.00155, "time": 0.33773}
+{"mode": "train", "epoch": 46, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00065, "acc_pose": 0.79977, "loss": 0.00065, "grad_norm": 0.00149, "time": 0.33637}
+{"mode": "train", "epoch": 46, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00065, "acc_pose": 0.81316, "loss": 0.00065, "grad_norm": 0.00152, "time": 0.33668}
+{"mode": "train", "epoch": 47, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04714, "heatmap_loss": 0.00065, "acc_pose": 0.79847, "loss": 0.00065, "grad_norm": 0.00148, "time": 0.38769}
+{"mode": "train", "epoch": 47, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00065, "acc_pose": 0.80256, "loss": 0.00065, "grad_norm": 0.00141, "time": 0.33302}
+{"mode": "train", "epoch": 47, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00064, "heatmap_loss": 0.00067, "acc_pose": 0.79847, "loss": 0.00067, "grad_norm": 0.00151, "time": 0.33536}
+{"mode": "train", "epoch": 47, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00066, "acc_pose": 0.79333, "loss": 0.00066, "grad_norm": 0.00157, "time": 0.3347}
+{"mode": "train", "epoch": 47, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00066, "acc_pose": 0.79586, "loss": 0.00066, "grad_norm": 0.00143, "time": 0.33575}
+{"mode": "train", "epoch": 48, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.047, "heatmap_loss": 0.00066, "acc_pose": 0.79189, "loss": 0.00066, "grad_norm": 0.00151, "time": 0.38552}
+{"mode": "train", "epoch": 48, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00064, "acc_pose": 0.81404, "loss": 0.00064, "grad_norm": 0.00145, "time": 0.33538}
+{"mode": "train", "epoch": 48, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00065, "acc_pose": 0.78923, "loss": 0.00065, "grad_norm": 0.00153, "time": 0.33581}
+{"mode": "train", "epoch": 48, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00066, "acc_pose": 0.79664, "loss": 0.00066, "grad_norm": 0.00149, "time": 0.336}
+{"mode": "train", "epoch": 48, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00066, "acc_pose": 0.79736, "loss": 0.00066, "grad_norm": 0.00152, "time": 0.33694}
+{"mode": "train", "epoch": 49, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04819, "heatmap_loss": 0.00066, "acc_pose": 0.79115, "loss": 0.00066, "grad_norm": 0.00146, "time": 0.38769}
+{"mode": "train", "epoch": 49, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00068, "acc_pose": 0.78194, "loss": 0.00068, "grad_norm": 0.00163, "time": 0.33733}
+{"mode": "train", "epoch": 49, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00053, "heatmap_loss": 0.00065, "acc_pose": 0.79345, "loss": 0.00065, "grad_norm": 0.00144, "time": 0.33648}
+{"mode": "train", "epoch": 49, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00065, "acc_pose": 0.78361, "loss": 0.00065, "grad_norm": 0.00146, "time": 0.3368}
+{"mode": "train", "epoch": 49, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00065, "acc_pose": 0.80556, "loss": 0.00065, "grad_norm": 0.00148, "time": 0.3367}
+{"mode": "train", "epoch": 50, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04709, "heatmap_loss": 0.00065, "acc_pose": 0.81693, "loss": 0.00065, "grad_norm": 0.00144, "time": 0.38499}
+{"mode": "train", "epoch": 50, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00066, "acc_pose": 0.80127, "loss": 0.00066, "grad_norm": 0.00142, "time": 0.33434}
+{"mode": "train", "epoch": 50, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00065, "acc_pose": 0.79834, "loss": 0.00065, "grad_norm": 0.00144, "time": 0.33446}
+{"mode": "train", "epoch": 50, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00065, "acc_pose": 0.78893, "loss": 0.00065, "grad_norm": 0.0015, "time": 0.33385}
+{"mode": "train", "epoch": 50, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00064, "acc_pose": 0.77737, "loss": 0.00064, "grad_norm": 0.00146, "time": 0.3366}
+{"mode": "val", "epoch": 50, "iter": 204, "lr": 0.0, "AP": 0.76895, "AP .5": 0.90937, "AP .75": 0.84362, "AP (M)": 0.6952, "AP (L)": 0.7984, "AR": 0.82272, "AR .5": 0.94994, "AR .75": 0.88822, "AR (M)": 0.78082, "AR (L)": 0.8841}
+{"mode": "train", "epoch": 51, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04689, "heatmap_loss": 0.00065, "acc_pose": 0.79649, "loss": 0.00065, "grad_norm": 0.00146, "time": 0.38164}
+{"mode": "train", "epoch": 51, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00065, "acc_pose": 0.80442, "loss": 0.00065, "grad_norm": 0.00147, "time": 0.33401}
+{"mode": "train", "epoch": 51, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00065, "acc_pose": 0.79142, "loss": 0.00065, "grad_norm": 0.00147, "time": 0.33582}
+{"mode": "train", "epoch": 51, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00065, "acc_pose": 0.79836, "loss": 0.00065, "grad_norm": 0.0015, "time": 0.33546}
+{"mode": "train", "epoch": 51, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00065, "acc_pose": 0.78636, "loss": 0.00065, "grad_norm": 0.00156, "time": 0.33405}
+{"mode": "train", "epoch": 52, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04715, "heatmap_loss": 0.00065, "acc_pose": 0.79131, "loss": 0.00065, "grad_norm": 0.00141, "time": 0.38871}
+{"mode": "train", "epoch": 52, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00064, "acc_pose": 0.80077, "loss": 0.00064, "grad_norm": 0.00142, "time": 0.33519}
+{"mode": "train", "epoch": 52, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00065, "acc_pose": 0.81402, "loss": 0.00065, "grad_norm": 0.0015, "time": 0.33852}
+{"mode": "train", "epoch": 52, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00064, "acc_pose": 0.80053, "loss": 0.00064, "grad_norm": 0.00148, "time": 0.33692}
+{"mode": "train", "epoch": 52, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00059, "heatmap_loss": 0.00065, "acc_pose": 0.79431, "loss": 0.00065, "grad_norm": 0.00139, "time": 0.33806}
+{"mode": "train", "epoch": 53, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04724, "heatmap_loss": 0.00064, "acc_pose": 0.79813, "loss": 0.00064, "grad_norm": 0.00141, "time": 0.386}
+{"mode": "train", "epoch": 53, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00064, "acc_pose": 0.80101, "loss": 0.00064, "grad_norm": 0.00141, "time": 0.33393}
+{"mode": "train", "epoch": 53, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00064, "acc_pose": 0.80871, "loss": 0.00064, "grad_norm": 0.00146, "time": 0.33802}
+{"mode": "train", "epoch": 53, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00064, "acc_pose": 0.79996, "loss": 0.00064, "grad_norm": 0.00139, "time": 0.33697}
+{"mode": "train", "epoch": 53, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00064, "acc_pose": 0.80484, "loss": 0.00064, "grad_norm": 0.00143, "time": 0.33994}
+{"mode": "train", "epoch": 54, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04729, "heatmap_loss": 0.00064, "acc_pose": 0.78863, "loss": 0.00064, "grad_norm": 0.00134, "time": 0.3876}
+{"mode": "train", "epoch": 54, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00064, "acc_pose": 0.81466, "loss": 0.00064, "grad_norm": 0.0014, "time": 0.33362}
+{"mode": "train", "epoch": 54, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00063, "acc_pose": 0.80664, "loss": 0.00063, "grad_norm": 0.00134, "time": 0.33501}
+{"mode": "train", "epoch": 54, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00064, "acc_pose": 0.79997, "loss": 0.00064, "grad_norm": 0.0015, "time": 0.33449}
+{"mode": "train", "epoch": 54, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00065, "acc_pose": 0.81176, "loss": 0.00065, "grad_norm": 0.00143, "time": 0.33443}
+{"mode": "train", "epoch": 55, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04738, "heatmap_loss": 0.00064, "acc_pose": 0.80555, "loss": 0.00064, "grad_norm": 0.00148, "time": 0.38644}
+{"mode": "train", "epoch": 55, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00064, "acc_pose": 0.8002, "loss": 0.00064, "grad_norm": 0.00133, "time": 0.33329}
+{"mode": "train", "epoch": 55, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00064, "acc_pose": 0.79641, "loss": 0.00064, "grad_norm": 0.00138, "time": 0.33374}
+{"mode": "train", "epoch": 55, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00063, "acc_pose": 0.80807, "loss": 0.00063, "grad_norm": 0.00141, "time": 0.33583}
+{"mode": "train", "epoch": 55, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00063, "acc_pose": 0.80559, "loss": 0.00063, "grad_norm": 0.00146, "time": 0.33545}
+{"mode": "train", "epoch": 56, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04717, "heatmap_loss": 0.00064, "acc_pose": 0.79183, "loss": 0.00064, "grad_norm": 0.00137, "time": 0.38496}
+{"mode": "train", "epoch": 56, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00063, "acc_pose": 0.82086, "loss": 0.00063, "grad_norm": 0.00143, "time": 0.33477}
+{"mode": "train", "epoch": 56, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00063, "acc_pose": 0.79241, "loss": 0.00063, "grad_norm": 0.0015, "time": 0.33751}
+{"mode": "train", "epoch": 56, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00063, "acc_pose": 0.79301, "loss": 0.00063, "grad_norm": 0.00138, "time": 0.33604}
+{"mode": "train", "epoch": 56, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00063, "acc_pose": 0.79112, "loss": 0.00063, "grad_norm": 0.00142, "time": 0.33577}
+{"mode": "train", "epoch": 57, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04708, "heatmap_loss": 0.00064, "acc_pose": 0.80065, "loss": 0.00064, "grad_norm": 0.00144, "time": 0.38866}
+{"mode": "train", "epoch": 57, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00063, "acc_pose": 0.80415, "loss": 0.00063, "grad_norm": 0.0014, "time": 0.33644}
+{"mode": "train", "epoch": 57, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00063, "acc_pose": 0.79827, "loss": 0.00063, "grad_norm": 0.00136, "time": 0.33766}
+{"mode": "train", "epoch": 57, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00063, "acc_pose": 0.81207, "loss": 0.00063, "grad_norm": 0.00155, "time": 0.33501}
+{"mode": "train", "epoch": 57, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00064, "acc_pose": 0.78988, "loss": 0.00064, "grad_norm": 0.00138, "time": 0.33608}
+{"mode": "train", "epoch": 58, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04705, "heatmap_loss": 0.00064, "acc_pose": 0.80396, "loss": 0.00064, "grad_norm": 0.00142, "time": 0.3884}
+{"mode": "train", "epoch": 58, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00063, "acc_pose": 0.80656, "loss": 0.00063, "grad_norm": 0.00138, "time": 0.33808}
+{"mode": "train", "epoch": 58, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00063, "acc_pose": 0.80739, "loss": 0.00063, "grad_norm": 0.00143, "time": 0.33418}
+{"mode": "train", "epoch": 58, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00063, "acc_pose": 0.80733, "loss": 0.00063, "grad_norm": 0.00138, "time": 0.33588}
+{"mode": "train", "epoch": 58, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00063, "acc_pose": 0.79086, "loss": 0.00063, "grad_norm": 0.00135, "time": 0.33673}
+{"mode": "train", "epoch": 59, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04738, "heatmap_loss": 0.00063, "acc_pose": 0.80894, "loss": 0.00063, "grad_norm": 0.00144, "time": 0.38852}
+{"mode": "train", "epoch": 59, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00063, "acc_pose": 0.80312, "loss": 0.00063, "grad_norm": 0.00141, "time": 0.33613}
+{"mode": "train", "epoch": 59, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00063, "acc_pose": 0.81124, "loss": 0.00063, "grad_norm": 0.00133, "time": 0.33633}
+{"mode": "train", "epoch": 59, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00062, "acc_pose": 0.79697, "loss": 0.00062, "grad_norm": 0.0014, "time": 0.34053}
+{"mode": "train", "epoch": 59, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00052, "heatmap_loss": 0.00063, "acc_pose": 0.82115, "loss": 0.00063, "grad_norm": 0.00142, "time": 0.33886}
+{"mode": "train", "epoch": 60, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04733, "heatmap_loss": 0.00063, "acc_pose": 0.81256, "loss": 0.00063, "grad_norm": 0.0014, "time": 0.38515}
+{"mode": "train", "epoch": 60, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00062, "acc_pose": 0.81092, "loss": 0.00062, "grad_norm": 0.00149, "time": 0.33402}
+{"mode": "train", "epoch": 60, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00063, "acc_pose": 0.80677, "loss": 0.00063, "grad_norm": 0.0014, "time": 0.33406}
+{"mode": "train", "epoch": 60, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00063, "acc_pose": 0.81114, "loss": 0.00063, "grad_norm": 0.00143, "time": 0.33394}
+{"mode": "train", "epoch": 60, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00063, "acc_pose": 0.80344, "loss": 0.00063, "grad_norm": 0.00147, "time": 0.33611}
+{"mode": "val", "epoch": 60, "iter": 204, "lr": 0.0, "AP": 0.77286, "AP .5": 0.91075, "AP .75": 0.84527, "AP (M)": 0.69948, "AP (L)": 0.80437, "AR": 0.82467, "AR .5": 0.94946, "AR .75": 0.88791, "AR (M)": 0.78233, "AR (L)": 0.88655}
+{"mode": "train", "epoch": 61, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04702, "heatmap_loss": 0.00062, "acc_pose": 0.79793, "loss": 0.00062, "grad_norm": 0.00134, "time": 0.38755}
+{"mode": "train", "epoch": 61, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00065, "acc_pose": 0.79435, "loss": 0.00065, "grad_norm": 0.00166, "time": 0.33883}
+{"mode": "train", "epoch": 61, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00062, "acc_pose": 0.81395, "loss": 0.00062, "grad_norm": 0.00136, "time": 0.33817}
+{"mode": "train", "epoch": 61, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00063, "acc_pose": 0.79548, "loss": 0.00063, "grad_norm": 0.00139, "time": 0.33729}
+{"mode": "train", "epoch": 61, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00063, "acc_pose": 0.81552, "loss": 0.00063, "grad_norm": 0.00144, "time": 0.33622}
+{"mode": "train", "epoch": 62, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04732, "heatmap_loss": 0.00063, "acc_pose": 0.80037, "loss": 0.00063, "grad_norm": 0.00142, "time": 0.38477}
+{"mode": "train", "epoch": 62, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00063, "acc_pose": 0.80578, "loss": 0.00063, "grad_norm": 0.00143, "time": 0.33664}
+{"mode": "train", "epoch": 62, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00062, "acc_pose": 0.81735, "loss": 0.00062, "grad_norm": 0.00137, "time": 0.33691}
+{"mode": "train", "epoch": 62, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00063, "acc_pose": 0.80593, "loss": 0.00063, "grad_norm": 0.00136, "time": 0.33577}
+{"mode": "train", "epoch": 62, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00062, "acc_pose": 0.80774, "loss": 0.00062, "grad_norm": 0.00144, "time": 0.33526}
+{"mode": "train", "epoch": 63, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04712, "heatmap_loss": 0.00062, "acc_pose": 0.80081, "loss": 0.00062, "grad_norm": 0.00138, "time": 0.38884}
+{"mode": "train", "epoch": 63, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00062, "acc_pose": 0.80198, "loss": 0.00062, "grad_norm": 0.00141, "time": 0.33491}
+{"mode": "train", "epoch": 63, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00063, "acc_pose": 0.80659, "loss": 0.00063, "grad_norm": 0.00138, "time": 0.33619}
+{"mode": "train", "epoch": 63, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00062, "acc_pose": 0.80235, "loss": 0.00062, "grad_norm": 0.0014, "time": 0.33637}
+{"mode": "train", "epoch": 63, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00062, "acc_pose": 0.81408, "loss": 0.00062, "grad_norm": 0.00135, "time": 0.33807}
+{"mode": "train", "epoch": 64, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04738, "heatmap_loss": 0.00061, "acc_pose": 0.80458, "loss": 0.00061, "grad_norm": 0.00134, "time": 0.39249}
+{"mode": "train", "epoch": 64, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00061, "acc_pose": 0.81635, "loss": 0.00061, "grad_norm": 0.0014, "time": 0.33897}
+{"mode": "train", "epoch": 64, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00062, "acc_pose": 0.80646, "loss": 0.00062, "grad_norm": 0.00141, "time": 0.3393}
+{"mode": "train", "epoch": 64, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00062, "acc_pose": 0.78707, "loss": 0.00062, "grad_norm": 0.0014, "time": 0.33594}
+{"mode": "train", "epoch": 64, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00062, "acc_pose": 0.80933, "loss": 0.00062, "grad_norm": 0.00138, "time": 0.33669}
+{"mode": "train", "epoch": 65, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04731, "heatmap_loss": 0.00062, "acc_pose": 0.80898, "loss": 0.00062, "grad_norm": 0.00136, "time": 0.38711}
+{"mode": "train", "epoch": 65, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00062, "acc_pose": 0.81412, "loss": 0.00062, "grad_norm": 0.00139, "time": 0.33441}
+{"mode": "train", "epoch": 65, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00046, "heatmap_loss": 0.00062, "acc_pose": 0.80944, "loss": 0.00062, "grad_norm": 0.00139, "time": 0.33541}
+{"mode": "train", "epoch": 65, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00061, "acc_pose": 0.80488, "loss": 0.00061, "grad_norm": 0.00143, "time": 0.33522}
+{"mode": "train", "epoch": 65, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00062, "acc_pose": 0.81408, "loss": 0.00062, "grad_norm": 0.00134, "time": 0.33542}
+{"mode": "train", "epoch": 66, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04707, "heatmap_loss": 0.00062, "acc_pose": 0.81592, "loss": 0.00062, "grad_norm": 0.00199, "time": 0.38826}
+{"mode": "train", "epoch": 66, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00062, "acc_pose": 0.81624, "loss": 0.00062, "grad_norm": 0.00144, "time": 0.33453}
+{"mode": "train", "epoch": 66, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00062, "acc_pose": 0.79986, "loss": 0.00062, "grad_norm": 0.00144, "time": 0.33508}
+{"mode": "train", "epoch": 66, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00062, "acc_pose": 0.79971, "loss": 0.00062, "grad_norm": 0.00133, "time": 0.33616}
+{"mode": "train", "epoch": 66, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00061, "acc_pose": 0.79098, "loss": 0.00061, "grad_norm": 0.00148, "time": 0.33405}
+{"mode": "train", "epoch": 67, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04726, "heatmap_loss": 0.00062, "acc_pose": 0.80922, "loss": 0.00062, "grad_norm": 0.00138, "time": 0.38644}
+{"mode": "train", "epoch": 67, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00061, "acc_pose": 0.82826, "loss": 0.00061, "grad_norm": 0.0013, "time": 0.33393}
+{"mode": "train", "epoch": 67, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00062, "acc_pose": 0.80693, "loss": 0.00062, "grad_norm": 0.00141, "time": 0.33829}
+{"mode": "train", "epoch": 67, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00061, "acc_pose": 0.80079, "loss": 0.00061, "grad_norm": 0.00136, "time": 0.33729}
+{"mode": "train", "epoch": 67, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00062, "acc_pose": 0.81203, "loss": 0.00062, "grad_norm": 0.00142, "time": 0.3359}
+{"mode": "train", "epoch": 68, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04743, "heatmap_loss": 0.00061, "acc_pose": 0.80518, "loss": 0.00061, "grad_norm": 0.0013, "time": 0.38514}
+{"mode": "train", "epoch": 68, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00061, "acc_pose": 0.79657, "loss": 0.00061, "grad_norm": 0.00133, "time": 0.3346}
+{"mode": "train", "epoch": 68, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00062, "acc_pose": 0.81837, "loss": 0.00062, "grad_norm": 0.00133, "time": 0.33431}
+{"mode": "train", "epoch": 68, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00062, "acc_pose": 0.80202, "loss": 0.00062, "grad_norm": 0.00142, "time": 0.33493}
+{"mode": "train", "epoch": 68, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00062, "acc_pose": 0.81926, "loss": 0.00062, "grad_norm": 0.00137, "time": 0.3348}
+{"mode": "train", "epoch": 69, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04757, "heatmap_loss": 0.00062, "acc_pose": 0.80276, "loss": 0.00062, "grad_norm": 0.00138, "time": 0.38823}
+{"mode": "train", "epoch": 69, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00061, "acc_pose": 0.82005, "loss": 0.00061, "grad_norm": 0.00143, "time": 0.3384}
+{"mode": "train", "epoch": 69, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00056, "heatmap_loss": 0.00061, "acc_pose": 0.81598, "loss": 0.00061, "grad_norm": 0.00136, "time": 0.3377}
+{"mode": "train", "epoch": 69, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00062, "acc_pose": 0.80567, "loss": 0.00062, "grad_norm": 0.00134, "time": 0.33439}
+{"mode": "train", "epoch": 69, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00063, "heatmap_loss": 0.00062, "acc_pose": 0.8048, "loss": 0.00062, "grad_norm": 0.00133, "time": 0.33668}
+{"mode": "train", "epoch": 70, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04709, "heatmap_loss": 0.00061, "acc_pose": 0.81476, "loss": 0.00061, "grad_norm": 0.00134, "time": 0.38708}
+{"mode": "train", "epoch": 70, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00061, "acc_pose": 0.81769, "loss": 0.00061, "grad_norm": 0.00146, "time": 0.33913}
+{"mode": "train", "epoch": 70, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00061, "acc_pose": 0.80406, "loss": 0.00061, "grad_norm": 0.00136, "time": 0.33749}
+{"mode": "train", "epoch": 70, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00062, "acc_pose": 0.80287, "loss": 0.00062, "grad_norm": 0.00137, "time": 0.33794}
+{"mode": "train", "epoch": 70, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00061, "acc_pose": 0.81436, "loss": 0.00061, "grad_norm": 0.00147, "time": 0.33693}
+{"mode": "val", "epoch": 70, "iter": 204, "lr": 0.0, "AP": 0.77446, "AP .5": 0.91254, "AP .75": 0.84454, "AP (M)": 0.69984, "AP (L)": 0.80548, "AR": 0.82679, "AR .5": 0.95025, "AR .75": 0.8887, "AR (M)": 0.78476, "AR (L)": 0.88811}
+{"mode": "train", "epoch": 71, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04689, "heatmap_loss": 0.00061, "acc_pose": 0.81639, "loss": 0.00061, "grad_norm": 0.00131, "time": 0.38536}
+{"mode": "train", "epoch": 71, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00061, "acc_pose": 0.80946, "loss": 0.00061, "grad_norm": 0.00135, "time": 0.33741}
+{"mode": "train", "epoch": 71, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00053, "heatmap_loss": 0.00062, "acc_pose": 0.80596, "loss": 0.00062, "grad_norm": 0.00136, "time": 0.33569}
+{"mode": "train", "epoch": 71, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00061, "acc_pose": 0.80743, "loss": 0.00061, "grad_norm": 0.00135, "time": 0.33458}
+{"mode": "train", "epoch": 71, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00061, "acc_pose": 0.82504, "loss": 0.00061, "grad_norm": 0.00139, "time": 0.33762}
+{"mode": "train", "epoch": 72, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04729, "heatmap_loss": 0.00061, "acc_pose": 0.81344, "loss": 0.00061, "grad_norm": 0.00134, "time": 0.3895}
+{"mode": "train", "epoch": 72, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00061, "acc_pose": 0.819, "loss": 0.00061, "grad_norm": 0.0014, "time": 0.33906}
+{"mode": "train", "epoch": 72, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00061, "acc_pose": 0.80561, "loss": 0.00061, "grad_norm": 0.00143, "time": 0.33979}
+{"mode": "train", "epoch": 72, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00061, "acc_pose": 0.81303, "loss": 0.00061, "grad_norm": 0.00135, "time": 0.33962}
+{"mode": "train", "epoch": 72, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00061, "acc_pose": 0.80633, "loss": 0.00061, "grad_norm": 0.00131, "time": 0.33956}
+{"mode": "train", "epoch": 73, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.0485, "heatmap_loss": 0.00061, "acc_pose": 0.80483, "loss": 0.00061, "grad_norm": 0.0014, "time": 0.38615}
+{"mode": "train", "epoch": 73, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00053, "heatmap_loss": 0.00061, "acc_pose": 0.81726, "loss": 0.00061, "grad_norm": 0.00135, "time": 0.33474}
+{"mode": "train", "epoch": 73, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00061, "acc_pose": 0.80545, "loss": 0.00061, "grad_norm": 0.00133, "time": 0.33459}
+{"mode": "train", "epoch": 73, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.0006, "acc_pose": 0.81753, "loss": 0.0006, "grad_norm": 0.00131, "time": 0.33332}
+{"mode": "train", "epoch": 73, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00061, "acc_pose": 0.81838, "loss": 0.00061, "grad_norm": 0.00131, "time": 0.33443}
+{"mode": "train", "epoch": 74, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04716, "heatmap_loss": 0.00061, "acc_pose": 0.81594, "loss": 0.00061, "grad_norm": 0.00138, "time": 0.38818}
+{"mode": "train", "epoch": 74, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.0006, "acc_pose": 0.8002, "loss": 0.0006, "grad_norm": 0.0013, "time": 0.33867}
+{"mode": "train", "epoch": 74, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.0006, "acc_pose": 0.79808, "loss": 0.0006, "grad_norm": 0.00135, "time": 0.33684}
+{"mode": "train", "epoch": 74, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.0006, "acc_pose": 0.80556, "loss": 0.0006, "grad_norm": 0.00136, "time": 0.33431}
+{"mode": "train", "epoch": 74, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00061, "acc_pose": 0.80017, "loss": 0.00061, "grad_norm": 0.00132, "time": 0.33402}
+{"mode": "train", "epoch": 75, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04711, "heatmap_loss": 0.00061, "acc_pose": 0.82033, "loss": 0.00061, "grad_norm": 0.00128, "time": 0.39197}
+{"mode": "train", "epoch": 75, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.0006, "acc_pose": 0.80535, "loss": 0.0006, "grad_norm": 0.0014, "time": 0.33547}
+{"mode": "train", "epoch": 75, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.0006, "acc_pose": 0.81483, "loss": 0.0006, "grad_norm": 0.0013, "time": 0.33581}
+{"mode": "train", "epoch": 75, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00061, "acc_pose": 0.80653, "loss": 0.00061, "grad_norm": 0.00136, "time": 0.33392}
+{"mode": "train", "epoch": 75, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00061, "acc_pose": 0.81621, "loss": 0.00061, "grad_norm": 0.00145, "time": 0.33411}
+{"mode": "train", "epoch": 76, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04711, "heatmap_loss": 0.0006, "acc_pose": 0.80615, "loss": 0.0006, "grad_norm": 0.00136, "time": 0.38675}
+{"mode": "train", "epoch": 76, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00061, "acc_pose": 0.81975, "loss": 0.00061, "grad_norm": 0.00131, "time": 0.33434}
+{"mode": "train", "epoch": 76, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.0006, "acc_pose": 0.82868, "loss": 0.0006, "grad_norm": 0.00134, "time": 0.33512}
+{"mode": "train", "epoch": 76, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.0006, "acc_pose": 0.81412, "loss": 0.0006, "grad_norm": 0.0013, "time": 0.33369}
+{"mode": "train", "epoch": 76, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00061, "acc_pose": 0.8132, "loss": 0.00061, "grad_norm": 0.00136, "time": 0.33498}
+{"mode": "train", "epoch": 77, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04737, "heatmap_loss": 0.0006, "acc_pose": 0.80821, "loss": 0.0006, "grad_norm": 0.00139, "time": 0.38677}
+{"mode": "train", "epoch": 77, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00061, "acc_pose": 0.81447, "loss": 0.00061, "grad_norm": 0.00143, "time": 0.33441}
+{"mode": "train", "epoch": 77, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00061, "heatmap_loss": 0.0006, "acc_pose": 0.81714, "loss": 0.0006, "grad_norm": 0.00138, "time": 0.33534}
+{"mode": "train", "epoch": 77, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.0006, "acc_pose": 0.81137, "loss": 0.0006, "grad_norm": 0.00128, "time": 0.33447}
+{"mode": "train", "epoch": 77, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00046, "heatmap_loss": 0.0006, "acc_pose": 0.81757, "loss": 0.0006, "grad_norm": 0.0014, "time": 0.33552}
+{"mode": "train", "epoch": 78, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04718, "heatmap_loss": 0.0006, "acc_pose": 0.82578, "loss": 0.0006, "grad_norm": 0.00135, "time": 0.38414}
+{"mode": "train", "epoch": 78, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00059, "acc_pose": 0.83002, "loss": 0.00059, "grad_norm": 0.0014, "time": 0.33491}
+{"mode": "train", "epoch": 78, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.0006, "acc_pose": 0.82652, "loss": 0.0006, "grad_norm": 0.00138, "time": 0.3349}
+{"mode": "train", "epoch": 78, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.0006, "acc_pose": 0.80484, "loss": 0.0006, "grad_norm": 0.00135, "time": 0.3355}
+{"mode": "train", "epoch": 78, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.0006, "acc_pose": 0.81862, "loss": 0.0006, "grad_norm": 0.00136, "time": 0.33473}
+{"mode": "train", "epoch": 79, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04704, "heatmap_loss": 0.0006, "acc_pose": 0.81849, "loss": 0.0006, "grad_norm": 0.00137, "time": 0.38663}
+{"mode": "train", "epoch": 79, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.0006, "acc_pose": 0.82441, "loss": 0.0006, "grad_norm": 0.00145, "time": 0.33355}
+{"mode": "train", "epoch": 79, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00052, "heatmap_loss": 0.0006, "acc_pose": 0.80771, "loss": 0.0006, "grad_norm": 0.0013, "time": 0.33266}
+{"mode": "train", "epoch": 79, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00053, "heatmap_loss": 0.0006, "acc_pose": 0.82817, "loss": 0.0006, "grad_norm": 0.00126, "time": 0.33317}
+{"mode": "train", "epoch": 79, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.0006, "acc_pose": 0.81566, "loss": 0.0006, "grad_norm": 0.0013, "time": 0.33306}
+{"mode": "train", "epoch": 80, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04887, "heatmap_loss": 0.00061, "acc_pose": 0.82191, "loss": 0.00061, "grad_norm": 0.00134, "time": 0.38593}
+{"mode": "train", "epoch": 80, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.0006, "acc_pose": 0.81764, "loss": 0.0006, "grad_norm": 0.00139, "time": 0.33404}
+{"mode": "train", "epoch": 80, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00059, "acc_pose": 0.81815, "loss": 0.00059, "grad_norm": 0.00129, "time": 0.33295}
+{"mode": "train", "epoch": 80, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.0006, "acc_pose": 0.81302, "loss": 0.0006, "grad_norm": 0.00133, "time": 0.33466}
+{"mode": "train", "epoch": 80, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.0006, "acc_pose": 0.80725, "loss": 0.0006, "grad_norm": 0.0013, "time": 0.33335}
+{"mode": "val", "epoch": 80, "iter": 204, "lr": 0.0, "AP": 0.77814, "AP .5": 0.91362, "AP .75": 0.85079, "AP (M)": 0.70428, "AP (L)": 0.8087, "AR": 0.83057, "AR .5": 0.9512, "AR .75": 0.89389, "AR (M)": 0.78883, "AR (L)": 0.89223}
+{"mode": "train", "epoch": 81, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04796, "heatmap_loss": 0.0006, "acc_pose": 0.81763, "loss": 0.0006, "grad_norm": 0.00128, "time": 0.38293}
+{"mode": "train", "epoch": 81, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.0006, "acc_pose": 0.82531, "loss": 0.0006, "grad_norm": 0.0013, "time": 0.33788}
+{"mode": "train", "epoch": 81, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00055, "heatmap_loss": 0.0006, "acc_pose": 0.81697, "loss": 0.0006, "grad_norm": 0.00138, "time": 0.33664}
+{"mode": "train", "epoch": 81, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.0006, "acc_pose": 0.81899, "loss": 0.0006, "grad_norm": 0.0014, "time": 0.33462}
+{"mode": "train", "epoch": 81, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.0006, "acc_pose": 0.81305, "loss": 0.0006, "grad_norm": 0.0013, "time": 0.33412}
+{"mode": "train", "epoch": 82, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04804, "heatmap_loss": 0.0006, "acc_pose": 0.81968, "loss": 0.0006, "grad_norm": 0.00137, "time": 0.38696}
+{"mode": "train", "epoch": 82, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.0006, "acc_pose": 0.84184, "loss": 0.0006, "grad_norm": 0.00137, "time": 0.33525}
+{"mode": "train", "epoch": 82, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.0006, "acc_pose": 0.8042, "loss": 0.0006, "grad_norm": 0.00125, "time": 0.33532}
+{"mode": "train", "epoch": 82, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.0006, "acc_pose": 0.82822, "loss": 0.0006, "grad_norm": 0.00141, "time": 0.33364}
+{"mode": "train", "epoch": 82, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.0006, "acc_pose": 0.80407, "loss": 0.0006, "grad_norm": 0.00135, "time": 0.33407}
+{"mode": "train", "epoch": 83, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04807, "heatmap_loss": 0.00059, "acc_pose": 0.80674, "loss": 0.00059, "grad_norm": 0.00136, "time": 0.38548}
+{"mode": "train", "epoch": 83, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.0006, "acc_pose": 0.8133, "loss": 0.0006, "grad_norm": 0.00129, "time": 0.33357}
+{"mode": "train", "epoch": 83, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.0006, "acc_pose": 0.81889, "loss": 0.0006, "grad_norm": 0.0013, "time": 0.33331}
+{"mode": "train", "epoch": 83, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.0006, "acc_pose": 0.81569, "loss": 0.0006, "grad_norm": 0.00137, "time": 0.33298}
+{"mode": "train", "epoch": 83, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.0006, "acc_pose": 0.82754, "loss": 0.0006, "grad_norm": 0.00132, "time": 0.33382}
+{"mode": "train", "epoch": 84, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.0498, "heatmap_loss": 0.0006, "acc_pose": 0.80601, "loss": 0.0006, "grad_norm": 0.00135, "time": 0.38718}
+{"mode": "train", "epoch": 84, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00059, "acc_pose": 0.81891, "loss": 0.00059, "grad_norm": 0.00137, "time": 0.33402}
+{"mode": "train", "epoch": 84, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00059, "acc_pose": 0.81421, "loss": 0.00059, "grad_norm": 0.00124, "time": 0.33436}
+{"mode": "train", "epoch": 84, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.0006, "acc_pose": 0.82815, "loss": 0.0006, "grad_norm": 0.00135, "time": 0.33377}
+{"mode": "train", "epoch": 84, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.0006, "acc_pose": 0.80829, "loss": 0.0006, "grad_norm": 0.00132, "time": 0.33459}
+{"mode": "train", "epoch": 85, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.0469, "heatmap_loss": 0.0006, "acc_pose": 0.81747, "loss": 0.0006, "grad_norm": 0.00129, "time": 0.38801}
+{"mode": "train", "epoch": 85, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.0006, "acc_pose": 0.82376, "loss": 0.0006, "grad_norm": 0.00128, "time": 0.33411}
+{"mode": "train", "epoch": 85, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.0006, "acc_pose": 0.81768, "loss": 0.0006, "grad_norm": 0.0013, "time": 0.33409}
+{"mode": "train", "epoch": 85, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00059, "acc_pose": 0.82466, "loss": 0.00059, "grad_norm": 0.00132, "time": 0.3368}
+{"mode": "train", "epoch": 85, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00059, "heatmap_loss": 0.00059, "acc_pose": 0.83143, "loss": 0.00059, "grad_norm": 0.00129, "time": 0.33583}
+{"mode": "train", "epoch": 86, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04682, "heatmap_loss": 0.0006, "acc_pose": 0.81594, "loss": 0.0006, "grad_norm": 0.00128, "time": 0.38827}
+{"mode": "train", "epoch": 86, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00059, "acc_pose": 0.81652, "loss": 0.00059, "grad_norm": 0.00135, "time": 0.33489}
+{"mode": "train", "epoch": 86, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.0006, "acc_pose": 0.82475, "loss": 0.0006, "grad_norm": 0.00132, "time": 0.33526}
+{"mode": "train", "epoch": 86, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00059, "acc_pose": 0.81145, "loss": 0.00059, "grad_norm": 0.00128, "time": 0.33347}
+{"mode": "train", "epoch": 86, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00059, "acc_pose": 0.81998, "loss": 0.00059, "grad_norm": 0.00136, "time": 0.33379}
+{"mode": "train", "epoch": 87, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.0467, "heatmap_loss": 0.00059, "acc_pose": 0.83136, "loss": 0.00059, "grad_norm": 0.00136, "time": 0.38516}
+{"mode": "train", "epoch": 87, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00059, "acc_pose": 0.81457, "loss": 0.00059, "grad_norm": 0.0013, "time": 0.33354}
+{"mode": "train", "epoch": 87, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00052, "heatmap_loss": 0.00059, "acc_pose": 0.82536, "loss": 0.00059, "grad_norm": 0.00124, "time": 0.33509}
+{"mode": "train", "epoch": 87, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00056, "heatmap_loss": 0.00059, "acc_pose": 0.82359, "loss": 0.00059, "grad_norm": 0.00127, "time": 0.33574}
+{"mode": "train", "epoch": 87, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00059, "acc_pose": 0.82564, "loss": 0.00059, "grad_norm": 0.00135, "time": 0.33386}
+{"mode": "train", "epoch": 88, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04675, "heatmap_loss": 0.00058, "acc_pose": 0.81904, "loss": 0.00058, "grad_norm": 0.00133, "time": 0.38495}
+{"mode": "train", "epoch": 88, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00059, "acc_pose": 0.81497, "loss": 0.00059, "grad_norm": 0.0013, "time": 0.3333}
+{"mode": "train", "epoch": 88, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00059, "acc_pose": 0.83335, "loss": 0.00059, "grad_norm": 0.00138, "time": 0.33417}
+{"mode": "train", "epoch": 88, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00059, "acc_pose": 0.82408, "loss": 0.00059, "grad_norm": 0.00124, "time": 0.33227}
+{"mode": "train", "epoch": 88, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00059, "acc_pose": 0.82758, "loss": 0.00059, "grad_norm": 0.00134, "time": 0.33337}
+{"mode": "train", "epoch": 89, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04697, "heatmap_loss": 0.00059, "acc_pose": 0.81913, "loss": 0.00059, "grad_norm": 0.00127, "time": 0.39144}
+{"mode": "train", "epoch": 89, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00059, "acc_pose": 0.82876, "loss": 0.00059, "grad_norm": 0.00133, "time": 0.33972}
+{"mode": "train", "epoch": 89, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00052, "heatmap_loss": 0.00059, "acc_pose": 0.82925, "loss": 0.00059, "grad_norm": 0.0014, "time": 0.33868}
+{"mode": "train", "epoch": 89, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00059, "acc_pose": 0.82585, "loss": 0.00059, "grad_norm": 0.00123, "time": 0.33683}
+{"mode": "train", "epoch": 89, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00058, "acc_pose": 0.82709, "loss": 0.00058, "grad_norm": 0.00133, "time": 0.33362}
+{"mode": "train", "epoch": 90, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04698, "heatmap_loss": 0.00059, "acc_pose": 0.81464, "loss": 0.00059, "grad_norm": 0.00134, "time": 0.38502}
+{"mode": "train", "epoch": 90, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00059, "acc_pose": 0.82448, "loss": 0.00059, "grad_norm": 0.00128, "time": 0.33468}
+{"mode": "train", "epoch": 90, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00059, "acc_pose": 0.83001, "loss": 0.00059, "grad_norm": 0.00134, "time": 0.33369}
+{"mode": "train", "epoch": 90, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00059, "acc_pose": 0.83098, "loss": 0.00059, "grad_norm": 0.00135, "time": 0.33418}
+{"mode": "train", "epoch": 90, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00058, "acc_pose": 0.81628, "loss": 0.00058, "grad_norm": 0.00127, "time": 0.33424}
+{"mode": "val", "epoch": 90, "iter": 204, "lr": 0.0, "AP": 0.77926, "AP .5": 0.91429, "AP .75": 0.84969, "AP (M)": 0.70574, "AP (L)": 0.8087, "AR": 0.83049, "AR .5": 0.95183, "AR .75": 0.89106, "AR (M)": 0.78896, "AR (L)": 0.89175}
+{"mode": "train", "epoch": 91, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04773, "heatmap_loss": 0.00059, "acc_pose": 0.82535, "loss": 0.00059, "grad_norm": 0.0013, "time": 0.38219}
+{"mode": "train", "epoch": 91, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00052, "heatmap_loss": 0.00059, "acc_pose": 0.81581, "loss": 0.00059, "grad_norm": 0.00124, "time": 0.33631}
+{"mode": "train", "epoch": 91, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00059, "acc_pose": 0.81531, "loss": 0.00059, "grad_norm": 0.00125, "time": 0.33766}
+{"mode": "train", "epoch": 91, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00059, "acc_pose": 0.82174, "loss": 0.00059, "grad_norm": 0.00125, "time": 0.33797}
+{"mode": "train", "epoch": 91, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00059, "acc_pose": 0.82242, "loss": 0.00059, "grad_norm": 0.00144, "time": 0.33914}
+{"mode": "train", "epoch": 92, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04692, "heatmap_loss": 0.00059, "acc_pose": 0.83771, "loss": 0.00059, "grad_norm": 0.00125, "time": 0.38324}
+{"mode": "train", "epoch": 92, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00058, "acc_pose": 0.82298, "loss": 0.00058, "grad_norm": 0.00139, "time": 0.3337}
+{"mode": "train", "epoch": 92, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00058, "acc_pose": 0.81551, "loss": 0.00058, "grad_norm": 0.00125, "time": 0.33684}
+{"mode": "train", "epoch": 92, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00059, "acc_pose": 0.81646, "loss": 0.00059, "grad_norm": 0.00132, "time": 0.33584}
+{"mode": "train", "epoch": 92, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00058, "acc_pose": 0.82121, "loss": 0.00058, "grad_norm": 0.00127, "time": 0.33794}
+{"mode": "train", "epoch": 93, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04691, "heatmap_loss": 0.00058, "acc_pose": 0.82188, "loss": 0.00058, "grad_norm": 0.00135, "time": 0.38581}
+{"mode": "train", "epoch": 93, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00057, "heatmap_loss": 0.00059, "acc_pose": 0.81714, "loss": 0.00059, "grad_norm": 0.00127, "time": 0.33623}
+{"mode": "train", "epoch": 93, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00059, "acc_pose": 0.82847, "loss": 0.00059, "grad_norm": 0.0013, "time": 0.33495}
+{"mode": "train", "epoch": 93, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00059, "acc_pose": 0.82818, "loss": 0.00059, "grad_norm": 0.00134, "time": 0.33418}
+{"mode": "train", "epoch": 93, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00058, "acc_pose": 0.83929, "loss": 0.00058, "grad_norm": 0.0013, "time": 0.33298}
+{"mode": "train", "epoch": 94, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04683, "heatmap_loss": 0.00058, "acc_pose": 0.82838, "loss": 0.00058, "grad_norm": 0.00119, "time": 0.38533}
+{"mode": "train", "epoch": 94, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00059, "acc_pose": 0.8333, "loss": 0.00059, "grad_norm": 0.00125, "time": 0.3368}
+{"mode": "train", "epoch": 94, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00059, "acc_pose": 0.81467, "loss": 0.00059, "grad_norm": 0.00127, "time": 0.33492}
+{"mode": "train", "epoch": 94, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00059, "acc_pose": 0.82683, "loss": 0.00059, "grad_norm": 0.00128, "time": 0.33581}
+{"mode": "train", "epoch": 94, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00058, "acc_pose": 0.82862, "loss": 0.00058, "grad_norm": 0.0013, "time": 0.33466}
+{"mode": "train", "epoch": 95, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04721, "heatmap_loss": 0.00058, "acc_pose": 0.81387, "loss": 0.00058, "grad_norm": 0.00128, "time": 0.38533}
+{"mode": "train", "epoch": 95, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00053, "heatmap_loss": 0.00058, "acc_pose": 0.83, "loss": 0.00058, "grad_norm": 0.00132, "time": 0.33491}
+{"mode": "train", "epoch": 95, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00059, "acc_pose": 0.8214, "loss": 0.00059, "grad_norm": 0.00149, "time": 0.33424}
+{"mode": "train", "epoch": 95, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00052, "heatmap_loss": 0.00058, "acc_pose": 0.82336, "loss": 0.00058, "grad_norm": 0.00125, "time": 0.33303}
+{"mode": "train", "epoch": 95, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00058, "acc_pose": 0.82441, "loss": 0.00058, "grad_norm": 0.0013, "time": 0.33387}
+{"mode": "train", "epoch": 96, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.047, "heatmap_loss": 0.00058, "acc_pose": 0.83248, "loss": 0.00058, "grad_norm": 0.00124, "time": 0.38572}
+{"mode": "train", "epoch": 96, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00058, "acc_pose": 0.83893, "loss": 0.00058, "grad_norm": 0.00137, "time": 0.33342}
+{"mode": "train", "epoch": 96, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00058, "acc_pose": 0.8263, "loss": 0.00058, "grad_norm": 0.00125, "time": 0.33417}
+{"mode": "train", "epoch": 96, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00058, "acc_pose": 0.83154, "loss": 0.00058, "grad_norm": 0.00126, "time": 0.33271}
+{"mode": "train", "epoch": 96, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00059, "acc_pose": 0.81896, "loss": 0.00059, "grad_norm": 0.00125, "time": 0.33464}
+{"mode": "train", "epoch": 97, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04787, "heatmap_loss": 0.00058, "acc_pose": 0.82622, "loss": 0.00058, "grad_norm": 0.00129, "time": 0.38496}
+{"mode": "train", "epoch": 97, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00058, "acc_pose": 0.81974, "loss": 0.00058, "grad_norm": 0.00124, "time": 0.33421}
+{"mode": "train", "epoch": 97, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00058, "acc_pose": 0.83179, "loss": 0.00058, "grad_norm": 0.00128, "time": 0.33444}
+{"mode": "train", "epoch": 97, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00058, "acc_pose": 0.81775, "loss": 0.00058, "grad_norm": 0.0013, "time": 0.33317}
+{"mode": "train", "epoch": 97, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00058, "acc_pose": 0.8162, "loss": 0.00058, "grad_norm": 0.00125, "time": 0.33458}
+{"mode": "train", "epoch": 98, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04686, "heatmap_loss": 0.00058, "acc_pose": 0.82324, "loss": 0.00058, "grad_norm": 0.00129, "time": 0.38837}
+{"mode": "train", "epoch": 98, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00058, "acc_pose": 0.82292, "loss": 0.00058, "grad_norm": 0.00142, "time": 0.33314}
+{"mode": "train", "epoch": 98, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00058, "acc_pose": 0.82726, "loss": 0.00058, "grad_norm": 0.00125, "time": 0.33378}
+{"mode": "train", "epoch": 98, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00058, "acc_pose": 0.8103, "loss": 0.00058, "grad_norm": 0.00124, "time": 0.33377}
+{"mode": "train", "epoch": 98, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00059, "acc_pose": 0.83039, "loss": 0.00059, "grad_norm": 0.00134, "time": 0.3349}
+{"mode": "train", "epoch": 99, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04662, "heatmap_loss": 0.00058, "acc_pose": 0.83325, "loss": 0.00058, "grad_norm": 0.00125, "time": 0.3897}
+{"mode": "train", "epoch": 99, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00058, "acc_pose": 0.83892, "loss": 0.00058, "grad_norm": 0.00137, "time": 0.33469}
+{"mode": "train", "epoch": 99, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00059, "acc_pose": 0.81197, "loss": 0.00059, "grad_norm": 0.00131, "time": 0.33361}
+{"mode": "train", "epoch": 99, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00058, "acc_pose": 0.83128, "loss": 0.00058, "grad_norm": 0.00126, "time": 0.33512}
+{"mode": "train", "epoch": 99, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00053, "heatmap_loss": 0.00058, "acc_pose": 0.82106, "loss": 0.00058, "grad_norm": 0.0013, "time": 0.33434}
+{"mode": "train", "epoch": 100, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04721, "heatmap_loss": 0.00058, "acc_pose": 0.837, "loss": 0.00058, "grad_norm": 0.00123, "time": 0.38541}
+{"mode": "train", "epoch": 100, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00058, "acc_pose": 0.82253, "loss": 0.00058, "grad_norm": 0.00124, "time": 0.33407}
+{"mode": "train", "epoch": 100, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00058, "acc_pose": 0.81616, "loss": 0.00058, "grad_norm": 0.00131, "time": 0.3341}
+{"mode": "train", "epoch": 100, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00058, "acc_pose": 0.8375, "loss": 0.00058, "grad_norm": 0.0013, "time": 0.33326}
+{"mode": "train", "epoch": 100, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00058, "acc_pose": 0.81211, "loss": 0.00058, "grad_norm": 0.00134, "time": 0.33275}
+{"mode": "val", "epoch": 100, "iter": 204, "lr": 0.0, "AP": 0.78106, "AP .5": 0.91408, "AP .75": 0.85203, "AP (M)": 0.70683, "AP (L)": 0.81149, "AR": 0.83334, "AR .5": 0.95246, "AR .75": 0.89436, "AR (M)": 0.79156, "AR (L)": 0.89506}
+{"mode": "train", "epoch": 101, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04681, "heatmap_loss": 0.00058, "acc_pose": 0.82892, "loss": 0.00058, "grad_norm": 0.0012, "time": 0.38246}
+{"mode": "train", "epoch": 101, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00058, "acc_pose": 0.83022, "loss": 0.00058, "grad_norm": 0.00125, "time": 0.33381}
+{"mode": "train", "epoch": 101, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00053, "heatmap_loss": 0.00058, "acc_pose": 0.8207, "loss": 0.00058, "grad_norm": 0.0013, "time": 0.33293}
+{"mode": "train", "epoch": 101, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00058, "acc_pose": 0.82914, "loss": 0.00058, "grad_norm": 0.00125, "time": 0.33382}
+{"mode": "train", "epoch": 101, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00052, "heatmap_loss": 0.00057, "acc_pose": 0.81526, "loss": 0.00057, "grad_norm": 0.00135, "time": 0.33422}
+{"mode": "train", "epoch": 102, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04701, "heatmap_loss": 0.00058, "acc_pose": 0.82215, "loss": 0.00058, "grad_norm": 0.00127, "time": 0.38464}
+{"mode": "train", "epoch": 102, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00058, "acc_pose": 0.82931, "loss": 0.00058, "grad_norm": 0.00132, "time": 0.33398}
+{"mode": "train", "epoch": 102, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00058, "acc_pose": 0.81644, "loss": 0.00058, "grad_norm": 0.0013, "time": 0.33341}
+{"mode": "train", "epoch": 102, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00058, "acc_pose": 0.8199, "loss": 0.00058, "grad_norm": 0.00128, "time": 0.33448}
+{"mode": "train", "epoch": 102, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00058, "acc_pose": 0.83807, "loss": 0.00058, "grad_norm": 0.00135, "time": 0.33394}
+{"mode": "train", "epoch": 103, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04685, "heatmap_loss": 0.00058, "acc_pose": 0.8207, "loss": 0.00058, "grad_norm": 0.00129, "time": 0.38645}
+{"mode": "train", "epoch": 103, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00057, "acc_pose": 0.82246, "loss": 0.00057, "grad_norm": 0.0012, "time": 0.33442}
+{"mode": "train", "epoch": 103, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00058, "acc_pose": 0.84264, "loss": 0.00058, "grad_norm": 0.00135, "time": 0.33455}
+{"mode": "train", "epoch": 103, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00058, "acc_pose": 0.8126, "loss": 0.00058, "grad_norm": 0.00128, "time": 0.3348}
+{"mode": "train", "epoch": 103, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00058, "acc_pose": 0.82855, "loss": 0.00058, "grad_norm": 0.00126, "time": 0.33427}
+{"mode": "train", "epoch": 104, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04704, "heatmap_loss": 0.00058, "acc_pose": 0.83283, "loss": 0.00058, "grad_norm": 0.0013, "time": 0.38566}
+{"mode": "train", "epoch": 104, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00057, "acc_pose": 0.82197, "loss": 0.00057, "grad_norm": 0.00125, "time": 0.3368}
+{"mode": "train", "epoch": 104, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00053, "heatmap_loss": 0.00058, "acc_pose": 0.82291, "loss": 0.00058, "grad_norm": 0.00128, "time": 0.3384}
+{"mode": "train", "epoch": 104, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00052, "heatmap_loss": 0.00058, "acc_pose": 0.82631, "loss": 0.00058, "grad_norm": 0.0012, "time": 0.33529}
+{"mode": "train", "epoch": 104, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00058, "acc_pose": 0.81903, "loss": 0.00058, "grad_norm": 0.00122, "time": 0.33339}
+{"mode": "train", "epoch": 105, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04721, "heatmap_loss": 0.00058, "acc_pose": 0.82661, "loss": 0.00058, "grad_norm": 0.00125, "time": 0.38537}
+{"mode": "train", "epoch": 105, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00058, "acc_pose": 0.8274, "loss": 0.00058, "grad_norm": 0.00132, "time": 0.33409}
+{"mode": "train", "epoch": 105, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00058, "acc_pose": 0.8197, "loss": 0.00058, "grad_norm": 0.00129, "time": 0.33377}
+{"mode": "train", "epoch": 105, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00058, "acc_pose": 0.82808, "loss": 0.00058, "grad_norm": 0.00125, "time": 0.33349}
+{"mode": "train", "epoch": 105, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00053, "heatmap_loss": 0.00058, "acc_pose": 0.81814, "loss": 0.00058, "grad_norm": 0.00129, "time": 0.33367}
+{"mode": "train", "epoch": 106, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04684, "heatmap_loss": 0.00058, "acc_pose": 0.82173, "loss": 0.00058, "grad_norm": 0.00122, "time": 0.38419}
+{"mode": "train", "epoch": 106, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00057, "acc_pose": 0.82742, "loss": 0.00057, "grad_norm": 0.00129, "time": 0.33285}
+{"mode": "train", "epoch": 106, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00057, "heatmap_loss": 0.00057, "acc_pose": 0.83016, "loss": 0.00057, "grad_norm": 0.00125, "time": 0.33372}
+{"mode": "train", "epoch": 106, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00057, "acc_pose": 0.833, "loss": 0.00057, "grad_norm": 0.00128, "time": 0.33352}
+{"mode": "train", "epoch": 106, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00052, "heatmap_loss": 0.00057, "acc_pose": 0.82114, "loss": 0.00057, "grad_norm": 0.00127, "time": 0.33575}
+{"mode": "train", "epoch": 107, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04709, "heatmap_loss": 0.00057, "acc_pose": 0.82985, "loss": 0.00057, "grad_norm": 0.00127, "time": 0.38464}
+{"mode": "train", "epoch": 107, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00057, "acc_pose": 0.81406, "loss": 0.00057, "grad_norm": 0.00137, "time": 0.33317}
+{"mode": "train", "epoch": 107, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00057, "acc_pose": 0.8261, "loss": 0.00057, "grad_norm": 0.00124, "time": 0.33685}
+{"mode": "train", "epoch": 107, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00057, "acc_pose": 0.82782, "loss": 0.00057, "grad_norm": 0.00117, "time": 0.33412}
+{"mode": "train", "epoch": 107, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00057, "acc_pose": 0.82632, "loss": 0.00057, "grad_norm": 0.00126, "time": 0.33496}
+{"mode": "train", "epoch": 108, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04714, "heatmap_loss": 0.00058, "acc_pose": 0.82615, "loss": 0.00058, "grad_norm": 0.00126, "time": 0.38442}
+{"mode": "train", "epoch": 108, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00058, "acc_pose": 0.8241, "loss": 0.00058, "grad_norm": 0.00127, "time": 0.33382}
+{"mode": "train", "epoch": 108, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00058, "acc_pose": 0.81112, "loss": 0.00058, "grad_norm": 0.00129, "time": 0.33326}
+{"mode": "train", "epoch": 108, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00057, "acc_pose": 0.83953, "loss": 0.00057, "grad_norm": 0.0013, "time": 0.33252}
+{"mode": "train", "epoch": 108, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00057, "acc_pose": 0.8302, "loss": 0.00057, "grad_norm": 0.00128, "time": 0.3338}
+{"mode": "train", "epoch": 109, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04715, "heatmap_loss": 0.00057, "acc_pose": 0.82612, "loss": 0.00057, "grad_norm": 0.00125, "time": 0.38567}
+{"mode": "train", "epoch": 109, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00058, "acc_pose": 0.82458, "loss": 0.00058, "grad_norm": 0.00129, "time": 0.33474}
+{"mode": "train", "epoch": 109, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00058, "acc_pose": 0.83208, "loss": 0.00058, "grad_norm": 0.00135, "time": 0.3353}
+{"mode": "train", "epoch": 109, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00057, "acc_pose": 0.82812, "loss": 0.00057, "grad_norm": 0.00126, "time": 0.33377}
+{"mode": "train", "epoch": 109, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00057, "acc_pose": 0.81978, "loss": 0.00057, "grad_norm": 0.0012, "time": 0.33497}
+{"mode": "train", "epoch": 110, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04764, "heatmap_loss": 0.00057, "acc_pose": 0.82044, "loss": 0.00057, "grad_norm": 0.00144, "time": 0.3858}
+{"mode": "train", "epoch": 110, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00052, "heatmap_loss": 0.00058, "acc_pose": 0.82116, "loss": 0.00058, "grad_norm": 0.0013, "time": 0.33366}
+{"mode": "train", "epoch": 110, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00057, "acc_pose": 0.8284, "loss": 0.00057, "grad_norm": 0.00125, "time": 0.33463}
+{"mode": "train", "epoch": 110, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00057, "acc_pose": 0.83666, "loss": 0.00057, "grad_norm": 0.00127, "time": 0.33339}
+{"mode": "train", "epoch": 110, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00057, "acc_pose": 0.82435, "loss": 0.00057, "grad_norm": 0.00127, "time": 0.33483}
+{"mode": "val", "epoch": 110, "iter": 204, "lr": 0.0, "AP": 0.78115, "AP .5": 0.9141, "AP .75": 0.85008, "AP (M)": 0.70736, "AP (L)": 0.81217, "AR": 0.83292, "AR .5": 0.95183, "AR .75": 0.89232, "AR (M)": 0.7912, "AR (L)": 0.89443}
+{"mode": "train", "epoch": 111, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04691, "heatmap_loss": 0.00057, "acc_pose": 0.81984, "loss": 0.00057, "grad_norm": 0.00121, "time": 0.38461}
+{"mode": "train", "epoch": 111, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00057, "acc_pose": 0.83205, "loss": 0.00057, "grad_norm": 0.00123, "time": 0.33613}
+{"mode": "train", "epoch": 111, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00057, "acc_pose": 0.83536, "loss": 0.00057, "grad_norm": 0.00137, "time": 0.33431}
+{"mode": "train", "epoch": 111, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00057, "acc_pose": 0.82137, "loss": 0.00057, "grad_norm": 0.00123, "time": 0.33536}
+{"mode": "train", "epoch": 111, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00057, "acc_pose": 0.81306, "loss": 0.00057, "grad_norm": 0.00128, "time": 0.33451}
+{"mode": "train", "epoch": 112, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04708, "heatmap_loss": 0.00057, "acc_pose": 0.82765, "loss": 0.00057, "grad_norm": 0.00134, "time": 0.38569}
+{"mode": "train", "epoch": 112, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00057, "acc_pose": 0.82606, "loss": 0.00057, "grad_norm": 0.00124, "time": 0.33381}
+{"mode": "train", "epoch": 112, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00057, "acc_pose": 0.84154, "loss": 0.00057, "grad_norm": 0.00124, "time": 0.33401}
+{"mode": "train", "epoch": 112, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00057, "acc_pose": 0.82767, "loss": 0.00057, "grad_norm": 0.00126, "time": 0.33545}
+{"mode": "train", "epoch": 112, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00057, "acc_pose": 0.83768, "loss": 0.00057, "grad_norm": 0.00126, "time": 0.33313}
+{"mode": "train", "epoch": 113, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04725, "heatmap_loss": 0.00057, "acc_pose": 0.83544, "loss": 0.00057, "grad_norm": 0.00124, "time": 0.39139}
+{"mode": "train", "epoch": 113, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00057, "acc_pose": 0.84289, "loss": 0.00057, "grad_norm": 0.00128, "time": 0.33603}
+{"mode": "train", "epoch": 113, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00057, "acc_pose": 0.82602, "loss": 0.00057, "grad_norm": 0.00122, "time": 0.33609}
+{"mode": "train", "epoch": 113, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00057, "acc_pose": 0.83652, "loss": 0.00057, "grad_norm": 0.00122, "time": 0.33548}
+{"mode": "train", "epoch": 113, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00057, "acc_pose": 0.83055, "loss": 0.00057, "grad_norm": 0.00138, "time": 0.33495}
+{"mode": "train", "epoch": 114, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04748, "heatmap_loss": 0.00057, "acc_pose": 0.8328, "loss": 0.00057, "grad_norm": 0.00127, "time": 0.38918}
+{"mode": "train", "epoch": 114, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00057, "acc_pose": 0.82983, "loss": 0.00057, "grad_norm": 0.00122, "time": 0.33594}
+{"mode": "train", "epoch": 114, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00057, "acc_pose": 0.82906, "loss": 0.00057, "grad_norm": 0.00123, "time": 0.33625}
+{"mode": "train", "epoch": 114, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00057, "acc_pose": 0.83637, "loss": 0.00057, "grad_norm": 0.00124, "time": 0.33771}
+{"mode": "train", "epoch": 114, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00056, "acc_pose": 0.83331, "loss": 0.00056, "grad_norm": 0.00125, "time": 0.33546}
+{"mode": "train", "epoch": 115, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04701, "heatmap_loss": 0.00057, "acc_pose": 0.82781, "loss": 0.00057, "grad_norm": 0.00158, "time": 0.38457}
+{"mode": "train", "epoch": 115, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00057, "acc_pose": 0.83112, "loss": 0.00057, "grad_norm": 0.00124, "time": 0.33468}
+{"mode": "train", "epoch": 115, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00057, "acc_pose": 0.8311, "loss": 0.00057, "grad_norm": 0.00129, "time": 0.33388}
+{"mode": "train", "epoch": 115, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00057, "acc_pose": 0.83177, "loss": 0.00057, "grad_norm": 0.00127, "time": 0.33326}
+{"mode": "train", "epoch": 115, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00057, "acc_pose": 0.8284, "loss": 0.00057, "grad_norm": 0.00122, "time": 0.33423}
+{"mode": "train", "epoch": 116, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04743, "heatmap_loss": 0.00057, "acc_pose": 0.84011, "loss": 0.00057, "grad_norm": 0.0013, "time": 0.38713}
+{"mode": "train", "epoch": 116, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00056, "acc_pose": 0.82021, "loss": 0.00056, "grad_norm": 0.00124, "time": 0.33416}
+{"mode": "train", "epoch": 116, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00056, "acc_pose": 0.82908, "loss": 0.00056, "grad_norm": 0.00115, "time": 0.33477}
+{"mode": "train", "epoch": 116, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00052, "heatmap_loss": 0.00056, "acc_pose": 0.84915, "loss": 0.00056, "grad_norm": 0.00125, "time": 0.33436}
+{"mode": "train", "epoch": 116, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00057, "acc_pose": 0.84059, "loss": 0.00057, "grad_norm": 0.0012, "time": 0.33325}
+{"mode": "train", "epoch": 117, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04727, "heatmap_loss": 0.00057, "acc_pose": 0.82188, "loss": 0.00057, "grad_norm": 0.00121, "time": 0.38504}
+{"mode": "train", "epoch": 117, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00056, "heatmap_loss": 0.00057, "acc_pose": 0.83248, "loss": 0.00057, "grad_norm": 0.00132, "time": 0.33382}
+{"mode": "train", "epoch": 117, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00056, "acc_pose": 0.83616, "loss": 0.00056, "grad_norm": 0.0012, "time": 0.33364}
+{"mode": "train", "epoch": 117, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00056, "acc_pose": 0.8422, "loss": 0.00056, "grad_norm": 0.00124, "time": 0.33309}
+{"mode": "train", "epoch": 117, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00057, "acc_pose": 0.82583, "loss": 0.00057, "grad_norm": 0.00123, "time": 0.33415}
+{"mode": "train", "epoch": 118, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04733, "heatmap_loss": 0.00057, "acc_pose": 0.8267, "loss": 0.00057, "grad_norm": 0.00125, "time": 0.38525}
+{"mode": "train", "epoch": 118, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00057, "acc_pose": 0.83275, "loss": 0.00057, "grad_norm": 0.00126, "time": 0.33401}
+{"mode": "train", "epoch": 118, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00057, "acc_pose": 0.83488, "loss": 0.00057, "grad_norm": 0.00128, "time": 0.33523}
+{"mode": "train", "epoch": 118, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00057, "acc_pose": 0.8256, "loss": 0.00057, "grad_norm": 0.00127, "time": 0.33424}
+{"mode": "train", "epoch": 118, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00057, "acc_pose": 0.83701, "loss": 0.00057, "grad_norm": 0.00123, "time": 0.33631}
+{"mode": "train", "epoch": 119, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04722, "heatmap_loss": 0.00056, "acc_pose": 0.83969, "loss": 0.00056, "grad_norm": 0.00123, "time": 0.38847}
+{"mode": "train", "epoch": 119, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00056, "acc_pose": 0.82823, "loss": 0.00056, "grad_norm": 0.00119, "time": 0.33697}
+{"mode": "train", "epoch": 119, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00052, "heatmap_loss": 0.00056, "acc_pose": 0.82657, "loss": 0.00056, "grad_norm": 0.00133, "time": 0.33765}
+{"mode": "train", "epoch": 119, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00057, "acc_pose": 0.83752, "loss": 0.00057, "grad_norm": 0.00128, "time": 0.33523}
+{"mode": "train", "epoch": 119, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00057, "acc_pose": 0.8361, "loss": 0.00057, "grad_norm": 0.00132, "time": 0.33529}
+{"mode": "train", "epoch": 120, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04698, "heatmap_loss": 0.00056, "acc_pose": 0.8382, "loss": 0.00056, "grad_norm": 0.00121, "time": 0.38492}
+{"mode": "train", "epoch": 120, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00056, "acc_pose": 0.84134, "loss": 0.00056, "grad_norm": 0.00125, "time": 0.33397}
+{"mode": "train", "epoch": 120, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00056, "acc_pose": 0.83699, "loss": 0.00056, "grad_norm": 0.00125, "time": 0.33441}
+{"mode": "train", "epoch": 120, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00057, "acc_pose": 0.82447, "loss": 0.00057, "grad_norm": 0.00125, "time": 0.33284}
+{"mode": "train", "epoch": 120, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00056, "acc_pose": 0.83909, "loss": 0.00056, "grad_norm": 0.00122, "time": 0.33379}
+{"mode": "val", "epoch": 120, "iter": 204, "lr": 0.0, "AP": 0.7829, "AP .5": 0.91432, "AP .75": 0.85217, "AP (M)": 0.70862, "AP (L)": 0.81443, "AR": 0.83408, "AR .5": 0.95183, "AR .75": 0.89499, "AR (M)": 0.79257, "AR (L)": 0.89506}
+{"mode": "train", "epoch": 121, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04708, "heatmap_loss": 0.00056, "acc_pose": 0.82548, "loss": 0.00056, "grad_norm": 0.0012, "time": 0.38043}
+{"mode": "train", "epoch": 121, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00052, "heatmap_loss": 0.00056, "acc_pose": 0.85259, "loss": 0.00056, "grad_norm": 0.00121, "time": 0.33292}
+{"mode": "train", "epoch": 121, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00057, "acc_pose": 0.83967, "loss": 0.00057, "grad_norm": 0.00127, "time": 0.33421}
+{"mode": "train", "epoch": 121, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00056, "acc_pose": 0.82963, "loss": 0.00056, "grad_norm": 0.00116, "time": 0.33446}
+{"mode": "train", "epoch": 121, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00056, "acc_pose": 0.83942, "loss": 0.00056, "grad_norm": 0.00119, "time": 0.33408}
+{"mode": "train", "epoch": 122, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04731, "heatmap_loss": 0.00056, "acc_pose": 0.82357, "loss": 0.00056, "grad_norm": 0.00124, "time": 0.38532}
+{"mode": "train", "epoch": 122, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00057, "acc_pose": 0.83218, "loss": 0.00057, "grad_norm": 0.00123, "time": 0.33382}
+{"mode": "train", "epoch": 122, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00057, "acc_pose": 0.83367, "loss": 0.00057, "grad_norm": 0.00121, "time": 0.33291}
+{"mode": "train", "epoch": 122, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00056, "acc_pose": 0.82639, "loss": 0.00056, "grad_norm": 0.00128, "time": 0.33351}
+{"mode": "train", "epoch": 122, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00057, "acc_pose": 0.81703, "loss": 0.00057, "grad_norm": 0.00128, "time": 0.33201}
+{"mode": "train", "epoch": 123, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04732, "heatmap_loss": 0.00056, "acc_pose": 0.82297, "loss": 0.00056, "grad_norm": 0.00128, "time": 0.38678}
+{"mode": "train", "epoch": 123, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00056, "acc_pose": 0.83027, "loss": 0.00056, "grad_norm": 0.00125, "time": 0.33421}
+{"mode": "train", "epoch": 123, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00056, "acc_pose": 0.8372, "loss": 0.00056, "grad_norm": 0.0012, "time": 0.33295}
+{"mode": "train", "epoch": 123, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00056, "acc_pose": 0.83362, "loss": 0.00056, "grad_norm": 0.00127, "time": 0.33361}
+{"mode": "train", "epoch": 123, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00056, "acc_pose": 0.84014, "loss": 0.00056, "grad_norm": 0.00127, "time": 0.33316}
+{"mode": "train", "epoch": 124, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04733, "heatmap_loss": 0.00056, "acc_pose": 0.83965, "loss": 0.00056, "grad_norm": 0.0012, "time": 0.38499}
+{"mode": "train", "epoch": 124, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00056, "acc_pose": 0.84021, "loss": 0.00056, "grad_norm": 0.00122, "time": 0.33395}
+{"mode": "train", "epoch": 124, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00056, "acc_pose": 0.82455, "loss": 0.00056, "grad_norm": 0.00131, "time": 0.33246}
+{"mode": "train", "epoch": 124, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00056, "acc_pose": 0.83804, "loss": 0.00056, "grad_norm": 0.00129, "time": 0.33382}
+{"mode": "train", "epoch": 124, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00056, "acc_pose": 0.84304, "loss": 0.00056, "grad_norm": 0.00127, "time": 0.33243}
+{"mode": "train", "epoch": 125, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04707, "heatmap_loss": 0.00056, "acc_pose": 0.83188, "loss": 0.00056, "grad_norm": 0.00126, "time": 0.38467}
+{"mode": "train", "epoch": 125, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00056, "acc_pose": 0.83053, "loss": 0.00056, "grad_norm": 0.00135, "time": 0.33415}
+{"mode": "train", "epoch": 125, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00056, "acc_pose": 0.82929, "loss": 0.00056, "grad_norm": 0.0012, "time": 0.33247}
+{"mode": "train", "epoch": 125, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00056, "acc_pose": 0.83729, "loss": 0.00056, "grad_norm": 0.00125, "time": 0.33418}
+{"mode": "train", "epoch": 125, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00056, "acc_pose": 0.82959, "loss": 0.00056, "grad_norm": 0.00122, "time": 0.33239}
+{"mode": "train", "epoch": 126, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04732, "heatmap_loss": 0.00056, "acc_pose": 0.82674, "loss": 0.00056, "grad_norm": 0.00125, "time": 0.38436}
+{"mode": "train", "epoch": 126, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00056, "acc_pose": 0.83548, "loss": 0.00056, "grad_norm": 0.00128, "time": 0.33474}
+{"mode": "train", "epoch": 126, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00056, "acc_pose": 0.84025, "loss": 0.00056, "grad_norm": 0.00116, "time": 0.33341}
+{"mode": "train", "epoch": 126, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00056, "acc_pose": 0.83755, "loss": 0.00056, "grad_norm": 0.0013, "time": 0.33475}
+{"mode": "train", "epoch": 126, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00056, "acc_pose": 0.83344, "loss": 0.00056, "grad_norm": 0.00127, "time": 0.33425}
+{"mode": "train", "epoch": 127, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04716, "heatmap_loss": 0.00056, "acc_pose": 0.82754, "loss": 0.00056, "grad_norm": 0.00123, "time": 0.38577}
+{"mode": "train", "epoch": 127, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00057, "acc_pose": 0.8266, "loss": 0.00057, "grad_norm": 0.00119, "time": 0.33494}
+{"mode": "train", "epoch": 127, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00055, "acc_pose": 0.83047, "loss": 0.00055, "grad_norm": 0.00129, "time": 0.33423}
+{"mode": "train", "epoch": 127, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00056, "acc_pose": 0.84254, "loss": 0.00056, "grad_norm": 0.00123, "time": 0.3349}
+{"mode": "train", "epoch": 127, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00056, "acc_pose": 0.82548, "loss": 0.00056, "grad_norm": 0.00127, "time": 0.33261}
+{"mode": "train", "epoch": 128, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04721, "heatmap_loss": 0.00056, "acc_pose": 0.83473, "loss": 0.00056, "grad_norm": 0.0012, "time": 0.38485}
+{"mode": "train", "epoch": 128, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00056, "acc_pose": 0.83281, "loss": 0.00056, "grad_norm": 0.00121, "time": 0.33305}
+{"mode": "train", "epoch": 128, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00056, "acc_pose": 0.83017, "loss": 0.00056, "grad_norm": 0.00122, "time": 0.33368}
+{"mode": "train", "epoch": 128, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00056, "acc_pose": 0.8385, "loss": 0.00056, "grad_norm": 0.00118, "time": 0.3332}
+{"mode": "train", "epoch": 128, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00056, "acc_pose": 0.83904, "loss": 0.00056, "grad_norm": 0.00126, "time": 0.33326}
+{"mode": "train", "epoch": 129, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04717, "heatmap_loss": 0.00056, "acc_pose": 0.82912, "loss": 0.00056, "grad_norm": 0.00131, "time": 0.38652}
+{"mode": "train", "epoch": 129, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00056, "acc_pose": 0.83403, "loss": 0.00056, "grad_norm": 0.00115, "time": 0.33351}
+{"mode": "train", "epoch": 129, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00056, "acc_pose": 0.82143, "loss": 0.00056, "grad_norm": 0.00129, "time": 0.33353}
+{"mode": "train", "epoch": 129, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00056, "acc_pose": 0.82898, "loss": 0.00056, "grad_norm": 0.00122, "time": 0.33442}
+{"mode": "train", "epoch": 129, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00057, "acc_pose": 0.82493, "loss": 0.00057, "grad_norm": 0.00129, "time": 0.33351}
+{"mode": "train", "epoch": 130, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04735, "heatmap_loss": 0.00056, "acc_pose": 0.84199, "loss": 0.00056, "grad_norm": 0.00118, "time": 0.38633}
+{"mode": "train", "epoch": 130, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00056, "acc_pose": 0.82493, "loss": 0.00056, "grad_norm": 0.00124, "time": 0.33405}
+{"mode": "train", "epoch": 130, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00056, "acc_pose": 0.83151, "loss": 0.00056, "grad_norm": 0.00124, "time": 0.33345}
+{"mode": "train", "epoch": 130, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00055, "acc_pose": 0.8327, "loss": 0.00055, "grad_norm": 0.0013, "time": 0.33381}
+{"mode": "train", "epoch": 130, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00055, "acc_pose": 0.82437, "loss": 0.00055, "grad_norm": 0.00126, "time": 0.33395}
+{"mode": "val", "epoch": 130, "iter": 204, "lr": 0.0, "AP": 0.78452, "AP .5": 0.91531, "AP .75": 0.85197, "AP (M)": 0.70994, "AP (L)": 0.81721, "AR": 0.83517, "AR .5": 0.95246, "AR .75": 0.89436, "AR (M)": 0.79273, "AR (L)": 0.89762}
+{"mode": "train", "epoch": 131, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04711, "heatmap_loss": 0.00055, "acc_pose": 0.84708, "loss": 0.00055, "grad_norm": 0.00126, "time": 0.38209}
+{"mode": "train", "epoch": 131, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00056, "acc_pose": 0.84145, "loss": 0.00056, "grad_norm": 0.00119, "time": 0.33199}
+{"mode": "train", "epoch": 131, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00056, "acc_pose": 0.83458, "loss": 0.00056, "grad_norm": 0.00128, "time": 0.33469}
+{"mode": "train", "epoch": 131, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00056, "acc_pose": 0.82075, "loss": 0.00056, "grad_norm": 0.00126, "time": 0.33315}
+{"mode": "train", "epoch": 131, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00056, "acc_pose": 0.84044, "loss": 0.00056, "grad_norm": 0.0013, "time": 0.33454}
+{"mode": "train", "epoch": 132, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04723, "heatmap_loss": 0.00056, "acc_pose": 0.84326, "loss": 0.00056, "grad_norm": 0.00123, "time": 0.38508}
+{"mode": "train", "epoch": 132, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00056, "acc_pose": 0.83106, "loss": 0.00056, "grad_norm": 0.00126, "time": 0.33331}
+{"mode": "train", "epoch": 132, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00056, "acc_pose": 0.83615, "loss": 0.00056, "grad_norm": 0.00124, "time": 0.3339}
+{"mode": "train", "epoch": 132, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00056, "acc_pose": 0.83328, "loss": 0.00056, "grad_norm": 0.00122, "time": 0.33423}
+{"mode": "train", "epoch": 132, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00055, "acc_pose": 0.84002, "loss": 0.00055, "grad_norm": 0.0012, "time": 0.33471}
+{"mode": "train", "epoch": 133, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04762, "heatmap_loss": 0.00055, "acc_pose": 0.82447, "loss": 0.00055, "grad_norm": 0.00114, "time": 0.38623}
+{"mode": "train", "epoch": 133, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00055, "acc_pose": 0.85243, "loss": 0.00055, "grad_norm": 0.00119, "time": 0.33377}
+{"mode": "train", "epoch": 133, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00056, "acc_pose": 0.83646, "loss": 0.00056, "grad_norm": 0.00114, "time": 0.33328}
+{"mode": "train", "epoch": 133, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00056, "acc_pose": 0.82862, "loss": 0.00056, "grad_norm": 0.00129, "time": 0.33271}
+{"mode": "train", "epoch": 133, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00056, "acc_pose": 0.82968, "loss": 0.00056, "grad_norm": 0.00124, "time": 0.33301}
+{"mode": "train", "epoch": 134, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04728, "heatmap_loss": 0.00055, "acc_pose": 0.82953, "loss": 0.00055, "grad_norm": 0.00122, "time": 0.38841}
+{"mode": "train", "epoch": 134, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00056, "acc_pose": 0.84207, "loss": 0.00056, "grad_norm": 0.00125, "time": 0.33425}
+{"mode": "train", "epoch": 134, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00055, "acc_pose": 0.83657, "loss": 0.00055, "grad_norm": 0.00125, "time": 0.33397}
+{"mode": "train", "epoch": 134, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00055, "acc_pose": 0.83898, "loss": 0.00055, "grad_norm": 0.00133, "time": 0.33377}
+{"mode": "train", "epoch": 134, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00056, "acc_pose": 0.83189, "loss": 0.00056, "grad_norm": 0.00117, "time": 0.33324}
+{"mode": "train", "epoch": 135, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04728, "heatmap_loss": 0.00055, "acc_pose": 0.84608, "loss": 0.00055, "grad_norm": 0.00131, "time": 0.38571}
+{"mode": "train", "epoch": 135, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00055, "acc_pose": 0.82863, "loss": 0.00055, "grad_norm": 0.00122, "time": 0.33455}
+{"mode": "train", "epoch": 135, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00055, "acc_pose": 0.82701, "loss": 0.00055, "grad_norm": 0.00121, "time": 0.33362}
+{"mode": "train", "epoch": 135, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00056, "acc_pose": 0.8366, "loss": 0.00056, "grad_norm": 0.00126, "time": 0.33403}
+{"mode": "train", "epoch": 135, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00055, "acc_pose": 0.84008, "loss": 0.00055, "grad_norm": 0.00119, "time": 0.33536}
+{"mode": "train", "epoch": 136, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04706, "heatmap_loss": 0.00056, "acc_pose": 0.83576, "loss": 0.00056, "grad_norm": 0.00114, "time": 0.38665}
+{"mode": "train", "epoch": 136, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00056, "acc_pose": 0.83096, "loss": 0.00056, "grad_norm": 0.00123, "time": 0.33465}
+{"mode": "train", "epoch": 136, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00055, "acc_pose": 0.83347, "loss": 0.00055, "grad_norm": 0.00114, "time": 0.33446}
+{"mode": "train", "epoch": 136, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00055, "acc_pose": 0.83676, "loss": 0.00055, "grad_norm": 0.0012, "time": 0.33317}
+{"mode": "train", "epoch": 136, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00055, "acc_pose": 0.83334, "loss": 0.00055, "grad_norm": 0.00117, "time": 0.33346}
+{"mode": "train", "epoch": 137, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04703, "heatmap_loss": 0.00056, "acc_pose": 0.81974, "loss": 0.00056, "grad_norm": 0.00121, "time": 0.39088}
+{"mode": "train", "epoch": 137, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00056, "acc_pose": 0.84337, "loss": 0.00056, "grad_norm": 0.00124, "time": 0.33689}
+{"mode": "train", "epoch": 137, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00056, "acc_pose": 0.84055, "loss": 0.00056, "grad_norm": 0.00123, "time": 0.33629}
+{"mode": "train", "epoch": 137, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00055, "acc_pose": 0.84702, "loss": 0.00055, "grad_norm": 0.00122, "time": 0.33649}
+{"mode": "train", "epoch": 137, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00055, "acc_pose": 0.83059, "loss": 0.00055, "grad_norm": 0.00122, "time": 0.33466}
+{"mode": "train", "epoch": 138, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04721, "heatmap_loss": 0.00056, "acc_pose": 0.83983, "loss": 0.00056, "grad_norm": 0.00129, "time": 0.3841}
+{"mode": "train", "epoch": 138, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00055, "acc_pose": 0.83783, "loss": 0.00055, "grad_norm": 0.00118, "time": 0.33472}
+{"mode": "train", "epoch": 138, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00056, "acc_pose": 0.8339, "loss": 0.00056, "grad_norm": 0.00117, "time": 0.33243}
+{"mode": "train", "epoch": 138, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00055, "acc_pose": 0.84021, "loss": 0.00055, "grad_norm": 0.00123, "time": 0.33424}
+{"mode": "train", "epoch": 138, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00055, "acc_pose": 0.84466, "loss": 0.00055, "grad_norm": 0.00126, "time": 0.33348}
+{"mode": "train", "epoch": 139, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04711, "heatmap_loss": 0.00055, "acc_pose": 0.82912, "loss": 0.00055, "grad_norm": 0.00115, "time": 0.38502}
+{"mode": "train", "epoch": 139, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00055, "acc_pose": 0.8352, "loss": 0.00055, "grad_norm": 0.00122, "time": 0.33696}
+{"mode": "train", "epoch": 139, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00055, "acc_pose": 0.8422, "loss": 0.00055, "grad_norm": 0.00123, "time": 0.33553}
+{"mode": "train", "epoch": 139, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00055, "acc_pose": 0.8362, "loss": 0.00055, "grad_norm": 0.00121, "time": 0.33632}
+{"mode": "train", "epoch": 139, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00055, "acc_pose": 0.82986, "loss": 0.00055, "grad_norm": 0.00124, "time": 0.33445}
+{"mode": "train", "epoch": 140, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04717, "heatmap_loss": 0.00055, "acc_pose": 0.85153, "loss": 0.00055, "grad_norm": 0.00128, "time": 0.38425}
+{"mode": "train", "epoch": 140, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00055, "acc_pose": 0.8381, "loss": 0.00055, "grad_norm": 0.00129, "time": 0.33526}
+{"mode": "train", "epoch": 140, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00055, "acc_pose": 0.83913, "loss": 0.00055, "grad_norm": 0.00118, "time": 0.3359}
+{"mode": "train", "epoch": 140, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00057, "heatmap_loss": 0.00056, "acc_pose": 0.84042, "loss": 0.00056, "grad_norm": 0.00133, "time": 0.33705}
+{"mode": "train", "epoch": 140, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00055, "acc_pose": 0.8377, "loss": 0.00055, "grad_norm": 0.0013, "time": 0.33628}
+{"mode": "val", "epoch": 140, "iter": 204, "lr": 0.0, "AP": 0.78596, "AP .5": 0.91584, "AP .75": 0.85355, "AP (M)": 0.71168, "AP (L)": 0.81774, "AR": 0.83624, "AR .5": 0.9534, "AR .75": 0.89562, "AR (M)": 0.79484, "AR (L)": 0.89706}
+{"mode": "train", "epoch": 141, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04687, "heatmap_loss": 0.00055, "acc_pose": 0.82666, "loss": 0.00055, "grad_norm": 0.00118, "time": 0.38025}
+{"mode": "train", "epoch": 141, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00055, "acc_pose": 0.83215, "loss": 0.00055, "grad_norm": 0.00118, "time": 0.33232}
+{"mode": "train", "epoch": 141, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00055, "acc_pose": 0.82867, "loss": 0.00055, "grad_norm": 0.00118, "time": 0.33472}
+{"mode": "train", "epoch": 141, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00056, "acc_pose": 0.83996, "loss": 0.00056, "grad_norm": 0.00121, "time": 0.33491}
+{"mode": "train", "epoch": 141, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00055, "acc_pose": 0.83651, "loss": 0.00055, "grad_norm": 0.00119, "time": 0.33476}
+{"mode": "train", "epoch": 142, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04723, "heatmap_loss": 0.00055, "acc_pose": 0.84234, "loss": 0.00055, "grad_norm": 0.00113, "time": 0.38567}
+{"mode": "train", "epoch": 142, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00055, "acc_pose": 0.83114, "loss": 0.00055, "grad_norm": 0.00125, "time": 0.33367}
+{"mode": "train", "epoch": 142, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00055, "acc_pose": 0.83571, "loss": 0.00055, "grad_norm": 0.00124, "time": 0.33465}
+{"mode": "train", "epoch": 142, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00055, "acc_pose": 0.83048, "loss": 0.00055, "grad_norm": 0.00122, "time": 0.33247}
+{"mode": "train", "epoch": 142, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00054, "acc_pose": 0.83661, "loss": 0.00054, "grad_norm": 0.00111, "time": 0.33369}
+{"mode": "train", "epoch": 143, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.0473, "heatmap_loss": 0.00055, "acc_pose": 0.84672, "loss": 0.00055, "grad_norm": 0.00123, "time": 0.38539}
+{"mode": "train", "epoch": 143, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00056, "acc_pose": 0.8203, "loss": 0.00056, "grad_norm": 0.00127, "time": 0.333}
+{"mode": "train", "epoch": 143, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00055, "acc_pose": 0.83816, "loss": 0.00055, "grad_norm": 0.00127, "time": 0.33336}
+{"mode": "train", "epoch": 143, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00055, "acc_pose": 0.84442, "loss": 0.00055, "grad_norm": 0.00123, "time": 0.33552}
+{"mode": "train", "epoch": 143, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00055, "acc_pose": 0.83886, "loss": 0.00055, "grad_norm": 0.00121, "time": 0.33401}
+{"mode": "train", "epoch": 144, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04706, "heatmap_loss": 0.00055, "acc_pose": 0.83119, "loss": 0.00055, "grad_norm": 0.00116, "time": 0.38992}
+{"mode": "train", "epoch": 144, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00055, "acc_pose": 0.84159, "loss": 0.00055, "grad_norm": 0.00118, "time": 0.33413}
+{"mode": "train", "epoch": 144, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00055, "acc_pose": 0.84513, "loss": 0.00055, "grad_norm": 0.00118, "time": 0.33632}
+{"mode": "train", "epoch": 144, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00052, "heatmap_loss": 0.00055, "acc_pose": 0.82844, "loss": 0.00055, "grad_norm": 0.00126, "time": 0.33684}
+{"mode": "train", "epoch": 144, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00036, "heatmap_loss": 0.00055, "acc_pose": 0.84543, "loss": 0.00055, "grad_norm": 0.00124, "time": 0.33849}
+{"mode": "train", "epoch": 145, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04736, "heatmap_loss": 0.00055, "acc_pose": 0.84915, "loss": 0.00055, "grad_norm": 0.00128, "time": 0.38599}
+{"mode": "train", "epoch": 145, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00055, "acc_pose": 0.85658, "loss": 0.00055, "grad_norm": 0.0012, "time": 0.33404}
+{"mode": "train", "epoch": 145, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00055, "acc_pose": 0.83314, "loss": 0.00055, "grad_norm": 0.00121, "time": 0.33334}
+{"mode": "train", "epoch": 145, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00055, "acc_pose": 0.84068, "loss": 0.00055, "grad_norm": 0.00128, "time": 0.33487}
+{"mode": "train", "epoch": 145, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00055, "acc_pose": 0.83912, "loss": 0.00055, "grad_norm": 0.00128, "time": 0.33548}
+{"mode": "train", "epoch": 146, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04705, "heatmap_loss": 0.00055, "acc_pose": 0.84561, "loss": 0.00055, "grad_norm": 0.00119, "time": 0.3856}
+{"mode": "train", "epoch": 146, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00055, "acc_pose": 0.8452, "loss": 0.00055, "grad_norm": 0.0013, "time": 0.33503}
+{"mode": "train", "epoch": 146, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00055, "acc_pose": 0.83454, "loss": 0.00055, "grad_norm": 0.00123, "time": 0.33701}
+{"mode": "train", "epoch": 146, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00054, "acc_pose": 0.84439, "loss": 0.00054, "grad_norm": 0.00124, "time": 0.3353}
+{"mode": "train", "epoch": 146, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00055, "acc_pose": 0.82957, "loss": 0.00055, "grad_norm": 0.00122, "time": 0.33495}
+{"mode": "train", "epoch": 147, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.0471, "heatmap_loss": 0.00055, "acc_pose": 0.83401, "loss": 0.00055, "grad_norm": 0.00125, "time": 0.38758}
+{"mode": "train", "epoch": 147, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00054, "acc_pose": 0.84279, "loss": 0.00054, "grad_norm": 0.00114, "time": 0.33544}
+{"mode": "train", "epoch": 147, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00055, "acc_pose": 0.83991, "loss": 0.00055, "grad_norm": 0.00121, "time": 0.33613}
+{"mode": "train", "epoch": 147, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00054, "heatmap_loss": 0.00055, "acc_pose": 0.83648, "loss": 0.00055, "grad_norm": 0.00128, "time": 0.3344}
+{"mode": "train", "epoch": 147, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00054, "acc_pose": 0.84656, "loss": 0.00054, "grad_norm": 0.00126, "time": 0.33413}
+{"mode": "train", "epoch": 148, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04702, "heatmap_loss": 0.00055, "acc_pose": 0.84423, "loss": 0.00055, "grad_norm": 0.00125, "time": 0.38481}
+{"mode": "train", "epoch": 148, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00055, "acc_pose": 0.83744, "loss": 0.00055, "grad_norm": 0.00136, "time": 0.33455}
+{"mode": "train", "epoch": 148, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00055, "acc_pose": 0.83293, "loss": 0.00055, "grad_norm": 0.00114, "time": 0.33436}
+{"mode": "train", "epoch": 148, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00055, "heatmap_loss": 0.00055, "acc_pose": 0.82103, "loss": 0.00055, "grad_norm": 0.00132, "time": 0.33379}
+{"mode": "train", "epoch": 148, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00055, "acc_pose": 0.82906, "loss": 0.00055, "grad_norm": 0.00124, "time": 0.33435}
+{"mode": "train", "epoch": 149, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04717, "heatmap_loss": 0.00055, "acc_pose": 0.84014, "loss": 0.00055, "grad_norm": 0.00124, "time": 0.3854}
+{"mode": "train", "epoch": 149, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00055, "acc_pose": 0.83132, "loss": 0.00055, "grad_norm": 0.00125, "time": 0.33499}
+{"mode": "train", "epoch": 149, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00054, "acc_pose": 0.84485, "loss": 0.00054, "grad_norm": 0.00123, "time": 0.33526}
+{"mode": "train", "epoch": 149, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00055, "acc_pose": 0.83095, "loss": 0.00055, "grad_norm": 0.00117, "time": 0.33542}
+{"mode": "train", "epoch": 149, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00055, "acc_pose": 0.8552, "loss": 0.00055, "grad_norm": 0.00127, "time": 0.33474}
+{"mode": "train", "epoch": 150, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04843, "heatmap_loss": 0.00055, "acc_pose": 0.84033, "loss": 0.00055, "grad_norm": 0.0012, "time": 0.3843}
+{"mode": "train", "epoch": 150, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00054, "acc_pose": 0.8443, "loss": 0.00054, "grad_norm": 0.00118, "time": 0.33383}
+{"mode": "train", "epoch": 150, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00055, "acc_pose": 0.84412, "loss": 0.00055, "grad_norm": 0.00121, "time": 0.33731}
+{"mode": "train", "epoch": 150, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00054, "heatmap_loss": 0.00055, "acc_pose": 0.82873, "loss": 0.00055, "grad_norm": 0.00116, "time": 0.33668}
+{"mode": "train", "epoch": 150, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00052, "heatmap_loss": 0.00055, "acc_pose": 0.84383, "loss": 0.00055, "grad_norm": 0.00115, "time": 0.33358}
+{"mode": "val", "epoch": 150, "iter": 204, "lr": 0.0, "AP": 0.78647, "AP .5": 0.91615, "AP .75": 0.85368, "AP (M)": 0.71303, "AP (L)": 0.81741, "AR": 0.83709, "AR .5": 0.95309, "AR .75": 0.89531, "AR (M)": 0.79547, "AR (L)": 0.89818}
+{"mode": "train", "epoch": 151, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04679, "heatmap_loss": 0.00055, "acc_pose": 0.82483, "loss": 0.00055, "grad_norm": 0.00122, "time": 0.3839}
+{"mode": "train", "epoch": 151, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00054, "acc_pose": 0.84024, "loss": 0.00054, "grad_norm": 0.00116, "time": 0.33513}
+{"mode": "train", "epoch": 151, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00055, "acc_pose": 0.84228, "loss": 0.00055, "grad_norm": 0.00112, "time": 0.33468}
+{"mode": "train", "epoch": 151, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00055, "acc_pose": 0.82807, "loss": 0.00055, "grad_norm": 0.00123, "time": 0.33642}
+{"mode": "train", "epoch": 151, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00055, "acc_pose": 0.84449, "loss": 0.00055, "grad_norm": 0.00121, "time": 0.33637}
+{"mode": "train", "epoch": 152, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04707, "heatmap_loss": 0.00054, "acc_pose": 0.83767, "loss": 0.00054, "grad_norm": 0.00115, "time": 0.39142}
+{"mode": "train", "epoch": 152, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00055, "acc_pose": 0.83931, "loss": 0.00055, "grad_norm": 0.0012, "time": 0.33941}
+{"mode": "train", "epoch": 152, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00055, "acc_pose": 0.84038, "loss": 0.00055, "grad_norm": 0.00116, "time": 0.33728}
+{"mode": "train", "epoch": 152, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00055, "acc_pose": 0.84415, "loss": 0.00055, "grad_norm": 0.00124, "time": 0.33851}
+{"mode": "train", "epoch": 152, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00054, "heatmap_loss": 0.00054, "acc_pose": 0.84059, "loss": 0.00054, "grad_norm": 0.00122, "time": 0.33875}
+{"mode": "train", "epoch": 153, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04709, "heatmap_loss": 0.00055, "acc_pose": 0.85124, "loss": 0.00055, "grad_norm": 0.0012, "time": 0.3901}
+{"mode": "train", "epoch": 153, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00054, "acc_pose": 0.84132, "loss": 0.00054, "grad_norm": 0.00118, "time": 0.33813}
+{"mode": "train", "epoch": 153, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00054, "acc_pose": 0.84515, "loss": 0.00054, "grad_norm": 0.00111, "time": 0.33751}
+{"mode": "train", "epoch": 153, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00055, "acc_pose": 0.8321, "loss": 0.00055, "grad_norm": 0.00126, "time": 0.3363}
+{"mode": "train", "epoch": 153, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00054, "acc_pose": 0.85333, "loss": 0.00054, "grad_norm": 0.0012, "time": 0.33859}
+{"mode": "train", "epoch": 154, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04709, "heatmap_loss": 0.00055, "acc_pose": 0.83877, "loss": 0.00055, "grad_norm": 0.00131, "time": 0.38876}
+{"mode": "train", "epoch": 154, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00055, "acc_pose": 0.84354, "loss": 0.00055, "grad_norm": 0.00127, "time": 0.33574}
+{"mode": "train", "epoch": 154, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00055, "acc_pose": 0.84444, "loss": 0.00055, "grad_norm": 0.00122, "time": 0.33575}
+{"mode": "train", "epoch": 154, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00054, "acc_pose": 0.83451, "loss": 0.00054, "grad_norm": 0.00116, "time": 0.33478}
+{"mode": "train", "epoch": 154, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00054, "acc_pose": 0.84114, "loss": 0.00054, "grad_norm": 0.00114, "time": 0.33542}
+{"mode": "train", "epoch": 155, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04713, "heatmap_loss": 0.00054, "acc_pose": 0.8354, "loss": 0.00054, "grad_norm": 0.00119, "time": 0.38769}
+{"mode": "train", "epoch": 155, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00054, "acc_pose": 0.84145, "loss": 0.00054, "grad_norm": 0.00122, "time": 0.33386}
+{"mode": "train", "epoch": 155, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00054, "acc_pose": 0.85241, "loss": 0.00054, "grad_norm": 0.00124, "time": 0.3359}
+{"mode": "train", "epoch": 155, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00055, "acc_pose": 0.83489, "loss": 0.00055, "grad_norm": 0.00127, "time": 0.33545}
+{"mode": "train", "epoch": 155, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00054, "acc_pose": 0.837, "loss": 0.00054, "grad_norm": 0.00115, "time": 0.33638}
+{"mode": "train", "epoch": 156, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04727, "heatmap_loss": 0.00054, "acc_pose": 0.8327, "loss": 0.00054, "grad_norm": 0.00124, "time": 0.3893}
+{"mode": "train", "epoch": 156, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00055, "acc_pose": 0.84802, "loss": 0.00055, "grad_norm": 0.00111, "time": 0.33837}
+{"mode": "train", "epoch": 156, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00054, "acc_pose": 0.8347, "loss": 0.00054, "grad_norm": 0.00126, "time": 0.33764}
+{"mode": "train", "epoch": 156, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00054, "acc_pose": 0.84737, "loss": 0.00054, "grad_norm": 0.0012, "time": 0.33561}
+{"mode": "train", "epoch": 156, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00054, "acc_pose": 0.83736, "loss": 0.00054, "grad_norm": 0.00122, "time": 0.33402}
+{"mode": "train", "epoch": 157, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04885, "heatmap_loss": 0.00054, "acc_pose": 0.85141, "loss": 0.00054, "grad_norm": 0.00134, "time": 0.38539}
+{"mode": "train", "epoch": 157, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00054, "acc_pose": 0.85276, "loss": 0.00054, "grad_norm": 0.00116, "time": 0.33295}
+{"mode": "train", "epoch": 157, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00054, "acc_pose": 0.83787, "loss": 0.00054, "grad_norm": 0.00116, "time": 0.33737}
+{"mode": "train", "epoch": 157, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00054, "acc_pose": 0.83928, "loss": 0.00054, "grad_norm": 0.00117, "time": 0.33461}
+{"mode": "train", "epoch": 157, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00054, "acc_pose": 0.81991, "loss": 0.00054, "grad_norm": 0.00119, "time": 0.33306}
+{"mode": "train", "epoch": 158, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04729, "heatmap_loss": 0.00054, "acc_pose": 0.83197, "loss": 0.00054, "grad_norm": 0.00122, "time": 0.38638}
+{"mode": "train", "epoch": 158, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00055, "acc_pose": 0.83984, "loss": 0.00055, "grad_norm": 0.00127, "time": 0.33496}
+{"mode": "train", "epoch": 158, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00054, "acc_pose": 0.83205, "loss": 0.00054, "grad_norm": 0.00115, "time": 0.33445}
+{"mode": "train", "epoch": 158, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00054, "acc_pose": 0.84282, "loss": 0.00054, "grad_norm": 0.00115, "time": 0.33814}
+{"mode": "train", "epoch": 158, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00054, "acc_pose": 0.84055, "loss": 0.00054, "grad_norm": 0.00111, "time": 0.33805}
+{"mode": "train", "epoch": 159, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04717, "heatmap_loss": 0.00054, "acc_pose": 0.84408, "loss": 0.00054, "grad_norm": 0.0012, "time": 0.38918}
+{"mode": "train", "epoch": 159, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00054, "acc_pose": 0.83447, "loss": 0.00054, "grad_norm": 0.00122, "time": 0.33703}
+{"mode": "train", "epoch": 159, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00054, "acc_pose": 0.85241, "loss": 0.00054, "grad_norm": 0.00108, "time": 0.33549}
+{"mode": "train", "epoch": 159, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00054, "acc_pose": 0.83622, "loss": 0.00054, "grad_norm": 0.00115, "time": 0.33569}
+{"mode": "train", "epoch": 159, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00054, "acc_pose": 0.83795, "loss": 0.00054, "grad_norm": 0.0012, "time": 0.3379}
+{"mode": "train", "epoch": 160, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.0474, "heatmap_loss": 0.00055, "acc_pose": 0.83642, "loss": 0.00055, "grad_norm": 0.00116, "time": 0.38673}
+{"mode": "train", "epoch": 160, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00054, "acc_pose": 0.84596, "loss": 0.00054, "grad_norm": 0.00123, "time": 0.33518}
+{"mode": "train", "epoch": 160, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00054, "acc_pose": 0.84351, "loss": 0.00054, "grad_norm": 0.00127, "time": 0.33486}
+{"mode": "train", "epoch": 160, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00054, "acc_pose": 0.83283, "loss": 0.00054, "grad_norm": 0.00113, "time": 0.33586}
+{"mode": "train", "epoch": 160, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00054, "acc_pose": 0.82653, "loss": 0.00054, "grad_norm": 0.00122, "time": 0.33337}
+{"mode": "val", "epoch": 160, "iter": 204, "lr": 0.0, "AP": 0.78504, "AP .5": 0.91558, "AP .75": 0.85247, "AP (M)": 0.71099, "AP (L)": 0.81552, "AR": 0.83632, "AR .5": 0.95309, "AR .75": 0.89547, "AR (M)": 0.79418, "AR (L)": 0.89822}
+{"mode": "train", "epoch": 161, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04678, "heatmap_loss": 0.00055, "acc_pose": 0.85463, "loss": 0.00055, "grad_norm": 0.00127, "time": 0.38128}
+{"mode": "train", "epoch": 161, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00054, "acc_pose": 0.84497, "loss": 0.00054, "grad_norm": 0.00119, "time": 0.33396}
+{"mode": "train", "epoch": 161, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00054, "acc_pose": 0.84603, "loss": 0.00054, "grad_norm": 0.00113, "time": 0.33273}
+{"mode": "train", "epoch": 161, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00054, "acc_pose": 0.84408, "loss": 0.00054, "grad_norm": 0.00116, "time": 0.33457}
+{"mode": "train", "epoch": 161, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00054, "acc_pose": 0.82908, "loss": 0.00054, "grad_norm": 0.0012, "time": 0.33811}
+{"mode": "train", "epoch": 162, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04703, "heatmap_loss": 0.00054, "acc_pose": 0.84941, "loss": 0.00054, "grad_norm": 0.00112, "time": 0.38819}
+{"mode": "train", "epoch": 162, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00054, "acc_pose": 0.84324, "loss": 0.00054, "grad_norm": 0.00116, "time": 0.33777}
+{"mode": "train", "epoch": 162, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00054, "acc_pose": 0.84754, "loss": 0.00054, "grad_norm": 0.00124, "time": 0.33667}
+{"mode": "train", "epoch": 162, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00054, "acc_pose": 0.85476, "loss": 0.00054, "grad_norm": 0.00122, "time": 0.33584}
+{"mode": "train", "epoch": 162, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00054, "acc_pose": 0.83779, "loss": 0.00054, "grad_norm": 0.00121, "time": 0.33402}
+{"mode": "train", "epoch": 163, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04706, "heatmap_loss": 0.00054, "acc_pose": 0.82911, "loss": 0.00054, "grad_norm": 0.00117, "time": 0.38764}
+{"mode": "train", "epoch": 163, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00053, "heatmap_loss": 0.00054, "acc_pose": 0.84099, "loss": 0.00054, "grad_norm": 0.00116, "time": 0.33644}
+{"mode": "train", "epoch": 163, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00054, "acc_pose": 0.83229, "loss": 0.00054, "grad_norm": 0.00114, "time": 0.33619}
+{"mode": "train", "epoch": 163, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00054, "acc_pose": 0.83967, "loss": 0.00054, "grad_norm": 0.00118, "time": 0.33741}
+{"mode": "train", "epoch": 163, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00054, "acc_pose": 0.84235, "loss": 0.00054, "grad_norm": 0.00122, "time": 0.33705}
+{"mode": "train", "epoch": 164, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04738, "heatmap_loss": 0.00054, "acc_pose": 0.85386, "loss": 0.00054, "grad_norm": 0.00118, "time": 0.38576}
+{"mode": "train", "epoch": 164, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00054, "acc_pose": 0.84079, "loss": 0.00054, "grad_norm": 0.00117, "time": 0.33346}
+{"mode": "train", "epoch": 164, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00054, "acc_pose": 0.84368, "loss": 0.00054, "grad_norm": 0.00113, "time": 0.3343}
+{"mode": "train", "epoch": 164, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00054, "acc_pose": 0.85393, "loss": 0.00054, "grad_norm": 0.00118, "time": 0.33606}
+{"mode": "train", "epoch": 164, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00054, "acc_pose": 0.84531, "loss": 0.00054, "grad_norm": 0.00118, "time": 0.33641}
+{"mode": "train", "epoch": 165, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04698, "heatmap_loss": 0.00054, "acc_pose": 0.86035, "loss": 0.00054, "grad_norm": 0.00122, "time": 0.38759}
+{"mode": "train", "epoch": 165, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00054, "acc_pose": 0.84377, "loss": 0.00054, "grad_norm": 0.00123, "time": 0.33605}
+{"mode": "train", "epoch": 165, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00054, "acc_pose": 0.84781, "loss": 0.00054, "grad_norm": 0.00119, "time": 0.33505}
+{"mode": "train", "epoch": 165, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00054, "heatmap_loss": 0.00053, "acc_pose": 0.84475, "loss": 0.00053, "grad_norm": 0.00113, "time": 0.33524}
+{"mode": "train", "epoch": 165, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00054, "acc_pose": 0.84254, "loss": 0.00054, "grad_norm": 0.00126, "time": 0.33901}
+{"mode": "train", "epoch": 166, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04743, "heatmap_loss": 0.00054, "acc_pose": 0.83741, "loss": 0.00054, "grad_norm": 0.00112, "time": 0.3856}
+{"mode": "train", "epoch": 166, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00053, "acc_pose": 0.84352, "loss": 0.00053, "grad_norm": 0.00122, "time": 0.33429}
+{"mode": "train", "epoch": 166, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00054, "acc_pose": 0.83752, "loss": 0.00054, "grad_norm": 0.00115, "time": 0.33401}
+{"mode": "train", "epoch": 166, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00053, "acc_pose": 0.84252, "loss": 0.00053, "grad_norm": 0.00124, "time": 0.33269}
+{"mode": "train", "epoch": 166, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00054, "acc_pose": 0.83519, "loss": 0.00054, "grad_norm": 0.00114, "time": 0.33425}
+{"mode": "train", "epoch": 167, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04714, "heatmap_loss": 0.00054, "acc_pose": 0.8487, "loss": 0.00054, "grad_norm": 0.00112, "time": 0.38991}
+{"mode": "train", "epoch": 167, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00054, "acc_pose": 0.85046, "loss": 0.00054, "grad_norm": 0.00123, "time": 0.33632}
+{"mode": "train", "epoch": 167, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00054, "acc_pose": 0.83349, "loss": 0.00054, "grad_norm": 0.00118, "time": 0.33727}
+{"mode": "train", "epoch": 167, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00054, "acc_pose": 0.84835, "loss": 0.00054, "grad_norm": 0.00111, "time": 0.33649}
+{"mode": "train", "epoch": 167, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00053, "heatmap_loss": 0.00054, "acc_pose": 0.83618, "loss": 0.00054, "grad_norm": 0.00122, "time": 0.33567}
+{"mode": "train", "epoch": 168, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04697, "heatmap_loss": 0.00054, "acc_pose": 0.83013, "loss": 0.00054, "grad_norm": 0.00115, "time": 0.3859}
+{"mode": "train", "epoch": 168, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00053, "acc_pose": 0.84263, "loss": 0.00053, "grad_norm": 0.00114, "time": 0.33554}
+{"mode": "train", "epoch": 168, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00056, "heatmap_loss": 0.00054, "acc_pose": 0.83271, "loss": 0.00054, "grad_norm": 0.00119, "time": 0.33896}
+{"mode": "train", "epoch": 168, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00054, "heatmap_loss": 0.00054, "acc_pose": 0.84049, "loss": 0.00054, "grad_norm": 0.00118, "time": 0.33969}
+{"mode": "train", "epoch": 168, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00054, "acc_pose": 0.83544, "loss": 0.00054, "grad_norm": 0.00119, "time": 0.34015}
+{"mode": "train", "epoch": 169, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04711, "heatmap_loss": 0.00053, "acc_pose": 0.85305, "loss": 0.00053, "grad_norm": 0.00116, "time": 0.39044}
+{"mode": "train", "epoch": 169, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00054, "acc_pose": 0.83405, "loss": 0.00054, "grad_norm": 0.00119, "time": 0.34074}
+{"mode": "train", "epoch": 169, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00054, "acc_pose": 0.84843, "loss": 0.00054, "grad_norm": 0.00116, "time": 0.33788}
+{"mode": "train", "epoch": 169, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00054, "acc_pose": 0.84221, "loss": 0.00054, "grad_norm": 0.00123, "time": 0.33639}
+{"mode": "train", "epoch": 169, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00057, "heatmap_loss": 0.00054, "acc_pose": 0.852, "loss": 0.00054, "grad_norm": 0.00116, "time": 0.33468}
+{"mode": "train", "epoch": 170, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04729, "heatmap_loss": 0.00054, "acc_pose": 0.82139, "loss": 0.00054, "grad_norm": 0.00119, "time": 0.38759}
+{"mode": "train", "epoch": 170, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00053, "acc_pose": 0.84453, "loss": 0.00053, "grad_norm": 0.00122, "time": 0.33473}
+{"mode": "train", "epoch": 170, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00052, "heatmap_loss": 0.00054, "acc_pose": 0.84593, "loss": 0.00054, "grad_norm": 0.00116, "time": 0.3364}
+{"mode": "train", "epoch": 170, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00053, "acc_pose": 0.84218, "loss": 0.00053, "grad_norm": 0.00122, "time": 0.33589}
+{"mode": "train", "epoch": 170, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00053, "acc_pose": 0.84024, "loss": 0.00053, "grad_norm": 0.00115, "time": 0.33342}
+{"mode": "val", "epoch": 170, "iter": 204, "lr": 0.0, "AP": 0.78793, "AP .5": 0.91601, "AP .75": 0.85584, "AP (M)": 0.71474, "AP (L)": 0.81939, "AR": 0.83794, "AR .5": 0.95293, "AR .75": 0.8983, "AR (M)": 0.7971, "AR (L)": 0.89773}
+{"mode": "train", "epoch": 171, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04696, "heatmap_loss": 0.00054, "acc_pose": 0.83822, "loss": 0.00054, "grad_norm": 0.0012, "time": 0.3809}
+{"mode": "train", "epoch": 171, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00053, "acc_pose": 0.85071, "loss": 0.00053, "grad_norm": 0.00112, "time": 0.33255}
+{"mode": "train", "epoch": 171, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00053, "acc_pose": 0.84039, "loss": 0.00053, "grad_norm": 0.00121, "time": 0.3333}
+{"mode": "train", "epoch": 171, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00053, "acc_pose": 0.84298, "loss": 0.00053, "grad_norm": 0.00119, "time": 0.33329}
+{"mode": "train", "epoch": 171, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00053, "acc_pose": 0.83611, "loss": 0.00053, "grad_norm": 0.00109, "time": 0.33403}
+{"mode": "train", "epoch": 172, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04722, "heatmap_loss": 0.00053, "acc_pose": 0.83313, "loss": 0.00053, "grad_norm": 0.0011, "time": 0.38858}
+{"mode": "train", "epoch": 172, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00053, "heatmap_loss": 0.00053, "acc_pose": 0.84514, "loss": 0.00053, "grad_norm": 0.00117, "time": 0.33687}
+{"mode": "train", "epoch": 172, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00053, "acc_pose": 0.84871, "loss": 0.00053, "grad_norm": 0.00113, "time": 0.34089}
+{"mode": "train", "epoch": 172, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00053, "acc_pose": 0.84127, "loss": 0.00053, "grad_norm": 0.00118, "time": 0.33688}
+{"mode": "train", "epoch": 172, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00053, "acc_pose": 0.8417, "loss": 0.00053, "grad_norm": 0.00116, "time": 0.33763}
+{"mode": "train", "epoch": 173, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04716, "heatmap_loss": 0.00052, "acc_pose": 0.83501, "loss": 0.00052, "grad_norm": 0.00119, "time": 0.39003}
+{"mode": "train", "epoch": 173, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00053, "acc_pose": 0.84846, "loss": 0.00053, "grad_norm": 0.00117, "time": 0.33601}
+{"mode": "train", "epoch": 173, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00053, "acc_pose": 0.8501, "loss": 0.00053, "grad_norm": 0.00112, "time": 0.33609}
+{"mode": "train", "epoch": 173, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00053, "acc_pose": 0.85204, "loss": 0.00053, "grad_norm": 0.00113, "time": 0.33477}
+{"mode": "train", "epoch": 173, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00053, "acc_pose": 0.84293, "loss": 0.00053, "grad_norm": 0.00112, "time": 0.33855}
+{"mode": "train", "epoch": 174, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04721, "heatmap_loss": 0.00053, "acc_pose": 0.84677, "loss": 0.00053, "grad_norm": 0.00109, "time": 0.3873}
+{"mode": "train", "epoch": 174, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.84812, "loss": 0.00052, "grad_norm": 0.00117, "time": 0.33524}
+{"mode": "train", "epoch": 174, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00053, "acc_pose": 0.83964, "loss": 0.00053, "grad_norm": 0.00118, "time": 0.33626}
+{"mode": "train", "epoch": 174, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00053, "acc_pose": 0.85197, "loss": 0.00053, "grad_norm": 0.00117, "time": 0.33562}
+{"mode": "train", "epoch": 174, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00053, "acc_pose": 0.84037, "loss": 0.00053, "grad_norm": 0.00115, "time": 0.33515}
+{"mode": "train", "epoch": 175, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04704, "heatmap_loss": 0.00052, "acc_pose": 0.85242, "loss": 0.00052, "grad_norm": 0.00106, "time": 0.38691}
+{"mode": "train", "epoch": 175, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00053, "acc_pose": 0.86029, "loss": 0.00053, "grad_norm": 0.00118, "time": 0.33512}
+{"mode": "train", "epoch": 175, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00053, "acc_pose": 0.85167, "loss": 0.00053, "grad_norm": 0.00125, "time": 0.3341}
+{"mode": "train", "epoch": 175, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00052, "heatmap_loss": 0.00052, "acc_pose": 0.8528, "loss": 0.00052, "grad_norm": 0.00117, "time": 0.33361}
+{"mode": "train", "epoch": 175, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00052, "acc_pose": 0.85135, "loss": 0.00052, "grad_norm": 0.00109, "time": 0.33481}
+{"mode": "train", "epoch": 176, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04739, "heatmap_loss": 0.00053, "acc_pose": 0.83338, "loss": 0.00053, "grad_norm": 0.00121, "time": 0.38598}
+{"mode": "train", "epoch": 176, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00054, "heatmap_loss": 0.00052, "acc_pose": 0.85662, "loss": 0.00052, "grad_norm": 0.00112, "time": 0.33472}
+{"mode": "train", "epoch": 176, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.8526, "loss": 0.00052, "grad_norm": 0.0012, "time": 0.33694}
+{"mode": "train", "epoch": 176, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00053, "acc_pose": 0.85029, "loss": 0.00053, "grad_norm": 0.00123, "time": 0.33416}
+{"mode": "train", "epoch": 176, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00052, "acc_pose": 0.84545, "loss": 0.00052, "grad_norm": 0.00122, "time": 0.33663}
+{"mode": "train", "epoch": 177, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04724, "heatmap_loss": 0.00053, "acc_pose": 0.84586, "loss": 0.00053, "grad_norm": 0.00116, "time": 0.39103}
+{"mode": "train", "epoch": 177, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00052, "acc_pose": 0.85533, "loss": 0.00052, "grad_norm": 0.00115, "time": 0.33987}
+{"mode": "train", "epoch": 177, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00054, "heatmap_loss": 0.00053, "acc_pose": 0.83958, "loss": 0.00053, "grad_norm": 0.00117, "time": 0.33745}
+{"mode": "train", "epoch": 177, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00052, "acc_pose": 0.84476, "loss": 0.00052, "grad_norm": 0.00118, "time": 0.33683}
+{"mode": "train", "epoch": 177, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00052, "acc_pose": 0.86309, "loss": 0.00052, "grad_norm": 0.00108, "time": 0.33838}
+{"mode": "train", "epoch": 178, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04734, "heatmap_loss": 0.00053, "acc_pose": 0.85222, "loss": 0.00053, "grad_norm": 0.00107, "time": 0.38917}
+{"mode": "train", "epoch": 178, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00052, "acc_pose": 0.85422, "loss": 0.00052, "grad_norm": 0.00112, "time": 0.33543}
+{"mode": "train", "epoch": 178, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00052, "acc_pose": 0.85153, "loss": 0.00052, "grad_norm": 0.00119, "time": 0.33611}
+{"mode": "train", "epoch": 178, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.84984, "loss": 0.00052, "grad_norm": 0.00111, "time": 0.33434}
+{"mode": "train", "epoch": 178, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00053, "acc_pose": 0.84525, "loss": 0.00053, "grad_norm": 0.00118, "time": 0.33512}
+{"mode": "train", "epoch": 179, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04707, "heatmap_loss": 0.00052, "acc_pose": 0.84311, "loss": 0.00052, "grad_norm": 0.00119, "time": 0.38739}
+{"mode": "train", "epoch": 179, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00052, "acc_pose": 0.85044, "loss": 0.00052, "grad_norm": 0.00116, "time": 0.33423}
+{"mode": "train", "epoch": 179, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00052, "acc_pose": 0.84195, "loss": 0.00052, "grad_norm": 0.00119, "time": 0.33577}
+{"mode": "train", "epoch": 179, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00052, "acc_pose": 0.86852, "loss": 0.00052, "grad_norm": 0.0012, "time": 0.33528}
+{"mode": "train", "epoch": 179, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00052, "acc_pose": 0.84884, "loss": 0.00052, "grad_norm": 0.00123, "time": 0.33731}
+{"mode": "train", "epoch": 180, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04768, "heatmap_loss": 0.00052, "acc_pose": 0.85438, "loss": 0.00052, "grad_norm": 0.00119, "time": 0.38964}
+{"mode": "train", "epoch": 180, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00052, "acc_pose": 0.84898, "loss": 0.00052, "grad_norm": 0.00119, "time": 0.33871}
+{"mode": "train", "epoch": 180, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00046, "heatmap_loss": 0.00052, "acc_pose": 0.85412, "loss": 0.00052, "grad_norm": 0.00102, "time": 0.33805}
+{"mode": "train", "epoch": 180, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00052, "acc_pose": 0.84426, "loss": 0.00052, "grad_norm": 0.0011, "time": 0.33858}
+{"mode": "train", "epoch": 180, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00052, "acc_pose": 0.86151, "loss": 0.00052, "grad_norm": 0.00113, "time": 0.33848}
+{"mode": "val", "epoch": 180, "iter": 204, "lr": 0.0, "AP": 0.78831, "AP .5": 0.91564, "AP .75": 0.85561, "AP (M)": 0.71489, "AP (L)": 0.81969, "AR": 0.83876, "AR .5": 0.9534, "AR .75": 0.89798, "AR (M)": 0.7973, "AR (L)": 0.89929}
+{"mode": "train", "epoch": 181, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.047, "heatmap_loss": 0.00052, "acc_pose": 0.85817, "loss": 0.00052, "grad_norm": 0.00112, "time": 0.38178}
+{"mode": "train", "epoch": 181, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00052, "acc_pose": 0.84656, "loss": 0.00052, "grad_norm": 0.00116, "time": 0.33467}
+{"mode": "train", "epoch": 181, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.84194, "loss": 0.00052, "grad_norm": 0.00118, "time": 0.33299}
+{"mode": "train", "epoch": 181, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00057, "heatmap_loss": 0.00053, "acc_pose": 0.83865, "loss": 0.00053, "grad_norm": 0.00108, "time": 0.33771}
+{"mode": "train", "epoch": 181, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.85102, "loss": 0.00052, "grad_norm": 0.00114, "time": 0.33702}
+{"mode": "train", "epoch": 182, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04695, "heatmap_loss": 0.00052, "acc_pose": 0.84026, "loss": 0.00052, "grad_norm": 0.00109, "time": 0.38488}
+{"mode": "train", "epoch": 182, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.8596, "loss": 0.00052, "grad_norm": 0.00105, "time": 0.33683}
+{"mode": "train", "epoch": 182, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00053, "acc_pose": 0.84181, "loss": 0.00053, "grad_norm": 0.0011, "time": 0.33502}
+{"mode": "train", "epoch": 182, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00052, "acc_pose": 0.84507, "loss": 0.00052, "grad_norm": 0.00112, "time": 0.33502}
+{"mode": "train", "epoch": 182, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00052, "acc_pose": 0.8334, "loss": 0.00052, "grad_norm": 0.00119, "time": 0.33542}
+{"mode": "train", "epoch": 183, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04738, "heatmap_loss": 0.00052, "acc_pose": 0.8551, "loss": 0.00052, "grad_norm": 0.00111, "time": 0.38915}
+{"mode": "train", "epoch": 183, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.84938, "loss": 0.00052, "grad_norm": 0.00112, "time": 0.33458}
+{"mode": "train", "epoch": 183, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00052, "acc_pose": 0.85829, "loss": 0.00052, "grad_norm": 0.00117, "time": 0.3355}
+{"mode": "train", "epoch": 183, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.84993, "loss": 0.00052, "grad_norm": 0.00105, "time": 0.33461}
+{"mode": "train", "epoch": 183, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.84569, "loss": 0.00052, "grad_norm": 0.0011, "time": 0.33467}
+{"mode": "train", "epoch": 184, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.0472, "heatmap_loss": 0.00053, "acc_pose": 0.86026, "loss": 0.00053, "grad_norm": 0.00114, "time": 0.38593}
+{"mode": "train", "epoch": 184, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00052, "acc_pose": 0.85698, "loss": 0.00052, "grad_norm": 0.00108, "time": 0.33704}
+{"mode": "train", "epoch": 184, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00053, "acc_pose": 0.83392, "loss": 0.00053, "grad_norm": 0.0011, "time": 0.33418}
+{"mode": "train", "epoch": 184, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00052, "acc_pose": 0.85112, "loss": 0.00052, "grad_norm": 0.00113, "time": 0.33445}
+{"mode": "train", "epoch": 184, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00052, "acc_pose": 0.85379, "loss": 0.00052, "grad_norm": 0.00108, "time": 0.33389}
+{"mode": "train", "epoch": 185, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04738, "heatmap_loss": 0.00052, "acc_pose": 0.84404, "loss": 0.00052, "grad_norm": 0.00126, "time": 0.38608}
+{"mode": "train", "epoch": 185, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00053, "acc_pose": 0.8528, "loss": 0.00053, "grad_norm": 0.00124, "time": 0.33252}
+{"mode": "train", "epoch": 185, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00052, "acc_pose": 0.86194, "loss": 0.00052, "grad_norm": 0.00111, "time": 0.33385}
+{"mode": "train", "epoch": 185, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00052, "acc_pose": 0.86198, "loss": 0.00052, "grad_norm": 0.00113, "time": 0.33298}
+{"mode": "train", "epoch": 185, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00052, "acc_pose": 0.83467, "loss": 0.00052, "grad_norm": 0.00114, "time": 0.33507}
+{"mode": "train", "epoch": 186, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04714, "heatmap_loss": 0.00052, "acc_pose": 0.83819, "loss": 0.00052, "grad_norm": 0.00111, "time": 0.38607}
+{"mode": "train", "epoch": 186, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00052, "acc_pose": 0.84876, "loss": 0.00052, "grad_norm": 0.00115, "time": 0.33404}
+{"mode": "train", "epoch": 186, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00052, "acc_pose": 0.85774, "loss": 0.00052, "grad_norm": 0.0011, "time": 0.33535}
+{"mode": "train", "epoch": 186, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00052, "acc_pose": 0.85001, "loss": 0.00052, "grad_norm": 0.00115, "time": 0.33237}
+{"mode": "train", "epoch": 186, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00051, "acc_pose": 0.84151, "loss": 0.00051, "grad_norm": 0.00111, "time": 0.33455}
+{"mode": "train", "epoch": 187, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.0471, "heatmap_loss": 0.00052, "acc_pose": 0.85252, "loss": 0.00052, "grad_norm": 0.00114, "time": 0.3863}
+{"mode": "train", "epoch": 187, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00052, "acc_pose": 0.84405, "loss": 0.00052, "grad_norm": 0.00108, "time": 0.33383}
+{"mode": "train", "epoch": 187, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00052, "heatmap_loss": 0.00052, "acc_pose": 0.84188, "loss": 0.00052, "grad_norm": 0.0011, "time": 0.33343}
+{"mode": "train", "epoch": 187, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00052, "acc_pose": 0.84876, "loss": 0.00052, "grad_norm": 0.00115, "time": 0.33355}
+{"mode": "train", "epoch": 187, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00052, "acc_pose": 0.84604, "loss": 0.00052, "grad_norm": 0.00117, "time": 0.33437}
+{"mode": "train", "epoch": 188, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.0472, "heatmap_loss": 0.00052, "acc_pose": 0.85534, "loss": 0.00052, "grad_norm": 0.00116, "time": 0.38702}
+{"mode": "train", "epoch": 188, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.84282, "loss": 0.00052, "grad_norm": 0.0012, "time": 0.33474}
+{"mode": "train", "epoch": 188, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.85502, "loss": 0.00052, "grad_norm": 0.0012, "time": 0.33856}
+{"mode": "train", "epoch": 188, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00052, "acc_pose": 0.85569, "loss": 0.00052, "grad_norm": 0.00109, "time": 0.3388}
+{"mode": "train", "epoch": 188, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00052, "heatmap_loss": 0.00052, "acc_pose": 0.85678, "loss": 0.00052, "grad_norm": 0.00113, "time": 0.33895}
+{"mode": "train", "epoch": 189, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04715, "heatmap_loss": 0.00052, "acc_pose": 0.84338, "loss": 0.00052, "grad_norm": 0.00118, "time": 0.38684}
+{"mode": "train", "epoch": 189, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.85521, "loss": 0.00052, "grad_norm": 0.00122, "time": 0.33355}
+{"mode": "train", "epoch": 189, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00052, "acc_pose": 0.84315, "loss": 0.00052, "grad_norm": 0.00112, "time": 0.3355}
+{"mode": "train", "epoch": 189, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00052, "acc_pose": 0.84805, "loss": 0.00052, "grad_norm": 0.00112, "time": 0.33483}
+{"mode": "train", "epoch": 189, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00051, "acc_pose": 0.85516, "loss": 0.00051, "grad_norm": 0.00107, "time": 0.33516}
+{"mode": "train", "epoch": 190, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04716, "heatmap_loss": 0.00052, "acc_pose": 0.85228, "loss": 0.00052, "grad_norm": 0.00111, "time": 0.38489}
+{"mode": "train", "epoch": 190, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00052, "acc_pose": 0.84166, "loss": 0.00052, "grad_norm": 0.0011, "time": 0.33339}
+{"mode": "train", "epoch": 190, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00052, "acc_pose": 0.8582, "loss": 0.00052, "grad_norm": 0.00114, "time": 0.33517}
+{"mode": "train", "epoch": 190, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.85125, "loss": 0.00052, "grad_norm": 0.00121, "time": 0.33313}
+{"mode": "train", "epoch": 190, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00052, "acc_pose": 0.85391, "loss": 0.00052, "grad_norm": 0.00111, "time": 0.3345}
+{"mode": "val", "epoch": 190, "iter": 204, "lr": 0.0, "AP": 0.78872, "AP .5": 0.91592, "AP .75": 0.85591, "AP (M)": 0.71607, "AP (L)": 0.81952, "AR": 0.83918, "AR .5": 0.95419, "AR .75": 0.89767, "AR (M)": 0.79806, "AR (L)": 0.89922}
+{"mode": "train", "epoch": 191, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04695, "heatmap_loss": 0.00052, "acc_pose": 0.85043, "loss": 0.00052, "grad_norm": 0.00106, "time": 0.38471}
+{"mode": "train", "epoch": 191, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00052, "heatmap_loss": 0.00052, "acc_pose": 0.85698, "loss": 0.00052, "grad_norm": 0.00117, "time": 0.33662}
+{"mode": "train", "epoch": 191, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00053, "heatmap_loss": 0.00052, "acc_pose": 0.85357, "loss": 0.00052, "grad_norm": 0.00117, "time": 0.33352}
+{"mode": "train", "epoch": 191, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00053, "heatmap_loss": 0.00052, "acc_pose": 0.85175, "loss": 0.00052, "grad_norm": 0.00107, "time": 0.33449}
+{"mode": "train", "epoch": 191, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00053, "heatmap_loss": 0.00052, "acc_pose": 0.84448, "loss": 0.00052, "grad_norm": 0.00122, "time": 0.33292}
+{"mode": "train", "epoch": 192, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04728, "heatmap_loss": 0.00052, "acc_pose": 0.85138, "loss": 0.00052, "grad_norm": 0.00118, "time": 0.38794}
+{"mode": "train", "epoch": 192, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00052, "acc_pose": 0.84401, "loss": 0.00052, "grad_norm": 0.0012, "time": 0.33778}
+{"mode": "train", "epoch": 192, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00052, "acc_pose": 0.85355, "loss": 0.00052, "grad_norm": 0.00108, "time": 0.33658}
+{"mode": "train", "epoch": 192, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00052, "acc_pose": 0.84898, "loss": 0.00052, "grad_norm": 0.0011, "time": 0.33605}
+{"mode": "train", "epoch": 192, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00052, "acc_pose": 0.85042, "loss": 0.00052, "grad_norm": 0.00116, "time": 0.33608}
+{"mode": "train", "epoch": 193, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04734, "heatmap_loss": 0.00052, "acc_pose": 0.84098, "loss": 0.00052, "grad_norm": 0.00115, "time": 0.3892}
+{"mode": "train", "epoch": 193, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00052, "acc_pose": 0.83501, "loss": 0.00052, "grad_norm": 0.00115, "time": 0.33589}
+{"mode": "train", "epoch": 193, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.84836, "loss": 0.00052, "grad_norm": 0.00114, "time": 0.33601}
+{"mode": "train", "epoch": 193, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00052, "acc_pose": 0.83398, "loss": 0.00052, "grad_norm": 0.00112, "time": 0.33561}
+{"mode": "train", "epoch": 193, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00052, "acc_pose": 0.8577, "loss": 0.00052, "grad_norm": 0.00111, "time": 0.33513}
+{"mode": "train", "epoch": 194, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04703, "heatmap_loss": 0.00052, "acc_pose": 0.85209, "loss": 0.00052, "grad_norm": 0.00103, "time": 0.38676}
+{"mode": "train", "epoch": 194, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00052, "acc_pose": 0.84618, "loss": 0.00052, "grad_norm": 0.0011, "time": 0.33407}
+{"mode": "train", "epoch": 194, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00052, "acc_pose": 0.84611, "loss": 0.00052, "grad_norm": 0.00114, "time": 0.33327}
+{"mode": "train", "epoch": 194, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00052, "heatmap_loss": 0.00052, "acc_pose": 0.85806, "loss": 0.00052, "grad_norm": 0.00115, "time": 0.33493}
+{"mode": "train", "epoch": 194, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00052, "acc_pose": 0.8556, "loss": 0.00052, "grad_norm": 0.00117, "time": 0.33295}
+{"mode": "train", "epoch": 195, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04719, "heatmap_loss": 0.00052, "acc_pose": 0.8456, "loss": 0.00052, "grad_norm": 0.00109, "time": 0.3854}
+{"mode": "train", "epoch": 195, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00052, "acc_pose": 0.83727, "loss": 0.00052, "grad_norm": 0.00112, "time": 0.33489}
+{"mode": "train", "epoch": 195, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00052, "heatmap_loss": 0.00052, "acc_pose": 0.85682, "loss": 0.00052, "grad_norm": 0.00113, "time": 0.33422}
+{"mode": "train", "epoch": 195, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00051, "acc_pose": 0.84861, "loss": 0.00051, "grad_norm": 0.00119, "time": 0.33276}
+{"mode": "train", "epoch": 195, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00052, "acc_pose": 0.84995, "loss": 0.00052, "grad_norm": 0.00116, "time": 0.33355}
+{"mode": "train", "epoch": 196, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04726, "heatmap_loss": 0.00052, "acc_pose": 0.84843, "loss": 0.00052, "grad_norm": 0.00115, "time": 0.38606}
+{"mode": "train", "epoch": 196, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.84923, "loss": 0.00052, "grad_norm": 0.00108, "time": 0.336}
+{"mode": "train", "epoch": 196, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00052, "acc_pose": 0.84706, "loss": 0.00052, "grad_norm": 0.00115, "time": 0.33546}
+{"mode": "train", "epoch": 196, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00052, "acc_pose": 0.84978, "loss": 0.00052, "grad_norm": 0.00111, "time": 0.33611}
+{"mode": "train", "epoch": 196, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00052, "acc_pose": 0.84537, "loss": 0.00052, "grad_norm": 0.0012, "time": 0.33472}
+{"mode": "train", "epoch": 197, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04731, "heatmap_loss": 0.00052, "acc_pose": 0.84694, "loss": 0.00052, "grad_norm": 0.00117, "time": 0.38762}
+{"mode": "train", "epoch": 197, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.85111, "loss": 0.00052, "grad_norm": 0.00114, "time": 0.3333}
+{"mode": "train", "epoch": 197, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00046, "heatmap_loss": 0.00052, "acc_pose": 0.85177, "loss": 0.00052, "grad_norm": 0.00108, "time": 0.33321}
+{"mode": "train", "epoch": 197, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00052, "acc_pose": 0.84406, "loss": 0.00052, "grad_norm": 0.00105, "time": 0.33243}
+{"mode": "train", "epoch": 197, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00052, "acc_pose": 0.83895, "loss": 0.00052, "grad_norm": 0.00109, "time": 0.33532}
+{"mode": "train", "epoch": 198, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04718, "heatmap_loss": 0.00052, "acc_pose": 0.83653, "loss": 0.00052, "grad_norm": 0.00115, "time": 0.38739}
+{"mode": "train", "epoch": 198, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00052, "acc_pose": 0.8386, "loss": 0.00052, "grad_norm": 0.00106, "time": 0.33334}
+{"mode": "train", "epoch": 198, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00052, "acc_pose": 0.84356, "loss": 0.00052, "grad_norm": 0.00118, "time": 0.33358}
+{"mode": "train", "epoch": 198, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00052, "acc_pose": 0.85152, "loss": 0.00052, "grad_norm": 0.0011, "time": 0.33359}
+{"mode": "train", "epoch": 198, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00052, "acc_pose": 0.85819, "loss": 0.00052, "grad_norm": 0.00112, "time": 0.33441}
+{"mode": "train", "epoch": 199, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.0473, "heatmap_loss": 0.00052, "acc_pose": 0.8416, "loss": 0.00052, "grad_norm": 0.00118, "time": 0.38699}
+{"mode": "train", "epoch": 199, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00051, "acc_pose": 0.85801, "loss": 0.00051, "grad_norm": 0.0011, "time": 0.33314}
+{"mode": "train", "epoch": 199, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00052, "acc_pose": 0.84693, "loss": 0.00052, "grad_norm": 0.00106, "time": 0.33415}
+{"mode": "train", "epoch": 199, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00052, "acc_pose": 0.84928, "loss": 0.00052, "grad_norm": 0.00118, "time": 0.33349}
+{"mode": "train", "epoch": 199, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00052, "acc_pose": 0.83571, "loss": 0.00052, "grad_norm": 0.00116, "time": 0.33384}
+{"mode": "train", "epoch": 200, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04718, "heatmap_loss": 0.00052, "acc_pose": 0.84902, "loss": 0.00052, "grad_norm": 0.00108, "time": 0.38727}
+{"mode": "train", "epoch": 200, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00052, "acc_pose": 0.84852, "loss": 0.00052, "grad_norm": 0.00114, "time": 0.33332}
+{"mode": "train", "epoch": 200, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00052, "heatmap_loss": 0.00052, "acc_pose": 0.85003, "loss": 0.00052, "grad_norm": 0.00122, "time": 0.33426}
+{"mode": "train", "epoch": 200, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00052, "acc_pose": 0.85713, "loss": 0.00052, "grad_norm": 0.00116, "time": 0.33301}
+{"mode": "train", "epoch": 200, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00052, "acc_pose": 0.85013, "loss": 0.00052, "grad_norm": 0.00113, "time": 0.33457}
+{"mode": "val", "epoch": 200, "iter": 204, "lr": 0.0, "AP": 0.78889, "AP .5": 0.916, "AP .75": 0.85571, "AP (M)": 0.71595, "AP (L)": 0.8197, "AR": 0.83934, "AR .5": 0.95356, "AR .75": 0.89814, "AR (M)": 0.79831, "AR (L)": 0.89952}
+{"mode": "train", "epoch": 201, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04696, "heatmap_loss": 0.00052, "acc_pose": 0.83664, "loss": 0.00052, "grad_norm": 0.00114, "time": 0.38552}
+{"mode": "train", "epoch": 201, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00052, "acc_pose": 0.84926, "loss": 0.00052, "grad_norm": 0.00111, "time": 0.33818}
+{"mode": "train", "epoch": 201, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00052, "acc_pose": 0.84952, "loss": 0.00052, "grad_norm": 0.00113, "time": 0.33634}
+{"mode": "train", "epoch": 201, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00051, "acc_pose": 0.85904, "loss": 0.00051, "grad_norm": 0.00113, "time": 0.33695}
+{"mode": "train", "epoch": 201, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00051, "acc_pose": 0.84526, "loss": 0.00051, "grad_norm": 0.00114, "time": 0.33497}
+{"mode": "train", "epoch": 202, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04728, "heatmap_loss": 0.00052, "acc_pose": 0.85755, "loss": 0.00052, "grad_norm": 0.00113, "time": 0.38818}
+{"mode": "train", "epoch": 202, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00052, "heatmap_loss": 0.00052, "acc_pose": 0.85324, "loss": 0.00052, "grad_norm": 0.00118, "time": 0.33583}
+{"mode": "train", "epoch": 202, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00052, "acc_pose": 0.849, "loss": 0.00052, "grad_norm": 0.00113, "time": 0.33725}
+{"mode": "train", "epoch": 202, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00052, "acc_pose": 0.83817, "loss": 0.00052, "grad_norm": 0.00113, "time": 0.33817}
+{"mode": "train", "epoch": 202, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00053, "heatmap_loss": 0.00052, "acc_pose": 0.84794, "loss": 0.00052, "grad_norm": 0.00113, "time": 0.33606}
+{"mode": "train", "epoch": 203, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04715, "heatmap_loss": 0.00053, "acc_pose": 0.84629, "loss": 0.00053, "grad_norm": 0.00123, "time": 0.3895}
+{"mode": "train", "epoch": 203, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00051, "acc_pose": 0.85102, "loss": 0.00051, "grad_norm": 0.00112, "time": 0.33858}
+{"mode": "train", "epoch": 203, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00051, "acc_pose": 0.85173, "loss": 0.00051, "grad_norm": 0.00112, "time": 0.33496}
+{"mode": "train", "epoch": 203, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00052, "acc_pose": 0.85939, "loss": 0.00052, "grad_norm": 0.00112, "time": 0.33482}
+{"mode": "train", "epoch": 203, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00052, "acc_pose": 0.84414, "loss": 0.00052, "grad_norm": 0.00113, "time": 0.33504}
+{"mode": "train", "epoch": 204, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04735, "heatmap_loss": 0.00052, "acc_pose": 0.84862, "loss": 0.00052, "grad_norm": 0.0012, "time": 0.38838}
+{"mode": "train", "epoch": 204, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00052, "acc_pose": 0.84099, "loss": 0.00052, "grad_norm": 0.00105, "time": 0.33718}
+{"mode": "train", "epoch": 204, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.85072, "loss": 0.00052, "grad_norm": 0.00106, "time": 0.33824}
+{"mode": "train", "epoch": 204, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00052, "acc_pose": 0.83625, "loss": 0.00052, "grad_norm": 0.0011, "time": 0.33841}
+{"mode": "train", "epoch": 204, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00051, "acc_pose": 0.85497, "loss": 0.00051, "grad_norm": 0.00112, "time": 0.33668}
+{"mode": "train", "epoch": 205, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04719, "heatmap_loss": 0.00052, "acc_pose": 0.84991, "loss": 0.00052, "grad_norm": 0.00111, "time": 0.38757}
+{"mode": "train", "epoch": 205, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.83909, "loss": 0.00052, "grad_norm": 0.00109, "time": 0.3355}
+{"mode": "train", "epoch": 205, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.85577, "loss": 0.00052, "grad_norm": 0.00113, "time": 0.33532}
+{"mode": "train", "epoch": 205, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00052, "acc_pose": 0.85189, "loss": 0.00052, "grad_norm": 0.00122, "time": 0.33439}
+{"mode": "train", "epoch": 205, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.85356, "loss": 0.00052, "grad_norm": 0.00116, "time": 0.33622}
+{"mode": "train", "epoch": 206, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04735, "heatmap_loss": 0.00052, "acc_pose": 0.85097, "loss": 0.00052, "grad_norm": 0.00112, "time": 0.38857}
+{"mode": "train", "epoch": 206, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00052, "acc_pose": 0.85485, "loss": 0.00052, "grad_norm": 0.00116, "time": 0.33817}
+{"mode": "train", "epoch": 206, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00051, "acc_pose": 0.85313, "loss": 0.00051, "grad_norm": 0.00115, "time": 0.33595}
+{"mode": "train", "epoch": 206, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.85893, "loss": 0.00052, "grad_norm": 0.00107, "time": 0.33715}
+{"mode": "train", "epoch": 206, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00052, "acc_pose": 0.85403, "loss": 0.00052, "grad_norm": 0.00114, "time": 0.3382}
+{"mode": "train", "epoch": 207, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04722, "heatmap_loss": 0.00052, "acc_pose": 0.854, "loss": 0.00052, "grad_norm": 0.00113, "time": 0.39022}
+{"mode": "train", "epoch": 207, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00052, "heatmap_loss": 0.00052, "acc_pose": 0.85532, "loss": 0.00052, "grad_norm": 0.00109, "time": 0.33389}
+{"mode": "train", "epoch": 207, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00052, "acc_pose": 0.85341, "loss": 0.00052, "grad_norm": 0.00112, "time": 0.33523}
+{"mode": "train", "epoch": 207, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00052, "acc_pose": 0.85475, "loss": 0.00052, "grad_norm": 0.00119, "time": 0.33316}
+{"mode": "train", "epoch": 207, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00064, "heatmap_loss": 0.00052, "acc_pose": 0.84303, "loss": 0.00052, "grad_norm": 0.00118, "time": 0.33397}
+{"mode": "train", "epoch": 208, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04717, "heatmap_loss": 0.00052, "acc_pose": 0.84961, "loss": 0.00052, "grad_norm": 0.00113, "time": 0.3891}
+{"mode": "train", "epoch": 208, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00051, "acc_pose": 0.86339, "loss": 0.00051, "grad_norm": 0.00108, "time": 0.3361}
+{"mode": "train", "epoch": 208, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00052, "acc_pose": 0.85601, "loss": 0.00052, "grad_norm": 0.00117, "time": 0.33557}
+{"mode": "train", "epoch": 208, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00052, "acc_pose": 0.83866, "loss": 0.00052, "grad_norm": 0.00111, "time": 0.33538}
+{"mode": "train", "epoch": 208, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00052, "acc_pose": 0.8509, "loss": 0.00052, "grad_norm": 0.00108, "time": 0.33382}
+{"mode": "train", "epoch": 209, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04707, "heatmap_loss": 0.00051, "acc_pose": 0.85747, "loss": 0.00051, "grad_norm": 0.00112, "time": 0.38559}
+{"mode": "train", "epoch": 209, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00047, "heatmap_loss": 0.00052, "acc_pose": 0.85995, "loss": 0.00052, "grad_norm": 0.00114, "time": 0.33181}
+{"mode": "train", "epoch": 209, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00052, "acc_pose": 0.8621, "loss": 0.00052, "grad_norm": 0.0011, "time": 0.33323}
+{"mode": "train", "epoch": 209, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00052, "acc_pose": 0.84733, "loss": 0.00052, "grad_norm": 0.00109, "time": 0.33279}
+{"mode": "train", "epoch": 209, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.00051, "heatmap_loss": 0.00051, "acc_pose": 0.86004, "loss": 0.00051, "grad_norm": 0.00115, "time": 0.33477}
+{"mode": "train", "epoch": 210, "iter": 50, "lr": 0.0, "memory": 24830, "data_time": 0.04726, "heatmap_loss": 0.00052, "acc_pose": 0.86195, "loss": 0.00052, "grad_norm": 0.00109, "time": 0.38732}
+{"mode": "train", "epoch": 210, "iter": 100, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00051, "acc_pose": 0.85057, "loss": 0.00051, "grad_norm": 0.00111, "time": 0.33679}
+{"mode": "train", "epoch": 210, "iter": 150, "lr": 0.0, "memory": 24830, "data_time": 0.00049, "heatmap_loss": 0.00052, "acc_pose": 0.84483, "loss": 0.00052, "grad_norm": 0.00118, "time": 0.33405}
+{"mode": "train", "epoch": 210, "iter": 200, "lr": 0.0, "memory": 24830, "data_time": 0.00048, "heatmap_loss": 0.00051, "acc_pose": 0.84714, "loss": 0.00051, "grad_norm": 0.00114, "time": 0.33343}
+{"mode": "train", "epoch": 210, "iter": 250, "lr": 0.0, "memory": 24830, "data_time": 0.0005, "heatmap_loss": 0.00051, "acc_pose": 0.84807, "loss": 0.00051, "grad_norm": 0.00106, "time": 0.33371}
+{"mode": "val", "epoch": 210, "iter": 204, "lr": 0.0, "AP": 0.78904, "AP .5": 0.91575, "AP .75": 0.85585, "AP (M)": 0.71575, "AP (L)": 0.81985, "AR": 0.83953, "AR .5": 0.95356, "AR .75": 0.8983, "AR (M)": 0.79792, "AR (L)": 0.89996}
diff --git a/vendor/ViTPose/logs/vitpose-h.log.json b/vendor/ViTPose/logs/vitpose-h.log.json
new file mode 100644
index 0000000000000000000000000000000000000000..d552903f596d246e16af425c2900ba883b402f2a
--- /dev/null
+++ b/vendor/ViTPose/logs/vitpose-h.log.json
@@ -0,0 +1,1072 @@
+{"env_info": "sys.platform: linux\nPython: 3.8.10 | packaged by conda-forge | (default, May 11 2021, 07:01:05) [GCC 9.3.0]\nCUDA available: True\nGPU 0,1,2,3,4,5,6,7: A100-SXM4-40GB\nCUDA_HOME: /usr/local/cuda\nNVCC: Build cuda_11.3.r11.3/compiler.29920130_0\nGCC: gcc (Ubuntu 9.3.0-17ubuntu1~20.04) 9.3.0\nPyTorch: 1.9.0a0+c3d40fd\nPyTorch compiling details: PyTorch built with:\n - GCC 9.3\n - C++ Version: 201402\n - Intel(R) Math Kernel Library Version 2019.0.5 Product Build 20190808 for Intel(R) 64 architecture applications\n - Intel(R) MKL-DNN v2.1.2 (Git Hash N/A)\n - OpenMP 201511 (a.k.a. OpenMP 4.5)\n - NNPACK is enabled\n - CPU capability usage: AVX2\n - CUDA Runtime 11.3\n - NVCC architecture flags: -gencode;arch=compute_52,code=sm_52;-gencode;arch=compute_60,code=sm_60;-gencode;arch=compute_61,code=sm_61;-gencode;arch=compute_70,code=sm_70;-gencode;arch=compute_75,code=sm_75;-gencode;arch=compute_80,code=sm_80;-gencode;arch=compute_86,code=sm_86;-gencode;arch=compute_86,code=compute_86\n - CuDNN 8.2.1\n - Magma 2.5.2\n - Build settings: BLAS_INFO=mkl, BUILD_TYPE=Release, CUDA_VERSION=11.3, CUDNN_VERSION=8.2.1, CXX_COMPILER=/usr/bin/c++, CXX_FLAGS= -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_KINETO -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DUSE_XNNPACK -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -O2 -fPIC -Wno-narrowing -Wall -Wextra -Werror=return-type -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wno-sign-compare -Wno-unused-parameter -Wno-unused-variable -Wno-unused-function -Wno-unused-result -Wno-unused-local-typedefs -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-psabi -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Werror=cast-function-type -Wno-stringop-overflow, LAPACK_INFO=mkl, PERF_WITH_AVX=1, PERF_WITH_AVX2=1, PERF_WITH_AVX512=1, TORCH_VERSION=1.9.0, USE_CUDA=ON, USE_CUDNN=ON, USE_EXCEPTION_PTR=1, USE_GFLAGS=OFF, USE_GLOG=OFF, USE_MKL=ON, USE_MKLDNN=ON, USE_MPI=ON, USE_NCCL=ON, USE_NNPACK=ON, USE_OPENMP=ON, \n\nTorchVision: 0.10.0a0\nOpenCV: 4.5.5\nMMCV: 1.3.9\nMMCV Compiler: GCC 9.3\nMMCV CUDA Compiler: 11.3\nMMPose: 0.24.0+1041e5c", "seed": 0, "hook_msgs": {}}
+{"mode": "train", "epoch": 1, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.05567, "heatmap_loss": 0.00215, "acc_pose": 0.04953, "loss": 0.00215, "grad_norm": 0.00637, "time": 0.51652}
+{"mode": "train", "epoch": 1, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00053, "heatmap_loss": 0.00205, "acc_pose": 0.16094, "loss": 0.00205, "grad_norm": 0.0038, "time": 0.32774}
+{"mode": "train", "epoch": 1, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.00202, "acc_pose": 0.20773, "loss": 0.00202, "grad_norm": 0.00515, "time": 0.32836}
+{"mode": "train", "epoch": 1, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00197, "acc_pose": 0.21174, "loss": 0.00197, "grad_norm": 0.00459, "time": 0.32729}
+{"mode": "train", "epoch": 1, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00192, "acc_pose": 0.25739, "loss": 0.00192, "grad_norm": 0.00462, "time": 0.32776}
+{"mode": "train", "epoch": 2, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04664, "heatmap_loss": 0.0018, "acc_pose": 0.27058, "loss": 0.0018, "grad_norm": 0.00605, "time": 0.37812}
+{"mode": "train", "epoch": 2, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00166, "acc_pose": 0.38175, "loss": 0.00166, "grad_norm": 0.00501, "time": 0.32823}
+{"mode": "train", "epoch": 2, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00149, "acc_pose": 0.44795, "loss": 0.00149, "grad_norm": 0.0052, "time": 0.32869}
+{"mode": "train", "epoch": 2, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.00136, "acc_pose": 0.50362, "loss": 0.00136, "grad_norm": 0.00529, "time": 0.32729}
+{"mode": "train", "epoch": 2, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00128, "acc_pose": 0.53678, "loss": 0.00128, "grad_norm": 0.00533, "time": 0.32817}
+{"mode": "train", "epoch": 3, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04839, "heatmap_loss": 0.00116, "acc_pose": 0.55837, "loss": 0.00116, "grad_norm": 0.00525, "time": 0.37551}
+{"mode": "train", "epoch": 3, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00112, "acc_pose": 0.61204, "loss": 0.00112, "grad_norm": 0.00425, "time": 0.32576}
+{"mode": "train", "epoch": 3, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00107, "acc_pose": 0.62502, "loss": 0.00107, "grad_norm": 0.00422, "time": 0.32452}
+{"mode": "train", "epoch": 3, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00105, "acc_pose": 0.62267, "loss": 0.00105, "grad_norm": 0.00382, "time": 0.32268}
+{"mode": "train", "epoch": 3, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00104, "acc_pose": 0.65149, "loss": 0.00104, "grad_norm": 0.00415, "time": 0.32428}
+{"mode": "train", "epoch": 4, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04662, "heatmap_loss": 0.001, "acc_pose": 0.66093, "loss": 0.001, "grad_norm": 0.00492, "time": 0.3765}
+{"mode": "train", "epoch": 4, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00098, "acc_pose": 0.65781, "loss": 0.00098, "grad_norm": 0.00407, "time": 0.32553}
+{"mode": "train", "epoch": 4, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00095, "acc_pose": 0.68332, "loss": 0.00095, "grad_norm": 0.00374, "time": 0.32545}
+{"mode": "train", "epoch": 4, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00095, "acc_pose": 0.6549, "loss": 0.00095, "grad_norm": 0.00411, "time": 0.32473}
+{"mode": "train", "epoch": 4, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00093, "acc_pose": 0.69335, "loss": 0.00093, "grad_norm": 0.00375, "time": 0.32527}
+{"mode": "train", "epoch": 5, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04661, "heatmap_loss": 0.00092, "acc_pose": 0.68647, "loss": 0.00092, "grad_norm": 0.00393, "time": 0.37438}
+{"mode": "train", "epoch": 5, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00091, "acc_pose": 0.69951, "loss": 0.00091, "grad_norm": 0.0036, "time": 0.32636}
+{"mode": "train", "epoch": 5, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00089, "acc_pose": 0.71795, "loss": 0.00089, "grad_norm": 0.00383, "time": 0.32515}
+{"mode": "train", "epoch": 5, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00091, "acc_pose": 0.703, "loss": 0.00091, "grad_norm": 0.00384, "time": 0.32477}
+{"mode": "train", "epoch": 5, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.00089, "acc_pose": 0.70371, "loss": 0.00089, "grad_norm": 0.00385, "time": 0.32549}
+{"mode": "train", "epoch": 6, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04647, "heatmap_loss": 0.00087, "acc_pose": 0.69495, "loss": 0.00087, "grad_norm": 0.00343, "time": 0.37482}
+{"mode": "train", "epoch": 6, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00087, "acc_pose": 0.69909, "loss": 0.00087, "grad_norm": 0.00402, "time": 0.32374}
+{"mode": "train", "epoch": 6, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00086, "acc_pose": 0.72449, "loss": 0.00086, "grad_norm": 0.00367, "time": 0.32429}
+{"mode": "train", "epoch": 6, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00085, "acc_pose": 0.70728, "loss": 0.00085, "grad_norm": 0.00395, "time": 0.32813}
+{"mode": "train", "epoch": 6, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00052, "heatmap_loss": 0.00085, "acc_pose": 0.71269, "loss": 0.00085, "grad_norm": 0.00346, "time": 0.32571}
+{"mode": "train", "epoch": 7, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04693, "heatmap_loss": 0.00084, "acc_pose": 0.71703, "loss": 0.00084, "grad_norm": 0.00351, "time": 0.37268}
+{"mode": "train", "epoch": 7, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00083, "acc_pose": 0.73078, "loss": 0.00083, "grad_norm": 0.00341, "time": 0.32417}
+{"mode": "train", "epoch": 7, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00082, "acc_pose": 0.71971, "loss": 0.00082, "grad_norm": 0.00367, "time": 0.32406}
+{"mode": "train", "epoch": 7, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00083, "acc_pose": 0.70956, "loss": 0.00083, "grad_norm": 0.00354, "time": 0.3234}
+{"mode": "train", "epoch": 7, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00082, "acc_pose": 0.73589, "loss": 0.00082, "grad_norm": 0.00309, "time": 0.3237}
+{"mode": "train", "epoch": 8, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04671, "heatmap_loss": 0.00081, "acc_pose": 0.72192, "loss": 0.00081, "grad_norm": 0.00384, "time": 0.37257}
+{"mode": "train", "epoch": 8, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.00081, "acc_pose": 0.72415, "loss": 0.00081, "grad_norm": 0.00343, "time": 0.32438}
+{"mode": "train", "epoch": 8, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00054, "heatmap_loss": 0.00082, "acc_pose": 0.73011, "loss": 0.00082, "grad_norm": 0.00349, "time": 0.32396}
+{"mode": "train", "epoch": 8, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00052, "heatmap_loss": 0.00081, "acc_pose": 0.72514, "loss": 0.00081, "grad_norm": 0.0034, "time": 0.32601}
+{"mode": "train", "epoch": 8, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00052, "heatmap_loss": 0.00079, "acc_pose": 0.74923, "loss": 0.00079, "grad_norm": 0.00313, "time": 0.32248}
+{"mode": "train", "epoch": 9, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04663, "heatmap_loss": 0.00079, "acc_pose": 0.73709, "loss": 0.00079, "grad_norm": 0.00327, "time": 0.3722}
+{"mode": "train", "epoch": 9, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00079, "acc_pose": 0.73952, "loss": 0.00079, "grad_norm": 0.00341, "time": 0.3255}
+{"mode": "train", "epoch": 9, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00079, "acc_pose": 0.75505, "loss": 0.00079, "grad_norm": 0.00366, "time": 0.32313}
+{"mode": "train", "epoch": 9, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00057, "heatmap_loss": 0.00078, "acc_pose": 0.73787, "loss": 0.00078, "grad_norm": 0.00329, "time": 0.32486}
+{"mode": "train", "epoch": 9, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00078, "acc_pose": 0.74848, "loss": 0.00078, "grad_norm": 0.00347, "time": 0.32403}
+{"mode": "train", "epoch": 10, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04647, "heatmap_loss": 0.00077, "acc_pose": 0.74953, "loss": 0.00077, "grad_norm": 0.00349, "time": 0.37392}
+{"mode": "train", "epoch": 10, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00077, "acc_pose": 0.7363, "loss": 0.00077, "grad_norm": 0.00329, "time": 0.32384}
+{"mode": "train", "epoch": 10, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00078, "acc_pose": 0.74774, "loss": 0.00078, "grad_norm": 0.00316, "time": 0.32244}
+{"mode": "train", "epoch": 10, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.00077, "acc_pose": 0.74192, "loss": 0.00077, "grad_norm": 0.00331, "time": 0.32408}
+{"mode": "train", "epoch": 10, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00077, "acc_pose": 0.73766, "loss": 0.00077, "grad_norm": 0.00302, "time": 0.32297}
+{"mode": "val", "epoch": 10, "iter": 204, "lr": 0.0, "AP": 0.74147, "AP .5": 0.90127, "AP .75": 0.81772, "AP (M)": 0.66661, "AP (L)": 0.76941, "AR": 0.79775, "AR .5": 0.94112, "AR .75": 0.86508, "AR (M)": 0.75356, "AR (L)": 0.86191}
+{"mode": "train", "epoch": 11, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04723, "heatmap_loss": 0.00077, "acc_pose": 0.7569, "loss": 0.00077, "grad_norm": 0.00411, "time": 0.37294}
+{"mode": "train", "epoch": 11, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00075, "acc_pose": 0.75355, "loss": 0.00075, "grad_norm": 0.00387, "time": 0.3239}
+{"mode": "train", "epoch": 11, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00076, "acc_pose": 0.74638, "loss": 0.00076, "grad_norm": 0.0034, "time": 0.32541}
+{"mode": "train", "epoch": 11, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00076, "acc_pose": 0.76275, "loss": 0.00076, "grad_norm": 0.00315, "time": 0.32635}
+{"mode": "train", "epoch": 11, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00075, "acc_pose": 0.75953, "loss": 0.00075, "grad_norm": 0.00306, "time": 0.32487}
+{"mode": "train", "epoch": 12, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04791, "heatmap_loss": 0.00076, "acc_pose": 0.74813, "loss": 0.00076, "grad_norm": 0.00329, "time": 0.375}
+{"mode": "train", "epoch": 12, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00075, "acc_pose": 0.76311, "loss": 0.00075, "grad_norm": 0.00288, "time": 0.32557}
+{"mode": "train", "epoch": 12, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00075, "acc_pose": 0.75648, "loss": 0.00075, "grad_norm": 0.00326, "time": 0.32452}
+{"mode": "train", "epoch": 12, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00075, "acc_pose": 0.75389, "loss": 0.00075, "grad_norm": 0.00347, "time": 0.32649}
+{"mode": "train", "epoch": 12, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00074, "acc_pose": 0.76147, "loss": 0.00074, "grad_norm": 0.00306, "time": 0.32264}
+{"mode": "train", "epoch": 13, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04682, "heatmap_loss": 0.00075, "acc_pose": 0.74689, "loss": 0.00075, "grad_norm": 0.00341, "time": 0.37283}
+{"mode": "train", "epoch": 13, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00075, "acc_pose": 0.77314, "loss": 0.00075, "grad_norm": 0.00326, "time": 0.32424}
+{"mode": "train", "epoch": 13, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00045, "heatmap_loss": 0.00074, "acc_pose": 0.76252, "loss": 0.00074, "grad_norm": 0.00367, "time": 0.32401}
+{"mode": "train", "epoch": 13, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00074, "acc_pose": 0.77588, "loss": 0.00074, "grad_norm": 0.00316, "time": 0.3243}
+{"mode": "train", "epoch": 13, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00074, "acc_pose": 0.75686, "loss": 0.00074, "grad_norm": 0.00301, "time": 0.32372}
+{"mode": "train", "epoch": 14, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04668, "heatmap_loss": 0.00073, "acc_pose": 0.75356, "loss": 0.00073, "grad_norm": 0.00316, "time": 0.37254}
+{"mode": "train", "epoch": 14, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00073, "acc_pose": 0.78212, "loss": 0.00073, "grad_norm": 0.00328, "time": 0.32467}
+{"mode": "train", "epoch": 14, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00073, "acc_pose": 0.76846, "loss": 0.00073, "grad_norm": 0.00317, "time": 0.32352}
+{"mode": "train", "epoch": 14, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.00073, "acc_pose": 0.76538, "loss": 0.00073, "grad_norm": 0.00345, "time": 0.32407}
+{"mode": "train", "epoch": 14, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00072, "acc_pose": 0.77255, "loss": 0.00072, "grad_norm": 0.00311, "time": 0.32324}
+{"mode": "train", "epoch": 15, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04669, "heatmap_loss": 0.00072, "acc_pose": 0.75011, "loss": 0.00072, "grad_norm": 0.003, "time": 0.37476}
+{"mode": "train", "epoch": 15, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00072, "acc_pose": 0.77722, "loss": 0.00072, "grad_norm": 0.00345, "time": 0.32702}
+{"mode": "train", "epoch": 15, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00073, "acc_pose": 0.75457, "loss": 0.00073, "grad_norm": 0.00282, "time": 0.32461}
+{"mode": "train", "epoch": 15, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00072, "acc_pose": 0.75458, "loss": 0.00072, "grad_norm": 0.00313, "time": 0.32447}
+{"mode": "train", "epoch": 15, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00072, "acc_pose": 0.74511, "loss": 0.00072, "grad_norm": 0.00285, "time": 0.32312}
+{"mode": "train", "epoch": 16, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04693, "heatmap_loss": 0.00072, "acc_pose": 0.77851, "loss": 0.00072, "grad_norm": 0.00297, "time": 0.37769}
+{"mode": "train", "epoch": 16, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00071, "acc_pose": 0.77297, "loss": 0.00071, "grad_norm": 0.00305, "time": 0.32719}
+{"mode": "train", "epoch": 16, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00071, "acc_pose": 0.76157, "loss": 0.00071, "grad_norm": 0.00312, "time": 0.32386}
+{"mode": "train", "epoch": 16, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00072, "acc_pose": 0.77714, "loss": 0.00072, "grad_norm": 0.00327, "time": 0.3259}
+{"mode": "train", "epoch": 16, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00071, "acc_pose": 0.77534, "loss": 0.00071, "grad_norm": 0.00327, "time": 0.32303}
+{"mode": "train", "epoch": 17, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04655, "heatmap_loss": 0.00071, "acc_pose": 0.77685, "loss": 0.00071, "grad_norm": 0.00298, "time": 0.37197}
+{"mode": "train", "epoch": 17, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00045, "heatmap_loss": 0.0007, "acc_pose": 0.77639, "loss": 0.0007, "grad_norm": 0.00269, "time": 0.32322}
+{"mode": "train", "epoch": 17, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00045, "heatmap_loss": 0.0007, "acc_pose": 0.7884, "loss": 0.0007, "grad_norm": 0.00276, "time": 0.32356}
+{"mode": "train", "epoch": 17, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00045, "heatmap_loss": 0.00071, "acc_pose": 0.76703, "loss": 0.00071, "grad_norm": 0.0027, "time": 0.32467}
+{"mode": "train", "epoch": 17, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.0007, "acc_pose": 0.77956, "loss": 0.0007, "grad_norm": 0.0029, "time": 0.32498}
+{"mode": "train", "epoch": 18, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04669, "heatmap_loss": 0.0007, "acc_pose": 0.77039, "loss": 0.0007, "grad_norm": 0.00279, "time": 0.37451}
+{"mode": "train", "epoch": 18, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.0007, "acc_pose": 0.76741, "loss": 0.0007, "grad_norm": 0.00302, "time": 0.32604}
+{"mode": "train", "epoch": 18, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.0007, "acc_pose": 0.78325, "loss": 0.0007, "grad_norm": 0.00297, "time": 0.32585}
+{"mode": "train", "epoch": 18, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.0007, "acc_pose": 0.77032, "loss": 0.0007, "grad_norm": 0.00285, "time": 0.32445}
+{"mode": "train", "epoch": 18, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.0007, "acc_pose": 0.78363, "loss": 0.0007, "grad_norm": 0.0028, "time": 0.32458}
+{"mode": "train", "epoch": 19, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04668, "heatmap_loss": 0.0007, "acc_pose": 0.77448, "loss": 0.0007, "grad_norm": 0.00279, "time": 0.37387}
+{"mode": "train", "epoch": 19, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.0007, "acc_pose": 0.79098, "loss": 0.0007, "grad_norm": 0.0032, "time": 0.32374}
+{"mode": "train", "epoch": 19, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00069, "acc_pose": 0.77327, "loss": 0.00069, "grad_norm": 0.00324, "time": 0.32371}
+{"mode": "train", "epoch": 19, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00069, "acc_pose": 0.77982, "loss": 0.00069, "grad_norm": 0.00288, "time": 0.32536}
+{"mode": "train", "epoch": 19, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00069, "acc_pose": 0.76326, "loss": 0.00069, "grad_norm": 0.00261, "time": 0.32777}
+{"mode": "train", "epoch": 20, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04674, "heatmap_loss": 0.00069, "acc_pose": 0.77948, "loss": 0.00069, "grad_norm": 0.00283, "time": 0.37649}
+{"mode": "train", "epoch": 20, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00054, "heatmap_loss": 0.00069, "acc_pose": 0.79765, "loss": 0.00069, "grad_norm": 0.00265, "time": 0.32734}
+{"mode": "train", "epoch": 20, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00069, "acc_pose": 0.78873, "loss": 0.00069, "grad_norm": 0.00308, "time": 0.32836}
+{"mode": "train", "epoch": 20, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00069, "acc_pose": 0.76957, "loss": 0.00069, "grad_norm": 0.00317, "time": 0.32703}
+{"mode": "train", "epoch": 20, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00069, "acc_pose": 0.78062, "loss": 0.00069, "grad_norm": 0.00283, "time": 0.32454}
+{"mode": "val", "epoch": 20, "iter": 204, "lr": 0.0, "AP": 0.76181, "AP .5": 0.90579, "AP .75": 0.8328, "AP (M)": 0.68739, "AP (L)": 0.79194, "AR": 0.81544, "AR .5": 0.94584, "AR .75": 0.87815, "AR (M)": 0.77307, "AR (L)": 0.87748}
+{"mode": "train", "epoch": 21, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04729, "heatmap_loss": 0.00068, "acc_pose": 0.77734, "loss": 0.00068, "grad_norm": 0.00273, "time": 0.3686}
+{"mode": "train", "epoch": 21, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00068, "acc_pose": 0.78499, "loss": 0.00068, "grad_norm": 0.00298, "time": 0.3222}
+{"mode": "train", "epoch": 21, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00069, "acc_pose": 0.78703, "loss": 0.00069, "grad_norm": 0.00269, "time": 0.32471}
+{"mode": "train", "epoch": 21, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00068, "acc_pose": 0.774, "loss": 0.00068, "grad_norm": 0.00275, "time": 0.32458}
+{"mode": "train", "epoch": 21, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00069, "acc_pose": 0.78752, "loss": 0.00069, "grad_norm": 0.00301, "time": 0.32456}
+{"mode": "train", "epoch": 22, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04821, "heatmap_loss": 0.00068, "acc_pose": 0.7961, "loss": 0.00068, "grad_norm": 0.00291, "time": 0.37742}
+{"mode": "train", "epoch": 22, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00068, "acc_pose": 0.78779, "loss": 0.00068, "grad_norm": 0.00312, "time": 0.32715}
+{"mode": "train", "epoch": 22, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00067, "acc_pose": 0.79456, "loss": 0.00067, "grad_norm": 0.00248, "time": 0.32443}
+{"mode": "train", "epoch": 22, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00068, "acc_pose": 0.7921, "loss": 0.00068, "grad_norm": 0.0024, "time": 0.32632}
+{"mode": "train", "epoch": 22, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00067, "acc_pose": 0.79573, "loss": 0.00067, "grad_norm": 0.00269, "time": 0.32581}
+{"mode": "train", "epoch": 23, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.0467, "heatmap_loss": 0.00067, "acc_pose": 0.79427, "loss": 0.00067, "grad_norm": 0.00284, "time": 0.37374}
+{"mode": "train", "epoch": 23, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00045, "heatmap_loss": 0.00067, "acc_pose": 0.79648, "loss": 0.00067, "grad_norm": 0.0031, "time": 0.32376}
+{"mode": "train", "epoch": 23, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00067, "acc_pose": 0.78753, "loss": 0.00067, "grad_norm": 0.00267, "time": 0.32437}
+{"mode": "train", "epoch": 23, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00067, "acc_pose": 0.77981, "loss": 0.00067, "grad_norm": 0.00265, "time": 0.32518}
+{"mode": "train", "epoch": 23, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00068, "acc_pose": 0.78753, "loss": 0.00068, "grad_norm": 0.00309, "time": 0.32531}
+{"mode": "train", "epoch": 24, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04662, "heatmap_loss": 0.00067, "acc_pose": 0.77909, "loss": 0.00067, "grad_norm": 0.00247, "time": 0.37338}
+{"mode": "train", "epoch": 24, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00067, "acc_pose": 0.79459, "loss": 0.00067, "grad_norm": 0.0025, "time": 0.32574}
+{"mode": "train", "epoch": 24, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00067, "acc_pose": 0.78856, "loss": 0.00067, "grad_norm": 0.00244, "time": 0.32599}
+{"mode": "train", "epoch": 24, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00067, "acc_pose": 0.77849, "loss": 0.00067, "grad_norm": 0.00257, "time": 0.32663}
+{"mode": "train", "epoch": 24, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00067, "acc_pose": 0.7888, "loss": 0.00067, "grad_norm": 0.00318, "time": 0.32298}
+{"mode": "train", "epoch": 25, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04694, "heatmap_loss": 0.00066, "acc_pose": 0.78427, "loss": 0.00066, "grad_norm": 0.00262, "time": 0.37552}
+{"mode": "train", "epoch": 25, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00066, "acc_pose": 0.7923, "loss": 0.00066, "grad_norm": 0.00251, "time": 0.32359}
+{"mode": "train", "epoch": 25, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00067, "acc_pose": 0.80074, "loss": 0.00067, "grad_norm": 0.0028, "time": 0.32286}
+{"mode": "train", "epoch": 25, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00067, "acc_pose": 0.7923, "loss": 0.00067, "grad_norm": 0.00294, "time": 0.32265}
+{"mode": "train", "epoch": 25, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00066, "acc_pose": 0.78118, "loss": 0.00066, "grad_norm": 0.0027, "time": 0.32251}
+{"mode": "train", "epoch": 26, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.0465, "heatmap_loss": 0.00066, "acc_pose": 0.79343, "loss": 0.00066, "grad_norm": 0.00275, "time": 0.37459}
+{"mode": "train", "epoch": 26, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.00066, "acc_pose": 0.81051, "loss": 0.00066, "grad_norm": 0.00248, "time": 0.32458}
+{"mode": "train", "epoch": 26, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00066, "acc_pose": 0.78514, "loss": 0.00066, "grad_norm": 0.00286, "time": 0.32319}
+{"mode": "train", "epoch": 26, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00066, "acc_pose": 0.79984, "loss": 0.00066, "grad_norm": 0.00271, "time": 0.32487}
+{"mode": "train", "epoch": 26, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00066, "acc_pose": 0.79718, "loss": 0.00066, "grad_norm": 0.00262, "time": 0.32554}
+{"mode": "train", "epoch": 27, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.0468, "heatmap_loss": 0.00066, "acc_pose": 0.78902, "loss": 0.00066, "grad_norm": 0.00253, "time": 0.37498}
+{"mode": "train", "epoch": 27, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00066, "acc_pose": 0.78745, "loss": 0.00066, "grad_norm": 0.00278, "time": 0.32276}
+{"mode": "train", "epoch": 27, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00066, "acc_pose": 0.80874, "loss": 0.00066, "grad_norm": 0.00268, "time": 0.32333}
+{"mode": "train", "epoch": 27, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00066, "acc_pose": 0.77729, "loss": 0.00066, "grad_norm": 0.00255, "time": 0.3233}
+{"mode": "train", "epoch": 27, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00065, "acc_pose": 0.78313, "loss": 0.00065, "grad_norm": 0.00244, "time": 0.32467}
+{"mode": "train", "epoch": 28, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04662, "heatmap_loss": 0.00065, "acc_pose": 0.80567, "loss": 0.00065, "grad_norm": 0.00229, "time": 0.37404}
+{"mode": "train", "epoch": 28, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00065, "acc_pose": 0.79293, "loss": 0.00065, "grad_norm": 0.0026, "time": 0.32376}
+{"mode": "train", "epoch": 28, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00066, "acc_pose": 0.78567, "loss": 0.00066, "grad_norm": 0.00253, "time": 0.32464}
+{"mode": "train", "epoch": 28, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00065, "acc_pose": 0.79375, "loss": 0.00065, "grad_norm": 0.0026, "time": 0.32409}
+{"mode": "train", "epoch": 28, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00065, "acc_pose": 0.78837, "loss": 0.00065, "grad_norm": 0.00269, "time": 0.3228}
+{"mode": "train", "epoch": 29, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04697, "heatmap_loss": 0.00065, "acc_pose": 0.78903, "loss": 0.00065, "grad_norm": 0.00271, "time": 0.37452}
+{"mode": "train", "epoch": 29, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00066, "acc_pose": 0.79228, "loss": 0.00066, "grad_norm": 0.00269, "time": 0.32377}
+{"mode": "train", "epoch": 29, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00066, "acc_pose": 0.80083, "loss": 0.00066, "grad_norm": 0.00251, "time": 0.32388}
+{"mode": "train", "epoch": 29, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00052, "heatmap_loss": 0.00064, "acc_pose": 0.79593, "loss": 0.00064, "grad_norm": 0.00287, "time": 0.32343}
+{"mode": "train", "epoch": 29, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.00065, "acc_pose": 0.79332, "loss": 0.00065, "grad_norm": 0.00254, "time": 0.32499}
+{"mode": "train", "epoch": 30, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04669, "heatmap_loss": 0.00065, "acc_pose": 0.78827, "loss": 0.00065, "grad_norm": 0.00246, "time": 0.37406}
+{"mode": "train", "epoch": 30, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00066, "acc_pose": 0.80152, "loss": 0.00066, "grad_norm": 0.00296, "time": 0.32405}
+{"mode": "train", "epoch": 30, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00065, "acc_pose": 0.79767, "loss": 0.00065, "grad_norm": 0.00269, "time": 0.32473}
+{"mode": "train", "epoch": 30, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00065, "acc_pose": 0.80328, "loss": 0.00065, "grad_norm": 0.00248, "time": 0.32272}
+{"mode": "train", "epoch": 30, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00065, "acc_pose": 0.78245, "loss": 0.00065, "grad_norm": 0.00268, "time": 0.32496}
+{"mode": "val", "epoch": 30, "iter": 204, "lr": 0.0, "AP": 0.76987, "AP .5": 0.90803, "AP .75": 0.84154, "AP (M)": 0.69658, "AP (L)": 0.79928, "AR": 0.82303, "AR .5": 0.94868, "AR .75": 0.88665, "AR (M)": 0.78009, "AR (L)": 0.8861}
+{"mode": "train", "epoch": 31, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04735, "heatmap_loss": 0.00065, "acc_pose": 0.80687, "loss": 0.00065, "grad_norm": 0.00282, "time": 0.3717}
+{"mode": "train", "epoch": 31, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00064, "acc_pose": 0.80407, "loss": 0.00064, "grad_norm": 0.0023, "time": 0.32339}
+{"mode": "train", "epoch": 31, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00064, "acc_pose": 0.79027, "loss": 0.00064, "grad_norm": 0.00225, "time": 0.32718}
+{"mode": "train", "epoch": 31, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00065, "acc_pose": 0.80901, "loss": 0.00065, "grad_norm": 0.00246, "time": 0.32403}
+{"mode": "train", "epoch": 31, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00064, "acc_pose": 0.80149, "loss": 0.00064, "grad_norm": 0.00246, "time": 0.32728}
+{"mode": "train", "epoch": 32, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04663, "heatmap_loss": 0.00064, "acc_pose": 0.80231, "loss": 0.00064, "grad_norm": 0.00233, "time": 0.37194}
+{"mode": "train", "epoch": 32, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00065, "acc_pose": 0.81558, "loss": 0.00065, "grad_norm": 0.0024, "time": 0.32341}
+{"mode": "train", "epoch": 32, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00064, "acc_pose": 0.80226, "loss": 0.00064, "grad_norm": 0.00237, "time": 0.32303}
+{"mode": "train", "epoch": 32, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00064, "acc_pose": 0.80177, "loss": 0.00064, "grad_norm": 0.00244, "time": 0.32479}
+{"mode": "train", "epoch": 32, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00064, "acc_pose": 0.79815, "loss": 0.00064, "grad_norm": 0.00244, "time": 0.32605}
+{"mode": "train", "epoch": 33, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04669, "heatmap_loss": 0.00064, "acc_pose": 0.80332, "loss": 0.00064, "grad_norm": 0.00254, "time": 0.37399}
+{"mode": "train", "epoch": 33, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00064, "acc_pose": 0.80367, "loss": 0.00064, "grad_norm": 0.0024, "time": 0.32551}
+{"mode": "train", "epoch": 33, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00055, "heatmap_loss": 0.00063, "acc_pose": 0.80105, "loss": 0.00063, "grad_norm": 0.00228, "time": 0.32477}
+{"mode": "train", "epoch": 33, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00064, "acc_pose": 0.80586, "loss": 0.00064, "grad_norm": 0.00242, "time": 0.32522}
+{"mode": "train", "epoch": 33, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00064, "acc_pose": 0.80469, "loss": 0.00064, "grad_norm": 0.00244, "time": 0.32487}
+{"mode": "train", "epoch": 34, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04674, "heatmap_loss": 0.00064, "acc_pose": 0.79638, "loss": 0.00064, "grad_norm": 0.00249, "time": 0.37359}
+{"mode": "train", "epoch": 34, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00064, "acc_pose": 0.79067, "loss": 0.00064, "grad_norm": 0.00238, "time": 0.32286}
+{"mode": "train", "epoch": 34, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00063, "acc_pose": 0.80854, "loss": 0.00063, "grad_norm": 0.00239, "time": 0.32345}
+{"mode": "train", "epoch": 34, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00064, "acc_pose": 0.80345, "loss": 0.00064, "grad_norm": 0.00263, "time": 0.32227}
+{"mode": "train", "epoch": 34, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00064, "acc_pose": 0.80514, "loss": 0.00064, "grad_norm": 0.00228, "time": 0.32335}
+{"mode": "train", "epoch": 35, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04668, "heatmap_loss": 0.00063, "acc_pose": 0.80378, "loss": 0.00063, "grad_norm": 0.00226, "time": 0.37463}
+{"mode": "train", "epoch": 35, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00063, "acc_pose": 0.80854, "loss": 0.00063, "grad_norm": 0.00234, "time": 0.32296}
+{"mode": "train", "epoch": 35, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00063, "acc_pose": 0.80346, "loss": 0.00063, "grad_norm": 0.00223, "time": 0.32441}
+{"mode": "train", "epoch": 35, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00064, "acc_pose": 0.79795, "loss": 0.00064, "grad_norm": 0.00262, "time": 0.32383}
+{"mode": "train", "epoch": 35, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00063, "acc_pose": 0.80019, "loss": 0.00063, "grad_norm": 0.00266, "time": 0.32397}
+{"mode": "train", "epoch": 36, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04672, "heatmap_loss": 0.00063, "acc_pose": 0.79098, "loss": 0.00063, "grad_norm": 0.00234, "time": 0.37553}
+{"mode": "train", "epoch": 36, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00063, "acc_pose": 0.80415, "loss": 0.00063, "grad_norm": 0.00239, "time": 0.32501}
+{"mode": "train", "epoch": 36, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00063, "acc_pose": 0.79769, "loss": 0.00063, "grad_norm": 0.00268, "time": 0.32599}
+{"mode": "train", "epoch": 36, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00063, "acc_pose": 0.79619, "loss": 0.00063, "grad_norm": 0.0025, "time": 0.32387}
+{"mode": "train", "epoch": 36, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00063, "acc_pose": 0.80829, "loss": 0.00063, "grad_norm": 0.00232, "time": 0.32519}
+{"mode": "train", "epoch": 37, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04665, "heatmap_loss": 0.00063, "acc_pose": 0.79413, "loss": 0.00063, "grad_norm": 0.00248, "time": 0.37406}
+{"mode": "train", "epoch": 37, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00063, "acc_pose": 0.79704, "loss": 0.00063, "grad_norm": 0.0023, "time": 0.32319}
+{"mode": "train", "epoch": 37, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00063, "acc_pose": 0.80057, "loss": 0.00063, "grad_norm": 0.00226, "time": 0.32433}
+{"mode": "train", "epoch": 37, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00063, "acc_pose": 0.81598, "loss": 0.00063, "grad_norm": 0.00233, "time": 0.32215}
+{"mode": "train", "epoch": 37, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00063, "acc_pose": 0.78691, "loss": 0.00063, "grad_norm": 0.00241, "time": 0.32327}
+{"mode": "train", "epoch": 38, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04681, "heatmap_loss": 0.00063, "acc_pose": 0.79838, "loss": 0.00063, "grad_norm": 0.00231, "time": 0.37246}
+{"mode": "train", "epoch": 38, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00063, "acc_pose": 0.8094, "loss": 0.00063, "grad_norm": 0.00246, "time": 0.32231}
+{"mode": "train", "epoch": 38, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00063, "acc_pose": 0.82011, "loss": 0.00063, "grad_norm": 0.00251, "time": 0.32397}
+{"mode": "train", "epoch": 38, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00062, "acc_pose": 0.8025, "loss": 0.00062, "grad_norm": 0.00198, "time": 0.3224}
+{"mode": "train", "epoch": 38, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00063, "acc_pose": 0.81782, "loss": 0.00063, "grad_norm": 0.00226, "time": 0.32359}
+{"mode": "train", "epoch": 39, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04681, "heatmap_loss": 0.00063, "acc_pose": 0.81769, "loss": 0.00063, "grad_norm": 0.00246, "time": 0.37451}
+{"mode": "train", "epoch": 39, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00062, "acc_pose": 0.79848, "loss": 0.00062, "grad_norm": 0.00228, "time": 0.32261}
+{"mode": "train", "epoch": 39, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00062, "acc_pose": 0.81221, "loss": 0.00062, "grad_norm": 0.00269, "time": 0.3251}
+{"mode": "train", "epoch": 39, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00063, "acc_pose": 0.7865, "loss": 0.00063, "grad_norm": 0.00213, "time": 0.32487}
+{"mode": "train", "epoch": 39, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00063, "acc_pose": 0.80351, "loss": 0.00063, "grad_norm": 0.00223, "time": 0.3245}
+{"mode": "train", "epoch": 40, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04662, "heatmap_loss": 0.00062, "acc_pose": 0.80077, "loss": 0.00062, "grad_norm": 0.00247, "time": 0.37405}
+{"mode": "train", "epoch": 40, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00063, "acc_pose": 0.80651, "loss": 0.00063, "grad_norm": 0.00246, "time": 0.32519}
+{"mode": "train", "epoch": 40, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00063, "acc_pose": 0.80995, "loss": 0.00063, "grad_norm": 0.00258, "time": 0.32624}
+{"mode": "train", "epoch": 40, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00062, "acc_pose": 0.81279, "loss": 0.00062, "grad_norm": 0.0023, "time": 0.32556}
+{"mode": "train", "epoch": 40, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00062, "acc_pose": 0.80071, "loss": 0.00062, "grad_norm": 0.00212, "time": 0.32476}
+{"mode": "val", "epoch": 40, "iter": 204, "lr": 0.0, "AP": 0.77527, "AP .5": 0.90982, "AP .75": 0.84488, "AP (M)": 0.7031, "AP (L)": 0.80372, "AR": 0.82724, "AR .5": 0.94962, "AR .75": 0.88854, "AR (M)": 0.78522, "AR (L)": 0.88844}
+{"mode": "train", "epoch": 41, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04791, "heatmap_loss": 0.00062, "acc_pose": 0.80798, "loss": 0.00062, "grad_norm": 0.00245, "time": 0.37099}
+{"mode": "train", "epoch": 41, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00062, "acc_pose": 0.80335, "loss": 0.00062, "grad_norm": 0.00248, "time": 0.32094}
+{"mode": "train", "epoch": 41, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00062, "acc_pose": 0.81895, "loss": 0.00062, "grad_norm": 0.00207, "time": 0.3256}
+{"mode": "train", "epoch": 41, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00062, "acc_pose": 0.80211, "loss": 0.00062, "grad_norm": 0.00236, "time": 0.32565}
+{"mode": "train", "epoch": 41, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00062, "acc_pose": 0.80961, "loss": 0.00062, "grad_norm": 0.00251, "time": 0.32428}
+{"mode": "train", "epoch": 42, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04633, "heatmap_loss": 0.00062, "acc_pose": 0.81503, "loss": 0.00062, "grad_norm": 0.00216, "time": 0.37276}
+{"mode": "train", "epoch": 42, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00062, "acc_pose": 0.80271, "loss": 0.00062, "grad_norm": 0.0021, "time": 0.32589}
+{"mode": "train", "epoch": 42, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00062, "acc_pose": 0.81108, "loss": 0.00062, "grad_norm": 0.0022, "time": 0.32594}
+{"mode": "train", "epoch": 42, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.00061, "acc_pose": 0.81603, "loss": 0.00061, "grad_norm": 0.00224, "time": 0.32518}
+{"mode": "train", "epoch": 42, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00062, "acc_pose": 0.80624, "loss": 0.00062, "grad_norm": 0.00241, "time": 0.32429}
+{"mode": "train", "epoch": 43, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04684, "heatmap_loss": 0.00062, "acc_pose": 0.8041, "loss": 0.00062, "grad_norm": 0.00229, "time": 0.37462}
+{"mode": "train", "epoch": 43, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00061, "acc_pose": 0.81752, "loss": 0.00061, "grad_norm": 0.0022, "time": 0.32539}
+{"mode": "train", "epoch": 43, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00061, "acc_pose": 0.81031, "loss": 0.00061, "grad_norm": 0.00213, "time": 0.32659}
+{"mode": "train", "epoch": 43, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00062, "acc_pose": 0.81225, "loss": 0.00062, "grad_norm": 0.00226, "time": 0.32587}
+{"mode": "train", "epoch": 43, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00062, "acc_pose": 0.79246, "loss": 0.00062, "grad_norm": 0.00211, "time": 0.32419}
+{"mode": "train", "epoch": 44, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04685, "heatmap_loss": 0.00061, "acc_pose": 0.80308, "loss": 0.00061, "grad_norm": 0.002, "time": 0.37716}
+{"mode": "train", "epoch": 44, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00062, "acc_pose": 0.81306, "loss": 0.00062, "grad_norm": 0.00221, "time": 0.32558}
+{"mode": "train", "epoch": 44, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00061, "acc_pose": 0.80618, "loss": 0.00061, "grad_norm": 0.002, "time": 0.3244}
+{"mode": "train", "epoch": 44, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00061, "acc_pose": 0.81786, "loss": 0.00061, "grad_norm": 0.0022, "time": 0.32464}
+{"mode": "train", "epoch": 44, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00062, "acc_pose": 0.80442, "loss": 0.00062, "grad_norm": 0.00221, "time": 0.32578}
+{"mode": "train", "epoch": 45, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04661, "heatmap_loss": 0.00062, "acc_pose": 0.81906, "loss": 0.00062, "grad_norm": 0.00208, "time": 0.37692}
+{"mode": "train", "epoch": 45, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00061, "acc_pose": 0.80903, "loss": 0.00061, "grad_norm": 0.00232, "time": 0.3259}
+{"mode": "train", "epoch": 45, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00061, "acc_pose": 0.79061, "loss": 0.00061, "grad_norm": 0.00202, "time": 0.32505}
+{"mode": "train", "epoch": 45, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00061, "acc_pose": 0.80422, "loss": 0.00061, "grad_norm": 0.00246, "time": 0.32514}
+{"mode": "train", "epoch": 45, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00053, "heatmap_loss": 0.00061, "acc_pose": 0.81755, "loss": 0.00061, "grad_norm": 0.00244, "time": 0.32439}
+{"mode": "train", "epoch": 46, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04681, "heatmap_loss": 0.00061, "acc_pose": 0.80317, "loss": 0.00061, "grad_norm": 0.0021, "time": 0.37394}
+{"mode": "train", "epoch": 46, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00061, "acc_pose": 0.82051, "loss": 0.00061, "grad_norm": 0.00219, "time": 0.32411}
+{"mode": "train", "epoch": 46, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.00062, "acc_pose": 0.79971, "loss": 0.00062, "grad_norm": 0.00223, "time": 0.32342}
+{"mode": "train", "epoch": 46, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00061, "acc_pose": 0.81712, "loss": 0.00061, "grad_norm": 0.00225, "time": 0.32393}
+{"mode": "train", "epoch": 46, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.00061, "acc_pose": 0.82368, "loss": 0.00061, "grad_norm": 0.00241, "time": 0.32388}
+{"mode": "train", "epoch": 47, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04673, "heatmap_loss": 0.00061, "acc_pose": 0.81654, "loss": 0.00061, "grad_norm": 0.00208, "time": 0.37596}
+{"mode": "train", "epoch": 47, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00061, "acc_pose": 0.82008, "loss": 0.00061, "grad_norm": 0.00219, "time": 0.32299}
+{"mode": "train", "epoch": 47, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00062, "acc_pose": 0.81185, "loss": 0.00062, "grad_norm": 0.00222, "time": 0.3227}
+{"mode": "train", "epoch": 47, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00061, "acc_pose": 0.8129, "loss": 0.00061, "grad_norm": 0.00221, "time": 0.32316}
+{"mode": "train", "epoch": 47, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00061, "acc_pose": 0.815, "loss": 0.00061, "grad_norm": 0.00214, "time": 0.32539}
+{"mode": "train", "epoch": 48, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04669, "heatmap_loss": 0.00061, "acc_pose": 0.81022, "loss": 0.00061, "grad_norm": 0.00239, "time": 0.37541}
+{"mode": "train", "epoch": 48, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.0006, "acc_pose": 0.83373, "loss": 0.0006, "grad_norm": 0.00212, "time": 0.32371}
+{"mode": "train", "epoch": 48, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00061, "acc_pose": 0.80039, "loss": 0.00061, "grad_norm": 0.00212, "time": 0.32411}
+{"mode": "train", "epoch": 48, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00061, "acc_pose": 0.81076, "loss": 0.00061, "grad_norm": 0.00212, "time": 0.32457}
+{"mode": "train", "epoch": 48, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00061, "acc_pose": 0.8164, "loss": 0.00061, "grad_norm": 0.002, "time": 0.32445}
+{"mode": "train", "epoch": 49, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04669, "heatmap_loss": 0.00061, "acc_pose": 0.81441, "loss": 0.00061, "grad_norm": 0.0021, "time": 0.37358}
+{"mode": "train", "epoch": 49, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00061, "acc_pose": 0.8015, "loss": 0.00061, "grad_norm": 0.00212, "time": 0.32577}
+{"mode": "train", "epoch": 49, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.0006, "acc_pose": 0.80528, "loss": 0.0006, "grad_norm": 0.00213, "time": 0.32353}
+{"mode": "train", "epoch": 49, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00061, "acc_pose": 0.80637, "loss": 0.00061, "grad_norm": 0.00209, "time": 0.32247}
+{"mode": "train", "epoch": 49, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00061, "acc_pose": 0.82295, "loss": 0.00061, "grad_norm": 0.00211, "time": 0.32411}
+{"mode": "train", "epoch": 50, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04653, "heatmap_loss": 0.0006, "acc_pose": 0.83505, "loss": 0.0006, "grad_norm": 0.00213, "time": 0.37412}
+{"mode": "train", "epoch": 50, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00061, "acc_pose": 0.82471, "loss": 0.00061, "grad_norm": 0.00198, "time": 0.32448}
+{"mode": "train", "epoch": 50, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.0006, "acc_pose": 0.81746, "loss": 0.0006, "grad_norm": 0.00212, "time": 0.32352}
+{"mode": "train", "epoch": 50, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.0006, "acc_pose": 0.81096, "loss": 0.0006, "grad_norm": 0.00216, "time": 0.32281}
+{"mode": "train", "epoch": 50, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.0006, "acc_pose": 0.79586, "loss": 0.0006, "grad_norm": 0.00216, "time": 0.32329}
+{"mode": "val", "epoch": 50, "iter": 204, "lr": 0.0, "AP": 0.77826, "AP .5": 0.91146, "AP .75": 0.84951, "AP (M)": 0.70476, "AP (L)": 0.80784, "AR": 0.8304, "AR .5": 0.95025, "AR .75": 0.8931, "AR (M)": 0.78913, "AR (L)": 0.89082}
+{"mode": "train", "epoch": 51, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04772, "heatmap_loss": 0.0006, "acc_pose": 0.81534, "loss": 0.0006, "grad_norm": 0.00215, "time": 0.37225}
+{"mode": "train", "epoch": 51, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.0006, "acc_pose": 0.81989, "loss": 0.0006, "grad_norm": 0.00226, "time": 0.32598}
+{"mode": "train", "epoch": 51, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.0006, "acc_pose": 0.81183, "loss": 0.0006, "grad_norm": 0.00212, "time": 0.32561}
+{"mode": "train", "epoch": 51, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00061, "acc_pose": 0.80716, "loss": 0.00061, "grad_norm": 0.0021, "time": 0.32582}
+{"mode": "train", "epoch": 51, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.0006, "acc_pose": 0.80474, "loss": 0.0006, "grad_norm": 0.00206, "time": 0.3254}
+{"mode": "train", "epoch": 52, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.0465, "heatmap_loss": 0.0006, "acc_pose": 0.81029, "loss": 0.0006, "grad_norm": 0.00202, "time": 0.37238}
+{"mode": "train", "epoch": 52, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.0006, "acc_pose": 0.81564, "loss": 0.0006, "grad_norm": 0.00236, "time": 0.32469}
+{"mode": "train", "epoch": 52, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00061, "acc_pose": 0.8246, "loss": 0.00061, "grad_norm": 0.00212, "time": 0.32499}
+{"mode": "train", "epoch": 52, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.0006, "acc_pose": 0.82232, "loss": 0.0006, "grad_norm": 0.00215, "time": 0.32407}
+{"mode": "train", "epoch": 52, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00061, "acc_pose": 0.80406, "loss": 0.00061, "grad_norm": 0.00223, "time": 0.32436}
+{"mode": "train", "epoch": 53, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04648, "heatmap_loss": 0.0006, "acc_pose": 0.81122, "loss": 0.0006, "grad_norm": 0.00208, "time": 0.3744}
+{"mode": "train", "epoch": 53, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.0006, "acc_pose": 0.81502, "loss": 0.0006, "grad_norm": 0.0021, "time": 0.32329}
+{"mode": "train", "epoch": 53, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.0006, "acc_pose": 0.82556, "loss": 0.0006, "grad_norm": 0.00248, "time": 0.32325}
+{"mode": "train", "epoch": 53, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.0006, "acc_pose": 0.81675, "loss": 0.0006, "grad_norm": 0.0021, "time": 0.32332}
+{"mode": "train", "epoch": 53, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.0006, "acc_pose": 0.82025, "loss": 0.0006, "grad_norm": 0.00216, "time": 0.3242}
+{"mode": "train", "epoch": 54, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04679, "heatmap_loss": 0.0006, "acc_pose": 0.80938, "loss": 0.0006, "grad_norm": 0.00189, "time": 0.37577}
+{"mode": "train", "epoch": 54, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.0006, "acc_pose": 0.82723, "loss": 0.0006, "grad_norm": 0.00186, "time": 0.32359}
+{"mode": "train", "epoch": 54, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00059, "acc_pose": 0.82362, "loss": 0.00059, "grad_norm": 0.00207, "time": 0.32349}
+{"mode": "train", "epoch": 54, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.0006, "acc_pose": 0.81575, "loss": 0.0006, "grad_norm": 0.00206, "time": 0.32285}
+{"mode": "train", "epoch": 54, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00061, "acc_pose": 0.82504, "loss": 0.00061, "grad_norm": 0.00205, "time": 0.32354}
+{"mode": "train", "epoch": 55, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04692, "heatmap_loss": 0.0006, "acc_pose": 0.82531, "loss": 0.0006, "grad_norm": 0.00222, "time": 0.37591}
+{"mode": "train", "epoch": 55, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00053, "heatmap_loss": 0.0006, "acc_pose": 0.82411, "loss": 0.0006, "grad_norm": 0.00192, "time": 0.32524}
+{"mode": "train", "epoch": 55, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.0006, "acc_pose": 0.80836, "loss": 0.0006, "grad_norm": 0.00229, "time": 0.32515}
+{"mode": "train", "epoch": 55, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00059, "acc_pose": 0.82613, "loss": 0.00059, "grad_norm": 0.00194, "time": 0.3268}
+{"mode": "train", "epoch": 55, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00059, "acc_pose": 0.81638, "loss": 0.00059, "grad_norm": 0.00205, "time": 0.32444}
+{"mode": "train", "epoch": 56, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.0466, "heatmap_loss": 0.0006, "acc_pose": 0.80914, "loss": 0.0006, "grad_norm": 0.00202, "time": 0.37639}
+{"mode": "train", "epoch": 56, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.0006, "acc_pose": 0.83261, "loss": 0.0006, "grad_norm": 0.00194, "time": 0.32552}
+{"mode": "train", "epoch": 56, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00059, "acc_pose": 0.81487, "loss": 0.00059, "grad_norm": 0.00204, "time": 0.32555}
+{"mode": "train", "epoch": 56, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.0006, "acc_pose": 0.81048, "loss": 0.0006, "grad_norm": 0.00197, "time": 0.32534}
+{"mode": "train", "epoch": 56, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.0006, "acc_pose": 0.81336, "loss": 0.0006, "grad_norm": 0.00196, "time": 0.32759}
+{"mode": "train", "epoch": 57, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04673, "heatmap_loss": 0.0006, "acc_pose": 0.81712, "loss": 0.0006, "grad_norm": 0.00203, "time": 0.37999}
+{"mode": "train", "epoch": 57, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00052, "heatmap_loss": 0.00059, "acc_pose": 0.81657, "loss": 0.00059, "grad_norm": 0.00213, "time": 0.32524}
+{"mode": "train", "epoch": 57, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00059, "acc_pose": 0.8166, "loss": 0.00059, "grad_norm": 0.00198, "time": 0.32649}
+{"mode": "train", "epoch": 57, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00059, "acc_pose": 0.82524, "loss": 0.00059, "grad_norm": 0.0022, "time": 0.32619}
+{"mode": "train", "epoch": 57, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.0006, "acc_pose": 0.80569, "loss": 0.0006, "grad_norm": 0.00196, "time": 0.32309}
+{"mode": "train", "epoch": 58, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04711, "heatmap_loss": 0.0006, "acc_pose": 0.81482, "loss": 0.0006, "grad_norm": 0.00227, "time": 0.37658}
+{"mode": "train", "epoch": 58, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00056, "heatmap_loss": 0.00059, "acc_pose": 0.81926, "loss": 0.00059, "grad_norm": 0.00233, "time": 0.32597}
+{"mode": "train", "epoch": 58, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00053, "heatmap_loss": 0.00059, "acc_pose": 0.82175, "loss": 0.00059, "grad_norm": 0.00202, "time": 0.32441}
+{"mode": "train", "epoch": 58, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00052, "heatmap_loss": 0.00059, "acc_pose": 0.81385, "loss": 0.00059, "grad_norm": 0.00209, "time": 0.32461}
+{"mode": "train", "epoch": 58, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00055, "heatmap_loss": 0.00059, "acc_pose": 0.80919, "loss": 0.00059, "grad_norm": 0.00203, "time": 0.32585}
+{"mode": "train", "epoch": 59, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04734, "heatmap_loss": 0.00059, "acc_pose": 0.82157, "loss": 0.00059, "grad_norm": 0.00188, "time": 0.37461}
+{"mode": "train", "epoch": 59, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00053, "heatmap_loss": 0.00059, "acc_pose": 0.82724, "loss": 0.00059, "grad_norm": 0.00198, "time": 0.32555}
+{"mode": "train", "epoch": 59, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00053, "heatmap_loss": 0.00059, "acc_pose": 0.82494, "loss": 0.00059, "grad_norm": 0.00186, "time": 0.32434}
+{"mode": "train", "epoch": 59, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.00058, "acc_pose": 0.81015, "loss": 0.00058, "grad_norm": 0.00191, "time": 0.32457}
+{"mode": "train", "epoch": 59, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00052, "heatmap_loss": 0.00059, "acc_pose": 0.83173, "loss": 0.00059, "grad_norm": 0.00199, "time": 0.3248}
+{"mode": "train", "epoch": 60, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04732, "heatmap_loss": 0.00059, "acc_pose": 0.83082, "loss": 0.00059, "grad_norm": 0.00192, "time": 0.38675}
+{"mode": "train", "epoch": 60, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00059, "acc_pose": 0.82079, "loss": 0.00059, "grad_norm": 0.00193, "time": 0.32474}
+{"mode": "train", "epoch": 60, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00059, "acc_pose": 0.82183, "loss": 0.00059, "grad_norm": 0.00203, "time": 0.32465}
+{"mode": "train", "epoch": 60, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00059, "acc_pose": 0.82888, "loss": 0.00059, "grad_norm": 0.002, "time": 0.32343}
+{"mode": "train", "epoch": 60, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00059, "acc_pose": 0.81649, "loss": 0.00059, "grad_norm": 0.00198, "time": 0.32449}
+{"mode": "val", "epoch": 60, "iter": 204, "lr": 0.0, "AP": 0.7812, "AP .5": 0.91322, "AP .75": 0.85134, "AP (M)": 0.70776, "AP (L)": 0.81289, "AR": 0.83201, "AR .5": 0.95057, "AR .75": 0.89263, "AR (M)": 0.78995, "AR (L)": 0.89365}
+{"mode": "train", "epoch": 61, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04806, "heatmap_loss": 0.00059, "acc_pose": 0.81255, "loss": 0.00059, "grad_norm": 0.00192, "time": 0.37146}
+{"mode": "train", "epoch": 61, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00059, "acc_pose": 0.81422, "loss": 0.00059, "grad_norm": 0.00211, "time": 0.32402}
+{"mode": "train", "epoch": 61, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00058, "acc_pose": 0.82988, "loss": 0.00058, "grad_norm": 0.00205, "time": 0.32494}
+{"mode": "train", "epoch": 61, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00059, "acc_pose": 0.81741, "loss": 0.00059, "grad_norm": 0.0022, "time": 0.32623}
+{"mode": "train", "epoch": 61, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00059, "acc_pose": 0.8299, "loss": 0.00059, "grad_norm": 0.00192, "time": 0.32394}
+{"mode": "train", "epoch": 62, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04738, "heatmap_loss": 0.00059, "acc_pose": 0.81353, "loss": 0.00059, "grad_norm": 0.00193, "time": 0.37389}
+{"mode": "train", "epoch": 62, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00054, "heatmap_loss": 0.00059, "acc_pose": 0.82365, "loss": 0.00059, "grad_norm": 0.00201, "time": 0.32446}
+{"mode": "train", "epoch": 62, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00059, "acc_pose": 0.82347, "loss": 0.00059, "grad_norm": 0.00189, "time": 0.32509}
+{"mode": "train", "epoch": 62, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00053, "heatmap_loss": 0.00059, "acc_pose": 0.82416, "loss": 0.00059, "grad_norm": 0.00204, "time": 0.32465}
+{"mode": "train", "epoch": 62, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00056, "heatmap_loss": 0.00059, "acc_pose": 0.81794, "loss": 0.00059, "grad_norm": 0.00175, "time": 0.32445}
+{"mode": "train", "epoch": 63, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04702, "heatmap_loss": 0.00058, "acc_pose": 0.81888, "loss": 0.00058, "grad_norm": 0.00205, "time": 0.37401}
+{"mode": "train", "epoch": 63, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00059, "acc_pose": 0.81626, "loss": 0.00059, "grad_norm": 0.00185, "time": 0.324}
+{"mode": "train", "epoch": 63, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00059, "acc_pose": 0.81957, "loss": 0.00059, "grad_norm": 0.00193, "time": 0.32397}
+{"mode": "train", "epoch": 63, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00058, "acc_pose": 0.81482, "loss": 0.00058, "grad_norm": 0.00179, "time": 0.32295}
+{"mode": "train", "epoch": 63, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00059, "acc_pose": 0.82809, "loss": 0.00059, "grad_norm": 0.00181, "time": 0.32526}
+{"mode": "train", "epoch": 64, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04692, "heatmap_loss": 0.00058, "acc_pose": 0.81634, "loss": 0.00058, "grad_norm": 0.00194, "time": 0.37399}
+{"mode": "train", "epoch": 64, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00058, "acc_pose": 0.82989, "loss": 0.00058, "grad_norm": 0.00181, "time": 0.32216}
+{"mode": "train", "epoch": 64, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00059, "acc_pose": 0.81992, "loss": 0.00059, "grad_norm": 0.002, "time": 0.32305}
+{"mode": "train", "epoch": 64, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00059, "acc_pose": 0.80223, "loss": 0.00059, "grad_norm": 0.00202, "time": 0.32214}
+{"mode": "train", "epoch": 64, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00058, "acc_pose": 0.81832, "loss": 0.00058, "grad_norm": 0.00196, "time": 0.32335}
+{"mode": "train", "epoch": 65, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04688, "heatmap_loss": 0.00058, "acc_pose": 0.83473, "loss": 0.00058, "grad_norm": 0.00172, "time": 0.37457}
+{"mode": "train", "epoch": 65, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00059, "acc_pose": 0.82924, "loss": 0.00059, "grad_norm": 0.002, "time": 0.32386}
+{"mode": "train", "epoch": 65, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00059, "acc_pose": 0.82494, "loss": 0.00059, "grad_norm": 0.00191, "time": 0.32293}
+{"mode": "train", "epoch": 65, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00058, "acc_pose": 0.8223, "loss": 0.00058, "grad_norm": 0.00189, "time": 0.32311}
+{"mode": "train", "epoch": 65, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00058, "acc_pose": 0.82878, "loss": 0.00058, "grad_norm": 0.00195, "time": 0.32305}
+{"mode": "train", "epoch": 66, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04667, "heatmap_loss": 0.00058, "acc_pose": 0.82713, "loss": 0.00058, "grad_norm": 0.00226, "time": 0.37311}
+{"mode": "train", "epoch": 66, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00058, "acc_pose": 0.82899, "loss": 0.00058, "grad_norm": 0.00207, "time": 0.32468}
+{"mode": "train", "epoch": 66, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00045, "heatmap_loss": 0.00058, "acc_pose": 0.80596, "loss": 0.00058, "grad_norm": 0.002, "time": 0.32382}
+{"mode": "train", "epoch": 66, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00045, "heatmap_loss": 0.00059, "acc_pose": 0.8162, "loss": 0.00059, "grad_norm": 0.00185, "time": 0.3227}
+{"mode": "train", "epoch": 66, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00058, "acc_pose": 0.80683, "loss": 0.00058, "grad_norm": 0.0021, "time": 0.32448}
+{"mode": "train", "epoch": 67, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04725, "heatmap_loss": 0.00059, "acc_pose": 0.82287, "loss": 0.00059, "grad_norm": 0.00217, "time": 0.3741}
+{"mode": "train", "epoch": 67, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00059, "heatmap_loss": 0.00058, "acc_pose": 0.84392, "loss": 0.00058, "grad_norm": 0.00171, "time": 0.32303}
+{"mode": "train", "epoch": 67, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00052, "heatmap_loss": 0.00058, "acc_pose": 0.82026, "loss": 0.00058, "grad_norm": 0.00187, "time": 0.32374}
+{"mode": "train", "epoch": 67, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00058, "acc_pose": 0.81405, "loss": 0.00058, "grad_norm": 0.00187, "time": 0.32247}
+{"mode": "train", "epoch": 67, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00055, "heatmap_loss": 0.00059, "acc_pose": 0.82171, "loss": 0.00059, "grad_norm": 0.00192, "time": 0.32269}
+{"mode": "train", "epoch": 68, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04703, "heatmap_loss": 0.00058, "acc_pose": 0.81843, "loss": 0.00058, "grad_norm": 0.00176, "time": 0.3749}
+{"mode": "train", "epoch": 68, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.0006, "heatmap_loss": 0.00058, "acc_pose": 0.81513, "loss": 0.00058, "grad_norm": 0.00173, "time": 0.32419}
+{"mode": "train", "epoch": 68, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00055, "heatmap_loss": 0.00058, "acc_pose": 0.83275, "loss": 0.00058, "grad_norm": 0.00172, "time": 0.32335}
+{"mode": "train", "epoch": 68, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00058, "acc_pose": 0.81304, "loss": 0.00058, "grad_norm": 0.00182, "time": 0.32388}
+{"mode": "train", "epoch": 68, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00058, "acc_pose": 0.83381, "loss": 0.00058, "grad_norm": 0.00192, "time": 0.32232}
+{"mode": "train", "epoch": 69, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04731, "heatmap_loss": 0.00058, "acc_pose": 0.82444, "loss": 0.00058, "grad_norm": 0.00202, "time": 0.37272}
+{"mode": "train", "epoch": 69, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00058, "acc_pose": 0.83099, "loss": 0.00058, "grad_norm": 0.00188, "time": 0.32437}
+{"mode": "train", "epoch": 69, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00057, "acc_pose": 0.8264, "loss": 0.00057, "grad_norm": 0.00187, "time": 0.32445}
+{"mode": "train", "epoch": 69, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00058, "acc_pose": 0.82165, "loss": 0.00058, "grad_norm": 0.00183, "time": 0.32371}
+{"mode": "train", "epoch": 69, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00058, "acc_pose": 0.81817, "loss": 0.00058, "grad_norm": 0.00181, "time": 0.32354}
+{"mode": "train", "epoch": 70, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04691, "heatmap_loss": 0.00058, "acc_pose": 0.82072, "loss": 0.00058, "grad_norm": 0.00184, "time": 0.37456}
+{"mode": "train", "epoch": 70, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00058, "acc_pose": 0.82685, "loss": 0.00058, "grad_norm": 0.00191, "time": 0.32248}
+{"mode": "train", "epoch": 70, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00057, "heatmap_loss": 0.00058, "acc_pose": 0.81899, "loss": 0.00058, "grad_norm": 0.00176, "time": 0.32271}
+{"mode": "train", "epoch": 70, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00058, "acc_pose": 0.81657, "loss": 0.00058, "grad_norm": 0.00184, "time": 0.32282}
+{"mode": "train", "epoch": 70, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00058, "acc_pose": 0.82357, "loss": 0.00058, "grad_norm": 0.00199, "time": 0.32328}
+{"mode": "val", "epoch": 70, "iter": 204, "lr": 0.0, "AP": 0.78122, "AP .5": 0.91408, "AP .75": 0.85029, "AP (M)": 0.7083, "AP (L)": 0.81029, "AR": 0.83309, "AR .5": 0.95088, "AR .75": 0.89247, "AR (M)": 0.79175, "AR (L)": 0.89365}
+{"mode": "train", "epoch": 71, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04785, "heatmap_loss": 0.00058, "acc_pose": 0.82612, "loss": 0.00058, "grad_norm": 0.00176, "time": 0.37086}
+{"mode": "train", "epoch": 71, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00058, "acc_pose": 0.82591, "loss": 0.00058, "grad_norm": 0.00192, "time": 0.32135}
+{"mode": "train", "epoch": 71, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00058, "acc_pose": 0.81656, "loss": 0.00058, "grad_norm": 0.00191, "time": 0.32212}
+{"mode": "train", "epoch": 71, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00058, "acc_pose": 0.81699, "loss": 0.00058, "grad_norm": 0.002, "time": 0.32615}
+{"mode": "train", "epoch": 71, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00058, "acc_pose": 0.83871, "loss": 0.00058, "grad_norm": 0.00183, "time": 0.32577}
+{"mode": "train", "epoch": 72, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04673, "heatmap_loss": 0.00058, "acc_pose": 0.83006, "loss": 0.00058, "grad_norm": 0.00195, "time": 0.37481}
+{"mode": "train", "epoch": 72, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00058, "acc_pose": 0.83039, "loss": 0.00058, "grad_norm": 0.00191, "time": 0.32499}
+{"mode": "train", "epoch": 72, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00058, "acc_pose": 0.82023, "loss": 0.00058, "grad_norm": 0.00202, "time": 0.32552}
+{"mode": "train", "epoch": 72, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00058, "acc_pose": 0.83315, "loss": 0.00058, "grad_norm": 0.00195, "time": 0.32443}
+{"mode": "train", "epoch": 72, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00058, "acc_pose": 0.81654, "loss": 0.00058, "grad_norm": 0.00176, "time": 0.32468}
+{"mode": "train", "epoch": 73, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04676, "heatmap_loss": 0.00058, "acc_pose": 0.81892, "loss": 0.00058, "grad_norm": 0.00195, "time": 0.37514}
+{"mode": "train", "epoch": 73, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00058, "acc_pose": 0.83026, "loss": 0.00058, "grad_norm": 0.00193, "time": 0.3222}
+{"mode": "train", "epoch": 73, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00058, "acc_pose": 0.82083, "loss": 0.00058, "grad_norm": 0.00186, "time": 0.32231}
+{"mode": "train", "epoch": 73, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00057, "acc_pose": 0.8325, "loss": 0.00057, "grad_norm": 0.00162, "time": 0.32216}
+{"mode": "train", "epoch": 73, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00057, "acc_pose": 0.82851, "loss": 0.00057, "grad_norm": 0.00161, "time": 0.32237}
+{"mode": "train", "epoch": 74, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04684, "heatmap_loss": 0.00057, "acc_pose": 0.82623, "loss": 0.00057, "grad_norm": 0.00187, "time": 0.37475}
+{"mode": "train", "epoch": 74, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00057, "acc_pose": 0.81404, "loss": 0.00057, "grad_norm": 0.00178, "time": 0.32289}
+{"mode": "train", "epoch": 74, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00045, "heatmap_loss": 0.00057, "acc_pose": 0.80968, "loss": 0.00057, "grad_norm": 0.00183, "time": 0.32378}
+{"mode": "train", "epoch": 74, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00057, "acc_pose": 0.81875, "loss": 0.00057, "grad_norm": 0.00188, "time": 0.32325}
+{"mode": "train", "epoch": 74, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00058, "acc_pose": 0.8195, "loss": 0.00058, "grad_norm": 0.00187, "time": 0.32299}
+{"mode": "train", "epoch": 75, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04692, "heatmap_loss": 0.00058, "acc_pose": 0.82799, "loss": 0.00058, "grad_norm": 0.00168, "time": 0.37366}
+{"mode": "train", "epoch": 75, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.00057, "acc_pose": 0.82129, "loss": 0.00057, "grad_norm": 0.00168, "time": 0.32404}
+{"mode": "train", "epoch": 75, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00057, "acc_pose": 0.82157, "loss": 0.00057, "grad_norm": 0.00184, "time": 0.32246}
+{"mode": "train", "epoch": 75, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00058, "acc_pose": 0.81599, "loss": 0.00058, "grad_norm": 0.00184, "time": 0.32304}
+{"mode": "train", "epoch": 75, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00057, "acc_pose": 0.82517, "loss": 0.00057, "grad_norm": 0.00191, "time": 0.32373}
+{"mode": "train", "epoch": 76, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04683, "heatmap_loss": 0.00057, "acc_pose": 0.8244, "loss": 0.00057, "grad_norm": 0.00181, "time": 0.37642}
+{"mode": "train", "epoch": 76, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00052, "heatmap_loss": 0.00057, "acc_pose": 0.8268, "loss": 0.00057, "grad_norm": 0.00167, "time": 0.32435}
+{"mode": "train", "epoch": 76, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00057, "acc_pose": 0.83775, "loss": 0.00057, "grad_norm": 0.00185, "time": 0.32268}
+{"mode": "train", "epoch": 76, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00057, "acc_pose": 0.82536, "loss": 0.00057, "grad_norm": 0.00198, "time": 0.3231}
+{"mode": "train", "epoch": 76, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00058, "acc_pose": 0.82471, "loss": 0.00058, "grad_norm": 0.00186, "time": 0.32249}
+{"mode": "train", "epoch": 77, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04677, "heatmap_loss": 0.00057, "acc_pose": 0.81674, "loss": 0.00057, "grad_norm": 0.00181, "time": 0.37376}
+{"mode": "train", "epoch": 77, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00058, "acc_pose": 0.82685, "loss": 0.00058, "grad_norm": 0.00186, "time": 0.32347}
+{"mode": "train", "epoch": 77, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00057, "acc_pose": 0.82432, "loss": 0.00057, "grad_norm": 0.00157, "time": 0.32212}
+{"mode": "train", "epoch": 77, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00057, "acc_pose": 0.82485, "loss": 0.00057, "grad_norm": 0.00174, "time": 0.32259}
+{"mode": "train", "epoch": 77, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00057, "acc_pose": 0.82895, "loss": 0.00057, "grad_norm": 0.00189, "time": 0.32295}
+{"mode": "train", "epoch": 78, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04682, "heatmap_loss": 0.00057, "acc_pose": 0.83481, "loss": 0.00057, "grad_norm": 0.0018, "time": 0.37486}
+{"mode": "train", "epoch": 78, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.00056, "acc_pose": 0.84069, "loss": 0.00056, "grad_norm": 0.00181, "time": 0.32349}
+{"mode": "train", "epoch": 78, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00057, "acc_pose": 0.84064, "loss": 0.00057, "grad_norm": 0.00192, "time": 0.32375}
+{"mode": "train", "epoch": 78, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00057, "acc_pose": 0.81104, "loss": 0.00057, "grad_norm": 0.00184, "time": 0.32362}
+{"mode": "train", "epoch": 78, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00057, "acc_pose": 0.83269, "loss": 0.00057, "grad_norm": 0.0017, "time": 0.32246}
+{"mode": "train", "epoch": 79, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04665, "heatmap_loss": 0.00057, "acc_pose": 0.83341, "loss": 0.00057, "grad_norm": 0.00189, "time": 0.37313}
+{"mode": "train", "epoch": 79, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00045, "heatmap_loss": 0.00057, "acc_pose": 0.83499, "loss": 0.00057, "grad_norm": 0.002, "time": 0.32287}
+{"mode": "train", "epoch": 79, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00052, "heatmap_loss": 0.00057, "acc_pose": 0.82071, "loss": 0.00057, "grad_norm": 0.00174, "time": 0.32277}
+{"mode": "train", "epoch": 79, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00057, "acc_pose": 0.84178, "loss": 0.00057, "grad_norm": 0.00178, "time": 0.32267}
+{"mode": "train", "epoch": 79, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00057, "acc_pose": 0.82363, "loss": 0.00057, "grad_norm": 0.00173, "time": 0.32322}
+{"mode": "train", "epoch": 80, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04689, "heatmap_loss": 0.00057, "acc_pose": 0.83408, "loss": 0.00057, "grad_norm": 0.00168, "time": 0.3747}
+{"mode": "train", "epoch": 80, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00057, "acc_pose": 0.82497, "loss": 0.00057, "grad_norm": 0.00183, "time": 0.32281}
+{"mode": "train", "epoch": 80, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00057, "acc_pose": 0.82721, "loss": 0.00057, "grad_norm": 0.00178, "time": 0.325}
+{"mode": "train", "epoch": 80, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00057, "acc_pose": 0.82681, "loss": 0.00057, "grad_norm": 0.00173, "time": 0.32579}
+{"mode": "train", "epoch": 80, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00057, "acc_pose": 0.81293, "loss": 0.00057, "grad_norm": 0.0017, "time": 0.32525}
+{"mode": "val", "epoch": 80, "iter": 204, "lr": 0.0, "AP": 0.78264, "AP .5": 0.91413, "AP .75": 0.85018, "AP (M)": 0.70972, "AP (L)": 0.81137, "AR": 0.83426, "AR .5": 0.95198, "AR .75": 0.89247, "AR (M)": 0.79323, "AR (L)": 0.89498}
+{"mode": "train", "epoch": 81, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.0479, "heatmap_loss": 0.00057, "acc_pose": 0.82726, "loss": 0.00057, "grad_norm": 0.00171, "time": 0.37028}
+{"mode": "train", "epoch": 81, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00057, "acc_pose": 0.83478, "loss": 0.00057, "grad_norm": 0.00188, "time": 0.32128}
+{"mode": "train", "epoch": 81, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00057, "acc_pose": 0.82884, "loss": 0.00057, "grad_norm": 0.00192, "time": 0.32139}
+{"mode": "train", "epoch": 81, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00057, "acc_pose": 0.82936, "loss": 0.00057, "grad_norm": 0.00177, "time": 0.32253}
+{"mode": "train", "epoch": 81, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00057, "acc_pose": 0.82465, "loss": 0.00057, "grad_norm": 0.00181, "time": 0.32386}
+{"mode": "train", "epoch": 82, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04659, "heatmap_loss": 0.00057, "acc_pose": 0.82879, "loss": 0.00057, "grad_norm": 0.00182, "time": 0.37249}
+{"mode": "train", "epoch": 82, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00057, "acc_pose": 0.8477, "loss": 0.00057, "grad_norm": 0.0018, "time": 0.32238}
+{"mode": "train", "epoch": 82, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00057, "acc_pose": 0.82578, "loss": 0.00057, "grad_norm": 0.00171, "time": 0.32358}
+{"mode": "train", "epoch": 82, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00057, "acc_pose": 0.83724, "loss": 0.00057, "grad_norm": 0.00187, "time": 0.3224}
+{"mode": "train", "epoch": 82, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00057, "acc_pose": 0.81853, "loss": 0.00057, "grad_norm": 0.00176, "time": 0.3237}
+{"mode": "train", "epoch": 83, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04676, "heatmap_loss": 0.00057, "acc_pose": 0.81293, "loss": 0.00057, "grad_norm": 0.00178, "time": 0.37295}
+{"mode": "train", "epoch": 83, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00057, "acc_pose": 0.82644, "loss": 0.00057, "grad_norm": 0.00171, "time": 0.32344}
+{"mode": "train", "epoch": 83, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00057, "acc_pose": 0.82546, "loss": 0.00057, "grad_norm": 0.00162, "time": 0.32218}
+{"mode": "train", "epoch": 83, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00045, "heatmap_loss": 0.00057, "acc_pose": 0.82836, "loss": 0.00057, "grad_norm": 0.0016, "time": 0.32259}
+{"mode": "train", "epoch": 83, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00045, "heatmap_loss": 0.00057, "acc_pose": 0.8386, "loss": 0.00057, "grad_norm": 0.0017, "time": 0.32218}
+{"mode": "train", "epoch": 84, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04689, "heatmap_loss": 0.00057, "acc_pose": 0.82124, "loss": 0.00057, "grad_norm": 0.00164, "time": 0.37477}
+{"mode": "train", "epoch": 84, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00056, "acc_pose": 0.83104, "loss": 0.00056, "grad_norm": 0.00167, "time": 0.32263}
+{"mode": "train", "epoch": 84, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.00056, "acc_pose": 0.82701, "loss": 0.00056, "grad_norm": 0.00165, "time": 0.32307}
+{"mode": "train", "epoch": 84, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00057, "acc_pose": 0.83927, "loss": 0.00057, "grad_norm": 0.00178, "time": 0.32301}
+{"mode": "train", "epoch": 84, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00057, "acc_pose": 0.82391, "loss": 0.00057, "grad_norm": 0.00181, "time": 0.32375}
+{"mode": "train", "epoch": 85, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04669, "heatmap_loss": 0.00057, "acc_pose": 0.8238, "loss": 0.00057, "grad_norm": 0.00168, "time": 0.3741}
+{"mode": "train", "epoch": 85, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00057, "acc_pose": 0.8354, "loss": 0.00057, "grad_norm": 0.00154, "time": 0.32326}
+{"mode": "train", "epoch": 85, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00057, "acc_pose": 0.83149, "loss": 0.00057, "grad_norm": 0.00183, "time": 0.32388}
+{"mode": "train", "epoch": 85, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00057, "acc_pose": 0.83354, "loss": 0.00057, "grad_norm": 0.00175, "time": 0.32291}
+{"mode": "train", "epoch": 85, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00056, "acc_pose": 0.84317, "loss": 0.00056, "grad_norm": 0.0018, "time": 0.32255}
+{"mode": "train", "epoch": 86, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04958, "heatmap_loss": 0.00057, "acc_pose": 0.82247, "loss": 0.00057, "grad_norm": 0.00173, "time": 0.37489}
+{"mode": "train", "epoch": 86, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00056, "acc_pose": 0.82678, "loss": 0.00056, "grad_norm": 0.00174, "time": 0.32343}
+{"mode": "train", "epoch": 86, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00057, "acc_pose": 0.83642, "loss": 0.00057, "grad_norm": 0.00174, "time": 0.3247}
+{"mode": "train", "epoch": 86, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00057, "acc_pose": 0.82733, "loss": 0.00057, "grad_norm": 0.00174, "time": 0.32363}
+{"mode": "train", "epoch": 86, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00056, "acc_pose": 0.82931, "loss": 0.00056, "grad_norm": 0.00169, "time": 0.3238}
+{"mode": "train", "epoch": 87, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.0466, "heatmap_loss": 0.00056, "acc_pose": 0.84047, "loss": 0.00056, "grad_norm": 0.00168, "time": 0.37501}
+{"mode": "train", "epoch": 87, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00045, "heatmap_loss": 0.00056, "acc_pose": 0.82529, "loss": 0.00056, "grad_norm": 0.00168, "time": 0.32525}
+{"mode": "train", "epoch": 87, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00055, "heatmap_loss": 0.00056, "acc_pose": 0.83666, "loss": 0.00056, "grad_norm": 0.00171, "time": 0.32614}
+{"mode": "train", "epoch": 87, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00056, "acc_pose": 0.83482, "loss": 0.00056, "grad_norm": 0.00168, "time": 0.3257}
+{"mode": "train", "epoch": 87, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00056, "acc_pose": 0.83973, "loss": 0.00056, "grad_norm": 0.00162, "time": 0.32486}
+{"mode": "train", "epoch": 88, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04661, "heatmap_loss": 0.00056, "acc_pose": 0.82566, "loss": 0.00056, "grad_norm": 0.00175, "time": 0.37489}
+{"mode": "train", "epoch": 88, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00052, "heatmap_loss": 0.00056, "acc_pose": 0.82147, "loss": 0.00056, "grad_norm": 0.00164, "time": 0.32552}
+{"mode": "train", "epoch": 88, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00056, "acc_pose": 0.84105, "loss": 0.00056, "grad_norm": 0.00155, "time": 0.32588}
+{"mode": "train", "epoch": 88, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00056, "acc_pose": 0.83633, "loss": 0.00056, "grad_norm": 0.0016, "time": 0.32463}
+{"mode": "train", "epoch": 88, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00056, "acc_pose": 0.8416, "loss": 0.00056, "grad_norm": 0.00181, "time": 0.3244}
+{"mode": "train", "epoch": 89, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04688, "heatmap_loss": 0.00056, "acc_pose": 0.83969, "loss": 0.00056, "grad_norm": 0.00167, "time": 0.37469}
+{"mode": "train", "epoch": 89, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00056, "acc_pose": 0.84024, "loss": 0.00056, "grad_norm": 0.00163, "time": 0.32414}
+{"mode": "train", "epoch": 89, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00057, "acc_pose": 0.83663, "loss": 0.00057, "grad_norm": 0.00178, "time": 0.32295}
+{"mode": "train", "epoch": 89, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00056, "acc_pose": 0.83602, "loss": 0.00056, "grad_norm": 0.00158, "time": 0.32184}
+{"mode": "train", "epoch": 89, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00056, "acc_pose": 0.83117, "loss": 0.00056, "grad_norm": 0.00159, "time": 0.32251}
+{"mode": "train", "epoch": 90, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04688, "heatmap_loss": 0.00056, "acc_pose": 0.82081, "loss": 0.00056, "grad_norm": 0.00177, "time": 0.37256}
+{"mode": "train", "epoch": 90, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00056, "acc_pose": 0.83686, "loss": 0.00056, "grad_norm": 0.00166, "time": 0.32191}
+{"mode": "train", "epoch": 90, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00056, "acc_pose": 0.83808, "loss": 0.00056, "grad_norm": 0.00156, "time": 0.3227}
+{"mode": "train", "epoch": 90, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00056, "acc_pose": 0.84136, "loss": 0.00056, "grad_norm": 0.00172, "time": 0.32301}
+{"mode": "train", "epoch": 90, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00056, "acc_pose": 0.82473, "loss": 0.00056, "grad_norm": 0.00159, "time": 0.32292}
+{"mode": "val", "epoch": 90, "iter": 204, "lr": 0.0, "AP": 0.7844, "AP .5": 0.91422, "AP .75": 0.85271, "AP (M)": 0.71217, "AP (L)": 0.81393, "AR": 0.83534, "AR .5": 0.95151, "AR .75": 0.89484, "AR (M)": 0.79405, "AR (L)": 0.89654}
+{"mode": "train", "epoch": 91, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04762, "heatmap_loss": 0.00056, "acc_pose": 0.83593, "loss": 0.00056, "grad_norm": 0.00178, "time": 0.36886}
+{"mode": "train", "epoch": 91, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00056, "acc_pose": 0.82744, "loss": 0.00056, "grad_norm": 0.00161, "time": 0.32141}
+{"mode": "train", "epoch": 91, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00054, "heatmap_loss": 0.00056, "acc_pose": 0.82708, "loss": 0.00056, "grad_norm": 0.0016, "time": 0.32312}
+{"mode": "train", "epoch": 91, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00056, "acc_pose": 0.83185, "loss": 0.00056, "grad_norm": 0.00167, "time": 0.32204}
+{"mode": "train", "epoch": 91, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00056, "acc_pose": 0.83184, "loss": 0.00056, "grad_norm": 0.00169, "time": 0.32417}
+{"mode": "train", "epoch": 92, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04683, "heatmap_loss": 0.00056, "acc_pose": 0.85065, "loss": 0.00056, "grad_norm": 0.00164, "time": 0.37356}
+{"mode": "train", "epoch": 92, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.00056, "acc_pose": 0.83257, "loss": 0.00056, "grad_norm": 0.00176, "time": 0.32513}
+{"mode": "train", "epoch": 92, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00052, "heatmap_loss": 0.00056, "acc_pose": 0.81859, "loss": 0.00056, "grad_norm": 0.00169, "time": 0.32552}
+{"mode": "train", "epoch": 92, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00056, "acc_pose": 0.82274, "loss": 0.00056, "grad_norm": 0.00176, "time": 0.32501}
+{"mode": "train", "epoch": 92, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00056, "acc_pose": 0.82962, "loss": 0.00056, "grad_norm": 0.00156, "time": 0.32532}
+{"mode": "train", "epoch": 93, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04677, "heatmap_loss": 0.00056, "acc_pose": 0.82971, "loss": 0.00056, "grad_norm": 0.00166, "time": 0.3754}
+{"mode": "train", "epoch": 93, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00056, "acc_pose": 0.83076, "loss": 0.00056, "grad_norm": 0.00163, "time": 0.32471}
+{"mode": "train", "epoch": 93, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00056, "acc_pose": 0.84144, "loss": 0.00056, "grad_norm": 0.00157, "time": 0.32569}
+{"mode": "train", "epoch": 93, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00056, "acc_pose": 0.83866, "loss": 0.00056, "grad_norm": 0.0016, "time": 0.32308}
+{"mode": "train", "epoch": 93, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00055, "acc_pose": 0.85047, "loss": 0.00055, "grad_norm": 0.00149, "time": 0.32385}
+{"mode": "train", "epoch": 94, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04665, "heatmap_loss": 0.00055, "acc_pose": 0.83607, "loss": 0.00055, "grad_norm": 0.00151, "time": 0.37658}
+{"mode": "train", "epoch": 94, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00056, "acc_pose": 0.84064, "loss": 0.00056, "grad_norm": 0.00169, "time": 0.32368}
+{"mode": "train", "epoch": 94, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00056, "acc_pose": 0.8235, "loss": 0.00056, "grad_norm": 0.00157, "time": 0.32566}
+{"mode": "train", "epoch": 94, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00056, "acc_pose": 0.83957, "loss": 0.00056, "grad_norm": 0.00158, "time": 0.32377}
+{"mode": "train", "epoch": 94, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00055, "acc_pose": 0.83991, "loss": 0.00055, "grad_norm": 0.00182, "time": 0.3251}
+{"mode": "train", "epoch": 95, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04701, "heatmap_loss": 0.00056, "acc_pose": 0.82319, "loss": 0.00056, "grad_norm": 0.0017, "time": 0.3738}
+{"mode": "train", "epoch": 95, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00055, "acc_pose": 0.83785, "loss": 0.00055, "grad_norm": 0.00167, "time": 0.32317}
+{"mode": "train", "epoch": 95, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00056, "acc_pose": 0.82905, "loss": 0.00056, "grad_norm": 0.00179, "time": 0.32278}
+{"mode": "train", "epoch": 95, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00055, "acc_pose": 0.83589, "loss": 0.00055, "grad_norm": 0.00161, "time": 0.32307}
+{"mode": "train", "epoch": 95, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00056, "acc_pose": 0.84266, "loss": 0.00056, "grad_norm": 0.00184, "time": 0.32518}
+{"mode": "train", "epoch": 96, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04659, "heatmap_loss": 0.00055, "acc_pose": 0.84008, "loss": 0.00055, "grad_norm": 0.00176, "time": 0.37333}
+{"mode": "train", "epoch": 96, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00055, "acc_pose": 0.84531, "loss": 0.00055, "grad_norm": 0.00166, "time": 0.32317}
+{"mode": "train", "epoch": 96, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00055, "acc_pose": 0.83799, "loss": 0.00055, "grad_norm": 0.00149, "time": 0.3224}
+{"mode": "train", "epoch": 96, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00056, "acc_pose": 0.84133, "loss": 0.00056, "grad_norm": 0.00162, "time": 0.32297}
+{"mode": "train", "epoch": 96, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00056, "acc_pose": 0.83151, "loss": 0.00056, "grad_norm": 0.00161, "time": 0.32359}
+{"mode": "train", "epoch": 97, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04699, "heatmap_loss": 0.00056, "acc_pose": 0.83488, "loss": 0.00056, "grad_norm": 0.00175, "time": 0.37326}
+{"mode": "train", "epoch": 97, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00055, "acc_pose": 0.82973, "loss": 0.00055, "grad_norm": 0.00172, "time": 0.32274}
+{"mode": "train", "epoch": 97, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00055, "acc_pose": 0.84194, "loss": 0.00055, "grad_norm": 0.00159, "time": 0.32246}
+{"mode": "train", "epoch": 97, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00056, "acc_pose": 0.82935, "loss": 0.00056, "grad_norm": 0.00149, "time": 0.32407}
+{"mode": "train", "epoch": 97, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00056, "acc_pose": 0.8308, "loss": 0.00056, "grad_norm": 0.00157, "time": 0.32269}
+{"mode": "train", "epoch": 98, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04676, "heatmap_loss": 0.00055, "acc_pose": 0.83556, "loss": 0.00055, "grad_norm": 0.00159, "time": 0.37354}
+{"mode": "train", "epoch": 98, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00056, "acc_pose": 0.8335, "loss": 0.00056, "grad_norm": 0.00165, "time": 0.32389}
+{"mode": "train", "epoch": 98, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00055, "acc_pose": 0.83886, "loss": 0.00055, "grad_norm": 0.00157, "time": 0.32353}
+{"mode": "train", "epoch": 98, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00055, "acc_pose": 0.8244, "loss": 0.00055, "grad_norm": 0.00158, "time": 0.32398}
+{"mode": "train", "epoch": 98, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00056, "acc_pose": 0.84274, "loss": 0.00056, "grad_norm": 0.00167, "time": 0.32236}
+{"mode": "train", "epoch": 99, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04654, "heatmap_loss": 0.00055, "acc_pose": 0.8453, "loss": 0.00055, "grad_norm": 0.00152, "time": 0.37594}
+{"mode": "train", "epoch": 99, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00055, "acc_pose": 0.84524, "loss": 0.00055, "grad_norm": 0.00167, "time": 0.3263}
+{"mode": "train", "epoch": 99, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00045, "heatmap_loss": 0.00056, "acc_pose": 0.82581, "loss": 0.00056, "grad_norm": 0.0016, "time": 0.32426}
+{"mode": "train", "epoch": 99, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00056, "acc_pose": 0.84046, "loss": 0.00056, "grad_norm": 0.0016, "time": 0.32439}
+{"mode": "train", "epoch": 99, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00055, "acc_pose": 0.83108, "loss": 0.00055, "grad_norm": 0.00173, "time": 0.32358}
+{"mode": "train", "epoch": 100, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04728, "heatmap_loss": 0.00055, "acc_pose": 0.8458, "loss": 0.00055, "grad_norm": 0.0016, "time": 0.37394}
+{"mode": "train", "epoch": 100, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.00055, "acc_pose": 0.83713, "loss": 0.00055, "grad_norm": 0.00148, "time": 0.32401}
+{"mode": "train", "epoch": 100, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00056, "acc_pose": 0.83033, "loss": 0.00056, "grad_norm": 0.00156, "time": 0.32336}
+{"mode": "train", "epoch": 100, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00056, "acc_pose": 0.84711, "loss": 0.00056, "grad_norm": 0.00159, "time": 0.32336}
+{"mode": "train", "epoch": 100, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00065, "heatmap_loss": 0.00056, "acc_pose": 0.82294, "loss": 0.00056, "grad_norm": 0.00158, "time": 0.32299}
+{"mode": "val", "epoch": 100, "iter": 204, "lr": 0.0, "AP": 0.78551, "AP .5": 0.91569, "AP .75": 0.85367, "AP (M)": 0.71227, "AP (L)": 0.81505, "AR": 0.83679, "AR .5": 0.95309, "AR .75": 0.89657, "AR (M)": 0.79577, "AR (L)": 0.8974}
+{"mode": "train", "epoch": 101, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04792, "heatmap_loss": 0.00055, "acc_pose": 0.83899, "loss": 0.00055, "grad_norm": 0.00147, "time": 0.37107}
+{"mode": "train", "epoch": 101, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00055, "acc_pose": 0.8393, "loss": 0.00055, "grad_norm": 0.00151, "time": 0.32244}
+{"mode": "train", "epoch": 101, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00056, "acc_pose": 0.83298, "loss": 0.00056, "grad_norm": 0.00158, "time": 0.32177}
+{"mode": "train", "epoch": 101, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00056, "acc_pose": 0.83714, "loss": 0.00056, "grad_norm": 0.00148, "time": 0.3237}
+{"mode": "train", "epoch": 101, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00055, "acc_pose": 0.82673, "loss": 0.00055, "grad_norm": 0.00165, "time": 0.32159}
+{"mode": "train", "epoch": 102, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04671, "heatmap_loss": 0.00055, "acc_pose": 0.83198, "loss": 0.00055, "grad_norm": 0.00156, "time": 0.3709}
+{"mode": "train", "epoch": 102, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00055, "acc_pose": 0.83533, "loss": 0.00055, "grad_norm": 0.00157, "time": 0.32212}
+{"mode": "train", "epoch": 102, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00045, "heatmap_loss": 0.00055, "acc_pose": 0.83127, "loss": 0.00055, "grad_norm": 0.00159, "time": 0.32171}
+{"mode": "train", "epoch": 102, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00055, "acc_pose": 0.83327, "loss": 0.00055, "grad_norm": 0.00161, "time": 0.32389}
+{"mode": "train", "epoch": 102, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00055, "acc_pose": 0.84696, "loss": 0.00055, "grad_norm": 0.00152, "time": 0.32163}
+{"mode": "train", "epoch": 103, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04671, "heatmap_loss": 0.00055, "acc_pose": 0.83395, "loss": 0.00055, "grad_norm": 0.00167, "time": 0.3742}
+{"mode": "train", "epoch": 103, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00054, "heatmap_loss": 0.00055, "acc_pose": 0.83654, "loss": 0.00055, "grad_norm": 0.00161, "time": 0.32353}
+{"mode": "train", "epoch": 103, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00055, "acc_pose": 0.84397, "loss": 0.00055, "grad_norm": 0.00168, "time": 0.32231}
+{"mode": "train", "epoch": 103, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00055, "acc_pose": 0.82611, "loss": 0.00055, "grad_norm": 0.00148, "time": 0.32384}
+{"mode": "train", "epoch": 103, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00055, "acc_pose": 0.84366, "loss": 0.00055, "grad_norm": 0.00151, "time": 0.32263}
+{"mode": "train", "epoch": 104, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.0468, "heatmap_loss": 0.00055, "acc_pose": 0.8418, "loss": 0.00055, "grad_norm": 0.00162, "time": 0.37398}
+{"mode": "train", "epoch": 104, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00055, "acc_pose": 0.83313, "loss": 0.00055, "grad_norm": 0.00141, "time": 0.32322}
+{"mode": "train", "epoch": 104, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00055, "acc_pose": 0.82789, "loss": 0.00055, "grad_norm": 0.00163, "time": 0.32318}
+{"mode": "train", "epoch": 104, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00055, "acc_pose": 0.83747, "loss": 0.00055, "grad_norm": 0.00175, "time": 0.32463}
+{"mode": "train", "epoch": 104, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.00055, "acc_pose": 0.82998, "loss": 0.00055, "grad_norm": 0.00151, "time": 0.32483}
+{"mode": "train", "epoch": 105, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04684, "heatmap_loss": 0.00055, "acc_pose": 0.8364, "loss": 0.00055, "grad_norm": 0.00168, "time": 0.37736}
+{"mode": "train", "epoch": 105, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00055, "acc_pose": 0.83504, "loss": 0.00055, "grad_norm": 0.00167, "time": 0.32586}
+{"mode": "train", "epoch": 105, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00055, "acc_pose": 0.82722, "loss": 0.00055, "grad_norm": 0.00156, "time": 0.32452}
+{"mode": "train", "epoch": 105, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00055, "acc_pose": 0.83675, "loss": 0.00055, "grad_norm": 0.00161, "time": 0.32424}
+{"mode": "train", "epoch": 105, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00055, "acc_pose": 0.82881, "loss": 0.00055, "grad_norm": 0.00149, "time": 0.32419}
+{"mode": "train", "epoch": 106, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04655, "heatmap_loss": 0.00055, "acc_pose": 0.82801, "loss": 0.00055, "grad_norm": 0.00159, "time": 0.3729}
+{"mode": "train", "epoch": 106, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00055, "acc_pose": 0.83482, "loss": 0.00055, "grad_norm": 0.00148, "time": 0.32245}
+{"mode": "train", "epoch": 106, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00055, "acc_pose": 0.84111, "loss": 0.00055, "grad_norm": 0.00152, "time": 0.323}
+{"mode": "train", "epoch": 106, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00055, "acc_pose": 0.84235, "loss": 0.00055, "grad_norm": 0.00155, "time": 0.32376}
+{"mode": "train", "epoch": 106, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00055, "acc_pose": 0.83476, "loss": 0.00055, "grad_norm": 0.00146, "time": 0.32343}
+{"mode": "train", "epoch": 107, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04692, "heatmap_loss": 0.00055, "acc_pose": 0.8354, "loss": 0.00055, "grad_norm": 0.00164, "time": 0.37461}
+{"mode": "train", "epoch": 107, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00055, "acc_pose": 0.834, "loss": 0.00055, "grad_norm": 0.00154, "time": 0.32222}
+{"mode": "train", "epoch": 107, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00044, "heatmap_loss": 0.00055, "acc_pose": 0.84247, "loss": 0.00055, "grad_norm": 0.00156, "time": 0.32232}
+{"mode": "train", "epoch": 107, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00055, "acc_pose": 0.83295, "loss": 0.00055, "grad_norm": 0.0015, "time": 0.32308}
+{"mode": "train", "epoch": 107, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.00055, "acc_pose": 0.83696, "loss": 0.00055, "grad_norm": 0.00165, "time": 0.32297}
+{"mode": "train", "epoch": 108, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04686, "heatmap_loss": 0.00055, "acc_pose": 0.83707, "loss": 0.00055, "grad_norm": 0.00151, "time": 0.37517}
+{"mode": "train", "epoch": 108, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00055, "acc_pose": 0.83565, "loss": 0.00055, "grad_norm": 0.00154, "time": 0.32325}
+{"mode": "train", "epoch": 108, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00055, "acc_pose": 0.82455, "loss": 0.00055, "grad_norm": 0.00149, "time": 0.32333}
+{"mode": "train", "epoch": 108, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00055, "acc_pose": 0.84403, "loss": 0.00055, "grad_norm": 0.00157, "time": 0.32281}
+{"mode": "train", "epoch": 108, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.00055, "acc_pose": 0.84203, "loss": 0.00055, "grad_norm": 0.00153, "time": 0.3227}
+{"mode": "train", "epoch": 109, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04687, "heatmap_loss": 0.00054, "acc_pose": 0.83285, "loss": 0.00054, "grad_norm": 0.00155, "time": 0.37332}
+{"mode": "train", "epoch": 109, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00055, "acc_pose": 0.8352, "loss": 0.00055, "grad_norm": 0.00149, "time": 0.32251}
+{"mode": "train", "epoch": 109, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00056, "acc_pose": 0.84333, "loss": 0.00056, "grad_norm": 0.0015, "time": 0.32218}
+{"mode": "train", "epoch": 109, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00055, "acc_pose": 0.83545, "loss": 0.00055, "grad_norm": 0.00144, "time": 0.32183}
+{"mode": "train", "epoch": 109, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00054, "acc_pose": 0.83334, "loss": 0.00054, "grad_norm": 0.00147, "time": 0.32216}
+{"mode": "train", "epoch": 110, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04699, "heatmap_loss": 0.00055, "acc_pose": 0.83143, "loss": 0.00055, "grad_norm": 0.00151, "time": 0.37369}
+{"mode": "train", "epoch": 110, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00055, "acc_pose": 0.82743, "loss": 0.00055, "grad_norm": 0.00155, "time": 0.32273}
+{"mode": "train", "epoch": 110, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00055, "acc_pose": 0.83242, "loss": 0.00055, "grad_norm": 0.00144, "time": 0.32285}
+{"mode": "train", "epoch": 110, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00054, "acc_pose": 0.83825, "loss": 0.00054, "grad_norm": 0.00156, "time": 0.3224}
+{"mode": "train", "epoch": 110, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.0004, "heatmap_loss": 0.00055, "acc_pose": 0.83209, "loss": 0.00055, "grad_norm": 0.00155, "time": 0.32354}
+{"mode": "val", "epoch": 110, "iter": 204, "lr": 0.0, "AP": 0.78462, "AP .5": 0.91392, "AP .75": 0.85323, "AP (M)": 0.71225, "AP (L)": 0.81267, "AR": 0.83627, "AR .5": 0.95167, "AR .75": 0.89625, "AR (M)": 0.7953, "AR (L)": 0.89647}
+{"mode": "train", "epoch": 111, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04644, "heatmap_loss": 0.00054, "acc_pose": 0.82911, "loss": 0.00054, "grad_norm": 0.00145, "time": 0.36888}
+{"mode": "train", "epoch": 111, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00054, "acc_pose": 0.84072, "loss": 0.00054, "grad_norm": 0.00146, "time": 0.32182}
+{"mode": "train", "epoch": 111, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00055, "acc_pose": 0.8407, "loss": 0.00055, "grad_norm": 0.00167, "time": 0.32188}
+{"mode": "train", "epoch": 111, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00055, "acc_pose": 0.83206, "loss": 0.00055, "grad_norm": 0.00158, "time": 0.32166}
+{"mode": "train", "epoch": 111, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00055, "acc_pose": 0.82827, "loss": 0.00055, "grad_norm": 0.00155, "time": 0.32261}
+{"mode": "train", "epoch": 112, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04673, "heatmap_loss": 0.00054, "acc_pose": 0.84251, "loss": 0.00054, "grad_norm": 0.00162, "time": 0.374}
+{"mode": "train", "epoch": 112, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00055, "acc_pose": 0.83644, "loss": 0.00055, "grad_norm": 0.00154, "time": 0.32268}
+{"mode": "train", "epoch": 112, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00054, "acc_pose": 0.85086, "loss": 0.00054, "grad_norm": 0.00143, "time": 0.32322}
+{"mode": "train", "epoch": 112, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00055, "acc_pose": 0.84343, "loss": 0.00055, "grad_norm": 0.00163, "time": 0.32294}
+{"mode": "train", "epoch": 112, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00055, "acc_pose": 0.84368, "loss": 0.00055, "grad_norm": 0.00149, "time": 0.3241}
+{"mode": "train", "epoch": 113, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04682, "heatmap_loss": 0.00054, "acc_pose": 0.84573, "loss": 0.00054, "grad_norm": 0.00145, "time": 0.37316}
+{"mode": "train", "epoch": 113, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00055, "acc_pose": 0.84943, "loss": 0.00055, "grad_norm": 0.0015, "time": 0.32319}
+{"mode": "train", "epoch": 113, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00055, "acc_pose": 0.83476, "loss": 0.00055, "grad_norm": 0.00144, "time": 0.32209}
+{"mode": "train", "epoch": 113, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00056, "heatmap_loss": 0.00054, "acc_pose": 0.84924, "loss": 0.00054, "grad_norm": 0.00151, "time": 0.32277}
+{"mode": "train", "epoch": 113, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00054, "acc_pose": 0.84131, "loss": 0.00054, "grad_norm": 0.00153, "time": 0.32338}
+{"mode": "train", "epoch": 114, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04953, "heatmap_loss": 0.00055, "acc_pose": 0.83987, "loss": 0.00055, "grad_norm": 0.00155, "time": 0.37338}
+{"mode": "train", "epoch": 114, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.00054, "acc_pose": 0.84475, "loss": 0.00054, "grad_norm": 0.00136, "time": 0.32312}
+{"mode": "train", "epoch": 114, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00054, "acc_pose": 0.83363, "loss": 0.00054, "grad_norm": 0.00141, "time": 0.32353}
+{"mode": "train", "epoch": 114, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00054, "acc_pose": 0.84499, "loss": 0.00054, "grad_norm": 0.00149, "time": 0.32325}
+{"mode": "train", "epoch": 114, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00054, "acc_pose": 0.83971, "loss": 0.00054, "grad_norm": 0.00142, "time": 0.32303}
+{"mode": "train", "epoch": 115, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.0467, "heatmap_loss": 0.00055, "acc_pose": 0.83767, "loss": 0.00055, "grad_norm": 0.00196, "time": 0.37367}
+{"mode": "train", "epoch": 115, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00054, "acc_pose": 0.84253, "loss": 0.00054, "grad_norm": 0.00149, "time": 0.32327}
+{"mode": "train", "epoch": 115, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00054, "acc_pose": 0.83707, "loss": 0.00054, "grad_norm": 0.00147, "time": 0.32372}
+{"mode": "train", "epoch": 115, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00054, "acc_pose": 0.84355, "loss": 0.00054, "grad_norm": 0.00149, "time": 0.3225}
+{"mode": "train", "epoch": 115, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00055, "acc_pose": 0.82501, "loss": 0.00055, "grad_norm": 0.00142, "time": 0.32182}
+{"mode": "train", "epoch": 116, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04698, "heatmap_loss": 0.00055, "acc_pose": 0.84829, "loss": 0.00055, "grad_norm": 0.00164, "time": 0.37295}
+{"mode": "train", "epoch": 116, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00054, "acc_pose": 0.82977, "loss": 0.00054, "grad_norm": 0.00142, "time": 0.32459}
+{"mode": "train", "epoch": 116, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00054, "acc_pose": 0.83735, "loss": 0.00054, "grad_norm": 0.00134, "time": 0.32498}
+{"mode": "train", "epoch": 116, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00054, "acc_pose": 0.85713, "loss": 0.00054, "grad_norm": 0.0014, "time": 0.32484}
+{"mode": "train", "epoch": 116, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00054, "acc_pose": 0.84761, "loss": 0.00054, "grad_norm": 0.00136, "time": 0.32527}
+{"mode": "train", "epoch": 117, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04693, "heatmap_loss": 0.00054, "acc_pose": 0.82432, "loss": 0.00054, "grad_norm": 0.0014, "time": 0.37388}
+{"mode": "train", "epoch": 117, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00055, "acc_pose": 0.83854, "loss": 0.00055, "grad_norm": 0.00147, "time": 0.32426}
+{"mode": "train", "epoch": 117, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00054, "acc_pose": 0.84439, "loss": 0.00054, "grad_norm": 0.0014, "time": 0.3232}
+{"mode": "train", "epoch": 117, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00054, "acc_pose": 0.84993, "loss": 0.00054, "grad_norm": 0.0015, "time": 0.32248}
+{"mode": "train", "epoch": 117, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00054, "acc_pose": 0.83644, "loss": 0.00054, "grad_norm": 0.00149, "time": 0.32225}
+{"mode": "train", "epoch": 118, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04697, "heatmap_loss": 0.00054, "acc_pose": 0.84206, "loss": 0.00054, "grad_norm": 0.00156, "time": 0.37273}
+{"mode": "train", "epoch": 118, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00054, "acc_pose": 0.84147, "loss": 0.00054, "grad_norm": 0.00146, "time": 0.32342}
+{"mode": "train", "epoch": 118, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00053, "heatmap_loss": 0.00054, "acc_pose": 0.84558, "loss": 0.00054, "grad_norm": 0.00138, "time": 0.32496}
+{"mode": "train", "epoch": 118, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00055, "acc_pose": 0.82912, "loss": 0.00055, "grad_norm": 0.00149, "time": 0.32337}
+{"mode": "train", "epoch": 118, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00055, "acc_pose": 0.84626, "loss": 0.00055, "grad_norm": 0.00142, "time": 0.32292}
+{"mode": "train", "epoch": 119, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04688, "heatmap_loss": 0.00054, "acc_pose": 0.84743, "loss": 0.00054, "grad_norm": 0.00143, "time": 0.37416}
+{"mode": "train", "epoch": 119, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00054, "acc_pose": 0.83944, "loss": 0.00054, "grad_norm": 0.00147, "time": 0.32276}
+{"mode": "train", "epoch": 119, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00054, "acc_pose": 0.84383, "loss": 0.00054, "grad_norm": 0.00159, "time": 0.32298}
+{"mode": "train", "epoch": 119, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00054, "acc_pose": 0.84903, "loss": 0.00054, "grad_norm": 0.00149, "time": 0.32209}
+{"mode": "train", "epoch": 119, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00054, "acc_pose": 0.84025, "loss": 0.00054, "grad_norm": 0.0016, "time": 0.32471}
+{"mode": "train", "epoch": 120, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04668, "heatmap_loss": 0.00054, "acc_pose": 0.84816, "loss": 0.00054, "grad_norm": 0.00138, "time": 0.37537}
+{"mode": "train", "epoch": 120, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00053, "acc_pose": 0.84777, "loss": 0.00053, "grad_norm": 0.00145, "time": 0.3228}
+{"mode": "train", "epoch": 120, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00054, "acc_pose": 0.8423, "loss": 0.00054, "grad_norm": 0.0014, "time": 0.32323}
+{"mode": "train", "epoch": 120, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00055, "acc_pose": 0.83179, "loss": 0.00055, "grad_norm": 0.00142, "time": 0.32332}
+{"mode": "train", "epoch": 120, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00054, "acc_pose": 0.84624, "loss": 0.00054, "grad_norm": 0.00147, "time": 0.32333}
+{"mode": "val", "epoch": 120, "iter": 204, "lr": 0.0, "AP": 0.78706, "AP .5": 0.91593, "AP .75": 0.85463, "AP (M)": 0.71543, "AP (L)": 0.81557, "AR": 0.83764, "AR .5": 0.95403, "AR .75": 0.89657, "AR (M)": 0.79798, "AR (L)": 0.8968}
+{"mode": "train", "epoch": 121, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04817, "heatmap_loss": 0.00054, "acc_pose": 0.83374, "loss": 0.00054, "grad_norm": 0.00149, "time": 0.37107}
+{"mode": "train", "epoch": 121, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00054, "acc_pose": 0.85857, "loss": 0.00054, "grad_norm": 0.00147, "time": 0.3242}
+{"mode": "train", "epoch": 121, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00054, "acc_pose": 0.84313, "loss": 0.00054, "grad_norm": 0.00152, "time": 0.32244}
+{"mode": "train", "epoch": 121, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00054, "acc_pose": 0.83581, "loss": 0.00054, "grad_norm": 0.00153, "time": 0.32481}
+{"mode": "train", "epoch": 121, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00054, "acc_pose": 0.84806, "loss": 0.00054, "grad_norm": 0.0015, "time": 0.32497}
+{"mode": "train", "epoch": 122, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04997, "heatmap_loss": 0.00054, "acc_pose": 0.83863, "loss": 0.00054, "grad_norm": 0.00153, "time": 0.37481}
+{"mode": "train", "epoch": 122, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00054, "acc_pose": 0.84265, "loss": 0.00054, "grad_norm": 0.00136, "time": 0.32485}
+{"mode": "train", "epoch": 122, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00054, "acc_pose": 0.84507, "loss": 0.00054, "grad_norm": 0.00156, "time": 0.32394}
+{"mode": "train", "epoch": 122, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00054, "acc_pose": 0.83637, "loss": 0.00054, "grad_norm": 0.0014, "time": 0.32511}
+{"mode": "train", "epoch": 122, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00054, "acc_pose": 0.82739, "loss": 0.00054, "grad_norm": 0.00151, "time": 0.32509}
+{"mode": "train", "epoch": 123, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04683, "heatmap_loss": 0.00054, "acc_pose": 0.83431, "loss": 0.00054, "grad_norm": 0.00151, "time": 0.37499}
+{"mode": "train", "epoch": 123, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00054, "acc_pose": 0.83991, "loss": 0.00054, "grad_norm": 0.00142, "time": 0.32408}
+{"mode": "train", "epoch": 123, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00054, "acc_pose": 0.84679, "loss": 0.00054, "grad_norm": 0.00139, "time": 0.32283}
+{"mode": "train", "epoch": 123, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00054, "acc_pose": 0.84322, "loss": 0.00054, "grad_norm": 0.00144, "time": 0.3243}
+{"mode": "train", "epoch": 123, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00053, "acc_pose": 0.84929, "loss": 0.00053, "grad_norm": 0.00151, "time": 0.32328}
+{"mode": "train", "epoch": 124, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04691, "heatmap_loss": 0.00054, "acc_pose": 0.8455, "loss": 0.00054, "grad_norm": 0.00142, "time": 0.37194}
+{"mode": "train", "epoch": 124, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00054, "acc_pose": 0.85055, "loss": 0.00054, "grad_norm": 0.00155, "time": 0.32324}
+{"mode": "train", "epoch": 124, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00054, "acc_pose": 0.83033, "loss": 0.00054, "grad_norm": 0.00165, "time": 0.32368}
+{"mode": "train", "epoch": 124, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00059, "heatmap_loss": 0.00054, "acc_pose": 0.84022, "loss": 0.00054, "grad_norm": 0.00148, "time": 0.32213}
+{"mode": "train", "epoch": 124, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00054, "acc_pose": 0.85678, "loss": 0.00054, "grad_norm": 0.00145, "time": 0.32283}
+{"mode": "train", "epoch": 125, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04669, "heatmap_loss": 0.00054, "acc_pose": 0.8416, "loss": 0.00054, "grad_norm": 0.00147, "time": 0.37652}
+{"mode": "train", "epoch": 125, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.00054, "acc_pose": 0.83447, "loss": 0.00054, "grad_norm": 0.00142, "time": 0.32439}
+{"mode": "train", "epoch": 125, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00053, "acc_pose": 0.847, "loss": 0.00053, "grad_norm": 0.00132, "time": 0.32455}
+{"mode": "train", "epoch": 125, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00054, "acc_pose": 0.84383, "loss": 0.00054, "grad_norm": 0.00142, "time": 0.32404}
+{"mode": "train", "epoch": 125, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00054, "acc_pose": 0.83526, "loss": 0.00054, "grad_norm": 0.0014, "time": 0.32371}
+{"mode": "train", "epoch": 126, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04689, "heatmap_loss": 0.00054, "acc_pose": 0.83938, "loss": 0.00054, "grad_norm": 0.00151, "time": 0.37445}
+{"mode": "train", "epoch": 126, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00054, "acc_pose": 0.84382, "loss": 0.00054, "grad_norm": 0.00152, "time": 0.32262}
+{"mode": "train", "epoch": 126, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00054, "acc_pose": 0.8484, "loss": 0.00054, "grad_norm": 0.00142, "time": 0.32259}
+{"mode": "train", "epoch": 126, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00054, "acc_pose": 0.84793, "loss": 0.00054, "grad_norm": 0.0014, "time": 0.32263}
+{"mode": "train", "epoch": 126, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00054, "acc_pose": 0.84912, "loss": 0.00054, "grad_norm": 0.00135, "time": 0.32244}
+{"mode": "train", "epoch": 127, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04667, "heatmap_loss": 0.00053, "acc_pose": 0.84154, "loss": 0.00053, "grad_norm": 0.00139, "time": 0.37556}
+{"mode": "train", "epoch": 127, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00054, "acc_pose": 0.83471, "loss": 0.00054, "grad_norm": 0.00144, "time": 0.32383}
+{"mode": "train", "epoch": 127, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00053, "acc_pose": 0.84061, "loss": 0.00053, "grad_norm": 0.00137, "time": 0.32467}
+{"mode": "train", "epoch": 127, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00054, "acc_pose": 0.84952, "loss": 0.00054, "grad_norm": 0.00144, "time": 0.32376}
+{"mode": "train", "epoch": 127, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00054, "acc_pose": 0.83731, "loss": 0.00054, "grad_norm": 0.00162, "time": 0.32447}
+{"mode": "train", "epoch": 128, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04707, "heatmap_loss": 0.00053, "acc_pose": 0.84829, "loss": 0.00053, "grad_norm": 0.00138, "time": 0.37635}
+{"mode": "train", "epoch": 128, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00053, "acc_pose": 0.84218, "loss": 0.00053, "grad_norm": 0.00138, "time": 0.32391}
+{"mode": "train", "epoch": 128, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00054, "acc_pose": 0.8433, "loss": 0.00054, "grad_norm": 0.00142, "time": 0.32507}
+{"mode": "train", "epoch": 128, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00054, "acc_pose": 0.84648, "loss": 0.00054, "grad_norm": 0.00143, "time": 0.32347}
+{"mode": "train", "epoch": 128, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00054, "acc_pose": 0.8401, "loss": 0.00054, "grad_norm": 0.00144, "time": 0.32287}
+{"mode": "train", "epoch": 129, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04698, "heatmap_loss": 0.00054, "acc_pose": 0.83464, "loss": 0.00054, "grad_norm": 0.00144, "time": 0.37396}
+{"mode": "train", "epoch": 129, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00045, "heatmap_loss": 0.00053, "acc_pose": 0.84045, "loss": 0.00053, "grad_norm": 0.00138, "time": 0.32259}
+{"mode": "train", "epoch": 129, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00053, "acc_pose": 0.8342, "loss": 0.00053, "grad_norm": 0.00139, "time": 0.324}
+{"mode": "train", "epoch": 129, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00053, "acc_pose": 0.83954, "loss": 0.00053, "grad_norm": 0.00135, "time": 0.32246}
+{"mode": "train", "epoch": 129, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00054, "acc_pose": 0.83573, "loss": 0.00054, "grad_norm": 0.00148, "time": 0.32293}
+{"mode": "train", "epoch": 130, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04697, "heatmap_loss": 0.00053, "acc_pose": 0.8509, "loss": 0.00053, "grad_norm": 0.00134, "time": 0.37622}
+{"mode": "train", "epoch": 130, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.00054, "acc_pose": 0.83549, "loss": 0.00054, "grad_norm": 0.00142, "time": 0.3243}
+{"mode": "train", "epoch": 130, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.00053, "acc_pose": 0.83871, "loss": 0.00053, "grad_norm": 0.00143, "time": 0.32478}
+{"mode": "train", "epoch": 130, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.00053, "acc_pose": 0.8426, "loss": 0.00053, "grad_norm": 0.00157, "time": 0.32464}
+{"mode": "train", "epoch": 130, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.00053, "acc_pose": 0.83628, "loss": 0.00053, "grad_norm": 0.00133, "time": 0.32392}
+{"mode": "val", "epoch": 130, "iter": 204, "lr": 0.0, "AP": 0.78806, "AP .5": 0.91484, "AP .75": 0.85457, "AP (M)": 0.71582, "AP (L)": 0.81705, "AR": 0.83838, "AR .5": 0.95198, "AR .75": 0.89798, "AR (M)": 0.79743, "AR (L)": 0.89881}
+{"mode": "train", "epoch": 131, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04818, "heatmap_loss": 0.00053, "acc_pose": 0.85731, "loss": 0.00053, "grad_norm": 0.0016, "time": 0.37229}
+{"mode": "train", "epoch": 131, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00054, "acc_pose": 0.85021, "loss": 0.00054, "grad_norm": 0.00144, "time": 0.32173}
+{"mode": "train", "epoch": 131, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00054, "acc_pose": 0.84052, "loss": 0.00054, "grad_norm": 0.00141, "time": 0.32349}
+{"mode": "train", "epoch": 131, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00053, "acc_pose": 0.83505, "loss": 0.00053, "grad_norm": 0.0014, "time": 0.32492}
+{"mode": "train", "epoch": 131, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00054, "acc_pose": 0.84913, "loss": 0.00054, "grad_norm": 0.00137, "time": 0.32288}
+{"mode": "train", "epoch": 132, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04672, "heatmap_loss": 0.00053, "acc_pose": 0.852, "loss": 0.00053, "grad_norm": 0.00146, "time": 0.37209}
+{"mode": "train", "epoch": 132, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00054, "acc_pose": 0.83966, "loss": 0.00054, "grad_norm": 0.00138, "time": 0.32345}
+{"mode": "train", "epoch": 132, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00053, "acc_pose": 0.84438, "loss": 0.00053, "grad_norm": 0.00139, "time": 0.32295}
+{"mode": "train", "epoch": 132, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00053, "acc_pose": 0.84021, "loss": 0.00053, "grad_norm": 0.00134, "time": 0.32297}
+{"mode": "train", "epoch": 132, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00053, "acc_pose": 0.85464, "loss": 0.00053, "grad_norm": 0.00154, "time": 0.32336}
+{"mode": "train", "epoch": 133, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04675, "heatmap_loss": 0.00053, "acc_pose": 0.83308, "loss": 0.00053, "grad_norm": 0.00127, "time": 0.3738}
+{"mode": "train", "epoch": 133, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00053, "acc_pose": 0.85895, "loss": 0.00053, "grad_norm": 0.00136, "time": 0.32255}
+{"mode": "train", "epoch": 133, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00053, "acc_pose": 0.84569, "loss": 0.00053, "grad_norm": 0.00136, "time": 0.32348}
+{"mode": "train", "epoch": 133, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00053, "acc_pose": 0.84147, "loss": 0.00053, "grad_norm": 0.00151, "time": 0.32368}
+{"mode": "train", "epoch": 133, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00054, "acc_pose": 0.84349, "loss": 0.00054, "grad_norm": 0.00146, "time": 0.324}
+{"mode": "train", "epoch": 134, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.047, "heatmap_loss": 0.00053, "acc_pose": 0.83679, "loss": 0.00053, "grad_norm": 0.00133, "time": 0.37462}
+{"mode": "train", "epoch": 134, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00053, "acc_pose": 0.84828, "loss": 0.00053, "grad_norm": 0.00132, "time": 0.32209}
+{"mode": "train", "epoch": 134, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00053, "acc_pose": 0.84391, "loss": 0.00053, "grad_norm": 0.00146, "time": 0.32377}
+{"mode": "train", "epoch": 134, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00053, "acc_pose": 0.84398, "loss": 0.00053, "grad_norm": 0.00155, "time": 0.32317}
+{"mode": "train", "epoch": 134, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00054, "acc_pose": 0.84059, "loss": 0.00054, "grad_norm": 0.00132, "time": 0.32347}
+{"mode": "train", "epoch": 135, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04696, "heatmap_loss": 0.00053, "acc_pose": 0.85619, "loss": 0.00053, "grad_norm": 0.00136, "time": 0.37517}
+{"mode": "train", "epoch": 135, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00053, "acc_pose": 0.83608, "loss": 0.00053, "grad_norm": 0.00136, "time": 0.32318}
+{"mode": "train", "epoch": 135, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00053, "acc_pose": 0.83932, "loss": 0.00053, "grad_norm": 0.00136, "time": 0.32299}
+{"mode": "train", "epoch": 135, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00053, "acc_pose": 0.84019, "loss": 0.00053, "grad_norm": 0.00136, "time": 0.32215}
+{"mode": "train", "epoch": 135, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00053, "acc_pose": 0.85492, "loss": 0.00053, "grad_norm": 0.00135, "time": 0.32419}
+{"mode": "train", "epoch": 136, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04665, "heatmap_loss": 0.00054, "acc_pose": 0.84504, "loss": 0.00054, "grad_norm": 0.00148, "time": 0.37747}
+{"mode": "train", "epoch": 136, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00045, "heatmap_loss": 0.00053, "acc_pose": 0.84123, "loss": 0.00053, "grad_norm": 0.00148, "time": 0.3262}
+{"mode": "train", "epoch": 136, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00053, "acc_pose": 0.84325, "loss": 0.00053, "grad_norm": 0.00133, "time": 0.32576}
+{"mode": "train", "epoch": 136, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00053, "acc_pose": 0.85067, "loss": 0.00053, "grad_norm": 0.00139, "time": 0.32426}
+{"mode": "train", "epoch": 136, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00053, "acc_pose": 0.83843, "loss": 0.00053, "grad_norm": 0.0014, "time": 0.32448}
+{"mode": "train", "epoch": 137, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04748, "heatmap_loss": 0.00053, "acc_pose": 0.82879, "loss": 0.00053, "grad_norm": 0.00144, "time": 0.37676}
+{"mode": "train", "epoch": 137, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.0006, "heatmap_loss": 0.00053, "acc_pose": 0.85159, "loss": 0.00053, "grad_norm": 0.00135, "time": 0.32547}
+{"mode": "train", "epoch": 137, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.00053, "acc_pose": 0.85017, "loss": 0.00053, "grad_norm": 0.00141, "time": 0.32564}
+{"mode": "train", "epoch": 137, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00052, "heatmap_loss": 0.00053, "acc_pose": 0.8524, "loss": 0.00053, "grad_norm": 0.00136, "time": 0.3252}
+{"mode": "train", "epoch": 137, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00053, "acc_pose": 0.84219, "loss": 0.00053, "grad_norm": 0.00132, "time": 0.32605}
+{"mode": "train", "epoch": 138, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04889, "heatmap_loss": 0.00053, "acc_pose": 0.84944, "loss": 0.00053, "grad_norm": 0.00147, "time": 0.37555}
+{"mode": "train", "epoch": 138, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00055, "heatmap_loss": 0.00053, "acc_pose": 0.84248, "loss": 0.00053, "grad_norm": 0.00131, "time": 0.32481}
+{"mode": "train", "epoch": 138, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00053, "acc_pose": 0.8435, "loss": 0.00053, "grad_norm": 0.00137, "time": 0.32336}
+{"mode": "train", "epoch": 138, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00053, "acc_pose": 0.8487, "loss": 0.00053, "grad_norm": 0.00138, "time": 0.32433}
+{"mode": "train", "epoch": 138, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00053, "acc_pose": 0.85314, "loss": 0.00053, "grad_norm": 0.00145, "time": 0.32556}
+{"mode": "train", "epoch": 139, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04677, "heatmap_loss": 0.00053, "acc_pose": 0.83572, "loss": 0.00053, "grad_norm": 0.00146, "time": 0.37606}
+{"mode": "train", "epoch": 139, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00053, "acc_pose": 0.84608, "loss": 0.00053, "grad_norm": 0.00137, "time": 0.32358}
+{"mode": "train", "epoch": 139, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00045, "heatmap_loss": 0.00053, "acc_pose": 0.85297, "loss": 0.00053, "grad_norm": 0.00145, "time": 0.32417}
+{"mode": "train", "epoch": 139, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00053, "acc_pose": 0.83869, "loss": 0.00053, "grad_norm": 0.00149, "time": 0.32322}
+{"mode": "train", "epoch": 139, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00053, "acc_pose": 0.83774, "loss": 0.00053, "grad_norm": 0.0013, "time": 0.32534}
+{"mode": "train", "epoch": 140, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04686, "heatmap_loss": 0.00053, "acc_pose": 0.85942, "loss": 0.00053, "grad_norm": 0.00132, "time": 0.37683}
+{"mode": "train", "epoch": 140, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00053, "acc_pose": 0.84563, "loss": 0.00053, "grad_norm": 0.00147, "time": 0.32467}
+{"mode": "train", "epoch": 140, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00053, "acc_pose": 0.85034, "loss": 0.00053, "grad_norm": 0.00133, "time": 0.32392}
+{"mode": "train", "epoch": 140, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00053, "acc_pose": 0.84773, "loss": 0.00053, "grad_norm": 0.00136, "time": 0.32374}
+{"mode": "train", "epoch": 140, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00053, "acc_pose": 0.85061, "loss": 0.00053, "grad_norm": 0.00134, "time": 0.32383}
+{"mode": "val", "epoch": 140, "iter": 204, "lr": 0.0, "AP": 0.7877, "AP .5": 0.91544, "AP .75": 0.85469, "AP (M)": 0.71485, "AP (L)": 0.81659, "AR": 0.8384, "AR .5": 0.95324, "AR .75": 0.89814, "AR (M)": 0.79784, "AR (L)": 0.89788}
+{"mode": "train", "epoch": 141, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04666, "heatmap_loss": 0.00053, "acc_pose": 0.8377, "loss": 0.00053, "grad_norm": 0.00144, "time": 0.37098}
+{"mode": "train", "epoch": 141, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00053, "acc_pose": 0.84193, "loss": 0.00053, "grad_norm": 0.0013, "time": 0.32421}
+{"mode": "train", "epoch": 141, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00053, "acc_pose": 0.83676, "loss": 0.00053, "grad_norm": 0.00133, "time": 0.32537}
+{"mode": "train", "epoch": 141, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00053, "acc_pose": 0.85091, "loss": 0.00053, "grad_norm": 0.00139, "time": 0.32505}
+{"mode": "train", "epoch": 141, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00052, "heatmap_loss": 0.00053, "acc_pose": 0.84813, "loss": 0.00053, "grad_norm": 0.00142, "time": 0.32522}
+{"mode": "train", "epoch": 142, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04691, "heatmap_loss": 0.00053, "acc_pose": 0.84799, "loss": 0.00053, "grad_norm": 0.00139, "time": 0.37564}
+{"mode": "train", "epoch": 142, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00045, "heatmap_loss": 0.00053, "acc_pose": 0.84164, "loss": 0.00053, "grad_norm": 0.00132, "time": 0.32414}
+{"mode": "train", "epoch": 142, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00053, "acc_pose": 0.84599, "loss": 0.00053, "grad_norm": 0.00134, "time": 0.32534}
+{"mode": "train", "epoch": 142, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00053, "acc_pose": 0.83866, "loss": 0.00053, "grad_norm": 0.00144, "time": 0.32417}
+{"mode": "train", "epoch": 142, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00052, "acc_pose": 0.84532, "loss": 0.00052, "grad_norm": 0.00125, "time": 0.32186}
+{"mode": "train", "epoch": 143, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04712, "heatmap_loss": 0.00052, "acc_pose": 0.85715, "loss": 0.00052, "grad_norm": 0.00134, "time": 0.37421}
+{"mode": "train", "epoch": 143, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00053, "acc_pose": 0.83543, "loss": 0.00053, "grad_norm": 0.00135, "time": 0.32325}
+{"mode": "train", "epoch": 143, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00053, "acc_pose": 0.85129, "loss": 0.00053, "grad_norm": 0.00138, "time": 0.32331}
+{"mode": "train", "epoch": 143, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00053, "acc_pose": 0.85214, "loss": 0.00053, "grad_norm": 0.00124, "time": 0.32373}
+{"mode": "train", "epoch": 143, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.85005, "loss": 0.00052, "grad_norm": 0.00139, "time": 0.3224}
+{"mode": "train", "epoch": 144, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04673, "heatmap_loss": 0.00053, "acc_pose": 0.84036, "loss": 0.00053, "grad_norm": 0.00138, "time": 0.37458}
+{"mode": "train", "epoch": 144, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00055, "heatmap_loss": 0.00053, "acc_pose": 0.8517, "loss": 0.00053, "grad_norm": 0.00131, "time": 0.32376}
+{"mode": "train", "epoch": 144, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00053, "acc_pose": 0.84748, "loss": 0.00053, "grad_norm": 0.0013, "time": 0.32304}
+{"mode": "train", "epoch": 144, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00053, "acc_pose": 0.83601, "loss": 0.00053, "grad_norm": 0.00129, "time": 0.32382}
+{"mode": "train", "epoch": 144, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00053, "acc_pose": 0.8511, "loss": 0.00053, "grad_norm": 0.00138, "time": 0.3231}
+{"mode": "train", "epoch": 145, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04696, "heatmap_loss": 0.00053, "acc_pose": 0.8585, "loss": 0.00053, "grad_norm": 0.00143, "time": 0.37606}
+{"mode": "train", "epoch": 145, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.86452, "loss": 0.00052, "grad_norm": 0.0013, "time": 0.32404}
+{"mode": "train", "epoch": 145, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00053, "acc_pose": 0.83956, "loss": 0.00053, "grad_norm": 0.00141, "time": 0.32222}
+{"mode": "train", "epoch": 145, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00053, "acc_pose": 0.84948, "loss": 0.00053, "grad_norm": 0.00126, "time": 0.32289}
+{"mode": "train", "epoch": 145, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00053, "acc_pose": 0.84417, "loss": 0.00053, "grad_norm": 0.00134, "time": 0.32272}
+{"mode": "train", "epoch": 146, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04665, "heatmap_loss": 0.00052, "acc_pose": 0.85805, "loss": 0.00052, "grad_norm": 0.00132, "time": 0.37511}
+{"mode": "train", "epoch": 146, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.8488, "loss": 0.00052, "grad_norm": 0.00138, "time": 0.32419}
+{"mode": "train", "epoch": 146, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00053, "acc_pose": 0.83771, "loss": 0.00053, "grad_norm": 0.00132, "time": 0.32347}
+{"mode": "train", "epoch": 146, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00052, "acc_pose": 0.85286, "loss": 0.00052, "grad_norm": 0.00133, "time": 0.32284}
+{"mode": "train", "epoch": 146, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00052, "heatmap_loss": 0.00053, "acc_pose": 0.84219, "loss": 0.00053, "grad_norm": 0.00133, "time": 0.32474}
+{"mode": "train", "epoch": 147, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04676, "heatmap_loss": 0.00053, "acc_pose": 0.84297, "loss": 0.00053, "grad_norm": 0.00143, "time": 0.37374}
+{"mode": "train", "epoch": 147, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.8551, "loss": 0.00052, "grad_norm": 0.00128, "time": 0.32321}
+{"mode": "train", "epoch": 147, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00053, "acc_pose": 0.8489, "loss": 0.00053, "grad_norm": 0.00148, "time": 0.32506}
+{"mode": "train", "epoch": 147, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00053, "acc_pose": 0.84306, "loss": 0.00053, "grad_norm": 0.00138, "time": 0.32433}
+{"mode": "train", "epoch": 147, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.8586, "loss": 0.00052, "grad_norm": 0.00138, "time": 0.32332}
+{"mode": "train", "epoch": 148, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.0472, "heatmap_loss": 0.00052, "acc_pose": 0.8469, "loss": 0.00052, "grad_norm": 0.00141, "time": 0.37663}
+{"mode": "train", "epoch": 148, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.00053, "acc_pose": 0.84872, "loss": 0.00053, "grad_norm": 0.00129, "time": 0.32357}
+{"mode": "train", "epoch": 148, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00052, "acc_pose": 0.84538, "loss": 0.00052, "grad_norm": 0.00125, "time": 0.32257}
+{"mode": "train", "epoch": 148, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00053, "acc_pose": 0.82596, "loss": 0.00053, "grad_norm": 0.0014, "time": 0.32258}
+{"mode": "train", "epoch": 148, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.00052, "acc_pose": 0.84147, "loss": 0.00052, "grad_norm": 0.0013, "time": 0.32402}
+{"mode": "train", "epoch": 149, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04677, "heatmap_loss": 0.00053, "acc_pose": 0.84923, "loss": 0.00053, "grad_norm": 0.00134, "time": 0.37322}
+{"mode": "train", "epoch": 149, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.84248, "loss": 0.00052, "grad_norm": 0.00141, "time": 0.3228}
+{"mode": "train", "epoch": 149, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00052, "acc_pose": 0.85336, "loss": 0.00052, "grad_norm": 0.00139, "time": 0.32383}
+{"mode": "train", "epoch": 149, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.00053, "acc_pose": 0.83902, "loss": 0.00053, "grad_norm": 0.00144, "time": 0.32488}
+{"mode": "train", "epoch": 149, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.00052, "acc_pose": 0.85668, "loss": 0.00052, "grad_norm": 0.0014, "time": 0.32432}
+{"mode": "train", "epoch": 150, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.0467, "heatmap_loss": 0.00052, "acc_pose": 0.85003, "loss": 0.00052, "grad_norm": 0.00143, "time": 0.37445}
+{"mode": "train", "epoch": 150, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00045, "heatmap_loss": 0.00052, "acc_pose": 0.85067, "loss": 0.00052, "grad_norm": 0.00132, "time": 0.32363}
+{"mode": "train", "epoch": 150, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00052, "acc_pose": 0.85412, "loss": 0.00052, "grad_norm": 0.00135, "time": 0.32303}
+{"mode": "train", "epoch": 150, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00052, "acc_pose": 0.83574, "loss": 0.00052, "grad_norm": 0.00139, "time": 0.32235}
+{"mode": "train", "epoch": 150, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00053, "acc_pose": 0.85379, "loss": 0.00053, "grad_norm": 0.00129, "time": 0.32244}
+{"mode": "val", "epoch": 150, "iter": 204, "lr": 0.0, "AP": 0.78925, "AP .5": 0.91713, "AP .75": 0.85579, "AP (M)": 0.71799, "AP (L)": 0.81716, "AR": 0.84005, "AR .5": 0.95497, "AR .75": 0.89893, "AR (M)": 0.79959, "AR (L)": 0.89955}
+{"mode": "train", "epoch": 151, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04631, "heatmap_loss": 0.00052, "acc_pose": 0.83867, "loss": 0.00052, "grad_norm": 0.00128, "time": 0.36983}
+{"mode": "train", "epoch": 151, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.85009, "loss": 0.00052, "grad_norm": 0.00127, "time": 0.32287}
+{"mode": "train", "epoch": 151, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.84811, "loss": 0.00052, "grad_norm": 0.00143, "time": 0.32362}
+{"mode": "train", "epoch": 151, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00053, "acc_pose": 0.82644, "loss": 0.00053, "grad_norm": 0.00136, "time": 0.32436}
+{"mode": "train", "epoch": 151, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00053, "acc_pose": 0.85167, "loss": 0.00053, "grad_norm": 0.00132, "time": 0.32395}
+{"mode": "train", "epoch": 152, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04661, "heatmap_loss": 0.00052, "acc_pose": 0.84907, "loss": 0.00052, "grad_norm": 0.00128, "time": 0.377}
+{"mode": "train", "epoch": 152, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00045, "heatmap_loss": 0.00053, "acc_pose": 0.8465, "loss": 0.00053, "grad_norm": 0.00133, "time": 0.32343}
+{"mode": "train", "epoch": 152, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00045, "heatmap_loss": 0.00052, "acc_pose": 0.84971, "loss": 0.00052, "grad_norm": 0.0013, "time": 0.32379}
+{"mode": "train", "epoch": 152, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00053, "acc_pose": 0.85493, "loss": 0.00053, "grad_norm": 0.00132, "time": 0.32236}
+{"mode": "train", "epoch": 152, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.84986, "loss": 0.00052, "grad_norm": 0.00131, "time": 0.32266}
+{"mode": "train", "epoch": 153, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.0467, "heatmap_loss": 0.00052, "acc_pose": 0.85877, "loss": 0.00052, "grad_norm": 0.00128, "time": 0.3751}
+{"mode": "train", "epoch": 153, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00052, "acc_pose": 0.85377, "loss": 0.00052, "grad_norm": 0.00126, "time": 0.32333}
+{"mode": "train", "epoch": 153, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00052, "acc_pose": 0.85281, "loss": 0.00052, "grad_norm": 0.00131, "time": 0.32404}
+{"mode": "train", "epoch": 153, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00053, "acc_pose": 0.83992, "loss": 0.00053, "grad_norm": 0.00131, "time": 0.32382}
+{"mode": "train", "epoch": 153, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.86184, "loss": 0.00052, "grad_norm": 0.00131, "time": 0.32413}
+{"mode": "train", "epoch": 154, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.0467, "heatmap_loss": 0.00053, "acc_pose": 0.84864, "loss": 0.00053, "grad_norm": 0.00143, "time": 0.37633}
+{"mode": "train", "epoch": 154, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00052, "acc_pose": 0.85049, "loss": 0.00052, "grad_norm": 0.00144, "time": 0.32615}
+{"mode": "train", "epoch": 154, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00052, "acc_pose": 0.85065, "loss": 0.00052, "grad_norm": 0.0013, "time": 0.32745}
+{"mode": "train", "epoch": 154, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00052, "acc_pose": 0.84132, "loss": 0.00052, "grad_norm": 0.00133, "time": 0.32536}
+{"mode": "train", "epoch": 154, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.85079, "loss": 0.00052, "grad_norm": 0.00127, "time": 0.32496}
+{"mode": "train", "epoch": 155, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04671, "heatmap_loss": 0.00052, "acc_pose": 0.8402, "loss": 0.00052, "grad_norm": 0.00129, "time": 0.37488}
+{"mode": "train", "epoch": 155, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.85192, "loss": 0.00052, "grad_norm": 0.00132, "time": 0.32236}
+{"mode": "train", "epoch": 155, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.85848, "loss": 0.00052, "grad_norm": 0.00139, "time": 0.32211}
+{"mode": "train", "epoch": 155, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00052, "acc_pose": 0.84776, "loss": 0.00052, "grad_norm": 0.00131, "time": 0.32271}
+{"mode": "train", "epoch": 155, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.84585, "loss": 0.00052, "grad_norm": 0.00129, "time": 0.32169}
+{"mode": "train", "epoch": 156, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.0468, "heatmap_loss": 0.00052, "acc_pose": 0.8407, "loss": 0.00052, "grad_norm": 0.00132, "time": 0.37327}
+{"mode": "train", "epoch": 156, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.0006, "heatmap_loss": 0.00052, "acc_pose": 0.85095, "loss": 0.00052, "grad_norm": 0.00123, "time": 0.32542}
+{"mode": "train", "epoch": 156, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00052, "acc_pose": 0.84246, "loss": 0.00052, "grad_norm": 0.00137, "time": 0.3242}
+{"mode": "train", "epoch": 156, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00052, "acc_pose": 0.85356, "loss": 0.00052, "grad_norm": 0.00124, "time": 0.3255}
+{"mode": "train", "epoch": 156, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.84789, "loss": 0.00052, "grad_norm": 0.0013, "time": 0.32456}
+{"mode": "train", "epoch": 157, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04674, "heatmap_loss": 0.00052, "acc_pose": 0.85741, "loss": 0.00052, "grad_norm": 0.00146, "time": 0.37483}
+{"mode": "train", "epoch": 157, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.8602, "loss": 0.00052, "grad_norm": 0.00131, "time": 0.32423}
+{"mode": "train", "epoch": 157, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00052, "acc_pose": 0.85002, "loss": 0.00052, "grad_norm": 0.00129, "time": 0.32361}
+{"mode": "train", "epoch": 157, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00052, "acc_pose": 0.84893, "loss": 0.00052, "grad_norm": 0.00128, "time": 0.32325}
+{"mode": "train", "epoch": 157, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.00052, "acc_pose": 0.83053, "loss": 0.00052, "grad_norm": 0.00127, "time": 0.32525}
+{"mode": "train", "epoch": 158, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04682, "heatmap_loss": 0.00052, "acc_pose": 0.83324, "loss": 0.00052, "grad_norm": 0.00131, "time": 0.37495}
+{"mode": "train", "epoch": 158, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00052, "acc_pose": 0.84695, "loss": 0.00052, "grad_norm": 0.00136, "time": 0.32349}
+{"mode": "train", "epoch": 158, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00052, "acc_pose": 0.83715, "loss": 0.00052, "grad_norm": 0.00127, "time": 0.32241}
+{"mode": "train", "epoch": 158, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00052, "acc_pose": 0.84974, "loss": 0.00052, "grad_norm": 0.00126, "time": 0.32144}
+{"mode": "train", "epoch": 158, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.84928, "loss": 0.00052, "grad_norm": 0.0013, "time": 0.32288}
+{"mode": "train", "epoch": 159, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04689, "heatmap_loss": 0.00052, "acc_pose": 0.85114, "loss": 0.00052, "grad_norm": 0.00134, "time": 0.37471}
+{"mode": "train", "epoch": 159, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.84625, "loss": 0.00052, "grad_norm": 0.00127, "time": 0.32554}
+{"mode": "train", "epoch": 159, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00053, "heatmap_loss": 0.00052, "acc_pose": 0.85489, "loss": 0.00052, "grad_norm": 0.00124, "time": 0.32537}
+{"mode": "train", "epoch": 159, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.00052, "acc_pose": 0.84569, "loss": 0.00052, "grad_norm": 0.00128, "time": 0.32466}
+{"mode": "train", "epoch": 159, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.8434, "loss": 0.00052, "grad_norm": 0.00129, "time": 0.32377}
+{"mode": "train", "epoch": 160, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04692, "heatmap_loss": 0.00053, "acc_pose": 0.84779, "loss": 0.00053, "grad_norm": 0.00124, "time": 0.37273}
+{"mode": "train", "epoch": 160, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00052, "acc_pose": 0.85846, "loss": 0.00052, "grad_norm": 0.00128, "time": 0.32355}
+{"mode": "train", "epoch": 160, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00052, "acc_pose": 0.85471, "loss": 0.00052, "grad_norm": 0.00139, "time": 0.32483}
+{"mode": "train", "epoch": 160, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00051, "acc_pose": 0.84363, "loss": 0.00051, "grad_norm": 0.00121, "time": 0.32458}
+{"mode": "train", "epoch": 160, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.83996, "loss": 0.00052, "grad_norm": 0.0013, "time": 0.32469}
+{"mode": "val", "epoch": 160, "iter": 204, "lr": 0.0, "AP": 0.78764, "AP .5": 0.91492, "AP .75": 0.85561, "AP (M)": 0.71576, "AP (L)": 0.81589, "AR": 0.83866, "AR .5": 0.95293, "AR .75": 0.89861, "AR (M)": 0.7985, "AR (L)": 0.89807}
+{"mode": "train", "epoch": 161, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04661, "heatmap_loss": 0.00052, "acc_pose": 0.85927, "loss": 0.00052, "grad_norm": 0.00137, "time": 0.36831}
+{"mode": "train", "epoch": 161, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.85145, "loss": 0.00052, "grad_norm": 0.00124, "time": 0.32129}
+{"mode": "train", "epoch": 161, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.85768, "loss": 0.00052, "grad_norm": 0.00125, "time": 0.32301}
+{"mode": "train", "epoch": 161, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00052, "acc_pose": 0.85227, "loss": 0.00052, "grad_norm": 0.00133, "time": 0.32297}
+{"mode": "train", "epoch": 161, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.00052, "acc_pose": 0.8391, "loss": 0.00052, "grad_norm": 0.00134, "time": 0.32197}
+{"mode": "train", "epoch": 162, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04673, "heatmap_loss": 0.00052, "acc_pose": 0.85649, "loss": 0.00052, "grad_norm": 0.00127, "time": 0.37515}
+{"mode": "train", "epoch": 162, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00052, "acc_pose": 0.85031, "loss": 0.00052, "grad_norm": 0.00124, "time": 0.32459}
+{"mode": "train", "epoch": 162, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00052, "acc_pose": 0.85081, "loss": 0.00052, "grad_norm": 0.00124, "time": 0.32229}
+{"mode": "train", "epoch": 162, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.85991, "loss": 0.00052, "grad_norm": 0.00125, "time": 0.32213}
+{"mode": "train", "epoch": 162, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.84697, "loss": 0.00052, "grad_norm": 0.00131, "time": 0.32243}
+{"mode": "train", "epoch": 163, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04667, "heatmap_loss": 0.00052, "acc_pose": 0.84037, "loss": 0.00052, "grad_norm": 0.00134, "time": 0.37305}
+{"mode": "train", "epoch": 163, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00062, "heatmap_loss": 0.00052, "acc_pose": 0.84844, "loss": 0.00052, "grad_norm": 0.00132, "time": 0.3224}
+{"mode": "train", "epoch": 163, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.84125, "loss": 0.00052, "grad_norm": 0.00117, "time": 0.32218}
+{"mode": "train", "epoch": 163, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00052, "acc_pose": 0.85077, "loss": 0.00052, "grad_norm": 0.00127, "time": 0.32406}
+{"mode": "train", "epoch": 163, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.8458, "loss": 0.00052, "grad_norm": 0.00134, "time": 0.32203}
+{"mode": "train", "epoch": 164, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04691, "heatmap_loss": 0.00052, "acc_pose": 0.86019, "loss": 0.00052, "grad_norm": 0.0013, "time": 0.37486}
+{"mode": "train", "epoch": 164, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.848, "loss": 0.00052, "grad_norm": 0.0013, "time": 0.3231}
+{"mode": "train", "epoch": 164, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00062, "heatmap_loss": 0.00052, "acc_pose": 0.85179, "loss": 0.00052, "grad_norm": 0.00124, "time": 0.32424}
+{"mode": "train", "epoch": 164, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.86123, "loss": 0.00052, "grad_norm": 0.00129, "time": 0.32373}
+{"mode": "train", "epoch": 164, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.85284, "loss": 0.00052, "grad_norm": 0.0013, "time": 0.32529}
+{"mode": "train", "epoch": 165, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04667, "heatmap_loss": 0.00052, "acc_pose": 0.86908, "loss": 0.00052, "grad_norm": 0.00124, "time": 0.37401}
+{"mode": "train", "epoch": 165, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00052, "acc_pose": 0.8493, "loss": 0.00052, "grad_norm": 0.00127, "time": 0.32301}
+{"mode": "train", "epoch": 165, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00052, "acc_pose": 0.85276, "loss": 0.00052, "grad_norm": 0.00132, "time": 0.32341}
+{"mode": "train", "epoch": 165, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00052, "heatmap_loss": 0.00051, "acc_pose": 0.85359, "loss": 0.00051, "grad_norm": 0.00122, "time": 0.32313}
+{"mode": "train", "epoch": 165, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00051, "acc_pose": 0.84933, "loss": 0.00051, "grad_norm": 0.00136, "time": 0.32504}
+{"mode": "train", "epoch": 166, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04679, "heatmap_loss": 0.00052, "acc_pose": 0.84394, "loss": 0.00052, "grad_norm": 0.00121, "time": 0.37622}
+{"mode": "train", "epoch": 166, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00052, "heatmap_loss": 0.00051, "acc_pose": 0.85081, "loss": 0.00051, "grad_norm": 0.00135, "time": 0.32463}
+{"mode": "train", "epoch": 166, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.84814, "loss": 0.00052, "grad_norm": 0.0013, "time": 0.32373}
+{"mode": "train", "epoch": 166, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00051, "acc_pose": 0.85569, "loss": 0.00051, "grad_norm": 0.00129, "time": 0.32373}
+{"mode": "train", "epoch": 166, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00052, "acc_pose": 0.84315, "loss": 0.00052, "grad_norm": 0.00132, "time": 0.32527}
+{"mode": "train", "epoch": 167, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04665, "heatmap_loss": 0.00051, "acc_pose": 0.85611, "loss": 0.00051, "grad_norm": 0.00127, "time": 0.37592}
+{"mode": "train", "epoch": 167, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00052, "acc_pose": 0.86024, "loss": 0.00052, "grad_norm": 0.0013, "time": 0.32389}
+{"mode": "train", "epoch": 167, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00052, "acc_pose": 0.83754, "loss": 0.00052, "grad_norm": 0.00126, "time": 0.32481}
+{"mode": "train", "epoch": 167, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00052, "acc_pose": 0.8629, "loss": 0.00052, "grad_norm": 0.00122, "time": 0.32287}
+{"mode": "train", "epoch": 167, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.84715, "loss": 0.00052, "grad_norm": 0.00126, "time": 0.32211}
+{"mode": "train", "epoch": 168, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04673, "heatmap_loss": 0.00052, "acc_pose": 0.83933, "loss": 0.00052, "grad_norm": 0.00131, "time": 0.37609}
+{"mode": "train", "epoch": 168, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00051, "acc_pose": 0.85393, "loss": 0.00051, "grad_norm": 0.00126, "time": 0.32369}
+{"mode": "train", "epoch": 168, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00045, "heatmap_loss": 0.00052, "acc_pose": 0.84599, "loss": 0.00052, "grad_norm": 0.00126, "time": 0.32167}
+{"mode": "train", "epoch": 168, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.85264, "loss": 0.00052, "grad_norm": 0.00124, "time": 0.32206}
+{"mode": "train", "epoch": 168, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.8441, "loss": 0.00052, "grad_norm": 0.00125, "time": 0.32307}
+{"mode": "train", "epoch": 169, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04672, "heatmap_loss": 0.00051, "acc_pose": 0.86042, "loss": 0.00051, "grad_norm": 0.00126, "time": 0.37432}
+{"mode": "train", "epoch": 169, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00051, "acc_pose": 0.84259, "loss": 0.00051, "grad_norm": 0.00127, "time": 0.32237}
+{"mode": "train", "epoch": 169, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00051, "acc_pose": 0.85274, "loss": 0.00051, "grad_norm": 0.0015, "time": 0.32297}
+{"mode": "train", "epoch": 169, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.85022, "loss": 0.00052, "grad_norm": 0.00136, "time": 0.3223}
+{"mode": "train", "epoch": 169, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00051, "acc_pose": 0.85731, "loss": 0.00051, "grad_norm": 0.0013, "time": 0.32228}
+{"mode": "train", "epoch": 170, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04694, "heatmap_loss": 0.00051, "acc_pose": 0.83989, "loss": 0.00051, "grad_norm": 0.00131, "time": 0.374}
+{"mode": "train", "epoch": 170, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00045, "heatmap_loss": 0.00051, "acc_pose": 0.85015, "loss": 0.00051, "grad_norm": 0.00128, "time": 0.32297}
+{"mode": "train", "epoch": 170, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.8488, "loss": 0.00052, "grad_norm": 0.00123, "time": 0.32193}
+{"mode": "train", "epoch": 170, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00045, "heatmap_loss": 0.00051, "acc_pose": 0.85079, "loss": 0.00051, "grad_norm": 0.00126, "time": 0.32316}
+{"mode": "train", "epoch": 170, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00051, "acc_pose": 0.84861, "loss": 0.00051, "grad_norm": 0.00126, "time": 0.32329}
+{"mode": "val", "epoch": 170, "iter": 204, "lr": 0.0, "AP": 0.78986, "AP .5": 0.91652, "AP .75": 0.85505, "AP (M)": 0.71856, "AP (L)": 0.81948, "AR": 0.83933, "AR .5": 0.95293, "AR .75": 0.89688, "AR (M)": 0.79885, "AR (L)": 0.89885}
+{"mode": "train", "epoch": 171, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04803, "heatmap_loss": 0.00052, "acc_pose": 0.84725, "loss": 0.00052, "grad_norm": 0.00111, "time": 0.37107}
+{"mode": "train", "epoch": 171, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00051, "acc_pose": 0.85656, "loss": 0.00051, "grad_norm": 0.0011, "time": 0.32286}
+{"mode": "train", "epoch": 171, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00051, "acc_pose": 0.8481, "loss": 0.00051, "grad_norm": 0.00113, "time": 0.32432}
+{"mode": "train", "epoch": 171, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00051, "acc_pose": 0.84873, "loss": 0.00051, "grad_norm": 0.00107, "time": 0.32425}
+{"mode": "train", "epoch": 171, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.0005, "acc_pose": 0.84721, "loss": 0.0005, "grad_norm": 0.00111, "time": 0.32364}
+{"mode": "train", "epoch": 172, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04669, "heatmap_loss": 0.00051, "acc_pose": 0.84247, "loss": 0.00051, "grad_norm": 0.00105, "time": 0.37092}
+{"mode": "train", "epoch": 172, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.0005, "acc_pose": 0.85699, "loss": 0.0005, "grad_norm": 0.00107, "time": 0.32526}
+{"mode": "train", "epoch": 172, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.0005, "acc_pose": 0.85591, "loss": 0.0005, "grad_norm": 0.00104, "time": 0.32412}
+{"mode": "train", "epoch": 172, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.0005, "acc_pose": 0.85781, "loss": 0.0005, "grad_norm": 0.00115, "time": 0.32457}
+{"mode": "train", "epoch": 172, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00051, "acc_pose": 0.84559, "loss": 0.00051, "grad_norm": 0.00105, "time": 0.32548}
+{"mode": "train", "epoch": 173, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04682, "heatmap_loss": 0.0005, "acc_pose": 0.83973, "loss": 0.0005, "grad_norm": 0.00103, "time": 0.3729}
+{"mode": "train", "epoch": 173, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.0005, "acc_pose": 0.85455, "loss": 0.0005, "grad_norm": 0.00114, "time": 0.32251}
+{"mode": "train", "epoch": 173, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.0005, "acc_pose": 0.85967, "loss": 0.0005, "grad_norm": 0.00109, "time": 0.32263}
+{"mode": "train", "epoch": 173, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.0005, "acc_pose": 0.85858, "loss": 0.0005, "grad_norm": 0.00103, "time": 0.32452}
+{"mode": "train", "epoch": 173, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.0005, "acc_pose": 0.84533, "loss": 0.0005, "grad_norm": 0.00105, "time": 0.32255}
+{"mode": "train", "epoch": 174, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04683, "heatmap_loss": 0.00051, "acc_pose": 0.85468, "loss": 0.00051, "grad_norm": 0.00108, "time": 0.37481}
+{"mode": "train", "epoch": 174, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.0005, "acc_pose": 0.85693, "loss": 0.0005, "grad_norm": 0.00107, "time": 0.3237}
+{"mode": "train", "epoch": 174, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00051, "acc_pose": 0.84826, "loss": 0.00051, "grad_norm": 0.00112, "time": 0.32364}
+{"mode": "train", "epoch": 174, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00052, "heatmap_loss": 0.0005, "acc_pose": 0.86155, "loss": 0.0005, "grad_norm": 0.00111, "time": 0.32476}
+{"mode": "train", "epoch": 174, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.0005, "acc_pose": 0.84747, "loss": 0.0005, "grad_norm": 0.00103, "time": 0.32349}
+{"mode": "train", "epoch": 175, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04702, "heatmap_loss": 0.0005, "acc_pose": 0.86316, "loss": 0.0005, "grad_norm": 0.00105, "time": 0.3745}
+{"mode": "train", "epoch": 175, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.0005, "acc_pose": 0.86745, "loss": 0.0005, "grad_norm": 0.00109, "time": 0.32273}
+{"mode": "train", "epoch": 175, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.0005, "acc_pose": 0.86057, "loss": 0.0005, "grad_norm": 0.00112, "time": 0.32201}
+{"mode": "train", "epoch": 175, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.0005, "acc_pose": 0.85869, "loss": 0.0005, "grad_norm": 0.0011, "time": 0.32346}
+{"mode": "train", "epoch": 175, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.0005, "acc_pose": 0.85628, "loss": 0.0005, "grad_norm": 0.00108, "time": 0.32293}
+{"mode": "train", "epoch": 176, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04684, "heatmap_loss": 0.00051, "acc_pose": 0.83981, "loss": 0.00051, "grad_norm": 0.00109, "time": 0.37362}
+{"mode": "train", "epoch": 176, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.0005, "acc_pose": 0.86347, "loss": 0.0005, "grad_norm": 0.00107, "time": 0.32648}
+{"mode": "train", "epoch": 176, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.0005, "acc_pose": 0.86156, "loss": 0.0005, "grad_norm": 0.00108, "time": 0.32357}
+{"mode": "train", "epoch": 176, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.0005, "acc_pose": 0.86033, "loss": 0.0005, "grad_norm": 0.00111, "time": 0.3227}
+{"mode": "train", "epoch": 176, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00049, "acc_pose": 0.85551, "loss": 0.00049, "grad_norm": 0.00109, "time": 0.32387}
+{"mode": "train", "epoch": 177, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04672, "heatmap_loss": 0.0005, "acc_pose": 0.85526, "loss": 0.0005, "grad_norm": 0.00108, "time": 0.37576}
+{"mode": "train", "epoch": 177, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.0005, "acc_pose": 0.86632, "loss": 0.0005, "grad_norm": 0.00113, "time": 0.32467}
+{"mode": "train", "epoch": 177, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.0005, "acc_pose": 0.84786, "loss": 0.0005, "grad_norm": 0.00111, "time": 0.32414}
+{"mode": "train", "epoch": 177, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.0005, "acc_pose": 0.85411, "loss": 0.0005, "grad_norm": 0.00107, "time": 0.3232}
+{"mode": "train", "epoch": 177, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.0005, "acc_pose": 0.87172, "loss": 0.0005, "grad_norm": 0.00102, "time": 0.32286}
+{"mode": "train", "epoch": 178, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.0468, "heatmap_loss": 0.0005, "acc_pose": 0.86226, "loss": 0.0005, "grad_norm": 0.00108, "time": 0.37361}
+{"mode": "train", "epoch": 178, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.0005, "acc_pose": 0.85991, "loss": 0.0005, "grad_norm": 0.00102, "time": 0.32268}
+{"mode": "train", "epoch": 178, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.0005, "acc_pose": 0.85982, "loss": 0.0005, "grad_norm": 0.0011, "time": 0.32455}
+{"mode": "train", "epoch": 178, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.0005, "acc_pose": 0.86132, "loss": 0.0005, "grad_norm": 0.00108, "time": 0.323}
+{"mode": "train", "epoch": 178, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.0005, "acc_pose": 0.85304, "loss": 0.0005, "grad_norm": 0.00108, "time": 0.32302}
+{"mode": "train", "epoch": 179, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04678, "heatmap_loss": 0.0005, "acc_pose": 0.8523, "loss": 0.0005, "grad_norm": 0.00106, "time": 0.37645}
+{"mode": "train", "epoch": 179, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.0005, "acc_pose": 0.85938, "loss": 0.0005, "grad_norm": 0.00111, "time": 0.32406}
+{"mode": "train", "epoch": 179, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00054, "heatmap_loss": 0.0005, "acc_pose": 0.85456, "loss": 0.0005, "grad_norm": 0.00105, "time": 0.32461}
+{"mode": "train", "epoch": 179, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.0005, "acc_pose": 0.87401, "loss": 0.0005, "grad_norm": 0.00117, "time": 0.32453}
+{"mode": "train", "epoch": 179, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.0005, "acc_pose": 0.86148, "loss": 0.0005, "grad_norm": 0.00109, "time": 0.32559}
+{"mode": "train", "epoch": 180, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04678, "heatmap_loss": 0.0005, "acc_pose": 0.86298, "loss": 0.0005, "grad_norm": 0.00109, "time": 0.37385}
+{"mode": "train", "epoch": 180, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.0005, "acc_pose": 0.8563, "loss": 0.0005, "grad_norm": 0.0012, "time": 0.32251}
+{"mode": "train", "epoch": 180, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.0005, "acc_pose": 0.86703, "loss": 0.0005, "grad_norm": 0.00098, "time": 0.32397}
+{"mode": "train", "epoch": 180, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.0005, "acc_pose": 0.85615, "loss": 0.0005, "grad_norm": 0.00102, "time": 0.32606}
+{"mode": "train", "epoch": 180, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.0005, "acc_pose": 0.86934, "loss": 0.0005, "grad_norm": 0.00111, "time": 0.32338}
+{"mode": "val", "epoch": 180, "iter": 204, "lr": 0.0, "AP": 0.79054, "AP .5": 0.9165, "AP .75": 0.85682, "AP (M)": 0.71893, "AP (L)": 0.81926, "AR": 0.84063, "AR .5": 0.95387, "AR .75": 0.89956, "AR (M)": 0.79984, "AR (L)": 0.90026}
+{"mode": "train", "epoch": 181, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04787, "heatmap_loss": 0.0005, "acc_pose": 0.86933, "loss": 0.0005, "grad_norm": 0.00106, "time": 0.37109}
+{"mode": "train", "epoch": 181, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.0005, "acc_pose": 0.8506, "loss": 0.0005, "grad_norm": 0.0011, "time": 0.32193}
+{"mode": "train", "epoch": 181, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.0005, "acc_pose": 0.85227, "loss": 0.0005, "grad_norm": 0.00108, "time": 0.3249}
+{"mode": "train", "epoch": 181, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.0005, "acc_pose": 0.84878, "loss": 0.0005, "grad_norm": 0.00109, "time": 0.32654}
+{"mode": "train", "epoch": 181, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.0005, "acc_pose": 0.85482, "loss": 0.0005, "grad_norm": 0.00113, "time": 0.32432}
+{"mode": "train", "epoch": 182, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04651, "heatmap_loss": 0.0005, "acc_pose": 0.84654, "loss": 0.0005, "grad_norm": 0.00112, "time": 0.37079}
+{"mode": "train", "epoch": 182, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00049, "acc_pose": 0.87001, "loss": 0.00049, "grad_norm": 0.00103, "time": 0.3231}
+{"mode": "train", "epoch": 182, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.0005, "acc_pose": 0.85067, "loss": 0.0005, "grad_norm": 0.0011, "time": 0.32343}
+{"mode": "train", "epoch": 182, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.0005, "acc_pose": 0.85372, "loss": 0.0005, "grad_norm": 0.00109, "time": 0.32223}
+{"mode": "train", "epoch": 182, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.0005, "acc_pose": 0.84675, "loss": 0.0005, "grad_norm": 0.00113, "time": 0.32281}
+{"mode": "train", "epoch": 183, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04681, "heatmap_loss": 0.0005, "acc_pose": 0.86125, "loss": 0.0005, "grad_norm": 0.001, "time": 0.37324}
+{"mode": "train", "epoch": 183, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00052, "heatmap_loss": 0.00049, "acc_pose": 0.86066, "loss": 0.00049, "grad_norm": 0.00108, "time": 0.32157}
+{"mode": "train", "epoch": 183, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00049, "acc_pose": 0.87019, "loss": 0.00049, "grad_norm": 0.00106, "time": 0.322}
+{"mode": "train", "epoch": 183, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.0005, "acc_pose": 0.85801, "loss": 0.0005, "grad_norm": 0.00107, "time": 0.32314}
+{"mode": "train", "epoch": 183, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.0005, "acc_pose": 0.8515, "loss": 0.0005, "grad_norm": 0.00108, "time": 0.32236}
+{"mode": "train", "epoch": 184, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.0468, "heatmap_loss": 0.0005, "acc_pose": 0.86858, "loss": 0.0005, "grad_norm": 0.00104, "time": 0.37279}
+{"mode": "train", "epoch": 184, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.0005, "acc_pose": 0.86261, "loss": 0.0005, "grad_norm": 0.00108, "time": 0.32284}
+{"mode": "train", "epoch": 184, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.0005, "acc_pose": 0.84357, "loss": 0.0005, "grad_norm": 0.00108, "time": 0.32193}
+{"mode": "train", "epoch": 184, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.0005, "acc_pose": 0.85889, "loss": 0.0005, "grad_norm": 0.00104, "time": 0.32435}
+{"mode": "train", "epoch": 184, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00049, "acc_pose": 0.86366, "loss": 0.00049, "grad_norm": 0.00107, "time": 0.3232}
+{"mode": "train", "epoch": 185, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04683, "heatmap_loss": 0.00049, "acc_pose": 0.85775, "loss": 0.00049, "grad_norm": 0.0011, "time": 0.37489}
+{"mode": "train", "epoch": 185, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.0005, "acc_pose": 0.86119, "loss": 0.0005, "grad_norm": 0.00104, "time": 0.32409}
+{"mode": "train", "epoch": 185, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.0005, "acc_pose": 0.87505, "loss": 0.0005, "grad_norm": 0.00103, "time": 0.32343}
+{"mode": "train", "epoch": 185, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00049, "acc_pose": 0.86851, "loss": 0.00049, "grad_norm": 0.00105, "time": 0.32244}
+{"mode": "train", "epoch": 185, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.0005, "acc_pose": 0.84717, "loss": 0.0005, "grad_norm": 0.0011, "time": 0.32327}
+{"mode": "train", "epoch": 186, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04673, "heatmap_loss": 0.0005, "acc_pose": 0.84567, "loss": 0.0005, "grad_norm": 0.00104, "time": 0.37307}
+{"mode": "train", "epoch": 186, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00049, "acc_pose": 0.85563, "loss": 0.00049, "grad_norm": 0.00098, "time": 0.32161}
+{"mode": "train", "epoch": 186, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.0005, "acc_pose": 0.86497, "loss": 0.0005, "grad_norm": 0.00103, "time": 0.32306}
+{"mode": "train", "epoch": 186, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.0005, "acc_pose": 0.86035, "loss": 0.0005, "grad_norm": 0.00109, "time": 0.32273}
+{"mode": "train", "epoch": 186, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00049, "acc_pose": 0.85215, "loss": 0.00049, "grad_norm": 0.00107, "time": 0.32286}
+{"mode": "train", "epoch": 187, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04802, "heatmap_loss": 0.00049, "acc_pose": 0.86525, "loss": 0.00049, "grad_norm": 0.00115, "time": 0.3731}
+{"mode": "train", "epoch": 187, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.00049, "acc_pose": 0.85384, "loss": 0.00049, "grad_norm": 0.00101, "time": 0.32346}
+{"mode": "train", "epoch": 187, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.0005, "acc_pose": 0.85261, "loss": 0.0005, "grad_norm": 0.00106, "time": 0.32466}
+{"mode": "train", "epoch": 187, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.0005, "acc_pose": 0.86147, "loss": 0.0005, "grad_norm": 0.00108, "time": 0.32333}
+{"mode": "train", "epoch": 187, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.0005, "acc_pose": 0.85646, "loss": 0.0005, "grad_norm": 0.00114, "time": 0.32392}
+{"mode": "train", "epoch": 188, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04675, "heatmap_loss": 0.00049, "acc_pose": 0.86708, "loss": 0.00049, "grad_norm": 0.00105, "time": 0.37421}
+{"mode": "train", "epoch": 188, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00049, "acc_pose": 0.85401, "loss": 0.00049, "grad_norm": 0.0011, "time": 0.3256}
+{"mode": "train", "epoch": 188, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00108, "heatmap_loss": 0.0005, "acc_pose": 0.86692, "loss": 0.0005, "grad_norm": 0.00104, "time": 0.32693}
+{"mode": "train", "epoch": 188, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.0005, "acc_pose": 0.86209, "loss": 0.0005, "grad_norm": 0.00105, "time": 0.32586}
+{"mode": "train", "epoch": 188, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.0005, "acc_pose": 0.86565, "loss": 0.0005, "grad_norm": 0.00101, "time": 0.32591}
+{"mode": "train", "epoch": 189, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.0468, "heatmap_loss": 0.0005, "acc_pose": 0.85598, "loss": 0.0005, "grad_norm": 0.00111, "time": 0.37417}
+{"mode": "train", "epoch": 189, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00049, "acc_pose": 0.86088, "loss": 0.00049, "grad_norm": 0.00107, "time": 0.32353}
+{"mode": "train", "epoch": 189, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.0005, "acc_pose": 0.85178, "loss": 0.0005, "grad_norm": 0.0011, "time": 0.32371}
+{"mode": "train", "epoch": 189, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.0005, "acc_pose": 0.86095, "loss": 0.0005, "grad_norm": 0.00103, "time": 0.3232}
+{"mode": "train", "epoch": 189, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00049, "acc_pose": 0.86351, "loss": 0.00049, "grad_norm": 0.00107, "time": 0.32266}
+{"mode": "train", "epoch": 190, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04673, "heatmap_loss": 0.0005, "acc_pose": 0.86477, "loss": 0.0005, "grad_norm": 0.00107, "time": 0.37471}
+{"mode": "train", "epoch": 190, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.0005, "acc_pose": 0.84958, "loss": 0.0005, "grad_norm": 0.00107, "time": 0.32227}
+{"mode": "train", "epoch": 190, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00049, "acc_pose": 0.87141, "loss": 0.00049, "grad_norm": 0.00117, "time": 0.32304}
+{"mode": "train", "epoch": 190, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.0005, "acc_pose": 0.85828, "loss": 0.0005, "grad_norm": 0.00105, "time": 0.32294}
+{"mode": "train", "epoch": 190, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.0005, "acc_pose": 0.86192, "loss": 0.0005, "grad_norm": 0.00105, "time": 0.32263}
+{"mode": "val", "epoch": 190, "iter": 204, "lr": 0.0, "AP": 0.78958, "AP .5": 0.91593, "AP .75": 0.85621, "AP (M)": 0.7175, "AP (L)": 0.81813, "AR": 0.84022, "AR .5": 0.9534, "AR .75": 0.89924, "AR (M)": 0.79891, "AR (L)": 0.90063}
+{"mode": "train", "epoch": 191, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04687, "heatmap_loss": 0.0005, "acc_pose": 0.86127, "loss": 0.0005, "grad_norm": 0.00102, "time": 0.36929}
+{"mode": "train", "epoch": 191, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00049, "acc_pose": 0.86395, "loss": 0.00049, "grad_norm": 0.00109, "time": 0.3212}
+{"mode": "train", "epoch": 191, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00049, "acc_pose": 0.86421, "loss": 0.00049, "grad_norm": 0.00111, "time": 0.32297}
+{"mode": "train", "epoch": 191, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.0005, "acc_pose": 0.86283, "loss": 0.0005, "grad_norm": 0.00106, "time": 0.32245}
+{"mode": "train", "epoch": 191, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00049, "acc_pose": 0.85537, "loss": 0.00049, "grad_norm": 0.00114, "time": 0.32506}
+{"mode": "train", "epoch": 192, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04688, "heatmap_loss": 0.00049, "acc_pose": 0.857, "loss": 0.00049, "grad_norm": 0.00108, "time": 0.37272}
+{"mode": "train", "epoch": 192, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00049, "acc_pose": 0.85581, "loss": 0.00049, "grad_norm": 0.001, "time": 0.32327}
+{"mode": "train", "epoch": 192, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.0005, "acc_pose": 0.86274, "loss": 0.0005, "grad_norm": 0.00102, "time": 0.32254}
+{"mode": "train", "epoch": 192, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00049, "acc_pose": 0.85256, "loss": 0.00049, "grad_norm": 0.0011, "time": 0.32265}
+{"mode": "train", "epoch": 192, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.0005, "acc_pose": 0.8594, "loss": 0.0005, "grad_norm": 0.00107, "time": 0.32242}
+{"mode": "train", "epoch": 193, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04729, "heatmap_loss": 0.00049, "acc_pose": 0.85098, "loss": 0.00049, "grad_norm": 0.00107, "time": 0.37391}
+{"mode": "train", "epoch": 193, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00049, "acc_pose": 0.85483, "loss": 0.00049, "grad_norm": 0.00107, "time": 0.32281}
+{"mode": "train", "epoch": 193, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00052, "heatmap_loss": 0.0005, "acc_pose": 0.85323, "loss": 0.0005, "grad_norm": 0.00122, "time": 0.32195}
+{"mode": "train", "epoch": 193, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.0005, "acc_pose": 0.84336, "loss": 0.0005, "grad_norm": 0.00105, "time": 0.32238}
+{"mode": "train", "epoch": 193, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00049, "acc_pose": 0.86848, "loss": 0.00049, "grad_norm": 0.00106, "time": 0.32423}
+{"mode": "train", "epoch": 194, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04673, "heatmap_loss": 0.00049, "acc_pose": 0.86147, "loss": 0.00049, "grad_norm": 0.001, "time": 0.37283}
+{"mode": "train", "epoch": 194, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00049, "acc_pose": 0.85407, "loss": 0.00049, "grad_norm": 0.00107, "time": 0.32454}
+{"mode": "train", "epoch": 194, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.0005, "acc_pose": 0.85441, "loss": 0.0005, "grad_norm": 0.00099, "time": 0.32221}
+{"mode": "train", "epoch": 194, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.0005, "acc_pose": 0.86135, "loss": 0.0005, "grad_norm": 0.00109, "time": 0.323}
+{"mode": "train", "epoch": 194, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00054, "heatmap_loss": 0.00049, "acc_pose": 0.86483, "loss": 0.00049, "grad_norm": 0.0011, "time": 0.32248}
+{"mode": "train", "epoch": 195, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04678, "heatmap_loss": 0.00049, "acc_pose": 0.85724, "loss": 0.00049, "grad_norm": 0.00112, "time": 0.37386}
+{"mode": "train", "epoch": 195, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00054, "heatmap_loss": 0.00049, "acc_pose": 0.84723, "loss": 0.00049, "grad_norm": 0.00103, "time": 0.32241}
+{"mode": "train", "epoch": 195, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00049, "acc_pose": 0.86895, "loss": 0.00049, "grad_norm": 0.00104, "time": 0.32266}
+{"mode": "train", "epoch": 195, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00049, "acc_pose": 0.85632, "loss": 0.00049, "grad_norm": 0.00106, "time": 0.32363}
+{"mode": "train", "epoch": 195, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00049, "acc_pose": 0.86181, "loss": 0.00049, "grad_norm": 0.00102, "time": 0.32308}
+{"mode": "train", "epoch": 196, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04688, "heatmap_loss": 0.00049, "acc_pose": 0.85642, "loss": 0.00049, "grad_norm": 0.00111, "time": 0.37348}
+{"mode": "train", "epoch": 196, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00049, "acc_pose": 0.85915, "loss": 0.00049, "grad_norm": 0.00105, "time": 0.32298}
+{"mode": "train", "epoch": 196, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00049, "acc_pose": 0.85752, "loss": 0.00049, "grad_norm": 0.00103, "time": 0.32261}
+{"mode": "train", "epoch": 196, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00049, "acc_pose": 0.85418, "loss": 0.00049, "grad_norm": 0.00103, "time": 0.32311}
+{"mode": "train", "epoch": 196, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.0005, "acc_pose": 0.85527, "loss": 0.0005, "grad_norm": 0.0011, "time": 0.32262}
+{"mode": "train", "epoch": 197, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04683, "heatmap_loss": 0.00049, "acc_pose": 0.85781, "loss": 0.00049, "grad_norm": 0.00104, "time": 0.37565}
+{"mode": "train", "epoch": 197, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.0005, "acc_pose": 0.864, "loss": 0.0005, "grad_norm": 0.00112, "time": 0.32381}
+{"mode": "train", "epoch": 197, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00049, "acc_pose": 0.8594, "loss": 0.00049, "grad_norm": 0.00111, "time": 0.32493}
+{"mode": "train", "epoch": 197, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00049, "acc_pose": 0.84926, "loss": 0.00049, "grad_norm": 0.00104, "time": 0.32581}
+{"mode": "train", "epoch": 197, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.0005, "acc_pose": 0.85096, "loss": 0.0005, "grad_norm": 0.00112, "time": 0.32359}
+{"mode": "train", "epoch": 198, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04687, "heatmap_loss": 0.00049, "acc_pose": 0.84343, "loss": 0.00049, "grad_norm": 0.0011, "time": 0.37428}
+{"mode": "train", "epoch": 198, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.0005, "acc_pose": 0.85499, "loss": 0.0005, "grad_norm": 0.00099, "time": 0.325}
+{"mode": "train", "epoch": 198, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00049, "acc_pose": 0.85271, "loss": 0.00049, "grad_norm": 0.00111, "time": 0.32446}
+{"mode": "train", "epoch": 198, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00049, "acc_pose": 0.8585, "loss": 0.00049, "grad_norm": 0.00103, "time": 0.32342}
+{"mode": "train", "epoch": 198, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00049, "acc_pose": 0.86432, "loss": 0.00049, "grad_norm": 0.00102, "time": 0.32318}
+{"mode": "train", "epoch": 199, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04689, "heatmap_loss": 0.00049, "acc_pose": 0.85437, "loss": 0.00049, "grad_norm": 0.00105, "time": 0.3745}
+{"mode": "train", "epoch": 199, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00049, "acc_pose": 0.86869, "loss": 0.00049, "grad_norm": 0.00104, "time": 0.32543}
+{"mode": "train", "epoch": 199, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00054, "heatmap_loss": 0.00049, "acc_pose": 0.85417, "loss": 0.00049, "grad_norm": 0.00099, "time": 0.32574}
+{"mode": "train", "epoch": 199, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00049, "acc_pose": 0.86205, "loss": 0.00049, "grad_norm": 0.00107, "time": 0.32395}
+{"mode": "train", "epoch": 199, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.0005, "acc_pose": 0.84767, "loss": 0.0005, "grad_norm": 0.00109, "time": 0.32286}
+{"mode": "train", "epoch": 200, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04674, "heatmap_loss": 0.00049, "acc_pose": 0.85541, "loss": 0.00049, "grad_norm": 0.00106, "time": 0.37715}
+{"mode": "train", "epoch": 200, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00049, "acc_pose": 0.85468, "loss": 0.00049, "grad_norm": 0.00108, "time": 0.32583}
+{"mode": "train", "epoch": 200, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00049, "acc_pose": 0.86156, "loss": 0.00049, "grad_norm": 0.00109, "time": 0.3233}
+{"mode": "train", "epoch": 200, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00049, "acc_pose": 0.86614, "loss": 0.00049, "grad_norm": 0.00109, "time": 0.32448}
+{"mode": "train", "epoch": 200, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00049, "acc_pose": 0.86275, "loss": 0.00049, "grad_norm": 0.00104, "time": 0.32348}
+{"mode": "val", "epoch": 200, "iter": 204, "lr": 0.0, "AP": 0.78987, "AP .5": 0.91568, "AP .75": 0.85612, "AP (M)": 0.71717, "AP (L)": 0.81886, "AR": 0.84048, "AR .5": 0.95277, "AR .75": 0.89924, "AR (M)": 0.79896, "AR (L)": 0.90104}
+{"mode": "train", "epoch": 201, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04675, "heatmap_loss": 0.00049, "acc_pose": 0.84667, "loss": 0.00049, "grad_norm": 0.00107, "time": 0.36962}
+{"mode": "train", "epoch": 201, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00049, "acc_pose": 0.85353, "loss": 0.00049, "grad_norm": 0.00108, "time": 0.32224}
+{"mode": "train", "epoch": 201, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00049, "acc_pose": 0.86284, "loss": 0.00049, "grad_norm": 0.00103, "time": 0.32332}
+{"mode": "train", "epoch": 201, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00049, "acc_pose": 0.86738, "loss": 0.00049, "grad_norm": 0.00105, "time": 0.32324}
+{"mode": "train", "epoch": 201, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00049, "acc_pose": 0.85159, "loss": 0.00049, "grad_norm": 0.00102, "time": 0.3243}
+{"mode": "train", "epoch": 202, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04703, "heatmap_loss": 0.00049, "acc_pose": 0.86622, "loss": 0.00049, "grad_norm": 0.00099, "time": 0.37556}
+{"mode": "train", "epoch": 202, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00049, "acc_pose": 0.86302, "loss": 0.00049, "grad_norm": 0.001, "time": 0.32581}
+{"mode": "train", "epoch": 202, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00049, "acc_pose": 0.86288, "loss": 0.00049, "grad_norm": 0.001, "time": 0.32337}
+{"mode": "train", "epoch": 202, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00049, "acc_pose": 0.85241, "loss": 0.00049, "grad_norm": 0.00103, "time": 0.32251}
+{"mode": "train", "epoch": 202, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00049, "acc_pose": 0.85676, "loss": 0.00049, "grad_norm": 0.00105, "time": 0.3225}
+{"mode": "train", "epoch": 203, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04678, "heatmap_loss": 0.0005, "acc_pose": 0.85659, "loss": 0.0005, "grad_norm": 0.0011, "time": 0.37434}
+{"mode": "train", "epoch": 203, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00049, "acc_pose": 0.86464, "loss": 0.00049, "grad_norm": 0.00101, "time": 0.32314}
+{"mode": "train", "epoch": 203, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00049, "acc_pose": 0.85911, "loss": 0.00049, "grad_norm": 0.00099, "time": 0.32281}
+{"mode": "train", "epoch": 203, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00053, "heatmap_loss": 0.00049, "acc_pose": 0.87028, "loss": 0.00049, "grad_norm": 0.00098, "time": 0.32288}
+{"mode": "train", "epoch": 203, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00049, "acc_pose": 0.85486, "loss": 0.00049, "grad_norm": 0.00101, "time": 0.32388}
+{"mode": "train", "epoch": 204, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04706, "heatmap_loss": 0.00049, "acc_pose": 0.85848, "loss": 0.00049, "grad_norm": 0.00103, "time": 0.3765}
+{"mode": "train", "epoch": 204, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00049, "acc_pose": 0.85455, "loss": 0.00049, "grad_norm": 0.00098, "time": 0.32454}
+{"mode": "train", "epoch": 204, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00049, "acc_pose": 0.86096, "loss": 0.00049, "grad_norm": 0.00102, "time": 0.32486}
+{"mode": "train", "epoch": 204, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00049, "acc_pose": 0.84853, "loss": 0.00049, "grad_norm": 0.00107, "time": 0.32485}
+{"mode": "train", "epoch": 204, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00049, "acc_pose": 0.86495, "loss": 0.00049, "grad_norm": 0.00105, "time": 0.32557}
+{"mode": "train", "epoch": 205, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04694, "heatmap_loss": 0.00049, "acc_pose": 0.85921, "loss": 0.00049, "grad_norm": 0.00105, "time": 0.37403}
+{"mode": "train", "epoch": 205, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00049, "acc_pose": 0.85244, "loss": 0.00049, "grad_norm": 0.00104, "time": 0.32432}
+{"mode": "train", "epoch": 205, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00049, "acc_pose": 0.86384, "loss": 0.00049, "grad_norm": 0.00102, "time": 0.32239}
+{"mode": "train", "epoch": 205, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.00049, "acc_pose": 0.85922, "loss": 0.00049, "grad_norm": 0.00106, "time": 0.32317}
+{"mode": "train", "epoch": 205, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00049, "acc_pose": 0.86467, "loss": 0.00049, "grad_norm": 0.00104, "time": 0.32417}
+{"mode": "train", "epoch": 206, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04707, "heatmap_loss": 0.00049, "acc_pose": 0.86402, "loss": 0.00049, "grad_norm": 0.00106, "time": 0.37678}
+{"mode": "train", "epoch": 206, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00049, "acc_pose": 0.85906, "loss": 0.00049, "grad_norm": 0.00102, "time": 0.32445}
+{"mode": "train", "epoch": 206, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00049, "acc_pose": 0.86334, "loss": 0.00049, "grad_norm": 0.00102, "time": 0.32692}
+{"mode": "train", "epoch": 206, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00049, "acc_pose": 0.86804, "loss": 0.00049, "grad_norm": 0.001, "time": 0.32586}
+{"mode": "train", "epoch": 206, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00053, "heatmap_loss": 0.00049, "acc_pose": 0.86223, "loss": 0.00049, "grad_norm": 0.00106, "time": 0.32536}
+{"mode": "train", "epoch": 207, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04704, "heatmap_loss": 0.00049, "acc_pose": 0.86083, "loss": 0.00049, "grad_norm": 0.00104, "time": 0.3783}
+{"mode": "train", "epoch": 207, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00049, "acc_pose": 0.86502, "loss": 0.00049, "grad_norm": 0.00104, "time": 0.32547}
+{"mode": "train", "epoch": 207, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00049, "acc_pose": 0.85839, "loss": 0.00049, "grad_norm": 0.00104, "time": 0.32422}
+{"mode": "train", "epoch": 207, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00049, "acc_pose": 0.86901, "loss": 0.00049, "grad_norm": 0.00104, "time": 0.32372}
+{"mode": "train", "epoch": 207, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.0005, "acc_pose": 0.84884, "loss": 0.0005, "grad_norm": 0.00108, "time": 0.32386}
+{"mode": "train", "epoch": 208, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04683, "heatmap_loss": 0.00049, "acc_pose": 0.86017, "loss": 0.00049, "grad_norm": 0.00104, "time": 0.37522}
+{"mode": "train", "epoch": 208, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00049, "acc_pose": 0.86999, "loss": 0.00049, "grad_norm": 0.001, "time": 0.32276}
+{"mode": "train", "epoch": 208, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00049, "acc_pose": 0.86133, "loss": 0.00049, "grad_norm": 0.00108, "time": 0.3227}
+{"mode": "train", "epoch": 208, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00049, "acc_pose": 0.85387, "loss": 0.00049, "grad_norm": 0.00104, "time": 0.32296}
+{"mode": "train", "epoch": 208, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00052, "heatmap_loss": 0.00049, "acc_pose": 0.85796, "loss": 0.00049, "grad_norm": 0.00104, "time": 0.32256}
+{"mode": "train", "epoch": 209, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.0467, "heatmap_loss": 0.00049, "acc_pose": 0.86387, "loss": 0.00049, "grad_norm": 0.00103, "time": 0.37469}
+{"mode": "train", "epoch": 209, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00049, "acc_pose": 0.86792, "loss": 0.00049, "grad_norm": 0.00104, "time": 0.32384}
+{"mode": "train", "epoch": 209, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.0005, "heatmap_loss": 0.00049, "acc_pose": 0.8725, "loss": 0.00049, "grad_norm": 0.00103, "time": 0.32397}
+{"mode": "train", "epoch": 209, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00049, "acc_pose": 0.85694, "loss": 0.00049, "grad_norm": 0.00099, "time": 0.32445}
+{"mode": "train", "epoch": 209, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00049, "heatmap_loss": 0.00049, "acc_pose": 0.87064, "loss": 0.00049, "grad_norm": 0.00107, "time": 0.32289}
+{"mode": "train", "epoch": 210, "iter": 50, "lr": 0.0, "memory": 24462, "data_time": 0.04691, "heatmap_loss": 0.00049, "acc_pose": 0.86493, "loss": 0.00049, "grad_norm": 0.001, "time": 0.37391}
+{"mode": "train", "epoch": 210, "iter": 100, "lr": 0.0, "memory": 24462, "data_time": 0.00048, "heatmap_loss": 0.00048, "acc_pose": 0.85559, "loss": 0.00048, "grad_norm": 0.00103, "time": 0.32314}
+{"mode": "train", "epoch": 210, "iter": 150, "lr": 0.0, "memory": 24462, "data_time": 0.00047, "heatmap_loss": 0.00049, "acc_pose": 0.85734, "loss": 0.00049, "grad_norm": 0.00106, "time": 0.3226}
+{"mode": "train", "epoch": 210, "iter": 200, "lr": 0.0, "memory": 24462, "data_time": 0.00046, "heatmap_loss": 0.00049, "acc_pose": 0.86224, "loss": 0.00049, "grad_norm": 0.00106, "time": 0.32269}
+{"mode": "train", "epoch": 210, "iter": 250, "lr": 0.0, "memory": 24462, "data_time": 0.00051, "heatmap_loss": 0.00049, "acc_pose": 0.86098, "loss": 0.00049, "grad_norm": 0.00097, "time": 0.32308}
+{"mode": "val", "epoch": 210, "iter": 204, "lr": 0.0, "AP": 0.78994, "AP .5": 0.91587, "AP .75": 0.85625, "AP (M)": 0.71787, "AP (L)": 0.81901, "AR": 0.84055, "AR .5": 0.95356, "AR .75": 0.89861, "AR (M)": 0.79986, "AR (L)": 0.90052}
diff --git a/vendor/ViTPose/logs/vitpose-l-simple.log.json b/vendor/ViTPose/logs/vitpose-l-simple.log.json
new file mode 100644
index 0000000000000000000000000000000000000000..93037b0c7cb2eda160ce25b5a970937a30d8dbc4
--- /dev/null
+++ b/vendor/ViTPose/logs/vitpose-l-simple.log.json
@@ -0,0 +1,1072 @@
+{"env_info": "sys.platform: linux\nPython: 3.8.10 | packaged by conda-forge | (default, May 11 2021, 07:01:05) [GCC 9.3.0]\nCUDA available: True\nGPU 0,1,2,3,4,5,6,7: A100-SXM4-40GB\nCUDA_HOME: /usr/local/cuda\nNVCC: Build cuda_11.3.r11.3/compiler.29920130_0\nGCC: gcc (Ubuntu 9.3.0-17ubuntu1~20.04) 9.3.0\nPyTorch: 1.9.0a0+c3d40fd\nPyTorch compiling details: PyTorch built with:\n - GCC 9.3\n - C++ Version: 201402\n - Intel(R) Math Kernel Library Version 2019.0.5 Product Build 20190808 for Intel(R) 64 architecture applications\n - Intel(R) MKL-DNN v2.1.2 (Git Hash N/A)\n - OpenMP 201511 (a.k.a. OpenMP 4.5)\n - NNPACK is enabled\n - CPU capability usage: AVX2\n - CUDA Runtime 11.3\n - NVCC architecture flags: -gencode;arch=compute_52,code=sm_52;-gencode;arch=compute_60,code=sm_60;-gencode;arch=compute_61,code=sm_61;-gencode;arch=compute_70,code=sm_70;-gencode;arch=compute_75,code=sm_75;-gencode;arch=compute_80,code=sm_80;-gencode;arch=compute_86,code=sm_86;-gencode;arch=compute_86,code=compute_86\n - CuDNN 8.2.1\n - Magma 2.5.2\n - Build settings: BLAS_INFO=mkl, BUILD_TYPE=Release, CUDA_VERSION=11.3, CUDNN_VERSION=8.2.1, CXX_COMPILER=/usr/bin/c++, CXX_FLAGS= -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_KINETO -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DUSE_XNNPACK -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -O2 -fPIC -Wno-narrowing -Wall -Wextra -Werror=return-type -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wno-sign-compare -Wno-unused-parameter -Wno-unused-variable -Wno-unused-function -Wno-unused-result -Wno-unused-local-typedefs -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-psabi -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Werror=cast-function-type -Wno-stringop-overflow, LAPACK_INFO=mkl, PERF_WITH_AVX=1, PERF_WITH_AVX2=1, PERF_WITH_AVX512=1, TORCH_VERSION=1.9.0, USE_CUDA=ON, USE_CUDNN=ON, USE_EXCEPTION_PTR=1, USE_GFLAGS=OFF, USE_GLOG=OFF, USE_MKL=ON, USE_MKLDNN=ON, USE_MPI=ON, USE_NCCL=ON, USE_NNPACK=ON, USE_OPENMP=ON, \n\nTorchVision: 0.10.0a0\nOpenCV: 4.5.5\nMMCV: 1.3.9\nMMCV Compiler: GCC 9.3\nMMCV CUDA Compiler: 11.3\nMMPose: 0.24.0+94ca136", "seed": 0, "hook_msgs": {}}
+{"mode": "train", "epoch": 1, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.06538, "heatmap_loss": 0.00291, "acc_pose": 0.00785, "loss": 0.00291, "grad_norm": 0.25708, "time": 0.84648}
+{"mode": "train", "epoch": 1, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0004, "heatmap_loss": 0.00226, "acc_pose": 0.03368, "loss": 0.00226, "grad_norm": 0.09541, "time": 0.69663}
+{"mode": "train", "epoch": 1, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00224, "acc_pose": 0.07765, "loss": 0.00224, "grad_norm": 0.17212, "time": 0.69597}
+{"mode": "train", "epoch": 1, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00223, "acc_pose": 0.1182, "loss": 0.00223, "grad_norm": 0.21995, "time": 0.69584}
+{"mode": "train", "epoch": 1, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00213, "acc_pose": 0.16296, "loss": 0.00213, "grad_norm": 0.14615, "time": 0.69562}
+{"mode": "train", "epoch": 2, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05601, "heatmap_loss": 0.00205, "acc_pose": 0.21299, "loss": 0.00205, "grad_norm": 0.16281, "time": 0.75353}
+{"mode": "train", "epoch": 2, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00198, "acc_pose": 0.25391, "loss": 0.00198, "grad_norm": 0.21748, "time": 0.69704}
+{"mode": "train", "epoch": 2, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00035, "heatmap_loss": 0.00183, "acc_pose": 0.31657, "loss": 0.00183, "grad_norm": 0.24283, "time": 0.69783}
+{"mode": "train", "epoch": 2, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00164, "acc_pose": 0.37912, "loss": 0.00164, "grad_norm": 0.17538, "time": 0.69786}
+{"mode": "train", "epoch": 2, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00151, "acc_pose": 0.43824, "loss": 0.00151, "grad_norm": 0.16043, "time": 0.69738}
+{"mode": "train", "epoch": 3, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05524, "heatmap_loss": 0.00137, "acc_pose": 0.51359, "loss": 0.00137, "grad_norm": 0.14373, "time": 0.75447}
+{"mode": "train", "epoch": 3, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00128, "acc_pose": 0.54235, "loss": 0.00128, "grad_norm": 0.12366, "time": 0.69807}
+{"mode": "train", "epoch": 3, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00125, "acc_pose": 0.5573, "loss": 0.00125, "grad_norm": 0.12072, "time": 0.69635}
+{"mode": "train", "epoch": 3, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00122, "acc_pose": 0.57748, "loss": 0.00122, "grad_norm": 0.14141, "time": 0.69692}
+{"mode": "train", "epoch": 3, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0012, "acc_pose": 0.58849, "loss": 0.0012, "grad_norm": 0.14754, "time": 0.69556}
+{"mode": "train", "epoch": 4, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05528, "heatmap_loss": 0.00114, "acc_pose": 0.6095, "loss": 0.00114, "grad_norm": 0.12635, "time": 0.7535}
+{"mode": "train", "epoch": 4, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00113, "acc_pose": 0.61405, "loss": 0.00113, "grad_norm": 0.14789, "time": 0.69587}
+{"mode": "train", "epoch": 4, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00108, "acc_pose": 0.63081, "loss": 0.00108, "grad_norm": 0.08684, "time": 0.69598}
+{"mode": "train", "epoch": 4, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00037, "heatmap_loss": 0.00108, "acc_pose": 0.6349, "loss": 0.00108, "grad_norm": 0.11365, "time": 0.69639}
+{"mode": "train", "epoch": 4, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00027, "heatmap_loss": 0.00106, "acc_pose": 0.64164, "loss": 0.00106, "grad_norm": 0.10001, "time": 0.69615}
+{"mode": "train", "epoch": 5, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.055, "heatmap_loss": 0.00103, "acc_pose": 0.65137, "loss": 0.00103, "grad_norm": 0.09576, "time": 0.75338}
+{"mode": "train", "epoch": 5, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00103, "acc_pose": 0.64747, "loss": 0.00103, "grad_norm": 0.11236, "time": 0.69706}
+{"mode": "train", "epoch": 5, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00101, "acc_pose": 0.65191, "loss": 0.00101, "grad_norm": 0.08795, "time": 0.6965}
+{"mode": "train", "epoch": 5, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.001, "acc_pose": 0.665, "loss": 0.001, "grad_norm": 0.0911, "time": 0.69663}
+{"mode": "train", "epoch": 5, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00099, "acc_pose": 0.67084, "loss": 0.00099, "grad_norm": 0.09352, "time": 0.69671}
+{"mode": "train", "epoch": 6, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.0544, "heatmap_loss": 0.00097, "acc_pose": 0.67444, "loss": 0.00097, "grad_norm": 0.09012, "time": 0.75498}
+{"mode": "train", "epoch": 6, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00097, "acc_pose": 0.67268, "loss": 0.00097, "grad_norm": 0.09774, "time": 0.69616}
+{"mode": "train", "epoch": 6, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00098, "acc_pose": 0.67355, "loss": 0.00098, "grad_norm": 0.12428, "time": 0.69681}
+{"mode": "train", "epoch": 6, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00095, "acc_pose": 0.67892, "loss": 0.00095, "grad_norm": 0.08697, "time": 0.69609}
+{"mode": "train", "epoch": 6, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00094, "acc_pose": 0.68988, "loss": 0.00094, "grad_norm": 0.04047, "time": 0.69643}
+{"mode": "train", "epoch": 7, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05581, "heatmap_loss": 0.00093, "acc_pose": 0.68849, "loss": 0.00093, "grad_norm": 0.07157, "time": 0.75393}
+{"mode": "train", "epoch": 7, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00034, "heatmap_loss": 0.00092, "acc_pose": 0.6881, "loss": 0.00092, "grad_norm": 0.06267, "time": 0.69656}
+{"mode": "train", "epoch": 7, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00091, "acc_pose": 0.6877, "loss": 0.00091, "grad_norm": 0.06026, "time": 0.69655}
+{"mode": "train", "epoch": 7, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00026, "heatmap_loss": 0.00091, "acc_pose": 0.69898, "loss": 0.00091, "grad_norm": 0.0694, "time": 0.6961}
+{"mode": "train", "epoch": 7, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0009, "acc_pose": 0.70037, "loss": 0.0009, "grad_norm": 0.05356, "time": 0.69638}
+{"mode": "train", "epoch": 8, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05451, "heatmap_loss": 0.0009, "acc_pose": 0.70245, "loss": 0.0009, "grad_norm": 0.07093, "time": 0.75451}
+{"mode": "train", "epoch": 8, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00089, "acc_pose": 0.70572, "loss": 0.00089, "grad_norm": 0.07298, "time": 0.69624}
+{"mode": "train", "epoch": 8, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00088, "acc_pose": 0.70575, "loss": 0.00088, "grad_norm": 0.03863, "time": 0.69637}
+{"mode": "train", "epoch": 8, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00088, "acc_pose": 0.71028, "loss": 0.00088, "grad_norm": 0.05938, "time": 0.69636}
+{"mode": "train", "epoch": 8, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00087, "acc_pose": 0.70469, "loss": 0.00087, "grad_norm": 0.0476, "time": 0.69654}
+{"mode": "train", "epoch": 9, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05835, "heatmap_loss": 0.00086, "acc_pose": 0.71661, "loss": 0.00086, "grad_norm": 0.05424, "time": 0.75687}
+{"mode": "train", "epoch": 9, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00087, "acc_pose": 0.7197, "loss": 0.00087, "grad_norm": 0.07312, "time": 0.69576}
+{"mode": "train", "epoch": 9, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00086, "acc_pose": 0.72063, "loss": 0.00086, "grad_norm": 0.04031, "time": 0.69645}
+{"mode": "train", "epoch": 9, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00086, "acc_pose": 0.71881, "loss": 0.00086, "grad_norm": 0.03684, "time": 0.69628}
+{"mode": "train", "epoch": 9, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00085, "acc_pose": 0.72263, "loss": 0.00085, "grad_norm": 0.04102, "time": 0.69541}
+{"mode": "train", "epoch": 10, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05499, "heatmap_loss": 0.00085, "acc_pose": 0.72914, "loss": 0.00085, "grad_norm": 0.04856, "time": 0.75393}
+{"mode": "train", "epoch": 10, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00085, "acc_pose": 0.71337, "loss": 0.00085, "grad_norm": 0.05241, "time": 0.69609}
+{"mode": "train", "epoch": 10, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00084, "acc_pose": 0.72701, "loss": 0.00084, "grad_norm": 0.03831, "time": 0.69696}
+{"mode": "train", "epoch": 10, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00083, "acc_pose": 0.72863, "loss": 0.00083, "grad_norm": 0.04784, "time": 0.69664}
+{"mode": "train", "epoch": 10, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00084, "acc_pose": 0.73316, "loss": 0.00084, "grad_norm": 0.05382, "time": 0.69643}
+{"mode": "val", "epoch": 10, "iter": 407, "lr": 0.0, "AP": 0.70828, "AP .5": 0.89337, "AP .75": 0.78857, "AP (M)": 0.63201, "AP (L)": 0.73693, "AR": 0.76637, "AR .5": 0.93372, "AR .75": 0.838, "AR (M)": 0.72267, "AR (L)": 0.82936}
+{"mode": "train", "epoch": 11, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05503, "heatmap_loss": 0.00083, "acc_pose": 0.728, "loss": 0.00083, "grad_norm": 0.0389, "time": 0.74856}
+{"mode": "train", "epoch": 11, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00083, "acc_pose": 0.7275, "loss": 0.00083, "grad_norm": 0.04898, "time": 0.69513}
+{"mode": "train", "epoch": 11, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00034, "heatmap_loss": 0.00083, "acc_pose": 0.73019, "loss": 0.00083, "grad_norm": 0.03439, "time": 0.69578}
+{"mode": "train", "epoch": 11, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00082, "acc_pose": 0.7264, "loss": 0.00082, "grad_norm": 0.03532, "time": 0.69585}
+{"mode": "train", "epoch": 11, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00082, "acc_pose": 0.73625, "loss": 0.00082, "grad_norm": 0.05058, "time": 0.69563}
+{"mode": "train", "epoch": 12, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05623, "heatmap_loss": 0.00081, "acc_pose": 0.74029, "loss": 0.00081, "grad_norm": 0.02524, "time": 0.75372}
+{"mode": "train", "epoch": 12, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0008, "acc_pose": 0.73636, "loss": 0.0008, "grad_norm": 0.02423, "time": 0.69556}
+{"mode": "train", "epoch": 12, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00082, "acc_pose": 0.73611, "loss": 0.00082, "grad_norm": 0.041, "time": 0.69578}
+{"mode": "train", "epoch": 12, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.0008, "acc_pose": 0.7301, "loss": 0.0008, "grad_norm": 0.0322, "time": 0.69583}
+{"mode": "train", "epoch": 12, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00081, "acc_pose": 0.73332, "loss": 0.00081, "grad_norm": 0.02841, "time": 0.69584}
+{"mode": "train", "epoch": 13, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05503, "heatmap_loss": 0.0008, "acc_pose": 0.73849, "loss": 0.0008, "grad_norm": 0.03616, "time": 0.75385}
+{"mode": "train", "epoch": 13, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00079, "acc_pose": 0.74161, "loss": 0.00079, "grad_norm": 0.01908, "time": 0.69629}
+{"mode": "train", "epoch": 13, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00079, "acc_pose": 0.74179, "loss": 0.00079, "grad_norm": 0.02257, "time": 0.69606}
+{"mode": "train", "epoch": 13, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00081, "acc_pose": 0.742, "loss": 0.00081, "grad_norm": 0.0412, "time": 0.69601}
+{"mode": "train", "epoch": 13, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00079, "acc_pose": 0.74822, "loss": 0.00079, "grad_norm": 0.02212, "time": 0.69649}
+{"mode": "train", "epoch": 14, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05544, "heatmap_loss": 0.00079, "acc_pose": 0.74519, "loss": 0.00079, "grad_norm": 0.02162, "time": 0.7532}
+{"mode": "train", "epoch": 14, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00079, "acc_pose": 0.75213, "loss": 0.00079, "grad_norm": 0.02677, "time": 0.69651}
+{"mode": "train", "epoch": 14, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00078, "acc_pose": 0.74337, "loss": 0.00078, "grad_norm": 0.01776, "time": 0.69604}
+{"mode": "train", "epoch": 14, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00078, "acc_pose": 0.75158, "loss": 0.00078, "grad_norm": 0.0255, "time": 0.6959}
+{"mode": "train", "epoch": 14, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00078, "acc_pose": 0.75101, "loss": 0.00078, "grad_norm": 0.01759, "time": 0.69577}
+{"mode": "train", "epoch": 15, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05446, "heatmap_loss": 0.00078, "acc_pose": 0.74275, "loss": 0.00078, "grad_norm": 0.01758, "time": 0.75393}
+{"mode": "train", "epoch": 15, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00078, "acc_pose": 0.74625, "loss": 0.00078, "grad_norm": 0.01843, "time": 0.69559}
+{"mode": "train", "epoch": 15, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00081, "acc_pose": 0.73808, "loss": 0.00081, "grad_norm": 0.05078, "time": 0.69623}
+{"mode": "train", "epoch": 15, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00078, "acc_pose": 0.75355, "loss": 0.00078, "grad_norm": 0.01383, "time": 0.69757}
+{"mode": "train", "epoch": 15, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00077, "acc_pose": 0.75089, "loss": 0.00077, "grad_norm": 0.0101, "time": 0.69659}
+{"mode": "train", "epoch": 16, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05638, "heatmap_loss": 0.00077, "acc_pose": 0.75619, "loss": 0.00077, "grad_norm": 0.00984, "time": 0.75447}
+{"mode": "train", "epoch": 16, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00076, "acc_pose": 0.75551, "loss": 0.00076, "grad_norm": 0.00916, "time": 0.69566}
+{"mode": "train", "epoch": 16, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00076, "acc_pose": 0.74815, "loss": 0.00076, "grad_norm": 0.0089, "time": 0.69635}
+{"mode": "train", "epoch": 16, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00034, "heatmap_loss": 0.00076, "acc_pose": 0.75545, "loss": 0.00076, "grad_norm": 0.00951, "time": 0.69588}
+{"mode": "train", "epoch": 16, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00076, "acc_pose": 0.75955, "loss": 0.00076, "grad_norm": 0.0114, "time": 0.6956}
+{"mode": "train", "epoch": 17, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05582, "heatmap_loss": 0.00076, "acc_pose": 0.75128, "loss": 0.00076, "grad_norm": 0.01854, "time": 0.75305}
+{"mode": "train", "epoch": 17, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00075, "acc_pose": 0.75477, "loss": 0.00075, "grad_norm": 0.00872, "time": 0.69558}
+{"mode": "train", "epoch": 17, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00075, "acc_pose": 0.76379, "loss": 0.00075, "grad_norm": 0.00724, "time": 0.69556}
+{"mode": "train", "epoch": 17, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00075, "acc_pose": 0.76293, "loss": 0.00075, "grad_norm": 0.00833, "time": 0.69586}
+{"mode": "train", "epoch": 17, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00075, "acc_pose": 0.76286, "loss": 0.00075, "grad_norm": 0.00799, "time": 0.69576}
+{"mode": "train", "epoch": 18, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05658, "heatmap_loss": 0.00075, "acc_pose": 0.75753, "loss": 0.00075, "grad_norm": 0.00795, "time": 0.75423}
+{"mode": "train", "epoch": 18, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00049, "heatmap_loss": 0.00075, "acc_pose": 0.76101, "loss": 0.00075, "grad_norm": 0.00973, "time": 0.69582}
+{"mode": "train", "epoch": 18, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00075, "acc_pose": 0.76092, "loss": 0.00075, "grad_norm": 0.01187, "time": 0.69622}
+{"mode": "train", "epoch": 18, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00074, "acc_pose": 0.76321, "loss": 0.00074, "grad_norm": 0.00721, "time": 0.69551}
+{"mode": "train", "epoch": 18, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00035, "heatmap_loss": 0.00074, "acc_pose": 0.76138, "loss": 0.00074, "grad_norm": 0.01141, "time": 0.69554}
+{"mode": "train", "epoch": 19, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05614, "heatmap_loss": 0.00074, "acc_pose": 0.75963, "loss": 0.00074, "grad_norm": 0.00706, "time": 0.75256}
+{"mode": "train", "epoch": 19, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00074, "acc_pose": 0.75992, "loss": 0.00074, "grad_norm": 0.00695, "time": 0.69615}
+{"mode": "train", "epoch": 19, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00074, "acc_pose": 0.74971, "loss": 0.00074, "grad_norm": 0.00932, "time": 0.6961}
+{"mode": "train", "epoch": 19, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00041, "heatmap_loss": 0.00075, "acc_pose": 0.75948, "loss": 0.00075, "grad_norm": 0.01314, "time": 0.69617}
+{"mode": "train", "epoch": 19, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00073, "acc_pose": 0.77009, "loss": 0.00073, "grad_norm": 0.00619, "time": 0.69573}
+{"mode": "train", "epoch": 20, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05706, "heatmap_loss": 0.00073, "acc_pose": 0.76716, "loss": 0.00073, "grad_norm": 0.0055, "time": 0.75365}
+{"mode": "train", "epoch": 20, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00034, "heatmap_loss": 0.00073, "acc_pose": 0.77197, "loss": 0.00073, "grad_norm": 0.00362, "time": 0.69555}
+{"mode": "train", "epoch": 20, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00034, "heatmap_loss": 0.00073, "acc_pose": 0.76223, "loss": 0.00073, "grad_norm": 0.00499, "time": 0.69552}
+{"mode": "train", "epoch": 20, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00034, "heatmap_loss": 0.00074, "acc_pose": 0.76941, "loss": 0.00074, "grad_norm": 0.00545, "time": 0.69573}
+{"mode": "train", "epoch": 20, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00034, "heatmap_loss": 0.00073, "acc_pose": 0.76357, "loss": 0.00073, "grad_norm": 0.00496, "time": 0.69584}
+{"mode": "val", "epoch": 20, "iter": 407, "lr": 0.0, "AP": 0.73847, "AP .5": 0.90222, "AP .75": 0.81752, "AP (M)": 0.66397, "AP (L)": 0.76326, "AR": 0.79444, "AR .5": 0.94159, "AR .75": 0.86477, "AR (M)": 0.75198, "AR (L)": 0.85563}
+{"mode": "train", "epoch": 21, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05688, "heatmap_loss": 0.00073, "acc_pose": 0.77141, "loss": 0.00073, "grad_norm": 0.00477, "time": 0.75252}
+{"mode": "train", "epoch": 21, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00073, "acc_pose": 0.77438, "loss": 0.00073, "grad_norm": 0.00378, "time": 0.69598}
+{"mode": "train", "epoch": 21, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00073, "acc_pose": 0.76814, "loss": 0.00073, "grad_norm": 0.00325, "time": 0.69589}
+{"mode": "train", "epoch": 21, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00073, "acc_pose": 0.76952, "loss": 0.00073, "grad_norm": 0.00336, "time": 0.69543}
+{"mode": "train", "epoch": 21, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00073, "acc_pose": 0.77607, "loss": 0.00073, "grad_norm": 0.00387, "time": 0.69595}
+{"mode": "train", "epoch": 22, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05665, "heatmap_loss": 0.00073, "acc_pose": 0.77325, "loss": 0.00073, "grad_norm": 0.00528, "time": 0.75276}
+{"mode": "train", "epoch": 22, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00072, "acc_pose": 0.77093, "loss": 0.00072, "grad_norm": 0.00412, "time": 0.6955}
+{"mode": "train", "epoch": 22, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00072, "acc_pose": 0.76606, "loss": 0.00072, "grad_norm": 0.00334, "time": 0.69533}
+{"mode": "train", "epoch": 22, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00072, "acc_pose": 0.78132, "loss": 0.00072, "grad_norm": 0.00272, "time": 0.69581}
+{"mode": "train", "epoch": 22, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00072, "acc_pose": 0.77508, "loss": 0.00072, "grad_norm": 0.00249, "time": 0.6952}
+{"mode": "train", "epoch": 23, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05586, "heatmap_loss": 0.00072, "acc_pose": 0.77034, "loss": 0.00072, "grad_norm": 0.00413, "time": 0.75358}
+{"mode": "train", "epoch": 23, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00072, "acc_pose": 0.76627, "loss": 0.00072, "grad_norm": 0.00213, "time": 0.6956}
+{"mode": "train", "epoch": 23, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00071, "acc_pose": 0.77458, "loss": 0.00071, "grad_norm": 0.0025, "time": 0.69597}
+{"mode": "train", "epoch": 23, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00071, "acc_pose": 0.7784, "loss": 0.00071, "grad_norm": 0.00205, "time": 0.69571}
+{"mode": "train", "epoch": 23, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00071, "acc_pose": 0.77409, "loss": 0.00071, "grad_norm": 0.00193, "time": 0.69616}
+{"mode": "train", "epoch": 24, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05606, "heatmap_loss": 0.00071, "acc_pose": 0.77467, "loss": 0.00071, "grad_norm": 0.00204, "time": 0.75288}
+{"mode": "train", "epoch": 24, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00071, "acc_pose": 0.78462, "loss": 0.00071, "grad_norm": 0.00205, "time": 0.69509}
+{"mode": "train", "epoch": 24, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00071, "acc_pose": 0.77292, "loss": 0.00071, "grad_norm": 0.00185, "time": 0.69528}
+{"mode": "train", "epoch": 24, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00071, "acc_pose": 0.76935, "loss": 0.00071, "grad_norm": 0.00177, "time": 0.69535}
+{"mode": "train", "epoch": 24, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00071, "acc_pose": 0.77851, "loss": 0.00071, "grad_norm": 0.002, "time": 0.69535}
+{"mode": "train", "epoch": 25, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05588, "heatmap_loss": 0.0007, "acc_pose": 0.78087, "loss": 0.0007, "grad_norm": 0.00188, "time": 0.75351}
+{"mode": "train", "epoch": 25, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.0007, "acc_pose": 0.77671, "loss": 0.0007, "grad_norm": 0.00169, "time": 0.69555}
+{"mode": "train", "epoch": 25, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0007, "acc_pose": 0.77389, "loss": 0.0007, "grad_norm": 0.00166, "time": 0.69565}
+{"mode": "train", "epoch": 25, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00071, "acc_pose": 0.77568, "loss": 0.00071, "grad_norm": 0.00171, "time": 0.69577}
+{"mode": "train", "epoch": 25, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0007, "acc_pose": 0.77717, "loss": 0.0007, "grad_norm": 0.00162, "time": 0.69543}
+{"mode": "train", "epoch": 26, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05625, "heatmap_loss": 0.0007, "acc_pose": 0.77567, "loss": 0.0007, "grad_norm": 0.00164, "time": 0.75267}
+{"mode": "train", "epoch": 26, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0007, "acc_pose": 0.77489, "loss": 0.0007, "grad_norm": 0.00149, "time": 0.69565}
+{"mode": "train", "epoch": 26, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0007, "acc_pose": 0.77794, "loss": 0.0007, "grad_norm": 0.00141, "time": 0.69618}
+{"mode": "train", "epoch": 26, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0007, "acc_pose": 0.77684, "loss": 0.0007, "grad_norm": 0.00151, "time": 0.69577}
+{"mode": "train", "epoch": 26, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00069, "acc_pose": 0.78441, "loss": 0.00069, "grad_norm": 0.00151, "time": 0.69577}
+{"mode": "train", "epoch": 27, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.0558, "heatmap_loss": 0.0007, "acc_pose": 0.78548, "loss": 0.0007, "grad_norm": 0.00156, "time": 0.75392}
+{"mode": "train", "epoch": 27, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.0007, "acc_pose": 0.78606, "loss": 0.0007, "grad_norm": 0.00152, "time": 0.69585}
+{"mode": "train", "epoch": 27, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.0007, "acc_pose": 0.78338, "loss": 0.0007, "grad_norm": 0.00141, "time": 0.69585}
+{"mode": "train", "epoch": 27, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0007, "acc_pose": 0.78702, "loss": 0.0007, "grad_norm": 0.0014, "time": 0.69551}
+{"mode": "train", "epoch": 27, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00069, "acc_pose": 0.77891, "loss": 0.00069, "grad_norm": 0.00141, "time": 0.69551}
+{"mode": "train", "epoch": 28, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05625, "heatmap_loss": 0.00069, "acc_pose": 0.78498, "loss": 0.00069, "grad_norm": 0.0014, "time": 0.75421}
+{"mode": "train", "epoch": 28, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00069, "acc_pose": 0.77939, "loss": 0.00069, "grad_norm": 0.0013, "time": 0.69555}
+{"mode": "train", "epoch": 28, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00035, "heatmap_loss": 0.00069, "acc_pose": 0.7789, "loss": 0.00069, "grad_norm": 0.00135, "time": 0.69601}
+{"mode": "train", "epoch": 28, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00069, "acc_pose": 0.78564, "loss": 0.00069, "grad_norm": 0.00136, "time": 0.69531}
+{"mode": "train", "epoch": 28, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00069, "acc_pose": 0.78303, "loss": 0.00069, "grad_norm": 0.00132, "time": 0.69523}
+{"mode": "train", "epoch": 29, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05669, "heatmap_loss": 0.00069, "acc_pose": 0.7868, "loss": 0.00069, "grad_norm": 0.00138, "time": 0.75283}
+{"mode": "train", "epoch": 29, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00069, "acc_pose": 0.78239, "loss": 0.00069, "grad_norm": 0.00132, "time": 0.69546}
+{"mode": "train", "epoch": 29, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00035, "heatmap_loss": 0.00069, "acc_pose": 0.78125, "loss": 0.00069, "grad_norm": 0.00127, "time": 0.69588}
+{"mode": "train", "epoch": 29, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00069, "acc_pose": 0.78721, "loss": 0.00069, "grad_norm": 0.00128, "time": 0.69577}
+{"mode": "train", "epoch": 29, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00068, "acc_pose": 0.78377, "loss": 0.00068, "grad_norm": 0.00128, "time": 0.69511}
+{"mode": "train", "epoch": 30, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05613, "heatmap_loss": 0.00068, "acc_pose": 0.77982, "loss": 0.00068, "grad_norm": 0.00127, "time": 0.75285}
+{"mode": "train", "epoch": 30, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00069, "acc_pose": 0.78863, "loss": 0.00069, "grad_norm": 0.00134, "time": 0.69521}
+{"mode": "train", "epoch": 30, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00068, "acc_pose": 0.7862, "loss": 0.00068, "grad_norm": 0.00128, "time": 0.69517}
+{"mode": "train", "epoch": 30, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00068, "acc_pose": 0.78756, "loss": 0.00068, "grad_norm": 0.00126, "time": 0.69538}
+{"mode": "train", "epoch": 30, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00068, "acc_pose": 0.78774, "loss": 0.00068, "grad_norm": 0.00129, "time": 0.69569}
+{"mode": "val", "epoch": 30, "iter": 407, "lr": 0.0, "AP": 0.75186, "AP .5": 0.90538, "AP .75": 0.82958, "AP (M)": 0.67827, "AP (L)": 0.77732, "AR": 0.80705, "AR .5": 0.94616, "AR .75": 0.87531, "AR (M)": 0.76575, "AR (L)": 0.86696}
+{"mode": "train", "epoch": 31, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05478, "heatmap_loss": 0.00068, "acc_pose": 0.78942, "loss": 0.00068, "grad_norm": 0.00126, "time": 0.74822}
+{"mode": "train", "epoch": 31, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00068, "acc_pose": 0.78511, "loss": 0.00068, "grad_norm": 0.00128, "time": 0.69449}
+{"mode": "train", "epoch": 31, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00068, "acc_pose": 0.78658, "loss": 0.00068, "grad_norm": 0.00131, "time": 0.69496}
+{"mode": "train", "epoch": 31, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00068, "acc_pose": 0.7889, "loss": 0.00068, "grad_norm": 0.00127, "time": 0.69466}
+{"mode": "train", "epoch": 31, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00068, "acc_pose": 0.79464, "loss": 0.00068, "grad_norm": 0.00125, "time": 0.69499}
+{"mode": "train", "epoch": 32, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.0565, "heatmap_loss": 0.00068, "acc_pose": 0.79264, "loss": 0.00068, "grad_norm": 0.00124, "time": 0.75355}
+{"mode": "train", "epoch": 32, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00068, "acc_pose": 0.79763, "loss": 0.00068, "grad_norm": 0.00122, "time": 0.69604}
+{"mode": "train", "epoch": 32, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00028, "heatmap_loss": 0.00067, "acc_pose": 0.78514, "loss": 0.00067, "grad_norm": 0.00124, "time": 0.69561}
+{"mode": "train", "epoch": 32, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00067, "acc_pose": 0.79703, "loss": 0.00067, "grad_norm": 0.00128, "time": 0.69527}
+{"mode": "train", "epoch": 32, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00067, "acc_pose": 0.79587, "loss": 0.00067, "grad_norm": 0.0013, "time": 0.69536}
+{"mode": "train", "epoch": 33, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05627, "heatmap_loss": 0.00067, "acc_pose": 0.7946, "loss": 0.00067, "grad_norm": 0.00128, "time": 0.75283}
+{"mode": "train", "epoch": 33, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00068, "acc_pose": 0.78967, "loss": 0.00068, "grad_norm": 0.00126, "time": 0.69522}
+{"mode": "train", "epoch": 33, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00067, "acc_pose": 0.79698, "loss": 0.00067, "grad_norm": 0.00124, "time": 0.69536}
+{"mode": "train", "epoch": 33, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00068, "acc_pose": 0.79289, "loss": 0.00068, "grad_norm": 0.00131, "time": 0.69505}
+{"mode": "train", "epoch": 33, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00067, "acc_pose": 0.79768, "loss": 0.00067, "grad_norm": 0.00123, "time": 0.6952}
+{"mode": "train", "epoch": 34, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05585, "heatmap_loss": 0.00067, "acc_pose": 0.7883, "loss": 0.00067, "grad_norm": 0.00126, "time": 0.7524}
+{"mode": "train", "epoch": 34, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00034, "heatmap_loss": 0.00067, "acc_pose": 0.79129, "loss": 0.00067, "grad_norm": 0.00133, "time": 0.69481}
+{"mode": "train", "epoch": 34, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00067, "acc_pose": 0.7955, "loss": 0.00067, "grad_norm": 0.00127, "time": 0.69519}
+{"mode": "train", "epoch": 34, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00048, "heatmap_loss": 0.00067, "acc_pose": 0.79428, "loss": 0.00067, "grad_norm": 0.0013, "time": 0.69498}
+{"mode": "train", "epoch": 34, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00067, "acc_pose": 0.79421, "loss": 0.00067, "grad_norm": 0.00131, "time": 0.69574}
+{"mode": "train", "epoch": 35, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.0596, "heatmap_loss": 0.00066, "acc_pose": 0.79367, "loss": 0.00066, "grad_norm": 0.00126, "time": 0.75606}
+{"mode": "train", "epoch": 35, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00028, "heatmap_loss": 0.00067, "acc_pose": 0.79199, "loss": 0.00067, "grad_norm": 0.00123, "time": 0.69544}
+{"mode": "train", "epoch": 35, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00066, "acc_pose": 0.78903, "loss": 0.00066, "grad_norm": 0.00124, "time": 0.69548}
+{"mode": "train", "epoch": 35, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00067, "acc_pose": 0.79751, "loss": 0.00067, "grad_norm": 0.00126, "time": 0.69575}
+{"mode": "train", "epoch": 35, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00066, "acc_pose": 0.80051, "loss": 0.00066, "grad_norm": 0.00133, "time": 0.69487}
+{"mode": "train", "epoch": 36, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05567, "heatmap_loss": 0.00066, "acc_pose": 0.79199, "loss": 0.00066, "grad_norm": 0.0012, "time": 0.75207}
+{"mode": "train", "epoch": 36, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00067, "acc_pose": 0.79775, "loss": 0.00067, "grad_norm": 0.0013, "time": 0.69516}
+{"mode": "train", "epoch": 36, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00066, "acc_pose": 0.79125, "loss": 0.00066, "grad_norm": 0.00119, "time": 0.6953}
+{"mode": "train", "epoch": 36, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00066, "acc_pose": 0.79808, "loss": 0.00066, "grad_norm": 0.00134, "time": 0.6955}
+{"mode": "train", "epoch": 36, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00066, "acc_pose": 0.79217, "loss": 0.00066, "grad_norm": 0.00121, "time": 0.69509}
+{"mode": "train", "epoch": 37, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05562, "heatmap_loss": 0.00066, "acc_pose": 0.79065, "loss": 0.00066, "grad_norm": 0.00126, "time": 0.7542}
+{"mode": "train", "epoch": 37, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00026, "heatmap_loss": 0.00067, "acc_pose": 0.79073, "loss": 0.00067, "grad_norm": 0.00124, "time": 0.69587}
+{"mode": "train", "epoch": 37, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00066, "acc_pose": 0.79235, "loss": 0.00066, "grad_norm": 0.0012, "time": 0.69514}
+{"mode": "train", "epoch": 37, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00066, "acc_pose": 0.80341, "loss": 0.00066, "grad_norm": 0.00123, "time": 0.69534}
+{"mode": "train", "epoch": 37, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00066, "acc_pose": 0.79145, "loss": 0.00066, "grad_norm": 0.00117, "time": 0.6949}
+{"mode": "train", "epoch": 38, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05623, "heatmap_loss": 0.00066, "acc_pose": 0.79894, "loss": 0.00066, "grad_norm": 0.0012, "time": 0.7547}
+{"mode": "train", "epoch": 38, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00066, "acc_pose": 0.79898, "loss": 0.00066, "grad_norm": 0.00125, "time": 0.69532}
+{"mode": "train", "epoch": 38, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00066, "acc_pose": 0.79647, "loss": 0.00066, "grad_norm": 0.00125, "time": 0.6955}
+{"mode": "train", "epoch": 38, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00066, "acc_pose": 0.79656, "loss": 0.00066, "grad_norm": 0.0012, "time": 0.6949}
+{"mode": "train", "epoch": 38, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00066, "acc_pose": 0.79245, "loss": 0.00066, "grad_norm": 0.0012, "time": 0.69484}
+{"mode": "train", "epoch": 39, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05602, "heatmap_loss": 0.00066, "acc_pose": 0.79636, "loss": 0.00066, "grad_norm": 0.00124, "time": 0.75158}
+{"mode": "train", "epoch": 39, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00065, "acc_pose": 0.79728, "loss": 0.00065, "grad_norm": 0.00134, "time": 0.69523}
+{"mode": "train", "epoch": 39, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00065, "acc_pose": 0.79335, "loss": 0.00065, "grad_norm": 0.00128, "time": 0.69534}
+{"mode": "train", "epoch": 39, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00066, "acc_pose": 0.79153, "loss": 0.00066, "grad_norm": 0.00119, "time": 0.69505}
+{"mode": "train", "epoch": 39, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00066, "acc_pose": 0.79425, "loss": 0.00066, "grad_norm": 0.00128, "time": 0.69472}
+{"mode": "train", "epoch": 40, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05592, "heatmap_loss": 0.00065, "acc_pose": 0.8023, "loss": 0.00065, "grad_norm": 0.00118, "time": 0.75257}
+{"mode": "train", "epoch": 40, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00065, "acc_pose": 0.79401, "loss": 0.00065, "grad_norm": 0.00122, "time": 0.69539}
+{"mode": "train", "epoch": 40, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00066, "acc_pose": 0.80023, "loss": 0.00066, "grad_norm": 0.00121, "time": 0.6952}
+{"mode": "train", "epoch": 40, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00066, "acc_pose": 0.79573, "loss": 0.00066, "grad_norm": 0.00119, "time": 0.69521}
+{"mode": "train", "epoch": 40, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00065, "acc_pose": 0.80177, "loss": 0.00065, "grad_norm": 0.00122, "time": 0.69537}
+{"mode": "val", "epoch": 40, "iter": 407, "lr": 0.0, "AP": 0.75691, "AP .5": 0.90678, "AP .75": 0.83128, "AP (M)": 0.68208, "AP (L)": 0.78327, "AR": 0.81272, "AR .5": 0.94789, "AR .75": 0.87736, "AR (M)": 0.77088, "AR (L)": 0.87347}
+{"mode": "train", "epoch": 41, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05499, "heatmap_loss": 0.00065, "acc_pose": 0.80236, "loss": 0.00065, "grad_norm": 0.00119, "time": 0.74832}
+{"mode": "train", "epoch": 41, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00065, "acc_pose": 0.79906, "loss": 0.00065, "grad_norm": 0.00126, "time": 0.69511}
+{"mode": "train", "epoch": 41, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00065, "acc_pose": 0.80588, "loss": 0.00065, "grad_norm": 0.0012, "time": 0.69574}
+{"mode": "train", "epoch": 41, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00065, "acc_pose": 0.80054, "loss": 0.00065, "grad_norm": 0.00117, "time": 0.69512}
+{"mode": "train", "epoch": 41, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00065, "acc_pose": 0.79445, "loss": 0.00065, "grad_norm": 0.00123, "time": 0.69537}
+{"mode": "train", "epoch": 42, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05526, "heatmap_loss": 0.00065, "acc_pose": 0.79951, "loss": 0.00065, "grad_norm": 0.00117, "time": 0.75122}
+{"mode": "train", "epoch": 42, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00065, "acc_pose": 0.79579, "loss": 0.00065, "grad_norm": 0.00121, "time": 0.69532}
+{"mode": "train", "epoch": 42, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00065, "acc_pose": 0.79467, "loss": 0.00065, "grad_norm": 0.0012, "time": 0.69531}
+{"mode": "train", "epoch": 42, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00065, "acc_pose": 0.80078, "loss": 0.00065, "grad_norm": 0.00119, "time": 0.69528}
+{"mode": "train", "epoch": 42, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00065, "acc_pose": 0.79756, "loss": 0.00065, "grad_norm": 0.00127, "time": 0.69499}
+{"mode": "train", "epoch": 43, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05633, "heatmap_loss": 0.00065, "acc_pose": 0.80595, "loss": 0.00065, "grad_norm": 0.00118, "time": 0.75211}
+{"mode": "train", "epoch": 43, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00065, "acc_pose": 0.80364, "loss": 0.00065, "grad_norm": 0.00121, "time": 0.69534}
+{"mode": "train", "epoch": 43, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00065, "acc_pose": 0.80246, "loss": 0.00065, "grad_norm": 0.00125, "time": 0.69532}
+{"mode": "train", "epoch": 43, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00065, "acc_pose": 0.80166, "loss": 0.00065, "grad_norm": 0.00121, "time": 0.69563}
+{"mode": "train", "epoch": 43, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00064, "acc_pose": 0.81199, "loss": 0.00064, "grad_norm": 0.00118, "time": 0.69509}
+{"mode": "train", "epoch": 44, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.0557, "heatmap_loss": 0.00064, "acc_pose": 0.80713, "loss": 0.00064, "grad_norm": 0.0012, "time": 0.75205}
+{"mode": "train", "epoch": 44, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00064, "acc_pose": 0.80058, "loss": 0.00064, "grad_norm": 0.00119, "time": 0.69514}
+{"mode": "train", "epoch": 44, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00065, "acc_pose": 0.80109, "loss": 0.00065, "grad_norm": 0.00119, "time": 0.69507}
+{"mode": "train", "epoch": 44, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00064, "acc_pose": 0.80349, "loss": 0.00064, "grad_norm": 0.00118, "time": 0.69531}
+{"mode": "train", "epoch": 44, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00064, "acc_pose": 0.8025, "loss": 0.00064, "grad_norm": 0.00116, "time": 0.69527}
+{"mode": "train", "epoch": 45, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05665, "heatmap_loss": 0.00064, "acc_pose": 0.80466, "loss": 0.00064, "grad_norm": 0.00121, "time": 0.75215}
+{"mode": "train", "epoch": 45, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00064, "acc_pose": 0.8008, "loss": 0.00064, "grad_norm": 0.00123, "time": 0.69552}
+{"mode": "train", "epoch": 45, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00064, "acc_pose": 0.79911, "loss": 0.00064, "grad_norm": 0.00118, "time": 0.69516}
+{"mode": "train", "epoch": 45, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00041, "heatmap_loss": 0.00064, "acc_pose": 0.79881, "loss": 0.00064, "grad_norm": 0.0012, "time": 0.69511}
+{"mode": "train", "epoch": 45, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00064, "acc_pose": 0.80615, "loss": 0.00064, "grad_norm": 0.00118, "time": 0.69479}
+{"mode": "train", "epoch": 46, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05651, "heatmap_loss": 0.00064, "acc_pose": 0.8037, "loss": 0.00064, "grad_norm": 0.00122, "time": 0.75194}
+{"mode": "train", "epoch": 46, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00064, "acc_pose": 0.80651, "loss": 0.00064, "grad_norm": 0.00119, "time": 0.69526}
+{"mode": "train", "epoch": 46, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00064, "acc_pose": 0.79929, "loss": 0.00064, "grad_norm": 0.00122, "time": 0.69502}
+{"mode": "train", "epoch": 46, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00064, "acc_pose": 0.80247, "loss": 0.00064, "grad_norm": 0.00123, "time": 0.6954}
+{"mode": "train", "epoch": 46, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00064, "acc_pose": 0.80379, "loss": 0.00064, "grad_norm": 0.00126, "time": 0.69502}
+{"mode": "train", "epoch": 47, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05638, "heatmap_loss": 0.00064, "acc_pose": 0.80186, "loss": 0.00064, "grad_norm": 0.00119, "time": 0.75305}
+{"mode": "train", "epoch": 47, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00064, "acc_pose": 0.8113, "loss": 0.00064, "grad_norm": 0.00123, "time": 0.69552}
+{"mode": "train", "epoch": 47, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00028, "heatmap_loss": 0.00064, "acc_pose": 0.79661, "loss": 0.00064, "grad_norm": 0.00116, "time": 0.69491}
+{"mode": "train", "epoch": 47, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00064, "acc_pose": 0.80651, "loss": 0.00064, "grad_norm": 0.00126, "time": 0.69508}
+{"mode": "train", "epoch": 47, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00064, "acc_pose": 0.81079, "loss": 0.00064, "grad_norm": 0.00114, "time": 0.69425}
+{"mode": "train", "epoch": 48, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05617, "heatmap_loss": 0.00063, "acc_pose": 0.80848, "loss": 0.00063, "grad_norm": 0.00117, "time": 0.75455}
+{"mode": "train", "epoch": 48, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00063, "acc_pose": 0.80096, "loss": 0.00063, "grad_norm": 0.00121, "time": 0.6954}
+{"mode": "train", "epoch": 48, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00063, "acc_pose": 0.80798, "loss": 0.00063, "grad_norm": 0.00122, "time": 0.69587}
+{"mode": "train", "epoch": 48, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00064, "acc_pose": 0.80545, "loss": 0.00064, "grad_norm": 0.00118, "time": 0.69584}
+{"mode": "train", "epoch": 48, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00036, "heatmap_loss": 0.00064, "acc_pose": 0.80954, "loss": 0.00064, "grad_norm": 0.00116, "time": 0.69527}
+{"mode": "train", "epoch": 49, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05579, "heatmap_loss": 0.00064, "acc_pose": 0.80389, "loss": 0.00064, "grad_norm": 0.00119, "time": 0.75266}
+{"mode": "train", "epoch": 49, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00064, "acc_pose": 0.80133, "loss": 0.00064, "grad_norm": 0.00125, "time": 0.69473}
+{"mode": "train", "epoch": 49, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00041, "heatmap_loss": 0.00063, "acc_pose": 0.80561, "loss": 0.00063, "grad_norm": 0.00115, "time": 0.69569}
+{"mode": "train", "epoch": 49, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00063, "acc_pose": 0.8016, "loss": 0.00063, "grad_norm": 0.00119, "time": 0.69541}
+{"mode": "train", "epoch": 49, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00064, "acc_pose": 0.8109, "loss": 0.00064, "grad_norm": 0.00119, "time": 0.69534}
+{"mode": "train", "epoch": 50, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05531, "heatmap_loss": 0.00063, "acc_pose": 0.81558, "loss": 0.00063, "grad_norm": 0.00119, "time": 0.7517}
+{"mode": "train", "epoch": 50, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00063, "acc_pose": 0.80449, "loss": 0.00063, "grad_norm": 0.00119, "time": 0.69551}
+{"mode": "train", "epoch": 50, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00063, "acc_pose": 0.80852, "loss": 0.00063, "grad_norm": 0.00119, "time": 0.69565}
+{"mode": "train", "epoch": 50, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00063, "acc_pose": 0.80748, "loss": 0.00063, "grad_norm": 0.0012, "time": 0.69537}
+{"mode": "train", "epoch": 50, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00034, "heatmap_loss": 0.00063, "acc_pose": 0.80117, "loss": 0.00063, "grad_norm": 0.00117, "time": 0.69476}
+{"mode": "val", "epoch": 50, "iter": 407, "lr": 0.0, "AP": 0.76138, "AP .5": 0.90762, "AP .75": 0.83584, "AP (M)": 0.68764, "AP (L)": 0.78745, "AR": 0.81633, "AR .5": 0.94915, "AR .75": 0.88098, "AR (M)": 0.77506, "AR (L)": 0.8764}
+{"mode": "train", "epoch": 51, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05631, "heatmap_loss": 0.00062, "acc_pose": 0.81414, "loss": 0.00062, "grad_norm": 0.00121, "time": 0.75093}
+{"mode": "train", "epoch": 51, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00063, "acc_pose": 0.80669, "loss": 0.00063, "grad_norm": 0.00117, "time": 0.69523}
+{"mode": "train", "epoch": 51, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00063, "acc_pose": 0.80804, "loss": 0.00063, "grad_norm": 0.00123, "time": 0.69488}
+{"mode": "train", "epoch": 51, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00063, "acc_pose": 0.81175, "loss": 0.00063, "grad_norm": 0.00119, "time": 0.69524}
+{"mode": "train", "epoch": 51, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00063, "acc_pose": 0.8133, "loss": 0.00063, "grad_norm": 0.00114, "time": 0.69539}
+{"mode": "train", "epoch": 52, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05542, "heatmap_loss": 0.00063, "acc_pose": 0.81117, "loss": 0.00063, "grad_norm": 0.0012, "time": 0.75106}
+{"mode": "train", "epoch": 52, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00063, "acc_pose": 0.81516, "loss": 0.00063, "grad_norm": 0.00115, "time": 0.6959}
+{"mode": "train", "epoch": 52, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00063, "acc_pose": 0.811, "loss": 0.00063, "grad_norm": 0.00122, "time": 0.69578}
+{"mode": "train", "epoch": 52, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00062, "acc_pose": 0.80993, "loss": 0.00062, "grad_norm": 0.00115, "time": 0.69555}
+{"mode": "train", "epoch": 52, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00063, "acc_pose": 0.80685, "loss": 0.00063, "grad_norm": 0.00118, "time": 0.69518}
+{"mode": "train", "epoch": 53, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05555, "heatmap_loss": 0.00063, "acc_pose": 0.81119, "loss": 0.00063, "grad_norm": 0.00118, "time": 0.75264}
+{"mode": "train", "epoch": 53, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00028, "heatmap_loss": 0.00063, "acc_pose": 0.80723, "loss": 0.00063, "grad_norm": 0.00114, "time": 0.6954}
+{"mode": "train", "epoch": 53, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00049, "heatmap_loss": 0.00062, "acc_pose": 0.81115, "loss": 0.00062, "grad_norm": 0.00116, "time": 0.69584}
+{"mode": "train", "epoch": 53, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00039, "heatmap_loss": 0.00063, "acc_pose": 0.81204, "loss": 0.00063, "grad_norm": 0.00117, "time": 0.69562}
+{"mode": "train", "epoch": 53, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00063, "acc_pose": 0.80801, "loss": 0.00063, "grad_norm": 0.00121, "time": 0.69576}
+{"mode": "train", "epoch": 54, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05649, "heatmap_loss": 0.00062, "acc_pose": 0.8128, "loss": 0.00062, "grad_norm": 0.00116, "time": 0.75318}
+{"mode": "train", "epoch": 54, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00063, "acc_pose": 0.80764, "loss": 0.00063, "grad_norm": 0.00116, "time": 0.69499}
+{"mode": "train", "epoch": 54, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00062, "acc_pose": 0.81188, "loss": 0.00062, "grad_norm": 0.00114, "time": 0.69576}
+{"mode": "train", "epoch": 54, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00063, "acc_pose": 0.81275, "loss": 0.00063, "grad_norm": 0.00113, "time": 0.69496}
+{"mode": "train", "epoch": 54, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00063, "acc_pose": 0.81171, "loss": 0.00063, "grad_norm": 0.00115, "time": 0.69471}
+{"mode": "train", "epoch": 55, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05622, "heatmap_loss": 0.00062, "acc_pose": 0.81553, "loss": 0.00062, "grad_norm": 0.00116, "time": 0.75293}
+{"mode": "train", "epoch": 55, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00062, "acc_pose": 0.80452, "loss": 0.00062, "grad_norm": 0.00114, "time": 0.69566}
+{"mode": "train", "epoch": 55, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00063, "acc_pose": 0.8055, "loss": 0.00063, "grad_norm": 0.00117, "time": 0.69504}
+{"mode": "train", "epoch": 55, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00062, "acc_pose": 0.8147, "loss": 0.00062, "grad_norm": 0.00111, "time": 0.69498}
+{"mode": "train", "epoch": 55, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00062, "acc_pose": 0.81093, "loss": 0.00062, "grad_norm": 0.00117, "time": 0.69484}
+{"mode": "train", "epoch": 56, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05885, "heatmap_loss": 0.00063, "acc_pose": 0.81078, "loss": 0.00063, "grad_norm": 0.00118, "time": 0.75666}
+{"mode": "train", "epoch": 56, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00062, "acc_pose": 0.81164, "loss": 0.00062, "grad_norm": 0.00115, "time": 0.69502}
+{"mode": "train", "epoch": 56, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00062, "acc_pose": 0.80789, "loss": 0.00062, "grad_norm": 0.00124, "time": 0.69524}
+{"mode": "train", "epoch": 56, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00062, "acc_pose": 0.80512, "loss": 0.00062, "grad_norm": 0.00118, "time": 0.69569}
+{"mode": "train", "epoch": 56, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00062, "acc_pose": 0.80859, "loss": 0.00062, "grad_norm": 0.00121, "time": 0.69533}
+{"mode": "train", "epoch": 57, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05641, "heatmap_loss": 0.00062, "acc_pose": 0.81332, "loss": 0.00062, "grad_norm": 0.00116, "time": 0.75287}
+{"mode": "train", "epoch": 57, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00061, "acc_pose": 0.80848, "loss": 0.00061, "grad_norm": 0.00116, "time": 0.69623}
+{"mode": "train", "epoch": 57, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00062, "acc_pose": 0.81301, "loss": 0.00062, "grad_norm": 0.00112, "time": 0.69515}
+{"mode": "train", "epoch": 57, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00062, "acc_pose": 0.81936, "loss": 0.00062, "grad_norm": 0.00115, "time": 0.69557}
+{"mode": "train", "epoch": 57, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00062, "acc_pose": 0.81109, "loss": 0.00062, "grad_norm": 0.00112, "time": 0.69499}
+{"mode": "train", "epoch": 58, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05697, "heatmap_loss": 0.00062, "acc_pose": 0.81522, "loss": 0.00062, "grad_norm": 0.00119, "time": 0.75304}
+{"mode": "train", "epoch": 58, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00062, "acc_pose": 0.8105, "loss": 0.00062, "grad_norm": 0.00119, "time": 0.69518}
+{"mode": "train", "epoch": 58, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00062, "acc_pose": 0.81129, "loss": 0.00062, "grad_norm": 0.00116, "time": 0.69533}
+{"mode": "train", "epoch": 58, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00062, "acc_pose": 0.8194, "loss": 0.00062, "grad_norm": 0.00116, "time": 0.69551}
+{"mode": "train", "epoch": 58, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00062, "acc_pose": 0.81521, "loss": 0.00062, "grad_norm": 0.00119, "time": 0.69544}
+{"mode": "train", "epoch": 59, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05695, "heatmap_loss": 0.00061, "acc_pose": 0.81845, "loss": 0.00061, "grad_norm": 0.00113, "time": 0.75261}
+{"mode": "train", "epoch": 59, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00062, "acc_pose": 0.815, "loss": 0.00062, "grad_norm": 0.00116, "time": 0.69566}
+{"mode": "train", "epoch": 59, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00062, "acc_pose": 0.81527, "loss": 0.00062, "grad_norm": 0.00118, "time": 0.69559}
+{"mode": "train", "epoch": 59, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00061, "acc_pose": 0.81372, "loss": 0.00061, "grad_norm": 0.0012, "time": 0.69485}
+{"mode": "train", "epoch": 59, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00062, "acc_pose": 0.81618, "loss": 0.00062, "grad_norm": 0.00115, "time": 0.69541}
+{"mode": "train", "epoch": 60, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05572, "heatmap_loss": 0.00061, "acc_pose": 0.81602, "loss": 0.00061, "grad_norm": 0.00112, "time": 0.75183}
+{"mode": "train", "epoch": 60, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00061, "acc_pose": 0.80952, "loss": 0.00061, "grad_norm": 0.00114, "time": 0.69514}
+{"mode": "train", "epoch": 60, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00062, "acc_pose": 0.80912, "loss": 0.00062, "grad_norm": 0.0011, "time": 0.6951}
+{"mode": "train", "epoch": 60, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00062, "acc_pose": 0.81187, "loss": 0.00062, "grad_norm": 0.00113, "time": 0.69503}
+{"mode": "train", "epoch": 60, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00061, "acc_pose": 0.8055, "loss": 0.00061, "grad_norm": 0.00115, "time": 0.69457}
+{"mode": "val", "epoch": 60, "iter": 407, "lr": 0.0, "AP": 0.76504, "AP .5": 0.90827, "AP .75": 0.83948, "AP (M)": 0.69105, "AP (L)": 0.79177, "AR": 0.81955, "AR .5": 0.94884, "AR .75": 0.88445, "AR (M)": 0.77823, "AR (L)": 0.87986}
+{"mode": "train", "epoch": 61, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05635, "heatmap_loss": 0.00061, "acc_pose": 0.80604, "loss": 0.00061, "grad_norm": 0.0011, "time": 0.74937}
+{"mode": "train", "epoch": 61, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00048, "heatmap_loss": 0.00061, "acc_pose": 0.80755, "loss": 0.00061, "grad_norm": 0.00109, "time": 0.69518}
+{"mode": "train", "epoch": 61, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00027, "heatmap_loss": 0.00061, "acc_pose": 0.81048, "loss": 0.00061, "grad_norm": 0.00112, "time": 0.69526}
+{"mode": "train", "epoch": 61, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00061, "acc_pose": 0.81522, "loss": 0.00061, "grad_norm": 0.00113, "time": 0.69513}
+{"mode": "train", "epoch": 61, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00062, "acc_pose": 0.81409, "loss": 0.00062, "grad_norm": 0.00113, "time": 0.69528}
+{"mode": "train", "epoch": 62, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05559, "heatmap_loss": 0.00061, "acc_pose": 0.81028, "loss": 0.00061, "grad_norm": 0.00116, "time": 0.75207}
+{"mode": "train", "epoch": 62, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00061, "acc_pose": 0.81159, "loss": 0.00061, "grad_norm": 0.00117, "time": 0.69539}
+{"mode": "train", "epoch": 62, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00062, "acc_pose": 0.81012, "loss": 0.00062, "grad_norm": 0.00116, "time": 0.69571}
+{"mode": "train", "epoch": 62, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00035, "heatmap_loss": 0.00061, "acc_pose": 0.81963, "loss": 0.00061, "grad_norm": 0.0011, "time": 0.69566}
+{"mode": "train", "epoch": 62, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00034, "heatmap_loss": 0.00061, "acc_pose": 0.81821, "loss": 0.00061, "grad_norm": 0.00113, "time": 0.69576}
+{"mode": "train", "epoch": 63, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05595, "heatmap_loss": 0.00061, "acc_pose": 0.814, "loss": 0.00061, "grad_norm": 0.0012, "time": 0.75363}
+{"mode": "train", "epoch": 63, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00061, "acc_pose": 0.81585, "loss": 0.00061, "grad_norm": 0.00124, "time": 0.69553}
+{"mode": "train", "epoch": 63, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00061, "acc_pose": 0.81838, "loss": 0.00061, "grad_norm": 0.00115, "time": 0.69624}
+{"mode": "train", "epoch": 63, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00061, "acc_pose": 0.81914, "loss": 0.00061, "grad_norm": 0.00111, "time": 0.69588}
+{"mode": "train", "epoch": 63, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00061, "acc_pose": 0.81817, "loss": 0.00061, "grad_norm": 0.00114, "time": 0.6953}
+{"mode": "train", "epoch": 64, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05784, "heatmap_loss": 0.00061, "acc_pose": 0.81454, "loss": 0.00061, "grad_norm": 0.00112, "time": 0.75324}
+{"mode": "train", "epoch": 64, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00061, "acc_pose": 0.81538, "loss": 0.00061, "grad_norm": 0.00112, "time": 0.69566}
+{"mode": "train", "epoch": 64, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00028, "heatmap_loss": 0.00061, "acc_pose": 0.81937, "loss": 0.00061, "grad_norm": 0.00115, "time": 0.69519}
+{"mode": "train", "epoch": 64, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00061, "acc_pose": 0.81444, "loss": 0.00061, "grad_norm": 0.00117, "time": 0.69504}
+{"mode": "train", "epoch": 64, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00061, "acc_pose": 0.81472, "loss": 0.00061, "grad_norm": 0.00116, "time": 0.695}
+{"mode": "train", "epoch": 65, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05716, "heatmap_loss": 0.00061, "acc_pose": 0.81647, "loss": 0.00061, "grad_norm": 0.00116, "time": 0.75321}
+{"mode": "train", "epoch": 65, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00061, "acc_pose": 0.81645, "loss": 0.00061, "grad_norm": 0.00112, "time": 0.69517}
+{"mode": "train", "epoch": 65, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00061, "acc_pose": 0.81739, "loss": 0.00061, "grad_norm": 0.00115, "time": 0.69513}
+{"mode": "train", "epoch": 65, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00061, "acc_pose": 0.81346, "loss": 0.00061, "grad_norm": 0.00118, "time": 0.69572}
+{"mode": "train", "epoch": 65, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00061, "acc_pose": 0.81467, "loss": 0.00061, "grad_norm": 0.00119, "time": 0.6951}
+{"mode": "train", "epoch": 66, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05605, "heatmap_loss": 0.0006, "acc_pose": 0.82169, "loss": 0.0006, "grad_norm": 0.00109, "time": 0.75307}
+{"mode": "train", "epoch": 66, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00034, "heatmap_loss": 0.00061, "acc_pose": 0.81172, "loss": 0.00061, "grad_norm": 0.00117, "time": 0.69554}
+{"mode": "train", "epoch": 66, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00061, "acc_pose": 0.81819, "loss": 0.00061, "grad_norm": 0.00114, "time": 0.6956}
+{"mode": "train", "epoch": 66, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0006, "acc_pose": 0.81894, "loss": 0.0006, "grad_norm": 0.0011, "time": 0.69469}
+{"mode": "train", "epoch": 66, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00061, "acc_pose": 0.81551, "loss": 0.00061, "grad_norm": 0.00116, "time": 0.69454}
+{"mode": "train", "epoch": 67, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05544, "heatmap_loss": 0.00061, "acc_pose": 0.81986, "loss": 0.00061, "grad_norm": 0.00117, "time": 0.75299}
+{"mode": "train", "epoch": 67, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00061, "acc_pose": 0.81193, "loss": 0.00061, "grad_norm": 0.0011, "time": 0.69466}
+{"mode": "train", "epoch": 67, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00061, "acc_pose": 0.81924, "loss": 0.00061, "grad_norm": 0.00117, "time": 0.69497}
+{"mode": "train", "epoch": 67, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0006, "acc_pose": 0.8205, "loss": 0.0006, "grad_norm": 0.00113, "time": 0.69519}
+{"mode": "train", "epoch": 67, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00061, "acc_pose": 0.81886, "loss": 0.00061, "grad_norm": 0.00109, "time": 0.69581}
+{"mode": "train", "epoch": 68, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05609, "heatmap_loss": 0.0006, "acc_pose": 0.80955, "loss": 0.0006, "grad_norm": 0.00118, "time": 0.75312}
+{"mode": "train", "epoch": 68, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00028, "heatmap_loss": 0.0006, "acc_pose": 0.81646, "loss": 0.0006, "grad_norm": 0.00111, "time": 0.69587}
+{"mode": "train", "epoch": 68, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00027, "heatmap_loss": 0.0006, "acc_pose": 0.819, "loss": 0.0006, "grad_norm": 0.00119, "time": 0.69532}
+{"mode": "train", "epoch": 68, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.0006, "acc_pose": 0.81624, "loss": 0.0006, "grad_norm": 0.00117, "time": 0.69501}
+{"mode": "train", "epoch": 68, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00061, "acc_pose": 0.81778, "loss": 0.00061, "grad_norm": 0.00116, "time": 0.69506}
+{"mode": "train", "epoch": 69, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05599, "heatmap_loss": 0.0006, "acc_pose": 0.81688, "loss": 0.0006, "grad_norm": 0.00109, "time": 0.75437}
+{"mode": "train", "epoch": 69, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0006, "acc_pose": 0.81513, "loss": 0.0006, "grad_norm": 0.00114, "time": 0.69531}
+{"mode": "train", "epoch": 69, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.0006, "acc_pose": 0.81312, "loss": 0.0006, "grad_norm": 0.00113, "time": 0.69532}
+{"mode": "train", "epoch": 69, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.0006, "acc_pose": 0.82249, "loss": 0.0006, "grad_norm": 0.00111, "time": 0.69486}
+{"mode": "train", "epoch": 69, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00061, "acc_pose": 0.81901, "loss": 0.00061, "grad_norm": 0.00114, "time": 0.69448}
+{"mode": "train", "epoch": 70, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05618, "heatmap_loss": 0.0006, "acc_pose": 0.81631, "loss": 0.0006, "grad_norm": 0.00115, "time": 0.75329}
+{"mode": "train", "epoch": 70, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0006, "acc_pose": 0.81876, "loss": 0.0006, "grad_norm": 0.00105, "time": 0.69566}
+{"mode": "train", "epoch": 70, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0006, "acc_pose": 0.81163, "loss": 0.0006, "grad_norm": 0.00108, "time": 0.69606}
+{"mode": "train", "epoch": 70, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0006, "acc_pose": 0.8223, "loss": 0.0006, "grad_norm": 0.00111, "time": 0.69579}
+{"mode": "train", "epoch": 70, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0006, "acc_pose": 0.81437, "loss": 0.0006, "grad_norm": 0.00112, "time": 0.69576}
+{"mode": "val", "epoch": 70, "iter": 407, "lr": 0.0, "AP": 0.76747, "AP .5": 0.91137, "AP .75": 0.84067, "AP (M)": 0.69403, "AP (L)": 0.79471, "AR": 0.82143, "AR .5": 0.95057, "AR .75": 0.88508, "AR (M)": 0.78082, "AR (L)": 0.88101}
+{"mode": "train", "epoch": 71, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05583, "heatmap_loss": 0.0006, "acc_pose": 0.82052, "loss": 0.0006, "grad_norm": 0.0011, "time": 0.74912}
+{"mode": "train", "epoch": 71, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00035, "heatmap_loss": 0.0006, "acc_pose": 0.81508, "loss": 0.0006, "grad_norm": 0.00114, "time": 0.6947}
+{"mode": "train", "epoch": 71, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00034, "heatmap_loss": 0.0006, "acc_pose": 0.82013, "loss": 0.0006, "grad_norm": 0.00109, "time": 0.69461}
+{"mode": "train", "epoch": 71, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00034, "heatmap_loss": 0.0006, "acc_pose": 0.82301, "loss": 0.0006, "grad_norm": 0.00106, "time": 0.69488}
+{"mode": "train", "epoch": 71, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00036, "heatmap_loss": 0.0006, "acc_pose": 0.82477, "loss": 0.0006, "grad_norm": 0.00114, "time": 0.69514}
+{"mode": "train", "epoch": 72, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.0569, "heatmap_loss": 0.0006, "acc_pose": 0.82152, "loss": 0.0006, "grad_norm": 0.00114, "time": 0.75336}
+{"mode": "train", "epoch": 72, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.0006, "acc_pose": 0.81743, "loss": 0.0006, "grad_norm": 0.00113, "time": 0.69535}
+{"mode": "train", "epoch": 72, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0006, "acc_pose": 0.81248, "loss": 0.0006, "grad_norm": 0.00114, "time": 0.69555}
+{"mode": "train", "epoch": 72, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.0006, "acc_pose": 0.82302, "loss": 0.0006, "grad_norm": 0.00115, "time": 0.69499}
+{"mode": "train", "epoch": 72, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0006, "acc_pose": 0.81692, "loss": 0.0006, "grad_norm": 0.00111, "time": 0.69558}
+{"mode": "train", "epoch": 73, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05625, "heatmap_loss": 0.00059, "acc_pose": 0.82287, "loss": 0.00059, "grad_norm": 0.00124, "time": 0.75181}
+{"mode": "train", "epoch": 73, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0006, "acc_pose": 0.8226, "loss": 0.0006, "grad_norm": 0.00118, "time": 0.69522}
+{"mode": "train", "epoch": 73, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0006, "acc_pose": 0.81172, "loss": 0.0006, "grad_norm": 0.00111, "time": 0.69519}
+{"mode": "train", "epoch": 73, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0006, "acc_pose": 0.82349, "loss": 0.0006, "grad_norm": 0.00113, "time": 0.69492}
+{"mode": "train", "epoch": 73, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.0006, "acc_pose": 0.82207, "loss": 0.0006, "grad_norm": 0.00118, "time": 0.69542}
+{"mode": "train", "epoch": 74, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05643, "heatmap_loss": 0.0006, "acc_pose": 0.81865, "loss": 0.0006, "grad_norm": 0.00109, "time": 0.75324}
+{"mode": "train", "epoch": 74, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00027, "heatmap_loss": 0.0006, "acc_pose": 0.81702, "loss": 0.0006, "grad_norm": 0.0011, "time": 0.69508}
+{"mode": "train", "epoch": 74, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00042, "heatmap_loss": 0.0006, "acc_pose": 0.81331, "loss": 0.0006, "grad_norm": 0.00104, "time": 0.69551}
+{"mode": "train", "epoch": 74, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.0006, "acc_pose": 0.82315, "loss": 0.0006, "grad_norm": 0.00115, "time": 0.69501}
+{"mode": "train", "epoch": 74, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.0006, "acc_pose": 0.81714, "loss": 0.0006, "grad_norm": 0.0011, "time": 0.69504}
+{"mode": "train", "epoch": 75, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05659, "heatmap_loss": 0.0006, "acc_pose": 0.82422, "loss": 0.0006, "grad_norm": 0.00113, "time": 0.75326}
+{"mode": "train", "epoch": 75, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00059, "acc_pose": 0.82231, "loss": 0.00059, "grad_norm": 0.00115, "time": 0.69496}
+{"mode": "train", "epoch": 75, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00059, "acc_pose": 0.81814, "loss": 0.00059, "grad_norm": 0.00116, "time": 0.69556}
+{"mode": "train", "epoch": 75, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0006, "acc_pose": 0.82412, "loss": 0.0006, "grad_norm": 0.00118, "time": 0.69484}
+{"mode": "train", "epoch": 75, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00059, "acc_pose": 0.81916, "loss": 0.00059, "grad_norm": 0.00109, "time": 0.69525}
+{"mode": "train", "epoch": 76, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05704, "heatmap_loss": 0.0006, "acc_pose": 0.81864, "loss": 0.0006, "grad_norm": 0.00116, "time": 0.75426}
+{"mode": "train", "epoch": 76, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0004, "heatmap_loss": 0.0006, "acc_pose": 0.82061, "loss": 0.0006, "grad_norm": 0.00116, "time": 0.69489}
+{"mode": "train", "epoch": 76, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00028, "heatmap_loss": 0.00059, "acc_pose": 0.826, "loss": 0.00059, "grad_norm": 0.00107, "time": 0.69514}
+{"mode": "train", "epoch": 76, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00059, "acc_pose": 0.82402, "loss": 0.00059, "grad_norm": 0.00113, "time": 0.69525}
+{"mode": "train", "epoch": 76, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0006, "acc_pose": 0.82206, "loss": 0.0006, "grad_norm": 0.00117, "time": 0.69508}
+{"mode": "train", "epoch": 77, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.0565, "heatmap_loss": 0.00059, "acc_pose": 0.8199, "loss": 0.00059, "grad_norm": 0.00112, "time": 0.75396}
+{"mode": "train", "epoch": 77, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0006, "acc_pose": 0.81595, "loss": 0.0006, "grad_norm": 0.00114, "time": 0.69497}
+{"mode": "train", "epoch": 77, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00059, "acc_pose": 0.82232, "loss": 0.00059, "grad_norm": 0.0011, "time": 0.69563}
+{"mode": "train", "epoch": 77, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00059, "acc_pose": 0.81917, "loss": 0.00059, "grad_norm": 0.00116, "time": 0.6951}
+{"mode": "train", "epoch": 77, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00059, "acc_pose": 0.82565, "loss": 0.00059, "grad_norm": 0.00109, "time": 0.69502}
+{"mode": "train", "epoch": 78, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05812, "heatmap_loss": 0.00059, "acc_pose": 0.82859, "loss": 0.00059, "grad_norm": 0.00117, "time": 0.75391}
+{"mode": "train", "epoch": 78, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00059, "acc_pose": 0.83061, "loss": 0.00059, "grad_norm": 0.00112, "time": 0.69503}
+{"mode": "train", "epoch": 78, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0006, "acc_pose": 0.82154, "loss": 0.0006, "grad_norm": 0.00113, "time": 0.69522}
+{"mode": "train", "epoch": 78, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00059, "acc_pose": 0.81727, "loss": 0.00059, "grad_norm": 0.00122, "time": 0.69535}
+{"mode": "train", "epoch": 78, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00059, "acc_pose": 0.82317, "loss": 0.00059, "grad_norm": 0.00115, "time": 0.69567}
+{"mode": "train", "epoch": 79, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05863, "heatmap_loss": 0.00059, "acc_pose": 0.82554, "loss": 0.00059, "grad_norm": 0.00111, "time": 0.75691}
+{"mode": "train", "epoch": 79, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00039, "heatmap_loss": 0.00059, "acc_pose": 0.81472, "loss": 0.00059, "grad_norm": 0.00116, "time": 0.69514}
+{"mode": "train", "epoch": 79, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00059, "acc_pose": 0.8165, "loss": 0.00059, "grad_norm": 0.00111, "time": 0.69522}
+{"mode": "train", "epoch": 79, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00059, "acc_pose": 0.82533, "loss": 0.00059, "grad_norm": 0.00104, "time": 0.69536}
+{"mode": "train", "epoch": 79, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00059, "acc_pose": 0.82552, "loss": 0.00059, "grad_norm": 0.00112, "time": 0.69551}
+{"mode": "train", "epoch": 80, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05622, "heatmap_loss": 0.00059, "acc_pose": 0.82789, "loss": 0.00059, "grad_norm": 0.00109, "time": 0.75329}
+{"mode": "train", "epoch": 80, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00059, "acc_pose": 0.82823, "loss": 0.00059, "grad_norm": 0.00107, "time": 0.69517}
+{"mode": "train", "epoch": 80, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00059, "acc_pose": 0.81794, "loss": 0.00059, "grad_norm": 0.00106, "time": 0.69513}
+{"mode": "train", "epoch": 80, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00059, "acc_pose": 0.82521, "loss": 0.00059, "grad_norm": 0.00112, "time": 0.69498}
+{"mode": "train", "epoch": 80, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00059, "acc_pose": 0.82079, "loss": 0.00059, "grad_norm": 0.00115, "time": 0.69516}
+{"mode": "val", "epoch": 80, "iter": 407, "lr": 0.0, "AP": 0.76984, "AP .5": 0.91211, "AP .75": 0.8411, "AP (M)": 0.69614, "AP (L)": 0.79653, "AR": 0.82365, "AR .5": 0.95057, "AR .75": 0.88618, "AR (M)": 0.78317, "AR (L)": 0.88276}
+{"mode": "train", "epoch": 81, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05487, "heatmap_loss": 0.00059, "acc_pose": 0.82501, "loss": 0.00059, "grad_norm": 0.00104, "time": 0.74719}
+{"mode": "train", "epoch": 81, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00059, "acc_pose": 0.81928, "loss": 0.00059, "grad_norm": 0.00116, "time": 0.69432}
+{"mode": "train", "epoch": 81, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00059, "acc_pose": 0.81822, "loss": 0.00059, "grad_norm": 0.00108, "time": 0.69481}
+{"mode": "train", "epoch": 81, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00059, "acc_pose": 0.82629, "loss": 0.00059, "grad_norm": 0.00108, "time": 0.69474}
+{"mode": "train", "epoch": 81, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00035, "heatmap_loss": 0.00059, "acc_pose": 0.82429, "loss": 0.00059, "grad_norm": 0.0011, "time": 0.69484}
+{"mode": "train", "epoch": 82, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05587, "heatmap_loss": 0.00059, "acc_pose": 0.82811, "loss": 0.00059, "grad_norm": 0.00108, "time": 0.75121}
+{"mode": "train", "epoch": 82, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00028, "heatmap_loss": 0.00059, "acc_pose": 0.82706, "loss": 0.00059, "grad_norm": 0.00108, "time": 0.69462}
+{"mode": "train", "epoch": 82, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00058, "acc_pose": 0.82845, "loss": 0.00058, "grad_norm": 0.00111, "time": 0.69502}
+{"mode": "train", "epoch": 82, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00059, "acc_pose": 0.82593, "loss": 0.00059, "grad_norm": 0.00106, "time": 0.69458}
+{"mode": "train", "epoch": 82, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00059, "acc_pose": 0.82492, "loss": 0.00059, "grad_norm": 0.00112, "time": 0.69508}
+{"mode": "train", "epoch": 83, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05512, "heatmap_loss": 0.00059, "acc_pose": 0.82533, "loss": 0.00059, "grad_norm": 0.00116, "time": 0.75365}
+{"mode": "train", "epoch": 83, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00059, "acc_pose": 0.82026, "loss": 0.00059, "grad_norm": 0.0011, "time": 0.69534}
+{"mode": "train", "epoch": 83, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00028, "heatmap_loss": 0.00059, "acc_pose": 0.82045, "loss": 0.00059, "grad_norm": 0.00112, "time": 0.69505}
+{"mode": "train", "epoch": 83, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00059, "acc_pose": 0.82101, "loss": 0.00059, "grad_norm": 0.00111, "time": 0.69513}
+{"mode": "train", "epoch": 83, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00059, "acc_pose": 0.82314, "loss": 0.00059, "grad_norm": 0.00111, "time": 0.6953}
+{"mode": "train", "epoch": 84, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05593, "heatmap_loss": 0.00058, "acc_pose": 0.82891, "loss": 0.00058, "grad_norm": 0.00108, "time": 0.75308}
+{"mode": "train", "epoch": 84, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00059, "acc_pose": 0.82238, "loss": 0.00059, "grad_norm": 0.00111, "time": 0.69529}
+{"mode": "train", "epoch": 84, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00058, "acc_pose": 0.82204, "loss": 0.00058, "grad_norm": 0.00111, "time": 0.69518}
+{"mode": "train", "epoch": 84, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00058, "acc_pose": 0.8288, "loss": 0.00058, "grad_norm": 0.00109, "time": 0.69478}
+{"mode": "train", "epoch": 84, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00059, "acc_pose": 0.81996, "loss": 0.00059, "grad_norm": 0.00111, "time": 0.69498}
+{"mode": "train", "epoch": 85, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.0565, "heatmap_loss": 0.00059, "acc_pose": 0.82341, "loss": 0.00059, "grad_norm": 0.00111, "time": 0.75196}
+{"mode": "train", "epoch": 85, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00059, "acc_pose": 0.83231, "loss": 0.00059, "grad_norm": 0.00109, "time": 0.69521}
+{"mode": "train", "epoch": 85, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00059, "acc_pose": 0.82428, "loss": 0.00059, "grad_norm": 0.00112, "time": 0.69467}
+{"mode": "train", "epoch": 85, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00058, "acc_pose": 0.8285, "loss": 0.00058, "grad_norm": 0.00118, "time": 0.69511}
+{"mode": "train", "epoch": 85, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00059, "acc_pose": 0.83052, "loss": 0.00059, "grad_norm": 0.0011, "time": 0.69553}
+{"mode": "train", "epoch": 86, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.0561, "heatmap_loss": 0.00058, "acc_pose": 0.82959, "loss": 0.00058, "grad_norm": 0.00114, "time": 0.75282}
+{"mode": "train", "epoch": 86, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00059, "acc_pose": 0.82372, "loss": 0.00059, "grad_norm": 0.00107, "time": 0.69515}
+{"mode": "train", "epoch": 86, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00042, "heatmap_loss": 0.00059, "acc_pose": 0.82058, "loss": 0.00059, "grad_norm": 0.00112, "time": 0.69498}
+{"mode": "train", "epoch": 86, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00058, "acc_pose": 0.82496, "loss": 0.00058, "grad_norm": 0.00114, "time": 0.69458}
+{"mode": "train", "epoch": 86, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00058, "acc_pose": 0.82715, "loss": 0.00058, "grad_norm": 0.00113, "time": 0.6942}
+{"mode": "train", "epoch": 87, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05806, "heatmap_loss": 0.00058, "acc_pose": 0.82948, "loss": 0.00058, "grad_norm": 0.00113, "time": 0.75499}
+{"mode": "train", "epoch": 87, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00058, "acc_pose": 0.83271, "loss": 0.00058, "grad_norm": 0.0011, "time": 0.69561}
+{"mode": "train", "epoch": 87, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00059, "acc_pose": 0.81985, "loss": 0.00059, "grad_norm": 0.00105, "time": 0.69553}
+{"mode": "train", "epoch": 87, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00058, "acc_pose": 0.82861, "loss": 0.00058, "grad_norm": 0.00108, "time": 0.69576}
+{"mode": "train", "epoch": 87, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00058, "acc_pose": 0.82787, "loss": 0.00058, "grad_norm": 0.0011, "time": 0.69528}
+{"mode": "train", "epoch": 88, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.0557, "heatmap_loss": 0.00058, "acc_pose": 0.82915, "loss": 0.00058, "grad_norm": 0.00111, "time": 0.75538}
+{"mode": "train", "epoch": 88, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00058, "acc_pose": 0.82629, "loss": 0.00058, "grad_norm": 0.0011, "time": 0.69522}
+{"mode": "train", "epoch": 88, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00058, "acc_pose": 0.82565, "loss": 0.00058, "grad_norm": 0.00112, "time": 0.69568}
+{"mode": "train", "epoch": 88, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00058, "acc_pose": 0.82801, "loss": 0.00058, "grad_norm": 0.00107, "time": 0.69591}
+{"mode": "train", "epoch": 88, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00058, "acc_pose": 0.83369, "loss": 0.00058, "grad_norm": 0.0011, "time": 0.69526}
+{"mode": "train", "epoch": 89, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.0565, "heatmap_loss": 0.00058, "acc_pose": 0.81622, "loss": 0.00058, "grad_norm": 0.0011, "time": 0.75529}
+{"mode": "train", "epoch": 89, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00058, "acc_pose": 0.82569, "loss": 0.00058, "grad_norm": 0.00114, "time": 0.69567}
+{"mode": "train", "epoch": 89, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00059, "acc_pose": 0.82154, "loss": 0.00059, "grad_norm": 0.00112, "time": 0.69554}
+{"mode": "train", "epoch": 89, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00058, "acc_pose": 0.82535, "loss": 0.00058, "grad_norm": 0.00108, "time": 0.69542}
+{"mode": "train", "epoch": 89, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00057, "acc_pose": 0.83295, "loss": 0.00057, "grad_norm": 0.00107, "time": 0.6958}
+{"mode": "train", "epoch": 90, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05641, "heatmap_loss": 0.00058, "acc_pose": 0.8281, "loss": 0.00058, "grad_norm": 0.00114, "time": 0.75442}
+{"mode": "train", "epoch": 90, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00047, "heatmap_loss": 0.00058, "acc_pose": 0.82692, "loss": 0.00058, "grad_norm": 0.00107, "time": 0.69632}
+{"mode": "train", "epoch": 90, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00058, "acc_pose": 0.81635, "loss": 0.00058, "grad_norm": 0.00109, "time": 0.69585}
+{"mode": "train", "epoch": 90, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00059, "acc_pose": 0.82739, "loss": 0.00059, "grad_norm": 0.00108, "time": 0.69601}
+{"mode": "train", "epoch": 90, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00058, "acc_pose": 0.82972, "loss": 0.00058, "grad_norm": 0.00111, "time": 0.69576}
+{"mode": "val", "epoch": 90, "iter": 407, "lr": 0.0, "AP": 0.77309, "AP .5": 0.91237, "AP .75": 0.84841, "AP (M)": 0.70115, "AP (L)": 0.79969, "AR": 0.82547, "AR .5": 0.95041, "AR .75": 0.89074, "AR (M)": 0.78541, "AR (L)": 0.88417}
+{"mode": "train", "epoch": 91, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05569, "heatmap_loss": 0.00058, "acc_pose": 0.83298, "loss": 0.00058, "grad_norm": 0.00116, "time": 0.75061}
+{"mode": "train", "epoch": 91, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00058, "acc_pose": 0.82929, "loss": 0.00058, "grad_norm": 0.00109, "time": 0.6949}
+{"mode": "train", "epoch": 91, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00058, "acc_pose": 0.83041, "loss": 0.00058, "grad_norm": 0.0011, "time": 0.69537}
+{"mode": "train", "epoch": 91, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00058, "acc_pose": 0.82427, "loss": 0.00058, "grad_norm": 0.00111, "time": 0.69528}
+{"mode": "train", "epoch": 91, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00058, "acc_pose": 0.82944, "loss": 0.00058, "grad_norm": 0.00109, "time": 0.69547}
+{"mode": "train", "epoch": 92, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05542, "heatmap_loss": 0.00058, "acc_pose": 0.82948, "loss": 0.00058, "grad_norm": 0.00112, "time": 0.75321}
+{"mode": "train", "epoch": 92, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00058, "acc_pose": 0.82789, "loss": 0.00058, "grad_norm": 0.00105, "time": 0.69623}
+{"mode": "train", "epoch": 92, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00057, "acc_pose": 0.82615, "loss": 0.00057, "grad_norm": 0.00107, "time": 0.69554}
+{"mode": "train", "epoch": 92, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00058, "acc_pose": 0.83071, "loss": 0.00058, "grad_norm": 0.00116, "time": 0.69585}
+{"mode": "train", "epoch": 92, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00058, "acc_pose": 0.83118, "loss": 0.00058, "grad_norm": 0.0011, "time": 0.69558}
+{"mode": "train", "epoch": 93, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05681, "heatmap_loss": 0.00057, "acc_pose": 0.82929, "loss": 0.00057, "grad_norm": 0.00108, "time": 0.75443}
+{"mode": "train", "epoch": 93, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00058, "acc_pose": 0.82289, "loss": 0.00058, "grad_norm": 0.00111, "time": 0.69557}
+{"mode": "train", "epoch": 93, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00058, "acc_pose": 0.83108, "loss": 0.00058, "grad_norm": 0.00117, "time": 0.69584}
+{"mode": "train", "epoch": 93, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00058, "acc_pose": 0.83133, "loss": 0.00058, "grad_norm": 0.00109, "time": 0.69522}
+{"mode": "train", "epoch": 93, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00057, "acc_pose": 0.83573, "loss": 0.00057, "grad_norm": 0.00111, "time": 0.69569}
+{"mode": "train", "epoch": 94, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05834, "heatmap_loss": 0.00057, "acc_pose": 0.82674, "loss": 0.00057, "grad_norm": 0.00104, "time": 0.75467}
+{"mode": "train", "epoch": 94, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00036, "heatmap_loss": 0.00058, "acc_pose": 0.8346, "loss": 0.00058, "grad_norm": 0.00105, "time": 0.69626}
+{"mode": "train", "epoch": 94, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00057, "acc_pose": 0.82927, "loss": 0.00057, "grad_norm": 0.0011, "time": 0.69541}
+{"mode": "train", "epoch": 94, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00034, "heatmap_loss": 0.00058, "acc_pose": 0.83256, "loss": 0.00058, "grad_norm": 0.00108, "time": 0.69561}
+{"mode": "train", "epoch": 94, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00058, "acc_pose": 0.83434, "loss": 0.00058, "grad_norm": 0.00108, "time": 0.69558}
+{"mode": "train", "epoch": 95, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05752, "heatmap_loss": 0.00058, "acc_pose": 0.82944, "loss": 0.00058, "grad_norm": 0.00117, "time": 0.75624}
+{"mode": "train", "epoch": 95, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00057, "acc_pose": 0.82633, "loss": 0.00057, "grad_norm": 0.00107, "time": 0.69625}
+{"mode": "train", "epoch": 95, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00058, "acc_pose": 0.82389, "loss": 0.00058, "grad_norm": 0.00108, "time": 0.69613}
+{"mode": "train", "epoch": 95, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00057, "acc_pose": 0.83085, "loss": 0.00057, "grad_norm": 0.00109, "time": 0.69559}
+{"mode": "train", "epoch": 95, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00057, "acc_pose": 0.82999, "loss": 0.00057, "grad_norm": 0.00106, "time": 0.69603}
+{"mode": "train", "epoch": 96, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.0578, "heatmap_loss": 0.00057, "acc_pose": 0.83148, "loss": 0.00057, "grad_norm": 0.00108, "time": 0.75479}
+{"mode": "train", "epoch": 96, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00057, "acc_pose": 0.83595, "loss": 0.00057, "grad_norm": 0.00114, "time": 0.69595}
+{"mode": "train", "epoch": 96, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00057, "acc_pose": 0.83185, "loss": 0.00057, "grad_norm": 0.00107, "time": 0.6956}
+{"mode": "train", "epoch": 96, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00058, "acc_pose": 0.82817, "loss": 0.00058, "grad_norm": 0.00113, "time": 0.69562}
+{"mode": "train", "epoch": 96, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00058, "acc_pose": 0.83462, "loss": 0.00058, "grad_norm": 0.00114, "time": 0.6965}
+{"mode": "train", "epoch": 97, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.06016, "heatmap_loss": 0.00057, "acc_pose": 0.83122, "loss": 0.00057, "grad_norm": 0.00105, "time": 0.75667}
+{"mode": "train", "epoch": 97, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00058, "acc_pose": 0.8329, "loss": 0.00058, "grad_norm": 0.00109, "time": 0.69538}
+{"mode": "train", "epoch": 97, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00057, "acc_pose": 0.83203, "loss": 0.00057, "grad_norm": 0.00104, "time": 0.69568}
+{"mode": "train", "epoch": 97, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00057, "acc_pose": 0.82951, "loss": 0.00057, "grad_norm": 0.00103, "time": 0.69537}
+{"mode": "train", "epoch": 97, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00058, "acc_pose": 0.83128, "loss": 0.00058, "grad_norm": 0.00111, "time": 0.69504}
+{"mode": "train", "epoch": 98, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05701, "heatmap_loss": 0.00057, "acc_pose": 0.82594, "loss": 0.00057, "grad_norm": 0.00109, "time": 0.75482}
+{"mode": "train", "epoch": 98, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00036, "heatmap_loss": 0.00057, "acc_pose": 0.83112, "loss": 0.00057, "grad_norm": 0.00107, "time": 0.6959}
+{"mode": "train", "epoch": 98, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00057, "acc_pose": 0.83181, "loss": 0.00057, "grad_norm": 0.00111, "time": 0.69555}
+{"mode": "train", "epoch": 98, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00058, "acc_pose": 0.83415, "loss": 0.00058, "grad_norm": 0.00106, "time": 0.6955}
+{"mode": "train", "epoch": 98, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00058, "acc_pose": 0.82934, "loss": 0.00058, "grad_norm": 0.00112, "time": 0.69525}
+{"mode": "train", "epoch": 99, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05632, "heatmap_loss": 0.00057, "acc_pose": 0.83629, "loss": 0.00057, "grad_norm": 0.00106, "time": 0.75378}
+{"mode": "train", "epoch": 99, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00057, "acc_pose": 0.82914, "loss": 0.00057, "grad_norm": 0.00108, "time": 0.69581}
+{"mode": "train", "epoch": 99, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00057, "acc_pose": 0.83368, "loss": 0.00057, "grad_norm": 0.00111, "time": 0.69554}
+{"mode": "train", "epoch": 99, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00057, "acc_pose": 0.82654, "loss": 0.00057, "grad_norm": 0.00104, "time": 0.69528}
+{"mode": "train", "epoch": 99, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00057, "acc_pose": 0.83351, "loss": 0.00057, "grad_norm": 0.00109, "time": 0.69557}
+{"mode": "train", "epoch": 100, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05628, "heatmap_loss": 0.00056, "acc_pose": 0.83458, "loss": 0.00056, "grad_norm": 0.00106, "time": 0.75787}
+{"mode": "train", "epoch": 100, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00057, "acc_pose": 0.82982, "loss": 0.00057, "grad_norm": 0.00109, "time": 0.69485}
+{"mode": "train", "epoch": 100, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00057, "acc_pose": 0.8321, "loss": 0.00057, "grad_norm": 0.00111, "time": 0.69524}
+{"mode": "train", "epoch": 100, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00057, "acc_pose": 0.83695, "loss": 0.00057, "grad_norm": 0.00113, "time": 0.69489}
+{"mode": "train", "epoch": 100, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00058, "acc_pose": 0.8287, "loss": 0.00058, "grad_norm": 0.0011, "time": 0.69471}
+{"mode": "val", "epoch": 100, "iter": 407, "lr": 0.0, "AP": 0.77593, "AP .5": 0.91417, "AP .75": 0.84768, "AP (M)": 0.70196, "AP (L)": 0.80539, "AR": 0.82771, "AR .5": 0.95135, "AR .75": 0.89027, "AR (M)": 0.78637, "AR (L)": 0.88789}
+{"mode": "train", "epoch": 101, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05542, "heatmap_loss": 0.00057, "acc_pose": 0.82542, "loss": 0.00057, "grad_norm": 0.00117, "time": 0.74883}
+{"mode": "train", "epoch": 101, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00057, "acc_pose": 0.82386, "loss": 0.00057, "grad_norm": 0.00111, "time": 0.69523}
+{"mode": "train", "epoch": 101, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00057, "acc_pose": 0.83518, "loss": 0.00057, "grad_norm": 0.00108, "time": 0.69557}
+{"mode": "train", "epoch": 101, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00057, "acc_pose": 0.83335, "loss": 0.00057, "grad_norm": 0.00109, "time": 0.69548}
+{"mode": "train", "epoch": 101, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00034, "heatmap_loss": 0.00057, "acc_pose": 0.83293, "loss": 0.00057, "grad_norm": 0.0011, "time": 0.69539}
+{"mode": "train", "epoch": 102, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05617, "heatmap_loss": 0.00056, "acc_pose": 0.83922, "loss": 0.00056, "grad_norm": 0.00106, "time": 0.75304}
+{"mode": "train", "epoch": 102, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00057, "acc_pose": 0.82856, "loss": 0.00057, "grad_norm": 0.00106, "time": 0.69548}
+{"mode": "train", "epoch": 102, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00057, "acc_pose": 0.82713, "loss": 0.00057, "grad_norm": 0.00113, "time": 0.69608}
+{"mode": "train", "epoch": 102, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00058, "acc_pose": 0.83579, "loss": 0.00058, "grad_norm": 0.00111, "time": 0.69622}
+{"mode": "train", "epoch": 102, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00057, "acc_pose": 0.83647, "loss": 0.00057, "grad_norm": 0.00113, "time": 0.69595}
+{"mode": "train", "epoch": 103, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05782, "heatmap_loss": 0.00057, "acc_pose": 0.83566, "loss": 0.00057, "grad_norm": 0.00108, "time": 0.75442}
+{"mode": "train", "epoch": 103, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00028, "heatmap_loss": 0.00057, "acc_pose": 0.8292, "loss": 0.00057, "grad_norm": 0.00108, "time": 0.69543}
+{"mode": "train", "epoch": 103, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00028, "heatmap_loss": 0.00057, "acc_pose": 0.83108, "loss": 0.00057, "grad_norm": 0.00108, "time": 0.69521}
+{"mode": "train", "epoch": 103, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00056, "acc_pose": 0.8319, "loss": 0.00056, "grad_norm": 0.0011, "time": 0.69518}
+{"mode": "train", "epoch": 103, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00057, "acc_pose": 0.83317, "loss": 0.00057, "grad_norm": 0.00114, "time": 0.69519}
+{"mode": "train", "epoch": 104, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05651, "heatmap_loss": 0.00057, "acc_pose": 0.82987, "loss": 0.00057, "grad_norm": 0.00107, "time": 0.75397}
+{"mode": "train", "epoch": 104, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00056, "acc_pose": 0.8349, "loss": 0.00056, "grad_norm": 0.00102, "time": 0.69527}
+{"mode": "train", "epoch": 104, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00057, "acc_pose": 0.83236, "loss": 0.00057, "grad_norm": 0.00103, "time": 0.69561}
+{"mode": "train", "epoch": 104, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00057, "acc_pose": 0.8365, "loss": 0.00057, "grad_norm": 0.00107, "time": 0.69532}
+{"mode": "train", "epoch": 104, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00034, "heatmap_loss": 0.00057, "acc_pose": 0.83351, "loss": 0.00057, "grad_norm": 0.0011, "time": 0.69537}
+{"mode": "train", "epoch": 105, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05603, "heatmap_loss": 0.00057, "acc_pose": 0.83631, "loss": 0.00057, "grad_norm": 0.00107, "time": 0.75329}
+{"mode": "train", "epoch": 105, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00056, "acc_pose": 0.83687, "loss": 0.00056, "grad_norm": 0.00106, "time": 0.69535}
+{"mode": "train", "epoch": 105, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00034, "heatmap_loss": 0.00057, "acc_pose": 0.83357, "loss": 0.00057, "grad_norm": 0.00107, "time": 0.69515}
+{"mode": "train", "epoch": 105, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00056, "acc_pose": 0.84087, "loss": 0.00056, "grad_norm": 0.00104, "time": 0.6955}
+{"mode": "train", "epoch": 105, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00057, "acc_pose": 0.82999, "loss": 0.00057, "grad_norm": 0.00108, "time": 0.69607}
+{"mode": "train", "epoch": 106, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05965, "heatmap_loss": 0.00056, "acc_pose": 0.83234, "loss": 0.00056, "grad_norm": 0.00107, "time": 0.75705}
+{"mode": "train", "epoch": 106, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00027, "heatmap_loss": 0.00057, "acc_pose": 0.83123, "loss": 0.00057, "grad_norm": 0.00104, "time": 0.69552}
+{"mode": "train", "epoch": 106, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00057, "acc_pose": 0.82566, "loss": 0.00057, "grad_norm": 0.00108, "time": 0.69537}
+{"mode": "train", "epoch": 106, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00034, "heatmap_loss": 0.00057, "acc_pose": 0.83544, "loss": 0.00057, "grad_norm": 0.0011, "time": 0.69571}
+{"mode": "train", "epoch": 106, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00057, "acc_pose": 0.83563, "loss": 0.00057, "grad_norm": 0.00102, "time": 0.6955}
+{"mode": "train", "epoch": 107, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05687, "heatmap_loss": 0.00056, "acc_pose": 0.83607, "loss": 0.00056, "grad_norm": 0.00104, "time": 0.75462}
+{"mode": "train", "epoch": 107, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00057, "acc_pose": 0.83127, "loss": 0.00057, "grad_norm": 0.00112, "time": 0.69623}
+{"mode": "train", "epoch": 107, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00057, "acc_pose": 0.83706, "loss": 0.00057, "grad_norm": 0.00102, "time": 0.69574}
+{"mode": "train", "epoch": 107, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00057, "acc_pose": 0.83149, "loss": 0.00057, "grad_norm": 0.00111, "time": 0.69587}
+{"mode": "train", "epoch": 107, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00057, "acc_pose": 0.83123, "loss": 0.00057, "grad_norm": 0.00108, "time": 0.69553}
+{"mode": "train", "epoch": 108, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05684, "heatmap_loss": 0.00056, "acc_pose": 0.83748, "loss": 0.00056, "grad_norm": 0.00112, "time": 0.75411}
+{"mode": "train", "epoch": 108, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00056, "acc_pose": 0.83274, "loss": 0.00056, "grad_norm": 0.00105, "time": 0.69552}
+{"mode": "train", "epoch": 108, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00057, "acc_pose": 0.83274, "loss": 0.00057, "grad_norm": 0.00116, "time": 0.69616}
+{"mode": "train", "epoch": 108, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00057, "acc_pose": 0.83546, "loss": 0.00057, "grad_norm": 0.00104, "time": 0.69514}
+{"mode": "train", "epoch": 108, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00056, "acc_pose": 0.83331, "loss": 0.00056, "grad_norm": 0.00109, "time": 0.69497}
+{"mode": "train", "epoch": 109, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05664, "heatmap_loss": 0.00056, "acc_pose": 0.83873, "loss": 0.00056, "grad_norm": 0.00105, "time": 0.75339}
+{"mode": "train", "epoch": 109, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00057, "acc_pose": 0.83222, "loss": 0.00057, "grad_norm": 0.00104, "time": 0.69564}
+{"mode": "train", "epoch": 109, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00057, "acc_pose": 0.83869, "loss": 0.00057, "grad_norm": 0.00104, "time": 0.69573}
+{"mode": "train", "epoch": 109, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00056, "acc_pose": 0.83733, "loss": 0.00056, "grad_norm": 0.00107, "time": 0.69562}
+{"mode": "train", "epoch": 109, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00056, "acc_pose": 0.83388, "loss": 0.00056, "grad_norm": 0.00103, "time": 0.6955}
+{"mode": "train", "epoch": 110, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05911, "heatmap_loss": 0.00057, "acc_pose": 0.82931, "loss": 0.00057, "grad_norm": 0.00111, "time": 0.75681}
+{"mode": "train", "epoch": 110, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00034, "heatmap_loss": 0.00056, "acc_pose": 0.83354, "loss": 0.00056, "grad_norm": 0.00115, "time": 0.69595}
+{"mode": "train", "epoch": 110, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00036, "heatmap_loss": 0.00057, "acc_pose": 0.83345, "loss": 0.00057, "grad_norm": 0.00109, "time": 0.69541}
+{"mode": "train", "epoch": 110, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00056, "acc_pose": 0.84429, "loss": 0.00056, "grad_norm": 0.00112, "time": 0.69531}
+{"mode": "train", "epoch": 110, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00056, "acc_pose": 0.83877, "loss": 0.00056, "grad_norm": 0.0011, "time": 0.69548}
+{"mode": "val", "epoch": 110, "iter": 407, "lr": 0.0, "AP": 0.77469, "AP .5": 0.91314, "AP .75": 0.84845, "AP (M)": 0.70217, "AP (L)": 0.80104, "AR": 0.82739, "AR .5": 0.95041, "AR .75": 0.89169, "AR (M)": 0.78806, "AR (L)": 0.8851}
+{"mode": "train", "epoch": 111, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05587, "heatmap_loss": 0.00056, "acc_pose": 0.83448, "loss": 0.00056, "grad_norm": 0.00108, "time": 0.7488}
+{"mode": "train", "epoch": 111, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00057, "acc_pose": 0.83324, "loss": 0.00057, "grad_norm": 0.00108, "time": 0.69543}
+{"mode": "train", "epoch": 111, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00056, "acc_pose": 0.83176, "loss": 0.00056, "grad_norm": 0.00108, "time": 0.69552}
+{"mode": "train", "epoch": 111, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00056, "acc_pose": 0.83781, "loss": 0.00056, "grad_norm": 0.00108, "time": 0.69538}
+{"mode": "train", "epoch": 111, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00056, "acc_pose": 0.83089, "loss": 0.00056, "grad_norm": 0.00109, "time": 0.69565}
+{"mode": "train", "epoch": 112, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05523, "heatmap_loss": 0.00056, "acc_pose": 0.83813, "loss": 0.00056, "grad_norm": 0.00107, "time": 0.7573}
+{"mode": "train", "epoch": 112, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00056, "acc_pose": 0.83034, "loss": 0.00056, "grad_norm": 0.00107, "time": 0.69503}
+{"mode": "train", "epoch": 112, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00056, "acc_pose": 0.83757, "loss": 0.00056, "grad_norm": 0.00107, "time": 0.69605}
+{"mode": "train", "epoch": 112, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00056, "acc_pose": 0.84285, "loss": 0.00056, "grad_norm": 0.00113, "time": 0.69549}
+{"mode": "train", "epoch": 112, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00056, "acc_pose": 0.83599, "loss": 0.00056, "grad_norm": 0.00105, "time": 0.69525}
+{"mode": "train", "epoch": 113, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05518, "heatmap_loss": 0.00056, "acc_pose": 0.83693, "loss": 0.00056, "grad_norm": 0.00106, "time": 0.75311}
+{"mode": "train", "epoch": 113, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00057, "acc_pose": 0.83579, "loss": 0.00057, "grad_norm": 0.00108, "time": 0.69545}
+{"mode": "train", "epoch": 113, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00057, "acc_pose": 0.83445, "loss": 0.00057, "grad_norm": 0.00106, "time": 0.69575}
+{"mode": "train", "epoch": 113, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00056, "acc_pose": 0.83735, "loss": 0.00056, "grad_norm": 0.00108, "time": 0.69537}
+{"mode": "train", "epoch": 113, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00056, "acc_pose": 0.83106, "loss": 0.00056, "grad_norm": 0.00105, "time": 0.6956}
+{"mode": "train", "epoch": 114, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05674, "heatmap_loss": 0.00056, "acc_pose": 0.83178, "loss": 0.00056, "grad_norm": 0.00104, "time": 0.75341}
+{"mode": "train", "epoch": 114, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00056, "acc_pose": 0.83772, "loss": 0.00056, "grad_norm": 0.00104, "time": 0.69509}
+{"mode": "train", "epoch": 114, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00056, "acc_pose": 0.83084, "loss": 0.00056, "grad_norm": 0.00104, "time": 0.69533}
+{"mode": "train", "epoch": 114, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00056, "acc_pose": 0.83939, "loss": 0.00056, "grad_norm": 0.001, "time": 0.69501}
+{"mode": "train", "epoch": 114, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00056, "acc_pose": 0.83941, "loss": 0.00056, "grad_norm": 0.00105, "time": 0.69527}
+{"mode": "train", "epoch": 115, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05623, "heatmap_loss": 0.00056, "acc_pose": 0.83412, "loss": 0.00056, "grad_norm": 0.00111, "time": 0.75383}
+{"mode": "train", "epoch": 115, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00045, "heatmap_loss": 0.00055, "acc_pose": 0.8366, "loss": 0.00055, "grad_norm": 0.00103, "time": 0.6955}
+{"mode": "train", "epoch": 115, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00056, "acc_pose": 0.83339, "loss": 0.00056, "grad_norm": 0.00104, "time": 0.69552}
+{"mode": "train", "epoch": 115, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00034, "heatmap_loss": 0.00056, "acc_pose": 0.8363, "loss": 0.00056, "grad_norm": 0.00102, "time": 0.69521}
+{"mode": "train", "epoch": 115, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00036, "heatmap_loss": 0.00056, "acc_pose": 0.8367, "loss": 0.00056, "grad_norm": 0.0011, "time": 0.69481}
+{"mode": "train", "epoch": 116, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.0566, "heatmap_loss": 0.00056, "acc_pose": 0.84223, "loss": 0.00056, "grad_norm": 0.00104, "time": 0.75404}
+{"mode": "train", "epoch": 116, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00056, "acc_pose": 0.82977, "loss": 0.00056, "grad_norm": 0.00112, "time": 0.69539}
+{"mode": "train", "epoch": 116, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00042, "heatmap_loss": 0.00056, "acc_pose": 0.83209, "loss": 0.00056, "grad_norm": 0.00107, "time": 0.69578}
+{"mode": "train", "epoch": 116, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00028, "heatmap_loss": 0.00056, "acc_pose": 0.83922, "loss": 0.00056, "grad_norm": 0.00104, "time": 0.69541}
+{"mode": "train", "epoch": 116, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00056, "acc_pose": 0.83781, "loss": 0.00056, "grad_norm": 0.00103, "time": 0.69531}
+{"mode": "train", "epoch": 117, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05643, "heatmap_loss": 0.00056, "acc_pose": 0.83376, "loss": 0.00056, "grad_norm": 0.00103, "time": 0.75342}
+{"mode": "train", "epoch": 117, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00056, "acc_pose": 0.83888, "loss": 0.00056, "grad_norm": 0.00107, "time": 0.69531}
+{"mode": "train", "epoch": 117, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00056, "acc_pose": 0.83936, "loss": 0.00056, "grad_norm": 0.00098, "time": 0.69492}
+{"mode": "train", "epoch": 117, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00056, "acc_pose": 0.83149, "loss": 0.00056, "grad_norm": 0.00107, "time": 0.69485}
+{"mode": "train", "epoch": 117, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00056, "acc_pose": 0.84118, "loss": 0.00056, "grad_norm": 0.00104, "time": 0.6947}
+{"mode": "train", "epoch": 118, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.0558, "heatmap_loss": 0.00056, "acc_pose": 0.83893, "loss": 0.00056, "grad_norm": 0.00106, "time": 0.75348}
+{"mode": "train", "epoch": 118, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00035, "heatmap_loss": 0.00056, "acc_pose": 0.83234, "loss": 0.00056, "grad_norm": 0.00105, "time": 0.69581}
+{"mode": "train", "epoch": 118, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00035, "heatmap_loss": 0.00056, "acc_pose": 0.83662, "loss": 0.00056, "grad_norm": 0.00105, "time": 0.6955}
+{"mode": "train", "epoch": 118, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00035, "heatmap_loss": 0.00056, "acc_pose": 0.83833, "loss": 0.00056, "grad_norm": 0.001, "time": 0.69538}
+{"mode": "train", "epoch": 118, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00036, "heatmap_loss": 0.00056, "acc_pose": 0.83843, "loss": 0.00056, "grad_norm": 0.00109, "time": 0.69498}
+{"mode": "train", "epoch": 119, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05709, "heatmap_loss": 0.00055, "acc_pose": 0.84482, "loss": 0.00055, "grad_norm": 0.00114, "time": 0.75256}
+{"mode": "train", "epoch": 119, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00055, "acc_pose": 0.841, "loss": 0.00055, "grad_norm": 0.00102, "time": 0.69569}
+{"mode": "train", "epoch": 119, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00056, "acc_pose": 0.83112, "loss": 0.00056, "grad_norm": 0.00112, "time": 0.69521}
+{"mode": "train", "epoch": 119, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00056, "acc_pose": 0.83614, "loss": 0.00056, "grad_norm": 0.00105, "time": 0.69565}
+{"mode": "train", "epoch": 119, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00056, "acc_pose": 0.83427, "loss": 0.00056, "grad_norm": 0.00104, "time": 0.69549}
+{"mode": "train", "epoch": 120, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05583, "heatmap_loss": 0.00056, "acc_pose": 0.8424, "loss": 0.00056, "grad_norm": 0.00103, "time": 0.75627}
+{"mode": "train", "epoch": 120, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00056, "acc_pose": 0.83964, "loss": 0.00056, "grad_norm": 0.00103, "time": 0.69545}
+{"mode": "train", "epoch": 120, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00055, "acc_pose": 0.83556, "loss": 0.00055, "grad_norm": 0.00101, "time": 0.69562}
+{"mode": "train", "epoch": 120, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00056, "acc_pose": 0.8364, "loss": 0.00056, "grad_norm": 0.00105, "time": 0.69527}
+{"mode": "train", "epoch": 120, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00055, "acc_pose": 0.84282, "loss": 0.00055, "grad_norm": 0.00103, "time": 0.69509}
+{"mode": "val", "epoch": 120, "iter": 407, "lr": 0.0, "AP": 0.77656, "AP .5": 0.91384, "AP .75": 0.85017, "AP (M)": 0.70304, "AP (L)": 0.80356, "AR": 0.82917, "AR .5": 0.95167, "AR .75": 0.8931, "AR (M)": 0.78916, "AR (L)": 0.88785}
+{"mode": "train", "epoch": 121, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05622, "heatmap_loss": 0.00056, "acc_pose": 0.83682, "loss": 0.00056, "grad_norm": 0.00104, "time": 0.75079}
+{"mode": "train", "epoch": 121, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00055, "acc_pose": 0.841, "loss": 0.00055, "grad_norm": 0.00109, "time": 0.695}
+{"mode": "train", "epoch": 121, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00034, "heatmap_loss": 0.00056, "acc_pose": 0.83884, "loss": 0.00056, "grad_norm": 0.00107, "time": 0.69488}
+{"mode": "train", "epoch": 121, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00055, "acc_pose": 0.8388, "loss": 0.00055, "grad_norm": 0.00104, "time": 0.6947}
+{"mode": "train", "epoch": 121, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00055, "acc_pose": 0.83907, "loss": 0.00055, "grad_norm": 0.00103, "time": 0.69536}
+{"mode": "train", "epoch": 122, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05651, "heatmap_loss": 0.00055, "acc_pose": 0.83479, "loss": 0.00055, "grad_norm": 0.00112, "time": 0.75218}
+{"mode": "train", "epoch": 122, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00056, "acc_pose": 0.84188, "loss": 0.00056, "grad_norm": 0.00103, "time": 0.69549}
+{"mode": "train", "epoch": 122, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00055, "acc_pose": 0.83966, "loss": 0.00055, "grad_norm": 0.001, "time": 0.69538}
+{"mode": "train", "epoch": 122, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00056, "acc_pose": 0.83993, "loss": 0.00056, "grad_norm": 0.0011, "time": 0.69539}
+{"mode": "train", "epoch": 122, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00056, "acc_pose": 0.83576, "loss": 0.00056, "grad_norm": 0.00107, "time": 0.69486}
+{"mode": "train", "epoch": 123, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05737, "heatmap_loss": 0.00055, "acc_pose": 0.84265, "loss": 0.00055, "grad_norm": 0.00107, "time": 0.75289}
+{"mode": "train", "epoch": 123, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00055, "acc_pose": 0.84256, "loss": 0.00055, "grad_norm": 0.00107, "time": 0.69526}
+{"mode": "train", "epoch": 123, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00055, "acc_pose": 0.84307, "loss": 0.00055, "grad_norm": 0.00106, "time": 0.69518}
+{"mode": "train", "epoch": 123, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00055, "acc_pose": 0.84008, "loss": 0.00055, "grad_norm": 0.00107, "time": 0.6954}
+{"mode": "train", "epoch": 123, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00056, "acc_pose": 0.84115, "loss": 0.00056, "grad_norm": 0.00105, "time": 0.69533}
+{"mode": "train", "epoch": 124, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05656, "heatmap_loss": 0.00055, "acc_pose": 0.83227, "loss": 0.00055, "grad_norm": 0.001, "time": 0.75651}
+{"mode": "train", "epoch": 124, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00055, "acc_pose": 0.83619, "loss": 0.00055, "grad_norm": 0.00103, "time": 0.6958}
+{"mode": "train", "epoch": 124, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00055, "acc_pose": 0.83871, "loss": 0.00055, "grad_norm": 0.00104, "time": 0.69575}
+{"mode": "train", "epoch": 124, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00044, "heatmap_loss": 0.00056, "acc_pose": 0.83732, "loss": 0.00056, "grad_norm": 0.00109, "time": 0.69533}
+{"mode": "train", "epoch": 124, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00055, "acc_pose": 0.83844, "loss": 0.00055, "grad_norm": 0.00102, "time": 0.69458}
+{"mode": "train", "epoch": 125, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05708, "heatmap_loss": 0.00055, "acc_pose": 0.83829, "loss": 0.00055, "grad_norm": 0.00103, "time": 0.75496}
+{"mode": "train", "epoch": 125, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00055, "acc_pose": 0.83766, "loss": 0.00055, "grad_norm": 0.001, "time": 0.69575}
+{"mode": "train", "epoch": 125, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00055, "acc_pose": 0.83641, "loss": 0.00055, "grad_norm": 0.00099, "time": 0.69553}
+{"mode": "train", "epoch": 125, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00055, "acc_pose": 0.83146, "loss": 0.00055, "grad_norm": 0.00104, "time": 0.69471}
+{"mode": "train", "epoch": 125, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00055, "acc_pose": 0.84098, "loss": 0.00055, "grad_norm": 0.00103, "time": 0.69485}
+{"mode": "train", "epoch": 126, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05601, "heatmap_loss": 0.00055, "acc_pose": 0.83725, "loss": 0.00055, "grad_norm": 0.00107, "time": 0.75344}
+{"mode": "train", "epoch": 126, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00055, "acc_pose": 0.8387, "loss": 0.00055, "grad_norm": 0.00107, "time": 0.69496}
+{"mode": "train", "epoch": 126, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00056, "acc_pose": 0.83917, "loss": 0.00056, "grad_norm": 0.00108, "time": 0.69529}
+{"mode": "train", "epoch": 126, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00055, "acc_pose": 0.84468, "loss": 0.00055, "grad_norm": 0.00112, "time": 0.6954}
+{"mode": "train", "epoch": 126, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00055, "acc_pose": 0.84261, "loss": 0.00055, "grad_norm": 0.00106, "time": 0.6951}
+{"mode": "train", "epoch": 127, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05662, "heatmap_loss": 0.00055, "acc_pose": 0.84359, "loss": 0.00055, "grad_norm": 0.00105, "time": 0.75305}
+{"mode": "train", "epoch": 127, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00056, "acc_pose": 0.83524, "loss": 0.00056, "grad_norm": 0.00105, "time": 0.69538}
+{"mode": "train", "epoch": 127, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00055, "acc_pose": 0.83941, "loss": 0.00055, "grad_norm": 0.00103, "time": 0.69568}
+{"mode": "train", "epoch": 127, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00055, "acc_pose": 0.84158, "loss": 0.00055, "grad_norm": 0.00107, "time": 0.69569}
+{"mode": "train", "epoch": 127, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00055, "acc_pose": 0.84173, "loss": 0.00055, "grad_norm": 0.00113, "time": 0.69566}
+{"mode": "train", "epoch": 128, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05587, "heatmap_loss": 0.00055, "acc_pose": 0.84009, "loss": 0.00055, "grad_norm": 0.00102, "time": 0.75325}
+{"mode": "train", "epoch": 128, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00055, "acc_pose": 0.83958, "loss": 0.00055, "grad_norm": 0.00105, "time": 0.69458}
+{"mode": "train", "epoch": 128, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00055, "acc_pose": 0.84433, "loss": 0.00055, "grad_norm": 0.00102, "time": 0.69485}
+{"mode": "train", "epoch": 128, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00039, "heatmap_loss": 0.00055, "acc_pose": 0.83185, "loss": 0.00055, "grad_norm": 0.00102, "time": 0.69465}
+{"mode": "train", "epoch": 128, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00055, "acc_pose": 0.84169, "loss": 0.00055, "grad_norm": 0.001, "time": 0.69475}
+{"mode": "train", "epoch": 129, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05581, "heatmap_loss": 0.00055, "acc_pose": 0.84144, "loss": 0.00055, "grad_norm": 0.00103, "time": 0.75412}
+{"mode": "train", "epoch": 129, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00055, "acc_pose": 0.84217, "loss": 0.00055, "grad_norm": 0.00099, "time": 0.69554}
+{"mode": "train", "epoch": 129, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00055, "acc_pose": 0.83753, "loss": 0.00055, "grad_norm": 0.0011, "time": 0.69497}
+{"mode": "train", "epoch": 129, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00055, "acc_pose": 0.84145, "loss": 0.00055, "grad_norm": 0.00111, "time": 0.69546}
+{"mode": "train", "epoch": 129, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00055, "acc_pose": 0.83594, "loss": 0.00055, "grad_norm": 0.0011, "time": 0.6955}
+{"mode": "train", "epoch": 130, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05693, "heatmap_loss": 0.00055, "acc_pose": 0.84311, "loss": 0.00055, "grad_norm": 0.00106, "time": 0.75357}
+{"mode": "train", "epoch": 130, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00056, "acc_pose": 0.83146, "loss": 0.00056, "grad_norm": 0.00108, "time": 0.69498}
+{"mode": "train", "epoch": 130, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00055, "acc_pose": 0.83605, "loss": 0.00055, "grad_norm": 0.00101, "time": 0.69503}
+{"mode": "train", "epoch": 130, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00055, "acc_pose": 0.84034, "loss": 0.00055, "grad_norm": 0.00114, "time": 0.69475}
+{"mode": "train", "epoch": 130, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00055, "acc_pose": 0.84298, "loss": 0.00055, "grad_norm": 0.00105, "time": 0.69508}
+{"mode": "val", "epoch": 130, "iter": 407, "lr": 0.0, "AP": 0.77538, "AP .5": 0.91309, "AP .75": 0.84818, "AP (M)": 0.70127, "AP (L)": 0.80338, "AR": 0.82813, "AR .5": 0.95135, "AR .75": 0.89122, "AR (M)": 0.78727, "AR (L)": 0.88803}
+{"mode": "train", "epoch": 131, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05511, "heatmap_loss": 0.00055, "acc_pose": 0.84618, "loss": 0.00055, "grad_norm": 0.00098, "time": 0.74839}
+{"mode": "train", "epoch": 131, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00055, "acc_pose": 0.84069, "loss": 0.00055, "grad_norm": 0.00108, "time": 0.69474}
+{"mode": "train", "epoch": 131, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00055, "acc_pose": 0.83695, "loss": 0.00055, "grad_norm": 0.00105, "time": 0.69535}
+{"mode": "train", "epoch": 131, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.84609, "loss": 0.00054, "grad_norm": 0.00102, "time": 0.69528}
+{"mode": "train", "epoch": 131, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00055, "acc_pose": 0.84108, "loss": 0.00055, "grad_norm": 0.00105, "time": 0.6953}
+{"mode": "train", "epoch": 132, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05718, "heatmap_loss": 0.00054, "acc_pose": 0.84062, "loss": 0.00054, "grad_norm": 0.00112, "time": 0.75307}
+{"mode": "train", "epoch": 132, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00056, "acc_pose": 0.84358, "loss": 0.00056, "grad_norm": 0.00113, "time": 0.69521}
+{"mode": "train", "epoch": 132, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00055, "acc_pose": 0.83816, "loss": 0.00055, "grad_norm": 0.00104, "time": 0.69532}
+{"mode": "train", "epoch": 132, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00055, "acc_pose": 0.84091, "loss": 0.00055, "grad_norm": 0.00102, "time": 0.69585}
+{"mode": "train", "epoch": 132, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00055, "acc_pose": 0.84824, "loss": 0.00055, "grad_norm": 0.0011, "time": 0.69565}
+{"mode": "train", "epoch": 133, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05694, "heatmap_loss": 0.00054, "acc_pose": 0.83653, "loss": 0.00054, "grad_norm": 0.00098, "time": 0.75308}
+{"mode": "train", "epoch": 133, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00035, "heatmap_loss": 0.00055, "acc_pose": 0.83807, "loss": 0.00055, "grad_norm": 0.00102, "time": 0.6954}
+{"mode": "train", "epoch": 133, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00055, "acc_pose": 0.83988, "loss": 0.00055, "grad_norm": 0.00103, "time": 0.69604}
+{"mode": "train", "epoch": 133, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00055, "acc_pose": 0.83784, "loss": 0.00055, "grad_norm": 0.00107, "time": 0.69528}
+{"mode": "train", "epoch": 133, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00034, "heatmap_loss": 0.00055, "acc_pose": 0.83536, "loss": 0.00055, "grad_norm": 0.00108, "time": 0.69457}
+{"mode": "train", "epoch": 134, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05636, "heatmap_loss": 0.00054, "acc_pose": 0.83996, "loss": 0.00054, "grad_norm": 0.00104, "time": 0.75388}
+{"mode": "train", "epoch": 134, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00055, "acc_pose": 0.83903, "loss": 0.00055, "grad_norm": 0.00106, "time": 0.69544}
+{"mode": "train", "epoch": 134, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.83732, "loss": 0.00054, "grad_norm": 0.00105, "time": 0.69503}
+{"mode": "train", "epoch": 134, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00054, "acc_pose": 0.84938, "loss": 0.00054, "grad_norm": 0.00122, "time": 0.69587}
+{"mode": "train", "epoch": 134, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00056, "acc_pose": 0.83481, "loss": 0.00056, "grad_norm": 0.00106, "time": 0.69535}
+{"mode": "train", "epoch": 135, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05686, "heatmap_loss": 0.00054, "acc_pose": 0.84195, "loss": 0.00054, "grad_norm": 0.00103, "time": 0.75261}
+{"mode": "train", "epoch": 135, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00055, "acc_pose": 0.83855, "loss": 0.00055, "grad_norm": 0.00105, "time": 0.69514}
+{"mode": "train", "epoch": 135, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00055, "acc_pose": 0.83887, "loss": 0.00055, "grad_norm": 0.00111, "time": 0.69541}
+{"mode": "train", "epoch": 135, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00055, "acc_pose": 0.84167, "loss": 0.00055, "grad_norm": 0.00109, "time": 0.6957}
+{"mode": "train", "epoch": 135, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00055, "acc_pose": 0.84354, "loss": 0.00055, "grad_norm": 0.00104, "time": 0.6957}
+{"mode": "train", "epoch": 136, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05603, "heatmap_loss": 0.00055, "acc_pose": 0.84085, "loss": 0.00055, "grad_norm": 0.00101, "time": 0.75447}
+{"mode": "train", "epoch": 136, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00055, "acc_pose": 0.84701, "loss": 0.00055, "grad_norm": 0.00105, "time": 0.69584}
+{"mode": "train", "epoch": 136, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.83795, "loss": 0.00054, "grad_norm": 0.00106, "time": 0.69499}
+{"mode": "train", "epoch": 136, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.83869, "loss": 0.00054, "grad_norm": 0.00105, "time": 0.69487}
+{"mode": "train", "epoch": 136, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00054, "acc_pose": 0.84529, "loss": 0.00054, "grad_norm": 0.00104, "time": 0.69516}
+{"mode": "train", "epoch": 137, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05573, "heatmap_loss": 0.00055, "acc_pose": 0.84151, "loss": 0.00055, "grad_norm": 0.00105, "time": 0.75369}
+{"mode": "train", "epoch": 137, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00055, "acc_pose": 0.8383, "loss": 0.00055, "grad_norm": 0.00108, "time": 0.6959}
+{"mode": "train", "epoch": 137, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00054, "acc_pose": 0.83859, "loss": 0.00054, "grad_norm": 0.00104, "time": 0.69528}
+{"mode": "train", "epoch": 137, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00055, "acc_pose": 0.84322, "loss": 0.00055, "grad_norm": 0.00114, "time": 0.69507}
+{"mode": "train", "epoch": 137, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00054, "acc_pose": 0.84287, "loss": 0.00054, "grad_norm": 0.001, "time": 0.69509}
+{"mode": "train", "epoch": 138, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05659, "heatmap_loss": 0.00055, "acc_pose": 0.84101, "loss": 0.00055, "grad_norm": 0.00103, "time": 0.75393}
+{"mode": "train", "epoch": 138, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00054, "acc_pose": 0.8441, "loss": 0.00054, "grad_norm": 0.00114, "time": 0.69495}
+{"mode": "train", "epoch": 138, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00054, "acc_pose": 0.84073, "loss": 0.00054, "grad_norm": 0.00101, "time": 0.69537}
+{"mode": "train", "epoch": 138, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.84445, "loss": 0.00054, "grad_norm": 0.00102, "time": 0.69553}
+{"mode": "train", "epoch": 138, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00054, "acc_pose": 0.84726, "loss": 0.00054, "grad_norm": 0.00099, "time": 0.69536}
+{"mode": "train", "epoch": 139, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05716, "heatmap_loss": 0.00054, "acc_pose": 0.83731, "loss": 0.00054, "grad_norm": 0.00101, "time": 0.7542}
+{"mode": "train", "epoch": 139, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00054, "acc_pose": 0.84424, "loss": 0.00054, "grad_norm": 0.00102, "time": 0.69534}
+{"mode": "train", "epoch": 139, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00055, "acc_pose": 0.84318, "loss": 0.00055, "grad_norm": 0.00103, "time": 0.69591}
+{"mode": "train", "epoch": 139, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00054, "acc_pose": 0.84337, "loss": 0.00054, "grad_norm": 0.00102, "time": 0.69535}
+{"mode": "train", "epoch": 139, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00054, "acc_pose": 0.8401, "loss": 0.00054, "grad_norm": 0.001, "time": 0.695}
+{"mode": "train", "epoch": 140, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05628, "heatmap_loss": 0.00054, "acc_pose": 0.84353, "loss": 0.00054, "grad_norm": 0.00106, "time": 0.75313}
+{"mode": "train", "epoch": 140, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00054, "acc_pose": 0.84044, "loss": 0.00054, "grad_norm": 0.00103, "time": 0.69542}
+{"mode": "train", "epoch": 140, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.84041, "loss": 0.00054, "grad_norm": 0.00101, "time": 0.69514}
+{"mode": "train", "epoch": 140, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00055, "acc_pose": 0.8411, "loss": 0.00055, "grad_norm": 0.00108, "time": 0.69544}
+{"mode": "train", "epoch": 140, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.84269, "loss": 0.00054, "grad_norm": 0.00103, "time": 0.69529}
+{"mode": "val", "epoch": 140, "iter": 407, "lr": 0.0, "AP": 0.77693, "AP .5": 0.91334, "AP .75": 0.84867, "AP (M)": 0.70369, "AP (L)": 0.80391, "AR": 0.82966, "AR .5": 0.95214, "AR .75": 0.89137, "AR (M)": 0.78929, "AR (L)": 0.88874}
+{"mode": "train", "epoch": 141, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05657, "heatmap_loss": 0.00055, "acc_pose": 0.84298, "loss": 0.00055, "grad_norm": 0.001, "time": 0.75014}
+{"mode": "train", "epoch": 141, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00054, "acc_pose": 0.84914, "loss": 0.00054, "grad_norm": 0.00106, "time": 0.69449}
+{"mode": "train", "epoch": 141, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.83568, "loss": 0.00054, "grad_norm": 0.00109, "time": 0.69505}
+{"mode": "train", "epoch": 141, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.8446, "loss": 0.00054, "grad_norm": 0.00103, "time": 0.6951}
+{"mode": "train", "epoch": 141, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00054, "acc_pose": 0.8443, "loss": 0.00054, "grad_norm": 0.00102, "time": 0.69571}
+{"mode": "train", "epoch": 142, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.0587, "heatmap_loss": 0.00054, "acc_pose": 0.84699, "loss": 0.00054, "grad_norm": 0.00106, "time": 0.7567}
+{"mode": "train", "epoch": 142, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00055, "acc_pose": 0.83559, "loss": 0.00055, "grad_norm": 0.00104, "time": 0.69505}
+{"mode": "train", "epoch": 142, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.8419, "loss": 0.00054, "grad_norm": 0.00105, "time": 0.69555}
+{"mode": "train", "epoch": 142, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.84458, "loss": 0.00054, "grad_norm": 0.00103, "time": 0.69534}
+{"mode": "train", "epoch": 142, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00054, "acc_pose": 0.84248, "loss": 0.00054, "grad_norm": 0.00099, "time": 0.69557}
+{"mode": "train", "epoch": 143, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05612, "heatmap_loss": 0.00054, "acc_pose": 0.85031, "loss": 0.00054, "grad_norm": 0.00105, "time": 0.75369}
+{"mode": "train", "epoch": 143, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00055, "acc_pose": 0.84192, "loss": 0.00055, "grad_norm": 0.00109, "time": 0.69571}
+{"mode": "train", "epoch": 143, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00054, "acc_pose": 0.84238, "loss": 0.00054, "grad_norm": 0.00101, "time": 0.69569}
+{"mode": "train", "epoch": 143, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00054, "acc_pose": 0.8429, "loss": 0.00054, "grad_norm": 0.00098, "time": 0.69558}
+{"mode": "train", "epoch": 143, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00054, "acc_pose": 0.84491, "loss": 0.00054, "grad_norm": 0.00109, "time": 0.69579}
+{"mode": "train", "epoch": 144, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05618, "heatmap_loss": 0.00054, "acc_pose": 0.83934, "loss": 0.00054, "grad_norm": 0.00104, "time": 0.75341}
+{"mode": "train", "epoch": 144, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00054, "acc_pose": 0.83989, "loss": 0.00054, "grad_norm": 0.00102, "time": 0.69557}
+{"mode": "train", "epoch": 144, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.83828, "loss": 0.00054, "grad_norm": 0.0011, "time": 0.69562}
+{"mode": "train", "epoch": 144, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00055, "acc_pose": 0.83876, "loss": 0.00055, "grad_norm": 0.00104, "time": 0.69505}
+{"mode": "train", "epoch": 144, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00054, "acc_pose": 0.84324, "loss": 0.00054, "grad_norm": 0.001, "time": 0.69538}
+{"mode": "train", "epoch": 145, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.06011, "heatmap_loss": 0.00054, "acc_pose": 0.84465, "loss": 0.00054, "grad_norm": 0.00103, "time": 0.75692}
+{"mode": "train", "epoch": 145, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00053, "acc_pose": 0.84467, "loss": 0.00053, "grad_norm": 0.00101, "time": 0.69551}
+{"mode": "train", "epoch": 145, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00054, "acc_pose": 0.84161, "loss": 0.00054, "grad_norm": 0.00106, "time": 0.69546}
+{"mode": "train", "epoch": 145, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00054, "acc_pose": 0.83903, "loss": 0.00054, "grad_norm": 0.00106, "time": 0.6963}
+{"mode": "train", "epoch": 145, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00054, "acc_pose": 0.84999, "loss": 0.00054, "grad_norm": 0.00103, "time": 0.69514}
+{"mode": "train", "epoch": 146, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05586, "heatmap_loss": 0.00054, "acc_pose": 0.83882, "loss": 0.00054, "grad_norm": 0.00108, "time": 0.75466}
+{"mode": "train", "epoch": 146, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.84193, "loss": 0.00054, "grad_norm": 0.00107, "time": 0.69582}
+{"mode": "train", "epoch": 146, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.83415, "loss": 0.00054, "grad_norm": 0.00097, "time": 0.69579}
+{"mode": "train", "epoch": 146, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.84322, "loss": 0.00053, "grad_norm": 0.00099, "time": 0.6958}
+{"mode": "train", "epoch": 146, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00054, "acc_pose": 0.84566, "loss": 0.00054, "grad_norm": 0.00105, "time": 0.69595}
+{"mode": "train", "epoch": 147, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.0556, "heatmap_loss": 0.00054, "acc_pose": 0.85007, "loss": 0.00054, "grad_norm": 0.00102, "time": 0.75373}
+{"mode": "train", "epoch": 147, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00054, "acc_pose": 0.84072, "loss": 0.00054, "grad_norm": 0.001, "time": 0.69532}
+{"mode": "train", "epoch": 147, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00054, "acc_pose": 0.84305, "loss": 0.00054, "grad_norm": 0.00112, "time": 0.6954}
+{"mode": "train", "epoch": 147, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.84009, "loss": 0.00054, "grad_norm": 0.0011, "time": 0.69589}
+{"mode": "train", "epoch": 147, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00034, "heatmap_loss": 0.00054, "acc_pose": 0.83907, "loss": 0.00054, "grad_norm": 0.00102, "time": 0.69549}
+{"mode": "train", "epoch": 148, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05597, "heatmap_loss": 0.00054, "acc_pose": 0.84233, "loss": 0.00054, "grad_norm": 0.00107, "time": 0.75318}
+{"mode": "train", "epoch": 148, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.84475, "loss": 0.00054, "grad_norm": 0.00106, "time": 0.69554}
+{"mode": "train", "epoch": 148, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00054, "acc_pose": 0.84382, "loss": 0.00054, "grad_norm": 0.00102, "time": 0.6954}
+{"mode": "train", "epoch": 148, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.84704, "loss": 0.00054, "grad_norm": 0.00107, "time": 0.69534}
+{"mode": "train", "epoch": 148, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.84723, "loss": 0.00054, "grad_norm": 0.00104, "time": 0.69544}
+{"mode": "train", "epoch": 149, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05551, "heatmap_loss": 0.00053, "acc_pose": 0.84117, "loss": 0.00053, "grad_norm": 0.00102, "time": 0.75361}
+{"mode": "train", "epoch": 149, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00054, "acc_pose": 0.85128, "loss": 0.00054, "grad_norm": 0.00103, "time": 0.69528}
+{"mode": "train", "epoch": 149, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.85039, "loss": 0.00054, "grad_norm": 0.00096, "time": 0.69578}
+{"mode": "train", "epoch": 149, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.84278, "loss": 0.00054, "grad_norm": 0.00105, "time": 0.69581}
+{"mode": "train", "epoch": 149, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.85287, "loss": 0.00054, "grad_norm": 0.00107, "time": 0.69577}
+{"mode": "train", "epoch": 150, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05693, "heatmap_loss": 0.00054, "acc_pose": 0.84796, "loss": 0.00054, "grad_norm": 0.00109, "time": 0.75383}
+{"mode": "train", "epoch": 150, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.85291, "loss": 0.00053, "grad_norm": 0.001, "time": 0.69487}
+{"mode": "train", "epoch": 150, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00054, "acc_pose": 0.84636, "loss": 0.00054, "grad_norm": 0.00101, "time": 0.69553}
+{"mode": "train", "epoch": 150, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.84972, "loss": 0.00053, "grad_norm": 0.00113, "time": 0.69512}
+{"mode": "train", "epoch": 150, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00054, "acc_pose": 0.84542, "loss": 0.00054, "grad_norm": 0.00101, "time": 0.69539}
+{"mode": "val", "epoch": 150, "iter": 407, "lr": 0.0, "AP": 0.77833, "AP .5": 0.91398, "AP .75": 0.84911, "AP (M)": 0.70482, "AP (L)": 0.80475, "AR": 0.83114, "AR .5": 0.95309, "AR .75": 0.89185, "AR (M)": 0.79131, "AR (L)": 0.88945}
+{"mode": "train", "epoch": 151, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05784, "heatmap_loss": 0.00054, "acc_pose": 0.84057, "loss": 0.00054, "grad_norm": 0.00101, "time": 0.75142}
+{"mode": "train", "epoch": 151, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.84718, "loss": 0.00053, "grad_norm": 0.00104, "time": 0.69492}
+{"mode": "train", "epoch": 151, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00054, "acc_pose": 0.84586, "loss": 0.00054, "grad_norm": 0.00101, "time": 0.69506}
+{"mode": "train", "epoch": 151, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00035, "heatmap_loss": 0.00054, "acc_pose": 0.84522, "loss": 0.00054, "grad_norm": 0.00108, "time": 0.69503}
+{"mode": "train", "epoch": 151, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00054, "acc_pose": 0.84812, "loss": 0.00054, "grad_norm": 0.0011, "time": 0.69537}
+{"mode": "train", "epoch": 152, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05639, "heatmap_loss": 0.00053, "acc_pose": 0.84548, "loss": 0.00053, "grad_norm": 0.00103, "time": 0.75245}
+{"mode": "train", "epoch": 152, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00054, "acc_pose": 0.84867, "loss": 0.00054, "grad_norm": 0.00103, "time": 0.69541}
+{"mode": "train", "epoch": 152, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.84896, "loss": 0.00054, "grad_norm": 0.00106, "time": 0.69519}
+{"mode": "train", "epoch": 152, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.84611, "loss": 0.00054, "grad_norm": 0.00099, "time": 0.69541}
+{"mode": "train", "epoch": 152, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00054, "acc_pose": 0.85242, "loss": 0.00054, "grad_norm": 0.00111, "time": 0.69519}
+{"mode": "train", "epoch": 153, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05587, "heatmap_loss": 0.00053, "acc_pose": 0.85125, "loss": 0.00053, "grad_norm": 0.00105, "time": 0.75504}
+{"mode": "train", "epoch": 153, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00053, "acc_pose": 0.85215, "loss": 0.00053, "grad_norm": 0.00101, "time": 0.69539}
+{"mode": "train", "epoch": 153, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00053, "acc_pose": 0.84631, "loss": 0.00053, "grad_norm": 0.00101, "time": 0.6956}
+{"mode": "train", "epoch": 153, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00054, "acc_pose": 0.84571, "loss": 0.00054, "grad_norm": 0.00105, "time": 0.69545}
+{"mode": "train", "epoch": 153, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00054, "acc_pose": 0.84365, "loss": 0.00054, "grad_norm": 0.001, "time": 0.69548}
+{"mode": "train", "epoch": 154, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.0558, "heatmap_loss": 0.00053, "acc_pose": 0.84466, "loss": 0.00053, "grad_norm": 0.001, "time": 0.75421}
+{"mode": "train", "epoch": 154, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00053, "acc_pose": 0.84982, "loss": 0.00053, "grad_norm": 0.00103, "time": 0.69579}
+{"mode": "train", "epoch": 154, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00054, "acc_pose": 0.83772, "loss": 0.00054, "grad_norm": 0.00103, "time": 0.69526}
+{"mode": "train", "epoch": 154, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.84302, "loss": 0.00053, "grad_norm": 0.00102, "time": 0.69506}
+{"mode": "train", "epoch": 154, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00053, "acc_pose": 0.84831, "loss": 0.00053, "grad_norm": 0.00103, "time": 0.69544}
+{"mode": "train", "epoch": 155, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.0561, "heatmap_loss": 0.00054, "acc_pose": 0.84602, "loss": 0.00054, "grad_norm": 0.00095, "time": 0.75339}
+{"mode": "train", "epoch": 155, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.84937, "loss": 0.00053, "grad_norm": 0.001, "time": 0.69569}
+{"mode": "train", "epoch": 155, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00053, "acc_pose": 0.85239, "loss": 0.00053, "grad_norm": 0.00103, "time": 0.69495}
+{"mode": "train", "epoch": 155, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00053, "acc_pose": 0.84639, "loss": 0.00053, "grad_norm": 0.00101, "time": 0.69586}
+{"mode": "train", "epoch": 155, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00028, "heatmap_loss": 0.00053, "acc_pose": 0.84598, "loss": 0.00053, "grad_norm": 0.00099, "time": 0.69522}
+{"mode": "train", "epoch": 156, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05615, "heatmap_loss": 0.00053, "acc_pose": 0.84551, "loss": 0.00053, "grad_norm": 0.00098, "time": 0.75405}
+{"mode": "train", "epoch": 156, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00053, "acc_pose": 0.84412, "loss": 0.00053, "grad_norm": 0.00099, "time": 0.69493}
+{"mode": "train", "epoch": 156, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00054, "acc_pose": 0.84306, "loss": 0.00054, "grad_norm": 0.00102, "time": 0.69525}
+{"mode": "train", "epoch": 156, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00053, "acc_pose": 0.84651, "loss": 0.00053, "grad_norm": 0.00105, "time": 0.69517}
+{"mode": "train", "epoch": 156, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00053, "acc_pose": 0.84568, "loss": 0.00053, "grad_norm": 0.001, "time": 0.69534}
+{"mode": "train", "epoch": 157, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05638, "heatmap_loss": 0.00053, "acc_pose": 0.85289, "loss": 0.00053, "grad_norm": 0.001, "time": 0.75252}
+{"mode": "train", "epoch": 157, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00054, "acc_pose": 0.85332, "loss": 0.00054, "grad_norm": 0.00103, "time": 0.69493}
+{"mode": "train", "epoch": 157, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00053, "acc_pose": 0.84787, "loss": 0.00053, "grad_norm": 0.00102, "time": 0.69516}
+{"mode": "train", "epoch": 157, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00053, "acc_pose": 0.85357, "loss": 0.00053, "grad_norm": 0.00101, "time": 0.69535}
+{"mode": "train", "epoch": 157, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00053, "acc_pose": 0.84509, "loss": 0.00053, "grad_norm": 0.00101, "time": 0.69505}
+{"mode": "train", "epoch": 158, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05908, "heatmap_loss": 0.00054, "acc_pose": 0.84379, "loss": 0.00054, "grad_norm": 0.00106, "time": 0.75611}
+{"mode": "train", "epoch": 158, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00028, "heatmap_loss": 0.00053, "acc_pose": 0.84641, "loss": 0.00053, "grad_norm": 0.00104, "time": 0.69523}
+{"mode": "train", "epoch": 158, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00053, "acc_pose": 0.84279, "loss": 0.00053, "grad_norm": 0.00094, "time": 0.69501}
+{"mode": "train", "epoch": 158, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00054, "acc_pose": 0.85146, "loss": 0.00054, "grad_norm": 0.00102, "time": 0.69559}
+{"mode": "train", "epoch": 158, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.8484, "loss": 0.00053, "grad_norm": 0.00099, "time": 0.69533}
+{"mode": "train", "epoch": 159, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05597, "heatmap_loss": 0.00053, "acc_pose": 0.84242, "loss": 0.00053, "grad_norm": 0.00102, "time": 0.75367}
+{"mode": "train", "epoch": 159, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.8399, "loss": 0.00053, "grad_norm": 0.00098, "time": 0.6954}
+{"mode": "train", "epoch": 159, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00053, "acc_pose": 0.84751, "loss": 0.00053, "grad_norm": 0.00102, "time": 0.69565}
+{"mode": "train", "epoch": 159, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.84713, "loss": 0.00053, "grad_norm": 0.00102, "time": 0.69535}
+{"mode": "train", "epoch": 159, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00053, "acc_pose": 0.84482, "loss": 0.00053, "grad_norm": 0.00109, "time": 0.69542}
+{"mode": "train", "epoch": 160, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05601, "heatmap_loss": 0.00054, "acc_pose": 0.85055, "loss": 0.00054, "grad_norm": 0.00104, "time": 0.75399}
+{"mode": "train", "epoch": 160, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00054, "acc_pose": 0.84841, "loss": 0.00054, "grad_norm": 0.00103, "time": 0.69512}
+{"mode": "train", "epoch": 160, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00053, "acc_pose": 0.84769, "loss": 0.00053, "grad_norm": 0.00098, "time": 0.69554}
+{"mode": "train", "epoch": 160, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00053, "acc_pose": 0.84411, "loss": 0.00053, "grad_norm": 0.00102, "time": 0.69543}
+{"mode": "train", "epoch": 160, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00053, "acc_pose": 0.84519, "loss": 0.00053, "grad_norm": 0.00104, "time": 0.69567}
+{"mode": "val", "epoch": 160, "iter": 407, "lr": 0.0, "AP": 0.77764, "AP .5": 0.91324, "AP .75": 0.85034, "AP (M)": 0.70411, "AP (L)": 0.80411, "AR": 0.83064, "AR .5": 0.95214, "AR .75": 0.89373, "AR (M)": 0.78981, "AR (L)": 0.88997}
+{"mode": "train", "epoch": 161, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05547, "heatmap_loss": 0.00053, "acc_pose": 0.85137, "loss": 0.00053, "grad_norm": 0.00102, "time": 0.7486}
+{"mode": "train", "epoch": 161, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00053, "acc_pose": 0.85481, "loss": 0.00053, "grad_norm": 0.00095, "time": 0.69488}
+{"mode": "train", "epoch": 161, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00053, "acc_pose": 0.84522, "loss": 0.00053, "grad_norm": 0.00104, "time": 0.6945}
+{"mode": "train", "epoch": 161, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00028, "heatmap_loss": 0.00053, "acc_pose": 0.85163, "loss": 0.00053, "grad_norm": 0.001, "time": 0.69481}
+{"mode": "train", "epoch": 161, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.84339, "loss": 0.00053, "grad_norm": 0.00101, "time": 0.69522}
+{"mode": "train", "epoch": 162, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05509, "heatmap_loss": 0.00053, "acc_pose": 0.85147, "loss": 0.00053, "grad_norm": 0.00103, "time": 0.75382}
+{"mode": "train", "epoch": 162, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.84482, "loss": 0.00053, "grad_norm": 0.00101, "time": 0.69503}
+{"mode": "train", "epoch": 162, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.85166, "loss": 0.00053, "grad_norm": 0.00107, "time": 0.69557}
+{"mode": "train", "epoch": 162, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.84557, "loss": 0.00053, "grad_norm": 0.00103, "time": 0.69487}
+{"mode": "train", "epoch": 162, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.84765, "loss": 0.00053, "grad_norm": 0.00099, "time": 0.69558}
+{"mode": "train", "epoch": 163, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05567, "heatmap_loss": 0.00053, "acc_pose": 0.85141, "loss": 0.00053, "grad_norm": 0.00099, "time": 0.75301}
+{"mode": "train", "epoch": 163, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.84664, "loss": 0.00053, "grad_norm": 0.00095, "time": 0.69525}
+{"mode": "train", "epoch": 163, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00053, "acc_pose": 0.84346, "loss": 0.00053, "grad_norm": 0.00104, "time": 0.69559}
+{"mode": "train", "epoch": 163, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.84345, "loss": 0.00053, "grad_norm": 0.00102, "time": 0.69614}
+{"mode": "train", "epoch": 163, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.84655, "loss": 0.00053, "grad_norm": 0.00104, "time": 0.69533}
+{"mode": "train", "epoch": 164, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05993, "heatmap_loss": 0.00053, "acc_pose": 0.84749, "loss": 0.00053, "grad_norm": 0.00101, "time": 0.75698}
+{"mode": "train", "epoch": 164, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00028, "heatmap_loss": 0.00053, "acc_pose": 0.84674, "loss": 0.00053, "grad_norm": 0.00104, "time": 0.69561}
+{"mode": "train", "epoch": 164, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00027, "heatmap_loss": 0.00053, "acc_pose": 0.84488, "loss": 0.00053, "grad_norm": 0.00104, "time": 0.6955}
+{"mode": "train", "epoch": 164, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00053, "acc_pose": 0.84826, "loss": 0.00053, "grad_norm": 0.00106, "time": 0.69546}
+{"mode": "train", "epoch": 164, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00053, "acc_pose": 0.8534, "loss": 0.00053, "grad_norm": 0.00102, "time": 0.69518}
+{"mode": "train", "epoch": 165, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05632, "heatmap_loss": 0.00053, "acc_pose": 0.84978, "loss": 0.00053, "grad_norm": 0.00101, "time": 0.75458}
+{"mode": "train", "epoch": 165, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00053, "acc_pose": 0.84881, "loss": 0.00053, "grad_norm": 0.00102, "time": 0.69507}
+{"mode": "train", "epoch": 165, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00053, "acc_pose": 0.85397, "loss": 0.00053, "grad_norm": 0.00106, "time": 0.69548}
+{"mode": "train", "epoch": 165, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00053, "acc_pose": 0.84909, "loss": 0.00053, "grad_norm": 0.00101, "time": 0.69529}
+{"mode": "train", "epoch": 165, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00053, "acc_pose": 0.85702, "loss": 0.00053, "grad_norm": 0.00097, "time": 0.69502}
+{"mode": "train", "epoch": 166, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05706, "heatmap_loss": 0.00053, "acc_pose": 0.85043, "loss": 0.00053, "grad_norm": 0.00106, "time": 0.75387}
+{"mode": "train", "epoch": 166, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.84804, "loss": 0.00053, "grad_norm": 0.00111, "time": 0.69583}
+{"mode": "train", "epoch": 166, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00053, "acc_pose": 0.8501, "loss": 0.00053, "grad_norm": 0.00101, "time": 0.69552}
+{"mode": "train", "epoch": 166, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00052, "acc_pose": 0.85016, "loss": 0.00052, "grad_norm": 0.00104, "time": 0.69527}
+{"mode": "train", "epoch": 166, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.85066, "loss": 0.00053, "grad_norm": 0.00101, "time": 0.69522}
+{"mode": "train", "epoch": 167, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05544, "heatmap_loss": 0.00053, "acc_pose": 0.85454, "loss": 0.00053, "grad_norm": 0.00106, "time": 0.75421}
+{"mode": "train", "epoch": 167, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00053, "acc_pose": 0.85042, "loss": 0.00053, "grad_norm": 0.00108, "time": 0.69524}
+{"mode": "train", "epoch": 167, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00053, "acc_pose": 0.84468, "loss": 0.00053, "grad_norm": 0.001, "time": 0.69528}
+{"mode": "train", "epoch": 167, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00052, "acc_pose": 0.85816, "loss": 0.00052, "grad_norm": 0.00101, "time": 0.69496}
+{"mode": "train", "epoch": 167, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00053, "acc_pose": 0.84438, "loss": 0.00053, "grad_norm": 0.00101, "time": 0.69484}
+{"mode": "train", "epoch": 168, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05681, "heatmap_loss": 0.00053, "acc_pose": 0.85729, "loss": 0.00053, "grad_norm": 0.00103, "time": 0.75387}
+{"mode": "train", "epoch": 168, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00052, "acc_pose": 0.85427, "loss": 0.00052, "grad_norm": 0.00098, "time": 0.6954}
+{"mode": "train", "epoch": 168, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00053, "acc_pose": 0.84701, "loss": 0.00053, "grad_norm": 0.00099, "time": 0.69495}
+{"mode": "train", "epoch": 168, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00053, "acc_pose": 0.84841, "loss": 0.00053, "grad_norm": 0.00104, "time": 0.6954}
+{"mode": "train", "epoch": 168, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00039, "heatmap_loss": 0.00053, "acc_pose": 0.85386, "loss": 0.00053, "grad_norm": 0.00116, "time": 0.69526}
+{"mode": "train", "epoch": 169, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05543, "heatmap_loss": 0.00053, "acc_pose": 0.85378, "loss": 0.00053, "grad_norm": 0.00102, "time": 0.75409}
+{"mode": "train", "epoch": 169, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00034, "heatmap_loss": 0.00052, "acc_pose": 0.84656, "loss": 0.00052, "grad_norm": 0.00105, "time": 0.69538}
+{"mode": "train", "epoch": 169, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00034, "heatmap_loss": 0.00053, "acc_pose": 0.85528, "loss": 0.00053, "grad_norm": 0.00103, "time": 0.69529}
+{"mode": "train", "epoch": 169, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.8506, "loss": 0.00053, "grad_norm": 0.00103, "time": 0.69511}
+{"mode": "train", "epoch": 169, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.85611, "loss": 0.00053, "grad_norm": 0.00102, "time": 0.69548}
+{"mode": "train", "epoch": 170, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05536, "heatmap_loss": 0.00053, "acc_pose": 0.85035, "loss": 0.00053, "grad_norm": 0.00095, "time": 0.75391}
+{"mode": "train", "epoch": 170, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00052, "acc_pose": 0.84327, "loss": 0.00052, "grad_norm": 0.00101, "time": 0.69499}
+{"mode": "train", "epoch": 170, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.84512, "loss": 0.00053, "grad_norm": 0.00102, "time": 0.69496}
+{"mode": "train", "epoch": 170, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00052, "acc_pose": 0.84987, "loss": 0.00052, "grad_norm": 0.00104, "time": 0.69583}
+{"mode": "train", "epoch": 170, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00052, "acc_pose": 0.85043, "loss": 0.00052, "grad_norm": 0.00106, "time": 0.69529}
+{"mode": "val", "epoch": 170, "iter": 407, "lr": 0.0, "AP": 0.77895, "AP .5": 0.91391, "AP .75": 0.85122, "AP (M)": 0.70606, "AP (L)": 0.80577, "AR": 0.83141, "AR .5": 0.95246, "AR .75": 0.89405, "AR (M)": 0.79137, "AR (L)": 0.89}
+{"mode": "train", "epoch": 171, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05643, "heatmap_loss": 0.00052, "acc_pose": 0.85244, "loss": 0.00052, "grad_norm": 0.00103, "time": 0.74984}
+{"mode": "train", "epoch": 171, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00052, "acc_pose": 0.85471, "loss": 0.00052, "grad_norm": 0.00098, "time": 0.69468}
+{"mode": "train", "epoch": 171, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00052, "acc_pose": 0.85711, "loss": 0.00052, "grad_norm": 0.00102, "time": 0.69478}
+{"mode": "train", "epoch": 171, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00027, "heatmap_loss": 0.00052, "acc_pose": 0.85901, "loss": 0.00052, "grad_norm": 0.00102, "time": 0.69491}
+{"mode": "train", "epoch": 171, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00051, "acc_pose": 0.85206, "loss": 0.00051, "grad_norm": 0.00094, "time": 0.69478}
+{"mode": "train", "epoch": 172, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05667, "heatmap_loss": 0.00051, "acc_pose": 0.85311, "loss": 0.00051, "grad_norm": 0.00093, "time": 0.75191}
+{"mode": "train", "epoch": 172, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00052, "acc_pose": 0.84762, "loss": 0.00052, "grad_norm": 0.00099, "time": 0.69521}
+{"mode": "train", "epoch": 172, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00052, "acc_pose": 0.85267, "loss": 0.00052, "grad_norm": 0.00096, "time": 0.69508}
+{"mode": "train", "epoch": 172, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00051, "acc_pose": 0.858, "loss": 0.00051, "grad_norm": 0.00101, "time": 0.69501}
+{"mode": "train", "epoch": 172, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00051, "acc_pose": 0.85898, "loss": 0.00051, "grad_norm": 0.00095, "time": 0.69537}
+{"mode": "train", "epoch": 173, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05669, "heatmap_loss": 0.00051, "acc_pose": 0.8513, "loss": 0.00051, "grad_norm": 0.00094, "time": 0.75378}
+{"mode": "train", "epoch": 173, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00051, "acc_pose": 0.85369, "loss": 0.00051, "grad_norm": 0.00098, "time": 0.69536}
+{"mode": "train", "epoch": 173, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00051, "acc_pose": 0.85318, "loss": 0.00051, "grad_norm": 0.00099, "time": 0.69533}
+{"mode": "train", "epoch": 173, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00051, "acc_pose": 0.86007, "loss": 0.00051, "grad_norm": 0.00099, "time": 0.69531}
+{"mode": "train", "epoch": 173, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00051, "acc_pose": 0.85503, "loss": 0.00051, "grad_norm": 0.00101, "time": 0.69578}
+{"mode": "train", "epoch": 174, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05721, "heatmap_loss": 0.00052, "acc_pose": 0.85516, "loss": 0.00052, "grad_norm": 0.00102, "time": 0.7548}
+{"mode": "train", "epoch": 174, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00027, "heatmap_loss": 0.00051, "acc_pose": 0.85018, "loss": 0.00051, "grad_norm": 0.00095, "time": 0.69466}
+{"mode": "train", "epoch": 174, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00051, "acc_pose": 0.85647, "loss": 0.00051, "grad_norm": 0.00094, "time": 0.69535}
+{"mode": "train", "epoch": 174, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.0005, "acc_pose": 0.85664, "loss": 0.0005, "grad_norm": 0.00094, "time": 0.69521}
+{"mode": "train", "epoch": 174, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00051, "acc_pose": 0.852, "loss": 0.00051, "grad_norm": 0.00095, "time": 0.69512}
+{"mode": "train", "epoch": 175, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05616, "heatmap_loss": 0.0005, "acc_pose": 0.85791, "loss": 0.0005, "grad_norm": 0.00098, "time": 0.75407}
+{"mode": "train", "epoch": 175, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00051, "acc_pose": 0.85735, "loss": 0.00051, "grad_norm": 0.00093, "time": 0.69528}
+{"mode": "train", "epoch": 175, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00051, "acc_pose": 0.85407, "loss": 0.00051, "grad_norm": 0.00103, "time": 0.69515}
+{"mode": "train", "epoch": 175, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00051, "acc_pose": 0.85776, "loss": 0.00051, "grad_norm": 0.00105, "time": 0.69534}
+{"mode": "train", "epoch": 175, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00051, "acc_pose": 0.85933, "loss": 0.00051, "grad_norm": 0.00091, "time": 0.69508}
+{"mode": "train", "epoch": 176, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05644, "heatmap_loss": 0.00051, "acc_pose": 0.85528, "loss": 0.00051, "grad_norm": 0.00092, "time": 0.75402}
+{"mode": "train", "epoch": 176, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00051, "acc_pose": 0.85417, "loss": 0.00051, "grad_norm": 0.00097, "time": 0.69546}
+{"mode": "train", "epoch": 176, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00051, "acc_pose": 0.84979, "loss": 0.00051, "grad_norm": 0.001, "time": 0.69517}
+{"mode": "train", "epoch": 176, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00051, "acc_pose": 0.85035, "loss": 0.00051, "grad_norm": 0.00101, "time": 0.69533}
+{"mode": "train", "epoch": 176, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0005, "acc_pose": 0.85415, "loss": 0.0005, "grad_norm": 0.00098, "time": 0.69546}
+{"mode": "train", "epoch": 177, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.06039, "heatmap_loss": 0.0005, "acc_pose": 0.85835, "loss": 0.0005, "grad_norm": 0.00099, "time": 0.7571}
+{"mode": "train", "epoch": 177, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00051, "acc_pose": 0.85425, "loss": 0.00051, "grad_norm": 0.00097, "time": 0.69576}
+{"mode": "train", "epoch": 177, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00051, "acc_pose": 0.85262, "loss": 0.00051, "grad_norm": 0.00095, "time": 0.69491}
+{"mode": "train", "epoch": 177, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00051, "acc_pose": 0.85688, "loss": 0.00051, "grad_norm": 0.00094, "time": 0.69497}
+{"mode": "train", "epoch": 177, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00051, "acc_pose": 0.85301, "loss": 0.00051, "grad_norm": 0.001, "time": 0.69567}
+{"mode": "train", "epoch": 178, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05577, "heatmap_loss": 0.00051, "acc_pose": 0.85724, "loss": 0.00051, "grad_norm": 0.00099, "time": 0.75476}
+{"mode": "train", "epoch": 178, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.00051, "acc_pose": 0.85669, "loss": 0.00051, "grad_norm": 0.00096, "time": 0.69555}
+{"mode": "train", "epoch": 178, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00051, "acc_pose": 0.8602, "loss": 0.00051, "grad_norm": 0.00099, "time": 0.6958}
+{"mode": "train", "epoch": 178, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.0005, "acc_pose": 0.85271, "loss": 0.0005, "grad_norm": 0.00092, "time": 0.69524}
+{"mode": "train", "epoch": 178, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00035, "heatmap_loss": 0.00051, "acc_pose": 0.86198, "loss": 0.00051, "grad_norm": 0.00094, "time": 0.69532}
+{"mode": "train", "epoch": 179, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05595, "heatmap_loss": 0.0005, "acc_pose": 0.85457, "loss": 0.0005, "grad_norm": 0.00095, "time": 0.7524}
+{"mode": "train", "epoch": 179, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00051, "acc_pose": 0.85508, "loss": 0.00051, "grad_norm": 0.00097, "time": 0.69526}
+{"mode": "train", "epoch": 179, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.85269, "loss": 0.0005, "grad_norm": 0.00094, "time": 0.69544}
+{"mode": "train", "epoch": 179, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.86078, "loss": 0.0005, "grad_norm": 0.00096, "time": 0.69568}
+{"mode": "train", "epoch": 179, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00051, "acc_pose": 0.85984, "loss": 0.00051, "grad_norm": 0.00093, "time": 0.69557}
+{"mode": "train", "epoch": 180, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05887, "heatmap_loss": 0.00051, "acc_pose": 0.85966, "loss": 0.00051, "grad_norm": 0.00095, "time": 0.75691}
+{"mode": "train", "epoch": 180, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.00051, "acc_pose": 0.86141, "loss": 0.00051, "grad_norm": 0.001, "time": 0.6961}
+{"mode": "train", "epoch": 180, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00028, "heatmap_loss": 0.00051, "acc_pose": 0.8567, "loss": 0.00051, "grad_norm": 0.00103, "time": 0.69524}
+{"mode": "train", "epoch": 180, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00051, "acc_pose": 0.85853, "loss": 0.00051, "grad_norm": 0.00101, "time": 0.69513}
+{"mode": "train", "epoch": 180, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.0005, "acc_pose": 0.85607, "loss": 0.0005, "grad_norm": 0.00094, "time": 0.69565}
+{"mode": "val", "epoch": 180, "iter": 407, "lr": 0.0, "AP": 0.78132, "AP .5": 0.91426, "AP .75": 0.85289, "AP (M)": 0.7082, "AP (L)": 0.80753, "AR": 0.83383, "AR .5": 0.95403, "AR .75": 0.89578, "AR (M)": 0.79314, "AR (L)": 0.89309}
+{"mode": "train", "epoch": 181, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05569, "heatmap_loss": 0.00051, "acc_pose": 0.85729, "loss": 0.00051, "grad_norm": 0.00096, "time": 0.74839}
+{"mode": "train", "epoch": 181, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0005, "acc_pose": 0.86094, "loss": 0.0005, "grad_norm": 0.00097, "time": 0.69496}
+{"mode": "train", "epoch": 181, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00051, "acc_pose": 0.857, "loss": 0.00051, "grad_norm": 0.00097, "time": 0.69504}
+{"mode": "train", "epoch": 181, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00051, "acc_pose": 0.85756, "loss": 0.00051, "grad_norm": 0.00095, "time": 0.69494}
+{"mode": "train", "epoch": 181, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.0005, "acc_pose": 0.85642, "loss": 0.0005, "grad_norm": 0.00097, "time": 0.69517}
+{"mode": "train", "epoch": 182, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05613, "heatmap_loss": 0.0005, "acc_pose": 0.8591, "loss": 0.0005, "grad_norm": 0.00093, "time": 0.75366}
+{"mode": "train", "epoch": 182, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00051, "acc_pose": 0.85682, "loss": 0.00051, "grad_norm": 0.001, "time": 0.69546}
+{"mode": "train", "epoch": 182, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00051, "acc_pose": 0.85569, "loss": 0.00051, "grad_norm": 0.00095, "time": 0.6949}
+{"mode": "train", "epoch": 182, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.85746, "loss": 0.0005, "grad_norm": 0.00095, "time": 0.69526}
+{"mode": "train", "epoch": 182, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00051, "acc_pose": 0.85658, "loss": 0.00051, "grad_norm": 0.00101, "time": 0.69507}
+{"mode": "train", "epoch": 183, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05663, "heatmap_loss": 0.0005, "acc_pose": 0.85679, "loss": 0.0005, "grad_norm": 0.00093, "time": 0.75204}
+{"mode": "train", "epoch": 183, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00051, "acc_pose": 0.85301, "loss": 0.00051, "grad_norm": 0.00098, "time": 0.69493}
+{"mode": "train", "epoch": 183, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.0005, "acc_pose": 0.85494, "loss": 0.0005, "grad_norm": 0.0009, "time": 0.69485}
+{"mode": "train", "epoch": 183, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0005, "acc_pose": 0.86237, "loss": 0.0005, "grad_norm": 0.00096, "time": 0.69477}
+{"mode": "train", "epoch": 183, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.0005, "acc_pose": 0.8592, "loss": 0.0005, "grad_norm": 0.00097, "time": 0.69479}
+{"mode": "train", "epoch": 184, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05554, "heatmap_loss": 0.00051, "acc_pose": 0.85533, "loss": 0.00051, "grad_norm": 0.00093, "time": 0.75444}
+{"mode": "train", "epoch": 184, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0005, "acc_pose": 0.85943, "loss": 0.0005, "grad_norm": 0.00097, "time": 0.69491}
+{"mode": "train", "epoch": 184, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00051, "acc_pose": 0.85412, "loss": 0.00051, "grad_norm": 0.00094, "time": 0.69515}
+{"mode": "train", "epoch": 184, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.0005, "acc_pose": 0.85284, "loss": 0.0005, "grad_norm": 0.00099, "time": 0.6952}
+{"mode": "train", "epoch": 184, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.0005, "acc_pose": 0.85933, "loss": 0.0005, "grad_norm": 0.001, "time": 0.69516}
+{"mode": "train", "epoch": 185, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05617, "heatmap_loss": 0.0005, "acc_pose": 0.86186, "loss": 0.0005, "grad_norm": 0.00099, "time": 0.75221}
+{"mode": "train", "epoch": 185, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00051, "acc_pose": 0.85714, "loss": 0.00051, "grad_norm": 0.00096, "time": 0.6948}
+{"mode": "train", "epoch": 185, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.86224, "loss": 0.0005, "grad_norm": 0.00087, "time": 0.69517}
+{"mode": "train", "epoch": 185, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.85868, "loss": 0.0005, "grad_norm": 0.00099, "time": 0.69498}
+{"mode": "train", "epoch": 185, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.85917, "loss": 0.0005, "grad_norm": 0.00094, "time": 0.69553}
+{"mode": "train", "epoch": 186, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05796, "heatmap_loss": 0.0005, "acc_pose": 0.85101, "loss": 0.0005, "grad_norm": 0.00096, "time": 0.75576}
+{"mode": "train", "epoch": 186, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.0005, "acc_pose": 0.85396, "loss": 0.0005, "grad_norm": 0.00098, "time": 0.69529}
+{"mode": "train", "epoch": 186, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.85616, "loss": 0.0005, "grad_norm": 0.00093, "time": 0.69534}
+{"mode": "train", "epoch": 186, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00051, "acc_pose": 0.85855, "loss": 0.00051, "grad_norm": 0.00095, "time": 0.69527}
+{"mode": "train", "epoch": 186, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.0005, "acc_pose": 0.85996, "loss": 0.0005, "grad_norm": 0.00095, "time": 0.69506}
+{"mode": "train", "epoch": 187, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05495, "heatmap_loss": 0.0005, "acc_pose": 0.86065, "loss": 0.0005, "grad_norm": 0.001, "time": 0.75518}
+{"mode": "train", "epoch": 187, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.85926, "loss": 0.0005, "grad_norm": 0.00094, "time": 0.69491}
+{"mode": "train", "epoch": 187, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0005, "acc_pose": 0.85561, "loss": 0.0005, "grad_norm": 0.00099, "time": 0.69519}
+{"mode": "train", "epoch": 187, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.85572, "loss": 0.0005, "grad_norm": 0.00095, "time": 0.69524}
+{"mode": "train", "epoch": 187, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.0005, "acc_pose": 0.85897, "loss": 0.0005, "grad_norm": 0.00095, "time": 0.69483}
+{"mode": "train", "epoch": 188, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05667, "heatmap_loss": 0.0005, "acc_pose": 0.85713, "loss": 0.0005, "grad_norm": 0.00093, "time": 0.75205}
+{"mode": "train", "epoch": 188, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.0005, "acc_pose": 0.86301, "loss": 0.0005, "grad_norm": 0.00092, "time": 0.69535}
+{"mode": "train", "epoch": 188, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00036, "heatmap_loss": 0.00051, "acc_pose": 0.85923, "loss": 0.00051, "grad_norm": 0.00097, "time": 0.69526}
+{"mode": "train", "epoch": 188, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0005, "acc_pose": 0.8589, "loss": 0.0005, "grad_norm": 0.00091, "time": 0.69558}
+{"mode": "train", "epoch": 188, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.0005, "acc_pose": 0.86169, "loss": 0.0005, "grad_norm": 0.00095, "time": 0.69561}
+{"mode": "train", "epoch": 189, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05676, "heatmap_loss": 0.0005, "acc_pose": 0.8601, "loss": 0.0005, "grad_norm": 0.00095, "time": 0.75238}
+{"mode": "train", "epoch": 189, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.0005, "acc_pose": 0.85815, "loss": 0.0005, "grad_norm": 0.00093, "time": 0.69466}
+{"mode": "train", "epoch": 189, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.85583, "loss": 0.0005, "grad_norm": 0.00098, "time": 0.69562}
+{"mode": "train", "epoch": 189, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.0005, "acc_pose": 0.85683, "loss": 0.0005, "grad_norm": 0.00092, "time": 0.69501}
+{"mode": "train", "epoch": 189, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.86572, "loss": 0.0005, "grad_norm": 0.00094, "time": 0.6948}
+{"mode": "train", "epoch": 190, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05635, "heatmap_loss": 0.00051, "acc_pose": 0.85608, "loss": 0.00051, "grad_norm": 0.00098, "time": 0.75364}
+{"mode": "train", "epoch": 190, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.0005, "acc_pose": 0.85841, "loss": 0.0005, "grad_norm": 0.00096, "time": 0.69505}
+{"mode": "train", "epoch": 190, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0005, "acc_pose": 0.86091, "loss": 0.0005, "grad_norm": 0.00089, "time": 0.6948}
+{"mode": "train", "epoch": 190, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.86077, "loss": 0.0005, "grad_norm": 0.00092, "time": 0.69481}
+{"mode": "train", "epoch": 190, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.86024, "loss": 0.0005, "grad_norm": 0.00093, "time": 0.69481}
+{"mode": "val", "epoch": 190, "iter": 407, "lr": 0.0, "AP": 0.78167, "AP .5": 0.91369, "AP .75": 0.85324, "AP (M)": 0.70808, "AP (L)": 0.80864, "AR": 0.83408, "AR .5": 0.9534, "AR .75": 0.89578, "AR (M)": 0.7929, "AR (L)": 0.89424}
+{"mode": "train", "epoch": 191, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05794, "heatmap_loss": 0.0005, "acc_pose": 0.86008, "loss": 0.0005, "grad_norm": 0.00094, "time": 0.7516}
+{"mode": "train", "epoch": 191, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.0005, "acc_pose": 0.86128, "loss": 0.0005, "grad_norm": 0.00101, "time": 0.69457}
+{"mode": "train", "epoch": 191, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.0005, "acc_pose": 0.85908, "loss": 0.0005, "grad_norm": 0.00091, "time": 0.69446}
+{"mode": "train", "epoch": 191, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.0005, "acc_pose": 0.86084, "loss": 0.0005, "grad_norm": 0.00095, "time": 0.6946}
+{"mode": "train", "epoch": 191, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.0005, "acc_pose": 0.85624, "loss": 0.0005, "grad_norm": 0.00091, "time": 0.69481}
+{"mode": "train", "epoch": 192, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.0557, "heatmap_loss": 0.0005, "acc_pose": 0.85738, "loss": 0.0005, "grad_norm": 0.00098, "time": 0.75123}
+{"mode": "train", "epoch": 192, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0005, "acc_pose": 0.85743, "loss": 0.0005, "grad_norm": 0.00092, "time": 0.69498}
+{"mode": "train", "epoch": 192, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0005, "acc_pose": 0.85701, "loss": 0.0005, "grad_norm": 0.00093, "time": 0.69497}
+{"mode": "train", "epoch": 192, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.85873, "loss": 0.0005, "grad_norm": 0.00097, "time": 0.69504}
+{"mode": "train", "epoch": 192, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.86521, "loss": 0.0005, "grad_norm": 0.00096, "time": 0.69495}
+{"mode": "train", "epoch": 193, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05647, "heatmap_loss": 0.0005, "acc_pose": 0.85765, "loss": 0.0005, "grad_norm": 0.00094, "time": 0.75295}
+{"mode": "train", "epoch": 193, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.86157, "loss": 0.0005, "grad_norm": 0.00097, "time": 0.69507}
+{"mode": "train", "epoch": 193, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.0005, "acc_pose": 0.85949, "loss": 0.0005, "grad_norm": 0.00097, "time": 0.6948}
+{"mode": "train", "epoch": 193, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.0005, "acc_pose": 0.85739, "loss": 0.0005, "grad_norm": 0.00095, "time": 0.69485}
+{"mode": "train", "epoch": 193, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.85567, "loss": 0.0005, "grad_norm": 0.00092, "time": 0.69529}
+{"mode": "train", "epoch": 194, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.0562, "heatmap_loss": 0.0005, "acc_pose": 0.85981, "loss": 0.0005, "grad_norm": 0.00095, "time": 0.75217}
+{"mode": "train", "epoch": 194, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0005, "acc_pose": 0.858, "loss": 0.0005, "grad_norm": 0.0009, "time": 0.69496}
+{"mode": "train", "epoch": 194, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.0005, "acc_pose": 0.85641, "loss": 0.0005, "grad_norm": 0.00091, "time": 0.69513}
+{"mode": "train", "epoch": 194, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.86409, "loss": 0.0005, "grad_norm": 0.00088, "time": 0.69509}
+{"mode": "train", "epoch": 194, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00049, "acc_pose": 0.86149, "loss": 0.00049, "grad_norm": 0.00102, "time": 0.69487}
+{"mode": "train", "epoch": 195, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05851, "heatmap_loss": 0.0005, "acc_pose": 0.8566, "loss": 0.0005, "grad_norm": 0.00099, "time": 0.75561}
+{"mode": "train", "epoch": 195, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0005, "acc_pose": 0.85363, "loss": 0.0005, "grad_norm": 0.00098, "time": 0.69467}
+{"mode": "train", "epoch": 195, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.86281, "loss": 0.0005, "grad_norm": 0.00099, "time": 0.69518}
+{"mode": "train", "epoch": 195, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00049, "acc_pose": 0.85706, "loss": 0.00049, "grad_norm": 0.00093, "time": 0.69495}
+{"mode": "train", "epoch": 195, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0005, "acc_pose": 0.86146, "loss": 0.0005, "grad_norm": 0.00106, "time": 0.69484}
+{"mode": "train", "epoch": 196, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05664, "heatmap_loss": 0.0005, "acc_pose": 0.8589, "loss": 0.0005, "grad_norm": 0.00094, "time": 0.75273}
+{"mode": "train", "epoch": 196, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00034, "heatmap_loss": 0.0005, "acc_pose": 0.86809, "loss": 0.0005, "grad_norm": 0.00089, "time": 0.69504}
+{"mode": "train", "epoch": 196, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.85332, "loss": 0.0005, "grad_norm": 0.00089, "time": 0.69485}
+{"mode": "train", "epoch": 196, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.86372, "loss": 0.0005, "grad_norm": 0.00097, "time": 0.69503}
+{"mode": "train", "epoch": 196, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.0005, "acc_pose": 0.85762, "loss": 0.0005, "grad_norm": 0.00091, "time": 0.69471}
+{"mode": "train", "epoch": 197, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05621, "heatmap_loss": 0.0005, "acc_pose": 0.86058, "loss": 0.0005, "grad_norm": 0.00103, "time": 0.75392}
+{"mode": "train", "epoch": 197, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0005, "acc_pose": 0.86226, "loss": 0.0005, "grad_norm": 0.00095, "time": 0.6942}
+{"mode": "train", "epoch": 197, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0005, "acc_pose": 0.85104, "loss": 0.0005, "grad_norm": 0.00093, "time": 0.69455}
+{"mode": "train", "epoch": 197, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00042, "heatmap_loss": 0.0005, "acc_pose": 0.8562, "loss": 0.0005, "grad_norm": 0.00089, "time": 0.69477}
+{"mode": "train", "epoch": 197, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0005, "acc_pose": 0.85832, "loss": 0.0005, "grad_norm": 0.00096, "time": 0.69475}
+{"mode": "train", "epoch": 198, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05675, "heatmap_loss": 0.0005, "acc_pose": 0.86594, "loss": 0.0005, "grad_norm": 0.00093, "time": 0.75342}
+{"mode": "train", "epoch": 198, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00029, "heatmap_loss": 0.0005, "acc_pose": 0.85845, "loss": 0.0005, "grad_norm": 0.00094, "time": 0.69492}
+{"mode": "train", "epoch": 198, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00028, "heatmap_loss": 0.0005, "acc_pose": 0.85904, "loss": 0.0005, "grad_norm": 0.00098, "time": 0.69495}
+{"mode": "train", "epoch": 198, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0005, "acc_pose": 0.85645, "loss": 0.0005, "grad_norm": 0.00102, "time": 0.69488}
+{"mode": "train", "epoch": 198, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.8635, "loss": 0.0005, "grad_norm": 0.00093, "time": 0.69522}
+{"mode": "train", "epoch": 199, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05539, "heatmap_loss": 0.0005, "acc_pose": 0.8588, "loss": 0.0005, "grad_norm": 0.00093, "time": 0.75308}
+{"mode": "train", "epoch": 199, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00049, "acc_pose": 0.86261, "loss": 0.00049, "grad_norm": 0.00095, "time": 0.69585}
+{"mode": "train", "epoch": 199, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.85812, "loss": 0.0005, "grad_norm": 0.00098, "time": 0.69519}
+{"mode": "train", "epoch": 199, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.85742, "loss": 0.0005, "grad_norm": 0.00097, "time": 0.69499}
+{"mode": "train", "epoch": 199, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00052, "heatmap_loss": 0.0005, "acc_pose": 0.86443, "loss": 0.0005, "grad_norm": 0.00102, "time": 0.69501}
+{"mode": "train", "epoch": 200, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.0555, "heatmap_loss": 0.0005, "acc_pose": 0.86041, "loss": 0.0005, "grad_norm": 0.00096, "time": 0.75401}
+{"mode": "train", "epoch": 200, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0005, "acc_pose": 0.86071, "loss": 0.0005, "grad_norm": 0.00096, "time": 0.69466}
+{"mode": "train", "epoch": 200, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0005, "acc_pose": 0.85184, "loss": 0.0005, "grad_norm": 0.00095, "time": 0.69463}
+{"mode": "train", "epoch": 200, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00049, "acc_pose": 0.86382, "loss": 0.00049, "grad_norm": 0.00093, "time": 0.69593}
+{"mode": "train", "epoch": 200, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.86135, "loss": 0.0005, "grad_norm": 0.00096, "time": 0.69549}
+{"mode": "val", "epoch": 200, "iter": 407, "lr": 0.0, "AP": 0.78169, "AP .5": 0.9144, "AP .75": 0.85288, "AP (M)": 0.70858, "AP (L)": 0.80822, "AR": 0.83391, "AR .5": 0.9534, "AR .75": 0.89531, "AR (M)": 0.7938, "AR (L)": 0.89253}
+{"mode": "train", "epoch": 201, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05477, "heatmap_loss": 0.0005, "acc_pose": 0.85915, "loss": 0.0005, "grad_norm": 0.00093, "time": 0.74857}
+{"mode": "train", "epoch": 201, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.85649, "loss": 0.0005, "grad_norm": 0.00094, "time": 0.6947}
+{"mode": "train", "epoch": 201, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.85957, "loss": 0.0005, "grad_norm": 0.00093, "time": 0.6946}
+{"mode": "train", "epoch": 201, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.0005, "acc_pose": 0.86209, "loss": 0.0005, "grad_norm": 0.00095, "time": 0.6948}
+{"mode": "train", "epoch": 201, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.85767, "loss": 0.0005, "grad_norm": 0.00098, "time": 0.6946}
+{"mode": "train", "epoch": 202, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05654, "heatmap_loss": 0.0005, "acc_pose": 0.85442, "loss": 0.0005, "grad_norm": 0.00092, "time": 0.75243}
+{"mode": "train", "epoch": 202, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00027, "heatmap_loss": 0.0005, "acc_pose": 0.861, "loss": 0.0005, "grad_norm": 0.00092, "time": 0.69485}
+{"mode": "train", "epoch": 202, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0004, "heatmap_loss": 0.00049, "acc_pose": 0.86006, "loss": 0.00049, "grad_norm": 0.00095, "time": 0.69512}
+{"mode": "train", "epoch": 202, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0005, "acc_pose": 0.86045, "loss": 0.0005, "grad_norm": 0.00099, "time": 0.69542}
+{"mode": "train", "epoch": 202, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.86602, "loss": 0.0005, "grad_norm": 0.00088, "time": 0.69485}
+{"mode": "train", "epoch": 203, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05626, "heatmap_loss": 0.0005, "acc_pose": 0.85855, "loss": 0.0005, "grad_norm": 0.00099, "time": 0.75156}
+{"mode": "train", "epoch": 203, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00033, "heatmap_loss": 0.0005, "acc_pose": 0.86466, "loss": 0.0005, "grad_norm": 0.00094, "time": 0.69465}
+{"mode": "train", "epoch": 203, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.00049, "acc_pose": 0.86163, "loss": 0.00049, "grad_norm": 0.00095, "time": 0.69445}
+{"mode": "train", "epoch": 203, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.0005, "acc_pose": 0.85818, "loss": 0.0005, "grad_norm": 0.00102, "time": 0.69455}
+{"mode": "train", "epoch": 203, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00049, "acc_pose": 0.86038, "loss": 0.00049, "grad_norm": 0.0009, "time": 0.69477}
+{"mode": "train", "epoch": 204, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05632, "heatmap_loss": 0.00049, "acc_pose": 0.85628, "loss": 0.00049, "grad_norm": 0.00096, "time": 0.75326}
+{"mode": "train", "epoch": 204, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0005, "acc_pose": 0.8614, "loss": 0.0005, "grad_norm": 0.00093, "time": 0.69463}
+{"mode": "train", "epoch": 204, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00049, "acc_pose": 0.86057, "loss": 0.00049, "grad_norm": 0.00093, "time": 0.69468}
+{"mode": "train", "epoch": 204, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0005, "acc_pose": 0.85863, "loss": 0.0005, "grad_norm": 0.00095, "time": 0.69474}
+{"mode": "train", "epoch": 204, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0005, "acc_pose": 0.85883, "loss": 0.0005, "grad_norm": 0.00095, "time": 0.69436}
+{"mode": "train", "epoch": 205, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05653, "heatmap_loss": 0.00049, "acc_pose": 0.86453, "loss": 0.00049, "grad_norm": 0.00095, "time": 0.75417}
+{"mode": "train", "epoch": 205, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.86031, "loss": 0.0005, "grad_norm": 0.00087, "time": 0.69521}
+{"mode": "train", "epoch": 205, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00032, "heatmap_loss": 0.0005, "acc_pose": 0.86178, "loss": 0.0005, "grad_norm": 0.0009, "time": 0.69502}
+{"mode": "train", "epoch": 205, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00049, "acc_pose": 0.86704, "loss": 0.00049, "grad_norm": 0.00103, "time": 0.69519}
+{"mode": "train", "epoch": 205, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00049, "acc_pose": 0.86177, "loss": 0.00049, "grad_norm": 0.00092, "time": 0.69542}
+{"mode": "train", "epoch": 206, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05597, "heatmap_loss": 0.0005, "acc_pose": 0.86078, "loss": 0.0005, "grad_norm": 0.00094, "time": 0.75467}
+{"mode": "train", "epoch": 206, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0005, "acc_pose": 0.85392, "loss": 0.0005, "grad_norm": 0.00095, "time": 0.69506}
+{"mode": "train", "epoch": 206, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00049, "acc_pose": 0.85725, "loss": 0.00049, "grad_norm": 0.00091, "time": 0.69556}
+{"mode": "train", "epoch": 206, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00028, "heatmap_loss": 0.0005, "acc_pose": 0.86507, "loss": 0.0005, "grad_norm": 0.00095, "time": 0.69496}
+{"mode": "train", "epoch": 206, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00042, "heatmap_loss": 0.0005, "acc_pose": 0.86552, "loss": 0.0005, "grad_norm": 0.00092, "time": 0.6949}
+{"mode": "train", "epoch": 207, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05628, "heatmap_loss": 0.00049, "acc_pose": 0.85832, "loss": 0.00049, "grad_norm": 0.00098, "time": 0.75324}
+{"mode": "train", "epoch": 207, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00034, "heatmap_loss": 0.0005, "acc_pose": 0.85485, "loss": 0.0005, "grad_norm": 0.0009, "time": 0.69514}
+{"mode": "train", "epoch": 207, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.86354, "loss": 0.0005, "grad_norm": 0.00093, "time": 0.69555}
+{"mode": "train", "epoch": 207, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00049, "acc_pose": 0.8606, "loss": 0.00049, "grad_norm": 0.00089, "time": 0.69481}
+{"mode": "train", "epoch": 207, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.8655, "loss": 0.0005, "grad_norm": 0.00093, "time": 0.69535}
+{"mode": "train", "epoch": 208, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05578, "heatmap_loss": 0.00049, "acc_pose": 0.86224, "loss": 0.00049, "grad_norm": 0.00091, "time": 0.7526}
+{"mode": "train", "epoch": 208, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00049, "acc_pose": 0.86093, "loss": 0.00049, "grad_norm": 0.00099, "time": 0.69479}
+{"mode": "train", "epoch": 208, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0005, "acc_pose": 0.85722, "loss": 0.0005, "grad_norm": 0.00093, "time": 0.69511}
+{"mode": "train", "epoch": 208, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00034, "heatmap_loss": 0.0005, "acc_pose": 0.86088, "loss": 0.0005, "grad_norm": 0.00089, "time": 0.69499}
+{"mode": "train", "epoch": 208, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.86282, "loss": 0.0005, "grad_norm": 0.00092, "time": 0.69501}
+{"mode": "train", "epoch": 209, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05911, "heatmap_loss": 0.00049, "acc_pose": 0.85923, "loss": 0.00049, "grad_norm": 0.001, "time": 0.75628}
+{"mode": "train", "epoch": 209, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00028, "heatmap_loss": 0.0005, "acc_pose": 0.86426, "loss": 0.0005, "grad_norm": 0.00094, "time": 0.69487}
+{"mode": "train", "epoch": 209, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00049, "acc_pose": 0.85536, "loss": 0.00049, "grad_norm": 0.00099, "time": 0.69501}
+{"mode": "train", "epoch": 209, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00049, "acc_pose": 0.86371, "loss": 0.00049, "grad_norm": 0.00089, "time": 0.69506}
+{"mode": "train", "epoch": 209, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.0005, "acc_pose": 0.86392, "loss": 0.0005, "grad_norm": 0.00092, "time": 0.69552}
+{"mode": "train", "epoch": 210, "iter": 50, "lr": 0.0, "memory": 9430, "data_time": 0.05676, "heatmap_loss": 0.0005, "acc_pose": 0.85934, "loss": 0.0005, "grad_norm": 0.00093, "time": 0.75548}
+{"mode": "train", "epoch": 210, "iter": 100, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.86196, "loss": 0.0005, "grad_norm": 0.00093, "time": 0.69532}
+{"mode": "train", "epoch": 210, "iter": 150, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.85591, "loss": 0.0005, "grad_norm": 0.00096, "time": 0.69534}
+{"mode": "train", "epoch": 210, "iter": 200, "lr": 0.0, "memory": 9430, "data_time": 0.00031, "heatmap_loss": 0.00049, "acc_pose": 0.86334, "loss": 0.00049, "grad_norm": 0.00094, "time": 0.69505}
+{"mode": "train", "epoch": 210, "iter": 250, "lr": 0.0, "memory": 9430, "data_time": 0.0003, "heatmap_loss": 0.00049, "acc_pose": 0.85899, "loss": 0.00049, "grad_norm": 0.00099, "time": 0.6952}
+{"mode": "val", "epoch": 210, "iter": 407, "lr": 0.0, "AP": 0.78183, "AP .5": 0.91391, "AP .75": 0.85347, "AP (M)": 0.70853, "AP (L)": 0.80858, "AR": 0.83408, "AR .5": 0.9534, "AR .75": 0.89578, "AR (M)": 0.79391, "AR (L)": 0.89279}
diff --git a/vendor/ViTPose/logs/vitpose-l.log.json b/vendor/ViTPose/logs/vitpose-l.log.json
new file mode 100644
index 0000000000000000000000000000000000000000..bbe7fea82542c54f33c8318a8ad5d17fe64d7eeb
--- /dev/null
+++ b/vendor/ViTPose/logs/vitpose-l.log.json
@@ -0,0 +1,1072 @@
+{"env_info": "sys.platform: linux\nPython: 3.8.10 | packaged by conda-forge | (default, May 11 2021, 07:01:05) [GCC 9.3.0]\nCUDA available: True\nGPU 0,1,2,3,4,5,6,7: A100-SXM4-40GB\nCUDA_HOME: /usr/local/cuda\nNVCC: Build cuda_11.3.r11.3/compiler.29920130_0\nGCC: gcc (Ubuntu 9.3.0-17ubuntu1~20.04) 9.3.0\nPyTorch: 1.9.0a0+c3d40fd\nPyTorch compiling details: PyTorch built with:\n - GCC 9.3\n - C++ Version: 201402\n - Intel(R) Math Kernel Library Version 2019.0.5 Product Build 20190808 for Intel(R) 64 architecture applications\n - Intel(R) MKL-DNN v2.1.2 (Git Hash N/A)\n - OpenMP 201511 (a.k.a. OpenMP 4.5)\n - NNPACK is enabled\n - CPU capability usage: AVX2\n - CUDA Runtime 11.3\n - NVCC architecture flags: -gencode;arch=compute_52,code=sm_52;-gencode;arch=compute_60,code=sm_60;-gencode;arch=compute_61,code=sm_61;-gencode;arch=compute_70,code=sm_70;-gencode;arch=compute_75,code=sm_75;-gencode;arch=compute_80,code=sm_80;-gencode;arch=compute_86,code=sm_86;-gencode;arch=compute_86,code=compute_86\n - CuDNN 8.2.1\n - Magma 2.5.2\n - Build settings: BLAS_INFO=mkl, BUILD_TYPE=Release, CUDA_VERSION=11.3, CUDNN_VERSION=8.2.1, CXX_COMPILER=/usr/bin/c++, CXX_FLAGS= -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_KINETO -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DUSE_XNNPACK -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -O2 -fPIC -Wno-narrowing -Wall -Wextra -Werror=return-type -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wno-sign-compare -Wno-unused-parameter -Wno-unused-variable -Wno-unused-function -Wno-unused-result -Wno-unused-local-typedefs -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-psabi -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Werror=cast-function-type -Wno-stringop-overflow, LAPACK_INFO=mkl, PERF_WITH_AVX=1, PERF_WITH_AVX2=1, PERF_WITH_AVX512=1, TORCH_VERSION=1.9.0, USE_CUDA=ON, USE_CUDNN=ON, USE_EXCEPTION_PTR=1, USE_GFLAGS=OFF, USE_GLOG=OFF, USE_MKL=ON, USE_MKLDNN=ON, USE_MPI=ON, USE_NCCL=ON, USE_NNPACK=ON, USE_OPENMP=ON, \n\nTorchVision: 0.10.0a0\nOpenCV: 4.5.5\nMMCV: 1.3.9\nMMCV Compiler: GCC 9.3\nMMCV CUDA Compiler: 11.3\nMMPose: 0.24.0+71c8bf8", "seed": 0, "hook_msgs": {}}
+{"mode": "train", "epoch": 1, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.06845, "heatmap_loss": 0.00215, "acc_pose": 0.04833, "loss": 0.00215, "grad_norm": 0.00662, "time": 0.80814}
+{"mode": "train", "epoch": 1, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00034, "heatmap_loss": 0.00202, "acc_pose": 0.17241, "loss": 0.00202, "grad_norm": 0.00301, "time": 0.65605}
+{"mode": "train", "epoch": 1, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.0019, "acc_pose": 0.25311, "loss": 0.0019, "grad_norm": 0.00397, "time": 0.65634}
+{"mode": "train", "epoch": 1, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.0017, "acc_pose": 0.35247, "loss": 0.0017, "grad_norm": 0.00441, "time": 0.65623}
+{"mode": "train", "epoch": 1, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00147, "acc_pose": 0.45338, "loss": 0.00147, "grad_norm": 0.00428, "time": 0.65609}
+{"mode": "train", "epoch": 2, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.0561, "heatmap_loss": 0.00124, "acc_pose": 0.55135, "loss": 0.00124, "grad_norm": 0.00409, "time": 0.71186}
+{"mode": "train", "epoch": 2, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00117, "acc_pose": 0.5917, "loss": 0.00117, "grad_norm": 0.00369, "time": 0.65627}
+{"mode": "train", "epoch": 2, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00112, "acc_pose": 0.60123, "loss": 0.00112, "grad_norm": 0.00398, "time": 0.65624}
+{"mode": "train", "epoch": 2, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00035, "heatmap_loss": 0.00108, "acc_pose": 0.61332, "loss": 0.00108, "grad_norm": 0.00387, "time": 0.65709}
+{"mode": "train", "epoch": 2, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00105, "acc_pose": 0.63425, "loss": 0.00105, "grad_norm": 0.00365, "time": 0.65695}
+{"mode": "train", "epoch": 3, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05631, "heatmap_loss": 0.001, "acc_pose": 0.65555, "loss": 0.001, "grad_norm": 0.00352, "time": 0.71304}
+{"mode": "train", "epoch": 3, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00097, "acc_pose": 0.66405, "loss": 0.00097, "grad_norm": 0.00368, "time": 0.65644}
+{"mode": "train", "epoch": 3, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00097, "acc_pose": 0.66894, "loss": 0.00097, "grad_norm": 0.00311, "time": 0.65626}
+{"mode": "train", "epoch": 3, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00094, "acc_pose": 0.68423, "loss": 0.00094, "grad_norm": 0.00349, "time": 0.65671}
+{"mode": "train", "epoch": 3, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00093, "acc_pose": 0.68407, "loss": 0.00093, "grad_norm": 0.00323, "time": 0.65689}
+{"mode": "train", "epoch": 4, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05676, "heatmap_loss": 0.00091, "acc_pose": 0.69757, "loss": 0.00091, "grad_norm": 0.00321, "time": 0.71421}
+{"mode": "train", "epoch": 4, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00028, "heatmap_loss": 0.0009, "acc_pose": 0.69656, "loss": 0.0009, "grad_norm": 0.00362, "time": 0.65668}
+{"mode": "train", "epoch": 4, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00089, "acc_pose": 0.70636, "loss": 0.00089, "grad_norm": 0.00313, "time": 0.65721}
+{"mode": "train", "epoch": 4, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00088, "acc_pose": 0.71063, "loss": 0.00088, "grad_norm": 0.00294, "time": 0.65713}
+{"mode": "train", "epoch": 4, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00087, "acc_pose": 0.71051, "loss": 0.00087, "grad_norm": 0.00328, "time": 0.65686}
+{"mode": "train", "epoch": 5, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05683, "heatmap_loss": 0.00086, "acc_pose": 0.7147, "loss": 0.00086, "grad_norm": 0.00325, "time": 0.71401}
+{"mode": "train", "epoch": 5, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00086, "acc_pose": 0.71026, "loss": 0.00086, "grad_norm": 0.00316, "time": 0.65613}
+{"mode": "train", "epoch": 5, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00045, "heatmap_loss": 0.00085, "acc_pose": 0.71429, "loss": 0.00085, "grad_norm": 0.00324, "time": 0.65694}
+{"mode": "train", "epoch": 5, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00085, "acc_pose": 0.72067, "loss": 0.00085, "grad_norm": 0.00327, "time": 0.65665}
+{"mode": "train", "epoch": 5, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00083, "acc_pose": 0.72617, "loss": 0.00083, "grad_norm": 0.00371, "time": 0.65642}
+{"mode": "train", "epoch": 6, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05546, "heatmap_loss": 0.00083, "acc_pose": 0.72704, "loss": 0.00083, "grad_norm": 0.00315, "time": 0.71233}
+{"mode": "train", "epoch": 6, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00082, "acc_pose": 0.72234, "loss": 0.00082, "grad_norm": 0.00284, "time": 0.65668}
+{"mode": "train", "epoch": 6, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00082, "acc_pose": 0.72467, "loss": 0.00082, "grad_norm": 0.00332, "time": 0.65648}
+{"mode": "train", "epoch": 6, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00081, "acc_pose": 0.72821, "loss": 0.00081, "grad_norm": 0.00341, "time": 0.65652}
+{"mode": "train", "epoch": 6, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00036, "heatmap_loss": 0.00082, "acc_pose": 0.73683, "loss": 0.00082, "grad_norm": 0.00299, "time": 0.65639}
+{"mode": "train", "epoch": 7, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.0558, "heatmap_loss": 0.0008, "acc_pose": 0.73265, "loss": 0.0008, "grad_norm": 0.00278, "time": 0.71353}
+{"mode": "train", "epoch": 7, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.0008, "acc_pose": 0.73282, "loss": 0.0008, "grad_norm": 0.00284, "time": 0.65649}
+{"mode": "train", "epoch": 7, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00079, "acc_pose": 0.73592, "loss": 0.00079, "grad_norm": 0.00303, "time": 0.65669}
+{"mode": "train", "epoch": 7, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00079, "acc_pose": 0.73794, "loss": 0.00079, "grad_norm": 0.00297, "time": 0.65615}
+{"mode": "train", "epoch": 7, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00079, "acc_pose": 0.74212, "loss": 0.00079, "grad_norm": 0.00345, "time": 0.6571}
+{"mode": "train", "epoch": 8, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05573, "heatmap_loss": 0.00078, "acc_pose": 0.74219, "loss": 0.00078, "grad_norm": 0.00357, "time": 0.71237}
+{"mode": "train", "epoch": 8, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00036, "heatmap_loss": 0.00078, "acc_pose": 0.7449, "loss": 0.00078, "grad_norm": 0.00296, "time": 0.65738}
+{"mode": "train", "epoch": 8, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00041, "heatmap_loss": 0.00078, "acc_pose": 0.74136, "loss": 0.00078, "grad_norm": 0.00276, "time": 0.65769}
+{"mode": "train", "epoch": 8, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00078, "acc_pose": 0.74911, "loss": 0.00078, "grad_norm": 0.00293, "time": 0.65678}
+{"mode": "train", "epoch": 8, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00077, "acc_pose": 0.75009, "loss": 0.00077, "grad_norm": 0.00339, "time": 0.65675}
+{"mode": "train", "epoch": 9, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.0565, "heatmap_loss": 0.00076, "acc_pose": 0.75381, "loss": 0.00076, "grad_norm": 0.00287, "time": 0.71405}
+{"mode": "train", "epoch": 9, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00076, "acc_pose": 0.75417, "loss": 0.00076, "grad_norm": 0.00278, "time": 0.6574}
+{"mode": "train", "epoch": 9, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00028, "heatmap_loss": 0.00077, "acc_pose": 0.75353, "loss": 0.00077, "grad_norm": 0.00299, "time": 0.6565}
+{"mode": "train", "epoch": 9, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00076, "acc_pose": 0.75399, "loss": 0.00076, "grad_norm": 0.00335, "time": 0.65658}
+{"mode": "train", "epoch": 9, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00076, "acc_pose": 0.75727, "loss": 0.00076, "grad_norm": 0.00308, "time": 0.65668}
+{"mode": "train", "epoch": 10, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05596, "heatmap_loss": 0.00076, "acc_pose": 0.76032, "loss": 0.00076, "grad_norm": 0.0031, "time": 0.71269}
+{"mode": "train", "epoch": 10, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00076, "acc_pose": 0.75087, "loss": 0.00076, "grad_norm": 0.00275, "time": 0.65637}
+{"mode": "train", "epoch": 10, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00034, "heatmap_loss": 0.00075, "acc_pose": 0.75933, "loss": 0.00075, "grad_norm": 0.00322, "time": 0.65722}
+{"mode": "train", "epoch": 10, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00075, "acc_pose": 0.75828, "loss": 0.00075, "grad_norm": 0.00317, "time": 0.65661}
+{"mode": "train", "epoch": 10, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00075, "acc_pose": 0.76572, "loss": 0.00075, "grad_norm": 0.00281, "time": 0.65638}
+{"mode": "val", "epoch": 10, "iter": 407, "lr": 0.0, "AP": 0.73634, "AP .5": 0.90274, "AP .75": 0.81459, "AP (M)": 0.6623, "AP (L)": 0.76279, "AR": 0.79213, "AR .5": 0.94238, "AR .75": 0.86004, "AR (M)": 0.75026, "AR (L)": 0.85295}
+{"mode": "train", "epoch": 11, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05645, "heatmap_loss": 0.00074, "acc_pose": 0.76148, "loss": 0.00074, "grad_norm": 0.0027, "time": 0.71099}
+{"mode": "train", "epoch": 11, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00074, "acc_pose": 0.75961, "loss": 0.00074, "grad_norm": 0.00305, "time": 0.65704}
+{"mode": "train", "epoch": 11, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00074, "acc_pose": 0.76053, "loss": 0.00074, "grad_norm": 0.00281, "time": 0.65666}
+{"mode": "train", "epoch": 11, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00074, "acc_pose": 0.75765, "loss": 0.00074, "grad_norm": 0.00268, "time": 0.65682}
+{"mode": "train", "epoch": 11, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00074, "acc_pose": 0.76331, "loss": 0.00074, "grad_norm": 0.00305, "time": 0.65683}
+{"mode": "train", "epoch": 12, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05767, "heatmap_loss": 0.00073, "acc_pose": 0.76707, "loss": 0.00073, "grad_norm": 0.00278, "time": 0.71396}
+{"mode": "train", "epoch": 12, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00073, "acc_pose": 0.76483, "loss": 0.00073, "grad_norm": 0.00268, "time": 0.6568}
+{"mode": "train", "epoch": 12, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00074, "acc_pose": 0.76696, "loss": 0.00074, "grad_norm": 0.00287, "time": 0.65677}
+{"mode": "train", "epoch": 12, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00073, "acc_pose": 0.75617, "loss": 0.00073, "grad_norm": 0.00373, "time": 0.65685}
+{"mode": "train", "epoch": 12, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00073, "acc_pose": 0.76287, "loss": 0.00073, "grad_norm": 0.0025, "time": 0.65653}
+{"mode": "train", "epoch": 13, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05686, "heatmap_loss": 0.00072, "acc_pose": 0.7653, "loss": 0.00072, "grad_norm": 0.0024, "time": 0.71344}
+{"mode": "train", "epoch": 13, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00072, "acc_pose": 0.77061, "loss": 0.00072, "grad_norm": 0.0029, "time": 0.65681}
+{"mode": "train", "epoch": 13, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00072, "acc_pose": 0.7689, "loss": 0.00072, "grad_norm": 0.00257, "time": 0.65688}
+{"mode": "train", "epoch": 13, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00072, "acc_pose": 0.7716, "loss": 0.00072, "grad_norm": 0.00276, "time": 0.65697}
+{"mode": "train", "epoch": 13, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00072, "acc_pose": 0.77556, "loss": 0.00072, "grad_norm": 0.00267, "time": 0.65706}
+{"mode": "train", "epoch": 14, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05703, "heatmap_loss": 0.00072, "acc_pose": 0.77378, "loss": 0.00072, "grad_norm": 0.00279, "time": 0.71362}
+{"mode": "train", "epoch": 14, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00072, "acc_pose": 0.77664, "loss": 0.00072, "grad_norm": 0.00277, "time": 0.65683}
+{"mode": "train", "epoch": 14, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00072, "acc_pose": 0.77005, "loss": 0.00072, "grad_norm": 0.00306, "time": 0.65695}
+{"mode": "train", "epoch": 14, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00071, "acc_pose": 0.77354, "loss": 0.00071, "grad_norm": 0.00292, "time": 0.6572}
+{"mode": "train", "epoch": 14, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00071, "acc_pose": 0.77582, "loss": 0.00071, "grad_norm": 0.00293, "time": 0.65693}
+{"mode": "train", "epoch": 15, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05657, "heatmap_loss": 0.00071, "acc_pose": 0.76827, "loss": 0.00071, "grad_norm": 0.00297, "time": 0.71309}
+{"mode": "train", "epoch": 15, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00027, "heatmap_loss": 0.00071, "acc_pose": 0.77158, "loss": 0.00071, "grad_norm": 0.0027, "time": 0.65664}
+{"mode": "train", "epoch": 15, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00071, "acc_pose": 0.7631, "loss": 0.00071, "grad_norm": 0.00271, "time": 0.65702}
+{"mode": "train", "epoch": 15, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00027, "heatmap_loss": 0.00071, "acc_pose": 0.77626, "loss": 0.00071, "grad_norm": 0.00257, "time": 0.65689}
+{"mode": "train", "epoch": 15, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00071, "acc_pose": 0.77703, "loss": 0.00071, "grad_norm": 0.0025, "time": 0.65729}
+{"mode": "train", "epoch": 16, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05767, "heatmap_loss": 0.0007, "acc_pose": 0.77805, "loss": 0.0007, "grad_norm": 0.00292, "time": 0.71429}
+{"mode": "train", "epoch": 16, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.0007, "acc_pose": 0.7804, "loss": 0.0007, "grad_norm": 0.00266, "time": 0.65664}
+{"mode": "train", "epoch": 16, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.0007, "acc_pose": 0.77341, "loss": 0.0007, "grad_norm": 0.00251, "time": 0.65675}
+{"mode": "train", "epoch": 16, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.0007, "acc_pose": 0.77406, "loss": 0.0007, "grad_norm": 0.00244, "time": 0.65659}
+{"mode": "train", "epoch": 16, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.0007, "acc_pose": 0.77973, "loss": 0.0007, "grad_norm": 0.00278, "time": 0.6568}
+{"mode": "train", "epoch": 17, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05657, "heatmap_loss": 0.0007, "acc_pose": 0.77578, "loss": 0.0007, "grad_norm": 0.00252, "time": 0.71304}
+{"mode": "train", "epoch": 17, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00069, "acc_pose": 0.77618, "loss": 0.00069, "grad_norm": 0.00258, "time": 0.65659}
+{"mode": "train", "epoch": 17, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00069, "acc_pose": 0.78352, "loss": 0.00069, "grad_norm": 0.00287, "time": 0.65694}
+{"mode": "train", "epoch": 17, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.0007, "acc_pose": 0.78323, "loss": 0.0007, "grad_norm": 0.00288, "time": 0.65677}
+{"mode": "train", "epoch": 17, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00069, "acc_pose": 0.78667, "loss": 0.00069, "grad_norm": 0.00247, "time": 0.65689}
+{"mode": "train", "epoch": 18, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05919, "heatmap_loss": 0.00069, "acc_pose": 0.78029, "loss": 0.00069, "grad_norm": 0.00281, "time": 0.71619}
+{"mode": "train", "epoch": 18, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00069, "acc_pose": 0.78093, "loss": 0.00069, "grad_norm": 0.00262, "time": 0.6566}
+{"mode": "train", "epoch": 18, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00069, "acc_pose": 0.7824, "loss": 0.00069, "grad_norm": 0.00272, "time": 0.6568}
+{"mode": "train", "epoch": 18, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00069, "acc_pose": 0.78795, "loss": 0.00069, "grad_norm": 0.00243, "time": 0.65679}
+{"mode": "train", "epoch": 18, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00069, "acc_pose": 0.78204, "loss": 0.00069, "grad_norm": 0.00237, "time": 0.65655}
+{"mode": "train", "epoch": 19, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05722, "heatmap_loss": 0.00069, "acc_pose": 0.78159, "loss": 0.00069, "grad_norm": 0.00233, "time": 0.71384}
+{"mode": "train", "epoch": 19, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00069, "acc_pose": 0.78203, "loss": 0.00069, "grad_norm": 0.00281, "time": 0.65693}
+{"mode": "train", "epoch": 19, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00069, "acc_pose": 0.76887, "loss": 0.00069, "grad_norm": 0.0026, "time": 0.65673}
+{"mode": "train", "epoch": 19, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00068, "acc_pose": 0.78149, "loss": 0.00068, "grad_norm": 0.0024, "time": 0.65665}
+{"mode": "train", "epoch": 19, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00068, "acc_pose": 0.79064, "loss": 0.00068, "grad_norm": 0.00261, "time": 0.65678}
+{"mode": "train", "epoch": 20, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05914, "heatmap_loss": 0.00068, "acc_pose": 0.78764, "loss": 0.00068, "grad_norm": 0.00248, "time": 0.71588}
+{"mode": "train", "epoch": 20, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00068, "acc_pose": 0.79079, "loss": 0.00068, "grad_norm": 0.00231, "time": 0.65671}
+{"mode": "train", "epoch": 20, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00068, "acc_pose": 0.78168, "loss": 0.00068, "grad_norm": 0.00254, "time": 0.65712}
+{"mode": "train", "epoch": 20, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00068, "acc_pose": 0.78905, "loss": 0.00068, "grad_norm": 0.00277, "time": 0.65708}
+{"mode": "train", "epoch": 20, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00068, "acc_pose": 0.78481, "loss": 0.00068, "grad_norm": 0.00257, "time": 0.65717}
+{"mode": "val", "epoch": 20, "iter": 407, "lr": 0.0, "AP": 0.75447, "AP .5": 0.90483, "AP .75": 0.83072, "AP (M)": 0.68124, "AP (L)": 0.78224, "AR": 0.8088, "AR .5": 0.94443, "AR .75": 0.8772, "AR (M)": 0.76741, "AR (L)": 0.86942}
+{"mode": "train", "epoch": 21, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05636, "heatmap_loss": 0.00068, "acc_pose": 0.78704, "loss": 0.00068, "grad_norm": 0.00253, "time": 0.70903}
+{"mode": "train", "epoch": 21, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00067, "acc_pose": 0.78842, "loss": 0.00067, "grad_norm": 0.00239, "time": 0.65572}
+{"mode": "train", "epoch": 21, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00068, "acc_pose": 0.78461, "loss": 0.00068, "grad_norm": 0.00234, "time": 0.65658}
+{"mode": "train", "epoch": 21, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00068, "acc_pose": 0.7906, "loss": 0.00068, "grad_norm": 0.00227, "time": 0.6565}
+{"mode": "train", "epoch": 21, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00068, "acc_pose": 0.7923, "loss": 0.00068, "grad_norm": 0.00247, "time": 0.65654}
+{"mode": "train", "epoch": 22, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05757, "heatmap_loss": 0.00067, "acc_pose": 0.7911, "loss": 0.00067, "grad_norm": 0.00245, "time": 0.71461}
+{"mode": "train", "epoch": 22, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00067, "acc_pose": 0.78852, "loss": 0.00067, "grad_norm": 0.00235, "time": 0.65702}
+{"mode": "train", "epoch": 22, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00067, "acc_pose": 0.78798, "loss": 0.00067, "grad_norm": 0.00248, "time": 0.657}
+{"mode": "train", "epoch": 22, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00067, "acc_pose": 0.79555, "loss": 0.00067, "grad_norm": 0.00228, "time": 0.65754}
+{"mode": "train", "epoch": 22, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00067, "acc_pose": 0.79277, "loss": 0.00067, "grad_norm": 0.00243, "time": 0.65689}
+{"mode": "train", "epoch": 23, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.0568, "heatmap_loss": 0.00067, "acc_pose": 0.78734, "loss": 0.00067, "grad_norm": 0.00247, "time": 0.71378}
+{"mode": "train", "epoch": 23, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00067, "acc_pose": 0.78432, "loss": 0.00067, "grad_norm": 0.00233, "time": 0.6565}
+{"mode": "train", "epoch": 23, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00066, "acc_pose": 0.79388, "loss": 0.00066, "grad_norm": 0.00288, "time": 0.65699}
+{"mode": "train", "epoch": 23, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00066, "acc_pose": 0.79624, "loss": 0.00066, "grad_norm": 0.00263, "time": 0.65732}
+{"mode": "train", "epoch": 23, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00067, "acc_pose": 0.7932, "loss": 0.00067, "grad_norm": 0.00246, "time": 0.65695}
+{"mode": "train", "epoch": 24, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05651, "heatmap_loss": 0.00066, "acc_pose": 0.79224, "loss": 0.00066, "grad_norm": 0.00243, "time": 0.71345}
+{"mode": "train", "epoch": 24, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00066, "acc_pose": 0.80346, "loss": 0.00066, "grad_norm": 0.00242, "time": 0.65711}
+{"mode": "train", "epoch": 24, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00066, "acc_pose": 0.78652, "loss": 0.00066, "grad_norm": 0.00239, "time": 0.65696}
+{"mode": "train", "epoch": 24, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00036, "heatmap_loss": 0.00066, "acc_pose": 0.78495, "loss": 0.00066, "grad_norm": 0.00242, "time": 0.65686}
+{"mode": "train", "epoch": 24, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00066, "acc_pose": 0.79419, "loss": 0.00066, "grad_norm": 0.00265, "time": 0.65697}
+{"mode": "train", "epoch": 25, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05675, "heatmap_loss": 0.00066, "acc_pose": 0.79865, "loss": 0.00066, "grad_norm": 0.00238, "time": 0.7138}
+{"mode": "train", "epoch": 25, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00066, "acc_pose": 0.79146, "loss": 0.00066, "grad_norm": 0.00228, "time": 0.65673}
+{"mode": "train", "epoch": 25, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00066, "acc_pose": 0.7884, "loss": 0.00066, "grad_norm": 0.00246, "time": 0.65713}
+{"mode": "train", "epoch": 25, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00066, "acc_pose": 0.79075, "loss": 0.00066, "grad_norm": 0.00281, "time": 0.657}
+{"mode": "train", "epoch": 25, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00066, "acc_pose": 0.79164, "loss": 0.00066, "grad_norm": 0.00225, "time": 0.65685}
+{"mode": "train", "epoch": 26, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05648, "heatmap_loss": 0.00066, "acc_pose": 0.79291, "loss": 0.00066, "grad_norm": 0.00232, "time": 0.7138}
+{"mode": "train", "epoch": 26, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00066, "acc_pose": 0.79163, "loss": 0.00066, "grad_norm": 0.00246, "time": 0.65683}
+{"mode": "train", "epoch": 26, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00065, "acc_pose": 0.79363, "loss": 0.00065, "grad_norm": 0.00236, "time": 0.65707}
+{"mode": "train", "epoch": 26, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00066, "acc_pose": 0.79388, "loss": 0.00066, "grad_norm": 0.00224, "time": 0.657}
+{"mode": "train", "epoch": 26, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00065, "acc_pose": 0.80029, "loss": 0.00065, "grad_norm": 0.00238, "time": 0.6573}
+{"mode": "train", "epoch": 27, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05678, "heatmap_loss": 0.00065, "acc_pose": 0.80022, "loss": 0.00065, "grad_norm": 0.00228, "time": 0.71494}
+{"mode": "train", "epoch": 27, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00035, "heatmap_loss": 0.00065, "acc_pose": 0.79938, "loss": 0.00065, "grad_norm": 0.00236, "time": 0.65729}
+{"mode": "train", "epoch": 27, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00066, "acc_pose": 0.7979, "loss": 0.00066, "grad_norm": 0.00244, "time": 0.65686}
+{"mode": "train", "epoch": 27, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00065, "acc_pose": 0.80485, "loss": 0.00065, "grad_norm": 0.00239, "time": 0.65675}
+{"mode": "train", "epoch": 27, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00065, "acc_pose": 0.79318, "loss": 0.00065, "grad_norm": 0.00242, "time": 0.65687}
+{"mode": "train", "epoch": 28, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05666, "heatmap_loss": 0.00065, "acc_pose": 0.80145, "loss": 0.00065, "grad_norm": 0.00214, "time": 0.71301}
+{"mode": "train", "epoch": 28, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00065, "acc_pose": 0.79412, "loss": 0.00065, "grad_norm": 0.00236, "time": 0.65659}
+{"mode": "train", "epoch": 28, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00065, "acc_pose": 0.79594, "loss": 0.00065, "grad_norm": 0.00235, "time": 0.65713}
+{"mode": "train", "epoch": 28, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00065, "acc_pose": 0.80472, "loss": 0.00065, "grad_norm": 0.00258, "time": 0.65712}
+{"mode": "train", "epoch": 28, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00065, "acc_pose": 0.79781, "loss": 0.00065, "grad_norm": 0.00226, "time": 0.65698}
+{"mode": "train", "epoch": 29, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05731, "heatmap_loss": 0.00065, "acc_pose": 0.80365, "loss": 0.00065, "grad_norm": 0.00225, "time": 0.71396}
+{"mode": "train", "epoch": 29, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00065, "acc_pose": 0.79638, "loss": 0.00065, "grad_norm": 0.00224, "time": 0.65703}
+{"mode": "train", "epoch": 29, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00065, "acc_pose": 0.79311, "loss": 0.00065, "grad_norm": 0.00243, "time": 0.65693}
+{"mode": "train", "epoch": 29, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00065, "acc_pose": 0.80223, "loss": 0.00065, "grad_norm": 0.00237, "time": 0.65687}
+{"mode": "train", "epoch": 29, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00064, "acc_pose": 0.80321, "loss": 0.00064, "grad_norm": 0.00227, "time": 0.65697}
+{"mode": "train", "epoch": 30, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05733, "heatmap_loss": 0.00064, "acc_pose": 0.79573, "loss": 0.00064, "grad_norm": 0.00208, "time": 0.71382}
+{"mode": "train", "epoch": 30, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00065, "acc_pose": 0.80052, "loss": 0.00065, "grad_norm": 0.00226, "time": 0.65685}
+{"mode": "train", "epoch": 30, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00064, "acc_pose": 0.79942, "loss": 0.00064, "grad_norm": 0.00235, "time": 0.65738}
+{"mode": "train", "epoch": 30, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00064, "acc_pose": 0.80231, "loss": 0.00064, "grad_norm": 0.00235, "time": 0.6572}
+{"mode": "train", "epoch": 30, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00064, "acc_pose": 0.80187, "loss": 0.00064, "grad_norm": 0.00206, "time": 0.65701}
+{"mode": "val", "epoch": 30, "iter": 407, "lr": 0.0, "AP": 0.7629, "AP .5": 0.90698, "AP .75": 0.8369, "AP (M)": 0.68864, "AP (L)": 0.78944, "AR": 0.81725, "AR .5": 0.94773, "AR .75": 0.8824, "AR (M)": 0.77596, "AR (L)": 0.87726}
+{"mode": "train", "epoch": 31, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05601, "heatmap_loss": 0.00064, "acc_pose": 0.80354, "loss": 0.00064, "grad_norm": 0.00247, "time": 0.70822}
+{"mode": "train", "epoch": 31, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00064, "acc_pose": 0.80007, "loss": 0.00064, "grad_norm": 0.00228, "time": 0.65626}
+{"mode": "train", "epoch": 31, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00064, "acc_pose": 0.8007, "loss": 0.00064, "grad_norm": 0.00212, "time": 0.65666}
+{"mode": "train", "epoch": 31, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00064, "acc_pose": 0.80342, "loss": 0.00064, "grad_norm": 0.00236, "time": 0.65671}
+{"mode": "train", "epoch": 31, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00064, "acc_pose": 0.80814, "loss": 0.00064, "grad_norm": 0.00212, "time": 0.65668}
+{"mode": "train", "epoch": 32, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05673, "heatmap_loss": 0.00064, "acc_pose": 0.80551, "loss": 0.00064, "grad_norm": 0.00223, "time": 0.7132}
+{"mode": "train", "epoch": 32, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00064, "acc_pose": 0.81187, "loss": 0.00064, "grad_norm": 0.0021, "time": 0.65662}
+{"mode": "train", "epoch": 32, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00064, "acc_pose": 0.80193, "loss": 0.00064, "grad_norm": 0.00223, "time": 0.65656}
+{"mode": "train", "epoch": 32, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00064, "acc_pose": 0.80625, "loss": 0.00064, "grad_norm": 0.00219, "time": 0.65656}
+{"mode": "train", "epoch": 32, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00064, "acc_pose": 0.81177, "loss": 0.00064, "grad_norm": 0.00218, "time": 0.65691}
+{"mode": "train", "epoch": 33, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05709, "heatmap_loss": 0.00063, "acc_pose": 0.8111, "loss": 0.00063, "grad_norm": 0.00209, "time": 0.71417}
+{"mode": "train", "epoch": 33, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00064, "acc_pose": 0.80279, "loss": 0.00064, "grad_norm": 0.00208, "time": 0.65693}
+{"mode": "train", "epoch": 33, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00063, "acc_pose": 0.80847, "loss": 0.00063, "grad_norm": 0.0024, "time": 0.65722}
+{"mode": "train", "epoch": 33, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00064, "acc_pose": 0.80424, "loss": 0.00064, "grad_norm": 0.00242, "time": 0.65747}
+{"mode": "train", "epoch": 33, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00064, "acc_pose": 0.81241, "loss": 0.00064, "grad_norm": 0.00213, "time": 0.65754}
+{"mode": "train", "epoch": 34, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05658, "heatmap_loss": 0.00063, "acc_pose": 0.80267, "loss": 0.00063, "grad_norm": 0.00223, "time": 0.7144}
+{"mode": "train", "epoch": 34, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00063, "acc_pose": 0.80298, "loss": 0.00063, "grad_norm": 0.00218, "time": 0.65704}
+{"mode": "train", "epoch": 34, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00063, "acc_pose": 0.80791, "loss": 0.00063, "grad_norm": 0.00196, "time": 0.65662}
+{"mode": "train", "epoch": 34, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00063, "acc_pose": 0.80471, "loss": 0.00063, "grad_norm": 0.00194, "time": 0.65676}
+{"mode": "train", "epoch": 34, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00063, "acc_pose": 0.80862, "loss": 0.00063, "grad_norm": 0.00203, "time": 0.65672}
+{"mode": "train", "epoch": 35, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05735, "heatmap_loss": 0.00062, "acc_pose": 0.80915, "loss": 0.00062, "grad_norm": 0.00201, "time": 0.71445}
+{"mode": "train", "epoch": 35, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00063, "acc_pose": 0.80721, "loss": 0.00063, "grad_norm": 0.00229, "time": 0.65716}
+{"mode": "train", "epoch": 35, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00063, "acc_pose": 0.80209, "loss": 0.00063, "grad_norm": 0.00213, "time": 0.65709}
+{"mode": "train", "epoch": 35, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00063, "acc_pose": 0.80965, "loss": 0.00063, "grad_norm": 0.00199, "time": 0.65707}
+{"mode": "train", "epoch": 35, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00063, "acc_pose": 0.81439, "loss": 0.00063, "grad_norm": 0.00209, "time": 0.65748}
+{"mode": "train", "epoch": 36, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05685, "heatmap_loss": 0.00062, "acc_pose": 0.80001, "loss": 0.00062, "grad_norm": 0.00212, "time": 0.71369}
+{"mode": "train", "epoch": 36, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00063, "acc_pose": 0.81158, "loss": 0.00063, "grad_norm": 0.00213, "time": 0.65685}
+{"mode": "train", "epoch": 36, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00063, "acc_pose": 0.80463, "loss": 0.00063, "grad_norm": 0.00199, "time": 0.65727}
+{"mode": "train", "epoch": 36, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00063, "acc_pose": 0.81261, "loss": 0.00063, "grad_norm": 0.00238, "time": 0.65702}
+{"mode": "train", "epoch": 36, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00063, "acc_pose": 0.807, "loss": 0.00063, "grad_norm": 0.0021, "time": 0.65756}
+{"mode": "train", "epoch": 37, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05616, "heatmap_loss": 0.00062, "acc_pose": 0.80485, "loss": 0.00062, "grad_norm": 0.00207, "time": 0.71275}
+{"mode": "train", "epoch": 37, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00063, "acc_pose": 0.80202, "loss": 0.00063, "grad_norm": 0.00221, "time": 0.65701}
+{"mode": "train", "epoch": 37, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00062, "acc_pose": 0.80508, "loss": 0.00062, "grad_norm": 0.00217, "time": 0.65683}
+{"mode": "train", "epoch": 37, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00062, "acc_pose": 0.8172, "loss": 0.00062, "grad_norm": 0.0021, "time": 0.65735}
+{"mode": "train", "epoch": 37, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00063, "acc_pose": 0.80337, "loss": 0.00063, "grad_norm": 0.00239, "time": 0.65719}
+{"mode": "train", "epoch": 38, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05708, "heatmap_loss": 0.00062, "acc_pose": 0.81093, "loss": 0.00062, "grad_norm": 0.00189, "time": 0.71382}
+{"mode": "train", "epoch": 38, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00062, "acc_pose": 0.81207, "loss": 0.00062, "grad_norm": 0.00218, "time": 0.65653}
+{"mode": "train", "epoch": 38, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00063, "acc_pose": 0.80568, "loss": 0.00063, "grad_norm": 0.00222, "time": 0.65702}
+{"mode": "train", "epoch": 38, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00062, "acc_pose": 0.80719, "loss": 0.00062, "grad_norm": 0.00201, "time": 0.65683}
+{"mode": "train", "epoch": 38, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00062, "acc_pose": 0.80346, "loss": 0.00062, "grad_norm": 0.00202, "time": 0.65681}
+{"mode": "train", "epoch": 39, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05773, "heatmap_loss": 0.00062, "acc_pose": 0.80809, "loss": 0.00062, "grad_norm": 0.00196, "time": 0.71442}
+{"mode": "train", "epoch": 39, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00062, "acc_pose": 0.80958, "loss": 0.00062, "grad_norm": 0.00209, "time": 0.65664}
+{"mode": "train", "epoch": 39, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00062, "acc_pose": 0.80484, "loss": 0.00062, "grad_norm": 0.00221, "time": 0.65657}
+{"mode": "train", "epoch": 39, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00062, "acc_pose": 0.80376, "loss": 0.00062, "grad_norm": 0.00191, "time": 0.65658}
+{"mode": "train", "epoch": 39, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00063, "acc_pose": 0.80851, "loss": 0.00063, "grad_norm": 0.00193, "time": 0.65665}
+{"mode": "train", "epoch": 40, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05697, "heatmap_loss": 0.00061, "acc_pose": 0.81252, "loss": 0.00061, "grad_norm": 0.00197, "time": 0.71327}
+{"mode": "train", "epoch": 40, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00062, "acc_pose": 0.80708, "loss": 0.00062, "grad_norm": 0.00192, "time": 0.6566}
+{"mode": "train", "epoch": 40, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00062, "acc_pose": 0.81383, "loss": 0.00062, "grad_norm": 0.00225, "time": 0.65661}
+{"mode": "train", "epoch": 40, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00062, "acc_pose": 0.80746, "loss": 0.00062, "grad_norm": 0.0021, "time": 0.65657}
+{"mode": "train", "epoch": 40, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00062, "acc_pose": 0.8129, "loss": 0.00062, "grad_norm": 0.002, "time": 0.65666}
+{"mode": "val", "epoch": 40, "iter": 407, "lr": 0.0, "AP": 0.76736, "AP .5": 0.91117, "AP .75": 0.84085, "AP (M)": 0.69408, "AP (L)": 0.79345, "AR": 0.82218, "AR .5": 0.95057, "AR .75": 0.88744, "AR (M)": 0.7826, "AR (L)": 0.88023}
+{"mode": "train", "epoch": 41, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05551, "heatmap_loss": 0.00061, "acc_pose": 0.81245, "loss": 0.00061, "grad_norm": 0.00209, "time": 0.70817}
+{"mode": "train", "epoch": 41, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00062, "acc_pose": 0.81238, "loss": 0.00062, "grad_norm": 0.00219, "time": 0.65606}
+{"mode": "train", "epoch": 41, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00062, "acc_pose": 0.8174, "loss": 0.00062, "grad_norm": 0.002, "time": 0.65666}
+{"mode": "train", "epoch": 41, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00062, "acc_pose": 0.81264, "loss": 0.00062, "grad_norm": 0.00192, "time": 0.65627}
+{"mode": "train", "epoch": 41, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00062, "acc_pose": 0.80506, "loss": 0.00062, "grad_norm": 0.00199, "time": 0.65645}
+{"mode": "train", "epoch": 42, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05694, "heatmap_loss": 0.00061, "acc_pose": 0.81002, "loss": 0.00061, "grad_norm": 0.00186, "time": 0.71393}
+{"mode": "train", "epoch": 42, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00062, "acc_pose": 0.80699, "loss": 0.00062, "grad_norm": 0.00199, "time": 0.65706}
+{"mode": "train", "epoch": 42, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00062, "acc_pose": 0.80476, "loss": 0.00062, "grad_norm": 0.00198, "time": 0.65707}
+{"mode": "train", "epoch": 42, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00061, "acc_pose": 0.81603, "loss": 0.00061, "grad_norm": 0.00214, "time": 0.65692}
+{"mode": "train", "epoch": 42, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00062, "acc_pose": 0.81092, "loss": 0.00062, "grad_norm": 0.00183, "time": 0.6569}
+{"mode": "train", "epoch": 43, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05743, "heatmap_loss": 0.00061, "acc_pose": 0.81699, "loss": 0.00061, "grad_norm": 0.00196, "time": 0.71498}
+{"mode": "train", "epoch": 43, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00062, "acc_pose": 0.8144, "loss": 0.00062, "grad_norm": 0.002, "time": 0.6571}
+{"mode": "train", "epoch": 43, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00061, "acc_pose": 0.81477, "loss": 0.00061, "grad_norm": 0.0021, "time": 0.6572}
+{"mode": "train", "epoch": 43, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00062, "acc_pose": 0.81315, "loss": 0.00062, "grad_norm": 0.00215, "time": 0.65708}
+{"mode": "train", "epoch": 43, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00061, "acc_pose": 0.82042, "loss": 0.00061, "grad_norm": 0.00175, "time": 0.65718}
+{"mode": "train", "epoch": 44, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05689, "heatmap_loss": 0.00061, "acc_pose": 0.8148, "loss": 0.00061, "grad_norm": 0.00189, "time": 0.71416}
+{"mode": "train", "epoch": 44, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00061, "acc_pose": 0.81225, "loss": 0.00061, "grad_norm": 0.00189, "time": 0.65707}
+{"mode": "train", "epoch": 44, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00061, "acc_pose": 0.81535, "loss": 0.00061, "grad_norm": 0.00191, "time": 0.65667}
+{"mode": "train", "epoch": 44, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00061, "acc_pose": 0.81262, "loss": 0.00061, "grad_norm": 0.00202, "time": 0.65691}
+{"mode": "train", "epoch": 44, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00061, "acc_pose": 0.81162, "loss": 0.00061, "grad_norm": 0.00207, "time": 0.65685}
+{"mode": "train", "epoch": 45, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05714, "heatmap_loss": 0.00061, "acc_pose": 0.81749, "loss": 0.00061, "grad_norm": 0.0023, "time": 0.71418}
+{"mode": "train", "epoch": 45, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00061, "acc_pose": 0.81231, "loss": 0.00061, "grad_norm": 0.00205, "time": 0.65681}
+{"mode": "train", "epoch": 45, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00061, "acc_pose": 0.80782, "loss": 0.00061, "grad_norm": 0.00211, "time": 0.65668}
+{"mode": "train", "epoch": 45, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00061, "acc_pose": 0.81186, "loss": 0.00061, "grad_norm": 0.00192, "time": 0.6564}
+{"mode": "train", "epoch": 45, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00061, "acc_pose": 0.81904, "loss": 0.00061, "grad_norm": 0.00176, "time": 0.65684}
+{"mode": "train", "epoch": 46, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05756, "heatmap_loss": 0.00061, "acc_pose": 0.81589, "loss": 0.00061, "grad_norm": 0.00198, "time": 0.71438}
+{"mode": "train", "epoch": 46, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00061, "acc_pose": 0.81722, "loss": 0.00061, "grad_norm": 0.00196, "time": 0.65715}
+{"mode": "train", "epoch": 46, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00061, "acc_pose": 0.81133, "loss": 0.00061, "grad_norm": 0.00204, "time": 0.65692}
+{"mode": "train", "epoch": 46, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00061, "acc_pose": 0.81781, "loss": 0.00061, "grad_norm": 0.00184, "time": 0.65711}
+{"mode": "train", "epoch": 46, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00061, "acc_pose": 0.81913, "loss": 0.00061, "grad_norm": 0.00176, "time": 0.65706}
+{"mode": "train", "epoch": 47, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05738, "heatmap_loss": 0.00061, "acc_pose": 0.81312, "loss": 0.00061, "grad_norm": 0.00186, "time": 0.71485}
+{"mode": "train", "epoch": 47, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00061, "acc_pose": 0.82257, "loss": 0.00061, "grad_norm": 0.00206, "time": 0.65705}
+{"mode": "train", "epoch": 47, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00061, "acc_pose": 0.80699, "loss": 0.00061, "grad_norm": 0.00185, "time": 0.65675}
+{"mode": "train", "epoch": 47, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00061, "acc_pose": 0.81639, "loss": 0.00061, "grad_norm": 0.00186, "time": 0.65665}
+{"mode": "train", "epoch": 47, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00061, "acc_pose": 0.82266, "loss": 0.00061, "grad_norm": 0.00192, "time": 0.65689}
+{"mode": "train", "epoch": 48, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05725, "heatmap_loss": 0.0006, "acc_pose": 0.81726, "loss": 0.0006, "grad_norm": 0.00199, "time": 0.71377}
+{"mode": "train", "epoch": 48, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.0006, "acc_pose": 0.81297, "loss": 0.0006, "grad_norm": 0.00177, "time": 0.65701}
+{"mode": "train", "epoch": 48, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.0006, "acc_pose": 0.81833, "loss": 0.0006, "grad_norm": 0.00189, "time": 0.65673}
+{"mode": "train", "epoch": 48, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00061, "acc_pose": 0.816, "loss": 0.00061, "grad_norm": 0.00182, "time": 0.65683}
+{"mode": "train", "epoch": 48, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00061, "acc_pose": 0.82057, "loss": 0.00061, "grad_norm": 0.00182, "time": 0.65672}
+{"mode": "train", "epoch": 49, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05622, "heatmap_loss": 0.0006, "acc_pose": 0.81674, "loss": 0.0006, "grad_norm": 0.00179, "time": 0.71502}
+{"mode": "train", "epoch": 49, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00061, "acc_pose": 0.81351, "loss": 0.00061, "grad_norm": 0.00197, "time": 0.65644}
+{"mode": "train", "epoch": 49, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.0006, "acc_pose": 0.81712, "loss": 0.0006, "grad_norm": 0.00192, "time": 0.6573}
+{"mode": "train", "epoch": 49, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.0006, "acc_pose": 0.81285, "loss": 0.0006, "grad_norm": 0.00192, "time": 0.65737}
+{"mode": "train", "epoch": 49, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00061, "acc_pose": 0.82138, "loss": 0.00061, "grad_norm": 0.00189, "time": 0.65679}
+{"mode": "train", "epoch": 50, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05602, "heatmap_loss": 0.0006, "acc_pose": 0.82519, "loss": 0.0006, "grad_norm": 0.00206, "time": 0.71324}
+{"mode": "train", "epoch": 50, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.0006, "acc_pose": 0.81546, "loss": 0.0006, "grad_norm": 0.00195, "time": 0.65656}
+{"mode": "train", "epoch": 50, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.0006, "acc_pose": 0.81672, "loss": 0.0006, "grad_norm": 0.00201, "time": 0.65666}
+{"mode": "train", "epoch": 50, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.0006, "acc_pose": 0.81819, "loss": 0.0006, "grad_norm": 0.00182, "time": 0.65668}
+{"mode": "train", "epoch": 50, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.0006, "acc_pose": 0.81157, "loss": 0.0006, "grad_norm": 0.00171, "time": 0.65672}
+{"mode": "val", "epoch": 50, "iter": 407, "lr": 0.0, "AP": 0.7695, "AP .5": 0.90845, "AP .75": 0.8426, "AP (M)": 0.69611, "AP (L)": 0.79689, "AR": 0.82338, "AR .5": 0.94962, "AR .75": 0.88948, "AR (M)": 0.78249, "AR (L)": 0.88305}
+{"mode": "train", "epoch": 51, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.0575, "heatmap_loss": 0.0006, "acc_pose": 0.82292, "loss": 0.0006, "grad_norm": 0.00171, "time": 0.71111}
+{"mode": "train", "epoch": 51, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.0006, "acc_pose": 0.81437, "loss": 0.0006, "grad_norm": 0.00178, "time": 0.65664}
+{"mode": "train", "epoch": 51, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.0006, "acc_pose": 0.81762, "loss": 0.0006, "grad_norm": 0.00196, "time": 0.65677}
+{"mode": "train", "epoch": 51, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.0006, "acc_pose": 0.82175, "loss": 0.0006, "grad_norm": 0.00172, "time": 0.65676}
+{"mode": "train", "epoch": 51, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.0006, "acc_pose": 0.82446, "loss": 0.0006, "grad_norm": 0.00172, "time": 0.65641}
+{"mode": "train", "epoch": 52, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05672, "heatmap_loss": 0.0006, "acc_pose": 0.81974, "loss": 0.0006, "grad_norm": 0.00175, "time": 0.71319}
+{"mode": "train", "epoch": 52, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.0006, "acc_pose": 0.82396, "loss": 0.0006, "grad_norm": 0.00175, "time": 0.65688}
+{"mode": "train", "epoch": 52, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.0006, "acc_pose": 0.82181, "loss": 0.0006, "grad_norm": 0.00177, "time": 0.6566}
+{"mode": "train", "epoch": 52, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00059, "acc_pose": 0.8208, "loss": 0.00059, "grad_norm": 0.00165, "time": 0.65677}
+{"mode": "train", "epoch": 52, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00039, "heatmap_loss": 0.0006, "acc_pose": 0.81904, "loss": 0.0006, "grad_norm": 0.00171, "time": 0.6569}
+{"mode": "train", "epoch": 53, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05652, "heatmap_loss": 0.0006, "acc_pose": 0.82065, "loss": 0.0006, "grad_norm": 0.00175, "time": 0.71288}
+{"mode": "train", "epoch": 53, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.0006, "acc_pose": 0.81997, "loss": 0.0006, "grad_norm": 0.00208, "time": 0.65697}
+{"mode": "train", "epoch": 53, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.0006, "acc_pose": 0.81721, "loss": 0.0006, "grad_norm": 0.00211, "time": 0.65695}
+{"mode": "train", "epoch": 53, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.0006, "acc_pose": 0.81958, "loss": 0.0006, "grad_norm": 0.00172, "time": 0.65705}
+{"mode": "train", "epoch": 53, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00034, "heatmap_loss": 0.0006, "acc_pose": 0.81644, "loss": 0.0006, "grad_norm": 0.00176, "time": 0.65698}
+{"mode": "train", "epoch": 54, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05678, "heatmap_loss": 0.00059, "acc_pose": 0.82299, "loss": 0.00059, "grad_norm": 0.00197, "time": 0.71395}
+{"mode": "train", "epoch": 54, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.0006, "acc_pose": 0.81762, "loss": 0.0006, "grad_norm": 0.00185, "time": 0.65703}
+{"mode": "train", "epoch": 54, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00059, "acc_pose": 0.81921, "loss": 0.00059, "grad_norm": 0.00191, "time": 0.65715}
+{"mode": "train", "epoch": 54, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.0006, "acc_pose": 0.8209, "loss": 0.0006, "grad_norm": 0.00177, "time": 0.65693}
+{"mode": "train", "epoch": 54, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.0006, "acc_pose": 0.82029, "loss": 0.0006, "grad_norm": 0.00187, "time": 0.65696}
+{"mode": "train", "epoch": 55, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05693, "heatmap_loss": 0.00059, "acc_pose": 0.82807, "loss": 0.00059, "grad_norm": 0.0019, "time": 0.71359}
+{"mode": "train", "epoch": 55, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00059, "acc_pose": 0.81812, "loss": 0.00059, "grad_norm": 0.00169, "time": 0.65691}
+{"mode": "train", "epoch": 55, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.0006, "acc_pose": 0.81426, "loss": 0.0006, "grad_norm": 0.0017, "time": 0.65708}
+{"mode": "train", "epoch": 55, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00059, "acc_pose": 0.82184, "loss": 0.00059, "grad_norm": 0.00177, "time": 0.65705}
+{"mode": "train", "epoch": 55, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00059, "acc_pose": 0.81941, "loss": 0.00059, "grad_norm": 0.00179, "time": 0.65738}
+{"mode": "train", "epoch": 56, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05687, "heatmap_loss": 0.0006, "acc_pose": 0.82346, "loss": 0.0006, "grad_norm": 0.00182, "time": 0.71316}
+{"mode": "train", "epoch": 56, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00059, "acc_pose": 0.82, "loss": 0.00059, "grad_norm": 0.00163, "time": 0.65698}
+{"mode": "train", "epoch": 56, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00059, "acc_pose": 0.81471, "loss": 0.00059, "grad_norm": 0.00168, "time": 0.65705}
+{"mode": "train", "epoch": 56, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00059, "acc_pose": 0.81356, "loss": 0.00059, "grad_norm": 0.0018, "time": 0.65683}
+{"mode": "train", "epoch": 56, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00059, "acc_pose": 0.82136, "loss": 0.00059, "grad_norm": 0.00193, "time": 0.65699}
+{"mode": "train", "epoch": 57, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05828, "heatmap_loss": 0.0006, "acc_pose": 0.82503, "loss": 0.0006, "grad_norm": 0.00175, "time": 0.71609}
+{"mode": "train", "epoch": 57, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00059, "acc_pose": 0.81867, "loss": 0.00059, "grad_norm": 0.00173, "time": 0.65682}
+{"mode": "train", "epoch": 57, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00059, "acc_pose": 0.82435, "loss": 0.00059, "grad_norm": 0.00184, "time": 0.65675}
+{"mode": "train", "epoch": 57, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00059, "acc_pose": 0.82809, "loss": 0.00059, "grad_norm": 0.00185, "time": 0.65704}
+{"mode": "train", "epoch": 57, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00059, "acc_pose": 0.82382, "loss": 0.00059, "grad_norm": 0.00151, "time": 0.65713}
+{"mode": "train", "epoch": 58, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05677, "heatmap_loss": 0.00059, "acc_pose": 0.82895, "loss": 0.00059, "grad_norm": 0.00178, "time": 0.71376}
+{"mode": "train", "epoch": 58, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00059, "acc_pose": 0.82192, "loss": 0.00059, "grad_norm": 0.00178, "time": 0.65675}
+{"mode": "train", "epoch": 58, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00059, "acc_pose": 0.82081, "loss": 0.00059, "grad_norm": 0.00183, "time": 0.65696}
+{"mode": "train", "epoch": 58, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00059, "acc_pose": 0.82535, "loss": 0.00059, "grad_norm": 0.00185, "time": 0.65704}
+{"mode": "train", "epoch": 58, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00059, "acc_pose": 0.82581, "loss": 0.00059, "grad_norm": 0.00174, "time": 0.65672}
+{"mode": "train", "epoch": 59, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.0569, "heatmap_loss": 0.00059, "acc_pose": 0.82467, "loss": 0.00059, "grad_norm": 0.00177, "time": 0.71399}
+{"mode": "train", "epoch": 59, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00059, "acc_pose": 0.82657, "loss": 0.00059, "grad_norm": 0.00169, "time": 0.65696}
+{"mode": "train", "epoch": 59, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00059, "acc_pose": 0.82659, "loss": 0.00059, "grad_norm": 0.00159, "time": 0.657}
+{"mode": "train", "epoch": 59, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00059, "acc_pose": 0.82456, "loss": 0.00059, "grad_norm": 0.00173, "time": 0.65688}
+{"mode": "train", "epoch": 59, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00059, "acc_pose": 0.82844, "loss": 0.00059, "grad_norm": 0.0018, "time": 0.6567}
+{"mode": "train", "epoch": 60, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05726, "heatmap_loss": 0.00059, "acc_pose": 0.82544, "loss": 0.00059, "grad_norm": 0.00185, "time": 0.71382}
+{"mode": "train", "epoch": 60, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00058, "acc_pose": 0.82381, "loss": 0.00058, "grad_norm": 0.00178, "time": 0.65696}
+{"mode": "train", "epoch": 60, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00059, "acc_pose": 0.81943, "loss": 0.00059, "grad_norm": 0.00158, "time": 0.65683}
+{"mode": "train", "epoch": 60, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00059, "acc_pose": 0.82322, "loss": 0.00059, "grad_norm": 0.0018, "time": 0.65674}
+{"mode": "train", "epoch": 60, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00059, "acc_pose": 0.81461, "loss": 0.00059, "grad_norm": 0.0016, "time": 0.6567}
+{"mode": "val", "epoch": 60, "iter": 407, "lr": 0.0, "AP": 0.7715, "AP .5": 0.90828, "AP .75": 0.84254, "AP (M)": 0.69783, "AP (L)": 0.7985, "AR": 0.82549, "AR .5": 0.94978, "AR .75": 0.88933, "AR (M)": 0.78465, "AR (L)": 0.88543}
+{"mode": "train", "epoch": 61, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05577, "heatmap_loss": 0.00058, "acc_pose": 0.8157, "loss": 0.00058, "grad_norm": 0.00169, "time": 0.70941}
+{"mode": "train", "epoch": 61, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00059, "acc_pose": 0.81693, "loss": 0.00059, "grad_norm": 0.00164, "time": 0.65674}
+{"mode": "train", "epoch": 61, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00058, "acc_pose": 0.82073, "loss": 0.00058, "grad_norm": 0.00168, "time": 0.65646}
+{"mode": "train", "epoch": 61, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00059, "acc_pose": 0.82426, "loss": 0.00059, "grad_norm": 0.00172, "time": 0.65661}
+{"mode": "train", "epoch": 61, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00059, "acc_pose": 0.8228, "loss": 0.00059, "grad_norm": 0.00158, "time": 0.65678}
+{"mode": "train", "epoch": 62, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05698, "heatmap_loss": 0.00059, "acc_pose": 0.82012, "loss": 0.00059, "grad_norm": 0.00175, "time": 0.7142}
+{"mode": "train", "epoch": 62, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00059, "acc_pose": 0.82056, "loss": 0.00059, "grad_norm": 0.00167, "time": 0.65676}
+{"mode": "train", "epoch": 62, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00059, "acc_pose": 0.8217, "loss": 0.00059, "grad_norm": 0.00166, "time": 0.65708}
+{"mode": "train", "epoch": 62, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00037, "heatmap_loss": 0.00058, "acc_pose": 0.82686, "loss": 0.00058, "grad_norm": 0.00171, "time": 0.65712}
+{"mode": "train", "epoch": 62, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00058, "acc_pose": 0.82564, "loss": 0.00058, "grad_norm": 0.00166, "time": 0.65662}
+{"mode": "train", "epoch": 63, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05673, "heatmap_loss": 0.00058, "acc_pose": 0.82614, "loss": 0.00058, "grad_norm": 0.00167, "time": 0.71485}
+{"mode": "train", "epoch": 63, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00058, "acc_pose": 0.82129, "loss": 0.00058, "grad_norm": 0.00172, "time": 0.65638}
+{"mode": "train", "epoch": 63, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00058, "acc_pose": 0.82737, "loss": 0.00058, "grad_norm": 0.0016, "time": 0.65687}
+{"mode": "train", "epoch": 63, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00058, "acc_pose": 0.82741, "loss": 0.00058, "grad_norm": 0.00161, "time": 0.6567}
+{"mode": "train", "epoch": 63, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00059, "acc_pose": 0.82388, "loss": 0.00059, "grad_norm": 0.00154, "time": 0.6567}
+{"mode": "train", "epoch": 64, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05703, "heatmap_loss": 0.00058, "acc_pose": 0.82538, "loss": 0.00058, "grad_norm": 0.00159, "time": 0.7138}
+{"mode": "train", "epoch": 64, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00037, "heatmap_loss": 0.00058, "acc_pose": 0.82421, "loss": 0.00058, "grad_norm": 0.00175, "time": 0.65719}
+{"mode": "train", "epoch": 64, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00058, "acc_pose": 0.82758, "loss": 0.00058, "grad_norm": 0.00168, "time": 0.65683}
+{"mode": "train", "epoch": 64, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00058, "acc_pose": 0.82337, "loss": 0.00058, "grad_norm": 0.0017, "time": 0.65666}
+{"mode": "train", "epoch": 64, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00058, "acc_pose": 0.82223, "loss": 0.00058, "grad_norm": 0.00169, "time": 0.65676}
+{"mode": "train", "epoch": 65, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05733, "heatmap_loss": 0.00058, "acc_pose": 0.82486, "loss": 0.00058, "grad_norm": 0.00173, "time": 0.71437}
+{"mode": "train", "epoch": 65, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00039, "heatmap_loss": 0.00058, "acc_pose": 0.82677, "loss": 0.00058, "grad_norm": 0.00167, "time": 0.65722}
+{"mode": "train", "epoch": 65, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00059, "acc_pose": 0.82432, "loss": 0.00059, "grad_norm": 0.00171, "time": 0.65669}
+{"mode": "train", "epoch": 65, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00058, "acc_pose": 0.82353, "loss": 0.00058, "grad_norm": 0.0016, "time": 0.65698}
+{"mode": "train", "epoch": 65, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00058, "acc_pose": 0.82503, "loss": 0.00058, "grad_norm": 0.00167, "time": 0.65697}
+{"mode": "train", "epoch": 66, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05689, "heatmap_loss": 0.00058, "acc_pose": 0.82984, "loss": 0.00058, "grad_norm": 0.00161, "time": 0.71375}
+{"mode": "train", "epoch": 66, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00058, "acc_pose": 0.82217, "loss": 0.00058, "grad_norm": 0.00147, "time": 0.65714}
+{"mode": "train", "epoch": 66, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00058, "acc_pose": 0.82611, "loss": 0.00058, "grad_norm": 0.00152, "time": 0.6568}
+{"mode": "train", "epoch": 66, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00058, "acc_pose": 0.82553, "loss": 0.00058, "grad_norm": 0.0016, "time": 0.65693}
+{"mode": "train", "epoch": 66, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00058, "acc_pose": 0.8253, "loss": 0.00058, "grad_norm": 0.00163, "time": 0.65702}
+{"mode": "train", "epoch": 67, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05675, "heatmap_loss": 0.00058, "acc_pose": 0.83023, "loss": 0.00058, "grad_norm": 0.0018, "time": 0.71412}
+{"mode": "train", "epoch": 67, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00058, "acc_pose": 0.82033, "loss": 0.00058, "grad_norm": 0.00166, "time": 0.65699}
+{"mode": "train", "epoch": 67, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00058, "acc_pose": 0.82873, "loss": 0.00058, "grad_norm": 0.00166, "time": 0.65743}
+{"mode": "train", "epoch": 67, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00058, "acc_pose": 0.83106, "loss": 0.00058, "grad_norm": 0.00149, "time": 0.6574}
+{"mode": "train", "epoch": 67, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00058, "acc_pose": 0.82847, "loss": 0.00058, "grad_norm": 0.00186, "time": 0.65727}
+{"mode": "train", "epoch": 68, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05657, "heatmap_loss": 0.00058, "acc_pose": 0.8212, "loss": 0.00058, "grad_norm": 0.00157, "time": 0.71291}
+{"mode": "train", "epoch": 68, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00057, "acc_pose": 0.82535, "loss": 0.00057, "grad_norm": 0.00162, "time": 0.65684}
+{"mode": "train", "epoch": 68, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00058, "acc_pose": 0.83185, "loss": 0.00058, "grad_norm": 0.00156, "time": 0.65717}
+{"mode": "train", "epoch": 68, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00058, "acc_pose": 0.82545, "loss": 0.00058, "grad_norm": 0.00156, "time": 0.6569}
+{"mode": "train", "epoch": 68, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00058, "acc_pose": 0.82609, "loss": 0.00058, "grad_norm": 0.00166, "time": 0.65705}
+{"mode": "train", "epoch": 69, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05671, "heatmap_loss": 0.00058, "acc_pose": 0.82484, "loss": 0.00058, "grad_norm": 0.00178, "time": 0.71452}
+{"mode": "train", "epoch": 69, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00058, "acc_pose": 0.82546, "loss": 0.00058, "grad_norm": 0.00158, "time": 0.65688}
+{"mode": "train", "epoch": 69, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00057, "acc_pose": 0.82441, "loss": 0.00057, "grad_norm": 0.00146, "time": 0.65706}
+{"mode": "train", "epoch": 69, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00057, "acc_pose": 0.83666, "loss": 0.00057, "grad_norm": 0.00148, "time": 0.65728}
+{"mode": "train", "epoch": 69, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00058, "acc_pose": 0.82822, "loss": 0.00058, "grad_norm": 0.00153, "time": 0.6572}
+{"mode": "train", "epoch": 70, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05632, "heatmap_loss": 0.00058, "acc_pose": 0.82515, "loss": 0.00058, "grad_norm": 0.00169, "time": 0.71348}
+{"mode": "train", "epoch": 70, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00058, "acc_pose": 0.82766, "loss": 0.00058, "grad_norm": 0.0016, "time": 0.65706}
+{"mode": "train", "epoch": 70, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00058, "acc_pose": 0.81953, "loss": 0.00058, "grad_norm": 0.0017, "time": 0.65678}
+{"mode": "train", "epoch": 70, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00057, "acc_pose": 0.82841, "loss": 0.00057, "grad_norm": 0.00181, "time": 0.65709}
+{"mode": "train", "epoch": 70, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00057, "acc_pose": 0.82441, "loss": 0.00057, "grad_norm": 0.00159, "time": 0.65674}
+{"mode": "val", "epoch": 70, "iter": 407, "lr": 0.0, "AP": 0.77484, "AP .5": 0.91393, "AP .75": 0.84832, "AP (M)": 0.70247, "AP (L)": 0.80235, "AR": 0.82645, "AR .5": 0.95135, "AR .75": 0.89106, "AR (M)": 0.78724, "AR (L)": 0.88424}
+{"mode": "train", "epoch": 71, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.0558, "heatmap_loss": 0.00057, "acc_pose": 0.83013, "loss": 0.00057, "grad_norm": 0.00158, "time": 0.70853}
+{"mode": "train", "epoch": 71, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00058, "acc_pose": 0.82467, "loss": 0.00058, "grad_norm": 0.00158, "time": 0.65615}
+{"mode": "train", "epoch": 71, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00058, "acc_pose": 0.82643, "loss": 0.00058, "grad_norm": 0.00155, "time": 0.65678}
+{"mode": "train", "epoch": 71, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00057, "acc_pose": 0.83304, "loss": 0.00057, "grad_norm": 0.00163, "time": 0.6566}
+{"mode": "train", "epoch": 71, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00058, "acc_pose": 0.83419, "loss": 0.00058, "grad_norm": 0.00162, "time": 0.65663}
+{"mode": "train", "epoch": 72, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05737, "heatmap_loss": 0.00057, "acc_pose": 0.83018, "loss": 0.00057, "grad_norm": 0.00162, "time": 0.71422}
+{"mode": "train", "epoch": 72, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00058, "acc_pose": 0.82693, "loss": 0.00058, "grad_norm": 0.00175, "time": 0.65712}
+{"mode": "train", "epoch": 72, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00058, "acc_pose": 0.82107, "loss": 0.00058, "grad_norm": 0.00147, "time": 0.65713}
+{"mode": "train", "epoch": 72, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00057, "acc_pose": 0.83376, "loss": 0.00057, "grad_norm": 0.00151, "time": 0.65703}
+{"mode": "train", "epoch": 72, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00058, "acc_pose": 0.82327, "loss": 0.00058, "grad_norm": 0.0016, "time": 0.65668}
+{"mode": "train", "epoch": 73, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05674, "heatmap_loss": 0.00057, "acc_pose": 0.83319, "loss": 0.00057, "grad_norm": 0.00179, "time": 0.71364}
+{"mode": "train", "epoch": 73, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00057, "acc_pose": 0.83417, "loss": 0.00057, "grad_norm": 0.0016, "time": 0.65723}
+{"mode": "train", "epoch": 73, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00057, "acc_pose": 0.82045, "loss": 0.00057, "grad_norm": 0.00157, "time": 0.65696}
+{"mode": "train", "epoch": 73, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.0004, "heatmap_loss": 0.00057, "acc_pose": 0.82964, "loss": 0.00057, "grad_norm": 0.0015, "time": 0.65707}
+{"mode": "train", "epoch": 73, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00058, "acc_pose": 0.83056, "loss": 0.00058, "grad_norm": 0.00149, "time": 0.65706}
+{"mode": "train", "epoch": 74, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05711, "heatmap_loss": 0.00057, "acc_pose": 0.82944, "loss": 0.00057, "grad_norm": 0.00157, "time": 0.71438}
+{"mode": "train", "epoch": 74, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00057, "acc_pose": 0.82638, "loss": 0.00057, "grad_norm": 0.00162, "time": 0.65682}
+{"mode": "train", "epoch": 74, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00057, "acc_pose": 0.81976, "loss": 0.00057, "grad_norm": 0.00141, "time": 0.65735}
+{"mode": "train", "epoch": 74, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00041, "heatmap_loss": 0.00057, "acc_pose": 0.83306, "loss": 0.00057, "grad_norm": 0.00151, "time": 0.65709}
+{"mode": "train", "epoch": 74, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00057, "acc_pose": 0.82448, "loss": 0.00057, "grad_norm": 0.00146, "time": 0.65717}
+{"mode": "train", "epoch": 75, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05736, "heatmap_loss": 0.00057, "acc_pose": 0.83018, "loss": 0.00057, "grad_norm": 0.00156, "time": 0.71519}
+{"mode": "train", "epoch": 75, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00057, "acc_pose": 0.83104, "loss": 0.00057, "grad_norm": 0.00161, "time": 0.65695}
+{"mode": "train", "epoch": 75, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00057, "acc_pose": 0.82661, "loss": 0.00057, "grad_norm": 0.00143, "time": 0.65728}
+{"mode": "train", "epoch": 75, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00057, "acc_pose": 0.83354, "loss": 0.00057, "grad_norm": 0.00163, "time": 0.65732}
+{"mode": "train", "epoch": 75, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00057, "acc_pose": 0.82859, "loss": 0.00057, "grad_norm": 0.00144, "time": 0.65701}
+{"mode": "train", "epoch": 76, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05659, "heatmap_loss": 0.00057, "acc_pose": 0.83072, "loss": 0.00057, "grad_norm": 0.00145, "time": 0.71463}
+{"mode": "train", "epoch": 76, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00042, "heatmap_loss": 0.00057, "acc_pose": 0.82958, "loss": 0.00057, "grad_norm": 0.00144, "time": 0.65736}
+{"mode": "train", "epoch": 76, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00035, "heatmap_loss": 0.00057, "acc_pose": 0.8354, "loss": 0.00057, "grad_norm": 0.00148, "time": 0.65681}
+{"mode": "train", "epoch": 76, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00057, "acc_pose": 0.83055, "loss": 0.00057, "grad_norm": 0.00145, "time": 0.65688}
+{"mode": "train", "epoch": 76, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00057, "acc_pose": 0.83113, "loss": 0.00057, "grad_norm": 0.00162, "time": 0.65729}
+{"mode": "train", "epoch": 77, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05678, "heatmap_loss": 0.00057, "acc_pose": 0.82797, "loss": 0.00057, "grad_norm": 0.00157, "time": 0.71348}
+{"mode": "train", "epoch": 77, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00057, "acc_pose": 0.82584, "loss": 0.00057, "grad_norm": 0.00174, "time": 0.65716}
+{"mode": "train", "epoch": 77, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00056, "acc_pose": 0.83372, "loss": 0.00056, "grad_norm": 0.00149, "time": 0.65687}
+{"mode": "train", "epoch": 77, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00057, "acc_pose": 0.82734, "loss": 0.00057, "grad_norm": 0.00162, "time": 0.65682}
+{"mode": "train", "epoch": 77, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00057, "acc_pose": 0.83362, "loss": 0.00057, "grad_norm": 0.00156, "time": 0.65688}
+{"mode": "train", "epoch": 78, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05715, "heatmap_loss": 0.00057, "acc_pose": 0.83866, "loss": 0.00057, "grad_norm": 0.00153, "time": 0.71466}
+{"mode": "train", "epoch": 78, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00056, "acc_pose": 0.83775, "loss": 0.00056, "grad_norm": 0.00146, "time": 0.65721}
+{"mode": "train", "epoch": 78, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00057, "acc_pose": 0.82986, "loss": 0.00057, "grad_norm": 0.00149, "time": 0.65759}
+{"mode": "train", "epoch": 78, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00057, "acc_pose": 0.82398, "loss": 0.00057, "grad_norm": 0.00151, "time": 0.65726}
+{"mode": "train", "epoch": 78, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00057, "acc_pose": 0.83179, "loss": 0.00057, "grad_norm": 0.0015, "time": 0.6574}
+{"mode": "train", "epoch": 79, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05617, "heatmap_loss": 0.00057, "acc_pose": 0.83269, "loss": 0.00057, "grad_norm": 0.0015, "time": 0.71348}
+{"mode": "train", "epoch": 79, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00056, "acc_pose": 0.82072, "loss": 0.00056, "grad_norm": 0.0015, "time": 0.65749}
+{"mode": "train", "epoch": 79, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00056, "acc_pose": 0.82593, "loss": 0.00056, "grad_norm": 0.00144, "time": 0.65682}
+{"mode": "train", "epoch": 79, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00057, "acc_pose": 0.83449, "loss": 0.00057, "grad_norm": 0.00152, "time": 0.65695}
+{"mode": "train", "epoch": 79, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00057, "acc_pose": 0.83447, "loss": 0.00057, "grad_norm": 0.00148, "time": 0.65704}
+{"mode": "train", "epoch": 80, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05661, "heatmap_loss": 0.00057, "acc_pose": 0.83598, "loss": 0.00057, "grad_norm": 0.00154, "time": 0.71436}
+{"mode": "train", "epoch": 80, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00056, "acc_pose": 0.83556, "loss": 0.00056, "grad_norm": 0.0016, "time": 0.65746}
+{"mode": "train", "epoch": 80, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00056, "acc_pose": 0.82544, "loss": 0.00056, "grad_norm": 0.00142, "time": 0.6573}
+{"mode": "train", "epoch": 80, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00056, "acc_pose": 0.8326, "loss": 0.00056, "grad_norm": 0.0014, "time": 0.65725}
+{"mode": "train", "epoch": 80, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00028, "heatmap_loss": 0.00057, "acc_pose": 0.82995, "loss": 0.00057, "grad_norm": 0.00152, "time": 0.65745}
+{"mode": "val", "epoch": 80, "iter": 407, "lr": 0.0, "AP": 0.77541, "AP .5": 0.9128, "AP .75": 0.84733, "AP (M)": 0.70222, "AP (L)": 0.80208, "AR": 0.82856, "AR .5": 0.95135, "AR .75": 0.89185, "AR (M)": 0.78831, "AR (L)": 0.88737}
+{"mode": "train", "epoch": 81, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05556, "heatmap_loss": 0.00056, "acc_pose": 0.83358, "loss": 0.00056, "grad_norm": 0.00151, "time": 0.7082}
+{"mode": "train", "epoch": 81, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00056, "acc_pose": 0.82997, "loss": 0.00056, "grad_norm": 0.00172, "time": 0.65616}
+{"mode": "train", "epoch": 81, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00039, "heatmap_loss": 0.00057, "acc_pose": 0.82811, "loss": 0.00057, "grad_norm": 0.0016, "time": 0.65665}
+{"mode": "train", "epoch": 81, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00057, "acc_pose": 0.83257, "loss": 0.00057, "grad_norm": 0.0015, "time": 0.65663}
+{"mode": "train", "epoch": 81, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00056, "acc_pose": 0.8344, "loss": 0.00056, "grad_norm": 0.00148, "time": 0.65657}
+{"mode": "train", "epoch": 82, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05603, "heatmap_loss": 0.00056, "acc_pose": 0.83675, "loss": 0.00056, "grad_norm": 0.00144, "time": 0.71245}
+{"mode": "train", "epoch": 82, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00056, "acc_pose": 0.83571, "loss": 0.00056, "grad_norm": 0.00138, "time": 0.65694}
+{"mode": "train", "epoch": 82, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00026, "heatmap_loss": 0.00056, "acc_pose": 0.83438, "loss": 0.00056, "grad_norm": 0.00143, "time": 0.65706}
+{"mode": "train", "epoch": 82, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00056, "acc_pose": 0.83221, "loss": 0.00056, "grad_norm": 0.00155, "time": 0.65709}
+{"mode": "train", "epoch": 82, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00056, "acc_pose": 0.83136, "loss": 0.00056, "grad_norm": 0.00148, "time": 0.65711}
+{"mode": "train", "epoch": 83, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05657, "heatmap_loss": 0.00056, "acc_pose": 0.83412, "loss": 0.00056, "grad_norm": 0.00149, "time": 0.71352}
+{"mode": "train", "epoch": 83, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00057, "acc_pose": 0.83382, "loss": 0.00057, "grad_norm": 0.00143, "time": 0.65687}
+{"mode": "train", "epoch": 83, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00041, "heatmap_loss": 0.00057, "acc_pose": 0.83112, "loss": 0.00057, "grad_norm": 0.00148, "time": 0.65717}
+{"mode": "train", "epoch": 83, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00056, "acc_pose": 0.83051, "loss": 0.00056, "grad_norm": 0.00146, "time": 0.65704}
+{"mode": "train", "epoch": 83, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00056, "acc_pose": 0.83451, "loss": 0.00056, "grad_norm": 0.00147, "time": 0.65684}
+{"mode": "train", "epoch": 84, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05866, "heatmap_loss": 0.00056, "acc_pose": 0.83733, "loss": 0.00056, "grad_norm": 0.00139, "time": 0.7154}
+{"mode": "train", "epoch": 84, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00056, "acc_pose": 0.82854, "loss": 0.00056, "grad_norm": 0.00145, "time": 0.65701}
+{"mode": "train", "epoch": 84, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00056, "acc_pose": 0.83025, "loss": 0.00056, "grad_norm": 0.00136, "time": 0.65685}
+{"mode": "train", "epoch": 84, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00056, "acc_pose": 0.83769, "loss": 0.00056, "grad_norm": 0.00146, "time": 0.65742}
+{"mode": "train", "epoch": 84, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00056, "acc_pose": 0.82786, "loss": 0.00056, "grad_norm": 0.00142, "time": 0.65741}
+{"mode": "train", "epoch": 85, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05833, "heatmap_loss": 0.00056, "acc_pose": 0.83268, "loss": 0.00056, "grad_norm": 0.00152, "time": 0.715}
+{"mode": "train", "epoch": 85, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00056, "acc_pose": 0.83988, "loss": 0.00056, "grad_norm": 0.00152, "time": 0.65685}
+{"mode": "train", "epoch": 85, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00056, "acc_pose": 0.83257, "loss": 0.00056, "grad_norm": 0.00146, "time": 0.65706}
+{"mode": "train", "epoch": 85, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00056, "acc_pose": 0.83623, "loss": 0.00056, "grad_norm": 0.00147, "time": 0.6571}
+{"mode": "train", "epoch": 85, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00056, "acc_pose": 0.83882, "loss": 0.00056, "grad_norm": 0.00152, "time": 0.65727}
+{"mode": "train", "epoch": 86, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05634, "heatmap_loss": 0.00056, "acc_pose": 0.8374, "loss": 0.00056, "grad_norm": 0.00155, "time": 0.71347}
+{"mode": "train", "epoch": 86, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00056, "acc_pose": 0.83034, "loss": 0.00056, "grad_norm": 0.00144, "time": 0.65737}
+{"mode": "train", "epoch": 86, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00056, "acc_pose": 0.83195, "loss": 0.00056, "grad_norm": 0.00142, "time": 0.65746}
+{"mode": "train", "epoch": 86, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00056, "acc_pose": 0.83396, "loss": 0.00056, "grad_norm": 0.00134, "time": 0.6572}
+{"mode": "train", "epoch": 86, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00056, "acc_pose": 0.8358, "loss": 0.00056, "grad_norm": 0.00143, "time": 0.65736}
+{"mode": "train", "epoch": 87, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05638, "heatmap_loss": 0.00056, "acc_pose": 0.83896, "loss": 0.00056, "grad_norm": 0.00147, "time": 0.71333}
+{"mode": "train", "epoch": 87, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00056, "acc_pose": 0.84188, "loss": 0.00056, "grad_norm": 0.00146, "time": 0.65707}
+{"mode": "train", "epoch": 87, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00056, "acc_pose": 0.82784, "loss": 0.00056, "grad_norm": 0.00134, "time": 0.65671}
+{"mode": "train", "epoch": 87, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00056, "acc_pose": 0.8396, "loss": 0.00056, "grad_norm": 0.00138, "time": 0.65669}
+{"mode": "train", "epoch": 87, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00056, "acc_pose": 0.83626, "loss": 0.00056, "grad_norm": 0.00135, "time": 0.65708}
+{"mode": "train", "epoch": 88, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05628, "heatmap_loss": 0.00056, "acc_pose": 0.83514, "loss": 0.00056, "grad_norm": 0.00139, "time": 0.71336}
+{"mode": "train", "epoch": 88, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00056, "acc_pose": 0.83413, "loss": 0.00056, "grad_norm": 0.00141, "time": 0.65722}
+{"mode": "train", "epoch": 88, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00056, "acc_pose": 0.83355, "loss": 0.00056, "grad_norm": 0.00141, "time": 0.65699}
+{"mode": "train", "epoch": 88, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00034, "heatmap_loss": 0.00056, "acc_pose": 0.83653, "loss": 0.00056, "grad_norm": 0.00139, "time": 0.65744}
+{"mode": "train", "epoch": 88, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00034, "heatmap_loss": 0.00056, "acc_pose": 0.84423, "loss": 0.00056, "grad_norm": 0.00145, "time": 0.65725}
+{"mode": "train", "epoch": 89, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05656, "heatmap_loss": 0.00056, "acc_pose": 0.82526, "loss": 0.00056, "grad_norm": 0.00139, "time": 0.71371}
+{"mode": "train", "epoch": 89, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00056, "acc_pose": 0.83401, "loss": 0.00056, "grad_norm": 0.00142, "time": 0.65733}
+{"mode": "train", "epoch": 89, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00056, "acc_pose": 0.83129, "loss": 0.00056, "grad_norm": 0.00154, "time": 0.657}
+{"mode": "train", "epoch": 89, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00043, "heatmap_loss": 0.00056, "acc_pose": 0.83589, "loss": 0.00056, "grad_norm": 0.00154, "time": 0.65702}
+{"mode": "train", "epoch": 89, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00035, "heatmap_loss": 0.00055, "acc_pose": 0.83994, "loss": 0.00055, "grad_norm": 0.00144, "time": 0.65707}
+{"mode": "train", "epoch": 90, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05727, "heatmap_loss": 0.00056, "acc_pose": 0.83491, "loss": 0.00056, "grad_norm": 0.00141, "time": 0.7142}
+{"mode": "train", "epoch": 90, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00055, "acc_pose": 0.83712, "loss": 0.00055, "grad_norm": 0.00134, "time": 0.65668}
+{"mode": "train", "epoch": 90, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00056, "acc_pose": 0.82813, "loss": 0.00056, "grad_norm": 0.00143, "time": 0.65687}
+{"mode": "train", "epoch": 90, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00056, "acc_pose": 0.83801, "loss": 0.00056, "grad_norm": 0.00146, "time": 0.6571}
+{"mode": "train", "epoch": 90, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00055, "acc_pose": 0.83847, "loss": 0.00055, "grad_norm": 0.00134, "time": 0.65672}
+{"mode": "val", "epoch": 90, "iter": 407, "lr": 0.0, "AP": 0.77853, "AP .5": 0.91432, "AP .75": 0.85026, "AP (M)": 0.70669, "AP (L)": 0.80589, "AR": 0.8298, "AR .5": 0.95198, "AR .75": 0.892, "AR (M)": 0.78984, "AR (L)": 0.88844}
+{"mode": "train", "epoch": 91, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05629, "heatmap_loss": 0.00055, "acc_pose": 0.84163, "loss": 0.00055, "grad_norm": 0.00136, "time": 0.7097}
+{"mode": "train", "epoch": 91, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00055, "acc_pose": 0.83793, "loss": 0.00055, "grad_norm": 0.00141, "time": 0.65611}
+{"mode": "train", "epoch": 91, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00056, "acc_pose": 0.84206, "loss": 0.00056, "grad_norm": 0.00151, "time": 0.65683}
+{"mode": "train", "epoch": 91, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00056, "acc_pose": 0.83179, "loss": 0.00056, "grad_norm": 0.0014, "time": 0.65641}
+{"mode": "train", "epoch": 91, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00055, "acc_pose": 0.83985, "loss": 0.00055, "grad_norm": 0.00144, "time": 0.65686}
+{"mode": "train", "epoch": 92, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05658, "heatmap_loss": 0.00056, "acc_pose": 0.83673, "loss": 0.00056, "grad_norm": 0.00135, "time": 0.71307}
+{"mode": "train", "epoch": 92, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00055, "acc_pose": 0.8361, "loss": 0.00055, "grad_norm": 0.00136, "time": 0.65689}
+{"mode": "train", "epoch": 92, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00055, "acc_pose": 0.83213, "loss": 0.00055, "grad_norm": 0.00135, "time": 0.65681}
+{"mode": "train", "epoch": 92, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00056, "acc_pose": 0.83469, "loss": 0.00056, "grad_norm": 0.00156, "time": 0.65711}
+{"mode": "train", "epoch": 92, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00056, "acc_pose": 0.83977, "loss": 0.00056, "grad_norm": 0.00143, "time": 0.65704}
+{"mode": "train", "epoch": 93, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.0563, "heatmap_loss": 0.00055, "acc_pose": 0.83472, "loss": 0.00055, "grad_norm": 0.00164, "time": 0.71465}
+{"mode": "train", "epoch": 93, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00056, "acc_pose": 0.83178, "loss": 0.00056, "grad_norm": 0.00138, "time": 0.65711}
+{"mode": "train", "epoch": 93, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00055, "acc_pose": 0.84042, "loss": 0.00055, "grad_norm": 0.00135, "time": 0.65746}
+{"mode": "train", "epoch": 93, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00056, "acc_pose": 0.83957, "loss": 0.00056, "grad_norm": 0.00135, "time": 0.65708}
+{"mode": "train", "epoch": 93, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00055, "acc_pose": 0.84322, "loss": 0.00055, "grad_norm": 0.00133, "time": 0.65734}
+{"mode": "train", "epoch": 94, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05685, "heatmap_loss": 0.00055, "acc_pose": 0.83533, "loss": 0.00055, "grad_norm": 0.00138, "time": 0.71346}
+{"mode": "train", "epoch": 94, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00055, "acc_pose": 0.84367, "loss": 0.00055, "grad_norm": 0.00136, "time": 0.65706}
+{"mode": "train", "epoch": 94, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00055, "acc_pose": 0.83308, "loss": 0.00055, "grad_norm": 0.00145, "time": 0.65707}
+{"mode": "train", "epoch": 94, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00055, "acc_pose": 0.84063, "loss": 0.00055, "grad_norm": 0.00136, "time": 0.65702}
+{"mode": "train", "epoch": 94, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00055, "acc_pose": 0.84384, "loss": 0.00055, "grad_norm": 0.00136, "time": 0.65699}
+{"mode": "train", "epoch": 95, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05684, "heatmap_loss": 0.00055, "acc_pose": 0.83765, "loss": 0.00055, "grad_norm": 0.00139, "time": 0.71404}
+{"mode": "train", "epoch": 95, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00055, "acc_pose": 0.83556, "loss": 0.00055, "grad_norm": 0.00162, "time": 0.6572}
+{"mode": "train", "epoch": 95, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00055, "acc_pose": 0.82883, "loss": 0.00055, "grad_norm": 0.00142, "time": 0.65725}
+{"mode": "train", "epoch": 95, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00055, "acc_pose": 0.83672, "loss": 0.00055, "grad_norm": 0.00149, "time": 0.65709}
+{"mode": "train", "epoch": 95, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00055, "acc_pose": 0.83771, "loss": 0.00055, "grad_norm": 0.0014, "time": 0.65694}
+{"mode": "train", "epoch": 96, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05721, "heatmap_loss": 0.00055, "acc_pose": 0.84125, "loss": 0.00055, "grad_norm": 0.00132, "time": 0.71457}
+{"mode": "train", "epoch": 96, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00055, "acc_pose": 0.84113, "loss": 0.00055, "grad_norm": 0.00143, "time": 0.65754}
+{"mode": "train", "epoch": 96, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00055, "acc_pose": 0.83835, "loss": 0.00055, "grad_norm": 0.0013, "time": 0.65773}
+{"mode": "train", "epoch": 96, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00055, "acc_pose": 0.83685, "loss": 0.00055, "grad_norm": 0.00139, "time": 0.65787}
+{"mode": "train", "epoch": 96, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00056, "acc_pose": 0.83913, "loss": 0.00056, "grad_norm": 0.00147, "time": 0.65736}
+{"mode": "train", "epoch": 97, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05691, "heatmap_loss": 0.00055, "acc_pose": 0.84006, "loss": 0.00055, "grad_norm": 0.00131, "time": 0.71376}
+{"mode": "train", "epoch": 97, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00055, "acc_pose": 0.84337, "loss": 0.00055, "grad_norm": 0.00137, "time": 0.65768}
+{"mode": "train", "epoch": 97, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00043, "heatmap_loss": 0.00055, "acc_pose": 0.8387, "loss": 0.00055, "grad_norm": 0.00136, "time": 0.65709}
+{"mode": "train", "epoch": 97, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00055, "acc_pose": 0.83729, "loss": 0.00055, "grad_norm": 0.00153, "time": 0.65726}
+{"mode": "train", "epoch": 97, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00055, "acc_pose": 0.83963, "loss": 0.00055, "grad_norm": 0.00138, "time": 0.65715}
+{"mode": "train", "epoch": 98, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05676, "heatmap_loss": 0.00055, "acc_pose": 0.8338, "loss": 0.00055, "grad_norm": 0.00139, "time": 0.71284}
+{"mode": "train", "epoch": 98, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00055, "acc_pose": 0.83853, "loss": 0.00055, "grad_norm": 0.00141, "time": 0.65696}
+{"mode": "train", "epoch": 98, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.0004, "heatmap_loss": 0.00055, "acc_pose": 0.83717, "loss": 0.00055, "grad_norm": 0.00131, "time": 0.65684}
+{"mode": "train", "epoch": 98, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00055, "acc_pose": 0.84119, "loss": 0.00055, "grad_norm": 0.00136, "time": 0.65688}
+{"mode": "train", "epoch": 98, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00034, "heatmap_loss": 0.00056, "acc_pose": 0.83817, "loss": 0.00056, "grad_norm": 0.00133, "time": 0.65695}
+{"mode": "train", "epoch": 99, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05831, "heatmap_loss": 0.00055, "acc_pose": 0.84306, "loss": 0.00055, "grad_norm": 0.00128, "time": 0.71504}
+{"mode": "train", "epoch": 99, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00055, "acc_pose": 0.83934, "loss": 0.00055, "grad_norm": 0.00131, "time": 0.65651}
+{"mode": "train", "epoch": 99, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00055, "acc_pose": 0.84081, "loss": 0.00055, "grad_norm": 0.00137, "time": 0.65707}
+{"mode": "train", "epoch": 99, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00055, "acc_pose": 0.83275, "loss": 0.00055, "grad_norm": 0.00138, "time": 0.65726}
+{"mode": "train", "epoch": 99, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00055, "acc_pose": 0.84036, "loss": 0.00055, "grad_norm": 0.00148, "time": 0.65707}
+{"mode": "train", "epoch": 100, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05796, "heatmap_loss": 0.00054, "acc_pose": 0.83852, "loss": 0.00054, "grad_norm": 0.00136, "time": 0.71517}
+{"mode": "train", "epoch": 100, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00055, "acc_pose": 0.83882, "loss": 0.00055, "grad_norm": 0.00133, "time": 0.65711}
+{"mode": "train", "epoch": 100, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00055, "acc_pose": 0.83768, "loss": 0.00055, "grad_norm": 0.00136, "time": 0.65697}
+{"mode": "train", "epoch": 100, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00034, "heatmap_loss": 0.00055, "acc_pose": 0.84679, "loss": 0.00055, "grad_norm": 0.00144, "time": 0.65692}
+{"mode": "train", "epoch": 100, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00055, "acc_pose": 0.83539, "loss": 0.00055, "grad_norm": 0.00141, "time": 0.65681}
+{"mode": "val", "epoch": 100, "iter": 407, "lr": 0.0, "AP": 0.77876, "AP .5": 0.91447, "AP .75": 0.84989, "AP (M)": 0.70522, "AP (L)": 0.80754, "AR": 0.83079, "AR .5": 0.95246, "AR .75": 0.89373, "AR (M)": 0.79006, "AR (L)": 0.89082}
+{"mode": "train", "epoch": 101, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05541, "heatmap_loss": 0.00055, "acc_pose": 0.83334, "loss": 0.00055, "grad_norm": 0.00137, "time": 0.70814}
+{"mode": "train", "epoch": 101, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00055, "acc_pose": 0.83331, "loss": 0.00055, "grad_norm": 0.00133, "time": 0.656}
+{"mode": "train", "epoch": 101, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00055, "acc_pose": 0.84162, "loss": 0.00055, "grad_norm": 0.00134, "time": 0.65669}
+{"mode": "train", "epoch": 101, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00055, "acc_pose": 0.8401, "loss": 0.00055, "grad_norm": 0.00126, "time": 0.65646}
+{"mode": "train", "epoch": 101, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00055, "acc_pose": 0.83998, "loss": 0.00055, "grad_norm": 0.00131, "time": 0.6563}
+{"mode": "train", "epoch": 102, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05705, "heatmap_loss": 0.00054, "acc_pose": 0.84441, "loss": 0.00054, "grad_norm": 0.00134, "time": 0.71373}
+{"mode": "train", "epoch": 102, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00054, "acc_pose": 0.83761, "loss": 0.00054, "grad_norm": 0.00137, "time": 0.65698}
+{"mode": "train", "epoch": 102, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00055, "acc_pose": 0.83366, "loss": 0.00055, "grad_norm": 0.00125, "time": 0.65692}
+{"mode": "train", "epoch": 102, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00042, "heatmap_loss": 0.00055, "acc_pose": 0.84533, "loss": 0.00055, "grad_norm": 0.00135, "time": 0.65687}
+{"mode": "train", "epoch": 102, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00055, "acc_pose": 0.84376, "loss": 0.00055, "grad_norm": 0.00135, "time": 0.65723}
+{"mode": "train", "epoch": 103, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05651, "heatmap_loss": 0.00055, "acc_pose": 0.8442, "loss": 0.00055, "grad_norm": 0.0013, "time": 0.71465}
+{"mode": "train", "epoch": 103, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00043, "heatmap_loss": 0.00055, "acc_pose": 0.83679, "loss": 0.00055, "grad_norm": 0.00139, "time": 0.65713}
+{"mode": "train", "epoch": 103, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00055, "acc_pose": 0.83936, "loss": 0.00055, "grad_norm": 0.0013, "time": 0.65687}
+{"mode": "train", "epoch": 103, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00054, "acc_pose": 0.84205, "loss": 0.00054, "grad_norm": 0.00123, "time": 0.65712}
+{"mode": "train", "epoch": 103, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00055, "acc_pose": 0.84296, "loss": 0.00055, "grad_norm": 0.00139, "time": 0.6566}
+{"mode": "train", "epoch": 104, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05648, "heatmap_loss": 0.00055, "acc_pose": 0.83513, "loss": 0.00055, "grad_norm": 0.00137, "time": 0.71444}
+{"mode": "train", "epoch": 104, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00041, "heatmap_loss": 0.00054, "acc_pose": 0.84415, "loss": 0.00054, "grad_norm": 0.00125, "time": 0.657}
+{"mode": "train", "epoch": 104, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00055, "acc_pose": 0.842, "loss": 0.00055, "grad_norm": 0.0013, "time": 0.65683}
+{"mode": "train", "epoch": 104, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00055, "acc_pose": 0.84579, "loss": 0.00055, "grad_norm": 0.00131, "time": 0.65694}
+{"mode": "train", "epoch": 104, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00055, "acc_pose": 0.841, "loss": 0.00055, "grad_norm": 0.00136, "time": 0.65711}
+{"mode": "train", "epoch": 105, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05687, "heatmap_loss": 0.00055, "acc_pose": 0.84483, "loss": 0.00055, "grad_norm": 0.00135, "time": 0.71404}
+{"mode": "train", "epoch": 105, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00054, "acc_pose": 0.84139, "loss": 0.00054, "grad_norm": 0.00121, "time": 0.65685}
+{"mode": "train", "epoch": 105, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.84053, "loss": 0.00054, "grad_norm": 0.0013, "time": 0.6569}
+{"mode": "train", "epoch": 105, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00054, "acc_pose": 0.84766, "loss": 0.00054, "grad_norm": 0.00131, "time": 0.65696}
+{"mode": "train", "epoch": 105, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00055, "acc_pose": 0.83673, "loss": 0.00055, "grad_norm": 0.00139, "time": 0.6572}
+{"mode": "train", "epoch": 106, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05663, "heatmap_loss": 0.00054, "acc_pose": 0.84065, "loss": 0.00054, "grad_norm": 0.0013, "time": 0.71382}
+{"mode": "train", "epoch": 106, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00054, "acc_pose": 0.84077, "loss": 0.00054, "grad_norm": 0.00133, "time": 0.6573}
+{"mode": "train", "epoch": 106, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00054, "acc_pose": 0.83362, "loss": 0.00054, "grad_norm": 0.00128, "time": 0.65728}
+{"mode": "train", "epoch": 106, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00054, "acc_pose": 0.84614, "loss": 0.00054, "grad_norm": 0.00132, "time": 0.65711}
+{"mode": "train", "epoch": 106, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00054, "acc_pose": 0.8407, "loss": 0.00054, "grad_norm": 0.00135, "time": 0.65734}
+{"mode": "train", "epoch": 107, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05779, "heatmap_loss": 0.00054, "acc_pose": 0.8427, "loss": 0.00054, "grad_norm": 0.00131, "time": 0.71435}
+{"mode": "train", "epoch": 107, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00036, "heatmap_loss": 0.00055, "acc_pose": 0.83935, "loss": 0.00055, "grad_norm": 0.00134, "time": 0.65704}
+{"mode": "train", "epoch": 107, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00035, "heatmap_loss": 0.00054, "acc_pose": 0.84513, "loss": 0.00054, "grad_norm": 0.00125, "time": 0.65714}
+{"mode": "train", "epoch": 107, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00036, "heatmap_loss": 0.00055, "acc_pose": 0.84292, "loss": 0.00055, "grad_norm": 0.00131, "time": 0.65672}
+{"mode": "train", "epoch": 107, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00036, "heatmap_loss": 0.00054, "acc_pose": 0.84003, "loss": 0.00054, "grad_norm": 0.00139, "time": 0.65744}
+{"mode": "train", "epoch": 108, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05731, "heatmap_loss": 0.00054, "acc_pose": 0.84476, "loss": 0.00054, "grad_norm": 0.00122, "time": 0.71413}
+{"mode": "train", "epoch": 108, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00034, "heatmap_loss": 0.00054, "acc_pose": 0.84255, "loss": 0.00054, "grad_norm": 0.00124, "time": 0.65659}
+{"mode": "train", "epoch": 108, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00035, "heatmap_loss": 0.00054, "acc_pose": 0.84191, "loss": 0.00054, "grad_norm": 0.00137, "time": 0.65675}
+{"mode": "train", "epoch": 108, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00034, "heatmap_loss": 0.00054, "acc_pose": 0.84296, "loss": 0.00054, "grad_norm": 0.00128, "time": 0.657}
+{"mode": "train", "epoch": 108, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00054, "acc_pose": 0.84243, "loss": 0.00054, "grad_norm": 0.00127, "time": 0.65697}
+{"mode": "train", "epoch": 109, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05741, "heatmap_loss": 0.00054, "acc_pose": 0.84587, "loss": 0.00054, "grad_norm": 0.00125, "time": 0.71426}
+{"mode": "train", "epoch": 109, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00055, "acc_pose": 0.84048, "loss": 0.00055, "grad_norm": 0.00135, "time": 0.65659}
+{"mode": "train", "epoch": 109, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00054, "acc_pose": 0.84597, "loss": 0.00054, "grad_norm": 0.00129, "time": 0.65709}
+{"mode": "train", "epoch": 109, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00054, "acc_pose": 0.84404, "loss": 0.00054, "grad_norm": 0.00135, "time": 0.65725}
+{"mode": "train", "epoch": 109, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00027, "heatmap_loss": 0.00054, "acc_pose": 0.84457, "loss": 0.00054, "grad_norm": 0.0013, "time": 0.65668}
+{"mode": "train", "epoch": 110, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05659, "heatmap_loss": 0.00054, "acc_pose": 0.83876, "loss": 0.00054, "grad_norm": 0.00135, "time": 0.71366}
+{"mode": "train", "epoch": 110, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.84223, "loss": 0.00054, "grad_norm": 0.00146, "time": 0.6567}
+{"mode": "train", "epoch": 110, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00054, "acc_pose": 0.84047, "loss": 0.00054, "grad_norm": 0.00125, "time": 0.65677}
+{"mode": "train", "epoch": 110, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00054, "acc_pose": 0.85076, "loss": 0.00054, "grad_norm": 0.00131, "time": 0.657}
+{"mode": "train", "epoch": 110, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00054, "acc_pose": 0.84737, "loss": 0.00054, "grad_norm": 0.00128, "time": 0.65728}
+{"mode": "val", "epoch": 110, "iter": 407, "lr": 0.0, "AP": 0.77874, "AP .5": 0.91472, "AP .75": 0.85021, "AP (M)": 0.70734, "AP (L)": 0.80531, "AR": 0.83032, "AR .5": 0.95246, "AR .75": 0.89373, "AR (M)": 0.79039, "AR (L)": 0.88863}
+{"mode": "train", "epoch": 111, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05759, "heatmap_loss": 0.00054, "acc_pose": 0.84228, "loss": 0.00054, "grad_norm": 0.00128, "time": 0.71015}
+{"mode": "train", "epoch": 111, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00054, "acc_pose": 0.83947, "loss": 0.00054, "grad_norm": 0.0014, "time": 0.65602}
+{"mode": "train", "epoch": 111, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.83783, "loss": 0.00054, "grad_norm": 0.00146, "time": 0.65669}
+{"mode": "train", "epoch": 111, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.84481, "loss": 0.00054, "grad_norm": 0.00139, "time": 0.65658}
+{"mode": "train", "epoch": 111, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00054, "acc_pose": 0.84181, "loss": 0.00054, "grad_norm": 0.0013, "time": 0.65656}
+{"mode": "train", "epoch": 112, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05794, "heatmap_loss": 0.00054, "acc_pose": 0.84649, "loss": 0.00054, "grad_norm": 0.00127, "time": 0.71447}
+{"mode": "train", "epoch": 112, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.83705, "loss": 0.00054, "grad_norm": 0.00122, "time": 0.65693}
+{"mode": "train", "epoch": 112, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00054, "acc_pose": 0.84702, "loss": 0.00054, "grad_norm": 0.00132, "time": 0.65692}
+{"mode": "train", "epoch": 112, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.85025, "loss": 0.00054, "grad_norm": 0.00124, "time": 0.65669}
+{"mode": "train", "epoch": 112, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00054, "acc_pose": 0.84401, "loss": 0.00054, "grad_norm": 0.00124, "time": 0.65712}
+{"mode": "train", "epoch": 113, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05669, "heatmap_loss": 0.00054, "acc_pose": 0.84632, "loss": 0.00054, "grad_norm": 0.00125, "time": 0.71341}
+{"mode": "train", "epoch": 113, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00054, "acc_pose": 0.84328, "loss": 0.00054, "grad_norm": 0.00126, "time": 0.65705}
+{"mode": "train", "epoch": 113, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.84354, "loss": 0.00054, "grad_norm": 0.00123, "time": 0.6579}
+{"mode": "train", "epoch": 113, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00054, "acc_pose": 0.84807, "loss": 0.00054, "grad_norm": 0.00126, "time": 0.65742}
+{"mode": "train", "epoch": 113, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.83915, "loss": 0.00054, "grad_norm": 0.0013, "time": 0.65744}
+{"mode": "train", "epoch": 114, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05639, "heatmap_loss": 0.00054, "acc_pose": 0.83833, "loss": 0.00054, "grad_norm": 0.00129, "time": 0.71333}
+{"mode": "train", "epoch": 114, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.84189, "loss": 0.00054, "grad_norm": 0.0013, "time": 0.65674}
+{"mode": "train", "epoch": 114, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00054, "acc_pose": 0.83938, "loss": 0.00054, "grad_norm": 0.0013, "time": 0.65671}
+{"mode": "train", "epoch": 114, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00054, "acc_pose": 0.84824, "loss": 0.00054, "grad_norm": 0.00124, "time": 0.65683}
+{"mode": "train", "epoch": 114, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.84732, "loss": 0.00054, "grad_norm": 0.00126, "time": 0.65717}
+{"mode": "train", "epoch": 115, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05674, "heatmap_loss": 0.00054, "acc_pose": 0.84381, "loss": 0.00054, "grad_norm": 0.00117, "time": 0.71398}
+{"mode": "train", "epoch": 115, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00053, "acc_pose": 0.84608, "loss": 0.00053, "grad_norm": 0.00134, "time": 0.6573}
+{"mode": "train", "epoch": 115, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00054, "acc_pose": 0.83948, "loss": 0.00054, "grad_norm": 0.00122, "time": 0.65703}
+{"mode": "train", "epoch": 115, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00053, "acc_pose": 0.846, "loss": 0.00053, "grad_norm": 0.00128, "time": 0.65722}
+{"mode": "train", "epoch": 115, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00054, "acc_pose": 0.84605, "loss": 0.00054, "grad_norm": 0.00124, "time": 0.65707}
+{"mode": "train", "epoch": 116, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05649, "heatmap_loss": 0.00054, "acc_pose": 0.84872, "loss": 0.00054, "grad_norm": 0.00128, "time": 0.71352}
+{"mode": "train", "epoch": 116, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00053, "acc_pose": 0.83899, "loss": 0.00053, "grad_norm": 0.00133, "time": 0.65722}
+{"mode": "train", "epoch": 116, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.84177, "loss": 0.00054, "grad_norm": 0.0013, "time": 0.65731}
+{"mode": "train", "epoch": 116, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00054, "acc_pose": 0.84491, "loss": 0.00054, "grad_norm": 0.00125, "time": 0.65727}
+{"mode": "train", "epoch": 116, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.84412, "loss": 0.00054, "grad_norm": 0.0013, "time": 0.65721}
+{"mode": "train", "epoch": 117, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05678, "heatmap_loss": 0.00054, "acc_pose": 0.84178, "loss": 0.00054, "grad_norm": 0.00125, "time": 0.71343}
+{"mode": "train", "epoch": 117, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.84487, "loss": 0.00054, "grad_norm": 0.00118, "time": 0.65752}
+{"mode": "train", "epoch": 117, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00053, "acc_pose": 0.84635, "loss": 0.00053, "grad_norm": 0.00123, "time": 0.6575}
+{"mode": "train", "epoch": 117, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00054, "acc_pose": 0.84112, "loss": 0.00054, "grad_norm": 0.00129, "time": 0.65724}
+{"mode": "train", "epoch": 117, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00054, "acc_pose": 0.84887, "loss": 0.00054, "grad_norm": 0.00124, "time": 0.657}
+{"mode": "train", "epoch": 118, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05637, "heatmap_loss": 0.00054, "acc_pose": 0.84469, "loss": 0.00054, "grad_norm": 0.00145, "time": 0.7132}
+{"mode": "train", "epoch": 118, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.84073, "loss": 0.00054, "grad_norm": 0.00125, "time": 0.65747}
+{"mode": "train", "epoch": 118, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.84637, "loss": 0.00054, "grad_norm": 0.00118, "time": 0.65735}
+{"mode": "train", "epoch": 118, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.84605, "loss": 0.00053, "grad_norm": 0.00132, "time": 0.65751}
+{"mode": "train", "epoch": 118, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00054, "acc_pose": 0.84699, "loss": 0.00054, "grad_norm": 0.00129, "time": 0.65756}
+{"mode": "train", "epoch": 119, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05647, "heatmap_loss": 0.00053, "acc_pose": 0.85215, "loss": 0.00053, "grad_norm": 0.00125, "time": 0.71454}
+{"mode": "train", "epoch": 119, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00044, "heatmap_loss": 0.00053, "acc_pose": 0.85015, "loss": 0.00053, "grad_norm": 0.00111, "time": 0.65756}
+{"mode": "train", "epoch": 119, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00054, "acc_pose": 0.83735, "loss": 0.00054, "grad_norm": 0.00122, "time": 0.65733}
+{"mode": "train", "epoch": 119, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00034, "heatmap_loss": 0.00054, "acc_pose": 0.84803, "loss": 0.00054, "grad_norm": 0.00125, "time": 0.65754}
+{"mode": "train", "epoch": 119, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00053, "acc_pose": 0.84083, "loss": 0.00053, "grad_norm": 0.0012, "time": 0.65735}
+{"mode": "train", "epoch": 120, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05733, "heatmap_loss": 0.00053, "acc_pose": 0.8509, "loss": 0.00053, "grad_norm": 0.00115, "time": 0.71403}
+{"mode": "train", "epoch": 120, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00053, "acc_pose": 0.84607, "loss": 0.00053, "grad_norm": 0.00128, "time": 0.6571}
+{"mode": "train", "epoch": 120, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00034, "heatmap_loss": 0.00053, "acc_pose": 0.8458, "loss": 0.00053, "grad_norm": 0.00121, "time": 0.65768}
+{"mode": "train", "epoch": 120, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00054, "acc_pose": 0.84454, "loss": 0.00054, "grad_norm": 0.00125, "time": 0.65755}
+{"mode": "train", "epoch": 120, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.84816, "loss": 0.00053, "grad_norm": 0.00124, "time": 0.65738}
+{"mode": "val", "epoch": 120, "iter": 407, "lr": 0.0, "AP": 0.77938, "AP .5": 0.91283, "AP .75": 0.85084, "AP (M)": 0.70665, "AP (L)": 0.80764, "AR": 0.83111, "AR .5": 0.95088, "AR .75": 0.89358, "AR (M)": 0.79096, "AR (L)": 0.89045}
+{"mode": "train", "epoch": 121, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05619, "heatmap_loss": 0.00053, "acc_pose": 0.84398, "loss": 0.00053, "grad_norm": 0.00122, "time": 0.71076}
+{"mode": "train", "epoch": 121, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.851, "loss": 0.00053, "grad_norm": 0.00129, "time": 0.65721}
+{"mode": "train", "epoch": 121, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00054, "acc_pose": 0.84794, "loss": 0.00054, "grad_norm": 0.00125, "time": 0.65743}
+{"mode": "train", "epoch": 121, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.84888, "loss": 0.00053, "grad_norm": 0.00122, "time": 0.65702}
+{"mode": "train", "epoch": 121, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.84608, "loss": 0.00053, "grad_norm": 0.00122, "time": 0.65743}
+{"mode": "train", "epoch": 122, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05804, "heatmap_loss": 0.00053, "acc_pose": 0.84551, "loss": 0.00053, "grad_norm": 0.00128, "time": 0.71487}
+{"mode": "train", "epoch": 122, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00054, "acc_pose": 0.8491, "loss": 0.00054, "grad_norm": 0.0012, "time": 0.65647}
+{"mode": "train", "epoch": 122, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00034, "heatmap_loss": 0.00053, "acc_pose": 0.84665, "loss": 0.00053, "grad_norm": 0.00125, "time": 0.65684}
+{"mode": "train", "epoch": 122, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00053, "acc_pose": 0.84878, "loss": 0.00053, "grad_norm": 0.00112, "time": 0.65674}
+{"mode": "train", "epoch": 122, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00034, "heatmap_loss": 0.00054, "acc_pose": 0.84239, "loss": 0.00054, "grad_norm": 0.00131, "time": 0.65704}
+{"mode": "train", "epoch": 123, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05666, "heatmap_loss": 0.00053, "acc_pose": 0.85217, "loss": 0.00053, "grad_norm": 0.00126, "time": 0.71302}
+{"mode": "train", "epoch": 123, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00053, "acc_pose": 0.8504, "loss": 0.00053, "grad_norm": 0.00129, "time": 0.65668}
+{"mode": "train", "epoch": 123, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00053, "acc_pose": 0.84989, "loss": 0.00053, "grad_norm": 0.00133, "time": 0.65699}
+{"mode": "train", "epoch": 123, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.84575, "loss": 0.00053, "grad_norm": 0.00126, "time": 0.65678}
+{"mode": "train", "epoch": 123, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00053, "acc_pose": 0.84772, "loss": 0.00053, "grad_norm": 0.00115, "time": 0.65704}
+{"mode": "train", "epoch": 124, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05729, "heatmap_loss": 0.00053, "acc_pose": 0.84173, "loss": 0.00053, "grad_norm": 0.00124, "time": 0.71422}
+{"mode": "train", "epoch": 124, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00053, "acc_pose": 0.84397, "loss": 0.00053, "grad_norm": 0.00114, "time": 0.6567}
+{"mode": "train", "epoch": 124, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00053, "acc_pose": 0.84799, "loss": 0.00053, "grad_norm": 0.00123, "time": 0.65716}
+{"mode": "train", "epoch": 124, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00054, "acc_pose": 0.84447, "loss": 0.00054, "grad_norm": 0.00126, "time": 0.65688}
+{"mode": "train", "epoch": 124, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00042, "heatmap_loss": 0.00053, "acc_pose": 0.84556, "loss": 0.00053, "grad_norm": 0.00117, "time": 0.65719}
+{"mode": "train", "epoch": 125, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05682, "heatmap_loss": 0.00053, "acc_pose": 0.84609, "loss": 0.00053, "grad_norm": 0.00128, "time": 0.71327}
+{"mode": "train", "epoch": 125, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00053, "acc_pose": 0.84684, "loss": 0.00053, "grad_norm": 0.0012, "time": 0.65645}
+{"mode": "train", "epoch": 125, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.84376, "loss": 0.00053, "grad_norm": 0.00114, "time": 0.6566}
+{"mode": "train", "epoch": 125, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.8407, "loss": 0.00053, "grad_norm": 0.00115, "time": 0.65661}
+{"mode": "train", "epoch": 125, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00035, "heatmap_loss": 0.00053, "acc_pose": 0.84701, "loss": 0.00053, "grad_norm": 0.00114, "time": 0.65673}
+{"mode": "train", "epoch": 126, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05699, "heatmap_loss": 0.00053, "acc_pose": 0.84801, "loss": 0.00053, "grad_norm": 0.00124, "time": 0.71349}
+{"mode": "train", "epoch": 126, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00053, "acc_pose": 0.84636, "loss": 0.00053, "grad_norm": 0.00123, "time": 0.65708}
+{"mode": "train", "epoch": 126, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00037, "heatmap_loss": 0.00053, "acc_pose": 0.84539, "loss": 0.00053, "grad_norm": 0.0013, "time": 0.65689}
+{"mode": "train", "epoch": 126, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.85116, "loss": 0.00053, "grad_norm": 0.00125, "time": 0.65711}
+{"mode": "train", "epoch": 126, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00053, "acc_pose": 0.84817, "loss": 0.00053, "grad_norm": 0.00118, "time": 0.65687}
+{"mode": "train", "epoch": 127, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05678, "heatmap_loss": 0.00053, "acc_pose": 0.85082, "loss": 0.00053, "grad_norm": 0.00117, "time": 0.71338}
+{"mode": "train", "epoch": 127, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00054, "acc_pose": 0.84249, "loss": 0.00054, "grad_norm": 0.00112, "time": 0.65721}
+{"mode": "train", "epoch": 127, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00053, "acc_pose": 0.84715, "loss": 0.00053, "grad_norm": 0.00118, "time": 0.65712}
+{"mode": "train", "epoch": 127, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.84955, "loss": 0.00053, "grad_norm": 0.00125, "time": 0.65719}
+{"mode": "train", "epoch": 127, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.85065, "loss": 0.00053, "grad_norm": 0.0012, "time": 0.65699}
+{"mode": "train", "epoch": 128, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.0567, "heatmap_loss": 0.00053, "acc_pose": 0.8483, "loss": 0.00053, "grad_norm": 0.00123, "time": 0.7137}
+{"mode": "train", "epoch": 128, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00053, "acc_pose": 0.84864, "loss": 0.00053, "grad_norm": 0.00121, "time": 0.65713}
+{"mode": "train", "epoch": 128, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00053, "acc_pose": 0.85122, "loss": 0.00053, "grad_norm": 0.00119, "time": 0.6574}
+{"mode": "train", "epoch": 128, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00053, "acc_pose": 0.8363, "loss": 0.00053, "grad_norm": 0.00134, "time": 0.65711}
+{"mode": "train", "epoch": 128, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00053, "acc_pose": 0.84676, "loss": 0.00053, "grad_norm": 0.00117, "time": 0.65708}
+{"mode": "train", "epoch": 129, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05888, "heatmap_loss": 0.00053, "acc_pose": 0.85016, "loss": 0.00053, "grad_norm": 0.00131, "time": 0.71521}
+{"mode": "train", "epoch": 129, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.84811, "loss": 0.00053, "grad_norm": 0.00127, "time": 0.65692}
+{"mode": "train", "epoch": 129, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00053, "acc_pose": 0.84545, "loss": 0.00053, "grad_norm": 0.00118, "time": 0.65683}
+{"mode": "train", "epoch": 129, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00053, "acc_pose": 0.85016, "loss": 0.00053, "grad_norm": 0.00122, "time": 0.65717}
+{"mode": "train", "epoch": 129, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.84181, "loss": 0.00053, "grad_norm": 0.00116, "time": 0.65676}
+{"mode": "train", "epoch": 130, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05732, "heatmap_loss": 0.00053, "acc_pose": 0.84994, "loss": 0.00053, "grad_norm": 0.00119, "time": 0.71449}
+{"mode": "train", "epoch": 130, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00053, "acc_pose": 0.83903, "loss": 0.00053, "grad_norm": 0.00114, "time": 0.65714}
+{"mode": "train", "epoch": 130, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00053, "acc_pose": 0.84364, "loss": 0.00053, "grad_norm": 0.00118, "time": 0.65722}
+{"mode": "train", "epoch": 130, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.84641, "loss": 0.00053, "grad_norm": 0.00125, "time": 0.65726}
+{"mode": "train", "epoch": 130, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00053, "acc_pose": 0.85063, "loss": 0.00053, "grad_norm": 0.0012, "time": 0.65723}
+{"mode": "val", "epoch": 130, "iter": 407, "lr": 0.0, "AP": 0.77908, "AP .5": 0.91447, "AP .75": 0.85039, "AP (M)": 0.7058, "AP (L)": 0.80735, "AR": 0.83105, "AR .5": 0.9534, "AR .75": 0.89295, "AR (M)": 0.79014, "AR (L)": 0.89108}
+{"mode": "train", "epoch": 131, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05603, "heatmap_loss": 0.00053, "acc_pose": 0.85422, "loss": 0.00053, "grad_norm": 0.00119, "time": 0.70867}
+{"mode": "train", "epoch": 131, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.84952, "loss": 0.00053, "grad_norm": 0.0012, "time": 0.65598}
+{"mode": "train", "epoch": 131, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.84699, "loss": 0.00053, "grad_norm": 0.00128, "time": 0.6568}
+{"mode": "train", "epoch": 131, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00052, "acc_pose": 0.85026, "loss": 0.00052, "grad_norm": 0.00117, "time": 0.65674}
+{"mode": "train", "epoch": 131, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00053, "acc_pose": 0.85034, "loss": 0.00053, "grad_norm": 0.00123, "time": 0.65671}
+{"mode": "train", "epoch": 132, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.057, "heatmap_loss": 0.00052, "acc_pose": 0.84568, "loss": 0.00052, "grad_norm": 0.00121, "time": 0.71468}
+{"mode": "train", "epoch": 132, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00036, "heatmap_loss": 0.00053, "acc_pose": 0.84953, "loss": 0.00053, "grad_norm": 0.00111, "time": 0.65724}
+{"mode": "train", "epoch": 132, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00053, "acc_pose": 0.84687, "loss": 0.00053, "grad_norm": 0.00117, "time": 0.65703}
+{"mode": "train", "epoch": 132, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00052, "acc_pose": 0.84784, "loss": 0.00052, "grad_norm": 0.0012, "time": 0.65674}
+{"mode": "train", "epoch": 132, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00053, "acc_pose": 0.85471, "loss": 0.00053, "grad_norm": 0.00122, "time": 0.65683}
+{"mode": "train", "epoch": 133, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05711, "heatmap_loss": 0.00052, "acc_pose": 0.84423, "loss": 0.00052, "grad_norm": 0.0011, "time": 0.71506}
+{"mode": "train", "epoch": 133, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00052, "acc_pose": 0.8486, "loss": 0.00052, "grad_norm": 0.00114, "time": 0.6566}
+{"mode": "train", "epoch": 133, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00053, "acc_pose": 0.84618, "loss": 0.00053, "grad_norm": 0.0012, "time": 0.65708}
+{"mode": "train", "epoch": 133, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00052, "acc_pose": 0.84365, "loss": 0.00052, "grad_norm": 0.00118, "time": 0.65717}
+{"mode": "train", "epoch": 133, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00053, "acc_pose": 0.84428, "loss": 0.00053, "grad_norm": 0.00115, "time": 0.65727}
+{"mode": "train", "epoch": 134, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05676, "heatmap_loss": 0.00052, "acc_pose": 0.85121, "loss": 0.00052, "grad_norm": 0.00108, "time": 0.71353}
+{"mode": "train", "epoch": 134, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00052, "acc_pose": 0.84783, "loss": 0.00052, "grad_norm": 0.00117, "time": 0.6566}
+{"mode": "train", "epoch": 134, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00052, "acc_pose": 0.84734, "loss": 0.00052, "grad_norm": 0.00115, "time": 0.65696}
+{"mode": "train", "epoch": 134, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00052, "acc_pose": 0.85444, "loss": 0.00052, "grad_norm": 0.00123, "time": 0.65694}
+{"mode": "train", "epoch": 134, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00053, "acc_pose": 0.84108, "loss": 0.00053, "grad_norm": 0.00115, "time": 0.65683}
+{"mode": "train", "epoch": 135, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05689, "heatmap_loss": 0.00052, "acc_pose": 0.85049, "loss": 0.00052, "grad_norm": 0.00121, "time": 0.71385}
+{"mode": "train", "epoch": 135, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00052, "acc_pose": 0.84649, "loss": 0.00052, "grad_norm": 0.00109, "time": 0.65686}
+{"mode": "train", "epoch": 135, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00053, "acc_pose": 0.84787, "loss": 0.00053, "grad_norm": 0.00114, "time": 0.657}
+{"mode": "train", "epoch": 135, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00053, "acc_pose": 0.85078, "loss": 0.00053, "grad_norm": 0.00129, "time": 0.65661}
+{"mode": "train", "epoch": 135, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00053, "acc_pose": 0.85285, "loss": 0.00053, "grad_norm": 0.00118, "time": 0.65725}
+{"mode": "train", "epoch": 136, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05711, "heatmap_loss": 0.00053, "acc_pose": 0.84831, "loss": 0.00053, "grad_norm": 0.00113, "time": 0.71548}
+{"mode": "train", "epoch": 136, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00053, "acc_pose": 0.85523, "loss": 0.00053, "grad_norm": 0.00121, "time": 0.65779}
+{"mode": "train", "epoch": 136, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00052, "acc_pose": 0.84833, "loss": 0.00052, "grad_norm": 0.00121, "time": 0.65732}
+{"mode": "train", "epoch": 136, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00052, "acc_pose": 0.84791, "loss": 0.00052, "grad_norm": 0.0012, "time": 0.65741}
+{"mode": "train", "epoch": 136, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00052, "acc_pose": 0.85182, "loss": 0.00052, "grad_norm": 0.00114, "time": 0.65698}
+{"mode": "train", "epoch": 137, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05639, "heatmap_loss": 0.00052, "acc_pose": 0.84786, "loss": 0.00052, "grad_norm": 0.00112, "time": 0.71416}
+{"mode": "train", "epoch": 137, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00053, "acc_pose": 0.84618, "loss": 0.00053, "grad_norm": 0.00117, "time": 0.65723}
+{"mode": "train", "epoch": 137, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00052, "acc_pose": 0.84786, "loss": 0.00052, "grad_norm": 0.00117, "time": 0.65756}
+{"mode": "train", "epoch": 137, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00052, "acc_pose": 0.85243, "loss": 0.00052, "grad_norm": 0.00119, "time": 0.6574}
+{"mode": "train", "epoch": 137, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00052, "acc_pose": 0.85031, "loss": 0.00052, "grad_norm": 0.00119, "time": 0.65747}
+{"mode": "train", "epoch": 138, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05694, "heatmap_loss": 0.00052, "acc_pose": 0.84605, "loss": 0.00052, "grad_norm": 0.00115, "time": 0.71453}
+{"mode": "train", "epoch": 138, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00052, "acc_pose": 0.85464, "loss": 0.00052, "grad_norm": 0.00116, "time": 0.65752}
+{"mode": "train", "epoch": 138, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00052, "acc_pose": 0.85005, "loss": 0.00052, "grad_norm": 0.0012, "time": 0.65704}
+{"mode": "train", "epoch": 138, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00052, "acc_pose": 0.84815, "loss": 0.00052, "grad_norm": 0.00112, "time": 0.65739}
+{"mode": "train", "epoch": 138, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00052, "acc_pose": 0.85362, "loss": 0.00052, "grad_norm": 0.00113, "time": 0.65709}
+{"mode": "train", "epoch": 139, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05632, "heatmap_loss": 0.00052, "acc_pose": 0.84716, "loss": 0.00052, "grad_norm": 0.00114, "time": 0.71346}
+{"mode": "train", "epoch": 139, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00052, "acc_pose": 0.84746, "loss": 0.00052, "grad_norm": 0.00116, "time": 0.65696}
+{"mode": "train", "epoch": 139, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00048, "heatmap_loss": 0.00052, "acc_pose": 0.84988, "loss": 0.00052, "grad_norm": 0.00111, "time": 0.65739}
+{"mode": "train", "epoch": 139, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00052, "acc_pose": 0.84964, "loss": 0.00052, "grad_norm": 0.00123, "time": 0.65728}
+{"mode": "train", "epoch": 139, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00052, "acc_pose": 0.849, "loss": 0.00052, "grad_norm": 0.00118, "time": 0.65751}
+{"mode": "train", "epoch": 140, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05726, "heatmap_loss": 0.00052, "acc_pose": 0.85255, "loss": 0.00052, "grad_norm": 0.0011, "time": 0.71404}
+{"mode": "train", "epoch": 140, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00052, "acc_pose": 0.84767, "loss": 0.00052, "grad_norm": 0.0011, "time": 0.65706}
+{"mode": "train", "epoch": 140, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00034, "heatmap_loss": 0.00052, "acc_pose": 0.85084, "loss": 0.00052, "grad_norm": 0.00114, "time": 0.65763}
+{"mode": "train", "epoch": 140, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00027, "heatmap_loss": 0.00053, "acc_pose": 0.85029, "loss": 0.00053, "grad_norm": 0.00114, "time": 0.65724}
+{"mode": "train", "epoch": 140, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00052, "acc_pose": 0.84992, "loss": 0.00052, "grad_norm": 0.00114, "time": 0.65753}
+{"mode": "val", "epoch": 140, "iter": 407, "lr": 0.0, "AP": 0.78109, "AP .5": 0.91405, "AP .75": 0.85084, "AP (M)": 0.70818, "AP (L)": 0.80947, "AR": 0.8327, "AR .5": 0.95277, "AR .75": 0.89373, "AR (M)": 0.79246, "AR (L)": 0.89194}
+{"mode": "train", "epoch": 141, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05856, "heatmap_loss": 0.00052, "acc_pose": 0.84929, "loss": 0.00052, "grad_norm": 0.00122, "time": 0.71139}
+{"mode": "train", "epoch": 141, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00052, "acc_pose": 0.85332, "loss": 0.00052, "grad_norm": 0.00121, "time": 0.65637}
+{"mode": "train", "epoch": 141, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00052, "acc_pose": 0.84396, "loss": 0.00052, "grad_norm": 0.00115, "time": 0.65672}
+{"mode": "train", "epoch": 141, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00052, "acc_pose": 0.8524, "loss": 0.00052, "grad_norm": 0.00116, "time": 0.65696}
+{"mode": "train", "epoch": 141, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00052, "acc_pose": 0.84799, "loss": 0.00052, "grad_norm": 0.00116, "time": 0.65681}
+{"mode": "train", "epoch": 142, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05875, "heatmap_loss": 0.00052, "acc_pose": 0.85404, "loss": 0.00052, "grad_norm": 0.0012, "time": 0.71591}
+{"mode": "train", "epoch": 142, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00052, "acc_pose": 0.84473, "loss": 0.00052, "grad_norm": 0.00118, "time": 0.65757}
+{"mode": "train", "epoch": 142, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00052, "acc_pose": 0.85301, "loss": 0.00052, "grad_norm": 0.00113, "time": 0.65716}
+{"mode": "train", "epoch": 142, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00052, "acc_pose": 0.84956, "loss": 0.00052, "grad_norm": 0.00115, "time": 0.65693}
+{"mode": "train", "epoch": 142, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00052, "acc_pose": 0.85032, "loss": 0.00052, "grad_norm": 0.0011, "time": 0.65679}
+{"mode": "train", "epoch": 143, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05687, "heatmap_loss": 0.00052, "acc_pose": 0.8587, "loss": 0.00052, "grad_norm": 0.00121, "time": 0.71376}
+{"mode": "train", "epoch": 143, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00052, "acc_pose": 0.85236, "loss": 0.00052, "grad_norm": 0.00109, "time": 0.65614}
+{"mode": "train", "epoch": 143, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00052, "acc_pose": 0.85418, "loss": 0.00052, "grad_norm": 0.00114, "time": 0.65642}
+{"mode": "train", "epoch": 143, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00052, "acc_pose": 0.84939, "loss": 0.00052, "grad_norm": 0.0011, "time": 0.65689}
+{"mode": "train", "epoch": 143, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00052, "acc_pose": 0.84998, "loss": 0.00052, "grad_norm": 0.00119, "time": 0.657}
+{"mode": "train", "epoch": 144, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05727, "heatmap_loss": 0.00052, "acc_pose": 0.84693, "loss": 0.00052, "grad_norm": 0.00108, "time": 0.71444}
+{"mode": "train", "epoch": 144, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00052, "acc_pose": 0.84856, "loss": 0.00052, "grad_norm": 0.00111, "time": 0.65712}
+{"mode": "train", "epoch": 144, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00052, "acc_pose": 0.8478, "loss": 0.00052, "grad_norm": 0.00124, "time": 0.65686}
+{"mode": "train", "epoch": 144, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00052, "acc_pose": 0.84685, "loss": 0.00052, "grad_norm": 0.00118, "time": 0.65702}
+{"mode": "train", "epoch": 144, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00052, "acc_pose": 0.85095, "loss": 0.00052, "grad_norm": 0.00115, "time": 0.65701}
+{"mode": "train", "epoch": 145, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05712, "heatmap_loss": 0.00052, "acc_pose": 0.85204, "loss": 0.00052, "grad_norm": 0.00121, "time": 0.71472}
+{"mode": "train", "epoch": 145, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00051, "acc_pose": 0.85361, "loss": 0.00051, "grad_norm": 0.00109, "time": 0.65737}
+{"mode": "train", "epoch": 145, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00052, "acc_pose": 0.84824, "loss": 0.00052, "grad_norm": 0.00124, "time": 0.65684}
+{"mode": "train", "epoch": 145, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00052, "acc_pose": 0.84676, "loss": 0.00052, "grad_norm": 0.00113, "time": 0.65713}
+{"mode": "train", "epoch": 145, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00052, "acc_pose": 0.85812, "loss": 0.00052, "grad_norm": 0.0011, "time": 0.65693}
+{"mode": "train", "epoch": 146, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05762, "heatmap_loss": 0.00052, "acc_pose": 0.84946, "loss": 0.00052, "grad_norm": 0.00115, "time": 0.71431}
+{"mode": "train", "epoch": 146, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00051, "acc_pose": 0.84975, "loss": 0.00051, "grad_norm": 0.00109, "time": 0.65665}
+{"mode": "train", "epoch": 146, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00052, "acc_pose": 0.84659, "loss": 0.00052, "grad_norm": 0.00105, "time": 0.6567}
+{"mode": "train", "epoch": 146, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00037, "heatmap_loss": 0.00051, "acc_pose": 0.85168, "loss": 0.00051, "grad_norm": 0.00113, "time": 0.65682}
+{"mode": "train", "epoch": 146, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00052, "acc_pose": 0.85453, "loss": 0.00052, "grad_norm": 0.00116, "time": 0.65708}
+{"mode": "train", "epoch": 147, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05734, "heatmap_loss": 0.00051, "acc_pose": 0.85656, "loss": 0.00051, "grad_norm": 0.0011, "time": 0.71427}
+{"mode": "train", "epoch": 147, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00051, "acc_pose": 0.85206, "loss": 0.00051, "grad_norm": 0.00116, "time": 0.65674}
+{"mode": "train", "epoch": 147, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00052, "acc_pose": 0.85233, "loss": 0.00052, "grad_norm": 0.00115, "time": 0.65712}
+{"mode": "train", "epoch": 147, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00052, "acc_pose": 0.84621, "loss": 0.00052, "grad_norm": 0.00117, "time": 0.65664}
+{"mode": "train", "epoch": 147, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00035, "heatmap_loss": 0.00052, "acc_pose": 0.84798, "loss": 0.00052, "grad_norm": 0.00109, "time": 0.65709}
+{"mode": "train", "epoch": 148, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05604, "heatmap_loss": 0.00052, "acc_pose": 0.8513, "loss": 0.00052, "grad_norm": 0.00115, "time": 0.71365}
+{"mode": "train", "epoch": 148, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00052, "acc_pose": 0.85127, "loss": 0.00052, "grad_norm": 0.00116, "time": 0.65685}
+{"mode": "train", "epoch": 148, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00052, "acc_pose": 0.85418, "loss": 0.00052, "grad_norm": 0.00109, "time": 0.6569}
+{"mode": "train", "epoch": 148, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00052, "acc_pose": 0.85583, "loss": 0.00052, "grad_norm": 0.00114, "time": 0.65751}
+{"mode": "train", "epoch": 148, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00052, "acc_pose": 0.85662, "loss": 0.00052, "grad_norm": 0.0011, "time": 0.65702}
+{"mode": "train", "epoch": 149, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05679, "heatmap_loss": 0.00051, "acc_pose": 0.84781, "loss": 0.00051, "grad_norm": 0.00113, "time": 0.71351}
+{"mode": "train", "epoch": 149, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00052, "acc_pose": 0.86024, "loss": 0.00052, "grad_norm": 0.00108, "time": 0.65727}
+{"mode": "train", "epoch": 149, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00051, "acc_pose": 0.85976, "loss": 0.00051, "grad_norm": 0.00108, "time": 0.65741}
+{"mode": "train", "epoch": 149, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00052, "acc_pose": 0.84839, "loss": 0.00052, "grad_norm": 0.00119, "time": 0.65731}
+{"mode": "train", "epoch": 149, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00052, "acc_pose": 0.85611, "loss": 0.00052, "grad_norm": 0.00115, "time": 0.65733}
+{"mode": "train", "epoch": 150, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05725, "heatmap_loss": 0.00051, "acc_pose": 0.8541, "loss": 0.00051, "grad_norm": 0.00108, "time": 0.71509}
+{"mode": "train", "epoch": 150, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00047, "heatmap_loss": 0.00051, "acc_pose": 0.85749, "loss": 0.00051, "grad_norm": 0.00119, "time": 0.65716}
+{"mode": "train", "epoch": 150, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00052, "acc_pose": 0.85398, "loss": 0.00052, "grad_norm": 0.00109, "time": 0.65666}
+{"mode": "train", "epoch": 150, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00051, "acc_pose": 0.85894, "loss": 0.00051, "grad_norm": 0.00117, "time": 0.65689}
+{"mode": "train", "epoch": 150, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00052, "acc_pose": 0.85217, "loss": 0.00052, "grad_norm": 0.00113, "time": 0.65669}
+{"mode": "val", "epoch": 150, "iter": 407, "lr": 0.0, "AP": 0.77962, "AP .5": 0.91525, "AP .75": 0.84975, "AP (M)": 0.70633, "AP (L)": 0.80897, "AR": 0.83145, "AR .5": 0.95293, "AR .75": 0.89342, "AR (M)": 0.78995, "AR (L)": 0.89238}
+{"mode": "train", "epoch": 151, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05581, "heatmap_loss": 0.00051, "acc_pose": 0.8527, "loss": 0.00051, "grad_norm": 0.00117, "time": 0.70883}
+{"mode": "train", "epoch": 151, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00051, "acc_pose": 0.85459, "loss": 0.00051, "grad_norm": 0.00114, "time": 0.65641}
+{"mode": "train", "epoch": 151, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00051, "acc_pose": 0.85422, "loss": 0.00051, "grad_norm": 0.00112, "time": 0.65688}
+{"mode": "train", "epoch": 151, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00052, "acc_pose": 0.85115, "loss": 0.00052, "grad_norm": 0.00116, "time": 0.65638}
+{"mode": "train", "epoch": 151, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00052, "acc_pose": 0.8583, "loss": 0.00052, "grad_norm": 0.00112, "time": 0.65654}
+{"mode": "train", "epoch": 152, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05705, "heatmap_loss": 0.00051, "acc_pose": 0.85502, "loss": 0.00051, "grad_norm": 0.00113, "time": 0.71334}
+{"mode": "train", "epoch": 152, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00052, "acc_pose": 0.8564, "loss": 0.00052, "grad_norm": 0.0011, "time": 0.65647}
+{"mode": "train", "epoch": 152, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00051, "acc_pose": 0.85617, "loss": 0.00051, "grad_norm": 0.00115, "time": 0.65683}
+{"mode": "train", "epoch": 152, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00052, "acc_pose": 0.8516, "loss": 0.00052, "grad_norm": 0.00114, "time": 0.65692}
+{"mode": "train", "epoch": 152, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00052, "acc_pose": 0.85976, "loss": 0.00052, "grad_norm": 0.00111, "time": 0.65679}
+{"mode": "train", "epoch": 153, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.0566, "heatmap_loss": 0.00051, "acc_pose": 0.85681, "loss": 0.00051, "grad_norm": 0.00112, "time": 0.71384}
+{"mode": "train", "epoch": 153, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00051, "acc_pose": 0.86106, "loss": 0.00051, "grad_norm": 0.00111, "time": 0.65695}
+{"mode": "train", "epoch": 153, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00051, "acc_pose": 0.85669, "loss": 0.00051, "grad_norm": 0.00107, "time": 0.65724}
+{"mode": "train", "epoch": 153, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00052, "acc_pose": 0.85156, "loss": 0.00052, "grad_norm": 0.00109, "time": 0.65683}
+{"mode": "train", "epoch": 153, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00051, "acc_pose": 0.8537, "loss": 0.00051, "grad_norm": 0.00106, "time": 0.6573}
+{"mode": "train", "epoch": 154, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05675, "heatmap_loss": 0.00051, "acc_pose": 0.85228, "loss": 0.00051, "grad_norm": 0.00106, "time": 0.7132}
+{"mode": "train", "epoch": 154, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.0005, "heatmap_loss": 0.00051, "acc_pose": 0.85556, "loss": 0.00051, "grad_norm": 0.00116, "time": 0.65731}
+{"mode": "train", "epoch": 154, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00052, "acc_pose": 0.847, "loss": 0.00052, "grad_norm": 0.00113, "time": 0.65681}
+{"mode": "train", "epoch": 154, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00051, "acc_pose": 0.85169, "loss": 0.00051, "grad_norm": 0.00116, "time": 0.65664}
+{"mode": "train", "epoch": 154, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00034, "heatmap_loss": 0.00051, "acc_pose": 0.85216, "loss": 0.00051, "grad_norm": 0.00104, "time": 0.6568}
+{"mode": "train", "epoch": 155, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05697, "heatmap_loss": 0.00051, "acc_pose": 0.85386, "loss": 0.00051, "grad_norm": 0.00113, "time": 0.71366}
+{"mode": "train", "epoch": 155, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00051, "acc_pose": 0.85138, "loss": 0.00051, "grad_norm": 0.00112, "time": 0.65708}
+{"mode": "train", "epoch": 155, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00051, "acc_pose": 0.85623, "loss": 0.00051, "grad_norm": 0.00117, "time": 0.65689}
+{"mode": "train", "epoch": 155, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00051, "acc_pose": 0.85458, "loss": 0.00051, "grad_norm": 0.00111, "time": 0.65701}
+{"mode": "train", "epoch": 155, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00051, "acc_pose": 0.85395, "loss": 0.00051, "grad_norm": 0.00111, "time": 0.65664}
+{"mode": "train", "epoch": 156, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05735, "heatmap_loss": 0.00051, "acc_pose": 0.85045, "loss": 0.00051, "grad_norm": 0.00108, "time": 0.71435}
+{"mode": "train", "epoch": 156, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00051, "acc_pose": 0.8529, "loss": 0.00051, "grad_norm": 0.00113, "time": 0.65735}
+{"mode": "train", "epoch": 156, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00052, "acc_pose": 0.85239, "loss": 0.00052, "grad_norm": 0.00113, "time": 0.65714}
+{"mode": "train", "epoch": 156, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00051, "acc_pose": 0.85453, "loss": 0.00051, "grad_norm": 0.00109, "time": 0.657}
+{"mode": "train", "epoch": 156, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00051, "acc_pose": 0.85226, "loss": 0.00051, "grad_norm": 0.00113, "time": 0.65728}
+{"mode": "train", "epoch": 157, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05923, "heatmap_loss": 0.00051, "acc_pose": 0.86102, "loss": 0.00051, "grad_norm": 0.0011, "time": 0.71594}
+{"mode": "train", "epoch": 157, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00051, "acc_pose": 0.86106, "loss": 0.00051, "grad_norm": 0.00108, "time": 0.6571}
+{"mode": "train", "epoch": 157, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00051, "acc_pose": 0.85417, "loss": 0.00051, "grad_norm": 0.00112, "time": 0.65669}
+{"mode": "train", "epoch": 157, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00051, "acc_pose": 0.86083, "loss": 0.00051, "grad_norm": 0.00114, "time": 0.65705}
+{"mode": "train", "epoch": 157, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00034, "heatmap_loss": 0.00051, "acc_pose": 0.85465, "loss": 0.00051, "grad_norm": 0.00112, "time": 0.65667}
+{"mode": "train", "epoch": 158, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05626, "heatmap_loss": 0.00052, "acc_pose": 0.85075, "loss": 0.00052, "grad_norm": 0.00121, "time": 0.71427}
+{"mode": "train", "epoch": 158, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00051, "acc_pose": 0.85457, "loss": 0.00051, "grad_norm": 0.00112, "time": 0.65665}
+{"mode": "train", "epoch": 158, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00051, "acc_pose": 0.85012, "loss": 0.00051, "grad_norm": 0.00106, "time": 0.65695}
+{"mode": "train", "epoch": 158, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00051, "acc_pose": 0.85645, "loss": 0.00051, "grad_norm": 0.00108, "time": 0.65688}
+{"mode": "train", "epoch": 158, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00051, "acc_pose": 0.85554, "loss": 0.00051, "grad_norm": 0.00106, "time": 0.65708}
+{"mode": "train", "epoch": 159, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05645, "heatmap_loss": 0.00051, "acc_pose": 0.85191, "loss": 0.00051, "grad_norm": 0.0011, "time": 0.71356}
+{"mode": "train", "epoch": 159, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00051, "acc_pose": 0.84796, "loss": 0.00051, "grad_norm": 0.00111, "time": 0.65667}
+{"mode": "train", "epoch": 159, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00051, "acc_pose": 0.85715, "loss": 0.00051, "grad_norm": 0.00108, "time": 0.65701}
+{"mode": "train", "epoch": 159, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00051, "acc_pose": 0.85444, "loss": 0.00051, "grad_norm": 0.00115, "time": 0.65704}
+{"mode": "train", "epoch": 159, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00051, "acc_pose": 0.8519, "loss": 0.00051, "grad_norm": 0.00108, "time": 0.65716}
+{"mode": "train", "epoch": 160, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05713, "heatmap_loss": 0.00052, "acc_pose": 0.85729, "loss": 0.00052, "grad_norm": 0.00112, "time": 0.71378}
+{"mode": "train", "epoch": 160, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00051, "acc_pose": 0.85758, "loss": 0.00051, "grad_norm": 0.00114, "time": 0.65677}
+{"mode": "train", "epoch": 160, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00051, "acc_pose": 0.85362, "loss": 0.00051, "grad_norm": 0.00104, "time": 0.65678}
+{"mode": "train", "epoch": 160, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00051, "acc_pose": 0.85279, "loss": 0.00051, "grad_norm": 0.00113, "time": 0.65708}
+{"mode": "train", "epoch": 160, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00051, "acc_pose": 0.85205, "loss": 0.00051, "grad_norm": 0.00117, "time": 0.6574}
+{"mode": "val", "epoch": 160, "iter": 407, "lr": 0.0, "AP": 0.78006, "AP .5": 0.91366, "AP .75": 0.85084, "AP (M)": 0.70701, "AP (L)": 0.80802, "AR": 0.83259, "AR .5": 0.95324, "AR .75": 0.89468, "AR (M)": 0.79145, "AR (L)": 0.89294}
+{"mode": "train", "epoch": 161, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05641, "heatmap_loss": 0.00051, "acc_pose": 0.85867, "loss": 0.00051, "grad_norm": 0.0011, "time": 0.70935}
+{"mode": "train", "epoch": 161, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00051, "acc_pose": 0.8618, "loss": 0.00051, "grad_norm": 0.00108, "time": 0.65629}
+{"mode": "train", "epoch": 161, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00051, "acc_pose": 0.85212, "loss": 0.00051, "grad_norm": 0.00114, "time": 0.65658}
+{"mode": "train", "epoch": 161, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00051, "acc_pose": 0.85741, "loss": 0.00051, "grad_norm": 0.00114, "time": 0.65636}
+{"mode": "train", "epoch": 161, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00034, "heatmap_loss": 0.00051, "acc_pose": 0.85065, "loss": 0.00051, "grad_norm": 0.00115, "time": 0.65655}
+{"mode": "train", "epoch": 162, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05615, "heatmap_loss": 0.0005, "acc_pose": 0.85865, "loss": 0.0005, "grad_norm": 0.00104, "time": 0.71418}
+{"mode": "train", "epoch": 162, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00051, "acc_pose": 0.85413, "loss": 0.00051, "grad_norm": 0.00109, "time": 0.65678}
+{"mode": "train", "epoch": 162, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00051, "acc_pose": 0.85805, "loss": 0.00051, "grad_norm": 0.00113, "time": 0.65685}
+{"mode": "train", "epoch": 162, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00051, "acc_pose": 0.85584, "loss": 0.00051, "grad_norm": 0.00104, "time": 0.65685}
+{"mode": "train", "epoch": 162, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00051, "acc_pose": 0.8553, "loss": 0.00051, "grad_norm": 0.00105, "time": 0.65683}
+{"mode": "train", "epoch": 163, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05594, "heatmap_loss": 0.0005, "acc_pose": 0.85999, "loss": 0.0005, "grad_norm": 0.0011, "time": 0.71418}
+{"mode": "train", "epoch": 163, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00051, "acc_pose": 0.85198, "loss": 0.00051, "grad_norm": 0.00105, "time": 0.65654}
+{"mode": "train", "epoch": 163, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00051, "acc_pose": 0.85115, "loss": 0.00051, "grad_norm": 0.00116, "time": 0.65695}
+{"mode": "train", "epoch": 163, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00051, "acc_pose": 0.85101, "loss": 0.00051, "grad_norm": 0.00111, "time": 0.6567}
+{"mode": "train", "epoch": 163, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00051, "acc_pose": 0.85243, "loss": 0.00051, "grad_norm": 0.00114, "time": 0.65691}
+{"mode": "train", "epoch": 164, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05712, "heatmap_loss": 0.00051, "acc_pose": 0.85402, "loss": 0.00051, "grad_norm": 0.00108, "time": 0.71412}
+{"mode": "train", "epoch": 164, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00051, "acc_pose": 0.85376, "loss": 0.00051, "grad_norm": 0.00116, "time": 0.65694}
+{"mode": "train", "epoch": 164, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00051, "acc_pose": 0.85442, "loss": 0.00051, "grad_norm": 0.00114, "time": 0.65701}
+{"mode": "train", "epoch": 164, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00051, "acc_pose": 0.85498, "loss": 0.00051, "grad_norm": 0.0011, "time": 0.65699}
+{"mode": "train", "epoch": 164, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00051, "acc_pose": 0.86116, "loss": 0.00051, "grad_norm": 0.00105, "time": 0.65702}
+{"mode": "train", "epoch": 165, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05654, "heatmap_loss": 0.00051, "acc_pose": 0.85641, "loss": 0.00051, "grad_norm": 0.00109, "time": 0.71412}
+{"mode": "train", "epoch": 165, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00051, "acc_pose": 0.85707, "loss": 0.00051, "grad_norm": 0.00109, "time": 0.65668}
+{"mode": "train", "epoch": 165, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00051, "acc_pose": 0.86117, "loss": 0.00051, "grad_norm": 0.00113, "time": 0.65679}
+{"mode": "train", "epoch": 165, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.0005, "acc_pose": 0.8561, "loss": 0.0005, "grad_norm": 0.00103, "time": 0.65691}
+{"mode": "train", "epoch": 165, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.0005, "acc_pose": 0.86619, "loss": 0.0005, "grad_norm": 0.00102, "time": 0.65688}
+{"mode": "train", "epoch": 166, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05717, "heatmap_loss": 0.00051, "acc_pose": 0.85879, "loss": 0.00051, "grad_norm": 0.00115, "time": 0.71451}
+{"mode": "train", "epoch": 166, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.85532, "loss": 0.0005, "grad_norm": 0.0011, "time": 0.6566}
+{"mode": "train", "epoch": 166, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.85744, "loss": 0.0005, "grad_norm": 0.00114, "time": 0.65665}
+{"mode": "train", "epoch": 166, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.0005, "acc_pose": 0.85521, "loss": 0.0005, "grad_norm": 0.00109, "time": 0.65702}
+{"mode": "train", "epoch": 166, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00051, "acc_pose": 0.85835, "loss": 0.00051, "grad_norm": 0.00116, "time": 0.65668}
+{"mode": "train", "epoch": 167, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05639, "heatmap_loss": 0.00051, "acc_pose": 0.85976, "loss": 0.00051, "grad_norm": 0.0011, "time": 0.71281}
+{"mode": "train", "epoch": 167, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00028, "heatmap_loss": 0.00051, "acc_pose": 0.85688, "loss": 0.00051, "grad_norm": 0.00112, "time": 0.65674}
+{"mode": "train", "epoch": 167, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00051, "acc_pose": 0.8546, "loss": 0.00051, "grad_norm": 0.00102, "time": 0.65742}
+{"mode": "train", "epoch": 167, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.0005, "acc_pose": 0.86503, "loss": 0.0005, "grad_norm": 0.00108, "time": 0.65691}
+{"mode": "train", "epoch": 167, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00051, "acc_pose": 0.8534, "loss": 0.00051, "grad_norm": 0.00106, "time": 0.65712}
+{"mode": "train", "epoch": 168, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05706, "heatmap_loss": 0.00051, "acc_pose": 0.86455, "loss": 0.00051, "grad_norm": 0.00114, "time": 0.71354}
+{"mode": "train", "epoch": 168, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.85966, "loss": 0.0005, "grad_norm": 0.00108, "time": 0.65635}
+{"mode": "train", "epoch": 168, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00051, "acc_pose": 0.8537, "loss": 0.00051, "grad_norm": 0.0011, "time": 0.65671}
+{"mode": "train", "epoch": 168, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00051, "acc_pose": 0.85605, "loss": 0.00051, "grad_norm": 0.0011, "time": 0.65709}
+{"mode": "train", "epoch": 168, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00051, "acc_pose": 0.86197, "loss": 0.00051, "grad_norm": 0.00108, "time": 0.65689}
+{"mode": "train", "epoch": 169, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.0563, "heatmap_loss": 0.0005, "acc_pose": 0.86231, "loss": 0.0005, "grad_norm": 0.00109, "time": 0.7125}
+{"mode": "train", "epoch": 169, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00034, "heatmap_loss": 0.0005, "acc_pose": 0.84999, "loss": 0.0005, "grad_norm": 0.0011, "time": 0.65638}
+{"mode": "train", "epoch": 169, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00051, "acc_pose": 0.86195, "loss": 0.00051, "grad_norm": 0.00107, "time": 0.65633}
+{"mode": "train", "epoch": 169, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.0005, "acc_pose": 0.85814, "loss": 0.0005, "grad_norm": 0.00107, "time": 0.6567}
+{"mode": "train", "epoch": 169, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00051, "acc_pose": 0.86322, "loss": 0.00051, "grad_norm": 0.00102, "time": 0.65671}
+{"mode": "train", "epoch": 170, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05726, "heatmap_loss": 0.00051, "acc_pose": 0.85875, "loss": 0.00051, "grad_norm": 0.00111, "time": 0.71374}
+{"mode": "train", "epoch": 170, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.85467, "loss": 0.0005, "grad_norm": 0.00111, "time": 0.65748}
+{"mode": "train", "epoch": 170, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00043, "heatmap_loss": 0.0005, "acc_pose": 0.8534, "loss": 0.0005, "grad_norm": 0.00106, "time": 0.65759}
+{"mode": "train", "epoch": 170, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00026, "heatmap_loss": 0.0005, "acc_pose": 0.8583, "loss": 0.0005, "grad_norm": 0.0011, "time": 0.6572}
+{"mode": "train", "epoch": 170, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.0005, "acc_pose": 0.85659, "loss": 0.0005, "grad_norm": 0.00109, "time": 0.65715}
+{"mode": "val", "epoch": 170, "iter": 407, "lr": 0.0, "AP": 0.77922, "AP .5": 0.9135, "AP .75": 0.84918, "AP (M)": 0.70737, "AP (L)": 0.80591, "AR": 0.83147, "AR .5": 0.95277, "AR .75": 0.89279, "AR (M)": 0.79131, "AR (L)": 0.89101}
+{"mode": "train", "epoch": 171, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05626, "heatmap_loss": 0.0005, "acc_pose": 0.85899, "loss": 0.0005, "grad_norm": 0.00102, "time": 0.70928}
+{"mode": "train", "epoch": 171, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00049, "acc_pose": 0.86102, "loss": 0.00049, "grad_norm": 0.00099, "time": 0.65604}
+{"mode": "train", "epoch": 171, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.0005, "acc_pose": 0.86637, "loss": 0.0005, "grad_norm": 0.00095, "time": 0.6564}
+{"mode": "train", "epoch": 171, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00049, "acc_pose": 0.86336, "loss": 0.00049, "grad_norm": 0.00097, "time": 0.65656}
+{"mode": "train", "epoch": 171, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00049, "acc_pose": 0.85939, "loss": 0.00049, "grad_norm": 0.00094, "time": 0.65668}
+{"mode": "train", "epoch": 172, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05711, "heatmap_loss": 0.00049, "acc_pose": 0.86151, "loss": 0.00049, "grad_norm": 0.00094, "time": 0.71424}
+{"mode": "train", "epoch": 172, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00049, "acc_pose": 0.85441, "loss": 0.00049, "grad_norm": 0.00097, "time": 0.65683}
+{"mode": "train", "epoch": 172, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.0005, "acc_pose": 0.86065, "loss": 0.0005, "grad_norm": 0.00094, "time": 0.65662}
+{"mode": "train", "epoch": 172, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00049, "acc_pose": 0.86565, "loss": 0.00049, "grad_norm": 0.001, "time": 0.65678}
+{"mode": "train", "epoch": 172, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00049, "acc_pose": 0.86478, "loss": 0.00049, "grad_norm": 0.00093, "time": 0.65654}
+{"mode": "train", "epoch": 173, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05738, "heatmap_loss": 0.00049, "acc_pose": 0.86233, "loss": 0.00049, "grad_norm": 0.00092, "time": 0.71383}
+{"mode": "train", "epoch": 173, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00049, "acc_pose": 0.8643, "loss": 0.00049, "grad_norm": 0.00094, "time": 0.65711}
+{"mode": "train", "epoch": 173, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00049, "acc_pose": 0.86127, "loss": 0.00049, "grad_norm": 0.00091, "time": 0.65697}
+{"mode": "train", "epoch": 173, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00049, "acc_pose": 0.86706, "loss": 0.00049, "grad_norm": 0.00097, "time": 0.65696}
+{"mode": "train", "epoch": 173, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00049, "acc_pose": 0.86308, "loss": 0.00049, "grad_norm": 0.00101, "time": 0.6572}
+{"mode": "train", "epoch": 174, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05649, "heatmap_loss": 0.00049, "acc_pose": 0.86405, "loss": 0.00049, "grad_norm": 0.00097, "time": 0.71284}
+{"mode": "train", "epoch": 174, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00049, "acc_pose": 0.85893, "loss": 0.00049, "grad_norm": 0.00092, "time": 0.65671}
+{"mode": "train", "epoch": 174, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00049, "acc_pose": 0.86518, "loss": 0.00049, "grad_norm": 0.00092, "time": 0.65701}
+{"mode": "train", "epoch": 174, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00051, "heatmap_loss": 0.00048, "acc_pose": 0.86721, "loss": 0.00048, "grad_norm": 0.00094, "time": 0.65687}
+{"mode": "train", "epoch": 174, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00048, "acc_pose": 0.85961, "loss": 0.00048, "grad_norm": 0.00092, "time": 0.65682}
+{"mode": "train", "epoch": 175, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05635, "heatmap_loss": 0.00048, "acc_pose": 0.86773, "loss": 0.00048, "grad_norm": 0.00091, "time": 0.71329}
+{"mode": "train", "epoch": 175, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00048, "acc_pose": 0.86362, "loss": 0.00048, "grad_norm": 0.0009, "time": 0.657}
+{"mode": "train", "epoch": 175, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00049, "acc_pose": 0.8661, "loss": 0.00049, "grad_norm": 0.00096, "time": 0.65697}
+{"mode": "train", "epoch": 175, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00048, "acc_pose": 0.86775, "loss": 0.00048, "grad_norm": 0.00095, "time": 0.65688}
+{"mode": "train", "epoch": 175, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00048, "acc_pose": 0.86936, "loss": 0.00048, "grad_norm": 0.00095, "time": 0.65702}
+{"mode": "train", "epoch": 176, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05734, "heatmap_loss": 0.00049, "acc_pose": 0.86182, "loss": 0.00049, "grad_norm": 0.00092, "time": 0.71409}
+{"mode": "train", "epoch": 176, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00034, "heatmap_loss": 0.00048, "acc_pose": 0.86429, "loss": 0.00048, "grad_norm": 0.00096, "time": 0.65699}
+{"mode": "train", "epoch": 176, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00049, "acc_pose": 0.857, "loss": 0.00049, "grad_norm": 0.00094, "time": 0.65712}
+{"mode": "train", "epoch": 176, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00048, "acc_pose": 0.85722, "loss": 0.00048, "grad_norm": 0.00094, "time": 0.6572}
+{"mode": "train", "epoch": 176, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00048, "acc_pose": 0.86566, "loss": 0.00048, "grad_norm": 0.00095, "time": 0.65715}
+{"mode": "train", "epoch": 177, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05706, "heatmap_loss": 0.00048, "acc_pose": 0.86746, "loss": 0.00048, "grad_norm": 0.00093, "time": 0.71446}
+{"mode": "train", "epoch": 177, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00049, "acc_pose": 0.86263, "loss": 0.00049, "grad_norm": 0.00092, "time": 0.65704}
+{"mode": "train", "epoch": 177, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00049, "acc_pose": 0.86036, "loss": 0.00049, "grad_norm": 0.00097, "time": 0.65695}
+{"mode": "train", "epoch": 177, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00048, "acc_pose": 0.86487, "loss": 0.00048, "grad_norm": 0.00092, "time": 0.65687}
+{"mode": "train", "epoch": 177, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00048, "acc_pose": 0.86228, "loss": 0.00048, "grad_norm": 0.00097, "time": 0.65709}
+{"mode": "train", "epoch": 178, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05618, "heatmap_loss": 0.00048, "acc_pose": 0.867, "loss": 0.00048, "grad_norm": 0.00095, "time": 0.71339}
+{"mode": "train", "epoch": 178, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00048, "acc_pose": 0.86565, "loss": 0.00048, "grad_norm": 0.00098, "time": 0.65646}
+{"mode": "train", "epoch": 178, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00048, "acc_pose": 0.86769, "loss": 0.00048, "grad_norm": 0.00099, "time": 0.65675}
+{"mode": "train", "epoch": 178, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00048, "acc_pose": 0.8629, "loss": 0.00048, "grad_norm": 0.00089, "time": 0.65683}
+{"mode": "train", "epoch": 178, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00048, "acc_pose": 0.86777, "loss": 0.00048, "grad_norm": 0.00091, "time": 0.65678}
+{"mode": "train", "epoch": 179, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05762, "heatmap_loss": 0.00048, "acc_pose": 0.86307, "loss": 0.00048, "grad_norm": 0.00099, "time": 0.71486}
+{"mode": "train", "epoch": 179, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00048, "acc_pose": 0.86203, "loss": 0.00048, "grad_norm": 0.00096, "time": 0.65664}
+{"mode": "train", "epoch": 179, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00048, "acc_pose": 0.86441, "loss": 0.00048, "grad_norm": 0.0009, "time": 0.65698}
+{"mode": "train", "epoch": 179, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00048, "acc_pose": 0.86904, "loss": 0.00048, "grad_norm": 0.0009, "time": 0.65693}
+{"mode": "train", "epoch": 179, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00048, "acc_pose": 0.86992, "loss": 0.00048, "grad_norm": 0.00092, "time": 0.65723}
+{"mode": "train", "epoch": 180, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05692, "heatmap_loss": 0.00048, "acc_pose": 0.86621, "loss": 0.00048, "grad_norm": 0.00088, "time": 0.71343}
+{"mode": "train", "epoch": 180, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00048, "acc_pose": 0.86856, "loss": 0.00048, "grad_norm": 0.00098, "time": 0.65676}
+{"mode": "train", "epoch": 180, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00028, "heatmap_loss": 0.00048, "acc_pose": 0.86146, "loss": 0.00048, "grad_norm": 0.00102, "time": 0.65666}
+{"mode": "train", "epoch": 180, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00048, "acc_pose": 0.86684, "loss": 0.00048, "grad_norm": 0.00096, "time": 0.65664}
+{"mode": "train", "epoch": 180, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00048, "acc_pose": 0.86713, "loss": 0.00048, "grad_norm": 0.00094, "time": 0.65693}
+{"mode": "val", "epoch": 180, "iter": 407, "lr": 0.0, "AP": 0.78293, "AP .5": 0.91406, "AP .75": 0.85147, "AP (M)": 0.70998, "AP (L)": 0.81009, "AR": 0.83462, "AR .5": 0.95356, "AR .75": 0.89452, "AR (M)": 0.79394, "AR (L)": 0.8945}
+{"mode": "train", "epoch": 181, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05604, "heatmap_loss": 0.00048, "acc_pose": 0.86597, "loss": 0.00048, "grad_norm": 0.00095, "time": 0.70879}
+{"mode": "train", "epoch": 181, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00048, "acc_pose": 0.86711, "loss": 0.00048, "grad_norm": 0.00091, "time": 0.65614}
+{"mode": "train", "epoch": 181, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00034, "heatmap_loss": 0.00048, "acc_pose": 0.8635, "loss": 0.00048, "grad_norm": 0.00096, "time": 0.6568}
+{"mode": "train", "epoch": 181, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00048, "acc_pose": 0.86352, "loss": 0.00048, "grad_norm": 0.00097, "time": 0.65682}
+{"mode": "train", "epoch": 181, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00048, "acc_pose": 0.86593, "loss": 0.00048, "grad_norm": 0.00094, "time": 0.65664}
+{"mode": "train", "epoch": 182, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05724, "heatmap_loss": 0.00048, "acc_pose": 0.86557, "loss": 0.00048, "grad_norm": 0.0009, "time": 0.71434}
+{"mode": "train", "epoch": 182, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00048, "acc_pose": 0.86851, "loss": 0.00048, "grad_norm": 0.00088, "time": 0.65681}
+{"mode": "train", "epoch": 182, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00025, "heatmap_loss": 0.00048, "acc_pose": 0.86275, "loss": 0.00048, "grad_norm": 0.00092, "time": 0.65695}
+{"mode": "train", "epoch": 182, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00048, "acc_pose": 0.86809, "loss": 0.00048, "grad_norm": 0.00094, "time": 0.65718}
+{"mode": "train", "epoch": 182, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00048, "acc_pose": 0.8652, "loss": 0.00048, "grad_norm": 0.00098, "time": 0.65708}
+{"mode": "train", "epoch": 183, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05663, "heatmap_loss": 0.00048, "acc_pose": 0.86418, "loss": 0.00048, "grad_norm": 0.0009, "time": 0.71417}
+{"mode": "train", "epoch": 183, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00048, "acc_pose": 0.86417, "loss": 0.00048, "grad_norm": 0.00095, "time": 0.65714}
+{"mode": "train", "epoch": 183, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00048, "acc_pose": 0.86381, "loss": 0.00048, "grad_norm": 0.00088, "time": 0.6569}
+{"mode": "train", "epoch": 183, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00048, "acc_pose": 0.86722, "loss": 0.00048, "grad_norm": 0.001, "time": 0.65729}
+{"mode": "train", "epoch": 183, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00048, "acc_pose": 0.86688, "loss": 0.00048, "grad_norm": 0.00091, "time": 0.65704}
+{"mode": "train", "epoch": 184, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05733, "heatmap_loss": 0.00049, "acc_pose": 0.86064, "loss": 0.00049, "grad_norm": 0.00097, "time": 0.71401}
+{"mode": "train", "epoch": 184, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00047, "acc_pose": 0.86872, "loss": 0.00047, "grad_norm": 0.00094, "time": 0.65712}
+{"mode": "train", "epoch": 184, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00043, "heatmap_loss": 0.00048, "acc_pose": 0.86355, "loss": 0.00048, "grad_norm": 0.00089, "time": 0.65676}
+{"mode": "train", "epoch": 184, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00048, "acc_pose": 0.86084, "loss": 0.00048, "grad_norm": 0.00092, "time": 0.65694}
+{"mode": "train", "epoch": 184, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00048, "acc_pose": 0.8685, "loss": 0.00048, "grad_norm": 0.00093, "time": 0.65665}
+{"mode": "train", "epoch": 185, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05934, "heatmap_loss": 0.00048, "acc_pose": 0.87037, "loss": 0.00048, "grad_norm": 0.00092, "time": 0.71632}
+{"mode": "train", "epoch": 185, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00048, "acc_pose": 0.86775, "loss": 0.00048, "grad_norm": 0.00097, "time": 0.65698}
+{"mode": "train", "epoch": 185, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00048, "acc_pose": 0.86937, "loss": 0.00048, "grad_norm": 0.00085, "time": 0.65717}
+{"mode": "train", "epoch": 185, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00048, "acc_pose": 0.86908, "loss": 0.00048, "grad_norm": 0.00096, "time": 0.65702}
+{"mode": "train", "epoch": 185, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00048, "acc_pose": 0.86604, "loss": 0.00048, "grad_norm": 0.00092, "time": 0.65704}
+{"mode": "train", "epoch": 186, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05863, "heatmap_loss": 0.00048, "acc_pose": 0.86317, "loss": 0.00048, "grad_norm": 0.00089, "time": 0.71512}
+{"mode": "train", "epoch": 186, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00048, "acc_pose": 0.86595, "loss": 0.00048, "grad_norm": 0.00094, "time": 0.65726}
+{"mode": "train", "epoch": 186, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00048, "acc_pose": 0.86666, "loss": 0.00048, "grad_norm": 0.00092, "time": 0.65689}
+{"mode": "train", "epoch": 186, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00048, "acc_pose": 0.86551, "loss": 0.00048, "grad_norm": 0.00091, "time": 0.65666}
+{"mode": "train", "epoch": 186, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00047, "acc_pose": 0.86902, "loss": 0.00047, "grad_norm": 0.00094, "time": 0.65702}
+{"mode": "train", "epoch": 187, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05567, "heatmap_loss": 0.00048, "acc_pose": 0.87353, "loss": 0.00048, "grad_norm": 0.00093, "time": 0.71262}
+{"mode": "train", "epoch": 187, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00047, "acc_pose": 0.86678, "loss": 0.00047, "grad_norm": 0.00088, "time": 0.6568}
+{"mode": "train", "epoch": 187, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00048, "acc_pose": 0.8663, "loss": 0.00048, "grad_norm": 0.00092, "time": 0.65727}
+{"mode": "train", "epoch": 187, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00048, "acc_pose": 0.86625, "loss": 0.00048, "grad_norm": 0.0009, "time": 0.65664}
+{"mode": "train", "epoch": 187, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00048, "acc_pose": 0.86853, "loss": 0.00048, "grad_norm": 0.00098, "time": 0.65681}
+{"mode": "train", "epoch": 188, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05633, "heatmap_loss": 0.00047, "acc_pose": 0.8657, "loss": 0.00047, "grad_norm": 0.00091, "time": 0.71328}
+{"mode": "train", "epoch": 188, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00048, "acc_pose": 0.87236, "loss": 0.00048, "grad_norm": 0.0009, "time": 0.65674}
+{"mode": "train", "epoch": 188, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00048, "acc_pose": 0.86851, "loss": 0.00048, "grad_norm": 0.00099, "time": 0.65651}
+{"mode": "train", "epoch": 188, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00035, "heatmap_loss": 0.00048, "acc_pose": 0.86704, "loss": 0.00048, "grad_norm": 0.0009, "time": 0.65692}
+{"mode": "train", "epoch": 188, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00048, "acc_pose": 0.87131, "loss": 0.00048, "grad_norm": 0.00091, "time": 0.65688}
+{"mode": "train", "epoch": 189, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05741, "heatmap_loss": 0.00048, "acc_pose": 0.87024, "loss": 0.00048, "grad_norm": 0.00087, "time": 0.7138}
+{"mode": "train", "epoch": 189, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00047, "acc_pose": 0.86724, "loss": 0.00047, "grad_norm": 0.00091, "time": 0.65687}
+{"mode": "train", "epoch": 189, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00048, "acc_pose": 0.86375, "loss": 0.00048, "grad_norm": 0.00094, "time": 0.65701}
+{"mode": "train", "epoch": 189, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00048, "acc_pose": 0.86574, "loss": 0.00048, "grad_norm": 0.00089, "time": 0.65724}
+{"mode": "train", "epoch": 189, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00047, "acc_pose": 0.87527, "loss": 0.00047, "grad_norm": 0.00083, "time": 0.65705}
+{"mode": "train", "epoch": 190, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05735, "heatmap_loss": 0.00048, "acc_pose": 0.86331, "loss": 0.00048, "grad_norm": 0.00096, "time": 0.71426}
+{"mode": "train", "epoch": 190, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00048, "acc_pose": 0.87089, "loss": 0.00048, "grad_norm": 0.00091, "time": 0.6567}
+{"mode": "train", "epoch": 190, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00048, "acc_pose": 0.86881, "loss": 0.00048, "grad_norm": 0.00089, "time": 0.6566}
+{"mode": "train", "epoch": 190, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00047, "acc_pose": 0.87141, "loss": 0.00047, "grad_norm": 0.00087, "time": 0.65702}
+{"mode": "train", "epoch": 190, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00048, "acc_pose": 0.87044, "loss": 0.00048, "grad_norm": 0.00088, "time": 0.65673}
+{"mode": "val", "epoch": 190, "iter": 407, "lr": 0.0, "AP": 0.78185, "AP .5": 0.91344, "AP .75": 0.84973, "AP (M)": 0.70883, "AP (L)": 0.80934, "AR": 0.83336, "AR .5": 0.95246, "AR .75": 0.89185, "AR (M)": 0.79219, "AR (L)": 0.89368}
+{"mode": "train", "epoch": 191, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05561, "heatmap_loss": 0.00048, "acc_pose": 0.87075, "loss": 0.00048, "grad_norm": 0.0009, "time": 0.70966}
+{"mode": "train", "epoch": 191, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00048, "acc_pose": 0.86917, "loss": 0.00048, "grad_norm": 0.00093, "time": 0.65675}
+{"mode": "train", "epoch": 191, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00048, "acc_pose": 0.86928, "loss": 0.00048, "grad_norm": 0.00092, "time": 0.65702}
+{"mode": "train", "epoch": 191, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00048, "acc_pose": 0.86987, "loss": 0.00048, "grad_norm": 0.0009, "time": 0.6569}
+{"mode": "train", "epoch": 191, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00028, "heatmap_loss": 0.00047, "acc_pose": 0.86658, "loss": 0.00047, "grad_norm": 0.0009, "time": 0.65667}
+{"mode": "train", "epoch": 192, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05717, "heatmap_loss": 0.00048, "acc_pose": 0.8661, "loss": 0.00048, "grad_norm": 0.00098, "time": 0.71503}
+{"mode": "train", "epoch": 192, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00047, "acc_pose": 0.8691, "loss": 0.00047, "grad_norm": 0.00089, "time": 0.6567}
+{"mode": "train", "epoch": 192, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00047, "acc_pose": 0.86644, "loss": 0.00047, "grad_norm": 0.00092, "time": 0.65688}
+{"mode": "train", "epoch": 192, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00048, "acc_pose": 0.86721, "loss": 0.00048, "grad_norm": 0.00094, "time": 0.65673}
+{"mode": "train", "epoch": 192, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00048, "acc_pose": 0.87417, "loss": 0.00048, "grad_norm": 0.0009, "time": 0.65683}
+{"mode": "train", "epoch": 193, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05686, "heatmap_loss": 0.00048, "acc_pose": 0.86665, "loss": 0.00048, "grad_norm": 0.00092, "time": 0.7135}
+{"mode": "train", "epoch": 193, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00047, "acc_pose": 0.87074, "loss": 0.00047, "grad_norm": 0.00086, "time": 0.65703}
+{"mode": "train", "epoch": 193, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00048, "acc_pose": 0.86945, "loss": 0.00048, "grad_norm": 0.00095, "time": 0.65705}
+{"mode": "train", "epoch": 193, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00047, "acc_pose": 0.8672, "loss": 0.00047, "grad_norm": 0.0009, "time": 0.65663}
+{"mode": "train", "epoch": 193, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00047, "acc_pose": 0.868, "loss": 0.00047, "grad_norm": 0.00091, "time": 0.65701}
+{"mode": "train", "epoch": 194, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05701, "heatmap_loss": 0.00048, "acc_pose": 0.87018, "loss": 0.00048, "grad_norm": 0.00093, "time": 0.71435}
+{"mode": "train", "epoch": 194, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00047, "acc_pose": 0.8689, "loss": 0.00047, "grad_norm": 0.0009, "time": 0.65704}
+{"mode": "train", "epoch": 194, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00047, "acc_pose": 0.86628, "loss": 0.00047, "grad_norm": 0.00091, "time": 0.65696}
+{"mode": "train", "epoch": 194, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00047, "acc_pose": 0.87296, "loss": 0.00047, "grad_norm": 0.00092, "time": 0.65699}
+{"mode": "train", "epoch": 194, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00047, "acc_pose": 0.87231, "loss": 0.00047, "grad_norm": 0.00092, "time": 0.65731}
+{"mode": "train", "epoch": 195, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05666, "heatmap_loss": 0.00047, "acc_pose": 0.86747, "loss": 0.00047, "grad_norm": 0.0009, "time": 0.71438}
+{"mode": "train", "epoch": 195, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00047, "acc_pose": 0.86382, "loss": 0.00047, "grad_norm": 0.00093, "time": 0.65702}
+{"mode": "train", "epoch": 195, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00047, "acc_pose": 0.86944, "loss": 0.00047, "grad_norm": 0.00094, "time": 0.65691}
+{"mode": "train", "epoch": 195, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00034, "heatmap_loss": 0.00047, "acc_pose": 0.86731, "loss": 0.00047, "grad_norm": 0.00097, "time": 0.65708}
+{"mode": "train", "epoch": 195, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00047, "acc_pose": 0.87118, "loss": 0.00047, "grad_norm": 0.00099, "time": 0.65662}
+{"mode": "train", "epoch": 196, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05715, "heatmap_loss": 0.00047, "acc_pose": 0.86723, "loss": 0.00047, "grad_norm": 0.00093, "time": 0.71372}
+{"mode": "train", "epoch": 196, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00047, "acc_pose": 0.87617, "loss": 0.00047, "grad_norm": 0.0009, "time": 0.65621}
+{"mode": "train", "epoch": 196, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00048, "acc_pose": 0.86245, "loss": 0.00048, "grad_norm": 0.00093, "time": 0.65699}
+{"mode": "train", "epoch": 196, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00047, "acc_pose": 0.87498, "loss": 0.00047, "grad_norm": 0.00091, "time": 0.65708}
+{"mode": "train", "epoch": 196, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00047, "acc_pose": 0.86658, "loss": 0.00047, "grad_norm": 0.00093, "time": 0.65694}
+{"mode": "train", "epoch": 197, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05728, "heatmap_loss": 0.00047, "acc_pose": 0.87066, "loss": 0.00047, "grad_norm": 0.00092, "time": 0.71417}
+{"mode": "train", "epoch": 197, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00047, "acc_pose": 0.87252, "loss": 0.00047, "grad_norm": 0.00088, "time": 0.65699}
+{"mode": "train", "epoch": 197, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00047, "acc_pose": 0.86194, "loss": 0.00047, "grad_norm": 0.00097, "time": 0.657}
+{"mode": "train", "epoch": 197, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00047, "acc_pose": 0.86723, "loss": 0.00047, "grad_norm": 0.00092, "time": 0.65684}
+{"mode": "train", "epoch": 197, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00047, "acc_pose": 0.87027, "loss": 0.00047, "grad_norm": 0.00095, "time": 0.65681}
+{"mode": "train", "epoch": 198, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05727, "heatmap_loss": 0.00047, "acc_pose": 0.87597, "loss": 0.00047, "grad_norm": 0.00092, "time": 0.71412}
+{"mode": "train", "epoch": 198, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00048, "acc_pose": 0.86943, "loss": 0.00048, "grad_norm": 0.00092, "time": 0.65694}
+{"mode": "train", "epoch": 198, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00039, "heatmap_loss": 0.00047, "acc_pose": 0.86821, "loss": 0.00047, "grad_norm": 0.00096, "time": 0.65695}
+{"mode": "train", "epoch": 198, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00047, "acc_pose": 0.8656, "loss": 0.00047, "grad_norm": 0.00094, "time": 0.65702}
+{"mode": "train", "epoch": 198, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00034, "heatmap_loss": 0.00047, "acc_pose": 0.87097, "loss": 0.00047, "grad_norm": 0.0009, "time": 0.65753}
+{"mode": "train", "epoch": 199, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05705, "heatmap_loss": 0.00047, "acc_pose": 0.87127, "loss": 0.00047, "grad_norm": 0.00092, "time": 0.71421}
+{"mode": "train", "epoch": 199, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00047, "acc_pose": 0.87154, "loss": 0.00047, "grad_norm": 0.0009, "time": 0.65717}
+{"mode": "train", "epoch": 199, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00028, "heatmap_loss": 0.00048, "acc_pose": 0.86719, "loss": 0.00048, "grad_norm": 0.00095, "time": 0.65721}
+{"mode": "train", "epoch": 199, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00047, "acc_pose": 0.86873, "loss": 0.00047, "grad_norm": 0.00095, "time": 0.65707}
+{"mode": "train", "epoch": 199, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00047, "acc_pose": 0.87264, "loss": 0.00047, "grad_norm": 0.00095, "time": 0.65706}
+{"mode": "train", "epoch": 200, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.0592, "heatmap_loss": 0.00047, "acc_pose": 0.86813, "loss": 0.00047, "grad_norm": 0.00094, "time": 0.71561}
+{"mode": "train", "epoch": 200, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00047, "acc_pose": 0.86916, "loss": 0.00047, "grad_norm": 0.00096, "time": 0.65676}
+{"mode": "train", "epoch": 200, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00034, "heatmap_loss": 0.00047, "acc_pose": 0.86388, "loss": 0.00047, "grad_norm": 0.00093, "time": 0.65706}
+{"mode": "train", "epoch": 200, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00039, "heatmap_loss": 0.00047, "acc_pose": 0.87428, "loss": 0.00047, "grad_norm": 0.00091, "time": 0.65703}
+{"mode": "train", "epoch": 200, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00047, "acc_pose": 0.86857, "loss": 0.00047, "grad_norm": 0.00089, "time": 0.65746}
+{"mode": "val", "epoch": 200, "iter": 407, "lr": 0.0, "AP": 0.78268, "AP .5": 0.91405, "AP .75": 0.8517, "AP (M)": 0.70939, "AP (L)": 0.81027, "AR": 0.83459, "AR .5": 0.9534, "AR .75": 0.89421, "AR (M)": 0.79334, "AR (L)": 0.89498}
+{"mode": "train", "epoch": 201, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05586, "heatmap_loss": 0.00047, "acc_pose": 0.8669, "loss": 0.00047, "grad_norm": 0.00095, "time": 0.7095}
+{"mode": "train", "epoch": 201, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00029, "heatmap_loss": 0.00047, "acc_pose": 0.86595, "loss": 0.00047, "grad_norm": 0.00087, "time": 0.65619}
+{"mode": "train", "epoch": 201, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00047, "acc_pose": 0.86781, "loss": 0.00047, "grad_norm": 0.00095, "time": 0.65682}
+{"mode": "train", "epoch": 201, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00047, "acc_pose": 0.87448, "loss": 0.00047, "grad_norm": 0.00088, "time": 0.65671}
+{"mode": "train", "epoch": 201, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00036, "heatmap_loss": 0.00047, "acc_pose": 0.86799, "loss": 0.00047, "grad_norm": 0.00091, "time": 0.65678}
+{"mode": "train", "epoch": 202, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05686, "heatmap_loss": 0.00047, "acc_pose": 0.86668, "loss": 0.00047, "grad_norm": 0.00088, "time": 0.71356}
+{"mode": "train", "epoch": 202, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00048, "acc_pose": 0.87259, "loss": 0.00048, "grad_norm": 0.0009, "time": 0.65658}
+{"mode": "train", "epoch": 202, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00047, "acc_pose": 0.86752, "loss": 0.00047, "grad_norm": 0.00093, "time": 0.65678}
+{"mode": "train", "epoch": 202, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00047, "acc_pose": 0.86947, "loss": 0.00047, "grad_norm": 0.00093, "time": 0.65676}
+{"mode": "train", "epoch": 202, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00047, "acc_pose": 0.87506, "loss": 0.00047, "grad_norm": 0.00086, "time": 0.65645}
+{"mode": "train", "epoch": 203, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.0562, "heatmap_loss": 0.00047, "acc_pose": 0.86458, "loss": 0.00047, "grad_norm": 0.00091, "time": 0.71249}
+{"mode": "train", "epoch": 203, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00047, "acc_pose": 0.87133, "loss": 0.00047, "grad_norm": 0.00088, "time": 0.65669}
+{"mode": "train", "epoch": 203, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00047, "acc_pose": 0.87278, "loss": 0.00047, "grad_norm": 0.00087, "time": 0.65708}
+{"mode": "train", "epoch": 203, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00036, "heatmap_loss": 0.00047, "acc_pose": 0.86824, "loss": 0.00047, "grad_norm": 0.00095, "time": 0.65682}
+{"mode": "train", "epoch": 203, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00047, "acc_pose": 0.87015, "loss": 0.00047, "grad_norm": 0.00088, "time": 0.6576}
+{"mode": "train", "epoch": 204, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05734, "heatmap_loss": 0.00047, "acc_pose": 0.86884, "loss": 0.00047, "grad_norm": 0.00091, "time": 0.71482}
+{"mode": "train", "epoch": 204, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00047, "acc_pose": 0.87174, "loss": 0.00047, "grad_norm": 0.00086, "time": 0.65717}
+{"mode": "train", "epoch": 204, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00047, "acc_pose": 0.87004, "loss": 0.00047, "grad_norm": 0.0009, "time": 0.65708}
+{"mode": "train", "epoch": 204, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00036, "heatmap_loss": 0.00047, "acc_pose": 0.86835, "loss": 0.00047, "grad_norm": 0.00089, "time": 0.65708}
+{"mode": "train", "epoch": 204, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00047, "acc_pose": 0.86763, "loss": 0.00047, "grad_norm": 0.00089, "time": 0.65735}
+{"mode": "train", "epoch": 205, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05738, "heatmap_loss": 0.00047, "acc_pose": 0.87289, "loss": 0.00047, "grad_norm": 0.00088, "time": 0.71413}
+{"mode": "train", "epoch": 205, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00047, "acc_pose": 0.86988, "loss": 0.00047, "grad_norm": 0.00085, "time": 0.65691}
+{"mode": "train", "epoch": 205, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00047, "acc_pose": 0.87018, "loss": 0.00047, "grad_norm": 0.00093, "time": 0.65714}
+{"mode": "train", "epoch": 205, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00047, "acc_pose": 0.87679, "loss": 0.00047, "grad_norm": 0.00087, "time": 0.65687}
+{"mode": "train", "epoch": 205, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00047, "acc_pose": 0.87297, "loss": 0.00047, "grad_norm": 0.00089, "time": 0.65685}
+{"mode": "train", "epoch": 206, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05756, "heatmap_loss": 0.00047, "acc_pose": 0.87096, "loss": 0.00047, "grad_norm": 0.00089, "time": 0.71383}
+{"mode": "train", "epoch": 206, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00044, "heatmap_loss": 0.00047, "acc_pose": 0.86364, "loss": 0.00047, "grad_norm": 0.00095, "time": 0.65681}
+{"mode": "train", "epoch": 206, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00035, "heatmap_loss": 0.00047, "acc_pose": 0.86934, "loss": 0.00047, "grad_norm": 0.0009, "time": 0.65669}
+{"mode": "train", "epoch": 206, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00034, "heatmap_loss": 0.00047, "acc_pose": 0.87196, "loss": 0.00047, "grad_norm": 0.00094, "time": 0.65704}
+{"mode": "train", "epoch": 206, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00047, "acc_pose": 0.87375, "loss": 0.00047, "grad_norm": 0.00087, "time": 0.65715}
+{"mode": "train", "epoch": 207, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05672, "heatmap_loss": 0.00047, "acc_pose": 0.86894, "loss": 0.00047, "grad_norm": 0.00088, "time": 0.71386}
+{"mode": "train", "epoch": 207, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00047, "acc_pose": 0.86576, "loss": 0.00047, "grad_norm": 0.0009, "time": 0.65703}
+{"mode": "train", "epoch": 207, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00047, "acc_pose": 0.86995, "loss": 0.00047, "grad_norm": 0.0009, "time": 0.65698}
+{"mode": "train", "epoch": 207, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00047, "acc_pose": 0.86979, "loss": 0.00047, "grad_norm": 0.00087, "time": 0.65662}
+{"mode": "train", "epoch": 207, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00047, "acc_pose": 0.8701, "loss": 0.00047, "grad_norm": 0.00094, "time": 0.65677}
+{"mode": "train", "epoch": 208, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05685, "heatmap_loss": 0.00047, "acc_pose": 0.87002, "loss": 0.00047, "grad_norm": 0.00088, "time": 0.71378}
+{"mode": "train", "epoch": 208, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00047, "acc_pose": 0.86923, "loss": 0.00047, "grad_norm": 0.00092, "time": 0.657}
+{"mode": "train", "epoch": 208, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00047, "acc_pose": 0.86864, "loss": 0.00047, "grad_norm": 0.0009, "time": 0.65702}
+{"mode": "train", "epoch": 208, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00047, "acc_pose": 0.87145, "loss": 0.00047, "grad_norm": 0.00089, "time": 0.6567}
+{"mode": "train", "epoch": 208, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00047, "acc_pose": 0.87036, "loss": 0.00047, "grad_norm": 0.00088, "time": 0.65686}
+{"mode": "train", "epoch": 209, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05764, "heatmap_loss": 0.00047, "acc_pose": 0.87082, "loss": 0.00047, "grad_norm": 0.00087, "time": 0.71463}
+{"mode": "train", "epoch": 209, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00047, "acc_pose": 0.87421, "loss": 0.00047, "grad_norm": 0.00092, "time": 0.65657}
+{"mode": "train", "epoch": 209, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00047, "acc_pose": 0.86906, "loss": 0.00047, "grad_norm": 0.0009, "time": 0.65694}
+{"mode": "train", "epoch": 209, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.0003, "heatmap_loss": 0.00047, "acc_pose": 0.87368, "loss": 0.00047, "grad_norm": 0.0009, "time": 0.65677}
+{"mode": "train", "epoch": 209, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00031, "heatmap_loss": 0.00047, "acc_pose": 0.87518, "loss": 0.00047, "grad_norm": 0.0009, "time": 0.65698}
+{"mode": "train", "epoch": 210, "iter": 50, "lr": 0.0, "memory": 8639, "data_time": 0.05699, "heatmap_loss": 0.00047, "acc_pose": 0.86707, "loss": 0.00047, "grad_norm": 0.00091, "time": 0.71379}
+{"mode": "train", "epoch": 210, "iter": 100, "lr": 0.0, "memory": 8639, "data_time": 0.00034, "heatmap_loss": 0.00047, "acc_pose": 0.87464, "loss": 0.00047, "grad_norm": 0.00089, "time": 0.65728}
+{"mode": "train", "epoch": 210, "iter": 150, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00047, "acc_pose": 0.86555, "loss": 0.00047, "grad_norm": 0.00091, "time": 0.65717}
+{"mode": "train", "epoch": 210, "iter": 200, "lr": 0.0, "memory": 8639, "data_time": 0.00032, "heatmap_loss": 0.00047, "acc_pose": 0.87329, "loss": 0.00047, "grad_norm": 0.00088, "time": 0.65737}
+{"mode": "train", "epoch": 210, "iter": 250, "lr": 0.0, "memory": 8639, "data_time": 0.00033, "heatmap_loss": 0.00047, "acc_pose": 0.8687, "loss": 0.00047, "grad_norm": 0.00091, "time": 0.65728}
+{"mode": "val", "epoch": 210, "iter": 407, "lr": 0.0, "AP": 0.78321, "AP .5": 0.91374, "AP .75": 0.85213, "AP (M)": 0.7103, "AP (L)": 0.81079, "AR": 0.83487, "AR .5": 0.95293, "AR .75": 0.89452, "AR (M)": 0.79342, "AR (L)": 0.89554}
diff --git a/vendor/ViTPose/mmcv_custom/__init__.py b/vendor/ViTPose/mmcv_custom/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..23cb66e9336d6e87483eba5313976c3aa2de5e61
--- /dev/null
+++ b/vendor/ViTPose/mmcv_custom/__init__.py
@@ -0,0 +1,7 @@
+# -*- coding: utf-8 -*-
+
+from .checkpoint import load_checkpoint
+from .layer_decay_optimizer_constructor import LayerDecayOptimizerConstructor
+from .apex_runner.optimizer import DistOptimizerHook_custom
+
+__all__ = ['load_checkpoint', 'LayerDecayOptimizerConstructor', 'DistOptimizerHook_custom']
diff --git a/vendor/ViTPose/mmcv_custom/apex_runner/__init__.py b/vendor/ViTPose/mmcv_custom/apex_runner/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..8b90d2cbaa978c67c83ce3a8393d172d5714e210
--- /dev/null
+++ b/vendor/ViTPose/mmcv_custom/apex_runner/__init__.py
@@ -0,0 +1,8 @@
+# Copyright (c) Open-MMLab. All rights reserved.
+from .checkpoint import save_checkpoint
+from .apex_iter_based_runner import IterBasedRunnerAmp
+
+
+__all__ = [
+ 'save_checkpoint', 'IterBasedRunnerAmp',
+]
diff --git a/vendor/ViTPose/mmcv_custom/apex_runner/apex_iter_based_runner.py b/vendor/ViTPose/mmcv_custom/apex_runner/apex_iter_based_runner.py
new file mode 100644
index 0000000000000000000000000000000000000000..571733b091574607ba1ba39648da6a051a769d34
--- /dev/null
+++ b/vendor/ViTPose/mmcv_custom/apex_runner/apex_iter_based_runner.py
@@ -0,0 +1,103 @@
+# Copyright (c) Open-MMLab. All rights reserved.
+import os.path as osp
+import platform
+import shutil
+
+import torch
+from torch.optim import Optimizer
+
+import mmcv
+from mmcv.runner import RUNNERS, IterBasedRunner
+from .checkpoint import save_checkpoint
+
+try:
+ import apex
+except:
+ print('apex is not installed')
+
+
+@RUNNERS.register_module()
+class IterBasedRunnerAmp(IterBasedRunner):
+ """Iteration-based Runner with AMP support.
+
+ This runner train models iteration by iteration.
+ """
+
+ def save_checkpoint(self,
+ out_dir,
+ filename_tmpl='iter_{}.pth',
+ meta=None,
+ save_optimizer=True,
+ create_symlink=False):
+ """Save checkpoint to file.
+
+ Args:
+ out_dir (str): Directory to save checkpoint files.
+ filename_tmpl (str, optional): Checkpoint file template.
+ Defaults to 'iter_{}.pth'.
+ meta (dict, optional): Metadata to be saved in checkpoint.
+ Defaults to None.
+ save_optimizer (bool, optional): Whether save optimizer.
+ Defaults to True.
+ create_symlink (bool, optional): Whether create symlink to the
+ latest checkpoint file. Defaults to True.
+ """
+ if meta is None:
+ meta = dict(iter=self.iter + 1, epoch=self.epoch + 1)
+ elif isinstance(meta, dict):
+ meta.update(iter=self.iter + 1, epoch=self.epoch + 1)
+ else:
+ raise TypeError(
+ f'meta should be a dict or None, but got {type(meta)}')
+ if self.meta is not None:
+ meta.update(self.meta)
+
+ filename = filename_tmpl.format(self.iter + 1)
+ filepath = osp.join(out_dir, filename)
+ optimizer = self.optimizer if save_optimizer else None
+ save_checkpoint(self.model, filepath, optimizer=optimizer, meta=meta)
+ # in some environments, `os.symlink` is not supported, you may need to
+ # set `create_symlink` to False
+ # if create_symlink:
+ # dst_file = osp.join(out_dir, 'latest.pth')
+ # if platform.system() != 'Windows':
+ # mmcv.symlink(filename, dst_file)
+ # else:
+ # shutil.copy(filepath, dst_file)
+
+ def resume(self,
+ checkpoint,
+ resume_optimizer=True,
+ map_location='default'):
+ if map_location == 'default':
+ if torch.cuda.is_available():
+ device_id = torch.cuda.current_device()
+ checkpoint = self.load_checkpoint(
+ checkpoint,
+ map_location=lambda storage, loc: storage.cuda(device_id))
+ else:
+ checkpoint = self.load_checkpoint(checkpoint)
+ else:
+ checkpoint = self.load_checkpoint(
+ checkpoint, map_location=map_location)
+
+ self._epoch = checkpoint['meta']['epoch']
+ self._iter = checkpoint['meta']['iter']
+ self._inner_iter = checkpoint['meta']['iter']
+ if 'optimizer' in checkpoint and resume_optimizer:
+ if isinstance(self.optimizer, Optimizer):
+ self.optimizer.load_state_dict(checkpoint['optimizer'])
+ elif isinstance(self.optimizer, dict):
+ for k in self.optimizer.keys():
+ self.optimizer[k].load_state_dict(
+ checkpoint['optimizer'][k])
+ else:
+ raise TypeError(
+ 'Optimizer should be dict or torch.optim.Optimizer '
+ f'but got {type(self.optimizer)}')
+
+ if 'amp' in checkpoint:
+ apex.amp.load_state_dict(checkpoint['amp'])
+ self.logger.info('load amp state dict')
+
+ self.logger.info(f'resumed from epoch: {self.epoch}, iter {self.iter}')
diff --git a/vendor/ViTPose/mmcv_custom/apex_runner/checkpoint.py b/vendor/ViTPose/mmcv_custom/apex_runner/checkpoint.py
new file mode 100644
index 0000000000000000000000000000000000000000..b04167e0fc5f16bc33e793830ebb9c4ef15ef1ed
--- /dev/null
+++ b/vendor/ViTPose/mmcv_custom/apex_runner/checkpoint.py
@@ -0,0 +1,85 @@
+# Copyright (c) Open-MMLab. All rights reserved.
+import os.path as osp
+import time
+from tempfile import TemporaryDirectory
+
+import torch
+from torch.optim import Optimizer
+
+import mmcv
+from mmcv.parallel import is_module_wrapper
+from mmcv.runner.checkpoint import weights_to_cpu, get_state_dict
+
+try:
+ import apex
+except:
+ print('apex is not installed')
+
+
+def save_checkpoint(model, filename, optimizer=None, meta=None):
+ """Save checkpoint to file.
+
+ The checkpoint will have 4 fields: ``meta``, ``state_dict`` and
+ ``optimizer``, ``amp``. By default ``meta`` will contain version
+ and time info.
+
+ Args:
+ model (Module): Module whose params are to be saved.
+ filename (str): Checkpoint filename.
+ optimizer (:obj:`Optimizer`, optional): Optimizer to be saved.
+ meta (dict, optional): Metadata to be saved in checkpoint.
+ """
+ if meta is None:
+ meta = {}
+ elif not isinstance(meta, dict):
+ raise TypeError(f'meta must be a dict or None, but got {type(meta)}')
+ meta.update(mmcv_version=mmcv.__version__, time=time.asctime())
+
+ if is_module_wrapper(model):
+ model = model.module
+
+ if hasattr(model, 'CLASSES') and model.CLASSES is not None:
+ # save class name to the meta
+ meta.update(CLASSES=model.CLASSES)
+
+ checkpoint = {
+ 'meta': meta,
+ 'state_dict': weights_to_cpu(get_state_dict(model))
+ }
+ # save optimizer state dict in the checkpoint
+ if isinstance(optimizer, Optimizer):
+ checkpoint['optimizer'] = optimizer.state_dict()
+ elif isinstance(optimizer, dict):
+ checkpoint['optimizer'] = {}
+ for name, optim in optimizer.items():
+ checkpoint['optimizer'][name] = optim.state_dict()
+
+ # save amp state dict in the checkpoint
+ checkpoint['amp'] = apex.amp.state_dict()
+
+ if filename.startswith('pavi://'):
+ try:
+ from pavi import modelcloud
+ from pavi.exception import NodeNotFoundError
+ except ImportError:
+ raise ImportError(
+ 'Please install pavi to load checkpoint from modelcloud.')
+ model_path = filename[7:]
+ root = modelcloud.Folder()
+ model_dir, model_name = osp.split(model_path)
+ try:
+ model = modelcloud.get(model_dir)
+ except NodeNotFoundError:
+ model = root.create_training_model(model_dir)
+ with TemporaryDirectory() as tmp_dir:
+ checkpoint_file = osp.join(tmp_dir, model_name)
+ with open(checkpoint_file, 'wb') as f:
+ torch.save(checkpoint, f)
+ f.flush()
+ model.create_file(checkpoint_file, name=model_name)
+ else:
+ mmcv.mkdir_or_exist(osp.dirname(filename))
+ # immediately flush buffer
+ with open(filename, 'wb') as f:
+ torch.save(checkpoint, f)
+ f.flush()
diff --git a/vendor/ViTPose/mmcv_custom/apex_runner/optimizer.py b/vendor/ViTPose/mmcv_custom/apex_runner/optimizer.py
new file mode 100644
index 0000000000000000000000000000000000000000..dbc42989b569e63bbf008bbbd2700fe217399e9f
--- /dev/null
+++ b/vendor/ViTPose/mmcv_custom/apex_runner/optimizer.py
@@ -0,0 +1,33 @@
+from mmcv.runner import OptimizerHook, HOOKS
+try:
+ import apex
+except:
+ print('apex is not installed')
+
+
+@HOOKS.register_module()
+class DistOptimizerHook_custom(OptimizerHook):
+ """Optimizer hook for distributed training."""
+
+ def __init__(self, update_interval=1, grad_clip=None, coalesce=True, bucket_size_mb=-1, use_fp16=False):
+ self.grad_clip = grad_clip
+ self.coalesce = coalesce
+ self.bucket_size_mb = bucket_size_mb
+ self.update_interval = update_interval
+ self.use_fp16 = use_fp16
+
+ def before_run(self, runner):
+ runner.optimizer.zero_grad()
+
+ def after_train_iter(self, runner):
+ runner.outputs['loss'] /= self.update_interval
+ if self.use_fp16:
+ with apex.amp.scale_loss(runner.outputs['loss'], runner.optimizer) as scaled_loss:
+ scaled_loss.backward()
+ else:
+ runner.outputs['loss'].backward()
+ if self.every_n_iters(runner, self.update_interval):
+ if self.grad_clip is not None:
+ self.clip_grads(runner.model.parameters())
+ runner.optimizer.step()
+ runner.optimizer.zero_grad()
diff --git a/vendor/ViTPose/mmcv_custom/checkpoint.py b/vendor/ViTPose/mmcv_custom/checkpoint.py
new file mode 100644
index 0000000000000000000000000000000000000000..52c9bac8a5eb89a4009e837ea338cd271e0a5bc7
--- /dev/null
+++ b/vendor/ViTPose/mmcv_custom/checkpoint.py
@@ -0,0 +1,552 @@
+# Copyright (c) Open-MMLab. All rights reserved.
+import io
+import os
+import os.path as osp
+import pkgutil
+import time
+import warnings
+from collections import OrderedDict
+from importlib import import_module
+from tempfile import TemporaryDirectory
+
+import torch
+import torchvision
+from torch.optim import Optimizer
+from torch.utils import model_zoo
+from torch.nn import functional as F
+
+import mmcv
+from mmcv.fileio import FileClient
+from mmcv.fileio import load as load_file
+from mmcv.parallel import is_module_wrapper
+from mmcv.utils import mkdir_or_exist
+from mmcv.runner import get_dist_info
+
+from scipy import interpolate
+import numpy as np
+import math
+import re
+import copy
+
+ENV_MMCV_HOME = 'MMCV_HOME'
+ENV_XDG_CACHE_HOME = 'XDG_CACHE_HOME'
+DEFAULT_CACHE_DIR = '~/.cache'
+
+
+def _get_mmcv_home():
+ mmcv_home = os.path.expanduser(
+ os.getenv(
+ ENV_MMCV_HOME,
+ os.path.join(
+ os.getenv(ENV_XDG_CACHE_HOME, DEFAULT_CACHE_DIR), 'mmcv')))
+
+ mkdir_or_exist(mmcv_home)
+ return mmcv_home
+
+
+def load_state_dict(module, state_dict, strict=False, logger=None):
+ """Load state_dict to a module.
+
+ This method is modified from :meth:`torch.nn.Module.load_state_dict`.
+ Default value for ``strict`` is set to ``False`` and the message for
+ param mismatch will be shown even if strict is False.
+
+ Args:
+ module (Module): Module that receives the state_dict.
+ state_dict (OrderedDict): Weights.
+ strict (bool): whether to strictly enforce that the keys
+ in :attr:`state_dict` match the keys returned by this module's
+ :meth:`~torch.nn.Module.state_dict` function. Default: ``False``.
+ logger (:obj:`logging.Logger`, optional): Logger to log the error
+ message. If not specified, print function will be used.
+ """
+ unexpected_keys = []
+ all_missing_keys = []
+ err_msg = []
+
+ metadata = getattr(state_dict, '_metadata', None)
+ state_dict = state_dict.copy()
+ if metadata is not None:
+ state_dict._metadata = metadata
+
+ # use _load_from_state_dict to enable checkpoint version control
+ def load(module, prefix=''):
+ # recursively check parallel module in case that the model has a
+ # complicated structure, e.g., nn.Module(nn.Module(DDP))
+ if is_module_wrapper(module):
+ module = module.module
+ local_metadata = {} if metadata is None else metadata.get(
+ prefix[:-1], {})
+ module._load_from_state_dict(state_dict, prefix, local_metadata, True,
+ all_missing_keys, unexpected_keys,
+ err_msg)
+ for name, child in module._modules.items():
+ if child is not None:
+ load(child, prefix + name + '.')
+
+ load(module)
+ load = None # break load->load reference cycle
+
+ # ignore "num_batches_tracked" of BN layers
+ missing_keys = [
+ key for key in all_missing_keys if 'num_batches_tracked' not in key
+ ]
+
+ if unexpected_keys:
+ err_msg.append('unexpected key in source '
+ f'state_dict: {", ".join(unexpected_keys)}\n')
+ if missing_keys:
+ err_msg.append(
+ f'missing keys in source state_dict: {", ".join(missing_keys)}\n')
+
+ rank, _ = get_dist_info()
+ if len(err_msg) > 0 and rank == 0:
+ err_msg.insert(
+ 0, 'The model and loaded state dict do not match exactly\n')
+ err_msg = '\n'.join(err_msg)
+ if strict:
+ raise RuntimeError(err_msg)
+ elif logger is not None:
+ logger.warning(err_msg)
+ else:
+ print(err_msg)
+
+
+def load_url_dist(url, model_dir=None, map_location="cpu"):
+ """In distributed setting, this function only download checkpoint at local
+ rank 0."""
+ rank, world_size = get_dist_info()
+ rank = int(os.environ.get('LOCAL_RANK', rank))
+ if rank == 0:
+ checkpoint = model_zoo.load_url(url, model_dir=model_dir, map_location=map_location)
+ if world_size > 1:
+ torch.distributed.barrier()
+ if rank > 0:
+ checkpoint = model_zoo.load_url(url, model_dir=model_dir, map_location=map_location)
+ return checkpoint
+
+
+def load_pavimodel_dist(model_path, map_location=None):
+ """In distributed setting, this function only download checkpoint at local
+ rank 0."""
+ try:
+ from pavi import modelcloud
+ except ImportError:
+ raise ImportError(
+ 'Please install pavi to load checkpoint from modelcloud.')
+ rank, world_size = get_dist_info()
+ rank = int(os.environ.get('LOCAL_RANK', rank))
+ if rank == 0:
+ model = modelcloud.get(model_path)
+ with TemporaryDirectory() as tmp_dir:
+ downloaded_file = osp.join(tmp_dir, model.name)
+ model.download(downloaded_file)
+ checkpoint = torch.load(downloaded_file, map_location=map_location)
+ if world_size > 1:
+ torch.distributed.barrier()
+ if rank > 0:
+ model = modelcloud.get(model_path)
+ with TemporaryDirectory() as tmp_dir:
+ downloaded_file = osp.join(tmp_dir, model.name)
+ model.download(downloaded_file)
+ checkpoint = torch.load(
+ downloaded_file, map_location=map_location)
+ return checkpoint
+
+
+def load_fileclient_dist(filename, backend, map_location):
+ """In distributed setting, this function only download checkpoint at local
+ rank 0."""
+ rank, world_size = get_dist_info()
+ rank = int(os.environ.get('LOCAL_RANK', rank))
+ allowed_backends = ['ceph']
+ if backend not in allowed_backends:
+ raise ValueError(f'Load from Backend {backend} is not supported.')
+ if rank == 0:
+ fileclient = FileClient(backend=backend)
+ buffer = io.BytesIO(fileclient.get(filename))
+ checkpoint = torch.load(buffer, map_location=map_location)
+ if world_size > 1:
+ torch.distributed.barrier()
+ if rank > 0:
+ fileclient = FileClient(backend=backend)
+ buffer = io.BytesIO(fileclient.get(filename))
+ checkpoint = torch.load(buffer, map_location=map_location)
+ return checkpoint
+
+
+def get_torchvision_models():
+ model_urls = dict()
+ for _, name, ispkg in pkgutil.walk_packages(torchvision.models.__path__):
+ if ispkg:
+ continue
+ _zoo = import_module(f'torchvision.models.{name}')
+ if hasattr(_zoo, 'model_urls'):
+ _urls = getattr(_zoo, 'model_urls')
+ model_urls.update(_urls)
+ return model_urls
+
+
+def get_external_models():
+ mmcv_home = _get_mmcv_home()
+ default_json_path = osp.join(mmcv.__path__[0], 'model_zoo/open_mmlab.json')
+ default_urls = load_file(default_json_path)
+ assert isinstance(default_urls, dict)
+ external_json_path = osp.join(mmcv_home, 'open_mmlab.json')
+ if osp.exists(external_json_path):
+ external_urls = load_file(external_json_path)
+ assert isinstance(external_urls, dict)
+ default_urls.update(external_urls)
+
+ return default_urls
+
+
+def get_mmcls_models():
+ mmcls_json_path = osp.join(mmcv.__path__[0], 'model_zoo/mmcls.json')
+ mmcls_urls = load_file(mmcls_json_path)
+
+ return mmcls_urls
+
+
+def get_deprecated_model_names():
+ deprecate_json_path = osp.join(mmcv.__path__[0],
+ 'model_zoo/deprecated.json')
+ deprecate_urls = load_file(deprecate_json_path)
+ assert isinstance(deprecate_urls, dict)
+
+ return deprecate_urls
+
+
+def _process_mmcls_checkpoint(checkpoint):
+ state_dict = checkpoint['state_dict']
+ new_state_dict = OrderedDict()
+ for k, v in state_dict.items():
+ if k.startswith('backbone.'):
+ new_state_dict[k[9:]] = v
+ new_checkpoint = dict(state_dict=new_state_dict)
+
+ return new_checkpoint
+
+
+def _load_checkpoint(filename, map_location=None):
+ """Load checkpoint from somewhere (modelzoo, file, url).
+
+ Args:
+ filename (str): Accept local filepath, URL, ``torchvision://xxx``,
+ ``open-mmlab://xxx``. Please refer to ``docs/model_zoo.md`` for
+ details.
+ map_location (str | None): Same as :func:`torch.load`. Default: None.
+
+ Returns:
+ dict | OrderedDict: The loaded checkpoint. It can be either an
+ OrderedDict storing model weights or a dict containing other
+ information, which depends on the checkpoint.
+ """
+ if filename.startswith('modelzoo://'):
+ warnings.warn('The URL scheme of "modelzoo://" is deprecated, please '
+ 'use "torchvision://" instead')
+ model_urls = get_torchvision_models()
+ model_name = filename[11:]
+ checkpoint = load_url_dist(model_urls[model_name])
+ elif filename.startswith('torchvision://'):
+ model_urls = get_torchvision_models()
+ model_name = filename[14:]
+ checkpoint = load_url_dist(model_urls[model_name])
+ elif filename.startswith('open-mmlab://'):
+ model_urls = get_external_models()
+ model_name = filename[13:]
+ deprecated_urls = get_deprecated_model_names()
+ if model_name in deprecated_urls:
+ warnings.warn(f'open-mmlab://{model_name} is deprecated in favor '
+ f'of open-mmlab://{deprecated_urls[model_name]}')
+ model_name = deprecated_urls[model_name]
+ model_url = model_urls[model_name]
+ # check if is url
+ if model_url.startswith(('http://', 'https://')):
+ checkpoint = load_url_dist(model_url)
+ else:
+ filename = osp.join(_get_mmcv_home(), model_url)
+ if not osp.isfile(filename):
+ raise IOError(f'{filename} is not a checkpoint file')
+ checkpoint = torch.load(filename, map_location=map_location)
+ elif filename.startswith('mmcls://'):
+ model_urls = get_mmcls_models()
+ model_name = filename[8:]
+ checkpoint = load_url_dist(model_urls[model_name])
+ checkpoint = _process_mmcls_checkpoint(checkpoint)
+ elif filename.startswith(('http://', 'https://')):
+ checkpoint = load_url_dist(filename)
+ elif filename.startswith('pavi://'):
+ model_path = filename[7:]
+ checkpoint = load_pavimodel_dist(model_path, map_location=map_location)
+ elif filename.startswith('s3://'):
+ checkpoint = load_fileclient_dist(
+ filename, backend='ceph', map_location=map_location)
+ else:
+ if not osp.isfile(filename):
+ raise IOError(f'{filename} is not a checkpoint file')
+ checkpoint = torch.load(filename, map_location=map_location)
+ return checkpoint
+
+
+def cosine_scheduler(base_value, final_value, epochs, niter_per_ep, warmup_epochs=0,
+ start_warmup_value=0, warmup_steps=-1):
+ warmup_schedule = np.array([])
+ warmup_iters = warmup_epochs * niter_per_ep
+ if warmup_steps > 0:
+ warmup_iters = warmup_steps
+ print("Set warmup steps = %d" % warmup_iters)
+ if warmup_epochs > 0:
+ warmup_schedule = np.linspace(start_warmup_value, base_value, warmup_iters)
+
+ iters = np.arange(epochs * niter_per_ep - warmup_iters)
+ schedule = np.array(
+ [final_value + 0.5 * (base_value - final_value) * (1 + math.cos(math.pi * i / (len(iters)))) for i in iters])
+
+ schedule = np.concatenate((warmup_schedule, schedule))
+
+ assert len(schedule) == epochs * niter_per_ep
+ return schedule
+
+
+def load_checkpoint(model,
+ filename,
+ map_location='cpu',
+ strict=False,
+ logger=None,
+ patch_padding='pad',
+ part_features=None
+ ):
+ """Load checkpoint from a file or URI.
+
+ Args:
+ model (Module): Module to load checkpoint.
+ filename (str): Accept local filepath, URL, ``torchvision://xxx``,
+ ``open-mmlab://xxx``. Please refer to ``docs/model_zoo.md`` for
+ details.
+ map_location (str): Same as :func:`torch.load`.
+ strict (bool): Whether to allow different params for the model and
+ checkpoint.
+ logger (:mod:`logging.Logger` or None): The logger for error message.
+ patch_padding (str): 'pad' or 'bilinear' or 'bicubic', used for interpolate patch embed from 14x14 to 16x16
+
+ Returns:
+ dict or OrderedDict: The loaded checkpoint.
+ """
+ checkpoint = _load_checkpoint(filename, map_location)
+ # OrderedDict is a subclass of dict
+ if not isinstance(checkpoint, dict):
+ raise RuntimeError(
+ f'No state_dict found in checkpoint file {filename}')
+ # get state_dict from checkpoint
+ if 'state_dict' in checkpoint:
+ state_dict = checkpoint['state_dict']
+ elif 'model' in checkpoint:
+ state_dict = checkpoint['model']
+ elif 'module' in checkpoint:
+ state_dict = checkpoint['module']
+ else:
+ state_dict = checkpoint
+ # strip prefix of state_dict
+ if list(state_dict.keys())[0].startswith('module.'):
+ state_dict = {k[7:]: v for k, v in state_dict.items()}
+
+ # for MoBY, load model of online branch
+ if sorted(list(state_dict.keys()))[0].startswith('encoder'):
+ state_dict = {k.replace('encoder.', ''): v for k, v in state_dict.items() if k.startswith('encoder.')}
+
+ rank, _ = get_dist_info()
+
+ if 'patch_embed.proj.weight' in state_dict:
+ proj_weight = state_dict['patch_embed.proj.weight']
+ orig_size = proj_weight.shape[2:]
+ current_size = model.patch_embed.proj.weight.shape[2:]
+ padding_size = current_size[0] - orig_size[0]
+ padding_l = padding_size // 2
+ padding_r = padding_size - padding_l
+ if orig_size != current_size:
+ if 'pad' in patch_padding:
+ proj_weight = torch.nn.functional.pad(proj_weight, (padding_l, padding_r, padding_l, padding_r))
+ elif 'bilinear' in patch_padding:
+ proj_weight = torch.nn.functional.interpolate(proj_weight, size=current_size, mode='bilinear', align_corners=False)
+ elif 'bicubic' in patch_padding:
+ proj_weight = torch.nn.functional.interpolate(proj_weight, size=current_size, mode='bicubic', align_corners=False)
+ state_dict['patch_embed.proj.weight'] = proj_weight
+
+ if 'pos_embed' in state_dict:
+ pos_embed_checkpoint = state_dict['pos_embed']
+ embedding_size = pos_embed_checkpoint.shape[-1]
+ H, W = model.patch_embed.patch_shape
+ num_patches = model.patch_embed.num_patches
+ num_extra_tokens = model.pos_embed.shape[-2] - num_patches
+ # height (== width) for the checkpoint position embedding
+ orig_size = int((pos_embed_checkpoint.shape[-2] - num_extra_tokens) ** 0.5)
+ if rank == 0:
+ print("Position interpolate from %dx%d to %dx%d" % (orig_size, orig_size, H, W))
+ extra_tokens = pos_embed_checkpoint[:, :num_extra_tokens]
+ # only the position tokens are interpolated
+ pos_tokens = pos_embed_checkpoint[:, num_extra_tokens:]
+ pos_tokens = pos_tokens.reshape(-1, orig_size, orig_size, embedding_size).permute(0, 3, 1, 2)
+ pos_tokens = torch.nn.functional.interpolate(
+ pos_tokens, size=(H, W), mode='bicubic', align_corners=False)
+ pos_tokens = pos_tokens.permute(0, 2, 3, 1).flatten(1, 2)
+ new_pos_embed = torch.cat((extra_tokens, pos_tokens), dim=1)
+ state_dict['pos_embed'] = new_pos_embed
+
+ new_state_dict = copy.deepcopy(state_dict)
+ if part_features is not None:
+ current_keys = list(model.state_dict().keys())
+ for key in current_keys:
+ if "mlp.experts" in key:
+ source_key = re.sub(r'experts.\d+.', 'fc2.', key)
+ new_state_dict[key] = state_dict[source_key][-part_features:]
+ elif 'fc2' in key:
+ new_state_dict[key] = state_dict[key][:-part_features]
+
+ # load state_dict
+ load_state_dict(model, new_state_dict, strict, logger)
+ return checkpoint
+
+
+def weights_to_cpu(state_dict):
+ """Copy a model state_dict to cpu.
+
+ Args:
+ state_dict (OrderedDict): Model weights on GPU.
+
+ Returns:
+ OrderedDict: Model weights on GPU.
+ """
+ state_dict_cpu = OrderedDict()
+ for key, val in state_dict.items():
+ state_dict_cpu[key] = val.cpu()
+ return state_dict_cpu
+
+
+def _save_to_state_dict(module, destination, prefix, keep_vars):
+ """Saves module state to `destination` dictionary.
+
+ This method is modified from :meth:`torch.nn.Module._save_to_state_dict`.
+
+ Args:
+ module (nn.Module): The module to generate state_dict.
+ destination (dict): A dict where state will be stored.
+ prefix (str): The prefix for parameters and buffers used in this
+ module.
+ """
+ for name, param in module._parameters.items():
+ if param is not None:
+ destination[prefix + name] = param if keep_vars else param.detach()
+ for name, buf in module._buffers.items():
+ # remove check of _non_persistent_buffers_set to allow nn.BatchNorm2d
+ if buf is not None:
+ destination[prefix + name] = buf if keep_vars else buf.detach()
+
+
+def get_state_dict(module, destination=None, prefix='', keep_vars=False):
+ """Returns a dictionary containing a whole state of the module.
+
+ Both parameters and persistent buffers (e.g. running averages) are
+ included. Keys are corresponding parameter and buffer names.
+
+ This method is modified from :meth:`torch.nn.Module.state_dict` to
+ recursively check parallel module in case that the model has a complicated
+ structure, e.g., nn.Module(nn.Module(DDP)).
+
+ Args:
+ module (nn.Module): The module to generate state_dict.
+ destination (OrderedDict): Returned dict for the state of the
+ module.
+ prefix (str): Prefix of the key.
+ keep_vars (bool): Whether to keep the variable property of the
+ parameters. Default: False.
+
+ Returns:
+ dict: A dictionary containing a whole state of the module.
+ """
+ # recursively check parallel module in case that the model has a
+ # complicated structure, e.g., nn.Module(nn.Module(DDP))
+ if is_module_wrapper(module):
+ module = module.module
+
+ # below is the same as torch.nn.Module.state_dict()
+ if destination is None:
+ destination = OrderedDict()
+ destination._metadata = OrderedDict()
+ destination._metadata[prefix[:-1]] = local_metadata = dict(
+ version=module._version)
+ _save_to_state_dict(module, destination, prefix, keep_vars)
+ for name, child in module._modules.items():
+ if child is not None:
+ get_state_dict(
+ child, destination, prefix + name + '.', keep_vars=keep_vars)
+ for hook in module._state_dict_hooks.values():
+ hook_result = hook(module, destination, prefix, local_metadata)
+ if hook_result is not None:
+ destination = hook_result
+ return destination
+
+
+def save_checkpoint(model, filename, optimizer=None, meta=None):
+ """Save checkpoint to file.
+
+ The checkpoint will have 3 fields: ``meta``, ``state_dict`` and
+ ``optimizer``. By default ``meta`` will contain version and time info.
+
+ Args:
+ model (Module): Module whose params are to be saved.
+ filename (str): Checkpoint filename.
+ optimizer (:obj:`Optimizer`, optional): Optimizer to be saved.
+ meta (dict, optional): Metadata to be saved in checkpoint.
+ """
+ if meta is None:
+ meta = {}
+ elif not isinstance(meta, dict):
+ raise TypeError(f'meta must be a dict or None, but got {type(meta)}')
+ meta.update(mmcv_version=mmcv.__version__, time=time.asctime())
+
+ if is_module_wrapper(model):
+ model = model.module
+
+ if hasattr(model, 'CLASSES') and model.CLASSES is not None:
+ # save class name to the meta
+ meta.update(CLASSES=model.CLASSES)
+
+ checkpoint = {
+ 'meta': meta,
+ 'state_dict': weights_to_cpu(get_state_dict(model))
+ }
+ # save optimizer state dict in the checkpoint
+ if isinstance(optimizer, Optimizer):
+ checkpoint['optimizer'] = optimizer.state_dict()
+ elif isinstance(optimizer, dict):
+ checkpoint['optimizer'] = {}
+ for name, optim in optimizer.items():
+ checkpoint['optimizer'][name] = optim.state_dict()
+
+ if filename.startswith('pavi://'):
+ try:
+ from pavi import modelcloud
+ from pavi.exception import NodeNotFoundError
+ except ImportError:
+ raise ImportError(
+ 'Please install pavi to load checkpoint from modelcloud.')
+ model_path = filename[7:]
+ root = modelcloud.Folder()
+ model_dir, model_name = osp.split(model_path)
+ try:
+ model = modelcloud.get(model_dir)
+ except NodeNotFoundError:
+ model = root.create_training_model(model_dir)
+ with TemporaryDirectory() as tmp_dir:
+ checkpoint_file = osp.join(tmp_dir, model_name)
+ with open(checkpoint_file, 'wb') as f:
+ torch.save(checkpoint, f)
+ f.flush()
+ model.create_file(checkpoint_file, name=model_name)
+ else:
+ mmcv.mkdir_or_exist(osp.dirname(filename))
+ # immediately flush buffer
+ with open(filename, 'wb') as f:
+ torch.save(checkpoint, f)
+ f.flush()
diff --git a/vendor/ViTPose/mmcv_custom/layer_decay_optimizer_constructor.py b/vendor/ViTPose/mmcv_custom/layer_decay_optimizer_constructor.py
new file mode 100644
index 0000000000000000000000000000000000000000..1357082e66d0a91c2544ee83440745f0e93b5175
--- /dev/null
+++ b/vendor/ViTPose/mmcv_custom/layer_decay_optimizer_constructor.py
@@ -0,0 +1,78 @@
+import json
+from mmcv.runner import OPTIMIZER_BUILDERS, DefaultOptimizerConstructor
+from mmcv.runner import get_dist_info
+
+
+def get_num_layer_for_vit(var_name, num_max_layer):
+ if var_name in ("backbone.cls_token", "backbone.mask_token", "backbone.pos_embed"):
+ return 0
+ elif var_name.startswith("backbone.patch_embed"):
+ return 0
+ elif var_name.startswith("backbone.blocks"):
+ layer_id = int(var_name.split('.')[2])
+ return layer_id + 1
+ else:
+ return num_max_layer - 1
+
+@OPTIMIZER_BUILDERS.register_module()
+class LayerDecayOptimizerConstructor(DefaultOptimizerConstructor):
+ def add_params(self, params, module, prefix='', is_dcn_module=None):
+ """Add all parameters of module to the params list.
+ The parameters of the given module will be added to the list of param
+ groups, with specific rules defined by paramwise_cfg.
+ Args:
+ params (list[dict]): A list of param groups, it will be modified
+ in place.
+ module (nn.Module): The module to be added.
+ prefix (str): The prefix of the module
+ is_dcn_module (int|float|None): If the current module is a
+ submodule of DCN, `is_dcn_module` will be passed to
+ control conv_offset layer's learning rate. Defaults to None.
+ """
+ parameter_groups = {}
+ print(self.paramwise_cfg)
+ num_layers = self.paramwise_cfg.get('num_layers') + 2
+ layer_decay_rate = self.paramwise_cfg.get('layer_decay_rate')
+ print("Build LayerDecayOptimizerConstructor %f - %d" % (layer_decay_rate, num_layers))
+ weight_decay = self.base_wd
+
+ for name, param in module.named_parameters():
+ if not param.requires_grad:
+ continue # frozen weights
+ if len(param.shape) == 1 or name.endswith(".bias") or 'pos_embed' in name:
+ group_name = "no_decay"
+ this_weight_decay = 0.
+ else:
+ group_name = "decay"
+ this_weight_decay = weight_decay
+
+ layer_id = get_num_layer_for_vit(name, num_layers)
+ group_name = "layer_%d_%s" % (layer_id, group_name)
+
+ if group_name not in parameter_groups:
+ scale = layer_decay_rate ** (num_layers - layer_id - 1)
+
+ parameter_groups[group_name] = {
+ "weight_decay": this_weight_decay,
+ "params": [],
+ "param_names": [],
+ "lr_scale": scale,
+ "group_name": group_name,
+ "lr": scale * self.base_lr,
+ }
+
+ parameter_groups[group_name]["params"].append(param)
+ parameter_groups[group_name]["param_names"].append(name)
+ rank, _ = get_dist_info()
+ if rank == 0:
+ to_display = {}
+ for key in parameter_groups:
+ to_display[key] = {
+ "param_names": parameter_groups[key]["param_names"],
+ "lr_scale": parameter_groups[key]["lr_scale"],
+ "lr": parameter_groups[key]["lr"],
+ "weight_decay": parameter_groups[key]["weight_decay"],
+ }
+ print("Param groups = %s" % json.dumps(to_display, indent=2))
+
+ params.extend(parameter_groups.values())
diff --git a/vendor/ViTPose/mmpose/.mim/model-index.yml b/vendor/ViTPose/mmpose/.mim/model-index.yml
new file mode 100644
index 0000000000000000000000000000000000000000..c5522f6fc18c959f604864464998a1b9ed53f9ef
--- /dev/null
+++ b/vendor/ViTPose/mmpose/.mim/model-index.yml
@@ -0,0 +1,139 @@
+Import:
+- configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/hrnet_animalpose.yml
+- configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/animalpose/resnet_animalpose.yml
+- configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/hrnet_ap10k.yml
+- configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/ap10k/resnet_ap10k.yml
+- configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/hrnet_atrw.yml
+- configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/atrw/resnet_atrw.yml
+- configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/fly/resnet_fly.yml
+- configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/hrnet_horse10.yml
+- configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/horse10/resnet_horse10.yml
+- configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/locust/resnet_locust.yml
+- configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/hrnet_macaque.yml
+- configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/macaque/resnet_macaque.yml
+- configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap/zebra/resnet_zebra.yml
+- configs/body/2d_kpt_sview_rgb_img/associative_embedding/aic/higherhrnet_aic.yml
+- configs/body/2d_kpt_sview_rgb_img/associative_embedding/aic/hrnet_aic.yml
+- configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_coco.yml
+- configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/higherhrnet_udp_coco.yml
+- configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hourglass_ae_coco.yml
+- configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_coco.yml
+- configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/hrnet_udp_coco.yml
+- configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/mobilenetv2_coco.yml
+- configs/body/2d_kpt_sview_rgb_img/associative_embedding/coco/resnet_coco.yml
+- configs/body/2d_kpt_sview_rgb_img/associative_embedding/crowdpose/higherhrnet_crowdpose.yml
+- configs/body/2d_kpt_sview_rgb_img/associative_embedding/mhp/hrnet_mhp.yml
+- configs/body/2d_kpt_sview_rgb_img/deeppose/coco/resnet_coco.yml
+- configs/body/2d_kpt_sview_rgb_img/deeppose/mpii/resnet_mpii.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/hrnet_aic.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/resnet_aic.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/alexnet_coco.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/cpm_coco.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hourglass_coco.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrformer_coco.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_augmentation_coco.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_coco.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_dark_coco.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_fp16_coco.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_udp_coco.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/litehrnet_coco.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/mobilenetv2_coco.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/mspn_coco.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnest_coco.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnet_coco.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnet_dark_coco.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnet_fp16_coco.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnetv1d_coco.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/resnext_coco.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/rsn_coco.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/scnet_coco.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/seresnet_coco.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/shufflenetv1_coco.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/shufflenetv2_coco.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vgg_coco.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/vipnas_coco.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/hrnet_crowdpose.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/resnet_crowdpose.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/h36m/hrnet_h36m.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/cpm_jhmdb.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/jhmdb/resnet_jhmdb.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mhp/resnet_mhp.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/cpm_mpii.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hourglass_mpii.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_dark_mpii.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/hrnet_mpii.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/litehrnet_mpii.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/mobilenetv2_mpii.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnet_mpii.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnetv1d_mpii.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/resnext_mpii.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/scnet_mpii.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/seresnet_mpii.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/shufflenetv1_mpii.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/shufflenetv2_mpii.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii_trb/resnet_mpii_trb.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/hrnet_ochuman.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/resnet_ochuman.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/hrnet_posetrack18.yml
+- configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/posetrack18/resnet_posetrack18.yml
+- configs/body/2d_kpt_sview_rgb_vid/posewarper/posetrack18/hrnet_posetrack18_posewarper.yml
+- configs/body/3d_kpt_mview_rgb_img/voxelpose/panoptic/voxelpose_prn64x64x64_cpn80x80x20_panoptic_cam5.yml
+- configs/body/3d_kpt_sview_rgb_img/pose_lift/h36m/simplebaseline3d_h36m.yml
+- configs/body/3d_kpt_sview_rgb_img/pose_lift/mpi_inf_3dhp/simplebaseline3d_mpi-inf-3dhp.yml
+- configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/h36m/videopose3d_h36m.yml
+- configs/body/3d_kpt_sview_rgb_vid/video_pose_lift/mpi_inf_3dhp/videopose3d_mpi-inf-3dhp.yml
+- configs/body/3d_mesh_sview_rgb_img/hmr/mixed/resnet_mixed.yml
+- configs/face/2d_kpt_sview_rgb_img/deeppose/wflw/resnet_softwingloss_wflw.yml
+- configs/face/2d_kpt_sview_rgb_img/deeppose/wflw/resnet_wflw.yml
+- configs/face/2d_kpt_sview_rgb_img/deeppose/wflw/resnet_wingloss_wflw.yml
+- configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/300w/hrnetv2_300w.yml
+- configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/aflw/hrnetv2_aflw.yml
+- configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/aflw/hrnetv2_dark_aflw.yml
+- configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/hourglass_coco_wholebody_face.yml
+- configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/hrnetv2_coco_wholebody_face.yml
+- configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/hrnetv2_dark_coco_wholebody_face.yml
+- configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/mobilenetv2_coco_wholebody_face.yml
+- configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/resnet_coco_wholebody_face.yml
+- configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_face/scnet_coco_wholebody_face.yml
+- configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/cofw/hrnetv2_cofw.yml
+- configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/hrnetv2_awing_wflw.yml
+- configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/hrnetv2_dark_wflw.yml
+- configs/face/2d_kpt_sview_rgb_img/topdown_heatmap/wflw/hrnetv2_wflw.yml
+- configs/fashion/2d_kpt_sview_rgb_img/deeppose/deepfashion/resnet_deepfashion.yml
+- configs/fashion/2d_kpt_sview_rgb_img/topdown_heatmap/deepfashion/resnet_deepfashion.yml
+- configs/hand/2d_kpt_sview_rgb_img/deeppose/onehand10k/resnet_onehand10k.yml
+- configs/hand/2d_kpt_sview_rgb_img/deeppose/panoptic2d/resnet_panoptic2d.yml
+- configs/hand/2d_kpt_sview_rgb_img/deeppose/rhd2d/resnet_rhd2d.yml
+- configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/hourglass_coco_wholebody_hand.yml
+- configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/hrnetv2_coco_wholebody_hand.yml
+- configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/hrnetv2_dark_coco_wholebody_hand.yml
+- configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/litehrnet_coco_wholebody_hand.yml
+- configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/mobilenetv2_coco_wholebody_hand.yml
+- configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/resnet_coco_wholebody_hand.yml
+- configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/coco_wholebody_hand/scnet_coco_wholebody_hand.yml
+- configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/freihand2d/resnet_freihand2d.yml
+- configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/interhand2d/resnet_interhand2d.yml
+- configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/hrnetv2_dark_onehand10k.yml
+- configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/hrnetv2_onehand10k.yml
+- configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/hrnetv2_udp_onehand10k.yml
+- configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/mobilenetv2_onehand10k.yml
+- configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/resnet_onehand10k.yml
+- configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/hrnetv2_dark_panoptic2d.yml
+- configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/hrnetv2_panoptic2d.yml
+- configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/hrnetv2_udp_panoptic2d.yml
+- configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/mobilenetv2_panoptic2d.yml
+- configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/panoptic2d/resnet_panoptic2d.yml
+- configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/hrnetv2_dark_rhd2d.yml
+- configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/hrnetv2_rhd2d.yml
+- configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/hrnetv2_udp_rhd2d.yml
+- configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/mobilenetv2_rhd2d.yml
+- configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/rhd2d/resnet_rhd2d.yml
+- configs/hand/3d_kpt_sview_rgb_img/internet/interhand3d/internet_interhand3d.yml
+- configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/higherhrnet_coco-wholebody.yml
+- configs/wholebody/2d_kpt_sview_rgb_img/associative_embedding/coco-wholebody/hrnet_coco-wholebody.yml
+- configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_coco-wholebody.yml
+- configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/hrnet_dark_coco-wholebody.yml
+- configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/resnet_coco-wholebody.yml
+- configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/vipnas_coco-wholebody.yml
+- configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/coco-wholebody/vipnas_dark_coco-wholebody.yml
+- configs/wholebody/2d_kpt_sview_rgb_img/topdown_heatmap/halpe/hrnet_dark_halpe.yml
diff --git a/vendor/ViTPose/mmpose/__init__.py b/vendor/ViTPose/mmpose/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e52beb9ddfd6534895ae93bdaa1ab7098f510d81
--- /dev/null
+++ b/vendor/ViTPose/mmpose/__init__.py
@@ -0,0 +1,29 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import mmcv
+
+from .version import __version__, short_version
+
+
+def digit_version(version_str):
+ digit_version = []
+ for x in version_str.split('.'):
+ if x.isdigit():
+ digit_version.append(int(x))
+ elif x.find('rc') != -1:
+ patch_version = x.split('rc')
+ digit_version.append(int(patch_version[0]) - 1)
+ digit_version.append(int(patch_version[1]))
+ return digit_version
+
+
+mmcv_minimum_version = '1.3.8'
+mmcv_maximum_version = '1.5.0'
+mmcv_version = digit_version(mmcv.__version__)
+
+
+assert (mmcv_version >= digit_version(mmcv_minimum_version)
+ and mmcv_version <= digit_version(mmcv_maximum_version)), \
+ f'MMCV=={mmcv.__version__} is used but incompatible. ' \
+ f'Please install mmcv>={mmcv_minimum_version}, <={mmcv_maximum_version}.'
+
+__all__ = ['__version__', 'short_version']
diff --git a/vendor/ViTPose/mmpose/apis/__init__.py b/vendor/ViTPose/mmpose/apis/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..0e263edc4d6aa0a3380a3c2e8dc85e1a696bb164
--- /dev/null
+++ b/vendor/ViTPose/mmpose/apis/__init__.py
@@ -0,0 +1,20 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .inference import (inference_bottom_up_pose_model,
+ inference_top_down_pose_model, init_pose_model,
+ process_mmdet_results, vis_pose_result)
+from .inference_3d import (extract_pose_sequence, inference_interhand_3d_model,
+ inference_mesh_model, inference_pose_lifter_model,
+ vis_3d_mesh_result, vis_3d_pose_result)
+from .inference_tracking import get_track_id, vis_pose_tracking_result
+from .test import multi_gpu_test, single_gpu_test
+from .train import init_random_seed, train_model
+
+__all__ = [
+ 'train_model', 'init_pose_model', 'inference_top_down_pose_model',
+ 'inference_bottom_up_pose_model', 'multi_gpu_test', 'single_gpu_test',
+ 'vis_pose_result', 'get_track_id', 'vis_pose_tracking_result',
+ 'inference_pose_lifter_model', 'vis_3d_pose_result',
+ 'inference_interhand_3d_model', 'extract_pose_sequence',
+ 'inference_mesh_model', 'vis_3d_mesh_result', 'process_mmdet_results',
+ 'init_random_seed'
+]
diff --git a/vendor/ViTPose/mmpose/apis/inference.py b/vendor/ViTPose/mmpose/apis/inference.py
new file mode 100644
index 0000000000000000000000000000000000000000..5363d40c3f8680af79b470f59b5144941a0c4436
--- /dev/null
+++ b/vendor/ViTPose/mmpose/apis/inference.py
@@ -0,0 +1,833 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import warnings
+
+import mmcv
+import numpy as np
+import torch
+from mmcv.parallel import collate, scatter
+from mmcv.runner import load_checkpoint
+from PIL import Image
+
+from mmpose.core.post_processing import oks_nms
+from mmpose.datasets.dataset_info import DatasetInfo
+from mmpose.datasets.pipelines import Compose
+from mmpose.models import build_posenet
+from mmpose.utils.hooks import OutputHook
+
+os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
+
+
+def init_pose_model(config, checkpoint=None, device='cuda:0'):
+ """Initialize a pose model from config file.
+
+ Args:
+ config (str or :obj:`mmcv.Config`): Config file path or the config
+ object.
+ checkpoint (str, optional): Checkpoint path. If left as None, the model
+ will not load any weights.
+
+ Returns:
+ nn.Module: The constructed detector.
+ """
+ if isinstance(config, str):
+ config = mmcv.Config.fromfile(config)
+ elif not isinstance(config, mmcv.Config):
+ raise TypeError('config must be a filename or Config object, '
+ f'but got {type(config)}')
+ config.model.pretrained = None
+ model = build_posenet(config.model)
+ if checkpoint is not None:
+ # load model checkpoint
+ load_checkpoint(model, checkpoint, map_location='cpu')
+ # save the config in the model for convenience
+ model.cfg = config
+ model.to(device)
+ model.eval()
+ return model
+
+
+def _xyxy2xywh(bbox_xyxy):
+ """Transform the bbox format from x1y1x2y2 to xywh.
+
+ Args:
+ bbox_xyxy (np.ndarray): Bounding boxes (with scores), shaped (n, 4) or
+ (n, 5). (left, top, right, bottom, [score])
+
+ Returns:
+ np.ndarray: Bounding boxes (with scores),
+ shaped (n, 4) or (n, 5). (left, top, width, height, [score])
+ """
+ bbox_xywh = bbox_xyxy.copy()
+ bbox_xywh[:, 2] = bbox_xywh[:, 2] - bbox_xywh[:, 0] + 1
+ bbox_xywh[:, 3] = bbox_xywh[:, 3] - bbox_xywh[:, 1] + 1
+
+ return bbox_xywh
+
+
+def _xywh2xyxy(bbox_xywh):
+ """Transform the bbox format from xywh to x1y1x2y2.
+
+ Args:
+ bbox_xywh (ndarray): Bounding boxes (with scores),
+ shaped (n, 4) or (n, 5). (left, top, width, height, [score])
+ Returns:
+ np.ndarray: Bounding boxes (with scores), shaped (n, 4) or
+ (n, 5). (left, top, right, bottom, [score])
+ """
+ bbox_xyxy = bbox_xywh.copy()
+ bbox_xyxy[:, 2] = bbox_xyxy[:, 2] + bbox_xyxy[:, 0] - 1
+ bbox_xyxy[:, 3] = bbox_xyxy[:, 3] + bbox_xyxy[:, 1] - 1
+
+ return bbox_xyxy
+
+
+def _box2cs(cfg, box):
+ """This encodes bbox(x,y,w,h) into (center, scale)
+
+ Args:
+ x, y, w, h
+
+ Returns:
+ tuple: A tuple containing center and scale.
+
+ - np.ndarray[float32](2,): Center of the bbox (x, y).
+ - np.ndarray[float32](2,): Scale of the bbox w & h.
+ """
+
+ x, y, w, h = box[:4]
+ input_size = cfg.data_cfg['image_size']
+ aspect_ratio = input_size[0] / input_size[1]
+ center = np.array([x + w * 0.5, y + h * 0.5], dtype=np.float32)
+
+ if w > aspect_ratio * h:
+ h = w * 1.0 / aspect_ratio
+ elif w < aspect_ratio * h:
+ w = h * aspect_ratio
+
+ # pixel std is 200.0
+ scale = np.array([w / 200.0, h / 200.0], dtype=np.float32)
+ scale = scale * 1.25
+
+ return center, scale
+
+
+def _inference_single_pose_model(model,
+ img_or_path,
+ bboxes,
+ dataset='TopDownCocoDataset',
+ dataset_info=None,
+ return_heatmap=False):
+ """Inference human bounding boxes.
+
+ Note:
+ - num_bboxes: N
+ - num_keypoints: K
+
+ Args:
+ model (nn.Module): The loaded pose model.
+ img_or_path (str | np.ndarray): Image filename or loaded image.
+ bboxes (list | np.ndarray): All bounding boxes (with scores),
+ shaped (N, 4) or (N, 5). (left, top, width, height, [score])
+ where N is number of bounding boxes.
+ dataset (str): Dataset name. Deprecated.
+ dataset_info (DatasetInfo): A class containing all dataset info.
+ outputs (list[str] | tuple[str]): Names of layers whose output is
+ to be returned, default: None
+
+ Returns:
+ ndarray[NxKx3]: Predicted pose x, y, score.
+ heatmap[N, K, H, W]: Model output heatmap.
+ """
+
+ cfg = model.cfg
+ device = next(model.parameters()).device
+ if device.type == 'cpu':
+ device = -1
+
+ # build the data pipeline
+ test_pipeline = Compose(cfg.test_pipeline)
+
+ assert len(bboxes[0]) in [4, 5]
+
+ if dataset_info is not None:
+ dataset_name = dataset_info.dataset_name
+ flip_pairs = dataset_info.flip_pairs
+ else:
+ warnings.warn(
+ 'dataset is deprecated.'
+ 'Please set `dataset_info` in the config.'
+ 'Check https://github.com/open-mmlab/mmpose/pull/663 for details.',
+ DeprecationWarning)
+ # TODO: These will be removed in the later versions.
+ if dataset in ('TopDownCocoDataset', 'TopDownOCHumanDataset',
+ 'AnimalMacaqueDataset'):
+ flip_pairs = [[1, 2], [3, 4], [5, 6], [7, 8], [9, 10], [11, 12],
+ [13, 14], [15, 16]]
+ elif dataset == 'TopDownCocoWholeBodyDataset':
+ body = [[1, 2], [3, 4], [5, 6], [7, 8], [9, 10], [11, 12],
+ [13, 14], [15, 16]]
+ foot = [[17, 20], [18, 21], [19, 22]]
+
+ face = [[23, 39], [24, 38], [25, 37], [26, 36], [27, 35], [28, 34],
+ [29, 33], [30, 32], [40, 49], [41, 48], [42, 47], [43, 46],
+ [44, 45], [54, 58], [55, 57], [59, 68], [60, 67], [61, 66],
+ [62, 65], [63, 70], [64, 69], [71, 77], [72, 76], [73, 75],
+ [78, 82], [79, 81], [83, 87], [84, 86], [88, 90]]
+
+ hand = [[91, 112], [92, 113], [93, 114], [94, 115], [95, 116],
+ [96, 117], [97, 118], [98, 119], [99, 120], [100, 121],
+ [101, 122], [102, 123], [103, 124], [104, 125], [105, 126],
+ [106, 127], [107, 128], [108, 129], [109, 130], [110, 131],
+ [111, 132]]
+ flip_pairs = body + foot + face + hand
+ elif dataset == 'TopDownAicDataset':
+ flip_pairs = [[0, 3], [1, 4], [2, 5], [6, 9], [7, 10], [8, 11]]
+ elif dataset == 'TopDownMpiiDataset':
+ flip_pairs = [[0, 5], [1, 4], [2, 3], [10, 15], [11, 14], [12, 13]]
+ elif dataset == 'TopDownMpiiTrbDataset':
+ flip_pairs = [[0, 1], [2, 3], [4, 5], [6, 7], [8, 9], [10, 11],
+ [14, 15], [16, 22], [28, 34], [17, 23], [29, 35],
+ [18, 24], [30, 36], [19, 25], [31, 37], [20, 26],
+ [32, 38], [21, 27], [33, 39]]
+ elif dataset in ('OneHand10KDataset', 'FreiHandDataset',
+ 'PanopticDataset', 'InterHand2DDataset'):
+ flip_pairs = []
+ elif dataset in 'Face300WDataset':
+ flip_pairs = [[0, 16], [1, 15], [2, 14], [3, 13], [4, 12], [5, 11],
+ [6, 10], [7, 9], [17, 26], [18, 25], [19, 24],
+ [20, 23], [21, 22], [31, 35], [32, 34], [36, 45],
+ [37, 44], [38, 43], [39, 42], [40, 47], [41, 46],
+ [48, 54], [49, 53], [50, 52], [61, 63], [60, 64],
+ [67, 65], [58, 56], [59, 55]]
+
+ elif dataset in 'FaceAFLWDataset':
+ flip_pairs = [[0, 5], [1, 4], [2, 3], [6, 11], [7, 10], [8, 9],
+ [12, 14], [15, 17]]
+
+ elif dataset in 'FaceCOFWDataset':
+ flip_pairs = [[0, 1], [4, 6], [2, 3], [5, 7], [8, 9], [10, 11],
+ [12, 14], [16, 17], [13, 15], [18, 19], [22, 23]]
+
+ elif dataset in 'FaceWFLWDataset':
+ flip_pairs = [[0, 32], [1, 31], [2, 30], [3, 29], [4, 28], [5, 27],
+ [6, 26], [7, 25], [8, 24], [9, 23], [10, 22],
+ [11, 21], [12, 20], [13, 19], [14, 18], [15, 17],
+ [33, 46], [34, 45], [35, 44], [36, 43], [37, 42],
+ [38, 50], [39, 49], [40, 48], [41, 47], [60, 72],
+ [61, 71], [62, 70], [63, 69], [64, 68], [65, 75],
+ [66, 74], [67, 73], [55, 59], [56, 58], [76, 82],
+ [77, 81], [78, 80], [87, 83], [86, 84], [88, 92],
+ [89, 91], [95, 93], [96, 97]]
+
+ elif dataset in 'AnimalFlyDataset':
+ flip_pairs = [[1, 2], [6, 18], [7, 19], [8, 20], [9, 21], [10, 22],
+ [11, 23], [12, 24], [13, 25], [14, 26], [15, 27],
+ [16, 28], [17, 29], [30, 31]]
+ elif dataset in 'AnimalHorse10Dataset':
+ flip_pairs = []
+
+ elif dataset in 'AnimalLocustDataset':
+ flip_pairs = [[5, 20], [6, 21], [7, 22], [8, 23], [9, 24],
+ [10, 25], [11, 26], [12, 27], [13, 28], [14, 29],
+ [15, 30], [16, 31], [17, 32], [18, 33], [19, 34]]
+
+ elif dataset in 'AnimalZebraDataset':
+ flip_pairs = [[3, 4], [5, 6]]
+
+ elif dataset in 'AnimalPoseDataset':
+ flip_pairs = [[0, 1], [2, 3], [8, 9], [10, 11], [12, 13], [14, 15],
+ [16, 17], [18, 19]]
+ else:
+ raise NotImplementedError()
+ dataset_name = dataset
+
+ batch_data = []
+ for bbox in bboxes:
+ center, scale = _box2cs(cfg, bbox)
+
+ # prepare data
+ data = {
+ 'center':
+ center,
+ 'scale':
+ scale,
+ 'bbox_score':
+ bbox[4] if len(bbox) == 5 else 1,
+ 'bbox_id':
+ 0, # need to be assigned if batch_size > 1
+ 'dataset':
+ dataset_name,
+ 'joints_3d':
+ np.zeros((cfg.data_cfg.num_joints, 3), dtype=np.float32),
+ 'joints_3d_visible':
+ np.zeros((cfg.data_cfg.num_joints, 3), dtype=np.float32),
+ 'rotation':
+ 0,
+ 'ann_info': {
+ 'image_size': np.array(cfg.data_cfg['image_size']),
+ 'num_joints': cfg.data_cfg['num_joints'],
+ 'flip_pairs': flip_pairs
+ }
+ }
+ if isinstance(img_or_path, np.ndarray):
+ data['img'] = img_or_path
+ else:
+ data['image_file'] = img_or_path
+
+ data = test_pipeline(data)
+ batch_data.append(data)
+
+ batch_data = collate(batch_data, samples_per_gpu=len(batch_data))
+ batch_data = scatter(batch_data, [device])[0]
+
+ # forward the model
+ with torch.no_grad():
+ result = model(
+ img=batch_data['img'],
+ img_metas=batch_data['img_metas'],
+ return_loss=False,
+ return_heatmap=return_heatmap)
+
+ return result['preds'], result['output_heatmap']
+
+
+def inference_top_down_pose_model(model,
+ img_or_path,
+ person_results=None,
+ bbox_thr=None,
+ format='xywh',
+ dataset='TopDownCocoDataset',
+ dataset_info=None,
+ return_heatmap=False,
+ outputs=None):
+ """Inference a single image with a list of person bounding boxes.
+
+ Note:
+ - num_people: P
+ - num_keypoints: K
+ - bbox height: H
+ - bbox width: W
+
+ Args:
+ model (nn.Module): The loaded pose model.
+ img_or_path (str| np.ndarray): Image filename or loaded image.
+ person_results (list(dict), optional): a list of detected persons that
+ contains ``bbox`` and/or ``track_id``:
+
+ - ``bbox`` (4, ) or (5, ): The person bounding box, which contains
+ 4 box coordinates (and score).
+ - ``track_id`` (int): The unique id for each human instance. If
+ not provided, a dummy person result with a bbox covering
+ the entire image will be used. Default: None.
+ bbox_thr (float | None): Threshold for bounding boxes. Only bboxes
+ with higher scores will be fed into the pose detector.
+ If bbox_thr is None, all boxes will be used.
+ format (str): bbox format ('xyxy' | 'xywh'). Default: 'xywh'.
+
+ - `xyxy` means (left, top, right, bottom),
+ - `xywh` means (left, top, width, height).
+ dataset (str): Dataset name, e.g. 'TopDownCocoDataset'.
+ It is deprecated. Please use dataset_info instead.
+ dataset_info (DatasetInfo): A class containing all dataset info.
+ return_heatmap (bool) : Flag to return heatmap, default: False
+ outputs (list(str) | tuple(str)) : Names of layers whose outputs
+ need to be returned. Default: None.
+
+ Returns:
+ tuple:
+ - pose_results (list[dict]): The bbox & pose info. \
+ Each item in the list is a dictionary, \
+ containing the bbox: (left, top, right, bottom, [score]) \
+ and the pose (ndarray[Kx3]): x, y, score.
+ - returned_outputs (list[dict[np.ndarray[N, K, H, W] | \
+ torch.Tensor[N, K, H, W]]]): \
+ Output feature maps from layers specified in `outputs`. \
+ Includes 'heatmap' if `return_heatmap` is True.
+ """
+ # get dataset info
+ if (dataset_info is None and hasattr(model, 'cfg')
+ and 'dataset_info' in model.cfg):
+ dataset_info = DatasetInfo(model.cfg.dataset_info)
+ if dataset_info is None:
+ warnings.warn(
+ 'dataset is deprecated.'
+ 'Please set `dataset_info` in the config.'
+ 'Check https://github.com/open-mmlab/mmpose/pull/663'
+ ' for details.', DeprecationWarning)
+
+ # only two kinds of bbox format is supported.
+ assert format in ['xyxy', 'xywh']
+
+ pose_results = []
+ returned_outputs = []
+
+ if person_results is None:
+ # create dummy person results
+ if isinstance(img_or_path, str):
+ width, height = Image.open(img_or_path).size
+ else:
+ height, width = img_or_path.shape[:2]
+ person_results = [{'bbox': np.array([0, 0, width, height])}]
+
+ if len(person_results) == 0:
+ return pose_results, returned_outputs
+
+ # Change for-loop preprocess each bbox to preprocess all bboxes at once.
+ bboxes = np.array([box['bbox'] for box in person_results])
+
+ # Select bboxes by score threshold
+ if bbox_thr is not None:
+ assert bboxes.shape[1] == 5
+ valid_idx = np.where(bboxes[:, 4] > bbox_thr)[0]
+ bboxes = bboxes[valid_idx]
+ person_results = [person_results[i] for i in valid_idx]
+
+ if format == 'xyxy':
+ bboxes_xyxy = bboxes
+ bboxes_xywh = _xyxy2xywh(bboxes)
+ else:
+ # format is already 'xywh'
+ bboxes_xywh = bboxes
+ bboxes_xyxy = _xywh2xyxy(bboxes)
+
+ # if bbox_thr remove all bounding box
+ if len(bboxes_xywh) == 0:
+ return [], []
+
+ with OutputHook(model, outputs=outputs, as_tensor=False) as h:
+ # poses is results['pred'] # N x 17x 3
+ poses, heatmap = _inference_single_pose_model(
+ model,
+ img_or_path,
+ bboxes_xywh,
+ dataset=dataset,
+ dataset_info=dataset_info,
+ return_heatmap=return_heatmap)
+
+ if return_heatmap:
+ h.layer_outputs['heatmap'] = heatmap
+
+ returned_outputs.append(h.layer_outputs)
+
+ assert len(poses) == len(person_results), print(
+ len(poses), len(person_results), len(bboxes_xyxy))
+ for pose, person_result, bbox_xyxy in zip(poses, person_results,
+ bboxes_xyxy):
+ pose_result = person_result.copy()
+ pose_result['keypoints'] = pose
+ pose_result['bbox'] = bbox_xyxy
+ pose_results.append(pose_result)
+
+ return pose_results, returned_outputs
+
+
+def inference_bottom_up_pose_model(model,
+ img_or_path,
+ dataset='BottomUpCocoDataset',
+ dataset_info=None,
+ pose_nms_thr=0.9,
+ return_heatmap=False,
+ outputs=None):
+ """Inference a single image with a bottom-up pose model.
+
+ Note:
+ - num_people: P
+ - num_keypoints: K
+ - bbox height: H
+ - bbox width: W
+
+ Args:
+ model (nn.Module): The loaded pose model.
+ img_or_path (str| np.ndarray): Image filename or loaded image.
+ dataset (str): Dataset name, e.g. 'BottomUpCocoDataset'.
+ It is deprecated. Please use dataset_info instead.
+ dataset_info (DatasetInfo): A class containing all dataset info.
+ pose_nms_thr (float): retain oks overlap < pose_nms_thr, default: 0.9.
+ return_heatmap (bool) : Flag to return heatmap, default: False.
+ outputs (list(str) | tuple(str)) : Names of layers whose outputs
+ need to be returned, default: None.
+
+ Returns:
+ tuple:
+ - pose_results (list[np.ndarray]): The predicted pose info. \
+ The length of the list is the number of people (P). \
+ Each item in the list is a ndarray, containing each \
+ person's pose (np.ndarray[Kx3]): x, y, score.
+ - returned_outputs (list[dict[np.ndarray[N, K, H, W] | \
+ torch.Tensor[N, K, H, W]]]): \
+ Output feature maps from layers specified in `outputs`. \
+ Includes 'heatmap' if `return_heatmap` is True.
+ """
+ # get dataset info
+ if (dataset_info is None and hasattr(model, 'cfg')
+ and 'dataset_info' in model.cfg):
+ dataset_info = DatasetInfo(model.cfg.dataset_info)
+
+ if dataset_info is not None:
+ dataset_name = dataset_info.dataset_name
+ flip_index = dataset_info.flip_index
+ sigmas = getattr(dataset_info, 'sigmas', None)
+ else:
+ warnings.warn(
+ 'dataset is deprecated.'
+ 'Please set `dataset_info` in the config.'
+ 'Check https://github.com/open-mmlab/mmpose/pull/663 for details.',
+ DeprecationWarning)
+ assert (dataset == 'BottomUpCocoDataset')
+ dataset_name = dataset
+ flip_index = [0, 2, 1, 4, 3, 6, 5, 8, 7, 10, 9, 12, 11, 14, 13, 16, 15]
+ sigmas = None
+
+ pose_results = []
+ returned_outputs = []
+
+ cfg = model.cfg
+ device = next(model.parameters()).device
+ if device.type == 'cpu':
+ device = -1
+
+ # build the data pipeline
+ test_pipeline = Compose(cfg.test_pipeline)
+
+ # prepare data
+ data = {
+ 'dataset': dataset_name,
+ 'ann_info': {
+ 'image_size': np.array(cfg.data_cfg['image_size']),
+ 'num_joints': cfg.data_cfg['num_joints'],
+ 'flip_index': flip_index,
+ }
+ }
+ if isinstance(img_or_path, np.ndarray):
+ data['img'] = img_or_path
+ else:
+ data['image_file'] = img_or_path
+
+ data = test_pipeline(data)
+ data = collate([data], samples_per_gpu=1)
+ data = scatter(data, [device])[0]
+
+ with OutputHook(model, outputs=outputs, as_tensor=False) as h:
+ # forward the model
+ with torch.no_grad():
+ result = model(
+ img=data['img'],
+ img_metas=data['img_metas'],
+ return_loss=False,
+ return_heatmap=return_heatmap)
+
+ if return_heatmap:
+ h.layer_outputs['heatmap'] = result['output_heatmap']
+
+ returned_outputs.append(h.layer_outputs)
+
+ for idx, pred in enumerate(result['preds']):
+ area = (np.max(pred[:, 0]) - np.min(pred[:, 0])) * (
+ np.max(pred[:, 1]) - np.min(pred[:, 1]))
+ pose_results.append({
+ 'keypoints': pred[:, :3],
+ 'score': result['scores'][idx],
+ 'area': area,
+ })
+
+ # pose nms
+ score_per_joint = cfg.model.test_cfg.get('score_per_joint', False)
+ keep = oks_nms(
+ pose_results,
+ pose_nms_thr,
+ sigmas,
+ score_per_joint=score_per_joint)
+ pose_results = [pose_results[_keep] for _keep in keep]
+
+ return pose_results, returned_outputs
+
+
+def vis_pose_result(model,
+ img,
+ result,
+ radius=4,
+ thickness=1,
+ kpt_score_thr=0.3,
+ bbox_color='green',
+ dataset='TopDownCocoDataset',
+ dataset_info=None,
+ show=False,
+ out_file=None):
+ """Visualize the detection results on the image.
+
+ Args:
+ model (nn.Module): The loaded detector.
+ img (str | np.ndarray): Image filename or loaded image.
+ result (list[dict]): The results to draw over `img`
+ (bbox_result, pose_result).
+ radius (int): Radius of circles.
+ thickness (int): Thickness of lines.
+ kpt_score_thr (float): The threshold to visualize the keypoints.
+ skeleton (list[tuple()]): Default None.
+ show (bool): Whether to show the image. Default True.
+ out_file (str|None): The filename of the output visualization image.
+ """
+
+ # get dataset info
+ if (dataset_info is None and hasattr(model, 'cfg')
+ and 'dataset_info' in model.cfg):
+ dataset_info = DatasetInfo(model.cfg.dataset_info)
+
+ if dataset_info is not None:
+ skeleton = dataset_info.skeleton
+ pose_kpt_color = dataset_info.pose_kpt_color
+ pose_link_color = dataset_info.pose_link_color
+ else:
+ warnings.warn(
+ 'dataset is deprecated.'
+ 'Please set `dataset_info` in the config.'
+ 'Check https://github.com/open-mmlab/mmpose/pull/663 for details.',
+ DeprecationWarning)
+ # TODO: These will be removed in the later versions.
+ palette = np.array([[255, 128, 0], [255, 153, 51], [255, 178, 102],
+ [230, 230, 0], [255, 153, 255], [153, 204, 255],
+ [255, 102, 255], [255, 51, 255], [102, 178, 255],
+ [51, 153, 255], [255, 153, 153], [255, 102, 102],
+ [255, 51, 51], [153, 255, 153], [102, 255, 102],
+ [51, 255, 51], [0, 255, 0], [0, 0, 255],
+ [255, 0, 0], [255, 255, 255]])
+
+ if dataset in ('TopDownCocoDataset', 'BottomUpCocoDataset',
+ 'TopDownOCHumanDataset', 'AnimalMacaqueDataset'):
+ # show the results
+ skeleton = [[15, 13], [13, 11], [16, 14], [14, 12], [11, 12],
+ [5, 11], [6, 12], [5, 6], [5, 7], [6, 8], [7, 9],
+ [8, 10], [1, 2], [0, 1], [0, 2], [1, 3], [2, 4],
+ [3, 5], [4, 6]]
+
+ pose_link_color = palette[[
+ 0, 0, 0, 0, 7, 7, 7, 9, 9, 9, 9, 9, 16, 16, 16, 16, 16, 16, 16
+ ]]
+ pose_kpt_color = palette[[
+ 16, 16, 16, 16, 16, 9, 9, 9, 9, 9, 9, 0, 0, 0, 0, 0, 0
+ ]]
+
+ elif dataset == 'TopDownCocoWholeBodyDataset':
+ # show the results
+ skeleton = [[15, 13], [13, 11], [16, 14], [14, 12], [11, 12],
+ [5, 11], [6, 12], [5, 6], [5, 7], [6, 8], [7, 9],
+ [8, 10], [1, 2], [0, 1], [0, 2],
+ [1, 3], [2, 4], [3, 5], [4, 6], [15, 17], [15, 18],
+ [15, 19], [16, 20], [16, 21], [16, 22], [91, 92],
+ [92, 93], [93, 94], [94, 95], [91, 96], [96, 97],
+ [97, 98], [98, 99], [91, 100], [100, 101], [101, 102],
+ [102, 103], [91, 104], [104, 105], [105, 106],
+ [106, 107], [91, 108], [108, 109], [109, 110],
+ [110, 111], [112, 113], [113, 114], [114, 115],
+ [115, 116], [112, 117], [117, 118], [118, 119],
+ [119, 120], [112, 121], [121, 122], [122, 123],
+ [123, 124], [112, 125], [125, 126], [126, 127],
+ [127, 128], [112, 129], [129, 130], [130, 131],
+ [131, 132]]
+
+ pose_link_color = palette[[
+ 0, 0, 0, 0, 7, 7, 7, 9, 9, 9, 9, 9, 16, 16, 16, 16, 16, 16, 16
+ ] + [16, 16, 16, 16, 16, 16] + [
+ 0, 0, 0, 0, 4, 4, 4, 4, 8, 8, 8, 8, 12, 12, 12, 12, 16, 16, 16,
+ 16
+ ] + [
+ 0, 0, 0, 0, 4, 4, 4, 4, 8, 8, 8, 8, 12, 12, 12, 12, 16, 16, 16,
+ 16
+ ]]
+ pose_kpt_color = palette[
+ [16, 16, 16, 16, 16, 9, 9, 9, 9, 9, 9, 0, 0, 0, 0, 0, 0] +
+ [0, 0, 0, 0, 0, 0] + [19] * (68 + 42)]
+
+ elif dataset == 'TopDownAicDataset':
+ skeleton = [[2, 1], [1, 0], [0, 13], [13, 3], [3, 4], [4, 5],
+ [8, 7], [7, 6], [6, 9], [9, 10], [10, 11], [12, 13],
+ [0, 6], [3, 9]]
+
+ pose_link_color = palette[[
+ 9, 9, 9, 9, 9, 9, 16, 16, 16, 16, 16, 0, 7, 7
+ ]]
+ pose_kpt_color = palette[[
+ 9, 9, 9, 9, 9, 9, 16, 16, 16, 16, 16, 16, 0, 0
+ ]]
+
+ elif dataset == 'TopDownMpiiDataset':
+ skeleton = [[0, 1], [1, 2], [2, 6], [6, 3], [3, 4], [4, 5], [6, 7],
+ [7, 8], [8, 9], [8, 12], [12, 11], [11, 10], [8, 13],
+ [13, 14], [14, 15]]
+
+ pose_link_color = palette[[
+ 16, 16, 16, 16, 16, 16, 7, 7, 0, 9, 9, 9, 9, 9, 9
+ ]]
+ pose_kpt_color = palette[[
+ 16, 16, 16, 16, 16, 16, 7, 7, 0, 0, 9, 9, 9, 9, 9, 9
+ ]]
+
+ elif dataset == 'TopDownMpiiTrbDataset':
+ skeleton = [[12, 13], [13, 0], [13, 1], [0, 2], [1, 3], [2, 4],
+ [3, 5], [0, 6], [1, 7], [6, 7], [6, 8], [7,
+ 9], [8, 10],
+ [9, 11], [14, 15], [16, 17], [18, 19], [20, 21],
+ [22, 23], [24, 25], [26, 27], [28, 29], [30, 31],
+ [32, 33], [34, 35], [36, 37], [38, 39]]
+
+ pose_link_color = palette[[16] * 14 + [19] * 13]
+ pose_kpt_color = palette[[16] * 14 + [0] * 26]
+
+ elif dataset in ('OneHand10KDataset', 'FreiHandDataset',
+ 'PanopticDataset'):
+ skeleton = [[0, 1], [1, 2], [2, 3], [3, 4], [0, 5], [5, 6], [6, 7],
+ [7, 8], [0, 9], [9, 10], [10, 11], [11, 12], [0, 13],
+ [13, 14], [14, 15], [15, 16], [0, 17], [17, 18],
+ [18, 19], [19, 20]]
+
+ pose_link_color = palette[[
+ 0, 0, 0, 0, 4, 4, 4, 4, 8, 8, 8, 8, 12, 12, 12, 12, 16, 16, 16,
+ 16
+ ]]
+ pose_kpt_color = palette[[
+ 0, 0, 0, 0, 0, 4, 4, 4, 4, 8, 8, 8, 8, 12, 12, 12, 12, 16, 16,
+ 16, 16
+ ]]
+
+ elif dataset == 'InterHand2DDataset':
+ skeleton = [[0, 1], [1, 2], [2, 3], [4, 5], [5, 6], [6, 7], [8, 9],
+ [9, 10], [10, 11], [12, 13], [13, 14], [14, 15],
+ [16, 17], [17, 18], [18, 19], [3, 20], [7, 20],
+ [11, 20], [15, 20], [19, 20]]
+
+ pose_link_color = palette[[
+ 0, 0, 0, 4, 4, 4, 8, 8, 8, 12, 12, 12, 16, 16, 16, 0, 4, 8, 12,
+ 16
+ ]]
+ pose_kpt_color = palette[[
+ 0, 0, 0, 0, 4, 4, 4, 4, 8, 8, 8, 8, 12, 12, 12, 12, 16, 16, 16,
+ 16, 0
+ ]]
+
+ elif dataset == 'Face300WDataset':
+ # show the results
+ skeleton = []
+
+ pose_link_color = palette[[]]
+ pose_kpt_color = palette[[19] * 68]
+ kpt_score_thr = 0
+
+ elif dataset == 'FaceAFLWDataset':
+ # show the results
+ skeleton = []
+
+ pose_link_color = palette[[]]
+ pose_kpt_color = palette[[19] * 19]
+ kpt_score_thr = 0
+
+ elif dataset == 'FaceCOFWDataset':
+ # show the results
+ skeleton = []
+
+ pose_link_color = palette[[]]
+ pose_kpt_color = palette[[19] * 29]
+ kpt_score_thr = 0
+
+ elif dataset == 'FaceWFLWDataset':
+ # show the results
+ skeleton = []
+
+ pose_link_color = palette[[]]
+ pose_kpt_color = palette[[19] * 98]
+ kpt_score_thr = 0
+
+ elif dataset == 'AnimalHorse10Dataset':
+ skeleton = [[0, 1], [1, 12], [12, 16], [16, 21], [21, 17],
+ [17, 11], [11, 10], [10, 8], [8, 9], [9, 12], [2, 3],
+ [3, 4], [5, 6], [6, 7], [13, 14], [14, 15], [18, 19],
+ [19, 20]]
+
+ pose_link_color = palette[[4] * 10 + [6] * 2 + [6] * 2 + [7] * 2 +
+ [7] * 2]
+ pose_kpt_color = palette[[
+ 4, 4, 6, 6, 6, 6, 6, 6, 4, 4, 4, 4, 4, 7, 7, 7, 4, 4, 7, 7, 7,
+ 4
+ ]]
+
+ elif dataset == 'AnimalFlyDataset':
+ skeleton = [[1, 0], [2, 0], [3, 0], [4, 3], [5, 4], [7, 6], [8, 7],
+ [9, 8], [11, 10], [12, 11], [13, 12], [15, 14],
+ [16, 15], [17, 16], [19, 18], [20, 19], [21, 20],
+ [23, 22], [24, 23], [25, 24], [27, 26], [28, 27],
+ [29, 28], [30, 3], [31, 3]]
+
+ pose_link_color = palette[[0] * 25]
+ pose_kpt_color = palette[[0] * 32]
+
+ elif dataset == 'AnimalLocustDataset':
+ skeleton = [[1, 0], [2, 1], [3, 2], [4, 3], [6, 5], [7, 6], [9, 8],
+ [10, 9], [11, 10], [13, 12], [14, 13], [15, 14],
+ [17, 16], [18, 17], [19, 18], [21, 20], [22, 21],
+ [24, 23], [25, 24], [26, 25], [28, 27], [29, 28],
+ [30, 29], [32, 31], [33, 32], [34, 33]]
+
+ pose_link_color = palette[[0] * 26]
+ pose_kpt_color = palette[[0] * 35]
+
+ elif dataset == 'AnimalZebraDataset':
+ skeleton = [[1, 0], [2, 1], [3, 2], [4, 2], [5, 7], [6, 7], [7, 2],
+ [8, 7]]
+
+ pose_link_color = palette[[0] * 8]
+ pose_kpt_color = palette[[0] * 9]
+
+ elif dataset in 'AnimalPoseDataset':
+ skeleton = [[0, 1], [0, 2], [1, 3], [0, 4], [1, 4], [4, 5], [5, 7],
+ [6, 7], [5, 8], [8, 12], [12, 16], [5, 9], [9, 13],
+ [13, 17], [6, 10], [10, 14], [14, 18], [6, 11],
+ [11, 15], [15, 19]]
+
+ pose_link_color = palette[[0] * 20]
+ pose_kpt_color = palette[[0] * 20]
+ else:
+ NotImplementedError()
+
+ if hasattr(model, 'module'):
+ model = model.module
+
+ img = model.show_result(
+ img,
+ result,
+ skeleton,
+ radius=radius,
+ thickness=thickness,
+ pose_kpt_color=pose_kpt_color,
+ pose_link_color=pose_link_color,
+ kpt_score_thr=kpt_score_thr,
+ bbox_color=bbox_color,
+ show=show,
+ out_file=out_file)
+
+ return img
+
+
+def process_mmdet_results(mmdet_results, cat_id=1):
+ """Process mmdet results, and return a list of bboxes.
+
+ Args:
+ mmdet_results (list|tuple): mmdet results.
+ cat_id (int): category id (default: 1 for human)
+
+ Returns:
+ person_results (list): a list of detected bounding boxes
+ """
+ if isinstance(mmdet_results, tuple):
+ det_results = mmdet_results[0]
+ else:
+ det_results = mmdet_results
+
+ bboxes = det_results[cat_id - 1]
+
+ person_results = []
+ for bbox in bboxes:
+ person = {}
+ person['bbox'] = bbox
+ person_results.append(person)
+
+ return person_results
diff --git a/vendor/ViTPose/mmpose/apis/inference_3d.py b/vendor/ViTPose/mmpose/apis/inference_3d.py
new file mode 100644
index 0000000000000000000000000000000000000000..f59f20a1d0794f542c60c2bcfc20bfa4a014a55a
--- /dev/null
+++ b/vendor/ViTPose/mmpose/apis/inference_3d.py
@@ -0,0 +1,791 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import numpy as np
+import torch
+from mmcv.parallel import collate, scatter
+
+from mmpose.datasets.pipelines import Compose
+from .inference import _box2cs, _xywh2xyxy, _xyxy2xywh
+
+
+def extract_pose_sequence(pose_results, frame_idx, causal, seq_len, step=1):
+ """Extract the target frame from 2D pose results, and pad the sequence to a
+ fixed length.
+
+ Args:
+ pose_results (list[list[dict]]): Multi-frame pose detection results
+ stored in a nested list. Each element of the outer list is the
+ pose detection results of a single frame, and each element of the
+ inner list is the pose information of one person, which contains:
+
+ - keypoints (ndarray[K, 2 or 3]): x, y, [score]
+ - track_id (int): unique id of each person, required \
+ when ``with_track_id==True``.
+ - bbox ((4, ) or (5, )): left, right, top, bottom, [score]
+
+ frame_idx (int): The index of the frame in the original video.
+ causal (bool): If True, the target frame is the last frame in
+ a sequence. Otherwise, the target frame is in the middle of
+ a sequence.
+ seq_len (int): The number of frames in the input sequence.
+ step (int): Step size to extract frames from the video.
+
+ Returns:
+ list[list[dict]]: Multi-frame pose detection results stored \
+ in a nested list with a length of seq_len.
+ """
+
+ if causal:
+ frames_left = seq_len - 1
+ frames_right = 0
+ else:
+ frames_left = (seq_len - 1) // 2
+ frames_right = frames_left
+ num_frames = len(pose_results)
+
+ # get the padded sequence
+ pad_left = max(0, frames_left - frame_idx // step)
+ pad_right = max(0, frames_right - (num_frames - 1 - frame_idx) // step)
+ start = max(frame_idx % step, frame_idx - frames_left * step)
+ end = min(num_frames - (num_frames - 1 - frame_idx) % step,
+ frame_idx + frames_right * step + 1)
+ pose_results_seq = [pose_results[0]] * pad_left + \
+ pose_results[start:end:step] + [pose_results[-1]] * pad_right
+ return pose_results_seq
+
+
+def _gather_pose_lifter_inputs(pose_results,
+ bbox_center,
+ bbox_scale,
+ norm_pose_2d=False):
+ """Gather input data (keypoints and track_id) for pose lifter model.
+
+ Note:
+ - The temporal length of the pose detection results: T
+ - The number of the person instances: N
+ - The number of the keypoints: K
+ - The channel number of each keypoint: C
+
+ Args:
+ pose_results (List[List[Dict]]): Multi-frame pose detection results
+ stored in a nested list. Each element of the outer list is the
+ pose detection results of a single frame, and each element of the
+ inner list is the pose information of one person, which contains:
+
+ - keypoints (ndarray[K, 2 or 3]): x, y, [score]
+ - track_id (int): unique id of each person, required when
+ ``with_track_id==True```
+ - bbox ((4, ) or (5, )): left, right, top, bottom, [score]
+
+ bbox_center (ndarray[1, 2]): x, y. The average center coordinate of the
+ bboxes in the dataset.
+ bbox_scale (int|float): The average scale of the bboxes in the dataset.
+ norm_pose_2d (bool): If True, scale the bbox (along with the 2D
+ pose) to bbox_scale, and move the bbox (along with the 2D pose) to
+ bbox_center. Default: False.
+
+ Returns:
+ list[list[dict]]: Multi-frame pose detection results
+ stored in a nested list. Each element of the outer list is the
+ pose detection results of a single frame, and each element of the
+ inner list is the pose information of one person, which contains:
+
+ - keypoints (ndarray[K, 2 or 3]): x, y, [score]
+ - track_id (int): unique id of each person, required when
+ ``with_track_id==True``
+ """
+ sequence_inputs = []
+ for frame in pose_results:
+ frame_inputs = []
+ for res in frame:
+ inputs = dict()
+
+ if norm_pose_2d:
+ bbox = res['bbox']
+ center = np.array([[(bbox[0] + bbox[2]) / 2,
+ (bbox[1] + bbox[3]) / 2]])
+ scale = max(bbox[2] - bbox[0], bbox[3] - bbox[1])
+ inputs['keypoints'] = (res['keypoints'][:, :2] - center) \
+ / scale * bbox_scale + bbox_center
+ else:
+ inputs['keypoints'] = res['keypoints'][:, :2]
+
+ if res['keypoints'].shape[1] == 3:
+ inputs['keypoints'] = np.concatenate(
+ [inputs['keypoints'], res['keypoints'][:, 2:]], axis=1)
+
+ if 'track_id' in res:
+ inputs['track_id'] = res['track_id']
+ frame_inputs.append(inputs)
+ sequence_inputs.append(frame_inputs)
+ return sequence_inputs
+
+
+def _collate_pose_sequence(pose_results, with_track_id=True, target_frame=-1):
+ """Reorganize multi-frame pose detection results into individual pose
+ sequences.
+
+ Note:
+ - The temporal length of the pose detection results: T
+ - The number of the person instances: N
+ - The number of the keypoints: K
+ - The channel number of each keypoint: C
+
+ Args:
+ pose_results (List[List[Dict]]): Multi-frame pose detection results
+ stored in a nested list. Each element of the outer list is the
+ pose detection results of a single frame, and each element of the
+ inner list is the pose information of one person, which contains:
+
+ - keypoints (ndarray[K, 2 or 3]): x, y, [score]
+ - track_id (int): unique id of each person, required when
+ ``with_track_id==True```
+
+ with_track_id (bool): If True, the element in pose_results is expected
+ to contain "track_id", which will be used to gather the pose
+ sequence of a person from multiple frames. Otherwise, the pose
+ results in each frame are expected to have a consistent number and
+ order of identities. Default is True.
+ target_frame (int): The index of the target frame. Default: -1.
+ """
+ T = len(pose_results)
+ assert T > 0
+
+ target_frame = (T + target_frame) % T # convert negative index to positive
+
+ N = len(pose_results[target_frame]) # use identities in the target frame
+ if N == 0:
+ return []
+
+ K, C = pose_results[target_frame][0]['keypoints'].shape
+
+ track_ids = None
+ if with_track_id:
+ track_ids = [res['track_id'] for res in pose_results[target_frame]]
+
+ pose_sequences = []
+ for idx in range(N):
+ pose_seq = dict()
+ # gather static information
+ for k, v in pose_results[target_frame][idx].items():
+ if k != 'keypoints':
+ pose_seq[k] = v
+ # gather keypoints
+ if not with_track_id:
+ pose_seq['keypoints'] = np.stack(
+ [frame[idx]['keypoints'] for frame in pose_results])
+ else:
+ keypoints = np.zeros((T, K, C), dtype=np.float32)
+ keypoints[target_frame] = pose_results[target_frame][idx][
+ 'keypoints']
+ # find the left most frame containing track_ids[idx]
+ for frame_idx in range(target_frame - 1, -1, -1):
+ contains_idx = False
+ for res in pose_results[frame_idx]:
+ if res['track_id'] == track_ids[idx]:
+ keypoints[frame_idx] = res['keypoints']
+ contains_idx = True
+ break
+ if not contains_idx:
+ # replicate the left most frame
+ keypoints[:frame_idx + 1] = keypoints[frame_idx + 1]
+ break
+ # find the right most frame containing track_idx[idx]
+ for frame_idx in range(target_frame + 1, T):
+ contains_idx = False
+ for res in pose_results[frame_idx]:
+ if res['track_id'] == track_ids[idx]:
+ keypoints[frame_idx] = res['keypoints']
+ contains_idx = True
+ break
+ if not contains_idx:
+ # replicate the right most frame
+ keypoints[frame_idx + 1:] = keypoints[frame_idx]
+ break
+ pose_seq['keypoints'] = keypoints
+ pose_sequences.append(pose_seq)
+
+ return pose_sequences
+
+
+def inference_pose_lifter_model(model,
+ pose_results_2d,
+ dataset=None,
+ dataset_info=None,
+ with_track_id=True,
+ image_size=None,
+ norm_pose_2d=False):
+ """Inference 3D pose from 2D pose sequences using a pose lifter model.
+
+ Args:
+ model (nn.Module): The loaded pose lifter model
+ pose_results_2d (list[list[dict]]): The 2D pose sequences stored in a
+ nested list. Each element of the outer list is the 2D pose results
+ of a single frame, and each element of the inner list is the 2D
+ pose of one person, which contains:
+
+ - "keypoints" (ndarray[K, 2 or 3]): x, y, [score]
+ - "track_id" (int)
+ dataset (str): Dataset name, e.g. 'Body3DH36MDataset'
+ with_track_id: If True, the element in pose_results_2d is expected to
+ contain "track_id", which will be used to gather the pose sequence
+ of a person from multiple frames. Otherwise, the pose results in
+ each frame are expected to have a consistent number and order of
+ identities. Default is True.
+ image_size (tuple|list): image width, image height. If None, image size
+ will not be contained in dict ``data``.
+ norm_pose_2d (bool): If True, scale the bbox (along with the 2D
+ pose) to the average bbox scale of the dataset, and move the bbox
+ (along with the 2D pose) to the average bbox center of the dataset.
+
+ Returns:
+ list[dict]: 3D pose inference results. Each element is the result of \
+ an instance, which contains:
+
+ - "keypoints_3d" (ndarray[K, 3]): predicted 3D keypoints
+ - "keypoints" (ndarray[K, 2 or 3]): from the last frame in \
+ ``pose_results_2d``.
+ - "track_id" (int): from the last frame in ``pose_results_2d``. \
+ If there is no valid instance, an empty list will be \
+ returned.
+ """
+ cfg = model.cfg
+ test_pipeline = Compose(cfg.test_pipeline)
+
+ device = next(model.parameters()).device
+ if device.type == 'cpu':
+ device = -1
+
+ if dataset_info is not None:
+ flip_pairs = dataset_info.flip_pairs
+ assert 'stats_info' in dataset_info._dataset_info
+ bbox_center = dataset_info._dataset_info['stats_info']['bbox_center']
+ bbox_scale = dataset_info._dataset_info['stats_info']['bbox_scale']
+ else:
+ warnings.warn(
+ 'dataset is deprecated.'
+ 'Please set `dataset_info` in the config.'
+ 'Check https://github.com/open-mmlab/mmpose/pull/663 for details.',
+ DeprecationWarning)
+ # TODO: These will be removed in the later versions.
+ if dataset == 'Body3DH36MDataset':
+ flip_pairs = [[1, 4], [2, 5], [3, 6], [11, 14], [12, 15], [13, 16]]
+ bbox_center = np.array([[528, 427]], dtype=np.float32)
+ bbox_scale = 400
+ else:
+ raise NotImplementedError()
+
+ target_idx = -1 if model.causal else len(pose_results_2d) // 2
+ pose_lifter_inputs = _gather_pose_lifter_inputs(pose_results_2d,
+ bbox_center, bbox_scale,
+ norm_pose_2d)
+ pose_sequences_2d = _collate_pose_sequence(pose_lifter_inputs,
+ with_track_id, target_idx)
+
+ if not pose_sequences_2d:
+ return []
+
+ batch_data = []
+ for seq in pose_sequences_2d:
+ pose_2d = seq['keypoints'].astype(np.float32)
+ T, K, C = pose_2d.shape
+
+ input_2d = pose_2d[..., :2]
+ input_2d_visible = pose_2d[..., 2:3]
+ if C > 2:
+ input_2d_visible = pose_2d[..., 2:3]
+ else:
+ input_2d_visible = np.ones((T, K, 1), dtype=np.float32)
+
+ # TODO: Will be removed in the later versions
+ # Dummy 3D input
+ # This is for compatibility with configs in mmpose<=v0.14.0, where a
+ # 3D input is required to generate denormalization parameters. This
+ # part will be removed in the future.
+ target = np.zeros((K, 3), dtype=np.float32)
+ target_visible = np.ones((K, 1), dtype=np.float32)
+
+ # Dummy image path
+ # This is for compatibility with configs in mmpose<=v0.14.0, where
+ # target_image_path is required. This part will be removed in the
+ # future.
+ target_image_path = None
+
+ data = {
+ 'input_2d': input_2d,
+ 'input_2d_visible': input_2d_visible,
+ 'target': target,
+ 'target_visible': target_visible,
+ 'target_image_path': target_image_path,
+ 'ann_info': {
+ 'num_joints': K,
+ 'flip_pairs': flip_pairs
+ }
+ }
+
+ if image_size is not None:
+ assert len(image_size) == 2
+ data['image_width'] = image_size[0]
+ data['image_height'] = image_size[1]
+
+ data = test_pipeline(data)
+ batch_data.append(data)
+
+ batch_data = collate(batch_data, samples_per_gpu=len(batch_data))
+ batch_data = scatter(batch_data, target_gpus=[device])[0]
+
+ with torch.no_grad():
+ result = model(
+ input=batch_data['input'],
+ metas=batch_data['metas'],
+ return_loss=False)
+
+ poses_3d = result['preds']
+ if poses_3d.shape[-1] != 4:
+ assert poses_3d.shape[-1] == 3
+ dummy_score = np.ones(
+ poses_3d.shape[:-1] + (1, ), dtype=poses_3d.dtype)
+ poses_3d = np.concatenate((poses_3d, dummy_score), axis=-1)
+ pose_results = []
+ for pose_2d, pose_3d in zip(pose_sequences_2d, poses_3d):
+ pose_result = pose_2d.copy()
+ pose_result['keypoints_3d'] = pose_3d
+ pose_results.append(pose_result)
+
+ return pose_results
+
+
+def vis_3d_pose_result(model,
+ result,
+ img=None,
+ dataset='Body3DH36MDataset',
+ dataset_info=None,
+ kpt_score_thr=0.3,
+ radius=8,
+ thickness=2,
+ num_instances=-1,
+ show=False,
+ out_file=None):
+ """Visualize the 3D pose estimation results.
+
+ Args:
+ model (nn.Module): The loaded model.
+ result (list[dict])
+ """
+
+ if dataset_info is not None:
+ skeleton = dataset_info.skeleton
+ pose_kpt_color = dataset_info.pose_kpt_color
+ pose_link_color = dataset_info.pose_link_color
+ else:
+ warnings.warn(
+ 'dataset is deprecated.'
+ 'Please set `dataset_info` in the config.'
+ 'Check https://github.com/open-mmlab/mmpose/pull/663 for details.',
+ DeprecationWarning)
+ # TODO: These will be removed in the later versions.
+ palette = np.array([[255, 128, 0], [255, 153, 51], [255, 178, 102],
+ [230, 230, 0], [255, 153, 255], [153, 204, 255],
+ [255, 102, 255], [255, 51, 255], [102, 178, 255],
+ [51, 153, 255], [255, 153, 153], [255, 102, 102],
+ [255, 51, 51], [153, 255, 153], [102, 255, 102],
+ [51, 255, 51], [0, 255, 0], [0, 0, 255],
+ [255, 0, 0], [255, 255, 255]])
+
+ if dataset == 'Body3DH36MDataset':
+ skeleton = [[0, 1], [1, 2], [2, 3], [0, 4], [4, 5], [5, 6], [0, 7],
+ [7, 8], [8, 9], [9, 10], [8, 11], [11, 12], [12, 13],
+ [8, 14], [14, 15], [15, 16]]
+
+ pose_kpt_color = palette[[
+ 9, 0, 0, 0, 16, 16, 16, 9, 9, 9, 9, 16, 16, 16, 0, 0, 0
+ ]]
+ pose_link_color = palette[[
+ 0, 0, 0, 16, 16, 16, 9, 9, 9, 9, 16, 16, 16, 0, 0, 0
+ ]]
+
+ elif dataset == 'InterHand3DDataset':
+ skeleton = [[0, 1], [1, 2], [2, 3], [3, 20], [4, 5], [5, 6],
+ [6, 7], [7, 20], [8, 9], [9, 10], [10, 11], [11, 20],
+ [12, 13], [13, 14], [14, 15], [15, 20], [16, 17],
+ [17, 18], [18, 19], [19, 20], [21, 22], [22, 23],
+ [23, 24], [24, 41], [25, 26], [26, 27], [27, 28],
+ [28, 41], [29, 30], [30, 31], [31, 32], [32, 41],
+ [33, 34], [34, 35], [35, 36], [36, 41], [37, 38],
+ [38, 39], [39, 40], [40, 41]]
+
+ pose_kpt_color = [[14, 128, 250], [14, 128, 250], [14, 128, 250],
+ [14, 128, 250], [80, 127, 255], [80, 127, 255],
+ [80, 127, 255], [80, 127, 255], [71, 99, 255],
+ [71, 99, 255], [71, 99, 255], [71, 99, 255],
+ [0, 36, 255], [0, 36, 255], [0, 36, 255],
+ [0, 36, 255], [0, 0, 230], [0, 0, 230],
+ [0, 0, 230], [0, 0, 230], [0, 0, 139],
+ [237, 149, 100], [237, 149, 100],
+ [237, 149, 100], [237, 149, 100], [230, 128, 77],
+ [230, 128, 77], [230, 128, 77], [230, 128, 77],
+ [255, 144, 30], [255, 144, 30], [255, 144, 30],
+ [255, 144, 30], [153, 51, 0], [153, 51, 0],
+ [153, 51, 0], [153, 51, 0], [255, 51, 13],
+ [255, 51, 13], [255, 51, 13], [255, 51, 13],
+ [103, 37, 8]]
+
+ pose_link_color = [[14, 128, 250], [14, 128, 250], [14, 128, 250],
+ [14, 128, 250], [80, 127, 255], [80, 127, 255],
+ [80, 127, 255], [80, 127, 255], [71, 99, 255],
+ [71, 99, 255], [71, 99, 255], [71, 99, 255],
+ [0, 36, 255], [0, 36, 255], [0, 36, 255],
+ [0, 36, 255], [0, 0, 230], [0, 0, 230],
+ [0, 0, 230], [0, 0, 230], [237, 149, 100],
+ [237, 149, 100], [237, 149, 100],
+ [237, 149, 100], [230, 128, 77], [230, 128, 77],
+ [230, 128, 77], [230, 128, 77], [255, 144, 30],
+ [255, 144, 30], [255, 144, 30], [255, 144, 30],
+ [153, 51, 0], [153, 51, 0], [153, 51, 0],
+ [153, 51, 0], [255, 51, 13], [255, 51, 13],
+ [255, 51, 13], [255, 51, 13]]
+ else:
+ raise NotImplementedError
+
+ if hasattr(model, 'module'):
+ model = model.module
+
+ img = model.show_result(
+ result,
+ img,
+ skeleton,
+ radius=radius,
+ thickness=thickness,
+ pose_kpt_color=pose_kpt_color,
+ pose_link_color=pose_link_color,
+ num_instances=num_instances,
+ show=show,
+ out_file=out_file)
+
+ return img
+
+
+def inference_interhand_3d_model(model,
+ img_or_path,
+ det_results,
+ bbox_thr=None,
+ format='xywh',
+ dataset='InterHand3DDataset'):
+ """Inference a single image with a list of hand bounding boxes.
+
+ Note:
+ - num_bboxes: N
+ - num_keypoints: K
+
+ Args:
+ model (nn.Module): The loaded pose model.
+ img_or_path (str | np.ndarray): Image filename or loaded image.
+ det_results (list[dict]): The 2D bbox sequences stored in a list.
+ Each each element of the list is the bbox of one person, whose
+ shape is (ndarray[4 or 5]), containing 4 box coordinates
+ (and score).
+ dataset (str): Dataset name.
+ format: bbox format ('xyxy' | 'xywh'). Default: 'xywh'.
+ 'xyxy' means (left, top, right, bottom),
+ 'xywh' means (left, top, width, height).
+
+ Returns:
+ list[dict]: 3D pose inference results. Each element is the result \
+ of an instance, which contains the predicted 3D keypoints with \
+ shape (ndarray[K,3]). If there is no valid instance, an \
+ empty list will be returned.
+ """
+
+ assert format in ['xyxy', 'xywh']
+
+ pose_results = []
+
+ if len(det_results) == 0:
+ return pose_results
+
+ # Change for-loop preprocess each bbox to preprocess all bboxes at once.
+ bboxes = np.array([box['bbox'] for box in det_results])
+
+ # Select bboxes by score threshold
+ if bbox_thr is not None:
+ assert bboxes.shape[1] == 5
+ valid_idx = np.where(bboxes[:, 4] > bbox_thr)[0]
+ bboxes = bboxes[valid_idx]
+ det_results = [det_results[i] for i in valid_idx]
+
+ if format == 'xyxy':
+ bboxes_xyxy = bboxes
+ bboxes_xywh = _xyxy2xywh(bboxes)
+ else:
+ # format is already 'xywh'
+ bboxes_xywh = bboxes
+ bboxes_xyxy = _xywh2xyxy(bboxes)
+
+ # if bbox_thr remove all bounding box
+ if len(bboxes_xywh) == 0:
+ return []
+
+ cfg = model.cfg
+ device = next(model.parameters()).device
+ if device.type == 'cpu':
+ device = -1
+
+ # build the data pipeline
+ test_pipeline = Compose(cfg.test_pipeline)
+
+ assert len(bboxes[0]) in [4, 5]
+
+ if dataset == 'InterHand3DDataset':
+ flip_pairs = [[i, 21 + i] for i in range(21)]
+ else:
+ raise NotImplementedError()
+
+ batch_data = []
+ for bbox in bboxes:
+ center, scale = _box2cs(cfg, bbox)
+
+ # prepare data
+ data = {
+ 'center':
+ center,
+ 'scale':
+ scale,
+ 'bbox_score':
+ bbox[4] if len(bbox) == 5 else 1,
+ 'bbox_id':
+ 0, # need to be assigned if batch_size > 1
+ 'dataset':
+ dataset,
+ 'joints_3d':
+ np.zeros((cfg.data_cfg.num_joints, 3), dtype=np.float32),
+ 'joints_3d_visible':
+ np.zeros((cfg.data_cfg.num_joints, 3), dtype=np.float32),
+ 'rotation':
+ 0,
+ 'ann_info': {
+ 'image_size': np.array(cfg.data_cfg['image_size']),
+ 'num_joints': cfg.data_cfg['num_joints'],
+ 'flip_pairs': flip_pairs,
+ 'heatmap3d_depth_bound': cfg.data_cfg['heatmap3d_depth_bound'],
+ 'heatmap_size_root': cfg.data_cfg['heatmap_size_root'],
+ 'root_depth_bound': cfg.data_cfg['root_depth_bound']
+ }
+ }
+
+ if isinstance(img_or_path, np.ndarray):
+ data['img'] = img_or_path
+ else:
+ data['image_file'] = img_or_path
+
+ data = test_pipeline(data)
+ batch_data.append(data)
+
+ batch_data = collate(batch_data, samples_per_gpu=len(batch_data))
+ batch_data = scatter(batch_data, [device])[0]
+
+ # forward the model
+ with torch.no_grad():
+ result = model(
+ img=batch_data['img'],
+ img_metas=batch_data['img_metas'],
+ return_loss=False)
+
+ poses_3d = result['preds']
+ rel_root_depth = result['rel_root_depth']
+ hand_type = result['hand_type']
+ if poses_3d.shape[-1] != 4:
+ assert poses_3d.shape[-1] == 3
+ dummy_score = np.ones(
+ poses_3d.shape[:-1] + (1, ), dtype=poses_3d.dtype)
+ poses_3d = np.concatenate((poses_3d, dummy_score), axis=-1)
+
+ # add relative root depth to left hand joints
+ poses_3d[:, 21:, 2] += rel_root_depth
+
+ # set joint scores according to hand type
+ poses_3d[:, :21, 3] *= hand_type[:, [0]]
+ poses_3d[:, 21:, 3] *= hand_type[:, [1]]
+
+ pose_results = []
+ for pose_3d, person_res, bbox_xyxy in zip(poses_3d, det_results,
+ bboxes_xyxy):
+ pose_res = person_res.copy()
+ pose_res['keypoints_3d'] = pose_3d
+ pose_res['bbox'] = bbox_xyxy
+ pose_results.append(pose_res)
+
+ return pose_results
+
+
+def inference_mesh_model(model,
+ img_or_path,
+ det_results,
+ bbox_thr=None,
+ format='xywh',
+ dataset='MeshH36MDataset'):
+ """Inference a single image with a list of bounding boxes.
+
+ Note:
+ - num_bboxes: N
+ - num_keypoints: K
+ - num_vertices: V
+ - num_faces: F
+
+ Args:
+ model (nn.Module): The loaded pose model.
+ img_or_path (str | np.ndarray): Image filename or loaded image.
+ det_results (list[dict]): The 2D bbox sequences stored in a list.
+ Each element of the list is the bbox of one person.
+ "bbox" (ndarray[4 or 5]): The person bounding box,
+ which contains 4 box coordinates (and score).
+ bbox_thr (float | None): Threshold for bounding boxes.
+ Only bboxes with higher scores will be fed into the pose
+ detector. If bbox_thr is None, all boxes will be used.
+ format (str): bbox format ('xyxy' | 'xywh'). Default: 'xywh'.
+
+ - 'xyxy' means (left, top, right, bottom),
+ - 'xywh' means (left, top, width, height).
+ dataset (str): Dataset name.
+
+ Returns:
+ list[dict]: 3D pose inference results. Each element \
+ is the result of an instance, which contains:
+
+ - 'bbox' (ndarray[4]): instance bounding bbox
+ - 'center' (ndarray[2]): bbox center
+ - 'scale' (ndarray[2]): bbox scale
+ - 'keypoints_3d' (ndarray[K,3]): predicted 3D keypoints
+ - 'camera' (ndarray[3]): camera parameters
+ - 'vertices' (ndarray[V, 3]): predicted 3D vertices
+ - 'faces' (ndarray[F, 3]): mesh faces
+
+ If there is no valid instance, an empty list
+ will be returned.
+ """
+
+ assert format in ['xyxy', 'xywh']
+
+ pose_results = []
+
+ if len(det_results) == 0:
+ return pose_results
+
+ # Change for-loop preprocess each bbox to preprocess all bboxes at once.
+ bboxes = np.array([box['bbox'] for box in det_results])
+
+ # Select bboxes by score threshold
+ if bbox_thr is not None:
+ assert bboxes.shape[1] == 5
+ valid_idx = np.where(bboxes[:, 4] > bbox_thr)[0]
+ bboxes = bboxes[valid_idx]
+ det_results = [det_results[i] for i in valid_idx]
+
+ if format == 'xyxy':
+ bboxes_xyxy = bboxes
+ bboxes_xywh = _xyxy2xywh(bboxes)
+ else:
+ # format is already 'xywh'
+ bboxes_xywh = bboxes
+ bboxes_xyxy = _xywh2xyxy(bboxes)
+
+ # if bbox_thr remove all bounding box
+ if len(bboxes_xywh) == 0:
+ return []
+
+ cfg = model.cfg
+ device = next(model.parameters()).device
+ if device.type == 'cpu':
+ device = -1
+
+ # build the data pipeline
+ test_pipeline = Compose(cfg.test_pipeline)
+
+ assert len(bboxes[0]) in [4, 5]
+
+ if dataset == 'MeshH36MDataset':
+ flip_pairs = [[0, 5], [1, 4], [2, 3], [6, 11], [7, 10], [8, 9],
+ [20, 21], [22, 23]]
+ else:
+ raise NotImplementedError()
+
+ batch_data = []
+ for bbox in bboxes:
+ center, scale = _box2cs(cfg, bbox)
+
+ # prepare data
+ data = {
+ 'image_file':
+ img_or_path,
+ 'center':
+ center,
+ 'scale':
+ scale,
+ 'rotation':
+ 0,
+ 'bbox_score':
+ bbox[4] if len(bbox) == 5 else 1,
+ 'dataset':
+ dataset,
+ 'joints_2d':
+ np.zeros((cfg.data_cfg.num_joints, 2), dtype=np.float32),
+ 'joints_2d_visible':
+ np.zeros((cfg.data_cfg.num_joints, 1), dtype=np.float32),
+ 'joints_3d':
+ np.zeros((cfg.data_cfg.num_joints, 3), dtype=np.float32),
+ 'joints_3d_visible':
+ np.zeros((cfg.data_cfg.num_joints, 3), dtype=np.float32),
+ 'pose':
+ np.zeros(72, dtype=np.float32),
+ 'beta':
+ np.zeros(10, dtype=np.float32),
+ 'has_smpl':
+ 0,
+ 'ann_info': {
+ 'image_size': np.array(cfg.data_cfg['image_size']),
+ 'num_joints': cfg.data_cfg['num_joints'],
+ 'flip_pairs': flip_pairs,
+ }
+ }
+
+ data = test_pipeline(data)
+ batch_data.append(data)
+
+ batch_data = collate(batch_data, samples_per_gpu=len(batch_data))
+ batch_data = scatter(batch_data, target_gpus=[device])[0]
+
+ # forward the model
+ with torch.no_grad():
+ preds = model(
+ img=batch_data['img'],
+ img_metas=batch_data['img_metas'],
+ return_loss=False,
+ return_vertices=True,
+ return_faces=True)
+
+ for idx in range(len(det_results)):
+ pose_res = det_results[idx].copy()
+ pose_res['bbox'] = bboxes_xyxy[idx]
+ pose_res['center'] = batch_data['img_metas'][idx]['center']
+ pose_res['scale'] = batch_data['img_metas'][idx]['scale']
+ pose_res['keypoints_3d'] = preds['keypoints_3d'][idx]
+ pose_res['camera'] = preds['camera'][idx]
+ pose_res['vertices'] = preds['vertices'][idx]
+ pose_res['faces'] = preds['faces']
+ pose_results.append(pose_res)
+ return pose_results
+
+
+def vis_3d_mesh_result(model, result, img=None, show=False, out_file=None):
+ """Visualize the 3D mesh estimation results.
+
+ Args:
+ model (nn.Module): The loaded model.
+ result (list[dict]): 3D mesh estimation results.
+ """
+ if hasattr(model, 'module'):
+ model = model.module
+
+ img = model.show_result(result, img, show=show, out_file=out_file)
+
+ return img
diff --git a/vendor/ViTPose/mmpose/apis/inference_tracking.py b/vendor/ViTPose/mmpose/apis/inference_tracking.py
new file mode 100644
index 0000000000000000000000000000000000000000..9494fbaa75ca54840bd2c3f8bbbfcc7955e3a05d
--- /dev/null
+++ b/vendor/ViTPose/mmpose/apis/inference_tracking.py
@@ -0,0 +1,347 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import numpy as np
+
+from mmpose.core import OneEuroFilter, oks_iou
+
+
+def _compute_iou(bboxA, bboxB):
+ """Compute the Intersection over Union (IoU) between two boxes .
+
+ Args:
+ bboxA (list): The first bbox info (left, top, right, bottom, score).
+ bboxB (list): The second bbox info (left, top, right, bottom, score).
+
+ Returns:
+ float: The IoU value.
+ """
+
+ x1 = max(bboxA[0], bboxB[0])
+ y1 = max(bboxA[1], bboxB[1])
+ x2 = min(bboxA[2], bboxB[2])
+ y2 = min(bboxA[3], bboxB[3])
+
+ inter_area = max(0, x2 - x1) * max(0, y2 - y1)
+
+ bboxA_area = (bboxA[2] - bboxA[0]) * (bboxA[3] - bboxA[1])
+ bboxB_area = (bboxB[2] - bboxB[0]) * (bboxB[3] - bboxB[1])
+ union_area = float(bboxA_area + bboxB_area - inter_area)
+ if union_area == 0:
+ union_area = 1e-5
+ warnings.warn('union_area=0 is unexpected')
+
+ iou = inter_area / union_area
+
+ return iou
+
+
+def _track_by_iou(res, results_last, thr):
+ """Get track id using IoU tracking greedily.
+
+ Args:
+ res (dict): The bbox & pose results of the person instance.
+ results_last (list[dict]): The bbox & pose & track_id info of the
+ last frame (bbox_result, pose_result, track_id).
+ thr (float): The threshold for iou tracking.
+
+ Returns:
+ int: The track id for the new person instance.
+ list[dict]: The bbox & pose & track_id info of the persons
+ that have not been matched on the last frame.
+ dict: The matched person instance on the last frame.
+ """
+
+ bbox = list(res['bbox'])
+
+ max_iou_score = -1
+ max_index = -1
+ match_result = {}
+ for index, res_last in enumerate(results_last):
+ bbox_last = list(res_last['bbox'])
+
+ iou_score = _compute_iou(bbox, bbox_last)
+ if iou_score > max_iou_score:
+ max_iou_score = iou_score
+ max_index = index
+
+ if max_iou_score > thr:
+ track_id = results_last[max_index]['track_id']
+ match_result = results_last[max_index]
+ del results_last[max_index]
+ else:
+ track_id = -1
+
+ return track_id, results_last, match_result
+
+
+def _track_by_oks(res, results_last, thr):
+ """Get track id using OKS tracking greedily.
+
+ Args:
+ res (dict): The pose results of the person instance.
+ results_last (list[dict]): The pose & track_id info of the
+ last frame (pose_result, track_id).
+ thr (float): The threshold for oks tracking.
+
+ Returns:
+ int: The track id for the new person instance.
+ list[dict]: The pose & track_id info of the persons
+ that have not been matched on the last frame.
+ dict: The matched person instance on the last frame.
+ """
+ pose = res['keypoints'].reshape((-1))
+ area = res['area']
+ max_index = -1
+ match_result = {}
+
+ if len(results_last) == 0:
+ return -1, results_last, match_result
+
+ pose_last = np.array(
+ [res_last['keypoints'].reshape((-1)) for res_last in results_last])
+ area_last = np.array([res_last['area'] for res_last in results_last])
+
+ oks_score = oks_iou(pose, pose_last, area, area_last)
+
+ max_index = np.argmax(oks_score)
+
+ if oks_score[max_index] > thr:
+ track_id = results_last[max_index]['track_id']
+ match_result = results_last[max_index]
+ del results_last[max_index]
+ else:
+ track_id = -1
+
+ return track_id, results_last, match_result
+
+
+def _get_area(results):
+ """Get bbox for each person instance on the current frame.
+
+ Args:
+ results (list[dict]): The pose results of the current frame
+ (pose_result).
+ Returns:
+ list[dict]: The bbox & pose info of the current frame
+ (bbox_result, pose_result, area).
+ """
+ for result in results:
+ if 'bbox' in result:
+ result['area'] = ((result['bbox'][2] - result['bbox'][0]) *
+ (result['bbox'][3] - result['bbox'][1]))
+ else:
+ xmin = np.min(
+ result['keypoints'][:, 0][result['keypoints'][:, 0] > 0],
+ initial=1e10)
+ xmax = np.max(result['keypoints'][:, 0])
+ ymin = np.min(
+ result['keypoints'][:, 1][result['keypoints'][:, 1] > 0],
+ initial=1e10)
+ ymax = np.max(result['keypoints'][:, 1])
+ result['area'] = (xmax - xmin) * (ymax - ymin)
+ result['bbox'] = np.array([xmin, ymin, xmax, ymax])
+ return results
+
+
+def _temporal_refine(result, match_result, fps=None):
+ """Refine koypoints using tracked person instance on last frame.
+
+ Args:
+ results (dict): The pose results of the current frame
+ (pose_result).
+ match_result (dict): The pose results of the last frame
+ (match_result)
+ Returns:
+ (array): The person keypoints after refine.
+ """
+ if 'one_euro' in match_result:
+ result['keypoints'][:, :2] = match_result['one_euro'](
+ result['keypoints'][:, :2])
+ result['one_euro'] = match_result['one_euro']
+ else:
+ result['one_euro'] = OneEuroFilter(result['keypoints'][:, :2], fps=fps)
+ return result['keypoints']
+
+
+def get_track_id(results,
+ results_last,
+ next_id,
+ min_keypoints=3,
+ use_oks=False,
+ tracking_thr=0.3,
+ use_one_euro=False,
+ fps=None):
+ """Get track id for each person instance on the current frame.
+
+ Args:
+ results (list[dict]): The bbox & pose results of the current frame
+ (bbox_result, pose_result).
+ results_last (list[dict]): The bbox & pose & track_id info of the
+ last frame (bbox_result, pose_result, track_id).
+ next_id (int): The track id for the new person instance.
+ min_keypoints (int): Minimum number of keypoints recognized as person.
+ default: 3.
+ use_oks (bool): Flag to using oks tracking. default: False.
+ tracking_thr (float): The threshold for tracking.
+ use_one_euro (bool): Option to use one-euro-filter. default: False.
+ fps (optional): Parameters that d_cutoff
+ when one-euro-filter is used as a video input
+
+ Returns:
+ tuple:
+ - results (list[dict]): The bbox & pose & track_id info of the \
+ current frame (bbox_result, pose_result, track_id).
+ - next_id (int): The track id for the new person instance.
+ """
+ results = _get_area(results)
+
+ if use_oks:
+ _track = _track_by_oks
+ else:
+ _track = _track_by_iou
+
+ for result in results:
+ track_id, results_last, match_result = _track(result, results_last,
+ tracking_thr)
+ if track_id == -1:
+ if np.count_nonzero(result['keypoints'][:, 1]) > min_keypoints:
+ result['track_id'] = next_id
+ next_id += 1
+ else:
+ # If the number of keypoints detected is small,
+ # delete that person instance.
+ result['keypoints'][:, 1] = -10
+ result['bbox'] *= 0
+ result['track_id'] = -1
+ else:
+ result['track_id'] = track_id
+ if use_one_euro:
+ result['keypoints'] = _temporal_refine(
+ result, match_result, fps=fps)
+ del match_result
+
+ return results, next_id
+
+
+def vis_pose_tracking_result(model,
+ img,
+ result,
+ radius=4,
+ thickness=1,
+ kpt_score_thr=0.3,
+ dataset='TopDownCocoDataset',
+ dataset_info=None,
+ show=False,
+ out_file=None):
+ """Visualize the pose tracking results on the image.
+
+ Args:
+ model (nn.Module): The loaded detector.
+ img (str | np.ndarray): Image filename or loaded image.
+ result (list[dict]): The results to draw over `img`
+ (bbox_result, pose_result).
+ radius (int): Radius of circles.
+ thickness (int): Thickness of lines.
+ kpt_score_thr (float): The threshold to visualize the keypoints.
+ skeleton (list[tuple]): Default None.
+ show (bool): Whether to show the image. Default True.
+ out_file (str|None): The filename of the output visualization image.
+ """
+ if hasattr(model, 'module'):
+ model = model.module
+
+ palette = np.array([[255, 128, 0], [255, 153, 51], [255, 178, 102],
+ [230, 230, 0], [255, 153, 255], [153, 204, 255],
+ [255, 102, 255], [255, 51, 255], [102, 178, 255],
+ [51, 153, 255], [255, 153, 153], [255, 102, 102],
+ [255, 51, 51], [153, 255, 153], [102, 255, 102],
+ [51, 255, 51], [0, 255, 0], [0, 0, 255], [255, 0, 0],
+ [255, 255, 255]])
+
+ if dataset_info is None and dataset is not None:
+ warnings.warn(
+ 'dataset is deprecated.'
+ 'Please set `dataset_info` in the config.'
+ 'Check https://github.com/open-mmlab/mmpose/pull/663 for details.',
+ DeprecationWarning)
+ # TODO: These will be removed in the later versions.
+ if dataset in ('TopDownCocoDataset', 'BottomUpCocoDataset',
+ 'TopDownOCHumanDataset'):
+ kpt_num = 17
+ skeleton = [[15, 13], [13, 11], [16, 14], [14, 12], [11, 12],
+ [5, 11], [6, 12], [5, 6], [5, 7], [6, 8], [7, 9],
+ [8, 10], [1, 2], [0, 1], [0, 2], [1, 3], [2, 4],
+ [3, 5], [4, 6]]
+
+ elif dataset == 'TopDownCocoWholeBodyDataset':
+ kpt_num = 133
+ skeleton = [[15, 13], [13, 11], [16, 14], [14, 12], [11, 12],
+ [5, 11], [6, 12], [5, 6], [5, 7], [6, 8], [7, 9],
+ [8, 10], [1, 2], [0, 1], [0, 2],
+ [1, 3], [2, 4], [3, 5], [4, 6], [15, 17], [15, 18],
+ [15, 19], [16, 20], [16, 21], [16, 22], [91, 92],
+ [92, 93], [93, 94], [94, 95], [91, 96], [96, 97],
+ [97, 98], [98, 99], [91, 100], [100, 101], [101, 102],
+ [102, 103], [91, 104], [104, 105], [105, 106],
+ [106, 107], [91, 108], [108, 109], [109, 110],
+ [110, 111], [112, 113], [113, 114], [114, 115],
+ [115, 116], [112, 117], [117, 118], [118, 119],
+ [119, 120], [112, 121], [121, 122], [122, 123],
+ [123, 124], [112, 125], [125, 126], [126, 127],
+ [127, 128], [112, 129], [129, 130], [130, 131],
+ [131, 132]]
+ radius = 1
+
+ elif dataset == 'TopDownAicDataset':
+ kpt_num = 14
+ skeleton = [[2, 1], [1, 0], [0, 13], [13, 3], [3, 4], [4, 5],
+ [8, 7], [7, 6], [6, 9], [9, 10], [10, 11], [12, 13],
+ [0, 6], [3, 9]]
+
+ elif dataset == 'TopDownMpiiDataset':
+ kpt_num = 16
+ skeleton = [[0, 1], [1, 2], [2, 6], [6, 3], [3, 4], [4, 5], [6, 7],
+ [7, 8], [8, 9], [8, 12], [12, 11], [11, 10], [8, 13],
+ [13, 14], [14, 15]]
+
+ elif dataset in ('OneHand10KDataset', 'FreiHandDataset',
+ 'PanopticDataset'):
+ kpt_num = 21
+ skeleton = [[0, 1], [1, 2], [2, 3], [3, 4], [0, 5], [5, 6], [6, 7],
+ [7, 8], [0, 9], [9, 10], [10, 11], [11, 12], [0, 13],
+ [13, 14], [14, 15], [15, 16], [0, 17], [17, 18],
+ [18, 19], [19, 20]]
+
+ elif dataset == 'InterHand2DDataset':
+ kpt_num = 21
+ skeleton = [[0, 1], [1, 2], [2, 3], [4, 5], [5, 6], [6, 7], [8, 9],
+ [9, 10], [10, 11], [12, 13], [13, 14], [14, 15],
+ [16, 17], [17, 18], [18, 19], [3, 20], [7, 20],
+ [11, 20], [15, 20], [19, 20]]
+
+ else:
+ raise NotImplementedError()
+
+ elif dataset_info is not None:
+ kpt_num = dataset_info.keypoint_num
+ skeleton = dataset_info.skeleton
+
+ for res in result:
+ track_id = res['track_id']
+ bbox_color = palette[track_id % len(palette)]
+ pose_kpt_color = palette[[track_id % len(palette)] * kpt_num]
+ pose_link_color = palette[[track_id % len(palette)] * len(skeleton)]
+ img = model.show_result(
+ img, [res],
+ skeleton,
+ radius=radius,
+ thickness=thickness,
+ pose_kpt_color=pose_kpt_color,
+ pose_link_color=pose_link_color,
+ bbox_color=tuple(bbox_color.tolist()),
+ kpt_score_thr=kpt_score_thr,
+ show=show,
+ out_file=out_file)
+
+ return img
diff --git a/vendor/ViTPose/mmpose/apis/test.py b/vendor/ViTPose/mmpose/apis/test.py
new file mode 100644
index 0000000000000000000000000000000000000000..3843b5a594c03cf82144f6c3b3805a9221f16d72
--- /dev/null
+++ b/vendor/ViTPose/mmpose/apis/test.py
@@ -0,0 +1,191 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+import pickle
+import shutil
+import tempfile
+
+import mmcv
+import torch
+import torch.distributed as dist
+from mmcv.runner import get_dist_info
+
+
+def single_gpu_test(model, data_loader):
+ """Test model with a single gpu.
+
+ This method tests model with a single gpu and displays test progress bar.
+
+ Args:
+ model (nn.Module): Model to be tested.
+ data_loader (nn.Dataloader): Pytorch data loader.
+
+
+ Returns:
+ list: The prediction results.
+ """
+
+ model.eval()
+ results = []
+ dataset = data_loader.dataset
+ prog_bar = mmcv.ProgressBar(len(dataset))
+ for data in data_loader:
+ with torch.no_grad():
+ result = model(return_loss=False, **data)
+ results.append(result)
+
+ # use the first key as main key to calculate the batch size
+ batch_size = len(next(iter(data.values())))
+ for _ in range(batch_size):
+ prog_bar.update()
+ return results
+
+
+def multi_gpu_test(model, data_loader, tmpdir=None, gpu_collect=False):
+ """Test model with multiple gpus.
+
+ This method tests model with multiple gpus and collects the results
+ under two different modes: gpu and cpu modes. By setting 'gpu_collect=True'
+ it encodes results to gpu tensors and use gpu communication for results
+ collection. On cpu mode it saves the results on different gpus to 'tmpdir'
+ and collects them by the rank 0 worker.
+
+ Args:
+ model (nn.Module): Model to be tested.
+ data_loader (nn.Dataloader): Pytorch data loader.
+ tmpdir (str): Path of directory to save the temporary results from
+ different gpus under cpu mode.
+ gpu_collect (bool): Option to use either gpu or cpu to collect results.
+
+ Returns:
+ list: The prediction results.
+ """
+ model.eval()
+ results = []
+ dataset = data_loader.dataset
+ rank, world_size = get_dist_info()
+ if rank == 0:
+ prog_bar = mmcv.ProgressBar(len(dataset))
+ for data in data_loader:
+ with torch.no_grad():
+ result = model(return_loss=False, **data)
+ results.append(result)
+
+ if rank == 0:
+ # use the first key as main key to calculate the batch size
+ batch_size = len(next(iter(data.values())))
+ for _ in range(batch_size * world_size):
+ prog_bar.update()
+
+ # collect results from all ranks
+ if gpu_collect:
+ results = collect_results_gpu(results, len(dataset))
+ else:
+ results = collect_results_cpu(results, len(dataset), tmpdir)
+ return results
+
+
+def collect_results_cpu(result_part, size, tmpdir=None):
+ """Collect results in cpu mode.
+
+ It saves the results on different gpus to 'tmpdir' and collects
+ them by the rank 0 worker.
+
+ Args:
+ result_part (list): Results to be collected
+ size (int): Result size.
+ tmpdir (str): Path of directory to save the temporary results from
+ different gpus under cpu mode. Default: None
+
+ Returns:
+ list: Ordered results.
+ """
+ rank, world_size = get_dist_info()
+ # create a tmp dir if it is not specified
+ if tmpdir is None:
+ MAX_LEN = 512
+ # 32 is whitespace
+ dir_tensor = torch.full((MAX_LEN, ),
+ 32,
+ dtype=torch.uint8,
+ device='cuda')
+ if rank == 0:
+ mmcv.mkdir_or_exist('.dist_test')
+ tmpdir = tempfile.mkdtemp(dir='.dist_test')
+ tmpdir = torch.tensor(
+ bytearray(tmpdir.encode()), dtype=torch.uint8, device='cuda')
+ dir_tensor[:len(tmpdir)] = tmpdir
+ dist.broadcast(dir_tensor, 0)
+ tmpdir = dir_tensor.cpu().numpy().tobytes().decode().rstrip()
+ else:
+ mmcv.mkdir_or_exist(tmpdir)
+ # synchronizes all processes to make sure tmpdir exist
+ dist.barrier()
+ # dump the part result to the dir
+ mmcv.dump(result_part, osp.join(tmpdir, f'part_{rank}.pkl'))
+ # synchronizes all processes for loading pickle file
+ dist.barrier()
+ # collect all parts
+ if rank != 0:
+ return None
+
+ # load results of all parts from tmp dir
+ part_list = []
+ for i in range(world_size):
+ part_file = osp.join(tmpdir, f'part_{i}.pkl')
+ part_list.append(mmcv.load(part_file))
+ # sort the results
+ ordered_results = []
+ for res in zip(*part_list):
+ ordered_results.extend(list(res))
+ # the dataloader may pad some samples
+ ordered_results = ordered_results[:size]
+ # remove tmp dir
+ shutil.rmtree(tmpdir)
+ return ordered_results
+
+
+def collect_results_gpu(result_part, size):
+ """Collect results in gpu mode.
+
+ It encodes results to gpu tensors and use gpu communication for results
+ collection.
+
+ Args:
+ result_part (list): Results to be collected
+ size (int): Result size.
+
+ Returns:
+ list: Ordered results.
+ """
+
+ rank, world_size = get_dist_info()
+ # dump result part to tensor with pickle
+ part_tensor = torch.tensor(
+ bytearray(pickle.dumps(result_part)), dtype=torch.uint8, device='cuda')
+ # gather all result part tensor shape
+ shape_tensor = torch.tensor(part_tensor.shape, device='cuda')
+ shape_list = [shape_tensor.clone() for _ in range(world_size)]
+ dist.all_gather(shape_list, shape_tensor)
+ # padding result part tensor to max length
+ shape_max = torch.tensor(shape_list).max()
+ part_send = torch.zeros(shape_max, dtype=torch.uint8, device='cuda')
+ part_send[:shape_tensor[0]] = part_tensor
+ part_recv_list = [
+ part_tensor.new_zeros(shape_max) for _ in range(world_size)
+ ]
+ # gather all result part
+ dist.all_gather(part_recv_list, part_send)
+
+ if rank == 0:
+ part_list = []
+ for recv, shape in zip(part_recv_list, shape_list):
+ part_list.append(
+ pickle.loads(recv[:shape[0]].cpu().numpy().tobytes()))
+ # sort the results
+ ordered_results = []
+ for res in zip(*part_list):
+ ordered_results.extend(list(res))
+ # the dataloader may pad some samples
+ ordered_results = ordered_results[:size]
+ return ordered_results
+ return None
diff --git a/vendor/ViTPose/mmpose/apis/train.py b/vendor/ViTPose/mmpose/apis/train.py
new file mode 100644
index 0000000000000000000000000000000000000000..7c31f8b0b1ace6d27feb14b8d441fec6436ad9e2
--- /dev/null
+++ b/vendor/ViTPose/mmpose/apis/train.py
@@ -0,0 +1,200 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import mmcv
+import numpy as np
+import torch
+import torch.distributed as dist
+from mmcv.parallel import MMDataParallel, MMDistributedDataParallel
+from mmcv.runner import (DistSamplerSeedHook, EpochBasedRunner, OptimizerHook,
+ get_dist_info)
+from mmcv.utils import digit_version
+
+from mmpose.core import DistEvalHook, EvalHook, build_optimizers
+from mmpose.core.distributed_wrapper import DistributedDataParallelWrapper
+from mmpose.datasets import build_dataloader, build_dataset
+from mmpose.utils import get_root_logger
+
+try:
+ from mmcv.runner import Fp16OptimizerHook
+except ImportError:
+ warnings.warn(
+ 'Fp16OptimizerHook from mmpose will be deprecated from '
+ 'v0.15.0. Please install mmcv>=1.1.4', DeprecationWarning)
+ from mmpose.core import Fp16OptimizerHook
+
+
+def init_random_seed(seed=None, device='cuda'):
+ """Initialize random seed.
+
+ If the seed is not set, the seed will be automatically randomized,
+ and then broadcast to all processes to prevent some potential bugs.
+
+ Args:
+ seed (int, Optional): The seed. Default to None.
+ device (str): The device where the seed will be put on.
+ Default to 'cuda'.
+
+ Returns:
+ int: Seed to be used.
+ """
+ if seed is not None:
+ return seed
+
+ # Make sure all ranks share the same random seed to prevent
+ # some potential bugs. Please refer to
+ # https://github.com/open-mmlab/mmdetection/issues/6339
+ rank, world_size = get_dist_info()
+ seed = np.random.randint(2**31)
+ if world_size == 1:
+ return seed
+
+ if rank == 0:
+ random_num = torch.tensor(seed, dtype=torch.int32, device=device)
+ else:
+ random_num = torch.tensor(0, dtype=torch.int32, device=device)
+ dist.broadcast(random_num, src=0)
+ return random_num.item()
+
+
+def train_model(model,
+ dataset,
+ cfg,
+ distributed=False,
+ validate=False,
+ timestamp=None,
+ meta=None):
+ """Train model entry function.
+
+ Args:
+ model (nn.Module): The model to be trained.
+ dataset (Dataset): Train dataset.
+ cfg (dict): The config dict for training.
+ distributed (bool): Whether to use distributed training.
+ Default: False.
+ validate (bool): Whether to do evaluation. Default: False.
+ timestamp (str | None): Local time for runner. Default: None.
+ meta (dict | None): Meta dict to record some important information.
+ Default: None
+ """
+ logger = get_root_logger(cfg.log_level)
+
+ # prepare data loaders
+ dataset = dataset if isinstance(dataset, (list, tuple)) else [dataset]
+ # step 1: give default values and override (if exist) from cfg.data
+ loader_cfg = {
+ **dict(
+ seed=cfg.get('seed'),
+ drop_last=False,
+ dist=distributed,
+ num_gpus=len(cfg.gpu_ids)),
+ **({} if torch.__version__ != 'parrots' else dict(
+ prefetch_num=2,
+ pin_memory=False,
+ )),
+ **dict((k, cfg.data[k]) for k in [
+ 'samples_per_gpu',
+ 'workers_per_gpu',
+ 'shuffle',
+ 'seed',
+ 'drop_last',
+ 'prefetch_num',
+ 'pin_memory',
+ 'persistent_workers',
+ ] if k in cfg.data)
+ }
+
+ # step 2: cfg.data.train_dataloader has highest priority
+ train_loader_cfg = dict(loader_cfg, **cfg.data.get('train_dataloader', {}))
+
+ data_loaders = [build_dataloader(ds, **train_loader_cfg) for ds in dataset]
+
+ # determine whether use adversarial training precess or not
+ use_adverserial_train = cfg.get('use_adversarial_train', False)
+
+ # put model on gpus
+ if distributed:
+ find_unused_parameters = cfg.get('find_unused_parameters', False)
+ # Sets the `find_unused_parameters` parameter in
+ # torch.nn.parallel.DistributedDataParallel
+
+ if use_adverserial_train:
+ # Use DistributedDataParallelWrapper for adversarial training
+ model = DistributedDataParallelWrapper(
+ model,
+ device_ids=[torch.cuda.current_device()],
+ broadcast_buffers=False,
+ find_unused_parameters=find_unused_parameters)
+ else:
+ model = MMDistributedDataParallel(
+ model.cuda(),
+ device_ids=[torch.cuda.current_device()],
+ broadcast_buffers=False,
+ find_unused_parameters=find_unused_parameters)
+ else:
+ if digit_version(mmcv.__version__) >= digit_version(
+ '1.4.4') or torch.cuda.is_available():
+ model = MMDataParallel(model, device_ids=cfg.gpu_ids)
+ else:
+ warnings.warn(
+ 'We recommend to use MMCV >= 1.4.4 for CPU training. '
+ 'See https://github.com/open-mmlab/mmpose/pull/1157 for '
+ 'details.')
+
+ # build runner
+ optimizer = build_optimizers(model, cfg.optimizer)
+
+ runner = EpochBasedRunner(
+ model,
+ optimizer=optimizer,
+ work_dir=cfg.work_dir,
+ logger=logger,
+ meta=meta)
+ # an ugly workaround to make .log and .log.json filenames the same
+ runner.timestamp = timestamp
+
+ if use_adverserial_train:
+ # The optimizer step process is included in the train_step function
+ # of the model, so the runner should NOT include optimizer hook.
+ optimizer_config = None
+ else:
+ # fp16 setting
+ fp16_cfg = cfg.get('fp16', None)
+ if fp16_cfg is not None:
+ optimizer_config = Fp16OptimizerHook(
+ **cfg.optimizer_config, **fp16_cfg, distributed=distributed)
+ elif distributed and 'type' not in cfg.optimizer_config:
+ optimizer_config = OptimizerHook(**cfg.optimizer_config)
+ else:
+ optimizer_config = cfg.optimizer_config
+
+ # register hooks
+ runner.register_training_hooks(cfg.lr_config, optimizer_config,
+ cfg.checkpoint_config, cfg.log_config,
+ cfg.get('momentum_config', None))
+ if distributed:
+ runner.register_hook(DistSamplerSeedHook())
+
+ # register eval hooks
+ if validate:
+ eval_cfg = cfg.get('evaluation', {})
+ val_dataset = build_dataset(cfg.data.val, dict(test_mode=True))
+ dataloader_setting = dict(
+ samples_per_gpu=1,
+ workers_per_gpu=cfg.data.get('workers_per_gpu', 1),
+ # cfg.gpus will be ignored if distributed
+ num_gpus=len(cfg.gpu_ids),
+ dist=distributed,
+ drop_last=False,
+ shuffle=False)
+ dataloader_setting = dict(dataloader_setting,
+ **cfg.data.get('val_dataloader', {}))
+ val_dataloader = build_dataloader(val_dataset, **dataloader_setting)
+ eval_hook = DistEvalHook if distributed else EvalHook
+ runner.register_hook(eval_hook(val_dataloader, **eval_cfg))
+
+ if cfg.resume_from:
+ runner.resume(cfg.resume_from)
+ elif cfg.load_from:
+ runner.load_checkpoint(cfg.load_from)
+ runner.run(data_loaders, cfg.workflow, cfg.total_epochs)
diff --git a/vendor/ViTPose/mmpose/core/__init__.py b/vendor/ViTPose/mmpose/core/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..66185b72c47c99a0d296bf65c72f50a47f2d080c
--- /dev/null
+++ b/vendor/ViTPose/mmpose/core/__init__.py
@@ -0,0 +1,8 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .camera import * # noqa: F401, F403
+from .evaluation import * # noqa: F401, F403
+from .fp16 import * # noqa: F401, F403
+from .optimizer import * # noqa: F401, F403
+from .post_processing import * # noqa: F401, F403
+from .utils import * # noqa: F401, F403
+from .visualization import * # noqa: F401, F403
diff --git a/vendor/ViTPose/mmpose/core/camera/__init__.py b/vendor/ViTPose/mmpose/core/camera/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..a4a3c5526560996791a85f0d84a72a66286486ca
--- /dev/null
+++ b/vendor/ViTPose/mmpose/core/camera/__init__.py
@@ -0,0 +1,6 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .camera_base import CAMERAS
+from .single_camera import SimpleCamera
+from .single_camera_torch import SimpleCameraTorch
+
+__all__ = ['CAMERAS', 'SimpleCamera', 'SimpleCameraTorch']
diff --git a/vendor/ViTPose/mmpose/core/camera/camera_base.py b/vendor/ViTPose/mmpose/core/camera/camera_base.py
new file mode 100644
index 0000000000000000000000000000000000000000..28b23e7c6279e3613265a949df91f6ced0413b99
--- /dev/null
+++ b/vendor/ViTPose/mmpose/core/camera/camera_base.py
@@ -0,0 +1,45 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import ABCMeta, abstractmethod
+
+from mmcv.utils import Registry
+
+CAMERAS = Registry('camera')
+
+
+class SingleCameraBase(metaclass=ABCMeta):
+ """Base class for single camera model.
+
+ Args:
+ param (dict): Camera parameters
+
+ Methods:
+ world_to_camera: Project points from world coordinates to camera
+ coordinates
+ camera_to_world: Project points from camera coordinates to world
+ coordinates
+ camera_to_pixel: Project points from camera coordinates to pixel
+ coordinates
+ world_to_pixel: Project points from world coordinates to pixel
+ coordinates
+ """
+
+ @abstractmethod
+ def __init__(self, param):
+ """Load camera parameters and check validity."""
+
+ def world_to_camera(self, X):
+ """Project points from world coordinates to camera coordinates."""
+ raise NotImplementedError
+
+ def camera_to_world(self, X):
+ """Project points from camera coordinates to world coordinates."""
+ raise NotImplementedError
+
+ def camera_to_pixel(self, X):
+ """Project points from camera coordinates to pixel coordinates."""
+ raise NotImplementedError
+
+ def world_to_pixel(self, X):
+ """Project points from world coordinates to pixel coordinates."""
+ _X = self.world_to_camera(X)
+ return self.camera_to_pixel(_X)
diff --git a/vendor/ViTPose/mmpose/core/camera/single_camera.py b/vendor/ViTPose/mmpose/core/camera/single_camera.py
new file mode 100644
index 0000000000000000000000000000000000000000..cabd79941af5c81110876e94ce6103cc02ea5078
--- /dev/null
+++ b/vendor/ViTPose/mmpose/core/camera/single_camera.py
@@ -0,0 +1,123 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+
+from .camera_base import CAMERAS, SingleCameraBase
+
+
+@CAMERAS.register_module()
+class SimpleCamera(SingleCameraBase):
+ """Camera model to calculate coordinate transformation with given
+ intrinsic/extrinsic camera parameters.
+
+ Note:
+ The keypoint coordinate should be an np.ndarray with a shape of
+ [...,J, C] where J is the keypoint number of an instance, and C is
+ the coordinate dimension. For example:
+
+ [J, C]: shape of joint coordinates of a person with J joints.
+ [N, J, C]: shape of a batch of person joint coordinates.
+ [N, T, J, C]: shape of a batch of pose sequences.
+
+ Args:
+ param (dict): camera parameters including:
+ - R: 3x3, camera rotation matrix (camera-to-world)
+ - T: 3x1, camera translation (camera-to-world)
+ - K: (optional) 2x3, camera intrinsic matrix
+ - k: (optional) nx1, camera radial distortion coefficients
+ - p: (optional) mx1, camera tangential distortion coefficients
+ - f: (optional) 2x1, camera focal length
+ - c: (optional) 2x1, camera center
+ if K is not provided, it will be calculated from f and c.
+
+ Methods:
+ world_to_camera: Project points from world coordinates to camera
+ coordinates
+ camera_to_pixel: Project points from camera coordinates to pixel
+ coordinates
+ world_to_pixel: Project points from world coordinates to pixel
+ coordinates
+ """
+
+ def __init__(self, param):
+
+ self.param = {}
+ # extrinsic param
+ R = np.array(param['R'], dtype=np.float32)
+ T = np.array(param['T'], dtype=np.float32)
+ assert R.shape == (3, 3)
+ assert T.shape == (3, 1)
+ # The camera matrices are transposed in advance because the joint
+ # coordinates are stored as row vectors.
+ self.param['R_c2w'] = R.T
+ self.param['T_c2w'] = T.T
+ self.param['R_w2c'] = R
+ self.param['T_w2c'] = -self.param['T_c2w'] @ self.param['R_w2c']
+
+ # intrinsic param
+ if 'K' in param:
+ K = np.array(param['K'], dtype=np.float32)
+ assert K.shape == (2, 3)
+ self.param['K'] = K.T
+ self.param['f'] = np.array([K[0, 0], K[1, 1]])[:, np.newaxis]
+ self.param['c'] = np.array([K[0, 2], K[1, 2]])[:, np.newaxis]
+ elif 'f' in param and 'c' in param:
+ f = np.array(param['f'], dtype=np.float32)
+ c = np.array(param['c'], dtype=np.float32)
+ assert f.shape == (2, 1)
+ assert c.shape == (2, 1)
+ self.param['K'] = np.concatenate((np.diagflat(f), c), axis=-1).T
+ self.param['f'] = f
+ self.param['c'] = c
+ else:
+ raise ValueError('Camera intrinsic parameters are missing. '
+ 'Either "K" or "f"&"c" should be provided.')
+
+ # distortion param
+ if 'k' in param and 'p' in param:
+ self.undistortion = True
+ self.param['k'] = np.array(param['k'], dtype=np.float32).flatten()
+ self.param['p'] = np.array(param['p'], dtype=np.float32).flatten()
+ assert self.param['k'].size in {3, 6}
+ assert self.param['p'].size == 2
+ else:
+ self.undistortion = False
+
+ def world_to_camera(self, X):
+ assert isinstance(X, np.ndarray)
+ assert X.ndim >= 2 and X.shape[-1] == 3
+ return X @ self.param['R_w2c'] + self.param['T_w2c']
+
+ def camera_to_world(self, X):
+ assert isinstance(X, np.ndarray)
+ assert X.ndim >= 2 and X.shape[-1] == 3
+ return X @ self.param['R_c2w'] + self.param['T_c2w']
+
+ def camera_to_pixel(self, X):
+ assert isinstance(X, np.ndarray)
+ assert X.ndim >= 2 and X.shape[-1] == 3
+
+ _X = X / X[..., 2:]
+
+ if self.undistortion:
+ k = self.param['k']
+ p = self.param['p']
+ _X_2d = _X[..., :2]
+ r2 = (_X_2d**2).sum(-1)
+ radial = 1 + sum(ki * r2**(i + 1) for i, ki in enumerate(k[:3]))
+ if k.size == 6:
+ radial /= 1 + sum(
+ (ki * r2**(i + 1) for i, ki in enumerate(k[3:])))
+
+ tangential = 2 * (p[1] * _X[..., 0] + p[0] * _X[..., 1])
+
+ _X[..., :2] = _X_2d * (radial + tangential)[..., None] + np.outer(
+ r2, p[::-1]).reshape(_X_2d.shape)
+ return _X @ self.param['K']
+
+ def pixel_to_camera(self, X):
+ assert isinstance(X, np.ndarray)
+ assert X.ndim >= 2 and X.shape[-1] == 3
+ _X = X.copy()
+ _X[:, :2] = (X[:, :2] - self.param['c'].T) / self.param['f'].T * X[:,
+ [2]]
+ return _X
diff --git a/vendor/ViTPose/mmpose/core/camera/single_camera_torch.py b/vendor/ViTPose/mmpose/core/camera/single_camera_torch.py
new file mode 100644
index 0000000000000000000000000000000000000000..22eb72f23d6eecf1b5c5a9b570a4f142fcf6e02a
--- /dev/null
+++ b/vendor/ViTPose/mmpose/core/camera/single_camera_torch.py
@@ -0,0 +1,118 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from .camera_base import CAMERAS, SingleCameraBase
+
+
+@CAMERAS.register_module()
+class SimpleCameraTorch(SingleCameraBase):
+ """Camera model to calculate coordinate transformation with given
+ intrinsic/extrinsic camera parameters.
+
+ Notes:
+ The keypoint coordinate should be an np.ndarray with a shape of
+ [...,J, C] where J is the keypoint number of an instance, and C is
+ the coordinate dimension. For example:
+
+ [J, C]: shape of joint coordinates of a person with J joints.
+ [N, J, C]: shape of a batch of person joint coordinates.
+ [N, T, J, C]: shape of a batch of pose sequences.
+
+ Args:
+ param (dict): camera parameters including:
+ - R: 3x3, camera rotation matrix (camera-to-world)
+ - T: 3x1, camera translation (camera-to-world)
+ - K: (optional) 2x3, camera intrinsic matrix
+ - k: (optional) nx1, camera radial distortion coefficients
+ - p: (optional) mx1, camera tangential distortion coefficients
+ - f: (optional) 2x1, camera focal length
+ - c: (optional) 2x1, camera center
+ if K is not provided, it will be calculated from f and c.
+
+ Methods:
+ world_to_camera: Project points from world coordinates to camera
+ coordinates
+ camera_to_pixel: Project points from camera coordinates to pixel
+ coordinates
+ world_to_pixel: Project points from world coordinates to pixel
+ coordinates
+ """
+
+ def __init__(self, param, device):
+
+ self.param = {}
+ # extrinsic param
+ R = torch.tensor(param['R'], device=device)
+ T = torch.tensor(param['T'], device=device)
+
+ assert R.shape == (3, 3)
+ assert T.shape == (3, 1)
+ # The camera matrices are transposed in advance because the joint
+ # coordinates are stored as row vectors.
+ self.param['R_c2w'] = R.T
+ self.param['T_c2w'] = T.T
+ self.param['R_w2c'] = R
+ self.param['T_w2c'] = -self.param['T_c2w'] @ self.param['R_w2c']
+
+ # intrinsic param
+ if 'K' in param:
+ K = torch.tensor(param['K'], device=device)
+ assert K.shape == (2, 3)
+ self.param['K'] = K.T
+ self.param['f'] = torch.tensor([[K[0, 0]], [K[1, 1]]],
+ device=device)
+ self.param['c'] = torch.tensor([[K[0, 2]], [K[1, 2]]],
+ device=device)
+ elif 'f' in param and 'c' in param:
+ f = torch.tensor(param['f'], device=device)
+ c = torch.tensor(param['c'], device=device)
+ assert f.shape == (2, 1)
+ assert c.shape == (2, 1)
+ self.param['K'] = torch.cat([torch.diagflat(f), c], dim=-1).T
+ self.param['f'] = f
+ self.param['c'] = c
+ else:
+ raise ValueError('Camera intrinsic parameters are missing. '
+ 'Either "K" or "f"&"c" should be provided.')
+
+ # distortion param
+ if 'k' in param and 'p' in param:
+ self.undistortion = True
+ self.param['k'] = torch.tensor(param['k'], device=device).view(-1)
+ self.param['p'] = torch.tensor(param['p'], device=device).view(-1)
+ assert len(self.param['k']) in {3, 6}
+ assert len(self.param['p']) == 2
+ else:
+ self.undistortion = False
+
+ def world_to_camera(self, X):
+ assert isinstance(X, torch.Tensor)
+ assert X.ndim >= 2 and X.shape[-1] == 3
+ return X @ self.param['R_w2c'] + self.param['T_w2c']
+
+ def camera_to_world(self, X):
+ assert isinstance(X, torch.Tensor)
+ assert X.ndim >= 2 and X.shape[-1] == 3
+ return X @ self.param['R_c2w'] + self.param['T_c2w']
+
+ def camera_to_pixel(self, X):
+ assert isinstance(X, torch.Tensor)
+ assert X.ndim >= 2 and X.shape[-1] == 3
+
+ _X = X / X[..., 2:]
+
+ if self.undistortion:
+ k = self.param['k']
+ p = self.param['p']
+ _X_2d = _X[..., :2]
+ r2 = (_X_2d**2).sum(-1)
+ radial = 1 + sum(ki * r2**(i + 1) for i, ki in enumerate(k[:3]))
+ if k.size == 6:
+ radial /= 1 + sum(
+ (ki * r2**(i + 1) for i, ki in enumerate(k[3:])))
+
+ tangential = 2 * (p[1] * _X[..., 0] + p[0] * _X[..., 1])
+
+ _X[..., :2] = _X_2d * (radial + tangential)[..., None] + torch.ger(
+ r2, p.flip([0])).reshape(_X_2d.shape)
+ return _X @ self.param['K']
diff --git a/vendor/ViTPose/mmpose/core/distributed_wrapper.py b/vendor/ViTPose/mmpose/core/distributed_wrapper.py
new file mode 100644
index 0000000000000000000000000000000000000000..c67aceec992085e9952ea70c62009e9ec1db30ca
--- /dev/null
+++ b/vendor/ViTPose/mmpose/core/distributed_wrapper.py
@@ -0,0 +1,143 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv.parallel import MODULE_WRAPPERS as MMCV_MODULE_WRAPPERS
+from mmcv.parallel import MMDistributedDataParallel
+from mmcv.parallel.scatter_gather import scatter_kwargs
+from mmcv.utils import Registry
+from torch.cuda._utils import _get_device_index
+
+MODULE_WRAPPERS = Registry('module wrapper', parent=MMCV_MODULE_WRAPPERS)
+
+
+@MODULE_WRAPPERS.register_module()
+class DistributedDataParallelWrapper(nn.Module):
+ """A DistributedDataParallel wrapper for models in 3D mesh estimation task.
+
+ In 3D mesh estimation task, there is a need to wrap different modules in
+ the models with separate DistributedDataParallel. Otherwise, it will cause
+ errors for GAN training.
+ More specific, the GAN model, usually has two sub-modules:
+ generator and discriminator. If we wrap both of them in one
+ standard DistributedDataParallel, it will cause errors during training,
+ because when we update the parameters of the generator (or discriminator),
+ the parameters of the discriminator (or generator) is not updated, which is
+ not allowed for DistributedDataParallel.
+ So we design this wrapper to separately wrap DistributedDataParallel
+ for generator and discriminator.
+
+ In this wrapper, we perform two operations:
+ 1. Wrap the modules in the models with separate MMDistributedDataParallel.
+ Note that only modules with parameters will be wrapped.
+ 2. Do scatter operation for 'forward', 'train_step' and 'val_step'.
+
+ Note that the arguments of this wrapper is the same as those in
+ `torch.nn.parallel.distributed.DistributedDataParallel`.
+
+ Args:
+ module (nn.Module): Module that needs to be wrapped.
+ device_ids (list[int | `torch.device`]): Same as that in
+ `torch.nn.parallel.distributed.DistributedDataParallel`.
+ dim (int, optional): Same as that in the official scatter function in
+ pytorch. Defaults to 0.
+ broadcast_buffers (bool): Same as that in
+ `torch.nn.parallel.distributed.DistributedDataParallel`.
+ Defaults to False.
+ find_unused_parameters (bool, optional): Same as that in
+ `torch.nn.parallel.distributed.DistributedDataParallel`.
+ Traverse the autograd graph of all tensors contained in returned
+ value of the wrapped module’s forward function. Defaults to False.
+ kwargs (dict): Other arguments used in
+ `torch.nn.parallel.distributed.DistributedDataParallel`.
+ """
+
+ def __init__(self,
+ module,
+ device_ids,
+ dim=0,
+ broadcast_buffers=False,
+ find_unused_parameters=False,
+ **kwargs):
+ super().__init__()
+ assert len(device_ids) == 1, (
+ 'Currently, DistributedDataParallelWrapper only supports one'
+ 'single CUDA device for each process.'
+ f'The length of device_ids must be 1, but got {len(device_ids)}.')
+ self.module = module
+ self.dim = dim
+ self.to_ddp(
+ device_ids=device_ids,
+ dim=dim,
+ broadcast_buffers=broadcast_buffers,
+ find_unused_parameters=find_unused_parameters,
+ **kwargs)
+ self.output_device = _get_device_index(device_ids[0], True)
+
+ def to_ddp(self, device_ids, dim, broadcast_buffers,
+ find_unused_parameters, **kwargs):
+ """Wrap models with separate MMDistributedDataParallel.
+
+ It only wraps the modules with parameters.
+ """
+ for name, module in self.module._modules.items():
+ if next(module.parameters(), None) is None:
+ module = module.cuda()
+ elif all(not p.requires_grad for p in module.parameters()):
+ module = module.cuda()
+ else:
+ module = MMDistributedDataParallel(
+ module.cuda(),
+ device_ids=device_ids,
+ dim=dim,
+ broadcast_buffers=broadcast_buffers,
+ find_unused_parameters=find_unused_parameters,
+ **kwargs)
+ self.module._modules[name] = module
+
+ def scatter(self, inputs, kwargs, device_ids):
+ """Scatter function.
+
+ Args:
+ inputs (Tensor): Input Tensor.
+ kwargs (dict): Args for
+ ``mmcv.parallel.scatter_gather.scatter_kwargs``.
+ device_ids (int): Device id.
+ """
+ return scatter_kwargs(inputs, kwargs, device_ids, dim=self.dim)
+
+ def forward(self, *inputs, **kwargs):
+ """Forward function.
+
+ Args:
+ inputs (tuple): Input data.
+ kwargs (dict): Args for
+ ``mmcv.parallel.scatter_gather.scatter_kwargs``.
+ """
+ inputs, kwargs = self.scatter(inputs, kwargs,
+ [torch.cuda.current_device()])
+ return self.module(*inputs[0], **kwargs[0])
+
+ def train_step(self, *inputs, **kwargs):
+ """Train step function.
+
+ Args:
+ inputs (Tensor): Input Tensor.
+ kwargs (dict): Args for
+ ``mmcv.parallel.scatter_gather.scatter_kwargs``.
+ """
+ inputs, kwargs = self.scatter(inputs, kwargs,
+ [torch.cuda.current_device()])
+ output = self.module.train_step(*inputs[0], **kwargs[0])
+ return output
+
+ def val_step(self, *inputs, **kwargs):
+ """Validation step function.
+
+ Args:
+ inputs (tuple): Input data.
+ kwargs (dict): Args for ``scatter_kwargs``.
+ """
+ inputs, kwargs = self.scatter(inputs, kwargs,
+ [torch.cuda.current_device()])
+ output = self.module.val_step(*inputs[0], **kwargs[0])
+ return output
diff --git a/vendor/ViTPose/mmpose/core/evaluation/__init__.py b/vendor/ViTPose/mmpose/core/evaluation/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..5f9378429c8ddaa15f7ac17446bc9d484987df16
--- /dev/null
+++ b/vendor/ViTPose/mmpose/core/evaluation/__init__.py
@@ -0,0 +1,22 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .bottom_up_eval import (aggregate_scale, aggregate_stage_flip,
+ flip_feature_maps, get_group_preds,
+ split_ae_outputs)
+from .eval_hooks import DistEvalHook, EvalHook
+from .mesh_eval import compute_similarity_transform
+from .pose3d_eval import keypoint_3d_auc, keypoint_3d_pck, keypoint_mpjpe
+from .top_down_eval import (keypoint_auc, keypoint_epe, keypoint_pck_accuracy,
+ keypoints_from_heatmaps, keypoints_from_heatmaps3d,
+ keypoints_from_regression,
+ multilabel_classification_accuracy,
+ pose_pck_accuracy, post_dark_udp)
+
+__all__ = [
+ 'EvalHook', 'DistEvalHook', 'pose_pck_accuracy', 'keypoints_from_heatmaps',
+ 'keypoints_from_regression', 'keypoint_pck_accuracy', 'keypoint_3d_pck',
+ 'keypoint_3d_auc', 'keypoint_auc', 'keypoint_epe', 'get_group_preds',
+ 'split_ae_outputs', 'flip_feature_maps', 'aggregate_stage_flip',
+ 'aggregate_scale', 'compute_similarity_transform', 'post_dark_udp',
+ 'keypoint_mpjpe', 'keypoints_from_heatmaps3d',
+ 'multilabel_classification_accuracy'
+]
diff --git a/vendor/ViTPose/mmpose/core/evaluation/bottom_up_eval.py b/vendor/ViTPose/mmpose/core/evaluation/bottom_up_eval.py
new file mode 100644
index 0000000000000000000000000000000000000000..7b37d7c98e684284e3863922e7c7d2abedce0e24
--- /dev/null
+++ b/vendor/ViTPose/mmpose/core/evaluation/bottom_up_eval.py
@@ -0,0 +1,333 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+import torch
+
+from mmpose.core.post_processing import (get_warp_matrix, transform_preds,
+ warp_affine_joints)
+
+
+def split_ae_outputs(outputs, num_joints, with_heatmaps, with_ae,
+ select_output_index):
+ """Split multi-stage outputs into heatmaps & tags.
+
+ Args:
+ outputs (list(Tensor)): Outputs of network
+ num_joints (int): Number of joints
+ with_heatmaps (list[bool]): Option to output
+ heatmaps for different stages.
+ with_ae (list[bool]): Option to output
+ ae tags for different stages.
+ select_output_index (list[int]): Output keep the selected index
+
+ Returns:
+ tuple: A tuple containing multi-stage outputs.
+
+ - list[Tensor]: multi-stage heatmaps.
+ - list[Tensor]: multi-stage tags.
+ """
+
+ heatmaps = []
+ tags = []
+
+ # aggregate heatmaps from different stages
+ for i, output in enumerate(outputs):
+ if i not in select_output_index:
+ continue
+ # staring index of the associative embeddings
+ offset_feat = num_joints if with_heatmaps[i] else 0
+ if with_heatmaps[i]:
+ heatmaps.append(output[:, :num_joints])
+ if with_ae[i]:
+ tags.append(output[:, offset_feat:])
+
+ return heatmaps, tags
+
+
+def flip_feature_maps(feature_maps, flip_index=None):
+ """Flip the feature maps and swap the channels.
+
+ Args:
+ feature_maps (list[Tensor]): Feature maps.
+ flip_index (list[int] | None): Channel-flip indexes.
+ If None, do not flip channels.
+
+ Returns:
+ list[Tensor]: Flipped feature_maps.
+ """
+ flipped_feature_maps = []
+ for feature_map in feature_maps:
+ feature_map = torch.flip(feature_map, [3])
+ if flip_index is not None:
+ flipped_feature_maps.append(feature_map[:, flip_index, :, :])
+ else:
+ flipped_feature_maps.append(feature_map)
+
+ return flipped_feature_maps
+
+
+def _resize_average(feature_maps, align_corners, index=-1, resize_size=None):
+ """Resize the feature maps and compute the average.
+
+ Args:
+ feature_maps (list[Tensor]): Feature maps.
+ align_corners (bool): Align corners when performing interpolation.
+ index (int): Only used when `resize_size' is None.
+ If `resize_size' is None, the target size is the size
+ of the indexed feature maps.
+ resize_size (list[int, int]): The target size [w, h].
+
+ Returns:
+ list[Tensor]: Averaged feature_maps.
+ """
+
+ if feature_maps is None:
+ return None
+ feature_maps_avg = 0
+
+ feature_map_list = _resize_concate(
+ feature_maps, align_corners, index=index, resize_size=resize_size)
+ for feature_map in feature_map_list:
+ feature_maps_avg += feature_map
+
+ feature_maps_avg /= len(feature_map_list)
+ return [feature_maps_avg]
+
+
+def _resize_unsqueeze_concat(feature_maps,
+ align_corners,
+ index=-1,
+ resize_size=None):
+ """Resize, unsqueeze and concatenate the feature_maps.
+
+ Args:
+ feature_maps (list[Tensor]): Feature maps.
+ align_corners (bool): Align corners when performing interpolation.
+ index (int): Only used when `resize_size' is None.
+ If `resize_size' is None, the target size is the size
+ of the indexed feature maps.
+ resize_size (list[int, int]): The target size [w, h].
+
+ Returns:
+ list[Tensor]: Averaged feature_maps.
+ """
+ if feature_maps is None:
+ return None
+ feature_map_list = _resize_concate(
+ feature_maps, align_corners, index=index, resize_size=resize_size)
+
+ feat_dim = len(feature_map_list[0].shape) - 1
+ output_feature_maps = torch.cat(
+ [torch.unsqueeze(fmap, dim=feat_dim + 1) for fmap in feature_map_list],
+ dim=feat_dim + 1)
+ return [output_feature_maps]
+
+
+def _resize_concate(feature_maps, align_corners, index=-1, resize_size=None):
+ """Resize and concatenate the feature_maps.
+
+ Args:
+ feature_maps (list[Tensor]): Feature maps.
+ align_corners (bool): Align corners when performing interpolation.
+ index (int): Only used when `resize_size' is None.
+ If `resize_size' is None, the target size is the size
+ of the indexed feature maps.
+ resize_size (list[int, int]): The target size [w, h].
+
+ Returns:
+ list[Tensor]: Averaged feature_maps.
+ """
+ if feature_maps is None:
+ return None
+
+ feature_map_list = []
+
+ if index < 0:
+ index += len(feature_maps)
+
+ if resize_size is None:
+ resize_size = (feature_maps[index].size(2),
+ feature_maps[index].size(3))
+
+ for feature_map in feature_maps:
+ ori_size = (feature_map.size(2), feature_map.size(3))
+ if ori_size != resize_size:
+ feature_map = torch.nn.functional.interpolate(
+ feature_map,
+ size=resize_size,
+ mode='bilinear',
+ align_corners=align_corners)
+
+ feature_map_list.append(feature_map)
+
+ return feature_map_list
+
+
+def aggregate_stage_flip(feature_maps,
+ feature_maps_flip,
+ index=-1,
+ project2image=True,
+ size_projected=None,
+ align_corners=False,
+ aggregate_stage='concat',
+ aggregate_flip='average'):
+ """Inference the model to get multi-stage outputs (heatmaps & tags), and
+ resize them to base sizes.
+
+ Args:
+ feature_maps (list[Tensor]): feature_maps can be heatmaps,
+ tags, and pafs.
+ feature_maps_flip (list[Tensor] | None): flipped feature_maps.
+ feature maps can be heatmaps, tags, and pafs.
+ project2image (bool): Option to resize to base scale.
+ size_projected (list[int, int]): Base size of heatmaps [w, h].
+ align_corners (bool): Align corners when performing interpolation.
+ aggregate_stage (str): Methods to aggregate multi-stage feature maps.
+ Options: 'concat', 'average'. Default: 'concat.
+
+ - 'concat': Concatenate the original and the flipped feature maps.
+ - 'average': Get the average of the original and the flipped
+ feature maps.
+ aggregate_flip (str): Methods to aggregate the original and
+ the flipped feature maps. Options: 'concat', 'average', 'none'.
+ Default: 'average.
+
+ - 'concat': Concatenate the original and the flipped feature maps.
+ - 'average': Get the average of the original and the flipped
+ feature maps..
+ - 'none': no flipped feature maps.
+
+ Returns:
+ list[Tensor]: Aggregated feature maps with shape [NxKxWxH].
+ """
+
+ if feature_maps_flip is None:
+ aggregate_flip = 'none'
+
+ output_feature_maps = []
+
+ if aggregate_stage == 'average':
+ _aggregate_stage_func = _resize_average
+ elif aggregate_stage == 'concat':
+ _aggregate_stage_func = _resize_concate
+ else:
+ NotImplementedError()
+
+ if project2image and size_projected:
+ _origin = _aggregate_stage_func(
+ feature_maps,
+ align_corners,
+ index=index,
+ resize_size=(size_projected[1], size_projected[0]))
+
+ _flipped = _aggregate_stage_func(
+ feature_maps_flip,
+ align_corners,
+ index=index,
+ resize_size=(size_projected[1], size_projected[0]))
+ else:
+ _origin = _aggregate_stage_func(
+ feature_maps, align_corners, index=index, resize_size=None)
+ _flipped = _aggregate_stage_func(
+ feature_maps_flip, align_corners, index=index, resize_size=None)
+
+ if aggregate_flip == 'average':
+ assert feature_maps_flip is not None
+ for _ori, _fli in zip(_origin, _flipped):
+ output_feature_maps.append((_ori + _fli) / 2.0)
+
+ elif aggregate_flip == 'concat':
+ assert feature_maps_flip is not None
+ output_feature_maps.append(*_origin)
+ output_feature_maps.append(*_flipped)
+
+ elif aggregate_flip == 'none':
+ if isinstance(_origin, list):
+ output_feature_maps.append(*_origin)
+ else:
+ output_feature_maps.append(_origin)
+ else:
+ NotImplementedError()
+
+ return output_feature_maps
+
+
+def aggregate_scale(feature_maps_list,
+ align_corners=False,
+ aggregate_scale='average'):
+ """Aggregate multi-scale outputs.
+
+ Note:
+ batch size: N
+ keypoints num : K
+ heatmap width: W
+ heatmap height: H
+
+ Args:
+ feature_maps_list (list[Tensor]): Aggregated feature maps.
+ project2image (bool): Option to resize to base scale.
+ align_corners (bool): Align corners when performing interpolation.
+ aggregate_scale (str): Methods to aggregate multi-scale feature maps.
+ Options: 'average', 'unsqueeze_concat'.
+
+ - 'average': Get the average of the feature maps.
+ - 'unsqueeze_concat': Concatenate the feature maps along new axis.
+ Default: 'average.
+
+ Returns:
+ Tensor: Aggregated feature maps.
+ """
+
+ if aggregate_scale == 'average':
+ output_feature_maps = _resize_average(
+ feature_maps_list, align_corners, index=0, resize_size=None)
+
+ elif aggregate_scale == 'unsqueeze_concat':
+ output_feature_maps = _resize_unsqueeze_concat(
+ feature_maps_list, align_corners, index=0, resize_size=None)
+ else:
+ NotImplementedError()
+
+ return output_feature_maps[0]
+
+
+def get_group_preds(grouped_joints,
+ center,
+ scale,
+ heatmap_size,
+ use_udp=False):
+ """Transform the grouped joints back to the image.
+
+ Args:
+ grouped_joints (list): Grouped person joints.
+ center (np.ndarray[2, ]): Center of the bounding box (x, y).
+ scale (np.ndarray[2, ]): Scale of the bounding box
+ wrt [width, height].
+ heatmap_size (np.ndarray[2, ]): Size of the destination heatmaps.
+ use_udp (bool): Unbiased data processing.
+ Paper ref: Huang et al. The Devil is in the Details: Delving into
+ Unbiased Data Processing for Human Pose Estimation (CVPR'2020).
+
+ Returns:
+ list: List of the pose result for each person.
+ """
+ if len(grouped_joints) == 0:
+ return []
+
+ if use_udp:
+ if grouped_joints[0].shape[0] > 0:
+ heatmap_size_t = np.array(heatmap_size, dtype=np.float32) - 1.0
+ trans = get_warp_matrix(
+ theta=0,
+ size_input=heatmap_size_t,
+ size_dst=scale,
+ size_target=heatmap_size_t)
+ grouped_joints[0][..., :2] = \
+ warp_affine_joints(grouped_joints[0][..., :2], trans)
+ results = [person for person in grouped_joints[0]]
+ else:
+ results = []
+ for person in grouped_joints[0]:
+ joints = transform_preds(person, center, scale, heatmap_size)
+ results.append(joints)
+
+ return results
diff --git a/vendor/ViTPose/mmpose/core/evaluation/eval_hooks.py b/vendor/ViTPose/mmpose/core/evaluation/eval_hooks.py
new file mode 100644
index 0000000000000000000000000000000000000000..cf36a038859ee7d7a77b68706ee96c2154fc39cc
--- /dev/null
+++ b/vendor/ViTPose/mmpose/core/evaluation/eval_hooks.py
@@ -0,0 +1,98 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+from mmcv.runner import DistEvalHook as _DistEvalHook
+from mmcv.runner import EvalHook as _EvalHook
+
+MMPOSE_GREATER_KEYS = [
+ 'acc', 'ap', 'ar', 'pck', 'auc', '3dpck', 'p-3dpck', '3dauc', 'p-3dauc'
+]
+MMPOSE_LESS_KEYS = ['loss', 'epe', 'nme', 'mpjpe', 'p-mpjpe', 'n-mpjpe']
+
+
+class EvalHook(_EvalHook):
+
+ def __init__(self,
+ dataloader,
+ start=None,
+ interval=1,
+ by_epoch=True,
+ save_best=None,
+ rule=None,
+ test_fn=None,
+ greater_keys=MMPOSE_GREATER_KEYS,
+ less_keys=MMPOSE_LESS_KEYS,
+ **eval_kwargs):
+
+ if test_fn is None:
+ from mmpose.apis import single_gpu_test
+ test_fn = single_gpu_test
+
+ # to be compatible with the config before v0.16.0
+
+ # remove "gpu_collect" from eval_kwargs
+ if 'gpu_collect' in eval_kwargs:
+ warnings.warn(
+ '"gpu_collect" will be deprecated in EvalHook.'
+ 'Please remove it from the config.', DeprecationWarning)
+ _ = eval_kwargs.pop('gpu_collect')
+
+ # update "save_best" according to "key_indicator" and remove the
+ # latter from eval_kwargs
+ if 'key_indicator' in eval_kwargs or isinstance(save_best, bool):
+ warnings.warn(
+ '"key_indicator" will be deprecated in EvalHook.'
+ 'Please use "save_best" to specify the metric key,'
+ 'e.g., save_best="AP".', DeprecationWarning)
+
+ key_indicator = eval_kwargs.pop('key_indicator', 'AP')
+ if save_best is True and key_indicator is None:
+ raise ValueError('key_indicator should not be None, when '
+ 'save_best is set to True.')
+ save_best = key_indicator
+
+ super().__init__(dataloader, start, interval, by_epoch, save_best,
+ rule, test_fn, greater_keys, less_keys, **eval_kwargs)
+
+
+class DistEvalHook(_DistEvalHook):
+
+ def __init__(self,
+ dataloader,
+ start=None,
+ interval=1,
+ by_epoch=True,
+ save_best=None,
+ rule=None,
+ test_fn=None,
+ greater_keys=MMPOSE_GREATER_KEYS,
+ less_keys=MMPOSE_LESS_KEYS,
+ broadcast_bn_buffer=True,
+ tmpdir=None,
+ gpu_collect=False,
+ **eval_kwargs):
+
+ if test_fn is None:
+ from mmpose.apis import multi_gpu_test
+ test_fn = multi_gpu_test
+
+ # to be compatible with the config before v0.16.0
+
+ # update "save_best" according to "key_indicator" and remove the
+ # latter from eval_kwargs
+ if 'key_indicator' in eval_kwargs or isinstance(save_best, bool):
+ warnings.warn(
+ '"key_indicator" will be deprecated in EvalHook.'
+ 'Please use "save_best" to specify the metric key,'
+ 'e.g., save_best="AP".', DeprecationWarning)
+
+ key_indicator = eval_kwargs.pop('key_indicator', 'AP')
+ if save_best is True and key_indicator is None:
+ raise ValueError('key_indicator should not be None, when '
+ 'save_best is set to True.')
+ save_best = key_indicator
+
+ super().__init__(dataloader, start, interval, by_epoch, save_best,
+ rule, test_fn, greater_keys, less_keys,
+ broadcast_bn_buffer, tmpdir, gpu_collect,
+ **eval_kwargs)
diff --git a/vendor/ViTPose/mmpose/core/evaluation/mesh_eval.py b/vendor/ViTPose/mmpose/core/evaluation/mesh_eval.py
new file mode 100644
index 0000000000000000000000000000000000000000..683b4539b29d1829a324de424c6d9f85a7037e5d
--- /dev/null
+++ b/vendor/ViTPose/mmpose/core/evaluation/mesh_eval.py
@@ -0,0 +1,66 @@
+# ------------------------------------------------------------------------------
+# Adapted from https://github.com/akanazawa/hmr
+# Original licence: Copyright (c) 2018 akanazawa, under the MIT License.
+# ------------------------------------------------------------------------------
+
+import numpy as np
+
+
+def compute_similarity_transform(source_points, target_points):
+ """Computes a similarity transform (sR, t) that takes a set of 3D points
+ source_points (N x 3) closest to a set of 3D points target_points, where R
+ is an 3x3 rotation matrix, t 3x1 translation, s scale. And return the
+ transformed 3D points source_points_hat (N x 3). i.e. solves the orthogonal
+ Procrutes problem.
+
+ Note:
+ Points number: N
+
+ Args:
+ source_points (np.ndarray): Source point set with shape [N, 3].
+ target_points (np.ndarray): Target point set with shape [N, 3].
+
+ Returns:
+ np.ndarray: Transformed source point set with shape [N, 3].
+ """
+
+ assert target_points.shape[0] == source_points.shape[0]
+ assert target_points.shape[1] == 3 and source_points.shape[1] == 3
+
+ source_points = source_points.T
+ target_points = target_points.T
+
+ # 1. Remove mean.
+ mu1 = source_points.mean(axis=1, keepdims=True)
+ mu2 = target_points.mean(axis=1, keepdims=True)
+ X1 = source_points - mu1
+ X2 = target_points - mu2
+
+ # 2. Compute variance of X1 used for scale.
+ var1 = np.sum(X1**2)
+
+ # 3. The outer product of X1 and X2.
+ K = X1.dot(X2.T)
+
+ # 4. Solution that Maximizes trace(R'K) is R=U*V', where U, V are
+ # singular vectors of K.
+ U, _, Vh = np.linalg.svd(K)
+ V = Vh.T
+ # Construct Z that fixes the orientation of R to get det(R)=1.
+ Z = np.eye(U.shape[0])
+ Z[-1, -1] *= np.sign(np.linalg.det(U.dot(V.T)))
+ # Construct R.
+ R = V.dot(Z.dot(U.T))
+
+ # 5. Recover scale.
+ scale = np.trace(R.dot(K)) / var1
+
+ # 6. Recover translation.
+ t = mu2 - scale * (R.dot(mu1))
+
+ # 7. Transform the source points:
+ source_points_hat = scale * R.dot(source_points) + t
+
+ source_points_hat = source_points_hat.T
+
+ return source_points_hat
diff --git a/vendor/ViTPose/mmpose/core/evaluation/pose3d_eval.py b/vendor/ViTPose/mmpose/core/evaluation/pose3d_eval.py
new file mode 100644
index 0000000000000000000000000000000000000000..545778ca7441c2d3e8ec58449c8ca7b162322e9e
--- /dev/null
+++ b/vendor/ViTPose/mmpose/core/evaluation/pose3d_eval.py
@@ -0,0 +1,171 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+
+from .mesh_eval import compute_similarity_transform
+
+
+def keypoint_mpjpe(pred, gt, mask, alignment='none'):
+ """Calculate the mean per-joint position error (MPJPE) and the error after
+ rigid alignment with the ground truth (P-MPJPE).
+
+ Note:
+ - batch_size: N
+ - num_keypoints: K
+ - keypoint_dims: C
+
+ Args:
+ pred (np.ndarray): Predicted keypoint location with shape [N, K, C].
+ gt (np.ndarray): Groundtruth keypoint location with shape [N, K, C].
+ mask (np.ndarray): Visibility of the target with shape [N, K].
+ False for invisible joints, and True for visible.
+ Invisible joints will be ignored for accuracy calculation.
+ alignment (str, optional): method to align the prediction with the
+ groundtruth. Supported options are:
+
+ - ``'none'``: no alignment will be applied
+ - ``'scale'``: align in the least-square sense in scale
+ - ``'procrustes'``: align in the least-square sense in
+ scale, rotation and translation.
+ Returns:
+ tuple: A tuple containing joint position errors
+
+ - (float | np.ndarray): mean per-joint position error (mpjpe).
+ - (float | np.ndarray): mpjpe after rigid alignment with the
+ ground truth (p-mpjpe).
+ """
+ assert mask.any()
+
+ if alignment == 'none':
+ pass
+ elif alignment == 'procrustes':
+ pred = np.stack([
+ compute_similarity_transform(pred_i, gt_i)
+ for pred_i, gt_i in zip(pred, gt)
+ ])
+ elif alignment == 'scale':
+ pred_dot_pred = np.einsum('nkc,nkc->n', pred, pred)
+ pred_dot_gt = np.einsum('nkc,nkc->n', pred, gt)
+ scale_factor = pred_dot_gt / pred_dot_pred
+ pred = pred * scale_factor[:, None, None]
+ else:
+ raise ValueError(f'Invalid value for alignment: {alignment}')
+
+ error = np.linalg.norm(pred - gt, ord=2, axis=-1)[mask].mean()
+
+ return error
+
+
+def keypoint_3d_pck(pred, gt, mask, alignment='none', threshold=0.15):
+ """Calculate the Percentage of Correct Keypoints (3DPCK) w. or w/o rigid
+ alignment.
+
+ Paper ref: `Monocular 3D Human Pose Estimation In The Wild Using Improved
+ CNN Supervision' 3DV'2017. RSN (ECCV'2020)
+ +```bibtex +@misc{cai2020learning, + title={Learning Delicate Local Representations for Multi-Person Pose Estimation}, + author={Yuanhao Cai and Zhicheng Wang and Zhengxiong Luo and Binyi Yin and Angang Du and Haoqian Wang and Xinyu Zhou and Erjin Zhou and Xiangyu Zhang and Jian Sun}, + year={2020}, + eprint={2003.04030}, + archivePrefix={arXiv}, + primaryClass={cs.CV} +} +``` + +
+ +
+MMPose Webcam API Overview
+
+
+## Requirements
+
+* Python >= 3.7.0
+* MMPose >= 0.23.0
+* MMDetection >= 2.21.0
+
+## Tutorials
+
+* [Get started with MMPose Webcam API (Chinese)](/tools/webcam/docs/get_started_cn.md)
+* [Build a Webcam App: A Step-by-step Instruction (Chinese)](/tools/webcam/docs/example_cn.md)
+
+## Examples
+
+* [Pose Estimation](/tools/webcam/configs/examples/): A simple example to estimate and visualize human/animal pose.
+* [Eye Effects](/tools/webcam/configs/eyes/): Apply sunglasses and bug-eye effects.
+* [Face Swap](/tools/webcam/configs/face_swap/): Everybody gets someone else's face.
+* [Meow Dwen Dwen](/tools/webcam/configs/meow_dwen_dwen/): Dress up your cat in Bing Dwen Dwen costume.
+* [Super Saiyan](/tools/webcam/configs/supersaiyan/): Super Saiyan transformation!
+* [New Year](/tools/webcam/configs/newyear/): Set off some firecrackers to celebrate Chinese New Year.
diff --git a/vendor/ViTPose/tools/webcam/configs/background/README.md b/vendor/ViTPose/tools/webcam/configs/background/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..7be8782e38717c6d537648e313921fb8c48b124e
--- /dev/null
+++ b/vendor/ViTPose/tools/webcam/configs/background/README.md
@@ -0,0 +1,73 @@
+# Matting Effects
+
+We can apply background matting to the videos.
+
+## Instruction
+
+### Get started
+
+Launch the demo from the mmpose root directory:
+
+```shell
+python tools/webcam/run_webcam.py --config tools/webcam/configs/background/background.py
+```
+
+### Hotkeys
+
+| Hotkey | Function |
+| -- | -- |
+| b | Toggle the background matting effect on/off. |
+| h | Show help information. |
+| m | Show the monitoring information. |
+| q | Exit. |
+
+Note that the demo will automatically save the output video into a file `record.mp4`.
+
+### Configuration
+
+- **Choose a detection model**
+
+Users can choose detection models from the [MMDetection Model Zoo](https://mmdetection.readthedocs.io/en/v2.20.0/model_zoo.html). Just set the `model_config` and `model_checkpoint` in the detector node accordingly, and the model will be automatically downloaded and loaded.
+Note that in order to perform background matting, the model should be able to produce segmentation masks.
+
+```python
+# 'DetectorNode':
+# This node performs object detection from the frame image using an
+# MMDetection model.
+dict(
+ type='DetectorNode',
+ name='Detector',
+ model_config='demo/mmdetection_cfg/mask_rcnn_r50_fpn_2x_coco.py',
+ model_checkpoint='https://download.openmmlab.com/'
+ 'mmdetection/v2.0/mask_rcnn/mask_rcnn_r50_fpn_2x_coco/'
+ 'mask_rcnn_r50_fpn_2x_coco_bbox_mAP-0.392'
+ '__segm_mAP-0.354_20200505_003907-3e542a40.pth',
+ input_buffer='_input_', # `_input_` is a runner-reserved buffer
+ output_buffer='det_result'),
+```
+
+- **Run the demo without GPU**
+
+If you don't have GPU and CUDA in your device, the demo can run with only CPU by setting `device='cpu'` in all model nodes. For example:
+
+```python
+dict(
+ type='DetectorNode',
+ name='Detector',
+ model_config='demo/mmdetection_cfg/mask_rcnn_r50_fpn_2x_coco.py',
+ model_checkpoint='https://download.openmmlab.com/'
+ 'mmdetection/v2.0/mask_rcnn/mask_rcnn_r50_fpn_2x_coco/'
+ 'mask_rcnn_r50_fpn_2x_coco_bbox_mAP-0.392'
+ '__segm_mAP-0.354_20200505_003907-3e542a40.pth',
+ device='cpu',
+ input_buffer='_input_', # `_input_` is a runner-reserved buffer
+ output_buffer='det_result'),
+```
+
+- **Debug webcam and display**
+
+You can launch the webcam runner with a debug config:
+
+```shell
+python tools/webcam/run_webcam.py --config tools/webcam/configs/examples/test_camera.py
+```
diff --git a/vendor/ViTPose/tools/webcam/configs/background/background.py b/vendor/ViTPose/tools/webcam/configs/background/background.py
new file mode 100644
index 0000000000000000000000000000000000000000..fb9f4d616e929cbe7f3c789a729ce2c07d40b9a1
--- /dev/null
+++ b/vendor/ViTPose/tools/webcam/configs/background/background.py
@@ -0,0 +1,93 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+runner = dict(
+ # Basic configurations of the runner
+ name='Matting Effects',
+ camera_id=0,
+ camera_fps=10,
+ synchronous=False,
+ # Define nodes.
+ # The configuration of a node usually includes:
+ # 1. 'type': Node class name
+ # 2. 'name': Node name
+ # 3. I/O buffers (e.g. 'input_buffer', 'output_buffer'): specify the
+ # input and output buffer names. This may depend on the node class.
+ # 4. 'enable_key': assign a hot-key to toggle enable/disable this node.
+ # This may depend on the node class.
+ # 5. Other class-specific arguments
+ nodes=[
+ # 'DetectorNode':
+ # This node performs object detection from the frame image using an
+ # MMDetection model.
+ dict(
+ type='DetectorNode',
+ name='Detector',
+ model_config='demo/mmdetection_cfg/mask_rcnn_r50_fpn_2x_coco.py',
+ model_checkpoint='https://download.openmmlab.com/'
+ 'mmdetection/v2.0/mask_rcnn/mask_rcnn_r50_fpn_2x_coco/'
+ 'mask_rcnn_r50_fpn_2x_coco_bbox_mAP-0.392'
+ '__segm_mAP-0.354_20200505_003907-3e542a40.pth',
+ input_buffer='_input_', # `_input_` is a runner-reserved buffer
+ output_buffer='det_result'),
+ # 'TopDownPoseEstimatorNode':
+ # This node performs keypoint detection from the frame image using an
+ # MMPose top-down model. Detection results is needed.
+ dict(
+ type='TopDownPoseEstimatorNode',
+ name='Human Pose Estimator',
+ model_config='configs/wholebody/2d_kpt_sview_rgb_img/'
+ 'topdown_heatmap/coco-wholebody/'
+ 'vipnas_mbv3_coco_wholebody_256x192_dark.py',
+ model_checkpoint='https://openmmlab-share.oss-cn-hangz'
+ 'hou.aliyuncs.com/mmpose/top_down/vipnas/vipnas_mbv3_co'
+ 'co_wholebody_256x192_dark-e2158108_20211205.pth',
+ cls_names=['person'],
+ input_buffer='det_result',
+ output_buffer='human_pose'),
+ # 'ModelResultBindingNode':
+ # This node binds the latest model inference result with the current
+ # frame. (This means the frame image and inference result may be
+ # asynchronous).
+ dict(
+ type='ModelResultBindingNode',
+ name='ResultBinder',
+ frame_buffer='_frame_', # `_frame_` is a runner-reserved buffer
+ result_buffer='human_pose',
+ output_buffer='frame'),
+ # 'MattingNode':
+ # This node draw the matting visualization result in the frame image.
+ # mask results is needed.
+ dict(
+ type='BackgroundNode',
+ name='Visualizer',
+ enable_key='b',
+ enable=True,
+ frame_buffer='frame',
+ output_buffer='vis_bg',
+ cls_names=['person']),
+ # 'NoticeBoardNode':
+ # This node show a notice board with given content, e.g. help
+ # information.
+ dict(
+ type='NoticeBoardNode',
+ name='Helper',
+ enable_key='h',
+ frame_buffer='vis_bg',
+ output_buffer='vis',
+ content_lines=[
+ 'This is a demo for background changing effects. Have fun!',
+ '', 'Hot-keys:', '"b": Change background',
+ '"h": Show help information',
+ '"m": Show diagnostic information', '"q": Exit'
+ ],
+ ),
+ # 'MonitorNode':
+ # This node show diagnostic information in the frame image. It can
+ # be used for debugging or monitoring system resource status.
+ dict(
+ type='MonitorNode',
+ name='Monitor',
+ enable_key='m',
+ enable=False,
+ frame_buffer='vis',
+ output_buffer='_display_') # `_frame_` is a runner-reserved buffer
+ ])
diff --git a/vendor/ViTPose/tools/webcam/configs/examples/README.md b/vendor/ViTPose/tools/webcam/configs/examples/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..ec9b961d284631478b3c326872d75942437a7f0e
--- /dev/null
+++ b/vendor/ViTPose/tools/webcam/configs/examples/README.md
@@ -0,0 +1,110 @@
+# Pose Estimation Demo
+
+This demo performs human bounding box and keypoint detection, and visualizes results.
+
+
+
+ 
+
+
+## Instruction
+
+### Get started
+
+Launch the demo from the mmpose root directory:
+
+```shell
+python tools/webcam/run_webcam.py --config tools/webcam/configs/examples/pose_estimation.py
+```
+
+### Hotkeys
+
+| Hotkey | Function |
+| -- | -- |
+| v | Toggle the pose visualization on/off. |
+| h | Show help information. |
+| m | Show the monitoring information. |
+| q | Exit. |
+
+Note that the demo will automatically save the output video into a file `record.mp4`.
+
+### Configuration
+
+- **Choose a detection model**
+
+Users can choose detection models from the [MMDetection Model Zoo](https://mmdetection.readthedocs.io/en/v2.20.0/model_zoo.html). Just set the `model_config` and `model_checkpoint` in the detector node accordingly, and the model will be automatically downloaded and loaded.
+
+```python
+# 'DetectorNode':
+ # This node performs object detection from the frame image using an
+ # MMDetection model.
+dict(
+ type='DetectorNode',
+ name='Detector',
+ model_config='demo/mmdetection_cfg/'
+ 'ssdlite_mobilenetv2_scratch_600e_coco.py',
+ model_checkpoint='https://download.openmmlab.com'
+ '/mmdetection/v2.0/ssd/'
+ 'ssdlite_mobilenetv2_scratch_600e_coco/ssdlite_mobilenetv2_'
+ 'scratch_600e_coco_20210629_110627-974d9307.pth',
+ input_buffer='_input_',
+ output_buffer='det_result')
+```
+
+- **Choose a or more pose models**
+
+In this demo we use two [top-down](https://github.com/open-mmlab/mmpose/tree/master/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap) pose estimation models for humans and animals respectively. Users can choose models from the [MMPose Model Zoo](https://mmpose.readthedocs.io/en/latest/modelzoo.html). To apply different pose models on different instance types, you can add multiple pose estimator nodes with `cls_names` set accordingly.
+
+```python
+# 'TopDownPoseEstimatorNode':
+# This node performs keypoint detection from the frame image using an
+# MMPose top-down model. Detection results is needed.
+dict(
+ type='TopDownPoseEstimatorNode',
+ name='Human Pose Estimator',
+ model_config='configs/wholebody/2d_kpt_sview_rgb_img/'
+ 'topdown_heatmap/coco-wholebody/'
+ 'vipnas_mbv3_coco_wholebody_256x192_dark.py',
+ model_checkpoint='https://openmmlab-share.oss-cn-hangz'
+ 'hou.aliyuncs.com/mmpose/top_down/vipnas/vipnas_mbv3_co'
+ 'co_wholebody_256x192_dark-e2158108_20211205.pth',
+ cls_names=['person'],
+ input_buffer='det_result',
+ output_buffer='human_pose'),
+dict(
+ type='TopDownPoseEstimatorNode',
+ name='Animal Pose Estimator',
+ model_config='configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap'
+ '/animalpose/hrnet_w32_animalpose_256x256.py',
+ model_checkpoint='https://download.openmmlab.com/mmpose/animal/'
+ 'hrnet/hrnet_w32_animalpose_256x256-1aa7f075_20210426.pth',
+ cls_names=['cat', 'dog', 'horse', 'sheep', 'cow'],
+ input_buffer='human_pose',
+ output_buffer='animal_pose')
+```
+
+- **Run the demo without GPU**
+
+If you don't have GPU and CUDA in your device, the demo can run with only CPU by setting `device='cpu'` in all model nodes. For example:
+
+```python
+dict(
+ type='DetectorNode',
+ name='Detector',
+ model_config='demo/mmdetection_cfg/'
+ 'ssdlite_mobilenetv2_scratch_600e_coco.py',
+ model_checkpoint='https://download.openmmlab.com'
+ '/mmdetection/v2.0/ssd/'
+ 'ssdlite_mobilenetv2_scratch_600e_coco/ssdlite_mobilenetv2_'
+ 'scratch_600e_coco_20210629_110627-974d9307.pth',
+ device='cpu',
+ input_buffer='_input_',
+ output_buffer='det_result')
+```
+
+- **Debug webcam and display**
+
+You can lanch the webcam runner with a debug config:
+
+```shell
+python tools/webcam/run_webcam.py --config tools/webcam/configs/examples/test_camera.py
+```
diff --git a/vendor/ViTPose/tools/webcam/configs/examples/pose_estimation.py b/vendor/ViTPose/tools/webcam/configs/examples/pose_estimation.py
new file mode 100644
index 0000000000000000000000000000000000000000..471333a448530c5b99f9016729b269953099f466
--- /dev/null
+++ b/vendor/ViTPose/tools/webcam/configs/examples/pose_estimation.py
@@ -0,0 +1,115 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+runner = dict(
+ # Basic configurations of the runner
+ name='Pose Estimation',
+ camera_id=0,
+ camera_fps=20,
+ synchronous=False,
+ # Define nodes.
+ # The configuration of a node usually includes:
+ # 1. 'type': Node class name
+ # 2. 'name': Node name
+ # 3. I/O buffers (e.g. 'input_buffer', 'output_buffer'): specify the
+ # input and output buffer names. This may depend on the node class.
+ # 4. 'enable_key': assign a hot-key to toggle enable/disable this node.
+ # This may depend on the node class.
+ # 5. Other class-specific arguments
+ nodes=[
+ # 'DetectorNode':
+ # This node performs object detection from the frame image using an
+ # MMDetection model.
+ dict(
+ type='DetectorNode',
+ name='Detector',
+ model_config='demo/mmdetection_cfg/'
+ 'ssdlite_mobilenetv2_scratch_600e_coco.py',
+ model_checkpoint='https://download.openmmlab.com'
+ '/mmdetection/v2.0/ssd/'
+ 'ssdlite_mobilenetv2_scratch_600e_coco/ssdlite_mobilenetv2_'
+ 'scratch_600e_coco_20210629_110627-974d9307.pth',
+ input_buffer='_input_', # `_input_` is a runner-reserved buffer
+ output_buffer='det_result'),
+ # 'TopDownPoseEstimatorNode':
+ # This node performs keypoint detection from the frame image using an
+ # MMPose top-down model. Detection results is needed.
+ dict(
+ type='TopDownPoseEstimatorNode',
+ name='Human Pose Estimator',
+ model_config='configs/wholebody/2d_kpt_sview_rgb_img/'
+ 'topdown_heatmap/coco-wholebody/'
+ 'vipnas_mbv3_coco_wholebody_256x192_dark.py',
+ model_checkpoint='https://download.openmmlab.com/mmpose/top_down/'
+ 'vipnas/vipnas_mbv3_coco_wholebody_256x192_dark'
+ '-e2158108_20211205.pth',
+ cls_names=['person'],
+ input_buffer='det_result',
+ output_buffer='human_pose'),
+ dict(
+ type='TopDownPoseEstimatorNode',
+ name='Animal Pose Estimator',
+ model_config='configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap'
+ '/animalpose/hrnet_w32_animalpose_256x256.py',
+ model_checkpoint='https://download.openmmlab.com/mmpose/animal/'
+ 'hrnet/hrnet_w32_animalpose_256x256-1aa7f075_20210426.pth',
+ cls_names=['cat', 'dog', 'horse', 'sheep', 'cow'],
+ input_buffer='human_pose',
+ output_buffer='animal_pose'),
+ # 'ModelResultBindingNode':
+ # This node binds the latest model inference result with the current
+ # frame. (This means the frame image and inference result may be
+ # asynchronous).
+ dict(
+ type='ModelResultBindingNode',
+ name='ResultBinder',
+ frame_buffer='_frame_', # `_frame_` is a runner-reserved buffer
+ result_buffer='animal_pose',
+ output_buffer='frame'),
+ # 'PoseVisualizerNode':
+ # This node draw the pose visualization result in the frame image.
+ # Pose results is needed.
+ dict(
+ type='PoseVisualizerNode',
+ name='Visualizer',
+ enable_key='v',
+ frame_buffer='frame',
+ output_buffer='vis'),
+ # 'NoticeBoardNode':
+ # This node show a notice board with given content, e.g. help
+ # information.
+ dict(
+ type='NoticeBoardNode',
+ name='Helper',
+ enable_key='h',
+ enable=True,
+ frame_buffer='vis',
+ output_buffer='vis_notice',
+ content_lines=[
+ 'This is a demo for pose visualization and simple image '
+ 'effects. Have fun!', '', 'Hot-keys:',
+ '"v": Pose estimation result visualization',
+ '"s": Sunglasses effect B-)', '"b": Bug-eye effect 0_0',
+ '"h": Show help information',
+ '"m": Show diagnostic information', '"q": Exit'
+ ],
+ ),
+ # 'MonitorNode':
+ # This node show diagnostic information in the frame image. It can
+ # be used for debugging or monitoring system resource status.
+ dict(
+ type='MonitorNode',
+ name='Monitor',
+ enable_key='m',
+ enable=False,
+ frame_buffer='vis_notice',
+ output_buffer='display'),
+ # 'RecorderNode':
+ # This node save the output video into a file.
+ dict(
+ type='RecorderNode',
+ name='Recorder',
+ out_video_file='record.mp4',
+ frame_buffer='display',
+ output_buffer='_display_'
+ # `_display_` is a runner-reserved buffer
+ )
+ ])
diff --git a/vendor/ViTPose/tools/webcam/configs/examples/test_camera.py b/vendor/ViTPose/tools/webcam/configs/examples/test_camera.py
new file mode 100644
index 0000000000000000000000000000000000000000..c0c1677f4f1cbe8fe3dad081c7b9889602a39956
--- /dev/null
+++ b/vendor/ViTPose/tools/webcam/configs/examples/test_camera.py
@@ -0,0 +1,19 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+runner = dict(
+ name='Debug CamRunner',
+ camera_id=0,
+ camera_fps=20,
+ nodes=[
+ dict(
+ type='MonitorNode',
+ name='Monitor',
+ enable_key='m',
+ frame_buffer='_frame_',
+ output_buffer='display'),
+ dict(
+ type='RecorderNode',
+ name='Recorder',
+ out_video_file='webcam_output.mp4',
+ frame_buffer='display',
+ output_buffer='_display_')
+ ])
diff --git a/vendor/ViTPose/tools/webcam/configs/eyes/README.md b/vendor/ViTPose/tools/webcam/configs/eyes/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..f9c37695eecb18a0e4becdbcc1aa59bde4e75247
--- /dev/null
+++ b/vendor/ViTPose/tools/webcam/configs/eyes/README.md
@@ -0,0 +1,31 @@
+# Sunglasses and Bug-eye Effects
+
+We can apply fun effects on videos with pose estimation results, like adding sunglasses on the face, or make the eyes look bigger.
+
++
+
+
+
+## Instruction
+
+### Get started
+
+Launch the demo from the mmpose root directory:
+
+```shell
+python tools/webcam/run_webcam.py --config tools/webcam/configs/examples/pose_estimation.py
+```
+
+### Hotkeys
+
+| Hotkey | Function |
+| -- | -- |
+| s | Toggle the sunglasses effect on/off. |
+| b | Toggle the bug-eye effect on/off. |
+| h | Show help information. |
+| m | Show the monitoring information. |
+| q | Exit. |
+
+### Configuration
+
+See the [README](/tools/webcam/configs/examples/README.md#configuration) of pose estimation demo for model configurations.
diff --git a/vendor/ViTPose/tools/webcam/configs/eyes/eyes.py b/vendor/ViTPose/tools/webcam/configs/eyes/eyes.py
new file mode 100644
index 0000000000000000000000000000000000000000..91bbfba9d9f89f7c7071375bedcc73a1e18d1783
--- /dev/null
+++ b/vendor/ViTPose/tools/webcam/configs/eyes/eyes.py
@@ -0,0 +1,114 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+runner = dict(
+ # Basic configurations of the runner
+ name='Eye Effects',
+ camera_id=0,
+ camera_fps=20,
+ synchronous=False,
+ # Define nodes.
+ # The configuration of a node usually includes:
+ # 1. 'type': Node class name
+ # 2. 'name': Node name
+ # 3. I/O buffers (e.g. 'input_buffer', 'output_buffer'): specify the
+ # input and output buffer names. This may depend on the node class.
+ # 4. 'enable_key': assign a hot-key to toggle enable/disable this node.
+ # This may depend on the node class.
+ # 5. Other class-specific arguments
+ nodes=[
+ # 'DetectorNode':
+ # This node performs object detection from the frame image using an
+ # MMDetection model.
+ dict(
+ type='DetectorNode',
+ name='Detector',
+ model_config='demo/mmdetection_cfg/'
+ 'ssdlite_mobilenetv2_scratch_600e_coco.py',
+ model_checkpoint='https://download.openmmlab.com'
+ '/mmdetection/v2.0/ssd/'
+ 'ssdlite_mobilenetv2_scratch_600e_coco/ssdlite_mobilenetv2_'
+ 'scratch_600e_coco_20210629_110627-974d9307.pth',
+ input_buffer='_input_', # `_input_` is a runner-reserved buffer
+ output_buffer='det_result'),
+ # 'TopDownPoseEstimatorNode':
+ # This node performs keypoint detection from the frame image using an
+ # MMPose top-down model. Detection results is needed.
+ dict(
+ type='TopDownPoseEstimatorNode',
+ name='Human Pose Estimator',
+ model_config='configs/wholebody/2d_kpt_sview_rgb_img/'
+ 'topdown_heatmap/coco-wholebody/'
+ 'vipnas_mbv3_coco_wholebody_256x192_dark.py',
+ model_checkpoint='https://openmmlab-share.oss-cn-hangz'
+ 'hou.aliyuncs.com/mmpose/top_down/vipnas/vipnas_mbv3_co'
+ 'co_wholebody_256x192_dark-e2158108_20211205.pth',
+ cls_names=['person'],
+ input_buffer='det_result',
+ output_buffer='human_pose'),
+ dict(
+ type='TopDownPoseEstimatorNode',
+ name='Animal Pose Estimator',
+ model_config='configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap'
+ '/animalpose/hrnet_w32_animalpose_256x256.py',
+ model_checkpoint='https://download.openmmlab.com/mmpose/animal/'
+ 'hrnet/hrnet_w32_animalpose_256x256-1aa7f075_20210426.pth',
+ cls_names=['cat', 'dog', 'horse', 'sheep', 'cow'],
+ input_buffer='human_pose',
+ output_buffer='animal_pose'),
+ # 'ModelResultBindingNode':
+ # This node binds the latest model inference result with the current
+ # frame. (This means the frame image and inference result may be
+ # asynchronous).
+ dict(
+ type='ModelResultBindingNode',
+ name='ResultBinder',
+ frame_buffer='_frame_', # `_frame_` is a runner-reserved buffer
+ result_buffer='animal_pose',
+ output_buffer='frame'),
+ # 'SunglassesNode':
+ # This node draw the sunglasses effect in the frame image.
+ # Pose results is needed.
+ dict(
+ type='SunglassesNode',
+ name='Visualizer',
+ enable_key='s',
+ enable=True,
+ frame_buffer='frame',
+ output_buffer='vis_sunglasses'),
+ # 'BugEyeNode':
+ # This node draw the bug-eye effetc in the frame image.
+ # Pose results is needed.
+ dict(
+ type='BugEyeNode',
+ name='Visualizer',
+ enable_key='b',
+ enable=False,
+ frame_buffer='vis_sunglasses',
+ output_buffer='vis_bugeye'),
+ # 'NoticeBoardNode':
+ # This node show a notice board with given content, e.g. help
+ # information.
+ dict(
+ type='NoticeBoardNode',
+ name='Helper',
+ enable_key='h',
+ frame_buffer='vis_bugeye',
+ output_buffer='vis',
+ content_lines=[
+ 'This is a demo for pose visualization and simple image '
+ 'effects. Have fun!', '', 'Hot-keys:',
+ '"s": Sunglasses effect B-)', '"b": Bug-eye effect 0_0',
+ '"h": Show help information',
+ '"m": Show diagnostic information', '"q": Exit'
+ ],
+ ),
+ # 'MonitorNode':
+ # This node show diagnostic information in the frame image. It can
+ # be used for debugging or monitoring system resource status.
+ dict(
+ type='MonitorNode',
+ name='Monitor',
+ enable_key='m',
+ enable=False,
+ frame_buffer='vis',
+ output_buffer='_display_') # `_frame_` is a runner-reserved buffer
+ ])
diff --git a/vendor/ViTPose/tools/webcam/configs/face_swap/README.md b/vendor/ViTPose/tools/webcam/configs/face_swap/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..02f4c8aa855702bf6a668970f8e7e071611caf8e
--- /dev/null
+++ b/vendor/ViTPose/tools/webcam/configs/face_swap/README.md
@@ -0,0 +1,31 @@
+# Sunglasses and Bug-eye Effects
+
+Look! Where is my face?:eyes: And whose face is it?:laughing:
+
++
+ 
+
+
+## Instruction
+
+### Get started
+
+Launch the demo from the mmpose root directory:
+
+```shell
+python tools/webcam/run_webcam.py --config tools/webcam/configs/face_swap/face_swap.py
+```
+
+### Hotkeys
+
+| Hotkey | Function |
+| -- | -- |
+| s | Switch between modes +
- Shuffle: Randomly shuffle all faces
- Clone: Choose one face and clone it for everyone
- None: Nothing happens and everyone is safe :)
+ 
+
+
+Now you can dress your cat up in this costume and TA-DA! Be prepared for super cute **Meow Dwen Dwen**.
+
++
+ 
+
+
+You are a dog fan? Hold on, here comes Woof Dwen Dwen.
+
++
+ 
+
+
+## Instruction
+
+### Get started
+
+Launch the demo from the mmpose root directory:
+
+```shell
+python tools/webcam/run_webcam.py --config tools/webcam/configs/meow_dwen_dwen/meow_dwen_dwen.py
+```
+
+### Hotkeys
+
+| Hotkey | Function |
+| -- | -- |
+| s | Change the background. |
+| h | Show help information. |
+| m | Show diagnostic information. |
+| q | Exit. |
+
+### Configuration
+
+- **Use video input**
+
+As you can see in the config, we set `camera_id` as the path of the input image. You can also set it as a video file path (or url), or a webcam ID number (e.g. `camera_id=0`), to capture the dynamic face from the video input.
diff --git a/vendor/ViTPose/tools/webcam/configs/meow_dwen_dwen/meow_dwen_dwen.py b/vendor/ViTPose/tools/webcam/configs/meow_dwen_dwen/meow_dwen_dwen.py
new file mode 100644
index 0000000000000000000000000000000000000000..399d01cf7c8df103772913294f1c0612979330e6
--- /dev/null
+++ b/vendor/ViTPose/tools/webcam/configs/meow_dwen_dwen/meow_dwen_dwen.py
@@ -0,0 +1,92 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+runner = dict(
+ # Basic configurations of the runner
+ name='Little fans of 2022 Beijing Winter Olympics',
+ # Cat image
+ camera_id='https://user-images.githubusercontent.com/'
+ '15977946/152932036-b5554cf8-24cf-40d6-a358-35a106013f11.jpeg',
+ # Dog image
+ # camera_id='https://user-images.githubusercontent.com/'
+ # '15977946/152932051-cd280b35-8066-45a0-8f52-657c8631aaba.jpg',
+ camera_fps=20,
+ nodes=[
+ dict(
+ type='DetectorNode',
+ name='Detector',
+ model_config='demo/mmdetection_cfg/'
+ 'ssdlite_mobilenetv2_scratch_600e_coco.py',
+ model_checkpoint='https://download.openmmlab.com'
+ '/mmdetection/v2.0/ssd/'
+ 'ssdlite_mobilenetv2_scratch_600e_coco/ssdlite_mobilenetv2_'
+ 'scratch_600e_coco_20210629_110627-974d9307.pth',
+ input_buffer='_input_', # `_input_` is a runner-reserved buffer
+ output_buffer='det_result'),
+ dict(
+ type='TopDownPoseEstimatorNode',
+ name='Animal Pose Estimator',
+ model_config='configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap'
+ '/ap10k/hrnet_w32_ap10k_256x256.py',
+ model_checkpoint='https://download.openmmlab.com/mmpose/animal/'
+ 'hrnet/hrnet_w32_ap10k_256x256-18aac840_20211029.pth',
+ cls_names=['cat', 'dog'],
+ input_buffer='det_result',
+ output_buffer='animal_pose'),
+ dict(
+ type='TopDownPoseEstimatorNode',
+ name='TopDown Pose Estimator',
+ model_config='configs/wholebody/2d_kpt_sview_rgb_img/'
+ 'topdown_heatmap/coco-wholebody/'
+ 'vipnas_res50_coco_wholebody_256x192_dark.py',
+ model_checkpoint='https://openmmlab-share.oss-cn-hangzhou'
+ '.aliyuncs.com/mmpose/top_down/vipnas/'
+ 'vipnas_res50_wholebody_256x192_dark-67c0ce35_20211112.pth',
+ device='cpu',
+ cls_names=['person'],
+ input_buffer='animal_pose',
+ output_buffer='human_pose'),
+ dict(
+ type='ModelResultBindingNode',
+ name='ResultBinder',
+ frame_buffer='_frame_', # `_frame_` is a runner-reserved buffer
+ result_buffer='human_pose',
+ output_buffer='frame'),
+ dict(
+ type='XDwenDwenNode',
+ name='XDwenDwen',
+ mode_key='s',
+ resource_file='tools/webcam/configs/meow_dwen_dwen/'
+ 'resource-info.json',
+ out_shape=(480, 480),
+ frame_buffer='frame',
+ output_buffer='vis'),
+ dict(
+ type='NoticeBoardNode',
+ name='Helper',
+ enable_key='h',
+ enable=False,
+ frame_buffer='vis',
+ output_buffer='vis_notice',
+ content_lines=[
+ 'Let your pet put on a costume of Bing-Dwen-Dwen, '
+ 'the mascot of 2022 Beijing Winter Olympics. Have fun!', '',
+ 'Hot-keys:', '"s": Change the background',
+ '"h": Show help information',
+ '"m": Show diagnostic information', '"q": Exit'
+ ],
+ ),
+ dict(
+ type='MonitorNode',
+ name='Monitor',
+ enable_key='m',
+ enable=False,
+ frame_buffer='vis_notice',
+ output_buffer='display'),
+ dict(
+ type='RecorderNode',
+ name='Recorder',
+ out_video_file='record.mp4',
+ frame_buffer='display',
+ output_buffer='_display_'
+ # `_display_` is a runner-reserved buffer
+ )
+ ])
diff --git a/vendor/ViTPose/tools/webcam/configs/meow_dwen_dwen/resource-info.json b/vendor/ViTPose/tools/webcam/configs/meow_dwen_dwen/resource-info.json
new file mode 100644
index 0000000000000000000000000000000000000000..adb811cc7f3eafea56ff4d3f577ec28e33e80f0a
--- /dev/null
+++ b/vendor/ViTPose/tools/webcam/configs/meow_dwen_dwen/resource-info.json
@@ -0,0 +1,26 @@
+[
+ {
+ "id": 1,
+ "result": "{\"width\":690,\"height\":713,\"valid\":true,\"rotate\":0,\"step_1\":{\"toolName\":\"pointTool\",\"result\":[{\"x\":374.86387434554973,\"y\":262.8020942408377,\"attribute\":\"\",\"valid\":true,\"id\":\"8SK9cVyu\",\"sourceID\":\"\",\"textAttribute\":\"\",\"order\":2},{\"x\":492.8261780104712,\"y\":285.2,\"attribute\":\"\",\"valid\":true,\"id\":\"qDk54WsI\",\"sourceID\":\"\",\"textAttribute\":\"\",\"order\":1},{\"x\":430.11204188481673,\"y\":318.0502617801047,\"attribute\":\"\",\"valid\":true,\"id\":\"4H80L7lL\",\"sourceID\":\"\",\"textAttribute\":\"\",\"order\":3}]},\"step_2\":{\"dataSourceStep\":0,\"toolName\":\"polygonTool\",\"result\":[{\"id\":\"pwUsrf9u\",\"sourceID\":\"\",\"valid\":true,\"textAttribute\":\"\",\"pointList\":[{\"x\":423.3926701570681,\"y\":191.87539267015708},{\"x\":488.3465968586388,\"y\":209.04712041884818},{\"x\":535.3821989528797,\"y\":248.6167539267016},{\"x\":549.5675392670157,\"y\":306.8513089005236},{\"x\":537.6219895287959,\"y\":349.407329842932},{\"x\":510.74450261780106,\"y\":381.51099476439794},{\"x\":480.1340314136126,\"y\":394.9497382198953},{\"x\":411.4471204188482,\"y\":390.47015706806286},{\"x\":355.45235602094243,\"y\":373.29842931937173},{\"x\":306.17696335078534,\"y\":327.00942408376966},{\"x\":294.97801047120424,\"y\":284.45340314136126},{\"x\":306.9235602094241,\"y\":245.6303664921466},{\"x\":333.8010471204189,\"y\":217.25968586387435},{\"x\":370.3842931937173,\"y\":196.35497382198955}],\"attribute\":\"\",\"order\":1}]}}",
+ "url": "https://user-images.githubusercontent.com/15977946/152742677-35fe8a01-bd06-4a12-a02e-949e7d71f28a.jpg",
+ "fileName": "bing_dwen_dwen1.jpg"
+ },
+ {
+ "id": 2,
+ "result": "{\"width\":690,\"height\":659,\"valid\":true,\"rotate\":0,\"step_1\":{\"dataSourceStep\":0,\"toolName\":\"pointTool\",\"result\":[{\"x\":293.2460732984293,\"y\":242.89842931937173,\"attribute\":\"\",\"valid\":true,\"id\":\"KgPs39bY\",\"sourceID\":\"\",\"textAttribute\":\"\",\"order\":1},{\"x\":170.41675392670155,\"y\":270.50052356020944,\"attribute\":\"\",\"valid\":true,\"id\":\"XwHyoBFU\",\"sourceID\":\"\",\"textAttribute\":\"\",\"order\":2},{\"x\":224.24083769633506,\"y\":308.45340314136126,\"attribute\":\"\",\"valid\":true,\"id\":\"Qfs4YfuB\",\"sourceID\":\"\",\"textAttribute\":\"\",\"order\":3}]},\"step_2\":{\"dataSourceStep\":0,\"toolName\":\"polygonTool\",\"result\":[{\"id\":\"ts5jlJxb\",\"sourceID\":\"\",\"valid\":true,\"textAttribute\":\"\",\"pointList\":[{\"x\":178.69738219895285,\"y\":184.93403141361256},{\"x\":204.91937172774865,\"y\":172.5130890052356},{\"x\":252.5329842931937,\"y\":169.0628272251309},{\"x\":295.3162303664921,\"y\":175.27329842931937},{\"x\":333.95916230366487,\"y\":195.2848167539267},{\"x\":360.18115183246067,\"y\":220.1267015706806},{\"x\":376.0523560209424,\"y\":262.909947643979},{\"x\":373.98219895287957,\"y\":296.0324607329843},{\"x\":344.99999999999994,\"y\":335.365445026178},{\"x\":322.22827225130885,\"y\":355.37696335078533},{\"x\":272.544502617801,\"y\":378.1486910994764},{\"x\":221.48062827225127,\"y\":386.42931937172773},{\"x\":187.6680628272251,\"y\":385.7392670157068},{\"x\":158.68586387434553,\"y\":369.1780104712042},{\"x\":137.98429319371724,\"y\":337.43560209424083},{\"x\":127.63350785340312,\"y\":295.34240837696336},{\"x\":131.0837696335078,\"y\":242.89842931937173},{\"x\":147.64502617801045,\"y\":208.3958115183246}],\"attribute\":\"\",\"order\":1}]}}",
+ "url": "https://user-images.githubusercontent.com/15977946/152742707-c0c51844-e1d0-42d0-9a12-e369002e082f.jpg",
+ "fileName": "bing_dwen_dwen2.jpg"
+ },
+ {
+ "id": 3,
+ "result": "{\"width\":690,\"height\":811,\"valid\":true,\"rotate\":0,\"step_1\":{\"dataSourceStep\":0,\"toolName\":\"pointTool\",\"result\":[{\"x\":361.13507853403144,\"y\":300.62198952879584,\"attribute\":\"\",\"valid\":true,\"id\":\"uAtbXtf2\",\"sourceID\":\"\",\"textAttribute\":\"\",\"order\":1},{\"x\":242.24502617801048,\"y\":317.60628272251313,\"attribute\":\"\",\"valid\":true,\"id\":\"iLtceHMA\",\"sourceID\":\"\",\"textAttribute\":\"\",\"order\":2},{\"x\":302.5392670157068,\"y\":356.67015706806285,\"attribute\":\"\",\"valid\":true,\"id\":\"n9MTlJ6A\",\"sourceID\":\"\",\"textAttribute\":\"\",\"order\":3}]},\"step_2\":{\"dataSourceStep\":0,\"toolName\":\"polygonTool\",\"result\":[{\"id\":\"5sTLU5wF\",\"sourceID\":\"\",\"valid\":true,\"textAttribute\":\"\",\"pointList\":[{\"x\":227.80837696335078,\"y\":247.12146596858642},{\"x\":248.18952879581153,\"y\":235.23246073298432},{\"x\":291.4994764397906,\"y\":225.04188481675394},{\"x\":351.7937172774869,\"y\":229.28795811518327},{\"x\":393.40523560209425,\"y\":245.42303664921468},{\"x\":424.8261780104712,\"y\":272.59790575916236},{\"x\":443.5089005235602,\"y\":298.07434554973827},{\"x\":436.7151832460733,\"y\":345.6303664921466},{\"x\":406.1434554973822,\"y\":382.9958115183247},{\"x\":355.1905759162304,\"y\":408.4722513089006},{\"x\":313.57905759162304,\"y\":419.5120418848168},{\"x\":262.6261780104712,\"y\":417.81361256544506},{\"x\":224.41151832460733,\"y\":399.9801047120419},{\"x\":201.48272251308902,\"y\":364.3130890052356},{\"x\":194.68900523560208,\"y\":315.0586387434555},{\"x\":202.33193717277487,\"y\":272.59790575916236}],\"attribute\":\"\",\"order\":1}]}}",
+ "url": "https://user-images.githubusercontent.com/15977946/152742728-99392ecf-8f5c-46cf-b5c4-fe7fb6b39976.jpg",
+ "fileName": "bing_dwen_dwen3.jpg"
+ },
+ {
+ "id": 4,
+ "result": "{\"width\":690,\"height\":690,\"valid\":true,\"rotate\":0,\"step_1\":{\"dataSourceStep\":0,\"toolName\":\"pointTool\",\"result\":[{\"x\":365.9528795811519,\"y\":464.5759162303665,\"attribute\":\"\",\"valid\":true,\"id\":\"IKprTuHS\",\"sourceID\":\"\",\"textAttribute\":\"\",\"order\":1},{\"x\":470.71727748691103,\"y\":445.06806282722516,\"attribute\":\"\",\"valid\":true,\"id\":\"Z90CWkEI\",\"sourceID\":\"\",\"textAttribute\":\"\",\"order\":2},{\"x\":410.74869109947645,\"y\":395.2146596858639,\"attribute\":\"\",\"valid\":true,\"id\":\"UWRstKZk\",\"sourceID\":\"\",\"textAttribute\":\"\",\"order\":3}]},\"step_2\":{\"dataSourceStep\":0,\"toolName\":\"polygonTool\",\"result\":[{\"id\":\"C30Pc9Ww\",\"sourceID\":\"\",\"valid\":true,\"textAttribute\":\"\",\"pointList\":[{\"x\":412.91623036649213,\"y\":325.85340314136124},{\"x\":468.5497382198953,\"y\":335.9685863874345},{\"x\":501.78534031413614,\"y\":369.2041884816754},{\"x\":514.0680628272252,\"y\":415.44502617801044},{\"x\":504.67539267015707,\"y\":472.5235602094241},{\"x\":484.44502617801044,\"y\":497.0890052356021},{\"x\":443.26178010471205,\"y\":512.9842931937172},{\"x\":389.7958115183246,\"y\":518.7643979057591},{\"x\":336.32984293193715,\"y\":504.31413612565444},{\"x\":302.3717277486911,\"y\":462.40837696335075},{\"x\":298.0366492146597,\"y\":416.89005235602093},{\"x\":318.26701570680626,\"y\":372.0942408376963},{\"x\":363.0628272251309,\"y\":341.0261780104712}],\"attribute\":\"\",\"order\":1}]}}",
+ "url": "https://user-images.githubusercontent.com/15977946/152742755-9dc75f89-4156-4103-9c6d-f35f1f409d11.jpg",
+ "fileName": "bing_dwen_dwen4.jpg"
+ }
+]
diff --git a/vendor/ViTPose/tools/webcam/configs/newyear/README.md b/vendor/ViTPose/tools/webcam/configs/newyear/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..8c655c121e236146a00a378b5bf495dbf24e6888
--- /dev/null
+++ b/vendor/ViTPose/tools/webcam/configs/newyear/README.md
@@ -0,0 +1,31 @@
+# New Year Hat and Firecracker Effects
+
+This demo provides new year effects with pose estimation results, like adding hat on the head and firecracker in the hands.
+
++
+ 
+
+
+## Instruction
+
+### Get started
+
+Launch the demo from the mmpose root directory:
+
+```shell
+python tools/webcam/run_webcam.py --config tools/webcam/configs/newyear/new_year.py
+```
+
+### Hotkeys
+
+| Hotkey | Function |
+| -- | -- |
+| t | Toggle the hat effect on/off. |
+| f | Toggle the firecracker effect on/off. |
+| h | Show help information. |
+| m | Show the monitoring information. |
+| q | Exit. |
+
+### Configuration
+
+See the [README](/tools/webcam/configs/examples/README.md#configuration) of pose estimation demo for model configurations.
diff --git a/vendor/ViTPose/tools/webcam/configs/newyear/new_year.py b/vendor/ViTPose/tools/webcam/configs/newyear/new_year.py
new file mode 100644
index 0000000000000000000000000000000000000000..3551184053312da288ccac95ae9f37e7f116dd1b
--- /dev/null
+++ b/vendor/ViTPose/tools/webcam/configs/newyear/new_year.py
@@ -0,0 +1,122 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+runner = dict(
+ # Basic configurations of the runner
+ name='Pose Estimation',
+ camera_id=0,
+ camera_fps=20,
+ synchronous=False,
+ # Define nodes.
+ # The configuration of a node usually includes:
+ # 1. 'type': Node class name
+ # 2. 'name': Node name
+ # 3. I/O buffers (e.g. 'input_buffer', 'output_buffer'): specify the
+ # input and output buffer names. This may depend on the node class.
+ # 4. 'enable_key': assign a hot-key to toggle enable/disable this node.
+ # This may depend on the node class.
+ # 5. Other class-specific arguments
+ nodes=[
+ # 'DetectorNode':
+ # This node performs object detection from the frame image using an
+ # MMDetection model.
+ dict(
+ type='DetectorNode',
+ name='Detector',
+ model_config='demo/mmdetection_cfg/'
+ 'ssdlite_mobilenetv2_scratch_600e_coco.py',
+ model_checkpoint='https://download.openmmlab.com'
+ '/mmdetection/v2.0/ssd/'
+ 'ssdlite_mobilenetv2_scratch_600e_coco/ssdlite_mobilenetv2_'
+ 'scratch_600e_coco_20210629_110627-974d9307.pth',
+ input_buffer='_input_', # `_input_` is a runner-reserved buffer
+ output_buffer='det_result'),
+ # 'TopDownPoseEstimatorNode':
+ # This node performs keypoint detection from the frame image using an
+ # MMPose top-down model. Detection results is needed.
+ dict(
+ type='TopDownPoseEstimatorNode',
+ name='Human Pose Estimator',
+ model_config='configs/wholebody/2d_kpt_sview_rgb_img/'
+ 'topdown_heatmap/coco-wholebody/'
+ 'vipnas_mbv3_coco_wholebody_256x192_dark.py',
+ model_checkpoint='https://openmmlab-share.oss-cn-hangz'
+ 'hou.aliyuncs.com/mmpose/top_down/vipnas/vipnas_mbv3_co'
+ 'co_wholebody_256x192_dark-e2158108_20211205.pth',
+ cls_names=['person'],
+ input_buffer='det_result',
+ output_buffer='human_pose'),
+ dict(
+ type='TopDownPoseEstimatorNode',
+ name='Animal Pose Estimator',
+ model_config='configs/animal/2d_kpt_sview_rgb_img/topdown_heatmap'
+ '/animalpose/hrnet_w32_animalpose_256x256.py',
+ model_checkpoint='https://download.openmmlab.com/mmpose/animal/'
+ 'hrnet/hrnet_w32_animalpose_256x256-1aa7f075_20210426.pth',
+ cls_names=['cat', 'dog', 'horse', 'sheep', 'cow'],
+ input_buffer='human_pose',
+ output_buffer='animal_pose'),
+ # 'ModelResultBindingNode':
+ # This node binds the latest model inference result with the current
+ # frame. (This means the frame image and inference result may be
+ # asynchronous).
+ dict(
+ type='ModelResultBindingNode',
+ name='ResultBinder',
+ frame_buffer='_frame_', # `_frame_` is a runner-reserved buffer
+ result_buffer='animal_pose',
+ output_buffer='frame'),
+ # 'HatNode':
+ # This node draw the hat effect in the frame image.
+ # Pose results is needed.
+ dict(
+ type='HatNode',
+ name='Visualizer',
+ enable_key='t',
+ frame_buffer='frame',
+ output_buffer='vis_hat'),
+ # 'FirecrackerNode':
+ # This node draw the firecracker effect in the frame image.
+ # Pose results is needed.
+ dict(
+ type='FirecrackerNode',
+ name='Visualizer',
+ enable_key='f',
+ frame_buffer='vis_hat',
+ output_buffer='vis_firecracker'),
+ # 'NoticeBoardNode':
+ # This node show a notice board with given content, e.g. help
+ # information.
+ dict(
+ type='NoticeBoardNode',
+ name='Helper',
+ enable_key='h',
+ enable=True,
+ frame_buffer='vis_firecracker',
+ output_buffer='vis_notice',
+ content_lines=[
+ 'This is a demo for pose visualization and simple image '
+ 'effects. Have fun!', '', 'Hot-keys:', '"t": Hat effect',
+ '"f": Firecracker effect', '"h": Show help information',
+ '"m": Show diagnostic information', '"q": Exit'
+ ],
+ ),
+ # 'MonitorNode':
+ # This node show diagnostic information in the frame image. It can
+ # be used for debugging or monitoring system resource status.
+ dict(
+ type='MonitorNode',
+ name='Monitor',
+ enable_key='m',
+ enable=False,
+ frame_buffer='vis_notice',
+ output_buffer='display'),
+ # 'RecorderNode':
+ # This node save the output video into a file.
+ dict(
+ type='RecorderNode',
+ name='Recorder',
+ out_video_file='record.mp4',
+ frame_buffer='display',
+ output_buffer='_display_'
+ # `_display_` is a runner-reserved buffer
+ )
+ ])
diff --git a/vendor/ViTPose/tools/webcam/configs/supersaiyan/README.md b/vendor/ViTPose/tools/webcam/configs/supersaiyan/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..9e9aef1bbaa7c62277a039cfad995a01e0491a10
--- /dev/null
+++ b/vendor/ViTPose/tools/webcam/configs/supersaiyan/README.md
@@ -0,0 +1,96 @@
+# Super Saiyan Effects
+
+We can apply fun effects on videos with pose estimation results, like Super Saiyan transformation.
+
+https://user-images.githubusercontent.com/11788150/150138076-2192079f-068a-4d43-bf27-2f1fd708cabc.mp4
+
+## Instruction
+
+### Get started
+
+Launch the demo from the mmpose root directory:
+
+```shell
+python tools/webcam/run_webcam.py --config tools/webcam/configs/supersaiyan/saiyan.py
+```
+
+### Hotkeys
+
+| Hotkey | Function |
+| -- | -- |
+| s | Toggle the Super Saiyan effect on/off. |
+| h | Show help information. |
+| m | Show the monitoring information. |
+| q | Exit. |
+
+Note that the demo will automatically save the output video into a file `record.mp4`.
+
+### Configuration
+
+- **Choose a detection model**
+
+Users can choose detection models from the [MMDetection Model Zoo](https://mmdetection.readthedocs.io/en/v2.20.0/model_zoo.html). Just set the `model_config` and `model_checkpoint` in the detector node accordingly, and the model will be automatically downloaded and loaded.
+
+```python
+# 'DetectorNode':
+# This node performs object detection from the frame image using an
+# MMDetection model.
+dict(
+ type='DetectorNode',
+ name='Detector',
+ model_config='demo/mmdetection_cfg/mask_rcnn_r50_fpn_2x_coco.py',
+ model_checkpoint='https://download.openmmlab.com/'
+ 'mmdetection/v2.0/mask_rcnn/mask_rcnn_r50_fpn_2x_coco/'
+ 'mask_rcnn_r50_fpn_2x_coco_bbox_mAP-0.392'
+ '__segm_mAP-0.354_20200505_003907-3e542a40.pth',
+ input_buffer='_input_', # `_input_` is a runner-reserved buffer
+ output_buffer='det_result'),
+```
+
+- **Choose a or more pose models**
+
+In this demo we use two [top-down](https://github.com/open-mmlab/mmpose/tree/master/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap) pose estimation models for humans and animals respectively. Users can choose models from the [MMPose Model Zoo](https://mmpose.readthedocs.io/en/latest/modelzoo.html). To apply different pose models on different instance types, you can add multiple pose estimator nodes with `cls_names` set accordingly.
+
+```python
+# 'TopDownPoseEstimatorNode':
+# This node performs keypoint detection from the frame image using an
+# MMPose top-down model. Detection results is needed.
+dict(
+ type='TopDownPoseEstimatorNode',
+ name='Human Pose Estimator',
+ model_config='configs/wholebody/2d_kpt_sview_rgb_img/'
+ 'topdown_heatmap/coco-wholebody/'
+ 'vipnas_mbv3_coco_wholebody_256x192_dark.py',
+ model_checkpoint='https://openmmlab-share.oss-cn-hangz'
+ 'hou.aliyuncs.com/mmpose/top_down/vipnas/vipnas_mbv3_co'
+ 'co_wholebody_256x192_dark-e2158108_20211205.pth',
+ cls_names=['person'],
+ input_buffer='det_result',
+ output_buffer='human_pose')
+```
+
+- **Run the demo without GPU**
+
+If you don't have GPU and CUDA in your device, the demo can run with only CPU by setting `device='cpu'` in all model nodes. For example:
+
+```python
+dict(
+ type='DetectorNode',
+ name='Detector',
+ model_config='demo/mmdetection_cfg/mask_rcnn_r50_fpn_2x_coco.py',
+ model_checkpoint='https://download.openmmlab.com/'
+ 'mmdetection/v2.0/mask_rcnn/mask_rcnn_r50_fpn_2x_coco/'
+ 'mask_rcnn_r50_fpn_2x_coco_bbox_mAP-0.392'
+ '__segm_mAP-0.354_20200505_003907-3e542a40.pth',
+ device='cpu',
+ input_buffer='_input_', # `_input_` is a runner-reserved buffer
+ output_buffer='det_result'),
+```
+
+- **Debug webcam and display**
+
+You can launch the webcam runner with a debug config:
+
+```shell
+python tools/webcam/run_webcam.py --config tools/webcam/configs/examples/test_camera.py
+```
diff --git a/vendor/ViTPose/tools/webcam/configs/supersaiyan/saiyan.py b/vendor/ViTPose/tools/webcam/configs/supersaiyan/saiyan.py
new file mode 100644
index 0000000000000000000000000000000000000000..5a8e7bc82c7ca53fb6a0350ce8b0bd3e3ac6e737
--- /dev/null
+++ b/vendor/ViTPose/tools/webcam/configs/supersaiyan/saiyan.py
@@ -0,0 +1,93 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+runner = dict(
+ # Basic configurations of the runner
+ name='Super Saiyan Effects',
+ camera_id=0,
+ camera_fps=30,
+ synchronous=False,
+ # Define nodes.
+ # The configuration of a node usually includes:
+ # 1. 'type': Node class name
+ # 2. 'name': Node name
+ # 3. I/O buffers (e.g. 'input_buffer', 'output_buffer'): specify the
+ # input and output buffer names. This may depend on the node class.
+ # 4. 'enable_key': assign a hot-key to toggle enable/disable this node.
+ # This may depend on the node class.
+ # 5. Other class-specific arguments
+ nodes=[
+ # 'DetectorNode':
+ # This node performs object detection from the frame image using an
+ # MMDetection model.
+ dict(
+ type='DetectorNode',
+ name='Detector',
+ model_config='demo/mmdetection_cfg/mask_rcnn_r50_fpn_2x_coco.py',
+ model_checkpoint='https://download.openmmlab.com/'
+ 'mmdetection/v2.0/mask_rcnn/mask_rcnn_r50_fpn_2x_coco/'
+ 'mask_rcnn_r50_fpn_2x_coco_bbox_mAP-0.392'
+ '__segm_mAP-0.354_20200505_003907-3e542a40.pth',
+ input_buffer='_input_', # `_input_` is a runner-reserved buffer
+ output_buffer='det_result'),
+ # 'TopDownPoseEstimatorNode':
+ # This node performs keypoint detection from the frame image using an
+ # MMPose top-down model. Detection results is needed.
+ dict(
+ type='TopDownPoseEstimatorNode',
+ name='Human Pose Estimator',
+ model_config='configs/wholebody/2d_kpt_sview_rgb_img/'
+ 'topdown_heatmap/coco-wholebody/'
+ 'vipnas_mbv3_coco_wholebody_256x192_dark.py',
+ model_checkpoint='https://openmmlab-share.oss-cn-hangz'
+ 'hou.aliyuncs.com/mmpose/top_down/vipnas/vipnas_mbv3_co'
+ 'co_wholebody_256x192_dark-e2158108_20211205.pth',
+ cls_names=['person'],
+ input_buffer='det_result',
+ output_buffer='human_pose'),
+ # 'ModelResultBindingNode':
+ # This node binds the latest model inference result with the current
+ # frame. (This means the frame image and inference result may be
+ # asynchronous).
+ dict(
+ type='ModelResultBindingNode',
+ name='ResultBinder',
+ frame_buffer='_frame_', # `_frame_` is a runner-reserved buffer
+ result_buffer='human_pose',
+ output_buffer='frame'),
+ # 'SaiyanNode':
+ # This node draw the Super Saiyan effect in the frame image.
+ # Pose results is needed.
+ dict(
+ type='SaiyanNode',
+ name='Visualizer',
+ enable_key='s',
+ cls_names=['person'],
+ enable=True,
+ frame_buffer='frame',
+ output_buffer='vis_saiyan'),
+ # 'NoticeBoardNode':
+ # This node show a notice board with given content, e.g. help
+ # information.
+ dict(
+ type='NoticeBoardNode',
+ name='Helper',
+ enable_key='h',
+ frame_buffer='vis_saiyan',
+ output_buffer='vis',
+ content_lines=[
+ 'This is a demo for super saiyan effects. Have fun!', '',
+ 'Hot-keys:', '"s": Saiyan effect',
+ '"h": Show help information',
+ '"m": Show diagnostic information', '"q": Exit'
+ ],
+ ),
+ # 'MonitorNode':
+ # This node show diagnostic information in the frame image. It can
+ # be used for debugging or monitoring system resource status.
+ dict(
+ type='MonitorNode',
+ name='Monitor',
+ enable_key='m',
+ enable=False,
+ frame_buffer='vis',
+ output_buffer='_display_') # `_frame_` is a runner-reserved buffer
+ ])
diff --git a/vendor/ViTPose/tools/webcam/configs/valentinemagic/README.md b/vendor/ViTPose/tools/webcam/configs/valentinemagic/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..8063d2e18640a4312167ed1c022fce3cf613937e
--- /dev/null
+++ b/vendor/ViTPose/tools/webcam/configs/valentinemagic/README.md
@@ -0,0 +1,35 @@
+# Valentine Magic
+
+Do you want to show your **love** to your beloved one, especially on Valentine's Day? Express it with your pose using MMPose right away and see the Valentine Magic!
+
+Try to pose a hand heart gesture, and see what will happen?
+
+Prefer a blow kiss? Here comes your flying heart~
+
++
+ 
+
+
+## Instruction
+
+### Get started
+
+Launch the demo from the mmpose root directory:
+
+```shell
+python tools/webcam/run_webcam.py --config tools/webcam/configs/valentinemagic/valentinemagic.py
+```
+
+### Hotkeys
+
+| Hotkey | Function |
+| -- | -- |
+| l | Toggle the Valentine Magic effect on/off. |
+| v | Toggle the pose visualization on/off. |
+| h | Show help information. |
+| m | Show diagnostic information. |
+| q | Exit. |
+
+### Configuration
+
+See the [README](/tools/webcam/configs/examples/README.md#configuration) of pose estimation demo for model configurations.
diff --git a/vendor/ViTPose/tools/webcam/configs/valentinemagic/valentinemagic.py b/vendor/ViTPose/tools/webcam/configs/valentinemagic/valentinemagic.py
new file mode 100644
index 0000000000000000000000000000000000000000..5f921b07901805b490be264c28e12c7de3648f8b
--- /dev/null
+++ b/vendor/ViTPose/tools/webcam/configs/valentinemagic/valentinemagic.py
@@ -0,0 +1,118 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+runner = dict(
+ # Basic configurations of the runner
+ name='Human Pose and Effects',
+ camera_id=0,
+ camera_fps=30,
+
+ # Define nodes.
+ #
+ # The configuration of a node usually includes:
+ # 1. 'type': Node class name
+ # 2. 'name': Node name
+ # 3. I/O buffers (e.g. 'input_buffer', 'output_buffer'): specify the
+ # input and output buffer names. This may depend on the node class.
+ # 4. 'enable_key': assign a hot-key to toggle enable/disable this node.
+ # This may depend on the node class.
+ # 5. Other class-specific arguments
+ nodes=[
+ # 'DetectorNode':
+ # This node performs object detection from the frame image using an
+ # MMDetection model.
+ dict(
+ type='DetectorNode',
+ name='Detector',
+ model_config='demo/mmdetection_cfg/'
+ 'ssdlite_mobilenetv2_scratch_600e_coco.py',
+ model_checkpoint='https://download.openmmlab.com'
+ '/mmdetection/v2.0/ssd/'
+ 'ssdlite_mobilenetv2_scratch_600e_coco/ssdlite_mobilenetv2_'
+ 'scratch_600e_coco_20210629_110627-974d9307.pth',
+ input_buffer='_input_', # `_input_` is a runner-reserved buffer
+ output_buffer='det_result'),
+ # 'TopDownPoseEstimatorNode':
+ # This node performs keypoint detection from the frame image using an
+ # MMPose top-down model. Detection results is needed.
+ dict(
+ type='TopDownPoseEstimatorNode',
+ name='Human Pose Estimator',
+ model_config='configs/wholebody/2d_kpt_sview_rgb_img/'
+ 'topdown_heatmap/coco-wholebody/'
+ 'vipnas_mbv3_coco_wholebody_256x192_dark.py',
+ model_checkpoint='https://download.openmmlab.com/mmpose/top_down/'
+ 'vipnas/vipnas_mbv3_coco_wholebody_256x192_dark'
+ '-e2158108_20211205.pth',
+ cls_names=['person'],
+ input_buffer='det_result',
+ output_buffer='pose_result'),
+ # 'ModelResultBindingNode':
+ # This node binds the latest model inference result with the current
+ # frame. (This means the frame image and inference result may be
+ # asynchronous).
+ dict(
+ type='ModelResultBindingNode',
+ name='ResultBinder',
+ frame_buffer='_frame_', # `_frame_` is a runner-reserved buffer
+ result_buffer='pose_result',
+ output_buffer='frame'),
+ # 'PoseVisualizerNode':
+ # This node draw the pose visualization result in the frame image.
+ # Pose results is needed.
+ dict(
+ type='PoseVisualizerNode',
+ name='Visualizer',
+ enable_key='v',
+ enable=False,
+ frame_buffer='frame',
+ output_buffer='vis'),
+ # 'ValentineMagicNode':
+ # This node draw heart in the image.
+ # It can launch dynamically expanding heart from the middle of
+ # hands if the persons pose a "hand heart" gesture or blow a kiss.
+ # Only there are two persons in the image can trigger this effect.
+ # Pose results is needed.
+ dict(
+ type='ValentineMagicNode',
+ name='Visualizer',
+ enable_key='l',
+ frame_buffer='vis',
+ output_buffer='vis_heart',
+ ),
+ # 'NoticeBoardNode':
+ # This node show a notice board with given content, e.g. help
+ # information.
+ dict(
+ type='NoticeBoardNode',
+ name='Helper',
+ enable_key='h',
+ enable=False,
+ frame_buffer='vis_heart',
+ output_buffer='vis_notice',
+ content_lines=[
+ 'This is a demo for pose visualization and simple image '
+ 'effects. Have fun!', '', 'Hot-keys:',
+ '"h": Show help information', '"l": LoveHeart Effect',
+ '"v": PoseVisualizer', '"m": Show diagnostic information',
+ '"q": Exit'
+ ],
+ ),
+ # 'MonitorNode':
+ # This node show diagnostic information in the frame image. It can
+ # be used for debugging or monitoring system resource status.
+ dict(
+ type='MonitorNode',
+ name='Monitor',
+ enable_key='m',
+ enable=False,
+ frame_buffer='vis_notice',
+ output_buffer='display'), # `_frame_` is a runner-reserved buffer
+ # 'RecorderNode':
+ # This node record the frames into a local file. It can save the
+ # visualiztion results. Uncommit the following lines to turn it on.
+ dict(
+ type='RecorderNode',
+ name='Recorder',
+ out_video_file='record.mp4',
+ frame_buffer='display',
+ output_buffer='_display_')
+ ])
diff --git a/vendor/ViTPose/tools/webcam/docs/example_cn.md b/vendor/ViTPose/tools/webcam/docs/example_cn.md
new file mode 100644
index 0000000000000000000000000000000000000000..69b9898c3237ab6c81b6af28dfcb50224ac424df
--- /dev/null
+++ b/vendor/ViTPose/tools/webcam/docs/example_cn.md
@@ -0,0 +1,171 @@
+# 开发示例:给猫咪戴上太阳镜
+
+## 设计思路
+
+在动手之前,我们先考虑如何实现这个功能:
+
+- 首先,要做目标检测,找到图像中的猫咪
+- 接着,要估计猫咪的关键点位置,比如左右眼的位置
+- 最后,把太阳镜素材图片贴在合适的位置,TA-DA!
+
+按照这个思路,下面我们来看如何一步一步实现它。
+
+## Step 1:从一个现成的 Config 开始
+
+在 WebcamAPI 中,已经添加了一些实现常用功能的 Node,并提供了对应的 config 示例。利用这些可以减少用户的开发量。例如,我们可以以上面的姿态估计 demo 为基础。它的 config 位于 `tools/webcam/configs/example/pose_estimation.py`。为了更直观,我们把这个 config 中的功能节点表示成以下流程图:
+
++
+ +
+Pose Estimation Config 示意
+
+
+可以看到,这个 config 已经实现了我们设计思路中“1-目标检测”和“2-关键点检测”的功能。我们还需要实现“3-贴素材图”功能,这就需要定义一个新的 Node了。
+
+## Step 2:实现一个新 Node
+
+在 WebcamAPI 我们定义了以下 2 个 Node 基类:
+
+1. Node:所有 node 的基类,实现了初始化,绑定 runner,启动运行,数据输入输出等基本功能。子类通过重写抽象方法`process()`方法定义具体的 node 功能。
+2. FrameDrawingNode:用来绘制图像的 node 基类。FrameDrawingNode继承自 Node 并进一步封装了`process()`方法,提供了抽象方法`draw()`供子类实现具体的图像绘制功能。
+
+显然,“贴素材图”这个功能属于图像绘制,因此我们只需要继承 BaseFrameEffectNode 类即可。具体实现如下:
+
+```python
+# 假设该文件路径为
+#
+
+ +
+太阳镜特效原理示意
+
+
+### Get Advanced:关于 Node 和 FrameEffectNode
+
+[Node 类](/tools/webcam/webcam_apis/nodes/node.py) :继承自 Thread 类。正如我们在前面 数据流 部分提到的,所有节点都在各自的线程中彼此异步运行。在`Node.run()` 方法中定义了节点的基本运行逻辑:
+
+1. 当 buffer 中有数据时,会触发一次运行
+2. 调用`process()`来执行具体的功能。`process()`是一个抽象接口,由子类具体实现
+ - 特别地,如果节点需要实现“开/关”功能,则还需要实现`bypass()`方法,以定义节点“关”时的行为。`bypass()`与`process()`的输入输出接口完全相同。在run()中会根据`Node.enable`的状态,调用`process()`或`bypass()`
+3. 将运行结果发送到输出 buffer
+
+在继承 Node 类实现具体的节点类时,通常需要完成以下工作:
+
+1. 在__init__()中注册输入、输出 buffer,并调用基类的__init__()方法
+2. 实现process()和bypass()(如需要)方法
+
+[FrameDrawingNode 类](tools/webcam/webcam_apis/nodes/frame_drawing_node.py) :继承自 Node 类,对`process()`和`bypass()`方法做了进一步封装:
+
+- process():从接到输入中提取帧图像,传入draw()方法中绘图。draw()是一个抽象接口,有子类实现
+- bypass():直接将节点输入返回
+
+### Get Advanced: 关于节点的输入、输出格式
+
+我们定义了[FrameMessage 类](tools/webcam/webcam_apis/utils/message.py)作为节点间通信的数据结构。也就是说,通常情况下节点的输入、输出和 buffer 中存储的元素,都是 FrameMessage 类的实例。FrameMessage 通常用来存储视频中1帧的信息,它提供了简单的接口,用来提取和存入数据:
+
+- `get_image()`:返回图像
+- `set_image()`:设置图像
+- `add_detection_result()`:添加一个目标检测模型的结果
+- `get_detection_results()`:返回所有目标检测结果
+- `add_pose_result()`:添加一个姿态估计模型的结果
+- `get_pose_results()`:返回所有姿态估计结果
+
+## Step 3:调整 Config
+
+有了 Step 2 中实现的 SunglassesNode,我们只要把它加入 config 里就可以使用了。比如,我们可以把它放在“Visualizer” node 之后:
+
+
+
+ +
+修改后的 Config,添加了 SunglassesNode 节点
+
+
+具体的写法如下:
+
+```python
+runner = dict(
+ # runner的基本参数
+ name='Everybody Wears Sunglasses',
+ camera_id=0,
+ camera_fps=20,
+ # 定义了若干节点(node)
+ nodes=[
+ ...,
+ dict(
+ type='SunglassesNode', # 节点类名称
+ name='Sunglasses', # 节点名,由用户自己定义
+ frame_buffer='vis', # 输入
+ output_buffer='sunglasses', # 输出
+ enable_key='s', # 定义开关快捷键
+ enable=True,) # 启动时默认的开关状态
+ ...] # 更多节点
+)
+```
+
+此外,用户还可以根据需求调整 config 中的参数。一些常用的设置包括:
+
+1. 选择摄像头:可以通过设置camera_id参数指定使用的摄像头。通常电脑上的默认摄像头 id 为 0,如果有多个则 id 数字依次增大。此外,也可以给camera_id设置一个本地视频文件的路径,从而使用该视频文件作为应用程序的输入
+2. 选择模型:可以通过模型推理节点(如 DetectorNode,TopDownPoseEstimationNode)的model_config和model_checkpoint参数来配置。用户可以根据自己的需求(如目标物体类别,关键点类别等)和硬件情况选用合适的模型
+3. 设置快捷键:一些 node 支持使用快捷键开关,用户可以设置对应的enable_key(快捷键)和enable(默认开关状态)参数
+4. 提示信息:通过设置 NoticeBoardNode 的 content_lines参数,可以在程序运行时在画面上显示提示信息,帮助使用者快速了解这个应用程序的功能和操作方法
+
+最后,将修改过的 config 存到文件`tools/webcam/configs/sunglasses.py`中,就可以运行了:
+
+```shell
+python tools/webcam/run_webcam.py --config tools/webcam/configs/sunglasses.py
+```
diff --git a/vendor/ViTPose/tools/webcam/docs/get_started_cn.md b/vendor/ViTPose/tools/webcam/docs/get_started_cn.md
new file mode 100644
index 0000000000000000000000000000000000000000..561ac10cd4d3f1eeeb0b808bf7526271deaa18c9
--- /dev/null
+++ b/vendor/ViTPose/tools/webcam/docs/get_started_cn.md
@@ -0,0 +1,123 @@
+# MMPose Webcam API 快速上手
+
+## 什么是 MMPose Webcam API
+
+MMPose WebcamAPI 是一套简单的应用开发接口,可以帮助用户方便的调用 MMPose 以及其他 OpenMMLab 算法库中的算法,实现基于摄像头输入视频的交互式应用。
+
+
+
+
+MMPose Webcam API 框架概览
+
+
+## 运行一个 Demo
+
+我们将从一个简单的 Demo 开始,向您介绍 MMPose WebcamAPI 的功能和特性,并详细展示如何基于这个 API 搭建自己的应用。为了使用 MMPose WebcamAPI,您只需要做简单的准备:
+
+1. 一台计算机(最好有 GPU 和 CUDA 环境,但这并不是必须的)
+1. 一个摄像头。计算机自带摄像头或者外接 USB 摄像头均可
+1. 安装 MMPose
+ - 在 OpenMMLab [官方仓库](https://github.com/open-mmlab/mmpose) fork MMPose 到自己的 github,并 clone 到本地
+ - 安装 MMPose,只需要按照我们的 [安装文档](https://mmpose.readthedocs.io/zh_CN/latest/install.html) 中的步骤操作即可
+
+完成准备工作后,请在命令行进入 MMPose 根目录,执行以下指令,即可运行 demo:
+
+```shell
+python tools/webcam/run_webcam.py --config tools/webcam/configs/examples/pose_estimation.py
+```
+
+这个 demo 实现了目标检测,姿态估计和可视化功能,效果如下:
+
+
+
+ +
+Pose Estimation Demo 效果
+
+
+## Demo 里面有什么?
+
+### 从 Config 说起
+
+成功运行 demo 后,我们来看一下它是怎样工作的。在启动脚本 `tools/webcam/run_webcam.py` 中可以看到,这里的操作很简单:首先读取了一个 config 文件,接着使用 config 构建了一个 runner ,最后调用了 runner 的 `run()` 方法,这样 demo 就开始运行了。
+
+```python
+# tools/webcam/run_webcam.py
+
+def launch():
+ # 读取 config 文件
+ args = parse_args()
+ cfg = mmcv.Config.fromfile(args.config)
+ # 构建 runner(WebcamRunner类的实例)
+ runner = WebcamRunner(**cfg.runner)
+ # 调用 run()方法,启动程序
+ runner.run()
+
+
+if __name__ == '__main__':
+ launch()
+```
+
+我们先不深究 runner 为何物,而是接着看一下这个 config 文件的内容。省略掉细节和注释,可以发现 config 的结构大致包含两部分(如下图所示):
+
+1. Runner 的基本参数,如 camera_id,camera_fps 等。这部分比較好理解,是一些在读取视频时的必要设置
+2. 一系列"节点"(Node),每个节点属于特定的类型(type),并有对应的一些参数
+
+```python
+runner = dict(
+ # runner的基本参数
+ name='Pose Estimation',
+ camera_id=0,
+ camera_fps=20,
+ # 定义了若干节点(Node)
+ Nodes=[
+ dict(
+ type='DetectorNode', # 节点1类型
+ name='Detector', # 节点1名字
+ input_buffer='_input_', # 节点1数据输入
+ output_buffer='det_result', # 节点1数据输出
+ ...), # 节点1其他参数
+ dict(
+ type='TopDownPoseEstimatorNode', # 节点2类型
+ name='Human Pose Estimator', # 节点2名字
+ input_buffer='det_result', # 节点2数据输入
+ output_buffer='pose_result', # 节点2数据输出
+ ...), # 节点2参数
+ ...] # 更多节点
+)
+```
+
+### 核心概念:Runner 和 Node
+
+到这里,我们已经引出了 MMPose WebcamAPI 的2个最重要的概念:runner 和 Node,下面做正式介绍:
+
+- Runner:Runner 类是程序的主体,提供了程序启动的入口runner.run()方法,并负责视频读入,输出显示等功能。此外,runner 中会包含若干个 Node,分别负责在视频帧的处理中执行不同的功能。
+- Node:Node 类用来定义功能模块,例如模型推理,可视化,特效绘制等都可以通过定义一个对应的 Node 来实现。如上面的 config 例子中,2 个节点的功能分别是做目标检测(Detector)和姿态估计(TopDownPoseEstimator)
+
+Runner 和 Node 的关系简单来说如下图所示:
+
+
+
+ +
+Runner 和 Node 逻辑关系示意
+
+
+### 数据流
+
+一个重要的问题是:当一帧视频数据被 runner 读取后,会按照怎样的顺序通过所有的 Node 并最终被输出(显示)呢?
+答案就是 config 中每个 Node 的输入输出配置。如示例 config 中,可以看到每个 Node 都有`input_buffer`,`output_buffer`等参数,用来定义该节点的输入输出。通过这种连接关系,所有的 Node 构成了一个有向无环图结构,如下图所示:
+
+
+
+ +
+数据流示意
+
+
+图中的每个 Data Buffer 就是一个用来存放数据的容器。用户不需要关注 buffer 的具体细节,只需要将其简单理解成 Node 输入输出的名字即可。用户在 config 中可以任意定义这些名字,不过要注意有以下几个特殊的名字:
+
+- _input_:存放 runner 读入的视频帧,用于模型推理
+- _frame_ :存放 runner 读入的视频帧,用于可视化
+- _display_:存放经过所以 Node 处理后的结果,用于在屏幕上显示
+
+当一帧视频数据被 runner 读入后,会被放进 _input_ 和 _frame_ 两个 buffer 中,然后按照 config 中定义的 Node 连接关系依次通过各个 Node ,最终到达 _display_ ,并被 runner 读出显示在屏幕上。
+
+#### Get Advanced: 关于 buffer
+
+- Buffer 本质是一个有限长度的队列,在 runner 中会包含一个 BufferManager 实例(见`mmpose/tools/webcam/webcam_apis/buffer.py')来生成和管理所有 buffer。Node 会按照 config 从对应的 buffer 中读出或写入数据。
+- 当一个 buffer 已满(达到最大长度)时,写入数据的操作通常不会被 block,而是会将 buffer 中已有的最早一条数据“挤出去”。
+- 为什么有_input_和_frame_两个输入呢?因为有些 Node 的操作较为耗时(如目标检测,姿态估计等需要模型推理的 Node)。为了保证显示的流畅,我们通常用_input_来作为这类耗时较大的操作的输入,而用_frame_来实时绘制可视化的结果。因为各个节点是异步运行的,这样就可以保证可视化的实时和流畅。
diff --git a/vendor/ViTPose/tools/webcam/run_webcam.py b/vendor/ViTPose/tools/webcam/run_webcam.py
new file mode 100644
index 0000000000000000000000000000000000000000..ce8d92e78e385d5bfaf2782cfc5b9d627531d20b
--- /dev/null
+++ b/vendor/ViTPose/tools/webcam/run_webcam.py
@@ -0,0 +1,38 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+
+from argparse import ArgumentParser
+
+from mmcv import Config, DictAction
+from webcam_apis import WebcamRunner
+
+
+def parse_args():
+ parser = ArgumentParser('Lauch webcam runner')
+ parser.add_argument(
+ '--config',
+ type=str,
+ default='tools/webcam/configs/meow_dwen_dwen/meow_dwen_dwen.py')
+
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ default={},
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. For example, '
+ "'--cfg-options runner.camera_id=1 runner.synchronous=True'")
+
+ return parser.parse_args()
+
+
+def launch():
+ args = parse_args()
+ cfg = Config.fromfile(args.config)
+ cfg.merge_from_dict(args.cfg_options)
+
+ runner = WebcamRunner(**cfg.runner)
+ runner.run()
+
+
+if __name__ == '__main__':
+ launch()
diff --git a/vendor/ViTPose/tools/webcam/webcam_apis/__init__.py b/vendor/ViTPose/tools/webcam/webcam_apis/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..1c8a2f5e0f6bf8d3c1b3d766dbe7a7d2c69cfaa4
--- /dev/null
+++ b/vendor/ViTPose/tools/webcam/webcam_apis/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .webcam_runner import WebcamRunner
+
+__all__ = ['WebcamRunner']
diff --git a/vendor/ViTPose/tools/webcam/webcam_apis/nodes/__init__.py b/vendor/ViTPose/tools/webcam/webcam_apis/nodes/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..a882030b4a1b5aac87206e84fe69041bcd83035f
--- /dev/null
+++ b/vendor/ViTPose/tools/webcam/webcam_apis/nodes/__init__.py
@@ -0,0 +1,18 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .builder import NODES
+from .faceswap_node import FaceSwapNode
+from .frame_effect_node import (BackgroundNode, BugEyeNode, MoustacheNode,
+ NoticeBoardNode, PoseVisualizerNode,
+ SaiyanNode, SunglassesNode)
+from .helper_node import ModelResultBindingNode, MonitorNode, RecorderNode
+from .mmdet_node import DetectorNode
+from .mmpose_node import TopDownPoseEstimatorNode
+from .valentinemagic_node import ValentineMagicNode
+from .xdwendwen_node import XDwenDwenNode
+
+__all__ = [
+ 'NODES', 'PoseVisualizerNode', 'DetectorNode', 'TopDownPoseEstimatorNode',
+ 'MonitorNode', 'BugEyeNode', 'SunglassesNode', 'ModelResultBindingNode',
+ 'NoticeBoardNode', 'RecorderNode', 'FaceSwapNode', 'MoustacheNode',
+ 'SaiyanNode', 'BackgroundNode', 'XDwenDwenNode', 'ValentineMagicNode'
+]
diff --git a/vendor/ViTPose/tools/webcam/webcam_apis/nodes/builder.py b/vendor/ViTPose/tools/webcam/webcam_apis/nodes/builder.py
new file mode 100644
index 0000000000000000000000000000000000000000..44900b7efdc9822e693ce572cca16dafda388640
--- /dev/null
+++ b/vendor/ViTPose/tools/webcam/webcam_apis/nodes/builder.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmcv.utils import Registry
+
+NODES = Registry('node')
diff --git a/vendor/ViTPose/tools/webcam/webcam_apis/nodes/faceswap_node.py b/vendor/ViTPose/tools/webcam/webcam_apis/nodes/faceswap_node.py
new file mode 100644
index 0000000000000000000000000000000000000000..5ac44207fc363680aef49cfa1ea2b77707682484
--- /dev/null
+++ b/vendor/ViTPose/tools/webcam/webcam_apis/nodes/faceswap_node.py
@@ -0,0 +1,254 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from enum import IntEnum
+from typing import List, Union
+
+import cv2
+import numpy as np
+
+from mmpose.datasets import DatasetInfo
+from .builder import NODES
+from .frame_drawing_node import FrameDrawingNode
+
+
+class Mode(IntEnum):
+ NONE = 0,
+ SHUFFLE = 1,
+ CLONE = 2
+
+
+@NODES.register_module()
+class FaceSwapNode(FrameDrawingNode):
+
+ def __init__(
+ self,
+ name: str,
+ frame_buffer: str,
+ output_buffer: Union[str, List[str]],
+ mode_key: Union[str, int],
+ ):
+ super().__init__(name, frame_buffer, output_buffer, enable=True)
+
+ self.mode_key = mode_key
+ self.mode_index = 0
+ self.register_event(
+ self.mode_key, is_keyboard=True, handler_func=self.switch_mode)
+ self.history = dict(mode=None)
+ self._mode = Mode.SHUFFLE
+
+ @property
+ def mode(self):
+ return self._mode
+
+ def switch_mode(self):
+ """Switch modes by updating mode index."""
+ self._mode = Mode((self._mode + 1) % len(Mode))
+
+ def draw(self, frame_msg):
+
+ if self.mode == Mode.NONE:
+ self.history = {'mode': Mode.NONE}
+ return frame_msg.get_image()
+
+ # Init history
+ if self.history['mode'] != self.mode:
+ self.history = {'mode': self.mode, 'target_map': {}}
+
+ # Merge pose results
+ pose_preds = self._merge_pose_results(frame_msg.get_pose_results())
+ num_target = len(pose_preds)
+
+ # Show mode
+ img = frame_msg.get_image()
+ canvas = img.copy()
+ if self.mode == Mode.SHUFFLE:
+ mode_txt = 'Shuffle'
+ else:
+ mode_txt = 'Clone'
+
+ cv2.putText(canvas, mode_txt, (10, 50), cv2.FONT_HERSHEY_DUPLEX, 0.8,
+ (255, 126, 0), 1)
+
+ # Skip if target number is less than 2
+ if num_target >= 2:
+ # Generate new mapping if target number changes
+ if num_target != len(self.history['target_map']):
+ if self.mode == Mode.SHUFFLE:
+ self.history['target_map'] = self._get_swap_map(num_target)
+ else:
+ self.history['target_map'] = np.repeat(
+ np.random.choice(num_target), num_target)
+
+ # # Draw on canvas
+ for tar_idx, src_idx in enumerate(self.history['target_map']):
+ face_src = self._get_face_info(pose_preds[src_idx])
+ face_tar = self._get_face_info(pose_preds[tar_idx])
+ canvas = self._swap_face(img, canvas, face_src, face_tar)
+
+ return canvas
+
+ def _crop_face_by_contour(self, img, contour):
+ mask = np.zeros(img.shape[:2], dtype=np.uint8)
+ cv2.fillPoly(mask, [contour.astype(np.int32)], 1)
+ mask = cv2.dilate(
+ mask, kernel=np.ones((9, 9), dtype=np.uint8), anchor=(4, 0))
+ x1, y1, w, h = cv2.boundingRect(mask)
+ x2 = x1 + w
+ y2 = y1 + h
+ bbox = np.array([x1, y1, x2, y2], dtype=np.int64)
+ patch = img[y1:y2, x1:x2]
+ mask = mask[y1:y2, x1:x2]
+
+ return bbox, patch, mask
+
+ def _swap_face(self, img_src, img_tar, face_src, face_tar):
+
+ if face_src['dataset'] == face_tar['dataset']:
+ # Use full keypoints for face alignment
+ kpts_src = face_src['contour']
+ kpts_tar = face_tar['contour']
+ else:
+ # Use only common landmarks (eyes and nose) for face alignment if
+ # source and target have differenet data type
+ # (e.g. human vs animal)
+ kpts_src = face_src['landmarks']
+ kpts_tar = face_tar['landmarks']
+
+ # Get everything local
+ bbox_src, patch_src, mask_src = self._crop_face_by_contour(
+ img_src, face_src['contour'])
+
+ bbox_tar, _, mask_tar = self._crop_face_by_contour(
+ img_tar, face_tar['contour'])
+
+ kpts_src = kpts_src - bbox_src[:2]
+ kpts_tar = kpts_tar - bbox_tar[:2]
+
+ # Compute affine transformation matrix
+ trans_mat, _ = cv2.estimateAffine2D(
+ kpts_src.astype(np.float32), kpts_tar.astype(np.float32))
+ patch_warp = cv2.warpAffine(
+ patch_src,
+ trans_mat,
+ dsize=tuple(bbox_tar[2:] - bbox_tar[:2]),
+ borderValue=(0, 0, 0))
+ mask_warp = cv2.warpAffine(
+ mask_src,
+ trans_mat,
+ dsize=tuple(bbox_tar[2:] - bbox_tar[:2]),
+ borderValue=(0, 0, 0))
+
+ # Target mask
+ mask_tar = mask_tar & mask_warp
+ mask_tar_soft = cv2.GaussianBlur(mask_tar * 255, (3, 3), 3)
+
+ # Blending
+ center = tuple((0.5 * (bbox_tar[:2] + bbox_tar[2:])).astype(np.int64))
+ img_tar = cv2.seamlessClone(patch_warp, img_tar, mask_tar_soft, center,
+ cv2.NORMAL_CLONE)
+ return img_tar
+
+ @staticmethod
+ def _get_face_info(pose_pred):
+ keypoints = pose_pred['keypoints'][:, :2]
+ model_cfg = pose_pred['model_cfg']
+ dataset_info = DatasetInfo(model_cfg.data.test.dataset_info)
+
+ face_info = {
+ 'dataset': dataset_info.dataset_name,
+ 'landmarks': None, # For alignment
+ 'contour': None, # For mask generation
+ 'bbox': None # For image warping
+ }
+
+ # Fall back to hard coded keypoint id
+
+ if face_info['dataset'] == 'coco':
+ face_info['landmarks'] = np.stack([
+ keypoints[1], # left eye
+ keypoints[2], # right eye
+ keypoints[0], # nose
+ 0.5 * (keypoints[5] + keypoints[6]), # neck (shoulder center)
+ ])
+ elif face_info['dataset'] == 'coco_wholebody':
+ face_info['landmarks'] = np.stack([
+ keypoints[1], # left eye
+ keypoints[2], # right eye
+ keypoints[0], # nose
+ keypoints[32], # chin
+ ])
+ contour_ids = list(range(23, 40)) + list(range(40, 50))[::-1]
+ face_info['contour'] = keypoints[contour_ids]
+ elif face_info['dataset'] == 'ap10k':
+ face_info['landmarks'] = np.stack([
+ keypoints[0], # left eye
+ keypoints[1], # right eye
+ keypoints[2], # nose
+ keypoints[3], # neck
+ ])
+ elif face_info['dataset'] == 'animalpose':
+ face_info['landmarks'] = np.stack([
+ keypoints[0], # left eye
+ keypoints[1], # right eye
+ keypoints[4], # nose
+ keypoints[5], # throat
+ ])
+ elif face_info['dataset'] == 'wflw':
+ face_info['landmarks'] = np.stack([
+ keypoints[97], # left eye
+ keypoints[96], # right eye
+ keypoints[54], # nose
+ keypoints[16], # chine
+ ])
+ contour_ids = list(range(33))[::-1] + list(range(33, 38)) + list(
+ range(42, 47))
+ face_info['contour'] = keypoints[contour_ids]
+ else:
+ raise ValueError('Can not obtain face landmark information'
+ f'from dataset: {face_info["type"]}')
+
+ # Face region
+ if face_info['contour'] is None:
+ # Manually defined counter of face region
+ left_eye, right_eye, nose = face_info['landmarks'][:3]
+ eye_center = 0.5 * (left_eye + right_eye)
+ w_vec = right_eye - left_eye
+ eye_dist = np.linalg.norm(w_vec) + 1e-6
+ w_vec = w_vec / eye_dist
+ h_vec = np.array([w_vec[1], -w_vec[0]], dtype=w_vec.dtype)
+ w = max(0.5 * eye_dist, np.abs(np.dot(nose - eye_center, w_vec)))
+ h = np.abs(np.dot(nose - eye_center, h_vec))
+
+ left_top = eye_center + 1.5 * w * w_vec - 0.5 * h * h_vec
+ right_top = eye_center - 1.5 * w * w_vec - 0.5 * h * h_vec
+ left_bottom = eye_center + 1.5 * w * w_vec + 4 * h * h_vec
+ right_bottom = eye_center - 1.5 * w * w_vec + 4 * h * h_vec
+
+ face_info['contour'] = np.stack(
+ [left_top, right_top, right_bottom, left_bottom])
+
+ # Get tight bbox of face region
+ face_info['bbox'] = np.array([
+ face_info['contour'][:, 0].min(), face_info['contour'][:, 1].min(),
+ face_info['contour'][:, 0].max(), face_info['contour'][:, 1].max()
+ ]).astype(np.int64)
+
+ return face_info
+
+ @staticmethod
+ def _merge_pose_results(pose_results):
+ preds = []
+ if pose_results is not None:
+ for prefix, pose_result in enumerate(pose_results):
+ model_cfg = pose_result['model_cfg']
+ for idx, _pred in enumerate(pose_result['preds']):
+ pred = _pred.copy()
+ pred['id'] = f'{prefix}.{_pred.get("track_id", str(idx))}'
+ pred['model_cfg'] = model_cfg
+ preds.append(pred)
+ return preds
+
+ @staticmethod
+ def _get_swap_map(num_target):
+ ids = np.random.choice(num_target, num_target, replace=False)
+ target_map = ids[(ids + 1) % num_target]
+ return target_map
diff --git a/vendor/ViTPose/tools/webcam/webcam_apis/nodes/frame_drawing_node.py b/vendor/ViTPose/tools/webcam/webcam_apis/nodes/frame_drawing_node.py
new file mode 100644
index 0000000000000000000000000000000000000000..cfc3511cadc2e8db0fb393ba1f821ee8091fcada
--- /dev/null
+++ b/vendor/ViTPose/tools/webcam/webcam_apis/nodes/frame_drawing_node.py
@@ -0,0 +1,65 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import abstractmethod
+from typing import Dict, List, Optional, Union
+
+import numpy as np
+
+from ..utils import FrameMessage, Message
+from .node import Node
+
+
+class FrameDrawingNode(Node):
+ """Base class for Node that draw on single frame images.
+
+ Args:
+ name (str, optional): The node name (also thread name).
+ frame_buffer (str): The name of the input buffer.
+ output_buffer (str | list): The name(s) of the output buffer(s).
+ enable_key (str | int, optional): Set a hot-key to toggle
+ enable/disable of the node. If an int value is given, it will be
+ treated as an ascii code of a key. Please note:
+ 1. If enable_key is set, the bypass method need to be
+ overridden to define the node behavior when disabled
+ 2. Some hot-key has been use for particular use. For example:
+ 'q', 'Q' and 27 are used for quit
+ Default: None
+ enable (bool): Default enable/disable status. Default: True.
+ """
+
+ def __init__(self,
+ name: str,
+ frame_buffer: str,
+ output_buffer: Union[str, List[str]],
+ enable_key: Optional[Union[str, int]] = None,
+ enable: bool = True):
+
+ super().__init__(name=name, enable_key=enable_key)
+
+ # Register buffers
+ self.register_input_buffer(frame_buffer, 'frame', essential=True)
+ self.register_output_buffer(output_buffer)
+
+ self._enabled = enable
+
+ def process(self, input_msgs: Dict[str, Message]) -> Union[Message, None]:
+ frame_msg = input_msgs['frame']
+
+ img = self.draw(frame_msg)
+ frame_msg.set_image(img)
+
+ return frame_msg
+
+ def bypass(self, input_msgs: Dict[str, Message]) -> Union[Message, None]:
+ return input_msgs['frame']
+
+ @abstractmethod
+ def draw(self, frame_msg: FrameMessage) -> np.ndarray:
+ """Draw on the frame image with information from the single frame.
+
+ Args:
+ frame_meg (FrameMessage): The frame to get information from and
+ draw on.
+
+ Returns:
+ array: The output image
+ """
diff --git a/vendor/ViTPose/tools/webcam/webcam_apis/nodes/frame_effect_node.py b/vendor/ViTPose/tools/webcam/webcam_apis/nodes/frame_effect_node.py
new file mode 100644
index 0000000000000000000000000000000000000000..c248c3820a944e6b5e7f0613794d6290fcda7bcc
--- /dev/null
+++ b/vendor/ViTPose/tools/webcam/webcam_apis/nodes/frame_effect_node.py
@@ -0,0 +1,917 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Tuple, Union
+
+import cv2
+import numpy as np
+from mmcv import color_val
+
+from mmpose.core import (apply_bugeye_effect, apply_sunglasses_effect,
+ imshow_bboxes, imshow_keypoints)
+from mmpose.datasets import DatasetInfo
+from ..utils import (FrameMessage, copy_and_paste, expand_and_clamp,
+ get_cached_file_path, get_eye_keypoint_ids,
+ get_face_keypoint_ids, get_wrist_keypoint_ids,
+ load_image_from_disk_or_url, screen_matting)
+from .builder import NODES
+from .frame_drawing_node import FrameDrawingNode
+
+try:
+ import psutil
+ psutil_proc = psutil.Process()
+except (ImportError, ModuleNotFoundError):
+ psutil_proc = None
+
+
+@NODES.register_module()
+class PoseVisualizerNode(FrameDrawingNode):
+ """Draw the bbox and keypoint detection results.
+
+ Args:
+ name (str, optional): The node name (also thread name).
+ frame_buffer (str): The name of the input buffer.
+ output_buffer (str|list): The name(s) of the output buffer(s).
+ enable_key (str|int, optional): Set a hot-key to toggle enable/disable
+ of the node. If an int value is given, it will be treated as an
+ ascii code of a key. Please note:
+ 1. If enable_key is set, the bypass method need to be
+ overridden to define the node behavior when disabled
+ 2. Some hot-key has been use for particular use. For example:
+ 'q', 'Q' and 27 are used for quit
+ Default: None
+ enable (bool): Default enable/disable status. Default: True.
+ kpt_thr (float): The threshold of keypoint score. Default: 0.3.
+ radius (int): The radius of keypoint. Default: 4.
+ thickness (int): The thickness of skeleton. Default: 2.
+ bbox_color (str|tuple|dict): If a single color (a str like 'green' or
+ a tuple like (0, 255, 0)), it will used to draw the bbox.
+ Optionally, a dict can be given as a map from class labels to
+ colors.
+ """
+
+ default_bbox_color = {
+ 'person': (148, 139, 255),
+ 'cat': (255, 255, 0),
+ 'dog': (255, 255, 0),
+ }
+
+ def __init__(self,
+ name: str,
+ frame_buffer: str,
+ output_buffer: Union[str, List[str]],
+ enable_key: Optional[Union[str, int]] = None,
+ enable: bool = True,
+ kpt_thr: float = 0.3,
+ radius: int = 4,
+ thickness: int = 2,
+ bbox_color: Optional[Union[str, Tuple, Dict]] = None):
+
+ super().__init__(name, frame_buffer, output_buffer, enable_key, enable)
+
+ self.kpt_thr = kpt_thr
+ self.radius = radius
+ self.thickness = thickness
+ if bbox_color is None:
+ self.bbox_color = self.default_bbox_color
+ elif isinstance(bbox_color, dict):
+ self.bbox_color = {k: color_val(v) for k, v in bbox_color.items()}
+ else:
+ self.bbox_color = color_val(bbox_color)
+
+ def draw(self, frame_msg):
+ canvas = frame_msg.get_image()
+ pose_results = frame_msg.get_pose_results()
+
+ if not pose_results:
+ return canvas
+
+ for pose_result in frame_msg.get_pose_results():
+ model_cfg = pose_result['model_cfg']
+ dataset_info = DatasetInfo(model_cfg.dataset_info)
+
+ # Extract bboxes and poses
+ bbox_preds = []
+ bbox_labels = []
+ pose_preds = []
+ for pred in pose_result['preds']:
+ if 'bbox' in pred:
+ bbox_preds.append(pred['bbox'])
+ bbox_labels.append(pred.get('label', None))
+ pose_preds.append(pred['keypoints'])
+
+ # Get bbox colors
+ if isinstance(self.bbox_color, dict):
+ bbox_colors = [
+ self.bbox_color.get(label, (0, 255, 0))
+ for label in bbox_labels
+ ]
+ else:
+ bbox_labels = self.bbox_color
+
+ # Draw bboxes
+ if bbox_preds:
+ bboxes = np.vstack(bbox_preds)
+
+ imshow_bboxes(
+ canvas,
+ bboxes,
+ labels=bbox_labels,
+ colors=bbox_colors,
+ text_color='white',
+ font_scale=0.5,
+ show=False)
+
+ # Draw poses
+ if pose_preds:
+ imshow_keypoints(
+ canvas,
+ pose_preds,
+ skeleton=dataset_info.skeleton,
+ kpt_score_thr=0.3,
+ pose_kpt_color=dataset_info.pose_kpt_color,
+ pose_link_color=dataset_info.pose_link_color,
+ radius=self.radius,
+ thickness=self.thickness)
+
+ return canvas
+
+
+@NODES.register_module()
+class SunglassesNode(FrameDrawingNode):
+
+ def __init__(self,
+ name: str,
+ frame_buffer: str,
+ output_buffer: Union[str, List[str]],
+ enable_key: Optional[Union[str, int]] = None,
+ enable: bool = True,
+ src_img_path: Optional[str] = None):
+
+ super().__init__(name, frame_buffer, output_buffer, enable_key, enable)
+
+ if src_img_path is None:
+ # The image attributes to:
+ # https://www.vecteezy.com/free-vector/glass
+ # Glass Vectors by Vecteezy
+ src_img_path = 'demo/resources/sunglasses.jpg'
+ self.src_img = load_image_from_disk_or_url(src_img_path)
+
+ def draw(self, frame_msg):
+ canvas = frame_msg.get_image()
+ pose_results = frame_msg.get_pose_results()
+ if not pose_results:
+ return canvas
+ for pose_result in pose_results:
+ model_cfg = pose_result['model_cfg']
+ preds = pose_result['preds']
+ left_eye_idx, right_eye_idx = get_eye_keypoint_ids(model_cfg)
+
+ canvas = apply_sunglasses_effect(canvas, preds, self.src_img,
+ left_eye_idx, right_eye_idx)
+ return canvas
+
+
+@NODES.register_module()
+class SpriteNode(FrameDrawingNode):
+
+ def __init__(self,
+ name: str,
+ frame_buffer: str,
+ output_buffer: Union[str, List[str]],
+ enable_key: Optional[Union[str, int]] = None,
+ enable: bool = True,
+ src_img_path: Optional[str] = None):
+
+ super().__init__(name, frame_buffer, output_buffer, enable_key, enable)
+
+ if src_img_path is None:
+ # Sprites of Touhou characters :)
+ # Come from https://www.deviantart.com/shadowbendy/art/Touhou-rpg-maker-vx-Sprite-1-812746920 # noqa: E501
+ src_img_path = (
+ 'https://user-images.githubusercontent.com/'
+ '26739999/151532276-33f968d9-917f-45e3-8a99-ebde60be83bb.png')
+ self.src_img = load_image_from_disk_or_url(
+ src_img_path, cv2.IMREAD_UNCHANGED)[:144, :108]
+ tmp = np.array(np.split(self.src_img, range(36, 144, 36), axis=0))
+ tmp = np.array(np.split(tmp, range(36, 108, 36), axis=2))
+ self.sprites = tmp
+ self.pos = None
+ self.anime_frame = 0
+
+ def apply_sprite_effect(self,
+ img,
+ pose_results,
+ left_hand_index,
+ right_hand_index,
+ kpt_thr=0.5):
+ """Apply sprite effect.
+
+ Args:
+ img (np.ndarray): Image data.
+ pose_results (list[dict]): The pose estimation results containing:
+ - "keypoints" ([K,3]): detection result in [x, y, score]
+ left_hand_index (int): Keypoint index of left hand
+ right_hand_index (int): Keypoint index of right hand
+ kpt_thr (float): The score threshold of required keypoints.
+ """
+
+ hm, wm = self.sprites.shape[2:4]
+ # anchor points in the sunglasses mask
+ if self.pos is None:
+ self.pos = [img.shape[0] // 2, img.shape[1] // 2]
+
+ if len(pose_results) == 0:
+ return img
+
+ kpts = pose_results[0]['keypoints']
+
+ if kpts[left_hand_index, 2] < kpt_thr and kpts[right_hand_index,
+ 2] < kpt_thr:
+ aim = self.pos
+ else:
+ kpt_lhand = kpts[left_hand_index, :2][::-1]
+ kpt_rhand = kpts[right_hand_index, :2][::-1]
+
+ def distance(a, b):
+ return (a[0] - b[0])**2 + (a[1] - b[1])**2
+
+ # Go to the nearest hand
+ if distance(kpt_lhand, self.pos) < distance(kpt_rhand, self.pos):
+ aim = kpt_lhand
+ else:
+ aim = kpt_rhand
+
+ pos_thr = 15
+ if aim[0] < self.pos[0] - pos_thr:
+ # Go down
+ sprite = self.sprites[self.anime_frame][3]
+ self.pos[0] -= 1
+ elif aim[0] > self.pos[0] + pos_thr:
+ # Go up
+ sprite = self.sprites[self.anime_frame][0]
+ self.pos[0] += 1
+ elif aim[1] < self.pos[1] - pos_thr:
+ # Go right
+ sprite = self.sprites[self.anime_frame][1]
+ self.pos[1] -= 1
+ elif aim[1] > self.pos[1] + pos_thr:
+ # Go left
+ sprite = self.sprites[self.anime_frame][2]
+ self.pos[1] += 1
+ else:
+ # Stay
+ self.anime_frame = 0
+ sprite = self.sprites[self.anime_frame][0]
+
+ if self.anime_frame < 2:
+ self.anime_frame += 1
+ else:
+ self.anime_frame = 0
+
+ x = self.pos[0] - hm // 2
+ y = self.pos[1] - wm // 2
+ x = max(0, min(x, img.shape[0] - hm))
+ y = max(0, min(y, img.shape[0] - wm))
+
+ # Overlay image with transparent
+ img[x:x + hm, y:y +
+ wm] = (img[x:x + hm, y:y + wm] * (1 - sprite[:, :, 3:] / 255) +
+ sprite[:, :, :3] * (sprite[:, :, 3:] / 255)).astype('uint8')
+
+ return img
+
+ def draw(self, frame_msg):
+ canvas = frame_msg.get_image()
+ pose_results = frame_msg.get_pose_results()
+ if not pose_results:
+ return canvas
+ for pose_result in pose_results:
+ model_cfg = pose_result['model_cfg']
+ preds = pose_result['preds']
+ # left_hand_idx, right_hand_idx = get_wrist_keypoint_ids(model_cfg) # noqa: E501
+ left_hand_idx, right_hand_idx = get_eye_keypoint_ids(model_cfg)
+
+ canvas = self.apply_sprite_effect(canvas, preds, left_hand_idx,
+ right_hand_idx)
+ return canvas
+
+
+@NODES.register_module()
+class BackgroundNode(FrameDrawingNode):
+
+ def __init__(self,
+ name: str,
+ frame_buffer: str,
+ output_buffer: Union[str, List[str]],
+ enable_key: Optional[Union[str, int]] = None,
+ enable: bool = True,
+ src_img_path: Optional[str] = None,
+ cls_ids: Optional[List] = None,
+ cls_names: Optional[List] = None):
+
+ super().__init__(name, frame_buffer, output_buffer, enable_key, enable)
+
+ self.cls_ids = cls_ids
+ self.cls_names = cls_names
+
+ if src_img_path is None:
+ src_img_path = 'https://user-images.githubusercontent.com/'\
+ '11788150/149731957-abd5c908-9c7f-45b2-b7bf-'\
+ '821ab30c6a3e.jpg'
+ self.src_img = load_image_from_disk_or_url(src_img_path)
+
+ def apply_background_effect(self,
+ img,
+ det_results,
+ background_img,
+ effect_region=(0.2, 0.2, 0.8, 0.8)):
+ """Change background.
+
+ Args:
+ img (np.ndarray): Image data.
+ det_results (list[dict]): The detection results containing:
+
+ - "cls_id" (int): Class index.
+ - "label" (str): Class label (e.g. 'person').
+ - "bbox" (ndarray:(5, )): bounding box result
+ [x, y, w, h, score].
+ - "mask" (ndarray:(w, h)): instance segmentation result.
+ background_img (np.ndarray): Background image.
+ effect_region (tuple(4, )): The region to apply mask,
+ the coordinates are normalized (x1, y1, x2, y2).
+ """
+ if len(det_results) > 0:
+ # Choose the one with the highest score.
+ det_result = det_results[0]
+ bbox = det_result['bbox']
+ mask = det_result['mask'].astype(np.uint8)
+ img = copy_and_paste(img, background_img, mask, bbox,
+ effect_region)
+ return img
+ else:
+ return background_img
+
+ def draw(self, frame_msg):
+ canvas = frame_msg.get_image()
+ if canvas.shape != self.src_img.shape:
+ self.src_img = cv2.resize(self.src_img, canvas.shape[:2])
+ det_results = frame_msg.get_detection_results()
+ if not det_results:
+ return canvas
+
+ full_preds = []
+ for det_result in det_results:
+ preds = det_result['preds']
+ if self.cls_ids:
+ # Filter results by class ID
+ filtered_preds = [
+ p for p in preds if p['cls_id'] in self.cls_ids
+ ]
+ elif self.cls_names:
+ # Filter results by class name
+ filtered_preds = [
+ p for p in preds if p['label'] in self.cls_names
+ ]
+ else:
+ filtered_preds = preds
+ full_preds.extend(filtered_preds)
+
+ canvas = self.apply_background_effect(canvas, full_preds, self.src_img)
+
+ return canvas
+
+
+@NODES.register_module()
+class SaiyanNode(FrameDrawingNode):
+
+ def __init__(self,
+ name: str,
+ frame_buffer: str,
+ output_buffer: Union[str, List[str]],
+ enable_key: Optional[Union[str, int]] = None,
+ enable: bool = True,
+ hair_img_path: Optional[str] = None,
+ light_video_path: Optional[str] = None,
+ cls_ids: Optional[List] = None,
+ cls_names: Optional[List] = None):
+
+ super().__init__(name, frame_buffer, output_buffer, enable_key, enable)
+
+ self.cls_ids = cls_ids
+ self.cls_names = cls_names
+
+ if hair_img_path is None:
+ hair_img_path = 'https://user-images.githubusercontent.com/'\
+ '11788150/149732117-fcd2d804-dc2c-426c-bee7-'\
+ '94be6146e05c.png'
+ self.hair_img = load_image_from_disk_or_url(hair_img_path)
+
+ if light_video_path is None:
+ light_video_path = get_cached_file_path(
+ 'https://'
+ 'user-images.githubusercontent.com/11788150/149732080'
+ '-ea6cfeda-0dc5-4bbb-892a-3831e5580520.mp4')
+ self.light_video_path = light_video_path
+ self.light_video = cv2.VideoCapture(self.light_video_path)
+
+ def apply_saiyan_effect(self,
+ img,
+ pose_results,
+ saiyan_img,
+ light_frame,
+ face_indices,
+ bbox_thr=0.3,
+ kpt_thr=0.5):
+ """Apply saiyan hair effect.
+
+ Args:
+ img (np.ndarray): Image data.
+ pose_results (list[dict]): The pose estimation results containing:
+ - "keypoints" ([K,3]): keypoint detection result
+ in [x, y, score]
+ saiyan_img (np.ndarray): Saiyan image with transparent background.
+ light_frame (np.ndarray): Light image with green screen.
+ face_indices (int): Keypoint index of the face
+ kpt_thr (float): The score threshold of required keypoints.
+ """
+ img = img.copy()
+ im_shape = img.shape
+ # Apply lightning effects.
+ light_mask = screen_matting(light_frame, color='green')
+
+ # anchor points in the mask
+ pts_src = np.array(
+ [
+ [84, 398], # face kpt 0
+ [331, 393], # face kpt 16
+ [84, 145],
+ [331, 140]
+ ],
+ dtype=np.float32)
+
+ for pose in pose_results:
+ bbox = pose['bbox']
+
+ if bbox[-1] < bbox_thr:
+ continue
+
+ mask_inst = pose['mask']
+ # cache
+ fg = img[np.where(mask_inst)]
+
+ bbox = expand_and_clamp(bbox[:4], im_shape, s=3.0)
+ # Apply light effects between fg and bg
+ img = copy_and_paste(
+ light_frame,
+ img,
+ light_mask,
+ effect_region=(bbox[0] / im_shape[1], bbox[1] / im_shape[0],
+ bbox[2] / im_shape[1], bbox[3] / im_shape[0]))
+ # pop
+ img[np.where(mask_inst)] = fg
+
+ # Apply Saiyan hair effects
+ kpts = pose['keypoints']
+ if kpts[face_indices[0], 2] < kpt_thr or kpts[face_indices[16],
+ 2] < kpt_thr:
+ continue
+
+ kpt_0 = kpts[face_indices[0], :2]
+ kpt_16 = kpts[face_indices[16], :2]
+ # orthogonal vector
+ vo = (kpt_0 - kpt_16)[::-1] * [-1, 1]
+
+ # anchor points in the image by eye positions
+ pts_tar = np.vstack([kpt_0, kpt_16, kpt_0 + vo, kpt_16 + vo])
+
+ h_mat, _ = cv2.findHomography(pts_src, pts_tar)
+ patch = cv2.warpPerspective(
+ saiyan_img,
+ h_mat,
+ dsize=(img.shape[1], img.shape[0]),
+ borderValue=(0, 0, 0))
+ mask_patch = cv2.cvtColor(patch, cv2.COLOR_BGR2GRAY)
+ mask_patch = (mask_patch > 1).astype(np.uint8)
+ img = cv2.copyTo(patch, mask_patch, img)
+
+ return img
+
+ def draw(self, frame_msg):
+ canvas = frame_msg.get_image()
+
+ det_results = frame_msg.get_detection_results()
+ if not det_results:
+ return canvas
+
+ pose_results = frame_msg.get_pose_results()
+ if not pose_results:
+ return canvas
+
+ for pose_result in pose_results:
+ model_cfg = pose_result['model_cfg']
+ preds = pose_result['preds']
+ face_indices = get_face_keypoint_ids(model_cfg)
+
+ ret, frame = self.light_video.read()
+ if not ret:
+ self.light_video = cv2.VideoCapture(self.light_video_path)
+ ret, frame = self.light_video.read()
+
+ canvas = self.apply_saiyan_effect(canvas, preds, self.hair_img,
+ frame, face_indices)
+
+ return canvas
+
+
+@NODES.register_module()
+class MoustacheNode(FrameDrawingNode):
+
+ def __init__(self,
+ name: str,
+ frame_buffer: str,
+ output_buffer: Union[str, List[str]],
+ enable_key: Optional[Union[str, int]] = None,
+ enable: bool = True,
+ src_img_path: Optional[str] = None):
+
+ super().__init__(name, frame_buffer, output_buffer, enable_key, enable)
+
+ if src_img_path is None:
+ src_img_path = 'https://user-images.githubusercontent.com/'\
+ '11788150/149732141-3afbab55-252a-428c-b6d8'\
+ '-0e352f432651.jpeg'
+ self.src_img = load_image_from_disk_or_url(src_img_path)
+
+ def apply_moustache_effect(self,
+ img,
+ pose_results,
+ moustache_img,
+ face_indices,
+ kpt_thr=0.5):
+ """Apply moustache effect.
+
+ Args:
+ img (np.ndarray): Image data.
+ pose_results (list[dict]): The pose estimation results containing:
+ - "keypoints" ([K,3]): keypoint detection result
+ in [x, y, score]
+ moustache_img (np.ndarray): Moustache image with white background.
+ left_eye_index (int): Keypoint index of left eye
+ right_eye_index (int): Keypoint index of right eye
+ kpt_thr (float): The score threshold of required keypoints.
+ """
+
+ hm, wm = moustache_img.shape[:2]
+ # anchor points in the moustache mask
+ pts_src = np.array([[1164, 741], [1729, 741], [1164, 1244],
+ [1729, 1244]],
+ dtype=np.float32)
+
+ for pose in pose_results:
+ kpts = pose['keypoints']
+ if kpts[face_indices[32], 2] < kpt_thr \
+ or kpts[face_indices[34], 2] < kpt_thr \
+ or kpts[face_indices[61], 2] < kpt_thr \
+ or kpts[face_indices[63], 2] < kpt_thr:
+ continue
+
+ kpt_32 = kpts[face_indices[32], :2]
+ kpt_34 = kpts[face_indices[34], :2]
+ kpt_61 = kpts[face_indices[61], :2]
+ kpt_63 = kpts[face_indices[63], :2]
+ # anchor points in the image by eye positions
+ pts_tar = np.vstack([kpt_32, kpt_34, kpt_61, kpt_63])
+
+ h_mat, _ = cv2.findHomography(pts_src, pts_tar)
+ patch = cv2.warpPerspective(
+ moustache_img,
+ h_mat,
+ dsize=(img.shape[1], img.shape[0]),
+ borderValue=(255, 255, 255))
+ # mask the white background area in the patch with a threshold 200
+ mask = cv2.cvtColor(patch, cv2.COLOR_BGR2GRAY)
+ mask = (mask < 200).astype(np.uint8)
+ img = cv2.copyTo(patch, mask, img)
+
+ return img
+
+ def draw(self, frame_msg):
+ canvas = frame_msg.get_image()
+ pose_results = frame_msg.get_pose_results()
+ if not pose_results:
+ return canvas
+ for pose_result in pose_results:
+ model_cfg = pose_result['model_cfg']
+ preds = pose_result['preds']
+ face_indices = get_face_keypoint_ids(model_cfg)
+ canvas = self.apply_moustache_effect(canvas, preds, self.src_img,
+ face_indices)
+ return canvas
+
+
+@NODES.register_module()
+class BugEyeNode(FrameDrawingNode):
+
+ def draw(self, frame_msg):
+ canvas = frame_msg.get_image()
+ pose_results = frame_msg.get_pose_results()
+ if not pose_results:
+ return canvas
+ for pose_result in pose_results:
+ model_cfg = pose_result['model_cfg']
+ preds = pose_result['preds']
+ left_eye_idx, right_eye_idx = get_eye_keypoint_ids(model_cfg)
+
+ canvas = apply_bugeye_effect(canvas, preds, left_eye_idx,
+ right_eye_idx)
+ return canvas
+
+
+@NODES.register_module()
+class NoticeBoardNode(FrameDrawingNode):
+
+ default_content_lines = ['This is a notice board!']
+
+ def __init__(
+ self,
+ name: str,
+ frame_buffer: str,
+ output_buffer: Union[str, List[str]],
+ enable_key: Optional[Union[str, int]] = None,
+ enable: bool = True,
+ content_lines: Optional[List[str]] = None,
+ x_offset: int = 20,
+ y_offset: int = 20,
+ y_delta: int = 15,
+ text_color: Union[str, Tuple[int, int, int]] = 'black',
+ background_color: Union[str, Tuple[int, int, int]] = (255, 183, 0),
+ text_scale: float = 0.4,
+ ):
+ super().__init__(name, frame_buffer, output_buffer, enable_key, enable)
+
+ self.x_offset = x_offset
+ self.y_offset = y_offset
+ self.y_delta = y_delta
+ self.text_color = color_val(text_color)
+ self.background_color = color_val(background_color)
+ self.text_scale = text_scale
+
+ if content_lines:
+ self.content_lines = content_lines
+ else:
+ self.content_lines = self.default_content_lines
+
+ def draw(self, frame_msg: FrameMessage) -> np.ndarray:
+ img = frame_msg.get_image()
+ canvas = np.full(img.shape, self.background_color, dtype=img.dtype)
+
+ x = self.x_offset
+ y = self.y_offset
+
+ max_len = max([len(line) for line in self.content_lines])
+
+ def _put_line(line=''):
+ nonlocal y
+ cv2.putText(canvas, line, (x, y), cv2.FONT_HERSHEY_DUPLEX,
+ self.text_scale, self.text_color, 1)
+ y += self.y_delta
+
+ for line in self.content_lines:
+ _put_line(line)
+
+ x1 = max(0, self.x_offset)
+ x2 = min(img.shape[1], int(x + max_len * self.text_scale * 20))
+ y1 = max(0, self.y_offset - self.y_delta)
+ y2 = min(img.shape[0], y)
+
+ src1 = canvas[y1:y2, x1:x2]
+ src2 = img[y1:y2, x1:x2]
+ img[y1:y2, x1:x2] = cv2.addWeighted(src1, 0.5, src2, 0.5, 0)
+
+ return img
+
+
+@NODES.register_module()
+class HatNode(FrameDrawingNode):
+
+ def __init__(self,
+ name: str,
+ frame_buffer: str,
+ output_buffer: Union[str, List[str]],
+ enable_key: Optional[Union[str, int]] = None,
+ src_img_path: Optional[str] = None):
+
+ super().__init__(name, frame_buffer, output_buffer, enable_key)
+
+ if src_img_path is None:
+ # The image attributes to:
+ # http://616pic.com/sucai/1m9i70p52.html
+ src_img_path = 'https://user-images.githubusercontent.' \
+ 'com/28900607/149766271-2f591c19-9b67-4' \
+ 'd92-8f94-c272396ca141.png'
+ self.src_img = load_image_from_disk_or_url(src_img_path,
+ cv2.IMREAD_UNCHANGED)
+
+ @staticmethod
+ def apply_hat_effect(img,
+ pose_results,
+ hat_img,
+ left_eye_index,
+ right_eye_index,
+ kpt_thr=0.5):
+ """Apply hat effect.
+ Args:
+ img (np.ndarray): Image data.
+ pose_results (list[dict]): The pose estimation results containing:
+ - "keypoints" ([K,3]): keypoint detection result in
+ [x, y, score]
+ hat_img (np.ndarray): Hat image with white alpha channel.
+ left_eye_index (int): Keypoint index of left eye
+ right_eye_index (int): Keypoint index of right eye
+ kpt_thr (float): The score threshold of required keypoints.
+ """
+ img_orig = img.copy()
+
+ img = img_orig.copy()
+ hm, wm = hat_img.shape[:2]
+ # anchor points in the sunglasses mask
+ a = 0.3
+ b = 0.7
+ pts_src = np.array([[a * wm, a * hm], [a * wm, b * hm],
+ [b * wm, a * hm], [b * wm, b * hm]],
+ dtype=np.float32)
+
+ for pose in pose_results:
+ kpts = pose['keypoints']
+
+ if kpts[left_eye_index, 2] < kpt_thr or \
+ kpts[right_eye_index, 2] < kpt_thr:
+ continue
+
+ kpt_leye = kpts[left_eye_index, :2]
+ kpt_reye = kpts[right_eye_index, :2]
+ # orthogonal vector to the left-to-right eyes
+ vo = 0.5 * (kpt_reye - kpt_leye)[::-1] * [-1, 1]
+ veye = 0.5 * (kpt_reye - kpt_leye)
+
+ # anchor points in the image by eye positions
+ pts_tar = np.vstack([
+ kpt_reye + 1 * veye + 5 * vo, kpt_reye + 1 * veye + 1 * vo,
+ kpt_leye - 1 * veye + 5 * vo, kpt_leye - 1 * veye + 1 * vo
+ ])
+
+ h_mat, _ = cv2.findHomography(pts_src, pts_tar)
+ patch = cv2.warpPerspective(
+ hat_img,
+ h_mat,
+ dsize=(img.shape[1], img.shape[0]),
+ borderValue=(255, 255, 255))
+ # mask the white background area in the patch with a threshold 200
+ mask = (patch[:, :, -1] > 128)
+ patch = patch[:, :, :-1]
+ mask = mask * (cv2.cvtColor(patch, cv2.COLOR_BGR2GRAY) > 30)
+ mask = mask.astype(np.uint8)
+
+ img = cv2.copyTo(patch, mask, img)
+ return img
+
+ def draw(self, frame_msg):
+ canvas = frame_msg.get_image()
+ pose_results = frame_msg.get_pose_results()
+ if not pose_results:
+ return canvas
+ for pose_result in pose_results:
+ model_cfg = pose_result['model_cfg']
+ preds = pose_result['preds']
+ left_eye_idx, right_eye_idx = get_eye_keypoint_ids(model_cfg)
+
+ canvas = self.apply_hat_effect(canvas, preds, self.src_img,
+ left_eye_idx, right_eye_idx)
+ return canvas
+
+
+@NODES.register_module()
+class FirecrackerNode(FrameDrawingNode):
+
+ def __init__(self,
+ name: str,
+ frame_buffer: str,
+ output_buffer: Union[str, List[str]],
+ enable_key: Optional[Union[str, int]] = None,
+ src_img_path: Optional[str] = None):
+
+ super().__init__(name, frame_buffer, output_buffer, enable_key)
+
+ if src_img_path is None:
+ self.src_img_path = 'https://user-images.githubusercontent' \
+ '.com/28900607/149766281-6376055c-ed8b' \
+ '-472b-991f-60e6ae6ee1da.gif'
+ src_img = cv2.VideoCapture(self.src_img_path)
+
+ self.frame_list = []
+ ret, frame = src_img.read()
+ while frame is not None:
+ self.frame_list.append(frame)
+ ret, frame = src_img.read()
+ self.num_frames = len(self.frame_list)
+ self.frame_idx = 0
+ self.frame_period = 4 # each frame in gif lasts for 4 frames in video
+
+ @staticmethod
+ def apply_firecracker_effect(img,
+ pose_results,
+ firecracker_img,
+ left_wrist_idx,
+ right_wrist_idx,
+ kpt_thr=0.5):
+ """Apply firecracker effect.
+ Args:
+ img (np.ndarray): Image data.
+ pose_results (list[dict]): The pose estimation results containing:
+ - "keypoints" ([K,3]): keypoint detection result in
+ [x, y, score]
+ firecracker_img (np.ndarray): Firecracker image with white
+ background.
+ left_wrist_idx (int): Keypoint index of left wrist
+ right_wrist_idx (int): Keypoint index of right wrist
+ kpt_thr (float): The score threshold of required keypoints.
+ """
+
+ hm, wm = firecracker_img.shape[:2]
+ # anchor points in the firecracker mask
+ pts_src = np.array([[0. * wm, 0. * hm], [0. * wm, 1. * hm],
+ [1. * wm, 0. * hm], [1. * wm, 1. * hm]],
+ dtype=np.float32)
+
+ h, w = img.shape[:2]
+ h_tar = h / 3
+ w_tar = h_tar / hm * wm
+
+ for pose in pose_results:
+ kpts = pose['keypoints']
+
+ if kpts[left_wrist_idx, 2] > kpt_thr:
+ kpt_lwrist = kpts[left_wrist_idx, :2]
+ # anchor points in the image by eye positions
+ pts_tar = np.vstack([
+ kpt_lwrist - [w_tar / 2, 0],
+ kpt_lwrist - [w_tar / 2, -h_tar],
+ kpt_lwrist + [w_tar / 2, 0],
+ kpt_lwrist + [w_tar / 2, h_tar]
+ ])
+
+ h_mat, _ = cv2.findHomography(pts_src, pts_tar)
+ patch = cv2.warpPerspective(
+ firecracker_img,
+ h_mat,
+ dsize=(img.shape[1], img.shape[0]),
+ borderValue=(255, 255, 255))
+ # mask the white background area in the patch with
+ # a threshold 200
+ mask = cv2.cvtColor(patch, cv2.COLOR_BGR2GRAY)
+ mask = (mask < 240).astype(np.uint8)
+ img = cv2.copyTo(patch, mask, img)
+
+ if kpts[right_wrist_idx, 2] > kpt_thr:
+ kpt_rwrist = kpts[right_wrist_idx, :2]
+
+ # anchor points in the image by eye positions
+ pts_tar = np.vstack([
+ kpt_rwrist - [w_tar / 2, 0],
+ kpt_rwrist - [w_tar / 2, -h_tar],
+ kpt_rwrist + [w_tar / 2, 0],
+ kpt_rwrist + [w_tar / 2, h_tar]
+ ])
+
+ h_mat, _ = cv2.findHomography(pts_src, pts_tar)
+ patch = cv2.warpPerspective(
+ firecracker_img,
+ h_mat,
+ dsize=(img.shape[1], img.shape[0]),
+ borderValue=(255, 255, 255))
+ # mask the white background area in the patch with
+ # a threshold 200
+ mask = cv2.cvtColor(patch, cv2.COLOR_BGR2GRAY)
+ mask = (mask < 240).astype(np.uint8)
+ img = cv2.copyTo(patch, mask, img)
+
+ return img
+
+ def draw(self, frame_msg):
+ canvas = frame_msg.get_image()
+ pose_results = frame_msg.get_pose_results()
+ if not pose_results:
+ return canvas
+
+ frame = self.frame_list[self.frame_idx // self.frame_period]
+ for pose_result in pose_results:
+ model_cfg = pose_result['model_cfg']
+ preds = pose_result['preds']
+ left_wrist_idx, right_wrist_idx = get_wrist_keypoint_ids(model_cfg)
+
+ canvas = self.apply_firecracker_effect(canvas, preds, frame,
+ left_wrist_idx,
+ right_wrist_idx)
+ self.frame_idx = (self.frame_idx + 1) % (
+ self.num_frames * self.frame_period)
+
+ return canvas
diff --git a/vendor/ViTPose/tools/webcam/webcam_apis/nodes/helper_node.py b/vendor/ViTPose/tools/webcam/webcam_apis/nodes/helper_node.py
new file mode 100644
index 0000000000000000000000000000000000000000..349c4f423456781a092d83fc6382d7f9f3376fd8
--- /dev/null
+++ b/vendor/ViTPose/tools/webcam/webcam_apis/nodes/helper_node.py
@@ -0,0 +1,296 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import logging
+import time
+from queue import Full, Queue
+from threading import Thread
+from typing import List, Optional, Union
+
+import cv2
+import numpy as np
+from mmcv import color_val
+
+from mmpose.utils.timer import RunningAverage
+from .builder import NODES
+from .node import Node
+
+try:
+ import psutil
+ psutil_proc = psutil.Process()
+except (ImportError, ModuleNotFoundError):
+ psutil_proc = None
+
+
+@NODES.register_module()
+class ModelResultBindingNode(Node):
+
+ def __init__(self, name: str, frame_buffer: str, result_buffer: str,
+ output_buffer: Union[str, List[str]]):
+ super().__init__(name=name, enable=True)
+ self.synchronous = None
+
+ # Cache the latest model result
+ self.last_result_msg = None
+ self.last_output_msg = None
+
+ # Inference speed analysis
+ self.frame_fps = RunningAverage(window=10)
+ self.frame_lag = RunningAverage(window=10)
+ self.result_fps = RunningAverage(window=10)
+ self.result_lag = RunningAverage(window=10)
+
+ # Register buffers
+ # Note that essential buffers will be set in set_runner() because
+ # it depends on the runner.synchronous attribute.
+ self.register_input_buffer(result_buffer, 'result', essential=False)
+ self.register_input_buffer(frame_buffer, 'frame', essential=False)
+ self.register_output_buffer(output_buffer)
+
+ def set_runner(self, runner):
+ super().set_runner(runner)
+
+ # Set synchronous according to the runner
+ if runner.synchronous:
+ self.synchronous = True
+ essential_input = 'result'
+ else:
+ self.synchronous = False
+ essential_input = 'frame'
+
+ # Set essential input buffer according to the synchronous setting
+ for buffer_info in self._input_buffers:
+ if buffer_info.input_name == essential_input:
+ buffer_info.essential = True
+
+ def process(self, input_msgs):
+ result_msg = input_msgs['result']
+
+ # Update last result
+ if result_msg is not None:
+ # Update result FPS
+ if self.last_result_msg is not None:
+ self.result_fps.update(
+ 1.0 /
+ (result_msg.timestamp - self.last_result_msg.timestamp))
+ # Update inference latency
+ self.result_lag.update(time.time() - result_msg.timestamp)
+ # Update last inference result
+ self.last_result_msg = result_msg
+
+ if not self.synchronous:
+ # Asynchronous mode: Bind the latest result with the current frame.
+ frame_msg = input_msgs['frame']
+
+ self.frame_lag.update(time.time() - frame_msg.timestamp)
+
+ # Bind result to frame
+ if self.last_result_msg is not None:
+ frame_msg.set_full_results(
+ self.last_result_msg.get_full_results())
+ frame_msg.merge_route_info(
+ self.last_result_msg.get_route_info())
+
+ output_msg = frame_msg
+
+ else:
+ # Synchronous mode: Directly output the frame that the model result
+ # was obtained from.
+ self.frame_lag.update(time.time() - result_msg.timestamp)
+ output_msg = result_msg
+
+ # Update frame fps and lag
+ if self.last_output_msg is not None:
+ self.frame_lag.update(time.time() - output_msg.timestamp)
+ self.frame_fps.update(
+ 1.0 / (output_msg.timestamp - self.last_output_msg.timestamp))
+ self.last_output_msg = output_msg
+
+ return output_msg
+
+ def _get_node_info(self):
+ info = super()._get_node_info()
+ info['result_fps'] = self.result_fps.average()
+ info['result_lag (ms)'] = self.result_lag.average() * 1000
+ info['frame_fps'] = self.frame_fps.average()
+ info['frame_lag (ms)'] = self.frame_lag.average() * 1000
+ return info
+
+
+@NODES.register_module()
+class MonitorNode(Node):
+
+ _default_ignore_items = ['timestamp']
+
+ def __init__(self,
+ name: str,
+ frame_buffer: str,
+ output_buffer: Union[str, List[str]],
+ enable_key: Optional[Union[str, int]] = None,
+ enable: bool = False,
+ x_offset=20,
+ y_offset=20,
+ y_delta=15,
+ text_color='black',
+ background_color=(255, 183, 0),
+ text_scale=0.4,
+ ignore_items: Optional[List[str]] = None):
+ super().__init__(name=name, enable_key=enable_key, enable=enable)
+
+ self.x_offset = x_offset
+ self.y_offset = y_offset
+ self.y_delta = y_delta
+ self.text_color = color_val(text_color)
+ self.background_color = color_val(background_color)
+ self.text_scale = text_scale
+ if ignore_items is None:
+ self.ignore_items = self._default_ignore_items
+ else:
+ self.ignore_items = ignore_items
+
+ self.register_input_buffer(frame_buffer, 'frame', essential=True)
+ self.register_output_buffer(output_buffer)
+
+ def process(self, input_msgs):
+ frame_msg = input_msgs['frame']
+
+ frame_msg.update_route_info(
+ node_name='System Info',
+ node_type='dummy',
+ info=self._get_system_info())
+
+ img = frame_msg.get_image()
+ route_info = frame_msg.get_route_info()
+ img = self._show_route_info(img, route_info)
+
+ frame_msg.set_image(img)
+ return frame_msg
+
+ def _get_system_info(self):
+ sys_info = {}
+ if psutil_proc is not None:
+ sys_info['CPU(%)'] = psutil_proc.cpu_percent()
+ sys_info['Memory(%)'] = psutil_proc.memory_percent()
+ return sys_info
+
+ def _show_route_info(self, img, route_info):
+ canvas = np.full(img.shape, self.background_color, dtype=img.dtype)
+
+ x = self.x_offset
+ y = self.y_offset
+
+ max_len = 0
+
+ def _put_line(line=''):
+ nonlocal y, max_len
+ cv2.putText(canvas, line, (x, y), cv2.FONT_HERSHEY_DUPLEX,
+ self.text_scale, self.text_color, 1)
+ y += self.y_delta
+ max_len = max(max_len, len(line))
+
+ for node_info in route_info:
+ title = f'{node_info["node"]}({node_info["node_type"]})'
+ _put_line(title)
+ for k, v in node_info['info'].items():
+ if k in self.ignore_items:
+ continue
+ if isinstance(v, float):
+ v = f'{v:.1f}'
+ _put_line(f' {k}: {v}')
+
+ x1 = max(0, self.x_offset)
+ x2 = min(img.shape[1], int(x + max_len * self.text_scale * 20))
+ y1 = max(0, self.y_offset - self.y_delta)
+ y2 = min(img.shape[0], y)
+
+ src1 = canvas[y1:y2, x1:x2]
+ src2 = img[y1:y2, x1:x2]
+ img[y1:y2, x1:x2] = cv2.addWeighted(src1, 0.5, src2, 0.5, 0)
+
+ return img
+
+ def bypass(self, input_msgs):
+ return input_msgs['frame']
+
+
+@NODES.register_module()
+class RecorderNode(Node):
+ """Record the frames into a local file."""
+
+ def __init__(
+ self,
+ name: str,
+ frame_buffer: str,
+ output_buffer: Union[str, List[str]],
+ out_video_file: str,
+ out_video_fps: int = 30,
+ out_video_codec: str = 'mp4v',
+ buffer_size: int = 30,
+ ):
+ super().__init__(name=name, enable_key=None, enable=True)
+
+ self.queue = Queue(maxsize=buffer_size)
+ self.out_video_file = out_video_file
+ self.out_video_fps = out_video_fps
+ self.out_video_codec = out_video_codec
+ self.vwriter = None
+
+ # Register buffers
+ self.register_input_buffer(frame_buffer, 'frame', essential=True)
+ self.register_output_buffer(output_buffer)
+
+ # Start a new thread to write frame
+ self.t_record = Thread(target=self._record, args=(), daemon=True)
+ self.t_record.start()
+
+ def process(self, input_msgs):
+
+ frame_msg = input_msgs['frame']
+ img = frame_msg.get_image() if frame_msg is not None else None
+ img_queued = False
+
+ while not img_queued:
+ try:
+ self.queue.put(img, timeout=1)
+ img_queued = True
+ logging.info(f'{self.name}: recorder received one frame!')
+ except Full:
+ logging.info(f'{self.name}: recorder jamed!')
+
+ return frame_msg
+
+ def _record(self):
+
+ while True:
+
+ img = self.queue.get()
+
+ if img is None:
+ break
+
+ if self.vwriter is None:
+ fourcc = cv2.VideoWriter_fourcc(*self.out_video_codec)
+ fps = self.out_video_fps
+ frame_size = (img.shape[1], img.shape[0])
+ self.vwriter = cv2.VideoWriter(self.out_video_file, fourcc,
+ fps, frame_size)
+ assert self.vwriter.isOpened()
+
+ self.vwriter.write(img)
+
+ logging.info('Video recorder released!')
+ if self.vwriter is not None:
+ self.vwriter.release()
+
+ def on_exit(self):
+ try:
+ # Try putting a None into the output queue so the self.vwriter will
+ # be released after all queue frames have been written to file.
+ self.queue.put(None, timeout=1)
+ self.t_record.join(timeout=1)
+ except Full:
+ pass
+
+ if self.t_record.is_alive():
+ # Force to release self.vwriter
+ logging.info('Video recorder forced release!')
+ if self.vwriter is not None:
+ self.vwriter.release()
diff --git a/vendor/ViTPose/tools/webcam/webcam_apis/nodes/mmdet_node.py b/vendor/ViTPose/tools/webcam/webcam_apis/nodes/mmdet_node.py
new file mode 100644
index 0000000000000000000000000000000000000000..4207647c927dfbd34af225454ed5c2ef7466a012
--- /dev/null
+++ b/vendor/ViTPose/tools/webcam/webcam_apis/nodes/mmdet_node.py
@@ -0,0 +1,84 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Union
+
+from .builder import NODES
+from .node import Node
+
+try:
+ from mmdet.apis import inference_detector, init_detector
+ has_mmdet = True
+except (ImportError, ModuleNotFoundError):
+ has_mmdet = False
+
+
+@NODES.register_module()
+class DetectorNode(Node):
+
+ def __init__(self,
+ name: str,
+ model_config: str,
+ model_checkpoint: str,
+ input_buffer: str,
+ output_buffer: Union[str, List[str]],
+ enable_key: Optional[Union[str, int]] = None,
+ device: str = 'cuda:0'):
+ # Check mmdetection is installed
+ assert has_mmdet, 'Please install mmdet to run the demo.'
+ super().__init__(name=name, enable_key=enable_key, enable=True)
+
+ self.model_config = model_config
+ self.model_checkpoint = model_checkpoint
+ self.device = device.lower()
+
+ # Init model
+ self.model = init_detector(
+ self.model_config,
+ self.model_checkpoint,
+ device=self.device.lower())
+
+ # Register buffers
+ self.register_input_buffer(input_buffer, 'input', essential=True)
+ self.register_output_buffer(output_buffer)
+
+ def bypass(self, input_msgs):
+ return input_msgs['input']
+
+ def process(self, input_msgs):
+ input_msg = input_msgs['input']
+
+ img = input_msg.get_image()
+
+ preds = inference_detector(self.model, img)
+ det_result = self._post_process(preds)
+
+ input_msg.add_detection_result(det_result, tag=self.name)
+ return input_msg
+
+ def _post_process(self, preds):
+ if isinstance(preds, tuple):
+ dets = preds[0]
+ segms = preds[1]
+ else:
+ dets = preds
+ segms = [None] * len(dets)
+
+ assert len(dets) == len(self.model.CLASSES)
+ assert len(segms) == len(self.model.CLASSES)
+ result = {'preds': [], 'model_cfg': self.model.cfg.copy()}
+
+ for i, (cls_name, bboxes,
+ masks) in enumerate(zip(self.model.CLASSES, dets, segms)):
+ if masks is None:
+ masks = [None] * len(bboxes)
+ else:
+ assert len(masks) == len(bboxes)
+
+ preds_i = [{
+ 'cls_id': i,
+ 'label': cls_name,
+ 'bbox': bbox,
+ 'mask': mask,
+ } for (bbox, mask) in zip(bboxes, masks)]
+ result['preds'].extend(preds_i)
+
+ return result
diff --git a/vendor/ViTPose/tools/webcam/webcam_apis/nodes/mmpose_node.py b/vendor/ViTPose/tools/webcam/webcam_apis/nodes/mmpose_node.py
new file mode 100644
index 0000000000000000000000000000000000000000..167d7413ea48943b9373525bf5f392b5f1aa248b
--- /dev/null
+++ b/vendor/ViTPose/tools/webcam/webcam_apis/nodes/mmpose_node.py
@@ -0,0 +1,122 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import time
+from typing import Dict, List, Optional, Union
+
+from mmpose.apis import (get_track_id, inference_top_down_pose_model,
+ init_pose_model)
+from ..utils import Message
+from .builder import NODES
+from .node import Node
+
+
+@NODES.register_module()
+class TopDownPoseEstimatorNode(Node):
+
+ def __init__(self,
+ name: str,
+ model_config: str,
+ model_checkpoint: str,
+ input_buffer: str,
+ output_buffer: Union[str, List[str]],
+ enable_key: Optional[Union[str, int]] = None,
+ enable: bool = True,
+ device: str = 'cuda:0',
+ cls_ids: Optional[List] = None,
+ cls_names: Optional[List] = None,
+ bbox_thr: float = 0.5):
+ super().__init__(name=name, enable_key=enable_key, enable=enable)
+
+ # Init model
+ self.model_config = model_config
+ self.model_checkpoint = model_checkpoint
+ self.device = device.lower()
+
+ self.cls_ids = cls_ids
+ self.cls_names = cls_names
+ self.bbox_thr = bbox_thr
+
+ # Init model
+ self.model = init_pose_model(
+ self.model_config,
+ self.model_checkpoint,
+ device=self.device.lower())
+
+ # Store history for pose tracking
+ self.track_info = {
+ 'next_id': 0,
+ 'last_pose_preds': [],
+ 'last_time': None
+ }
+
+ # Register buffers
+ self.register_input_buffer(input_buffer, 'input', essential=True)
+ self.register_output_buffer(output_buffer)
+
+ def bypass(self, input_msgs):
+ return input_msgs['input']
+
+ def process(self, input_msgs: Dict[str, Message]) -> Message:
+
+ input_msg = input_msgs['input']
+ img = input_msg.get_image()
+ det_results = input_msg.get_detection_results()
+
+ if det_results is None:
+ raise ValueError(
+ 'No detection results are found in the frame message.'
+ f'{self.__class__.__name__} should be used after a '
+ 'detector node.')
+
+ full_det_preds = []
+ for det_result in det_results:
+ det_preds = det_result['preds']
+ if self.cls_ids:
+ # Filter detection results by class ID
+ det_preds = [
+ p for p in det_preds if p['cls_id'] in self.cls_ids
+ ]
+ elif self.cls_names:
+ # Filter detection results by class name
+ det_preds = [
+ p for p in det_preds if p['label'] in self.cls_names
+ ]
+ full_det_preds.extend(det_preds)
+
+ # Inference pose
+ pose_preds, _ = inference_top_down_pose_model(
+ self.model,
+ img,
+ full_det_preds,
+ bbox_thr=self.bbox_thr,
+ format='xyxy')
+
+ # Pose tracking
+ current_time = time.time()
+ if self.track_info['last_time'] is None:
+ fps = None
+ elif self.track_info['last_time'] >= current_time:
+ fps = None
+ else:
+ fps = 1.0 / (current_time - self.track_info['last_time'])
+
+ pose_preds, next_id = get_track_id(
+ pose_preds,
+ self.track_info['last_pose_preds'],
+ self.track_info['next_id'],
+ use_oks=False,
+ tracking_thr=0.3,
+ use_one_euro=True,
+ fps=fps)
+
+ self.track_info['next_id'] = next_id
+ self.track_info['last_pose_preds'] = pose_preds.copy()
+ self.track_info['last_time'] = current_time
+
+ pose_result = {
+ 'preds': pose_preds,
+ 'model_cfg': self.model.cfg.copy(),
+ }
+
+ input_msg.add_pose_result(pose_result, tag=self.name)
+
+ return input_msg
diff --git a/vendor/ViTPose/tools/webcam/webcam_apis/nodes/node.py b/vendor/ViTPose/tools/webcam/webcam_apis/nodes/node.py
new file mode 100644
index 0000000000000000000000000000000000000000..31e48d089dd18f8845125f50676cc175dbc2d24d
--- /dev/null
+++ b/vendor/ViTPose/tools/webcam/webcam_apis/nodes/node.py
@@ -0,0 +1,372 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import logging
+import time
+from abc import ABCMeta, abstractmethod
+from dataclasses import dataclass
+from queue import Empty
+from threading import Thread
+from typing import Callable, Dict, List, Optional, Tuple, Union
+
+from mmcv.utils.misc import is_method_overridden
+
+from mmpose.utils import StopWatch
+from ..utils import Message, VideoEndingMessage, limit_max_fps
+
+
+@dataclass
+class BufferInfo():
+ """Dataclass for buffer information."""
+ buffer_name: str
+ input_name: Optional[str] = None
+ essential: bool = False
+
+
+@dataclass
+class EventInfo():
+ """Dataclass for event handler information."""
+ event_name: str
+ is_keyboard: bool = False
+ handler_func: Optional[Callable] = None
+
+
+class Node(Thread, metaclass=ABCMeta):
+ """Base interface of functional module.
+
+ Parameters:
+ name (str, optional): The node name (also thread name).
+ enable_key (str|int, optional): Set a hot-key to toggle enable/disable
+ of the node. If an int value is given, it will be treated as an
+ ascii code of a key. Please note:
+ 1. If enable_key is set, the bypass method need to be
+ overridden to define the node behavior when disabled
+ 2. Some hot-key has been use for particular use. For example:
+ 'q', 'Q' and 27 are used for quit
+ Default: None
+ max_fps (int): Maximum FPS of the node. This is to avoid the node
+ running unrestrictedly and causing large resource consuming.
+ Default: 30
+ input_check_interval (float): Minimum interval (in millisecond) between
+ checking if input is ready. Default: 0.001
+ enable (bool): Default enable/disable status. Default: True.
+ daemon (bool): Whether node is a daemon. Default: True.
+ """
+
+ def __init__(self,
+ name: Optional[str] = None,
+ enable_key: Optional[Union[str, int]] = None,
+ max_fps: int = 30,
+ input_check_interval: float = 0.01,
+ enable: bool = True,
+ daemon=False):
+ super().__init__(name=name, daemon=daemon)
+ self._runner = None
+ self._enabled = enable
+ self.enable_key = enable_key
+ self.max_fps = max_fps
+ self.input_check_interval = input_check_interval
+
+ # A partitioned buffer manager the runner's buffer manager that
+ # only accesses the buffers related to the node
+ self._buffer_manager = None
+
+ # Input/output buffers are a list of registered buffers' information
+ self._input_buffers = []
+ self._output_buffers = []
+
+ # Event manager is a copy of assigned runner's event manager
+ self._event_manager = None
+
+ # A list of registered event information
+ # See register_event() for more information
+ # Note that we recommend to handle events in nodes by registering
+ # handlers, but one can still access the raw event by _event_manager
+ self._registered_events = []
+
+ # A list of (listener_threads, event_info)
+ # See set_runner() for more information
+ self._event_listener_threads = []
+
+ # A timer to calculate node FPS
+ self._timer = StopWatch(window=10)
+
+ # Register enable toggle key
+ if self.enable_key:
+ # If the node allows toggling enable, it should override the
+ # `bypass` method to define the node behavior when disabled.
+ if not is_method_overridden('bypass', Node, self.__class__):
+ raise NotImplementedError(
+ f'The node {self.__class__} does not support toggling'
+ 'enable but got argument `enable_key`. To support toggling'
+ 'enable, please override the `bypass` method of the node.')
+
+ self.register_event(
+ event_name=self.enable_key,
+ is_keyboard=True,
+ handler_func=self._toggle_enable,
+ )
+
+ @property
+ def registered_buffers(self):
+ return self._input_buffers + self._output_buffers
+
+ @property
+ def registered_events(self):
+ return self._registered_events.copy()
+
+ def _toggle_enable(self):
+ self._enabled = not self._enabled
+
+ def register_input_buffer(self,
+ buffer_name: str,
+ input_name: str,
+ essential: bool = False):
+ """Register an input buffer, so that Node can automatically check if
+ data is ready, fetch data from the buffers and format the inputs to
+ feed into `process` method.
+
+ This method can be invoked multiple times to register multiple input
+ buffers.
+
+ The subclass of Node should invoke `register_input_buffer` in its
+ `__init__` method.
+
+ Args:
+ buffer_name (str): The name of the buffer
+ input_name (str): The name of the fetched message from the
+ corresponding buffer
+ essential (bool): An essential input means the node will wait
+ until the input is ready before processing. Otherwise, an
+ inessential input will not block the processing, instead
+ a None will be fetched if the buffer is not ready.
+ """
+ buffer_info = BufferInfo(buffer_name, input_name, essential)
+ self._input_buffers.append(buffer_info)
+
+ def register_output_buffer(self, buffer_name: Union[str, List[str]]):
+ """Register one or multiple output buffers, so that the Node can
+ automatically send the output of the `process` method to these buffers.
+
+ The subclass of Node should invoke `register_output_buffer` in its
+ `__init__` method.
+
+ Args:
+ buffer_name (str|list): The name(s) of the output buffer(s).
+ """
+
+ if not isinstance(buffer_name, list):
+ buffer_name = [buffer_name]
+
+ for name in buffer_name:
+ buffer_info = BufferInfo(name)
+ self._output_buffers.append(buffer_info)
+
+ def register_event(self,
+ event_name: str,
+ is_keyboard: bool = False,
+ handler_func: Optional[Callable] = None):
+ """Register an event. All events used in the node need to be registered
+ in __init__(). If a callable handler is given, a thread will be create
+ to listen and handle the event when the node starts.
+
+ Args:
+ Args:
+ event_name (str|int): The event name. If is_keyboard==True,
+ event_name should be a str (as char) or an int (as ascii)
+ is_keyboard (bool): Indicate whether it is an keyboard
+ event. If True, the argument event_name will be regarded as a
+ key indicator.
+ handler_func (callable, optional): The event handler function,
+ which should be a collable object with no arguments or
+ return values. Default: None.
+ """
+ event_info = EventInfo(event_name, is_keyboard, handler_func)
+ self._registered_events.append(event_info)
+
+ def set_runner(self, runner):
+ # Get partitioned buffer manager
+ buffer_names = [
+ buffer.buffer_name
+ for buffer in self._input_buffers + self._output_buffers
+ ]
+ self._buffer_manager = runner.buffer_manager.get_sub_manager(
+ buffer_names)
+
+ # Get event manager
+ self._event_manager = runner.event_manager
+
+ def _get_input_from_buffer(self) -> Tuple[bool, Optional[Dict]]:
+ """Get and pack input data if it's ready. The function returns a tuple
+ of a status flag and a packed data dictionary. If input_buffer is
+ ready, the status flag will be True, and the packed data is a dict
+ whose items are buffer names and corresponding messages (unready
+ additional buffers will give a `None`). Otherwise, the status flag is
+ False and the packed data is None.
+
+ Returns:
+ bool: status flag
+ dict[str, Message]: the packed inputs where the key is the buffer
+ name and the value is the Message got from the corresponding
+ buffer.
+ """
+ buffer_manager = self._buffer_manager
+
+ if buffer_manager is None:
+ raise ValueError(f'{self.name}: Runner not set!')
+
+ # Check that essential buffers are ready
+ for buffer_info in self._input_buffers:
+ if buffer_info.essential and buffer_manager.is_empty(
+ buffer_info.buffer_name):
+ return False, None
+
+ # Default input
+ result = {
+ buffer_info.input_name: None
+ for buffer_info in self._input_buffers
+ }
+
+ for buffer_info in self._input_buffers:
+ try:
+ result[buffer_info.input_name] = buffer_manager.get(
+ buffer_info.buffer_name, block=False)
+ except Empty:
+ if buffer_info.essential:
+ # Return unsuccessful flag if any
+ # essential input is unready
+ return False, None
+
+ return True, result
+
+ def _send_output_to_buffers(self, output_msg):
+ """Send output of the process method to registered output buffers.
+
+ Args:
+ output_msg (Message): output message
+ force (bool, optional): If True, block until the output message
+ has been put into all output buffers. Default: False
+ """
+ for buffer_info in self._output_buffers:
+ buffer_name = buffer_info.buffer_name
+ self._buffer_manager.put_force(buffer_name, output_msg)
+
+ @abstractmethod
+ def process(self, input_msgs: Dict[str, Message]) -> Union[Message, None]:
+ """The core method that implement the function of the node. This method
+ will be invoked when the node is enabled and the input data is ready.
+
+ All subclasses of Node should override this method.
+
+ Args:
+ input_msgs (dict): The input data collected from the buffers. For
+ each item, the key is the `input_name` of the registered input
+ buffer, while the value is a Message instance fetched from the
+ buffer (or None if the buffer is unessential and not ready).
+
+ Returns:
+ Message: The output message of the node. It will be send to all
+ registered output buffers.
+ """
+
+ def bypass(self, input_msgs: Dict[str, Message]) -> Union[Message, None]:
+ """The method that defines the node behavior when disabled. Note that
+ if the node has an `enable_key`, this method should be override.
+
+ The method input/output is same as it of `process` method.
+
+ Args:
+ input_msgs (dict): The input data collected from the buffers. For
+ each item, the key is the `input_name` of the registered input
+ buffer, while the value is a Message instance fetched from the
+ buffer (or None if the buffer is unessential and not ready).
+
+ Returns:
+ Message: The output message of the node. It will be send to all
+ registered output buffers.
+ """
+ raise NotImplementedError
+
+ def _get_node_info(self):
+ """Get route information of the node."""
+ info = {'fps': self._timer.report('_FPS_'), 'timestamp': time.time()}
+ return info
+
+ def on_exit(self):
+ """This method will be invoked on event `_exit_`.
+
+ Subclasses should override this method to specifying the exiting
+ behavior.
+ """
+
+ def run(self):
+ """Method representing the Node's activity.
+
+ This method override the standard run() method of Thread. Users should
+ not override this method in subclasses.
+ """
+
+ logging.info(f'Node {self.name} starts')
+
+ # Create event listener threads
+ for event_info in self._registered_events:
+
+ if event_info.handler_func is None:
+ continue
+
+ def event_listener():
+ while True:
+ with self._event_manager.wait_and_handle(
+ event_info.event_name, event_info.is_keyboard):
+ event_info.handler_func()
+
+ t_listener = Thread(target=event_listener, args=(), daemon=True)
+ t_listener.start()
+ self._event_listener_threads.append(t_listener)
+
+ # Loop
+ while True:
+ # Exit
+ if self._event_manager.is_set('_exit_'):
+ self.on_exit()
+ break
+
+ # Check if input is ready
+ input_status, input_msgs = self._get_input_from_buffer()
+
+ # Input is not ready
+ if not input_status:
+ time.sleep(self.input_check_interval)
+ continue
+
+ # If a VideoEndingMessage is received, broadcast the signal
+ # without invoking process() or bypass()
+ video_ending = False
+ for _, msg in input_msgs.items():
+ if isinstance(msg, VideoEndingMessage):
+ self._send_output_to_buffers(msg)
+ video_ending = True
+ break
+
+ if video_ending:
+ self.on_exit()
+ break
+
+ # Check if enabled
+ if not self._enabled:
+ # Override bypass method to define node behavior when disabled
+ output_msg = self.bypass(input_msgs)
+ else:
+ with self._timer.timeit():
+ with limit_max_fps(self.max_fps):
+ # Process
+ output_msg = self.process(input_msgs)
+
+ if output_msg:
+ # Update route information
+ node_info = self._get_node_info()
+ output_msg.update_route_info(node=self, info=node_info)
+
+ # Send output message
+ if output_msg is not None:
+ self._send_output_to_buffers(output_msg)
+
+ logging.info(f'{self.name}: process ending.')
diff --git a/vendor/ViTPose/tools/webcam/webcam_apis/nodes/valentinemagic_node.py b/vendor/ViTPose/tools/webcam/webcam_apis/nodes/valentinemagic_node.py
new file mode 100644
index 0000000000000000000000000000000000000000..8b1c6a585065416b50f1c889272d7e869942354e
--- /dev/null
+++ b/vendor/ViTPose/tools/webcam/webcam_apis/nodes/valentinemagic_node.py
@@ -0,0 +1,340 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import time
+from dataclasses import dataclass
+from typing import Dict, List, Optional, Tuple, Union
+
+import cv2
+import numpy as np
+
+from ..utils import (FrameMessage, get_eye_keypoint_ids, get_hand_keypoint_ids,
+ get_mouth_keypoint_ids, load_image_from_disk_or_url)
+from .builder import NODES
+from .frame_drawing_node import FrameDrawingNode
+
+
+@dataclass
+class HeartInfo():
+ """Dataclass for heart information."""
+ heart_type: int
+ start_time: float
+ start_pos: Tuple[int, int]
+ end_pos: Tuple[int, int]
+
+
+@NODES.register_module()
+class ValentineMagicNode(FrameDrawingNode):
+
+ def __init__(self,
+ name: str,
+ frame_buffer: str,
+ output_buffer: Union[str, List[str]],
+ enable_key: Optional[Union[str, int]] = None,
+ kpt_vis_thr: float = 0.3,
+ hand_heart_angle_thr: float = 90.0,
+ longest_duration: float = 2.0,
+ largest_ratio: float = 0.25,
+ hand_heart_img_path: Optional[str] = None,
+ flying_heart_img_path: Optional[str] = None,
+ hand_heart_dis_ratio_thr: float = 1.0,
+ flying_heart_dis_ratio_thr: float = 3.5,
+ num_persons: int = 2):
+
+ super().__init__(
+ name, frame_buffer, output_buffer, enable_key=enable_key)
+
+ if hand_heart_img_path is None:
+ hand_heart_img_path = 'https://user-images.githubusercontent.com/'\
+ '87690686/149731850-ea946766-a4e8-4efa-82f5'\
+ '-e2f0515db8ae.png'
+ if flying_heart_img_path is None:
+ flying_heart_img_path = 'https://user-images.githubusercontent.'\
+ 'com/87690686/153554948-937ce496-33dd-4'\
+ '9ab-9829-0433fd7c13c4.png'
+
+ self.hand_heart = load_image_from_disk_or_url(hand_heart_img_path)
+ self.flying_heart = load_image_from_disk_or_url(flying_heart_img_path)
+
+ self.kpt_vis_thr = kpt_vis_thr
+ self.hand_heart_angle_thr = hand_heart_angle_thr
+ self.hand_heart_dis_ratio_thr = hand_heart_dis_ratio_thr
+ self.flying_heart_dis_ratio_thr = flying_heart_dis_ratio_thr
+ self.longest_duration = longest_duration
+ self.largest_ratio = largest_ratio
+ self.num_persons = num_persons
+
+ # record the heart infos for each person
+ self.heart_infos = {}
+
+ def _cal_distance(self, p1: np.ndarray, p2: np.ndarray) -> np.float64:
+ """calculate the distance of points p1 and p2."""
+ return np.sqrt((p1[0] - p2[0])**2 + (p1[1] - p2[1])**2)
+
+ def _cal_angle(self, p1: np.ndarray, p2: np.ndarray, p3: np.ndarray,
+ p4: np.ndarray) -> np.float64:
+ """calculate the angle of vectors v1(constructed by points p2 and p1)
+ and v2(constructed by points p4 and p3)"""
+ v1 = p2 - p1
+ v2 = p4 - p3
+
+ vector_prod = v1[0] * v2[0] + v1[1] * v2[1]
+ length_prod = np.sqrt(pow(v1[0], 2) + pow(v1[1], 2)) * np.sqrt(
+ pow(v2[0], 2) + pow(v2[1], 2))
+ cos = vector_prod * 1.0 / (length_prod * 1.0 + 1e-6)
+
+ return (np.arccos(cos) / np.pi) * 180
+
+ def _check_heart(self, pred: Dict[str,
+ np.ndarray], hand_indices: List[int],
+ mouth_index: int, eye_indices: List[int]) -> int:
+ """Check the type of Valentine Magic based on the pose results and
+ keypoint indices of hand, mouth. and eye.
+
+ Args:
+ pred(dict): The pose estimation results containing:
+ - "keypoints" (np.ndarray[K,3]): keypoint detection result
+ in [x, y, score]
+ hand_indices(list[int]): keypoint indices of hand
+ mouth_index(int): keypoint index of mouth
+ eye_indices(list[int]): keypoint indices of eyes
+
+ Returns:
+ int: a number representing the type of heart pose,
+ 0: None, 1: hand heart, 2: left hand blow kiss,
+ 3: right hand blow kiss
+ """
+ kpts = pred['keypoints']
+
+ left_eye_idx, right_eye_idx = eye_indices
+ left_eye_pos = kpts[left_eye_idx][:2]
+ right_eye_pos = kpts[right_eye_idx][:2]
+ eye_dis = self._cal_distance(left_eye_pos, right_eye_pos)
+
+ # these indices are corresoponding to the following keypoints:
+ # left_hand_root, left_pinky_finger1,
+ # left_pinky_finger3, left_pinky_finger4,
+ # right_hand_root, right_pinky_finger1
+ # right_pinky_finger3, right_pinky_finger4
+
+ both_hands_vis = True
+ for i in [0, 17, 19, 20, 21, 38, 40, 41]:
+ if kpts[hand_indices[i]][2] < self.kpt_vis_thr:
+ both_hands_vis = False
+
+ if both_hands_vis:
+ p1 = kpts[hand_indices[20]][:2]
+ p2 = kpts[hand_indices[19]][:2]
+ p3 = kpts[hand_indices[17]][:2]
+ p4 = kpts[hand_indices[0]][:2]
+ left_angle = self._cal_angle(p1, p2, p3, p4)
+
+ p1 = kpts[hand_indices[41]][:2]
+ p2 = kpts[hand_indices[40]][:2]
+ p3 = kpts[hand_indices[38]][:2]
+ p4 = kpts[hand_indices[21]][:2]
+ right_angle = self._cal_angle(p1, p2, p3, p4)
+
+ hand_dis = self._cal_distance(kpts[hand_indices[20]][:2],
+ kpts[hand_indices[41]][:2])
+
+ if (left_angle < self.hand_heart_angle_thr
+ and right_angle < self.hand_heart_angle_thr
+ and hand_dis / eye_dis < self.hand_heart_dis_ratio_thr):
+ return 1
+
+ # these indices are corresoponding to the following keypoints:
+ # left_middle_finger1, left_middle_finger4,
+ left_hand_vis = True
+ for i in [9, 12]:
+ if kpts[hand_indices[i]][2] < self.kpt_vis_thr:
+ left_hand_vis = False
+ break
+ # right_middle_finger1, right_middle_finger4
+
+ right_hand_vis = True
+ for i in [30, 33]:
+ if kpts[hand_indices[i]][2] < self.kpt_vis_thr:
+ right_hand_vis = False
+ break
+
+ mouth_vis = True
+ if kpts[mouth_index][2] < self.kpt_vis_thr:
+ mouth_vis = False
+
+ if (not left_hand_vis and not right_hand_vis) or not mouth_vis:
+ return 0
+
+ mouth_pos = kpts[mouth_index]
+
+ left_mid_hand_pos = (kpts[hand_indices[9]][:2] +
+ kpts[hand_indices[12]][:2]) / 2
+ lefthand_mouth_dis = self._cal_distance(left_mid_hand_pos, mouth_pos)
+
+ if lefthand_mouth_dis / eye_dis < self.flying_heart_dis_ratio_thr:
+ return 2
+
+ right_mid_hand_pos = (kpts[hand_indices[30]][:2] +
+ kpts[hand_indices[33]][:2]) / 2
+ righthand_mouth_dis = self._cal_distance(right_mid_hand_pos, mouth_pos)
+
+ if righthand_mouth_dis / eye_dis < self.flying_heart_dis_ratio_thr:
+ return 3
+
+ return 0
+
+ def _get_heart_route(self, heart_type: int, cur_pred: Dict[str,
+ np.ndarray],
+ tar_pred: Dict[str,
+ np.ndarray], hand_indices: List[int],
+ mouth_index: int) -> Tuple[int, int]:
+ """get the start and end position of the heart, based on two keypoint
+ results and keypoint indices of hand and mouth.
+
+ Args:
+ cur_pred(dict): The pose estimation results of current person,
+ containing: the following keys:
+ - "keypoints" (np.ndarray[K,3]): keypoint detection result
+ in [x, y, score]
+ tar_pred(dict): The pose estimation results of target person,
+ containing: the following keys:
+ - "keypoints" (np.ndarray[K,3]): keypoint detection result
+ in [x, y, score]
+ hand_indices(list[int]): keypoint indices of hand
+ mouth_index(int): keypoint index of mouth
+
+ Returns:
+ tuple(int): the start position of heart
+ tuple(int): the end position of heart
+ """
+ cur_kpts = cur_pred['keypoints']
+
+ assert heart_type in [1, 2,
+ 3], 'Can not determine the type of heart effect'
+
+ if heart_type == 1:
+ p1 = cur_kpts[hand_indices[20]][:2]
+ p2 = cur_kpts[hand_indices[41]][:2]
+ elif heart_type == 2:
+ p1 = cur_kpts[hand_indices[9]][:2]
+ p2 = cur_kpts[hand_indices[12]][:2]
+ elif heart_type == 3:
+ p1 = cur_kpts[hand_indices[30]][:2]
+ p2 = cur_kpts[hand_indices[33]][:2]
+
+ cur_x, cur_y = (p1 + p2) / 2
+ # the mid point of two fingers
+ start_pos = (int(cur_x), int(cur_y))
+
+ tar_kpts = tar_pred['keypoints']
+ end_pos = tar_kpts[mouth_index][:2]
+
+ return start_pos, end_pos
+
+ def _draw_heart(self, canvas: np.ndarray, heart_info: HeartInfo,
+ t_pass: float) -> np.ndarray:
+ """draw the heart according to heart info and time."""
+ start_x, start_y = heart_info.start_pos
+ end_x, end_y = heart_info.end_pos
+
+ scale = t_pass / self.longest_duration
+
+ max_h, max_w = canvas.shape[:2]
+ hm, wm = self.largest_ratio * max_h, self.largest_ratio * max_h
+ new_h, new_w = int(hm * scale), int(wm * scale)
+
+ x = int(start_x + scale * (end_x - start_x))
+ y = int(start_y + scale * (end_y - start_y))
+
+ y1 = max(0, y - int(new_h / 2))
+ y2 = min(max_h - 1, y + int(new_h / 2))
+
+ x1 = max(0, x - int(new_w / 2))
+ x2 = min(max_w - 1, x + int(new_w / 2))
+
+ target = canvas[y1:y2 + 1, x1:x2 + 1].copy()
+ new_h, new_w = target.shape[:2]
+
+ if new_h == 0 or new_w == 0:
+ return canvas
+
+ assert heart_info.heart_type in [
+ 1, 2, 3
+ ], 'Can not determine the type of heart effect'
+ if heart_info.heart_type == 1: # hand heart
+ patch = self.hand_heart.copy()
+ elif heart_info.heart_type >= 2: # hand blow kiss
+ patch = self.flying_heart.copy()
+ if heart_info.start_pos[0] > heart_info.end_pos[0]:
+ patch = patch[:, ::-1]
+
+ patch = cv2.resize(patch, (new_w, new_h))
+ mask = cv2.cvtColor(patch, cv2.COLOR_BGR2GRAY)
+ mask = (mask < 100)[..., None].astype(np.float32) * 0.8
+
+ canvas[y1:y2 + 1, x1:x2 + 1] = patch * mask + target * (1 - mask)
+
+ return canvas
+
+ def draw(self, frame_msg: FrameMessage) -> np.ndarray:
+ canvas = frame_msg.get_image()
+
+ pose_results = frame_msg.get_pose_results()
+ if not pose_results:
+ return canvas
+
+ for pose_result in pose_results:
+ model_cfg = pose_result['model_cfg']
+
+ preds = [pred.copy() for pred in pose_result['preds']]
+ # if number of persons in the image is less than 2,
+ # no heart effect will be triggered
+ if len(preds) < self.num_persons:
+ continue
+
+ # if number of persons in the image is more than 2,
+ # only use the first two pose results
+ preds = preds[:self.num_persons]
+ ids = [preds[i]['track_id'] for i in range(self.num_persons)]
+
+ for id in self.heart_infos.copy():
+ if id not in ids:
+ # if the id of a person not in previous heart_infos,
+ # delete the corresponding field
+ del self.heart_infos[id]
+
+ for i in range(self.num_persons):
+ id = preds[i]['track_id']
+
+ # if the predicted person in previous heart_infos,
+ # draw the heart
+ if id in self.heart_infos.copy():
+ t_pass = time.time() - self.heart_infos[id].start_time
+
+ # the time passed since last heart pose less than
+ # longest_duration, continue to draw the heart
+ if t_pass < self.longest_duration:
+ canvas = self._draw_heart(canvas, self.heart_infos[id],
+ t_pass)
+ # reset corresponding heart info
+ else:
+ del self.heart_infos[id]
+ else:
+ hand_indices = get_hand_keypoint_ids(model_cfg)
+ mouth_index = get_mouth_keypoint_ids(model_cfg)
+ eye_indices = get_eye_keypoint_ids(model_cfg)
+
+ # check the type of Valentine Magic based on pose results
+ # and keypoint indices of hand and mouth
+ heart_type = self._check_heart(preds[i], hand_indices,
+ mouth_index, eye_indices)
+ # trigger a Valentine Magic effect
+ if heart_type:
+ # get the route of heart
+ start_pos, end_pos = self._get_heart_route(
+ heart_type, preds[i],
+ preds[self.num_persons - 1 - i], hand_indices,
+ mouth_index)
+ start_time = time.time()
+ self.heart_infos[id] = HeartInfo(
+ heart_type, start_time, start_pos, end_pos)
+
+ return canvas
diff --git a/vendor/ViTPose/tools/webcam/webcam_apis/nodes/xdwendwen_node.py b/vendor/ViTPose/tools/webcam/webcam_apis/nodes/xdwendwen_node.py
new file mode 100644
index 0000000000000000000000000000000000000000..1a0914d3bf473f278023ed1569ae18d6d1b5fcf3
--- /dev/null
+++ b/vendor/ViTPose/tools/webcam/webcam_apis/nodes/xdwendwen_node.py
@@ -0,0 +1,240 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import json
+from dataclasses import dataclass
+from typing import List, Tuple, Union
+
+import cv2
+import numpy as np
+
+from mmpose.datasets.dataset_info import DatasetInfo
+from ..utils import load_image_from_disk_or_url
+from .builder import NODES
+from .frame_drawing_node import FrameDrawingNode
+
+
+@dataclass
+class DynamicInfo:
+ pos_curr: Tuple[int, int] = (0, 0)
+ pos_step: Tuple[int, int] = (0, 0)
+ step_curr: int = 0
+
+
+@NODES.register_module()
+class XDwenDwenNode(FrameDrawingNode):
+ """An effect drawing node that captures the face of a cat or dog and blend
+ it into a Bing-Dwen-Dwen (the mascot of 2022 Beijing Winter Olympics).
+
+ Parameters:
+ name (str, optional): The node name (also thread name).
+ frame_buffer (str): The name of the input buffer.
+ output_buffer (str | list): The name(s) of the output buffer(s).
+ mode_key (str | int): A hot key to switch the background image.
+ resource_file (str): The annotation file of resource images, which
+ should be in Labelbee format and contain both facial keypoint and
+ region annotations.
+ out_shape (tuple): The shape of output frame in (width, height).
+ """
+
+ dynamic_scale = 0.15
+ dynamic_max_step = 15
+
+ def __init__(
+ self,
+ name: str,
+ frame_buffer: str,
+ output_buffer: Union[str, List[str]],
+ mode_key: Union[str, int],
+ resource_file: str,
+ out_shape: Tuple[int, int] = (480, 480),
+ rigid_transform: bool = True,
+ ):
+ super().__init__(name, frame_buffer, output_buffer, enable=True)
+
+ self.mode_key = mode_key
+ self.mode_index = 0
+ self.out_shape = out_shape
+ self.rigid = rigid_transform
+
+ self.latest_pred = None
+
+ self.dynamic_info = DynamicInfo()
+
+ self.register_event(
+ self.mode_key, is_keyboard=True, handler_func=self.switch_mode)
+
+ self._init_resource(resource_file)
+
+ def _init_resource(self, resource_file):
+
+ # The resource_file is a JSON file that contains the facial
+ # keypoint and mask annotation information of the resource files.
+ # The annotations should follow the label-bee standard format.
+ # See https://github.com/open-mmlab/labelbee-client for details.
+ with open(resource_file) as f:
+ anns = json.load(f)
+ resource_infos = []
+
+ for ann in anns:
+ # Load image
+ img = load_image_from_disk_or_url(ann['url'])
+ # Load result
+ rst = json.loads(ann['result'])
+
+ # Check facial keypoint information
+ assert rst['step_1']['toolName'] == 'pointTool'
+ assert len(rst['step_1']['result']) == 3
+
+ keypoints = sorted(
+ rst['step_1']['result'], key=lambda x: x['order'])
+ keypoints = np.array([[pt['x'], pt['y']] for pt in keypoints])
+
+ # Check facial mask
+ assert rst['step_2']['toolName'] == 'polygonTool'
+ assert len(rst['step_2']['result']) == 1
+ assert len(rst['step_2']['result'][0]['pointList']) > 2
+
+ mask_pts = np.array(
+ [[pt['x'], pt['y']]
+ for pt in rst['step_2']['result'][0]['pointList']])
+
+ mul = 1.0 + self.dynamic_scale
+
+ w_scale = self.out_shape[0] / img.shape[1] * mul
+ h_scale = self.out_shape[1] / img.shape[0] * mul
+
+ img = cv2.resize(
+ img,
+ dsize=None,
+ fx=w_scale,
+ fy=h_scale,
+ interpolation=cv2.INTER_CUBIC)
+
+ keypoints *= [w_scale, h_scale]
+ mask_pts *= [w_scale, h_scale]
+
+ mask = cv2.fillPoly(
+ np.zeros(img.shape[:2], dtype=np.uint8),
+ [mask_pts.astype(np.int32)],
+ color=1)
+
+ res = {
+ 'img': img,
+ 'keypoints': keypoints,
+ 'mask': mask,
+ }
+ resource_infos.append(res)
+
+ self.resource_infos = resource_infos
+
+ self._reset_dynamic()
+
+ def switch_mode(self):
+ self.mode_index = (self.mode_index + 1) % len(self.resource_infos)
+
+ def _reset_dynamic(self):
+ x_tar = np.random.randint(int(self.out_shape[0] * self.dynamic_scale))
+ y_tar = np.random.randint(int(self.out_shape[1] * self.dynamic_scale))
+
+ x_step = (x_tar -
+ self.dynamic_info.pos_curr[0]) / self.dynamic_max_step
+ y_step = (y_tar -
+ self.dynamic_info.pos_curr[1]) / self.dynamic_max_step
+
+ self.dynamic_info.pos_step = (x_step, y_step)
+ self.dynamic_info.step_curr = 0
+
+ def draw(self, frame_msg):
+
+ full_pose_results = frame_msg.get_pose_results()
+
+ pred = None
+ if full_pose_results:
+ for pose_results in full_pose_results:
+ if not pose_results['preds']:
+ continue
+
+ pred = pose_results['preds'][0].copy()
+ pred['dataset'] = DatasetInfo(pose_results['model_cfg'].data.
+ test.dataset_info).dataset_name
+
+ self.latest_pred = pred
+ break
+
+ # Use the latest pose result if there is none available in
+ # the current frame.
+ if pred is None:
+ pred = self.latest_pred
+
+ # Get the background image and facial annotations
+ res = self.resource_infos[self.mode_index]
+ img = frame_msg.get_image()
+ canvas = res['img'].copy()
+ mask = res['mask']
+ kpts_tar = res['keypoints']
+
+ if pred is not None:
+ if pred['dataset'] == 'ap10k':
+ # left eye: 0, right eye: 1, nose: 2
+ kpts_src = pred['keypoints'][[0, 1, 2], :2]
+ elif pred['dataset'] == 'coco_wholebody':
+ # left eye: 1, right eye 2, nose: 0
+ kpts_src = pred['keypoints'][[1, 2, 0], :2]
+ else:
+ raise ValueError('Can not obtain face landmark information'
+ f'from dataset: {pred["type"]}')
+
+ trans_mat = self._get_transform(kpts_src, kpts_tar)
+
+ warp = cv2.warpAffine(img, trans_mat, dsize=canvas.shape[:2])
+ cv2.copyTo(warp, mask, canvas)
+
+ # Add random movement to the background
+ xc, yc = self.dynamic_info.pos_curr
+ xs, ys = self.dynamic_info.pos_step
+ w, h = self.out_shape
+
+ x = min(max(int(xc), 0), canvas.shape[1] - w + 1)
+ y = min(max(int(yc), 0), canvas.shape[0] - h + 1)
+
+ canvas = canvas[y:y + h, x:x + w]
+
+ self.dynamic_info.pos_curr = (xc + xs, yc + ys)
+ self.dynamic_info.step_curr += 1
+
+ if self.dynamic_info.step_curr == self.dynamic_max_step:
+ self._reset_dynamic()
+
+ return canvas
+
+ def _get_transform(self, kpts_src, kpts_tar):
+ if self.rigid:
+ # rigid transform
+ n = kpts_src.shape[0]
+ X = np.zeros((n * 2, 4), dtype=np.float32)
+ U = np.zeros((n * 2, 1), dtype=np.float32)
+ X[:n, :2] = kpts_src
+ X[:n, 2] = 1
+ X[n:, 0] = kpts_src[:, 1]
+ X[n:, 1] = -kpts_src[:, 0]
+ X[n:, 3] = 1
+
+ U[:n, 0] = kpts_tar[:, 0]
+ U[n:, 0] = kpts_tar[:, 1]
+
+ M = np.linalg.pinv(X).dot(U).flatten()
+
+ trans_mat = np.array([[M[0], M[1], M[2]], [-M[1], M[0], M[3]]],
+ dtype=np.float32)
+
+ else:
+ # normal affine transform
+ # adaptive horizontal flipping
+ if (np.linalg.norm(kpts_tar[0] - kpts_tar[2]) -
+ np.linalg.norm(kpts_tar[1] - kpts_tar[2])) * (
+ np.linalg.norm(kpts_src[0] - kpts_src[2]) -
+ np.linalg.norm(kpts_src[1] - kpts_src[2])) < 0:
+ kpts_src = kpts_src[[1, 0, 2], :]
+ trans_mat, _ = cv2.estimateAffine2D(
+ kpts_src.astype(np.float32), kpts_tar.astype(np.float32))
+
+ return trans_mat
diff --git a/vendor/ViTPose/tools/webcam/webcam_apis/utils/__init__.py b/vendor/ViTPose/tools/webcam/webcam_apis/utils/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..d906df0748cd6e5f87642ea6fdc9511e833e22ff
--- /dev/null
+++ b/vendor/ViTPose/tools/webcam/webcam_apis/utils/__init__.py
@@ -0,0 +1,31 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .buffer import BufferManager
+from .event import EventManager
+from .message import FrameMessage, Message, VideoEndingMessage
+from .misc import (ImageCapture, copy_and_paste, expand_and_clamp,
+ get_cached_file_path, is_image_file, limit_max_fps,
+ load_image_from_disk_or_url, screen_matting)
+from .pose import (get_eye_keypoint_ids, get_face_keypoint_ids,
+ get_hand_keypoint_ids, get_mouth_keypoint_ids,
+ get_wrist_keypoint_ids)
+
+__all__ = [
+ 'BufferManager',
+ 'EventManager',
+ 'FrameMessage',
+ 'Message',
+ 'limit_max_fps',
+ 'VideoEndingMessage',
+ 'load_image_from_disk_or_url',
+ 'get_cached_file_path',
+ 'screen_matting',
+ 'expand_and_clamp',
+ 'copy_and_paste',
+ 'is_image_file',
+ 'ImageCapture',
+ 'get_eye_keypoint_ids',
+ 'get_face_keypoint_ids',
+ 'get_wrist_keypoint_ids',
+ 'get_mouth_keypoint_ids',
+ 'get_hand_keypoint_ids',
+]
diff --git a/vendor/ViTPose/tools/webcam/webcam_apis/utils/buffer.py b/vendor/ViTPose/tools/webcam/webcam_apis/utils/buffer.py
new file mode 100644
index 0000000000000000000000000000000000000000..b9fca4c392703bccb710a9659db21f56ea92e282
--- /dev/null
+++ b/vendor/ViTPose/tools/webcam/webcam_apis/utils/buffer.py
@@ -0,0 +1,106 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from functools import wraps
+from queue import Queue
+from typing import Dict, List, Optional
+
+from mmcv import is_seq_of
+
+__all__ = ['BufferManager']
+
+
+def check_buffer_registered(exist=True):
+
+ def wrapper(func):
+
+ @wraps(func)
+ def wrapped(manager, name, *args, **kwargs):
+ if exist:
+ # Assert buffer exist
+ if name not in manager:
+ raise ValueError(f'Fail to call {func.__name__}: '
+ f'buffer "{name}" is not registered.')
+ else:
+ # Assert buffer not exist
+ if name in manager:
+ raise ValueError(f'Fail to call {func.__name__}: '
+ f'buffer "{name}" is already registered.')
+ return func(manager, name, *args, **kwargs)
+
+ return wrapped
+
+ return wrapper
+
+
+class Buffer(Queue):
+
+ def put_force(self, item):
+ """Force to put an item into the buffer.
+
+ If the buffer is already full, the earliest item in the buffer will be
+ remove to make room for the incoming item.
+ """
+ with self.mutex:
+ if self.maxsize > 0:
+ while self._qsize() >= self.maxsize:
+ _ = self._get()
+ self.unfinished_tasks -= 1
+
+ self._put(item)
+ self.unfinished_tasks += 1
+ self.not_empty.notify()
+
+
+class BufferManager():
+
+ def __init__(self,
+ buffer_type: type = Buffer,
+ buffers: Optional[Dict] = None):
+ self.buffer_type = buffer_type
+ if buffers is None:
+ self._buffers = {}
+ else:
+ if is_seq_of(list(buffers.values()), buffer_type):
+ self._buffers = buffers.copy()
+ else:
+ raise ValueError('The values of buffers should be instance '
+ f'of {buffer_type}')
+
+ def __contains__(self, name):
+ return name in self._buffers
+
+ @check_buffer_registered(False)
+ def register_buffer(self, name, maxsize=0):
+ self._buffers[name] = self.buffer_type(maxsize)
+
+ @check_buffer_registered()
+ def put(self, name, item, block=True, timeout=None):
+ self._buffers[name].put(item, block, timeout)
+
+ @check_buffer_registered()
+ def put_force(self, name, item):
+ self._buffers[name].put_force(item)
+
+ @check_buffer_registered()
+ def get(self, name, block=True, timeout=None):
+ return self._buffers[name].get(block, timeout)
+
+ @check_buffer_registered()
+ def is_empty(self, name):
+ return self._buffers[name].empty()
+
+ @check_buffer_registered()
+ def is_full(self, name):
+ return self._buffers[name].full()
+
+ def get_sub_manager(self, buffer_names: List[str]):
+ buffers = {name: self._buffers[name] for name in buffer_names}
+ return BufferManager(self.buffer_type, buffers)
+
+ def get_info(self):
+ buffer_info = {}
+ for name, buffer in self._buffers.items():
+ buffer_info[name] = {
+ 'size': buffer.size,
+ 'maxsize': buffer.maxsize
+ }
+ return buffer_info
diff --git a/vendor/ViTPose/tools/webcam/webcam_apis/utils/event.py b/vendor/ViTPose/tools/webcam/webcam_apis/utils/event.py
new file mode 100644
index 0000000000000000000000000000000000000000..ceab26f72b63d03bc574cda3a713fed67f20f0c0
--- /dev/null
+++ b/vendor/ViTPose/tools/webcam/webcam_apis/utils/event.py
@@ -0,0 +1,59 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from collections import defaultdict
+from contextlib import contextmanager
+from threading import Event
+from typing import Optional
+
+
+class EventManager():
+
+ def __init__(self):
+ self._events = defaultdict(Event)
+
+ def register_event(self,
+ event_name: str = None,
+ is_keyboard: bool = False):
+ if is_keyboard:
+ event_name = self._get_keyboard_event_name(event_name)
+ self._events[event_name] = Event()
+
+ def set(self, event_name: str = None, is_keyboard: bool = False):
+ if is_keyboard:
+ event_name = self._get_keyboard_event_name(event_name)
+ return self._events[event_name].set()
+
+ def wait(self,
+ event_name: str = None,
+ is_keyboard: Optional[bool] = False,
+ timeout: Optional[float] = None):
+ if is_keyboard:
+ event_name = self._get_keyboard_event_name(event_name)
+ return self._events[event_name].wait(timeout)
+
+ def is_set(self,
+ event_name: str = None,
+ is_keyboard: Optional[bool] = False):
+ if is_keyboard:
+ event_name = self._get_keyboard_event_name(event_name)
+ return self._events[event_name].is_set()
+
+ def clear(self,
+ event_name: str = None,
+ is_keyboard: Optional[bool] = False):
+ if is_keyboard:
+ event_name = self._get_keyboard_event_name(event_name)
+ return self._events[event_name].clear()
+
+ @staticmethod
+ def _get_keyboard_event_name(key):
+ return f'_keyboard_{chr(key) if isinstance(key,int) else key}'
+
+ @contextmanager
+ def wait_and_handle(self,
+ event_name: str = None,
+ is_keyboard: Optional[bool] = False):
+ self.wait(event_name, is_keyboard)
+ try:
+ yield
+ finally:
+ self.clear(event_name, is_keyboard)
diff --git a/vendor/ViTPose/tools/webcam/webcam_apis/utils/message.py b/vendor/ViTPose/tools/webcam/webcam_apis/utils/message.py
new file mode 100644
index 0000000000000000000000000000000000000000..d7b1529c5ece3970dfae189d910720786f32612d
--- /dev/null
+++ b/vendor/ViTPose/tools/webcam/webcam_apis/utils/message.py
@@ -0,0 +1,204 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import time
+import uuid
+import warnings
+from typing import Dict, List, Optional
+
+import numpy as np
+
+
+class Message():
+ """Message base class.
+
+ All message class should inherit this class. The basic use of a Message
+ instance is to carray a piece of text message (self.msg) and a dict that
+ stores structured data (self.data), e.g. frame image, model prediction,
+ et al.
+
+ A message may also hold route information, which is composed of
+ information of all nodes the message has passed through.
+
+ Parameters:
+ msg (str): The text message.
+ data (dict, optional): The structured data.
+ """
+
+ def __init__(self, msg: str = '', data: Optional[Dict] = None):
+ self.msg = msg
+ self.data = data if data else {}
+ self.route_info = []
+ self.timestamp = time.time()
+ self.id = uuid.uuid4()
+
+ def update_route_info(self,
+ node=None,
+ node_name: Optional[str] = None,
+ node_type: Optional[str] = None,
+ info: Optional[Dict] = None):
+ """Append new node information to the route information.
+
+ Args:
+ node (Node, optional): An instance of Node that provides basic
+ information like the node name and type. Default: None.
+ node_name (str, optional): The node name. If node is given,
+ node_name will be ignored. Default: None.
+ node_type (str, optional): The class name of the node. If node
+ is given, node_type will be ignored. Default: None.
+ info (dict, optional): The node information, which is usually
+ given by node.get_node_info(). Default: None.
+ """
+ if node is not None:
+ if node_name is not None or node_type is not None:
+ warnings.warn(
+ '`node_name` and `node_type` will be overridden if node'
+ 'is provided.')
+ node_name = node.name
+ node_type = node.__class__.__name__
+
+ node_info = {'node': node_name, 'node_type': node_type, 'info': info}
+ self.route_info.append(node_info)
+
+ def set_route_info(self, route_info: List):
+ """Directly set the entire route information.
+
+ Args:
+ route_info (list): route information to set to the message.
+ """
+ self.route_info = route_info
+
+ def merge_route_info(self, route_info: List):
+ """Merge the given route information into the original one of the
+ message. This is used for combining route information from multiple
+ messages. The node information in the route will be reordered according
+ to their timestamps.
+
+ Args:
+ route_info (list): route information to merge.
+ """
+ self.route_info += route_info
+ self.route_info.sort(key=lambda x: x.get('timestamp', np.inf))
+
+ def get_route_info(self) -> List:
+ return self.route_info.copy()
+
+
+class VideoEndingMessage(Message):
+ """A special message to indicate the input video is ending."""
+
+
+class FrameMessage(Message):
+ """The message to store information of a video frame.
+
+ A FrameMessage instance usually holds following data in self.data:
+ - image (array): The frame image
+ - detection_results (list): A list to hold detection results of
+ multiple detectors. Each element is a tuple (tag, result)
+ - pose_results (list): A list to hold pose estimation results of
+ multiple pose estimator. Each element is a tuple (tag, result)
+ """
+
+ def __init__(self, img):
+ super().__init__(data=dict(image=img))
+
+ def get_image(self):
+ """Get the frame image.
+
+ Returns:
+ array: The frame image.
+ """
+ return self.data.get('image', None)
+
+ def set_image(self, img):
+ """Set the frame image to the message."""
+ self.data['image'] = img
+
+ def add_detection_result(self, result, tag: str = None):
+ """Add the detection result from one model into the message's
+ detection_results.
+
+ Args:
+ tag (str, optional): Give a tag to the result, which can be used
+ to retrieve specific results.
+ """
+ if 'detection_results' not in self.data:
+ self.data['detection_results'] = []
+ self.data['detection_results'].append((tag, result))
+
+ def get_detection_results(self, tag: str = None):
+ """Get detection results of the message.
+
+ Args:
+ tag (str, optional): If given, only the results with the tag
+ will be retrieved. Otherwise all results will be retrieved.
+ Default: None.
+
+ Returns:
+ list[dict]: The retrieved detection results
+ """
+ if 'detection_results' not in self.data:
+ return None
+ if tag is None:
+ results = [res for _, res in self.data['detection_results']]
+ else:
+ results = [
+ res for _tag, res in self.data['detection_results']
+ if _tag == tag
+ ]
+ return results
+
+ def add_pose_result(self, result, tag=None):
+ """Add the pose estimation result from one model into the message's
+ pose_results.
+
+ Args:
+ tag (str, optional): Give a tag to the result, which can be used
+ to retrieve specific results.
+ """
+ if 'pose_results' not in self.data:
+ self.data['pose_results'] = []
+ self.data['pose_results'].append((tag, result))
+
+ def get_pose_results(self, tag=None):
+ """Get pose estimation results of the message.
+
+ Args:
+ tag (str, optional): If given, only the results with the tag
+ will be retrieved. Otherwise all results will be retrieved.
+ Default: None.
+
+ Returns:
+ list[dict]: The retrieved pose results
+ """
+ if 'pose_results' not in self.data:
+ return None
+ if tag is None:
+ results = [res for _, res in self.data['pose_results']]
+ else:
+ results = [
+ res for _tag, res in self.data['pose_results'] if _tag == tag
+ ]
+ return results
+
+ def get_full_results(self):
+ """Get all model predictions of the message.
+
+ See set_full_results() for inference.
+
+ Returns:
+ dict: All model predictions, including:
+ - detection_results
+ - pose_results
+ """
+ result_keys = ['detection_results', 'pose_results']
+ results = {k: self.data[k] for k in result_keys}
+ return results
+
+ def set_full_results(self, results):
+ """Set full model results directly.
+
+ Args:
+ results (dict): All model predictions including:
+ - detection_results (list): see also add_detection_results()
+ - pose_results (list): see also add_pose_results()
+ """
+ self.data.update(results)
diff --git a/vendor/ViTPose/tools/webcam/webcam_apis/utils/misc.py b/vendor/ViTPose/tools/webcam/webcam_apis/utils/misc.py
new file mode 100644
index 0000000000000000000000000000000000000000..c64f4179db8a3618b38e3d6933992e9b3294af55
--- /dev/null
+++ b/vendor/ViTPose/tools/webcam/webcam_apis/utils/misc.py
@@ -0,0 +1,343 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import os.path as osp
+import sys
+import time
+from contextlib import contextmanager
+from typing import Optional
+from urllib.parse import urlparse
+from urllib.request import urlopen
+
+import cv2
+import numpy as np
+from torch.hub import HASH_REGEX, download_url_to_file
+
+
+@contextmanager
+def limit_max_fps(fps: Optional[float]):
+ t_start = time.time()
+ try:
+ yield
+ finally:
+ t_end = time.time()
+ if fps is not None:
+ t_sleep = 1.0 / fps - t_end + t_start
+ if t_sleep > 0:
+ time.sleep(t_sleep)
+
+
+def _is_url(filename):
+ """Check if the file is a url link.
+
+ Args:
+ filename (str): the file name or url link.
+
+ Returns:
+ bool: is url or not.
+ """
+ prefixes = ['http://', 'https://']
+ for p in prefixes:
+ if filename.startswith(p):
+ return True
+ return False
+
+
+def load_image_from_disk_or_url(filename, readFlag=cv2.IMREAD_COLOR):
+ """Load an image file, from disk or url.
+
+ Args:
+ filename (str): file name on the disk or url link.
+ readFlag (int): readFlag for imdecode.
+
+ Returns:
+ np.ndarray: A loaded image
+ """
+ if _is_url(filename):
+ # download the image, convert it to a NumPy array, and then read
+ # it into OpenCV format
+ resp = urlopen(filename)
+ image = np.asarray(bytearray(resp.read()), dtype='uint8')
+ image = cv2.imdecode(image, readFlag)
+ return image
+ else:
+ image = cv2.imread(filename, readFlag)
+ return image
+
+
+def mkdir_or_exist(dir_name, mode=0o777):
+ if dir_name == '':
+ return
+ dir_name = osp.expanduser(dir_name)
+ os.makedirs(dir_name, mode=mode, exist_ok=True)
+
+
+def get_cached_file_path(url,
+ save_dir=None,
+ progress=True,
+ check_hash=False,
+ file_name=None):
+ r"""Loads the Torch serialized object at the given URL.
+
+ If downloaded file is a zip file, it will be automatically decompressed
+
+ If the object is already present in `model_dir`, it's deserialized and
+ returned.
+ The default value of ``model_dir`` is ``
+| CUDA | torch 1.10 | torch 1.9 | torch 1.8 |
|---|---|---|---|
| 11.3 | install | ||
| 11.1 | install | install | install |
| 10.2 | install | install | install |
| 10.1 | install | ||
| cpu | install | install | install |
+
+ +This usually happens when detectron2 or torchvision is not +compiled with the version of PyTorch you're running. + +If the error comes from a pre-built torchvision, uninstall torchvision and pytorch and reinstall them +following [pytorch.org](http://pytorch.org). So the versions will match. + +If the error comes from a pre-built detectron2, check [release notes](https://github.com/facebookresearch/detectron2/releases), +uninstall and reinstall the correct pre-built detectron2 that matches pytorch version. + +If the error comes from detectron2 or torchvision that you built manually from source, +remove files you built (`build/`, `**/*.so`) and rebuild it so it can pick up the version of pytorch currently in your environment. + +If the above instructions do not resolve this problem, please provide an environment (e.g. a dockerfile) that can reproduce the issue. +
+
++Undefined symbols that looks like "TH..","at::Tensor...","torch..." +
++ +This usually happens when detectron2 or torchvision is not +compiled with the version of PyTorch you're running. + +If the error comes from a pre-built torchvision, uninstall torchvision and pytorch and reinstall them +following [pytorch.org](http://pytorch.org). So the versions will match. + +If the error comes from a pre-built detectron2, check [release notes](https://github.com/facebookresearch/detectron2/releases), +uninstall and reinstall the correct pre-built detectron2 that matches pytorch version. + +If the error comes from detectron2 or torchvision that you built manually from source, +remove files you built (`build/`, `**/*.so`) and rebuild it so it can pick up the version of pytorch currently in your environment. + +If the above instructions do not resolve this problem, please provide an environment (e.g. a dockerfile) that can reproduce the issue. +
+
+
++Missing torch dynamic libraries, OR segmentation fault immediately when using detectron2. +
+This usually happens when detectron2 or torchvision is not +compiled with the version of PyTorch you're running. See the previous common issue for the solution. +
+
+Usually it's because the library is compiled with a newer C++ compiler but run with an old C++ runtime. + +This often happens with old anaconda. +It may help to run `conda update libgcc` to upgrade its runtime. + +The fundamental solution is to avoid the mismatch, either by compiling using older version of C++ +compiler, or run the code with proper C++ runtime. +To run the code with a specific C++ runtime, you can use environment variable `LD_PRELOAD=/path/to/libstdc++.so`. + +
+
++Undefined C++ symbols (e.g. "GLIBCXX..") or C++ symbols not found. +
++Usually it's because the library is compiled with a newer C++ compiler but run with an old C++ runtime. + +This often happens with old anaconda. +It may help to run `conda update libgcc` to upgrade its runtime. + +The fundamental solution is to avoid the mismatch, either by compiling using older version of C++ +compiler, or run the code with proper C++ runtime. +To run the code with a specific C++ runtime, you can use environment variable `LD_PRELOAD=/path/to/libstdc++.so`. + +
+
+CUDA is not found when building detectron2. +You should make sure + +``` +python -c 'import torch; from torch.utils.cpp_extension import CUDA_HOME; print(torch.cuda.is_available(), CUDA_HOME)' +``` + +print `(True, a directory with cuda)` at the time you build detectron2. + +Most models can run inference (but not training) without GPU support. To use CPUs, set `MODEL.DEVICE='cpu'` in the config. +
+
++"nvcc not found" or "Not compiled with GPU support" or "Detectron2 CUDA Compiler: not available". +
++CUDA is not found when building detectron2. +You should make sure + +``` +python -c 'import torch; from torch.utils.cpp_extension import CUDA_HOME; print(torch.cuda.is_available(), CUDA_HOME)' +``` + +print `(True, a directory with cuda)` at the time you build detectron2. + +Most models can run inference (but not training) without GPU support. To use CPUs, set `MODEL.DEVICE='cpu'` in the config. +
+
+Two possibilities: + +* You build detectron2 with one version of CUDA but run it with a different version. + + To check whether it is the case, + use `python -m detectron2.utils.collect_env` to find out inconsistent CUDA versions. + In the output of this command, you should expect "Detectron2 CUDA Compiler", "CUDA_HOME", "PyTorch built with - CUDA" + to contain cuda libraries of the same version. + + When they are inconsistent, + you need to either install a different build of PyTorch (or build by yourself) + to match your local CUDA installation, or install a different version of CUDA to match PyTorch. + +* PyTorch/torchvision/Detectron2 is not built for the correct GPU SM architecture (aka. compute capability). + + The architecture included by PyTorch/detectron2/torchvision is available in the "architecture flags" in + `python -m detectron2.utils.collect_env`. It must include + the architecture of your GPU, which can be found at [developer.nvidia.com/cuda-gpus](https://developer.nvidia.com/cuda-gpus). + + If you're using pre-built PyTorch/detectron2/torchvision, they have included support for most popular GPUs already. + If not supported, you need to build them from source. + + When building detectron2/torchvision from source, they detect the GPU device and build for only the device. + This means the compiled code may not work on a different GPU device. + To recompile them for the correct architecture, remove all installed/compiled files, + and rebuild them with the `TORCH_CUDA_ARCH_LIST` environment variable set properly. + For example, `export TORCH_CUDA_ARCH_LIST="6.0;7.0"` makes it compile for both P100s and V100s. +
+
++"invalid device function" or "no kernel image is available for execution". +
++Two possibilities: + +* You build detectron2 with one version of CUDA but run it with a different version. + + To check whether it is the case, + use `python -m detectron2.utils.collect_env` to find out inconsistent CUDA versions. + In the output of this command, you should expect "Detectron2 CUDA Compiler", "CUDA_HOME", "PyTorch built with - CUDA" + to contain cuda libraries of the same version. + + When they are inconsistent, + you need to either install a different build of PyTorch (or build by yourself) + to match your local CUDA installation, or install a different version of CUDA to match PyTorch. + +* PyTorch/torchvision/Detectron2 is not built for the correct GPU SM architecture (aka. compute capability). + + The architecture included by PyTorch/detectron2/torchvision is available in the "architecture flags" in + `python -m detectron2.utils.collect_env`. It must include + the architecture of your GPU, which can be found at [developer.nvidia.com/cuda-gpus](https://developer.nvidia.com/cuda-gpus). + + If you're using pre-built PyTorch/detectron2/torchvision, they have included support for most popular GPUs already. + If not supported, you need to build them from source. + + When building detectron2/torchvision from source, they detect the GPU device and build for only the device. + This means the compiled code may not work on a different GPU device. + To recompile them for the correct architecture, remove all installed/compiled files, + and rebuild them with the `TORCH_CUDA_ARCH_LIST` environment variable set properly. + For example, `export TORCH_CUDA_ARCH_LIST="6.0;7.0"` makes it compile for both P100s and V100s. +
+
+The version of NVCC you use to build detectron2 or torchvision does +not match the version of CUDA you are running with. +This often happens when using anaconda's CUDA runtime. + +Use `python -m detectron2.utils.collect_env` to find out inconsistent CUDA versions. +In the output of this command, you should expect "Detectron2 CUDA Compiler", "CUDA_HOME", "PyTorch built with - CUDA" +to contain cuda libraries of the same version. + +When they are inconsistent, +you need to either install a different build of PyTorch (or build by yourself) +to match your local CUDA installation, or install a different version of CUDA to match PyTorch. +
+
+
++Undefined CUDA symbols; Cannot open libcudart.so +
++The version of NVCC you use to build detectron2 or torchvision does +not match the version of CUDA you are running with. +This often happens when using anaconda's CUDA runtime. + +Use `python -m detectron2.utils.collect_env` to find out inconsistent CUDA versions. +In the output of this command, you should expect "Detectron2 CUDA Compiler", "CUDA_HOME", "PyTorch built with - CUDA" +to contain cuda libraries of the same version. + +When they are inconsistent, +you need to either install a different build of PyTorch (or build by yourself) +to match your local CUDA installation, or install a different version of CUDA to match PyTorch. +
+
+A few possibilities: + +1. Local CUDA/NVCC version has to match the CUDA version of your PyTorch. Both can be found in `python collect_env.py` + (download from [here](./detectron2/utils/collect_env.py)). + When they are inconsistent, you need to either install a different build of PyTorch (or build by yourself) + to match your local CUDA installation, or install a different version of CUDA to match PyTorch. + +2. Local CUDA/NVCC version shall support the SM architecture (a.k.a. compute capability) of your GPU. + The capability of your GPU can be found at [developer.nvidia.com/cuda-gpus](https://developer.nvidia.com/cuda-gpus). + The capability supported by NVCC is listed at [here](https://gist.github.com/ax3l/9489132). + If your NVCC version is too old, this can be workaround by setting environment variable + `TORCH_CUDA_ARCH_LIST` to a lower, supported capability. + +3. The combination of NVCC and GCC you use is incompatible. You need to change one of their versions. + See [here](https://gist.github.com/ax3l/9489132) for some valid combinations. + Notably, CUDA<=10.1.105 doesn't support GCC>7.3. + + The CUDA/GCC version used by PyTorch can be found by `print(torch.__config__.show())`. + +
+
+
++C++ compilation errors from NVCC / NVRTC, or "Unsupported gpu architecture" +
++A few possibilities: + +1. Local CUDA/NVCC version has to match the CUDA version of your PyTorch. Both can be found in `python collect_env.py` + (download from [here](./detectron2/utils/collect_env.py)). + When they are inconsistent, you need to either install a different build of PyTorch (or build by yourself) + to match your local CUDA installation, or install a different version of CUDA to match PyTorch. + +2. Local CUDA/NVCC version shall support the SM architecture (a.k.a. compute capability) of your GPU. + The capability of your GPU can be found at [developer.nvidia.com/cuda-gpus](https://developer.nvidia.com/cuda-gpus). + The capability supported by NVCC is listed at [here](https://gist.github.com/ax3l/9489132). + If your NVCC version is too old, this can be workaround by setting environment variable + `TORCH_CUDA_ARCH_LIST` to a lower, supported capability. + +3. The combination of NVCC and GCC you use is incompatible. You need to change one of their versions. + See [here](https://gist.github.com/ax3l/9489132) for some valid combinations. + Notably, CUDA<=10.1.105 doesn't support GCC>7.3. + + The CUDA/GCC version used by PyTorch can be found by `print(torch.__config__.show())`. + +
+
+Please build and install detectron2 following the instructions above. + +Or, if you are running code from detectron2's root directory, `cd` to a different one. +Otherwise you may not import the code that you installed. +
+
+
++"ImportError: cannot import name '_C'". +
++Please build and install detectron2 following the instructions above. + +Or, if you are running code from detectron2's root directory, `cd` to a different one. +Otherwise you may not import the code that you installed. +
+
+ +Detectron2 is continuously built on windows with [CircleCI](https://app.circleci.com/pipelines/github/facebookresearch/detectron2?branch=main). +However we do not provide official support for it. +PRs that improves code compatibility on windows are welcome. +
+
++Any issue on windows. +
++ +Detectron2 is continuously built on windows with [CircleCI](https://app.circleci.com/pipelines/github/facebookresearch/detectron2?branch=main). +However we do not provide official support for it. +PRs that improves code compatibility on windows are welcome. +
+
+The ONNX package is compiled with a too old compiler. + +Please build and install ONNX from its source code using a compiler +whose version is closer to what's used by PyTorch (available in `torch.__config__.show()`). +
+
+
++ONNX conversion segfault after some "TraceWarning". +
++The ONNX package is compiled with a too old compiler. + +Please build and install ONNX from its source code using a compiler +whose version is closer to what's used by PyTorch (available in `torch.__config__.show()`). +
+
+ +See [this stackoverflow answer](https://stackoverflow.com/questions/56083725/macos-build-issues-lstdc-not-found-while-building-python-package). + +
+
+
+### Installation inside specific environments:
+
+* __Colab__: see our [Colab Tutorial](https://colab.research.google.com/drive/16jcaJoc6bCFAQ96jDe2HwtXj7BMD_-m5)
+ which has step-by-step instructions.
+
+* __Docker__: The official [Dockerfile](docker) installs detectron2 with a few simple commands.
diff --git a/vendor/detectron2/LICENSE b/vendor/detectron2/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..cd1b070674331757508398d99c830664dce6eaec
--- /dev/null
+++ b/vendor/detectron2/LICENSE
@@ -0,0 +1,202 @@
+Apache License
+Version 2.0, January 2004
+http://www.apache.org/licenses/
+
+TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+1. Definitions.
+
+"License" shall mean the terms and conditions for use, reproduction,
+and distribution as defined by Sections 1 through 9 of this document.
+
+"Licensor" shall mean the copyright owner or entity authorized by
+the copyright owner that is granting the License.
+
+"Legal Entity" shall mean the union of the acting entity and all
+other entities that control, are controlled by, or are under common
+control with that entity. For the purposes of this definition,
+"control" means (i) the power, direct or indirect, to cause the
+direction or management of such entity, whether by contract or
+otherwise, or (ii) ownership of fifty percent (50%) or more of the
+outstanding shares, or (iii) beneficial ownership of such entity.
+
+"You" (or "Your") shall mean an individual or Legal Entity
+exercising permissions granted by this License.
+
+"Source" form shall mean the preferred form for making modifications,
+including but not limited to software source code, documentation
+source, and configuration files.
+
+"Object" form shall mean any form resulting from mechanical
+transformation or translation of a Source form, including but
+not limited to compiled object code, generated documentation,
+and conversions to other media types.
+
+"Work" shall mean the work of authorship, whether in Source or
+Object form, made available under the License, as indicated by a
+copyright notice that is included in or attached to the work
+(an example is provided in the Appendix below).
+
+"Derivative Works" shall mean any work, whether in Source or Object
+form, that is based on (or derived from) the Work and for which the
+editorial revisions, annotations, elaborations, or other modifications
+represent, as a whole, an original work of authorship. For the purposes
+of this License, Derivative Works shall not include works that remain
+separable from, or merely link (or bind by name) to the interfaces of,
+the Work and Derivative Works thereof.
+
+"Contribution" shall mean any work of authorship, including
+the original version of the Work and any modifications or additions
+to that Work or Derivative Works thereof, that is intentionally
+submitted to Licensor for inclusion in the Work by the copyright owner
+or by an individual or Legal Entity authorized to submit on behalf of
+the copyright owner. For the purposes of this definition, "submitted"
+means any form of electronic, verbal, or written communication sent
+to the Licensor or its representatives, including but not limited to
+communication on electronic mailing lists, source code control systems,
+and issue tracking systems that are managed by, or on behalf of, the
+Licensor for the purpose of discussing and improving the Work, but
+excluding communication that is conspicuously marked or otherwise
+designated in writing by the copyright owner as "Not a Contribution."
+
+"Contributor" shall mean Licensor and any individual or Legal Entity
+on behalf of whom a Contribution has been received by Licensor and
+subsequently incorporated within the Work.
+
+2. Grant of Copyright License. Subject to the terms and conditions of
+this License, each Contributor hereby grants to You a perpetual,
+worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+copyright license to reproduce, prepare Derivative Works of,
+publicly display, publicly perform, sublicense, and distribute the
+Work and such Derivative Works in Source or Object form.
+
+3. Grant of Patent License. Subject to the terms and conditions of
+this License, each Contributor hereby grants to You a perpetual,
+worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+(except as stated in this section) patent license to make, have made,
+use, offer to sell, sell, import, and otherwise transfer the Work,
+where such license applies only to those patent claims licensable
+by such Contributor that are necessarily infringed by their
+Contribution(s) alone or by combination of their Contribution(s)
+with the Work to which such Contribution(s) was submitted. If You
+institute patent litigation against any entity (including a
+cross-claim or counterclaim in a lawsuit) alleging that the Work
+or a Contribution incorporated within the Work constitutes direct
+or contributory patent infringement, then any patent licenses
+granted to You under this License for that Work shall terminate
+as of the date such litigation is filed.
+
+4. Redistribution. You may reproduce and distribute copies of the
+Work or Derivative Works thereof in any medium, with or without
+modifications, and in Source or Object form, provided that You
+meet the following conditions:
+
+(a) You must give any other recipients of the Work or
+Derivative Works a copy of this License; and
+
+(b) You must cause any modified files to carry prominent notices
+stating that You changed the files; and
+
+(c) You must retain, in the Source form of any Derivative Works
+that You distribute, all copyright, patent, trademark, and
+attribution notices from the Source form of the Work,
+excluding those notices that do not pertain to any part of
+the Derivative Works; and
+
+(d) If the Work includes a "NOTICE" text file as part of its
+distribution, then any Derivative Works that You distribute must
+include a readable copy of the attribution notices contained
+within such NOTICE file, excluding those notices that do not
+pertain to any part of the Derivative Works, in at least one
+of the following places: within a NOTICE text file distributed
+as part of the Derivative Works; within the Source form or
+documentation, if provided along with the Derivative Works; or,
+within a display generated by the Derivative Works, if and
+wherever such third-party notices normally appear. The contents
+of the NOTICE file are for informational purposes only and
+do not modify the License. You may add Your own attribution
+notices within Derivative Works that You distribute, alongside
+or as an addendum to the NOTICE text from the Work, provided
+that such additional attribution notices cannot be construed
+as modifying the License.
+
+You may add Your own copyright statement to Your modifications and
+may provide additional or different license terms and conditions
+for use, reproduction, or distribution of Your modifications, or
+for any such Derivative Works as a whole, provided Your use,
+reproduction, and distribution of the Work otherwise complies with
+the conditions stated in this License.
+
+5. Submission of Contributions. Unless You explicitly state otherwise,
+any Contribution intentionally submitted for inclusion in the Work
+by You to the Licensor shall be under the terms and conditions of
+this License, without any additional terms or conditions.
+Notwithstanding the above, nothing herein shall supersede or modify
+the terms of any separate license agreement you may have executed
+with Licensor regarding such Contributions.
+
+6. Trademarks. This License does not grant permission to use the trade
+names, trademarks, service marks, or product names of the Licensor,
+except as required for reasonable and customary use in describing the
+origin of the Work and reproducing the content of the NOTICE file.
+
+7. Disclaimer of Warranty. Unless required by applicable law or
+agreed to in writing, Licensor provides the Work (and each
+Contributor provides its Contributions) on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+implied, including, without limitation, any warranties or conditions
+of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+PARTICULAR PURPOSE. You are solely responsible for determining the
+appropriateness of using or redistributing the Work and assume any
+risks associated with Your exercise of permissions under this License.
+
+8. Limitation of Liability. In no event and under no legal theory,
+whether in tort (including negligence), contract, or otherwise,
+unless required by applicable law (such as deliberate and grossly
+negligent acts) or agreed to in writing, shall any Contributor be
+liable to You for damages, including any direct, indirect, special,
+incidental, or consequential damages of any character arising as a
+result of this License or out of the use or inability to use the
+Work (including but not limited to damages for loss of goodwill,
+work stoppage, computer failure or malfunction, or any and all
+other commercial damages or losses), even if such Contributor
+has been advised of the possibility of such damages.
+
+9. Accepting Warranty or Additional Liability. While redistributing
+the Work or Derivative Works thereof, You may choose to offer,
+and charge a fee for, acceptance of support, warranty, indemnity,
+or other liability obligations and/or rights consistent with this
+License. However, in accepting such obligations, You may act only
+on Your own behalf and on Your sole responsibility, not on behalf
+of any other Contributor, and only if You agree to indemnify,
+defend, and hold each Contributor harmless for any liability
+incurred by, or claims asserted against, such Contributor by reason
+of your accepting any such warranty or additional liability.
+
+END OF TERMS AND CONDITIONS
+
+APPENDIX: How to apply the Apache License to your work.
+
+To apply the Apache License to your work, attach the following
+boilerplate notice, with the fields enclosed by brackets "[]"
+replaced with your own identifying information. (Don't include
+the brackets!) The text should be enclosed in the appropriate
+comment syntax for the file format. We also recommend that a
+file or class name and description of purpose be included on the
+same "printed page" as the copyright notice for easier
+identification within third-party archives.
+
+Copyright [yyyy] [name of copyright owner]
+
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
diff --git a/vendor/detectron2/MODEL_ZOO.md b/vendor/detectron2/MODEL_ZOO.md
new file mode 100644
index 0000000000000000000000000000000000000000..69db2728563c680e89a0d5d3e6ba272b8d78bdbd
--- /dev/null
+++ b/vendor/detectron2/MODEL_ZOO.md
@@ -0,0 +1,1052 @@
+# Detectron2 Model Zoo and Baselines
+
+## Introduction
+
+This file documents a large collection of baselines trained
+with detectron2 in Sep-Oct, 2019.
+All numbers were obtained on [Big Basin](https://engineering.fb.com/data-center-engineering/introducing-big-basin-our-next-generation-ai-hardware/)
+servers with 8 NVIDIA V100 GPUs & NVLink. The speed numbers are periodically updated with latest PyTorch/CUDA/cuDNN versions.
+You can access these models from code using [detectron2.model_zoo](https://detectron2.readthedocs.io/modules/model_zoo.html) APIs.
+
+In addition to these official baseline models, you can find more models in [projects/](projects/).
+
+#### How to Read the Tables
+* The "Name" column contains a link to the config file. Models can be reproduced using `tools/train_net.py` with the corresponding yaml config file,
+ or `tools/lazyconfig_train_net.py` for python config files.
+* Training speed is averaged across the entire training.
+ We keep updating the speed with latest version of detectron2/pytorch/etc.,
+ so they might be different from the `metrics` file.
+ Training speed for multi-machine jobs is not provided.
+* Inference speed is measured by `tools/train_net.py --eval-only`, or [inference_on_dataset()](https://detectron2.readthedocs.io/modules/evaluation.html#detectron2.evaluation.inference_on_dataset),
+ with batch size 1 in detectron2 directly.
+ Measuring it with custom code may introduce other overhead.
+ Actual deployment in production should in general be faster than the given inference
+ speed due to more optimizations.
+* The *model id* column is provided for ease of reference.
+ To check downloaded file integrity, any model on this page contains its md5 prefix in its file name.
+* Training curves and other statistics can be found in `metrics` for each model.
+
+#### Common Settings for COCO Models
+* All COCO models were trained on `train2017` and evaluated on `val2017`.
+* The default settings are __not directly comparable__ with Detectron's standard settings.
+ For example, our default training data augmentation uses scale jittering in addition to horizontal flipping.
+
+ To make fair comparisons with Detectron's settings, see
+ [Detectron1-Comparisons](configs/Detectron1-Comparisons/) for accuracy comparison,
+ and [benchmarks](https://detectron2.readthedocs.io/notes/benchmarks.html)
+ for speed comparison.
+* For Faster/Mask R-CNN, we provide baselines based on __3 different backbone combinations__:
+ * __FPN__: Use a ResNet+FPN backbone with standard conv and FC heads for mask and box prediction,
+ respectively. It obtains the best
+ speed/accuracy tradeoff, but the other two are still useful for research.
+ * __C4__: Use a ResNet conv4 backbone with conv5 head. The original baseline in the Faster R-CNN paper.
+ * __DC5__ (Dilated-C5): Use a ResNet conv5 backbone with dilations in conv5, and standard conv and FC heads
+ for mask and box prediction, respectively.
+ This is used by the Deformable ConvNet paper.
+* Most models are trained with the 3x schedule (~37 COCO epochs).
+ Although 1x models are heavily under-trained, we provide some ResNet-50 models with the 1x (~12 COCO epochs)
+ training schedule for comparison when doing quick research iteration.
+
+#### ImageNet Pretrained Models
+
+It's common to initialize from backbone models pre-trained on ImageNet classification tasks. The following backbone models are available:
+
+* [R-50.pkl](https://dl.fbaipublicfiles.com/detectron2/ImageNetPretrained/MSRA/R-50.pkl): converted copy of [MSRA's original ResNet-50](https://github.com/KaimingHe/deep-residual-networks) model.
+* [R-101.pkl](https://dl.fbaipublicfiles.com/detectron2/ImageNetPretrained/MSRA/R-101.pkl): converted copy of [MSRA's original ResNet-101](https://github.com/KaimingHe/deep-residual-networks) model.
+* [X-101-32x8d.pkl](https://dl.fbaipublicfiles.com/detectron2/ImageNetPretrained/FAIR/X-101-32x8d.pkl): ResNeXt-101-32x8d model trained with Caffe2 at FB.
+* [R-50.pkl (torchvision)](https://dl.fbaipublicfiles.com/detectron2/ImageNetPretrained/torchvision/R-50.pkl): converted copy of [torchvision's ResNet-50](https://pytorch.org/docs/stable/torchvision/models.html#torchvision.models.resnet50) model.
+ More details can be found in [the conversion script](tools/convert-torchvision-to-d2.py).
+
+Note that the above models have __different__ format from those provided in Detectron: we do not fuse BatchNorm into an affine layer.
+Pretrained models in Detectron's format can still be used. For example:
+* [X-152-32x8d-IN5k.pkl](https://dl.fbaipublicfiles.com/detectron/ImageNetPretrained/25093814/X-152-32x8d-IN5k.pkl):
+ ResNeXt-152-32x8d model trained on ImageNet-5k with Caffe2 at FB (see ResNeXt paper for details on ImageNet-5k).
+* [R-50-GN.pkl](https://dl.fbaipublicfiles.com/detectron/ImageNetPretrained/47261647/R-50-GN.pkl):
+ ResNet-50 with Group Normalization.
+* [R-101-GN.pkl](https://dl.fbaipublicfiles.com/detectron/ImageNetPretrained/47592356/R-101-GN.pkl):
+ ResNet-101 with Group Normalization.
+
+These models require slightly different settings regarding normalization and architecture. See the model zoo configs for reference.
+
+#### License
+
+All models available for download through this document are licensed under the
+[Creative Commons Attribution-ShareAlike 3.0 license](https://creativecommons.org/licenses/by-sa/3.0/).
+
+### COCO Object Detection Baselines
+
+#### Faster R-CNN:
+
+
+
++"library not found for -lstdc++" on older version of MacOS +
++ +See [this stackoverflow answer](https://stackoverflow.com/questions/56083725/macos-build-issues-lstdc-not-found-while-building-python-package). + +
| Name | +lr sched |
+train time (s/iter) |
+inference time (s/im) |
+train mem (GB) |
+box AP |
+model id | +download | + + +
|---|---|---|---|---|---|---|---|
| R50-C4 | +1x | +0.551 | +0.102 | +4.8 | +35.7 | +137257644 | +model | metrics | +
| R50-DC5 | +1x | +0.380 | +0.068 | +5.0 | +37.3 | +137847829 | +model | metrics | +
| R50-FPN | +1x | +0.210 | +0.038 | +3.0 | +37.9 | +137257794 | +model | metrics | +
| R50-C4 | +3x | +0.543 | +0.104 | +4.8 | +38.4 | +137849393 | +model | metrics | +
| R50-DC5 | +3x | +0.378 | +0.070 | +5.0 | +39.0 | +137849425 | +model | metrics | +
| R50-FPN | +3x | +0.209 | +0.038 | +3.0 | +40.2 | +137849458 | +model | metrics | +
| R101-C4 | +3x | +0.619 | +0.139 | +5.9 | +41.1 | +138204752 | +model | metrics | +
| R101-DC5 | +3x | +0.452 | +0.086 | +6.1 | +40.6 | +138204841 | +model | metrics | +
| R101-FPN | +3x | +0.286 | +0.051 | +4.1 | +42.0 | +137851257 | +model | metrics | +
| X101-FPN | +3x | +0.638 | +0.098 | +6.7 | +43.0 | +139173657 | +model | metrics | +
| Name | +lr sched |
+train time (s/iter) |
+inference time (s/im) |
+train mem (GB) |
+box AP |
+model id | +download | + + +
|---|---|---|---|---|---|---|---|
| R50 | +1x | +0.205 | +0.041 | +4.1 | +37.4 | +190397773 | +model | metrics | +
| R50 | +3x | +0.205 | +0.041 | +4.1 | +38.7 | +190397829 | +model | metrics | +
| R101 | +3x | +0.291 | +0.054 | +5.2 | +40.4 | +190397697 | +model | metrics | +
| Name | +lr sched |
+train time (s/iter) |
+inference time (s/im) |
+train mem (GB) |
+box AP |
+prop. AR |
+model id | +download | + + +
|---|---|---|---|---|---|---|---|---|
| RPN R50-C4 | +1x | +0.130 | +0.034 | +1.5 | ++ | 51.6 | +137258005 | +model | metrics | +
| RPN R50-FPN | +1x | +0.186 | +0.032 | +2.7 | ++ | 58.0 | +137258492 | +model | metrics | +
| Fast R-CNN R50-FPN | +1x | +0.140 | +0.029 | +2.6 | +37.8 | ++ | 137635226 | +model | metrics | +
| Name | +lr sched |
+train time (s/iter) |
+inference time (s/im) |
+train mem (GB) |
+box AP |
+mask AP |
+model id | +download | + + +
|---|---|---|---|---|---|---|---|---|
| R50-C4 | +1x | +0.584 | +0.110 | +5.2 | +36.8 | +32.2 | +137259246 | +model | metrics | +
| R50-DC5 | +1x | +0.471 | +0.076 | +6.5 | +38.3 | +34.2 | +137260150 | +model | metrics | +
| R50-FPN | +1x | +0.261 | +0.043 | +3.4 | +38.6 | +35.2 | +137260431 | +model | metrics | +
| R50-C4 | +3x | +0.575 | +0.111 | +5.2 | +39.8 | +34.4 | +137849525 | +model | metrics | +
| R50-DC5 | +3x | +0.470 | +0.076 | +6.5 | +40.0 | +35.9 | +137849551 | +model | metrics | +
| R50-FPN | +3x | +0.261 | +0.043 | +3.4 | +41.0 | +37.2 | +137849600 | +model | metrics | +
| R101-C4 | +3x | +0.652 | +0.145 | +6.3 | +42.6 | +36.7 | +138363239 | +model | metrics | +
| R101-DC5 | +3x | +0.545 | +0.092 | +7.6 | +41.9 | +37.3 | +138363294 | +model | metrics | +
| R101-FPN | +3x | +0.340 | +0.056 | +4.6 | +42.9 | +38.6 | +138205316 | +model | metrics | +
| X101-FPN | +3x | +0.690 | +0.103 | +7.2 | +44.3 | +39.5 | +139653917 | +model | metrics | +
| Name | +epochs | +train time (s/im) |
+inference time (s/im) |
+box AP |
+mask AP |
+model id | +download | + + +
|---|---|---|---|---|---|---|---|
| R50-FPN | +100 | +0.376 | +0.069 | +44.6 | +40.3 | +42047764 | +model | metrics | +
| R50-FPN | +200 | +0.376 | +0.069 | +46.3 | +41.7 | +42047638 | +model | metrics | +
| R50-FPN | +400 | +0.376 | +0.069 | +47.4 | +42.5 | +42019571 | +model | metrics | +
| R101-FPN | +100 | +0.518 | +0.073 | +46.4 | +41.6 | +42025812 | +model | metrics | +
| R101-FPN | +200 | +0.518 | +0.073 | +48.0 | +43.1 | +42131867 | +model | metrics | +
| R101-FPN | +400 | +0.518 | +0.073 | +48.9 | +43.7 | +42073830 | +model | metrics | +
| regnetx_4gf_dds_FPN | +100 | +0.474 | +0.071 | +46.0 | +41.3 | +42047771 | +model | metrics | +
| regnetx_4gf_dds_FPN | +200 | +0.474 | +0.071 | +48.1 | +43.1 | +42132721 | +model | metrics | +
| regnetx_4gf_dds_FPN | +400 | +0.474 | +0.071 | +48.6 | +43.5 | +42025447 | +model | metrics | +
| regnety_4gf_dds_FPN | +100 | +0.487 | +0.073 | +46.1 | +41.6 | +42047784 | +model | metrics | +
| regnety_4gf_dds_FPN | +200 | +0.487 | +0.072 | +47.8 | +43.0 | +42047642 | +model | metrics | +
| regnety_4gf_dds_FPN | +400 | +0.487 | +0.072 | +48.2 | +43.3 | +42045954 | +model | metrics | +
| Name | +lr sched |
+train time (s/iter) |
+inference time (s/im) |
+train mem (GB) |
+box AP |
+kp. AP |
+model id | +download | + + +
|---|---|---|---|---|---|---|---|---|
| R50-FPN | +1x | +0.315 | +0.072 | +5.0 | +53.6 | +64.0 | +137261548 | +model | metrics | +
| R50-FPN | +3x | +0.316 | +0.066 | +5.0 | +55.4 | +65.5 | +137849621 | +model | metrics | +
| R101-FPN | +3x | +0.390 | +0.076 | +6.1 | +56.4 | +66.1 | +138363331 | +model | metrics | +
| X101-FPN | +3x | +0.738 | +0.121 | +8.7 | +57.3 | +66.0 | +139686956 | +model | metrics | +
| Name | +lr sched |
+train time (s/iter) |
+inference time (s/im) |
+train mem (GB) |
+box AP |
+mask AP |
+PQ | +model id | +download | + + +
|---|---|---|---|---|---|---|---|---|---|
| R50-FPN | +1x | +0.304 | +0.053 | +4.8 | +37.6 | +34.7 | +39.4 | +139514544 | +model | metrics | +
| R50-FPN | +3x | +0.302 | +0.053 | +4.8 | +40.0 | +36.5 | +41.5 | +139514569 | +model | metrics | +
| R101-FPN | +3x | +0.392 | +0.066 | +6.0 | +42.4 | +38.5 | +43.0 | +139514519 | +model | metrics | +
| Name | +lr sched |
+train time (s/iter) |
+inference time (s/im) |
+train mem (GB) |
+box AP |
+mask AP |
+model id | +download | + + +
|---|---|---|---|---|---|---|---|---|
| R50-FPN | +1x | +0.292 | +0.107 | +7.1 | +23.6 | +24.4 | +144219072 | +model | metrics | +
| R101-FPN | +1x | +0.371 | +0.114 | +7.8 | +25.6 | +25.9 | +144219035 | +model | metrics | +
| X101-FPN | +1x | +0.712 | +0.151 | +10.2 | +26.7 | +27.1 | +144219108 | +model | metrics | +
| Name | +train time (s/iter) |
+inference time (s/im) |
+train mem (GB) |
+box AP |
+box AP50 |
+mask AP |
+model id | +download | + + +
|---|---|---|---|---|---|---|---|---|
| R50-FPN, Cityscapes | +0.240 | +0.078 | +4.4 | ++ | + | 36.5 | +142423278 | +model | metrics | +
| R50-C4, VOC | +0.537 | +0.081 | +4.8 | +51.9 | +80.3 | ++ | 142202221 | +model | metrics | +
| Name | +lr sched |
+train time (s/iter) |
+inference time (s/im) |
+train mem (GB) |
+box AP |
+mask AP |
+model id | +download | + + +
|---|---|---|---|---|---|---|---|---|
| Baseline R50-FPN | +1x | +0.261 | +0.043 | +3.4 | +38.6 | +35.2 | +137260431 | +model | metrics | +
| Deformable Conv | +1x | +0.342 | +0.048 | +3.5 | +41.5 | +37.5 | +138602867 | +model | metrics | +
| Cascade R-CNN | +1x | +0.317 | +0.052 | +4.0 | +42.1 | +36.4 | +138602847 | +model | metrics | +
| Baseline R50-FPN | +3x | +0.261 | +0.043 | +3.4 | +41.0 | +37.2 | +137849600 | +model | metrics | +
| Deformable Conv | +3x | +0.349 | +0.047 | +3.5 | +42.7 | +38.5 | +144998336 | +model | metrics | +
| Cascade R-CNN | +3x | +0.328 | +0.053 | +4.0 | +44.3 | +38.5 | +144998488 | +model | metrics | +
| Name | +lr sched |
+train time (s/iter) |
+inference time (s/im) |
+train mem (GB) |
+box AP |
+mask AP |
+model id | +download | + + +
|---|---|---|---|---|---|---|---|---|
| Baseline R50-FPN | +3x | +0.261 | +0.043 | +3.4 | +41.0 | +37.2 | +137849600 | +model | metrics | +
| GN | +3x | +0.309 | +0.060 | +5.6 | +42.6 | +38.6 | +138602888 | +model | metrics | +
| SyncBN | +3x | +0.345 | +0.053 | +5.5 | +41.9 | +37.8 | +169527823 | +model | metrics | +
| GN (from scratch) | +3x | +0.338 | +0.061 | +7.2 | +39.9 | +36.6 | +138602908 | +model | metrics | +
| GN (from scratch) | +9x | +N/A | +0.061 | +7.2 | +43.7 | +39.6 | +183808979 | +model | metrics | +
| SyncBN (from scratch) | +9x | +N/A | +0.055 | +7.2 | +43.6 | +39.3 | +184226666 | +model | metrics | +
| Name | +inference time (s/im) |
+train mem (GB) |
+box AP |
+mask AP |
+PQ | +model id | +download | + + +
|---|---|---|---|---|---|---|---|
| Panoptic FPN R101 | +0.098 | +11.4 | +47.4 | +41.3 | +46.1 | +139797668 | +model | metrics | +
| Mask R-CNN X152 | +0.234 | +15.1 | +50.2 | +44.0 | ++ | 18131413 | +model | metrics | +
| above + test-time aug. | ++ | + | 51.9 | +45.9 | ++ | + | + |
+  +
+
+
++ +## Learn More about Detectron2 + +Explain Like I’m 5: Detectron2 | Using Machine Learning with Detectron2 +:-------------------------:|:-------------------------: +[](https://www.youtube.com/watch?v=1oq1Ye7dFqc) | [](https://www.youtube.com/watch?v=eUSgtfK4ivk) + +## What's New +* Includes new capabilities such as panoptic segmentation, Densepose, Cascade R-CNN, rotated bounding boxes, PointRend, + DeepLab, ViTDet, MViTv2 etc. +* Used as a library to support building [research projects](projects/) on top of it. +* Models can be exported to TorchScript format or Caffe2 format for deployment. +* It [trains much faster](https://detectron2.readthedocs.io/notes/benchmarks.html). + +See our [blog post](https://ai.facebook.com/blog/-detectron2-a-pytorch-based-modular-object-detection-library-/) +to see more demos and learn about detectron2. + +## Installation + +See [installation instructions](https://detectron2.readthedocs.io/tutorials/install.html). + +## Getting Started + +See [Getting Started with Detectron2](https://detectron2.readthedocs.io/tutorials/getting_started.html), +and the [Colab Notebook](https://colab.research.google.com/drive/16jcaJoc6bCFAQ96jDe2HwtXj7BMD_-m5) +to learn about basic usage. + +Learn more at our [documentation](https://detectron2.readthedocs.org). +And see [projects/](projects/) for some projects that are built on top of detectron2. + +## Model Zoo and Baselines + +We provide a large set of baseline results and trained models available for download in the [Detectron2 Model Zoo](MODEL_ZOO.md). + +## License + +Detectron2 is released under the [Apache 2.0 license](LICENSE). + +## Citing Detectron2 + +If you use Detectron2 in your research or wish to refer to the baseline results published in the [Model Zoo](MODEL_ZOO.md), please use the following BibTeX entry. + +```BibTeX +@misc{wu2019detectron2, + author = {Yuxin Wu and Alexander Kirillov and Francisco Massa and + Wan-Yen Lo and Ross Girshick}, + title = {Detectron2}, + howpublished = {\url{https://github.com/facebookresearch/detectron2}}, + year = {2019} +} +``` diff --git a/vendor/detectron2/configs/Base-RCNN-C4.yaml b/vendor/detectron2/configs/Base-RCNN-C4.yaml new file mode 100644 index 0000000000000000000000000000000000000000..fbf34a0ea57a587e09997edd94c4012d69d0b6ad --- /dev/null +++ b/vendor/detectron2/configs/Base-RCNN-C4.yaml @@ -0,0 +1,18 @@ +MODEL: + META_ARCHITECTURE: "GeneralizedRCNN" + RPN: + PRE_NMS_TOPK_TEST: 6000 + POST_NMS_TOPK_TEST: 1000 + ROI_HEADS: + NAME: "Res5ROIHeads" +DATASETS: + TRAIN: ("coco_2017_train",) + TEST: ("coco_2017_val",) +SOLVER: + IMS_PER_BATCH: 16 + BASE_LR: 0.02 + STEPS: (60000, 80000) + MAX_ITER: 90000 +INPUT: + MIN_SIZE_TRAIN: (640, 672, 704, 736, 768, 800) +VERSION: 2 diff --git a/vendor/detectron2/configs/Base-RCNN-DilatedC5.yaml b/vendor/detectron2/configs/Base-RCNN-DilatedC5.yaml new file mode 100644 index 0000000000000000000000000000000000000000..c0d6d16bdaf532f09e4976f0aa240a49e748da27 --- /dev/null +++ b/vendor/detectron2/configs/Base-RCNN-DilatedC5.yaml @@ -0,0 +1,31 @@ +MODEL: + META_ARCHITECTURE: "GeneralizedRCNN" + RESNETS: + OUT_FEATURES: ["res5"] + RES5_DILATION: 2 + RPN: + IN_FEATURES: ["res5"] + PRE_NMS_TOPK_TEST: 6000 + POST_NMS_TOPK_TEST: 1000 + ROI_HEADS: + NAME: "StandardROIHeads" + IN_FEATURES: ["res5"] + ROI_BOX_HEAD: + NAME: "FastRCNNConvFCHead" + NUM_FC: 2 + POOLER_RESOLUTION: 7 + ROI_MASK_HEAD: + NAME: "MaskRCNNConvUpsampleHead" + NUM_CONV: 4 + POOLER_RESOLUTION: 14 +DATASETS: + TRAIN: ("coco_2017_train",) + TEST: ("coco_2017_val",) +SOLVER: + IMS_PER_BATCH: 16 + BASE_LR: 0.02 + STEPS: (60000, 80000) + MAX_ITER: 90000 +INPUT: + MIN_SIZE_TRAIN: (640, 672, 704, 736, 768, 800) +VERSION: 2 diff --git a/vendor/detectron2/configs/Base-RCNN-FPN.yaml b/vendor/detectron2/configs/Base-RCNN-FPN.yaml new file mode 100644 index 0000000000000000000000000000000000000000..3e020f2e7b2f26765be317f907126a1556621abf --- /dev/null +++ b/vendor/detectron2/configs/Base-RCNN-FPN.yaml @@ -0,0 +1,42 @@ +MODEL: + META_ARCHITECTURE: "GeneralizedRCNN" + BACKBONE: + NAME: "build_resnet_fpn_backbone" + RESNETS: + OUT_FEATURES: ["res2", "res3", "res4", "res5"] + FPN: + IN_FEATURES: ["res2", "res3", "res4", "res5"] + ANCHOR_GENERATOR: + SIZES: [[32], [64], [128], [256], [512]] # One size for each in feature map + ASPECT_RATIOS: [[0.5, 1.0, 2.0]] # Three aspect ratios (same for all in feature maps) + RPN: + IN_FEATURES: ["p2", "p3", "p4", "p5", "p6"] + PRE_NMS_TOPK_TRAIN: 2000 # Per FPN level + PRE_NMS_TOPK_TEST: 1000 # Per FPN level + # Detectron1 uses 2000 proposals per-batch, + # (See "modeling/rpn/rpn_outputs.py" for details of this legacy issue) + # which is approximately 1000 proposals per-image since the default batch size for FPN is 2. + POST_NMS_TOPK_TRAIN: 1000 + POST_NMS_TOPK_TEST: 1000 + ROI_HEADS: + NAME: "StandardROIHeads" + IN_FEATURES: ["p2", "p3", "p4", "p5"] + ROI_BOX_HEAD: + NAME: "FastRCNNConvFCHead" + NUM_FC: 2 + POOLER_RESOLUTION: 7 + ROI_MASK_HEAD: + NAME: "MaskRCNNConvUpsampleHead" + NUM_CONV: 4 + POOLER_RESOLUTION: 14 +DATASETS: + TRAIN: ("coco_2017_train",) + TEST: ("coco_2017_val",) +SOLVER: + IMS_PER_BATCH: 16 + BASE_LR: 0.02 + STEPS: (60000, 80000) + MAX_ITER: 90000 +INPUT: + MIN_SIZE_TRAIN: (640, 672, 704, 736, 768, 800) +VERSION: 2 diff --git a/vendor/detectron2/configs/Base-RetinaNet.yaml b/vendor/detectron2/configs/Base-RetinaNet.yaml new file mode 100644 index 0000000000000000000000000000000000000000..8b45b982bbf84b34d2a6a172ab0a946b1029f7c8 --- /dev/null +++ b/vendor/detectron2/configs/Base-RetinaNet.yaml @@ -0,0 +1,25 @@ +MODEL: + META_ARCHITECTURE: "RetinaNet" + BACKBONE: + NAME: "build_retinanet_resnet_fpn_backbone" + RESNETS: + OUT_FEATURES: ["res3", "res4", "res5"] + ANCHOR_GENERATOR: + SIZES: !!python/object/apply:eval ["[[x, x * 2**(1.0/3), x * 2**(2.0/3) ] for x in [32, 64, 128, 256, 512 ]]"] + FPN: + IN_FEATURES: ["res3", "res4", "res5"] + RETINANET: + IOU_THRESHOLDS: [0.4, 0.5] + IOU_LABELS: [0, -1, 1] + SMOOTH_L1_LOSS_BETA: 0.0 +DATASETS: + TRAIN: ("coco_2017_train",) + TEST: ("coco_2017_val",) +SOLVER: + IMS_PER_BATCH: 16 + BASE_LR: 0.01 # Note that RetinaNet uses a different default learning rate + STEPS: (60000, 80000) + MAX_ITER: 90000 +INPUT: + MIN_SIZE_TRAIN: (640, 672, 704, 736, 768, 800) +VERSION: 2 diff --git a/vendor/detectron2/configs/COCO-Detection/fast_rcnn_R_50_FPN_1x.yaml b/vendor/detectron2/configs/COCO-Detection/fast_rcnn_R_50_FPN_1x.yaml new file mode 100644 index 0000000000000000000000000000000000000000..773ac10e87c626760d00d831bf664ce9ff073c49 --- /dev/null +++ b/vendor/detectron2/configs/COCO-Detection/fast_rcnn_R_50_FPN_1x.yaml @@ -0,0 +1,17 @@ +_BASE_: "../Base-RCNN-FPN.yaml" +MODEL: + WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-50.pkl" + MASK_ON: False + LOAD_PROPOSALS: True + RESNETS: + DEPTH: 50 + PROPOSAL_GENERATOR: + NAME: "PrecomputedProposals" +DATASETS: + TRAIN: ("coco_2017_train",) + PROPOSAL_FILES_TRAIN: ("detectron2://COCO-Detection/rpn_R_50_FPN_1x/137258492/coco_2017_train_box_proposals_21bc3a.pkl", ) + TEST: ("coco_2017_val",) + PROPOSAL_FILES_TEST: ("detectron2://COCO-Detection/rpn_R_50_FPN_1x/137258492/coco_2017_val_box_proposals_ee0dad.pkl", ) +DATALOADER: + # proposals are part of the dataset_dicts, and take a lot of RAM + NUM_WORKERS: 2 diff --git a/vendor/detectron2/configs/COCO-Detection/faster_rcnn_R_101_C4_3x.yaml b/vendor/detectron2/configs/COCO-Detection/faster_rcnn_R_101_C4_3x.yaml new file mode 100644 index 0000000000000000000000000000000000000000..db142cd671c1841b4f64cf130bee7f7954ecdd28 --- /dev/null +++ b/vendor/detectron2/configs/COCO-Detection/faster_rcnn_R_101_C4_3x.yaml @@ -0,0 +1,9 @@ +_BASE_: "../Base-RCNN-C4.yaml" +MODEL: + WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-101.pkl" + MASK_ON: False + RESNETS: + DEPTH: 101 +SOLVER: + STEPS: (210000, 250000) + MAX_ITER: 270000 diff --git a/vendor/detectron2/configs/COCO-Detection/faster_rcnn_R_101_DC5_3x.yaml b/vendor/detectron2/configs/COCO-Detection/faster_rcnn_R_101_DC5_3x.yaml new file mode 100644 index 0000000000000000000000000000000000000000..bceb6b343618d8cd9a6c414ff9eb86ab31cc230a --- /dev/null +++ b/vendor/detectron2/configs/COCO-Detection/faster_rcnn_R_101_DC5_3x.yaml @@ -0,0 +1,9 @@ +_BASE_: "../Base-RCNN-DilatedC5.yaml" +MODEL: + WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-101.pkl" + MASK_ON: False + RESNETS: + DEPTH: 101 +SOLVER: + STEPS: (210000, 250000) + MAX_ITER: 270000 diff --git a/vendor/detectron2/configs/COCO-Detection/faster_rcnn_R_101_FPN_3x.yaml b/vendor/detectron2/configs/COCO-Detection/faster_rcnn_R_101_FPN_3x.yaml new file mode 100644 index 0000000000000000000000000000000000000000..57a098f53ee8c54ecfa354cc96efefd890dc1b72 --- /dev/null +++ b/vendor/detectron2/configs/COCO-Detection/faster_rcnn_R_101_FPN_3x.yaml @@ -0,0 +1,9 @@ +_BASE_: "../Base-RCNN-FPN.yaml" +MODEL: + WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-101.pkl" + MASK_ON: False + RESNETS: + DEPTH: 101 +SOLVER: + STEPS: (210000, 250000) + MAX_ITER: 270000 diff --git a/vendor/detectron2/configs/COCO-Detection/faster_rcnn_R_50_C4_1x.yaml b/vendor/detectron2/configs/COCO-Detection/faster_rcnn_R_50_C4_1x.yaml new file mode 100644 index 0000000000000000000000000000000000000000..f96130105c3ba6ab393e0932870903875f5cb732 --- /dev/null +++ b/vendor/detectron2/configs/COCO-Detection/faster_rcnn_R_50_C4_1x.yaml @@ -0,0 +1,6 @@ +_BASE_: "../Base-RCNN-C4.yaml" +MODEL: + WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-50.pkl" + MASK_ON: False + RESNETS: + DEPTH: 50 diff --git a/vendor/detectron2/configs/COCO-Detection/faster_rcnn_R_50_C4_3x.yaml b/vendor/detectron2/configs/COCO-Detection/faster_rcnn_R_50_C4_3x.yaml new file mode 100644 index 0000000000000000000000000000000000000000..bc51bce390a85ee3529ffdcebde05748e1646be0 --- /dev/null +++ b/vendor/detectron2/configs/COCO-Detection/faster_rcnn_R_50_C4_3x.yaml @@ -0,0 +1,9 @@ +_BASE_: "../Base-RCNN-C4.yaml" +MODEL: + WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-50.pkl" + MASK_ON: False + RESNETS: + DEPTH: 50 +SOLVER: + STEPS: (210000, 250000) + MAX_ITER: 270000 diff --git a/vendor/detectron2/configs/COCO-Detection/faster_rcnn_R_50_DC5_1x.yaml b/vendor/detectron2/configs/COCO-Detection/faster_rcnn_R_50_DC5_1x.yaml new file mode 100644 index 0000000000000000000000000000000000000000..0fe96f57febdac5790ea4cec168fa4b97ac4807a --- /dev/null +++ b/vendor/detectron2/configs/COCO-Detection/faster_rcnn_R_50_DC5_1x.yaml @@ -0,0 +1,6 @@ +_BASE_: "../Base-RCNN-DilatedC5.yaml" +MODEL: + WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-50.pkl" + MASK_ON: False + RESNETS: + DEPTH: 50 diff --git a/vendor/detectron2/configs/COCO-Detection/faster_rcnn_R_50_DC5_3x.yaml b/vendor/detectron2/configs/COCO-Detection/faster_rcnn_R_50_DC5_3x.yaml new file mode 100644 index 0000000000000000000000000000000000000000..33fadeb87d1ef67ab2b55926b9a652ab4ac4a27d --- /dev/null +++ b/vendor/detectron2/configs/COCO-Detection/faster_rcnn_R_50_DC5_3x.yaml @@ -0,0 +1,9 @@ +_BASE_: "../Base-RCNN-DilatedC5.yaml" +MODEL: + WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-50.pkl" + MASK_ON: False + RESNETS: + DEPTH: 50 +SOLVER: + STEPS: (210000, 250000) + MAX_ITER: 270000 diff --git a/vendor/detectron2/configs/COCO-Detection/faster_rcnn_R_50_FPN_1x.yaml b/vendor/detectron2/configs/COCO-Detection/faster_rcnn_R_50_FPN_1x.yaml new file mode 100644 index 0000000000000000000000000000000000000000..3262019a1211b910d3b371569199ed1afaacf6a4 --- /dev/null +++ b/vendor/detectron2/configs/COCO-Detection/faster_rcnn_R_50_FPN_1x.yaml @@ -0,0 +1,6 @@ +_BASE_: "../Base-RCNN-FPN.yaml" +MODEL: + WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-50.pkl" + MASK_ON: False + RESNETS: + DEPTH: 50 diff --git a/vendor/detectron2/configs/COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml b/vendor/detectron2/configs/COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml new file mode 100644 index 0000000000000000000000000000000000000000..41395182bf5c9dd8ab1241c4414068817298d554 --- /dev/null +++ b/vendor/detectron2/configs/COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml @@ -0,0 +1,9 @@ +_BASE_: "../Base-RCNN-FPN.yaml" +MODEL: + WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-50.pkl" + MASK_ON: False + RESNETS: + DEPTH: 50 +SOLVER: + STEPS: (210000, 250000) + MAX_ITER: 270000 diff --git a/vendor/detectron2/configs/COCO-Detection/faster_rcnn_X_101_32x8d_FPN_3x.yaml b/vendor/detectron2/configs/COCO-Detection/faster_rcnn_X_101_32x8d_FPN_3x.yaml new file mode 100644 index 0000000000000000000000000000000000000000..9c9b5ab77157baa581d90d9847c045c19ed6ffa3 --- /dev/null +++ b/vendor/detectron2/configs/COCO-Detection/faster_rcnn_X_101_32x8d_FPN_3x.yaml @@ -0,0 +1,13 @@ +_BASE_: "../Base-RCNN-FPN.yaml" +MODEL: + MASK_ON: False + WEIGHTS: "detectron2://ImageNetPretrained/FAIR/X-101-32x8d.pkl" + PIXEL_STD: [57.375, 57.120, 58.395] + RESNETS: + STRIDE_IN_1X1: False # this is a C2 model + NUM_GROUPS: 32 + WIDTH_PER_GROUP: 8 + DEPTH: 101 +SOLVER: + STEPS: (210000, 250000) + MAX_ITER: 270000 diff --git a/vendor/detectron2/configs/COCO-Detection/fcos_R_50_FPN_1x.py b/vendor/detectron2/configs/COCO-Detection/fcos_R_50_FPN_1x.py new file mode 100644 index 0000000000000000000000000000000000000000..86f83c68786f5995c462ade5f3067072d69f047e --- /dev/null +++ b/vendor/detectron2/configs/COCO-Detection/fcos_R_50_FPN_1x.py @@ -0,0 +1,11 @@ +from ..common.optim import SGD as optimizer +from ..common.coco_schedule import lr_multiplier_1x as lr_multiplier +from ..common.data.coco import dataloader +from ..common.models.fcos import model +from ..common.train import train + +dataloader.train.mapper.use_instance_mask = False +optimizer.lr = 0.01 + +model.backbone.bottom_up.freeze_at = 2 +train.init_checkpoint = "detectron2://ImageNetPretrained/MSRA/R-50.pkl" diff --git a/vendor/detectron2/configs/COCO-Detection/retinanet_R_101_FPN_3x.yaml b/vendor/detectron2/configs/COCO-Detection/retinanet_R_101_FPN_3x.yaml new file mode 100644 index 0000000000000000000000000000000000000000..4abb1b9a547957aa6afc0b29129e00f89cf98d59 --- /dev/null +++ b/vendor/detectron2/configs/COCO-Detection/retinanet_R_101_FPN_3x.yaml @@ -0,0 +1,8 @@ +_BASE_: "../Base-RetinaNet.yaml" +MODEL: + WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-101.pkl" + RESNETS: + DEPTH: 101 +SOLVER: + STEPS: (210000, 250000) + MAX_ITER: 270000 diff --git a/vendor/detectron2/configs/COCO-Detection/retinanet_R_50_FPN_1x.py b/vendor/detectron2/configs/COCO-Detection/retinanet_R_50_FPN_1x.py new file mode 100644 index 0000000000000000000000000000000000000000..43057a8eeed38c78183e26d21b74261eb4dbc1b9 --- /dev/null +++ b/vendor/detectron2/configs/COCO-Detection/retinanet_R_50_FPN_1x.py @@ -0,0 +1,11 @@ +from ..common.optim import SGD as optimizer +from ..common.coco_schedule import lr_multiplier_1x as lr_multiplier +from ..common.data.coco import dataloader +from ..common.models.retinanet import model +from ..common.train import train + +dataloader.train.mapper.use_instance_mask = False +model.backbone.bottom_up.freeze_at = 2 +optimizer.lr = 0.01 + +train.init_checkpoint = "detectron2://ImageNetPretrained/MSRA/R-50.pkl" diff --git a/vendor/detectron2/configs/COCO-Detection/retinanet_R_50_FPN_1x.yaml b/vendor/detectron2/configs/COCO-Detection/retinanet_R_50_FPN_1x.yaml new file mode 100644 index 0000000000000000000000000000000000000000..4a24ce3a9a108a8792e18c8aabfb7b712f0d3725 --- /dev/null +++ b/vendor/detectron2/configs/COCO-Detection/retinanet_R_50_FPN_1x.yaml @@ -0,0 +1,5 @@ +_BASE_: "../Base-RetinaNet.yaml" +MODEL: + WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-50.pkl" + RESNETS: + DEPTH: 50 diff --git a/vendor/detectron2/configs/COCO-Detection/retinanet_R_50_FPN_3x.yaml b/vendor/detectron2/configs/COCO-Detection/retinanet_R_50_FPN_3x.yaml new file mode 100644 index 0000000000000000000000000000000000000000..3b5412d4a7aef1d6c3f7c1e34f94007de639b833 --- /dev/null +++ b/vendor/detectron2/configs/COCO-Detection/retinanet_R_50_FPN_3x.yaml @@ -0,0 +1,8 @@ +_BASE_: "../Base-RetinaNet.yaml" +MODEL: + WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-50.pkl" + RESNETS: + DEPTH: 50 +SOLVER: + STEPS: (210000, 250000) + MAX_ITER: 270000 diff --git a/vendor/detectron2/configs/COCO-Detection/rpn_R_50_C4_1x.yaml b/vendor/detectron2/configs/COCO-Detection/rpn_R_50_C4_1x.yaml new file mode 100644 index 0000000000000000000000000000000000000000..e04821156b0376ba5215d5ce5b7010a36b43e6a1 --- /dev/null +++ b/vendor/detectron2/configs/COCO-Detection/rpn_R_50_C4_1x.yaml @@ -0,0 +1,10 @@ +_BASE_: "../Base-RCNN-C4.yaml" +MODEL: + META_ARCHITECTURE: "ProposalNetwork" + WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-50.pkl" + MASK_ON: False + RESNETS: + DEPTH: 50 + RPN: + PRE_NMS_TOPK_TEST: 12000 + POST_NMS_TOPK_TEST: 2000 diff --git a/vendor/detectron2/configs/COCO-Detection/rpn_R_50_FPN_1x.yaml b/vendor/detectron2/configs/COCO-Detection/rpn_R_50_FPN_1x.yaml new file mode 100644 index 0000000000000000000000000000000000000000..dc9c95203b1c3c9cd9bb9876bb8d9a5dd9b31d9a --- /dev/null +++ b/vendor/detectron2/configs/COCO-Detection/rpn_R_50_FPN_1x.yaml @@ -0,0 +1,9 @@ +_BASE_: "../Base-RCNN-FPN.yaml" +MODEL: + META_ARCHITECTURE: "ProposalNetwork" + WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-50.pkl" + MASK_ON: False + RESNETS: + DEPTH: 50 + RPN: + POST_NMS_TOPK_TEST: 2000 diff --git a/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_101_C4_3x.yaml b/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_101_C4_3x.yaml new file mode 100644 index 0000000000000000000000000000000000000000..1a94cc45a0f2aaa8c92e14871c553b736545e327 --- /dev/null +++ b/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_101_C4_3x.yaml @@ -0,0 +1,9 @@ +_BASE_: "../Base-RCNN-C4.yaml" +MODEL: + WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-101.pkl" + MASK_ON: True + RESNETS: + DEPTH: 101 +SOLVER: + STEPS: (210000, 250000) + MAX_ITER: 270000 diff --git a/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_101_DC5_3x.yaml b/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_101_DC5_3x.yaml new file mode 100644 index 0000000000000000000000000000000000000000..67b70cf4be8c19f5dc735b6f55a8690698f34b69 --- /dev/null +++ b/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_101_DC5_3x.yaml @@ -0,0 +1,9 @@ +_BASE_: "../Base-RCNN-DilatedC5.yaml" +MODEL: + WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-101.pkl" + MASK_ON: True + RESNETS: + DEPTH: 101 +SOLVER: + STEPS: (210000, 250000) + MAX_ITER: 270000 diff --git a/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_101_FPN_3x.yaml b/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_101_FPN_3x.yaml new file mode 100644 index 0000000000000000000000000000000000000000..1935a302d2d0fa7f69553b3fd50b5a7082c6c0d1 --- /dev/null +++ b/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_101_FPN_3x.yaml @@ -0,0 +1,9 @@ +_BASE_: "../Base-RCNN-FPN.yaml" +MODEL: + WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-101.pkl" + MASK_ON: True + RESNETS: + DEPTH: 101 +SOLVER: + STEPS: (210000, 250000) + MAX_ITER: 270000 diff --git a/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_C4_1x.py b/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_C4_1x.py new file mode 100644 index 0000000000000000000000000000000000000000..22016be150df4abbe912700d7ca29f8b7b72554a --- /dev/null +++ b/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_C4_1x.py @@ -0,0 +1,8 @@ +from ..common.train import train +from ..common.optim import SGD as optimizer +from ..common.coco_schedule import lr_multiplier_1x as lr_multiplier +from ..common.data.coco import dataloader +from ..common.models.mask_rcnn_c4 import model + +model.backbone.freeze_at = 2 +train.init_checkpoint = "detectron2://ImageNetPretrained/MSRA/R-50.pkl" diff --git a/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_C4_1x.yaml b/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_C4_1x.yaml new file mode 100644 index 0000000000000000000000000000000000000000..a9aeb4eac38026dbb867e799f9fd3a8d8eb3af80 --- /dev/null +++ b/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_C4_1x.yaml @@ -0,0 +1,6 @@ +_BASE_: "../Base-RCNN-C4.yaml" +MODEL: + WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-50.pkl" + MASK_ON: True + RESNETS: + DEPTH: 50 diff --git a/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_C4_3x.yaml b/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_C4_3x.yaml new file mode 100644 index 0000000000000000000000000000000000000000..38ed867d897dfec839cbcf11a2e2dc8abb92f07c --- /dev/null +++ b/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_C4_3x.yaml @@ -0,0 +1,9 @@ +_BASE_: "../Base-RCNN-C4.yaml" +MODEL: + WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-50.pkl" + MASK_ON: True + RESNETS: + DEPTH: 50 +SOLVER: + STEPS: (210000, 250000) + MAX_ITER: 270000 diff --git a/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_DC5_1x.yaml b/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_DC5_1x.yaml new file mode 100644 index 0000000000000000000000000000000000000000..b13eefab2a049c48d94d5051c82ceb6dbde40579 --- /dev/null +++ b/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_DC5_1x.yaml @@ -0,0 +1,6 @@ +_BASE_: "../Base-RCNN-DilatedC5.yaml" +MODEL: + WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-50.pkl" + MASK_ON: True + RESNETS: + DEPTH: 50 diff --git a/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_DC5_3x.yaml b/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_DC5_3x.yaml new file mode 100644 index 0000000000000000000000000000000000000000..d401016358f967f6619d88b1c9bd5673a1cdeba8 --- /dev/null +++ b/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_DC5_3x.yaml @@ -0,0 +1,9 @@ +_BASE_: "../Base-RCNN-DilatedC5.yaml" +MODEL: + WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-50.pkl" + MASK_ON: True + RESNETS: + DEPTH: 50 +SOLVER: + STEPS: (210000, 250000) + MAX_ITER: 270000 diff --git a/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_1x.py b/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_1x.py new file mode 100644 index 0000000000000000000000000000000000000000..40844ddeb8d47ff58a6af49ab35bad84e14f5721 --- /dev/null +++ b/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_1x.py @@ -0,0 +1,8 @@ +from ..common.optim import SGD as optimizer +from ..common.coco_schedule import lr_multiplier_1x as lr_multiplier +from ..common.data.coco import dataloader +from ..common.models.mask_rcnn_fpn import model +from ..common.train import train + +model.backbone.bottom_up.freeze_at = 2 +train.init_checkpoint = "detectron2://ImageNetPretrained/MSRA/R-50.pkl" diff --git a/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_1x.yaml b/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_1x.yaml new file mode 100644 index 0000000000000000000000000000000000000000..d50fb866ca7811a87b42555c7213f88e00bf6df1 --- /dev/null +++ b/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_1x.yaml @@ -0,0 +1,6 @@ +_BASE_: "../Base-RCNN-FPN.yaml" +MODEL: + WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-50.pkl" + MASK_ON: True + RESNETS: + DEPTH: 50 diff --git a/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_1x_giou.yaml b/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_1x_giou.yaml new file mode 100644 index 0000000000000000000000000000000000000000..bec680ee17a474fefe527b7b79d26266e75c09f0 --- /dev/null +++ b/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_1x_giou.yaml @@ -0,0 +1,12 @@ +_BASE_: "../Base-RCNN-FPN.yaml" +MODEL: + WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-50.pkl" + MASK_ON: True + RESNETS: + DEPTH: 50 + RPN: + BBOX_REG_LOSS_TYPE: "giou" + BBOX_REG_LOSS_WEIGHT: 2.0 + ROI_BOX_HEAD: + BBOX_REG_LOSS_TYPE: "giou" + BBOX_REG_LOSS_WEIGHT: 10.0 diff --git a/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml b/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml new file mode 100644 index 0000000000000000000000000000000000000000..be7d06b8e0f032ee7fcaabd7c122158518489fd2 --- /dev/null +++ b/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml @@ -0,0 +1,9 @@ +_BASE_: "../Base-RCNN-FPN.yaml" +MODEL: + WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-50.pkl" + MASK_ON: True + RESNETS: + DEPTH: 50 +SOLVER: + STEPS: (210000, 250000) + MAX_ITER: 270000 diff --git a/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_X_101_32x8d_FPN_3x.yaml b/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_X_101_32x8d_FPN_3x.yaml new file mode 100644 index 0000000000000000000000000000000000000000..d14c63f74383bfc308750f51d51344398b02a239 --- /dev/null +++ b/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_X_101_32x8d_FPN_3x.yaml @@ -0,0 +1,13 @@ +_BASE_: "../Base-RCNN-FPN.yaml" +MODEL: + MASK_ON: True + WEIGHTS: "detectron2://ImageNetPretrained/FAIR/X-101-32x8d.pkl" + PIXEL_STD: [57.375, 57.120, 58.395] + RESNETS: + STRIDE_IN_1X1: False # this is a C2 model + NUM_GROUPS: 32 + WIDTH_PER_GROUP: 8 + DEPTH: 101 +SOLVER: + STEPS: (210000, 250000) + MAX_ITER: 270000 diff --git a/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_regnetx_4gf_dds_fpn_1x.py b/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_regnetx_4gf_dds_fpn_1x.py new file mode 100644 index 0000000000000000000000000000000000000000..d7bbdd7d00505f1e51154379c99ab621cb648a6d --- /dev/null +++ b/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_regnetx_4gf_dds_fpn_1x.py @@ -0,0 +1,34 @@ +from ..common.optim import SGD as optimizer +from ..common.coco_schedule import lr_multiplier_1x as lr_multiplier +from ..common.data.coco import dataloader +from ..common.models.mask_rcnn_fpn import model +from ..common.train import train + +from detectron2.config import LazyCall as L +from detectron2.modeling.backbone import RegNet +from detectron2.modeling.backbone.regnet import SimpleStem, ResBottleneckBlock + + +# Replace default ResNet with RegNetX-4GF from the DDS paper. Config source: +# https://github.com/facebookresearch/pycls/blob/2c152a6e5d913e898cca4f0a758f41e6b976714d/configs/dds_baselines/regnetx/RegNetX-4.0GF_dds_8gpu.yaml#L4-L9 # noqa +model.backbone.bottom_up = L(RegNet)( + stem_class=SimpleStem, + stem_width=32, + block_class=ResBottleneckBlock, + depth=23, + w_a=38.65, + w_0=96, + w_m=2.43, + group_width=40, + freeze_at=2, + norm="FrozenBN", + out_features=["s1", "s2", "s3", "s4"], +) +model.pixel_std = [57.375, 57.120, 58.395] + +optimizer.weight_decay = 5e-5 +train.init_checkpoint = ( + "https://dl.fbaipublicfiles.com/pycls/dds_baselines/160906383/RegNetX-4.0GF_dds_8gpu.pyth" +) +# RegNets benefit from enabling cudnn benchmark mode +train.cudnn_benchmark = True diff --git a/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_regnety_4gf_dds_fpn_1x.py b/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_regnety_4gf_dds_fpn_1x.py new file mode 100644 index 0000000000000000000000000000000000000000..72c6b7a5c8939970bd0e1e4a3c1155695943b19a --- /dev/null +++ b/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_regnety_4gf_dds_fpn_1x.py @@ -0,0 +1,35 @@ +from ..common.optim import SGD as optimizer +from ..common.coco_schedule import lr_multiplier_1x as lr_multiplier +from ..common.data.coco import dataloader +from ..common.models.mask_rcnn_fpn import model +from ..common.train import train + +from detectron2.config import LazyCall as L +from detectron2.modeling.backbone import RegNet +from detectron2.modeling.backbone.regnet import SimpleStem, ResBottleneckBlock + + +# Replace default ResNet with RegNetY-4GF from the DDS paper. Config source: +# https://github.com/facebookresearch/pycls/blob/2c152a6e5d913e898cca4f0a758f41e6b976714d/configs/dds_baselines/regnety/RegNetY-4.0GF_dds_8gpu.yaml#L4-L10 # noqa +model.backbone.bottom_up = L(RegNet)( + stem_class=SimpleStem, + stem_width=32, + block_class=ResBottleneckBlock, + depth=22, + w_a=31.41, + w_0=96, + w_m=2.24, + group_width=64, + se_ratio=0.25, + freeze_at=2, + norm="FrozenBN", + out_features=["s1", "s2", "s3", "s4"], +) +model.pixel_std = [57.375, 57.120, 58.395] + +optimizer.weight_decay = 5e-5 +train.init_checkpoint = ( + "https://dl.fbaipublicfiles.com/pycls/dds_baselines/160906838/RegNetY-4.0GF_dds_8gpu.pyth" +) +# RegNets benefit from enabling cudnn benchmark mode +train.cudnn_benchmark = True diff --git a/vendor/detectron2/configs/COCO-Keypoints/Base-Keypoint-RCNN-FPN.yaml b/vendor/detectron2/configs/COCO-Keypoints/Base-Keypoint-RCNN-FPN.yaml new file mode 100644 index 0000000000000000000000000000000000000000..4e03944a42d2e497da5ceca17c8fda797dac3f82 --- /dev/null +++ b/vendor/detectron2/configs/COCO-Keypoints/Base-Keypoint-RCNN-FPN.yaml @@ -0,0 +1,15 @@ +_BASE_: "../Base-RCNN-FPN.yaml" +MODEL: + KEYPOINT_ON: True + ROI_HEADS: + NUM_CLASSES: 1 + ROI_BOX_HEAD: + SMOOTH_L1_BETA: 0.5 # Keypoint AP degrades (though box AP improves) when using plain L1 loss + RPN: + # Detectron1 uses 2000 proposals per-batch, but this option is per-image in detectron2. + # 1000 proposals per-image is found to hurt box AP. + # Therefore we increase it to 1500 per-image. + POST_NMS_TOPK_TRAIN: 1500 +DATASETS: + TRAIN: ("keypoints_coco_2017_train",) + TEST: ("keypoints_coco_2017_val",) diff --git a/vendor/detectron2/configs/COCO-Keypoints/keypoint_rcnn_R_101_FPN_3x.yaml b/vendor/detectron2/configs/COCO-Keypoints/keypoint_rcnn_R_101_FPN_3x.yaml new file mode 100644 index 0000000000000000000000000000000000000000..9309535c57a1aa7d23297aac80a9bd78a6c79fcc --- /dev/null +++ b/vendor/detectron2/configs/COCO-Keypoints/keypoint_rcnn_R_101_FPN_3x.yaml @@ -0,0 +1,8 @@ +_BASE_: "Base-Keypoint-RCNN-FPN.yaml" +MODEL: + WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-101.pkl" + RESNETS: + DEPTH: 101 +SOLVER: + STEPS: (210000, 250000) + MAX_ITER: 270000 diff --git a/vendor/detectron2/configs/COCO-Keypoints/keypoint_rcnn_R_50_FPN_1x.py b/vendor/detectron2/configs/COCO-Keypoints/keypoint_rcnn_R_50_FPN_1x.py new file mode 100644 index 0000000000000000000000000000000000000000..1aad53bfef62fb584d5022585d567e346f671a55 --- /dev/null +++ b/vendor/detectron2/configs/COCO-Keypoints/keypoint_rcnn_R_50_FPN_1x.py @@ -0,0 +1,8 @@ +from ..common.optim import SGD as optimizer +from ..common.coco_schedule import lr_multiplier_1x as lr_multiplier +from ..common.data.coco_keypoint import dataloader +from ..common.models.keypoint_rcnn_fpn import model +from ..common.train import train + +model.backbone.bottom_up.freeze_at = 2 +train.init_checkpoint = "detectron2://ImageNetPretrained/MSRA/R-50.pkl" diff --git a/vendor/detectron2/configs/COCO-Keypoints/keypoint_rcnn_R_50_FPN_1x.yaml b/vendor/detectron2/configs/COCO-Keypoints/keypoint_rcnn_R_50_FPN_1x.yaml new file mode 100644 index 0000000000000000000000000000000000000000..7bf85cf745b53b3e7ab28fe94b7f4f9e7fe6e335 --- /dev/null +++ b/vendor/detectron2/configs/COCO-Keypoints/keypoint_rcnn_R_50_FPN_1x.yaml @@ -0,0 +1,5 @@ +_BASE_: "Base-Keypoint-RCNN-FPN.yaml" +MODEL: + WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-50.pkl" + RESNETS: + DEPTH: 50 diff --git a/vendor/detectron2/configs/COCO-Keypoints/keypoint_rcnn_R_50_FPN_3x.yaml b/vendor/detectron2/configs/COCO-Keypoints/keypoint_rcnn_R_50_FPN_3x.yaml new file mode 100644 index 0000000000000000000000000000000000000000..a07f243f650a497b9372501e3face75194cf0941 --- /dev/null +++ b/vendor/detectron2/configs/COCO-Keypoints/keypoint_rcnn_R_50_FPN_3x.yaml @@ -0,0 +1,8 @@ +_BASE_: "Base-Keypoint-RCNN-FPN.yaml" +MODEL: + WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-50.pkl" + RESNETS: + DEPTH: 50 +SOLVER: + STEPS: (210000, 250000) + MAX_ITER: 270000 diff --git a/vendor/detectron2/configs/COCO-Keypoints/keypoint_rcnn_X_101_32x8d_FPN_3x.yaml b/vendor/detectron2/configs/COCO-Keypoints/keypoint_rcnn_X_101_32x8d_FPN_3x.yaml new file mode 100644 index 0000000000000000000000000000000000000000..d4bfa20a98c0a65c6bd60e93b07e8f4b7d92a867 --- /dev/null +++ b/vendor/detectron2/configs/COCO-Keypoints/keypoint_rcnn_X_101_32x8d_FPN_3x.yaml @@ -0,0 +1,12 @@ +_BASE_: "Base-Keypoint-RCNN-FPN.yaml" +MODEL: + WEIGHTS: "detectron2://ImageNetPretrained/FAIR/X-101-32x8d.pkl" + PIXEL_STD: [57.375, 57.120, 58.395] + RESNETS: + STRIDE_IN_1X1: False # this is a C2 model + NUM_GROUPS: 32 + WIDTH_PER_GROUP: 8 + DEPTH: 101 +SOLVER: + STEPS: (210000, 250000) + MAX_ITER: 270000 diff --git a/vendor/detectron2/configs/COCO-PanopticSegmentation/Base-Panoptic-FPN.yaml b/vendor/detectron2/configs/COCO-PanopticSegmentation/Base-Panoptic-FPN.yaml new file mode 100644 index 0000000000000000000000000000000000000000..f00d54b760c2b9271c75643e0a1ab1ffc0d9543a --- /dev/null +++ b/vendor/detectron2/configs/COCO-PanopticSegmentation/Base-Panoptic-FPN.yaml @@ -0,0 +1,11 @@ +_BASE_: "../Base-RCNN-FPN.yaml" +MODEL: + META_ARCHITECTURE: "PanopticFPN" + MASK_ON: True + SEM_SEG_HEAD: + LOSS_WEIGHT: 0.5 +DATASETS: + TRAIN: ("coco_2017_train_panoptic_separated",) + TEST: ("coco_2017_val_panoptic_separated",) +DATALOADER: + FILTER_EMPTY_ANNOTATIONS: False diff --git a/vendor/detectron2/configs/COCO-PanopticSegmentation/panoptic_fpn_R_101_3x.yaml b/vendor/detectron2/configs/COCO-PanopticSegmentation/panoptic_fpn_R_101_3x.yaml new file mode 100644 index 0000000000000000000000000000000000000000..0e01f6fb31e9b00b1857b7de3b5074184d1f4a21 --- /dev/null +++ b/vendor/detectron2/configs/COCO-PanopticSegmentation/panoptic_fpn_R_101_3x.yaml @@ -0,0 +1,8 @@ +_BASE_: "Base-Panoptic-FPN.yaml" +MODEL: + WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-101.pkl" + RESNETS: + DEPTH: 101 +SOLVER: + STEPS: (210000, 250000) + MAX_ITER: 270000 diff --git a/vendor/detectron2/configs/COCO-PanopticSegmentation/panoptic_fpn_R_50_1x.py b/vendor/detectron2/configs/COCO-PanopticSegmentation/panoptic_fpn_R_50_1x.py new file mode 100644 index 0000000000000000000000000000000000000000..40cf18131810307157a9a7d1f6d5922b00fd73d5 --- /dev/null +++ b/vendor/detectron2/configs/COCO-PanopticSegmentation/panoptic_fpn_R_50_1x.py @@ -0,0 +1,8 @@ +from ..common.optim import SGD as optimizer +from ..common.coco_schedule import lr_multiplier_1x as lr_multiplier +from ..common.data.coco_panoptic_separated import dataloader +from ..common.models.panoptic_fpn import model +from ..common.train import train + +model.backbone.bottom_up.freeze_at = 2 +train.init_checkpoint = "detectron2://ImageNetPretrained/MSRA/R-50.pkl" diff --git a/vendor/detectron2/configs/COCO-PanopticSegmentation/panoptic_fpn_R_50_1x.yaml b/vendor/detectron2/configs/COCO-PanopticSegmentation/panoptic_fpn_R_50_1x.yaml new file mode 100644 index 0000000000000000000000000000000000000000..6afa2c1cc92495309ed1553a17359fe5d7d6566e --- /dev/null +++ b/vendor/detectron2/configs/COCO-PanopticSegmentation/panoptic_fpn_R_50_1x.yaml @@ -0,0 +1,5 @@ +_BASE_: "Base-Panoptic-FPN.yaml" +MODEL: + WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-50.pkl" + RESNETS: + DEPTH: 50 diff --git a/vendor/detectron2/configs/COCO-PanopticSegmentation/panoptic_fpn_R_50_3x.yaml b/vendor/detectron2/configs/COCO-PanopticSegmentation/panoptic_fpn_R_50_3x.yaml new file mode 100644 index 0000000000000000000000000000000000000000..b956b3f673e78649184fe2c50e2700b3f1f14794 --- /dev/null +++ b/vendor/detectron2/configs/COCO-PanopticSegmentation/panoptic_fpn_R_50_3x.yaml @@ -0,0 +1,8 @@ +_BASE_: "Base-Panoptic-FPN.yaml" +MODEL: + WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-50.pkl" + RESNETS: + DEPTH: 50 +SOLVER: + STEPS: (210000, 250000) + MAX_ITER: 270000 diff --git a/vendor/detectron2/configs/Cityscapes/mask_rcnn_R_50_FPN.yaml b/vendor/detectron2/configs/Cityscapes/mask_rcnn_R_50_FPN.yaml new file mode 100644 index 0000000000000000000000000000000000000000..1a7aaeb961581ed9492c4cfe5a69a1eb60495b3e --- /dev/null +++ b/vendor/detectron2/configs/Cityscapes/mask_rcnn_R_50_FPN.yaml @@ -0,0 +1,27 @@ +_BASE_: "../Base-RCNN-FPN.yaml" +MODEL: + # WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-50.pkl" + # For better, more stable performance initialize from COCO + WEIGHTS: "detectron2://COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x/137849600/model_final_f10217.pkl" + MASK_ON: True + ROI_HEADS: + NUM_CLASSES: 8 +# This is similar to the setting used in Mask R-CNN paper, Appendix A +# But there are some differences, e.g., we did not initialize the output +# layer using the corresponding classes from COCO +INPUT: + MIN_SIZE_TRAIN: (800, 832, 864, 896, 928, 960, 992, 1024) + MIN_SIZE_TRAIN_SAMPLING: "choice" + MIN_SIZE_TEST: 1024 + MAX_SIZE_TRAIN: 2048 + MAX_SIZE_TEST: 2048 +DATASETS: + TRAIN: ("cityscapes_fine_instance_seg_train",) + TEST: ("cityscapes_fine_instance_seg_val",) +SOLVER: + BASE_LR: 0.01 + STEPS: (18000,) + MAX_ITER: 24000 + IMS_PER_BATCH: 8 +TEST: + EVAL_PERIOD: 8000 diff --git a/vendor/detectron2/configs/Detectron1-Comparisons/README.md b/vendor/detectron2/configs/Detectron1-Comparisons/README.md new file mode 100644 index 0000000000000000000000000000000000000000..924fd00af642ddf1a4ff4c4f5947f676134eb7de --- /dev/null +++ b/vendor/detectron2/configs/Detectron1-Comparisons/README.md @@ -0,0 +1,84 @@ + +Detectron2 model zoo's experimental settings and a few implementation details are different from Detectron. + +The differences in implementation details are shared in +[Compatibility with Other Libraries](../../docs/notes/compatibility.md). + +The differences in model zoo's experimental settings include: +* Use scale augmentation during training. This improves AP with lower training cost. +* Use L1 loss instead of smooth L1 loss for simplicity. This sometimes improves box AP but may + affect other AP. +* Use `POOLER_SAMPLING_RATIO=0` instead of 2. This does not significantly affect AP. +* Use `ROIAlignV2`. This does not significantly affect AP. + +In this directory, we provide a few configs that __do not__ have the above changes. +They mimic Detectron's behavior as close as possible, +and provide a fair comparison of accuracy and speed against Detectron. + + + + +
| Name | +lr sched |
+train time (s/iter) |
+inference time (s/im) |
+train mem (GB) |
+box AP |
+mask AP |
+kp. AP |
+model id | +download | + + +
|---|---|---|---|---|---|---|---|---|---|
| Faster R-CNN | +1x | +0.219 | +0.038 | +3.1 | +36.9 | ++ | + | 137781054 | +model | metrics | +
| Keypoint R-CNN | +1x | +0.313 | +0.071 | +5.0 | +53.1 | ++ | 64.2 | +137781195 | +model | metrics | +
| Mask R-CNN | +1x | +0.273 | +0.043 | +3.4 | +37.8 | +34.9 | ++ | 137781281 | +model | metrics | +