# Using KerasCV Stable Diffusion Checkpoints in Diffusers
This is an experimental feature.
[KerasCV](https://github.com/keras-team/keras-cv/) provides APIs for implementing various computer vision workflows. It
also provides the Stable Diffusion [v1 and v2](https://github.com/keras-team/keras-cv/blob/master/keras_cv/models/stable_diffusion)
models. Many practitioners find it easy to fine-tune the Stable Diffusion models shipped by KerasCV. However, as of this writing, KerasCV offers limited support to experiment with Stable Diffusion models for inference and deployment. On the other hand,
Diffusers provides tooling dedicated to this purpose (and more), such as different [noise schedulers](https://huggingface.co/docs/diffusers/using-diffusers/schedulers), [flash attention](https://huggingface.co/docs/diffusers/optimization/xformers), and [other
optimization techniques](https://huggingface.co/docs/diffusers/optimization/fp16).
How about fine-tuning Stable Diffusion models in KerasCV and exporting them such that they become compatible with Diffusers to combine the
best of both worlds? We have created a [tool](https://huggingface.co/spaces/sayakpaul/convert-kerascv-sd-diffusers) that
lets you do just that! It takes KerasCV Stable Diffusion checkpoints and exports them to Diffusers-compatible checkpoints.
More specifically, it first converts the checkpoints to PyTorch and then wraps them into a
[`StableDiffusionPipeline`](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/overview) which is ready
for inference. Finally, it pushes the converted checkpoints to a repository on the Hugging Face Hub.
We welcome you to try out the tool [here](https://huggingface.co/spaces/sayakpaul/convert-kerascv-sd-diffusers)
and share feedback via [discussions](https://huggingface.co/spaces/sayakpaul/convert-kerascv-sd-diffusers/discussions/new).
## Getting Started
First, you need to obtain the fine-tuned KerasCV Stable Diffusion checkpoints. We provide an
overview of the different ways Stable Diffusion models can be fine-tuned [using `diffusers`](https://huggingface.co/docs/diffusers/training/overview). For the Keras implementation of some of these methods, you can check out these resources:
* [Teach StableDiffusion new concepts via Textual Inversion](https://keras.io/examples/generative/fine_tune_via_textual_inversion/)
* [Fine-tuning Stable Diffusion](https://keras.io/examples/generative/finetune_stable_diffusion/)
* [DreamBooth](https://keras.io/examples/generative/dreambooth/)
* [Prompt-to-Prompt editing](https://github.com/miguelCalado/prompt-to-prompt-tensorflow)
Stable Diffusion is comprised of the following models:
* Text encoder
* UNet
* VAE
Depending on the fine-tuning task, we may fine-tune one or more of these components (the VAE is almost always left untouched). Here are some common combinations:
* DreamBooth: UNet and text encoder
* Classical text to image fine-tuning: UNet
* Textual Inversion: Just the newly initialized embeddings in the text encoder
### Performing the Conversion
Let's use [this checkpoint](https://huggingface.co/sayakpaul/textual-inversion-kerasio/resolve/main/textual_inversion_kerasio.h5) which was generated
by conducting Textual Inversion with the following "placeholder token": ``.
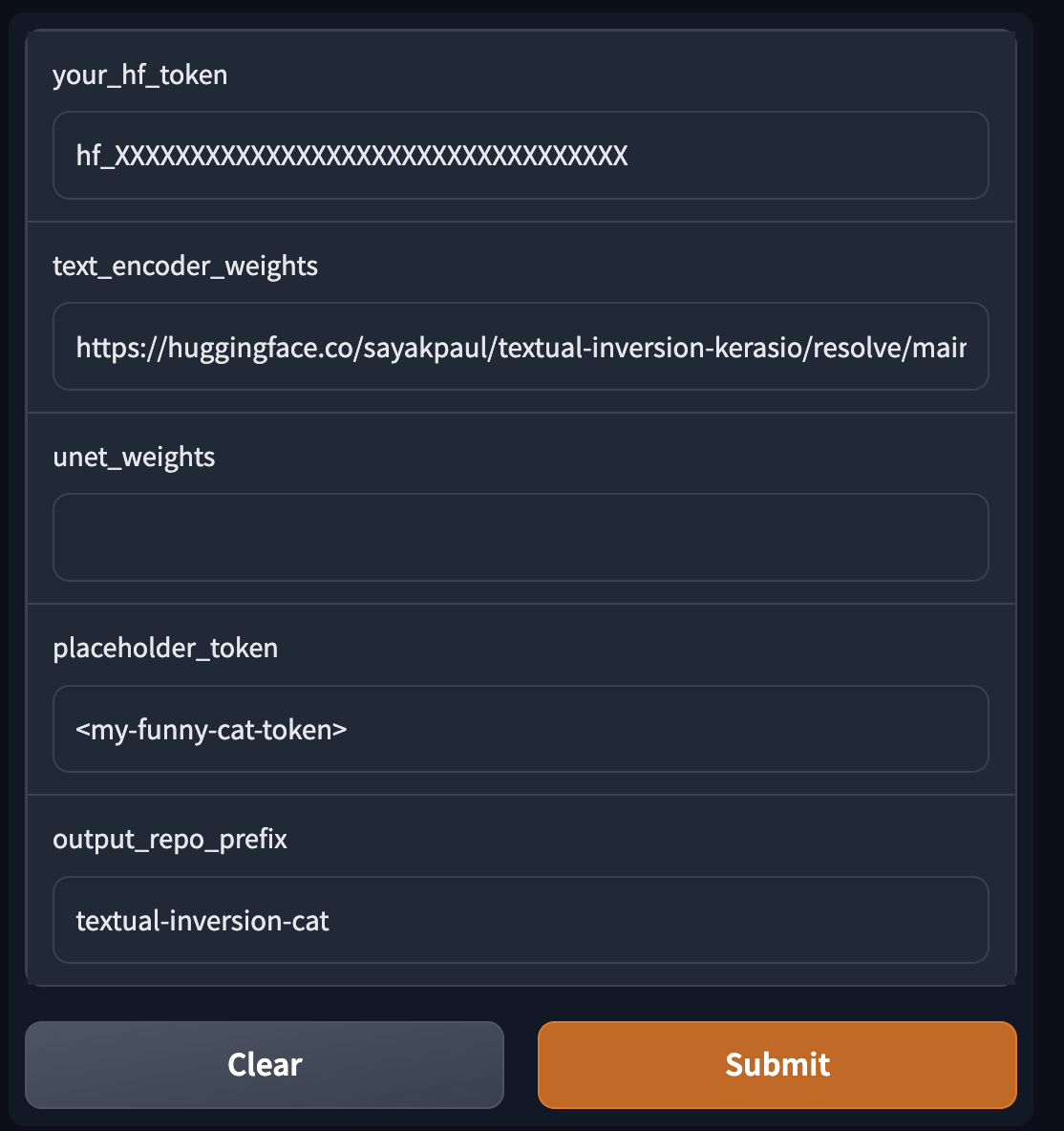
On the tool, we supply the following things:
* Path(s) to download the fine-tuned checkpoint(s) (KerasCV)
* An HF token
* Placeholder token (only applicable for Textual Inversion)
As soon as you hit "Submit", the conversion process will begin. Once it's complete, you should see the following:
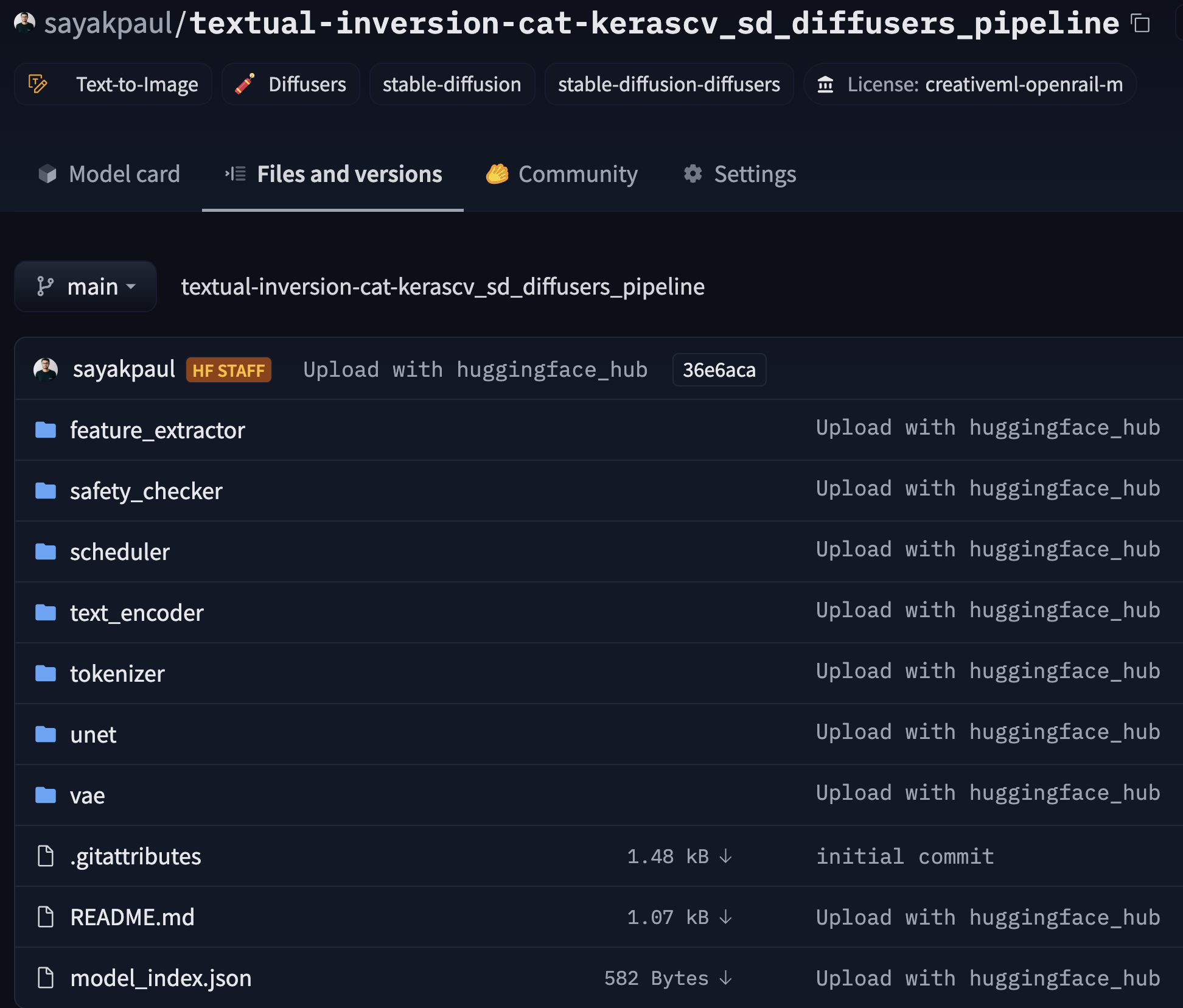
If you click the [link](https://huggingface.co/sayakpaul/textual-inversion-cat-kerascv_sd_diffusers_pipeline/tree/main), you
should see something like so:
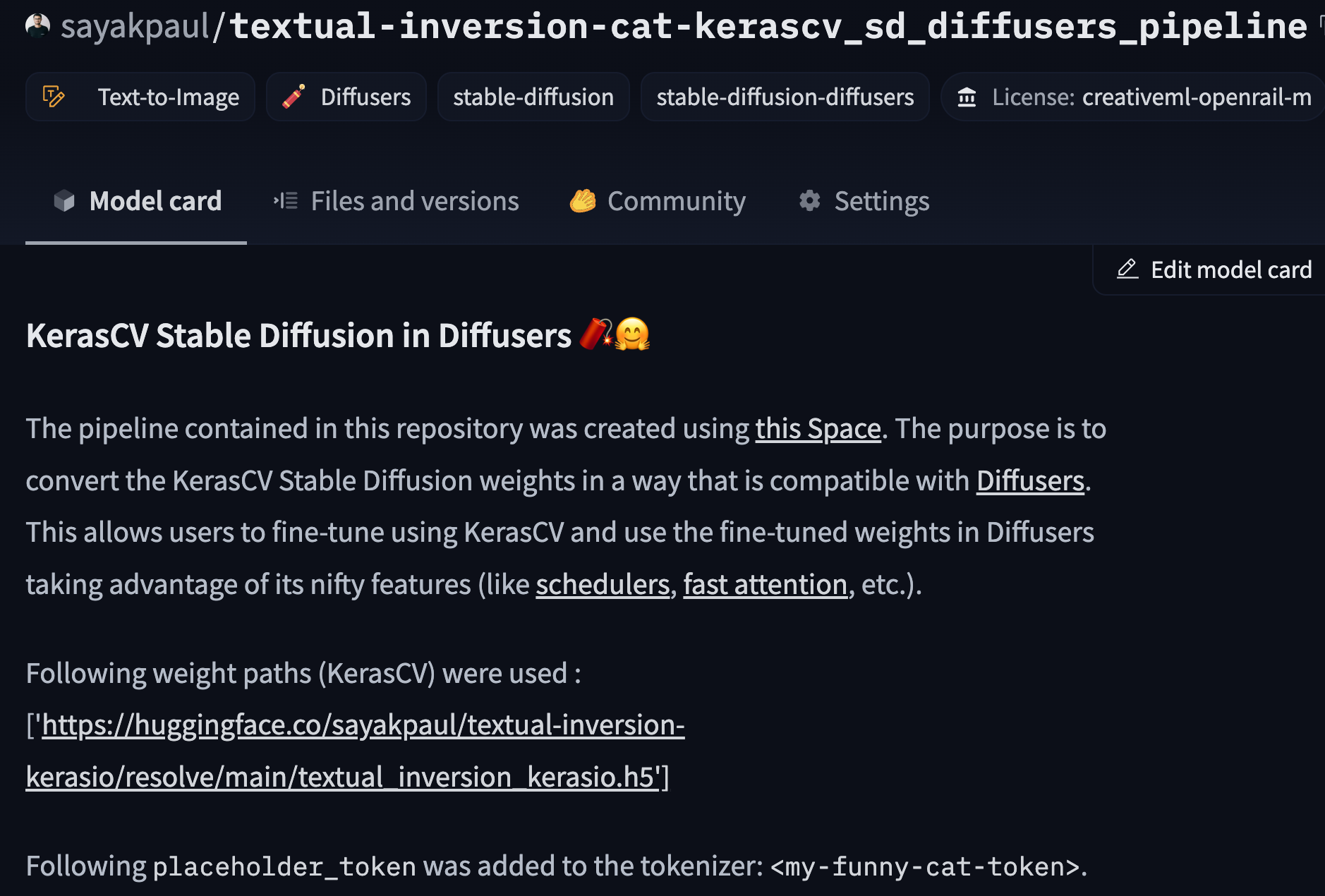
If you head over to the [model card of the repository](https://huggingface.co/sayakpaul/textual-inversion-cat-kerascv_sd_diffusers_pipeline), the
following should appear:
Note that we're not specifying the UNet weights here since the UNet is not fine-tuned during Textual Inversion.
And that's it! You now have your fine-tuned KerasCV Stable Diffusion model in Diffusers 🧨.
## Using the Converted Model in Diffusers
Just beside the model card of the [repository](https://huggingface.co/sayakpaul/textual-inversion-cat-kerascv_sd_diffusers_pipeline),
you'd notice an inference widget to try out the model directly from the UI 🤗
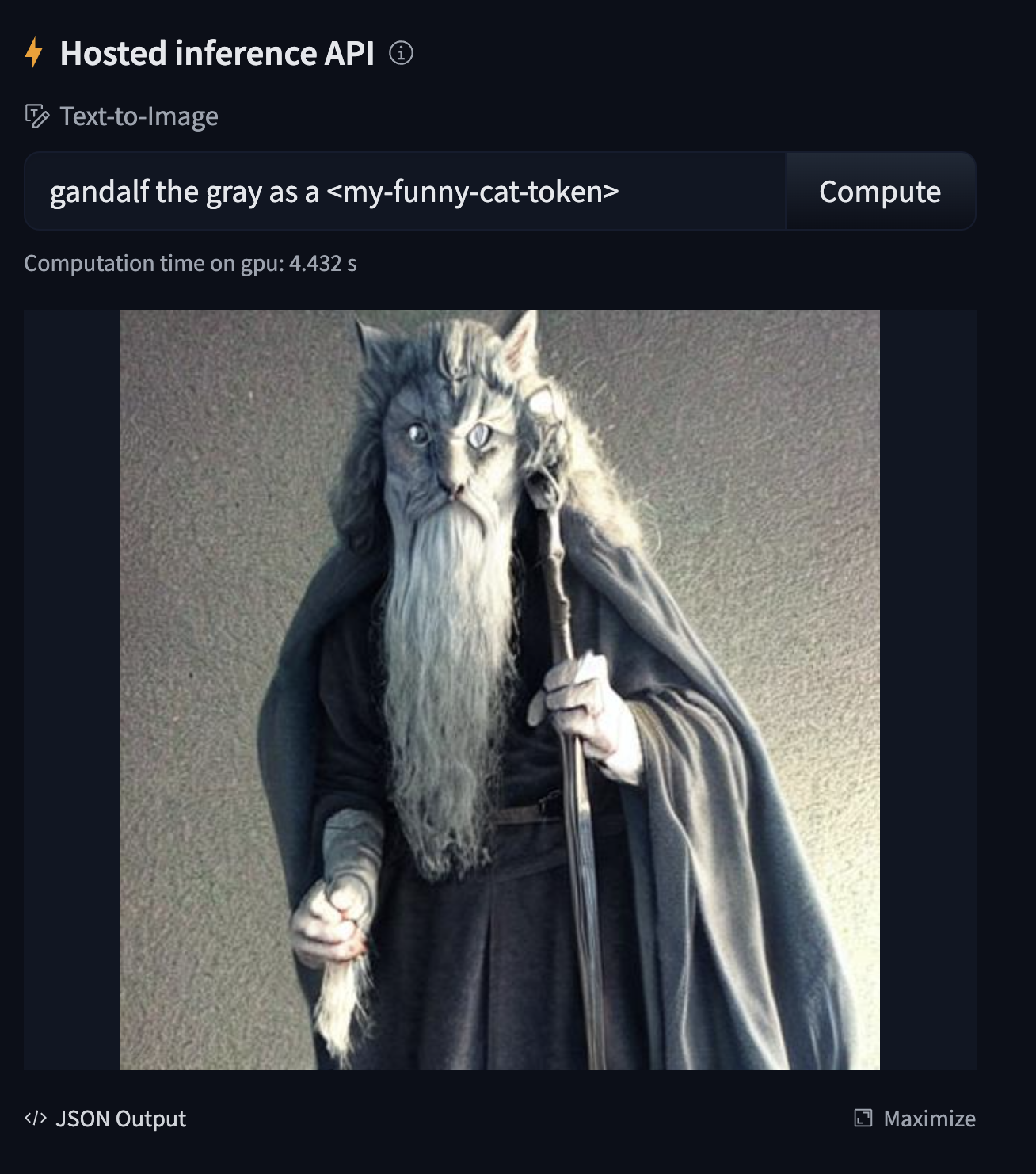
On the top right hand side, we provide a "Use in Diffusers" button. If you click the button, you should see the following code-snippet:
```py
from diffusers import DiffusionPipeline
pipeline = DiffusionPipeline.from_pretrained("sayakpaul/textual-inversion-cat-kerascv_sd_diffusers_pipeline")
```
The model is in standard `diffusers` format. Let's perform inference!
```py
from diffusers import DiffusionPipeline
pipeline = DiffusionPipeline.from_pretrained("sayakpaul/textual-inversion-cat-kerascv_sd_diffusers_pipeline")
pipeline.to("cuda")
placeholder_token = ""
prompt = f"two {placeholder_token} getting married, photorealistic, high quality"
image = pipeline(prompt, num_inference_steps=50).images[0]
```
And we get:
_**Note that if you specified a `placeholder_token` while performing the conversion, the tool will log it accordingly. Refer
to the model card of [this repository](https://huggingface.co/sayakpaul/textual-inversion-cat-kerascv_sd_diffusers_pipeline)
as an example.**_
We welcome you to use the tool for various Stable Diffusion fine-tuning scenarios and let us know your feedback! Here are some examples
of Diffusers checkpoints that were obtained using the tool:
* [sayakpaul/text-unet-dogs-kerascv_sd_diffusers_pipeline](https://huggingface.co/sayakpaul/text-unet-dogs-kerascv_sd_diffusers_pipeline) (DreamBooth with both the text encoder and UNet fine-tuned)
* [sayakpaul/unet-dogs-kerascv_sd_diffusers_pipeline](https://huggingface.co/sayakpaul/unet-dogs-kerascv_sd_diffusers_pipeline) (DreamBooth with only the UNet fine-tuned)
## Incorporating Diffusers Goodies 🎁
Diffusers provides various options that one can leverage to experiment with different inference setups. One particularly
useful option is the use of a different noise scheduler during inference other than what was used during fine-tuning.
Let's try out the [`DPMSolverMultistepScheduler`](https://huggingface.co/docs/diffusers/main/en/api/schedulers/multistep_dpm_solver)
which is different from the one ([`DDPMScheduler`](https://huggingface.co/docs/diffusers/main/en/api/schedulers/ddpm)) used during
fine-tuning.
You can read more details about this process in [this section](https://huggingface.co/docs/diffusers/using-diffusers/schedulers).
```py
from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler
pipeline = DiffusionPipeline.from_pretrained("sayakpaul/textual-inversion-cat-kerascv_sd_diffusers_pipeline")
pipeline.scheduler = DPMSolverMultistepScheduler.from_config(pipeline.scheduler.config)
pipeline.to("cuda")
placeholder_token = ""
prompt = f"two {placeholder_token} getting married, photorealistic, high quality"
image = pipeline(prompt, num_inference_steps=50).images[0]
```
One can also continue fine-tuning from these Diffusers checkpoints by leveraging some relevant tools from Diffusers. Refer [here](https://huggingface.co/docs/diffusers/training/overview) for
more details. For inference-specific optimizations, refer [here](https://huggingface.co/docs/diffusers/main/en/optimization/fp16).
## Known Limitations
* Only Stable Diffusion v1 checkpoints are supported for conversion in this tool.