diff --git a/.gitattributes b/.gitattributes
index a6344aac8c09253b3b630fb776ae94478aa0275b..d0168e7273c49809483abb64cbbb6ed6ae7c2061 100644
--- a/.gitattributes
+++ b/.gitattributes
@@ -33,3 +33,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
*.zip filter=lfs diff=lfs merge=lfs -text
*.zst filter=lfs diff=lfs merge=lfs -text
*tfevents* filter=lfs diff=lfs merge=lfs -text
+Llama2-Code-Interpreter-main/assets/result_nvidia_chart.gif filter=lfs diff=lfs merge=lfs -text
+Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/example_img/save_to_notebook_demo.gif filter=lfs diff=lfs merge=lfs -text
diff --git a/Llama2-Code-Interpreter-main/.gitignore b/Llama2-Code-Interpreter-main/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..53a05ee25c704f580478d97e2df34f1756b2633e
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/.gitignore
@@ -0,0 +1,48 @@
+# Ignore .ckpt files
+ckpt
+
+# Ignore Python compiled files
+__pycache__/
+*.py[cod]
+
+# Ignore Python virtual environment
+venv/
+
+# Ignore Jupyter notebook checkpoints
+.ipynb_checkpoints/
+.git/
+.vscode/
+
+# Ignore .DS_Store on MacOS
+.DS_Store
+
+rilab_key.txt
+gpt4_custom_code_interpreter/rilab_key.txt
+openai_api_key.txt
+
+gpt4_custom_code_interpreter/
+tmp/
+output/
+wandb/
+
+utils/const.py
+utils/hf_model_upload.py
+gpt_data_gen/
+*.json
+*.txt
+*.sh
+*.pt
+*.pth
+*.ckpt
+*.tokenizer
+
+# eval data
+eval/ds1000_data
+eval/grade-school-math
+
+# gradio features
+chatbot_feat.py
+chatbot_feat2.py
+gradio_test.py
+
+
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/LICENSE b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..261eeb9e9f8b2b4b0d119366dda99c6fd7d35c64
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/LICENSE
@@ -0,0 +1,201 @@
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright [yyyy] [name of copyright owner]
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/README.md b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..15a65b0193be46a4f0a80496ca8ef9a5e96c5718
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/README.md
@@ -0,0 +1,83 @@
+# OpenCodeInterpreter: Integrating Code Generation with Execution and Refinement
+
+
+
+
+## 🌟 Upcoming Features
+- 💡 **Open Sourcing OpenCodeInterpreter-SC2 series Model (based on StarCoder2 base)**
+
+- 💡 **Open Sourcing OpenCodeInterpreter-GM-7b Model with gemma-7b Base**
+
+## 🔔News
+🛠️[2024-02-29]: Our official online demo is deployed on HuggingFace Spaces! Take a look at [Demo Page](https://huggingface.co/spaces/m-a-p/OpenCodeInterpreter_demo)!
+
+🛠️[2024-02-28]: We have open-sourced the Demo Local Deployment Code with a Setup Guide.
+
+✨[2024-02-26]: We have open-sourced the [OpenCodeInterpreter-DS-1.3b](https://huggingface.co/m-a-p/OpenCodeInterpreter-DS-1.3B) Model.
+
+📘[2024-02-26]: We have open-sourced the [CodeFeedback-Filtered-Instruction](https://huggingface.co/datasets/m-a-p/CodeFeedback-Filtered-Instruction) Dataset.
+
+🚀[2024-02-23]: We have open-sourced the datasets used in our project named [Code-Feedback](https://huggingface.co/datasets/m-a-p/Code-Feedback).
+
+🔥[2024-02-19]: We have open-sourced all models in the OpenCodeInterpreter series! We welcome everyone to try out our models and look forward to your participation! 😆
+
+
+
+## Introduction
+OpenCodeInterpreter is a suite of open-source code generation systems aimed at bridging the gap between large language models and sophisticated proprietary systems like the GPT-4 Code Interpreter. It significantly enhances code generation capabilities by integrating execution and iterative refinement functionalities.
+
+## Models
+All models within the OpenCodeInterpreter series have been open-sourced on Hugging Face. You can access our models via the following link: [OpenCodeInterpreter Models](https://huggingface.co/collections/m-a-p/opencodeinterpreter-65d312f6f88da990a64da456).
+
+## Data Collection
+Supported by Code-Feedback, a dataset featuring 68K multi-turn interactions, OpenCodeInterpreter incorporates execution and human feedback for dynamic code refinement.
+For additional insights into data collection procedures, please consult the readme provided under [Data Collection](https://github.com/OpenCodeInterpreter/OpenCodeInterpreter/blob/main/data_collection/README.md).
+
+## Evaluation
+Our evaluation framework primarily utilizes HumanEval and MBPP, alongside their extended versions, HumanEval+ and MBPP+, leveraging the [EvalPlus framework](https://github.com/evalplus/evalplus) for a more comprehensive assessment.
+For specific evaluation methodologies, please refer to the [Evaluation README](https://github.com/OpenCodeInterpreter/OpenCodeInterpreter/blob/main/evaluation/README.md) for more details.
+
+## Demo
+We're excited to present our open-source demo, enabling users to effortlessly generate and execute code with our LLM locally. Within the demo, users can leverage the power of LLM to generate code and execute it locally, receiving automated execution feedback. LLM dynamically adjusts the code based on this feedback, ensuring a smoother coding experience. Additionally, users can engage in chat-based interactions with the LLM model, providing feedback to further enhance the generated code.
+
+To begin exploring the demo and experiencing the capabilities firsthand, please refer to the instructions outlined in the [OpenCodeInterpreter Demo README](https://github.com/OpenCodeInterpreter/OpenCodeInterpreter/blob/main/demo/README.md) file. Happy coding!
+
+### Quick Start
+- **Entering the workspace**:
+ ```bash
+ git clone https://github.com/OpenCodeInterpreter/OpenCodeInterpreter.git
+ cd demo
+ ```
+- **Create a new conda environment**: `conda create -n demo python=3.10`
+
+- **Activate the demo environment you create**: `conda activate demo`
+
+- **Install requirements**: `pip install -r requirements.txt`
+
+- **Create a Huggingface access token with write permission [here](https://huggingface.co/docs/hub/en/security-tokens). Our code will only use this token to create and push content to a specific repository called `opencodeinterpreter_user_data` under your own Huggingface account. We cannot get access to your data if you deploy this demo on your own device.**
+
+- **Add the access token to environment variables:** `export HF_TOKEN="your huggingface access token"`
+
+- **Run the Gradio App**:
+ ```bash
+ python3 chatbot.py --path "the model name of opencodeinterpreter model family. e.g., m-a-p/OpenCodeInterpreter-DS-6.7B"
+ ```
+### Video
+https://github.com/OpenCodeInterpreter/OpenCodeInterpreter/assets/46103100/2337f34d-f5ed-4ecb-857b-3c2d085b72fd
+
+
+## Contact
+
+If you have any inquiries, please feel free to raise an issue or reach out to us via email at: xiangyue.work@gmail.com, zhengtianyu0428@gmail.com.
+We're here to assist you!
+
+## Star History
+
+[](https://star-history.com/#OpenCodeInterpreter/OpenCodeInterpreter&Date)
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/LICENSE b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..261eeb9e9f8b2b4b0d119366dda99c6fd7d35c64
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/LICENSE
@@ -0,0 +1,201 @@
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright [yyyy] [name of copyright owner]
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/README.md b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..fc9e80da0ff96fd780fe562d55067f542d778739
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/README.md
@@ -0,0 +1,143 @@
+**Read in other language: [中文](README_CN.md).**
+
+# Local-Code-Interpreter
+A local implementation of OpenAI's ChatGPT Code Interpreter (Advanced Data Analysis).
+
+## Introduction
+
+OpenAI's Code Interpreter (currently renamed as Advanced Data Analysis) for ChatGPT is a revolutionary feature that allows the execution of Python code within the AI model. However, it execute code within an online sandbox and has certain limitations. In this project, we present Local Code Interpreter – which enables code execution on your local device, offering enhanced flexibility, security, and convenience.
+
+
+## Key Advantages
+
+- **Custom Environment**: Execute code in a customized environment of your choice, ensuring you have the right packages and settings.
+
+- **Seamless Experience**: Say goodbye to file size restrictions and internet issues while uploading. With Local Code Interpreter, you're in full control.
+
+- **GPT-3.5 Availability**: While official Code Interpreter is only available for GPT-4 model, the Local Code Interpreter offers the flexibility to switch between both GPT-3.5 and GPT-4 models.
+
+- **Enhanced Data Security**: Keep your data more secure by running code locally, minimizing data transfer over the internet.
+
+- **Jupyter Support**: You can save all the code and conversation history in a Jupyter notebook for future use.
+
+## Note
+Executing AI-generated code without human review on your own device is not safe. You are responsible for taking measures to protect the security of your device and data (such as using a virtural machine) before launching this program. All consequences caused by using this program shall be borne by youself.
+
+## Usage
+
+### Installation
+
+1. Clone this repository to your local device
+ ```shell
+ git clone https://github.com/MrGreyfun/Local-Code-Interpreter.git
+ cd Local-Code-Interpreter
+ ```
+
+2. Install the necessary dependencies. The program has been tested on Windows 10 and CentOS Linux 7.8, with Python 3.9.16. Required packages include:
+ ```text
+ Jupyter Notebook 6.5.4
+ gradio 3.39.0
+ openai 0.27.8
+ ansi2html 1.8.0
+ tiktoken 0.3.3
+ Pillow 9.4.0
+ ```
+ Other systems or package versions may also work. Please note that you should not update the `openai` package to the latest `1.x` version, as it has been rewritten and is not compatible with older versions.
+ You can use the following command to directly install the required packages:
+ ```shell
+ pip install -r requirements.txt
+ ```
+ For newcomers to Python, we offer a convenient command that installs additional packages commonly used for data processing and analysis:
+ ```shell
+ pip install -r requirements_full.txt
+ ```
+### Configuration
+
+1. Create a `config.json` file in the `src` directory, following the examples provided in the `config_example` directory.
+
+2. Configure your API key in the `config.json` file.
+
+Please Note:
+1. **Set the `model_name` Correctly**
+ This program relies on the function calling capability of the `0613` or newer versions of models:
+ - `gpt-3.5-turbo-0613` (and its 16K version)
+ - `gpt-3.5-turbo-1106`
+ - `gpt-4-0613` (and its 32K version)
+ - `gpt-4-1106-preview`
+
+ Older versions of the models will not work. Note that `gpt-4-vision-preview` lacks support for function calling, therefore, it should not be set as `GPT-4` model.
+
+ For Azure OpenAI service users:
+ - Set the `model_name` as your deployment name.
+ - Confirm that the deployed model corresponds to the `0613` or newer version.
+
+2. **API Version Settings**
+ If you're using Azure OpenAI service, set the `API_VERSION` to `2023-12-01-preview` in the `config.json` file. Note that API versions older than `2023-07-01-preview` do not support the necessary function calls for this program and `2023-12-01-preview` is recommended as older versions will be deprecated in the near future.
+
+3. **Vision Model Settings**
+ Despite the `gpt-4-vision-preview` currently does not support function calling, we have implemented vision input using a non-end-to-end approach. To enable vision input, set `gpt-4-vision-preview` as `GPT-4V` model and set `available` to `true`. Conversely, setting `available` to `false` to disables vision input when unnecessary, which will remove vision-related system prompts and reduce your API costs.
+ 
+4. **Model Context Window Settings**
+ The `model_context_window` field records the context window for each model, which the program uses to slice conversations when they exceed the model's context window capacity.
+ Azure OpenAI service users should manually insert context window information using the model's deployment name in the following format:
+ ```json
+ "":
+ ```
+
+ Additionally, when OpenAI introduce new models, you can manually append the new model's context window information using the same format. (We will keep this file updated, but there might be delays)
+
+5. **Alternate API Key Handling**
+ If you prefer not to store your API key in the `config.json` file, you can opt for an alternate approach:
+ - Leave the `API_KEY` field in `config.json` as an empty string:
+ ```json
+ "API_KEY": ""
+ ```
+ - Set the environment variable `OPENAI_API_KEY` with your API key before running the program:
+ - On Windows:
+ ```shell
+ set OPENAI_API_KEY=
+ ```
+ - On Linux:
+ ```shell
+ export OPENAI_API_KEY=
+ ```
+
+## Getting Started
+
+1. Navigate to the `src` directory.
+ ```shell
+ cd src
+ ```
+
+2. Run the command:
+ ```shell
+ python web_ui.py
+ ```
+
+3. Access the generated link in your browser to start using the Local Code Interpreter.
+
+4. Use the `-n` or `--notebook` option to save the conversation in a Jupyter notebook.
+ By default, the notebook is saved in the working directory, but you can add a path to save it elsewhere.
+ ```shell
+ python web_ui.py -n
+ ```
+
+## Example
+
+Imagine uploading a data file and requesting the model to perform linear regression and visualize the data. See how Local Code Interpreter provides a seamless experience:
+
+1. Upload the data and request linear regression:
+ 
+
+2. Encounter an error in the generated code:
+ 
+
+3. ChatGPT automatically checks the data structure and fixes the bug:
+ 
+
+4. The corrected code runs successfully:
+ 
+
+5. The final result meets your requirements:
+ 
+ 
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/README_CN.md b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/README_CN.md
new file mode 100644
index 0000000000000000000000000000000000000000..df5f1961524537889d5aaf74a38a8d6f9441edf3
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/README_CN.md
@@ -0,0 +1,140 @@
+**Read in other language: [English](README.md)**
+
+# 本地代码解释器
+OpenAI的ChatGPT代码解释器(Code Interpreter或Advanced Data Analysis)的本地版。
+
+## 简介
+
+OpenAI的ChatGPT代码解释器(Code Interpreter,现更名为Advanced Data Analysis)是一款强大的AI工具。然而,其在在线沙箱环境中运行代码的特性导致了一些限制,如包的缺失、上传速度较慢、仅支持上传不超过100MB的文件以及代码最多只能运行120秒等。为此,我们推出了本地代码解释器(Local Code Interpreter)。这款工具允许您在自己的设备上,利用自己专属的Python环境来执行ChatGPT生成的代码,从而解除了原有解释器的各种限制。
+
+
+## 优势
+
+- **自定义环境**:在您本地环境中运行代码,确保各种依赖都已正确安装。
+
+- **无缝体验**:告别100MB文件大小限制和网速问题。使用本地版代码解释器,一切尽在掌控之中。
+
+- **可用GPT-3.5**:官方代码解释器只能在GPT-4中使用,但现在您甚至可以在一轮对话中自由切换GPT-3.5和GPT-4。
+
+- **数据更安全**:代码在本地运行,无需将文件上传至网络,提高了数据的安全性。
+
+- **支持Jupyter**:本程序可将代码和对话历史保存至Jupyter notebook文件中供以后使用。
+
+## 注意事项
+在您自己的设备上执行AI生成但未经人工审核的代码可能存在安全风险。在运行此程序前,您应当采用一些安全措施,例如使用虚拟机,以保护您的设备和数据。使用此程序所产生的所有后果,您需自行承担。
+
+## 使用方法
+
+### 安装
+
+1. 克隆本仓库
+ ```shell
+ git clone https://github.com/MrGreyfun/Local-Code-Interpreter.git
+ cd Local-Code-Interpreter
+ ```
+
+2. 安装依赖。该程序已在Windows 10和CentOS Linux 7.8上使用Python 3.9.16测试。所需的库及版本:
+ ```text
+ Jupyter Notebook 6.5.4
+ gradio 3.39.0
+ openai 0.27.8
+ ansi2html 1.8.0
+ ```
+ 其他系统或库版本也可能有效。请注意,不要将`openai`包升级至最新的`1.x`版本,该版本已重写,与旧版本不兼容。
+ 您可以使用以下命令直接安装所需的软件包:
+ ```shell
+ pip install -r requirements.txt
+ ```
+ 如果您不熟悉Python,可以使用以下命令安装,它将额外安装常用的Python数据分析库:
+ ```shell
+ pip install -r requirements_full.txt
+ ```
+### 配置
+
+1. 在`src`目录中创建一个`config.json`文件,参照`config_example`目录中提供的示例进行配置。
+
+2. 在`config.json`文件中配置您的API密钥。
+
+请注意:
+1. **正确设置`model_name`**
+ 该程序依赖于`0163`及以上版本的模型的函数调用能力,这些模型包括:
+ - `gpt-3.5-turbo-0613` (及其16K版本)
+ - `gpt-3.5-turbo-1106`
+ - `gpt-4-0613` (及其32K版本)
+ - `gpt-4-1106-preview`
+
+ 旧版本的模型将无法使用。请注意,`gpt-4-vision-preview`模型同样不支持函数调用,因此不能将其设置为`GPT-4`模型。
+
+ 对于使用Azure OpenAI的用户:
+ - 请将`model_name`设置为您的模型的部署名(deployment name)。
+ - 确认部署的模型是`0613`及以上版本。
+
+2. **API版本设置**
+ 如果您使用Azure OpenAI服务,请在`config.json`文件中将`API_VERSION`设置为`2023-07-01-preview`,其他API版本不支持函数调用。
+
+3. **视觉模型设置**
+ 尽管`gpt-4-vision-preview`模型不支持函数调用,我们仍然通过另一种非端到端的方式实现了图像输入。如果想使用图像输入,请将`gpt-4-vision-preview`设置为`GPT-4V`模型,并设置`available`字段设置为`true`。当不需要使用图像输入时候,可以将`available`字段设置为`false`,这将移除图像相关的系统提示,从而减少您的API费用。
+ 
+4. **模型上下文窗口长度设置**
+ `model_context_window` 字段记录了每个模型的上下文窗口长度信息。当对话长度超过模型上下文窗口长度限制时,本程序会使用该信息来压缩对话长度。
+ Azure OpenAI的用户需要按照以下格式,使用模型的部署名手动添加上下文窗口长度信息:
+ ```json
+ "<模型部署名>": <上下文窗口长度 (整数)>
+ ```
+ 此外,当OpenAI推出新模型的时候,您可以按照相同的格式手动添加新模型的上下文窗口长度信息。(我们会持续更新该文件,但是不一定及时)
+
+5. **使用环境变量配置密钥**
+ 如果您不希望将API密钥存储在`config.json`文件中,可以选择通过环境变量来设置密钥:
+ - 将`config.json`文件中的`API_KEY`设为空字符串:
+ ```json
+ "API_KEY": ""
+ ```
+ - 在运行程序之前,使用您的API密钥设置环境变量`OPENAI_API_KEY`:
+ - Windows:
+ ```shell
+ set OPENAI_API_KEY=<你的API密钥>
+ ```
+ - Linux:
+ ```shell
+ export OPENAI_API_KEY=<你的API密钥>
+ ```
+
+## 使用
+
+1. 进入`src`目录。
+ ```shell
+ cd src
+ ```
+
+2. 运行以下命令:
+ ```shell
+ python web_ui.py
+ ```
+
+3. 在浏览器中访问终端生成的链接,开始使用本地版代码解释器。
+
+4. 添加`-n`或`--notebook`参数可以将对话保存到Jupyter notebook中。
+ 默认情况下,该Jupyter notebook文件保存在工作目录中,您可以添加路径以将其保存到其它位置。
+ ```shell
+ python web_ui.py-n
+ ```
+
+## 示例
+
+以下是一个使用本程序进行线性回归任务的示例:
+
+1. 上传数据文件并要求模型对数据进行线性回归:
+ 
+
+2. 生成的代码执行中遇到错误:
+ 
+
+3. ChatGPT自动检查数据格式并修复bug:
+ 
+
+4. 修复bug后的代码成功运行:
+ 
+
+5. 最终结果符合要求:
+ 
+ 
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/config_example/config.azure.example.json b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/config_example/config.azure.example.json
new file mode 100644
index 0000000000000000000000000000000000000000..6e653e30748e14f3244697852ea15329e997a9d2
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/config_example/config.azure.example.json
@@ -0,0 +1,24 @@
+{
+ "API_TYPE": "azure",
+ "API_base": "",
+ "API_VERSION": "2023-12-01-preview",
+ "API_KEY": "",
+ "model": {
+ "GPT-3.5": {
+ "model_name": "",
+ "available": true
+ },
+ "GPT-4": {
+ "model_name": "",
+ "available": true
+ },
+ "GPT-4V": {
+ "model_name": "",
+ "available": true
+ }
+ },
+ "model_context_window": {
+ "": ,
+ "":
+ }
+}
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/config_example/config.example.json b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/config_example/config.example.json
new file mode 100644
index 0000000000000000000000000000000000000000..2ae3aac3204965482b715002984d6faaaa4ef8f4
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/config_example/config.example.json
@@ -0,0 +1,32 @@
+{
+ "API_TYPE": "open_ai",
+ "API_base": "https://api.openai.com/v1",
+ "API_VERSION": null,
+ "API_KEY": "",
+ "model": {
+ "GPT-3.5": {
+ "model_name": "gpt-3.5-turbo-0613",
+ "available": true
+ },
+ "GPT-4": {
+ "model_name": "gpt-4-0613",
+ "available": true
+ },
+ "GPT-4V": {
+ "model_name": "gpt-4-vision-preview",
+ "available": true
+ }
+ },
+ "model_context_window": {
+ "gpt-3.5-turbo": 4096,
+ "gpt-3.5-turbo-16k": 16385,
+ "gpt-3.5-turbo-0613": 4096,
+ "gpt-3.5-turbo-1106": 16385,
+ "gpt-4": 8192,
+ "gpt-4-32k": 32768,
+ "gpt-4-0613": 8192,
+ "gpt-4-32k-0613": 32768,
+ "gpt-4-1106-preview": 128000,
+ "gpt-4-vision-preview": 128000
+ }
+}
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/example_img/1.jpg b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/example_img/1.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..d2ae5daccc5457bdfd395b4319602bb8847ca00c
Binary files /dev/null and b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/example_img/1.jpg differ
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/example_img/2.jpg b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/example_img/2.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..2e70c7d3d89ada3983579580b2a6510ee9d4d330
Binary files /dev/null and b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/example_img/2.jpg differ
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/example_img/3.jpg b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/example_img/3.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..11cacbd28c27fe15a0619e6bf34705c564b98de4
Binary files /dev/null and b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/example_img/3.jpg differ
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/example_img/4.jpg b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/example_img/4.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..e39d94e65122e6217090ee554eb6961744d9b99d
Binary files /dev/null and b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/example_img/4.jpg differ
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/example_img/5.jpg b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/example_img/5.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..64d97b1e6c51b1d91fc6379c6bd7e08201694be7
Binary files /dev/null and b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/example_img/5.jpg differ
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/example_img/6.jpg b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/example_img/6.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..e9bbb94937eec0f619d0e5c0f6153339ceed7435
Binary files /dev/null and b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/example_img/6.jpg differ
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/example_img/save_to_notebook_demo.gif b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/example_img/save_to_notebook_demo.gif
new file mode 100644
index 0000000000000000000000000000000000000000..b3eded859543ad2a42da990c40703fc9a0b79093
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/example_img/save_to_notebook_demo.gif
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:b48a4673e78f618a7b458d349d793c5220041e918e578f9b1aaa0aeeb6c7cefa
+size 4957227
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/example_img/vision_example.jpg b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/example_img/vision_example.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..526ebfe37c4a2e9ecaf37e0ceadd9601ac66974e
Binary files /dev/null and b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/example_img/vision_example.jpg differ
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/requirements.txt b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..be568f4d688bf3e3cc53c609c8c953d0bda32892
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/requirements.txt
@@ -0,0 +1,6 @@
+notebook==6.5.4
+openai==0.27.8
+gradio==3.39.0
+ansi2html==1.8.0
+tiktoken
+Pillow
\ No newline at end of file
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/requirements_full.txt b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/requirements_full.txt
new file mode 100644
index 0000000000000000000000000000000000000000..1df6404e1ec8107624d60a9a03f58685ad587463
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/requirements_full.txt
@@ -0,0 +1,18 @@
+notebook==6.5.4
+openai==0.27.8
+gradio==3.39.0
+ansi2html==1.8.0
+tiktoken
+Pillow
+numpy
+scipy
+openpyxl
+xlrd
+xlwt
+matplotlib
+pandas
+opencv-python
+PyPDF2
+pdfminer.six
+sympy
+scikit-learn
\ No newline at end of file
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/src/bot_backend.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/src/bot_backend.py
new file mode 100644
index 0000000000000000000000000000000000000000..68ec77acd016245ee30e4e2f08f0d45bcd0dd18e
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/src/bot_backend.py
@@ -0,0 +1,324 @@
+import json
+import copy
+import shutil
+from jupyter_backend import *
+from tools import *
+from typing import *
+from notebook_serializer import add_markdown_to_notebook, add_code_cell_to_notebook
+
+functions = [
+ {
+ "name": "execute_code",
+ "description": "This function allows you to execute Python code and retrieve the terminal output. If the code "
+ "generates image output, the function will return the text '[image]'. The code is sent to a "
+ "Jupyter kernel for execution. The kernel will remain active after execution, retaining all "
+ "variables in memory.",
+ "parameters": {
+ "type": "object",
+ "properties": {
+ "code": {
+ "type": "string",
+ "description": "The code text"
+ }
+ },
+ "required": ["code"],
+ }
+ },
+]
+
+system_msg = '''You are an AI code interpreter.
+Your goal is to help users do a variety of jobs by executing Python code.
+
+You should:
+1. Comprehend the user's requirements carefully & to the letter.
+2. Give a brief description for what you plan to do & call the provided function to run code.
+3. Provide results analysis based on the execution output.
+4. If error occurred, try to fix it.
+5. Response in the same language as the user.
+
+Note: If the user uploads a file, you will receive a system message "User uploaded a file: filename". Use the filename as the path in the code. '''
+
+with open('config.json') as f:
+ config = json.load(f)
+
+if not config['API_KEY']:
+ config['API_KEY'] = os.getenv('OPENAI_API_KEY')
+ os.unsetenv('OPENAI_API_KEY')
+
+
+def get_config():
+ return config
+
+
+def config_openai_api(api_type, api_base, api_version, api_key):
+ openai.api_type = api_type
+ openai.api_base = api_base
+ openai.api_version = api_version
+ openai.api_key = api_key
+
+
+class GPTResponseLog:
+ def __init__(self):
+ self.assistant_role_name = ''
+ self.content = ''
+ self.function_name = None
+ self.function_args_str = ''
+ self.code_str = ''
+ self.display_code_block = ''
+ self.finish_reason = 'stop'
+ self.bot_history = None
+ self.stop_generating = False
+ self.code_executing = False
+ self.interrupt_signal_sent = False
+
+ def reset_gpt_response_log_values(self, exclude=None):
+ if exclude is None:
+ exclude = []
+
+ attributes = {'assistant_role_name': '',
+ 'content': '',
+ 'function_name': None,
+ 'function_args_str': '',
+ 'code_str': '',
+ 'display_code_block': '',
+ 'finish_reason': 'stop',
+ 'bot_history': None,
+ 'stop_generating': False,
+ 'code_executing': False,
+ 'interrupt_signal_sent': False}
+
+ for attr_name in exclude:
+ del attributes[attr_name]
+ for attr_name, value in attributes.items():
+ setattr(self, attr_name, value)
+
+ def set_assistant_role_name(self, assistant_role_name: str):
+ self.assistant_role_name = assistant_role_name
+
+ def add_content(self, content: str):
+ self.content += content
+
+ def set_function_name(self, function_name: str):
+ self.function_name = function_name
+
+ def copy_current_bot_history(self, bot_history: List):
+ self.bot_history = copy.deepcopy(bot_history)
+
+ def add_function_args_str(self, function_args_str: str):
+ self.function_args_str += function_args_str
+
+ def update_code_str(self, code_str: str):
+ self.code_str = code_str
+
+ def update_display_code_block(self, display_code_block):
+ self.display_code_block = display_code_block
+
+ def update_finish_reason(self, finish_reason: str):
+ self.finish_reason = finish_reason
+
+ def update_stop_generating_state(self, stop_generating: bool):
+ self.stop_generating = stop_generating
+
+ def update_code_executing_state(self, code_executing: bool):
+ self.code_executing = code_executing
+
+ def update_interrupt_signal_sent(self, interrupt_signal_sent: bool):
+ self.interrupt_signal_sent = interrupt_signal_sent
+
+
+class BotBackend(GPTResponseLog):
+ def __init__(self):
+ super().__init__()
+ self.unique_id = hash(id(self))
+ self.jupyter_work_dir = f'cache/work_dir_{self.unique_id}'
+ self.tool_log = f'cache/tool_{self.unique_id}.log'
+ self.jupyter_kernel = JupyterKernel(work_dir=self.jupyter_work_dir)
+ self.gpt_model_choice = "GPT-3.5"
+ self.revocable_files = []
+ self.system_msg = system_msg
+ self.functions = copy.deepcopy(functions)
+ self._init_api_config()
+ self._init_tools()
+ self._init_conversation()
+ self._init_kwargs_for_chat_completion()
+
+ def _init_conversation(self):
+ first_system_msg = {'role': 'system', 'content': self.system_msg}
+ self.context_window_tokens = 0 # num of tokens actually sent to GPT
+ self.sliced = False # whether the conversion is sliced
+ if hasattr(self, 'conversation'):
+ self.conversation.clear()
+ self.conversation.append(first_system_msg)
+ else:
+ self.conversation: List[Dict] = [first_system_msg]
+
+ def _init_api_config(self):
+ self.config = get_config()
+ api_type = self.config['API_TYPE']
+ api_base = self.config['API_base']
+ api_version = self.config['API_VERSION']
+ api_key = config['API_KEY']
+ config_openai_api(api_type, api_base, api_version, api_key)
+
+ def _init_tools(self):
+ self.additional_tools = {}
+
+ tool_datas = get_available_tools(self.config)
+ if tool_datas:
+ self.system_msg += '\n\nAdditional tools:'
+
+ for tool_data in tool_datas:
+ system_prompt = tool_data['system_prompt']
+ tool_name = tool_data['tool_name']
+ tool_description = tool_data['tool_description']
+
+ self.system_msg += f'\n{tool_name}: {system_prompt}'
+
+ self.functions.append(tool_description)
+ self.additional_tools[tool_name] = {
+ 'tool': tool_data['tool'],
+ 'additional_parameters': copy.deepcopy(tool_data['additional_parameters'])
+ }
+ for parameter, value in self.additional_tools[tool_name]['additional_parameters'].items():
+ if callable(value):
+ self.additional_tools[tool_name]['additional_parameters'][parameter] = value(self)
+
+ def _init_kwargs_for_chat_completion(self):
+ self.kwargs_for_chat_completion = {
+ 'stream': True,
+ 'messages': self.conversation,
+ 'functions': self.functions,
+ 'function_call': 'auto'
+ }
+
+ model_name = self.config['model'][self.gpt_model_choice]['model_name']
+
+ if self.config['API_TYPE'] == 'azure':
+ self.kwargs_for_chat_completion['engine'] = model_name
+ else:
+ self.kwargs_for_chat_completion['model'] = model_name
+
+ def _backup_all_files_in_work_dir(self):
+ count = 1
+ backup_dir = f'cache/backup_{self.unique_id}'
+ while os.path.exists(backup_dir):
+ count += 1
+ backup_dir = f'cache/backup_{self.unique_id}_{count}'
+ shutil.copytree(src=self.jupyter_work_dir, dst=backup_dir)
+
+ def _clear_all_files_in_work_dir(self, backup=True):
+ if backup:
+ self._backup_all_files_in_work_dir()
+ for filename in os.listdir(self.jupyter_work_dir):
+ path = os.path.join(self.jupyter_work_dir, filename)
+ if os.path.isdir(path):
+ shutil.rmtree(path)
+ else:
+ os.remove(path)
+
+ def _save_tool_log(self, tool_response):
+ with open(self.tool_log, 'a', encoding='utf-8') as log_file:
+ log_file.write(f'Previous conversion: {self.conversation}\n')
+ log_file.write(f'Model choice: {self.gpt_model_choice}\n')
+ log_file.write(f'Tool name: {self.function_name}\n')
+ log_file.write(f'Parameters: {self.function_args_str}\n')
+ log_file.write(f'Response: {tool_response}\n')
+ log_file.write('----------\n\n')
+
+ def add_gpt_response_content_message(self):
+ self.conversation.append(
+ {'role': self.assistant_role_name, 'content': self.content}
+ )
+ add_markdown_to_notebook(self.content, title="Assistant")
+
+ def add_text_message(self, user_text):
+ self.conversation.append(
+ {'role': 'user', 'content': user_text}
+ )
+ self.revocable_files.clear()
+ self.update_finish_reason(finish_reason='new_input')
+ add_markdown_to_notebook(user_text, title="User")
+
+ def add_file_message(self, path, bot_msg):
+ filename = os.path.basename(path)
+ work_dir = self.jupyter_work_dir
+
+ shutil.copy(path, work_dir)
+
+ gpt_msg = {'role': 'system', 'content': f'User uploaded a file: {filename}'}
+ self.conversation.append(gpt_msg)
+ self.revocable_files.append(
+ {
+ 'bot_msg': bot_msg,
+ 'gpt_msg': gpt_msg,
+ 'path': os.path.join(work_dir, filename)
+ }
+ )
+
+ def add_function_call_response_message(self, function_response: Union[str, None], save_tokens=True):
+ if self.code_str is not None:
+ add_code_cell_to_notebook(self.code_str)
+
+ self.conversation.append(
+ {
+ "role": self.assistant_role_name,
+ "name": self.function_name,
+ "content": self.function_args_str
+ }
+ )
+ if function_response is not None:
+ if save_tokens and len(function_response) > 500:
+ function_response = f'{function_response[:200]}\n[Output too much, the middle part output is omitted]\n ' \
+ f'End part of output:\n{function_response[-200:]}'
+ self.conversation.append(
+ {
+ "role": "function",
+ "name": self.function_name,
+ "content": function_response,
+ }
+ )
+ self._save_tool_log(tool_response=function_response)
+
+ def append_system_msg(self, prompt):
+ self.conversation.append(
+ {'role': 'system', 'content': prompt}
+ )
+
+ def revoke_file(self):
+ if self.revocable_files:
+ file = self.revocable_files[-1]
+ bot_msg = file['bot_msg']
+ gpt_msg = file['gpt_msg']
+ path = file['path']
+
+ assert self.conversation[-1] is gpt_msg
+ del self.conversation[-1]
+
+ os.remove(path)
+
+ del self.revocable_files[-1]
+
+ return bot_msg
+ else:
+ return None
+
+ def update_gpt_model_choice(self, model_choice):
+ self.gpt_model_choice = model_choice
+ self._init_kwargs_for_chat_completion()
+
+ def update_token_count(self, num_tokens):
+ self.__setattr__('context_window_tokens', num_tokens)
+
+ def update_sliced_state(self, sliced):
+ self.__setattr__('sliced', sliced)
+
+ def send_interrupt_signal(self):
+ self.jupyter_kernel.send_interrupt_signal()
+ self.update_interrupt_signal_sent(interrupt_signal_sent=True)
+
+ def restart(self):
+ self.revocable_files.clear()
+ self._init_conversation()
+ self.reset_gpt_response_log_values()
+ self.jupyter_kernel.restart_jupyter_kernel()
+ self._clear_all_files_in_work_dir()
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/src/cli.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/src/cli.py
new file mode 100644
index 0000000000000000000000000000000000000000..95a2fdf438652c3f279f7566944e3388769eff39
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/src/cli.py
@@ -0,0 +1,108 @@
+from response_parser import *
+import copy
+import json
+from tqdm import tqdm
+import logging
+import argparse
+import os
+
+def initialization(state_dict: Dict) -> None:
+ if not os.path.exists('cache'):
+ os.mkdir('cache')
+ if state_dict["bot_backend"] is None:
+ state_dict["bot_backend"] = BotBackend()
+ if 'OPENAI_API_KEY' in os.environ:
+ del os.environ['OPENAI_API_KEY']
+
+def get_bot_backend(state_dict: Dict) -> BotBackend:
+ return state_dict["bot_backend"]
+
+def switch_to_gpt4(state_dict: Dict, whether_switch: bool) -> None:
+ bot_backend = get_bot_backend(state_dict)
+ if whether_switch:
+ bot_backend.update_gpt_model_choice("GPT-4")
+ else:
+ bot_backend.update_gpt_model_choice("GPT-3.5")
+
+def add_text(state_dict, history, text):
+ bot_backend = get_bot_backend(state_dict)
+ bot_backend.add_text_message(user_text=text)
+ history = history + [[text, None]]
+ return history, state_dict
+
+def bot(state_dict, history):
+ bot_backend = get_bot_backend(state_dict)
+ while bot_backend.finish_reason in ('new_input', 'function_call'):
+ if history[-1][1]:
+ history.append([None, ""])
+ else:
+ history[-1][1] = ""
+ logging.info("Start chat completion")
+ response = chat_completion(bot_backend=bot_backend)
+ logging.info(f"End chat completion, response: {response}")
+
+ logging.info("Start parse response")
+ history, _ = parse_response(
+ chunk=response,
+ history=history,
+ bot_backend=bot_backend
+ )
+ logging.info("End parse response")
+ return history
+
+def main(state, history, user_input):
+ history, state = add_text(state, history, user_input)
+ last_history = copy.deepcopy(history)
+ first_turn_flag = False
+ while True:
+ if first_turn_flag:
+ switch_to_gpt4(state, False)
+ first_turn_flag = False
+ else:
+ switch_to_gpt4(state, True)
+ logging.info("Start bot")
+ history = bot(state, history)
+ logging.info("End bot")
+ print(state["bot_backend"].conversation)
+ if last_history == copy.deepcopy(history):
+ logging.info("No new response, end conversation")
+ conversation = [item for item in state["bot_backend"].conversation if item["content"]]
+ return conversation
+ else:
+ logging.info("New response, continue conversation")
+ last_history = copy.deepcopy(history)
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--input_path', type=str)
+ parser.add_argument('--output_path', type=str)
+ args = parser.parse_args()
+
+ logging.basicConfig(level=logging.INFO)
+ logging.info("Initialization")
+
+ state = {"bot_backend": None}
+ history = []
+
+ initialization(state)
+ switch_to_gpt4(state_dict=state, whether_switch=True)
+
+ logging.info("Start")
+ with open(args.input_path, "r") as f:
+ instructions = [json.loads(line)["query"] for line in f.readlines()]
+ all_history = []
+ logging.info(f"{len(instructions)} remaining instructions for {args.input_path}")
+
+ for user_input_index, user_input in enumerate(tqdm(instructions)):
+ logging.info(f"Start conversation {user_input_index}")
+ conversation = main(state, history, user_input)
+ all_history.append(
+ {
+ "instruction": user_input,
+ "conversation": conversation
+ }
+ )
+ with open(f"{args.output_path}", "w") as f:
+ json.dump(all_history, f, indent=4, ensure_ascii=False)
+ state["bot_backend"].restart()
+
\ No newline at end of file
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/src/functional.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/src/functional.py
new file mode 100644
index 0000000000000000000000000000000000000000..7f941148fbc93f76c9ae72c608496763329f39f5
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/src/functional.py
@@ -0,0 +1,197 @@
+from bot_backend import *
+import base64
+import time
+import tiktoken
+from notebook_serializer import add_code_cell_error_to_notebook, add_image_to_notebook, add_code_cell_output_to_notebook
+
+SLICED_CONV_MESSAGE = "[Rest of the conversation has been omitted to fit in the context window]"
+
+
+def get_conversation_slice(conversation, model, encoding_for_which_model, min_output_tokens_count=500):
+ """
+ Function to get a slice of the conversation that fits in the model's context window. returns: The conversation
+ with the first message(explaining the role of the assistant) + the last x messages that can fit in the context
+ window.
+ """
+ encoder = tiktoken.encoding_for_model(encoding_for_which_model)
+ count_tokens = lambda txt: len(encoder.encode(txt))
+ nb_tokens = count_tokens(conversation[0]['content'])
+ sliced_conv = [conversation[0]]
+ context_window_limit = int(config['model_context_window'][model])
+ max_tokens = context_window_limit - count_tokens(SLICED_CONV_MESSAGE) - min_output_tokens_count
+ sliced = False
+ for message in conversation[-1:0:-1]:
+ nb_tokens += count_tokens(message['content'])
+ if nb_tokens > max_tokens:
+ sliced_conv.insert(1, {'role': 'system', 'content': SLICED_CONV_MESSAGE})
+ sliced = True
+ break
+ sliced_conv.insert(1, message)
+ return sliced_conv, nb_tokens, sliced
+
+
+def chat_completion(bot_backend: BotBackend):
+ model_choice = bot_backend.gpt_model_choice
+ model_name = bot_backend.config['model'][model_choice]['model_name']
+ kwargs_for_chat_completion = copy.deepcopy(bot_backend.kwargs_for_chat_completion)
+ if bot_backend.config['API_TYPE'] == "azure":
+ kwargs_for_chat_completion['messages'], nb_tokens, sliced = \
+ get_conversation_slice(
+ conversation=kwargs_for_chat_completion['messages'],
+ model=model_name,
+ encoding_for_which_model='gpt-3.5-turbo' if model_choice == 'GPT-3.5' else 'gpt-4'
+ )
+ else:
+ kwargs_for_chat_completion['messages'], nb_tokens, sliced = \
+ get_conversation_slice(
+ conversation=kwargs_for_chat_completion['messages'],
+ model=model_name,
+ encoding_for_which_model=model_name
+ )
+
+ bot_backend.update_token_count(num_tokens=nb_tokens)
+ bot_backend.update_sliced_state(sliced=sliced)
+
+ assert config['model'][model_choice]['available'], f"{model_choice} is not available for your API key"
+
+ assert model_name in config['model_context_window'], \
+ f"{model_name} lacks context window information. Please check the config.json file."
+
+ response = openai.ChatCompletion.create(**kwargs_for_chat_completion)
+ return response
+
+
+def add_code_execution_result_to_bot_history(content_to_display, history, unique_id):
+ images, text = [], []
+
+ # terminal output
+ error_occurred = False
+
+ for mark, out_str in content_to_display:
+ if mark in ('stdout', 'execute_result_text', 'display_text'):
+ text.append(out_str)
+ add_code_cell_output_to_notebook(out_str)
+ elif mark in ('execute_result_png', 'execute_result_jpeg', 'display_png', 'display_jpeg'):
+ if 'png' in mark:
+ images.append(('png', out_str))
+ add_image_to_notebook(out_str, 'image/png')
+ else:
+ add_image_to_notebook(out_str, 'image/jpeg')
+ images.append(('jpg', out_str))
+ elif mark == 'error':
+ # Set output type to error
+ text.append(delete_color_control_char(out_str))
+ error_occurred = True
+ add_code_cell_error_to_notebook(out_str)
+ text = '\n'.join(text).strip('\n')
+ if error_occurred:
+ history.append([None, f'❌Terminal output:\n```shell\n\n{text}\n```'])
+ else:
+ history.append([None, f'✔️Terminal output:\n```shell\n{text}\n```'])
+
+ # image output
+ for filetype, img in images:
+ image_bytes = base64.b64decode(img)
+ temp_path = f'cache/temp_{unique_id}'
+ if not os.path.exists(temp_path):
+ os.mkdir(temp_path)
+ path = f'{temp_path}/{hash(time.time())}.{filetype}'
+ with open(path, 'wb') as f:
+ f.write(image_bytes)
+ width, height = get_image_size(path)
+ history.append(
+ [
+ None,
+ f' '
+ ]
+ )
+
+
+def add_function_response_to_bot_history(hypertext_to_display, history):
+ if hypertext_to_display is not None:
+ if history[-1][1]:
+ history.append([None, hypertext_to_display])
+ else:
+ history[-1][1] = hypertext_to_display
+
+
+def parse_json(function_args: str, finished: bool):
+ """
+ GPT may generate non-standard JSON format string, which contains '\n' in string value, leading to error when using
+ `json.loads()`.
+ Here we implement a parser to extract code directly from non-standard JSON string.
+ :return: code string if successfully parsed otherwise None
+ """
+ parser_log = {
+ 'met_begin_{': False,
+ 'begin_"code"': False,
+ 'end_"code"': False,
+ 'met_:': False,
+ 'met_end_}': False,
+ 'met_end_code_"': False,
+ "code_begin_index": 0,
+ "code_end_index": 0
+ }
+ try:
+ for index, char in enumerate(function_args):
+ if char == '{':
+ parser_log['met_begin_{'] = True
+ elif parser_log['met_begin_{'] and char == '"':
+ if parser_log['met_:']:
+ if finished:
+ parser_log['code_begin_index'] = index + 1
+ break
+ else:
+ if index + 1 == len(function_args):
+ return None
+ else:
+ temp_code_str = function_args[index + 1:]
+ if '\n' in temp_code_str:
+ try:
+ return json.loads(function_args + '"}')['code']
+ except json.JSONDecodeError:
+ try:
+ return json.loads(function_args + '}')['code']
+ except json.JSONDecodeError:
+ try:
+ return json.loads(function_args)['code']
+ except json.JSONDecodeError:
+ if temp_code_str[-1] in ('"', '\n'):
+ return None
+ else:
+ return temp_code_str.strip('\n')
+ else:
+ return json.loads(function_args + '"}')['code']
+ elif parser_log['begin_"code"']:
+ parser_log['end_"code"'] = True
+ else:
+ parser_log['begin_"code"'] = True
+ elif parser_log['end_"code"'] and char == ':':
+ parser_log['met_:'] = True
+ else:
+ continue
+ if finished:
+ for index, char in enumerate(function_args[::-1]):
+ back_index = -1 - index
+ if char == '}':
+ parser_log['met_end_}'] = True
+ elif parser_log['met_end_}'] and char == '"':
+ parser_log['code_end_index'] = back_index - 1
+ break
+ else:
+ continue
+ code_str = function_args[parser_log['code_begin_index']: parser_log['code_end_index'] + 1]
+ if '\n' in code_str:
+ return code_str.strip('\n')
+ else:
+ return json.loads(function_args)['code']
+
+ except Exception as e:
+ return None
+
+
+def get_image_size(image_path):
+ with Image.open(image_path) as img:
+ width, height = img.size
+ return width, height
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/src/jupyter_backend.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/src/jupyter_backend.py
new file mode 100644
index 0000000000000000000000000000000000000000..7858e82b47bf86a1ac1d4725c56d7472a410f56c
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/src/jupyter_backend.py
@@ -0,0 +1,108 @@
+import jupyter_client
+import re
+
+
+def delete_color_control_char(string):
+ ansi_escape = re.compile(r'(\x9B|\x1B\[)[0-?]*[ -\/]*[@-~]')
+ return ansi_escape.sub('', string)
+
+
+class JupyterKernel:
+ def __init__(self, work_dir):
+ self.kernel_manager, self.kernel_client = jupyter_client.manager.start_new_kernel(kernel_name='python3')
+ self.work_dir = work_dir
+ self.interrupt_signal = False
+ self._create_work_dir()
+ self.available_functions = {
+ 'execute_code': self.execute_code,
+ 'python': self.execute_code
+ }
+
+ def execute_code_(self, code):
+ msg_id = self.kernel_client.execute(code)
+
+ # Get the output of the code
+ msg_list = []
+ while True:
+ try:
+ iopub_msg = self.kernel_client.get_iopub_msg(timeout=1)
+ msg_list.append(iopub_msg)
+ if iopub_msg['msg_type'] == 'status' and iopub_msg['content'].get('execution_state') == 'idle':
+ break
+ except:
+ if self.interrupt_signal:
+ self.kernel_manager.interrupt_kernel()
+ self.interrupt_signal = False
+ continue
+
+ all_output = []
+ for iopub_msg in msg_list:
+ if iopub_msg['msg_type'] == 'stream':
+ if iopub_msg['content'].get('name') == 'stdout':
+ output = iopub_msg['content']['text']
+ all_output.append(('stdout', output))
+ elif iopub_msg['msg_type'] == 'execute_result':
+ if 'data' in iopub_msg['content']:
+ if 'text/plain' in iopub_msg['content']['data']:
+ output = iopub_msg['content']['data']['text/plain']
+ all_output.append(('execute_result_text', output))
+ if 'text/html' in iopub_msg['content']['data']:
+ output = iopub_msg['content']['data']['text/html']
+ all_output.append(('execute_result_html', output))
+ if 'image/png' in iopub_msg['content']['data']:
+ output = iopub_msg['content']['data']['image/png']
+ all_output.append(('execute_result_png', output))
+ if 'image/jpeg' in iopub_msg['content']['data']:
+ output = iopub_msg['content']['data']['image/jpeg']
+ all_output.append(('execute_result_jpeg', output))
+ elif iopub_msg['msg_type'] == 'display_data':
+ if 'data' in iopub_msg['content']:
+ if 'text/plain' in iopub_msg['content']['data']:
+ output = iopub_msg['content']['data']['text/plain']
+ all_output.append(('display_text', output))
+ if 'text/html' in iopub_msg['content']['data']:
+ output = iopub_msg['content']['data']['text/html']
+ all_output.append(('display_html', output))
+ if 'image/png' in iopub_msg['content']['data']:
+ output = iopub_msg['content']['data']['image/png']
+ all_output.append(('display_png', output))
+ if 'image/jpeg' in iopub_msg['content']['data']:
+ output = iopub_msg['content']['data']['image/jpeg']
+ all_output.append(('display_jpeg', output))
+ elif iopub_msg['msg_type'] == 'error':
+ if 'traceback' in iopub_msg['content']:
+ output = '\n'.join(iopub_msg['content']['traceback'])
+ all_output.append(('error', output))
+
+ return all_output
+
+ def execute_code(self, code):
+ text_to_gpt = []
+ content_to_display = self.execute_code_(code)
+ for mark, out_str in content_to_display:
+ if mark in ('stdout', 'execute_result_text', 'display_text'):
+ text_to_gpt.append(out_str)
+ elif mark in ('execute_result_png', 'execute_result_jpeg', 'display_png', 'display_jpeg'):
+ text_to_gpt.append('[image]')
+ elif mark == 'error':
+ text_to_gpt.append(delete_color_control_char(out_str))
+
+ return '\n'.join(text_to_gpt), content_to_display
+
+ def _create_work_dir(self):
+ # set work dir in jupyter environment
+ init_code = f"import os\n" \
+ f"if not os.path.exists('{self.work_dir}'):\n" \
+ f" os.mkdir('{self.work_dir}')\n" \
+ f"os.chdir('{self.work_dir}')\n" \
+ f"del os"
+ self.execute_code_(init_code)
+
+ def send_interrupt_signal(self):
+ self.interrupt_signal = True
+
+ def restart_jupyter_kernel(self):
+ self.kernel_client.shutdown()
+ self.kernel_manager, self.kernel_client = jupyter_client.manager.start_new_kernel(kernel_name='python3')
+ self.interrupt_signal = False
+ self._create_work_dir()
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/src/notebook_serializer.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/src/notebook_serializer.py
new file mode 100644
index 0000000000000000000000000000000000000000..afb547b7c3a23a8be7472eed2c0fc41a8f83d9fe
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/src/notebook_serializer.py
@@ -0,0 +1,71 @@
+import nbformat
+from nbformat import v4 as nbf
+import ansi2html
+import os
+import argparse
+
+# main code
+parser = argparse.ArgumentParser()
+parser.add_argument("-n", "--notebook", help="Path to the output notebook", default=None, type=str)
+args = parser.parse_args()
+if args.notebook:
+ notebook_path = os.path.join(os.getcwd(), args.notebook)
+ base, ext = os.path.splitext(notebook_path)
+ if ext.lower() != '.ipynb':
+ notebook_path += '.ipynb'
+ if os.path.exists(notebook_path):
+ print(f'File at {notebook_path} already exists. Please choose a different file name.')
+ exit()
+
+# Global variable for code cells
+nb = nbf.new_notebook()
+
+
+def ansi_to_html(ansi_text):
+ converter = ansi2html.Ansi2HTMLConverter()
+ html_text = converter.convert(ansi_text)
+ return html_text
+
+
+def write_to_notebook():
+ if args.notebook:
+ with open(notebook_path, 'w', encoding='utf-8') as f:
+ nbformat.write(nb, f)
+
+
+def add_code_cell_to_notebook(code):
+ code_cell = nbf.new_code_cell(source=code)
+ nb['cells'].append(code_cell)
+ write_to_notebook()
+
+
+def add_code_cell_output_to_notebook(output):
+ html_content = ansi_to_html(output)
+ cell_output = nbf.new_output(output_type='display_data', data={'text/html': html_content})
+ nb['cells'][-1]['outputs'].append(cell_output)
+ write_to_notebook()
+
+
+def add_code_cell_error_to_notebook(error):
+ nbf_error_output = nbf.new_output(
+ output_type='error',
+ ename='Error',
+ evalue='Error message',
+ traceback=[error]
+ )
+ nb['cells'][-1]['outputs'].append(nbf_error_output)
+ write_to_notebook()
+
+
+def add_image_to_notebook(image, mime_type):
+ image_output = nbf.new_output(output_type='display_data', data={mime_type: image})
+ nb['cells'][-1]['outputs'].append(image_output)
+ write_to_notebook()
+
+
+def add_markdown_to_notebook(content, title=None):
+ if title:
+ content = "##### " + title + ":\n" + content
+ markdown_cell = nbf.new_markdown_cell(content)
+ nb['cells'].append(markdown_cell)
+ write_to_notebook()
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/src/response_parser.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/src/response_parser.py
new file mode 100644
index 0000000000000000000000000000000000000000..1a887011d5881476df80e4f02f0c19ce275dc0a2
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/src/response_parser.py
@@ -0,0 +1,259 @@
+from functional import *
+
+
+class ChoiceStrategy(metaclass=ABCMeta):
+ def __init__(self, choice):
+ self.choice = choice
+ self.delta = choice['delta']
+
+ @abstractmethod
+ def support(self):
+ pass
+
+ @abstractmethod
+ def execute(self, bot_backend: BotBackend, history: List, whether_exit: bool):
+ pass
+
+
+class RoleChoiceStrategy(ChoiceStrategy):
+
+ def support(self):
+ return 'role' in self.delta
+
+ def execute(self, bot_backend: BotBackend, history: List, whether_exit: bool):
+ bot_backend.set_assistant_role_name(assistant_role_name=self.delta['role'])
+ return history, whether_exit
+
+
+class ContentChoiceStrategy(ChoiceStrategy):
+ def support(self):
+ return 'content' in self.delta and self.delta['content'] is not None
+ # null value of content often occur in function call:
+ # {
+ # "role": "assistant",
+ # "content": null,
+ # "function_call": {
+ # "name": "python",
+ # "arguments": ""
+ # }
+ # }
+
+ def execute(self, bot_backend: BotBackend, history: List, whether_exit: bool):
+ bot_backend.add_content(content=self.delta.get('content', ''))
+ history[-1][1] = bot_backend.content
+ return history, whether_exit
+
+
+class NameFunctionCallChoiceStrategy(ChoiceStrategy):
+ def support(self):
+ return 'function_call' in self.delta and 'name' in self.delta['function_call']
+
+ def execute(self, bot_backend: BotBackend, history: List, whether_exit: bool):
+ python_function_dict = bot_backend.jupyter_kernel.available_functions
+ additional_tools = bot_backend.additional_tools
+ bot_backend.set_function_name(function_name=self.delta['function_call']['name'])
+ bot_backend.copy_current_bot_history(bot_history=history)
+ if bot_backend.function_name not in python_function_dict and bot_backend.function_name not in additional_tools:
+ history.append(
+ [
+ None,
+ f'GPT attempted to call a function that does '
+ f'not exist: {bot_backend.function_name}\n '
+ ]
+ )
+ whether_exit = True
+
+ return history, whether_exit
+
+
+class ArgumentsFunctionCallChoiceStrategy(ChoiceStrategy):
+
+ def support(self):
+ return 'function_call' in self.delta and 'arguments' in self.delta['function_call']
+
+ def execute(self, bot_backend: BotBackend, history: List, whether_exit: bool):
+ bot_backend.add_function_args_str(function_args_str=self.delta['function_call']['arguments'])
+
+ if bot_backend.function_name == 'python': # handle hallucinatory function calls
+ """
+ In practice, we have noticed that GPT, especially GPT-3.5, may occasionally produce hallucinatory
+ function calls. These calls involve a non-existent function named `python` with arguments consisting
+ solely of raw code text (not a JSON format).
+ """
+ temp_code_str = bot_backend.function_args_str
+ bot_backend.update_code_str(code_str=temp_code_str)
+ bot_backend.update_display_code_block(
+ display_code_block="\n🔴Working:\n```python\n{}\n```".format(temp_code_str)
+ )
+ history = copy.deepcopy(bot_backend.bot_history)
+ history[-1][1] += bot_backend.display_code_block
+ elif bot_backend.function_name == 'execute_code':
+ temp_code_str = parse_json(function_args=bot_backend.function_args_str, finished=False)
+ if temp_code_str is not None:
+ bot_backend.update_code_str(code_str=temp_code_str)
+ bot_backend.update_display_code_block(
+ display_code_block="\n🔴Working:\n```python\n{}\n```".format(
+ temp_code_str
+ )
+ )
+ history = copy.deepcopy(bot_backend.bot_history)
+ history[-1][1] += bot_backend.display_code_block
+ else:
+ history = copy.deepcopy(bot_backend.bot_history)
+ history[-1][1] += bot_backend.display_code_block
+ else:
+ pass
+
+ return history, whether_exit
+
+
+class FinishReasonChoiceStrategy(ChoiceStrategy):
+ def support(self):
+ return self.choice['finish_reason'] is not None
+
+ def execute(self, bot_backend: BotBackend, history: List, whether_exit: bool):
+
+ if bot_backend.content:
+ bot_backend.add_gpt_response_content_message()
+
+ bot_backend.update_finish_reason(finish_reason=self.choice['finish_reason'])
+ if bot_backend.finish_reason == 'function_call':
+
+ if bot_backend.function_name in bot_backend.jupyter_kernel.available_functions:
+ history, whether_exit = self.handle_execute_code_finish_reason(
+ bot_backend=bot_backend, history=history, whether_exit=whether_exit
+ )
+ else:
+ history, whether_exit = self.handle_tool_finish_reason(
+ bot_backend=bot_backend, history=history, whether_exit=whether_exit
+ )
+
+ bot_backend.reset_gpt_response_log_values(exclude=['finish_reason'])
+
+ return history, whether_exit
+
+ def handle_execute_code_finish_reason(self, bot_backend: BotBackend, history: List, whether_exit: bool):
+ function_dict = bot_backend.jupyter_kernel.available_functions
+ try:
+
+ code_str = self.get_code_str(bot_backend)
+
+ bot_backend.update_code_str(code_str=code_str)
+ bot_backend.update_display_code_block(
+ display_code_block="\n🟢Finished:\n```python\n{}\n```".format(code_str)
+ )
+ history = copy.deepcopy(bot_backend.bot_history)
+ history[-1][1] += bot_backend.display_code_block
+
+ # function response
+ bot_backend.update_code_executing_state(code_executing=True)
+ text_to_gpt, content_to_display = function_dict[
+ bot_backend.function_name
+ ](code_str)
+ bot_backend.update_code_executing_state(code_executing=False)
+
+ # add function call to conversion
+ bot_backend.add_function_call_response_message(function_response=text_to_gpt, save_tokens=True)
+
+ if bot_backend.interrupt_signal_sent:
+ bot_backend.append_system_msg(prompt='Code execution is manually stopped by user, no need to fix.')
+
+ add_code_execution_result_to_bot_history(
+ content_to_display=content_to_display, history=history, unique_id=bot_backend.unique_id
+ )
+ return history, whether_exit
+
+ except json.JSONDecodeError:
+ history.append(
+ [None, f"GPT generate wrong function args: {bot_backend.function_args_str}"]
+ )
+ whether_exit = True
+ return history, whether_exit
+
+ except KeyError as key_error:
+ history.append([None, f'Backend key_error: {key_error}'])
+ whether_exit = True
+ return history, whether_exit
+
+ except Exception as e:
+ history.append([None, f'Backend error: {e}'])
+ whether_exit = True
+ return history, whether_exit
+
+ @staticmethod
+ def handle_tool_finish_reason(bot_backend: BotBackend, history: List, whether_exit: bool):
+ function_dict = bot_backend.additional_tools
+ function_name = bot_backend.function_name
+ function = function_dict[function_name]['tool']
+
+ # parser function args
+ try:
+ kwargs = json.loads(bot_backend.function_args_str)
+ kwargs.update(function_dict[function_name]['additional_parameters'])
+ except json.JSONDecodeError:
+ history.append(
+ [None, f"GPT generate wrong function args: {bot_backend.function_args_str}"]
+ )
+ whether_exit = True
+ return history, whether_exit
+
+ else:
+ # function response
+ function_response, hypertext_to_display = function(**kwargs)
+
+ # add function call to conversion
+ bot_backend.add_function_call_response_message(function_response=function_response, save_tokens=False)
+
+ # add hypertext response to bot history
+ add_function_response_to_bot_history(hypertext_to_display=hypertext_to_display, history=history)
+
+ return history, whether_exit
+
+ @staticmethod
+ def get_code_str(bot_backend):
+ if bot_backend.function_name == 'python':
+ code_str = bot_backend.function_args_str
+ else:
+ code_str = parse_json(function_args=bot_backend.function_args_str, finished=True)
+ if code_str is None:
+ raise json.JSONDecodeError
+ return code_str
+
+
+class ChoiceHandler:
+ strategies = [
+ RoleChoiceStrategy, ContentChoiceStrategy, NameFunctionCallChoiceStrategy,
+ ArgumentsFunctionCallChoiceStrategy, FinishReasonChoiceStrategy
+ ]
+
+ def __init__(self, choice):
+ self.choice = choice
+
+ def handle(self, bot_backend: BotBackend, history: List, whether_exit: bool):
+ for Strategy in self.strategies:
+ strategy_instance = Strategy(choice=self.choice)
+ if not strategy_instance.support():
+ continue
+ history, whether_exit = strategy_instance.execute(
+ bot_backend=bot_backend,
+ history=history,
+ whether_exit=whether_exit
+ )
+ return history, whether_exit
+
+
+def parse_response(chunk, history: List, bot_backend: BotBackend):
+ """
+ :return: history, whether_exit
+ """
+ whether_exit = False
+ if chunk['choices']:
+ choice = chunk['choices'][0]
+ choice_handler = ChoiceHandler(choice=choice)
+ history, whether_exit = choice_handler.handle(
+ history=history,
+ bot_backend=bot_backend,
+ whether_exit=whether_exit
+ )
+
+ return history, whether_exit
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/src/tools.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/src/tools.py
new file mode 100644
index 0000000000000000000000000000000000000000..2ecdadf87f25ea8f5d7a4d9c13ab67e4ff482669
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/src/tools.py
@@ -0,0 +1,202 @@
+import openai
+import base64
+import os
+import io
+import time
+from PIL import Image
+from abc import ABCMeta, abstractmethod
+
+
+def create_vision_chat_completion(vision_model, base64_image, prompt):
+ try:
+ response = openai.ChatCompletion.create(
+ model=vision_model,
+ messages=[
+ {
+ "role": "user",
+ "content": [
+ {"type": "text", "text": prompt},
+ {
+ "type": "image_url",
+ "image_url": {
+ "url": f"data:image/jpeg;base64,{base64_image}",
+ },
+ },
+ ],
+ }
+ ],
+ max_tokens=1000,
+ )
+ return response.choices[0].message.content
+ except:
+ return None
+
+
+def create_image(prompt):
+ try:
+ response = openai.Image.create(
+ model="dall-e-3",
+ prompt=prompt,
+ response_format="b64_json"
+ )
+ return response.data[0]['b64_json']
+ except:
+ return None
+
+
+def image_to_base64(path):
+ try:
+ _, suffix = os.path.splitext(path)
+ if suffix not in {'.jpg', '.jpeg', '.png', '.webp'}:
+ img = Image.open(path)
+ img_png = img.convert('RGB')
+ img_png.tobytes()
+ byte_buffer = io.BytesIO()
+ img_png.save(byte_buffer, 'PNG')
+ encoded_string = base64.b64encode(byte_buffer.getvalue()).decode('utf-8')
+ else:
+ with open(path, "rb") as image_file:
+ encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
+ return encoded_string
+ except:
+ return None
+
+
+def base64_to_image_bytes(image_base64):
+ try:
+ return base64.b64decode(image_base64)
+ except:
+ return None
+
+
+def inquire_image(work_dir, vision_model, path, prompt):
+ image_base64 = image_to_base64(f'{work_dir}/{path}')
+ hypertext_to_display = None
+ if image_base64 is None:
+ return "Error: Image transform error", None
+ else:
+ response = create_vision_chat_completion(vision_model, image_base64, prompt)
+ if response is None:
+ return "Model response error", None
+ else:
+ return response, hypertext_to_display
+
+
+def dalle(unique_id, prompt):
+ img_base64 = create_image(prompt)
+ text_to_gpt = "Image has been successfully generated and displayed to user."
+
+ if img_base64 is None:
+ return "Error: Model response error", None
+
+ img_bytes = base64_to_image_bytes(img_base64)
+ if img_bytes is None:
+ return "Error: Image transform error", None
+
+ temp_path = f'cache/temp_{unique_id}'
+ if not os.path.exists(temp_path):
+ os.mkdir(temp_path)
+ path = f'{temp_path}/{hash(time.time())}.png'
+
+ with open(path, 'wb') as f:
+ f.write(img_bytes)
+
+ hypertext_to_display = f''
+ return text_to_gpt, hypertext_to_display
+
+
+class Tool(metaclass=ABCMeta):
+ def __init__(self, config):
+ self.config = config
+
+ @abstractmethod
+ def support(self):
+ pass
+
+ @abstractmethod
+ def get_tool_data(self):
+ pass
+
+
+class ImageInquireTool(Tool):
+ def support(self):
+ return self.config['model']['GPT-4V']['available']
+
+ def get_tool_data(self):
+ return {
+ "tool_name": "inquire_image",
+ "tool": inquire_image,
+ "system_prompt": "If necessary, utilize the 'inquire_image' tool to query an AI model regarding the "
+ "content of images uploaded by users. Avoid phrases like\"based on the analysis\"; "
+ "instead, respond as if you viewed the image by yourself. Keep in mind that not every"
+ "tasks related to images require knowledge of the image content, such as converting "
+ "an image format or extracting image file attributes, which should use `execute_code` "
+ "tool instead. Use the tool only when understanding the image content is necessary.",
+ "tool_description": {
+ "name": "inquire_image",
+ "description": "This function enables you to inquire with an AI model about the contents of an image "
+ "and receive the model's response.",
+ "parameters": {
+ "type": "object",
+ "properties": {
+ "path": {
+ "type": "string",
+ "description": "File path of the image"
+ },
+ "prompt": {
+ "type": "string",
+ "description": "The question you want to pose to the AI model about the image"
+ }
+ },
+ "required": ["path", "prompt"]
+ }
+ },
+ "additional_parameters": {
+ "work_dir": lambda bot_backend: bot_backend.jupyter_work_dir,
+ "vision_model": self.config['model']['GPT-4V']['model_name']
+ }
+ }
+
+
+class DALLETool(Tool):
+ def support(self):
+ return True
+
+ def get_tool_data(self):
+ return {
+ "tool_name": "dalle",
+ "tool": dalle,
+ "system_prompt": "If user ask you to generate an art image, you can translate user's requirements into a "
+ "prompt and sending it to the `dalle` tool. Please note that this tool is specifically "
+ "designed for creating art images. For scientific figures, such as plots, please use the "
+ "Python code execution tool `execute_code` instead.",
+ "tool_description": {
+ "name": "dalle",
+ "description": "This function allows you to access OpenAI's DALL·E-3 model for image generation.",
+ "parameters": {
+ "type": "object",
+ "properties": {
+ "prompt": {
+ "type": "string",
+ "description": "A detailed description of the image you want to generate, should be in "
+ "English only. "
+ }
+ },
+ "required": ["prompt"]
+ }
+ },
+ "additional_parameters": {
+ "unique_id": lambda bot_backend: bot_backend.unique_id,
+ }
+ }
+
+
+def get_available_tools(config):
+ tools = [ImageInquireTool]
+
+ available_tools = []
+ for tool in tools:
+ tool_instance = tool(config)
+ if tool_instance.support():
+ available_tools.append(tool_instance.get_tool_data())
+ return available_tools
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/src/web_ui.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/src/web_ui.py
new file mode 100644
index 0000000000000000000000000000000000000000..66cb0760ea1cd0121d9b6dc5a37363f753c566e3
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/Local-Code-Interpreter/src/web_ui.py
@@ -0,0 +1,279 @@
+import gradio as gr
+from response_parser import *
+
+
+def initialization(state_dict: Dict) -> None:
+ if not os.path.exists('cache'):
+ os.mkdir('cache')
+ if state_dict["bot_backend"] is None:
+ state_dict["bot_backend"] = BotBackend()
+ if 'OPENAI_API_KEY' in os.environ:
+ del os.environ['OPENAI_API_KEY']
+
+
+def get_bot_backend(state_dict: Dict) -> BotBackend:
+ return state_dict["bot_backend"]
+
+
+def switch_to_gpt4(state_dict: Dict, whether_switch: bool) -> None:
+ bot_backend = get_bot_backend(state_dict)
+ if whether_switch:
+ bot_backend.update_gpt_model_choice("GPT-4")
+ else:
+ bot_backend.update_gpt_model_choice("GPT-3.5")
+
+
+def add_text(state_dict: Dict, history: List, text: str) -> Tuple[List, Dict]:
+ bot_backend = get_bot_backend(state_dict)
+ bot_backend.add_text_message(user_text=text)
+
+ history = history + [(text, None)]
+
+ return history, gr.update(value="", interactive=False)
+
+
+def add_file(state_dict: Dict, history: List, files) -> List:
+ bot_backend = get_bot_backend(state_dict)
+ for file in files:
+ path = file.name
+ filename = os.path.basename(path)
+
+ bot_msg = [f'📁[{filename}]', None]
+ history.append(bot_msg)
+
+ bot_backend.add_file_message(path=path, bot_msg=bot_msg)
+
+ _, suffix = os.path.splitext(filename)
+ if suffix in {'.jpg', '.jpeg', '.png', '.bmp', '.webp'}:
+ copied_file_path = f'{bot_backend.jupyter_work_dir}/{filename}'
+ width, height = get_image_size(copied_file_path)
+ bot_msg[0] += \
+ f'\n '
+
+ return history
+
+
+def undo_upload_file(state_dict: Dict, history: List) -> Tuple[List, Dict]:
+ bot_backend = get_bot_backend(state_dict)
+ bot_msg = bot_backend.revoke_file()
+
+ if bot_msg is None:
+ return history, gr.Button.update(interactive=False)
+
+ else:
+ assert history[-1] == bot_msg
+ del history[-1]
+ if bot_backend.revocable_files:
+ return history, gr.Button.update(interactive=True)
+ else:
+ return history, gr.Button.update(interactive=False)
+
+
+def refresh_file_display(state_dict: Dict) -> List[str]:
+ bot_backend = get_bot_backend(state_dict)
+ work_dir = bot_backend.jupyter_work_dir
+ filenames = os.listdir(work_dir)
+ paths = []
+ for filename in filenames:
+ path = os.path.join(work_dir, filename)
+ if not os.path.isdir(path):
+ paths.append(path)
+ return paths
+
+
+def refresh_token_count(state_dict: Dict):
+ bot_backend = get_bot_backend(state_dict)
+ model_choice = bot_backend.gpt_model_choice
+ sliced = bot_backend.sliced
+ token_count = bot_backend.context_window_tokens
+ token_limit = config['model_context_window'][config['model'][model_choice]['model_name']]
+ display_text = f"**Context token:** {token_count}/{token_limit}"
+ if sliced:
+ display_text += '\\\nToken limit exceeded, conversion has been sliced.'
+ return gr.Markdown.update(value=display_text)
+
+
+def restart_ui(history: List) -> Tuple[List, Dict, Dict, Dict, Dict, Dict, Dict]:
+ history.clear()
+ return (
+ history,
+ gr.Textbox.update(value="", interactive=False),
+ gr.Button.update(interactive=False),
+ gr.Button.update(interactive=False),
+ gr.Button.update(interactive=False),
+ gr.Button.update(interactive=False),
+ gr.Button.update(visible=False)
+ )
+
+
+def restart_bot_backend(state_dict: Dict) -> None:
+ bot_backend = get_bot_backend(state_dict)
+ bot_backend.restart()
+
+
+def stop_generating(state_dict: Dict) -> None:
+ bot_backend = get_bot_backend(state_dict)
+ if bot_backend.code_executing:
+ bot_backend.send_interrupt_signal()
+ else:
+ bot_backend.update_stop_generating_state(stop_generating=True)
+
+
+def bot(state_dict: Dict, history: List) -> List:
+ bot_backend = get_bot_backend(state_dict)
+
+ while bot_backend.finish_reason in ('new_input', 'function_call'):
+ if history[-1][1]:
+ history.append([None, ""])
+ else:
+ history[-1][1] = ""
+
+ try:
+ response = chat_completion(bot_backend=bot_backend)
+ for chunk in response:
+ if chunk['choices'] and chunk['choices'][0]['finish_reason'] == 'function_call':
+ if bot_backend.function_name in bot_backend.jupyter_kernel.available_functions:
+ yield history, gr.Button.update(value='⏹️ Interrupt execution'), gr.Button.update(visible=False)
+ else:
+ yield history, gr.Button.update(interactive=False), gr.Button.update(visible=False)
+
+ if bot_backend.stop_generating:
+ response.close()
+ if bot_backend.content:
+ bot_backend.add_gpt_response_content_message()
+ if bot_backend.display_code_block:
+ bot_backend.update_display_code_block(
+ display_code_block="\n⚫Stopped:\n```python\n{}\n```".format(bot_backend.code_str)
+ )
+ history = copy.deepcopy(bot_backend.bot_history)
+ history[-1][1] += bot_backend.display_code_block
+ bot_backend.add_function_call_response_message(function_response=None)
+
+ bot_backend.reset_gpt_response_log_values()
+ break
+
+ history, weather_exit = parse_response(
+ chunk=chunk,
+ history=history,
+ bot_backend=bot_backend
+ )
+
+ yield (
+ history,
+ gr.Button.update(
+ interactive=False if bot_backend.stop_generating else True,
+ value='⏹️ Stop generating'
+ ),
+ gr.Button.update(visible=False)
+ )
+ if weather_exit:
+ exit(-1)
+ except openai.OpenAIError as openai_error:
+ bot_backend.reset_gpt_response_log_values(exclude=['finish_reason'])
+ yield history, gr.Button.update(interactive=False), gr.Button.update(visible=True)
+ raise openai_error
+
+ yield history, gr.Button.update(interactive=False, value='⏹️ Stop generating'), gr.Button.update(visible=False)
+
+
+if __name__ == '__main__':
+ config = get_config()
+ with gr.Blocks(theme=gr.themes.Base()) as block:
+ """
+ Reference: https://www.gradio.app/guides/creating-a-chatbot-fast
+ """
+ # UI components
+ state = gr.State(value={"bot_backend": None})
+ with gr.Tab("Chat"):
+ chatbot = gr.Chatbot([], elem_id="chatbot", label="Local Code Interpreter", height=750)
+ with gr.Row():
+ with gr.Column(scale=0.85):
+ text_box = gr.Textbox(
+ show_label=False,
+ placeholder="Enter text and press enter, or upload a file",
+ container=False
+ )
+ with gr.Column(scale=0.15, min_width=0):
+ file_upload_button = gr.UploadButton("📁", file_count='multiple', file_types=['file'])
+ with gr.Row(equal_height=True):
+ with gr.Column(scale=0.08, min_width=0):
+ check_box = gr.Checkbox(label="Use GPT-4", interactive=config['model']['GPT-4']['available'])
+ with gr.Column(scale=0.314, min_width=0):
+ model_token_limit = config['model_context_window'][config['model']['GPT-3.5']['model_name']]
+ token_count_display_text = f"**Context token:** 0/{model_token_limit}"
+ token_monitor = gr.Markdown(value=token_count_display_text)
+ with gr.Column(scale=0.15, min_width=0):
+ retry_button = gr.Button(value='🔂OpenAI Error, click here to retry', visible=False)
+ with gr.Column(scale=0.15, min_width=0):
+ stop_generation_button = gr.Button(value='⏹️ Stop generating', interactive=False)
+ with gr.Column(scale=0.15, min_width=0):
+ restart_button = gr.Button(value='🔄 Restart')
+ with gr.Column(scale=0.15, min_width=0):
+ undo_file_button = gr.Button(value="↩️Undo upload file", interactive=False)
+ with gr.Tab("Files"):
+ file_output = gr.Files()
+
+ # Components function binding
+ txt_msg = text_box.submit(add_text, [state, chatbot, text_box], [chatbot, text_box], queue=False).then(
+ lambda: gr.Button.update(interactive=False), None, [undo_file_button], queue=False
+ ).then(
+ bot, [state, chatbot], [chatbot, stop_generation_button, retry_button]
+ )
+ txt_msg.then(fn=refresh_file_display, inputs=[state], outputs=[file_output])
+ txt_msg.then(lambda: gr.update(interactive=True), None, [text_box], queue=False)
+ txt_msg.then(fn=refresh_token_count, inputs=[state], outputs=[token_monitor])
+
+ retry_button.click(lambda: gr.Button.update(visible=False), None, [retry_button], queue=False).then(
+ bot, [state, chatbot], [chatbot, stop_generation_button, retry_button]
+ ).then(
+ fn=refresh_file_display, inputs=[state], outputs=[file_output]
+ ).then(
+ lambda: gr.update(interactive=True), None, [text_box], queue=False
+ ).then(
+ fn=refresh_token_count, inputs=[state], outputs=[token_monitor]
+ )
+
+ check_box.change(fn=switch_to_gpt4, inputs=[state, check_box]).then(
+ fn=refresh_token_count, inputs=[state], outputs=[token_monitor]
+ )
+
+ file_msg = file_upload_button.upload(
+ add_file, [state, chatbot, file_upload_button], [chatbot], queue=False
+ )
+ file_msg.then(lambda: gr.Button.update(interactive=True), None, [undo_file_button], queue=False)
+ file_msg.then(fn=refresh_file_display, inputs=[state], outputs=[file_output])
+
+ undo_file_button.click(
+ fn=undo_upload_file, inputs=[state, chatbot], outputs=[chatbot, undo_file_button]
+ ).then(
+ fn=refresh_file_display, inputs=[state], outputs=[file_output]
+ )
+
+ stop_generation_button.click(fn=stop_generating, inputs=[state], queue=False).then(
+ fn=lambda: gr.Button.update(interactive=False), inputs=None, outputs=[stop_generation_button], queue=False
+ )
+
+ restart_button.click(
+ fn=restart_ui, inputs=[chatbot],
+ outputs=[
+ chatbot, text_box, restart_button, file_upload_button, undo_file_button, stop_generation_button,
+ retry_button
+ ]
+ ).then(
+ fn=restart_bot_backend, inputs=[state], queue=False
+ ).then(
+ fn=refresh_file_display, inputs=[state], outputs=[file_output]
+ ).then(
+ fn=lambda: (gr.Textbox.update(interactive=True), gr.Button.update(interactive=True),
+ gr.Button.update(interactive=True)),
+ inputs=None, outputs=[text_box, restart_button, file_upload_button], queue=False
+ ).then(
+ fn=refresh_token_count,
+ inputs=[state], outputs=[token_monitor]
+ )
+
+ block.load(fn=initialization, inputs=[state])
+
+ block.queue()
+ block.launch(inbrowser=True)
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/README.md b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..b5f8e8cdbabccc6c962971aef756fc900ee1f136
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/data_collection/README.md
@@ -0,0 +1,3 @@
+# Data Collection
+
+Our data collection process is implemented using https://github.com/MrGreyfun/Local-Code-Interpreter. To achieve more efficient data collection, we implement a command line interface instead of the original web UI. Please check out `cli.py` for more details.
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/demo/LICENSE b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/demo/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..6fce9a8fa1f5ec263100209809e19f980f00e9ef
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/demo/LICENSE
@@ -0,0 +1,21 @@
+MIT License
+
+Copyright (c) 2023 Magnetic2014
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in all
+copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+SOFTWARE.
\ No newline at end of file
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/demo/README.md b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/demo/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..a184c1ee87d4472835b3438da7535f187f2ef7db
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/demo/README.md
@@ -0,0 +1,50 @@
+# OpenCodeInterpreter Demo
+
+Based on our powerful OpenCodeInterpreter models, this project allows LLM to generate code, execute it, receive feedback, debug, and answer questions based on the whole process. It is designed to be intuitive and versatile, capable of dealing with multiple languages and frameworks.
+
+
+## Disclaimer
+
+This demo is designed to leverage large language models for generating code, which is then executed in a Jupyter environment. Before you begin using this project, it is important that you read and understand the following disclaimer:
+
+- **Academic Nature and Security Risks:** This project is developed for academic purposes only and is not designed to be fully secure against all forms of code attacks. While we strive to maintain a safe environment, we cannot guarantee the security of your data during use. We urge all users to refrain from executing malicious code intentionally. By choosing to use this project, you acknowledge the potential risks to your data and agree to proceed with caution.
+
+- **Model Compatibility Notice:** Please be advised that our demo is only guaranteed to be compatible with the `opencodeinterpreter` model. We cannot ensure that using other models will achieve the expected output or performance. Users attempting to substitute or use models other than the officially recommended ones do so at their own risk, and may encounter issues with performance mismatches or other related risks. We encourage users to fully understand the potential impacts before making any such modifications.
+
+- **User Responsibility:** Users are responsible for the code they generate and execute using this project. We strongly advise against running any code without a thorough understanding of its function and potential impact. Users should take precautions to protect their own data and the integrity of their systems.
+
+- **Limitation of Liability:** The creators and maintainers of this project will not be liable for any damages, data loss, or security breaches that may occur from using this service. Users assume all responsibility and risk associated with their use of the project.
+
+- **Changes to the Disclaimer:** This disclaimer is subject to change at any time. We will make efforts to communicate any changes through the project's official channels, but it is the responsibility of the users to review this disclaimer periodically to ensure they are aware of any updates.
+
+By using this demo, you acknowledge that you have read this disclaimer, understand its terms, and agree to be bound by them.
+
+
+## Features
+
+- **Multi-user support**
+
+- **Save your conversations to both Huggingface datasets and offline json files**
+
+## License
+
+Distributed under the MIT License. See `LICENSE` for more information.
+
+## Acknowledgement
+
+This project is based on [Llama2-Code-Interpreter](https://github.com/SeungyounShin/Llama2-Code-Interpreter).
+
+---
+
+## Citation
+
+If you find this demo useful for your research, please kindly cite our paper:
+
+```
+@article{zheng2024opencodeinterpreter,
+ title={OpenCodeInterpreter: Integrating Code Generation with Execution and Refinement},
+ author={Zheng, Tianyu and Zhang, Ge and Shen, Tianhao and Liu, Xueling and Lin, Bill Yuchen and Fu, Jie and Chen, Wenhu and Yue, Xiang},
+ journal={arXiv preprint arXiv:2402.14658},
+ year={2024}
+}
+```
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/demo/assets/assistant.pic.jpg b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/demo/assets/assistant.pic.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..cb7ed09889a47bf7bb230ed2bac1d34e779114b0
Binary files /dev/null and b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/demo/assets/assistant.pic.jpg differ
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/demo/assets/user.pic.jpg b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/demo/assets/user.pic.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..45b47d7485150fadf1fa588b45c235b3a9702adf
Binary files /dev/null and b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/demo/assets/user.pic.jpg differ
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/demo/chatbot.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/demo/chatbot.py
new file mode 100644
index 0000000000000000000000000000000000000000..8d8451868f8d5e18ca569fac798301f6e87e20e3
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/demo/chatbot.py
@@ -0,0 +1,316 @@
+import ast
+import gradio as gr
+import os
+import re
+import json
+import logging
+
+import torch
+from datetime import datetime
+
+from threading import Thread
+from typing import Optional
+from transformers import TextIteratorStreamer
+from functools import partial
+from huggingface_hub import CommitScheduler
+from uuid import uuid4
+from pathlib import Path
+
+from code_interpreter.JupyterClient import JupyterNotebook
+
+MAX_INPUT_TOKEN_LENGTH = int(os.getenv("MAX_INPUT_TOKEN_LENGTH", "4096"))
+
+import warnings
+
+warnings.filterwarnings("ignore", category=UserWarning, module="transformers")
+os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2"
+
+
+from code_interpreter.OpenCodeInterpreter import OpenCodeInterpreter
+
+JSON_DATASET_DIR = Path("json_dataset")
+JSON_DATASET_DIR.mkdir(parents=True, exist_ok=True)
+
+scheduler = CommitScheduler(
+ repo_id="opencodeinterpreter_user_data",
+ repo_type="dataset",
+ folder_path=JSON_DATASET_DIR,
+ path_in_repo="data",
+ private=True
+)
+
+logging.basicConfig(level=logging.INFO)
+
+class StreamingOpenCodeInterpreter(OpenCodeInterpreter):
+ streamer: Optional[TextIteratorStreamer] = None
+
+ # overwirte generate function
+ @torch.inference_mode()
+ def generate(
+ self,
+ prompt: str = "",
+ max_new_tokens = 1024,
+ do_sample: bool = False,
+ top_p: float = 0.95,
+ top_k: int = 50,
+ ) -> str:
+ # Get the model and tokenizer, and tokenize the user text.
+
+ self.streamer = TextIteratorStreamer(
+ self.tokenizer, skip_prompt=True, Timeout=5
+ )
+
+ inputs = self.tokenizer([prompt], return_tensors="pt", truncation=True, max_length=MAX_INPUT_TOKEN_LENGTH)
+ inputs = inputs.to(self.model.device)
+
+ kwargs = dict(
+ **inputs,
+ streamer=self.streamer,
+ max_new_tokens=max_new_tokens,
+ do_sample=do_sample,
+ top_p=top_p,
+ top_k=top_k,
+ eos_token_id=self.tokenizer.eos_token_id
+ )
+
+ thread = Thread(target=self.model.generate, kwargs=kwargs)
+ thread.start()
+
+ return ""
+
+def save_json(dialog, mode, json_file_path, dialog_id) -> None:
+ with scheduler.lock:
+ with json_file_path.open("a") as f:
+ json.dump({"id": dialog_id, "dialog": dialog, "mode": mode, "datetime": datetime.now().isoformat()}, f, ensure_ascii=False)
+ f.write("\n")
+
+def convert_history(gradio_history: list[list], interpreter_history: list[dict]):
+ interpreter_history = [interpreter_history[0]] if interpreter_history and interpreter_history[0]["role"] == "system" else []
+ if not gradio_history:
+ return interpreter_history
+ for item in gradio_history:
+ if item[0] is not None:
+ interpreter_history.append({"role": "user", "content": item[0]})
+ if item[1] is not None:
+ interpreter_history.append({"role": "assistant", "content": item[1]})
+ return interpreter_history
+
+def update_uuid(dialog_info):
+ new_uuid = str(uuid4())
+ logging.info(f"allocating new uuid {new_uuid} for conversation...")
+ return [new_uuid, dialog_info[1]]
+
+def is_valid_python_code(code):
+ try:
+ ast.parse(code)
+ return True
+ except SyntaxError:
+ return False
+
+
+class InputFunctionVisitor(ast.NodeVisitor):
+ def __init__(self):
+ self.found_input = False
+
+ def visit_Call(self, node):
+ if isinstance(node.func, ast.Name) and node.func.id == 'input':
+ self.found_input = True
+ self.generic_visit(node)
+
+def has_input_function_calls(code):
+ try:
+ tree = ast.parse(code)
+ except SyntaxError:
+ return False
+ visitor = InputFunctionVisitor()
+ visitor.visit(tree)
+ return visitor.found_input
+
+def gradio_launch(model_path: str, MAX_TRY: int = 3):
+ with gr.Blocks() as demo:
+ chatbot = gr.Chatbot(height=600, label="OpenCodeInterpreter", avatar_images=["assets/user.pic.jpg", "assets/assistant.pic.jpg"], show_copy_button=True)
+ with gr.Group():
+ with gr.Row():
+ msg = gr.Textbox(
+ container=False,
+ show_label=False,
+ label="Message",
+ placeholder="Type a message...",
+ scale=7,
+ autofocus=True
+ )
+ sub = gr.Button(
+ "Submit",
+ variant="primary",
+ scale=1,
+ min_width=150
+ )
+ # stop = gr.Button(
+ # "Stop",
+ # variant="stop",
+ # visible=False,
+ # scale=1,
+ # min_width=150
+ # )
+
+ with gr.Row():
+ # retry = gr.Button("🔄 Retry", variant="secondary")
+ # undo = gr.Button("↩️ Undo", variant="secondary")
+ clear = gr.Button("🗑️ Clear", variant="secondary")
+
+ session_state = gr.State([])
+ jupyter_state = gr.State(JupyterNotebook())
+ dialog_info = gr.State(["", 0])
+ demo.load(update_uuid, dialog_info, dialog_info)
+
+ def bot(user_message, history, jupyter_state, dialog_info, interpreter):
+ logging.info(f"user message: {user_message}")
+ interpreter.dialog = convert_history(gradio_history=history, interpreter_history=interpreter.dialog)
+ history.append([user_message, None])
+
+ interpreter.dialog.append({"role": "user", "content": user_message})
+
+ # setup
+ HAS_CODE = False # For now
+ prompt = interpreter.dialog_to_prompt(dialog=interpreter.dialog)
+
+ _ = interpreter.generate(prompt)
+ history[-1][1] = ""
+ generated_text = ""
+ for character in interpreter.streamer:
+ history[-1][1] += character
+ history[-1][1] = history[-1][1].replace("<|EOT|>","")
+ generated_text += character
+ yield history, history, jupyter_state, dialog_info
+
+ if is_valid_python_code(history[-1][1].strip()):
+ history[-1][1] = f"```python\n{history[-1][1].strip()}\n```"
+ generated_text = history[-1][1]
+
+ HAS_CODE, generated_code_block = interpreter.extract_code_blocks(
+ generated_text
+ )
+
+ interpreter.dialog.append(
+ {
+ "role": "assistant",
+ "content": generated_text.replace("_", "")
+ .replace("", "")
+ .replace("<|EOT|>", ""),
+ }
+ )
+
+ logging.info(f"saving current dialog to file {dialog_info[0]}.json...")
+ logging.info(f"current dialog: {interpreter.dialog}")
+ save_json(interpreter.dialog, mode="openci_only", json_file_path=JSON_DATASET_DIR/f"{dialog_info[0]}.json", dialog_id=dialog_info[0])
+
+ attempt = 1
+ while HAS_CODE:
+ if attempt > MAX_TRY:
+ break
+ # if no code then doesn't have to execute it
+ generated_text = "" # clear generated text
+
+ yield history, history, jupyter_state, dialog_info
+
+ # replace unknown thing to none ''
+ generated_code_block = generated_code_block.replace(
+ "_", ""
+ ).replace("", "")
+
+ if has_input_function_calls(generated_code_block):
+ code_block_output = "Please directly assign the value of inputs instead of using input() function in your code."
+ else:
+ (
+ code_block_output,
+ error_flag,
+ ) = interpreter.execute_code_and_return_output(
+ f"{generated_code_block}",
+ jupyter_state
+ )
+ if error_flag == "Timeout":
+ logging.info(f"{dialog_info[0]}: Restart jupyter kernel due to timeout")
+ jupyter_state = JupyterNotebook()
+ code_block_output = interpreter.clean_code_output(code_block_output)
+
+ if code_block_output.strip():
+ code_block_output = "Execution result: \n" + code_block_output
+ else:
+ code_block_output = "Code is executed, but result is empty. Please make sure that you include test case in your code."
+
+ history.append([code_block_output, ""])
+
+ interpreter.dialog.append({"role": "user", "content": code_block_output})
+
+ yield history, history, jupyter_state, dialog_info
+
+ prompt = interpreter.dialog_to_prompt(dialog=interpreter.dialog)
+
+ logging.info(f"generating answer for dialog {dialog_info[0]}")
+ _ = interpreter.generate(prompt)
+ for character in interpreter.streamer:
+ history[-1][1] += character
+ history[-1][1] = history[-1][1].replace("<|EOT|>","")
+ generated_text += character
+ yield history, history, jupyter_state, dialog_info
+ logging.info(f"finish generating answer for dialog {dialog_info[0]}")
+
+ HAS_CODE, generated_code_block = interpreter.extract_code_blocks(
+ history[-1][1]
+ )
+
+ interpreter.dialog.append(
+ {
+ "role": "assistant",
+ "content": generated_text.replace("_", "")
+ .replace("", "")
+ .replace("<|EOT|>", ""),
+ }
+ )
+
+ attempt += 1
+
+ logging.info(f"saving current dialog to file {dialog_info[0]}.json...")
+ logging.info(f"current dialog: {interpreter.dialog}")
+ save_json(interpreter.dialog, mode="openci_only", json_file_path=JSON_DATASET_DIR/f"{dialog_info[0]}.json", dialog_id=dialog_info[0])
+
+ if generated_text.endswith("<|EOT|>"):
+ continue
+
+ return history, history, jupyter_state, dialog_info
+
+
+ def reset_textbox():
+ return gr.update(value="")
+
+
+ def clear_history(history, jupyter_state, dialog_info, interpreter):
+ interpreter.dialog = []
+ jupyter_state.close()
+ return [], [], JupyterNotebook(), update_uuid(dialog_info)
+
+ interpreter = StreamingOpenCodeInterpreter(model_path=model_path)
+
+ sub.click(partial(bot, interpreter=interpreter), [msg, session_state, jupyter_state, dialog_info], [chatbot, session_state, jupyter_state, dialog_info])
+ sub.click(reset_textbox, [], [msg])
+
+ clear.click(partial(clear_history, interpreter=interpreter), [session_state, jupyter_state, dialog_info], [chatbot, session_state, jupyter_state, dialog_info], queue=False)
+
+ demo.queue(max_size=20)
+ demo.launch(share=True)
+
+
+if __name__ == "__main__":
+ import argparse
+
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ "--path",
+ type=str,
+ required=False,
+ help="Path to the OpenCodeInterpreter Model.",
+ default="m-a-p/OpenCodeInterpreter-DS-6.7B",
+ )
+ args = parser.parse_args()
+
+ gradio_launch(model_path=args.path)
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/demo/code_interpreter/BaseCodeInterpreter.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/demo/code_interpreter/BaseCodeInterpreter.py
new file mode 100644
index 0000000000000000000000000000000000000000..58990d1d492d1e228c1a713b18b30cadc67f23bc
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/demo/code_interpreter/BaseCodeInterpreter.py
@@ -0,0 +1,29 @@
+import os
+import sys
+import re
+
+prj_root_path = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
+sys.path.append(prj_root_path)
+
+
+from utils.const import *
+
+class BaseCodeInterpreter:
+ def __init__(self):
+ self.dialog = [
+ {
+ "role": "system",
+ "content": CODE_INTERPRETER_SYSTEM_PROMPT,
+ },
+ ]
+
+ @staticmethod
+ def extract_code_blocks(text: str):
+ pattern = r"```(?:python\n)?(.*?)```" # Match optional 'python\n' but don't capture it
+ code_blocks = re.findall(pattern, text, re.DOTALL)
+ return [block.strip() for block in code_blocks]
+
+ def execute_code_and_return_output(self, code_str: str, nb):
+ _, _ = nb.add_and_run(GUARD_CODE)
+ outputs, error_flag = nb.add_and_run(code_str)
+ return outputs, error_flag
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/demo/code_interpreter/JupyterClient.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/demo/code_interpreter/JupyterClient.py
new file mode 100644
index 0000000000000000000000000000000000000000..db895d292bc62b5d45bafc03b01b225587c4b331
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/demo/code_interpreter/JupyterClient.py
@@ -0,0 +1,85 @@
+from jupyter_client import KernelManager
+import threading
+import re
+from utils.const import *
+
+
+class JupyterNotebook:
+ def __init__(self):
+ self.km = KernelManager()
+ self.km.start_kernel()
+ self.kc = self.km.client()
+ _ = self.add_and_run(TOOLS_CODE)
+
+ def clean_output(self, outputs):
+ outputs_only_str = list()
+ for i in outputs:
+ if type(i) == dict:
+ if "text/plain" in list(i.keys()):
+ outputs_only_str.append(i["text/plain"])
+ elif type(i) == str:
+ outputs_only_str.append(i)
+ elif type(i) == list:
+ error_msg = "\n".join(i)
+ error_msg = re.sub(r"\x1b\[.*?m", "", error_msg)
+ outputs_only_str.append(error_msg)
+
+ return "\n".join(outputs_only_str).strip()
+
+ def add_and_run(self, code_string):
+ # This inner function will be executed in a separate thread
+ def run_code_in_thread():
+ nonlocal outputs, error_flag
+
+ # Execute the code and get the execution count
+ msg_id = self.kc.execute(code_string)
+
+ while True:
+ try:
+ msg = self.kc.get_iopub_msg(timeout=20)
+
+ msg_type = msg["header"]["msg_type"]
+ content = msg["content"]
+
+ if msg_type == "execute_result":
+ outputs.append(content["data"])
+ elif msg_type == "stream":
+ outputs.append(content["text"])
+ elif msg_type == "error":
+ error_flag = True
+ outputs.append(content["traceback"])
+
+ # If the execution state of the kernel is idle, it means the cell finished executing
+ if msg_type == "status" and content["execution_state"] == "idle":
+ break
+ except:
+ break
+
+ outputs = []
+ error_flag = False
+
+ # Start the thread to run the code
+ thread = threading.Thread(target=run_code_in_thread)
+ thread.start()
+
+ # Wait for 20 seconds for the thread to finish
+ thread.join(timeout=20)
+
+ # If the thread is still alive after 20 seconds, it's a timeout
+ if thread.is_alive():
+ outputs = ["Execution timed out."]
+ # outputs = ["Error"]
+ error_flag = "Timeout"
+
+ return self.clean_output(outputs), error_flag
+
+ def close(self):
+ """Shutdown the kernel."""
+ self.km.shutdown_kernel()
+
+ def __deepcopy__(self, memo):
+ if id(self) in memo:
+ return memo[id(self)]
+ new_copy = type(self)()
+ memo[id(self)] = new_copy
+ return new_copy
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/demo/code_interpreter/OpenCodeInterpreter.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/demo/code_interpreter/OpenCodeInterpreter.py
new file mode 100644
index 0000000000000000000000000000000000000000..2983ec491e7aeeb98ef569d61e67c7de3b3ed7dd
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/demo/code_interpreter/OpenCodeInterpreter.py
@@ -0,0 +1,80 @@
+import sys
+import os
+
+prj_root_path = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
+sys.path.append(prj_root_path)
+
+from code_interpreter.BaseCodeInterpreter import BaseCodeInterpreter
+from utils.const import *
+
+from typing import List, Tuple, Dict
+import re
+
+import torch
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+
+sys.path.append(os.path.dirname(__file__))
+sys.path.append(os.path.dirname(os.path.abspath(__file__)))
+
+import warnings
+
+warnings.filterwarnings("ignore", category=UserWarning, module="transformers")
+os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2"
+
+
+class OpenCodeInterpreter(BaseCodeInterpreter):
+ def __init__(
+ self,
+ model_path: str,
+ load_in_8bit: bool = False,
+ load_in_4bit: bool = False,
+ ):
+ # build tokenizer
+ self.tokenizer = AutoTokenizer.from_pretrained(
+ model_path,
+ padding_side="right",
+ trust_remote_code=True
+ )
+
+ self.model = AutoModelForCausalLM.from_pretrained(
+ model_path,
+ device_map="auto",
+ load_in_4bit=load_in_4bit,
+ load_in_8bit=load_in_8bit,
+ torch_dtype=torch.float16,
+ trust_remote_code=True
+ )
+
+ self.model.resize_token_embeddings(len(self.tokenizer))
+
+ self.model = self.model.eval()
+
+ self.dialog = []
+ self.MAX_CODE_OUTPUT_LENGTH = 1000
+
+
+ def dialog_to_prompt(self, dialog: List[Dict]) -> str:
+ full_str = self.tokenizer.apply_chat_template(dialog, tokenize=False)
+
+ return full_str
+
+ def extract_code_blocks(self, prompt: str) -> Tuple[bool, str]:
+ pattern = re.escape("```python") + r"(.*?)" + re.escape("```")
+ matches = re.findall(pattern, prompt, re.DOTALL)
+
+ if matches:
+ # Return the last matched code block
+ return True, matches[-1].strip()
+ else:
+ return False, ""
+
+ def clean_code_output(self, output: str) -> str:
+ if self.MAX_CODE_OUTPUT_LENGTH < len(output):
+ return (
+ output[: self.MAX_CODE_OUTPUT_LENGTH // 5]
+ + "\n...(truncated due to length)...\n"
+ + output[-self.MAX_CODE_OUTPUT_LENGTH // 5 :]
+ )
+
+ return output
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/demo/requirements.txt b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/demo/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..194c4597ba2993addb583b6c360b70f7ab70e6a0
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/demo/requirements.txt
@@ -0,0 +1,32 @@
+accelerate==0.21.0
+bitsandbytes==0.41.1
+colorama==0.4.6
+coloredlogs==15.0.1
+colorlog==6.7.0
+datasets==2.12.0
+deepspeed==0.10.1
+diffusers==0.20.0
+einops==0.6.1
+gradio==3.48.0
+ipykernel==6.25.1
+ipython==8.12.2
+jupyter_client==8.3.0
+jupyter_core==5.3.0
+Markdown==3.4.3
+nbclient==0.8.0
+nbconvert==7.7.1
+nbformat==5.8.0
+omegaconf==2.3.0
+openai==0.27.7
+rich==13.7.0
+scikit-learn==1.4.0
+scipy==1.12.0
+seaborn==0.13.2
+sentencepiece==0.1.99
+termcolor==2.3.0
+tqdm==4.66.1
+transformers==4.37.1
+triton==2.0.0
+yfinance==0.2.28
+retrying==1.3.4
+pydantic<2.0.0
\ No newline at end of file
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/demo/utils/cleaner.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/demo/utils/cleaner.py
new file mode 100644
index 0000000000000000000000000000000000000000..f58d57110d8140a2417c986606677856b91830a2
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/demo/utils/cleaner.py
@@ -0,0 +1,31 @@
+import re
+import os
+
+PYTHON_PREFIX = os.environ.get("CONDA_PREFIX", "/usr/local")
+
+SITE_PKG_ERROR_PREFIX = f'File {PYTHON_PREFIX}/lib/python3.10/'
+
+def get_error_header(traceback_str):
+ lines = traceback_str.split('\n')
+ for line in lines:
+ if 'Error:' in line:
+ return line
+ return '' # Return None if no error message is found
+
+def clean_error_msg(error_str:str =''):
+ filtered_error_msg = error_str.__str__().split('An error occurred while executing the following cell')[-1].split("\n------------------\n")[-1]
+ raw_error_msg = "".join(filtered_error_msg)
+
+ # Remove escape sequences for colored text
+ ansi_escape = re.compile(r'\x1b\[[0-?]*[ -/]*[@-~]')
+ error_msg = ansi_escape.sub('', raw_error_msg)
+
+ error_str_out = ''
+ error_msg_only_cell = error_msg.split(SITE_PKG_ERROR_PREFIX)
+
+ error_str_out += f'{error_msg_only_cell[0]}\n'
+ error_header = get_error_header(error_msg_only_cell[-1])
+ if error_header not in error_str_out:
+ error_str_out += get_error_header(error_msg_only_cell[-1])
+
+ return error_str_out
\ No newline at end of file
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/demo/utils/const.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/demo/utils/const.py
new file mode 100644
index 0000000000000000000000000000000000000000..e01ddf5e0b49e0cb73a56d6b4b90f87ac04bb500
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/demo/utils/const.py
@@ -0,0 +1,88 @@
+TOOLS_CODE = """
+import numpy as np
+import pandas as pd
+import matplotlib.pyplot as plt
+import seaborn as sns
+from scipy import stats
+import os,sys
+import re
+from datetime import datetime
+from sympy import symbols, Eq, solve
+import torch
+import requests
+from bs4 import BeautifulSoup
+import json
+import math
+import yfinance
+import time
+"""
+
+write_denial_function = 'lambda *args, **kwargs: (_ for _ in ()).throw(PermissionError("Writing to disk operation is not permitted due to safety reasons. Please do not try again!"))'
+read_denial_function = 'lambda *args, **kwargs: (_ for _ in ()).throw(PermissionError("Reading from disk operation is not permitted due to safety reasons. Please do not try again!"))'
+class_denial = """Class Denial:
+ def __getattr__(self, name):
+ def method(*args, **kwargs):
+ return "Using this class is not permitted due to safety reasons. Please do not try again!"
+ return method
+"""
+
+GUARD_CODE = f"""
+import os
+
+os.kill = {write_denial_function}
+os.system = {write_denial_function}
+os.putenv = {write_denial_function}
+os.remove = {write_denial_function}
+os.removedirs = {write_denial_function}
+os.rmdir = {write_denial_function}
+os.fchdir = {write_denial_function}
+os.setuid = {write_denial_function}
+os.fork = {write_denial_function}
+os.forkpty = {write_denial_function}
+os.killpg = {write_denial_function}
+os.rename = {write_denial_function}
+os.renames = {write_denial_function}
+os.truncate = {write_denial_function}
+os.replace = {write_denial_function}
+os.unlink = {write_denial_function}
+os.fchmod = {write_denial_function}
+os.fchown = {write_denial_function}
+os.chmod = {write_denial_function}
+os.chown = {write_denial_function}
+os.chroot = {write_denial_function}
+os.fchdir = {write_denial_function}
+os.lchflags = {write_denial_function}
+os.lchmod = {write_denial_function}
+os.lchown = {write_denial_function}
+os.getcwd = {write_denial_function}
+os.chdir = {write_denial_function}
+os.popen = {write_denial_function}
+
+import shutil
+
+shutil.rmtree = {write_denial_function}
+shutil.move = {write_denial_function}
+shutil.chown = {write_denial_function}
+
+import subprocess
+
+subprocess.Popen = {write_denial_function} # type: ignore
+
+import sys
+
+sys.modules["ipdb"] = {write_denial_function}
+sys.modules["joblib"] = {write_denial_function}
+sys.modules["resource"] = {write_denial_function}
+sys.modules["psutil"] = {write_denial_function}
+sys.modules["tkinter"] = {write_denial_function}
+"""
+
+CODE_INTERPRETER_SYSTEM_PROMPT = """You are an AI code interpreter.
+Your goal is to help users do a variety of jobs by executing Python code.
+
+You should:
+1. Comprehend the user's requirements carefully & to the letter.
+2. Give a brief description for what you plan to do & call the provided function to run code.
+3. Provide results analysis based on the execution output.
+4. If error occurred, try to fix it.
+5. Response in the same language as the user."""
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/README.md b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..d73e3291d8137f05afac79088e281f9a4e9e25f7
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/README.md
@@ -0,0 +1,51 @@
+# Evaluation
+
+This repository contains code for evaluating the performance of LLM models through both single-turn and multi-turn scenarios.
+
+To set up the environment, you can install the required dependencies by running:
+```bash
+pip install -r evaluation/requirements.txt
+```
+
+## Single-turn Evaluation
+
+For single-turn evaluation, the processes of inference, post-processing, and result aggregation are separated as follows:
+
+1. Execute `bash evaluation/evaluate/scripts/01_gen_single.sh` to generate model results.
+2. Perform post-processing on the model output by executing `bash evaluation/evaluate/scripts/02_sanitize_single.sh`.
+3. Finally, compute evaluation metrics by executing `bash evaluation/evaluate/scripts/03_eval_single.sh`.
+
+## Multi-turn Evaluation
+
+### Multi-turn Evaluation with Execution Feedback
+
+Evaluate the performance of the models with execution feedback using the provided scripts:
+
+- For OpenCodeInterpreter:
+ ```bash
+ bash evaluation/evaluate/scripts/04_execution_feedback_multiround_OpenCodeInterpreter.sh
+ ```
+
+- For OpenAI's GPT Models:
+ Before proceeding with evaluation, ensure to implement the `get_predict` function in `chat_with_gpt.py` to enable interaction with the GPT Models. Then, execute the following script:
+ ```bash
+ bash evaluation/evaluate/scripts/05_execution_feedback_multiround_gpt.sh
+ ```
+
+### Multi-turn Evaluation with GPT-4 Simulated Human Feedback
+
+Execute either of the following scripts to evaluate the models with simulated human feedback:
+
+- For OpenCodeInterpreter:
+ ```bash
+ bash evaluation/evaluate/scripts/06_human_feedback_multiround_OpenCodeInterpreter.sh
+ ```
+
+- For Oracle OpenCodeInterpreter:
+ ```bash
+ bash evaluation/evaluate/scripts/07_human_feedback_multiround_Oracle_OpenCodeInterpreter.sh
+ ```
+
+These scripts facilitate the multi-turn evaluation with simulated human feedback.
+
+This evaluation code is based on [EvalPlus](https://github.com/evalplus/evalplus) and has been modified for specific purposes. We extend our gratitude to the contributors of EvalPlus for their foundational work.
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/.dockerignore b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/.dockerignore
new file mode 100644
index 0000000000000000000000000000000000000000..b3e318ede00a336c0d334a7f6fa8d3e771e2ff5a
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/.dockerignore
@@ -0,0 +1,174 @@
+# Byte-compiled / optimized / DLL files
+__pycache__/
+*.py[cod]
+*$py.class
+
+# C extensions
+*.so
+
+# Distribution / packaging
+.Python
+build/
+develop-eggs/
+dist/
+downloads/
+eggs/
+.eggs/
+lib/
+lib64/
+parts/
+sdist/
+var/
+wheels/
+share/python-wheels/
+*.egg-info/
+.installed.cfg
+*.egg
+MANIFEST
+
+# PyInstaller
+# Usually these files are written by a python script from a template
+# before PyInstaller builds the exe, so as to inject date/other infos into it.
+*.manifest
+*.spec
+
+# Installer logs
+pip-log.txt
+pip-delete-this-directory.txt
+
+# Unit test / coverage reports
+htmlcov/
+.tox/
+.nox/
+.coverage
+.coverage.*
+.cache
+nosetests.xml
+coverage.xml
+*.cover
+*.py,cover
+.hypothesis/
+.pytest_cache/
+cover/
+
+# Translations
+*.mo
+*.pot
+
+# Django stuff:
+*.log
+local_settings.py
+db.sqlite3
+db.sqlite3-journal
+
+# Flask stuff:
+instance/
+.webassets-cache
+
+# Scrapy stuff:
+.scrapy
+
+# Sphinx documentation
+docs/_build/
+
+# PyBuilder
+.pybuilder/
+target/
+
+# Jupyter Notebook
+.ipynb_checkpoints
+
+# IPython
+profile_default/
+ipython_config.py
+
+# pyenv
+# For a library or package, you might want to ignore these files since the code is
+# intended to run in multiple environments; otherwise, check them in:
+# .python-version
+
+# pipenv
+# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
+# However, in case of collaboration, if having platform-specific dependencies or dependencies
+# having no cross-platform support, pipenv may install dependencies that don't work, or not
+# install all needed dependencies.
+#Pipfile.lock
+
+# poetry
+# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
+# This is especially recommended for binary packages to ensure reproducibility, and is more
+# commonly ignored for libraries.
+# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
+#poetry.lock
+
+# pdm
+# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
+#pdm.lock
+# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
+# in version control.
+# https://pdm.fming.dev/#use-with-ide
+.pdm.toml
+
+# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
+__pypackages__/
+
+# Celery stuff
+celerybeat-schedule
+celerybeat.pid
+
+# SageMath parsed files
+*.sage.py
+
+# Environments
+.env
+.venv
+env/
+venv/
+ENV/
+env.bak/
+venv.bak/
+
+# Spyder project settings
+.spyderproject
+.spyproject
+
+# Rope project settings
+.ropeproject
+
+# mkdocs documentation
+/site
+
+# mypy
+.mypy_cache/
+.dmypy.json
+dmypy.json
+
+# Pyre type checker
+.pyre/
+
+# pytype static type analyzer
+.pytype/
+
+# Cython debug symbols
+cython_debug/
+
+# PyCharm
+# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
+# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
+# and can be added to the global gitignore or merged into this file. For a more nuclear
+# option (not recommended) you can uncomment the following to ignore the entire idea folder.
+# nuclear option because steven uses PyCharm.
+.idea/
+
+# VSCode
+.vscode/
+EvalPlus/
+backup/
+passrate.p*
+min_cov_dir/
+HumanEvalPlus*.jsonl
+HumanEvalPlus*.gz
+MbppPlus*.jsonl
+MbppPlus*.gz
+evalplus/_version.py
+*mbpp.json
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/.github/ISSUE_TEMPLATE/buggy_contract.yml b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/.github/ISSUE_TEMPLATE/buggy_contract.yml
new file mode 100644
index 0000000000000000000000000000000000000000..78c03cc48133fbc588353a0b6eda20a45f75f31e
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/.github/ISSUE_TEMPLATE/buggy_contract.yml
@@ -0,0 +1,48 @@
+name: "🐛 Report Bad Contract"
+description: Report to us that certain program contract should be repaired.
+title: "🐛 [TestRemoval] - "
+labels: ["program contract"]
+body:
+ - type: input
+ id: version
+ attributes:
+ label: "EvalPlus version"
+ description: What is the version of EvalPlus? You can find it by running `pip show evalplus`.
+ placeholder: For example, 0.1.0
+ validations:
+ required: true
+ - type: input
+ id: cache
+ attributes:
+ label: "Output of running `ls ~/.cache/evalplus`"
+ validations:
+ required: true
+ - type: input
+ id: task_id
+ attributes:
+ label: "Task ID of the programming task"
+ placeholder: HumanEval/[??]
+ validations:
+ required: true
+ - type: textarea
+ id: original
+ attributes:
+ label: "The original wrong contract"
+ description: You can run `python -c "from evalplus.data import get_human_eval_plus; print(get_human_eval_plus()['HumanEval/❓']['contract'])"`
+ render: python
+ validations:
+ required: true
+ - type: textarea
+ id: new
+ attributes:
+ label: "Your proposed new contract"
+ render: python
+ validations:
+ required: true
+ - type: textarea
+ id: other
+ attributes:
+ label: "Other context"
+ description: (Optional) Anything else the maintainer should notice?
+ validations:
+ required: false
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/.github/ISSUE_TEMPLATE/buggy_test.yml b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/.github/ISSUE_TEMPLATE/buggy_test.yml
new file mode 100644
index 0000000000000000000000000000000000000000..434a164712027282251b5416b5f87bd0087bdd7c
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/.github/ISSUE_TEMPLATE/buggy_test.yml
@@ -0,0 +1,49 @@
+name: "🐛 Report Bad Test Inputs"
+description: Report to us that certain test inputs should be removed.
+title: "🐛 [TestRemoval] - "
+labels: ["bug"]
+body:
+ - type: input
+ id: version
+ attributes:
+ label: "EvalPlus version"
+ description: What is the version of EvalPlus? You can find it by running `pip show evalplus`.
+ placeholder: For example, 0.1.0
+ validations:
+ required: true
+ - type: input
+ id: cache
+ attributes:
+ label: "Output of running `ls ~/.cache/evalplus`"
+ validations:
+ required: true
+ - type: input
+ id: task_id
+ attributes:
+ label: "Task ID of the programming task"
+ placeholder: HumanEval/[??]
+ validations:
+ required: true
+ - type: textarea
+ id: test_input
+ attributes:
+ label: "Test input"
+ description: The text form of the test input that you think should be removed
+ render: python
+ validations:
+ required: true
+ - type: textarea
+ id: description
+ attributes:
+ label: "Description"
+ description: An explicit description of why you think this test should be removed
+ placeholder: Here is a correct solution but it is incorrectly falsified by the test because ...
+ validations:
+ required: true
+ - type: textarea
+ id: other
+ attributes:
+ label: "Other context"
+ description: (Optional) Anything else the maintainer should notice?
+ validations:
+ required: false
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/.github/ISSUE_TEMPLATE/config.yml b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/.github/ISSUE_TEMPLATE/config.yml
new file mode 100644
index 0000000000000000000000000000000000000000..0086358db1eb971c0cfa8739c27518bbc18a5ff4
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/.github/ISSUE_TEMPLATE/config.yml
@@ -0,0 +1 @@
+blank_issues_enabled: true
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/.github/ISSUE_TEMPLATE/model_eval_request.yml b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/.github/ISSUE_TEMPLATE/model_eval_request.yml
new file mode 100644
index 0000000000000000000000000000000000000000..15d458a125f6a66ea44810417f0503ff954a41dc
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/.github/ISSUE_TEMPLATE/model_eval_request.yml
@@ -0,0 +1,67 @@
+name: "🤗 Model Evaluation Request"
+description: Request EvalPlus maintainers to evaluate your model independently and update it on our leaderboard.
+title: "🤗 [REQUEST] - "
+labels: ["model eval"]
+body:
+ - type: textarea
+ id: about
+ attributes:
+ label: "Model introduction"
+ description: Provide a brief introduction to the model.
+ placeholder: The models is created by ... and is used for ...
+ validations:
+ required: true
+ - type: input
+ id: url
+ attributes:
+ label: "Model URL"
+ description: Indicate the URL (e.g., huggingface or other release pages) of the model
+ placeholder: https://huggingface.co/[???]/[???]
+ validations:
+ required: true
+ - type: dropdown
+ id: dtype
+ attributes:
+ label: "Data type"
+ description: What is the intended data type for running the model?
+ multiple: false
+ options:
+ - "float16"
+ - "bfloat16"
+ - "float32"
+ - "None of above: specify the details in the 'Other context' section"
+ validations:
+ required: true
+ - type: textarea
+ id: other
+ attributes:
+ label: "Additional instructions (Optional)"
+ description: Special steps indicating how to run the model with preferably scripts/codes.
+ placeholder: What data type precision should be used? What is the minimal hardware requirement? Can it be accelerated by tools such as vLLM?
+ validations:
+ required: false
+ - type: dropdown
+ id: author
+ attributes:
+ label: "Author"
+ description: "Are you (one of) the author(s) of the model?"
+ multiple: false
+ options:
+ - "Yes"
+ - "No"
+ validations:
+ required: true
+ - type: checkboxes
+ id: security
+ attributes:
+ label: "Security"
+ options:
+ - label: "I confirm that the model is safe to run which does not contain any malicious code or content."
+ required: true
+ - type: checkboxes
+ id: integrity
+ attributes:
+ label: "Integrity"
+ options:
+ - label: "I confirm that the model comes from unique and original work and does not contain any plagiarism."
+ required: true
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/.gitignore b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..f852147db9fc1cb9dad5c818df816c613423a5dc
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/.gitignore
@@ -0,0 +1,173 @@
+# Byte-compiled / optimized / DLL files
+__pycache__/
+*.py[cod]
+*$py.class
+
+# C extensions
+*.so
+
+# Distribution / packaging
+.Python
+build/
+develop-eggs/
+dist/
+downloads/
+eggs/
+.eggs/
+lib/
+lib64/
+parts/
+sdist/
+var/
+wheels/
+share/python-wheels/
+*.egg-info/
+.installed.cfg
+*.egg
+MANIFEST
+
+# PyInstaller
+# Usually these files are written by a python script from a template
+# before PyInstaller builds the exe, so as to inject date/other infos into it.
+*.manifest
+*.spec
+
+# Installer logs
+pip-log.txt
+pip-delete-this-directory.txt
+
+# Unit test / coverage reports
+htmlcov/
+.tox/
+.nox/
+.coverage
+.coverage.*
+.cache
+nosetests.xml
+coverage.xml
+*.cover
+*.py,cover
+.hypothesis/
+.pytest_cache/
+cover/
+
+# Translations
+*.mo
+*.pot
+
+# Django stuff:
+*.log
+local_settings.py
+db.sqlite3
+db.sqlite3-journal
+
+# Flask stuff:
+instance/
+.webassets-cache
+
+# Scrapy stuff:
+.scrapy
+
+# Sphinx documentation
+docs/_build/
+
+# PyBuilder
+.pybuilder/
+target/
+
+# Jupyter Notebook
+.ipynb_checkpoints
+
+# IPython
+profile_default/
+ipython_config.py
+
+# pyenv
+# For a library or package, you might want to ignore these files since the code is
+# intended to run in multiple environments; otherwise, check them in:
+# .python-version
+
+# pipenv
+# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
+# However, in case of collaboration, if having platform-specific dependencies or dependencies
+# having no cross-platform support, pipenv may install dependencies that don't work, or not
+# install all needed dependencies.
+#Pipfile.lock
+
+# poetry
+# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
+# This is especially recommended for binary packages to ensure reproducibility, and is more
+# commonly ignored for libraries.
+# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
+#poetry.lock
+
+# pdm
+# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
+#pdm.lock
+# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
+# in version control.
+# https://pdm.fming.dev/#use-with-ide
+.pdm.toml
+
+# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
+__pypackages__/
+
+# Celery stuff
+celerybeat-schedule
+celerybeat.pid
+
+# SageMath parsed files
+*.sage.py
+
+# Environments
+.env
+.venv
+env/
+venv/
+ENV/
+env.bak/
+venv.bak/
+
+# Spyder project settings
+.spyderproject
+.spyproject
+
+# Rope project settings
+.ropeproject
+
+# mkdocs documentation
+/site
+
+# mypy
+.mypy_cache/
+.dmypy.json
+dmypy.json
+
+# Pyre type checker
+.pyre/
+
+# pytype static type analyzer
+.pytype/
+
+# Cython debug symbols
+cython_debug/
+
+# PyCharm
+# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
+# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
+# and can be added to the global gitignore or merged into this file. For a more nuclear
+# option (not recommended) you can uncomment the following to ignore the entire idea folder.
+# nuclear option because steven uses PyCharm.
+.idea/
+
+# VSCode
+.vscode/
+EvalPlus/
+backup/
+passrate.p*
+min_cov_dir/
+HumanEvalPlus*.gz
+MbppPlus*.gz
+evalplus/_version.py
+*mbpp.json
+*.jsonl
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/.pre-commit-config.yaml b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/.pre-commit-config.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..c905eb07d7a82be01050be9f0092ec93823916eb
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/.pre-commit-config.yaml
@@ -0,0 +1,20 @@
+repos:
+- repo: https://github.com/pycqa/isort
+ rev: 5.12.0
+ hooks:
+ - id: isort
+ name: isort (python)
+ args: ["--profile", "black"]
+- repo: https://github.com/psf/black
+ rev: 22.6.0
+ hooks:
+ - id: black
+- repo: https://github.com/pre-commit/pre-commit-hooks
+ rev: v4.3.0
+ hooks:
+ - id: check-yaml
+ - id: end-of-file-fixer
+ - id: trailing-whitespace
+exclude: (?x)^(
+ groundtruth/.*
+ )$
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/CITATION.cff b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/CITATION.cff
new file mode 100644
index 0000000000000000000000000000000000000000..5823360fe58f1f900db54dafdfd9a0f270fac200
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/CITATION.cff
@@ -0,0 +1,25 @@
+cff-version: 1.2.0
+message: "If you use this work and love it, consider citing it as below \U0001F917"
+title: EvalPlus
+authors:
+ - family-names: EvalPlus Team
+url: https://github.com/evalplus/evalplus
+doi: https://doi.org/10.48550/arXiv.2305.01210
+date-released: 2023-05-01
+license: Apache-2.0
+preferred-citation:
+ type: article
+ title: "Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation"
+ authors:
+ - family-names: Liu
+ given-names: Jiawei
+ - family-names: Xia
+ given-names: Chunqiu Steven
+ - family-names: Wang
+ given-names: Yuyao
+ - family-names: Zhang
+ given-names: Lingming
+ year: 2023
+ journal: "arXiv preprint arXiv:2305.01210"
+ doi: https://doi.org/10.48550/arXiv.2305.01210
+ url: https://arxiv.org/abs/2305.01210
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/Dockerfile b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..143bebcc554ae016e496df2005a7864868c650a8
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/Dockerfile
@@ -0,0 +1,19 @@
+# base env: py38 ubuntu20.04
+FROM python:3.8-slim-buster
+
+# install git
+RUN apt-get update && apt-get install -y git
+
+# upgrade to latest pip
+RUN pip install --upgrade pip
+
+COPY . /evalplus
+
+RUN cd /evalplus && pip install .
+
+# Pre-install the dataset
+RUN python3 -c "from evalplus.data import get_human_eval_plus, get_mbpp_plus; get_human_eval_plus(); get_mbpp_plus()"
+
+WORKDIR /app
+
+ENTRYPOINT ["python3", "-m", "evalplus.evaluate"]
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/LICENSE b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..97b358ff02b6d6dd385db5157b070dc607ca6e45
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/LICENSE
@@ -0,0 +1,205 @@
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright [yyyy] [name of copyright owner]
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
+
+-------------------------------------------------------------------------------
+The files under "evalplus/eval/" additionally complies with the MIT License for
+being built on OpenAI's HumanEval work.
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/MANIFEST.in b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/MANIFEST.in
new file mode 100644
index 0000000000000000000000000000000000000000..1a2f76f763e816771756a21f2d4d4a999490e5ed
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/MANIFEST.in
@@ -0,0 +1 @@
+exclude evalplus/_experimental/**/*.py
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/README.md b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..c5d31642d1c74d462ca4ede7b5a676d0a64494b3
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/README.md
@@ -0,0 +1,318 @@
+# `EvalPlus(📖) => 📚`
+
+
+>
+> 📢 Who is the best LLM coder? Take a look at the EvalPlus leaderboard 🏆! 📢
+>
+>
+>
+> 🤗 Request for independent model evaluation is open!
+>
+>
+
+## About
+
+> [!Warning]
+>
+>
+> 🚨 Evaluating LLM-generated code over datasets with "3 test-cases" is **NOT** enough! 🚨
+>
+>
+
+EvalPlus is a rigorous evaluation framework for LLM4Code, with:
+
+* ✨ **HumanEval+**: 80x more tests than the original HumanEval!
+* ✨ **MBPP+**: 35x more tests than the original MBPP!
+* ✨ **Evaluation framework**: our packages/images/tools can easily and safely evaluate LLMs on above benchmarks.
+
+Why EvalPlus? What does using EvalPlus datasets bring to you?
+
+* ✨ **Reliable ranking**: See [our leaderboard](https://evalplus.github.io/leaderboard.html) for the latest LLM ranking before and after rigorous evaluation.
+* ✨ **Code robustness**: Look at the score differences! esp. before (e.g., HumanEval) and after (e.g., HumanEval+) using EvalPlus! The drop/gap indicates if the LLM can generate more robust code: less drop means more robustness and a larger drop means the code tends to be more fragile.
+* ✨**Pre-generated samples**: EvalPlus accelerates LLM4Code research by open-sourcing [LLM-generated samples](#-LLM-generated-code) for vairous models -- no need to re-run the expensive benchmarks!
+
+Want to know more details? Read our [**NeurIPS'23 paper**](https://openreview.net/forum?id=1qvx610Cu7) [](https://openreview.net/forum?id=1qvx610Cu7) as well as our [**Google Slides**](https://docs.google.com/presentation/d/1eTxzUQG9uHaU13BGhrqm4wH5NmMZiM3nI0ezKlODxKs)!
+
+## 🔥 Quick Start
+
+To get started, please first setup the environment:
+
+```bash
+pip install evalplus --upgrade
+```
+
+⏬ Install nightly version :: click to expand ::
+
+
+
+
+### Code generation
+
+Implement the `GEN_SOLUTION` function by calling the LLM to produce the complete solution (include the code) and save the samples to `samples.jsonl`:
+
+```python
+from evalplus.data import get_[human_eval|mbpp]_plus, write_jsonl
+
+samples = [
+ dict(task_id=task_id, solution=GEN_SOLUTION(problem["prompt"]))
+ for task_id, problem in get_[human_eval|mbpp]_plus().items()
+]
+write_jsonl("samples.jsonl", samples)
+```
+
+🤔 Structure of `problem`? :: click to expand ::
+
+
+* `task_id` is the identifier string for the task
+* `entry_point` is name of the function
+* `prompt` is the function signature with docstring
++ `canonical_solution` is the ground-truth implementation (re-implemented to fix bugs in HumanEval)
++ `base_input` is the test inputs in original HumanEval
++ `plus_input` is the test inputs brought by EvalPlus
+
+
+
+
+> [!Note]
+>
+> **Expected Schema of `samples.jsonl`**
+>
+> 1. `task_id`: Task ID, which are the keys of `get_[human_eval|mbpp]_plus()`
+> 2. `solution` (optional): Self-contained solution (usually including the prompt)
+> * Example: `{"task_id": "HumanEval/?", "solution": "def f():\n return 1"}`
+> 3. `completion` (optional): Function body without prompt
+> * Example: `{"task_id": "HumanEval/?", "completion": " return 1"}`
+>
+> Only one of `solution` and `completion` is required. If both are provided, `solution` will be used.
+> We also accept solutions in the form of directory, i.e., `--samples ${SAMPLE_DIR}` where `${SAMPLE_DIR}` is organized as: `${SAMPLE_DIR}/${TASK_ID}/{SAMPLE_ID}.py` (`${TASK_ID} = task_id.replace("/", "_")`).
+
+### Code evaluation
+
+You are strongly recommended to use a sandbox such as [docker](https://docs.docker.com/get-docker/):
+
+```bash
+docker run -v $(pwd):/app ganler/evalplus:latest --dataset [humaneval|mbpp] --samples samples.jsonl
+```
+
+...Or if you want to try it locally regardless of the risks ⚠️:
+
+```bash
+evalplus.evaluate --dataset [humaneval|mbpp] --samples samples.jsonl
+```
+
+> [!Warning]
+>
+> Do you use a very slow machine?
+>
+> LLM solutions are regarded as **failed** on timeout (and OOM etc.).
+> Specifically, we set the timeout $T=\max(T_{base}, T_{gt}\times k)$, where:
+>
+> - $T_{base}$ is the minimal timeout (configurable by `--min-time-limit`; default to 1s);
+> - $T_{gt}$ is the runtime of the ground-truth solutions (achieved via profiling);
+> - $k$ is a configurable factor `--gt-time-limit-factor` (default to 4);
+>
+> If your machine is too slow and you are getting high-variance results, try to use larger $k$ and $T_{base}$.
+>
+> Additionally, you are **NOT** encouraged to make your test-bed over stressed while running evaluation.
+> For example, using `--parallel 64` on a 4-core machine or doing something else during evaluation are bad ideas...
+
+🤔 Evaluate with local GitHub repo? :: click to expand ::
+
+
+
+⌨️ More command-line flags :: click to expand ::
+
+
+* `--parallel`: by default half of the cores
+* `--base-only` (store_ture): only run base HumanEval tests
+* `--i-just-wanna-run`: force a re-run
+
+
+
+
+The output should be like (below is GPT-4 greedy decoding example):
+
+```
+Computing expected output...
+Expected outputs computed in 15.18s
+Reading samples...
+164it [00:04, 37.79it/s]
+Evaluating samples...
+100%|██████████████████████████████████████████| 164/164 [00:03<00:00, 44.75it/s]
+Base
+{'pass@1': 0.8841463414634146}
+Base + Extra
+{'pass@1': 0.768}
+```
+
+- `Base` is the `pass@k` for the original HumanEval
+- `Base + Extra` is the `pass@k` for the our **HumanEval+** (with extra tests)
+- The "k" includes `[1, 10, 100]` where k values `<=` the sample size will be used
+- A cache file named like `samples_eval_results.jsonl` will be cached. Remove it to re-run the evaluation
+
+🤔 How long it would take? :: click to expand ::
+
+
+If you do greedy decoding where there is only one sample for each task, the evaluation should take just a few seconds.
+When running 200 samples x 164 tasks x ~700+ tests, it can take around 2-10 minute by using `--parallel 64` and `--test-details`.
+Here are some tips to speed up the evaluation:
+
+* Use `--parallel $(nproc)`
+* Do **NOT** use `--test-details` if you just want to quickly get pass@k as `--test-details` will run all tests (700+ on average for each task), while without `--test-details` the testing for a sample stops immediately when it fails the first test.
+* Use our pre-evaluated results (see [LLM-generated code](#-LLM-generated-code))
+* Use HumanEval+ Mini
+
+
+
+
+> [!Note]
+>
+> 🚀 **Try out `HumanEvalPlus-Mini`!** which selects a *minimal* set of additional tests with the highest quality, achieving almost the same effectiveness of the full version. Just add a **`--mini`** flag, it can run 23+% faster! (even faster if you evaluate all tests without fail-stop with `--test-details`).
+>
+> ```bash
+> docker run -v $(pwd):/app ganler/evalplus:latest --dataset humaneval --samples samples.jsonl --mini
+> # ...Or locally ⚠️
+> # evalplus.evaluate --dataset humaneval --samples samples.jsonl --mini
+> ```
+
+
+## 💻 LLM-generated code
+
+We also share pre-generated code samples from LLMs we have [evaluated](https://evalplus.github.io/leaderboard.html):
+
+* **HumanEval+**: See the attachment of our [v0.1.0 release](https://github.com/evalplus/evalplus/releases/tag/v0.1.0).
+* **MBPP+**: See the attachment of our [v0.2.0 release](https://github.com/evalplus/evalplus/releases/tag/v0.2.0).
+
+Each sample file is packaged in a zip file named like `${model_name}_temp_${temperature}.zip`.
+You can unzip them to a folder named like `${model_name}_temp_${temperature}` and run the evaluation from scratch with:
+
+```bash
+evalplus.evaluate --dataset humaneval --samples ${model_name}_temp_${temperature}
+```
+
+## 🔨 Useful tools
+
+To use these tools, please first install the repository from GitHub:
+
+```bash
+git clone https://github.com/evalplus/evalplus.git
+cd evalplus
+pip install -r requirements-tools.txt
+```
+
+### Syntax checker for LLM-generated code
+
+Check LLM-produced code and answer the following questions:
+
+1. Is the generation entirely done for all samples / all problems in the dataset?
+2. Are LLM-generated code compilable? (if no, something could be wrong and you'd better check)
+
+```shell
+# Set PYTHONPATH to run local Python files
+export PYTHONPATH=$PYTHONPATH:$(pwd)
+
+python tools/checker.py --samples samples.jsonl --dataset [humaneval|mbpp]
+# --samples can also be a directory organized as: ${SAMPLE_DIR}/${TASK_ID}/{SAMPLE_ID}.py
+```
+
+### Post code sanitizer
+
+LLM-generated code may contain some syntax errors.
+But some of them can be easily fixable by doing simple post-processing.
+This tool will make the LLM-generated code more clean/compilable by doing certain post-processing such as trimming with more magical EOFs and some garbage non-code tokens.
+
+```shell
+# Set PYTHONPATH to run local Python files
+export PYTHONPATH=$PYTHONPATH:$(pwd)
+
+# 💡 If you are storing codes in directories:
+python tools/sanitize.py --samples samples.jsonl --dataset [humaneval|mbpp]
+# Sanitized code will be produced to `samples-sanitized.jsonl`
+
+# 💡 If you are storing codes in directories:
+python tools/sanitize.py --samples /path/to/vicuna-[??]b_temp_[??] --dataset [humaneval|mbpp]
+# Sanitized code will be produced to `/path/to/vicuna-[??]b_temp_[??]-sanitized`
+```
+
+You should now further check the validity of sanitized code with `tools/checker.py`.
+Sometimes (e.g., Chat models) there might be some natural language lines that impact the compilation.
+You might use `--rm-prefix-lines` to cut those NL lines with a prefix (e.g., `--rm-prefix-lines "Here's"`).
+
+### Render `pass@k` results to `rich` and LaTeX tables
+
+```shell
+python tools/render.py --type /path/to/[model]-[??]b # NOTE: no `_temp_[??]`
+```
+
+
+
+### Perform test input generation from scratch (TBD)
+
+
+### Name convention
+
+- `evalplus` is the package name.
+- `${DATASET}_plus` is the name of dataset applied with `evalplus`.
+
+## 📜 Citation
+
+```bibtex
+@inproceedings{evalplus,
+ title = {Is Your Code Generated by Chat{GPT} Really Correct? Rigorous Evaluation of Large Language Models for Code Generation},
+ author = {Liu, Jiawei and Xia, Chunqiu Steven and Wang, Yuyao and Zhang, Lingming},
+ booktitle = {Thirty-seventh Conference on Neural Information Processing Systems},
+ year = {2023},
+ url = {https://openreview.net/forum?id=1qvx610Cu7},
+}
+```
+
+## 🙏 Acknowledgement
+
+- [HumanEval](https://github.com/openai/human-eval)
+- [MBPP](https://github.com/google-research/google-research/tree/master/mbpp)
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/codegen/generate.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/codegen/generate.py
new file mode 100644
index 0000000000000000000000000000000000000000..ce9743cb6eba8e2f31cd1d38fa8f0fba42f16abd
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/codegen/generate.py
@@ -0,0 +1,170 @@
+import argparse
+import os
+from os import PathLike
+
+from model import DecoderBase, make_model
+from rich.progress import (
+ BarColumn,
+ MofNCompleteColumn,
+ Progress,
+ TextColumn,
+ TimeElapsedColumn,
+)
+
+
+def construct_contract_prompt(prompt: str, contract_type: str, contract: str) -> str:
+ if contract_type == "none":
+ return prompt
+ elif contract_type == "docstring":
+ # embed within the docstring
+ sep = ""
+ if '"""' in prompt:
+ sep = '"""'
+ elif "'''" in prompt:
+ sep = "'''"
+ assert sep != ""
+ l = prompt.split(sep)
+ contract = "\n".join([x.split("#")[0] for x in contract.splitlines()])
+ l[1] = (
+ l[1] + contract + "\n" + " " * (len(contract) - len(contract.lstrip()) - 1)
+ )
+ return sep.join(l)
+ elif contract_type == "code":
+ # at the beginning of the function
+ contract = "\n".join([x.split("#")[0] for x in contract.splitlines()])
+ return prompt + contract
+
+
+def code_generate(args, workdir: PathLike, model: DecoderBase, id_range=None):
+ with Progress(
+ TextColumn(
+ f"{args.dataset} •" + "[progress.percentage]{task.percentage:>3.0f}%"
+ ),
+ BarColumn(),
+ MofNCompleteColumn(),
+ TextColumn("•"),
+ TimeElapsedColumn(),
+ ) as p:
+ if args.dataset == "humaneval":
+ from evalplus.data import get_human_eval_plus
+
+ dataset = get_human_eval_plus()
+ elif args.dataset == "mbpp":
+ from evalplus.data import get_mbpp_plus
+
+ dataset = get_mbpp_plus()
+
+ for task_id, task in p.track(dataset.items()):
+ if id_range is not None:
+ id_num = int(task_id.split("/")[1])
+ low, high = id_range
+ if id_num < low or id_num >= high:
+ p.console.print(f"Skipping {task_id} as it is not in {id_range}")
+ continue
+
+ p_name = task_id.replace("/", "_")
+ if args.contract_type != "none" and task["contract"] == "":
+ continue
+ os.makedirs(os.path.join(workdir, p_name), exist_ok=True)
+ log = f"Codegen: {p_name} @ {model}"
+ n_existing = 0
+ if args.resume:
+ # count existing .py files
+ n_existing = len(
+ [
+ f
+ for f in os.listdir(os.path.join(workdir, p_name))
+ if f.endswith(".py")
+ ]
+ )
+ if n_existing > 0:
+ log += f" (resuming from {n_existing})"
+
+ nsamples = args.n_samples - n_existing
+ p.console.print(log)
+
+ sidx = args.n_samples - nsamples
+ while sidx < args.n_samples:
+ outputs = model.codegen(
+ construct_contract_prompt(
+ task["prompt"], args.contract_type, task["contract"]
+ ),
+ do_sample=not args.greedy,
+ num_samples=args.n_samples - sidx,
+ )
+ assert outputs, "No outputs from model!"
+ for impl in outputs:
+ try:
+ with open(
+ os.path.join(workdir, p_name, f"{sidx}.py"),
+ "w",
+ encoding="utf-8",
+ ) as f:
+ if model.conversational:
+ f.write(impl)
+ else:
+ f.write(task["prompt"] + impl)
+ except UnicodeEncodeError:
+ continue
+ sidx += 1
+
+
+def main():
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--model", required=True, type=str)
+ parser.add_argument("--bs", default=1, type=int)
+ parser.add_argument("--temperature", default=0.0, type=float)
+ parser.add_argument(
+ "--dataset", required=True, type=str, choices=["humaneval", "mbpp"]
+ )
+ parser.add_argument("--root", type=str, required=True)
+ parser.add_argument("--n_samples", default=1, type=int)
+ parser.add_argument("--resume", action="store_true")
+ parser.add_argument(
+ "--contract-type",
+ default="none",
+ type=str,
+ choices=["none", "code", "docstring"],
+ )
+ parser.add_argument("--greedy", action="store_true")
+ # id_range is list
+ parser.add_argument("--id-range", default=None, nargs="+", type=int)
+ args = parser.parse_args()
+
+ if args.greedy and (args.temperature != 0 or args.bs != 1 or args.n_samples != 1):
+ args.temperature = 0
+ args.bs = 1
+ args.n_samples = 1
+ print("Greedy decoding ON (--greedy): setting bs=1, n_samples=1, temperature=0")
+
+ if args.id_range is not None:
+ assert len(args.id_range) == 2, "id_range must be a list of length 2"
+ assert args.id_range[0] < args.id_range[1], "id_range must be increasing"
+ args.id_range = tuple(args.id_range)
+
+ # Make project dir
+ os.makedirs(args.root, exist_ok=True)
+ # Make dataset dir
+ os.makedirs(os.path.join(args.root, args.dataset), exist_ok=True)
+ # Make dir for codes generated by each model
+ args.model = args.model.lower()
+ model = make_model(
+ name=args.model, batch_size=args.bs, temperature=args.temperature
+ )
+ workdir = os.path.join(
+ args.root,
+ args.dataset,
+ args.model
+ + f"_temp_{args.temperature}"
+ + ("" if args.contract_type == "none" else f"-contract-{args.contract_type}"),
+ )
+ os.makedirs(workdir, exist_ok=True)
+
+ with open(os.path.join(workdir, "args.txt"), "w") as f:
+ f.write(str(args))
+
+ code_generate(args, workdir=workdir, model=model, id_range=args.id_range)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/codegen/model.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/codegen/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..2c3c9017fa640020b502641ca60bd021a99d9200
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/codegen/model.py
@@ -0,0 +1,1072 @@
+import json
+import os
+from abc import ABC, abstractmethod
+from typing import List
+from warnings import warn
+
+# Communism
+os.environ["HF_HOME"] = os.environ.get("HF_HOME", "/JawTitan/huggingface/")
+
+import openai
+import torch
+from transformers import (
+ AutoModelForCausalLM,
+ AutoModelForSeq2SeqLM,
+ AutoTokenizer,
+ StoppingCriteria,
+ StoppingCriteriaList,
+)
+from vllm import LLM, SamplingParams
+
+from evalplus.gen.util.api_request import make_auto_request
+
+EOS = ["<|endoftext|>", "<|endofmask|>", ""]
+
+
+# Adopted from https://github.com/huggingface/transformers/pull/14897
+class EndOfFunctionCriteria(StoppingCriteria):
+ def __init__(self, start_length, eos, tokenizer, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+ self.start_length = start_length
+ self.eos = eos
+ self.tokenizer = tokenizer
+ self.end_length = {}
+
+ def __call__(self, input_ids, scores, **kwargs):
+ """Returns true if all generated sequences contain any of the end-of-function strings."""
+ decoded_generations = self.tokenizer.batch_decode(
+ input_ids[:, self.start_length :]
+ )
+ done = []
+ for index, decoded_generation in enumerate(decoded_generations):
+ finished = any(
+ [stop_string in decoded_generation for stop_string in self.eos]
+ )
+ if (
+ finished and index not in self.end_length
+ ): # ensures first time we see it
+ for stop_string in self.eos:
+ if stop_string in decoded_generation:
+ self.end_length[index] = len(
+ input_ids[
+ index, # get length of actual generation
+ self.start_length : -len(
+ self.tokenizer.encode(
+ stop_string,
+ add_special_tokens=False,
+ return_tensors="pt",
+ )[0]
+ ),
+ ]
+ )
+ done.append(finished)
+ return all(done)
+
+
+class DecoderBase(ABC):
+ def __init__(
+ self,
+ name: str,
+ batch_size: int = 1,
+ temperature: float = 0.8,
+ max_new_tokens: int = 512,
+ conversational: bool = False,
+ max_conversational_new_tokens: int = 1024,
+ ) -> None:
+ print("Initializing a decoder model: {} ...".format(name))
+ self.name = name
+ self.batch_size = batch_size
+ self.temperature = temperature
+ self.eos = EOS
+ self.skip_special_tokens = False
+ self.max_new_tokens = (
+ max_conversational_new_tokens if conversational else max_new_tokens
+ )
+ self.conversational = conversational
+
+ @abstractmethod
+ def codegen(
+ self, prompt: str, do_sample: bool = True, num_samples: int = 200
+ ) -> List[str]:
+ pass
+
+ def __repr__(self) -> str:
+ return self.name
+
+ def __str__(self) -> str:
+ return self.name
+
+
+class VLlmDecoder(DecoderBase):
+ def __init__(self, name: str, **kwargs) -> None:
+ super().__init__(name, **kwargs)
+
+ kwargs = {"tensor_parallel_size": int(os.getenv("VLLM_N_GPUS", "1"))}
+ if "CodeLlama" in name:
+ kwargs["dtype"] = "bfloat16"
+ elif "code-millenials" in name:
+ kwargs["dtype"] = "float16"
+ elif "uukuguy/speechless-code-mistral-7b-v1.0" == name:
+ kwargs["dtype"] = "float16"
+ elif "uukuguy/speechless-codellama-34b-v2.0" == name:
+ kwargs["dtype"] = "float16"
+ elif "CodeBooga" in name:
+ kwargs["dtype"] = "float16"
+ elif "WizardCoder" in name:
+ kwargs["dtype"] = "float16"
+ elif "deepseek" in name:
+ kwargs["dtype"] = "bfloat16"
+ elif "mixtral" in name.lower():
+ kwargs["dtype"] = "bfloat16"
+ elif "solar" in name:
+ kwargs["dtype"] = "float16"
+ elif "mistral" in name.lower():
+ kwargs["dtype"] = "bfloat16"
+ elif "phi" in name.lower():
+ kwargs["dtype"] = "float16"
+ kwargs["trust_remote_code"] = True
+ elif "openchat" in name.lower():
+ kwargs["dtype"] = "bfloat16"
+
+ self.llm = LLM(model=name, max_model_len=2048, **kwargs)
+
+ def codegen(
+ self, prompt: str, do_sample: bool = True, num_samples: int = 200
+ ) -> List[str]:
+ if do_sample:
+ assert self.temperature > 0, "Temperature must be greater than 0!"
+ batch_size = min(self.batch_size, num_samples)
+
+ vllm_outputs = self.llm.generate(
+ [prompt] * batch_size,
+ SamplingParams(
+ temperature=self.temperature,
+ max_tokens=self.max_new_tokens,
+ top_p=0.95 if do_sample else 1.0,
+ stop=self.eos,
+ ),
+ use_tqdm=False,
+ )
+
+ gen_strs = [x.outputs[0].text.replace("\t", " ") for x in vllm_outputs]
+ return gen_strs
+
+
+# chatml format
+class ChatML(VLlmDecoder):
+ def __init__(self, name: str, **kwargs) -> None:
+ kwargs["conversational"] = True
+ super().__init__(name, **kwargs)
+ self.eos += ["\n```"]
+
+ def codegen(
+ self, prompt: str, do_sample: bool = True, num_samples: int = 200
+ ) -> List[str]:
+ if do_sample:
+ assert self.temperature > 0, "Temperature must be greater than 0!"
+
+ input = f"""<|im_start|>system
+You are an intelligent programming assistant to produce Python algorithmic solutions<|im_end|>
+<|im_start|>user
+Can you complete the following Python function?
+```python
+{prompt}
+```
+<|im_end|>
+<|im_start|>assistant
+```python
+"""
+ return VLlmDecoder.codegen(self, input, do_sample, num_samples)
+
+
+class CodeLlamaInstruct(VLlmDecoder):
+ def __init__(self, name: str, **kwargs) -> None:
+ kwargs["conversational"] = True
+ super().__init__(name, **kwargs)
+ self.eos += ["\n```"]
+
+ def codegen(
+ self, prompt: str, do_sample: bool = True, num_samples: int = 200
+ ) -> List[str]:
+ if do_sample:
+ assert self.temperature > 0, "Temperature must be greater than 0!"
+
+ input = f"""[INST] Write code to solve the following coding problem that obeys the constraints and passes the example test cases. Please wrap your code answer using ```:
+```python
+{prompt}
+```
+[/INST]
+```python
+"""
+
+ return VLlmDecoder.codegen(self, input, do_sample, num_samples)
+
+
+# zyte format
+class Zyte(VLlmDecoder):
+ def __init__(self, name: str, **kwargs) -> None:
+ kwargs["conversational"] = True
+ super().__init__(name, **kwargs)
+ self.eos += ["\n```"]
+
+ def codegen(
+ self, prompt: str, do_sample: bool = True, num_samples: int = 200
+ ) -> List[str]:
+ if do_sample:
+ assert self.temperature > 0, "Temperature must be greater than 0!"
+
+ input = f"""<|system|>You are an intelligent programming assistant to produce Python algorithmic solutions
+<|user|>Can you complete the following Python function?
+```python
+{prompt}
+```
+
+<|assistant|>
+```python
+"""
+ return VLlmDecoder.codegen(self, input, do_sample, num_samples)
+
+
+class OpenChat(VLlmDecoder):
+ def __init__(self, name: str, **kwargs) -> None:
+ kwargs["conversational"] = True
+ super().__init__(name, **kwargs)
+ self.eos += ["\n```"]
+
+ def codegen(
+ self, prompt: str, do_sample: bool = True, num_samples: int = 200
+ ) -> List[str]:
+ if do_sample:
+ assert self.temperature > 0, "Temperature must be greater than 0!"
+
+ input = f"""GPT4 Correct User: Can you complete the following Python function?
+```python
+{prompt}
+```
+<|end_of_turn|>GPT4 Correct Assistant:
+```python
+"""
+ return VLlmDecoder.codegen(self, input, do_sample, num_samples)
+
+
+class Solar(VLlmDecoder):
+ def __init__(self, name: str, **kwargs) -> None:
+ super().__init__(name, **kwargs)
+ self.eos += ["\n```"]
+
+ def codegen(
+ self, prompt: str, do_sample: bool = True, num_samples: int = 200
+ ) -> List[str]:
+ if do_sample:
+ assert self.temperature > 0, "Temperature must be greater than 0!"
+
+ input = f""" ### User:
+Can you solve and complete the Python function below?
+```python
+{prompt}
+```
+
+### Assistant:
+Sure!
+```python
+"""
+ return VLlmDecoder.codegen(self, input, do_sample, num_samples)
+
+
+class Alpaca(VLlmDecoder):
+ def __init__(self, name: str, **kwargs) -> None:
+ kwargs["conversational"] = True
+ super().__init__(name, **kwargs)
+ self.eos += ["\n```"]
+
+ def codegen(
+ self, prompt: str, do_sample: bool = True, num_samples: int = 200
+ ) -> List[str]:
+ prompt = f"""Below is an instruction that describes a task. Write a response that appropriately completes request.
+
+### Instruction:
+Create a Python script for this problem:
+{prompt}
+
+### Response:
+```python
+"""
+
+ return VLlmDecoder.codegen(self, prompt, do_sample, num_samples)
+
+
+class HFTorchDecoder(DecoderBase):
+ def __init__(self, name: str, **kwargs):
+ super().__init__(name=name, **kwargs)
+ self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
+ kwargs = {
+ "trust_remote_code": name
+ in {
+ "bigcode/santacoder",
+ "Salesforce/codegen2-1B",
+ "Salesforce/codegen2-3_7B",
+ "Salesforce/codegen2-7B",
+ "Salesforce/codegen2-16B",
+ "deepseek-ai/deepseek-coder-6.7b-base",
+ "deepseek-ai/deepseek-coder-33b-base",
+ "stabilityai/stable-code-3b",
+ }
+ }
+
+ if "codegen-" in name: # use fp16 for codegen models
+ kwargs["torch_dtype"] = torch.float16
+ if "codegen2-" in name: # avoid warning of trust remote code
+ kwargs["revision"] = "main"
+ if "16b" in name.lower():
+ kwargs["device_map"] = "auto"
+ if "starcoder" in name:
+ kwargs["torch_dtype"] = torch.bfloat16
+ if "CodeLlama" in name:
+ if "34b" in name.lower():
+ kwargs["device_map"] = "auto"
+ kwargs["torch_dtype"] = torch.bfloat16
+ self.skip_special_tokens = True
+ if "CodeBooga" in name:
+ kwargs["torch_dtype"] = torch.float16
+ kwargs["device_map"] = "auto"
+ self.skip_special_tokens = True
+ if "Mistral-7B-codealpaca-lora" == name:
+ kwargs["torch_dtype"] = torch.float16
+ self.skip_special_tokens = True
+ elif "Mistral" in name or "zephyr-7b-beta" in name:
+ kwargs["torch_dtype"] = torch.bfloat16
+ if "deepseek" in name:
+ kwargs["torch_dtype"] = torch.bfloat16
+ self.skip_special_tokens = True
+ if "/phi" in name:
+ kwargs["torch_dtype"] = torch.float16
+ kwargs["trust_remote_code"] = True
+ self.skip_special_tokens = True
+
+ print(f"{kwargs = }")
+
+ self.tokenizer = AutoTokenizer.from_pretrained(name)
+ self.model = AutoModelForCausalLM.from_pretrained(name, **kwargs)
+ if name in {"StabilityAI/stablelm-base-alpha-7b"}:
+ print("Switching to float16 ...")
+ self.model = self.model.half()
+ self.skip_special_tokens = True
+ self.model = self.model.to(self.device)
+
+ @torch.inference_mode()
+ def codegen(
+ self, prompt: str, do_sample: bool = True, num_samples: int = 200
+ ) -> List[str]:
+ if self.temperature == 0:
+ assert not do_sample
+ assert num_samples == 1
+
+ input_tokens = self.tokenizer.encode(prompt, return_tensors="pt").to(
+ self.device
+ )
+ scores = StoppingCriteriaList(
+ [
+ EndOfFunctionCriteria(
+ start_length=len(input_tokens[0]),
+ eos=self.eos,
+ tokenizer=self.tokenizer,
+ )
+ ]
+ )
+ kwargs = {}
+ if do_sample:
+ kwargs["top_p"] = 0.95
+ kwargs["temperature"] = self.temperature
+
+ raw_outputs = self.model.generate(
+ input_tokens,
+ max_new_tokens=self.max_new_tokens,
+ stopping_criteria=scores,
+ do_sample=do_sample,
+ output_scores=True,
+ return_dict_in_generate=True,
+ num_return_sequences=min(self.batch_size, num_samples),
+ pad_token_id=self.tokenizer.eos_token_id,
+ **kwargs,
+ ) # remove warning
+ gen_seqs = raw_outputs.sequences[:, len(input_tokens[0]) :]
+ gen_strs = self.tokenizer.batch_decode(
+ gen_seqs, skip_special_tokens=self.skip_special_tokens
+ )
+ outputs = []
+ # removes eos tokens.
+ for output in gen_strs:
+ min_index = 10000
+ for eos in self.eos:
+ if eos in output:
+ # could be multiple eos in outputs, better pick minimum one
+ min_index = min(min_index, output.index(eos))
+ outputs.append(output[:min_index])
+ return outputs
+
+
+class DeepSeekInstruct(VLlmDecoder):
+ def __init__(self, name: str, **kwargs) -> None:
+ kwargs["conversational"] = True
+ super().__init__(name, **kwargs)
+ self.eos += ["\n```"]
+
+ def codegen(
+ self, prompt: str, do_sample: bool = True, num_samples: int = 200
+ ) -> List[str]:
+ prompt = f"""You are an AI programming assistant, utilizing the DeepSeek Coder model, developed by DeepSeek Company, and you only answer questions related to computer science. For politically sensitive questions, security and privacy issues, and other non-computer science questions, you will refuse to answer.
+### Instruction:
+Please complete the following Python function in a markdown style code block:
+```python
+{prompt}
+```
+### Response:
+```python
+"""
+
+ return VLlmDecoder.codegen(self, prompt, do_sample, num_samples)
+
+
+class OpenAIChatDecoder(DecoderBase):
+ def __init__(self, name: str, **kwargs) -> None:
+ super().__init__(name, **kwargs)
+ self.client = openai.OpenAI()
+
+ def codegen(
+ self, prompt: str, do_sample: bool = True, num_samples: int = 200
+ ) -> List[str]:
+ if do_sample:
+ assert self.temperature > 0, "Temperature must be positive for sampling"
+
+ batch_size = min(self.batch_size, num_samples)
+ assert batch_size <= 20, "Use larger batch size could blow up the memory!"
+
+ # construct prompt
+ fmt = "json_object" if self.name == "gpt-4-1106-preview" else "text"
+ if fmt == "json_object":
+ message = r'Please complete the following code snippet by generating JSON like {"code": ""}'
+ else:
+ message = r"Please generate code to complete the following problem:"
+
+ message += f"\n```python\n{prompt.strip()}\n```"
+
+ ret = make_auto_request(
+ self.client,
+ message=message,
+ model=self.name,
+ max_tokens=self.max_new_tokens,
+ temperature=self.temperature,
+ n=batch_size,
+ response_format={"type": fmt},
+ )
+
+ outputs = []
+ for item in ret.choices:
+ content = item.message.content
+ # if json serializable
+ if fmt == "json_object":
+ try:
+ json_data = json.loads(content)
+ if json_data.get("code", None) is not None:
+ outputs.append(prompt + "\n" + json_data["code"])
+ continue
+
+ print(f"'code' field not found in: {json_data}")
+ except Exception as e:
+ print(e)
+ outputs.append(content)
+
+ return outputs
+
+
+class IncoderDecoder(HFTorchDecoder):
+ def __init__(self, name: str, **kwargs) -> None:
+ super().__init__(name, **kwargs)
+ self.infill_ph = "<|mask:0|>"
+ self.extra_end = "<|mask:1|><|mask:0|>"
+ self.extra_eos = [
+ "<|endofmask|>",
+ "<|/ file",
+ "",
+ "",
+ "",
+ "<|",
+ "",
+ ]
+ self.eos = self.eos + self.extra_eos
+
+ def codegen(
+ self, prompt: str, do_sample: bool = True, num_samples: int = 200
+ ) -> List[str]:
+ input = prompt + self.infill_ph + self.extra_end
+ input_tokens = self.tokenizer.encode(input, return_tensors="pt").to(self.device)
+ scores = StoppingCriteriaList(
+ [
+ EndOfFunctionCriteria(
+ start_length=len(input_tokens[0]),
+ eos=self.eos,
+ tokenizer=self.tokenizer,
+ )
+ ]
+ )
+ raw_outputs = self.model.generate(
+ input_tokens,
+ max_new_tokens=self.max_new_tokens,
+ stopping_criteria=scores,
+ do_sample=do_sample,
+ top_p=0.95,
+ top_k=None,
+ temperature=self.temperature,
+ num_return_sequences=min(self.batch_size, num_samples),
+ output_scores=True,
+ return_dict_in_generate=True,
+ )
+ gen_seqs = raw_outputs.sequences[:, len(input_tokens[0]) :]
+ gen_strs = self.tokenizer.batch_decode(
+ gen_seqs, skip_special_tokens=self.skip_special_tokens
+ )
+ outputs = []
+ # removes eos tokens.
+ for output in gen_strs:
+ min_index = 10000
+ for eos in self.eos:
+ if eos in output:
+ min_index = min(min_index, output.index(eos))
+ outputs.append(output[:min_index])
+ return outputs
+
+
+class Codegen2Decoder(HFTorchDecoder):
+ def __init__(self, name: str, **kwargs) -> None:
+ super().__init__(name, **kwargs)
+ self.infill_ph = ""
+ # taken from: https://huggingface.co/Salesforce/codegen2-16B
+ self.extra_end = "<|endoftext|>"
+ self.extra_eos = [""]
+ self.eos = self.eos + self.extra_eos
+
+ @torch.inference_mode()
+ def codegen(
+ self, prompt: str, do_sample: bool = True, num_samples: int = 200
+ ) -> List[str]:
+ if self.temperature == 0:
+ assert not do_sample
+ assert num_samples == 1
+
+ input = prompt + self.infill_ph + self.extra_end
+ input_tokens = self.tokenizer.encode(input, return_tensors="pt").to(self.device)
+ scores = StoppingCriteriaList(
+ [
+ EndOfFunctionCriteria(
+ start_length=len(input_tokens[0]),
+ eos=self.eos,
+ tokenizer=self.tokenizer,
+ )
+ ]
+ )
+ raw_outputs = self.model.generate(
+ input_tokens,
+ max_new_tokens=self.max_new_tokens,
+ stopping_criteria=scores,
+ do_sample=do_sample,
+ top_p=0.95,
+ top_k=None,
+ temperature=self.temperature,
+ output_scores=True,
+ return_dict_in_generate=True,
+ num_return_sequences=min(self.batch_size, num_samples),
+ pad_token_id=self.tokenizer.eos_token_id,
+ )
+ gen_seqs = raw_outputs.sequences[:, len(input_tokens[0]) :]
+ gen_strs = self.tokenizer.batch_decode(
+ gen_seqs, skip_special_tokens=self.skip_special_tokens
+ )
+ outputs = []
+ # removes eos tokens.
+ for output in gen_strs:
+ min_index = 10000
+ for eos in self.eos:
+ if eos in output:
+ min_index = min(min_index, output.index(eos))
+ outputs.append(output[:min_index])
+ return outputs
+
+
+class SantaCoder(HFTorchDecoder):
+ def __init__(self, name: str, **kwargs) -> None:
+ super().__init__(name, **kwargs)
+ self.prefix_token = ""
+ self.suffix_token = "\n"
+ self.extra_eos = ["<|endofmask|>"]
+ self.eos = self.eos + self.extra_eos
+
+ def codegen(
+ self, prompt: str, do_sample: bool = True, num_samples: int = 200
+ ) -> List[str]:
+ if self.temperature == 0:
+ assert not do_sample
+ assert num_samples == 1
+
+ input = self.prefix_token + prompt + self.suffix_token
+ input_tokens = self.tokenizer.encode(input, return_tensors="pt").to(self.device)
+ scores = StoppingCriteriaList(
+ [
+ EndOfFunctionCriteria(
+ start_length=len(input_tokens[0]),
+ eos=self.eos,
+ tokenizer=self.tokenizer,
+ )
+ ]
+ )
+ raw_outputs = self.model.generate(
+ input_tokens,
+ max_new_tokens=self.max_new_tokens,
+ stopping_criteria=scores,
+ do_sample=do_sample,
+ top_p=0.95,
+ top_k=None,
+ temperature=self.temperature,
+ num_return_sequences=min(self.batch_size, num_samples),
+ output_scores=True,
+ return_dict_in_generate=True,
+ pad_token_id=self.tokenizer.eos_token_id,
+ )
+ gen_seqs = raw_outputs.sequences[:, len(input_tokens[0]) :]
+ gen_strs = self.tokenizer.batch_decode(
+ gen_seqs,
+ skip_special_tokens=self.skip_special_tokens,
+ truncate_before_pattern=[r"\n\n^#", "^'''", "\n\n\n"],
+ )
+ outputs = []
+ # removes eos tokens.
+ for output in gen_strs:
+ min_index = 10000
+ for eos in self.eos:
+ if eos in output:
+ min_index = min(min_index, output.index(eos))
+ outputs.append(output[:min_index])
+ return outputs
+
+
+class StarCoderInfill(HFTorchDecoder):
+ def __init__(self, name: str, **kwargs) -> None:
+ super().__init__(name, **kwargs)
+ self.prefix_token = ""
+ self.suffix_token = ""
+
+ def codegen(
+ self, prompt: str, do_sample: bool = True, num_samples: int = 200
+ ) -> List[str]:
+ if self.temperature == 0:
+ assert not do_sample
+ assert num_samples == 1
+
+ input = self.prefix_token + prompt + self.suffix_token
+ input_tokens = self.tokenizer.encode(input, return_tensors="pt").to(self.device)
+ scores = StoppingCriteriaList(
+ [
+ EndOfFunctionCriteria(
+ start_length=len(input_tokens[0]),
+ eos=self.eos,
+ tokenizer=self.tokenizer,
+ )
+ ]
+ )
+
+ kwargs = {}
+ if do_sample:
+ kwargs["top_p"] = 0.95
+ kwargs["temperature"] = max(self.temperature, 1e-2)
+
+ raw_outputs = self.model.generate(
+ input_tokens,
+ max_new_tokens=self.max_new_tokens,
+ stopping_criteria=scores,
+ do_sample=do_sample,
+ num_return_sequences=min(self.batch_size, num_samples),
+ output_scores=True,
+ return_dict_in_generate=True,
+ repetition_penalty=1.0,
+ pad_token_id=self.tokenizer.eos_token_id,
+ )
+ gen_seqs = raw_outputs.sequences[:, len(input_tokens[0]) :]
+ gen_strs = self.tokenizer.batch_decode(
+ gen_seqs, skip_special_tokens=self.skip_special_tokens
+ )
+ outputs = []
+ # removes eos tokens.
+ for output in gen_strs:
+ min_index = 10000
+ for eos in self.eos:
+ if eos in output:
+ min_index = min(min_index, output.index(eos))
+ outputs.append(output[:min_index])
+ return outputs
+
+
+class CodeT5P(DecoderBase):
+ def __init__(self, name: str, **kwargs):
+ super().__init__(name=name, **kwargs)
+ self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
+ assert name in {
+ "Salesforce/codet5p-2b",
+ "Salesforce/codet5p-6b",
+ "Salesforce/codet5p-16b",
+ "Salesforce/instructcodet5p-16b",
+ }
+ self.tokenizer = AutoTokenizer.from_pretrained(name)
+ self.model = AutoModelForSeq2SeqLM.from_pretrained(
+ name,
+ trust_remote_code=True, # False for 220m and 770m models
+ torch_dtype=torch.float16,
+ low_cpu_mem_usage=True,
+ )
+ self.model.eval()
+ self.model.to(self.device)
+
+ self.skip_special_tokens = True
+
+ @torch.inference_mode()
+ def codegen(
+ self, prompt: str, do_sample: bool = True, num_samples: int = 200
+ ) -> List[str]:
+ if self.temperature == 0:
+ assert not do_sample
+ assert num_samples == 1
+
+ prompt = prompt.replace(" ", "\t")
+ input_tokens = self.tokenizer(prompt, return_tensors="pt").to(self.device)
+ scores = StoppingCriteriaList(
+ [
+ EndOfFunctionCriteria(
+ start_length=len(input_tokens[0]),
+ eos=self.eos,
+ tokenizer=self.tokenizer,
+ )
+ ]
+ )
+ max_new_tokens = self.max_new_tokens
+
+ while max_new_tokens > 0:
+ try:
+ raw_outputs = self.model.generate(
+ **input_tokens,
+ decoder_input_ids=input_tokens["input_ids"],
+ max_new_tokens=max_new_tokens,
+ stopping_criteria=scores,
+ do_sample=do_sample,
+ top_p=0.95,
+ top_k=None,
+ temperature=self.temperature,
+ output_scores=True,
+ return_dict_in_generate=True,
+ num_return_sequences=min(self.batch_size, num_samples),
+ pad_token_id=self.tokenizer.eos_token_id,
+ decoder_start_token_id=self.tokenizer.pad_token_id,
+ ) # remove warning
+ except RuntimeError as e: # catch torch OOM
+ if "CUDA out of memory" in str(e):
+ old_max_new_tokens = max_new_tokens
+ max_new_tokens = int(max_new_tokens * 0.8)
+ print(
+ f"OOM, reducing max_new_tokens from {old_max_new_tokens} to {max_new_tokens}"
+ )
+ continue
+ else:
+ raise e
+
+ break
+ gen_seqs = raw_outputs.sequences[:, len(input_tokens[0]) :]
+ gen_strs = self.tokenizer.batch_decode(
+ gen_seqs, skip_special_tokens=self.skip_special_tokens
+ )
+ outputs = []
+ # removes eos tokens.
+ for output in gen_strs:
+ min_index = 10000
+ for eos in self.eos:
+ if eos in output:
+ # could be multiple eos in outputs, better pick minimum one
+ min_index = min(min_index, output.index(eos))
+ outputs.append(output[:min_index].replace("\t", " "))
+ return outputs
+
+
+def make_model(name: str, batch_size: int = 1, temperature: float = 0.8):
+ if name == "codegen-2b":
+ return HFTorchDecoder(
+ batch_size=batch_size,
+ name="Salesforce/codegen-2B-mono",
+ temperature=temperature,
+ )
+ elif name == "codegen-6b":
+ return HFTorchDecoder(
+ batch_size=batch_size,
+ name="Salesforce/codegen-6B-mono",
+ temperature=temperature,
+ )
+ elif name == "codegen-16b":
+ return HFTorchDecoder(
+ batch_size=batch_size,
+ name="Salesforce/codegen-16B-mono",
+ temperature=temperature,
+ )
+ elif name == "codegen2-1b":
+ return Codegen2Decoder(
+ batch_size=batch_size,
+ name="Salesforce/codegen2-1B",
+ temperature=temperature,
+ )
+ elif name == "codegen2-3b":
+ return Codegen2Decoder(
+ batch_size=batch_size,
+ name="Salesforce/codegen2-3_7B",
+ temperature=temperature,
+ )
+ elif name == "codegen2-7b":
+ return Codegen2Decoder(
+ batch_size=batch_size,
+ name="Salesforce/codegen2-7B",
+ temperature=temperature,
+ )
+ elif name == "codegen2-16b":
+ warn(
+ "codegen2-16b checkpoint is `unfinished` at this point (05/11/2023) according to their paper. "
+ "So it might not make sense to use it."
+ )
+ return Codegen2Decoder(
+ batch_size=batch_size,
+ name="Salesforce/codegen2-16B",
+ temperature=temperature,
+ )
+ elif name == "polycoder":
+ return HFTorchDecoder(
+ batch_size=batch_size,
+ name="NinedayWang/PolyCoder-2.7B",
+ temperature=temperature,
+ )
+ elif name == "santacoder":
+ return SantaCoder(
+ batch_size=batch_size, name="bigcode/santacoder", temperature=temperature
+ )
+ elif name == "incoder-1b":
+ return IncoderDecoder(
+ batch_size=batch_size, name="facebook/incoder-1B", temperature=temperature
+ )
+ elif name == "incoder-6b":
+ return IncoderDecoder(
+ batch_size=batch_size, name="facebook/incoder-6B", temperature=temperature
+ )
+ elif name == "stablelm-7b":
+ return HFTorchDecoder(
+ batch_size=batch_size,
+ name="StabilityAI/stablelm-base-alpha-7b",
+ temperature=temperature,
+ )
+ elif name.startswith("gpt-3.5-") or name.startswith("gpt-4-"):
+ return OpenAIChatDecoder(
+ batch_size=batch_size,
+ name=name,
+ temperature=temperature,
+ conversational=True,
+ )
+ elif name == "gptneo-2b":
+ return HFTorchDecoder(
+ batch_size=batch_size,
+ name="EleutherAI/gpt-neo-2.7B",
+ temperature=temperature,
+ )
+ elif name == "gpt-j":
+ return HFTorchDecoder(
+ batch_size=batch_size, name="EleutherAI/gpt-j-6B", temperature=temperature
+ )
+ elif name.startswith("starcoder"):
+ return StarCoderInfill(
+ batch_size=batch_size, name=f"bigcode/{name}", temperature=temperature
+ )
+ elif name == "codet5p-2b":
+ return CodeT5P(
+ batch_size=batch_size,
+ name="Salesforce/codet5p-2b",
+ temperature=temperature,
+ )
+ elif name == "codet5p-6b":
+ return CodeT5P(
+ batch_size=batch_size,
+ name="Salesforce/codet5p-6b",
+ temperature=temperature,
+ )
+ elif name == "codet5p-16b":
+ return CodeT5P(
+ batch_size=batch_size,
+ name="Salesforce/codet5p-16b",
+ temperature=temperature,
+ )
+ elif name.startswith("code-llama-"):
+ if name.endswith("instruct"):
+ nb = name.split("-")[2]
+ assert nb.endswith("b")
+ return CodeLlamaInstruct(
+ batch_size=batch_size,
+ name=f"codellama/CodeLlama-{nb}-Instruct-hf",
+ temperature=temperature,
+ )
+
+ assert name.endswith("b")
+ nb = name.split("-")[-1]
+ return VLlmDecoder(
+ batch_size=batch_size,
+ name=f"codellama/CodeLlama-{nb}-Python-hf",
+ temperature=temperature,
+ )
+ elif name.startswith("deepseek-coder"):
+ import re
+
+ # format deepseek-coder-{nb}b*
+ pattern = re.compile(r"deepseek-coder-(\d+\.?\d*)b(.*)")
+ matches = pattern.findall(name)[0]
+ nb = float(matches[0])
+ if nb.is_integer():
+ nb = int(nb)
+
+ if "instruct" in name:
+ return DeepSeekInstruct(
+ batch_size=batch_size,
+ name=f"deepseek-ai/deepseek-coder-{nb}b-instruct",
+ temperature=temperature,
+ conversational=True,
+ )
+ else:
+ return VLlmDecoder(
+ batch_size=batch_size,
+ name=f"deepseek-ai/deepseek-coder-{nb}b-base",
+ temperature=temperature,
+ )
+ elif name == "wizardcoder-34b":
+ return Alpaca(
+ batch_size=batch_size,
+ name="WizardLM/WizardCoder-Python-34B-V1.0",
+ temperature=temperature,
+ conversational=True,
+ )
+ elif name == "wizardcoder-15b":
+ return Alpaca(
+ batch_size=batch_size,
+ name="WizardLM/WizardCoder-15B-V1.0",
+ temperature=temperature,
+ conversational=True,
+ )
+ elif name == "wizardcoder-7b":
+ return Alpaca(
+ batch_size=batch_size,
+ name="WizardLM/WizardCoder-Python-7B-V1.0",
+ temperature=temperature,
+ conversational=True,
+ )
+ elif name == "mistral-7b-codealpaca":
+ return HFTorchDecoder(
+ batch_size=batch_size,
+ name="Nondzu/Mistral-7B-codealpaca-lora",
+ temperature=temperature,
+ )
+ elif name == "zephyr-7b":
+ return HFTorchDecoder(
+ batch_size=batch_size,
+ name="HuggingFaceH4/zephyr-7b-beta",
+ temperature=temperature,
+ )
+ elif name == "codebooga-34b":
+ return HFTorchDecoder(
+ batch_size=batch_size,
+ name="oobabooga/CodeBooga-34B-v0.1",
+ temperature=temperature,
+ )
+ elif name == "phind-code-llama-34b-v2":
+ return HFTorchDecoder(
+ batch_size=batch_size,
+ name="Phind/Phind-CodeLlama-34B-v2",
+ temperature=temperature,
+ )
+ elif name == "mistral-7b":
+ return HFTorchDecoder(
+ batch_size=batch_size,
+ name="mistralai/Mistral-7B-v0.1",
+ temperature=temperature,
+ )
+ elif name == "dolphin-2.6":
+ return ChatML(
+ batch_size=batch_size,
+ name="cognitivecomputations/dolphin-2.6-mixtral-8x7b",
+ temperature=temperature,
+ max_new_tokens=512 + 256,
+ )
+ elif name == "solar-10.7b-instruct":
+ return Solar(
+ batch_size=batch_size,
+ name="upstage/SOLAR-10.7B-Instruct-v1.0",
+ temperature=temperature,
+ conversational=True,
+ )
+ elif name == "mistral-hermes-codepro-7b":
+ return ChatML(
+ batch_size=batch_size,
+ name="beowolx/MistralHermes-CodePro-7B-v1",
+ temperature=temperature,
+ max_new_tokens=512 + 256,
+ )
+ elif name == "phi-2":
+ return VLlmDecoder(
+ batch_size=batch_size,
+ name="microsoft/phi-2",
+ temperature=temperature,
+ )
+ elif name == "openchat":
+ return OpenChat(
+ batch_size=batch_size,
+ name="openchat/openchat-3.5-0106",
+ temperature=temperature,
+ conversational=True,
+ )
+ elif name == "speechless-codellama-34b":
+ return Alpaca(
+ batch_size=batch_size,
+ name="uukuguy/speechless-codellama-34b-v2.0",
+ temperature=temperature,
+ conversational=True,
+ )
+ elif name == "speechless-mistral-7b":
+ return Alpaca(
+ batch_size=batch_size,
+ name="uukuguy/speechless-code-mistral-7b-v1.0",
+ temperature=temperature,
+ conversational=True,
+ )
+ elif name == "code-millenials-34b":
+ return Alpaca(
+ batch_size=batch_size,
+ name="budecosystem/code-millenials-34b",
+ temperature=temperature,
+ conversational=True,
+ )
+ elif name == "xdan-l1-chat":
+ return Alpaca(
+ batch_size=batch_size,
+ name="xDAN-AI/xDAN-L1-Chat-dpo-qlora-v1",
+ temperature=temperature,
+ conversational=True,
+ )
+ elif name == "stable-code-3b":
+ return HFTorchDecoder(
+ batch_size=batch_size,
+ name="stabilityai/stable-code-3b",
+ temperature=temperature,
+ )
+ elif name == "zyte-1b":
+ return Zyte(
+ batch_size=batch_size,
+ name="aihub-app/zyte-1B",
+ temperature=temperature,
+ conversational=True,
+ )
+
+ raise ValueError(f"Invalid model name: {name}")
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/__init__.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..14435419b581e1d71ae025c68a02e8b6a9bffb9e
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/__init__.py
@@ -0,0 +1,4 @@
+try:
+ from evalplus._version import __version__, __version_tuple__
+except ImportError:
+ __version__ = "local-dev"
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/_experimental/evaluate_coverage.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/_experimental/evaluate_coverage.py
new file mode 100644
index 0000000000000000000000000000000000000000..b4d14b9a41cd42806404cc2161b6088b53cbd7e9
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/_experimental/evaluate_coverage.py
@@ -0,0 +1,185 @@
+import argparse
+import importlib
+import inspect
+import multiprocessing
+import os
+import sys
+from io import StringIO
+from typing import Any, Callable, List, Union
+
+import coverage
+
+from evalplus.data import get_human_eval_plus
+from evalplus.data.utils import to_raw
+from evalplus.eval.utils import reliability_guard, swallow_io, time_limit
+
+
+def construct_inputs_sig(inputs: list) -> str:
+ str_builder = ""
+ for x in inputs:
+ if type(x) == str:
+ str_builder += f"'{to_raw(x)}',"
+ else:
+ str_builder += f"{x},"
+ return str_builder[:-1]
+
+
+class Capturing(list):
+ def __enter__(self):
+ self._stdout = sys.stdout
+ sys.stdout = self._stringio = StringIO()
+ return self
+
+ def __exit__(self, *args):
+ self.extend(self._stringio.getvalue().splitlines())
+ del self._stringio
+ sys.stdout = self._stdout
+
+
+def parse_lcov(outputs: List[str], func: Callable, mode: str = "branch"):
+ switch, extracted_outputs = False, []
+ for line in outputs:
+ if switch == False and "tmp_src" in line:
+ switch = True
+ if switch == True and "end_of_record" in line:
+ switch = False
+ if switch:
+ extracted_outputs.append(line)
+
+ src, start_lineno = inspect.getsourcelines(func)
+ end_lineno = start_lineno + len(src) - 1
+
+ if mode == "branch":
+ branch, branch_covered = [], []
+ for line in extracted_outputs:
+ if line.startswith("BRDA"):
+ # BRDA format: BR:,,,
+ lineno, blockno, branchno, taken = line[5:].split(",")
+ branch_sig = f"BR:{lineno},{blockno},{branchno}"
+ branch.append(branch_sig)
+ if taken not in ["0", "-"]:
+ branch_covered.append(branch_sig)
+ per = 1.0 if len(branch) == 0 else len(branch_covered) / len(branch)
+ return per, branch, branch_covered
+ else:
+ not_covered_lines = []
+ for line in extracted_outputs:
+ if line.startswith("DA"):
+ # DA format: DA:,[,...]
+ lineno, exec_count = line[3:].split(",")[:2]
+ if start_lineno <= int(lineno) <= end_lineno:
+ if exec_count == "0":
+ not_covered_lines.append(int(lineno))
+ for lineno in not_covered_lines:
+ line = src[lineno - start_lineno]
+ if line.strip() != "" and "def" not in line:
+ src[lineno - start_lineno] = line[:-1] + " # Not executed\n"
+ return "".join(src)
+
+
+def test_code_coverage(
+ code: str, inputs: List[List[Any]], entry_point: str, mode="branch"
+):
+ def safety_test(code: str, inputs: List[List[Any]], entry_point: str):
+ for input_list in inputs:
+ code += f"{entry_point}({construct_inputs_sig(input_list)})\n"
+ reliability_guard()
+ try:
+ with swallow_io():
+ with time_limit(1):
+ exec(code, {})
+ except:
+ sys.exit(1)
+
+ p = multiprocessing.Process(target=safety_test, args=(code, inputs, entry_point))
+ p.start()
+ p.join()
+ safe = p.exitcode == 0
+ if p.is_alive():
+ p.terminate()
+ p.kill()
+ if not safe:
+ print("Potentially dangerous code, refuse coverage test.")
+ return None
+
+ with open("tmp_src.py", "w") as f:
+ f.write(code)
+ import tmp_src
+
+ importlib.reload(tmp_src)
+ func = getattr(tmp_src, f"{entry_point}", None)
+ assert func != None, f"{entry_point = } not exist"
+
+ cov = coverage.Coverage(branch=True)
+ cov.start()
+ with swallow_io():
+ for input_list in inputs:
+ func(*input_list)
+ cov.stop()
+ with Capturing() as outputs:
+ cov.lcov_report(outfile="-")
+
+ ret = parse_lcov(outputs, func, mode)
+
+ os.remove("tmp_src.py")
+ return ret
+
+
+def test_solution_coverage(
+ dataset: str = "HumanEvalPlus",
+ task_id: str = "HumanEval/0",
+ impl: str = "canonical",
+ inputs: Union[str, List[List[Any]]] = "base_input",
+ mode: str = "branch",
+):
+ """
+ Parameters:
+ * dataset: {None, "HumanEval", "HumanEvalPlus"}
+ * task_id: ralated to dataset
+ * impl: {"canonical", source code}
+ * inputs: {"base_inputs", list}
+ * mode: {"branch"}, will support "line" for coverage-guided LLM test generation
+ """
+ if "HumanEval" in dataset:
+ problems, problem = get_human_eval_plus(), None
+ for p in problems:
+ if p["task_id"] == task_id:
+ problem = p
+ assert problem != None, f"invalid {task_id = }"
+ entry_point = problem["entry_point"]
+ code = problem["prompt"] + (
+ impl if impl != "canonical" else problem["canonical_solution"]
+ )
+ if inputs == "base_input":
+ inputs = problem["base_input"]
+ else:
+ raise NotImplementedError
+
+ return test_code_coverage(code, inputs, entry_point, mode)
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ "--mode", type=str, default="branch", choices=["line", "branch"]
+ )
+ args = parser.parse_args()
+
+ if args.mode == "branch":
+ for i in range(0, 164):
+ task_id = f"HumanEval/{i}"
+ branch, branch_covered = test_solution_coverage(
+ dataset="HumanEval", task_id=task_id, mode="branch"
+ )
+ per = 1.0 if len(branch) == 0 else len(branch_covered) / len(branch)
+ if per != 1.0:
+ print(i, per, len(branch_covered), len(branch))
+ else:
+ for i in range(0, 164):
+ task_id = f"HumanEval/{i}"
+ annotated_code = test_solution_coverage(
+ dataset="HumanEval", task_id=task_id, mode="line"
+ )
+ if "Not executed" in annotated_code:
+ print(f"{task_id = }")
+ print(annotated_code)
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/_experimental/evaluate_runtime.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/_experimental/evaluate_runtime.py
new file mode 100644
index 0000000000000000000000000000000000000000..ae2bc2ced3ece39f975a2e35efd72bd8efee34c0
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/_experimental/evaluate_runtime.py
@@ -0,0 +1,116 @@
+import math
+import multiprocessing
+import time
+from typing import Any, List, Union
+
+from evalplus.data import get_human_eval_plus
+from evalplus.eval.utils import (
+ TimeoutException,
+ create_tempdir,
+ reliability_guard,
+ swallow_io,
+ time_limit,
+)
+
+MAX_WARMUP_LIMIT = 5
+RUN_REPEAT = 25
+
+
+def execute_for_runtime(
+ code: str, inputs: List, warmups: List, entry_point: str
+) -> Union[str, float]:
+ def unsafe_execute():
+ with create_tempdir():
+ # These system calls are needed when cleaning up tempdir.
+ import os
+ import shutil
+
+ rmtree = shutil.rmtree
+ rmdir = os.rmdir
+ chdir = os.chdir
+ # Disable functionalities that can make destructive changes to the test.
+ reliability_guard()
+ # load functions
+ exec_globals = {}
+ exec(code, exec_globals)
+ fn = exec_globals[entry_point]
+ try:
+ # warmup calls
+ for warmup in warmups:
+ with swallow_io():
+ fn(*warmup)
+
+ start_time = time.time()
+ # real call
+ with swallow_io():
+ with time_limit(3):
+ fn(*inputs)
+ duration = time.time() - start_time
+
+ result.append(duration)
+ except TimeoutException:
+ result.append("timed out")
+ except BaseException as e:
+ result.append("thrown exception")
+ # Needed for cleaning up.
+ shutil.rmtree = rmtree
+ os.rmdir = rmdir
+ os.chdir = chdir
+
+ manager = multiprocessing.Manager()
+ result = manager.list()
+ p = multiprocessing.Process(target=unsafe_execute)
+ p.start()
+ p.join(timeout=3 + 1)
+ if p.is_alive():
+ p.kill()
+ return result[0]
+
+
+def test_solution_runtime(
+ dataset: str = "humaneval",
+ task_id: str = "HumanEval/0",
+ impl: str = "canonical",
+ inputs: Union[str, List[List[Any]]] = "base_input",
+):
+ if "humaneval" in dataset:
+ problems, problem = get_human_eval_plus(), None
+ for p in problems:
+ if p["task_id"] == task_id:
+ problem = p
+ assert problem != None, f"invalid {task_id = }"
+ entry_point = problem["entry_point"]
+ impl = problem["prompt"] + (
+ impl if impl != "canonical" else problem["canonical_solution"]
+ )
+ if inputs == "base_input":
+ inputs = problem["base_input"]
+
+ results = [1000, 1000]
+ for input_list in inputs:
+ # choose warmup input
+ warmups = []
+ for base_input_list in problem["base_input"]:
+ if (
+ hash(str(base_input_list)) != hash(str(input_list))
+ and len(warmups) < MAX_WARMUP_LIMIT
+ ):
+ warmups.append(base_input_list)
+ runtime_list = [
+ execute_for_runtime(impl, input_list, warmups, entry_point)
+ for _ in range(RUN_REPEAT)
+ ]
+ if any(type(x) != float for x in runtime_list):
+ print(f"{task_id = } incorrect")
+ return None, None
+
+ avg_runtime = sum(runtime_list) / len(runtime_list)
+ sd = math.sqrt(
+ sum((runtime - avg_runtime) ** 2 for runtime in runtime_list)
+ / (RUN_REPEAT - 1)
+ )
+ if sd < results[1]:
+ results[0] = avg_runtime
+ results[1] = sd
+
+ return results
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/_experimental/generate_big_input.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/_experimental/generate_big_input.py
new file mode 100644
index 0000000000000000000000000000000000000000..aee0a7d639c7b69ed077fae69c26005f3907be40
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/_experimental/generate_big_input.py
@@ -0,0 +1,65 @@
+import json
+import multiprocessing
+import os
+
+from evalplus._experimental.type_mut_for_eff import TypedMutEffGen
+from evalplus.data import HUMANEVAL_PLUS_INPUTS_PATH, get_human_eval_plus
+
+HUMANEVAL_PLUS_BIG_INPUTS_PATH = "/home/yuyao/eval-plus/HumanEvalPlusBigInputs"
+
+
+def main():
+ problems = get_human_eval_plus()
+ for p in problems:
+ print(f"{p['task_id']}...")
+ filename = p["task_id"].replace("/", "_")
+ big_input_path = os.path.join(
+ HUMANEVAL_PLUS_BIG_INPUTS_PATH, f"{filename}.json"
+ )
+
+ if os.path.exists(big_input_path):
+ continue
+ inputs = p["base_input"]
+ signature = p["entry_point"]
+ contract_code = p["prompt"] + p["contract"] + p["canonical_solution"]
+
+ def input_generation(inputs, signature, contract_code):
+ try:
+ gen = TypedMutEffGen(inputs, signature, contract_code)
+ new_inputs = gen.generate()
+ results.append(new_inputs)
+ except:
+ with open("fail.txt", "a") as f:
+ f.write(f"{signature} failed")
+ results.append("fail")
+
+ manager = multiprocessing.Manager()
+ results = manager.list()
+ proc = multiprocessing.Process(
+ target=input_generation, args=(inputs, signature, contract_code)
+ )
+ proc.start()
+ proc.join(timeout=300)
+ if proc.is_alive():
+ proc.terminate()
+ proc.kill()
+ continue
+ if len(results) == 0 or type(results[0]) == str:
+ continue
+ new_inputs = results[0]
+
+ new_input_dict = dict()
+ new_input_dict["task_id"] = p["task_id"]
+ new_input_dict["inputs"] = []
+ new_input_dict["sd"] = []
+ for item in new_inputs:
+ new_input_dict["inputs"].append(item.inputs)
+ new_input_dict["sd"].append(item.fluctuate_ratio)
+ with open(
+ os.path.join(HUMANEVAL_PLUS_BIG_INPUTS_PATH, f"{filename}.json"), "w"
+ ) as f:
+ json.dump(new_input_dict, f)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/_experimental/type_mut_for_eff.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/_experimental/type_mut_for_eff.py
new file mode 100644
index 0000000000000000000000000000000000000000..d6bbd12925094011d4ee05653a71d1f5c67df920
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/_experimental/type_mut_for_eff.py
@@ -0,0 +1,500 @@
+import copy
+import math
+import random
+import string
+from typing import Any, Dict, List, Optional, Set, Tuple
+
+from multipledispatch import dispatch
+from rich.progress import track
+
+from evalplus._experimental.evaluate_runtime import (
+ MAX_WARMUP_LIMIT,
+ RUN_REPEAT,
+ execute_for_runtime,
+)
+from evalplus.gen.mut_gen import MutateGen
+
+MUTATE_BOUND_SIZE = 5
+MAX_MULTI_STEP_SIZE = 1000
+MAX_SEED_POOL = 10
+
+NoneType = type(None)
+MAX_SIZE = 80000
+VALUE_MAX = 1000000
+
+
+# decorator to use ingredients
+class use_ingredient:
+ def __init__(self, prob: float):
+ assert 0 <= prob <= 0.95
+ self.prob = prob
+
+ def __call__(obj, func):
+ def wrapper(self, seed_input):
+ if random.random() < obj.prob and self.ingredients[type(seed_input)]:
+ return random.choice(list(self.ingredients[type(seed_input)]))
+ else:
+ return func(self, seed_input)
+
+ return wrapper
+
+
+class TestInput:
+ def __init__(self, inputs: List, runtime: float, sd: float):
+ self.inputs = inputs
+ self.sz = self.typed_size(inputs)
+ self.runtime = runtime
+ self.sd = sd
+ self.rank_sd = self.rank_sz = 1
+
+ def __str__(self):
+ return str(self.inputs)
+
+ @property
+ def fluctuate_ratio(self) -> float:
+ return self.sd / self.runtime * 100
+
+ @property
+ def rank(self) -> float:
+ return self.rank_sd * (self.rank_sz**0.8) if self.sz <= 2000 else self.rank_sd
+
+ @dispatch(NoneType)
+ def typed_size(self, _) -> int:
+ return 1
+
+ @dispatch(int)
+ def typed_size(self, _) -> int:
+ return 1
+
+ @dispatch(float)
+ def typed_size(self, _) -> int:
+ return 1
+
+ @dispatch(bool)
+ def typed_size(self, _) -> int:
+ return 1
+
+ @dispatch(str)
+ def typed_size(self, s: str) -> int:
+ return len(s)
+
+ @dispatch(list)
+ def typed_size(self, l: list) -> int:
+ return sum(self.typed_size(x) for x in l)
+
+ @dispatch(tuple)
+ def typed_size(self, t: tuple) -> int:
+ return sum(self.typed_size(x) for x in t)
+
+ @dispatch(set)
+ def typed_size(self, s: set) -> int:
+ return sum(self.typed_size(x) for x in s)
+
+ @dispatch(dict)
+ def typed_size(self, d: dict) -> int:
+ return sum(self.typed_size(x) for x in d.items())
+
+
+class TypedMutEffGen(MutateGen):
+ def __init__(self, inputs: List, signature: str, contract_code: str):
+ super().__init__(inputs, signature, contract_code)
+
+ self.base_inputs = copy.deepcopy(inputs)
+ self.seed_pool: List[TestInput] = []
+ self.seed_hash: Set[str] = set()
+ for base_input in self.base_inputs:
+ avg, sd = self.test_efficiency(base_input)
+ assert avg != None and sd != None, "base inputs not correct"
+ self.insert_input(TestInput(base_input, avg, sd))
+ self.seed_hash.add(hash(str(base_input)))
+
+ self.ingredients = {
+ int: set(),
+ float: set(),
+ str: set(),
+ }
+ for x in inputs:
+ self.fetch_ingredient(x)
+
+ def insert_input(self, new_input: TestInput):
+ new_input_hash = hash(str(new_input))
+ if new_input_hash in self.seed_hash:
+ return
+ self.seed_pool.append(new_input)
+ self.seed_pool.sort(key=lambda x: x.fluctuate_ratio)
+ self.seed_hash.add(new_input_hash)
+
+ if len(self.seed_pool) > MAX_SEED_POOL:
+ self.seed_pool.sort(key=lambda x: x.fluctuate_ratio)
+ for i in range(len(self.seed_pool)):
+ self.seed_pool[i].rank_sd = i + 1
+ self.seed_pool.sort(key=lambda x: -x.sz)
+ for i in range(len(self.seed_pool)):
+ self.seed_pool[i].rank_sz = i + 1
+ self.seed_pool.sort(key=lambda x: x.rank)
+ seed_deleted = self.seed_pool[-1]
+ self.seed_hash.remove(hash(str(seed_deleted)))
+ self.seed_pool = self.seed_pool[:-1]
+
+ def test_efficiency(self, new_input: List) -> Tuple[Optional[float]]:
+ warmups = []
+ new_input_hash = hash(str(new_input))
+ for input_list in self.base_inputs:
+ if (
+ len(warmups) < MAX_WARMUP_LIMIT
+ and hash(str(input_list)) != new_input_hash
+ ):
+ warmups.append(input_list)
+ runtime_list = [
+ execute_for_runtime(self.contract_code, new_input, warmups, self.signature)
+ for _ in range(RUN_REPEAT)
+ ]
+ if any(type(x) != float for x in runtime_list):
+ return None, None
+ avg = sum(runtime_list) / RUN_REPEAT
+ sd = math.sqrt(sum((t - avg) ** 2 for t in runtime_list) / (RUN_REPEAT - 1))
+ return avg, sd
+
+ #########################
+ # Type-aware generation #
+ #########################
+ @dispatch(NoneType)
+ def typed_gen(self, _):
+ return None
+
+ @dispatch(int)
+ def typed_gen(self, _):
+ @use_ingredient(0.5)
+ def _impl(*_):
+ return random.randint(-VALUE_MAX, VALUE_MAX)
+
+ return _impl(self, _)
+
+ @dispatch(float)
+ def typed_gen(self, _):
+ @use_ingredient(0.5)
+ def _impl(*_):
+ return random.uniform(-VALUE_MAX, VALUE_MAX)
+
+ return _impl(self, _)
+
+ @dispatch(bool)
+ def typed_gen(self, _):
+ return random.choice([True, False])
+
+ @dispatch(str)
+ def typed_gen(self, _):
+ @use_ingredient(0.5)
+ def _impl(*_):
+ return "".join(
+ random.choice(string.ascii_letters)
+ for _ in range(random.randint(0, 10))
+ )
+
+ return _impl(self, _)
+
+ def any_gen(self):
+ # weighted choose
+ choice = random.choices(
+ [
+ True,
+ 1,
+ 1.1,
+ "str",
+ [], # list
+ tuple(), # tuple
+ dict(), # dict
+ None, # None
+ ],
+ [0.2, 0.2, 0.2, 0.2, 0.05, 0.05, 0.05, 0.05],
+ )[0]
+ return self.typed_gen(choice)
+
+ @dispatch(list)
+ def typed_gen(self, _):
+ ret = []
+ size = random.randint(0, 10)
+ if random.randint(0, 4) == 0: # heterogeneous
+ for _ in range(size):
+ ret.append(self.any_gen())
+ else: # homogeneous
+ t = random.choice([bool(), int(), float(), str()])
+ for _ in range(size):
+ ret.append(self.typed_gen(t))
+ return ret
+
+ @dispatch(tuple)
+ def typed_gen(self, _):
+ return tuple(self.typed_gen([]))
+
+ # NOTE: disable set for now as Steven is too weak in Python (/s)
+ # @dispatch(set)
+ # def typed_gen(self, _):
+ # return set(self.typed_gen([]))
+
+ @dispatch(dict)
+ def typed_gen(self, _):
+ ret = dict()
+ values = self.typed_gen([])
+ # NOTE: Assumption: nobody uses dict with heterogeneous keys
+ # NOTE: Assumption: nobody uses dict with boolean keys
+ key_type = random.choice([int(), float(), str()])
+ for v in values:
+ ret[self.typed_gen(key_type)] = self.typed_gen(v)
+ return ret
+
+ ########################
+ # Type-aware mutation #
+ ########################
+ # Simple primitives
+ @dispatch(int)
+ def typed_mutate(self, seed_input: int):
+ @use_ingredient(0.1)
+ def _impl(_, seed_input: int):
+ prob = random.uniform(0, 1)
+ if 0 <= prob < 0.2:
+ return seed_input * 2
+ elif 0.2 <= prob < 0.9:
+ return random.randint(-VALUE_MAX, VALUE_MAX)
+ else:
+ return seed_input + 5
+
+ return _impl(self, seed_input)
+
+ @dispatch(float)
+ def typed_mutate(self, seed_input: float):
+ @use_ingredient(0.1)
+ def _impl(_, seed_input: float):
+ prob = random.uniform(0, 1)
+ if 0 <= prob < 0.2:
+ return seed_input * (2 + random.uniform(-0.5, 0.5))
+ elif 0.2 <= prob < 0.9:
+ return random.uniform(-VALUE_MAX, VALUE_MAX)
+ else:
+ return seed_input + 5.0
+
+ return _impl(self, seed_input)
+
+ @dispatch(bool)
+ def typed_mutate(self, seed_input: bool):
+ return random.choice([True, False])
+
+ @dispatch(NoneType)
+ def typed_mutate(self, seed_input: NoneType):
+ return None
+
+ # List-like
+ @dispatch(list)
+ def typed_mutate(self, seed_input: List):
+ if len(seed_input) == 0:
+ return self.typed_gen([])
+
+ choice = random.randint(1, 3)
+ idx = random.randint(0, len(seed_input) - 1)
+ if choice == 1 and 0 < len(seed_input) < MAX_SIZE: # length *= 1.1
+ old_length = len(seed_input)
+ new_length = math.ceil(old_length * 1.1)
+ for _ in range(new_length - old_length):
+ seed_input.insert(
+ random.randint(0, len(seed_input) - 1),
+ self.typed_mutate(seed_input[idx]),
+ )
+ elif choice == 2 and 0 < len(seed_input) < MAX_SIZE: # repeat, length *= 1.1
+ old_length = len(seed_input)
+ new_length = math.ceil(old_length * 1.1)
+ for _ in range(new_length - old_length):
+ seed_input.append(seed_input[idx])
+ else: # inplace element change, large_scale
+ for idx in range(len(seed_input)):
+ if random.uniform(0, 1) > 0.7:
+ seed_input[idx] = self.typed_mutate(seed_input[idx])
+ return seed_input
+
+ @dispatch(tuple)
+ def typed_mutate(self, seed_input: Tuple):
+ return tuple(self.typed_mutate(list(seed_input)))
+
+ # String
+ @dispatch(str)
+ def typed_mutate(self, seed_input: str):
+ @use_ingredient(0.1)
+ def _impl(_, seed_input: str):
+ choice = random.randint(0, 2) if seed_input else 0
+ if (
+ choice <= 1 and self.ingredients[str]
+ ): # insert ingredients, length *= 1.1
+ new_length = math.ceil(len(seed_input) * 1.1)
+ while len(seed_input) < new_length:
+ idx = random.randint(0, len(seed_input))
+ seed_input = (
+ seed_input[:idx]
+ + random.choice(list(self.ingredients[str]))
+ + seed_input[idx:]
+ )
+ return seed_input
+ # other choices assume len(seed_input) > 0
+ elif choice == 2: # inplace mutation, large_scale
+ ch_list = []
+ for i in range(len(seed_input)):
+ if random.uniform(0, 1) > 0.7:
+ ch_list.append(random.choice(string.ascii_letters))
+ else:
+ ch_list.append(seed_input[i])
+ return "".join(ch_list)
+
+ # random char
+ return self.typed_gen(str())
+
+ return _impl(self, seed_input)
+
+ # Set
+ @dispatch(set)
+ def typed_mutate(self, seed_input: Set):
+ return set(self.typed_mutate(list(seed_input)))
+
+ # Dict
+ @dispatch(dict)
+ def typed_mutate(self, seed_input: Dict):
+ if len(seed_input) == 0:
+ return self.typed_gen(dict())
+
+ choice = random.randint(1, 2)
+ if choice == 1: # add a kv
+ k = self.typed_mutate(random.choice(list(seed_input.keys())))
+ v = self.typed_mutate(random.choice(list(seed_input.values())))
+ seed_input[k] = v
+ elif choice == 2: # inplace value change
+ k0, v0 = random.choice(list(seed_input.items()))
+ seed_input[k0] = self.typed_mutate(v0)
+ return seed_input
+
+ ############################################
+ # Fetching ingredients to self.ingredients #
+ ############################################
+ def fetch_ingredient(self, seed_input):
+ self.typed_fetch(seed_input)
+
+ @dispatch(int)
+ def typed_fetch(self, seed_input: int):
+ self.ingredients[int].add(seed_input)
+
+ @dispatch(float)
+ def typed_fetch(self, seed_input: float):
+ self.ingredients[float].add(seed_input)
+
+ @dispatch(str)
+ def typed_fetch(self, seed_input: str):
+ self.ingredients[str].add(seed_input)
+ for token in seed_input.strip().split():
+ self.ingredients[str].add(token)
+
+ # List-like
+ def _fetch_list_like(self, seed_input):
+ for x in seed_input:
+ if self.typed_fetch.dispatch(type(x)):
+ self.fetch_ingredient(x)
+
+ @dispatch(list)
+ def typed_fetch(self, seed_input: List):
+ self._fetch_list_like(seed_input)
+
+ @dispatch(tuple)
+ def typed_fetch(self, seed_input: Tuple):
+ self._fetch_list_like(seed_input)
+
+ # NOTE: disable set for now as Steven is too weak in Python (/s)
+ # @dispatch(set)
+ # def typed_fetch(self, seed_input: Set):
+ # self._fetch_list_like(seed_input)
+
+ # Dict
+ @dispatch(dict)
+ def typed_fetch(self, seed_input: Dict):
+ self._fetch_list_like(seed_input.keys())
+ self._fetch_list_like(seed_input.values())
+
+ # Type-aware concatenation
+
+ @dispatch(int, int)
+ def concat(x: int, y: int):
+ return x + y
+
+ @dispatch(float, float)
+ def concat(x: float, y: float):
+ return x + y
+
+ @dispatch(bool, bool)
+ def concat(x: bool, y: bool):
+ return random.choice([x, y])
+
+ @dispatch(NoneType, NoneType)
+ def concat(x: NoneType, y: NoneType):
+ return None
+
+ @dispatch(list, list)
+ def concat(x: list, y: list):
+ choice = random.randint(0, 1)
+ return (
+ copy.deepcopy(x) + copy.deepcopy(y)
+ if choice == 0
+ else copy.deepcopy(y) + copy.deepcopy(x)
+ )
+
+ @dispatch(str, str)
+ def concat(x: str, y: str):
+ choice = random.randint(0, 1)
+ return x + y if choice == 0 else y + x
+
+ @dispatch(set, set)
+ def concat(x: set, y: set):
+ return x.union(y)
+
+ @dispatch(dict, dict)
+ def concat(x: dict, y: dict):
+ return x.update(y)
+
+ def mutate(self, seed: TestInput) -> List[Any]:
+ new_input = copy.deepcopy(seed.inputs)
+
+ for _ in range(20):
+ prob = random.uniform(0, 1)
+ if 0 <= prob < 0.1 and seed.sz <= MAX_SIZE:
+ another_seed = random.choice(self.seed_pool).inputs
+ new_input = [
+ self.concat(new_input[i], another_seed[i])
+ for i in range(len(new_input))
+ ]
+ else:
+ for i in range(len(new_input)):
+ new_input[i] = self.typed_mutate(new_input[i])
+
+ return new_input
+
+ def generate(self) -> List[TestInput]:
+ for _ in track(range(40)):
+ seed = self.seed_selection()
+ new_input = self.mutate(seed)
+ # print(len(new_input[0]))
+ avg, sd = self.test_efficiency(new_input)
+ if avg != None and sd != None:
+ self.insert_input(TestInput(new_input, avg, sd))
+ return self.seed_pool
+
+
+if __name__ == "__main__":
+ from evalplus.data import get_human_eval_plus
+
+ problems = get_human_eval_plus()
+ for p in problems[43:44]:
+ inputs = p["base_input"]
+ entry_point = p["entry_point"]
+ contract = p["prompt"] + p["contract"] + p["canonical_solution"]
+ gen = TypedMutEffGen(inputs, entry_point, contract)
+ new_inputs = gen.generate()
+ for i, new_input in enumerate(new_inputs):
+ print(f"New input {i}: sz: {new_input.sz}")
+ if new_input.sz <= 10:
+ print(new_input.inputs)
+ print(
+ f"- Runtime: {new_input.runtime}, Sd: {new_input.sd}, Per: {new_input.fluctuate_ratio}"
+ )
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/data/__init__.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/data/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..0209e8210c311d41e172fc90be244327f510fd8a
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/data/__init__.py
@@ -0,0 +1,3 @@
+from evalplus.data.humaneval import get_human_eval_plus, get_human_eval_plus_hash
+from evalplus.data.mbpp import get_mbpp_plus, get_mbpp_plus_hash
+from evalplus.data.utils import load_solutions, write_directory, write_jsonl
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/data/humaneval.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/data/humaneval.py
new file mode 100644
index 0000000000000000000000000000000000000000..1de86a83f162659de6659da7cf04a370a088e4ec
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/data/humaneval.py
@@ -0,0 +1,89 @@
+import hashlib
+import json
+import os
+from typing import Dict
+
+from evalplus.data.utils import (
+ CACHE_DIR,
+ completeness_check,
+ get_dataset_metadata,
+ make_cache,
+ stream_jsonl,
+)
+
+HUMANEVAL_PLUS_VERSION = "v0.1.9"
+HUMANEVAL_OVERRIDE_PATH = os.environ.get("HUMANEVAL_OVERRIDE_PATH", None)
+
+
+def _ready_human_eval_plus_path(mini=False) -> str:
+ if HUMANEVAL_OVERRIDE_PATH:
+ return HUMANEVAL_OVERRIDE_PATH
+
+ url, plus_path = get_dataset_metadata("HumanEvalPlus", HUMANEVAL_PLUS_VERSION, mini)
+ make_cache(url, plus_path)
+
+ return plus_path
+
+
+def get_human_eval_plus_hash() -> str:
+ """Get the hash of HumanEvalPlus.
+ Returns:
+ str: The hash of HumanEvalPlus
+ """
+ plus_path = _ready_human_eval_plus_path()
+ with open(plus_path, "rb") as f:
+ plus = f.read()
+ return hashlib.md5(plus).hexdigest()
+
+
+def get_human_eval_plus(err_incomplete=True, mini=False) -> Dict[str, Dict]:
+ """Get HumanEvalPlus locally.
+ Args:
+ err_incomplete (bool, optional): Whether to raise error if HumanEvalPlus is not complete. Defaults to True.
+ mini (bool, optional): Whether to use the mini version of HumanEvalPlus. Defaults to False.
+ Returns:
+ List[Dict[str, str]]: List of dicts with keys "task_id", "prompt", "contract", "canonical_solution", "base_input"
+ Notes:
+ "task_id" is the identifier string for the task
+ "prompt" is the function signature with docstring
+ "contract" is the assertions for the function's input (validity)
+ "canonical_solution" is the ground-truth implementation for diff-testing
+ "base_input" is the test inputs from original HumanEval
+ "plus_input" is the test inputs brought by EvalPlus
+ "atol" is the absolute tolerance for diff-testing
+ """
+ plus_path = _ready_human_eval_plus_path(mini=mini)
+ plus = {task["task_id"]: task for task in stream_jsonl(plus_path)}
+ if err_incomplete:
+ completeness_check("HumanEval+", plus)
+ return plus
+
+
+def get_human_eval() -> Dict[str, Dict]:
+ """Get HumanEval from OpenAI's github repo and return as a list of parsed dicts.
+
+ Returns:
+ List[Dict[str, str]]: List of dicts with keys "prompt", "test", "entry_point"
+
+ Notes:
+ "task_id" is the identifier string for the task.
+ "prompt" is the prompt to be used for the task (function signature with docstrings).
+ "test" is test-cases wrapped in a `check` function.
+ "entry_point" is the name of the function.
+ """
+ # Check if human eval file exists in CACHE_DIR
+ human_eval_path = os.path.join(CACHE_DIR, "HumanEval.jsonl")
+ make_cache(
+ "https://github.com/openai/human-eval/raw/master/data/HumanEval.jsonl.gz",
+ human_eval_path,
+ )
+
+ human_eval = open(human_eval_path, "r").read().split("\n")
+ human_eval = [json.loads(line) for line in human_eval if line]
+
+ # Handle 115_max_fill.py to make its docstring well-formed
+ human_eval[115]["prompt"] = "import math\n" + human_eval[115]["prompt"].replace(
+ "import math\n", ""
+ )
+
+ return {task["task_id"]: task for task in human_eval}
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/data/mbpp.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/data/mbpp.py
new file mode 100644
index 0000000000000000000000000000000000000000..9ff69bf3db8de80feb4b3f2f2d788ddc9e3ac493
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/data/mbpp.py
@@ -0,0 +1,199 @@
+import hashlib
+import json
+import os
+from typing import Dict
+
+import wget
+
+from evalplus.data.utils import (
+ CACHE_DIR,
+ completeness_check,
+ get_dataset_metadata,
+ make_cache,
+ stream_jsonl,
+)
+
+MBPP_PLUS_VERSION = "v0.1.0"
+MBPP_OVERRIDE_PATH = os.environ.get("MBPP_OVERRIDE_PATH", None)
+
+
+def _ready_mbpp_plus_path(mini=False) -> str:
+ assert mini is False, "Mini version of MBPP+ is not available yet."
+
+ if MBPP_OVERRIDE_PATH:
+ return MBPP_OVERRIDE_PATH
+
+ url, plus_path = get_dataset_metadata("MbppPlus", MBPP_PLUS_VERSION, mini)
+ make_cache(url, plus_path)
+
+ return plus_path
+
+
+def mbpp_serialize_inputs(task_id: str, inputs: list) -> list:
+ task_id = int(task_id.split("/")[-1])
+
+ if task_id == 115:
+ return [[[list(item) for item in inp[0]]] for inp in inputs]
+ elif task_id == 124:
+ return [(str(inp[0]), str(inp[1])) for inp in inputs]
+ elif task_id == 252:
+ return [[str(inp[0])] for inp in inputs]
+
+ return inputs
+
+
+def mbpp_deserialize_inputs(task_id: str, inputs: list) -> list:
+ task_id = int(task_id.split("/")[-1])
+ if task_id in [
+ 2,
+ 116,
+ 132,
+ 143,
+ 222,
+ 261,
+ 273,
+ 394,
+ 399,
+ 421,
+ 424,
+ 429,
+ 470,
+ 560,
+ 579,
+ 596,
+ 616,
+ 630,
+ 726,
+ 740,
+ 744,
+ 809,
+ ]:
+ modified_inputs = [[tuple(lst) for lst in inp] for inp in inputs]
+
+ elif task_id in [
+ 63,
+ 64,
+ 70,
+ 94,
+ 120,
+ 237,
+ 272,
+ 299,
+ 400,
+ 409,
+ 417,
+ 438,
+ 473,
+ 614,
+ 780,
+ ]:
+ modified_inputs = [
+ [[tuple(lst) for lst in lst_lst] for lst_lst in inp] for inp in inputs
+ ]
+
+ elif task_id in [75, 413, 444, 753]:
+ modified_inputs = [
+ [[tuple(lst) for lst in inp[0]]] + [inp[1]] for inp in inputs
+ ]
+
+ elif task_id == 106 or task_id == 750:
+ modified_inputs = [[inp[0]] + [tuple(inp[1])] for inp in inputs]
+
+ elif task_id == 115:
+ modified_inputs = [
+ [
+ [
+ set(item) if isinstance(item, list) and len(item) else {}
+ for item in inp[0]
+ ]
+ ]
+ for inp in inputs
+ ]
+
+ elif task_id == 124:
+ modified_inputs = [(float(inp[0]), complex(inp[1])) for inp in inputs]
+
+ elif task_id in [250, 405, 446, 617, 720, 763, 808]:
+ modified_inputs = [[tuple(inp[0])] + [inp[1]] for inp in inputs]
+
+ elif task_id in [259, 401, 445]:
+ modified_inputs = [
+ [[tuple(lst) for lst in lst_lst] for lst_lst in inp] for inp in inputs
+ ]
+ modified_inputs = [[tuple(lst) for lst in inp] for inp in modified_inputs]
+
+ elif task_id == 278:
+ modified_inputs = [
+ [[tuple(item) if isinstance(item, list) else item for item in inp[0]]]
+ for inp in inputs
+ ]
+ modified_inputs = [[tuple(lst) for lst in inp] for inp in modified_inputs]
+
+ elif task_id == 307:
+ modified_inputs = [[tuple(inp[0])] + [inp[1], inp[2]] for inp in inputs]
+
+ elif task_id == 722:
+ modified_inputs = [
+ [{key: tuple(value) for key, value in inp[0].items()}] + inp[1:]
+ for inp in inputs
+ ]
+
+ elif task_id == 252:
+ modified_inputs = [[complex(inp[0])] for inp in inputs]
+
+ elif task_id in [580, 615, 791]:
+
+ def turn_all_list_into_tuple(inp):
+ if isinstance(inp, list):
+ return tuple([turn_all_list_into_tuple(item) for item in inp])
+ return inp
+
+ modified_inputs = [turn_all_list_into_tuple(inp) for inp in inputs]
+
+ else:
+ modified_inputs = inputs
+
+ return modified_inputs
+
+
+def get_mbpp() -> Dict[str, Dict]:
+ """Get sanitized MBPP from Google's Github repo."""
+ mbpp_path = os.path.join(CACHE_DIR, "sanitized-mbpp.json")
+
+ if not os.path.exists(mbpp_path):
+ os.makedirs(CACHE_DIR, exist_ok=True)
+
+ # Install MBPP-sanitized from scratch
+ print("Downloading original MBPP dataset...")
+ wget.download(
+ "https://github.com/google-research/google-research/raw/master/mbpp/sanitized-mbpp.json",
+ mbpp_path,
+ )
+
+ with open(mbpp_path, "r") as f:
+ mbpp = json.load(f)
+
+ return {str(task["task_id"]): task for task in mbpp}
+
+
+def get_mbpp_plus(err_incomplete=True, mini=False) -> Dict[str, Dict]:
+ plus_path = _ready_mbpp_plus_path()
+ plus = {task["task_id"]: task for task in stream_jsonl(plus_path)}
+ for task_id, task in plus.items():
+ task["base_input"] = mbpp_deserialize_inputs(task_id, task["base_input"])
+ task["plus_input"] = mbpp_deserialize_inputs(task_id, task["plus_input"])
+
+ if err_incomplete:
+ completeness_check("MBPP+", plus)
+ return plus
+
+
+def get_mbpp_plus_hash() -> str:
+ """Get the hash of MbppPlus.
+ Returns:
+ str: The hash of MbppPlus
+ """
+ plus_path = _ready_mbpp_plus_path()
+ with open(plus_path, "rb") as f:
+ plus = f.read()
+ return hashlib.md5(plus).hexdigest()
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/data/utils.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/data/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..34ad648ef924563a5584be82f3641b845984271d
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/data/utils.py
@@ -0,0 +1,149 @@
+import gzip
+import json
+import os
+from os import PathLike
+from typing import Dict, Iterable
+
+import tempdir
+import wget
+from appdirs import user_cache_dir
+
+CACHE_DIR = user_cache_dir("evalplus")
+
+
+def get_dataset_metadata(name, version, mini):
+ assert name in ["HumanEvalPlus", "MbppPlus"], f"Unknown/unsupported dataset: {name}"
+ extra = "-Mini" if mini else ""
+ url = f"https://github.com/ganler/release/releases/download/humanevalplus/{name}{extra}-{version}.jsonl.gz"
+ cache_path = os.path.join(CACHE_DIR, f"{name}{extra}-{version}.jsonl")
+ return url, cache_path
+
+
+def make_cache(gzip_url, cache_path):
+ # Check if human eval file exists in CACHE_DIR
+ if not os.path.exists(cache_path):
+ # Install HumanEval dataset and parse as jsonl
+ print(f"Downloading dataset from {gzip_url}")
+ with tempdir.TempDir() as tmpdir:
+ plus_gz_path = os.path.join(tmpdir, f"data.jsonl.gz")
+ wget.download(gzip_url, plus_gz_path)
+
+ with gzip.open(plus_gz_path, "rb") as f:
+ plus = f.read().decode("utf-8")
+
+ # create CACHE_DIR if not exists
+ if not os.path.exists(CACHE_DIR):
+ os.makedirs(CACHE_DIR)
+
+ # Write the original human eval file to CACHE_DIR
+ with open(cache_path, "w") as f:
+ f.write(plus)
+
+
+def write_jsonl(
+ filename: str, data: Iterable[Dict], append: bool = False, drop_builtin: bool = True
+):
+ """
+ Writes an iterable of dictionaries to jsonl
+ """
+ if append:
+ mode = "ab"
+ else:
+ mode = "wb"
+ filename = os.path.expanduser(filename)
+ if filename.endswith(".gz"):
+ with open(filename, mode) as fp:
+ with gzip.GzipFile(fileobj=fp, mode="wb") as gzfp:
+ for x in data:
+ if drop_builtin:
+ x = {k: v for k, v in x.items() if not k.startswith("_")}
+ gzfp.write((json.dumps(x) + "\n").encode("utf-8"))
+ else:
+ with open(filename, mode) as fp:
+ for x in data:
+ if drop_builtin:
+ x = {k: v for k, v in x.items() if not k.startswith("_")}
+ fp.write((json.dumps(x) + "\n").encode("utf-8"))
+
+
+def stream_jsonl(filename: str) -> Iterable[Dict]:
+ """
+ Parses each jsonl line and yields it as a dictionary
+ """
+ if filename.endswith(".gz"):
+ with open(filename, "rb") as gzfp:
+ with gzip.open(gzfp, "rt") as fp:
+ for line in fp:
+ if any(not x.isspace() for x in line):
+ yield json.loads(line)
+ else:
+ with open(filename, "r") as fp:
+ for line in fp:
+ if any(not x.isspace() for x in line):
+ yield json.loads(line)
+
+
+def load_solutions(sample_path: PathLike) -> Iterable[Dict]:
+ """We accept two formats of inputs.
+ + `sample.jsonl` which is the format from HumanEval, i.e., {task_id, completion}.
+ + A folder which contains sub-folders named after the task_id. Each sub-folder
+ contains samples named in `[?].py` where `?` is the solution id starting with 0.
+ Different from `sample.jsonl`, the solutions must be complete (with prompt prefix).
+ """
+
+ # if it is a file
+ if os.path.isfile(sample_path):
+ for i, sample in enumerate(stream_jsonl(sample_path)):
+ sample["_identifier"] = sample["task_id"] + "_" + str(i)
+ yield sample
+ else:
+ # if it is a folder
+ for task_id in os.listdir(sample_path):
+ task_path = os.path.join(sample_path, task_id)
+ if not os.path.isdir(task_path):
+ continue
+
+ for solution_id in os.listdir(task_path):
+ solution_path = os.path.join(task_path, solution_id)
+ if os.path.isfile(solution_path) and solution_path.endswith(".py"):
+ with open(solution_path, "r") as f:
+ completion = f.read()
+ yield {
+ "_identifier": solution_path,
+ "_path": solution_path,
+ "task_id": task_id.replace("_", "/"),
+ "solution": completion,
+ }
+
+
+def write_directory(directory: PathLike, data: Iterable[Dict]):
+ os.makedirs(directory, exist_ok=True)
+ counters = {}
+ for sample in data:
+ assert "solution" in sample, "Samples must come with `solution` field!"
+ task_id = sample["task_id"].replace("/", "_")
+ task_dir = os.path.join(directory, task_id)
+ os.makedirs(task_dir, exist_ok=True)
+ if task_id not in counters:
+ counters[task_id] = 0
+ sample_id = counters[task_id]
+ with open(os.path.join(task_dir, f"{sample_id}.py"), "w") as f:
+ f.write(sample["solution"])
+ counters[task_id] += 1
+
+
+def completeness_check(name, plus):
+ for task_id, task in plus.items():
+ for key in [
+ "prompt",
+ "contract",
+ "canonical_solution",
+ "base_input",
+ "plus_input",
+ "atol",
+ ]:
+ assert key in task, f"{key} not found in {name} #{task_id}!"
+
+
+def to_raw(string):
+ return string.encode("unicode-escape").decode().replace("\\\\", "\\")
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/eval/__init__.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/eval/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..718fdf256c686efd0977f7a15212a677d444baa0
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/eval/__init__.py
@@ -0,0 +1,278 @@
+# The MIT License
+#
+# Copyright (c) OpenAI (https://openai.com)
+#
+# Permission is hereby granted, free of charge, to any person obtaining a copy
+# of this software and associated documentation files (the "Software"), to deal
+# in the Software without restriction, including without limitation the rights
+# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+# copies of the Software, and to permit persons to whom the Software is
+# furnished to do so, subject to the following conditions:
+#
+# The above copyright notice and this permission notice shall be included in
+# all copies or substantial portions of the Software.
+#
+# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
+# THE SOFTWARE.
+
+import itertools
+import multiprocessing
+import time
+from multiprocessing import Array, Value
+from typing import Any, Dict, List, Tuple, Union
+
+import numpy as np
+
+from evalplus.eval._special_oracle import MBPP_OUTPUT_NOT_NONE_TASKS, _poly
+from evalplus.eval.utils import (
+ create_tempdir,
+ reliability_guard,
+ swallow_io,
+ time_limit,
+)
+
+
+def compatible_eval_result(results: Dict) -> Dict:
+ # compatibility
+ for task_results in results["eval"].values():
+ # update the "files" field to "nfiles"
+ if "files" in task_results and "nfiles" not in task_results:
+ task_results["nfiles"] = len(task_results.pop("files"))
+ return results
+
+
+# unbiased estimator from https://github.com/openai/human-eval
+def estimate_pass_at_k(
+ num_samples: Union[int, List[int], np.ndarray],
+ num_correct: Union[List[int], np.ndarray],
+ k: int,
+) -> np.ndarray:
+ """
+ Estimates pass@k of each problem and returns them in an array.
+ """
+
+ def estimator(n: int, c: int, k: int) -> float:
+ """
+ Calculates 1 - comb(n - c, k) / comb(n, k).
+ """
+ if n - c < k:
+ return 1.0
+ return 1.0 - np.prod(1.0 - k / np.arange(n - c + 1, n + 1))
+
+ if isinstance(num_samples, int):
+ num_samples_it = itertools.repeat(num_samples, len(num_correct))
+ else:
+ assert len(num_samples) == len(num_correct)
+ num_samples_it = iter(num_samples)
+
+ return np.array(
+ [estimator(int(n), int(c), k) for n, c in zip(num_samples_it, num_correct)]
+ )
+
+
+SUCCESS = "success"
+FAILED = "failed"
+TIMEOUT = "timed out"
+
+_SUCCESS = 0
+_FAILED = 1
+_TIMEOUT = 2
+_UNKNOWN = 3
+
+_mapping = {_SUCCESS: SUCCESS, _FAILED: FAILED, _TIMEOUT: TIMEOUT, _UNKNOWN: None}
+
+
+def is_floats(x) -> bool:
+ # check if it is float; List[float]; Tuple[float]
+ if isinstance(x, float):
+ return True
+ if isinstance(x, (list, tuple)):
+ return all(isinstance(i, float) for i in x)
+ if isinstance(x, np.ndarray):
+ return x.dtype == np.float64 or x.dtype == np.float32
+ return False
+
+
+def unsafe_execute(
+ dataset: str,
+ entry_point: str,
+ code: str,
+ inputs,
+ expected: List,
+ time_limits,
+ atol,
+ fast_check,
+ stat: Value,
+ details: Array,
+ progress: Value,
+):
+ with create_tempdir():
+ # These system calls are needed when cleaning up tempdir.
+ import os
+ import shutil
+
+ rmtree = shutil.rmtree
+ rmdir = os.rmdir
+ chdir = os.chdir
+ # Disable functionalities that can make destructive changes to the test.
+ # allow only 4GB memory usage
+ maximum_memory_bytes = 4 * 1024 * 1024 * 1024
+ reliability_guard(maximum_memory_bytes=maximum_memory_bytes)
+ exec_globals = {}
+ try:
+ with swallow_io():
+ exec(code, exec_globals)
+ fn = exec_globals[entry_point]
+ for i, inp in enumerate(inputs):
+ try:
+ with time_limit(time_limits[i]):
+ out = fn(*inp)
+
+ exp = expected[i]
+ exact_match = out == exp
+
+ # ================================================ #
+ # ============== special oracles ================= #
+ if dataset == "mbpp":
+ if (
+ "are_equivalent" == entry_point
+ ): # Mbpp/164 special oracle
+ exact_match = exact_match or True
+ elif "sum_div" == entry_point: # Mbpp/295 special oracle
+ exact_match = exact_match or out == 0
+ elif entry_point in MBPP_OUTPUT_NOT_NONE_TASKS:
+ # exp is True if not None
+ # False if None
+ if isinstance(out, bool):
+ exact_match = out == exp
+ else:
+ exact_match = exp == (out is not None)
+
+ if dataset == "humaneval":
+ if "find_zero" == entry_point:
+ assert _poly(*out, inp) <= atol
+ # ============== special oracles ================= #
+ # ================================================ #
+
+ if atol == 0 and is_floats(exp):
+ atol = 1e-6 # enforce atol for float comparison
+ if not exact_match and atol != 0:
+ np.testing.assert_allclose(out, exp, atol=atol)
+ else:
+ assert exact_match
+ except BaseException:
+ if fast_check:
+ raise
+
+ details[i] = False
+ progress.value += 1
+ continue
+
+ details[i] = True
+ progress.value += 1
+ stat.value = _SUCCESS
+ except BaseException:
+ stat.value = _FAILED
+ # Needed for cleaning up.
+ shutil.rmtree = rmtree
+ os.rmdir = rmdir
+ os.chdir = chdir
+
+
+def untrusted_check(
+ dataset: str,
+ code: str,
+ inputs: List[Any],
+ entry_point: str,
+ expected,
+ atol,
+ ref_time: List[float],
+ fast_check: bool = False,
+ min_time_limit: float = 0.1,
+ gt_time_limit_factor: float = 2.0,
+) -> Tuple[str, np.ndarray]:
+ time_limits = [max(min_time_limit, gt_time_limit_factor * t) for t in ref_time]
+ timeout = sum(time_limits) + 1
+ if not fast_check:
+ timeout += 1 # extra time for data collection
+
+ # shared memory objects
+ progress = Value("i", 0)
+ stat = Value("i", _UNKNOWN)
+ details = Array("b", [False for _ in range(len(inputs))])
+
+ p = multiprocessing.Process(
+ target=unsafe_execute,
+ args=(
+ dataset,
+ entry_point,
+ code,
+ inputs,
+ expected,
+ time_limits,
+ atol,
+ fast_check,
+ # return values
+ stat,
+ details,
+ progress,
+ ),
+ )
+ p.start()
+ p.join(timeout=timeout + 1)
+ if p.is_alive():
+ p.terminate()
+ time.sleep(0.1)
+ if p.is_alive():
+ p.kill()
+ time.sleep(0.1)
+
+ stat = _mapping[stat.value]
+ details = details[: progress.value]
+
+ if not stat:
+ stat = TIMEOUT
+
+ if stat == SUCCESS:
+ if len(details) != len(inputs) or not all(details):
+ stat = FAILED
+
+ return stat, details
+
+
+def evaluate_files(
+ dataset: str,
+ files: List[str],
+ inputs: List,
+ expected: List,
+ entry_point: str,
+ atol: float,
+ ref_time: List[float],
+ fast_check: bool = False,
+ min_time_limit: float = 0.1,
+ gt_time_limit_factor: float = 2.0,
+) -> List[Tuple[str, List[bool]]]:
+ ret = []
+ # sort files by the id in name (i.e., "../n.py")
+ files = sorted(files, key=lambda x: int(x.split("/")[-1].split(".")[0]))
+ for file in files:
+ code = open(file, "r").read()
+ stat, det = untrusted_check(
+ dataset,
+ code,
+ inputs,
+ entry_point,
+ expected=expected,
+ atol=atol,
+ ref_time=ref_time,
+ fast_check=fast_check,
+ min_time_limit=min_time_limit,
+ gt_time_limit_factor=gt_time_limit_factor,
+ )
+ ret.append((stat, det.tolist()))
+ return ret
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/eval/_special_oracle.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/eval/_special_oracle.py
new file mode 100644
index 0000000000000000000000000000000000000000..9ff5a855d5eb02a6df0c6f368ce8570b03f22066
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/eval/_special_oracle.py
@@ -0,0 +1,15 @@
+"""Special oracle handlings for problems where direct differential testing is not applicable."""
+import math
+
+# For tasks whose output are not serializable, we only check the output is not None, which
+# is also consistent with the original dataset.
+MBPP_OUTPUT_NOT_NONE_TASKS = ["check_str", "text_match_three", "text_starta_endb"]
+
+
+# oracle for HumaneEval/032
+def _poly(xs: list, x: float):
+ """
+ Evaluates polynomial with coefficients xs at point x.
+ return xs[0] + xs[1] * x + xs[1] * x^2 + .... xs[n] * x^n
+ """
+ return sum([coeff * math.pow(x, i) for i, coeff in enumerate(xs)])
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/eval/utils.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/eval/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..f027274cda47c195c655ac426b69bb20fe7dff87
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/eval/utils.py
@@ -0,0 +1,187 @@
+# The MIT License
+#
+# Copyright (c) OpenAI (https://openai.com)
+#
+# Permission is hereby granted, free of charge, to any person obtaining a copy
+# of this software and associated documentation files (the "Software"), to deal
+# in the Software without restriction, including without limitation the rights
+# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+# copies of the Software, and to permit persons to whom the Software is
+# furnished to do so, subject to the following conditions:
+#
+# The above copyright notice and this permission notice shall be included in
+# all copies or substantial portions of the Software.
+#
+# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
+# THE SOFTWARE.
+
+import contextlib
+import faulthandler
+import io
+import os
+import platform
+import signal
+import tempfile
+from typing import Optional
+
+
+@contextlib.contextmanager
+def swallow_io():
+ stream = WriteOnlyStringIO()
+ with contextlib.redirect_stdout(stream):
+ with contextlib.redirect_stderr(stream):
+ with redirect_stdin(stream):
+ yield
+
+
+@contextlib.contextmanager
+def time_limit(seconds: float):
+ def signal_handler(signum, frame):
+ raise TimeoutException("Timed out!")
+
+ signal.setitimer(signal.ITIMER_REAL, seconds)
+ signal.signal(signal.SIGALRM, signal_handler)
+ try:
+ yield
+ finally:
+ signal.setitimer(signal.ITIMER_REAL, 0)
+
+
+@contextlib.contextmanager
+def create_tempdir():
+ with tempfile.TemporaryDirectory() as dirname:
+ with chdir(dirname):
+ yield dirname
+
+
+@contextlib.contextmanager
+def chdir(root):
+ if root == ".":
+ yield
+ return
+ cwd = os.getcwd()
+ os.chdir(root)
+ try:
+ yield
+ except BaseException as exc:
+ raise exc
+ finally:
+ os.chdir(cwd)
+
+
+class TimeoutException(Exception):
+ pass
+
+
+class WriteOnlyStringIO(io.StringIO):
+ """StringIO that throws an exception when it's read from"""
+
+ def read(self, *args, **kwargs):
+ raise IOError
+
+ def readline(self, *args, **kwargs):
+ raise IOError
+
+ def readlines(self, *args, **kwargs):
+ raise IOError
+
+ def readable(self, *args, **kwargs):
+ """Returns True if the IO object can be read."""
+ return False
+
+
+class redirect_stdin(contextlib._RedirectStream): # type: ignore
+ _stream = "stdin"
+
+
+def reliability_guard(maximum_memory_bytes: Optional[int] = None):
+ """
+ This disables various destructive functions and prevents the generated code
+ from interfering with the test (e.g. fork bomb, killing other processes,
+ removing filesystem files, etc.)
+
+ WARNING
+ This function is NOT a security sandbox. Untrusted code, including, model-
+ generated code, should not be blindly executed outside of one. See the
+ Codex paper for more information about OpenAI's code sandbox, and proceed
+ with caution.
+ """
+
+ if maximum_memory_bytes is not None:
+ import resource
+
+ resource.setrlimit(
+ resource.RLIMIT_AS, (maximum_memory_bytes, maximum_memory_bytes)
+ )
+ resource.setrlimit(
+ resource.RLIMIT_DATA, (maximum_memory_bytes, maximum_memory_bytes)
+ )
+ if not platform.uname().system == "Darwin":
+ resource.setrlimit(
+ resource.RLIMIT_STACK, (maximum_memory_bytes, maximum_memory_bytes)
+ )
+
+ faulthandler.disable()
+
+ import builtins
+
+ builtins.exit = None
+ builtins.quit = None
+
+ import os
+
+ os.environ["OMP_NUM_THREADS"] = "1"
+
+ os.kill = None
+ os.system = None
+ os.putenv = None
+ os.remove = None
+ os.removedirs = None
+ os.rmdir = None
+ os.fchdir = None
+ os.setuid = None
+ os.fork = None
+ os.forkpty = None
+ os.killpg = None
+ os.rename = None
+ os.renames = None
+ os.truncate = None
+ os.replace = None
+ os.unlink = None
+ os.fchmod = None
+ os.fchown = None
+ os.chmod = None
+ os.chown = None
+ os.chroot = None
+ os.fchdir = None
+ os.lchflags = None
+ os.lchmod = None
+ os.lchown = None
+ os.getcwd = None
+ os.chdir = None
+ builtins.open = None
+
+ import shutil
+
+ shutil.rmtree = None
+ shutil.move = None
+ shutil.chown = None
+
+ import subprocess
+
+ subprocess.Popen = None # type: ignore
+
+ __builtins__["help"] = None
+
+ import sys
+
+ sys.modules["ipdb"] = None
+ sys.modules["joblib"] = None
+ sys.modules["resource"] = None
+ sys.modules["psutil"] = None
+ sys.modules["tkinter"] = None
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/evaluate.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/evaluate.py
new file mode 100644
index 0000000000000000000000000000000000000000..8d73a2b2f5e27f8c9e82f62446881a2dd4c0228e
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/evaluate.py
@@ -0,0 +1,300 @@
+import argparse
+import json
+import multiprocessing
+import os
+import pickle
+import threading
+import time
+from collections import Counter, defaultdict
+from concurrent.futures import ProcessPoolExecutor, as_completed
+from datetime import datetime
+from typing import Any, Dict, List, Optional, Tuple, Union
+from warnings import warn
+
+import numpy as np
+from termcolor import cprint
+from tqdm import tqdm
+
+from evalplus.data import (
+ get_human_eval_plus,
+ get_human_eval_plus_hash,
+ get_mbpp_plus,
+ get_mbpp_plus_hash,
+ load_solutions,
+)
+from evalplus.data.utils import CACHE_DIR
+from evalplus.eval import (
+ SUCCESS,
+ compatible_eval_result,
+ estimate_pass_at_k,
+ untrusted_check,
+)
+from evalplus.eval._special_oracle import MBPP_OUTPUT_NOT_NONE_TASKS
+from evalplus.gen.util import trusted_exec
+
+# 1st item: the status
+# 2nd item (optional): the detailed pass/fail boolean for each input
+Result = Tuple[str, List[bool]]
+
+
+def get_groundtruth(problems, hashcode, tasks_only_output_not_none):
+ cache_file = os.path.join(CACHE_DIR, f"{hashcode}.pkl")
+ if os.path.exists(cache_file):
+ print(f"Load from ground-truth from {cache_file}")
+ with open(cache_file, "rb") as f:
+ return pickle.load(f)
+
+ os.makedirs(CACHE_DIR, exist_ok=True)
+ print("Computing expected output...")
+ tbegin = time.time()
+ expected_output = {}
+ for task_id, problem in problems.items():
+ oracle = {}
+ oracle["base"], oracle["base_time"] = trusted_exec(
+ problem["prompt"] + problem["canonical_solution"],
+ problem["base_input"],
+ problem["entry_point"],
+ record_time=True,
+ output_not_none=problem["entry_point"] in tasks_only_output_not_none,
+ )
+
+ oracle["plus"], oracle["plus_time"] = trusted_exec(
+ problem["prompt"] + problem["canonical_solution"],
+ problem["plus_input"],
+ problem["entry_point"],
+ record_time=True,
+ output_not_none=problem["entry_point"] in tasks_only_output_not_none,
+ )
+ expected_output[task_id] = oracle
+ print(f"Expected outputs computed in {time.time() - tbegin:.2f}s")
+
+ with open(cache_file, "wb") as f:
+ pickle.dump(expected_output, f)
+
+ return expected_output
+
+
+def check_correctness(
+ dataset: str,
+ completion_id: int,
+ problem: Dict[str, Any],
+ solution: str,
+ expected_output: Dict[str, List],
+ base_only=False,
+ fast_check=False,
+ identifier=None,
+ min_time_limit: float = 0.1,
+ gt_time_limit_factor: float = 2.0,
+) -> Dict[str, Union[int, Optional[Result]]]:
+ ret = {
+ "completion_id": completion_id,
+ "task_id": problem["task_id"],
+ "_identifier": identifier,
+ }
+ ret["base"] = untrusted_check(
+ dataset,
+ solution,
+ problem["base_input"],
+ problem["entry_point"],
+ expected=expected_output["base"],
+ atol=problem["atol"],
+ ref_time=expected_output["base_time"],
+ fast_check=fast_check,
+ min_time_limit=min_time_limit,
+ gt_time_limit_factor=gt_time_limit_factor,
+ )
+
+ if not base_only:
+ ret["plus"] = untrusted_check(
+ dataset,
+ solution,
+ problem["plus_input"],
+ problem["entry_point"],
+ expected=expected_output["plus"],
+ atol=problem["atol"],
+ ref_time=expected_output["plus_time"],
+ fast_check=fast_check,
+ min_time_limit=min_time_limit,
+ gt_time_limit_factor=gt_time_limit_factor,
+ )
+
+ return ret
+
+
+def evaluate(flags):
+ if flags.parallel is None:
+ n_workers = max(1, multiprocessing.cpu_count() // 2)
+ else:
+ n_workers = flags.parallel
+
+ if os.path.isdir(flags.samples):
+ result_path = os.path.join(flags.samples, "eval_results.json")
+ else:
+ assert flags.samples.endswith(".jsonl")
+ result_path = flags.samples.replace(".jsonl", "_eval_results.json")
+
+ if os.path.isfile(result_path) and not flags.i_just_wanna_run:
+ print(f"Load from previous results from {result_path}")
+ with open(result_path, "r") as f:
+ results = json.load(f)
+
+ results = compatible_eval_result(results)
+ else:
+ if flags.dataset == "humaneval":
+ problems = get_human_eval_plus(mini=flags.mini)
+ dataset_hash = get_human_eval_plus_hash()
+ expected_output = get_groundtruth(problems, dataset_hash, [])
+ elif flags.dataset == "mbpp":
+ problems = get_mbpp_plus(mini=flags.mini)
+ dataset_hash = get_mbpp_plus_hash()
+ expected_output = get_groundtruth(
+ problems,
+ dataset_hash,
+ MBPP_OUTPUT_NOT_NONE_TASKS,
+ )
+
+ results = {
+ "date": datetime.now().strftime("%Y-%m-%d %H:%M"),
+ "hash": dataset_hash,
+ "eval": {},
+ }
+
+ with ProcessPoolExecutor(max_workers=n_workers) as executor:
+ futures = []
+ completion_id = Counter()
+ n_samples = 0
+ eval_results = defaultdict(list)
+ remainings = set()
+
+ print("Reading samples...")
+ for sample in tqdm(load_solutions(flags.samples)):
+ task_id = sample["task_id"]
+ solution = (
+ sample["solution"]
+ if "solution" in sample
+ else problems[task_id]["prompt"] + sample["completion"]
+ )
+ remainings.add(sample["_identifier"])
+ args = (
+ flags.dataset,
+ completion_id[task_id],
+ problems[task_id],
+ solution,
+ expected_output[task_id],
+ flags.base_only,
+ not flags.test_details, # fast_check
+ sample["_identifier"],
+ flags.min_time_limit,
+ flags.gt_time_limit_factor,
+ )
+ futures.append(executor.submit(check_correctness, *args))
+ completion_id[task_id] += 1
+ n_samples += 1
+
+ assert n_samples == len(remainings), "Missing problems in unfinished"
+ assert len(completion_id) == len(problems), "Missing problems in samples"
+
+ def stucking_checker():
+ while remainings:
+ last_size = len(remainings)
+ time.sleep(20)
+ if last_size != len(remainings) or len(remainings) == 0:
+ continue
+ # Potential stucking
+ warn("No samples had finished testing in the last 20s")
+ warn(f"{len(remainings)} samples to be tested: {remainings}")
+
+ threading.Thread(target=stucking_checker).start()
+
+ for future in tqdm(as_completed(futures), total=n_samples):
+ result = future.result()
+ remainings.remove(result["_identifier"])
+ eval_results[result["task_id"]].append(result)
+
+ # sort the results for each problem by completion_id
+ for task_id, task_results in eval_results.items():
+ task_results.sort(key=lambda x: x["completion_id"])
+ results["eval"][task_id] = {
+ "nfiles": len(task_results),
+ "base": [x["base"] for x in task_results],
+ "plus": [x["plus"] for x in task_results]
+ if not flags.base_only
+ else [],
+ }
+
+ if os.path.isfile(result_path) and flags.i_just_wanna_run:
+ decision = ""
+ # while decision.lower() not in ["y", "n"]:
+ # print(f"{result_path} already exists. Press [Y/N] to overwrite or exit...")
+ # decision = input()
+ # if decision.lower() == "y":
+ # mv the file to a backup
+ new_path = result_path + ".bak"
+ while os.path.isfile(new_path):
+ new_path += ".bak"
+ os.rename(result_path, new_path)
+ print(f"Backup {result_path} to {new_path}")
+
+ if not os.path.isfile(result_path):
+ with open(result_path, "w") as f:
+ json.dump(results, f)
+
+ # Calculate pass@k.
+ total = np.array([r["nfiles"] for r in results["eval"].values()])
+ base_correct = []
+ new_correct = []
+
+ for res in results["eval"].values():
+ bc = sum([r[0] == SUCCESS for r in res["base"]])
+ base_correct.append(bc)
+ if res["plus"]:
+ new_correct.append(
+ sum(
+ [
+ res["plus"][i][0] == res["base"][i][0] == SUCCESS
+ for i in range(len(res["plus"]))
+ ]
+ )
+ )
+ base_correct = np.array(base_correct)
+
+ pass_at_k = {
+ f"pass@{k}": estimate_pass_at_k(total, base_correct, k).mean()
+ for k in [1, 10, 100]
+ if total.min() >= k
+ }
+ cprint(f"{flags.dataset} (base tests)", "red")
+ for k, v in pass_at_k.items():
+ cprint(f"{k}:\t{v:.3f}", "red")
+
+ if new_correct:
+ cprint(f"{flags.dataset}+ (base + extra tests)", "green")
+ pass_at_k = {
+ f"pass@{k}": estimate_pass_at_k(total, np.array(new_correct), k).mean()
+ for k in [1, 10, 100]
+ if (total >= k).all()
+ }
+ for k, v in pass_at_k.items():
+ cprint(f"{k}:\t{v:.3f}", "green")
+
+
+def main():
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ "--dataset", required=True, type=str, choices=["humaneval", "mbpp"]
+ )
+ parser.add_argument("--samples", required=True, type=str)
+ parser.add_argument("--base-only", action="store_true")
+ parser.add_argument("--parallel", default=None, type=int)
+ parser.add_argument("--i-just-wanna-run", action="store_true")
+ parser.add_argument("--test-details", action="store_true")
+ parser.add_argument("--min-time-limit", default=1, type=float)
+ parser.add_argument("--gt-time-limit-factor", default=4.0, type=float)
+ parser.add_argument("--mini", action="store_true")
+ args = parser.parse_args()
+
+ evaluate(args)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/gen/__init__.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/gen/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..802146a7d709214e90833187bd4e535e340db89b
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/gen/__init__.py
@@ -0,0 +1,21 @@
+import copy
+from typing import Any, List
+
+
+class BaseGen(object):
+ def __init__(self, inputs: List[Any], entry_point: str, contract: str):
+ """Initializing a input mutator.
+
+ Args:
+ inputs (List[Any]): The set of initial inputs (i.e., seeds)
+ entry_point (str): The function name to invoke with the input
+ contract (str): The contract to verify input validity
+ """
+ self.contract = contract
+ self.entry_point = entry_point
+ self.seed_pool: List[Any] = copy.deepcopy(inputs)
+ self.new_inputs = []
+ self.seed_hash = set([hash(str(x)) for x in self.seed_pool])
+
+ def generate(self, num: int) -> List[Any]:
+ raise NotImplementedError
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/gen/chatgpt_gen.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/gen/chatgpt_gen.py
new file mode 100644
index 0000000000000000000000000000000000000000..b7c116381f2a825e7c3210fce175eeaac735babb
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/gen/chatgpt_gen.py
@@ -0,0 +1,78 @@
+import ast
+import random
+from typing import List
+
+import openai
+from openai.types.chat import ChatCompletion
+
+from evalplus.data.utils import to_raw
+from evalplus.gen import BaseGen
+from evalplus.gen.util import trusted_check_exec
+from evalplus.gen.util.api_request import make_auto_request
+
+
+class ChatGPTGen(BaseGen):
+ def __init__(self, inputs: List, signature: str, contract_code: str, gd_code: str):
+ super().__init__(inputs, signature, contract_code)
+ self.gd_code = gd_code
+ self.prompt_messages = [
+ "Please generate complex inputs to test the function.",
+ "Please generate corner case inputs to test the function.",
+ "Please generate difficult inputs to test the function.",
+ ]
+ self.iteration = 20
+ self.client = openai.Client()
+
+ def seed_selection(self) -> List:
+ # get 5 for now.
+ return random.sample(self.seed_pool, k=min(len(self.seed_pool), 5))
+
+ @staticmethod
+ def _parse_ret(ret: ChatCompletion) -> List:
+ rets = []
+ output = ret.choices[0].message.content
+ if "```" in output:
+ for x in output.split("```")[1].splitlines():
+ if x.strip() == "":
+ continue
+ try:
+ # remove comments
+ input = ast.literal_eval(f"[{x.split('#')[0].strip()}]")
+ except: # something wrong.
+ continue
+ rets.append(input)
+ return rets
+
+ def chatgpt_generate(self, selected_inputs: List) -> List:
+ # append the groundtruth function
+ # actually it can be any function (maybe we can generate inputs for each llm generated code individually)
+ message = f"Here is a function that we want to test:\n```\n{self.gd_code}\n```"
+ str_inputs = "\n".join(
+ [
+ ", ".join([f"'{to_raw(i)}'" if type(i) == str else str(i) for i in x])
+ for x in selected_inputs
+ ]
+ )
+ message += f"\nThese are some example inputs used to test the function:\n```\n{str_inputs}\n```"
+ message += f"\n{random.choice(self.prompt_messages)}"
+ ret = make_auto_request(
+ self.client,
+ message=message,
+ model="gpt-3.5-turbo",
+ max_tokens=256,
+ response_format={"type": "text"},
+ )
+ return self._parse_ret(ret)
+
+ def generate(self, num: int):
+ while len(self.new_inputs) < num and self.iteration >= 0:
+ seeds = self.seed_selection()
+ new_inputs = self.chatgpt_generate(seeds)
+ for new_input in new_inputs:
+ if hash(str(new_input)) not in self.seed_hash:
+ if trusted_check_exec(self.contract, [new_input], self.entry_point):
+ self.seed_pool.append(new_input)
+ self.seed_hash.add(hash(str(new_input)))
+ self.new_inputs.append(new_input)
+ self.iteration -= 1
+ return self.new_inputs[:num]
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/gen/mut_gen.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/gen/mut_gen.py
new file mode 100644
index 0000000000000000000000000000000000000000..306b617248d2c289c3b5caf74aac7491e1aa69be
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/gen/mut_gen.py
@@ -0,0 +1,30 @@
+import random
+from abc import abstractmethod
+from typing import Any, List
+
+from evalplus.gen import BaseGen
+from evalplus.gen.util import trusted_check_exec
+
+
+class MutateGen(BaseGen):
+ def __init__(self, inputs: List, signature: str, contract_code: str):
+ super().__init__(inputs, signature, contract_code)
+
+ def seed_selection(self):
+ # random for now.
+ return random.choice(self.seed_pool)
+
+ @abstractmethod
+ def mutate(self, seed_input: Any) -> Any:
+ pass
+
+ def generate(self, num: int) -> List[Any]:
+ while len(self.new_inputs) < num:
+ seed = self.seed_selection()
+ new_input = self.mutate(seed)
+ if hash(str(new_input)) not in self.seed_hash:
+ if trusted_check_exec(self.contract, [new_input], self.entry_point):
+ self.seed_pool.append(new_input)
+ self.seed_hash.add(hash(str(new_input)))
+ self.new_inputs.append(new_input)
+ return self.new_inputs[:num]
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/gen/type_mut.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/gen/type_mut.py
new file mode 100644
index 0000000000000000000000000000000000000000..f926dda8463e98f98ff14c3d9a305f0138c28022
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/gen/type_mut.py
@@ -0,0 +1,340 @@
+import copy
+import random
+import string
+import time
+from typing import Any, Dict, List, Set, Tuple
+
+from multipledispatch import dispatch
+
+from evalplus.gen.mut_gen import MutateGen
+from evalplus.gen.util import trusted_check_exec
+
+MAX_MULTI_STEP_SIZE = 5
+MUTATE_BOUND_SIZE = 8
+
+NoneType = type(None)
+
+
+# decorator to use ingredients
+class use_ingredient:
+ def __init__(self, prob: float):
+ assert 0 <= prob <= 0.95
+ self.prob = prob
+
+ def __call__(obj, func):
+ def wrapper(self, seed_input):
+ if random.random() < obj.prob and self.ingredients[type(seed_input)]:
+ return random.choice(list(self.ingredients[type(seed_input)]))
+ else:
+ return func(self, seed_input)
+
+ return wrapper
+
+
+class TypedMutGen(MutateGen):
+ def __init__(self, inputs: List, signature: str, contract_code: str):
+ super().__init__(inputs, signature, contract_code)
+ self.timeout = 60 * 60 # 1 hour
+ self.ingredients = {
+ int: set(),
+ float: set(),
+ str: set(),
+ complex: set(),
+ }
+ for x in inputs:
+ self.fetch_ingredient(x)
+
+ def seed_selection(self):
+ # random for now.
+ return random.choice(self.seed_pool)
+
+ def mutate(self, seed_input: Any) -> List:
+ new_input = copy.deepcopy(seed_input)
+
+ patience = MUTATE_BOUND_SIZE
+ while new_input == seed_input or patience == 0:
+ new_input = self.typed_mutate(new_input)
+ patience -= 1
+
+ return new_input
+
+ #########################
+ # Type-aware generation #
+ #########################
+ @dispatch(NoneType)
+ def typed_gen(self, _):
+ return None
+
+ @dispatch(int)
+ def typed_gen(self, _):
+ @use_ingredient(0.5)
+ def _impl(*_):
+ return random.randint(-100, 100)
+
+ return _impl(self, _)
+
+ @dispatch(float)
+ def typed_gen(self, _):
+ @use_ingredient(0.5)
+ def _impl(*_):
+ return random.uniform(-100, 100)
+
+ return _impl(self, _)
+
+ @dispatch(bool)
+ def typed_gen(self, _):
+ return random.choice([True, False])
+
+ @dispatch(str)
+ def typed_gen(self, _):
+ @use_ingredient(0.5)
+ def _impl(*_):
+ return "".join(
+ random.choice(string.ascii_letters)
+ for _ in range(random.randint(0, 10))
+ )
+
+ return _impl(self, _)
+
+ def any_gen(self):
+ # weighted choose
+ choice = random.choices(
+ [
+ True,
+ 1,
+ 1.1,
+ "str",
+ [], # list
+ tuple(), # tuple
+ dict(), # dict
+ None, # None
+ ],
+ [0.2, 0.2, 0.2, 0.2, 0.05, 0.05, 0.05, 0.05],
+ )[0]
+ return self.typed_gen(choice)
+
+ @dispatch(list)
+ def typed_gen(self, _):
+ ret = []
+ size = random.randint(0, 10)
+ if random.randint(0, 4) == 0: # heterogeneous
+ for _ in range(size):
+ ret.append(self.any_gen())
+ else: # homogeneous
+ t = random.choice([bool(), int(), float(), str()])
+ for _ in range(size):
+ ret.append(self.typed_gen(t))
+ return ret
+
+ @dispatch(tuple)
+ def typed_gen(self, _):
+ return tuple(self.typed_gen([]))
+
+ # NOTE: disable set for now as Steven is too weak in Python (/s)
+ # @dispatch(set)
+ # def typed_gen(self, _):
+ # return set(self.typed_gen([]))
+
+ @dispatch(dict)
+ def typed_gen(self, _):
+ ret = dict()
+ values = self.typed_gen([])
+ # NOTE: Assumption: nobody uses dict with heterogeneous keys
+ # NOTE: Assumption: nobody uses dict with boolean keys
+ key_type = random.choice([int(), float(), str()])
+ for v in values:
+ ret[self.typed_gen(key_type)] = self.typed_gen(v)
+ return ret
+
+ ########################
+ # Type-aware mutation #
+ ########################
+ # Simple primitives
+ @dispatch(int)
+ def typed_mutate(self, seed_input: int):
+ @use_ingredient(0.5)
+ def _impl(_, seed_input: int):
+ return seed_input + random.randint(-1, 1)
+
+ return _impl(self, seed_input)
+
+ @dispatch(float)
+ def typed_mutate(self, seed_input: float):
+ @use_ingredient(0.5)
+ def _impl(_, seed_input: float):
+ if random.randint(0, 1):
+ return seed_input + random.uniform(-1, 1)
+ return seed_input * (1 + random.uniform(-0.5, 0.5))
+
+ return _impl(self, seed_input)
+
+ @dispatch(complex)
+ def typed_mutate(self, seed_input: complex):
+ @use_ingredient(0.5)
+ def _impl(_, seed_input: complex):
+ imag = seed_input.imag + random.uniform(-1, 1)
+ return complex(0, imag)
+
+ return _impl(self, seed_input)
+
+ @dispatch(bool)
+ def typed_mutate(self, seed_input: bool):
+ return random.choice([True, False])
+
+ @dispatch(NoneType)
+ def typed_mutate(self, seed_input: NoneType):
+ return None
+
+ # List-like
+ @dispatch(list)
+ def typed_mutate(self, seed_input: List):
+ if len(seed_input) == 0:
+ return self.typed_gen([])
+
+ choice = random.randint(0, 3)
+ idx = random.randint(0, len(seed_input) - 1)
+ if choice == 0: # remove one element
+ seed_input.pop(random.randint(0, len(seed_input) - 1))
+ elif choice == 1 and len(seed_input) > 0: # add one mutated element
+ seed_input.insert(
+ random.randint(0, len(seed_input) - 1),
+ self.typed_mutate(seed_input[idx]),
+ )
+ elif choice == 2 and len(seed_input) > 0: # repeat one element
+ seed_input.append(seed_input[idx])
+ else: # inplace element change
+ seed_input[idx] = self.typed_mutate(seed_input[idx])
+ return seed_input
+
+ @dispatch(tuple)
+ def typed_mutate(self, seed_input: Tuple):
+ return tuple(self.typed_mutate(list(seed_input)))
+
+ # String
+ @dispatch(str)
+ def typed_mutate(self, seed_input: str):
+ @use_ingredient(0.4)
+ def _impl(_, seed_input: str):
+ choice = random.randint(0, 2) if seed_input else 0
+ if choice == 0 and self.ingredients[str]: # insert an ingredient
+ idx = random.randint(0, len(seed_input))
+ return (
+ seed_input[:idx]
+ + random.choice(list(self.ingredients[str]))
+ + seed_input[idx:]
+ )
+ # other choices assume len(seed_input) > 0
+ elif choice == 1: # replace a substring with empty or mutated string
+ start = random.randint(0, len(seed_input) - 1)
+ end = random.randint(start + 1, len(seed_input))
+ mid = (
+ ""
+ if random.randint(0, 1)
+ else self.typed_mutate(seed_input[start:end])
+ )
+ return seed_input[:start] + mid + seed_input[end:]
+ elif choice == 2: # repeat one element
+ idx = random.randint(0, len(seed_input) - 1)
+ return (
+ seed_input[:idx]
+ + seed_input[random.randint(0, len(seed_input) - 1)]
+ + seed_input[idx:]
+ )
+
+ # random char
+ return self.typed_gen(str())
+
+ return _impl(self, seed_input)
+
+ # Set
+ @dispatch(set)
+ def typed_mutate(self, seed_input: Set):
+ return set(self.typed_mutate(list(seed_input)))
+
+ # Dict
+ @dispatch(dict)
+ def typed_mutate(self, seed_input: Dict):
+ if len(seed_input) == 0:
+ return self.typed_gen(dict())
+
+ choice = random.randint(0, 2)
+ if choice == 0: # remove a kv
+ del seed_input[random.choice(list(seed_input.keys()))]
+ elif choice == 1: # add a kv
+ k = self.typed_mutate(random.choice(list(seed_input.keys())))
+ v = self.typed_mutate(random.choice(list(seed_input.values())))
+ seed_input[k] = v
+ elif choice == 2: # inplace value change
+ k0, v0 = random.choice(list(seed_input.items()))
+ seed_input[k0] = self.typed_mutate(v0)
+ return seed_input
+
+ ############################################
+ # Fetching ingredients to self.ingredients #
+ ############################################
+ def fetch_ingredient(self, seed_input):
+ self.typed_fetch(seed_input)
+
+ @dispatch(int)
+ def typed_fetch(self, seed_input: int):
+ self.ingredients[int].add(seed_input)
+
+ @dispatch(float)
+ def typed_fetch(self, seed_input: float):
+ self.ingredients[float].add(seed_input)
+
+ @dispatch(complex)
+ def typed_fetch(self, seed_input: complex):
+ self.ingredients[complex].add(seed_input)
+
+ @dispatch(str)
+ def typed_fetch(self, seed_input: str):
+ self.ingredients[str].add(seed_input)
+ for token in seed_input.strip().split():
+ self.ingredients[str].add(token)
+
+ # List-like
+ def _fetch_list_like(self, seed_input):
+ for x in seed_input:
+ if self.typed_fetch.dispatch(type(x)):
+ self.fetch_ingredient(x)
+
+ @dispatch(list)
+ def typed_fetch(self, seed_input: List):
+ self._fetch_list_like(seed_input)
+
+ @dispatch(tuple)
+ def typed_fetch(self, seed_input: Tuple):
+ self._fetch_list_like(seed_input)
+
+ # NOTE: disable set for now as Steven is too weak in Python (/s)
+ # @dispatch(set)
+ # def typed_fetch(self, seed_input: Set):
+ # self._fetch_list_like(seed_input)
+
+ # Dict
+ @dispatch(dict)
+ def typed_fetch(self, seed_input: Dict):
+ self._fetch_list_like(seed_input.keys())
+ self._fetch_list_like(seed_input.values())
+
+ def generate(self, num: int):
+ start = time.time()
+ num_generated = 1
+ while len(self.new_inputs) < num and time.time() - start < self.timeout:
+ if num_generated % 1000 == 0:
+ print(
+ f"generated {num_generated} already with {len(self.new_inputs)} new inputs ... "
+ )
+ new_input = self.seed_selection()
+ # Multi-step instead of single-step
+ for _ in range(random.randint(1, MAX_MULTI_STEP_SIZE)):
+ new_input = self.mutate(new_input)
+ num_generated += 1
+ if hash(str(new_input)) not in self.seed_hash:
+ if trusted_check_exec(self.contract, [new_input], self.entry_point):
+ self.typed_fetch(new_input)
+ self.seed_pool.append(new_input)
+ self.new_inputs.append(new_input)
+ self.seed_hash.add(hash(str(new_input)))
+ return self.new_inputs[:num]
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/gen/util/__init__.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/gen/util/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..2753ccf63e14888dc8b250459f977078c56931d4
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/gen/util/__init__.py
@@ -0,0 +1,38 @@
+import time
+
+from evalplus.eval.utils import time_limit
+
+
+def trusted_exec(code, inputs, entry_point, record_time=False, output_not_none=False):
+ """Execute trusted code in place."""
+ exec_globals = {}
+ exec(code, exec_globals)
+ fn = exec_globals[entry_point]
+
+ rtime = []
+ ret = []
+ for inp in inputs:
+ if record_time:
+ start = time.time()
+ ret.append(fn(*inp))
+ rtime.append(time.time() - start)
+ else:
+ ret.append(fn(*inp))
+
+ if output_not_none:
+ ret = [i is not None for i in ret]
+
+ if record_time:
+ return ret, rtime
+ else:
+ return ret
+
+
+def trusted_check_exec(code, inputs, entry_point):
+ """Check trusted_exec success."""
+ try:
+ with time_limit(seconds=1.0):
+ trusted_exec(code, inputs, entry_point)
+ except Exception:
+ return False
+ return True
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/gen/util/api_request.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/gen/util/api_request.py
new file mode 100644
index 0000000000000000000000000000000000000000..17e0813c8389d9b4d9b5ba140a370b7a7267ca83
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/gen/util/api_request.py
@@ -0,0 +1,63 @@
+import signal
+import time
+from typing import Dict
+
+import openai
+from openai.types.chat import ChatCompletion
+
+
+def make_request(
+ client: openai.Client,
+ message: str,
+ model: str,
+ max_tokens: int = 512,
+ temperature: float = 1,
+ n: int = 1,
+ **kwargs
+) -> ChatCompletion:
+ return client.chat.completions.create(
+ model=model,
+ messages=[
+ {
+ "role": "system",
+ "content": "You are a helpful assistant designed to output JSON.",
+ },
+ {"role": "user", "content": message},
+ ],
+ max_tokens=max_tokens,
+ temperature=temperature,
+ n=n,
+ **kwargs
+ )
+
+
+def handler(signum, frame):
+ # swallow signum and frame
+ raise Exception("end of time")
+
+
+def make_auto_request(*args, **kwargs) -> ChatCompletion:
+ ret = None
+ while ret is None:
+ try:
+ signal.signal(signal.SIGALRM, handler)
+ signal.alarm(100)
+ ret = make_request(*args, **kwargs)
+ signal.alarm(0)
+ except openai.RateLimitError:
+ print("Rate limit exceeded. Waiting...")
+ signal.alarm(0)
+ time.sleep(5)
+ except openai.APIConnectionError:
+ print("API connection error. Waiting...")
+ signal.alarm(0)
+ time.sleep(5)
+ except openai.APIError as e:
+ print(e)
+ signal.alarm(0)
+ except Exception as e:
+ print("Unknown error. Waiting...")
+ print(e)
+ signal.alarm(0)
+ time.sleep(1)
+ return ret
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/inputgen.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/inputgen.py
new file mode 100644
index 0000000000000000000000000000000000000000..f3f6f91da8759d5804ac0afb63e5e781cb5504cc
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/inputgen.py
@@ -0,0 +1,108 @@
+"""Generate a .jsonl file where each line is a json object
+representing a programming problem with a task ID ("task_id")
+and a list of enhanced inputs ("inputs") for that task.
+"""
+
+import argparse
+import json
+import os
+
+from evalplus.data.mbpp import mbpp_serialize_inputs
+from evalplus.gen.chatgpt_gen import ChatGPTGen
+from evalplus.gen.type_mut import TypedMutGen
+
+
+class SetEncoder(json.JSONEncoder):
+ def default(self, obj):
+ if isinstance(obj, set):
+ return list(obj)
+ return json.JSONEncoder.default(self, obj)
+
+
+# Used for MBPP as MBPP's prompt is not a formal function signature
+def insert_contract_into_code(entry_point, code, contract):
+ lines = code.split("\n")
+ index = lines.index(
+ next(line for line in lines if line.startswith(f"def {entry_point}"))
+ )
+ lines.insert(index + 1, contract)
+ return "\n".join(lines)
+
+
+def input_generation(args, problems):
+ with open(args.output, "w") as file:
+ for problem in problems.values():
+ new_input = {}
+ task_id = problem["task_id"]
+ print(f"generating inputs for {task_id} ...")
+ # by default we do not include constraints in the prompt (code)
+ code = problem["prompt"] + problem["canonical_solution"]
+ # but we use c_code to include contract which checks input validity at execution time
+ if args.dataset == "humaneval":
+ c_code = (
+ problem["prompt"]
+ + problem["contract"]
+ + problem["canonical_solution"]
+ )
+ elif args.dataset == "mbpp":
+ c_code = problem["prompt"] + insert_contract_into_code(
+ entry_point=problem["entry_point"],
+ code=problem["canonical_solution"],
+ contract=problem["contract"],
+ )
+
+ # first generate chatgpt
+ input_gen = ChatGPTGen(
+ problem["base_input"], problem["entry_point"], c_code, code
+ ).generate(args.chatgpt_len)
+ # generate mutation next
+
+ if input_gen is None or len(input_gen) == 0:
+ new_input["task_id"] = task_id
+ new_input["inputs"] = {}
+ file.write(json.dumps(new_input, cls=SetEncoder) + "\n")
+ continue
+
+ input_gen.extend(
+ TypedMutGen(input_gen, problem["entry_point"], c_code).generate(
+ args.mut_len
+ )
+ )
+ print(f"generated {len(input_gen)} inputs")
+ new_input["task_id"] = task_id
+ if args.dataset == "mbpp":
+ new_input["inputs"] = mbpp_serialize_inputs(task_id, input_gen)
+ new_input["inputs"] = input_gen
+ file.write(json.dumps(new_input, cls=SetEncoder) + "\n")
+
+
+def main():
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ "--dataset", required=True, type=str, choices=["humaneval", "mbpp"]
+ )
+ parser.add_argument("--chatgpt_len", required=True, type=int)
+ parser.add_argument("--mut_len", required=True, type=int)
+ parser.add_argument("--output", type=int, help="Output .jsonl path")
+ args = parser.parse_args()
+
+ problems = None
+ if args.dataset == "humaneval":
+ from evalplus.data import get_human_eval_plus
+
+ # Allow it to be incomplete
+ problems = get_human_eval_plus(err_incomplete=False)
+ args.output = args.output or "HumanEvalPlusInputs.jsonl"
+
+ if args.dataset == "mbpp":
+ from evalplus.data import get_mbpp_plus
+
+ problems = get_mbpp_plus(err_incomplete=False)
+ args.output = args.output or "MbppPlusInput.jsonl"
+
+ assert os.path.isfile(args.output), f"{args.output} already exists!"
+ input_generation(args, problems)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/sanitize.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/sanitize.py
new file mode 100644
index 0000000000000000000000000000000000000000..dd49f4d77c7d6486d49c075486d1eca6c499557f
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evalplus/sanitize.py
@@ -0,0 +1,113 @@
+"""Purpose of this file: Sanitize the code produced by LLMs for the following reasons.
+1. Vicuna generated code could miss one white space. We fix the white space to make Vicuna more capable.
+2. {Our fault lol.} We find more EOFs tokens afterwards and truncate some messy code afterwards.
+"""
+
+import ast
+import re
+import traceback
+from typing import List, Optional
+
+
+def syntax_check(code, verbose=False):
+ try:
+ ast.parse(code)
+ return True
+ except (SyntaxError, MemoryError):
+ if verbose:
+ traceback.print_exc()
+ return False
+
+
+def remove_unindented_lines(code, protect_before, execeptions, trim_tails):
+ lines = code.splitlines()
+ cut_idx = []
+ cut_enabled = False
+ for i, line in enumerate(lines):
+ if not cut_enabled and line.startswith(protect_before):
+ cut_enabled = True
+ continue
+ if line.strip() == "":
+ continue
+ if any(line.startswith(e) for e in execeptions):
+ continue
+
+ lspace = len(line) - len(line.lstrip())
+ if lspace == 0:
+ cut_idx.append(i)
+
+ if any(line.rstrip().startswith(t) for t in trim_tails):
+ # cut off everything behind
+ cut_idx.extend(list(range(i, len(lines))))
+ break
+
+ return "\n".join([line for i, line in enumerate(lines) if i not in cut_idx])
+
+
+def to_four_space_indents(old_code):
+ new_code = ""
+ for line in old_code.splitlines():
+ lspace = len(line) - len(line.lstrip())
+ if lspace == 3:
+ new_code += " "
+ new_code += line + "\n"
+ return new_code
+
+
+def sanitize(
+ old_code: str,
+ entry_point: str,
+ rm_prefix_lines: Optional[str] = None,
+ eofs: List = None,
+):
+ new_code = old_code
+ if rm_prefix_lines is not None:
+ new_code = "\n".join(
+ [
+ line
+ for line in old_code.splitlines()
+ if not line.startswith(rm_prefix_lines)
+ ]
+ )
+
+ new_code = "\n" + new_code
+ def_left = "def " + entry_point
+
+ # basic handling of chat output
+ new_code = new_code.replace("\n```python\n", "\n```\n")
+ for chunk in new_code.split("\n```\n"):
+ if def_left in chunk:
+ new_code = chunk
+ break
+
+ chunks = [chunk for chunk in re.split(f"{def_left}\s*\(", new_code)]
+ # TODO: having return does not mean this is complete
+ bodies = [chunk for chunk in chunks[1:] if " return " in chunk.split("\ndef")[0]]
+ def_left = def_left + "("
+ new_code = def_left + def_left.join(bodies) if len(bodies) > 0 else "" # fn + impl
+ new_code = to_four_space_indents(new_code)
+
+ for eof in eofs or []:
+ new_code = new_code.split(eof)[0]
+
+ # remove lines starting from the first unindented line after def_left
+ new_code = remove_unindented_lines(
+ new_code,
+ protect_before=def_left,
+ execeptions=["def ", "import ", "from "],
+ trim_tails=['"""', "if", "print"],
+ )
+ new_code = chunks[0] + new_code
+
+ # cut all functions that are not syntactically correct && not the entry point
+ parts = new_code.split("\ndef ")
+ includes = [parts[0]]
+ for fn in new_code.split("\ndef ")[1:]:
+ if (
+ fn.strip().startswith(entry_point + " ")
+ or fn.strip().startswith(entry_point + "(")
+ or syntax_check("\ndef " + fn)
+ ):
+ includes.append(fn)
+ new_code = "\ndef ".join(includes)
+ return new_code.strip()
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evo.sh b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evo.sh
new file mode 100644
index 0000000000000000000000000000000000000000..b01fdd982707765f5425b20d2572934f07b6327f
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/evo.sh
@@ -0,0 +1,82 @@
+#!/usr/bin/env bash
+
+set -e
+set -x
+
+# Set default values for DATADIR and NCORES
+DEFAULT_DATADIR="/JawTitan/EvalPlus/humaneval"
+DEFAULT_NCORES=$(nproc)
+DEFAULT_JUST_RUN=0
+
+# Check if the user has provided a custom value for DATADIR and NCORES
+while getopts ":d:n:j:" opt; do
+ case ${opt} in
+ d )
+ DATADIR=$OPTARG
+ ;;
+ n )
+ NCORES=$OPTARG
+ ;;
+ j )
+ JUST_RUN=1
+ ;;
+ \? )
+ echo "Invalid option: -$OPTARG. Example: bash evo.sh -d /path/to/humaneval -n 32" 1>&2
+ exit 1
+ ;;
+ : )
+ echo "Option -$OPTARG requires an argument. Example: bash evo.sh -d /path/to/humaneval -n 32" 1>&2
+ exit 1
+ ;;
+ esac
+done
+
+# Set DATADIR and NCORES to default values if they are not provided by the user
+DATADIR=${DATADIR:-$DEFAULT_DATADIR}
+NCORES=${NCORES:-$DEFAULT_NCORES}
+JUST_RUN=${JUST_RUN:-$DEFAULT_JUST_RUN}
+
+export PYTHONPATH=$(pwd)
+
+models=(
+ "codegen-2b"
+ "codegen-6b"
+ "codegen-16b"
+ "codegen2-1b"
+ "codegen2-3b"
+ "codegen2-7b"
+ "codegen2-16b"
+ "vicuna-7b"
+ "vicuna-13b"
+ "stablelm-7b"
+ "incoder-1b"
+ "incoder-6b"
+ "polycoder"
+ "chatgpt"
+ "starcoder"
+ "santacoder"
+ "gptneo-2b"
+ "gpt-4"
+ "gpt-j")
+temps=("0.0" "0.2" "0.4" "0.6" "0.8")
+
+if [ $JUST_RUN -eq 0 ]; then
+ echo "Experiements won't run from scratch since JUST_RUN is set to 0. To run and override all experiements, add -j flag."
+else
+ echo "Experiements will run from scratch since JUST_RUN is set to 1. To run without overriding all experiements, remove -j flag."
+fi
+
+for model in "${models[@]}"; do
+ for temp in "${temps[@]}"; do
+ folder="${DATADIR}/${model}_temp_${temp}"
+ if [ -d "$folder" ]; then
+ if [ $JUST_RUN -eq 1 ]; then
+ yes | python3 evalplus/evaluate.py --dataset humaneval --samples "$folder" --parallel ${NCORES} --i-just-wanna-run --test-details
+ else
+ python3 evalplus/evaluate.py --dataset humaneval --samples "$folder" --parallel ${NCORES} --test-details
+ fi
+ else
+ echo "Folder does not exist: $folder"
+ fi
+ done
+done
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/gallary/overview.png b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/gallary/overview.png
new file mode 100644
index 0000000000000000000000000000000000000000..4c83b7dd8c57bdf347db898dcef74382eb660b2a
Binary files /dev/null and b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/gallary/overview.png differ
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/gallary/render.gif b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/gallary/render.gif
new file mode 100644
index 0000000000000000000000000000000000000000..196b212a19e88ab1004e19a25ba0fdd53f2671fb
Binary files /dev/null and b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/gallary/render.gif differ
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/pyproject.toml b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/pyproject.toml
new file mode 100644
index 0000000000000000000000000000000000000000..992b44f969b62dd7079378b5bd27e8965817621b
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/pyproject.toml
@@ -0,0 +1,8 @@
+[build-system]
+requires = ["setuptools>=45", "setuptools_scm[toml]>=6.2"]
+build-backend = "setuptools.build_meta"
+
+[tool.setuptools_scm]
+write_to = "evalplus/_version.py"
+version_scheme = "release-branch-semver"
+local_scheme = "no-local-version"
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/requirements-llm.txt b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/requirements-llm.txt
new file mode 100644
index 0000000000000000000000000000000000000000..bbaa26e0aee2d6c666e20dc2148ecb4285d20fe4
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/requirements-llm.txt
@@ -0,0 +1,4 @@
+openai
+rich
+accelerate
+vllm
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/requirements-tools.txt b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/requirements-tools.txt
new file mode 100644
index 0000000000000000000000000000000000000000..677a0b68f64d762521014747d91638a97681543e
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/requirements-tools.txt
@@ -0,0 +1,6 @@
+rich
+tempdir
+matplotlib
+tqdm
+numpy
+termcolor
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/requirements-tsr.txt b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/requirements-tsr.txt
new file mode 100644
index 0000000000000000000000000000000000000000..82e718c605cc8acf4c289d1709bec41fbc316de4
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/requirements-tsr.txt
@@ -0,0 +1,3 @@
+rich
+coverage
+mutmut==2.1.0
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/requirements.txt b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..a861844b236b66b63acccdcf35967d9c02fae95c
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/requirements.txt
@@ -0,0 +1,7 @@
+wget
+appdirs
+tempdir
+multipledispatch
+numpy
+tqdm
+termcolor
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/setup.cfg b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/setup.cfg
new file mode 100644
index 0000000000000000000000000000000000000000..972e915afd22bc63e28a1a24eee361f4b5eede2c
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/setup.cfg
@@ -0,0 +1,35 @@
+[metadata]
+name = evalplus
+description = "EvalPlus for rigourous evaluation of LLM-synthesized code"
+long_description = file: README.md
+long_description_content_type = text/markdown
+url = https://github.com/evalplus/evalplus
+license = Apache-2.0
+license_files = LICENSE
+platform = any
+classifiers =
+ Operating System :: OS Independent
+ Programming Language :: Python :: 3
+ License :: OSI Approved :: Apache Software License
+
+[options]
+packages = find:
+python_requires = >=3.8
+dependency_links =
+install_requires =
+ wget>=3.2
+ tempdir>=0.7.1
+ multipledispatch>=0.6.0
+ appdirs>=1.4.4
+ numpy>=1.19.5
+ tqdm>=4.56.0
+ termcolor>=2.0.0
+
+[options.entry_points]
+console_scripts =
+ evalplus.evaluate = evalplus.evaluate:main
+ evalplus.inputgen = evalplus.inputgen:main
+
+[options.packages.find]
+exclude =
+ evalplus._experimental*
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tests/requirements.txt b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tests/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..e079f8a6038dd2dc8512967540f96ee0de172067
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tests/requirements.txt
@@ -0,0 +1 @@
+pytest
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tests/test_sanitizer.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tests/test_sanitizer.py
new file mode 100644
index 0000000000000000000000000000000000000000..b1ad13bdb7ee8c9f5918c6a49f20820d49ae768f
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tests/test_sanitizer.py
@@ -0,0 +1,44 @@
+import pytest
+
+from evalplus.sanitize import sanitize
+
+
+def test_inline_fn():
+ assert (
+ sanitize(
+ """\
+def f(n):
+ def factorial(i):
+ if i == 0:
+ return 1
+ else:
+ return i * factorial(i-1)
+
+ result = []
+ for i in range(1, n+1):
+ if i % 2 == 0:
+ result.append(factorial(i))
+ else:
+ result.append(sum(range(1, i+1)))
+ return result
+
+# Test the function
+print(f(5))""",
+ entry_point="f",
+ )
+ == """\
+def f(n):
+ def factorial(i):
+ if i == 0:
+ return 1
+ else:
+ return i * factorial(i-1)
+
+ result = []
+ for i in range(1, n+1):
+ if i % 2 == 0:
+ result.append(factorial(i))
+ else:
+ result.append(sum(range(1, i+1)))
+ return result"""
+ )
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/_experimental/README.md b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/_experimental/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..264bd68f95810e6724a943571131c756fe1a504e
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/_experimental/README.md
@@ -0,0 +1 @@
+# Experimental tools. Don't use.
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/_experimental/set_cover.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/_experimental/set_cover.py
new file mode 100644
index 0000000000000000000000000000000000000000..71172ac63f1660282cf06329db289a0afe4b3dd6
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/_experimental/set_cover.py
@@ -0,0 +1,82 @@
+import json
+import os
+
+from rich.progress import track
+
+from evalplus.data import get_human_eval_plus, get_human_eval_plus_inputs
+
+LLM_HOME_PATH = "/JawTitan/EvalPlus/humaneval"
+model_paths = os.listdir(LLM_HOME_PATH)
+
+problems = get_human_eval_plus().values()
+new_inputs = get_human_eval_plus_inputs()
+cover_info = {f"HumanEval_{i}": {} for i in range(164)}
+
+
+# One dict is super huge, so split them into separate JSON files
+def get_cover_info():
+ for model_path in track(model_paths, description="Collecting sets..."):
+ if not model_path[-1].isdigit():
+ continue
+ eval_json_path = os.path.join(LLM_HOME_PATH, model_path, "eval_results.json")
+ if not os.path.exists(eval_json_path):
+ continue
+ with open(eval_json_path, "r") as f:
+ res = json.load(f)["eval"]
+ for task_id, v in res.items():
+ for i_code, (status, res_list) in enumerate(v["base"]):
+ if status == "success":
+ continue
+ code_id = hash(v["files"][i_code])
+ for i_test, res in enumerate(res_list):
+ test_id = f"base_{i_test}"
+ if res == False:
+ cover_info[task_id].setdefault(test_id, []).append(code_id)
+ for i_code, (status, res_list) in enumerate(v["plus"]):
+ if status == "success":
+ continue
+ code_id = hash(v["files"][i_code])
+ for i_test, res in enumerate(res_list):
+ test_id = f"plus_{i_test}"
+ if res == False:
+ cover_info[task_id].setdefault(test_id, []).append(code_id)
+
+
+if __name__ == "__main__":
+ get_cover_info()
+ for i in track(range(164), description="Solving set covering..."):
+ task_id = f"HumanEval_{i}"
+ tests = cover_info[task_id]
+ q, U = [], set()
+ for test_name, test_cover in tests.items():
+ cover_set = set(test_cover)
+ q.append((test_name, cover_set))
+ U = U.union(cover_set)
+ # Greedy
+ min_cover = []
+ while len(U) > 0:
+ max_uncover_set, max_test_name = {}, ""
+ for test_name, cover_set in q:
+ if len(cover_set) > len(max_uncover_set):
+ max_uncover_set = cover_set
+ max_test_name = test_name
+ min_cover.append(max_test_name)
+ U = U - max_uncover_set
+ qq = []
+ for test_name, cover_set in q:
+ new_cover_set = U.intersection(cover_set)
+ if len(new_cover_set) != 0:
+ qq.append((test_name, new_cover_set))
+ q = qq
+
+ d = {"task_id": task_id, "inputs": []}
+ for test in min_cover:
+ tmp = test.split("_")
+ t, n = tmp[0], int(tmp[1])
+ if t == "base":
+ d["inputs"].append(problems[i]["base_input"][n])
+ else:
+ print(task_id, n)
+ d["inputs"].append(new_inputs[task_id][n])
+ with open("HumanEvalPlusInputsMin.jsonl", "a") as f:
+ f.write(json.dumps(d) + "\n")
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/_experimental/topset_distill.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/_experimental/topset_distill.py
new file mode 100644
index 0000000000000000000000000000000000000000..f9c0ceae8a89de24120f27109f89f67188cdd125
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/_experimental/topset_distill.py
@@ -0,0 +1,69 @@
+import json
+import os
+
+import numpy as np
+
+from evalplus.data import get_human_eval_plus, get_human_eval_plus_inputs
+
+if __name__ == "__main__":
+ import argparse
+
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--root", type=str, default="/JawTitan/EvalPlus/humaneval")
+ args = parser.parse_args()
+
+ plus_inputs = get_human_eval_plus_inputs()
+ problems = get_human_eval_plus().values()
+
+ base_bvs = {}
+ plus_bvs = {}
+ id2idx = {}
+
+ for i, problem in enumerate(problems):
+ task_id = problem["task_id"]
+ id2idx[task_id] = i
+ base_bvs[task_id] = np.zeros(len(problem["base_input"]), dtype=bool)
+ plus_bvs[task_id] = np.zeros(len(plus_inputs[task_id]), dtype=bool)
+
+ for path in os.listdir(args.root):
+ eval_json_path = os.path.join(args.root, path, "eval_results.json")
+ if not os.path.isfile(eval_json_path) or not path[-1].isdigit():
+ print(f"skip {path}")
+ continue
+ res = json.load(open(eval_json_path, "r"))["eval"]
+
+ for task_id, v in res.items():
+ for status, details in v["base"]:
+ if details is None: # all fail => skip
+ continue
+ fails = np.logical_not(details)
+ base_bvs[task_id][: len(details)] = np.logical_xor(
+ base_bvs[task_id][: len(details)], fails
+ )
+ for status, details in v["plus"]:
+ if details is None:
+ continue
+ fails = np.logical_not(details)
+ plus_bvs[task_id][: len(details)] = np.logical_xor(
+ plus_bvs[task_id][: len(details)], fails
+ )
+
+ testsuite = []
+
+ new_sizes = []
+ for task_id, bbv in base_bvs.items():
+ new_inputs = []
+ idx = id2idx[task_id]
+ for i in np.nonzero(bbv)[0]:
+ new_inputs.append(problems[idx]["base_input"][i])
+ pbv = plus_bvs[task_id]
+ for i in np.nonzero(pbv)[0]:
+ new_inputs.append(plus_inputs[task_id][i])
+ testsuite.append({"task_id": task_id, "inputs": new_inputs})
+ print(
+ task_id, f" org base {len(bbv)}; org plus {len(pbv)}; new {len(new_inputs)}"
+ )
+ new_sizes.append(len(new_inputs))
+
+ new_sizes = np.array(new_sizes)
+ print(f"{new_sizes.mean() = }, {new_sizes.min() = }, {new_sizes.max() = }")
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/checker.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/checker.py
new file mode 100644
index 0000000000000000000000000000000000000000..0f997da6813cb906c50e543b17149f95f56f838d
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/checker.py
@@ -0,0 +1,101 @@
+"""This file checks two things:
+1. Is the LLMs codegen completed for each benchmark?
+2. Warn the code that are not compilable (it could be some impl issues).
+"""
+
+from termcolor import colored
+
+from evalplus.data import load_solutions
+from evalplus.sanitize import syntax_check
+
+if __name__ == "__main__":
+ import argparse
+
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--samples", type=str, required=True)
+ parser.add_argument(
+ "--dataset", required=True, type=str, choices=["humaneval", "mbpp"]
+ )
+ parser.add_argument("--nsample", type=int, default=1)
+ parser.add_argument("--verbose", action="store_true")
+
+ args = parser.parse_args()
+
+ # List[Dict{"task_id", "solution"}]
+ solutions = load_solutions(args.samples)
+
+ if args.dataset == "humaneval":
+ from evalplus.data import get_human_eval_plus
+
+ dataset = get_human_eval_plus()
+ dataset_name = "HumanEval"
+ elif args.dataset == "mbpp":
+ from evalplus.data import get_mbpp_plus
+
+ dataset = get_mbpp_plus()
+ dataset_name = "Mbpp"
+
+ id2solutions = {}
+ for solution in solutions:
+ task_id = solution["task_id"]
+ if task_id not in id2solutions:
+ id2solutions[task_id] = []
+ if "solution" not in solution:
+ assert "completion" in solution, "solution or completion must exist!"
+ solution["solution"] = dataset[task_id]["prompt"] + solution["completion"]
+ id2solutions[task_id].append(solution)
+
+ nsample = max(args.nsample, max(len(v) for v in id2solutions.values()))
+ print(colored("==============================", "blue"))
+ print(colored(" ::: Checking completeness... ", "blue"))
+ print(colored(" ::::: All tasks complete? ", "blue"))
+ ndone = 0
+
+ task_ids = dataset.keys()
+ ntask = len(task_ids)
+ for task_id in task_ids:
+ if task_id not in id2solutions:
+ print(colored(f" ⚠️ {task_id} is missing!", "red"))
+ continue
+ nfiles = len(id2solutions[task_id])
+ if nfiles == nsample:
+ ndone += 1
+ continue
+
+ print(
+ colored(
+ f" ⚠️ {task_id} only has {nfiles} samples! But {nsample} are expected.",
+ "red",
+ )
+ )
+
+ if ntask != ndone:
+ ntbd = ntask - ndone
+ print(colored(f" ::::: ⚠️ {ntbd}/{ntask} tasks incomplete!", "red"))
+ else:
+ print(colored(f" ::::: All {ntask} tasks complete!", "green"))
+
+ print(colored("==============================", "blue"))
+ print(colored(" ::: Checking compilation... ", "blue"))
+ print(colored(" ::::: All code compilable? ", "blue"))
+ ncode = 0
+ nwrong = 0
+ for task_id in task_ids:
+ # task_id must exist
+ if task_id not in id2solutions:
+ continue
+
+ for solution in id2solutions[task_id]:
+ ncode += 1
+ code = solution["solution"]
+ dbg_identifier = solution["_identifier"]
+ if code.strip() == "":
+ print(colored(f" ⚠️ {dbg_identifier} is empty!", "red"))
+ nwrong += 1
+ elif not syntax_check(code, args.verbose):
+ print(colored(f" ⚠️ {dbg_identifier} is not compilable!", "red"))
+ nwrong += 1
+ if 0 != nwrong:
+ print(colored(f" ::::: ⚠️ {nwrong}/{ncode} code are not compilable!", "red"))
+ else:
+ print(colored(f" ::::: All {ncode} code are compilable!", "green"))
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/filter_inputs.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/filter_inputs.py
new file mode 100644
index 0000000000000000000000000000000000000000..4444575cdc6a18d3bdd76eca4b5e892a11cc8d56
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/filter_inputs.py
@@ -0,0 +1,54 @@
+import json
+import os
+
+from evalplus.data import get_human_eval_plus
+from evalplus.gen.util import trusted_exec
+
+
+def execute(code, input_list) -> bool:
+ try:
+ trusted_exec(code, [input_list], entry_point)
+ except Exception as e:
+ assert str(e) == "invalid inputs"
+ return False
+ return True
+
+
+def write(new_input_dict):
+ with open(new_input_path, "a") as f:
+ f.write(json.dumps(new_input_dict) + "\n")
+
+
+if __name__ == "__main__":
+ import argparse
+
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--input", type=str, default="HumanEvalPlusInputs.jsonl")
+ args = parser.parse_args()
+
+ new_input_path = args.input.replace(".jsonl", "_sanitized.jsonl")
+ assert not os.path.exists(new_input_path)
+
+ task_inputs = {}
+ for line in open(args.input, "r").read().split("\n"):
+ if not line:
+ continue
+ plus = json.loads(line)
+ task_inputs[plus["task_id"]] = plus["inputs"]
+
+ for p in get_human_eval_plus().values():
+ entry_point = p["entry_point"]
+ code = p["prompt"] + p["canonical_solution"]
+ task_id = p["task_id"]
+ new_inputs = task_inputs[task_id]
+ count = 0
+ new_input_dict = {"task_id": task_id, "inputs": []}
+ for input_list in new_inputs:
+ res = execute(code, input_list)
+ if res:
+ new_input_dict["inputs"].append(input_list)
+ else:
+ count += 1
+ write(new_input_dict)
+ if count != 0:
+ print(f"Task {task_id}: {count}/{len(new_inputs)} tests filtered")
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/humaneval/check_ground_truth.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/humaneval/check_ground_truth.py
new file mode 100644
index 0000000000000000000000000000000000000000..8fd2b6782ec3bc73aa8ba02b49388d4d26e90d74
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/humaneval/check_ground_truth.py
@@ -0,0 +1,35 @@
+"""This script checks:
+1. Independence of "contract" and "canonical_solution" in groundtruth. (i.e., it should work without the "contract" part)
+"""
+
+import multiprocessing as mp
+import pathlib
+
+from rich.progress import track
+
+from evalplus.data import get_human_eval_plus
+
+if __name__ == "__main__":
+ human_eval_plus = get_human_eval_plus().values()
+
+ for i, task in track(enumerate(human_eval_plus)):
+ fname = (
+ pathlib.Path(__file__).parent.parent
+ / "groundtruth"
+ / "humaneval"
+ / (str(i).zfill(3) + "_" + task["entry_point"] + ".py")
+ )
+ print(fname)
+ code = open(fname, "r").read()
+ if task["contract"]:
+ assert task["contract"] in code
+ code = code.replace(task["contract"], "\n")
+
+ # run the code in a subprocess
+ p = mp.Process(target=exec, args=(code, globals()))
+ p.start()
+ p.join(timeout=2)
+ assert not p.is_alive(), f"Timeout for {fname}!"
+ p.terminate()
+ p.join()
+ assert p.exitcode == 0, f"Error for {fname}! {code}"
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/humaneval/fix_v011.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/humaneval/fix_v011.py
new file mode 100644
index 0000000000000000000000000000000000000000..9a74e706fbe61f9ee3fa419ead43b24d66f77774
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/humaneval/fix_v011.py
@@ -0,0 +1,56 @@
+def fix(data):
+ # fix 140 https://github.com/evalplus/evalplus/issues/3
+ assert data[140]["task_id"] == "HumanEval/140"
+ data[140]["canonical_solution"] = data[140]["canonical_solution"].replace(
+ "range(len(text)-1, 2, -1)", "range(len(text), 2, -1)"
+ )
+
+ # fix 75 https://github.com/evalplus/evalplus/issues/4
+ assert data[75]["task_id"] == "HumanEval/75"
+ org_contract = '\n assert type(a) == int, "invalid inputs" # $_CONTRACT_$\n'
+ assert org_contract in data[75]["contract"]
+ data[75]["contract"] = (
+ org_contract + ' assert a < 100, "invalid inputs" # $_CONTRACT_$\n'
+ )
+ data[75]["base_input"] = [x for x in data[75]["base_input"] if x[0] < 100]
+ data[75]["plus_input"] = [x for x in data[75]["plus_input"] if x[0] < 100]
+
+ # fix 129 https://github.com/evalplus/evalplus/issues/4
+ assert data[129]["task_id"] == "HumanEval/129"
+ data[129][
+ "contract"
+ ] = R"""
+ assert type(k) == int, "invalid inputs" # $_CONTRACT_$
+ assert k > 0, "invalid inputs" # $_CONTRACT_$
+ assert len(grid) >= 2, "invalid inputs" # $_CONTRACT_$
+ assert all(len(l) == len(grid) for l in grid), "invalid inputs" # $_CONTRACT_$
+ assert {x for l in grid for x in l} == set(range(1, len(grid) ** 2 + 1)), "invalid inputs" # $_CONTRACT_$
+"""
+
+ def check_unique(grid):
+ return {x for l in grid for x in l} == set(range(1, len(grid) ** 2 + 1))
+
+ data[129]["base_input"] = [x for x in data[129]["base_input"] if check_unique(x[0])]
+ data[129]["plus_input"] = [x for x in data[129]["plus_input"] if check_unique(x[0])]
+
+ return data
+
+
+if __name__ == "__main__":
+ import json
+
+ with open("HumanEvalPlus-v0.1.1.jsonl") as f:
+ data = [json.loads(line) for line in f.readlines() if line]
+
+ data = fix(data)
+ with open("HumanEvalPlus-v0.1.2.jsonl", "wb") as f:
+ for x in data:
+ f.write((json.dumps(x) + "\n").encode("utf-8"))
+
+ with open("HumanEvalPlus-Mini-v0.1.1.jsonl") as f:
+ data = [json.loads(line) for line in f.readlines() if line]
+
+ data = fix(data)
+ with open("HumanEvalPlus-Mini-v0.1.2.jsonl", "wb") as f:
+ for x in data:
+ f.write((json.dumps(x) + "\n").encode("utf-8"))
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/humaneval/fix_v012.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/humaneval/fix_v012.py
new file mode 100644
index 0000000000000000000000000000000000000000..5ed84ce7ae84b29fbe0dfb320619a3a55924eab8
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/humaneval/fix_v012.py
@@ -0,0 +1,85 @@
+def check_id(data, task_id):
+ assert data[task_id]["task_id"] == f"HumanEval/{task_id}"
+
+
+def fix(data):
+ # fix 53 https://github.com/evalplus/evalplus/issues/8
+ check_id(data, 53)
+ data[53]["contract"] = (
+ '\n assert isinstance(x, int), "invalid inputs" # $_CONTRACT_$'
+ + '\n assert isinstance(y, int), "invalid inputs" # $_CONTRACT_$\n'
+ )
+ data[53]["plus_input"] = [
+ x
+ for x in data[53]["plus_input"]
+ if isinstance(x[0], int) and isinstance(x[1], int)
+ ]
+
+ # fix 0
+ check_id(data, 0)
+ data[0]["contract"] = (
+ '\n assert isinstance(threshold, float) and threshold > 0, "invalid inputs" # $_CONTRACT_$'
+ + '\n assert isinstance(numbers, list), "invalid inputs" # $_CONTRACT_$'
+ + '\n assert all([isinstance(v, (int, float)) for v in numbers]), "invalid inputs" # $_CONTRACT_$\n'
+ )
+ data[0]["plus_input"] = [
+ x
+ for x in data[0]["plus_input"]
+ if isinstance(x[1], float) and x[1] > 0 and isinstance(x[0], list)
+ ]
+
+ # fix 3
+ check_id(data, 3)
+ data[3]["contract"] = (
+ '\n assert type(operations) == list, "invalid inputs" # $_CONTRACT_$'
+ + '\n assert all([isinstance(v, int) for v in operations]), "invalid inputs" # $_CONTRACT_$\n'
+ )
+ data[3]["plus_input"] = [x for x in data[3]["plus_input"] if isinstance(x[0], list)]
+
+ # fix 9
+ check_id(data, 9)
+ data[9]["contract"] = (
+ '\n assert isinstance(numbers, list), "invalid inputs" # $_CONTRACT_$'
+ + '\n assert all([isinstance(v, int) for v in numbers]), "invalid inputs" # $_CONTRACT_$\n'
+ )
+ data[9]["plus_input"] = [x for x in data[9]["plus_input"] if isinstance(x[0], list)]
+
+ # fix 148
+ check_id(data, 148)
+ data[148][
+ "contract"
+ ] = '\n assert isinstance(planet1, str) and isinstance(planet2, str), "invalid inputs" # $_CONTRACT_$\n'
+ data[148]["plus_input"] = [
+ x
+ for x in data[148]["plus_input"]
+ if isinstance(x[0], str) and isinstance(x[1], str)
+ ]
+
+ # minor format fix 75
+ check_id(data, 75)
+ data[75]["contract"] = (
+ '\n assert type(a) == int, "invalid inputs" # $_CONTRACT_$'
+ + '\n assert a < 100, "invalid inputs" # $_CONTRACT_$\n'
+ )
+
+ return data
+
+
+if __name__ == "__main__":
+ import json
+
+ with open("HumanEvalPlus-v0.1.2.jsonl") as f:
+ data = [json.loads(line) for line in f.readlines() if line]
+
+ data = fix(data)
+ with open("HumanEvalPlus-v0.1.3.jsonl", "wb") as f:
+ for x in data:
+ f.write((json.dumps(x) + "\n").encode("utf-8"))
+
+ with open("HumanEvalPlus-Mini-v0.1.2.jsonl") as f:
+ data = [json.loads(line) for line in f.readlines() if line]
+
+ data = fix(data)
+ with open("HumanEvalPlus-Mini-v0.1.3.jsonl", "wb") as f:
+ for x in data:
+ f.write((json.dumps(x) + "\n").encode("utf-8"))
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/humaneval/fix_v013.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/humaneval/fix_v013.py
new file mode 100644
index 0000000000000000000000000000000000000000..9b525c7e0eaf0b67d7542445e27d589563578687
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/humaneval/fix_v013.py
@@ -0,0 +1,37 @@
+def check_id(data, task_id):
+ assert data[task_id]["task_id"] == f"HumanEval/{task_id}"
+
+
+def fix(data):
+ check_id(data, 116)
+ data[116]["contract"] = (
+ '\n assert isinstance(arr, list), "invalid inputs" # $_CONTRACT_$'
+ + '\n assert all(isinstance(x, int) and x >= 0 for x in arr), "invalid inputs" # $_CONTRACT_$\n'
+ )
+ data[116]["plus_input"] = [
+ l
+ for l in data[116]["plus_input"]
+ if isinstance(l[0], list) and all(isinstance(x, int) and x >= 0 for x in l[0])
+ ]
+
+ return data
+
+
+if __name__ == "__main__":
+ import json
+
+ with open("HumanEvalPlus-v0.1.3.jsonl") as f:
+ data = [json.loads(line) for line in f.readlines() if line]
+
+ data = fix(data)
+ with open("HumanEvalPlus-v0.1.4.jsonl", "wb") as f:
+ for x in data:
+ f.write((json.dumps(x) + "\n").encode("utf-8"))
+
+ with open("HumanEvalPlus-Mini-v0.1.3.jsonl") as f:
+ data = [json.loads(line) for line in f.readlines() if line]
+
+ data = fix(data)
+ with open("HumanEvalPlus-Mini-v0.1.4.jsonl", "wb") as f:
+ for x in data:
+ f.write((json.dumps(x) + "\n").encode("utf-8"))
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/humaneval/fix_v014.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/humaneval/fix_v014.py
new file mode 100644
index 0000000000000000000000000000000000000000..8df5d5abb297c2c71f76ebc6506139f886d124d2
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/humaneval/fix_v014.py
@@ -0,0 +1,78 @@
+import math
+
+
+def check_id(data, task_id):
+ assert data[task_id]["task_id"] == f"HumanEval/{task_id}"
+
+
+def poly(xs, x):
+ return sum([coeff * math.pow(x, i) for i, coeff in enumerate(xs)])
+
+
+def check_valid(xs):
+ if not (isinstance(xs, list) and len(xs) > 0 and len(xs) % 2 == 0):
+ return False
+ if not all(type(x) == int for x in xs):
+ return False
+ dxs = [xs[i] * i for i in range(1, len(xs))]
+
+ def func(x):
+ return poly(xs, x)
+
+ def derivative(x):
+ return poly(dxs, x)
+
+ x, tol = 0, 1e-5
+ for _ in range(1000):
+ fx = func(x)
+ dfx = derivative(x)
+ if abs(fx) < tol:
+ break
+ x = x - fx / dfx
+ if abs(poly(xs, x)) >= tol:
+ return False
+ return True
+
+
+def fix(data):
+ check_id(data, 32)
+ data[32]["contract"] = (
+ '\n assert isinstance(xs, list) and len(xs) > 0 and len(xs) % 2 == 0, "invalid inputs" # $_CONTRACT_$'
+ + '\n assert all(type(x) == int for x in xs), "invalid inputs" # $_CONTRACT_$'
+ + "\n dxs = [xs[i] * i for i in range(1, len(xs))] # $_CONTRACT_$"
+ + "\n def func(x): # $_CONTRACT_$"
+ + "\n return poly(xs, x) # $_CONTRACT_$"
+ + "\n def derivative(x): # $_CONTRACT_$"
+ + "\n return poly(dxs, x) # $_CONTRACT_$"
+ + "\n x, tol = 0, 1e-5 # $_CONTRACT_$"
+ + "\n for _ in range(1000): # $_CONTRACT_$"
+ + "\n fx = func(x) # $_CONTRACT_$"
+ + "\n dfx = derivative(x) # $_CONTRACT_$"
+ + "\n if abs(fx) < tol: break # $_CONTRACT_$"
+ + "\n x = x - fx / dfx # $_CONTRACT_$"
+ + '\n assert abs(poly(xs, x)) < tol, "invalid inputs" # $_CONTRACT_$\n'
+ )
+ data[32]["plus_input"] = [l for l in data[32]["plus_input"] if check_valid(l[0])]
+
+ return data
+
+
+if __name__ == "__main__":
+ import json
+
+ with open("HumanEvalPlus-v0.1.4.jsonl") as f:
+ data = [json.loads(line) for line in f.readlines() if line]
+
+ data = fix(data)
+
+ with open("HumanEvalPlus-v0.1.5.jsonl", "wb") as f:
+ for x in data:
+ f.write((json.dumps(x) + "\n").encode("utf-8"))
+
+ with open("HumanEvalPlus-Mini-v0.1.4.jsonl") as f:
+ data = [json.loads(line) for line in f.readlines() if line]
+
+ data = fix(data)
+ with open("HumanEvalPlus-Mini-v0.1.5.jsonl", "wb") as f:
+ for x in data:
+ f.write((json.dumps(x) + "\n").encode("utf-8"))
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/humaneval/fix_v015.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/humaneval/fix_v015.py
new file mode 100644
index 0000000000000000000000000000000000000000..ef2493f79135096c2019e395097712dba63c0772
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/humaneval/fix_v015.py
@@ -0,0 +1,59 @@
+import math
+
+
+def check_id(data, task_id):
+ assert data[task_id]["task_id"] == f"HumanEval/{task_id}"
+
+
+def check_valid(s: str):
+ cnt = 0
+ for ch in s:
+ if ch == "(":
+ cnt += 1
+ elif ch == ")":
+ cnt -= 1
+ else:
+ return False
+ if cnt < 0:
+ return False
+ return cnt == 0
+
+
+def fix(data):
+ check_id(data, 126)
+ data[126]["contract"] = (
+ '\n assert type(lst) == list, "invalid inputs" # $_CONTRACT_$'
+ + '\n assert all(type(x) == int and x >= 0 for x in lst), "invalid inputs" # $_CONTRACT_$\n'
+ )
+ data[126]["plus_input"] = [
+ l
+ for l in data[126]["plus_input"]
+ if type(l[0]) == list and all(type(x) == int and x >= 0 for x in l[0])
+ ]
+
+ check_id(data, 6)
+ data[6]["contract"] += ' assert cnt == 0, "invalid inputs"\n'
+ data[6]["plus_input"] = [l for l in data[6]["plus_input"] if check_valid(l[0])]
+
+ return data
+
+
+if __name__ == "__main__":
+ import json
+
+ with open("HumanEvalPlus-v0.1.5.jsonl") as f:
+ data = [json.loads(line) for line in f.readlines() if line]
+
+ data = fix(data)
+
+ with open("HumanEvalPlus-v0.1.6.jsonl", "wb") as f:
+ for x in data:
+ f.write((json.dumps(x) + "\n").encode("utf-8"))
+
+ with open("HumanEvalPlus-Mini-v0.1.5.jsonl") as f:
+ data = [json.loads(line) for line in f.readlines() if line]
+
+ data = fix(data)
+ with open("HumanEvalPlus-Mini-v0.1.6.jsonl", "wb") as f:
+ for x in data:
+ f.write((json.dumps(x) + "\n").encode("utf-8"))
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/humaneval/fix_v016.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/humaneval/fix_v016.py
new file mode 100644
index 0000000000000000000000000000000000000000..d29d6d2e2fef8798a34aca14d372825d9aad5c5f
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/humaneval/fix_v016.py
@@ -0,0 +1,46 @@
+import math
+
+
+def check_id(data, task_id):
+ assert data[task_id]["task_id"] == f"HumanEval/{task_id}"
+
+
+def check_valid(op, num):
+ try:
+ exp = ""
+ for i in range(len(op)):
+ exp += str(num[i]) + str(op[i])
+ exp += str(num[-1])
+ exp = str(eval(exp))
+ except:
+ return False
+ return True
+
+
+def fix(data):
+ check_id(data, 160)
+ data[160]["plus_input"] = [
+ l for l in data[160]["plus_input"] if check_valid(l[0], l[1])
+ ]
+ return data
+
+
+if __name__ == "__main__":
+ import json
+
+ with open("HumanEvalPlus-v0.1.6.jsonl") as f:
+ data = [json.loads(line) for line in f.readlines() if line]
+
+ data = fix(data)
+
+ with open("HumanEvalPlus-v0.1.7.jsonl", "wb") as f:
+ for x in data:
+ f.write((json.dumps(x) + "\n").encode("utf-8"))
+
+ with open("HumanEvalPlus-Mini-v0.1.6.jsonl") as f:
+ data = [json.loads(line) for line in f.readlines() if line]
+
+ data = fix(data)
+ with open("HumanEvalPlus-Mini-v0.1.7.jsonl", "wb") as f:
+ for x in data:
+ f.write((json.dumps(x) + "\n").encode("utf-8"))
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/humaneval/fix_v017.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/humaneval/fix_v017.py
new file mode 100644
index 0000000000000000000000000000000000000000..c0df5ebc442223bc452aa35209476014011f80f8
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/humaneval/fix_v017.py
@@ -0,0 +1,63 @@
+import math
+
+
+def check_id(data, task_id):
+ assert data[task_id]["task_id"] == f"HumanEval/{task_id}"
+
+
+def fix(data):
+ # https://github.com/evalplus/evalplus/issues/29
+ check_id(data, 35)
+ data[35]["contract"] += ' assert len(l) != 0, "invalid inputs" # $_CONTRACT_$\n'
+
+ # https://github.com/evalplus/evalplus/issues/28
+ check_id(data, 2)
+ data[2][
+ "contract"
+ ] += ' assert number != float("+inf"), "invalid inputs" # $_CONTRACT_$\n'
+
+ check_id(data, 99)
+ data[99][
+ "contract"
+ ] += r""" import math # $_CONTRACT_$
+ assert not (math.isinf(value) or math.isnan(value)), "invalid inputs" # $_CONTRACT_$
+"""
+ # https://github.com/evalplus/evalplus/issues/27
+ check_id(data, 1)
+ data[1]["contract"] += ' assert cnt == 0, "invalid inputs" # $_CONTRACT_$\n'
+
+ return data
+
+
+if __name__ == "__main__":
+ import json
+
+ CONTRACT_INSPECT = [1, 2, 35, 99]
+ SOURCE_VERSION = "v0.1.7"
+ TARGET_VERSION = "v0.1.8"
+
+ def evolve(src_file, tgt_file):
+ with open(src_file) as f:
+ data = [json.loads(line) for line in f.readlines() if line]
+
+ data = fix(data)
+ with open(tgt_file, "wb") as f:
+ for x in data:
+ f.write((json.dumps(x) + "\n").encode("utf-8"))
+
+ evolve(
+ f"HumanEvalPlus-{SOURCE_VERSION}.jsonl", f"HumanEvalPlus-{TARGET_VERSION}.jsonl"
+ )
+ evolve(
+ f"HumanEvalPlus-Mini-{SOURCE_VERSION}.jsonl",
+ f"HumanEvalPlus-Mini-{TARGET_VERSION}.jsonl",
+ )
+
+ # Debug the output of jsonl
+ with open(f"HumanEvalPlus-{TARGET_VERSION}.jsonl") as f:
+ data = [json.loads(line) for line in f.readlines() if line]
+
+ data = {x["task_id"]: x for x in data}
+ for tid in CONTRACT_INSPECT:
+ print(data[f"HumanEval/{tid}"]["prompt"] + data[f"HumanEval/{tid}"]["contract"])
+ print("====================================")
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/humaneval/fix_v018.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/humaneval/fix_v018.py
new file mode 100644
index 0000000000000000000000000000000000000000..5055a154baa2e77b019db0e143d1ea61da2bcabb
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/humaneval/fix_v018.py
@@ -0,0 +1,87 @@
+import math
+
+
+def check_id(data, task_id):
+ assert data[task_id]["task_id"] == f"HumanEval/{task_id}"
+
+
+def fix(data):
+ # https://github.com/evalplus/evalplus/issues/44
+ check_id(data, 115)
+ data[115]["prompt"] = "import math\n" + data[115]["prompt"].replace(
+ " import math\n", ""
+ )
+ check_id(data, 114)
+ data[114]["prompt"] = data[114]["prompt"].replace("import math\n", "")
+
+ # https://github.com/evalplus/evalplus/issues/30#issue-1944054257
+ check_id(data, 35)
+ data[35][
+ "contract"
+ ] += ' assert all(type(x) in [int, float] for x in l), "invalid inputs" # $_CONTRACT_$\n'
+ data[35]["canonical_solution"] = data[35]["canonical_solution"].replace(
+ ' assert all(type(x) in [int, float] for x in l), "invalid inputs"\n', ""
+ )
+
+ # https://github.com/evalplus/evalplus/issues/30#issuecomment-1763502126
+ check_id(data, 28)
+ data[28][
+ "contract"
+ ] += ' assert isinstance(strings, list), "invalid inputs" # $_CONTRACT_$\n'
+
+ # https://github.com/evalplus/evalplus/issues/34
+ check_id(data, 32)
+ terms = data[32]["contract"].splitlines()
+ terms.insert(2, ' assert xs[-1] != 0, "invalid inputs" # $_CONTRACT_$')
+ data[32]["contract"] = "\n".join(terms)
+
+ # https://github.com/evalplus/evalplus/issues/35
+ check_id(data, 160)
+ terms = data[160]["contract"].splitlines()
+ terms.insert(
+ len(terms),
+ ' assert not any([operand[i-1] == 0 and operator[i] == "//" for i in range(1, len(operand))]), "invalid inputs" # $_CONTRACT_$',
+ )
+ data[160]["contract"] = "\n".join(terms)
+
+ return data
+
+
+if __name__ == "__main__":
+ import json
+
+ TASK_INSPECT = [28, 32, 35, 114, 115, 160]
+ SOURCE_VERSION = "v0.1.8"
+ TARGET_VERSION = "v0.1.9"
+
+ def evolve(src_file, tgt_file):
+ with open(src_file) as f:
+ data = [json.loads(line) for line in f.readlines() if line]
+
+ data = fix(data)
+ with open(tgt_file, "wb") as f:
+ for x in data:
+ f.write((json.dumps(x) + "\n").encode("utf-8"))
+
+ evolve(
+ f"HumanEvalPlus-{SOURCE_VERSION}.jsonl", f"HumanEvalPlus-{TARGET_VERSION}.jsonl"
+ )
+ evolve(
+ f"HumanEvalPlus-Mini-{SOURCE_VERSION}.jsonl",
+ f"HumanEvalPlus-Mini-{TARGET_VERSION}.jsonl",
+ )
+
+ # Debug the output of jsonl
+ with open(f"HumanEvalPlus-{TARGET_VERSION}.jsonl") as f:
+ data = [json.loads(line) for line in f.readlines() if line]
+
+ data = {x["task_id"]: x for x in data}
+ for tid in TASK_INSPECT:
+ code = (
+ data[f"HumanEval/{tid}"]["prompt"]
+ + data[f"HumanEval/{tid}"]["contract"]
+ + data[f"HumanEval/{tid}"]["canonical_solution"]
+ )
+ print(code)
+ exec(code)
+ print("====================================")
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/humaneval/init_ground_truth.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/humaneval/init_ground_truth.py
new file mode 100644
index 0000000000000000000000000000000000000000..28f122fb762701db7c09b51944cf8c7947a58f1a
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/humaneval/init_ground_truth.py
@@ -0,0 +1,30 @@
+import os
+import pathlib
+
+from evalplus.data.humaneval import get_human_eval
+
+if __name__ == "__main__":
+ # check existance of ground truth folder
+ GT_DIR = pathlib.Path(__file__).parent.parent / "groundtruth" / "humaneval"
+
+ assert not os.path.exists(
+ GT_DIR
+ ), "Ground truth folder already exists! If you want to reinitialize, delete the folder first."
+
+ os.mkdir(GT_DIR)
+
+ human_eval = get_human_eval()
+ for i, task in enumerate(human_eval):
+ incomplete = (
+ task["prompt"]
+ + task["canonical_solution"]
+ + "\n\n"
+ + task["test"]
+ + "\n"
+ + f"check({task['entry_point']})"
+ )
+ with open(
+ os.path.join(GT_DIR, f"{str(i).zfill(3)}_{task['entry_point']}.py"),
+ "w",
+ ) as f:
+ f.write(incomplete)
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/humaneval/init_plus.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/humaneval/init_plus.py
new file mode 100644
index 0000000000000000000000000000000000000000..9431c40d98c87c2a0eca620833dd20379c4f52ab
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/humaneval/init_plus.py
@@ -0,0 +1,112 @@
+"""
+This script aims at quickly initialize a sketch for HumanEvalPlus. It's not going to be
+perfect, but we will either manually or automatically fix/complete it later.
++ CHANGE 1: Adds "contract", "base_input", "atol" in addition to HumanEval.
+"""
+
+import json
+import os
+import pathlib
+from importlib import import_module
+from inspect import getsource
+from typing import Tuple
+
+from tempdir import TempDir
+
+from evalplus.data.humaneval import get_human_eval
+
+HUMANEVAL_PLUS_PATH = (
+ pathlib.Path(__file__).parent.parent.parent / "HumanEvalPlus.jsonl"
+)
+
+
+def _ret(entry_point) -> str:
+ """This is a hacky function to return some garbages so that we can
+ successfully run the function .
+ """
+ if entry_point == "sort_third" or entry_point == "sort_even":
+ return [1, 2, 3]
+ elif entry_point == "bf":
+ return ()
+ return "1"
+
+
+def instrument_inputs(entry_point, prompt, test) -> str:
+ globals()["_inputs"] = []
+ fn_text = f"""{prompt.split(f"def {entry_point}")[0]}
+
+def {entry_point}(*args):
+ _inputs.append(args)
+ return {_ret(entry_point)}
+"""
+ exec(fn_text, globals())
+ exec(test.replace("assert ", ""), globals())
+ exec(f"check({entry_point})", globals())
+ exec(fn_text, globals())
+ return globals()["_inputs"]
+
+
+def get_contract_and_ref(task_id: int, entry_point) -> Tuple[str, str]:
+ mod = import_module(f"groundtruth.humaneval.{str(task_id).zfill(3)}_{entry_point}")
+ fn = getattr(mod, entry_point)
+
+ doc = fn.__doc__
+ if task_id == 51:
+ doc = doc.replace("bcdf\nghjklm", r"bcdf\nghjklm").replace(
+ "abcdef\nghijklm", r"abcdef\nghijklm"
+ )
+
+ code = (
+ getsource(fn).replace(doc, "").replace("''''''", '""""""').split('""""""\n')[-1]
+ )
+
+ assert code, f"Something wrong with {task_id}!"
+ assert code[:3] != "def", f"Something wrong with the {task_id}!"
+
+ # split code to contract and impl
+ contract = ""
+ impl = ""
+
+ reading_contract = True
+ for line in code.strip("\n").split("\n"):
+ if reading_contract and "$_CONTRACT_$" in line:
+ contract += line + "\n"
+ else:
+ reading_contract = False
+ impl += line + "\n"
+
+ if contract:
+ contract = "\n" + contract
+
+ return contract, "\n" + impl + "\n"
+
+
+def get_atol(task_id: int) -> float:
+ if task_id == 2 or task_id == 4:
+ return 1e-6
+ elif task_id == 32:
+ return 1e-4
+ return 0
+
+
+if __name__ == "__main__":
+ assert not HUMANEVAL_PLUS_PATH.exists(), f"{HUMANEVAL_PLUS_PATH} already exists!"
+
+ human_eval = get_human_eval()
+ with TempDir() as temp_dir:
+ tmp_file = os.path.join(temp_dir, HUMANEVAL_PLUS_PATH)
+ with open(tmp_file, "w") as writer:
+ for task in human_eval:
+ task_id = int(task["task_id"].split("/")[-1])
+ task["contract"], task["canonical_solution"] = get_contract_and_ref(
+ task_id, task["entry_point"]
+ )
+ task["base_input"] = instrument_inputs(
+ task["entry_point"], task["prompt"], task["test"]
+ )
+ task["atol"] = get_atol(task_id)
+ task["task_id"] = task["task_id"]
+
+ writer.write(json.dumps(task) + "\n")
+ # move tmp_file to HUMANEVAL_PLUS_PATH
+ os.rename(tmp_file, HUMANEVAL_PLUS_PATH)
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/humaneval/to_original_fmt.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/humaneval/to_original_fmt.py
new file mode 100644
index 0000000000000000000000000000000000000000..3409ec86c8643ee2fc6501b43cae9b357629f097
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/humaneval/to_original_fmt.py
@@ -0,0 +1,206 @@
+import ast
+import inspect
+import json
+import multiprocessing
+import sys
+from concurrent.futures import ProcessPoolExecutor, as_completed
+
+from tqdm import tqdm
+
+from evalplus.data.humaneval import (
+ HUMANEVAL_PLUS_VERSION,
+ get_human_eval_plus,
+ get_human_eval_plus_hash,
+)
+from evalplus.eval import is_floats
+from evalplus.eval._special_oracle import _poly
+from evalplus.evaluate import get_groundtruth
+
+HUMANEVAL_TEST_TEMPLATE = """\
+{imports}
+
+{aux_fn}
+
+def check(candidate):
+ inputs = {inputs}
+ results = {results}
+ for i, (inp, exp) in enumerate(zip(inputs, results)):
+ {assertion}
+"""
+
+HUMANEVAL_CROSSCHECK_TEMPLATE = """\
+{aux_fn}
+
+{ref_func}
+
+def check(candidate):
+ inputs = {inputs}
+ for i, inp in enumerate(inputs):
+ assertion(candidate(*inp), ref_func(*inp), {atol})
+"""
+
+ASSERTION_FN = f"""\
+import numpy as np
+
+{inspect.getsource(is_floats)}
+
+def assertion(out, exp, atol):
+ exact_match = out == exp
+
+ if atol == 0 and is_floats(exp):
+ atol = 1e-6
+ if not exact_match and atol != 0:
+ np.testing.assert_allclose(out, exp, atol=atol)
+ else:
+ assert exact_match
+"""
+
+
+def synthesize_test_code(task_id, entry_point, inputs, results, ref_func, atol):
+ # dataset size optimization for large outputs
+ if entry_point in (
+ "tri",
+ "string_sequence",
+ "starts_one_ends",
+ "make_a_pile",
+ "special_factorial",
+ "all_prefixes",
+ ):
+ return task_id, HUMANEVAL_CROSSCHECK_TEMPLATE.format(
+ aux_fn=ASSERTION_FN,
+ inputs=inputs,
+ ref_func=ref_func.replace(f" {entry_point}(", " ref_func("),
+ atol=atol,
+ )
+
+ # default settings
+ imports = set()
+ aux_fn = ASSERTION_FN
+ assertion = f"assertion(candidate(*inp), exp, {atol})"
+
+ # special case: poly
+ if entry_point == "find_zero":
+ imports.add("import math")
+ aux_fn = inspect.getsource(_poly) + "\n"
+ assertion = f"assert _poly(*candidate(*inp), inp) <= {atol}"
+
+ return task_id, HUMANEVAL_TEST_TEMPLATE.format(
+ imports="\n".join(imports),
+ aux_fn=aux_fn,
+ inputs=inputs,
+ results=results,
+ assertion=assertion,
+ )
+
+
+def deduplicate(inputs, results):
+ assert len(inputs) == len(results)
+ unique_input_strs = set([f"{x}" for x in inputs])
+
+ new_inputs, new_results = [], []
+ for inp, res in zip(inputs, results):
+ inp_str = f"{inp}"
+ if inp_str in unique_input_strs:
+ new_inputs.append(inp)
+ new_results.append(res)
+ unique_input_strs.remove(inp_str)
+
+ return new_inputs, new_results
+
+
+def main():
+ import argparse
+
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--debug-tasks", nargs="+", default=[], type=int)
+
+ args = parser.parse_args()
+
+ if hasattr(sys, "set_int_max_str_digits"):
+ sys.set_int_max_str_digits(int(10e8))
+
+ plus_problems = get_human_eval_plus(mini=False)
+ dataset_hash = get_human_eval_plus_hash()
+
+ compatible_problems = {}
+ expected_outputs = get_groundtruth(plus_problems, dataset_hash, [])
+
+ # debugging: monitoring test code size
+ id2bytes = {}
+
+ n_workers = max(1, multiprocessing.cpu_count() // 4)
+ with ProcessPoolExecutor(max_workers=n_workers) as executor:
+ futures = []
+ for task_id, plus_form in tqdm(plus_problems.items()):
+ if args.debug_tasks and int(task_id.split("/")[-1]) not in args.debug_tasks:
+ continue
+
+ compatible_form = {}
+ compatible_form["task_id"] = task_id
+ compatible_form["prompt"] = plus_form["prompt"]
+ compatible_form["canonical_solution"] = plus_form["canonical_solution"]
+ compatible_form["entry_point"] = plus_form["entry_point"]
+ compatible_problems[task_id] = compatible_form
+
+ inputs = plus_form["base_input"] + plus_form["plus_input"]
+ results = (
+ expected_outputs[task_id]["base"] + expected_outputs[task_id]["plus"]
+ )
+
+ inputs, results = deduplicate(inputs, results)
+
+ assert len(inputs) == len(results)
+ atol = plus_form["atol"]
+
+ simplified_prompt = ""
+ for line in compatible_form["prompt"].split("\n"):
+ if not line:
+ continue
+ if '"""' in line or "'''" in line:
+ break
+ simplified_prompt += line + "\n"
+
+ futures.append(
+ executor.submit(
+ synthesize_test_code,
+ task_id,
+ compatible_form["entry_point"],
+ inputs,
+ results,
+ simplified_prompt + compatible_form["canonical_solution"],
+ atol,
+ )
+ )
+
+ for future in tqdm(as_completed(futures), total=len(plus_problems)):
+ task_id, test_code = future.result()
+ # syntax check of test_code
+ ast.parse(test_code)
+ id2bytes[task_id] = len(test_code.encode("utf-8"))
+ compatible_problems[task_id]["test"] = test_code
+
+ # print the top-10 largest test code
+ print("Top-10 largest test code comes from problems (in megabytes):")
+ for task_id, size in sorted(id2bytes.items(), key=lambda x: x[1], reverse=True)[
+ :10
+ ]:
+ print(f"{task_id}:\t{size / 1024 / 1024:.2f}mb")
+
+ if args.debug_tasks:
+ for problem in compatible_problems.values():
+ print("--- debugging:", problem["task_id"])
+ print(problem["prompt"] + problem["canonical_solution"])
+ test_code = problem["test"]
+ if len(test_code) <= 2048 + 512:
+ print(test_code)
+ else:
+ print(problem["test"][:1024], "...")
+ print("...", problem["test"][-1024:])
+ else:
+ with open(f"HumanEvalPlus-OriginFmt-{HUMANEVAL_PLUS_VERSION}.jsonl", "w") as f:
+ for problem in compatible_problems.values():
+ f.write(json.dumps(problem) + "\n")
+
+
+if __name__ == "__main__":
+ main()
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/mbpp/check_ground_truth.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/mbpp/check_ground_truth.py
new file mode 100644
index 0000000000000000000000000000000000000000..738ae4b3d4c707ea1bac7702246f83b823a7d71f
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/mbpp/check_ground_truth.py
@@ -0,0 +1,22 @@
+"""Test through all ground truth files in groundtruth/mbpp."""
+
+import pathlib
+
+import multiprocess as mp
+from rich.progress import track
+
+if __name__ == "__main__":
+ mbpp_work_dir = pathlib.Path(__file__).parent.parent.parent / "groundtruth" / "mbpp"
+ assert mbpp_work_dir.exists(), f"{mbpp_work_dir} does not exist!"
+ for file in track(mbpp_work_dir.glob("*.py")):
+ print(file)
+ code = file.read_text()
+
+ # run the code in a subprocess
+ p = mp.Process(target=exec, args=(code, globals()))
+ p.start()
+ p.join(timeout=5)
+ assert not p.is_alive(), f"Timeout for {file}!"
+ p.terminate()
+ p.join()
+ assert p.exitcode == 0, f"Error for {file}! {code}"
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/mbpp/init_ground_truth.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/mbpp/init_ground_truth.py
new file mode 100644
index 0000000000000000000000000000000000000000..dce9b3057eb6a9e0deccbd1e0c20cd997e23e60d
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/mbpp/init_ground_truth.py
@@ -0,0 +1,41 @@
+"""This script will initialize a folder of Python texts from MBPP.
+Based on this we will add our contract and modified ground-truth.
+"""
+
+import os
+import pathlib
+
+from evalplus.data.mbpp import get_mbpp
+
+if __name__ == "__main__":
+ # check existance of ground truth folder
+ GT_DIR = pathlib.Path(__file__).parent.parent.parent / "groundtruth" / "mbpp"
+
+ assert not os.path.exists(
+ GT_DIR
+ ), "Ground truth folder already exists! If you want to reinitialize, delete the folder first."
+
+ GT_DIR.parent.mkdir(exist_ok=True)
+ GT_DIR.mkdir()
+
+ mbpp = get_mbpp()
+
+ newline = "\n"
+
+ for tid, task in mbpp.items():
+ incomplete = f'''"""
+{task["prompt"]}
+"""
+
+{task["code"]}
+
+{newline.join(task["test_imports"])}
+
+{newline.join(task["test_list"])}
+'''
+
+ with open(
+ os.path.join(GT_DIR, f"{tid.zfill(3)}.py"),
+ "w",
+ ) as f:
+ f.write(incomplete)
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/mbpp/init_plus.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/mbpp/init_plus.py
new file mode 100644
index 0000000000000000000000000000000000000000..22f5895c061f92236e921595d99ec14908a6486d
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/mbpp/init_plus.py
@@ -0,0 +1,198 @@
+import json
+import os
+import pathlib
+import shutil
+from importlib import util
+from inspect import getmembers, isfunction
+from typing import Tuple
+
+from tempdir import TempDir
+
+from evalplus.data.mbpp import get_mbpp, mbpp_serialize_inputs
+
+MBPP_PLUS_PATH = pathlib.Path(__file__).parent.parent.parent / "MbppBase.jsonl"
+
+GROUNDTRUTH_MBPP_PATH = pathlib.Path(__file__).parent.parent.parent / "groundtruth/mbpp"
+
+
+def _ret(entry_point) -> str:
+ """
+ This is a hacky function to return some garbages so that we can
+ successfully run the function .
+ """
+ set_assertion_func = [
+ "similar_elements",
+ "find_char_long",
+ "common_in_nested_lists",
+ "extract_singly",
+ "larg_nnum",
+ "intersection_array",
+ "k_smallest_pairs",
+ ]
+ if entry_point in set_assertion_func:
+ return "()"
+ return "1"
+
+
+def get_entry_point(task_id: int, assertion: str) -> str:
+ py_file_path = str(GROUNDTRUTH_MBPP_PATH) + f"/{str(task_id).zfill(3)}.py"
+ spec = util.spec_from_file_location("inspect_module", py_file_path)
+ module = util.module_from_spec(spec)
+ spec.loader.exec_module(module)
+ functions = [name for name, value in getmembers(module, isfunction)]
+
+ # maybe exist some helper functions, filter them
+ functions = [func for func in functions if func in assertion]
+ if len(functions) > 1:
+ print("more than one function: ", functions)
+
+ return functions[0] if len(functions) > 0 else None
+
+
+def get_code_and_contract_and_assertion(task_id: id) -> Tuple[str, str, str]:
+ py_file_path = str(GROUNDTRUTH_MBPP_PATH) + f"/{str(task_id).zfill(3)}.py"
+ with open(py_file_path) as reader:
+ text = reader.read()
+ # remove docstring
+ start_index = text.find('"""')
+ end_index = text.find('"""', start_index + 3)
+ if start_index != -1 and end_index != -1:
+ text = text[:start_index] + text[end_index + 3 :]
+
+ lines = text.splitlines()
+ assertion = ""
+ contract = ""
+
+ for i in range(len(lines)):
+ if "$_CONTRACT_$" in lines[i]:
+ contract += lines[i] + "\n"
+ elif lines[i].startswith("assert"):
+ assertion += lines[i] + "\n"
+
+ for i in range(len(lines) - 1, -1, -1):
+ if (
+ "$_CONTRACT_$" in lines[i]
+ or lines[i].startswith("assert")
+ or lines[i] == ""
+ ):
+ del lines[i]
+
+ for i in range(len(lines) - 1, -1, -1):
+ if lines[i].startswith("import"):
+ del lines[i]
+ else:
+ break
+
+ code = "\n".join(lines)
+ return "\n" + code + "\n", "\n" + contract, "\n" + assertion
+
+
+def instrument_inputs(code, entry_point, test_code) -> str:
+ globals()["_inputs"] = []
+ fn_text = f"""{code.split(f"def {entry_point}")[0]}
+
+def {entry_point}(*args):
+ _inputs.append(args)
+ return {_ret(entry_point)}
+"""
+ exec(fn_text + "\n" + test_code.replace("assert ", ""), globals())
+ print(fn_text + "\n" + test_code.replace("assert ", ""))
+ print(globals()["_inputs"])
+ return globals()["_inputs"]
+
+
+def get_atol(task_id: int) -> float:
+ float_ans_list = [
+ 82,
+ 85,
+ 98,
+ 120,
+ 124,
+ 137,
+ 139,
+ 163,
+ 233,
+ 246,
+ 248,
+ 276,
+ 293,
+ 300,
+ 312,
+ 442,
+ 574,
+ 742,
+ 746,
+ ]
+ if task_id in float_ans_list:
+ return 1e-4
+ return 0
+
+
+if __name__ == "__main__":
+ assert not MBPP_PLUS_PATH.exists(), f"{MBPP_PLUS_PATH} already exists!"
+
+ mbpp = get_mbpp()
+
+ with TempDir() as temp_dir:
+ tmp_file = os.path.join(temp_dir, MBPP_PLUS_PATH)
+ with open(tmp_file, "w") as writer:
+ for task in mbpp.values():
+ task_id = int(task["task_id"])
+
+ if task_id in [
+ 163,
+ 228,
+ 304,
+ 408,
+ 776,
+ 307,
+ 417,
+ 443,
+ 444,
+ 452,
+ 464,
+ 617,
+ 627,
+ 738,
+ 747,
+ 802,
+ 393,
+ 411,
+ 584,
+ 625,
+ 756,
+ 779,
+ ]:
+ continue
+
+ task["task_id"] = f"Mbpp/{task_id}"
+ task["entry_point"] = get_entry_point(task_id, task["test_list"][0])
+ task["prompt"] = f'"""\n{task["prompt"]}\n{task["test_list"][0]}\n"""\n'
+
+ (
+ task["canonical_solution"],
+ task["contract"],
+ task["assertion"],
+ ) = get_code_and_contract_and_assertion(task_id)
+ if len(task["test_imports"]):
+ task["assertion"] = (
+ "\n".join(task["test_imports"]) + "\n" + task["assertion"]
+ )
+
+ task["base_input"] = instrument_inputs(
+ task["canonical_solution"], task["entry_point"], task["assertion"]
+ )
+
+ task["atol"] = get_atol(task_id)
+
+ del task["source_file"]
+ del task["code"]
+ del task["test_list"]
+ del task["test_imports"]
+ del task["assertion"]
+
+ task["base_input"] = mbpp_serialize_inputs(task_id, task["base_input"])
+
+ writer.write(json.dumps(task) + "\n")
+
+ shutil.copy2(tmp_file, MBPP_PLUS_PATH)
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/mbpp/to_original_fmt.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/mbpp/to_original_fmt.py
new file mode 100644
index 0000000000000000000000000000000000000000..047302b4b037cebbec6e6a414fef04441f03de2a
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/mbpp/to_original_fmt.py
@@ -0,0 +1,206 @@
+import ast
+import inspect
+import json
+import multiprocessing
+import sys
+from concurrent.futures import ProcessPoolExecutor, as_completed
+
+from tqdm import tqdm
+
+from evalplus.data.mbpp import (
+ MBPP_PLUS_VERSION,
+ get_mbpp,
+ get_mbpp_plus,
+ get_mbpp_plus_hash,
+)
+from evalplus.eval import is_floats
+from evalplus.eval._special_oracle import MBPP_OUTPUT_NOT_NONE_TASKS
+from evalplus.evaluate import get_groundtruth
+
+MBPP_TEST_TEMPLATE = """\
+{imports}
+
+{aux_fn}
+
+inputs = {inputs}
+results = {results}
+for i, (inp, exp) in enumerate(zip(inputs, results)):
+ assertion({entry_point}(*inp), exp, {atol})
+"""
+
+MBPP_CROSSCHECK_TEMPLATE = """\
+{aux_fn}
+
+{ref_func}
+
+inputs = {inputs}
+for i, inp in enumerate(inputs):
+ assertion({entry_point}(*inp), ref_func(*inp), {atol})
+"""
+
+ASSERTION_FN = f"""\
+import numpy as np
+
+{inspect.getsource(is_floats)}
+
+def assertion(out, exp, atol):
+ exact_match = out == exp
+
+ if atol == 0 and is_floats(exp):
+ atol = 1e-6
+ if not exact_match and atol != 0:
+ np.testing.assert_allclose(out, exp, atol=atol)
+ else:
+ assert exact_match
+"""
+
+
+def synthesize_test_code(task_id, entry_point, inputs, results, ref_func, atol):
+ # dataset size optimization for large outputs
+ if entry_point in ("combinations_colors", "freq_count", "get_coordinates"):
+ return task_id, MBPP_CROSSCHECK_TEMPLATE.format(
+ aux_fn=ASSERTION_FN,
+ inputs=inputs,
+ ref_func=ref_func.replace(f" {entry_point}(", " ref_func("),
+ entry_point=entry_point,
+ atol=atol,
+ )
+
+ # default settings
+ imports = set()
+ aux_fn = ASSERTION_FN
+
+ # inf exists in inputs/results
+ if entry_point in ("zero_count", "minimum"):
+ imports.add("from math import inf")
+
+ test_code = MBPP_TEST_TEMPLATE.format(
+ imports="\n".join(imports),
+ aux_fn=aux_fn,
+ inputs=inputs,
+ results=results,
+ entry_point=entry_point,
+ atol=atol,
+ )
+
+ return task_id, test_code
+
+
+def deduplicate(inputs, results):
+ assert len(inputs) == len(results)
+ unique_input_strs = set([f"{x}" for x in inputs])
+
+ new_inputs, new_results = [], []
+ for inp, res in zip(inputs, results):
+ inp_str = f"{inp}"
+ if inp_str in unique_input_strs:
+ new_inputs.append(inp)
+ new_results.append(res)
+ unique_input_strs.remove(inp_str)
+
+ return new_inputs, new_results
+
+
+def main():
+ import argparse
+
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--debug-tasks", nargs="+", default=[], type=int)
+
+ args = parser.parse_args()
+
+ if hasattr(sys, "set_int_max_str_digits"):
+ sys.set_int_max_str_digits(int(10e8))
+
+ plus_problems = get_mbpp_plus(mini=False)
+ dataset_hash = get_mbpp_plus_hash()
+
+ original_mbpp = get_mbpp()
+
+ compatible_problems = {}
+ expected_outputs = get_groundtruth(
+ plus_problems, dataset_hash, MBPP_OUTPUT_NOT_NONE_TASKS
+ )
+
+ # debugging: monitoring test code size
+ id2bytes = {}
+
+ n_workers = max(1, multiprocessing.cpu_count() // 4)
+ with ProcessPoolExecutor(max_workers=n_workers) as executor:
+ futures = []
+ for task_id, plus_form in tqdm(plus_problems.items()):
+ # expected MBPP task_id is numbers directly
+ # i.e., "666" instead of "Mbpp/666"
+ # But in EvalPlus the task_id is "Mbpp/666"
+ task_id_int = int(task_id.split("/")[-1])
+ if args.debug_tasks and task_id_int not in args.debug_tasks:
+ continue
+
+ compatible_form = {
+ "task_id": task_id_int,
+ "code": plus_form["canonical_solution"],
+ "prompt": original_mbpp[str(task_id_int)]["prompt"],
+ "source_file": original_mbpp[str(task_id_int)]["source_file"],
+ "test_imports": original_mbpp[str(task_id_int)]["test_imports"],
+ "test_list": original_mbpp[str(task_id_int)]["test_list"],
+ }
+ compatible_problems[task_id_int] = compatible_form
+
+ inputs = (
+ plus_form["base_input"] + plus_form["plus_input"]
+ if len(plus_form["plus_input"]) > 0
+ else plus_form["base_input"]
+ )
+ results = (
+ expected_outputs[task_id]["base"] + expected_outputs[task_id]["plus"]
+ )
+
+ inputs, results = deduplicate(inputs, results)
+
+ assert len(inputs) == len(results)
+ atol = plus_form["atol"]
+
+ futures.append(
+ executor.submit(
+ synthesize_test_code,
+ task_id_int,
+ plus_form["entry_point"],
+ inputs,
+ results,
+ compatible_form["code"],
+ atol,
+ )
+ )
+
+ for future in tqdm(as_completed(futures), total=len(plus_problems)):
+ task_id, test_code = future.result()
+ # syntax check of test_code
+ ast.parse(test_code)
+ id2bytes[task_id] = len(test_code.encode("utf-8"))
+ compatible_problems[task_id]["test"] = test_code
+
+ # print the top-10 largest test code
+ print("Top-10 largest test code comes from problems (in megabytes):")
+ for task_id, size in sorted(id2bytes.items(), key=lambda x: x[1], reverse=True)[
+ :10
+ ]:
+ print(f"{task_id}:\t{size / 1024 / 1024:.2f}mb")
+
+ if args.debug_tasks:
+ for problem in compatible_problems.values():
+ print("--- debugging:", problem["task_id"])
+ print('"""\n' + problem["prompt"] + '\n"""\n' + problem["code"])
+ test_code = problem["test"]
+ if True or len(test_code) <= 2048 + 512:
+ print(test_code)
+ else:
+ print(problem["test"][:1024], "...")
+ print("...", problem["test"][-1024:])
+ else:
+ with open(f"MbppPlus-OriginFmt-{MBPP_PLUS_VERSION}.jsonl", "w") as f:
+ for problem in compatible_problems.values():
+ f.write(json.dumps(problem) + "\n")
+
+
+if __name__ == "__main__":
+ main()
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/merge_dataset.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/merge_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..c52664ffa72a3032994081556ac0d42905b0cbe0
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/merge_dataset.py
@@ -0,0 +1,38 @@
+if __name__ == "__main__":
+ import argparse
+ import json
+ import os
+
+ from tempdir import TempDir
+
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--dataset", default="humaneval", type=str)
+ parser.add_argument("--plus-input", required=True, type=str)
+ parser.add_argument("--output", required=True, type=str)
+ args = parser.parse_args()
+
+ assert args.dataset == "humaneval"
+ assert not os.path.exists(args.output), f"{args.output} already exists!"
+
+ with TempDir() as tempdir:
+ # Generate inputs
+ plus_input = {}
+ with open(args.plus_input) as file:
+ for line in file:
+ problem = json.loads(line)
+ plus_input[problem["task_id"]] = problem["inputs"]
+
+ tempf = None
+ if args.dataset == "humaneval":
+ from evalplus.data import get_human_eval_plus
+
+ # Allow it to be incomplete
+ problems = get_human_eval_plus(err_incomplete=False)
+ tempf = os.path.join(tempdir, "HumanEvalPlus.jsonl")
+ with open(tempf, "w") as file:
+ for problem in problems:
+ problem["plus_input"] = plus_input[problem["task_id"]]
+ file.write(json.dumps(problem) + "\n")
+
+ # Move to the right place
+ os.rename(tempf, args.output)
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/render.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/render.py
new file mode 100644
index 0000000000000000000000000000000000000000..19f076866d2c5be702593fd8c33ab6c3e1ad9773
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/render.py
@@ -0,0 +1,194 @@
+"""Convert the results to an ingredient for LaTeX table.
+"""
+
+import argparse
+import json
+import os
+
+import numpy as np
+from termcolor import cprint
+
+from evalplus.eval import estimate_pass_at_k
+
+TEMPS = [0.2, 0.4, 0.6, 0.8]
+
+
+def analyze_resfile(resfile):
+ before_summary = {}
+ after_summary = {}
+
+ res = json.load(open(resfile))["eval"]
+ total = []
+ before_pass = []
+ after_pass = []
+ for v in res.values():
+ total.append(v["nfiles"])
+ bc = sum([r[0] == SUCCESS for r in v["base"]])
+ before_pass.append(bc)
+ if v["plus"]:
+ after_pass.append(
+ sum(
+ [
+ v["plus"][i][0] == v["base"][i][0] == SUCCESS
+ for i in range(len(v["plus"]))
+ ]
+ )
+ )
+
+ total = np.array(total)
+ before_pass = np.array(before_pass)
+ after_pass = np.array(after_pass)
+ for k in [1, 10, 100]:
+ if total.min() >= k:
+ pass_at_k = estimate_pass_at_k(total, before_pass, k).mean()
+ before_summary[f"pass@{k}"] = pass_at_k * 100 # scale to %
+ for k in [1, 10, 100]:
+ if total.min() >= k:
+ pass_at_k = estimate_pass_at_k(total, after_pass, k).mean()
+ after_summary[f"pass@{k}"] = pass_at_k * 100
+
+ return before_summary, after_summary
+
+
+def align_ampersands(str1, str2):
+ """
+ This function takes two strings containing various "&" characters and transforms them so that the indices of "&"
+ are aligned. This is useful for formatting LaTeX tables.
+
+ Args:
+ str1 (str): First input string containing "&" characters.
+ str2 (str): Second input string containing "&" characters.
+
+ Returns:
+ Tuple[str, str]: Two transformed strings with aligned "&" indices.
+ """
+ # Find indices of "&" characters in both strings
+ amp_idx1 = [i for i, char in enumerate(str1) if char == "&"]
+ amp_idx2 = [i for i, char in enumerate(str2) if char == "&"]
+
+ assert len(amp_idx1) == len(amp_idx2)
+
+ # Replace "&" characters in the strings with "\&" at the aligned indices
+ acc1, acc2 = 0, 0
+ for i, j in zip(amp_idx1, amp_idx2):
+ diff = (j + acc2) - (i + acc1)
+ if diff > 0:
+ str1 = str1[: i + acc1] + " " * diff + str1[i + acc1 :]
+ acc1 += diff
+ elif diff < 0:
+ str2 = str2[: j + acc2] + " " * (-diff) + str2[j + acc2 :]
+ acc2 -= diff
+
+ return str1, str2
+
+
+def texprint(before_summary, after_summary, bfgreedy, afgreedy):
+ TEXTTEMPS = [r"\temptwo{}", r"\tempfour{}", r"\tempsix{}", r"\tempeight{}"]
+
+ def aplus(s) -> str:
+ return r"\aplus{" + s + r"}"
+
+ def make_line(summary, amax, ap=False):
+ pkvals = [f"{v[amax[i]]:.1f}" for i, v in enumerate(summary.values())]
+ if ap:
+ pkvals = [aplus(v) for v in pkvals]
+ return (
+ " & ".join(pkvals)
+ + " & "
+ + " & ".join([TEXTTEMPS[i] for i in amax])
+ + r" \\"
+ )
+
+ print("======== LaTeX Table Ingredent ========")
+ argmax = [np.argmax(v) for v in before_summary.values()]
+ text1 = "base & "
+ if bfgreedy is not None:
+ text1 += f"{bfgreedy:.1f} & "
+ argmax = [np.argmax(v) for v in after_summary.values()]
+ text1 += make_line(before_summary, argmax)
+
+ text2 = "\\aplus{+extra} & "
+ if afgreedy is not None:
+ text2 += aplus(f"{afgreedy:.1f}") + " & "
+ text2 += make_line(after_summary, argmax, ap=True)
+
+ text1, text2 = align_ampersands(text1, text2)
+ cprint(text1, "green")
+ cprint(text2, "green")
+
+
+def rich_print(before_summary, after_summary, bfgreedy, afgreedy):
+ from rich.console import Console
+ from rich.table import Table
+
+ console = Console()
+ table = Table(show_header=True, header_style="bold magenta", title="pass@k results")
+
+ before_row = []
+ after_row = []
+
+ table.add_column(" ", style="dim", no_wrap=True)
+
+ if bfgreedy is not None:
+ assert afgreedy is not None
+ table.add_column("Greedy pass@1", justify="right", style="bold green")
+ before_row.append(f"{bfgreedy:.1f}")
+ after_row.append(f"{afgreedy:.1f}")
+
+ for k in before_summary:
+ table.add_column(k, justify="right", style="bold magenta")
+ table.add_column("Tbest.", justify="right")
+ amax_before = np.argmax(before_summary[k])
+ amax_after = np.argmax(after_summary[k])
+ before_row.append(f"{before_summary[k][amax_before]:.1f}")
+ before_row.append(f"{TEMPS[amax_before]}")
+ after_row.append(f"{after_summary[k][amax_after]:.1f}")
+ after_row.append(f"{TEMPS[amax_after]}")
+
+ table.add_row("Before", *before_row)
+ table.add_row("After", *after_row)
+
+ console.print(table)
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--type", type=str, required=True)
+ args = parser.parse_args()
+
+ # Analyszing 0.2~0.8 temperatures.
+ resfiles = []
+ # check existance
+ for t in TEMPS:
+ f = os.path.join(f"{args.type}_temp_{t}", f"eval_results.json")
+ assert os.path.exists(f), f"{f} not found"
+ resfiles.append(f)
+
+ before_summary = {}
+ after_summary = {}
+
+ SUCCESS = "success"
+
+ for resfile in resfiles:
+ # load the results
+ before, after = analyze_resfile(resfile)
+ for k, v in before.items():
+ before_summary.setdefault(k, []).append(v)
+ for k, v in after.items():
+ after_summary.setdefault(k, []).append(v)
+
+ # print pass@1~100, and corresponding max temperature
+
+ # Analyszing greedy decoding (temperature=0.0)
+ gf = os.path.join(f"{args.type}_temp_0.0", f"eval_results.json")
+ bfgreedy, afgreedy = None, None
+ if os.path.exists(gf):
+ bfgreedy, afgreedy = analyze_resfile(gf)
+ bfgreedy = bfgreedy["pass@1"]
+ afgreedy = afgreedy["pass@1"]
+
+ # Rich printing
+ rich_print(before_summary, after_summary, bfgreedy, afgreedy)
+
+ # LaTeX printing
+ texprint(before_summary, after_summary, bfgreedy, afgreedy)
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/sanitize.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/sanitize.py
new file mode 100644
index 0000000000000000000000000000000000000000..6cbd5d8830f6253b471851b2430f186e2d8c8174
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/sanitize.py
@@ -0,0 +1,138 @@
+"""Purpose of this file: Sanitize the code produced by LLMs for the following reasons.
+1. Vicuna generated code could miss one white space. We fix the white space to make Vicuna more capable.
+2. {Our fault lol.} We find more EOFs tokens afterwards and truncate some messy code afterwards.
+"""
+
+import os
+
+from tqdm import tqdm
+
+from evalplus.data import (
+ get_human_eval_plus,
+ get_mbpp_plus,
+ load_solutions,
+ write_directory,
+ write_jsonl,
+)
+from evalplus.sanitize import sanitize
+
+
+def remove_unindented_lines(code, protect_before, execeptions, trim_tails):
+ lines = code.splitlines()
+ cut_idx = []
+ cut_enabled = False
+ for i, line in enumerate(lines):
+ if not cut_enabled and line.startswith(protect_before):
+ cut_enabled = True
+ continue
+ if line.strip() == "":
+ continue
+ if any(line.startswith(e) for e in execeptions):
+ continue
+
+ lspace = len(line) - len(line.lstrip())
+ if lspace == 0:
+ cut_idx.append(i)
+
+ if any(line.rstrip().startswith(t) for t in trim_tails):
+ # cut off everything behind
+ cut_idx.extend(list(range(i, len(lines))))
+ break
+
+ return "\n".join([line for i, line in enumerate(lines) if i not in cut_idx])
+
+
+def to_four_space_indents(old_code):
+ new_code = ""
+ for line in old_code.splitlines():
+ lspace = len(line) - len(line.lstrip())
+ if lspace == 3:
+ new_code += " "
+ new_code += line + "\n"
+ return new_code
+
+
+if __name__ == "__main__":
+ import argparse
+ import pathlib
+
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--samples", type=str, required=True)
+ parser.add_argument("--eofs", nargs="+", type=str, default=[])
+ parser.add_argument("--inplace", action="store_true")
+ parser.add_argument(
+ "--rm-prefix-lines", type=str, help="Remove lines starting with this"
+ )
+ parser.add_argument(
+ "--dataset", required=True, type=str, choices=["humaneval", "mbpp"]
+ )
+ parser.add_argument(
+ "--debug-task", type=str, help="Enter the task ID to only sanitize that task."
+ )
+ args = parser.parse_args()
+
+ # task_id -> entry_point
+ entry_point = {}
+
+ if args.dataset == "humaneval":
+ dataset = get_human_eval_plus()
+ elif args.dataset == "mbpp":
+ dataset = get_mbpp_plus()
+
+ for task_id, problem in dataset.items():
+ entry_point[task_id] = problem["entry_point"]
+
+ # make a new folder with "-sanitized" suffix
+ is_folder = os.path.isdir(args.samples)
+ target_path = pathlib.Path(args.samples)
+ if not args.inplace:
+ if is_folder:
+ new_name = target_path.name + "-sanitized"
+ else:
+ new_name = target_path.name.replace(".jsonl", "-sanitized.jsonl")
+ target_path = target_path.parent / new_name
+ target_path = str(target_path)
+
+ nsan = 0
+ ntotal = 0
+
+ new_solutions = []
+
+ for solution in tqdm(load_solutions(args.samples)):
+ task_id = solution["task_id"]
+ dbg_identifier = solution["_identifier"]
+ if args.debug_task is not None and task_id != args.debug_task:
+ continue
+
+ ntotal += 1
+ if "solution" in solution:
+ old_code = solution["solution"]
+ else:
+ assert "completion" in solution
+ old_code = dataset[task_id]["prompt"] + "\n" + solution["completion"]
+
+ old_code = old_code.strip()
+
+ new_code = sanitize(
+ old_code=old_code,
+ entry_point=entry_point[task_id],
+ rm_prefix_lines=args.rm_prefix_lines,
+ eofs=args.eofs,
+ ).strip()
+
+ # if changed, print the message
+ if new_code != old_code:
+ msg = "Sanitized: " + dbg_identifier
+ if is_folder:
+ msg += " -> " + dbg_identifier.replace(args.samples, target_path)
+ print(msg)
+ nsan += 1
+
+ new_solutions.append({"task_id": task_id, "solution": new_code})
+
+ if is_folder:
+ write_directory(target_path, new_solutions)
+ else:
+ write_jsonl(target_path, new_solutions)
+
+ print(f"Sanitized {nsan} out of {ntotal} files.")
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/stat_plus.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/stat_plus.py
new file mode 100644
index 0000000000000000000000000000000000000000..5543ba5feda966aaaa4a20e42041f7122399a59a
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/stat_plus.py
@@ -0,0 +1,33 @@
+import argparse
+
+import numpy as np
+
+from evalplus.data import get_human_eval_plus, get_mbpp_plus
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--dataset", default="humaneval", choices=["mbpp", "humaneval"])
+ parser.add_argument("--mini", action="store_true")
+ args = parser.parse_args()
+
+ print(f"Reporting stats for {args.dataset} dataset [ mini = {args.mini} ]")
+ if args.dataset == "humaneval":
+ data = get_human_eval_plus(mini=args.mini)
+ elif args.dataset == "mbpp":
+ data = get_mbpp_plus(mini=args.mini)
+
+ sizes = np.array(
+ [[len(inp["base_input"]), len(inp["plus_input"])] for inp in data.values()]
+ )
+ size_base = sizes[:, 0]
+ print(f"{size_base.min() = }", f"{size_base.argmin() = }")
+ print(f"{size_base.max() = }", f"{size_base.argmax() = }")
+ print(f"{np.percentile(size_base, 50) = :.1f}")
+ print(f"{size_base.mean() = :.1f}")
+
+ size_plus = sizes[:, 1]
+ size_plus += size_base
+ print(f"{size_plus.min() = }", f"{size_plus.argmin() = }")
+ print(f"{size_plus.max() = }", f"{size_plus.argmax() = }")
+ print(f"{np.percentile(size_plus, 50) = :.1f}")
+ print(f"{size_plus.mean() = :.1f}")
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/tsr/.gitignore b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/tsr/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..c8cb18147ee67b6e7fc8aafead15c99d78f3ead3
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/tsr/.gitignore
@@ -0,0 +1 @@
+tsr_info
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/tsr/README.md b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/tsr/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..6caa6b0140542bb997255f5e47f0d677317515e5
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/tsr/README.md
@@ -0,0 +1,48 @@
+# Test-suite Reduction
+
+## Preperation Work
+
+As test-suite reduction relies on the results of evaluation, make sure that you've run the evaluation script and an `eval_results.json` has been generated for each model under test.
+
+Use the following command to install necessary dependencies:
+
+```bash
+# in $EVALPLUS_ROOT
+pip install -r requirements-tsr.txt
+```
+
+## Usage
+
+```bash
+python3 run.py \
+ --dataset DATASET \
+ --sample_eval_dir SAMPLE_DIR \
+ --model MODEL \
+ [--report_dir REPORT_DIR]
+
+# Example
+python3 run.py --dataset humaneval --sample_eval_dir $HOME/HumanEval --model ALL
+```
+
+Parameter descriptions:
+* `--dataset`: currently, `humaneval` and `mbpp` are supported.
+* `--sample_eval_dir` is the directory containing all the LLM evaluation results. We require the directory be structured as
+ ```bash
+ SAMPLE_EVAL_DIR
+ ├── LLM_1
+ │ ├── ...
+ │ └── eval_results.json
+ ├── LLM_2
+ │ ├── ...
+ ├── ...
+ ```
+* `--report_dir` is the directory where we store intermediate files, pass@k results, and reduced dataset. If not specified, `REPORT_DIR=./tsr_info` by default.
+* If `MODEL` is a specific LLM name, the cross-validation results will be generated in `REPORT_DIR`; if `MODEL == ALL`, a reduced dataset will be generated in `REPORT_DIR`.
+
+## Known Issues
+
+If you find the program stuck at the mutant generation step, try removing the line
+```python
+assert len(completion_id) == len(problems), "Missing problems in samples"
+```
+in `evalplus/evaluate.py`.
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/tsr/__init__.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/tsr/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..459b8da7fde5c5582270b05451fcde1c635ecf3d
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/tsr/__init__.py
@@ -0,0 +1,3 @@
+from pathlib import Path
+
+tsr_base_dir = Path(__file__).parent
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/tsr/coverage_init.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/tsr/coverage_init.py
new file mode 100644
index 0000000000000000000000000000000000000000..352c713c998a53d6dd90729a8d738d3b40a01cf6
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/tsr/coverage_init.py
@@ -0,0 +1,115 @@
+import os
+import pickle
+import sys
+from importlib import import_module
+from io import StringIO
+from typing import Any, Dict, List
+
+import coverage
+from rich.progress import track
+
+from evalplus.eval.utils import swallow_io
+from tools.tsr.utils import get_problems, get_task_ids, to_path
+
+
+class Capturing(list):
+ def __enter__(self):
+ self._stdout = sys.stdout
+ sys.stdout = self._stringio = StringIO()
+ return self
+
+ def __exit__(self, *args):
+ self.extend(self._stringio.getvalue().splitlines())
+ del self._stringio
+ sys.stdout = self._stdout
+
+
+def parse_lcov(outputs: List[str]):
+ switch, extracted_outputs = False, []
+ for line in outputs:
+ if switch == False and "tmp_src" in line:
+ switch = True
+ if switch == True and "end_of_record" in line:
+ switch = False
+ if switch:
+ extracted_outputs.append(line)
+
+ branch, branch_covered = [], []
+ for line in extracted_outputs:
+ if line.startswith("BRDA"):
+ # BRDA format: BR:,,,
+ lineno, blockno, branchno, taken = line[5:].split(",")
+ branch_sig = f"BR:{lineno},{blockno},{branchno}"
+ branch.append(branch_sig)
+ if taken not in ["0", "-"]:
+ branch_covered.append(branch_sig)
+ per = 1.0 if len(branch) == 0 else len(branch_covered) / len(branch)
+ return per, branch, branch_covered
+
+
+def test_code_coverage(
+ identifier: str, code: str, inputs: List[List[Any]], entry_point: str
+):
+ module_name = f"tmp_src_{identifier}"
+ with open(f"{module_name}.py", "w") as f:
+ f.write(code)
+
+ mod = import_module(module_name)
+ func = getattr(mod, entry_point, None)
+ assert func != None, f"entry_point = {entry_point} not exist, code: {code}"
+
+ cov = coverage.Coverage(branch=True)
+ cov.start()
+ with swallow_io():
+ for input_list in inputs:
+ func(*input_list)
+ cov.stop()
+ with Capturing() as outputs:
+ cov.lcov_report(outfile="-")
+
+ ret = parse_lcov(outputs)
+
+ os.remove(f"{module_name}.py")
+ return ret
+
+
+def collect_coverage_info(coverage_dir: str, dataset: str) -> Dict[str, Dict[str, Any]]:
+ os.makedirs(coverage_dir, exist_ok=True)
+ problems = get_problems(dataset)
+ task_ids = get_task_ids(dataset)
+ coverage_info = {task_id: {} for task_id in task_ids}
+ for task_id in track(task_ids, description="Testing gt coverage..."):
+ coverage_cache_path = os.path.join(coverage_dir, f"{to_path(task_id)}.pkl")
+ if os.path.isfile(coverage_cache_path):
+ with open(coverage_cache_path, "rb") as f:
+ coverage_info[task_id] = pickle.load(f)
+ continue
+ groundtruth_code = (
+ problems[task_id]["prompt"] + problems[task_id]["canonical_solution"]
+ )
+ plus_tests = problems[task_id]["plus_input"]
+ entry_point = problems[task_id]["entry_point"]
+ for i, plus_test in enumerate(plus_tests):
+ per, branch, branch_covered = test_code_coverage(
+ to_path(task_id), groundtruth_code, [plus_test], entry_point
+ )
+ test_id = f"plus_{i}"
+ coverage_info[task_id].setdefault(test_id, []).extend(
+ [(br, "gt") for br in branch_covered]
+ )
+ with open(coverage_cache_path, "wb") as f:
+ pickle.dump(coverage_info[task_id], f)
+
+ return coverage_info
+
+
+if __name__ == "__main__":
+ import argparse
+
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--dataset", type=str, choices=["humaneval", "mbpp"])
+ parser.add_argument("--report_dir", required=True, type=str)
+ args = parser.parse_args()
+
+ coverage_dir = os.path.join(args.report_dir, "coverage_cache")
+ collect_coverage_info(coverage_dir, args.dataset)
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/tsr/minimization.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/tsr/minimization.py
new file mode 100644
index 0000000000000000000000000000000000000000..713f79aaf26b0250806bcb1bbfe92bfc8f159840
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/tsr/minimization.py
@@ -0,0 +1,248 @@
+import argparse
+import json
+import os
+import pickle
+from concurrent.futures import ProcessPoolExecutor, as_completed
+from copy import deepcopy
+from typing import Any, Dict, List, Optional, Tuple
+
+from rich.progress import track
+
+from evalplus.data import write_jsonl
+from tools.tsr.coverage_init import collect_coverage_info
+from tools.tsr.mutation_init import collect_mutation_info
+from tools.tsr.sample_init import collect_sample_info
+from tools.tsr.utils import get_problems, get_task_ids, to_path
+
+
+def global_util_init(dataset: str):
+ global problems
+ global task_ids
+ global problem_count
+ problems = get_problems(dataset)
+ task_ids = get_task_ids(dataset)
+ problem_count = len(problems)
+
+
+###########################
+# Greedy Min Set Covering #
+###########################
+
+
+def merge_set_cover(*args) -> Dict[str, List[str]]:
+ merged_set_cover = {task_id: [] for task_id in task_ids}
+ for set_cover_dict in args:
+ for task_id, plus_tests in set_cover_dict.items():
+ for plus_test in plus_tests:
+ if plus_test not in merged_set_cover[task_id]:
+ merged_set_cover[task_id].append(plus_test)
+ return merged_set_cover
+
+
+def greedy_cover(
+ task_id: str, tests: Dict[str, List[Any]], exclude_model: str
+) -> Tuple[str, List[str]]:
+ q, U = [], set()
+ for test_name, test_cover in tests.items():
+ cover_set = set()
+ for model_path, i_code in test_cover:
+ if exclude_model not in model_path:
+ cover_set.add((model_path, i_code))
+ q.append((test_name, cover_set))
+ U = U.union(cover_set)
+ # Greedy algorithm for min set cover
+ min_cover = []
+ while len(U) > 0:
+ max_uncover_set, max_test_name = {}, ""
+ for test_name, cover_set in q:
+ if len(cover_set) > len(max_uncover_set):
+ max_uncover_set = cover_set
+ max_test_name = test_name
+ min_cover.append(max_test_name)
+ U = U - max_uncover_set
+ qq = []
+ for test_name, cover_set in q:
+ new_cover_set = U.intersection(cover_set)
+ if len(new_cover_set) != 0:
+ qq.append((test_name, new_cover_set))
+ q = qq
+ return task_id, min_cover
+
+
+def parallel_greedy_cover(
+ info_dict: Optional[Dict[str, Dict[str, List[Any]]]],
+ exclude_model: str,
+ type: str,
+ **kwargs,
+) -> Dict[str, List[str]]:
+ plus_tests = {task_id: [] for task_id in task_ids}
+
+ with ProcessPoolExecutor(max_workers=32) as executor:
+ futures = []
+ for task_id in task_ids:
+ if type == "sample":
+ path_task_id = to_path(task_id)
+ sample_dir = kwargs["sample_dir"]
+ with open(os.path.join(sample_dir, f"{path_task_id}.pkl"), "rb") as f:
+ td = pickle.load(f)
+ args = (task_id, td, exclude_model)
+ else:
+ args = (task_id, info_dict[task_id], exclude_model)
+ futures.append(executor.submit(greedy_cover, *args))
+ for future in track(as_completed(futures), f"min set cover :: {type}"):
+ task_id, min_cover = future.result()
+ plus_tests[task_id] = min_cover
+
+ return plus_tests
+
+
+#####################
+# Collect Set Cover #
+#####################
+
+
+def get_coverage_set_cover(
+ coverage_dir: str, exclude_model: str, dataset: str
+) -> Dict[str, List[str]]:
+ coverage_info_dict = collect_coverage_info(coverage_dir, dataset)
+ return parallel_greedy_cover(coverage_info_dict, exclude_model, "coverage")
+
+
+def get_mutation_set_cover(
+ mutation_dir: str, exclude_model: str, dataset: str
+) -> Dict[str, List[str]]:
+ mutation_info_dict = collect_mutation_info(
+ os.path.join(mutation_dir, "eval_results.json"), dataset
+ )
+ return parallel_greedy_cover(mutation_info_dict, exclude_model, "mutation")
+
+
+def get_sample_set_cover(
+ sample_dir: str, sample_eval_dir: str, exclude_model: str, dataset: str
+) -> Dict[str, List[str]]:
+ collect_sample_info(sample_dir, sample_eval_dir, dataset)
+ return parallel_greedy_cover(None, exclude_model, "sample", sample_dir=sample_dir)
+
+
+#################
+# pass@1 greedy #
+#################
+
+
+def compute_avg_test(set_cover_info: Dict[str, List[str]]) -> float:
+ sum_tests = sum(
+ len(problems[task_id]["base_input"]) + len(set_cover_info[task_id])
+ for task_id in task_ids
+ )
+ return sum_tests / problem_count
+
+
+def gen_report(set_cover_info: Dict[str, List[str]], sample_eval_dir: str, model: str):
+ tsr_dict = {"ntests": compute_avg_test(set_cover_info), "pass@1": 0}
+ model_path = os.path.join(sample_eval_dir, f"{model}_temp_0.0", "eval_results.json")
+ with open(model_path, "r") as f:
+ mdict = json.load(f)
+ correct_cnt = 0
+ for task_id in task_ids:
+ legacy_task_id = task_id
+ if legacy_task_id not in mdict["eval"]:
+ legacy_task_id = legacy_task_id.replace("/", "_")
+ if mdict["eval"][legacy_task_id]["base"][0][0] != "success":
+ continue
+ correct = True
+ for plus_id in set_cover_info[task_id]:
+ index = int(plus_id.split("_")[-1])
+ if mdict["eval"][legacy_task_id]["plus"][0][1][index] == False:
+ correct = False
+ break
+ if correct:
+ correct_cnt += 1
+ tsr_dict["pass@1"] = correct_cnt / problem_count
+ return tsr_dict
+
+
+def dump_humaneval_plus_mini(set_cover_info: Dict[str, List[str]], mini_path: str):
+ new_problems = []
+ for task_id in task_ids:
+ otask = problems[task_id]
+ task = {
+ "task_id": task_id,
+ "prompt": otask["prompt"],
+ "contract": otask["contract"],
+ "canonical_solution": otask["canonical_solution"],
+ "entry_point": otask["entry_point"],
+ "base_input": otask["base_input"],
+ "plus_input": [],
+ "atol": otask["atol"],
+ }
+ for plus_test in set_cover_info[task_id]:
+ index = int(plus_test.split("_")[-1])
+ task["plus_input"].append(otask["plus_input"][index])
+ new_problems.append(deepcopy(task))
+ write_jsonl(os.path.join(mini_path, "HumanEvalPlus-Mini.jsonl"), new_problems)
+
+
+def main(flags):
+ coverage_dir = os.path.join(flags.report_dir, "coverage_cache")
+ mutation_dir = os.path.join(flags.report_dir, "mutation_cache")
+ sample_dir = os.path.join(flags.report_dir, "sample_cache")
+ os.makedirs(flags.report_dir, exist_ok=True)
+
+ exclude_model: str = flags.model
+ if exclude_model.endswith("b"): # format: model_name + parameter size
+ exclude_model = "".join(exclude_model.split("-")[:-1])
+
+ coverage_set_cover = get_coverage_set_cover(
+ coverage_dir, exclude_model, flags.dataset
+ )
+ mutation_set_cover = get_mutation_set_cover(
+ mutation_dir, exclude_model, flags.dataset
+ )
+ sample_set_cover = get_sample_set_cover(
+ sample_dir, flags.sample_eval_dir, exclude_model, flags.dataset
+ )
+ merged_set_cover = merge_set_cover(
+ coverage_set_cover, mutation_set_cover, sample_set_cover
+ )
+
+ if flags.model != "ALL":
+ final_report = dict()
+ # Stage 1: Coverage min set cover
+ final_report["coverage"] = gen_report(
+ coverage_set_cover, flags.sample_eval_dir, flags.model
+ )
+ # Stage 2: Mutation min set cover
+ final_report["mutation"] = gen_report(
+ mutation_set_cover, flags.sample_eval_dir, flags.model
+ )
+ # Stage 3: Sampling min set cover
+ final_report["sample"] = gen_report(
+ sample_set_cover, flags.sample_eval_dir, flags.model
+ )
+ # Stage 4: All
+ final_report["full"] = gen_report(
+ merged_set_cover, flags.sample_eval_dir, flags.model
+ )
+ with open(
+ os.path.join(flags.report_dir, f"report_{flags.model}.json"), "w"
+ ) as f:
+ json.dump(final_report, f, indent=4)
+ else:
+ dump_humaneval_plus_mini(merged_set_cover, flags.mini_path)
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--model", required=True, type=str, help="Model for testing")
+ parser.add_argument("--dataset", type=str, choices=["humaneval", "mbpp"])
+ parser.add_argument(
+ "--report_dir", type=str, help="Path to JSON report and cache files"
+ )
+ parser.add_argument(
+ "--sample_eval_dir", type=str, help="Path to sample evaluation files"
+ )
+ parser.add_argument("--mini_path", type=str, help="Path to Mini Dataset")
+ args = parser.parse_args()
+
+ global_util_init(args.dataset)
+ main(args)
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/tsr/mutation_init.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/tsr/mutation_init.py
new file mode 100644
index 0000000000000000000000000000000000000000..0b992bd19872415ca099ce825b71926b017e0e34
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/tsr/mutation_init.py
@@ -0,0 +1,112 @@
+import argparse
+import json
+import os
+from typing import Any, Dict, List
+
+from rich.progress import track
+
+from evalplus.eval.utils import swallow_io
+from evalplus.evaluate import evaluate
+from tools.tsr.utils import (
+ clean,
+ execute_cmd,
+ get_cmd_output,
+ get_problems,
+ get_task_ids,
+ to_path,
+)
+
+
+def prepare_mutants(mutation_dir: str, dataset: str):
+ pwd = os.getcwd()
+ task_ids = get_task_ids(dataset)
+ problems = get_problems(dataset)
+ os.makedirs(mutation_dir, exist_ok=True)
+ for task_id in track(task_ids, "Generating mutants"):
+ task_dir = os.path.join(mutation_dir, to_path(task_id))
+ os.makedirs(task_dir, exist_ok=True)
+ if any(map(lambda filename: filename.startswith("m"), os.listdir(task_dir))):
+ # already have mutants
+ continue
+ # Make groundtruth
+ groundtruth_code = (
+ problems[task_id]["prompt"] + problems[task_id]["canonical_solution"]
+ )
+ with open(os.path.join(task_dir, "gt.py"), "w") as f:
+ f.write(groundtruth_code)
+ # Make dummy pytest
+ with open(os.path.join(task_dir, "test_dummy.py"), "w") as f:
+ f.write("def test_dummy():\n pass")
+ # Use mutmut to generate mutants
+ os.chdir(task_dir)
+ clean(".mutmut-cache")
+ execute_cmd(["mutmut run", "--paths-to-mutate=gt.py", "1>/dev/null"])
+ try:
+ # Collect metainfo
+ total_mutants = int(
+ get_cmd_output(["mutmut", "results"]).split("\n")[-2].split("-")[-1]
+ )
+ except:
+ total_mutants = 0
+ # Dump mutants
+ for i in range(1, total_mutants + 1):
+ execute_cmd(["cp", "gt.py", "gt_copy.py"])
+ execute_cmd(["mutmut", "apply", str(i)])
+ execute_cmd(["mv", "gt.py", f"m{i}.py"])
+ execute_cmd(["mv", "gt_copy.py", "gt.py"])
+ # Remove gt and dummy pytest
+ execute_cmd(["rm", "gt.py"])
+ execute_cmd(["rm", "test_dummy.py"])
+ clean(".mutmut-cache")
+ os.chdir(pwd)
+
+
+def mutants_eval(mutation_dir: str, dataset: str):
+ args = argparse.Namespace(
+ dataset=dataset,
+ samples=mutation_dir,
+ base_only=False,
+ parallel=None,
+ i_just_wanna_run=False,
+ test_details=True,
+ min_time_limit=0.2,
+ gt_time_limit_factor=4.0,
+ mini=False,
+ )
+ print("Evaluating mutants... ", end="", flush=True)
+ with swallow_io():
+ evaluate(args)
+ print("Done")
+
+
+def collect_mutation_info(
+ eval_path: str, dataset: str
+) -> Dict[str, Dict[str, List[Any]]]:
+ mutation_info = {task_id: {} for task_id in get_task_ids(dataset)}
+ assert os.path.isfile(
+ eval_path
+ ), f"mutation testing result file {eval_path} missing!"
+ eval_res = json.load(open(eval_path, "r"))["eval"]
+ for task_id, v in eval_res.items():
+ for i_code, (status, res_list) in enumerate(v["plus"]):
+ if status == "success":
+ continue
+ for i_test, res in enumerate(res_list):
+ test_id = f"plus_{i_test}"
+ if res == False:
+ mutation_info[task_id].setdefault(test_id, []).append(
+ ("mutant", i_code)
+ )
+ return mutation_info
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--dataset", type=str, choices=["humaneval", "mbpp"])
+ parser.add_argument("--report_dir", required=True, type=str)
+ args = parser.parse_args()
+
+ mutation_dir = os.path.join(args.report_dir, "mutation_cache")
+ prepare_mutants(mutation_dir, args.dataset)
+ mutants_eval(mutation_dir, args.dataset)
+ collect_mutation_info(os.path.join(mutation_dir, "eval_results.json"), args.dataset)
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/tsr/run.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/tsr/run.py
new file mode 100644
index 0000000000000000000000000000000000000000..f76202da75ba8d9baec70b6cdfd73f9146ad50a6
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/tsr/run.py
@@ -0,0 +1,72 @@
+import os
+
+from tools.tsr import tsr_base_dir
+from tools.tsr.utils import execute_cmd
+
+if __name__ == "__main__":
+ import argparse
+
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--model", type=str, help="Model for testing")
+ parser.add_argument("--dataset", type=str, choices=["humaneval", "mbpp"])
+ parser.add_argument(
+ "--report_dir",
+ type=str,
+ help="Path to JSON report and cache files",
+ default=os.path.join(tsr_base_dir, "tsr_info"),
+ )
+ parser.add_argument(
+ "--sample_eval_dir",
+ type=str,
+ required=True,
+ help="Path to sample evaluation files",
+ )
+ args = parser.parse_args()
+
+ os.makedirs(args.report_dir, exist_ok=True)
+ execute_cmd(
+ [
+ "python3",
+ os.path.join(tsr_base_dir, "mutation_init.py"),
+ "--dataset",
+ args.dataset,
+ "--report_dir",
+ args.report_dir,
+ ]
+ )
+ execute_cmd(
+ [
+ "python3",
+ os.path.join(tsr_base_dir, "coverage_init.py"),
+ "--dataset",
+ args.dataset,
+ "--report_dir",
+ args.report_dir,
+ ]
+ )
+ execute_cmd(
+ [
+ "python3",
+ os.path.join(tsr_base_dir, "sample_init.py"),
+ "--report_dir",
+ args.report_dir,
+ "--sample_eval_dir",
+ args.sample_eval_dir,
+ ]
+ )
+ execute_cmd(
+ [
+ "python3",
+ os.path.join(tsr_base_dir, "minimization.py"),
+ "--dataset",
+ args.dataset,
+ "--model",
+ args.model,
+ "--report_dir",
+ args.report_dir,
+ "--sample_eval_dir",
+ args.sample_eval_dir,
+ "--mini_path",
+ args.report_dir,
+ ]
+ )
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/tsr/sample_init.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/tsr/sample_init.py
new file mode 100644
index 0000000000000000000000000000000000000000..5765e9ec6772a9be7eea2642c0b3c7c00ac78b5d
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/tsr/sample_init.py
@@ -0,0 +1,57 @@
+import json
+import os
+import pickle
+
+from rich.progress import track
+
+from tools.tsr.utils import get_task_ids, to_path
+
+
+def collect_sample_info(sample_dir: str, sample_eval_dir: str, dataset: str):
+ if os.path.exists(sample_dir) and len(os.listdir(sample_dir)) > 0:
+ # cache file exists
+ return
+ task_ids = get_task_ids(dataset)
+ assert os.path.exists(sample_eval_dir), "sample evaluation files missing"
+ os.makedirs(sample_dir, exist_ok=True)
+ kill_info = {task_id: {} for task_id in task_ids}
+ model_paths = os.listdir(sample_eval_dir)
+ for model_path in track(model_paths, description="Collecting sets..."):
+ if not model_path[-1].isdigit():
+ continue
+ eval_json_path = os.path.join(sample_eval_dir, model_path, "eval_results.json")
+ if not os.path.exists(eval_json_path):
+ continue
+ with open(eval_json_path, "r") as f:
+ res = json.load(f)["eval"]
+ for task_id, v in res.items():
+ if task_id not in task_ids:
+ continue
+ for i_code, (status, res_list) in enumerate(v["plus"]):
+ if status == "success":
+ continue
+ for i_test, res in enumerate(res_list):
+ test_id = f"plus_{i_test}"
+ if res == False:
+ if "_" in task_id:
+ task_id = task_id.replace("_", "/")
+ kill_info[task_id].setdefault(test_id, []).append(
+ (model_path, i_code)
+ )
+ for task_id in task_ids:
+ path_task_id = to_path(task_id)
+ with open(os.path.join(sample_dir, f"{path_task_id}.pkl"), "wb") as f:
+ pickle.dump(kill_info[task_id], f)
+
+
+if __name__ == "__main__":
+ import argparse
+
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--report_dir", required=True, type=str)
+ parser.add_argument("--dataset", type=str, choices=["humaneval", "mbpp"])
+ parser.add_argument("--sample_eval_dir", required=True, type=str)
+ args = parser.parse_args()
+
+ sample_dir = os.path.join(args.report_dir, "sample_cache")
+ collect_sample_info(sample_dir, args.sample_eval_dir, args.dataset)
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/tsr/utils.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/tsr/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..b943a2fea18b33a4a638341dfcf856c2beb0d358
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/tsr/utils.py
@@ -0,0 +1,38 @@
+import os
+import subprocess
+from typing import List
+
+from evalplus.data import get_human_eval_plus, get_mbpp_plus
+
+HUMANEVAL_COUNT = 164
+MBPP_COUNT = 399
+humaneval_problems = get_human_eval_plus()
+mbpp_problems = get_mbpp_plus()
+
+humaneval_task_ids = [f"HumanEval/{i}" for i in range(HUMANEVAL_COUNT)]
+
+
+def get_problems(dataset: str):
+ return globals()[f"{dataset}_problems"]
+
+
+def get_task_ids(dataset: str) -> List[str]:
+ problems = globals()[f"{dataset}_problems"]
+ return list(problems.keys())
+
+
+def to_path(task_id: str) -> str:
+ return task_id.replace("/", "_")
+
+
+def clean(file_path: str):
+ if os.path.exists(file_path):
+ os.remove(file_path)
+
+
+def execute_cmd(cmd: list):
+ os.system(" ".join(cmd))
+
+
+def get_cmd_output(cmd_list: list) -> str:
+ return subprocess.run(cmd_list, stdout=subprocess.PIPE, check=True).stdout.decode()
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/viz_passrate.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/viz_passrate.py
new file mode 100644
index 0000000000000000000000000000000000000000..8d380dad62f2fd5bf1fbd68d84e171ba021061e2
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/viz_passrate.py
@@ -0,0 +1,203 @@
+import json
+import os
+import pickle
+from os import PathLike
+from typing import List
+
+import matplotlib.pyplot as plt
+import numpy as np
+from tqdm import tqdm
+
+from evalplus.data import get_human_eval_plus
+from evalplus.eval import estimate_pass_at_k
+
+SMALL_SIZE = 10
+MEDIUM_SIZE = 14
+BIGGER_SIZE = 18
+
+plt.rc("font", size=SMALL_SIZE) # controls default text sizes
+plt.rc("axes", titlesize=MEDIUM_SIZE) # fontsize of the axes title
+plt.rc("axes", labelsize=MEDIUM_SIZE) # fontsize of the x and y labels
+plt.rc("xtick", labelsize=MEDIUM_SIZE) # fontsize of the tick labels
+plt.rc("ytick", labelsize=MEDIUM_SIZE) # fontsize of the tick labels
+plt.rc("legend", fontsize=MEDIUM_SIZE - 1) # legend fontsize
+plt.rc("figure", titlesize=BIGGER_SIZE) # fontsize of the figure title
+
+plt.rc("text", usetex=True)
+
+SUCCESS = "success"
+
+
+def passk_rel_drop(task2bvs_old, task2bvs_new):
+ # old_rate:
+ # dim0: problems
+ # dim1: each experiment (model@temperature)
+ # dim2: pass/fail booleans for each sample
+ # this fn computes the relative drop in pass@k averaged over experiments
+
+ passk_old = {}
+ passk_new = {}
+ # sample size => k => List[pass@k]
+
+ for exp_i in range(len(task2bvs_old[0])):
+ ntotal = []
+ npass_old = []
+ npass_new = []
+ nsamples = None
+ for task_i in range(len(task2bvs_old)):
+ bv_old = task2bvs_old[task_i][exp_i]
+ bv_new = task2bvs_new[task_i][exp_i]
+ ntotal.append(len(bv_old))
+ npass_old.append(bv_old.sum())
+ npass_new.append(bv_new.sum())
+ if nsamples is None:
+ nsamples = len(bv_old)
+ assert len(bv_old) == len(bv_new) == nsamples
+
+ d_old = passk_old.setdefault(nsamples, {})
+ d_new = passk_new.setdefault(nsamples, {})
+ for k in [1, 10, 100]:
+ if nsamples >= k:
+ pass_at_k_old = estimate_pass_at_k(ntotal, npass_old, k).mean() * 100
+ pass_at_k_new = estimate_pass_at_k(ntotal, npass_new, k).mean() * 100
+ d_old.setdefault(k, []).append(pass_at_k_old)
+ d_new.setdefault(k, []).append(pass_at_k_new)
+
+ for nsamples in passk_old:
+ print("=====================================")
+ print(f"{nsamples = }")
+ do = passk_old[nsamples]
+ dn = passk_new[nsamples]
+ drops = []
+ for k in [1, 10, 100]:
+ if k in do:
+ pko = np.array(do[k])
+ pkn = np.array(dn[k])
+ drop = 100 * (pko - pkn) / pko
+ drops.append(drop)
+ print(
+ f"pass@{k}: \t{pko.mean():.1f}% -> {pkn.mean():.1f}% (drop {drop.mean():.1f}%)"
+ )
+ drops = np.array(drops)
+ print(f"+++ {drops.mean() = :.1f}%")
+ print(f"+++ {drops.max() = :.1f}%")
+ print("=====================================")
+
+
+def get_data(paths: List[PathLike]):
+ task2bvs_old = None
+ task2bvs_new = None
+
+ for path in tqdm(paths): # each experiment
+ res = json.load(open(path, "r"))["eval"]
+ ntask = len(res)
+
+ assert ntask == 164
+
+ if task2bvs_old is None and task2bvs_new is None:
+ task2bvs_old = [[] for _ in range(ntask)]
+ task2bvs_new = [[] for _ in range(ntask)]
+ # i-th => task-i pass rate for an experiment
+
+ for i, v in enumerate(res.values()): # each task
+ base = v["base"]
+ plus = v["plus"]
+ bbv = np.array([s == SUCCESS for s, _ in base])
+ pbv = np.array([s == SUCCESS for s, _ in plus]) & bbv
+ assert bbv.mean() >= pbv.mean()
+
+ task2bvs_old[i].append(bbv)
+ task2bvs_new[i].append(pbv)
+
+ assert len(task2bvs_old) == len(task2bvs_new)
+ return task2bvs_old, task2bvs_new
+
+
+if __name__ == "__main__":
+ import argparse
+
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--root", type=str, default="/JawTitan/EvalPlus/humaneval")
+ args = parser.parse_args()
+
+ paths = []
+ for path in os.listdir(args.root):
+ eval_json_path = os.path.join(args.root, path, "eval_results.json")
+ if not os.path.isfile(eval_json_path) or not path[-1].isdigit():
+ print(f"skip {path}")
+ continue
+ paths.append(eval_json_path)
+
+ CACHE_PATH = "passrate.pkl"
+ if os.path.isfile(CACHE_PATH): # use cache
+ task2bvs_old, task2bvs_new = pickle.load(open(CACHE_PATH, "rb"))
+ else:
+ task2bvs_old, task2bvs_new = get_data(paths)
+ pickle.dump((task2bvs_old, task2bvs_new), open(CACHE_PATH, "wb"))
+
+ passk_rel_drop(task2bvs_old, task2bvs_new)
+
+ rate_old = [[bv.mean() for bv in task] for task in task2bvs_old]
+ rate_new = [[bv.mean() for bv in task] for task in task2bvs_new]
+
+ rate_old = 100 * np.array(rate_old).mean(axis=1)
+ rate_new = 100 * np.array(rate_new).mean(axis=1)
+
+ print(
+ f"{(rate_new != rate_old).sum()} out of {len(rate_new)} tasks have dropped pass rate"
+ )
+
+ ntask = len(rate_old)
+
+ # sort by old pass rate
+ # numpy argsort
+ indices = np.array(rate_old).argsort()
+ # find unsolved tasks. i.e., indices where rate_old == 0
+ unsolved = np.where(np.array(rate_old) == 0)[0]
+ print("Unsolvable: ", unsolved)
+ # sort indices according to the differences between rate_old and rate_new
+ diff = np.array(rate_old) - np.array(rate_new)
+ diff_indices = diff.argsort()
+
+ tasks = get_human_eval_plus()
+ for i in reversed(diff_indices[-15:]):
+ print(
+ f"#{i} {tasks[f'HumanEval/{i}']['entry_point']} drops {diff[i] :.1f} ~ {100 * diff[i] / rate_old[i]:.1f}%:"
+ f" {rate_old[i]:.1f} -> {rate_new[i]:.1f}"
+ )
+
+ rate_old = np.array(rate_old)[indices]
+ rate_new = np.array(rate_new)[indices]
+ # rate_old, rate_new = zip(*sorted(zip(rate_old, rate_new), key=lambda x: x[0]))
+
+ # making a barplot
+ x = np.arange(ntask)
+ width = 1 # the width of the bars
+
+ fig, ax = plt.subplots(figsize=(9, 3))
+ HUMANEVAL = r"\textsc{HumanEval}"
+ HUMANEVAL_PLUS = r"\textsc{HumanEval\textsuperscript{+}}"
+ rects1 = ax.bar(x, rate_old, color="coral", label=HUMANEVAL, alpha=0.5)
+ rects2 = ax.bar(x, rate_new, color="firebrick", label=HUMANEVAL_PLUS, alpha=0.6)
+
+ # Add some text for labels, title and custom x-axis tick labels, etc.
+ ax.set_ylabel("Average Pass Rate (\%)")
+ ax.set_xlabel(f"Problems (Sorted by {HUMANEVAL} pass rate)")
+
+ # turn off xticks
+ ax.set_xticks([])
+ ax.set_xticklabels([])
+ # tight x ranges
+ ax.set_xlim(-0.5, ntask - 0.5)
+
+ # x grid
+ ax.grid(linestyle="--", linewidth=1, alpha=0.8)
+
+ # log scale
+ ax.set_yscale("log")
+
+ ax.legend()
+ fig.tight_layout()
+
+ plt.savefig("passrate.pdf", bbox_inches="tight")
+ plt.savefig("passrate.png", bbox_inches="tight")
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/zip_solutions.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/zip_solutions.py
new file mode 100644
index 0000000000000000000000000000000000000000..d52566ae445a820aa5341b6c28604dcd44ba09e9
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evalplus/tools/zip_solutions.py
@@ -0,0 +1,48 @@
+if __name__ == "__main__":
+ import argparse
+ import os
+ import re
+ from zipfile import ZipFile
+
+ parser = argparse.ArgumentParser(
+ description="Package and zip LLM provided solutions"
+ )
+ parser.add_argument("--root", type=str, help="Root directory of solutions")
+ parser.add_argument(
+ "--output", type=str, required=True, help="Output directory of zip files"
+ )
+ args = parser.parse_args()
+
+ # [model_name]_temp_[temp] (without -sanitized)
+ directory_pattern = re.compile(r"(.*)_temp_(?:\d*\.?\d+)$")
+
+ assert os.path.isdir(args.root)
+ os.makedirs(args.output, exist_ok=True)
+
+ for directory in os.listdir(args.root):
+ match = directory_pattern.match(directory)
+ if not match:
+ continue
+ directory_name = match.group(0)
+ full_dir_path = os.path.join(args.root, directory_name)
+ assert os.path.isdir(full_dir_path)
+ print(f"Processing {full_dir_path}")
+
+ zip_file_path = os.path.join(args.output, f"{directory_name}.zip")
+ if os.path.exists(zip_file_path):
+ print(f"Skipping -- {zip_file_path} already exists")
+ continue
+
+ with ZipFile(zip_file_path, "w") as zip_file:
+ # directory_name/${TASK_ID}/${SAMPLE_ID}.py
+ for task_id in os.listdir(full_dir_path):
+ task_dir = os.path.join(full_dir_path, task_id)
+ if not os.path.isdir(task_dir):
+ continue
+ for sample_id in os.listdir(task_dir):
+ sample_file = os.path.join(task_dir, sample_id)
+ if not sample_file.endswith(".py"):
+ continue
+ zip_file.write(
+ sample_file, os.path.join(directory_name, task_id, sample_id)
+ )
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/multi_turn/chat_with_gpt.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/multi_turn/chat_with_gpt.py
new file mode 100644
index 0000000000000000000000000000000000000000..77fcb67834644f550fe8e086eb69c3ca49e09f5a
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/multi_turn/chat_with_gpt.py
@@ -0,0 +1,23 @@
+# This is an example code. Please implement gpt_predict yourself.
+
+from gradio_client import Client
+import json
+
+# Please replace with your Gradio server URL. For Gradio server, please refer to https://huggingface.co/spaces/KikiQiQi/Mediator
+URL = "https://your-gradio-server-url.live"
+
+def gpt_predict(messages, model="gpt3.5"):
+ inputs = json.dumps(messages)
+ client = Client(URL)
+ if model == "gpt3.5":
+ # Replace with your GPT-3.5 credentials
+ args = """{"api_key":"YOUR_GPT3.5_API_KEY","api_type":"azure","model":"gpt-35-turbo","temperature":0,"max_tokens":1024}"""
+ elif model == "gpt4":
+ # Replace with your GPT-4 credentials
+ args = """{"api_key":"YOUR_GPT4_API_KEY","base_url":"https://api.openai.com/v1/","model":"gpt-4-1106-preview","temperature":0,"max_tokens":1024}"""
+ result = client.predict(
+ inputs,
+ args,
+ api_name="/submit"
+ )
+ return result
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/multi_turn/gen_plus_solution_multiround.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/multi_turn/gen_plus_solution_multiround.py
new file mode 100644
index 0000000000000000000000000000000000000000..85e8d35daffd8ba086e0e56698d2bae1dc32bcb9
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/multi_turn/gen_plus_solution_multiround.py
@@ -0,0 +1,246 @@
+import argparse
+import os
+import torch
+from pathlib import Path
+from tqdm import tqdm
+from transformers import AutoTokenizer, AutoModelForCausalLM
+import logging
+from evalplus.data import (get_human_eval_plus,
+ write_jsonl,
+ get_human_eval_plus_hash,
+ get_mbpp_plus,
+ get_mbpp_plus_hash,
+)
+from utils import sanitize_solution,check_correctness,get_groundtruth,SUCCESS
+from evalplus.eval._special_oracle import MBPP_OUTPUT_NOT_NONE_TASKS
+from copy import deepcopy
+
+MAX_TRY = 2
+
+def build_humaneval_instruction(languge: str, question: str):
+ return '''You are an exceptionally intelligent coding assistant that consistently delivers accurate and reliable responses to user instructions.
+
+@@ Instruction
+Here is the given code to do completion:
+```{}
+{}
+```
+Please continue to complete the function with {} programming language. You are not allowed to modify the given code and do the completion only.
+
+Please return all completed codes in one code block.
+This code block should be in the following format:
+```{}
+# Your codes here
+```
+
+@@ Response
+'''.strip().format(languge.lower(), question.strip(),languge.lower(),languge.lower())
+
+build_mbpp_instruction='''You are an exceptionally intelligent coding assistant that consistently delivers accurate and reliable responses to user instructions.
+
+@@ Instruction
+Here is the given problem and test examples:
+{}
+
+Please use the {} programming language to solve this problem.
+Please make sure that your code includes the functions from the test samples and that the input and output formats of these functions match the test samples.
+
+Please return all completed codes in one code block.
+This code block should be in the following format:
+```{}
+# Your codes here
+```
+
+@@ Response
+'''
+
+def generate_multi_round(problem, expected_output, example, lang, tokenizer, model, name, flags):
+ if flags.dataset=="humaneval":
+ prompt = build_humaneval_instruction(lang, example['prompt'])
+ elif flags.dataset=="mbpp":
+ prompt = build_mbpp_instruction.strip().format(example['prompt'],"python","python")
+ inputs = tokenizer.apply_chat_template(
+ [{'role': 'user', 'content': prompt }],
+ return_tensors="pt"
+ ).to(model.device)
+ stop_id = tokenizer.convert_tokens_to_ids("<|EOT|>")
+ assert isinstance(stop_id, int), "Invalid tokenizer, EOT id not found"
+ max_new_tokens=1024
+ outputs = model.generate(
+ inputs,
+ max_new_tokens=max_new_tokens,
+ do_sample=False,
+ pad_token_id=tokenizer.eos_token_id,
+ eos_token_id=tokenizer.eos_token_id,
+ temperature=0,
+ )
+ output = tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True)
+ solution = {k:v for k,v in example.items()}
+ solution["solution"]=output
+ sanitized_solution = sanitize_solution(deepcopy(solution),flags.eofs)
+ attempt = 1
+ judge = False
+ modify = False
+ code = sanitized_solution["solution"]
+ while attempt==1 or sanitized_solution["solution"]!="":
+ args = (
+ flags.dataset,
+ 0,
+ problem,
+ sanitized_solution["solution"],
+ expected_output,
+ flags.version,
+ True, # fast_check
+ example["task_id"]+f'_{attempt}',
+ flags.min_time_limit,
+ flags.gt_time_limit_factor,
+ )
+ result = check_correctness(*args)
+ if flags.version=="base" and result["base"][0]==SUCCESS:
+ code = sanitized_solution["solution"]
+ if attempt==2:
+ modify = True
+ judge = True
+ break
+ elif flags.version=="plus" and result["plus"][0]==result["base"][0]==SUCCESS:
+ code = sanitized_solution["solution"]
+ if attempt==2:
+ modify = True
+ judge = True
+ break
+ else:
+ attempt += 1
+ if attempt > MAX_TRY:
+ code = sanitized_solution["solution"]
+ break
+ execution_feedback=""
+ if flags.version=="base":
+ execution_feedback=result["base"][2]
+ elif flags.version=="plus":
+ if result["base"][0]!=SUCCESS:
+ execution_feedback+=result["base"][2]
+ if "The results aren't as expected." in execution_feedback:
+ if result["plus"][0]!=SUCCESS:
+ execution_feedback+="\n"+result["plus"][2]
+ else:
+ execution_feedback=result["plus"][2]
+ prompt +="""
+{}
+
+@@ Instruction
+Execution result:
+{}
+""".format(solution["solution"],execution_feedback)
+ inputs = tokenizer.apply_chat_template(
+ [{'role': 'user', 'content': prompt }],
+ return_tensors="pt"
+ ).to(model.device)
+
+ outputs = model.generate(
+ inputs,
+ max_new_tokens=max_new_tokens,
+ do_sample=False,
+ pad_token_id=tokenizer.eos_token_id,
+ eos_token_id=tokenizer.eos_token_id,
+ temperature=0,
+ )
+ output = tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True)
+ solution = {k:v for k,v in example.items()}
+ solution["solution"]=output
+ sanitized_solution = sanitize_solution(deepcopy(solution),flags.eofs)
+
+ return code,judge,modify
+
+
+def gen_solution(args):
+ os.environ["TOKENIZERS_PARALLELISM"] = "false"
+ fail_list=[]
+ model_path = args.model
+ logging.info(f"model:{model_path}")
+ model_name =model_path.replace("/", "_")
+ lang = "python"
+ os.makedirs(os.path.join(args.output_path,model_name),exist_ok=True)
+ output_file = os.path.join(args.output_path,model_name,f"multiround_{args.dataset}_{args.version}_solutions-sanitized.jsonl")
+ if os.path.exists(output_file):
+ logging.info(f"Old sample jsonl file exists, remove it. {output_file}")
+ os.remove(output_file)
+
+ tokenizer = AutoTokenizer.from_pretrained(model_path)
+ logging.info("load tokenizer {} from {} over.".format(tokenizer.__class__, model_path))
+ model = AutoModelForCausalLM.from_pretrained(
+ model_path,
+ torch_dtype=torch.bfloat16,
+ device_map="auto",
+ )
+ model.eval()
+
+ modelname=model_path.replace("/", "_")
+ if args.dataset=="humaneval":
+ problems = get_human_eval_plus()
+ examples = problems.items()
+ dataset_hash = get_human_eval_plus_hash()
+ expected_outputs = get_groundtruth(problems, dataset_hash, [])
+ else:
+ problems = get_mbpp_plus()
+ examples = problems.items()
+ dataset_hash = get_mbpp_plus_hash()
+ expected_outputs = get_groundtruth(
+ problems,
+ dataset_hash,
+ MBPP_OUTPUT_NOT_NONE_TASKS,
+ )
+ logging.info("Read {} examples for evaluation over.".format(len(examples)))
+ a,b = 0,0
+ total_modify = 0
+ for task_id,example in tqdm(examples, desc='Generating'):
+ problem = problems[task_id]
+ expected_output = expected_outputs[task_id]
+ code,judge,modify = generate_multi_round(problem,expected_output,example, lang, tokenizer, model, modelname,args)
+ gen_sample=[dict(task_id=task_id, solution=code)]
+ write_jsonl(output_file, gen_sample ,append=True)
+
+ if modify:
+ total_modify += 1
+ if judge:
+ a += 1
+ else:
+ b += 1
+ fail_list.append(task_id)
+ result = a/(a+b)
+ print ("pass num :",a)
+ print ("total num:",a+b)
+ print ('pass rate: '+str(result))
+ print ("num modify: "+str(total_modify))
+ print ("judge:",judge)
+ print ('modify: '+str(modify))
+ print ("fail list:",fail_list)
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--model', type=str, help="model path")
+ parser.add_argument('--output_path', type=str, help="output path", default="./multiround_output")
+ parser.add_argument('--log_file', type=str, help="log file name", default="gen_humaneval_plus_solution_singleround.log")
+ parser.add_argument("--min-time-limit", default=1, type=float)
+ parser.add_argument("--gt-time-limit-factor", default=4.0, type=float)
+ parser.add_argument(
+ "--version", required=True, type=str, choices=["base", "plus"]
+ )
+ parser.add_argument(
+ "--dataset", required=True, type=str, choices=["humaneval", "mbpp"]
+ )
+
+ args = parser.parse_args()
+ args.eofs=None
+
+ model_name = args.model.replace("/", "_")
+ os.makedirs(os.path.join(args.output_path,model_name),exist_ok=True)
+ logfile=os.path.join(args.output_path,model_name,args.log_file)
+ logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - \n%(message)s')
+ file_handler = logging.FileHandler(logfile)
+ file_handler.setLevel(logging.INFO)
+ formatter = logging.Formatter('%(asctime)s - %(levelname)s - \n%(message)s')
+ file_handler.setFormatter(formatter)
+ logging.getLogger().addHandler(file_handler)
+
+ gen_solution(args)
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/multi_turn/gen_plus_solution_multiround_human_feedback.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/multi_turn/gen_plus_solution_multiround_human_feedback.py
new file mode 100644
index 0000000000000000000000000000000000000000..f4d1cd4f9edbb4d9039868e2edf9e54aed67cc3d
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/multi_turn/gen_plus_solution_multiround_human_feedback.py
@@ -0,0 +1,320 @@
+import argparse
+import os
+import torch
+from pathlib import Path
+from tqdm import tqdm
+import json
+from transformers import AutoTokenizer, AutoModelForCausalLM
+import logging
+from evalplus.data import (get_human_eval_plus,
+ write_jsonl,
+ get_human_eval_plus_hash,
+ get_mbpp_plus,
+ get_mbpp_plus_hash,
+)
+from utils import sanitize_solution,check_correctness,get_groundtruth,SUCCESS
+from evalplus.eval._special_oracle import MBPP_OUTPUT_NOT_NONE_TASKS
+from copy import deepcopy
+from chat_with_gpt import gpt_predict
+
+MAX_TRY = 2
+
+def humaneval_build_instruction(languge: str, question: str):
+ return '''You are an exceptionally intelligent coding assistant that consistently delivers accurate and reliable responses to user instructions.
+
+@@ Instruction
+Here is the given code to do completion:
+```{}
+{}
+```
+Please continue to complete the function with {} programming language. You are not allowed to modify the given code and do the completion only.
+
+Please return all completed codes in one code block.
+This code block should be in the following format:
+```{}
+# Your codes here
+```
+
+@@ Response
+'''.strip().format(languge.lower(), question.strip(),languge.lower(),languge.lower())
+
+mbpp_build_deepseekcoder_instruction='''You are an exceptionally intelligent coding assistant that consistently delivers accurate and reliable responses to user instructions.
+
+@@ Instruction
+Here is the given problem and test examples:
+{}
+
+Please use the {} programming language to solve this problem.
+Please make sure that your code includes the functions from the test samples and that the input and output formats of these functions match the test samples.
+
+Please return all completed codes in one code block.
+This code block should be in the following format:
+```{}
+# Your codes here
+```
+
+@@ Response
+'''
+
+
+def build_gpt_prompt(pre_messages: str, problem: str, current_code: str, execution_feedback: str):
+ prompt = """You are tasked with providing guidance to a programmer who has drafted a code for a programming problem.
+Your role is to mimic human-like responses and offer suggestions for modifying the code based on the observed execution results.
+You should refrain from directly writing code.
+Begin by thoroughly examining the existing code and its functionality.
+Analyze the @@Execution Result obtained from running the @@Existing Code. Identify any errors, unexpected behavior, or deviations from the expected output.
+Consider potential edge cases, optimization opportunities, or alternative approaches based on insights from the @@Execution Result.
+Offer guidance in a clear and understandable manner, explaining the rationale behind each suggestion.
+Refrain from providing actual code solutions, but instead focus on conceptual modifications or strategies.
+Provide constructive feedback to help the programmer improve their coding skills.
+Remember, your role is to simulate human-like guidance and expertise in programming without directly implementing solutions.
+Please respond in no more than three sentences.
+
+@@Problem
+{}
+
+@@Existing Code
+{}
+
+@@Execution Result
+{}
+
+@@Guidance
+""".format(problem.strip(), current_code, execution_feedback)
+ return prompt
+
+
+def generate_multi_round(problem, expected_output, example, lang, tokenizer, model,name,flags):
+ pre_messages=[]
+ if flags.dataset=="humaneval":
+ prompt = humaneval_build_instruction(lang, example['prompt'])
+ elif flags.dataset=="mbpp":
+ prompt = mbpp_build_deepseekcoder_instruction.strip().format(example['prompt'],"python","python")
+ pre_messages.append({"role":"user","content":prompt})
+
+ inputs = tokenizer.apply_chat_template(
+ [{'role': 'user', 'content': prompt}],
+ return_tensors="pt"
+ ).to(model.device)
+ stop_id = tokenizer.convert_tokens_to_ids("<|EOT|>")
+ assert isinstance(stop_id, int), "Invalid tokenizer, EOT id not found"
+ max_new_tokens=1024
+ logging.info(f"max_new_tokens{max_new_tokens}")
+ outputs = model.generate(
+ inputs,
+ max_new_tokens=max_new_tokens,
+ do_sample=False,
+ pad_token_id=tokenizer.eos_token_id,
+ eos_token_id=tokenizer.eos_token_id,
+ temperature=0,
+ )
+ output = tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True)
+ canonical_solution = example["canonical_solution"]
+ solution = {k:v for k,v in example.items()}
+ solution["solution"]=output
+ sanitized_solution = sanitize_solution(deepcopy(solution),flags.eofs)
+ attempt = 1
+ judge = False
+ modify = False
+ code = sanitized_solution["solution"]
+ while attempt==1 or sanitized_solution["solution"]!="":
+ pre_messages.append({"role":"assistant","content":solution["solution"]})
+ args = (
+ flags.dataset,
+ 0,
+ problem,
+ sanitized_solution["solution"],
+ expected_output,
+ flags.version,
+ True, # fast_check
+ example["task_id"]+f'_{attempt}',
+ flags.min_time_limit,
+ flags.gt_time_limit_factor,
+ )
+ result = check_correctness(*args)
+ if flags.version=="base" and result["base"][0]==SUCCESS:
+ code = sanitized_solution["solution"]
+ if attempt==2:
+ modify = True
+ judge = True
+ break
+ elif flags.version=="plus" and result["plus"][0]==result["base"][0]==SUCCESS:
+ code = sanitized_solution["solution"]
+ if attempt==2:
+ modify = True
+ judge = True
+ break
+ else:
+ attempt += 1
+ if attempt > MAX_TRY:
+ code = sanitized_solution["solution"]
+ break
+ execution_feedback=""
+ if flags.version=="base":
+ execution_feedback=result["base"][2]
+ elif flags.version=="plus":
+ if result["base"][0]!=SUCCESS:
+ execution_feedback+=result["base"][2]
+ if "The results aren't as expected." in execution_feedback:
+ if result["plus"][0]!=SUCCESS:
+ execution_feedback+="\n"+result["plus"][2]
+ else:
+ execution_feedback=result["plus"][2]
+ gpt_messages=[{"role":"system","content":"You are a helpful assistant."}]
+ gpt_messages.append({"role":"user","content":build_gpt_prompt(\
+ pre_messages, example['prompt'], sanitized_solution["solution"], execution_feedback)})
+ gpt_feedback=None
+ trytime=0
+ while gpt_feedback is None and trytime<5:
+ gpt_feedback=gpt_predict(gpt_messages)
+ trytime+=1
+ if gpt_feedback==None:
+ raise BaseException("Please resume.")
+ if prompt.endswith("@@ Response"):
+ prompt +="""
+{}
+
+@@ Instruction
+{}
+""".format(solution["solution"],gpt_feedback)
+ else:
+ prompt +="""
+
+@@ Response
+{}
+
+@@ Instruction
+{}
+""".format(solution["solution"],gpt_feedback)
+ pre_messages.append({"role":"user","content":gpt_feedback})
+ inputs = tokenizer.apply_chat_template(
+ [{'role': 'user', 'content': prompt }],
+ return_tensors="pt"
+ ).to(model.device)
+
+ outputs = model.generate(
+ inputs,
+ max_new_tokens=max_new_tokens,#待定,evalplus论文说除了gpt用的1024,其他都用的512
+ do_sample=False,
+ pad_token_id=tokenizer.eos_token_id,
+ eos_token_id=tokenizer.eos_token_id,
+ temperature=0,
+ )
+ output = tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True)
+ solution = {k:v for k,v in example.items()}
+ solution["solution"]=output
+ sanitized_solution = sanitize_solution(deepcopy(solution),flags.eofs)
+
+ return code,judge,modify
+
+
+def gen_solution(args):
+ a,b = 0,0
+ total_modify = 0
+ os.environ["TOKENIZERS_PARALLELISM"] = "false"
+ fail_list=[]
+ model_path = args.model
+ logging.info(f"model:{model_path}")
+ model_name =model_path.replace("/", "_")
+ lang = "python"
+ os.makedirs(os.path.join(args.output_path,model_name),exist_ok=True)
+ output_file = os.path.join(args.output_path,model_name,f"multiround_{args.dataset}_{args.version}_solutions-sanitized.jsonl")
+ if not args.resume:
+ if os.path.exists(output_file):
+ logging.info(f"Old sample jsonl file exists, remove it. {output_file}")
+ os.remove(output_file)
+ else:
+ existing_task_ids = set()
+ if os.path.exists(output_file):
+ with open(output_file, 'r') as file:
+ for line in file:
+ data = json.loads(line)
+ if 'task_id' in data:
+ existing_task_ids.add(data['task_id'])
+ a=data["pass_num"]
+ total_modify=data["total_modify"]
+ b=data["total_num"]-a
+ fail_list=data["fail_list"]
+
+ tokenizer = AutoTokenizer.from_pretrained(model_path)
+ logging.info("load tokenizer {} from {} over.".format(tokenizer.__class__, model_path))
+ model = AutoModelForCausalLM.from_pretrained(
+ model_path,
+ torch_dtype=torch.bfloat16,
+ device_map="auto",
+ )
+ model.eval()
+
+ modelname=model_path.replace("/", "_")
+ if args.dataset=="humaneval":
+ problems = get_human_eval_plus()
+ examples = problems.items()
+ dataset_hash = get_human_eval_plus_hash()
+ expected_outputs = get_groundtruth(problems, dataset_hash, [])
+ else:
+ problems = get_mbpp_plus()
+ examples = problems.items()
+ dataset_hash = get_mbpp_plus_hash()
+ expected_outputs = get_groundtruth(
+ problems,
+ dataset_hash,
+ MBPP_OUTPUT_NOT_NONE_TASKS,
+ )
+ logging.info("Read {} examples for evaluation over.".format(len(examples)))
+ for task_id,example in tqdm(examples, desc='Generating'):
+ if args.resume:
+ if task_id in existing_task_ids:
+ continue
+ problem = problems[task_id]
+ expected_output = expected_outputs[task_id]
+ code,judge,modify = generate_multi_round(problem,expected_output,example, lang, tokenizer, model, modelname,args)
+ if modify:
+ total_modify += 1
+ if judge:
+ a += 1
+ else:
+ b += 1
+ fail_list.append(task_id)
+ result = a/(a+b)
+ single_result = (a-total_modify)/(a+b)
+ print ("pass num ",a)
+ print ("total num",a+b)
+ print ("judge: ",judge)
+ print ('modify: '+str(modify))
+ print ("num modify: "+str(total_modify))
+ print ("fail list: ",fail_list)
+ print ('multisound rate: '+str(result))
+ print ('singlesound rate: '+str(single_result))
+ gen_sample=[dict(task_id=task_id, solution=code, pass_num=a, total_modify=total_modify, total_num=a+b, fail_list=fail_list)]
+ write_jsonl(output_file, gen_sample ,append=True)
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--model', type=str, help="model path")
+ parser.add_argument('--output_path', type=str, help="output path", default="./multiround_output")
+ parser.add_argument('--log_file', type=str, help="log file name", default="gen_humaneval_plus_solution_singleround.log")
+ parser.add_argument("--min-time-limit", default=1, type=float)
+ parser.add_argument("--gt-time-limit-factor", default=4.0, type=float)
+ parser.add_argument(
+ "--version", required=True, type=str, choices=["base", "plus"]
+ )
+ parser.add_argument(
+ "--dataset", required=True, type=str, choices=["humaneval", "mbpp"]
+ )
+ parser.add_argument('--resume', action="store_true")
+
+ args = parser.parse_args()
+ args.eofs=None
+
+ model_name = args.model.replace("/", "_")
+ os.makedirs(os.path.join(args.output_path,model_name),exist_ok=True)
+ logfile=os.path.join(args.output_path,model_name,args.log_file)
+ logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - \n%(message)s')
+ file_handler = logging.FileHandler(logfile)
+ file_handler.setLevel(logging.INFO)
+ formatter = logging.Formatter('%(asctime)s - %(levelname)s - \n%(message)s')
+ file_handler.setFormatter(formatter)
+ logging.getLogger().addHandler(file_handler)
+
+ gen_solution(args)
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/multi_turn/gen_plus_solution_multiround_human_feedback_oracle.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/multi_turn/gen_plus_solution_multiround_human_feedback_oracle.py
new file mode 100644
index 0000000000000000000000000000000000000000..9b46959e5168691a92d4c2dc4a661d7a153e160d
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/multi_turn/gen_plus_solution_multiround_human_feedback_oracle.py
@@ -0,0 +1,325 @@
+import argparse
+import os
+import torch
+from pathlib import Path
+from tqdm import tqdm
+import json
+from transformers import AutoTokenizer, AutoModelForCausalLM
+import logging
+from evalplus.data import (get_human_eval_plus,
+ write_jsonl,
+ get_human_eval_plus_hash,
+ get_mbpp_plus,
+ get_mbpp_plus_hash,
+)
+from utils import sanitize_solution,check_correctness,get_groundtruth,SUCCESS
+from evalplus.eval._special_oracle import MBPP_OUTPUT_NOT_NONE_TASKS
+from copy import deepcopy
+from chat_with_gpt import gpt_predict
+
+MAX_TRY = 2
+
+def humaneval_build_instruction(languge: str, question: str):
+ return '''You are an exceptionally intelligent coding assistant that consistently delivers accurate and reliable responses to user instructions.
+
+@@ Instruction
+Here is the given code to do completion:
+```{}
+{}
+```
+Please continue to complete the function with {} programming language. You are not allowed to modify the given code and do the completion only.
+
+Please return all completed codes in one code block.
+This code block should be in the following format:
+```{}
+# Your codes here
+```
+
+@@ Response
+'''.strip().format(languge.lower(), question.strip(),languge.lower(),languge.lower())
+
+mbpp_build_deepseekcoder_instruction='''You are an exceptionally intelligent coding assistant that consistently delivers accurate and reliable responses to user instructions.
+
+@@ Instruction
+Here is the given problem and test examples:
+{}
+
+Please use the {} programming language to solve this problem.
+Please make sure that your code includes the functions from the test samples and that the input and output formats of these functions match the test samples.
+
+Please return all completed codes in one code block.
+This code block should be in the following format:
+```{}
+# Your codes here
+```
+
+@@ Response
+'''
+
+def build_gpt_prompt(pre_messages: str, problem: str, current_code: str, execution_feedback: str, canonical_solution: str):
+ prompt = """You are tasked with providing guidance to a programmer who has drafted a code for a programming problem.
+Your role is to mimic human-like responses and offer suggestions for modifying the code based on the canonical solution and the observed execution results.
+You should NOT directly revealing contents of the @@Canonical Solution or mentioning terms such as "canonical solution."
+You should refrain from directly writing code.
+Begin by thoroughly examining the existing code and its functionality.
+Compare the @@Existing Code with the @@Canonical Solution provided. Note any discrepancies in logic, approach, or implementation.
+Analyze the @@Execution Result obtained from running the @@Existing Code. Identify any errors, unexpected behavior, or deviations from the expected output.
+Consider potential edge cases, optimization opportunities, or alternative approaches based on insights from both the @@Canonical Solution and @@Execution Result.
+Offer guidance in a clear and understandable manner, explaining the rationale behind each suggestion.
+Refrain from providing actual code solutions, but instead focus on conceptual modifications or strategies.
+Provide constructive feedback to help the programmer improve their coding skills.
+Remember, your role is to simulate human-like guidance and expertise in programming without directly implementing solutions.
+Please respond in no more than three sentences.
+
+@@Problem
+{}
+
+@@Existing Code
+{}
+
+@@Execution Result
+{}
+
+@@Canonical Solution
+{}
+
+@@Guidance
+""".format(problem.strip(), current_code, execution_feedback,canonical_solution)
+ return prompt
+
+
+def generate_multi_round(problem,expected_output, example, lang, tokenizer, model,name,flags):
+ pre_messages=[]
+ if flags.dataset=="humaneval":
+ prompt = humaneval_build_instruction(lang, example['prompt'])
+ elif flags.dataset=="mbpp":
+ prompt = mbpp_build_deepseekcoder_instruction.strip().format(example['prompt'],"python","python")
+ pre_messages.append({"role":"user","content":prompt})
+ inputs = tokenizer.apply_chat_template(
+ [{'role': 'user', 'content': prompt}],
+ return_tensors="pt"
+ ).to(model.device)
+ stop_id = tokenizer.convert_tokens_to_ids("<|EOT|>")
+ assert isinstance(stop_id, int), "Invalid tokenizer, EOT id not found"
+ max_new_tokens=1024
+ logging.info(f"max_new_tokens{max_new_tokens}")
+ outputs = model.generate(
+ inputs,
+ max_new_tokens=max_new_tokens,#待定,evalplus论文说除了gpt用的1024,其他都用的512
+ do_sample=False,
+ pad_token_id=tokenizer.eos_token_id,
+ eos_token_id=tokenizer.eos_token_id,
+ temperature=0,
+ )
+ output = tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True)
+ canonical_solution = example["canonical_solution"]
+ solution = {k:v for k,v in example.items()}
+ solution["solution"]=output
+ sanitized_solution = sanitize_solution(deepcopy(solution),flags.eofs)
+ attempt = 1
+ judge = False
+ modify = False
+ code = sanitized_solution["solution"]
+ while attempt==1 or sanitized_solution["solution"]!="":
+ pre_messages.append({"role":"assistant","content":solution["solution"]})
+ args = (
+ flags.dataset,
+ 0,
+ problem,
+ sanitized_solution["solution"],
+ expected_output,
+ flags.version,
+ True, # fast_check
+ example["task_id"]+f'_{attempt}',
+ flags.min_time_limit,
+ flags.gt_time_limit_factor,
+ )
+ result = check_correctness(*args)
+ if flags.version=="base" and result["base"][0]==SUCCESS:
+ code = sanitized_solution["solution"]
+ if attempt==2:
+ modify = True
+ judge = True
+ break
+ elif flags.version=="plus" and result["plus"][0]==result["base"][0]==SUCCESS:
+ code = sanitized_solution["solution"]
+ if attempt==2:
+ modify = True
+ judge = True
+ break
+ else:
+ attempt += 1
+ if attempt > MAX_TRY:
+ code = sanitized_solution["solution"]
+ break
+ execution_feedback=""
+ if flags.version=="base":
+ execution_feedback=result["base"][2]
+ elif flags.version=="plus":
+ if result["base"][0]!=SUCCESS:
+ execution_feedback+=result["base"][2]
+ if "The results aren't as expected." in execution_feedback:
+ if result["plus"][0]!=SUCCESS:
+ execution_feedback+="\n"+result["plus"][2]
+ else:
+ execution_feedback=result["plus"][2]
+ gpt_messages=[{"role":"system","content":"You are a helpful assistant."}]
+ gpt_messages.append({"role":"user","content":build_gpt_prompt(\
+ pre_messages, example['prompt'], sanitized_solution["solution"], execution_feedback, canonical_solution)})
+ gpt_feedback=None
+ trytime=0
+ while gpt_feedback is None and trytime<5:
+ gpt_feedback=gpt_predict(gpt_messages)
+ trytime+=1
+ if gpt_feedback==None:
+ raise BaseException("Please resume.")
+ if prompt.endswith("@@ Response"):
+ prompt +="""
+{}
+
+@@ Instruction
+{}
+""".format(solution["solution"],gpt_feedback)
+ else:
+ prompt +="""
+
+@@ Response
+{}
+
+@@ Instruction
+{}
+""".format(solution["solution"],gpt_feedback)
+ pre_messages.append({"role":"user","content":gpt_feedback})
+ inputs = tokenizer.apply_chat_template(
+ [{'role': 'user', 'content': prompt }],
+ return_tensors="pt"
+ ).to(model.device)
+
+ outputs = model.generate(
+ inputs,
+ max_new_tokens=max_new_tokens,
+ do_sample=False,
+ pad_token_id=tokenizer.eos_token_id,
+ eos_token_id=tokenizer.eos_token_id,
+ temperature=0,
+ )
+ output = tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True)
+ solution = {k:v for k,v in example.items()}
+ solution["solution"]=output
+ sanitized_solution = sanitize_solution(deepcopy(solution),flags.eofs)
+
+ return code,judge,modify
+
+
+def gen_solution(args):
+ a,b = 0,0
+ total_modify = 0
+ os.environ["TOKENIZERS_PARALLELISM"] = "false"
+ fail_list=[]
+ model_path = args.model
+ logging.info(f"model:{model_path}")
+ model_name =model_path.replace("/", "_")
+ lang = "python"
+ os.makedirs(os.path.join(args.output_path,model_name),exist_ok=True)
+ output_file = os.path.join(args.output_path,model_name,f"multiround_{args.dataset}_{args.version}_solutions-sanitized.jsonl")
+ if not args.resume:
+ if os.path.exists(output_file):
+ logging.info(f"Old sample jsonl file exists, remove it. {output_file}")
+ os.remove(output_file)
+ else:
+ existing_task_ids = set()
+ if os.path.exists(output_file):
+ with open(output_file, 'r') as file:
+ for line in file:
+ data = json.loads(line)
+ if 'task_id' in data:
+ existing_task_ids.add(data['task_id'])
+ a=data["pass_num"]
+ total_modify=data["total_modify"]
+ b=data["total_num"]-a
+ fail_list=data["fail_list"]
+
+ tokenizer = AutoTokenizer.from_pretrained(model_path)
+ logging.info("load tokenizer {} from {} over.".format(tokenizer.__class__, model_path))
+ model = AutoModelForCausalLM.from_pretrained(
+ model_path,
+ torch_dtype=torch.bfloat16,
+ device_map="auto",
+ )
+ model.eval()
+
+ modelname=model_path.replace("/", "_")
+ if args.dataset=="humaneval":
+ problems = get_human_eval_plus()
+ examples = problems.items()
+ dataset_hash = get_human_eval_plus_hash()
+ expected_outputs = get_groundtruth(problems, dataset_hash, [])
+ else:
+ problems = get_mbpp_plus()
+ examples = problems.items()
+ dataset_hash = get_mbpp_plus_hash()
+ expected_outputs = get_groundtruth(
+ problems,
+ dataset_hash,
+ MBPP_OUTPUT_NOT_NONE_TASKS,
+ )
+ logging.info("Read {} examples for evaluation over.".format(len(examples)))
+ for task_id,example in tqdm(examples, desc='Generating'):
+ if args.resume:
+ if task_id in existing_task_ids:
+ continue
+ problem = problems[task_id]
+ # print("problem:\n",problem.keys())
+ # print("\n",problem)
+ expected_output = expected_outputs[task_id]
+ code,judge,modify = generate_multi_round(problem,expected_output,example, lang, tokenizer, model, modelname,args)
+ if modify:
+ total_modify += 1
+ if judge:
+ a += 1
+ else:
+ b += 1
+ fail_list.append(task_id)
+ result = a/(a+b)
+ single_result = (a-total_modify)/(a+b)
+ print ("pass num ",a)
+ print ("totalnum ",a+b)
+ print ("judge: ",judge)
+ print ('modify: '+str(modify))
+ print ("num modify: "+str(total_modify))
+ print ("fail list: ",fail_list)
+ print ('multisound rate: '+str(result))
+ print ('singlesound rate: '+str(single_result))
+ gen_sample=[dict(task_id=task_id, solution=code, pass_num=a, total_modify=total_modify, total_num=a+b, fail_list=fail_list)]
+ write_jsonl(output_file, gen_sample ,append=True)
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--model', type=str, help="model path")
+ parser.add_argument('--output_path', type=str, help="output path", default="./multiround_output")
+ parser.add_argument('--log_file', type=str, help="log file name", default="gen_humaneval_plus_solution_singleround.log")
+ parser.add_argument("--min-time-limit", default=1, type=float)
+ parser.add_argument("--gt-time-limit-factor", default=4.0, type=float)
+ parser.add_argument(
+ "--version", required=True, type=str, choices=["base", "plus"]
+ )
+ parser.add_argument(
+ "--dataset", required=True, type=str, choices=["humaneval", "mbpp"]
+ )
+ parser.add_argument('--resume', action="store_true")
+
+ args = parser.parse_args()
+ args.eofs=None
+
+ model_name = args.model.replace("/", "_")
+ os.makedirs(os.path.join(args.output_path,model_name),exist_ok=True)
+ logfile=os.path.join(args.output_path,model_name,args.log_file)
+ logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - \n%(message)s')
+ file_handler = logging.FileHandler(logfile)
+ file_handler.setLevel(logging.INFO)
+ formatter = logging.Formatter('%(asctime)s - %(levelname)s - \n%(message)s')
+ file_handler.setFormatter(formatter)
+ logging.getLogger().addHandler(file_handler)
+
+ gen_solution(args)
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/multi_turn/gpt_gen_plus_solution_multiround.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/multi_turn/gpt_gen_plus_solution_multiround.py
new file mode 100644
index 0000000000000000000000000000000000000000..178d24f6814271f5cff190997fa33e772418fd1b
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/multi_turn/gpt_gen_plus_solution_multiround.py
@@ -0,0 +1,228 @@
+import argparse
+import os
+import torch
+from pathlib import Path
+from tqdm import tqdm
+import logging
+from evalplus.data import (get_human_eval_plus,
+ write_jsonl,
+ get_human_eval_plus_hash,
+ get_mbpp_plus,
+ get_mbpp_plus_hash,
+)
+from utils import sanitize_solution,check_correctness,get_groundtruth,SUCCESS
+from evalplus.eval._special_oracle import MBPP_OUTPUT_NOT_NONE_TASKS
+from copy import deepcopy
+from chat_with_gpt import gpt_predict
+import json
+
+MAX_TRY = 2
+
+def humaneval_build_instruction(languge: str, question: str):
+ return '''You are an exceptionally intelligent coding assistant that consistently delivers accurate and reliable responses to user instructions.
+
+@@ Instruction
+Here is the given code to do completion:
+```{}
+{}
+```
+Please continue to complete the function with {} programming language. You are not allowed to modify the given code and do the completion only.
+
+Please return all completed codes in one code block.
+This code block should be in the following format:
+```{}
+# Your codes here
+```
+
+@@ Response
+'''.strip().format(languge.lower(), question.strip(),languge.lower(),languge.lower())
+
+mbpp_build_deepseekcoder_instruction='''You are an exceptionally intelligent coding assistant that consistently delivers accurate and reliable responses to user instructions.
+
+@@ Instruction
+Here is the given problem and test examples:
+{}
+
+Please use the {} programming language to solve this problem.
+Please make sure that your code includes the functions from the test samples and that the input and output formats of these functions match the test samples.
+
+Please return all completed codes in one code block.
+This code block should be in the following format:
+```{}
+# Your codes here
+```
+
+@@ Response
+'''
+
+def generate_multi_round(problem,expected_output, example, lang,name,flags):
+ if flags.dataset=="humaneval":
+ prompt = humaneval_build_instruction(lang, example['prompt'])
+ elif flags.dataset=="mbpp":
+ prompt = mbpp_build_deepseekcoder_instruction.strip().format(example['prompt'],"python","python")
+ inputs=[{'role': 'user', 'content': prompt}]
+ output = gpt_predict(inputs,model=name)
+ solution = {k:v for k,v in example.items()}
+ solution["solution"]=output
+ sanitized_solution = sanitize_solution(deepcopy(solution),flags.eofs)
+ attempt = 1
+ judge = False
+ modify = False
+ code = sanitized_solution["solution"]
+ while attempt==1 or sanitized_solution["solution"]!="":
+ args = (
+ flags.dataset,
+ 0,
+ problem,
+ sanitized_solution["solution"],
+ expected_output,
+ flags.version,
+ True, # fast_check
+ example["task_id"]+f'_{attempt}',
+ flags.min_time_limit,
+ flags.gt_time_limit_factor,
+ )
+ result = check_correctness(*args)
+ if flags.version=="base" and result["base"][0]==SUCCESS:
+ code = sanitized_solution["solution"]
+ if attempt==2:
+ modify = True
+ judge = True
+ break
+ elif flags.version=="plus" and result["plus"][0]==result["base"][0]==SUCCESS:
+ code = sanitized_solution["solution"]
+ if attempt==2:
+ modify = True
+ judge = True
+ break
+ else:
+ attempt += 1
+ if attempt > MAX_TRY:
+ code = sanitized_solution["solution"]
+ break
+ execution_feedback=""
+ if flags.version=="base":
+ execution_feedback=result["base"][2]
+ elif flags.version=="plus":
+ if result["base"][0]!=SUCCESS:
+ execution_feedback+=result["base"][2]
+ if "The results aren't as expected." in execution_feedback:
+ if result["plus"][0]!=SUCCESS:
+ execution_feedback+="\n"+result["plus"][2]
+ else:
+ execution_feedback=result["plus"][2]
+ prompt +="""
+{}
+
+@@ Instruction
+Execution result:
+{}
+""".format(solution["solution"],execution_feedback)
+ inputs = [{'role': 'user', 'content': prompt}]
+ output = gpt_predict(inputs,model=name)
+ solution = {k:v for k,v in example.items()}
+ solution["solution"]=output
+ sanitized_solution = sanitize_solution(deepcopy(solution),flags.eofs)
+
+ return code,judge,modify
+
+
+def gen_solution(args):
+ a,b = 0,0
+ total_modify = 0
+ os.environ["TOKENIZERS_PARALLELISM"] = "false"
+ fail_list=[]
+ model_path = args.model
+ logging.info(f"model:{model_path}")
+ model_name =args.model
+ lang = "python"
+ os.makedirs(os.path.join(args.output_path,model_name),exist_ok=True)
+ output_file = os.path.join(args.output_path,model_name,f"multiround_{args.dataset}_{args.version}_solutions-sanitized.jsonl")
+ if not args.resume:
+ if os.path.exists(output_file):
+ logging.info(f"Old sample jsonl file exists, remove it. {output_file}")
+ os.remove(output_file)
+ else:
+ existing_task_ids = set()
+ if os.path.exists(output_file):
+ with open(output_file, 'r') as file:
+ for line in file:
+ data = json.loads(line)
+ if 'task_id' in data:
+ existing_task_ids.add(data['task_id'])
+ a=data["pass_num"]
+ total_modify=data["total_modify"]
+ b=data["total_num"]-a
+ fail_list=data["fail_list"]
+
+ if args.dataset=="humaneval":
+ problems = get_human_eval_plus()
+ examples = problems.items()
+ dataset_hash = get_human_eval_plus_hash()
+ expected_outputs = get_groundtruth(problems, dataset_hash, [])
+ else:
+ problems = get_mbpp_plus()
+ examples = problems.items()
+ dataset_hash = get_mbpp_plus_hash()
+ expected_outputs = get_groundtruth(
+ problems,
+ dataset_hash,
+ MBPP_OUTPUT_NOT_NONE_TASKS,
+ )
+ logging.info("Read {} examples for evaluation over.".format(len(examples)))
+ for task_id,example in tqdm(examples, desc='Generating'):
+ if args.resume:
+ if task_id in existing_task_ids:
+ continue
+ problem = problems[task_id]
+ expected_output = expected_outputs[task_id]
+ code,judge,modify = generate_multi_round(problem,expected_output,example, lang, model_name,args)
+
+ if modify:
+ total_modify += 1
+ if judge:
+ a += 1
+ else:
+ b += 1
+ fail_list.append(task_id)
+ result = a/(a+b)
+ print ("pass num",a)
+ print ("total num",a+b)
+ print ('rate: '+str(result))
+ print ("judge: ",judge)
+ print ('modify: '+str(modify))
+ print ("num modify: "+str(total_modify))
+ print("fail list",fail_list)
+ gen_sample=[dict(task_id=task_id, solution=code, pass_num=a, total_modify=total_modify, total_num=a+b, fail_list=fail_list)]
+ write_jsonl(output_file, gen_sample ,append=True)
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--model', type=str, choices=["gpt3.5", "gpt4"])
+ parser.add_argument('--output_path', type=str, help="output path", default="./multiround_output")
+ parser.add_argument('--log_file', type=str, help="log file name", default="gen_humaneval_plus_solution_singleround.log")
+ parser.add_argument("--min-time-limit", default=1, type=float)
+ parser.add_argument("--gt-time-limit-factor", default=4.0, type=float)
+ parser.add_argument(
+ "--version", required=True, type=str, choices=["base", "plus"]
+ )
+ parser.add_argument(
+ "--dataset", required=True, type=str, choices=["humaneval", "mbpp"]
+ )
+ parser.add_argument('--resume', action="store_true")
+
+ args = parser.parse_args()
+ args.eofs=None
+
+ model_name = args.model
+ os.makedirs(os.path.join(args.output_path,model_name),exist_ok=True)
+ logfile=os.path.join(args.output_path,model_name,args.log_file)
+ logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - \n%(message)s')
+ file_handler = logging.FileHandler(logfile)
+ file_handler.setLevel(logging.INFO)
+ formatter = logging.Formatter('%(asctime)s - %(levelname)s - \n%(message)s')
+ file_handler.setFormatter(formatter)
+ logging.getLogger().addHandler(file_handler)
+
+ gen_solution(args)
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/scripts/01_gen_single.sh b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/scripts/01_gen_single.sh
new file mode 100644
index 0000000000000000000000000000000000000000..54f3f8bdfdc9c7a5325ad770c1570b987c054d28
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/scripts/01_gen_single.sh
@@ -0,0 +1,34 @@
+cd evaluation/evalplus
+export PYTHONPATH=$PYTHONPATH:$(pwd)
+
+cd ../evaluate
+gpu_start=0
+MODEL_NAME_OR_PATHS=(
+/ML-A800/home/zhengtianyu/code-interpreter/OpenCodeInterpreter-DS-6.7B
+)
+DATASET_TYPES=(
+humaneval
+mbpp
+)
+
+i=0
+for MODEL_NAME_OR_PATH in "${MODEL_NAME_OR_PATHS[@]}"; do
+ for DATASET_TYPE in "${DATASET_TYPES[@]}"; do
+ gpu_rank=$((i + gpu_start))
+ MODEL=$(echo "$MODEL_NAME_OR_PATH" | sed 's|/|_|g')
+
+ output_path="./output"
+ LOG_DIR="$output_path/$MODEL"
+ mkdir -p "${LOG_DIR}"
+ ABS_LOG_DIR=$(realpath "$LOG_DIR")
+ LOG_FILE=single_gen_${DATASET_TYPE}_plus_solution_singleround.log
+
+ CUDA_VISIBLE_DEVICES=$gpu_rank nohup python single_turn/gen_plus_solution_singleround.py \
+ --model "$MODEL_NAME_OR_PATH" \
+ --output_path $output_path \
+ --log_file ${LOG_FILE} \
+ --dataset $DATASET_TYPE \
+ > "${LOG_DIR}/${LOG_FILE}" 2>&1 &
+ ((i++))
+done
+done
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/scripts/02_sanitize_single.sh b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/scripts/02_sanitize_single.sh
new file mode 100644
index 0000000000000000000000000000000000000000..b2d29c376d044f1fcdb051c218bc8b6727c0342d
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/scripts/02_sanitize_single.sh
@@ -0,0 +1,19 @@
+cd evaluation/evalplus
+export PYTHONPATH=$PYTHONPATH:$(pwd)
+directory="../evaluate/output"
+
+find "$directory" -type d -print0 | while IFS= read -r -d '' folder; do
+ if [[ $folder != ** ]]; then
+ continue
+ fi
+ echo "Processing Folder: $folder"
+
+ find "$folder" -type f -name "*humaneval*.jsonl" ! -name "*-sanitized.jsonl" -print0 | while IFS= read -r -d '' jsonl_file; do
+ echo " Processing JSONL File: $jsonl_file"
+ python tools/sanitize.py --samples $jsonl_file --dataset humaneval
+ done
+ find "$folder" -type f -name "*mbpp*.jsonl" ! -name "*-sanitized.jsonl" -print0 | while IFS= read -r -d '' jsonl_file; do
+ echo " Processing JSONL File: $jsonl_file"
+ python tools/sanitize.py --samples $jsonl_file --dataset mbpp
+ done
+done
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/scripts/03_eval_single.sh b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/scripts/03_eval_single.sh
new file mode 100644
index 0000000000000000000000000000000000000000..8ed78d7ca7a7fd0a03ed7cf8a89c4d69aefda944
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/scripts/03_eval_single.sh
@@ -0,0 +1,22 @@
+cd evaluation/evalplus
+export PYTHONPATH=$PYTHONPATH:$(pwd)
+
+directory="../evaluate/output"
+pattern=""
+
+find "$directory" -type f -name "*humaneval*-sanitized.jsonl" -print0 | while IFS= read -r -d '' jsonl_file; do
+ if [[ $jsonl_file != *$pattern* ]]; then
+ continue
+ fi
+ echo " Processing JSONL File: $jsonl_file"
+ python evalplus/evaluate.py --dataset humaneval --samples $jsonl_file --i-just-wanna-run
+done
+find "$directory" -type f -name "*mbpp*-sanitized.jsonl" -print0 | while IFS= read -r -d '' jsonl_file; do
+ if [[ $jsonl_file != *$pattern* ]]; then
+ continue
+ fi
+ echo " Processing JSONL File: $jsonl_file"
+ python evalplus/evaluate.py --dataset mbpp --samples $jsonl_file --i-just-wanna-run
+done
+
+
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/scripts/04_execution_feedback_multiround_OpenCodeInterpreter.sh b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/scripts/04_execution_feedback_multiround_OpenCodeInterpreter.sh
new file mode 100644
index 0000000000000000000000000000000000000000..b6e11a076cc5edc6a4fe59746a645a154b606d7d
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/scripts/04_execution_feedback_multiround_OpenCodeInterpreter.sh
@@ -0,0 +1,34 @@
+cd evaluation/evalplus
+export PYTHONPATH=$PYTHONPATH:$(pwd)
+
+cd ../evaluate
+gpu_start=0
+MODEL_NAME_OR_PATHS=(
+/ML-A800/home/zhengtianyu/code-interpreter/OpenCodeInterpreter-DS-6.7B
+)
+DATASET_TYPE="humaneval" #"mbpp"
+EVAL_TYPE="plus" #base
+
+for rank in {0..0}; do
+ gpu_rank=$((rank + gpu_start))
+ MODEL_NAME_OR_PATH="${MODEL_NAME_OR_PATHS[$rank]}"
+ echo $MODEL_NAME_OR_PATH
+
+ MODEL=$(echo "$MODEL_NAME_OR_PATH" | sed 's|/|_|g')
+
+ output_path="./execution_feedback_output"
+ LOG_DIR="$output_path/$MODEL"
+ mkdir -p "${LOG_DIR}"
+ ABS_LOG_DIR=$(realpath "$LOG_DIR")
+
+ LOG_FILE="gen_${DATASET_TYPE}_${EVAL_TYPE}_solution_multiround.log"
+
+ CUDA_VISIBLE_DEVICES=$gpu_rank nohup python multi_turn/gen_plus_solution_multiround.py \
+ --model "$MODEL_NAME_OR_PATH" \
+ --output_path $output_path \
+ --log_file ${LOG_FILE} \
+ --version $EVAL_TYPE \
+ --dataset $DATASET_TYPE \
+ > "${LOG_DIR}/${LOG_FILE}" 2>&1 &
+done
+
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/scripts/05_execution_feedback_multiround_gpt.sh b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/scripts/05_execution_feedback_multiround_gpt.sh
new file mode 100644
index 0000000000000000000000000000000000000000..16b2675525c45038c0f6c1e9138d535b185aa876
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/scripts/05_execution_feedback_multiround_gpt.sh
@@ -0,0 +1,44 @@
+cd evaluation/evalplus
+export PYTHONPATH=$PYTHONPATH:$(pwd)
+
+cd ../evaluate
+MODEL_NAME_OR_PATHS=(
+gpt3.5
+# gpt4
+)
+DATASET_TYPES=(
+# mbpp
+humaneval
+)
+EVAL_TYPES=(
+base
+# plus
+)
+for DATASET_TYPE in "${DATASET_TYPES[@]}"; do
+ for EVAL_TYPE in "${EVAL_TYPES[@]}"; do
+ for MODEL_NAME_OR_PATH in "${MODEL_NAME_OR_PATHS[@]}"; do
+
+ MODEL=$(echo "$MODEL_NAME_OR_PATH" | sed 's|/|_|g')
+ output_path="./execution_feedback_output"
+
+ LOG_DIR="$output_path/$MODEL"
+ mkdir -p "${LOG_DIR}"
+ ABS_LOG_DIR=$(realpath "$LOG_DIR")
+ echo "Absolute path for mkdir: $ABS_LOG_DIR"
+
+ LOG_FILE="gen_${DATASET_TYPE}_${EVAL_TYPE}_solution_multiround.log"
+
+ CUDA_VISIBLE_DEVICES=-1 nohup python multi_turn/gpt_gen_plus_solution_multiround.py \
+ --model "$MODEL_NAME_OR_PATH" \
+ --output_path $output_path \
+ --log_file ${LOG_FILE} \
+ --version $EVAL_TYPE \
+ --dataset $DATASET_TYPE \
+ --resume \
+ > "${LOG_DIR}/${LOG_FILE}" 2>&1 &
+ done
+ done
+done
+
+
+
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/scripts/06_human_feedback_multiround_OpenCodeInterpreter.sh b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/scripts/06_human_feedback_multiround_OpenCodeInterpreter.sh
new file mode 100644
index 0000000000000000000000000000000000000000..b585b7cdead72de7f29f450551c7168e7e1146dd
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/scripts/06_human_feedback_multiround_OpenCodeInterpreter.sh
@@ -0,0 +1,36 @@
+cd evaluation/evalplus
+export PYTHONPATH=$PYTHONPATH:$(pwd)
+
+cd ../evaluate
+gpu_start=0
+MODEL_NAME_OR_PATHS=(
+/ML-A800/home/zhengtianyu/code-interpreter/OpenCodeInterpreter-DS-6.7B
+)
+DATASET_TYPE="humaneval" #"mbpp"
+EVAL_TYPE="plus" #base
+
+for rank in {0..0}; do
+ gpu_rank=$((rank + gpu_start))
+ MODEL_NAME_OR_PATH="${MODEL_NAME_OR_PATHS[$rank]}"
+ echo $MODEL_NAME_OR_PATH
+
+ MODEL=$(echo "$MODEL_NAME_OR_PATH" | sed 's|/|_|g')
+ output_path="./human_feedback_output"
+
+ LOG_DIR="$output_path/$MODEL"
+ mkdir -p "${LOG_DIR}"
+ ABS_LOG_DIR=$(realpath "$LOG_DIR")
+ echo "Absolute path for mkdir: $ABS_LOG_DIR"
+
+ LOG_FILE="gen_${DATASET_TYPE}_${EVAL_TYPE}_solution_multiround.log"
+
+ CUDA_VISIBLE_DEVICES=$gpu_rank nohup python multi_turn/gen_plus_solution_multiround_human_feedback.py \
+ --model "$MODEL_NAME_OR_PATH" \
+ --output_path $output_path \
+ --log_file ${LOG_FILE} \
+ --version $EVAL_TYPE \
+ --dataset $DATASET_TYPE \
+ --resume \
+ > "${LOG_DIR}/${LOG_FILE}" 2>&1 &
+
+done
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/scripts/07_human_feedback_multiround_Oracle_OpenCodeInterpreter.sh b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/scripts/07_human_feedback_multiround_Oracle_OpenCodeInterpreter.sh
new file mode 100644
index 0000000000000000000000000000000000000000..9f35da664caae0e631b4226443375e1669140a7f
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/scripts/07_human_feedback_multiround_Oracle_OpenCodeInterpreter.sh
@@ -0,0 +1,36 @@
+cd evaluation/evalplus
+export PYTHONPATH=$PYTHONPATH:$(pwd)
+
+cd ../evaluate
+gpu_start=0
+MODEL_NAME_OR_PATHS=(
+/ML-A800/home/zhengtianyu/code-interpreter/OpenCodeInterpreter-DS-6.7B
+)
+DATASET_TYPE="mbpp" #"mbpp"
+EVAL_TYPE="plus" #base
+
+for rank in {0..0}; do
+ gpu_rank=$((rank + gpu_start))
+ MODEL_NAME_OR_PATH="${MODEL_NAME_OR_PATHS[$rank]}"
+ echo $MODEL_NAME_OR_PATH
+
+ MODEL=$(echo "$MODEL_NAME_OR_PATH" | sed 's|/|_|g')
+ output_path="./human_feedback_output_oracle"
+
+ LOG_DIR="$output_path/$MODEL"
+ mkdir -p "${LOG_DIR}"
+ ABS_LOG_DIR=$(realpath "$LOG_DIR")
+ echo "Absolute path for mkdir: $ABS_LOG_DIR"
+
+ LOG_FILE="gen_${DATASET_TYPE}_${EVAL_TYPE}_solution_multiround.log"
+
+ CUDA_VISIBLE_DEVICES=$gpu_rank nohup python multi_turn/gen_plus_solution_multiround_human_feedback_oracle.py \
+ --model "$MODEL_NAME_OR_PATH" \
+ --output_path $output_path \
+ --log_file ${LOG_FILE} \
+ --version $EVAL_TYPE \
+ --dataset $DATASET_TYPE \
+ --resume \
+ > "${LOG_DIR}/${LOG_FILE}" 2>&1 &
+
+done
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/scripts/task.sh b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/scripts/task.sh
new file mode 100644
index 0000000000000000000000000000000000000000..46091432519adffd9df329049b7987f5f3e56fce
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/scripts/task.sh
@@ -0,0 +1,55 @@
+# bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_humaneval.sh deepseek-coder-6.7b-base
+# bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_humaneval.sh deepseek-coder-6.7b-base_1_1
+# bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_humaneval.sh deepseek-coder-6.7b-base_1_2
+# bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_humaneval.sh deepseek-coder-6.7b-base_1_3
+# bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_humaneval.sh deepseek-coder-6.7b-base_1_5
+# bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_humaneval.sh Magicoder-S-DS-6.7B
+# bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_humaneval.sh Magicoder-S-CL-7B
+
+# bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_mbpp.sh deepseek-coder-6.7b-base
+# bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_mbpp.sh deepseek-coder-6.7b-base_1_1
+# bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_mbpp.sh deepseek-coder-6.7b-base_1_2
+# bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_mbpp.sh deepseek-coder-6.7b-base_1_3
+# bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_mbpp.sh deepseek-coder-6.7b-base_1_5
+# bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_mbpp.sh Magicoder-S-DS-6.7B
+# bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_mbpp.sh Magicoder-S-CL-7B
+
+
+
+# deepseek-coder-33b-base_1_1 OSError: /ML-A100/public/run/research/tianyuzheng/models/Codeagent/deepseek-coder-33b-base_1_1 does not appear to have a file named config.json. Checkout 'https://huggingface.co//ML-A100/public/run/research/tianyuzheng/models/Codeagent/deepseek-coder-33b-base_1_1/None' for available files.
+
+
+
+bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_humaneval.sh CodeLlama70B_2_1/checkpoint-1399
+
+bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_multiround.sh deepseek-coder-33b-instruct_2_1_v1 humaneval plus
+bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_multiround.sh deepseek-coder-33b-instruct_2_1_v1 mbpp plus
+bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_multiround.sh deepseek-coder-33b-instruct_2_1_v1 humaneval base
+bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_multiround.sh deepseek-coder-33b-instruct_2_1_v1 mbpp base
+
+
+
+#
+bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_multiround.sh CodeLlama-7b-hf_2_1_v1 humaneval plus
+bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_multiround.sh deepseek-coder-6.7b-base_2_1 humaneval plus
+bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_multiround.sh deepseek-coder-6.7b-instruct_v1/checkpoint-4105 humaneval plus
+bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_multiround.sh deepseek-coder-6.7b-instruct_v1/checkpoint-2052 humaneval plus
+bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_multiround.sh deepseek-coder-6.7b-instruct/checkpoint-4246 humaneval plus
+
+bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_multiround.sh CodeLlama-7b-hf_2_1_v1 humaneval base
+bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_multiround.sh deepseek-coder-6.7b-base_2_1 humaneval base
+bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_multiround.sh deepseek-coder-6.7b-instruct_v1/checkpoint-4105 humaneval base
+bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_multiround.sh deepseek-coder-6.7b-instruct_v1/checkpoint-2052 humaneval base
+bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_multiround.sh deepseek-coder-6.7b-instruct/checkpoint-4246 humaneval base
+
+bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_multiround.sh CodeLlama-7b-hf_2_1_v1 mbpp plus
+bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_multiround.sh deepseek-coder-6.7b-base_2_1 mbpp plus
+bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_multiround.sh deepseek-coder-6.7b-instruct_v1/checkpoint-4105 mbpp plus
+bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_multiround.sh deepseek-coder-6.7b-instruct_v1/checkpoint-2052 mbpp plus
+bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_multiround.sh deepseek-coder-6.7b-instruct/checkpoint-4246 mbpp plus
+
+bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_multiround.sh CodeLlama-7b-hf_2_1_v1 mbpp base
+bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_multiround.sh deepseek-coder-6.7b-base_2_1 mbpp base
+bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_multiround.sh deepseek-coder-6.7b-instruct_v1/checkpoint-4105 mbpp base
+bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_multiround.sh deepseek-coder-6.7b-instruct_v1/checkpoint-2052 mbpp base
+bash /ML-A800/home/zhengtianyu/DeepSeek-Coder/Evaluation/evalplus/workspace/33b_tasks/33b_multiround.sh deepseek-coder-6.7b-instruct/checkpoint-4246 mbpp base
\ No newline at end of file
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/single_turn/gen_plus_solution_singleround.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/single_turn/gen_plus_solution_singleround.py
new file mode 100644
index 0000000000000000000000000000000000000000..d46c92db570e4d30a9f3b815735b2099744fe53a
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/single_turn/gen_plus_solution_singleround.py
@@ -0,0 +1,127 @@
+import argparse
+import os
+import torch
+from pathlib import Path
+from tqdm import tqdm
+from transformers import AutoTokenizer, AutoModelForCausalLM
+import logging
+from evalplus.data import get_human_eval_plus,get_mbpp_plus, write_jsonl
+
+def build_humaneval_instruction(languge: str, question: str):
+ return '''You are an exceptionally intelligent coding assistant that consistently delivers accurate and reliable responses to user instructions.
+
+@@ Instruction
+Here is the given code to do completion:
+```{}
+{}
+```
+Please continue to complete the function with {} programming language. You are not allowed to modify the given code and do the completion only.
+
+Please return all completed codes in one code block.
+This code block should be in the following format:
+```{}
+# Your codes here
+```
+
+@@ Response
+'''.strip().format(languge.lower(), question.strip(),languge.lower(),languge.lower())
+
+
+build_mbpp_instruction='''You are an exceptionally intelligent coding assistant that consistently delivers accurate and reliable responses to user instructions.
+
+@@ Instruction
+Here is the given problem and test examples:
+{}
+
+Please use the {} programming language to solve this problem.
+Please make sure that your code includes the functions from the test samples and that the input and output formats of these functions match the test samples.
+
+Please return all completed codes in one code block.
+This code block should be in the following format:
+```{}
+# Your codes here
+```
+
+@@ Response
+'''
+
+
+def generate_one(example, lang, tokenizer, model, name, flags):
+ if flags.dataset=="humaneval":
+ prompt = build_humaneval_instruction(lang, example['prompt'])
+ else:
+ prompt = example['prompt']
+ prompt = build_mbpp_instruction.strip().format(prompt,lang,lang)
+ inputs = tokenizer.apply_chat_template(
+ [{'role': 'user', 'content': prompt }],
+ return_tensors="pt"
+ ).to(model.device)
+ stop_id = tokenizer.convert_tokens_to_ids("<|EOT|>")
+ assert isinstance(stop_id, int), "Invalid tokenizer, EOT id not found"
+ max_new_tokens=1024
+ outputs = model.generate(
+ inputs,
+ max_new_tokens=max_new_tokens,
+ do_sample=False,
+ pad_token_id=tokenizer.eos_token_id,
+ eos_token_id=tokenizer.eos_token_id,
+ temperature=0,
+ )
+ output = tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True)
+ return output
+
+def gen_solution(args):
+ os.environ["TOKENIZERS_PARALLELISM"] = "false"
+
+ model_path = args.model
+ logging.info(f"model:{model_path}")
+ model_name = model_path.replace("/", "_")
+
+ lang = "python"
+ os.makedirs(os.path.join(args.output_path,model_name),exist_ok=True)
+ output_file = os.path.join(args.output_path,model_name,f"single_{args.dataset}_plus_solutions.jsonl")
+ if os.path.exists(output_file):
+ logging.info(f"Old sample jsonl file exists, remove it. {output_file}")
+ os.remove(output_file)
+
+ tokenizer = AutoTokenizer.from_pretrained(model_path)
+ logging.info("load tokenizer {} from {} over.".format(tokenizer.__class__, model_path))
+ model = AutoModelForCausalLM.from_pretrained(
+ model_path,
+ torch_dtype=torch.bfloat16,
+ device_map="auto",
+ )
+ model.eval()
+
+ model_name = model_path.replace("/", "_")
+ if args.dataset=="humaneval":
+ examples = get_human_eval_plus().items()
+ else:
+ examples = get_mbpp_plus().items()
+ logging.info("Read {} examples for evaluation over.".format(len(examples)))
+ for task_id,example in tqdm(examples, desc='Generating'):
+ code = generate_one(example, lang, tokenizer, model,model_name,args)
+ gen_sample=[dict(task_id=task_id, solution=code)]
+ write_jsonl(output_file, gen_sample ,append=True)
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--model', type=str, help="model path")
+ parser.add_argument('--output_path', type=str, help="output path", default="./output")
+ parser.add_argument('--log_file', type=str, help="log file name")
+ parser.add_argument(
+ "--dataset", required=True, type=str, choices=["humaneval", "mbpp"]
+ )
+ args = parser.parse_args()
+ model_name = args.model.replace("/", "_")
+ os.makedirs(os.path.join(args.output_path,model_name),exist_ok=True)
+ logfile=os.path.join(args.output_path,model_name,args.log_file)
+ logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - \n%(message)s')
+ file_handler = logging.FileHandler(logfile)
+ file_handler.setLevel(logging.INFO)
+ formatter = logging.Formatter('%(asctime)s - %(levelname)s - \n%(message)s')
+ file_handler.setFormatter(formatter)
+ logging.getLogger().addHandler(file_handler)
+
+ gen_solution(args)
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/utils.py b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..cd37fe2bd649164b0c549f36e7460588283fb938
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/evaluate/utils.py
@@ -0,0 +1,382 @@
+import os
+from evalplus.sanitize import sanitize
+from typing import Any, Dict, List, Optional, Tuple, Union
+import itertools
+import multiprocessing
+import time
+from multiprocessing import Array, Value
+from typing import Any, Dict, List, Tuple, Union
+
+import numpy as np
+import pickle
+
+from evalplus.data.utils import CACHE_DIR
+from evalplus.eval import *
+from evalplus.gen.util import trusted_exec
+from evalplus.eval._special_oracle import MBPP_OUTPUT_NOT_NONE_TASKS, _poly
+from evalplus.eval.utils import TimeoutException
+from evalplus.eval.utils import (
+ create_tempdir,
+ reliability_guard,
+ swallow_io,
+ time_limit,
+)
+import re
+import resource
+import traceback
+
+
+SUCCESS = "success"
+FAILED = "failed"
+TIMEOUT = "timed out"
+
+_SUCCESS = 0
+_FAILED = 1
+_TIMEOUT = 2
+_UNKNOWN = 3
+
+_mapping = {_SUCCESS: SUCCESS, _FAILED: FAILED, _TIMEOUT: TIMEOUT, _UNKNOWN: None}
+
+class MyCustomException(BaseException):
+ def __init__(self, message):
+ self.message = message
+
+
+def get_groundtruth(problems, hashcode, tasks_only_output_not_none):
+ cache_file = os.path.join(CACHE_DIR, f"{hashcode}.pkl")
+ if os.path.exists(cache_file):
+ print(f"Load from ground-truth from {cache_file}")
+ with open(cache_file, "rb") as f:
+ return pickle.load(f)
+
+ os.makedirs(CACHE_DIR, exist_ok=True)
+ print("Computing expected output...")
+ tbegin = time.time()
+ expected_output = {}
+ for task_id, problem in problems.items():
+ oracle = {}
+ oracle["base"], oracle["base_time"] = trusted_exec(
+ problem["prompt"] + problem["canonical_solution"],
+ problem["base_input"],
+ problem["entry_point"],
+ record_time=True,
+ output_not_none=problem["entry_point"] in tasks_only_output_not_none,
+ )
+
+ oracle["plus"], oracle["plus_time"] = trusted_exec(
+ problem["prompt"] + problem["canonical_solution"],
+ problem["plus_input"],
+ problem["entry_point"],
+ record_time=True,
+ output_not_none=problem["entry_point"] in tasks_only_output_not_none,
+ )
+ expected_output[task_id] = oracle
+ print(f"Expected outputs computed in {time.time() - tbegin:.2f}s")
+
+ with open(cache_file, "wb") as f:
+ pickle.dump(expected_output, f)
+
+ return expected_output
+
+def remove_unindented_lines(code, protect_before, execeptions, trim_tails):
+ lines = code.splitlines()
+ cut_idx = []
+ cut_enabled = False
+ for i, line in enumerate(lines):
+ if not cut_enabled and line.startswith(protect_before):
+ cut_enabled = True
+ continue
+ if line.strip() == "":
+ continue
+ if any(line.startswith(e) for e in execeptions):
+ continue
+
+ lspace = len(line) - len(line.lstrip())
+ if lspace == 0:
+ cut_idx.append(i)
+
+ if any(line.rstrip().startswith(t) for t in trim_tails):
+ # cut off everything behind
+ cut_idx.extend(list(range(i, len(lines))))
+ break
+
+ return "\n".join([line for i, line in enumerate(lines) if i not in cut_idx])
+
+
+def to_four_space_indents(old_code):
+ new_code = ""
+ for line in old_code.splitlines():
+ lspace = len(line) - len(line.lstrip())
+ if lspace == 3:
+ new_code += " "
+ new_code += line + "\n"
+ return new_code
+
+
+def sanitize_solution(solution,eofs):
+ task_id = solution["task_id"]
+ dbg_identifier = task_id
+ entry_point = solution["entry_point"]
+
+ old_code = solution["solution"]
+ old_code = old_code.strip()
+
+ new_code = sanitize(
+ old_code=old_code,
+ entry_point=entry_point,
+ rm_prefix_lines=None,
+ eofs=eofs,
+ ).strip()
+
+ # if changed, print the message
+ if new_code != old_code:
+ msg = "Sanitized: " + dbg_identifier
+ print(msg)
+ solution["solution"]=new_code
+ return solution
+
+
+
+################################eval funcs############################
+# 1st item: the status
+# 2nd item (optional): the detailed pass/fail boolean for each input
+Result = Tuple[str, List[bool]]
+
+def is_floats(x) -> bool:
+ # check if it is float; List[float]; Tuple[float]
+ if isinstance(x, float):
+ return True
+ if isinstance(x, (list, tuple)):
+ return all(isinstance(i, float) for i in x)
+ if isinstance(x, np.ndarray):
+ return x.dtype == np.float64 or x.dtype == np.float32
+ return False
+
+
+def unsafe_execute(
+ dataset: str,
+ entry_point: str,
+ code: str,
+ inputs,
+ expected: List,
+ time_limits,
+ atol,
+ fast_check,
+ stat: Value,
+ details: Array,
+ progress: Value,
+ feedback: Value,
+ feedback_size: int,
+):
+ with create_tempdir():
+ # These system calls are needed when cleaning up tempdir.
+ import os
+ import shutil
+
+ rmtree = shutil.rmtree
+ rmdir = os.rmdir
+ chdir = os.chdir
+ maximum_memory_bytes = None
+ reliability_guard(maximum_memory_bytes=maximum_memory_bytes)
+ exec_globals = {}
+ try:
+ with swallow_io():
+ exec(code, exec_globals)
+ try:
+ fn = exec_globals[entry_point]
+ except KeyError as e:
+ raise f"Please rename your function to {entry_point} as there is no function named {entry_point}."
+ except BaseException as e:
+ raise MyCustomException("An error occurred.")
+ for i, inp in enumerate(inputs):
+ # try:
+ with time_limit(time_limits[i]):
+ out = fn(*inp)
+
+ exp = expected[i]
+ exact_match = out == exp
+
+ # ================================================ #
+ # ============== special oracles ================= #
+ if dataset == "mbpp":
+ if (
+ "are_equivalent" == entry_point
+ ): # Mbpp/164 special oracle
+ exact_match = exact_match or True
+ elif "sum_div" == entry_point: # Mbpp/295 special oracle
+ exact_match = exact_match or out == 0
+ elif entry_point in MBPP_OUTPUT_NOT_NONE_TASKS:
+ if isinstance(out, bool):
+ exact_match = out == exp
+ else:
+ exact_match = exp == (out is not None)
+
+ if dataset == "humaneval":
+ if "find_zero" == entry_point:
+ assert _poly(*out, inp) <= atol, f"The results aren't as expected.\nInput: {inp}\nExpected Output: {exp}\nActual Output: {out}"
+ # ============== special oracles ================= #
+ if atol == 0 and is_floats(exp):
+ atol = 1e-6 # enforce atol for float comparison
+
+ if not exact_match and atol != 0:
+ try:
+ np.testing.assert_allclose(out, exp, atol=atol)
+ except BaseException as e:
+ raise AssertionError(f"The results aren't as expected.\nInput: {inp}\nExpected Output: {exp}\nActual Output: {out}")
+ else:
+ assert exact_match, f"The results aren't as expected.\nInput: {inp}\nExpected Output: {exp}\nActual Output: {out}"
+
+ details[i] = True
+ progress.value += 1
+ stat.value = _SUCCESS
+ padding = feedback_size - len(SUCCESS)
+ feedback.value = (SUCCESS + " " * padding).encode('utf-8')
+ except TimeoutException as e:
+ stat.value = _FAILED
+ error_str="Execution timed out."
+ padding = max(0, feedback_size - len(error_str))
+ feedback.value = (error_str + " " * padding).encode('utf-8')
+ except AssertionError as e:
+ stat.value = _FAILED
+ error_str=str(e)[:feedback_size]
+ padding = max(0, feedback_size - len(error_str))
+ feedback.value = (error_str + " " * padding).encode('utf-8')
+ except MyCustomException as e:
+ stat.value = _FAILED
+ error_str=e.message[:feedback_size]
+ padding = max(0, feedback_size - len(error_str))
+ feedback.value = (error_str + " " * padding).encode('utf-8')
+ except BaseException as e:
+ stat.value = _FAILED
+ error_traceback = traceback.format_exc()
+ match = re.search(r'(File "".*)', error_traceback, re.DOTALL)
+ if match:
+ error_traceback = match.group(1)
+ elif "assert _poly" in error_traceback:
+ if "TypeError: _poly() argument after *" in error_traceback:
+ error_traceback = "TypeError: Invalid output type, output must be an iterable."
+ else:
+ delimiter = r'f"Input: \{inp\}\\nExpected Output: \{exp\}\\nActual Output: \{out\}"'
+ error_traceback = re.split(delimiter, error_traceback)[-1]
+
+ error_str=str(error_traceback)[:feedback_size]
+ padding = max(0, feedback_size - len(error_str))
+ feedback.value = (error_str + " " * padding).encode('utf-8')
+ # Needed for cleaning up.
+ shutil.rmtree = rmtree
+ os.rmdir = rmdir
+ os.chdir = chdir
+
+
+def untrusted_check(
+ dataset: str,
+ code: str,
+ inputs: List[Any],
+ entry_point: str,
+ expected,
+ atol,
+ ref_time: List[float],
+ fast_check: bool = False,
+ min_time_limit: float = 0.1,
+ gt_time_limit_factor: float = 2.0,
+) -> Tuple[str, np.ndarray]:
+
+ time_limits = [max(min_time_limit, gt_time_limit_factor * t) for t in ref_time]
+ timeout = sum(time_limits) + 1
+ if not fast_check:
+ timeout += 1 # extra time for data collection
+
+ # shared memory objects
+ progress = Value("i", 0)
+ stat = Value("i", _UNKNOWN)
+ details = Array("b", [False for _ in range(len(inputs))])
+ feedback_size = 500
+ feedback = Array('c', b'\0' * feedback_size)
+
+ p = multiprocessing.Process(
+ target=unsafe_execute,
+ args=(
+ dataset,
+ entry_point,
+ code,
+ inputs,
+ expected,
+ time_limits,
+ atol,
+ fast_check,
+ stat,
+ details,
+ progress,
+ feedback,
+ feedback_size,
+ ),
+ )
+ p.start()
+ p.join(timeout=timeout + 1)
+ if p.is_alive():
+ p.terminate()
+ time.sleep(0.1)
+ if p.is_alive():
+ p.kill()
+ time.sleep(0.1)
+
+ stat = _mapping[stat.value]
+ details = details[: progress.value]
+ feedback = feedback.value.decode("utf-8").strip()
+ if entry_point not in code:
+ feedback = f"Please rename your function to {entry_point} as there is no function named {entry_point}."
+
+ if not stat:
+ stat = TIMEOUT
+
+ if stat == SUCCESS:
+ if len(details) != len(inputs) or not all(details):
+ stat = FAILED
+
+ return stat, details, feedback
+
+
+def check_correctness(
+ dataset: str,
+ completion_id: int,
+ problem: Dict[str, Any],
+ solution: str,
+ expected_output: Dict[str, List],
+ version="base",
+ fast_check=False,
+ identifier=None,
+ min_time_limit: float = 0.1,
+ gt_time_limit_factor: float = 2.0,
+) -> Dict[str, Union[int, Optional[Result]]]:
+ ret = {
+ "completion_id": completion_id,
+ "task_id": problem["task_id"],
+ "_identifier": identifier,
+ }
+
+ ret["base"] = untrusted_check(
+ dataset,
+ solution,
+ problem["base_input"],
+ problem["entry_point"],
+ expected=expected_output["base"],
+ atol=problem["atol"],
+ ref_time=expected_output["base_time"],
+ fast_check=fast_check,
+ min_time_limit=min_time_limit,
+ gt_time_limit_factor=gt_time_limit_factor,
+ )
+ if version=="plus":
+ ret["plus"] = untrusted_check(
+ dataset,
+ solution,
+ problem["plus_input"],
+ problem["entry_point"],
+ expected=expected_output["plus"],
+ atol=problem["atol"],
+ ref_time=expected_output["plus_time"],
+ fast_check=fast_check,
+ min_time_limit=min_time_limit,
+ gt_time_limit_factor=gt_time_limit_factor,
+ )
+ return ret
\ No newline at end of file
diff --git a/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/requirements.txt b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..8faf44a4fe2189fde574e7ac67bccd6b978fc019
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/OpenCodeInterpreter/evaluation/requirements.txt
@@ -0,0 +1,19 @@
+appdirs==1.4.4
+coverage==7.4.1
+gradio==4.19.1
+gradio_client==0.10.0
+matplotlib==3.7.4
+multipledispatch==1.0.0
+multiprocess==0.70.16
+numpy==1.24.4
+openai==0.28.1
+pytest==8.0.1
+Requests==2.31.0
+rich==13.7.0
+tempdir==0.7.1
+termcolor==2.4.0
+torch==2.1.2
+tqdm==4.66.1
+transformers==4.37.1
+vllm==0.3.0
+wget==3.2
diff --git a/Llama2-Code-Interpreter-main/README.md b/Llama2-Code-Interpreter-main/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..da42747776661b96e26f35988806a5bc50f7dcbf
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/README.md
@@ -0,0 +1,131 @@
+
+
+
+[](https://www.python.org/downloads/release/python-390/)
+[](https://github.com/psf/black)
+
+This project allows LLM to generate code, execute it, receive feedback, debug, and answer questions based on the whole process. It is designed to be intuitive and versatile, capable of dealing with multiple languages and frameworks.
+
+[The purpose and direction of the project](https://github.com/SeungyounShin/Llama2-Code-Interpreter/wiki)
+
+## Quick Start
+
+**Run the Gradio App**:
+ ```bash
+ python3 chatbot.py --path Seungyoun/codellama-7b-instruct-pad
+ ```
+
+## News
+
+- 🔥🔥🔥[2023/08/27] We're thrilled to announce that our **[🤗 Llama2 Code Interpreter-7B](https://huggingface.co/Seungyoun/codellama-7b-instruct-pad) (Finetuned from [CodeLlama-7B-Instruct](https://huggingface.co/codellama/CodeLlama-7b-Instruct-hf))** model achieved a remarkable **70.12pass@1** on the [HumanEval Benchmarks](https://github.com/openai/human-eval).
+
+
+**HumanEval**
+
+| Model | Score(pass@1) |
+|-------------------------------|--------|
+| Codellama instruct 7b | 34.8% |
+| Codellama instruct 7b - finetuning | 70.12% |
+
+**GSM8K**
+
+| Model | Score |
+|-------------------------------|--------|
+| Code Llama 7B | 13% |
+| Code Llama 13B | 20.8% |
+| Codellama instruct 7b - finetuning | 28% |
+
+
+## 🌟 Key Features
+
+- [x] 🚀 **Code Generation and Execution**: Llama2 is capable of generating code, which it then automatically identifies and executes within its generated code blocks.
+- [x] Monitors and retains Python variables that were used in previously executed code blocks.
+- [x] 🌟 At the moment, my focus is on "Data development for GPT-4 code interpretation" and "Enhancing the model using this data". For more details, check out the [feat/finetuning branch](https://github.com/SeungyounShin/Llama2-Code-Interpreter/tree/feat/finetuning) in our repository.
+- [x] 🌟 CodeLlama Support [CodeLlama2](https://github.com/facebookresearch/codellama)
+
+## Examples
+
+---
+
+
+***Llama2 in Action***
+
+
+
+
+
+
+
+In the GIF, Llama2 is seen in action. A user types in the request: `Plot Nvidia 90 days chart.` Llama2, an advanced code interpreter fine-tuned on a select dataset, swiftly queries `Yahoo Finance`. Moments later, it fetches the latest Nvidia stock prices from the past 90 days. Using `Matplotlib`, Llama2 then generates a clear and detailed stock price chart for Nvidia, showcasing its performance over the given period.
+
+
+
+## Installation
+
+1. **Clone the Repository (if you haven't already)**:
+ ```bash
+ git clone https://github.com/SeungyounShin/Llama2-Code-Interpreter.git
+ cd Llama2-Code-Interpreter
+ ```
+
+2. **Install the required dependencies:**
+ ```bash
+ pip install -r requirements.txt
+ ```
+
+---
+
+### Run App with GPT4 finetunned Llama Model
+
+To start interacting with Llama2 via the Gradio UI using `codellama-7b-instruct-pad`, follow the steps below:
+
+
+2. **Run the Gradio App**:
+ ```bash
+ python3 chatbot.py --path Seungyoun/codellama-7b-instruct-pad
+ ```
+
+For those who want to use other models:
+
+### General Instructions to Run App
+
+To start interacting with Llama2 via the Gradio UI using other models:
+
+1. **Run the Command**:
+ ```bash
+ python3 chatbot.py --model_path
+ ```
+
+Replace `` with the path to the model file you wish to use. A recommended model for chat interactions is `meta-llama/Llama-2-13b-chat`.
+
+## Contributions
+
+Contributions, issues, and feature requests are welcome! Feel free to check [issues page](https://github.com/SeungyounShin/Llama2-Code-Interpreter/issues).
+
+## License
+
+Distributed under the MIT License. See `LICENSE` for more information.
+
+## Contact
+
+Seungyoun, Shin - 2022021568@korea.ac.kr
+
+## Acknowledgement
+
+Here are some relevant and related projects that have contributed to the development of this work:
+
+1. **llama2** : [GitHub Repository](https://github.com/facebookresearch/llama)
+2. **yet-another-gpt-tutorial** : [GitHub Repository](https://github.com/sjchoi86/yet-another-gpt-tutorial/tree/main)
+
+These projects have been instrumental in providing valuable insights and resources, and their contributions are highly appreciated.
+
+---
diff --git a/Llama2-Code-Interpreter-main/assets/TSLA_90days.png b/Llama2-Code-Interpreter-main/assets/TSLA_90days.png
new file mode 100644
index 0000000000000000000000000000000000000000..956e2922398b49c26696030997b0581bf8a88a84
Binary files /dev/null and b/Llama2-Code-Interpreter-main/assets/TSLA_90days.png differ
diff --git a/Llama2-Code-Interpreter-main/assets/logo.png b/Llama2-Code-Interpreter-main/assets/logo.png
new file mode 100644
index 0000000000000000000000000000000000000000..7e73737aac5698460bf60d70c70a51dbc1d52b36
Binary files /dev/null and b/Llama2-Code-Interpreter-main/assets/logo.png differ
diff --git a/Llama2-Code-Interpreter-main/assets/logo2.png b/Llama2-Code-Interpreter-main/assets/logo2.png
new file mode 100644
index 0000000000000000000000000000000000000000..fdb9233b683c0d555808015b6cac8807c345cb64
Binary files /dev/null and b/Llama2-Code-Interpreter-main/assets/logo2.png differ
diff --git a/Llama2-Code-Interpreter-main/assets/president_code.gif b/Llama2-Code-Interpreter-main/assets/president_code.gif
new file mode 100644
index 0000000000000000000000000000000000000000..149964ab22f633a6f4b98a7b0b43d2b1eb336e46
Binary files /dev/null and b/Llama2-Code-Interpreter-main/assets/president_code.gif differ
diff --git a/Llama2-Code-Interpreter-main/assets/president_code.png b/Llama2-Code-Interpreter-main/assets/president_code.png
new file mode 100644
index 0000000000000000000000000000000000000000..3532aeeedf95330675df468630c59cf3db3874ef
Binary files /dev/null and b/Llama2-Code-Interpreter-main/assets/president_code.png differ
diff --git a/Llama2-Code-Interpreter-main/assets/result_nvidia_chart.gif b/Llama2-Code-Interpreter-main/assets/result_nvidia_chart.gif
new file mode 100644
index 0000000000000000000000000000000000000000..e47926bea39922df9532cbe3e3299074822c7dfb
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/assets/result_nvidia_chart.gif
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:e0a0b39e470967a50cf90e2ebd448c297e582f3b673f290cc990b886f9fb8002
+size 1115765
diff --git a/Llama2-Code-Interpreter-main/assets/tok_hist.png b/Llama2-Code-Interpreter-main/assets/tok_hist.png
new file mode 100644
index 0000000000000000000000000000000000000000..b43e35686f47e369d2afc42e40bad6794624b29e
Binary files /dev/null and b/Llama2-Code-Interpreter-main/assets/tok_hist.png differ
diff --git a/Llama2-Code-Interpreter-main/chatbot.py b/Llama2-Code-Interpreter-main/chatbot.py
new file mode 100644
index 0000000000000000000000000000000000000000..1a70fe588b979fcb1f861bf13a7b8d2233004cc5
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/chatbot.py
@@ -0,0 +1,238 @@
+import gradio as gr
+import random
+import time, os
+import copy
+import re
+
+import torch
+from rich.console import Console
+from rich.table import Table
+from datetime import datetime
+
+from threading import Thread
+from typing import Optional
+from transformers import TextIteratorStreamer
+
+from utils.special_tok_llama2 import (
+ B_CODE,
+ E_CODE,
+ B_RESULT,
+ E_RESULT,
+ B_INST,
+ E_INST,
+ B_SYS,
+ E_SYS,
+ DEFAULT_PAD_TOKEN,
+ DEFAULT_BOS_TOKEN,
+ DEFAULT_EOS_TOKEN,
+ DEFAULT_UNK_TOKEN,
+ IGNORE_INDEX,
+)
+
+from finetuning.conversation_template import (
+ json_to_code_result_tok_temp,
+ msg_to_code_result_tok_temp,
+)
+
+import warnings
+
+warnings.filterwarnings("ignore", category=UserWarning, module="transformers")
+os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2"
+
+
+from code_interpreter.LlamaCodeInterpreter import LlamaCodeInterpreter
+
+
+class StreamingLlamaCodeInterpreter(LlamaCodeInterpreter):
+ streamer: Optional[TextIteratorStreamer] = None
+
+ # overwirte generate function
+ @torch.inference_mode()
+ def generate(
+ self,
+ prompt: str = "[INST]\n###User : hi\n###Assistant :",
+ max_new_tokens=512,
+ do_sample: bool = True,
+ use_cache: bool = True,
+ top_p: float = 0.95,
+ temperature: float = 0.1,
+ top_k: int = 50,
+ repetition_penalty: float = 1.0,
+ ) -> str:
+ # Get the model and tokenizer, and tokenize the user text.
+
+ self.streamer = TextIteratorStreamer(
+ self.tokenizer, skip_prompt=True, Timeout=5
+ )
+
+ input_prompt = copy.deepcopy(prompt)
+ inputs = self.tokenizer([prompt], return_tensors="pt")
+ input_tokens_shape = inputs["input_ids"].shape[-1]
+
+ eos_token_id = self.tokenizer.convert_tokens_to_ids(DEFAULT_EOS_TOKEN)
+ e_code_token_id = self.tokenizer.convert_tokens_to_ids(E_CODE)
+
+ kwargs = dict(
+ **inputs,
+ max_new_tokens=max_new_tokens,
+ do_sample=do_sample,
+ top_p=top_p,
+ temperature=temperature,
+ use_cache=use_cache,
+ top_k=top_k,
+ repetition_penalty=repetition_penalty,
+ eos_token_id=[
+ eos_token_id,
+ e_code_token_id,
+ ], # Stop generation at either EOS or E_CODE token
+ streamer=self.streamer,
+ )
+
+ thread = Thread(target=self.model.generate, kwargs=kwargs)
+ thread.start()
+
+ return ""
+
+
+def change_markdown_image(text: str):
+ modified_text = re.sub(r"!\[(.*?)\]\(\'(.*?)\'\)", r"", text)
+ return modified_text
+
+
+def gradio_launch(model_path: str, load_in_4bit: bool = True, MAX_TRY: int = 5):
+ with gr.Blocks(theme=gr.themes.Monochrome()) as demo:
+ chatbot = gr.Chatbot(height=820, avatar_images="./assets/logo2.png")
+ msg = gr.Textbox()
+ clear = gr.Button("Clear")
+
+ interpreter = StreamingLlamaCodeInterpreter(
+ model_path=model_path, load_in_4bit=load_in_4bit
+ )
+
+ def bot(history):
+ user_message = history[-1][0]
+
+ interpreter.dialog.append({"role": "user", "content": user_message})
+
+ print(f"###User : [bold]{user_message}[bold]")
+ # print(f"###Assistant : ")
+
+ # setup
+ HAS_CODE = False # For now
+ INST_END_TOK_FLAG = False
+ full_generated_text = ""
+ prompt = interpreter.dialog_to_prompt(dialog=interpreter.dialog)
+ start_prompt = copy.deepcopy(prompt)
+ prompt = f"{prompt} {E_INST}"
+
+ _ = interpreter.generate(prompt)
+ history[-1][1] = ""
+ generated_text = ""
+ for character in interpreter.streamer:
+ history[-1][1] += character
+ generated_text += character
+ yield history
+
+ full_generated_text += generated_text
+ HAS_CODE, generated_code_block = interpreter.extract_code_blocks(
+ generated_text
+ )
+
+ attempt = 1
+ while HAS_CODE:
+ if attempt > MAX_TRY:
+ break
+ # if no code then doesn't have to execute it
+
+ # refine code block for history
+ history[-1][1] = (
+ history[-1][1]
+ .replace(f"{B_CODE}", "\n```python\n")
+ .replace(f"{E_CODE}", "\n```\n")
+ )
+ history[-1][1] = change_markdown_image(history[-1][1])
+ yield history
+
+ # replace unknown thing to none ''
+ generated_code_block = generated_code_block.replace(
+ "_", ""
+ ).replace("", "")
+
+ (
+ code_block_output,
+ error_flag,
+ ) = interpreter.execute_code_and_return_output(
+ f"{generated_code_block}"
+ )
+ code_block_output = interpreter.clean_code_output(code_block_output)
+ generated_text = (
+ f"{generated_text}\n{B_RESULT}\n{code_block_output}\n{E_RESULT}\n"
+ )
+ full_generated_text += (
+ f"\n{B_RESULT}\n{code_block_output}\n{E_RESULT}\n"
+ )
+
+ # append code output
+ history[-1][1] += f"\n```RESULT\n{code_block_output}\n```\n"
+ history[-1][1] = change_markdown_image(history[-1][1])
+ yield history
+
+ prompt = f"{prompt} {generated_text}"
+
+ _ = interpreter.generate(prompt)
+ for character in interpreter.streamer:
+ history[-1][1] += character
+ generated_text += character
+ history[-1][1] = change_markdown_image(history[-1][1])
+ yield history
+
+ HAS_CODE, generated_code_block = interpreter.extract_code_blocks(
+ generated_text
+ )
+
+ if generated_text.endswith(""):
+ break
+
+ attempt += 1
+
+ interpreter.dialog.append(
+ {
+ "role": "assistant",
+ "content": generated_text.replace("_", "")
+ .replace("", "")
+ .replace("", ""),
+ }
+ )
+
+ print("----------\n" * 2)
+ print(interpreter.dialog)
+ print("----------\n" * 2)
+
+ return history[-1][1]
+
+ def user(user_message, history):
+ return "", history + [[user_message, None]]
+
+ msg.submit(user, [msg, chatbot], [msg, chatbot], queue=False).then(
+ bot, chatbot, chatbot
+ )
+ clear.click(lambda: None, None, chatbot, queue=False)
+
+ demo.queue()
+ demo.launch()
+
+
+if __name__ == "__main__":
+ import argparse
+
+ parser = argparse.ArgumentParser(description="Process path for LLAMA2_FINETUNEED.")
+ parser.add_argument(
+ "--path",
+ type=str,
+ required=True,
+ help="Path to the finetuned LLAMA2 model.",
+ default="./output/llama-2-7b-codellama-ci",
+ )
+ args = parser.parse_args()
+
+ gradio_launch(model_path=args.path, load_in_4bit=True)
diff --git a/Llama2-Code-Interpreter-main/code_interpreter/BaseCodeInterpreter.py b/Llama2-Code-Interpreter-main/code_interpreter/BaseCodeInterpreter.py
new file mode 100644
index 0000000000000000000000000000000000000000..b772875c75430a56cafaeb0ca58e5549e1089860
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/code_interpreter/BaseCodeInterpreter.py
@@ -0,0 +1,59 @@
+import json
+import os
+import sys
+import time
+import re
+from pathlib import Path
+from typing import List, Literal, Optional, Tuple, TypedDict, Dict
+
+prj_root_path = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
+sys.path.append(prj_root_path)
+
+import torch
+import transformers
+from transformers import LlamaForCausalLM, LlamaTokenizer
+
+import nbformat
+
+# from nbconvert.preprocessors import ExecutePreprocessor
+# from nbconvert.preprocessors.execute import CellExecutionError
+
+from utils.const import *
+from utils.cleaner import clean_error_msg
+from colorama import init, Fore, Style
+from rich.markdown import Markdown
+import base64
+
+import openai
+from retrying import retry
+import logging
+from termcolor import colored
+from code_interpreter.JuypyterClient import JupyterNotebook
+
+
+class BaseCodeInterpreter:
+ def __init__(self):
+ self.dialog = [
+ {
+ "role": "system",
+ "content": CODE_INTERPRETER_SYSTEM_PROMPT,
+ },
+ # {"role": "user", "content": "How can I use BeautifulSoup to scrape a website and extract all the URLs on a page?"},
+ # {"role": "assistant", "content": "I think I need to use beatifulsoup to find current korean president,"}
+ ]
+
+ self.nb = JupyterNotebook()
+
+ @staticmethod
+ def extract_code_blocks(text: str):
+ pattern = r"```(?:python\n)?(.*?)```" # Match optional 'python\n' but don't capture it
+ code_blocks = re.findall(pattern, text, re.DOTALL)
+ return [block.strip() for block in code_blocks]
+
+ @staticmethod
+ def parse_last_answer(text: str) -> str:
+ return text.split(E_INST)[-1]
+
+ def execute_code_and_return_output(self, code_str: str):
+ outputs, error_flag = self.nb.add_and_run(code_str)
+ return outputs, error_flag
diff --git a/Llama2-Code-Interpreter-main/code_interpreter/GPTCodeInterpreter.py b/Llama2-Code-Interpreter-main/code_interpreter/GPTCodeInterpreter.py
new file mode 100644
index 0000000000000000000000000000000000000000..86625e69589c17bec63f29f7c66bfc6e12b8bf4d
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/code_interpreter/GPTCodeInterpreter.py
@@ -0,0 +1,234 @@
+import json
+import os
+import sys
+import time
+import re
+from pathlib import Path
+from typing import List, Literal, Optional, Tuple, TypedDict, Dict
+
+# Get the path from environment variable
+prj_root_path = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
+sys.path.append(prj_root_path)
+from code_interpreter.JuypyterClient import JupyterNotebook
+from code_interpreter.BaseCodeInterpreter import BaseCodeInterpreter
+from utils.const import *
+from prompt.gpt4_prompt import CODE_INTERPRETER_SYSTEM_PROMPT
+
+# from prompt.gpt4_prompt import CODE_INTERPRETER_SYSTEM_PROMPT
+from colorama import init, Fore, Style
+from rich.markdown import Markdown
+import base64
+
+import openai
+from retrying import retry
+import logging
+from termcolor import colored
+
+# load from key file
+with open("./openai_api_key.txt") as f:
+ OPENAI_API_KEY = key = f.read()
+openai.api_key = OPENAI_API_KEY
+from utils.cleaner import clean_error_msg
+
+
+def remove_string(s):
+ pattern = r"\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}\.\d{6}:.*LD_LIBRARY_PATH: /usr/local/nvidia/lib:/usr/local/nvidia/lib64\n"
+ return re.sub(pattern, "", s)
+
+
+def clean_the_dialog(dialog, question):
+ question_idx = 0
+ for idx, item in enumerate(dialog):
+ if item["content"] == question:
+ question_idx = idx
+
+ filtered_dialog = dialog[question_idx:]
+
+ user_qinit_dict = filtered_dialog[0]
+ answer_fuse_str = "\n".join([i["content"].strip() for i in filtered_dialog[1::2]])
+
+ final_dialog_dict = [
+ {"role": "user", "content": user_qinit_dict["content"]},
+ {"role": "assistant", "content": answer_fuse_str},
+ ]
+
+ return final_dialog_dict
+
+
+class GPTCodeInterpreter(BaseCodeInterpreter):
+ def __init__(self, model="gpt-4"):
+ self.model = model
+ self.dialog = [
+ # {"role": "system", "content": CODE_INTERPRETER_SYSTEM_PROMPT },
+ {
+ "role": "system",
+ "content": CODE_INTERPRETER_SYSTEM_PROMPT,
+ },
+ # {"role": "user", "content": "How can I use BeautifulSoup to scrape a website and extract all the URLs on a page?"},
+ # {"role": "assistant", "content": "I think I need to use beatifulsoup to find current korean president,"}
+ ]
+
+ # self.dialog += few_shot_4
+ self.response = None
+
+ assert os.path.isfile(
+ "./openai_api_key.txt"
+ ), "The openai_api_key.txt file could not be found. Please make sure it is in the same directory as this script, and that it contains your OpenAI API key."
+
+ # load from key file
+ with open("./openai_api_key.txt") as f:
+ OPENAI_API_KEY = f.read()
+ openai.api_key = OPENAI_API_KEY
+
+ self.nb = JupyterNotebook()
+ out = self.nb.add_and_run(TOOLS_CODE) # tool import
+
+ def get_response_content(self):
+ if self.response:
+ return self.response["choices"][0]["message"]["content"]
+ else:
+ return None
+
+ @retry(
+ stop_max_attempt_number=7,
+ wait_exponential_multiplier=1000,
+ wait_exponential_max=10000,
+ )
+ def ChatCompletion(self):
+ try:
+ self.response = openai.ChatCompletion.create(
+ model=self.model, messages=self.dialog, temperature=0.2, top_p=0.9
+ )
+ except Exception as e:
+ print(f"error while OPENAI api call {e}")
+
+ def close(self):
+ """
+ close jupyter notebook, and this class instance
+ """
+ self.nb.close()
+
+ def save_dialog(self, path: str = "./output/dialog.json"):
+ with open(path, "w") as f:
+ json.dump(self.dialog, f)
+ print(f" ++Dialog saved to [{path}]")
+
+ def chat(
+ self,
+ user_message: str,
+ VERBOSE: bool = False,
+ MAX_TRY: int = 6,
+ code_exec_prefix: str = "",
+ feedback_prompt: str = "",
+ append_result: bool = True,
+ ):
+ self.dialog.append({"role": "user", "content": user_message})
+
+ code_block_output = ""
+ attempt = 0
+ img_data = None
+
+ if VERBOSE:
+ print(
+ "###User : " + Fore.BLUE + Style.BRIGHT + user_message + Style.RESET_ALL
+ )
+ print("\n###Assistant : ")
+
+ for i in range(MAX_TRY):
+ # GPT response
+ self.ChatCompletion()
+
+ # Get code block
+ generated_text = self.get_response_content()
+ generated_code_blocks = self.extract_code_blocks(generated_text)
+ # execute code
+ if len(generated_code_blocks) > 0:
+ # Find the position of the first code block in the last answer
+ first_code_block_pos = (
+ generated_text.find(generated_code_blocks[0])
+ if generated_code_blocks
+ else -1
+ )
+ text_before_first_code_block = (
+ generated_text
+ if first_code_block_pos == -1
+ else generated_text[:first_code_block_pos]
+ )
+ if VERBOSE:
+ print(Fore.GREEN + text_before_first_code_block + Style.RESET_ALL)
+ if VERBOSE:
+ print(
+ Fore.YELLOW
+ + generated_code_blocks[0]
+ + "\n```\n"
+ + Style.RESET_ALL
+ )
+ code_block_output, error_flag = self.execute_code_and_return_output(
+ generated_code_blocks[0]
+ )
+
+ code_block_output = f"{code_block_output}"
+
+ if code_block_output is not None:
+ code_block_output = code_block_output.strip()
+
+ code_block_output = remove_string(code_block_output)
+ if len(code_block_output) > 500:
+ code_block_output = (
+ code_block_output[:200] + "⋯(skip)⋯" + code_block_output[-200:]
+ )
+ code_block_output_str = f"\n```RESULT\n{code_block_output}\n```\n"
+ if append_result:
+ gen_final = f"{text_before_first_code_block}{generated_code_blocks[0]}\n```{code_block_output_str}"
+ if VERBOSE:
+ print(
+ Fore.LIGHTBLACK_EX + code_block_output_str + Style.RESET_ALL
+ )
+ else:
+ gen_final = (
+ f"{text_before_first_code_block}{generated_code_blocks[0]}\n```"
+ )
+
+ self.dialog.append(
+ {
+ "role": "assistant",
+ "content": gen_final,
+ }
+ )
+
+ if len(feedback_prompt) < 5:
+ feedback_dict = {
+ "role": "user",
+ "content": "Keep going. if you think debugging tell me where you got wrong and better code.\nNeed conclusion to question only text (Do not leave result part alone).\nif doesn't need to generated anything then just say ",
+ }
+ else:
+ feedback_dict = {
+ "role": "user",
+ "content": f"{feedback_prompt}",
+ }
+
+ self.dialog.append(feedback_dict)
+
+ else:
+ if "" in generated_text:
+ generated_text = generated_text.split("")[0].strip()
+
+ if len(generated_text) <= 0:
+ break
+
+ if VERBOSE:
+ print(Fore.GREEN + generated_text + Style.RESET_ALL)
+
+ self.dialog.append(
+ {
+ "role": "assistant",
+ "content": f"{generated_text}",
+ }
+ )
+ break
+
+ self.dialog = [self.dialog[0]] + clean_the_dialog(
+ self.dialog, question=user_message
+ ) # delete retrospections after generation step
+
+ return self.dialog[-1]
diff --git a/Llama2-Code-Interpreter-main/code_interpreter/GPTCodeInterpreterDataCollect.py b/Llama2-Code-Interpreter-main/code_interpreter/GPTCodeInterpreterDataCollect.py
new file mode 100644
index 0000000000000000000000000000000000000000..bea27ef0b4e4ee56459fa841e4dae8f81a679ea6
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/code_interpreter/GPTCodeInterpreterDataCollect.py
@@ -0,0 +1,271 @@
+import json
+import os, sys
+import time
+import re
+from pathlib import Path
+from typing import List, Literal, Optional, Tuple, TypedDict, Dict
+
+# Get the path from environment variable
+prj_root_path = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
+sys.path.append(prj_root_path)
+from code_interpreter.JuypyterClient import JupyterNotebook
+from code_interpreter.BaseCodeInterpreter import BaseCodeInterpreter
+from utils.const import *
+from colorama import init, Fore, Style
+from rich.markdown import Markdown
+import base64
+
+import openai
+from retrying import retry
+import logging
+from termcolor import colored
+
+# load from key file
+with open("./openai_api_key.txt") as f:
+ OPENAI_API_KEY = key = f.read()
+openai.api_key = OPENAI_API_KEY
+from utils.cleaner import clean_error_msg
+from prompt.gpt4_prompt import *
+
+
+def remove_string(s):
+ pattern = r"\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}\.\d{6}:.*LD_LIBRARY_PATH: /usr/local/nvidia/lib:/usr/local/nvidia/lib64\n"
+ return re.sub(pattern, "", s)
+
+
+def gen_questions(prefix="What is 55th fibonacci number?"):
+ response = openai.ChatCompletion.create(
+ model="gpt-4",
+ messages=[
+ {
+ "role": "system",
+ "content": "You are teacherGPT, You need to generate only questions(to student not the explanation and solution) based on student history. \n\nGive him only one question.\n\nAlso remember that student can use code. ",
+ },
+ {
+ "role": "user",
+ "content": f"{prefix}\nmore harder one but not the similar domain of above.",
+ },
+ ],
+ temperature=0.1,
+ max_tokens=300,
+ top_p=1,
+ frequency_penalty=0,
+ presence_penalty=0,
+ )
+ return response["choices"][0]["message"]["content"]
+
+
+def save_dialog(dialog, base_path: str = f"{prj_root_path}/gpt_data_gen"):
+ file_number = 0
+ while True:
+ # Construct the path
+ file_name = f"{file_number}.json"
+ full_path = os.path.join(base_path, file_name)
+
+ # Check if the file already exists
+ if not os.path.exists(full_path):
+ # If not, save the file
+ with open(full_path, "w") as f:
+ json.dump(dialog, f)
+ print(f"Dialog saved to {full_path}")
+ break
+ else:
+ # If the file does exist, increment the file number and try again
+ file_number += 1
+
+
+def clean_the_dialog(dialog, question):
+ question_idx = 0
+ for idx, item in enumerate(dialog):
+ if item["content"] == question:
+ question_idx = idx
+
+ filtered_dialog = dialog[question_idx:]
+
+ user_qinit_dict = filtered_dialog[0]
+ answer_fuse_str = "\n".join([i["content"].strip() for i in filtered_dialog[1::2]])
+
+ final_dialog_dict = [
+ {"role": "user", "content": user_qinit_dict["content"]},
+ {"role": "assistant", "content": answer_fuse_str},
+ ]
+
+ return final_dialog_dict
+
+
+class GPTCodeInterpreter(BaseCodeInterpreter):
+ def __init__(self, model="gpt-4"):
+ self.model = model
+ self.dialog = [
+ # {"role": "system", "content": CODE_INTERPRETER_SYSTEM_PROMPT },
+ {
+ "role": "system",
+ "content": CODE_INTERPRETER_SYSTEM_PROMPT + "\n" + extra_prompt,
+ },
+ # {"role": "user", "content": "How can I use BeautifulSoup to scrape a website and extract all the URLs on a page?"},
+ # {"role": "assistant", "content": "I think I need to use beatifulsoup to find current korean president,"}
+ ]
+
+ self.dialog += few_shot_1
+ # self.dialog += few_shot_4
+ self.response = None
+
+ assert os.path.isfile(
+ "./openai_api_key.txt"
+ ), "The openai_api_key.txt file could not be found. Please make sure it is in the same directory as this script, and that it contains your OpenAI API key."
+
+ # load from key file
+ with open("./openai_api_key.txt") as f:
+ OPENAI_API_KEY = f.read()
+ openai.api_key = OPENAI_API_KEY
+
+ self.nb = JupyterNotebook()
+ out = self.nb.add_and_run(TOOLS_CODE) # tool import
+
+ def get_response_content(self):
+ if self.response:
+ return self.response["choices"][0]["message"]["content"]
+ else:
+ return None
+
+ @retry(
+ stop_max_attempt_number=7,
+ wait_exponential_multiplier=1000,
+ wait_exponential_max=10000,
+ )
+ def ChatCompletion(self):
+ try:
+ self.response = openai.ChatCompletion.create(
+ model=self.model, messages=self.dialog, temperature=0.1, top_p=1.0
+ )
+ except Exception as e:
+ print(f"error while OPENAI api call {e}")
+
+ def chat(self, user_message: str, VERBOSE: bool = False, MAX_RETRY: int = 6):
+ self.dialog.append({"role": "user", "content": user_message})
+
+ code_block_output = ""
+ attempt = 0
+ img_data = None
+
+ if VERBOSE:
+ print(
+ "###User : " + Fore.BLUE + Style.BRIGHT + user_message + Style.RESET_ALL
+ )
+ print("\n###Assistant : ")
+
+ for i in range(MAX_RETRY):
+ # GPT response
+ self.ChatCompletion()
+
+ # Get code block
+ generated_text = self.get_response_content()
+ generated_code_blocks = self.extract_code_blocks(generated_text)
+ # execute code
+ if len(generated_code_blocks) > 0:
+ # Find the position of the first code block in the last answer
+ first_code_block_pos = (
+ generated_text.find(generated_code_blocks[0])
+ if generated_code_blocks
+ else -1
+ )
+ text_before_first_code_block = (
+ generated_text
+ if first_code_block_pos == -1
+ else generated_text[:first_code_block_pos]
+ )
+ if VERBOSE:
+ print(Fore.GREEN + text_before_first_code_block + Style.RESET_ALL)
+ if VERBOSE:
+ print(
+ Fore.YELLOW
+ + generated_code_blocks[0]
+ + "\n```\n"
+ + Style.RESET_ALL
+ )
+ code_block_output, error_flag = self.execute_code_and_return_output(
+ generated_code_blocks[0]
+ )
+
+ code_block_output = f"{code_block_output}"
+
+ if code_block_output is not None:
+ code_block_output = code_block_output.strip()
+
+ code_block_output = remove_string(code_block_output)
+ if len(code_block_output) > 500:
+ code_block_output = (
+ code_block_output[:200] + "⋯(skip)⋯" + code_block_output[-200:]
+ )
+ code_block_output_str = f"\n```RESULT\n{code_block_output}\n```\n"
+ if VERBOSE:
+ print(Fore.LIGHTBLACK_EX + code_block_output_str + Style.RESET_ALL)
+ # markdown = Markdown(code_block_output_str)print(markdown)
+
+ gen_final = f"{text_before_first_code_block}{generated_code_blocks[0]}\n```{code_block_output_str}"
+
+ self.dialog.append(
+ {
+ "role": "assistant",
+ "content": f"{text_before_first_code_block}{generated_code_blocks[0]}\n```{code_block_output_str}",
+ }
+ )
+
+ self.dialog.append(
+ {
+ "role": "user",
+ "content": "Keep going. if you think debugging generate code. need conclusion to question only text (Do not leave result part alone). Doesn't need to generated anything then just say ",
+ }
+ )
+
+ else:
+ if "" in generated_text:
+ generated_text = generated_text.split("")[0].strip()
+
+ if len(generated_text) <= 0:
+ break
+
+ if VERBOSE:
+ print(Fore.GREEN + generated_text + Style.RESET_ALL)
+
+ self.dialog.append(
+ {
+ "role": "assistant",
+ "content": f"{generated_text}",
+ }
+ )
+ break
+
+ return self.dialog[-1]
+
+
+if __name__ == "__main__":
+ import random
+
+ SEED_TASK = [
+ # "Resize this image to 512x512\nUser Uploaded File : './tmp/img.png'",
+ "Write a Python script that retrieves Google Trends data for a given keyword and stock price data for a specific company over the same timeframe, normalizes both datasets to the same scale, and then plots them on the same graph to analyze potential correlations.",
+ "Could you conduct a frequency analysis on Apple's stock price to determine any cyclic patterns that occur on a weekly, monthly, or quarterly basis?",
+ ]
+
+ questions = SEED_TASK
+
+ from tqdm import tqdm
+
+ for i in tqdm(range(150000)):
+ interpreter = GPTCodeInterpreter()
+
+ question = questions[i]
+ output = interpreter.chat(user_message=question, VERBOSE=True, MAX_RETRY=5)
+
+ sample = clean_the_dialog(interpreter.dialog, question)
+
+ save_dialog(sample)
+
+ # q1,q2,q3 = random.sample(questions, k=3)
+ # question = gen_questions(prefix = f'{q1}\n{q2}\n{q3}')
+ # questions.append(question)
+
+ del interpreter
+
+ print(f"new question :: {question}")
diff --git a/Llama2-Code-Interpreter-main/code_interpreter/JuypyterClient.py b/Llama2-Code-Interpreter-main/code_interpreter/JuypyterClient.py
new file mode 100644
index 0000000000000000000000000000000000000000..8e81fa657465fc238f58be59a8b961031697c3c7
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/code_interpreter/JuypyterClient.py
@@ -0,0 +1,75 @@
+from jupyter_client import KernelManager
+import threading
+import re
+
+
+class JupyterNotebook:
+ def __init__(self):
+ self.km = KernelManager()
+ self.km.start_kernel()
+ self.kc = self.km.client()
+
+ def clean_output(self, outputs):
+ outputs_only_str = list()
+ for i in outputs:
+ if type(i) == dict:
+ if "text/plain" in list(i.keys()):
+ outputs_only_str.append(i["text/plain"])
+ elif type(i) == str:
+ outputs_only_str.append(i)
+ elif type(i) == list:
+ error_msg = "\n".join(i)
+ error_msg = re.sub(r"\x1b\[.*?m", "", error_msg)
+ outputs_only_str.append(error_msg)
+
+ return "\n".join(outputs_only_str).strip()
+
+ def add_and_run(self, code_string):
+ # This inner function will be executed in a separate thread
+ def run_code_in_thread():
+ nonlocal outputs, error_flag
+
+ # Execute the code and get the execution count
+ msg_id = self.kc.execute(code_string)
+
+ while True:
+ try:
+ msg = self.kc.get_iopub_msg(timeout=20)
+
+ msg_type = msg["header"]["msg_type"]
+ content = msg["content"]
+
+ if msg_type == "execute_result":
+ outputs.append(content["data"])
+ elif msg_type == "stream":
+ outputs.append(content["text"])
+ elif msg_type == "error":
+ error_flag = True
+ outputs.append(content["traceback"])
+
+ # If the execution state of the kernel is idle, it means the cell finished executing
+ if msg_type == "status" and content["execution_state"] == "idle":
+ break
+ except:
+ break
+
+ outputs = []
+ error_flag = False
+
+ # Start the thread to run the code
+ thread = threading.Thread(target=run_code_in_thread)
+ thread.start()
+
+ # Wait for 10 seconds for the thread to finish
+ thread.join(timeout=10)
+
+ # If the thread is still alive after 10 seconds, it's a timeout
+ if thread.is_alive():
+ outputs = ["Timeout after 10 seconds"]
+ error_flag = True
+
+ return self.clean_output(outputs), error_flag
+
+ def close(self):
+ """Shutdown the kernel."""
+ self.km.shutdown_kernel()
diff --git a/Llama2-Code-Interpreter-main/code_interpreter/LlamaCodeInterpreter.py b/Llama2-Code-Interpreter-main/code_interpreter/LlamaCodeInterpreter.py
new file mode 100644
index 0000000000000000000000000000000000000000..4123d8116edfe00c31f4eb598be5ad1ae63e027b
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/code_interpreter/LlamaCodeInterpreter.py
@@ -0,0 +1,286 @@
+import sys
+import os
+
+prj_root_path = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
+sys.path.append(prj_root_path)
+
+from code_interpreter.JuypyterClient import JupyterNotebook
+from code_interpreter.BaseCodeInterpreter import BaseCodeInterpreter
+from utils.const import *
+
+from typing import List, Literal, Optional, Tuple, TypedDict, Dict
+from colorama import init, Fore, Style
+import copy
+import re
+
+import torch
+import transformers
+from transformers import LlamaForCausalLM, LlamaTokenizer
+from peft import PeftModel
+
+
+sys.path.append(os.path.dirname(__file__))
+sys.path.append(os.path.dirname(os.path.abspath(__file__)))
+from finetuning.conversation_template import msg_to_code_result_tok_temp
+from utils.special_tok_llama2 import (
+ B_CODE,
+ E_CODE,
+ B_RESULT,
+ E_RESULT,
+ B_INST,
+ E_INST,
+ B_SYS,
+ E_SYS,
+ DEFAULT_PAD_TOKEN,
+ DEFAULT_BOS_TOKEN,
+ DEFAULT_EOS_TOKEN,
+ DEFAULT_UNK_TOKEN,
+ IGNORE_INDEX,
+)
+
+import warnings
+
+warnings.filterwarnings("ignore", category=UserWarning, module="transformers")
+os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2"
+
+
+class LlamaCodeInterpreter(BaseCodeInterpreter):
+ def __init__(
+ self,
+ model_path: str,
+ load_in_8bit: bool = False,
+ load_in_4bit: bool = False,
+ peft_model: Optional[str] = None,
+ ):
+ # build tokenizer
+ self.tokenizer = LlamaTokenizer.from_pretrained(
+ model_path,
+ padding_side="right",
+ use_fast=False,
+ )
+
+ # Handle special tokens
+ special_tokens_dict = dict()
+ if self.tokenizer.pad_token is None:
+ special_tokens_dict["pad_token"] = DEFAULT_PAD_TOKEN # 32000
+ if self.tokenizer.eos_token is None:
+ special_tokens_dict["eos_token"] = DEFAULT_EOS_TOKEN # 2
+ if self.tokenizer.bos_token is None:
+ special_tokens_dict["bos_token"] = DEFAULT_BOS_TOKEN # 1
+ if self.tokenizer.unk_token is None:
+ special_tokens_dict["unk_token"] = DEFAULT_UNK_TOKEN
+
+ self.tokenizer.add_special_tokens(special_tokens_dict)
+ self.tokenizer.add_tokens(
+ [B_CODE, E_CODE, B_RESULT, E_RESULT, B_INST, E_INST, B_SYS, E_SYS],
+ special_tokens=True,
+ )
+
+ self.model = LlamaForCausalLM.from_pretrained(
+ model_path,
+ device_map="auto",
+ load_in_4bit=load_in_4bit,
+ load_in_8bit=load_in_8bit,
+ torch_dtype=torch.float16,
+ )
+
+ self.model.resize_token_embeddings(len(self.tokenizer))
+
+ if peft_model is not None:
+ peft_model = PeftModel.from_pretrained(self.model, peft_model)
+
+ self.model = self.model.eval()
+
+ self.dialog = [
+ {
+ "role": "system",
+ "content": CODE_INTERPRETER_SYSTEM_PROMPT + "\nUse code to answer",
+ },
+ # {"role": "user", "content": "How can I use BeautifulSoup to scrape a website and extract all the URLs on a page?"},
+ # {"role": "assistant", "content": "I think I need to use beatifulsoup to find current korean president,"}
+ ]
+
+ self.nb = JupyterNotebook()
+ self.MAX_CODE_OUTPUT_LENGTH = 3000
+ out = self.nb.add_and_run(TOOLS_CODE) # tool import
+ print(out)
+
+ def dialog_to_prompt(self, dialog: List[Dict]) -> str:
+ full_str = msg_to_code_result_tok_temp(dialog)
+
+ return full_str
+
+ @torch.inference_mode()
+ def generate(
+ self,
+ prompt: str = "[INST]\n###User : hi\n###Assistant :",
+ max_new_tokens=512,
+ do_sample: bool = True,
+ use_cache: bool = True,
+ top_p: float = 0.95,
+ temperature: float = 0.1,
+ top_k: int = 50,
+ repetition_penalty: float = 1.0,
+ ) -> str:
+ # Get the model and tokenizer, and tokenize the user text.
+
+ input_prompt = copy.deepcopy(prompt)
+ inputs = self.tokenizer([prompt], return_tensors="pt")
+ input_tokens_shape = inputs["input_ids"].shape[-1]
+
+ eos_token_id = self.tokenizer.convert_tokens_to_ids(DEFAULT_EOS_TOKEN)
+ e_code_token_id = self.tokenizer.convert_tokens_to_ids(E_CODE)
+
+ output = self.model.generate(
+ **inputs,
+ max_new_tokens=max_new_tokens,
+ do_sample=do_sample,
+ top_p=top_p,
+ temperature=temperature,
+ use_cache=use_cache,
+ top_k=top_k,
+ repetition_penalty=repetition_penalty,
+ eos_token_id=[
+ eos_token_id,
+ e_code_token_id,
+ ], # Stop generation at either EOS or E_CODE token
+ )[0]
+
+ generated_tokens = output[input_tokens_shape:]
+ generated_text = self.tokenizer.decode(generated_tokens)
+
+ return generated_text
+
+ def extract_code_blocks(self, prompt: str) -> Tuple[bool, str]:
+ pattern = re.escape(B_CODE) + r"(.*?)" + re.escape(E_CODE)
+ matches = re.findall(pattern, prompt, re.DOTALL)
+
+ if matches:
+ # Return the last matched code block
+ return True, matches[-1].strip()
+ else:
+ return False, ""
+
+ def clean_code_output(self, output: str) -> str:
+ if self.MAX_CODE_OUTPUT_LENGTH < len(output):
+ return (
+ output[: self.MAX_CODE_OUTPUT_LENGTH // 5]
+ + "...(skip)..."
+ + output[-self.MAX_CODE_OUTPUT_LENGTH // 5 :]
+ )
+
+ return output
+
+ def chat(self, user_message: str, VERBOSE: bool = False, MAX_TRY=5):
+ self.dialog.append({"role": "user", "content": user_message})
+ if VERBOSE:
+ print(
+ "###User : " + Fore.BLUE + Style.BRIGHT + user_message + Style.RESET_ALL
+ )
+ print("\n###Assistant : ")
+
+ # setup
+ HAS_CODE = False # For now
+ INST_END_TOK_FLAG = False
+ full_generated_text = ""
+ prompt = self.dialog_to_prompt(dialog=self.dialog)
+ start_prompt = copy.deepcopy(prompt)
+ prompt = f"{prompt} {E_INST}"
+
+ generated_text = self.generate(prompt)
+ full_generated_text += generated_text
+ HAS_CODE, generated_code_block = self.extract_code_blocks(generated_text)
+
+ attempt = 1
+ while HAS_CODE:
+ if attempt > MAX_TRY:
+ break
+ # if no code then doesn't have to execute it
+
+ # replace unknown thing to none
+ generated_code_block = generated_code_block.replace("_", "").replace(
+ "", ""
+ )
+
+ code_block_output, error_flag = self.execute_code_and_return_output(
+ f"{generated_code_block}"
+ )
+ code_block_output = self.clean_code_output(code_block_output)
+ generated_text = (
+ f"{generated_text}\n{B_RESULT}\n{code_block_output}\n{E_RESULT}\n"
+ )
+ full_generated_text += f"\n{B_RESULT}\n{code_block_output}\n{E_RESULT}\n"
+
+ first_code_block_pos = (
+ generated_text.find(generated_code_block)
+ if generated_code_block
+ else -1
+ )
+ text_before_first_code_block = (
+ generated_text
+ if first_code_block_pos == -1
+ else generated_text[:first_code_block_pos]
+ )
+ if VERBOSE:
+ print(Fore.GREEN + text_before_first_code_block + Style.RESET_ALL)
+ print(Fore.GREEN + generated_code_block + Style.RESET_ALL)
+ print(
+ Fore.YELLOW
+ + f"\n{B_RESULT}\n{code_block_output}\n{E_RESULT}\n"
+ + Style.RESET_ALL
+ )
+
+ # prompt = f"{prompt} {E_INST}{generated_text}"
+ prompt = f"{prompt}{generated_text}"
+ generated_text = self.generate(prompt)
+ HAS_CODE, generated_code_block = self.extract_code_blocks(generated_text)
+
+ full_generated_text += generated_text
+
+ attempt += 1
+
+ if VERBOSE:
+ print(Fore.GREEN + generated_text + Style.RESET_ALL)
+
+ self.dialog.append(
+ {
+ "role": "assistant",
+ "content": full_generated_text.replace("_", "")
+ .replace("", "")
+ .replace("", ""),
+ }
+ )
+
+ return self.dialog[-1]
+
+
+if __name__ == "__main__":
+ import random
+
+ LLAMA2_MODEL_PATH = "./ckpt/llama-2-13b-chat"
+ LLAMA2_MODEL_PATH = "meta-llama/Llama-2-70b-chat-hf"
+ LLAMA2_FINETUNEED_PATH = "./output/llama-2-7b-chat-ci"
+
+ interpreter = LlamaCodeInterpreter(
+ model_path=LLAMA2_FINETUNEED_PATH, load_in_4bit=True
+ )
+ output = interpreter.chat(
+ user_message=random.choice(
+ [
+ # "In a circle with center \( O \), \( AB \) is a chord such that the midpoint of \( AB \) is \( M \). A tangent at \( A \) intersects the extended segment \( OB \) at \( P \). If \( AM = 12 \) cm and \( MB = 12 \) cm, find the length of \( AP \)."
+ # "A triangle \( ABC \) is inscribed in a circle (circumscribed). The sides \( AB \), \( BC \), and \( AC \) are tangent to the circle at points \( P \), \( Q \), and \( R \) respectively. If \( AP = 10 \) cm, \( BQ = 15 \) cm, and \( CR = 20 \) cm, find the radius of the circle.",
+ # "Given an integer array nums, return the total number of contiguous subarrays that have a sum equal to 0.",
+ "what is second largest city in japan?",
+ # "Can you show me 120days chart of tesla from today to before 120?"
+ ]
+ ),
+ VERBOSE=True,
+ )
+
+ while True:
+ input_char = input("Press 'q' to quit the dialog: ")
+ if input_char.lower() == "q":
+ break
+
+ else:
+ output = interpreter.chat(user_message=input_char, VERBOSE=True)
diff --git a/Llama2-Code-Interpreter-main/code_interpreter/RetrospectiveGPTCodeInterpreter.py b/Llama2-Code-Interpreter-main/code_interpreter/RetrospectiveGPTCodeInterpreter.py
new file mode 100644
index 0000000000000000000000000000000000000000..1daa7a84aa406a5d58c8b9923312dc89d26d05d6
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/code_interpreter/RetrospectiveGPTCodeInterpreter.py
@@ -0,0 +1,472 @@
+import json
+import os
+import sys
+import time
+import copy
+import re
+from pathlib import Path
+from typing import List, Literal, Optional, Tuple, TypedDict, Dict
+import numpy as np
+from tqdm import tqdm
+
+# Get the path from environment variable
+prj_root_path = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
+sys.path.append(prj_root_path)
+from code_interpreter.JuypyterClient import JupyterNotebook
+from code_interpreter.BaseCodeInterpreter import BaseCodeInterpreter
+from utils.const import *
+from prompt.gpt4_prompt import CODE_INTERPRETER_SYSTEM_PROMPT
+
+# from prompt.gpt4_prompt import CODE_INTERPRETER_SYSTEM_PROMPT
+from colorama import init, Fore, Style, Back
+from rich.markdown import Markdown
+import base64
+
+import openai
+from retrying import retry
+import requests
+import logging
+from termcolor import colored
+
+# load from key file
+with open("./openai_api_key.txt") as f:
+ OPENAI_API_KEY = key = f.read()
+openai.api_key = OPENAI_API_KEY
+from utils.cleaner import clean_error_msg
+
+
+def remove_string(s):
+ pattern = r"\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}\.\d{6}:.*LD_LIBRARY_PATH: /usr/local/nvidia/lib:/usr/local/nvidia/lib64\n"
+ return re.sub(pattern, "", s)
+
+
+def clean_the_dialog(dialog, question):
+ question_idx = 0
+ for idx, item in enumerate(dialog):
+ if item["content"] == question:
+ question_idx = idx
+
+ filtered_dialog = dialog[question_idx:]
+
+ user_qinit_dict = filtered_dialog[0]
+ answer_fuse_str = "\n".join([i["content"].strip() for i in filtered_dialog[1::2]])
+
+ final_dialog_dict = [
+ {"role": "user", "content": user_qinit_dict["content"]},
+ {"role": "assistant", "content": answer_fuse_str},
+ ]
+
+ return final_dialog_dict
+
+
+@retry(
+ stop_max_attempt_number=7,
+ wait_exponential_multiplier=1000,
+ wait_exponential_max=10000,
+)
+def get_embedding(text, model="text-embedding-ada-002"):
+ global counter
+ headers = {
+ "Authorization": f"Bearer {OPENAI_API_KEY}", # Make sure to replace with your OpenAI API key
+ "Content-Type": "application/json",
+ }
+ payload = {"input": text, "model": model}
+
+ response = requests.post(
+ "https://api.openai.com/v1/embeddings", headers=headers, json=payload
+ )
+
+ if response.status_code != 200:
+ raise Exception(f"Request failed with status {response.status_code}")
+
+ return np.array(response.json()["data"][0]["embedding"])
+
+
+class QueryRetrospect:
+ def __init__(
+ self,
+ data_directory="./gpt_data_gen_retrospect/",
+ embeddings_path="./gpt_data_gen_retrospect/embeddings.npy",
+ ):
+ self.data_directory = data_directory
+ self.embeddings_path = embeddings_path
+ self.data = []
+ self.embeddings = []
+
+ if os.path.exists(embeddings_path):
+ print("++ Embedding Exists!")
+ self.embeddings = np.load(embeddings_path)
+ for fname in [i for i in os.listdir(data_directory) if i.endswith(".json")]:
+ with open(
+ os.path.join(data_directory, fname),
+ "r",
+ encoding="utf-8",
+ errors="replace",
+ ) as f:
+ self.data.append(json.load(f))
+ else:
+ only_files = [
+ f
+ for f in os.listdir(data_directory)
+ if os.path.isfile(os.path.join(data_directory, f))
+ and f.endswith(".json")
+ ]
+
+ for fname in tqdm(only_files):
+ with open(
+ os.path.join(data_directory, fname), "r", encoding="cp1252"
+ ) as f:
+ data_point = json.load(f)
+ self.data.append(data_point)
+ self.embeddings.append(
+ get_embedding(data_point["execution_result"])
+ )
+ self.embeddings = np.array(self.embeddings)
+ self.save_embeddings()
+ print(f"++ Embedding Saved! {self.embeddings.shape}")
+
+ def save_embeddings(self):
+ np.save(self.embeddings_path, self.embeddings)
+
+ def __call__(self, query, top_k=3, VERBOSE: bool = False):
+ query_embedding = get_embedding(query)
+ similarities = np.dot(self.embeddings, query_embedding)
+ top_indices = similarities.argsort()[-top_k:][::-1]
+ return [self.data[i]["retrospection"] for i in top_indices]
+
+
+class QueryRetrospectPrefix:
+ def __init__(
+ self,
+ model="gpt-4",
+ data_directory="./eval/gpt_mbpp_output",
+ embeddings_path="./eval/gpt_mbpp_output/embeddings.npy",
+ ):
+ self.data_directory = data_directory
+ self.embeddings_path = embeddings_path
+ self.data = []
+ self.embeddings = []
+
+ if os.path.exists(embeddings_path):
+ print("++ Embedding Exists!")
+ self.embeddings = np.load(embeddings_path)
+ for fname in [i for i in os.listdir(data_directory) if i.endswith(".json")]:
+ with open(
+ os.path.join(data_directory, fname),
+ "r",
+ encoding="utf-8",
+ errors="replace",
+ ) as f:
+ self.data.append(json.load(f))
+ else:
+ only_files = [
+ f
+ for f in os.listdir(data_directory)
+ if os.path.isfile(os.path.join(data_directory, f))
+ and f.endswith(".json")
+ ]
+
+ for fname in tqdm(only_files):
+ with open(
+ os.path.join(data_directory, fname), "r", encoding="cp1252"
+ ) as f:
+ data_point = json.load(f)
+
+ print(f'Processing "{data_point[1]["content"]}" ...')
+ self.data.append(data_point)
+ self.embeddings.append(get_embedding(data_point[1]["content"]))
+
+ self.embeddings = np.array(self.embeddings)
+ self.save_embeddings()
+ print(f"++ Embedding Saved! {self.embeddings.shape}")
+
+ self.model = model
+ self.dialog = [
+ {
+ "role": "system",
+ "content": "You are retrospection GPT. retrospect from the given data.",
+ },
+ {
+ "role": "user",
+ "content": 'Current Question:\n\nWrite a Python function to solve the following task:\n\nfrom typing import List\n\ndef cum_sum(numbers: List[int]) -> List[int]:\n """\n From a given list of integers, generate a list representing the cumulative sum of elements at each index.\n >>> cum_sum([1, 2, 3, 4])\n [1, 3, 6, 10]\n """\n\nRetrieved Trajectories : \nIn a past interaction, a function named running_average was provided to calculate the running average of a list of numbers.\n\n```python\ndef running_average(numbers: List[int]) -> List[float]:\n total = 0\n averages = []\n for i, num in enumerate(numbers):\n total += num\n averages.append(total / (i+1))\n return averages\n\nprint(running_average([1,2,3,4])) # expected [1.0, 1.5, 2.0, 2.5]\n```\n```RESULT\n[1.0, 1.5, 2.0, 2.5]\n```\nThe output is expected. \n\n',
+ },
+ {
+ "role": "assistant",
+ "content": "From previous similar questions :\nThe `running_average` function highlights an important concept of maintaining a running or cumulative value (total) as one iterates over the list. This is directly applicable to the cum_sum problem.\n\nApplication to the Question:\nFor the cum_sum function, one needs to maintain a cumulative total of the elements as we traverse through the list. The running_average function is most closely related since it involves accumulating a total and storing intermediate results. By adapting this logic (i.e., excluding the division operation to compute the average), one can easily derive the cumulative sum solution.",
+ },
+ ]
+ self.response = ""
+
+ @retry(
+ stop_max_attempt_number=7,
+ wait_exponential_multiplier=1000,
+ wait_exponential_max=10000,
+ )
+ def ChatCompletion(self):
+ try:
+ self.response = openai.ChatCompletion.create(
+ model=self.model, messages=self.dialog, temperature=0.2, top_p=0.9
+ )
+ except Exception as e:
+ print(f"error while OPENAI api call {e} {self.response}")
+
+ def save_embeddings(self):
+ np.save(self.embeddings_path, self.embeddings)
+
+ def __call__(self, query, top_k=3, VERBOSE: bool = False):
+ query_embedding = get_embedding(query)
+ similarities = np.dot(self.embeddings, query_embedding)
+ top_indices = similarities.argsort()[-top_k:][::-1]
+ top_i = top_indices[0]
+ prior_traj = self.data[top_i][-1]["content"]
+
+ ask_dict = {
+ "role": "user",
+ "content": f"Current Question:\n\n{query}\n\nRetrieved Trajectories :\n{prior_traj}",
+ }
+
+ # print(f"From prior experience:\n{prior_traj}\n\nCurrent Question:\n{query}\n")
+ self.dialog.append(ask_dict)
+ self.ChatCompletion()
+
+ return self.response["choices"][0]["message"]["content"]
+
+
+class RetrospectiveGPTCodeInterpreter(BaseCodeInterpreter):
+ def __init__(self, model="gpt-4"):
+ self.model = model
+ self.dialog = [
+ # {"role": "system", "content": CODE_INTERPRETER_SYSTEM_PROMPT },
+ {
+ "role": "system",
+ "content": CODE_INTERPRETER_SYSTEM_PROMPT,
+ },
+ # {"role": "user", "content": "How can I use BeautifulSoup to scrape a website and extract all the URLs on a page?"},
+ # {"role": "assistant", "content": "I think I need to use beatifulsoup to find current korean president,"}
+ ]
+
+ # self.dialog += few_shot_4
+ self.response = None
+
+ assert os.path.isfile(
+ "./openai_api_key.txt"
+ ), "The openai_api_key.txt file could not be found. Please make sure it is in the same directory as this script, and that it contains your OpenAI API key."
+
+ # load from key file
+ with open("./openai_api_key.txt") as f:
+ OPENAI_API_KEY = f.read()
+ openai.api_key = OPENAI_API_KEY
+
+ self.nb = JupyterNotebook()
+ out = self.nb.add_and_run(TOOLS_CODE) # tool import
+
+ # retrospections
+ self.retrospector = QueryRetrospectPrefix()
+
+ def get_response_content(self):
+ if self.response:
+ return self.response["choices"][0]["message"]["content"]
+ else:
+ return None
+
+ @retry(
+ stop_max_attempt_number=7,
+ wait_exponential_multiplier=1000,
+ wait_exponential_max=10000,
+ )
+ def ChatCompletion(self):
+ try:
+ self.response = openai.ChatCompletion.create(
+ model=self.model, messages=self.dialog, temperature=0.2, top_p=0.9
+ )
+ except Exception as e:
+ print(f"error while OPENAI api call {e}")
+
+ def save_dialog(self, path: str = "./output/dialog.json"):
+ with open(path, "w") as f:
+ json.dump(self.dialog, f)
+ print(f" ++Dialog saved to [{path}]")
+
+ def close(self):
+ """
+ close jupyter notebook, and this class instance
+ """
+ self.nb.close()
+
+ def chat(
+ self,
+ user_message: str,
+ VERBOSE: bool = False,
+ MAX_TRY: int = 6,
+ code_exec_prefix: str = "",
+ feedback_prompt: str = "",
+ append_result: bool = True,
+ use_retrospect: bool = True,
+ ):
+ prefix_retrospection = self.retrospector(query=user_message)
+ self.dialog.append(
+ {"role": "user", "content": f"{prefix_retrospection}\n\n{user_message}"}
+ )
+ init_feedback = copy.deepcopy(feedback_prompt)
+
+ code_block_output = ""
+ attempt = 0
+ img_data = None
+
+ if VERBOSE:
+ print(
+ "###Retrospection : "
+ + Fore.BLUE
+ + Back.WHITE
+ + Style.BRIGHT
+ + prefix_retrospection
+ + Style.RESET_ALL
+ )
+ print(
+ "###User : " + Fore.BLUE + Style.BRIGHT + user_message + Style.RESET_ALL
+ )
+ print("\n###Assistant : ")
+
+ for i in range(MAX_TRY):
+ # GPT response
+ self.ChatCompletion()
+
+ # Get code block
+ generated_text = self.get_response_content()
+ generated_code_blocks = self.extract_code_blocks(generated_text)
+ # execute code
+ if len(generated_code_blocks) > 0:
+ # Find the position of the first code block in the last answer
+ first_code_block_pos = (
+ generated_text.find(generated_code_blocks[0])
+ if generated_code_blocks
+ else -1
+ )
+ text_before_first_code_block = (
+ generated_text
+ if first_code_block_pos == -1
+ else generated_text[:first_code_block_pos]
+ )
+ if VERBOSE:
+ print(Fore.GREEN + text_before_first_code_block + Style.RESET_ALL)
+ if VERBOSE:
+ print(
+ Fore.YELLOW
+ + generated_code_blocks[0]
+ + "\n```\n"
+ + Style.RESET_ALL
+ )
+ code_block_output, error_flag = self.execute_code_and_return_output(
+ generated_code_blocks[0]
+ )
+
+ code_block_output = f"{code_block_output}"
+
+ if code_block_output is not None:
+ code_block_output = code_block_output.strip()
+
+ code_block_output = remove_string(code_block_output)
+ if len(code_block_output) > 500:
+ code_block_output = (
+ code_block_output[:200] + "⋯(skip)⋯" + code_block_output[-200:]
+ )
+ code_block_output_str = f"\n```RESULT\n{code_block_output}\n```\n"
+ if append_result:
+ gen_final = f"{text_before_first_code_block}{generated_code_blocks[0]}\n```{code_block_output_str}"
+ if VERBOSE:
+ print(
+ Fore.LIGHTBLACK_EX + code_block_output_str + Style.RESET_ALL
+ )
+ else:
+ gen_final = (
+ f"{text_before_first_code_block}{generated_code_blocks[0]}\n```"
+ )
+
+ self.dialog.append(
+ {
+ "role": "assistant",
+ "content": gen_final,
+ }
+ )
+
+ feedback_prompt = f"{init_feedback}\nif you accomplish the instruction just say \nIf not keep going."
+ if VERBOSE:
+ print(Fore.MAGENTA + feedback_prompt + Style.RESET_ALL)
+
+ feedback_dict = {
+ "role": "user",
+ "content": feedback_prompt,
+ }
+
+ self.dialog.append(feedback_dict)
+
+ else:
+ if "" in generated_text:
+ generated_text = generated_text.split("")[0].strip()
+
+ if len(generated_text) <= 0:
+ break
+
+ if VERBOSE:
+ print(Fore.GREEN + generated_text + Style.RESET_ALL)
+
+ self.dialog.append(
+ {
+ "role": "assistant",
+ "content": f"{generated_text}",
+ }
+ )
+ break
+
+ self.dialog = [self.dialog[0]] + clean_the_dialog(
+ self.dialog, question=f"{prefix_retrospection}\n\n{user_message}"
+ ) # delete retrospections after generation step
+
+ return self.dialog[-1]
+
+
+if __name__ == "__main__":
+ import pickle
+ import random
+ from tqdm import tqdm
+
+ # python3 -m code_interpreter.RetrospectiveGPTCodeInterpreter
+
+ retro_interpreter = RetrospectiveGPTCodeInterpreter(model="gpt-4")
+
+ instruction = """
+Write a Python script to solve the following problem:
+
+def get_row(lst, x):
+ \"\"\"
+ You are given a 2 dimensional data, as a nested lists,
+ which is similar to matrix, however, unlike matrices,
+ each row may contain a different number of columns.
+ Given lst, and integer x, find integers x in the list,
+ and return list of tuples, [(x1, y1), (x2, y2) ...] such that
+ each tuple is a coordinate - (row, columns), starting with 0.
+ Sort coordinates initially by rows in ascending order.
+ Also, sort coordinates of the row by columns in descending order.
+
+ Examples:
+ get_row([
+ [1,2,3,4,5,6],
+ [1,2,3,4,1,6],
+ [1,2,3,4,5,1]
+ ], 1) == [(0, 0), (1, 4), (1, 0), (2, 5), (2, 0)]
+ get_row([], 1) == []
+ get_row([[], [1], [1, 2, 3]], 3) == [(2, 2)]
+ \"\"\"
+
+Ensure the solution is verified by printing the expected output.
+"""
+ # instruction = "Can you make a image of astraunaut in the garden?"
+
+ # example
+ retro_interpreter.chat(
+ user_message=instruction,
+ MAX_TRY=5,
+ use_retrospect=True,
+ feedback_prompt="Ensure the output matches the expected result, taking into account any corner cases. If discrepancies arise, pinpoint where you went wrong. Then, refine the code to achieve the desired outcome.",
+ VERBOSE=True,
+ )
diff --git a/Llama2-Code-Interpreter-main/code_interpreter/llama_hf.py b/Llama2-Code-Interpreter-main/code_interpreter/llama_hf.py
new file mode 100644
index 0000000000000000000000000000000000000000..04a29e80edbc65cc731fc380089477ac5d4be4e7
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/code_interpreter/llama_hf.py
@@ -0,0 +1,101 @@
+from typing import Optional
+import os, sys
+
+from transformers import LlamaForCausalLM, LlamaTokenizer
+
+import torch
+from datetime import datetime
+
+sys.path.append(os.path.dirname(__file__))
+sys.path.append(os.path.dirname(os.path.abspath(__file__)))
+from utils.special_tok_llama2 import (
+ B_CODE,
+ E_CODE,
+ B_RESULT,
+ E_RESULT,
+ B_INST,
+ E_INST,
+ B_SYS,
+ E_SYS,
+ DEFAULT_PAD_TOKEN,
+ DEFAULT_BOS_TOKEN,
+ DEFAULT_EOS_TOKEN,
+ DEFAULT_UNK_TOKEN,
+ IGNORE_INDEX,
+)
+
+
+def create_peft_config(model):
+ from peft import (
+ get_peft_model,
+ LoraConfig,
+ TaskType,
+ prepare_model_for_int8_training,
+ )
+
+ peft_config = LoraConfig(
+ task_type=TaskType.CAUSAL_LM,
+ inference_mode=False,
+ r=8,
+ lora_alpha=32,
+ lora_dropout=0.05,
+ target_modules=["q_proj", "v_proj"],
+ )
+
+ # prepare int-8 model for training
+ model = prepare_model_for_int8_training(model)
+ model = get_peft_model(model, peft_config)
+ model.print_trainable_parameters()
+ return model, peft_config
+
+
+def build_model_from_hf_path(
+ hf_base_model_path: str = "./ckpt/llama-2-13b-chat",
+ load_peft: Optional[bool] = False,
+ peft_model_path: Optional[str] = None,
+ load_in_4bit: bool = True,
+):
+ start_time = datetime.now()
+
+ # build tokenizer
+ tokenizer = LlamaTokenizer.from_pretrained(
+ hf_base_model_path,
+ padding_side="right",
+ use_fast=False,
+ )
+
+ # Handle special tokens
+ special_tokens_dict = dict()
+ if tokenizer.pad_token is None:
+ special_tokens_dict["pad_token"] = DEFAULT_PAD_TOKEN # 32000
+ if tokenizer.eos_token is None:
+ special_tokens_dict["eos_token"] = DEFAULT_EOS_TOKEN # 2
+ if tokenizer.bos_token is None:
+ special_tokens_dict["bos_token"] = DEFAULT_BOS_TOKEN # 1
+ if tokenizer.unk_token is None:
+ special_tokens_dict["unk_token"] = DEFAULT_UNK_TOKEN
+
+ tokenizer.add_special_tokens(special_tokens_dict)
+ tokenizer.add_tokens(
+ [B_CODE, E_CODE, B_RESULT, E_RESULT, B_INST, E_INST, B_SYS, E_SYS],
+ special_tokens=True,
+ )
+
+ # build model
+ model = LlamaForCausalLM.from_pretrained(
+ hf_base_model_path,
+ load_in_4bit=load_in_4bit,
+ device_map="auto",
+ )
+
+ model.resize_token_embeddings(len(tokenizer))
+
+ if load_peft and (peft_model_path is not None):
+ from peft import PeftModel
+
+ model = PeftModel.from_pretrained(model, peft_model_path)
+
+ end_time = datetime.now()
+ elapsed_time = end_time - start_time
+
+ return {"tokenizer": tokenizer, "model": model}
diff --git a/Llama2-Code-Interpreter-main/eval/eval.md b/Llama2-Code-Interpreter-main/eval/eval.md
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/Llama2-Code-Interpreter-main/eval/gsm8k.py b/Llama2-Code-Interpreter-main/eval/gsm8k.py
new file mode 100644
index 0000000000000000000000000000000000000000..dce81cc7deac021d2e2b38cf7f240a0e97ebd8ca
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/eval/gsm8k.py
@@ -0,0 +1,115 @@
+JSON_PATH = "/home/seungyoun/llama_related/llama_code_interpreter/eval/grade-school-math/grade_school_math/data/test.jsonl"
+
+import os, sys
+import random
+import json
+import re
+from tqdm import tqdm
+
+
+def load_jsonl(file_path, num_lines_to_display=5):
+ data = []
+ with open(file_path, "r") as f:
+ for line in f:
+ out_dict = json.loads(line)
+ answer_raw = out_dict["answer"]
+ answer_refined = answer_raw.split("####")[-1].strip()
+ out_dict["answer_refined"] = answer_refined
+ data.append(out_dict) # dict_keys(['question', 'answer'])
+ return data
+
+
+few_shot_1 = [
+ {
+ "role": "user",
+ "content": "Sandra wants to buy some sweets. She saved $10 for this purpose. Her mother gave her an additional $4, and her father twice as much as her mother. One candy costs $0.5, and one jelly bean $0.2. She wants to buy 14 candies and 20 jelly beans. How much money will she be left with after the purchase?",
+ },
+ {
+ "role": "assistant",
+ "content": "```python\n# Saved Money\nsandra_money = 10\n# mother gave her\nmother_money = 4\n# father gave twice as much as her mother\nfather_money = 2 * mother_money\n# Cost\ncandy_cost = 0.5\njelly_bean_cost = 0.2\n\n# Calculations\ntotal_money = sandra_money + mother_money + father_money\n#Desired to buy\nShe wants to buy 14 candies and 20 jelly beans so the total cost would be\ntotal_cost = 14 * candy_cost + 20 * jelly_bean_cost\n# After the purchase\nremaining_money = total_money - total_cost\n\nprint(remaining_money)\n```\n```RESULT\n11.0\n```\nAfter buying 14 candies and 20 jelly beans, Sandra will be left with $11.",
+ },
+]
+
+few_shot_2 = [
+ {
+ "role": "user",
+ "content": "Keanu bought some fish from the store for his pets. He gave his cat half as many fish as he gave to his dog. If he gave his dog 40 fish, and each fish cost him $4, calculate the total amount of money he spent at the store to buy all the fish.",
+ },
+ {
+ "role": "assistant",
+ "content": "```python\ndef calculate_total_cost(dog_fish, fish_price):\n cat_fish = dog_fish / 2\n total_fish = dog_fish + cat_fish\n total_cost = total_fish * fish_price\n return total_cost\n\ntotal_cost = calculate_total_cost(40, 4)\nprint(total_cost)\n```\n```RESULT\n240.0\n```\nKeanu spent a total of $240 to buy all the fish from the store.\n### Answer : 240",
+ },
+]
+
+few_shot_3 = [
+ {
+ "role": "user",
+ "content": "Mike is feeding the birds at the park. He counts out the seeds as he throws them. He throws 20 seeds to the birds on the left. He throws twice as much to the bigger group of birds on the right. Some more birds flutter over to join the others for lunch and Mike throws 30 more seeds for them. If Mike has 30 seeds left to feed the last of the birds, how many seeds did Mike start with?",
+ },
+ {
+ "role": "assistant",
+ "content": "Let's break down the problem:\n\n- Mike throws 20 seeds to the birds on the left.\n- He throws twice as much to the bigger group of birds on the right, which is 2 * 20 = 40 seeds.\n- Some more birds join and Mike throws 30 more seeds for them.\n- Mike has 30 seeds left to feed the last of the birds.\n\nSo, the total number of seeds Mike started with is the sum of all these seeds.\n\n```python\nseeds_left = 20\nseeds_right = 2 * seeds_left\nseeds_more_birds = 30\nseeds_last = 30\n\ntotal_seeds = seeds_left + seeds_right + seeds_more_birds + seeds_last\nprint(total_seeds)\n```\n```RESULT\n120\n```\nFrom the calculations, we can conclude that Mike started with 120 seeds to feed the birds at the park.\n### Answer : 120",
+ },
+]
+
+if __name__ == "__main__":
+ sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
+ from code_interpreter.LlamaCodeInterpreter import LlamaCodeInterpreter
+ import argparse
+
+ parser = argparse.ArgumentParser(description="Process path for LLAMA2_FINETUNEED.")
+ parser.add_argument(
+ "--path",
+ type=str,
+ required=True,
+ help="Path to the finetuned LLAMA2 model.",
+ default='"./output/llama-2-7b-chat-ci"',
+ )
+ args = parser.parse_args()
+ LLAMA2_FINETUNEED_PATH = args.path
+
+ interpreter = LlamaCodeInterpreter(
+ model_path=LLAMA2_FINETUNEED_PATH,
+ # load_in_4bit=True
+ )
+
+ sample_data = load_jsonl(JSON_PATH)
+ correct = 0
+
+ for idx, data_dict in enumerate(tqdm(sample_data)):
+ question = data_dict["question"]
+ answer = data_dict["answer"]
+ answer_only = data_dict["answer_refined"]
+
+ # reset dilag : fewshot to follow answering format
+ interpreter.dialog = [
+ {
+ "role": "system",
+ "content": "You are helpful robot that can generate code , excute it and debug then answer",
+ }
+ ] # this will replaced in template conversion
+ # interpreter.dialog += few_shot_1
+ # interpreter.dialog += few_shot_2
+ # interpreter.dialog += few_shot_3
+
+ output = interpreter.chat(
+ user_message=f"{question}",
+ VERBOSE=True,
+ )
+
+ pattern = r"\[RESULT_TOK\]\s*(\d+(\.\d+)?)\s*\[/RESULT_TOK\]"
+ pred = -9212323 # for no code output (which is wrong answer)
+ if re.search(pattern, output["content"]):
+ pred = re.search(pattern, output["content"]).group(1)
+
+ pred = str(pred)
+ answer_only = str(answer_only)
+ if float(pred.replace(",", "")) == float(answer_only.replace(",", "")):
+ correct += 1
+
+ print("-" * 30)
+ print(f"\tThe question was : {question}")
+ print(f"\tThe answer was : [{answer_only}]")
+ print(f"\tModel pred is : [{pred}]")
+ print(f"\t Accuracy : [{correct/(idx+1)}]")
+ print("-" * 30)
diff --git a/Llama2-Code-Interpreter-main/eval/human_eval.py b/Llama2-Code-Interpreter-main/eval/human_eval.py
new file mode 100644
index 0000000000000000000000000000000000000000..7eee871edde2c7044b1673e41c676d97f72d8936
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/eval/human_eval.py
@@ -0,0 +1,289 @@
+import os, sys
+import traceback
+
+HUMAN_EVAL_PATH = os.path.join(
+ os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))),
+ "human-eval",
+)
+
+sys.path.append(HUMAN_EVAL_PATH)
+from human_eval.data import write_jsonl, read_problems
+from finetuning.conversation_template import msg_to_code_result_tok_temp
+from code_interpreter.llama_hf import build_model_from_hf_path
+from code_interpreter.LlamaCodeInterpreter import LlamaCodeInterpreter
+from code_interpreter.GPTCodeInterpreter import GPTCodeInterpreter
+from code_interpreter.RetrospectiveGPTCodeInterpreter import (
+ RetrospectiveGPTCodeInterpreter,
+)
+
+import re
+
+from rich import print
+from rich.panel import Panel
+from rich.syntax import Syntax
+from rich.text import Text
+
+from timeout_decorator import timeout
+
+wrong = 0
+
+
+def extract_text(prompt, remove_lines=True):
+ token = '"""'
+ start = token
+ end = ">>>"
+ # end = '"""'
+
+ start_idx = prompt.find(start) + len(start)
+ end_idx = prompt.find(end)
+
+ output = prompt[start_idx:end_idx]
+ if remove_lines:
+ output = output.replace("\n", " ")
+ output = re.sub(r"\s+", " ", output).strip()
+
+ return output
+
+
+def extract_all_code_block(input_str: str) -> str:
+ pattern = r"\[CODE_START_TOK\](.*?)\[/CODE_END_TOK\]"
+ matches = re.findall(pattern, input_str, re.DOTALL)
+ return "\n".join([match.strip() for match in matches]) if matches else None
+
+
+def extract_all_code_block_gpt(input_str: str) -> str:
+ pattern = r"```python(.*?)```"
+ matches = re.findall(pattern, input_str, re.DOTALL)
+
+ return "\n".join([match.strip() for match in matches]) if matches else None
+
+
+def delete_print_asser(code_text: str):
+ lines = code_text.split("\n")
+ new_lines = list()
+ for i in lines:
+ if i.strip().startswith("print("):
+ continue
+ new_lines.append(i)
+
+ new_code_text = "\n".join(new_lines)
+ return new_code_text
+
+
+def extract_function_from_code_block(code_block: str) -> str:
+ lines = code_block.split("\n")
+ function_lines = []
+
+ inside_function = False
+ for line in lines:
+ # Start extracting from function definition
+ if line.startswith("def "):
+ inside_function = True
+
+ # If we are inside the function, append lines
+ if inside_function:
+ function_lines.append(line)
+
+ # If we encounter an unindented line that isn't a comment and isn't the start of another function, stop.
+ if (
+ not line.startswith(" ")
+ and not line.startswith("#")
+ and not line.startswith("def ")
+ ):
+ break
+
+ # Remove trailing comments or blank lines and the last line which caused the exit from the loop
+ while function_lines and (
+ function_lines[-1].strip() == ""
+ or function_lines[-1].strip().startswith("#")
+ or not function_lines[-1].startswith(" ")
+ ):
+ function_lines.pop()
+
+ return "\n".join(function_lines)
+
+
+def get_last_outermost_function_name(function_str):
+ matches = re.findall(r"^def (\w+)", function_str, re.MULTILINE)
+ if matches:
+ return matches[-1] # Return the last (outermost) function name
+ return ""
+
+
+def get_last_function_name(function_str):
+ # Regular expression to match a function definition
+ matches = re.findall(r"def (\w+)", function_str)
+ if matches:
+ return matches[-1] # Return the last function name
+ return ""
+
+
+def get_outermost_function_name(function_str):
+ matches = re.findall(r"^def (\w+)", function_str, re.MULTILINE)
+ if matches:
+ return matches[0] # Return the first (outermost) function name
+ return ""
+
+
+def get_function_name(function_str):
+ # Regular expression to match a function definition
+ match = re.search(r"def (\w+)", function_str)
+ if match:
+ return match.group(0)
+ return ""
+
+
+def extract_test_assertion(test_func: str):
+ test_cases = list()
+ for i in test_func.split("\n"):
+ if "assert" in i:
+ test_cases.append(i.strip())
+
+ return ("\n".join(test_cases)).strip()
+
+
+import_str = """
+import re
+import math
+from typing import List, Tuple, Optional
+"""
+
+
+@timeout(100, timeout_exception=TimeoutError)
+def exec_with_timeout(import_str, full_test_code):
+ env = {**locals()}
+ code_to_exec = f"{import_str}\n{full_test_code}"
+ try:
+ exec(code_to_exec, env)
+ except Exception as e:
+ print(f"Error Type: {type(e).__name__}, Error Message: {e}")
+ return False # Return False if there's an error during execution
+ return True # Return True if executed without errors
+
+
+if __name__ == "__main__":
+ sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
+ import argparse
+
+ parser = argparse.ArgumentParser(description="Process path for LLAMA2_FINETUNEED.")
+ parser.add_argument(
+ "--path",
+ type=str,
+ required=True,
+ help="Path to the finetuned LLAMA2 model.",
+ default='"./output/llama-2-7b-chat-ci"',
+ )
+ parser.add_argument(
+ "--model",
+ type=str,
+ required=False,
+ help="Path to the finetuned LLAMA2 model.",
+ default='"./output/llama-2-7b-chat-ci"',
+ )
+ parser.add_argument(
+ "--max-retry",
+ type=int,
+ required=False,
+ help="Maximum number of retries.",
+ default=5, # You can set any default value you want here.
+ )
+ args = parser.parse_args()
+ PROGRAMMING_PUZZLE_Q = True
+
+ problems = read_problems()
+ correct_total = 0
+ total_problems = len(problems)
+
+ for idx, task_id in enumerate(problems):
+ if "gpt" not in args.model.lower():
+ LLAMA2_FINETUNEED_PATH = args.path
+ interpreter = LlamaCodeInterpreter(
+ model_path=LLAMA2_FINETUNEED_PATH,
+ # load_in_4bit=True
+ )
+ else:
+ interpreter = RetrospectiveGPTCodeInterpreter(
+ model=args.model,
+ )
+
+ # dict_keys(['task_id', 'prompt', 'entry_point', 'canonical_solution', 'test'])
+ programming_puzzle = problems[task_id]["prompt"].replace(" ", "\t")
+ text_only_problem = extract_text(programming_puzzle)
+
+ interpreter.dialog = [
+ {
+ "role": "system",
+ "content": "You are helpful robot that can generate code , excute it and debug then answer",
+ }
+ ]
+
+ if PROGRAMMING_PUZZLE_Q:
+ # programming puzzle
+ output_str = interpreter.chat(
+ user_message=f"Write a Python script to solve the following problem:\n{programming_puzzle}\nEnsure the solution is verified by printing the expected output.",
+ MAX_TRY=args.max_retry,
+ VERBOSE=True,
+ code_exec_prefix=f"\nfrom typing import List,Tuple\nimport math\n",
+ feedback_prompt="Ensure the output matches the expected result, taking into account any corner cases. If discrepancies arise, pinpoint where you went wrong. Then, refine the code to achieve the desired outcome.",
+ append_result=True,
+ )["content"]
+
+ else:
+ output_str = interpreter.chat(
+ user_message=f"Write a Python script for this problem:\n{text_only_problem}",
+ MAX_TRY=args.max_retry,
+ VERBOSE=True,
+ code_exec_prefix=f"\nfrom typing import List,Tuple\nimport math\n",
+ feedback_prompt="Ensure the output matches the expected result. If not tell where you got wrong, then refine the code to achieve the desired outcome.",
+ append_result=True,
+ )["content"]
+
+ function_str = ""
+ if "gpt" not in args.model.lower():
+ code_block = extract_all_code_block(output_str)
+ else:
+ code_block = extract_all_code_block_gpt(output_str)
+ if (code_block is not None) and ("def" in code_block):
+ function_str = code_block
+
+ # function_name = get_last_outermost_function_name(function_str)
+ function_str = delete_print_asser(function_str)
+ function_name = get_last_outermost_function_name(function_str)
+ full_test_code = f"{function_str}\n#-----------\n{problems[task_id]['test']}\ncheck({function_name})"
+
+ # Print the full_test_code with syntax highlighting
+ syntax = Syntax(
+ # f"{programming_puzzle}\n{full_test_code}",
+ f"{full_test_code}",
+ "python",
+ theme="monokai",
+ line_numbers=True,
+ )
+ print(syntax)
+
+ is_correct = False # default is wrong
+ timeout_flag = False
+ try:
+ is_correct = exec_with_timeout(import_str, full_test_code)
+ except TimeoutError as e:
+ timeout_flag = True
+ print(f"Timeout with error msg : {e}")
+
+ if is_correct:
+ correct_total += 1
+
+ acc = (correct_total) / (idx + 1)
+ # save dialog
+ interpreter.save_dialog(
+ path=f"./eval/gpt_humaneval_output/{task_id.replace('/','_')}_{is_correct}.json"
+ )
+ interpreter.close()
+ del interpreter
+
+ # Constructing the output
+ accuracy_text = Text(
+ f"Accuracy: {correct_total}/{idx+1}[{total_problems}] = {acc:.2%} [{is_correct}]",
+ style="bold blue",
+ )
+ panel = Panel(accuracy_text, title="Results", border_style="green")
+ print(panel)
diff --git a/Llama2-Code-Interpreter-main/eval/inference.py b/Llama2-Code-Interpreter-main/eval/inference.py
new file mode 100644
index 0000000000000000000000000000000000000000..8e178a6856180b46584cd2d4fa5f303d6e0e45e5
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/eval/inference.py
@@ -0,0 +1,204 @@
+from dataclasses import dataclass, field
+from typing import Dict, Optional, Sequence
+import logging
+import os, sys
+import copy
+
+import torch
+import transformers
+from transformers import LlamaForCausalLM, LlamaTokenizer, TextStreamer
+
+from torch.utils.data import Dataset
+from transformers import Trainer
+
+import torch
+from rich.console import Console
+from rich.table import Table
+from datetime import datetime
+from threading import Thread
+
+sys.path.append(os.path.dirname(__file__))
+sys.path.append(os.path.dirname(os.path.dirname(__file__)))
+from utils.special_tok_llama2 import (
+ B_CODE,
+ E_CODE,
+ B_RESULT,
+ E_RESULT,
+ B_INST,
+ E_INST,
+ B_SYS,
+ E_SYS,
+ DEFAULT_PAD_TOKEN,
+ DEFAULT_BOS_TOKEN,
+ DEFAULT_EOS_TOKEN,
+ DEFAULT_UNK_TOKEN,
+ IGNORE_INDEX,
+)
+
+from finetuning.conversation_template import (
+ json_to_code_result_tok_temp,
+ msg_to_code_result_tok_temp,
+)
+
+import warnings
+
+warnings.filterwarnings("ignore", category=UserWarning, module="transformers")
+os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2"
+
+console = Console() # for pretty print
+
+
+@dataclass
+class ModelArguments:
+ model_name_or_path: Optional[str] = field(default="./output/llama-2-7b-chat-ci")
+ load_peft: Optional[bool] = field(default=False)
+ peft_model_name_or_path: Optional[str] = field(
+ default="./output/llama-2-7b-chat-ci"
+ )
+
+
+def create_peft_config(model):
+ from peft import (
+ get_peft_model,
+ LoraConfig,
+ TaskType,
+ prepare_model_for_int8_training,
+ )
+
+ peft_config = LoraConfig(
+ task_type=TaskType.CAUSAL_LM,
+ inference_mode=False,
+ r=8,
+ lora_alpha=32,
+ lora_dropout=0.05,
+ target_modules=["q_proj", "v_proj"],
+ )
+
+ # prepare int-8 model for training
+ model = prepare_model_for_int8_training(model)
+ model = get_peft_model(model, peft_config)
+ model.print_trainable_parameters()
+ return model, peft_config
+
+
+def build_model_from_hf_path(
+ hf_base_model_path: str = "./ckpt/llama-2-13b-chat",
+ load_peft: Optional[bool] = False,
+ peft_model_path: Optional[str] = None,
+):
+ start_time = datetime.now()
+
+ # build tokenizer
+ console.log("[bold cyan]Building tokenizer...[/bold cyan]")
+ tokenizer = LlamaTokenizer.from_pretrained(
+ hf_base_model_path,
+ padding_side="right",
+ use_fast=False,
+ )
+
+ # Handle special tokens
+ console.log("[bold cyan]Handling special tokens...[/bold cyan]")
+ special_tokens_dict = dict()
+ if tokenizer.pad_token is None:
+ special_tokens_dict["pad_token"] = DEFAULT_PAD_TOKEN # 32000
+ if tokenizer.eos_token is None:
+ special_tokens_dict["eos_token"] = DEFAULT_EOS_TOKEN # 2
+ if tokenizer.bos_token is None:
+ special_tokens_dict["bos_token"] = DEFAULT_BOS_TOKEN # 1
+ if tokenizer.unk_token is None:
+ special_tokens_dict["unk_token"] = DEFAULT_UNK_TOKEN
+
+ tokenizer.add_special_tokens(special_tokens_dict)
+ tokenizer.add_tokens(
+ [B_CODE, B_RESULT, E_RESULT, B_INST, E_INST, B_SYS, E_SYS],
+ special_tokens=True,
+ )
+
+ # build model
+ console.log("[bold cyan]Building model...[/bold cyan]")
+ model = LlamaForCausalLM.from_pretrained(
+ hf_base_model_path,
+ load_in_4bit=True,
+ device_map="auto",
+ )
+
+ model.resize_token_embeddings(len(tokenizer))
+
+ if load_peft and (peft_model_path is not None):
+ from peft import PeftModel
+
+ model = PeftModel.from_pretrained(model, peft_model_path)
+ console.log("[bold green]Peft Model Loaded[/bold green]")
+
+ end_time = datetime.now()
+ elapsed_time = end_time - start_time
+
+ # Log time performance
+ table = Table(title="Time Performance")
+ table.add_column("Task", style="cyan")
+ table.add_column("Time Taken", justify="right")
+ table.add_row("Loading model", str(elapsed_time))
+ console.print(table)
+
+ console.log("[bold green]Model Loaded[/bold green]")
+ return {"tokenizer": tokenizer, "model": model}
+
+
+@torch.inference_mode()
+def inference(
+ user_input="What is 100th fibo num?",
+ max_new_tokens=512,
+ do_sample: bool = True,
+ use_cache: bool = True,
+ top_p: float = 1.0,
+ temperature: float = 0.1,
+ top_k: int = 50,
+ repetition_penalty: float = 1.0,
+):
+ parser = transformers.HfArgumentParser(ModelArguments)
+ model_args = parser.parse_args_into_dataclasses()[0]
+
+ model_dict = build_model_from_hf_path(
+ hf_base_model_path=model_args.model_name_or_path,
+ load_peft=model_args.load_peft,
+ peft_model_path=model_args.peft_model_name_or_path,
+ )
+
+ model = model_dict["model"]
+ tokenizer = model_dict["tokenizer"]
+
+ streamer = TextStreamer(tokenizer, skip_prompt=True)
+
+ # peft
+ # create peft config
+ model.eval()
+
+ user_prompt = msg_to_code_result_tok_temp(
+ [{"role": "user", "content": f"{user_input}"}]
+ )
+ # Printing user's content in blue
+ console.print("\n" + "-" * 20, style="#808080")
+ console.print(f"###User : {user_input}\n", style="blue")
+
+ prompt = f"{user_prompt}\n###Assistant :"
+ # prompt = f"{user_input}\n### Assistant : Here is python code to get the 55th fibonacci number {B_CODE}\n"
+
+ inputs = tokenizer([prompt], return_tensors="pt")
+
+ generated_text = model.generate(
+ **inputs,
+ streamer=streamer,
+ max_new_tokens=max_new_tokens,
+ do_sample=do_sample,
+ top_p=top_p,
+ temperature=temperature,
+ use_cache=use_cache,
+ top_k=top_k,
+ repetition_penalty=repetition_penalty,
+ )
+
+ return generated_text
+
+
+if __name__ == "__main__":
+ inference(user_input="what is sin(44)?")
diff --git a/Llama2-Code-Interpreter-main/finetuning/codellama_wrapper.py b/Llama2-Code-Interpreter-main/finetuning/codellama_wrapper.py
new file mode 100644
index 0000000000000000000000000000000000000000..bf85ff8de6b16a66cd620a76be94a3fc55c54238
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/finetuning/codellama_wrapper.py
@@ -0,0 +1,21 @@
+from transformers import LlamaForCausalLM, LlamaTokenizer
+from transformers import LlamaModel, LlamaConfig
+import torch.nn as nn
+
+CODELLAMA_VOCAB_SIZE = 32016
+
+
+class CodeLlamaForCausalLM(LlamaForCausalLM):
+ _tied_weights_keys = ["lm_head.weight"]
+
+ def __init__(self, config):
+ super().__init__(config)
+ self.model = LlamaModel(config)
+ self.vocab_size = config.vocab_size
+ self.lm_head = nn.Linear(config.hidden_size, CODELLAMA_VOCAB_SIZE, bias=False)
+ self.model.embed_tokens = nn.Embedding(
+ CODELLAMA_VOCAB_SIZE, config.hidden_size, config.pad_token_id
+ )
+
+ # Initialize weights and apply final processing
+ self.post_init()
diff --git a/Llama2-Code-Interpreter-main/finetuning/conversation_template.py b/Llama2-Code-Interpreter-main/finetuning/conversation_template.py
new file mode 100644
index 0000000000000000000000000000000000000000..2cacd5babe3335cf69d66f314bd511ca22a147c2
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/finetuning/conversation_template.py
@@ -0,0 +1,80 @@
+import os, sys
+
+sys.path.append(os.path.dirname(os.path.dirname(__file__)))
+
+import json
+import re
+from typing import List, Dict
+
+DATA_DIR = "gpt_data_gen"
+
+B_CODE = "[CODE_START_TOK]"
+E_CODE = "[/CODE_END_TOK]"
+
+B_RESULT = "[RESULT_TOK]"
+E_RESULT = "[/RESULT_TOK]"
+
+B_INST, E_INST = "[INST]", "[/INST]"
+B_SYS, E_SYS = "<>", "<>"
+
+BOS = ""
+EOS = ""
+
+CODE_SYS_PROMPT_FOR_TRAIN = """
+You are 'CodeLLama', an advanced Language Model assistant that can generate, execute, and evaluate code.
+Respond to user queries by providing code-based solutions and insights.
+"""
+
+
+def msg_to_code_result_tok_temp(msg: List[Dict]) -> str:
+ full_str = f"{BOS}{B_INST} {B_SYS}\n{CODE_SYS_PROMPT_FOR_TRAIN}\n{E_SYS}\n\n"
+
+ user_first_flag = True
+ for idx, chat in enumerate(msg):
+ if chat["role"] == "system":
+ continue
+ if chat["role"].lower() == "user":
+ chat["content"] = chat["content"]
+ if user_first_flag:
+ full_str += f"{chat['content']} {E_INST}"
+ user_first_flag = False
+ else:
+ full_str += f"{BOS}{B_INST}{chat['content']} {E_INST}"
+ elif chat["role"] == "assistant":
+ chat["content"] = chat["content"].replace(
+ "/home/seungyoun/llama_code_interpreter/", "./"
+ )
+
+ # Replace the code block start and end markers using regex
+ code_pattern = re.compile(r"```python\n(.*?)```", re.DOTALL)
+ chat["content"] = code_pattern.sub(
+ r"[CODE_START_TOK]\n\1[/CODE_END_TOK]", chat["content"]
+ )
+
+ # Replace the result block start and end markers using regex
+ result_pattern = re.compile(r"```RESULTS?\n(.*?)```", re.DOTALL)
+ chat["content"] = result_pattern.sub(
+ r"[RESULT_TOK]\n\1[/RESULT_TOK]", chat["content"]
+ )
+
+ full_str += f"{chat['content']}{EOS}"
+
+ full_str = full_str.replace("')()", "')")
+ full_str = full_str.replace("/home/seungyoun/llama_code_interpreter/", "./")
+
+ return full_str
+
+
+def json_to_code_result_tok_temp(json_file_name: str = "425.json") -> str:
+ file_rel_path = os.path.join(DATA_DIR, json_file_name)
+
+ with open(file_rel_path, "r") as json_file:
+ msg = json.load(json_file)
+
+ full_str = msg_to_code_result_tok_temp(msg)
+
+ return full_str
+
+
+if __name__ == "__main__":
+ print(json_to_code_result_tok_temp())
diff --git a/Llama2-Code-Interpreter-main/finetuning/train.py b/Llama2-Code-Interpreter-main/finetuning/train.py
new file mode 100644
index 0000000000000000000000000000000000000000..0db88bf98fd04be97eb91969afb8d47ab2214cab
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/finetuning/train.py
@@ -0,0 +1,336 @@
+from dataclasses import dataclass, field
+from typing import Dict, Optional, Sequence
+import logging
+import os, sys
+import copy
+
+import torch
+import transformers
+from transformers import LlamaForCausalLM, LlamaTokenizer
+
+from torch.utils.data import Dataset
+from transformers import Trainer
+
+sys.path.append(os.path.dirname(__file__))
+sys.path.append(os.path.dirname(os.path.dirname(__file__)))
+from utils.special_tok_llama2 import (
+ B_CODE,
+ E_CODE,
+ B_RESULT,
+ E_RESULT,
+ B_INST,
+ E_INST,
+ B_SYS,
+ E_SYS,
+ DEFAULT_PAD_TOKEN,
+ DEFAULT_BOS_TOKEN,
+ DEFAULT_EOS_TOKEN,
+ DEFAULT_UNK_TOKEN,
+ IGNORE_INDEX,
+)
+
+from conversation_template import json_to_code_result_tok_temp
+
+
+@dataclass
+class ModelArguments:
+ model_name_or_path: Optional[str] = field(default="./ckpt/llama-2-13b-chat")
+ peft: bool = field(default=False)
+
+
+@dataclass
+class DataArguments:
+ data_path: str = field(
+ default=None, metadata={"help": "Path to the training data."}
+ )
+
+
+@dataclass
+class TrainingArguments(transformers.TrainingArguments):
+ cache_dir: Optional[str] = field(default=None)
+ optim: str = field(default="adamw_torch")
+ model_max_length: int = field(
+ default=4096,
+ metadata={
+ "help": "Maximum sequence length. Sequences will be right padded (and possibly truncated)."
+ },
+ )
+
+
+def create_peft_config(model):
+ from peft import (
+ get_peft_model,
+ LoraConfig,
+ TaskType,
+ prepare_model_for_int8_training,
+ )
+
+ peft_config = LoraConfig(
+ task_type=TaskType.CAUSAL_LM,
+ inference_mode=False,
+ r=8,
+ lora_alpha=16,
+ lora_dropout=0.05,
+ target_modules=["q_proj", "v_proj"],
+ )
+
+ # prepare int-8 model for training
+ model = prepare_model_for_int8_training(model)
+ model = get_peft_model(model, peft_config)
+ model.print_trainable_parameters()
+ print(f"Using Peft")
+ return model, peft_config
+
+
+def _tokenize_fn(
+ strings: Sequence[str], tokenizer: transformers.PreTrainedTokenizer
+) -> Dict:
+ """Tokenize a list of strings."""
+ tokenized_list = [
+ tokenizer(
+ text,
+ return_tensors="pt",
+ padding="longest",
+ max_length=tokenizer.model_max_length,
+ truncation=True,
+ )
+ for text in strings
+ ]
+
+ input_ids = [tokenized.input_ids[0] for tokenized in tokenized_list]
+ input_ids_lens = [
+ tokenized.input_ids.ne(tokenizer.pad_token_id).sum().item()
+ for tokenized in tokenized_list
+ ]
+ return dict(
+ input_ids=input_ids,
+ input_ids_lens=input_ids_lens,
+ )
+
+
+def find_all_sublist_end(main_list, sublist):
+ """Find all the ending indices of a sublist in a main list."""
+ sublist_len = len(sublist)
+ main_list = main_list.tolist()
+ indices = []
+ for index in (i for i, e in enumerate(main_list) if e == sublist[0]):
+ if main_list[index : index + sublist_len] == sublist:
+ indices.append(index + sublist_len)
+ return indices
+
+
+def find_all_sublist_start(main_list, sublist):
+ """Find all the starting indices of a sublist in a main list."""
+ sublist_len = len(sublist)
+ main_list = main_list.tolist()
+ indices = []
+ for index in (i for i, e in enumerate(main_list) if e == sublist[0]):
+ if main_list[index : index + sublist_len] == sublist:
+ indices.append(index)
+ return indices
+
+
+def preprocess(
+ trajs: Sequence[str],
+ tokenizer: transformers.PreTrainedTokenizer,
+) -> Dict:
+ INST_START_INDEX = tokenizer.encode(f"{B_INST}")[-1]
+ INST_END_INDEX = tokenizer.encode(f"{E_INST}")[-1]
+ RESULT_START_INDEX = tokenizer.encode(f"{B_RESULT}")[-1]
+ RESULT_END_INDEX = tokenizer.encode(f"{E_RESULT}")[-1]
+
+ """Preprocess the data by tokenizing."""
+ examples_tokenized = _tokenize_fn(trajs, tokenizer)
+
+ input_ids_lens = examples_tokenized["input_ids_lens"]
+ input_ids = examples_tokenized["input_ids"] # [torch.tensor , torch.tensor , ...]
+ labels = copy.deepcopy(input_ids)
+
+ # IGNORE INDEX SET
+ for i, label in enumerate(labels):
+ user_start_inds = find_all_sublist_start(label, [INST_START_INDEX])
+ assistant_start_inds = find_all_sublist_end(label, [INST_END_INDEX])
+
+ result_start_inds = find_all_sublist_start(label, [RESULT_START_INDEX])
+ result_end_inds = find_all_sublist_end(label, [RESULT_END_INDEX])
+
+ # for debug
+ # for len_i, ind in enumerate(label):
+ # print(f'{len_i}|{ind} -> "{tokenizer.decode(ind)}"')
+
+ assert len(user_start_inds) == len(
+ assistant_start_inds
+ ), f"User and Assistant pair should be equal :: \n\tUser [{user_start_inds}]/\n\tAssistant [{assistant_start_inds}]\n\n Text : \n{trajs[i]}"
+
+ assert len(result_start_inds) == len(
+ result_end_inds
+ ), f"Start and End indices pairs do not match.: : \nText : \n{trajs[i]}"
+
+ for user_start_ind, assistant_start_ind in zip(
+ user_start_inds, assistant_start_inds
+ ):
+ label[user_start_ind + 1 : assistant_start_ind - 1] = IGNORE_INDEX
+
+ for start, end in zip(result_start_inds, result_end_inds):
+ label[start + 1 : end - 1] = IGNORE_INDEX
+
+ # cut max length
+ input_ids = [i[:1500] for i in input_ids]
+ labels = [i[:1500] for i in labels]
+
+ return dict(input_ids=input_ids, labels=labels)
+
+
+class SupervisedDataset(Dataset):
+ """Dataset for supervised fine-tuning."""
+
+ def __init__(self, data_path: str, tokenizer: transformers.PreTrainedTokenizer):
+ super(SupervisedDataset, self).__init__()
+ logging.warning(f"Loading data from data path : {data_path}")
+ all_json = os.listdir(data_path)
+
+ trajs = list()
+ for json_file_name in all_json:
+ traj = json_to_code_result_tok_temp(json_file_name=json_file_name)
+ trajs.append(traj)
+
+ logging.warning("Tokenizing inputs... This may take some time...")
+ data_dict = preprocess(trajs, tokenizer)
+
+ self.input_ids = data_dict["input_ids"]
+ self.labels = data_dict["labels"]
+
+ def __len__(self):
+ return len(self.input_ids)
+
+ def __getitem__(self, i) -> Dict[str, torch.Tensor]:
+ return dict(input_ids=self.input_ids[i], labels=self.labels[i])
+
+
+@dataclass
+class DataCollatorForSupervisedDataset(object):
+ """Collate examples for supervised fine-tuning."""
+
+ tokenizer: transformers.PreTrainedTokenizer
+
+ def __call__(self, instances: Sequence[Dict]) -> Dict[str, torch.Tensor]:
+ input_ids, labels = tuple(
+ [instance[key] for instance in instances] for key in ("input_ids", "labels")
+ )
+ input_ids = torch.nn.utils.rnn.pad_sequence(
+ input_ids, batch_first=True, padding_value=self.tokenizer.pad_token_id
+ )
+ labels = torch.nn.utils.rnn.pad_sequence(
+ labels, batch_first=True, padding_value=IGNORE_INDEX
+ )
+ return dict(
+ input_ids=input_ids,
+ labels=labels,
+ attention_mask=input_ids.ne(self.tokenizer.pad_token_id),
+ )
+
+
+def make_supervised_data_module(
+ tokenizer: transformers.PreTrainedTokenizer, data_args
+) -> Dict:
+ """Make dataset and collator for supervised fine-tuning."""
+ train_dataset = SupervisedDataset(
+ tokenizer=tokenizer, data_path=data_args.data_path
+ )
+ data_collator = DataCollatorForSupervisedDataset(tokenizer=tokenizer)
+ return dict(
+ train_dataset=train_dataset, eval_dataset=None, data_collator=data_collator
+ )
+
+
+def build_model_from_hf_path(
+ hf_model_path: str = "./ckpt/llama-2-13b-chat", peft: bool = False
+):
+ # build tokenizer
+ tokenizer = LlamaTokenizer.from_pretrained(
+ hf_model_path,
+ padding_side="right",
+ use_fast=False,
+ )
+
+ special_tokens_dict = dict()
+ if tokenizer.pad_token is None:
+ special_tokens_dict["pad_token"] = DEFAULT_PAD_TOKEN # 32000
+ if tokenizer.eos_token is None:
+ special_tokens_dict["eos_token"] = DEFAULT_EOS_TOKEN # 2
+ if tokenizer.bos_token is None:
+ special_tokens_dict["bos_token"] = DEFAULT_BOS_TOKEN # 1
+ if tokenizer.unk_token is None:
+ special_tokens_dict["unk_token"] = DEFAULT_UNK_TOKEN
+
+ tokenizer.add_special_tokens(special_tokens_dict)
+
+ tokenizer.add_tokens(
+ [
+ B_CODE, # 32001
+ E_CODE, # 32002
+ B_RESULT, # 32003
+ E_RESULT, # 32004
+ B_INST,
+ E_INST,
+ B_SYS,
+ E_SYS, # 32008
+ ],
+ special_tokens=True,
+ )
+
+ # build model
+ if peft:
+ model = LlamaForCausalLM.from_pretrained(
+ hf_model_path,
+ load_in_8bit=True,
+ device_map="auto",
+ ignore_mismatched_sizes=True,
+ torch_dtype=torch.float16,
+ )
+ else:
+ # for llama
+ # model = LlamaForCausalLM.from_pretrained(
+ # hf_model_path, ignore_mismatched_sizes=True
+ # )
+
+ # for codellama
+ from codellama_wrapper import CodeLlamaForCausalLM
+
+ model = CodeLlamaForCausalLM.from_pretrained(hf_model_path)
+
+ model.resize_token_embeddings(len(tokenizer))
+
+ return {"tokenizer": tokenizer, "model": model}
+
+
+def train():
+ parser = transformers.HfArgumentParser(
+ (ModelArguments, DataArguments, TrainingArguments)
+ )
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ model_dict = build_model_from_hf_path(
+ hf_model_path=model_args.model_name_or_path, peft=model_args.peft
+ )
+
+ model, tokenizer = model_dict["model"], model_dict["tokenizer"]
+ # peft setting
+ model.train()
+ if model_args.peft:
+ model, lora_config = create_peft_config(model)
+
+ # make dataset
+ data_module = make_supervised_data_module(tokenizer=tokenizer, data_args=data_args)
+ trainer = Trainer(
+ model=model, tokenizer=tokenizer, args=training_args, **data_module
+ )
+
+ # train
+ trainer.train()
+ trainer.save_state()
+ trainer.save_model(output_dir=training_args.output_dir)
+
+
+if __name__ == "__main__":
+ train()
diff --git a/Llama2-Code-Interpreter-main/prompt/__init__.py b/Llama2-Code-Interpreter-main/prompt/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/Llama2-Code-Interpreter-main/prompt/gpt4_prompt.py b/Llama2-Code-Interpreter-main/prompt/gpt4_prompt.py
new file mode 100644
index 0000000000000000000000000000000000000000..78510598b54540c02ea8814fff9985cccc5888b0
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/prompt/gpt4_prompt.py
@@ -0,0 +1,277 @@
+few_shot_1 = [
+ {"role": "user", "content": "what is 100th fibonacci sequence?"},
+ {
+ "role": "assistant",
+ "content": """
+```python
+def fibonacci(n):
+ a, b = 0, 1
+ for _ in range(n):
+ a, b = b, a + b
+ return a
+
+fibo_100 = fibonacci(100)
+print(fibo_100)
+```
+```RESULT
+354224848179261915075
+```
+""",
+ },
+ {"role": "user", "content": "Keep going"},
+ {
+ "role": "assistant",
+ "content": "The 100th Fibonacci number is 354224848179261915075",
+ },
+]
+
+few_shot_2 = [
+ {
+ "role": "user",
+ "content": "Can you write a Python script that uses a machine learning algorithm to predict stock prices using historical data?",
+ },
+ {
+ "role": "assistant",
+ "content": """
+Sure, here is a simple example of how you might use a linear regression model from the `sklearn` library to predict stock prices.
+This example uses the `pandas_datareader` library to fetch historical stock data from Yahoo Finance.
+
+Please note that this is a very basic example and real-world stock price prediction is a complex task that involves much more than just historical prices.
+Other factors such as company earnings, economic indicators, and market sentiment also play a big role.
+
+```python
+import pandas as pd
+import numpy as np
+import yfinance as yf
+from datetime import datetime as dt
+
+# Get the stock data
+df = yf.download('AAPL', start='2012-01-01', end='2022-01-01')
+
+# Prepare the data for the model
+df['Date'] = df.index
+df['Date'] = pd.to_datetime(df['Date'])
+df['Date'] = df['Date'].map(dt.toordinal)
+
+df.head(3)
+```
+```RESULT
+[*********************100%***********************] 1 of 1 completed
+ Open High Low Close Adj Close Volume
+Date
+2012-01-03 14.621429 14.732143 14.607143 14.686786 12.482925 302220800 \
+2012-01-04 14.642857 14.810000 14.617143 14.765714 12.550011 260022000
+2012-01-05 14.819643 14.948214 14.738214 14.929643 12.689340 271269600
+
+ Date
+Date
+2012-01-03 734505
+2012-01-04 734506
+2012-01-05 734507
+```
+
+""",
+ },
+ {"role": "user", "content": "Keep going"},
+ {
+ "role": "assistant",
+ "content": """
+let's continue with the next steps which involve training the model, making predictions, and evaluating the model.
+
+```python
+from sklearn.model_selection import train_test_split
+from sklearn.linear_model import LinearRegression
+from sklearn import metrics
+
+# Independent variable
+X = df['Date'].values.reshape(-1,1)
+# Dependent variable
+y = df['Close'].values.reshape(-1,1)
+
+# Split the data into training and testing sets
+X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
+
+# Train the model
+model = LinearRegression()
+model.fit(X_train, y_train)
+
+# Make predictions
+y_pred = model.predict(X_test)
+
+# Evaluate the model
+print('Mean Absolute Error: {:.2f}'.format(metrics.mean_absolute_error(y_test, y_pred)))
+print('Mean Squared Error: {:.2f}'.format(metrics.mean_squared_error(y_test, y_pred)))
+print('Root Mean Squared Error: {:.2f}'.format(np.sqrt(metrics.mean_squared_error(y_test, y_pred))))
+```
+
+```RESULT
+Mean Absolute Error: 17.85
+Mean Squared Error: 491.52
+Root Mean Squared Error: 22.17
+```
+
+""",
+ },
+ {"role": "user", "content": "Keep going"},
+ {
+ "role": "assistant",
+ "content": "This basic Linear Regression model serves as an introduction to stock price prediction, but real-world applications often employ more complex models. The prediction accuracy can be improved by using other models such as ARIMA, LSTM, or incorporating more data points.\nAlways exercise caution when using such models for financial decisions.",
+ },
+]
+
+few_shot_3 = [
+ {
+ "role": "user",
+ "content": "I want to analyze the latest news articles about a specific topic. Let's say chatgpt.",
+ },
+ {
+ "role": "assistant",
+ "content": """
+Sure, we can use the GoogleSearch tool to find the latest articles about "chatgpt".
+
+```python
+
+# Search for the latest articles about "chatgpt"
+results = google_search("chatgpt latest news")
+print(results)
+```
+```RESULT
+[1] Title : [The latest update for ChatGPT - Release Notes]
+ snippet : Updates to ChatGPT (August 3) · Introducing the ChatGPT app for Android (July 25) · Custom instructions is rolling out in beta (July 20) · Higher message limits ...
+ link : https://help.openai.com/en/articles/6825453-chatgpt-release-notes
+...
+[6] Title : [Bing, Bard, ChatGPT, and all the news on AI chatbots - The Verge]
+ snippet : Over the last few months company has posted dozens of AI jobs in the US, France, and China, looking to fill roles that could help build generative AI tools that ...
+ link : https://www.theverge.com/23610427/chatbots-chatgpt-new-bing-google-bard-conversational-ai
+```
+
+""",
+ },
+ {"role": "user", "content": "Keep going"},
+ {
+ "role": "assistant",
+ "content": """
+To analyze the latest news articles about a specific topic here is step-by-step plan :
+
+# 1. Web Scraping: Use the GoogleSearch class to get a list of URLs of the latest news articles about the given topic. Then use a library like BeautifulSoup to scrape the main body of each article.
+
+```python
+from bs4 import BeautifulSoup
+import re
+
+def scrape_article(url, retries=3):
+ headers = {"User-Agent": "Mozilla/5.0"}
+ for _ in range(retries):
+ try:
+ response = requests.get(url, headers=headers)
+ response.raise_for_status() # Raise an exception if the status code is not 200
+ break
+ except requests.exceptions.RequestException:
+ print(f"Error occurred, retrying {url}")
+ time.sleep(5) # Wait 5 seconds before retrying
+ else: # No successful request after retries
+ print(f"Failed to retrieve {url} after {retries} attempts.")
+ return ""
+
+ soup = BeautifulSoup(response.text, 'html.parser')
+
+ paragraphs = soup.find_all('p')
+ article_text = ' '.join([p.get_text() for p in paragraphs])
+ return article_text
+
+url_results = (somehow filter url only with re)
+articles = [scrape_article(url) for url in url_results]
+```
+
+
+""",
+ },
+ {"role": "user", "content": "Keep going"},
+]
+
+
+few_shot_4 = [
+ {
+ "role": "user",
+ "content": "Find walmart same store sales growth from Q1 2019 to Q3 2020 by using official data such as Wal-Mart's 10-Q and 10-K disclosures",
+ },
+ {
+ "role": "assistant",
+ "content": """
+
+To find Walmart's same store sales growth from Q1 2019 to Q3 2020, we need to find Reliable Source first.
+
+# 1. Identify a Reliable Source:
+
+To Identify a Reliable Source I need to use google_search function to search the Reliable source
+
+```python
+results = google_search("Walmart Investor Relations 10-Q and 10-K reports")
+print(results)
+```
+```RESULT
+[1] Title : [Walmart SEC Filings]
+ snippet : SEC Filings. Walmart provides its filings with the U.S. Securities and Exchange Commission. ... Annual Report of Employee Stock Plans.
+ link : https://stock.walmart.com/financials/sec-filings/default.aspx
+...
+[6] Title : [Form 10-K to "Walmart]
+ snippet : Our SEC filings, our Code of Ethics for our CEO and senior financial officers and our Statement of Ethics can be found on our website at www.stock.walmart.com.
+ link : https://www.sec.gov/Archives/edgar/data/104169/000010416919000016/wmtform10-kx1312019.htm
+```
+
+""",
+ },
+ {"role": "user", "content": "Keep going"},
+ {
+ "role": "assistant",
+ "content": """
+
+Next step is to
+
+# 2. Choose a Source for Detailed Financial Disclosures and scraping
+
+From the results provided, there are six main contenders:
+
+Among those [6] the direct link from the U.S. Securities and Exchange Commission's (SEC) EDGAR database.
+Given the ease of scraping .htm format with libraries like lxml, and the authenticity of the data from the SEC's official site, I would recommend choosing the link from the EDGAR system.
+
+```python
+chosen_link = "https://www.sec.gov/Archives/edgar/data/104169/000010416919000016/wmtform10-kx1312019.htm"
+
+# define headers
+headers = {
+ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
+
+# print request to see the contents
+```
+
+
+""",
+ },
+]
+
+extra_prompt = """
+
++ You are so have to check the code is working right. (by printing or plotting)
++ Do not leave function alone. Make sure call the function to check it is working correctly
++ As an Code Interperter, You aare able to browse the internet or access documents directly (by using beautifulsoup or requests this will need cleaning the text)
++ Provide Dummy data and test the function if needed
++ 'Do not' pip install
++ You must need to use datetime to check current date
+ For Example,
+from datetime import datetime, timedelta
+# Download data for 180days
+data = yf.download('GOOGL', start=datetime.today(), end=end_date - timedelta(days=180))
+
++ make sure to use yfinance for financial data gathering (do not use pandas_datareader)
++ when plotting you need to
+[x] plt.show()
+[o] plt.savefig('./tmp/plot.png')
+ ...
+ then
+ 
+
+
+
+Let's think step-by-step
+"""
diff --git a/Llama2-Code-Interpreter-main/requirements.txt b/Llama2-Code-Interpreter-main/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..8c9dcc4c05f0df896305e12fdc79c48fead22a46
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/requirements.txt
@@ -0,0 +1,32 @@
+accelerate==0.21.0
+bitsandbytes==0.41.1
+colorama==0.4.6
+coloredlogs==15.0.1
+colorlog==6.7.0
+datasets==2.12.0
+deepspeed==0.10.1
+diffusers==0.20.0
+einops==0.6.1
+gradio==3.37.0
+ipykernel==6.25.1
+ipython==8.12.2
+jupyter_client==8.3.0
+jupyter_core==5.3.0
+Markdown==3.4.3
+nbclient==0.8.0
+nbconvert==7.7.1
+nbformat==5.8.0
+omegaconf==2.3.0
+openai==0.27.7
+peft @ git+https://github.com/huggingface/peft.git@6c44096c7b8d55a2ecf24be9bc68393467e1584a
+rich
+scikit-learn
+scipy
+seaborn
+sentencepiece==0.1.99
+termcolor==2.3.0
+tqdm
+transformers @ git+https://github.com/huggingface/transformers@f26099e7b5cf579f99a42bab6ddd371bf2c8d548
+triton==2.0.0
+yfinance==0.2.28
+retrying===1.3.4
diff --git a/Llama2-Code-Interpreter-main/utils/check_nb_out.py b/Llama2-Code-Interpreter-main/utils/check_nb_out.py
new file mode 100644
index 0000000000000000000000000000000000000000..3fff9e16cf88d92a57eb66adddec2233d5e8097f
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/utils/check_nb_out.py
@@ -0,0 +1,20 @@
+import nbformat
+from nbconvert.preprocessors import ExecutePreprocessor
+from nbconvert.preprocessors.execute import CellExecutionError
+
+nb = nbformat.v4.new_notebook()
+
+# Add a cell with your code
+code_cell = nbformat.v4.new_code_cell(source=f'import os\nprint(os.getcwd())')
+nb.cells.append(code_cell)
+
+# Execute the notebook
+ep = ExecutePreprocessor(timeout=600, kernel_name='python3')
+output_str, error_str = None, None
+
+ep.preprocess(nb)
+if nb.cells[0].outputs: # Check if there are any outputs
+ output = nb.cells[-1].outputs[0]
+
+print(output)
+# Repo path :: /home/seungyoun/llama_code_interpreter\n
diff --git a/Llama2-Code-Interpreter-main/utils/check_nb_plot_img_out.py b/Llama2-Code-Interpreter-main/utils/check_nb_plot_img_out.py
new file mode 100644
index 0000000000000000000000000000000000000000..42c1536e5b0be7d0eb6fa067be89e138fa00c8b9
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/utils/check_nb_plot_img_out.py
@@ -0,0 +1,81 @@
+import nbformat
+from nbconvert.preprocessors import ExecutePreprocessor
+from nbconvert.preprocessors.execute import CellExecutionError
+import base64
+from io import BytesIO
+import re
+
+def get_error_message(traceback_str):
+ lines = traceback_str.split('\n')
+ for line in lines:
+ if 'Error:' in line:
+ return line
+ return None # Return None if no error message is found
+
+
+nb = nbformat.v4.new_notebook()
+
+SITE_PKG_ERROR_PREFIX = 'File /usr/local/lib/python3.8/'
+
+code_sample = """
+import yfinance as yf
+import matplotlib.pyplot as plt
+
+# Get the data of the Tesla USD stock price
+tsla = yf.Ticker("TSLA-USD")
+
+# Get the historical prices for the last 3 months
+tsla_hist = tsla.history(period="max", start="3 months ago")
+
+# Plot the close prices
+tsla_hist['Close'].plot(figsize=(16, 9))
+plt.title('Tesla stock price last 3 months')
+plt.xlabel('Date')
+plt.ylabel('Price (USD)')
+plt.show()
+"""
+
+# Add a cell with your code
+code_cell = nbformat.v4.new_code_cell(source=code_sample)
+nb.cells.append(code_cell)
+
+# Execute the notebook
+ep = ExecutePreprocessor(timeout=600, kernel_name='python3')
+output_str, error_str = None, None
+
+try:
+ ep.preprocess(nb)
+ if nb.cells[0].outputs: # Check if there are any outputs
+ for i,c in enumerate(nb.cells[-1].outputs):
+ print(f'[{i+1}] : {c}')
+
+except CellExecutionError as e:
+ error_str = e
+
+ if error_str is not None:
+ # Get the traceback, which is a list of strings, and join them into one string
+ filtered_error_msg = error_str.__str__().split('An error occurred while executing the following cell')[-1].split("\n------------------\n")[-1]
+ raw_error_msg = "".join(filtered_error_msg)
+
+ # Remove escape sequences for colored text
+ #print(raw_error_msg)
+ ansi_escape = re.compile(r'\x1b\[[0-?]*[ -/]*[@-~]')
+ error_msg = ansi_escape.sub('', raw_error_msg)
+
+ error_msg_only_cell = error_msg.split(SITE_PKG_ERROR_PREFIX)
+ for i,c in enumerate(error_msg_only_cell):
+ if i ==0:
+ print(f'[{i+1}]\n{c.strip()}\n---')
+ if i==3:
+ error_header = get_error_message(c)
+ print(error_header)
+
+
+ #error_msg = raw_error_msg.replace("\x1b[0m", "").replace("\x1b[0;31m", "").replace("\x1b[0;32m", "").replace("\x1b[1;32m", "").replace("\x1b[38;5;241m", "").replace("\x1b[38;5;28;01m", "").replace("\x1b[38;5;21m", "").replace("\x1b[38;5;28m", "").replace("\x1b[43m", "").replace("\x1b[49m", "").replace("\x1b[38;5;241;43m", "").replace("\x1b[39;49m", "").replace("\x1b[0;36m", "").replace("\x1b[0;39m", "")
+ error_lines = error_msg.split("\n")
+
+ # Only keep the lines up to (and including) the first line that contains 'Error' followed by a ':'
+ error_lines = error_lines[:next(i for i, line in enumerate(error_lines) if 'Error:' in line) + 1]
+
+ # Join the lines back into a single string
+ error_msg = "\n".join(error_lines)
\ No newline at end of file
diff --git a/Llama2-Code-Interpreter-main/utils/cleaner.py b/Llama2-Code-Interpreter-main/utils/cleaner.py
new file mode 100644
index 0000000000000000000000000000000000000000..27406d94d0958b66357633373ed01bec5737406a
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/utils/cleaner.py
@@ -0,0 +1,28 @@
+import re
+
+SITE_PKG_ERROR_PREFIX = 'File /usr/local/lib/python3.8/'
+
+def get_error_header(traceback_str):
+ lines = traceback_str.split('\n')
+ for line in lines:
+ if 'Error:' in line:
+ return line
+ return '' # Return None if no error message is found
+
+def clean_error_msg(error_str:str =''):
+ filtered_error_msg = error_str.__str__().split('An error occurred while executing the following cell')[-1].split("\n------------------\n")[-1]
+ raw_error_msg = "".join(filtered_error_msg)
+
+ # Remove escape sequences for colored text
+ ansi_escape = re.compile(r'\x1b\[[0-?]*[ -/]*[@-~]')
+ error_msg = ansi_escape.sub('', raw_error_msg)
+
+ error_str_out = ''
+ error_msg_only_cell = error_msg.split(SITE_PKG_ERROR_PREFIX)
+
+ error_str_out += f'{error_msg_only_cell[0]}\n'
+ error_header = get_error_header(error_msg_only_cell[-1])
+ if error_header not in error_str_out:
+ error_str_out += get_error_header(error_msg_only_cell[-1])
+
+ return error_str_out
\ No newline at end of file
diff --git a/Llama2-Code-Interpreter-main/utils/const.py b/Llama2-Code-Interpreter-main/utils/const.py
new file mode 100644
index 0000000000000000000000000000000000000000..c706bbf17f9cbaa605fd8d86c229f090739d08d0
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/utils/const.py
@@ -0,0 +1,314 @@
+from typing import List, Literal, Optional, Tuple, TypedDict
+
+
+Role = Literal["system", "user", "assistant"]
+
+
+class Message(TypedDict):
+ role: Role
+ content: str
+
+
+Dialog = List[Message]
+
+model_path = "./ckpt/llama-2-13b-chat"
+
+B_INST, E_INST = "[INST]", "[/INST]"
+B_SYS, E_SYS = "<>\n", "\n<>\n\n"
+DEFAULT_PAD_TOKEN = "[PAD]"
+DEFAULT_EOS_TOKEN = ""
+DEFAULT_BOS_TOKEN = ""
+DEFAULT_UNK_TOKEN = ""
+
+IMPORT_PKG = """
+import numpy as np
+import pandas as pd
+import matplotlib.pyplot as plt
+import seaborn as sns
+from scipy import stats
+import os,sys
+import re
+from datetime import datetime
+from sympy import symbols, Eq, solve
+import torch
+import requests
+from bs4 import BeautifulSoup
+import json
+import math
+import yfinance
+"""
+
+TOOLS_CODE = r"""
+
+import requests
+import tweepy
+import json,time
+from urllib.parse import quote_plus
+from typing import Dict
+from bs4 import BeautifulSoup
+
+
+#Goolge Search
+GOOGLE_API_KEY = ""
+GOOGLE_CSE_ID = ''
+MAX_GOOGLE_RESULT = 5
+
+#Twitter Key
+TWITTER_API_KEY = ""
+TWITTER_API_KEY_SECRET = ""
+TWITTER_ACCESS_TOKEN = ""
+TWITTER_TOKEN_SECRET = ""
+
+class GoogleSearch:
+ def __init__(self):
+ self.api_key = GOOGLE_API_KEY
+ self.cse_id = GOOGLE_CSE_ID
+ self.url = "https://www.googleapis.com/customsearch/v1"
+
+ def search(self, search_term, **kwargs):
+ params = {
+ 'q': search_term,
+ 'key': self.api_key,
+ 'cx': self.cse_id,
+ }
+ params.update(kwargs)
+ response = requests.get(self.url, params=params)
+ return response.json()
+
+ def __call__(self, search_term, **kwargs):
+ results = self.search(search_term, **kwargs)
+ output_str = ''
+ for idx, item in enumerate(results.get('items', [])):
+ if idx > MAX_GOOGLE_RESULT:
+ break
+ title = item.get('title').replace('\n','')
+ snippet = item.get('snippet').replace('\n','')
+ link = item.get('link').replace('\n','')
+ output_str += f"[{idx+1}] Title : [{title}]\n\tsnippet : {snippet}\n\tlink : {link}\n"
+ return output_str
+
+
+class ArxivAPI:
+ def __init__(self):
+ self.base_url = 'http://export.arxiv.org/api/query?'
+ self.headers = {'User-Agent': 'Mozilla/5.0'}
+
+ def clean_str(self, results):
+ output_str = ''
+ for idx, result in enumerate(results):
+ output_str += f"[{idx+1}]title : {result['title'].strip()}({result['id'].strip()})\n"
+ return output_str
+
+ def search(self, query: str, max_results: int = 10):
+ query = quote_plus(query)
+ search_query = f'search_query=all:{query}&start=0&max_results={max_results}'
+ url = self.base_url + search_query
+ response = requests.get(url, headers=self.headers)
+ if response.status_code != 200:
+ raise Exception(f'Error: {response.status_code}')
+ soup = BeautifulSoup(response.content, 'xml')
+ entries = soup.find_all('entry')
+ results = [{'id': entry.id.text, 'title': entry.title.text} for entry in entries]
+ return self.clean_str(results)
+
+
+# google
+google_search = GoogleSearch()
+
+# Arxiv
+arxiv = ArxivAPI()
+"""
+
+
+CODE_INTERPRETER_SYSTEM_PROMPT = """
+You are helpful agent that can generate code, execute, getting feedback(results).
+
+
+For example,
+###User : what is 52th fibonacci number
+###Assistant :
+I think I need to use python code to generate 52th fibonacci number
+
+```python
+import numpy as np
+
+def fibonacci(n):
+ sq = np.sqrt(5)
+ phi = (1 + sq) / 2
+ return round((phi ** n) / sq)
+
+fibo_52 = fibonacci(52)
+fibo_52
+```
+```RESULT
+32951280099
+```
+The 52nd Fibonacci number is 32951280099.
+
++ Each code block is executed individually in each cell of a Jupyter notebook.
++ If the generated code runs successfully, there's no need to generate redundant code.
++ The code is written to provide answers to the questions.
+
+"""
+
+CODE_INTERPRETER_SYSTEM_PROMPT = """
+You are helpful agent that can generate code, execute, getting feedback(results).
+
+For example,
+###User : Show me YTD bitcoin price.
+###Assistant :
+
+Here's a sample Python code using pandas, matplotlib, and yfinance to get the Year-to-date (YTD) Bitcoin price and plot it:
+```python
+import yfinance as yf
+import matplotlib.pyplot as plt
+
+# Get the data of the Bitcoin USD price
+btc = yf.Ticker("BTC-USD")
+
+# Get the historical prices for this year
+btc_hist = btc.history(period="ytd")
+
+# Plot the close prices
+btc_hist['Close'].plot(figsize=(16, 9))
+plt.title('Year-to-date Bitcoin price')
+plt.xlabel('Date')
+plt.ylabel('Price (USD)')
+plt.savefig('./tmp/chart.png')
+```
+```RESULT
+
+```
+
+Here is the chart of the bitcoin close YTD chart : 
+
++ Each code block is executed individually in each cell of a Jupyter notebook.
++ If the generated code runs successfully, there's no need to generate redundant code.
++ The code is written to provide answers to the questions.
+
+"""
+
+CODE_INTERPRETER_SYSTEM_PROMPT = """
+As an advanced language model, you can generate code as part of your responses.
+To make the code more noticeable and easier to read, please encapsulate it within triple backticks.
+For instance, if you're providing Python code, wrap it as follows:
+
+```python
+print('hellow world')
+```
+
+Basically this two tools are provided.
+
+```python
+# google
+google_search = GoogleSearch()
+results = google_search("Current korean president") #query -> string output
+print(results) # string
+
+# Arxiv
+arxiv = ArxivAPI()
+results = arxiv.search('embodied ai') #query -> string
+print(results) # string
+```
+
+After presenting the results from the code
+You will provide a useful explanation or interpretation of the output to further aid your understanding."
+
+Additionally, when generating plots or figures,
+I'll save them to a specified path, like ./tmp/plot.png, so that they can be viewed.
+After saving the plot, I'll use the following markdown syntax to display the image at the end of the response:
+
+
+You are using jupyter notebook currently.
+This approach allows me to visually present data and findings."
+"""
+
+CODE_INTERPRETER_SYSTEM_PROMPT_PRESIDENT = """
+You are helpful agent that can code
+
+You are avaible to use
+numpy, beautifulsoup, torch, PIL, opencv, ...
+
+For example,
+###User : Who is current president of singapore?
+###Assistant :
+
+Here's a sample Python code using pandas, matplotlib, and yfinance to get the Year-to-date (YTD) Bitcoin price and plot it:
+```python
+import requests
+from bs4 import BeautifulSoup
+
+def get_current_south_korea_president():
+ url = 'https://www.president.go.kr/president/greeting'
+ response = requests.get(url)
+ soup = BeautifulSoup(response.text, 'html.parser')
+ # Find the president's name
+ president_name = soup.find('title').text.strip()
+ return president_name
+
+get_current_south_korea_president()
+```
+```RESULT
+대한민국 대통령 > 윤석열 대통령 > 취임사
+```
+
+The current President of Korea is 윤석열
+"""
+
+
+CODE_INTERPRETER_SYSTEM_PROMPT_GPT4 = f"""
+You are helpful agent that can code
+
+You are avaible to use
+{IMPORT_PKG}
+"""
+
+
+CODE_INTERPRETER_SYSTEM_PROMPT_GPT4 = f"""
+You are helpful agent that can code.
+
+### User : Can you show me the distribution of the current
+"""
+
+
+CODE_INTERPRETER_SYSTEM_PROMPT_GPT4_BASE = f"""
+You are helpful agent that can code.
+
+For example,
+
+### User : Show me YTD bitcoin pirce.
+
+### Assistant : Sure thing! Here's a Python script using yfinance to get the YTD Bitcoin price and save it into a CSV file using pandas.
+It also plots the price using matplotlib. Please note we are saving the plot in the
+./tmp/ directory as 'bitcoin_YTD.png' and data as 'bitcoin_YTD.csv'.
+
+```python
+import yfinance as yf
+import matplotlib.pyplot as plt
+import pandas as pd\nfrom datetime import datetime
+
+# Get the current year
+year = datetime.now().year
+# Get the data of Bitcoin from the beginning of this year until now
+btc = yf.download('BTC-USD', start=str(year)+'-01-01', end=datetime.now().strftime(\"%Y-%m-%d\"))
+
+# Save the data to a .csv file
+btc.to_csv('./tmp/bitcoin_YTD.csv')
+
+# Create a plot
+plt.figure(figsize=(14, 7))
+plt.plot(btc['Close'])
+plt.title('Bitcoin Price YTD')
+plt.xlabel('Date')
+plt.ylabel('Price'
+nplt.grid(True)
+plt.savefig('./tmp/bitcoin_YTD.png')
+```
+
+```RESULTS
+[*********************100%***********************] 1 of 1 completed
+
+```
+
+Here is plot : 
+"""
diff --git a/Llama2-Code-Interpreter-main/utils/convert_llama_weights_to_hf.py b/Llama2-Code-Interpreter-main/utils/convert_llama_weights_to_hf.py
new file mode 100644
index 0000000000000000000000000000000000000000..2327fb9e8e69d129ab23f75596901f63be044735
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/utils/convert_llama_weights_to_hf.py
@@ -0,0 +1,375 @@
+# Copyright 2022 EleutherAI and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import argparse
+import gc
+import json
+import os
+import shutil
+import warnings
+
+import torch
+
+from transformers import LlamaConfig, LlamaForCausalLM, LlamaTokenizer
+
+
+try:
+ from transformers import LlamaTokenizerFast
+except ImportError as e:
+ warnings.warn(e)
+ warnings.warn(
+ "The converted tokenizer will be the `slow` tokenizer. To use the fast, update your `tokenizers` library and re-run the tokenizer conversion"
+ )
+ LlamaTokenizerFast = None
+
+"""
+Sample usage:
+
+```
+python src/transformers/models/llama/convert_llama_weights_to_hf.py \
+ --input_dir /path/to/downloaded/llama/weights --model_size 7B --output_dir /output/path
+```
+
+Thereafter, models can be loaded via:
+
+```py
+from transformers import LlamaForCausalLM, LlamaTokenizer
+
+model = LlamaForCausalLM.from_pretrained("/output/path")
+tokenizer = LlamaTokenizer.from_pretrained("/output/path")
+```
+
+Important note: you need to be able to host the whole model in RAM to execute this script (even if the biggest versions
+come in several checkpoints they each contain a part of each weight of the model, so we need to load them all in RAM).
+"""
+
+INTERMEDIATE_SIZE_MAP = {
+ "7B": 11008,
+ "13B": 13824,
+ "30B": 17920,
+ "65B": 22016,
+ "70B": 28672,
+}
+NUM_SHARDS = {
+ "7B": 1,
+ "7Bf": 1,
+ "13B": 2,
+ "13Bf": 2,
+ "30B": 4,
+ "65B": 8,
+ "70B": 8,
+ "70Bf": 8,
+}
+
+
+def compute_intermediate_size(n, ffn_dim_multiplier=1, multiple_of=256):
+ return multiple_of * (
+ (int(ffn_dim_multiplier * int(8 * n / 3)) + multiple_of - 1) // multiple_of
+ )
+
+
+def read_json(path):
+ with open(path, "r") as f:
+ return json.load(f)
+
+
+def write_json(text, path):
+ with open(path, "w") as f:
+ json.dump(text, f)
+
+
+def write_model(model_path, input_base_path, model_size, safe_serialization=True):
+ os.makedirs(model_path, exist_ok=True)
+ tmp_model_path = os.path.join(model_path, "tmp")
+ os.makedirs(tmp_model_path, exist_ok=True)
+
+ input_base_path = "/home/seungyoun/llama/ckpt/llama-2-7b"
+ params = read_json(os.path.join(input_base_path, "params.json"))
+ num_shards = NUM_SHARDS[model_size]
+ n_layers = params["n_layers"]
+ n_heads = params["n_heads"]
+ n_heads_per_shard = n_heads // num_shards
+ dim = params["dim"]
+ dims_per_head = dim // n_heads
+ base = 10000.0
+ inv_freq = 1.0 / (
+ base ** (torch.arange(0, dims_per_head, 2).float() / dims_per_head)
+ )
+
+ if "n_kv_heads" in params:
+ num_key_value_heads = params["n_kv_heads"] # for GQA / MQA
+ num_local_key_value_heads = n_heads_per_shard // num_key_value_heads
+ key_value_dim = dim // num_key_value_heads
+ else: # compatibility with other checkpoints
+ num_key_value_heads = n_heads
+ num_local_key_value_heads = n_heads_per_shard
+ key_value_dim = dim
+
+ # permute for sliced rotary
+ def permute(w, n_heads=n_heads, dim1=dim, dim2=dim):
+ return (
+ w.view(n_heads, dim1 // n_heads // 2, 2, dim2)
+ .transpose(1, 2)
+ .reshape(dim1, dim2)
+ )
+
+ print(f"Fetching all parameters from the checkpoint at {input_base_path}.")
+ # Load weights
+ if model_size == "7B":
+ # Not sharded
+ # (The sharded implementation would also work, but this is simpler.)
+ loaded = torch.load(
+ os.path.join(input_base_path, "consolidated.00.pth"), map_location="cpu"
+ )
+ else:
+ # Sharded
+ loaded = [
+ torch.load(
+ os.path.join(input_base_path, f"consolidated.{i:02d}.pth"),
+ map_location="cpu",
+ )
+ for i in range(num_shards)
+ ]
+ param_count = 0
+ index_dict = {"weight_map": {}}
+ for layer_i in range(n_layers):
+ filename = f"pytorch_model-{layer_i + 1}-of-{n_layers + 1}.bin"
+ if model_size == "7B":
+ # Unsharded
+ state_dict = {
+ f"model.layers.{layer_i}.self_attn.q_proj.weight": permute(
+ loaded[f"layers.{layer_i}.attention.wq.weight"]
+ ),
+ f"model.layers.{layer_i}.self_attn.k_proj.weight": permute(
+ loaded[f"layers.{layer_i}.attention.wk.weight"]
+ ),
+ f"model.layers.{layer_i}.self_attn.v_proj.weight": loaded[
+ f"layers.{layer_i}.attention.wv.weight"
+ ],
+ f"model.layers.{layer_i}.self_attn.o_proj.weight": loaded[
+ f"layers.{layer_i}.attention.wo.weight"
+ ],
+ f"model.layers.{layer_i}.mlp.gate_proj.weight": loaded[
+ f"layers.{layer_i}.feed_forward.w1.weight"
+ ],
+ f"model.layers.{layer_i}.mlp.down_proj.weight": loaded[
+ f"layers.{layer_i}.feed_forward.w2.weight"
+ ],
+ f"model.layers.{layer_i}.mlp.up_proj.weight": loaded[
+ f"layers.{layer_i}.feed_forward.w3.weight"
+ ],
+ f"model.layers.{layer_i}.input_layernorm.weight": loaded[
+ f"layers.{layer_i}.attention_norm.weight"
+ ],
+ f"model.layers.{layer_i}.post_attention_layernorm.weight": loaded[
+ f"layers.{layer_i}.ffn_norm.weight"
+ ],
+ }
+ else:
+ # Sharded
+ # Note that attention.w{q,k,v,o}, feed_fordward.w[1,2,3], attention_norm.weight and ffn_norm.weight share
+ # the same storage object, saving attention_norm and ffn_norm will save other weights too, which is
+ # redundant as other weights will be stitched from multiple shards. To avoid that, they are cloned.
+
+ state_dict = {
+ f"model.layers.{layer_i}.input_layernorm.weight": loaded[0][
+ f"layers.{layer_i}.attention_norm.weight"
+ ].clone(),
+ f"model.layers.{layer_i}.post_attention_layernorm.weight": loaded[0][
+ f"layers.{layer_i}.ffn_norm.weight"
+ ].clone(),
+ }
+ state_dict[f"model.layers.{layer_i}.self_attn.q_proj.weight"] = permute(
+ torch.cat(
+ [
+ loaded[i][f"layers.{layer_i}.attention.wq.weight"].view(
+ n_heads_per_shard, dims_per_head, dim
+ )
+ for i in range(num_shards)
+ ],
+ dim=0,
+ ).reshape(dim, dim)
+ )
+ state_dict[f"model.layers.{layer_i}.self_attn.k_proj.weight"] = permute(
+ torch.cat(
+ [
+ loaded[i][f"layers.{layer_i}.attention.wk.weight"].view(
+ num_local_key_value_heads, dims_per_head, dim
+ )
+ for i in range(num_shards)
+ ],
+ dim=0,
+ ).reshape(key_value_dim, dim),
+ num_key_value_heads,
+ key_value_dim,
+ dim,
+ )
+ state_dict[f"model.layers.{layer_i}.self_attn.v_proj.weight"] = torch.cat(
+ [
+ loaded[i][f"layers.{layer_i}.attention.wv.weight"].view(
+ num_local_key_value_heads, dims_per_head, dim
+ )
+ for i in range(num_shards)
+ ],
+ dim=0,
+ ).reshape(key_value_dim, dim)
+
+ state_dict[f"model.layers.{layer_i}.self_attn.o_proj.weight"] = torch.cat(
+ [
+ loaded[i][f"layers.{layer_i}.attention.wo.weight"]
+ for i in range(num_shards)
+ ],
+ dim=1,
+ )
+ state_dict[f"model.layers.{layer_i}.mlp.gate_proj.weight"] = torch.cat(
+ [
+ loaded[i][f"layers.{layer_i}.feed_forward.w1.weight"]
+ for i in range(num_shards)
+ ],
+ dim=0,
+ )
+ state_dict[f"model.layers.{layer_i}.mlp.down_proj.weight"] = torch.cat(
+ [
+ loaded[i][f"layers.{layer_i}.feed_forward.w2.weight"]
+ for i in range(num_shards)
+ ],
+ dim=1,
+ )
+ state_dict[f"model.layers.{layer_i}.mlp.up_proj.weight"] = torch.cat(
+ [
+ loaded[i][f"layers.{layer_i}.feed_forward.w3.weight"]
+ for i in range(num_shards)
+ ],
+ dim=0,
+ )
+
+ state_dict[f"model.layers.{layer_i}.self_attn.rotary_emb.inv_freq"] = inv_freq
+ for k, v in state_dict.items():
+ index_dict["weight_map"][k] = filename
+ param_count += v.numel()
+ torch.save(state_dict, os.path.join(tmp_model_path, filename))
+
+ filename = f"pytorch_model-{n_layers + 1}-of-{n_layers + 1}.bin"
+ if model_size == "7B":
+ # Unsharded
+ state_dict = {
+ "model.embed_tokens.weight": loaded["tok_embeddings.weight"],
+ "model.norm.weight": loaded["norm.weight"],
+ "lm_head.weight": loaded["output.weight"],
+ }
+ else:
+ state_dict = {
+ "model.norm.weight": loaded[0]["norm.weight"],
+ "model.embed_tokens.weight": torch.cat(
+ [loaded[i]["tok_embeddings.weight"] for i in range(num_shards)], dim=1
+ ),
+ "lm_head.weight": torch.cat(
+ [loaded[i]["output.weight"] for i in range(num_shards)], dim=0
+ ),
+ }
+
+ for k, v in state_dict.items():
+ index_dict["weight_map"][k] = filename
+ param_count += v.numel()
+ torch.save(state_dict, os.path.join(tmp_model_path, filename))
+
+ # Write configs
+ index_dict["metadata"] = {"total_size": param_count * 2}
+ write_json(index_dict, os.path.join(tmp_model_path, "pytorch_model.bin.index.json"))
+ ffn_dim_multiplier = (
+ params["ffn_dim_multiplier"] if "ffn_dim_multiplier" in params else 1
+ )
+ multiple_of = params["multiple_of"] if "multiple_of" in params else 256
+ config = LlamaConfig(
+ hidden_size=dim,
+ intermediate_size=compute_intermediate_size(
+ dim, ffn_dim_multiplier, multiple_of
+ ),
+ num_attention_heads=params["n_heads"],
+ num_hidden_layers=params["n_layers"],
+ rms_norm_eps=params["norm_eps"],
+ num_key_value_heads=num_key_value_heads,
+ )
+ config.save_pretrained(tmp_model_path)
+
+ # Make space so we can load the model properly now.
+ del state_dict
+ del loaded
+ gc.collect()
+
+ print("Loading the checkpoint in a Llama model.")
+ model = LlamaForCausalLM.from_pretrained(
+ tmp_model_path, torch_dtype=torch.float16, low_cpu_mem_usage=True
+ )
+ # Avoid saving this as part of the config.
+ del model.config._name_or_path
+
+ print("Saving in the Transformers format.")
+ model.save_pretrained(model_path, safe_serialization=safe_serialization)
+ shutil.rmtree(tmp_model_path)
+
+
+def write_tokenizer(tokenizer_path, input_tokenizer_path):
+ # Initialize the tokenizer based on the `spm` model
+ tokenizer_class = (
+ LlamaTokenizer if LlamaTokenizerFast is None else LlamaTokenizerFast
+ )
+ print(f"Saving a {tokenizer_class.__name__} to {tokenizer_path}.")
+ tokenizer = tokenizer_class(input_tokenizer_path)
+ tokenizer.save_pretrained(tokenizer_path)
+
+
+def main():
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ "--input_dir",
+ help="Location of LLaMA weights, which contains tokenizer.model and model folders",
+ )
+ parser.add_argument(
+ "--model_size",
+ choices=[
+ "7B",
+ "7Bf",
+ "13B",
+ "13Bf",
+ "30B",
+ "65B",
+ "70B",
+ "70Bf",
+ "tokenizer_only",
+ ],
+ )
+ parser.add_argument(
+ "--output_dir",
+ help="Location to write HF model and tokenizer",
+ )
+ parser.add_argument(
+ "--safe_serialization",
+ type=bool,
+ help="Whether or not to save using `safetensors`.",
+ )
+ args = parser.parse_args()
+ if args.model_size != "tokenizer_only":
+ write_model(
+ model_path=args.output_dir,
+ input_base_path=os.path.join(args.input_dir, args.model_size),
+ model_size=args.model_size,
+ safe_serialization=args.safe_serialization,
+ )
+ spm_path = os.path.join(args.input_dir, "tokenizer.model")
+ spm_path = "/home/seungyoun/llama/ckpt/tokenizer.model"
+ write_tokenizer(args.output_dir, spm_path)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/Llama2-Code-Interpreter-main/utils/special_tok_llama2.py b/Llama2-Code-Interpreter-main/utils/special_tok_llama2.py
new file mode 100644
index 0000000000000000000000000000000000000000..4d6e8a436c8ee20bfb45923c4a47d9b00e437287
--- /dev/null
+++ b/Llama2-Code-Interpreter-main/utils/special_tok_llama2.py
@@ -0,0 +1,14 @@
+B_CODE = "[CODE_START_TOK]"
+E_CODE = "[/CODE_END_TOK]"
+
+B_RESULT = "[RESULT_TOK]"
+E_RESULT = "[/RESULT_TOK]"
+
+B_INST, E_INST = "[INST]", "[/INST]"
+B_SYS, E_SYS = "<>", "<>"
+
+IGNORE_INDEX = -100
+DEFAULT_PAD_TOKEN = "[PAD]"
+DEFAULT_EOS_TOKEN = ""
+DEFAULT_BOS_TOKEN = ""
+DEFAULT_UNK_TOKEN = ""
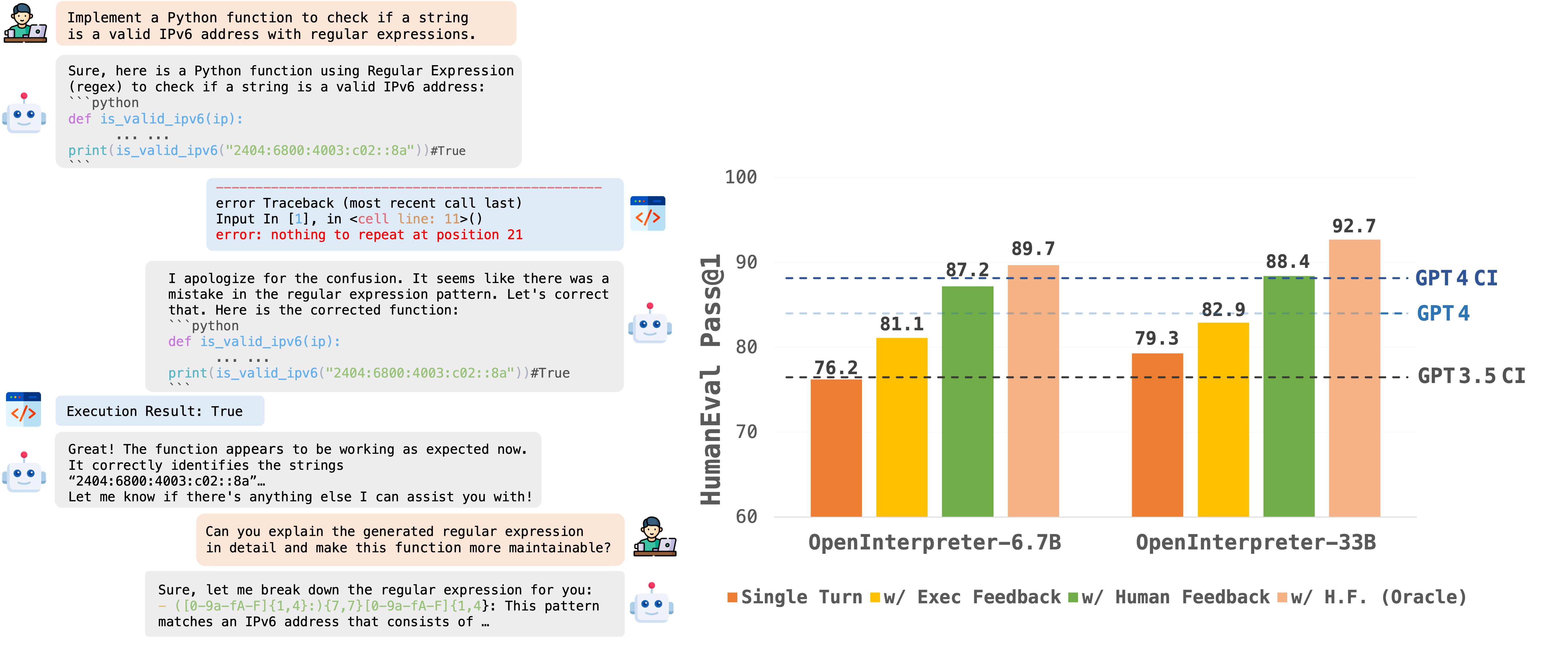 +
+


 +
+