| name | backbone | Data | box AP on COCO | Checkpoint | Config | |
|---|---|---|---|---|---|---|
| 1 | GroundingDINO-T | Swin-T | O365,GoldG,Cap4M | 48.4 (zero-shot) / 57.2 (fine-tune) | GitHub link | HF link | link |
| 2 | GroundingDINO-B | Swin-B | COCO,O365,GoldG,Cap4M,OpenImage,ODinW-35,RefCOCO | 56.7 | GitHub link | HF link | link |



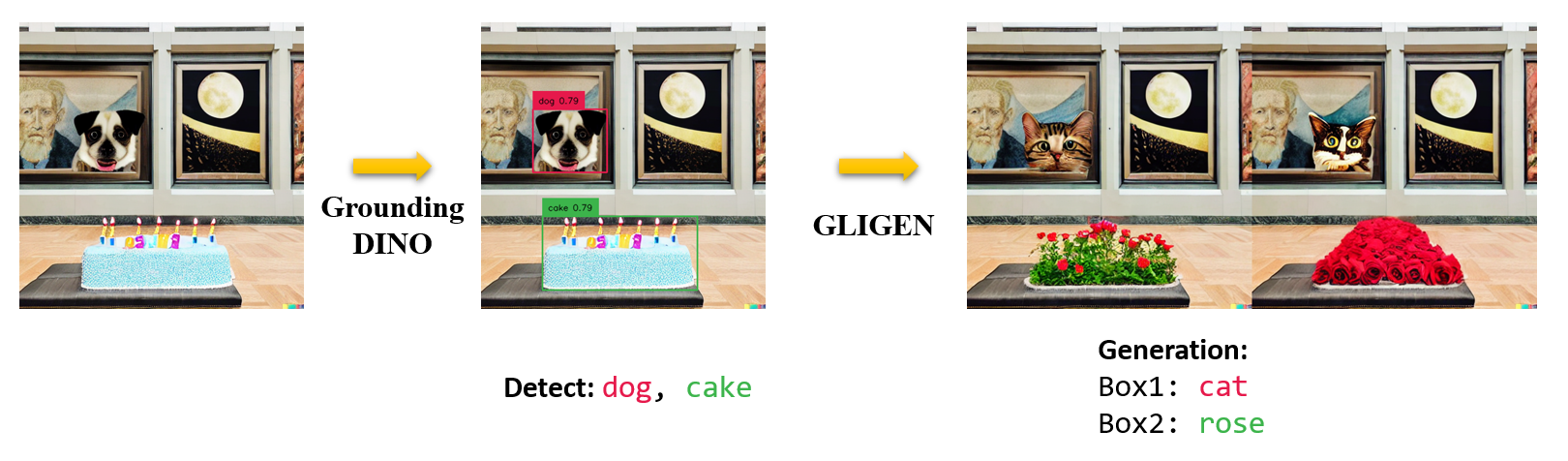
 Marrying
Marrying