# ImageGPT
## Overview
The ImageGPT model was proposed in [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt) by Mark
Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever. ImageGPT (iGPT) is a GPT-2-like
model trained to predict the next pixel value, allowing for both unconditional and conditional image generation.
The abstract from the paper is the following:
*Inspired by progress in unsupervised representation learning for natural language, we examine whether similar models
can learn useful representations for images. We train a sequence Transformer to auto-regressively predict pixels,
without incorporating knowledge of the 2D input structure. Despite training on low-resolution ImageNet without labels,
we find that a GPT-2 scale model learns strong image representations as measured by linear probing, fine-tuning, and
low-data classification. On CIFAR-10, we achieve 96.3% accuracy with a linear probe, outperforming a supervised Wide
ResNet, and 99.0% accuracy with full fine-tuning, matching the top supervised pre-trained models. We are also
competitive with self-supervised benchmarks on ImageNet when substituting pixels for a VQVAE encoding, achieving 69.0%
top-1 accuracy on a linear probe of our features.*
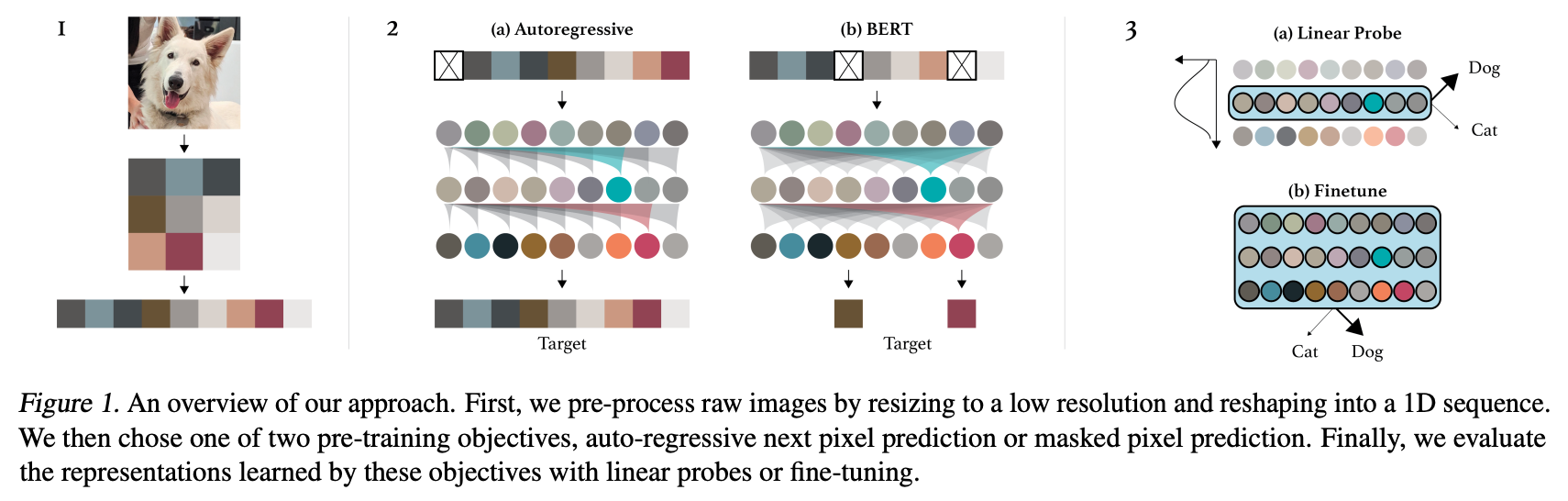 Summary of the approach. Taken from the [original paper](https://cdn.openai.com/papers/Generative_Pretraining_from_Pixels_V2.pdf).
This model was contributed by [nielsr](https://huggingface.co/nielsr), based on [this issue](https://github.com/openai/image-gpt/issues/7). The original code can be found
[here](https://github.com/openai/image-gpt).
Tips:
- ImageGPT is almost exactly the same as [GPT-2](gpt2), with the exception that a different activation
function is used (namely "quick gelu"), and the layer normalization layers don't mean center the inputs. ImageGPT
also doesn't have tied input- and output embeddings.
- As the time- and memory requirements of the attention mechanism of Transformers scales quadratically in the sequence
length, the authors pre-trained ImageGPT on smaller input resolutions, such as 32x32 and 64x64. However, feeding a
sequence of 32x32x3=3072 tokens from 0..255 into a Transformer is still prohibitively large. Therefore, the authors
applied k-means clustering to the (R,G,B) pixel values with k=512. This way, we only have a 32*32 = 1024-long
sequence, but now of integers in the range 0..511. So we are shrinking the sequence length at the cost of a bigger
embedding matrix. In other words, the vocabulary size of ImageGPT is 512, + 1 for a special "start of sentence" (SOS)
token, used at the beginning of every sequence. One can use [`ImageGPTImageProcessor`] to prepare
images for the model.
- Despite being pre-trained entirely unsupervised (i.e. without the use of any labels), ImageGPT produces fairly
performant image features useful for downstream tasks, such as image classification. The authors showed that the
features in the middle of the network are the most performant, and can be used as-is to train a linear model (such as
a sklearn logistic regression model for example). This is also referred to as "linear probing". Features can be
easily obtained by first forwarding the image through the model, then specifying `output_hidden_states=True`, and
then average-pool the hidden states at whatever layer you like.
- Alternatively, one can further fine-tune the entire model on a downstream dataset, similar to BERT. For this, you can
use [`ImageGPTForImageClassification`].
- ImageGPT comes in different sizes: there's ImageGPT-small, ImageGPT-medium and ImageGPT-large. The authors did also
train an XL variant, which they didn't release. The differences in size are summarized in the following table:
| **Model variant** | **Depths** | **Hidden sizes** | **Decoder hidden size** | **Params (M)** | **ImageNet-1k Top 1** |
|---|---|---|---|---|---|
| MiT-b0 | [2, 2, 2, 2] | [32, 64, 160, 256] | 256 | 3.7 | 70.5 |
| MiT-b1 | [2, 2, 2, 2] | [64, 128, 320, 512] | 256 | 14.0 | 78.7 |
| MiT-b2 | [3, 4, 6, 3] | [64, 128, 320, 512] | 768 | 25.4 | 81.6 |
| MiT-b3 | [3, 4, 18, 3] | [64, 128, 320, 512] | 768 | 45.2 | 83.1 |
| MiT-b4 | [3, 8, 27, 3] | [64, 128, 320, 512] | 768 | 62.6 | 83.6 |
| MiT-b5 | [3, 6, 40, 3] | [64, 128, 320, 512] | 768 | 82.0 | 83.8 |
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ImageGPT.
- Demo notebooks for ImageGPT can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/ImageGPT).
- [`ImageGPTForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
- See also: [Image classification task guide](../tasks/image_classification)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## ImageGPTConfig
[[autodoc]] ImageGPTConfig
## ImageGPTFeatureExtractor
[[autodoc]] ImageGPTFeatureExtractor
- __call__
## ImageGPTImageProcessor
[[autodoc]] ImageGPTImageProcessor
- preprocess
## ImageGPTModel
[[autodoc]] ImageGPTModel
- forward
## ImageGPTForCausalImageModeling
[[autodoc]] ImageGPTForCausalImageModeling
- forward
## ImageGPTForImageClassification
[[autodoc]] ImageGPTForImageClassification
- forward
Summary of the approach. Taken from the [original paper](https://cdn.openai.com/papers/Generative_Pretraining_from_Pixels_V2.pdf).
This model was contributed by [nielsr](https://huggingface.co/nielsr), based on [this issue](https://github.com/openai/image-gpt/issues/7). The original code can be found
[here](https://github.com/openai/image-gpt).
Tips:
- ImageGPT is almost exactly the same as [GPT-2](gpt2), with the exception that a different activation
function is used (namely "quick gelu"), and the layer normalization layers don't mean center the inputs. ImageGPT
also doesn't have tied input- and output embeddings.
- As the time- and memory requirements of the attention mechanism of Transformers scales quadratically in the sequence
length, the authors pre-trained ImageGPT on smaller input resolutions, such as 32x32 and 64x64. However, feeding a
sequence of 32x32x3=3072 tokens from 0..255 into a Transformer is still prohibitively large. Therefore, the authors
applied k-means clustering to the (R,G,B) pixel values with k=512. This way, we only have a 32*32 = 1024-long
sequence, but now of integers in the range 0..511. So we are shrinking the sequence length at the cost of a bigger
embedding matrix. In other words, the vocabulary size of ImageGPT is 512, + 1 for a special "start of sentence" (SOS)
token, used at the beginning of every sequence. One can use [`ImageGPTImageProcessor`] to prepare
images for the model.
- Despite being pre-trained entirely unsupervised (i.e. without the use of any labels), ImageGPT produces fairly
performant image features useful for downstream tasks, such as image classification. The authors showed that the
features in the middle of the network are the most performant, and can be used as-is to train a linear model (such as
a sklearn logistic regression model for example). This is also referred to as "linear probing". Features can be
easily obtained by first forwarding the image through the model, then specifying `output_hidden_states=True`, and
then average-pool the hidden states at whatever layer you like.
- Alternatively, one can further fine-tune the entire model on a downstream dataset, similar to BERT. For this, you can
use [`ImageGPTForImageClassification`].
- ImageGPT comes in different sizes: there's ImageGPT-small, ImageGPT-medium and ImageGPT-large. The authors did also
train an XL variant, which they didn't release. The differences in size are summarized in the following table:
| **Model variant** | **Depths** | **Hidden sizes** | **Decoder hidden size** | **Params (M)** | **ImageNet-1k Top 1** |
|---|---|---|---|---|---|
| MiT-b0 | [2, 2, 2, 2] | [32, 64, 160, 256] | 256 | 3.7 | 70.5 |
| MiT-b1 | [2, 2, 2, 2] | [64, 128, 320, 512] | 256 | 14.0 | 78.7 |
| MiT-b2 | [3, 4, 6, 3] | [64, 128, 320, 512] | 768 | 25.4 | 81.6 |
| MiT-b3 | [3, 4, 18, 3] | [64, 128, 320, 512] | 768 | 45.2 | 83.1 |
| MiT-b4 | [3, 8, 27, 3] | [64, 128, 320, 512] | 768 | 62.6 | 83.6 |
| MiT-b5 | [3, 6, 40, 3] | [64, 128, 320, 512] | 768 | 82.0 | 83.8 |
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ImageGPT.
- Demo notebooks for ImageGPT can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/ImageGPT).
- [`ImageGPTForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
- See also: [Image classification task guide](../tasks/image_classification)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## ImageGPTConfig
[[autodoc]] ImageGPTConfig
## ImageGPTFeatureExtractor
[[autodoc]] ImageGPTFeatureExtractor
- __call__
## ImageGPTImageProcessor
[[autodoc]] ImageGPTImageProcessor
- preprocess
## ImageGPTModel
[[autodoc]] ImageGPTModel
- forward
## ImageGPTForCausalImageModeling
[[autodoc]] ImageGPTForCausalImageModeling
- forward
## ImageGPTForImageClassification
[[autodoc]] ImageGPTForImageClassification
- forward