# Italian CLIP
With a few tricks, we have been able to fine-tune a competitive Italian CLIP model with **only 1.4 million** training samples. Our Italian CLIP model
is built upon the [Italian BERT](https://huggingface.co/dbmdz/bert-base-italian-xxl-cased) model provided by [dbmdz](https://huggingface.co/dbmdz) and the OpenAI
[vision transformer](https://huggingface.co/openai/clip-vit-base-patch32).
In building this project we kept in mind the following principles:
+ **Novel Contributions**: We created a dataset of ~1.4 million Italian image-text pairs and, to the best of our knowledge, we trained the best Italian CLIP model currently in existence;
+ **Scientific Validity**: Claim are easy, facts are hard. That's why validation is important to assess the real impact of a model. We thoroughly evaluated our models in several tasks and made the validation reproducible for everybody.
+ **Broader Outlook**: We always kept in mind which are the possible usages for this model.
We put our **hearts** and **souls** into the project during this week! Not only did we work on a cool project, but we were
able to make new friends and and learn a lot from each other to work towards a common goal!
Thank you for this amazing opportunity, we hope you will like the results. :heart:
# Demo
In this demo, we present two tasks:
+ *Text to Image*: This task is essentially an image retrieval task. The user is asked to input a string of text and CLIP is going to
compute the similarity between this string of text with respect to a set of images. The webapp is going to display the images that
have the highest similarity with the text query.
+ *Image to Text*: This task is essentially a zero-shot image classification task. The user is asked for an image and for a set of captions/labels and CLIP
is going to compute the similarity between the image and each label. The webapp is going to display a probability distribution over the captions.
+ *Examples and Applications*: This page showcases some interesting results we got from the model, we believe that there are
different applications that can start from here.
# Novel Contributions
The original CLIP model was trained on 400 million image-text pairs; this amount of data is not available for Italian.
We indeed worked in a **low-resource setting**. The only datasets for Italian captioning in the literature are MSCOCO-IT (a translated version of MSCOCO) and WIT.
To get competitive results we followed three strategies:
1. more and better data;
2. better augmentations;
3. better training.
For those interested, we have a :comet: [Comet](https://www.comet.ml/g8a9/clip-italian/reports/clip-italian-training-metrics) report
that shows a **subset** of the experiments we run. Different hyper-parameters played a role in reducing the validation
loss. The optimizer we used gave us great performance and huge conversion speed, more data and augmentations helped a lot in generalizing,
working on the training and on the loss gave us the final increase that you can see in the results.
## More and Better Data
We eventually had to deal with the fact that we do not have the same data that OpenAI had during the training of CLIP.
Thus, we tried to add as much data as possible while keeping the data-quality as high as possible.
We considered four main sources of data:
+ [WIT](https://github.com/google-research-datasets/wit) is an image-caption dataset collected from Wikipedia (see,
[Srinivasan et al., 2021](https://arxiv.org/pdf/2103.01913.pdf)). We focused on the *Reference Description* captions described in the paper as they are
the ones of highest quality. Nonetheless, many of these captions describe ontological knowledge and encyclopedic facts (e.g., Roberto Baggio in 1994).
However, this kind of text, without more information, is not useful to learn a good mapping between images and captions.
On the other hand, this text is written in Italian and it is of good quality. We cannot just remove short captions as some of those
are still good (e.g., "running dog"). Thus, to prevent polluting the data with captions that are not meaningful, we used *POS tagging*
on the text and removed all the captions that were composed for the 80% or more by PROPN (around ~10% of the data). This is a simple solution that allowed us to retain much
of the dataset, without introducing noise.
Captions like: *'Dora Riparia', 'Anna Maria Mozzoni', 'Joey Ramone Place', 'Kim Rhodes', 'Ralph George Hawtrey' * have been removed.
+ [MSCOCO-IT](https://github.com/crux82/mscoco-it). This image-caption dataset comes from the work by [Scaiella et al., 2019](http://www.ai-lc.it/IJCoL/v5n2/IJCOL_5_2_3___scaiella_et_al.pdf). The captions comes from the original
MSCOCO dataset and have been translated with Microsoft Translator. The 2017 version of the MSCOCO training set contains more than
100K images, for each image more than one caption is available.
+ [Conceptual Captions](https://ai.google.com/research/ConceptualCaptions/). This image-caption dataset comes from
the work by [Sharma et al., 2018](https://aclanthology.org/P18-1238.pdf). There are more than 3mln image-caption pairs in
this dataset and these have been collected from the web. We downloaded the images with the URLs provided by the dataset, but we
could not retrieve them all. Eventually, we had to translate the captions to Italian. We have been able to collect
a dataset with 700K translated captions.
+ [La Foto del Giorno](https://www.ilpost.it/foto-del-giorno/). This image-caption dataset is collected from [Il Post](https://www.ilpost.it/), a prominent Italian online newspaper. The collection contains almost 30K pairs: starting from early 2011, for each day, editors at Il Post pick several images picturing the most salient events in the world. Each photo comes along with an Italian caption.
### A Note on Translations
Instead of relying on open-source translators, we decided to use DeepL. **Translation quality** of the data was the main
reason of this choice. With the few images (wrt OpenAI) that we have, we cannot risk polluting our own data. CC is a great resource
but the captions have to be handled accordingly. We translated 700K captions and we evaluated their quality:
Three of us looked at a sample of 100 of the translations and rated them with scores from 1 to 4.
1: the sentence has lost is meaning or it's not possible to understand it; 2: it is possible to get the idea
but there something wrong; 3: good, however a native speaker might complain about some translations; 4: good translation.
The average score was of 3.78 and the two annotators had an inter-rater agreement - computed with [Gwet's AC1](https://bpspsychub.onlinelibrary.wiley.com/doi/full/10.1348/000711006X126600) using ordinal
weighting - of 0.858 (great agreement!).
| English Captions | Italian Captions |
| ----------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------|
| an endless cargo of tanks on a train pulled down tracks in an empty dry landscape | un carico infinito di carri armati su un treno trascinato lungo i binari in un paesaggio secco e vuoto |
| person walking down the aisle | persona che cammina lungo la navata |
| popular rides at night at the county fair | giostre popolari di notte alla fiera della contea |
We know that we annotated our own data; in the spirit of fairness we also share the annotations and the captions so
that those interested can check the quality. The Google Sheet is [here](https://docs.google.com/spreadsheets/d/1m6TkcpJbmJlEygL7SXURIq2w8ZHuVvsmdEuCIH0VENk/edit?usp=sharing).
## Better Augmentations
We knew that without a good augmentation strategy we could never get competitive results to a model trained on 400 million images. Therefor we implemented heavy augmentations to make the training more data efficient. They include random affine transformations and perspective changes, as well as occasional equalization and random changes to brightness, contrast, saturation and hue. We made sure to keep hue augmentations limited however to still give the model the ability to learn color definitions.
While we would have liked to have augmentations for the captions as well after some experimentation we settled with random sampling from the five captions available in MSCOCO and leaving the rest of the captions unmodified.
## Better Training
After different trials, we realized that the usual way of training this model was
not good enough to get good results. We thus modified three different parts of the
training pipeline: the optimizer, the training with frozen components and the logit_scale parameter.
### Optimizer
While the initial code used AdamW as an optimizer we soon noticed that it introduced some bad properties into the training. The model strated to overfit relatively quickly and the weight decay made this effect worse. We eventually decided to an optimization strategy that had worked well for us in similar cases and used AdaBelief with Adaptive Gradient Clipping (AGC) and a Cosine Annealing Schedule. Together with slightly tuning the learning rate this helped us to reduce the validation loss by 25%.
Our implementation is available online [here](https://github.com/clip-italian/clip-italian/blob/master/hybrid_clip/run_hybrid_clip.py#L667).
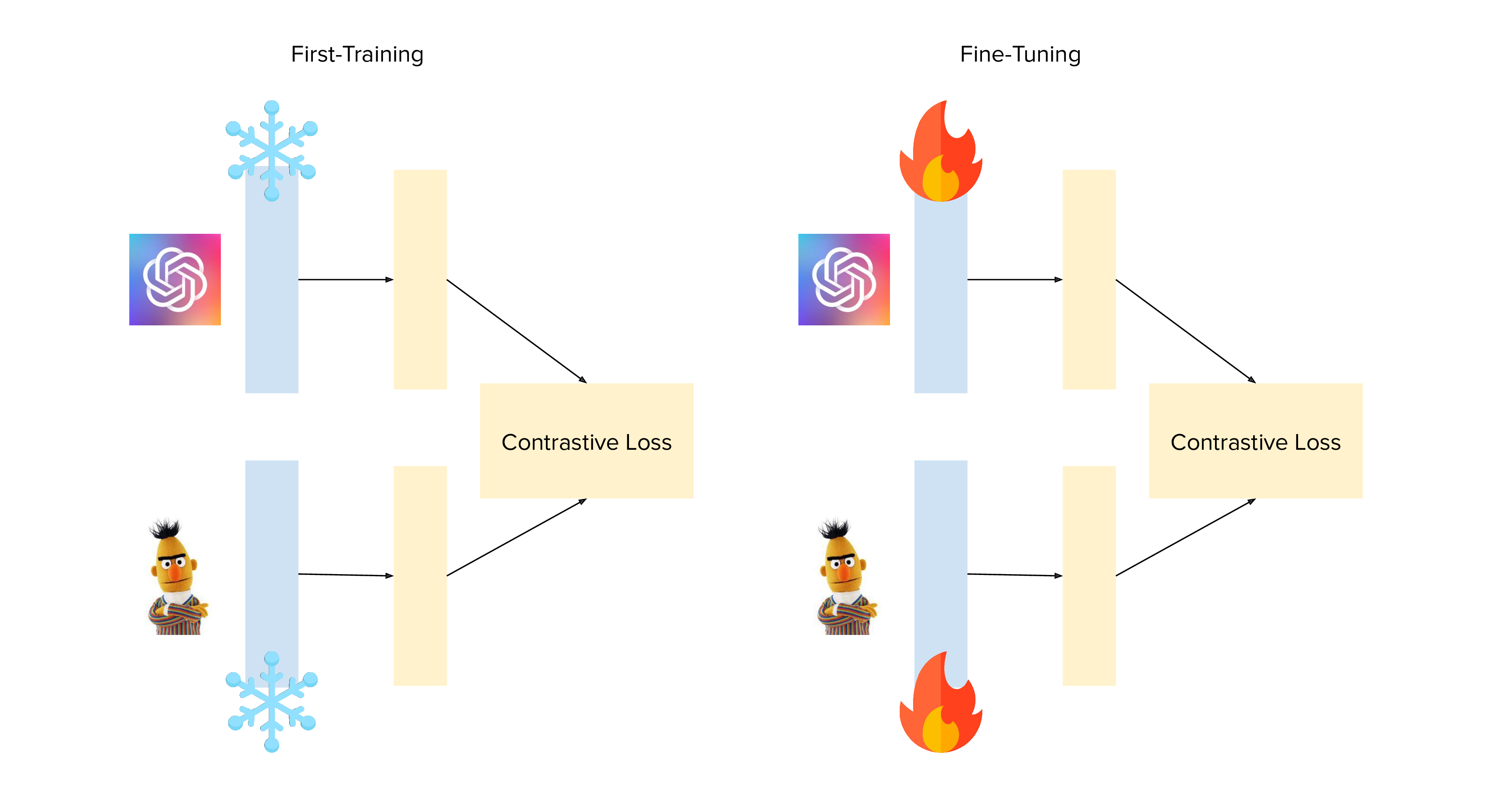
### Backbone Freezing
The ViT used by OpenAI was already trained on 400 million images and it is the element in our architecture that probably required less training.
The same is true for the BERT model we use. To allow the randomly initialized Re-projection Layers to warm up without messing with the tuned weights of the backbones we decided to do a first training with the backbones of our architecture completely frozen. Only after these layers converged we unfreezed the rest of the model to fine-tune all the components. This technique allowed us to reach a much better validation loss.
 ### Logit Scale
We tried to improve the loss function in different ways: for example, we tried something similar to a margin based loss but that experiments
didn't go well. Eventually, the thing that worked out the best was fixing the logit_scale value to 20. This value
is used after the computation of the similarity between the images and the texts in CLIP (see the code [here](https://github.com/clip-italian/clip-italian/blob/master/hybrid_clip/modeling_hybrid_clip.py#L64)).
We got this idea from Nils' [video](https://youtu.be/RHXZKUr8qOY) on sentence embeddings.
### Effect
The following picture showcase the effect that this edits have had on our loss:
### Logit Scale
We tried to improve the loss function in different ways: for example, we tried something similar to a margin based loss but that experiments
didn't go well. Eventually, the thing that worked out the best was fixing the logit_scale value to 20. This value
is used after the computation of the similarity between the images and the texts in CLIP (see the code [here](https://github.com/clip-italian/clip-italian/blob/master/hybrid_clip/modeling_hybrid_clip.py#L64)).
We got this idea from Nils' [video](https://youtu.be/RHXZKUr8qOY) on sentence embeddings.
### Effect
The following picture showcase the effect that this edits have had on our loss:
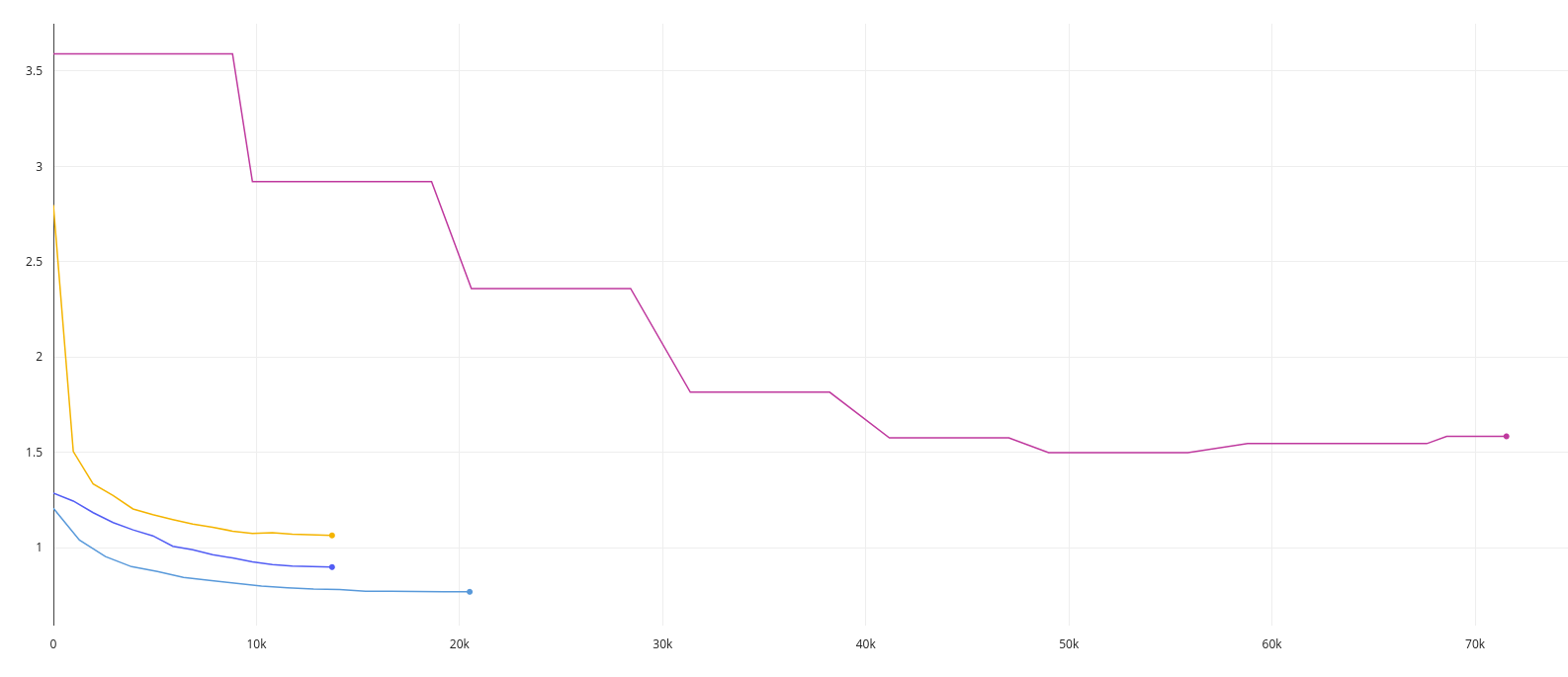 The purple line is the original training, you can see how many steps we needed to get the loss down. Yellow line is the
loss with the new optimizer, it is **striking** to see the time we save from this addition! Blue line shows the results when
fixed scaling is added with the new optimization. Finally, we added the backbone freezing part and you can see the
results in the light blue loss.
# Scientific Validity
## Quantitative Evaluation
Those images are definitely cool and interesting, but a model is nothing without validation.
To better understand how well our clip-italian model works we run an experimental evaluation. Since this is the first clip-based model in Italian, we used the multilingual CLIP model as a comparison baseline.
### mCLIP
The multilingual CLIP (henceforth, mCLIP), is a model introduced by [Nils Reimers](https://www.sbert.net/docs/pretrained_models.html) in his
[sentence-transformer](https://www.sbert.net/index.html) library. mCLIP is based on a multilingual encoder
that was created through multilingual knowledge distillation (see [Reimers et al., 2020](https://aclanthology.org/2020.emnlp-main.365/)).
### Tasks
We selected two different tasks:
+ image-retrieval
+ zero-shot classification
### Reproducibiliy
Both experiments should be very easy to replicate, we share the two colab notebook we used to compute the two results
+ [Image Retrieval](https://colab.research.google.com/drive/1bLVwVKpAndpEDHqjzxVPr_9nGrSbuOQd?usp=sharing)
+ [ImageNet Zero Shot Classification](https://colab.research.google.com/drive/1zfWeVWY79XXH63Ci-pk8xxx3Vu_RRgW-?usp=sharing)
### Image Retrieval
This experiment is run against the MSCOCO-IT validation set (that we haven't used in training). Given in input
a caption, we search for the most similar image in the MSCOCO-IT validation set. As evaluation metrics
we use the MRR@K.
| MRR | CLIP-Italian | mCLIP |
| --------------- | ------------ |-------|
| MRR@1 | **0.3797** | 0.2874|
| MRR@5 | **0.5039** | 0.3957|
| MRR@10 | **0.5204** | 0.4129|
It is true that we used MSCOCO-IT in training, and this might give us an advantage. However the original CLIP model was trained
on 400million images (and some of them probably were from MSCOCO).
### Zero-shot image classification
This experiment replicates the original one run by OpenAI on zero-shot image classification on ImageNet.
To do this, we used DeepL to translate the image labels in ImageNet. We evaluate the models computing the accuracy at different levels.
| Accuracy | CLIP-Italian | mCLIP |
| --------------- | ------------ |-------|
| Accuracy@1 | **22.11** | 20.15 |
| Accuracy@5 | **43.69** | 36.57 |
| Accuracy@10 | **52.55** | 42.91 |
| Accuracy@100 | **81.08** | 67.11 |
Our results confirm that CLIP-Italian is very competitive and beats mCLIP on the two different task
we have been testing. Note, however, that our results are lower than those shown in the original OpenAI
paper (see, [Radford et al., 2021](https://arxiv.org/abs/2103.00020)). However, considering that our results are in line with those obtained by mCLIP we think that
the translated image labels might have had an impact on the final scores.
## Qualitative Evaluation
We hereby show some very interesting properties of the model. One is its ability to detect colors,
then there is its (partial) counting ability and finally the ability of understanding more complex quries. To our own surprise, many of the answers the model gives make a lot of sense!
Look at the following - slightly cherry picked (but not even that much) - examples:
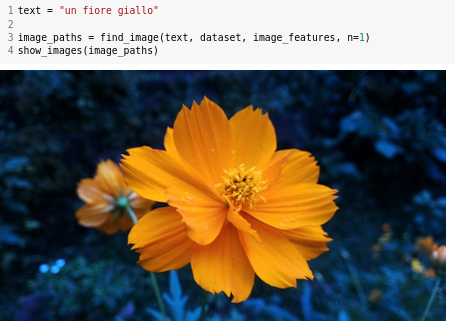
### Colors
Here's a yellow flower
The purple line is the original training, you can see how many steps we needed to get the loss down. Yellow line is the
loss with the new optimizer, it is **striking** to see the time we save from this addition! Blue line shows the results when
fixed scaling is added with the new optimization. Finally, we added the backbone freezing part and you can see the
results in the light blue loss.
# Scientific Validity
## Quantitative Evaluation
Those images are definitely cool and interesting, but a model is nothing without validation.
To better understand how well our clip-italian model works we run an experimental evaluation. Since this is the first clip-based model in Italian, we used the multilingual CLIP model as a comparison baseline.
### mCLIP
The multilingual CLIP (henceforth, mCLIP), is a model introduced by [Nils Reimers](https://www.sbert.net/docs/pretrained_models.html) in his
[sentence-transformer](https://www.sbert.net/index.html) library. mCLIP is based on a multilingual encoder
that was created through multilingual knowledge distillation (see [Reimers et al., 2020](https://aclanthology.org/2020.emnlp-main.365/)).
### Tasks
We selected two different tasks:
+ image-retrieval
+ zero-shot classification
### Reproducibiliy
Both experiments should be very easy to replicate, we share the two colab notebook we used to compute the two results
+ [Image Retrieval](https://colab.research.google.com/drive/1bLVwVKpAndpEDHqjzxVPr_9nGrSbuOQd?usp=sharing)
+ [ImageNet Zero Shot Classification](https://colab.research.google.com/drive/1zfWeVWY79XXH63Ci-pk8xxx3Vu_RRgW-?usp=sharing)
### Image Retrieval
This experiment is run against the MSCOCO-IT validation set (that we haven't used in training). Given in input
a caption, we search for the most similar image in the MSCOCO-IT validation set. As evaluation metrics
we use the MRR@K.
| MRR | CLIP-Italian | mCLIP |
| --------------- | ------------ |-------|
| MRR@1 | **0.3797** | 0.2874|
| MRR@5 | **0.5039** | 0.3957|
| MRR@10 | **0.5204** | 0.4129|
It is true that we used MSCOCO-IT in training, and this might give us an advantage. However the original CLIP model was trained
on 400million images (and some of them probably were from MSCOCO).
### Zero-shot image classification
This experiment replicates the original one run by OpenAI on zero-shot image classification on ImageNet.
To do this, we used DeepL to translate the image labels in ImageNet. We evaluate the models computing the accuracy at different levels.
| Accuracy | CLIP-Italian | mCLIP |
| --------------- | ------------ |-------|
| Accuracy@1 | **22.11** | 20.15 |
| Accuracy@5 | **43.69** | 36.57 |
| Accuracy@10 | **52.55** | 42.91 |
| Accuracy@100 | **81.08** | 67.11 |
Our results confirm that CLIP-Italian is very competitive and beats mCLIP on the two different task
we have been testing. Note, however, that our results are lower than those shown in the original OpenAI
paper (see, [Radford et al., 2021](https://arxiv.org/abs/2103.00020)). However, considering that our results are in line with those obtained by mCLIP we think that
the translated image labels might have had an impact on the final scores.
## Qualitative Evaluation
We hereby show some very interesting properties of the model. One is its ability to detect colors,
then there is its (partial) counting ability and finally the ability of understanding more complex quries. To our own surprise, many of the answers the model gives make a lot of sense!
Look at the following - slightly cherry picked (but not even that much) - examples:
### Colors
Here's a yellow flower
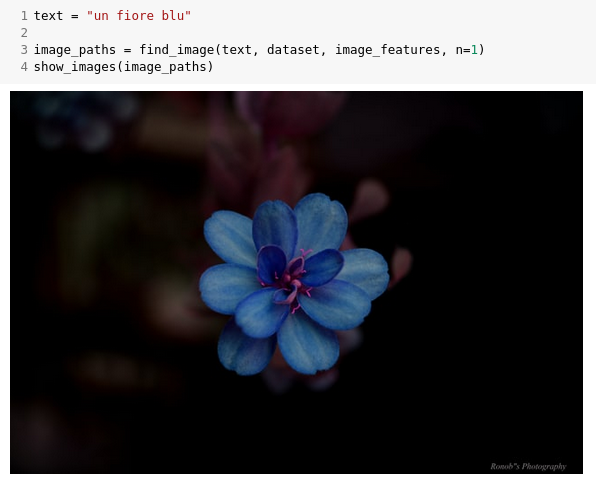
 And here's a blu flower
And here's a blu flower
 ### Counting
What about "one cat"?
### Counting
What about "one cat"?
 And what about "two cats"?
And what about "two cats"?
 ### Complex Queries
Have you ever seen "two brown horses"?
### Complex Queries
Have you ever seen "two brown horses"?
 And finally, here's a very nice "cat on a chair"
And finally, here's a very nice "cat on a chair"
 # Broader Outlook
We believe that this model can be useful for many different applications. From image classification
to clustering, a model like CLIP Italian can be used to support researchers and practitioners in many different tasks.
Indeed, not only it can be useful in research, but also in industry. A very interesting use-case is given by ecommerce platforms:
these website often deal with a main source of text that is the query engine and with lots of images of the products. CLIP Italian
can be a killer app in this context, providing a way to search for images and text. Nonetheless, Italy has many different collections
of photos in digital format. For example, the [Istituto Luce Cinecittà](https://it.wikipedia.org/wiki/Istituto_Luce_Cinecitt%C3%A0) is an Italian governative entity that collects photos of Italy since the
early 1900 and it is part of the largest movie studios in Europe (Cinecittà).
# Limitations and Bias
Currently, the model is not without limits. To mention one, its counting capabilities seem very cool, but from our experiments the model
finds difficult to count after three; this is a general limitation.
There are even more serious limitations: we found some emergence of biases and stereotypes that got in our model from different factors: searching for "una troia" ("a bitch") on the
CC dataset shows the picture of a woman. The model's capability even increase this issue, as searching for "due troie" ("two bitches")
gives again, as a results, the picture of two women. BERT models are not free from bias. Indeed, different BERT models - Italians included - are prone to create stereotyped sentences that are hurtful ([Nozza et al., 2021](https://www.aclweb.org/anthology/2021.naacl-main.191.pdf))
This issue is common to many machine learning algorithms (check [Abit et al., 2021](https://arxiv.org/abs/2101.05783) for bias in GPT-3 as an example) and
suggest we need to work even harder on this problem that affects our **society**.
# References
Abid, A., Farooqi, M., & Zou, J. (2021). [Persistent anti-muslim bias in large language models.](https://arxiv.org/abs/2101.05783) arXiv preprint arXiv:2101.05783.
Gwet, K. L. (2008). [Computing inter‐rater reliability and its variance in the presence of high agreement.](https://bpspsychub.onlinelibrary.wiley.com/doi/full/10.1348/000711006X126600) British Journal of Mathematical and Statistical Psychology, 61(1), 29-48.
Nozza, D., Bianchi, F., & Hovy, D. (2021, June). [HONEST: Measuring hurtful sentence completion in language models.](https://www.aclweb.org/anthology/2021.naacl-main.191.pdf) In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (pp. 2398-2406).
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., & Sutskever, I. (2021). [Learning Transferable Visual Models From Natural Language Supervision.](https://arxiv.org/abs/2103.00020) ICML.
Reimers, N., & Gurevych, I. (2020, November). [Making Monolingual Sentence Embeddings Multilingual Using Knowledge Distillation.](https://aclanthology.org/2020.emnlp-main.365/) In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) (pp. 4512-4525).
Scaiella, A., Croce, D., & Basili, R. (2019). [Large scale datasets for Image and Video Captioning in Italian.](http://www.ai-lc.it/IJCoL/v5n2/IJCOL_5_2_3___scaiella_et_al.pdf) IJCoL. Italian Journal of Computational Linguistics, 5(5-2), 49-60.
Sharma, P., Ding, N., Goodman, S., & Soricut, R. (2018, July). [Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning.](https://aclanthology.org/P18-1238.pdf) In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 2556-2565).
Srinivasan, K., Raman, K., Chen, J., Bendersky, M., & Najork, M. (2021). [WIT: Wikipedia-based image text dataset for multimodal multilingual machine learning](https://arxiv.org/pdf/2103.01913.pdf). arXiv preprint arXiv:2103.01913.
# Other Notes
This readme has been designed using resources from Flaticon.com
# Broader Outlook
We believe that this model can be useful for many different applications. From image classification
to clustering, a model like CLIP Italian can be used to support researchers and practitioners in many different tasks.
Indeed, not only it can be useful in research, but also in industry. A very interesting use-case is given by ecommerce platforms:
these website often deal with a main source of text that is the query engine and with lots of images of the products. CLIP Italian
can be a killer app in this context, providing a way to search for images and text. Nonetheless, Italy has many different collections
of photos in digital format. For example, the [Istituto Luce Cinecittà](https://it.wikipedia.org/wiki/Istituto_Luce_Cinecitt%C3%A0) is an Italian governative entity that collects photos of Italy since the
early 1900 and it is part of the largest movie studios in Europe (Cinecittà).
# Limitations and Bias
Currently, the model is not without limits. To mention one, its counting capabilities seem very cool, but from our experiments the model
finds difficult to count after three; this is a general limitation.
There are even more serious limitations: we found some emergence of biases and stereotypes that got in our model from different factors: searching for "una troia" ("a bitch") on the
CC dataset shows the picture of a woman. The model's capability even increase this issue, as searching for "due troie" ("two bitches")
gives again, as a results, the picture of two women. BERT models are not free from bias. Indeed, different BERT models - Italians included - are prone to create stereotyped sentences that are hurtful ([Nozza et al., 2021](https://www.aclweb.org/anthology/2021.naacl-main.191.pdf))
This issue is common to many machine learning algorithms (check [Abit et al., 2021](https://arxiv.org/abs/2101.05783) for bias in GPT-3 as an example) and
suggest we need to work even harder on this problem that affects our **society**.
# References
Abid, A., Farooqi, M., & Zou, J. (2021). [Persistent anti-muslim bias in large language models.](https://arxiv.org/abs/2101.05783) arXiv preprint arXiv:2101.05783.
Gwet, K. L. (2008). [Computing inter‐rater reliability and its variance in the presence of high agreement.](https://bpspsychub.onlinelibrary.wiley.com/doi/full/10.1348/000711006X126600) British Journal of Mathematical and Statistical Psychology, 61(1), 29-48.
Nozza, D., Bianchi, F., & Hovy, D. (2021, June). [HONEST: Measuring hurtful sentence completion in language models.](https://www.aclweb.org/anthology/2021.naacl-main.191.pdf) In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (pp. 2398-2406).
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., & Sutskever, I. (2021). [Learning Transferable Visual Models From Natural Language Supervision.](https://arxiv.org/abs/2103.00020) ICML.
Reimers, N., & Gurevych, I. (2020, November). [Making Monolingual Sentence Embeddings Multilingual Using Knowledge Distillation.](https://aclanthology.org/2020.emnlp-main.365/) In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) (pp. 4512-4525).
Scaiella, A., Croce, D., & Basili, R. (2019). [Large scale datasets for Image and Video Captioning in Italian.](http://www.ai-lc.it/IJCoL/v5n2/IJCOL_5_2_3___scaiella_et_al.pdf) IJCoL. Italian Journal of Computational Linguistics, 5(5-2), 49-60.
Sharma, P., Ding, N., Goodman, S., & Soricut, R. (2018, July). [Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning.](https://aclanthology.org/P18-1238.pdf) In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 2556-2565).
Srinivasan, K., Raman, K., Chen, J., Bendersky, M., & Najork, M. (2021). [WIT: Wikipedia-based image text dataset for multimodal multilingual machine learning](https://arxiv.org/pdf/2103.01913.pdf). arXiv preprint arXiv:2103.01913.
# Other Notes
This readme has been designed using resources from Flaticon.com