| Original text: A man kicks something or someone with his left leg. | |||
|---|---|---|---|
|
|
|
|
| Perturbed text: A human boots something or someone with his left leg. | |||
|
|
|
|
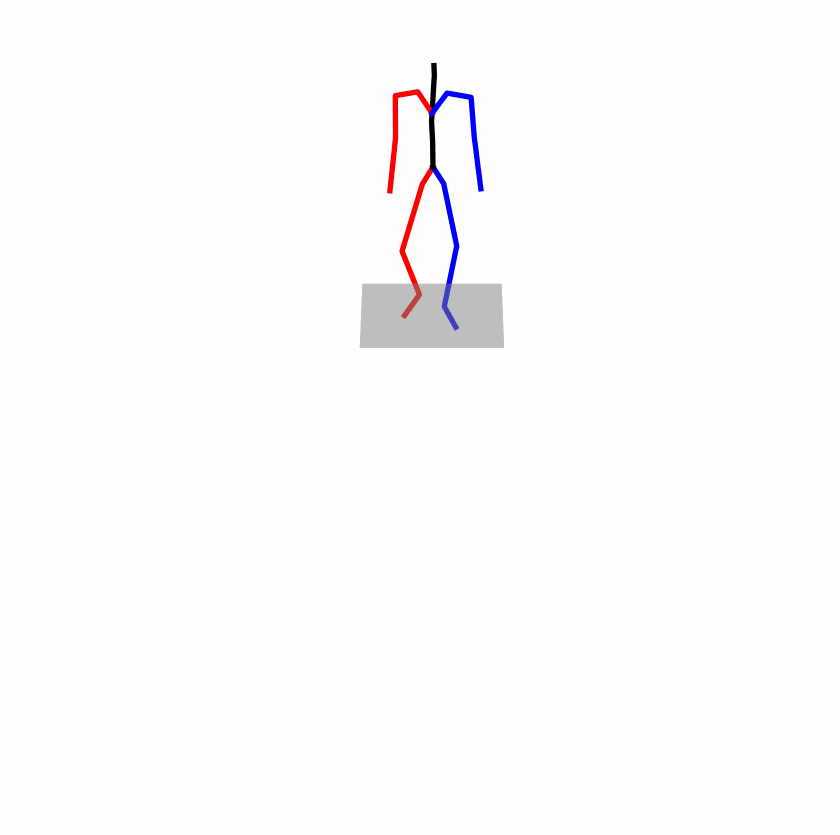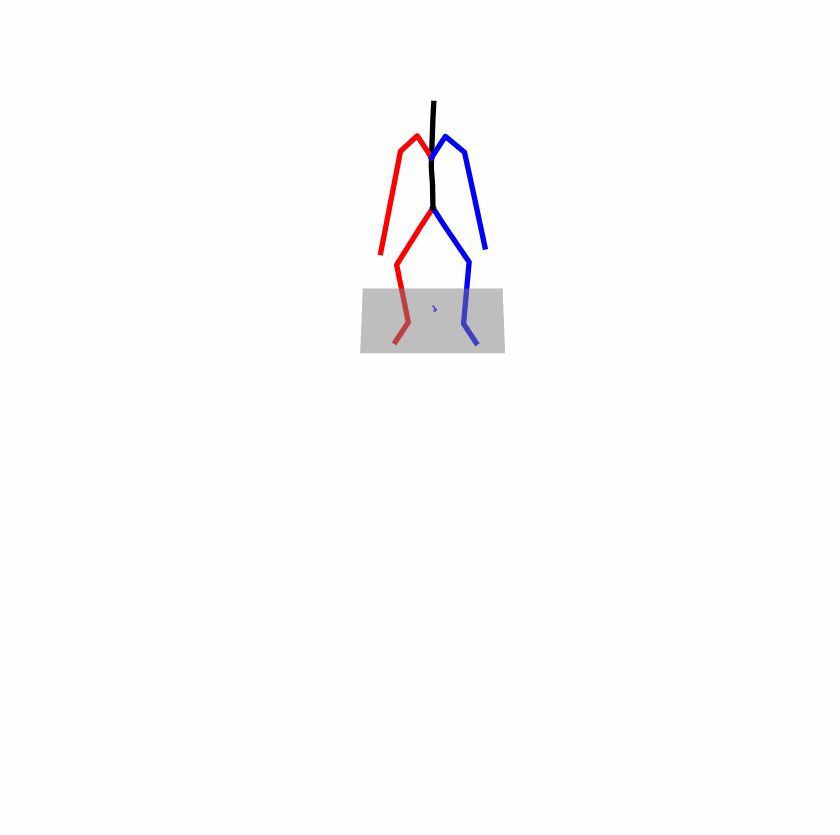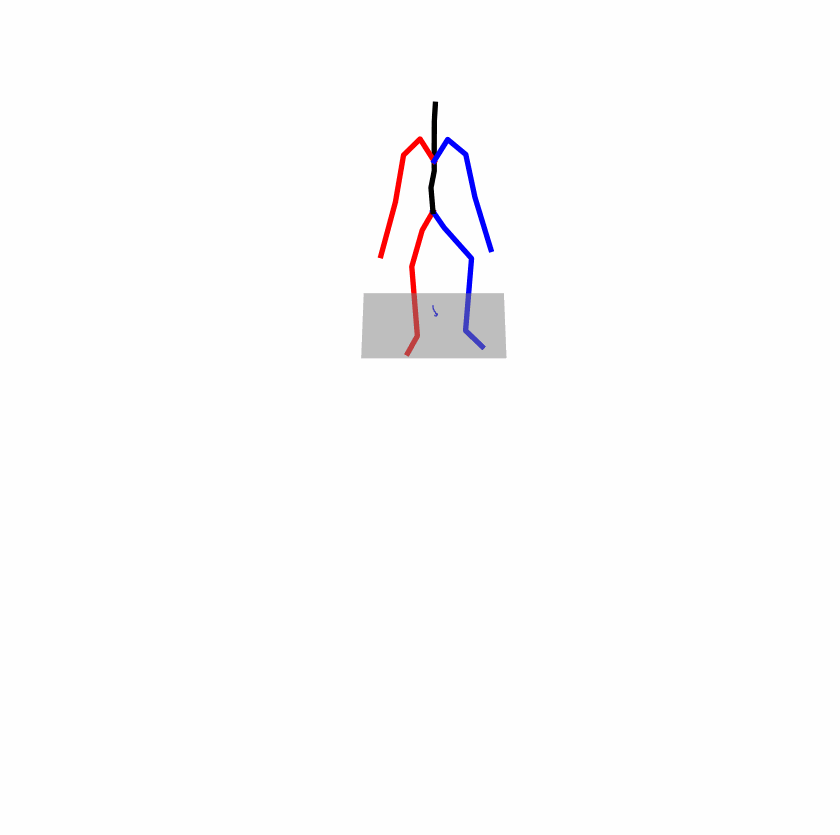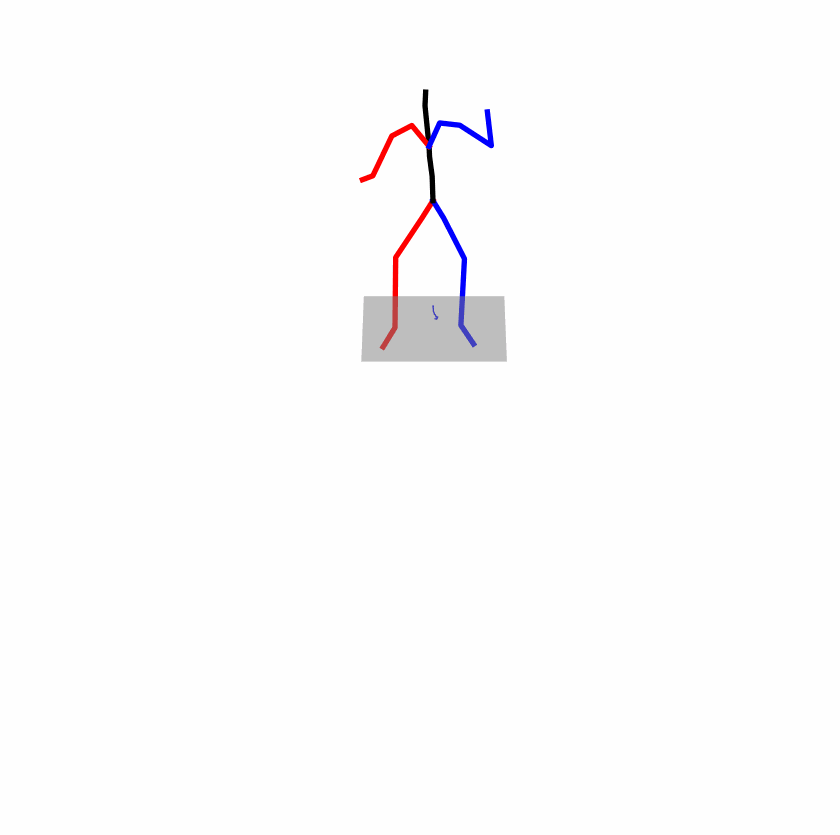
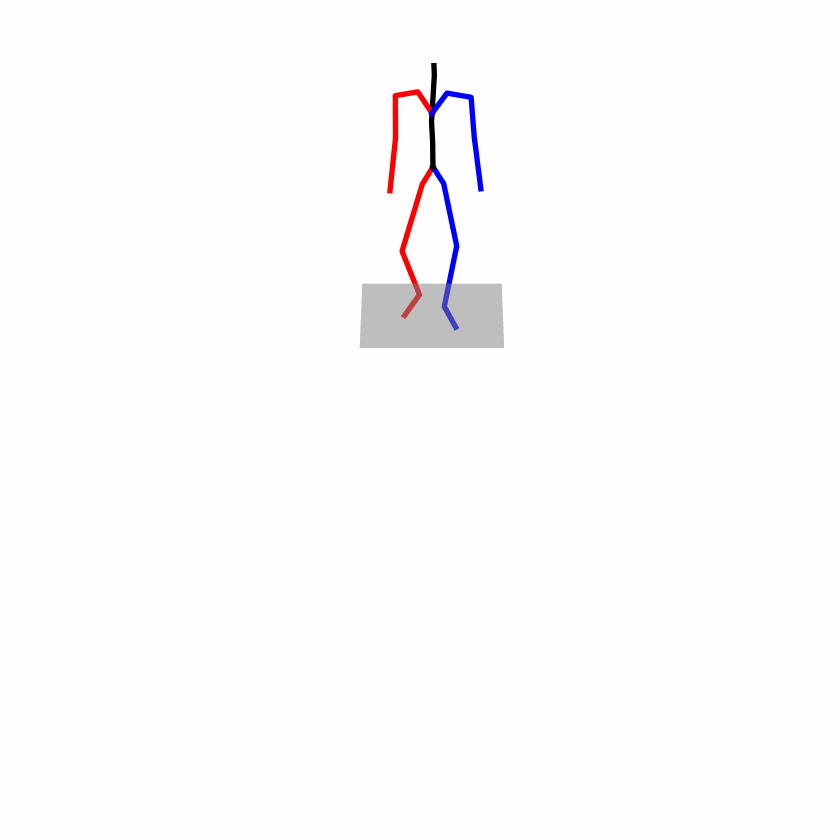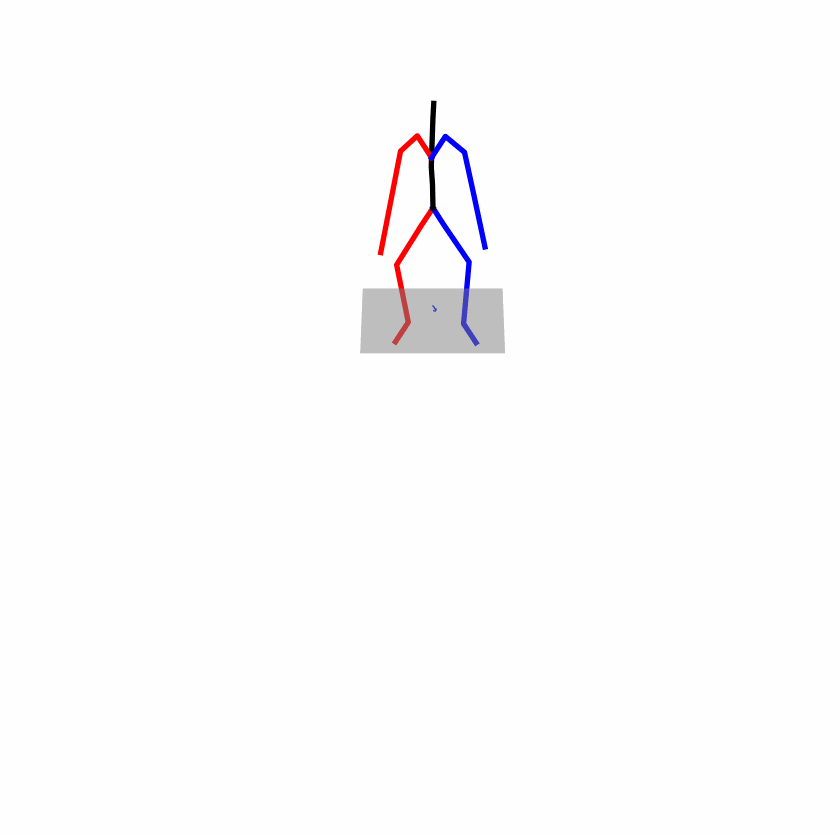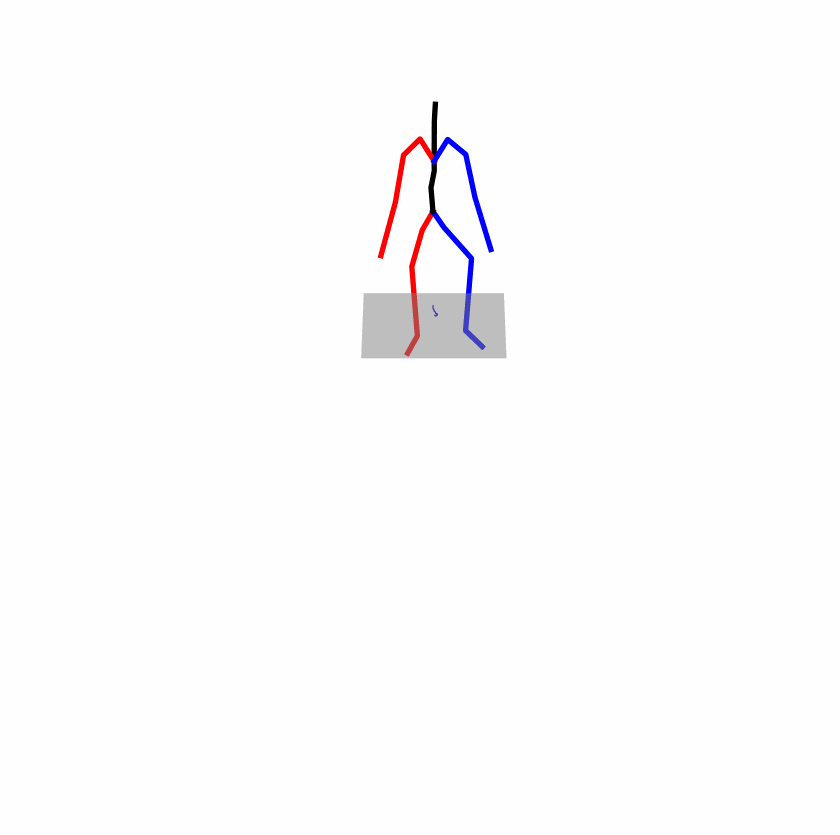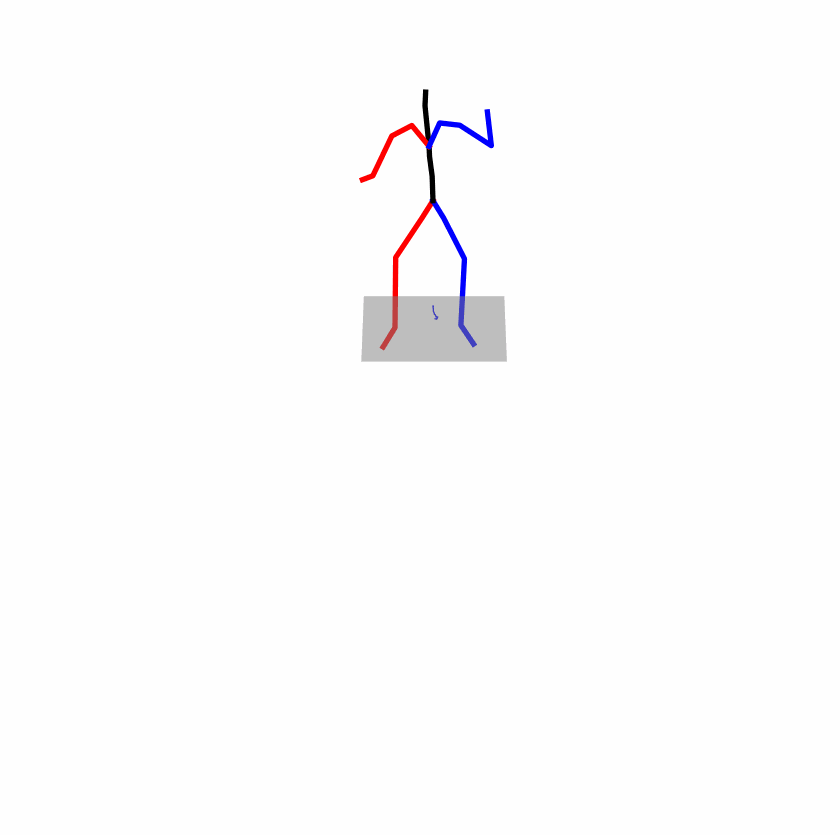
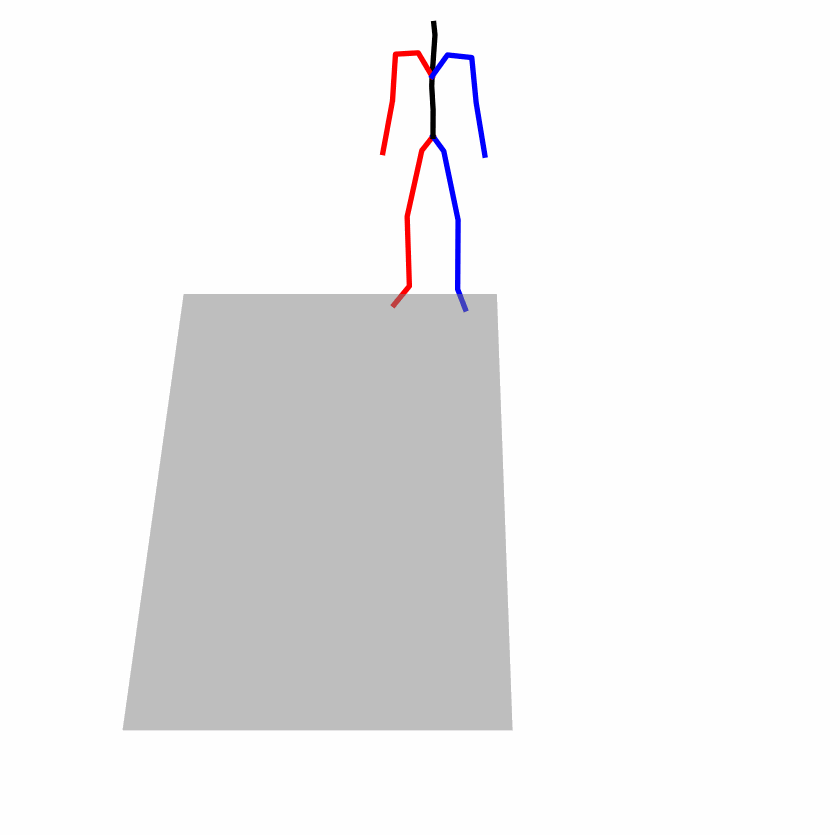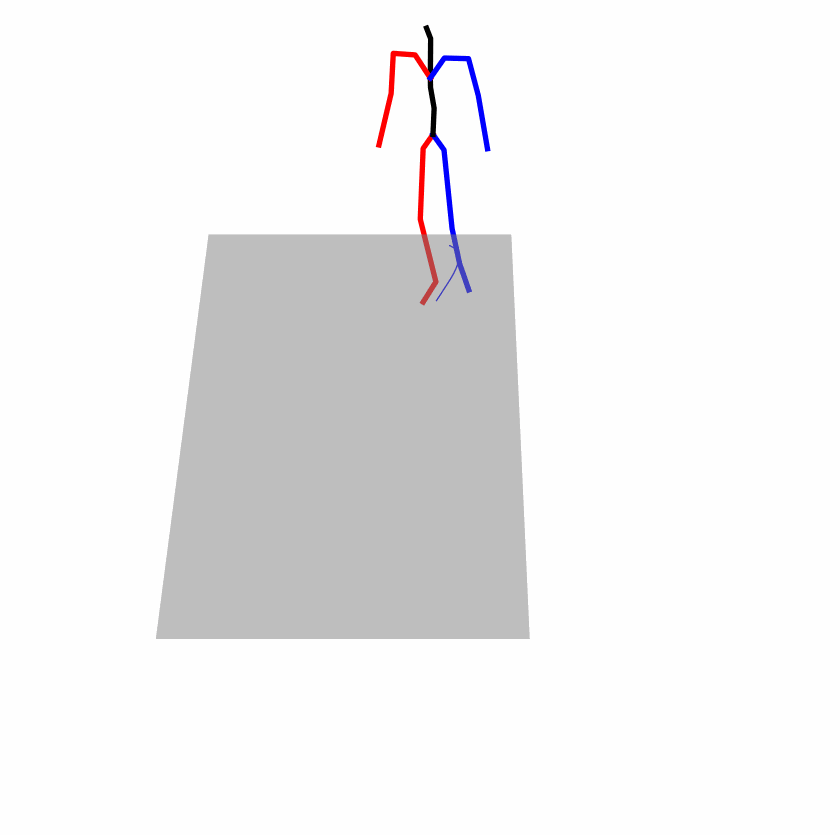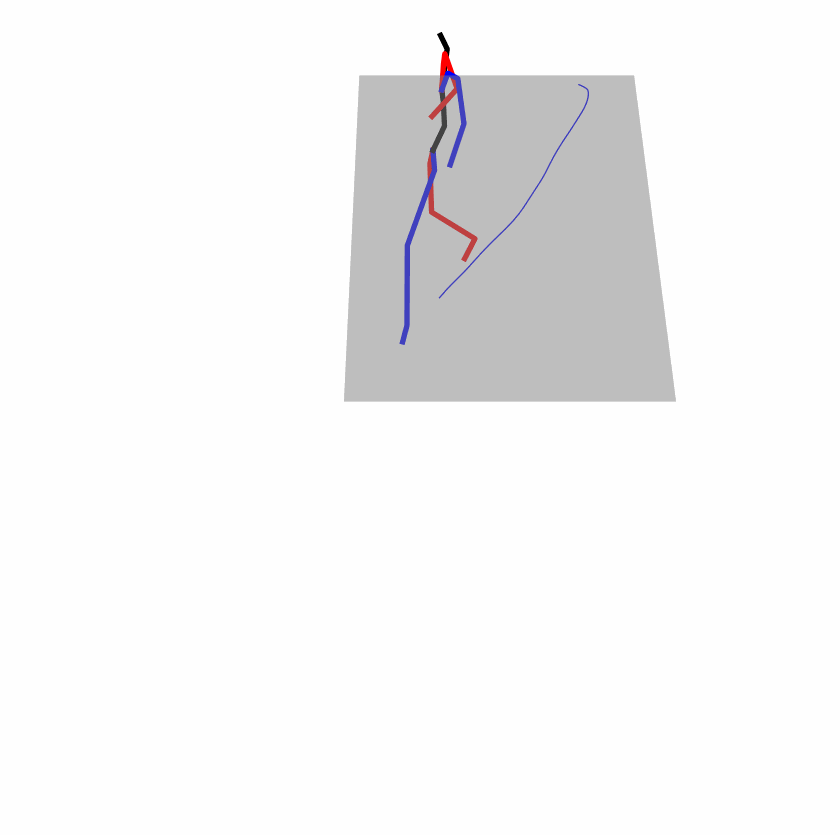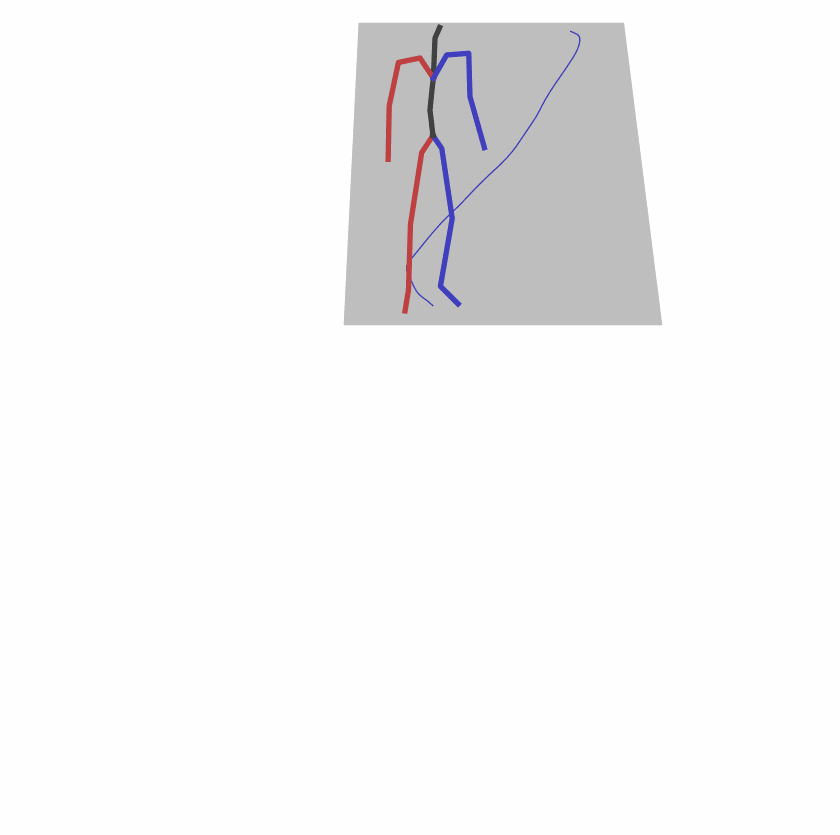
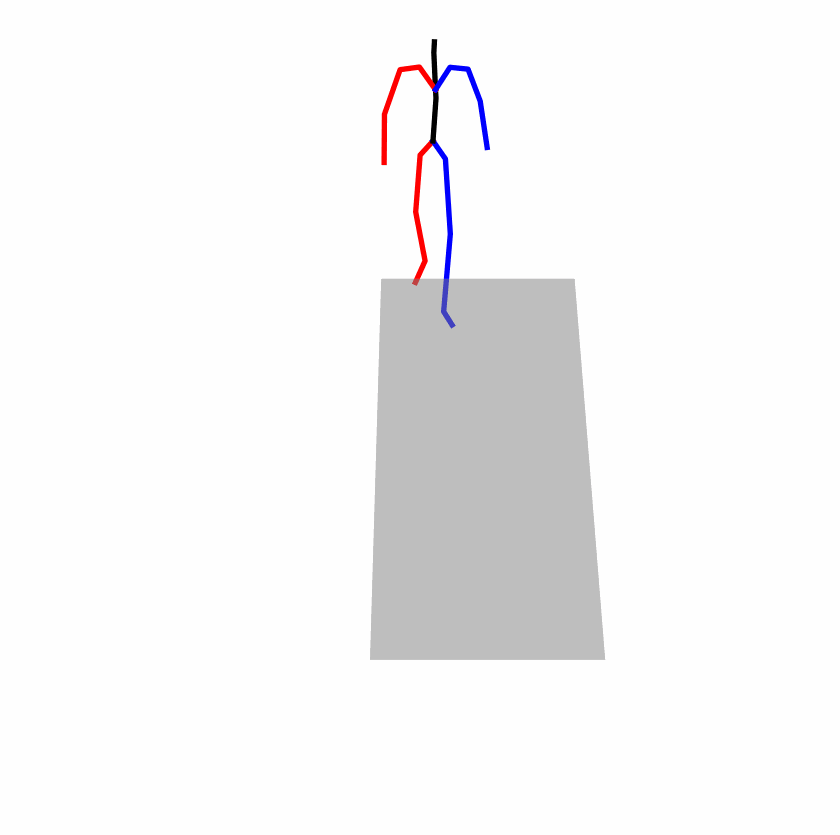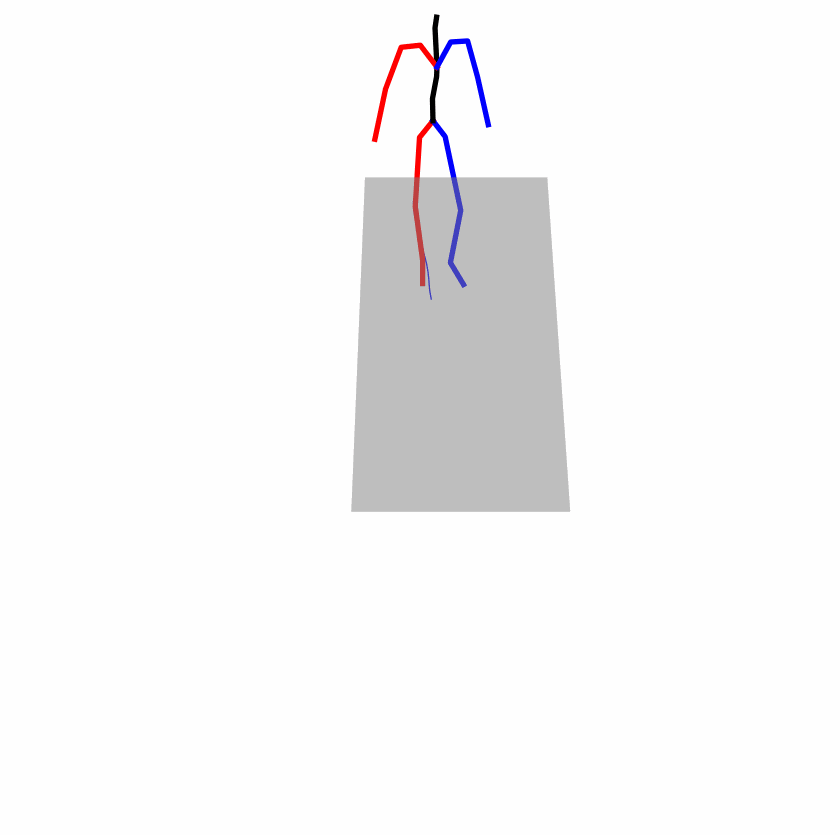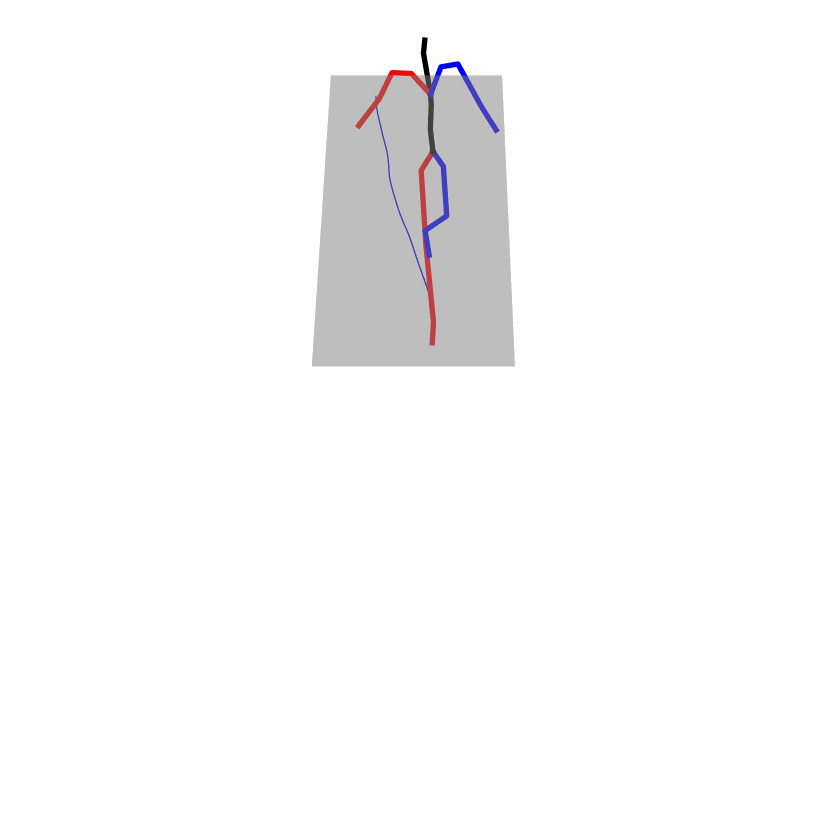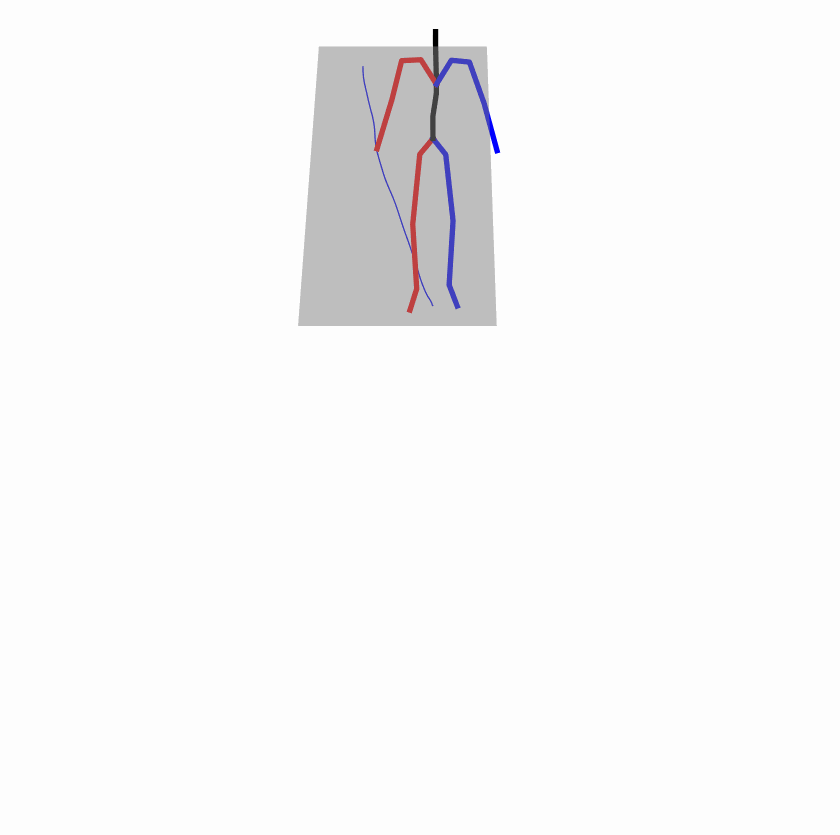
| Original text: person is walking normally in a circle. | |||
|---|---|---|---|
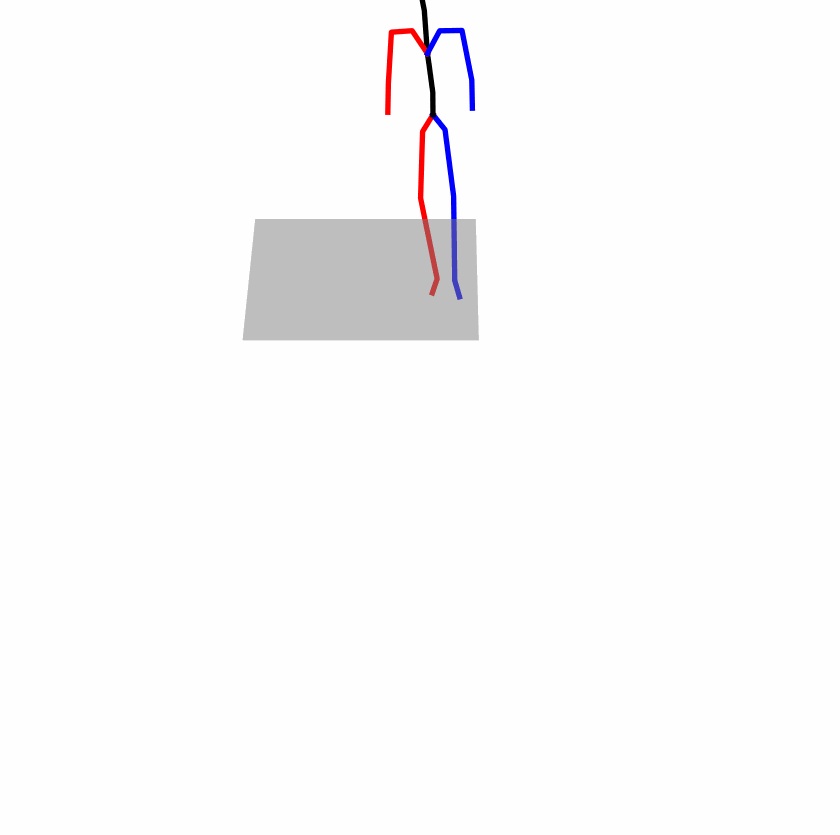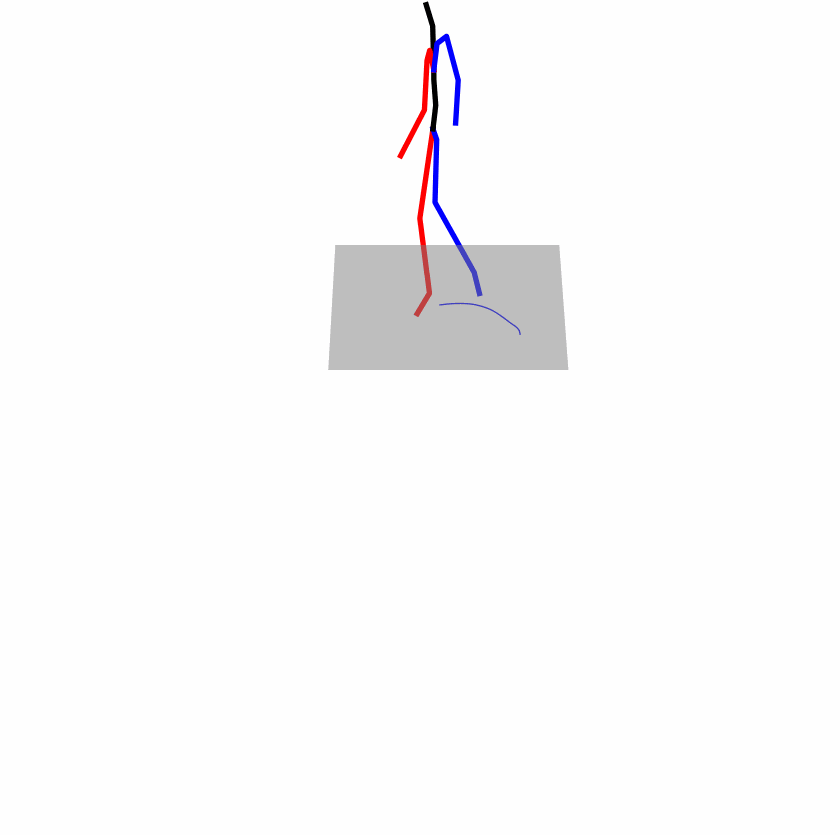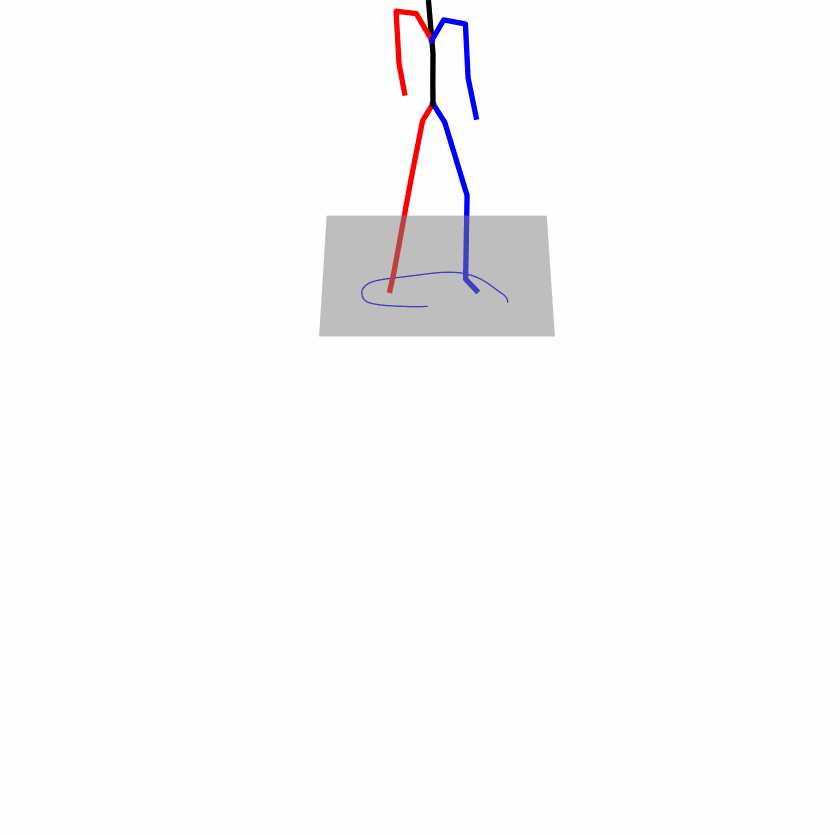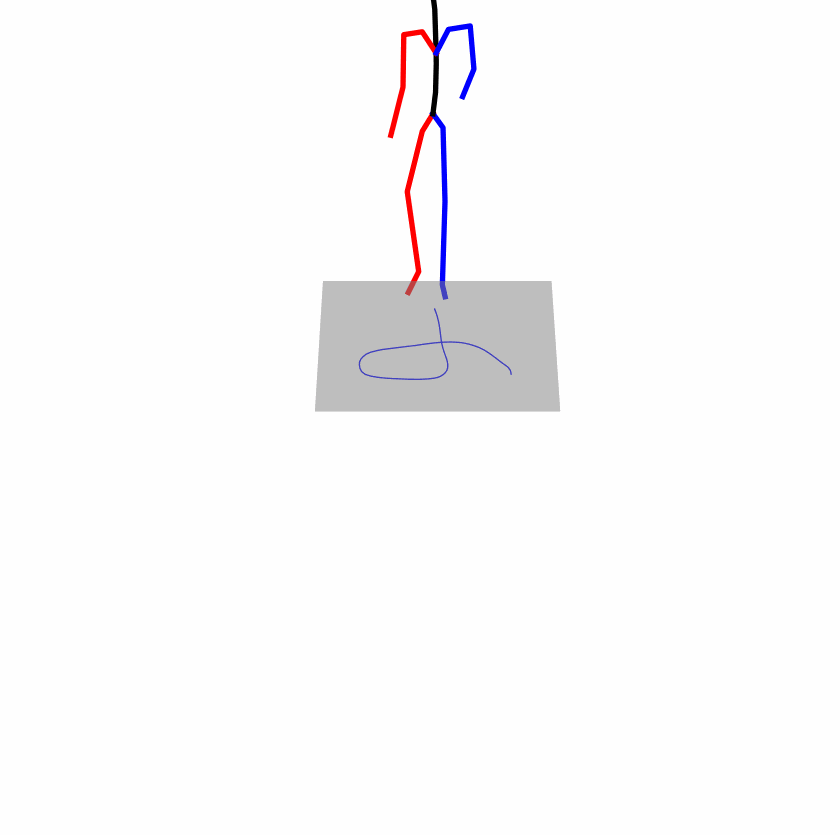 |
 |
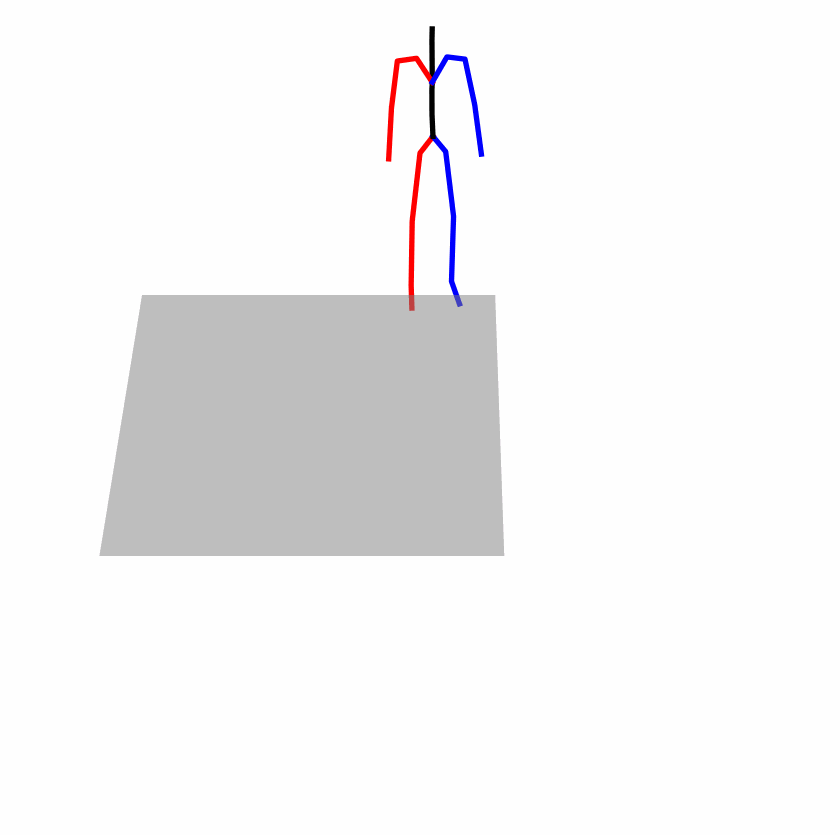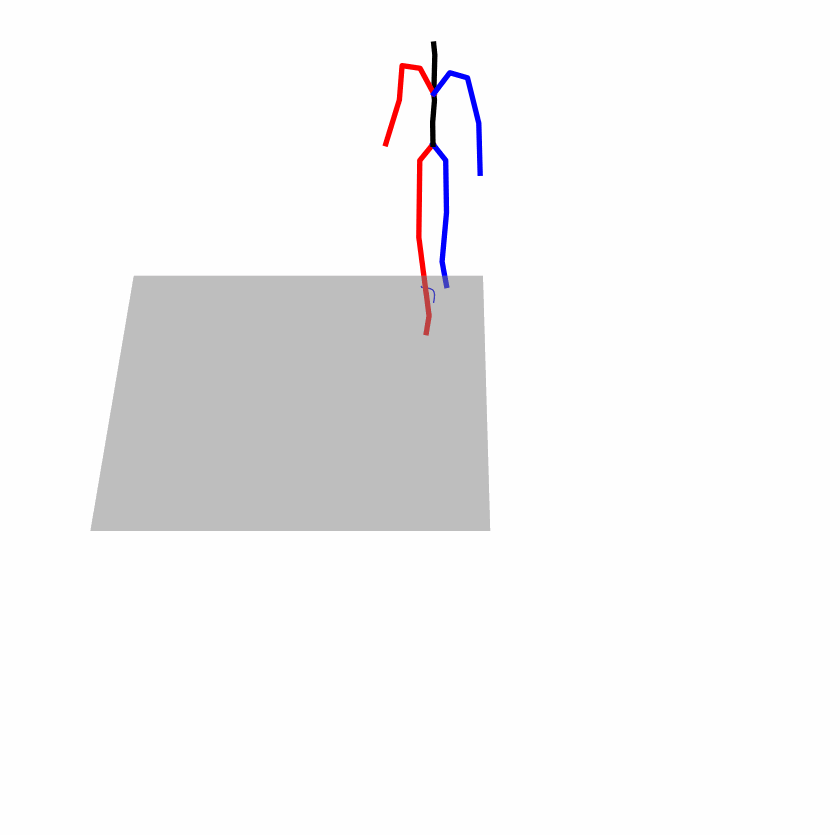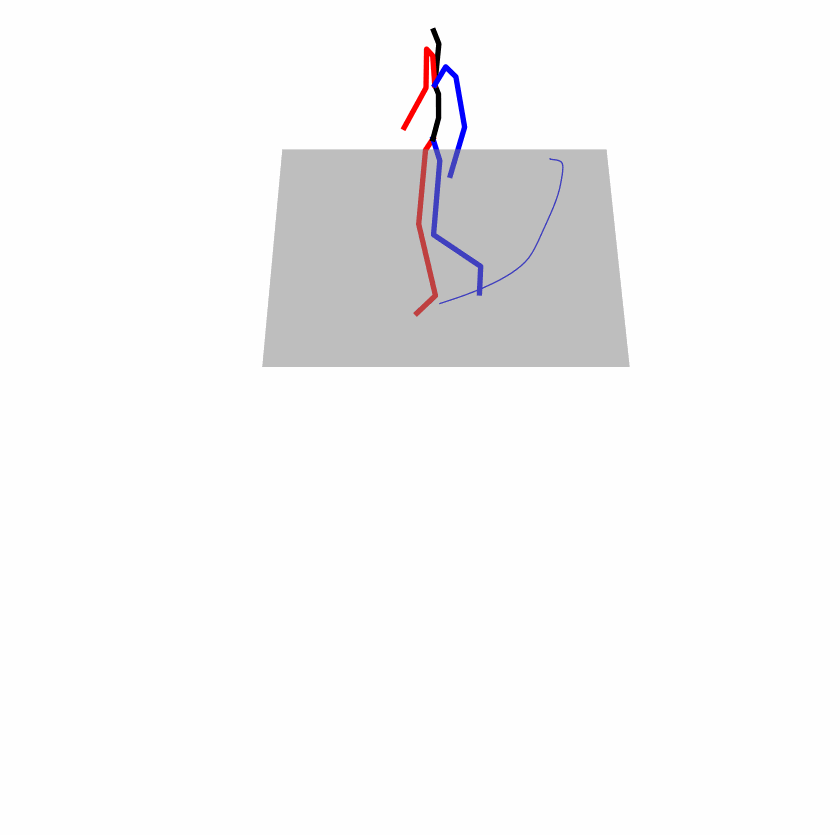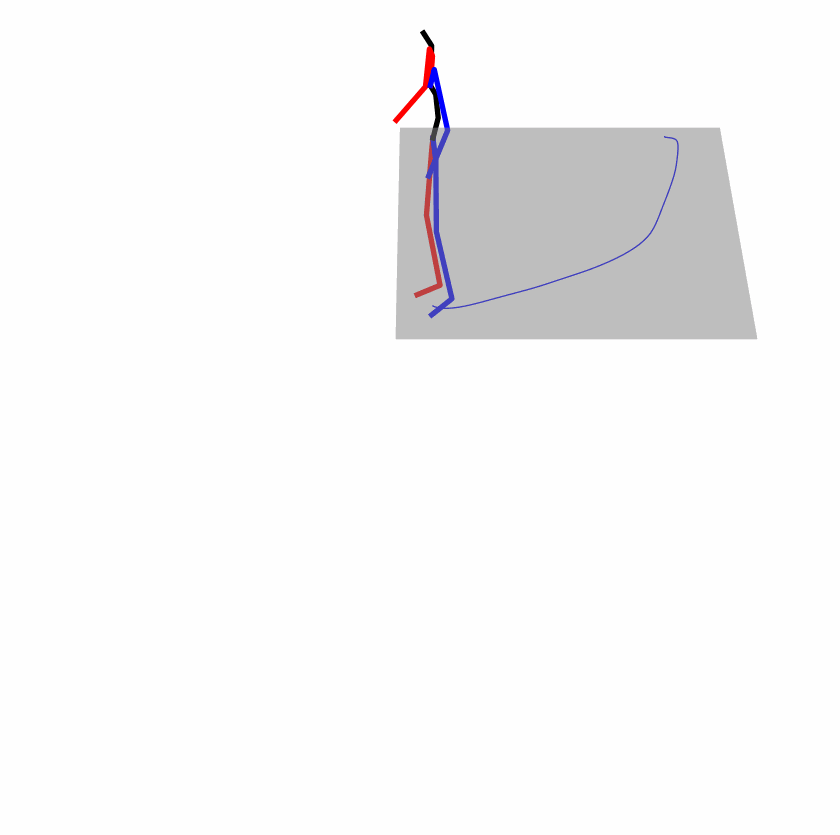 |
 |
| Perturbed text: human is walking usually in a loop. | |||
 |
 |
 |
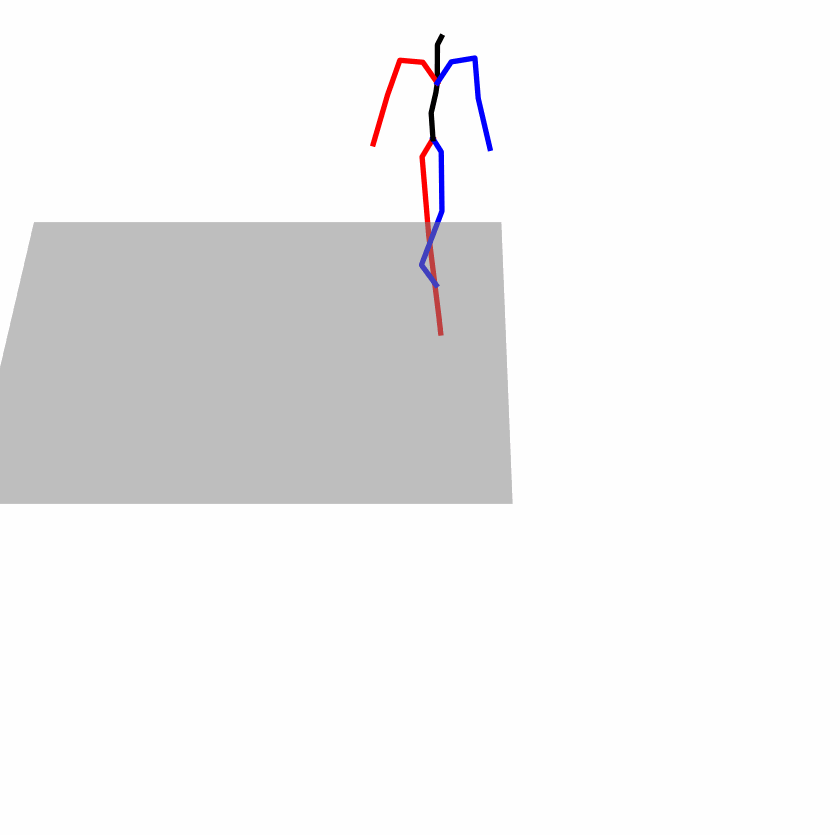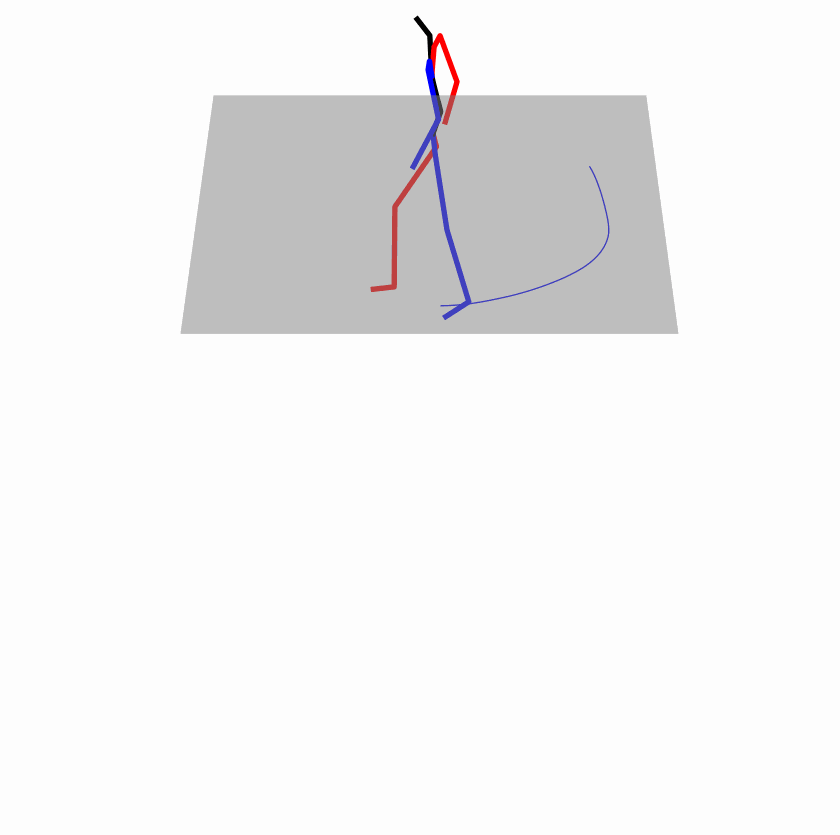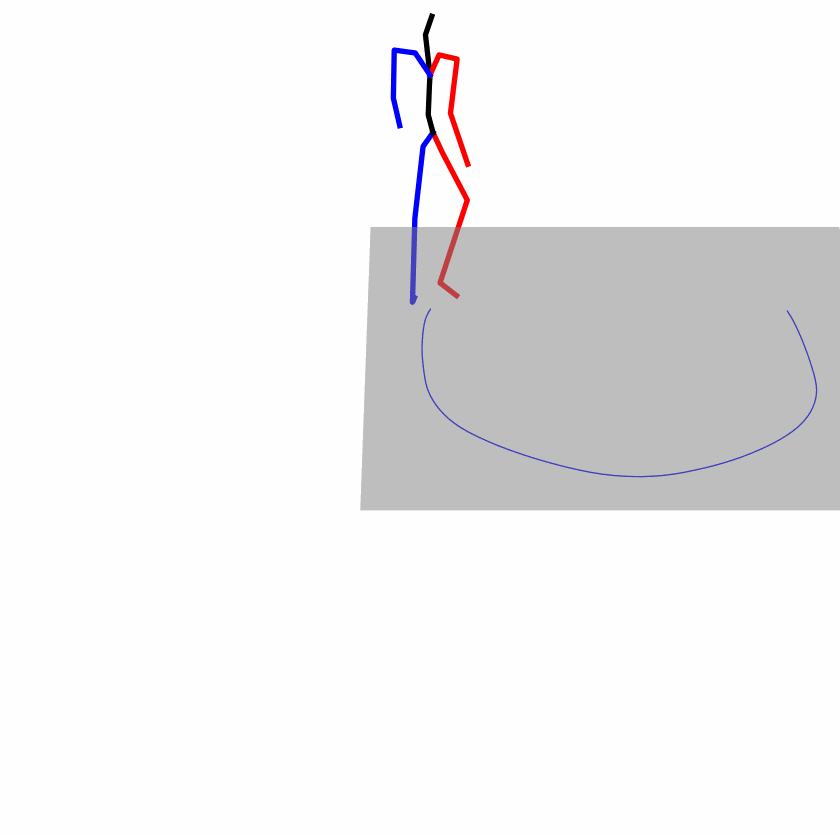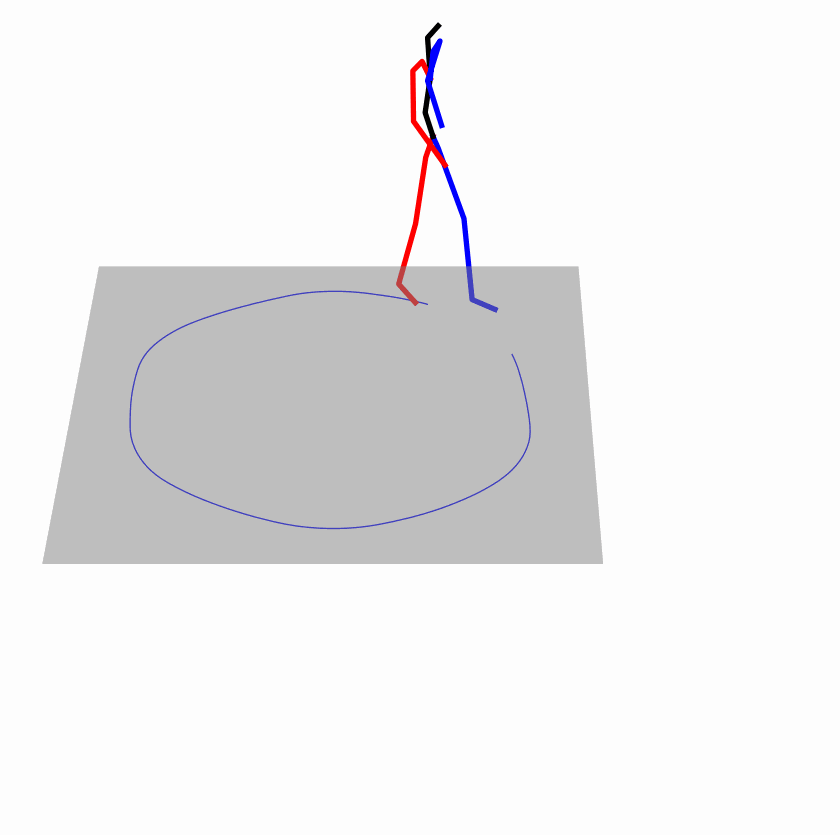 |
Explanation: T2M-GPT, MDM, and MoMask all don't walk in a loop.
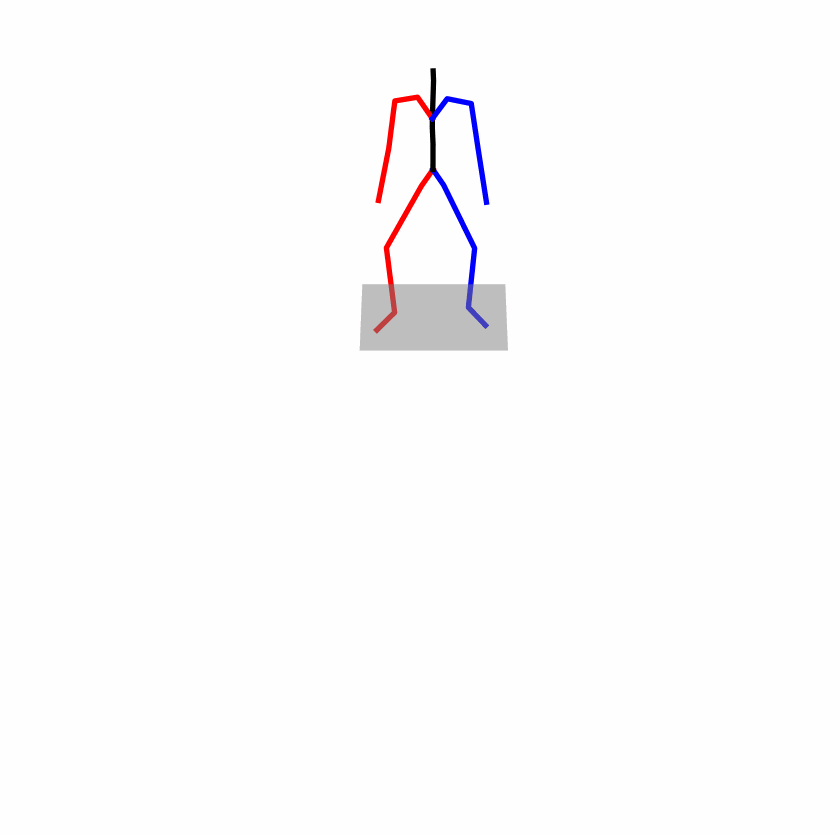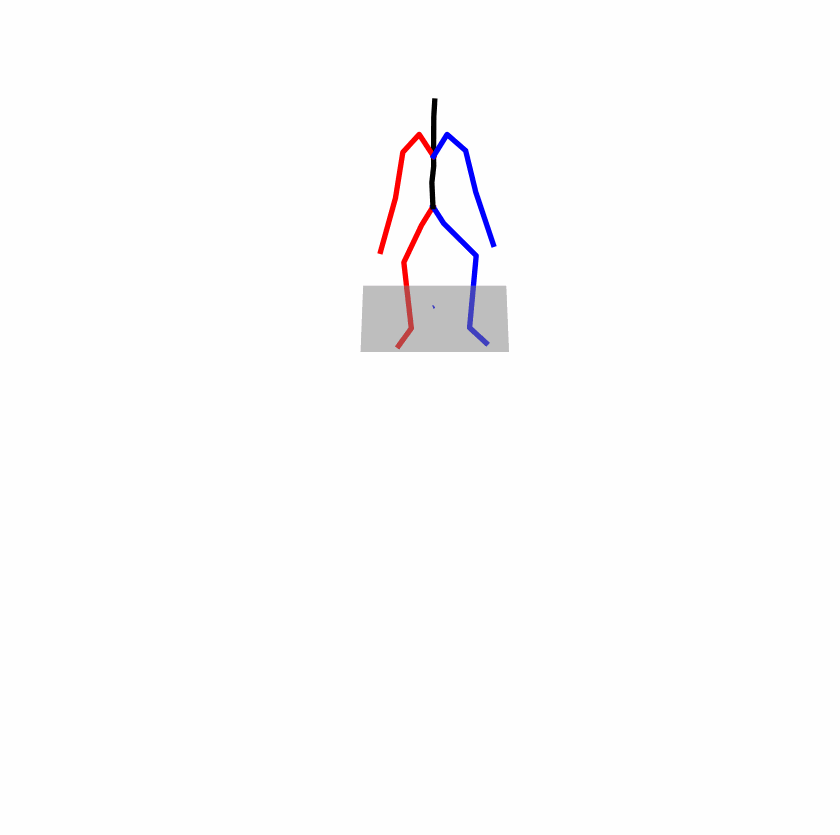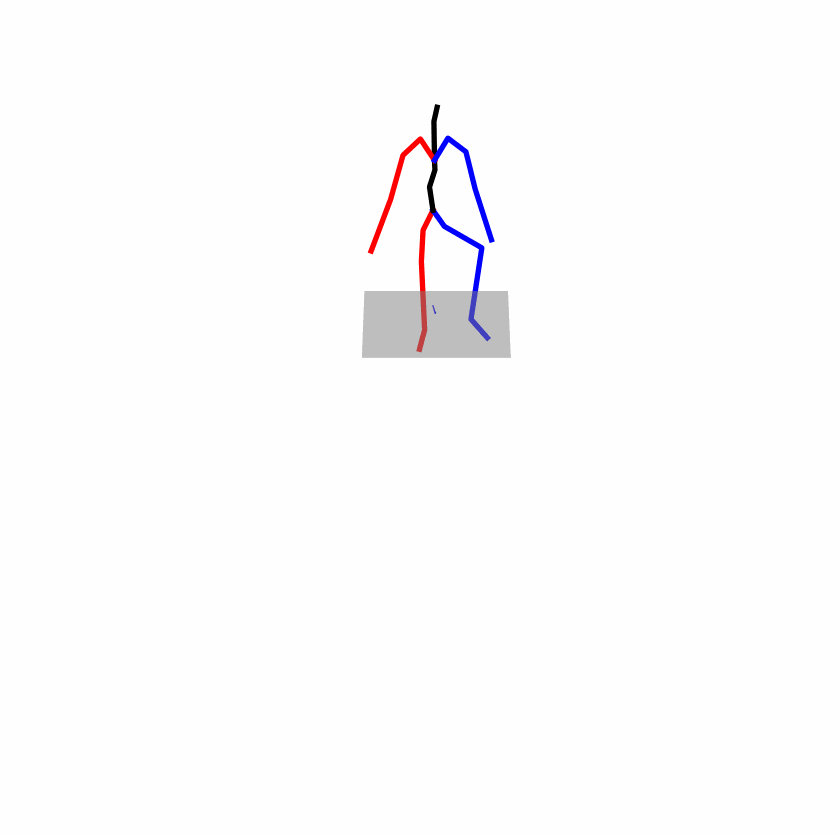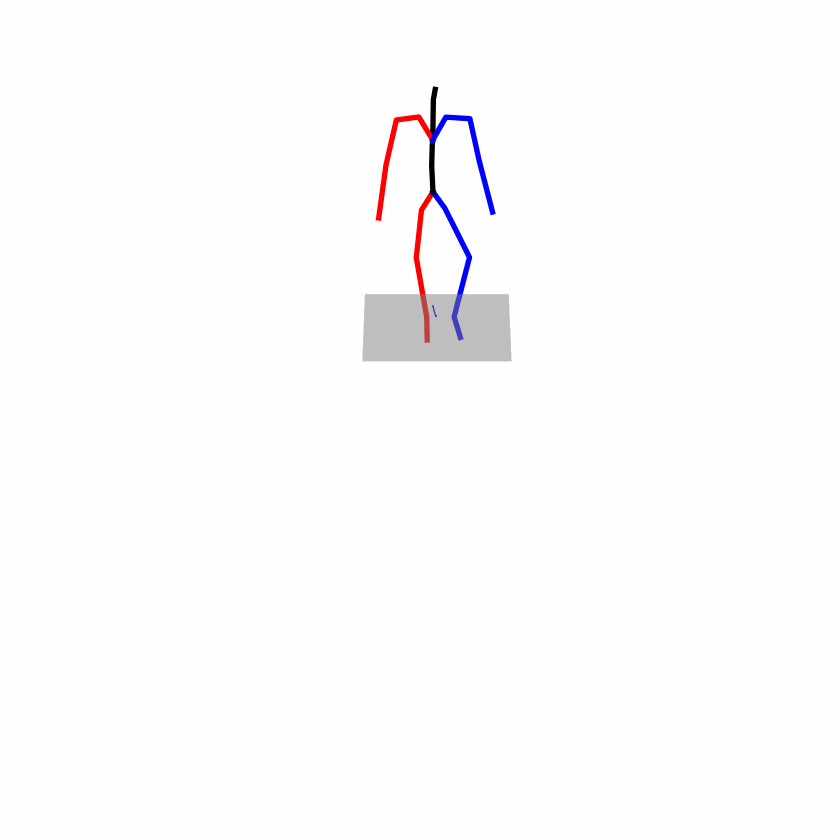
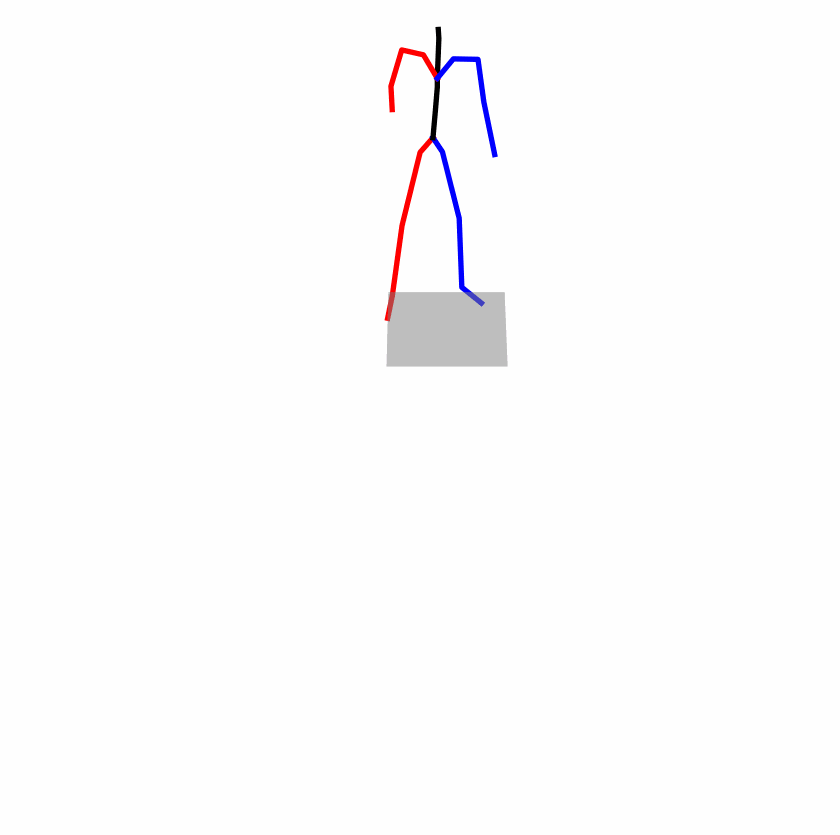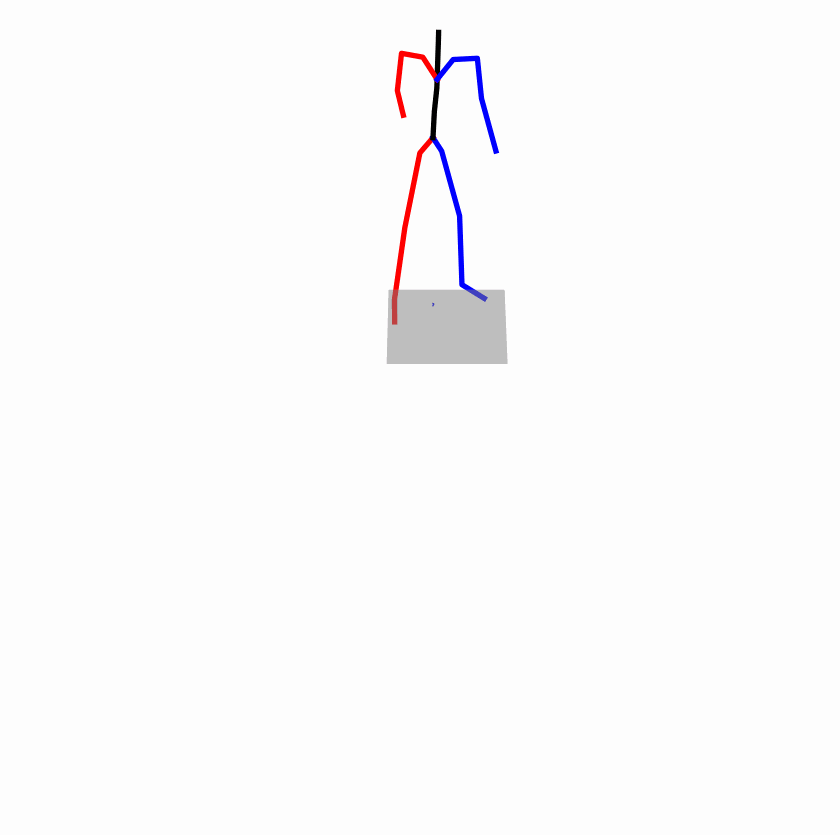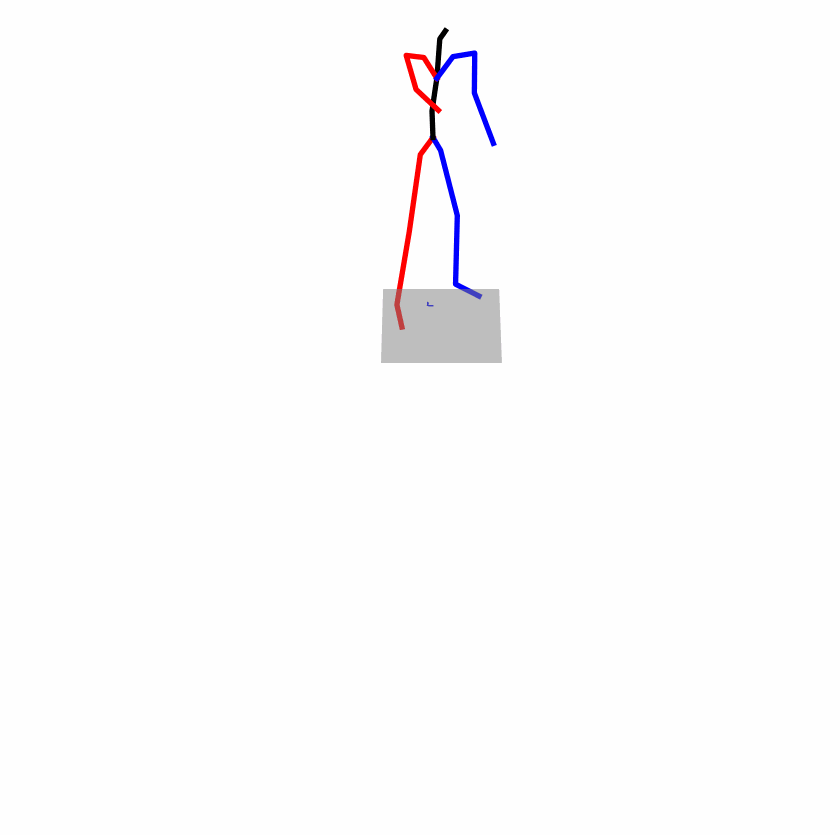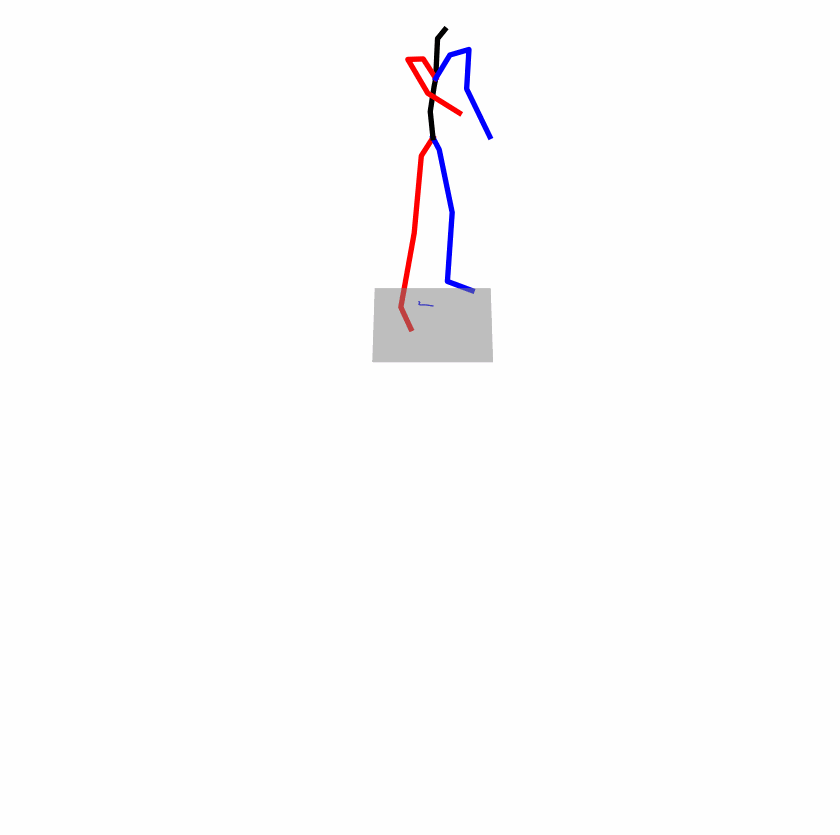
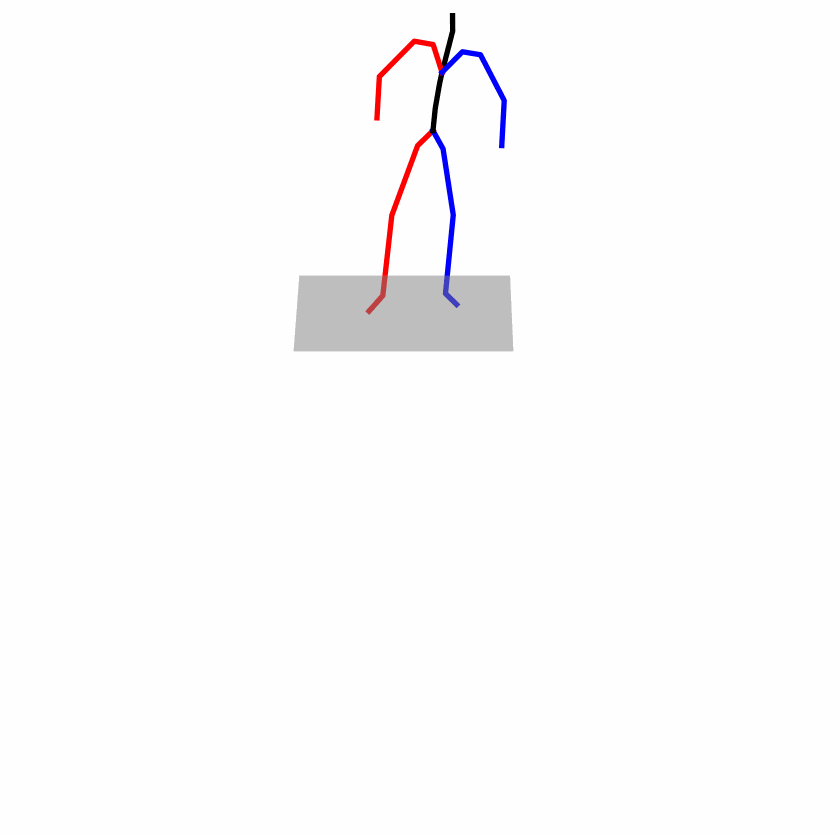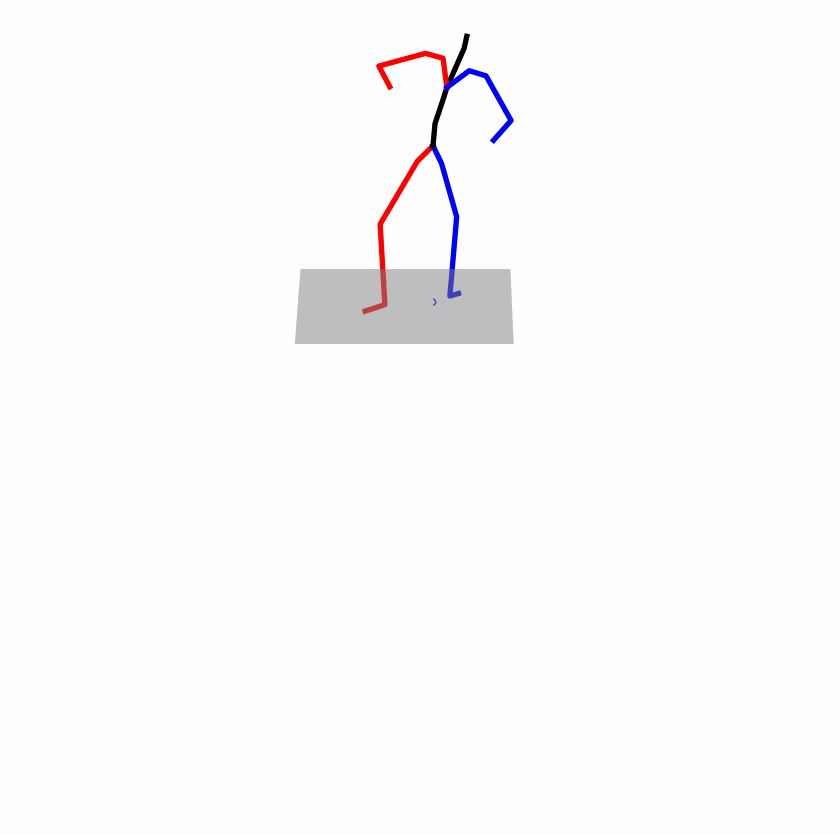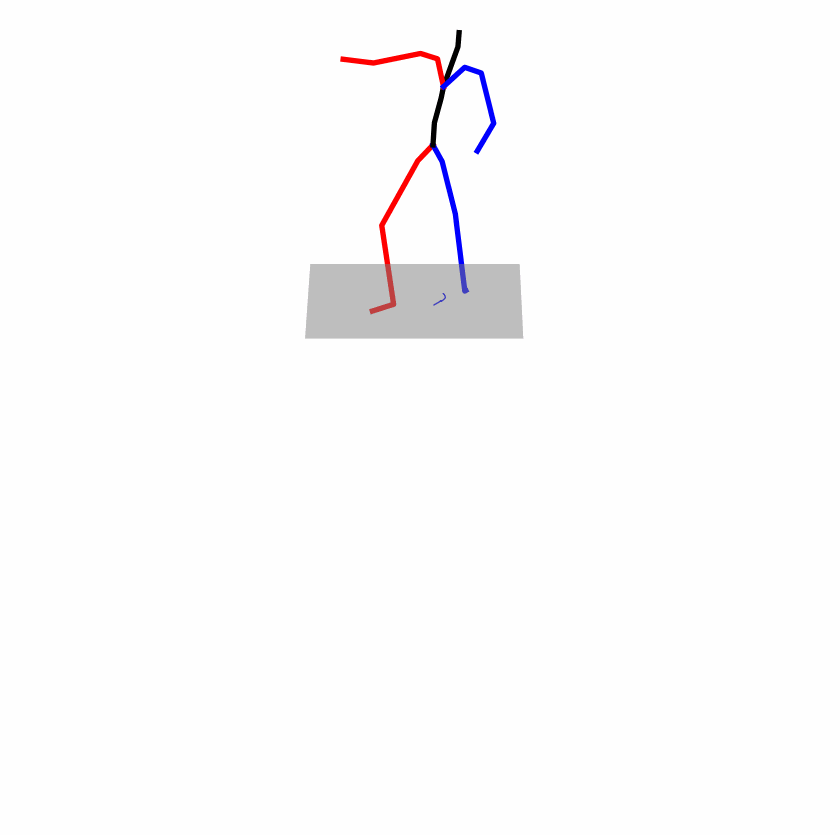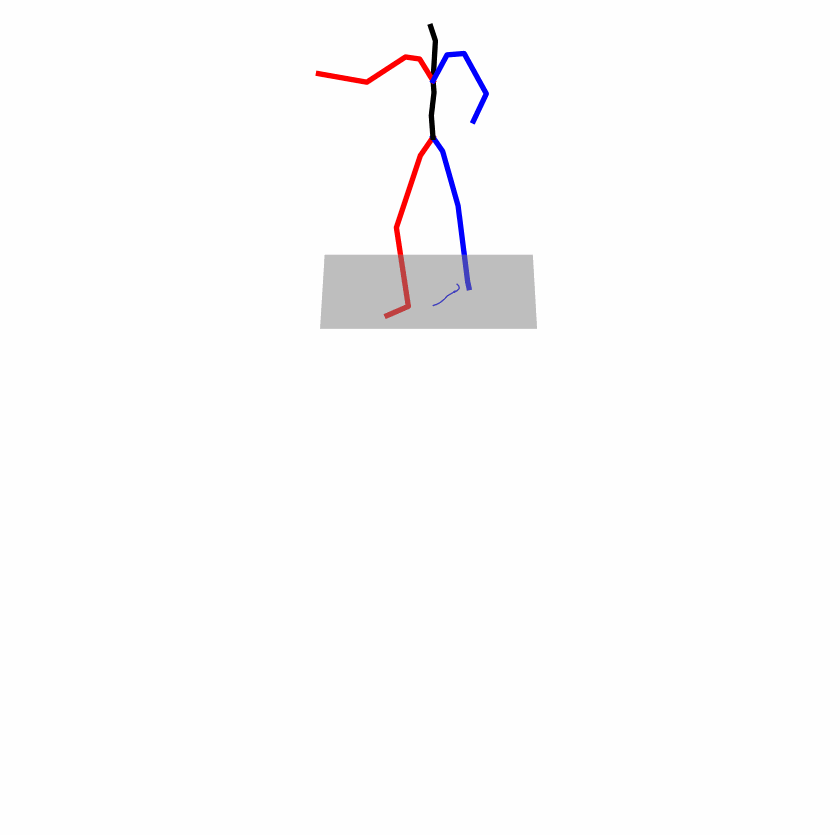
| Original text: a person uses his right arm to help himself to stand up. | |||
|---|---|---|---|
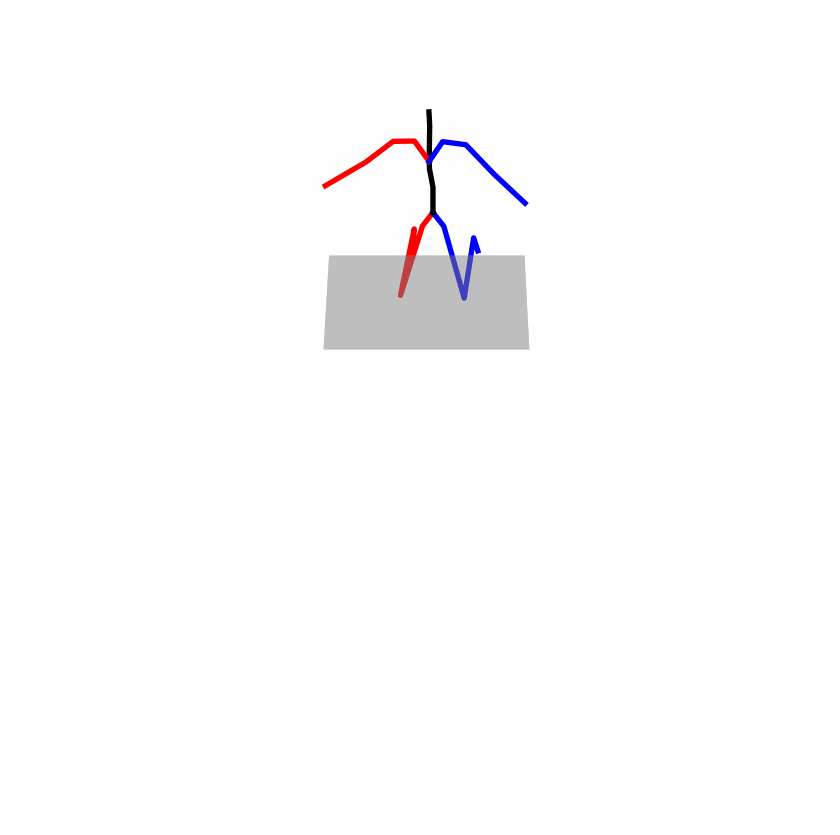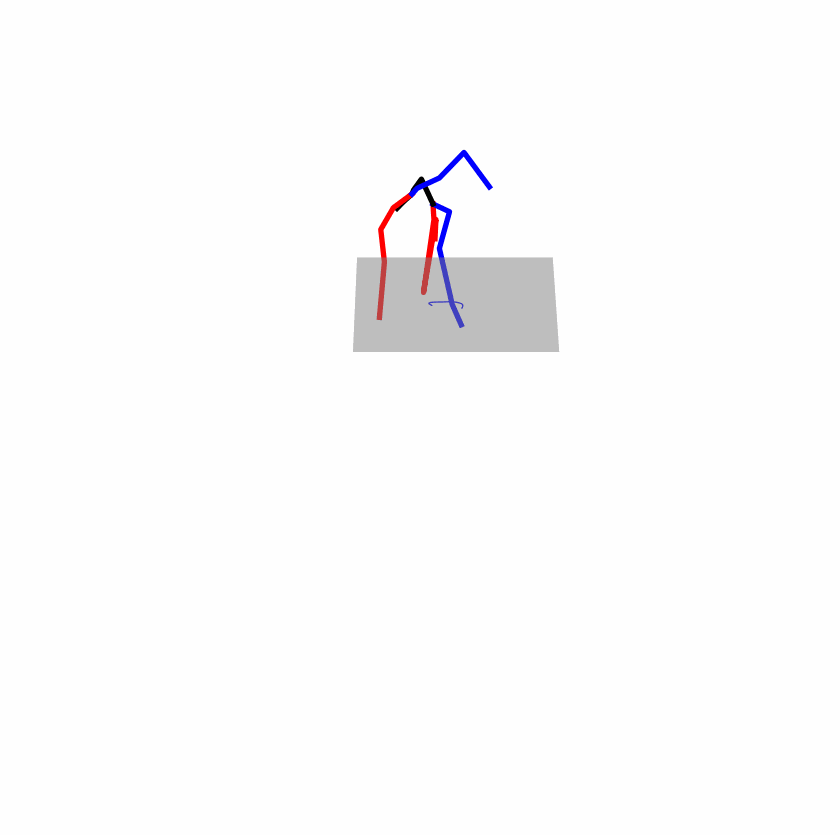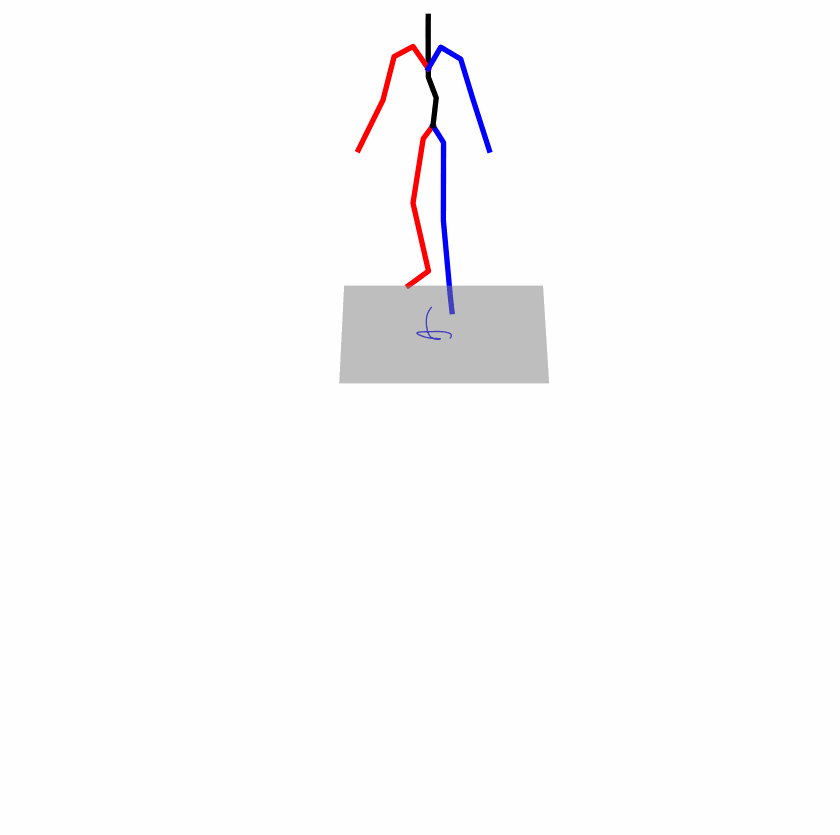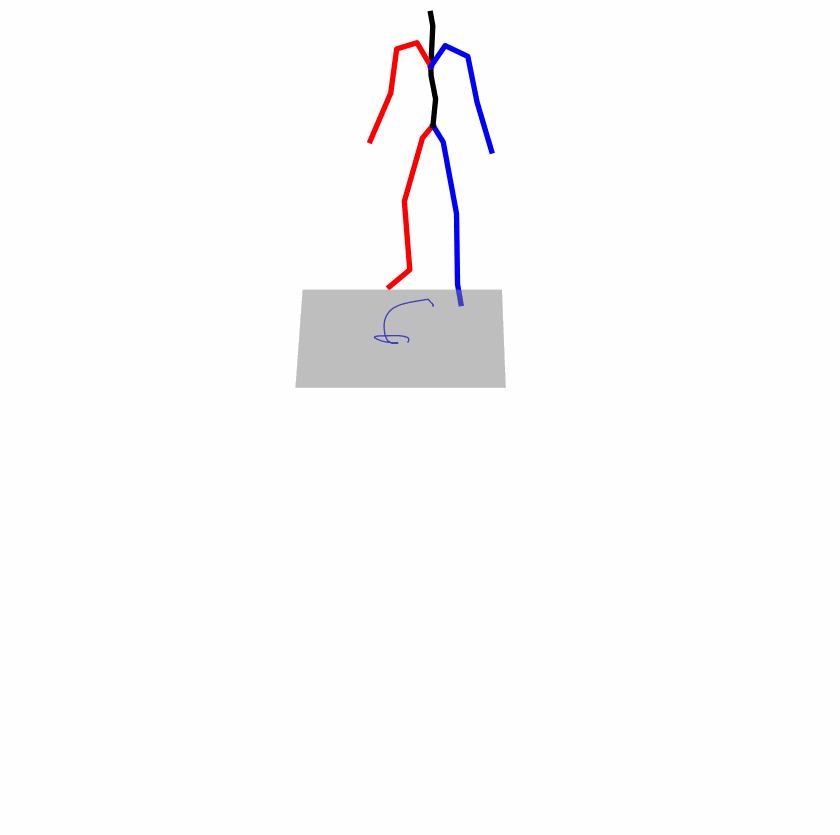 |
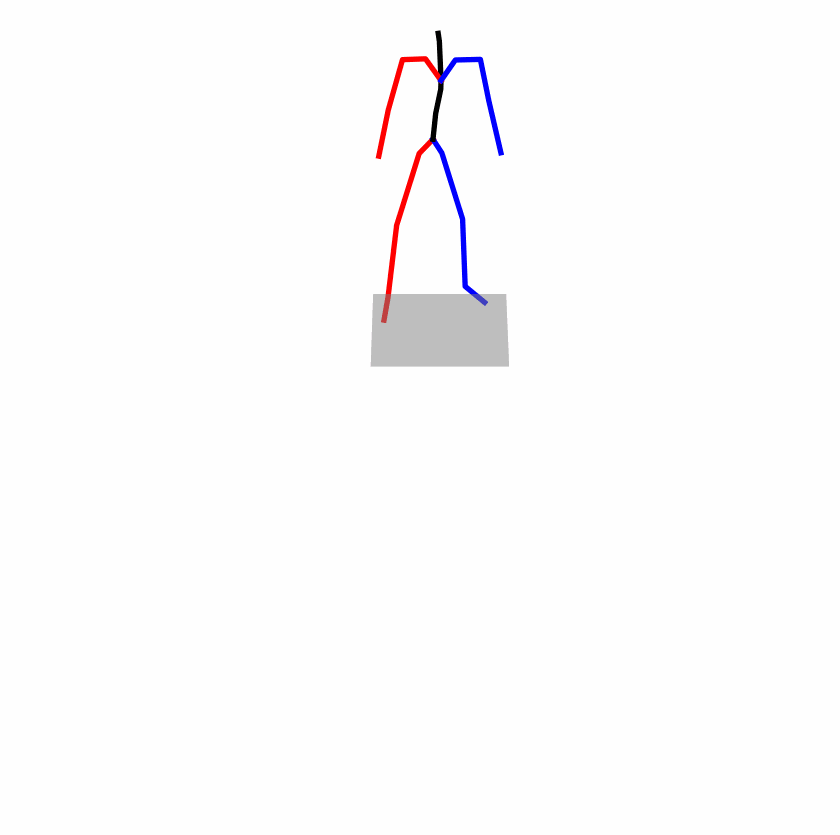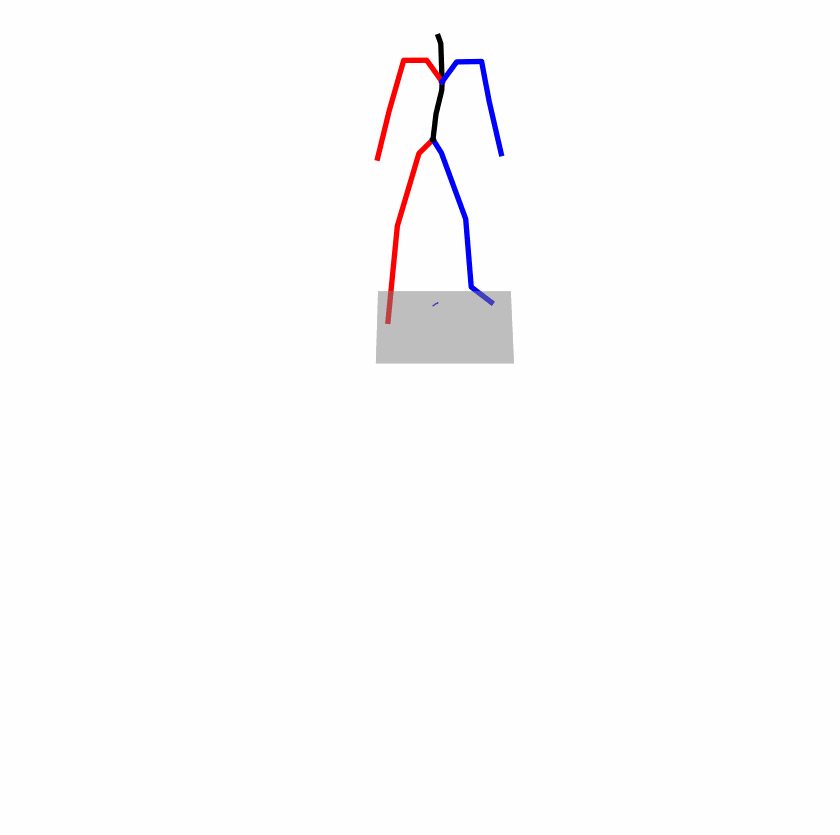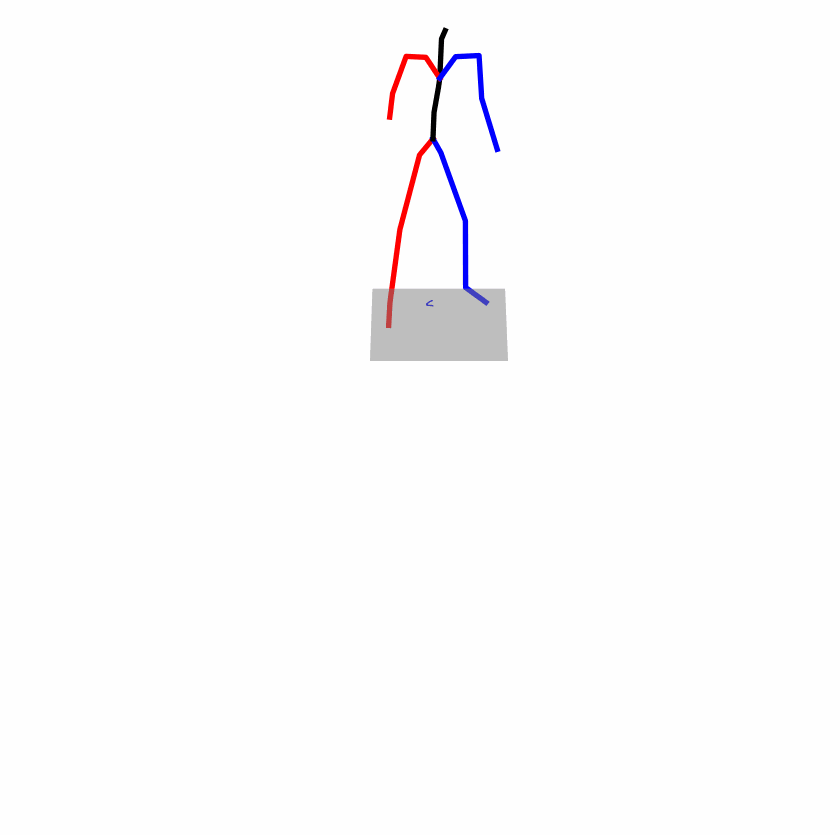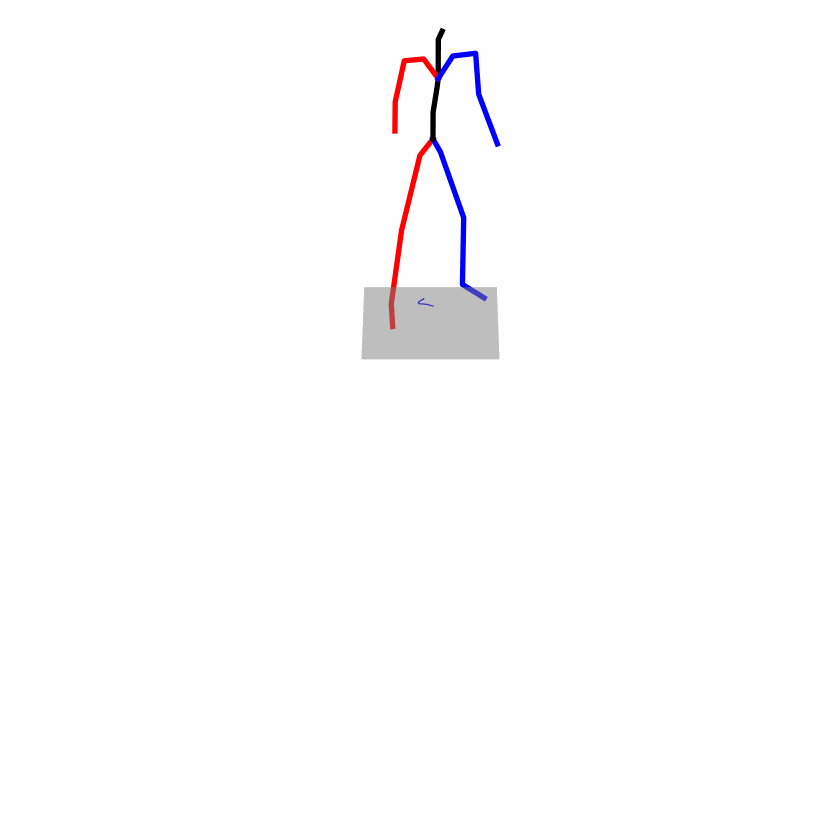 |
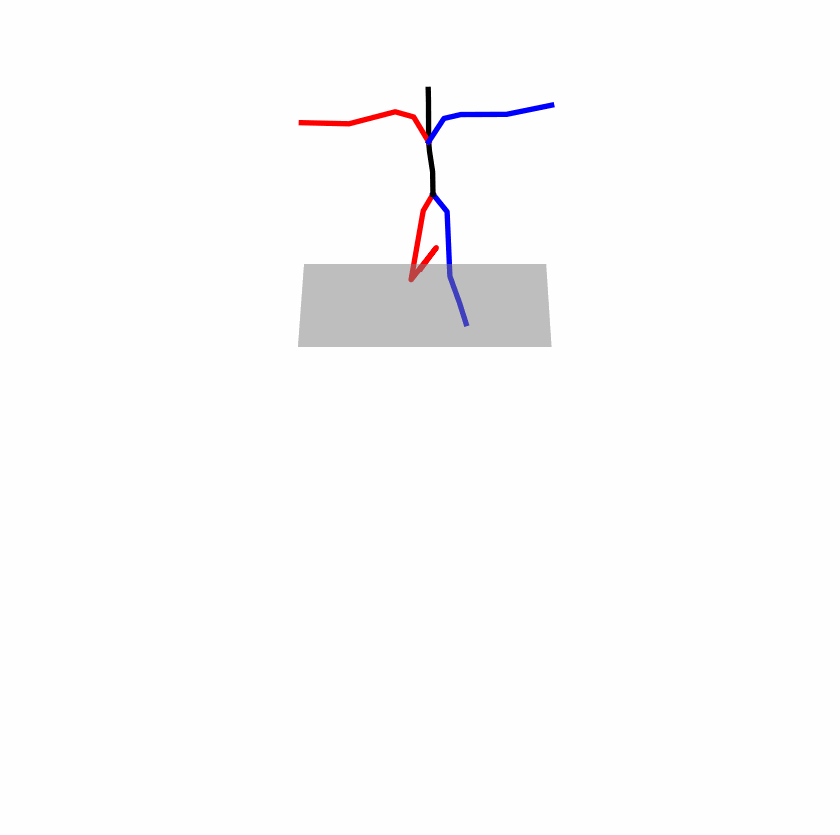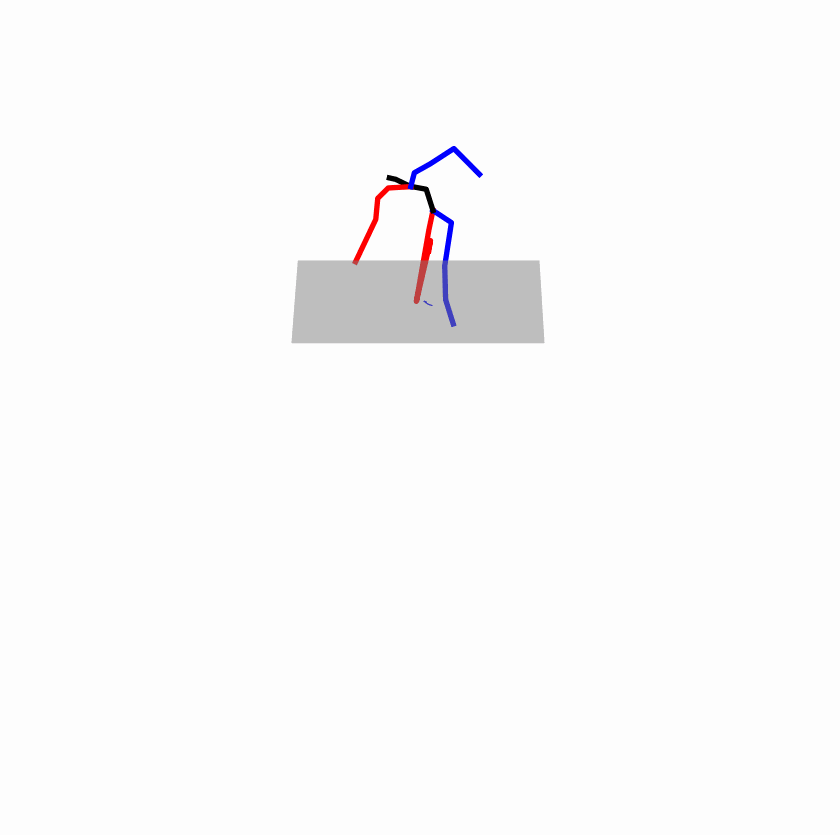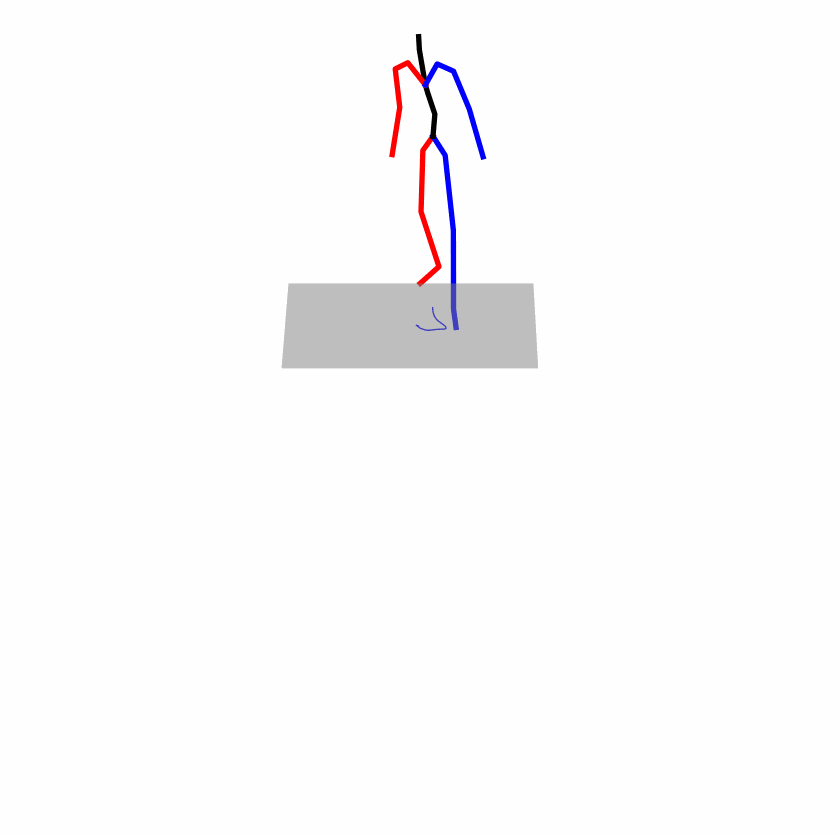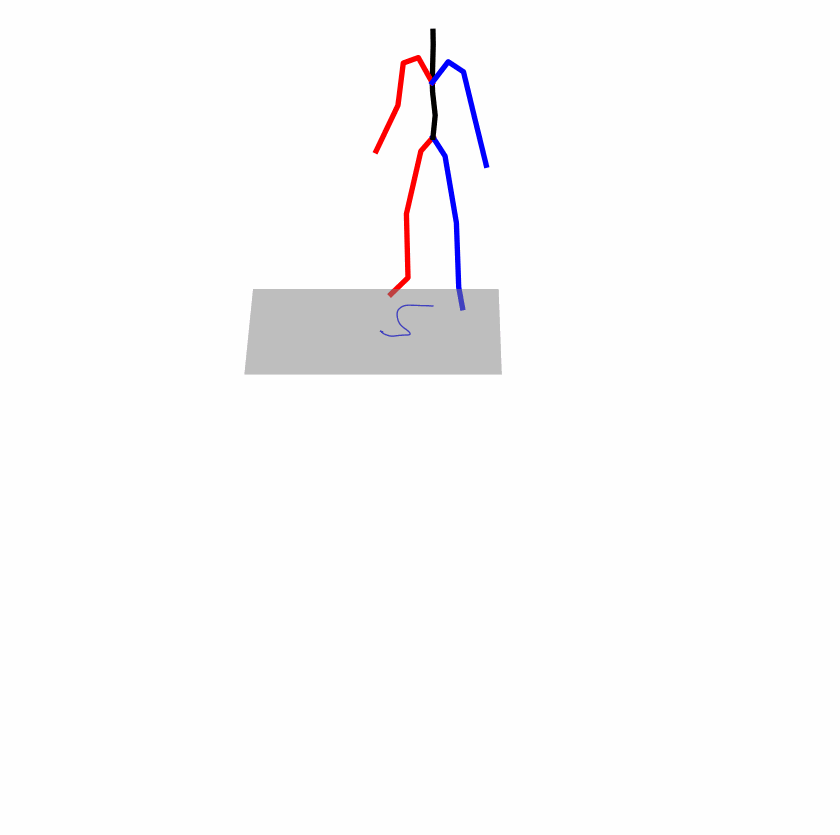 |
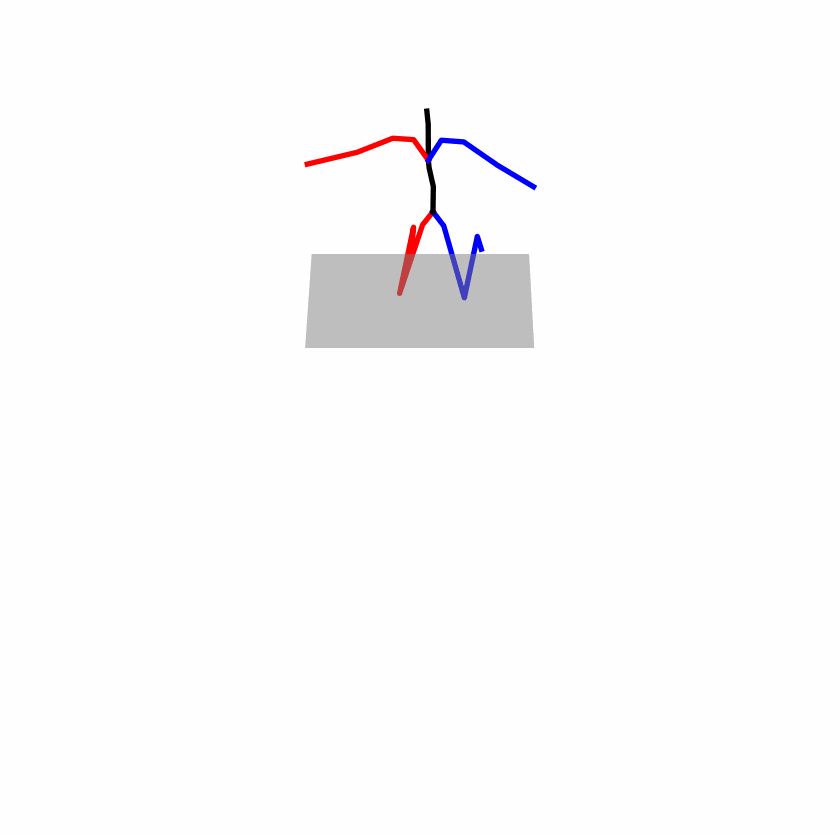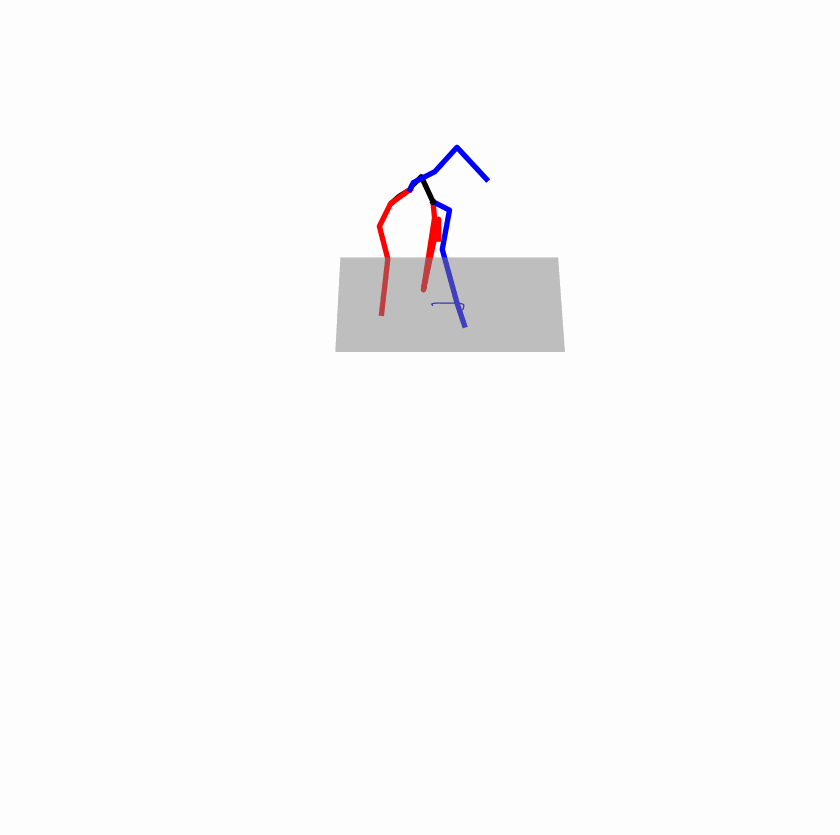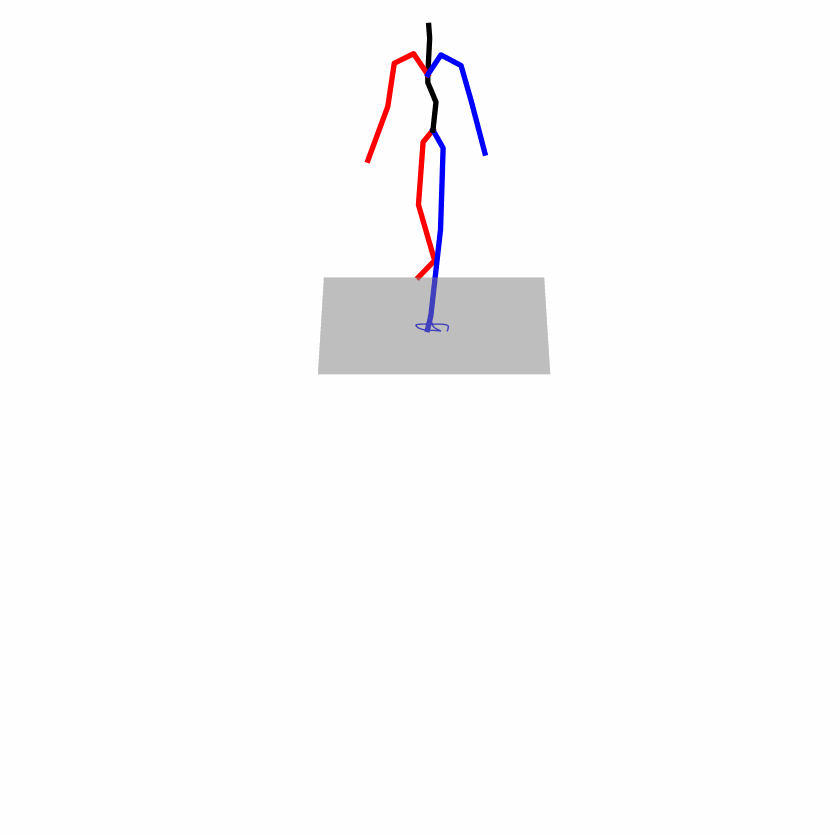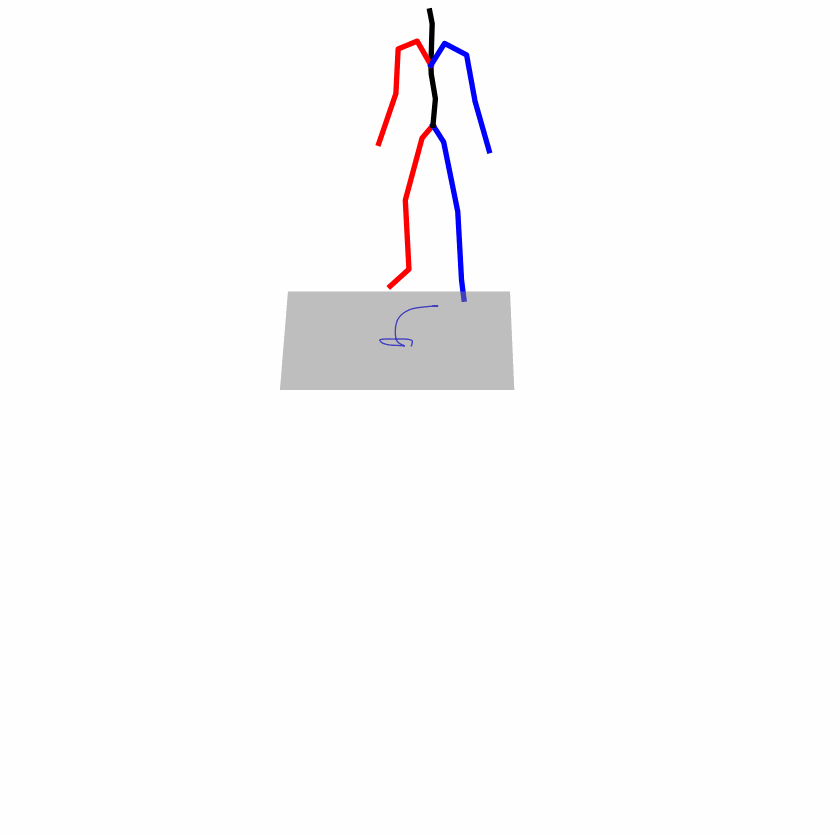 |
| Perturbed text: A human utilizes his right arm to help himself to stand up. | |||
 |
 |
 |
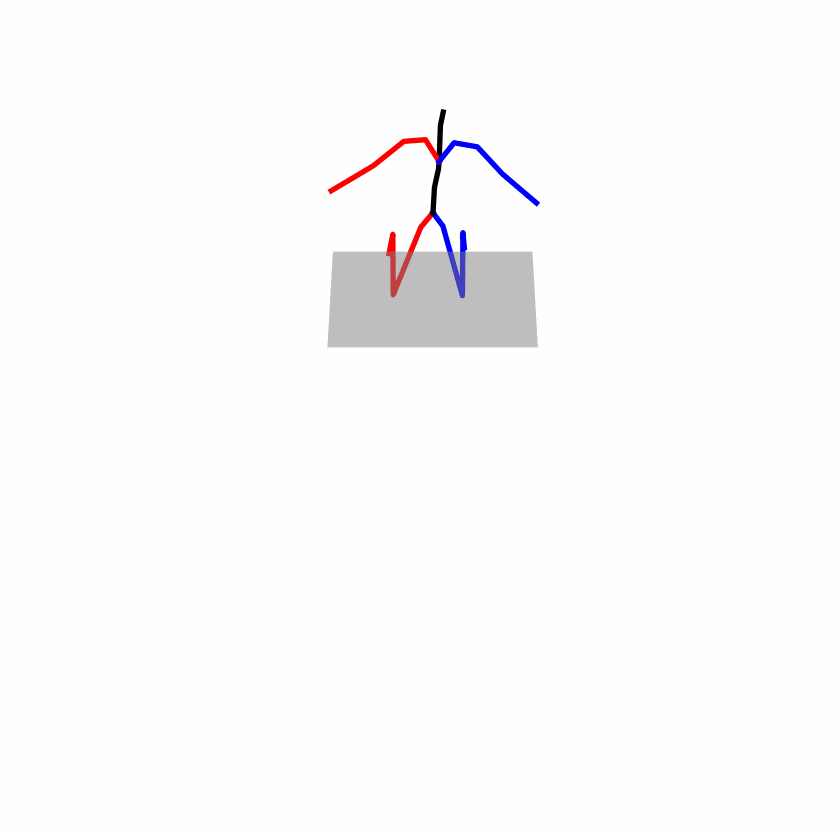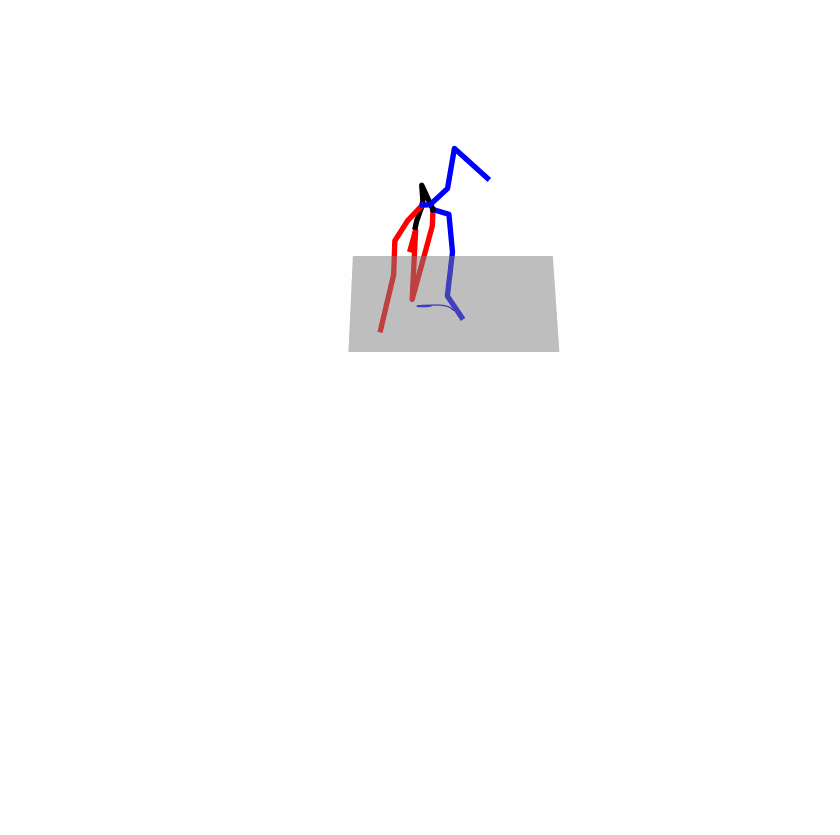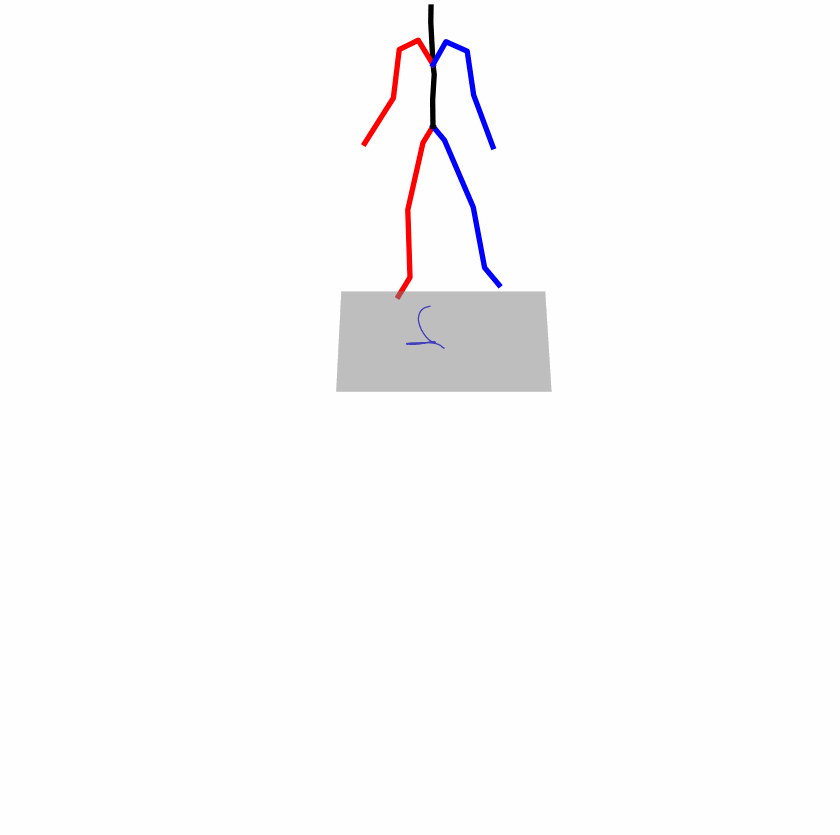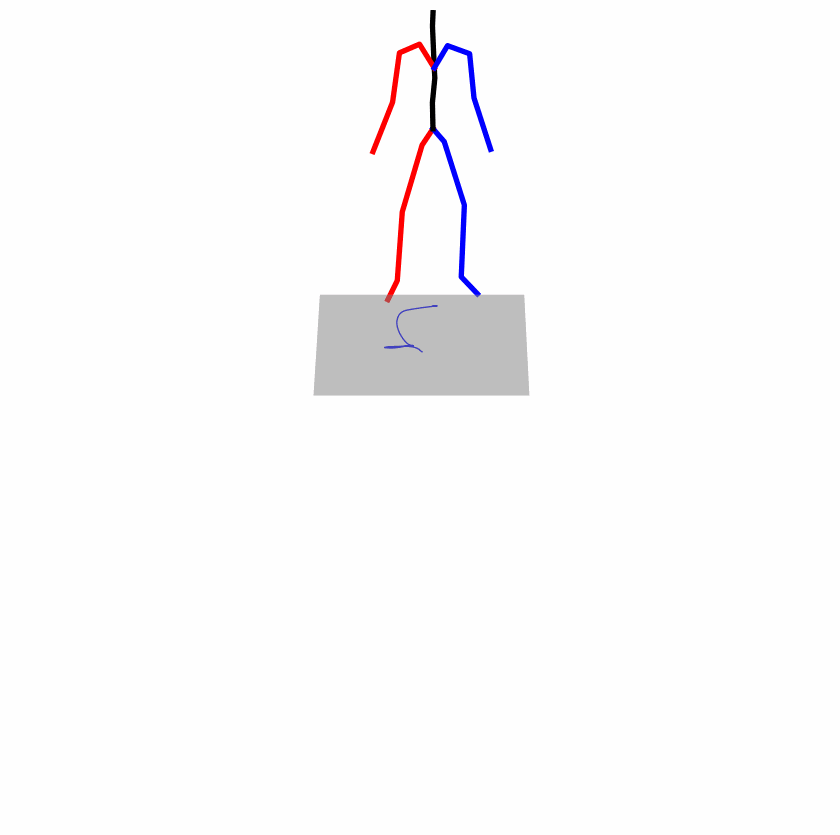 |
Explanation: T2M-GPT, MDM, and MoMask all lack the action of transitioning from squatting to standing up, resulting in a catastrophic error.
## How to Use the Code * [1. Setup and Installation](#setup) * [2.Dependencies](#Dependencies) * [3. Quick Start](#quickstart) * [4. Datasets](#datasets) * [4. Train](#train) * [5. Evaluation](#eval) * [6. Acknowledgments](#acknowledgements) ## Setup and Installation Clone the repository: ```shell git clone https://github.com/sato-team/Stable-Text-to-motion-Framework.git ``` Create fresh conda environment and install all the dependencies: ``` conda env create -f environment.yml conda activate SATO ``` The code was tested on Python 3.8 and PyTorch 1.8.1. ## Dependencies ```shell bash dataset/prepare/download_extractor.sh bash dataset/prepare/download_glove.sh ``` ## **Quick Start** A quick reference guide for using our code is provided in quickstart.ipynb. ## Datasets We are using two 3D human motion-language dataset: HumanML3D and KIT-ML. For both datasets, you could find the details as well as download [link](https://github.com/EricGuo5513/HumanML3D). We perturbed the input texts based on the two datasets mentioned. You can access the perturbed text dataset through the following [link](https://drive.google.com/file/d/1XLvu2jfG1YKyujdANhYHV_NfFTyOJPvP/view?usp=sharing). Take HumanML3D for an example, the dataset structure should look like this: ``` ./dataset/HumanML3D/ ├── new_joint_vecs/ ├── texts/ # You need to replace the 'texts' folder in the original dataset with the 'texts' folder from our dataset. ├── Mean.npy ├── Std.npy ├── train.txt ├── val.txt ├── test.txt ├── train_val.txt └── all.txt ``` ### **Train** We will release the training code soon. ### **Evaluation** You can download the pretrained models in this [link](https://drive.google.com/drive/folders/1rs8QPJ3UPzLW4H3vWAAX9hJn4ln7m_ts?usp=sharing). ```shell python eval_t2m.py --resume-pth pretrained/net_best_fid.pth --clip_path pretrained/clip_best_fid.pth ``` ## Acknowledgements We appreciate helps from : - Open Source Code:[T2M-GPT](https://github.com/Mael-zys/T2M-GPT), [MoMask ](https://github.com/EricGuo5513/momask-codes), [MDM](https://guytevet.github.io/mdm-page/), etc. - [Hongru Xiao](https://github.com/Hongru0306), [Erhang Zhang](https://github.com/zhangerhang), [Lijie Hu](https://sites.google.com/view/lijiehu/homepage), [Lei Wang](https://leiwangr.github.io/), [Mengyuan Liu](), [Chen Chen](https://www.crcv.ucf.edu/chenchen/) for discussions and guidance throughout the project, which has been instrumental to our work. - [Zhen Zhao](https://github.com/Zanebla) for project website. - If you find our work helpful, we would appreciate it if you could give our project a star! ## Citing If you find this code useful for your research, please consider citing the following paper: ```bibtex ```