[Paper](https://arxiv.org/abs/2312.01479) |
[Website](https://research.myshell.ai/open-voice)
## Join Our Community
Join our [Discord community](https://discord.gg/myshell) and select the `Developer` role upon joining to gain exclusive access to our developer-only channel! Don't miss out on valuable discussions and collaboration opportunities.
## Introduction
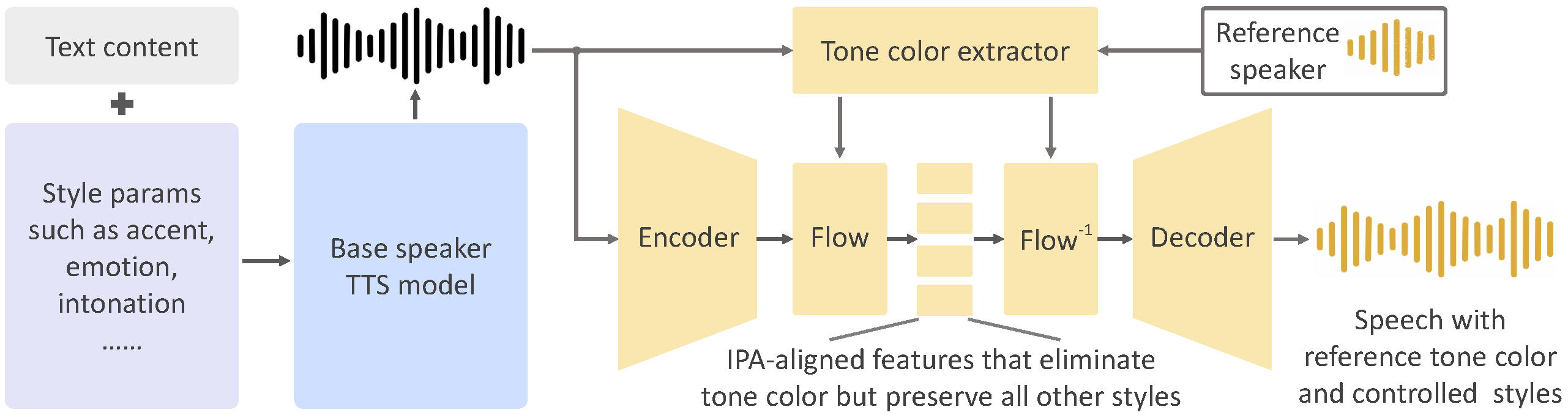
As we detailed in our [paper](https://arxiv.org/abs/2312.01479) and [website](https://research.myshell.ai/open-voice), the advantages of OpenVoice are three-fold:
**1. Accurate Tone Color Cloning.**
OpenVoice can accurately clone the reference tone color and generate speech in multiple languages and accents.
**2. Flexible Voice Style Control.**
OpenVoice enables granular control over voice styles, such as emotion and accent, as well as other style parameters including rhythm, pauses, and intonation.
**3. Zero-shot Cross-lingual Voice Cloning.**
Neither of the language of the generated speech nor the language of the reference speech needs to be presented in the massive-speaker multi-lingual training dataset.
[Video](https://github.com/myshell-ai/OpenVoice/assets/40556743/3cba936f-82bf-476c-9e52-09f0f417bb2f)