---
title: H2OGPT
app_file: gradio_runner.py
sdk: gradio
sdk_version: 3.35.2
---
## h2oGPT
[ Live h2oGPT Demo](https://gpt.h2o.ai/)
For questions, discussing, or just hanging out, come and join our Discord!
Technical Paper: [https://arxiv.org/pdf/2306.08161.pdf](https://arxiv.org/pdf/2306.08161.pdf)
h2oGPT is a large language model (LLM) fine-tuning framework and chatbot UI with document(s) question-answer capabilities. Documents help to **ground** LLMs against hallucinations by providing them context relevant to the instruction. h2oGPT is fully permissive Apache V2 open-source project for 100% private and secure use of LLMs and document embeddings for document question-answer.
Welcome! Join us and make an issue or a PR, and contribute to making the best fine-tuned LLMs, chatbot UI, and document question-answer framework!
Turn ★ into ⭐ (top-right corner) if you like the project!
* [Supported OS and Hardware](#supported-os-and-hardware)
* [Apache V2 ChatBot with LangChain Integration](#apache-v2-chatbot-with-langchain-integration)
* [Apache V2 Data Preparation code, Training code, and Models](#apache-v2-data-preparation-code-training-code-and-models)
* [Roadmap](#roadmap)
* [Getting Started](#getting-started)
* [TLDR Install & Run](#tldr)
* [GPU (CUDA)](docs/README_GPU.md)
* [CPU](docs/README_CPU.md)
* [MACOS](docs/README_MACOS.md#macos)
* [Windows 10/11](docs/README_WINDOWS.md)
* [CLI chat](docs/README_CLI.md)
* [Gradio UI](docs/README_GRADIOUI.md)
* [Client API](docs/README_CLIENT.md)
* [Connect to Inference Servers](docs/README_InferenceServers.md)
* [Python Wheel](docs/README_WHEEL.md)
* [Development](#development)
* [Help](#help)
* [LangChain file types supported](docs/README_LangChain.md#supported-datatypes)
* [CLI Database control](docs/README_LangChain.md#database-creation)
* [Why h2oGPT for Doc Q&A](docs/README_LangChain.md#what-is-h2ogpts-langchain-integration-like)
* [FAQ](docs/FAQ.md)
* [Useful Links](docs/LINKS.md)
* [Fine-Tuning](docs/FINETUNE.md)
* [Docker](docs/INSTALL-DOCKER.md)
* [Triton](docs/TRITON.md)
* [Acknowledgements](#acknowledgements)
* [Why H2O.ai?](#why-h2oai)
* [Disclaimer](#disclaimer)
### Supported OS and Hardware
[](https://raw.githubusercontent.com/h2oai/h2ogpt/main/LICENSE)




**GPU** mode requires CUDA support via torch and transformers. A 6.9B (or 12GB) model in 8-bit uses 8GB (or 13GB) of GPU memory. 8-bit or 4-bit precision can further reduce memory requirements down no more than about 6.5GB when asking a question about your documents (see [low-memory mode](docs/FAQ.md#low-memory-mode)).
**CPU** mode uses GPT4ALL and LLaMa.cpp, e.g. gpt4all-j, requiring about 14GB of system RAM in typical use.
GPU and CPU mode tested on variety of NVIDIA GPUs in Ubuntu 18-22, but any modern Linux variant should work. MACOS support tested on Macbook Pro running Monterey v12.3.1 using CPU mode.
### Apache V2 ChatBot with LangChain Integration
- [**LangChain**](docs/README_LangChain.md) equipped Chatbot integration and streaming responses
- **Persistent** database using Chroma or in-memory with FAISS
- **Original** content url links and scores to rank content against query
- **Private** offline database of any documents ([PDFs, Images, and many more](docs/README_LangChain.md#supported-datatypes))
- **Upload** documents via chatbot into shared space or only allow scratch space
- **Control** data sources and the context provided to LLM
- **Efficient** use of context using instruct-tuned LLMs (no need for many examples)
- **API** for client-server control
- **CPU and GPU** support from variety of HF models, and CPU support using GPT4ALL and LLaMa cpp
- **Linux, MAC, and Windows** support
Light mode with soft colors talking to cat image:
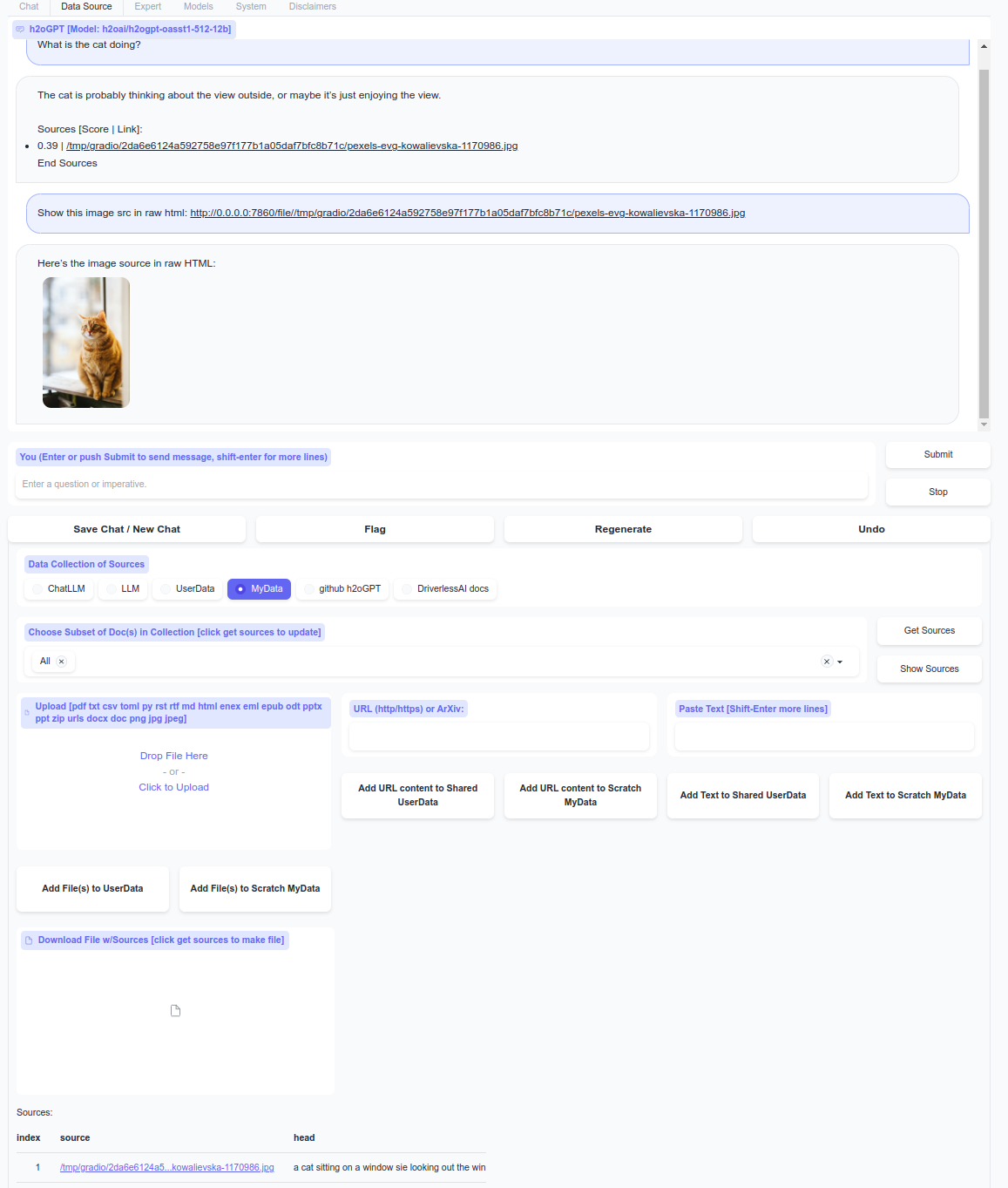
Dark mode with H2O.ai colors:
 ### Apache V2 Data Preparation code, Training code, and Models
- **Variety** of models (h2oGPT, WizardLM, Vicuna, OpenAssistant, etc.) supported
- **Fully Commercially** Apache V2 code, data and models
- **High-Quality** data cleaning of large open-source instruction datasets
- **LoRA** and **QLoRA** (low-rank approximation) efficient 4-bit, 8-bit and 16-bit fine-tuning and generation
- **Large** (up to 65B parameters) models built on commodity or enterprise GPUs (single or multi node)
- **Evaluate** performance using RLHF-based reward models
https://user-images.githubusercontent.com/6147661/232924684-6c0e2dfb-2f24-4098-848a-c3e4396f29f6.mov
All open-source datasets and models are posted on [🤗 H2O.ai's Hugging Face page](https://huggingface.co/h2oai/).
Also check out [H2O LLM Studio](https://github.com/h2oai/h2o-llmstudio) for our no-code LLM fine-tuning framework!
### Roadmap
- Integration of code and resulting LLMs with downstream applications and low/no-code platforms
- Complement h2oGPT chatbot with search and other APIs
- High-performance distributed training of larger models on trillion tokens
- Enhance the model's code completion, reasoning, and mathematical capabilities, ensure factual correctness, minimize hallucinations, and avoid repetitive output
- Add other tools like search
- Add agents for SQL and CSV question/answer
### Getting Started
First one needs a Python 3.10 environment. For help installing a Python 3.10 environment, see [Install Python 3.10 Environment](docs/INSTALL.md#install-python-environment). On newer Ubuntu systems and environment may be installed by just doing:
```bash
sudo apt-get install -y build-essential gcc python3.10-dev
virtualenv -p python3 h2ogpt
source h2ogpt/bin/activate
```
Check your installation by doing:
```bash
python --version # should say 3.10.xx
pip --version # should say pip 23.x.y ... (python 3.10)
```
On some systems, `pip` still refers back to the system one, then one can use `python -m pip` or `pip3` instead of `pip` or try `python3` instead of `python`.
#### TLDR
After Python 3.10 environment installed:
```bash
git clone https://github.com/h2oai/h2ogpt.git
cd h2ogpt
# fix any bad env
pip uninstall -y pandoc pypandoc pypandoc-binary
# broad support, but no training-time or data creation dependencies
for fil in requirements.txt reqs_optional/requirements_optional_langchain.txt reqs_optional/requirements_optional_gpt4all.txt reqs_optional/requirements_optional_langchain.gpllike.txt reqs_optional/requirements_optional_langchain.urls.txt ; do pip install -r $fil ; done
# Optional: support docx, pptx, ArXiv, etc.
sudo apt-get install -y libmagic-dev poppler-utils tesseract-ocr libreoffice
# Optional: for supporting unstructured package
python -m nltk.downloader all
````
Place all documents in `user_path` or upload in UI.
UI using GPU with at least 24GB with streaming:
```bash
python generate.py --base_model=h2oai/h2ogpt-oasst1-512-12b --load_8bit=True --score_model=None --langchain_mode='UserData' --user_path=user_path
```
UI using CPU
```bash
python generate.py --base_model='llama' --prompt_type=wizard2 --score_model=None --langchain_mode='UserData' --user_path=user_path
```
### Development
- To create a development environment for training and generation, follow the [installation instructions](docs/INSTALL.md).
- To fine-tune any LLM models on your data, follow the [fine-tuning instructions](docs/FINETUNE.md).
- To create a container for deployment, follow the [Docker instructions](docs/INSTALL-DOCKER.md).
### Help
- Flash attention support, see [Flash Attention](docs/INSTALL.md#flash-attention)
- [Docker](docs/INSTALL-DOCKER.md#containerized-installation-for-inference-on-linux-gpu-servers) for inference.
- [FAQs](docs/FAQ.md)
- [README for LangChain](docs/README_LangChain.md)
- More [Links](docs/LINKS.md), context, competitors, models, datasets
### Acknowledgements
* Some training code was based upon March 24 version of [Alpaca-LoRA](https://github.com/tloen/alpaca-lora/).
* Used high-quality created data by [OpenAssistant](https://open-assistant.io/).
* Used base models by [EleutherAI](https://www.eleuther.ai/).
* Used OIG data created by [LAION](https://laion.ai/blog/oig-dataset/).
### Why H2O.ai?
Our [Makers](https://h2o.ai/company/team/) at [H2O.ai](https://h2o.ai) have built several world-class Machine Learning, Deep Learning and AI platforms:
- #1 open-source machine learning platform for the enterprise [H2O-3](https://github.com/h2oai/h2o-3)
- The world's best AutoML (Automatic Machine Learning) with [H2O Driverless AI](https://h2o.ai/platform/ai-cloud/make/h2o-driverless-ai/)
- No-Code Deep Learning with [H2O Hydrogen Torch](https://h2o.ai/platform/ai-cloud/make/hydrogen-torch/)
- Document Processing with Deep Learning in [Document AI](https://h2o.ai/platform/ai-cloud/make/document-ai/)
We also built platforms for deployment and monitoring, and for data wrangling and governance:
- [H2O MLOps](https://h2o.ai/platform/ai-cloud/operate/h2o-mlops/) to deploy and monitor models at scale
- [H2O Feature Store](https://h2o.ai/platform/ai-cloud/make/feature-store/) in collaboration with AT&T
- Open-source Low-Code AI App Development Frameworks [Wave](https://wave.h2o.ai/) and [Nitro](https://nitro.h2o.ai/)
- Open-source Python [datatable](https://github.com/h2oai/datatable/) (the engine for H2O Driverless AI feature engineering)
Many of our customers are creating models and deploying them enterprise-wide and at scale in the [H2O AI Cloud](https://h2o.ai/platform/ai-cloud/):
- Multi-Cloud or on Premises
- [Managed Cloud (SaaS)](https://h2o.ai/platform/ai-cloud/managed)
- [Hybrid Cloud](https://h2o.ai/platform/ai-cloud/hybrid)
- [AI Appstore](https://docs.h2o.ai/h2o-ai-cloud/)
We are proud to have over 25 (of the world's 280) [Kaggle Grandmasters](https://h2o.ai/company/team/kaggle-grandmasters/) call H2O home, including three Kaggle Grandmasters who have made it to world #1.
### Disclaimer
Please read this disclaimer carefully before using the large language model provided in this repository. Your use of the model signifies your agreement to the following terms and conditions.
- Biases and Offensiveness: The large language model is trained on a diverse range of internet text data, which may contain biased, racist, offensive, or otherwise inappropriate content. By using this model, you acknowledge and accept that the generated content may sometimes exhibit biases or produce content that is offensive or inappropriate. The developers of this repository do not endorse, support, or promote any such content or viewpoints.
- Limitations: The large language model is an AI-based tool and not a human. It may produce incorrect, nonsensical, or irrelevant responses. It is the user's responsibility to critically evaluate the generated content and use it at their discretion.
- Use at Your Own Risk: Users of this large language model must assume full responsibility for any consequences that may arise from their use of the tool. The developers and contributors of this repository shall not be held liable for any damages, losses, or harm resulting from the use or misuse of the provided model.
- Ethical Considerations: Users are encouraged to use the large language model responsibly and ethically. By using this model, you agree not to use it for purposes that promote hate speech, discrimination, harassment, or any form of illegal or harmful activities.
- Reporting Issues: If you encounter any biased, offensive, or otherwise inappropriate content generated by the large language model, please report it to the repository maintainers through the provided channels. Your feedback will help improve the model and mitigate potential issues.
- Changes to this Disclaimer: The developers of this repository reserve the right to modify or update this disclaimer at any time without prior notice. It is the user's responsibility to periodically review the disclaimer to stay informed about any changes.
By using the large language model provided in this repository, you agree to accept and comply with the terms and conditions outlined in this disclaimer. If you do not agree with any part of this disclaimer, you should refrain from using the model and any content generated by it.
## Star History
[](https://star-history.com/#h2oai/h2ogpt&Timeline)
### Apache V2 Data Preparation code, Training code, and Models
- **Variety** of models (h2oGPT, WizardLM, Vicuna, OpenAssistant, etc.) supported
- **Fully Commercially** Apache V2 code, data and models
- **High-Quality** data cleaning of large open-source instruction datasets
- **LoRA** and **QLoRA** (low-rank approximation) efficient 4-bit, 8-bit and 16-bit fine-tuning and generation
- **Large** (up to 65B parameters) models built on commodity or enterprise GPUs (single or multi node)
- **Evaluate** performance using RLHF-based reward models
https://user-images.githubusercontent.com/6147661/232924684-6c0e2dfb-2f24-4098-848a-c3e4396f29f6.mov
All open-source datasets and models are posted on [🤗 H2O.ai's Hugging Face page](https://huggingface.co/h2oai/).
Also check out [H2O LLM Studio](https://github.com/h2oai/h2o-llmstudio) for our no-code LLM fine-tuning framework!
### Roadmap
- Integration of code and resulting LLMs with downstream applications and low/no-code platforms
- Complement h2oGPT chatbot with search and other APIs
- High-performance distributed training of larger models on trillion tokens
- Enhance the model's code completion, reasoning, and mathematical capabilities, ensure factual correctness, minimize hallucinations, and avoid repetitive output
- Add other tools like search
- Add agents for SQL and CSV question/answer
### Getting Started
First one needs a Python 3.10 environment. For help installing a Python 3.10 environment, see [Install Python 3.10 Environment](docs/INSTALL.md#install-python-environment). On newer Ubuntu systems and environment may be installed by just doing:
```bash
sudo apt-get install -y build-essential gcc python3.10-dev
virtualenv -p python3 h2ogpt
source h2ogpt/bin/activate
```
Check your installation by doing:
```bash
python --version # should say 3.10.xx
pip --version # should say pip 23.x.y ... (python 3.10)
```
On some systems, `pip` still refers back to the system one, then one can use `python -m pip` or `pip3` instead of `pip` or try `python3` instead of `python`.
#### TLDR
After Python 3.10 environment installed:
```bash
git clone https://github.com/h2oai/h2ogpt.git
cd h2ogpt
# fix any bad env
pip uninstall -y pandoc pypandoc pypandoc-binary
# broad support, but no training-time or data creation dependencies
for fil in requirements.txt reqs_optional/requirements_optional_langchain.txt reqs_optional/requirements_optional_gpt4all.txt reqs_optional/requirements_optional_langchain.gpllike.txt reqs_optional/requirements_optional_langchain.urls.txt ; do pip install -r $fil ; done
# Optional: support docx, pptx, ArXiv, etc.
sudo apt-get install -y libmagic-dev poppler-utils tesseract-ocr libreoffice
# Optional: for supporting unstructured package
python -m nltk.downloader all
````
Place all documents in `user_path` or upload in UI.
UI using GPU with at least 24GB with streaming:
```bash
python generate.py --base_model=h2oai/h2ogpt-oasst1-512-12b --load_8bit=True --score_model=None --langchain_mode='UserData' --user_path=user_path
```
UI using CPU
```bash
python generate.py --base_model='llama' --prompt_type=wizard2 --score_model=None --langchain_mode='UserData' --user_path=user_path
```
### Development
- To create a development environment for training and generation, follow the [installation instructions](docs/INSTALL.md).
- To fine-tune any LLM models on your data, follow the [fine-tuning instructions](docs/FINETUNE.md).
- To create a container for deployment, follow the [Docker instructions](docs/INSTALL-DOCKER.md).
### Help
- Flash attention support, see [Flash Attention](docs/INSTALL.md#flash-attention)
- [Docker](docs/INSTALL-DOCKER.md#containerized-installation-for-inference-on-linux-gpu-servers) for inference.
- [FAQs](docs/FAQ.md)
- [README for LangChain](docs/README_LangChain.md)
- More [Links](docs/LINKS.md), context, competitors, models, datasets
### Acknowledgements
* Some training code was based upon March 24 version of [Alpaca-LoRA](https://github.com/tloen/alpaca-lora/).
* Used high-quality created data by [OpenAssistant](https://open-assistant.io/).
* Used base models by [EleutherAI](https://www.eleuther.ai/).
* Used OIG data created by [LAION](https://laion.ai/blog/oig-dataset/).
### Why H2O.ai?
Our [Makers](https://h2o.ai/company/team/) at [H2O.ai](https://h2o.ai) have built several world-class Machine Learning, Deep Learning and AI platforms:
- #1 open-source machine learning platform for the enterprise [H2O-3](https://github.com/h2oai/h2o-3)
- The world's best AutoML (Automatic Machine Learning) with [H2O Driverless AI](https://h2o.ai/platform/ai-cloud/make/h2o-driverless-ai/)
- No-Code Deep Learning with [H2O Hydrogen Torch](https://h2o.ai/platform/ai-cloud/make/hydrogen-torch/)
- Document Processing with Deep Learning in [Document AI](https://h2o.ai/platform/ai-cloud/make/document-ai/)
We also built platforms for deployment and monitoring, and for data wrangling and governance:
- [H2O MLOps](https://h2o.ai/platform/ai-cloud/operate/h2o-mlops/) to deploy and monitor models at scale
- [H2O Feature Store](https://h2o.ai/platform/ai-cloud/make/feature-store/) in collaboration with AT&T
- Open-source Low-Code AI App Development Frameworks [Wave](https://wave.h2o.ai/) and [Nitro](https://nitro.h2o.ai/)
- Open-source Python [datatable](https://github.com/h2oai/datatable/) (the engine for H2O Driverless AI feature engineering)
Many of our customers are creating models and deploying them enterprise-wide and at scale in the [H2O AI Cloud](https://h2o.ai/platform/ai-cloud/):
- Multi-Cloud or on Premises
- [Managed Cloud (SaaS)](https://h2o.ai/platform/ai-cloud/managed)
- [Hybrid Cloud](https://h2o.ai/platform/ai-cloud/hybrid)
- [AI Appstore](https://docs.h2o.ai/h2o-ai-cloud/)
We are proud to have over 25 (of the world's 280) [Kaggle Grandmasters](https://h2o.ai/company/team/kaggle-grandmasters/) call H2O home, including three Kaggle Grandmasters who have made it to world #1.
### Disclaimer
Please read this disclaimer carefully before using the large language model provided in this repository. Your use of the model signifies your agreement to the following terms and conditions.
- Biases and Offensiveness: The large language model is trained on a diverse range of internet text data, which may contain biased, racist, offensive, or otherwise inappropriate content. By using this model, you acknowledge and accept that the generated content may sometimes exhibit biases or produce content that is offensive or inappropriate. The developers of this repository do not endorse, support, or promote any such content or viewpoints.
- Limitations: The large language model is an AI-based tool and not a human. It may produce incorrect, nonsensical, or irrelevant responses. It is the user's responsibility to critically evaluate the generated content and use it at their discretion.
- Use at Your Own Risk: Users of this large language model must assume full responsibility for any consequences that may arise from their use of the tool. The developers and contributors of this repository shall not be held liable for any damages, losses, or harm resulting from the use or misuse of the provided model.
- Ethical Considerations: Users are encouraged to use the large language model responsibly and ethically. By using this model, you agree not to use it for purposes that promote hate speech, discrimination, harassment, or any form of illegal or harmful activities.
- Reporting Issues: If you encounter any biased, offensive, or otherwise inappropriate content generated by the large language model, please report it to the repository maintainers through the provided channels. Your feedback will help improve the model and mitigate potential issues.
- Changes to this Disclaimer: The developers of this repository reserve the right to modify or update this disclaimer at any time without prior notice. It is the user's responsibility to periodically review the disclaimer to stay informed about any changes.
By using the large language model provided in this repository, you agree to accept and comply with the terms and conditions outlined in this disclaimer. If you do not agree with any part of this disclaimer, you should refrain from using the model and any content generated by it.
## Star History
[](https://star-history.com/#h2oai/h2ogpt&Timeline)