diff --git a/.idea/.gitignore b/.idea/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..eaf91e2ac647df635a09f01b8a2a254252aae8d7
--- /dev/null
+++ b/.idea/.gitignore
@@ -0,0 +1,3 @@
+# Default ignored files
+/shelf/
+/workspace.xml
diff --git a/.idea/.name b/.idea/.name
new file mode 100644
index 0000000000000000000000000000000000000000..aa15e3edae7c1e011ee80f1b76848b74036ac747
--- /dev/null
+++ b/.idea/.name
@@ -0,0 +1 @@
+app.py
\ No newline at end of file
diff --git a/.idea/Brain Tumour Detection.iml b/.idea/Brain Tumour Detection.iml
new file mode 100644
index 0000000000000000000000000000000000000000..d9e6024fc5bad71514b25a89333834e81d5cd8f4
--- /dev/null
+++ b/.idea/Brain Tumour Detection.iml
@@ -0,0 +1,8 @@
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/.idea/inspectionProfiles/Project_Default.xml b/.idea/inspectionProfiles/Project_Default.xml
new file mode 100644
index 0000000000000000000000000000000000000000..460df42a8ba0b05fe8b66fce3335dc07d1f7ad6e
--- /dev/null
+++ b/.idea/inspectionProfiles/Project_Default.xml
@@ -0,0 +1,12 @@
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/.idea/inspectionProfiles/profiles_settings.xml b/.idea/inspectionProfiles/profiles_settings.xml
new file mode 100644
index 0000000000000000000000000000000000000000..105ce2da2d6447d11dfe32bfb846c3d5b199fc99
--- /dev/null
+++ b/.idea/inspectionProfiles/profiles_settings.xml
@@ -0,0 +1,6 @@
+
+
+
+
+
+
\ No newline at end of file
diff --git a/.idea/misc.xml b/.idea/misc.xml
new file mode 100644
index 0000000000000000000000000000000000000000..f1bf6faf0a2b7cdd6d4f628a104b5bc582f0fc00
--- /dev/null
+++ b/.idea/misc.xml
@@ -0,0 +1,7 @@
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/.idea/modules.xml b/.idea/modules.xml
new file mode 100644
index 0000000000000000000000000000000000000000..d5cfaa55d8d86382e032d585d730fcfbd1fed701
--- /dev/null
+++ b/.idea/modules.xml
@@ -0,0 +1,8 @@
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/.idea/vcs.xml b/.idea/vcs.xml
new file mode 100644
index 0000000000000000000000000000000000000000..7e815362b765612fccf840793d3dac34df5c1589
--- /dev/null
+++ b/.idea/vcs.xml
@@ -0,0 +1,7 @@
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/.idea/workspace.xml b/.idea/workspace.xml
new file mode 100644
index 0000000000000000000000000000000000000000..aa42131345e04156cf7af03597b7716c6e1b3bfa
--- /dev/null
+++ b/.idea/workspace.xml
@@ -0,0 +1,58 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ {
+ "associatedIndex": 3
+}
+
+
+
+
+
+ {
+ "keyToString": {
+ "Python.app.executor": "Run",
+ "RunOnceActivity.OpenProjectViewOnStart": "true",
+ "RunOnceActivity.ShowReadmeOnStart": "true",
+ "git-widget-placeholder": "main",
+ "last_opened_file_path": "C:/Users/suhri/Documents/Brain Tumour Detection"
+ }
+}
+
+
+
+
+
+
+
+
+
+
+
+ 1724668778161
+
+
+ 1724668778161
+
+
+
+
\ No newline at end of file
diff --git a/README.md b/README.md
index 64a7721eec207c6ec152a7ce83dc74de21e6a7f0..6fd60713c227e2ea560dd7bad88400e8730d622a 100644
--- a/README.md
+++ b/README.md
@@ -1,12 +1,6 @@
---
-title: Brain Tumour Detection
-emoji: 📚
-colorFrom: pink
-colorTo: red
+title: Brain_Tumour_Detection
+app_file: app.py
sdk: gradio
sdk_version: 4.42.0
-app_file: app.py
-pinned: false
---
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/app.py b/app.py
new file mode 100644
index 0000000000000000000000000000000000000000..c01df448f1014a01f7804d91737ea8bb866e4d26
--- /dev/null
+++ b/app.py
@@ -0,0 +1,22 @@
+import gradio as gr
+import numpy as np
+import joblib
+from ultralytics import YOLO
+
+load_model = YOLO("best.pt")
+
+def predict(image):
+ result = load_model.predict(source=image, imgsz = 640, conf = 0.25)
+ annotated_img = result[0].plot()
+ annotated_img = annotated_img[:, :, ::-1]
+ return annotated_img
+
+app = gr.Interface(
+ fn = predict,
+ inputs = gr.Image(type="numpy", label="Upload an image"),
+ outputs = gr.Image(type="numpy", label="Detect Brain Tumor"),
+ title = "Brain Tumor Detection",
+ description="Upload an image. The model will detect and annotate brain tumor."
+)
+
+app.launch(share = True)
\ No newline at end of file
diff --git a/best.pt b/best.pt
new file mode 100644
index 0000000000000000000000000000000000000000..8a17b2437e632fa89a1507b226f2885d49fb7896
--- /dev/null
+++ b/best.pt
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:e407241a5f7694b5901d772875845937881b9f1b2f50bb0311eff3e214d88c6d
+size 5751283
diff --git a/requirements.txt b/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..b0f2a21636dee539b8e4ff6e6f09c67afaf58afb
--- /dev/null
+++ b/requirements.txt
@@ -0,0 +1,3 @@
+ultralytics == 8.2.82
+joblib == 1.4.2
+numpy == 1.26.4
\ No newline at end of file
diff --git a/ultralytics/.github/ISSUE_TEMPLATE/bug-report.yml b/ultralytics/.github/ISSUE_TEMPLATE/bug-report.yml
new file mode 100644
index 0000000000000000000000000000000000000000..05e433f17f5c8d7f8eedd04a57e3181133936d4a
--- /dev/null
+++ b/ultralytics/.github/ISSUE_TEMPLATE/bug-report.yml
@@ -0,0 +1,97 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+name: 🐛 Bug Report
+# title: " "
+description: Problems with Ultralytics YOLO
+labels: [bug, triage]
+body:
+ - type: markdown
+ attributes:
+ value: |
+ Thank you for submitting an Ultralytics YOLO 🐛 Bug Report!
+
+ - type: checkboxes
+ attributes:
+ label: Search before asking
+ description: >
+ Please search the Ultralytics [Docs](https://docs.ultralytics.com) and [issues](https://github.com/ultralytics/ultralytics/issues) to see if a similar bug report already exists.
+ options:
+ - label: >
+ I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and found no similar bug report.
+ required: true
+
+ - type: dropdown
+ attributes:
+ label: Ultralytics YOLO Component
+ description: |
+ Please select the Ultralytics YOLO component where you found the bug.
+ multiple: true
+ options:
+ - "Install"
+ - "Train"
+ - "Val"
+ - "Predict"
+ - "Export"
+ - "Multi-GPU"
+ - "Augmentation"
+ - "Hyperparameter Tuning"
+ - "Integrations"
+ - "Other"
+ validations:
+ required: false
+
+ - type: textarea
+ attributes:
+ label: Bug
+ description: Please provide as much information as possible. Copy and paste console output and error messages. Use [Markdown](https://docs.github.com/en/get-started/writing-on-github/getting-started-with-writing-and-formatting-on-github/basic-writing-and-formatting-syntax) to format text, code and logs. If necessary, include screenshots for visual elements only. Providing detailed information will help us resolve the issue more efficiently.
+ placeholder: |
+ 💡 ProTip! Include as much information as possible (logs, tracebacks, screenshots, etc.) to receive the most helpful response.
+ validations:
+ required: true
+
+ - type: textarea
+ attributes:
+ label: Environment
+ description: Many issues are often related to dependency versions and hardware. Please provide the output of `yolo checks` or `ultralytics.checks()` command to help us diagnose the problem.
+ placeholder: |
+ Paste output of `yolo checks` or `ultralytics.checks()` command, i.e.:
+ ```
+ Ultralytics YOLOv8.0.181 🚀 Python-3.11.2 torch-2.0.1 CPU (Apple M2)
+ Setup complete ✅ (8 CPUs, 16.0 GB RAM, 266.5/460.4 GB disk)
+
+ OS macOS-13.5.2
+ Environment Jupyter
+ Python 3.11.2
+ Install git
+ RAM 16.00 GB
+ CPU Apple M2
+ CUDA None
+ ```
+ validations:
+ required: true
+
+ - type: textarea
+ attributes:
+ label: Minimal Reproducible Example
+ description: >
+ When asking a question, people will be better able to provide help if you provide code that they can easily understand and use to **reproduce** the problem. This is referred to by community members as creating a [minimal reproducible example](https://docs.ultralytics.com/help/minimum_reproducible_example/).
+ placeholder: |
+ ```
+ # Code to reproduce your issue here
+ ```
+ validations:
+ required: true
+
+ - type: textarea
+ attributes:
+ label: Additional
+ description: Anything else you would like to share?
+
+ - type: checkboxes
+ attributes:
+ label: Are you willing to submit a PR?
+ description: >
+ (Optional) We encourage you to submit a [Pull Request](https://github.com/ultralytics/ultralytics/pulls) (PR) to help improve Ultralytics YOLO for everyone, especially if you have a good understanding of how to implement a fix or feature.
+ See the Ultralytics YOLO [Contributing Guide](https://docs.ultralytics.com/help/contributing) to get started.
+ options:
+ - label: Yes I'd like to help by submitting a PR!
diff --git a/ultralytics/.github/ISSUE_TEMPLATE/config.yml b/ultralytics/.github/ISSUE_TEMPLATE/config.yml
new file mode 100644
index 0000000000000000000000000000000000000000..2f00f0ab501b6a75c82fb5b305b1a76992d729dd
--- /dev/null
+++ b/ultralytics/.github/ISSUE_TEMPLATE/config.yml
@@ -0,0 +1,13 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+blank_issues_enabled: true
+contact_links:
+ - name: 📄 Docs
+ url: https://docs.ultralytics.com/
+ about: Full Ultralytics YOLOv8 Documentation
+ - name: 💬 Forum
+ url: https://community.ultralytics.com/
+ about: Ask on Ultralytics Community Forum
+ - name: 🎧 Discord
+ url: https://ultralytics.com/discord
+ about: Ask on Ultralytics Discord
diff --git a/ultralytics/.github/ISSUE_TEMPLATE/feature-request.yml b/ultralytics/.github/ISSUE_TEMPLATE/feature-request.yml
new file mode 100644
index 0000000000000000000000000000000000000000..bda7b3887594c4703b331a3db2a80f66f3949e48
--- /dev/null
+++ b/ultralytics/.github/ISSUE_TEMPLATE/feature-request.yml
@@ -0,0 +1,52 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+name: 🚀 Feature Request
+description: Suggest a YOLOv8 idea
+# title: " "
+labels: [enhancement]
+body:
+ - type: markdown
+ attributes:
+ value: |
+ Thank you for submitting a YOLOv8 🚀 Feature Request!
+
+ - type: checkboxes
+ attributes:
+ label: Search before asking
+ description: >
+ Please search the Ultralytics [Docs](https://docs.ultralytics.com) and [issues](https://github.com/ultralytics/ultralytics/issues) to see if a similar feature request already exists.
+ options:
+ - label: >
+ I have searched the YOLOv8 [issues](https://github.com/ultralytics/ultralytics/issues) and found no similar feature requests.
+ required: true
+
+ - type: textarea
+ attributes:
+ label: Description
+ description: A short description of your feature.
+ placeholder: |
+ What new feature would you like to see in YOLOv8?
+ validations:
+ required: true
+
+ - type: textarea
+ attributes:
+ label: Use case
+ description: |
+ Describe the use case of your feature request. It will help us understand and prioritize the feature request.
+ placeholder: |
+ How would this feature be used, and who would use it?
+
+ - type: textarea
+ attributes:
+ label: Additional
+ description: Anything else you would like to share?
+
+ - type: checkboxes
+ attributes:
+ label: Are you willing to submit a PR?
+ description: >
+ (Optional) We encourage you to submit a [Pull Request](https://github.com/ultralytics/ultralytics/pulls) (PR) to help improve YOLOv8 for everyone, especially if you have a good understanding of how to implement a fix or feature.
+ See the YOLOv8 [Contributing Guide](https://docs.ultralytics.com/help/contributing) to get started.
+ options:
+ - label: Yes I'd like to help by submitting a PR!
diff --git a/ultralytics/.github/ISSUE_TEMPLATE/question.yml b/ultralytics/.github/ISSUE_TEMPLATE/question.yml
new file mode 100644
index 0000000000000000000000000000000000000000..1f2577eefc4e005b908432b1e3f322b01482a47c
--- /dev/null
+++ b/ultralytics/.github/ISSUE_TEMPLATE/question.yml
@@ -0,0 +1,35 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+name: ❓ Question
+description: Ask an Ultralytics YOLO question
+# title: " "
+labels: [question]
+body:
+ - type: markdown
+ attributes:
+ value: |
+ Thank you for asking an Ultralytics YOLO ❓ Question!
+
+ - type: checkboxes
+ attributes:
+ label: Search before asking
+ description: >
+ Please search the Ultralytics [Docs](https://docs.ultralytics.com), [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/ultralytics/ultralytics/discussions) to see if a similar question already exists.
+ options:
+ - label: >
+ I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/ultralytics/ultralytics/discussions) and found no similar questions.
+ required: true
+
+ - type: textarea
+ attributes:
+ label: Question
+ description: What is your question? Please provide as much information as possible. Include detailed code examples to reproduce the problem and describe the context in which the issue occurs. Format your text and code using [Markdown](https://docs.github.com/en/get-started/writing-on-github/getting-started-with-writing-and-formatting-on-github/basic-writing-and-formatting-syntax) for clarity and readability. Following these guidelines will help us assist you more effectively.
+ placeholder: |
+ 💡 ProTip! Include as much information as possible (logs, tracebacks, screenshots etc.) to receive the most helpful response.
+ validations:
+ required: true
+
+ - type: textarea
+ attributes:
+ label: Additional
+ description: Anything else you would like to share?
diff --git a/ultralytics/.github/dependabot.yml b/ultralytics/.github/dependabot.yml
new file mode 100644
index 0000000000000000000000000000000000000000..3f38398f67112c4e7c188eca992d2a074a3100bb
--- /dev/null
+++ b/ultralytics/.github/dependabot.yml
@@ -0,0 +1,27 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# Dependabot for package version updates
+# https://docs.github.com/github/administering-a-repository/configuration-options-for-dependency-updates
+
+version: 2
+updates:
+ - package-ecosystem: pip
+ directory: "/"
+ schedule:
+ interval: weekly
+ time: "04:00"
+ open-pull-requests-limit: 10
+ reviewers:
+ - glenn-jocher
+ labels:
+ - dependencies
+
+ - package-ecosystem: github-actions
+ directory: "/.github/workflows"
+ schedule:
+ interval: weekly
+ time: "04:00"
+ open-pull-requests-limit: 5
+ reviewers:
+ - glenn-jocher
+ labels:
+ - dependencies
diff --git a/ultralytics/.github/workflows/ci.yaml b/ultralytics/.github/workflows/ci.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..10fd2f41378ba5362c3f850c4d1863733b768eb2
--- /dev/null
+++ b/ultralytics/.github/workflows/ci.yaml
@@ -0,0 +1,348 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# YOLO Continuous Integration (CI) GitHub Actions tests
+
+name: Ultralytics CI
+
+on:
+ push:
+ branches: [main]
+ pull_request:
+ branches: [main]
+ schedule:
+ - cron: "0 0 * * *" # runs at 00:00 UTC every day
+ workflow_dispatch:
+ inputs:
+ hub:
+ description: "Run HUB"
+ default: false
+ type: boolean
+ benchmarks:
+ description: "Run Benchmarks"
+ default: false
+ type: boolean
+ tests:
+ description: "Run Tests"
+ default: false
+ type: boolean
+ gpu:
+ description: "Run GPU"
+ default: false
+ type: boolean
+ raspberrypi:
+ description: "Run Raspberry Pi"
+ default: false
+ type: boolean
+ conda:
+ description: "Run Conda"
+ default: false
+ type: boolean
+
+jobs:
+ HUB:
+ if: github.repository == 'ultralytics/ultralytics' && (github.event_name == 'schedule' || github.event_name == 'push' || (github.event_name == 'workflow_dispatch' && github.event.inputs.hub == 'true'))
+ runs-on: ${{ matrix.os }}
+ strategy:
+ fail-fast: false
+ matrix:
+ os: [ubuntu-latest]
+ python-version: ["3.11"]
+ steps:
+ - uses: actions/checkout@v4
+ - uses: actions/setup-python@v5
+ with:
+ python-version: ${{ matrix.python-version }}
+ cache: "pip" # caching pip dependencies
+ - name: Install requirements
+ shell: bash # for Windows compatibility
+ run: |
+ python -m pip install --upgrade pip wheel
+ pip install -e . --extra-index-url https://download.pytorch.org/whl/cpu
+ - name: Check environment
+ run: |
+ yolo checks
+ pip list
+ - name: Test HUB training
+ shell: python
+ env:
+ API_KEY: ${{ secrets.ULTRALYTICS_HUB_API_KEY }}
+ MODEL_ID: ${{ secrets.ULTRALYTICS_HUB_MODEL_ID }}
+ run: |
+ import os
+ from ultralytics import YOLO, hub
+ api_key, model_id = os.environ['API_KEY'], os.environ['MODEL_ID']
+ hub.login(api_key)
+ hub.reset_model(model_id)
+ model = YOLO('https://hub.ultralytics.com/models/' + model_id)
+ model.train()
+ - name: Test HUB inference API
+ shell: python
+ env:
+ API_KEY: ${{ secrets.ULTRALYTICS_HUB_API_KEY }}
+ MODEL_ID: ${{ secrets.ULTRALYTICS_HUB_MODEL_ID }}
+ run: |
+ import os
+ import requests
+ import json
+ api_key, model_id = os.environ['API_KEY'], os.environ['MODEL_ID']
+ url = f"https://api.ultralytics.com/v1/predict/{model_id}"
+ headers = {"x-api-key": api_key}
+ data = {"size": 320, "confidence": 0.25, "iou": 0.45}
+ with open("ultralytics/assets/zidane.jpg", "rb") as f:
+ response = requests.post(url, headers=headers, data=data, files={"image": f})
+ assert response.status_code == 200, f'Status code {response.status_code}, Reason {response.reason}'
+ print(json.dumps(response.json(), indent=2))
+
+ Benchmarks:
+ if: github.event_name != 'workflow_dispatch' || github.event.inputs.benchmarks == 'true'
+ runs-on: ${{ matrix.os }}
+ strategy:
+ fail-fast: false
+ matrix:
+ os: [ubuntu-latest, macos-14]
+ python-version: ["3.11"]
+ model: [yolov8n]
+ steps:
+ - uses: actions/checkout@v4
+ - uses: actions/setup-python@v5
+ with:
+ python-version: ${{ matrix.python-version }}
+ cache: "pip" # caching pip dependencies
+ - name: Install requirements
+ shell: bash # for Windows compatibility
+ run: |
+ python -m pip install --upgrade pip wheel
+ pip install -e ".[export]" "coverage[toml]" --extra-index-url https://download.pytorch.org/whl/cpu
+ - name: Check environment
+ run: |
+ yolo checks
+ pip list
+ - name: Benchmark ClassificationModel
+ shell: bash
+ run: coverage run -a --source=ultralytics -m ultralytics.cfg.__init__ benchmark model='path with spaces/${{ matrix.model }}-cls.pt' imgsz=160 verbose=0.166
+ - name: Benchmark YOLOWorld DetectionModel
+ shell: bash
+ run: coverage run -a --source=ultralytics -m ultralytics.cfg.__init__ benchmark model='path with spaces/yolov8s-worldv2.pt' imgsz=160 verbose=0.318
+ - name: Benchmark SegmentationModel
+ shell: bash
+ run: coverage run -a --source=ultralytics -m ultralytics.cfg.__init__ benchmark model='path with spaces/${{ matrix.model }}-seg.pt' imgsz=160 verbose=0.279
+ - name: Benchmark PoseModel
+ shell: bash
+ run: coverage run -a --source=ultralytics -m ultralytics.cfg.__init__ benchmark model='path with spaces/${{ matrix.model }}-pose.pt' imgsz=160 verbose=0.183
+ - name: Benchmark OBBModel
+ shell: bash
+ run: coverage run -a --source=ultralytics -m ultralytics.cfg.__init__ benchmark model='path with spaces/${{ matrix.model }}-obb.pt' imgsz=160 verbose=0.472
+ - name: Benchmark YOLOv10Model
+ shell: bash
+ run: coverage run -a --source=ultralytics -m ultralytics.cfg.__init__ benchmark model='path with spaces/yolov10n.pt' imgsz=160 verbose=0.178
+ - name: Merge Coverage Reports
+ run: |
+ coverage xml -o coverage-benchmarks.xml
+ - name: Upload Coverage Reports to CodeCov
+ if: github.repository == 'ultralytics/ultralytics'
+ uses: codecov/codecov-action@v4
+ with:
+ flags: Benchmarks
+ env:
+ CODECOV_TOKEN: ${{ secrets.CODECOV_TOKEN }}
+ - name: Benchmark Summary
+ run: |
+ cat benchmarks.log
+ echo "$(cat benchmarks.log)" >> $GITHUB_STEP_SUMMARY
+
+ Tests:
+ if: github.event_name != 'workflow_dispatch' || github.event.inputs.tests == 'true'
+ timeout-minutes: 360
+ runs-on: ${{ matrix.os }}
+ strategy:
+ fail-fast: false
+ matrix:
+ os: [ubuntu-latest, macos-14]
+ python-version: ["3.11"]
+ torch: [latest]
+ include:
+ - os: ubuntu-latest
+ python-version: "3.8" # torch 1.8.0 requires python >=3.6, <=3.8
+ torch: "1.8.0" # min torch version CI https://pypi.org/project/torchvision/
+ steps:
+ - uses: actions/checkout@v4
+ - uses: actions/setup-python@v5
+ with:
+ python-version: ${{ matrix.python-version }}
+ cache: "pip" # caching pip dependencies
+ - name: Install requirements
+ shell: bash # for Windows compatibility
+ run: |
+ # CoreML must be installed before export due to protobuf error from AutoInstall
+ python -m pip install --upgrade pip wheel
+ slow=""
+ torch=""
+ if [ "${{ matrix.torch }}" == "1.8.0" ]; then
+ torch="torch==1.8.0 torchvision==0.9.0"
+ fi
+ if [[ "${{ github.event_name }}" =~ ^(schedule|workflow_dispatch)$ ]]; then
+ slow="pycocotools mlflow ray[tune]"
+ fi
+ pip install -e ".[export]" $torch $slow pytest-cov --extra-index-url https://download.pytorch.org/whl/cpu
+ - name: Check environment
+ run: |
+ yolo checks
+ pip list
+ - name: Pytest tests
+ shell: bash # for Windows compatibility
+ run: |
+ slow=""
+ if [[ "${{ github.event_name }}" =~ ^(schedule|workflow_dispatch)$ ]]; then
+ slow="--slow"
+ fi
+ pytest $slow --cov=ultralytics/ --cov-report xml tests/
+ - name: Upload Coverage Reports to CodeCov
+ if: github.repository == 'ultralytics/ultralytics' # && matrix.os == 'ubuntu-latest' && matrix.python-version == '3.11'
+ uses: codecov/codecov-action@v4
+ with:
+ flags: Tests
+ env:
+ CODECOV_TOKEN: ${{ secrets.CODECOV_TOKEN }}
+
+ GPU:
+ if: github.repository == 'ultralytics/ultralytics' && (github.event_name != 'workflow_dispatch' || github.event.inputs.gpu == 'true')
+ timeout-minutes: 360
+ runs-on: gpu-latest
+ steps:
+ - uses: actions/checkout@v4
+ - name: Install requirements
+ run: pip install -e . pytest-cov
+ - name: Check environment
+ run: |
+ yolo checks
+ pip list
+ - name: Pytest tests
+ run: |
+ slow=""
+ if [[ "${{ github.event_name }}" =~ ^(schedule|workflow_dispatch)$ ]]; then
+ slow="--slow"
+ fi
+ pytest $slow --cov=ultralytics/ --cov-report xml tests/test_cuda.py
+ - name: Upload Coverage Reports to CodeCov
+ uses: codecov/codecov-action@v4
+ with:
+ flags: GPU
+ env:
+ CODECOV_TOKEN: ${{ secrets.CODECOV_TOKEN }}
+
+ RaspberryPi:
+ if: github.repository == 'ultralytics/ultralytics' && (github.event_name == 'schedule' || github.event.inputs.raspberrypi == 'true')
+ timeout-minutes: 120
+ runs-on: raspberry-pi
+ steps:
+ - uses: actions/checkout@v4
+ - name: Activate Virtual Environment
+ run: |
+ python3.11 -m venv env
+ source env/bin/activate
+ echo PATH=$PATH >> $GITHUB_ENV
+ - name: Install requirements
+ run: |
+ python -m pip install --upgrade pip wheel
+ pip install -e ".[export]" pytest mlflow pycocotools "ray[tune]"
+ - name: Check environment
+ run: |
+ yolo checks
+ pip list
+ - name: Pytest tests
+ run: pytest --slow tests/
+ - name: Benchmark ClassificationModel
+ run: python -m ultralytics.cfg.__init__ benchmark model='yolov8n-cls.pt' imgsz=160 verbose=0.166
+ - name: Benchmark YOLOWorld DetectionModel
+ run: python -m ultralytics.cfg.__init__ benchmark model='yolov8s-worldv2.pt' imgsz=160 verbose=0.318
+ - name: Benchmark SegmentationModel
+ run: python -m ultralytics.cfg.__init__ benchmark model='yolov8n-seg.pt' imgsz=160 verbose=0.267
+ - name: Benchmark PoseModel
+ run: python -m ultralytics.cfg.__init__ benchmark model='yolov8n-pose.pt' imgsz=160 verbose=0.179
+ - name: Benchmark OBBModel
+ run: python -m ultralytics.cfg.__init__ benchmark model='yolov8n-obb.pt' imgsz=160 verbose=0.472
+ - name: Benchmark Summary
+ run: |
+ cat benchmarks.log
+ echo "$(cat benchmarks.log)" >> $GITHUB_STEP_SUMMARY
+ - name: Reboot # run a reboot command in the background to free resources for next run and not crash main thread
+ run: sudo bash -c "sleep 10; reboot" &
+
+ Conda:
+ if: github.repository == 'ultralytics/ultralytics' && (github.event_name == 'schedule' || github.event.inputs.conda == 'true')
+ runs-on: ${{ matrix.os }}
+ strategy:
+ fail-fast: false
+ matrix:
+ os: [ubuntu-latest]
+ python-version: ["3.11"]
+ defaults:
+ run:
+ shell: bash -el {0}
+ steps:
+ - uses: conda-incubator/setup-miniconda@v3
+ with:
+ python-version: ${{ matrix.python-version }}
+ mamba-version: "*"
+ channels: conda-forge,defaults
+ channel-priority: true
+ activate-environment: anaconda-client-env
+ - name: Cleanup toolcache
+ run: |
+ echo "Free space before deletion:"
+ df -h /
+ rm -rf /opt/hostedtoolcache
+ echo "Free space after deletion:"
+ df -h /
+ - name: Install Linux packages
+ run: |
+ # Fix cv2 ImportError: 'libEGL.so.1: cannot open shared object file: No such file or directory'
+ sudo apt-get update
+ sudo apt-get install -y libegl1 libopengl0
+ - name: Install Libmamba
+ run: |
+ conda config --set solver libmamba
+ - name: Install Ultralytics package from conda-forge
+ run: |
+ conda install -c pytorch -c conda-forge pytorch torchvision ultralytics openvino
+ - name: Install pip packages
+ run: |
+ # CoreML must be installed before export due to protobuf error from AutoInstall
+ pip install pytest "coremltools>=7.0; platform_system != 'Windows' and python_version <= '3.11'"
+ - name: Check environment
+ run: |
+ conda list
+ - name: Test CLI
+ run: |
+ yolo predict model=yolov8n.pt imgsz=320
+ yolo train model=yolov8n.pt data=coco8.yaml epochs=1 imgsz=32
+ yolo val model=yolov8n.pt data=coco8.yaml imgsz=32
+ yolo export model=yolov8n.pt format=torchscript imgsz=160
+ - name: Test Python
+ # Note this step must use the updated default bash environment, not a python environment
+ run: |
+ python -c "
+ from ultralytics import YOLO
+ model = YOLO('yolov8n.pt')
+ results = model.train(data='coco8.yaml', epochs=3, imgsz=160)
+ results = model.val(imgsz=160)
+ results = model.predict(imgsz=160)
+ results = model.export(format='onnx', imgsz=160)
+ "
+ - name: PyTest
+ run: |
+ git clone https://github.com/ultralytics/ultralytics
+ pytest ultralytics/tests
+
+ Summary:
+ runs-on: ubuntu-latest
+ needs: [HUB, Benchmarks, Tests, GPU, RaspberryPi, Conda] # Add job names that you want to check for failure
+ if: always() # This ensures the job runs even if previous jobs fail
+ steps:
+ - name: Check for failure and notify
+ if: (needs.HUB.result == 'failure' || needs.Benchmarks.result == 'failure' || needs.Tests.result == 'failure' || needs.GPU.result == 'failure' || needs.RaspberryPi.result == 'failure' || needs.Conda.result == 'failure' ) && github.repository == 'ultralytics/ultralytics' && (github.event_name == 'schedule' || github.event_name == 'push')
+ uses: slackapi/slack-github-action@v1.26.0
+ with:
+ payload: |
+ {"text": " GitHub Actions error for ${{ github.workflow }} ❌\n\n\n*Repository:* https://github.com/${{ github.repository }}\n*Action:* https://github.com/${{ github.repository }}/actions/runs/${{ github.run_id }}\n*Author:* ${{ github.actor }}\n*Event:* ${{ github.event_name }}\n"}
+ env:
+ SLACK_WEBHOOK_URL: ${{ secrets.SLACK_WEBHOOK_URL_YOLO }}
diff --git a/ultralytics/.github/workflows/cla.yml b/ultralytics/.github/workflows/cla.yml
new file mode 100644
index 0000000000000000000000000000000000000000..5475dc5cf5eb56362c07f21f9b21c02434c968c4
--- /dev/null
+++ b/ultralytics/.github/workflows/cla.yml
@@ -0,0 +1,44 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# Ultralytics Contributor License Agreement (CLA) action https://docs.ultralytics.com/help/CLA
+# This workflow automatically requests Pull Requests (PR) authors to sign the Ultralytics CLA before PRs can be merged
+
+name: CLA Assistant
+on:
+ issue_comment:
+ types:
+ - created
+ pull_request_target:
+ types:
+ - reopened
+ - opened
+ - synchronize
+
+permissions:
+ actions: write
+ contents: write
+ pull-requests: write
+ statuses: write
+
+jobs:
+ CLA:
+ if: github.repository == 'ultralytics/ultralytics'
+ runs-on: ubuntu-latest
+ steps:
+ - name: CLA Assistant
+ if: (github.event.comment.body == 'recheck' || github.event.comment.body == 'I have read the CLA Document and I sign the CLA') || github.event_name == 'pull_request_target'
+ uses: contributor-assistant/github-action@v2.5.1
+ env:
+ GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
+ # Must be repository secret PAT
+ PERSONAL_ACCESS_TOKEN: ${{ secrets.PERSONAL_ACCESS_TOKEN }}
+ with:
+ path-to-signatures: "signatures/version1/cla.json"
+ path-to-document: "https://docs.ultralytics.com/help/CLA" # CLA document
+ # Branch must not be protected
+ branch: cla-signatures
+ allowlist: dependabot[bot],github-actions,[pre-commit*,pre-commit*,bot*
+
+ remote-organization-name: ultralytics
+ remote-repository-name: cla
+ custom-pr-sign-comment: "I have read the CLA Document and I sign the CLA"
+ custom-allsigned-prcomment: All Contributors have signed the CLA. ✅
diff --git a/ultralytics/.github/workflows/codeql.yaml b/ultralytics/.github/workflows/codeql.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..b4a423d29bd1e5c3279a9952b4d1792f59d7b4ac
--- /dev/null
+++ b/ultralytics/.github/workflows/codeql.yaml
@@ -0,0 +1,42 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+name: "CodeQL"
+
+on:
+ schedule:
+ - cron: "0 0 1 * *"
+ workflow_dispatch:
+
+jobs:
+ analyze:
+ name: Analyze
+ runs-on: ${{ 'ubuntu-latest' }}
+ permissions:
+ actions: read
+ contents: read
+ security-events: write
+
+ strategy:
+ fail-fast: false
+ matrix:
+ language: ["python"]
+ # CodeQL supports [ 'cpp', 'csharp', 'go', 'java', 'javascript', 'python', 'ruby' ]
+
+ steps:
+ - name: Checkout repository
+ uses: actions/checkout@v4
+
+ # Initializes the CodeQL tools for scanning.
+ - name: Initialize CodeQL
+ uses: github/codeql-action/init@v3
+ with:
+ languages: ${{ matrix.language }}
+ # If you wish to specify custom queries, you can do so here or in a config file.
+ # By default, queries listed here will override any specified in a config file.
+ # Prefix the list here with "+" to use these queries and those in the config file.
+ # queries: security-extended,security-and-quality
+
+ - name: Perform CodeQL Analysis
+ uses: github/codeql-action/analyze@v3
+ with:
+ category: "/language:${{matrix.language}}"
diff --git a/ultralytics/.github/workflows/docker.yaml b/ultralytics/.github/workflows/docker.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..f2c629c5f4a642a43a46dc04dc5989edc296a308
--- /dev/null
+++ b/ultralytics/.github/workflows/docker.yaml
@@ -0,0 +1,186 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# Builds ultralytics/ultralytics:latest images on DockerHub https://hub.docker.com/r/ultralytics
+
+name: Publish Docker Images
+
+on:
+ push:
+ branches: [main]
+ paths-ignore:
+ - "docs/**"
+ - "mkdocs.yml"
+ workflow_dispatch:
+ inputs:
+ Dockerfile:
+ type: boolean
+ description: Use Dockerfile
+ default: true
+ Dockerfile-cpu:
+ type: boolean
+ description: Use Dockerfile-cpu
+ default: true
+ Dockerfile-arm64:
+ type: boolean
+ description: Use Dockerfile-arm64
+ default: true
+ Dockerfile-jetson-jetpack6:
+ type: boolean
+ description: Use Dockerfile-jetson-jetpack6
+ default: true
+ Dockerfile-jetson-jetpack5:
+ type: boolean
+ description: Use Dockerfile-jetson-jetpack5
+ default: true
+ Dockerfile-jetson-jetpack4:
+ type: boolean
+ description: Use Dockerfile-jetson-jetpack4
+ default: true
+ Dockerfile-python:
+ type: boolean
+ description: Use Dockerfile-python
+ default: true
+ Dockerfile-conda:
+ type: boolean
+ description: Use Dockerfile-conda
+ default: true
+ push:
+ type: boolean
+ description: Publish all Images to Docker Hub
+
+jobs:
+ docker:
+ if: github.repository == 'ultralytics/ultralytics'
+ name: Push
+ runs-on: ubuntu-latest
+ strategy:
+ fail-fast: false
+ max-parallel: 10
+ matrix:
+ include:
+ - dockerfile: "Dockerfile"
+ tags: "latest"
+ platforms: "linux/amd64"
+ - dockerfile: "Dockerfile-cpu"
+ tags: "latest-cpu"
+ platforms: "linux/amd64"
+ - dockerfile: "Dockerfile-arm64"
+ tags: "latest-arm64"
+ platforms: "linux/arm64"
+ - dockerfile: "Dockerfile-jetson-jetpack6"
+ tags: "latest-jetson-jetpack6"
+ platforms: "linux/arm64"
+ - dockerfile: "Dockerfile-jetson-jetpack5"
+ tags: "latest-jetson-jetpack5"
+ platforms: "linux/arm64"
+ - dockerfile: "Dockerfile-jetson-jetpack4"
+ tags: "latest-jetson-jetpack4"
+ platforms: "linux/arm64"
+ - dockerfile: "Dockerfile-python"
+ tags: "latest-python"
+ platforms: "linux/amd64"
+ # - dockerfile: "Dockerfile-conda"
+ # tags: "latest-conda"
+ # platforms: "linux/amd64"
+ steps:
+ - name: Cleanup toolcache
+ # Free up to 10GB of disk space per https://github.com/ultralytics/ultralytics/pull/14894
+ run: |
+ echo "Free space before deletion:"
+ df -h /
+ rm -rf /opt/hostedtoolcache
+ echo "Free space after deletion:"
+ df -h /
+
+ - name: Checkout repo
+ uses: actions/checkout@v4
+ with:
+ fetch-depth: 0 # copy full .git directory to access full git history in Docker images
+
+ - name: Set up QEMU
+ uses: docker/setup-qemu-action@v3
+
+ - name: Set up Docker Buildx
+ uses: docker/setup-buildx-action@v3
+
+ - name: Login to Docker Hub
+ uses: docker/login-action@v3
+ with:
+ username: ${{ secrets.DOCKERHUB_USERNAME }}
+ password: ${{ secrets.DOCKERHUB_TOKEN }}
+
+ - name: Retrieve Ultralytics version
+ id: get_version
+ run: |
+ VERSION=$(grep "^__version__ =" ultralytics/__init__.py | awk -F'"' '{print $2}')
+ echo "Retrieved Ultralytics version: $VERSION"
+ echo "version=$VERSION" >> $GITHUB_OUTPUT
+
+ VERSION_TAG=$(echo "${{ matrix.tags }}" | sed "s/latest/${VERSION}/")
+ echo "Intended version tag: $VERSION_TAG"
+ echo "version_tag=$VERSION_TAG" >> $GITHUB_OUTPUT
+
+ - name: Check if version tag exists on DockerHub
+ id: check_tag
+ run: |
+ RESPONSE=$(curl -s https://hub.docker.com/v2/repositories/ultralytics/ultralytics/tags/$VERSION_TAG)
+ MESSAGE=$(echo $RESPONSE | jq -r '.message')
+ if [[ "$MESSAGE" == "null" ]]; then
+ echo "Tag $VERSION_TAG already exists on DockerHub."
+ echo "exists=true" >> $GITHUB_OUTPUT
+ elif [[ "$MESSAGE" == *"404"* ]]; then
+ echo "Tag $VERSION_TAG does not exist on DockerHub."
+ echo "exists=false" >> $GITHUB_OUTPUT
+ else
+ echo "Unexpected response from DockerHub. Please check manually."
+ echo "exists=false" >> $GITHUB_OUTPUT
+ fi
+ env:
+ VERSION_TAG: ${{ steps.get_version.outputs.version_tag }}
+
+ - name: Build Image
+ if: github.event_name == 'push' || github.event.inputs[matrix.dockerfile] == 'true'
+ uses: nick-invision/retry@v3
+ with:
+ timeout_minutes: 120
+ retry_wait_seconds: 60
+ max_attempts: 2 # retry once
+ command: |
+ docker build \
+ --platform ${{ matrix.platforms }} \
+ -f docker/${{ matrix.dockerfile }} \
+ -t ultralytics/ultralytics:${{ matrix.tags }} \
+ -t ultralytics/ultralytics:${{ steps.get_version.outputs.version_tag }} \
+ .
+
+ - name: Run Tests
+ if: (github.event_name == 'push' || github.event.inputs[matrix.dockerfile] == 'true') && matrix.platforms == 'linux/amd64' && matrix.dockerfile != 'Dockerfile-conda' # arm64 images not supported on GitHub CI runners
+ run: docker run ultralytics/ultralytics:${{ matrix.tags }} /bin/bash -c "pip install pytest && pytest tests"
+
+ - name: Run Benchmarks
+ # WARNING: Dockerfile (GPU) error on TF.js export 'module 'numpy' has no attribute 'object'.
+ if: (github.event_name == 'push' || github.event.inputs[matrix.dockerfile] == 'true') && matrix.platforms == 'linux/amd64' && matrix.dockerfile != 'Dockerfile' && matrix.dockerfile != 'Dockerfile-conda' # arm64 images not supported on GitHub CI runners
+ run: docker run ultralytics/ultralytics:${{ matrix.tags }} yolo benchmark model=yolov8n.pt imgsz=160 verbose=0.318
+
+ - name: Push Docker Image with Ultralytics version tag
+ if: (github.event_name == 'push' || (github.event.inputs[matrix.dockerfile] == 'true' && github.event.inputs.push == 'true')) && steps.check_tag.outputs.exists == 'false' && matrix.dockerfile != 'Dockerfile-conda'
+ run: |
+ docker push ultralytics/ultralytics:${{ steps.get_version.outputs.version_tag }}
+
+ - name: Push Docker Image with latest tag
+ if: github.event_name == 'push' || (github.event.inputs[matrix.dockerfile] == 'true' && github.event.inputs.push == 'true')
+ run: |
+ docker push ultralytics/ultralytics:${{ matrix.tags }}
+ if [[ "${{ matrix.tags }}" == "latest" ]]; then
+ t=ultralytics/ultralytics:latest-runner
+ docker build -f docker/Dockerfile-runner -t $t .
+ docker push $t
+ fi
+
+ - name: Notify on failure
+ if: github.event_name == 'push' && failure() # do not notify on cancelled() as cancelling is performed by hand
+ uses: slackapi/slack-github-action@v1.26.0
+ with:
+ payload: |
+ {"text": " GitHub Actions error for ${{ github.workflow }} ❌\n\n\n*Repository:* https://github.com/${{ github.repository }}\n*Action:* https://github.com/${{ github.repository }}/actions/runs/${{ github.run_id }}\n*Author:* ${{ github.actor }}\n*Event:* ${{ github.event_name }}\n"}
+ env:
+ SLACK_WEBHOOK_URL: ${{ secrets.SLACK_WEBHOOK_URL_YOLO }}
diff --git a/ultralytics/.github/workflows/docs.yml b/ultralytics/.github/workflows/docs.yml
new file mode 100644
index 0000000000000000000000000000000000000000..20448a44b3733e59363dc78d906c617e5652b076
--- /dev/null
+++ b/ultralytics/.github/workflows/docs.yml
@@ -0,0 +1,101 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# Test and publish docs to https://docs.ultralytics.com
+# Ignores the following Docs rules to match Google-style docstrings:
+# D100: Missing docstring in public module
+# D104: Missing docstring in public package
+# D203: 1 blank line required before class docstring
+# D205: 1 blank line required between summary line and description
+# D212: Multi-line docstring summary should start at the first line
+# D213: Multi-line docstring summary should start at the second line
+# D401: First line of docstring should be in imperative mood
+# D406: Section name should end with a newline
+# D407: Missing dashed underline after section
+# D413: Missing blank line after last section
+
+name: Publish Docs
+
+on:
+ push:
+ branches: [main]
+ pull_request_target:
+ branches: [main]
+ workflow_dispatch:
+
+jobs:
+ Docs:
+ if: github.repository == 'ultralytics/ultralytics'
+ runs-on: macos-14
+ steps:
+ - name: Git config
+ run: |
+ git config --global user.name "UltralyticsAssistant"
+ git config --global user.email "web@ultralytics.com"
+ - name: Checkout Repository
+ uses: actions/checkout@v4
+ with:
+ repository: ${{ github.event.pull_request.head.repo.full_name || github.repository }}
+ token: ${{ secrets.GITHUB_TOKEN }}
+ ref: ${{ github.head_ref || github.ref }}
+ fetch-depth: 0
+ - name: Set up Python
+ uses: actions/setup-python@v5
+ with:
+ python-version: "3.x"
+ cache: "pip" # caching pip dependencies
+ - name: Install Dependencies
+ run: pip install ruff black tqdm mkdocs-material "mkdocstrings[python]" mkdocs-jupyter mkdocs-redirects mkdocs-ultralytics-plugin mkdocs-macros-plugin
+ - name: Ruff fixes
+ continue-on-error: true
+ run: ruff check --fix --fix-unsafe --select D --ignore=D100,D104,D203,D205,D212,D213,D401,D406,D407,D413 .
+ - name: Update Docs Reference Section and Push Changes
+ if: github.event_name == 'pull_request_target'
+ run: |
+ python docs/build_reference.py
+ git pull origin ${{ github.head_ref || github.ref }}
+ git add .
+ git reset HEAD -- .github/workflows/ # workflow changes are not permitted with default token
+ if ! git diff --staged --quiet; then
+ git commit -m "Auto-update Ultralytics Docs Reference by https://ultralytics.com/actions"
+ git push
+ else
+ echo "No changes to commit"
+ fi
+ - name: Ruff checks
+ run: ruff check --select D --ignore=D100,D104,D203,D205,D212,D213,D401,D406,D407,D413 .
+ - name: Build Docs and Check for Warnings
+ run: |
+ export JUPYTER_PLATFORM_DIRS=1
+ python docs/build_docs.py
+ - name: Commit and Push Docs changes
+ continue-on-error: true
+ if: always() && github.event_name == 'pull_request_target'
+ run: |
+ git pull origin ${{ github.head_ref || github.ref }}
+ git add --update # only add updated files
+ git reset HEAD -- .github/workflows/ # workflow changes are not permitted with default token
+ if ! git diff --staged --quiet; then
+ git commit -m "Auto-update Ultralytics Docs by https://ultralytics.com/actions"
+ git push
+ else
+ echo "No changes to commit"
+ fi
+ - name: Publish Docs to https://docs.ultralytics.com
+ if: github.event_name == 'push'
+ env:
+ PERSONAL_ACCESS_TOKEN: ${{ secrets.PERSONAL_ACCESS_TOKEN }}
+ INDEXNOW_KEY: ${{ secrets.INDEXNOW_KEY_DOCS }}
+ run: |
+ git clone https://github.com/ultralytics/docs.git docs-repo
+ cd docs-repo
+ git checkout gh-pages || git checkout -b gh-pages
+ rm -rf *
+ cp -R ../site/* .
+ echo "$INDEXNOW_KEY" > "$INDEXNOW_KEY.txt"
+ git add .
+ if git diff --staged --quiet; then
+ echo "No changes to commit"
+ else
+ LATEST_HASH=$(git rev-parse --short=7 HEAD)
+ git commit -m "Update Docs for 'ultralytics ${{ steps.check_pypi.outputs.version }} - $LATEST_HASH'"
+ git push https://$PERSONAL_ACCESS_TOKEN@github.com/ultralytics/docs.git gh-pages
+ fi
diff --git a/ultralytics/.github/workflows/format.yml b/ultralytics/.github/workflows/format.yml
new file mode 100644
index 0000000000000000000000000000000000000000..c2ba92f3df7c7e0e12be8d2bbacaafe2c7123303
--- /dev/null
+++ b/ultralytics/.github/workflows/format.yml
@@ -0,0 +1,29 @@
+# Ultralytics 🚀 - AGPL-3.0 License https://ultralytics.com/license
+# Ultralytics Actions https://github.com/ultralytics/actions
+# This workflow automatically formats code and documentation in PRs to official Ultralytics standards
+
+name: Ultralytics Actions
+
+on:
+ issues:
+ types: [opened, edited]
+ pull_request_target:
+ branches: [main]
+ types: [opened, closed, synchronize, review_requested]
+
+jobs:
+ format:
+ runs-on: macos-14
+ steps:
+ - name: Run Ultralytics Formatting
+ uses: ultralytics/actions@main
+ with:
+ token: ${{ secrets.PERSONAL_ACCESS_TOKEN || secrets.GITHUB_TOKEN }} # note GITHUB_TOKEN automatically generated
+ labels: true # autolabel issues and PRs
+ python: true # format Python code and docstrings
+ prettier: true # format YAML, JSON, Markdown and CSS
+ spelling: true # check spelling
+ links: false # check broken links
+ summary: true # print PR summary with GPT4o (requires 'openai_api_key')
+ openai_azure_api_key: ${{ secrets.OPENAI_AZURE_API_KEY }}
+ openai_azure_endpoint: ${{ secrets.OPENAI_AZURE_ENDPOINT }}
diff --git a/ultralytics/.github/workflows/greetings.yml b/ultralytics/.github/workflows/greetings.yml
new file mode 100644
index 0000000000000000000000000000000000000000..95834ccb30e782e930f9bb63aad68b0eee924e15
--- /dev/null
+++ b/ultralytics/.github/workflows/greetings.yml
@@ -0,0 +1,58 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+name: Greetings
+
+on:
+ pull_request_target:
+ types: [opened]
+ issues:
+ types: [opened]
+
+jobs:
+ greeting:
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/first-interaction@v1
+ with:
+ repo-token: ${{ secrets.GITHUB_TOKEN }}
+ pr-message: |
+ 👋 Hello @${{ github.actor }}, thank you for submitting an Ultralytics YOLOv8 🚀 PR! To allow your work to be integrated as seamlessly as possible, we advise you to:
+
+ - ✅ Verify your PR is **up-to-date** with `ultralytics/ultralytics` `main` branch. If your PR is behind you can update your code by clicking the 'Update branch' button or by running `git pull` and `git merge main` locally.
+ - ✅ Verify all YOLOv8 Continuous Integration (CI) **checks are passing**.
+ - ✅ Update YOLOv8 [Docs](https://docs.ultralytics.com) for any new or updated features.
+ - ✅ Reduce changes to the absolute **minimum** required for your bug fix or feature addition. _"It is not daily increase but daily decrease, hack away the unessential. The closer to the source, the less wastage there is."_ — Bruce Lee
+
+ See our [Contributing Guide](https://docs.ultralytics.com/help/contributing) for details and let us know if you have any questions!
+
+ issue-message: |
+ 👋 Hello @${{ github.actor }}, thank you for your interest in Ultralytics YOLOv8 🚀! We recommend a visit to the [Docs](https://docs.ultralytics.com) for new users where you can find many [Python](https://docs.ultralytics.com/usage/python/) and [CLI](https://docs.ultralytics.com/usage/cli/) usage examples and where many of the most common questions may already be answered.
+
+ If this is a 🐛 Bug Report, please provide a [minimum reproducible example](https://docs.ultralytics.com/help/minimum_reproducible_example/) to help us debug it.
+
+ If this is a custom training ❓ Question, please provide as much information as possible, including dataset image examples and training logs, and verify you are following our [Tips for Best Training Results](https://docs.ultralytics.com/guides/model-training-tips//).
+
+ Join the vibrant [Ultralytics Discord](https://ultralytics.com/discord) 🎧 community for real-time conversations and collaborations. This platform offers a perfect space to inquire, showcase your work, and connect with fellow Ultralytics users.
+
+ ## Install
+
+ Pip install the `ultralytics` package including all [requirements](https://github.com/ultralytics/ultralytics/blob/main/pyproject.toml) in a [**Python>=3.8**](https://www.python.org/) environment with [**PyTorch>=1.8**](https://pytorch.org/get-started/locally/).
+
+ ```bash
+ pip install ultralytics
+ ```
+
+ ## Environments
+
+ YOLOv8 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
+
+ - **Notebooks** with free GPU:
+ - **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)
+ - **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)
+ - **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/)
+
+ ## Status
+
+
+
+ If this badge is green, all [Ultralytics CI](https://github.com/ultralytics/ultralytics/actions/workflows/ci.yaml?query=event%3Aschedule) tests are currently passing. CI tests verify correct operation of all YOLOv8 [Modes](https://docs.ultralytics.com/modes/) and [Tasks](https://docs.ultralytics.com/tasks/) on macOS, Windows, and Ubuntu every 24 hours and on every commit.
diff --git a/ultralytics/.github/workflows/links.yml b/ultralytics/.github/workflows/links.yml
new file mode 100644
index 0000000000000000000000000000000000000000..39112baf0b879b2ea99db4248abfc0f545df28fd
--- /dev/null
+++ b/ultralytics/.github/workflows/links.yml
@@ -0,0 +1,93 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# Continuous Integration (CI) GitHub Actions tests broken link checker using https://github.com/lycheeverse/lychee
+# Ignores the following status codes to reduce false positives:
+# - 401(Vimeo, 'unauthorized')
+# - 403(OpenVINO, 'forbidden')
+# - 429(Instagram, 'too many requests')
+# - 500(Zenodo, 'cached')
+# - 502(Zenodo, 'bad gateway')
+# - 999(LinkedIn, 'unknown status code')
+
+name: Check Broken links
+
+on:
+ workflow_dispatch:
+ schedule:
+ - cron: "0 0 * * *" # runs at 00:00 UTC every day
+
+jobs:
+ Links:
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/checkout@v4
+
+ - name: Download and install lychee
+ run: |
+ LYCHEE_URL=$(curl -s https://api.github.com/repos/lycheeverse/lychee/releases/latest | grep "browser_download_url" | grep "x86_64-unknown-linux-gnu.tar.gz" | cut -d '"' -f 4)
+ curl -L $LYCHEE_URL -o lychee.tar.gz
+ tar xzf lychee.tar.gz
+ sudo mv lychee /usr/local/bin
+
+ - name: Test Markdown and HTML links with retry
+ uses: nick-invision/retry@v3
+ with:
+ timeout_minutes: 5
+ retry_wait_seconds: 60
+ max_attempts: 3
+ command: |
+ lychee \
+ --scheme https \
+ --timeout 60 \
+ --insecure \
+ --accept 401,403,429,500,502,999 \
+ --exclude-all-private \
+ --exclude 'https?://(www\.)?(linkedin\.com|twitter\.com|instagram\.com|kaggle\.com|fonts\.gstatic\.com|url\.com)' \
+ --exclude-path docs/zh \
+ --exclude-path docs/es \
+ --exclude-path docs/ru \
+ --exclude-path docs/pt \
+ --exclude-path docs/fr \
+ --exclude-path docs/de \
+ --exclude-path docs/ja \
+ --exclude-path docs/ko \
+ --exclude-path docs/hi \
+ --exclude-path docs/ar \
+ --github-token ${{ secrets.GITHUB_TOKEN }} \
+ --header "User-Agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.6478.183 Safari/537.36" \
+ './**/*.md' \
+ './**/*.html'
+
+ - name: Test Markdown, HTML, YAML, Python and Notebook links with retry
+ if: github.event_name == 'workflow_dispatch'
+ uses: nick-invision/retry@v3
+ with:
+ timeout_minutes: 5
+ retry_wait_seconds: 60
+ max_attempts: 3
+ command: |
+ lychee \
+ --scheme https \
+ --timeout 60 \
+ --insecure \
+ --accept 401,403,429,500,502,999 \
+ --exclude-all-private \
+ --exclude 'https?://(www\.)?(linkedin\.com|twitter\.com|instagram\.com|kaggle\.com|fonts\.gstatic\.com|url\.com)' \
+ --exclude-path '**/ci.yaml' \
+ --exclude-path docs/zh \
+ --exclude-path docs/es \
+ --exclude-path docs/ru \
+ --exclude-path docs/pt \
+ --exclude-path docs/fr \
+ --exclude-path docs/de \
+ --exclude-path docs/ja \
+ --exclude-path docs/ko \
+ --exclude-path docs/hi \
+ --exclude-path docs/ar \
+ --github-token ${{ secrets.GITHUB_TOKEN }} \
+ --header "User-Agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.6478.183 Safari/537.36" \
+ './**/*.md' \
+ './**/*.html' \
+ './**/*.yml' \
+ './**/*.yaml' \
+ './**/*.py' \
+ './**/*.ipynb'
diff --git a/ultralytics/.github/workflows/merge-main-into-prs.yml b/ultralytics/.github/workflows/merge-main-into-prs.yml
new file mode 100644
index 0000000000000000000000000000000000000000..7490ccadadb2356121754e728f762408fd18db0b
--- /dev/null
+++ b/ultralytics/.github/workflows/merge-main-into-prs.yml
@@ -0,0 +1,91 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# Automatically merges repository 'main' branch into all open PRs to keep them up-to-date
+# Action runs on updates to main branch so when one PR merges to main all others update
+
+name: Merge main into PRs
+
+on:
+ workflow_dispatch:
+ # push:
+ # branches:
+ # - ${{ github.event.repository.default_branch }}
+
+jobs:
+ Merge:
+ if: github.repository == 'ultralytics/ultralytics'
+ runs-on: ubuntu-latest
+ steps:
+ - name: Checkout repository
+ uses: actions/checkout@v4
+ with:
+ fetch-depth: 0
+ - uses: actions/setup-python@v5
+ with:
+ python-version: "3.x"
+ cache: "pip"
+ - name: Install requirements
+ run: |
+ pip install pygithub
+ - name: Merge default branch into PRs
+ shell: python
+ run: |
+ from github import Github
+ import os
+ import time
+
+ g = Github(os.getenv('GITHUB_TOKEN'))
+ repo = g.get_repo(os.getenv('GITHUB_REPOSITORY'))
+
+ # Fetch the default branch name
+ default_branch_name = repo.default_branch
+ default_branch = repo.get_branch(default_branch_name)
+
+ # Initialize counters
+ updated_branches = 0
+ up_to_date_branches = 0
+ errors = 0
+
+ for pr in repo.get_pulls(state='open', sort='created'):
+ try:
+ # Label PRs as popular for positive reactions
+ reactions = pr.as_issue().get_reactions()
+ if sum([(1 if r.content not in {"-1", "confused"} else 0) for r in reactions]) > 5:
+ pr.set_labels(*("popular",) + tuple(l.name for l in pr.get_labels()))
+
+ # Get full names for repositories and branches
+ base_repo_name = repo.full_name
+ head_repo_name = pr.head.repo.full_name
+ base_branch_name = pr.base.ref
+ head_branch_name = pr.head.ref
+
+ # Check if PR is behind the default branch
+ comparison = repo.compare(default_branch.commit.sha, pr.head.sha)
+ if comparison.behind_by > 0:
+ print(f"⚠️ PR #{pr.number} ({head_repo_name}:{head_branch_name} -> {base_repo_name}:{base_branch_name}) is behind {default_branch_name} by {comparison.behind_by} commit(s).")
+
+ # Attempt to update the branch
+ try:
+ success = pr.update_branch()
+ assert success, "Branch update failed"
+ print(f"✅ Successfully merged '{default_branch_name}' into PR #{pr.number} ({head_repo_name}:{head_branch_name} -> {base_repo_name}:{base_branch_name}).")
+ updated_branches += 1
+ time.sleep(10) # rate limit merges
+ except Exception as update_error:
+ print(f"❌ Could not update PR #{pr.number} ({head_repo_name}:{head_branch_name} -> {base_repo_name}:{base_branch_name}): {update_error}")
+ errors += 1
+ else:
+ print(f"✅ PR #{pr.number} ({head_repo_name}:{head_branch_name} -> {base_repo_name}:{base_branch_name}) is already up to date with {default_branch_name}, no merge required.")
+ up_to_date_branches += 1
+ except Exception as e:
+ print(f"❌ Could not process PR #{pr.number}: {e}")
+ errors += 1
+
+ # Print summary
+ print("\n\nSummary:")
+ print(f"Branches updated: {updated_branches}")
+ print(f"Branches already up-to-date: {up_to_date_branches}")
+ print(f"Total errors: {errors}")
+
+ env:
+ GITHUB_TOKEN: ${{ secrets.PERSONAL_ACCESS_TOKEN || secrets.GITHUB_TOKEN }}
+ GITHUB_REPOSITORY: ${{ github.repository }}
diff --git a/ultralytics/.github/workflows/publish.yml b/ultralytics/.github/workflows/publish.yml
new file mode 100644
index 0000000000000000000000000000000000000000..506f9f8ddfd8d725aece0d4817d4a85cc15b9f00
--- /dev/null
+++ b/ultralytics/.github/workflows/publish.yml
@@ -0,0 +1,206 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# Publish pip package to PyPI https://pypi.org/project/ultralytics/
+
+name: Publish to PyPI
+
+on:
+ push:
+ branches: [main]
+ workflow_dispatch:
+ inputs:
+ pypi:
+ type: boolean
+ description: Publish to PyPI
+
+jobs:
+ publish:
+ if: github.repository == 'ultralytics/ultralytics' && github.actor == 'glenn-jocher'
+ name: Publish
+ runs-on: ubuntu-latest
+ steps:
+ - name: Checkout code
+ uses: actions/checkout@v4
+ with:
+ token: ${{ secrets.PERSONAL_ACCESS_TOKEN || secrets.GITHUB_TOKEN }} # use your PAT here
+ - name: Git config
+ run: |
+ git config --global user.name "UltralyticsAssistant"
+ git config --global user.email "web@ultralytics.com"
+ - name: Set up Python environment
+ uses: actions/setup-python@v5
+ with:
+ python-version: "3.x"
+ cache: "pip" # caching pip dependencies
+ - name: Install dependencies
+ run: |
+ python -m pip install --upgrade pip wheel
+ pip install openai requests build twine toml
+ - name: Check PyPI version
+ shell: python
+ run: |
+ import os
+ import requests
+ import toml
+
+ # Load version and package name from pyproject.toml
+ pyproject = toml.load('pyproject.toml')
+ package_name = pyproject['project']['name']
+ local_version = pyproject['project'].get('version', 'dynamic')
+
+ # If version is dynamic, extract it from the specified file
+ if local_version == 'dynamic':
+ version_attr = pyproject['tool']['setuptools']['dynamic']['version']['attr']
+ module_path, attr_name = version_attr.rsplit('.', 1)
+ with open(f"{module_path.replace('.', '/')}/__init__.py") as f:
+ local_version = next(line.split('=')[1].strip().strip("'\"") for line in f if line.startswith(attr_name))
+
+ print(f"Local Version: {local_version}")
+
+ # Get online version from PyPI
+ response = requests.get(f"https://pypi.org/pypi/{package_name}/json")
+ online_version = response.json()['info']['version'] if response.status_code == 200 else None
+ print(f"Online Version: {online_version or 'Not Found'}")
+
+ # Determine if a new version should be published
+ publish = False
+ if online_version:
+ local_ver = tuple(map(int, local_version.split('.')))
+ online_ver = tuple(map(int, online_version.split('.')))
+ major_diff = local_ver[0] - online_ver[0]
+ minor_diff = local_ver[1] - online_ver[1]
+ patch_diff = local_ver[2] - online_ver[2]
+
+ publish = (
+ (major_diff == 0 and minor_diff == 0 and 0 < patch_diff <= 2) or
+ (major_diff == 0 and minor_diff == 1 and local_ver[2] == 0) or
+ (major_diff == 1 and local_ver[1] == 0 and local_ver[2] == 0)
+ )
+ else:
+ publish = True # First release
+
+ os.system(f'echo "increment={publish}" >> $GITHUB_OUTPUT')
+ os.system(f'echo "version={local_version}" >> $GITHUB_OUTPUT')
+ os.system(f'echo "previous_version={online_version or "N/A"}" >> $GITHUB_OUTPUT')
+
+ if publish:
+ print('Ready to publish new version to PyPI ✅.')
+ id: check_pypi
+ - name: Publish new tag
+ if: (github.event_name == 'push' || github.event.inputs.pypi == 'true') && steps.check_pypi.outputs.increment == 'True'
+ run: |
+ git tag -a "v${{ steps.check_pypi.outputs.version }}" -m "$(git log -1 --pretty=%B)" # i.e. "v0.1.2 commit message"
+ git push origin "v${{ steps.check_pypi.outputs.version }}"
+ - name: Publish new release
+ if: (github.event_name == 'push' || github.event.inputs.pypi == 'true') && steps.check_pypi.outputs.increment == 'True'
+ env:
+ OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
+ GITHUB_TOKEN: ${{ secrets.PERSONAL_ACCESS_TOKEN || secrets.GITHUB_TOKEN }}
+ CURRENT_TAG: ${{ steps.check_pypi.outputs.version }}
+ PREVIOUS_TAG: ${{ steps.check_pypi.outputs.previous_version }}
+ shell: python
+ run: |
+ import openai
+ import os
+ import requests
+ import json
+ import subprocess
+
+ # Retrieve environment variables
+ OPENAI_API_KEY = os.getenv('OPENAI_API_KEY')
+ GITHUB_TOKEN = os.getenv('GITHUB_TOKEN')
+ CURRENT_TAG = os.getenv('CURRENT_TAG')
+ PREVIOUS_TAG = os.getenv('PREVIOUS_TAG')
+
+ # Check for required environment variables
+ if not all([OPENAI_API_KEY, GITHUB_TOKEN, CURRENT_TAG, PREVIOUS_TAG]):
+ raise ValueError("One or more required environment variables are missing.")
+
+ latest_tag = f"v{CURRENT_TAG}"
+ previous_tag = f"v{PREVIOUS_TAG}"
+ repo = os.getenv('GITHUB_REPOSITORY')
+ headers = {"Authorization": f"token {GITHUB_TOKEN}", "Accept": "application/vnd.github.v3.diff"}
+
+ # Get the diff between the tags
+ url = f"https://api.github.com/repos/{repo}/compare/{previous_tag}...{latest_tag}"
+ response = requests.get(url, headers=headers)
+ diff = response.text if response.status_code == 200 else f"Failed to get diff: {response.content}"
+
+ # Get summary
+ messages = [
+ {
+ "role": "system",
+ "content": "You are an Ultralytics AI assistant skilled in software development and technical communication. Your task is to summarize GitHub releases in a way that is detailed, accurate, and understandable to both expert developers and non-expert users. Focus on highlighting the key changes and their impact in simple and intuitive terms."
+ },
+ {
+ "role": "user",
+ "content": f"Summarize the updates made in the '{latest_tag}' tag, focusing on major changes, their purpose, and potential impact. Keep the summary clear and suitable for a broad audience. Add emojis to enliven the summary. Reply directly with a summary along these example guidelines, though feel free to adjust as appropriate:\n\n"
+ f"## 🌟 Summary (single-line synopsis)\n"
+ f"## 📊 Key Changes (bullet points highlighting any major changes)\n"
+ f"## 🎯 Purpose & Impact (bullet points explaining any benefits and potential impact to users)\n"
+ f"\n\nHere's the release diff:\n\n{diff[:300000]}",
+ }
+ ]
+ client = openai.OpenAI(api_key=OPENAI_API_KEY)
+ completion = client.chat.completions.create(model="gpt-4o-2024-08-06", messages=messages)
+ summary = completion.choices[0].message.content.strip()
+
+ # Get the latest commit message
+ commit_message = subprocess.run(['git', 'log', '-1', '--pretty=%B'], check=True, text=True, capture_output=True).stdout.split("\n")[0].strip()
+
+ # Prepare release data
+ release = {
+ 'tag_name': latest_tag,
+ 'name': f"{latest_tag} - {commit_message}",
+ 'body': summary,
+ 'draft': False,
+ 'prerelease': False
+ }
+
+ # Create the release on GitHub
+ release_url = f"https://api.github.com/repos/{repo}/releases"
+ release_response = requests.post(release_url, headers=headers, data=json.dumps(release))
+ if release_response.status_code == 201:
+ print(f'Successfully created release {latest_tag}')
+ else:
+ print(f'Failed to create release {latest_tag}: {release_response.content}')
+ - name: Publish to PyPI
+ continue-on-error: true
+ if: (github.event_name == 'push' || github.event.inputs.pypi == 'true') && steps.check_pypi.outputs.increment == 'True'
+ env:
+ PYPI_TOKEN: ${{ secrets.PYPI_TOKEN }}
+ run: |
+ python -m build
+ python -m twine upload dist/* -u __token__ -p $PYPI_TOKEN
+ - name: Extract PR Details
+ env:
+ GH_TOKEN: ${{ secrets.PERSONAL_ACCESS_TOKEN || secrets.GITHUB_TOKEN }}
+ run: |
+ # Check if the event is a pull request or pull_request_target
+ if [ "${{ github.event_name }}" = "pull_request" ] || [ "${{ github.event_name }}" = "pull_request_target" ]; then
+ PR_NUMBER=${{ github.event.pull_request.number }}
+ PR_TITLE=$(gh pr view $PR_NUMBER --json title --jq '.title')
+ else
+ # Use gh to find the PR associated with the commit
+ COMMIT_SHA=${{ github.event.after }}
+ PR_JSON=$(gh pr list --search "${COMMIT_SHA}" --state merged --json number,title --jq '.[0]')
+ PR_NUMBER=$(echo $PR_JSON | jq -r '.number')
+ PR_TITLE=$(echo $PR_JSON | jq -r '.title')
+ fi
+ echo "PR_NUMBER=$PR_NUMBER" >> $GITHUB_ENV
+ echo "PR_TITLE=$PR_TITLE" >> $GITHUB_ENV
+ - name: Notify on Slack (Success)
+ if: success() && github.event_name == 'push' && steps.check_pypi.outputs.increment == 'True'
+ uses: slackapi/slack-github-action@v1.26.0
+ with:
+ payload: |
+ {"text": " GitHub Actions success for ${{ github.workflow }} ✅\n\n\n*Repository:* https://github.com/${{ github.repository }}\n*Action:* https://github.com/${{ github.repository }}/actions/runs/${{ github.run_id }}\n*Author:* ${{ github.actor }}\n*Event:* NEW '${{ github.repository }} v${{ steps.check_pypi.outputs.version }}' pip package published 😃\n*Job Status:* ${{ job.status }}\n*Pull Request:* ${{ env.PR_TITLE }}\n"}
+ env:
+ SLACK_WEBHOOK_URL: ${{ secrets.SLACK_WEBHOOK_URL_YOLO }}
+ - name: Notify on Slack (Failure)
+ if: failure()
+ uses: slackapi/slack-github-action@v1.26.0
+ with:
+ payload: |
+ {"text": " GitHub Actions error for ${{ github.workflow }} ❌\n\n\n*Repository:* https://github.com/${{ github.repository }}\n*Action:* https://github.com/${{ github.repository }}/actions/runs/${{ github.run_id }}\n*Author:* ${{ github.actor }}\n*Event:* ${{ github.event_name }}\n*Job Status:* ${{ job.status }}\n*Pull Request:* ${{ env.PR_TITLE }}\n"}
+ env:
+ SLACK_WEBHOOK_URL: ${{ secrets.SLACK_WEBHOOK_URL_YOLO }}
diff --git a/ultralytics/.github/workflows/stale.yml b/ultralytics/.github/workflows/stale.yml
new file mode 100644
index 0000000000000000000000000000000000000000..be93b4752e7e50bdb974a5b885cba1fa9ac0a0f5
--- /dev/null
+++ b/ultralytics/.github/workflows/stale.yml
@@ -0,0 +1,47 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+name: Close stale issues
+on:
+ schedule:
+ - cron: "0 0 * * *" # Runs at 00:00 UTC every day
+
+jobs:
+ stale:
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/stale@v9
+ with:
+ repo-token: ${{ secrets.GITHUB_TOKEN }}
+
+ stale-issue-message: |
+ 👋 Hello there! We wanted to give you a friendly reminder that this issue has not had any recent activity and may be closed soon, but don't worry - you can always reopen it if needed. If you still have any questions or concerns, please feel free to let us know how we can help.
+
+ For additional resources and information, please see the links below:
+
+ - **Docs**: https://docs.ultralytics.com
+ - **HUB**: https://hub.ultralytics.com
+ - **Community**: https://community.ultralytics.com
+
+ Feel free to inform us of any other **issues** you discover or **feature requests** that come to mind in the future. Pull Requests (PRs) are also always welcomed!
+
+ Thank you for your contributions to YOLO 🚀 and Vision AI ⭐
+
+ stale-pr-message: |
+ 👋 Hello there! We wanted to let you know that we've decided to close this pull request due to inactivity. We appreciate the effort you put into contributing to our project, but unfortunately, not all contributions are suitable or aligned with our product roadmap.
+
+ We hope you understand our decision, and please don't let it discourage you from contributing to open source projects in the future. We value all of our community members and their contributions, and we encourage you to keep exploring new projects and ways to get involved.
+
+ For additional resources and information, please see the links below:
+
+ - **Docs**: https://docs.ultralytics.com
+ - **HUB**: https://hub.ultralytics.com
+ - **Community**: https://community.ultralytics.com
+
+ Thank you for your contributions to YOLO 🚀 and Vision AI ⭐
+
+ days-before-issue-stale: 30
+ days-before-issue-close: 10
+ days-before-pr-stale: 90
+ days-before-pr-close: 30
+ exempt-issue-labels: "documentation,tutorial,TODO"
+ operations-per-run: 300 # The maximum number of operations per run, used to control rate limiting.
diff --git a/ultralytics/.gitignore b/ultralytics/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..2e1718a361d39a3f2cc52f62bb3a609aee5a1d1d
--- /dev/null
+++ b/ultralytics/.gitignore
@@ -0,0 +1,172 @@
+# Byte-compiled / optimized / DLL files
+__pycache__/
+*.py[cod]
+*$py.class
+
+# C extensions
+*.so
+
+# Distribution / packaging
+.Python
+build/
+develop-eggs/
+dist/
+downloads/
+eggs/
+.eggs/
+lib/
+lib64/
+parts/
+sdist/
+var/
+wheels/
+pip-wheel-metadata/
+share/python-wheels/
+*.egg-info/
+.installed.cfg
+*.egg
+MANIFEST
+requirements.txt
+setup.py
+ultralytics.egg-info
+
+# PyInstaller
+# Usually these files are written by a python script from a template
+# before PyInstaller builds the exe, so as to inject date/other info into it.
+*.manifest
+*.spec
+
+# Installer logs
+pip-log.txt
+pip-delete-this-directory.txt
+
+# Unit test / coverage reports
+htmlcov/
+.tox/
+.nox/
+.coverage
+.coverage.*
+.cache
+nosetests.xml
+coverage.xml
+*.cover
+*.py,cover
+.hypothesis/
+.pytest_cache/
+mlruns/
+
+# Translations
+*.mo
+*.pot
+
+# Django stuff:
+*.log
+local_settings.py
+db.sqlite3
+db.sqlite3-journal
+
+# Flask stuff:
+instance/
+.webassets-cache
+
+# Scrapy stuff:
+.scrapy
+
+# Sphinx documentation
+docs/_build/
+
+# PyBuilder
+target/
+
+# Jupyter Notebook
+.ipynb_checkpoints
+
+# IPython
+profile_default/
+ipython_config.py
+
+# Profiling
+*.pclprof
+
+# pyenv
+.python-version
+
+# pipenv
+# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
+# However, in case of collaboration, if having platform-specific dependencies or dependencies
+# having no cross-platform support, pipenv may install dependencies that don't work, or not
+# install all needed dependencies.
+#Pipfile.lock
+
+# PEP 582; used by e.g. github.com/David-OConnor/pyflow
+__pypackages__/
+
+# Celery stuff
+celerybeat-schedule
+celerybeat.pid
+
+# SageMath parsed files
+*.sage.py
+
+# Environments
+.env
+.venv
+.idea
+env/
+venv/
+ENV/
+env.bak/
+venv.bak/
+
+# Spyder project settings
+.spyderproject
+.spyproject
+
+# VSCode project settings
+.vscode/
+
+# Rope project settings
+.ropeproject
+
+# mkdocs documentation
+/site
+mkdocs_github_authors.yaml
+
+# mypy
+.mypy_cache/
+.dmypy.json
+dmypy.json
+
+# Pyre type checker
+.pyre/
+
+# datasets and projects
+datasets/
+runs/
+wandb/
+.DS_Store
+
+# Neural Network weights -----------------------------------------------------------------------------------------------
+weights/
+*.weights
+*.pt
+*.pb
+*.onnx
+*.engine
+*.mlmodel
+*.mlpackage
+*.torchscript
+*.tflite
+*.h5
+*_saved_model/
+*_web_model/
+*_openvino_model/
+*_paddle_model/
+*_ncnn_model/
+pnnx*
+
+# Autogenerated files for tests
+/ultralytics/assets/
+
+# calibration image
+calibration_*.npy
diff --git a/ultralytics/CITATION.cff b/ultralytics/CITATION.cff
new file mode 100644
index 0000000000000000000000000000000000000000..d735510001468d48d6b87eba590ddcc53d08a6a5
--- /dev/null
+++ b/ultralytics/CITATION.cff
@@ -0,0 +1,26 @@
+# This CITATION.cff file was generated with https://bit.ly/cffinit
+
+cff-version: 1.2.0
+title: Ultralytics YOLO
+message: >-
+ If you use this software, please cite it using the
+ metadata from this file.
+type: software
+authors:
+ - given-names: Glenn
+ family-names: Jocher
+ affiliation: Ultralytics
+ orcid: 'https://orcid.org/0000-0001-5950-6979'
+ - given-names: Ayush
+ family-names: Chaurasia
+ affiliation: Ultralytics
+ orcid: 'https://orcid.org/0000-0002-7603-6750'
+ - family-names: Qiu
+ given-names: Jing
+ affiliation: Ultralytics
+ orcid: 'https://orcid.org/0000-0003-3783-7069'
+repository-code: 'https://github.com/ultralytics/ultralytics'
+url: 'https://ultralytics.com'
+license: AGPL-3.0
+version: 8.0.0
+date-released: '2023-01-10'
diff --git a/ultralytics/CONTRIBUTING.md b/ultralytics/CONTRIBUTING.md
new file mode 100644
index 0000000000000000000000000000000000000000..3019ce872c4b5ce18a13ec28866dc1ba79d1f653
--- /dev/null
+++ b/ultralytics/CONTRIBUTING.md
@@ -0,0 +1,166 @@
+---
+comments: true
+description: Learn how to contribute to Ultralytics YOLO open-source repositories. Follow guidelines for pull requests, code of conduct, and bug reporting.
+keywords: Ultralytics, YOLO, open-source, contribution, pull request, code of conduct, bug reporting, GitHub, CLA, Google-style docstrings
+---
+
+# Contributing to Ultralytics Open-Source Projects
+
+Welcome! We're thrilled that you're considering contributing to our [Ultralytics](https://ultralytics.com) [open-source](https://github.com/ultralytics) projects. Your involvement not only helps enhance the quality of our repositories but also benefits the entire community. This guide provides clear guidelines and best practices to help you get started.
+
+
+
+
+## Table of Contents
+
+1. [Code of Conduct](#code-of-conduct)
+2. [Contributing via Pull Requests](#contributing-via-pull-requests)
+ - [CLA Signing](#cla-signing)
+ - [Google-Style Docstrings](#google-style-docstrings)
+ - [GitHub Actions CI Tests](#github-actions-ci-tests)
+3. [Reporting Bugs](#reporting-bugs)
+4. [License](#license)
+5. [Conclusion](#conclusion)
+6. [FAQ](#faq)
+
+## Code of Conduct
+
+To ensure a welcoming and inclusive environment for everyone, all contributors must adhere to our [Code of Conduct](https://docs.ultralytics.com/help/code_of_conduct). Respect, kindness, and professionalism are at the heart of our community.
+
+## Contributing via Pull Requests
+
+We greatly appreciate contributions in the form of pull requests. To make the review process as smooth as possible, please follow these steps:
+
+1. **[Fork the repository](https://docs.github.com/en/pull-requests/collaborating-with-pull-requests/working-with-forks/fork-a-repo):** Start by forking the Ultralytics YOLO repository to your GitHub account.
+
+2. **[Create a branch](https://docs.github.com/en/desktop/making-changes-in-a-branch/managing-branches-in-github-desktop):** Create a new branch in your forked repository with a clear, descriptive name that reflects your changes.
+
+3. **Make your changes:** Ensure your code adheres to the project's style guidelines and does not introduce any new errors or warnings.
+
+4. **[Test your changes](https://github.com/ultralytics/ultralytics/tree/main/tests):** Before submitting, test your changes locally to confirm they work as expected and don't cause any new issues.
+
+5. **[Commit your changes](https://docs.github.com/en/desktop/making-changes-in-a-branch/committing-and-reviewing-changes-to-your-project-in-github-desktop):** Commit your changes with a concise and descriptive commit message. If your changes address a specific issue, include the issue number in your commit message.
+
+6. **[Create a pull request](https://docs.github.com/en/pull-requests/collaborating-with-pull-requests/proposing-changes-to-your-work-with-pull-requests/creating-a-pull-request):** Submit a pull request from your forked repository to the main Ultralytics YOLO repository. Provide a clear and detailed explanation of your changes and how they improve the project.
+
+### CLA Signing
+
+Before we can merge your pull request, you must sign our [Contributor License Agreement (CLA)](https://docs.ultralytics.com/help/CLA). This legal agreement ensures that your contributions are properly licensed, allowing the project to continue being distributed under the AGPL-3.0 license.
+
+After submitting your pull request, the CLA bot will guide you through the signing process. To sign the CLA, simply add a comment in your PR stating:
+
+```
+I have read the CLA Document and I sign the CLA
+```
+
+### Google-Style Docstrings
+
+When adding new functions or classes, please include [Google-style docstrings](https://google.github.io/styleguide/pyguide.html). These docstrings provide clear, standardized documentation that helps other developers understand and maintain your code.
+
+#### Example
+
+This example illustrates a Google-style docstring. Ensure that both input and output `types` are always enclosed in parentheses, e.g., `(bool)`.
+
+```python
+def example_function(arg1, arg2=4):
+ """
+ Example function demonstrating Google-style docstrings.
+
+ Args:
+ arg1 (int): The first argument.
+ arg2 (int): The second argument, with a default value of 4.
+
+ Returns:
+ (bool): True if successful, False otherwise.
+
+ Examples:
+ >>> result = example_function(1, 2) # returns False
+ """
+ if arg1 == arg2:
+ return True
+ return False
+```
+
+#### Example with type hints
+
+This example includes both a Google-style docstring and type hints for arguments and returns, though using either independently is also acceptable.
+
+```python
+def example_function(arg1: int, arg2: int = 4) -> bool:
+ """
+ Example function demonstrating Google-style docstrings.
+
+ Args:
+ arg1: The first argument.
+ arg2: The second argument, with a default value of 4.
+
+ Returns:
+ True if successful, False otherwise.
+
+ Examples:
+ >>> result = example_function(1, 2) # returns False
+ """
+ if arg1 == arg2:
+ return True
+ return False
+```
+
+#### Example Single-line
+
+For smaller or simpler functions, a single-line docstring may be sufficient. The docstring must use three double-quotes, be a complete sentence, start with a capital letter, and end with a period.
+
+```python
+def example_small_function(arg1: int, arg2: int = 4) -> bool:
+ """Example function with a single-line docstring."""
+ return arg1 == arg2
+```
+
+### GitHub Actions CI Tests
+
+All pull requests must pass the GitHub Actions [Continuous Integration](https://docs.ultralytics.com/help/CI) (CI) tests before they can be merged. These tests include linting, unit tests, and other checks to ensure that your changes meet the project's quality standards. Review the CI output and address any issues that arise.
+
+## Reporting Bugs
+
+We highly value bug reports as they help us maintain the quality of our projects. When reporting a bug, please provide a [Minimum Reproducible Example](https://docs.ultralytics.com/help/minimum_reproducible_example)—a simple, clear code example that consistently reproduces the issue. This allows us to quickly identify and resolve the problem.
+
+## License
+
+Ultralytics uses the [GNU Affero General Public License v3.0 (AGPL-3.0)](https://github.com/ultralytics/ultralytics/blob/main/LICENSE) for its repositories. This license promotes openness, transparency, and collaborative improvement in software development. It ensures that all users have the freedom to use, modify, and share the software, fostering a strong community of collaboration and innovation.
+
+We encourage all contributors to familiarize themselves with the terms of the AGPL-3.0 license to contribute effectively and ethically to the Ultralytics open-source community.
+
+## Conclusion
+
+Thank you for your interest in contributing to [Ultralytics](https://ultralytics.com) [open-source](https://github.com/ultralytics) YOLO projects. Your participation is essential in shaping the future of our software and building a vibrant community of innovation and collaboration. Whether you're enhancing code, reporting bugs, or suggesting new features, your contributions are invaluable.
+
+We're excited to see your ideas come to life and appreciate your commitment to advancing object detection technology. Together, let's continue to grow and innovate in this exciting open-source journey. Happy coding! 🚀🌟
+
+## FAQ
+
+### Why should I contribute to Ultralytics YOLO open-source repositories?
+
+Contributing to Ultralytics YOLO open-source repositories improves the software, making it more robust and feature-rich for the entire community. Contributions can include code enhancements, bug fixes, documentation improvements, and new feature implementations. Additionally, contributing allows you to collaborate with other skilled developers and experts in the field, enhancing your own skills and reputation. For details on how to get started, refer to the [Contributing via Pull Requests](#contributing-via-pull-requests) section.
+
+### How do I sign the Contributor License Agreement (CLA) for Ultralytics YOLO?
+
+To sign the Contributor License Agreement (CLA), follow the instructions provided by the CLA bot after submitting your pull request. This process ensures that your contributions are properly licensed under the AGPL-3.0 license, maintaining the legal integrity of the open-source project. Add a comment in your pull request stating:
+
+```
+I have read the CLA Document and I sign the CLA.
+```
+
+For more information, see the [CLA Signing](#cla-signing) section.
+
+### What are Google-style docstrings, and why are they required for Ultralytics YOLO contributions?
+
+Google-style docstrings provide clear, concise documentation for functions and classes, improving code readability and maintainability. These docstrings outline the function's purpose, arguments, and return values with specific formatting rules. When contributing to Ultralytics YOLO, following Google-style docstrings ensures that your additions are well-documented and easily understood. For examples and guidelines, visit the [Google-Style Docstrings](#google-style-docstrings) section.
+
+### How can I ensure my changes pass the GitHub Actions CI tests?
+
+Before your pull request can be merged, it must pass all GitHub Actions Continuous Integration (CI) tests. These tests include linting, unit tests, and other checks to ensure the code meets
+
+the project's quality standards. Review the CI output and fix any issues. For detailed information on the CI process and troubleshooting tips, see the [GitHub Actions CI Tests](#github-actions-ci-tests) section.
+
+### How do I report a bug in Ultralytics YOLO repositories?
+
+To report a bug, provide a clear and concise [Minimum Reproducible Example](https://docs.ultralytics.com/help/minimum_reproducible_example) along with your bug report. This helps developers quickly identify and fix the issue. Ensure your example is minimal yet sufficient to replicate the problem. For more detailed steps on reporting bugs, refer to the [Reporting Bugs](#reporting-bugs) section.
diff --git a/ultralytics/LICENSE b/ultralytics/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..1468d07c88d6a48dae9360ed0094955b54370224
--- /dev/null
+++ b/ultralytics/LICENSE
@@ -0,0 +1,661 @@
+ GNU AFFERO GENERAL PUBLIC LICENSE
+ Version 3, 19 November 2007
+
+ Copyright (C) 2007 Free Software Foundation, Inc.
+ Everyone is permitted to copy and distribute verbatim copies
+ of this license document, but changing it is not allowed.
+
+ Preamble
+
+ The GNU Affero General Public License is a free, copyleft license for
+software and other kinds of works, specifically designed to ensure
+cooperation with the community in the case of network server software.
+
+ The licenses for most software and other practical works are designed
+to take away your freedom to share and change the works. By contrast,
+our General Public Licenses are intended to guarantee your freedom to
+share and change all versions of a program--to make sure it remains free
+software for all its users.
+
+ When we speak of free software, we are referring to freedom, not
+price. Our General Public Licenses are designed to make sure that you
+have the freedom to distribute copies of free software (and charge for
+them if you wish), that you receive source code or can get it if you
+want it, that you can change the software or use pieces of it in new
+free programs, and that you know you can do these things.
+
+ Developers that use our General Public Licenses protect your rights
+with two steps: (1) assert copyright on the software, and (2) offer
+you this License which gives you legal permission to copy, distribute
+and/or modify the software.
+
+ A secondary benefit of defending all users' freedom is that
+improvements made in alternate versions of the program, if they
+receive widespread use, become available for other developers to
+incorporate. Many developers of free software are heartened and
+encouraged by the resulting cooperation. However, in the case of
+software used on network servers, this result may fail to come about.
+The GNU General Public License permits making a modified version and
+letting the public access it on a server without ever releasing its
+source code to the public.
+
+ The GNU Affero General Public License is designed specifically to
+ensure that, in such cases, the modified source code becomes available
+to the community. It requires the operator of a network server to
+provide the source code of the modified version running there to the
+users of that server. Therefore, public use of a modified version, on
+a publicly accessible server, gives the public access to the source
+code of the modified version.
+
+ An older license, called the Affero General Public License and
+published by Affero, was designed to accomplish similar goals. This is
+a different license, not a version of the Affero GPL, but Affero has
+released a new version of the Affero GPL which permits relicensing under
+this license.
+
+ The precise terms and conditions for copying, distribution and
+modification follow.
+
+ TERMS AND CONDITIONS
+
+ 0. Definitions.
+
+ "This License" refers to version 3 of the GNU Affero General Public License.
+
+ "Copyright" also means copyright-like laws that apply to other kinds of
+works, such as semiconductor masks.
+
+ "The Program" refers to any copyrightable work licensed under this
+License. Each licensee is addressed as "you". "Licensees" and
+"recipients" may be individuals or organizations.
+
+ To "modify" a work means to copy from or adapt all or part of the work
+in a fashion requiring copyright permission, other than the making of an
+exact copy. The resulting work is called a "modified version" of the
+earlier work or a work "based on" the earlier work.
+
+ A "covered work" means either the unmodified Program or a work based
+on the Program.
+
+ To "propagate" a work means to do anything with it that, without
+permission, would make you directly or secondarily liable for
+infringement under applicable copyright law, except executing it on a
+computer or modifying a private copy. Propagation includes copying,
+distribution (with or without modification), making available to the
+public, and in some countries other activities as well.
+
+ To "convey" a work means any kind of propagation that enables other
+parties to make or receive copies. Mere interaction with a user through
+a computer network, with no transfer of a copy, is not conveying.
+
+ An interactive user interface displays "Appropriate Legal Notices"
+to the extent that it includes a convenient and prominently visible
+feature that (1) displays an appropriate copyright notice, and (2)
+tells the user that there is no warranty for the work (except to the
+extent that warranties are provided), that licensees may convey the
+work under this License, and how to view a copy of this License. If
+the interface presents a list of user commands or options, such as a
+menu, a prominent item in the list meets this criterion.
+
+ 1. Source Code.
+
+ The "source code" for a work means the preferred form of the work
+for making modifications to it. "Object code" means any non-source
+form of a work.
+
+ A "Standard Interface" means an interface that either is an official
+standard defined by a recognized standards body, or, in the case of
+interfaces specified for a particular programming language, one that
+is widely used among developers working in that language.
+
+ The "System Libraries" of an executable work include anything, other
+than the work as a whole, that (a) is included in the normal form of
+packaging a Major Component, but which is not part of that Major
+Component, and (b) serves only to enable use of the work with that
+Major Component, or to implement a Standard Interface for which an
+implementation is available to the public in source code form. A
+"Major Component", in this context, means a major essential component
+(kernel, window system, and so on) of the specific operating system
+(if any) on which the executable work runs, or a compiler used to
+produce the work, or an object code interpreter used to run it.
+
+ The "Corresponding Source" for a work in object code form means all
+the source code needed to generate, install, and (for an executable
+work) run the object code and to modify the work, including scripts to
+control those activities. However, it does not include the work's
+System Libraries, or general-purpose tools or generally available free
+programs which are used unmodified in performing those activities but
+which are not part of the work. For example, Corresponding Source
+includes interface definition files associated with source files for
+the work, and the source code for shared libraries and dynamically
+linked subprograms that the work is specifically designed to require,
+such as by intimate data communication or control flow between those
+subprograms and other parts of the work.
+
+ The Corresponding Source need not include anything that users
+can regenerate automatically from other parts of the Corresponding
+Source.
+
+ The Corresponding Source for a work in source code form is that
+same work.
+
+ 2. Basic Permissions.
+
+ All rights granted under this License are granted for the term of
+copyright on the Program, and are irrevocable provided the stated
+conditions are met. This License explicitly affirms your unlimited
+permission to run the unmodified Program. The output from running a
+covered work is covered by this License only if the output, given its
+content, constitutes a covered work. This License acknowledges your
+rights of fair use or other equivalent, as provided by copyright law.
+
+ You may make, run and propagate covered works that you do not
+convey, without conditions so long as your license otherwise remains
+in force. You may convey covered works to others for the sole purpose
+of having them make modifications exclusively for you, or provide you
+with facilities for running those works, provided that you comply with
+the terms of this License in conveying all material for which you do
+not control copyright. Those thus making or running the covered works
+for you must do so exclusively on your behalf, under your direction
+and control, on terms that prohibit them from making any copies of
+your copyrighted material outside their relationship with you.
+
+ Conveying under any other circumstances is permitted solely under
+the conditions stated below. Sublicensing is not allowed; section 10
+makes it unnecessary.
+
+ 3. Protecting Users' Legal Rights From Anti-Circumvention Law.
+
+ No covered work shall be deemed part of an effective technological
+measure under any applicable law fulfilling obligations under article
+11 of the WIPO copyright treaty adopted on 20 December 1996, or
+similar laws prohibiting or restricting circumvention of such
+measures.
+
+ When you convey a covered work, you waive any legal power to forbid
+circumvention of technological measures to the extent such circumvention
+is effected by exercising rights under this License with respect to
+the covered work, and you disclaim any intention to limit operation or
+modification of the work as a means of enforcing, against the work's
+users, your or third parties' legal rights to forbid circumvention of
+technological measures.
+
+ 4. Conveying Verbatim Copies.
+
+ You may convey verbatim copies of the Program's source code as you
+receive it, in any medium, provided that you conspicuously and
+appropriately publish on each copy an appropriate copyright notice;
+keep intact all notices stating that this License and any
+non-permissive terms added in accord with section 7 apply to the code;
+keep intact all notices of the absence of any warranty; and give all
+recipients a copy of this License along with the Program.
+
+ You may charge any price or no price for each copy that you convey,
+and you may offer support or warranty protection for a fee.
+
+ 5. Conveying Modified Source Versions.
+
+ You may convey a work based on the Program, or the modifications to
+produce it from the Program, in the form of source code under the
+terms of section 4, provided that you also meet all of these conditions:
+
+ a) The work must carry prominent notices stating that you modified
+ it, and giving a relevant date.
+
+ b) The work must carry prominent notices stating that it is
+ released under this License and any conditions added under section
+ 7. This requirement modifies the requirement in section 4 to
+ "keep intact all notices".
+
+ c) You must license the entire work, as a whole, under this
+ License to anyone who comes into possession of a copy. This
+ License will therefore apply, along with any applicable section 7
+ additional terms, to the whole of the work, and all its parts,
+ regardless of how they are packaged. This License gives no
+ permission to license the work in any other way, but it does not
+ invalidate such permission if you have separately received it.
+
+ d) If the work has interactive user interfaces, each must display
+ Appropriate Legal Notices; however, if the Program has interactive
+ interfaces that do not display Appropriate Legal Notices, your
+ work need not make them do so.
+
+ A compilation of a covered work with other separate and independent
+works, which are not by their nature extensions of the covered work,
+and which are not combined with it such as to form a larger program,
+in or on a volume of a storage or distribution medium, is called an
+"aggregate" if the compilation and its resulting copyright are not
+used to limit the access or legal rights of the compilation's users
+beyond what the individual works permit. Inclusion of a covered work
+in an aggregate does not cause this License to apply to the other
+parts of the aggregate.
+
+ 6. Conveying Non-Source Forms.
+
+ You may convey a covered work in object code form under the terms
+of sections 4 and 5, provided that you also convey the
+machine-readable Corresponding Source under the terms of this License,
+in one of these ways:
+
+ a) Convey the object code in, or embodied in, a physical product
+ (including a physical distribution medium), accompanied by the
+ Corresponding Source fixed on a durable physical medium
+ customarily used for software interchange.
+
+ b) Convey the object code in, or embodied in, a physical product
+ (including a physical distribution medium), accompanied by a
+ written offer, valid for at least three years and valid for as
+ long as you offer spare parts or customer support for that product
+ model, to give anyone who possesses the object code either (1) a
+ copy of the Corresponding Source for all the software in the
+ product that is covered by this License, on a durable physical
+ medium customarily used for software interchange, for a price no
+ more than your reasonable cost of physically performing this
+ conveying of source, or (2) access to copy the
+ Corresponding Source from a network server at no charge.
+
+ c) Convey individual copies of the object code with a copy of the
+ written offer to provide the Corresponding Source. This
+ alternative is allowed only occasionally and noncommercially, and
+ only if you received the object code with such an offer, in accord
+ with subsection 6b.
+
+ d) Convey the object code by offering access from a designated
+ place (gratis or for a charge), and offer equivalent access to the
+ Corresponding Source in the same way through the same place at no
+ further charge. You need not require recipients to copy the
+ Corresponding Source along with the object code. If the place to
+ copy the object code is a network server, the Corresponding Source
+ may be on a different server (operated by you or a third party)
+ that supports equivalent copying facilities, provided you maintain
+ clear directions next to the object code saying where to find the
+ Corresponding Source. Regardless of what server hosts the
+ Corresponding Source, you remain obligated to ensure that it is
+ available for as long as needed to satisfy these requirements.
+
+ e) Convey the object code using peer-to-peer transmission, provided
+ you inform other peers where the object code and Corresponding
+ Source of the work are being offered to the general public at no
+ charge under subsection 6d.
+
+ A separable portion of the object code, whose source code is excluded
+from the Corresponding Source as a System Library, need not be
+included in conveying the object code work.
+
+ A "User Product" is either (1) a "consumer product", which means any
+tangible personal property which is normally used for personal, family,
+or household purposes, or (2) anything designed or sold for incorporation
+into a dwelling. In determining whether a product is a consumer product,
+doubtful cases shall be resolved in favor of coverage. For a particular
+product received by a particular user, "normally used" refers to a
+typical or common use of that class of product, regardless of the status
+of the particular user or of the way in which the particular user
+actually uses, or expects or is expected to use, the product. A product
+is a consumer product regardless of whether the product has substantial
+commercial, industrial or non-consumer uses, unless such uses represent
+the only significant mode of use of the product.
+
+ "Installation Information" for a User Product means any methods,
+procedures, authorization keys, or other information required to install
+and execute modified versions of a covered work in that User Product from
+a modified version of its Corresponding Source. The information must
+suffice to ensure that the continued functioning of the modified object
+code is in no case prevented or interfered with solely because
+modification has been made.
+
+ If you convey an object code work under this section in, or with, or
+specifically for use in, a User Product, and the conveying occurs as
+part of a transaction in which the right of possession and use of the
+User Product is transferred to the recipient in perpetuity or for a
+fixed term (regardless of how the transaction is characterized), the
+Corresponding Source conveyed under this section must be accompanied
+by the Installation Information. But this requirement does not apply
+if neither you nor any third party retains the ability to install
+modified object code on the User Product (for example, the work has
+been installed in ROM).
+
+ The requirement to provide Installation Information does not include a
+requirement to continue to provide support service, warranty, or updates
+for a work that has been modified or installed by the recipient, or for
+the User Product in which it has been modified or installed. Access to a
+network may be denied when the modification itself materially and
+adversely affects the operation of the network or violates the rules and
+protocols for communication across the network.
+
+ Corresponding Source conveyed, and Installation Information provided,
+in accord with this section must be in a format that is publicly
+documented (and with an implementation available to the public in
+source code form), and must require no special password or key for
+unpacking, reading or copying.
+
+ 7. Additional Terms.
+
+ "Additional permissions" are terms that supplement the terms of this
+License by making exceptions from one or more of its conditions.
+Additional permissions that are applicable to the entire Program shall
+be treated as though they were included in this License, to the extent
+that they are valid under applicable law. If additional permissions
+apply only to part of the Program, that part may be used separately
+under those permissions, but the entire Program remains governed by
+this License without regard to the additional permissions.
+
+ When you convey a copy of a covered work, you may at your option
+remove any additional permissions from that copy, or from any part of
+it. (Additional permissions may be written to require their own
+removal in certain cases when you modify the work.) You may place
+additional permissions on material, added by you to a covered work,
+for which you have or can give appropriate copyright permission.
+
+ Notwithstanding any other provision of this License, for material you
+add to a covered work, you may (if authorized by the copyright holders of
+that material) supplement the terms of this License with terms:
+
+ a) Disclaiming warranty or limiting liability differently from the
+ terms of sections 15 and 16 of this License; or
+
+ b) Requiring preservation of specified reasonable legal notices or
+ author attributions in that material or in the Appropriate Legal
+ Notices displayed by works containing it; or
+
+ c) Prohibiting misrepresentation of the origin of that material, or
+ requiring that modified versions of such material be marked in
+ reasonable ways as different from the original version; or
+
+ d) Limiting the use for publicity purposes of names of licensors or
+ authors of the material; or
+
+ e) Declining to grant rights under trademark law for use of some
+ trade names, trademarks, or service marks; or
+
+ f) Requiring indemnification of licensors and authors of that
+ material by anyone who conveys the material (or modified versions of
+ it) with contractual assumptions of liability to the recipient, for
+ any liability that these contractual assumptions directly impose on
+ those licensors and authors.
+
+ All other non-permissive additional terms are considered "further
+restrictions" within the meaning of section 10. If the Program as you
+received it, or any part of it, contains a notice stating that it is
+governed by this License along with a term that is a further
+restriction, you may remove that term. If a license document contains
+a further restriction but permits relicensing or conveying under this
+License, you may add to a covered work material governed by the terms
+of that license document, provided that the further restriction does
+not survive such relicensing or conveying.
+
+ If you add terms to a covered work in accord with this section, you
+must place, in the relevant source files, a statement of the
+additional terms that apply to those files, or a notice indicating
+where to find the applicable terms.
+
+ Additional terms, permissive or non-permissive, may be stated in the
+form of a separately written license, or stated as exceptions;
+the above requirements apply either way.
+
+ 8. Termination.
+
+ You may not propagate or modify a covered work except as expressly
+provided under this License. Any attempt otherwise to propagate or
+modify it is void, and will automatically terminate your rights under
+this License (including any patent licenses granted under the third
+paragraph of section 11).
+
+ However, if you cease all violation of this License, then your
+license from a particular copyright holder is reinstated (a)
+provisionally, unless and until the copyright holder explicitly and
+finally terminates your license, and (b) permanently, if the copyright
+holder fails to notify you of the violation by some reasonable means
+prior to 60 days after the cessation.
+
+ Moreover, your license from a particular copyright holder is
+reinstated permanently if the copyright holder notifies you of the
+violation by some reasonable means, this is the first time you have
+received notice of violation of this License (for any work) from that
+copyright holder, and you cure the violation prior to 30 days after
+your receipt of the notice.
+
+ Termination of your rights under this section does not terminate the
+licenses of parties who have received copies or rights from you under
+this License. If your rights have been terminated and not permanently
+reinstated, you do not qualify to receive new licenses for the same
+material under section 10.
+
+ 9. Acceptance Not Required for Having Copies.
+
+ You are not required to accept this License in order to receive or
+run a copy of the Program. Ancillary propagation of a covered work
+occurring solely as a consequence of using peer-to-peer transmission
+to receive a copy likewise does not require acceptance. However,
+nothing other than this License grants you permission to propagate or
+modify any covered work. These actions infringe copyright if you do
+not accept this License. Therefore, by modifying or propagating a
+covered work, you indicate your acceptance of this License to do so.
+
+ 10. Automatic Licensing of Downstream Recipients.
+
+ Each time you convey a covered work, the recipient automatically
+receives a license from the original licensors, to run, modify and
+propagate that work, subject to this License. You are not responsible
+for enforcing compliance by third parties with this License.
+
+ An "entity transaction" is a transaction transferring control of an
+organization, or substantially all assets of one, or subdividing an
+organization, or merging organizations. If propagation of a covered
+work results from an entity transaction, each party to that
+transaction who receives a copy of the work also receives whatever
+licenses to the work the party's predecessor in interest had or could
+give under the previous paragraph, plus a right to possession of the
+Corresponding Source of the work from the predecessor in interest, if
+the predecessor has it or can get it with reasonable efforts.
+
+ You may not impose any further restrictions on the exercise of the
+rights granted or affirmed under this License. For example, you may
+not impose a license fee, royalty, or other charge for exercise of
+rights granted under this License, and you may not initiate litigation
+(including a cross-claim or counterclaim in a lawsuit) alleging that
+any patent claim is infringed by making, using, selling, offering for
+sale, or importing the Program or any portion of it.
+
+ 11. Patents.
+
+ A "contributor" is a copyright holder who authorizes use under this
+License of the Program or a work on which the Program is based. The
+work thus licensed is called the contributor's "contributor version".
+
+ A contributor's "essential patent claims" are all patent claims
+owned or controlled by the contributor, whether already acquired or
+hereafter acquired, that would be infringed by some manner, permitted
+by this License, of making, using, or selling its contributor version,
+but do not include claims that would be infringed only as a
+consequence of further modification of the contributor version. For
+purposes of this definition, "control" includes the right to grant
+patent sublicenses in a manner consistent with the requirements of
+this License.
+
+ Each contributor grants you a non-exclusive, worldwide, royalty-free
+patent license under the contributor's essential patent claims, to
+make, use, sell, offer for sale, import and otherwise run, modify and
+propagate the contents of its contributor version.
+
+ In the following three paragraphs, a "patent license" is any express
+agreement or commitment, however denominated, not to enforce a patent
+(such as an express permission to practice a patent or covenant not to
+sue for patent infringement). To "grant" such a patent license to a
+party means to make such an agreement or commitment not to enforce a
+patent against the party.
+
+ If you convey a covered work, knowingly relying on a patent license,
+and the Corresponding Source of the work is not available for anyone
+to copy, free of charge and under the terms of this License, through a
+publicly available network server or other readily accessible means,
+then you must either (1) cause the Corresponding Source to be so
+available, or (2) arrange to deprive yourself of the benefit of the
+patent license for this particular work, or (3) arrange, in a manner
+consistent with the requirements of this License, to extend the patent
+license to downstream recipients. "Knowingly relying" means you have
+actual knowledge that, but for the patent license, your conveying the
+covered work in a country, or your recipient's use of the covered work
+in a country, would infringe one or more identifiable patents in that
+country that you have reason to believe are valid.
+
+ If, pursuant to or in connection with a single transaction or
+arrangement, you convey, or propagate by procuring conveyance of, a
+covered work, and grant a patent license to some of the parties
+receiving the covered work authorizing them to use, propagate, modify
+or convey a specific copy of the covered work, then the patent license
+you grant is automatically extended to all recipients of the covered
+work and works based on it.
+
+ A patent license is "discriminatory" if it does not include within
+the scope of its coverage, prohibits the exercise of, or is
+conditioned on the non-exercise of one or more of the rights that are
+specifically granted under this License. You may not convey a covered
+work if you are a party to an arrangement with a third party that is
+in the business of distributing software, under which you make payment
+to the third party based on the extent of your activity of conveying
+the work, and under which the third party grants, to any of the
+parties who would receive the covered work from you, a discriminatory
+patent license (a) in connection with copies of the covered work
+conveyed by you (or copies made from those copies), or (b) primarily
+for and in connection with specific products or compilations that
+contain the covered work, unless you entered into that arrangement,
+or that patent license was granted, prior to 28 March 2007.
+
+ Nothing in this License shall be construed as excluding or limiting
+any implied license or other defenses to infringement that may
+otherwise be available to you under applicable patent law.
+
+ 12. No Surrender of Others' Freedom.
+
+ If conditions are imposed on you (whether by court order, agreement or
+otherwise) that contradict the conditions of this License, they do not
+excuse you from the conditions of this License. If you cannot convey a
+covered work so as to satisfy simultaneously your obligations under this
+License and any other pertinent obligations, then as a consequence you may
+not convey it at all. For example, if you agree to terms that obligate you
+to collect a royalty for further conveying from those to whom you convey
+the Program, the only way you could satisfy both those terms and this
+License would be to refrain entirely from conveying the Program.
+
+ 13. Remote Network Interaction; Use with the GNU General Public License.
+
+ Notwithstanding any other provision of this License, if you modify the
+Program, your modified version must prominently offer all users
+interacting with it remotely through a computer network (if your version
+supports such interaction) an opportunity to receive the Corresponding
+Source of your version by providing access to the Corresponding Source
+from a network server at no charge, through some standard or customary
+means of facilitating copying of software. This Corresponding Source
+shall include the Corresponding Source for any work covered by version 3
+of the GNU General Public License that is incorporated pursuant to the
+following paragraph.
+
+ Notwithstanding any other provision of this License, you have
+permission to link or combine any covered work with a work licensed
+under version 3 of the GNU General Public License into a single
+combined work, and to convey the resulting work. The terms of this
+License will continue to apply to the part which is the covered work,
+but the work with which it is combined will remain governed by version
+3 of the GNU General Public License.
+
+ 14. Revised Versions of this License.
+
+ The Free Software Foundation may publish revised and/or new versions of
+the GNU Affero General Public License from time to time. Such new versions
+will be similar in spirit to the present version, but may differ in detail to
+address new problems or concerns.
+
+ Each version is given a distinguishing version number. If the
+Program specifies that a certain numbered version of the GNU Affero General
+Public License "or any later version" applies to it, you have the
+option of following the terms and conditions either of that numbered
+version or of any later version published by the Free Software
+Foundation. If the Program does not specify a version number of the
+GNU Affero General Public License, you may choose any version ever published
+by the Free Software Foundation.
+
+ If the Program specifies that a proxy can decide which future
+versions of the GNU Affero General Public License can be used, that proxy's
+public statement of acceptance of a version permanently authorizes you
+to choose that version for the Program.
+
+ Later license versions may give you additional or different
+permissions. However, no additional obligations are imposed on any
+author or copyright holder as a result of your choosing to follow a
+later version.
+
+ 15. Disclaimer of Warranty.
+
+ THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
+APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
+HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
+OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
+THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
+PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
+IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
+ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
+
+ 16. Limitation of Liability.
+
+ IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
+WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
+THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
+GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
+USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
+DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
+PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
+EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
+SUCH DAMAGES.
+
+ 17. Interpretation of Sections 15 and 16.
+
+ If the disclaimer of warranty and limitation of liability provided
+above cannot be given local legal effect according to their terms,
+reviewing courts shall apply local law that most closely approximates
+an absolute waiver of all civil liability in connection with the
+Program, unless a warranty or assumption of liability accompanies a
+copy of the Program in return for a fee.
+
+ END OF TERMS AND CONDITIONS
+
+ How to Apply These Terms to Your New Programs
+
+ If you develop a new program, and you want it to be of the greatest
+possible use to the public, the best way to achieve this is to make it
+free software which everyone can redistribute and change under these terms.
+
+ To do so, attach the following notices to the program. It is safest
+to attach them to the start of each source file to most effectively
+state the exclusion of warranty; and each file should have at least
+the "copyright" line and a pointer to where the full notice is found.
+
+
+ Copyright (C)
+
+ This program is free software: you can redistribute it and/or modify
+ it under the terms of the GNU Affero General Public License as published by
+ the Free Software Foundation, either version 3 of the License, or
+ (at your option) any later version.
+
+ This program is distributed in the hope that it will be useful,
+ but WITHOUT ANY WARRANTY; without even the implied warranty of
+ MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
+ GNU Affero General Public License for more details.
+
+ You should have received a copy of the GNU Affero General Public License
+ along with this program. If not, see .
+
+Also add information on how to contact you by electronic and paper mail.
+
+ If your software can interact with users remotely through a computer
+network, you should also make sure that it provides a way for users to
+get its source. For example, if your program is a web application, its
+interface could display a "Source" link that leads users to an archive
+of the code. There are many ways you could offer source, and different
+solutions will be better for different programs; see section 13 for the
+specific requirements.
+
+ You should also get your employer (if you work as a programmer) or school,
+if any, to sign a "copyright disclaimer" for the program, if necessary.
+For more information on this, and how to apply and follow the GNU AGPL, see
+.
diff --git a/ultralytics/README.md b/ultralytics/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..dcadc69d0f6f273611a3f52821557f1251e0a355
--- /dev/null
+++ b/ultralytics/README.md
@@ -0,0 +1,297 @@
+
+
+
+[Ultralytics](https://ultralytics.com) [YOLOv8](https://github.com/ultralytics/ultralytics) is a cutting-edge, state-of-the-art (SOTA) model that builds upon the success of previous YOLO versions and introduces new features and improvements to further boost performance and flexibility. YOLOv8 is designed to be fast, accurate, and easy to use, making it an excellent choice for a wide range of object detection and tracking, instance segmentation, image classification and pose estimation tasks.
+
+We hope that the resources here will help you get the most out of YOLOv8. Please browse the YOLOv8 Docs for details, raise an issue on GitHub for support, and join our Discord community for questions and discussions!
+
+To request an Enterprise License please complete the form at [Ultralytics Licensing](https://ultralytics.com/license).
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+##
Documentation
+
+See below for a quickstart installation and usage example, and see the [YOLOv8 Docs](https://docs.ultralytics.com) for full documentation on training, validation, prediction and deployment.
+
+
+Install
+
+Pip install the ultralytics package including all [requirements](https://github.com/ultralytics/ultralytics/blob/main/pyproject.toml) in a [**Python>=3.8**](https://www.python.org/) environment with [**PyTorch>=1.8**](https://pytorch.org/get-started/locally/).
+
+[](https://pypi.org/project/ultralytics/) [](https://pepy.tech/project/ultralytics) [](https://pypi.org/project/ultralytics/)
+
+```bash
+pip install ultralytics
+```
+
+For alternative installation methods including [Conda](https://anaconda.org/conda-forge/ultralytics), [Docker](https://hub.docker.com/r/ultralytics/ultralytics), and Git, please refer to the [Quickstart Guide](https://docs.ultralytics.com/quickstart).
+
+[](https://anaconda.org/conda-forge/ultralytics) [](https://hub.docker.com/r/ultralytics/ultralytics)
+
+
+
+
+Usage
+
+### CLI
+
+YOLOv8 may be used directly in the Command Line Interface (CLI) with a `yolo` command:
+
+```bash
+yolo predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg'
+```
+
+`yolo` can be used for a variety of tasks and modes and accepts additional arguments, i.e. `imgsz=640`. See the YOLOv8 [CLI Docs](https://docs.ultralytics.com/usage/cli) for examples.
+
+### Python
+
+YOLOv8 may also be used directly in a Python environment, and accepts the same [arguments](https://docs.ultralytics.com/usage/cfg/) as in the CLI example above:
+
+```python
+from ultralytics import YOLO
+
+# Load a model
+model = YOLO("yolov8n.yaml") # build a new model from scratch
+model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+
+# Use the model
+model.train(data="coco8.yaml", epochs=3) # train the model
+metrics = model.val() # evaluate model performance on the validation set
+results = model("https://ultralytics.com/images/bus.jpg") # predict on an image
+path = model.export(format="onnx") # export the model to ONNX format
+```
+
+See YOLOv8 [Python Docs](https://docs.ultralytics.com/usage/python) for more examples.
+
+
+
+### Notebooks
+
+Ultralytics provides interactive notebooks for YOLOv8, covering training, validation, tracking, and more. Each notebook is paired with a [YouTube](https://youtube.com/ultralytics?sub_confirmation=1) tutorial, making it easy to learn and implement advanced YOLOv8 features.
+
+| Docs | Notebook | YouTube |
+| ---------------------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+| YOLOv8 Train, Val, Predict and Export Modes | |
+
+YOLOv8 [Detect](https://docs.ultralytics.com/tasks/detect), [Segment](https://docs.ultralytics.com/tasks/segment) and [Pose](https://docs.ultralytics.com/tasks/pose) models pretrained on the [COCO](https://docs.ultralytics.com/datasets/detect/coco) dataset are available here, as well as YOLOv8 [Classify](https://docs.ultralytics.com/tasks/classify) models pretrained on the [ImageNet](https://docs.ultralytics.com/datasets/classify/imagenet) dataset. [Track](https://docs.ultralytics.com/modes/track) mode is available for all Detect, Segment and Pose models.
+
+
+
+All [Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models) download automatically from the latest Ultralytics [release](https://github.com/ultralytics/assets/releases) on first use.
+
+Detection (COCO)
+
+See [Detection Docs](https://docs.ultralytics.com/tasks/detect/) for usage examples with these models trained on [COCO](https://docs.ultralytics.com/datasets/detect/coco/), which include 80 pre-trained classes.
+
+| Model | size (pixels) | mAPval 50-95 | Speed CPU ONNX (ms) | Speed A100 TensorRT (ms) | params (M) | FLOPs (B) |
+| ------------------------------------------------------------------------------------ | --------------------- | -------------------- | ------------------------------ | ----------------------------------- | ------------------ | ----------------- |
+| [YOLOv8n](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n.pt) | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
+| [YOLOv8s](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8s.pt) | 640 | 44.9 | 128.4 | 1.20 | 11.2 | 28.6 |
+| [YOLOv8m](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8m.pt) | 640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 |
+| [YOLOv8l](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8l.pt) | 640 | 52.9 | 375.2 | 2.39 | 43.7 | 165.2 |
+| [YOLOv8x](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8x.pt) | 640 | 53.9 | 479.1 | 3.53 | 68.2 | 257.8 |
+
+- **mAPval** values are for single-model single-scale on [COCO val2017](https://cocodataset.org) dataset. Reproduce by `yolo val detect data=coco.yaml device=0`
+- **Speed** averaged over COCO val images using an [Amazon EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/) instance. Reproduce by `yolo val detect data=coco.yaml batch=1 device=0|cpu`
+
+
+
+Detection (Open Image V7)
+
+See [Detection Docs](https://docs.ultralytics.com/tasks/detect/) for usage examples with these models trained on [Open Image V7](https://docs.ultralytics.com/datasets/detect/open-images-v7/), which include 600 pre-trained classes.
+
+| Model | size (pixels) | mAPval 50-95 | Speed CPU ONNX (ms) | Speed A100 TensorRT (ms) | params (M) | FLOPs (B) |
+| ----------------------------------------------------------------------------------------- | --------------------- | -------------------- | ------------------------------ | ----------------------------------- | ------------------ | ----------------- |
+| [YOLOv8n](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n-oiv7.pt) | 640 | 18.4 | 142.4 | 1.21 | 3.5 | 10.5 |
+| [YOLOv8s](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8s-oiv7.pt) | 640 | 27.7 | 183.1 | 1.40 | 11.4 | 29.7 |
+| [YOLOv8m](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8m-oiv7.pt) | 640 | 33.6 | 408.5 | 2.26 | 26.2 | 80.6 |
+| [YOLOv8l](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8l-oiv7.pt) | 640 | 34.9 | 596.9 | 2.43 | 44.1 | 167.4 |
+| [YOLOv8x](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8x-oiv7.pt) | 640 | 36.3 | 860.6 | 3.56 | 68.7 | 260.6 |
+
+- **mAPval** values are for single-model single-scale on [Open Image V7](https://docs.ultralytics.com/datasets/detect/open-images-v7/) dataset. Reproduce by `yolo val detect data=open-images-v7.yaml device=0`
+- **Speed** averaged over Open Image V7 val images using an [Amazon EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/) instance. Reproduce by `yolo val detect data=open-images-v7.yaml batch=1 device=0|cpu`
+
+
+
+Segmentation (COCO)
+
+See [Segmentation Docs](https://docs.ultralytics.com/tasks/segment/) for usage examples with these models trained on [COCO-Seg](https://docs.ultralytics.com/datasets/segment/coco/), which include 80 pre-trained classes.
+
+| Model | size (pixels) | mAPbox 50-95 | mAPmask 50-95 | Speed CPU ONNX (ms) | Speed A100 TensorRT (ms) | params (M) | FLOPs (B) |
+| -------------------------------------------------------------------------------------------- | --------------------- | -------------------- | --------------------- | ------------------------------ | ----------------------------------- | ------------------ | ----------------- |
+| [YOLOv8n-seg](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n-seg.pt) | 640 | 36.7 | 30.5 | 96.1 | 1.21 | 3.4 | 12.6 |
+| [YOLOv8s-seg](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8s-seg.pt) | 640 | 44.6 | 36.8 | 155.7 | 1.47 | 11.8 | 42.6 |
+| [YOLOv8m-seg](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8m-seg.pt) | 640 | 49.9 | 40.8 | 317.0 | 2.18 | 27.3 | 110.2 |
+| [YOLOv8l-seg](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8l-seg.pt) | 640 | 52.3 | 42.6 | 572.4 | 2.79 | 46.0 | 220.5 |
+| [YOLOv8x-seg](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8x-seg.pt) | 640 | 53.4 | 43.4 | 712.1 | 4.02 | 71.8 | 344.1 |
+
+- **mAPval** values are for single-model single-scale on [COCO val2017](https://cocodataset.org) dataset. Reproduce by `yolo val segment data=coco-seg.yaml device=0`
+- **Speed** averaged over COCO val images using an [Amazon EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/) instance. Reproduce by `yolo val segment data=coco-seg.yaml batch=1 device=0|cpu`
+
+
+
+Pose (COCO)
+
+See [Pose Docs](https://docs.ultralytics.com/tasks/pose/) for usage examples with these models trained on [COCO-Pose](https://docs.ultralytics.com/datasets/pose/coco/), which include 1 pre-trained class, person.
+
+| Model | size (pixels) | mAPpose 50-95 | mAPpose 50 | Speed CPU ONNX (ms) | Speed A100 TensorRT (ms) | params (M) | FLOPs (B) |
+| ---------------------------------------------------------------------------------------------------- | --------------------- | --------------------- | ------------------ | ------------------------------ | ----------------------------------- | ------------------ | ----------------- |
+| [YOLOv8n-pose](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n-pose.pt) | 640 | 50.4 | 80.1 | 131.8 | 1.18 | 3.3 | 9.2 |
+| [YOLOv8s-pose](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8s-pose.pt) | 640 | 60.0 | 86.2 | 233.2 | 1.42 | 11.6 | 30.2 |
+| [YOLOv8m-pose](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8m-pose.pt) | 640 | 65.0 | 88.8 | 456.3 | 2.00 | 26.4 | 81.0 |
+| [YOLOv8l-pose](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8l-pose.pt) | 640 | 67.6 | 90.0 | 784.5 | 2.59 | 44.4 | 168.6 |
+| [YOLOv8x-pose](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8x-pose.pt) | 640 | 69.2 | 90.2 | 1607.1 | 3.73 | 69.4 | 263.2 |
+| [YOLOv8x-pose-p6](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8x-pose-p6.pt) | 1280 | 71.6 | 91.2 | 4088.7 | 10.04 | 99.1 | 1066.4 |
+
+- **mAPval** values are for single-model single-scale on [COCO Keypoints val2017](https://cocodataset.org) dataset. Reproduce by `yolo val pose data=coco-pose.yaml device=0`
+- **Speed** averaged over COCO val images using an [Amazon EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/) instance. Reproduce by `yolo val pose data=coco-pose.yaml batch=1 device=0|cpu`
+
+
+
+OBB (DOTAv1)
+
+See [OBB Docs](https://docs.ultralytics.com/tasks/obb/) for usage examples with these models trained on [DOTAv1](https://docs.ultralytics.com/datasets/obb/dota-v2/#dota-v10/), which include 15 pre-trained classes.
+
+| Model | size (pixels) | mAPtest 50 | Speed CPU ONNX (ms) | Speed A100 TensorRT (ms) | params (M) | FLOPs (B) |
+| -------------------------------------------------------------------------------------------- | --------------------- | ------------------ | ------------------------------ | ----------------------------------- | ------------------ | ----------------- |
+| [YOLOv8n-obb](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n-obb.pt) | 1024 | 78.0 | 204.77 | 3.57 | 3.1 | 23.3 |
+| [YOLOv8s-obb](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8s-obb.pt) | 1024 | 79.5 | 424.88 | 4.07 | 11.4 | 76.3 |
+| [YOLOv8m-obb](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8m-obb.pt) | 1024 | 80.5 | 763.48 | 7.61 | 26.4 | 208.6 |
+| [YOLOv8l-obb](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8l-obb.pt) | 1024 | 80.7 | 1278.42 | 11.83 | 44.5 | 433.8 |
+| [YOLOv8x-obb](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8x-obb.pt) | 1024 | 81.36 | 1759.10 | 13.23 | 69.5 | 676.7 |
+
+- **mAPtest** values are for single-model multiscale on [DOTAv1](https://captain-whu.github.io/DOTA/index.html) dataset. Reproduce by `yolo val obb data=DOTAv1.yaml device=0 split=test` and submit merged results to [DOTA evaluation](https://captain-whu.github.io/DOTA/evaluation.html).
+- **Speed** averaged over DOTAv1 val images using an [Amazon EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/) instance. Reproduce by `yolo val obb data=DOTAv1.yaml batch=1 device=0|cpu`
+
+
+
+Classification (ImageNet)
+
+See [Classification Docs](https://docs.ultralytics.com/tasks/classify/) for usage examples with these models trained on [ImageNet](https://docs.ultralytics.com/datasets/classify/imagenet/), which include 1000 pretrained classes.
+
+| Model | size (pixels) | acc top1 | acc top5 | Speed CPU ONNX (ms) | Speed A100 TensorRT (ms) | params (M) | FLOPs (B) at 640 |
+| -------------------------------------------------------------------------------------------- | --------------------- | ---------------- | ---------------- | ------------------------------ | ----------------------------------- | ------------------ | ------------------------ |
+| [YOLOv8n-cls](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n-cls.pt) | 224 | 69.0 | 88.3 | 12.9 | 0.31 | 2.7 | 4.3 |
+| [YOLOv8s-cls](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8s-cls.pt) | 224 | 73.8 | 91.7 | 23.4 | 0.35 | 6.4 | 13.5 |
+| [YOLOv8m-cls](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8m-cls.pt) | 224 | 76.8 | 93.5 | 85.4 | 0.62 | 17.0 | 42.7 |
+| [YOLOv8l-cls](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8l-cls.pt) | 224 | 78.3 | 94.2 | 163.0 | 0.87 | 37.5 | 99.7 |
+| [YOLOv8x-cls](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8x-cls.pt) | 224 | 79.0 | 94.6 | 232.0 | 1.01 | 57.4 | 154.8 |
+
+- **acc** values are model accuracies on the [ImageNet](https://www.image-net.org/) dataset validation set. Reproduce by `yolo val classify data=path/to/ImageNet device=0`
+- **Speed** averaged over ImageNet val images using an [Amazon EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/) instance. Reproduce by `yolo val classify data=path/to/ImageNet batch=1 device=0|cpu`
+
+
+
+##
Integrations
+
+Our key integrations with leading AI platforms extend the functionality of Ultralytics' offerings, enhancing tasks like dataset labeling, training, visualization, and model management. Discover how Ultralytics, in collaboration with [Roboflow](https://roboflow.com/?ref=ultralytics), ClearML, [Comet](https://bit.ly/yolov8-readme-comet), Neural Magic and [OpenVINO](https://docs.ultralytics.com/integrations/openvino), can optimize your AI workflow.
+
+
+
+
+
+
+
+
+
+| Roboflow | ClearML ⭐ NEW | Comet ⭐ NEW | Neural Magic ⭐ NEW |
+| :--------------------------------------------------------------------------------------------------------------------------: | :-------------------------------------------------------------------------------------------------------------: | :-------------------------------------------------------------------------------------------------------------------------------------------------------: | :----------------------------------------------------------------------------------------------------: |
+| Label and export your custom datasets directly to YOLOv8 for training with [Roboflow](https://roboflow.com/?ref=ultralytics) | Automatically track, visualize and even remotely train YOLOv8 using [ClearML](https://clear.ml/) (open-source!) | Free forever, [Comet](https://bit.ly/yolov8-readme-comet) lets you save YOLOv8 models, resume training, and interactively visualize and debug predictions | Run YOLOv8 inference up to 6x faster with [Neural Magic DeepSparse](https://bit.ly/yolov5-neuralmagic) |
+
+##
Ultralytics HUB
+
+Experience seamless AI with [Ultralytics HUB](https://ultralytics.com/hub) ⭐, the all-in-one solution for data visualization, YOLOv5 and YOLOv8 🚀 model training and deployment, without any coding. Transform images into actionable insights and bring your AI visions to life with ease using our cutting-edge platform and user-friendly [Ultralytics App](https://ultralytics.com/app_install). Start your journey for **Free** now!
+
+
+
+
+##
Contribute
+
+We love your input! YOLOv5 and YOLOv8 would not be possible without help from our community. Please see our [Contributing Guide](https://docs.ultralytics.com/help/contributing) to get started, and fill out our [Survey](https://ultralytics.com/survey?utm_source=github&utm_medium=social&utm_campaign=Survey) to send us feedback on your experience. Thank you 🙏 to all our contributors!
+
+
+
+
+
+
+##
License
+
+Ultralytics offers two licensing options to accommodate diverse use cases:
+
+- **AGPL-3.0 License**: This [OSI-approved](https://opensource.org/licenses/) open-source license is ideal for students and enthusiasts, promoting open collaboration and knowledge sharing. See the [LICENSE](https://github.com/ultralytics/ultralytics/blob/main/LICENSE) file for more details.
+- **Enterprise License**: Designed for commercial use, this license permits seamless integration of Ultralytics software and AI models into commercial goods and services, bypassing the open-source requirements of AGPL-3.0. If your scenario involves embedding our solutions into a commercial offering, reach out through [Ultralytics Licensing](https://ultralytics.com/license).
+
+##
Contact
+
+For Ultralytics bug reports and feature requests please visit [GitHub Issues](https://github.com/ultralytics/ultralytics/issues), and join our [Discord](https://ultralytics.com/discord) community for questions and discussions!
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/ultralytics/README.zh-CN.md b/ultralytics/README.zh-CN.md
new file mode 100644
index 0000000000000000000000000000000000000000..bb645c35f1fa61891ec41bcb753dd7d28c0cb382
--- /dev/null
+++ b/ultralytics/README.zh-CN.md
@@ -0,0 +1,299 @@
+
diff --git a/ultralytics/docker/Dockerfile b/ultralytics/docker/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..0c9b001f5f05fb6d4ef871c9afa5e4e35561f454
--- /dev/null
+++ b/ultralytics/docker/Dockerfile
@@ -0,0 +1,89 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# Builds ultralytics/ultralytics:latest image on DockerHub https://hub.docker.com/r/ultralytics/ultralytics
+# Image is CUDA-optimized for YOLOv8 single/multi-GPU training and inference
+
+# Start FROM PyTorch image https://hub.docker.com/r/pytorch/pytorch or nvcr.io/nvidia/pytorch:23.03-py3
+FROM pytorch/pytorch:2.3.1-cuda12.1-cudnn8-runtime
+
+# Set environment variables
+# Avoid DDP error "MKL_THREADING_LAYER=INTEL is incompatible with libgomp.so.1 library" https://github.com/pytorch/pytorch/issues/37377
+ENV PYTHONUNBUFFERED=1 \
+ PYTHONDONTWRITEBYTECODE=1 \
+ PIP_NO_CACHE_DIR=1 \
+ PIP_BREAK_SYSTEM_PACKAGES=1 \
+ MKL_THREADING_LAYER=GNU
+
+# Downloads to user config dir
+ADD https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.ttf \
+ https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.Unicode.ttf \
+ /root/.config/Ultralytics/
+
+# Install linux packages
+# g++ required to build 'tflite_support' and 'lap' packages, libusb-1.0-0 required for 'tflite_support' package
+# libsm6 required by libqxcb to create QT-based windows for visualization; set 'QT_DEBUG_PLUGINS=1' to test in docker
+RUN apt update \
+ && apt install --no-install-recommends -y gcc git zip unzip wget curl htop libgl1 libglib2.0-0 libpython3-dev gnupg g++ libusb-1.0-0 libsm6
+
+# Security updates
+# https://security.snyk.io/vuln/SNYK-UBUNTU1804-OPENSSL-3314796
+RUN apt upgrade --no-install-recommends -y openssl tar
+
+# Create working directory
+WORKDIR /ultralytics
+
+# Copy contents and configure git
+COPY . .
+RUN sed -i '/^\[http "https:\/\/github\.com\/"\]/,+1d' .git/config
+ADD https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n.pt .
+
+# Install pip packages
+RUN python3 -m pip install --upgrade pip wheel
+# Pin TensorRT-cu12==10.1.0 to avoid 10.2.0 bug https://github.com/ultralytics/ultralytics/pull/14239 (note -cu12 must be used)
+RUN pip install -e ".[export]" "tensorrt-cu12==10.1.0" "albumentations>=1.4.6" comet pycocotools
+
+# Run exports to AutoInstall packages
+# Edge TPU export fails the first time so is run twice here
+RUN yolo export model=tmp/yolov8n.pt format=edgetpu imgsz=32 || yolo export model=tmp/yolov8n.pt format=edgetpu imgsz=32
+RUN yolo export model=tmp/yolov8n.pt format=ncnn imgsz=32
+# Requires <= Python 3.10, bug with paddlepaddle==2.5.0 https://github.com/PaddlePaddle/X2Paddle/issues/991
+RUN pip install "paddlepaddle>=2.6.0" x2paddle
+# Fix error: `np.bool` was a deprecated alias for the builtin `bool` segmentation error in Tests
+RUN pip install numpy==1.23.5
+# Remove exported models
+RUN rm -rf tmp
+
+
+# Usage Examples -------------------------------------------------------------------------------------------------------
+
+# Build and Push
+# t=ultralytics/ultralytics:latest && sudo docker build -f docker/Dockerfile -t $t . && sudo docker push $t
+
+# Pull and Run with access to all GPUs
+# t=ultralytics/ultralytics:latest && sudo docker pull $t && sudo docker run -it --ipc=host --gpus all $t
+
+# Pull and Run with access to GPUs 2 and 3 (inside container CUDA devices will appear as 0 and 1)
+# t=ultralytics/ultralytics:latest && sudo docker pull $t && sudo docker run -it --ipc=host --gpus '"device=2,3"' $t
+
+# Pull and Run with local directory access
+# t=ultralytics/ultralytics:latest && sudo docker pull $t && sudo docker run -it --ipc=host --gpus all -v "$(pwd)"/shared/datasets:/datasets $t
+
+# Kill all
+# sudo docker kill $(sudo docker ps -q)
+
+# Kill all image-based
+# sudo docker kill $(sudo docker ps -qa --filter ancestor=ultralytics/ultralytics:latest)
+
+# DockerHub tag update
+# t=ultralytics/ultralytics:latest tnew=ultralytics/ultralytics:v6.2 && sudo docker pull $t && sudo docker tag $t $tnew && sudo docker push $tnew
+
+# Clean up
+# sudo docker system prune -a --volumes
+
+# Update Ubuntu drivers
+# https://www.maketecheasier.com/install-nvidia-drivers-ubuntu/
+
+# DDP test
+# python -m torch.distributed.run --nproc_per_node 2 --master_port 1 train.py --epochs 3
+
+# GCP VM from Image
+# docker.io/ultralytics/ultralytics:latest
diff --git a/ultralytics/docker/Dockerfile-arm64 b/ultralytics/docker/Dockerfile-arm64
new file mode 100644
index 0000000000000000000000000000000000000000..36c5f878fcfbf6aca8ef554b0a66e73292779159
--- /dev/null
+++ b/ultralytics/docker/Dockerfile-arm64
@@ -0,0 +1,54 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# Builds ultralytics/ultralytics:latest-arm64 image on DockerHub https://hub.docker.com/r/ultralytics/ultralytics
+# Image is aarch64-compatible for Apple M1, M2, M3, Raspberry Pi and other ARM architectures
+
+# Start FROM Ubuntu image https://hub.docker.com/_/ubuntu with "FROM arm64v8/ubuntu:22.04" (deprecated)
+# Start FROM Debian image for arm64v8 https://hub.docker.com/r/arm64v8/debian (new)
+FROM arm64v8/debian:bookworm-slim
+
+# Set environment variables
+ENV PYTHONUNBUFFERED=1 \
+ PYTHONDONTWRITEBYTECODE=1 \
+ PIP_NO_CACHE_DIR=1 \
+ PIP_BREAK_SYSTEM_PACKAGES=1
+
+# Downloads to user config dir
+ADD https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.ttf \
+ https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.Unicode.ttf \
+ /root/.config/Ultralytics/
+
+# Install linux packages
+# g++ required to build 'tflite_support' and 'lap' packages, libusb-1.0-0 required for 'tflite_support' package
+# pkg-config and libhdf5-dev (not included) are needed to build 'h5py==3.11.0' aarch64 wheel required by 'tensorflow'
+RUN apt update \
+ && apt install --no-install-recommends -y python3-pip git zip unzip wget curl htop gcc libgl1 libglib2.0-0 libpython3-dev gnupg g++ libusb-1.0-0
+
+# Create working directory
+WORKDIR /ultralytics
+
+# Copy contents and configure git
+COPY . .
+RUN sed -i '/^\[http "https:\/\/github\.com\/"\]/,+1d' .git/config
+ADD https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n.pt .
+
+# Install pip packages
+RUN python3 -m pip install --upgrade pip wheel
+RUN pip install -e ".[export]"
+
+# Creates a symbolic link to make 'python' point to 'python3'
+RUN ln -sf /usr/bin/python3 /usr/bin/python
+
+
+# Usage Examples -------------------------------------------------------------------------------------------------------
+
+# Build and Push
+# t=ultralytics/ultralytics:latest-arm64 && sudo docker build --platform linux/arm64 -f docker/Dockerfile-arm64 -t $t . && sudo docker push $t
+
+# Run
+# t=ultralytics/ultralytics:latest-arm64 && sudo docker run -it --ipc=host $t
+
+# Pull and Run
+# t=ultralytics/ultralytics:latest-arm64 && sudo docker pull $t && sudo docker run -it --ipc=host $t
+
+# Pull and Run with local volume mounted
+# t=ultralytics/ultralytics:latest-arm64 && sudo docker pull $t && sudo docker run -it --ipc=host -v "$(pwd)"/shared/datasets:/datasets $t
diff --git a/ultralytics/docker/Dockerfile-conda b/ultralytics/docker/Dockerfile-conda
new file mode 100644
index 0000000000000000000000000000000000000000..7814b1a20bec13346b8e690f05a3eef410056887
--- /dev/null
+++ b/ultralytics/docker/Dockerfile-conda
@@ -0,0 +1,46 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# Builds ultralytics/ultralytics:latest-conda image on DockerHub https://hub.docker.com/r/ultralytics/ultralytics
+# Image is optimized for Ultralytics Anaconda (https://anaconda.org/conda-forge/ultralytics) installation and usage
+
+# Start FROM miniconda3 image https://hub.docker.com/r/continuumio/miniconda3
+FROM continuumio/miniconda3:latest
+
+# Set environment variables
+ENV PYTHONUNBUFFERED=1 \
+ PYTHONDONTWRITEBYTECODE=1 \
+ PIP_NO_CACHE_DIR=1 \
+ PIP_BREAK_SYSTEM_PACKAGES=1
+
+# Downloads to user config dir
+ADD https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.ttf \
+ https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.Unicode.ttf \
+ /root/.config/Ultralytics/
+
+# Install linux packages
+RUN apt update \
+ && apt install --no-install-recommends -y libgl1
+
+# Copy contents
+ADD https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n.pt .
+
+# Install conda packages
+# mkl required to fix 'OSError: libmkl_intel_lp64.so.2: cannot open shared object file: No such file or directory'
+RUN conda config --set solver libmamba && \
+ conda install pytorch torchvision pytorch-cuda=12.1 -c pytorch -c nvidia && \
+ conda install -c conda-forge ultralytics mkl
+ # conda install -c pytorch -c nvidia -c conda-forge pytorch torchvision pytorch-cuda=12.1 ultralytics mkl
+
+
+# Usage Examples -------------------------------------------------------------------------------------------------------
+
+# Build and Push
+# t=ultralytics/ultralytics:latest-conda && sudo docker build -f docker/Dockerfile-cpu -t $t . && sudo docker push $t
+
+# Run
+# t=ultralytics/ultralytics:latest-conda && sudo docker run -it --ipc=host $t
+
+# Pull and Run
+# t=ultralytics/ultralytics:latest-conda && sudo docker pull $t && sudo docker run -it --ipc=host $t
+
+# Pull and Run with local volume mounted
+# t=ultralytics/ultralytics:latest-conda && sudo docker pull $t && sudo docker run -it --ipc=host -v "$(pwd)"/shared/datasets:/datasets $t
diff --git a/ultralytics/docker/Dockerfile-cpu b/ultralytics/docker/Dockerfile-cpu
new file mode 100644
index 0000000000000000000000000000000000000000..a199dac655d016595a858f992ecdee95312444ce
--- /dev/null
+++ b/ultralytics/docker/Dockerfile-cpu
@@ -0,0 +1,60 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# Builds ultralytics/ultralytics:latest-cpu image on DockerHub https://hub.docker.com/r/ultralytics/ultralytics
+# Image is CPU-optimized for ONNX, OpenVINO and PyTorch YOLOv8 deployments
+
+# Start FROM Ubuntu image https://hub.docker.com/_/ubuntu
+FROM ubuntu:23.10
+
+# Set environment variables
+ENV PYTHONUNBUFFERED=1 \
+ PYTHONDONTWRITEBYTECODE=1 \
+ PIP_NO_CACHE_DIR=1 \
+ PIP_BREAK_SYSTEM_PACKAGES=1
+
+# Downloads to user config dir
+ADD https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.ttf \
+ https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.Unicode.ttf \
+ /root/.config/Ultralytics/
+
+# Install linux packages
+# g++ required to build 'tflite_support' and 'lap' packages, libusb-1.0-0 required for 'tflite_support' package
+RUN apt update \
+ && apt install --no-install-recommends -y python3-pip git zip unzip wget curl htop libgl1 libglib2.0-0 libpython3-dev gnupg g++ libusb-1.0-0
+
+# Create working directory
+WORKDIR /ultralytics
+
+# Copy contents and configure git
+COPY . .
+RUN sed -i '/^\[http "https:\/\/github\.com\/"\]/,+1d' .git/config
+ADD https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n.pt .
+
+# Install pip packages
+RUN python3 -m pip install --upgrade pip wheel
+RUN pip install -e ".[export]" --extra-index-url https://download.pytorch.org/whl/cpu
+
+# Run exports to AutoInstall packages
+RUN yolo export model=tmp/yolov8n.pt format=edgetpu imgsz=32
+RUN yolo export model=tmp/yolov8n.pt format=ncnn imgsz=32
+# Requires Python<=3.10, bug with paddlepaddle==2.5.0 https://github.com/PaddlePaddle/X2Paddle/issues/991
+# RUN pip install "paddlepaddle>=2.6.0" x2paddle
+# Remove exported models
+RUN rm -rf tmp
+
+# Creates a symbolic link to make 'python' point to 'python3'
+RUN ln -sf /usr/bin/python3 /usr/bin/python
+
+
+# Usage Examples -------------------------------------------------------------------------------------------------------
+
+# Build and Push
+# t=ultralytics/ultralytics:latest-cpu && sudo docker build -f docker/Dockerfile-cpu -t $t . && sudo docker push $t
+
+# Run
+# t=ultralytics/ultralytics:latest-cpu && sudo docker run -it --ipc=host --name NAME $t
+
+# Pull and Run
+# t=ultralytics/ultralytics:latest-cpu && sudo docker pull $t && sudo docker run -it --ipc=host --name NAME $t
+
+# Pull and Run with local volume mounted
+# t=ultralytics/ultralytics:latest-cpu && sudo docker pull $t && sudo docker run -it --ipc=host -v "$(pwd)"/shared/datasets:/datasets $t
diff --git a/ultralytics/docker/Dockerfile-jetson-jetpack4 b/ultralytics/docker/Dockerfile-jetson-jetpack4
new file mode 100644
index 0000000000000000000000000000000000000000..c2a6d2751093d32278202053efa4e380e955f72f
--- /dev/null
+++ b/ultralytics/docker/Dockerfile-jetson-jetpack4
@@ -0,0 +1,65 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# Builds ultralytics/ultralytics:jetson-jetpack4 image on DockerHub https://hub.docker.com/r/ultralytics/ultralytics
+# Supports JetPack4.x for YOLOv8 on Jetson Nano, TX2, Xavier NX, AGX Xavier
+
+# Start FROM https://catalog.ngc.nvidia.com/orgs/nvidia/containers/l4t-cuda
+FROM nvcr.io/nvidia/l4t-cuda:10.2.460-runtime
+
+# Set environment variables
+ENV PYTHONUNBUFFERED=1 \
+ PYTHONDONTWRITEBYTECODE=1
+
+# Downloads to user config dir
+ADD https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.ttf \
+ https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.Unicode.ttf \
+ /root/.config/Ultralytics/
+
+# Add NVIDIA repositories for TensorRT dependencies
+RUN wget -q -O - https://repo.download.nvidia.com/jetson/jetson-ota-public.asc | apt-key add - && \
+ echo "deb https://repo.download.nvidia.com/jetson/common r32.7 main" > /etc/apt/sources.list.d/nvidia-l4t-apt-source.list && \
+ echo "deb https://repo.download.nvidia.com/jetson/t194 r32.7 main" >> /etc/apt/sources.list.d/nvidia-l4t-apt-source.list
+
+# Install dependencies
+RUN apt update && \
+ apt install --no-install-recommends -y git python3.8 python3.8-dev python3-pip python3-libnvinfer libopenmpi-dev libopenblas-base libomp-dev gcc
+
+# Create symbolic links for python3.8 and pip3
+RUN ln -sf /usr/bin/python3.8 /usr/bin/python3
+RUN ln -s /usr/bin/pip3 /usr/bin/pip
+
+# Create working directory
+WORKDIR /ultralytics
+
+# Copy contents and configure git
+COPY . .
+RUN sed -i '/^\[http "https:\/\/github\.com\/"\]/,+1d' .git/config
+ADD https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n.pt .
+
+# Download onnxruntime-gpu 1.8.0 and tensorrt 8.2.0.6
+# Other versions can be seen in https://elinux.org/Jetson_Zoo and https://forums.developer.nvidia.com/t/pytorch-for-jetson/72048
+ADD https://nvidia.box.com/shared/static/gjqofg7rkg97z3gc8jeyup6t8n9j8xjw.whl onnxruntime_gpu-1.8.0-cp38-cp38-linux_aarch64.whl
+ADD https://forums.developer.nvidia.com/uploads/short-url/hASzFOm9YsJx6VVFrDW1g44CMmv.whl tensorrt-8.2.0.6-cp38-none-linux_aarch64.whl
+
+# Install pip packages
+RUN python3 -m pip install --upgrade pip wheel
+RUN pip install \
+ onnxruntime_gpu-1.8.0-cp38-cp38-linux_aarch64.whl \
+ tensorrt-8.2.0.6-cp38-none-linux_aarch64.whl \
+ https://github.com/ultralytics/assets/releases/download/v0.0.0/torch-1.11.0a0+gitbc2c6ed-cp38-cp38-linux_aarch64.whl \
+ https://github.com/ultralytics/assets/releases/download/v0.0.0/torchvision-0.12.0a0+9b5a3fe-cp38-cp38-linux_aarch64.whl
+RUN pip install -e ".[export]"
+RUN rm *.whl
+
+# Usage Examples -------------------------------------------------------------------------------------------------------
+
+# Build and Push
+# t=ultralytics/ultralytics:latest-jetson-jetpack4 && sudo docker build --platform linux/arm64 -f docker/Dockerfile-jetson-jetpack4 -t $t . && sudo docker push $t
+
+# Run
+# t=ultralytics/ultralytics:latest-jetson-jetpack4 && sudo docker run -it --ipc=host $t
+
+# Pull and Run
+# t=ultralytics/ultralytics:latest-jetson-jetpack4 && sudo docker pull $t && sudo docker run -it --ipc=host $t
+
+# Pull and Run with NVIDIA runtime
+# t=ultralytics/ultralytics:latest-jetson-jetpack4 && sudo docker pull $t && sudo docker run -it --ipc=host --runtime=nvidia $t
diff --git a/ultralytics/docker/Dockerfile-jetson-jetpack5 b/ultralytics/docker/Dockerfile-jetson-jetpack5
new file mode 100644
index 0000000000000000000000000000000000000000..6266246e6e110b2710c41f59ff8d0bc218db7ab7
--- /dev/null
+++ b/ultralytics/docker/Dockerfile-jetson-jetpack5
@@ -0,0 +1,59 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# Builds ultralytics/ultralytics:jetson-jetson-jetpack5 image on DockerHub https://hub.docker.com/r/ultralytics/ultralytics
+# Supports JetPack5.x for YOLOv8 on Jetson Xavier NX, AGX Xavier, AGX Orin, Orin Nano and Orin NX
+
+# Start FROM https://catalog.ngc.nvidia.com/orgs/nvidia/containers/l4t-pytorch
+FROM nvcr.io/nvidia/l4t-pytorch:r35.2.1-pth2.0-py3
+
+# Set environment variables
+ENV PYTHONUNBUFFERED=1 \
+ PYTHONDONTWRITEBYTECODE=1 \
+ PIP_NO_CACHE_DIR=1 \
+ PIP_BREAK_SYSTEM_PACKAGES=1
+
+# Downloads to user config dir
+ADD https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.ttf \
+ https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.Unicode.ttf \
+ /root/.config/Ultralytics/
+
+# Install linux packages
+# g++ required to build 'tflite_support' and 'lap' packages
+# libusb-1.0-0 required for 'tflite_support' package when exporting to TFLite
+# pkg-config and libhdf5-dev (not included) are needed to build 'h5py==3.11.0' aarch64 wheel required by 'tensorflow'
+RUN apt update \
+ && apt install --no-install-recommends -y gcc git zip unzip wget curl htop libgl1 libglib2.0-0 libpython3-dev gnupg g++ libusb-1.0-0
+
+# Create working directory
+WORKDIR /ultralytics
+
+# Copy contents and configure git
+COPY . .
+RUN sed -i '/^\[http "https:\/\/github\.com\/"\]/,+1d' .git/config
+ADD https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n.pt .
+
+# Remove opencv-python from Ultralytics dependencies as it conflicts with opencv-python installed in base image
+RUN sed -i '/opencv-python/d' pyproject.toml
+
+# Download onnxruntime-gpu 1.15.1 for Jetson Linux 35.2.1 (JetPack 5.1). Other versions can be seen in https://elinux.org/Jetson_Zoo#ONNX_Runtime
+ADD https://nvidia.box.com/shared/static/mvdcltm9ewdy2d5nurkiqorofz1s53ww.whl onnxruntime_gpu-1.15.1-cp38-cp38-linux_aarch64.whl
+
+# Install pip packages manually for TensorRT compatibility https://github.com/NVIDIA/TensorRT/issues/2567
+RUN python3 -m pip install --upgrade pip wheel
+RUN pip install onnxruntime_gpu-1.15.1-cp38-cp38-linux_aarch64.whl
+RUN pip install -e ".[export]"
+RUN rm *.whl
+
+
+# Usage Examples -------------------------------------------------------------------------------------------------------
+
+# Build and Push
+# t=ultralytics/ultralytics:latest-jetson-jetpack5 && sudo docker build --platform linux/arm64 -f docker/Dockerfile-jetson-jetpack5 -t $t . && sudo docker push $t
+
+# Run
+# t=ultralytics/ultralytics:latest-jetson-jetpack5 && sudo docker run -it --ipc=host $t
+
+# Pull and Run
+# t=ultralytics/ultralytics:latest-jetson-jetpack5 && sudo docker pull $t && sudo docker run -it --ipc=host $t
+
+# Pull and Run with NVIDIA runtime
+# t=ultralytics/ultralytics:latest-jetson-jetpack5 && sudo docker pull $t && sudo docker run -it --ipc=host --runtime=nvidia $t
diff --git a/ultralytics/docker/Dockerfile-jetson-jetpack6 b/ultralytics/docker/Dockerfile-jetson-jetpack6
new file mode 100644
index 0000000000000000000000000000000000000000..aacf8b3e77dd8e89123c6b85c9acd4f583a0f80a
--- /dev/null
+++ b/ultralytics/docker/Dockerfile-jetson-jetpack6
@@ -0,0 +1,55 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# Builds ultralytics/ultralytics:jetson-jetpack6 image on DockerHub https://hub.docker.com/r/ultralytics/ultralytics
+# Supports JetPack6.x for YOLOv8 on Jetson AGX Orin, Orin NX and Orin Nano Series
+
+# Start FROM https://catalog.ngc.nvidia.com/orgs/nvidia/containers/l4t-jetpack
+FROM nvcr.io/nvidia/l4t-jetpack:r36.3.0
+
+# Set environment variables
+ENV PYTHONUNBUFFERED=1 \
+ PYTHONDONTWRITEBYTECODE=1 \
+ PIP_NO_CACHE_DIR=1 \
+ PIP_BREAK_SYSTEM_PACKAGES=1
+
+# Downloads to user config dir
+ADD https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.ttf \
+ https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.Unicode.ttf \
+ /root/.config/Ultralytics/
+
+# Install dependencies
+RUN apt update && \
+ apt install --no-install-recommends -y git python3-pip libopenmpi-dev libopenblas-base libomp-dev
+
+# Create working directory
+WORKDIR /ultralytics
+
+# Copy contents and configure git
+COPY . .
+RUN sed -i '/^\[http "https:\/\/github\.com\/"\]/,+1d' .git/config
+ADD https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n.pt .
+
+# Download onnxruntime-gpu 1.18.0 from https://elinux.org/Jetson_Zoo and https://forums.developer.nvidia.com/t/pytorch-for-jetson/72048
+ADD https://nvidia.box.com/shared/static/48dtuob7meiw6ebgfsfqakc9vse62sg4.whl onnxruntime_gpu-1.18.0-cp310-cp310-linux_aarch64.whl
+
+# Pip install onnxruntime-gpu, torch, torchvision and ultralytics
+RUN python3 -m pip install --upgrade pip wheel
+RUN pip install \
+ onnxruntime_gpu-1.18.0-cp310-cp310-linux_aarch64.whl \
+ https://github.com/ultralytics/assets/releases/download/v0.0.0/torch-2.3.0-cp310-cp310-linux_aarch64.whl \
+ https://github.com/ultralytics/assets/releases/download/v0.0.0/torchvision-0.18.0a0+6043bc2-cp310-cp310-linux_aarch64.whl
+RUN pip install -e ".[export]"
+RUN rm *.whl
+
+# Usage Examples -------------------------------------------------------------------------------------------------------
+
+# Build and Push
+# t=ultralytics/ultralytics:latest-jetson-jetpack6 && sudo docker build --platform linux/arm64 -f docker/Dockerfile-jetson-jetpack6 -t $t . && sudo docker push $t
+
+# Run
+# t=ultralytics/ultralytics:latest-jetson-jetpack6 && sudo docker run -it --ipc=host $t
+
+# Pull and Run
+# t=ultralytics/ultralytics:latest-jetson-jetpack6 && sudo docker pull $t && sudo docker run -it --ipc=host $t
+
+# Pull and Run with NVIDIA runtime
+# t=ultralytics/ultralytics:latest-jetson-jetpack6 && sudo docker pull $t && sudo docker run -it --ipc=host --runtime=nvidia $t
diff --git a/ultralytics/docker/Dockerfile-python b/ultralytics/docker/Dockerfile-python
new file mode 100644
index 0000000000000000000000000000000000000000..03107b3d07c9338e56094bd5ae8350879785b0cf
--- /dev/null
+++ b/ultralytics/docker/Dockerfile-python
@@ -0,0 +1,57 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# Builds ultralytics/ultralytics:latest-cpu image on DockerHub https://hub.docker.com/r/ultralytics/ultralytics
+# Image is CPU-optimized for ONNX, OpenVINO and PyTorch YOLOv8 deployments
+
+# Use the official Python 3.10 slim-bookworm as base image
+FROM python:3.10-slim-bookworm
+
+# Set environment variables
+ENV PYTHONUNBUFFERED=1 \
+ PYTHONDONTWRITEBYTECODE=1 \
+ PIP_NO_CACHE_DIR=1 \
+ PIP_BREAK_SYSTEM_PACKAGES=1
+
+# Downloads to user config dir
+ADD https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.ttf \
+ https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.Unicode.ttf \
+ /root/.config/Ultralytics/
+
+# Install linux packages
+# g++ required to build 'tflite_support' and 'lap' packages, libusb-1.0-0 required for 'tflite_support' package
+RUN apt update \
+ && apt install --no-install-recommends -y python3-pip git zip unzip wget curl htop libgl1 libglib2.0-0 libpython3-dev gnupg g++ libusb-1.0-0
+
+# Create working directory
+WORKDIR /ultralytics
+
+# Copy contents and configure git
+COPY . .
+RUN sed -i '/^\[http "https:\/\/github\.com\/"\]/,+1d' .git/config
+ADD https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n.pt .
+
+# Install pip packages
+RUN python3 -m pip install --upgrade pip wheel
+RUN pip install -e ".[export]" --extra-index-url https://download.pytorch.org/whl/cpu
+
+# Run exports to AutoInstall packages
+RUN yolo export model=tmp/yolov8n.pt format=edgetpu imgsz=32
+RUN yolo export model=tmp/yolov8n.pt format=ncnn imgsz=32
+# Requires Python<=3.10, bug with paddlepaddle==2.5.0 https://github.com/PaddlePaddle/X2Paddle/issues/991
+RUN pip install "paddlepaddle>=2.6.0" x2paddle
+# Remove exported models
+RUN rm -rf tmp
+
+
+# Usage Examples -------------------------------------------------------------------------------------------------------
+
+# Build and Push
+# t=ultralytics/ultralytics:latest-python && sudo docker build -f docker/Dockerfile-python -t $t . && sudo docker push $t
+
+# Run
+# t=ultralytics/ultralytics:latest-python && sudo docker run -it --ipc=host $t
+
+# Pull and Run
+# t=ultralytics/ultralytics:latest-python && sudo docker pull $t && sudo docker run -it --ipc=host $t
+
+# Pull and Run with local volume mounted
+# t=ultralytics/ultralytics:latest-python && sudo docker pull $t && sudo docker run -it --ipc=host -v "$(pwd)"/shared/datasets:/datasets $t
diff --git a/ultralytics/docker/Dockerfile-runner b/ultralytics/docker/Dockerfile-runner
new file mode 100644
index 0000000000000000000000000000000000000000..e8f9655cb49764a2566b184aa150de40617d5100
--- /dev/null
+++ b/ultralytics/docker/Dockerfile-runner
@@ -0,0 +1,45 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# Builds GitHub actions CI runner image for deployment to DockerHub https://hub.docker.com/r/ultralytics/ultralytics
+# Image is CUDA-optimized for YOLOv8 single/multi-GPU training and inference tests
+
+# Start FROM Ultralytics GPU image
+FROM ultralytics/ultralytics:latest
+
+# Set environment variables
+ENV PYTHONUNBUFFERED=1 \
+ PYTHONDONTWRITEBYTECODE=1 \
+ PIP_NO_CACHE_DIR=1 \
+ PIP_BREAK_SYSTEM_PACKAGES=1 \
+ RUNNER_ALLOW_RUNASROOT=1 \
+ DEBIAN_FRONTEND=noninteractive
+
+# Set the working directory
+WORKDIR /actions-runner
+
+# Download and unpack the latest runner from https://github.com/actions/runner
+RUN FILENAME=actions-runner-linux-x64-2.317.0.tar.gz && \
+ curl -o $FILENAME -L https://github.com/actions/runner/releases/download/v2.317.0/$FILENAME && \
+ tar xzf $FILENAME && \
+ rm $FILENAME
+
+# Install runner dependencies
+RUN pip install pytest-cov
+RUN ./bin/installdependencies.sh && \
+ apt-get -y install libicu-dev
+
+# Inline ENTRYPOINT command to configure and start runner with default TOKEN and NAME
+ENTRYPOINT sh -c './config.sh --url https://github.com/ultralytics/ultralytics \
+ --token ${GITHUB_RUNNER_TOKEN:-TOKEN} \
+ --name ${GITHUB_RUNNER_NAME:-NAME} \
+ --labels gpu-latest \
+ --replace && \
+ ./run.sh'
+
+
+# Usage Examples -------------------------------------------------------------------------------------------------------
+
+# Build and Push
+# t=ultralytics/ultralytics:latest-runner && sudo docker build -f docker/Dockerfile-runner -t $t . && sudo docker push $t
+
+# Pull and Run in detached mode with access to GPUs 0 and 1
+# t=ultralytics/ultralytics:latest-runner && sudo docker run -d -e GITHUB_RUNNER_TOKEN=TOKEN -e GITHUB_RUNNER_NAME=NAME --ipc=host --gpus '"device=0,1"' $t
diff --git a/ultralytics/docs/README.md b/ultralytics/docs/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..3682539864b5b0f868288f024edf6b046d0cb494
--- /dev/null
+++ b/ultralytics/docs/README.md
@@ -0,0 +1,146 @@
+
+
+
+# 📚 Ultralytics Docs
+
+[Ultralytics](https://ultralytics.com) Docs are the gateway to understanding and utilizing our cutting-edge machine learning tools. These documents are deployed to [https://docs.ultralytics.com](https://docs.ultralytics.com) for your convenience.
+
+[](https://github.com/ultralytics/docs/actions/workflows/pages/pages-build-deployment)
+[](https://github.com/ultralytics/docs/actions/workflows/links.yml)
+[](https://github.com/ultralytics/docs/actions/workflows/check_domains.yml)
+[](https://github.com/ultralytics/docs/actions/workflows/format.yml)
+[](https://ultralytics.com/discord)
+[](https://community.ultralytics.com)
+
+## 🛠️ Installation
+
+[](https://pypi.org/project/ultralytics/)
+[](https://pepy.tech/project/ultralytics)
+[](https://pypi.org/project/ultralytics/)
+
+To install the ultralytics package in developer mode, ensure you have Git and Python 3 installed on your system. Then, follow these steps:
+
+1. Clone the ultralytics repository to your local machine using Git:
+
+ ```bash
+ git clone https://github.com/ultralytics/ultralytics.git
+ ```
+
+2. Navigate to the cloned repository's root directory:
+
+ ```bash
+ cd ultralytics
+ ```
+
+3. Install the package in developer mode using pip (or pip3 for Python 3):
+
+ ```bash
+ pip install -e '.[dev]'
+ ```
+
+- This command installs the ultralytics package along with all development dependencies, allowing you to modify the package code and have the changes immediately reflected in your Python environment.
+
+## 🚀 Building and Serving Locally
+
+The `mkdocs serve` command builds and serves a local version of your MkDocs documentation, ideal for development and testing:
+
+```bash
+mkdocs serve
+```
+
+- #### Command Breakdown:
+
+ - `mkdocs` is the main MkDocs command-line interface.
+ - `serve` is the subcommand to build and locally serve your documentation.
+
+- 🧐 Note:
+
+ - Grasp changes to the docs in real-time as `mkdocs serve` supports live reloading.
+ - To stop the local server, press `CTRL+C`.
+
+## 🌍 Building and Serving Multi-Language
+
+Supporting multi-language documentation? Follow these steps:
+
+1. Stage all new language \*.md files with Git:
+
+ ```bash
+ git add docs/**/*.md -f
+ ```
+
+2. Build all languages to the `/site` folder, ensuring relevant root-level files are present:
+
+ ```bash
+ # Clear existing /site directory
+ rm -rf site
+
+ # Loop through each language config file and build
+ mkdocs build -f docs/mkdocs.yml
+ for file in docs/mkdocs_*.yml; do
+ echo "Building MkDocs site with $file"
+ mkdocs build -f "$file"
+ done
+ ```
+
+3. To preview your site, initiate a simple HTTP server:
+
+ ```bash
+ cd site
+ python -m http.server
+ # Open in your preferred browser
+ ```
+
+- 🖥️ Access the live site at `http://localhost:8000`.
+
+## 📤 Deploying Your Documentation Site
+
+Choose a hosting provider and deployment method for your MkDocs documentation:
+
+- Configure `mkdocs.yml` with deployment settings.
+- Use `mkdocs deploy` to build and deploy your site.
+
+* ### GitHub Pages Deployment Example:
+
+ ```bash
+ mkdocs gh-deploy
+ ```
+
+- Update the "Custom domain" in your repository's settings for a personalized URL.
+
+
+
+- For detailed deployment guidance, consult the [MkDocs documentation](https://www.mkdocs.org/user-guide/deploying-your-docs/).
+
+## 💡 Contribute
+
+We cherish the community's input as it drives Ultralytics open-source initiatives. Dive into the [Contributing Guide](https://docs.ultralytics.com/help/contributing) and share your thoughts via our [Survey](https://ultralytics.com/survey?utm_source=github&utm_medium=social&utm_campaign=Survey). A heartfelt thank you 🙏 to each contributor!
+
+
+
+## 📜 License
+
+Ultralytics Docs presents two licensing options:
+
+- **AGPL-3.0 License**: Perfect for academia and open collaboration. Details are in the [LICENSE](https://github.com/ultralytics/docs/blob/main/LICENSE) file.
+- **Enterprise License**: Tailored for commercial usage, offering a seamless blend of Ultralytics technology in your products. Learn more at [Ultralytics Licensing](https://ultralytics.com/license).
+
+## ✉️ Contact
+
+For bug reports and feature requests, navigate to [GitHub Issues](https://github.com/ultralytics/docs/issues). Engage with peers and the Ultralytics team on [Discord](https://ultralytics.com/discord) for enriching conversations!
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/ultralytics/docs/build_docs.py b/ultralytics/docs/build_docs.py
new file mode 100644
index 0000000000000000000000000000000000000000..d2d563613fac6a1ae2cdecc22bed57d3775db8a6
--- /dev/null
+++ b/ultralytics/docs/build_docs.py
@@ -0,0 +1,258 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+"""
+Automates the building and post-processing of MkDocs documentation, particularly for projects with multilingual content.
+It streamlines the workflow for generating localized versions of the documentation and updating HTML links to ensure
+they are correctly formatted.
+
+Key Features:
+ - Automated building of MkDocs documentation: The script compiles both the main documentation and
+ any localized versions specified in separate MkDocs configuration files.
+ - Post-processing of generated HTML files: After the documentation is built, the script updates all
+ HTML files to remove the '.md' extension from internal links. This ensures that links in the built
+ HTML documentation correctly point to other HTML pages rather than Markdown files, which is crucial
+ for proper navigation within the web-based documentation.
+
+Usage:
+ - Run the script from the root directory of your MkDocs project.
+ - Ensure that MkDocs is installed and that all MkDocs configuration files (main and localized versions)
+ are present in the project directory.
+ - The script first builds the documentation using MkDocs, then scans the generated HTML files in the 'site'
+ directory to update the internal links.
+ - It's ideal for projects where the documentation is written in Markdown and needs to be served as a static website.
+
+Note:
+ - This script is built to be run in an environment where Python and MkDocs are installed and properly configured.
+"""
+
+import os
+import re
+import shutil
+import subprocess
+from pathlib import Path
+
+from bs4 import BeautifulSoup
+from tqdm import tqdm
+
+os.environ["JUPYTER_PLATFORM_DIRS"] = "1" # fix DeprecationWarning: Jupyter is migrating to use standard platformdirs
+DOCS = Path(__file__).parent.resolve()
+SITE = DOCS.parent / "site"
+
+
+def prepare_docs_markdown(clone_repos=True):
+ """Build docs using mkdocs."""
+ if SITE.exists():
+ print(f"Removing existing {SITE}")
+ shutil.rmtree(SITE)
+
+ # Get hub-sdk repo
+ if clone_repos:
+ repo = "https://github.com/ultralytics/hub-sdk"
+ local_dir = DOCS.parent / Path(repo).name
+ if not local_dir.exists():
+ os.system(f"git clone {repo} {local_dir}")
+ os.system(f"git -C {local_dir} pull") # update repo
+ shutil.rmtree(DOCS / "en/hub/sdk", ignore_errors=True) # delete if exists
+ shutil.copytree(local_dir / "docs", DOCS / "en/hub/sdk") # for docs
+ shutil.rmtree(DOCS.parent / "hub_sdk", ignore_errors=True) # delete if exists
+ shutil.copytree(local_dir / "hub_sdk", DOCS.parent / "hub_sdk") # for mkdocstrings
+ print(f"Cloned/Updated {repo} in {local_dir}")
+
+ # Add frontmatter
+ for file in tqdm((DOCS / "en").rglob("*.md"), desc="Adding frontmatter"):
+ update_markdown_files(file)
+
+
+def update_page_title(file_path: Path, new_title: str):
+ """Update the title of an HTML file."""
+ # Read the content of the file
+ with open(file_path, encoding="utf-8") as file:
+ content = file.read()
+
+ # Replace the existing title with the new title
+ updated_content = re.sub(r".*?", f"{new_title}", content)
+
+ # Write the updated content back to the file
+ with open(file_path, "w", encoding="utf-8") as file:
+ file.write(updated_content)
+
+
+def update_html_head(script=""):
+ """Update the HTML head section of each file."""
+ html_files = Path(SITE).rglob("*.html")
+ for html_file in tqdm(html_files, desc="Processing HTML files"):
+ with html_file.open("r", encoding="utf-8") as file:
+ html_content = file.read()
+
+ if script in html_content: # script already in HTML file
+ return
+
+ head_end_index = html_content.lower().rfind("")
+ if head_end_index != -1:
+ # Add the specified JavaScript to the HTML file just before the end of the head tag.
+ new_html_content = html_content[:head_end_index] + script + html_content[head_end_index:]
+ with html_file.open("w", encoding="utf-8") as file:
+ file.write(new_html_content)
+
+
+def update_subdir_edit_links(subdir="", docs_url=""):
+ """Update the HTML head section of each file."""
+ if str(subdir[0]) == "/":
+ subdir = str(subdir[0])[1:]
+ html_files = (SITE / subdir).rglob("*.html")
+ for html_file in tqdm(html_files, desc="Processing subdir files"):
+ with html_file.open("r", encoding="utf-8") as file:
+ soup = BeautifulSoup(file, "html.parser")
+
+ # Find the anchor tag and update its href attribute
+ a_tag = soup.find("a", {"class": "md-content__button md-icon"})
+ if a_tag and a_tag["title"] == "Edit this page":
+ a_tag["href"] = f"{docs_url}{a_tag['href'].split(subdir)[-1]}"
+
+ # Write the updated HTML back to the file
+ with open(html_file, "w", encoding="utf-8") as file:
+ file.write(str(soup))
+
+
+def update_markdown_files(md_filepath: Path):
+ """Creates or updates a Markdown file, ensuring frontmatter is present."""
+ if md_filepath.exists():
+ content = md_filepath.read_text().strip()
+
+ # Replace apostrophes
+ content = content.replace("‘", "'").replace("’", "'")
+
+ # Add frontmatter if missing
+ if not content.strip().startswith("---\n") and "macros" not in md_filepath.parts: # skip macros directory
+ header = "---\ncomments: true\ndescription: TODO ADD DESCRIPTION\nkeywords: TODO ADD KEYWORDS\n---\n\n"
+ content = header + content
+
+ # Ensure MkDocs admonitions "=== " lines are preceded and followed by empty newlines
+ lines = content.split("\n")
+ new_lines = []
+ for i, line in enumerate(lines):
+ stripped_line = line.strip()
+ if stripped_line.startswith("=== "):
+ if i > 0 and new_lines[-1] != "":
+ new_lines.append("")
+ new_lines.append(line)
+ if i < len(lines) - 1 and lines[i + 1].strip() != "":
+ new_lines.append("")
+ else:
+ new_lines.append(line)
+ content = "\n".join(new_lines)
+
+ # Add EOF newline if missing
+ if not content.endswith("\n"):
+ content += "\n"
+
+ # Save page
+ md_filepath.write_text(content)
+ return
+
+
+def update_docs_html():
+ """Updates titles, edit links, head sections, and converts plaintext links in HTML documentation."""
+ # Update 404 titles
+ update_page_title(SITE / "404.html", new_title="Ultralytics Docs - Not Found")
+
+ # Update edit links
+ update_subdir_edit_links(
+ subdir="hub/sdk/", # do not use leading slash
+ docs_url="https://github.com/ultralytics/hub-sdk/tree/main/docs/",
+ )
+
+ # Convert plaintext links to HTML hyperlinks
+ files_modified = 0
+ for html_file in tqdm(SITE.rglob("*.html"), desc="Converting plaintext links"):
+ with open(html_file, "r", encoding="utf-8") as file:
+ content = file.read()
+ updated_content = convert_plaintext_links_to_html(content)
+ if updated_content != content:
+ with open(html_file, "w", encoding="utf-8") as file:
+ file.write(updated_content)
+ files_modified += 1
+ print(f"Modified plaintext links in {files_modified} files.")
+
+ # Update HTML file head section
+ script = ""
+ if any(script):
+ update_html_head(script)
+
+ # Delete the /macros directory from the built site
+ macros_dir = SITE / "macros"
+ if macros_dir.exists():
+ print(f"Removing /macros directory from site: {macros_dir}")
+ shutil.rmtree(macros_dir)
+
+
+def convert_plaintext_links_to_html(content):
+ """Convert plaintext links to HTML hyperlinks in the main content area only."""
+ soup = BeautifulSoup(content, "html.parser")
+
+ # Find the main content area (adjust this selector based on your HTML structure)
+ main_content = soup.find("main") or soup.find("div", class_="md-content")
+ if not main_content:
+ return content # Return original content if main content area not found
+
+ modified = False
+ for paragraph in main_content.find_all(["p", "li"]): # Focus on paragraphs and list items
+ for text_node in paragraph.find_all(string=True, recursive=False):
+ if text_node.parent.name not in {"a", "code"}: # Ignore links and code blocks
+ new_text = re.sub(
+ r'(https?://[^\s()<>]+(?:\.[^\s()<>]+)+)(?\1',
+ str(text_node),
+ )
+ if " tuple:
+ """Extracts class and function names from a given Python file."""
+ content = filepath.read_text()
+ class_pattern = r"(?:^|\n)class\s(\w+)(?:\(|:)"
+ func_pattern = r"(?:^|\n)def\s(\w+)\("
+
+ classes = re.findall(class_pattern, content)
+ functions = re.findall(func_pattern, content)
+
+ return classes, functions
+
+
+def create_markdown(py_filepath: Path, module_path: str, classes: list, functions: list):
+ """Creates a Markdown file containing the API reference for the given Python module."""
+ md_filepath = py_filepath.with_suffix(".md")
+ exists = md_filepath.exists()
+
+ # Read existing content and keep header content between first two ---
+ header_content = ""
+ if exists:
+ existing_content = md_filepath.read_text()
+ header_parts = existing_content.split("---")
+ for part in header_parts:
+ if "description:" in part or "comments:" in part:
+ header_content += f"---{part}---\n\n"
+ if not any(header_content):
+ header_content = "---\ndescription: TODO ADD DESCRIPTION\nkeywords: TODO ADD KEYWORDS\n---\n\n"
+
+ module_name = module_path.replace(".__init__", "")
+ module_path = module_path.replace(".", "/")
+ url = f"https://github.com/{GITHUB_REPO}/blob/main/{module_path}.py"
+ edit = f"https://github.com/{GITHUB_REPO}/edit/main/{module_path}.py"
+ pretty = url.replace("__init__.py", "\\_\\_init\\_\\_.py") # properly display __init__.py filenames
+ title_content = (
+ f"# Reference for `{module_path}.py`\n\n"
+ f"!!! Note\n\n"
+ f" This file is available at [{pretty}]({url}). If you spot a problem please help fix it by [contributing]"
+ f"(https://docs.ultralytics.com/help/contributing/) a [Pull Request]({edit}) 🛠️. Thank you 🙏!\n\n"
+ )
+ md_content = [" \n"] + [f"## ::: {module_name}.{class_name}\n\n
\n" for class_name in classes]
+ md_content.extend(f"## ::: {module_name}.{func_name}\n\n
\n" for func_name in functions)
+ md_content[-1] = md_content[-1].replace(" ", "") # remove last horizontal line
+ md_content = header_content + title_content + "\n".join(md_content)
+ if not md_content.endswith("\n"):
+ md_content += "\n"
+
+ md_filepath.parent.mkdir(parents=True, exist_ok=True)
+ md_filepath.write_text(md_content)
+
+ if not exists:
+ # Add new markdown file to the git staging area
+ print(f"Created new file '{md_filepath}'")
+ subprocess.run(["git", "add", "-f", str(md_filepath)], check=True, cwd=PACKAGE_DIR)
+
+ return md_filepath.relative_to(PACKAGE_DIR.parent)
+
+
+def nested_dict() -> defaultdict:
+ """Creates and returns a nested defaultdict."""
+ return defaultdict(nested_dict)
+
+
+def sort_nested_dict(d: dict) -> dict:
+ """Sorts a nested dictionary recursively."""
+ return {key: sort_nested_dict(value) if isinstance(value, dict) else value for key, value in sorted(d.items())}
+
+
+def create_nav_menu_yaml(nav_items: list, save: bool = False):
+ """Creates a YAML file for the navigation menu based on the provided list of items."""
+ nav_tree = nested_dict()
+
+ for item_str in nav_items:
+ item = Path(item_str)
+ parts = item.parts
+ current_level = nav_tree["reference"]
+ for part in parts[2:-1]: # skip the first two parts (docs and reference) and the last part (filename)
+ current_level = current_level[part]
+
+ md_file_name = parts[-1].replace(".md", "")
+ current_level[md_file_name] = item
+
+ nav_tree_sorted = sort_nested_dict(nav_tree)
+
+ def _dict_to_yaml(d, level=0):
+ """Converts a nested dictionary to a YAML-formatted string with indentation."""
+ yaml_str = ""
+ indent = " " * level
+ for k, v in d.items():
+ if isinstance(v, dict):
+ yaml_str += f"{indent}- {k}:\n{_dict_to_yaml(v, level + 1)}"
+ else:
+ yaml_str += f"{indent}- {k}: {str(v).replace('docs/en/', '')}\n"
+ return yaml_str
+
+ # Print updated YAML reference section
+ print("Scan complete, new mkdocs.yaml reference section is:\n\n", _dict_to_yaml(nav_tree_sorted))
+
+ # Save new YAML reference section
+ if save:
+ (PACKAGE_DIR.parent / "nav_menu_updated.yml").write_text(_dict_to_yaml(nav_tree_sorted))
+
+
+def main():
+ """Main function to extract class and function names, create Markdown files, and generate a YAML navigation menu."""
+ nav_items = []
+
+ for py_filepath in PACKAGE_DIR.rglob("*.py"):
+ classes, functions = extract_classes_and_functions(py_filepath)
+
+ if classes or functions:
+ py_filepath_rel = py_filepath.relative_to(PACKAGE_DIR)
+ md_filepath = REFERENCE_DIR / py_filepath_rel
+ module_path = f"{PACKAGE_DIR.name}.{py_filepath_rel.with_suffix('').as_posix().replace('/', '.')}"
+ md_rel_filepath = create_markdown(md_filepath, module_path, classes, functions)
+ nav_items.append(str(md_rel_filepath))
+
+ create_nav_menu_yaml(nav_items)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/ultralytics/docs/coming_soon_template.md b/ultralytics/docs/coming_soon_template.md
new file mode 100644
index 0000000000000000000000000000000000000000..ea76a7c1111e393b9cb995989762716ce87753f4
--- /dev/null
+++ b/ultralytics/docs/coming_soon_template.md
@@ -0,0 +1,34 @@
+---
+description: Discover what's next for Ultralytics with our under-construction page, previewing new, groundbreaking AI and ML features coming soon.
+keywords: Ultralytics, coming soon, under construction, new features, AI updates, ML advancements, YOLO, technology preview
+---
+
+# Under Construction 🏗️🌟
+
+Welcome to the [Ultralytics](https://ultralytics.com) "Under Construction" page! Here, we're hard at work developing the next generation of AI and ML innovations. This page serves as a teaser for the exciting updates and new features we're eager to share with you!
+
+## Exciting New Features on the Way 🎉
+
+- **Innovative Breakthroughs:** Get ready for advanced features and services that will transform your AI and ML experience.
+- **New Horizons:** Anticipate novel products that redefine AI and ML capabilities.
+- **Enhanced Services:** We're upgrading our services for greater efficiency and user-friendliness.
+
+## Stay Updated 🚧
+
+This placeholder page is your first stop for upcoming developments. Keep an eye out for:
+
+- **Newsletter:** Subscribe [here](https://ultralytics.com/#newsletter) for the latest news.
+- **Social Media:** Follow us [here](https://www.linkedin.com/company/ultralytics) for updates and teasers.
+- **Blog:** Visit our [blog](https://ultralytics.com/blog) for detailed insights.
+
+## We Value Your Input 🗣️
+
+Your feedback shapes our future releases. Share your thoughts and suggestions [here](https://ultralytics.com/survey).
+
+## Thank You, Community! 🌍
+
+Your [contributions](https://docs.ultralytics.com/help/contributing) inspire our continuous [innovation](https://github.com/ultralytics/ultralytics). Stay tuned for the big reveal of what's next in AI and ML at Ultralytics!
+
+---
+
+Excited for what's coming? Bookmark this page and get ready for a transformative AI and ML journey with Ultralytics! 🛠️🤖
diff --git a/ultralytics/docs/en/CNAME b/ultralytics/docs/en/CNAME
new file mode 100644
index 0000000000000000000000000000000000000000..57c136a9aabdea642b5845b058455695979fff63
--- /dev/null
+++ b/ultralytics/docs/en/CNAME
@@ -0,0 +1 @@
+docs.ultralytics.com
diff --git a/ultralytics/docs/en/datasets/classify/caltech101.md b/ultralytics/docs/en/datasets/classify/caltech101.md
new file mode 100644
index 0000000000000000000000000000000000000000..08e6b852da8f123889c87423afcba4a28b34e197
--- /dev/null
+++ b/ultralytics/docs/en/datasets/classify/caltech101.md
@@ -0,0 +1,149 @@
+---
+comments: true
+description: Explore the widely-used Caltech-101 dataset with 9,000 images across 101 categories. Ideal for object recognition tasks in machine learning and computer vision.
+keywords: Caltech-101, dataset, object recognition, machine learning, computer vision, YOLO, deep learning, research, AI
+---
+
+# Caltech-101 Dataset
+
+The [Caltech-101](https://data.caltech.edu/records/mzrjq-6wc02) dataset is a widely used dataset for object recognition tasks, containing around 9,000 images from 101 object categories. The categories were chosen to reflect a variety of real-world objects, and the images themselves were carefully selected and annotated to provide a challenging benchmark for object recognition algorithms.
+
+## Key Features
+
+- The Caltech-101 dataset comprises around 9,000 color images divided into 101 categories.
+- The categories encompass a wide variety of objects, including animals, vehicles, household items, and people.
+- The number of images per category varies, with about 40 to 800 images in each category.
+- Images are of variable sizes, with most images being medium resolution.
+- Caltech-101 is widely used for training and testing in the field of machine learning, particularly for object recognition tasks.
+
+## Dataset Structure
+
+Unlike many other datasets, the Caltech-101 dataset is not formally split into training and testing sets. Users typically create their own splits based on their specific needs. However, a common practice is to use a random subset of images for training (e.g., 30 images per category) and the remaining images for testing.
+
+## Applications
+
+The Caltech-101 dataset is extensively used for training and evaluating deep learning models in object recognition tasks, such as Convolutional Neural Networks (CNNs), Support Vector Machines (SVMs), and various other machine learning algorithms. Its wide variety of categories and high-quality images make it an excellent dataset for research and development in the field of machine learning and computer vision.
+
+## Usage
+
+To train a YOLO model on the Caltech-101 dataset for 100 epochs, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="caltech101", epochs=100, imgsz=416)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo classify train data=caltech101 model=yolov8n-cls.pt epochs=100 imgsz=416
+ ```
+
+## Sample Images and Annotations
+
+The Caltech-101 dataset contains high-quality color images of various objects, providing a well-structured dataset for object recognition tasks. Here are some examples of images from the dataset:
+
+
+
+The example showcases the variety and complexity of the objects in the Caltech-101 dataset, emphasizing the significance of a diverse dataset for training robust object recognition models.
+
+## Citations and Acknowledgments
+
+If you use the Caltech-101 dataset in your research or development work, please cite the following paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @article{fei2007learning,
+ title={Learning generative visual models from few training examples: An incremental Bayesian approach tested on 101 object categories},
+ author={Fei-Fei, Li and Fergus, Rob and Perona, Pietro},
+ journal={Computer vision and Image understanding},
+ volume={106},
+ number={1},
+ pages={59--70},
+ year={2007},
+ publisher={Elsevier}
+ }
+ ```
+
+We would like to acknowledge Li Fei-Fei, Rob Fergus, and Pietro Perona for creating and maintaining the Caltech-101 dataset as a valuable resource for the machine learning and computer vision research community. For more information about the Caltech-101 dataset and its creators, visit the [Caltech-101 dataset website](https://data.caltech.edu/records/mzrjq-6wc02).
+
+## FAQ
+
+### What is the Caltech-101 dataset used for in machine learning?
+
+The [Caltech-101](https://data.caltech.edu/records/mzrjq-6wc02) dataset is widely used in machine learning for object recognition tasks. It contains around 9,000 images across 101 categories, providing a challenging benchmark for evaluating object recognition algorithms. Researchers leverage it to train and test models, especially Convolutional Neural Networks (CNNs) and Support Vector Machines (SVMs), in computer vision.
+
+### How can I train an Ultralytics YOLO model on the Caltech-101 dataset?
+
+To train an Ultralytics YOLO model on the Caltech-101 dataset, you can use the provided code snippets. For example, to train for 100 epochs:
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="caltech101", epochs=100, imgsz=416)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo classify train data=caltech101 model=yolov8n-cls.pt epochs=100 imgsz=416
+ ```
+For more detailed arguments and options, refer to the model [Training](../../modes/train.md) page.
+
+### What are the key features of the Caltech-101 dataset?
+
+The Caltech-101 dataset includes:
+- Around 9,000 color images across 101 categories.
+- Categories covering a diverse range of objects, including animals, vehicles, and household items.
+- Variable number of images per category, typically between 40 and 800.
+- Variable image sizes, with most being medium resolution.
+
+These features make it an excellent choice for training and evaluating object recognition models in machine learning and computer vision.
+
+### Why should I cite the Caltech-101 dataset in my research?
+
+Citing the Caltech-101 dataset in your research acknowledges the creators' contributions and provides a reference for others who might use the dataset. The recommended citation is:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @article{fei2007learning,
+ title={Learning generative visual models from few training examples: An incremental Bayesian approach tested on 101 object categories},
+ author={Fei-Fei, Li and Fergus, Rob and Perona, Pietro},
+ journal={Computer vision and Image understanding},
+ volume={106},
+ number={1},
+ pages={59--70},
+ year={2007},
+ publisher={Elsevier}
+ }
+ ```
+Citing helps in maintaining the integrity of academic work and assists peers in locating the original resource.
+
+### Can I use Ultralytics HUB for training models on the Caltech-101 dataset?
+
+Yes, you can use Ultralytics HUB for training models on the Caltech-101 dataset. Ultralytics HUB provides an intuitive platform for managing datasets, training models, and deploying them without extensive coding. For a detailed guide, refer to the [how to train your custom models with Ultralytics HUB](https://www.ultralytics.com/blog/how-to-train-your-custom-models-with-ultralytics-hub) blog post.
diff --git a/ultralytics/docs/en/datasets/classify/caltech256.md b/ultralytics/docs/en/datasets/classify/caltech256.md
new file mode 100644
index 0000000000000000000000000000000000000000..51b5faada65a87aadfe8b57cc3d7dc5a6a934775
--- /dev/null
+++ b/ultralytics/docs/en/datasets/classify/caltech256.md
@@ -0,0 +1,146 @@
+---
+comments: true
+description: Explore the Caltech-256 dataset, featuring 30,000 images across 257 categories, ideal for training and testing object recognition algorithms.
+keywords: Caltech-256 dataset, object classification, image dataset, machine learning, computer vision, deep learning, YOLO, training dataset
+---
+
+# Caltech-256 Dataset
+
+The [Caltech-256](https://data.caltech.edu/records/nyy15-4j048) dataset is an extensive collection of images used for object classification tasks. It contains around 30,000 images divided into 257 categories (256 object categories and 1 background category). The images are carefully curated and annotated to provide a challenging and diverse benchmark for object recognition algorithms.
+
+
+
+
+
+ Watch: How to Train Image Classification Model using Caltech-256 Dataset with Ultralytics HUB
+
+
+## Key Features
+
+- The Caltech-256 dataset comprises around 30,000 color images divided into 257 categories.
+- Each category contains a minimum of 80 images.
+- The categories encompass a wide variety of real-world objects, including animals, vehicles, household items, and people.
+- Images are of variable sizes and resolutions.
+- Caltech-256 is widely used for training and testing in the field of machine learning, particularly for object recognition tasks.
+
+## Dataset Structure
+
+Like Caltech-101, the Caltech-256 dataset does not have a formal split between training and testing sets. Users typically create their own splits according to their specific needs. A common practice is to use a random subset of images for training and the remaining images for testing.
+
+## Applications
+
+The Caltech-256 dataset is extensively used for training and evaluating deep learning models in object recognition tasks, such as Convolutional Neural Networks (CNNs), Support Vector Machines (SVMs), and various other machine learning algorithms. Its diverse set of categories and high-quality images make it an invaluable dataset for research and development in the field of machine learning and computer vision.
+
+## Usage
+
+To train a YOLO model on the Caltech-256 dataset for 100 epochs, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="caltech256", epochs=100, imgsz=416)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo classify train data=caltech256 model=yolov8n-cls.pt epochs=100 imgsz=416
+ ```
+
+## Sample Images and Annotations
+
+The Caltech-256 dataset contains high-quality color images of various objects, providing a comprehensive dataset for object recognition tasks. Here are some examples of images from the dataset ([credit](https://ml4a.github.io/demos/tsne_viewer.html)):
+
+
+
+The example showcases the diversity and complexity of the objects in the Caltech-256 dataset, emphasizing the importance of a varied dataset for training robust object recognition models.
+
+## Citations and Acknowledgments
+
+If you use the Caltech-256 dataset in your research or development work, please cite the following paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @article{griffin2007caltech,
+ title={Caltech-256 object category dataset},
+ author={Griffin, Gregory and Holub, Alex and Perona, Pietro},
+ year={2007}
+ }
+ ```
+
+We would like to acknowledge Gregory Griffin, Alex Holub, and Pietro Perona for creating and maintaining the Caltech-256 dataset as a valuable resource for the machine learning and computer vision research community. For more information about the
+
+Caltech-256 dataset and its creators, visit the [Caltech-256 dataset website](https://data.caltech.edu/records/nyy15-4j048).
+
+## FAQ
+
+### What is the Caltech-256 dataset and why is it important for machine learning?
+
+The [Caltech-256](https://data.caltech.edu/records/nyy15-4j048) dataset is a large image dataset used primarily for object classification tasks in machine learning and computer vision. It consists of around 30,000 color images divided into 257 categories, covering a wide range of real-world objects. The dataset's diverse and high-quality images make it an excellent benchmark for evaluating object recognition algorithms, which is crucial for developing robust machine learning models.
+
+### How can I train a YOLO model on the Caltech-256 dataset using Python or CLI?
+
+To train a YOLO model on the Caltech-256 dataset for 100 epochs, you can use the following code snippets. Refer to the model [Training](../../modes/train.md) page for additional options.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model
+
+ # Train the model
+ results = model.train(data="caltech256", epochs=100, imgsz=416)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo classify train data=caltech256 model=yolov8n-cls.pt epochs=100 imgsz=416
+ ```
+
+### What are the most common use cases for the Caltech-256 dataset?
+
+The Caltech-256 dataset is widely used for various object recognition tasks such as:
+
+- Training Convolutional Neural Networks (CNNs)
+- Evaluating the performance of Support Vector Machines (SVMs)
+- Benchmarking new deep learning algorithms
+- Developing object detection models using frameworks like Ultralytics YOLO
+
+Its diversity and comprehensive annotations make it ideal for research and development in machine learning and computer vision.
+
+### How is the Caltech-256 dataset structured and split for training and testing?
+
+The Caltech-256 dataset does not come with a predefined split for training and testing. Users typically create their own splits according to their specific needs. A common approach is to randomly select a subset of images for training and use the remaining images for testing. This flexibility allows users to tailor the dataset to their specific project requirements and experimental setups.
+
+### Why should I use Ultralytics YOLO for training models on the Caltech-256 dataset?
+
+Ultralytics YOLO models offer several advantages for training on the Caltech-256 dataset:
+
+- **High Accuracy**: YOLO models are known for their state-of-the-art performance in object detection tasks.
+- **Speed**: They provide real-time inference capabilities, making them suitable for applications requiring quick predictions.
+- **Ease of Use**: With Ultralytics HUB, users can train, validate, and deploy models without extensive coding.
+- **Pretrained Models**: Starting from pretrained models, like `yolov8n-cls.pt`, can significantly reduce training time and improve model accuracy.
+
+For more details, explore our [comprehensive training guide](../../modes/train.md).
diff --git a/ultralytics/docs/en/datasets/classify/cifar10.md b/ultralytics/docs/en/datasets/classify/cifar10.md
new file mode 100644
index 0000000000000000000000000000000000000000..bfa0798db6b538d4f1816da61256001b5e7cbfe3
--- /dev/null
+++ b/ultralytics/docs/en/datasets/classify/cifar10.md
@@ -0,0 +1,173 @@
+---
+comments: true
+description: Explore the CIFAR-10 dataset, featuring 60,000 color images in 10 classes. Learn about its structure, applications, and how to train models using YOLO.
+keywords: CIFAR-10, dataset, machine learning, computer vision, image classification, YOLO, deep learning, neural networks
+---
+
+# CIFAR-10 Dataset
+
+The [CIFAR-10](https://www.cs.toronto.edu/~kriz/cifar.html) (Canadian Institute For Advanced Research) dataset is a collection of images used widely for machine learning and computer vision algorithms. It was developed by researchers at the CIFAR institute and consists of 60,000 32x32 color images in 10 different classes.
+
+
+
+
+
+ Watch: How to Train an Image Classification Model with CIFAR-10 Dataset using Ultralytics YOLOv8
+
+
+## Key Features
+
+- The CIFAR-10 dataset consists of 60,000 images, divided into 10 classes.
+- Each class contains 6,000 images, split into 5,000 for training and 1,000 for testing.
+- The images are colored and of size 32x32 pixels.
+- The 10 different classes represent airplanes, cars, birds, cats, deer, dogs, frogs, horses, ships, and trucks.
+- CIFAR-10 is commonly used for training and testing in the field of machine learning and computer vision.
+
+## Dataset Structure
+
+The CIFAR-10 dataset is split into two subsets:
+
+1. **Training Set**: This subset contains 50,000 images used for training machine learning models.
+2. **Testing Set**: This subset consists of 10,000 images used for testing and benchmarking the trained models.
+
+## Applications
+
+The CIFAR-10 dataset is widely used for training and evaluating deep learning models in image classification tasks, such as Convolutional Neural Networks (CNNs), Support Vector Machines (SVMs), and various other machine learning algorithms. The diversity of the dataset in terms of classes and the presence of color images make it a well-rounded dataset for research and development in the field of machine learning and computer vision.
+
+## Usage
+
+To train a YOLO model on the CIFAR-10 dataset for 100 epochs with an image size of 32x32, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="cifar10", epochs=100, imgsz=32)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo classify train data=cifar10 model=yolov8n-cls.pt epochs=100 imgsz=32
+ ```
+
+## Sample Images and Annotations
+
+The CIFAR-10 dataset contains color images of various objects, providing a well-structured dataset for image classification tasks. Here are some examples of images from the dataset:
+
+
+
+The example showcases the variety and complexity of the objects in the CIFAR-10 dataset, highlighting the importance of a diverse dataset for training robust image classification models.
+
+## Citations and Acknowledgments
+
+If you use the CIFAR-10 dataset in your research or development work, please cite the following paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @TECHREPORT{Krizhevsky09learningmultiple,
+ author={Alex Krizhevsky},
+ title={Learning multiple layers of features from tiny images},
+ institution={},
+ year={2009}
+ }
+ ```
+
+We would like to acknowledge Alex Krizhevsky for creating and maintaining the CIFAR-10 dataset as a valuable resource for the machine learning and computer vision research community. For more information about the CIFAR-10 dataset and its creator, visit the [CIFAR-10 dataset website](https://www.cs.toronto.edu/~kriz/cifar.html).
+
+## FAQ
+
+### How can I train a YOLO model on the CIFAR-10 dataset?
+
+To train a YOLO model on the CIFAR-10 dataset using Ultralytics, you can follow the examples provided for both Python and CLI. Here is a basic example to train your model for 100 epochs with an image size of 32x32 pixels:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="cifar10", epochs=100, imgsz=32)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo classify train data=cifar10 model=yolov8n-cls.pt epochs=100 imgsz=32
+ ```
+
+For more details, refer to the model [Training](../../modes/train.md) page.
+
+### What are the key features of the CIFAR-10 dataset?
+
+The CIFAR-10 dataset consists of 60,000 color images divided into 10 classes. Each class contains 6,000 images, with 5,000 for training and 1,000 for testing. The images are 32x32 pixels in size and vary across the following categories:
+
+- Airplanes
+- Cars
+- Birds
+- Cats
+- Deer
+- Dogs
+- Frogs
+- Horses
+- Ships
+- Trucks
+
+This diverse dataset is essential for training image classification models in fields such as machine learning and computer vision. For more information, visit the CIFAR-10 sections on [dataset structure](#dataset-structure) and [applications](#applications).
+
+### Why use the CIFAR-10 dataset for image classification tasks?
+
+The CIFAR-10 dataset is an excellent benchmark for image classification due to its diversity and structure. It contains a balanced mix of 60,000 labeled images across 10 different categories, which helps in training robust and generalized models. It is widely used for evaluating deep learning models, including Convolutional Neural Networks (CNNs) and other machine learning algorithms. The dataset is relatively small, making it suitable for quick experimentation and algorithm development. Explore its numerous applications in the [applications](#applications) section.
+
+### How is the CIFAR-10 dataset structured?
+
+The CIFAR-10 dataset is structured into two main subsets:
+
+1. **Training Set**: Contains 50,000 images used for training machine learning models.
+2. **Testing Set**: Consists of 10,000 images for testing and benchmarking the trained models.
+
+Each subset comprises images categorized into 10 classes, with their annotations readily available for model training and evaluation. For more detailed information, refer to the [dataset structure](#dataset-structure) section.
+
+### How can I cite the CIFAR-10 dataset in my research?
+
+If you use the CIFAR-10 dataset in your research or development projects, make sure to cite the following paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @TECHREPORT{Krizhevsky09learningmultiple,
+ author={Alex Krizhevsky},
+ title={Learning multiple layers of features from tiny images},
+ institution={},
+ year={2009}
+ }
+ ```
+
+Acknowledging the dataset's creators helps support continued research and development in the field. For more details, see the [citations and acknowledgments](#citations-and-acknowledgments) section.
+
+### What are some practical examples of using the CIFAR-10 dataset?
+
+The CIFAR-10 dataset is often used for training image classification models, such as Convolutional Neural Networks (CNNs) and Support Vector Machines (SVMs). These models can be employed in various computer vision tasks including object detection, image recognition, and automated tagging. To see some practical examples, check the code snippets in the [usage](#usage) section.
diff --git a/ultralytics/docs/en/datasets/classify/cifar100.md b/ultralytics/docs/en/datasets/classify/cifar100.md
new file mode 100644
index 0000000000000000000000000000000000000000..88a863563a0c2512c6909ae8d0dd9ac6cd44b336
--- /dev/null
+++ b/ultralytics/docs/en/datasets/classify/cifar100.md
@@ -0,0 +1,130 @@
+---
+comments: true
+description: Explore the CIFAR-100 dataset, consisting of 60,000 32x32 color images across 100 classes. Ideal for machine learning and computer vision tasks.
+keywords: CIFAR-100, dataset, machine learning, computer vision, image classification, deep learning, YOLO, training, testing, Alex Krizhevsky
+---
+
+# CIFAR-100 Dataset
+
+The [CIFAR-100](https://www.cs.toronto.edu/~kriz/cifar.html) (Canadian Institute For Advanced Research) dataset is a significant extension of the CIFAR-10 dataset, composed of 60,000 32x32 color images in 100 different classes. It was developed by researchers at the CIFAR institute, offering a more challenging dataset for more complex machine learning and computer vision tasks.
+
+## Key Features
+
+- The CIFAR-100 dataset consists of 60,000 images, divided into 100 classes.
+- Each class contains 600 images, split into 500 for training and 100 for testing.
+- The images are colored and of size 32x32 pixels.
+- The 100 different classes are grouped into 20 coarse categories for higher level classification.
+- CIFAR-100 is commonly used for training and testing in the field of machine learning and computer vision.
+
+## Dataset Structure
+
+The CIFAR-100 dataset is split into two subsets:
+
+1. **Training Set**: This subset contains 50,000 images used for training machine learning models.
+2. **Testing Set**: This subset consists of 10,000 images used for testing and benchmarking the trained models.
+
+## Applications
+
+The CIFAR-100 dataset is extensively used for training and evaluating deep learning models in image classification tasks, such as Convolutional Neural Networks (CNNs), Support Vector Machines (SVMs), and various other machine learning algorithms. The diversity of the dataset in terms of classes and the presence of color images make it a more challenging and comprehensive dataset for research and development in the field of machine learning and computer vision.
+
+## Usage
+
+To train a YOLO model on the CIFAR-100 dataset for 100 epochs with an image size of 32x32, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="cifar100", epochs=100, imgsz=32)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo classify train data=cifar100 model=yolov8n-cls.pt epochs=100 imgsz=32
+ ```
+
+## Sample Images and Annotations
+
+The CIFAR-100 dataset contains color images of various objects, providing a well-structured dataset for image classification tasks. Here are some examples of images from the dataset:
+
+
+
+The example showcases the variety and complexity of the objects in the CIFAR-100 dataset, highlighting the importance of a diverse dataset for training robust image classification models.
+
+## Citations and Acknowledgments
+
+If you use the CIFAR-100 dataset in your research or development work, please cite the following paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @TECHREPORT{Krizhevsky09learningmultiple,
+ author={Alex Krizhevsky},
+ title={Learning multiple layers of features from tiny images},
+ institution={},
+ year={2009}
+ }
+ ```
+
+We would like to acknowledge Alex Krizhevsky for creating and maintaining the CIFAR-100 dataset as a valuable resource for the machine learning and computer vision research community. For more information about the CIFAR-100 dataset and its creator, visit the [CIFAR-100 dataset website](https://www.cs.toronto.edu/~kriz/cifar.html).
+
+## FAQ
+
+### What is the CIFAR-100 dataset and why is it significant?
+
+The [CIFAR-100 dataset](https://www.cs.toronto.edu/~kriz/cifar.html) is a large collection of 60,000 32x32 color images classified into 100 classes. Developed by the Canadian Institute For Advanced Research (CIFAR), it provides a challenging dataset ideal for complex machine learning and computer vision tasks. Its significance lies in the diversity of classes and the small size of the images, making it a valuable resource for training and testing deep learning models, like Convolutional Neural Networks (CNNs), using frameworks such as Ultralytics YOLO.
+
+### How do I train a YOLO model on the CIFAR-100 dataset?
+
+You can train a YOLO model on the CIFAR-100 dataset using either Python or CLI commands. Here's how:
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="cifar100", epochs=100, imgsz=32)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo classify train data=cifar100 model=yolov8n-cls.pt epochs=100 imgsz=32
+ ```
+
+For a comprehensive list of available arguments, please refer to the model [Training](../../modes/train.md) page.
+
+### What are the primary applications of the CIFAR-100 dataset?
+
+The CIFAR-100 dataset is extensively used in training and evaluating deep learning models for image classification. Its diverse set of 100 classes, grouped into 20 coarse categories, provides a challenging environment for testing algorithms such as Convolutional Neural Networks (CNNs), Support Vector Machines (SVMs), and various other machine learning approaches. This dataset is a key resource in research and development within machine learning and computer vision fields.
+
+### How is the CIFAR-100 dataset structured?
+
+The CIFAR-100 dataset is split into two main subsets:
+
+1. **Training Set**: Contains 50,000 images used for training machine learning models.
+2. **Testing Set**: Consists of 10,000 images used for testing and benchmarking the trained models.
+
+Each of the 100 classes contains 600 images, with 500 images for training and 100 for testing, making it uniquely suited for rigorous academic and industrial research.
+
+### Where can I find sample images and annotations from the CIFAR-100 dataset?
+
+The CIFAR-100 dataset includes a variety of color images of various objects, making it a structured dataset for image classification tasks. You can refer to the documentation page to see [sample images and annotations](#sample-images-and-annotations). These examples highlight the dataset's diversity and complexity, important for training robust image classification models.
diff --git a/ultralytics/docs/en/datasets/classify/fashion-mnist.md b/ultralytics/docs/en/datasets/classify/fashion-mnist.md
new file mode 100644
index 0000000000000000000000000000000000000000..28e9631ca519f6015b9f064a74eccffb6e5b191b
--- /dev/null
+++ b/ultralytics/docs/en/datasets/classify/fashion-mnist.md
@@ -0,0 +1,139 @@
+---
+comments: true
+description: Explore the Fashion-MNIST dataset, a modern replacement for MNIST with 70,000 Zalando article images. Ideal for benchmarking machine learning models.
+keywords: Fashion-MNIST, image classification, Zalando dataset, machine learning, deep learning, CNN, dataset overview
+---
+
+# Fashion-MNIST Dataset
+
+The [Fashion-MNIST](https://github.com/zalandoresearch/fashion-mnist) dataset is a database of Zalando's article images—consisting of a training set of 60,000 examples and a test set of 10,000 examples. Each example is a 28x28 grayscale image, associated with a label from 10 classes. Fashion-MNIST is intended to serve as a direct drop-in replacement for the original MNIST dataset for benchmarking machine learning algorithms.
+
+
+
+
+
+ Watch: How to do Image Classification on Fashion MNIST Dataset using Ultralytics YOLOv8
+
+
+## Key Features
+
+- Fashion-MNIST contains 60,000 training images and 10,000 testing images of Zalando's article images.
+- The dataset comprises grayscale images of size 28x28 pixels.
+- Each pixel has a single pixel-value associated with it, indicating the lightness or darkness of that pixel, with higher numbers meaning darker. This pixel-value is an integer between 0 and 255.
+- Fashion-MNIST is widely used for training and testing in the field of machine learning, especially for image classification tasks.
+
+## Dataset Structure
+
+The Fashion-MNIST dataset is split into two subsets:
+
+1. **Training Set**: This subset contains 60,000 images used for training machine learning models.
+2. **Testing Set**: This subset consists of 10,000 images used for testing and benchmarking the trained models.
+
+## Labels
+
+Each training and test example is assigned to one of the following labels:
+
+0. T-shirt/top
+1. Trouser
+2. Pullover
+3. Dress
+4. Coat
+5. Sandal
+6. Shirt
+7. Sneaker
+8. Bag
+9. Ankle boot
+
+## Applications
+
+The Fashion-MNIST dataset is widely used for training and evaluating deep learning models in image classification tasks, such as Convolutional Neural Networks (CNNs), Support Vector Machines (SVMs), and various other machine learning algorithms. The dataset's simple and well-structured format makes it an essential resource for researchers and practitioners in the field of machine learning and computer vision.
+
+## Usage
+
+To train a CNN model on the Fashion-MNIST dataset for 100 epochs with an image size of 28x28, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="fashion-mnist", epochs=100, imgsz=28)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo classify train data=fashion-mnist model=yolov8n-cls.pt epochs=100 imgsz=28
+ ```
+
+## Sample Images and Annotations
+
+The Fashion-MNIST dataset contains grayscale images of Zalando's article images, providing a well-structured dataset for image classification tasks. Here are some examples of images from the dataset:
+
+
+
+The example showcases the variety and complexity of the images in the Fashion-MNIST dataset, highlighting the importance of a diverse dataset for training robust image classification models.
+
+## Acknowledgments
+
+If you use the Fashion-MNIST dataset in your research or development work, please acknowledge the dataset by linking to the [GitHub repository](https://github.com/zalandoresearch/fashion-mnist). This dataset was made available by Zalando Research.
+
+## FAQ
+
+### What is the Fashion-MNIST dataset and how is it different from MNIST?
+
+The [Fashion-MNIST](https://github.com/zalandoresearch/fashion-mnist) dataset is a collection of 70,000 grayscale images of Zalando's article images, intended as a modern replacement for the original MNIST dataset. It serves as a benchmark for machine learning models in the context of image classification tasks. Unlike MNIST, which contains handwritten digits, Fashion-MNIST consists of 28x28-pixel images categorized into 10 fashion-related classes, such as T-shirt/top, trouser, and ankle boot.
+
+### How can I train a YOLO model on the Fashion-MNIST dataset?
+
+To train an Ultralytics YOLO model on the Fashion-MNIST dataset, you can use both Python and CLI commands. Here's a quick example to get you started:
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a pretrained model
+ model = YOLO("yolov8n-cls.pt")
+
+ # Train the model on Fashion-MNIST
+ results = model.train(data="fashion-mnist", epochs=100, imgsz=28)
+ ```
+
+
+ === "CLI"
+
+ ```bash
+ yolo classify train data=fashion-mnist model=yolov8n-cls.pt epochs=100 imgsz=28
+ ```
+
+For more detailed training parameters, refer to the [Training page](../../modes/train.md).
+
+### Why should I use the Fashion-MNIST dataset for benchmarking my machine learning models?
+
+The [Fashion-MNIST](https://github.com/zalandoresearch/fashion-mnist) dataset is widely recognized in the deep learning community as a robust alternative to MNIST. It offers a more complex and varied set of images, making it an excellent choice for benchmarking image classification models. The dataset's structure, comprising 60,000 training images and 10,000 testing images, each labeled with one of 10 classes, makes it ideal for evaluating the performance of different machine learning algorithms in a more challenging context.
+
+### Can I use Ultralytics YOLO for image classification tasks like Fashion-MNIST?
+
+Yes, Ultralytics YOLO models can be used for image classification tasks, including those involving the Fashion-MNIST dataset. YOLOv8, for example, supports various vision tasks such as detection, segmentation, and classification. To get started with image classification tasks, refer to the [Classification page](https://docs.ultralytics.com/tasks/classify/).
+
+### What are the key features and structure of the Fashion-MNIST dataset?
+
+The Fashion-MNIST dataset is divided into two main subsets: 60,000 training images and 10,000 testing images. Each image is a 28x28-pixel grayscale picture representing one of 10 fashion-related classes. The simplicity and well-structured format make it ideal for training and evaluating models in machine learning and computer vision tasks. For more details on the dataset structure, see the [Dataset Structure section](#dataset-structure).
+
+### How can I acknowledge the use of the Fashion-MNIST dataset in my research?
+
+If you utilize the Fashion-MNIST dataset in your research or development projects, it's important to acknowledge it by linking to the [GitHub repository](https://github.com/zalandoresearch/fashion-mnist). This helps in attributing the data to Zalando Research, who made the dataset available for public use.
diff --git a/ultralytics/docs/en/datasets/classify/imagenet.md b/ultralytics/docs/en/datasets/classify/imagenet.md
new file mode 100644
index 0000000000000000000000000000000000000000..76bb4d30aebcfe3c8ee92e24d84eae723c37d61a
--- /dev/null
+++ b/ultralytics/docs/en/datasets/classify/imagenet.md
@@ -0,0 +1,138 @@
+---
+comments: true
+description: Explore the extensive ImageNet dataset and discover its role in advancing deep learning in computer vision. Access pretrained models and training examples.
+keywords: ImageNet, deep learning, visual recognition, computer vision, pretrained models, YOLO, dataset, object detection, image classification
+---
+
+# ImageNet Dataset
+
+[ImageNet](https://www.image-net.org/) is a large-scale database of annotated images designed for use in visual object recognition research. It contains over 14 million images, with each image annotated using WordNet synsets, making it one of the most extensive resources available for training deep learning models in computer vision tasks.
+
+## ImageNet Pretrained Models
+
+| Model | size (pixels) | acc top1 | acc top5 | Speed CPU ONNX (ms) | Speed A100 TensorRT (ms) | params (M) | FLOPs (B) at 640 |
+|----------------------------------------------------------------------------------------------|-----------------------|------------------|------------------|--------------------------------|-------------------------------------|--------------------|--------------------------|
+| [YOLOv8n-cls](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n-cls.pt) | 224 | 69.0 | 88.3 | 12.9 | 0.31 | 2.7 | 4.3 |
+| [YOLOv8s-cls](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8s-cls.pt) | 224 | 73.8 | 91.7 | 23.4 | 0.35 | 6.4 | 13.5 |
+| [YOLOv8m-cls](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8m-cls.pt) | 224 | 76.8 | 93.5 | 85.4 | 0.62 | 17.0 | 42.7 |
+| [YOLOv8l-cls](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8l-cls.pt) | 224 | 76.8 | 93.5 | 163.0 | 0.87 | 37.5 | 99.7 |
+| [YOLOv8x-cls](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8x-cls.pt) | 224 | 79.0 | 94.6 | 232.0 | 1.01 | 57.4 | 154.8 |
+
+## Key Features
+
+- ImageNet contains over 14 million high-resolution images spanning thousands of object categories.
+- The dataset is organized according to the WordNet hierarchy, with each synset representing a category.
+- ImageNet is widely used for training and benchmarking in the field of computer vision, particularly for image classification and object detection tasks.
+- The annual ImageNet Large Scale Visual Recognition Challenge (ILSVRC) has been instrumental in advancing computer vision research.
+
+## Dataset Structure
+
+The ImageNet dataset is organized using the WordNet hierarchy. Each node in the hierarchy represents a category, and each category is described by a synset (a collection of synonymous terms). The images in ImageNet are annotated with one or more synsets, providing a rich resource for training models to recognize various objects and their relationships.
+
+## ImageNet Large Scale Visual Recognition Challenge (ILSVRC)
+
+The annual [ImageNet Large Scale Visual Recognition Challenge (ILSVRC)](https://image-net.org/challenges/LSVRC/) has been an important event in the field of computer vision. It has provided a platform for researchers and developers to evaluate their algorithms and models on a large-scale dataset with standardized evaluation metrics. The ILSVRC has led to significant advancements in the development of deep learning models for image classification, object detection, and other computer vision tasks.
+
+## Applications
+
+The ImageNet dataset is widely used for training and evaluating deep learning models in various computer vision tasks, such as image classification, object detection, and object localization. Some popular deep learning architectures, such as AlexNet, VGG, and ResNet, were developed and benchmarked using the ImageNet dataset.
+
+## Usage
+
+To train a deep learning model on the ImageNet dataset for 100 epochs with an image size of 224x224, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="imagenet", epochs=100, imgsz=224)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo classify train data=imagenet model=yolov8n-cls.pt epochs=100 imgsz=224
+ ```
+
+## Sample Images and Annotations
+
+The ImageNet dataset contains high-resolution images spanning thousands of object categories, providing a diverse and extensive dataset for training and evaluating computer vision models. Here are some examples of images from the dataset:
+
+
+
+The example showcases the variety and complexity of the images in the ImageNet dataset, highlighting the importance of a diverse dataset for training robust computer vision models.
+
+## Citations and Acknowledgments
+
+If you use the ImageNet dataset in your research or development work, please cite the following paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @article{ILSVRC15,
+ author = {Olga Russakovsky and Jia Deng and Hao Su and Jonathan Krause and Sanjeev Satheesh and Sean Ma and Zhiheng Huang and Andrej Karpathy and Aditya Khosla and Michael Bernstein and Alexander C. Berg and Li Fei-Fei},
+ title={ImageNet Large Scale Visual Recognition Challenge},
+ year={2015},
+ journal={International Journal of Computer Vision (IJCV)},
+ volume={115},
+ number={3},
+ pages={211-252}
+ }
+ ```
+
+We would like to acknowledge the ImageNet team, led by Olga Russakovsky, Jia Deng, and Li Fei-Fei, for creating and maintaining the ImageNet dataset as a valuable resource for the machine learning and computer vision research community. For more information about the ImageNet dataset and its creators, visit the [ImageNet website](https://www.image-net.org/).
+
+## FAQ
+
+### What is the ImageNet dataset and how is it used in computer vision?
+
+The [ImageNet dataset](https://www.image-net.org/) is a large-scale database consisting of over 14 million high-resolution images categorized using WordNet synsets. It is extensively used in visual object recognition research, including image classification and object detection. The dataset's annotations and sheer volume provide a rich resource for training deep learning models. Notably, models like AlexNet, VGG, and ResNet have been trained and benchmarked using ImageNet, showcasing its role in advancing computer vision.
+
+### How can I use a pretrained YOLO model for image classification on the ImageNet dataset?
+
+To use a pretrained Ultralytics YOLO model for image classification on the ImageNet dataset, follow these steps:
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="imagenet", epochs=100, imgsz=224)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo classify train data=imagenet model=yolov8n-cls.pt epochs=100 imgsz=224
+ ```
+
+For more in-depth training instruction, refer to our [Training page](../../modes/train.md).
+
+### Why should I use the Ultralytics YOLOv8 pretrained models for my ImageNet dataset projects?
+
+Ultralytics YOLOv8 pretrained models offer state-of-the-art performance in terms of speed and accuracy for various computer vision tasks. For example, the YOLOv8n-cls model, with a top-1 accuracy of 69.0% and a top-5 accuracy of 88.3%, is optimized for real-time applications. Pretrained models reduce the computational resources required for training from scratch and accelerate development cycles. Learn more about the performance metrics of YOLOv8 models in the [ImageNet Pretrained Models section](#imagenet-pretrained-models).
+
+### How is the ImageNet dataset structured, and why is it important?
+
+The ImageNet dataset is organized using the WordNet hierarchy, where each node in the hierarchy represents a category described by a synset (a collection of synonymous terms). This structure allows for detailed annotations, making it ideal for training models to recognize a wide variety of objects. The diversity and annotation richness of ImageNet make it a valuable dataset for developing robust and generalizable deep learning models. More about this organization can be found in the [Dataset Structure](#dataset-structure) section.
+
+### What role does the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) play in computer vision?
+
+The annual [ImageNet Large Scale Visual Recognition Challenge (ILSVRC)](https://image-net.org/challenges/LSVRC/) has been pivotal in driving advancements in computer vision by providing a competitive platform for evaluating algorithms on a large-scale, standardized dataset. It offers standardized evaluation metrics, fostering innovation and development in areas such as image classification, object detection, and image segmentation. The challenge has continuously pushed the boundaries of what is possible with deep learning and computer vision technologies.
diff --git a/ultralytics/docs/en/datasets/classify/imagenet10.md b/ultralytics/docs/en/datasets/classify/imagenet10.md
new file mode 100644
index 0000000000000000000000000000000000000000..82cd3c473ddb93adcf4abe6aba03795ed1b2ded2
--- /dev/null
+++ b/ultralytics/docs/en/datasets/classify/imagenet10.md
@@ -0,0 +1,127 @@
+---
+comments: true
+description: Discover ImageNet10 a compact version of ImageNet for rapid model testing and CI checks. Perfect for quick evaluations in computer vision tasks.
+keywords: ImageNet10, ImageNet, Ultralytics, CI tests, sanity checks, training pipelines, computer vision, deep learning, dataset
+---
+
+# ImageNet10 Dataset
+
+The [ImageNet10](https://github.com/ultralytics/assets/releases/download/v0.0.0/imagenet10.zip) dataset is a small-scale subset of the [ImageNet](https://www.image-net.org/) database, developed by [Ultralytics](https://ultralytics.com) and designed for CI tests, sanity checks, and fast testing of training pipelines. This dataset is composed of the first image in the training set and the first image from the validation set of the first 10 classes in ImageNet. Although significantly smaller, it retains the structure and diversity of the original ImageNet dataset.
+
+## Key Features
+
+- ImageNet10 is a compact version of ImageNet, with 20 images representing the first 10 classes of the original dataset.
+- The dataset is organized according to the WordNet hierarchy, mirroring the structure of the full ImageNet dataset.
+- It is ideally suited for CI tests, sanity checks, and rapid testing of training pipelines in computer vision tasks.
+- Although not designed for model benchmarking, it can provide a quick indication of a model's basic functionality and correctness.
+
+## Dataset Structure
+
+The ImageNet10 dataset, like the original ImageNet, is organized using the WordNet hierarchy. Each of the 10 classes in ImageNet10 is described by a synset (a collection of synonymous terms). The images in ImageNet10 are annotated with one or more synsets, providing a compact resource for testing models to recognize various objects and their relationships.
+
+## Applications
+
+The ImageNet10 dataset is useful for quickly testing and debugging computer vision models and pipelines. Its small size allows for rapid iteration, making it ideal for continuous integration tests and sanity checks. It can also be used for fast preliminary testing of new models or changes to existing models before moving on to full-scale testing with the complete ImageNet dataset.
+
+## Usage
+
+To test a deep learning model on the ImageNet10 dataset with an image size of 224x224, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+!!! Example "Test Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="imagenet10", epochs=5, imgsz=224)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo classify train data=imagenet10 model=yolov8n-cls.pt epochs=5 imgsz=224
+ ```
+
+## Sample Images and Annotations
+
+The ImageNet10 dataset contains a subset of images from the original ImageNet dataset. These images are chosen to represent the first 10 classes in the dataset, providing a diverse yet compact dataset for quick testing and evaluation.
+
+ The example showcases the variety and complexity of the images in the ImageNet10 dataset, highlighting its usefulness for sanity checks and quick testing of computer vision models.
+
+## Citations and Acknowledgments
+
+If you use the ImageNet10 dataset in your research or development work, please cite the original ImageNet paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @article{ILSVRC15,
+ author = {Olga Russakovsky and Jia Deng and Hao Su and Jonathan Krause and Sanjeev Satheesh and Sean Ma and Zhiheng Huang and Andrej Karpathy and Aditya Khosla and Michael Bernstein and Alexander C. Berg and Li Fei-Fei},
+ title={ImageNet Large Scale Visual Recognition Challenge},
+ year={2015},
+ journal={International Journal of Computer Vision (IJCV)},
+ volume={115},
+ number={3},
+ pages={211-252}
+ }
+ ```
+
+We would like to acknowledge the ImageNet team, led by Olga Russakovsky, Jia Deng, and Li Fei-Fei, for creating and maintaining the ImageNet dataset. The ImageNet10 dataset, while a compact subset, is a valuable resource for quick testing and debugging in the machine learning and computer vision research community. For more information about the ImageNet dataset and its creators, visit the [ImageNet website](https://www.image-net.org/).
+
+## FAQ
+
+### What is the ImageNet10 dataset and how is it different from the full ImageNet dataset?
+
+The [ImageNet10](https://github.com/ultralytics/assets/releases/download/v0.0.0/imagenet10.zip) dataset is a compact subset of the original [ImageNet](https://www.image-net.org/) database, created by Ultralytics for rapid CI tests, sanity checks, and training pipeline evaluations. ImageNet10 comprises only 20 images, representing the first image in the training and validation sets of the first 10 classes in ImageNet. Despite its small size, it maintains the structure and diversity of the full dataset, making it ideal for quick testing but not for benchmarking models.
+
+### How can I use the ImageNet10 dataset to test my deep learning model?
+
+To test your deep learning model on the ImageNet10 dataset with an image size of 224x224, use the following code snippets.
+
+!!! Example "Test Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="imagenet10", epochs=5, imgsz=224)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo classify train data=imagenet10 model=yolov8n-cls.pt epochs=5 imgsz=224
+ ```
+
+Refer to the [Training](../../modes/train.md) page for a comprehensive list of available arguments.
+
+### Why should I use the ImageNet10 dataset for CI tests and sanity checks?
+
+The ImageNet10 dataset is designed specifically for CI tests, sanity checks, and quick evaluations in deep learning pipelines. Its small size allows for rapid iteration and testing, making it perfect for continuous integration processes where speed is crucial. By maintaining the structural complexity and diversity of the original ImageNet dataset, ImageNet10 provides a reliable indication of a model's basic functionality and correctness without the overhead of processing a large dataset.
+
+### What are the main features of the ImageNet10 dataset?
+
+The ImageNet10 dataset has several key features:
+
+- **Compact Size**: With only 20 images, it allows for rapid testing and debugging.
+- **Structured Organization**: Follows the WordNet hierarchy, similar to the full ImageNet dataset.
+- **CI and Sanity Checks**: Ideally suited for continuous integration tests and sanity checks.
+- **Not for Benchmarking**: While useful for quick model evaluations, it is not designed for extensive benchmarking.
+
+### Where can I download the ImageNet10 dataset?
+
+You can download the ImageNet10 dataset from the [Ultralytics GitHub releases page](https://github.com/ultralytics/assets/releases/download/v0.0.0/imagenet10.zip). For more detailed information about its structure and applications, refer to the [ImageNet10 Dataset](imagenet10.md) page.
diff --git a/ultralytics/docs/en/datasets/classify/imagenette.md b/ultralytics/docs/en/datasets/classify/imagenette.md
new file mode 100644
index 0000000000000000000000000000000000000000..d62a4d9b69ea83b7595cd1f35da2dfb33358c336
--- /dev/null
+++ b/ultralytics/docs/en/datasets/classify/imagenette.md
@@ -0,0 +1,193 @@
+---
+comments: true
+description: Explore the ImageNette dataset, a subset of ImageNet with 10 classes for efficient training and evaluation of image classification models. Ideal for ML and CV projects.
+keywords: ImageNette dataset, ImageNet subset, image classification, machine learning, deep learning, YOLO, Convolutional Neural Networks, ML dataset, education, training
+---
+
+# ImageNette Dataset
+
+The [ImageNette](https://github.com/fastai/imagenette) dataset is a subset of the larger [Imagenet](https://www.image-net.org/) dataset, but it only includes 10 easily distinguishable classes. It was created to provide a quicker, easier-to-use version of Imagenet for software development and education.
+
+## Key Features
+
+- ImageNette contains images from 10 different classes such as tench, English springer, cassette player, chain saw, church, French horn, garbage truck, gas pump, golf ball, parachute.
+- The dataset comprises colored images of varying dimensions.
+- ImageNette is widely used for training and testing in the field of machine learning, especially for image classification tasks.
+
+## Dataset Structure
+
+The ImageNette dataset is split into two subsets:
+
+1. **Training Set**: This subset contains several thousands of images used for training machine learning models. The exact number varies per class.
+2. **Validation Set**: This subset consists of several hundreds of images used for validating and benchmarking the trained models. Again, the exact number varies per class.
+
+## Applications
+
+The ImageNette dataset is widely used for training and evaluating deep learning models in image classification tasks, such as Convolutional Neural Networks (CNNs), and various other machine learning algorithms. The dataset's straightforward format and well-chosen classes make it a handy resource for both beginner and experienced practitioners in the field of machine learning and computer vision.
+
+## Usage
+
+To train a model on the ImageNette dataset for 100 epochs with a standard image size of 224x224, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="imagenette", epochs=100, imgsz=224)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo classify train data=imagenette model=yolov8n-cls.pt epochs=100 imgsz=224
+ ```
+
+## Sample Images and Annotations
+
+The ImageNette dataset contains colored images of various objects and scenes, providing a diverse dataset for image classification tasks. Here are some examples of images from the dataset:
+
+
+
+The example showcases the variety and complexity of the images in the ImageNette dataset, highlighting the importance of a diverse dataset for training robust image classification models.
+
+## ImageNette160 and ImageNette320
+
+For faster prototyping and training, the ImageNette dataset is also available in two reduced sizes: ImageNette160 and ImageNette320. These datasets maintain the same classes and structure as the full ImageNette dataset, but the images are resized to a smaller dimension. As such, these versions of the dataset are particularly useful for preliminary model testing, or when computational resources are limited.
+
+To use these datasets, simply replace 'imagenette' with 'imagenette160' or 'imagenette320' in the training command. The following code snippets illustrate this:
+
+!!! Example "Train Example with ImageNette160"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
+
+ # Train the model with ImageNette160
+ results = model.train(data="imagenette160", epochs=100, imgsz=160)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model with ImageNette160
+ yolo classify train data=imagenette160 model=yolov8n-cls.pt epochs=100 imgsz=160
+ ```
+
+!!! Example "Train Example with ImageNette320"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
+
+ # Train the model with ImageNette320
+ results = model.train(data="imagenette320", epochs=100, imgsz=320)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model with ImageNette320
+ yolo classify train data=imagenette320 model=yolov8n-cls.pt epochs=100 imgsz=320
+ ```
+
+These smaller versions of the dataset allow for rapid iterations during the development process while still providing valuable and realistic image classification tasks.
+
+## Citations and Acknowledgments
+
+If you use the ImageNette dataset in your research or development work, please acknowledge it appropriately. For more information about the ImageNette dataset, visit the [ImageNette dataset GitHub page](https://github.com/fastai/imagenette).
+
+## FAQ
+
+### What is the ImageNette dataset?
+
+The [ImageNette dataset](https://github.com/fastai/imagenette) is a simplified subset of the larger [ImageNet dataset](https://www.image-net.org/), featuring only 10 easily distinguishable classes such as tench, English springer, and French horn. It was created to offer a more manageable dataset for efficient training and evaluation of image classification models. This dataset is particularly useful for quick software development and educational purposes in machine learning and computer vision.
+
+### How can I use the ImageNette dataset for training a YOLO model?
+
+To train a YOLO model on the ImageNette dataset for 100 epochs, you can use the following commands. Make sure to have the Ultralytics YOLO environment set up.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="imagenette", epochs=100, imgsz=224)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo classify train data=imagenette model=yolov8n-cls.pt epochs=100 imgsz=224
+ ```
+
+For more details, see the [Training](../../modes/train.md) documentation page.
+
+### Why should I use ImageNette for image classification tasks?
+
+The ImageNette dataset is advantageous for several reasons:
+
+- **Quick and Simple**: It contains only 10 classes, making it less complex and time-consuming compared to larger datasets.
+- **Educational Use**: Ideal for learning and teaching the basics of image classification since it requires less computational power and time.
+- **Versatility**: Widely used to train and benchmark various machine learning models, especially in image classification.
+
+For more details on model training and dataset management, explore the [Dataset Structure](#dataset-structure) section.
+
+### Can the ImageNette dataset be used with different image sizes?
+
+Yes, the ImageNette dataset is also available in two resized versions: ImageNette160 and ImageNette320. These versions help in faster prototyping and are especially useful when computational resources are limited.
+
+!!! Example "Train Example with ImageNette160"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-cls.pt")
+
+ # Train the model with ImageNette160
+ results = model.train(data="imagenette160", epochs=100, imgsz=160)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model with ImageNette160
+ yolo detect train data=imagenette160 model=yolov8n-cls.pt epochs=100 imgsz=160
+ ```
+
+For more information, refer to [Training with ImageNette160 and ImageNette320](#imagenette160-and-imagenette320).
+
+### What are some practical applications of the ImageNette dataset?
+
+The ImageNette dataset is extensively used in:
+
+- **Educational Settings**: To educate beginners in machine learning and computer vision.
+- **Software Development**: For rapid prototyping and development of image classification models.
+- **Deep Learning Research**: To evaluate and benchmark the performance of various deep learning models, especially Convolutional Neural Networks (CNNs).
+
+Explore the [Applications](#applications) section for detailed use cases.
diff --git a/ultralytics/docs/en/datasets/classify/imagewoof.md b/ultralytics/docs/en/datasets/classify/imagewoof.md
new file mode 100644
index 0000000000000000000000000000000000000000..f73f7f0243c6cbf9ffff979448873c99684ee728
--- /dev/null
+++ b/ultralytics/docs/en/datasets/classify/imagewoof.md
@@ -0,0 +1,148 @@
+---
+comments: true
+description: Explore the ImageWoof dataset, a challenging subset of ImageNet focusing on 10 dog breeds, designed to enhance image classification models. Learn more on Ultralytics Docs.
+keywords: ImageWoof dataset, ImageNet subset, dog breeds, image classification, deep learning, machine learning, Ultralytics, training dataset, noisy labels
+---
+
+# ImageWoof Dataset
+
+The [ImageWoof](https://github.com/fastai/imagenette) dataset is a subset of the ImageNet consisting of 10 classes that are challenging to classify, since they're all dog breeds. It was created as a more difficult task for image classification algorithms to solve, aiming at encouraging development of more advanced models.
+
+## Key Features
+
+- ImageWoof contains images of 10 different dog breeds: Australian terrier, Border terrier, Samoyed, Beagle, Shih-Tzu, English foxhound, Rhodesian ridgeback, Dingo, Golden retriever, and Old English sheepdog.
+- The dataset provides images at various resolutions (full size, 320px, 160px), accommodating for different computational capabilities and research needs.
+- It also includes a version with noisy labels, providing a more realistic scenario where labels might not always be reliable.
+
+## Dataset Structure
+
+The ImageWoof dataset structure is based on the dog breed classes, with each breed having its own directory of images.
+
+## Applications
+
+The ImageWoof dataset is widely used for training and evaluating deep learning models in image classification tasks, especially when it comes to more complex and similar classes. The dataset's challenge lies in the subtle differences between the dog breeds, pushing the limits of model's performance and generalization.
+
+## Usage
+
+To train a CNN model on the ImageWoof dataset for 100 epochs with an image size of 224x224, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="imagewoof", epochs=100, imgsz=224)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo classify train data=imagewoof model=yolov8n-cls.pt epochs=100 imgsz=224
+ ```
+
+## Dataset Variants
+
+ImageWoof dataset comes in three different sizes to accommodate various research needs and computational capabilities:
+
+1. **Full Size (imagewoof)**: This is the original version of the ImageWoof dataset. It contains full-sized images and is ideal for final training and performance benchmarking.
+
+2. **Medium Size (imagewoof320)**: This version contains images resized to have a maximum edge length of 320 pixels. It's suitable for faster training without significantly sacrificing model performance.
+
+3. **Small Size (imagewoof160)**: This version contains images resized to have a maximum edge length of 160 pixels. It's designed for rapid prototyping and experimentation where training speed is a priority.
+
+To use these variants in your training, simply replace 'imagewoof' in the dataset argument with 'imagewoof320' or 'imagewoof160'. For example:
+
+!!! Example "Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
+
+ # For medium-sized dataset
+ model.train(data="imagewoof320", epochs=100, imgsz=224)
+
+ # For small-sized dataset
+ model.train(data="imagewoof160", epochs=100, imgsz=224)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Load a pretrained model and train on the small-sized dataset
+ yolo classify train model=yolov8n-cls.pt data=imagewoof320 epochs=100 imgsz=224
+ ```
+
+It's important to note that using smaller images will likely yield lower performance in terms of classification accuracy. However, it's an excellent way to iterate quickly in the early stages of model development and prototyping.
+
+## Sample Images and Annotations
+
+The ImageWoof dataset contains colorful images of various dog breeds, providing a challenging dataset for image classification tasks. Here are some examples of images from the dataset:
+
+
+
+The example showcases the subtle differences and similarities among the different dog breeds in the ImageWoof dataset, highlighting the complexity and difficulty of the classification task.
+
+## Citations and Acknowledgments
+
+If you use the ImageWoof dataset in your research or development work, please make sure to acknowledge the creators of the dataset by linking to the [official dataset repository](https://github.com/fastai/imagenette).
+
+We would like to acknowledge the FastAI team for creating and maintaining the ImageWoof dataset as a valuable resource for the machine learning and computer vision research community. For more information about the ImageWoof dataset, visit the [ImageWoof dataset repository](https://github.com/fastai/imagenette).
+
+## FAQ
+
+### What is the ImageWoof dataset in Ultralytics?
+
+The [ImageWoof](https://github.com/fastai/imagenette) dataset is a challenging subset of ImageNet focusing on 10 specific dog breeds. Created to push the limits of image classification models, it features breeds like Beagle, Shih-Tzu, and Golden Retriever. The dataset includes images at various resolutions (full size, 320px, 160px) and even noisy labels for more realistic training scenarios. This complexity makes ImageWoof ideal for developing more advanced deep learning models.
+
+### How can I train a model using the ImageWoof dataset with Ultralytics YOLO?
+
+To train a Convolutional Neural Network (CNN) model on the ImageWoof dataset using Ultralytics YOLO for 100 epochs at an image size of 224x224, you can use the following code:
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ model = YOLO("yolov8n-cls.pt") # Load a pretrained model
+ results = model.train(data="imagewoof", epochs=100, imgsz=224)
+ ```
+
+
+ === "CLI"
+
+ ```bash
+ yolo classify train data=imagewoof model=yolov8n-cls.pt epochs=100 imgsz=224
+ ```
+
+For more details on available training arguments, refer to the [Training](../../modes/train.md) page.
+
+### What versions of the ImageWoof dataset are available?
+
+The ImageWoof dataset comes in three sizes:
+
+1. **Full Size (imagewoof)**: Ideal for final training and benchmarking, containing full-sized images.
+2. **Medium Size (imagewoof320)**: Resized images with a maximum edge length of 320 pixels, suited for faster training.
+3. **Small Size (imagewoof160)**: Resized images with a maximum edge length of 160 pixels, perfect for rapid prototyping.
+
+Use these versions by replacing 'imagewoof' in the dataset argument accordingly. Note, however, that smaller images may yield lower classification accuracy but can be useful for quicker iterations.
+
+### How do noisy labels in the ImageWoof dataset benefit training?
+
+Noisy labels in the ImageWoof dataset simulate real-world conditions where labels might not always be accurate. Training models with this data helps develop robustness and generalization in image classification tasks. This prepares the models to handle ambiguous or mislabeled data effectively, which is often encountered in practical applications.
+
+### What are the key challenges of using the ImageWoof dataset?
+
+The primary challenge of the ImageWoof dataset lies in the subtle differences among the dog breeds it includes. Since it focuses on 10 closely related breeds, distinguishing between them requires more advanced and fine-tuned image classification models. This makes ImageWoof an excellent benchmark to test the capabilities and improvements of deep learning models.
diff --git a/ultralytics/docs/en/datasets/classify/index.md b/ultralytics/docs/en/datasets/classify/index.md
new file mode 100644
index 0000000000000000000000000000000000000000..9520c4fc62f8e8eb30d810deca8de7fb060fc932
--- /dev/null
+++ b/ultralytics/docs/en/datasets/classify/index.md
@@ -0,0 +1,219 @@
+---
+comments: true
+description: Learn how to structure datasets for YOLO classification tasks. Detailed folder structure and usage examples for effective training.
+keywords: YOLO, image classification, dataset structure, CIFAR-10, Ultralytics, machine learning, training data, model evaluation
+---
+
+# Image Classification Datasets Overview
+
+### Dataset Structure for YOLO Classification Tasks
+
+For [Ultralytics](https://ultralytics.com) YOLO classification tasks, the dataset must be organized in a specific split-directory structure under the `root` directory to facilitate proper training, testing, and optional validation processes. This structure includes separate directories for training (`train`) and testing (`test`) phases, with an optional directory for validation (`val`).
+
+Each of these directories should contain one subdirectory for each class in the dataset. The subdirectories are named after the corresponding class and contain all the images for that class. Ensure that each image file is named uniquely and stored in a common format such as JPEG or PNG.
+
+**Folder Structure Example**
+
+Consider the CIFAR-10 dataset as an example. The folder structure should look like this:
+
+```
+cifar-10-/
+|
+|-- train/
+| |-- airplane/
+| | |-- 10008_airplane.png
+| | |-- 10009_airplane.png
+| | |-- ...
+| |
+| |-- automobile/
+| | |-- 1000_automobile.png
+| | |-- 1001_automobile.png
+| | |-- ...
+| |
+| |-- bird/
+| | |-- 10014_bird.png
+| | |-- 10015_bird.png
+| | |-- ...
+| |
+| |-- ...
+|
+|-- test/
+| |-- airplane/
+| | |-- 10_airplane.png
+| | |-- 11_airplane.png
+| | |-- ...
+| |
+| |-- automobile/
+| | |-- 100_automobile.png
+| | |-- 101_automobile.png
+| | |-- ...
+| |
+| |-- bird/
+| | |-- 1000_bird.png
+| | |-- 1001_bird.png
+| | |-- ...
+| |
+| |-- ...
+|
+|-- val/ (optional)
+| |-- airplane/
+| | |-- 105_airplane.png
+| | |-- 106_airplane.png
+| | |-- ...
+| |
+| |-- automobile/
+| | |-- 102_automobile.png
+| | |-- 103_automobile.png
+| | |-- ...
+| |
+| |-- bird/
+| | |-- 1045_bird.png
+| | |-- 1046_bird.png
+| | |-- ...
+| |
+| |-- ...
+```
+
+This structured approach ensures that the model can effectively learn from well-organized classes during the training phase and accurately evaluate performance during testing and validation phases.
+
+## Usage
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="path/to/dataset", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo detect train data=path/to/data model=yolov8n-cls.pt epochs=100 imgsz=640
+ ```
+
+## Supported Datasets
+
+Ultralytics supports the following datasets with automatic download:
+
+- [Caltech 101](caltech101.md): A dataset containing images of 101 object categories for image classification tasks.
+- [Caltech 256](caltech256.md): An extended version of Caltech 101 with 256 object categories and more challenging images.
+- [CIFAR-10](cifar10.md): A dataset of 60K 32x32 color images in 10 classes, with 6K images per class.
+- [CIFAR-100](cifar100.md): An extended version of CIFAR-10 with 100 object categories and 600 images per class.
+- [Fashion-MNIST](fashion-mnist.md): A dataset consisting of 70,000 grayscale images of 10 fashion categories for image classification tasks.
+- [ImageNet](imagenet.md): A large-scale dataset for object detection and image classification with over 14 million images and 20,000 categories.
+- [ImageNet-10](imagenet10.md): A smaller subset of ImageNet with 10 categories for faster experimentation and testing.
+- [Imagenette](imagenette.md): A smaller subset of ImageNet that contains 10 easily distinguishable classes for quicker training and testing.
+- [Imagewoof](imagewoof.md): A more challenging subset of ImageNet containing 10 dog breed categories for image classification tasks.
+- [MNIST](mnist.md): A dataset of 70,000 grayscale images of handwritten digits for image classification tasks.
+
+### Adding your own dataset
+
+If you have your own dataset and would like to use it for training classification models with Ultralytics, ensure that it follows the format specified above under "Dataset format" and then point your `data` argument to the dataset directory.
+
+## FAQ
+
+### How do I structure my dataset for YOLO classification tasks?
+
+To structure your dataset for Ultralytics YOLO classification tasks, you should follow a specific split-directory format. Organize your dataset into separate directories for `train`, `test`, and optionally `val`. Each of these directories should contain subdirectories named after each class, with the corresponding images inside. This facilitates smooth training and evaluation processes. For an example, consider the CIFAR-10 dataset format:
+
+```
+cifar-10-/
+|-- train/
+| |-- airplane/
+| |-- automobile/
+| |-- bird/
+| ...
+|-- test/
+| |-- airplane/
+| |-- automobile/
+| |-- bird/
+| ...
+|-- val/ (optional)
+| |-- airplane/
+| |-- automobile/
+| |-- bird/
+| ...
+```
+
+For more details, visit [Dataset Structure for YOLO Classification Tasks](#dataset-structure-for-yolo-classification-tasks).
+
+### What datasets are supported by Ultralytics YOLO for image classification?
+
+Ultralytics YOLO supports automatic downloading of several datasets for image classification, including:
+
+- [Caltech 101](caltech101.md)
+- [Caltech 256](caltech256.md)
+- [CIFAR-10](cifar10.md)
+- [CIFAR-100](cifar100.md)
+- [Fashion-MNIST](fashion-mnist.md)
+- [ImageNet](imagenet.md)
+- [ImageNet-10](imagenet10.md)
+- [Imagenette](imagenette.md)
+- [Imagewoof](imagewoof.md)
+- [MNIST](mnist.md)
+
+These datasets are structured in a way that makes them easy to use with YOLO. Each dataset's page provides further details about its structure and applications.
+
+### How do I add my own dataset for YOLO image classification?
+
+To use your own dataset with Ultralytics YOLO, ensure it follows the specified directory format required for the classification task, with separate `train`, `test`, and optionally `val` directories, and subdirectories for each class containing the respective images. Once your dataset is structured correctly, point the `data` argument to your dataset's root directory when initializing the training script. Here's an example in Python:
+
+```python
+from ultralytics import YOLO
+
+# Load a model
+model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
+
+# Train the model
+results = model.train(data="path/to/your/dataset", epochs=100, imgsz=640)
+```
+
+More details can be found in the [Adding your own dataset](#adding-your-own-dataset) section.
+
+### Why should I use Ultralytics YOLO for image classification?
+
+Ultralytics YOLO offers several benefits for image classification, including:
+
+- **Pretrained Models**: Load pretrained models like `yolov8n-cls.pt` to jump-start your training process.
+- **Ease of Use**: Simple API and CLI commands for training and evaluation.
+- **High Performance**: State-of-the-art accuracy and speed, ideal for real-time applications.
+- **Support for Multiple Datasets**: Seamless integration with various popular datasets like CIFAR-10, ImageNet, and more.
+- **Community and Support**: Access to extensive documentation and an active community for troubleshooting and improvements.
+
+For additional insights and real-world applications, you can explore [Ultralytics YOLO](https://www.ultralytics.com/yolo).
+
+### How can I train a model using Ultralytics YOLO?
+
+Training a model using Ultralytics YOLO can be done easily in both Python and CLI. Here's an example:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model
+
+ # Train the model
+ results = model.train(data="path/to/dataset", epochs=100, imgsz=640)
+ ```
+
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo detect train data=path/to/data model=yolov8n-cls.pt epochs=100 imgsz=640
+ ```
+
+These examples demonstrate the straightforward process of training a YOLO model using either approach. For more information, visit the [Usage](#usage) section.
diff --git a/ultralytics/docs/en/datasets/classify/mnist.md b/ultralytics/docs/en/datasets/classify/mnist.md
new file mode 100644
index 0000000000000000000000000000000000000000..f7734e96655089b5b1e7dcbbf5731575f1990db6
--- /dev/null
+++ b/ultralytics/docs/en/datasets/classify/mnist.md
@@ -0,0 +1,127 @@
+---
+comments: true
+description: Explore the MNIST dataset, a cornerstone in machine learning for handwritten digit recognition. Learn about its structure, features, and applications.
+keywords: MNIST, dataset, handwritten digits, image classification, deep learning, machine learning, training set, testing set, NIST
+---
+
+# MNIST Dataset
+
+The [MNIST](http://yann.lecun.com/exdb/mnist/) (Modified National Institute of Standards and Technology) dataset is a large database of handwritten digits that is commonly used for training various image processing systems and machine learning models. It was created by "re-mixing" the samples from NIST's original datasets and has become a benchmark for evaluating the performance of image classification algorithms.
+
+## Key Features
+
+- MNIST contains 60,000 training images and 10,000 testing images of handwritten digits.
+- The dataset comprises grayscale images of size 28x28 pixels.
+- The images are normalized to fit into a 28x28 pixel bounding box and anti-aliased, introducing grayscale levels.
+- MNIST is widely used for training and testing in the field of machine learning, especially for image classification tasks.
+
+## Dataset Structure
+
+The MNIST dataset is split into two subsets:
+
+1. **Training Set**: This subset contains 60,000 images of handwritten digits used for training machine learning models.
+2. **Testing Set**: This subset consists of 10,000 images used for testing and benchmarking the trained models.
+
+## Extended MNIST (EMNIST)
+
+Extended MNIST (EMNIST) is a newer dataset developed and released by NIST to be the successor to MNIST. While MNIST included images only of handwritten digits, EMNIST includes all the images from NIST Special Database 19, which is a large database of handwritten uppercase and lowercase letters as well as digits. The images in EMNIST were converted into the same 28x28 pixel format, by the same process, as were the MNIST images. Accordingly, tools that work with the older, smaller MNIST dataset will likely work unmodified with EMNIST.
+
+## Applications
+
+The MNIST dataset is widely used for training and evaluating deep learning models in image classification tasks, such as Convolutional Neural Networks (CNNs), Support Vector Machines (SVMs), and various other machine learning algorithms. The dataset's simple and well-structured format makes it an essential resource for researchers and practitioners in the field of machine learning and computer vision.
+
+## Usage
+
+To train a CNN model on the MNIST dataset for 100 epochs with an image size of 32x32, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="mnist", epochs=100, imgsz=32)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo classify train data=mnist model=yolov8n-cls.pt epochs=100 imgsz=28
+ ```
+
+## Sample Images and Annotations
+
+The MNIST dataset contains grayscale images of handwritten digits, providing a well-structured dataset for image classification tasks. Here are some examples of images from the dataset:
+
+
+
+The example showcases the variety and complexity of the handwritten digits in the MNIST dataset, highlighting the importance of a diverse dataset for training robust image classification models.
+
+## Citations and Acknowledgments
+
+If you use the MNIST dataset in your
+
+research or development work, please cite the following paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @article{lecun2010mnist,
+ title={MNIST handwritten digit database},
+ author={LeCun, Yann and Cortes, Corinna and Burges, CJ},
+ journal={ATT Labs [Online]. Available: http://yann.lecun.com/exdb/mnist},
+ volume={2},
+ year={2010}
+ }
+ ```
+
+We would like to acknowledge Yann LeCun, Corinna Cortes, and Christopher J.C. Burges for creating and maintaining the MNIST dataset as a valuable resource for the machine learning and computer vision research community. For more information about the MNIST dataset and its creators, visit the [MNIST dataset website](http://yann.lecun.com/exdb/mnist/).
+
+## FAQ
+
+### What is the MNIST dataset, and why is it important in machine learning?
+
+The [MNIST](http://yann.lecun.com/exdb/mnist/) dataset, or Modified National Institute of Standards and Technology dataset, is a widely-used collection of handwritten digits designed for training and testing image classification systems. It includes 60,000 training images and 10,000 testing images, all of which are grayscale and 28x28 pixels in size. The dataset's importance lies in its role as a standard benchmark for evaluating image classification algorithms, helping researchers and engineers to compare methods and track progress in the field.
+
+### How can I use Ultralytics YOLO to train a model on the MNIST dataset?
+
+To train a model on the MNIST dataset using Ultralytics YOLO, you can follow these steps:
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="mnist", epochs=100, imgsz=32)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo classify train data=mnist model=yolov8n-cls.pt epochs=100 imgsz=28
+ ```
+
+For a detailed list of available training arguments, refer to the [Training](../../modes/train.md) page.
+
+### What is the difference between the MNIST and EMNIST datasets?
+
+The MNIST dataset contains only handwritten digits, whereas the Extended MNIST (EMNIST) dataset includes both digits and uppercase and lowercase letters. EMNIST was developed as a successor to MNIST and utilizes the same 28x28 pixel format for the images, making it compatible with tools and models designed for the original MNIST dataset. This broader range of characters in EMNIST makes it useful for a wider variety of machine learning applications.
+
+### Can I use Ultralytics HUB to train models on custom datasets like MNIST?
+
+Yes, you can use Ultralytics HUB to train models on custom datasets like MNIST. Ultralytics HUB offers a user-friendly interface for uploading datasets, training models, and managing projects without needing extensive coding knowledge. For more details on how to get started, check out the [Ultralytics HUB Quickstart](https://docs.ultralytics.com/hub/quickstart/) page.
diff --git a/ultralytics/docs/en/datasets/detect/african-wildlife.md b/ultralytics/docs/en/datasets/detect/african-wildlife.md
new file mode 100644
index 0000000000000000000000000000000000000000..3fc9dabfa88007e0794e7d145a690917395cba38
--- /dev/null
+++ b/ultralytics/docs/en/datasets/detect/african-wildlife.md
@@ -0,0 +1,147 @@
+---
+comments: true
+description: Explore our African Wildlife Dataset featuring images of buffalo, elephant, rhino, and zebra for training computer vision models. Ideal for research and conservation.
+keywords: African Wildlife Dataset, South African animals, object detection, computer vision, YOLOv8, wildlife research, conservation, dataset
+---
+
+# African Wildlife Dataset
+
+This dataset showcases four common animal classes typically found in South African nature reserves. It includes images of African wildlife such as buffalo, elephant, rhino, and zebra, providing valuable insights into their characteristics. Essential for training computer vision algorithms, this dataset aids in identifying animals in various habitats, from zoos to forests, and supports wildlife research.
+
+
+
+## Dataset Structure
+
+The African wildlife objects detection dataset is split into three subsets:
+
+- **Training set**: Contains 1052 images, each with corresponding annotations.
+- **Validation set**: Includes 225 images, each with paired annotations.
+- **Testing set**: Comprises 227 images, each with paired annotations.
+
+## Applications
+
+This dataset can be applied in various computer vision tasks such as object detection, object tracking, and research. Specifically, it can be used to train and evaluate models for identifying African wildlife objects in images, which can have applications in wildlife conservation, ecological research, and monitoring efforts in natural reserves and protected areas. Additionally, it can serve as a valuable resource for educational purposes, enabling students and researchers to study and understand the characteristics and behaviors of different animal species.
+
+## Dataset YAML
+
+A YAML (Yet Another Markup Language) file defines the dataset configuration, including paths, classes, and other pertinent details. For the African wildlife dataset, the `african-wildlife.yaml` file is located at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/african-wildlife.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/african-wildlife.yaml).
+
+!!! Example "ultralytics/cfg/datasets/african-wildlife.yaml"
+
+ ```yaml
+ --8<-- "ultralytics/cfg/datasets/african-wildlife.yaml"
+ ```
+
+## Usage
+
+To train a YOLOv8n model on the African wildlife dataset for 100 epochs with an image size of 640, use the provided code samples. For a comprehensive list of available parameters, refer to the model's [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="african-wildlife.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo detect train data=african-wildlife.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+!!! Example "Inference Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("path/to/best.pt") # load a brain-tumor fine-tuned model
+
+ # Inference using the model
+ results = model.predict("https://ultralytics.com/assets/african-wildlife-sample.jpg")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start prediction with a finetuned *.pt model
+ yolo detect predict model='path/to/best.pt' imgsz=640 source="https://ultralytics.com/assets/african-wildlife-sample.jpg"
+ ```
+
+## Sample Images and Annotations
+
+The African wildlife dataset comprises a wide variety of images showcasing diverse animal species and their natural habitats. Below are examples of images from the dataset, each accompanied by its corresponding annotations.
+
+
+
+- **Mosaiced Image**: Here, we present a training batch consisting of mosaiced dataset images. Mosaicing, a training technique, combines multiple images into one, enriching batch diversity. This method helps enhance the model's ability to generalize across different object sizes, aspect ratios, and contexts.
+
+This example illustrates the variety and complexity of images in the African wildlife dataset, emphasizing the benefits of including mosaicing during the training process.
+
+## Citations and Acknowledgments
+
+The dataset has been released available under the [AGPL-3.0 License](https://github.com/ultralytics/ultralytics/blob/main/LICENSE).
+
+## FAQ
+
+### What is the African Wildlife Dataset, and how can it be used in computer vision projects?
+
+The African Wildlife Dataset includes images of four common animal species found in South African nature reserves: buffalo, elephant, rhino, and zebra. It is a valuable resource for training computer vision algorithms in object detection and animal identification. The dataset supports various tasks like object tracking, research, and conservation efforts. For more information on its structure and applications, refer to the [Dataset Structure](#dataset-structure) section and [Applications](#applications) of the dataset.
+
+### How do I train a YOLOv8 model using the African Wildlife Dataset?
+
+You can train a YOLOv8 model on the African Wildlife Dataset by using the `african-wildlife.yaml` configuration file. Below is an example of how to train the YOLOv8n model for 100 epochs with an image size of 640:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="african-wildlife.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo detect train data=african-wildlife.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+For additional training parameters and options, refer to the [Training](../../modes/train.md) documentation.
+
+### Where can I find the YAML configuration file for the African Wildlife Dataset?
+
+The YAML configuration file for the African Wildlife Dataset, named `african-wildlife.yaml`, can be found at [this GitHub link](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/african-wildlife.yaml). This file defines the dataset configuration, including paths, classes, and other details crucial for training machine learning models. See the [Dataset YAML](#dataset-yaml) section for more details.
+
+### Can I see sample images and annotations from the African Wildlife Dataset?
+
+Yes, the African Wildlife Dataset includes a wide variety of images showcasing diverse animal species in their natural habitats. You can view sample images and their corresponding annotations in the [Sample Images and Annotations](#sample-images-and-annotations) section. This section also illustrates the use of mosaicing technique to combine multiple images into one for enriched batch diversity, enhancing the model's generalization ability.
+
+### How can the African Wildlife Dataset be used to support wildlife conservation and research?
+
+The African Wildlife Dataset is ideal for supporting wildlife conservation and research by enabling the training and evaluation of models to identify African wildlife in different habitats. These models can assist in monitoring animal populations, studying their behavior, and recognizing conservation needs. Additionally, the dataset can be utilized for educational purposes, helping students and researchers understand the characteristics and behaviors of different animal species. More details can be found in the [Applications](#applications) section.
diff --git a/ultralytics/docs/en/datasets/detect/argoverse.md b/ultralytics/docs/en/datasets/detect/argoverse.md
new file mode 100644
index 0000000000000000000000000000000000000000..7e29fc653c08873ac3d7cea81bc137a39f2f38b1
--- /dev/null
+++ b/ultralytics/docs/en/datasets/detect/argoverse.md
@@ -0,0 +1,153 @@
+---
+comments: true
+description: Explore the comprehensive Argoverse dataset by Argo AI for 3D tracking, motion forecasting, and stereo depth estimation in autonomous driving research.
+keywords: Argoverse dataset, autonomous driving, 3D tracking, motion forecasting, stereo depth estimation, Argo AI, LiDAR point clouds, high-resolution images, HD maps
+---
+
+# Argoverse Dataset
+
+The [Argoverse](https://www.argoverse.org/) dataset is a collection of data designed to support research in autonomous driving tasks, such as 3D tracking, motion forecasting, and stereo depth estimation. Developed by Argo AI, the dataset provides a wide range of high-quality sensor data, including high-resolution images, LiDAR point clouds, and map data.
+
+!!! Note
+
+ The Argoverse dataset `*.zip` file required for training was removed from Amazon S3 after the shutdown of Argo AI by Ford, but we have made it available for manual download on [Google Drive](https://drive.google.com/file/d/1st9qW3BeIwQsnR0t8mRpvbsSWIo16ACi/view?usp=drive_link).
+
+## Key Features
+
+- Argoverse contains over 290K labeled 3D object tracks and 5 million object instances across 1,263 distinct scenes.
+- The dataset includes high-resolution camera images, LiDAR point clouds, and richly annotated HD maps.
+- Annotations include 3D bounding boxes for objects, object tracks, and trajectory information.
+- Argoverse provides multiple subsets for different tasks, such as 3D tracking, motion forecasting, and stereo depth estimation.
+
+## Dataset Structure
+
+The Argoverse dataset is organized into three main subsets:
+
+1. **Argoverse 3D Tracking**: This subset contains 113 scenes with over 290K labeled 3D object tracks, focusing on 3D object tracking tasks. It includes LiDAR point clouds, camera images, and sensor calibration information.
+2. **Argoverse Motion Forecasting**: This subset consists of 324K vehicle trajectories collected from 60 hours of driving data, suitable for motion forecasting tasks.
+3. **Argoverse Stereo Depth Estimation**: This subset is designed for stereo depth estimation tasks and includes over 10K stereo image pairs with corresponding LiDAR point clouds for ground truth depth estimation.
+
+## Applications
+
+The Argoverse dataset is widely used for training and evaluating deep learning models in autonomous driving tasks such as 3D object tracking, motion forecasting, and stereo depth estimation. The dataset's diverse set of sensor data, object annotations, and map information make it a valuable resource for researchers and practitioners in the field of autonomous driving.
+
+## Dataset YAML
+
+A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. For the case of the Argoverse dataset, the `Argoverse.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/Argoverse.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/Argoverse.yaml).
+
+!!! Example "ultralytics/cfg/datasets/Argoverse.yaml"
+
+ ```yaml
+ --8<-- "ultralytics/cfg/datasets/Argoverse.yaml"
+ ```
+
+## Usage
+
+To train a YOLOv8n model on the Argoverse dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="Argoverse.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo detect train data=Argoverse.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+## Sample Data and Annotations
+
+The Argoverse dataset contains a diverse set of sensor data, including camera images, LiDAR point clouds, and HD map information, providing rich context for autonomous driving tasks. Here are some examples of data from the dataset, along with their corresponding annotations:
+
+
+
+- **Argoverse 3D Tracking**: This image demonstrates an example of 3D object tracking, where objects are annotated with 3D bounding boxes. The dataset provides LiDAR point clouds and camera images to facilitate the development of models for this task.
+
+The example showcases the variety and complexity of the data in the Argoverse dataset and highlights the importance of high-quality sensor data for autonomous driving tasks.
+
+## Citations and Acknowledgments
+
+If you use the Argoverse dataset in your research or development work, please cite the following paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @inproceedings{chang2019argoverse,
+ title={Argoverse: 3D Tracking and Forecasting with Rich Maps},
+ author={Chang, Ming-Fang and Lambert, John and Sangkloy, Patsorn and Singh, Jagjeet and Bak, Slawomir and Hartnett, Andrew and Wang, Dequan and Carr, Peter and Lucey, Simon and Ramanan, Deva and others},
+ booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
+ pages={8748--8757},
+ year={2019}
+ }
+ ```
+
+We would like to acknowledge Argo AI for creating and maintaining the Argoverse dataset as a valuable resource for the autonomous driving research community. For more information about the Argoverse dataset and its creators, visit the [Argoverse dataset website](https://www.argoverse.org/).
+
+## FAQ
+
+### What is the Argoverse dataset and its key features?
+
+The [Argoverse](https://www.argoverse.org/) dataset, developed by Argo AI, supports autonomous driving research. It includes over 290K labeled 3D object tracks and 5 million object instances across 1,263 distinct scenes. The dataset provides high-resolution camera images, LiDAR point clouds, and annotated HD maps, making it valuable for tasks like 3D tracking, motion forecasting, and stereo depth estimation.
+
+### How can I train an Ultralytics YOLO model using the Argoverse dataset?
+
+To train a YOLOv8 model with the Argoverse dataset, use the provided YAML configuration file and the following code:
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="Argoverse.yaml", epochs=100, imgsz=640)
+ ```
+
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo detect train data=Argoverse.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+For a detailed explanation of the arguments, refer to the model [Training](../../modes/train.md) page.
+
+### What types of data and annotations are available in the Argoverse dataset?
+
+The Argoverse dataset includes various sensor data types such as high-resolution camera images, LiDAR point clouds, and HD map data. Annotations include 3D bounding boxes, object tracks, and trajectory information. These comprehensive annotations are essential for accurate model training in tasks like 3D object tracking, motion forecasting, and stereo depth estimation.
+
+### How is the Argoverse dataset structured?
+
+The dataset is divided into three main subsets:
+
+1. **Argoverse 3D Tracking**: Contains 113 scenes with over 290K labeled 3D object tracks, focusing on 3D object tracking tasks. It includes LiDAR point clouds, camera images, and sensor calibration information.
+2. **Argoverse Motion Forecasting**: Consists of 324K vehicle trajectories collected from 60 hours of driving data, suitable for motion forecasting tasks.
+3. **Argoverse Stereo Depth Estimation**: Includes over 10K stereo image pairs with corresponding LiDAR point clouds for ground truth depth estimation.
+
+### Where can I download the Argoverse dataset now that it has been removed from Amazon S3?
+
+The Argoverse dataset `*.zip` file, previously available on Amazon S3, can now be manually downloaded from [Google Drive](https://drive.google.com/file/d/1st9qW3BeIwQsnR0t8mRpvbsSWIo16ACi/view?usp=drive_link).
+
+### What is the YAML configuration file used for with the Argoverse dataset?
+
+A YAML file contains the dataset's paths, classes, and other essential information. For the Argoverse dataset, the configuration file, `Argoverse.yaml`, can be found at the following link: [Argoverse.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/Argoverse.yaml).
+
+For more information about YAML configurations, see our [datasets](../index.md) guide.
diff --git a/ultralytics/docs/en/datasets/detect/brain-tumor.md b/ultralytics/docs/en/datasets/detect/brain-tumor.md
new file mode 100644
index 0000000000000000000000000000000000000000..5c4e7fd8aec225016544e32bd91f839e47832986
--- /dev/null
+++ b/ultralytics/docs/en/datasets/detect/brain-tumor.md
@@ -0,0 +1,168 @@
+---
+comments: true
+description: Explore the brain tumor detection dataset with MRI/CT images. Essential for training AI models for early diagnosis and treatment planning.
+keywords: brain tumor dataset, MRI scans, CT scans, brain tumor detection, medical imaging, AI in healthcare, computer vision, early diagnosis, treatment planning
+---
+
+# Brain Tumor Dataset
+
+A brain tumor detection dataset consists of medical images from MRI or CT scans, containing information about brain tumor presence, location, and characteristics. This dataset is essential for training computer vision algorithms to automate brain tumor identification, aiding in early diagnosis and treatment planning.
+
+
+
+## Dataset Structure
+
+The brain tumor dataset is divided into two subsets:
+
+- **Training set**: Consisting of 893 images, each accompanied by corresponding annotations.
+- **Testing set**: Comprising 223 images, with annotations paired for each one.
+
+## Applications
+
+The application of brain tumor detection using computer vision enables early diagnosis, treatment planning, and monitoring of tumor progression. By analyzing medical imaging data like MRI or CT scans, computer vision systems assist in accurately identifying brain tumors, aiding in timely medical intervention and personalized treatment strategies.
+
+## Dataset YAML
+
+A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the brain tumor dataset, the `brain-tumor.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/brain-tumor.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/brain-tumor.yaml).
+
+!!! Example "ultralytics/cfg/datasets/brain-tumor.yaml"
+
+ ```yaml
+ --8<-- "ultralytics/cfg/datasets/brain-tumor.yaml"
+ ```
+
+## Usage
+
+To train a YOLOv8n model on the brain tumor dataset for 100 epochs with an image size of 640, utilize the provided code snippets. For a detailed list of available arguments, consult the model's [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="brain-tumor.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo detect train data=brain-tumor.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+!!! Example "Inference Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("path/to/best.pt") # load a brain-tumor fine-tuned model
+
+ # Inference using the model
+ results = model.predict("https://ultralytics.com/assets/brain-tumor-sample.jpg")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start prediction with a finetuned *.pt model
+ yolo detect predict model='path/to/best.pt' imgsz=640 source="https://ultralytics.com/assets/brain-tumor-sample.jpg"
+ ```
+
+## Sample Images and Annotations
+
+The brain tumor dataset encompasses a wide array of images featuring diverse object categories and intricate scenes. Presented below are examples of images from the dataset, accompanied by their respective annotations
+
+
+
+- **Mosaiced Image**: Displayed here is a training batch comprising mosaiced dataset images. Mosaicing, a training technique, consolidates multiple images into one, enhancing batch diversity. This approach aids in improving the model's capacity to generalize across various object sizes, aspect ratios, and contexts.
+
+This example highlights the diversity and intricacy of images within the brain tumor dataset, underscoring the advantages of incorporating mosaicing during the training phase.
+
+## Citations and Acknowledgments
+
+The dataset has been released available under the [AGPL-3.0 License](https://github.com/ultralytics/ultralytics/blob/main/LICENSE).
+
+## FAQ
+
+### What is the structure of the brain tumor dataset available in Ultralytics documentation?
+
+The brain tumor dataset is divided into two subsets: the **training set** consists of 893 images with corresponding annotations, while the **testing set** comprises 223 images with paired annotations. This structured division aids in developing robust and accurate computer vision models for detecting brain tumors. For more information on the dataset structure, visit the [Dataset Structure](#dataset-structure) section.
+
+### How can I train a YOLOv8 model on the brain tumor dataset using Ultralytics?
+
+You can train a YOLOv8 model on the brain tumor dataset for 100 epochs with an image size of 640px using both Python and CLI methods. Below are the examples for both:
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="brain-tumor.yaml", epochs=100, imgsz=640)
+ ```
+
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo detect train data=brain-tumor.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+For a detailed list of available arguments, refer to the [Training](../../modes/train.md) page.
+
+### What are the benefits of using the brain tumor dataset for AI in healthcare?
+
+Using the brain tumor dataset in AI projects enables early diagnosis and treatment planning for brain tumors. It helps in automating brain tumor identification through computer vision, facilitating accurate and timely medical interventions, and supporting personalized treatment strategies. This application holds significant potential in improving patient outcomes and medical efficiencies.
+
+### How do I perform inference using a fine-tuned YOLOv8 model on the brain tumor dataset?
+
+Inference using a fine-tuned YOLOv8 model can be performed with either Python or CLI approaches. Here are the examples:
+
+!!! Example "Inference Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("path/to/best.pt") # load a brain-tumor fine-tuned model
+
+ # Inference using the model
+ results = model.predict("https://ultralytics.com/assets/brain-tumor-sample.jpg")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start prediction with a finetuned *.pt model
+ yolo detect predict model='path/to/best.pt' imgsz=640 source="https://ultralytics.com/assets/brain-tumor-sample.jpg"
+ ```
+
+### Where can I find the YAML configuration for the brain tumor dataset?
+
+The YAML configuration file for the brain tumor dataset can be found at [brain-tumor.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/brain-tumor.yaml). This file includes paths, classes, and additional relevant information necessary for training and evaluating models on this dataset.
diff --git a/ultralytics/docs/en/datasets/detect/coco.md b/ultralytics/docs/en/datasets/detect/coco.md
new file mode 100644
index 0000000000000000000000000000000000000000..34390558ca23f948954baaa4e761b4c84b617140
--- /dev/null
+++ b/ultralytics/docs/en/datasets/detect/coco.md
@@ -0,0 +1,177 @@
+---
+comments: true
+description: Explore the COCO dataset for object detection and segmentation. Learn about its structure, usage, pretrained models, and key features.
+keywords: COCO dataset, object detection, segmentation, benchmarking, computer vision, pose estimation, YOLO models, COCO annotations
+---
+
+# COCO Dataset
+
+The [COCO](https://cocodataset.org/#home) (Common Objects in Context) dataset is a large-scale object detection, segmentation, and captioning dataset. It is designed to encourage research on a wide variety of object categories and is commonly used for benchmarking computer vision models. It is an essential dataset for researchers and developers working on object detection, segmentation, and pose estimation tasks.
+
+
+
+## COCO Pretrained Models
+
+| Model | size (pixels) | mAPval 50-95 | Speed CPU ONNX (ms) | Speed A100 TensorRT (ms) | params (M) | FLOPs (B) |
+|--------------------------------------------------------------------------------------|-----------------------|----------------------|--------------------------------|-------------------------------------|--------------------|-------------------|
+| [YOLOv8n](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n.pt) | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
+| [YOLOv8s](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8s.pt) | 640 | 44.9 | 128.4 | 1.20 | 11.2 | 28.6 |
+| [YOLOv8m](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8m.pt) | 640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 |
+| [YOLOv8l](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8l.pt) | 640 | 52.9 | 375.2 | 2.39 | 43.7 | 165.2 |
+| [YOLOv8x](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8x.pt) | 640 | 53.9 | 479.1 | 3.53 | 68.2 | 257.8 |
+
+## Key Features
+
+- COCO contains 330K images, with 200K images having annotations for object detection, segmentation, and captioning tasks.
+- The dataset comprises 80 object categories, including common objects like cars, bicycles, and animals, as well as more specific categories such as umbrellas, handbags, and sports equipment.
+- Annotations include object bounding boxes, segmentation masks, and captions for each image.
+- COCO provides standardized evaluation metrics like mean Average Precision (mAP) for object detection, and mean Average Recall (mAR) for segmentation tasks, making it suitable for comparing model performance.
+
+## Dataset Structure
+
+The COCO dataset is split into three subsets:
+
+1. **Train2017**: This subset contains 118K images for training object detection, segmentation, and captioning models.
+2. **Val2017**: This subset has 5K images used for validation purposes during model training.
+3. **Test2017**: This subset consists of 20K images used for testing and benchmarking the trained models. Ground truth annotations for this subset are not publicly available, and the results are submitted to the [COCO evaluation server](https://codalab.lisn.upsaclay.fr/competitions/7384) for performance evaluation.
+
+## Applications
+
+The COCO dataset is widely used for training and evaluating deep learning models in object detection (such as YOLO, Faster R-CNN, and SSD), instance segmentation (such as Mask R-CNN), and keypoint detection (such as OpenPose). The dataset's diverse set of object categories, large number of annotated images, and standardized evaluation metrics make it an essential resource for computer vision researchers and practitioners.
+
+## Dataset YAML
+
+A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the COCO dataset, the `coco.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml).
+
+!!! Example "ultralytics/cfg/datasets/coco.yaml"
+
+ ```yaml
+ --8<-- "ultralytics/cfg/datasets/coco.yaml"
+ ```
+
+## Usage
+
+To train a YOLOv8n model on the COCO dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="coco.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo detect train data=coco.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+## Sample Images and Annotations
+
+The COCO dataset contains a diverse set of images with various object categories and complex scenes. Here are some examples of images from the dataset, along with their corresponding annotations:
+
+
+
+- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
+
+The example showcases the variety and complexity of the images in the COCO dataset and the benefits of using mosaicing during the training process.
+
+## Citations and Acknowledgments
+
+If you use the COCO dataset in your research or development work, please cite the following paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @misc{lin2015microsoft,
+ title={Microsoft COCO: Common Objects in Context},
+ author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
+ year={2015},
+ eprint={1405.0312},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+ }
+ ```
+
+We would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
+
+## FAQ
+
+### What is the COCO dataset and why is it important for computer vision?
+
+The [COCO dataset](https://cocodataset.org/#home) (Common Objects in Context) is a large-scale dataset used for object detection, segmentation, and captioning. It contains 330K images with detailed annotations for 80 object categories, making it essential for benchmarking and training computer vision models. Researchers use COCO due to its diverse categories and standardized evaluation metrics like mean Average Precision (mAP).
+
+### How can I train a YOLO model using the COCO dataset?
+
+To train a YOLOv8 model using the COCO dataset, you can use the following code snippets:
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="coco.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo detect train data=coco.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+Refer to the [Training page](../../modes/train.md) for more details on available arguments.
+
+### What are the key features of the COCO dataset?
+
+The COCO dataset includes:
+
+- 330K images, with 200K annotated for object detection, segmentation, and captioning.
+- 80 object categories ranging from common items like cars and animals to specific ones like handbags and sports equipment.
+- Standardized evaluation metrics for object detection (mAP) and segmentation (mean Average Recall, mAR).
+- **Mosaicing** technique in training batches to enhance model generalization across various object sizes and contexts.
+
+### Where can I find pretrained YOLOv8 models trained on the COCO dataset?
+
+Pretrained YOLOv8 models on the COCO dataset can be downloaded from the links provided in the documentation. Examples include:
+
+- [YOLOv8n](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n.pt)
+- [YOLOv8s](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8s.pt)
+- [YOLOv8m](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8m.pt)
+
+These models vary in size, mAP, and inference speed, providing options for different performance and resource requirements.
+
+### How is the COCO dataset structured and how do I use it?
+
+The COCO dataset is split into three subsets:
+
+1. **Train2017**: 118K images for training.
+2. **Val2017**: 5K images for validation during training.
+3. **Test2017**: 20K images for benchmarking trained models. Results need to be submitted to the [COCO evaluation server](https://codalab.lisn.upsaclay.fr/competitions/7384) for performance evaluation.
+
+The dataset's YAML configuration file is available at [coco.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml), which defines paths, classes, and dataset details.
diff --git a/ultralytics/docs/en/datasets/detect/coco8.md b/ultralytics/docs/en/datasets/detect/coco8.md
new file mode 100644
index 0000000000000000000000000000000000000000..c2cec6ec5d11695e75a391b66dd32257bd85e509
--- /dev/null
+++ b/ultralytics/docs/en/datasets/detect/coco8.md
@@ -0,0 +1,135 @@
+---
+comments: true
+description: Explore the Ultralytics COCO8 dataset, a versatile and manageable set of 8 images perfect for testing object detection models and training pipelines.
+keywords: COCO8, Ultralytics, dataset, object detection, YOLOv8, training, validation, machine learning, computer vision
+---
+
+# COCO8 Dataset
+
+## Introduction
+
+[Ultralytics](https://ultralytics.com) COCO8 is a small, but versatile object detection dataset composed of the first 8 images of the COCO train 2017 set, 4 for training and 4 for validation. This dataset is ideal for testing and debugging object detection models, or for experimenting with new detection approaches. With 8 images, it is small enough to be easily manageable, yet diverse enough to test training pipelines for errors and act as a sanity check before training larger datasets.
+
+
+
+This dataset is intended for use with Ultralytics [HUB](https://hub.ultralytics.com) and [YOLOv8](https://github.com/ultralytics/ultralytics).
+
+## Dataset YAML
+
+A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the COCO8 dataset, the `coco8.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco8.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco8.yaml).
+
+!!! Example "ultralytics/cfg/datasets/coco8.yaml"
+
+ ```yaml
+ --8<-- "ultralytics/cfg/datasets/coco8.yaml"
+ ```
+
+## Usage
+
+To train a YOLOv8n model on the COCO8 dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo detect train data=coco8.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+## Sample Images and Annotations
+
+Here are some examples of images from the COCO8 dataset, along with their corresponding annotations:
+
+
+
+- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
+
+The example showcases the variety and complexity of the images in the COCO8 dataset and the benefits of using mosaicing during the training process.
+
+## Citations and Acknowledgments
+
+If you use the COCO dataset in your research or development work, please cite the following paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @misc{lin2015microsoft,
+ title={Microsoft COCO: Common Objects in Context},
+ author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
+ year={2015},
+ eprint={1405.0312},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+ }
+ ```
+
+We would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
+
+## FAQ
+
+### What is the Ultralytics COCO8 dataset used for?
+
+The Ultralytics COCO8 dataset is a compact yet versatile object detection dataset consisting of the first 8 images from the COCO train 2017 set, with 4 images for training and 4 for validation. It is designed for testing and debugging object detection models and experimentation with new detection approaches. Despite its small size, COCO8 offers enough diversity to act as a sanity check for your training pipelines before deploying larger datasets. For more details, view the [COCO8 dataset](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco8.yaml).
+
+### How do I train a YOLOv8 model using the COCO8 dataset?
+
+To train a YOLOv8 model using the COCO8 dataset, you can employ either Python or CLI commands. Here's how you can start:
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo detect train data=coco8.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+### Why should I use Ultralytics HUB for managing my COCO8 training?
+
+Ultralytics HUB is an all-in-one web tool designed to simplify the training and deployment of YOLO models, including the Ultralytics YOLOv8 models on the COCO8 dataset. It offers cloud training, real-time tracking, and seamless dataset management. HUB allows you to start training with a single click and avoids the complexities of manual setups. Discover more about [Ultralytics HUB](https://hub.ultralytics.com) and its benefits.
+
+### What are the benefits of using mosaic augmentation in training with the COCO8 dataset?
+
+Mosaic augmentation, demonstrated in the COCO8 dataset, combines multiple images into a single image during training. This technique increases the variety of objects and scenes in each training batch, improving the model's ability to generalize across different object sizes, aspect ratios, and contexts. This results in a more robust object detection model. For more details, refer to the [training guide](#usage).
+
+### How can I validate my YOLOv8 model trained on the COCO8 dataset?
+
+Validation of your YOLOv8 model trained on the COCO8 dataset can be performed using the model's validation commands. You can invoke the validation mode via CLI or Python script to evaluate the model's performance using precise metrics. For detailed instructions, visit the [Validation](../../modes/val.md) page.
diff --git a/ultralytics/docs/en/datasets/detect/globalwheat2020.md b/ultralytics/docs/en/datasets/detect/globalwheat2020.md
new file mode 100644
index 0000000000000000000000000000000000000000..ca77f862e2896617311e73383f78f3affa27ff53
--- /dev/null
+++ b/ultralytics/docs/en/datasets/detect/globalwheat2020.md
@@ -0,0 +1,145 @@
+---
+comments: true
+description: Explore the Global Wheat Head Dataset to develop accurate wheat head detection models. Includes training images, annotations, and usage for crop management.
+keywords: Global Wheat Head Dataset, wheat head detection, wheat phenotyping, crop management, deep learning, object detection, training datasets
+---
+
+# Global Wheat Head Dataset
+
+The [Global Wheat Head Dataset](https://www.global-wheat.com/) is a collection of images designed to support the development of accurate wheat head detection models for applications in wheat phenotyping and crop management. Wheat heads, also known as spikes, are the grain-bearing parts of the wheat plant. Accurate estimation of wheat head density and size is essential for assessing crop health, maturity, and yield potential. The dataset, created by a collaboration of nine research institutes from seven countries, covers multiple growing regions to ensure models generalize well across different environments.
+
+## Key Features
+
+- The dataset contains over 3,000 training images from Europe (France, UK, Switzerland) and North America (Canada).
+- It includes approximately 1,000 test images from Australia, Japan, and China.
+- Images are outdoor field images, capturing the natural variability in wheat head appearances.
+- Annotations include wheat head bounding boxes to support object detection tasks.
+
+## Dataset Structure
+
+The Global Wheat Head Dataset is organized into two main subsets:
+
+1. **Training Set**: This subset contains over 3,000 images from Europe and North America. The images are labeled with wheat head bounding boxes, providing ground truth for training object detection models.
+2. **Test Set**: This subset consists of approximately 1,000 images from Australia, Japan, and China. These images are used for evaluating the performance of trained models on unseen genotypes, environments, and observational conditions.
+
+## Applications
+
+The Global Wheat Head Dataset is widely used for training and evaluating deep learning models in wheat head detection tasks. The dataset's diverse set of images, capturing a wide range of appearances, environments, and conditions, make it a valuable resource for researchers and practitioners in the field of plant phenotyping and crop management.
+
+## Dataset YAML
+
+A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. For the case of the Global Wheat Head Dataset, the `GlobalWheat2020.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/GlobalWheat2020.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/GlobalWheat2020.yaml).
+
+!!! Example "ultralytics/cfg/datasets/GlobalWheat2020.yaml"
+
+ ```yaml
+ --8<-- "ultralytics/cfg/datasets/GlobalWheat2020.yaml"
+ ```
+
+## Usage
+
+To train a YOLOv8n model on the Global Wheat Head Dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="GlobalWheat2020.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo detect train data=GlobalWheat2020.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+## Sample Data and Annotations
+
+The Global Wheat Head Dataset contains a diverse set of outdoor field images, capturing the natural variability in wheat head appearances, environments, and conditions. Here are some examples of data from the dataset, along with their corresponding annotations:
+
+
+
+- **Wheat Head Detection**: This image demonstrates an example of wheat head detection, where wheat heads are annotated with bounding boxes. The dataset provides a variety of images to facilitate the development of models for this task.
+
+The example showcases the variety and complexity of the data in the Global Wheat Head Dataset and highlights the importance of accurate wheat head detection for applications in wheat phenotyping and crop management.
+
+## Citations and Acknowledgments
+
+If you use the Global Wheat Head Dataset in your research or development work, please cite the following paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @article{david2020global,
+ title={Global Wheat Head Detection (GWHD) Dataset: A Large and Diverse Dataset of High-Resolution RGB-Labelled Images to Develop and Benchmark Wheat Head Detection Methods},
+ author={David, Etienne and Madec, Simon and Sadeghi-Tehran, Pouria and Aasen, Helge and Zheng, Bangyou and Liu, Shouyang and Kirchgessner, Norbert and Ishikawa, Goro and Nagasawa, Koichi and Badhon, Minhajul and others},
+ journal={arXiv preprint arXiv:2005.02162},
+ year={2020}
+ }
+ ```
+
+We would like to acknowledge the researchers and institutions that contributed to the creation and maintenance of the Global Wheat Head Dataset as a valuable resource for the plant phenotyping and crop management research community. For more information about the dataset and its creators, visit the [Global Wheat Head Dataset website](https://www.global-wheat.com/).
+
+## FAQ
+
+### What is the Global Wheat Head Dataset used for?
+
+The Global Wheat Head Dataset is primarily used for developing and training deep learning models aimed at wheat head detection. This is crucial for applications in wheat phenotyping and crop management, allowing for more accurate estimations of wheat head density, size, and overall crop yield potential. Accurate detection methods help in assessing crop health and maturity, essential for efficient crop management.
+
+### How do I train a YOLOv8n model on the Global Wheat Head Dataset?
+
+To train a YOLOv8n model on the Global Wheat Head Dataset, you can use the following code snippets. Make sure you have the `GlobalWheat2020.yaml` configuration file specifying dataset paths and classes:
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a pre-trained model (recommended for training)
+ model = YOLO("yolov8n.pt")
+
+ # Train the model
+ results = model.train(data="GlobalWheat2020.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo detect train data=GlobalWheat2020.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+### What are the key features of the Global Wheat Head Dataset?
+
+Key features of the Global Wheat Head Dataset include:
+
+- Over 3,000 training images from Europe (France, UK, Switzerland) and North America (Canada).
+- Approximately 1,000 test images from Australia, Japan, and China.
+- High variability in wheat head appearances due to different growing environments.
+- Detailed annotations with wheat head bounding boxes to aid object detection models.
+
+These features facilitate the development of robust models capable of generalization across multiple regions.
+
+### Where can I find the configuration YAML file for the Global Wheat Head Dataset?
+
+The configuration YAML file for the Global Wheat Head Dataset, named `GlobalWheat2020.yaml`, is available on GitHub. You can access it at this [link](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/GlobalWheat2020.yaml). This file contains necessary information about dataset paths, classes, and other configuration details needed for model training in Ultralytics YOLO.
+
+### Why is wheat head detection important in crop management?
+
+Wheat head detection is critical in crop management because it enables accurate estimation of wheat head density and size, which are essential for evaluating crop health, maturity, and yield potential. By leveraging deep learning models trained on datasets like the Global Wheat Head Dataset, farmers and researchers can better monitor and manage crops, leading to improved productivity and optimized resource use in agricultural practices. This technological advancement supports sustainable agriculture and food security initiatives.
+
+For more information on applications of AI in agriculture, visit [AI in Agriculture](https://www.ultralytics.com/solutions/ai-in-agriculture).
diff --git a/ultralytics/docs/en/datasets/detect/index.md b/ultralytics/docs/en/datasets/detect/index.md
new file mode 100644
index 0000000000000000000000000000000000000000..dd6658bd159196a7ae0ef8f4440ffc92b9ccd27b
--- /dev/null
+++ b/ultralytics/docs/en/datasets/detect/index.md
@@ -0,0 +1,187 @@
+---
+comments: true
+description: Learn about dataset formats compatible with Ultralytics YOLO for robust object detection. Explore supported datasets and learn how to convert formats.
+keywords: Ultralytics, YOLO, object detection datasets, dataset formats, COCO, dataset conversion, training datasets
+---
+
+# Object Detection Datasets Overview
+
+Training a robust and accurate object detection model requires a comprehensive dataset. This guide introduces various formats of datasets that are compatible with the Ultralytics YOLO model and provides insights into their structure, usage, and how to convert between different formats.
+
+## Supported Dataset Formats
+
+### Ultralytics YOLO format
+
+The Ultralytics YOLO format is a dataset configuration format that allows you to define the dataset root directory, the relative paths to training/validation/testing image directories or `*.txt` files containing image paths, and a dictionary of class names. Here is an example:
+
+```yaml
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/coco8 # dataset root dir
+train: images/train # train images (relative to 'path') 4 images
+val: images/val # val images (relative to 'path') 4 images
+test: # test images (optional)
+
+# Classes (80 COCO classes)
+names:
+ 0: person
+ 1: bicycle
+ 2: car
+ # ...
+ 77: teddy bear
+ 78: hair drier
+ 79: toothbrush
+```
+
+Labels for this format should be exported to YOLO format with one `*.txt` file per image. If there are no objects in an image, no `*.txt` file is required. The `*.txt` file should be formatted with one row per object in `class x_center y_center width height` format. Box coordinates must be in **normalized xywh** format (from 0 to 1). If your boxes are in pixels, you should divide `x_center` and `width` by image width, and `y_center` and `height` by image height. Class numbers should be zero-indexed (start with 0).
+
+
+
+The label file corresponding to the above image contains 2 persons (class `0`) and a tie (class `27`):
+
+
+
+When using the Ultralytics YOLO format, organize your training and validation images and labels as shown in the [COCO8 dataset](coco8.md) example below.
+
+
+
+## Usage
+
+Here's how you can use these formats to train your model:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo detect train data=coco8.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+## Supported Datasets
+
+Here is a list of the supported datasets and a brief description for each:
+
+- [Argoverse](argoverse.md): A dataset containing 3D tracking and motion forecasting data from urban environments with rich annotations.
+- [COCO](coco.md): Common Objects in Context (COCO) is a large-scale object detection, segmentation, and captioning dataset with 80 object categories.
+- [LVIS](lvis.md): A large-scale object detection, segmentation, and captioning dataset with 1203 object categories.
+- [COCO8](coco8.md): A smaller subset of the first 4 images from COCO train and COCO val, suitable for quick tests.
+- [Global Wheat 2020](globalwheat2020.md): A dataset containing images of wheat heads for the Global Wheat Challenge 2020.
+- [Objects365](objects365.md): A high-quality, large-scale dataset for object detection with 365 object categories and over 600K annotated images.
+- [OpenImagesV7](open-images-v7.md): A comprehensive dataset by Google with 1.7M train images and 42k validation images.
+- [SKU-110K](sku-110k.md): A dataset featuring dense object detection in retail environments with over 11K images and 1.7 million bounding boxes.
+- [VisDrone](visdrone.md): A dataset containing object detection and multi-object tracking data from drone-captured imagery with over 10K images and video sequences.
+- [VOC](voc.md): The Pascal Visual Object Classes (VOC) dataset for object detection and segmentation with 20 object classes and over 11K images.
+- [xView](xview.md): A dataset for object detection in overhead imagery with 60 object categories and over 1 million annotated objects.
+- [Roboflow 100](roboflow-100.md): A diverse object detection benchmark with 100 datasets spanning seven imagery domains for comprehensive model evaluation.
+- [Brain-tumor](brain-tumor.md): A dataset for detecting brain tumors includes MRI or CT scan images with details on tumor presence, location, and characteristics.
+- [African-wildlife](african-wildlife.md): A dataset featuring images of African wildlife, including buffalo, elephant, rhino, and zebras.
+- [Signature](signature.md): A dataset featuring images of various documents with annotated signatures, supporting document verification and fraud detection research.
+
+### Adding your own dataset
+
+If you have your own dataset and would like to use it for training detection models with Ultralytics YOLO format, ensure that it follows the format specified above under "Ultralytics YOLO format". Convert your annotations to the required format and specify the paths, number of classes, and class names in the YAML configuration file.
+
+## Port or Convert Label Formats
+
+### COCO Dataset Format to YOLO Format
+
+You can easily convert labels from the popular COCO dataset format to the YOLO format using the following code snippet:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics.data.converter import convert_coco
+
+ convert_coco(labels_dir="path/to/coco/annotations/")
+ ```
+
+This conversion tool can be used to convert the COCO dataset or any dataset in the COCO format to the Ultralytics YOLO format.
+
+Remember to double-check if the dataset you want to use is compatible with your model and follows the necessary format conventions. Properly formatted datasets are crucial for training successful object detection models.
+
+## FAQ
+
+### What is the Ultralytics YOLO dataset format and how to structure it?
+
+The Ultralytics YOLO format is a structured configuration for defining datasets in your training projects. It involves setting paths to your training, validation, and testing images and corresponding labels. For example:
+
+```yaml
+path: ../datasets/coco8 # dataset root directory
+train: images/train # training images (relative to 'path')
+val: images/val # validation images (relative to 'path')
+test: # optional test images
+names:
+ 0: person
+ 1: bicycle
+ 2: car
+ # ...
+```
+
+Labels are saved in `*.txt` files with one file per image, formatted as `class x_center y_center width height` with normalized coordinates. For a detailed guide, see the [COCO8 dataset example](coco8.md).
+
+### How do I convert a COCO dataset to the YOLO format?
+
+You can convert a COCO dataset to the YOLO format using the Ultralytics conversion tools. Here's a quick method:
+
+```python
+from ultralytics.data.converter import convert_coco
+
+convert_coco(labels_dir="path/to/coco/annotations/")
+```
+
+This code will convert your COCO annotations to YOLO format, enabling seamless integration with Ultralytics YOLO models. For additional details, visit the [Port or Convert Label Formats](#port-or-convert-label-formats) section.
+
+### Which datasets are supported by Ultralytics YOLO for object detection?
+
+Ultralytics YOLO supports a wide range of datasets, including:
+
+- [Argoverse](argoverse.md)
+- [COCO](coco.md)
+- [LVIS](lvis.md)
+- [COCO8](coco8.md)
+- [Global Wheat 2020](globalwheat2020.md)
+- [Objects365](objects365.md)
+- [OpenImagesV7](open-images-v7.md)
+
+Each dataset page provides detailed information on the structure and usage tailored for efficient YOLOv8 training. Explore the full list in the [Supported Datasets](#supported-datasets) section.
+
+### How do I start training a YOLOv8 model using my dataset?
+
+To start training a YOLOv8 model, ensure your dataset is formatted correctly and the paths are defined in a YAML file. Use the following script to begin training:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ model = YOLO("yolov8n.pt") # Load a pretrained model
+ results = model.train(data="path/to/your_dataset.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo detect train data=path/to/your_dataset.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+Refer to the [Usage](#usage) section for more details on utilizing different modes, including CLI commands.
+
+### Where can I find practical examples of using Ultralytics YOLO for object detection?
+
+Ultralytics provides numerous examples and practical guides for using YOLOv8 in diverse applications. For a comprehensive overview, visit the [Ultralytics Blog](https://www.ultralytics.com/blog) where you can find case studies, detailed tutorials, and community stories showcasing object detection, segmentation, and more with YOLOv8. For specific examples, check the [Usage](../../modes/predict.md) section in the documentation.
diff --git a/ultralytics/docs/en/datasets/detect/lvis.md b/ultralytics/docs/en/datasets/detect/lvis.md
new file mode 100644
index 0000000000000000000000000000000000000000..3e6c6db24b3fd071be5b36905f5acdf4cb57a0ff
--- /dev/null
+++ b/ultralytics/docs/en/datasets/detect/lvis.md
@@ -0,0 +1,159 @@
+---
+comments: true
+description: Discover the LVIS dataset by Facebook AI Research, a benchmark for object detection and instance segmentation with a large, diverse vocabulary. Learn how to utilize it.
+keywords: LVIS dataset, object detection, instance segmentation, Facebook AI Research, YOLO, computer vision, model training, LVIS examples
+---
+
+# LVIS Dataset
+
+The [LVIS dataset](https://www.lvisdataset.org/) is a large-scale, fine-grained vocabulary-level annotation dataset developed and released by Facebook AI Research (FAIR). It is primarily used as a research benchmark for object detection and instance segmentation with a large vocabulary of categories, aiming to drive further advancements in computer vision field.
+
+
+
+
+
+ Watch: YOLO World training workflow with LVIS dataset
+
+
+
+
+
+
+## Key Features
+
+- LVIS contains 160k images and 2M instance annotations for object detection, segmentation, and captioning tasks.
+- The dataset comprises 1203 object categories, including common objects like cars, bicycles, and animals, as well as more specific categories such as umbrellas, handbags, and sports equipment.
+- Annotations include object bounding boxes, segmentation masks, and captions for each image.
+- LVIS provides standardized evaluation metrics like mean Average Precision (mAP) for object detection, and mean Average Recall (mAR) for segmentation tasks, making it suitable for comparing model performance.
+- LVIS uses exactly the same images as [COCO](./coco.md) dataset, but with different splits and different annotations.
+
+## Dataset Structure
+
+The LVIS dataset is split into three subsets:
+
+1. **Train**: This subset contains 100k images for training object detection, segmentation, and captioning models.
+2. **Val**: This subset has 20k images used for validation purposes during model training.
+3. **Minival**: This subset is exactly the same as COCO val2017 set which has 5k images used for validation purposes during model training.
+4. **Test**: This subset consists of 20k images used for testing and benchmarking the trained models. Ground truth annotations for this subset are not publicly available, and the results are submitted to the [LVIS evaluation server](https://eval.ai/web/challenges/challenge-page/675/overview) for performance evaluation.
+
+## Applications
+
+The LVIS dataset is widely used for training and evaluating deep learning models in object detection (such as YOLO, Faster R-CNN, and SSD), instance segmentation (such as Mask R-CNN). The dataset's diverse set of object categories, large number of annotated images, and standardized evaluation metrics make it an essential resource for computer vision researchers and practitioners.
+
+## Dataset YAML
+
+A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the LVIS dataset, the `lvis.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/lvis.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/lvis.yaml).
+
+!!! Example "ultralytics/cfg/datasets/lvis.yaml"
+
+ ```yaml
+ --8<-- "ultralytics/cfg/datasets/lvis.yaml"
+ ```
+
+## Usage
+
+To train a YOLOv8n model on the LVIS dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="lvis.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo detect train data=lvis.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+## Sample Images and Annotations
+
+The LVIS dataset contains a diverse set of images with various object categories and complex scenes. Here are some examples of images from the dataset, along with their corresponding annotations:
+
+
+
+- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
+
+The example showcases the variety and complexity of the images in the LVIS dataset and the benefits of using mosaicing during the training process.
+
+## Citations and Acknowledgments
+
+If you use the LVIS dataset in your research or development work, please cite the following paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @inproceedings{gupta2019lvis,
+ title={LVIS: A Dataset for Large Vocabulary Instance Segmentation},
+ author={Gupta, Agrim and Dollar, Piotr and Girshick, Ross},
+ booktitle={Proceedings of the {IEEE} Conference on Computer Vision and Pattern Recognition},
+ year={2019}
+ }
+ ```
+
+We would like to acknowledge the LVIS Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the LVIS dataset and its creators, visit the [LVIS dataset website](https://www.lvisdataset.org/).
+
+## FAQ
+
+### What is the LVIS dataset, and how is it used in computer vision?
+
+The [LVIS dataset](https://www.lvisdataset.org/) is a large-scale dataset with fine-grained vocabulary-level annotations developed by Facebook AI Research (FAIR). It is primarily used for object detection and instance segmentation, featuring over 1203 object categories and 2 million instance annotations. Researchers and practitioners use it to train and benchmark models like Ultralytics YOLO for advanced computer vision tasks. The dataset's extensive size and diversity make it an essential resource for pushing the boundaries of model performance in detection and segmentation.
+
+### How can I train a YOLOv8n model using the LVIS dataset?
+
+To train a YOLOv8n model on the LVIS dataset for 100 epochs with an image size of 640, follow the example below. This process utilizes Ultralytics' framework, which offers comprehensive training features.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="lvis.yaml", epochs=100, imgsz=640)
+ ```
+
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo detect train data=lvis.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+For detailed training configurations, refer to the [Training](../../modes/train.md) documentation.
+
+### How does the LVIS dataset differ from the COCO dataset?
+
+The images in the LVIS dataset are the same as those in the [COCO dataset](./coco.md), but the two differ in terms of splitting and annotations. LVIS provides a larger and more detailed vocabulary with 1203 object categories compared to COCO's 80 categories. Additionally, LVIS focuses on annotation completeness and diversity, aiming to push the limits of object detection and instance segmentation models by offering more nuanced and comprehensive data.
+
+### Why should I use Ultralytics YOLO for training on the LVIS dataset?
+
+Ultralytics YOLO models, including the latest YOLOv8, are optimized for real-time object detection with state-of-the-art accuracy and speed. They support a wide range of annotations, such as the fine-grained ones provided by the LVIS dataset, making them ideal for advanced computer vision applications. Moreover, Ultralytics offers seamless integration with various [training](../../modes/train.md), [validation](../../modes/val.md), and [prediction](../../modes/predict.md) modes, ensuring efficient model development and deployment.
+
+### Can I see some sample annotations from the LVIS dataset?
+
+Yes, the LVIS dataset includes a variety of images with diverse object categories and complex scenes. Here is an example of a sample image along with its annotations:
+
+
+
+This mosaiced image demonstrates a training batch composed of multiple dataset images combined into one. Mosaicing increases the variety of objects and scenes within each training batch, enhancing the model's ability to generalize across different contexts. For more details on the LVIS dataset, explore the [LVIS dataset documentation](#key-features).
diff --git a/ultralytics/docs/en/datasets/detect/objects365.md b/ultralytics/docs/en/datasets/detect/objects365.md
new file mode 100644
index 0000000000000000000000000000000000000000..7bef28bf8d0eceb4901209c7d8d68c22810239e2
--- /dev/null
+++ b/ultralytics/docs/en/datasets/detect/objects365.md
@@ -0,0 +1,140 @@
+---
+comments: true
+description: Explore the Objects365 Dataset with 2M images and 30M bounding boxes across 365 categories. Enhance your object detection models with diverse, high-quality data.
+keywords: Objects365 dataset, object detection, machine learning, deep learning, computer vision, annotated images, bounding boxes, YOLOv8, high-resolution images, dataset configuration
+---
+
+# Objects365 Dataset
+
+The [Objects365](https://www.objects365.org/) dataset is a large-scale, high-quality dataset designed to foster object detection research with a focus on diverse objects in the wild. Created by a team of [Megvii](https://en.megvii.com/) researchers, the dataset offers a wide range of high-resolution images with a comprehensive set of annotated bounding boxes covering 365 object categories.
+
+## Key Features
+
+- Objects365 contains 365 object categories, with 2 million images and over 30 million bounding boxes.
+- The dataset includes diverse objects in various scenarios, providing a rich and challenging benchmark for object detection tasks.
+- Annotations include bounding boxes for objects, making it suitable for training and evaluating object detection models.
+- Objects365 pre-trained models significantly outperform ImageNet pre-trained models, leading to better generalization on various tasks.
+
+## Dataset Structure
+
+The Objects365 dataset is organized into a single set of images with corresponding annotations:
+
+- **Images**: The dataset includes 2 million high-resolution images, each containing a variety of objects across 365 categories.
+- **Annotations**: The images are annotated with over 30 million bounding boxes, providing comprehensive ground truth information for object detection tasks.
+
+## Applications
+
+The Objects365 dataset is widely used for training and evaluating deep learning models in object detection tasks. The dataset's diverse set of object categories and high-quality annotations make it a valuable resource for researchers and practitioners in the field of computer vision.
+
+## Dataset YAML
+
+A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. For the case of the Objects365 Dataset, the `Objects365.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/Objects365.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/Objects365.yaml).
+
+!!! Example "ultralytics/cfg/datasets/Objects365.yaml"
+
+ ```yaml
+ --8<-- "ultralytics/cfg/datasets/Objects365.yaml"
+ ```
+
+## Usage
+
+To train a YOLOv8n model on the Objects365 dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="Objects365.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo detect train data=Objects365.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+## Sample Data and Annotations
+
+The Objects365 dataset contains a diverse set of high-resolution images with objects from 365 categories, providing rich context for object detection tasks. Here are some examples of the images in the dataset:
+
+
+
+- **Objects365**: This image demonstrates an example of object detection, where objects are annotated with bounding boxes. The dataset provides a wide range of images to facilitate the development of models for this task.
+
+The example showcases the variety and complexity of the data in the Objects365 dataset and highlights the importance of accurate object detection for computer vision applications.
+
+## Citations and Acknowledgments
+
+If you use the Objects365 dataset in your research or development work, please cite the following paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @inproceedings{shao2019objects365,
+ title={Objects365: A Large-scale, High-quality Dataset for Object Detection},
+ author={Shao, Shuai and Li, Zeming and Zhang, Tianyuan and Peng, Chao and Yu, Gang and Li, Jing and Zhang, Xiangyu and Sun, Jian},
+ booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
+ pages={8425--8434},
+ year={2019}
+ }
+ ```
+
+We would like to acknowledge the team of researchers who created and maintain the Objects365 dataset as a valuable resource for the computer vision research community. For more information about the Objects365 dataset and its creators, visit the [Objects365 dataset website](https://www.objects365.org/).
+
+## FAQ
+
+### What is the Objects365 dataset used for?
+
+The [Objects365 dataset](https://www.objects365.org/) is designed for object detection tasks in machine learning and computer vision. It provides a large-scale, high-quality dataset with 2 million annotated images and 30 million bounding boxes across 365 categories. Leveraging such a diverse dataset helps improve the performance and generalization of object detection models, making it invaluable for research and development in the field.
+
+### How can I train a YOLOv8 model on the Objects365 dataset?
+
+To train a YOLOv8n model using the Objects365 dataset for 100 epochs with an image size of 640, follow these instructions:
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="Objects365.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo detect train data=Objects365.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+Refer to the [Training](../../modes/train.md) page for a comprehensive list of available arguments.
+
+### Why should I use the Objects365 dataset for my object detection projects?
+
+The Objects365 dataset offers several advantages for object detection tasks:
+1. **Diversity**: It includes 2 million images with objects in diverse scenarios, covering 365 categories.
+2. **High-quality Annotations**: Over 30 million bounding boxes provide comprehensive ground truth data.
+3. **Performance**: Models pre-trained on Objects365 significantly outperform those trained on datasets like ImageNet, leading to better generalization.
+
+### Where can I find the YAML configuration file for the Objects365 dataset?
+
+The YAML configuration file for the Objects365 dataset is available at [Objects365.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/Objects365.yaml). This file contains essential information such as dataset paths and class labels, crucial for setting up your training environment.
+
+### How does the dataset structure of Objects365 enhance object detection modeling?
+
+The [Objects365 dataset](https://www.objects365.org/) is organized with 2 million high-resolution images and comprehensive annotations of over 30 million bounding boxes. This structure ensures a robust dataset for training deep learning models in object detection, offering a wide variety of objects and scenarios. Such diversity and volume help in developing models that are more accurate and capable of generalizing well to real-world applications. For more details on the dataset structure, refer to the [Dataset YAML](#dataset-yaml) section.
diff --git a/ultralytics/docs/en/datasets/detect/open-images-v7.md b/ultralytics/docs/en/datasets/detect/open-images-v7.md
new file mode 100644
index 0000000000000000000000000000000000000000..08b7a467b52184ac1de9b9ce7fd72e52a7415fb3
--- /dev/null
+++ b/ultralytics/docs/en/datasets/detect/open-images-v7.md
@@ -0,0 +1,199 @@
+---
+comments: true
+description: Explore the comprehensive Open Images V7 dataset by Google. Learn about its annotations, applications, and use YOLOv8 pretrained models for computer vision tasks.
+keywords: Open Images V7, Google dataset, computer vision, YOLOv8 models, object detection, image segmentation, visual relationships, AI research, Ultralytics
+---
+
+# Open Images V7 Dataset
+
+[Open Images V7](https://storage.googleapis.com/openimages/web/index.html) is a versatile and expansive dataset championed by Google. Aimed at propelling research in the realm of computer vision, it boasts a vast collection of images annotated with a plethora of data, including image-level labels, object bounding boxes, object segmentation masks, visual relationships, and localized narratives.
+
+
+
+
+
+ Watch: Object Detection using OpenImagesV7 Pretrained Model
+
+
+## Open Images V7 Pretrained Models
+
+| Model | size (pixels) | mAPval 50-95 | Speed CPU ONNX (ms) | Speed A100 TensorRT (ms) | params (M) | FLOPs (B) |
+|-------------------------------------------------------------------------------------------|-----------------------|----------------------|--------------------------------|-------------------------------------|--------------------|-------------------|
+| [YOLOv8n](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n-oiv7.pt) | 640 | 18.4 | 142.4 | 1.21 | 3.5 | 10.5 |
+| [YOLOv8s](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8s-oiv7.pt) | 640 | 27.7 | 183.1 | 1.40 | 11.4 | 29.7 |
+| [YOLOv8m](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8m-oiv7.pt) | 640 | 33.6 | 408.5 | 2.26 | 26.2 | 80.6 |
+| [YOLOv8l](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8l-oiv7.pt) | 640 | 34.9 | 596.9 | 2.43 | 44.1 | 167.4 |
+| [YOLOv8x](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8x-oiv7.pt) | 640 | 36.3 | 860.6 | 3.56 | 68.7 | 260.6 |
+
+
+
+## Key Features
+
+- Encompasses ~9M images annotated in various ways to suit multiple computer vision tasks.
+- Houses a staggering 16M bounding boxes across 600 object classes in 1.9M images. These boxes are primarily hand-drawn by experts ensuring high precision.
+- Visual relationship annotations totaling 3.3M are available, detailing 1,466 unique relationship triplets, object properties, and human activities.
+- V5 introduced segmentation masks for 2.8M objects across 350 classes.
+- V6 introduced 675k localized narratives that amalgamate voice, text, and mouse traces highlighting described objects.
+- V7 introduced 66.4M point-level labels on 1.4M images, spanning 5,827 classes.
+- Encompasses 61.4M image-level labels across a diverse set of 20,638 classes.
+- Provides a unified platform for image classification, object detection, relationship detection, instance segmentation, and multimodal image descriptions.
+
+## Dataset Structure
+
+Open Images V7 is structured in multiple components catering to varied computer vision challenges:
+
+- **Images**: About 9 million images, often showcasing intricate scenes with an average of 8.3 objects per image.
+- **Bounding Boxes**: Over 16 million boxes that demarcate objects across 600 categories.
+- **Segmentation Masks**: These detail the exact boundary of 2.8M objects across 350 classes.
+- **Visual Relationships**: 3.3M annotations indicating object relationships, properties, and actions.
+- **Localized Narratives**: 675k descriptions combining voice, text, and mouse traces.
+- **Point-Level Labels**: 66.4M labels across 1.4M images, suitable for zero/few-shot semantic segmentation.
+
+## Applications
+
+Open Images V7 is a cornerstone for training and evaluating state-of-the-art models in various computer vision tasks. The dataset's broad scope and high-quality annotations make it indispensable for researchers and developers specializing in computer vision.
+
+## Dataset YAML
+
+Typically, datasets come with a YAML (Yet Another Markup Language) file that delineates the dataset's configuration. For the case of Open Images V7, a hypothetical `OpenImagesV7.yaml` might exist. For accurate paths and configurations, one should refer to the dataset's official repository or documentation.
+
+!!! Example "OpenImagesV7.yaml"
+
+ ```yaml
+ --8<-- "ultralytics/cfg/datasets/open-images-v7.yaml"
+ ```
+
+## Usage
+
+To train a YOLOv8n model on the Open Images V7 dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+!!! Warning
+
+ The complete Open Images V7 dataset comprises 1,743,042 training images and 41,620 validation images, requiring approximately **561 GB of storage space** upon download.
+
+ Executing the commands provided below will trigger an automatic download of the full dataset if it's not already present locally. Before running the below example it's crucial to:
+
+ - Verify that your device has enough storage capacity.
+ - Ensure a robust and speedy internet connection.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a COCO-pretrained YOLOv8n model
+ model = YOLO("yolov8n.pt")
+
+ # Train the model on the Open Images V7 dataset
+ results = model.train(data="open-images-v7.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Train a COCO-pretrained YOLOv8n model on the Open Images V7 dataset
+ yolo detect train data=open-images-v7.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+## Sample Data and Annotations
+
+Illustrations of the dataset help provide insights into its richness:
+
+
+
+- **Open Images V7**: This image exemplifies the depth and detail of annotations available, including bounding boxes, relationships, and segmentation masks.
+
+Researchers can gain invaluable insights into the array of computer vision challenges that the dataset addresses, from basic object detection to intricate relationship identification.
+
+## Citations and Acknowledgments
+
+For those employing Open Images V7 in their work, it's prudent to cite the relevant papers and acknowledge the creators:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @article{OpenImages,
+ author = {Alina Kuznetsova and Hassan Rom and Neil Alldrin and Jasper Uijlings and Ivan Krasin and Jordi Pont-Tuset and Shahab Kamali and Stefan Popov and Matteo Malloci and Alexander Kolesnikov and Tom Duerig and Vittorio Ferrari},
+ title = {The Open Images Dataset V4: Unified image classification, object detection, and visual relationship detection at scale},
+ year = {2020},
+ journal = {IJCV}
+ }
+ ```
+
+A heartfelt acknowledgment goes out to the Google AI team for creating and maintaining the Open Images V7 dataset. For a deep dive into the dataset and its offerings, navigate to the [official Open Images V7 website](https://storage.googleapis.com/openimages/web/index.html).
+
+## FAQ
+
+### What is the Open Images V7 dataset?
+
+Open Images V7 is an extensive and versatile dataset created by Google, designed to advance research in computer vision. It includes image-level labels, object bounding boxes, object segmentation masks, visual relationships, and localized narratives, making it ideal for various computer vision tasks such as object detection, segmentation, and relationship detection.
+
+### How do I train a YOLOv8 model on the Open Images V7 dataset?
+
+To train a YOLOv8 model on the Open Images V7 dataset, you can use both Python and CLI commands. Here's an example of training the YOLOv8n model for 100 epochs with an image size of 640:
+
+!!! Example "Train Example"
+
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a COCO-pretrained YOLOv8n model
+ model = YOLO("yolov8n.pt")
+
+ # Train the model on the Open Images V7 dataset
+ results = model.train(data="open-images-v7.yaml", epochs=100, imgsz=640)
+ ```
+
+
+ === "CLI"
+
+ ```bash
+ # Train a COCO-pretrained YOLOv8n model on the Open Images V7 dataset
+ yolo detect train data=open-images-v7.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+For more details on arguments and settings, refer to the [Training](../../modes/train.md) page.
+
+### What are some key features of the Open Images V7 dataset?
+
+The Open Images V7 dataset includes approximately 9 million images with various annotations:
+- **Bounding Boxes**: 16 million bounding boxes across 600 object classes.
+- **Segmentation Masks**: Masks for 2.8 million objects across 350 classes.
+- **Visual Relationships**: 3.3 million annotations indicating relationships, properties, and actions.
+- **Localized Narratives**: 675,000 descriptions combining voice, text, and mouse traces.
+- **Point-Level Labels**: 66.4 million labels across 1.4 million images.
+- **Image-Level Labels**: 61.4 million labels across 20,638 classes.
+
+### What pretrained models are available for the Open Images V7 dataset?
+
+Ultralytics provides several YOLOv8 pretrained models for the Open Images V7 dataset, each with different sizes and performance metrics:
+
+| Model | size (pixels) | mAPval 50-95 | Speed CPU ONNX (ms) | Speed A100 TensorRT (ms) | params (M) | FLOPs (B) |
+|-------|-----------------------|----------------------|--------------------------------|-------------------------------------|--------------------|-------------------|
+| [YOLOv8n](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n-oiv7.pt) | 640 | 18.4 | 142.4 | 1.21 | 3.5 | 10.5 |
+| [YOLOv8s](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8s-oiv7.pt) | 640 | 27.7 | 183.1 | 1.40 | 11.4 | 29.7 |
+| [YOLOv8m](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8m-oiv7.pt) | 640 | 33.6 | 408.5 | 2.26 | 26.2 | 80.6 |
+| [YOLOv8l](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8l-oiv7.pt) | 640 | 34.9 | 596.9 | 2.43 | 44.1 | 167.4 |
+| [YOLOv8x](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8x-oiv7.pt) | 640 | 36.3 | 860.6 | 3.56 | 68.7 | 260.6 |
+
+### What applications can the Open Images V7 dataset be used for?
+
+The Open Images V7 dataset supports a variety of computer vision tasks including:
+- **Image Classification**
+- **Object Detection**
+- **Instance Segmentation**
+- **Visual Relationship Detection**
+- **Multimodal Image Descriptions**
+
+Its comprehensive annotations and broad scope make it suitable for training and evaluating advanced machine learning models, as highlighted in practical use cases detailed in our [applications](#applications) section.
diff --git a/ultralytics/docs/en/datasets/detect/roboflow-100.md b/ultralytics/docs/en/datasets/detect/roboflow-100.md
new file mode 100644
index 0000000000000000000000000000000000000000..33cc24447d7f868cf88db9642bde04d523cbde6e
--- /dev/null
+++ b/ultralytics/docs/en/datasets/detect/roboflow-100.md
@@ -0,0 +1,218 @@
+---
+comments: true
+description: Explore the Roboflow 100 dataset featuring 100 diverse datasets designed to test object detection models across various domains, from healthcare to video games.
+keywords: Roboflow 100, Ultralytics, object detection, dataset, benchmarking, machine learning, computer vision, diverse datasets, model evaluation
+---
+
+# Roboflow 100 Dataset
+
+Roboflow 100, developed by [Roboflow](https://roboflow.com/?ref=ultralytics) and sponsored by Intel, is a groundbreaking [object detection](../../tasks/detect.md) benchmark. It includes 100 diverse datasets sampled from over 90,000 public datasets. This benchmark is designed to test the adaptability of models to various domains, including healthcare, aerial imagery, and video games.
+
+
+
+
+
+## Key Features
+
+- Includes 100 datasets across seven domains: Aerial, Video games, Microscopic, Underwater, Documents, Electromagnetic, and Real World.
+- The benchmark comprises 224,714 images across 805 classes, thanks to over 11,170 hours of labeling efforts.
+- All images are resized to 640x640 pixels, with a focus on eliminating class ambiguity and filtering out underrepresented classes.
+- Annotations include bounding boxes for objects, making it suitable for [training](../../modes/train.md) and evaluating object detection models.
+
+## Dataset Structure
+
+The Roboflow 100 dataset is organized into seven categories, each with a distinct set of datasets, images, and classes:
+
+- **Aerial**: Consists of 7 datasets with a total of 9,683 images, covering 24 distinct classes.
+- **Video Games**: Includes 7 datasets, featuring 11,579 images across 88 classes.
+- **Microscopic**: Comprises 11 datasets with 13,378 images, spanning 28 classes.
+- **Underwater**: Contains 5 datasets, encompassing 18,003 images in 39 classes.
+- **Documents**: Consists of 8 datasets with 24,813 images, divided into 90 classes.
+- **Electromagnetic**: Made up of 12 datasets, totaling 36,381 images in 41 classes.
+- **Real World**: The largest category with 50 datasets, offering 110,615 images across 495 classes.
+
+This structure enables a diverse and extensive testing ground for object detection models, reflecting real-world application scenarios.
+
+## Benchmarking
+
+Dataset benchmarking evaluates machine learning model performance on specific datasets using standardized metrics like accuracy, mean average precision and F1-score.
+
+!!! Tip "Benchmarking"
+
+ Benchmarking results will be stored in "ultralytics-benchmarks/evaluation.txt"
+
+!!! Example "Benchmarking example"
+
+ === "Python"
+
+ ```python
+ import os
+ import shutil
+ from pathlib import Path
+
+ from ultralytics.utils.benchmarks import RF100Benchmark
+
+ # Initialize RF100Benchmark and set API key
+ benchmark = RF100Benchmark()
+ benchmark.set_key(api_key="YOUR_ROBOFLOW_API_KEY")
+
+ # Parse dataset and define file paths
+ names, cfg_yamls = benchmark.parse_dataset()
+ val_log_file = Path("ultralytics-benchmarks") / "validation.txt"
+ eval_log_file = Path("ultralytics-benchmarks") / "evaluation.txt"
+
+ # Run benchmarks on each dataset in RF100
+ for ind, path in enumerate(cfg_yamls):
+ path = Path(path)
+ if path.exists():
+ # Fix YAML file and run training
+ benchmark.fix_yaml(str(path))
+ os.system(f"yolo detect train data={path} model=yolov8s.pt epochs=1 batch=16")
+
+ # Run validation and evaluate
+ os.system(f"yolo detect val data={path} model=runs/detect/train/weights/best.pt > {val_log_file} 2>&1")
+ benchmark.evaluate(str(path), str(val_log_file), str(eval_log_file), ind)
+
+ # Remove the 'runs' directory
+ runs_dir = Path.cwd() / "runs"
+ shutil.rmtree(runs_dir)
+ else:
+ print("YAML file path does not exist")
+ continue
+
+ print("RF100 Benchmarking completed!")
+ ```
+
+## Applications
+
+Roboflow 100 is invaluable for various applications related to computer vision and deep learning. Researchers and engineers can use this benchmark to:
+
+- Evaluate the performance of object detection models in a multi-domain context.
+- Test the adaptability of models to real-world scenarios beyond common object recognition.
+- Benchmark the capabilities of object detection models across diverse datasets, including those in healthcare, aerial imagery, and video games.
+
+For more ideas and inspiration on real-world applications, be sure to check out [our guides on real-world projects](../../guides/index.md).
+
+## Usage
+
+The Roboflow 100 dataset is available on both [GitHub](https://github.com/roboflow/roboflow-100-benchmark) and [Roboflow Universe](https://universe.roboflow.com/roboflow-100).
+
+You can access it directly from the Roboflow 100 GitHub repository. In addition, on Roboflow Universe, you have the flexibility to download individual datasets by simply clicking the export button within each dataset.
+
+## Sample Data and Annotations
+
+Roboflow 100 consists of datasets with diverse images and videos captured from various angles and domains. Here's a look at examples of annotated images in the RF100 benchmark.
+
+
+
+
+
+The diversity in the Roboflow 100 benchmark that can be seen above is a significant advancement from traditional benchmarks which often focus on optimizing a single metric within a limited domain.
+
+## Citations and Acknowledgments
+
+If you use the Roboflow 100 dataset in your research or development work, please cite the following paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @misc{2211.13523,
+ Author = {Floriana Ciaglia and Francesco Saverio Zuppichini and Paul Guerrie and Mark McQuade and Jacob Solawetz},
+ Title = {Roboflow 100: A Rich, Multi-Domain Object Detection Benchmark},
+ Eprint = {arXiv:2211.13523},
+ }
+ ```
+
+Our thanks go to the Roboflow team and all the contributors for their hard work in creating and sustaining the Roboflow 100 dataset.
+
+If you are interested in exploring more datasets to enhance your object detection and machine learning projects, feel free to visit [our comprehensive dataset collection](../index.md).
+
+## FAQ
+
+### What is the Roboflow 100 dataset, and why is it significant for object detection?
+
+The **Roboflow 100** dataset, developed by [Roboflow](https://roboflow.com/?ref=ultralytics) and sponsored by Intel, is a crucial [object detection](../../tasks/detect.md) benchmark. It features 100 diverse datasets from over 90,000 public datasets, covering domains such as healthcare, aerial imagery, and video games. This diversity ensures that models can adapt to various real-world scenarios, enhancing their robustness and performance.
+
+### How can I use the Roboflow 100 dataset for benchmarking my object detection models?
+
+To use the Roboflow 100 dataset for benchmarking, you can implement the RF100Benchmark class from the Ultralytics library. Here's a brief example:
+
+!!! Example "Benchmarking example"
+
+ === "Python"
+
+ ```python
+ import os
+ import shutil
+ from pathlib import Path
+
+ from ultralytics.utils.benchmarks import RF100Benchmark
+
+ # Initialize RF100Benchmark and set API key
+ benchmark = RF100Benchmark()
+ benchmark.set_key(api_key="YOUR_ROBOFLOW_API_KEY")
+
+ # Parse dataset and define file paths
+ names, cfg_yamls = benchmark.parse_dataset()
+ val_log_file = Path("ultralytics-benchmarks") / "validation.txt"
+ eval_log_file = Path("ultralytics-benchmarks") / "evaluation.txt"
+
+ # Run benchmarks on each dataset in RF100
+ for ind, path in enumerate(cfg_yamls):
+ path = Path(path)
+ if path.exists():
+ # Fix YAML file and run training
+ benchmark.fix_yaml(str(path))
+ os.system(f"yolo detect train data={path} model=yolov8s.pt epochs=1 batch=16")
+
+ # Run validation and evaluate
+ os.system(f"yolo detect val data={path} model=runs/detect/train/weights/best.pt > {val_log_file} 2>&1")
+ benchmark.evaluate(str(path), str(val_log_file), str(eval_log_file), ind)
+
+ # Remove 'runs' directory
+ runs_dir = Path.cwd() / "runs"
+ shutil.rmtree(runs_dir)
+ else:
+ print("YAML file path does not exist")
+ continue
+
+ print("RF100 Benchmarking completed!")
+ ```
+
+### Which domains are covered by the Roboflow 100 dataset?
+
+The **Roboflow 100** dataset spans seven domains, each providing unique challenges and applications for object detection models:
+
+1. **Aerial**: 7 datasets, 9,683 images, 24 classes
+2. **Video Games**: 7 datasets, 11,579 images, 88 classes
+3. **Microscopic**: 11 datasets, 13,378 images, 28 classes
+4. **Underwater**: 5 datasets, 18,003 images, 39 classes
+5. **Documents**: 8 datasets, 24,813 images, 90 classes
+6. **Electromagnetic**: 12 datasets, 36,381 images, 41 classes
+7. **Real World**: 50 datasets, 110,615 images, 495 classes
+
+This setup allows for extensive and varied testing of models across different real-world applications.
+
+### How do I access and download the Roboflow 100 dataset?
+
+The **Roboflow 100** dataset is accessible on [GitHub](https://github.com/roboflow/roboflow-100-benchmark) and [Roboflow Universe](https://universe.roboflow.com/roboflow-100). You can download the entire dataset from GitHub or select individual datasets on Roboflow Universe using the export button.
+
+### What should I include when citing the Roboflow 100 dataset in my research?
+
+When using the Roboflow 100 dataset in your research, ensure to properly cite it. Here is the recommended citation:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @misc{2211.13523,
+ Author = {Floriana Ciaglia and Francesco Saverio Zuppichini and Paul Guerrie and Mark McQuade and Jacob Solawetz},
+ Title = {Roboflow 100: A Rich, Multi-Domain Object Detection Benchmark},
+ Eprint = {arXiv:2211.13523},
+ }
+ ```
+
+For more details, you can refer to our [comprehensive dataset collection](../index.md).
diff --git a/ultralytics/docs/en/datasets/detect/signature.md b/ultralytics/docs/en/datasets/detect/signature.md
new file mode 100644
index 0000000000000000000000000000000000000000..4d25650afa10d735386b283423832bc365d70ff6
--- /dev/null
+++ b/ultralytics/docs/en/datasets/detect/signature.md
@@ -0,0 +1,170 @@
+---
+comments: true
+description: Discover the Signature Detection Dataset for training models to identify and verify human signatures in various documents. Perfect for document verification and fraud prevention.
+keywords: Signature Detection Dataset, document verification, fraud detection, computer vision, YOLOv8, Ultralytics, annotated signatures, training dataset
+---
+
+# Signature Detection Dataset
+
+This dataset focuses on detecting human written signatures within documents. It includes a variety of document types with annotated signatures, providing valuable insights for applications in document verification and fraud detection. Essential for training computer vision algorithms, this dataset aids in identifying signatures in various document formats, supporting research and practical applications in document analysis.
+
+## Dataset Structure
+
+The signature detection dataset is split into three subsets:
+
+- **Training set**: Contains 143 images, each with corresponding annotations.
+- **Validation set**: Includes 35 images, each with paired annotations.
+
+## Applications
+
+This dataset can be applied in various computer vision tasks such as object detection, object tracking, and document analysis. Specifically, it can be used to train and evaluate models for identifying signatures in documents, which can have applications in document verification, fraud detection, and archival research. Additionally, it can serve as a valuable resource for educational purposes, enabling students and researchers to study and understand the characteristics and behaviors of signatures in different document types.
+
+## Dataset YAML
+
+A YAML (Yet Another Markup Language) file defines the dataset configuration, including paths and classes information. For the signature detection dataset, the `signature.yaml` file is located at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/signature.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/signature.yaml).
+
+!!! Example "ultralytics/cfg/datasets/signature.yaml"
+
+ ```yaml
+ --8<-- "ultralytics/cfg/datasets/signature.yaml"
+ ```
+
+## Usage
+
+To train a YOLOv8n model on the signature detection dataset for 100 epochs with an image size of 640, use the provided code samples. For a comprehensive list of available parameters, refer to the model's [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="signature.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo detect train data=signature.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+!!! Example "Inference Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("path/to/best.pt") # load a signature-detection fine-tuned model
+
+ # Inference using the model
+ results = model.predict("https://ultralytics.com/assets/signature-s.mp4", conf=0.75)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start prediction with a finetuned *.pt model
+ yolo detect predict model='path/to/best.pt' imgsz=640 source="https://ultralytics.com/assets/signature-s.mp4" conf=0.75
+ ```
+
+## Sample Images and Annotations
+
+The signature detection dataset comprises a wide variety of images showcasing different document types and annotated signatures. Below are examples of images from the dataset, each accompanied by its corresponding annotations.
+
+
+
+- **Mosaiced Image**: Here, we present a training batch consisting of mosaiced dataset images. Mosaicing, a training technique, combines multiple images into one, enriching batch diversity. This method helps enhance the model's ability to generalize across different signature sizes, aspect ratios, and contexts.
+
+This example illustrates the variety and complexity of images in the signature Detection Dataset, emphasizing the benefits of including mosaicing during the training process.
+
+## Citations and Acknowledgments
+
+The dataset has been released available under the [AGPL-3.0 License](https://github.com/ultralytics/ultralytics/blob/main/LICENSE).
+
+## FAQ
+
+### What is the Signature Detection Dataset, and how can it be used?
+
+The Signature Detection Dataset is a collection of annotated images aimed at detecting human signatures within various document types. It can be applied in computer vision tasks such as object detection and tracking, primarily for document verification, fraud detection, and archival research. This dataset helps train models to recognize signatures in different contexts, making it valuable for both research and practical applications.
+
+### How do I train a YOLOv8n model on the Signature Detection Dataset?
+
+To train a YOLOv8n model on the Signature Detection Dataset, follow these steps:
+
+1. Download the `signature.yaml` dataset configuration file from [signature.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/signature.yaml).
+2. Use the following Python script or CLI command to start training:
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a pretrained model
+ model = YOLO("yolov8n.pt")
+
+ # Train the model
+ results = model.train(data="signature.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo detect train data=signature.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+For more details, refer to the [Training](../../modes/train.md) page.
+
+### What are the main applications of the Signature Detection Dataset?
+
+The Signature Detection Dataset can be used for:
+
+1. **Document Verification**: Automatically verifying the presence and authenticity of human signatures in documents.
+2. **Fraud Detection**: Identifying forged or fraudulent signatures in legal and financial documents.
+3. **Archival Research**: Assisting historians and archivists in the digital analysis and cataloging of historical documents.
+4. **Education**: Supporting academic research and teaching in the fields of computer vision and machine learning.
+
+### How can I perform inference using a model trained on the Signature Detection Dataset?
+
+To perform inference using a model trained on the Signature Detection Dataset, follow these steps:
+
+1. Load your fine-tuned model.
+2. Use the below Python script or CLI command to perform inference:
+
+!!! Example "Inference Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load the fine-tuned model
+ model = YOLO("path/to/best.pt")
+
+ # Perform inference
+ results = model.predict("https://ultralytics.com/assets/signature-s.mp4", conf=0.75)
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo detect predict model='path/to/best.pt' imgsz=640 source="https://ultralytics.com/assets/signature-s.mp4" conf=0.75
+ ```
+
+### What is the structure of the Signature Detection Dataset, and where can I find more information?
+
+The Signature Detection Dataset is divided into two subsets:
+
+- **Training Set**: Contains 143 images with annotations.
+- **Validation Set**: Includes 35 images with annotations.
+
+For detailed information, you can refer to the [Dataset Structure](#dataset-structure) section. Additionally, view the complete dataset configuration in the `signature.yaml` file located at [signature.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/signature.yaml).
diff --git a/ultralytics/docs/en/datasets/detect/sku-110k.md b/ultralytics/docs/en/datasets/detect/sku-110k.md
new file mode 100644
index 0000000000000000000000000000000000000000..3e2dab317238d0e28735f9cd4155769b4413c37f
--- /dev/null
+++ b/ultralytics/docs/en/datasets/detect/sku-110k.md
@@ -0,0 +1,181 @@
+---
+comments: true
+description: Explore the SKU-110k dataset of densely packed retail shelf images, perfect for training and evaluating deep learning models in object detection tasks.
+keywords: SKU-110k, dataset, object detection, retail shelf images, deep learning, computer vision, model training
+---
+
+# SKU-110k Dataset
+
+The [SKU-110k](https://github.com/eg4000/SKU110K_CVPR19) dataset is a collection of densely packed retail shelf images, designed to support research in object detection tasks. Developed by Eran Goldman et al., the dataset contains over 110,000 unique store keeping unit (SKU) categories with densely packed objects, often looking similar or even identical, positioned in close proximity.
+
+
+
+
+
+ Watch: How to Train YOLOv10 on SKU-110k Dataset using Ultralytics | Retail Dataset
+
+
+
+
+## Key Features
+
+- SKU-110k contains images of store shelves from around the world, featuring densely packed objects that pose challenges for state-of-the-art object detectors.
+- The dataset includes over 110,000 unique SKU categories, providing a diverse range of object appearances.
+- Annotations include bounding boxes for objects and SKU category labels.
+
+## Dataset Structure
+
+The SKU-110k dataset is organized into three main subsets:
+
+1. **Training set**: This subset contains images and annotations used for training object detection models.
+2. **Validation set**: This subset consists of images and annotations used for model validation during training.
+3. **Test set**: This subset is designed for the final evaluation of trained object detection models.
+
+## Applications
+
+The SKU-110k dataset is widely used for training and evaluating deep learning models in object detection tasks, especially in densely packed scenes such as retail shelf displays. The dataset's diverse set of SKU categories and densely packed object arrangements make it a valuable resource for researchers and practitioners in the field of computer vision.
+
+## Dataset YAML
+
+A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. For the case of the SKU-110K dataset, the `SKU-110K.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/SKU-110K.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/SKU-110K.yaml).
+
+!!! Example "ultralytics/cfg/datasets/SKU-110K.yaml"
+
+ ```yaml
+ --8<-- "ultralytics/cfg/datasets/SKU-110K.yaml"
+ ```
+
+## Usage
+
+To train a YOLOv8n model on the SKU-110K dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="SKU-110K.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo detect train data=SKU-110K.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+## Sample Data and Annotations
+
+The SKU-110k dataset contains a diverse set of retail shelf images with densely packed objects, providing rich context for object detection tasks. Here are some examples of data from the dataset, along with their corresponding annotations:
+
+
+
+- **Densely packed retail shelf image**: This image demonstrates an example of densely packed objects in a retail shelf setting. Objects are annotated with bounding boxes and SKU category labels.
+
+The example showcases the variety and complexity of the data in the SKU-110k dataset and highlights the importance of high-quality data for object detection tasks.
+
+## Citations and Acknowledgments
+
+If you use the SKU-110k dataset in your research or development work, please cite the following paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @inproceedings{goldman2019dense,
+ author = {Eran Goldman and Roei Herzig and Aviv Eisenschtat and Jacob Goldberger and Tal Hassner},
+ title = {Precise Detection in Densely Packed Scenes},
+ booktitle = {Proc. Conf. Comput. Vision Pattern Recognition (CVPR)},
+ year = {2019}
+ }
+ ```
+
+We would like to acknowledge Eran Goldman et al. for creating and maintaining the SKU-110k dataset as a valuable resource for the computer vision research community. For more information about the SKU-110k dataset and its creators, visit the [SKU-110k dataset GitHub repository](https://github.com/eg4000/SKU110K_CVPR19).
+
+## FAQ
+
+### What is the SKU-110k dataset and why is it important for object detection?
+
+The SKU-110k dataset consists of densely packed retail shelf images designed to aid research in object detection tasks. Developed by Eran Goldman et al., it includes over 110,000 unique SKU categories. Its importance lies in its ability to challenge state-of-the-art object detectors with diverse object appearances and close proximity, making it an invaluable resource for researchers and practitioners in computer vision. Learn more about the dataset's structure and applications in our [SKU-110k Dataset](#sku-110k-dataset) section.
+
+### How do I train a YOLOv8 model using the SKU-110k dataset?
+
+Training a YOLOv8 model on the SKU-110k dataset is straightforward. Here's an example to train a YOLOv8n model for 100 epochs with an image size of 640:
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="SKU-110K.yaml", epochs=100, imgsz=640)
+ ```
+
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo detect train data=SKU-110K.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+### What are the main subsets of the SKU-110k dataset?
+
+The SKU-110k dataset is organized into three main subsets:
+
+1. **Training set**: Contains images and annotations used for training object detection models.
+2. **Validation set**: Consists of images and annotations used for model validation during training.
+3. **Test set**: Designed for the final evaluation of trained object detection models.
+
+Refer to the [Dataset Structure](#dataset-structure) section for more details.
+
+### How do I configure the SKU-110k dataset for training?
+
+The SKU-110k dataset configuration is defined in a YAML file, which includes details about the dataset's paths, classes, and other relevant information. The `SKU-110K.yaml` file is maintained at [SKU-110K.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/SKU-110K.yaml). For example, you can train a model using this configuration as shown in our [Usage](#usage) section.
+
+### What are the key features of the SKU-110k dataset in the context of deep learning?
+
+The SKU-110k dataset features images of store shelves from around the world, showcasing densely packed objects that pose significant challenges for object detectors:
+
+- Over 110,000 unique SKU categories
+- Diverse object appearances
+- Annotations include bounding boxes and SKU category labels
+
+These features make the SKU-110k dataset particularly valuable for training and evaluating deep learning models in object detection tasks. For more details, see the [Key Features](#key-features) section.
+
+### How do I cite the SKU-110k dataset in my research?
+
+If you use the SKU-110k dataset in your research or development work, please cite the following paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @inproceedings{goldman2019dense,
+ author = {Eran Goldman and Roei Herzig and Aviv Eisenschtat and Jacob Goldberger and Tal Hassner},
+ title = {Precise Detection in Densely Packed Scenes},
+ booktitle = {Proc. Conf. Comput. Vision Pattern Recognition (CVPR)},
+ year = {2019}
+ }
+ ```
+
+More information about the dataset can be found in the [Citations and Acknowledgments](#citations-and-acknowledgments) section.
diff --git a/ultralytics/docs/en/datasets/detect/visdrone.md b/ultralytics/docs/en/datasets/detect/visdrone.md
new file mode 100644
index 0000000000000000000000000000000000000000..d996cb5a06dcff6c18c7a53576fbb015c168a367
--- /dev/null
+++ b/ultralytics/docs/en/datasets/detect/visdrone.md
@@ -0,0 +1,177 @@
+---
+comments: true
+description: Explore the VisDrone Dataset, a large-scale benchmark for drone-based image and video analysis with over 2.6 million annotations for objects like pedestrians and vehicles.
+keywords: VisDrone, drone dataset, computer vision, object detection, object tracking, crowd counting, machine learning, deep learning
+---
+
+# VisDrone Dataset
+
+The [VisDrone Dataset](https://github.com/VisDrone/VisDrone-Dataset) is a large-scale benchmark created by the AISKYEYE team at the Lab of Machine Learning and Data Mining, Tianjin University, China. It contains carefully annotated ground truth data for various computer vision tasks related to drone-based image and video analysis.
+
+
+
+
+
+ Watch: How to Train Ultralytics YOLO Models on the VisDrone Dataset for Drone Image Analysis
+
+
+VisDrone is composed of 288 video clips with 261,908 frames and 10,209 static images, captured by various drone-mounted cameras. The dataset covers a wide range of aspects, including location (14 different cities across China), environment (urban and rural), objects (pedestrians, vehicles, bicycles, etc.), and density (sparse and crowded scenes). The dataset was collected using various drone platforms under different scenarios and weather and lighting conditions. These frames are manually annotated with over 2.6 million bounding boxes of targets such as pedestrians, cars, bicycles, and tricycles. Attributes like scene visibility, object class, and occlusion are also provided for better data utilization.
+
+## Dataset Structure
+
+The VisDrone dataset is organized into five main subsets, each focusing on a specific task:
+
+1. **Task 1**: Object detection in images
+2. **Task 2**: Object detection in videos
+3. **Task 3**: Single-object tracking
+4. **Task 4**: Multi-object tracking
+5. **Task 5**: Crowd counting
+
+## Applications
+
+The VisDrone dataset is widely used for training and evaluating deep learning models in drone-based computer vision tasks such as object detection, object tracking, and crowd counting. The dataset's diverse set of sensor data, object annotations, and attributes make it a valuable resource for researchers and practitioners in the field of drone-based computer vision.
+
+## Dataset YAML
+
+A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the Visdrone dataset, the `VisDrone.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/VisDrone.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/VisDrone.yaml).
+
+!!! Example "ultralytics/cfg/datasets/VisDrone.yaml"
+
+ ```yaml
+ --8<-- "ultralytics/cfg/datasets/VisDrone.yaml"
+ ```
+
+## Usage
+
+To train a YOLOv8n model on the VisDrone dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="VisDrone.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo detect train data=VisDrone.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+## Sample Data and Annotations
+
+The VisDrone dataset contains a diverse set of images and videos captured by drone-mounted cameras. Here are some examples of data from the dataset, along with their corresponding annotations:
+
+
+
+- **Task 1**: Object detection in images - This image demonstrates an example of object detection in images, where objects are annotated with bounding boxes. The dataset provides a wide variety of images taken from different locations, environments, and densities to facilitate the development of models for this task.
+
+The example showcases the variety and complexity of the data in the VisDrone dataset and highlights the importance of high-quality sensor data for drone-based computer vision tasks.
+
+## Citations and Acknowledgments
+
+If you use the VisDrone dataset in your research or development work, please cite the following paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @ARTICLE{9573394,
+ author={Zhu, Pengfei and Wen, Longyin and Du, Dawei and Bian, Xiao and Fan, Heng and Hu, Qinghua and Ling, Haibin},
+ journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
+ title={Detection and Tracking Meet Drones Challenge},
+ year={2021},
+ volume={},
+ number={},
+ pages={1-1},
+ doi={10.1109/TPAMI.2021.3119563}}
+ ```
+
+We would like to acknowledge the AISKYEYE team at the Lab of Machine Learning and Data Mining, Tianjin University, China, for creating and maintaining the VisDrone dataset as a valuable resource for the drone-based computer vision research community. For more information about the VisDrone dataset and its creators, visit the [VisDrone Dataset GitHub repository](https://github.com/VisDrone/VisDrone-Dataset).
+
+## FAQ
+
+### What is the VisDrone Dataset and what are its key features?
+
+The [VisDrone Dataset](https://github.com/VisDrone/VisDrone-Dataset) is a large-scale benchmark created by the AISKYEYE team at Tianjin University, China. It is designed for various computer vision tasks related to drone-based image and video analysis. Key features include:
+- **Composition**: 288 video clips with 261,908 frames and 10,209 static images.
+- **Annotations**: Over 2.6 million bounding boxes for objects like pedestrians, cars, bicycles, and tricycles.
+- **Diversity**: Collected across 14 cities, in urban and rural settings, under different weather and lighting conditions.
+- **Tasks**: Split into five main tasks—object detection in images and videos, single-object and multi-object tracking, and crowd counting.
+
+### How can I use the VisDrone Dataset to train a YOLOv8 model with Ultralytics?
+
+To train a YOLOv8 model on the VisDrone dataset for 100 epochs with an image size of 640, you can follow these steps:
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a pretrained model
+ model = YOLO("yolov8n.pt")
+
+ # Train the model
+ results = model.train(data="VisDrone.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo detect train data=VisDrone.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+For additional configuration options, please refer to the model [Training](../../modes/train.md) page.
+
+### What are the main subsets of the VisDrone dataset and their applications?
+
+The VisDrone dataset is divided into five main subsets, each tailored for a specific computer vision task:
+1. **Task 1**: Object detection in images.
+2. **Task 2**: Object detection in videos.
+3. **Task 3**: Single-object tracking.
+4. **Task 4**: Multi-object tracking.
+5. **Task 5**: Crowd counting.
+
+These subsets are widely used for training and evaluating deep learning models in drone-based applications such as surveillance, traffic monitoring, and public safety.
+
+### Where can I find the configuration file for the VisDrone dataset in Ultralytics?
+
+The configuration file for the VisDrone dataset, `VisDrone.yaml`, can be found in the Ultralytics repository at the following link:
+[VisDrone.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/VisDrone.yaml).
+
+### How can I cite the VisDrone dataset if I use it in my research?
+
+If you use the VisDrone dataset in your research or development work, please cite the following paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @ARTICLE{9573394,
+ author={Zhu, Pengfei and Wen, Longyin and Du, Dawei and Bian, Xiao and Fan, Heng and Hu, Qinghua and Ling, Haibin},
+ journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
+ title={Detection and Tracking Meet Drones Challenge},
+ year={2021},
+ volume={},
+ number={},
+ pages={1-1},
+ doi={10.1109/TPAMI.2021.3119563}
+ }
+ ```
diff --git a/ultralytics/docs/en/datasets/detect/voc.md b/ultralytics/docs/en/datasets/detect/voc.md
new file mode 100644
index 0000000000000000000000000000000000000000..e86a3ed42527d7a821c0e0499cfad5e6e3e0ccc5
--- /dev/null
+++ b/ultralytics/docs/en/datasets/detect/voc.md
@@ -0,0 +1,137 @@
+---
+comments: true
+description: Discover the PASCAL VOC dataset, essential for object detection, segmentation, and classification. Learn key features, applications, and usage tips.
+keywords: PASCAL VOC, VOC dataset, object detection, segmentation, classification, YOLO, Faster R-CNN, Mask R-CNN, image annotations, computer vision
+---
+
+# VOC Dataset
+
+The [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/) (Visual Object Classes) dataset is a well-known object detection, segmentation, and classification dataset. It is designed to encourage research on a wide variety of object categories and is commonly used for benchmarking computer vision models. It is an essential dataset for researchers and developers working on object detection, segmentation, and classification tasks.
+
+## Key Features
+
+- VOC dataset includes two main challenges: VOC2007 and VOC2012.
+- The dataset comprises 20 object categories, including common objects like cars, bicycles, and animals, as well as more specific categories such as boats, sofas, and dining tables.
+- Annotations include object bounding boxes and class labels for object detection and classification tasks, and segmentation masks for the segmentation tasks.
+- VOC provides standardized evaluation metrics like mean Average Precision (mAP) for object detection and classification, making it suitable for comparing model performance.
+
+## Dataset Structure
+
+The VOC dataset is split into three subsets:
+
+1. **Train**: This subset contains images for training object detection, segmentation, and classification models.
+2. **Validation**: This subset has images used for validation purposes during model training.
+3. **Test**: This subset consists of images used for testing and benchmarking the trained models. Ground truth annotations for this subset are not publicly available, and the results are submitted to the [PASCAL VOC evaluation server](http://host.robots.ox.ac.uk:8080/leaderboard/displaylb.php) for performance evaluation.
+
+## Applications
+
+The VOC dataset is widely used for training and evaluating deep learning models in object detection (such as YOLO, Faster R-CNN, and SSD), instance segmentation (such as Mask R-CNN), and image classification. The dataset's diverse set of object categories, large number of annotated images, and standardized evaluation metrics make it an essential resource for computer vision researchers and practitioners.
+
+## Dataset YAML
+
+A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the VOC dataset, the `VOC.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/VOC.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/VOC.yaml).
+
+!!! Example "ultralytics/cfg/datasets/VOC.yaml"
+
+ ```yaml
+ --8<-- "ultralytics/cfg/datasets/VOC.yaml"
+ ```
+
+## Usage
+
+To train a YOLOv8n model on the VOC dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="VOC.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo detect train data=VOC.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+## Sample Images and Annotations
+
+The VOC dataset contains a diverse set of images with various object categories and complex scenes. Here are some examples of images from the dataset, along with their corresponding annotations:
+
+
+
+- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
+
+The example showcases the variety and complexity of the images in the VOC dataset and the benefits of using mosaicing during the training process.
+
+## Citations and Acknowledgments
+
+If you use the VOC dataset in your research or development work, please cite the following paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @misc{everingham2010pascal,
+ title={The PASCAL Visual Object Classes (VOC) Challenge},
+ author={Mark Everingham and Luc Van Gool and Christopher K. I. Williams and John Winn and Andrew Zisserman},
+ year={2010},
+ eprint={0909.5206},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+ }
+ ```
+
+We would like to acknowledge the PASCAL VOC Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the VOC dataset and its creators, visit the [PASCAL VOC dataset website](http://host.robots.ox.ac.uk/pascal/VOC/).
+
+## FAQ
+
+### What is the PASCAL VOC dataset and why is it important for computer vision tasks?
+
+The [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/) (Visual Object Classes) dataset is a renowned benchmark for object detection, segmentation, and classification in computer vision. It includes comprehensive annotations like bounding boxes, class labels, and segmentation masks across 20 different object categories. Researchers use it widely to evaluate the performance of models like Faster R-CNN, YOLO, and Mask R-CNN due to its standardized evaluation metrics such as mean Average Precision (mAP).
+
+### How do I train a YOLOv8 model using the VOC dataset?
+
+To train a YOLOv8 model with the VOC dataset, you need the dataset configuration in a YAML file. Here's an example to start training a YOLOv8n model for 100 epochs with an image size of 640:
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="VOC.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo detect train data=VOC.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+### What are the primary challenges included in the VOC dataset?
+
+The VOC dataset includes two main challenges: VOC2007 and VOC2012. These challenges test object detection, segmentation, and classification across 20 diverse object categories. Each image is meticulously annotated with bounding boxes, class labels, and segmentation masks. The challenges provide standardized metrics like mAP, facilitating the comparison and benchmarking of different computer vision models.
+
+### How does the PASCAL VOC dataset enhance model benchmarking and evaluation?
+
+The PASCAL VOC dataset enhances model benchmarking and evaluation through its detailed annotations and standardized metrics like mean Average Precision (mAP). These metrics are crucial for assessing the performance of object detection and classification models. The dataset's diverse and complex images ensure comprehensive model evaluation across various real-world scenarios.
+
+### How do I use the VOC dataset for semantic segmentation in YOLO models?
+
+To use the VOC dataset for semantic segmentation tasks with YOLO models, you need to configure the dataset properly in a YAML file. The YAML file defines paths and classes needed for training segmentation models. Check the VOC dataset YAML configuration file at [VOC.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/VOC.yaml) for detailed setups.
diff --git a/ultralytics/docs/en/datasets/detect/xview.md b/ultralytics/docs/en/datasets/detect/xview.md
new file mode 100644
index 0000000000000000000000000000000000000000..abd4958f44d93307c290553f39c093d75218ca35
--- /dev/null
+++ b/ultralytics/docs/en/datasets/detect/xview.md
@@ -0,0 +1,162 @@
+---
+comments: true
+description: Explore the xView dataset, a rich resource of 1M+ object instances in high-resolution satellite imagery. Enhance detection, learning efficiency, and more.
+keywords: xView dataset, overhead imagery, satellite images, object detection, high resolution, bounding boxes, computer vision, TensorFlow, PyTorch, dataset structure
+---
+
+# xView Dataset
+
+The [xView](http://xviewdataset.org/) dataset is one of the largest publicly available datasets of overhead imagery, containing images from complex scenes around the world annotated using bounding boxes. The goal of the xView dataset is to accelerate progress in four computer vision frontiers:
+
+1. Reduce minimum resolution for detection.
+2. Improve learning efficiency.
+3. Enable discovery of more object classes.
+4. Improve detection of fine-grained classes.
+
+xView builds on the success of challenges like Common Objects in Context (COCO) and aims to leverage computer vision to analyze the growing amount of available imagery from space in order to understand the visual world in new ways and address a range of important applications.
+
+## Key Features
+
+- xView contains over 1 million object instances across 60 classes.
+- The dataset has a resolution of 0.3 meters, providing higher resolution imagery than most public satellite imagery datasets.
+- xView features a diverse collection of small, rare, fine-grained, and multi-type objects with bounding box annotation.
+- Comes with a pre-trained baseline model using the TensorFlow object detection API and an example for PyTorch.
+
+## Dataset Structure
+
+The xView dataset is composed of satellite images collected from WorldView-3 satellites at a 0.3m ground sample distance. It contains over 1 million objects across 60 classes in over 1,400 km² of imagery.
+
+## Applications
+
+The xView dataset is widely used for training and evaluating deep learning models for object detection in overhead imagery. The dataset's diverse set of object classes and high-resolution imagery make it a valuable resource for researchers and practitioners in the field of computer vision, especially for satellite imagery analysis.
+
+## Dataset YAML
+
+A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the xView dataset, the `xView.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/xView.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/xView.yaml).
+
+!!! Example "ultralytics/cfg/datasets/xView.yaml"
+
+ ```yaml
+ --8<-- "ultralytics/cfg/datasets/xView.yaml"
+ ```
+
+## Usage
+
+To train a model on the xView dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="xView.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo detect train data=xView.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+## Sample Data and Annotations
+
+The xView dataset contains high-resolution satellite images with a diverse set of objects annotated using bounding boxes. Here are some examples of data from the dataset, along with their corresponding annotations:
+
+
+
+- **Overhead Imagery**: This image demonstrates an example of object detection in overhead imagery, where objects are annotated with bounding boxes. The dataset provides high-resolution satellite images to facilitate the development of models for this task.
+
+The example showcases the variety and complexity of the data in the xView dataset and highlights the importance of high-quality satellite imagery for object detection tasks.
+
+## Citations and Acknowledgments
+
+If you use the xView dataset in your research or development work, please cite the following paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @misc{lam2018xview,
+ title={xView: Objects in Context in Overhead Imagery},
+ author={Darius Lam and Richard Kuzma and Kevin McGee and Samuel Dooley and Michael Laielli and Matthew Klaric and Yaroslav Bulatov and Brendan McCord},
+ year={2018},
+ eprint={1802.07856},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+ }
+ ```
+
+We would like to acknowledge the [Defense Innovation Unit](https://www.diu.mil/) (DIU) and the creators of the xView dataset for their valuable contribution to the computer vision research community. For more information about the xView dataset and its creators, visit the [xView dataset website](http://xviewdataset.org/).
+
+## FAQ
+
+### What is the xView dataset and how does it benefit computer vision research?
+
+The [xView](http://xviewdataset.org/) dataset is one of the largest publicly available collections of high-resolution overhead imagery, containing over 1 million object instances across 60 classes. It is designed to enhance various facets of computer vision research such as reducing the minimum resolution for detection, improving learning efficiency, discovering more object classes, and advancing fine-grained object detection.
+
+### How can I use Ultralytics YOLO to train a model on the xView dataset?
+
+To train a model on the xView dataset using Ultralytics YOLO, follow these steps:
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="xView.yaml", epochs=100, imgsz=640)
+ ```
+
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo detect train data=xView.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+For detailed arguments and settings, refer to the model [Training](../../modes/train.md) page.
+
+### What are the key features of the xView dataset?
+
+The xView dataset stands out due to its comprehensive set of features:
+- Over 1 million object instances across 60 distinct classes.
+- High-resolution imagery at 0.3 meters.
+- Diverse object types including small, rare, and fine-grained objects, all annotated with bounding boxes.
+- Availability of a pre-trained baseline model and examples in TensorFlow and PyTorch.
+
+### What is the dataset structure of xView, and how is it annotated?
+
+The xView dataset comprises high-resolution satellite images collected from WorldView-3 satellites at a 0.3m ground sample distance. It encompasses over 1 million objects across 60 classes in approximately 1,400 km² of imagery. Each object within the dataset is annotated with bounding boxes, making it ideal for training and evaluating deep learning models for object detection in overhead imagery. For a detailed overview, you can look at the dataset structure section [here](#dataset-structure).
+
+### How do I cite the xView dataset in my research?
+
+If you utilize the xView dataset in your research, please cite the following paper:
+
+!!! Quote "BibTeX"
+
+ ```bibtex
+ @misc{lam2018xview,
+ title={xView: Objects in Context in Overhead Imagery},
+ author={Darius Lam and Richard Kuzma and Kevin McGee and Samuel Dooley and Michael Laielli and Matthew Klaric and Yaroslav Bulatov and Brendan McCord},
+ year={2018},
+ eprint={1802.07856},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+ }
+ ```
+
+For more information about the xView dataset, visit the official [xView dataset website](http://xviewdataset.org/).
diff --git a/ultralytics/docs/en/datasets/explorer/api.md b/ultralytics/docs/en/datasets/explorer/api.md
new file mode 100644
index 0000000000000000000000000000000000000000..849e75f7f31a683701456331ccb2aafa0dfc2d3b
--- /dev/null
+++ b/ultralytics/docs/en/datasets/explorer/api.md
@@ -0,0 +1,386 @@
+---
+comments: true
+description: Explore the Ultralytics Explorer API for dataset exploration with SQL queries, vector similarity search, and semantic search. Learn installation and usage tips.
+keywords: Ultralytics, Explorer API, dataset exploration, SQL queries, similarity search, semantic search, Python API, LanceDB, embeddings, data analysis
+---
+
+# Ultralytics Explorer API
+
+## Introduction
+
+
+The Explorer API is a Python API for exploring your datasets. It supports filtering and searching your dataset using SQL queries, vector similarity search and semantic search.
+
+
+
+
+
+ Watch: Ultralytics Explorer API Overview
+
+
+## Installation
+
+Explorer depends on external libraries for some of its functionality. These are automatically installed on usage. To manually install these dependencies, use the following command:
+
+```bash
+pip install ultralytics[explorer]
+```
+
+## Usage
+
+```python
+from ultralytics import Explorer
+
+# Create an Explorer object
+explorer = Explorer(data="coco128.yaml", model="yolov8n.pt")
+
+# Create embeddings for your dataset
+explorer.create_embeddings_table()
+
+# Search for similar images to a given image/images
+dataframe = explorer.get_similar(img="path/to/image.jpg")
+
+# Or search for similar images to a given index/indices
+dataframe = explorer.get_similar(idx=0)
+```
+
+!!! Tip "Note"
+
+ Embeddings table for a given dataset and model pair is only created once and reused. These use [LanceDB](https://lancedb.github.io/lancedb/) under the hood, which scales on-disk, so you can create and reuse embeddings for large datasets like COCO without running out of memory.
+
+In case you want to force update the embeddings table, you can pass `force=True` to `create_embeddings_table` method.
+
+You can directly access the LanceDB table object to perform advanced analysis. Learn more about it in the [Working with Embeddings Table section](#4-working-with-embeddings-table)
+
+## 1. Similarity Search
+
+Similarity search is a technique for finding similar images to a given image. It is based on the idea that similar images will have similar embeddings. Once the embeddings table is built, you can get run semantic search in any of the following ways:
+
+- On a given index or list of indices in the dataset: `exp.get_similar(idx=[1,10], limit=10)`
+- On any image or list of images not in the dataset: `exp.get_similar(img=["path/to/img1", "path/to/img2"], limit=10)`
+
+In case of multiple inputs, the aggregate of their embeddings is used.
+
+You get a pandas dataframe with the `limit` number of most similar data points to the input, along with their distance in the embedding space. You can use this dataset to perform further filtering
+
+!!! Example "Semantic Search"
+
+ === "Using Images"
+
+ ```python
+ from ultralytics import Explorer
+
+ # create an Explorer object
+ exp = Explorer(data="coco128.yaml", model="yolov8n.pt")
+ exp.create_embeddings_table()
+
+ similar = exp.get_similar(img="https://ultralytics.com/images/bus.jpg", limit=10)
+ print(similar.head())
+
+ # Search using multiple indices
+ similar = exp.get_similar(
+ img=["https://ultralytics.com/images/bus.jpg", "https://ultralytics.com/images/bus.jpg"],
+ limit=10,
+ )
+ print(similar.head())
+ ```
+
+ === "Using Dataset Indices"
+
+ ```python
+ from ultralytics import Explorer
+
+ # create an Explorer object
+ exp = Explorer(data="coco128.yaml", model="yolov8n.pt")
+ exp.create_embeddings_table()
+
+ similar = exp.get_similar(idx=1, limit=10)
+ print(similar.head())
+
+ # Search using multiple indices
+ similar = exp.get_similar(idx=[1, 10], limit=10)
+ print(similar.head())
+ ```
+
+### Plotting Similar Images
+
+You can also plot the similar images using the `plot_similar` method. This method takes the same arguments as `get_similar` and plots the similar images in a grid.
+
+!!! Example "Plotting Similar Images"
+
+ === "Using Images"
+
+ ```python
+ from ultralytics import Explorer
+
+ # create an Explorer object
+ exp = Explorer(data="coco128.yaml", model="yolov8n.pt")
+ exp.create_embeddings_table()
+
+ plt = exp.plot_similar(img="https://ultralytics.com/images/bus.jpg", limit=10)
+ plt.show()
+ ```
+
+ === "Using Dataset Indices"
+
+ ```python
+ from ultralytics import Explorer
+
+ # create an Explorer object
+ exp = Explorer(data="coco128.yaml", model="yolov8n.pt")
+ exp.create_embeddings_table()
+
+ plt = exp.plot_similar(idx=1, limit=10)
+ plt.show()
+ ```
+
+## 2. Ask AI (Natural Language Querying)
+
+This allows you to write how you want to filter your dataset using natural language. You don't have to be proficient in writing SQL queries. Our AI powered query generator will automatically do that under the hood. For example - you can say - "show me 100 images with exactly one person and 2 dogs. There can be other objects too" and it'll internally generate the query and show you those results.
+Note: This works using LLMs under the hood so the results are probabilistic and might get things wrong sometimes
+
+!!! Example "Ask AI"
+
+ ```python
+ from ultralytics import Explorer
+ from ultralytics.data.explorer import plot_query_result
+
+ # create an Explorer object
+ exp = Explorer(data="coco128.yaml", model="yolov8n.pt")
+ exp.create_embeddings_table()
+
+ df = exp.ask_ai("show me 100 images with exactly one person and 2 dogs. There can be other objects too")
+ print(df.head())
+
+ # plot the results
+ plt = plot_query_result(df)
+ plt.show()
+ ```
+
+## 3. SQL Querying
+
+You can run SQL queries on your dataset using the `sql_query` method. This method takes a SQL query as input and returns a pandas dataframe with the results.
+
+!!! Example "SQL Query"
+
+ ```python
+ from ultralytics import Explorer
+
+ # create an Explorer object
+ exp = Explorer(data="coco128.yaml", model="yolov8n.pt")
+ exp.create_embeddings_table()
+
+ df = exp.sql_query("WHERE labels LIKE '%person%' AND labels LIKE '%dog%'")
+ print(df.head())
+ ```
+
+### Plotting SQL Query Results
+
+You can also plot the results of a SQL query using the `plot_sql_query` method. This method takes the same arguments as `sql_query` and plots the results in a grid.
+
+!!! Example "Plotting SQL Query Results"
+
+ ```python
+ from ultralytics import Explorer
+
+ # create an Explorer object
+ exp = Explorer(data="coco128.yaml", model="yolov8n.pt")
+ exp.create_embeddings_table()
+
+ # plot the SQL Query
+ exp.plot_sql_query("WHERE labels LIKE '%person%' AND labels LIKE '%dog%' LIMIT 10")
+ ```
+
+## 4. Working with Embeddings Table
+
+You can also work with the embeddings table directly. Once the embeddings table is created, you can access it using the `Explorer.table`
+
+!!! Tip "Explorer works on [LanceDB](https://lancedb.github.io/lancedb/) tables internally. You can access this table directly, using `Explorer.table` object and run raw queries, push down pre- and post-filters, etc."
+
+ ```python
+ from ultralytics import Explorer
+
+ exp = Explorer()
+ exp.create_embeddings_table()
+ table = exp.table
+ ```
+
+Here are some examples of what you can do with the table:
+
+### Get raw Embeddings
+
+!!! Example
+
+ ```python
+ from ultralytics import Explorer
+
+ exp = Explorer()
+ exp.create_embeddings_table()
+ table = exp.table
+
+ embeddings = table.to_pandas()["vector"]
+ print(embeddings)
+ ```
+
+### Advanced Querying with pre- and post-filters
+
+!!! Example
+
+ ```python
+ from ultralytics import Explorer
+
+ exp = Explorer(model="yolov8n.pt")
+ exp.create_embeddings_table()
+ table = exp.table
+
+ # Dummy embedding
+ embedding = [i for i in range(256)]
+ rs = table.search(embedding).metric("cosine").where("").limit(10)
+ ```
+
+### Create Vector Index
+
+When using large datasets, you can also create a dedicated vector index for faster querying. This is done using the `create_index` method on LanceDB table.
+
+```python
+table.create_index(num_partitions=..., num_sub_vectors=...)
+```
+
+Find more details on the type vector indices available and parameters [here](https://lancedb.github.io/lancedb/ann_indexes/#types-of-index) In the future, we will add support for creating vector indices directly from Explorer API.
+
+## 5. Embeddings Applications
+
+You can use the embeddings table to perform a variety of exploratory analysis. Here are some examples:
+
+### Similarity Index
+
+Explorer comes with a `similarity_index` operation:
+
+- It tries to estimate how similar each data point is with the rest of the dataset.
+- It does that by counting how many image embeddings lie closer than `max_dist` to the current image in the generated embedding space, considering `top_k` similar images at a time.
+
+It returns a pandas dataframe with the following columns:
+
+- `idx`: Index of the image in the dataset
+- `im_file`: Path to the image file
+- `count`: Number of images in the dataset that are closer than `max_dist` to the current image
+- `sim_im_files`: List of paths to the `count` similar images
+
+!!! Tip
+
+ For a given dataset, model, `max_dist` & `top_k` the similarity index once generated will be reused. In case, your dataset has changed, or you simply need to regenerate the similarity index, you can pass `force=True`.
+
+!!! Example "Similarity Index"
+
+ ```python
+ from ultralytics import Explorer
+
+ exp = Explorer()
+ exp.create_embeddings_table()
+
+ sim_idx = exp.similarity_index()
+ ```
+
+You can use similarity index to build custom conditions to filter out the dataset. For example, you can filter out images that are not similar to any other image in the dataset using the following code:
+
+```python
+import numpy as np
+
+sim_count = np.array(sim_idx["count"])
+sim_idx["im_file"][sim_count > 30]
+```
+
+### Visualize Embedding Space
+
+You can also visualize the embedding space using the plotting tool of your choice. For example here is a simple example using matplotlib:
+
+```python
+import matplotlib.pyplot as plt
+from sklearn.decomposition import PCA
+
+# Reduce dimensions using PCA to 3 components for visualization in 3D
+pca = PCA(n_components=3)
+reduced_data = pca.fit_transform(embeddings)
+
+# Create a 3D scatter plot using Matplotlib Axes3D
+fig = plt.figure(figsize=(8, 6))
+ax = fig.add_subplot(111, projection="3d")
+
+# Scatter plot
+ax.scatter(reduced_data[:, 0], reduced_data[:, 1], reduced_data[:, 2], alpha=0.5)
+ax.set_title("3D Scatter Plot of Reduced 256-Dimensional Data (PCA)")
+ax.set_xlabel("Component 1")
+ax.set_ylabel("Component 2")
+ax.set_zlabel("Component 3")
+
+plt.show()
+```
+
+Start creating your own CV dataset exploration reports using the Explorer API. For inspiration, check out the
+
+## Apps Built Using Ultralytics Explorer
+
+Try our GUI Demo based on Explorer API
+
+## Coming Soon
+
+- [ ] Merge specific labels from datasets. Example - Import all `person` labels from COCO and `car` labels from Cityscapes
+- [ ] Remove images that have a higher similarity index than the given threshold
+- [ ] Automatically persist new datasets after merging/removing entries
+- [ ] Advanced Dataset Visualizations
+
+## FAQ
+
+### What is the Ultralytics Explorer API used for?
+
+The Ultralytics Explorer API is designed for comprehensive dataset exploration. It allows users to filter and search datasets using SQL queries, vector similarity search, and semantic search. This powerful Python API can handle large datasets, making it ideal for various computer vision tasks using Ultralytics models.
+
+### How do I install the Ultralytics Explorer API?
+
+To install the Ultralytics Explorer API along with its dependencies, use the following command:
+```bash
+pip install ultralytics[explorer]
+```
+This will automatically install all necessary external libraries for the Explorer API functionality. For additional setup details, refer to the [installation section](#installation) of our documentation.
+
+### How can I use the Ultralytics Explorer API for similarity search?
+
+You can use the Ultralytics Explorer API to perform similarity searches by creating an embeddings table and querying it for similar images. Here's a basic example:
+```python
+from ultralytics import Explorer
+
+# Create an Explorer object
+explorer = Explorer(data="coco128.yaml", model="yolov8n.pt")
+explorer.create_embeddings_table()
+
+# Search for similar images to a given image
+similar_images_df = explorer.get_similar(img="path/to/image.jpg")
+print(similar_images_df.head())
+```
+For more details, please visit the [Similarity Search section](#1-similarity-search).
+
+### What are the benefits of using LanceDB with Ultralytics Explorer?
+
+LanceDB, used under the hood by Ultralytics Explorer, provides scalable, on-disk embeddings tables. This ensures that you can create and reuse embeddings for large datasets like COCO without running out of memory. These tables are only created once and can be reused, enhancing efficiency in data handling.
+
+### How does the Ask AI feature work in the Ultralytics Explorer API?
+
+The Ask AI feature allows users to filter datasets using natural language queries. This feature leverages LLMs to convert these queries into SQL queries behind the scenes. Here's an example:
+
+```python
+from ultralytics import Explorer
+
+# Create an Explorer object
+explorer = Explorer(data="coco128.yaml", model="yolov8n.pt")
+explorer.create_embeddings_table()
+
+# Query with natural language
+query_result = explorer.ask_ai("show me 100 images with exactly one person and 2 dogs. There can be other objects too")
+print(query_result.head())
+```
+
+For more examples, check out the [Ask AI section](#2-ask-ai-natural-language-querying).
diff --git a/ultralytics/docs/en/datasets/explorer/dashboard.md b/ultralytics/docs/en/datasets/explorer/dashboard.md
new file mode 100644
index 0000000000000000000000000000000000000000..e399756154df162cd3f68efe71fd8ac7855a42a1
--- /dev/null
+++ b/ultralytics/docs/en/datasets/explorer/dashboard.md
@@ -0,0 +1,122 @@
+---
+comments: true
+description: Unlock advanced data exploration with Ultralytics Explorer GUI. Utilize semantic search, run SQL queries, and ask AI for natural language data insights.
+keywords: Ultralytics Explorer GUI, semantic search, vector similarity, SQL queries, AI, natural language search, data exploration, machine learning, OpenAI, LLMs
+---
+
+# Explorer GUI
+
+Explorer GUI is like a playground build using [Ultralytics Explorer API](api.md). It allows you to run semantic/vector similarity search, SQL queries and even search using natural language using our ask AI feature powered by LLMs.
+
+
+
+
+
+
+
+
+
+ Watch: Ultralytics Explorer Dashboard Overview
+
+
+### Installation
+
+```bash
+pip install ultralytics[explorer]
+```
+
+!!! note "Note"
+
+ Ask AI feature works using OpenAI, so you'll be prompted to set the api key for OpenAI when you first run the GUI.
+ You can set it like this - `yolo settings openai_api_key="..."`
+
+## Vector Semantic Similarity Search
+
+Semantic search is a technique for finding similar images to a given image. It is based on the idea that similar images will have similar embeddings. In the UI, you can select one of more images and search for the images similar to them. This can be useful when you want to find images similar to a given image or a set of images that don't perform as expected.
+
+For example:
+In this VOC Exploration dashboard, user selects a couple airplane images like this:
+
+
+
+
+On performing similarity search, you should see a similar result:
+
+
+
+
+## Ask AI
+
+This allows you to write how you want to filter your dataset using natural language. You don't have to be proficient in writing SQL queries. Our AI powered query generator will automatically do that under the hood. For example - you can say - "show me 100 images with exactly one person and 2 dogs. There can be other objects too" and it'll internally generate the query and show you those results. Here's an example output when asked to "Show 10 images with exactly 5 persons" and you'll see a result like this:
+
+
+
+
+Note: This works using LLMs under the hood so the results are probabilistic and might get things wrong sometimes
+
+## Run SQL queries on your CV datasets
+
+You can run SQL queries on your dataset to filter it. It also works if you only provide the WHERE clause. Example SQL query would show only the images that have at least one 1 person and 1 dog in them:
+
+```sql
+WHERE labels LIKE '%person%' AND labels LIKE '%dog%'
+```
+
+
+
+
+
+This is a Demo build using the Explorer API. You can use the API to build your own exploratory notebooks or scripts to get insights into your datasets. Learn more about the Explorer API [here](api.md).
+
+## FAQ
+
+### What is Ultralytics Explorer GUI and how do I install it?
+
+Ultralytics Explorer GUI is a powerful interface that unlocks advanced data exploration capabilities using the [Ultralytics Explorer API](api.md). It allows you to run semantic/vector similarity search, SQL queries, and natural language queries using the Ask AI feature powered by Large Language Models (LLMs).
+
+To install the Explorer GUI, you can use pip:
+
+```bash
+pip install ultralytics[explorer]
+```
+
+Note: To use the Ask AI feature, you'll need to set the OpenAI API key: `yolo settings openai_api_key="..."`.
+
+### How does the semantic search feature in Ultralytics Explorer GUI work?
+
+The semantic search feature in Ultralytics Explorer GUI allows you to find images similar to a given image based on their embeddings. This technique is useful for identifying and exploring images that share visual similarities. To use this feature, select one or more images in the UI and execute a search for similar images. The result will display images that closely resemble the selected ones, facilitating efficient dataset exploration and anomaly detection.
+
+Learn more about semantic search and other features by visiting the [Feature Overview](#vector-semantic-similarity-search) section.
+
+### Can I use natural language to filter datasets in Ultralytics Explorer GUI?
+
+Yes, with the Ask AI feature powered by large language models (LLMs), you can filter your datasets using natural language queries. You don't need to be proficient in SQL. For instance, you can ask "Show me 100 images with exactly one person and 2 dogs. There can be other objects too," and the AI will generate the appropriate query under the hood to deliver the desired results.
+
+See an example of a natural language query [here](#ask-ai).
+
+### How do I run SQL queries on datasets using Ultralytics Explorer GUI?
+
+Ultralytics Explorer GUI allows you to run SQL queries directly on your dataset to filter and manage data efficiently. To run a query, navigate to the SQL query section in the GUI and write your query. For example, to show images with at least one person and one dog, you could use:
+
+```sql
+WHERE labels LIKE '%person%' AND labels LIKE '%dog%'
+```
+
+You can also provide only the WHERE clause, making the querying process more flexible.
+
+For more details, refer to the [SQL Queries Section](#run-sql-queries-on-your-cv-datasets).
+
+### What are the benefits of using Ultralytics Explorer GUI for data exploration?
+
+Ultralytics Explorer GUI enhances data exploration with features like semantic search, SQL querying, and natural language interactions through the Ask AI feature. These capabilities allow users to:
+- Efficiently find visually similar images.
+- Filter datasets using complex SQL queries.
+- Utilize AI to perform natural language searches, eliminating the need for advanced SQL expertise.
+
+These features make it a versatile tool for developers, researchers, and data scientists looking to gain deeper insights into their datasets.
+
+Explore more about these features in the [Explorer GUI Documentation](#explorer-gui).
diff --git a/ultralytics/docs/en/datasets/explorer/explorer.ipynb b/ultralytics/docs/en/datasets/explorer/explorer.ipynb
new file mode 100644
index 0000000000000000000000000000000000000000..0980d878f53ba8fb1bf87110adf5a1ab9aa2b546
--- /dev/null
+++ b/ultralytics/docs/en/datasets/explorer/explorer.ipynb
@@ -0,0 +1,601 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "aa923c26-81c8-4565-9277-1cb686e3702e",
+ "metadata": {
+ "id": "aa923c26-81c8-4565-9277-1cb686e3702e"
+ },
+ "source": [
+ "# VOC Exploration Example\n",
+ "
\n",
+ "\n",
+ " \n",
+ " \n",
+ "\n",
+ " [中文](https://docs.ultralytics.com/zh/) | [한국어](https://docs.ultralytics.com/ko/) | [日本語](https://docs.ultralytics.com/ja/) | [Русский](https://docs.ultralytics.com/ru/) | [Deutsch](https://docs.ultralytics.com/de/) | [Français](https://docs.ultralytics.com/fr/) | [Español](https://docs.ultralytics.com/es/) | [Português](https://docs.ultralytics.com/pt/) | [Türkçe](https://docs.ultralytics.com/tr/) | [Tiếng Việt](https://docs.ultralytics.com/vi/) | [العربية](https://docs.ultralytics.com/ar/)\n",
+ "\n",
+ " \n",
+ " \n",
+ " \n",
+ "\n",
+ "Welcome to the Ultralytics Explorer API notebook! This notebook serves as the starting point for exploring the various resources available to help you get started with using Ultralytics to explore your datasets using with the power of semantic search. You can utilities out of the box that allow you to examine specific types of labels using vector search or even SQL queries.\n",
+ "\n",
+ "We hope that the resources in this notebook will help you get the most out of Ultralytics. Please browse the Explorer Docs for details, raise an issue on GitHub for support, and join our Discord community for questions and discussions!\n",
+ "\n",
+ "Try `yolo explorer` powered by Exlorer API\n",
+ "\n",
+ "Simply `pip install ultralytics` and run `yolo explorer` in your terminal to run custom queries and semantic search on your datasets right inside your browser!\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2454d9ba-9db4-4b37-98e8-201ba285c92f",
+ "metadata": {
+ "id": "2454d9ba-9db4-4b37-98e8-201ba285c92f"
+ },
+ "source": [
+ "## Setup\n",
+ "Pip install `ultralytics` and [dependencies](https://github.com/ultralytics/ultralytics/blob/main/pyproject.toml) and check software and hardware."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "433f3a4d-a914-42cb-b0b6-be84a84e5e41",
+ "metadata": {
+ "id": "433f3a4d-a914-42cb-b0b6-be84a84e5e41"
+ },
+ "outputs": [],
+ "source": [
+ "%pip install ultralytics[explorer] openai\n",
+ "import ultralytics\n",
+ "ultralytics.checks()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ae602549-3419-4909-9f82-35cba515483f",
+ "metadata": {
+ "id": "ae602549-3419-4909-9f82-35cba515483f"
+ },
+ "outputs": [],
+ "source": [
+ "from ultralytics import Explorer"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d8c06350-be8e-45cf-b3a6-b5017bbd943c",
+ "metadata": {
+ "id": "d8c06350-be8e-45cf-b3a6-b5017bbd943c"
+ },
+ "source": [
+ "## Similarity search\n",
+ "Utilize the power of vector similarity search to find the similar data points in your dataset along with their distance in the embedding space. Simply create an embeddings table for the given dataset-model pair. It is only needed once and it is reused automatically.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "334619da-6deb-4b32-9fe0-74e0a79cee20",
+ "metadata": {
+ "id": "334619da-6deb-4b32-9fe0-74e0a79cee20"
+ },
+ "outputs": [],
+ "source": [
+ "exp = Explorer(\"VOC.yaml\", model=\"yolov8n.pt\")\n",
+ "exp.create_embeddings_table()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b6c5e42d-bc7e-4b4c-bde0-643072a2165d",
+ "metadata": {
+ "id": "b6c5e42d-bc7e-4b4c-bde0-643072a2165d"
+ },
+ "source": [
+ "One the embeddings table is built, you can get run semantic search in any of the following ways:\n",
+ "- On a given index / list of indices in the dataset like - `exp.get_similar(idx=[1,10], limit=10)`\n",
+ "- On any image/ list of images not in the dataset - `exp.get_similar(img=[\"path/to/img1\", \"path/to/img2\"], limit=10)`\n",
+ "In case of multiple inputs, the aggregade of their embeddings is used.\n",
+ "\n",
+ "You get a pandas dataframe with the `limit` number of most similar data points to the input, along with their distance in the embedding space. You can use this dataset to perform further filtering\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b485f05b-d92d-42bc-8da7-5e361667b341",
+ "metadata": {
+ "id": "b485f05b-d92d-42bc-8da7-5e361667b341"
+ },
+ "outputs": [],
+ "source": [
+ "similar = exp.get_similar(idx=1, limit=10)\n",
+ "similar.head()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "acf4b489-2161-4176-a1fe-d1d067d8083d",
+ "metadata": {
+ "id": "acf4b489-2161-4176-a1fe-d1d067d8083d"
+ },
+ "source": [
+ "You can use the also plot the similar samples directly using the `plot_similar` util\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0cea63f1-71f1-46da-af2b-b1b7d8f73553",
+ "metadata": {
+ "id": "0cea63f1-71f1-46da-af2b-b1b7d8f73553"
+ },
+ "source": [
+ "## 2. Ask AI: Search or filter with Natural Language\n",
+ "You can prompt the Explorer object with the kind of data points you want to see and it'll try to return a dataframe with those. Because it is powered by LLMs, it doesn't always get it right. In that case, it'll return None.\n",
+ "
\n",
+ "\n",
+ "\n",
+ "
\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "92fb92ac-7f76-465a-a9ba-ea7492498d9c",
+ "metadata": {
+ "id": "92fb92ac-7f76-465a-a9ba-ea7492498d9c"
+ },
+ "outputs": [],
+ "source": [
+ "df = exp.ask_ai(\"show me images containing more than 10 objects with at least 2 persons\")\n",
+ "df.head(5)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f2a7d26e-0ce5-4578-ad1a-b1253805280f",
+ "metadata": {
+ "id": "f2a7d26e-0ce5-4578-ad1a-b1253805280f"
+ },
+ "source": [
+ "for plotting these results you can use `plot_query_result` util\n",
+ "Example:\n",
+ "```\n",
+ "plt = plot_query_result(exp.ask_ai(\"show me 10 images containing exactly 2 persons\"))\n",
+ "Image.fromarray(plt)\n",
+ "```\n",
+ "
\n",
+ " \n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b1cfab84-9835-4da0-8e9a-42b30cf84511",
+ "metadata": {
+ "id": "b1cfab84-9835-4da0-8e9a-42b30cf84511"
+ },
+ "outputs": [],
+ "source": [
+ "# plot\n",
+ "from ultralytics.data.explorer import plot_query_result\n",
+ "from PIL import Image\n",
+ "\n",
+ "plt = plot_query_result(exp.ask_ai(\"show me 10 images containing exactly 2 persons\"))\n",
+ "Image.fromarray(plt)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "35315ae6-d827-40e4-8813-279f97a83b34",
+ "metadata": {
+ "id": "35315ae6-d827-40e4-8813-279f97a83b34"
+ },
+ "source": [
+ "## 3. Run SQL queries on your Dataset!\n",
+ "Sometimes you might want to investigate a certain type of entries in your dataset. For this Explorer allows you to execute SQL queries.\n",
+ "It accepts either of the formats:\n",
+ "- Queries beginning with \"WHERE\" will automatically select all columns. This can be thought of as a short-hand query\n",
+ "- You can also write full queries where you can specify which columns to select\n",
+ "\n",
+ "This can be used to investigate model performance and specific data points. For example:\n",
+ "- let's say your model struggles on images that have humans and dogs. You can write a query like this to select the points that have at least 2 humans AND at least one dog.\n",
+ "\n",
+ "You can combine SQL query and semantic search to filter down to specific type of results\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8cd1072f-3100-4331-a0e3-4e2f6b1005bf",
+ "metadata": {
+ "id": "8cd1072f-3100-4331-a0e3-4e2f6b1005bf"
+ },
+ "outputs": [],
+ "source": [
+ "table = exp.sql_query(\"WHERE labels LIKE '%person, person%' AND labels LIKE '%dog%' LIMIT 10\")\n",
+ "table"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "debf8a00-c9f6-448b-bd3b-454cf62f39ab",
+ "metadata": {
+ "id": "debf8a00-c9f6-448b-bd3b-454cf62f39ab"
+ },
+ "source": [
+ "Just like similarity search, you also get a util to directly plot the sql queries using `exp.plot_sql_query`\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "18b977e7-d048-4b22-b8c4-084a03b04f23",
+ "metadata": {
+ "id": "18b977e7-d048-4b22-b8c4-084a03b04f23"
+ },
+ "outputs": [],
+ "source": [
+ "exp.plot_sql_query(\"WHERE labels LIKE '%person, person%' AND labels LIKE '%dog%' LIMIT 10\", labels=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f26804c5-840b-4fd1-987f-e362f29e3e06",
+ "metadata": {
+ "id": "f26804c5-840b-4fd1-987f-e362f29e3e06"
+ },
+ "source": [
+ "## 3. Working with embeddings Table (Advanced)\n",
+ "Explorer works on [LanceDB](https://lancedb.github.io/lancedb/) tables internally. You can access this table directly, using `Explorer.table` object and run raw queries, push down pre and post filters, etc."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ea69260a-3407-40c9-9f42-8b34a6e6af7a",
+ "metadata": {
+ "id": "ea69260a-3407-40c9-9f42-8b34a6e6af7a"
+ },
+ "outputs": [],
+ "source": [
+ "table = exp.table\n",
+ "table.schema"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "238db292-8610-40b3-9af7-dfd6be174892",
+ "metadata": {
+ "id": "238db292-8610-40b3-9af7-dfd6be174892"
+ },
+ "source": [
+ "### Run raw queries\n",
+ "Vector Search finds the nearest vectors from the database. In a recommendation system or search engine, you can find similar products from the one you searched. In LLM and other AI applications, each data point can be presented by the embeddings generated from some models, it returns the most relevant features.\n",
+ "\n",
+ "A search in high-dimensional vector space, is to find K-Nearest-Neighbors (KNN) of the query vector.\n",
+ "\n",
+ "Metric\n",
+ "In LanceDB, a Metric is the way to describe the distance between a pair of vectors. Currently, it supports the following metrics:\n",
+ "- L2\n",
+ "- Cosine\n",
+ "- Dot\n",
+ "Explorer's similarity search uses L2 by default. You can run queries on tables directly, or use the lance format to build custom utilities to manage datasets. More details on available LanceDB table ops in the [docs](https://lancedb.github.io/lancedb/)\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d74430fe-5aee-45a1-8863-3f2c31338792",
+ "metadata": {
+ "id": "d74430fe-5aee-45a1-8863-3f2c31338792"
+ },
+ "outputs": [],
+ "source": [
+ "dummy_img_embedding = [i for i in range(256)]\n",
+ "table.search(dummy_img_embedding).limit(5).to_pandas()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "587486b4-0d19-4214-b994-f032fb2e8eb5",
+ "metadata": {
+ "id": "587486b4-0d19-4214-b994-f032fb2e8eb5"
+ },
+ "source": [
+ "### Inter-conversion to popular data formats"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "bb2876ea-999b-4eba-96bc-c196ba02c41c",
+ "metadata": {
+ "id": "bb2876ea-999b-4eba-96bc-c196ba02c41c"
+ },
+ "outputs": [],
+ "source": [
+ "df = table.to_pandas()\n",
+ "pa_table = table.to_arrow()\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "42659d63-ad76-49d6-8dfc-78d77278db72",
+ "metadata": {
+ "id": "42659d63-ad76-49d6-8dfc-78d77278db72"
+ },
+ "source": [
+ "### Work with Embeddings\n",
+ "You can access the raw embedding from lancedb Table and analyse it. The image embeddings are stored in column `vector`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "66d69e9b-046e-41c8-80d7-c0ee40be3bca",
+ "metadata": {
+ "id": "66d69e9b-046e-41c8-80d7-c0ee40be3bca"
+ },
+ "outputs": [],
+ "source": [
+ "import numpy as np\n",
+ "\n",
+ "embeddings = table.to_pandas()[\"vector\"].tolist()\n",
+ "embeddings = np.array(embeddings)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e8df0a49-9596-4399-954b-b8ae1fd7a602",
+ "metadata": {
+ "id": "e8df0a49-9596-4399-954b-b8ae1fd7a602"
+ },
+ "source": [
+ "### Scatterplot\n",
+ "One of the preliminary steps in analysing embeddings is by plotting them in 2D space via dimensionality reduction. Let's try an example\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d9a150e8-8092-41b3-82f8-2247f8187fc8",
+ "metadata": {
+ "id": "d9a150e8-8092-41b3-82f8-2247f8187fc8"
+ },
+ "outputs": [],
+ "source": [
+ "!pip install scikit-learn --q"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "196079c3-45a9-4325-81ab-af79a881e37a",
+ "metadata": {
+ "id": "196079c3-45a9-4325-81ab-af79a881e37a"
+ },
+ "outputs": [],
+ "source": [
+ "%matplotlib inline\n",
+ "import numpy as np\n",
+ "from sklearn.decomposition import PCA\n",
+ "import matplotlib.pyplot as plt\n",
+ "from mpl_toolkits.mplot3d import Axes3D\n",
+ "\n",
+ "# Reduce dimensions using PCA to 3 components for visualization in 3D\n",
+ "pca = PCA(n_components=3)\n",
+ "reduced_data = pca.fit_transform(embeddings)\n",
+ "\n",
+ "# Create a 3D scatter plot using Matplotlib's Axes3D\n",
+ "fig = plt.figure(figsize=(8, 6))\n",
+ "ax = fig.add_subplot(111, projection='3d')\n",
+ "\n",
+ "# Scatter plot\n",
+ "ax.scatter(reduced_data[:, 0], reduced_data[:, 1], reduced_data[:, 2], alpha=0.5)\n",
+ "ax.set_title('3D Scatter Plot of Reduced 256-Dimensional Data (PCA)')\n",
+ "ax.set_xlabel('Component 1')\n",
+ "ax.set_ylabel('Component 2')\n",
+ "ax.set_zlabel('Component 3')\n",
+ "\n",
+ "plt.show()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1c843c23-e3f2-490e-8d6c-212fa038a149",
+ "metadata": {
+ "id": "1c843c23-e3f2-490e-8d6c-212fa038a149"
+ },
+ "source": [
+ "## 4. Similarity Index\n",
+ "Here's a simple example of an operation powered by the embeddings table. Explorer comes with a `similarity_index` operation-\n",
+ "* It tries to estimate how similar each data point is with the rest of the dataset.\n",
+ "* It does that by counting how many image embeddings lie closer than `max_dist` to the current image in the generated embedding space, considering `top_k` similar images at a time.\n",
+ "\n",
+ "For a given dataset, model, `max_dist` & `top_k` the similarity index once generated will be reused. In case, your dataset has changed, or you simply need to regenerate the similarity index, you can pass `force=True`.\n",
+ "Similar to vector and SQL search, this also comes with a util to directly plot it. Let's look at the plot first\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "953c2a5f-1b61-4acf-a8e4-ed08547dbafc",
+ "metadata": {
+ "id": "953c2a5f-1b61-4acf-a8e4-ed08547dbafc"
+ },
+ "outputs": [],
+ "source": [
+ "exp.plot_similarity_index(max_dist=0.2, top_k=0.01)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "28228a9a-b727-45b5-8ca7-8db662c0b937",
+ "metadata": {
+ "id": "28228a9a-b727-45b5-8ca7-8db662c0b937"
+ },
+ "source": [
+ "Now let's look at the output of the operation"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f4161aaa-20e6-4df0-8e87-d2293ee0530a",
+ "metadata": {
+ "id": "f4161aaa-20e6-4df0-8e87-d2293ee0530a"
+ },
+ "outputs": [],
+ "source": [
+ "import numpy as np\n",
+ "\n",
+ "sim_idx = exp.similarity_index(max_dist=0.2, top_k=0.01, force=False)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b01d5b1a-9adb-4c3c-a873-217c71527c8d",
+ "metadata": {
+ "id": "b01d5b1a-9adb-4c3c-a873-217c71527c8d"
+ },
+ "outputs": [],
+ "source": [
+ "sim_idx"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "22b28e54-4fbb-400e-ad8c-7068cbba11c4",
+ "metadata": {
+ "id": "22b28e54-4fbb-400e-ad8c-7068cbba11c4"
+ },
+ "source": [
+ "Let's create a query to see what data points have similarity count of more than 30 and plot images similar to them."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "58d2557b-d401-43cf-937d-4f554c7bc808",
+ "metadata": {
+ "id": "58d2557b-d401-43cf-937d-4f554c7bc808"
+ },
+ "outputs": [],
+ "source": [
+ "import numpy as np\n",
+ "\n",
+ "sim_count = np.array(sim_idx[\"count\"])\n",
+ "sim_idx['im_file'][sim_count > 30]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a5ec8d76-271a-41ab-ac74-cf8c0084ba5e",
+ "metadata": {
+ "id": "a5ec8d76-271a-41ab-ac74-cf8c0084ba5e"
+ },
+ "source": [
+ "You should see something like this\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3a7b2ee3-9f35-48a2-9c38-38379516f4d2",
+ "metadata": {
+ "id": "3a7b2ee3-9f35-48a2-9c38-38379516f4d2"
+ },
+ "outputs": [],
+ "source": [
+ "exp.plot_similar(idx=[7146, 14035]) # Using avg embeddings of 2 images"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.9.6"
+ },
+ "colab": {
+ "provenance": []
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/ultralytics/docs/en/datasets/explorer/index.md b/ultralytics/docs/en/datasets/explorer/index.md
new file mode 100644
index 0000000000000000000000000000000000000000..111e398ef83df82c1ee5b2c9553e314caeb04ece
--- /dev/null
+++ b/ultralytics/docs/en/datasets/explorer/index.md
@@ -0,0 +1,108 @@
+---
+comments: true
+description: Discover Ultralytics Explorer for semantic search, SQL queries, vector similarity, and natural language dataset exploration. Enhance your CV datasets effortlessly.
+keywords: Ultralytics Explorer, CV datasets, semantic search, SQL queries, vector similarity, dataset visualization, python API, machine learning, computer vision
+---
+
+# Ultralytics Explorer
+
+
+
+
+
+
+Ultralytics Explorer is a tool for exploring CV datasets using semantic search, SQL queries, vector similarity search and even using natural language. It is also a Python API for accessing the same functionality.
+
+
+
+
+
+ Watch: Ultralytics Explorer API | Semantic Search, SQL Queries & Ask AI Features
+
+
+### Installation of optional dependencies
+
+Explorer depends on external libraries for some of its functionality. These are automatically installed on usage. To manually install these dependencies, use the following command:
+
+```bash
+pip install ultralytics[explorer]
+```
+
+!!! tip
+
+ Explorer works on embedding/semantic search & SQL querying and is powered by [LanceDB](https://lancedb.com/) serverless vector database. Unlike traditional in-memory DBs, it is persisted on disk without sacrificing performance, so you can scale locally to large datasets like COCO without running out of memory.
+
+### Explorer API
+
+This is a Python API for Exploring your datasets. It also powers the GUI Explorer. You can use this to create your own exploratory notebooks or scripts to get insights into your datasets.
+
+Learn more about the Explorer API [here](api.md).
+
+## GUI Explorer Usage
+
+The GUI demo runs in your browser allowing you to create embeddings for your dataset and search for similar images, run SQL queries and perform semantic search. It can be run using the following command:
+
+```bash
+yolo explorer
+```
+
+!!! note "Note"
+
+ Ask AI feature works using OpenAI, so you'll be prompted to set the api key for OpenAI when you first run the GUI.
+ You can set it like this - `yolo settings openai_api_key="..."`
+
+
+
+
+
+## FAQ
+
+### What is Ultralytics Explorer and how can it help with CV datasets?
+
+Ultralytics Explorer is a powerful tool designed for exploring computer vision (CV) datasets through semantic search, SQL queries, vector similarity search, and even natural language. This versatile tool provides both a GUI and a Python API, allowing users to seamlessly interact with their datasets. By leveraging technologies like LanceDB, Ultralytics Explorer ensures efficient, scalable access to large datasets without excessive memory usage. Whether you're performing detailed dataset analysis or exploring data patterns, Ultralytics Explorer streamlines the entire process.
+
+Learn more about the [Explorer API](api.md).
+
+### How do I install the dependencies for Ultralytics Explorer?
+
+To manually install the optional dependencies needed for Ultralytics Explorer, you can use the following `pip` command:
+
+```bash
+pip install ultralytics[explorer]
+```
+
+These dependencies are essential for the full functionality of semantic search and SQL querying. By including libraries powered by [LanceDB](https://lancedb.com/), the installation ensures that the database operations remain efficient and scalable, even for large datasets like COCO.
+
+### How can I use the GUI version of Ultralytics Explorer?
+
+Using the GUI version of Ultralytics Explorer is straightforward. After installing the necessary dependencies, you can launch the GUI with the following command:
+
+```bash
+yolo explorer
+```
+
+The GUI provides a user-friendly interface for creating dataset embeddings, searching for similar images, running SQL queries, and conducting semantic searches. Additionally, the integration with OpenAI's Ask AI feature allows you to query datasets using natural language, enhancing the flexibility and ease of use.
+
+For storage and scalability information, check out our [installation instructions](#installation-of-optional-dependencies).
+
+### What is the Ask AI feature in Ultralytics Explorer?
+
+The Ask AI feature in Ultralytics Explorer allows users to interact with their datasets using natural language queries. Powered by OpenAI, this feature enables you to ask complex questions and receive insightful answers without needing to write SQL queries or similar commands. To use this feature, you'll need to set your OpenAI API key the first time you run the GUI:
+
+```bash
+yolo settings openai_api_key="YOUR_API_KEY"
+```
+
+For more on this feature and how to integrate it, see our [GUI Explorer Usage](#gui-explorer-usage) section.
+
+### Can I run Ultralytics Explorer in Google Colab?
+
+Yes, Ultralytics Explorer can be run in Google Colab, providing a convenient and powerful environment for dataset exploration. You can start by opening the provided Colab notebook, which is pre-configured with all the necessary settings:
+
+
+
+This setup allows you to explore your datasets fully, taking advantage of Google's cloud resources. Learn more in our [Google Colab Guide](../../integrations/google-colab.md).
diff --git a/ultralytics/docs/en/datasets/index.md b/ultralytics/docs/en/datasets/index.md
new file mode 100644
index 0000000000000000000000000000000000000000..3f607ec36d18e1b83982650cc45545c60a23309d
--- /dev/null
+++ b/ultralytics/docs/en/datasets/index.md
@@ -0,0 +1,222 @@
+---
+comments: true
+description: Explore Ultralytics' diverse datasets for vision tasks like detection, segmentation, classification, and more. Enhance your projects with high-quality annotated data.
+keywords: Ultralytics, datasets, computer vision, object detection, instance segmentation, pose estimation, image classification, multi-object tracking
+---
+
+# Datasets Overview
+
+Ultralytics provides support for various datasets to facilitate computer vision tasks such as detection, instance segmentation, pose estimation, classification, and multi-object tracking. Below is a list of the main Ultralytics datasets, followed by a summary of each computer vision task and the respective datasets.
+
+
+
+
+
+ Watch: Ultralytics Datasets Overview
+
+
+## NEW 🚀 Ultralytics Explorer
+
+Create embeddings for your dataset, search for similar images, run SQL queries, perform semantic search and even search using natural language! You can get started with our GUI app or build your own using the API. Learn more [here](explorer/index.md).
+
+
+
+
+
+- Try the [GUI Demo](explorer/index.md)
+- Learn more about the [Explorer API](explorer/index.md)
+
+## [Object Detection](detect/index.md)
+
+Bounding box object detection is a computer vision technique that involves detecting and localizing objects in an image by drawing a bounding box around each object.
+
+- [Argoverse](detect/argoverse.md): A dataset containing 3D tracking and motion forecasting data from urban environments with rich annotations.
+- [COCO](detect/coco.md): Common Objects in Context (COCO) is a large-scale object detection, segmentation, and captioning dataset with 80 object categories.
+- [LVIS](detect/lvis.md): A large-scale object detection, segmentation, and captioning dataset with 1203 object categories.
+- [COCO8](detect/coco8.md): A smaller subset of the first 4 images from COCO train and COCO val, suitable for quick tests.
+- [Global Wheat 2020](detect/globalwheat2020.md): A dataset containing images of wheat heads for the Global Wheat Challenge 2020.
+- [Objects365](detect/objects365.md): A high-quality, large-scale dataset for object detection with 365 object categories and over 600K annotated images.
+- [OpenImagesV7](detect/open-images-v7.md): A comprehensive dataset by Google with 1.7M train images and 42k validation images.
+- [SKU-110K](detect/sku-110k.md): A dataset featuring dense object detection in retail environments with over 11K images and 1.7 million bounding boxes.
+- [VisDrone](detect/visdrone.md): A dataset containing object detection and multi-object tracking data from drone-captured imagery with over 10K images and video sequences.
+- [VOC](detect/voc.md): The Pascal Visual Object Classes (VOC) dataset for object detection and segmentation with 20 object classes and over 11K images.
+- [xView](detect/xview.md): A dataset for object detection in overhead imagery with 60 object categories and over 1 million annotated objects.
+- [Roboflow 100](detect/roboflow-100.md): A diverse object detection benchmark with 100 datasets spanning seven imagery domains for comprehensive model evaluation.
+- [Brain-tumor](detect/brain-tumor.md): A dataset for detecting brain tumors includes MRI or CT scan images with details on tumor presence, location, and characteristics.
+- [African-wildlife](detect/african-wildlife.md): A dataset featuring images of African wildlife, including buffalo, elephant, rhino, and zebras.
+- [Signature](detect/signature.md): A dataset featuring images of various documents with annotated signatures, supporting document verification and fraud detection research.
+
+## [Instance Segmentation](segment/index.md)
+
+Instance segmentation is a computer vision technique that involves identifying and localizing objects in an image at the pixel level.
+
+- [COCO](segment/coco.md): A large-scale dataset designed for object detection, segmentation, and captioning tasks with over 200K labeled images.
+- [COCO8-seg](segment/coco8-seg.md): A smaller dataset for instance segmentation tasks, containing a subset of 8 COCO images with segmentation annotations.
+- [Crack-seg](segment/crack-seg.md): Specifically crafted dataset for detecting cracks on roads and walls, applicable for both object detection and segmentation tasks.
+- [Package-seg](segment/package-seg.md): Tailored dataset for identifying packages in warehouses or industrial settings, suitable for both object detection and segmentation applications.
+- [Carparts-seg](segment/carparts-seg.md): Purpose-built dataset for identifying vehicle parts, catering to design, manufacturing, and research needs. It serves for both object detection and segmentation tasks.
+
+## [Pose Estimation](pose/index.md)
+
+Pose estimation is a technique used to determine the pose of the object relative to the camera or the world coordinate system.
+
+- [COCO](pose/coco.md): A large-scale dataset with human pose annotations designed for pose estimation tasks.
+- [COCO8-pose](pose/coco8-pose.md): A smaller dataset for pose estimation tasks, containing a subset of 8 COCO images with human pose annotations.
+- [Tiger-pose](pose/tiger-pose.md): A compact dataset consisting of 263 images focused on tigers, annotated with 12 keypoints per tiger for pose estimation tasks.
+
+## [Classification](classify/index.md)
+
+Image classification is a computer vision task that involves categorizing an image into one or more predefined classes or categories based on its visual content.
+
+- [Caltech 101](classify/caltech101.md): A dataset containing images of 101 object categories for image classification tasks.
+- [Caltech 256](classify/caltech256.md): An extended version of Caltech 101 with 256 object categories and more challenging images.
+- [CIFAR-10](classify/cifar10.md): A dataset of 60K 32x32 color images in 10 classes, with 6K images per class.
+- [CIFAR-100](classify/cifar100.md): An extended version of CIFAR-10 with 100 object categories and 600 images per class.
+- [Fashion-MNIST](classify/fashion-mnist.md): A dataset consisting of 70,000 grayscale images of 10 fashion categories for image classification tasks.
+- [ImageNet](classify/imagenet.md): A large-scale dataset for object detection and image classification with over 14 million images and 20,000 categories.
+- [ImageNet-10](classify/imagenet10.md): A smaller subset of ImageNet with 10 categories for faster experimentation and testing.
+- [Imagenette](classify/imagenette.md): A smaller subset of ImageNet that contains 10 easily distinguishable classes for quicker training and testing.
+- [Imagewoof](classify/imagewoof.md): A more challenging subset of ImageNet containing 10 dog breed categories for image classification tasks.
+- [MNIST](classify/mnist.md): A dataset of 70,000 grayscale images of handwritten digits for image classification tasks.
+
+## [Oriented Bounding Boxes (OBB)](obb/index.md)
+
+Oriented Bounding Boxes (OBB) is a method in computer vision for detecting angled objects in images using rotated bounding boxes, often applied to aerial and satellite imagery.
+
+- [DOTA-v2](obb/dota-v2.md): A popular OBB aerial imagery dataset with 1.7 million instances and 11,268 images.
+
+## [Multi-Object Tracking](track/index.md)
+
+Multi-object tracking is a computer vision technique that involves detecting and tracking multiple objects over time in a video sequence.
+
+- [Argoverse](detect/argoverse.md): A dataset containing 3D tracking and motion forecasting data from urban environments with rich annotations for multi-object tracking tasks.
+- [VisDrone](detect/visdrone.md): A dataset containing object detection and multi-object tracking data from drone-captured imagery with over 10K images and video sequences.
+
+## Contribute New Datasets
+
+Contributing a new dataset involves several steps to ensure that it aligns well with the existing infrastructure. Below are the necessary steps:
+
+### Steps to Contribute a New Dataset
+
+1. **Collect Images**: Gather the images that belong to the dataset. These could be collected from various sources, such as public databases or your own collection.
+2. **Annotate Images**: Annotate these images with bounding boxes, segments, or keypoints, depending on the task.
+3. **Export Annotations**: Convert these annotations into the YOLO `*.txt` file format which Ultralytics supports.
+4. **Organize Dataset**: Arrange your dataset into the correct folder structure. You should have `train/` and `val/` top-level directories, and within each, an `images/` and `labels/` subdirectory.
+
+ ```
+ dataset/
+ ├── train/
+ │ ├── images/
+ │ └── labels/
+ └── val/
+ ├── images/
+ └── labels/
+ ```
+
+5. **Create a `data.yaml` File**: In your dataset's root directory, create a `data.yaml` file that describes the dataset, classes, and other necessary information.
+6. **Optimize Images (Optional)**: If you want to reduce the size of the dataset for more efficient processing, you can optimize the images using the code below. This is not required, but recommended for smaller dataset sizes and faster download speeds.
+7. **Zip Dataset**: Compress the entire dataset folder into a zip file.
+8. **Document and PR**: Create a documentation page describing your dataset and how it fits into the existing framework. After that, submit a Pull Request (PR). Refer to [Ultralytics Contribution Guidelines](https://docs.ultralytics.com/help/contributing) for more details on how to submit a PR.
+
+### Example Code to Optimize and Zip a Dataset
+
+!!! Example "Optimize and Zip a Dataset"
+
+ === "Python"
+
+ ```python
+ from pathlib import Path
+
+ from ultralytics.data.utils import compress_one_image
+ from ultralytics.utils.downloads import zip_directory
+
+ # Define dataset directory
+ path = Path("path/to/dataset")
+
+ # Optimize images in dataset (optional)
+ for f in path.rglob("*.jpg"):
+ compress_one_image(f)
+
+ # Zip dataset into 'path/to/dataset.zip'
+ zip_directory(path)
+ ```
+
+By following these steps, you can contribute a new dataset that integrates well with Ultralytics' existing structure.
+
+## FAQ
+
+### What datasets does Ultralytics support for object detection?
+
+Ultralytics supports a wide variety of datasets for object detection, including:
+- [COCO](detect/coco.md): A large-scale object detection, segmentation, and captioning dataset with 80 object categories.
+- [LVIS](detect/lvis.md): An extensive dataset with 1203 object categories, designed for more fine-grained object detection and segmentation.
+- [Argoverse](detect/argoverse.md): A dataset containing 3D tracking and motion forecasting data from urban environments with rich annotations.
+- [VisDrone](detect/visdrone.md): A dataset with object detection and multi-object tracking data from drone-captured imagery.
+- [SKU-110K](detect/sku-110k.md): Featuring dense object detection in retail environments with over 11K images.
+
+These datasets facilitate training robust models for various object detection applications.
+
+### How do I contribute a new dataset to Ultralytics?
+
+Contributing a new dataset involves several steps:
+1. **Collect Images**: Gather images from public databases or personal collections.
+2. **Annotate Images**: Apply bounding boxes, segments, or keypoints, depending on the task.
+3. **Export Annotations**: Convert annotations into the YOLO `*.txt` format.
+4. **Organize Dataset**: Use the folder structure with `train/` and `val/` directories, each containing `images/` and `labels/` subdirectories.
+5. **Create a `data.yaml` File**: Include dataset descriptions, classes, and other relevant information.
+6. **Optimize Images (Optional)**: Reduce dataset size for efficiency.
+7. **Zip Dataset**: Compress the dataset into a zip file.
+8. **Document and PR**: Describe your dataset and submit a Pull Request following [Ultralytics Contribution Guidelines](https://docs.ultralytics.com/help/contributing).
+
+Visit [Contribute New Datasets](#contribute-new-datasets) for a comprehensive guide.
+
+### Why should I use Ultralytics Explorer for my dataset?
+
+Ultralytics Explorer offers powerful features for dataset analysis, including:
+- **Embeddings Generation**: Create vector embeddings for images.
+- **Semantic Search**: Search for similar images using embeddings or AI.
+- **SQL Queries**: Run advanced SQL queries for detailed data analysis.
+- **Natural Language Search**: Search using plain language queries for ease of use.
+
+Explore the [Ultralytics Explorer](explorer/index.md) for more information and to try the [GUI Demo](explorer/index.md).
+
+### What are the unique features of Ultralytics YOLO models for computer vision?
+
+Ultralytics YOLO models provide several unique features:
+- **Real-time Performance**: High-speed inference and training.
+- **Versatility**: Suitable for detection, segmentation, classification, and pose estimation tasks.
+- **Pretrained Models**: Access to high-performing, pretrained models for various applications.
+- **Extensive Community Support**: Active community and comprehensive documentation for troubleshooting and development.
+
+Discover more about YOLO on the [Ultralytics YOLO](https://www.ultralytics.com/yolo) page.
+
+### How can I optimize and zip a dataset using Ultralytics tools?
+
+To optimize and zip a dataset using Ultralytics tools, follow this example code:
+
+!!! Example "Optimize and Zip a Dataset"
+
+ === "Python"
+
+ ```python
+ from pathlib import Path
+
+ from ultralytics.data.utils import compress_one_image
+ from ultralytics.utils.downloads import zip_directory
+
+ # Define dataset directory
+ path = Path("path/to/dataset")
+
+ # Optimize images in dataset (optional)
+ for f in path.rglob("*.jpg"):
+ compress_one_image(f)
+
+ # Zip dataset into 'path/to/dataset.zip'
+ zip_directory(path)
+ ```
+
+Learn more on how to [Optimize and Zip a Dataset](#example-code-to-optimize-and-zip-a-dataset).
diff --git a/ultralytics/docs/en/datasets/obb/dota-v2.md b/ultralytics/docs/en/datasets/obb/dota-v2.md
new file mode 100644
index 0000000000000000000000000000000000000000..e2cd229a4cb17e1e1dd3a7367448a4ab95232121
--- /dev/null
+++ b/ultralytics/docs/en/datasets/obb/dota-v2.md
@@ -0,0 +1,232 @@
+---
+comments: true
+description: Explore the DOTA dataset for object detection in aerial images, featuring 1.7M Oriented Bounding Boxes across 18 categories. Ideal for aerial image analysis.
+keywords: DOTA dataset, object detection, aerial images, oriented bounding boxes, OBB, DOTA v1.0, DOTA v1.5, DOTA v2.0, multiscale detection, Ultralytics
+---
+
+# DOTA Dataset with OBB
+
+[DOTA](https://captain-whu.github.io/DOTA/index.html) stands as a specialized dataset, emphasizing object detection in aerial images. Originating from the DOTA series of datasets, it offers annotated images capturing a diverse array of aerial scenes with Oriented Bounding Boxes (OBB).
+
+
+
+## Key Features
+
+- Collection from various sensors and platforms, with image sizes ranging from 800 × 800 to 20,000 × 20,000 pixels.
+- Features more than 1.7M Oriented Bounding Boxes across 18 categories.
+- Encompasses multiscale object detection.
+- Instances are annotated by experts using arbitrary (8 d.o.f.) quadrilateral, capturing objects of different scales, orientations, and shapes.
+
+## Dataset Versions
+
+### DOTA-v1.0
+
+- Contains 15 common categories.
+- Comprises 2,806 images with 188,282 instances.
+- Split ratios: 1/2 for training, 1/6 for validation, and 1/3 for testing.
+
+### DOTA-v1.5
+
+- Incorporates the same images as DOTA-v1.0.
+- Very small instances (less than 10 pixels) are also annotated.
+- Addition of a new category: "container crane".
+- A total of 403,318 instances.
+- Released for the DOAI Challenge 2019 on Object Detection in Aerial Images.
+
+### DOTA-v2.0
+
+- Collections from Google Earth, GF-2 Satellite, and other aerial images.
+- Contains 18 common categories.
+- Comprises 11,268 images with a whopping 1,793,658 instances.
+- New categories introduced: "airport" and "helipad".
+- Image splits:
+ - Training: 1,830 images with 268,627 instances.
+ - Validation: 593 images with 81,048 instances.
+ - Test-dev: 2,792 images with 353,346 instances.
+ - Test-challenge: 6,053 images with 1,090,637 instances.
+
+## Dataset Structure
+
+DOTA exhibits a structured layout tailored for OBB object detection challenges:
+
+- **Images**: A vast collection of high-resolution aerial images capturing diverse terrains and structures.
+- **Oriented Bounding Boxes**: Annotations in the form of rotated rectangles encapsulating objects irrespective of their orientation, ideal for capturing objects like airplanes, ships, and buildings.
+
+## Applications
+
+DOTA serves as a benchmark for training and evaluating models specifically tailored for aerial image analysis. With the inclusion of OBB annotations, it provides a unique challenge, enabling the development of specialized object detection models that cater to aerial imagery's nuances.
+
+## Dataset YAML
+
+Typically, datasets incorporate a YAML (Yet Another Markup Language) file detailing the dataset's configuration. For DOTA v1 and DOTA v1.5, Ultralytics provides `DOTAv1.yaml` and `DOTAv1.5.yaml` files. For additional details on these as well as DOTA v2 please consult DOTA's official repository and documentation.
+
+!!! Example "DOTAv1.yaml"
+
+ ```yaml
+ --8<-- "ultralytics/cfg/datasets/DOTAv1.yaml"
+ ```
+
+## Split DOTA images
+
+To train DOTA dataset, we split original DOTA images with high-resolution into images with 1024x1024 resolution in multiscale way.
+
+!!! Example "Split images"
+
+ === "Python"
+
+ ```python
+ from ultralytics.data.split_dota import split_test, split_trainval
+
+ # split train and val set, with labels.
+ split_trainval(
+ data_root="path/to/DOTAv1.0/",
+ save_dir="path/to/DOTAv1.0-split/",
+ rates=[0.5, 1.0, 1.5], # multiscale
+ gap=500,
+ )
+ # split test set, without labels.
+ split_test(
+ data_root="path/to/DOTAv1.0/",
+ save_dir="path/to/DOTAv1.0-split/",
+ rates=[0.5, 1.0, 1.5], # multiscale
+ gap=500,
+ )
+ ```
+
+## Usage
+
+To train a model on the DOTA v1 dataset, you can utilize the following code snippets. Always refer to your model's documentation for a thorough list of available arguments.
+
+!!! Warning
+
+ Please note that all images and associated annotations in the DOTAv1 dataset can be used for academic purposes, but commercial use is prohibited. Your understanding and respect for the dataset creators' wishes are greatly appreciated!
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Create a new YOLOv8n-OBB model from scratch
+ model = YOLO("yolov8n-obb.yaml")
+
+ # Train the model on the DOTAv2 dataset
+ results = model.train(data="DOTAv1.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Train a new YOLOv8n-OBB model on the DOTAv2 dataset
+ yolo obb train data=DOTAv1.yaml model=yolov8n-obb.pt epochs=100 imgsz=640
+ ```
+
+## Sample Data and Annotations
+
+Having a glance at the dataset illustrates its depth:
+
+
+
+- **DOTA examples**: This snapshot underlines the complexity of aerial scenes and the significance of Oriented Bounding Box annotations, capturing objects in their natural orientation.
+
+The dataset's richness offers invaluable insights into object detection challenges exclusive to aerial imagery.
+
+## Citations and Acknowledgments
+
+For those leveraging DOTA in their endeavors, it's pertinent to cite the relevant research papers:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @article{9560031,
+ author={Ding, Jian and Xue, Nan and Xia, Gui-Song and Bai, Xiang and Yang, Wen and Yang, Michael and Belongie, Serge and Luo, Jiebo and Datcu, Mihai and Pelillo, Marcello and Zhang, Liangpei},
+ journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
+ title={Object Detection in Aerial Images: A Large-Scale Benchmark and Challenges},
+ year={2021},
+ volume={},
+ number={},
+ pages={1-1},
+ doi={10.1109/TPAMI.2021.3117983}
+ }
+ ```
+
+A special note of gratitude to the team behind the DOTA datasets for their commendable effort in curating this dataset. For an exhaustive understanding of the dataset and its nuances, please visit the [official DOTA website](https://captain-whu.github.io/DOTA/index.html).
+
+## FAQ
+
+### What is the DOTA dataset and why is it important for object detection in aerial images?
+
+The [DOTA dataset](https://captain-whu.github.io/DOTA/index.html) is a specialized dataset focused on object detection in aerial images. It features Oriented Bounding Boxes (OBB), providing annotated images from diverse aerial scenes. DOTA's diversity in object orientation, scale, and shape across its 1.7M annotations and 18 categories makes it ideal for developing and evaluating models tailored for aerial imagery analysis, such as those used in surveillance, environmental monitoring, and disaster management.
+
+### How does the DOTA dataset handle different scales and orientations in images?
+
+DOTA utilizes Oriented Bounding Boxes (OBB) for annotation, which are represented by rotated rectangles encapsulating objects regardless of their orientation. This method ensures that objects, whether small or at different angles, are accurately captured. The dataset's multiscale images, ranging from 800 × 800 to 20,000 × 20,000 pixels, further allow for the detection of both small and large objects effectively.
+
+### How can I train a model using the DOTA dataset?
+
+To train a model on the DOTA dataset, you can use the following example with Ultralytics YOLO:
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Create a new YOLOv8n-OBB model from scratch
+ model = YOLO("yolov8n-obb.yaml")
+
+ # Train the model on the DOTAv1 dataset
+ results = model.train(data="DOTAv1.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Train a new YOLOv8n-OBB model on the DOTAv1 dataset
+ yolo obb train data=DOTAv1.yaml model=yolov8n-obb.pt epochs=100 imgsz=640
+ ```
+
+For more details on how to split and preprocess the DOTA images, refer to the [split DOTA images section](#split-dota-images).
+
+### What are the differences between DOTA-v1.0, DOTA-v1.5, and DOTA-v2.0?
+
+- **DOTA-v1.0**: Includes 15 common categories across 2,806 images with 188,282 instances. The dataset is split into training, validation, and testing sets.
+
+- **DOTA-v1.5**: Builds upon DOTA-v1.0 by annotating very small instances (less than 10 pixels) and adding a new category, "container crane," totaling 403,318 instances.
+
+- **DOTA-v2.0**: Expands further with annotations from Google Earth and GF-2 Satellite, featuring 11,268 images and 1,793,658 instances. It includes new categories like "airport" and "helipad."
+
+For a detailed comparison and additional specifics, check the [dataset versions section](#dataset-versions).
+
+### How can I prepare high-resolution DOTA images for training?
+
+DOTA images, which can be very large, are split into smaller resolutions for manageable training. Here's a Python snippet to split images:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics.data.split_dota import split_test, split_trainval
+
+ # split train and val set, with labels.
+ split_trainval(
+ data_root="path/to/DOTAv1.0/",
+ save_dir="path/to/DOTAv1.0-split/",
+ rates=[0.5, 1.0, 1.5], # multiscale
+ gap=500,
+ )
+ # split test set, without labels.
+ split_test(
+ data_root="path/to/DOTAv1.0/",
+ save_dir="path/to/DOTAv1.0-split/",
+ rates=[0.5, 1.0, 1.5], # multiscale
+ gap=500,
+ )
+ ```
+
+This process facilitates better training efficiency and model performance. For detailed instructions, visit the [split DOTA images section](#split-dota-images).
diff --git a/ultralytics/docs/en/datasets/obb/dota8.md b/ultralytics/docs/en/datasets/obb/dota8.md
new file mode 100644
index 0000000000000000000000000000000000000000..ec111432417e385de7065beb690aa24489940b78
--- /dev/null
+++ b/ultralytics/docs/en/datasets/obb/dota8.md
@@ -0,0 +1,124 @@
+---
+comments: true
+description: Explore the DOTA8 dataset - a small, versatile oriented object detection dataset ideal for testing and debugging object detection models using Ultralytics YOLOv8.
+keywords: DOTA8 dataset, Ultralytics, YOLOv8, object detection, debugging, training models, oriented object detection, dataset YAML
+---
+
+# DOTA8 Dataset
+
+## Introduction
+
+[Ultralytics](https://ultralytics.com) DOTA8 is a small, but versatile oriented object detection dataset composed of the first 8 images of 8 images of the split DOTAv1 set, 4 for training and 4 for validation. This dataset is ideal for testing and debugging object detection models, or for experimenting with new detection approaches. With 8 images, it is small enough to be easily manageable, yet diverse enough to test training pipelines for errors and act as a sanity check before training larger datasets.
+
+This dataset is intended for use with Ultralytics [HUB](https://hub.ultralytics.com) and [YOLOv8](https://github.com/ultralytics/ultralytics).
+
+## Dataset YAML
+
+A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the DOTA8 dataset, the `dota8.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/dota8.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/dota8.yaml).
+
+!!! Example "ultralytics/cfg/datasets/dota8.yaml"
+
+ ```yaml
+ --8<-- "ultralytics/cfg/datasets/dota8.yaml"
+ ```
+
+## Usage
+
+To train a YOLOv8n-obb model on the DOTA8 dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-obb.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="dota8.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo obb train data=dota8.yaml model=yolov8n-obb.pt epochs=100 imgsz=640
+ ```
+
+## Sample Images and Annotations
+
+Here are some examples of images from the DOTA8 dataset, along with their corresponding annotations:
+
+
+
+- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
+
+The example showcases the variety and complexity of the images in the DOTA8 dataset and the benefits of using mosaicing during the training process.
+
+## Citations and Acknowledgments
+
+If you use the DOTA dataset in your research or development work, please cite the following paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @article{9560031,
+ author={Ding, Jian and Xue, Nan and Xia, Gui-Song and Bai, Xiang and Yang, Wen and Yang, Michael and Belongie, Serge and Luo, Jiebo and Datcu, Mihai and Pelillo, Marcello and Zhang, Liangpei},
+ journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
+ title={Object Detection in Aerial Images: A Large-Scale Benchmark and Challenges},
+ year={2021},
+ volume={},
+ number={},
+ pages={1-1},
+ doi={10.1109/TPAMI.2021.3117983}
+ }
+ ```
+
+A special note of gratitude to the team behind the DOTA datasets for their commendable effort in curating this dataset. For an exhaustive understanding of the dataset and its nuances, please visit the [official DOTA website](https://captain-whu.github.io/DOTA/index.html).
+
+## FAQ
+
+### What is the DOTA8 dataset and how can it be used?
+
+The DOTA8 dataset is a small, versatile oriented object detection dataset made up of the first 8 images from the DOTAv1 split set, with 4 images designated for training and 4 for validation. It's ideal for testing and debugging object detection models like Ultralytics YOLOv8. Due to its manageable size and diversity, it helps in identifying pipeline errors and running sanity checks before deploying larger datasets. Learn more about object detection with [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics).
+
+### How do I train a YOLOv8 model using the DOTA8 dataset?
+
+To train a YOLOv8n-obb model on the DOTA8 dataset for 100 epochs with an image size of 640, you can use the following code snippets. For comprehensive argument options, refer to the model [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-obb.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="dota8.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo obb train data=dota8.yaml model=yolov8n-obb.pt epochs=100 imgsz=640
+ ```
+
+### What are the key features of the DOTA dataset and where can I access the YAML file?
+
+The DOTA dataset is known for its large-scale benchmark and the challenges it presents for object detection in aerial images. The DOTA8 subset is a smaller, manageable dataset ideal for initial tests. You can access the `dota8.yaml` file, which contains paths, classes, and configuration details, at this [GitHub link](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/dota8.yaml).
+
+### How does mosaicing enhance model training with the DOTA8 dataset?
+
+Mosaicing combines multiple images into one during training, increasing the variety of objects and contexts within each batch. This improves a model's ability to generalize to different object sizes, aspect ratios, and scenes. This technique can be visually demonstrated through a training batch composed of mosaiced DOTA8 dataset images, helping in robust model development. Explore more about mosaicing and training techniques on our [Training](../../modes/train.md) page.
+
+### Why should I use Ultralytics YOLOv8 for object detection tasks?
+
+Ultralytics YOLOv8 provides state-of-the-art real-time object detection capabilities, including features like oriented bounding boxes (OBB), instance segmentation, and a highly versatile training pipeline. It's suitable for various applications and offers pretrained models for efficient fine-tuning. Explore further about the advantages and usage in the [Ultralytics YOLOv8 documentation](https://github.com/ultralytics/ultralytics).
diff --git a/ultralytics/docs/en/datasets/obb/index.md b/ultralytics/docs/en/datasets/obb/index.md
new file mode 100644
index 0000000000000000000000000000000000000000..b75cb502afadc5ba390656abe0bd5159b185fa4d
--- /dev/null
+++ b/ultralytics/docs/en/datasets/obb/index.md
@@ -0,0 +1,144 @@
+---
+comments: true
+description: Discover OBB dataset formats for Ultralytics YOLO models. Learn about their structure, application, and format conversions to enhance your object detection training.
+keywords: Oriented Bounding Box, OBB Datasets, YOLO, Ultralytics, Object Detection, Dataset Formats
+---
+
+# Oriented Bounding Box (OBB) Datasets Overview
+
+Training a precise object detection model with oriented bounding boxes (OBB) requires a thorough dataset. This guide explains the various OBB dataset formats compatible with Ultralytics YOLO models, offering insights into their structure, application, and methods for format conversions.
+
+## Supported OBB Dataset Formats
+
+### YOLO OBB Format
+
+The YOLO OBB format designates bounding boxes by their four corner points with coordinates normalized between 0 and 1. It follows this format:
+
+```bash
+class_index x1 y1 x2 y2 x3 y3 x4 y4
+```
+
+Internally, YOLO processes losses and outputs in the `xywhr` format, which represents the bounding box's center point (xy), width, height, and rotation.
+
+
+
+An example of a `*.txt` label file for the above image, which contains an object of class `0` in OBB format, could look like:
+
+```bash
+0 0.780811 0.743961 0.782371 0.74686 0.777691 0.752174 0.776131 0.749758
+```
+
+## Usage
+
+To train a model using these OBB formats:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Create a new YOLOv8n-OBB model from scratch
+ model = YOLO("yolov8n-obb.yaml")
+
+ # Train the model on the DOTAv2 dataset
+ results = model.train(data="DOTAv1.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Train a new YOLOv8n-OBB model on the DOTAv2 dataset
+ yolo obb train data=DOTAv1.yaml model=yolov8n-obb.pt epochs=100 imgsz=640
+ ```
+
+## Supported Datasets
+
+Currently, the following datasets with Oriented Bounding Boxes are supported:
+
+- [DOTA-v2](dota-v2.md): DOTA (A Large-scale Dataset for Object Detection in Aerial Images) version 2, emphasizes detection from aerial perspectives and contains oriented bounding boxes with 1.7 million instances and 11,268 images.
+- [DOTA8](dota8.md): A small, 8-image subset of the full DOTA dataset suitable for testing workflows and Continuous Integration (CI) checks of OBB training in the `ultralytics` repository.
+
+### Incorporating your own OBB dataset
+
+For those looking to introduce their own datasets with oriented bounding boxes, ensure compatibility with the "YOLO OBB format" mentioned above. Convert your annotations to this required format and detail the paths, classes, and class names in a corresponding YAML configuration file.
+
+## Convert Label Formats
+
+### DOTA Dataset Format to YOLO OBB Format
+
+Transitioning labels from the DOTA dataset format to the YOLO OBB format can be achieved with this script:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics.data.converter import convert_dota_to_yolo_obb
+
+ convert_dota_to_yolo_obb("path/to/DOTA")
+ ```
+
+This conversion mechanism is instrumental for datasets in the DOTA format, ensuring alignment with the Ultralytics YOLO OBB format.
+
+It's imperative to validate the compatibility of the dataset with your model and adhere to the necessary format conventions. Properly structured datasets are pivotal for training efficient object detection models with oriented bounding boxes.
+
+## FAQ
+
+### What are Oriented Bounding Boxes (OBB) and how are they used in Ultralytics YOLO models?
+
+Oriented Bounding Boxes (OBB) are a type of bounding box annotation where the box can be rotated to align more closely with the object being detected, rather than just being axis-aligned. This is particularly useful in aerial or satellite imagery where objects might not be aligned with the image axes. In Ultralytics YOLO models, OBBs are represented by their four corner points in the YOLO OBB format. This allows for more accurate object detection since the bounding boxes can rotate to fit the objects better.
+
+### How do I convert my existing DOTA dataset labels to YOLO OBB format for use with Ultralytics YOLOv8?
+
+You can convert DOTA dataset labels to YOLO OBB format using the `convert_dota_to_yolo_obb` function from Ultralytics. This conversion ensures compatibility with the Ultralytics YOLO models, enabling you to leverage the OBB capabilities for enhanced object detection. Here's a quick example:
+
+```python
+from ultralytics.data.converter import convert_dota_to_yolo_obb
+
+convert_dota_to_yolo_obb("path/to/DOTA")
+```
+
+This script will reformat your DOTA annotations into a YOLO-compatible format.
+
+### How do I train a YOLOv8 model with oriented bounding boxes (OBB) on my dataset?
+
+Training a YOLOv8 model with OBBs involves ensuring your dataset is in the YOLO OBB format and then using the Ultralytics API to train the model. Here's an example in both Python and CLI:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Create a new YOLOv8n-OBB model from scratch
+ model = YOLO("yolov8n-obb.yaml")
+
+ # Train the model on the custom dataset
+ results = model.train(data="your_dataset.yaml", epochs=100, imgsz=640)
+ ```
+
+
+ === "CLI"
+
+ ```bash
+ # Train a new YOLOv8n-OBB model on the custom dataset
+ yolo obb train data=your_dataset.yaml model=yolov8n-obb.yaml epochs=100 imgsz=640
+ ```
+
+This ensures your model leverages the detailed OBB annotations for improved detection accuracy.
+
+### What datasets are currently supported for OBB training in Ultralytics YOLO models?
+
+Currently, Ultralytics supports the following datasets for OBB training:
+
+- [DOTA-v2](dota-v2.md): This dataset includes 1.7 million instances with oriented bounding boxes and 11,268 images, primarily focusing on aerial object detection.
+- [DOTA8](dota8.md): A smaller, 8-image subset of the DOTA dataset used for testing and continuous integration (CI) checks.
+
+These datasets are tailored for scenarios where OBBs offer a significant advantage, such as aerial and satellite image analysis.
+
+### Can I use my own dataset with oriented bounding boxes for YOLOv8 training, and if so, how?
+
+Yes, you can use your own dataset with oriented bounding boxes for YOLOv8 training. Ensure your dataset annotations are converted to the YOLO OBB format, which involves defining bounding boxes by their four corner points. You can then create a YAML configuration file specifying the dataset paths, classes, and other necessary details. For more information on creating and configuring your datasets, refer to the [Supported Datasets](#supported-datasets) section.
diff --git a/ultralytics/docs/en/datasets/pose/coco.md b/ultralytics/docs/en/datasets/pose/coco.md
new file mode 100644
index 0000000000000000000000000000000000000000..25b24781707c27a7a7cdf892a92bac587152b478
--- /dev/null
+++ b/ultralytics/docs/en/datasets/pose/coco.md
@@ -0,0 +1,159 @@
+---
+comments: true
+description: Explore the COCO-Pose dataset for advanced pose estimation. Learn about datasets, pretrained models, metrics, and applications for training with YOLO.
+keywords: COCO-Pose, pose estimation, dataset, keypoints, COCO Keypoints 2017, YOLO, deep learning, computer vision
+---
+
+# COCO-Pose Dataset
+
+The [COCO-Pose](https://cocodataset.org/#keypoints-2017) dataset is a specialized version of the COCO (Common Objects in Context) dataset, designed for pose estimation tasks. It leverages the COCO Keypoints 2017 images and labels to enable the training of models like YOLO for pose estimation tasks.
+
+
+
+## COCO-Pose Pretrained Models
+
+| Model | size (pixels) | mAPpose 50-95 | mAPpose 50 | Speed CPU ONNX (ms) | Speed A100 TensorRT (ms) | params (M) | FLOPs (B) |
+|------------------------------------------------------------------------------------------------------|-----------------------|-----------------------|--------------------|--------------------------------|-------------------------------------|--------------------|-------------------|
+| [YOLOv8n-pose](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n-pose.pt) | 640 | 50.4 | 80.1 | 131.8 | 1.18 | 3.3 | 9.2 |
+| [YOLOv8s-pose](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8s-pose.pt) | 640 | 60.0 | 86.2 | 233.2 | 1.42 | 11.6 | 30.2 |
+| [YOLOv8m-pose](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8m-pose.pt) | 640 | 65.0 | 88.8 | 456.3 | 2.00 | 26.4 | 81.0 |
+| [YOLOv8l-pose](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8l-pose.pt) | 640 | 67.6 | 90.0 | 784.5 | 2.59 | 44.4 | 168.6 |
+| [YOLOv8x-pose](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8x-pose.pt) | 640 | 69.2 | 90.2 | 1607.1 | 3.73 | 69.4 | 263.2 |
+| [YOLOv8x-pose-p6](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8x-pose-p6.pt) | 1280 | 71.6 | 91.2 | 4088.7 | 10.04 | 99.1 | 1066.4 |
+
+## Key Features
+
+- COCO-Pose builds upon the COCO Keypoints 2017 dataset which contains 200K images labeled with keypoints for pose estimation tasks.
+- The dataset supports 17 keypoints for human figures, facilitating detailed pose estimation.
+- Like COCO, it provides standardized evaluation metrics, including Object Keypoint Similarity (OKS) for pose estimation tasks, making it suitable for comparing model performance.
+
+## Dataset Structure
+
+The COCO-Pose dataset is split into three subsets:
+
+1. **Train2017**: This subset contains a portion of the 118K images from the COCO dataset, annotated for training pose estimation models.
+2. **Val2017**: This subset has a selection of images used for validation purposes during model training.
+3. **Test2017**: This subset consists of images used for testing and benchmarking the trained models. Ground truth annotations for this subset are not publicly available, and the results are submitted to the [COCO evaluation server](https://codalab.lisn.upsaclay.fr/competitions/7384) for performance evaluation.
+
+## Applications
+
+The COCO-Pose dataset is specifically used for training and evaluating deep learning models in keypoint detection and pose estimation tasks, such as OpenPose. The dataset's large number of annotated images and standardized evaluation metrics make it an essential resource for computer vision researchers and practitioners focused on pose estimation.
+
+## Dataset YAML
+
+A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the COCO-Pose dataset, the `coco-pose.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco-pose.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco-pose.yaml).
+
+!!! Example "ultralytics/cfg/datasets/coco-pose.yaml"
+
+ ```yaml
+ --8<-- "ultralytics/cfg/datasets/coco-pose.yaml"
+ ```
+
+## Usage
+
+To train a YOLOv8n-pose model on the COCO-Pose dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-pose.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="coco-pose.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo pose train data=coco-pose.yaml model=yolov8n-pose.pt epochs=100 imgsz=640
+ ```
+
+## Sample Images and Annotations
+
+The COCO-Pose dataset contains a diverse set of images with human figures annotated with keypoints. Here are some examples of images from the dataset, along with their corresponding annotations:
+
+
+
+- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
+
+The example showcases the variety and complexity of the images in the COCO-Pose dataset and the benefits of using mosaicing during the training process.
+
+## Citations and Acknowledgments
+
+If you use the COCO-Pose dataset in your research or development work, please cite the following paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @misc{lin2015microsoft,
+ title={Microsoft COCO: Common Objects in Context},
+ author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
+ year={2015},
+ eprint={1405.0312},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+ }
+ ```
+
+We would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO-Pose dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
+
+## FAQ
+
+### What is the COCO-Pose dataset and how is it used with Ultralytics YOLO for pose estimation?
+
+The [COCO-Pose](https://cocodataset.org/#keypoints-2017) dataset is a specialized version of the COCO (Common Objects in Context) dataset designed for pose estimation tasks. It builds upon the COCO Keypoints 2017 images and annotations, allowing for the training of models like Ultralytics YOLO for detailed pose estimation. For instance, you can use the COCO-Pose dataset to train a YOLOv8n-pose model by loading a pretrained model and training it with a YAML configuration. For training examples, refer to the [Training](../../modes/train.md) documentation.
+
+### How can I train a YOLOv8 model on the COCO-Pose dataset?
+
+Training a YOLOv8 model on the COCO-Pose dataset can be accomplished using either Python or CLI commands. For example, to train a YOLOv8n-pose model for 100 epochs with an image size of 640, you can follow the steps below:
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-pose.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="coco-pose.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo pose train data=coco-pose.yaml model=yolov8n-pose.pt epochs=100 imgsz=640
+ ```
+
+For more details on the training process and available arguments, check the [training page](../../modes/train.md).
+
+### What are the different metrics provided by the COCO-Pose dataset for evaluating model performance?
+
+The COCO-Pose dataset provides several standardized evaluation metrics for pose estimation tasks, similar to the original COCO dataset. Key metrics include the Object Keypoint Similarity (OKS), which evaluates the accuracy of predicted keypoints against ground truth annotations. These metrics allow for thorough performance comparisons between different models. For instance, the COCO-Pose pretrained models such as YOLOv8n-pose, YOLOv8s-pose, and others have specific performance metrics listed in the documentation, like mAPpose50-95 and mAPpose50.
+
+### How is the dataset structured and split for the COCO-Pose dataset?
+
+The COCO-Pose dataset is split into three subsets:
+
+1. **Train2017**: Contains a portion of the 118K COCO images, annotated for training pose estimation models.
+2. **Val2017**: Selected images for validation purposes during model training.
+3. **Test2017**: Images used for testing and benchmarking trained models. Ground truth annotations for this subset are not publicly available; results are submitted to the [COCO evaluation server](https://codalab.lisn.upsaclay.fr/competitions/7384) for performance evaluation.
+
+These subsets help organize the training, validation, and testing phases effectively. For configuration details, explore the `coco-pose.yaml` file available on [GitHub](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco-pose.yaml).
+
+### What are the key features and applications of the COCO-Pose dataset?
+
+The COCO-Pose dataset extends the COCO Keypoints 2017 annotations to include 17 keypoints for human figures, enabling detailed pose estimation. Standardized evaluation metrics (e.g., OKS) facilitate comparisons across different models. Applications of the COCO-Pose dataset span various domains, such as sports analytics, healthcare, and human-computer interaction, wherever detailed pose estimation of human figures is required. For practical use, leveraging pretrained models like those provided in the documentation (e.g., YOLOv8n-pose) can significantly streamline the process ([Key Features](#key-features)).
+
+If you use the COCO-Pose dataset in your research or development work, please cite the paper with the following [BibTeX entry](#citations-and-acknowledgments).
diff --git a/ultralytics/docs/en/datasets/pose/coco8-pose.md b/ultralytics/docs/en/datasets/pose/coco8-pose.md
new file mode 100644
index 0000000000000000000000000000000000000000..fd959293eae1ac59993c43f39348d49d4bcb43fa
--- /dev/null
+++ b/ultralytics/docs/en/datasets/pose/coco8-pose.md
@@ -0,0 +1,131 @@
+---
+comments: true
+description: Explore the compact, versatile COCO8-Pose dataset for testing and debugging object detection models. Ideal for quick experiments with YOLOv8.
+keywords: COCO8-Pose, Ultralytics, pose detection dataset, object detection, YOLOv8, machine learning, computer vision, training data
+---
+
+# COCO8-Pose Dataset
+
+## Introduction
+
+[Ultralytics](https://ultralytics.com) COCO8-Pose is a small, but versatile pose detection dataset composed of the first 8 images of the COCO train 2017 set, 4 for training and 4 for validation. This dataset is ideal for testing and debugging object detection models, or for experimenting with new detection approaches. With 8 images, it is small enough to be easily manageable, yet diverse enough to test training pipelines for errors and act as a sanity check before training larger datasets.
+
+This dataset is intended for use with Ultralytics [HUB](https://hub.ultralytics.com) and [YOLOv8](https://github.com/ultralytics/ultralytics).
+
+## Dataset YAML
+
+A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the COCO8-Pose dataset, the `coco8-pose.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco8-pose.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco8-pose.yaml).
+
+!!! Example "ultralytics/cfg/datasets/coco8-pose.yaml"
+
+ ```yaml
+ --8<-- "ultralytics/cfg/datasets/coco8-pose.yaml"
+ ```
+
+## Usage
+
+To train a YOLOv8n-pose model on the COCO8-Pose dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-pose.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="coco8-pose.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo pose train data=coco8-pose.yaml model=yolov8n-pose.pt epochs=100 imgsz=640
+ ```
+
+## Sample Images and Annotations
+
+Here are some examples of images from the COCO8-Pose dataset, along with their corresponding annotations:
+
+
+
+- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
+
+The example showcases the variety and complexity of the images in the COCO8-Pose dataset and the benefits of using mosaicing during the training process.
+
+## Citations and Acknowledgments
+
+If you use the COCO dataset in your research or development work, please cite the following paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @misc{lin2015microsoft,
+ title={Microsoft COCO: Common Objects in Context},
+ author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
+ year={2015},
+ eprint={1405.0312},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+ }
+ ```
+
+We would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
+
+## FAQ
+
+### What is the COCO8-Pose dataset, and how is it used with Ultralytics YOLOv8?
+
+The COCO8-Pose dataset is a small, versatile pose detection dataset that includes the first 8 images from the COCO train 2017 set, with 4 images for training and 4 for validation. It's designed for testing and debugging object detection models and experimenting with new detection approaches. This dataset is ideal for quick experiments with [Ultralytics YOLOv8](https://docs.ultralytics.com/models/yolov8/). For more details on dataset configuration, check out the dataset YAML file [here](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco8-pose.yaml).
+
+### How do I train a YOLOv8 model using the COCO8-Pose dataset in Ultralytics?
+
+To train a YOLOv8n-pose model on the COCO8-Pose dataset for 100 epochs with an image size of 640, follow these examples:
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-pose.pt")
+
+ # Train the model
+ results = model.train(data="coco8-pose.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo pose train data=coco8-pose.yaml model=yolov8n-pose.pt epochs=100 imgsz=640
+ ```
+
+For a comprehensive list of training arguments, refer to the model [Training](../../modes/train.md) page.
+
+### What are the benefits of using the COCO8-Pose dataset?
+
+The COCO8-Pose dataset offers several benefits:
+
+- **Compact Size**: With only 8 images, it is easy to manage and perfect for quick experiments.
+- **Diverse Data**: Despite its small size, it includes a variety of scenes, useful for thorough pipeline testing.
+- **Error Debugging**: Ideal for identifying training errors and performing sanity checks before scaling up to larger datasets.
+
+For more about its features and usage, see the [Dataset Introduction](#introduction) section.
+
+### How does mosaicing benefit the YOLOv8 training process using the COCO8-Pose dataset?
+
+Mosaicing, demonstrated in the sample images of the COCO8-Pose dataset, combines multiple images into one, increasing the variety of objects and scenes within each training batch. This technique helps improve the model's ability to generalize across various object sizes, aspect ratios, and contexts, ultimately enhancing model performance. See the [Sample Images and Annotations](#sample-images-and-annotations) section for example images.
+
+### Where can I find the COCO8-Pose dataset YAML file and how do I use it?
+
+The COCO8-Pose dataset YAML file can be found [here](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco8-pose.yaml). This file defines the dataset configuration, including paths, classes, and other relevant information. Use this file with the YOLOv8 training scripts as mentioned in the [Train Example](#how-do-i-train-a-yolov8-model-using-the-coco8-pose-dataset-in-ultralytics) section.
+
+For more FAQs and detailed documentation, visit the [Ultralytics Documentation](https://docs.ultralytics.com/).
diff --git a/ultralytics/docs/en/datasets/pose/index.md b/ultralytics/docs/en/datasets/pose/index.md
new file mode 100644
index 0000000000000000000000000000000000000000..7386a8e207d604c9b7348985b84ac1a89acb8bc9
--- /dev/null
+++ b/ultralytics/docs/en/datasets/pose/index.md
@@ -0,0 +1,210 @@
+---
+comments: true
+description: Learn about Ultralytics YOLO format for pose estimation datasets, supported formats, COCO-Pose, COCO8-Pose, Tiger-Pose, and how to add your own dataset.
+keywords: pose estimation, Ultralytics, YOLO format, COCO-Pose, COCO8-Pose, Tiger-Pose, dataset conversion, keypoints
+---
+
+# Pose Estimation Datasets Overview
+
+## Supported Dataset Formats
+
+### Ultralytics YOLO format
+
+The dataset label format used for training YOLO pose models is as follows:
+
+1. One text file per image: Each image in the dataset has a corresponding text file with the same name as the image file and the ".txt" extension.
+2. One row per object: Each row in the text file corresponds to one object instance in the image.
+3. Object information per row: Each row contains the following information about the object instance:
+ - Object class index: An integer representing the class of the object (e.g., 0 for person, 1 for car, etc.).
+ - Object center coordinates: The x and y coordinates of the center of the object, normalized to be between 0 and 1.
+ - Object width and height: The width and height of the object, normalized to be between 0 and 1.
+ - Object keypoint coordinates: The keypoints of the object, normalized to be between 0 and 1.
+
+Here is an example of the label format for pose estimation task:
+
+Format with Dim = 2
+
+```
+ ...
+```
+
+Format with Dim = 3
+
+```
+
+```
+
+In this format, `` is the index of the class for the object,`` are coordinates of bounding box, and ` ... ` are the pixel coordinates of the keypoints. The coordinates are separated by spaces.
+
+### Dataset YAML format
+
+The Ultralytics framework uses a YAML file format to define the dataset and model configuration for training Detection Models. Here is an example of the YAML format used for defining a detection dataset:
+
+```yaml
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/coco8-pose # dataset root dir
+train: images/train # train images (relative to 'path') 4 images
+val: images/val # val images (relative to 'path') 4 images
+test: # test images (optional)
+
+# Keypoints
+kpt_shape: [17, 3] # number of keypoints, number of dims (2 for x,y or 3 for x,y,visible)
+flip_idx: [0, 2, 1, 4, 3, 6, 5, 8, 7, 10, 9, 12, 11, 14, 13, 16, 15]
+
+# Classes dictionary
+names:
+ 0: person
+```
+
+The `train` and `val` fields specify the paths to the directories containing the training and validation images, respectively.
+
+`names` is a dictionary of class names. The order of the names should match the order of the object class indices in the YOLO dataset files.
+
+(Optional) if the points are symmetric then need flip_idx, like left-right side of human or face. For example if we assume five keypoints of facial landmark: [left eye, right eye, nose, left mouth, right mouth], and the original index is [0, 1, 2, 3, 4], then flip_idx is [1, 0, 2, 4, 3] (just exchange the left-right index, i.e. 0-1 and 3-4, and do not modify others like nose in this example).
+
+## Usage
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-pose.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="coco8-pose.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo pose train data=coco8-pose.yaml model=yolov8n-pose.pt epochs=100 imgsz=640
+ ```
+
+## Supported Datasets
+
+This section outlines the datasets that are compatible with Ultralytics YOLO format and can be used for training pose estimation models:
+
+### COCO-Pose
+
+- **Description**: COCO-Pose is a large-scale object detection, segmentation, and pose estimation dataset. It is a subset of the popular COCO dataset and focuses on human pose estimation. COCO-Pose includes multiple keypoints for each human instance.
+- **Label Format**: Same as Ultralytics YOLO format as described above, with keypoints for human poses.
+- **Number of Classes**: 1 (Human).
+- **Keypoints**: 17 keypoints including nose, eyes, ears, shoulders, elbows, wrists, hips, knees, and ankles.
+- **Usage**: Suitable for training human pose estimation models.
+- **Additional Notes**: The dataset is rich and diverse, containing over 200k labeled images.
+- [Read more about COCO-Pose](coco.md)
+
+### COCO8-Pose
+
+- **Description**: [Ultralytics](https://ultralytics.com) COCO8-Pose is a small, but versatile pose detection dataset composed of the first 8 images of the COCO train 2017 set, 4 for training and 4 for validation.
+- **Label Format**: Same as Ultralytics YOLO format as described above, with keypoints for human poses.
+- **Number of Classes**: 1 (Human).
+- **Keypoints**: 17 keypoints including nose, eyes, ears, shoulders, elbows, wrists, hips, knees, and ankles.
+- **Usage**: Suitable for testing and debugging object detection models, or for experimenting with new detection approaches.
+- **Additional Notes**: COCO8-Pose is ideal for sanity checks and CI checks.
+- [Read more about COCO8-Pose](coco8-pose.md)
+
+### Tiger-Pose
+
+- **Description**: [Ultralytics](https://ultralytics.com) This animal pose dataset comprises 263 images sourced from a [YouTube Video](https://www.youtube.com/watch?v=MIBAT6BGE6U&pp=ygUbVGlnZXIgd2Fsa2luZyByZWZlcmVuY2UubXA0), with 210 images allocated for training and 53 for validation.
+- **Label Format**: Same as Ultralytics YOLO format as described above, with 12 keypoints for animal pose and no visible dimension.
+- **Number of Classes**: 1 (Tiger).
+- **Keypoints**: 12 keypoints.
+- **Usage**: Great for animal pose or any other pose that is not human-based.
+- [Read more about Tiger-Pose](tiger-pose.md)
+
+### Adding your own dataset
+
+If you have your own dataset and would like to use it for training pose estimation models with Ultralytics YOLO format, ensure that it follows the format specified above under "Ultralytics YOLO format". Convert your annotations to the required format and specify the paths, number of classes, and class names in the YAML configuration file.
+
+### Conversion Tool
+
+Ultralytics provides a convenient conversion tool to convert labels from the popular COCO dataset format to YOLO format:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics.data.converter import convert_coco
+
+ convert_coco(labels_dir="path/to/coco/annotations/", use_keypoints=True)
+ ```
+
+This conversion tool can be used to convert the COCO dataset or any dataset in the COCO format to the Ultralytics YOLO format. The `use_keypoints` parameter specifies whether to include keypoints (for pose estimation) in the converted labels.
+
+## FAQ
+
+### What is the Ultralytics YOLO format for pose estimation?
+
+The Ultralytics YOLO format for pose estimation datasets involves labeling each image with a corresponding text file. Each row of the text file stores information about an object instance:
+
+- Object class index
+- Object center coordinates (normalized x and y)
+- Object width and height (normalized)
+- Object keypoint coordinates (normalized pxn and pyn)
+
+For 2D poses, keypoints include pixel coordinates. For 3D, each keypoint also has a visibility flag. For more details, see [Ultralytics YOLO format](#ultralytics-yolo-format).
+
+### How do I use the COCO-Pose dataset with Ultralytics YOLO?
+
+To use the COCO-Pose dataset with Ultralytics YOLO:
+1. Download the dataset and prepare your label files in the YOLO format.
+2. Create a YAML configuration file specifying paths to training and validation images, keypoint shape, and class names.
+3. Use the configuration file for training:
+
+ ```python
+ from ultralytics import YOLO
+
+ model = YOLO("yolov8n-pose.pt") # load pretrained model
+ results = model.train(data="coco-pose.yaml", epochs=100, imgsz=640)
+ ```
+
+ For more information, visit [COCO-Pose](coco.md) and [train](../../modes/train.md) sections.
+
+### How can I add my own dataset for pose estimation in Ultralytics YOLO?
+
+To add your dataset:
+1. Convert your annotations to the Ultralytics YOLO format.
+2. Create a YAML configuration file specifying the dataset paths, number of classes, and class names.
+3. Use the configuration file to train your model:
+
+ ```python
+ from ultralytics import YOLO
+
+ model = YOLO("yolov8n-pose.pt")
+ results = model.train(data="your-dataset.yaml", epochs=100, imgsz=640)
+ ```
+
+ For complete steps, check the [Adding your own dataset](#adding-your-own-dataset) section.
+
+### What is the purpose of the dataset YAML file in Ultralytics YOLO?
+
+The dataset YAML file in Ultralytics YOLO defines the dataset and model configuration for training. It specifies paths to training, validation, and test images, keypoint shapes, class names, and other configuration options. This structured format helps streamline dataset management and model training. Here is an example YAML format:
+
+```yaml
+path: ../datasets/coco8-pose
+train: images/train
+val: images/val
+names:
+ 0: person
+```
+
+Read more about creating YAML configuration files in [Dataset YAML format](#dataset-yaml-format).
+
+### How can I convert COCO dataset labels to Ultralytics YOLO format for pose estimation?
+
+Ultralytics provides a conversion tool to convert COCO dataset labels to the YOLO format, including keypoint information:
+
+```python
+from ultralytics.data.converter import convert_coco
+
+convert_coco(labels_dir="path/to/coco/annotations/", use_keypoints=True)
+```
+
+This tool helps seamlessly integrate COCO datasets into YOLO projects. For details, refer to the [Conversion Tool](#conversion-tool) section.
diff --git a/ultralytics/docs/en/datasets/pose/tiger-pose.md b/ultralytics/docs/en/datasets/pose/tiger-pose.md
new file mode 100644
index 0000000000000000000000000000000000000000..2f4be69dee7c00e107d13c3b7c1c3b6abd02d206
--- /dev/null
+++ b/ultralytics/docs/en/datasets/pose/tiger-pose.md
@@ -0,0 +1,164 @@
+---
+comments: true
+description: Explore Ultralytics Tiger-Pose dataset with 263 diverse images. Ideal for testing, training, and refining pose estimation algorithms.
+keywords: Ultralytics, Tiger-Pose, dataset, pose estimation, YOLOv8, training data, machine learning, neural networks
+---
+
+# Tiger-Pose Dataset
+
+## Introduction
+
+[Ultralytics](https://ultralytics.com) introduces the Tiger-Pose dataset, a versatile collection designed for pose estimation tasks. This dataset comprises 263 images sourced from a [YouTube Video](https://www.youtube.com/watch?v=MIBAT6BGE6U&pp=ygUbVGlnZXIgd2Fsa2luZyByZWZlcmVuY2UubXA0), with 210 images allocated for training and 53 for validation. It serves as an excellent resource for testing and troubleshooting pose estimation algorithm.
+
+Despite its manageable size of 210 images, tiger-pose dataset offers diversity, making it suitable for assessing training pipelines, identifying potential errors, and serving as a valuable preliminary step before working with larger datasets for pose estimation.
+
+This dataset is intended for use with [Ultralytics HUB](https://hub.ultralytics.com) and [YOLOv8](https://github.com/ultralytics/ultralytics).
+
+
+
+
+
+ Watch: Train YOLOv8 Pose Model on Tiger-Pose Dataset Using Ultralytics HUB
+
+
+## Dataset YAML
+
+A YAML (Yet Another Markup Language) file serves as the means to specify the configuration details of a dataset. It encompasses crucial data such as file paths, class definitions, and other pertinent information. Specifically, for the `tiger-pose.yaml` file, you can check [Ultralytics Tiger-Pose Dataset Configuration File](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/tiger-pose.yaml).
+
+!!! Example "ultralytics/cfg/datasets/tiger-pose.yaml"
+
+ ```yaml
+ --8<-- "ultralytics/cfg/datasets/tiger-pose.yaml"
+ ```
+
+## Usage
+
+To train a YOLOv8n-pose model on the Tiger-Pose dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-pose.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="tiger-pose.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo task=pose mode=train data=tiger-pose.yaml model=yolov8n-pose.pt epochs=100 imgsz=640
+ ```
+
+## Sample Images and Annotations
+
+Here are some examples of images from the Tiger-Pose dataset, along with their corresponding annotations:
+
+
+
+- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
+
+The example showcases the variety and complexity of the images in the Tiger-Pose dataset and the benefits of using mosaicing during the training process.
+
+## Inference Example
+
+!!! Example "Inference Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("path/to/best.pt") # load a tiger-pose trained model
+
+ # Run inference
+ results = model.predict(source="https://youtu.be/MIBAT6BGE6U", show=True)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Run inference using a tiger-pose trained model
+ yolo task=pose mode=predict source="https://youtu.be/MIBAT6BGE6U" show=True model="path/to/best.pt"
+ ```
+
+## Citations and Acknowledgments
+
+The dataset has been released available under the [AGPL-3.0 License](https://github.com/ultralytics/ultralytics/blob/main/LICENSE).
+
+## FAQ
+
+### What is the Ultralytics Tiger-Pose dataset used for?
+
+The Ultralytics Tiger-Pose dataset is designed for pose estimation tasks, consisting of 263 images sourced from a [YouTube video](https://www.youtube.com/watch?v=MIBAT6BGE6U&pp=ygUbVGlnZXIgd2Fsa2luZyByZWZlcmVuY2UubXA0). The dataset is divided into 210 training images and 53 validation images. It is particularly useful for testing, training, and refining pose estimation algorithms using [Ultralytics HUB](https://hub.ultralytics.com) and [YOLOv8](https://github.com/ultralytics/ultralytics).
+
+### How do I train a YOLOv8 model on the Tiger-Pose dataset?
+
+To train a YOLOv8n-pose model on the Tiger-Pose dataset for 100 epochs with an image size of 640, use the following code snippets. For more details, visit the [Training](../../modes/train.md) page:
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-pose.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="tiger-pose.yaml", epochs=100, imgsz=640)
+ ```
+
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo task=pose mode=train data=tiger-pose.yaml model=yolov8n-pose.pt epochs=100 imgsz=640
+ ```
+
+### What configurations does the `tiger-pose.yaml` file include?
+
+The `tiger-pose.yaml` file is used to specify the configuration details of the Tiger-Pose dataset. It includes crucial data such as file paths and class definitions. To see the exact configuration, you can check out the [Ultralytics Tiger-Pose Dataset Configuration File](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/tiger-pose.yaml).
+
+### How can I run inference using a YOLOv8 model trained on the Tiger-Pose dataset?
+
+To perform inference using a YOLOv8 model trained on the Tiger-Pose dataset, you can use the following code snippets. For a detailed guide, visit the [Prediction](../../modes/predict.md) page:
+
+!!! Example "Inference Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("path/to/best.pt") # load a tiger-pose trained model
+
+ # Run inference
+ results = model.predict(source="https://youtu.be/MIBAT6BGE6U", show=True)
+ ```
+
+
+ === "CLI"
+
+ ```bash
+ # Run inference using a tiger-pose trained model
+ yolo task=pose mode=predict source="https://youtu.be/MIBAT6BGE6U" show=True model="path/to/best.pt"
+ ```
+
+### What are the benefits of using the Tiger-Pose dataset for pose estimation?
+
+The Tiger-Pose dataset, despite its manageable size of 210 images for training, provides a diverse collection of images that are ideal for testing pose estimation pipelines. The dataset helps identify potential errors and acts as a preliminary step before working with larger datasets. Additionally, the dataset supports the training and refinement of pose estimation algorithms using advanced tools like [Ultralytics HUB](https://hub.ultralytics.com) and [YOLOv8](https://github.com/ultralytics/ultralytics), enhancing model performance and accuracy.
diff --git a/ultralytics/docs/en/datasets/segment/carparts-seg.md b/ultralytics/docs/en/datasets/segment/carparts-seg.md
new file mode 100644
index 0000000000000000000000000000000000000000..03064d95a8e415c54ccee62d2c4a57b80fc23e22
--- /dev/null
+++ b/ultralytics/docs/en/datasets/segment/carparts-seg.md
@@ -0,0 +1,160 @@
+---
+comments: true
+description: Explore the Roboflow Carparts Segmentation Dataset for automotive AI applications. Enhance your segmentation models with rich, annotated data.
+keywords: Carparts Segmentation Dataset, Roboflow, computer vision, automotive AI, vehicle maintenance, Ultralytics
+---
+
+# Roboflow Universe Carparts Segmentation Dataset
+
+The [Roboflow](https://roboflow.com/?ref=ultralytics) [Carparts Segmentation Dataset](https://universe.roboflow.com/gianmarco-russo-vt9xr/car-seg-un1pm) is a curated collection of images and videos designed for computer vision applications, specifically focusing on segmentation tasks related to car parts. This dataset provides a diverse set of visuals captured from multiple perspectives, offering valuable annotated examples for training and testing segmentation models.
+
+Whether you're working on automotive research, developing AI solutions for vehicle maintenance, or exploring computer vision applications, the Carparts Segmentation Dataset serves as a valuable resource for enhancing accuracy and efficiency in your projects.
+
+
+
+## Dataset Structure
+
+The data distribution within the Carparts Segmentation Dataset is organized as outlined below:
+
+- **Training set**: Includes 3156 images, each accompanied by its corresponding annotations.
+- **Testing set**: Comprises 276 images, with each one paired with its respective annotations.
+- **Validation set**: Consists of 401 images, each having corresponding annotations.
+
+## Applications
+
+Carparts Segmentation finds applications in automotive quality control, auto repair, e-commerce cataloging, traffic monitoring, autonomous vehicles, insurance processing, recycling, and smart city initiatives. It streamlines processes by accurately identifying and categorizing different vehicle components, contributing to efficiency and automation in various industries.
+
+## Dataset YAML
+
+A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the Package Segmentation dataset, the `carparts-seg.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/carparts-seg.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/carparts-seg.yaml).
+
+!!! Example "ultralytics/cfg/datasets/carparts-seg.yaml"
+
+ ```yaml
+ --8<-- "ultralytics/cfg/datasets/carparts-seg.yaml"
+ ```
+
+## Usage
+
+To train Ultralytics YOLOv8n model on the Carparts Segmentation dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-seg.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="carparts-seg.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo segment train data=carparts-seg.yaml model=yolov8n-seg.pt epochs=100 imgsz=640
+ ```
+
+## Sample Data and Annotations
+
+The Carparts Segmentation dataset includes a diverse array of images and videos taken from various perspectives. Below, you'll find examples of data from the dataset along with their corresponding annotations:
+
+
+
+- This image illustrates object segmentation within a sample, featuring annotated bounding boxes with masks surrounding identified objects. The dataset consists of a varied set of images captured in various locations, environments, and densities, serving as a comprehensive resource for crafting models specific to this task.
+- This instance highlights the diversity and complexity inherent in the dataset, emphasizing the crucial role of high-quality data in computer vision tasks, particularly in the realm of car parts segmentation.
+
+## Citations and Acknowledgments
+
+If you integrate the Carparts Segmentation dataset into your research or development projects, please make reference to the following paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @misc{ car-seg-un1pm_dataset,
+ title = { car-seg Dataset },
+ type = { Open Source Dataset },
+ author = { Gianmarco Russo },
+ howpublished = { \url{ https://universe.roboflow.com/gianmarco-russo-vt9xr/car-seg-un1pm } },
+ url = { https://universe.roboflow.com/gianmarco-russo-vt9xr/car-seg-un1pm },
+ journal = { Roboflow Universe },
+ publisher = { Roboflow },
+ year = { 2023 },
+ month = { nov },
+ note = { visited on 2024-01-24 },
+ }
+ ```
+
+We extend our thanks to the Roboflow team for their dedication in developing and managing the Carparts Segmentation dataset, a valuable resource for vehicle maintenance and research projects. For additional details about the Carparts Segmentation dataset and its creators, please visit the [CarParts Segmentation Dataset Page](https://universe.roboflow.com/gianmarco-russo-vt9xr/car-seg-un1pm).
+
+## FAQ
+
+### What is the Roboflow Carparts Segmentation Dataset?
+
+The [Roboflow Carparts Segmentation Dataset](https://universe.roboflow.com/gianmarco-russo-vt9xr/car-seg-un1pm) is a curated collection of images and videos specifically designed for car part segmentation tasks in computer vision. This dataset includes a diverse range of visuals captured from multiple perspectives, making it an invaluable resource for training and testing segmentation models for automotive applications.
+
+### How can I use the Carparts Segmentation Dataset with Ultralytics YOLOv8?
+
+To train a YOLOv8 model on the Carparts Segmentation dataset, you can follow these steps:
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-seg.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="carparts-seg.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo segment train data=carparts-seg.yaml model=yolov8n-seg.pt epochs=100 imgsz=640
+ ```
+
+For more details, refer to the [Training](../../modes/train.md) documentation.
+
+### What are some applications of Carparts Segmentation?
+
+Carparts Segmentation can be widely applied in various fields such as:
+- **Automotive quality control**
+- **Auto repair and maintenance**
+- **E-commerce cataloging**
+- **Traffic monitoring**
+- **Autonomous vehicles**
+- **Insurance claim processing**
+- **Recycling initiatives**
+- **Smart city projects**
+
+This segmentation helps in accurately identifying and categorizing different vehicle components, enhancing the efficiency and automation in these industries.
+
+### Where can I find the dataset configuration file for Carparts Segmentation?
+
+The dataset configuration file for the Carparts Segmentation dataset, `carparts-seg.yaml`, can be found at the following location: [carparts-seg.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/carparts-seg.yaml).
+
+### Why should I use the Carparts Segmentation Dataset?
+
+The Carparts Segmentation Dataset provides rich, annotated data essential for developing high-accuracy segmentation models in automotive computer vision. This dataset's diversity and detailed annotations improve model training, making it ideal for applications like vehicle maintenance automation, enhancing vehicle safety systems, and supporting autonomous driving technologies. Partnering with a robust dataset accelerates AI development and ensures better model performance.
+
+For more details, visit the [CarParts Segmentation Dataset Page](https://universe.roboflow.com/gianmarco-russo-vt9xr/car-seg-un1pm).
diff --git a/ultralytics/docs/en/datasets/segment/coco.md b/ultralytics/docs/en/datasets/segment/coco.md
new file mode 100644
index 0000000000000000000000000000000000000000..491505371b2f1839f33d8f3c69a12a9b15931ea1
--- /dev/null
+++ b/ultralytics/docs/en/datasets/segment/coco.md
@@ -0,0 +1,164 @@
+---
+comments: true
+description: Explore the COCO-Seg dataset, an extension of COCO, with detailed segmentation annotations. Learn how to train YOLO models with COCO-Seg.
+keywords: COCO-Seg, dataset, YOLO models, instance segmentation, object detection, COCO dataset, YOLOv8, computer vision, Ultralytics, machine learning
+---
+
+# COCO-Seg Dataset
+
+The [COCO-Seg](https://cocodataset.org/#home) dataset, an extension of the COCO (Common Objects in Context) dataset, is specially designed to aid research in object instance segmentation. It uses the same images as COCO but introduces more detailed segmentation annotations. This dataset is a crucial resource for researchers and developers working on instance segmentation tasks, especially for training YOLO models.
+
+## COCO-Seg Pretrained Models
+
+| Model | size (pixels) | mAPbox 50-95 | mAPmask 50-95 | Speed CPU ONNX (ms) | Speed A100 TensorRT (ms) | params (M) | FLOPs (B) |
+|----------------------------------------------------------------------------------------------|-----------------------|----------------------|-----------------------|--------------------------------|-------------------------------------|--------------------|-------------------|
+| [YOLOv8n-seg](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n-seg.pt) | 640 | 36.7 | 30.5 | 96.1 | 1.21 | 3.4 | 12.6 |
+| [YOLOv8s-seg](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8s-seg.pt) | 640 | 44.6 | 36.8 | 155.7 | 1.47 | 11.8 | 42.6 |
+| [YOLOv8m-seg](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8m-seg.pt) | 640 | 49.9 | 40.8 | 317.0 | 2.18 | 27.3 | 110.2 |
+| [YOLOv8l-seg](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8l-seg.pt) | 640 | 52.3 | 42.6 | 572.4 | 2.79 | 46.0 | 220.5 |
+| [YOLOv8x-seg](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8x-seg.pt) | 640 | 53.4 | 43.4 | 712.1 | 4.02 | 71.8 | 344.1 |
+
+## Key Features
+
+- COCO-Seg retains the original 330K images from COCO.
+- The dataset consists of the same 80 object categories found in the original COCO dataset.
+- Annotations now include more detailed instance segmentation masks for each object in the images.
+- COCO-Seg provides standardized evaluation metrics like mean Average Precision (mAP) for object detection, and mean Average Recall (mAR) for instance segmentation tasks, enabling effective comparison of model performance.
+
+## Dataset Structure
+
+The COCO-Seg dataset is partitioned into three subsets:
+
+1. **Train2017**: This subset contains 118K images for training instance segmentation models.
+2. **Val2017**: This subset includes 5K images used for validation purposes during model training.
+3. **Test2017**: This subset encompasses 20K images used for testing and benchmarking the trained models. Ground truth annotations for this subset are not publicly available, and the results are submitted to the [COCO evaluation server](https://codalab.lisn.upsaclay.fr/competitions/7383) for performance evaluation.
+
+## Applications
+
+COCO-Seg is widely used for training and evaluating deep learning models in instance segmentation, such as the YOLO models. The large number of annotated images, the diversity of object categories, and the standardized evaluation metrics make it an indispensable resource for computer vision researchers and practitioners.
+
+## Dataset YAML
+
+A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the COCO-Seg dataset, the `coco.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml).
+
+!!! Example "ultralytics/cfg/datasets/coco.yaml"
+
+ ```yaml
+ --8<-- "ultralytics/cfg/datasets/coco.yaml"
+ ```
+
+## Usage
+
+To train a YOLOv8n-seg model on the COCO-Seg dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-seg.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="coco-seg.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo segment train data=coco-seg.yaml model=yolov8n-seg.pt epochs=100 imgsz=640
+ ```
+
+## Sample Images and Annotations
+
+COCO-Seg, like its predecessor COCO, contains a diverse set of images with various object categories and complex scenes. However, COCO-Seg introduces more detailed instance segmentation masks for each object in the images. Here are some examples of images from the dataset, along with their corresponding instance segmentation masks:
+
+
+
+- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This aids the model's ability to generalize to different object sizes, aspect ratios, and contexts.
+
+The example showcases the variety and complexity of the images in the COCO-Seg dataset and the benefits of using mosaicing during the training process.
+
+## Citations and Acknowledgments
+
+If you use the COCO-Seg dataset in your research or development work, please cite the original COCO paper and acknowledge the extension to COCO-Seg:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @misc{lin2015microsoft,
+ title={Microsoft COCO: Common Objects in Context},
+ author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
+ year={2015},
+ eprint={1405.0312},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+ }
+ ```
+
+We extend our thanks to the COCO Consortium for creating and maintaining this invaluable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
+
+## FAQ
+
+### What is the COCO-Seg dataset and how does it differ from the original COCO dataset?
+
+The [COCO-Seg](https://cocodataset.org/#home) dataset is an extension of the original COCO (Common Objects in Context) dataset, specifically designed for instance segmentation tasks. While it uses the same images as the COCO dataset, COCO-Seg includes more detailed segmentation annotations, making it a powerful resource for researchers and developers focusing on object instance segmentation.
+
+### How can I train a YOLOv8 model using the COCO-Seg dataset?
+
+To train a YOLOv8n-seg model on the COCO-Seg dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a detailed list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-seg.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="coco-seg.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo segment train data=coco-seg.yaml model=yolov8n-seg.pt epochs=100 imgsz=640
+ ```
+
+### What are the key features of the COCO-Seg dataset?
+
+The COCO-Seg dataset includes several key features:
+
+- Retains the original 330K images from the COCO dataset.
+- Annotates the same 80 object categories found in the original COCO.
+- Provides more detailed instance segmentation masks for each object.
+- Uses standardized evaluation metrics such as mean Average Precision (mAP) for object detection and mean Average Recall (mAR) for instance segmentation tasks.
+
+### What pretrained models are available for COCO-Seg, and what are their performance metrics?
+
+The COCO-Seg dataset supports multiple pretrained YOLOv8 segmentation models with varying performance metrics. Here's a summary of the available models and their key metrics:
+
+| Model | size (pixels) | mAPbox 50-95 | mAPmask 50-95 | Speed CPU ONNX (ms) | Speed A100 TensorRT (ms) | params (M) | FLOPs (B) |
+|----------------------------------------------------------------------------------------------|-----------------------|----------------------|-----------------------|--------------------------------|-------------------------------------|--------------------|-------------------|
+| [YOLOv8n-seg](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n-seg.pt) | 640 | 36.7 | 30.5 | 96.1 | 1.21 | 3.4 | 12.6 |
+| [YOLOv8s-seg](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8s-seg.pt) | 640 | 44.6 | 36.8 | 155.7 | 1.47 | 11.8 | 42.6 |
+| [YOLOv8m-seg](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8m-seg.pt) | 640 | 49.9 | 40.8 | 317.0 | 2.18 | 27.3 | 110.2 |
+| [YOLOv8l-seg](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8l-seg.pt) | 640 | 52.3 | 42.6 | 572.4 | 2.79 | 46.0 | 220.5 |
+| [YOLOv8x-seg](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8x-seg.pt) | 640 | 53.4 | 43.4 | 712.1 | 4.02 | 71.8 | 344.1 |
+
+### How is the COCO-Seg dataset structured and what subsets does it contain?
+
+The COCO-Seg dataset is partitioned into three subsets for specific training and evaluation needs:
+
+1. **Train2017**: Contains 118K images used primarily for training instance segmentation models.
+2. **Val2017**: Comprises 5K images utilized for validation during the training process.
+3. **Test2017**: Encompasses 20K images reserved for testing and benchmarking trained models. Note that ground truth annotations for this subset are not publicly available, and performance results are submitted to the [COCO evaluation server](https://codalab.lisn.upsaclay.fr/competitions/7383) for assessment.
diff --git a/ultralytics/docs/en/datasets/segment/coco8-seg.md b/ultralytics/docs/en/datasets/segment/coco8-seg.md
new file mode 100644
index 0000000000000000000000000000000000000000..054475ab8ddd07d0fb7411ee17ddac2ce1a47ff7
--- /dev/null
+++ b/ultralytics/docs/en/datasets/segment/coco8-seg.md
@@ -0,0 +1,124 @@
+---
+comments: true
+description: Discover the versatile and manageable COCO8-Seg dataset by Ultralytics, ideal for testing and debugging segmentation models or new detection approaches.
+keywords: COCO8-Seg, Ultralytics, segmentation dataset, YOLOv8, COCO 2017, model training, computer vision, dataset configuration
+---
+
+# COCO8-Seg Dataset
+
+## Introduction
+
+[Ultralytics](https://ultralytics.com) COCO8-Seg is a small, but versatile instance segmentation dataset composed of the first 8 images of the COCO train 2017 set, 4 for training and 4 for validation. This dataset is ideal for testing and debugging segmentation models, or for experimenting with new detection approaches. With 8 images, it is small enough to be easily manageable, yet diverse enough to test training pipelines for errors and act as a sanity check before training larger datasets.
+
+This dataset is intended for use with Ultralytics [HUB](https://hub.ultralytics.com) and [YOLOv8](https://github.com/ultralytics/ultralytics).
+
+## Dataset YAML
+
+A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the COCO8-Seg dataset, the `coco8-seg.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco8-seg.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco8-seg.yaml).
+
+!!! Example "ultralytics/cfg/datasets/coco8-seg.yaml"
+
+ ```yaml
+ --8<-- "ultralytics/cfg/datasets/coco8-seg.yaml"
+ ```
+
+## Usage
+
+To train a YOLOv8n-seg model on the COCO8-Seg dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-seg.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="coco8-seg.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo segment train data=coco8-seg.yaml model=yolov8n-seg.pt epochs=100 imgsz=640
+ ```
+
+## Sample Images and Annotations
+
+Here are some examples of images from the COCO8-Seg dataset, along with their corresponding annotations:
+
+
+
+- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
+
+The example showcases the variety and complexity of the images in the COCO8-Seg dataset and the benefits of using mosaicing during the training process.
+
+## Citations and Acknowledgments
+
+If you use the COCO dataset in your research or development work, please cite the following paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @misc{lin2015microsoft,
+ title={Microsoft COCO: Common Objects in Context},
+ author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
+ year={2015},
+ eprint={1405.0312},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+ }
+ ```
+
+We would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
+
+## FAQ
+
+### What is the COCO8-Seg dataset, and how is it used in Ultralytics YOLOv8?
+
+The **COCO8-Seg dataset** is a compact instance segmentation dataset by Ultralytics, consisting of the first 8 images from the COCO train 2017 set—4 images for training and 4 for validation. This dataset is tailored for testing and debugging segmentation models or experimenting with new detection methods. It is particularly useful with Ultralytics [YOLOv8](https://github.com/ultralytics/ultralytics) and [HUB](https://hub.ultralytics.com) for rapid iteration and pipeline error-checking before scaling to larger datasets. For detailed usage, refer to the model [Training](../../modes/train.md) page.
+
+### How can I train a YOLOv8n-seg model using the COCO8-Seg dataset?
+
+To train a **YOLOv8n-seg** model on the COCO8-Seg dataset for 100 epochs with an image size of 640, you can use Python or CLI commands. Here's a quick example:
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-seg.pt") # Load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="coco8-seg.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo segment train data=coco8-seg.yaml model=yolov8n-seg.pt epochs=100 imgsz=640
+ ```
+
+For a thorough explanation of available arguments and configuration options, you can check the [Training](../../modes/train.md) documentation.
+
+### Why is the COCO8-Seg dataset important for model development and debugging?
+
+The **COCO8-Seg dataset** is ideal for its manageability and diversity within a small size. It consists of only 8 images, providing a quick way to test and debug segmentation models or new detection approaches without the overhead of larger datasets. This makes it an efficient tool for sanity checks and pipeline error identification before committing to extensive training on large datasets. Learn more about dataset formats [here](https://docs.ultralytics.com/datasets/segment).
+
+### Where can I find the YAML configuration file for the COCO8-Seg dataset?
+
+The YAML configuration file for the **COCO8-Seg dataset** is available in the Ultralytics repository. You can access the file directly [here](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco8-seg.yaml). The YAML file includes essential information about dataset paths, classes, and configuration settings required for model training and validation.
+
+### What are some benefits of using mosaicing during training with the COCO8-Seg dataset?
+
+Using **mosaicing** during training helps increase the diversity and variety of objects and scenes in each training batch. This technique combines multiple images into a single composite image, enhancing the model's ability to generalize to different object sizes, aspect ratios, and contexts within the scene. Mosaicing is beneficial for improving a model's robustness and accuracy, especially when working with small datasets like COCO8-Seg. For an example of mosaiced images, see the [Sample Images and Annotations](#sample-images-and-annotations) section.
diff --git a/ultralytics/docs/en/datasets/segment/crack-seg.md b/ultralytics/docs/en/datasets/segment/crack-seg.md
new file mode 100644
index 0000000000000000000000000000000000000000..b274d077453f29eb5b30c13a3e0e8e6ce87fe5a0
--- /dev/null
+++ b/ultralytics/docs/en/datasets/segment/crack-seg.md
@@ -0,0 +1,157 @@
+---
+comments: true
+description: Explore the extensive Roboflow Crack Segmentation Dataset, perfect for transportation and public safety studies or self-driving car model development.
+keywords: Roboflow, Crack Segmentation Dataset, Ultralytics, transportation safety, public safety, self-driving cars, computer vision, road safety, infrastructure maintenance, dataset
+---
+
+# Roboflow Universe Crack Segmentation Dataset
+
+The [Roboflow](https://roboflow.com/?ref=ultralytics) [Crack Segmentation Dataset](https://universe.roboflow.com/university-bswxt/crack-bphdr) stands out as an extensive resource designed specifically for individuals involved in transportation and public safety studies. It is equally beneficial for those working on the development of self-driving car models or simply exploring computer vision applications for recreational purposes.
+
+Comprising a total of 4029 static images captured from diverse road and wall scenarios, this dataset emerges as a valuable asset for tasks related to crack segmentation. Whether you are delving into the intricacies of transportation research or seeking to enhance the accuracy of your self-driving car models, this dataset provides a rich and varied collection of images to support your endeavors.
+
+## Dataset Structure
+
+The division of data within the Crack Segmentation Dataset is outlined as follows:
+
+- **Training set**: Consists of 3717 images with corresponding annotations.
+- **Testing set**: Comprises 112 images along with their respective annotations.
+- **Validation set**: Includes 200 images with their corresponding annotations.
+
+## Applications
+
+Crack segmentation finds practical applications in infrastructure maintenance, aiding in the identification and assessment of structural damage. It also plays a crucial role in enhancing road safety by enabling automated systems to detect and address pavement cracks for timely repairs.
+
+## Dataset YAML
+
+A YAML (Yet Another Markup Language) file is employed to outline the configuration of the dataset, encompassing details about paths, classes, and other pertinent information. Specifically, for the Crack Segmentation dataset, the `crack-seg.yaml` file is managed and accessible at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/crack-seg.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/crack-seg.yaml).
+
+!!! Example "ultralytics/cfg/datasets/crack-seg.yaml"
+
+ ```yaml
+ --8<-- "ultralytics/cfg/datasets/crack-seg.yaml"
+ ```
+
+## Usage
+
+To train Ultralytics YOLOv8n model on the Crack Segmentation dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-seg.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="crack-seg.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo segment train data=crack-seg.yaml model=yolov8n-seg.pt epochs=100 imgsz=640
+ ```
+
+## Sample Data and Annotations
+
+The Crack Segmentation dataset comprises a varied collection of images and videos captured from multiple perspectives. Below are instances of data from the dataset, accompanied by their respective annotations:
+
+
+
+- This image presents an example of image object segmentation, featuring annotated bounding boxes with masks outlining identified objects. The dataset includes a diverse array of images taken in different locations, environments, and densities, making it a comprehensive resource for developing models designed for this particular task.
+
+- The example underscores the diversity and complexity found in the Crack segmentation dataset, emphasizing the crucial role of high-quality data in computer vision tasks.
+
+## Citations and Acknowledgments
+
+If you incorporate the crack segmentation dataset into your research or development endeavors, kindly reference the following paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @misc{ crack-bphdr_dataset,
+ title = { crack Dataset },
+ type = { Open Source Dataset },
+ author = { University },
+ howpublished = { \url{ https://universe.roboflow.com/university-bswxt/crack-bphdr } },
+ url = { https://universe.roboflow.com/university-bswxt/crack-bphdr },
+ journal = { Roboflow Universe },
+ publisher = { Roboflow },
+ year = { 2022 },
+ month = { dec },
+ note = { visited on 2024-01-23 },
+ }
+ ```
+
+We would like to acknowledge the Roboflow team for creating and maintaining the Crack Segmentation dataset as a valuable resource for the road safety and research projects. For more information about the Crack segmentation dataset and its creators, visit the [Crack Segmentation Dataset Page](https://universe.roboflow.com/university-bswxt/crack-bphdr).
+
+## FAQ
+
+### What is the Roboflow Crack Segmentation Dataset?
+
+The [Roboflow Crack Segmentation Dataset](https://universe.roboflow.com/university-bswxt/crack-bphdr) is a comprehensive collection of 4029 static images designed specifically for transportation and public safety studies. It is ideal for tasks such as self-driving car model development and infrastructure maintenance. The dataset includes training, testing, and validation sets, aiding in accurate crack detection and segmentation.
+
+### How do I train a model using the Crack Segmentation Dataset with Ultralytics YOLOv8?
+
+To train an Ultralytics YOLOv8 model on the Crack Segmentation dataset, use the following code snippets. Detailed instructions and further parameters can be found on the model [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-seg.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="crack-seg.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo segment train data=crack-seg.yaml model=yolov8n-seg.pt epochs=100 imgsz=640
+ ```
+
+### Why should I use the Crack Segmentation Dataset for my self-driving car project?
+
+The Crack Segmentation Dataset is exceptionally suited for self-driving car projects due to its diverse collection of 4029 road and wall images, which provide a varied range of scenarios. This diversity enhances the accuracy and robustness of models trained for crack detection, crucial for maintaining road safety and ensuring timely infrastructure repairs.
+
+### What unique features does Ultralytics YOLO offer for crack segmentation?
+
+Ultralytics YOLO offers advanced real-time object detection, segmentation, and classification capabilities that make it ideal for crack segmentation tasks. Its ability to handle large datasets and complex scenarios ensures high accuracy and efficiency. For example, the model [Training](../../modes/train.md), [Predict](../../modes/predict.md), and [Export](../../modes/export.md) modes cover comprehensive functionalities from training to deployment.
+
+### How do I cite the Roboflow Crack Segmentation Dataset in my research paper?
+
+If you incorporate the Crack Segmentation Dataset into your research, please use the following BibTeX reference:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @misc{ crack-bphdr_dataset,
+ title = { crack Dataset },
+ type = { Open Source Dataset },
+ author = { University },
+ howpublished = { \url{ https://universe.roboflow.com/university-bswxt/crack-bphdr } },
+ url = { https://universe.roboflow.com/university-bswxt/crack-bphdr },
+ journal = { Roboflow Universe },
+ publisher = { Roboflow },
+ year = { 2022 },
+ month = { dec },
+ note = { visited on 2024-01-23 },
+ }
+ ```
+
+This citation format ensures proper accreditation to the creators of the dataset and acknowledges its use in your research.
diff --git a/ultralytics/docs/en/datasets/segment/index.md b/ultralytics/docs/en/datasets/segment/index.md
new file mode 100644
index 0000000000000000000000000000000000000000..86617704fa6d9bf5873068ce1dd755fe5e57e995
--- /dev/null
+++ b/ultralytics/docs/en/datasets/segment/index.md
@@ -0,0 +1,200 @@
+---
+comments: true
+description: Explore the supported dataset formats for Ultralytics YOLO and learn how to prepare and use datasets for training object segmentation models.
+keywords: Ultralytics, YOLO, instance segmentation, dataset formats, auto-annotation, COCO, segmentation models, training data
+---
+
+# Instance Segmentation Datasets Overview
+
+## Supported Dataset Formats
+
+### Ultralytics YOLO format
+
+The dataset label format used for training YOLO segmentation models is as follows:
+
+1. One text file per image: Each image in the dataset has a corresponding text file with the same name as the image file and the ".txt" extension.
+2. One row per object: Each row in the text file corresponds to one object instance in the image.
+3. Object information per row: Each row contains the following information about the object instance:
+ - Object class index: An integer representing the class of the object (e.g., 0 for person, 1 for car, etc.).
+ - Object bounding coordinates: The bounding coordinates around the mask area, normalized to be between 0 and 1.
+
+The format for a single row in the segmentation dataset file is as follows:
+
+```
+ ...
+```
+
+In this format, `` is the index of the class for the object, and ` ... ` are the bounding coordinates of the object's segmentation mask. The coordinates are separated by spaces.
+
+Here is an example of the YOLO dataset format for a single image with two objects made up of a 3-point segment and a 5-point segment.
+
+```
+0 0.681 0.485 0.670 0.487 0.676 0.487
+1 0.504 0.000 0.501 0.004 0.498 0.004 0.493 0.010 0.492 0.0104
+```
+
+!!! Tip "Tip"
+
+ - The length of each row does **not** have to be equal.
+ - Each segmentation label must have a **minimum of 3 xy points**: ``
+
+### Dataset YAML format
+
+The Ultralytics framework uses a YAML file format to define the dataset and model configuration for training Detection Models. Here is an example of the YAML format used for defining a detection dataset:
+
+```yaml
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/coco8-seg # dataset root dir
+train: images/train # train images (relative to 'path') 4 images
+val: images/val # val images (relative to 'path') 4 images
+test: # test images (optional)
+
+# Classes (80 COCO classes)
+names:
+ 0: person
+ 1: bicycle
+ 2: car
+ # ...
+ 77: teddy bear
+ 78: hair drier
+ 79: toothbrush
+```
+
+The `train` and `val` fields specify the paths to the directories containing the training and validation images, respectively.
+
+`names` is a dictionary of class names. The order of the names should match the order of the object class indices in the YOLO dataset files.
+
+## Usage
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-seg.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="coco8-seg.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo segment train data=coco8-seg.yaml model=yolov8n-seg.pt epochs=100 imgsz=640
+ ```
+
+## Supported Datasets
+
+## Supported Datasets
+
+- [COCO](coco.md): A comprehensive dataset for object detection, segmentation, and captioning, featuring over 200K labeled images across a wide range of categories.
+- [COCO8-seg](coco8-seg.md): A compact, 8-image subset of COCO designed for quick testing of segmentation model training, ideal for CI checks and workflow validation in the `ultralytics` repository.
+- [Carparts-seg](carparts-seg.md): A specialized dataset focused on the segmentation of car parts, ideal for automotive applications. It includes a variety of vehicles with detailed annotations of individual car components.
+- [Crack-seg](crack-seg.md): A dataset tailored for the segmentation of cracks in various surfaces. Essential for infrastructure maintenance and quality control, it provides detailed imagery for training models to identify structural weaknesses.
+- [Package-seg](package-seg.md): A dataset dedicated to the segmentation of different types of packaging materials and shapes. It's particularly useful for logistics and warehouse automation, aiding in the development of systems for package handling and sorting.
+
+### Adding your own dataset
+
+If you have your own dataset and would like to use it for training segmentation models with Ultralytics YOLO format, ensure that it follows the format specified above under "Ultralytics YOLO format". Convert your annotations to the required format and specify the paths, number of classes, and class names in the YAML configuration file.
+
+## Port or Convert Label Formats
+
+### COCO Dataset Format to YOLO Format
+
+You can easily convert labels from the popular COCO dataset format to the YOLO format using the following code snippet:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics.data.converter import convert_coco
+
+ convert_coco(labels_dir="path/to/coco/annotations/", use_segments=True)
+ ```
+
+This conversion tool can be used to convert the COCO dataset or any dataset in the COCO format to the Ultralytics YOLO format.
+
+Remember to double-check if the dataset you want to use is compatible with your model and follows the necessary format conventions. Properly formatted datasets are crucial for training successful object detection models.
+
+## Auto-Annotation
+
+Auto-annotation is an essential feature that allows you to generate a segmentation dataset using a pre-trained detection model. It enables you to quickly and accurately annotate a large number of images without the need for manual labeling, saving time and effort.
+
+### Generate Segmentation Dataset Using a Detection Model
+
+To auto-annotate your dataset using the Ultralytics framework, you can use the `auto_annotate` function as shown below:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics.data.annotator import auto_annotate
+
+ auto_annotate(data="path/to/images", det_model="yolov8x.pt", sam_model="sam_b.pt")
+ ```
+
+| Argument | Type | Description | Default |
+|--------------|-------------------------|-------------------------------------------------------------------------------------------------------------|----------------|
+| `data` | `str` | Path to a folder containing images to be annotated. | `None` |
+| `det_model` | `str, optional` | Pre-trained YOLO detection model. Defaults to `'yolov8x.pt'`. | `'yolov8x.pt'` |
+| `sam_model` | `str, optional` | Pre-trained SAM segmentation model. Defaults to `'sam_b.pt'`. | `'sam_b.pt'` |
+| `device` | `str, optional` | Device to run the models on. Defaults to an empty string (CPU or GPU, if available). | `''` |
+| `output_dir` | `str or None, optional` | Directory to save the annotated results. Defaults to a `'labels'` folder in the same directory as `'data'`. | `None` |
+
+The `auto_annotate` function takes the path to your images, along with optional arguments for specifying the pre-trained detection and [SAM segmentation models](../../models/sam.md), the device to run the models on, and the output directory for saving the annotated results.
+
+By leveraging the power of pre-trained models, auto-annotation can significantly reduce the time and effort required for creating high-quality segmentation datasets. This feature is particularly useful for researchers and developers working with large image collections, as it allows them to focus on model development and evaluation rather than manual annotation.
+
+## FAQ
+
+### What dataset formats does Ultralytics YOLO support for instance segmentation?
+
+Ultralytics YOLO supports several dataset formats for instance segmentation, with the primary format being its own Ultralytics YOLO format. Each image in your dataset needs a corresponding text file with object information segmented into multiple rows (one row per object), listing the class index and normalized bounding coordinates. For more detailed instructions on the YOLO dataset format, visit the [Instance Segmentation Datasets Overview](#instance-segmentation-datasets-overview).
+
+### How can I convert COCO dataset annotations to the YOLO format?
+
+Converting COCO format annotations to YOLO format is straightforward using Ultralytics tools. You can use the `convert_coco` function from the `ultralytics.data.converter` module:
+
+```python
+from ultralytics.data.converter import convert_coco
+
+convert_coco(labels_dir="path/to/coco/annotations/", use_segments=True)
+```
+
+This script converts your COCO dataset annotations to the required YOLO format, making it suitable for training your YOLO models. For more details, refer to [Port or Convert Label Formats](#coco-dataset-format-to-yolo-format).
+
+### How do I prepare a YAML file for training Ultralytics YOLO models?
+
+To prepare a YAML file for training YOLO models with Ultralytics, you need to define the dataset paths and class names. Here's an example YAML configuration:
+
+```yaml
+path: ../datasets/coco8-seg # dataset root dir
+train: images/train # train images (relative to 'path')
+val: images/val # val images (relative to 'path')
+
+names:
+ 0: person
+ 1: bicycle
+ 2: car
+ # ...
+```
+
+Ensure you update the paths and class names according to your dataset. For more information, check the [Dataset YAML Format](#dataset-yaml-format) section.
+
+### What is the auto-annotation feature in Ultralytics YOLO?
+
+Auto-annotation in Ultralytics YOLO allows you to generate segmentation annotations for your dataset using a pre-trained detection model. This significantly reduces the need for manual labeling. You can use the `auto_annotate` function as follows:
+
+```python
+from ultralytics.data.annotator import auto_annotate
+
+auto_annotate(data="path/to/images", det_model="yolov8x.pt", sam_model="sam_b.pt")
+```
+
+This function automates the annotation process, making it faster and more efficient. For more details, explore the [Auto-Annotation](#auto-annotation) section.
diff --git a/ultralytics/docs/en/datasets/segment/package-seg.md b/ultralytics/docs/en/datasets/segment/package-seg.md
new file mode 100644
index 0000000000000000000000000000000000000000..df63f605365626a0138979e3384b7d1d4cf3e24e
--- /dev/null
+++ b/ultralytics/docs/en/datasets/segment/package-seg.md
@@ -0,0 +1,144 @@
+---
+comments: true
+description: Explore the Roboflow Package Segmentation Dataset. Optimize logistics and enhance vision models with curated images for package identification and sorting.
+keywords: Roboflow, Package Segmentation Dataset, computer vision, package identification, logistics, warehouse automation, segmentation models, training data
+---
+
+# Roboflow Universe Package Segmentation Dataset
+
+The [Roboflow](https://roboflow.com/?ref=ultralytics) [Package Segmentation Dataset](https://universe.roboflow.com/factorypackage/factory_package) is a curated collection of images specifically tailored for tasks related to package segmentation in the field of computer vision. This dataset is designed to assist researchers, developers, and enthusiasts working on projects related to package identification, sorting, and handling.
+
+Containing a diverse set of images showcasing various packages in different contexts and environments, the dataset serves as a valuable resource for training and evaluating segmentation models. Whether you are engaged in logistics, warehouse automation, or any application requiring precise package analysis, the Package Segmentation Dataset provides a targeted and comprehensive set of images to enhance the performance of your computer vision algorithms.
+
+## Dataset Structure
+
+The distribution of data in the Package Segmentation Dataset is structured as follows:
+
+- **Training set**: Encompasses 1920 images accompanied by their corresponding annotations.
+- **Testing set**: Consists of 89 images, each paired with its respective annotations.
+- **Validation set**: Comprises 188 images, each with corresponding annotations.
+
+## Applications
+
+Package segmentation, facilitated by the Package Segmentation Dataset, is crucial for optimizing logistics, enhancing last-mile delivery, improving manufacturing quality control, and contributing to smart city solutions. From e-commerce to security applications, this dataset is a key resource, fostering innovation in computer vision for diverse and efficient package analysis applications.
+
+## Dataset YAML
+
+A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the Package Segmentation dataset, the `package-seg.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/package-seg.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/package-seg.yaml).
+
+!!! Example "ultralytics/cfg/datasets/package-seg.yaml"
+
+ ```yaml
+ --8<-- "ultralytics/cfg/datasets/package-seg.yaml"
+ ```
+
+## Usage
+
+To train Ultralytics YOLOv8n model on the Package Segmentation dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-seg.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="package-seg.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo segment train data=package-seg.yaml model=yolov8n-seg.pt epochs=100 imgsz=640
+ ```
+
+## Sample Data and Annotations
+
+The Package Segmentation dataset comprises a varied collection of images and videos captured from multiple perspectives. Below are instances of data from the dataset, accompanied by their respective annotations:
+
+
+
+- This image displays an instance of image object detection, featuring annotated bounding boxes with masks outlining recognized objects. The dataset incorporates a diverse collection of images taken in different locations, environments, and densities. It serves as a comprehensive resource for developing models specific to this task.
+- The example emphasizes the diversity and complexity present in the VisDrone dataset, underscoring the significance of high-quality sensor data for computer vision tasks involving drones.
+
+## Citations and Acknowledgments
+
+If you integrate the crack segmentation dataset into your research or development initiatives, please cite the following paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @misc{ factory_package_dataset,
+ title = { factory_package Dataset },
+ type = { Open Source Dataset },
+ author = { factorypackage },
+ howpublished = { \url{ https://universe.roboflow.com/factorypackage/factory_package } },
+ url = { https://universe.roboflow.com/factorypackage/factory_package },
+ journal = { Roboflow Universe },
+ publisher = { Roboflow },
+ year = { 2024 },
+ month = { jan },
+ note = { visited on 2024-01-24 },
+ }
+ ```
+
+We express our gratitude to the Roboflow team for their efforts in creating and maintaining the Package Segmentation dataset, a valuable asset for logistics and research projects. For additional details about the Package Segmentation dataset and its creators, please visit the [Package Segmentation Dataset Page](https://universe.roboflow.com/factorypackage/factory_package).
+
+## FAQ
+
+### What is the Roboflow Package Segmentation Dataset and how can it help in computer vision projects?
+
+The [Roboflow Package Segmentation Dataset](https://universe.roboflow.com/factorypackage/factory_package) is a curated collection of images tailored for tasks involving package segmentation. It includes diverse images of packages in various contexts, making it invaluable for training and evaluating segmentation models. This dataset is particularly useful for applications in logistics, warehouse automation, and any project requiring precise package analysis. It helps optimize logistics and enhance vision models for accurate package identification and sorting.
+
+### How do I train an Ultralytics YOLOv8 model on the Package Segmentation Dataset?
+
+You can train an Ultralytics YOLOv8n model using both Python and CLI methods. Use the snippets below:
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-seg.pt") # load a pretrained model
+
+ # Train the model
+ results = model.train(data="package-seg.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo segment train data=package-seg.yaml model=yolov8n-seg.pt epochs=100 imgsz=640
+ ```
+
+Refer to the model [Training](../../modes/train.md) page for more details.
+
+### What are the components of the Package Segmentation Dataset, and how is it structured?
+
+The dataset is structured into three main components:
+- **Training set**: Contains 1920 images with annotations.
+- **Testing set**: Comprises 89 images with corresponding annotations.
+- **Validation set**: Includes 188 images with annotations.
+
+This structure ensures a balanced dataset for thorough model training, validation, and testing, enhancing the performance of segmentation algorithms.
+
+### Why should I use Ultralytics YOLOv8 with the Package Segmentation Dataset?
+
+Ultralytics YOLOv8 provides state-of-the-art accuracy and speed for real-time object detection and segmentation tasks. Using it with the Package Segmentation Dataset allows you to leverage YOLOv8's capabilities for precise package segmentation. This combination is especially beneficial for industries like logistics and warehouse automation, where accurate package identification is critical. For more information, check out our [page on YOLOv8 segmentation](https://docs.ultralytics.com/models/yolov8).
+
+### How can I access and use the package-seg.yaml file for the Package Segmentation Dataset?
+
+The `package-seg.yaml` file is hosted on Ultralytics' GitHub repository and contains essential information about the dataset's paths, classes, and configuration. You can download it from [here](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/package-seg.yaml). This file is crucial for configuring your models to utilize the dataset efficiently.
+
+For more insights and practical examples, explore our [Usage](https://docs.ultralytics.com/usage/python/) section.
diff --git a/ultralytics/docs/en/datasets/track/index.md b/ultralytics/docs/en/datasets/track/index.md
new file mode 100644
index 0000000000000000000000000000000000000000..d7a24f3a0aa9f0e42a0729d7d1c5b35696bf2d2e
--- /dev/null
+++ b/ultralytics/docs/en/datasets/track/index.md
@@ -0,0 +1,84 @@
+---
+comments: true
+description: Learn how to use Multi-Object Tracking with YOLO. Explore dataset formats and see upcoming features for training trackers. Start with Python or CLI examples.
+keywords: YOLO, Multi-Object Tracking, Tracking Datasets, Python Tracking Example, CLI Tracking Example, Object Detection, Ultralytics, AI, Machine Learning
+---
+
+# Multi-object Tracking Datasets Overview
+
+## Dataset Format (Coming Soon)
+
+Multi-Object Detector doesn't need standalone training and directly supports pre-trained detection, segmentation or Pose models. Support for training trackers alone is coming soon
+
+## Usage
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ model = YOLO("yolov8n.pt")
+ results = model.track(source="https://youtu.be/LNwODJXcvt4", conf=0.3, iou=0.5, show=True)
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo track model=yolov8n.pt source="https://youtu.be/LNwODJXcvt4" conf=0.3, iou=0.5 show
+ ```
+
+## FAQ
+
+### How do I use Multi-Object Tracking with Ultralytics YOLO?
+
+To use Multi-Object Tracking with Ultralytics YOLO, you can start by using the Python or CLI examples provided. Here is how you can get started:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ model = YOLO("yolov8n.pt") # Load the YOLOv8 model
+ results = model.track(source="https://youtu.be/LNwODJXcvt4", conf=0.3, iou=0.5, show=True)
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo track model=yolov8n.pt source="https://youtu.be/LNwODJXcvt4" conf=0.3 iou=0.5 show
+ ```
+
+These commands load the YOLOv8 model and use it for tracking objects in the given video source with specific confidence (`conf`) and Intersection over Union (`iou`) thresholds. For more details, refer to the [track mode documentation](../../modes/track.md).
+
+### What are the upcoming features for training trackers in Ultralytics?
+
+Ultralytics is continuously enhancing its AI models. An upcoming feature will enable the training of standalone trackers. Until then, Multi-Object Detector leverages pre-trained detection, segmentation, or Pose models for tracking without requiring standalone training. Stay updated by following our [blog](https://www.ultralytics.com/blog) or checking the [upcoming features](../../reference/trackers/track.md).
+
+### Why should I use Ultralytics YOLO for multi-object tracking?
+
+Ultralytics YOLO is a state-of-the-art object detection model known for its real-time performance and high accuracy. Using YOLO for multi-object tracking provides several advantages:
+
+- **Real-time tracking:** Achieve efficient and high-speed tracking ideal for dynamic environments.
+- **Flexibility with pre-trained models:** No need to train from scratch; simply use pre-trained detection, segmentation, or Pose models.
+- **Ease of use:** Simple API integration with both Python and CLI makes setting up tracking pipelines straightforward.
+- **Extensive documentation and community support:** Ultralytics provides comprehensive documentation and an active community forum to troubleshoot issues and enhance your tracking models.
+
+For more details on setting up and using YOLO for tracking, visit our [track usage guide](../../modes/track.md).
+
+### Can I use custom datasets for multi-object tracking with Ultralytics YOLO?
+
+Yes, you can use custom datasets for multi-object tracking with Ultralytics YOLO. While support for standalone tracker training is an upcoming feature, you can already use pre-trained models on your custom datasets. Prepare your datasets in the appropriate format compatible with YOLO and follow the documentation to integrate them.
+
+### How do I interpret the results from the Ultralytics YOLO tracking model?
+
+After running a tracking job with Ultralytics YOLO, the results include various data points such as tracked object IDs, their bounding boxes, and the confidence scores. Here's a brief overview of how to interpret these results:
+
+- **Tracked IDs:** Each object is assigned a unique ID, which helps in tracking it across frames.
+- **Bounding boxes:** These indicate the location of tracked objects within the frame.
+- **Confidence scores:** These reflect the model's confidence in detecting the tracked object.
+
+For detailed guidance on interpreting and visualizing these results, refer to the [results handling guide](../../reference/engine/results.md).
diff --git a/ultralytics/docs/en/guides/analytics.md b/ultralytics/docs/en/guides/analytics.md
new file mode 100644
index 0000000000000000000000000000000000000000..e2a2ea4708690d5b146c7538eab3e4424c5d48a8
--- /dev/null
+++ b/ultralytics/docs/en/guides/analytics.md
@@ -0,0 +1,493 @@
+---
+comments: true
+description: Learn to create line graphs, bar plots, and pie charts using Python with guided instructions and code snippets. Maximize your data visualization skills!.
+keywords: Ultralytics, YOLOv8, data visualization, line graphs, bar plots, pie charts, Python, analytics, tutorial, guide
+---
+
+# Analytics using Ultralytics YOLOv8
+
+## Introduction
+
+This guide provides a comprehensive overview of three fundamental types of data visualizations: line graphs, bar plots, and pie charts. Each section includes step-by-step instructions and code snippets on how to create these visualizations using Python.
+
+### Visual Samples
+
+| Line Graph | Bar Plot | Pie Chart |
+| :----------------------------------------------------------------------------------------------------------------: | :--------------------------------------------------------------------------------------------------------------: | :---------------------------------------------------------------------------------------------------------------: |
+|  |  |  |
+
+### Why Graphs are Important
+
+- Line graphs are ideal for tracking changes over short and long periods and for comparing changes for multiple groups over the same period.
+- Bar plots, on the other hand, are suitable for comparing quantities across different categories and showing relationships between a category and its numerical value.
+- Lastly, pie charts are effective for illustrating proportions among categories and showing parts of a whole.
+
+!!! Analytics "Analytics Examples"
+
+ === "Line Graph"
+
+ ```python
+ import cv2
+
+ from ultralytics import YOLO, solutions
+
+ model = YOLO("yolov8s.pt")
+
+ cap = cv2.VideoCapture("Path/to/video/file.mp4")
+ assert cap.isOpened(), "Error reading video file"
+ w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
+
+ out = cv2.VideoWriter("line_plot.avi", cv2.VideoWriter_fourcc(*"MJPG"), fps, (w, h))
+
+ analytics = solutions.Analytics(
+ type="line",
+ writer=out,
+ im0_shape=(w, h),
+ view_img=True,
+ )
+ total_counts = 0
+ frame_count = 0
+
+ while cap.isOpened():
+ success, frame = cap.read()
+
+ if success:
+ frame_count += 1
+ results = model.track(frame, persist=True, verbose=True)
+
+ if results[0].boxes.id is not None:
+ boxes = results[0].boxes.xyxy.cpu()
+ for box in boxes:
+ total_counts += 1
+
+ analytics.update_line(frame_count, total_counts)
+
+ total_counts = 0
+ if cv2.waitKey(1) & 0xFF == ord("q"):
+ break
+ else:
+ break
+
+ cap.release()
+ out.release()
+ cv2.destroyAllWindows()
+ ```
+
+ === "Multiple Lines"
+
+ ```python
+ import cv2
+
+ from ultralytics import YOLO, solutions
+
+ model = YOLO("yolov8s.pt")
+
+ cap = cv2.VideoCapture("Path/to/video/file.mp4")
+ assert cap.isOpened(), "Error reading video file"
+ w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
+ out = cv2.VideoWriter("multiple_line_plot.avi", cv2.VideoWriter_fourcc(*"MJPG"), fps, (w, h))
+
+ analytics = solutions.Analytics(
+ type="line",
+ writer=out,
+ im0_shape=(w, h),
+ view_img=True,
+ max_points=200,
+ )
+
+ frame_count = 0
+ data = {}
+ labels = []
+
+ while cap.isOpened():
+ success, frame = cap.read()
+
+ if success:
+ frame_count += 1
+
+ results = model.track(frame, persist=True)
+
+ if results[0].boxes.id is not None:
+ boxes = results[0].boxes.xyxy.cpu()
+ track_ids = results[0].boxes.id.int().cpu().tolist()
+ clss = results[0].boxes.cls.cpu().tolist()
+
+ for box, track_id, cls in zip(boxes, track_ids, clss):
+ # Store each class label
+ if model.names[int(cls)] not in labels:
+ labels.append(model.names[int(cls)])
+
+ # Store each class count
+ if model.names[int(cls)] in data:
+ data[model.names[int(cls)]] += 1
+ else:
+ data[model.names[int(cls)]] = 0
+
+ # update lines every frame
+ analytics.update_multiple_lines(data, labels, frame_count)
+ data = {} # clear the data list for next frame
+ else:
+ break
+
+ cap.release()
+ out.release()
+ cv2.destroyAllWindows()
+ ```
+
+ === "Pie Chart"
+
+ ```python
+ import cv2
+
+ from ultralytics import YOLO, solutions
+
+ model = YOLO("yolov8s.pt")
+
+ cap = cv2.VideoCapture("Path/to/video/file.mp4")
+ assert cap.isOpened(), "Error reading video file"
+ w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
+
+ out = cv2.VideoWriter("pie_chart.avi", cv2.VideoWriter_fourcc(*"MJPG"), fps, (w, h))
+
+ analytics = solutions.Analytics(
+ type="pie",
+ writer=out,
+ im0_shape=(w, h),
+ view_img=True,
+ )
+
+ clswise_count = {}
+
+ while cap.isOpened():
+ success, frame = cap.read()
+ if success:
+ results = model.track(frame, persist=True, verbose=True)
+ if results[0].boxes.id is not None:
+ boxes = results[0].boxes.xyxy.cpu()
+ clss = results[0].boxes.cls.cpu().tolist()
+ for box, cls in zip(boxes, clss):
+ if model.names[int(cls)] in clswise_count:
+ clswise_count[model.names[int(cls)]] += 1
+ else:
+ clswise_count[model.names[int(cls)]] = 1
+
+ analytics.update_pie(clswise_count)
+ clswise_count = {}
+
+ if cv2.waitKey(1) & 0xFF == ord("q"):
+ break
+ else:
+ break
+
+ cap.release()
+ out.release()
+ cv2.destroyAllWindows()
+ ```
+
+ === "Bar Plot"
+
+ ```python
+ import cv2
+
+ from ultralytics import YOLO, solutions
+
+ model = YOLO("yolov8s.pt")
+
+ cap = cv2.VideoCapture("Path/to/video/file.mp4")
+ assert cap.isOpened(), "Error reading video file"
+ w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
+
+ out = cv2.VideoWriter("bar_plot.avi", cv2.VideoWriter_fourcc(*"MJPG"), fps, (w, h))
+
+ analytics = solutions.Analytics(
+ type="bar",
+ writer=out,
+ im0_shape=(w, h),
+ view_img=True,
+ )
+
+ clswise_count = {}
+
+ while cap.isOpened():
+ success, frame = cap.read()
+ if success:
+ results = model.track(frame, persist=True, verbose=True)
+ if results[0].boxes.id is not None:
+ boxes = results[0].boxes.xyxy.cpu()
+ clss = results[0].boxes.cls.cpu().tolist()
+ for box, cls in zip(boxes, clss):
+ if model.names[int(cls)] in clswise_count:
+ clswise_count[model.names[int(cls)]] += 1
+ else:
+ clswise_count[model.names[int(cls)]] = 1
+
+ analytics.update_bar(clswise_count)
+ clswise_count = {}
+
+ if cv2.waitKey(1) & 0xFF == ord("q"):
+ break
+ else:
+ break
+
+ cap.release()
+ out.release()
+ cv2.destroyAllWindows()
+ ```
+
+ === "Area chart"
+
+ ```python
+ import cv2
+
+ from ultralytics import YOLO, solutions
+
+ model = YOLO("yolov8s.pt")
+
+ cap = cv2.VideoCapture("path/to/video/file.mp4")
+ assert cap.isOpened(), "Error reading video file"
+ w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
+
+ out = cv2.VideoWriter("area_plot.avi", cv2.VideoWriter_fourcc(*"MJPG"), fps, (w, h))
+
+ analytics = solutions.Analytics(
+ type="area",
+ writer=out,
+ im0_shape=(w, h),
+ view_img=True,
+ )
+
+ clswise_count = {}
+ frame_count = 0
+
+ while cap.isOpened():
+ success, frame = cap.read()
+ if success:
+ frame_count += 1
+ results = model.track(frame, persist=True, verbose=True)
+
+ if results[0].boxes.id is not None:
+ boxes = results[0].boxes.xyxy.cpu()
+ clss = results[0].boxes.cls.cpu().tolist()
+
+ for box, cls in zip(boxes, clss):
+ if model.names[int(cls)] in clswise_count:
+ clswise_count[model.names[int(cls)]] += 1
+ else:
+ clswise_count[model.names[int(cls)]] = 1
+
+ analytics.update_area(frame_count, clswise_count)
+ clswise_count = {}
+ if cv2.waitKey(1) & 0xFF == ord("q"):
+ break
+ else:
+ break
+
+ cap.release()
+ out.release()
+ cv2.destroyAllWindows()
+ ```
+
+### Argument `Analytics`
+
+Here's a table with the `Analytics` arguments:
+
+| Name | Type | Default | Description |
+| -------------- | ----------------- | ------------- | -------------------------------------------------------------------------------- |
+| `type` | `str` | `None` | Type of data or object. |
+| `im0_shape` | `tuple` | `None` | Shape of the initial image. |
+| `writer` | `cv2.VideoWriter` | `None` | Object for writing video files. |
+| `title` | `str` | `ultralytics` | Title for the visualization. |
+| `x_label` | `str` | `x` | Label for the x-axis. |
+| `y_label` | `str` | `y` | Label for the y-axis. |
+| `bg_color` | `str` | `white` | Background color. |
+| `fg_color` | `str` | `black` | Foreground color. |
+| `line_color` | `str` | `yellow` | Color of the lines. |
+| `line_width` | `int` | `2` | Width of the lines. |
+| `fontsize` | `int` | `13` | Font size for text. |
+| `view_img` | `bool` | `False` | Flag to display the image or video. |
+| `save_img` | `bool` | `True` | Flag to save the image or video. |
+| `max_points` | `int` | `50` | For multiple lines, total points drawn on frame, before deleting initial points. |
+| `points_width` | `int` | `15` | Width of line points highlighter. |
+
+### Arguments `model.track`
+
+| Name | Type | Default | Description |
+| --------- | ------- | -------------- | ----------------------------------------------------------- |
+| `source` | `im0` | `None` | source directory for images or videos |
+| `persist` | `bool` | `False` | persisting tracks between frames |
+| `tracker` | `str` | `botsort.yaml` | Tracking method 'bytetrack' or 'botsort' |
+| `conf` | `float` | `0.3` | Confidence Threshold |
+| `iou` | `float` | `0.5` | IOU Threshold |
+| `classes` | `list` | `None` | filter results by class, i.e. classes=0, or classes=[0,2,3] |
+| `verbose` | `bool` | `True` | Display the object tracking results |
+
+## Conclusion
+
+Understanding when and how to use different types of visualizations is crucial for effective data analysis. Line graphs, bar plots, and pie charts are fundamental tools that can help you convey your data's story more clearly and effectively.
+
+## FAQ
+
+### How do I create a line graph using Ultralytics YOLOv8 Analytics?
+
+To create a line graph using Ultralytics YOLOv8 Analytics, follow these steps:
+
+1. Load a YOLOv8 model and open your video file.
+2. Initialize the `Analytics` class with the type set to "line."
+3. Iterate through video frames, updating the line graph with relevant data, such as object counts per frame.
+4. Save the output video displaying the line graph.
+
+Example:
+
+```python
+import cv2
+
+from ultralytics import YOLO, solutions
+
+model = YOLO("yolov8s.pt")
+cap = cv2.VideoCapture("Path/to/video/file.mp4")
+out = cv2.VideoWriter("line_plot.avi", cv2.VideoWriter_fourcc(*"MJPG"), fps, (w, h))
+
+analytics = solutions.Analytics(type="line", writer=out, im0_shape=(w, h), view_img=True)
+
+while cap.isOpened():
+ success, frame = cap.read()
+ if success:
+ results = model.track(frame, persist=True)
+ total_counts = sum([1 for box in results[0].boxes.xyxy])
+ analytics.update_line(frame_count, total_counts)
+ if cv2.waitKey(1) & 0xFF == ord("q"):
+ break
+
+cap.release()
+out.release()
+cv2.destroyAllWindows()
+```
+
+For further details on configuring the `Analytics` class, visit the [Analytics using Ultralytics YOLOv8 📊](#analytics-using-ultralytics-yolov8) section.
+
+### What are the benefits of using Ultralytics YOLOv8 for creating bar plots?
+
+Using Ultralytics YOLOv8 for creating bar plots offers several benefits:
+
+1. **Real-time Data Visualization**: Seamlessly integrate object detection results into bar plots for dynamic updates.
+2. **Ease of Use**: Simple API and functions make it straightforward to implement and visualize data.
+3. **Customization**: Customize titles, labels, colors, and more to fit your specific requirements.
+4. **Efficiency**: Efficiently handle large amounts of data and update plots in real-time during video processing.
+
+Use the following example to generate a bar plot:
+
+```python
+import cv2
+
+from ultralytics import YOLO, solutions
+
+model = YOLO("yolov8s.pt")
+cap = cv2.VideoCapture("Path/to/video/file.mp4")
+out = cv2.VideoWriter("bar_plot.avi", cv2.VideoWriter_fourcc(*"MJPG"), fps, (w, h))
+
+analytics = solutions.Analytics(type="bar", writer=out, im0_shape=(w, h), view_img=True)
+
+while cap.isOpened():
+ success, frame = cap.read()
+ if success:
+ results = model.track(frame, persist=True)
+ clswise_count = {
+ model.names[int(cls)]: boxes.size(0)
+ for cls, boxes in zip(results[0].boxes.cls.tolist(), results[0].boxes.xyxy)
+ }
+ analytics.update_bar(clswise_count)
+ if cv2.waitKey(1) & 0xFF == ord("q"):
+ break
+
+cap.release()
+out.release()
+cv2.destroyAllWindows()
+```
+
+To learn more, visit the [Bar Plot](#visual-samples) section in the guide.
+
+### Why should I use Ultralytics YOLOv8 for creating pie charts in my data visualization projects?
+
+Ultralytics YOLOv8 is an excellent choice for creating pie charts because:
+
+1. **Integration with Object Detection**: Directly integrate object detection results into pie charts for immediate insights.
+2. **User-Friendly API**: Simple to set up and use with minimal code.
+3. **Customizable**: Various customization options for colors, labels, and more.
+4. **Real-time Updates**: Handle and visualize data in real-time, which is ideal for video analytics projects.
+
+Here's a quick example:
+
+```python
+import cv2
+
+from ultralytics import YOLO, solutions
+
+model = YOLO("yolov8s.pt")
+cap = cv2.VideoCapture("Path/to/video/file.mp4")
+out = cv2.VideoWriter("pie_chart.avi", cv2.VideoWriter_fourcc(*"MJPG"), fps, (w, h))
+
+analytics = solutions.Analytics(type="pie", writer=out, im0_shape=(w, h), view_img=True)
+
+while cap.isOpened():
+ success, frame = cap.read()
+ if success:
+ results = model.track(frame, persist=True)
+ clswise_count = {
+ model.names[int(cls)]: boxes.size(0)
+ for cls, boxes in zip(results[0].boxes.cls.tolist(), results[0].boxes.xyxy)
+ }
+ analytics.update_pie(clswise_count)
+ if cv2.waitKey(1) & 0xFF == ord("q"):
+ break
+
+cap.release()
+out.release()
+cv2.destroyAllWindows()
+```
+
+For more information, refer to the [Pie Chart](#visual-samples) section in the guide.
+
+### Can Ultralytics YOLOv8 be used to track objects and dynamically update visualizations?
+
+Yes, Ultralytics YOLOv8 can be used to track objects and dynamically update visualizations. It supports tracking multiple objects in real-time and can update various visualizations like line graphs, bar plots, and pie charts based on the tracked objects' data.
+
+Example for tracking and updating a line graph:
+
+```python
+import cv2
+
+from ultralytics import YOLO, solutions
+
+model = YOLO("yolov8s.pt")
+cap = cv2.VideoCapture("Path/to/video/file.mp4")
+out = cv2.VideoWriter("line_plot.avi", cv2.VideoWriter_fourcc(*"MJPG"), fps, (w, h))
+
+analytics = solutions.Analytics(type="line", writer=out, im0_shape=(w, h), view_img=True)
+
+while cap.isOpened():
+ success, frame = cap.read()
+ if success:
+ results = model.track(frame, persist=True)
+ total_counts = sum([1 for box in results[0].boxes.xyxy])
+ analytics.update_line(frame_count, total_counts)
+ if cv2.waitKey(1) & 0xFF == ord("q"):
+ break
+
+cap.release()
+out.release()
+cv2.destroyAllWindows()
+```
+
+To learn about the complete functionality, see the [Tracking](../modes/track.md) section.
+
+### What makes Ultralytics YOLOv8 different from other object detection solutions like OpenCV and TensorFlow?
+
+Ultralytics YOLOv8 stands out from other object detection solutions like OpenCV and TensorFlow for multiple reasons:
+
+1. **State-of-the-art Accuracy**: YOLOv8 provides superior accuracy in object detection, segmentation, and classification tasks.
+2. **Ease of Use**: User-friendly API allows for quick implementation and integration without extensive coding.
+3. **Real-time Performance**: Optimized for high-speed inference, suitable for real-time applications.
+4. **Diverse Applications**: Supports various tasks including multi-object tracking, custom model training, and exporting to different formats like ONNX, TensorRT, and CoreML.
+5. **Comprehensive Documentation**: Extensive [documentation](https://docs.ultralytics.com/) and [blog resources](https://www.ultralytics.com/blog) to guide users through every step.
+
+For more detailed comparisons and use cases, explore our [Ultralytics Blog](https://www.ultralytics.com/blog/ai-use-cases-transforming-your-future).
diff --git a/ultralytics/docs/en/guides/azureml-quickstart.md b/ultralytics/docs/en/guides/azureml-quickstart.md
new file mode 100644
index 0000000000000000000000000000000000000000..8791a07749b9adc13a3f32cfb6f1fc07ba21aac6
--- /dev/null
+++ b/ultralytics/docs/en/guides/azureml-quickstart.md
@@ -0,0 +1,227 @@
+---
+comments: true
+description: Learn how to run YOLOv8 on AzureML. Quickstart instructions for terminal and notebooks to harness Azure's cloud computing for efficient model training.
+keywords: YOLOv8, AzureML, machine learning, cloud computing, quickstart, terminal, notebooks, model training, Python SDK, AI, Ultralytics
+---
+
+# YOLOv8 🚀 on AzureML
+
+## What is Azure?
+
+[Azure](https://azure.microsoft.com/) is Microsoft's cloud computing platform, designed to help organizations move their workloads to the cloud from on-premises data centers. With the full spectrum of cloud services including those for computing, databases, analytics, machine learning, and networking, users can pick and choose from these services to develop and scale new applications, or run existing applications, in the public cloud.
+
+## What is Azure Machine Learning (AzureML)?
+
+Azure Machine Learning, commonly referred to as AzureML, is a fully managed cloud service that enables data scientists and developers to efficiently embed predictive analytics into their applications, helping organizations use massive data sets and bring all the benefits of the cloud to machine learning. AzureML offers a variety of services and capabilities aimed at making machine learning accessible, easy to use, and scalable. It provides capabilities like automated machine learning, drag-and-drop model training, as well as a robust Python SDK so that developers can make the most out of their machine learning models.
+
+## How Does AzureML Benefit YOLO Users?
+
+For users of YOLO (You Only Look Once), AzureML provides a robust, scalable, and efficient platform to both train and deploy machine learning models. Whether you are looking to run quick prototypes or scale up to handle more extensive data, AzureML's flexible and user-friendly environment offers various tools and services to fit your needs. You can leverage AzureML to:
+
+- Easily manage large datasets and computational resources for training.
+- Utilize built-in tools for data preprocessing, feature selection, and model training.
+- Collaborate more efficiently with capabilities for MLOps (Machine Learning Operations), including but not limited to monitoring, auditing, and versioning of models and data.
+
+In the subsequent sections, you will find a quickstart guide detailing how to run YOLOv8 object detection models using AzureML, either from a compute terminal or a notebook.
+
+## Prerequisites
+
+Before you can get started, make sure you have access to an AzureML workspace. If you don't have one, you can create a new [AzureML workspace](https://learn.microsoft.com/azure/machine-learning/concept-workspace?view=azureml-api-2) by following Azure's official documentation. This workspace acts as a centralized place to manage all AzureML resources.
+
+## Create a compute instance
+
+From your AzureML workspace, select Compute > Compute instances > New, select the instance with the resources you need.
+
+
+
+
+
+## Quickstart from Terminal
+
+Start your compute and open a Terminal:
+
+
+
+
+
+### Create virtualenv
+
+Create your conda virtualenv and install pip in it:
+
+```bash
+conda create --name yolov8env -y
+conda activate yolov8env
+conda install pip -y
+```
+
+Install the required dependencies:
+
+```bash
+cd ultralytics
+pip install -r requirements.txt
+pip install ultralytics
+pip install onnx>=1.12.0
+```
+
+### Perform YOLOv8 tasks
+
+Predict:
+
+```bash
+yolo predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg'
+```
+
+Train a detection model for 10 epochs with an initial learning_rate of 0.01:
+
+```bash
+yolo train data=coco8.yaml model=yolov8n.pt epochs=10 lr0=0.01
+```
+
+You can find more [instructions to use the Ultralytics CLI here](../quickstart.md#use-ultralytics-with-cli).
+
+## Quickstart from a Notebook
+
+### Create a new IPython kernel
+
+Open the compute Terminal.
+
+
+
+
+
+From your compute terminal, you need to create a new ipykernel that will be used by your notebook to manage your dependencies:
+
+```bash
+conda create --name yolov8env -y
+conda activate yolov8env
+conda install pip -y
+conda install ipykernel -y
+python -m ipykernel install --user --name yolov8env --display-name "yolov8env"
+```
+
+Close your terminal and create a new notebook. From your Notebook, you can select the new kernel.
+
+Then you can open a Notebook cell and install the required dependencies:
+
+```bash
+%%bash
+source activate yolov8env
+cd ultralytics
+pip install -r requirements.txt
+pip install ultralytics
+pip install onnx>=1.12.0
+```
+
+Note that we need to use the `source activate yolov8env` for all the %%bash cells, to make sure that the %%bash cell uses environment we want.
+
+Run some predictions using the [Ultralytics CLI](../quickstart.md#use-ultralytics-with-cli):
+
+```bash
+%%bash
+source activate yolov8env
+yolo predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg'
+```
+
+Or with the [Ultralytics Python interface](../quickstart.md#use-ultralytics-with-python), for example to train the model:
+
+```python
+from ultralytics import YOLO
+
+# Load a model
+model = YOLO("yolov8n.pt") # load an official YOLOv8n model
+
+# Use the model
+model.train(data="coco8.yaml", epochs=3) # train the model
+metrics = model.val() # evaluate model performance on the validation set
+results = model("https://ultralytics.com/images/bus.jpg") # predict on an image
+path = model.export(format="onnx") # export the model to ONNX format
+```
+
+You can use either the Ultralytics CLI or Python interface for running YOLOv8 tasks, as described in the terminal section above.
+
+By following these steps, you should be able to get YOLOv8 running quickly on AzureML for quick trials. For more advanced uses, you may refer to the full AzureML documentation linked at the beginning of this guide.
+
+## Explore More with AzureML
+
+This guide serves as an introduction to get you up and running with YOLOv8 on AzureML. However, it only scratches the surface of what AzureML can offer. To delve deeper and unlock the full potential of AzureML for your machine learning projects, consider exploring the following resources:
+
+- [Create a Data Asset](https://learn.microsoft.com/azure/machine-learning/how-to-create-data-assets): Learn how to set up and manage your data assets effectively within the AzureML environment.
+- [Initiate an AzureML Job](https://learn.microsoft.com/azure/machine-learning/how-to-train-model): Get a comprehensive understanding of how to kickstart your machine learning training jobs on AzureML.
+- [Register a Model](https://learn.microsoft.com/azure/machine-learning/how-to-manage-models): Familiarize yourself with model management practices including registration, versioning, and deployment.
+- [Train YOLOv8 with AzureML Python SDK](https://medium.com/@ouphi/how-to-train-the-yolov8-model-with-azure-machine-learning-python-sdk-8268696be8ba): Explore a step-by-step guide on using the AzureML Python SDK to train your YOLOv8 models.
+- [Train YOLOv8 with AzureML CLI](https://medium.com/@ouphi/how-to-train-the-yolov8-model-with-azureml-and-the-az-cli-73d3c870ba8e): Discover how to utilize the command-line interface for streamlined training and management of YOLOv8 models on AzureML.
+
+## FAQ
+
+### How do I run YOLOv8 on AzureML for model training?
+
+Running YOLOv8 on AzureML for model training involves several steps:
+
+1. **Create a Compute Instance**: From your AzureML workspace, navigate to Compute > Compute instances > New, and select the required instance.
+
+2. **Setup Environment**: Start your compute instance, open a terminal, and create a conda environment:
+
+ ```bash
+ conda create --name yolov8env -y
+ conda activate yolov8env
+ conda install pip -y
+ pip install ultralytics onnx>=1.12.0
+ ```
+
+3. **Run YOLOv8 Tasks**: Use the Ultralytics CLI to train your model:
+ ```bash
+ yolo train data=coco8.yaml model=yolov8n.pt epochs=10 lr0=0.01
+ ```
+
+For more details, you can refer to the [instructions to use the Ultralytics CLI](../quickstart.md#use-ultralytics-with-cli).
+
+### What are the benefits of using AzureML for YOLOv8 training?
+
+AzureML provides a robust and efficient ecosystem for training YOLOv8 models:
+
+- **Scalability**: Easily scale your compute resources as your data and model complexity grows.
+- **MLOps Integration**: Utilize features like versioning, monitoring, and auditing to streamline ML operations.
+- **Collaboration**: Share and manage resources within teams, enhancing collaborative workflows.
+
+These advantages make AzureML an ideal platform for projects ranging from quick prototypes to large-scale deployments. For more tips, check out [AzureML Jobs](https://learn.microsoft.com/azure/machine-learning/how-to-train-model).
+
+### How do I troubleshoot common issues when running YOLOv8 on AzureML?
+
+Troubleshooting common issues with YOLOv8 on AzureML can involve the following steps:
+
+- **Dependency Issues**: Ensure all required packages are installed. Refer to the `requirements.txt` file for dependencies.
+- **Environment Setup**: Verify that your conda environment is correctly activated before running commands.
+- **Resource Allocation**: Make sure your compute instances have sufficient resources to handle the training workload.
+
+For additional guidance, review our [YOLO Common Issues](https://docs.ultralytics.com/guides/yolo-common-issues/) documentation.
+
+### Can I use both the Ultralytics CLI and Python interface on AzureML?
+
+Yes, AzureML allows you to use both the Ultralytics CLI and the Python interface seamlessly:
+
+- **CLI**: Ideal for quick tasks and running standard scripts directly from the terminal.
+
+ ```bash
+ yolo predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg'
+ ```
+
+- **Python Interface**: Useful for more complex tasks requiring custom coding and integration within notebooks.
+
+ ```python
+ from ultralytics import YOLO
+
+ model = YOLO("yolov8n.pt")
+ model.train(data="coco8.yaml", epochs=3)
+ ```
+
+Refer to the quickstart guides for more detailed instructions [here](../quickstart.md#use-ultralytics-with-cli) and [here](../quickstart.md#use-ultralytics-with-python).
+
+### What is the advantage of using Ultralytics YOLOv8 over other object detection models?
+
+Ultralytics YOLOv8 offers several unique advantages over competing object detection models:
+
+- **Speed**: Faster inference and training times compared to models like Faster R-CNN and SSD.
+- **Accuracy**: High accuracy in detection tasks with features like anchor-free design and enhanced augmentation strategies.
+- **Ease of Use**: Intuitive API and CLI for quick setup, making it accessible both to beginners and experts.
+
+To explore more about YOLOv8's features, visit the [Ultralytics YOLO](https://www.ultralytics.com/yolo) page for detailed insights.
diff --git a/ultralytics/docs/en/guides/conda-quickstart.md b/ultralytics/docs/en/guides/conda-quickstart.md
new file mode 100644
index 0000000000000000000000000000000000000000..32d267537aed61635fe51efcee640ec6d45a41c2
--- /dev/null
+++ b/ultralytics/docs/en/guides/conda-quickstart.md
@@ -0,0 +1,192 @@
+---
+comments: true
+description: Learn to set up a Conda environment for Ultralytics projects. Follow our comprehensive guide for easy installation and initialization.
+keywords: Ultralytics, Conda, setup, installation, environment, guide, machine learning, data science
+---
+
+# Conda Quickstart Guide for Ultralytics
+
+
+
+
+
+This guide provides a comprehensive introduction to setting up a Conda environment for your Ultralytics projects. Conda is an open-source package and environment management system that offers an excellent alternative to pip for installing packages and dependencies. Its isolated environments make it particularly well-suited for data science and machine learning endeavors. For more details, visit the Ultralytics Conda package on [Anaconda](https://anaconda.org/conda-forge/ultralytics) and check out the Ultralytics feedstock repository for package updates on [GitHub](https://github.com/conda-forge/ultralytics-feedstock/).
+
+[](https://anaconda.org/conda-forge/ultralytics)
+[](https://anaconda.org/conda-forge/ultralytics)
+[](https://anaconda.org/conda-forge/ultralytics)
+[](https://anaconda.org/conda-forge/ultralytics)
+
+## What You Will Learn
+
+- Setting up a Conda environment
+- Installing Ultralytics via Conda
+- Initializing Ultralytics in your environment
+- Using Ultralytics Docker images with Conda
+
+---
+
+## Prerequisites
+
+- You should have Anaconda or Miniconda installed on your system. If not, download and install it from [Anaconda](https://www.anaconda.com/) or [Miniconda](https://docs.conda.io/projects/miniconda/en/latest/).
+
+---
+
+## Setting up a Conda Environment
+
+First, let's create a new Conda environment. Open your terminal and run the following command:
+
+```bash
+conda create --name ultralytics-env python=3.8 -y
+```
+
+Activate the new environment:
+
+```bash
+conda activate ultralytics-env
+```
+
+---
+
+## Installing Ultralytics
+
+You can install the Ultralytics package from the conda-forge channel. Execute the following command:
+
+```bash
+conda install -c conda-forge ultralytics
+```
+
+### Note on CUDA Environment
+
+If you're working in a CUDA-enabled environment, it's a good practice to install `ultralytics`, `pytorch`, and `pytorch-cuda` together to resolve any conflicts:
+
+```bash
+conda install -c pytorch -c nvidia -c conda-forge pytorch torchvision pytorch-cuda=11.8 ultralytics
+```
+
+---
+
+## Using Ultralytics
+
+With Ultralytics installed, you can now start using its robust features for object detection, instance segmentation, and more. For example, to predict an image, you can run:
+
+```python
+from ultralytics import YOLO
+
+model = YOLO("yolov8n.pt") # initialize model
+results = model("path/to/image.jpg") # perform inference
+results[0].show() # display results for the first image
+```
+
+---
+
+## Ultralytics Conda Docker Image
+
+If you prefer using Docker, Ultralytics offers Docker images with a Conda environment included. You can pull these images from [DockerHub](https://hub.docker.com/r/ultralytics/ultralytics).
+
+Pull the latest Ultralytics image:
+
+```bash
+# Set image name as a variable
+t=ultralytics/ultralytics:latest-conda
+
+# Pull the latest Ultralytics image from Docker Hub
+sudo docker pull $t
+```
+
+Run the image:
+
+```bash
+# Run the Ultralytics image in a container with GPU support
+sudo docker run -it --ipc=host --gpus all $t # all GPUs
+sudo docker run -it --ipc=host --gpus '"device=2,3"' $t # specify GPUs
+```
+
+## Speeding Up Installation with Libmamba
+
+If you're looking to [speed up the package installation](https://www.anaconda.com/blog/a-faster-conda-for-a-growing-community) process in Conda, you can opt to use `libmamba`, a fast, cross-platform, and dependency-aware package manager that serves as an alternative solver to Conda's default.
+
+### How to Enable Libmamba
+
+To enable `libmamba` as the solver for Conda, you can perform the following steps:
+
+1. First, install the `conda-libmamba-solver` package. This can be skipped if your Conda version is 4.11 or above, as `libmamba` is included by default.
+
+ ```bash
+ conda install conda-libmamba-solver
+ ```
+
+2. Next, configure Conda to use `libmamba` as the solver:
+
+ ```bash
+ conda config --set solver libmamba
+ ```
+
+And that's it! Your Conda installation will now use `libmamba` as the solver, which should result in a faster package installation process.
+
+---
+
+Congratulations! You have successfully set up a Conda environment, installed the Ultralytics package, and are now ready to explore its rich functionalities. Feel free to dive deeper into the [Ultralytics documentation](../index.md) for more advanced tutorials and examples.
+
+## FAQ
+
+### What is the process for setting up a Conda environment for Ultralytics projects?
+
+Setting up a Conda environment for Ultralytics projects is straightforward and ensures smooth package management. First, create a new Conda environment using the following command:
+
+```bash
+conda create --name ultralytics-env python=3.8 -y
+```
+
+Then, activate the new environment with:
+
+```bash
+conda activate ultralytics-env
+```
+
+Finally, install Ultralytics from the conda-forge channel:
+
+```bash
+conda install -c conda-forge ultralytics
+```
+
+### Why should I use Conda over pip for managing dependencies in Ultralytics projects?
+
+Conda is a robust package and environment management system that offers several advantages over pip. It manages dependencies efficiently and ensures that all necessary libraries are compatible. Conda's isolated environments prevent conflicts between packages, which is crucial in data science and machine learning projects. Additionally, Conda supports binary package distribution, speeding up the installation process.
+
+### Can I use Ultralytics YOLO in a CUDA-enabled environment for faster performance?
+
+Yes, you can enhance performance by utilizing a CUDA-enabled environment. Ensure that you install `ultralytics`, `pytorch`, and `pytorch-cuda` together to avoid conflicts:
+
+```bash
+conda install -c pytorch -c nvidia -c conda-forge pytorch torchvision pytorch-cuda=11.8 ultralytics
+```
+
+This setup enables GPU acceleration, crucial for intensive tasks like deep learning model training and inference. For more information, visit the [Ultralytics installation guide](../quickstart.md).
+
+### What are the benefits of using Ultralytics Docker images with a Conda environment?
+
+Using Ultralytics Docker images ensures a consistent and reproducible environment, eliminating "it works on my machine" issues. These images include a pre-configured Conda environment, simplifying the setup process. You can pull and run the latest Ultralytics Docker image with the following commands:
+
+```bash
+sudo docker pull ultralytics/ultralytics:latest-conda
+sudo docker run -it --ipc=host --gpus all ultralytics/ultralytics:latest-conda
+```
+
+This approach is ideal for deploying applications in production or running complex workflows without manual configuration. Learn more about [Ultralytics Conda Docker Image](../quickstart.md).
+
+### How can I speed up Conda package installation in my Ultralytics environment?
+
+You can speed up the package installation process by using `libmamba`, a fast dependency solver for Conda. First, install the `conda-libmamba-solver` package:
+
+```bash
+conda install conda-libmamba-solver
+```
+
+Then configure Conda to use `libmamba` as the solver:
+
+```bash
+conda config --set solver libmamba
+```
+
+This setup provides faster and more efficient package management. For more tips on optimizing your environment, read about [libmamba installation](../quickstart.md).
diff --git a/ultralytics/docs/en/guides/coral-edge-tpu-on-raspberry-pi.md b/ultralytics/docs/en/guides/coral-edge-tpu-on-raspberry-pi.md
new file mode 100644
index 0000000000000000000000000000000000000000..43a6f4a540817ab207f8e9df33b026a241107e0e
--- /dev/null
+++ b/ultralytics/docs/en/guides/coral-edge-tpu-on-raspberry-pi.md
@@ -0,0 +1,224 @@
+---
+comments: true
+description: Learn how to boost your Raspberry Pi's ML performance using Coral Edge TPU with Ultralytics YOLOv8. Follow our detailed setup and installation guide.
+keywords: Coral Edge TPU, Raspberry Pi, YOLOv8, Ultralytics, TensorFlow Lite, ML inference, machine learning, AI, installation guide, setup tutorial
+---
+
+# Coral Edge TPU on a Raspberry Pi with Ultralytics YOLOv8 🚀
+
+
+
+
+
+## What is a Coral Edge TPU?
+
+The Coral Edge TPU is a compact device that adds an Edge TPU coprocessor to your system. It enables low-power, high-performance ML inference for TensorFlow Lite models. Read more at the [Coral Edge TPU home page](https://coral.ai/products/accelerator).
+
+## Boost Raspberry Pi Model Performance with Coral Edge TPU
+
+Many people want to run their models on an embedded or mobile device such as a Raspberry Pi, since they are very power efficient and can be used in many different applications. However, the inference performance on these devices is usually poor even when using formats like [onnx](../integrations/onnx.md) or [openvino](../integrations/openvino.md). The Coral Edge TPU is a great solution to this problem, since it can be used with a Raspberry Pi and accelerate inference performance greatly.
+
+## Edge TPU on Raspberry Pi with TensorFlow Lite (New)⭐
+
+The [existing guide](https://coral.ai/docs/accelerator/get-started/) by Coral on how to use the Edge TPU with a Raspberry Pi is outdated, and the current Coral Edge TPU runtime builds do not work with the current TensorFlow Lite runtime versions anymore. In addition to that, Google seems to have completely abandoned the Coral project, and there have not been any updates between 2021 and 2024. This guide will show you how to get the Edge TPU working with the latest versions of the TensorFlow Lite runtime and an updated Coral Edge TPU runtime on a Raspberry Pi single board computer (SBC).
+
+## Prerequisites
+
+- [Raspberry Pi 4B](https://www.raspberrypi.com/products/raspberry-pi-4-model-b/) (2GB or more recommended) or [Raspberry Pi 5](https://www.raspberrypi.com/products/raspberry-pi-5/) (Recommended)
+- [Raspberry Pi OS](https://www.raspberrypi.com/software/) Bullseye/Bookworm (64-bit) with desktop (Recommended)
+- [Coral USB Accelerator](https://coral.ai/products/accelerator/)
+- A non-ARM based platform for exporting an Ultralytics PyTorch model
+
+## Installation Walkthrough
+
+This guide assumes that you already have a working Raspberry Pi OS install and have installed `ultralytics` and all dependencies. To get `ultralytics` installed, visit the [quickstart guide](../quickstart.md) to get setup before continuing here.
+
+### Installing the Edge TPU runtime
+
+First, we need to install the Edge TPU runtime. There are many different versions available, so you need to choose the right version for your operating system.
+
+| Raspberry Pi OS | High frequency mode | Version to download |
+| --------------- | :-----------------: | ------------------------------------------ |
+| Bullseye 32bit | No | `libedgetpu1-std_ ... .bullseye_armhf.deb` |
+| Bullseye 64bit | No | `libedgetpu1-std_ ... .bullseye_arm64.deb` |
+| Bullseye 32bit | Yes | `libedgetpu1-max_ ... .bullseye_armhf.deb` |
+| Bullseye 64bit | Yes | `libedgetpu1-max_ ... .bullseye_arm64.deb` |
+| Bookworm 32bit | No | `libedgetpu1-std_ ... .bookworm_armhf.deb` |
+| Bookworm 64bit | No | `libedgetpu1-std_ ... .bookworm_arm64.deb` |
+| Bookworm 32bit | Yes | `libedgetpu1-max_ ... .bookworm_armhf.deb` |
+| Bookworm 64bit | Yes | `libedgetpu1-max_ ... .bookworm_arm64.deb` |
+
+[Download the latest version from here](https://github.com/feranick/libedgetpu/releases).
+
+After downloading the file, you can install it with the following command:
+
+```bash
+sudo dpkg -i path/to/package.deb
+```
+
+After installing the runtime, you need to plug in your Coral Edge TPU into a USB 3.0 port on your Raspberry Pi. This is because, according to the official guide, a new `udev` rule needs to take effect after installation.
+
+???+ warning "Important"
+
+ If you already have the Coral Edge TPU runtime installed, uninstall it using the following command.
+
+ ```bash
+ # If you installed the standard version
+ sudo apt remove libedgetpu1-std
+
+ # If you installed the high frequency version
+ sudo apt remove libedgetpu1-max
+ ```
+
+## Export your model to a Edge TPU compatible model
+
+To use the Edge TPU, you need to convert your model into a compatible format. It is recommended that you run export on Google Colab, x86_64 Linux machine, using the official [Ultralytics Docker container](docker-quickstart.md), or using [Ultralytics HUB](../hub/quickstart.md), since the Edge TPU compiler is not available on ARM. See the [Export Mode](../modes/export.md) for the available arguments.
+
+!!! Exporting the model
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("path/to/model.pt") # Load an official model or custom model
+
+ # Export the model
+ model.export(format="edgetpu")
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo export model=path/to/model.pt format=edgetpu # Export an official model or custom model
+ ```
+
+The exported model will be saved in the `_saved_model/` folder with the name `_full_integer_quant_edgetpu.tflite`.
+
+## Running the model
+
+After exporting your model, you can run inference with it using the following code:
+
+!!! Running the model
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("path/to/edgetpu_model.tflite") # Load an official model or custom model
+
+ # Run Prediction
+ model.predict("path/to/source.png")
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo predict model=path/to/edgetpu_model.tflite source=path/to/source.png # Load an official model or custom model
+ ```
+
+Find comprehensive information on the [Predict](../modes/predict.md) page for full prediction mode details.
+
+???+ warning "Important"
+
+ You should run the model using `tflite-runtime` and not `tensorflow`.
+ If `tensorflow` is installed, uninstall tensorflow with the following command:
+
+ ```bash
+ pip uninstall tensorflow tensorflow-aarch64
+ ```
+
+ Then install/update `tflite-runtime`:
+
+ ```
+ pip install -U tflite-runtime
+ ```
+
+ If you want a `tflite-runtime` wheel for `tensorflow` 2.15.0 download it from [here](https://github.com/feranick/TFlite-builds/releases) and install it using `pip` or your package manager of choice.
+
+## FAQ
+
+### What is a Coral Edge TPU and how does it enhance Raspberry Pi's performance with Ultralytics YOLOv8?
+
+The Coral Edge TPU is a compact device designed to add an Edge TPU coprocessor to your system. This coprocessor enables low-power, high-performance machine learning inference, particularly optimized for TensorFlow Lite models. When using a Raspberry Pi, the Edge TPU accelerates ML model inference, significantly boosting performance, especially for Ultralytics YOLOv8 models. You can read more about the Coral Edge TPU on their [home page](https://coral.ai/products/accelerator).
+
+### How do I install the Coral Edge TPU runtime on a Raspberry Pi?
+
+To install the Coral Edge TPU runtime on your Raspberry Pi, download the appropriate `.deb` package for your Raspberry Pi OS version from [this link](https://github.com/feranick/libedgetpu/releases). Once downloaded, use the following command to install it:
+
+```bash
+sudo dpkg -i path/to/package.deb
+```
+
+Make sure to uninstall any previous Coral Edge TPU runtime versions by following the steps outlined in the [Installation Walkthrough](#installation-walkthrough) section.
+
+### Can I export my Ultralytics YOLOv8 model to be compatible with Coral Edge TPU?
+
+Yes, you can export your Ultralytics YOLOv8 model to be compatible with the Coral Edge TPU. It is recommended to perform the export on Google Colab, an x86_64 Linux machine, or using the [Ultralytics Docker container](docker-quickstart.md). You can also use Ultralytics HUB for exporting. Here is how you can export your model using Python and CLI:
+
+!!! Exporting the model
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("path/to/model.pt") # Load an official model or custom model
+
+ # Export the model
+ model.export(format="edgetpu")
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo export model=path/to/model.pt format=edgetpu # Export an official model or custom model
+ ```
+
+For more information, refer to the [Export Mode](../modes/export.md) documentation.
+
+### What should I do if TensorFlow is already installed on my Raspberry Pi but I want to use tflite-runtime instead?
+
+If you have TensorFlow installed on your Raspberry Pi and need to switch to `tflite-runtime`, you'll need to uninstall TensorFlow first using:
+
+```bash
+pip uninstall tensorflow tensorflow-aarch64
+```
+
+Then, install or update `tflite-runtime` with the following command:
+
+```bash
+pip install -U tflite-runtime
+```
+
+For a specific wheel, such as TensorFlow 2.15.0 `tflite-runtime`, you can download it from [this link](https://github.com/feranick/TFlite-builds/releases) and install it using `pip`. Detailed instructions are available in the section on running the model [Running the Model](#running-the-model).
+
+### How do I run inference with an exported YOLOv8 model on a Raspberry Pi using the Coral Edge TPU?
+
+After exporting your YOLOv8 model to an Edge TPU-compatible format, you can run inference using the following code snippets:
+
+!!! Running the model
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("path/to/edgetpu_model.tflite") # Load an official model or custom model
+
+ # Run Prediction
+ model.predict("path/to/source.png")
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo predict model=path/to/edgetpu_model.tflite source=path/to/source.png # Load an official model or custom model
+ ```
+
+Comprehensive details on full prediction mode features can be found on the [Predict Page](../modes/predict.md).
diff --git a/ultralytics/docs/en/guides/data-collection-and-annotation.md b/ultralytics/docs/en/guides/data-collection-and-annotation.md
new file mode 100644
index 0000000000000000000000000000000000000000..de49701ebc7b6769a92a8783bbf04a0237264922
--- /dev/null
+++ b/ultralytics/docs/en/guides/data-collection-and-annotation.md
@@ -0,0 +1,183 @@
+---
+comments: true
+description: Data collection and annotation are vital steps in any computer vision project. Explore the tools, techniques, and best practices for collecting and annotating data.
+keywords: What is Data Annotation, Data Annotation Tools, Annotating Data, Avoiding Bias in Data Collection, Ethical Data Collection, Annotation Strategies
+---
+
+# Data Collection and Annotation Strategies for Computer Vision
+
+## Introduction
+
+The key to success in any [computer vision project](./steps-of-a-cv-project.md) starts with effective data collection and annotation strategies. The quality of the data directly impacts model performance, so it's important to understand the best practices related to data collection and data annotation.
+
+Every consideration regarding the data should closely align with [your project's goals](./defining-project-goals.md). Changes in your annotation strategies could shift the project's focus or effectiveness and vice versa. With this in mind, let's take a closer look at the best ways to approach data collection and annotation.
+
+## Setting Up Classes and Collecting Data
+
+Collecting images and video for a computer vision project involves defining the number of classes, sourcing data, and considering ethical implications. Before you start gathering your data, you need to be clear about:
+
+### Choosing the Right Classes for Your Project
+
+One of the first questions when starting a computer vision project is how many classes to include. You need to determine the class membership, which is involves the different categories or labels that you want your model to recognize and differentiate. The number of classes should be determined by the specific goals of your project.
+
+For example, if you want to monitor traffic, your classes might include "car," "truck," "bus," "motorcycle," and "bicycle." On the other hand, for tracking items in a store, your classes could be "fruits," "vegetables," "beverages," and "snacks." Defining classes based on your project goals helps keep your dataset relevant and focused.
+
+When you define your classes, another important distinction to make is whether to choose coarse or fine class counts. 'Count' refers to the number of distinct classes you are interested in. This decision influences the granularity of your data and the complexity of your model. Here are the considerations for each approach:
+
+- **Coarse Class-Count**: These are broader, more inclusive categories, such as "vehicle" and "non-vehicle." They simplify annotation and require fewer computational resources but provide less detailed information, potentially limiting the model's effectiveness in complex scenarios.
+- **Fine Class-Count**: More categories with finer distinctions, such as "sedan," "SUV," "pickup truck," and "motorcycle." They capture more detailed information, improving model accuracy and performance. However, they are more time-consuming and labor-intensive to annotate and require more computational resources.
+
+Something to note is that starting with more specific classes can be very helpful, especially in complex projects where details are important. More specific classes lets you collect more detailed data, and gain deeper insights and clearer distinctions between categories. Not only does it improve the accuracy of the model, but it also makes it easier to adjust the model later if needed, saving both time and resources.
+
+### Sources of Data
+
+You can use public datasets or gather your own custom data. Public datasets like those on [Kaggle](https://www.kaggle.com/datasets) and [Google Dataset Search Engine](https://datasetsearch.research.google.com/) offer well-annotated, standardized data, making them great starting points for training and validating models.
+
+Custom data collection, on the other hand, allows you to customize your dataset to your specific needs. You might capture images and videos with cameras or drones, scrape the web for images, or use existing internal data from your organization. Custom data gives you more control over its quality and relevance. Combining both public and custom data sources helps create a diverse and comprehensive dataset.
+
+### Avoiding Bias in Data Collection
+
+Bias occurs when certain groups or scenarios are underrepresented or overrepresented in your dataset. It leads to a model that performs well on some data but poorly on others. It's crucial to avoid bias so that your computer vision model can perform well in a variety of scenarios.
+
+Here is how you can avoid bias while collecting data:
+
+- **Diverse Sources**: Collect data from many sources to capture different perspectives and scenarios.
+- **Balanced Representation**: Include balanced representation from all relevant groups. For example, consider different ages, genders, and ethnicities.
+- **Continuous Monitoring**: Regularly review and update your dataset to identify and address any emerging biases.
+- **Bias Mitigation Techniques**: Use methods like oversampling underrepresented classes, data augmentation, and fairness-aware algorithms.
+
+Following these practices helps create a more robust and fair model that can generalize well in real-world applications.
+
+## What is Data Annotation?
+
+Data annotation is the process of labeling data to make it usable for training machine learning models. In computer vision, this means labeling images or videos with the information that a model needs to learn from. Without properly annotated data, models cannot accurately learn the relationships between inputs and outputs.
+
+### Types of Data Annotation
+
+Depending on the specific requirements of a [computer vision task](../tasks/index.md), there are different types of data annotation. Here are some examples:
+
+- **Bounding Boxes**: Rectangular boxes drawn around objects in an image, used primarily for object detection tasks. These boxes are defined by their top-left and bottom-right coordinates.
+- **Polygons**: Detailed outlines for objects, allowing for more precise annotation than bounding boxes. Polygons are used in tasks like instance segmentation, where the shape of the object is important.
+- **Masks**: Binary masks where each pixel is either part of an object or the background. Masks are used in semantic segmentation tasks to provide pixel-level detail.
+- **Keypoints**: Specific points marked within an image to identify locations of interest. Keypoints are used in tasks like pose estimation and facial landmark detection.
+
+
+
+
+
+### Common Annotation Formats
+
+After selecting a type of annotation, it's important to choose the appropriate format for storing and sharing annotations.
+
+Commonly used formats include [COCO](../datasets/detect/coco.md), which supports various annotation types like object detection, keypoint detection, stuff segmentation, panoptic segmentation, and image captioning, stored in JSON. [Pascal VOC](../datasets/detect/voc.md) uses XML files and is popular for object detection tasks. YOLO, on the other hand, creates a .txt file for each image, containing annotations like object class, coordinates, height, and width, making it suitable for object detection.
+
+### Techniques of Annotation
+
+Now, assuming you've chosen a type of annotation and format, it's time to establish clear and objective labeling rules. These rules are like a roadmap for consistency and accuracy throughout the annotation process. Key aspects of these rules include:
+
+- **Clarity and Detail**: Make sure your instructions are clear. Use examples and illustrations to understand what's expected.
+- **Consistency**: Keep your annotations uniform. Set standard criteria for annotating different types of data, so all annotations follow the same rules.
+- **Reducing Bias**: Stay neutral. Train yourself to be objective and minimize personal biases to ensure fair annotations.
+- **Efficiency**: Work smarter, not harder. Use tools and workflows that automate repetitive tasks, making the annotation process faster and more efficient.
+
+Regularly reviewing and updating your labeling rules will help keep your annotations accurate, consistent, and aligned with your project goals.
+
+### Popular Annotation Tools
+
+Let's say you are ready to annotate now. There are several open-source tools available to help streamline the data annotation process. Here are some useful open annotation tools:
+
+- **[Label Studio](https://github.com/HumanSignal/label-studio)**: A flexible tool that supports a wide range of annotation tasks and includes features for managing projects and quality control.
+- **[CVAT](https://github.com/cvat-ai/cvat)**: A powerful tool that supports various annotation formats and customizable workflows, making it suitable for complex projects.
+- **[Labelme](https://github.com/labelmeai/labelme)**: A simple and easy-to-use tool that allows for quick annotation of images with polygons, making it ideal for straightforward tasks.
+
+
+
+
+
+These open-source tools are budget-friendly and provide a range of features to meet different annotation needs.
+
+### Some More Things to Consider Before Annotating Data
+
+Before you dive into annotating your data, there are a few more things to keep in mind. You should be aware of accuracy, precision, outliers, and quality control to avoid labeling your data in a counterproductive manner.
+
+#### Understanding Accuracy and Precision
+
+It's important to understand the difference between accuracy and precision and how it relates to annotation. Accuracy refers to how close the annotated data is to the true values. It helps us measure how closely the labels reflect real-world scenarios. Precision indicates the consistency of annotations. It checks if you are giving the same label to the same object or feature throughout the dataset. High accuracy and precision lead to better-trained models by reducing noise and improving the model's ability to generalize from the training data.
+
+
+
+
+
+#### Identifying Outliers
+
+Outliers are data points that deviate quite a bit from other observations in the dataset. With respect to annotations, an outlier could be an incorrectly labeled image or an annotation that doesn't fit with the rest of the dataset. Outliers are concerning because they can distort the model's learning process, leading to inaccurate predictions and poor generalization.
+
+You can use various methods to detect and correct outliers:
+
+- **Statistical Techniques**: To detect outliers in numerical features like pixel values, bounding box coordinates, or object sizes, you can use methods such as box plots, histograms, or z-scores.
+- **Visual Techniques**: To spot anomalies in categorical features like object classes, colors, or shapes, use visual methods like plotting images, labels, or heat maps.
+- **Algorithmic Methods**: Use tools like clustering (e.g., K-means clustering, DBSCAN) and anomaly detection algorithms to identify outliers based on data distribution patterns.
+
+#### Quality Control of Annotated Data
+
+Just like other technical projects, quality control is a must for annotated data. It is a good practice to regularly check annotations to make sure they are accurate and consistent. This can be done in a few different ways:
+
+- Reviewing samples of annotated data
+- Using automated tools to spot common errors
+- Having another person double-check the annotations
+
+If you are working with multiple people, consistency between different annotators is important. Good inter-annotator agreement means that the guidelines are clear and everyone is following them the same way. It keeps everyone on the same page and the annotations consistent.
+
+While reviewing, if you find errors, correct them and update the guidelines to avoid future mistakes. Provide feedback to annotators and offer regular training to help reduce errors. Having a strong process for handling errors keeps your dataset accurate and reliable.
+
+## Share Your Thoughts with the Community
+
+Bouncing your ideas and queries off other computer vision enthusiasts can help accelerate your projects. Here are some great ways to learn, troubleshoot, and network:
+
+### Where to Find Help and Support
+
+- **GitHub Issues:** Visit the YOLOv8 GitHub repository and use the [Issues tab](https://github.com/ultralytics/ultralytics/issues) to raise questions, report bugs, and suggest features. The community and maintainers are there to help with any issues you face.
+- **Ultralytics Discord Server:** Join the [Ultralytics Discord server](https://ultralytics.com/discord/) to connect with other users and developers, get support, share knowledge, and brainstorm ideas.
+
+### Official Documentation
+
+- **Ultralytics YOLOv8 Documentation:** Refer to the [official YOLOv8 documentation](./index.md) for thorough guides and valuable insights on numerous computer vision tasks and projects.
+
+## Conclusion
+
+By following the best practices for collecting and annotating data, avoiding bias, and using the right tools and techniques, you can significantly improve your model's performance. Engaging with the community and using available resources will keep you informed and help you troubleshoot issues effectively. Remember, quality data is the foundation of a successful project, and the right strategies will help you build robust and reliable models.
+
+## FAQ
+
+### What is the best way to avoid bias in data collection for computer vision projects?
+
+Avoiding bias in data collection ensures that your computer vision model performs well across various scenarios. To minimize bias, consider collecting data from diverse sources to capture different perspectives and scenarios. Ensure balanced representation among all relevant groups, such as different ages, genders, and ethnicities. Regularly review and update your dataset to identify and address any emerging biases. Techniques such as oversampling underrepresented classes, data augmentation, and fairness-aware algorithms can also help mitigate bias. By employing these strategies, you maintain a robust and fair dataset that enhances your model's generalization capability.
+
+### How can I ensure high consistency and accuracy in data annotation?
+
+Ensuring high consistency and accuracy in data annotation involves establishing clear and objective labeling guidelines. Your instructions should be detailed, with examples and illustrations to clarify expectations. Consistency is achieved by setting standard criteria for annotating various data types, ensuring all annotations follow the same rules. To reduce personal biases, train annotators to stay neutral and objective. Regular reviews and updates of labeling rules help maintain accuracy and alignment with project goals. Using automated tools to check for consistency and getting feedback from other annotators also contribute to maintaining high-quality annotations.
+
+### How many images do I need for training Ultralytics YOLO models?
+
+For effective transfer learning and object detection with Ultralytics YOLO models, start with a minimum of a few hundred annotated objects per class. If training for just one class, begin with at least 100 annotated images and train for approximately 100 epochs. More complex tasks might require thousands of images per class to achieve high reliability and performance. Quality annotations are crucial, so ensure your data collection and annotation processes are rigorous and aligned with your project's specific goals. Explore detailed training strategies in the [YOLOv8 training guide](../modes/train.md).
+
+### What are some popular tools for data annotation?
+
+Several popular open-source tools can streamline the data annotation process:
+
+- **[Label Studio](https://github.com/HumanSignal/label-studio)**: A flexible tool supporting various annotation tasks, project management, and quality control features.
+- **[CVAT](https://www.cvat.ai/)**: Offers multiple annotation formats and customizable workflows, making it suitable for complex projects.
+- **[Labelme](https://github.com/labelmeai/labelme)**: Ideal for quick and straightforward image annotation with polygons.
+
+These tools can help enhance the efficiency and accuracy of your annotation workflows. For extensive feature lists and guides, refer to our [data annotation tools documentation](../datasets/index.md).
+
+### What types of data annotation are commonly used in computer vision?
+
+Different types of data annotation cater to various computer vision tasks:
+
+- **Bounding Boxes**: Used primarily for object detection, these are rectangular boxes around objects in an image.
+- **Polygons**: Provide more precise object outlines suitable for instance segmentation tasks.
+- **Masks**: Offer pixel-level detail, used in semantic segmentation to differentiate objects from the background.
+- **Keypoints**: Identify specific points of interest within an image, useful for tasks like pose estimation and facial landmark detection.
+
+Selecting the appropriate annotation type depends on your project's requirements. Learn more about how to implement these annotations and their formats in our [data annotation guide](#what-is-data-annotation).
diff --git a/ultralytics/docs/en/guides/deepstream-nvidia-jetson.md b/ultralytics/docs/en/guides/deepstream-nvidia-jetson.md
new file mode 100644
index 0000000000000000000000000000000000000000..20103a6c2d5af9f952f992d3d0ecaa19f19dfb8c
--- /dev/null
+++ b/ultralytics/docs/en/guides/deepstream-nvidia-jetson.md
@@ -0,0 +1,341 @@
+---
+comments: true
+description: Learn how to deploy Ultralytics YOLOv8 on NVIDIA Jetson devices using TensorRT and DeepStream SDK. Explore performance benchmarks and maximize AI capabilities.
+keywords: Ultralytics, YOLOv8, NVIDIA Jetson, JetPack, AI deployment, embedded systems, deep learning, TensorRT, DeepStream SDK, computer vision
+---
+
+# Ultralytics YOLOv8 on NVIDIA Jetson using DeepStream SDK and TensorRT
+
+This comprehensive guide provides a detailed walkthrough for deploying Ultralytics YOLOv8 on [NVIDIA Jetson](https://www.nvidia.com/en-us/autonomous-machines/embedded-systems/) devices using DeepStream SDK and TensorRT. Here we use TensorRT to maximize the inference performance on the Jetson platform.
+
+
+
+!!! Note
+
+ This guide has been tested with both [Seeed Studio reComputer J4012](https://www.seeedstudio.com/reComputer-J4012-p-5586.html) which is based on NVIDIA Jetson Orin NX 16GB running JetPack release of [JP5.1.3](https://developer.nvidia.com/embedded/jetpack-sdk-513) and [Seeed Studio reComputer J1020 v2](https://www.seeedstudio.com/reComputer-J1020-v2-p-5498.html) which is based on NVIDIA Jetson Nano 4GB running JetPack release of [JP4.6.4](https://developer.nvidia.com/jetpack-sdk-464). It is expected to work across all the NVIDIA Jetson hardware lineup including latest and legacy.
+
+## What is NVIDIA DeepStream?
+
+[NVIDIA's DeepStream SDK](https://developer.nvidia.com/deepstream-sdk) is a complete streaming analytics toolkit based on GStreamer for AI-based multi-sensor processing, video, audio, and image understanding. It's ideal for vision AI developers, software partners, startups, and OEMs building IVA (Intelligent Video Analytics) apps and services. You can now create stream-processing pipelines that incorporate neural networks and other complex processing tasks like tracking, video encoding/decoding, and video rendering. These pipelines enable real-time analytics on video, image, and sensor data. DeepStream's multi-platform support gives you a faster, easier way to develop vision AI applications and services on-premise, at the edge, and in the cloud.
+
+## Prerequisites
+
+Before you start to follow this guide:
+
+- Visit our documentation, [Quick Start Guide: NVIDIA Jetson with Ultralytics YOLOv8](nvidia-jetson.md) to set up your NVIDIA Jetson device with Ultralytics YOLOv8
+- Install [DeepStream SDK](https://developer.nvidia.com/deepstream-getting-started) according to the JetPack version
+
+ - For JetPack 4.6.4, install [DeepStream 6.0.1](https://docs.nvidia.com/metropolis/deepstream/6.0.1/dev-guide/text/DS_Quickstart.html)
+ - For JetPack 5.1.3, install [DeepStream 6.3](https://docs.nvidia.com/metropolis/deepstream/6.3/dev-guide/text/DS_Quickstart.html)
+
+!!! Tip
+
+ In this guide we have used the Debian package method of installing DeepStream SDK to the Jetson device. You can also visit the [DeepStream SDK on Jetson (Archived)](https://developer.nvidia.com/embedded/deepstream-on-jetson-downloads-archived) to access legacy versions of DeepStream.
+
+## DeepStream Configuration for YOLOv8
+
+Here we are using [marcoslucianops/DeepStream-Yolo](https://github.com/marcoslucianops/DeepStream-Yolo) GitHub repository which includes NVIDIA DeepStream SDK support for YOLO models. We appreciate the efforts of marcoslucianops for his contributions!
+
+1. Install dependencies
+
+ ```bash
+ pip install cmake
+ pip install onnxsim
+ ```
+
+2. Clone the following repository
+
+ ```bash
+ git clone https://github.com/marcoslucianops/DeepStream-Yolo
+ cd DeepStream-Yolo
+ ```
+
+3. Download Ultralytics YOLOv8 detection model (.pt) of your choice from [YOLOv8 releases](https://github.com/ultralytics/assets/releases). Here we use [yolov8s.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8s.pt).
+
+ ```bash
+ wget https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8s.pt
+ ```
+
+ !!! Note
+
+ You can also use a [custom trained YOLOv8 model](https://docs.ultralytics.com/modes/train/).
+
+4. Convert model to ONNX
+
+ ```bash
+ python3 utils/export_yoloV8.py -w yolov8s.pt
+ ```
+
+ !!! Note "Pass the below arguments to the above command"
+
+ For DeepStream 6.0.1, use opset 12 or lower. The default opset is 16.
+
+ ```bash
+ --opset 12
+ ```
+
+ To change the inference size (default: 640)
+
+ ```bash
+ -s SIZE
+ --size SIZE
+ -s HEIGHT WIDTH
+ --size HEIGHT WIDTH
+ ```
+
+ Example for 1280:
+
+ ```bash
+ -s 1280
+ or
+ -s 1280 1280
+ ```
+
+ To simplify the ONNX model (DeepStream >= 6.0)
+
+ ```bash
+ --simplify
+ ```
+
+ To use dynamic batch-size (DeepStream >= 6.1)
+
+ ```bash
+ --dynamic
+ ```
+
+ To use static batch-size (example for batch-size = 4)
+
+ ```bash
+ --batch 4
+ ```
+
+5. Set the CUDA version according to the JetPack version installed
+
+ For JetPack 4.6.4:
+
+ ```bash
+ export CUDA_VER=10.2
+ ```
+
+ For JetPack 5.1.3:
+
+ ```bash
+ export CUDA_VER=11.4
+ ```
+
+6. Compile the library
+
+ ```bash
+ make -C nvdsinfer_custom_impl_Yolo clean && make -C nvdsinfer_custom_impl_Yolo
+ ```
+
+7. Edit the `config_infer_primary_yoloV8.txt` file according to your model (for YOLOv8s with 80 classes)
+
+ ```bash
+ [property]
+ ...
+ onnx-file=yolov8s.onnx
+ ...
+ num-detected-classes=80
+ ...
+ ```
+
+8. Edit the `deepstream_app_config` file
+
+ ```bash
+ ...
+ [primary-gie]
+ ...
+ config-file=config_infer_primary_yoloV8.txt
+ ```
+
+9. You can also change the video source in `deepstream_app_config` file. Here a default video file is loaded
+
+ ```bash
+ ...
+ [source0]
+ ...
+ uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
+ ```
+
+### Run Inference
+
+```bash
+deepstream-app -c deepstream_app_config.txt
+```
+
+!!! Note
+
+ It will take a long time to generate the TensorRT engine file before starting the inference. So please be patient.
+
+
+
+!!! Tip
+
+ If you want to convert the model to FP16 precision, simply set `model-engine-file=model_b1_gpu0_fp16.engine` and `network-mode=2` inside `config_infer_primary_yoloV8.txt`
+
+## INT8 Calibration
+
+If you want to use INT8 precision for inference, you need to follow the steps below
+
+1. Set `OPENCV` environment variable
+
+ ```bash
+ export OPENCV=1
+ ```
+
+2. Compile the library
+
+ ```bash
+ make -C nvdsinfer_custom_impl_Yolo clean && make -C nvdsinfer_custom_impl_Yolo
+ ```
+
+3. For COCO dataset, download the [val2017](http://images.cocodataset.org/zips/val2017.zip), extract, and move to `DeepStream-Yolo` folder
+
+4. Make a new directory for calibration images
+
+ ```bash
+ mkdir calibration
+ ```
+
+5. Run the following to select 1000 random images from COCO dataset to run calibration
+
+ ```bash
+ for jpg in $(ls -1 val2017/*.jpg | sort -R | head -1000); do \
+ cp ${jpg} calibration/; \
+ done
+ ```
+
+ !!! Note
+
+ NVIDIA recommends at least 500 images to get a good accuracy. On this example, 1000 images are chosen to get better accuracy (more images = more accuracy). You can set it from **head -1000**. For example, for 2000 images, **head -2000**. This process can take a long time.
+
+6. Create the `calibration.txt` file with all selected images
+
+ ```bash
+ realpath calibration/*jpg > calibration.txt
+ ```
+
+7. Set environment variables
+
+ ```bash
+ export INT8_CALIB_IMG_PATH=calibration.txt
+ export INT8_CALIB_BATCH_SIZE=1
+ ```
+
+ !!! Note
+
+ Higher INT8_CALIB_BATCH_SIZE values will result in more accuracy and faster calibration speed. Set it according to you GPU memory.
+
+8. Update the `config_infer_primary_yoloV8.txt` file
+
+ From
+
+ ```bash
+ ...
+ model-engine-file=model_b1_gpu0_fp32.engine
+ #int8-calib-file=calib.table
+ ...
+ network-mode=0
+ ...
+ ```
+
+ To
+
+ ```bash
+ ...
+ model-engine-file=model_b1_gpu0_int8.engine
+ int8-calib-file=calib.table
+ ...
+ network-mode=1
+ ...
+ ```
+
+### Run Inference
+
+```bash
+deepstream-app -c deepstream_app_config.txt
+```
+
+## MultiStream Setup
+
+To set up multiple streams under a single deepstream application, you can do the following changes to the `deepstream_app_config.txt` file
+
+1. Change the rows and columns to build a grid display according to the number of streams you want to have. For example, for 4 streams, we can add 2 rows and 2 columns.
+
+ ```bash
+ [tiled-display]
+ rows=2
+ columns=2
+ ```
+
+2. Set `num-sources=4` and add `uri` of all the 4 streams
+
+ ```bash
+ [source0]
+ enable=1
+ type=3
+ uri=
+ uri=
+ uri=
+ uri=
+ num-sources=4
+ ```
+
+### Run Inference
+
+```bash
+deepstream-app -c deepstream_app_config.txt
+```
+
+
+
+## Benchmark Results
+
+The following table summarizes how YOLOv8s models perform at different TensorRT precision levels with an input size of 640x640 on NVIDIA Jetson Orin NX 16GB.
+
+| Model Name | Precision | Inference Time (ms/im) | FPS |
+| ---------- | --------- | ---------------------- | --- |
+| YOLOv8s | FP32 | 15.63 | 64 |
+| | FP16 | 7.94 | 126 |
+| | INT8 | 5.53 | 181 |
+
+### Acknowledgements
+
+This guide was initially created by our friends at Seeed Studio, Lakshantha and Elaine.
+
+## FAQ
+
+### How do I set up Ultralytics YOLOv8 on an NVIDIA Jetson device?
+
+To set up Ultralytics YOLOv8 on an [NVIDIA Jetson](https://www.nvidia.com/en-us/autonomous-machines/embedded-systems/) device, you first need to install the [DeepStream SDK](https://developer.nvidia.com/deepstream-getting-started) compatible with your JetPack version. Follow the step-by-step guide in our [Quick Start Guide](nvidia-jetson.md) to configure your NVIDIA Jetson for YOLOv8 deployment.
+
+### What is the benefit of using TensorRT with YOLOv8 on NVIDIA Jetson?
+
+Using TensorRT with YOLOv8 optimizes the model for inference, significantly reducing latency and improving throughput on NVIDIA Jetson devices. TensorRT provides high-performance, low-latency deep learning inference through layer fusion, precision calibration, and kernel auto-tuning. This leads to faster and more efficient execution, particularly useful for real-time applications like video analytics and autonomous machines.
+
+### Can I run Ultralytics YOLOv8 with DeepStream SDK across different NVIDIA Jetson hardware?
+
+Yes, the guide for deploying Ultralytics YOLOv8 with the DeepStream SDK and TensorRT is compatible across the entire NVIDIA Jetson lineup. This includes devices like the Jetson Orin NX 16GB with [JetPack 5.1.3](https://developer.nvidia.com/embedded/jetpack-sdk-513) and the Jetson Nano 4GB with [JetPack 4.6.4](https://developer.nvidia.com/jetpack-sdk-464). Refer to the section [DeepStream Configuration for YOLOv8](#deepstream-configuration-for-yolov8) for detailed steps.
+
+### How can I convert a YOLOv8 model to ONNX for DeepStream?
+
+To convert a YOLOv8 model to ONNX format for deployment with DeepStream, use the `utils/export_yoloV8.py` script from the [DeepStream-Yolo](https://github.com/marcoslucianops/DeepStream-Yolo) repository.
+
+Here's an example command:
+
+```bash
+python3 utils/export_yoloV8.py -w yolov8s.pt --opset 12 --simplify
+```
+
+For more details on model conversion, check out our [model export section](../modes/export.md).
+
+### What are the performance benchmarks for YOLOv8 on NVIDIA Jetson Orin NX?
+
+The performance of YOLOv8 models on NVIDIA Jetson Orin NX 16GB varies based on TensorRT precision levels. For example, YOLOv8s models achieve:
+
+- **FP32 Precision**: 15.63 ms/im, 64 FPS
+- **FP16 Precision**: 7.94 ms/im, 126 FPS
+- **INT8 Precision**: 5.53 ms/im, 181 FPS
+
+These benchmarks underscore the efficiency and capability of using TensorRT-optimized YOLOv8 models on NVIDIA Jetson hardware. For further details, see our [Benchmark Results](#benchmark-results) section.
diff --git a/ultralytics/docs/en/guides/defining-project-goals.md b/ultralytics/docs/en/guides/defining-project-goals.md
new file mode 100644
index 0000000000000000000000000000000000000000..94b5f9a7b83d0b13511612eb0e59c6886c955e52
--- /dev/null
+++ b/ultralytics/docs/en/guides/defining-project-goals.md
@@ -0,0 +1,178 @@
+---
+comments: true
+description: Learn how to define clear goals and objectives for your computer vision project with our practical guide. Includes tips on problem statements, measurable objectives, and key decisions.
+keywords: computer vision, project planning, problem statement, measurable objectives, dataset preparation, model selection, YOLOv8, Ultralytics
+---
+
+# A Practical Guide for Defining Your Computer Vision Project
+
+## Introduction
+
+The first step in any computer vision project is defining what you want to achieve. It's crucial to have a clear roadmap from the start, which includes everything from data collection to deploying your model.
+
+If you need a quick refresher on the basics of a computer vision project, take a moment to read our guide on [the key steps in a computer vision project](./steps-of-a-cv-project.md). It'll give you a solid overview of the whole process. Once you're caught up, come back here to dive into how exactly you can define and refine the goals for your project.
+
+Now, let's get to the heart of defining a clear problem statement for your project and exploring the key decisions you'll need to make along the way.
+
+## Defining A Clear Problem Statement
+
+Setting clear goals and objectives for your project is the first big step toward finding the most effective solutions. Let's understand how you can clearly define your project's problem statement:
+
+- **Identify the Core Issue:** Pinpoint the specific challenge your computer vision project aims to solve.
+- **Determine the Scope:** Define the boundaries of your problem.
+- **Consider End Users and Stakeholders:** Identify who will be affected by the solution.
+- **Analyze Project Requirements and Constraints:** Assess available resources (time, budget, personnel) and identify any technical or regulatory constraints.
+
+### Example of a Business Problem Statement
+
+Let's walk through an example.
+
+Consider a computer vision project where you want to [estimate the speed of vehicles](./speed-estimation.md) on a highway. The core issue is that current speed monitoring methods are inefficient and error-prone due to outdated radar systems and manual processes. The project aims to develop a real-time computer vision system that can replace legacy [speed estimation](https://www.ultralytics.com/blog/ultralytics-yolov8-for-speed-estimation-in-computer-vision-projects) systems.
+
+
+
+
+
+Primary users include traffic management authorities and law enforcement, while secondary stakeholders are highway planners and the public benefiting from safer roads. Key requirements involve evaluating budget, time, and personnel, as well as addressing technical needs like high-resolution cameras and real-time data processing. Additionally, regulatory constraints on privacy and data security must be considered.
+
+### Setting Measurable Objectives
+
+Setting measurable objectives is key to the success of a computer vision project. These goals should be clear, achievable, and time-bound.
+
+For example, if you are developing a system to estimate vehicle speeds on a highway. You could consider the following measurable objectives:
+
+- To achieve at least 95% accuracy in speed detection within six months, using a dataset of 10,000 vehicle images.
+- The system should be able to process real-time video feeds at 30 frames per second with minimal delay.
+
+By setting specific and quantifiable goals, you can effectively track progress, identify areas for improvement, and ensure the project stays on course.
+
+## The Connection Between The Problem Statement and The Computer Vision Tasks
+
+Your problem statement helps you conceptualize which computer vision task can solve your issue.
+
+For example, if your problem is monitoring vehicle speeds on a highway, the relevant computer vision task is object tracking. [Object tracking](../modes/track.md) is suitable because it allows the system to continuously follow each vehicle in the video feed, which is crucial for accurately calculating their speeds.
+
+
+
+
+
+Other tasks, like [object detection](../tasks/detect.md), are not suitable as they don't provide continuous location or movement information. Once you've identified the appropriate computer vision task, it guides several critical aspects of your project, like model selection, dataset preparation, and model training approaches.
+
+## Which Comes First: Model Selection, Dataset Preparation, or Model Training Approach?
+
+The order of model selection, dataset preparation, and training approach depends on the specifics of your project. Here are a few tips to help you decide:
+
+- **Clear Understanding of the Problem**: If your problem and objectives are well-defined, start with model selection. Then, prepare your dataset and decide on the training approach based on the model's requirements.
+
+ - **Example**: Start by selecting a model for a traffic monitoring system that estimates vehicle speeds. Choose an object tracking model, gather and annotate highway videos, and then train the model with techniques for real-time video processing.
+
+- **Unique or Limited Data**: If your project is constrained by unique or limited data, begin with dataset preparation. For instance, if you have a rare dataset of medical images, annotate and prepare the data first. Then, select a model that performs well on such data, followed by choosing a suitable training approach.
+
+ - **Example**: Prepare the data first for a facial recognition system with a small dataset. Annotate it, then select a model that works well with limited data, such as a pre-trained model for transfer learning. Finally, decide on a training approach, including data augmentation, to expand the dataset.
+
+- **Need for Experimentation**: In projects where experimentation is crucial, start with the training approach. This is common in research projects where you might initially test different training techniques. Refine your model selection after identifying a promising method and prepare the dataset based on your findings.
+ - **Example**: In a project exploring new methods for detecting manufacturing defects, start with experimenting on a small data subset. Once you find a promising technique, select a model tailored to those findings and prepare a comprehensive dataset.
+
+## Common Discussion Points in the Community
+
+Next, let's look at a few common discussion points in the community regarding computer vision tasks and project planning.
+
+### What Are the Different Computer Vision Tasks?
+
+The most popular computer vision tasks include image classification, object detection, and image segmentation.
+
+
+
+
+
+For a detailed explanation of various tasks, please take a look at the Ultralytics Docs page on [YOLOv8 Tasks](../tasks/index.md).
+
+### Can a Pre-trained Model Remember Classes It Knew Before Custom Training?
+
+No, pre-trained models don't "remember" classes in the traditional sense. They learn patterns from massive datasets, and during custom training (fine-tuning), these patterns are adjusted for your specific task. The model's capacity is limited, and focusing on new information can overwrite some previous learnings.
+
+
+
+
+
+If you want to use the classes the model was pre-trained on, a practical approach is to use two models: one retains the original performance, and the other is fine-tuned for your specific task. This way, you can combine the outputs of both models. There are other options like freezing layers, using the pre-trained model as a feature extractor, and task-specific branching, but these are more complex solutions and require more expertise.
+
+### How Do Deployment Options Affect My Computer Vision Project?
+
+[Model deployment options](./model-deployment-options.md) critically impact the performance of your computer vision project. For instance, the deployment environment must handle the computational load of your model. Here are some practical examples:
+
+- **Edge Devices**: Deploying on edge devices like smartphones or IoT devices requires lightweight models due to their limited computational resources. Example technologies include [TensorFlow Lite](../integrations/tflite.md) and [ONNX Runtime](../integrations/onnx.md), which are optimized for such environments.
+- **Cloud Servers**: Cloud deployments can handle more complex models with larger computational demands. Cloud platforms like [AWS](../integrations/amazon-sagemaker.md), Google Cloud, and Azure offer robust hardware options that can scale based on the project's needs.
+- **On-Premise Servers**: For scenarios requiring high data privacy and security, deploying on-premise might be necessary. This involves significant upfront hardware investment but allows full control over the data and infrastructure.
+- **Hybrid Solutions**: Some projects might benefit from a hybrid approach, where some processing is done on the edge, while more complex analyses are offloaded to the cloud. This can balance performance needs with cost and latency considerations.
+
+Each deployment option offers different benefits and challenges, and the choice depends on specific project requirements like performance, cost, and security.
+
+## Connecting with the Community
+
+Connecting with other computer vision enthusiasts can be incredibly helpful for your projects by providing support, solutions, and new ideas. Here are some great ways to learn, troubleshoot, and network:
+
+### Community Support Channels
+
+- **GitHub Issues:** Head over to the YOLOv8 GitHub repository. You can use the [Issues tab](https://github.com/ultralytics/ultralytics/issues) to raise questions, report bugs, and suggest features. The community and maintainers can assist with specific problems you encounter.
+- **Ultralytics Discord Server:** Become part of the [Ultralytics Discord server](https://ultralytics.com/discord/). Connect with fellow users and developers, seek support, exchange knowledge, and discuss ideas.
+
+### Comprehensive Guides and Documentation
+
+- **Ultralytics YOLOv8 Documentation:** Explore the [official YOLOv8 documentation](./index.md) for in-depth guides and valuable tips on various computer vision tasks and projects.
+
+## Conclusion
+
+Defining a clear problem and setting measurable goals is key to a successful computer vision project. We've highlighted the importance of being clear and focused from the start. Having specific goals helps avoid oversight. Also, staying connected with others in the community through platforms like GitHub or Discord is important for learning and staying current. In short, good planning and engaging with the community is a huge part of successful computer vision projects.
+
+## FAQ
+
+### How do I define a clear problem statement for my Ultralytics computer vision project?
+
+To define a clear problem statement for your Ultralytics computer vision project, follow these steps:
+
+1. **Identify the Core Issue:** Pinpoint the specific challenge your project aims to solve.
+2. **Determine the Scope:** Clearly outline the boundaries of your problem.
+3. **Consider End Users and Stakeholders:** Identify who will be affected by your solution.
+4. **Analyze Project Requirements and Constraints:** Assess available resources and any technical or regulatory limitations.
+
+Providing a well-defined problem statement ensures that the project remains focused and aligned with your objectives. For a detailed guide, refer to our [practical guide](#defining-a-clear-problem-statement).
+
+### Why should I use Ultralytics YOLOv8 for speed estimation in my computer vision project?
+
+Ultralytics YOLOv8 is ideal for speed estimation because of its real-time object tracking capabilities, high accuracy, and robust performance in detecting and monitoring vehicle speeds. It overcomes inefficiencies and inaccuracies of traditional radar systems by leveraging cutting-edge computer vision technology. Check out our blog on [speed estimation using YOLOv8](https://www.ultralytics.com/blog/ultralytics-yolov8-for-speed-estimation-in-computer-vision-projects) for more insights and practical examples.
+
+### How do I set effective measurable objectives for my computer vision project with Ultralytics YOLOv8?
+
+Set effective and measurable objectives using the SMART criteria:
+
+- **Specific:** Define clear and detailed goals.
+- **Measurable:** Ensure objectives are quantifiable.
+- **Achievable:** Set realistic targets within your capabilities.
+- **Relevant:** Align objectives with your overall project goals.
+- **Time-bound:** Set deadlines for each objective.
+
+For example, "Achieve 95% accuracy in speed detection within six months using a 10,000 vehicle image dataset." This approach helps track progress and identifies areas for improvement. Read more about [setting measurable objectives](#setting-measurable-objectives).
+
+### How do deployment options affect the performance of my Ultralytics YOLO models?
+
+Deployment options critically impact the performance of your Ultralytics YOLO models. Here are key options:
+
+- **Edge Devices:** Use lightweight models like TensorFlow Lite or ONNX Runtime for deployment on devices with limited resources.
+- **Cloud Servers:** Utilize robust cloud platforms like AWS, Google Cloud, or Azure for handling complex models.
+- **On-Premise Servers:** High data privacy and security needs may require on-premise deployments.
+- **Hybrid Solutions:** Combine edge and cloud approaches for balanced performance and cost-efficiency.
+
+For more information, refer to our [detailed guide on model deployment options](./model-deployment-options.md).
+
+### What are the most common challenges in defining the problem for a computer vision project with Ultralytics?
+
+Common challenges include:
+
+- Vague or overly broad problem statements.
+- Unrealistic objectives.
+- Lack of stakeholder alignment.
+- Insufficient understanding of technical constraints.
+- Underestimating data requirements.
+
+Address these challenges through thorough initial research, clear communication with stakeholders, and iterative refinement of the problem statement and objectives. Learn more about these challenges in our [Computer Vision Project guide](steps-of-a-cv-project.md).
diff --git a/ultralytics/docs/en/guides/distance-calculation.md b/ultralytics/docs/en/guides/distance-calculation.md
new file mode 100644
index 0000000000000000000000000000000000000000..b756c6004f33876d614688ee8331ac5219406938
--- /dev/null
+++ b/ultralytics/docs/en/guides/distance-calculation.md
@@ -0,0 +1,138 @@
+---
+comments: true
+description: Learn how to calculate distances between objects using Ultralytics YOLOv8 for accurate spatial positioning and scene understanding.
+keywords: Ultralytics, YOLOv8, distance calculation, computer vision, object tracking, spatial positioning
+---
+
+# Distance Calculation using Ultralytics YOLOv8
+
+## What is Distance Calculation?
+
+Measuring the gap between two objects is known as distance calculation within a specified space. In the case of [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics), the bounding box centroid is employed to calculate the distance for bounding boxes highlighted by the user.
+
+
+
+## Visuals
+
+| Distance Calculation using Ultralytics YOLOv8 |
+| :---------------------------------------------------------------------------------------------------------------------------------------------: |
+|  |
+
+## Advantages of Distance Calculation?
+
+- **Localization Precision:** Enhances accurate spatial positioning in computer vision tasks.
+- **Size Estimation:** Allows estimation of physical sizes for better contextual understanding.
+- **Scene Understanding:** Contributes to a 3D understanding of the environment for improved decision-making.
+
+???+ tip "Distance Calculation"
+
+ - Click on any two bounding boxes with Left Mouse click for distance calculation
+
+!!! Example "Distance Calculation using YOLOv8 Example"
+
+ === "Video Stream"
+
+ ```python
+ import cv2
+
+ from ultralytics import YOLO, solutions
+
+ model = YOLO("yolov8n.pt")
+ names = model.model.names
+
+ cap = cv2.VideoCapture("path/to/video/file.mp4")
+ assert cap.isOpened(), "Error reading video file"
+ w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
+
+ # Video writer
+ video_writer = cv2.VideoWriter("distance_calculation.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
+
+ # Init distance-calculation obj
+ dist_obj = solutions.DistanceCalculation(names=names, view_img=True)
+
+ while cap.isOpened():
+ success, im0 = cap.read()
+ if not success:
+ print("Video frame is empty or video processing has been successfully completed.")
+ break
+
+ tracks = model.track(im0, persist=True, show=False)
+ im0 = dist_obj.start_process(im0, tracks)
+ video_writer.write(im0)
+
+ cap.release()
+ video_writer.release()
+ cv2.destroyAllWindows()
+ ```
+
+???+ tip "Note"
+
+ - Mouse Right Click will delete all drawn points
+ - Mouse Left Click can be used to draw points
+
+### Arguments `DistanceCalculation()`
+
+| `Name` | `Type` | `Default` | Description |
+| ------------------ | ------- | --------------- | --------------------------------------------------------- |
+| `names` | `dict` | `None` | Dictionary of classes names. |
+| `pixels_per_meter` | `int` | `10` | Conversion factor from pixels to meters. |
+| `view_img` | `bool` | `False` | Flag to indicate if the video stream should be displayed. |
+| `line_thickness` | `int` | `2` | Thickness of the lines drawn on the image. |
+| `line_color` | `tuple` | `(255, 255, 0)` | Color of the lines drawn on the image (BGR format). |
+| `centroid_color` | `tuple` | `(255, 0, 255)` | Color of the centroids drawn (BGR format). |
+
+### Arguments `model.track`
+
+| Name | Type | Default | Description |
+| --------- | ------- | -------------- | ----------------------------------------------------------- |
+| `source` | `im0` | `None` | source directory for images or videos |
+| `persist` | `bool` | `False` | persisting tracks between frames |
+| `tracker` | `str` | `botsort.yaml` | Tracking method 'bytetrack' or 'botsort' |
+| `conf` | `float` | `0.3` | Confidence Threshold |
+| `iou` | `float` | `0.5` | IOU Threshold |
+| `classes` | `list` | `None` | filter results by class, i.e. classes=0, or classes=[0,2,3] |
+| `verbose` | `bool` | `True` | Display the object tracking results |
+
+## FAQ
+
+### How do I calculate distances between objects using Ultralytics YOLOv8?
+
+To calculate distances between objects using [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics), you need to identify the bounding box centroids of the detected objects. This process involves initializing the `DistanceCalculation` class from Ultralytics' `solutions` module and using the model's tracking outputs to calculate the distances. You can refer to the implementation in the [distance calculation example](#distance-calculation-using-ultralytics-yolov8).
+
+### What are the advantages of using distance calculation with Ultralytics YOLOv8?
+
+Using distance calculation with Ultralytics YOLOv8 offers several advantages:
+
+- **Localization Precision:** Provides accurate spatial positioning for objects.
+- **Size Estimation:** Helps estimate physical sizes, contributing to better contextual understanding.
+- **Scene Understanding:** Enhances 3D scene comprehension, aiding improved decision-making in applications like autonomous driving and surveillance.
+
+### Can I perform distance calculation in real-time video streams with Ultralytics YOLOv8?
+
+Yes, you can perform distance calculation in real-time video streams with Ultralytics YOLOv8. The process involves capturing video frames using OpenCV, running YOLOv8 object detection, and using the `DistanceCalculation` class to calculate distances between objects in successive frames. For a detailed implementation, see the [video stream example](#distance-calculation-using-ultralytics-yolov8).
+
+### How do I delete points drawn during distance calculation using Ultralytics YOLOv8?
+
+To delete points drawn during distance calculation with Ultralytics YOLOv8, you can use a right mouse click. This action will clear all the points you have drawn. For more details, refer to the note section under the [distance calculation example](#distance-calculation-using-ultralytics-yolov8).
+
+### What are the key arguments for initializing the DistanceCalculation class in Ultralytics YOLOv8?
+
+The key arguments for initializing the `DistanceCalculation` class in Ultralytics YOLOv8 include:
+
+- `names`: Dictionary mapping class indices to class names.
+- `pixels_per_meter`: Conversion factor from pixels to meters.
+- `view_img`: Flag to indicate if the video stream should be displayed.
+- `line_thickness`: Thickness of the lines drawn on the image.
+- `line_color`: Color of the lines drawn on the image (BGR format).
+- `centroid_color`: Color of the centroids (BGR format).
+
+For an exhaustive list and default values, see the [arguments of DistanceCalculation](#arguments-distancecalculation).
diff --git a/ultralytics/docs/en/guides/docker-quickstart.md b/ultralytics/docs/en/guides/docker-quickstart.md
new file mode 100644
index 0000000000000000000000000000000000000000..3962661e3441e1b1f0634482cdee8a95cab4e830
--- /dev/null
+++ b/ultralytics/docs/en/guides/docker-quickstart.md
@@ -0,0 +1,283 @@
+---
+comments: true
+description: Learn to effortlessly set up Ultralytics in Docker, from installation to running with CPU/GPU support. Follow our comprehensive guide for seamless container experience.
+keywords: Ultralytics, Docker, Quickstart Guide, CPU support, GPU support, NVIDIA Docker, container setup, Docker environment, Docker Hub, Ultralytics projects
+---
+
+# Docker Quickstart Guide for Ultralytics
+
+
+
+
+
+This guide serves as a comprehensive introduction to setting up a Docker environment for your Ultralytics projects. [Docker](https://docker.com/) is a platform for developing, shipping, and running applications in containers. It is particularly beneficial for ensuring that the software will always run the same, regardless of where it's deployed. For more details, visit the Ultralytics Docker repository on [Docker Hub](https://hub.docker.com/r/ultralytics/ultralytics).
+
+[](https://hub.docker.com/r/ultralytics/ultralytics)
+[](https://hub.docker.com/r/ultralytics/ultralytics)
+
+## What You Will Learn
+
+- Setting up Docker with NVIDIA support
+- Installing Ultralytics Docker images
+- Running Ultralytics in a Docker container with CPU or GPU support
+- Using a Display Server with Docker to Show Ultralytics Detection Results
+- Mounting local directories into the container
+
+---
+
+## Prerequisites
+
+- Make sure Docker is installed on your system. If not, you can download and install it from [Docker's website](https://www.docker.com/products/docker-desktop).
+- Ensure that your system has an NVIDIA GPU and NVIDIA drivers are installed.
+
+---
+
+## Setting up Docker with NVIDIA Support
+
+First, verify that the NVIDIA drivers are properly installed by running:
+
+```bash
+nvidia-smi
+```
+
+### Installing NVIDIA Docker Runtime
+
+Now, let's install the NVIDIA Docker runtime to enable GPU support in Docker containers:
+
+```bash
+# Add NVIDIA package repositories
+curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
+distribution=$(lsb_release -cs)
+curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
+
+# Install NVIDIA Docker runtime
+sudo apt-get update
+sudo apt-get install -y nvidia-docker2
+
+# Restart Docker service to apply changes
+sudo systemctl restart docker
+```
+
+### Verify NVIDIA Runtime with Docker
+
+Run `docker info | grep -i runtime` to ensure that `nvidia` appears in the list of runtimes:
+
+```bash
+docker info | grep -i runtime
+```
+
+---
+
+## Installing Ultralytics Docker Images
+
+Ultralytics offers several Docker images optimized for various platforms and use-cases:
+
+- **Dockerfile:** GPU image, ideal for training.
+- **Dockerfile-arm64:** For ARM64 architecture, suitable for devices like [Raspberry Pi](raspberry-pi.md).
+- **Dockerfile-cpu:** CPU-only version for inference and non-GPU environments.
+- **Dockerfile-jetson:** Optimized for NVIDIA Jetson devices.
+- **Dockerfile-python:** Minimal Python environment for lightweight applications.
+- **Dockerfile-conda:** Includes [Miniconda3](https://docs.conda.io/projects/miniconda/en/latest/) and Ultralytics package installed via Conda.
+
+To pull the latest image:
+
+```bash
+# Set image name as a variable
+t=ultralytics/ultralytics:latest
+
+# Pull the latest Ultralytics image from Docker Hub
+sudo docker pull $t
+```
+
+---
+
+## Running Ultralytics in Docker Container
+
+Here's how to execute the Ultralytics Docker container:
+
+### Using only the CPU
+
+```bash
+# Run with all GPUs
+sudo docker run -it --ipc=host $t
+```
+
+### Using GPUs
+
+```bash
+# Run with all GPUs
+sudo docker run -it --ipc=host --gpus all $t
+
+# Run specifying which GPUs to use
+sudo docker run -it --ipc=host --gpus '"device=2,3"' $t
+```
+
+The `-it` flag assigns a pseudo-TTY and keeps stdin open, allowing you to interact with the container. The `--ipc=host` flag enables sharing of host's IPC namespace, essential for sharing memory between processes. The `--gpus` flag allows the container to access the host's GPUs.
+
+## Running Ultralytics in Docker Container
+
+Here's how to execute the Ultralytics Docker container:
+
+### Using only the CPU
+
+```bash
+# Run with all GPUs
+sudo docker run -it --ipc=host $t
+```
+
+### Using GPUs
+
+```bash
+# Run with all GPUs
+sudo docker run -it --ipc=host --gpus all $t
+
+# Run specifying which GPUs to use
+sudo docker run -it --ipc=host --gpus '"device=2,3"' $t
+```
+
+The `-it` flag assigns a pseudo-TTY and keeps stdin open, allowing you to interact with the container. The `--ipc=host` flag enables sharing of host's IPC namespace, essential for sharing memory between processes. The `--gpus` flag allows the container to access the host's GPUs.
+
+### Note on File Accessibility
+
+To work with files on your local machine within the container, you can use Docker volumes:
+
+```bash
+# Mount a local directory into the container
+sudo docker run -it --ipc=host --gpus all -v /path/on/host:/path/in/container $t
+```
+
+Replace `/path/on/host` with the directory path on your local machine and `/path/in/container` with the desired path inside the Docker container.
+
+## Run graphical user interface (GUI) applications in a Docker Container
+
+!!! danger "Highly Experimental - User Assumes All Risk"
+
+ The following instructions are experimental. Sharing a X11 socket with a Docker container poses potential security risks. Therefore, it's recommended to test this solution only in a controlled environment. For more information, refer to these resources on how to use `xhost`[(1)](http://users.stat.umn.edu/~geyer/secure.html)[(2)](https://linux.die.net/man/1/xhost).
+
+Docker is primarily used to containerize background applications and CLI programs, but it can also run graphical programs. In the Linux world, two main graphic servers handle graphical display: [X11](https://www.x.org/wiki/) (also known as the X Window System) and [Wayland](https://wayland.freedesktop.org/). Before starting, it's essential to determine which graphics server you are currently using. Run this command to find out:
+
+```bash
+env | grep -E -i 'x11|xorg|wayland'
+```
+
+Setup and configuration of an X11 or Wayland display server is outside the scope of this guide. If the above command returns nothing, then you'll need to start by getting either working for your system before continuing.
+
+### Running a Docker Container with a GUI
+
+!!! example
+
+ ??? info "Use GPUs"
+ If you're using [GPUs](#using-gpus), you can add the `--gpus all` flag to the command.
+
+ === "X11"
+
+ If you're using X11, you can run the following command to allow the Docker container to access the X11 socket:
+
+ ```bash
+ xhost +local:docker && docker run -e DISPLAY=$DISPLAY \
+ -v /tmp/.X11-unix:/tmp/.X11-unix \
+ -v ~/.Xauthority:/root/.Xauthority \
+ -it --ipc=host $t
+ ```
+
+ This command sets the `DISPLAY` environment variable to the host's display, mounts the X11 socket, and maps the `.Xauthority` file to the container. The `xhost +local:docker` command allows the Docker container to access the X11 server.
+
+
+ === "Wayland"
+
+ For Wayland, use the following command:
+
+ ```bash
+ xhost +local:docker && docker run -e DISPLAY=$DISPLAY \
+ -v $XDG_RUNTIME_DIR/$WAYLAND_DISPLAY:/tmp/$WAYLAND_DISPLAY \
+ --net=host -it --ipc=host $t
+ ```
+
+ This command sets the `DISPLAY` environment variable to the host's display, mounts the Wayland socket, and allows the Docker container to access the Wayland server.
+
+### Using Docker with a GUI
+
+Now you can display graphical applications inside your Docker container. For example, you can run the following [CLI command](../usage/cli.md) to visualize the [predictions](../modes/predict.md) from a [YOLOv8 model](../models/yolov8.md):
+
+```bash
+yolo predict model=yolov8n.pt show=True
+```
+
+??? info "Testing"
+
+ A simple way to validate that the Docker group has access to the X11 server is to run a container with a GUI program like [`xclock`](https://www.x.org/archive/X11R6.8.1/doc/xclock.1.html) or [`xeyes`](https://www.x.org/releases/X11R7.5/doc/man/man1/xeyes.1.html). Alternatively, you can also install these programs in the Ultralytics Docker container to test the access to the X11 server of your GNU-Linux display server. If you run into any problems, consider setting the environment variable `-e QT_DEBUG_PLUGINS=1`. Setting this environment variable enables the output of debugging information, aiding in the troubleshooting process.
+
+### When finished with Docker GUI
+
+!!! warning "Revoke access"
+
+ In both cases, don't forget to revoke access from the Docker group when you're done.
+
+ ```bash
+ xhost -local:docker
+ ```
+
+??? question "Want to view image results directly in the Terminal?"
+
+ Refer to the following guide on [viewing the image results using a terminal](./view-results-in-terminal.md)
+
+---
+
+Congratulations! You're now set up to use Ultralytics with Docker and ready to take advantage of its powerful capabilities. For alternate installation methods, feel free to explore the [Ultralytics quickstart documentation](../quickstart.md).
+
+## FAQ
+
+### How do I set up Ultralytics with Docker?
+
+To set up Ultralytics with Docker, first ensure that Docker is installed on your system. If you have an NVIDIA GPU, install the NVIDIA Docker runtime to enable GPU support. Then, pull the latest Ultralytics Docker image from Docker Hub using the following command:
+
+```bash
+sudo docker pull ultralytics/ultralytics:latest
+```
+
+For detailed steps, refer to our [Docker Quickstart Guide](../quickstart.md).
+
+### What are the benefits of using Ultralytics Docker images for machine learning projects?
+
+Using Ultralytics Docker images ensures a consistent environment across different machines, replicating the same software and dependencies. This is particularly useful for collaborating across teams, running models on various hardware, and maintaining reproducibility. For GPU-based training, Ultralytics provides optimized Docker images such as `Dockerfile` for general GPU usage and `Dockerfile-jetson` for NVIDIA Jetson devices. Explore [Ultralytics Docker Hub](https://hub.docker.com/r/ultralytics/ultralytics) for more details.
+
+### How can I run Ultralytics YOLO in a Docker container with GPU support?
+
+First, ensure that the NVIDIA Docker runtime is installed and configured. Then, use the following command to run Ultralytics YOLO with GPU support:
+
+```bash
+sudo docker run -it --ipc=host --gpus all ultralytics/ultralytics:latest
+```
+
+This command sets up a Docker container with GPU access. For additional details, see the [Docker Quickstart Guide](../quickstart.md).
+
+### How do I visualize YOLO prediction results in a Docker container with a display server?
+
+To visualize YOLO prediction results with a GUI in a Docker container, you need to allow Docker to access your display server. For systems running X11, the command is:
+
+```bash
+xhost +local:docker && docker run -e DISPLAY=$DISPLAY \
+-v /tmp/.X11-unix:/tmp/.X11-unix \
+-v ~/.Xauthority:/root/.Xauthority \
+-it --ipc=host ultralytics/ultralytics:latest
+```
+
+For systems running Wayland, use:
+
+```bash
+xhost +local:docker && docker run -e DISPLAY=$DISPLAY \
+-v $XDG_RUNTIME_DIR/$WAYLAND_DISPLAY:/tmp/$WAYLAND_DISPLAY \
+--net=host -it --ipc=host ultralytics/ultralytics:latest
+```
+
+More information can be found in the [Run graphical user interface (GUI) applications in a Docker Container](#run-graphical-user-interface-gui-applications-in-a-docker-container) section.
+
+### Can I mount local directories into the Ultralytics Docker container?
+
+Yes, you can mount local directories into the Ultralytics Docker container using the `-v` flag:
+
+```bash
+sudo docker run -it --ipc=host --gpus all -v /path/on/host:/path/in/container ultralytics/ultralytics:latest
+```
+
+Replace `/path/on/host` with the directory on your local machine and `/path/in/container` with the desired path inside the container. This setup allows you to work with your local files within the container. For more information, refer to the relevant section on [mounting local directories](../usage/python.md).
diff --git a/ultralytics/docs/en/guides/heatmaps.md b/ultralytics/docs/en/guides/heatmaps.md
new file mode 100644
index 0000000000000000000000000000000000000000..efcf427bd93e1be60a16fc5b868f3fa9b5551c96
--- /dev/null
+++ b/ultralytics/docs/en/guides/heatmaps.md
@@ -0,0 +1,403 @@
+---
+comments: true
+description: Transform complex data into insightful heatmaps using Ultralytics YOLOv8. Discover patterns, trends, and anomalies with vibrant visualizations.
+keywords: Ultralytics, YOLOv8, heatmaps, data visualization, data analysis, complex data, patterns, trends, anomalies
+---
+
+# Advanced Data Visualization: Heatmaps using Ultralytics YOLOv8 🚀
+
+## Introduction to Heatmaps
+
+A heatmap generated with [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) transforms complex data into a vibrant, color-coded matrix. This visual tool employs a spectrum of colors to represent varying data values, where warmer hues indicate higher intensities and cooler tones signify lower values. Heatmaps excel in visualizing intricate data patterns, correlations, and anomalies, offering an accessible and engaging approach to data interpretation across diverse domains.
+
+
+
+
+
+ Watch: Heatmaps using Ultralytics YOLOv8
+
+
+## Why Choose Heatmaps for Data Analysis?
+
+- **Intuitive Data Distribution Visualization:** Heatmaps simplify the comprehension of data concentration and distribution, converting complex datasets into easy-to-understand visual formats.
+- **Efficient Pattern Detection:** By visualizing data in heatmap format, it becomes easier to spot trends, clusters, and outliers, facilitating quicker analysis and insights.
+- **Enhanced Spatial Analysis and Decision-Making:** Heatmaps are instrumental in illustrating spatial relationships, aiding in decision-making processes in sectors such as business intelligence, environmental studies, and urban planning.
+
+## Real World Applications
+
+| Transportation | Retail |
+| :---------------------------------------------------------------------------------------------------------------------------------------------: | :-------------------------------------------------------------------------------------------------------------------------------------: |
+|  |  |
+| Ultralytics YOLOv8 Transportation Heatmap | Ultralytics YOLOv8 Retail Heatmap |
+
+!!! tip "Heatmap Configuration"
+
+ - `heatmap_alpha`: Ensure this value is within the range (0.0 - 1.0).
+ - `decay_factor`: Used for removing heatmap after an object is no longer in the frame, its value should also be in the range (0.0 - 1.0).
+
+!!! Example "Heatmaps using Ultralytics YOLOv8 Example"
+
+ === "Heatmap"
+
+ ```python
+ import cv2
+
+ from ultralytics import YOLO, solutions
+
+ model = YOLO("yolov8n.pt")
+ cap = cv2.VideoCapture("path/to/video/file.mp4")
+ assert cap.isOpened(), "Error reading video file"
+ w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
+
+ # Video writer
+ video_writer = cv2.VideoWriter("heatmap_output.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
+
+ # Init heatmap
+ heatmap_obj = solutions.Heatmap(
+ colormap=cv2.COLORMAP_PARULA,
+ view_img=True,
+ shape="circle",
+ names=model.names,
+ )
+
+ while cap.isOpened():
+ success, im0 = cap.read()
+ if not success:
+ print("Video frame is empty or video processing has been successfully completed.")
+ break
+ tracks = model.track(im0, persist=True, show=False)
+
+ im0 = heatmap_obj.generate_heatmap(im0, tracks)
+ video_writer.write(im0)
+
+ cap.release()
+ video_writer.release()
+ cv2.destroyAllWindows()
+ ```
+
+ === "Line Counting"
+
+ ```python
+ import cv2
+
+ from ultralytics import YOLO, solutions
+
+ model = YOLO("yolov8n.pt")
+ cap = cv2.VideoCapture("path/to/video/file.mp4")
+ assert cap.isOpened(), "Error reading video file"
+ w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
+
+ # Video writer
+ video_writer = cv2.VideoWriter("heatmap_output.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
+
+ line_points = [(20, 400), (1080, 404)] # line for object counting
+
+ # Init heatmap
+ heatmap_obj = solutions.Heatmap(
+ colormap=cv2.COLORMAP_PARULA,
+ view_img=True,
+ shape="circle",
+ count_reg_pts=line_points,
+ names=model.names,
+ )
+
+ while cap.isOpened():
+ success, im0 = cap.read()
+ if not success:
+ print("Video frame is empty or video processing has been successfully completed.")
+ break
+
+ tracks = model.track(im0, persist=True, show=False)
+ im0 = heatmap_obj.generate_heatmap(im0, tracks)
+ video_writer.write(im0)
+
+ cap.release()
+ video_writer.release()
+ cv2.destroyAllWindows()
+ ```
+
+ === "Polygon Counting"
+
+ ```python
+ import cv2
+
+ from ultralytics import YOLO, solutions
+
+ model = YOLO("yolov8n.pt")
+ cap = cv2.VideoCapture("path/to/video/file.mp4")
+ assert cap.isOpened(), "Error reading video file"
+ w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
+
+ # Video writer
+ video_writer = cv2.VideoWriter("heatmap_output.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
+
+ # Define polygon points
+ region_points = [(20, 400), (1080, 404), (1080, 360), (20, 360), (20, 400)]
+
+ # Init heatmap
+ heatmap_obj = solutions.Heatmap(
+ colormap=cv2.COLORMAP_PARULA,
+ view_img=True,
+ shape="circle",
+ count_reg_pts=region_points,
+ names=model.names,
+ )
+
+ while cap.isOpened():
+ success, im0 = cap.read()
+ if not success:
+ print("Video frame is empty or video processing has been successfully completed.")
+ break
+
+ tracks = model.track(im0, persist=True, show=False)
+ im0 = heatmap_obj.generate_heatmap(im0, tracks)
+ video_writer.write(im0)
+
+ cap.release()
+ video_writer.release()
+ cv2.destroyAllWindows()
+ ```
+
+ === "Region Counting"
+
+ ```python
+ import cv2
+
+ from ultralytics import YOLO, solutions
+
+ model = YOLO("yolov8n.pt")
+ cap = cv2.VideoCapture("path/to/video/file.mp4")
+ assert cap.isOpened(), "Error reading video file"
+ w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
+
+ # Video writer
+ video_writer = cv2.VideoWriter("heatmap_output.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
+
+ # Define region points
+ region_points = [(20, 400), (1080, 404), (1080, 360), (20, 360)]
+
+ # Init heatmap
+ heatmap_obj = solutions.Heatmap(
+ colormap=cv2.COLORMAP_PARULA,
+ view_img=True,
+ shape="circle",
+ count_reg_pts=region_points,
+ names=model.names,
+ )
+
+ while cap.isOpened():
+ success, im0 = cap.read()
+ if not success:
+ print("Video frame is empty or video processing has been successfully completed.")
+ break
+
+ tracks = model.track(im0, persist=True, show=False)
+ im0 = heatmap_obj.generate_heatmap(im0, tracks)
+ video_writer.write(im0)
+
+ cap.release()
+ video_writer.release()
+ cv2.destroyAllWindows()
+ ```
+
+ === "Im0"
+
+ ```python
+ import cv2
+
+ from ultralytics import YOLO, solutions
+
+ model = YOLO("yolov8s.pt") # YOLOv8 custom/pretrained model
+
+ im0 = cv2.imread("path/to/image.png") # path to image file
+ h, w = im0.shape[:2] # image height and width
+
+ # Heatmap Init
+ heatmap_obj = solutions.Heatmap(
+ colormap=cv2.COLORMAP_PARULA,
+ view_img=True,
+ shape="circle",
+ names=model.names,
+ )
+
+ results = model.track(im0, persist=True)
+ im0 = heatmap_obj.generate_heatmap(im0, tracks=results)
+ cv2.imwrite("ultralytics_output.png", im0)
+ ```
+
+ === "Specific Classes"
+
+ ```python
+ import cv2
+
+ from ultralytics import YOLO, solutions
+
+ model = YOLO("yolov8n.pt")
+ cap = cv2.VideoCapture("path/to/video/file.mp4")
+ assert cap.isOpened(), "Error reading video file"
+ w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
+
+ # Video writer
+ video_writer = cv2.VideoWriter("heatmap_output.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
+
+ classes_for_heatmap = [0, 2] # classes for heatmap
+
+ # Init heatmap
+ heatmap_obj = solutions.Heatmap(
+ colormap=cv2.COLORMAP_PARULA,
+ view_img=True,
+ shape="circle",
+ names=model.names,
+ )
+
+ while cap.isOpened():
+ success, im0 = cap.read()
+ if not success:
+ print("Video frame is empty or video processing has been successfully completed.")
+ break
+ tracks = model.track(im0, persist=True, show=False, classes=classes_for_heatmap)
+
+ im0 = heatmap_obj.generate_heatmap(im0, tracks)
+ video_writer.write(im0)
+
+ cap.release()
+ video_writer.release()
+ cv2.destroyAllWindows()
+ ```
+
+### Arguments `Heatmap()`
+
+| Name | Type | Default | Description |
+| ------------------ | ---------------- | ------------------ | ----------------------------------------------------------------- |
+| `names` | `list` | `None` | Dictionary of class names. |
+| `imw` | `int` | `0` | Image width. |
+| `imh` | `int` | `0` | Image height. |
+| `colormap` | `int` | `cv2.COLORMAP_JET` | Colormap to use for the heatmap. |
+| `heatmap_alpha` | `float` | `0.5` | Alpha blending value for heatmap overlay. |
+| `view_img` | `bool` | `False` | Whether to display the image with the heatmap overlay. |
+| `view_in_counts` | `bool` | `True` | Whether to display the count of objects entering the region. |
+| `view_out_counts` | `bool` | `True` | Whether to display the count of objects exiting the region. |
+| `count_reg_pts` | `list` or `None` | `None` | Points defining the counting region (either a line or a polygon). |
+| `count_txt_color` | `tuple` | `(0, 0, 0)` | Text color for displaying counts. |
+| `count_bg_color` | `tuple` | `(255, 255, 255)` | Background color for displaying counts. |
+| `count_reg_color` | `tuple` | `(255, 0, 255)` | Color for the counting region. |
+| `region_thickness` | `int` | `5` | Thickness of the region line. |
+| `line_dist_thresh` | `int` | `15` | Distance threshold for line-based counting. |
+| `line_thickness` | `int` | `2` | Thickness of the lines used in drawing. |
+| `decay_factor` | `float` | `0.99` | Decay factor for the heatmap to reduce intensity over time. |
+| `shape` | `str` | `"circle"` | Shape of the heatmap blobs ('circle' or 'rect'). |
+
+### Arguments `model.track`
+
+| Name | Type | Default | Description |
+| --------- | ------- | -------------- | ----------------------------------------------------------- |
+| `source` | `im0` | `None` | source directory for images or videos |
+| `persist` | `bool` | `False` | persisting tracks between frames |
+| `tracker` | `str` | `botsort.yaml` | Tracking method 'bytetrack' or 'botsort' |
+| `conf` | `float` | `0.3` | Confidence Threshold |
+| `iou` | `float` | `0.5` | IOU Threshold |
+| `classes` | `list` | `None` | filter results by class, i.e. classes=0, or classes=[0,2,3] |
+
+### Heatmap COLORMAPs
+
+| Colormap Name | Description |
+| ------------------------------- | -------------------------------------- |
+| `cv::COLORMAP_AUTUMN` | Autumn color map |
+| `cv::COLORMAP_BONE` | Bone color map |
+| `cv::COLORMAP_JET` | Jet color map |
+| `cv::COLORMAP_WINTER` | Winter color map |
+| `cv::COLORMAP_RAINBOW` | Rainbow color map |
+| `cv::COLORMAP_OCEAN` | Ocean color map |
+| `cv::COLORMAP_SUMMER` | Summer color map |
+| `cv::COLORMAP_SPRING` | Spring color map |
+| `cv::COLORMAP_COOL` | Cool color map |
+| `cv::COLORMAP_HSV` | HSV (Hue, Saturation, Value) color map |
+| `cv::COLORMAP_PINK` | Pink color map |
+| `cv::COLORMAP_HOT` | Hot color map |
+| `cv::COLORMAP_PARULA` | Parula color map |
+| `cv::COLORMAP_MAGMA` | Magma color map |
+| `cv::COLORMAP_INFERNO` | Inferno color map |
+| `cv::COLORMAP_PLASMA` | Plasma color map |
+| `cv::COLORMAP_VIRIDIS` | Viridis color map |
+| `cv::COLORMAP_CIVIDIS` | Cividis color map |
+| `cv::COLORMAP_TWILIGHT` | Twilight color map |
+| `cv::COLORMAP_TWILIGHT_SHIFTED` | Shifted Twilight color map |
+| `cv::COLORMAP_TURBO` | Turbo color map |
+| `cv::COLORMAP_DEEPGREEN` | Deep Green color map |
+
+These colormaps are commonly used for visualizing data with different color representations.
+
+## FAQ
+
+### How does Ultralytics YOLOv8 generate heatmaps and what are their benefits?
+
+Ultralytics YOLOv8 generates heatmaps by transforming complex data into a color-coded matrix where different hues represent data intensities. Heatmaps make it easier to visualize patterns, correlations, and anomalies in the data. Warmer hues indicate higher values, while cooler tones represent lower values. The primary benefits include intuitive visualization of data distribution, efficient pattern detection, and enhanced spatial analysis for decision-making. For more details and configuration options, refer to the [Heatmap Configuration](#arguments-heatmap) section.
+
+### Can I use Ultralytics YOLOv8 to perform object tracking and generate a heatmap simultaneously?
+
+Yes, Ultralytics YOLOv8 supports object tracking and heatmap generation concurrently. This can be achieved through its `Heatmap` solution integrated with object tracking models. To do so, you need to initialize the heatmap object and use YOLOv8's tracking capabilities. Here's a simple example:
+
+```python
+import cv2
+
+from ultralytics import YOLO, solutions
+
+model = YOLO("yolov8n.pt")
+cap = cv2.VideoCapture("path/to/video/file.mp4")
+heatmap_obj = solutions.Heatmap(colormap=cv2.COLORMAP_PARULA, view_img=True, shape="circle", names=model.names)
+
+while cap.isOpened():
+ success, im0 = cap.read()
+ if not success:
+ break
+ tracks = model.track(im0, persist=True, show=False)
+ im0 = heatmap_obj.generate_heatmap(im0, tracks)
+ cv2.imshow("Heatmap", im0)
+ if cv2.waitKey(1) & 0xFF == ord("q"):
+ break
+
+cap.release()
+cv2.destroyAllWindows()
+```
+
+For further guidance, check the [Tracking Mode](../modes/track.md) page.
+
+### What makes Ultralytics YOLOv8 heatmaps different from other data visualization tools like those from OpenCV or Matplotlib?
+
+Ultralytics YOLOv8 heatmaps are specifically designed for integration with its object detection and tracking models, providing an end-to-end solution for real-time data analysis. Unlike generic visualization tools like OpenCV or Matplotlib, YOLOv8 heatmaps are optimized for performance and automated processing, supporting features like persistent tracking, decay factor adjustment, and real-time video overlay. For more information on YOLOv8's unique features, visit the [Ultralytics YOLOv8 Introduction](https://www.ultralytics.com/blog/introducing-ultralytics-yolov8).
+
+### How can I visualize only specific object classes in heatmaps using Ultralytics YOLOv8?
+
+You can visualize specific object classes by specifying the desired classes in the `track()` method of the YOLO model. For instance, if you only want to visualize cars and persons (assuming their class indices are 0 and 2), you can set the `classes` parameter accordingly.
+
+```python
+import cv2
+
+from ultralytics import YOLO, solutions
+
+model = YOLO("yolov8n.pt")
+cap = cv2.VideoCapture("path/to/video/file.mp4")
+heatmap_obj = solutions.Heatmap(colormap=cv2.COLORMAP_PARULA, view_img=True, shape="circle", names=model.names)
+
+classes_for_heatmap = [0, 2] # Classes to visualize
+while cap.isOpened():
+ success, im0 = cap.read()
+ if not success:
+ break
+ tracks = model.track(im0, persist=True, show=False, classes=classes_for_heatmap)
+ im0 = heatmap_obj.generate_heatmap(im0, tracks)
+ cv2.imshow("Heatmap", im0)
+ if cv2.waitKey(1) & 0xFF == ord("q"):
+ break
+
+cap.release()
+cv2.destroyAllWindows()
+```
+
+### Why should businesses choose Ultralytics YOLOv8 for heatmap generation in data analysis?
+
+Ultralytics YOLOv8 offers seamless integration of advanced object detection and real-time heatmap generation, making it an ideal choice for businesses looking to visualize data more effectively. The key advantages include intuitive data distribution visualization, efficient pattern detection, and enhanced spatial analysis for better decision-making. Additionally, YOLOv8's cutting-edge features such as persistent tracking, customizable colormaps, and support for various export formats make it superior to other tools like TensorFlow and OpenCV for comprehensive data analysis. Learn more about business applications at [Ultralytics Plans](https://www.ultralytics.com/plans).
diff --git a/ultralytics/docs/en/guides/hyperparameter-tuning.md b/ultralytics/docs/en/guides/hyperparameter-tuning.md
new file mode 100644
index 0000000000000000000000000000000000000000..885256dfbc702bef87a232061c68265a81f1b800
--- /dev/null
+++ b/ultralytics/docs/en/guides/hyperparameter-tuning.md
@@ -0,0 +1,261 @@
+---
+comments: true
+description: Master hyperparameter tuning for Ultralytics YOLO to optimize model performance with our comprehensive guide. Elevate your machine learning models today!.
+keywords: Ultralytics YOLO, hyperparameter tuning, machine learning, model optimization, genetic algorithms, learning rate, batch size, epochs
+---
+
+# Ultralytics YOLO Hyperparameter Tuning Guide
+
+## Introduction
+
+Hyperparameter tuning is not just a one-time set-up but an iterative process aimed at optimizing the machine learning model's performance metrics, such as accuracy, precision, and recall. In the context of Ultralytics YOLO, these hyperparameters could range from learning rate to architectural details, such as the number of layers or types of activation functions used.
+
+### What are Hyperparameters?
+
+Hyperparameters are high-level, structural settings for the algorithm. They are set prior to the training phase and remain constant during it. Here are some commonly tuned hyperparameters in Ultralytics YOLO:
+
+- **Learning Rate** `lr0`: Determines the step size at each iteration while moving towards a minimum in the loss function.
+- **Batch Size** `batch`: Number of images processed simultaneously in a forward pass.
+- **Number of Epochs** `epochs`: An epoch is one complete forward and backward pass of all the training examples.
+- **Architecture Specifics**: Such as channel counts, number of layers, types of activation functions, etc.
+
+
+
+
+
+For a full list of augmentation hyperparameters used in YOLOv8 please refer to the [configurations page](../usage/cfg.md#augmentation-settings).
+
+### Genetic Evolution and Mutation
+
+Ultralytics YOLO uses genetic algorithms to optimize hyperparameters. Genetic algorithms are inspired by the mechanism of natural selection and genetics.
+
+- **Mutation**: In the context of Ultralytics YOLO, mutation helps in locally searching the hyperparameter space by applying small, random changes to existing hyperparameters, producing new candidates for evaluation.
+- **Crossover**: Although crossover is a popular genetic algorithm technique, it is not currently used in Ultralytics YOLO for hyperparameter tuning. The focus is mainly on mutation for generating new hyperparameter sets.
+
+## Preparing for Hyperparameter Tuning
+
+Before you begin the tuning process, it's important to:
+
+1. **Identify the Metrics**: Determine the metrics you will use to evaluate the model's performance. This could be AP50, F1-score, or others.
+2. **Set the Tuning Budget**: Define how much computational resources you're willing to allocate. Hyperparameter tuning can be computationally intensive.
+
+## Steps Involved
+
+### Initialize Hyperparameters
+
+Start with a reasonable set of initial hyperparameters. This could either be the default hyperparameters set by Ultralytics YOLO or something based on your domain knowledge or previous experiments.
+
+### Mutate Hyperparameters
+
+Use the `_mutate` method to produce a new set of hyperparameters based on the existing set.
+
+### Train Model
+
+Training is performed using the mutated set of hyperparameters. The training performance is then assessed.
+
+### Evaluate Model
+
+Use metrics like AP50, F1-score, or custom metrics to evaluate the model's performance.
+
+### Log Results
+
+It's crucial to log both the performance metrics and the corresponding hyperparameters for future reference.
+
+### Repeat
+
+The process is repeated until either the set number of iterations is reached or the performance metric is satisfactory.
+
+## Usage Example
+
+Here's how to use the `model.tune()` method to utilize the `Tuner` class for hyperparameter tuning of YOLOv8n on COCO8 for 30 epochs with an AdamW optimizer and skipping plotting, checkpointing and validation other than on final epoch for faster Tuning.
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Initialize the YOLO model
+ model = YOLO("yolov8n.pt")
+
+ # Tune hyperparameters on COCO8 for 30 epochs
+ model.tune(data="coco8.yaml", epochs=30, iterations=300, optimizer="AdamW", plots=False, save=False, val=False)
+ ```
+
+## Results
+
+After you've successfully completed the hyperparameter tuning process, you will obtain several files and directories that encapsulate the results of the tuning. The following describes each:
+
+### File Structure
+
+Here's what the directory structure of the results will look like. Training directories like `train1/` contain individual tuning iterations, i.e. one model trained with one set of hyperparameters. The `tune/` directory contains tuning results from all the individual model trainings:
+
+```plaintext
+runs/
+└── detect/
+ ├── train1/
+ ├── train2/
+ ├── ...
+ └── tune/
+ ├── best_hyperparameters.yaml
+ ├── best_fitness.png
+ ├── tune_results.csv
+ ├── tune_scatter_plots.png
+ └── weights/
+ ├── last.pt
+ └── best.pt
+```
+
+### File Descriptions
+
+#### best_hyperparameters.yaml
+
+This YAML file contains the best-performing hyperparameters found during the tuning process. You can use this file to initialize future trainings with these optimized settings.
+
+- **Format**: YAML
+- **Usage**: Hyperparameter results
+- **Example**:
+
+ ```yaml
+ # 558/900 iterations complete ✅ (45536.81s)
+ # Results saved to /usr/src/ultralytics/runs/detect/tune
+ # Best fitness=0.64297 observed at iteration 498
+ # Best fitness metrics are {'metrics/precision(B)': 0.87247, 'metrics/recall(B)': 0.71387, 'metrics/mAP50(B)': 0.79106, 'metrics/mAP50-95(B)': 0.62651, 'val/box_loss': 2.79884, 'val/cls_loss': 2.72386, 'val/dfl_loss': 0.68503, 'fitness': 0.64297}
+ # Best fitness model is /usr/src/ultralytics/runs/detect/train498
+ # Best fitness hyperparameters are printed below.
+
+ lr0: 0.00269
+ lrf: 0.00288
+ momentum: 0.73375
+ weight_decay: 0.00015
+ warmup_epochs: 1.22935
+ warmup_momentum: 0.1525
+ box: 18.27875
+ cls: 1.32899
+ dfl: 0.56016
+ hsv_h: 0.01148
+ hsv_s: 0.53554
+ hsv_v: 0.13636
+ degrees: 0.0
+ translate: 0.12431
+ scale: 0.07643
+ shear: 0.0
+ perspective: 0.0
+ flipud: 0.0
+ fliplr: 0.08631
+ mosaic: 0.42551
+ mixup: 0.0
+ copy_paste: 0.0
+ ```
+
+#### best_fitness.png
+
+This is a plot displaying fitness (typically a performance metric like AP50) against the number of iterations. It helps you visualize how well the genetic algorithm performed over time.
+
+- **Format**: PNG
+- **Usage**: Performance visualization
+
+
+
+
+
+#### tune_results.csv
+
+A CSV file containing detailed results of each iteration during the tuning. Each row in the file represents one iteration, and it includes metrics like fitness score, precision, recall, as well as the hyperparameters used.
+
+- **Format**: CSV
+- **Usage**: Per-iteration results tracking.
+- **Example**:
+ ```csv
+ fitness,lr0,lrf,momentum,weight_decay,warmup_epochs,warmup_momentum,box,cls,dfl,hsv_h,hsv_s,hsv_v,degrees,translate,scale,shear,perspective,flipud,fliplr,mosaic,mixup,copy_paste
+ 0.05021,0.01,0.01,0.937,0.0005,3.0,0.8,7.5,0.5,1.5,0.015,0.7,0.4,0.0,0.1,0.5,0.0,0.0,0.0,0.5,1.0,0.0,0.0
+ 0.07217,0.01003,0.00967,0.93897,0.00049,2.79757,0.81075,7.5,0.50746,1.44826,0.01503,0.72948,0.40658,0.0,0.0987,0.4922,0.0,0.0,0.0,0.49729,1.0,0.0,0.0
+ 0.06584,0.01003,0.00855,0.91009,0.00073,3.42176,0.95,8.64301,0.54594,1.72261,0.01503,0.59179,0.40658,0.0,0.0987,0.46955,0.0,0.0,0.0,0.49729,0.80187,0.0,0.0
+ ```
+
+#### tune_scatter_plots.png
+
+This file contains scatter plots generated from `tune_results.csv`, helping you visualize relationships between different hyperparameters and performance metrics. Note that hyperparameters initialized to 0 will not be tuned, such as `degrees` and `shear` below.
+
+- **Format**: PNG
+- **Usage**: Exploratory data analysis
+
+
+
+
+
+#### weights/
+
+This directory contains the saved PyTorch models for the last and the best iterations during the hyperparameter tuning process.
+
+- **`last.pt`**: The last.pt are the weights from the last epoch of training.
+- **`best.pt`**: The best.pt weights for the iteration that achieved the best fitness score.
+
+Using these results, you can make more informed decisions for your future model trainings and analyses. Feel free to consult these artifacts to understand how well your model performed and how you might improve it further.
+
+## Conclusion
+
+The hyperparameter tuning process in Ultralytics YOLO is simplified yet powerful, thanks to its genetic algorithm-based approach focused on mutation. Following the steps outlined in this guide will assist you in systematically tuning your model to achieve better performance.
+
+### Further Reading
+
+1. [Hyperparameter Optimization in Wikipedia](https://en.wikipedia.org/wiki/Hyperparameter_optimization)
+2. [YOLOv5 Hyperparameter Evolution Guide](../yolov5/tutorials/hyperparameter_evolution.md)
+3. [Efficient Hyperparameter Tuning with Ray Tune and YOLOv8](../integrations/ray-tune.md)
+
+For deeper insights, you can explore the `Tuner` class source code and accompanying documentation. Should you have any questions, feature requests, or need further assistance, feel free to reach out to us on [GitHub](https://github.com/ultralytics/ultralytics/issues/new/choose) or [Discord](https://ultralytics.com/discord).
+
+## FAQ
+
+### How do I optimize the learning rate for Ultralytics YOLO during hyperparameter tuning?
+
+To optimize the learning rate for Ultralytics YOLO, start by setting an initial learning rate using the `lr0` parameter. Common values range from `0.001` to `0.01`. During the hyperparameter tuning process, this value will be mutated to find the optimal setting. You can utilize the `model.tune()` method to automate this process. For example:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Initialize the YOLO model
+ model = YOLO("yolov8n.pt")
+
+ # Tune hyperparameters on COCO8 for 30 epochs
+ model.tune(data="coco8.yaml", epochs=30, iterations=300, optimizer="AdamW", plots=False, save=False, val=False)
+ ```
+
+For more details, check the [Ultralytics YOLO configuration page](../usage/cfg.md#augmentation-settings).
+
+### What are the benefits of using genetic algorithms for hyperparameter tuning in YOLOv8?
+
+Genetic algorithms in Ultralytics YOLOv8 provide a robust method for exploring the hyperparameter space, leading to highly optimized model performance. Key benefits include:
+
+- **Efficient Search**: Genetic algorithms like mutation can quickly explore a large set of hyperparameters.
+- **Avoiding Local Minima**: By introducing randomness, they help in avoiding local minima, ensuring better global optimization.
+- **Performance Metrics**: They adapt based on performance metrics such as AP50 and F1-score.
+
+To see how genetic algorithms can optimize hyperparameters, check out the [hyperparameter evolution guide](../yolov5/tutorials/hyperparameter_evolution.md).
+
+### How long does the hyperparameter tuning process take for Ultralytics YOLO?
+
+The time required for hyperparameter tuning with Ultralytics YOLO largely depends on several factors such as the size of the dataset, the complexity of the model architecture, the number of iterations, and the computational resources available. For instance, tuning YOLOv8n on a dataset like COCO8 for 30 epochs might take several hours to days, depending on the hardware.
+
+To effectively manage tuning time, define a clear tuning budget beforehand ([internal section link](#preparing-for-hyperparameter-tuning)). This helps in balancing resource allocation and optimization goals.
+
+### What metrics should I use to evaluate model performance during hyperparameter tuning in YOLO?
+
+When evaluating model performance during hyperparameter tuning in YOLO, you can use several key metrics:
+
+- **AP50**: The average precision at IoU threshold of 0.50.
+- **F1-Score**: The harmonic mean of precision and recall.
+- **Precision and Recall**: Individual metrics indicating the model's accuracy in identifying true positives versus false positives and false negatives.
+
+These metrics help you understand different aspects of your model's performance. Refer to the [Ultralytics YOLO performance metrics](../guides/yolo-performance-metrics.md) guide for a comprehensive overview.
+
+### Can I use Ultralytics HUB for hyperparameter tuning of YOLO models?
+
+Yes, you can use Ultralytics HUB for hyperparameter tuning of YOLO models. The HUB offers a no-code platform to easily upload datasets, train models, and perform hyperparameter tuning efficiently. It provides real-time tracking and visualization of tuning progress and results.
+
+Explore more about using Ultralytics HUB for hyperparameter tuning in the [Ultralytics HUB Cloud Training](../hub/cloud-training.md) documentation.
diff --git a/ultralytics/docs/en/guides/index.md b/ultralytics/docs/en/guides/index.md
new file mode 100644
index 0000000000000000000000000000000000000000..f05ee5950cf45e751be7dd32a5c2c827242434d3
--- /dev/null
+++ b/ultralytics/docs/en/guides/index.md
@@ -0,0 +1,104 @@
+---
+comments: true
+description: Master YOLO with Ultralytics tutorials covering training, deployment and optimization. Find solutions, improve metrics, and deploy with ease!.
+keywords: Ultralytics, YOLO, tutorials, guides, object detection, deep learning, PyTorch, training, deployment, optimization, computer vision
+---
+
+# Comprehensive Tutorials to Ultralytics YOLO
+
+Welcome to the Ultralytics' YOLO 🚀 Guides! Our comprehensive tutorials cover various aspects of the YOLO object detection model, ranging from training and prediction to deployment. Built on PyTorch, YOLO stands out for its exceptional speed and accuracy in real-time object detection tasks.
+
+Whether you're a beginner or an expert in deep learning, our tutorials offer valuable insights into the implementation and optimization of YOLO for your computer vision projects. Let's dive in!
+
+
+
+## Guides
+
+Here's a compilation of in-depth guides to help you master different aspects of Ultralytics YOLO.
+
+- [YOLO Common Issues](yolo-common-issues.md) ⭐ RECOMMENDED: Practical solutions and troubleshooting tips to the most frequently encountered issues when working with Ultralytics YOLO models.
+- [YOLO Performance Metrics](yolo-performance-metrics.md) ⭐ ESSENTIAL: Understand the key metrics like mAP, IoU, and F1 score used to evaluate the performance of your YOLO models. Includes practical examples and tips on how to improve detection accuracy and speed.
+- [Model Deployment Options](model-deployment-options.md): Overview of YOLO model deployment formats like ONNX, OpenVINO, and TensorRT, with pros and cons for each to inform your deployment strategy.
+- [K-Fold Cross Validation](kfold-cross-validation.md) 🚀 NEW: Learn how to improve model generalization using K-Fold cross-validation technique.
+- [Hyperparameter Tuning](hyperparameter-tuning.md) 🚀 NEW: Discover how to optimize your YOLO models by fine-tuning hyperparameters using the Tuner class and genetic evolution algorithms.
+- [SAHI Tiled Inference](sahi-tiled-inference.md) 🚀 NEW: Comprehensive guide on leveraging SAHI's sliced inference capabilities with YOLOv8 for object detection in high-resolution images.
+- [AzureML Quickstart](azureml-quickstart.md) 🚀 NEW: Get up and running with Ultralytics YOLO models on Microsoft's Azure Machine Learning platform. Learn how to train, deploy, and scale your object detection projects in the cloud.
+- [Conda Quickstart](conda-quickstart.md) 🚀 NEW: Step-by-step guide to setting up a [Conda](https://anaconda.org/conda-forge/ultralytics) environment for Ultralytics. Learn how to install and start using the Ultralytics package efficiently with Conda.
+- [Docker Quickstart](docker-quickstart.md) 🚀 NEW: Complete guide to setting up and using Ultralytics YOLO models with [Docker](https://hub.docker.com/r/ultralytics/ultralytics). Learn how to install Docker, manage GPU support, and run YOLO models in isolated containers for consistent development and deployment.
+- [Raspberry Pi](raspberry-pi.md) 🚀 NEW: Quickstart tutorial to run YOLO models to the latest Raspberry Pi hardware.
+- [NVIDIA Jetson](nvidia-jetson.md) 🚀 NEW: Quickstart guide for deploying YOLO models on NVIDIA Jetson devices.
+- [DeepStream on NVIDIA Jetson](deepstream-nvidia-jetson.md) 🚀 NEW: Quickstart guide for deploying YOLO models on NVIDIA Jetson devices using DeepStream and TensorRT.
+- [Triton Inference Server Integration](triton-inference-server.md) 🚀 NEW: Dive into the integration of Ultralytics YOLOv8 with NVIDIA's Triton Inference Server for scalable and efficient deep learning inference deployments.
+- [YOLO Thread-Safe Inference](yolo-thread-safe-inference.md) 🚀 NEW: Guidelines for performing inference with YOLO models in a thread-safe manner. Learn the importance of thread safety and best practices to prevent race conditions and ensure consistent predictions.
+- [Isolating Segmentation Objects](isolating-segmentation-objects.md) 🚀 NEW: Step-by-step recipe and explanation on how to extract and/or isolate objects from images using Ultralytics Segmentation.
+- [Edge TPU on Raspberry Pi](coral-edge-tpu-on-raspberry-pi.md): [Google Edge TPU](https://coral.ai/products/accelerator) accelerates YOLO inference on [Raspberry Pi](https://www.raspberrypi.com/).
+- [View Inference Images in a Terminal](view-results-in-terminal.md): Use VSCode's integrated terminal to view inference results when using Remote Tunnel or SSH sessions.
+- [OpenVINO Latency vs Throughput Modes](optimizing-openvino-latency-vs-throughput-modes.md) - Learn latency and throughput optimization techniques for peak YOLO inference performance.
+- [Steps of a Computer Vision Project ](steps-of-a-cv-project.md) 🚀 NEW: Learn about the key steps involved in a computer vision project, including defining goals, selecting models, preparing data, and evaluating results.
+- [Defining A Computer Vision Project's Goals](defining-project-goals.md) 🚀 NEW: Walk through how to effectively define clear and measurable goals for your computer vision project. Learn the importance of a well-defined problem statement and how it creates a roadmap for your project.
+- [Data Collection and Annotation](data-collection-and-annotation.md) 🚀 NEW: Explore the tools, techniques, and best practices for collecting and annotating data to create high-quality inputs for your computer vision models.
+- [Preprocessing Annotated Data](preprocessing_annotated_data.md) 🚀 NEW: Learn about preprocessing and augmenting image data in computer vision projects using YOLOv8, including normalization, dataset augmentation, splitting, and exploratory data analysis (EDA).
+- [Tips for Model Training](model-training-tips.md) 🚀 NEW: Explore tips on optimizing batch sizes, using mixed precision, applying pre-trained weights, and more to make training your computer vision model a breeze.
+- [Insights on Model Evaluation and Fine-Tuning](model-evaluation-insights.md) 🚀 NEW: Gain insights into the strategies and best practices for evaluating and fine-tuning your computer vision models. Learn about the iterative process of refining models to achieve optimal results.
+- [A Guide on Model Testing](model-testing.md) 🚀 NEW: A thorough guide on testing your computer vision models in realistic settings. Learn how to verify accuracy, reliability, and performance in line with project goals.
+- [Best Practices for Model Deployment](model-deployment-practices.md) 🚀 NEW: Walk through tips and best practices for efficiently deploying models in computer vision projects, with a focus on optimization, troubleshooting, and security.
+- [Maintaining Your Computer Vision Model](model-monitoring-and-maintenance.md) 🚀 NEW: Understand the key practices for monitoring, maintaining, and documenting computer vision models to guarantee accuracy, spot anomalies, and mitigate data drift.
+- [ROS Quickstart](ros-quickstart.md) 🚀 NEW: Learn how to integrate YOLO with the Robot Operating System (ROS) for real-time object detection in robotics applications, including Point Cloud and Depth images.
+
+## Contribute to Our Guides
+
+We welcome contributions from the community! If you've mastered a particular aspect of Ultralytics YOLO that's not yet covered in our guides, we encourage you to share your expertise. Writing a guide is a great way to give back to the community and help us make our documentation more comprehensive and user-friendly.
+
+To get started, please read our [Contributing Guide](../help/contributing.md) for guidelines on how to open up a Pull Request (PR) 🛠️. We look forward to your contributions!
+
+Let's work together to make the Ultralytics YOLO ecosystem more robust and versatile 🙏!
+
+## FAQ
+
+### How do I train a custom object detection model using Ultralytics YOLO?
+
+Training a custom object detection model with Ultralytics YOLO is straightforward. Start by preparing your dataset in the correct format and installing the Ultralytics package. Use the following code to initiate training:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ model = YOLO("yolov8s.pt") # Load a pre-trained YOLO model
+ model.train(data="path/to/dataset.yaml", epochs=50) # Train on custom dataset
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo task=detect mode=train model=yolov8s.pt data=path/to/dataset.yaml epochs=50
+ ```
+
+For detailed dataset formatting and additional options, refer to our [Tips for Model Training](model-training-tips.md) guide.
+
+### What performance metrics should I use to evaluate my YOLO model?
+
+Evaluating your YOLO model performance is crucial to understanding its efficacy. Key metrics include Mean Average Precision (mAP), Intersection over Union (IoU), and F1 score. These metrics help assess the accuracy and precision of object detection tasks. You can learn more about these metrics and how to improve your model in our [YOLO Performance Metrics](yolo-performance-metrics.md) guide.
+
+### Why should I use Ultralytics HUB for my computer vision projects?
+
+Ultralytics HUB is a no-code platform that simplifies managing, training, and deploying YOLO models. It supports seamless integration, real-time tracking, and cloud training, making it ideal for both beginners and professionals. Discover more about its features and how it can streamline your workflow with our [Ultralytics HUB](https://docs.ultralytics.com/hub/) quickstart guide.
+
+### What are the common issues faced during YOLO model training, and how can I resolve them?
+
+Common issues during YOLO model training include data formatting errors, model architecture mismatches, and insufficient training data. To address these, ensure your dataset is correctly formatted, check for compatible model versions, and augment your training data. For a comprehensive list of solutions, refer to our [YOLO Common Issues](yolo-common-issues.md) guide.
+
+### How can I deploy my YOLO model for real-time object detection on edge devices?
+
+Deploying YOLO models on edge devices like NVIDIA Jetson and Raspberry Pi requires converting the model to a compatible format such as TensorRT or TFLite. Follow our step-by-step guides for [NVIDIA Jetson](nvidia-jetson.md) and [Raspberry Pi](raspberry-pi.md) deployments to get started with real-time object detection on edge hardware. These guides will walk you through installation, configuration, and performance optimization.
diff --git a/ultralytics/docs/en/guides/instance-segmentation-and-tracking.md b/ultralytics/docs/en/guides/instance-segmentation-and-tracking.md
new file mode 100644
index 0000000000000000000000000000000000000000..cae7fcaa161e54b007387925d1f23c931a00f57d
--- /dev/null
+++ b/ultralytics/docs/en/guides/instance-segmentation-and-tracking.md
@@ -0,0 +1,252 @@
+---
+comments: true
+description: Master instance segmentation and tracking with Ultralytics YOLOv8. Learn techniques for precise object identification and tracking.
+keywords: instance segmentation, tracking, YOLOv8, Ultralytics, object detection, machine learning, computer vision, python
+---
+
+# Instance Segmentation and Tracking using Ultralytics YOLOv8 🚀
+
+## What is Instance Segmentation?
+
+[Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) instance segmentation involves identifying and outlining individual objects in an image, providing a detailed understanding of spatial distribution. Unlike semantic segmentation, it uniquely labels and precisely delineates each object, crucial for tasks like object detection and medical imaging.
+
+There are two types of instance segmentation tracking available in the Ultralytics package:
+
+- **Instance Segmentation with Class Objects:** Each class object is assigned a unique color for clear visual separation.
+
+- **Instance Segmentation with Object Tracks:** Every track is represented by a distinct color, facilitating easy identification and tracking.
+
+
+
+
+
+ Watch: Instance Segmentation with Object Tracking using Ultralytics YOLOv8
+
+
+## Samples
+
+| Instance Segmentation | Instance Segmentation + Object Tracking |
+| :-------------------------------------------------------------------------------------------------------------------------------------: | :----------------------------------------------------------------------------------------------------------------------------------------------------------: |
+|  |  |
+| Ultralytics Instance Segmentation 😍 | Ultralytics Instance Segmentation with Object Tracking 🔥 |
+
+!!! Example "Instance Segmentation and Tracking"
+
+ === "Instance Segmentation"
+
+ ```python
+ import cv2
+
+ from ultralytics import YOLO
+ from ultralytics.utils.plotting import Annotator, colors
+
+ model = YOLO("yolov8n-seg.pt") # segmentation model
+ names = model.model.names
+ cap = cv2.VideoCapture("path/to/video/file.mp4")
+ w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
+
+ out = cv2.VideoWriter("instance-segmentation.avi", cv2.VideoWriter_fourcc(*"MJPG"), fps, (w, h))
+
+ while True:
+ ret, im0 = cap.read()
+ if not ret:
+ print("Video frame is empty or video processing has been successfully completed.")
+ break
+
+ results = model.predict(im0)
+ annotator = Annotator(im0, line_width=2)
+
+ if results[0].masks is not None:
+ clss = results[0].boxes.cls.cpu().tolist()
+ masks = results[0].masks.xy
+ for mask, cls in zip(masks, clss):
+ color = colors(int(cls), True)
+ txt_color = annotator.get_txt_color(color)
+ annotator.seg_bbox(mask=mask, mask_color=color, label=names[int(cls)], txt_color=txt_color)
+
+ out.write(im0)
+ cv2.imshow("instance-segmentation", im0)
+
+ if cv2.waitKey(1) & 0xFF == ord("q"):
+ break
+
+ out.release()
+ cap.release()
+ cv2.destroyAllWindows()
+ ```
+
+ === "Instance Segmentation with Object Tracking"
+
+ ```python
+ from collections import defaultdict
+
+ import cv2
+
+ from ultralytics import YOLO
+ from ultralytics.utils.plotting import Annotator, colors
+
+ track_history = defaultdict(lambda: [])
+
+ model = YOLO("yolov8n-seg.pt") # segmentation model
+ cap = cv2.VideoCapture("path/to/video/file.mp4")
+ w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
+
+ out = cv2.VideoWriter("instance-segmentation-object-tracking.avi", cv2.VideoWriter_fourcc(*"MJPG"), fps, (w, h))
+
+ while True:
+ ret, im0 = cap.read()
+ if not ret:
+ print("Video frame is empty or video processing has been successfully completed.")
+ break
+
+ annotator = Annotator(im0, line_width=2)
+
+ results = model.track(im0, persist=True)
+
+ if results[0].boxes.id is not None and results[0].masks is not None:
+ masks = results[0].masks.xy
+ track_ids = results[0].boxes.id.int().cpu().tolist()
+
+ for mask, track_id in zip(masks, track_ids):
+ color = colors(int(track_id), True)
+ txt_color = annotator.get_txt_color(color)
+ annotator.seg_bbox(mask=mask, mask_color=color, label=str(track_id), txt_color=txt_color)
+
+ out.write(im0)
+ cv2.imshow("instance-segmentation-object-tracking", im0)
+
+ if cv2.waitKey(1) & 0xFF == ord("q"):
+ break
+
+ out.release()
+ cap.release()
+ cv2.destroyAllWindows()
+ ```
+
+### `seg_bbox` Arguments
+
+| Name | Type | Default | Description |
+| ------------ | ------- | --------------- | -------------------------------------------- |
+| `mask` | `array` | `None` | Segmentation mask coordinates |
+| `mask_color` | `RGB` | `(255, 0, 255)` | Mask color for every segmented box |
+| `label` | `str` | `None` | Label for segmented object |
+| `txt_color` | `RGB` | `None` | Label color for segmented and tracked object |
+
+## Note
+
+For any inquiries, feel free to post your questions in the [Ultralytics Issue Section](https://github.com/ultralytics/ultralytics/issues/new/choose) or the discussion section mentioned below.
+
+## FAQ
+
+### How do I perform instance segmentation using Ultralytics YOLOv8?
+
+To perform instance segmentation using Ultralytics YOLOv8, initialize the YOLO model with a segmentation version of YOLOv8 and process video frames through it. Here's a simplified code example:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ import cv2
+
+ from ultralytics import YOLO
+ from ultralytics.utils.plotting import Annotator, colors
+
+ model = YOLO("yolov8n-seg.pt") # segmentation model
+ cap = cv2.VideoCapture("path/to/video/file.mp4")
+ w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
+
+ out = cv2.VideoWriter("instance-segmentation.avi", cv2.VideoWriter_fourcc(*"MJPG"), fps, (w, h))
+
+ while True:
+ ret, im0 = cap.read()
+ if not ret:
+ break
+
+ results = model.predict(im0)
+ annotator = Annotator(im0, line_width=2)
+
+ if results[0].masks is not None:
+ clss = results[0].boxes.cls.cpu().tolist()
+ masks = results[0].masks.xy
+ for mask, cls in zip(masks, clss):
+ annotator.seg_bbox(mask=mask, mask_color=colors(int(cls), True), det_label=model.model.names[int(cls)])
+
+ out.write(im0)
+ cv2.imshow("instance-segmentation", im0)
+ if cv2.waitKey(1) & 0xFF == ord("q"):
+ break
+
+ out.release()
+ cap.release()
+ cv2.destroyAllWindows()
+ ```
+
+Learn more about instance segmentation in the [Ultralytics YOLOv8 guide](#what-is-instance-segmentation).
+
+### What is the difference between instance segmentation and object tracking in Ultralytics YOLOv8?
+
+Instance segmentation identifies and outlines individual objects within an image, giving each object a unique label and mask. Object tracking extends this by assigning consistent labels to objects across video frames, facilitating continuous tracking of the same objects over time. Learn more about the distinctions in the [Ultralytics YOLOv8 documentation](#samples).
+
+### Why should I use Ultralytics YOLOv8 for instance segmentation and tracking over other models like Mask R-CNN or Faster R-CNN?
+
+Ultralytics YOLOv8 offers real-time performance, superior accuracy, and ease of use compared to other models like Mask R-CNN or Faster R-CNN. YOLOv8 provides a seamless integration with Ultralytics HUB, allowing users to manage models, datasets, and training pipelines efficiently. Discover more about the benefits of YOLOv8 in the [Ultralytics blog](https://www.ultralytics.com/blog/introducing-ultralytics-yolov8).
+
+### How can I implement object tracking using Ultralytics YOLOv8?
+
+To implement object tracking, use the `model.track` method and ensure that each object's ID is consistently assigned across frames. Below is a simple example:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from collections import defaultdict
+
+ import cv2
+
+ from ultralytics import YOLO
+ from ultralytics.utils.plotting import Annotator, colors
+
+ track_history = defaultdict(lambda: [])
+
+ model = YOLO("yolov8n-seg.pt") # segmentation model
+ cap = cv2.VideoCapture("path/to/video/file.mp4")
+ w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
+
+ out = cv2.VideoWriter("instance-segmentation-object-tracking.avi", cv2.VideoWriter_fourcc(*"MJPG"), fps, (w, h))
+
+ while True:
+ ret, im0 = cap.read()
+ if not ret:
+ break
+
+ annotator = Annotator(im0, line_width=2)
+ results = model.track(im0, persist=True)
+
+ if results[0].boxes.id is not None and results[0].masks is not None:
+ masks = results[0].masks.xy
+ track_ids = results[0].boxes.id.int().cpu().tolist()
+
+ for mask, track_id in zip(masks, track_ids):
+ annotator.seg_bbox(mask=mask, mask_color=colors(track_id, True), track_label=str(track_id))
+
+ out.write(im0)
+ cv2.imshow("instance-segmentation-object-tracking", im0)
+ if cv2.waitKey(1) & 0xFF == ord("q"):
+ break
+
+ out.release()
+ cap.release()
+ cv2.destroyAllWindows()
+ ```
+
+Find more in the [Instance Segmentation and Tracking section](#samples).
+
+### Are there any datasets provided by Ultralytics suitable for training YOLOv8 models for instance segmentation and tracking?
+
+Yes, Ultralytics offers several datasets suitable for training YOLOv8 models, including segmentation and tracking datasets. Dataset examples, structures, and instructions for use can be found in the [Ultralytics Datasets documentation](https://docs.ultralytics.com/datasets/).
diff --git a/ultralytics/docs/en/guides/isolating-segmentation-objects.md b/ultralytics/docs/en/guides/isolating-segmentation-objects.md
new file mode 100644
index 0000000000000000000000000000000000000000..fc901ebb18cd2feb1b92fe4aa64998e2605c083e
--- /dev/null
+++ b/ultralytics/docs/en/guides/isolating-segmentation-objects.md
@@ -0,0 +1,399 @@
+---
+comments: true
+description: Learn to extract isolated objects from inference results using Ultralytics Predict Mode. Step-by-step guide for segmentation object isolation.
+keywords: Ultralytics, segmentation, object isolation, Predict Mode, YOLOv8, machine learning, object detection, binary mask, image processing
+---
+
+# Isolating Segmentation Objects
+
+After performing the [Segment Task](../tasks/segment.md), it's sometimes desirable to extract the isolated objects from the inference results. This guide provides a generic recipe on how to accomplish this using the Ultralytics [Predict Mode](../modes/predict.md).
+
+
+
+
+
+## Recipe Walk Through
+
+1. See the [Ultralytics Quickstart Installation section](../quickstart.md) for a quick walkthrough on installing the required libraries.
+
+ ***
+
+2. Load a model and run `predict()` method on a source.
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-seg.pt")
+
+ # Run inference
+ results = model.predict()
+ ```
+
+ !!! question "No Prediction Arguments?"
+
+ Without specifying a source, the example images from the library will be used:
+
+ ```
+ 'ultralytics/assets/bus.jpg'
+ 'ultralytics/assets/zidane.jpg'
+ ```
+
+ This is helpful for rapid testing with the `predict()` method.
+
+ For additional information about Segmentation Models, visit the [Segment Task](../tasks/segment.md#models) page. To learn more about `predict()` method, see [Predict Mode](../modes/predict.md) section of the Documentation.
+
+ ***
+
+3. Now iterate over the results and the contours. For workflows that want to save an image to file, the source image `base-name` and the detection `class-label` are retrieved for later use (optional).
+
+ ```{ .py .annotate }
+ from pathlib import Path
+
+ import numpy as np
+
+ # (2) Iterate detection results (helpful for multiple images)
+ for r in res:
+ img = np.copy(r.orig_img)
+ img_name = Path(r.path).stem # source image base-name
+
+ # Iterate each object contour (multiple detections)
+ for ci, c in enumerate(r):
+ # (1) Get detection class name
+ label = c.names[c.boxes.cls.tolist().pop()]
+ ```
+
+ 1. To learn more about working with detection results, see [Boxes Section for Predict Mode](../modes/predict.md#boxes).
+ 2. To learn more about `predict()` results see [Working with Results for Predict Mode](../modes/predict.md#working-with-results)
+
+ ??? info "For-Loop"
+
+ A single image will only iterate the first loop once. A single image with only a single detection will iterate each loop _only_ once.
+
+ ***
+
+4. Start with generating a binary mask from the source image and then draw a filled contour onto the mask. This will allow the object to be isolated from the other parts of the image. An example from `bus.jpg` for one of the detected `person` class objects is shown on the right.
+
+ { width="240", align="right" }
+
+ ```{ .py .annotate }
+ import cv2
+
+ # Create binary mask
+ b_mask = np.zeros(img.shape[:2], np.uint8)
+
+ # (1) Extract contour result
+ contour = c.masks.xy.pop()
+ # (2) Changing the type
+ contour = contour.astype(np.int32)
+ # (3) Reshaping
+ contour = contour.reshape(-1, 1, 2)
+
+
+ # Draw contour onto mask
+ _ = cv2.drawContours(b_mask, [contour], -1, (255, 255, 255), cv2.FILLED)
+ ```
+
+ 1. For more info on `c.masks.xy` see [Masks Section from Predict Mode](../modes/predict.md#masks).
+
+ 2. Here the values are cast into `np.int32` for compatibility with `drawContours()` function from OpenCV.
+
+ 3. The OpenCV `drawContours()` function expects contours to have a shape of `[N, 1, 2]` expand section below for more details.
+
+
+ Expand to understand what is happening when defining the contour variable.
+
+
+ - `c.masks.xy` :: Provides the coordinates of the mask contour points in the format `(x, y)`. For more details, refer to the [Masks Section from Predict Mode](../modes/predict.md#masks).
+
+ - `.pop()` :: As `masks.xy` is a list containing a single element, this element is extracted using the `pop()` method.
+
+ - `.astype(np.int32)` :: Using `masks.xy` will return with a data type of `float32`, but this won't be compatible with the OpenCV `drawContours()` function, so this will change the data type to `int32` for compatibility.
+
+ - `.reshape(-1, 1, 2)` :: Reformats the data into the required shape of `[N, 1, 2]` where `N` is the number of contour points, with each point represented by a single entry `1`, and the entry is composed of `2` values. The `-1` denotes that the number of values along this dimension is flexible.
+
+
+
+
+ Expand for an explanation of the drawContours() configuration.
+
+
+ - Encapsulating the `contour` variable within square brackets, `[contour]`, was found to effectively generate the desired contour mask during testing.
+
+ - The value `-1` specified for the `drawContours()` parameter instructs the function to draw all contours present in the image.
+
+ - The `tuple` `(255, 255, 255)` represents the color white, which is the desired color for drawing the contour in this binary mask.
+
+ - The addition of `cv2.FILLED` will color all pixels enclosed by the contour boundary the same, in this case, all enclosed pixels will be white.
+
+ - See [OpenCV Documentation on `drawContours()`](https://docs.opencv.org/4.8.0/d6/d6e/group__imgproc__draw.html#ga746c0625f1781f1ffc9056259103edbc) for more information.
+
+
+
+
+ ***
+
+5. Next there are 2 options for how to move forward with the image from this point and a subsequent option for each.
+
+ ### Object Isolation Options
+
+ !!! example ""
+
+ === "Black Background Pixels"
+
+ ```py
+ # Create 3-channel mask
+ mask3ch = cv2.cvtColor(b_mask, cv2.COLOR_GRAY2BGR)
+
+ # Isolate object with binary mask
+ isolated = cv2.bitwise_and(mask3ch, img)
+ ```
+
+ ??? question "How does this work?"
+
+ - First, the binary mask is first converted from a single-channel image to a three-channel image. This conversion is necessary for the subsequent step where the mask and the original image are combined. Both images must have the same number of channels to be compatible with the blending operation.
+
+ - The original image and the three-channel binary mask are merged using the OpenCV function `bitwise_and()`. This operation retains only pixel values that are greater than zero `(> 0)` from both images. Since the mask pixels are greater than zero `(> 0)` only within the contour region, the pixels remaining from the original image are those that overlap with the contour.
+
+ ### Isolate with Black Pixels: Sub-options
+
+ ??? info "Full-size Image"
+
+ There are no additional steps required if keeping full size image.
+
+
+ { width=240 }
+ Example full-size output
+
+
+ ??? info "Cropped object Image"
+
+ Additional steps required to crop image to only include object region.
+
+ { align="right" }
+ ```{ .py .annotate }
+ # (1) Bounding box coordinates
+ x1, y1, x2, y2 = c.boxes.xyxy.cpu().numpy().squeeze().astype(np.int32)
+ # Crop image to object region
+ iso_crop = isolated[y1:y2, x1:x2]
+ ```
+
+ 1. For more information on bounding box results, see [Boxes Section from Predict Mode](../modes/predict.md/#boxes)
+
+ ??? question "What does this code do?"
+
+ - The `c.boxes.xyxy.cpu().numpy()` call retrieves the bounding boxes as a NumPy array in the `xyxy` format, where `xmin`, `ymin`, `xmax`, and `ymax` represent the coordinates of the bounding box rectangle. See [Boxes Section from Predict Mode](../modes/predict.md/#boxes) for more details.
+
+ - The `squeeze()` operation removes any unnecessary dimensions from the NumPy array, ensuring it has the expected shape.
+
+ - Converting the coordinate values using `.astype(np.int32)` changes the box coordinates data type from `float32` to `int32`, making them compatible for image cropping using index slices.
+
+ - Finally, the bounding box region is cropped from the image using index slicing. The bounds are defined by the `[ymin:ymax, xmin:xmax]` coordinates of the detection bounding box.
+
+ === "Transparent Background Pixels"
+
+ ```py
+ # Isolate object with transparent background (when saved as PNG)
+ isolated = np.dstack([img, b_mask])
+ ```
+
+ ??? question "How does this work?"
+
+ - Using the NumPy `dstack()` function (array stacking along depth-axis) in conjunction with the binary mask generated, will create an image with four channels. This allows for all pixels outside of the object contour to be transparent when saving as a `PNG` file.
+
+ ### Isolate with Transparent Pixels: Sub-options
+
+ ??? info "Full-size Image"
+
+ There are no additional steps required if keeping full size image.
+
+
+ { width=240 }
+ Example full-size output + transparent background
+
+
+ ??? info "Cropped object Image"
+
+ Additional steps required to crop image to only include object region.
+
+ { align="right" }
+ ```{ .py .annotate }
+ # (1) Bounding box coordinates
+ x1, y1, x2, y2 = c.boxes.xyxy.cpu().numpy().squeeze().astype(np.int32)
+ # Crop image to object region
+ iso_crop = isolated[y1:y2, x1:x2]
+ ```
+
+ 1. For more information on bounding box results, see [Boxes Section from Predict Mode](../modes/predict.md/#boxes)
+
+ ??? question "What does this code do?"
+
+ - When using `c.boxes.xyxy.cpu().numpy()`, the bounding boxes are returned as a NumPy array, using the `xyxy` box coordinates format, which correspond to the points `xmin, ymin, xmax, ymax` for the bounding box (rectangle), see [Boxes Section from Predict Mode](../modes/predict.md/#boxes) for more information.
+
+ - Adding `squeeze()` ensures that any extraneous dimensions are removed from the NumPy array.
+
+ - Converting the coordinate values using `.astype(np.int32)` changes the box coordinates data type from `float32` to `int32` which will be compatible when cropping the image using index slices.
+
+ - Finally the image region for the bounding box is cropped using index slicing, where the bounds are set using the `[ymin:ymax, xmin:xmax]` coordinates of the detection bounding box.
+
+ ??? question "What if I want the cropped object **including** the background?"
+
+ This is a built in feature for the Ultralytics library. See the `save_crop` argument for [Predict Mode Inference Arguments](../modes/predict.md/#inference-arguments) for details.
+
+ ***
+
+6. What to do next is entirely left to you as the developer. A basic example of one possible next step (saving the image to file for future use) is shown.
+
+ - **NOTE:** this step is optional and can be skipped if not required for your specific use case.
+
+ ??? example "Example Final Step"
+
+ ```py
+ # Save isolated object to file
+ _ = cv2.imwrite(f"{img_name}_{label}-{ci}.png", iso_crop)
+ ```
+
+ - In this example, the `img_name` is the base-name of the source image file, `label` is the detected class-name, and `ci` is the index of the object detection (in case of multiple instances with the same class name).
+
+## Full Example code
+
+Here, all steps from the previous section are combined into a single block of code. For repeated use, it would be optimal to define a function to do some or all commands contained in the `for`-loops, but that is an exercise left to the reader.
+
+```{ .py .annotate }
+from pathlib import Path
+
+import cv2
+import numpy as np
+
+from ultralytics import YOLO
+
+m = YOLO("yolov8n-seg.pt") # (4)!
+res = m.predict() # (3)!
+
+# Iterate detection results (5)
+for r in res:
+ img = np.copy(r.orig_img)
+ img_name = Path(r.path).stem
+
+ # Iterate each object contour (6)
+ for ci, c in enumerate(r):
+ label = c.names[c.boxes.cls.tolist().pop()]
+
+ b_mask = np.zeros(img.shape[:2], np.uint8)
+
+ # Create contour mask (1)
+ contour = c.masks.xy.pop().astype(np.int32).reshape(-1, 1, 2)
+ _ = cv2.drawContours(b_mask, [contour], -1, (255, 255, 255), cv2.FILLED)
+
+ # Choose one:
+
+ # OPTION-1: Isolate object with black background
+ mask3ch = cv2.cvtColor(b_mask, cv2.COLOR_GRAY2BGR)
+ isolated = cv2.bitwise_and(mask3ch, img)
+
+ # OPTION-2: Isolate object with transparent background (when saved as PNG)
+ isolated = np.dstack([img, b_mask])
+
+ # OPTIONAL: detection crop (from either OPT1 or OPT2)
+ x1, y1, x2, y2 = c.boxes.xyxy.cpu().numpy().squeeze().astype(np.int32)
+ iso_crop = isolated[y1:y2, x1:x2]
+
+ # TODO your actions go here (2)
+```
+
+1. The line populating `contour` is combined into a single line here, where it was split to multiple above.
+2. {==What goes here is up to you!==}
+3. See [Predict Mode](../modes/predict.md) for additional information.
+4. See [Segment Task](../tasks/segment.md#models) for more information.
+5. Learn more about [Working with Results](../modes/predict.md#working-with-results)
+6. Learn more about [Segmentation Mask Results](../modes/predict.md#masks)
+
+## FAQ
+
+### How do I isolate objects using Ultralytics YOLOv8 for segmentation tasks?
+
+To isolate objects using Ultralytics YOLOv8, follow these steps:
+
+1. **Load the model and run inference:**
+
+ ```python
+ from ultralytics import YOLO
+
+ model = YOLO("yolov8n-seg.pt")
+ results = model.predict(source="path/to/your/image.jpg")
+ ```
+
+2. **Generate a binary mask and draw contours:**
+
+ ```python
+ import cv2
+ import numpy as np
+
+ img = np.copy(results[0].orig_img)
+ b_mask = np.zeros(img.shape[:2], np.uint8)
+ contour = results[0].masks.xy[0].astype(np.int32).reshape(-1, 1, 2)
+ cv2.drawContours(b_mask, [contour], -1, (255, 255, 255), cv2.FILLED)
+ ```
+
+3. **Isolate the object using the binary mask:**
+ ```python
+ mask3ch = cv2.cvtColor(b_mask, cv2.COLOR_GRAY2BGR)
+ isolated = cv2.bitwise_and(mask3ch, img)
+ ```
+
+Refer to the guide on [Predict Mode](../modes/predict.md) and the [Segment Task](../tasks/segment.md) for more information.
+
+### What options are available for saving the isolated objects after segmentation?
+
+Ultralytics YOLOv8 offers two main options for saving isolated objects:
+
+1. **With a Black Background:**
+
+ ```python
+ mask3ch = cv2.cvtColor(b_mask, cv2.COLOR_GRAY2BGR)
+ isolated = cv2.bitwise_and(mask3ch, img)
+ ```
+
+2. **With a Transparent Background:**
+ ```python
+ isolated = np.dstack([img, b_mask])
+ ```
+
+For further details, visit the [Predict Mode](../modes/predict.md) section.
+
+### How can I crop isolated objects to their bounding boxes using Ultralytics YOLOv8?
+
+To crop isolated objects to their bounding boxes:
+
+1. **Retrieve bounding box coordinates:**
+
+ ```python
+ x1, y1, x2, y2 = results[0].boxes.xyxy[0].cpu().numpy().astype(np.int32)
+ ```
+
+2. **Crop the isolated image:**
+ ```python
+ iso_crop = isolated[y1:y2, x1:x2]
+ ```
+
+Learn more about bounding box results in the [Predict Mode](../modes/predict.md#boxes) documentation.
+
+### Why should I use Ultralytics YOLOv8 for object isolation in segmentation tasks?
+
+Ultralytics YOLOv8 provides:
+
+- **High-speed** real-time object detection and segmentation.
+- **Accurate bounding box and mask generation** for precise object isolation.
+- **Comprehensive documentation** and easy-to-use API for efficient development.
+
+Explore the benefits of using YOLO in the [Segment Task documentation](../tasks/segment.md).
+
+### Can I save isolated objects including the background using Ultralytics YOLOv8?
+
+Yes, this is a built-in feature in Ultralytics YOLOv8. Use the `save_crop` argument in the `predict()` method. For example:
+
+```python
+results = model.predict(source="path/to/your/image.jpg", save_crop=True)
+```
+
+Read more about the `save_crop` argument in the [Predict Mode Inference Arguments](../modes/predict.md#inference-arguments) section.
diff --git a/ultralytics/docs/en/guides/kfold-cross-validation.md b/ultralytics/docs/en/guides/kfold-cross-validation.md
new file mode 100644
index 0000000000000000000000000000000000000000..dcf5ca0f7666114b4c0b1afc498845f41d69d2ce
--- /dev/null
+++ b/ultralytics/docs/en/guides/kfold-cross-validation.md
@@ -0,0 +1,312 @@
+---
+comments: true
+description: Learn to implement K-Fold Cross Validation for object detection datasets using Ultralytics YOLO. Improve your model's reliability and robustness.
+keywords: Ultralytics, YOLO, K-Fold Cross Validation, object detection, sklearn, pandas, PyYaml, machine learning, dataset split
+---
+
+# K-Fold Cross Validation with Ultralytics
+
+## Introduction
+
+This comprehensive guide illustrates the implementation of K-Fold Cross Validation for object detection datasets within the Ultralytics ecosystem. We'll leverage the YOLO detection format and key Python libraries such as sklearn, pandas, and PyYaml to guide you through the necessary setup, the process of generating feature vectors, and the execution of a K-Fold dataset split.
+
+
+
+
+
+Whether your project involves the Fruit Detection dataset or a custom data source, this tutorial aims to help you comprehend and apply K-Fold Cross Validation to bolster the reliability and robustness of your machine learning models. While we're applying `k=5` folds for this tutorial, keep in mind that the optimal number of folds can vary depending on your dataset and the specifics of your project.
+
+Without further ado, let's dive in!
+
+## Setup
+
+- Your annotations should be in the [YOLO detection format](../datasets/detect/index.md).
+
+- This guide assumes that annotation files are locally available.
+
+- For our demonstration, we use the [Fruit Detection](https://www.kaggle.com/datasets/lakshaytyagi01/fruit-detection/code) dataset.
+ - This dataset contains a total of 8479 images.
+ - It includes 6 class labels, each with its total instance counts listed below.
+
+| Class Label | Instance Count |
+| :---------- | :------------: |
+| Apple | 7049 |
+| Grapes | 7202 |
+| Pineapple | 1613 |
+| Orange | 15549 |
+| Banana | 3536 |
+| Watermelon | 1976 |
+
+- Necessary Python packages include:
+
+ - `ultralytics`
+ - `sklearn`
+ - `pandas`
+ - `pyyaml`
+
+- This tutorial operates with `k=5` folds. However, you should determine the best number of folds for your specific dataset.
+
+1. Initiate a new Python virtual environment (`venv`) for your project and activate it. Use `pip` (or your preferred package manager) to install:
+
+ - The Ultralytics library: `pip install -U ultralytics`. Alternatively, you can clone the official [repo](https://github.com/ultralytics/ultralytics).
+ - Scikit-learn, pandas, and PyYAML: `pip install -U scikit-learn pandas pyyaml`.
+
+2. Verify that your annotations are in the [YOLO detection format](../datasets/detect/index.md).
+
+ - For this tutorial, all annotation files are found in the `Fruit-Detection/labels` directory.
+
+## Generating Feature Vectors for Object Detection Dataset
+
+1. Start by creating a new `example.py` Python file for the steps below.
+
+2. Proceed to retrieve all label files for your dataset.
+
+ ```python
+ from pathlib import Path
+
+ dataset_path = Path("./Fruit-detection") # replace with 'path/to/dataset' for your custom data
+ labels = sorted(dataset_path.rglob("*labels/*.txt")) # all data in 'labels'
+ ```
+
+3. Now, read the contents of the dataset YAML file and extract the indices of the class labels.
+
+ ```python
+ yaml_file = "path/to/data.yaml" # your data YAML with data directories and names dictionary
+ with open(yaml_file, "r", encoding="utf8") as y:
+ classes = yaml.safe_load(y)["names"]
+ cls_idx = sorted(classes.keys())
+ ```
+
+4. Initialize an empty `pandas` DataFrame.
+
+ ```python
+ import pandas as pd
+
+ indx = [label.stem for label in labels] # uses base filename as ID (no extension)
+ labels_df = pd.DataFrame([], columns=cls_idx, index=indx)
+ ```
+
+5. Count the instances of each class-label present in the annotation files.
+
+ ```python
+ from collections import Counter
+
+ for label in labels:
+ lbl_counter = Counter()
+
+ with open(label, "r") as lf:
+ lines = lf.readlines()
+
+ for line in lines:
+ # classes for YOLO label uses integer at first position of each line
+ lbl_counter[int(line.split(" ")[0])] += 1
+
+ labels_df.loc[label.stem] = lbl_counter
+
+ labels_df = labels_df.fillna(0.0) # replace `nan` values with `0.0`
+ ```
+
+6. The following is a sample view of the populated DataFrame:
+
+ ```pandas
+ 0 1 2 3 4 5
+ '0000a16e4b057580_jpg.rf.00ab48988370f64f5ca8ea4...' 0.0 0.0 0.0 0.0 0.0 7.0
+ '0000a16e4b057580_jpg.rf.7e6dce029fb67f01eb19aa7...' 0.0 0.0 0.0 0.0 0.0 7.0
+ '0000a16e4b057580_jpg.rf.bc4d31cdcbe229dd022957a...' 0.0 0.0 0.0 0.0 0.0 7.0
+ '00020ebf74c4881c_jpg.rf.508192a0a97aa6c4a3b6882...' 0.0 0.0 0.0 1.0 0.0 0.0
+ '00020ebf74c4881c_jpg.rf.5af192a2254c8ecc4188a25...' 0.0 0.0 0.0 1.0 0.0 0.0
+ ... ... ... ... ... ... ...
+ 'ff4cd45896de38be_jpg.rf.c4b5e967ca10c7ced3b9e97...' 0.0 0.0 0.0 0.0 0.0 2.0
+ 'ff4cd45896de38be_jpg.rf.ea4c1d37d2884b3e3cbce08...' 0.0 0.0 0.0 0.0 0.0 2.0
+ 'ff5fd9c3c624b7dc_jpg.rf.bb519feaa36fc4bf630a033...' 1.0 0.0 0.0 0.0 0.0 0.0
+ 'ff5fd9c3c624b7dc_jpg.rf.f0751c9c3aa4519ea3c9d6a...' 1.0 0.0 0.0 0.0 0.0 0.0
+ 'fffe28b31f2a70d4_jpg.rf.7ea16bd637ba0711c53b540...' 0.0 6.0 0.0 0.0 0.0 0.0
+ ```
+
+The rows index the label files, each corresponding to an image in your dataset, and the columns correspond to your class-label indices. Each row represents a pseudo feature-vector, with the count of each class-label present in your dataset. This data structure enables the application of K-Fold Cross Validation to an object detection dataset.
+
+## K-Fold Dataset Split
+
+1. Now we will use the `KFold` class from `sklearn.model_selection` to generate `k` splits of the dataset.
+
+ - Important:
+ - Setting `shuffle=True` ensures a randomized distribution of classes in your splits.
+ - By setting `random_state=M` where `M` is a chosen integer, you can obtain repeatable results.
+
+ ```python
+ from sklearn.model_selection import KFold
+
+ ksplit = 5
+ kf = KFold(n_splits=ksplit, shuffle=True, random_state=20) # setting random_state for repeatable results
+
+ kfolds = list(kf.split(labels_df))
+ ```
+
+2. The dataset has now been split into `k` folds, each having a list of `train` and `val` indices. We will construct a DataFrame to display these results more clearly.
+
+ ```python
+ folds = [f"split_{n}" for n in range(1, ksplit + 1)]
+ folds_df = pd.DataFrame(index=indx, columns=folds)
+
+ for idx, (train, val) in enumerate(kfolds, start=1):
+ folds_df[f"split_{idx}"].loc[labels_df.iloc[train].index] = "train"
+ folds_df[f"split_{idx}"].loc[labels_df.iloc[val].index] = "val"
+ ```
+
+3. Now we will calculate the distribution of class labels for each fold as a ratio of the classes present in `val` to those present in `train`.
+
+ ```python
+ fold_lbl_distrb = pd.DataFrame(index=folds, columns=cls_idx)
+
+ for n, (train_indices, val_indices) in enumerate(kfolds, start=1):
+ train_totals = labels_df.iloc[train_indices].sum()
+ val_totals = labels_df.iloc[val_indices].sum()
+
+ # To avoid division by zero, we add a small value (1E-7) to the denominator
+ ratio = val_totals / (train_totals + 1e-7)
+ fold_lbl_distrb.loc[f"split_{n}"] = ratio
+ ```
+
+ The ideal scenario is for all class ratios to be reasonably similar for each split and across classes. This, however, will be subject to the specifics of your dataset.
+
+4. Next, we create the directories and dataset YAML files for each split.
+
+ ```python
+ import datetime
+
+ supported_extensions = [".jpg", ".jpeg", ".png"]
+
+ # Initialize an empty list to store image file paths
+ images = []
+
+ # Loop through supported extensions and gather image files
+ for ext in supported_extensions:
+ images.extend(sorted((dataset_path / "images").rglob(f"*{ext}")))
+
+ # Create the necessary directories and dataset YAML files (unchanged)
+ save_path = Path(dataset_path / f"{datetime.date.today().isoformat()}_{ksplit}-Fold_Cross-val")
+ save_path.mkdir(parents=True, exist_ok=True)
+ ds_yamls = []
+
+ for split in folds_df.columns:
+ # Create directories
+ split_dir = save_path / split
+ split_dir.mkdir(parents=True, exist_ok=True)
+ (split_dir / "train" / "images").mkdir(parents=True, exist_ok=True)
+ (split_dir / "train" / "labels").mkdir(parents=True, exist_ok=True)
+ (split_dir / "val" / "images").mkdir(parents=True, exist_ok=True)
+ (split_dir / "val" / "labels").mkdir(parents=True, exist_ok=True)
+
+ # Create dataset YAML files
+ dataset_yaml = split_dir / f"{split}_dataset.yaml"
+ ds_yamls.append(dataset_yaml)
+
+ with open(dataset_yaml, "w") as ds_y:
+ yaml.safe_dump(
+ {
+ "path": split_dir.as_posix(),
+ "train": "train",
+ "val": "val",
+ "names": classes,
+ },
+ ds_y,
+ )
+ ```
+
+5. Lastly, copy images and labels into the respective directory ('train' or 'val') for each split.
+
+ - **NOTE:** The time required for this portion of the code will vary based on the size of your dataset and your system hardware.
+
+ ```python
+ import shutil
+
+ for image, label in zip(images, labels):
+ for split, k_split in folds_df.loc[image.stem].items():
+ # Destination directory
+ img_to_path = save_path / split / k_split / "images"
+ lbl_to_path = save_path / split / k_split / "labels"
+
+ # Copy image and label files to new directory (SamefileError if file already exists)
+ shutil.copy(image, img_to_path / image.name)
+ shutil.copy(label, lbl_to_path / label.name)
+ ```
+
+## Save Records (Optional)
+
+Optionally, you can save the records of the K-Fold split and label distribution DataFrames as CSV files for future reference.
+
+```python
+folds_df.to_csv(save_path / "kfold_datasplit.csv")
+fold_lbl_distrb.to_csv(save_path / "kfold_label_distribution.csv")
+```
+
+## Train YOLO using K-Fold Data Splits
+
+1. First, load the YOLO model.
+
+ ```python
+ from ultralytics import YOLO
+
+ weights_path = "path/to/weights.pt"
+ model = YOLO(weights_path, task="detect")
+ ```
+
+2. Next, iterate over the dataset YAML files to run training. The results will be saved to a directory specified by the `project` and `name` arguments. By default, this directory is 'exp/runs#' where # is an integer index.
+
+ ```python
+ results = {}
+
+ # Define your additional arguments here
+ batch = 16
+ project = "kfold_demo"
+ epochs = 100
+
+ for k in range(ksplit):
+ dataset_yaml = ds_yamls[k]
+ model.train(data=dataset_yaml, epochs=epochs, batch=batch, project=project) # include any train arguments
+ results[k] = model.metrics # save output metrics for further analysis
+ ```
+
+## Conclusion
+
+In this guide, we have explored the process of using K-Fold cross-validation for training the YOLO object detection model. We learned how to split our dataset into K partitions, ensuring a balanced class distribution across the different folds.
+
+We also explored the procedure for creating report DataFrames to visualize the data splits and label distributions across these splits, providing us a clear insight into the structure of our training and validation sets.
+
+Optionally, we saved our records for future reference, which could be particularly useful in large-scale projects or when troubleshooting model performance.
+
+Finally, we implemented the actual model training using each split in a loop, saving our training results for further analysis and comparison.
+
+This technique of K-Fold cross-validation is a robust way of making the most out of your available data, and it helps to ensure that your model performance is reliable and consistent across different data subsets. This results in a more generalizable and reliable model that is less likely to overfit to specific data patterns.
+
+Remember that although we used YOLO in this guide, these steps are mostly transferable to other machine learning models. Understanding these steps allows you to apply cross-validation effectively in your own machine learning projects. Happy coding!
+
+## FAQ
+
+### What is K-Fold Cross Validation and why is it useful in object detection?
+
+K-Fold Cross Validation is a technique where the dataset is divided into 'k' subsets (folds) to evaluate model performance more reliably. Each fold serves as both training and validation data. In the context of object detection, using K-Fold Cross Validation helps to ensure your Ultralytics YOLO model's performance is robust and generalizable across different data splits, enhancing its reliability. For detailed instructions on setting up K-Fold Cross Validation with Ultralytics YOLO, refer to [K-Fold Cross Validation with Ultralytics](#introduction).
+
+### How do I implement K-Fold Cross Validation using Ultralytics YOLO?
+
+To implement K-Fold Cross Validation with Ultralytics YOLO, you need to follow these steps:
+
+1. Verify annotations are in the [YOLO detection format](../datasets/detect/index.md).
+2. Use Python libraries like `sklearn`, `pandas`, and `pyyaml`.
+3. Create feature vectors from your dataset.
+4. Split your dataset using `KFold` from `sklearn.model_selection`.
+5. Train the YOLO model on each split.
+
+For a comprehensive guide, see the [K-Fold Dataset Split](#k-fold-dataset-split) section in our documentation.
+
+### Why should I use Ultralytics YOLO for object detection?
+
+Ultralytics YOLO offers state-of-the-art, real-time object detection with high accuracy and efficiency. It's versatile, supporting multiple computer vision tasks such as detection, segmentation, and classification. Additionally, it integrates seamlessly with tools like Ultralytics HUB for no-code model training and deployment. For more details, explore the benefits and features on our [Ultralytics YOLO page](https://www.ultralytics.com/yolo).
+
+### How can I ensure my annotations are in the correct format for Ultralytics YOLO?
+
+Your annotations should follow the YOLO detection format. Each annotation file must list the object class, alongside its bounding box coordinates in the image. The YOLO format ensures streamlined and standardized data processing for training object detection models. For more information on proper annotation formatting, visit the [YOLO detection format guide](../datasets/detect/index.md).
+
+### Can I use K-Fold Cross Validation with custom datasets other than Fruit Detection?
+
+Yes, you can use K-Fold Cross Validation with any custom dataset as long as the annotations are in the YOLO detection format. Replace the dataset paths and class labels with those specific to your custom dataset. This flexibility ensures that any object detection project can benefit from robust model evaluation using K-Fold Cross Validation. For a practical example, review our [Generating Feature Vectors](#generating-feature-vectors-for-object-detection-dataset) section.
diff --git a/ultralytics/docs/en/guides/model-deployment-options.md b/ultralytics/docs/en/guides/model-deployment-options.md
new file mode 100644
index 0000000000000000000000000000000000000000..874bab4643a2fdec1133a57c51f9109d28b248c0
--- /dev/null
+++ b/ultralytics/docs/en/guides/model-deployment-options.md
@@ -0,0 +1,370 @@
+---
+comments: true
+description: Learn about YOLOv8's diverse deployment options to maximize your model's performance. Explore PyTorch, TensorRT, OpenVINO, TF Lite, and more!.
+keywords: YOLOv8, deployment options, export formats, PyTorch, TensorRT, OpenVINO, TF Lite, machine learning, model deployment
+---
+
+# Understanding YOLOv8's Deployment Options
+
+## Introduction
+
+You've come a long way on your journey with YOLOv8. You've diligently collected data, meticulously annotated it, and put in the hours to train and rigorously evaluate your custom YOLOv8 model. Now, it's time to put your model to work for your specific application, use case, or project. But there's a critical decision that stands before you: how to export and deploy your model effectively.
+
+This guide walks you through YOLOv8's deployment options and the essential factors to consider to choose the right option for your project.
+
+## How to Select the Right Deployment Option for Your YOLOv8 Model
+
+When it's time to deploy your YOLOv8 model, selecting a suitable export format is very important. As outlined in the [Ultralytics YOLOv8 Modes documentation](../modes/export.md#usage-examples), the model.export() function allows for converting your trained model into a variety of formats tailored to diverse environments and performance requirements.
+
+The ideal format depends on your model's intended operational context, balancing speed, hardware constraints, and ease of integration. In the following section, we'll take a closer look at each export option, understanding when to choose each one.
+
+### YOLOv8's Deployment Options
+
+Let's walk through the different YOLOv8 deployment options. For a detailed walkthrough of the export process, visit the [Ultralytics documentation page on exporting](../modes/export.md).
+
+#### PyTorch
+
+PyTorch is an open-source machine learning library widely used for applications in deep learning and artificial intelligence. It provides a high level of flexibility and speed, which has made it a favorite among researchers and developers.
+
+- **Performance Benchmarks**: PyTorch is known for its ease of use and flexibility, which may result in a slight trade-off in raw performance when compared to other frameworks that are more specialized and optimized.
+
+- **Compatibility and Integration**: Offers excellent compatibility with various data science and machine learning libraries in Python.
+
+- **Community Support and Ecosystem**: One of the most vibrant communities, with extensive resources for learning and troubleshooting.
+
+- **Case Studies**: Commonly used in research prototypes, many academic papers reference models deployed in PyTorch.
+
+- **Maintenance and Updates**: Regular updates with active development and support for new features.
+
+- **Security Considerations**: Regular patches for security issues, but security is largely dependent on the overall environment it's deployed in.
+
+- **Hardware Acceleration**: Supports CUDA for GPU acceleration, essential for speeding up model training and inference.
+
+#### TorchScript
+
+TorchScript extends PyTorch's capabilities by allowing the exportation of models to be run in a C++ runtime environment. This makes it suitable for production environments where Python is unavailable.
+
+- **Performance Benchmarks**: Can offer improved performance over native PyTorch, especially in production environments.
+
+- **Compatibility and Integration**: Designed for seamless transition from PyTorch to C++ production environments, though some advanced features might not translate perfectly.
+
+- **Community Support and Ecosystem**: Benefits from PyTorch's large community but has a narrower scope of specialized developers.
+
+- **Case Studies**: Widely used in industry settings where Python's performance overhead is a bottleneck.
+
+- **Maintenance and Updates**: Maintained alongside PyTorch with consistent updates.
+
+- **Security Considerations**: Offers improved security by enabling the running of models in environments without full Python installations.
+
+- **Hardware Acceleration**: Inherits PyTorch's CUDA support, ensuring efficient GPU utilization.
+
+#### ONNX
+
+The Open Neural Network Exchange (ONNX) is a format that allows for model interoperability across different frameworks, which can be critical when deploying to various platforms.
+
+- **Performance Benchmarks**: ONNX models may experience a variable performance depending on the specific runtime they are deployed on.
+
+- **Compatibility and Integration**: High interoperability across multiple platforms and hardware due to its framework-agnostic nature.
+
+- **Community Support and Ecosystem**: Supported by many organizations, leading to a broad ecosystem and a variety of tools for optimization.
+
+- **Case Studies**: Frequently used to move models between different machine learning frameworks, demonstrating its flexibility.
+
+- **Maintenance and Updates**: As an open standard, ONNX is regularly updated to support new operations and models.
+
+- **Security Considerations**: As with any cross-platform tool, it's essential to ensure secure practices in the conversion and deployment pipeline.
+
+- **Hardware Acceleration**: With ONNX Runtime, models can leverage various hardware optimizations.
+
+#### OpenVINO
+
+OpenVINO is an Intel toolkit designed to facilitate the deployment of deep learning models across Intel hardware, enhancing performance and speed.
+
+- **Performance Benchmarks**: Specifically optimized for Intel CPUs, GPUs, and VPUs, offering significant performance boosts on compatible hardware.
+
+- **Compatibility and Integration**: Works best within the Intel ecosystem but also supports a range of other platforms.
+
+- **Community Support and Ecosystem**: Backed by Intel, with a solid user base especially in the computer vision domain.
+
+- **Case Studies**: Often utilized in IoT and edge computing scenarios where Intel hardware is prevalent.
+
+- **Maintenance and Updates**: Intel regularly updates OpenVINO to support the latest deep learning models and Intel hardware.
+
+- **Security Considerations**: Provides robust security features suitable for deployment in sensitive applications.
+
+- **Hardware Acceleration**: Tailored for acceleration on Intel hardware, leveraging dedicated instruction sets and hardware features.
+
+For more details on deployment using OpenVINO, refer to the Ultralytics Integration documentation: [Intel OpenVINO Export](../integrations/openvino.md).
+
+#### TensorRT
+
+TensorRT is a high-performance deep learning inference optimizer and runtime from NVIDIA, ideal for applications needing speed and efficiency.
+
+- **Performance Benchmarks**: Delivers top-tier performance on NVIDIA GPUs with support for high-speed inference.
+
+- **Compatibility and Integration**: Best suited for NVIDIA hardware, with limited support outside this environment.
+
+- **Community Support and Ecosystem**: Strong support network through NVIDIA's developer forums and documentation.
+
+- **Case Studies**: Widely adopted in industries requiring real-time inference on video and image data.
+
+- **Maintenance and Updates**: NVIDIA maintains TensorRT with frequent updates to enhance performance and support new GPU architectures.
+
+- **Security Considerations**: Like many NVIDIA products, it has a strong emphasis on security, but specifics depend on the deployment environment.
+
+- **Hardware Acceleration**: Exclusively designed for NVIDIA GPUs, providing deep optimization and acceleration.
+
+#### CoreML
+
+CoreML is Apple's machine learning framework, optimized for on-device performance in the Apple ecosystem, including iOS, macOS, watchOS, and tvOS.
+
+- **Performance Benchmarks**: Optimized for on-device performance on Apple hardware with minimal battery usage.
+
+- **Compatibility and Integration**: Exclusively for Apple's ecosystem, providing a streamlined workflow for iOS and macOS applications.
+
+- **Community Support and Ecosystem**: Strong support from Apple and a dedicated developer community, with extensive documentation and tools.
+
+- **Case Studies**: Commonly used in applications that require on-device machine learning capabilities on Apple products.
+
+- **Maintenance and Updates**: Regularly updated by Apple to support the latest machine learning advancements and Apple hardware.
+
+- **Security Considerations**: Benefits from Apple's focus on user privacy and data security.
+
+- **Hardware Acceleration**: Takes full advantage of Apple's neural engine and GPU for accelerated machine learning tasks.
+
+#### TF SavedModel
+
+TF SavedModel is TensorFlow's format for saving and serving machine learning models, particularly suited for scalable server environments.
+
+- **Performance Benchmarks**: Offers scalable performance in server environments, especially when used with TensorFlow Serving.
+
+- **Compatibility and Integration**: Wide compatibility across TensorFlow's ecosystem, including cloud and enterprise server deployments.
+
+- **Community Support and Ecosystem**: Large community support due to TensorFlow's popularity, with a vast array of tools for deployment and optimization.
+
+- **Case Studies**: Extensively used in production environments for serving deep learning models at scale.
+
+- **Maintenance and Updates**: Supported by Google and the TensorFlow community, ensuring regular updates and new features.
+
+- **Security Considerations**: Deployment using TensorFlow Serving includes robust security features for enterprise-grade applications.
+
+- **Hardware Acceleration**: Supports various hardware accelerations through TensorFlow's backends.
+
+#### TF GraphDef
+
+TF GraphDef is a TensorFlow format that represents the model as a graph, which is beneficial for environments where a static computation graph is required.
+
+- **Performance Benchmarks**: Provides stable performance for static computation graphs, with a focus on consistency and reliability.
+
+- **Compatibility and Integration**: Easily integrates within TensorFlow's infrastructure but less flexible compared to SavedModel.
+
+- **Community Support and Ecosystem**: Good support from TensorFlow's ecosystem, with many resources available for optimizing static graphs.
+
+- **Case Studies**: Useful in scenarios where a static graph is necessary, such as in certain embedded systems.
+
+- **Maintenance and Updates**: Regular updates alongside TensorFlow's core updates.
+
+- **Security Considerations**: Ensures safe deployment with TensorFlow's established security practices.
+
+- **Hardware Acceleration**: Can utilize TensorFlow's hardware acceleration options, though not as flexible as SavedModel.
+
+#### TF Lite
+
+TF Lite is TensorFlow's solution for mobile and embedded device machine learning, providing a lightweight library for on-device inference.
+
+- **Performance Benchmarks**: Designed for speed and efficiency on mobile and embedded devices.
+
+- **Compatibility and Integration**: Can be used on a wide range of devices due to its lightweight nature.
+
+- **Community Support and Ecosystem**: Backed by Google, it has a robust community and a growing number of resources for developers.
+
+- **Case Studies**: Popular in mobile applications that require on-device inference with minimal footprint.
+
+- **Maintenance and Updates**: Regularly updated to include the latest features and optimizations for mobile devices.
+
+- **Security Considerations**: Provides a secure environment for running models on end-user devices.
+
+- **Hardware Acceleration**: Supports a variety of hardware acceleration options, including GPU and DSP.
+
+#### TF Edge TPU
+
+TF Edge TPU is designed for high-speed, efficient computing on Google's Edge TPU hardware, perfect for IoT devices requiring real-time processing.
+
+- **Performance Benchmarks**: Specifically optimized for high-speed, efficient computing on Google's Edge TPU hardware.
+
+- **Compatibility and Integration**: Works exclusively with TensorFlow Lite models on Edge TPU devices.
+
+- **Community Support and Ecosystem**: Growing support with resources provided by Google and third-party developers.
+
+- **Case Studies**: Used in IoT devices and applications that require real-time processing with low latency.
+
+- **Maintenance and Updates**: Continually improved upon to leverage the capabilities of new Edge TPU hardware releases.
+
+- **Security Considerations**: Integrates with Google's robust security for IoT and edge devices.
+
+- **Hardware Acceleration**: Custom-designed to take full advantage of Google Coral devices.
+
+#### TF.js
+
+TensorFlow.js (TF.js) is a library that brings machine learning capabilities directly to the browser, offering a new realm of possibilities for web developers and users alike. It allows for the integration of machine learning models in web applications without the need for back-end infrastructure.
+
+- **Performance Benchmarks**: Enables machine learning directly in the browser with reasonable performance, depending on the client device.
+
+- **Compatibility and Integration**: High compatibility with web technologies, allowing for easy integration into web applications.
+
+- **Community Support and Ecosystem**: Support from a community of web and Node.js developers, with a variety of tools for deploying ML models in browsers.
+
+- **Case Studies**: Ideal for interactive web applications that benefit from client-side machine learning without the need for server-side processing.
+
+- **Maintenance and Updates**: Maintained by the TensorFlow team with contributions from the open-source community.
+
+- **Security Considerations**: Runs within the browser's secure context, utilizing the security model of the web platform.
+
+- **Hardware Acceleration**: Performance can be enhanced with web-based APIs that access hardware acceleration like WebGL.
+
+#### PaddlePaddle
+
+PaddlePaddle is an open-source deep learning framework developed by Baidu. It is designed to be both efficient for researchers and easy to use for developers. It's particularly popular in China and offers specialized support for Chinese language processing.
+
+- **Performance Benchmarks**: Offers competitive performance with a focus on ease of use and scalability.
+
+- **Compatibility and Integration**: Well-integrated within Baidu's ecosystem and supports a wide range of applications.
+
+- **Community Support and Ecosystem**: While the community is smaller globally, it's rapidly growing, especially in China.
+
+- **Case Studies**: Commonly used in Chinese markets and by developers looking for alternatives to other major frameworks.
+
+- **Maintenance and Updates**: Regularly updated with a focus on serving Chinese language AI applications and services.
+
+- **Security Considerations**: Emphasizes data privacy and security, catering to Chinese data governance standards.
+
+- **Hardware Acceleration**: Supports various hardware accelerations, including Baidu's own Kunlun chips.
+
+#### NCNN
+
+NCNN is a high-performance neural network inference framework optimized for the mobile platform. It stands out for its lightweight nature and efficiency, making it particularly well-suited for mobile and embedded devices where resources are limited.
+
+- **Performance Benchmarks**: Highly optimized for mobile platforms, offering efficient inference on ARM-based devices.
+
+- **Compatibility and Integration**: Suitable for applications on mobile phones and embedded systems with ARM architecture.
+
+- **Community Support and Ecosystem**: Supported by a niche but active community focused on mobile and embedded ML applications.
+
+- **Case Studies**: Favoured for mobile applications where efficiency and speed are critical on Android and other ARM-based systems.
+
+- **Maintenance and Updates**: Continuously improved to maintain high performance on a range of ARM devices.
+
+- **Security Considerations**: Focuses on running locally on the device, leveraging the inherent security of on-device processing.
+
+- **Hardware Acceleration**: Tailored for ARM CPUs and GPUs, with specific optimizations for these architectures.
+
+## Comparative Analysis of YOLOv8 Deployment Options
+
+The following table provides a snapshot of the various deployment options available for YOLOv8 models, helping you to assess which may best fit your project needs based on several critical criteria. For an in-depth look at each deployment option's format, please see the [Ultralytics documentation page on export formats](../modes/export.md#export-formats).
+
+| Deployment Option | Performance Benchmarks | Compatibility and Integration | Community Support and Ecosystem | Case Studies | Maintenance and Updates | Security Considerations | Hardware Acceleration |
+| ----------------- | ----------------------------------------------- | ---------------------------------------------- | --------------------------------------------- | ------------------------------------------ | ------------------------------------------- | ------------------------------------------------- | ---------------------------------- |
+| PyTorch | Good flexibility; may trade off raw performance | Excellent with Python libraries | Extensive resources and community | Research and prototypes | Regular, active development | Dependent on deployment environment | CUDA support for GPU acceleration |
+| TorchScript | Better for production than PyTorch | Smooth transition from PyTorch to C++ | Specialized but narrower than PyTorch | Industry where Python is a bottleneck | Consistent updates with PyTorch | Improved security without full Python | Inherits CUDA support from PyTorch |
+| ONNX | Variable depending on runtime | High across different frameworks | Broad ecosystem, supported by many orgs | Flexibility across ML frameworks | Regular updates for new operations | Ensure secure conversion and deployment practices | Various hardware optimizations |
+| OpenVINO | Optimized for Intel hardware | Best within Intel ecosystem | Solid in computer vision domain | IoT and edge with Intel hardware | Regular updates for Intel hardware | Robust features for sensitive applications | Tailored for Intel hardware |
+| TensorRT | Top-tier on NVIDIA GPUs | Best for NVIDIA hardware | Strong network through NVIDIA | Real-time video and image inference | Frequent updates for new GPUs | Emphasis on security | Designed for NVIDIA GPUs |
+| CoreML | Optimized for on-device Apple hardware | Exclusive to Apple ecosystem | Strong Apple and developer support | On-device ML on Apple products | Regular Apple updates | Focus on privacy and security | Apple neural engine and GPU |
+| TF SavedModel | Scalable in server environments | Wide compatibility in TensorFlow ecosystem | Large support due to TensorFlow popularity | Serving models at scale | Regular updates by Google and community | Robust features for enterprise | Various hardware accelerations |
+| TF GraphDef | Stable for static computation graphs | Integrates well with TensorFlow infrastructure | Resources for optimizing static graphs | Scenarios requiring static graphs | Updates alongside TensorFlow core | Established TensorFlow security practices | TensorFlow acceleration options |
+| TF Lite | Speed and efficiency on mobile/embedded | Wide range of device support | Robust community, Google backed | Mobile applications with minimal footprint | Latest features for mobile | Secure environment on end-user devices | GPU and DSP among others |
+| TF Edge TPU | Optimized for Google's Edge TPU hardware | Exclusive to Edge TPU devices | Growing with Google and third-party resources | IoT devices requiring real-time processing | Improvements for new Edge TPU hardware | Google's robust IoT security | Custom-designed for Google Coral |
+| TF.js | Reasonable in-browser performance | High with web technologies | Web and Node.js developers support | Interactive web applications | TensorFlow team and community contributions | Web platform security model | Enhanced with WebGL and other APIs |
+| PaddlePaddle | Competitive, easy to use and scalable | Baidu ecosystem, wide application support | Rapidly growing, especially in China | Chinese market and language processing | Focus on Chinese AI applications | Emphasizes data privacy and security | Including Baidu's Kunlun chips |
+| NCNN | Optimized for mobile ARM-based devices | Mobile and embedded ARM systems | Niche but active mobile/embedded ML community | Android and ARM systems efficiency | High performance maintenance on ARM | On-device security advantages | ARM CPUs and GPUs optimizations |
+
+This comparative analysis gives you a high-level overview. For deployment, it's essential to consider the specific requirements and constraints of your project, and consult the detailed documentation and resources available for each option.
+
+## Community and Support
+
+When you're getting started with YOLOv8, having a helpful community and support can make a significant impact. Here's how to connect with others who share your interests and get the assistance you need.
+
+### Engage with the Broader Community
+
+- **GitHub Discussions:** The YOLOv8 repository on GitHub has a "Discussions" section where you can ask questions, report issues, and suggest improvements.
+
+- **Ultralytics Discord Server:** Ultralytics has a [Discord server](https://ultralytics.com/discord/) where you can interact with other users and developers.
+
+### Official Documentation and Resources
+
+- **Ultralytics YOLOv8 Docs:** The [official documentation](../index.md) provides a comprehensive overview of YOLOv8, along with guides on installation, usage, and troubleshooting.
+
+These resources will help you tackle challenges and stay updated on the latest trends and best practices in the YOLOv8 community.
+
+## Conclusion
+
+In this guide, we've explored the different deployment options for YOLOv8. We've also discussed the important factors to consider when making your choice. These options allow you to customize your model for various environments and performance requirements, making it suitable for real-world applications.
+
+Don't forget that the YOLOv8 and Ultralytics community is a valuable source of help. Connect with other developers and experts to learn unique tips and solutions you might not find in regular documentation. Keep seeking knowledge, exploring new ideas, and sharing your experiences.
+
+Happy deploying!
+
+## FAQ
+
+### What are the deployment options available for YOLOv8 on different hardware platforms?
+
+Ultralytics YOLOv8 supports various deployment formats, each designed for specific environments and hardware platforms. Key formats include:
+
+- **PyTorch** for research and prototyping, with excellent Python integration.
+- **TorchScript** for production environments where Python is unavailable.
+- **ONNX** for cross-platform compatibility and hardware acceleration.
+- **OpenVINO** for optimized performance on Intel hardware.
+- **TensorRT** for high-speed inference on NVIDIA GPUs.
+
+Each format has unique advantages. For a detailed walkthrough, see our [export process documentation](../modes/export.md#usage-examples).
+
+### How do I improve the inference speed of my YOLOv8 model on an Intel CPU?
+
+To enhance inference speed on Intel CPUs, you can deploy your YOLOv8 model using Intel's OpenVINO toolkit. OpenVINO offers significant performance boosts by optimizing models to leverage Intel hardware efficiently.
+
+1. Convert your YOLOv8 model to the OpenVINO format using the `model.export()` function.
+2. Follow the detailed setup guide in the [Intel OpenVINO Export documentation](../integrations/openvino.md).
+
+For more insights, check out our [blog post](https://www.ultralytics.com/blog/achieve-faster-inference-speeds-ultralytics-yolov8-openvino).
+
+### Can I deploy YOLOv8 models on mobile devices?
+
+Yes, YOLOv8 models can be deployed on mobile devices using TensorFlow Lite (TF Lite) for both Android and iOS platforms. TF Lite is designed for mobile and embedded devices, providing efficient on-device inference.
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ # Export command for TFLite format
+ model.export(format="tflite")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # CLI command for TFLite export
+ yolo export --format tflite
+ ```
+
+For more details on deploying models to mobile, refer to our [TF Lite integration guide](../integrations/tflite.md).
+
+### What factors should I consider when choosing a deployment format for my YOLOv8 model?
+
+When choosing a deployment format for YOLOv8, consider the following factors:
+
+- **Performance**: Some formats like TensorRT provide exceptional speeds on NVIDIA GPUs, while OpenVINO is optimized for Intel hardware.
+- **Compatibility**: ONNX offers broad compatibility across different platforms.
+- **Ease of Integration**: Formats like CoreML or TF Lite are tailored for specific ecosystems like iOS and Android, respectively.
+- **Community Support**: Formats like PyTorch and TensorFlow have extensive community resources and support.
+
+For a comparative analysis, refer to our [export formats documentation](../modes/export.md#export-formats).
+
+### How can I deploy YOLOv8 models in a web application?
+
+To deploy YOLOv8 models in a web application, you can use TensorFlow.js (TF.js), which allows for running machine learning models directly in the browser. This approach eliminates the need for backend infrastructure and provides real-time performance.
+
+1. Export the YOLOv8 model to the TF.js format.
+2. Integrate the exported model into your web application.
+
+For step-by-step instructions, refer to our guide on [TensorFlow.js integration](../integrations/tfjs.md).
diff --git a/ultralytics/docs/en/guides/model-deployment-practices.md b/ultralytics/docs/en/guides/model-deployment-practices.md
new file mode 100644
index 0000000000000000000000000000000000000000..9d35d266bf083ee227849944aab8c5c1b42cb112
--- /dev/null
+++ b/ultralytics/docs/en/guides/model-deployment-practices.md
@@ -0,0 +1,159 @@
+---
+comments: true
+description: Learn essential tips, insights, and best practices for deploying computer vision models with a focus on efficiency, optimization, troubleshooting, and maintaining security.
+keywords: Model Deployment, Machine Learning Model Deployment, ML Model Deployment, AI Model Deployment, How to Deploy a Machine Learning Model, How to Deploy ML Models
+---
+
+# Best Practices for Model Deployment
+
+## Introduction
+
+Model deployment is the [step in a computer vision project](./steps-of-a-cv-project.md) that brings a model from the development phase into a real-world application. There are various [model deployment options](./model-deployment-options.md): cloud deployment offers scalability and ease of access, edge deployment reduces latency by bringing the model closer to the data source, and local deployment ensures privacy and control. Choosing the right strategy depends on your application's needs, balancing speed, security, and scalability.
+
+It's also important to follow best practices when deploying a model because deployment can significantly impact the effectiveness and reliability of the model's performance. In this guide, we'll focus on how to make sure that your model deployment is smooth, efficient, and secure.
+
+## Model Deployment Options
+
+Often times, once a model is [trained](./model-training-tips.md), [evaluated](./model-evaluation-insights.md), and [tested](./model-testing.md), it needs to be converted into specific formats to be deployed effectively in various environments, such as cloud, edge, or local devices.
+
+With respect to YOLOv8, you can [export your model](../modes/export.md) to different formats. For example, when you need to transfer your model between different frameworks, ONNX is an excellent tool and [exporting to YOLOv8 to ONNX](../integrations/onnx.md) is easy. You can check out more options about integrating your model into different environments smoothly and effectively [here](../integrations/index.md).
+
+### Choosing a Deployment Environment
+
+Choosing where to deploy your computer vision model depends on multiple factors. Different environments have unique benefits and challenges, so it's essential to pick the one that best fits your needs.
+
+#### Cloud Deployment
+
+Cloud deployment is great for applications that need to scale up quickly and handle large amounts of data. Platforms like AWS, [Google Cloud](../yolov5/environments/google_cloud_quickstart_tutorial.md), and Azure make it easy to manage your models from training to deployment. They offer services like [AWS SageMaker](../integrations/amazon-sagemaker.md), Google AI Platform, and [Azure Machine Learning](./azureml-quickstart.md) to help you throughout the process.
+
+However, using the cloud can be expensive, especially with high data usage, and you might face latency issues if your users are far from the data centers. To manage costs and performance, it's important to optimize resource use and ensure compliance with data privacy rules.
+
+#### Edge Deployment
+
+Edge deployment works well for applications needing real-time responses and low latency, particularly in places with limited or no internet access. Deploying models on edge devices like smartphones or IoT gadgets ensures fast processing and keeps data local, which enhances privacy. Deploying on edge also saves bandwidth due to reduced data sent to the cloud.
+
+However, edge devices often have limited processing power, so you'll need to optimize your models. Tools like [TensorFlow Lite](../integrations/tflite.md) and [NVIDIA Jetson](./nvidia-jetson.md) can help. Despite the benefits, maintaining and updating many devices can be challenging.
+
+#### Local Deployment
+
+Local Deployment is best when data privacy is critical or when there's unreliable or no internet access. Running models on local servers or desktops gives you full control and keeps your data secure. It can also reduce latency if the server is near the user.
+
+However, scaling locally can be tough, and maintenance can be time-consuming. Using tools like [Docker](./docker-quickstart.md) for containerization and Kubernetes for management can help make local deployments more efficient. Regular updates and maintenance are necessary to keep everything running smoothly.
+
+## Model Optimization Techniques
+
+Optimizing your computer vision model helps it runs efficiently, especially when deploying in environments with limited resources like edge devices. Here are some key techniques for optimizing your model.
+
+### Model Pruning
+
+Pruning reduces the size of the model by removing weights that contribute little to the final output. It makes the model smaller and faster without significantly affecting accuracy. Pruning involves identifying and eliminating unnecessary parameters, resulting in a lighter model that requires less computational power. It is particularly useful for deploying models on devices with limited resources.
+
+
+
+
+
+### Model Quantization
+
+Quantization converts the model's weights and activations from high precision (like 32-bit floats) to lower precision (like 8-bit integers). By reducing the model size, it speeds up inference. Quantization-aware training (QAT) is a method where the model is trained with quantization in mind, preserving accuracy better than post-training quantization. By handling quantization during the training phase, the model learns to adjust to lower precision, maintaining performance while reducing computational demands.
+
+
+
+
+
+### Knowledge Distillation
+
+Knowledge distillation involves training a smaller, simpler model (the student) to mimic the outputs of a larger, more complex model (the teacher). The student model learns to approximate the teacher's predictions, resulting in a compact model that retains much of the teacher's accuracy. This technique is beneficial for creating efficient models suitable for deployment on edge devices with constrained resources.
+
+
+
+
+
+## Troubleshooting Deployment Issues
+
+You may face challenges while deploying your computer vision models, but understanding common problems and solutions can make the process smoother. Here are some general troubleshooting tips and best practices to help you navigate deployment issues.
+
+### Your Model is Less Accurate After Deployment
+
+Experiencing a drop in your model's accuracy after deployment can be frustrating. This issue can stem from various factors. Here are some steps to help you identify and resolve the problem:
+
+- **Check Data Consistency:** Check that the data your model is processing post-deployment is consistent with the data it was trained on. Differences in data distribution, quality, or format can significantly impact performance.
+- **Validate Preprocessing Steps:** Verify that all preprocessing steps applied during training are also applied consistently during deployment. This includes resizing images, normalizing pixel values, and other data transformations.
+- **Evaluate the Model's Environment:** Ensure that the hardware and software configurations used during deployment match those used during training. Differences in libraries, versions, and hardware capabilities can introduce discrepancies.
+- **Monitor Model Inference:** Log inputs and outputs at various stages of the inference pipeline to detect any anomalies. It can help identify issues like data corruption or improper handling of model outputs.
+- **Review Model Export and Conversion:** Re-export the model and make sure that the conversion process maintains the integrity of the model weights and architecture.
+- **Test with a Controlled Dataset:** Deploy the model in a test environment with a dataset you control and compare the results with the training phase. You can identify if the issue is with the deployment environment or the data.
+
+When deploying YOLOv8, several factors can affect model accuracy. Converting models to formats like [TensorRT](../integrations/tensorrt.md) involves optimizations such as weight quantization and layer fusion, which can cause minor precision losses. Using FP16 (half-precision) instead of FP32 (full-precision) can speed up inference but may introduce numerical precision errors. Also, hardware constraints, like those on the [Jetson Nano](./nvidia-jetson.md), with lower CUDA core counts and reduced memory bandwidth, can impact performance.
+
+### Inferences Are Taking Longer Than You Expected
+
+When deploying machine learning models, it's important that they run efficiently. If inferences are taking longer than expected, it can affect the user experience and the effectiveness of your application. Here are some steps to help you identify and resolve the problem:
+
+- **Implement Warm-Up Runs**: Initial runs often include setup overhead, which can skew latency measurements. Perform a few warm-up inferences before measuring latency. Excluding these initial runs provides a more accurate measurement of the model's performance.
+- **Optimize the Inference Engine:** Double-check that the inference engine is fully optimized for your specific GPU architecture. Use the latest drivers and software versions tailored to your hardware to ensure maximum performance and compatibility.
+- **Use Asynchronous Processing:** Asynchronous processing can help manage workloads more efficiently. Use asynchronous processing techniques to handle multiple inferences concurrently, which can help distribute the load and reduce wait times.
+- **Profile the Inference Pipeline:** Identifying bottlenecks in the inference pipeline can help pinpoint the source of delays. Use profiling tools to analyze each step of the inference process, identifying and addressing any stages that cause significant delays, such as inefficient layers or data transfer issues.
+- **Use Appropriate Precision:** Using higher precision than necessary can slow down inference times. Experiment with using lower precision, such as FP16 (half-precision), instead of FP32 (full-precision). While FP16 can reduce inference time, also keep in mind that it can impact model accuracy.
+
+If you are facing this issue while deploying YOLOv8, consider that YOLOv8 offers [various model sizes](../models/yolov8.md), such as YOLOv8n (nano) for devices with lower memory capacity and YOLOv8x (extra-large) for more powerful GPUs. Choosing the right model variant for your hardware can help balance memory usage and processing time.
+
+Also keep in mind that the size of the input images directly impacts memory usage and processing time. Lower resolutions reduce memory usage and speed up inference, while higher resolutions improve accuracy but require more memory and processing power.
+
+## Security Considerations in Model Deployment
+
+Another important aspect of deployment is security. The security of your deployed models is critical to protect sensitive data and intellectual property. Here are some best practices you can follow related to secure model deployment.
+
+### Secure Data Transmission
+
+Making sure data sent between clients and servers is secure is very important to prevent it from being intercepted or accessed by unauthorized parties. You can use encryption protocols like TLS (Transport Layer Security) to encrypt data while it's being transmitted. Even if someone intercepts the data, they won't be able to read it. You can also use end-to-end encryption that protects the data all the way from the source to the destination, so no one in between can access it.
+
+### Access Controls
+
+It's essential to control who can access your model and its data to prevent unauthorized use. Use strong authentication methods to verify the identity of users or systems trying to access the model, and consider adding extra security with multi-factor authentication (MFA). Set up role-based access control (RBAC) to assign permissions based on user roles so that people only have access to what they need. Keep detailed audit logs to track all access and changes to the model and its data, and regularly review these logs to spot any suspicious activity.
+
+### Model Obfuscation
+
+Protecting your model from being reverse-engineered or misuse can be done through model obfuscation. It involves encrypting model parameters, such as weights and biases in neural networks, to make it difficult for unauthorized individuals to understand or alter the model. You can also obfuscate the model's architecture by renaming layers and parameters or adding dummy layers, making it harder for attackers to reverse-engineer it. You can also serve the model in a secure environment, like a secure enclave or using a trusted execution environment (TEE), can provide an extra layer of protection during inference.
+
+## Share Ideas With Your Peers
+
+Being part of a community of computer vision enthusiasts can help you solve problems and learn faster. Here are some ways to connect, get help, and share ideas.
+
+### Community Resources
+
+- **GitHub Issues:** Explore the [YOLOv8 GitHub repository](https://github.com/ultralytics/ultralytics/issues) and use the Issues tab to ask questions, report bugs, and suggest new features. The community and maintainers are very active and ready to help.
+- **Ultralytics Discord Server:** Join the [Ultralytics Discord server](https://ultralytics.com/discord/) to chat with other users and developers, get support, and share your experiences.
+
+### Official Documentation
+
+- **Ultralytics YOLOv8 Documentation:** Visit the [official YOLOv8 documentation](./index.md) for detailed guides and helpful tips on various computer vision projects.
+
+Using these resources will help you solve challenges and stay up-to-date with the latest trends and practices in the computer vision community.
+
+## Conclusion and Next Steps
+
+We walked through some best practices to follow when deploying computer vision models. By securing data, controlling access, and obfuscating model details, you can protect sensitive information while keeping your models running smoothly. We also discussed how to address common issues like reduced accuracy and slow inferences using strategies such as warm-up runs, optimizing engines, asynchronous processing, profiling pipelines, and choosing the right precision.
+
+After deploying your model, the next step would be monitoring, maintaining, and documenting your application. Regular monitoring helps catch and fix issues quickly, maintenance keeps your models up-to-date and functional, and good documentation tracks all changes and updates. These steps will help you achieve the [goals of your computer vision project](./defining-project-goals.md).
+
+## FAQ
+
+### What are the best practices for deploying a machine learning model using Ultralytics YOLOv8?
+
+Deploying a machine learning model, particularly with Ultralytics YOLOv8, involves several best practices to ensure efficiency and reliability. First, choose the deployment environment that suits your needs—cloud, edge, or local. Optimize your model through techniques like [pruning, quantization, and knowledge distillation](#model-optimization-techniques) for efficient deployment in resource-constrained environments. Lastly, ensure data consistency and preprocessing steps align with the training phase to maintain performance. You can also refer to [model deployment options](./model-deployment-options.md) for more detailed guidelines.
+
+### How can I troubleshoot common deployment issues with Ultralytics YOLOv8 models?
+
+Troubleshooting deployment issues can be broken down into a few key steps. If your model's accuracy drops after deployment, check for data consistency, validate preprocessing steps, and ensure the hardware/software environment matches what you used during training. For slow inference times, perform warm-up runs, optimize your inference engine, use asynchronous processing, and profile your inference pipeline. Refer to [troubleshooting deployment issues](#troubleshooting-deployment-issues) for a detailed guide on these best practices.
+
+### How does Ultralytics YOLOv8 optimization enhance model performance on edge devices?
+
+Optimizing Ultralytics YOLOv8 models for edge devices involves using techniques like pruning to reduce the model size, quantization to convert weights to lower precision, and knowledge distillation to train smaller models that mimic larger ones. These techniques ensure the model runs efficiently on devices with limited computational power. Tools like [TensorFlow Lite](../integrations/tflite.md) and [NVIDIA Jetson](./nvidia-jetson.md) are particularly useful for these optimizations. Learn more about these techniques in our section on [model optimization](#model-optimization-techniques).
+
+### What are the security considerations for deploying machine learning models with Ultralytics YOLOv8?
+
+Security is paramount when deploying machine learning models. Ensure secure data transmission using encryption protocols like TLS. Implement robust access controls, including strong authentication and role-based access control (RBAC). Model obfuscation techniques, such as encrypting model parameters and serving models in a secure environment like a trusted execution environment (TEE), offer additional protection. For detailed practices, refer to [security considerations](#security-considerations-in-model-deployment).
+
+### How do I choose the right deployment environment for my Ultralytics YOLOv8 model?
+
+Selecting the optimal deployment environment for your Ultralytics YOLOv8 model depends on your application's specific needs. Cloud deployment offers scalability and ease of access, making it ideal for applications with high data volumes. Edge deployment is best for low-latency applications requiring real-time responses, using tools like [TensorFlow Lite](../integrations/tflite.md). Local deployment suits scenarios needing stringent data privacy and control. For a comprehensive overview of each environment, check out our section on [choosing a deployment environment](#choosing-a-deployment-environment).
diff --git a/ultralytics/docs/en/guides/model-evaluation-insights.md b/ultralytics/docs/en/guides/model-evaluation-insights.md
new file mode 100644
index 0000000000000000000000000000000000000000..b6d04f33abdb95479affd0f377d7a08def8aa022
--- /dev/null
+++ b/ultralytics/docs/en/guides/model-evaluation-insights.md
@@ -0,0 +1,188 @@
+---
+comments: true
+description: Explore the most effective ways to assess and refine YOLOv8 models for better performance. Learn about evaluation metrics, fine-tuning processes, and how to customize your model for specific needs.
+keywords: Model Evaluation, Machine Learning Model Evaluation, Fine Tuning Machine Learning, Fine Tune Model, Evaluating Models, Model Fine Tuning, How to Fine Tune a Model
+---
+
+# Insights on Model Evaluation and Fine-Tuning
+
+## Introduction
+
+Once you've [trained](./model-training-tips.md) your computer vision model, evaluating and refining it to perform optimally is essential. Just training your model isn't enough. You need to make sure that your model is accurate, efficient, and fulfills the [objective](./defining-project-goals.md) of your computer vision project. By evaluating and fine-tuning your model, you can identify weaknesses, improve its accuracy, and boost overall performance.
+
+In this guide, we'll share insights on model evaluation and fine-tuning that'll make this [step of a computer vision project](./steps-of-a-cv-project.md) more approachable. We'll discuss how to understand evaluation metrics and implement fine-tuning techniques, giving you the knowledge to elevate your model's capabilities.
+
+## Evaluating Model Performance Using Metrics
+
+Evaluating how well a model performs helps us understand how effectively it works. Various metrics are used to measure performance. These [performance metrics](./yolo-performance-metrics.md) provide clear, numerical insights that can guide improvements toward making sure the model meets its intended goals. Let's take a closer look at a few key metrics.
+
+### Confidence Score
+
+The confidence score represents the model's certainty that a detected object belongs to a particular class. It ranges from 0 to 1, with higher scores indicating greater confidence. The confidence score helps filter predictions; only detections with confidence scores above a specified threshold are considered valid.
+
+_Quick Tip:_ When running inferences, if you aren't seeing any predictions and you've checked everything else, try lowering the confidence score. Sometimes, the threshold is too high, causing the model to ignore valid predictions. Lowering the score allows the model to consider more possibilities. This might not meet your project goals, but it's a good way to see what the model can do and decide how to fine-tune it.
+
+### Intersection over Union
+
+Intersection over Union (IoU) is a metric in object detection that measures how well the predicted bounding box overlaps with the ground truth bounding box. IoU values range from 0 to 1, where one stands for a perfect match. IoU is essential because it measures how closely the predicted boundaries match the actual object boundaries.
+
+
+
+
+
+### Mean Average Precision
+
+Mean Average Precision (mAP) is a way to measure how well an object detection model performs. It looks at the precision of detecting each object class, averages these scores, and gives an overall number that shows how accurately the model can identify and classify objects.
+
+Let's focus on two specific mAP metrics:
+
+- *mAP@.5:* Measures the average precision at a single IoU (Intersection over Union) threshold of 0.5. This metric checks if the model can correctly find objects with a looser accuracy requirement. It focuses on whether the object is roughly in the right place, not needing perfect placement. It helps see if the model is generally good at spotting objects.
+- *mAP@.5:.95:* Averages the mAP values calculated at multiple IoU thresholds, from 0.5 to 0.95 in 0.05 increments. This metric is more detailed and strict. It gives a fuller picture of how accurately the model can find objects at different levels of strictness and is especially useful for applications that need precise object detection.
+
+Other mAP metrics include mAP@0.75, which uses a stricter IoU threshold of 0.75, and mAP@small, medium, and large, which evaluate precision across objects of different sizes.
+
+
+
+
+
+## Evaluating YOLOv8 Model Performance
+
+With respect to YOLOv8, you can use the [validation mode](../modes/val.md) to evaluate the model. Also, be sure to take a look at our guide that goes in-depth into [YOLOv8 performance metrics](./yolo-performance-metrics.md) and how they can be interpreted.
+
+### Common Community Questions
+
+When evaluating your YOLOv8 model, you might run into a few hiccups. Based on common community questions, here are some tips to help you get the most out of your YOLOv8 model:
+
+#### Handling Variable Image Sizes
+
+Evaluating your YOLOv8 model with images of different sizes can help you understand its performance on diverse datasets. Using the `rect=true` validation parameter, YOLOv8 adjusts the network's stride for each batch based on the image sizes, allowing the model to handle rectangular images without forcing them to a single size.
+
+The `imgsz` validation parameter sets the maximum dimension for image resizing, which is 640 by default. You can adjust this based on your dataset's maximum dimensions and the GPU memory available. Even with `imgsz` set, `rect=true` lets the model manage varying image sizes effectively by dynamically adjusting the stride.
+
+#### Accessing YOLOv8 Metrics
+
+If you want to get a deeper understanding of your YOLOv8 model's performance, you can easily access specific evaluation metrics with a few lines of Python code. The code snippet below will let you load your model, run an evaluation, and print out various metrics that show how well your model is doing.
+
+!!! Example "Usage"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load the model
+ model = YOLO("yolov8n.pt")
+
+ # Run the evaluation
+ results = model.val(data="coco8.yaml")
+
+ # Print specific metrics
+ print("Class indices with average precision:", results.ap_class_index)
+ print("Average precision for all classes:", results.box.all_ap)
+ print("Average precision:", results.box.ap)
+ print("Average precision at IoU=0.50:", results.box.ap50)
+ print("Class indices for average precision:", results.box.ap_class_index)
+ print("Class-specific results:", results.box.class_result)
+ print("F1 score:", results.box.f1)
+ print("F1 score curve:", results.box.f1_curve)
+ print("Overall fitness score:", results.box.fitness)
+ print("Mean average precision:", results.box.map)
+ print("Mean average precision at IoU=0.50:", results.box.map50)
+ print("Mean average precision at IoU=0.75:", results.box.map75)
+ print("Mean average precision for different IoU thresholds:", results.box.maps)
+ print("Mean results for different metrics:", results.box.mean_results)
+ print("Mean precision:", results.box.mp)
+ print("Mean recall:", results.box.mr)
+ print("Precision:", results.box.p)
+ print("Precision curve:", results.box.p_curve)
+ print("Precision values:", results.box.prec_values)
+ print("Specific precision metrics:", results.box.px)
+ print("Recall:", results.box.r)
+ print("Recall curve:", results.box.r_curve)
+ ```
+
+The results object also includes speed metrics like preprocess time, inference time, loss, and postprocess time. By analyzing these metrics, you can fine-tune and optimize your YOLOv8 model for better performance, making it more effective for your specific use case.
+
+## How Does Fine-Tuning Work?
+
+Fine-tuning involves taking a pre-trained model and adjusting its parameters to improve performance on a specific task or dataset. The process, also known as model retraining, allows the model to better understand and predict outcomes for the specific data it will encounter in real-world applications. You can retrain your model based on your model evaluation to achieve optimal results.
+
+## Tips for Fine-Tuning Your Model
+
+Fine-tuning a model means paying close attention to several vital parameters and techniques to achieve optimal performance. Here are some essential tips to guide you through the process.
+
+### Starting With a Higher Learning Rate
+
+Usually, during the initial training epochs, the learning rate starts low and gradually increases to stabilize the training process. However, since your model has already learned some features from the previous dataset, starting with a higher learning rate right away can be more beneficial.
+
+When evaluating your YOLOv8 model, you can set the `warmup_epochs` validation parameter to `warmup_epochs=0` to prevent the learning rate from starting too high. By following this process, the training will continue from the provided weights, adjusting to the nuances of your new data.
+
+### Image Tiling for Small Objects
+
+Image tiling can improve detection accuracy for small objects. By dividing larger images into smaller segments, such as splitting 1280x1280 images into multiple 640x640 segments, you maintain the original resolution, and the model can learn from high-resolution fragments. When using YOLOv8, make sure to adjust your labels for these new segments correctly.
+
+## Engage with the Community
+
+Sharing your ideas and questions with other computer vision enthusiasts can inspire creative solutions to roadblocks in your projects. Here are some excellent ways to learn, troubleshoot, and connect.
+
+### Finding Help and Support
+
+- **GitHub Issues:** Explore the YOLOv8 GitHub repository and use the [Issues tab](https://github.com/ultralytics/ultralytics/issues) to ask questions, report bugs, and suggest features. The community and maintainers are available to assist with any issues you encounter.
+- **Ultralytics Discord Server:** Join the [Ultralytics Discord server](https://ultralytics.com/discord/) to connect with other users and developers, get support, share knowledge, and brainstorm ideas.
+
+### Official Documentation
+
+- **Ultralytics YOLOv8 Documentation:** Check out the [official YOLOv8 documentation](./index.md) for comprehensive guides and valuable insights on various computer vision tasks and projects.
+
+## Final Thoughts
+
+Evaluating and fine-tuning your computer vision model are important steps for successful model deployment. These steps help make sure that your model is accurate, efficient, and suited to your overall application. The key to training the best model possible is continuous experimentation and learning. Don't hesitate to tweak parameters, try new techniques, and explore different datasets. Keep experimenting and pushing the boundaries of what's possible!
+
+## FAQ
+
+### What are the key metrics for evaluating YOLOv8 model performance?
+
+To evaluate YOLOv8 model performance, important metrics include Confidence Score, Intersection over Union (IoU), and Mean Average Precision (mAP). Confidence Score measures the model's certainty for each detected object class. IoU evaluates how well the predicted bounding box overlaps with the ground truth. Mean Average Precision (mAP) aggregates precision scores across classes, with mAP@.5 and mAP@.5:.95 being two common types for varying IoU thresholds. Learn more about these metrics in our [YOLOv8 performance metrics guide](./yolo-performance-metrics.md).
+
+### How can I fine-tune a pre-trained YOLOv8 model for my specific dataset?
+
+Fine-tuning a pre-trained YOLOv8 model involves adjusting its parameters to improve performance on a specific task or dataset. Start by evaluating your model using metrics, then set a higher initial learning rate by adjusting the `warmup_epochs` parameter to 0 for immediate stability. Use parameters like `rect=true` for handling varied image sizes effectively. For more detailed guidance, refer to our section on [fine-tuning YOLOv8 models](#how-does-fine-tuning-work).
+
+### How can I handle variable image sizes when evaluating my YOLOv8 model?
+
+To handle variable image sizes during evaluation, use the `rect=true` parameter in YOLOv8, which adjusts the network's stride for each batch based on image sizes. The `imgsz` parameter sets the maximum dimension for image resizing, defaulting to 640. Adjust `imgsz` to suit your dataset and GPU memory. For more details, visit our [section on handling variable image sizes](#handling-variable-image-sizes).
+
+### What practical steps can I take to improve mean average precision for my YOLOv8 model?
+
+Improving mean average precision (mAP) for a YOLOv8 model involves several steps:
+
+1. **Tuning Hyperparameters**: Experiment with different learning rates, batch sizes, and image augmentations.
+2. **Data Augmentation**: Use techniques like Mosaic and MixUp to create diverse training samples.
+3. **Image Tiling**: Split larger images into smaller tiles to improve detection accuracy for small objects.
+ Refer to our detailed guide on [model fine-tuning](#tips-for-fine-tuning-your-model) for specific strategies.
+
+### How do I access YOLOv8 model evaluation metrics in Python?
+
+You can access YOLOv8 model evaluation metrics using Python with the following steps:
+
+!!! Example "Usage"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load the model
+ model = YOLO("yolov8n.pt")
+
+ # Run the evaluation
+ results = model.val(data="coco8.yaml")
+
+ # Print specific metrics
+ print("Class indices with average precision:", results.ap_class_index)
+ print("Average precision for all classes:", results.box.all_ap)
+ print("Mean average precision at IoU=0.50:", results.box.map50)
+ print("Mean recall:", results.box.mr)
+ ```
+
+Analyzing these metrics helps fine-tune and optimize your YOLOv8 model. For a deeper dive, check out our guide on [YOLOv8 metrics](../modes/val.md).
diff --git a/ultralytics/docs/en/guides/model-monitoring-and-maintenance.md b/ultralytics/docs/en/guides/model-monitoring-and-maintenance.md
new file mode 100644
index 0000000000000000000000000000000000000000..57fda1d3636d42c4d679954d843a4ecd6b9d97b3
--- /dev/null
+++ b/ultralytics/docs/en/guides/model-monitoring-and-maintenance.md
@@ -0,0 +1,172 @@
+---
+comments: true
+description: Understand the key practices for monitoring, maintaining, and documenting computer vision models to guarantee accuracy, spot anomalies, and mitigate data drift.
+keywords: Computer Vision Models, AI Model Monitoring, Data Drift Detection, Anomaly Detection in AI, Model Monitoring
+---
+
+# Maintaining Your Computer Vision Models After Deployment
+
+## Introduction
+
+If you are here, we can assume you've completed many [steps in your computer vision project](./steps-of-a-cv-project.md): from [gathering requirements](./defining-project-goals.md), [annotating data](./data-collection-and-annotation.md), and [training the model](./model-training-tips.md) to finally [deploying](./model-deployment-practices.md) it. Your application is now running in production, but your project doesn't end here. The most important part of a computer vision project is making sure your model continues to fulfill your [project's objectives](./defining-project-goals.md) over time, and that's where monitoring, maintaining, and documenting your computer vision model enters the picture.
+
+In this guide, we'll take a closer look at how you can maintain your computer vision models after deployment. We'll explore how model monitoring can help you catch problems early on, how to keep your model accurate and up-to-date, and why documentation is important for troubleshooting.
+
+## Model Monitoring is Key
+
+Keeping a close eye on your deployed computer vision models is essential. Without proper monitoring, models can lose accuracy. A common issue is data distribution shift or data drift, where the data the model encounters changes from what it was trained on. When the model has to make predictions on data it doesn't recognize, it can lead to misinterpretations and poor performance. Outliers, or unusual data points, can also throw off the model's accuracy.
+
+Regular model monitoring helps developers track the [model's performance](./model-evaluation-insights.md), spot anomalies, and quickly address problems like data drift. It also helps manage resources by indicating when updates are needed, avoiding expensive overhauls, and keeping the model relevant.
+
+### Best Practices for Model Monitoring
+
+Here are some best practices to keep in mind while monitoring your computer vision model in production:
+
+- **Track Performance Regularly**: Continuously monitor the model's performance to detect changes over time.
+- **Double Check the Data Quality**: Check for missing values or anomalies in the data.
+- **Use Diverse Data Sources**: Monitor data from various sources to get a comprehensive view of the model's performance.
+- **Combine Monitoring Techniques**: Use a mix of drift detection algorithms and rule-based approaches to identify a wide range of issues.
+- **Monitor Inputs and Outputs**: Keep an eye on both the data the model processes and the results it produces to make sure everything is functioning correctly.
+- **Set Up Alerts**: Implement alerts for unusual behavior, such as performance drops, to be able to make quick corrective actions.
+
+### Tools for AI Model Monitoring
+
+You can use automated monitoring tools to make it easier to monitor models after deployment. Many tools offer real-time insights and alerting capabilities. Here are some examples of open-source model monitoring tools that can work together:
+
+- **[Prometheus](https://prometheus.io/)**: Prometheus is an open-source monitoring tool that collects and stores metrics for detailed performance tracking. It integrates easily with Kubernetes and Docker, collecting data at set intervals and storing it in a time-series database. Prometheus can also scrape HTTP endpoints to gather real-time metrics. Collected data can be queried using the PromQL language.
+- **[Grafana](https://grafana.com/)**: Grafana is an open-source data visualization and monitoring tool that allows you to query, visualize, alert on, and understand your metrics no matter where they are stored. It works well with Prometheus and offers advanced data visualization features. You can create custom dashboards to show important metrics for your computer vision models, like inference latency, error rates, and resource usage. Grafana turns collected data into easy-to-read dashboards with line graphs, heat maps, and histograms. It also supports alerts, which can be sent through channels like Slack to quickly notify teams of any issues.
+- **[Evidently AI](https://www.evidentlyai.com/)**: Evidently AI is an open-source tool designed for monitoring and debugging machine learning models in production. It generates interactive reports from pandas DataFrames, helping analyze machine learning models. Evidently AI can detect data drift, model performance degradation, and other issues that may arise with your deployed models.
+
+The three tools introduced above, Evidently AI, Prometheus, and Grafana, can work together seamlessly as a fully open-source ML monitoring solution that is ready for production. Evidently AI is used to collect and calculate metrics, Prometheus stores these metrics, and Grafana displays them and sets up alerts. While there are many other tools available, this setup is an exciting open-source option that provides robust capabilities for monitoring and maintaining your models.
+
+
+
+
+
+### Anomaly Detection and Alert Systems
+
+An anomaly is any data point or pattern that deviates quite a bit from what is expected. With respect to computer vision models, anomalies can be images that are very different from the ones the model was trained on. These unexpected images can be signs of issues like changes in data distribution, outliers, or behaviors that might reduce model performance. Setting up alert systems to detect these anomalies is an important part of model monitoring.
+
+By setting standard performance levels and limits for key metrics, you can catch problems early. When performance goes outside these limits, alerts are triggered, prompting quick fixes. Regularly updating and retraining models with new data keeps them relevant and accurate as the data changes.
+
+#### Things to Keep in Mind When Configuring Thresholds and Alerts
+
+When you are setting up your alert systems, keep these best practices in mind:
+
+- **Standardized Alerts**: Use consistent tools and formats for all alerts, such as email or messaging apps like Slack. Standardization makes it easier for you to quickly understand and respond to alerts.
+- **Include Expected Behavior**: Alert messages should clearly state what went wrong, what was expected, and the timeframe evaluated. It helps you gauge the urgency and context of the alert.
+- **Configurable Alerts**: Make alerts easily configurable to adapt to changing conditions. Allow yourself to edit thresholds, snooze, disable, or acknowledge alerts.
+
+### Data Drift Detection
+
+Data drift detection is a concept that helps identify when the statistical properties of the input data change over time, which can degrade model performance. Before you decide to retrain or adjust your models, this technique helps spot that there is an issue. Data drift deals with changes in the overall data landscape over time, while anomaly detection focuses on identifying rare or unexpected data points that may require immediate attention.
+
+
+
+
+
+Here are several methods to detect data drift:
+
+**Continuous Monitoring**: Regularly monitor the model's input data and outputs for signs of drift. Track key metrics and compare them against historical data to identify significant changes.
+
+**Statistical Techniques**: Use methods like the Kolmogorov-Smirnov test or Population Stability Index (PSI) to detect changes in data distributions. These tests compare the distribution of new data with the training data to identify significant differences.
+
+**Feature Drift**: Monitor individual features for drift. Sometimes, the overall data distribution may remain stable, but individual features may drift. Identifying which features are drifting helps in fine-tuning the retraining process.
+
+## Model Maintenance
+
+Model maintenance is crucial to keep computer vision models accurate and relevant over time. Model maintenance involves regularly updating and retraining models, addressing data drift, and ensuring the model stays relevant as data and environments change. You might be wondering how model maintenance differs from model monitoring. Monitoring is about watching the model's performance in real time to catch issues early. Maintenance, on the other hand, is about fixing these issues.
+
+### Regular Updates and Re-training
+
+Once a model is deployed, while monitoring, you may notice changes in data patterns or performance, indicating model drift. Regular updates and re-training become essential parts of model maintenance to ensure the model can handle new patterns and scenarios. There are a few techniques you can use based on how your data is changing.
+
+
+
+
+
+For example, if the data is changing gradually over time, incremental learning is a good approach. Incremental learning involves updating the model with new data without completely retraining it from scratch, saving computational resources and time. However, if the data has changed drastically, a periodic full re-training might be a better option to ensure the model does not overfit on the new data while losing track of older patterns.
+
+Regardless of the method, validation and testing are a must after updates. It is important to validate the model on a separate [test dataset](./model-testing.md) to check for performance improvements or degradation.
+
+### Deciding When to Retrain Your Model
+
+The frequency of retraining your computer vision model depends on data changes and model performance. Retrain your model whenever you observe a significant performance drop or detect data drift. Regular evaluations can help determine the right retraining schedule by testing the model against new data. Monitoring performance metrics and data patterns lets you decide if your model needs more frequent updates to maintain accuracy.
+
+
+
+
+
+## Documentation
+
+Documenting a computer vision project makes it easier to understand, reproduce, and collaborate on. Good documentation covers model architecture, hyperparameters, datasets, evaluation metrics, and more. It provides transparency, helping team members and stakeholders understand what has been done and why. Documentation also aids in troubleshooting, maintenance, and future enhancements by providing a clear reference of past decisions and methods.
+
+### Key Elements to Document
+
+These are some of the key elements that should be included in project documentation:
+
+- **[Project Overview](./steps-of-a-cv-project.md)**: Provide a high-level summary of the project, including the problem statement, solution approach, expected outcomes, and project scope. Explain the role of computer vision in addressing the problem and outline the stages and deliverables.
+- **Model Architecture**: Detail the structure and design of the model, including its components, layers, and connections. Explain the chosen hyperparameters and the rationale behind these choices.
+- **[Data Preparation](./data-collection-and-annotation.md)**: Describe the data sources, types, formats, sizes, and preprocessing steps. Discuss data quality, reliability, and any transformations applied before training the model.
+- **[Training Process](./model-training-tips.md)**: Document the training procedure, including the datasets used, training parameters, and loss functions. Explain how the model was trained and any challenges encountered during training.
+- **[Evaluation Metrics](./model-evaluation-insights.md)**: Specify the metrics used to evaluate the model's performance, such as accuracy, precision, recall, and F1-score. Include performance results and an analysis of these metrics.
+- **[Deployment Steps](./model-deployment-options.md)**: Outline the steps taken to deploy the model, including the tools and platforms used, deployment configurations, and any specific challenges or considerations.
+- **Monitoring and Maintenance Procedure**: Provide a detailed plan for monitoring the model's performance post-deployment. Include methods for detecting and addressing data and model drift, and describe the process for regular updates and retraining.
+
+### Tools for Documentation
+
+There are many options when it comes to documenting AI projects, with open-source tools being particularly popular. Two of these are Jupyter Notebooks and MkDocs. Jupyter Notebooks allow you to create interactive documents with embedded code, visualizations, and text, making them ideal for sharing experiments and analyses. MkDocs is a static site generator that is easy to set up and deploy and is perfect for creating and hosting project documentation online.
+
+## Connect with the Community
+
+Joining a community of computer vision enthusiasts can help you solve problems and learn more quickly. Here are some ways to connect, get support, and share ideas.
+
+### Community Resources
+
+- **GitHub Issues:** Check out the [YOLOv8 GitHub repository](https://github.com/ultralytics/ultralytics/issues) and use the Issues tab to ask questions, report bugs, and suggest new features. The community and maintainers are highly active and supportive.
+- **Ultralytics Discord Server:** Join the [Ultralytics Discord server](https://ultralytics.com/discord/) to chat with other users and developers, get support, and share your experiences.
+
+### Official Documentation
+
+- **Ultralytics YOLOv8 Documentation:** Visit the [official YOLOv8 documentation](./index.md) for detailed guides and helpful tips on various computer vision projects.
+
+Using these resources will help you solve challenges and stay up-to-date with the latest trends and practices in the computer vision community.
+
+## Key Takeaways
+
+We covered key tips for monitoring, maintaining, and documenting your computer vision models. Regular updates and re-training help the model adapt to new data patterns. Detecting and fixing data drift helps your model stay accurate. Continuous monitoring catches issues early, and good documentation makes collaboration and future updates easier. Following these steps will help your computer vision project stay successful and effective over time.
+
+## FAQ
+
+### How do I monitor the performance of my deployed computer vision model?
+
+Monitoring the performance of your deployed computer vision model is crucial to ensure its accuracy and reliability over time. You can use tools like [Prometheus](https://prometheus.io/), [Grafana](https://grafana.com/), and [Evidently AI](https://www.evidentlyai.com/) to track key metrics, detect anomalies, and identify data drift. Regularly monitor inputs and outputs, set up alerts for unusual behavior, and use diverse data sources to get a comprehensive view of your model's performance. For more details, check out our section on [Model Monitoring](#model-monitoring-is-key).
+
+### What are the best practices for maintaining computer vision models after deployment?
+
+Maintaining computer vision models involves regular updates, retraining, and monitoring to ensure continued accuracy and relevance. Best practices include:
+
+- **Continuous Monitoring**: Track performance metrics and data quality regularly.
+- **Data Drift Detection**: Use statistical techniques to identify changes in data distributions.
+- **Regular Updates and Retraining**: Implement incremental learning or periodic full retraining based on data changes.
+- **Documentation**: Maintain detailed documentation of model architecture, training processes, and evaluation metrics. For more insights, visit our [Model Maintenance](#model-maintenance) section.
+
+### Why is data drift detection important for AI models?
+
+Data drift detection is essential because it helps identify when the statistical properties of the input data change over time, which can degrade model performance. Techniques like continuous monitoring, statistical tests (e.g., Kolmogorov-Smirnov test), and feature drift analysis can help spot issues early. Addressing data drift ensures that your model remains accurate and relevant in changing environments. Learn more about data drift detection in our [Data Drift Detection](#data-drift-detection) section.
+
+### What tools can I use for anomaly detection in computer vision models?
+
+For anomaly detection in computer vision models, tools like [Prometheus](https://prometheus.io/), [Grafana](https://grafana.com/), and [Evidently AI](https://www.evidentlyai.com/) are highly effective. These tools can help you set up alert systems to detect unusual data points or patterns that deviate from expected behavior. Configurable alerts and standardized messages can help you respond quickly to potential issues. Explore more in our [Anomaly Detection and Alert Systems](#anomaly-detection-and-alert-systems) section.
+
+### How can I document my computer vision project effectively?
+
+Effective documentation of a computer vision project should include:
+
+- **Project Overview**: High-level summary, problem statement, and solution approach.
+- **Model Architecture**: Details of the model structure, components, and hyperparameters.
+- **Data Preparation**: Information on data sources, preprocessing steps, and transformations.
+- **Training Process**: Description of the training procedure, datasets used, and challenges encountered.
+- **Evaluation Metrics**: Metrics used for performance evaluation and analysis.
+- **Deployment Steps**: Steps taken for model deployment and any specific challenges.
+- **Monitoring and Maintenance Procedure**: Plan for ongoing monitoring and maintenance. For more comprehensive guidelines, refer to our [Documentation](#documentation) section.
diff --git a/ultralytics/docs/en/guides/model-testing.md b/ultralytics/docs/en/guides/model-testing.md
new file mode 100644
index 0000000000000000000000000000000000000000..432c976b067e7d08489e91883045925b9ebf5eda
--- /dev/null
+++ b/ultralytics/docs/en/guides/model-testing.md
@@ -0,0 +1,200 @@
+---
+comments: true
+description: Explore effective methods for testing computer vision models to make sure they are reliable, perform well, and are ready to be deployed.
+keywords: Overfitting and Underfitting in Machine Learning, Model Testing, Data Leakage Machine Learning, Testing a Model, Testing Machine Learning Models, How to Test AI Models
+---
+
+# A Guide on Model Testing
+
+## Introduction
+
+After [training](./model-training-tips.md) and [evaluating](./model-evaluation-insights.md) your model, it's time to test it. Model testing involves assessing how well it performs in real-world scenarios. Testing considers factors like accuracy, reliability, fairness, and how easy it is to understand the model's decisions. The goal is to make sure the model performs as intended, delivers the expected results, and fits into the [overall objective of your application](./defining-project-goals.md) or project.
+
+Model testing is quite similar to model evaluation, but they are two distinct [steps in a computer vision project](./steps-of-a-cv-project.md). Model evaluation involves metrics and plots to assess the model's accuracy. On the other hand, model testing checks if the model's learned behavior is the same as expectations. In this guide, we'll explore strategies for testing your computer vision models.
+
+## Model Testing Vs. Model Evaluation
+
+First, let's understand the difference between model evaluation and testing with an example.
+
+Suppose you have trained a computer vision model to recognize cats and dogs, and you want to deploy this model at a pet store to monitor the animals. During the model evaluation phase, you use a labeled dataset to calculate metrics like accuracy, precision, recall, and F1 score. For instance, the model might have an accuracy of 98% in distinguishing between cats and dogs in a given dataset.
+
+After evaluation, you test the model using images from a pet store to see how well it identifies cats and dogs in more varied and realistic conditions. You check if it can correctly label cats and dogs when they are moving, in different lighting conditions, or partially obscured by objects like toys or furniture. Model testing checks that the model behaves as expected outside the controlled evaluation environment.
+
+## Preparing for Model Testing
+
+Computer vision models learn from datasets by detecting patterns, making predictions, and evaluating their performance. These [datasets](./preprocessing_annotated_data.md) are usually divided into training and testing sets to simulate real-world conditions. Training data teaches the model while testing data verifies its accuracy.
+
+Here are two points to keep in mind before testing your model:
+
+- **Realistic Representation:** The previously unseen testing data should be similar to the data that the model will have to handle when deployed. This helps get a realistic understanding of the model's capabilities.
+- **Sufficient Size:** The size of the testing dataset needs to be large enough to provide reliable insights into how well the model performs.
+
+## Testing Your Computer Vision Model
+
+Here are the key steps to take to test your computer vision model and understand its performance.
+
+- **Run Predictions:** Use the model to make predictions on the test dataset.
+- **Compare Predictions:** Check how well the model's predictions match the actual labels (ground truth).
+- **Calculate Performance Metrics:** [Compute metrics](./yolo-performance-metrics.md) like accuracy, precision, recall, and F1 score to understand the model's strengths and weaknesses. Testing focuses on how these metrics reflect real-world performance.
+- **Visualize Results:** Create visual aids like confusion matrices and ROC curves. These help you spot specific areas where the model might not be performing well in practical applications.
+
+Next, the testing results can be analyzed:
+
+- **Misclassified Images:** Identify and review images that the model misclassified to understand where it is going wrong.
+- **Error Analysis:** Perform a thorough error analysis to understand the types of errors (e.g., false positives vs. false negatives) and their potential causes.
+- **Bias and Fairness:** Check for any biases in the model's predictions. Ensure that the model performs equally well across different subsets of the data, especially if it includes sensitive attributes like race, gender, or age.
+
+## Testing Your YOLOv8 Model
+
+To test your YOLOv8 model, you can use the validation mode. It's a straightforward way to understand the model's strengths and areas that need improvement. Also, you'll need to format your test dataset correctly for YOLOv8. For more details on how to use the validation mode, check out the [Model Validation](../modes/val.md) docs page.
+
+## Using YOLOv8 to Predict on Multiple Test Images
+
+If you want to test your trained YOLOv8 model on multiple images stored in a folder, you can easily do so in one go. Instead of using the validation mode, which is typically used to evaluate model performance on a validation set and provide detailed metrics, you might just want to see predictions on all images in your test set. For this, you can use the [prediction mode](../modes/predict.md).
+
+### Difference Between Validation and Prediction Modes
+
+- **[Validation Mode](../modes/val.md):** Used to evaluate the model's performance by comparing predictions against known labels (ground truth). It provides detailed metrics such as accuracy, precision, recall, and F1 score.
+- **[Prediction Mode](../modes/predict.md):** Used to run the model on new, unseen data to generate predictions. It does not provide detailed performance metrics but allows you to see how the model performs on real-world images.
+
+## Running YOLOv8 Predictions Without Custom Training
+
+If you are interested in testing the basic YOLOv8 model to understand whether it can be used for your application without custom training, you can use the prediction mode. While the model is pre-trained on datasets like COCO, running predictions on your own dataset can give you a quick sense of how well it might perform in your specific context.
+
+## Overfitting and Underfitting in Machine Learning
+
+When testing a machine learning model, especially in computer vision, it's important to watch out for overfitting and underfitting. These issues can significantly affect how well your model works with new data.
+
+### Overfitting
+
+Overfitting happens when your model learns the training data too well, including the noise and details that don't generalize to new data. In computer vision, this means your model might do great with training images but struggle with new ones.
+
+#### Signs of Overfitting
+
+- **High Training Accuracy, Low Validation Accuracy:** If your model performs very well on training data but poorly on validation or test data, it's likely overfitting.
+- **Visual Inspection:** Sometimes, you can see overfitting if your model is too sensitive to minor changes or irrelevant details in images.
+
+### Underfitting
+
+Underfitting occurs when your model can't capture the underlying patterns in the data. In computer vision, an underfitted model might not even recognize objects correctly in the training images.
+
+#### Signs of Underfitting
+
+- **Low Training Accuracy:** If your model can't achieve high accuracy on the training set, it might be underfitting.
+- **Visual Misclassification:** Consistent failure to recognize obvious features or objects suggests underfitting.
+
+### Balancing Overfitting and Underfitting
+
+The key is to find a balance between overfitting and underfitting. Ideally, a model should perform well on both training and validation datasets. Regularly monitoring your model's performance through metrics and visual inspections, along with applying the right strategies, can help you achieve the best results.
+
+
+
+
+
+## Data Leakage in Computer Vision and How to Avoid It
+
+While testing your model, something important to keep in mind is data leakage. Data leakage happens when information from outside the training dataset accidentally gets used to train the model. The model may seem very accurate during training, but it won't perform well on new, unseen data when data leakage occurs.
+
+### Why Data Leakage Happens
+
+Data leakage can be tricky to spot and often comes from hidden biases in the training data. Here are some common ways it can happen in computer vision:
+
+- **Camera Bias:** Different angles, lighting, shadows, and camera movements can introduce unwanted patterns.
+- **Overlay Bias:** Logos, timestamps, or other overlays in images can mislead the model.
+- **Font and Object Bias:** Specific fonts or objects that frequently appear in certain classes can skew the model's learning.
+- **Spatial Bias:** Imbalances in foreground-background, bounding box distributions, and object locations can affect training.
+- **Label and Domain Bias:** Incorrect labels or shifts in data types can lead to leakage.
+
+### Detecting Data Leakage
+
+To find data leakage, you can:
+
+- **Check Performance:** If the model's results are surprisingly good, it might be leaking.
+- **Look at Feature Importance:** If one feature is much more important than others, it could indicate leakage.
+- **Visual Inspection:** Double-check that the model's decisions make sense intuitively.
+- **Verify Data Separation:** Make sure data was divided correctly before any processing.
+
+### Avoiding Data Leakage
+
+To prevent data leakage, use a diverse dataset with images or videos from different cameras and environments. Carefully review your data and check that there are no hidden biases, such as all positive samples being taken at a specific time of day. Avoiding data leakage will help make your computer vision models more reliable and effective in real-world situations.
+
+## What Comes After Model Testing
+
+After testing your model, the next steps depend on the results. If your model performs well, you can deploy it into a real-world environment. If the results aren't satisfactory, you'll need to make improvements. This might involve analyzing errors, [gathering more data](./data-collection-and-annotation.md), improving data quality, [adjusting hyperparameters](./hyperparameter-tuning.md), and retraining the model.
+
+## Join the AI Conversation
+
+Becoming part of a community of computer vision enthusiasts can aid in solving problems and learning more efficiently. Here are some ways to connect, seek help, and share your thoughts.
+
+### Community Resources
+
+- **GitHub Issues:** Explore the [YOLOv8 GitHub repository](https://github.com/ultralytics/ultralytics/issues) and use the Issues tab to ask questions, report bugs, and suggest new features. The community and maintainers are very active and ready to help.
+- **Ultralytics Discord Server:** Join the [Ultralytics Discord server](https://ultralytics.com/discord/) to chat with other users and developers, get support, and share your experiences.
+
+### Official Documentation
+
+- **Ultralytics YOLOv8 Documentation:** Check out the [official YOLOv8 documentation](./index.md) for detailed guides and helpful tips on various computer vision projects.
+
+These resources will help you navigate challenges and remain updated on the latest trends and practices within the computer vision community.
+
+## In Summary
+
+Building trustworthy computer vision models relies on rigorous model testing. By testing the model with previously unseen data, we can analyze it and spot weaknesses like overfitting and data leakage. Addressing these issues before deployment helps the model perform well in real-world applications. It's important to remember that model testing is just as crucial as model evaluation in guaranteeing the model's long-term success and effectiveness.
+
+## FAQ
+
+### What are the key differences between model evaluation and model testing in computer vision?
+
+Model evaluation and model testing are distinct steps in a computer vision project. Model evaluation involves using a labeled dataset to compute metrics such as accuracy, precision, recall, and F1 score, providing insights into the model's performance with a controlled dataset. Model testing, on the other hand, assesses the model's performance in real-world scenarios by applying it to new, unseen data, ensuring the model's learned behavior aligns with expectations outside the evaluation environment. For a detailed guide, refer to the [steps in a computer vision project](./steps-of-a-cv-project.md).
+
+### How can I test my Ultralytics YOLOv8 model on multiple images?
+
+To test your Ultralytics YOLOv8 model on multiple images, you can use the [prediction mode](../modes/predict.md). This mode allows you to run the model on new, unseen data to generate predictions without providing detailed metrics. This is ideal for real-world performance testing on larger image sets stored in a folder. For evaluating performance metrics, use the [validation mode](../modes/val.md) instead.
+
+### What should I do if my computer vision model shows signs of overfitting or underfitting?
+
+To address **overfitting**:
+
+- Regularization techniques like dropout.
+- Increase the size of the training dataset.
+- Simplify the model architecture.
+
+To address **underfitting**:
+
+- Use a more complex model.
+- Provide more relevant features.
+- Increase training iterations or epochs.
+
+Review misclassified images, perform thorough error analysis, and regularly track performance metrics to maintain a balance. For more information on these concepts, explore our section on [Overfitting and Underfitting](#overfitting-and-underfitting-in-machine-learning).
+
+### How can I detect and avoid data leakage in computer vision?
+
+To detect data leakage:
+
+- Verify that the testing performance is not unusually high.
+- Check feature importance for unexpected insights.
+- Intuitively review model decisions.
+- Ensure correct data division before processing.
+
+To avoid data leakage:
+
+- Use diverse datasets with various environments.
+- Carefully review data for hidden biases.
+- Ensure no overlapping information between training and testing sets.
+
+For detailed strategies on preventing data leakage, refer to our section on [Data Leakage in Computer Vision](#data-leakage-in-computer-vision-and-how-to-avoid-it).
+
+### What steps should I take after testing my computer vision model?
+
+Post-testing, if the model performance meets the project goals, proceed with deployment. If the results are unsatisfactory, consider:
+
+- Error analysis.
+- Gathering more diverse and high-quality data.
+- Hyperparameter tuning.
+- Retraining the model.
+
+Gain insights from the [Model Testing Vs. Model Evaluation](#model-testing-vs-model-evaluation) section to refine and enhance model effectiveness in real-world applications.
+
+### How do I run YOLOv8 predictions without custom training?
+
+You can run predictions using the pre-trained YOLOv8 model on your dataset to see if it suits your application needs. Utilize the [prediction mode](../modes/predict.md) to get a quick sense of performance results without diving into custom training.
diff --git a/ultralytics/docs/en/guides/model-training-tips.md b/ultralytics/docs/en/guides/model-training-tips.md
new file mode 100644
index 0000000000000000000000000000000000000000..017f82b7cef1fcd7cfa113fdbda49e8714b7ab7d
--- /dev/null
+++ b/ultralytics/docs/en/guides/model-training-tips.md
@@ -0,0 +1,182 @@
+---
+comments: true
+description: Find best practices, optimization strategies, and troubleshooting advice for training computer vision models. Improve your model training efficiency and accuracy.
+keywords: Model Training Machine Learning, AI Model Training, Number of Epochs, How to Train a Model in Machine Learning, Machine Learning Best Practices, What is Model Training
+---
+
+# Machine Learning Best Practices and Tips for Model Training
+
+## Introduction
+
+One of the most important steps when working on a [computer vision project](./steps-of-a-cv-project.md) is model training. Before reaching this step, you need to [define your goals](./defining-project-goals.md) and [collect and annotate your data](./data-collection-and-annotation.md). After [preprocessing the data](./preprocessing_annotated_data.md) to make sure it is clean and consistent, you can move on to training your model.
+
+So, what is [model training](../modes/train.md)? Model training is the process of teaching your model to recognize visual patterns and make predictions based on your data. It directly impacts the performance and accuracy of your application. In this guide, we'll cover best practices, optimization techniques, and troubleshooting tips to help you train your computer vision models effectively.
+
+## How to Train a Machine Learning Model
+
+A computer vision model is trained by adjusting its internal parameters to minimize errors. Initially, the model is fed a large set of labeled images. It makes predictions about what is in these images, and the predictions are compared to the actual labels or contents to calculate errors. These errors show how far off the model's predictions are from the true values.
+
+During training, the model iteratively makes predictions, calculates errors, and updates its parameters through a process called backpropagation. In this process, the model adjusts its internal parameters (weights and biases) to reduce the errors. By repeating this cycle many times, the model gradually improves its accuracy. Over time, it learns to recognize complex patterns such as shapes, colors, and textures.
+
+
+
+
+
+This learning process makes it possible for the computer vision model to perform various [tasks](../tasks/index.md), including [object detection](../tasks/detect.md), [instance segmentation](../tasks/segment.md), and [image classification](../tasks/classify.md). The ultimate goal is to create a model that can generalize its learning to new, unseen images so that it can accurately understand visual data in real-world applications.
+
+Now that we know what is happening behind the scenes when we train a model, let's look at points to consider when training a model.
+
+## Training on Large Datasets
+
+There are a few different aspects to think about when you are planning on using a large dataset to train a model. For example, you can adjust the batch size, control the GPU utilization, choose to use multiscale training, etc. Let's walk through each of these options in detail.
+
+### Batch Size and GPU Utilization
+
+When training models on large datasets, efficiently utilizing your GPU is key. Batch size is an important factor. It is the number of data samples that a machine learning model processes in a single training iteration.
+Using the maximum batch size supported by your GPU, you can fully take advantage of its capabilities and reduce the time model training takes. However, you want to avoid running out of GPU memory. If you encounter memory errors, reduce the batch size incrementally until the model trains smoothly.
+
+With respect to YOLOv8, you can set the `batch_size` parameter in the [training configuration](../modes/train.md) to match your GPU capacity. Also, setting `batch=-1` in your training script will automatically determine the batch size that can be efficiently processed based on your device's capabilities. By fine-tuning the batch size, you can make the most of your GPU resources and improve the overall training process.
+
+### Subset Training
+
+Subset training is a smart strategy that involves training your model on a smaller set of data that represents the larger dataset. It can save time and resources, especially during initial model development and testing. If you are running short on time or experimenting with different model configurations, subset training is a good option.
+
+When it comes to YOLOv8, you can easily implement subset training by using the `fraction` parameter. This parameter lets you specify what fraction of your dataset to use for training. For example, setting `fraction=0.1` will train your model on 10% of the data. You can use this technique for quick iterations and tuning your model before committing to training a model using a full dataset. Subset training helps you make rapid progress and identify potential issues early on.
+
+### Multi-scale Training
+
+Multiscale training is a technique that improves your model's ability to generalize by training it on images of varying sizes. Your model can learn to detect objects at different scales and distances and become more robust.
+
+For example, when you train YOLOv8, you can enable multiscale training by setting the `scale` parameter. This parameter adjusts the size of training images by a specified factor, simulating objects at different distances. For example, setting `scale=0.5` will reduce the image size by half, while `scale=2.0` will double it. Configuring this parameter allows your model to experience a variety of image scales and improve its detection capabilities across different object sizes and scenarios.
+
+### Caching
+
+Caching is an important technique to improve the efficiency of training machine learning models. By storing preprocessed images in memory, caching reduces the time the GPU spends waiting for data to be loaded from the disk. The model can continuously receive data without delays caused by disk I/O operations.
+
+Caching can be controlled when training YOLOv8 using the `cache` parameter:
+
+- _`cache=True`_: Stores dataset images in RAM, providing the fastest access speed but at the cost of increased memory usage.
+- _`cache='disk'`_: Stores the images on disk, slower than RAM but faster than loading fresh data each time.
+- _`cache=False`_: Disables caching, relying entirely on disk I/O, which is the slowest option.
+
+### Mixed Precision Training
+
+Mixed precision training uses both 16-bit (FP16) and 32-bit (FP32) floating-point types. The strengths of both FP16 and FP32 are leveraged by using FP16 for faster computation and FP32 to maintain precision where needed. Most of the neural network's operations are done in FP16 to benefit from faster computation and lower memory usage. However, a master copy of the model's weights is kept in FP32 to ensure accuracy during the weight update steps. You can handle larger models or larger batch sizes within the same hardware constraints.
+
+
+
+
+
+To implement mixed precision training, you'll need to modify your training scripts and ensure your hardware (like GPUs) supports it. Many modern deep learning frameworks, such as Tensorflow, offer built-in support for mixed precision.
+
+Mixed precision training is straightforward when working with YOLOv8. You can use the `amp` flag in your training configuration. Setting `amp=True` enables Automatic Mixed Precision (AMP) training. Mixed precision training is a simple yet effective way to optimize your model training process.
+
+### Pre-trained Weights
+
+Using pretrained weights is a smart way to speed up your model's training process. Pretrained weights come from models already trained on large datasets, giving your model a head start. Transfer learning adapts pretrained models to new, related tasks. Fine-tuning a pre-trained model involves starting with these weights and then continuing training on your specific dataset. This method of training results in faster training times and often better performance because the model starts with a solid understanding of basic features.
+
+The `pretrained` parameter makes transfer learning easy with YOLOv8. Setting `pretrained=True` will use default pre-trained weights, or you can specify a path to a custom pre-trained model. Using pre-trained weights and transfer learning effectively boosts your model's capabilities and reduces training costs.
+
+### Other Techniques to Consider When Handling a Large Dataset
+
+There are a couple of other techniques to consider when handling a large dataset:
+
+- **Learning Rate Schedulers**: Implementing learning rate schedulers dynamically adjusts the learning rate during training. A well-tuned learning rate can prevent the model from overshooting minima and improve stability. When training YOLOv8, the `lrf` parameter helps manage learning rate scheduling by setting the final learning rate as a fraction of the initial rate.
+- **Distributed Training**: For handling large datasets, distributed training can be a game-changer. You can reduce the training time by spreading the training workload across multiple GPUs or machines.
+
+## The Number of Epochs To Train For
+
+When training a model, an epoch refers to one complete pass through the entire training dataset. During an epoch, the model processes each example in the training set once and updates its parameters based on the learning algorithm. Multiple epochs are usually needed to allow the model to learn and refine its parameters over time.
+
+A common question that comes up is how to determine the number of epochs to train the model for. A good starting point is 300 epochs. If the model overfits early, you can reduce the number of epochs. If overfitting does not occur after 300 epochs, you can extend the training to 600, 1200, or more epochs.
+
+However, the ideal number of epochs can vary based on your dataset's size and project goals. Larger datasets might require more epochs for the model to learn effectively, while smaller datasets might need fewer epochs to avoid overfitting. With respect to YOLOv8, you can set the `epochs` parameter in your training script.
+
+## Early Stopping
+
+Early stopping is a valuable technique for optimizing model training. By monitoring validation performance, you can halt training once the model stops improving. You can save computational resources and prevent overfitting.
+
+The process involves setting a patience parameter that determines how many epochs to wait for an improvement in validation metrics before stopping training. If the model's performance does not improve within these epochs, training is stopped to avoid wasting time and resources.
+
+
+
+
+
+For YOLOv8, you can enable early stopping by setting the patience parameter in your training configuration. For example, `patience=5` means training will stop if there's no improvement in validation metrics for 5 consecutive epochs. Using this method ensures the training process remains efficient and achieves optimal performance without excessive computation.
+
+## Choosing Between Cloud and Local Training
+
+There are two options for training your model: cloud training and local training.
+
+Cloud training offers scalability and powerful hardware and is ideal for handling large datasets and complex models. Platforms like Google Cloud, AWS, and Azure provide on-demand access to high-performance GPUs and TPUs, speeding up training times and enabling experiments with larger models. However, cloud training can be expensive, especially for long periods, and data transfer can add to costs and latency.
+
+Local training provides greater control and customization, letting you tailor your environment to specific needs and avoid ongoing cloud costs. It can be more economical for long-term projects, and since your data stays on-premises, it's more secure. However, local hardware may have resource limitations and require maintenance, which can lead to longer training times for large models.
+
+## Selecting an Optimizer
+
+An optimizer is an algorithm that adjusts the weights of your neural network to minimize the loss function, which measures how well the model is performing. In simpler terms, the optimizer helps the model learn by tweaking its parameters to reduce errors. Choosing the right optimizer directly affects how quickly and accurately the model learns.
+
+You can also fine-tune optimizer parameters to improve model performance. Adjusting the learning rate sets the size of the steps when updating parameters. For stability, you might start with a moderate learning rate and gradually decrease it over time to improve long-term learning. Additionally, setting the momentum determines how much influence past updates have on current updates. A common value for momentum is around 0.9. It generally provides a good balance.
+
+### Common Optimizers
+
+Different optimizers have various strengths and weaknesses. Let's take a glimpse at a few common optimizers.
+
+- **SGD (Stochastic Gradient Descent)**:
+
+ - Updates model parameters using the gradient of the loss function with respect to the parameters.
+ - Simple and efficient but can be slow to converge and might get stuck in local minima.
+
+- **Adam (Adaptive Moment Estimation)**:
+
+ - Combines the benefits of both SGD with momentum and RMSProp.
+ - Adjusts the learning rate for each parameter based on estimates of the first and second moments of the gradients.
+ - Well-suited for noisy data and sparse gradients.
+ - Efficient and generally requires less tuning, making it a recommended optimizer for YOLOv8.
+
+- **RMSProp (Root Mean Square Propagation)**:
+ - Adjusts the learning rate for each parameter by dividing the gradient by a running average of the magnitudes of recent gradients.
+ - Helps in handling the vanishing gradient problem and is effective for recurrent neural networks.
+
+For YOLOv8, the `optimizer` parameter lets you choose from various optimizers, including SGD, Adam, AdamW, NAdam, RAdam, and RMSProp, or you can set it to `auto` for automatic selection based on model configuration.
+
+## Connecting with the Community
+
+Being part of a community of computer vision enthusiasts can help you solve problems and learn faster. Here are some ways to connect, get help, and share ideas.
+
+### Community Resources
+
+- **GitHub Issues:** Visit the [YOLOv8 GitHub repository](https://github.com/ultralytics/ultralytics/issues) and use the Issues tab to ask questions, report bugs, and suggest new features. The community and maintainers are very active and ready to help.
+- **Ultralytics Discord Server:** Join the [Ultralytics Discord server](https://ultralytics.com/discord/) to chat with other users and developers, get support, and share your experiences.
+
+### Official Documentation
+
+- **Ultralytics YOLOv8 Documentation:** Check out the [official YOLOv8 documentation](./index.md) for detailed guides and helpful tips on various computer vision projects.
+
+Using these resources will help you solve challenges and stay up-to-date with the latest trends and practices in the computer vision community.
+
+## Key Takeaways
+
+Training computer vision models involves following good practices, optimizing your strategies, and solving problems as they arise. Techniques like adjusting batch sizes, mixed precision training, and starting with pre-trained weights can make your models work better and train faster. Methods like subset training and early stopping help you save time and resources. Staying connected with the community and keeping up with new trends will help you keep improving your model training skills.
+
+## FAQ
+
+### How can I improve GPU utilization when training a large dataset with Ultralytics YOLO?
+
+To improve GPU utilization, set the `batch_size` parameter in your training configuration to the maximum size supported by your GPU. This ensures that you make full use of the GPU's capabilities, reducing training time. If you encounter memory errors, incrementally reduce the batch size until training runs smoothly. For YOLOv8, setting `batch=-1` in your training script will automatically determine the optimal batch size for efficient processing. For further information, refer to the [training configuration](../modes/train.md).
+
+### What is mixed precision training, and how do I enable it in YOLOv8?
+
+Mixed precision training utilizes both 16-bit (FP16) and 32-bit (FP32) floating-point types to balance computational speed and precision. This approach speeds up training and reduces memory usage without sacrificing model accuracy. To enable mixed precision training in YOLOv8, set the `amp` parameter to `True` in your training configuration. This activates Automatic Mixed Precision (AMP) training. For more details on this optimization technique, see the [training configuration](../modes/train.md).
+
+### How does multiscale training enhance YOLOv8 model performance?
+
+Multiscale training enhances model performance by training on images of varying sizes, allowing the model to better generalize across different scales and distances. In YOLOv8, you can enable multiscale training by setting the `scale` parameter in the training configuration. For example, `scale=0.5` reduces the image size by half, while `scale=2.0` doubles it. This technique simulates objects at different distances, making the model more robust across various scenarios. For settings and more details, check out the [training configuration](../modes/train.md).
+
+### How can I use pre-trained weights to speed up training in YOLOv8?
+
+Using pre-trained weights can significantly reduce training times and improve model performance by starting from a model that already understands basic features. In YOLOv8, you can set the `pretrained` parameter to `True` or specify a path to custom pre-trained weights in your training configuration. This approach, known as transfer learning, leverages knowledge from large datasets to adapt to your specific task. Learn more about pre-trained weights and their advantages [here](../modes/train.md).
+
+### What is the recommended number of epochs for training a model, and how do I set this in YOLOv8?
+
+The number of epochs refers to the complete passes through the training dataset during model training. A typical starting point is 300 epochs. If your model overfits early, you can reduce the number. Alternatively, if overfitting isn't observed, you might extend training to 600, 1200, or more epochs. To set this in YOLOv8, use the `epochs` parameter in your training script. For additional advice on determining the ideal number of epochs, refer to this section on [number of epochs](#the-number-of-epochs-to-train-for).
diff --git a/ultralytics/docs/en/guides/nvidia-jetson.md b/ultralytics/docs/en/guides/nvidia-jetson.md
new file mode 100644
index 0000000000000000000000000000000000000000..caf8d75fdec5c8a300ff0cd8cd371159c34f237c
--- /dev/null
+++ b/ultralytics/docs/en/guides/nvidia-jetson.md
@@ -0,0 +1,466 @@
+---
+comments: true
+description: Learn to deploy Ultralytics YOLOv8 on NVIDIA Jetson devices with our detailed guide. Explore performance benchmarks and maximize AI capabilities.
+keywords: Ultralytics, YOLOv8, NVIDIA Jetson, JetPack, AI deployment, performance benchmarks, embedded systems, deep learning, TensorRT, computer vision
+---
+
+# Quick Start Guide: NVIDIA Jetson with Ultralytics YOLOv8
+
+This comprehensive guide provides a detailed walkthrough for deploying Ultralytics YOLOv8 on [NVIDIA Jetson](https://www.nvidia.com/en-us/autonomous-machines/embedded-systems/) devices. Additionally, it showcases performance benchmarks to demonstrate the capabilities of YOLOv8 on these small and powerful devices.
+
+
+
+
+
+ Watch: How to Setup NVIDIA Jetson with Ultralytics YOLOv8
+
+
+
+
+!!! Note
+
+ This guide has been tested with both [Seeed Studio reComputer J4012](https://www.seeedstudio.com/reComputer-J4012-p-5586.html) which is based on NVIDIA Jetson Orin NX 16GB running the latest stable JetPack release of [JP6.0](https://developer.nvidia.com/embedded/jetpack-sdk-60), JetPack release of [JP5.1.3](https://developer.nvidia.com/embedded/jetpack-sdk-513) and [Seeed Studio reComputer J1020 v2](https://www.seeedstudio.com/reComputer-J1020-v2-p-5498.html) which is based on NVIDIA Jetson Nano 4GB running JetPack release of [JP4.6.1](https://developer.nvidia.com/embedded/jetpack-sdk-461). It is expected to work across all the NVIDIA Jetson hardware lineup including latest and legacy.
+
+## What is NVIDIA Jetson?
+
+NVIDIA Jetson is a series of embedded computing boards designed to bring accelerated AI (artificial intelligence) computing to edge devices. These compact and powerful devices are built around NVIDIA's GPU architecture and are capable of running complex AI algorithms and deep learning models directly on the device, without needing to rely on cloud computing resources. Jetson boards are often used in robotics, autonomous vehicles, industrial automation, and other applications where AI inference needs to be performed locally with low latency and high efficiency. Additionally, these boards are based on the ARM64 architecture and runs on lower power compared to traditional GPU computing devices.
+
+## NVIDIA Jetson Series Comparison
+
+[Jetson Orin](https://www.nvidia.com/en-us/autonomous-machines/embedded-systems/jetson-orin/) is the latest iteration of the NVIDIA Jetson family based on NVIDIA Ampere architecture which brings drastically improved AI performance when compared to the previous generations. Below table compared few of the Jetson devices in the ecosystem.
+
+| | Jetson AGX Orin 64GB | Jetson Orin NX 16GB | Jetson Orin Nano 8GB | Jetson AGX Xavier | Jetson Xavier NX | Jetson Nano |
+| ----------------- | ----------------------------------------------------------------- | ---------------------------------------------------------------- | ------------------------------------------------------------- | ----------------------------------------------------------- | ------------------------------------------------------------- | --------------------------------------------- |
+| AI Performance | 275 TOPS | 100 TOPS | 40 TOPs | 32 TOPS | 21 TOPS | 472 GFLOPS |
+| GPU | 2048-core NVIDIA Ampere architecture GPU with 64 Tensor Cores | 1024-core NVIDIA Ampere architecture GPU with 32 Tensor Cores | 1024-core NVIDIA Ampere architecture GPU with 32 Tensor Cores | 512-core NVIDIA Volta architecture GPU with 64 Tensor Cores | 384-core NVIDIA Volta™ architecture GPU with 48 Tensor Cores | 128-core NVIDIA Maxwell™ architecture GPU |
+| GPU Max Frequency | 1.3 GHz | 918 MHz | 625 MHz | 1377 MHz | 1100 MHz | 921MHz |
+| CPU | 12-core NVIDIA Arm® Cortex A78AE v8.2 64-bit CPU 3MB L2 + 6MB L3 | 8-core NVIDIA Arm® Cortex A78AE v8.2 64-bit CPU 2MB L2 + 4MB L3 | 6-core Arm® Cortex®-A78AE v8.2 64-bit CPU 1.5MB L2 + 4MB L3 | 8-core NVIDIA Carmel Arm®v8.2 64-bit CPU 8MB L2 + 4MB L3 | 6-core NVIDIA Carmel Arm®v8.2 64-bit CPU 6MB L2 + 4MB L3 | Quad-Core Arm® Cortex®-A57 MPCore processor |
+| CPU Max Frequency | 2.2 GHz | 2.0 GHz | 1.5 GHz | 2.2 GHz | 1.9 GHz | 1.43GHz |
+| Memory | 64GB 256-bit LPDDR5 204.8GB/s | 16GB 128-bit LPDDR5 102.4GB/s | 8GB 128-bit LPDDR5 68 GB/s | 32GB 256-bit LPDDR4x 136.5GB/s | 8GB 128-bit LPDDR4x 59.7GB/s | 4GB 64-bit LPDDR4 25.6GB/s" |
+
+For a more detailed comparison table, please visit the **Technical Specifications** section of [official NVIDIA Jetson page](https://developer.nvidia.com/embedded/jetson-modules).
+
+## What is NVIDIA JetPack?
+
+[NVIDIA JetPack SDK](https://developer.nvidia.com/embedded/jetpack) powering the Jetson modules is the most comprehensive solution and provides full development environment for building end-to-end accelerated AI applications and shortens time to market. JetPack includes Jetson Linux with bootloader, Linux kernel, Ubuntu desktop environment, and a complete set of libraries for acceleration of GPU computing, multimedia, graphics, and computer vision. It also includes samples, documentation, and developer tools for both host computer and developer kit, and supports higher level SDKs such as DeepStream for streaming video analytics, Isaac for robotics, and Riva for conversational AI.
+
+## Flash JetPack to NVIDIA Jetson
+
+The first step after getting your hands on an NVIDIA Jetson device is to flash NVIDIA JetPack to the device. There are several different way of flashing NVIDIA Jetson devices.
+
+1. If you own an official NVIDIA Development Kit such as the Jetson Orin Nano Developer Kit, you can [download an image and prepare an SD card with JetPack for booting the device](https://developer.nvidia.com/embedded/learn/get-started-jetson-orin-nano-devkit).
+2. If you own any other NVIDIA Development Kit, you can [flash JetPack to the device using SDK Manager](https://docs.nvidia.com/sdk-manager/install-with-sdkm-jetson/index.html).
+3. If you own a Seeed Studio reComputer J4012 device, you can [flash JetPack to the included SSD](https://wiki.seeedstudio.com/reComputer_J4012_Flash_Jetpack) and if you own a Seeed Studio reComputer J1020 v2 device, you can [flash JetPack to the eMMC/ SSD](https://wiki.seeedstudio.com/reComputer_J2021_J202_Flash_Jetpack).
+4. If you own any other third party device powered by the NVIDIA Jetson module, it is recommended to follow [command-line flashing](https://docs.nvidia.com/jetson/archives/r35.5.0/DeveloperGuide/IN/QuickStart.html).
+
+!!! Note
+
+ For methods 3 and 4 above, after flashing the system and booting the device, please enter "sudo apt update && sudo apt install nvidia-jetpack -y" on the device terminal to install all the remaining JetPack components needed.
+
+## JetPack Support Based on Jetson Device
+
+The below table highlights NVIDIA JetPack versions supported by different NVIDIA Jetson devices.
+
+| | JetPack 4 | JetPack 5 | JetPack 6 |
+| ----------------- | --------- | --------- | --------- |
+| Jetson Nano | ✅ | ❌ | ❌ |
+| Jetson TX2 | ✅ | ❌ | ❌ |
+| Jetson Xavier NX | ✅ | ✅ | ❌ |
+| Jetson AGX Xavier | ✅ | ✅ | ❌ |
+| Jetson AGX Orin | ❌ | ✅ | ✅ |
+| Jetson Orin NX | ❌ | ✅ | ✅ |
+| Jetson Orin Nano | ❌ | ✅ | ✅ |
+
+## Quick Start with Docker
+
+The fastest way to get started with Ultralytics YOLOv8 on NVIDIA Jetson is to run with pre-built docker images for Jetson. Refer to the table above and choose the JetPack version according to the Jetson device you own.
+
+=== "JetPack 4"
+
+ ```bash
+ t=ultralytics/ultralytics:latest-jetson-jetpack4
+ sudo docker pull $t && sudo docker run -it --ipc=host --runtime=nvidia $t
+ ```
+
+=== "JetPack 5"
+
+ ```bash
+ t=ultralytics/ultralytics:latest-jetson-jetpack5
+ sudo docker pull $t && sudo docker run -it --ipc=host --runtime=nvidia $t
+ ```
+
+=== "JetPack 6"
+
+ ```bash
+ t=ultralytics/ultralytics:latest-jetson-jetpack6
+ sudo docker pull $t && sudo docker run -it --ipc=host --runtime=nvidia $t
+ ```
+
+After this is done, skip to [Use TensorRT on NVIDIA Jetson section](#use-tensorrt-on-nvidia-jetson).
+
+## Start with Native Installation
+
+For a native installation without Docker, please refer to the steps below.
+
+### Run on JetPack 6.x
+
+#### Install Ultralytics Package
+
+Here we will install Ultralytics package on the Jetson with optional dependencies so that we can export the PyTorch models to other different formats. We will mainly focus on [NVIDIA TensorRT exports](../integrations/tensorrt.md) because TensorRT will make sure we can get the maximum performance out of the Jetson devices.
+
+1. Update packages list, install pip and upgrade to latest
+
+ ```bash
+ sudo apt update
+ sudo apt install python3-pip -y
+ pip install -U pip
+ ```
+
+2. Install `ultralytics` pip package with optional dependencies
+
+ ```bash
+ pip install ultralytics[export]
+ ```
+
+3. Reboot the device
+
+ ```bash
+ sudo reboot
+ ```
+
+#### Install PyTorch and Torchvision
+
+The above ultralytics installation will install Torch and Torchvision. However, these 2 packages installed via pip are not compatible to run on Jetson platform which is based on ARM64 architecture. Therefore, we need to manually install pre-built PyTorch pip wheel and compile/ install Torchvision from source.
+
+Install `torch 2.3.0` and `torchvision 0.18` according to JP6.0
+
+```bash
+sudo apt-get install libopenmpi-dev libopenblas-base libomp-dev -y
+pip install https://github.com/ultralytics/assets/releases/download/v0.0.0/torch-2.3.0-cp310-cp310-linux_aarch64.whl
+pip install https://github.com/ultralytics/assets/releases/download/v0.0.0/torchvision-0.18.0a0+6043bc2-cp310-cp310-linux_aarch64.whl
+```
+
+Visit the [PyTorch for Jetson page](https://forums.developer.nvidia.com/t/pytorch-for-jetson/72048) to access all different versions of PyTorch for different JetPack versions. For a more detailed list on the PyTorch, Torchvision compatibility, visit the [PyTorch and Torchvision compatibility page](https://github.com/pytorch/vision).
+
+#### Install `onnxruntime-gpu`
+
+The [onnxruntime-gpu](https://pypi.org/project/onnxruntime-gpu/) package hosted in PyPI does not have `aarch64` binaries for the Jetson. So we need to manually install this package. This package is needed for some of the exports.
+
+All different `onnxruntime-gpu` packages corresponding to different JetPack and Python versions are listed [here](https://elinux.org/Jetson_Zoo#ONNX_Runtime). However, here we will download and install `onnxruntime-gpu 1.18.0` with `Python3.10` support.
+
+```bash
+wget https://nvidia.box.com/shared/static/48dtuob7meiw6ebgfsfqakc9vse62sg4.whl -O onnxruntime_gpu-1.18.0-cp310-cp310-linux_aarch64.whl
+pip install onnxruntime_gpu-1.18.0-cp310-cp310-linux_aarch64.whl
+```
+
+!!! Note
+
+ `onnxruntime-gpu` will automatically revert back the numpy version to latest. So we need to reinstall numpy to `1.23.5` to fix an issue by executing:
+
+ `pip install numpy==1.23.5`
+
+### Run on JetPack 5.x
+
+#### Install Ultralytics Package
+
+Here we will install Ultralytics package on the Jetson with optional dependencies so that we can export the PyTorch models to other different formats. We will mainly focus on [NVIDIA TensorRT exports](../integrations/tensorrt.md) because TensorRT will make sure we can get the maximum performance out of the Jetson devices.
+
+1. Update packages list, install pip and upgrade to latest
+
+ ```bash
+ sudo apt update
+ sudo apt install python3-pip -y
+ pip install -U pip
+ ```
+
+2. Install `ultralytics` pip package with optional dependencies
+
+ ```bash
+ pip install ultralytics[export]
+ ```
+
+3. Reboot the device
+
+ ```bash
+ sudo reboot
+ ```
+
+#### Install PyTorch and Torchvision
+
+The above ultralytics installation will install Torch and Torchvision. However, these 2 packages installed via pip are not compatible to run on Jetson platform which is based on ARM64 architecture. Therefore, we need to manually install pre-built PyTorch pip wheel and compile/ install Torchvision from source.
+
+1. Uninstall currently installed PyTorch and Torchvision
+
+ ```bash
+ pip uninstall torch torchvision
+ ```
+
+2. Install PyTorch 2.1.0 according to JP5.1.3
+
+ ```bash
+ sudo apt-get install -y libopenblas-base libopenmpi-dev
+ wget https://developer.download.nvidia.com/compute/redist/jp/v512/pytorch/torch-2.1.0a0+41361538.nv23.06-cp38-cp38-linux_aarch64.whl -O torch-2.1.0a0+41361538.nv23.06-cp38-cp38-linux_aarch64.whl
+ pip install torch-2.1.0a0+41361538.nv23.06-cp38-cp38-linux_aarch64.whl
+ ```
+
+3. Install Torchvision v0.16.2 according to PyTorch v2.1.0
+
+ ```bash
+ sudo apt install -y libjpeg-dev zlib1g-dev
+ git clone https://github.com/pytorch/vision torchvision
+ cd torchvision
+ git checkout v0.16.2
+ python3 setup.py install --user
+ ```
+
+Visit the [PyTorch for Jetson page](https://forums.developer.nvidia.com/t/pytorch-for-jetson/72048) to access all different versions of PyTorch for different JetPack versions. For a more detailed list on the PyTorch, Torchvision compatibility, visit the [PyTorch and Torchvision compatibility page](https://github.com/pytorch/vision).
+
+#### Install `onnxruntime-gpu`
+
+The [onnxruntime-gpu](https://pypi.org/project/onnxruntime-gpu/) package hosted in PyPI does not have `aarch64` binaries for the Jetson. So we need to manually install this package. This package is needed for some of the exports.
+
+All different `onnxruntime-gpu` packages corresponding to different JetPack and Python versions are listed [here](https://elinux.org/Jetson_Zoo#ONNX_Runtime). However, here we will download and install `onnxruntime-gpu 1.17.0` with `Python3.8` support.
+
+```bash
+wget https://nvidia.box.com/shared/static/zostg6agm00fb6t5uisw51qi6kpcuwzd.whl -O onnxruntime_gpu-1.17.0-cp38-cp38-linux_aarch64.whl
+pip install onnxruntime_gpu-1.17.0-cp38-cp38-linux_aarch64.whl
+```
+
+!!! Note
+
+ `onnxruntime-gpu` will automatically revert back the numpy version to latest. So we need to reinstall numpy to `1.23.5` to fix an issue by executing:
+
+ `pip install numpy==1.23.5`
+
+## Use TensorRT on NVIDIA Jetson
+
+Out of all the model export formats supported by Ultralytics, TensorRT delivers the best inference performance when working with NVIDIA Jetson devices and our recommendation is to use TensorRT with Jetson. We also have a detailed document on TensorRT [here](../integrations/tensorrt.md).
+
+## Convert Model to TensorRT and Run Inference
+
+The YOLOv8n model in PyTorch format is converted to TensorRT to run inference with the exported model.
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a YOLOv8n PyTorch model
+ model = YOLO("yolov8n.pt")
+
+ # Export the model
+ model.export(format="engine") # creates 'yolov8n.engine'
+
+ # Load the exported TensorRT model
+ trt_model = YOLO("yolov8n.engine")
+
+ # Run inference
+ results = trt_model("https://ultralytics.com/images/bus.jpg")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Export a YOLOv8n PyTorch model to TensorRT format
+ yolo export model=yolov8n.pt format=engine # creates 'yolov8n.engine'
+
+ # Run inference with the exported model
+ yolo predict model=yolov8n.engine source='https://ultralytics.com/images/bus.jpg'
+ ```
+
+!!! Note
+
+ Visit the [Export page](../modes/export.md#arguments) to access additional arguments when exporting models to different model formats
+
+## NVIDIA Jetson Orin YOLOv8 Benchmarks
+
+YOLOv8 benchmarks were run by the Ultralytics team on 10 different model formats measuring speed and accuracy: PyTorch, TorchScript, ONNX, OpenVINO, TensorRT, TF SavedModel, TF GraphDef, TF Lite, PaddlePaddle, NCNN. Benchmarks were run on Seeed Studio reComputer J4012 powered by Jetson Orin NX 16GB device at FP32 precision with default input image size of 640.
+
+### Comparison Chart
+
+Even though all model exports are working with NVIDIA Jetson, we have only included **PyTorch, TorchScript, TensorRT** for the comparison chart below because, they make use of the GPU on the Jetson and are guaranteed to produce the best results. All the other exports only utilize the CPU and the performance is not as good as the above three. You can find benchmarks for all exports in the section after this chart.
+
+
+
+
+
+### Detailed Comparison Table
+
+The below table represents the benchmark results for five different models (YOLOv8n, YOLOv8s, YOLOv8m, YOLOv8l, YOLOv8x) across ten different formats (PyTorch, TorchScript, ONNX, OpenVINO, TensorRT, TF SavedModel, TF GraphDef, TF Lite, PaddlePaddle, NCNN), giving us the status, size, mAP50-95(B) metric, and inference time for each combination.
+
+!!! Performance
+
+ === "YOLOv8n"
+
+ | Format | Status | Size on disk (MB) | mAP50-95(B) | Inference time (ms/im) |
+ |---------------|--------|-----------|-------------|------------------------|
+ | PyTorch | ✅ | 6.2 | 0.6381 | 14.3 |
+ | TorchScript | ✅ | 12.4 | 0.6117 | 13.3 |
+ | ONNX | ✅ | 12.2 | 0.6092 | 70.6 |
+ | OpenVINO | ✅ | 12.3 | 0.6092 | 104.2 |
+ | TensorRT | ✅ | 13.6 | 0.6117 | 8.9 |
+ | TF SavedModel | ✅ | 30.6 | 0.6092 | 141.74 |
+ | TF GraphDef | ✅ | 12.3 | 0.6092 | 199.93 |
+ | TF Lite | ✅ | 12.3 | 0.6092 | 349.18 |
+ | PaddlePaddle | ✅ | 24.4 | 0.6030 | 555 |
+ | NCNN | ✅ | 12.2 | 0.6092 | 32 |
+
+ === "YOLOv8s"
+
+ | Format | Status | Size on disk (MB) | mAP50-95(B) | Inference time (ms/im) |
+ |---------------|--------|-----------|-------------|------------------------|
+ | PyTorch | ✅ | 21.5 | 0.6967 | 18 |
+ | TorchScript | ✅ | 43.0 | 0.7136 | 23.81 |
+ | ONNX | ✅ | 42.8 | 0.7136 | 185.55 |
+ | OpenVINO | ✅ | 42.9 | 0.7136 | 243.97 |
+ | TensorRT | ✅ | 44.0 | 0.7136 | 14.82 |
+ | TF SavedModel | ✅ | 107 | 0.7136 | 260.03 |
+ | TF GraphDef | ✅ | 42.8 | 0.7136 | 423.4 |
+ | TF Lite | ✅ | 42.8 | 0.7136 | 1046.64 |
+ | PaddlePaddle | ✅ | 85.5 | 0.7140 | 1464 |
+ | NCNN | ✅ | 42.7 | 0.7200 | 63 |
+
+ === "YOLOv8m"
+
+ | Format | Status | Size on disk (MB) | mAP50-95(B) | Inference time (ms/im) |
+ |---------------|--------|-----------|-------------|------------------------|
+ | PyTorch | ✅ | 49.7 | 0.7370 | 36.4 |
+ | TorchScript | ✅ | 99.2 | 0.7285 | 53.58 |
+ | ONNX | ✅ | 99 | 0.7280 | 452.09 |
+ | OpenVINO | ✅ | 99.1 | 0.7280 | 544.36 |
+ | TensorRT | ✅ | 100.3 | 0.7285 | 33.21 |
+ | TF SavedModel | ✅ | 247.5 | 0.7280 | 543.65 |
+ | TF GraphDef | ✅ | 99 | 0.7280 | 906.63 |
+ | TF Lite | ✅ | 99 | 0.7280 | 2758.08 |
+ | PaddlePaddle | ✅ | 197.9 | 0.7280 | 3678 |
+ | NCNN | ✅ | 98.9 | 0.7260 | 135 |
+
+ === "YOLOv8l"
+
+ | Format | Status | Size on disk (MB) | mAP50-95(B) | Inference time (ms/im) |
+ |---------------|--------|-----------|-------------|------------------------|
+ | PyTorch | ✅ | 83.7 | 0.7768 | 61.3 |
+ | TorchScript | ✅ | 167.2 | 0.7554 | 87.9 |
+ | ONNX | ✅ | 166.8 | 0.7551 | 852.29 |
+ | OpenVINO | ✅ | 167 | 0.7551 | 1012.6 |
+ | TensorRT | ✅ | 168.4 | 0.7554 | 51.23 |
+ | TF SavedModel | ✅ | 417.2 | 0.7551 | 990.45 |
+ | TF GraphDef | ✅ | 166.9 | 0.7551 | 1649.86 |
+ | TF Lite | ✅ | 166.9 | 0.7551 | 5652.37 |
+ | PaddlePaddle | ✅ | 333.6 | 0.7551 | 7114.67 |
+ | NCNN | ✅ | 166.8 | 0.7685 | 231.9 |
+
+ === "YOLOv8x"
+
+ | Format | Status | Size on disk (MB) | mAP50-95(B) | Inference time (ms/im) |
+ |---------------|--------|-----------|-------------|------------------------|
+ | PyTorch | ✅ | 130.5 | 0.7759 | 93 |
+ | TorchScript | ✅ | 260.7 | 0.7472 | 135.1 |
+ | ONNX | ✅ | 260.4 | 0.7479 | 1296.13 |
+ | OpenVINO | ✅ | 260.6 | 0.7479 | 1502.15 |
+ | TensorRT | ✅ | 261.8 | 0.7469 | 84.53 |
+ | TF SavedModel | ✅ | 651.1 | 0.7479 | 1451.76 |
+ | TF GraphDef | ✅ | 260.5 | 0.7479 | 4029.36 |
+ | TF Lite | ✅ | 260.4 | 0.7479 | 8772.86 |
+ | PaddlePaddle | ✅ | 520.8 | 0.7479 | 10619.53 |
+ | NCNN | ✅ | 260.4 | 0.7646 | 376.38 |
+
+[Explore more benchmarking efforts by Seeed Studio](https://www.seeedstudio.com/blog/2023/03/30/yolov8-performance-benchmarks-on-nvidia-jetson-devices) running on different versions of NVIDIA Jetson hardware.
+
+## Reproduce Our Results
+
+To reproduce the above Ultralytics benchmarks on all export [formats](../modes/export.md) run this code:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a YOLOv8n PyTorch model
+ model = YOLO("yolov8n.pt")
+
+ # Benchmark YOLOv8n speed and accuracy on the COCO8 dataset for all all export formats
+ results = model.benchmarks(data="coco8.yaml", imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Benchmark YOLOv8n speed and accuracy on the COCO8 dataset for all all export formats
+ yolo benchmark model=yolov8n.pt data=coco8.yaml imgsz=640
+ ```
+
+ Note that benchmarking results might vary based on the exact hardware and software configuration of a system, as well as the current workload of the system at the time the benchmarks are run. For the most reliable results use a dataset with a large number of images, i.e. `data='coco8.yaml' (4 val images), or `data='coco.yaml'` (5000 val images).
+
+## Best Practices when using NVIDIA Jetson
+
+When using NVIDIA Jetson, there are a couple of best practices to follow in order to enable maximum performance on the NVIDIA Jetson running YOLOv8.
+
+1. Enable MAX Power Mode
+
+ Enabling MAX Power Mode on the Jetson will make sure all CPU, GPU cores are turned on.
+
+ ```bash
+ sudo nvpmodel -m 0
+ ```
+
+2. Enable Jetson Clocks
+
+ Enabling Jetson Clocks will make sure all CPU, GPU cores are clocked at their maximum frequency.
+
+ ```bash
+ sudo jetson_clocks
+ ```
+
+3. Install Jetson Stats Application
+
+ We can use jetson stats application to monitor the temperatures of the system components and check other system details such as view CPU, GPU, RAM utilization, change power modes, set to max clocks, check JetPack information
+
+ ```bash
+ sudo apt update
+ sudo pip install jetson-stats
+ sudo reboot
+ jtop
+ ```
+
+
+
+## Next Steps
+
+Congratulations on successfully setting up YOLOv8 on your NVIDIA Jetson! For further learning and support, visit more guide at [Ultralytics YOLOv8 Docs](../index.md)!
+
+## FAQ
+
+### How do I deploy Ultralytics YOLOv8 on NVIDIA Jetson devices?
+
+Deploying Ultralytics YOLOv8 on NVIDIA Jetson devices is a straightforward process. First, flash your Jetson device with the NVIDIA JetPack SDK. Then, either use a pre-built Docker image for quick setup or manually install the required packages. Detailed steps for each approach can be found in sections [Quick Start with Docker](#quick-start-with-docker) and [Start with Native Installation](#start-with-native-installation).
+
+### What performance benchmarks can I expect from YOLOv8 models on NVIDIA Jetson devices?
+
+YOLOv8 models have been benchmarked on various NVIDIA Jetson devices showing significant performance improvements. For example, the TensorRT format delivers the best inference performance. The table in the [Detailed Comparison Table](#detailed-comparison-table) section provides a comprehensive view of performance metrics like mAP50-95 and inference time across different model formats.
+
+### Why should I use TensorRT for deploying YOLOv8 on NVIDIA Jetson?
+
+TensorRT is highly recommended for deploying YOLOv8 models on NVIDIA Jetson due to its optimal performance. It accelerates inference by leveraging the Jetson's GPU capabilities, ensuring maximum efficiency and speed. Learn more about how to convert to TensorRT and run inference in the [Use TensorRT on NVIDIA Jetson](#use-tensorrt-on-nvidia-jetson) section.
+
+### How can I install PyTorch and Torchvision on NVIDIA Jetson?
+
+To install PyTorch and Torchvision on NVIDIA Jetson, first uninstall any existing versions that may have been installed via pip. Then, manually install the compatible PyTorch and Torchvision versions for the Jetson's ARM64 architecture. Detailed instructions for this process are provided in the [Install PyTorch and Torchvision](#install-pytorch-and-torchvision) section.
+
+### What are the best practices for maximizing performance on NVIDIA Jetson when using YOLOv8?
+
+To maximize performance on NVIDIA Jetson with YOLOv8, follow these best practices:
+
+1. Enable MAX Power Mode to utilize all CPU and GPU cores.
+2. Enable Jetson Clocks to run all cores at their maximum frequency.
+3. Install the Jetson Stats application for monitoring system metrics.
+
+For commands and additional details, refer to the [Best Practices when using NVIDIA Jetson](#best-practices-when-using-nvidia-jetson) section.
diff --git a/ultralytics/docs/en/guides/object-blurring.md b/ultralytics/docs/en/guides/object-blurring.md
new file mode 100644
index 0000000000000000000000000000000000000000..04eae1674fd7c4385f3865e3e7133685a2b2bb5a
--- /dev/null
+++ b/ultralytics/docs/en/guides/object-blurring.md
@@ -0,0 +1,155 @@
+---
+comments: true
+description: Learn how to use Ultralytics YOLOv8 for real-time object blurring to enhance privacy and focus in your images and videos.
+keywords: YOLOv8, object blurring, real-time processing, privacy protection, image manipulation, video editing, Ultralytics
+---
+
+# Object Blurring using Ultralytics YOLOv8 🚀
+
+## What is Object Blurring?
+
+Object blurring with [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) involves applying a blurring effect to specific detected objects in an image or video. This can be achieved using the YOLOv8 model capabilities to identify and manipulate objects within a given scene.
+
+
+
+## Advantages of Object Blurring?
+
+- **Privacy Protection**: Object blurring is an effective tool for safeguarding privacy by concealing sensitive or personally identifiable information in images or videos.
+- **Selective Focus**: YOLOv8 allows for selective blurring, enabling users to target specific objects, ensuring a balance between privacy and retaining relevant visual information.
+- **Real-time Processing**: YOLOv8's efficiency enables object blurring in real-time, making it suitable for applications requiring on-the-fly privacy enhancements in dynamic environments.
+
+!!! Example "Object Blurring using YOLOv8 Example"
+
+ === "Object Blurring"
+
+ ```python
+ import cv2
+
+ from ultralytics import YOLO
+ from ultralytics.utils.plotting import Annotator, colors
+
+ model = YOLO("yolov8n.pt")
+ names = model.names
+
+ cap = cv2.VideoCapture("path/to/video/file.mp4")
+ assert cap.isOpened(), "Error reading video file"
+ w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
+
+ # Blur ratio
+ blur_ratio = 50
+
+ # Video writer
+ video_writer = cv2.VideoWriter("object_blurring_output.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
+
+ while cap.isOpened():
+ success, im0 = cap.read()
+ if not success:
+ print("Video frame is empty or video processing has been successfully completed.")
+ break
+
+ results = model.predict(im0, show=False)
+ boxes = results[0].boxes.xyxy.cpu().tolist()
+ clss = results[0].boxes.cls.cpu().tolist()
+ annotator = Annotator(im0, line_width=2, example=names)
+
+ if boxes is not None:
+ for box, cls in zip(boxes, clss):
+ annotator.box_label(box, color=colors(int(cls), True), label=names[int(cls)])
+
+ obj = im0[int(box[1]) : int(box[3]), int(box[0]) : int(box[2])]
+ blur_obj = cv2.blur(obj, (blur_ratio, blur_ratio))
+
+ im0[int(box[1]) : int(box[3]), int(box[0]) : int(box[2])] = blur_obj
+
+ cv2.imshow("ultralytics", im0)
+ video_writer.write(im0)
+ if cv2.waitKey(1) & 0xFF == ord("q"):
+ break
+
+ cap.release()
+ video_writer.release()
+ cv2.destroyAllWindows()
+ ```
+
+### Arguments `model.predict`
+
+| Name | Type | Default | Description |
+| --------------- | -------------- | ---------------------- | -------------------------------------------------------------------------- |
+| `source` | `str` | `'ultralytics/assets'` | source directory for images or videos |
+| `conf` | `float` | `0.25` | object confidence threshold for detection |
+| `iou` | `float` | `0.7` | intersection over union (IoU) threshold for NMS |
+| `imgsz` | `int or tuple` | `640` | image size as scalar or (h, w) list, i.e. (640, 480) |
+| `half` | `bool` | `False` | use half precision (FP16) |
+| `device` | `None or str` | `None` | device to run on, i.e. cuda device=0/1/2/3 or device=cpu |
+| `max_det` | `int` | `300` | maximum number of detections per image |
+| `vid_stride` | `bool` | `False` | video frame-rate stride |
+| `stream_buffer` | `bool` | `False` | buffer all streaming frames (True) or return the most recent frame (False) |
+| `visualize` | `bool` | `False` | visualize model features |
+| `augment` | `bool` | `False` | apply image augmentation to prediction sources |
+| `agnostic_nms` | `bool` | `False` | class-agnostic NMS |
+| `classes` | `list[int]` | `None` | filter results by class, i.e. classes=0, or classes=[0,2,3] |
+| `retina_masks` | `bool` | `False` | use high-resolution segmentation masks |
+| `embed` | `list[int]` | `None` | return feature vectors/embeddings from given layers |
+
+## FAQ
+
+### What is object blurring with Ultralytics YOLOv8?
+
+Object blurring with [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) involves automatically detecting and applying a blurring effect to specific objects in images or videos. This technique enhances privacy by concealing sensitive information while retaining relevant visual data. YOLOv8's real-time processing capabilities make it suitable for applications requiring immediate privacy protection and selective focus adjustments.
+
+### How can I implement real-time object blurring using YOLOv8?
+
+To implement real-time object blurring with YOLOv8, follow the provided Python example. This involves using YOLOv8 for object detection and OpenCV for applying the blur effect. Here's a simplified version:
+
+```python
+import cv2
+
+from ultralytics import YOLO
+
+model = YOLO("yolov8n.pt")
+cap = cv2.VideoCapture("path/to/video/file.mp4")
+
+while cap.isOpened():
+ success, im0 = cap.read()
+ if not success:
+ break
+
+ results = model.predict(im0, show=False)
+ for box in results[0].boxes.xyxy.cpu().tolist():
+ obj = im0[int(box[1]) : int(box[3]), int(box[0]) : int(box[2])]
+ im0[int(box[1]) : int(box[3]), int(box[0]) : int(box[2])] = cv2.blur(obj, (50, 50))
+
+ cv2.imshow("YOLOv8 Blurring", im0)
+ if cv2.waitKey(1) & 0xFF == ord("q"):
+ break
+
+cap.release()
+cv2.destroyAllWindows()
+```
+
+### What are the benefits of using Ultralytics YOLOv8 for object blurring?
+
+Ultralytics YOLOv8 offers several advantages for object blurring:
+
+- **Privacy Protection**: Effectively obscure sensitive or identifiable information.
+- **Selective Focus**: Target specific objects for blurring, maintaining essential visual content.
+- **Real-time Processing**: Execute object blurring efficiently in dynamic environments, suitable for instant privacy enhancements.
+
+For more detailed applications, check the [advantages of object blurring section](#advantages-of-object-blurring).
+
+### Can I use Ultralytics YOLOv8 to blur faces in a video for privacy reasons?
+
+Yes, Ultralytics YOLOv8 can be configured to detect and blur faces in videos to protect privacy. By training or using a pre-trained model to specifically recognize faces, the detection results can be processed with OpenCV to apply a blur effect. Refer to our guide on [object detection with YOLOv8](https://docs.ultralytics.com/models/yolov8) and modify the code to target face detection.
+
+### How does YOLOv8 compare to other object detection models like Faster R-CNN for object blurring?
+
+Ultralytics YOLOv8 typically outperforms models like Faster R-CNN in terms of speed, making it more suitable for real-time applications. While both models offer accurate detection, YOLOv8's architecture is optimized for rapid inference, which is critical for tasks like real-time object blurring. Learn more about the technical differences and performance metrics in our [YOLOv8 documentation](https://docs.ultralytics.com/models/yolov8).
diff --git a/ultralytics/docs/en/guides/object-counting.md b/ultralytics/docs/en/guides/object-counting.md
new file mode 100644
index 0000000000000000000000000000000000000000..474744e815cbcf9eefab53b6bffc7853d6399333
--- /dev/null
+++ b/ultralytics/docs/en/guides/object-counting.md
@@ -0,0 +1,377 @@
+---
+comments: true
+description: Learn to accurately identify and count objects in real-time using Ultralytics YOLOv8 for applications like crowd analysis and surveillance.
+keywords: object counting, YOLOv8, Ultralytics, real-time object detection, AI, deep learning, object tracking, crowd analysis, surveillance, resource optimization
+---
+
+# Object Counting using Ultralytics YOLOv8
+
+## What is Object Counting?
+
+Object counting with [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) involves accurate identification and counting of specific objects in videos and camera streams. YOLOv8 excels in real-time applications, providing efficient and precise object counting for various scenarios like crowd analysis and surveillance, thanks to its state-of-the-art algorithms and deep learning capabilities.
+
+
+
+
+
+
+ Watch: Object Counting using Ultralytics YOLOv8
+
+
+## Advantages of Object Counting?
+
+- **Resource Optimization:** Object counting facilitates efficient resource management by providing accurate counts, and optimizing resource allocation in applications like inventory management.
+- **Enhanced Security:** Object counting enhances security and surveillance by accurately tracking and counting entities, aiding in proactive threat detection.
+- **Informed Decision-Making:** Object counting offers valuable insights for decision-making, optimizing processes in retail, traffic management, and various other domains.
+
+## Real World Applications
+
+| Logistics | Aquaculture |
+| :-----------------------------------------------------------------------------------------------------------------------------------------------------------: | :-------------------------------------------------------------------------------------------------------------------------------------------------: |
+|  |  |
+| Conveyor Belt Packets Counting Using Ultralytics YOLOv8 | Fish Counting in Sea using Ultralytics YOLOv8 |
+
+!!! Example "Object Counting using YOLOv8 Example"
+
+ === "Count in Region"
+
+ ```python
+ import cv2
+
+ from ultralytics import YOLO, solutions
+
+ model = YOLO("yolov8n.pt")
+ cap = cv2.VideoCapture("path/to/video/file.mp4")
+ assert cap.isOpened(), "Error reading video file"
+ w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
+
+ # Define region points
+ region_points = [(20, 400), (1080, 404), (1080, 360), (20, 360)]
+
+ # Video writer
+ video_writer = cv2.VideoWriter("object_counting_output.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
+
+ # Init Object Counter
+ counter = solutions.ObjectCounter(
+ view_img=True,
+ reg_pts=region_points,
+ names=model.names,
+ draw_tracks=True,
+ line_thickness=2,
+ )
+
+ while cap.isOpened():
+ success, im0 = cap.read()
+ if not success:
+ print("Video frame is empty or video processing has been successfully completed.")
+ break
+ tracks = model.track(im0, persist=True, show=False)
+
+ im0 = counter.start_counting(im0, tracks)
+ video_writer.write(im0)
+
+ cap.release()
+ video_writer.release()
+ cv2.destroyAllWindows()
+ ```
+
+ === "Count in Polygon"
+
+ ```python
+ import cv2
+
+ from ultralytics import YOLO, solutions
+
+ model = YOLO("yolov8n.pt")
+ cap = cv2.VideoCapture("path/to/video/file.mp4")
+ assert cap.isOpened(), "Error reading video file"
+ w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
+
+ # Define region points as a polygon with 5 points
+ region_points = [(20, 400), (1080, 404), (1080, 360), (20, 360), (20, 400)]
+
+ # Video writer
+ video_writer = cv2.VideoWriter("object_counting_output.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
+
+ # Init Object Counter
+ counter = solutions.ObjectCounter(
+ view_img=True,
+ reg_pts=region_points,
+ names=model.names,
+ draw_tracks=True,
+ line_thickness=2,
+ )
+
+ while cap.isOpened():
+ success, im0 = cap.read()
+ if not success:
+ print("Video frame is empty or video processing has been successfully completed.")
+ break
+ tracks = model.track(im0, persist=True, show=False)
+
+ im0 = counter.start_counting(im0, tracks)
+ video_writer.write(im0)
+
+ cap.release()
+ video_writer.release()
+ cv2.destroyAllWindows()
+ ```
+
+ === "Count in Line"
+
+ ```python
+ import cv2
+
+ from ultralytics import YOLO, solutions
+
+ model = YOLO("yolov8n.pt")
+ cap = cv2.VideoCapture("path/to/video/file.mp4")
+ assert cap.isOpened(), "Error reading video file"
+ w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
+
+ # Define line points
+ line_points = [(20, 400), (1080, 400)]
+
+ # Video writer
+ video_writer = cv2.VideoWriter("object_counting_output.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
+
+ # Init Object Counter
+ counter = solutions.ObjectCounter(
+ view_img=True,
+ reg_pts=line_points,
+ names=model.names,
+ draw_tracks=True,
+ line_thickness=2,
+ )
+
+ while cap.isOpened():
+ success, im0 = cap.read()
+ if not success:
+ print("Video frame is empty or video processing has been successfully completed.")
+ break
+ tracks = model.track(im0, persist=True, show=False)
+
+ im0 = counter.start_counting(im0, tracks)
+ video_writer.write(im0)
+
+ cap.release()
+ video_writer.release()
+ cv2.destroyAllWindows()
+ ```
+
+ === "Specific Classes"
+
+ ```python
+ import cv2
+
+ from ultralytics import YOLO, solutions
+
+ model = YOLO("yolov8n.pt")
+ cap = cv2.VideoCapture("path/to/video/file.mp4")
+ assert cap.isOpened(), "Error reading video file"
+ w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
+
+ line_points = [(20, 400), (1080, 400)] # line or region points
+ classes_to_count = [0, 2] # person and car classes for count
+
+ # Video writer
+ video_writer = cv2.VideoWriter("object_counting_output.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
+
+ # Init Object Counter
+ counter = solutions.ObjectCounter(
+ view_img=True,
+ reg_pts=line_points,
+ names=model.names,
+ draw_tracks=True,
+ line_thickness=2,
+ )
+
+ while cap.isOpened():
+ success, im0 = cap.read()
+ if not success:
+ print("Video frame is empty or video processing has been successfully completed.")
+ break
+ tracks = model.track(im0, persist=True, show=False, classes=classes_to_count)
+
+ im0 = counter.start_counting(im0, tracks)
+ video_writer.write(im0)
+
+ cap.release()
+ video_writer.release()
+ cv2.destroyAllWindows()
+ ```
+
+???+ tip "Region is Movable"
+
+ You can move the region anywhere in the frame by clicking on its edges
+
+### Argument `ObjectCounter`
+
+Here's a table with the `ObjectCounter` arguments:
+
+| Name | Type | Default | Description |
+| -------------------- | ------- | -------------------------- | ---------------------------------------------------------------------- |
+| `names` | `dict` | `None` | Dictionary of classes names. |
+| `reg_pts` | `list` | `[(20, 400), (1260, 400)]` | List of points defining the counting region. |
+| `count_reg_color` | `tuple` | `(255, 0, 255)` | RGB color of the counting region. |
+| `count_txt_color` | `tuple` | `(0, 0, 0)` | RGB color of the count text. |
+| `count_bg_color` | `tuple` | `(255, 255, 255)` | RGB color of the count text background. |
+| `line_thickness` | `int` | `2` | Line thickness for bounding boxes. |
+| `track_thickness` | `int` | `2` | Thickness of the track lines. |
+| `view_img` | `bool` | `False` | Flag to control whether to display the video stream. |
+| `view_in_counts` | `bool` | `True` | Flag to control whether to display the in counts on the video stream. |
+| `view_out_counts` | `bool` | `True` | Flag to control whether to display the out counts on the video stream. |
+| `draw_tracks` | `bool` | `False` | Flag to control whether to draw the object tracks. |
+| `track_color` | `tuple` | `None` | RGB color of the tracks. |
+| `region_thickness` | `int` | `5` | Thickness of the object counting region. |
+| `line_dist_thresh` | `int` | `15` | Euclidean distance threshold for line counter. |
+| `cls_txtdisplay_gap` | `int` | `50` | Display gap between each class count. |
+
+### Arguments `model.track`
+
+| Name | Type | Default | Description |
+| --------- | ------- | -------------- | ----------------------------------------------------------- |
+| `source` | `im0` | `None` | source directory for images or videos |
+| `persist` | `bool` | `False` | persisting tracks between frames |
+| `tracker` | `str` | `botsort.yaml` | Tracking method 'bytetrack' or 'botsort' |
+| `conf` | `float` | `0.3` | Confidence Threshold |
+| `iou` | `float` | `0.5` | IOU Threshold |
+| `classes` | `list` | `None` | filter results by class, i.e. classes=0, or classes=[0,2,3] |
+| `verbose` | `bool` | `True` | Display the object tracking results |
+
+## FAQ
+
+### How do I count objects in a video using Ultralytics YOLOv8?
+
+To count objects in a video using Ultralytics YOLOv8, you can follow these steps:
+
+1. Import the necessary libraries (`cv2`, `ultralytics`).
+2. Load a pretrained YOLOv8 model.
+3. Define the counting region (e.g., a polygon, line, etc.).
+4. Set up the video capture and initialize the object counter.
+5. Process each frame to track objects and count them within the defined region.
+
+Here's a simple example for counting in a region:
+
+```python
+import cv2
+
+from ultralytics import YOLO, solutions
+
+
+def count_objects_in_region(video_path, output_video_path, model_path):
+ """Count objects in a specific region within a video."""
+ model = YOLO(model_path)
+ cap = cv2.VideoCapture(video_path)
+ assert cap.isOpened(), "Error reading video file"
+ w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
+ region_points = [(20, 400), (1080, 404), (1080, 360), (20, 360)]
+ video_writer = cv2.VideoWriter(output_video_path, cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
+ counter = solutions.ObjectCounter(
+ view_img=True, reg_pts=region_points, names=model.names, draw_tracks=True, line_thickness=2
+ )
+
+ while cap.isOpened():
+ success, im0 = cap.read()
+ if not success:
+ print("Video frame is empty or video processing has been successfully completed.")
+ break
+ tracks = model.track(im0, persist=True, show=False)
+ im0 = counter.start_counting(im0, tracks)
+ video_writer.write(im0)
+
+ cap.release()
+ video_writer.release()
+ cv2.destroyAllWindows()
+
+
+count_objects_in_region("path/to/video.mp4", "output_video.avi", "yolov8n.pt")
+```
+
+Explore more configurations and options in the [Object Counting](#object-counting-using-ultralytics-yolov8) section.
+
+### What are the advantages of using Ultralytics YOLOv8 for object counting?
+
+Using Ultralytics YOLOv8 for object counting offers several advantages:
+
+1. **Resource Optimization:** It facilitates efficient resource management by providing accurate counts, helping optimize resource allocation in industries like inventory management.
+2. **Enhanced Security:** It enhances security and surveillance by accurately tracking and counting entities, aiding in proactive threat detection.
+3. **Informed Decision-Making:** It offers valuable insights for decision-making, optimizing processes in domains like retail, traffic management, and more.
+
+For real-world applications and code examples, visit the [Advantages of Object Counting](#advantages-of-object-counting) section.
+
+### How can I count specific classes of objects using Ultralytics YOLOv8?
+
+To count specific classes of objects using Ultralytics YOLOv8, you need to specify the classes you are interested in during the tracking phase. Below is a Python example:
+
+```python
+import cv2
+
+from ultralytics import YOLO, solutions
+
+
+def count_specific_classes(video_path, output_video_path, model_path, classes_to_count):
+ """Count specific classes of objects in a video."""
+ model = YOLO(model_path)
+ cap = cv2.VideoCapture(video_path)
+ assert cap.isOpened(), "Error reading video file"
+ w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
+ line_points = [(20, 400), (1080, 400)]
+ video_writer = cv2.VideoWriter(output_video_path, cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
+ counter = solutions.ObjectCounter(
+ view_img=True, reg_pts=line_points, names=model.names, draw_tracks=True, line_thickness=2
+ )
+
+ while cap.isOpened():
+ success, im0 = cap.read()
+ if not success:
+ print("Video frame is empty or video processing has been successfully completed.")
+ break
+ tracks = model.track(im0, persist=True, show=False, classes=classes_to_count)
+ im0 = counter.start_counting(im0, tracks)
+ video_writer.write(im0)
+
+ cap.release()
+ video_writer.release()
+ cv2.destroyAllWindows()
+
+
+count_specific_classes("path/to/video.mp4", "output_specific_classes.avi", "yolov8n.pt", [0, 2])
+```
+
+In this example, `classes_to_count=[0, 2]`, which means it counts objects of class `0` and `2` (e.g., person and car).
+
+### Why should I use YOLOv8 over other object detection models for real-time applications?
+
+Ultralytics YOLOv8 provides several advantages over other object detection models like Faster R-CNN, SSD, and previous YOLO versions:
+
+1. **Speed and Efficiency:** YOLOv8 offers real-time processing capabilities, making it ideal for applications requiring high-speed inference, such as surveillance and autonomous driving.
+2. **Accuracy:** It provides state-of-the-art accuracy for object detection and tracking tasks, reducing the number of false positives and improving overall system reliability.
+3. **Ease of Integration:** YOLOv8 offers seamless integration with various platforms and devices, including mobile and edge devices, which is crucial for modern AI applications.
+4. **Flexibility:** Supports various tasks like object detection, segmentation, and tracking with configurable models to meet specific use-case requirements.
+
+Check out Ultralytics [YOLOv8 Documentation](https://docs.ultralytics.com/models/yolov8) for a deeper dive into its features and performance comparisons.
+
+### Can I use YOLOv8 for advanced applications like crowd analysis and traffic management?
+
+Yes, Ultralytics YOLOv8 is perfectly suited for advanced applications like crowd analysis and traffic management due to its real-time detection capabilities, scalability, and integration flexibility. Its advanced features allow for high-accuracy object tracking, counting, and classification in dynamic environments. Example use cases include:
+
+- **Crowd Analysis:** Monitor and manage large gatherings, ensuring safety and optimizing crowd flow.
+- **Traffic Management:** Track and count vehicles, analyze traffic patterns, and manage congestion in real-time.
+
+For more information and implementation details, refer to the guide on [Real World Applications](#real-world-applications) of object counting with YOLOv8.
diff --git a/ultralytics/docs/en/guides/object-cropping.md b/ultralytics/docs/en/guides/object-cropping.md
new file mode 100644
index 0000000000000000000000000000000000000000..879545bec7a63e8f96e2aa3ebf0a588b3d0e802d
--- /dev/null
+++ b/ultralytics/docs/en/guides/object-cropping.md
@@ -0,0 +1,135 @@
+---
+comments: true
+description: Learn how to crop and extract objects using Ultralytics YOLOv8 for focused analysis, reduced data volume, and enhanced precision.
+keywords: Ultralytics, YOLOv8, object cropping, object detection, image processing, video analysis, AI, machine learning
+---
+
+# Object Cropping using Ultralytics YOLOv8
+
+## What is Object Cropping?
+
+Object cropping with [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) involves isolating and extracting specific detected objects from an image or video. The YOLOv8 model capabilities are utilized to accurately identify and delineate objects, enabling precise cropping for further analysis or manipulation.
+
+
+
+## Advantages of Object Cropping?
+
+- **Focused Analysis**: YOLOv8 facilitates targeted object cropping, allowing for in-depth examination or processing of individual items within a scene.
+- **Reduced Data Volume**: By extracting only relevant objects, object cropping helps in minimizing data size, making it efficient for storage, transmission, or subsequent computational tasks.
+- **Enhanced Precision**: YOLOv8's object detection accuracy ensures that the cropped objects maintain their spatial relationships, preserving the integrity of the visual information for detailed analysis.
+
+## Visuals
+
+| Airport Luggage |
+| :--------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+|  |
+| Suitcases Cropping at airport conveyor belt using Ultralytics YOLOv8 |
+
+!!! Example "Object Cropping using YOLOv8 Example"
+
+ === "Object Cropping"
+
+ ```python
+ import os
+
+ import cv2
+
+ from ultralytics import YOLO
+ from ultralytics.utils.plotting import Annotator, colors
+
+ model = YOLO("yolov8n.pt")
+ names = model.names
+
+ cap = cv2.VideoCapture("path/to/video/file.mp4")
+ assert cap.isOpened(), "Error reading video file"
+ w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
+
+ crop_dir_name = "ultralytics_crop"
+ if not os.path.exists(crop_dir_name):
+ os.mkdir(crop_dir_name)
+
+ # Video writer
+ video_writer = cv2.VideoWriter("object_cropping_output.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
+
+ idx = 0
+ while cap.isOpened():
+ success, im0 = cap.read()
+ if not success:
+ print("Video frame is empty or video processing has been successfully completed.")
+ break
+
+ results = model.predict(im0, show=False)
+ boxes = results[0].boxes.xyxy.cpu().tolist()
+ clss = results[0].boxes.cls.cpu().tolist()
+ annotator = Annotator(im0, line_width=2, example=names)
+
+ if boxes is not None:
+ for box, cls in zip(boxes, clss):
+ idx += 1
+ annotator.box_label(box, color=colors(int(cls), True), label=names[int(cls)])
+
+ crop_obj = im0[int(box[1]) : int(box[3]), int(box[0]) : int(box[2])]
+
+ cv2.imwrite(os.path.join(crop_dir_name, str(idx) + ".png"), crop_obj)
+
+ cv2.imshow("ultralytics", im0)
+ video_writer.write(im0)
+
+ if cv2.waitKey(1) & 0xFF == ord("q"):
+ break
+
+ cap.release()
+ video_writer.release()
+ cv2.destroyAllWindows()
+ ```
+
+### Arguments `model.predict`
+
+| Argument | Type | Default | Description |
+| --------------- | -------------- | ---------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
+| `source` | `str` | `'ultralytics/assets'` | Specifies the data source for inference. Can be an image path, video file, directory, URL, or device ID for live feeds. Supports a wide range of formats and sources, enabling flexible application across different types of input. |
+| `conf` | `float` | `0.25` | Sets the minimum confidence threshold for detections. Objects detected with confidence below this threshold will be disregarded. Adjusting this value can help reduce false positives. |
+| `iou` | `float` | `0.7` | Intersection Over Union (IoU) threshold for Non-Maximum Suppression (NMS). Lower values result in fewer detections by eliminating overlapping boxes, useful for reducing duplicates. |
+| `imgsz` | `int or tuple` | `640` | Defines the image size for inference. Can be a single integer `640` for square resizing or a (height, width) tuple. Proper sizing can improve detection accuracy and processing speed. |
+| `half` | `bool` | `False` | Enables half-precision (FP16) inference, which can speed up model inference on supported GPUs with minimal impact on accuracy. |
+| `device` | `str` | `None` | Specifies the device for inference (e.g., `cpu`, `cuda:0` or `0`). Allows users to select between CPU, a specific GPU, or other compute devices for model execution. |
+| `max_det` | `int` | `300` | Maximum number of detections allowed per image. Limits the total number of objects the model can detect in a single inference, preventing excessive outputs in dense scenes. |
+| `vid_stride` | `int` | `1` | Frame stride for video inputs. Allows skipping frames in videos to speed up processing at the cost of temporal resolution. A value of 1 processes every frame, higher values skip frames. |
+| `stream_buffer` | `bool` | `False` | Determines if all frames should be buffered when processing video streams (`True`), or if the model should return the most recent frame (`False`). Useful for real-time applications. |
+| `visualize` | `bool` | `False` | Activates visualization of model features during inference, providing insights into what the model is "seeing". Useful for debugging and model interpretation. |
+| `augment` | `bool` | `False` | Enables test-time augmentation (TTA) for predictions, potentially improving detection robustness at the cost of inference speed. |
+| `agnostic_nms` | `bool` | `False` | Enables class-agnostic Non-Maximum Suppression (NMS), which merges overlapping boxes of different classes. Useful in multi-class detection scenarios where class overlap is common. |
+| `classes` | `list[int]` | `None` | Filters predictions to a set of class IDs. Only detections belonging to the specified classes will be returned. Useful for focusing on relevant objects in multi-class detection tasks. |
+| `retina_masks` | `bool` | `False` | Uses high-resolution segmentation masks if available in the model. This can enhance mask quality for segmentation tasks, providing finer detail. |
+| `embed` | `list[int]` | `None` | Specifies the layers from which to extract feature vectors or embeddings. Useful for downstream tasks like clustering or similarity search. |
+
+## FAQ
+
+### What is object cropping in Ultralytics YOLOv8 and how does it work?
+
+Object cropping using [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics) involves isolating and extracting specific objects from an image or video based on YOLOv8's detection capabilities. This process allows for focused analysis, reduced data volume, and enhanced precision by leveraging YOLOv8 to identify objects with high accuracy and crop them accordingly. For an in-depth tutorial, refer to the [object cropping example](#object-cropping-using-ultralytics-yolov8).
+
+### Why should I use Ultralytics YOLOv8 for object cropping over other solutions?
+
+Ultralytics YOLOv8 stands out due to its precision, speed, and ease of use. It allows detailed and accurate object detection and cropping, essential for [focused analysis](#advantages-of-object-cropping) and applications needing high data integrity. Moreover, YOLOv8 integrates seamlessly with tools like OpenVINO and TensorRT for deployments requiring real-time capabilities and optimization on diverse hardware. Explore the benefits in the [guide on model export](../modes/export.md).
+
+### How can I reduce the data volume of my dataset using object cropping?
+
+By using Ultralytics YOLOv8 to crop only relevant objects from your images or videos, you can significantly reduce the data size, making it more efficient for storage and processing. This process involves training the model to detect specific objects and then using the results to crop and save these portions only. For more information on exploiting Ultralytics YOLOv8's capabilities, visit our [quickstart guide](../quickstart.md).
+
+### Can I use Ultralytics YOLOv8 for real-time video analysis and object cropping?
+
+Yes, Ultralytics YOLOv8 can process real-time video feeds to detect and crop objects dynamically. The model's high-speed inference capabilities make it ideal for real-time applications such as surveillance, sports analysis, and automated inspection systems. Check out the [tracking and prediction modes](../modes/predict.md) to understand how to implement real-time processing.
+
+### What are the hardware requirements for efficiently running YOLOv8 for object cropping?
+
+Ultralytics YOLOv8 is optimized for both CPU and GPU environments, but to achieve optimal performance, especially for real-time or high-volume inference, a dedicated GPU (e.g., NVIDIA Tesla, RTX series) is recommended. For deployment on lightweight devices, consider using CoreML for iOS or TFLite for Android. More details on supported devices and formats can be found in our [model deployment options](../guides/model-deployment-options.md).
diff --git a/ultralytics/docs/en/guides/optimizing-openvino-latency-vs-throughput-modes.md b/ultralytics/docs/en/guides/optimizing-openvino-latency-vs-throughput-modes.md
new file mode 100644
index 0000000000000000000000000000000000000000..aec35bfdd155b36422469b8b08d556e45c693463
--- /dev/null
+++ b/ultralytics/docs/en/guides/optimizing-openvino-latency-vs-throughput-modes.md
@@ -0,0 +1,128 @@
+---
+comments: true
+description: Discover how to enhance Ultralytics YOLO model performance using Intel's OpenVINO toolkit. Boost latency and throughput efficiently.
+keywords: Ultralytics YOLO, OpenVINO optimization, deep learning, model inference, throughput optimization, latency optimization, AI deployment, Intel's OpenVINO, performance tuning
+---
+
+# Optimizing OpenVINO Inference for Ultralytics YOLO Models: A Comprehensive Guide
+
+
+
+## Introduction
+
+When deploying deep learning models, particularly those for object detection such as Ultralytics YOLO models, achieving optimal performance is crucial. This guide delves into leveraging Intel's OpenVINO toolkit to optimize inference, focusing on latency and throughput. Whether you're working on consumer-grade applications or large-scale deployments, understanding and applying these optimization strategies will ensure your models run efficiently on various devices.
+
+## Optimizing for Latency
+
+Latency optimization is vital for applications requiring immediate response from a single model given a single input, typical in consumer scenarios. The goal is to minimize the delay between input and inference result. However, achieving low latency involves careful consideration, especially when running concurrent inferences or managing multiple models.
+
+### Key Strategies for Latency Optimization:
+
+- **Single Inference per Device:** The simplest way to achieve low latency is by limiting to one inference at a time per device. Additional concurrency often leads to increased latency.
+- **Leveraging Sub-Devices:** Devices like multi-socket CPUs or multi-tile GPUs can execute multiple requests with minimal latency increase by utilizing their internal sub-devices.
+- **OpenVINO Performance Hints:** Utilizing OpenVINO's `ov::hint::PerformanceMode::LATENCY` for the `ov::hint::performance_mode` property during model compilation simplifies performance tuning, offering a device-agnostic and future-proof approach.
+
+### Managing First-Inference Latency:
+
+- **Model Caching:** To mitigate model load and compile times impacting latency, use model caching where possible. For scenarios where caching isn't viable, CPUs generally offer the fastest model load times.
+- **Model Mapping vs. Reading:** To reduce load times, OpenVINO replaced model reading with mapping. However, if the model is on a removable or network drive, consider using `ov::enable_mmap(false)` to switch back to reading.
+- **AUTO Device Selection:** This mode begins inference on the CPU, shifting to an accelerator once ready, seamlessly reducing first-inference latency.
+
+## Optimizing for Throughput
+
+Throughput optimization is crucial for scenarios serving numerous inference requests simultaneously, maximizing resource utilization without significantly sacrificing individual request performance.
+
+### Approaches to Throughput Optimization:
+
+1. **OpenVINO Performance Hints:** A high-level, future-proof method to enhance throughput across devices using performance hints.
+
+ ```python
+ import openvino.properties.hint as hints
+
+ config = {hints.performance_mode: hints.PerformanceMode.THROUGHPUT}
+ compiled_model = core.compile_model(model, "GPU", config)
+ ```
+
+2. **Explicit Batching and Streams:** A more granular approach involving explicit batching and the use of streams for advanced performance tuning.
+
+### Designing Throughput-Oriented Applications:
+
+To maximize throughput, applications should:
+
+- Process inputs in parallel, making full use of the device's capabilities.
+- Decompose data flow into concurrent inference requests, scheduled for parallel execution.
+- Utilize the Async API with callbacks to maintain efficiency and avoid device starvation.
+
+### Multi-Device Execution:
+
+OpenVINO's multi-device mode simplifies scaling throughput by automatically balancing inference requests across devices without requiring application-level device management.
+
+## Conclusion
+
+Optimizing Ultralytics YOLO models for latency and throughput with OpenVINO can significantly enhance your application's performance. By carefully applying the strategies outlined in this guide, developers can ensure their models run efficiently, meeting the demands of various deployment scenarios. Remember, the choice between optimizing for latency or throughput depends on your specific application needs and the characteristics of the deployment environment.
+
+For more detailed technical information and the latest updates, refer to the [OpenVINO documentation](https://docs.openvino.ai/latest/index.html) and [Ultralytics YOLO repository](https://github.com/ultralytics/ultralytics). These resources provide in-depth guides, tutorials, and community support to help you get the most out of your deep learning models.
+
+---
+
+Ensuring your models achieve optimal performance is not just about tweaking configurations; it's about understanding your application's needs and making informed decisions. Whether you're optimizing for real-time responses or maximizing throughput for large-scale processing, the combination of Ultralytics YOLO models and OpenVINO offers a powerful toolkit for developers to deploy high-performance AI solutions.
+
+## FAQ
+
+### How do I optimize Ultralytics YOLO models for low latency using OpenVINO?
+
+Optimizing Ultralytics YOLO models for low latency involves several key strategies:
+
+1. **Single Inference per Device:** Limit inferences to one at a time per device to minimize delays.
+2. **Leveraging Sub-Devices:** Utilize devices like multi-socket CPUs or multi-tile GPUs which can handle multiple requests with minimal latency increase.
+3. **OpenVINO Performance Hints:** Use OpenVINO's `ov::hint::PerformanceMode::LATENCY` during model compilation for simplified, device-agnostic tuning.
+
+For more practical tips on optimizing latency, check out the [Latency Optimization section](#optimizing-for-latency) of our guide.
+
+### Why should I use OpenVINO for optimizing Ultralytics YOLO throughput?
+
+OpenVINO enhances Ultralytics YOLO model throughput by maximizing device resource utilization without sacrificing performance. Key benefits include:
+
+- **Performance Hints:** Simple, high-level performance tuning across devices.
+- **Explicit Batching and Streams:** Fine-tuning for advanced performance.
+- **Multi-Device Execution:** Automated inference load balancing, easing application-level management.
+
+Example configuration:
+
+```python
+import openvino.properties.hint as hints
+
+config = {hints.performance_mode: hints.PerformanceMode.THROUGHPUT}
+compiled_model = core.compile_model(model, "GPU", config)
+```
+
+Learn more about throughput optimization in the [Throughput Optimization section](#optimizing-for-throughput) of our detailed guide.
+
+### What is the best practice for reducing first-inference latency in OpenVINO?
+
+To reduce first-inference latency, consider these practices:
+
+1. **Model Caching:** Use model caching to decrease load and compile times.
+2. **Model Mapping vs. Reading:** Use mapping (`ov::enable_mmap(true)`) by default but switch to reading (`ov::enable_mmap(false)`) if the model is on a removable or network drive.
+3. **AUTO Device Selection:** Utilize AUTO mode to start with CPU inference and transition to an accelerator seamlessly.
+
+For detailed strategies on managing first-inference latency, refer to the [Managing First-Inference Latency section](#managing-first-inference-latency).
+
+### How do I balance optimizing for latency and throughput with Ultralytics YOLO and OpenVINO?
+
+Balancing latency and throughput optimization requires understanding your application needs:
+
+- **Latency Optimization:** Ideal for real-time applications requiring immediate responses (e.g., consumer-grade apps).
+- **Throughput Optimization:** Best for scenarios with many concurrent inferences, maximizing resource use (e.g., large-scale deployments).
+
+Using OpenVINO's high-level performance hints and multi-device modes can help strike the right balance. Choose the appropriate [OpenVINO Performance hints](https://docs.ultralytics.com/integrations/openvino#openvino-performance-hints) based on your specific requirements.
+
+### Can I use Ultralytics YOLO models with other AI frameworks besides OpenVINO?
+
+Yes, Ultralytics YOLO models are highly versatile and can be integrated with various AI frameworks. Options include:
+
+- **TensorRT:** For NVIDIA GPU optimization, follow the [TensorRT integration guide](https://docs.ultralytics.com/integrations/tensorrt).
+- **CoreML:** For Apple devices, refer to our [CoreML export instructions](https://docs.ultralytics.com/integrations/coreml).
+- **TensorFlow.js:** For web and Node.js apps, see the [TF.js conversion guide](https://docs.ultralytics.com/integrations/tfjs).
+
+Explore more integrations on the [Ultralytics Integrations page](https://docs.ultralytics.com/integrations).
diff --git a/ultralytics/docs/en/guides/parking-management.md b/ultralytics/docs/en/guides/parking-management.md
new file mode 100644
index 0000000000000000000000000000000000000000..e3352c9bd2b1be42762b599e5fdacbbec60425c4
--- /dev/null
+++ b/ultralytics/docs/en/guides/parking-management.md
@@ -0,0 +1,167 @@
+---
+comments: true
+description: Optimize parking spaces and enhance safety with Ultralytics YOLOv8. Explore real-time vehicle detection and smart parking solutions.
+keywords: parking management, YOLOv8, Ultralytics, vehicle detection, real-time tracking, parking lot optimization, smart parking
+---
+
+# Parking Management using Ultralytics YOLOv8 🚀
+
+## What is Parking Management System?
+
+Parking management with [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) ensures efficient and safe parking by organizing spaces and monitoring availability. YOLOv8 can improve parking lot management through real-time vehicle detection, and insights into parking occupancy.
+
+
+
+
+
+ Watch: How to Implement Parking Management Using Ultralytics YOLOv8 🚀
+
+
+## Advantages of Parking Management System?
+
+- **Efficiency**: Parking lot management optimizes the use of parking spaces and reduces congestion.
+- **Safety and Security**: Parking management using YOLOv8 improves the safety of both people and vehicles through surveillance and security measures.
+- **Reduced Emissions**: Parking management using YOLOv8 manages traffic flow to minimize idle time and emissions in parking lots.
+
+## Real World Applications
+
+| Parking Management System | Parking Management System |
+| :-----------------------------------------------------------------------------------------------------------------------------------------------------: | :----------------------------------------------------------------------------------------------------------------------------------------------------------: |
+|  |  |
+| Parking management Aerial View using Ultralytics YOLOv8 | Parking management Top View using Ultralytics YOLOv8 |
+
+## Parking Management System Code Workflow
+
+### Selection of Points
+
+!!! Tip "Point Selection is now Easy"
+
+ Choosing parking points is a critical and complex task in parking management systems. Ultralytics streamlines this process by providing a tool that lets you define parking lot areas, which can be utilized later for additional processing.
+
+- Capture a frame from the video or camera stream where you want to manage the parking lot.
+- Use the provided code to launch a graphical interface, where you can select an image and start outlining parking regions by mouse click to create polygons.
+
+!!! Warning "Image Size"
+
+ Max Image Size of 1920 * 1080 supported
+
+!!! Example "Parking slots Annotator Ultralytics YOLOv8"
+
+ === "Parking Annotator"
+
+ ```python
+ from ultralytics import solutions
+
+ solutions.ParkingPtsSelection()
+ ```
+
+- After defining the parking areas with polygons, click `save` to store a JSON file with the data in your working directory.
+
+
+
+### Python Code for Parking Management
+
+!!! Example "Parking management using YOLOv8 Example"
+
+ === "Parking Management"
+
+ ```python
+ import cv2
+
+ from ultralytics import solutions
+
+ # Path to json file, that created with above point selection app
+ polygon_json_path = "bounding_boxes.json"
+
+ # Video capture
+ cap = cv2.VideoCapture("Path/to/video/file.mp4")
+ assert cap.isOpened(), "Error reading video file"
+ w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
+
+ # Video writer
+ video_writer = cv2.VideoWriter("parking management.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
+
+ # Initialize parking management object
+ management = solutions.ParkingManagement(model_path="yolov8n.pt")
+
+ while cap.isOpened():
+ ret, im0 = cap.read()
+ if not ret:
+ break
+
+ json_data = management.parking_regions_extraction(polygon_json_path)
+ results = management.model.track(im0, persist=True, show=False)
+
+ if results[0].boxes.id is not None:
+ boxes = results[0].boxes.xyxy.cpu().tolist()
+ clss = results[0].boxes.cls.cpu().tolist()
+ management.process_data(json_data, im0, boxes, clss)
+
+ management.display_frames(im0)
+ video_writer.write(im0)
+
+ cap.release()
+ video_writer.release()
+ cv2.destroyAllWindows()
+ ```
+
+### Optional Arguments `ParkingManagement`
+
+| Name | Type | Default | Description |
+| ------------------------ | ------- | ----------------- | -------------------------------------- |
+| `model_path` | `str` | `None` | Path to the YOLOv8 model. |
+| `txt_color` | `tuple` | `(0, 0, 0)` | RGB color tuple for text. |
+| `bg_color` | `tuple` | `(255, 255, 255)` | RGB color tuple for background. |
+| `occupied_region_color` | `tuple` | `(0, 255, 0)` | RGB color tuple for occupied regions. |
+| `available_region_color` | `tuple` | `(0, 0, 255)` | RGB color tuple for available regions. |
+| `margin` | `int` | `10` | Margin for text display. |
+
+### Arguments `model.track`
+
+| Name | Type | Default | Description |
+| --------- | ------- | -------------- | ----------------------------------------------------------- |
+| `source` | `im0` | `None` | source directory for images or videos |
+| `persist` | `bool` | `False` | persisting tracks between frames |
+| `tracker` | `str` | `botsort.yaml` | Tracking method 'bytetrack' or 'botsort' |
+| `conf` | `float` | `0.3` | Confidence Threshold |
+| `iou` | `float` | `0.5` | IOU Threshold |
+| `classes` | `list` | `None` | filter results by class, i.e. classes=0, or classes=[0,2,3] |
+| `verbose` | `bool` | `True` | Display the object tracking results |
+
+## FAQ
+
+### How does Ultralytics YOLOv8 enhance parking management systems?
+
+Ultralytics YOLOv8 greatly enhances parking management systems by providing **real-time vehicle detection** and monitoring. This results in optimized usage of parking spaces, reduced congestion, and improved safety through continuous surveillance. The [Parking Management System](https://github.com/ultralytics/ultralytics) enables efficient traffic flow, minimizing idle times and emissions in parking lots, thereby contributing to environmental sustainability. For further details, refer to the [parking management code workflow](#python-code-for-parking-management).
+
+### What are the benefits of using Ultralytics YOLOv8 for smart parking?
+
+Using Ultralytics YOLOv8 for smart parking yields numerous benefits:
+
+- **Efficiency**: Optimizes the use of parking spaces and decreases congestion.
+- **Safety and Security**: Enhances surveillance and ensures the safety of vehicles and pedestrians.
+- **Environmental Impact**: Helps in reducing emissions by minimizing vehicle idle times. More details on the advantages can be seen [here](#advantages-of-parking-management-system).
+
+### How can I define parking spaces using Ultralytics YOLOv8?
+
+Defining parking spaces is straightforward with Ultralytics YOLOv8:
+
+1. Capture a frame from a video or camera stream.
+2. Use the provided code to launch a GUI for selecting an image and drawing polygons to define parking spaces.
+3. Save the labeled data in JSON format for further processing. For comprehensive instructions, check the [selection of points](#selection-of-points) section.
+
+### Can I customize the YOLOv8 model for specific parking management needs?
+
+Yes, Ultralytics YOLOv8 allows customization for specific parking management needs. You can adjust parameters such as the **occupied and available region colors**, margins for text display, and much more. Utilizing the `ParkingManagement` class's [optional arguments](#optional-arguments-parkingmanagement), you can tailor the model to suit your particular requirements, ensuring maximum efficiency and effectiveness.
+
+### What are some real-world applications of Ultralytics YOLOv8 in parking lot management?
+
+Ultralytics YOLOv8 is utilized in various real-world applications for parking lot management, including:
+
+- **Parking Space Detection**: Accurately identifying available and occupied spaces.
+- **Surveillance**: Enhancing security through real-time monitoring.
+- **Traffic Flow Management**: Reducing idle times and congestion with efficient traffic handling. Images showcasing these applications can be found in [real-world applications](#real-world-applications).
diff --git a/ultralytics/docs/en/guides/preprocessing_annotated_data.md b/ultralytics/docs/en/guides/preprocessing_annotated_data.md
new file mode 100644
index 0000000000000000000000000000000000000000..06c5d020ca4fb308c61ba6aacb40baa5dee12df0
--- /dev/null
+++ b/ultralytics/docs/en/guides/preprocessing_annotated_data.md
@@ -0,0 +1,171 @@
+---
+comments: true
+description: Learn essential data preprocessing techniques for annotated computer vision data, including resizing, normalizing, augmenting, and splitting datasets for optimal model training.
+keywords: data preprocessing, computer vision, image resizing, normalization, data augmentation, training dataset, validation dataset, test dataset, YOLOv8
+---
+
+# Data Preprocessing Techniques for Annotated Computer Vision Data
+
+## Introduction
+
+After you've defined your computer vision [project's goals](./defining-project-goals.md) and [collected and annotated data](./data-collection-and-annotation.md), the next step is to preprocess annotated data and prepare it for model training. Clean and consistent data are vital to creating a model that performs well.
+
+Preprocessing is a step in the [computer vision project workflow](./steps-of-a-cv-project.md) that includes resizing images, normalizing pixel values, augmenting the dataset, and splitting the data into training, validation, and test sets. Let's explore the essential techniques and best practices for cleaning your data!
+
+## Importance of Data Preprocessing
+
+We are already collecting and annotating our data carefully with multiple considerations in mind. Then, what makes data preprocessing so important to a computer vision project? Well, data preprocessing is all about getting your data into a suitable format for training that reduces the computational load and helps improve model performance. Here are some common issues in raw data that preprocessing addresses:
+
+- **Noise**: Irrelevant or random variations in data.
+- **Inconsistency**: Variations in image sizes, formats, and quality.
+- **Imbalance**: Unequal distribution of classes or categories in the dataset.
+
+## Data Preprocessing Techniques
+
+One of the first and foremost steps in data preprocessing is resizing. Some models are designed to handle variable input sizes, but many models require a consistent input size. Resizing images makes them uniform and reduces computational complexity.
+
+### Resizing Images
+
+You can resize your images using the following methods:
+
+- **Bilinear Interpolation**: Smooths pixel values by taking a weighted average of the four nearest pixel values.
+- **Nearest Neighbor**: Assigns the nearest pixel value without averaging, leading to a blocky image but faster computation.
+
+To make resizing a simpler task, you can use the following tools:
+
+- **OpenCV**: A popular computer vision library with extensive functions for image processing.
+- **PIL (Pillow)**: A Python Imaging Library for opening, manipulating, and saving image files.
+
+With respect to YOLOv8, the 'imgsz' parameter during [model training](../modes/train.md) allows for flexible input sizes. When set to a specific size, such as 640, the model will resize input images so their largest dimension is 640 pixels while maintaining the original aspect ratio.
+
+By evaluating your model's and dataset's specific needs, you can determine whether resizing is a necessary preprocessing step or if your model can efficiently handle images of varying sizes.
+
+### Normalizing Pixel Values
+
+Another preprocessing technique is normalization. Normalization scales the pixel values to a standard range, which helps in faster convergence during training and improves model performance. Here are some common normalization techniques:
+
+- **Min-Max Scaling**: Scales pixel values to a range of 0 to 1.
+- **Z-Score Normalization**: Scales pixel values based on their mean and standard deviation.
+
+With respect to YOLOv8, normalization is seamlessly handled as part of its preprocessing pipeline during model training. YOLOv8 automatically performs several preprocessing steps, including conversion to RGB, scaling pixel values to the range [0, 1], and normalization using predefined mean and standard deviation values.
+
+### Splitting the Dataset
+
+Once you've cleaned the data, you are ready to split the dataset. Splitting the data into training, validation, and test sets is done to ensure that the model can be evaluated on unseen data to assess its generalization performance. A common split is 70% for training, 20% for validation, and 10% for testing. There are various tools and libraries that you can use to split your data like scikit-learn or TensorFlow.
+
+Consider the following when splitting your dataset:
+
+- **Maintaining Data Distribution**: Ensure that the data distribution of classes is maintained across training, validation, and test sets.
+- **Avoiding Data Leakage**: Typically, data augmentation is done after the dataset is split. Data augmentation and any other preprocessing should only be applied to the training set to prevent information from the validation or test sets from influencing the model training. -**Balancing Classes**: For imbalanced datasets, consider techniques such as oversampling the minority class or under-sampling the majority class within the training set.
+
+### What is Data Augmentation?
+
+The most commonly discussed data preprocessing step is data augmentation. Data augmentation artificially increases the size of the dataset by creating modified versions of images. By augmenting your data, you can reduce overfitting and improve model generalization.
+
+Here are some other benefits of data augmentation:
+
+- **Creates a More Robust Dataset**: Data augmentation can make the model more robust to variations and distortions in the input data. This includes changes in lighting, orientation, and scale.
+- **Cost-Effective**: Data augmentation is a cost-effective way to increase the amount of training data without collecting and labeling new data.
+- **Better Use of Data**: Every available data point is used to its maximum potential by creating new variations
+
+#### Data Augmentation Methods
+
+Common augmentation techniques include flipping, rotation, scaling, and color adjustments. Several libraries, such as Albumentations, Imgaug, and TensorFlow's ImageDataGenerator, can generate these augmentations.
+
+
+
+
+
+With respect to YOLOv8, you can [augment your custom dataset](../modes/train.md) by modifying the dataset configuration file, a .yaml file. In this file, you can add an augmentation section with parameters that specify how you want to augment your data.
+
+The [Ultralytics YOLOv8 repository](https://github.com/ultralytics/ultralytics/tree/main) supports a wide range of data augmentations. You can apply various transformations such as:
+
+- Random Crops
+- Flipping: Images can be flipped horizontally or vertically.
+- Rotation: Images can be rotated by specific angles.
+- Distortion
+
+Also, you can adjust the intensity of these augmentation techniques through specific parameters to generate more data variety.
+
+## A Case Study of Preprocessing
+
+Consider a project aimed at developing a model to detect and classify different types of vehicles in traffic images using YOLOv8. We've collected traffic images and annotated them with bounding boxes and labels.
+
+Here's what each step of preprocessing would look like for this project:
+
+- Resizing Images: Since YOLOv8 handles flexible input sizes and performs resizing automatically, manual resizing is not required. The model will adjust the image size according to the specified 'imgsz' parameter during training.
+- Normalizing Pixel Values: YOLOv8 automatically normalizes pixel values to a range of 0 to 1 during preprocessing, so it's not required.
+- Splitting the Dataset: Divide the dataset into training (70%), validation (20%), and test (10%) sets using tools like scikit-learn.
+- Data Augmentation: Modify the dataset configuration file (.yaml) to include data augmentation techniques such as random crops, horizontal flips, and brightness adjustments.
+
+These steps make sure the dataset is prepared without any potential issues and is ready for Exploratory Data Analysis (EDA).
+
+## Exploratory Data Analysis Techniques
+
+After preprocessing and augmenting your dataset, the next step is to gain insights through Exploratory Data Analysis. EDA uses statistical techniques and visualization tools to understand the patterns and distributions in your data. You can identify issues like class imbalances or outliers and make informed decisions about further data preprocessing or model training adjustments.
+
+### Statistical EDA Techniques
+
+Statistical techniques often begin with calculating basic metrics such as mean, median, standard deviation, and range. These metrics provide a quick overview of your image dataset's properties, such as pixel intensity distributions. Understanding these basic statistics helps you grasp the overall quality and characteristics of your data, allowing you to spot any irregularities early on.
+
+### Visual EDA Techniques
+
+Visualizations are key in EDA for image datasets. For example, class imbalance analysis is another vital aspect of EDA. It helps determine if certain classes are underrepresented in your dataset, Visualizing the distribution of different image classes or categories using bar charts can quickly reveal any imbalances. Similarly, outliers can be identified using visualization tools like box plots, which highlight anomalies in pixel intensity or feature distributions. Outlier detection prevents unusual data points from skewing your results.
+
+Common tools for visualizations include:
+
+- Histograms and Box Plots: Useful for understanding the distribution of pixel values and identifying outliers.
+- Scatter Plots: Helpful for exploring relationships between image features or annotations.
+- Heatmaps: Effective for visualizing the distribution of pixel intensities or the spatial distribution of annotated features within images.
+
+### Using Ultralytics Explorer for EDA
+
+For a more advanced approach to EDA, you can use the Ultralytics Explorer tool. It offers robust capabilities for exploring computer vision datasets. By supporting semantic search, SQL queries, and vector similarity search, the tool makes it easy to analyze and understand your data. With Ultralytics Explorer, you can create embeddings for your dataset to find similar images, run SQL queries for detailed analysis, and perform semantic searches, all through a user-friendly graphical interface.
+
+
+
+
+
+## Reach Out and Connect
+
+Having discussions about your project with other computer vision enthusiasts can give you new ideas from different perspectives. Here are some great ways to learn, troubleshoot, and network:
+
+### Channels to Connect with the Community
+
+- **GitHub Issues:** Visit the YOLOv8 GitHub repository and use the [Issues tab](https://github.com/ultralytics/ultralytics/issues) to raise questions, report bugs, and suggest features. The community and maintainers are there to help with any issues you face.
+- **Ultralytics Discord Server:** Join the [Ultralytics Discord server](https://ultralytics.com/discord/) to connect with other users and developers, get support, share knowledge, and brainstorm ideas.
+
+### Official Documentation
+
+- **Ultralytics YOLOv8 Documentation:** Refer to the [official YOLOv8 documentation](./index.md) for thorough guides and valuable insights on numerous computer vision tasks and projects.
+
+## Your Dataset Is Ready!
+
+Properly resized, normalized, and augmented data improves model performance by reducing noise and improving generalization. By following the preprocessing techniques and best practices outlined in this guide, you can create a solid dataset. With your preprocessed dataset ready, you can confidently proceed to the next steps in your project.
+
+## FAQ
+
+### What is the importance of data preprocessing in computer vision projects?
+
+Data preprocessing is essential in computer vision projects because it ensures that the data is clean, consistent, and in a format that is optimal for model training. By addressing issues such as noise, inconsistency, and imbalance in raw data, preprocessing steps like resizing, normalization, augmentation, and dataset splitting help reduce computational load and improve model performance. For more details, visit the [steps of a computer vision project](../guides/steps-of-a-cv-project.md).
+
+### How can I use Ultralytics YOLO for data augmentation?
+
+For data augmentation with Ultralytics YOLOv8, you need to modify the dataset configuration file (.yaml). In this file, you can specify various augmentation techniques such as random crops, horizontal flips, and brightness adjustments. This can be effectively done using the training configurations [explained here](../modes/train.md). Data augmentation helps create a more robust dataset, reduce overfitting, and improve model generalization.
+
+### What are the best data normalization techniques for computer vision data?
+
+Normalization scales pixel values to a standard range for faster convergence and improved performance during training. Common techniques include:
+
+- **Min-Max Scaling**: Scales pixel values to a range of 0 to 1.
+- **Z-Score Normalization**: Scales pixel values based on their mean and standard deviation.
+
+For YOLOv8, normalization is handled automatically, including conversion to RGB and pixel value scaling. Learn more about it in the [model training section](../modes/train.md).
+
+### How should I split my annotated dataset for training?
+
+To split your dataset, a common practice is to divide it into 70% for training, 20% for validation, and 10% for testing. It is important to maintain the data distribution of classes across these splits and avoid data leakage by performing augmentation only on the training set. Use tools like scikit-learn or TensorFlow for efficient dataset splitting. See the detailed guide on [dataset preparation](../guides/data-collection-and-annotation.md).
+
+### Can I handle varying image sizes in YOLOv8 without manual resizing?
+
+Yes, Ultralytics YOLOv8 can handle varying image sizes through the 'imgsz' parameter during model training. This parameter ensures that images are resized so their largest dimension matches the specified size (e.g., 640 pixels), while maintaining the aspect ratio. For more flexible input handling and automatic adjustments, check the [model training section](../modes/train.md).
diff --git a/ultralytics/docs/en/guides/queue-management.md b/ultralytics/docs/en/guides/queue-management.md
new file mode 100644
index 0000000000000000000000000000000000000000..6ac4c2eda08db70651d417353d3f7056ad7c9f89
--- /dev/null
+++ b/ultralytics/docs/en/guides/queue-management.md
@@ -0,0 +1,250 @@
+---
+comments: true
+description: Learn how to manage and optimize queues using Ultralytics YOLOv8 to reduce wait times and increase efficiency in various real-world applications.
+keywords: queue management, YOLOv8, Ultralytics, reduce wait times, efficiency, customer satisfaction, retail, airports, healthcare, banks
+---
+
+# Queue Management using Ultralytics YOLOv8 🚀
+
+## What is Queue Management?
+
+Queue management using [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) involves organizing and controlling lines of people or vehicles to reduce wait times and enhance efficiency. It's about optimizing queues to improve customer satisfaction and system performance in various settings like retail, banks, airports, and healthcare facilities.
+
+
+
+
+
+ Watch: How to Implement Queue Management with Ultralytics YOLOv8 | Airport and Metro Station
+
+
+## Advantages of Queue Management?
+
+- **Reduced Waiting Times:** Queue management systems efficiently organize queues, minimizing wait times for customers. This leads to improved satisfaction levels as customers spend less time waiting and more time engaging with products or services.
+- **Increased Efficiency:** Implementing queue management allows businesses to allocate resources more effectively. By analyzing queue data and optimizing staff deployment, businesses can streamline operations, reduce costs, and improve overall productivity.
+
+## Real World Applications
+
+| Logistics | Retail |
+| :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | :--------------------------------------------------------------------------------------------------------------------------------------------------------: |
+|  |  |
+| Queue management at airport ticket counter Using Ultralytics YOLOv8 | Queue monitoring in crowd Ultralytics YOLOv8 |
+
+!!! Example "Queue Management using YOLOv8 Example"
+
+ === "Queue Manager"
+
+ ```python
+ import cv2
+
+ from ultralytics import YOLO, solutions
+
+ model = YOLO("yolov8n.pt")
+ cap = cv2.VideoCapture("path/to/video/file.mp4")
+
+ assert cap.isOpened(), "Error reading video file"
+ w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
+
+ video_writer = cv2.VideoWriter("queue_management.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
+
+ queue_region = [(20, 400), (1080, 404), (1080, 360), (20, 360)]
+
+ queue = solutions.QueueManager(
+ names=model.names,
+ reg_pts=queue_region,
+ line_thickness=3,
+ fontsize=1.0,
+ region_color=(255, 144, 31),
+ )
+
+ while cap.isOpened():
+ success, im0 = cap.read()
+
+ if success:
+ tracks = model.track(im0, show=False, persist=True, verbose=False)
+ out = queue.process_queue(im0, tracks)
+
+ video_writer.write(im0)
+ if cv2.waitKey(1) & 0xFF == ord("q"):
+ break
+ continue
+
+ print("Video frame is empty or video processing has been successfully completed.")
+ break
+
+ cap.release()
+ cv2.destroyAllWindows()
+ ```
+
+ === "Queue Manager Specific Classes"
+
+ ```python
+ import cv2
+
+ from ultralytics import YOLO, solutions
+
+ model = YOLO("yolov8n.pt")
+ cap = cv2.VideoCapture("path/to/video/file.mp4")
+
+ assert cap.isOpened(), "Error reading video file"
+ w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
+
+ video_writer = cv2.VideoWriter("queue_management.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
+
+ queue_region = [(20, 400), (1080, 404), (1080, 360), (20, 360)]
+
+ queue = solutions.QueueManager(
+ names=model.names,
+ reg_pts=queue_region,
+ line_thickness=3,
+ fontsize=1.0,
+ region_color=(255, 144, 31),
+ )
+
+ while cap.isOpened():
+ success, im0 = cap.read()
+
+ if success:
+ tracks = model.track(im0, show=False, persist=True, verbose=False, classes=0) # Only person class
+ out = queue.process_queue(im0, tracks)
+
+ video_writer.write(im0)
+ if cv2.waitKey(1) & 0xFF == ord("q"):
+ break
+ continue
+
+ print("Video frame is empty or video processing has been successfully completed.")
+ break
+
+ cap.release()
+ cv2.destroyAllWindows()
+ ```
+
+### Arguments `QueueManager`
+
+| Name | Type | Default | Description |
+| ------------------- | ---------------- | -------------------------- | ----------------------------------------------------------------------------------- |
+| `names` | `dict` | `model.names` | A dictionary mapping class IDs to class names. |
+| `reg_pts` | `list of tuples` | `[(20, 400), (1260, 400)]` | Points defining the counting region polygon. Defaults to a predefined rectangle. |
+| `line_thickness` | `int` | `2` | Thickness of the annotation lines. |
+| `track_thickness` | `int` | `2` | Thickness of the track lines. |
+| `view_img` | `bool` | `False` | Whether to display the image frames. |
+| `region_color` | `tuple` | `(255, 0, 255)` | Color of the counting region lines (BGR). |
+| `view_queue_counts` | `bool` | `True` | Whether to display the queue counts. |
+| `draw_tracks` | `bool` | `False` | Whether to draw tracks of the objects. |
+| `count_txt_color` | `tuple` | `(255, 255, 255)` | Color of the count text (BGR). |
+| `track_color` | `tuple` | `None` | Color of the tracks. If `None`, different colors will be used for different tracks. |
+| `region_thickness` | `int` | `5` | Thickness of the counting region lines. |
+| `fontsize` | `float` | `0.7` | Font size for the text annotations. |
+
+### Arguments `model.track`
+
+| Name | Type | Default | Description |
+| --------- | ------- | -------------- | ----------------------------------------------------------- |
+| `source` | `im0` | `None` | source directory for images or videos |
+| `persist` | `bool` | `False` | persisting tracks between frames |
+| `tracker` | `str` | `botsort.yaml` | Tracking method 'bytetrack' or 'botsort' |
+| `conf` | `float` | `0.3` | Confidence Threshold |
+| `iou` | `float` | `0.5` | IOU Threshold |
+| `classes` | `list` | `None` | filter results by class, i.e. classes=0, or classes=[0,2,3] |
+| `verbose` | `bool` | `True` | Display the object tracking results |
+
+## FAQ
+
+### How can I use Ultralytics YOLOv8 for real-time queue management?
+
+To use Ultralytics YOLOv8 for real-time queue management, you can follow these steps:
+
+1. Load the YOLOv8 model with `YOLO("yolov8n.pt")`.
+2. Capture the video feed using `cv2.VideoCapture`.
+3. Define the region of interest (ROI) for queue management.
+4. Process frames to detect objects and manage queues.
+
+Here's a minimal example:
+
+```python
+import cv2
+
+from ultralytics import YOLO, solutions
+
+model = YOLO("yolov8n.pt")
+cap = cv2.VideoCapture("path/to/video.mp4")
+queue_region = [(20, 400), (1080, 404), (1080, 360), (20, 360)]
+
+queue = solutions.QueueManager(
+ names=model.names,
+ reg_pts=queue_region,
+ line_thickness=3,
+ fontsize=1.0,
+ region_color=(255, 144, 31),
+)
+
+while cap.isOpened():
+ success, im0 = cap.read()
+ if success:
+ tracks = model.track(im0, show=False, persist=True, verbose=False)
+ out = queue.process_queue(im0, tracks)
+ cv2.imshow("Queue Management", im0)
+ if cv2.waitKey(1) & 0xFF == ord("q"):
+ break
+
+cap.release()
+cv2.destroyAllWindows()
+```
+
+Leveraging Ultralytics [HUB](https://docs.ultralytics.com/hub/) can streamline this process by providing a user-friendly platform for deploying and managing your queue management solution.
+
+### What are the key advantages of using Ultralytics YOLOv8 for queue management?
+
+Using Ultralytics YOLOv8 for queue management offers several benefits:
+
+- **Plummeting Waiting Times:** Efficiently organizes queues, reducing customer wait times and boosting satisfaction.
+- **Enhancing Efficiency:** Analyzes queue data to optimize staff deployment and operations, thereby reducing costs.
+- **Real-time Alerts:** Provides real-time notifications for long queues, enabling quick intervention.
+- **Scalability:** Easily scalable across different environments like retail, airports, and healthcare.
+
+For more details, explore our [Queue Management](https://docs.ultralytics.com/reference/solutions/queue_management/) solutions.
+
+### Why should I choose Ultralytics YOLOv8 over competitors like TensorFlow or Detectron2 for queue management?
+
+Ultralytics YOLOv8 has several advantages over TensorFlow and Detectron2 for queue management:
+
+- **Real-time Performance:** YOLOv8 is known for its real-time detection capabilities, offering faster processing speeds.
+- **Ease of Use:** Ultralytics provides a user-friendly experience, from training to deployment, via [Ultralytics HUB](https://docs.ultralytics.com/hub/).
+- **Pretrained Models:** Access to a range of pretrained models, minimizing the time needed for setup.
+- **Community Support:** Extensive documentation and active community support make problem-solving easier.
+
+Learn how to get started with [Ultralytics YOLO](https://docs.ultralytics.com/quickstart/).
+
+### Can Ultralytics YOLOv8 handle multiple types of queues, such as in airports and retail?
+
+Yes, Ultralytics YOLOv8 can manage various types of queues, including those in airports and retail environments. By configuring the QueueManager with specific regions and settings, YOLOv8 can adapt to different queue layouts and densities.
+
+Example for airports:
+
+```python
+queue_region_airport = [(50, 600), (1200, 600), (1200, 550), (50, 550)]
+queue_airport = solutions.QueueManager(
+ names=model.names,
+ reg_pts=queue_region_airport,
+ line_thickness=3,
+ fontsize=1.0,
+ region_color=(0, 255, 0),
+)
+```
+
+For more information on diverse applications, check out our [Real World Applications](#real-world-applications) section.
+
+### What are some real-world applications of Ultralytics YOLOv8 in queue management?
+
+Ultralytics YOLOv8 is used in various real-world applications for queue management:
+
+- **Retail:** Monitors checkout lines to reduce wait times and improve customer satisfaction.
+- **Airports:** Manages queues at ticket counters and security checkpoints for a smoother passenger experience.
+- **Healthcare:** Optimizes patient flow in clinics and hospitals.
+- **Banks:** Enhances customer service by managing queues efficiently in banks.
+
+Check our [blog on real-world queue management](https://www.ultralytics.com/blog/revolutionizing-queue-management-with-ultralytics-yolov8-and-openvino) to learn more.
diff --git a/ultralytics/docs/en/guides/raspberry-pi.md b/ultralytics/docs/en/guides/raspberry-pi.md
new file mode 100644
index 0000000000000000000000000000000000000000..b5c8f3e2ab3061b6ea91792bcd02444ad4d71b45
--- /dev/null
+++ b/ultralytics/docs/en/guides/raspberry-pi.md
@@ -0,0 +1,501 @@
+---
+comments: true
+description: Learn how to deploy Ultralytics YOLOv8 on Raspberry Pi with our comprehensive guide. Get performance benchmarks, setup instructions, and best practices.
+keywords: Ultralytics, YOLOv8, Raspberry Pi, setup, guide, benchmarks, computer vision, object detection, NCNN, Docker, camera modules
+---
+
+# Quick Start Guide: Raspberry Pi with Ultralytics YOLOv8
+
+This comprehensive guide provides a detailed walkthrough for deploying Ultralytics YOLOv8 on [Raspberry Pi](https://www.raspberrypi.com) devices. Additionally, it showcases performance benchmarks to demonstrate the capabilities of YOLOv8 on these small and powerful devices.
+
+
+
+
+
+ Watch: Raspberry Pi 5 updates and improvements.
+
+
+!!! Note
+
+ This guide has been tested with Raspberry Pi 4 and Raspberry Pi 5 running the latest [Raspberry Pi OS Bookworm (Debian 12)](https://www.raspberrypi.com/software/operating-systems/). Using this guide for older Raspberry Pi devices such as the Raspberry Pi 3 is expected to work as long as the same Raspberry Pi OS Bookworm is installed.
+
+## What is Raspberry Pi?
+
+Raspberry Pi is a small, affordable, single-board computer. It has become popular for a wide range of projects and applications, from hobbyist home automation to industrial uses. Raspberry Pi boards are capable of running a variety of operating systems, and they offer GPIO (General Purpose Input/Output) pins that allow for easy integration with sensors, actuators, and other hardware components. They come in different models with varying specifications, but they all share the same basic design philosophy of being low-cost, compact, and versatile.
+
+## Raspberry Pi Series Comparison
+
+| | Raspberry Pi 3 | Raspberry Pi 4 | Raspberry Pi 5 |
+| ----------------- | -------------------------------------- | -------------------------------------- | -------------------------------------- |
+| CPU | Broadcom BCM2837, Cortex-A53 64Bit SoC | Broadcom BCM2711, Cortex-A72 64Bit SoC | Broadcom BCM2712, Cortex-A76 64Bit SoC |
+| CPU Max Frequency | 1.4GHz | 1.8GHz | 2.4GHz |
+| GPU | Videocore IV | Videocore VI | VideoCore VII |
+| GPU Max Frequency | 400Mhz | 500Mhz | 800Mhz |
+| Memory | 1GB LPDDR2 SDRAM | 1GB, 2GB, 4GB, 8GB LPDDR4-3200 SDRAM | 4GB, 8GB LPDDR4X-4267 SDRAM |
+| PCIe | N/A | N/A | 1xPCIe 2.0 Interface |
+| Max Power Draw | 2.5A@5V | 3A@5V | 5A@5V (PD enabled) |
+
+## What is Raspberry Pi OS?
+
+[Raspberry Pi OS](https://www.raspberrypi.com/software) (formerly known as Raspbian) is a Unix-like operating system based on the Debian GNU/Linux distribution for the Raspberry Pi family of compact single-board computers distributed by the Raspberry Pi Foundation. Raspberry Pi OS is highly optimized for the Raspberry Pi with ARM CPUs and uses a modified LXDE desktop environment with the Openbox stacking window manager. Raspberry Pi OS is under active development, with an emphasis on improving the stability and performance of as many Debian packages as possible on Raspberry Pi.
+
+## Flash Raspberry Pi OS to Raspberry Pi
+
+The first thing to do after getting your hands on a Raspberry Pi is to flash a micro-SD card with Raspberry Pi OS, insert into the device and boot into the OS. Follow along with detailed [Getting Started Documentation by Raspberry Pi](https://www.raspberrypi.com/documentation/computers/getting-started.html) to prepare your device for first use.
+
+## Set Up Ultralytics
+
+There are two ways of setting up Ultralytics package on Raspberry Pi to build your next Computer Vision project. You can use either of them.
+
+- [Start with Docker](#start-with-docker)
+- [Start without Docker](#start-without-docker)
+
+### Start with Docker
+
+The fastest way to get started with Ultralytics YOLOv8 on Raspberry Pi is to run with pre-built docker image for Raspberry Pi.
+
+Execute the below command to pull the Docker container and run on Raspberry Pi. This is based on [arm64v8/debian](https://hub.docker.com/r/arm64v8/debian) docker image which contains Debian 12 (Bookworm) in a Python3 environment.
+
+```bash
+t=ultralytics/ultralytics:latest-arm64 && sudo docker pull $t && sudo docker run -it --ipc=host $t
+```
+
+After this is done, skip to [Use NCNN on Raspberry Pi section](#use-ncnn-on-raspberry-pi).
+
+### Start without Docker
+
+#### Install Ultralytics Package
+
+Here we will install Ultralytics package on the Raspberry Pi with optional dependencies so that we can export the PyTorch models to other different formats.
+
+1. Update packages list, install pip and upgrade to latest
+
+ ```bash
+ sudo apt update
+ sudo apt install python3-pip -y
+ pip install -U pip
+ ```
+
+2. Install `ultralytics` pip package with optional dependencies
+
+ ```bash
+ pip install ultralytics[export]
+ ```
+
+3. Reboot the device
+
+ ```bash
+ sudo reboot
+ ```
+
+## Use NCNN on Raspberry Pi
+
+Out of all the model export formats supported by Ultralytics, [NCNN](https://docs.ultralytics.com/integrations/ncnn) delivers the best inference performance when working with Raspberry Pi devices because NCNN is highly optimized for mobile/ embedded platforms (such as ARM architecture). Therefor our recommendation is to use NCNN with Raspberry Pi.
+
+## Convert Model to NCNN and Run Inference
+
+The YOLOv8n model in PyTorch format is converted to NCNN to run inference with the exported model.
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a YOLOv8n PyTorch model
+ model = YOLO("yolov8n.pt")
+
+ # Export the model to NCNN format
+ model.export(format="ncnn") # creates 'yolov8n_ncnn_model'
+
+ # Load the exported NCNN model
+ ncnn_model = YOLO("yolov8n_ncnn_model")
+
+ # Run inference
+ results = ncnn_model("https://ultralytics.com/images/bus.jpg")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Export a YOLOv8n PyTorch model to NCNN format
+ yolo export model=yolov8n.pt format=ncnn # creates 'yolov8n_ncnn_model'
+
+ # Run inference with the exported model
+ yolo predict model='yolov8n_ncnn_model' source='https://ultralytics.com/images/bus.jpg'
+ ```
+
+!!! Tip
+
+ For more details about supported export options, visit the [Ultralytics documentation page on deployment options](https://docs.ultralytics.com/guides/model-deployment-options).
+
+## Raspberry Pi 5 vs Raspberry Pi 4 YOLOv8 Benchmarks
+
+YOLOv8 benchmarks were run by the Ultralytics team on nine different model formats measuring speed and accuracy: PyTorch, TorchScript, ONNX, OpenVINO, TF SavedModel, TF GraphDef, TF Lite, PaddlePaddle, NCNN. Benchmarks were run on both Raspberry Pi 5 and Raspberry Pi 4 at FP32 precision with default input image size of 640.
+
+!!! Note
+
+ We have only included benchmarks for YOLOv8n and YOLOv8s models because other models sizes are too big to run on the Raspberry Pis and does not offer decent performance.
+
+### Comparison Chart
+
+!!! tip "Performance"
+
+ === "YOLOv8n"
+
+
+
+
+
+ === "YOLOv8s"
+
+
+
+
+
+### Detailed Comparison Table
+
+The below table represents the benchmark results for two different models (YOLOv8n, YOLOv8s) across nine different formats (PyTorch, TorchScript, ONNX, OpenVINO, TF SavedModel, TF GraphDef, TF Lite, PaddlePaddle, NCNN), running on both Raspberry Pi 4 and Raspberry Pi 5, giving us the status, size, mAP50-95(B) metric, and inference time for each combination.
+
+!!! tip "Performance"
+
+ === "YOLOv8n on RPi5"
+
+ | Format | Status | Size on disk (MB) | mAP50-95(B) | Inference time (ms/im) |
+ |---------------|--------|-------------------|-------------|------------------------|
+ | PyTorch | ✅ | 6.2 | 0.6381 | 508.61 |
+ | TorchScript | ✅ | 12.4 | 0.6092 | 558.38 |
+ | ONNX | ✅ | 12.2 | 0.6092 | 198.69 |
+ | OpenVINO | ✅ | 12.3 | 0.6092 | 704.70 |
+ | TF SavedModel | ✅ | 30.6 | 0.6092 | 367.64 |
+ | TF GraphDef | ✅ | 12.3 | 0.6092 | 473.22 |
+ | TF Lite | ✅ | 12.3 | 0.6092 | 380.67 |
+ | PaddlePaddle | ✅ | 24.4 | 0.6092 | 703.51 |
+ | NCNN | ✅ | 12.2 | 0.6034 | 94.28 |
+
+ === "YOLOv8s on RPi5"
+
+ | Format | Status | Size on disk (MB) | mAP50-95(B) | Inference time (ms/im) |
+ |---------------|--------|-------------------|-------------|------------------------|
+ | PyTorch | ✅ | 21.5 | 0.6967 | 969.49 |
+ | TorchScript | ✅ | 43.0 | 0.7136 | 1110.04 |
+ | ONNX | ✅ | 42.8 | 0.7136 | 451.37 |
+ | OpenVINO | ✅ | 42.9 | 0.7136 | 873.51 |
+ | TF SavedModel | ✅ | 107.0 | 0.7136 | 658.15 |
+ | TF GraphDef | ✅ | 42.8 | 0.7136 | 946.01 |
+ | TF Lite | ✅ | 42.8 | 0.7136 | 1013.27 |
+ | PaddlePaddle | ✅ | 85.5 | 0.7136 | 1560.23 |
+ | NCNN | ✅ | 42.7 | 0.7204 | 211.26 |
+
+ === "YOLOv8n on RPi4"
+
+ | Format | Status | Size on disk (MB) | mAP50-95(B) | Inference time (ms/im) |
+ |---------------|--------|-------------------|-------------|------------------------|
+ | PyTorch | ✅ | 6.2 | 0.6381 | 1068.42 |
+ | TorchScript | ✅ | 12.4 | 0.6092 | 1248.01 |
+ | ONNX | ✅ | 12.2 | 0.6092 | 560.04 |
+ | OpenVINO | ✅ | 12.3 | 0.6092 | 534.93 |
+ | TF SavedModel | ✅ | 30.6 | 0.6092 | 816.50 |
+ | TF GraphDef | ✅ | 12.3 | 0.6092 | 1007.57 |
+ | TF Lite | ✅ | 12.3 | 0.6092 | 950.29 |
+ | PaddlePaddle | ✅ | 24.4 | 0.6092 | 1507.75 |
+ | NCNN | ✅ | 12.2 | 0.6092 | 414.73 |
+
+ === "YOLOv8s on RPi4"
+
+ | Format | Status | Size on disk (MB) | mAP50-95(B) | Inference time (ms/im) |
+ |---------------|--------|-------------------|-------------|------------------------|
+ | PyTorch | ✅ | 21.5 | 0.6967 | 2589.58 |
+ | TorchScript | ✅ | 43.0 | 0.7136 | 2901.33 |
+ | ONNX | ✅ | 42.8 | 0.7136 | 1436.33 |
+ | OpenVINO | ✅ | 42.9 | 0.7136 | 1225.19 |
+ | TF SavedModel | ✅ | 107.0 | 0.7136 | 1770.95 |
+ | TF GraphDef | ✅ | 42.8 | 0.7136 | 2146.66 |
+ | TF Lite | ✅ | 42.8 | 0.7136 | 2945.03 |
+ | PaddlePaddle | ✅ | 85.5 | 0.7136 | 3962.62 |
+ | NCNN | ✅ | 42.7 | 0.7136 | 1042.39 |
+
+## Reproduce Our Results
+
+To reproduce the above Ultralytics benchmarks on all [export formats](../modes/export.md), run this code:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a YOLOv8n PyTorch model
+ model = YOLO("yolov8n.pt")
+
+ # Benchmark YOLOv8n speed and accuracy on the COCO8 dataset for all all export formats
+ results = model.benchmarks(data="coco8.yaml", imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Benchmark YOLOv8n speed and accuracy on the COCO8 dataset for all all export formats
+ yolo benchmark model=yolov8n.pt data=coco8.yaml imgsz=640
+ ```
+
+ Note that benchmarking results might vary based on the exact hardware and software configuration of a system, as well as the current workload of the system at the time the benchmarks are run. For the most reliable results use a dataset with a large number of images, i.e. `data='coco8.yaml' (4 val images), or `data='coco.yaml'` (5000 val images).
+
+## Use Raspberry Pi Camera
+
+When using Raspberry Pi for Computer Vision projects, it can be essentially to grab real-time video feeds to perform inference. The onboard MIPI CSI connector on the Raspberry Pi allows you to connect official Raspberry PI camera modules. In this guide, we have used a [Raspberry Pi Camera Module 3](https://www.raspberrypi.com/products/camera-module-3) to grab the video feeds and perform inference using YOLOv8 models.
+
+!!! Tip
+
+ Learn more about the [different camera modules offered by Raspberry Pi](https://www.raspberrypi.com/documentation/accessories/camera.html) and also [how to get started with the Raspberry Pi camera modules](https://www.raspberrypi.com/documentation/computers/camera_software.html#introducing-the-raspberry-pi-cameras).
+
+!!! Note
+
+ Raspberry Pi 5 uses smaller CSI connectors than the Raspberry Pi 4 (15-pin vs 22-pin), so you will need a [15-pin to 22pin adapter cable](https://www.raspberrypi.com/products/camera-cable) to connect to a Raspberry Pi Camera.
+
+### Test the Camera
+
+Execute the following command after connecting the camera to the Raspberry Pi. You should see a live video feed from the camera for about 5 seconds.
+
+```bash
+rpicam-hello
+```
+
+!!! Tip
+
+ Learn more about [`rpicam-hello` usage on official Raspberry Pi documentation](https://www.raspberrypi.com/documentation/computers/camera_software.html#rpicam-hello)
+
+### Inference with Camera
+
+There are 2 methods of using the Raspberry Pi Camera to inference YOLOv8 models.
+
+!!! Usage
+
+ === "Method 1"
+
+ We can use `picamera2`which comes pre-installed with Raspberry Pi OS to access the camera and inference YOLOv8 models.
+
+ !!! Example
+
+ === "Python"
+
+ ```python
+ import cv2
+ from picamera2 import Picamera2
+
+ from ultralytics import YOLO
+
+ # Initialize the Picamera2
+ picam2 = Picamera2()
+ picam2.preview_configuration.main.size = (1280, 720)
+ picam2.preview_configuration.main.format = "RGB888"
+ picam2.preview_configuration.align()
+ picam2.configure("preview")
+ picam2.start()
+
+ # Load the YOLOv8 model
+ model = YOLO("yolov8n.pt")
+
+ while True:
+ # Capture frame-by-frame
+ frame = picam2.capture_array()
+
+ # Run YOLOv8 inference on the frame
+ results = model(frame)
+
+ # Visualize the results on the frame
+ annotated_frame = results[0].plot()
+
+ # Display the resulting frame
+ cv2.imshow("Camera", annotated_frame)
+
+ # Break the loop if 'q' is pressed
+ if cv2.waitKey(1) == ord("q"):
+ break
+
+ # Release resources and close windows
+ cv2.destroyAllWindows()
+ ```
+
+ === "Method 2"
+
+ We need to initiate a TCP stream with `rpicam-vid` from the connected camera so that we can use this stream URL as an input when we are inferencing later. Execute the following command to start the TCP stream.
+
+ ```bash
+ rpicam-vid -n -t 0 --inline --listen -o tcp://127.0.0.1:8888
+ ```
+
+ Learn more about [`rpicam-vid` usage on official Raspberry Pi documentation](https://www.raspberrypi.com/documentation/computers/camera_software.html#rpicam-vid)
+
+ !!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a YOLOv8n PyTorch model
+ model = YOLO("yolov8n.pt")
+
+ # Run inference
+ results = model("tcp://127.0.0.1:8888")
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo predict model=yolov8n.pt source="tcp://127.0.0.1:8888"
+ ```
+
+!!! Tip
+
+ Check our document on [Inference Sources](https://docs.ultralytics.com/modes/predict/#inference-sources) if you want to change the image/ video input type
+
+## Best Practices when using Raspberry Pi
+
+There are a couple of best practices to follow in order to enable maximum performance on Raspberry Pis running YOLOv8.
+
+1. Use an SSD
+
+ When using Raspberry Pi for 24x7 continued usage, it is recommended to use an SSD for the system because an SD card will not be able to withstand continuous writes and might get broken. With the onboard PCIe connector on the Raspberry Pi 5, now you can connect SSDs using an adapter such as the [NVMe Base for Raspberry Pi 5](https://shop.pimoroni.com/products/nvme-base).
+
+2. Flash without GUI
+
+ When flashing Raspberry Pi OS, you can choose to not install the Desktop environment (Raspberry Pi OS Lite) and this can save a bit of RAM on the device, leaving more space for computer vision processing.
+
+## Next Steps
+
+Congratulations on successfully setting up YOLO on your Raspberry Pi! For further learning and support, visit [Ultralytics YOLOv8 Docs](../index.md) and [Kashmir World Foundation](https://www.kashmirworldfoundation.org/).
+
+## Acknowledgements and Citations
+
+This guide was initially created by Daan Eeltink for Kashmir World Foundation, an organization dedicated to the use of YOLO for the conservation of endangered species. We acknowledge their pioneering work and educational focus in the realm of object detection technologies.
+
+For more information about Kashmir World Foundation's activities, you can visit their [website](https://www.kashmirworldfoundation.org/).
+
+## FAQ
+
+### How do I set up Ultralytics YOLOv8 on a Raspberry Pi without using Docker?
+
+To set up Ultralytics YOLOv8 on a Raspberry Pi without Docker, follow these steps:
+
+1. Update the package list and install `pip`:
+ ```bash
+ sudo apt update
+ sudo apt install python3-pip -y
+ pip install -U pip
+ ```
+2. Install the Ultralytics package with optional dependencies:
+ ```bash
+ pip install ultralytics[export]
+ ```
+3. Reboot the device to apply changes:
+ ```bash
+ sudo reboot
+ ```
+
+For detailed instructions, refer to the [Start without Docker](#start-without-docker) section.
+
+### Why should I use Ultralytics YOLOv8's NCNN format on Raspberry Pi for AI tasks?
+
+Ultralytics YOLOv8's NCNN format is highly optimized for mobile and embedded platforms, making it ideal for running AI tasks on Raspberry Pi devices. NCNN maximizes inference performance by leveraging ARM architecture, providing faster and more efficient processing compared to other formats. For more details on supported export options, visit the [Ultralytics documentation page on deployment options](../modes/export.md).
+
+### How can I convert a YOLOv8 model to NCNN format for use on Raspberry Pi?
+
+You can convert a PyTorch YOLOv8 model to NCNN format using either Python or CLI commands:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a YOLOv8n PyTorch model
+ model = YOLO("yolov8n.pt")
+
+ # Export the model to NCNN format
+ model.export(format="ncnn") # creates 'yolov8n_ncnn_model'
+
+ # Load the exported NCNN model
+ ncnn_model = YOLO("yolov8n_ncnn_model")
+
+ # Run inference
+ results = ncnn_model("https://ultralytics.com/images/bus.jpg")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Export a YOLOv8n PyTorch model to NCNN format
+ yolo export model=yolov8n.pt format=ncnn # creates 'yolov8n_ncnn_model'
+
+ # Run inference with the exported model
+ yolo predict model='yolov8n_ncnn_model' source='https://ultralytics.com/images/bus.jpg'
+ ```
+
+For more details, see the [Use NCNN on Raspberry Pi](#use-ncnn-on-raspberry-pi) section.
+
+### What are the hardware differences between Raspberry Pi 4 and Raspberry Pi 5 relevant to running YOLOv8?
+
+Key differences include:
+
+- **CPU**: Raspberry Pi 4 uses Broadcom BCM2711, Cortex-A72 64-bit SoC, while Raspberry Pi 5 uses Broadcom BCM2712, Cortex-A76 64-bit SoC.
+- **Max CPU Frequency**: Raspberry Pi 4 has a max frequency of 1.8GHz, whereas Raspberry Pi 5 reaches 2.4GHz.
+- **Memory**: Raspberry Pi 4 offers up to 8GB of LPDDR4-3200 SDRAM, while Raspberry Pi 5 features LPDDR4X-4267 SDRAM, available in 4GB and 8GB variants.
+
+These enhancements contribute to better performance benchmarks for YOLOv8 models on Raspberry Pi 5 compared to Raspberry Pi 4. Refer to the [Raspberry Pi Series Comparison](#raspberry-pi-series-comparison) table for more details.
+
+### How can I set up a Raspberry Pi Camera Module to work with Ultralytics YOLOv8?
+
+There are two methods to set up a Raspberry Pi Camera for YOLOv8 inference:
+
+1. **Using `picamera2`**:
+
+ ```python
+ import cv2
+ from picamera2 import Picamera2
+
+ from ultralytics import YOLO
+
+ picam2 = Picamera2()
+ picam2.preview_configuration.main.size = (1280, 720)
+ picam2.preview_configuration.main.format = "RGB888"
+ picam2.preview_configuration.align()
+ picam2.configure("preview")
+ picam2.start()
+
+ model = YOLO("yolov8n.pt")
+
+ while True:
+ frame = picam2.capture_array()
+ results = model(frame)
+ annotated_frame = results[0].plot()
+ cv2.imshow("Camera", annotated_frame)
+
+ if cv2.waitKey(1) == ord("q"):
+ break
+
+ cv2.destroyAllWindows()
+ ```
+
+2. **Using a TCP Stream**:
+
+ ```bash
+ rpicam-vid -n -t 0 --inline --listen -o tcp://127.0.0.1:8888
+ ```
+
+ ```python
+ from ultralytics import YOLO
+
+ model = YOLO("yolov8n.pt")
+ results = model("tcp://127.0.0.1:8888")
+ ```
+
+For detailed setup instructions, visit the [Inference with Camera](#inference-with-camera) section.
diff --git a/ultralytics/docs/en/guides/region-counting.md b/ultralytics/docs/en/guides/region-counting.md
new file mode 100644
index 0000000000000000000000000000000000000000..f08493e982950ce75fd194cc6f053d26ceb684a5
--- /dev/null
+++ b/ultralytics/docs/en/guides/region-counting.md
@@ -0,0 +1,133 @@
+---
+comments: true
+description: Learn how to use Ultralytics YOLOv8 for precise object counting in specified regions, enhancing efficiency across various applications.
+keywords: object counting, regions, YOLOv8, computer vision, Ultralytics, efficiency, accuracy, automation, real-time, applications, surveillance, monitoring
+---
+
+# Object Counting in Different Regions using Ultralytics YOLOv8 🚀
+
+## What is Object Counting in Regions?
+
+[Object counting](../guides/object-counting.md) in regions with [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) involves precisely determining the number of objects within specified areas using advanced computer vision. This approach is valuable for optimizing processes, enhancing security, and improving efficiency in various applications.
+
+
+
+
+
+ Watch: Ultralytics YOLOv8 Object Counting in Multiple & Movable Regions
+
+
+## Advantages of Object Counting in Regions?
+
+- **Precision and Accuracy:** Object counting in regions with advanced computer vision ensures precise and accurate counts, minimizing errors often associated with manual counting.
+- **Efficiency Improvement:** Automated object counting enhances operational efficiency, providing real-time results and streamlining processes across different applications.
+- **Versatility and Application:** The versatility of object counting in regions makes it applicable across various domains, from manufacturing and surveillance to traffic monitoring, contributing to its widespread utility and effectiveness.
+
+## Real World Applications
+
+| Retail | Market Streets |
+| :----------------------------------------------------------------------------------------------------------------------------------------------------------------: | :---------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+|  |  |
+| People Counting in Different Region using Ultralytics YOLOv8 | Crowd Counting in Different Region using Ultralytics YOLOv8 |
+
+## Steps to Run
+
+### Step 1: Install Required Libraries
+
+Begin by cloning the Ultralytics repository, installing dependencies, and navigating to the local directory using the provided commands in Step 2.
+
+```bash
+# Clone Ultralytics repo
+git clone https://github.com/ultralytics/ultralytics
+
+# Navigate to the local directory
+cd ultralytics/examples/YOLOv8-Region-Counter
+```
+
+### Step 2: Run Region Counting Using Ultralytics YOLOv8
+
+Execute the following basic commands for inference.
+
+???+ tip "Region is Movable"
+
+ During video playback, you can interactively move the region within the video by clicking and dragging using the left mouse button.
+
+```bash
+# Save results
+python yolov8_region_counter.py --source "path/to/video.mp4" --save-img
+
+# Run model on CPU
+python yolov8_region_counter.py --source "path/to/video.mp4" --device cpu
+
+# Change model file
+python yolov8_region_counter.py --source "path/to/video.mp4" --weights "path/to/model.pt"
+
+# Detect specific classes (e.g., first and third classes)
+python yolov8_region_counter.py --source "path/to/video.mp4" --classes 0 2
+
+# View results without saving
+python yolov8_region_counter.py --source "path/to/video.mp4" --view-img
+```
+
+### Optional Arguments
+
+| Name | Type | Default | Description |
+| -------------------- | ------ | ------------ | ------------------------------------------ |
+| `--source` | `str` | `None` | Path to video file, for webcam 0 |
+| `--line_thickness` | `int` | `2` | Bounding Box thickness |
+| `--save-img` | `bool` | `False` | Save the predicted video/image |
+| `--weights` | `str` | `yolov8n.pt` | Weights file path |
+| `--classes` | `list` | `None` | Detect specific classes i.e. --classes 0 2 |
+| `--region-thickness` | `int` | `2` | Region Box thickness |
+| `--track-thickness` | `int` | `2` | Tracking line thickness |
+
+## FAQ
+
+### What is object counting in specified regions using Ultralytics YOLOv8?
+
+Object counting in specified regions with [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics) involves detecting and tallying the number of objects within defined areas using advanced computer vision. This precise method enhances efficiency and accuracy across various applications like manufacturing, surveillance, and traffic monitoring.
+
+### How do I run the object counting script with Ultralytics YOLOv8?
+
+Follow these steps to run object counting in Ultralytics YOLOv8:
+
+1. Clone the Ultralytics repository and navigate to the directory:
+
+ ```bash
+ git clone https://github.com/ultralytics/ultralytics
+ cd ultralytics/examples/YOLOv8-Region-Counter
+ ```
+
+2. Execute the region counting script:
+ ```bash
+ python yolov8_region_counter.py --source "path/to/video.mp4" --save-img
+ ```
+
+For more options, visit the [Run Region Counting](#steps-to-run) section.
+
+### Why should I use Ultralytics YOLOv8 for object counting in regions?
+
+Using Ultralytics YOLOv8 for object counting in regions offers several advantages:
+
+- **Precision and Accuracy:** Minimizes errors often seen in manual counting.
+- **Efficiency Improvement:** Provides real-time results and streamlines processes.
+- **Versatility and Application:** Applies to various domains, enhancing its utility.
+
+Explore deeper benefits in the [Advantages](#advantages-of-object-counting-in-regions) section.
+
+### Can the defined regions be adjusted during video playback?
+
+Yes, with Ultralytics YOLOv8, regions can be interactively moved during video playback. Simply click and drag with the left mouse button to reposition the region. This feature enhances flexibility for dynamic environments. Learn more in the tip section for [movable regions](#step-2-run-region-counting-using-ultralytics-yolov8).
+
+### What are some real-world applications of object counting in regions?
+
+Object counting with Ultralytics YOLOv8 can be applied to numerous real-world scenarios:
+
+- **Retail:** Counting people for foot traffic analysis.
+- **Market Streets:** Crowd density management.
+
+Explore more examples in the [Real World Applications](#real-world-applications) section.
diff --git a/ultralytics/docs/en/guides/ros-quickstart.md b/ultralytics/docs/en/guides/ros-quickstart.md
new file mode 100644
index 0000000000000000000000000000000000000000..ab37131b57054fb411d427ca57e8ef78c038f71f
--- /dev/null
+++ b/ultralytics/docs/en/guides/ros-quickstart.md
@@ -0,0 +1,626 @@
+---
+comments: true
+description: Learn to integrate Ultralytics YOLO with your robot running ROS Noetic, utilizing RGB images, depth images, and point clouds for efficient object detection, segmentation, and enhanced robotic perception.
+keywords: Ultralytics, YOLO, object detection, deep learning, machine learning, guide, ROS, Robot Operating System, robotics, ROS Noetic, Python, Ubuntu, simulation, visualization, communication, middleware, hardware abstraction, tools, utilities, ecosystem, Noetic Ninjemys, autonomous vehicle, AMV
+---
+
+# ROS (Robot Operating System) quickstart guide
+
+
+
+## What is ROS?
+
+The [Robot Operating System (ROS)](https://www.ros.org/) is an open-source framework widely used in robotics research and industry. ROS provides a collection of [libraries and tools](https://www.ros.org/blog/ecosystem/) to help developers create robot applications. ROS is designed to work with various [robotic platforms](https://robots.ros.org/), making it a flexible and powerful tool for roboticists.
+
+### Key Features of ROS
+
+1. **Modular Architecture**: ROS has a modular architecture, allowing developers to build complex systems by combining smaller, reusable components called [nodes](https://wiki.ros.org/ROS/Tutorials/UnderstandingNodes). Each node typically performs a specific function, and nodes communicate with each other using messages over [topics](https://wiki.ros.org/ROS/Tutorials/UnderstandingTopics) or [services](https://wiki.ros.org/ROS/Tutorials/UnderstandingServicesParams).
+
+2. **Communication Middleware**: ROS offers a robust communication infrastructure that supports inter-process communication and distributed computing. This is achieved through a publish-subscribe model for data streams (topics) and a request-reply model for service calls.
+
+3. **Hardware Abstraction**: ROS provides a layer of abstraction over the hardware, enabling developers to write device-agnostic code. This allows the same code to be used with different hardware setups, facilitating easier integration and experimentation.
+
+4. **Tools and Utilities**: ROS comes with a rich set of tools and utilities for visualization, debugging, and simulation. For instance, RViz is used for visualizing sensor data and robot state information, while Gazebo provides a powerful simulation environment for testing algorithms and robot designs.
+
+5. **Extensive Ecosystem**: The ROS ecosystem is vast and continually growing, with numerous packages available for different robotic applications, including navigation, manipulation, perception, and more. The community actively contributes to the development and maintenance of these packages.
+
+???+ note "Evolution of ROS Versions"
+
+ Since its development in 2007, ROS has evolved through [multiple versions](https://wiki.ros.org/Distributions), each introducing new features and improvements to meet the growing needs of the robotics community. The development of ROS can be categorized into two main series: ROS 1 and ROS 2. This guide focuses on the Long Term Support (LTS) version of ROS 1, known as ROS Noetic Ninjemys, the code should also work with earlier versions.
+
+ ### ROS 1 vs. ROS 2
+
+ While ROS 1 provided a solid foundation for robotic development, ROS 2 addresses its shortcomings by offering:
+
+ - **Real-time Performance**: Improved support for real-time systems and deterministic behavior.
+ - **Security**: Enhanced security features for safe and reliable operation in various environments.
+ - **Scalability**: Better support for multi-robot systems and large-scale deployments.
+ - **Cross-platform Support**: Expanded compatibility with various operating systems beyond Linux, including Windows and macOS.
+ - **Flexible Communication**: Use of DDS for more flexible and efficient inter-process communication.
+
+### ROS Messages and Topics
+
+In ROS, communication between nodes is facilitated through [messages](https://wiki.ros.org/Messages) and [topics](https://wiki.ros.org/Topics). A message is a data structure that defines the information exchanged between nodes, while a topic is a named channel over which messages are sent and received. Nodes can publish messages to a topic or subscribe to messages from a topic, enabling them to communicate with each other. This publish-subscribe model allows for asynchronous communication and decoupling between nodes. Each sensor or actuator in a robotic system typically publishes data to a topic, which can then be consumed by other nodes for processing or control. For the purpose of this guide, we will focus on Image, Depth and PointCloud messages and camera topics.
+
+## Setting Up Ultralytics YOLO with ROS
+
+This guide has been tested using [this ROS environment](https://github.com/ambitious-octopus/rosbot_ros/tree/noetic), which is a fork of the [ROSbot ROS repository](https://github.com/husarion/rosbot_ros). This environment includes the Ultralytics YOLO package, a Docker container for easy setup, comprehensive ROS packages, and Gazebo worlds for rapid testing. It is designed to work with the [Husarion ROSbot 2 PRO](https://husarion.com/manuals/rosbot/). The code examples provided will work in any ROS Noetic/Melodic environment, including both simulation and real-world.
+
+
+
+
+
+### Dependencies Installation
+
+Apart from the ROS environment, you will need to install the following dependencies:
+
+- **[ROS Numpy package](https://github.com/eric-wieser/ros_numpy)**: This is required for fast conversion between ROS Image messages and numpy arrays.
+
+ ```bash
+ pip install ros_numpy
+ ```
+
+- **Ultralytics package**:
+
+ ```bash
+ pip install ultralytics
+ ```
+
+## Use Ultralytics with ROS `sensor_msgs/Image`
+
+The `sensor_msgs/Image` [message type](https://docs.ros.org/en/api/sensor_msgs/html/msg/Image.html) is commonly used in ROS for representing image data. It contains fields for encoding, height, width, and pixel data, making it suitable for transmitting images captured by cameras or other sensors. Image messages are widely used in robotic applications for tasks such as visual perception, object detection, and navigation.
+
+
+
+
+
+### Image Step-by-Step Usage
+
+The following code snippet demonstrates how to use the Ultralytics YOLO package with ROS. In this example, we subscribe to a camera topic, process the incoming image using YOLO, and publish the detected objects to new topics for [detection](../tasks/detect.md) and [segmentation](../tasks/segment.md).
+
+First, import the necessary libraries and instantiate two models: one for [segmentation](../tasks/segment.md) and one for [detection](../tasks/detect.md). Initialize a ROS node (with the name `ultralytics`) to enable communication with the ROS master. To ensure a stable connection, we include a brief pause, giving the node sufficient time to establish the connection before proceeding.
+
+```python
+import time
+
+import rospy
+
+from ultralytics import YOLO
+
+detection_model = YOLO("yolov8m.pt")
+segmentation_model = YOLO("yolov8m-seg.pt")
+rospy.init_node("ultralytics")
+time.sleep(1)
+```
+
+Initialize two ROS topics: one for [detection](../tasks/detect.md) and one for [segmentation](../tasks/segment.md). These topics will be used to publish the annotated images, making them accessible for further processing. The communication between nodes is facilitated using `sensor_msgs/Image` messages.
+
+```python
+from sensor_msgs.msg import Image
+
+det_image_pub = rospy.Publisher("/ultralytics/detection/image", Image, queue_size=5)
+seg_image_pub = rospy.Publisher("/ultralytics/segmentation/image", Image, queue_size=5)
+```
+
+Finally, create a subscriber that listens to messages on the `/camera/color/image_raw` topic and calls a callback function for each new message. This callback function receives messages of type `sensor_msgs/Image`, converts them into a numpy array using `ros_numpy`, processes the images with the previously instantiated YOLO models, annotates the images, and then publishes them back to the respective topics: `/ultralytics/detection/image` for detection and `/ultralytics/segmentation/image` for segmentation.
+
+```python
+import ros_numpy
+
+
+def callback(data):
+ """Callback function to process image and publish annotated images."""
+ array = ros_numpy.numpify(data)
+ if det_image_pub.get_num_connections():
+ det_result = detection_model(array)
+ det_annotated = det_result[0].plot(show=False)
+ det_image_pub.publish(ros_numpy.msgify(Image, det_annotated, encoding="rgb8"))
+
+ if seg_image_pub.get_num_connections():
+ seg_result = segmentation_model(array)
+ seg_annotated = seg_result[0].plot(show=False)
+ seg_image_pub.publish(ros_numpy.msgify(Image, seg_annotated, encoding="rgb8"))
+
+
+rospy.Subscriber("/camera/color/image_raw", Image, callback)
+
+while True:
+ rospy.spin()
+```
+
+??? Example "Complete code"
+
+ ```python
+ import time
+
+ import ros_numpy
+ import rospy
+ from sensor_msgs.msg import Image
+
+ from ultralytics import YOLO
+
+ detection_model = YOLO("yolov8m.pt")
+ segmentation_model = YOLO("yolov8m-seg.pt")
+ rospy.init_node("ultralytics")
+ time.sleep(1)
+
+ det_image_pub = rospy.Publisher("/ultralytics/detection/image", Image, queue_size=5)
+ seg_image_pub = rospy.Publisher("/ultralytics/segmentation/image", Image, queue_size=5)
+
+
+ def callback(data):
+ """Callback function to process image and publish annotated images."""
+ array = ros_numpy.numpify(data)
+ if det_image_pub.get_num_connections():
+ det_result = detection_model(array)
+ det_annotated = det_result[0].plot(show=False)
+ det_image_pub.publish(ros_numpy.msgify(Image, det_annotated, encoding="rgb8"))
+
+ if seg_image_pub.get_num_connections():
+ seg_result = segmentation_model(array)
+ seg_annotated = seg_result[0].plot(show=False)
+ seg_image_pub.publish(ros_numpy.msgify(Image, seg_annotated, encoding="rgb8"))
+
+
+ rospy.Subscriber("/camera/color/image_raw", Image, callback)
+
+ while True:
+ rospy.spin()
+ ```
+
+???+ tip "Debugging"
+
+ Debugging ROS (Robot Operating System) nodes can be challenging due to the system's distributed nature. Several tools can assist with this process:
+
+ 1. `rostopic echo ` : This command allows you to view messages published on a specific topic, helping you inspect the data flow.
+ 2. `rostopic list`: Use this command to list all available topics in the ROS system, giving you an overview of the active data streams.
+ 3. `rqt_graph`: This visualization tool displays the communication graph between nodes, providing insights into how nodes are interconnected and how they interact.
+ 4. For more complex visualizations, such as 3D representations, you can use [RViz](https://wiki.ros.org/rviz). RViz (ROS Visualization) is a powerful 3D visualization tool for ROS. It allows you to visualize the state of your robot and its environment in real-time. With RViz, you can view sensor data (e.g. `sensors_msgs/Image`), robot model states, and various other types of information, making it easier to debug and understand the behavior of your robotic system.
+
+### Publish Detected Classes with `std_msgs/String`
+
+Standard ROS messages also include `std_msgs/String` messages. In many applications, it is not necessary to republish the entire annotated image; instead, only the classes present in the robot's view are needed. The following example demonstrates how to use `std_msgs/String` [messages](https://docs.ros.org/en/noetic/api/std_msgs/html/msg/String.html) to republish the detected classes on the `/ultralytics/detection/classes` topic. These messages are more lightweight and provide essential information, making them valuable for various applications.
+
+#### Example Use Case
+
+Consider a warehouse robot equipped with a camera and object [detection model](../tasks/detect.md). Instead of sending large annotated images over the network, the robot can publish a list of detected classes as `std_msgs/String` messages. For instance, when the robot detects objects like "box", "pallet" and "forklift" it publishes these classes to the `/ultralytics/detection/classes` topic. This information can then be used by a central monitoring system to track the inventory in real-time, optimize the robot's path planning to avoid obstacles, or trigger specific actions such as picking up a detected box. This approach reduces the bandwidth required for communication and focuses on transmitting critical data.
+
+### String Step-by-Step Usage
+
+This example demonstrates how to use the Ultralytics YOLO package with ROS. In this example, we subscribe to a camera topic, process the incoming image using YOLO, and publish the detected objects to new topic `/ultralytics/detection/classes` using `std_msgs/String` messages. The `ros_numpy` package is used to convert the ROS Image message to a numpy array for processing with YOLO.
+
+```python
+import time
+
+import ros_numpy
+import rospy
+from sensor_msgs.msg import Image
+from std_msgs.msg import String
+
+from ultralytics import YOLO
+
+detection_model = YOLO("yolov8m.pt")
+rospy.init_node("ultralytics")
+time.sleep(1)
+classes_pub = rospy.Publisher("/ultralytics/detection/classes", String, queue_size=5)
+
+
+def callback(data):
+ """Callback function to process image and publish detected classes."""
+ array = ros_numpy.numpify(data)
+ if classes_pub.get_num_connections():
+ det_result = detection_model(array)
+ classes = det_result[0].boxes.cls.cpu().numpy().astype(int)
+ names = [det_result[0].names[i] for i in classes]
+ classes_pub.publish(String(data=str(names)))
+
+
+rospy.Subscriber("/camera/color/image_raw", Image, callback)
+while True:
+ rospy.spin()
+```
+
+## Use Ultralytics with ROS Depth Images
+
+In addition to RGB images, ROS supports [depth images](https://en.wikipedia.org/wiki/Depth_map), which provide information about the distance of objects from the camera. Depth images are crucial for robotic applications such as obstacle avoidance, 3D mapping, and localization.
+
+A depth image is an image where each pixel represents the distance from the camera to an object. Unlike RGB images that capture color, depth images capture spatial information, enabling robots to perceive the 3D structure of their environment.
+
+!!! tip "Obtaining Depth Images"
+
+ Depth images can be obtained using various sensors:
+
+ 1. [Stereo Cameras](https://en.wikipedia.org/wiki/Stereo_camera): Use two cameras to calculate depth based on image disparity.
+ 2. [Time-of-Flight (ToF) Cameras](https://en.wikipedia.org/wiki/Time-of-flight_camera): Measure the time light takes to return from an object.
+ 3. [Structured Light Sensors](https://en.wikipedia.org/wiki/Structured-light_3D_scanner): Project a pattern and measure its deformation on surfaces.
+
+### Using YOLO with Depth Images
+
+In ROS, depth images are represented by the `sensor_msgs/Image` message type, which includes fields for encoding, height, width, and pixel data. The encoding field for depth images often uses a format like "16UC1", indicating a 16-bit unsigned integer per pixel, where each value represents the distance to the object. Depth images are commonly used in conjunction with RGB images to provide a more comprehensive view of the environment.
+
+Using YOLO, it is possible to extract and combine information from both RGB and depth images. For instance, YOLO can detect objects within an RGB image, and this detection can be used to pinpoint corresponding regions in the depth image. This allows for the extraction of precise depth information for detected objects, enhancing the robot's ability to understand its environment in three dimensions.
+
+!!! warning "RGB-D Cameras"
+
+ When working with depth images, it is essential to ensure that the RGB and depth images are correctly aligned. RGB-D cameras, such as the [Intel RealSense](https://www.intelrealsense.com/) series, provide synchronized RGB and depth images, making it easier to combine information from both sources. If using separate RGB and depth cameras, it is crucial to calibrate them to ensure accurate alignment.
+
+#### Depth Step-by-Step Usage
+
+In this example, we use YOLO to segment an image and apply the extracted mask to segment the object in the depth image. This allows us to determine the distance of each pixel of the object of interest from the camera's focal center. By obtaining this distance information, we can calculate the distance between the camera and the specific object in the scene. Begin by importing the necessary libraries, creating a ROS node, and instantiating a segmentation model and a ROS topic.
+
+```python
+import time
+
+import rospy
+from std_msgs.msg import String
+
+from ultralytics import YOLO
+
+rospy.init_node("ultralytics")
+time.sleep(1)
+
+segmentation_model = YOLO("yolov8m-seg.pt")
+
+classes_pub = rospy.Publisher("/ultralytics/detection/distance", String, queue_size=5)
+```
+
+Next, define a callback function that processes the incoming depth image message. The function waits for the depth image and RGB image messages, converts them into numpy arrays, and applies the segmentation model to the RGB image. It then extracts the segmentation mask for each detected object and calculates the average distance of the object from the camera using the depth image. Most sensors have a maximum distance, known as the clip distance, beyond which values are represented as inf (`np.inf`). Before processing, it is important to filter out these null values and assign them a value of `0`. Finally, it publishes the detected objects along with their average distances to the `/ultralytics/detection/distance` topic.
+
+```python
+import numpy as np
+import ros_numpy
+from sensor_msgs.msg import Image
+
+
+def callback(data):
+ """Callback function to process depth image and RGB image."""
+ image = rospy.wait_for_message("/camera/color/image_raw", Image)
+ image = ros_numpy.numpify(image)
+ depth = ros_numpy.numpify(data)
+ result = segmentation_model(image)
+
+ for index, cls in enumerate(result[0].boxes.cls):
+ class_index = int(cls.cpu().numpy())
+ name = result[0].names[class_index]
+ mask = result[0].masks.data.cpu().numpy()[index, :, :].astype(int)
+ obj = depth[mask == 1]
+ obj = obj[~np.isnan(obj)]
+ avg_distance = np.mean(obj) if len(obj) else np.inf
+
+ classes_pub.publish(String(data=str(all_objects)))
+
+
+rospy.Subscriber("/camera/depth/image_raw", Image, callback)
+
+while True:
+ rospy.spin()
+```
+
+??? Example "Complete code"
+
+ ```python
+ import time
+
+ import numpy as np
+ import ros_numpy
+ import rospy
+ from sensor_msgs.msg import Image
+ from std_msgs.msg import String
+
+ from ultralytics import YOLO
+
+ rospy.init_node("ultralytics")
+ time.sleep(1)
+
+ segmentation_model = YOLO("yolov8m-seg.pt")
+
+ classes_pub = rospy.Publisher("/ultralytics/detection/distance", String, queue_size=5)
+
+
+ def callback(data):
+ """Callback function to process depth image and RGB image."""
+ image = rospy.wait_for_message("/camera/color/image_raw", Image)
+ image = ros_numpy.numpify(image)
+ depth = ros_numpy.numpify(data)
+ result = segmentation_model(image)
+
+ for index, cls in enumerate(result[0].boxes.cls):
+ class_index = int(cls.cpu().numpy())
+ name = result[0].names[class_index]
+ mask = result[0].masks.data.cpu().numpy()[index, :, :].astype(int)
+ obj = depth[mask == 1]
+ obj = obj[~np.isnan(obj)]
+ avg_distance = np.mean(obj) if len(obj) else np.inf
+
+ classes_pub.publish(String(data=str(all_objects)))
+
+
+ rospy.Subscriber("/camera/depth/image_raw", Image, callback)
+
+ while True:
+ rospy.spin()
+ ```
+
+## Use Ultralytics with ROS `sensor_msgs/PointCloud2`
+
+
+
+
+
+The `sensor_msgs/PointCloud2` [message type](https://docs.ros.org/en/api/sensor_msgs/html/msg/PointCloud2.html) is a data structure used in ROS to represent 3D point cloud data. This message type is integral to robotic applications, enabling tasks such as 3D mapping, object recognition, and localization.
+
+A point cloud is a collection of data points defined within a three-dimensional coordinate system. These data points represent the external surface of an object or a scene, captured via 3D scanning technologies. Each point in the cloud has `X`, `Y`, and `Z` coordinates, which correspond to its position in space, and may also include additional information such as color and intensity.
+
+!!! warning "Reference frame"
+
+ When working with `sensor_msgs/PointCloud2`, it's essential to consider the reference frame of the sensor from which the point cloud data was acquired. The point cloud is initially captured in the sensor's reference frame. You can determine this reference frame by listening to the `/tf_static` topic. However, depending on your specific application requirements, you might need to convert the point cloud into another reference frame. This transformation can be achieved using the `tf2_ros` package, which provides tools for managing coordinate frames and transforming data between them.
+
+!!! tip "Obtaining Point clouds"
+
+ Point Clouds can be obtained using various sensors:
+
+ 1. **LIDAR (Light Detection and Ranging)**: Uses laser pulses to measure distances to objects and create high-precision 3D maps.
+ 2. **Depth Cameras**: Capture depth information for each pixel, allowing for 3D reconstruction of the scene.
+ 3. **Stereo Cameras**: Utilize two or more cameras to obtain depth information through triangulation.
+ 4. **Structured Light Scanners**: Project a known pattern onto a surface and measure the deformation to calculate depth.
+
+### Using YOLO with Point Clouds
+
+To integrate YOLO with `sensor_msgs/PointCloud2` type messages, we can employ a method similar to the one used for depth maps. By leveraging the color information embedded in the point cloud, we can extract a 2D image, perform segmentation on this image using YOLO, and then apply the resulting mask to the three-dimensional points to isolate the 3D object of interest.
+
+For handling point clouds, we recommend using Open3D (`pip install open3d`), a user-friendly Python library. Open3D provides robust tools for managing point cloud data structures, visualizing them, and executing complex operations seamlessly. This library can significantly simplify the process and enhance our ability to manipulate and analyze point clouds in conjunction with YOLO-based segmentation.
+
+#### Point Clouds Step-by-Step Usage
+
+Import the necessary libraries and instantiate the YOLO model for segmentation.
+
+```python
+import time
+
+import rospy
+
+from ultralytics import YOLO
+
+rospy.init_node("ultralytics")
+time.sleep(1)
+segmentation_model = YOLO("yolov8m-seg.pt")
+```
+
+Create a function `pointcloud2_to_array`, which transforms a `sensor_msgs/PointCloud2` message into two numpy arrays. The `sensor_msgs/PointCloud2` messages contain `n` points based on the `width` and `height` of the acquired image. For instance, a `480 x 640` image will have `307,200` points. Each point includes three spatial coordinates (`xyz`) and the corresponding color in `RGB` format. These can be considered as two separate channels of information.
+
+The function returns the `xyz` coordinates and `RGB` values in the format of the original camera resolution (`width x height`). Most sensors have a maximum distance, known as the clip distance, beyond which values are represented as inf (`np.inf`). Before processing, it is important to filter out these null values and assign them a value of `0`.
+
+```python
+import numpy as np
+import ros_numpy
+
+
+def pointcloud2_to_array(pointcloud2: PointCloud2) -> tuple:
+ """
+ Convert a ROS PointCloud2 message to a numpy array.
+
+ Args:
+ pointcloud2 (PointCloud2): the PointCloud2 message
+
+ Returns:
+ (tuple): tuple containing (xyz, rgb)
+ """
+ pc_array = ros_numpy.point_cloud2.pointcloud2_to_array(pointcloud2)
+ split = ros_numpy.point_cloud2.split_rgb_field(pc_array)
+ rgb = np.stack([split["b"], split["g"], split["r"]], axis=2)
+ xyz = ros_numpy.point_cloud2.get_xyz_points(pc_array, remove_nans=False)
+ xyz = np.array(xyz).reshape((pointcloud2.height, pointcloud2.width, 3))
+ nan_rows = np.isnan(xyz).all(axis=2)
+ xyz[nan_rows] = [0, 0, 0]
+ rgb[nan_rows] = [0, 0, 0]
+ return xyz, rgb
+```
+
+Next, subscribe to the `/camera/depth/points` topic to receive the point cloud message and convert the `sensor_msgs/PointCloud2` message into numpy arrays containing the XYZ coordinates and RGB values (using the `pointcloud2_to_array` function). Process the RGB image using the YOLO model to extract segmented objects. For each detected object, extract the segmentation mask and apply it to both the RGB image and the XYZ coordinates to isolate the object in 3D space.
+
+Processing the mask is straightforward since it consists of binary values, with `1` indicating the presence of the object and `0` indicating the absence. To apply the mask, simply multiply the original channels by the mask. This operation effectively isolates the object of interest within the image. Finally, create an Open3D point cloud object and visualize the segmented object in 3D space with associated colors.
+
+```python
+import sys
+
+import open3d as o3d
+
+ros_cloud = rospy.wait_for_message("/camera/depth/points", PointCloud2)
+xyz, rgb = pointcloud2_to_array(ros_cloud)
+result = segmentation_model(rgb)
+
+if not len(result[0].boxes.cls):
+ print("No objects detected")
+ sys.exit()
+
+classes = result[0].boxes.cls.cpu().numpy().astype(int)
+for index, class_id in enumerate(classes):
+ mask = result[0].masks.data.cpu().numpy()[index, :, :].astype(int)
+ mask_expanded = np.stack([mask, mask, mask], axis=2)
+
+ obj_rgb = rgb * mask_expanded
+ obj_xyz = xyz * mask_expanded
+
+ pcd = o3d.geometry.PointCloud()
+ pcd.points = o3d.utility.Vector3dVector(obj_xyz.reshape((ros_cloud.height * ros_cloud.width, 3)))
+ pcd.colors = o3d.utility.Vector3dVector(obj_rgb.reshape((ros_cloud.height * ros_cloud.width, 3)) / 255)
+ o3d.visualization.draw_geometries([pcd])
+```
+
+??? Example "Complete code"
+
+ ```python
+ import sys
+ import time
+
+ import numpy as np
+ import open3d as o3d
+ import ros_numpy
+ import rospy
+
+ from ultralytics import YOLO
+
+ rospy.init_node("ultralytics")
+ time.sleep(1)
+ segmentation_model = YOLO("yolov8m-seg.pt")
+
+
+ def pointcloud2_to_array(pointcloud2: PointCloud2) -> tuple:
+ """
+ Convert a ROS PointCloud2 message to a numpy array.
+
+ Args:
+ pointcloud2 (PointCloud2): the PointCloud2 message
+
+ Returns:
+ (tuple): tuple containing (xyz, rgb)
+ """
+ pc_array = ros_numpy.point_cloud2.pointcloud2_to_array(pointcloud2)
+ split = ros_numpy.point_cloud2.split_rgb_field(pc_array)
+ rgb = np.stack([split["b"], split["g"], split["r"]], axis=2)
+ xyz = ros_numpy.point_cloud2.get_xyz_points(pc_array, remove_nans=False)
+ xyz = np.array(xyz).reshape((pointcloud2.height, pointcloud2.width, 3))
+ nan_rows = np.isnan(xyz).all(axis=2)
+ xyz[nan_rows] = [0, 0, 0]
+ rgb[nan_rows] = [0, 0, 0]
+ return xyz, rgb
+
+
+ ros_cloud = rospy.wait_for_message("/camera/depth/points", PointCloud2)
+ xyz, rgb = pointcloud2_to_array(ros_cloud)
+ result = segmentation_model(rgb)
+
+ if not len(result[0].boxes.cls):
+ print("No objects detected")
+ sys.exit()
+
+ classes = result[0].boxes.cls.cpu().numpy().astype(int)
+ for index, class_id in enumerate(classes):
+ mask = result[0].masks.data.cpu().numpy()[index, :, :].astype(int)
+ mask_expanded = np.stack([mask, mask, mask], axis=2)
+
+ obj_rgb = rgb * mask_expanded
+ obj_xyz = xyz * mask_expanded
+
+ pcd = o3d.geometry.PointCloud()
+ pcd.points = o3d.utility.Vector3dVector(obj_xyz.reshape((ros_cloud.height * ros_cloud.width, 3)))
+ pcd.colors = o3d.utility.Vector3dVector(obj_rgb.reshape((ros_cloud.height * ros_cloud.width, 3)) / 255)
+ o3d.visualization.draw_geometries([pcd])
+ ```
+
+
+
+
+
+## FAQ
+
+### What is the Robot Operating System (ROS)?
+
+The [Robot Operating System (ROS)](https://www.ros.org/) is an open-source framework commonly used in robotics to help developers create robust robot applications. It provides a collection of [libraries and tools](https://www.ros.org/blog/ecosystem/) for building and interfacing with robotic systems, enabling easier development of complex applications. ROS supports communication between nodes using messages over [topics](https://wiki.ros.org/ROS/Tutorials/UnderstandingTopics) or [services](https://wiki.ros.org/ROS/Tutorials/UnderstandingServicesParams).
+
+### How do I integrate Ultralytics YOLO with ROS for real-time object detection?
+
+Integrating Ultralytics YOLO with ROS involves setting up a ROS environment and using YOLO for processing sensor data. Begin by installing the required dependencies like `ros_numpy` and Ultralytics YOLO:
+
+```bash
+pip install ros_numpy ultralytics
+```
+
+Next, create a ROS node and subscribe to an [image topic](../tasks/detect.md) to process the incoming data. Here is a minimal example:
+
+```python
+import ros_numpy
+import rospy
+from sensor_msgs.msg import Image
+
+from ultralytics import YOLO
+
+detection_model = YOLO("yolov8m.pt")
+rospy.init_node("ultralytics")
+det_image_pub = rospy.Publisher("/ultralytics/detection/image", Image, queue_size=5)
+
+
+def callback(data):
+ array = ros_numpy.numpify(data)
+ det_result = detection_model(array)
+ det_annotated = det_result[0].plot(show=False)
+ det_image_pub.publish(ros_numpy.msgify(Image, det_annotated, encoding="rgb8"))
+
+
+rospy.Subscriber("/camera/color/image_raw", Image, callback)
+rospy.spin()
+```
+
+### What are ROS topics and how are they used in Ultralytics YOLO?
+
+ROS topics facilitate communication between nodes in a ROS network by using a publish-subscribe model. A topic is a named channel that nodes use to send and receive messages asynchronously. In the context of Ultralytics YOLO, you can make a node subscribe to an image topic, process the images using YOLO for tasks like detection or segmentation, and publish outcomes to new topics.
+
+For example, subscribe to a camera topic and process the incoming image for detection:
+
+```python
+rospy.Subscriber("/camera/color/image_raw", Image, callback)
+```
+
+### Why use depth images with Ultralytics YOLO in ROS?
+
+Depth images in ROS, represented by `sensor_msgs/Image`, provide the distance of objects from the camera, crucial for tasks like obstacle avoidance, 3D mapping, and localization. By [using depth information](https://en.wikipedia.org/wiki/Depth_map) along with RGB images, robots can better understand their 3D environment.
+
+With YOLO, you can extract segmentation masks from RGB images and apply these masks to depth images to obtain precise 3D object information, improving the robot's ability to navigate and interact with its surroundings.
+
+### How can I visualize 3D point clouds with YOLO in ROS?
+
+To visualize 3D point clouds in ROS with YOLO:
+
+1. Convert `sensor_msgs/PointCloud2` messages to numpy arrays.
+2. Use YOLO to segment RGB images.
+3. Apply the segmentation mask to the point cloud.
+
+Here's an example using Open3D for visualization:
+
+```python
+import sys
+
+import open3d as o3d
+import ros_numpy
+import rospy
+from sensor_msgs.msg import PointCloud2
+
+from ultralytics import YOLO
+
+rospy.init_node("ultralytics")
+segmentation_model = YOLO("yolov8m-seg.pt")
+
+
+def pointcloud2_to_array(pointcloud2):
+ pc_array = ros_numpy.point_cloud2.pointcloud2_to_array(pointcloud2)
+ split = ros_numpy.point_cloud2.split_rgb_field(pc_array)
+ rgb = np.stack([split["b"], split["g"], split["r"]], axis=2)
+ xyz = ros_numpy.point_cloud2.get_xyz_points(pc_array, remove_nans=False)
+ xyz = np.array(xyz).reshape((pointcloud2.height, pointcloud2.width, 3))
+ return xyz, rgb
+
+
+ros_cloud = rospy.wait_for_message("/camera/depth/points", PointCloud2)
+xyz, rgb = pointcloud2_to_array(ros_cloud)
+result = segmentation_model(rgb)
+
+if not len(result[0].boxes.cls):
+ print("No objects detected")
+ sys.exit()
+
+classes = result[0].boxes.cls.cpu().numpy().astype(int)
+for index, class_id in enumerate(classes):
+ mask = result[0].masks.data.cpu().numpy()[index, :, :].astype(int)
+ mask_expanded = np.stack([mask, mask, mask], axis=2)
+
+ obj_rgb = rgb * mask_expanded
+ obj_xyz = xyz * mask_expanded
+
+ pcd = o3d.geometry.PointCloud()
+ pcd.points = o3d.utility.Vector3dVector(obj_xyz.reshape((-1, 3)))
+ pcd.colors = o3d.utility.Vector3dVector(obj_rgb.reshape((-1, 3)) / 255)
+ o3d.visualization.draw_geometries([pcd])
+```
+
+This approach provides a 3D visualization of segmented objects, useful for tasks like navigation and manipulation.
diff --git a/ultralytics/docs/en/guides/sahi-tiled-inference.md b/ultralytics/docs/en/guides/sahi-tiled-inference.md
new file mode 100644
index 0000000000000000000000000000000000000000..2bbddb3dc8fd4b94c072a5775f668b56f9c82ec1
--- /dev/null
+++ b/ultralytics/docs/en/guides/sahi-tiled-inference.md
@@ -0,0 +1,295 @@
+---
+comments: true
+description: Learn how to implement YOLOv8 with SAHI for sliced inference. Optimize memory usage and enhance detection accuracy for large-scale applications.
+keywords: YOLOv8, SAHI, Sliced Inference, Object Detection, Ultralytics, High-resolution Images, Computational Efficiency, Integration Guide
+---
+
+# Ultralytics Docs: Using YOLOv8 with SAHI for Sliced Inference
+
+Welcome to the Ultralytics documentation on how to use YOLOv8 with [SAHI](https://github.com/obss/sahi) (Slicing Aided Hyper Inference). This comprehensive guide aims to furnish you with all the essential knowledge you'll need to implement SAHI alongside YOLOv8. We'll deep-dive into what SAHI is, why sliced inference is critical for large-scale applications, and how to integrate these functionalities with YOLOv8 for enhanced object detection performance.
+
+
+
+
+
+## Introduction to SAHI
+
+SAHI (Slicing Aided Hyper Inference) is an innovative library designed to optimize object detection algorithms for large-scale and high-resolution imagery. Its core functionality lies in partitioning images into manageable slices, running object detection on each slice, and then stitching the results back together. SAHI is compatible with a range of object detection models, including the YOLO series, thereby offering flexibility while ensuring optimized use of computational resources.
+
+
+
+
+
+ Watch: Inference with SAHI (Slicing Aided Hyper Inference) using Ultralytics YOLOv8
+
+
+### Key Features of SAHI
+
+- **Seamless Integration**: SAHI integrates effortlessly with YOLO models, meaning you can start slicing and detecting without a lot of code modification.
+- **Resource Efficiency**: By breaking down large images into smaller parts, SAHI optimizes the memory usage, allowing you to run high-quality detection on hardware with limited resources.
+- **High Accuracy**: SAHI maintains the detection accuracy by employing smart algorithms to merge overlapping detection boxes during the stitching process.
+
+## What is Sliced Inference?
+
+Sliced Inference refers to the practice of subdividing a large or high-resolution image into smaller segments (slices), conducting object detection on these slices, and then recompiling the slices to reconstruct the object locations on the original image. This technique is invaluable in scenarios where computational resources are limited or when working with extremely high-resolution images that could otherwise lead to memory issues.
+
+### Benefits of Sliced Inference
+
+- **Reduced Computational Burden**: Smaller image slices are faster to process, and they consume less memory, enabling smoother operation on lower-end hardware.
+
+- **Preserved Detection Quality**: Since each slice is treated independently, there is no reduction in the quality of object detection, provided the slices are large enough to capture the objects of interest.
+
+- **Enhanced Scalability**: The technique allows for object detection to be more easily scaled across different sizes and resolutions of images, making it ideal for a wide range of applications from satellite imagery to medical diagnostics.
+
+
+
+
YOLOv8 without SAHI
+
YOLOv8 with SAHI
+
+
+
+
+
+
+
+## Installation and Preparation
+
+### Installation
+
+To get started, install the latest versions of SAHI and Ultralytics:
+
+```bash
+pip install -U ultralytics sahi
+```
+
+### Import Modules and Download Resources
+
+Here's how to import the necessary modules and download a YOLOv8 model and some test images:
+
+```python
+from sahi.utils.file import download_from_url
+from sahi.utils.yolov8 import download_yolov8s_model
+
+# Download YOLOv8 model
+yolov8_model_path = "models/yolov8s.pt"
+download_yolov8s_model(yolov8_model_path)
+
+# Download test images
+download_from_url(
+ "https://raw.githubusercontent.com/obss/sahi/main/demo/demo_data/small-vehicles1.jpeg",
+ "demo_data/small-vehicles1.jpeg",
+)
+download_from_url(
+ "https://raw.githubusercontent.com/obss/sahi/main/demo/demo_data/terrain2.png",
+ "demo_data/terrain2.png",
+)
+```
+
+## Standard Inference with YOLOv8
+
+### Instantiate the Model
+
+You can instantiate a YOLOv8 model for object detection like this:
+
+```python
+from sahi import AutoDetectionModel
+
+detection_model = AutoDetectionModel.from_pretrained(
+ model_type="yolov8",
+ model_path=yolov8_model_path,
+ confidence_threshold=0.3,
+ device="cpu", # or 'cuda:0'
+)
+```
+
+### Perform Standard Prediction
+
+Perform standard inference using an image path or a numpy image.
+
+```python
+from sahi.predict import get_prediction
+
+# With an image path
+result = get_prediction("demo_data/small-vehicles1.jpeg", detection_model)
+
+# With a numpy image
+result = get_prediction(read_image("demo_data/small-vehicles1.jpeg"), detection_model)
+```
+
+### Visualize Results
+
+Export and visualize the predicted bounding boxes and masks:
+
+```python
+result.export_visuals(export_dir="demo_data/")
+Image("demo_data/prediction_visual.png")
+```
+
+## Sliced Inference with YOLOv8
+
+Perform sliced inference by specifying the slice dimensions and overlap ratios:
+
+```python
+from sahi.predict import get_sliced_prediction
+
+result = get_sliced_prediction(
+ "demo_data/small-vehicles1.jpeg",
+ detection_model,
+ slice_height=256,
+ slice_width=256,
+ overlap_height_ratio=0.2,
+ overlap_width_ratio=0.2,
+)
+```
+
+## Handling Prediction Results
+
+SAHI provides a `PredictionResult` object, which can be converted into various annotation formats:
+
+```python
+# Access the object prediction list
+object_prediction_list = result.object_prediction_list
+
+# Convert to COCO annotation, COCO prediction, imantics, and fiftyone formats
+result.to_coco_annotations()[:3]
+result.to_coco_predictions(image_id=1)[:3]
+result.to_imantics_annotations()[:3]
+result.to_fiftyone_detections()[:3]
+```
+
+## Batch Prediction
+
+For batch prediction on a directory of images:
+
+```python
+from sahi.predict import predict
+
+predict(
+ model_type="yolov8",
+ model_path="path/to/yolov8n.pt",
+ model_device="cpu", # or 'cuda:0'
+ model_confidence_threshold=0.4,
+ source="path/to/dir",
+ slice_height=256,
+ slice_width=256,
+ overlap_height_ratio=0.2,
+ overlap_width_ratio=0.2,
+)
+```
+
+That's it! Now you're equipped to use YOLOv8 with SAHI for both standard and sliced inference.
+
+## Citations and Acknowledgments
+
+If you use SAHI in your research or development work, please cite the original SAHI paper and acknowledge the authors:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @article{akyon2022sahi,
+ title={Slicing Aided Hyper Inference and Fine-tuning for Small Object Detection},
+ author={Akyon, Fatih Cagatay and Altinuc, Sinan Onur and Temizel, Alptekin},
+ journal={2022 IEEE International Conference on Image Processing (ICIP)},
+ doi={10.1109/ICIP46576.2022.9897990},
+ pages={966-970},
+ year={2022}
+ }
+ ```
+
+We extend our thanks to the SAHI research group for creating and maintaining this invaluable resource for the computer vision community. For more information about SAHI and its creators, visit the [SAHI GitHub repository](https://github.com/obss/sahi).
+
+## FAQ
+
+### How can I integrate YOLOv8 with SAHI for sliced inference in object detection?
+
+Integrating Ultralytics YOLOv8 with SAHI (Slicing Aided Hyper Inference) for sliced inference optimizes your object detection tasks on high-resolution images by partitioning them into manageable slices. This approach improves memory usage and ensures high detection accuracy. To get started, you need to install the ultralytics and sahi libraries:
+
+```bash
+pip install -U ultralytics sahi
+```
+
+Then, download a YOLOv8 model and test images:
+
+```python
+from sahi.utils.file import download_from_url
+from sahi.utils.yolov8 import download_yolov8s_model
+
+# Download YOLOv8 model
+yolov8_model_path = "models/yolov8s.pt"
+download_yolov8s_model(yolov8_model_path)
+
+# Download test images
+download_from_url(
+ "https://raw.githubusercontent.com/obss/sahi/main/demo/demo_data/small-vehicles1.jpeg",
+ "demo_data/small-vehicles1.jpeg",
+)
+```
+
+For more detailed instructions, refer to our [Sliced Inference guide](#sliced-inference-with-yolov8).
+
+### Why should I use SAHI with YOLOv8 for object detection on large images?
+
+Using SAHI with Ultralytics YOLOv8 for object detection on large images offers several benefits:
+
+- **Reduced Computational Burden**: Smaller slices are faster to process and consume less memory, making it feasible to run high-quality detections on hardware with limited resources.
+- **Maintained Detection Accuracy**: SAHI uses intelligent algorithms to merge overlapping boxes, preserving the detection quality.
+- **Enhanced Scalability**: By scaling object detection tasks across different image sizes and resolutions, SAHI becomes ideal for various applications, such as satellite imagery analysis and medical diagnostics.
+
+Learn more about the [benefits of sliced inference](#benefits-of-sliced-inference) in our documentation.
+
+### Can I visualize prediction results when using YOLOv8 with SAHI?
+
+Yes, you can visualize prediction results when using YOLOv8 with SAHI. Here's how you can export and visualize the results:
+
+```python
+from IPython.display import Image
+
+result.export_visuals(export_dir="demo_data/")
+Image("demo_data/prediction_visual.png")
+```
+
+This command will save the visualized predictions to the specified directory and you can then load the image to view it in your notebook or application. For a detailed guide, check out the [Standard Inference section](#visualize-results).
+
+### What features does SAHI offer for improving YOLOv8 object detection?
+
+SAHI (Slicing Aided Hyper Inference) offers several features that complement Ultralytics YOLOv8 for object detection:
+
+- **Seamless Integration**: SAHI easily integrates with YOLO models, requiring minimal code adjustments.
+- **Resource Efficiency**: It partitions large images into smaller slices, which optimizes memory usage and speed.
+- **High Accuracy**: By effectively merging overlapping detection boxes during the stitching process, SAHI maintains high detection accuracy.
+
+For a deeper understanding, read about SAHI's [key features](#key-features-of-sahi).
+
+### How do I handle large-scale inference projects using YOLOv8 and SAHI?
+
+To handle large-scale inference projects using YOLOv8 and SAHI, follow these best practices:
+
+1. **Install Required Libraries**: Ensure that you have the latest versions of ultralytics and sahi.
+2. **Configure Sliced Inference**: Determine the optimal slice dimensions and overlap ratios for your specific project.
+3. **Run Batch Predictions**: Use SAHI's capabilities to perform batch predictions on a directory of images, which improves efficiency.
+
+Example for batch prediction:
+
+```python
+from sahi.predict import predict
+
+predict(
+ model_type="yolov8",
+ model_path="path/to/yolov8n.pt",
+ model_device="cpu", # or 'cuda:0'
+ model_confidence_threshold=0.4,
+ source="path/to/dir",
+ slice_height=256,
+ slice_width=256,
+ overlap_height_ratio=0.2,
+ overlap_width_ratio=0.2,
+)
+```
+
+For more detailed steps, visit our section on [Batch Prediction](#batch-prediction).
diff --git a/ultralytics/docs/en/guides/security-alarm-system.md b/ultralytics/docs/en/guides/security-alarm-system.md
new file mode 100644
index 0000000000000000000000000000000000000000..6d41b08f961abff1430400c9366e3f91e304c65d
--- /dev/null
+++ b/ultralytics/docs/en/guides/security-alarm-system.md
@@ -0,0 +1,200 @@
+---
+comments: true
+description: Enhance your security with real-time object detection using Ultralytics YOLOv8. Reduce false positives and integrate seamlessly with existing systems.
+keywords: YOLOv8, Security Alarm System, real-time object detection, Ultralytics, computer vision, integration, false positives
+---
+
+# Security Alarm System Project Using Ultralytics YOLOv8
+
+
+
+The Security Alarm System Project utilizing Ultralytics YOLOv8 integrates advanced computer vision capabilities to enhance security measures. YOLOv8, developed by Ultralytics, provides real-time object detection, allowing the system to identify and respond to potential security threats promptly. This project offers several advantages:
+
+- **Real-time Detection:** YOLOv8's efficiency enables the Security Alarm System to detect and respond to security incidents in real-time, minimizing response time.
+- **Accuracy:** YOLOv8 is known for its accuracy in object detection, reducing false positives and enhancing the reliability of the security alarm system.
+- **Integration Capabilities:** The project can be seamlessly integrated with existing security infrastructure, providing an upgraded layer of intelligent surveillance.
+
+
+
+
+
+ Watch: Security Alarm System Project with Ultralytics YOLOv8 Object Detection
+
+
+### Code
+
+#### Set up the parameters of the message
+
+???+ tip "Note"
+
+ App Password Generation is necessary
+
+- Navigate to [App Password Generator](https://myaccount.google.com/apppasswords), designate an app name such as "security project," and obtain a 16-digit password. Copy this password and paste it into the designated password field as instructed.
+
+```python
+password = ""
+from_email = "" # must match the email used to generate the password
+to_email = "" # receiver email
+```
+
+#### Server creation and authentication
+
+```python
+import smtplib
+
+server = smtplib.SMTP("smtp.gmail.com: 587")
+server.starttls()
+server.login(from_email, password)
+```
+
+#### Email Send Function
+
+```python
+from email.mime.multipart import MIMEMultipart
+from email.mime.text import MIMEText
+
+
+def send_email(to_email, from_email, object_detected=1):
+ """Sends an email notification indicating the number of objects detected; defaults to 1 object."""
+ message = MIMEMultipart()
+ message["From"] = from_email
+ message["To"] = to_email
+ message["Subject"] = "Security Alert"
+ # Add in the message body
+ message_body = f"ALERT - {object_detected} objects has been detected!!"
+
+ message.attach(MIMEText(message_body, "plain"))
+ server.sendmail(from_email, to_email, message.as_string())
+```
+
+#### Object Detection and Alert Sender
+
+```python
+from time import time
+
+import cv2
+import torch
+
+from ultralytics import YOLO
+from ultralytics.utils.plotting import Annotator, colors
+
+
+class ObjectDetection:
+ def __init__(self, capture_index):
+ """Initializes an ObjectDetection instance with a given camera index."""
+ self.capture_index = capture_index
+ self.email_sent = False
+
+ # model information
+ self.model = YOLO("yolov8n.pt")
+
+ # visual information
+ self.annotator = None
+ self.start_time = 0
+ self.end_time = 0
+
+ # device information
+ self.device = "cuda" if torch.cuda.is_available() else "cpu"
+
+ def predict(self, im0):
+ """Run prediction using a YOLO model for the input image `im0`."""
+ results = self.model(im0)
+ return results
+
+ def display_fps(self, im0):
+ """Displays the FPS on an image `im0` by calculating and overlaying as white text on a black rectangle."""
+ self.end_time = time()
+ fps = 1 / round(self.end_time - self.start_time, 2)
+ text = f"FPS: {int(fps)}"
+ text_size = cv2.getTextSize(text, cv2.FONT_HERSHEY_SIMPLEX, 1.0, 2)[0]
+ gap = 10
+ cv2.rectangle(
+ im0,
+ (20 - gap, 70 - text_size[1] - gap),
+ (20 + text_size[0] + gap, 70 + gap),
+ (255, 255, 255),
+ -1,
+ )
+ cv2.putText(im0, text, (20, 70), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (0, 0, 0), 2)
+
+ def plot_bboxes(self, results, im0):
+ """Plots bounding boxes on an image given detection results; returns annotated image and class IDs."""
+ class_ids = []
+ self.annotator = Annotator(im0, 3, results[0].names)
+ boxes = results[0].boxes.xyxy.cpu()
+ clss = results[0].boxes.cls.cpu().tolist()
+ names = results[0].names
+ for box, cls in zip(boxes, clss):
+ class_ids.append(cls)
+ self.annotator.box_label(box, label=names[int(cls)], color=colors(int(cls), True))
+ return im0, class_ids
+
+ def __call__(self):
+ """Run object detection on video frames from a camera stream, plotting and showing the results."""
+ cap = cv2.VideoCapture(self.capture_index)
+ assert cap.isOpened()
+ cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640)
+ cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 480)
+ frame_count = 0
+ while True:
+ self.start_time = time()
+ ret, im0 = cap.read()
+ assert ret
+ results = self.predict(im0)
+ im0, class_ids = self.plot_bboxes(results, im0)
+
+ if len(class_ids) > 0: # Only send email If not sent before
+ if not self.email_sent:
+ send_email(to_email, from_email, len(class_ids))
+ self.email_sent = True
+ else:
+ self.email_sent = False
+
+ self.display_fps(im0)
+ cv2.imshow("YOLOv8 Detection", im0)
+ frame_count += 1
+ if cv2.waitKey(5) & 0xFF == 27:
+ break
+ cap.release()
+ cv2.destroyAllWindows()
+ server.quit()
+```
+
+#### Call the Object Detection class and Run the Inference
+
+```python
+detector = ObjectDetection(capture_index=0)
+detector()
+```
+
+That's it! When you execute the code, you'll receive a single notification on your email if any object is detected. The notification is sent immediately, not repeatedly. However, feel free to customize the code to suit your project requirements.
+
+#### Email Received Sample
+
+
+
+## FAQ
+
+### How does Ultralytics YOLOv8 improve the accuracy of a security alarm system?
+
+Ultralytics YOLOv8 enhances security alarm systems by delivering high-accuracy, real-time object detection. Its advanced algorithms significantly reduce false positives, ensuring that the system only responds to genuine threats. This increased reliability can be seamlessly integrated with existing security infrastructure, upgrading the overall surveillance quality.
+
+### Can I integrate Ultralytics YOLOv8 with my existing security infrastructure?
+
+Yes, Ultralytics YOLOv8 can be seamlessly integrated with your existing security infrastructure. The system supports various modes and provides flexibility for customization, allowing you to enhance your existing setup with advanced object detection capabilities. For detailed instructions on integrating YOLOv8 in your projects, visit the [integration section](https://docs.ultralytics.com/integrations/).
+
+### What are the storage requirements for running Ultralytics YOLOv8?
+
+Running Ultralytics YOLOv8 on a standard setup typically requires around 5GB of free disk space. This includes space for storing the YOLOv8 model and any additional dependencies. For cloud-based solutions, Ultralytics HUB offers efficient project management and dataset handling, which can optimize storage needs. Learn more about the [Pro Plan](../hub/pro.md) for enhanced features including extended storage.
+
+### What makes Ultralytics YOLOv8 different from other object detection models like Faster R-CNN or SSD?
+
+Ultralytics YOLOv8 provides an edge over models like Faster R-CNN or SSD with its real-time detection capabilities and higher accuracy. Its unique architecture allows it to process images much faster without compromising on precision, making it ideal for time-sensitive applications like security alarm systems. For a comprehensive comparison of object detection models, you can explore our [guide](https://docs.ultralytics.com/models).
+
+### How can I reduce the frequency of false positives in my security system using Ultralytics YOLOv8?
+
+To reduce false positives, ensure your Ultralytics YOLOv8 model is adequately trained with a diverse and well-annotated dataset. Fine-tuning hyperparameters and regularly updating the model with new data can significantly improve detection accuracy. Detailed hyperparameter tuning techniques can be found in our [hyperparameter tuning guide](../guides/hyperparameter-tuning.md).
diff --git a/ultralytics/docs/en/guides/speed-estimation.md b/ultralytics/docs/en/guides/speed-estimation.md
new file mode 100644
index 0000000000000000000000000000000000000000..c3e668d6cb4acf0f21eced8e4f15719be5a8ff9f
--- /dev/null
+++ b/ultralytics/docs/en/guides/speed-estimation.md
@@ -0,0 +1,193 @@
+---
+comments: true
+description: Learn how to estimate object speed using Ultralytics YOLOv8 for applications in traffic control, autonomous navigation, and surveillance.
+keywords: Ultralytics YOLOv8, speed estimation, object tracking, computer vision, traffic control, autonomous navigation, surveillance, security
+---
+
+# Speed Estimation using Ultralytics YOLOv8 🚀
+
+## What is Speed Estimation?
+
+[Speed estimation](https://www.ultralytics.com/blog/ultralytics-yolov8-for-speed-estimation-in-computer-vision-projects) is the process of calculating the rate of movement of an object within a given context, often employed in computer vision applications. Using [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) you can now calculate the speed of object using [object tracking](../modes/track.md) alongside distance and time data, crucial for tasks like traffic and surveillance. The accuracy of speed estimation directly influences the efficiency and reliability of various applications, making it a key component in the advancement of intelligent systems and real-time decision-making processes.
+
+
+
+!!! tip "Check Out Our Blog"
+
+ For deeper insights into speed estimation, check out our blog post: [Ultralytics YOLOv8 for Speed Estimation in Computer Vision Projects](https://www.ultralytics.com/blog/ultralytics-yolov8-for-speed-estimation-in-computer-vision-projects)
+
+## Advantages of Speed Estimation?
+
+- **Efficient Traffic Control:** Accurate speed estimation aids in managing traffic flow, enhancing safety, and reducing congestion on roadways.
+- **Precise Autonomous Navigation:** In autonomous systems like self-driving cars, reliable speed estimation ensures safe and accurate vehicle navigation.
+- **Enhanced Surveillance Security:** Speed estimation in surveillance analytics helps identify unusual behaviors or potential threats, improving the effectiveness of security measures.
+
+## Real World Applications
+
+| Transportation | Transportation |
+| :-----------------------------------------------------------------------------------------------------------------------------------------------------: | :-------------------------------------------------------------------------------------------------------------------------------------------------------: |
+|  | 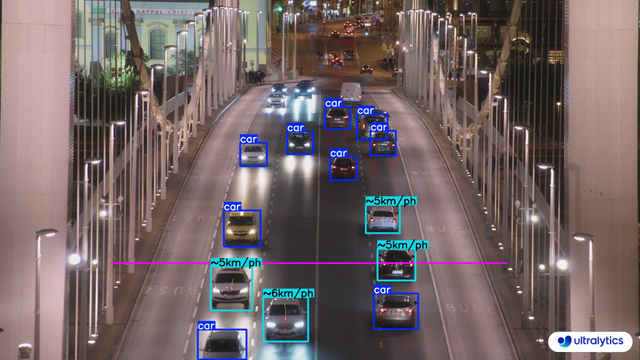 |
+| Speed Estimation on Road using Ultralytics YOLOv8 | Speed Estimation on Bridge using Ultralytics YOLOv8 |
+
+!!! Example "Speed Estimation using YOLOv8 Example"
+
+ === "Speed Estimation"
+
+ ```python
+ import cv2
+
+ from ultralytics import YOLO, solutions
+
+ model = YOLO("yolov8n.pt")
+ names = model.model.names
+
+ cap = cv2.VideoCapture("path/to/video/file.mp4")
+ assert cap.isOpened(), "Error reading video file"
+ w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
+
+ # Video writer
+ video_writer = cv2.VideoWriter("speed_estimation.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
+
+ line_pts = [(0, 360), (1280, 360)]
+
+ # Init speed-estimation obj
+ speed_obj = solutions.SpeedEstimator(
+ reg_pts=line_pts,
+ names=names,
+ view_img=True,
+ )
+
+ while cap.isOpened():
+ success, im0 = cap.read()
+ if not success:
+ print("Video frame is empty or video processing has been successfully completed.")
+ break
+
+ tracks = model.track(im0, persist=True, show=False)
+
+ im0 = speed_obj.estimate_speed(im0, tracks)
+ video_writer.write(im0)
+
+ cap.release()
+ video_writer.release()
+ cv2.destroyAllWindows()
+ ```
+
+???+ warning "Speed is Estimate"
+
+ Speed will be an estimate and may not be completely accurate. Additionally, the estimation can vary depending on GPU speed.
+
+### Arguments `SpeedEstimator`
+
+| Name | Type | Default | Description |
+| ------------------ | ------ | -------------------------- | ---------------------------------------------------- |
+| `names` | `dict` | `None` | Dictionary of class names. |
+| `reg_pts` | `list` | `[(20, 400), (1260, 400)]` | List of region points for speed estimation. |
+| `view_img` | `bool` | `False` | Whether to display the image with annotations. |
+| `line_thickness` | `int` | `2` | Thickness of the lines for drawing boxes and tracks. |
+| `region_thickness` | `int` | `5` | Thickness of the region lines. |
+| `spdl_dist_thresh` | `int` | `10` | Distance threshold for speed calculation. |
+
+### Arguments `model.track`
+
+| Name | Type | Default | Description |
+| --------- | ------- | -------------- | ----------------------------------------------------------- |
+| `source` | `im0` | `None` | source directory for images or videos |
+| `persist` | `bool` | `False` | persisting tracks between frames |
+| `tracker` | `str` | `botsort.yaml` | Tracking method 'bytetrack' or 'botsort' |
+| `conf` | `float` | `0.3` | Confidence Threshold |
+| `iou` | `float` | `0.5` | IOU Threshold |
+| `classes` | `list` | `None` | filter results by class, i.e. classes=0, or classes=[0,2,3] |
+| `verbose` | `bool` | `True` | Display the object tracking results |
+
+## FAQ
+
+### How do I estimate object speed using Ultralytics YOLOv8?
+
+Estimating object speed with Ultralytics YOLOv8 involves combining object detection and tracking techniques. First, you need to detect objects in each frame using the YOLOv8 model. Then, track these objects across frames to calculate their movement over time. Finally, use the distance traveled by the object between frames and the frame rate to estimate its speed.
+
+**Example**:
+
+```python
+import cv2
+
+from ultralytics import YOLO, solutions
+
+model = YOLO("yolov8n.pt")
+names = model.model.names
+
+cap = cv2.VideoCapture("path/to/video/file.mp4")
+w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
+video_writer = cv2.VideoWriter("speed_estimation.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
+
+# Initialize SpeedEstimator
+speed_obj = solutions.SpeedEstimator(
+ reg_pts=[(0, 360), (1280, 360)],
+ names=names,
+ view_img=True,
+)
+
+while cap.isOpened():
+ success, im0 = cap.read()
+ if not success:
+ break
+ tracks = model.track(im0, persist=True, show=False)
+ im0 = speed_obj.estimate_speed(im0, tracks)
+ video_writer.write(im0)
+
+cap.release()
+video_writer.release()
+cv2.destroyAllWindows()
+```
+
+For more details, refer to our [official blog post](https://www.ultralytics.com/blog/ultralytics-yolov8-for-speed-estimation-in-computer-vision-projects).
+
+### What are the benefits of using Ultralytics YOLOv8 for speed estimation in traffic management?
+
+Using Ultralytics YOLOv8 for speed estimation offers significant advantages in traffic management:
+
+- **Enhanced Safety**: Accurately estimate vehicle speeds to detect over-speeding and improve road safety.
+- **Real-Time Monitoring**: Benefit from YOLOv8's real-time object detection capability to monitor traffic flow and congestion effectively.
+- **Scalability**: Deploy the model on various hardware setups, from edge devices to servers, ensuring flexible and scalable solutions for large-scale implementations.
+
+For more applications, see [advantages of speed estimation](#advantages-of-speed-estimation).
+
+### Can YOLOv8 be integrated with other AI frameworks like TensorFlow or PyTorch?
+
+Yes, YOLOv8 can be integrated with other AI frameworks like TensorFlow and PyTorch. Ultralytics provides support for exporting YOLOv8 models to various formats like ONNX, TensorRT, and CoreML, ensuring smooth interoperability with other ML frameworks.
+
+To export a YOLOv8 model to ONNX format:
+
+```bash
+yolo export --weights yolov8n.pt --include onnx
+```
+
+Learn more about exporting models in our [guide on export](../modes/export.md).
+
+### How accurate is the speed estimation using Ultralytics YOLOv8?
+
+The accuracy of speed estimation using Ultralytics YOLOv8 depends on several factors, including the quality of the object tracking, the resolution and frame rate of the video, and environmental variables. While the speed estimator provides reliable estimates, it may not be 100% accurate due to variances in frame processing speed and object occlusion.
+
+**Note**: Always consider margin of error and validate the estimates with ground truth data when possible.
+
+For further accuracy improvement tips, check the [Arguments `SpeedEstimator` section](#arguments-speedestimator).
+
+### Why choose Ultralytics YOLOv8 over other object detection models like TensorFlow Object Detection API?
+
+Ultralytics YOLOv8 offers several advantages over other object detection models, such as the TensorFlow Object Detection API:
+
+- **Real-Time Performance**: YOLOv8 is optimized for real-time detection, providing high speed and accuracy.
+- **Ease of Use**: Designed with a user-friendly interface, YOLOv8 simplifies model training and deployment.
+- **Versatility**: Supports multiple tasks, including object detection, segmentation, and pose estimation.
+- **Community and Support**: YOLOv8 is backed by an active community and extensive documentation, ensuring developers have the resources they need.
+
+For more information on the benefits of YOLOv8, explore our detailed [model page](../models/yolov8.md).
diff --git a/ultralytics/docs/en/guides/steps-of-a-cv-project.md b/ultralytics/docs/en/guides/steps-of-a-cv-project.md
new file mode 100644
index 0000000000000000000000000000000000000000..9f3db139ef48ae1b423f765bea619262c9c98184
--- /dev/null
+++ b/ultralytics/docs/en/guides/steps-of-a-cv-project.md
@@ -0,0 +1,241 @@
+---
+comments: true
+description: Discover essential steps for launching a successful computer vision project, from defining goals to model deployment and maintenance. Boost your AI capabilities now!.
+keywords: Computer Vision, AI, Object Detection, Image Classification, Instance Segmentation, Data Annotation, Model Training, Model Evaluation, Model Deployment
+---
+
+# Understanding the Key Steps in a Computer Vision Project
+
+## Introduction
+
+Computer vision is a subfield of artificial intelligence (AI) that helps computers see and understand the world like humans do. It processes and analyzes images or videos to extract information, recognize patterns, and make decisions based on that data.
+
+
+
+
+
+ Watch: How to Do Computer Vision Projects | A Step-by-Step Guide
+
+
+Computer vision techniques like [object detection](../tasks/detect.md), [image classification](../tasks/classify.md), and [instance segmentation](../tasks/segment.md) can be applied across various industries, from [autonomous driving](https://www.ultralytics.com/solutions/ai-in-self-driving) to [medical imaging](https://www.ultralytics.com/solutions/ai-in-healthcare) to gain valuable insights.
+
+
+
+
+
+Working on your own computer vision projects is a great way to understand and learn more about computer vision. However, a computer vision project can consist of many steps, and it might seem confusing at first. By the end of this guide, you'll be familiar with the steps involved in a computer vision project. We'll walk through everything from the beginning to the end of a project, explaining why each part is important. Let's get started and make your computer vision project a success!
+
+## An Overview of a Computer Vision Project
+
+Before discussing the details of each step involved in a computer vision project, let's look at the overall process. If you started a computer vision project today, you'd take the following steps:
+
+- Your first priority would be to understand your project's requirements.
+- Then, you'd collect and accurately label the images that will help train your model.
+- Next, you'd clean your data and apply augmentation techniques to prepare it for model training.
+- After model training, you'd thoroughly test and evaluate your model to make sure it performs consistently under different conditions.
+- Finally, you'd deploy your model into the real world and update it based on new insights and feedback.
+
+
+
+
+
+Now that we know what to expect, let's dive right into the steps and get your project moving forward.
+
+## Step 1: Defining Your Project's Goals
+
+The first step in any computer vision project is clearly defining the problem you're trying to solve. Knowing the end goal helps you start to build a solution. This is especially true when it comes to computer vision because your project's objective will directly affect which computer vision task you need to focus on.
+
+Here are some examples of project objectives and the computer vision tasks that can be used to reach these objectives:
+
+- **Objective:** To develop a system that can monitor and manage the flow of different vehicle types on highways, improving traffic management and safety.
+
+ - **Computer Vision Task:** Object detection is ideal for traffic monitoring because it efficiently locates and identifies multiple vehicles. It is less computationally demanding than image segmentation, which provides unnecessary detail for this task, ensuring faster, real-time analysis.
+
+- **Objective:** To develop a tool that assists radiologists by providing precise, pixel-level outlines of tumors in medical imaging scans.
+
+ - **Computer Vision Task:** Image segmentation is suitable for medical imaging because it provides accurate and detailed boundaries of tumors that are crucial for assessing size, shape, and treatment planning.
+
+- **Objective:** To create a digital system that categorizes various documents (e.g., invoices, receipts, legal paperwork) to improve organizational efficiency and document retrieval.
+ - **Computer Vision Task:** Image classification is ideal here as it handles one document at a time, without needing to consider the document's position in the image. This approach simplifies and accelerates the sorting process.
+
+### Step 1.5: Selecting the Right Model and Training Approach
+
+After understanding the project objective and suitable computer vision tasks, an essential part of defining the project goal is [selecting the right model](../models/index.md) and training approach.
+
+Depending on the objective, you might choose to select the model first or after seeing what data you are able to collect in Step 2. For example, suppose your project is highly dependent on the availability of specific types of data. In that case, it may be more practical to gather and analyze the data first before selecting a model. On the other hand, if you have a clear understanding of the model requirements, you can choose the model first and then collect data that fits those specifications.
+
+Choosing between training from scratch or using transfer learning affects how you prepare your data. Training from scratch requires a diverse dataset to build the model's understanding from the ground up. Transfer learning, on the other hand, allows you to use a pre-trained model and adapt it with a smaller, more specific dataset. Also, choosing a specific model to train will determine how you need to prepare your data, such as resizing images or adding annotations, according to the model's specific requirements.
+
+
+
+
+
+Note: When choosing a model, consider its [deployment](./model-deployment-options.md) to ensure compatibility and performance. For example, lightweight models are ideal for edge computing due to their efficiency on resource-constrained devices. To learn more about the key points related to defining your project, read [our guide](./defining-project-goals.md) on defining your project's goals and selecting the right model.
+
+Before getting into the hands-on work of a computer vision project, it's important to have a clear understanding of these details. Double-check that you've considered the following before moving on to Step 2:
+
+- Clearly define the problem you're trying to solve.
+- Determine the end goal of your project.
+- Identify the specific computer vision task needed (e.g., object detection, image classification, image segmentation).
+- Decide whether to train a model from scratch or use transfer learning.
+- Select the appropriate model for your task and deployment needs.
+
+## Step 2: Data Collection and Data Annotation
+
+The quality of your computer vision models depend on the quality of your dataset. You can either collect images from the internet, take your own pictures, or use pre-existing datasets. Here are some great resources for downloading high-quality datasets: [Google Dataset Search Engine](https://datasetsearch.research.google.com/), [UC Irvine Machine Learning Repository](https://archive.ics.uci.edu/), and [Kaggle Datasets](https://www.kaggle.com/datasets).
+
+Some libraries, like Ultralytics, provide [built-in support for various datasets](../datasets/index.md), making it easier to get started with high-quality data. These libraries often include utilities for using popular datasets seamlessly, which can save you a lot of time and effort in the initial stages of your project.
+
+However, if you choose to collect images or take your own pictures, you'll need to annotate your data. Data annotation is the process of labeling your data to impart knowledge to your model. The type of data annotation you'll work with depends on your specific computer vision technique. Here are some examples:
+
+- **Image Classification:** You'll label the entire image as a single class.
+- **Object Detection:** You'll draw bounding boxes around each object in the image and label each box.
+- **Image Segmentation:** You'll label each pixel in the image according to the object it belongs to, creating detailed object boundaries.
+
+
+
+
+
+[Data collection and annotation](./data-collection-and-annotation.md) can be a time-consuming manual effort. Annotation tools can help make this process easier. Here are some useful open annotation tools: [LabeI Studio](https://github.com/HumanSignal/label-studio), [CVAT](https://github.com/cvat-ai/cvat), and [Labelme](https://github.com/labelmeai/labelme).
+
+## Step 3: Data Augmentation and Splitting Your Dataset
+
+After collecting and annotating your image data, it's important to first split your dataset into training, validation, and test sets before performing data augmentation. Splitting your dataset before augmentation is crucial to test and validate your model on original, unaltered data. It helps accurately assess how well the model generalizes to new, unseen data.
+
+Here's how to split your data:
+
+- **Training Set:** It is the largest portion of your data, typically 70-80% of the total, used to train your model.
+- **Validation Set:** Usually around 10-15% of your data; this set is used to tune hyperparameters and validate the model during training, helping to prevent overfitting.
+- **Test Set:** The remaining 10-15% of your data is set aside as the test set. It is used to evaluate the model's performance on unseen data after training is complete.
+
+After splitting your data, you can perform data augmentation by applying transformations like rotating, scaling, and flipping images to artificially increase the size of your dataset. Data augmentation makes your model more robust to variations and improves its performance on unseen images.
+
+
+
+
+
+Libraries like OpenCV, Albumentations, and TensorFlow offer flexible augmentation functions that you can use. Additionally, some libraries, such as Ultralytics, have [built-in augmentation settings](../modes/train.md) directly within its model training function, simplifying the process.
+
+To understand your data better, you can use tools like [Matplotlib](https://matplotlib.org/) or [Seaborn](https://seaborn.pydata.org/) to visualize the images and analyze their distribution and characteristics. Visualizing your data helps identify patterns, anomalies, and the effectiveness of your augmentation techniques. You can also use [Ultralytics Explorer](../datasets/explorer/index.md), a tool for exploring computer vision datasets with semantic search, SQL queries, and vector similarity search.
+
+
+
+
+
+By properly [understanding, splitting, and augmenting your data](./preprocessing_annotated_data.md), you can develop a well-trained, validated, and tested model that performs well in real-world applications.
+
+## Step 4: Model Training
+
+Once your dataset is ready for training, you can focus on setting up the necessary environment, managing your datasets, and training your model.
+
+First, you'll need to make sure your environment is configured correctly. Typically, this includes the following:
+
+- Installing essential libraries and frameworks like TensorFlow, PyTorch, or [Ultralytics](../quickstart.md).
+- If you are using a GPU, installing libraries like CUDA and cuDNN will help enable GPU acceleration and speed up the training process.
+
+Then, you can load your training and validation datasets into your environment. Normalize and preprocess the data through resizing, format conversion, or augmentation. With your model selected, configure the layers and specify hyperparameters. Compile the model by setting the loss function, optimizer, and performance metrics.
+
+Libraries like Ultralytics simplify the training process. You can [start training](../modes/train.md) by feeding data into the model with minimal code. These libraries handle weight adjustments, backpropagation, and validation automatically. They also offer tools to monitor progress and adjust hyperparameters easily. After training, save the model and its weights with a few commands.
+
+It's important to keep in mind that proper dataset management is vital for efficient training. Use version control for datasets to track changes and ensure reproducibility. Tools like [DVC (Data Version Control)](../integrations/dvc.md) can help manage large datasets.
+
+## Step 5: Model Evaluation and Model Finetuning
+
+It's important to assess your model's performance using various metrics and refine it to improve accuracy. [Evaluating](../modes/val.md) helps identify areas where the model excels and where it may need improvement. Fine-tuning ensures the model is optimized for the best possible performance.
+
+- **[Performance Metrics](./yolo-performance-metrics.md):** Use metrics like accuracy, precision, recall, and F1-score to evaluate your model's performance. These metrics provide insights into how well your model is making predictions.
+- **[Hyperparameter Tuning](./hyperparameter-tuning.md):** Adjust hyperparameters to optimize model performance. Techniques like grid search or random search can help find the best hyperparameter values.
+
+- Fine-Tuning: Make small adjustments to the model architecture or training process to enhance performance. This might involve tweaking learning rates, batch sizes, or other model parameters.
+
+## Step 6: Model Testing
+
+In this step, you can make sure that your model performs well on completely unseen data, confirming its readiness for deployment. The difference between model testing and model evaluation is that it focuses on verifying the final model's performance rather than iteratively improving it.
+
+It's important to thoroughly test and debug any common issues that may arise. Test your model on a separate test dataset that was not used during training or validation. This dataset should represent real-world scenarios to ensure the model's performance is consistent and reliable.
+
+Also, address common problems such as overfitting, underfitting, and data leakage. Use techniques like cross-validation and anomaly detection to identify and fix these issues.
+
+## Step 7: Model Deployment
+
+Once your model has been thoroughly tested, it's time to deploy it. Deployment involves making your model available for use in a production environment. Here are the steps to deploy a computer vision model:
+
+- Setting Up the Environment: Configure the necessary infrastructure for your chosen deployment option, whether it's cloud-based (AWS, Google Cloud, Azure) or edge-based (local devices, IoT).
+
+- **[Exporting the Model](../modes/export.md):** Export your model to the appropriate format (e.g., ONNX, TensorRT, CoreML for YOLOv8) to ensure compatibility with your deployment platform.
+- **Deploying the Model:** Deploy the model by setting up APIs or endpoints and integrating it with your application.
+- **Ensuring Scalability**: Implement load balancers, auto-scaling groups, and monitoring tools to manage resources and handle increasing data and user requests.
+
+## Step 8: Monitoring, Maintenance, and Documentation
+
+Once your model is deployed, it's important to continuously monitor its performance, maintain it to handle any issues, and document the entire process for future reference and improvements.
+
+Monitoring tools can help you track key performance indicators (KPIs) and detect anomalies or drops in accuracy. By monitoring the model, you can be aware of model drift, where the model's performance declines over time due to changes in the input data. Periodically retrain the model with updated data to maintain accuracy and relevance.
+
+
+
+
+
+In addition to monitoring and maintenance, documentation is also key. Thoroughly document the entire process, including model architecture, training procedures, hyperparameters, data preprocessing steps, and any changes made during deployment and maintenance. Good documentation ensures reproducibility and makes future updates or troubleshooting easier. By effectively monitoring, maintaining, and documenting your model, you can ensure it remains accurate, reliable, and easy to manage over its lifecycle.
+
+## Engaging with the Community
+
+Connecting with a community of computer vision enthusiasts can help you tackle any issues you face while working on your computer vision project with confidence. Here are some ways to learn, troubleshoot, and network effectively.
+
+### Community Resources
+
+- **GitHub Issues:** Check out the [YOLOv8 GitHub repository](https://github.com/ultralytics/ultralytics/issues) and use the Issues tab to ask questions, report bugs, and suggest new features. The active community and maintainers are there to help with specific issues.
+- **Ultralytics Discord Server:** Join the [Ultralytics Discord server](https://ultralytics.com/discord/) to interact with other users and developers, get support, and share insights.
+
+### Official Documentation
+
+- **Ultralytics YOLOv8 Documentation:** Explore the [official YOLOv8 documentation](./index.md) for detailed guides with helpful tips on different computer vision tasks and projects.
+
+Using these resources will help you overcome challenges and stay updated with the latest trends and best practices in the computer vision community.
+
+## Kickstart Your Computer Vision Project Today!
+
+Taking on a computer vision project can be exciting and rewarding. By following the steps in this guide, you can build a solid foundation for success. Each step is crucial for developing a solution that meets your objectives and works well in real-world scenarios. As you gain experience, you'll discover advanced techniques and tools to improve your projects. Stay curious, keep learning, and explore new methods and innovations!
+
+## FAQ
+
+### How do I choose the right computer vision task for my project?
+
+Choosing the right computer vision task depends on your project's end goal. For instance, if you want to monitor traffic, **object detection** is suitable as it can locate and identify multiple vehicle types in real-time. For medical imaging, **image segmentation** is ideal for providing detailed boundaries of tumors, aiding in diagnosis and treatment planning. Learn more about specific tasks like [object detection](../tasks/detect.md), [image classification](../tasks/classify.md), and [instance segmentation](../tasks/segment.md).
+
+### Why is data annotation crucial in computer vision projects?
+
+Data annotation is vital for teaching your model to recognize patterns. The type of annotation varies with the task:
+
+- **Image Classification**: Entire image labeled as a single class.
+- **Object Detection**: Bounding boxes drawn around objects.
+- **Image Segmentation**: Each pixel labeled according to the object it belongs to.
+
+Tools like [Label Studio](https://github.com/HumanSignal/label-studio), [CVAT](https://github.com/cvat-ai/cvat), and [Labelme](https://github.com/labelmeai/labelme) can assist in this process. For more details, refer to our [data collection and annotation guide](./data-collection-and-annotation.md).
+
+### What steps should I follow to augment and split my dataset effectively?
+
+Splitting your dataset before augmentation helps validate model performance on original, unaltered data. Follow these steps:
+
+- **Training Set**: 70-80% of your data.
+- **Validation Set**: 10-15% for hyperparameter tuning.
+- **Test Set**: Remaining 10-15% for final evaluation.
+
+After splitting, apply data augmentation techniques like rotation, scaling, and flipping to increase dataset diversity. Libraries such as Albumentations and OpenCV can help. Ultralytics also offers [built-in augmentation settings](../modes/train.md) for convenience.
+
+### How can I export my trained computer vision model for deployment?
+
+Exporting your model ensures compatibility with different deployment platforms. Ultralytics provides multiple formats, including ONNX, TensorRT, and CoreML. To export your YOLOv8 model, follow this guide:
+
+- Use the `export` function with the desired format parameter.
+- Ensure the exported model fits the specifications of your deployment environment (e.g., edge devices, cloud).
+
+For more information, check out the [model export guide](../modes/export.md).
+
+### What are the best practices for monitoring and maintaining a deployed computer vision model?
+
+Continuous monitoring and maintenance are essential for a model's long-term success. Implement tools for tracking Key Performance Indicators (KPIs) and detecting anomalies. Regularly retrain the model with updated data to counteract model drift. Document the entire process, including model architecture, hyperparameters, and changes, to ensure reproducibility and ease of future updates. Learn more in our [monitoring and maintenance guide](#step-8-monitoring-maintenance-and-documentation).
diff --git a/ultralytics/docs/en/guides/streamlit-live-inference.md b/ultralytics/docs/en/guides/streamlit-live-inference.md
new file mode 100644
index 0000000000000000000000000000000000000000..c9c7102da00f12bcdffab2469fbf74881df9bd7e
--- /dev/null
+++ b/ultralytics/docs/en/guides/streamlit-live-inference.md
@@ -0,0 +1,154 @@
+---
+comments: true
+description: Learn how to set up a real-time object detection application using Streamlit and Ultralytics YOLOv8. Follow this step-by-step guide to implement webcam-based object detection.
+keywords: Streamlit, YOLOv8, Real-time Object Detection, Streamlit Application, YOLOv8 Streamlit Tutorial, Webcam Object Detection
+---
+
+# Live Inference with Streamlit Application using Ultralytics YOLOv8
+
+## Introduction
+
+Streamlit makes it simple to build and deploy interactive web applications. Combining this with Ultralytics YOLOv8 allows for real-time object detection and analysis directly in your browser. YOLOv8 high accuracy and speed ensure seamless performance for live video streams, making it ideal for applications in security, retail, and beyond.
+
+| Aquaculture | Animals husbandry |
+| :---------------------------------------------------------------------------------------------------------------------------------------------: | :------------------------------------------------------------------------------------------------------------------------------------------------: |
+|  |  |
+| Fish Detection using Ultralytics YOLOv8 | Animals Detection using Ultralytics YOLOv8 |
+
+## Advantages of Live Inference
+
+- **Seamless Real-Time Object Detection**: Streamlit combined with YOLOv8 enables real-time object detection directly from your webcam feed. This allows for immediate analysis and insights, making it ideal for applications requiring instant feedback.
+- **User-Friendly Deployment**: Streamlit's interactive interface makes it easy to deploy and use the application without extensive technical knowledge. Users can start live inference with a simple click, enhancing accessibility and usability.
+- **Efficient Resource Utilization**: YOLOv8 optimized algorithm ensure high-speed processing with minimal computational resources. This efficiency allows for smooth and reliable webcam inference even on standard hardware, making advanced computer vision accessible to a wider audience.
+
+## Streamlit Application Code
+
+!!! tip "Ultralytics Installation"
+
+ Before you start building the application, ensure you have the Ultralytics Python Package installed. You can install it using the command **pip install ultralytics**
+
+!!! Example "Streamlit Application"
+
+ === "Python"
+
+ ```python
+ from ultralytics import solutions
+
+ solutions.inference()
+
+ ### Make sure to run the file using command `streamlit run `
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo streamlit-predict
+ ```
+
+This will launch the Streamlit application in your default web browser. You will see the main title, subtitle, and the sidebar with configuration options. Select your desired YOLOv8 model, set the confidence and NMS thresholds, and click the "Start" button to begin the real-time object detection.
+
+You can optionally supply a specific model in Python:
+
+!!! Example "Streamlit Application with a custom model"
+
+ === "Python"
+
+ ```python
+ from ultralytics import solutions
+
+ # Pass a model as an argument
+ solutions.inference(model="path/to/model.pt")
+
+ ### Make sure to run the file using command `streamlit run `
+ ```
+
+## Conclusion
+
+By following this guide, you have successfully created a real-time object detection application using Streamlit and Ultralytics YOLOv8. This application allows you to experience the power of YOLOv8 in detecting objects through your webcam, with a user-friendly interface and the ability to stop the video stream at any time.
+
+For further enhancements, you can explore adding more features such as recording the video stream, saving the annotated frames, or integrating with other computer vision libraries.
+
+## Share Your Thoughts with the Community
+
+Engage with the community to learn more, troubleshoot issues, and share your projects:
+
+### Where to Find Help and Support
+
+- **GitHub Issues:** Visit the [Ultralytics GitHub repository](https://github.com/ultralytics/ultralytics/issues) to raise questions, report bugs, and suggest features.
+- **Ultralytics Discord Server:** Join the [Ultralytics Discord server](https://ultralytics.com/discord/) to connect with other users and developers, get support, share knowledge, and brainstorm ideas.
+
+### Official Documentation
+
+- **Ultralytics YOLOv8 Documentation:** Refer to the [official YOLOv8 documentation](https://docs.ultralytics.com/) for comprehensive guides and insights on various computer vision tasks and projects.
+
+## FAQ
+
+### How can I set up a real-time object detection application using Streamlit and Ultralytics YOLOv8?
+
+Setting up a real-time object detection application with Streamlit and Ultralytics YOLOv8 is straightforward. First, ensure you have the Ultralytics Python package installed using:
+
+```bash
+pip install ultralytics
+```
+
+Then, you can create a basic Streamlit application to run live inference:
+
+!!! Example "Streamlit Application"
+
+ === "Python"
+
+ ```python
+ from ultralytics import solutions
+
+ solutions.inference()
+
+ ### Make sure to run the file using command `streamlit run `
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo streamlit-predict
+ ```
+
+For more details on the practical setup, refer to the [Streamlit Application Code section](#streamlit-application-code) of the documentation.
+
+### What are the main advantages of using Ultralytics YOLOv8 with Streamlit for real-time object detection?
+
+Using Ultralytics YOLOv8 with Streamlit for real-time object detection offers several advantages:
+
+- **Seamless Real-Time Detection**: Achieve high-accuracy, real-time object detection directly from webcam feeds.
+- **User-Friendly Interface**: Streamlit's intuitive interface allows easy use and deployment without extensive technical knowledge.
+- **Resource Efficiency**: YOLOv8's optimized algorithms ensure high-speed processing with minimal computational resources.
+
+Discover more about these advantages [here](#advantages-of-live-inference).
+
+### How do I deploy a Streamlit object detection application in my web browser?
+
+After coding your Streamlit application integrating Ultralytics YOLOv8, you can deploy it by running:
+
+```bash
+streamlit run
+```
+
+This command will launch the application in your default web browser, enabling you to select YOLOv8 models, set confidence, and NMS thresholds, and start real-time object detection with a simple click. For a detailed guide, refer to the [Streamlit Application Code](#streamlit-application-code) section.
+
+### What are some use cases for real-time object detection using Streamlit and Ultralytics YOLOv8?
+
+Real-time object detection using Streamlit and Ultralytics YOLOv8 can be applied in various sectors:
+
+- **Security**: Real-time monitoring for unauthorized access.
+- **Retail**: Customer counting, shelf management, and more.
+- **Wildlife and Agriculture**: Monitoring animals and crop conditions.
+
+For more in-depth use cases and examples, explore [Ultralytics Solutions](https://docs.ultralytics.com/solutions).
+
+### How does Ultralytics YOLOv8 compare to other object detection models like YOLOv5 and RCNNs?
+
+Ultralytics YOLOv8 provides several enhancements over prior models like YOLOv5 and RCNNs:
+
+- **Higher Speed and Accuracy**: Improved performance for real-time applications.
+- **Ease of Use**: Simplified interfaces and deployment.
+- **Resource Efficiency**: Optimized for better speed with minimal computational requirements.
+
+For a comprehensive comparison, check [Ultralytics YOLOv8 Documentation](https://docs.ultralytics.com/models/yolov8) and related blog posts discussing model performance.
diff --git a/ultralytics/docs/en/guides/triton-inference-server.md b/ultralytics/docs/en/guides/triton-inference-server.md
new file mode 100644
index 0000000000000000000000000000000000000000..c4f3df026e2cabd714d5371a6e27775e8cb828c8
--- /dev/null
+++ b/ultralytics/docs/en/guides/triton-inference-server.md
@@ -0,0 +1,267 @@
+---
+comments: true
+description: Learn how to integrate Ultralytics YOLOv8 with NVIDIA Triton Inference Server for scalable, high-performance AI model deployment.
+keywords: Triton Inference Server, YOLOv8, Ultralytics, NVIDIA, deep learning, AI model deployment, ONNX, scalable inference
+---
+
+# Triton Inference Server with Ultralytics YOLOv8
+
+The [Triton Inference Server](https://developer.nvidia.com/nvidia-triton-inference-server) (formerly known as TensorRT Inference Server) is an open-source software solution developed by NVIDIA. It provides a cloud inference solution optimized for NVIDIA GPUs. Triton simplifies the deployment of AI models at scale in production. Integrating Ultralytics YOLOv8 with Triton Inference Server allows you to deploy scalable, high-performance deep learning inference workloads. This guide provides steps to set up and test the integration.
+
+
+
+
+
+ Watch: Getting Started with NVIDIA Triton Inference Server.
+
+
+## What is Triton Inference Server?
+
+Triton Inference Server is designed to deploy a variety of AI models in production. It supports a wide range of deep learning and machine learning frameworks, including TensorFlow, PyTorch, ONNX Runtime, and many others. Its primary use cases are:
+
+- Serving multiple models from a single server instance.
+- Dynamic model loading and unloading without server restart.
+- Ensemble inference, allowing multiple models to be used together to achieve results.
+- Model versioning for A/B testing and rolling updates.
+
+## Prerequisites
+
+Ensure you have the following prerequisites before proceeding:
+
+- Docker installed on your machine.
+- Install `tritonclient`:
+ ```bash
+ pip install tritonclient[all]
+ ```
+
+## Exporting YOLOv8 to ONNX Format
+
+Before deploying the model on Triton, it must be exported to the ONNX format. ONNX (Open Neural Network Exchange) is a format that allows models to be transferred between different deep learning frameworks. Use the `export` function from the `YOLO` class:
+
+```python
+from ultralytics import YOLO
+
+# Load a model
+model = YOLO("yolov8n.pt") # load an official model
+
+# Export the model
+onnx_file = model.export(format="onnx", dynamic=True)
+```
+
+## Setting Up Triton Model Repository
+
+The Triton Model Repository is a storage location where Triton can access and load models.
+
+1. Create the necessary directory structure:
+
+ ```python
+ from pathlib import Path
+
+ # Define paths
+ model_name = "yolo"
+ triton_repo_path = Path("tmp") / "triton_repo"
+ triton_model_path = triton_repo_path / model_name
+
+ # Create directories
+ (triton_model_path / "1").mkdir(parents=True, exist_ok=True)
+ ```
+
+2. Move the exported ONNX model to the Triton repository:
+
+ ```python
+ from pathlib import Path
+
+ # Move ONNX model to Triton Model path
+ Path(onnx_file).rename(triton_model_path / "1" / "model.onnx")
+
+ # Create config file
+ (triton_model_path / "config.pbtxt").touch()
+ ```
+
+## Running Triton Inference Server
+
+Run the Triton Inference Server using Docker:
+
+```python
+import contextlib
+import subprocess
+import time
+
+from tritonclient.http import InferenceServerClient
+
+# Define image https://catalog.ngc.nvidia.com/orgs/nvidia/containers/tritonserver
+tag = "nvcr.io/nvidia/tritonserver:23.09-py3" # 6.4 GB
+
+# Pull the image
+subprocess.call(f"docker pull {tag}", shell=True)
+
+# Run the Triton server and capture the container ID
+container_id = (
+ subprocess.check_output(
+ f"docker run -d --rm -v {triton_repo_path}:/models -p 8000:8000 {tag} tritonserver --model-repository=/models",
+ shell=True,
+ )
+ .decode("utf-8")
+ .strip()
+)
+
+# Wait for the Triton server to start
+triton_client = InferenceServerClient(url="localhost:8000", verbose=False, ssl=False)
+
+# Wait until model is ready
+for _ in range(10):
+ with contextlib.suppress(Exception):
+ assert triton_client.is_model_ready(model_name)
+ break
+ time.sleep(1)
+```
+
+Then run inference using the Triton Server model:
+
+```python
+from ultralytics import YOLO
+
+# Load the Triton Server model
+model = YOLO("http://localhost:8000/yolo", task="detect")
+
+# Run inference on the server
+results = model("path/to/image.jpg")
+```
+
+Cleanup the container:
+
+```python
+# Kill and remove the container at the end of the test
+subprocess.call(f"docker kill {container_id}", shell=True)
+```
+
+---
+
+By following the above steps, you can deploy and run Ultralytics YOLOv8 models efficiently on Triton Inference Server, providing a scalable and high-performance solution for deep learning inference tasks. If you face any issues or have further queries, refer to the [official Triton documentation](https://docs.nvidia.com/deeplearning/triton-inference-server/user-guide/docs/index.html) or reach out to the Ultralytics community for support.
+
+## FAQ
+
+### How do I set up Ultralytics YOLOv8 with NVIDIA Triton Inference Server?
+
+Setting up [Ultralytics YOLOv8](https://docs.ultralytics.com/models/yolov8) with [NVIDIA Triton Inference Server](https://developer.nvidia.com/nvidia-triton-inference-server) involves a few key steps:
+
+1. **Export YOLOv8 to ONNX format**:
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt") # load an official model
+
+ # Export the model to ONNX format
+ onnx_file = model.export(format="onnx", dynamic=True)
+ ```
+
+2. **Set up Triton Model Repository**:
+
+ ```python
+ from pathlib import Path
+
+ # Define paths
+ model_name = "yolo"
+ triton_repo_path = Path("tmp") / "triton_repo"
+ triton_model_path = triton_repo_path / model_name
+
+ # Create directories
+ (triton_model_path / "1").mkdir(parents=True, exist_ok=True)
+ Path(onnx_file).rename(triton_model_path / "1" / "model.onnx")
+ (triton_model_path / "config.pbtxt").touch()
+ ```
+
+3. **Run the Triton Server**:
+
+ ```python
+ import contextlib
+ import subprocess
+ import time
+
+ from tritonclient.http import InferenceServerClient
+
+ # Define image https://catalog.ngc.nvidia.com/orgs/nvidia/containers/tritonserver
+ tag = "nvcr.io/nvidia/tritonserver:23.09-py3"
+
+ subprocess.call(f"docker pull {tag}", shell=True)
+
+ container_id = (
+ subprocess.check_output(
+ f"docker run -d --rm -v {triton_repo_path}/models -p 8000:8000 {tag} tritonserver --model-repository=/models",
+ shell=True,
+ )
+ .decode("utf-8")
+ .strip()
+ )
+
+ triton_client = InferenceServerClient(url="localhost:8000", verbose=False, ssl=False)
+
+ for _ in range(10):
+ with contextlib.suppress(Exception):
+ assert triton_client.is_model_ready(model_name)
+ break
+ time.sleep(1)
+ ```
+
+This setup can help you efficiently deploy YOLOv8 models at scale on Triton Inference Server for high-performance AI model inference.
+
+### What benefits does using Ultralytics YOLOv8 with NVIDIA Triton Inference Server offer?
+
+Integrating [Ultralytics YOLOv8](../models/yolov8.md) with [NVIDIA Triton Inference Server](https://developer.nvidia.com/nvidia-triton-inference-server) provides several advantages:
+
+- **Scalable AI Inference**: Triton allows serving multiple models from a single server instance, supporting dynamic model loading and unloading, making it highly scalable for diverse AI workloads.
+- **High Performance**: Optimized for NVIDIA GPUs, Triton Inference Server ensures high-speed inference operations, perfect for real-time applications such as object detection.
+- **Ensemble and Model Versioning**: Triton's ensemble mode enables combining multiple models to improve results, and its model versioning supports A/B testing and rolling updates.
+
+For detailed instructions on setting up and running YOLOv8 with Triton, you can refer to the [setup guide](#setting-up-triton-model-repository).
+
+### Why should I export my YOLOv8 model to ONNX format before using Triton Inference Server?
+
+Using ONNX (Open Neural Network Exchange) format for your [Ultralytics YOLOv8](../models/yolov8.md) model before deploying it on [NVIDIA Triton Inference Server](https://developer.nvidia.com/nvidia-triton-inference-server) offers several key benefits:
+
+- **Interoperability**: ONNX format supports transfer between different deep learning frameworks (such as PyTorch, TensorFlow), ensuring broader compatibility.
+- **Optimization**: Many deployment environments, including Triton, optimize for ONNX, enabling faster inference and better performance.
+- **Ease of Deployment**: ONNX is widely supported across frameworks and platforms, simplifying the deployment process in various operating systems and hardware configurations.
+
+To export your model, use:
+
+```python
+from ultralytics import YOLO
+
+model = YOLO("yolov8n.pt")
+onnx_file = model.export(format="onnx", dynamic=True)
+```
+
+You can follow the steps in the [exporting guide](../modes/export.md) to complete the process.
+
+### Can I run inference using the Ultralytics YOLOv8 model on Triton Inference Server?
+
+Yes, you can run inference using the [Ultralytics YOLOv8](../models/yolov8.md) model on [NVIDIA Triton Inference Server](https://developer.nvidia.com/nvidia-triton-inference-server). Once your model is set up in the Triton Model Repository and the server is running, you can load and run inference on your model as follows:
+
+```python
+from ultralytics import YOLO
+
+# Load the Triton Server model
+model = YOLO("http://localhost:8000/yolo", task="detect")
+
+# Run inference on the server
+results = model("path/to/image.jpg")
+```
+
+For an in-depth guide on setting up and running Triton Server with YOLOv8, refer to the [running triton inference server](#running-triton-inference-server) section.
+
+### How does Ultralytics YOLOv8 compare to TensorFlow and PyTorch models for deployment?
+
+[Ultralytics YOLOv8](https://docs.ultralytics.com/models/yolov8) offers several unique advantages compared to TensorFlow and PyTorch models for deployment:
+
+- **Real-time Performance**: Optimized for real-time object detection tasks, YOLOv8 provides state-of-the-art accuracy and speed, making it ideal for applications requiring live video analytics.
+- **Ease of Use**: YOLOv8 integrates seamlessly with Triton Inference Server and supports diverse export formats (ONNX, TensorRT, CoreML), making it flexible for various deployment scenarios.
+- **Advanced Features**: YOLOv8 includes features like dynamic model loading, model versioning, and ensemble inference, which are crucial for scalable and reliable AI deployments.
+
+For more details, compare the deployment options in the [model deployment guide](../modes/export.md).
diff --git a/ultralytics/docs/en/guides/view-results-in-terminal.md b/ultralytics/docs/en/guides/view-results-in-terminal.md
new file mode 100644
index 0000000000000000000000000000000000000000..9b65faba6be031e99f9dcd3a86cd01d8094d317f
--- /dev/null
+++ b/ultralytics/docs/en/guides/view-results-in-terminal.md
@@ -0,0 +1,243 @@
+---
+comments: true
+description: Learn how to visualize YOLO inference results directly in a VSCode terminal using sixel on Linux and MacOS.
+keywords: YOLO, inference results, VSCode terminal, sixel, display images, Linux, MacOS
+---
+
+# Viewing Inference Results in a Terminal
+
+
+
+
+
+Image from the [libsixel](https://saitoha.github.io/libsixel/) website.
+
+## Motivation
+
+When connecting to a remote machine, normally visualizing image results is not possible or requires moving data to a local device with a GUI. The VSCode integrated terminal allows for directly rendering images. This is a short demonstration on how to use this in conjunction with `ultralytics` with [prediction results](../modes/predict.md).
+
+!!! warning
+
+ Only compatible with Linux and MacOS. Check the [VSCode repository](https://github.com/microsoft/vscode), check [Issue status](https://github.com/microsoft/vscode/issues/198622), or [documentation](https://code.visualstudio.com/docs) for updates about Windows support to view images in terminal with `sixel`.
+
+The VSCode compatible protocols for viewing images using the integrated terminal are [`sixel`](https://en.wikipedia.org/wiki/Sixel) and [`iTerm`](https://iterm2.com/documentation-images.html). This guide will demonstrate use of the `sixel` protocol.
+
+## Process
+
+1. First, you must enable settings `terminal.integrated.enableImages` and `terminal.integrated.gpuAcceleration` in VSCode.
+
+ ```yaml
+ "terminal.integrated.gpuAcceleration": "auto" # "auto" is default, can also use "on"
+ "terminal.integrated.enableImages": false
+ ```
+
+
+
+
+
+2. Install the `python-sixel` library in your virtual environment. This is a [fork](https://github.com/lubosz/python-sixel?tab=readme-ov-file) of the `PySixel` library, which is no longer maintained.
+
+ ```bash
+ pip install sixel
+ ```
+
+3. Load a model and execute inference, then plot the results and store in a variable. See more about inference arguments and working with results on the [predict mode](../modes/predict.md) page.
+
+ ```{ .py .annotate }
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt")
+
+ # Run inference on an image
+ results = model.predict(source="ultralytics/assets/bus.jpg")
+
+ # Plot inference results
+ plot = results[0].plot() # (1)!
+ ```
+
+ 1. See [plot method parameters](../modes/predict.md#plot-method-parameters) to see possible arguments to use.
+
+4. Now, use OpenCV to convert the `numpy.ndarray` to `bytes` data. Then use `io.BytesIO` to make a "file-like" object.
+
+ ```{ .py .annotate }
+ import io
+
+ import cv2
+
+ # Results image as bytes
+ im_bytes = cv2.imencode(
+ ".png", # (1)!
+ plot,
+ )[1].tobytes() # (2)!
+
+ # Image bytes as a file-like object
+ mem_file = io.BytesIO(im_bytes)
+ ```
+
+ 1. It's possible to use other image extensions as well.
+ 2. Only the object at index `1` that is returned is needed.
+
+5. Create a `SixelWriter` instance, and then use the `.draw()` method to draw the image in the terminal.
+
+ ```python
+ from sixel import SixelWriter
+
+ # Create sixel writer object
+ w = SixelWriter()
+
+ # Draw the sixel image in the terminal
+ w.draw(mem_file)
+ ```
+
+## Example Inference Results
+
+
+
+
+
+!!! danger
+
+ Using this example with videos or animated GIF frames has **not** been tested. Attempt at your own risk.
+
+## Full Code Example
+
+```{ .py .annotate }
+import io
+
+import cv2
+from sixel import SixelWriter
+
+from ultralytics import YOLO
+
+# Load a model
+model = YOLO("yolov8n.pt")
+
+# Run inference on an image
+results = model.predict(source="ultralytics/assets/bus.jpg")
+
+# Plot inference results
+plot = results[0].plot() # (3)!
+
+# Results image as bytes
+im_bytes = cv2.imencode(
+ ".png", # (1)!
+ plot,
+)[1].tobytes() # (2)!
+
+mem_file = io.BytesIO(im_bytes)
+w = SixelWriter()
+w.draw(mem_file)
+```
+
+1. It's possible to use other image extensions as well.
+2. Only the object at index `1` that is returned is needed.
+3. See [plot method parameters](../modes/predict.md#plot-method-parameters) to see possible arguments to use.
+
+---
+
+!!! tip
+
+ You may need to use `clear` to "erase" the view of the image in the terminal.
+
+## FAQ
+
+### How can I view YOLO inference results in a VSCode terminal on macOS or Linux?
+
+To view YOLO inference results in a VSCode terminal on macOS or Linux, follow these steps:
+
+1. Enable the necessary VSCode settings:
+
+ ```yaml
+ "terminal.integrated.enableImages": true
+ "terminal.integrated.gpuAcceleration": "auto"
+ ```
+
+2. Install the sixel library:
+
+ ```bash
+ pip install sixel
+ ```
+
+3. Load your YOLO model and run inference:
+
+ ```python
+ from ultralytics import YOLO
+
+ model = YOLO("yolov8n.pt")
+ results = model.predict(source="path_to_image")
+ plot = results[0].plot()
+ ```
+
+4. Convert the inference result image to bytes and display it in the terminal:
+
+ ```python
+ import io
+
+ import cv2
+ from sixel import SixelWriter
+
+ im_bytes = cv2.imencode(".png", plot)[1].tobytes()
+ mem_file = io.BytesIO(im_bytes)
+ SixelWriter().draw(mem_file)
+ ```
+
+For further details, visit the [predict mode](../modes/predict.md) page.
+
+### Why does the sixel protocol only work on Linux and macOS?
+
+The sixel protocol is currently only supported on Linux and macOS because these platforms have native terminal capabilities compatible with sixel graphics. Windows support for terminal graphics using sixel is still under development. For updates on Windows compatibility, check the [VSCode Issue status](https://github.com/microsoft/vscode/issues/198622) and [documentation](https://code.visualstudio.com/docs).
+
+### What if I encounter issues with displaying images in the VSCode terminal?
+
+If you encounter issues displaying images in the VSCode terminal using sixel:
+
+1. Ensure the necessary settings in VSCode are enabled:
+
+ ```yaml
+ "terminal.integrated.enableImages": true
+ "terminal.integrated.gpuAcceleration": "auto"
+ ```
+
+2. Verify the sixel library installation:
+
+ ```bash
+ pip install sixel
+ ```
+
+3. Check your image data conversion and plotting code for errors. For example:
+
+ ```python
+ import io
+
+ import cv2
+ from sixel import SixelWriter
+
+ im_bytes = cv2.imencode(".png", plot)[1].tobytes()
+ mem_file = io.BytesIO(im_bytes)
+ SixelWriter().draw(mem_file)
+ ```
+
+If problems persist, consult the [VSCode repository](https://github.com/microsoft/vscode), and visit the [plot method parameters](../modes/predict.md#plot-method-parameters) section for additional guidance.
+
+### Can YOLO display video inference results in the terminal using sixel?
+
+Displaying video inference results or animated GIF frames using sixel in the terminal is currently untested and may not be supported. We recommend starting with static images and verifying compatibility. Attempt video results at your own risk, keeping in mind performance constraints. For more information on plotting inference results, visit the [predict mode](../modes/predict.md) page.
+
+### How can I troubleshoot issues with the `python-sixel` library?
+
+To troubleshoot issues with the `python-sixel` library:
+
+1. Ensure the library is correctly installed in your virtual environment:
+
+ ```bash
+ pip install sixel
+ ```
+
+2. Verify that you have the necessary Python and system dependencies.
+
+3. Refer to the [python-sixel GitHub repository](https://github.com/lubosz/python-sixel) for additional documentation and community support.
+
+4. Double-check your code for potential errors, specifically the usage of `SixelWriter` and image data conversion steps.
+
+For further assistance on working with YOLO models and sixel integration, see the [export](../modes/export.md) and [predict mode](../modes/predict.md) documentation pages.
diff --git a/ultralytics/docs/en/guides/vision-eye.md b/ultralytics/docs/en/guides/vision-eye.md
new file mode 100644
index 0000000000000000000000000000000000000000..8dbd9a9437de21c4c4b8548bdc073fa092dc0f46
--- /dev/null
+++ b/ultralytics/docs/en/guides/vision-eye.md
@@ -0,0 +1,308 @@
+---
+comments: true
+description: Discover VisionEye's object mapping and tracking powered by Ultralytics YOLOv8. Simulate human eye precision, track objects, and calculate distances effortlessly.
+keywords: VisionEye, YOLOv8, Ultralytics, object mapping, object tracking, distance calculation, computer vision, AI, machine learning, Python, tutorial
+---
+
+# VisionEye View Object Mapping using Ultralytics YOLOv8 🚀
+
+## What is VisionEye Object Mapping?
+
+[Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) VisionEye offers the capability for computers to identify and pinpoint objects, simulating the observational precision of the human eye. This functionality enables computers to discern and focus on specific objects, much like the way the human eye observes details from a particular viewpoint.
+
+## Samples
+
+| VisionEye View | VisionEye View With Object Tracking | VisionEye View With Distance Calculation |
+| :----------------------------------------------------------------------------------------------------------------------------------------------------------: | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | :-----------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+|  | 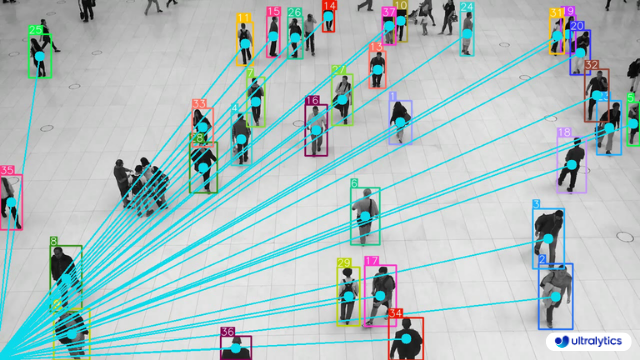 |  |
+| VisionEye View Object Mapping using Ultralytics YOLOv8 | VisionEye View Object Mapping with Object Tracking using Ultralytics YOLOv8 | VisionEye View with Distance Calculation using Ultralytics YOLOv8 |
+
+!!! Example "VisionEye Object Mapping using YOLOv8"
+
+ === "VisionEye Object Mapping"
+
+ ```python
+ import cv2
+
+ from ultralytics import YOLO
+ from ultralytics.utils.plotting import Annotator, colors
+
+ model = YOLO("yolov8n.pt")
+ names = model.model.names
+ cap = cv2.VideoCapture("path/to/video/file.mp4")
+ w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
+
+ out = cv2.VideoWriter("visioneye-pinpoint.avi", cv2.VideoWriter_fourcc(*"MJPG"), fps, (w, h))
+
+ center_point = (-10, h)
+
+ while True:
+ ret, im0 = cap.read()
+ if not ret:
+ print("Video frame is empty or video processing has been successfully completed.")
+ break
+
+ results = model.predict(im0)
+ boxes = results[0].boxes.xyxy.cpu()
+ clss = results[0].boxes.cls.cpu().tolist()
+
+ annotator = Annotator(im0, line_width=2)
+
+ for box, cls in zip(boxes, clss):
+ annotator.box_label(box, label=names[int(cls)], color=colors(int(cls)))
+ annotator.visioneye(box, center_point)
+
+ out.write(im0)
+ cv2.imshow("visioneye-pinpoint", im0)
+
+ if cv2.waitKey(1) & 0xFF == ord("q"):
+ break
+
+ out.release()
+ cap.release()
+ cv2.destroyAllWindows()
+ ```
+
+ === "VisionEye Object Mapping with Object Tracking"
+
+ ```python
+ import cv2
+
+ from ultralytics import YOLO
+ from ultralytics.utils.plotting import Annotator, colors
+
+ model = YOLO("yolov8n.pt")
+ cap = cv2.VideoCapture("path/to/video/file.mp4")
+ w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
+
+ out = cv2.VideoWriter("visioneye-pinpoint.avi", cv2.VideoWriter_fourcc(*"MJPG"), fps, (w, h))
+
+ center_point = (-10, h)
+
+ while True:
+ ret, im0 = cap.read()
+ if not ret:
+ print("Video frame is empty or video processing has been successfully completed.")
+ break
+
+ annotator = Annotator(im0, line_width=2)
+
+ results = model.track(im0, persist=True)
+ boxes = results[0].boxes.xyxy.cpu()
+
+ if results[0].boxes.id is not None:
+ track_ids = results[0].boxes.id.int().cpu().tolist()
+
+ for box, track_id in zip(boxes, track_ids):
+ annotator.box_label(box, label=str(track_id), color=colors(int(track_id)))
+ annotator.visioneye(box, center_point)
+
+ out.write(im0)
+ cv2.imshow("visioneye-pinpoint", im0)
+
+ if cv2.waitKey(1) & 0xFF == ord("q"):
+ break
+
+ out.release()
+ cap.release()
+ cv2.destroyAllWindows()
+ ```
+
+ === "VisionEye with Distance Calculation"
+
+ ```python
+ import math
+
+ import cv2
+
+ from ultralytics import YOLO
+ from ultralytics.utils.plotting import Annotator
+
+ model = YOLO("yolov8s.pt")
+ cap = cv2.VideoCapture("Path/to/video/file.mp4")
+
+ w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
+
+ out = cv2.VideoWriter("visioneye-distance-calculation.avi", cv2.VideoWriter_fourcc(*"MJPG"), fps, (w, h))
+
+ center_point = (0, h)
+ pixel_per_meter = 10
+
+ txt_color, txt_background, bbox_clr = ((0, 0, 0), (255, 255, 255), (255, 0, 255))
+
+ while True:
+ ret, im0 = cap.read()
+ if not ret:
+ print("Video frame is empty or video processing has been successfully completed.")
+ break
+
+ annotator = Annotator(im0, line_width=2)
+
+ results = model.track(im0, persist=True)
+ boxes = results[0].boxes.xyxy.cpu()
+
+ if results[0].boxes.id is not None:
+ track_ids = results[0].boxes.id.int().cpu().tolist()
+
+ for box, track_id in zip(boxes, track_ids):
+ annotator.box_label(box, label=str(track_id), color=bbox_clr)
+ annotator.visioneye(box, center_point)
+
+ x1, y1 = int((box[0] + box[2]) // 2), int((box[1] + box[3]) // 2) # Bounding box centroid
+
+ distance = (math.sqrt((x1 - center_point[0]) ** 2 + (y1 - center_point[1]) ** 2)) / pixel_per_meter
+
+ text_size, _ = cv2.getTextSize(f"Distance: {distance:.2f} m", cv2.FONT_HERSHEY_SIMPLEX, 1.2, 3)
+ cv2.rectangle(im0, (x1, y1 - text_size[1] - 10), (x1 + text_size[0] + 10, y1), txt_background, -1)
+ cv2.putText(im0, f"Distance: {distance:.2f} m", (x1, y1 - 5), cv2.FONT_HERSHEY_SIMPLEX, 1.2, txt_color, 3)
+
+ out.write(im0)
+ cv2.imshow("visioneye-distance-calculation", im0)
+
+ if cv2.waitKey(1) & 0xFF == ord("q"):
+ break
+
+ out.release()
+ cap.release()
+ cv2.destroyAllWindows()
+ ```
+
+### `visioneye` Arguments
+
+| Name | Type | Default | Description |
+| ----------- | ------- | ---------------- | ------------------------------ |
+| `color` | `tuple` | `(235, 219, 11)` | Line and object centroid color |
+| `pin_color` | `tuple` | `(255, 0, 255)` | VisionEye pinpoint color |
+
+## Note
+
+For any inquiries, feel free to post your questions in the [Ultralytics Issue Section](https://github.com/ultralytics/ultralytics/issues/new/choose) or the discussion section mentioned below.
+
+## FAQ
+
+### How do I start using VisionEye Object Mapping with Ultralytics YOLOv8?
+
+To start using VisionEye Object Mapping with Ultralytics YOLOv8, first, you'll need to install the Ultralytics YOLO package via pip. Then, you can use the sample code provided in the documentation to set up object detection with VisionEye. Here's a simple example to get you started:
+
+```python
+import cv2
+
+from ultralytics import YOLO
+
+model = YOLO("yolov8n.pt")
+cap = cv2.VideoCapture("path/to/video/file.mp4")
+
+while True:
+ ret, frame = cap.read()
+ if not ret:
+ break
+
+ results = model.predict(frame)
+ for result in results:
+ # Perform custom logic with result
+ pass
+
+ cv2.imshow("visioneye", frame)
+ if cv2.waitKey(1) & 0xFF == ord("q"):
+ break
+
+cap.release()
+cv2.destroyAllWindows()
+```
+
+### What are the key features of VisionEye's object tracking capability using Ultralytics YOLOv8?
+
+VisionEye's object tracking with Ultralytics YOLOv8 allows users to follow the movement of objects within a video frame. Key features include:
+
+1. **Real-Time Object Tracking**: Keeps up with objects as they move.
+2. **Object Identification**: Utilizes YOLOv8's powerful detection algorithms.
+3. **Distance Calculation**: Calculates distances between objects and specified points.
+4. **Annotation and Visualization**: Provides visual markers for tracked objects.
+
+Here's a brief code snippet demonstrating tracking with VisionEye:
+
+```python
+import cv2
+
+from ultralytics import YOLO
+
+model = YOLO("yolov8n.pt")
+cap = cv2.VideoCapture("path/to/video/file.mp4")
+
+while True:
+ ret, frame = cap.read()
+ if not ret:
+ break
+
+ results = model.track(frame, persist=True)
+ for result in results:
+ # Annotate and visualize tracking
+ pass
+
+ cv2.imshow("visioneye-tracking", frame)
+ if cv2.waitKey(1) & 0xFF == ord("q"):
+ break
+
+cap.release()
+cv2.destroyAllWindows()
+```
+
+For a comprehensive guide, visit the [VisionEye Object Mapping with Object Tracking](#samples).
+
+### How can I calculate distances with VisionEye's YOLOv8 model?
+
+Distance calculation with VisionEye and Ultralytics YOLOv8 involves determining the distance of detected objects from a specified point in the frame. It enhances spatial analysis capabilities, useful in applications such as autonomous driving and surveillance.
+
+Here's a simplified example:
+
+```python
+import math
+
+import cv2
+
+from ultralytics import YOLO
+
+model = YOLO("yolov8s.pt")
+cap = cv2.VideoCapture("path/to/video/file.mp4")
+center_point = (0, 480) # Example center point
+pixel_per_meter = 10
+
+while True:
+ ret, frame = cap.read()
+ if not ret:
+ break
+
+ results = model.track(frame, persist=True)
+ for result in results:
+ # Calculate distance logic
+ distances = [
+ (math.sqrt((box[0] - center_point[0]) ** 2 + (box[1] - center_point[1]) ** 2)) / pixel_per_meter
+ for box in results
+ ]
+
+ cv2.imshow("visioneye-distance", frame)
+ if cv2.waitKey(1) & 0xFF == ord("q"):
+ break
+
+cap.release()
+cv2.destroyAllWindows()
+```
+
+For detailed instructions, refer to the [VisionEye with Distance Calculation](#samples).
+
+### Why should I use Ultralytics YOLOv8 for object mapping and tracking?
+
+Ultralytics YOLOv8 is renowned for its speed, accuracy, and ease of integration, making it a top choice for object mapping and tracking. Key advantages include:
+
+1. **State-of-the-art Performance**: Delivers high accuracy in real-time object detection.
+2. **Flexibility**: Supports various tasks such as detection, tracking, and distance calculation.
+3. **Community and Support**: Extensive documentation and active GitHub community for troubleshooting and enhancements.
+4. **Ease of Use**: Intuitive API simplifies complex tasks, allowing for rapid deployment and iteration.
+
+For more information on applications and benefits, check out the [Ultralytics YOLOv8 documentation](https://docs.ultralytics.com/models/yolov8/).
+
+### How can I integrate VisionEye with other machine learning tools like Comet or ClearML?
+
+Ultralytics YOLOv8 can integrate seamlessly with various machine learning tools like Comet and ClearML, enhancing experiment tracking, collaboration, and reproducibility. Follow the detailed guides on [how to use YOLOv5 with Comet](https://www.ultralytics.com/blog/how-to-use-yolov5-with-comet) and [integrate YOLOv8 with ClearML](https://docs.ultralytics.com/integrations/clearml/) to get started.
+
+For further exploration and integration examples, check our [Ultralytics Integrations Guide](https://docs.ultralytics.com/integrations/).
diff --git a/ultralytics/docs/en/guides/workouts-monitoring.md b/ultralytics/docs/en/guides/workouts-monitoring.md
new file mode 100644
index 0000000000000000000000000000000000000000..c680862f16708a087c6dced61dfc901ae624d4f0
--- /dev/null
+++ b/ultralytics/docs/en/guides/workouts-monitoring.md
@@ -0,0 +1,261 @@
+---
+comments: true
+description: Optimize your fitness routine with real-time workouts monitoring using Ultralytics YOLOv8. Track and improve your exercise form and performance.
+keywords: workouts monitoring, Ultralytics YOLOv8, pose estimation, fitness tracking, exercise assessment, real-time feedback, exercise form, performance metrics
+---
+
+# Workouts Monitoring using Ultralytics YOLOv8
+
+Monitoring workouts through pose estimation with [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) enhances exercise assessment by accurately tracking key body landmarks and joints in real-time. This technology provides instant feedback on exercise form, tracks workout routines, and measures performance metrics, optimizing training sessions for users and trainers alike.
+
+
+
+
+
+ Watch: Workouts Monitoring using Ultralytics YOLOv8 | Pushups, Pullups, Ab Workouts
+
+
+## Advantages of Workouts Monitoring?
+
+- **Optimized Performance:** Tailoring workouts based on monitoring data for better results.
+- **Goal Achievement:** Track and adjust fitness goals for measurable progress.
+- **Personalization:** Customized workout plans based on individual data for effectiveness.
+- **Health Awareness:** Early detection of patterns indicating health issues or over-training.
+- **Informed Decisions:** Data-driven decisions for adjusting routines and setting realistic goals.
+
+## Real World Applications
+
+| Workouts Monitoring | Workouts Monitoring |
+| :--------------------------------------------------------------------------------------------------------------------: | :--------------------------------------------------------------------------------------------------------------------: |
+|  |  |
+| PushUps Counting | PullUps Counting |
+
+!!! Example "Workouts Monitoring Example"
+
+ === "Workouts Monitoring"
+
+ ```python
+ import cv2
+
+ from ultralytics import YOLO, solutions
+
+ model = YOLO("yolov8n-pose.pt")
+ cap = cv2.VideoCapture("path/to/video/file.mp4")
+ assert cap.isOpened(), "Error reading video file"
+ w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
+
+ gym_object = solutions.AIGym(
+ line_thickness=2,
+ view_img=True,
+ pose_type="pushup",
+ kpts_to_check=[6, 8, 10],
+ )
+
+ while cap.isOpened():
+ success, im0 = cap.read()
+ if not success:
+ print("Video frame is empty or video processing has been successfully completed.")
+ break
+ results = model.track(im0, verbose=False) # Tracking recommended
+ # results = model.predict(im0) # Prediction also supported
+ im0 = gym_object.start_counting(im0, results)
+
+ cv2.destroyAllWindows()
+ ```
+
+ === "Workouts Monitoring with Save Output"
+
+ ```python
+ import cv2
+
+ from ultralytics import YOLO, solutions
+
+ model = YOLO("yolov8n-pose.pt")
+ cap = cv2.VideoCapture("path/to/video/file.mp4")
+ assert cap.isOpened(), "Error reading video file"
+ w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
+
+ video_writer = cv2.VideoWriter("workouts.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
+
+ gym_object = solutions.AIGym(
+ line_thickness=2,
+ view_img=True,
+ pose_type="pushup",
+ kpts_to_check=[6, 8, 10],
+ )
+
+ while cap.isOpened():
+ success, im0 = cap.read()
+ if not success:
+ print("Video frame is empty or video processing has been successfully completed.")
+ break
+ results = model.track(im0, verbose=False) # Tracking recommended
+ # results = model.predict(im0) # Prediction also supported
+ im0 = gym_object.start_counting(im0, results)
+ video_writer.write(im0)
+
+ cv2.destroyAllWindows()
+ video_writer.release()
+ ```
+
+???+ tip "Support"
+
+ "pushup", "pullup" and "abworkout" supported
+
+### KeyPoints Map
+
+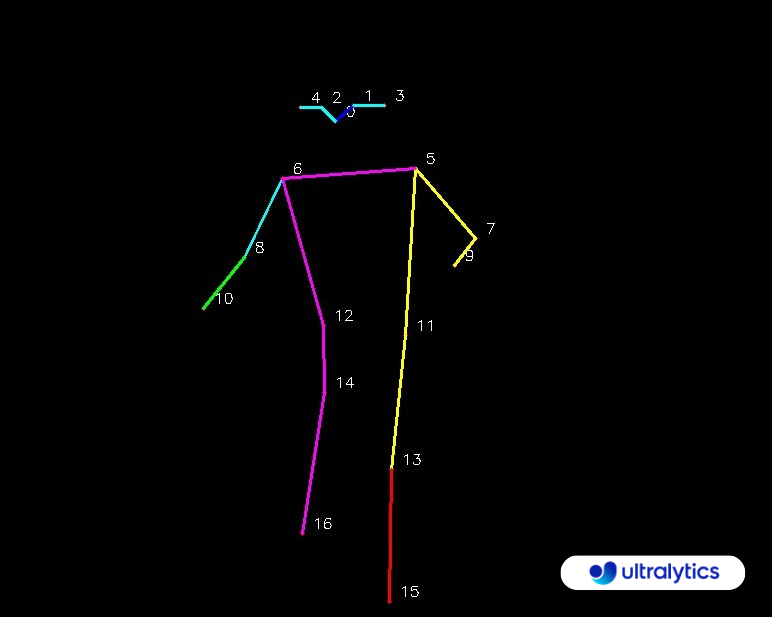
+
+### Arguments `AIGym`
+
+| Name | Type | Default | Description |
+| ----------------- | ------- | -------- | -------------------------------------------------------------------------------------- |
+| `kpts_to_check` | `list` | `None` | List of three keypoints index, for counting specific workout, followed by keypoint Map |
+| `line_thickness` | `int` | `2` | Thickness of the lines drawn. |
+| `view_img` | `bool` | `False` | Flag to display the image. |
+| `pose_up_angle` | `float` | `145.0` | Angle threshold for the 'up' pose. |
+| `pose_down_angle` | `float` | `90.0` | Angle threshold for the 'down' pose. |
+| `pose_type` | `str` | `pullup` | Type of pose to detect (`'pullup`', `pushup`, `abworkout`, `squat`). |
+
+### Arguments `model.predict`
+
+| Name | Type | Default | Description |
+| --------------- | -------------- | ---------------------- | -------------------------------------------------------------------------- |
+| `source` | `str` | `'ultralytics/assets'` | source directory for images or videos |
+| `conf` | `float` | `0.25` | object confidence threshold for detection |
+| `iou` | `float` | `0.7` | intersection over union (IoU) threshold for NMS |
+| `imgsz` | `int or tuple` | `640` | image size as scalar or (h, w) list, i.e. (640, 480) |
+| `half` | `bool` | `False` | use half precision (FP16) |
+| `device` | `None or str` | `None` | device to run on, i.e. cuda device=0/1/2/3 or device=cpu |
+| `max_det` | `int` | `300` | maximum number of detections per image |
+| `vid_stride` | `bool` | `False` | video frame-rate stride |
+| `stream_buffer` | `bool` | `False` | buffer all streaming frames (True) or return the most recent frame (False) |
+| `visualize` | `bool` | `False` | visualize model features |
+| `augment` | `bool` | `False` | apply image augmentation to prediction sources |
+| `agnostic_nms` | `bool` | `False` | class-agnostic NMS |
+| `classes` | `list[int]` | `None` | filter results by class, i.e. classes=0, or classes=[0,2,3] |
+| `retina_masks` | `bool` | `False` | use high-resolution segmentation masks |
+| `embed` | `list[int]` | `None` | return feature vectors/embeddings from given layers |
+
+### Arguments `model.track`
+
+| Name | Type | Default | Description |
+| --------- | ------- | -------------- | ----------------------------------------------------------- |
+| `source` | `im0` | `None` | source directory for images or videos |
+| `persist` | `bool` | `False` | persisting tracks between frames |
+| `tracker` | `str` | `botsort.yaml` | Tracking method 'bytetrack' or 'botsort' |
+| `conf` | `float` | `0.3` | Confidence Threshold |
+| `iou` | `float` | `0.5` | IOU Threshold |
+| `classes` | `list` | `None` | filter results by class, i.e. classes=0, or classes=[0,2,3] |
+| `verbose` | `bool` | `True` | Display the object tracking results |
+
+## FAQ
+
+### How do I monitor my workouts using Ultralytics YOLOv8?
+
+To monitor your workouts using Ultralytics YOLOv8, you can utilize the pose estimation capabilities to track and analyze key body landmarks and joints in real-time. This allows you to receive instant feedback on your exercise form, count repetitions, and measure performance metrics. You can start by using the provided example code for pushups, pullups, or ab workouts as shown:
+
+```python
+import cv2
+
+from ultralytics import YOLO, solutions
+
+model = YOLO("yolov8n-pose.pt")
+cap = cv2.VideoCapture("path/to/video/file.mp4")
+assert cap.isOpened(), "Error reading video file"
+w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
+
+gym_object = solutions.AIGym(
+ line_thickness=2,
+ view_img=True,
+ pose_type="pushup",
+ kpts_to_check=[6, 8, 10],
+)
+
+while cap.isOpened():
+ success, im0 = cap.read()
+ if not success:
+ print("Video frame is empty or video processing has been successfully completed.")
+ break
+ results = model.track(im0, verbose=False)
+ im0 = gym_object.start_counting(im0, results)
+
+cv2.destroyAllWindows()
+```
+
+For further customization and settings, you can refer to the [AIGym](#arguments-aigym) section in the documentation.
+
+### What are the benefits of using Ultralytics YOLOv8 for workout monitoring?
+
+Using Ultralytics YOLOv8 for workout monitoring provides several key benefits:
+
+- **Optimized Performance:** By tailoring workouts based on monitoring data, you can achieve better results.
+- **Goal Achievement:** Easily track and adjust fitness goals for measurable progress.
+- **Personalization:** Get customized workout plans based on your individual data for optimal effectiveness.
+- **Health Awareness:** Early detection of patterns that indicate potential health issues or over-training.
+- **Informed Decisions:** Make data-driven decisions to adjust routines and set realistic goals.
+
+You can watch a [YouTube video demonstration](https://www.youtube.com/watch?v=LGGxqLZtvuw) to see these benefits in action.
+
+### How accurate is Ultralytics YOLOv8 in detecting and tracking exercises?
+
+Ultralytics YOLOv8 is highly accurate in detecting and tracking exercises due to its state-of-the-art pose estimation capabilities. It can accurately track key body landmarks and joints, providing real-time feedback on exercise form and performance metrics. The model's pretrained weights and robust architecture ensure high precision and reliability. For real-world examples, check out the [real-world applications](#real-world-applications) section in the documentation, which showcases pushups and pullups counting.
+
+### Can I use Ultralytics YOLOv8 for custom workout routines?
+
+Yes, Ultralytics YOLOv8 can be adapted for custom workout routines. The `AIGym` class supports different pose types such as "pushup", "pullup", and "abworkout." You can specify keypoints and angles to detect specific exercises. Here is an example setup:
+
+```python
+from ultralytics import solutions
+
+gym_object = solutions.AIGym(
+ line_thickness=2,
+ view_img=True,
+ pose_type="squat",
+ kpts_to_check=[6, 8, 10],
+)
+```
+
+For more details on setting arguments, refer to the [Arguments `AIGym`](#arguments-aigym) section. This flexibility allows you to monitor various exercises and customize routines based on your needs.
+
+### How can I save the workout monitoring output using Ultralytics YOLOv8?
+
+To save the workout monitoring output, you can modify the code to include a video writer that saves the processed frames. Here's an example:
+
+```python
+import cv2
+
+from ultralytics import YOLO, solutions
+
+model = YOLO("yolov8n-pose.pt")
+cap = cv2.VideoCapture("path/to/video/file.mp4")
+assert cap.isOpened(), "Error reading video file"
+w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
+
+video_writer = cv2.VideoWriter("workouts.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
+
+gym_object = solutions.AIGym(
+ line_thickness=2,
+ view_img=True,
+ pose_type="pushup",
+ kpts_to_check=[6, 8, 10],
+)
+
+while cap.isOpened():
+ success, im0 = cap.read()
+ if not success:
+ print("Video frame is empty or video processing has been successfully completed.")
+ break
+ results = model.track(im0, verbose=False)
+ im0 = gym_object.start_counting(im0, results)
+ video_writer.write(im0)
+
+cv2.destroyAllWindows()
+video_writer.release()
+```
+
+This setup writes the monitored video to an output file. For more details, refer to the [Workouts Monitoring with Save Output](#workouts-monitoring-using-ultralytics-yolov8) section.
diff --git a/ultralytics/docs/en/guides/yolo-common-issues.md b/ultralytics/docs/en/guides/yolo-common-issues.md
new file mode 100644
index 0000000000000000000000000000000000000000..15aec20e396641ade750cf340f73f39eb539bfc8
--- /dev/null
+++ b/ultralytics/docs/en/guides/yolo-common-issues.md
@@ -0,0 +1,319 @@
+---
+comments: true
+description: Comprehensive guide to troubleshoot common YOLOv8 issues, from installation errors to model training challenges. Enhance your Ultralytics projects with our expert tips.
+keywords: YOLO, YOLOv8, troubleshooting, installation errors, model training, GPU issues, Ultralytics, AI, computer vision, deep learning, Python, CUDA, PyTorch, debugging
+---
+
+# Troubleshooting Common YOLO Issues
+
+
+
+
+
+## Introduction
+
+This guide serves as a comprehensive aid for troubleshooting common issues encountered while working with YOLOv8 on your Ultralytics projects. Navigating through these issues can be a breeze with the right guidance, ensuring your projects remain on track without unnecessary delays.
+
+
+
+
+
+ Watch: Ultralytics YOLOv8 Common Issues | Installation Errors, Model Training Issues
+
+
+## Common Issues
+
+### Installation Errors
+
+Installation errors can arise due to various reasons, such as incompatible versions, missing dependencies, or incorrect environment setups. First, check to make sure you are doing the following:
+
+- You're using Python 3.8 or later as recommended.
+
+- Ensure that you have the correct version of PyTorch (1.8 or later) installed.
+
+- Consider using virtual environments to avoid conflicts.
+
+- Follow the [official installation guide](../quickstart.md) step by step.
+
+Additionally, here are some common installation issues users have encountered, along with their respective solutions:
+
+- Import Errors or Dependency Issues - If you're getting errors during the import of YOLOv8, or you're having issues related to dependencies, consider the following troubleshooting steps:
+
+ - **Fresh Installation**: Sometimes, starting with a fresh installation can resolve unexpected issues. Especially with libraries like Ultralytics, where updates might introduce changes to the file tree structure or functionalities.
+
+ - **Update Regularly**: Ensure you're using the latest version of the library. Older versions might not be compatible with recent updates, leading to potential conflicts or issues.
+
+ - **Check Dependencies**: Verify that all required dependencies are correctly installed and are of the compatible versions.
+
+ - **Review Changes**: If you initially cloned or installed an older version, be aware that significant updates might affect the library's structure or functionalities. Always refer to the official documentation or changelogs to understand any major changes.
+
+ - Remember, keeping your libraries and dependencies up-to-date is crucial for a smooth and error-free experience.
+
+- Running YOLOv8 on GPU - If you're having trouble running YOLOv8 on GPU, consider the following troubleshooting steps:
+
+ - **Verify CUDA Compatibility and Installation**: Ensure your GPU is CUDA compatible and that CUDA is correctly installed. Use the `nvidia-smi` command to check the status of your NVIDIA GPU and CUDA version.
+
+ - **Check PyTorch and CUDA Integration**: Ensure PyTorch can utilize CUDA by running `import torch; print(torch.cuda.is_available())` in a Python terminal. If it returns 'True', PyTorch is set up to use CUDA.
+
+ - **Environment Activation**: Ensure you're in the correct environment where all necessary packages are installed.
+
+ - **Update Your Packages**: Outdated packages might not be compatible with your GPU. Keep them updated.
+
+ - **Program Configuration**: Check if the program or code specifies GPU usage. In YOLOv8, this might be in the settings or configuration.
+
+### Model Training Issues
+
+This section will address common issues faced while training and their respective explanations and solutions.
+
+#### Verification of Configuration Settings
+
+**Issue**: You are unsure whether the configuration settings in the `.yaml` file are being applied correctly during model training.
+
+**Solution**: The configuration settings in the `.yaml` file should be applied when using the `model.train()` function. To ensure that these settings are correctly applied, follow these steps:
+
+- Confirm that the path to your `.yaml` configuration file is correct.
+- Make sure you pass the path to your `.yaml` file as the `data` argument when calling `model.train()`, as shown below:
+
+```python
+model.train(data="/path/to/your/data.yaml", batch=4)
+```
+
+#### Accelerating Training with Multiple GPUs
+
+**Issue**: Training is slow on a single GPU, and you want to speed up the process using multiple GPUs.
+
+**Solution**: Increasing the batch size can accelerate training, but it's essential to consider GPU memory capacity. To speed up training with multiple GPUs, follow these steps:
+
+- Ensure that you have multiple GPUs available.
+
+- Modify your .yaml configuration file to specify the number of GPUs to use, e.g., gpus: 4.
+
+- Increase the batch size accordingly to fully utilize the multiple GPUs without exceeding memory limits.
+
+- Modify your training command to utilize multiple GPUs:
+
+```python
+# Adjust the batch size and other settings as needed to optimize training speed
+model.train(data="/path/to/your/data.yaml", batch=32, multi_scale=True)
+```
+
+#### Continuous Monitoring Parameters
+
+**Issue**: You want to know which parameters should be continuously monitored during training, apart from loss.
+
+**Solution**: While loss is a crucial metric to monitor, it's also essential to track other metrics for model performance optimization. Some key metrics to monitor during training include:
+
+- Precision
+- Recall
+- Mean Average Precision (mAP)
+
+You can access these metrics from the training logs or by using tools like TensorBoard or wandb for visualization. Implementing early stopping based on these metrics can help you achieve better results.
+
+#### Tools for Tracking Training Progress
+
+**Issue**: You are looking for recommendations on tools to track training progress.
+
+**Solution**: To track and visualize training progress, you can consider using the following tools:
+
+- [TensorBoard](https://www.tensorflow.org/tensorboard): TensorBoard is a popular choice for visualizing training metrics, including loss, accuracy, and more. You can integrate it with your YOLOv8 training process.
+- [Comet](https://bit.ly/yolov8-readme-comet): Comet provides an extensive toolkit for experiment tracking and comparison. It allows you to track metrics, hyperparameters, and even model weights. Integration with YOLO models is also straightforward, providing you with a complete overview of your experiment cycle.
+- [Ultralytics HUB](https://hub.ultralytics.com): Ultralytics HUB offers a specialized environment for tracking YOLO models, giving you a one-stop platform to manage metrics, datasets, and even collaborate with your team. Given its tailored focus on YOLO, it offers more customized tracking options.
+
+Each of these tools offers its own set of advantages, so you may want to consider the specific needs of your project when making a choice.
+
+#### How to Check if Training is Happening on the GPU
+
+**Issue**: The 'device' value in the training logs is 'null,' and you're unsure if training is happening on the GPU.
+
+**Solution**: The 'device' value being 'null' typically means that the training process is set to automatically use an available GPU, which is the default behavior. To ensure training occurs on a specific GPU, you can manually set the 'device' value to the GPU index (e.g., '0' for the first GPU) in your .yaml configuration file:
+
+```yaml
+device: 0
+```
+
+This will explicitly assign the training process to the specified GPU. If you wish to train on the CPU, set 'device' to 'cpu'.
+
+Keep an eye on the 'runs' folder for logs and metrics to monitor training progress effectively.
+
+#### Key Considerations for Effective Model Training
+
+Here are some things to keep in mind, if you are facing issues related to model training.
+
+**Dataset Format and Labels**
+
+- Importance: The foundation of any machine learning model lies in the quality and format of the data it is trained on.
+
+- Recommendation: Ensure that your custom dataset and its associated labels adhere to the expected format. It's crucial to verify that annotations are accurate and of high quality. Incorrect or subpar annotations can derail the model's learning process, leading to unpredictable outcomes.
+
+**Model Convergence**
+
+- Importance: Achieving model convergence ensures that the model has sufficiently learned from the training data.
+
+- Recommendation: When training a model 'from scratch', it's vital to ensure that the model reaches a satisfactory level of convergence. This might necessitate a longer training duration, with more epochs, compared to when you're fine-tuning an existing model.
+
+**Learning Rate and Batch Size**
+
+- Importance: These hyperparameters play a pivotal role in determining how the model updates its weights during training.
+
+- Recommendation: Regularly evaluate if the chosen learning rate and batch size are optimal for your specific dataset. Parameters that are not in harmony with the dataset's characteristics can hinder the model's performance.
+
+**Class Distribution**
+
+- Importance: The distribution of classes in your dataset can influence the model's prediction tendencies.
+
+- Recommendation: Regularly assess the distribution of classes within your dataset. If there's a class imbalance, there's a risk that the model will develop a bias towards the more prevalent class. This bias can be evident in the confusion matrix, where the model might predominantly predict the majority class.
+
+**Cross-Check with Pretrained Weights**
+
+- Importance: Leveraging pretrained weights can provide a solid starting point for model training, especially when data is limited.
+
+- Recommendation: As a diagnostic step, consider training your model using the same data but initializing it with pretrained weights. If this approach yields a well-formed confusion matrix, it could suggest that the 'from scratch' model might require further training or adjustments.
+
+### Issues Related to Model Predictions
+
+This section will address common issues faced during model prediction.
+
+#### Getting Bounding Box Predictions With Your YOLOv8 Custom Model
+
+**Issue**: When running predictions with a custom YOLOv8 model, there are challenges with the format and visualization of the bounding box coordinates.
+
+**Solution**:
+
+- Coordinate Format: YOLOv8 provides bounding box coordinates in absolute pixel values. To convert these to relative coordinates (ranging from 0 to 1), you need to divide by the image dimensions. For example, let's say your image size is 640x640. Then you would do the following:
+
+```python
+# Convert absolute coordinates to relative coordinates
+x1 = x1 / 640 # Divide x-coordinates by image width
+x2 = x2 / 640
+y1 = y1 / 640 # Divide y-coordinates by image height
+y2 = y2 / 640
+```
+
+- File Name: To obtain the file name of the image you're predicting on, access the image file path directly from the result object within your prediction loop.
+
+#### Filtering Objects in YOLOv8 Predictions
+
+**Issue**: Facing issues with how to filter and display only specific objects in the prediction results when running YOLOv8 using the Ultralytics library.
+
+**Solution**: To detect specific classes use the classes argument to specify the classes you want to include in the output. For instance, to detect only cars (assuming 'cars' have class index 2):
+
+```shell
+yolo task=detect mode=segment model=yolov8n-seg.pt source='path/to/car.mp4' show=True classes=2
+```
+
+#### Understanding Precision Metrics in YOLOv8
+
+**Issue**: Confusion regarding the difference between box precision, mask precision, and confusion matrix precision in YOLOv8.
+
+**Solution**: Box precision measures the accuracy of predicted bounding boxes compared to the actual ground truth boxes using IoU (Intersection over Union) as the metric. Mask precision assesses the agreement between predicted segmentation masks and ground truth masks in pixel-wise object classification. Confusion matrix precision, on the other hand, focuses on overall classification accuracy across all classes and does not consider the geometric accuracy of predictions. It's important to note that a bounding box can be geometrically accurate (true positive) even if the class prediction is wrong, leading to differences between box precision and confusion matrix precision. These metrics evaluate distinct aspects of a model's performance, reflecting the need for different evaluation metrics in various tasks.
+
+#### Extracting Object Dimensions in YOLOv8
+
+**Issue**: Difficulty in retrieving the length and height of detected objects in YOLOv8, especially when multiple objects are detected in an image.
+
+**Solution**: To retrieve the bounding box dimensions, first use the Ultralytics YOLOv8 model to predict objects in an image. Then, extract the width and height information of bounding boxes from the prediction results.
+
+```python
+from ultralytics import YOLO
+
+# Load a pre-trained YOLOv8 model
+model = YOLO("yolov8n.pt")
+
+# Specify the source image
+source = "https://ultralytics.com/images/bus.jpg"
+
+# Make predictions
+results = model.predict(source, save=True, imgsz=320, conf=0.5)
+
+# Extract bounding box dimensions
+boxes = results[0].boxes.xywh.cpu()
+for box in boxes:
+ x, y, w, h = box
+ print(f"Width of Box: {w}, Height of Box: {h}")
+```
+
+### Deployment Challenges
+
+#### GPU Deployment Issues
+
+**Issue:** Deploying models in a multi-GPU environment can sometimes lead to unexpected behaviors like unexpected memory usage, inconsistent results across GPUs, etc.
+
+**Solution:** Check for default GPU initialization. Some frameworks, like PyTorch, might initialize CUDA operations on a default GPU before transitioning to the designated GPUs. To bypass unexpected default initializations, specify the GPU directly during deployment and prediction. Then, use tools to monitor GPU utilization and memory usage to identify any anomalies in real-time. Also, ensure you're using the latest version of the framework or library.
+
+#### Model Conversion/Exporting Issues
+
+**Issue:** During the process of converting or exporting machine learning models to different formats or platforms, users might encounter errors or unexpected behaviors.
+
+**Solution:**
+
+- Compatibility Check: Ensure that you are using versions of libraries and frameworks that are compatible with each other. Mismatched versions can lead to unexpected errors during conversion.
+
+- Environment Reset: If you're using an interactive environment like Jupyter or Colab, consider restarting your environment after making significant changes or installations. A fresh start can sometimes resolve underlying issues.
+
+- Official Documentation: Always refer to the official documentation of the tool or library you are using for conversion. It often contains specific guidelines and best practices for model exporting.
+
+- Community Support: Check the library or framework's official repository for similar issues reported by other users. The maintainers or community might have provided solutions or workarounds in discussion threads.
+
+- Update Regularly: Ensure that you are using the latest version of the tool or library. Developers frequently release updates that fix known bugs or improve functionality.
+
+- Test Incrementally: Before performing a full conversion, test the process with a smaller model or dataset to identify potential issues early on.
+
+## Community and Support
+
+Engaging with a community of like-minded individuals can significantly enhance your experience and success in working with YOLOv8. Below are some channels and resources you may find helpful.
+
+### Forums and Channels for Getting Help
+
+**GitHub Issues:** The YOLOv8 repository on GitHub has an [Issues tab](https://github.com/ultralytics/ultralytics/issues) where you can ask questions, report bugs, and suggest new features. The community and maintainers are active here, and it's a great place to get help with specific problems.
+
+**Ultralytics Discord Server:** Ultralytics has a [Discord server](https://ultralytics.com/discord/) where you can interact with other users and the developers.
+
+### Official Documentation and Resources
+
+**Ultralytics YOLOv8 Docs**: The [official documentation](../index.md) provides a comprehensive overview of YOLOv8, along with guides on installation, usage, and troubleshooting.
+
+These resources should provide a solid foundation for troubleshooting and improving your YOLOv8 projects, as well as connecting with others in the YOLOv8 community.
+
+## Conclusion
+
+Troubleshooting is an integral part of any development process, and being equipped with the right knowledge can significantly reduce the time and effort spent in resolving issues. This guide aimed to address the most common challenges faced by users of the YOLOv8 model within the Ultralytics ecosystem. By understanding and addressing these common issues, you can ensure smoother project progress and achieve better results with your computer vision tasks.
+
+Remember, the Ultralytics community is a valuable resource. Engaging with fellow developers and experts can provide additional insights and solutions that might not be covered in standard documentation. Always keep learning, experimenting, and sharing your experiences to contribute to the collective knowledge of the community.
+
+Happy troubleshooting!
+
+## FAQ
+
+### How do I resolve installation errors with YOLOv8?
+
+Installation errors can often be due to compatibility issues or missing dependencies. Ensure you use Python 3.8 or later and have PyTorch 1.8 or later installed. It's beneficial to use virtual environments to avoid conflicts. For a step-by-step installation guide, follow our [official installation guide](../quickstart.md). If you encounter import errors, try a fresh installation or update the library to the latest version.
+
+### Why is my YOLOv8 model training slow on a single GPU?
+
+Training on a single GPU might be slow due to large batch sizes or insufficient memory. To speed up training, use multiple GPUs. Ensure your system has multiple GPUs available and adjust your `.yaml` configuration file to specify the number of GPUs, e.g., `gpus: 4`. Increase the batch size accordingly to fully utilize the GPUs without exceeding memory limits. Example command:
+
+```python
+model.train(data="/path/to/your/data.yaml", batch=32, multi_scale=True)
+```
+
+### How can I ensure my YOLOv8 model is training on the GPU?
+
+If the 'device' value shows 'null' in the training logs, it generally means the training process is set to automatically use an available GPU. To explicitly assign a specific GPU, set the 'device' value in your `.yaml` configuration file. For instance:
+
+```yaml
+device: 0
+```
+
+This sets the training process to the first GPU. Consult the `nvidia-smi` command to confirm your CUDA setup.
+
+### How can I monitor and track my YOLOv8 model training progress?
+
+Tracking and visualizing training progress can be efficiently managed through tools like [TensorBoard](https://www.tensorflow.org/tensorboard), [Comet](https://bit.ly/yolov8-readme-comet), and [Ultralytics HUB](https://hub.ultralytics.com). These tools allow you to log and visualize metrics such as loss, precision, recall, and mAP. Implementing [early stopping](#continuous-monitoring-parameters) based on these metrics can also help achieve better training outcomes.
+
+### What should I do if YOLOv8 is not recognizing my dataset format?
+
+Ensure your dataset and labels conform to the expected format. Verify that annotations are accurate and of high quality. If you face any issues, refer to the [Data Collection and Annotation](https://docs.ultralytics.com/guides/data-collection-and-annotation/) guide for best practices. For more dataset-specific guidance, check the [Datasets](https://docs.ultralytics.com/datasets/) section in the documentation.
diff --git a/ultralytics/docs/en/guides/yolo-performance-metrics.md b/ultralytics/docs/en/guides/yolo-performance-metrics.md
new file mode 100644
index 0000000000000000000000000000000000000000..8b70ee86b8596ff2b4bf8853b42034f220417682
--- /dev/null
+++ b/ultralytics/docs/en/guides/yolo-performance-metrics.md
@@ -0,0 +1,212 @@
+---
+comments: true
+description: Explore essential YOLOv8 performance metrics like mAP, IoU, F1 Score, Precision, and Recall. Learn how to calculate and interpret them for model evaluation.
+keywords: YOLOv8 performance metrics, mAP, IoU, F1 Score, Precision, Recall, object detection, Ultralytics
+---
+
+# Performance Metrics Deep Dive
+
+## Introduction
+
+Performance metrics are key tools to evaluate the accuracy and efficiency of object detection models. They shed light on how effectively a model can identify and localize objects within images. Additionally, they help in understanding the model's handling of false positives and false negatives. These insights are crucial for evaluating and enhancing the model's performance. In this guide, we will explore various performance metrics associated with YOLOv8, their significance, and how to interpret them.
+
+
+
+## Object Detection Metrics
+
+Let's start by discussing some metrics that are not only important to YOLOv8 but are broadly applicable across different object detection models.
+
+- **Intersection over Union (IoU):** IoU is a measure that quantifies the overlap between a predicted bounding box and a ground truth bounding box. It plays a fundamental role in evaluating the accuracy of object localization.
+
+- **Average Precision (AP):** AP computes the area under the precision-recall curve, providing a single value that encapsulates the model's precision and recall performance.
+
+- **Mean Average Precision (mAP):** mAP extends the concept of AP by calculating the average AP values across multiple object classes. This is useful in multi-class object detection scenarios to provide a comprehensive evaluation of the model's performance.
+
+- **Precision and Recall:** Precision quantifies the proportion of true positives among all positive predictions, assessing the model's capability to avoid false positives. On the other hand, Recall calculates the proportion of true positives among all actual positives, measuring the model's ability to detect all instances of a class.
+
+- **F1 Score:** The F1 Score is the harmonic mean of precision and recall, providing a balanced assessment of a model's performance while considering both false positives and false negatives.
+
+## How to Calculate Metrics for YOLOv8 Model
+
+Now, we can explore [YOLOv8's Validation mode](../modes/val.md) that can be used to compute the above discussed evaluation metrics.
+
+Using the validation mode is simple. Once you have a trained model, you can invoke the model.val() function. This function will then process the validation dataset and return a variety of performance metrics. But what do these metrics mean? And how should you interpret them?
+
+### Interpreting the Output
+
+Let's break down the output of the model.val() function and understand each segment of the output.
+
+#### Class-wise Metrics
+
+One of the sections of the output is the class-wise breakdown of performance metrics. This granular information is useful when you are trying to understand how well the model is doing for each specific class, especially in datasets with a diverse range of object categories. For each class in the dataset the following is provided:
+
+- **Class**: This denotes the name of the object class, such as "person", "car", or "dog".
+
+- **Images**: This metric tells you the number of images in the validation set that contain the object class.
+
+- **Instances**: This provides the count of how many times the class appears across all images in the validation set.
+
+- **Box(P, R, mAP50, mAP50-95)**: This metric provides insights into the model's performance in detecting objects:
+
+ - **P (Precision)**: The accuracy of the detected objects, indicating how many detections were correct.
+
+ - **R (Recall)**: The ability of the model to identify all instances of objects in the images.
+
+ - **mAP50**: Mean average precision calculated at an intersection over union (IoU) threshold of 0.50. It's a measure of the model's accuracy considering only the "easy" detections.
+
+ - **mAP50-95**: The average of the mean average precision calculated at varying IoU thresholds, ranging from 0.50 to 0.95. It gives a comprehensive view of the model's performance across different levels of detection difficulty.
+
+#### Speed Metrics
+
+The speed of inference can be as critical as accuracy, especially in real-time object detection scenarios. This section breaks down the time taken for various stages of the validation process, from preprocessing to post-processing.
+
+#### COCO Metrics Evaluation
+
+For users validating on the COCO dataset, additional metrics are calculated using the COCO evaluation script. These metrics give insights into precision and recall at different IoU thresholds and for objects of different sizes.
+
+#### Visual Outputs
+
+The model.val() function, apart from producing numeric metrics, also yields visual outputs that can provide a more intuitive understanding of the model's performance. Here's a breakdown of the visual outputs you can expect:
+
+- **F1 Score Curve (`F1_curve.png`)**: This curve represents the F1 score across various thresholds. Interpreting this curve can offer insights into the model's balance between false positives and false negatives over different thresholds.
+
+- **Precision-Recall Curve (`PR_curve.png`)**: An integral visualization for any classification problem, this curve showcases the trade-offs between precision and recall at varied thresholds. It becomes especially significant when dealing with imbalanced classes.
+
+- **Precision Curve (`P_curve.png`)**: A graphical representation of precision values at different thresholds. This curve helps in understanding how precision varies as the threshold changes.
+
+- **Recall Curve (`R_curve.png`)**: Correspondingly, this graph illustrates how the recall values change across different thresholds.
+
+- **Confusion Matrix (`confusion_matrix.png`)**: The confusion matrix provides a detailed view of the outcomes, showcasing the counts of true positives, true negatives, false positives, and false negatives for each class.
+
+- **Normalized Confusion Matrix (`confusion_matrix_normalized.png`)**: This visualization is a normalized version of the confusion matrix. It represents the data in proportions rather than raw counts. This format makes it simpler to compare the performance across classes.
+
+- **Validation Batch Labels (`val_batchX_labels.jpg`)**: These images depict the ground truth labels for distinct batches from the validation dataset. They provide a clear picture of what the objects are and their respective locations as per the dataset.
+
+- **Validation Batch Predictions (`val_batchX_pred.jpg`)**: Contrasting the label images, these visuals display the predictions made by the YOLOv8 model for the respective batches. By comparing these to the label images, you can easily assess how well the model detects and classifies objects visually.
+
+#### Results Storage
+
+For future reference, the results are saved to a directory, typically named runs/detect/val.
+
+## Choosing the Right Metrics
+
+Choosing the right metrics to evaluate often depends on the specific application.
+
+- **mAP:** Suitable for a broad assessment of model performance.
+
+- **IoU:** Essential when precise object location is crucial.
+
+- **Precision:** Important when minimizing false detections is a priority.
+
+- **Recall:** Vital when it's important to detect every instance of an object.
+
+- **F1 Score:** Useful when a balance between precision and recall is needed.
+
+For real-time applications, speed metrics like FPS (Frames Per Second) and latency are crucial to ensure timely results.
+
+## Interpretation of Results
+
+It's important to understand the metrics. Here's what some of the commonly observed lower scores might suggest:
+
+- **Low mAP:** Indicates the model may need general refinements.
+
+- **Low IoU:** The model might be struggling to pinpoint objects accurately. Different bounding box methods could help.
+
+- **Low Precision:** The model may be detecting too many non-existent objects. Adjusting confidence thresholds might reduce this.
+
+- **Low Recall:** The model could be missing real objects. Improving feature extraction or using more data might help.
+
+- **Imbalanced F1 Score:** There's a disparity between precision and recall.
+
+- **Class-specific AP:** Low scores here can highlight classes the model struggles with.
+
+## Case Studies
+
+Real-world examples can help clarify how these metrics work in practice.
+
+### Case 1
+
+- **Situation:** mAP and F1 Score are suboptimal, but while Recall is good, Precision isn't.
+
+- **Interpretation & Action:** There might be too many incorrect detections. Tightening confidence thresholds could reduce these, though it might also slightly decrease recall.
+
+### Case 2
+
+- **Situation:** mAP and Recall are acceptable, but IoU is lacking.
+
+- **Interpretation & Action:** The model detects objects well but might not be localizing them precisely. Refining bounding box predictions might help.
+
+### Case 3
+
+- **Situation:** Some classes have a much lower AP than others, even with a decent overall mAP.
+
+- **Interpretation & Action:** These classes might be more challenging for the model. Using more data for these classes or adjusting class weights during training could be beneficial.
+
+## Connect and Collaborate
+
+Tapping into a community of enthusiasts and experts can amplify your journey with YOLOv8. Here are some avenues that can facilitate learning, troubleshooting, and networking.
+
+### Engage with the Broader Community
+
+- **GitHub Issues:** The YOLOv8 repository on GitHub has an [Issues tab](https://github.com/ultralytics/ultralytics/issues) where you can ask questions, report bugs, and suggest new features. The community and maintainers are active here, and it's a great place to get help with specific problems.
+
+- **Ultralytics Discord Server:** Ultralytics has a [Discord server](https://ultralytics.com/discord/) where you can interact with other users and the developers.
+
+### Official Documentation and Resources:
+
+- **Ultralytics YOLOv8 Docs:** The [official documentation](../index.md) provides a comprehensive overview of YOLOv8, along with guides on installation, usage, and troubleshooting.
+
+Using these resources will not only guide you through any challenges but also keep you updated with the latest trends and best practices in the YOLOv8 community.
+
+## Conclusion
+
+In this guide, we've taken a close look at the essential performance metrics for YOLOv8. These metrics are key to understanding how well a model is performing and are vital for anyone aiming to fine-tune their models. They offer the necessary insights for improvements and to make sure the model works effectively in real-life situations.
+
+Remember, the YOLOv8 and Ultralytics community is an invaluable asset. Engaging with fellow developers and experts can open doors to insights and solutions not found in standard documentation. As you journey through object detection, keep the spirit of learning alive, experiment with new strategies, and share your findings. By doing so, you contribute to the community's collective wisdom and ensure its growth.
+
+Happy object detecting!
+
+## FAQ
+
+### What is the significance of Mean Average Precision (mAP) in evaluating YOLOv8 model performance?
+
+Mean Average Precision (mAP) is crucial for evaluating YOLOv8 models as it provides a single metric encapsulating precision and recall across multiple classes. mAP@0.50 measures precision at an IoU threshold of 0.50, focusing on the model's ability to detect objects correctly. mAP@0.50:0.95 averages precision across a range of IoU thresholds, offering a comprehensive assessment of detection performance. High mAP scores indicate that the model effectively balances precision and recall, essential for applications like autonomous driving and surveillance.
+
+### How do I interpret the Intersection over Union (IoU) value for YOLOv8 object detection?
+
+Intersection over Union (IoU) measures the overlap between the predicted and ground truth bounding boxes. IoU values range from 0 to 1, where higher values indicate better localization accuracy. An IoU of 1.0 means perfect alignment. Typically, an IoU threshold of 0.50 is used to define true positives in metrics like mAP. Lower IoU values suggest that the model struggles with precise object localization, which can be improved by refining bounding box regression or increasing annotation accuracy.
+
+### Why is the F1 Score important for evaluating YOLOv8 models in object detection?
+
+The F1 Score is important for evaluating YOLOv8 models because it provides a harmonic mean of precision and recall, balancing both false positives and false negatives. It is particularly valuable when dealing with imbalanced datasets or applications where either precision or recall alone is insufficient. A high F1 Score indicates that the model effectively detects objects while minimizing both missed detections and false alarms, making it suitable for critical applications like security systems and medical imaging.
+
+### What are the key advantages of using Ultralytics YOLOv8 for real-time object detection?
+
+Ultralytics YOLOv8 offers multiple advantages for real-time object detection:
+
+- **Speed and Efficiency**: Optimized for high-speed inference, suitable for applications requiring low latency.
+- **High Accuracy**: Advanced algorithm ensures high mAP and IoU scores, balancing precision and recall.
+- **Flexibility**: Supports various tasks including object detection, segmentation, and classification.
+- **Ease of Use**: User-friendly interfaces, extensive documentation, and seamless integration with platforms like Ultralytics HUB ([HUB Quickstart](../hub/quickstart.md)).
+
+This makes YOLOv8 ideal for diverse applications from autonomous vehicles to smart city solutions.
+
+### How can validation metrics from YOLOv8 help improve model performance?
+
+Validation metrics from YOLOv8 like precision, recall, mAP, and IoU help diagnose and improve model performance by providing insights into different aspects of detection:
+
+- **Precision**: Helps identify and minimize false positives.
+- **Recall**: Ensures all relevant objects are detected.
+- **mAP**: Offers an overall performance snapshot, guiding general improvements.
+- **IoU**: Helps fine-tune object localization accuracy.
+
+By analyzing these metrics, specific weaknesses can be targeted, such as adjusting confidence thresholds to improve precision or gathering more diverse data to enhance recall. For detailed explanations of these metrics and how to interpret them, check [Object Detection Metrics](#object-detection-metrics).
diff --git a/ultralytics/docs/en/guides/yolo-thread-safe-inference.md b/ultralytics/docs/en/guides/yolo-thread-safe-inference.md
new file mode 100644
index 0000000000000000000000000000000000000000..b7c1bb1cb87d45ac6926aeb37344a270571f24c3
--- /dev/null
+++ b/ultralytics/docs/en/guides/yolo-thread-safe-inference.md
@@ -0,0 +1,188 @@
+---
+comments: true
+description: Learn how to ensure thread-safe YOLO model inference in Python. Avoid race conditions and run your multi-threaded tasks reliably with best practices.
+keywords: YOLO models, thread-safe, Python threading, model inference, concurrency, race conditions, multi-threaded, parallelism, Python GIL
+---
+
+# Thread-Safe Inference with YOLO Models
+
+Running YOLO models in a multi-threaded environment requires careful consideration to ensure thread safety. Python's `threading` module allows you to run several threads concurrently, but when it comes to using YOLO models across these threads, there are important safety issues to be aware of. This page will guide you through creating thread-safe YOLO model inference.
+
+## Understanding Python Threading
+
+Python threads are a form of parallelism that allow your program to run multiple operations at once. However, Python's Global Interpreter Lock (GIL) means that only one thread can execute Python bytecode at a time.
+
+
+
+
+
+While this sounds like a limitation, threads can still provide concurrency, especially for I/O-bound operations or when using operations that release the GIL, like those performed by YOLO's underlying C libraries.
+
+## The Danger of Shared Model Instances
+
+Instantiating a YOLO model outside your threads and sharing this instance across multiple threads can lead to race conditions, where the internal state of the model is inconsistently modified due to concurrent accesses. This is particularly problematic when the model or its components hold state that is not designed to be thread-safe.
+
+### Non-Thread-Safe Example: Single Model Instance
+
+When using threads in Python, it's important to recognize patterns that can lead to concurrency issues. Here is what you should avoid: sharing a single YOLO model instance across multiple threads.
+
+```python
+# Unsafe: Sharing a single model instance across threads
+from threading import Thread
+
+from ultralytics import YOLO
+
+# Instantiate the model outside the thread
+shared_model = YOLO("yolov8n.pt")
+
+
+def predict(image_path):
+ """Predicts objects in an image using a preloaded YOLO model, take path string to image as argument."""
+ results = shared_model.predict(image_path)
+ # Process results
+
+
+# Starting threads that share the same model instance
+Thread(target=predict, args=("image1.jpg",)).start()
+Thread(target=predict, args=("image2.jpg",)).start()
+```
+
+In the example above, the `shared_model` is used by multiple threads, which can lead to unpredictable results because `predict` could be executed simultaneously by multiple threads.
+
+### Non-Thread-Safe Example: Multiple Model Instances
+
+Similarly, here is an unsafe pattern with multiple YOLO model instances:
+
+```python
+# Unsafe: Sharing multiple model instances across threads can still lead to issues
+from threading import Thread
+
+from ultralytics import YOLO
+
+# Instantiate multiple models outside the thread
+shared_model_1 = YOLO("yolov8n_1.pt")
+shared_model_2 = YOLO("yolov8n_2.pt")
+
+
+def predict(model, image_path):
+ """Runs prediction on an image using a specified YOLO model, returning the results."""
+ results = model.predict(image_path)
+ # Process results
+
+
+# Starting threads with individual model instances
+Thread(target=predict, args=(shared_model_1, "image1.jpg")).start()
+Thread(target=predict, args=(shared_model_2, "image2.jpg")).start()
+```
+
+Even though there are two separate model instances, the risk of concurrency issues still exists. If the internal implementation of `YOLO` is not thread-safe, using separate instances might not prevent race conditions, especially if these instances share any underlying resources or states that are not thread-local.
+
+## Thread-Safe Inference
+
+To perform thread-safe inference, you should instantiate a separate YOLO model within each thread. This ensures that each thread has its own isolated model instance, eliminating the risk of race conditions.
+
+### Thread-Safe Example
+
+Here's how to instantiate a YOLO model inside each thread for safe parallel inference:
+
+```python
+# Safe: Instantiating a single model inside each thread
+from threading import Thread
+
+from ultralytics import YOLO
+
+
+def thread_safe_predict(image_path):
+ """Predict on an image using a new YOLO model instance in a thread-safe manner; takes image path as input."""
+ local_model = YOLO("yolov8n.pt")
+ results = local_model.predict(image_path)
+ # Process results
+
+
+# Starting threads that each have their own model instance
+Thread(target=thread_safe_predict, args=("image1.jpg",)).start()
+Thread(target=thread_safe_predict, args=("image2.jpg",)).start()
+```
+
+In this example, each thread creates its own `YOLO` instance. This prevents any thread from interfering with the model state of another, thus ensuring that each thread performs inference safely and without unexpected interactions with the other threads.
+
+## Conclusion
+
+When using YOLO models with Python's `threading`, always instantiate your models within the thread that will use them to ensure thread safety. This practice avoids race conditions and makes sure that your inference tasks run reliably.
+
+For more advanced scenarios and to further optimize your multi-threaded inference performance, consider using process-based parallelism with `multiprocessing` or leveraging a task queue with dedicated worker processes.
+
+## FAQ
+
+### How can I avoid race conditions when using YOLO models in a multi-threaded Python environment?
+
+To prevent race conditions when using Ultralytics YOLO models in a multi-threaded Python environment, instantiate a separate YOLO model within each thread. This ensures that each thread has its own isolated model instance, avoiding concurrent modification of the model state.
+
+Example:
+
+```python
+from threading import Thread
+
+from ultralytics import YOLO
+
+
+def thread_safe_predict(image_path):
+ """Predict on an image in a thread-safe manner."""
+ local_model = YOLO("yolov8n.pt")
+ results = local_model.predict(image_path)
+ # Process results
+
+
+Thread(target=thread_safe_predict, args=("image1.jpg",)).start()
+Thread(target=thread_safe_predict, args=("image2.jpg",)).start()
+```
+
+For more information on ensuring thread safety, visit the [Thread-Safe Inference with YOLO Models](#thread-safe-inference).
+
+### What are the best practices for running multi-threaded YOLO model inference in Python?
+
+To run multi-threaded YOLO model inference safely in Python, follow these best practices:
+
+1. Instantiate YOLO models within each thread rather than sharing a single model instance across threads.
+2. Use Python's `multiprocessing` module for parallel processing to avoid issues related to Global Interpreter Lock (GIL).
+3. Release the GIL by using operations performed by YOLO's underlying C libraries.
+
+Example for thread-safe model instantiation:
+
+```python
+from threading import Thread
+
+from ultralytics import YOLO
+
+
+def thread_safe_predict(image_path):
+ """Runs inference in a thread-safe manner with a new YOLO model instance."""
+ model = YOLO("yolov8n.pt")
+ results = model.predict(image_path)
+ # Process results
+
+
+# Initiate multiple threads
+Thread(target=thread_safe_predict, args=("image1.jpg",)).start()
+Thread(target=thread_safe_predict, args=("image2.jpg",)).start()
+```
+
+For additional context, refer to the section on [Thread-Safe Inference](#thread-safe-inference).
+
+### Why should each thread have its own YOLO model instance?
+
+Each thread should have its own YOLO model instance to prevent race conditions. When a single model instance is shared among multiple threads, concurrent accesses can lead to unpredictable behavior and modifications of the model's internal state. By using separate instances, you ensure thread isolation, making your multi-threaded tasks reliable and safe.
+
+For detailed guidance, check the [Non-Thread-Safe Example: Single Model Instance](#non-thread-safe-example-single-model-instance) and [Thread-Safe Example](#thread-safe-example) sections.
+
+### How does Python's Global Interpreter Lock (GIL) affect YOLO model inference?
+
+Python's Global Interpreter Lock (GIL) allows only one thread to execute Python bytecode at a time, which can limit the performance of CPU-bound multi-threading tasks. However, for I/O-bound operations or processes that use libraries releasing the GIL, like YOLO's C libraries, you can still achieve concurrency. For enhanced performance, consider using process-based parallelism with Python's `multiprocessing` module.
+
+For more about threading in Python, see the [Understanding Python Threading](#understanding-python-threading) section.
+
+### Is it safer to use process-based parallelism instead of threading for YOLO model inference?
+
+Yes, using Python's `multiprocessing` module is safer and often more efficient for running YOLO model inference in parallel. Process-based parallelism creates separate memory spaces, avoiding the Global Interpreter Lock (GIL) and reducing the risk of concurrency issues. Each process will operate independently with its own YOLO model instance.
+
+For further details on process-based parallelism with YOLO models, refer to the page on [Thread-Safe Inference](#thread-safe-inference).
diff --git a/ultralytics/docs/en/help/CI.md b/ultralytics/docs/en/help/CI.md
new file mode 100644
index 0000000000000000000000000000000000000000..cfd588f49ce1009daff1f53ddb2f97ad252f7739
--- /dev/null
+++ b/ultralytics/docs/en/help/CI.md
@@ -0,0 +1,87 @@
+---
+comments: true
+description: Learn about Ultralytics CI actions, Docker deployment, broken link checks, CodeQL analysis, and PyPI publishing to ensure high-quality code.
+keywords: Ultralytics, Continuous Integration, CI, Docker deployment, CodeQL, PyPI publishing, code quality, automated testing
+---
+
+# Continuous Integration (CI)
+
+Continuous Integration (CI) is an essential aspect of software development which involves integrating changes and testing them automatically. CI allows us to maintain high-quality code by catching issues early and often in the development process. At Ultralytics, we use various CI tests to ensure the quality and integrity of our codebase.
+
+## CI Actions
+
+Here's a brief description of our CI actions:
+
+- **[CI](https://github.com/ultralytics/ultralytics/actions/workflows/ci.yaml):** This is our primary CI test that involves running unit tests, linting checks, and sometimes more comprehensive tests depending on the repository.
+- **[Docker Deployment](https://github.com/ultralytics/ultralytics/actions/workflows/docker.yaml):** This test checks the deployment of the project using Docker to ensure the Dockerfile and related scripts are working correctly.
+- **[Broken Links](https://github.com/ultralytics/ultralytics/actions/workflows/links.yml):** This test scans the codebase for any broken or dead links in our markdown or HTML files.
+- **[CodeQL](https://github.com/ultralytics/ultralytics/actions/workflows/codeql.yaml):** CodeQL is a tool from GitHub that performs semantic analysis on our code, helping to find potential security vulnerabilities and maintain high-quality code.
+- **[PyPI Publishing](https://github.com/ultralytics/ultralytics/actions/workflows/publish.yml):** This test checks if the project can be packaged and published to PyPi without any errors.
+
+### CI Results
+
+Below is the table showing the status of these CI tests for our main repositories:
+
+| Repository | CI | Docker Deployment | Broken Links | CodeQL | PyPI and Docs Publishing |
+| --------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| [yolov3](https://github.com/ultralytics/yolov3) | [](https://github.com/ultralytics/yolov3/actions/workflows/ci-testing.yml) | [](https://github.com/ultralytics/yolov3/actions/workflows/docker.yml) | [](https://github.com/ultralytics/yolov3/actions/workflows/links.yml) | [](https://github.com/ultralytics/yolov3/actions/workflows/codeql-analysis.yml) | |
+| [yolov5](https://github.com/ultralytics/yolov5) | [](https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml) | [](https://github.com/ultralytics/yolov5/actions/workflows/docker.yml) | [](https://github.com/ultralytics/yolov5/actions/workflows/links.yml) | [](https://github.com/ultralytics/yolov5/actions/workflows/codeql-analysis.yml) | |
+| [ultralytics](https://github.com/ultralytics/ultralytics) | [](https://github.com/ultralytics/ultralytics/actions/workflows/ci.yaml) | [](https://github.com/ultralytics/ultralytics/actions/workflows/docker.yaml) | [](https://github.com/ultralytics/ultralytics/actions/workflows/links.yml) | [](https://github.com/ultralytics/ultralytics/actions/workflows/codeql.yaml) | [](https://github.com/ultralytics/ultralytics/actions/workflows/publish.yml) |
+| [hub](https://github.com/ultralytics/hub) | [](https://github.com/ultralytics/hub/actions/workflows/ci.yaml) | | [](https://github.com/ultralytics/hub/actions/workflows/links.yml) | | |
+| [docs](https://github.com/ultralytics/docs) | | | [](https://github.com/ultralytics/docs/actions/workflows/links.yml)[](https://github.com/ultralytics/docs/actions/workflows/check_domains.yml) | | [](https://github.com/ultralytics/docs/actions/workflows/pages/pages-build-deployment) |
+
+Each badge shows the status of the last run of the corresponding CI test on the `main` branch of the respective repository. If a test fails, the badge will display a "failing" status, and if it passes, it will display a "passing" status.
+
+If you notice a test failing, it would be a great help if you could report it through a GitHub issue in the respective repository.
+
+Remember, a successful CI test does not mean that everything is perfect. It is always recommended to manually review the code before deployment or merging changes.
+
+## Code Coverage
+
+Code coverage is a metric that represents the percentage of your codebase that is executed when your tests run. It provides insight into how well your tests exercise your code and can be crucial in identifying untested parts of your application. A high code coverage percentage is often associated with a lower likelihood of bugs. However, it's essential to understand that code coverage does not guarantee the absence of defects. It merely indicates which parts of the code have been executed by the tests.
+
+### Integration with [codecov.io](https://codecov.io/)
+
+At Ultralytics, we have integrated our repositories with [codecov.io](https://codecov.io/), a popular online platform for measuring and visualizing code coverage. Codecov provides detailed insights, coverage comparisons between commits, and visual overlays directly on your code, indicating which lines were covered.
+
+By integrating with Codecov, we aim to maintain and improve the quality of our code by focusing on areas that might be prone to errors or need further testing.
+
+### Coverage Results
+
+To quickly get a glimpse of the code coverage status of the `ultralytics` python package, we have included a badge and sunburst visual of the `ultralytics` coverage results. These images show the percentage of code covered by our tests, offering an at-a-glance metric of our testing efforts. For full details please see https://codecov.io/github/ultralytics/ultralytics.
+
+| Repository | Code Coverage |
+| --------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| [ultralytics](https://github.com/ultralytics/ultralytics) | [](https://codecov.io/gh/ultralytics/ultralytics) |
+
+In the sunburst graphic below, the innermost circle is the entire project, moving away from the center are folders then, finally, a single file. The size and color of each slice is representing the number of statements and the coverage, respectively.
+
+
+
+
+
+## FAQ
+
+### What is Continuous Integration (CI) in Ultralytics?
+
+Continuous Integration (CI) in Ultralytics involves automatically integrating and testing code changes to ensure high-quality standards. Our CI setup includes running [unit tests, linting checks, and comprehensive tests](https://github.com/ultralytics/ultralytics/actions/workflows/ci.yaml). Additionally, we perform [Docker deployment](https://github.com/ultralytics/ultralytics/actions/workflows/docker.yaml), [broken link checks](https://github.com/ultralytics/ultralytics/actions/workflows/links.yml), [CodeQL analysis](https://github.com/ultralytics/ultralytics/actions/workflows/codeql.yaml) for security vulnerabilities, and [PyPI publishing](https://github.com/ultralytics/ultralytics/actions/workflows/publish.yml) to package and distribute our software.
+
+### How does Ultralytics check for broken links in documentation and code?
+
+Ultralytics uses a specific CI action to [check for broken links](https://github.com/ultralytics/ultralytics/actions/workflows/links.yml) within our markdown and HTML files. This helps maintain the integrity of our documentation by scanning and identifying dead or broken links, ensuring that users always have access to accurate and live resources.
+
+### Why is CodeQL analysis important for Ultralytics' codebase?
+
+[CodeQL analysis](https://github.com/ultralytics/ultralytics/actions/workflows/codeql.yaml) is crucial for Ultralytics as it performs semantic code analysis to find potential security vulnerabilities and maintain high-quality standards. With CodeQL, we can proactively identify and mitigate risks in our code, helping us deliver robust and secure software solutions.
+
+### How does Ultralytics utilize Docker for deployment?
+
+Ultralytics employs Docker to validate the deployment of our projects through a dedicated CI action. This process ensures that our [Dockerfile and associated scripts](https://github.com/ultralytics/ultralytics/actions/workflows/docker.yaml) are functioning correctly, allowing for consistent and reproducible deployment environments which are critical for scalable and reliable AI solutions.
+
+### What is the role of automated PyPI publishing in Ultralytics?
+
+Automated [PyPI publishing](https://github.com/ultralytics/ultralytics/actions/workflows/publish.yml) ensures that our projects can be packaged and published without errors. This step is essential for distributing Ultralytics' Python packages, allowing users to easily install and use our tools via the Python Package Index (PyPI).
+
+### How does Ultralytics measure code coverage and why is it important?
+
+Ultralytics measures code coverage by integrating with [Codecov](https://codecov.io/github/ultralytics/ultralytics), providing insights into how much of the codebase is executed during tests. High code coverage can indicate well-tested code, helping to uncover untested areas that might be prone to bugs. Detailed code coverage metrics can be explored via badges displayed on our main repositories or directly on [Codecov](https://codecov.io/gh/ultralytics/ultralytics).
diff --git a/ultralytics/docs/en/help/CLA.md b/ultralytics/docs/en/help/CLA.md
new file mode 100644
index 0000000000000000000000000000000000000000..2b317aef5af1400d5c4fe8a238bb7764e7f54795
--- /dev/null
+++ b/ultralytics/docs/en/help/CLA.md
@@ -0,0 +1,50 @@
+---
+description: Review the terms for contributing to Ultralytics projects. Learn about copyright, patent licenses, and moral rights for your contributions.
+keywords: Ultralytics, Contributor License Agreement, open source, contributions, copyright license, patent license, moral rights
+---
+
+# Ultralytics Individual Contributor License Agreement
+
+Thank you for your interest in contributing to open source software projects (“Projects”) made available by Ultralytics Inc. (“Ultralytics”). This Individual Contributor License Agreement (“Agreement”) sets out the terms governing any source code, object code, bug fixes, configuration changes, tools, specifications, documentation, data, materials, feedback, information or other works of authorship that you submit or have submitted, in any form and in any manner, to Ultralytics in respect of any Projects (collectively “Contributions”). If you have any questions respecting this Agreement, please contact hello@ultralytics.com.
+
+You agree that the following terms apply to all of your past, present and future Contributions. Except for the licenses granted in this Agreement, you retain all of your right, title and interest in and to your Contributions.
+
+**Copyright License.** You hereby grant, and agree to grant, to Ultralytics a non-exclusive, perpetual, irrevocable, worldwide, fully-paid, royalty-free, transferable copyright license to reproduce, prepare derivative works of, publicly display, publicly perform, and distribute your Contributions and such derivative works, with the right to sublicense the foregoing rights through multiple tiers of sublicensees.
+
+**Patent License.** You hereby grant, and agree to grant, to Ultralytics a non-exclusive, perpetual, irrevocable, worldwide, fully-paid, royalty-free, transferable patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer your Contributions, where such license applies only to those patent claims licensable by you that are necessarily infringed by your Contributions alone or by combination of your Contributions with the Project to which such Contributions were submitted, with the right to sublicense the foregoing rights through multiple tiers of sublicensees.
+
+**Moral Rights.** To the fullest extent permitted under applicable law, you hereby waive, and agree not to assert, all of your “moral rights” in or relating to your Contributions for the benefit of Ultralytics, its assigns, and their respective direct and indirect sublicensees.
+
+**Third Party Content/Rights.** If your Contribution includes or is based on any source code, object code, bug fixes, configuration changes, tools, specifications, documentation, data, materials, feedback, information or other works of authorship that were not authored by you (“Third Party Content”) or if you are aware of any third party intellectual property or proprietary rights associated with your Contribution (“Third Party Rights”), then you agree to include with the submission of your Contribution full details respecting such Third Party Content and Third Party Rights, including, without limitation, identification of which aspects of your Contribution contain Third Party Content or are associated with Third Party Rights, the owner/author of the Third Party Content and Third Party Rights, where you obtained the Third Party Content, and any applicable third party license terms or restrictions respecting the Third Party Content and Third Party Rights. For greater certainty, the foregoing obligations respecting the identification of Third Party Content and Third Party Rights do not apply to any portion of a Project that is incorporated into your Contribution to that same Project.
+
+**Representations.** You represent that, other than the Third Party Content and Third Party Rights identified by you in accordance with this Agreement, you are the sole author of your Contributions and are legally entitled to grant the foregoing licenses and waivers in respect of your Contributions. If your Contributions were created in the course of your employment with your past or present employer(s), you represent that such employer(s) has authorized you to make your Contributions on behalf of such employer(s) or such employer(s) has waived all of their right, title or interest in or to your Contributions.
+
+**Disclaimer.** To the fullest extent permitted under applicable law, your Contributions are provided on an "asis" basis, without any warranties or conditions, express or implied, including, without limitation, any implied warranties or conditions of non-infringement, merchantability or fitness for a particular purpose. You are not required to provide support for your Contributions, except to the extent you desire to provide support.
+
+**No Obligation.** You acknowledge that Ultralytics is under no obligation to use or incorporate your Contributions into any of the Projects. The decision to use or incorporate your Contributions into any of the Projects will be made at the sole discretion of Ultralytics or its authorized delegates.
+
+**Disputes.** This Agreement shall be governed by and construed in accordance with the laws of the State of New York, United States of America, without giving effect to its principles or rules regarding conflicts of laws, other than such principles directing application of New York law. The parties hereby submit to venue in, and jurisdiction of the courts located in New York, New York for purposes relating to this Agreement. In the event that any of the provisions of this Agreement shall be held by a court or other tribunal of competent jurisdiction to be unenforceable, the remaining portions hereof shall remain in full force and effect.
+
+**Assignment.** You agree that Ultralytics may assign this Agreement, and all of its rights, obligations and licenses hereunder.
+
+## FAQ
+
+### What is the purpose of the Ultralytics Individual Contributor License Agreement?
+
+The Ultralytics Individual Contributor License Agreement (ICLA) governs the terms under which you contribute to Ultralytics' open-source projects. It sets out the rights and obligations related to your contributions, including granting copyright and patent licenses, waiving moral rights, and disclosing any third-party content.
+
+### Why do I need to agree to the Copyright License in the ICLA?
+
+Agreeing to the Copyright License allows Ultralytics to use and distribute your contributions, including making derivative works. This ensures that your contributions can be integrated into Ultralytics projects and shared with the community, fostering collaboration and software development.
+
+### How does the Patent License benefit both contributors and Ultralytics?
+
+The Patent License grants Ultralytics the rights to use, make, and sell contributions covered by your patents, which is crucial for product development and commercialization. In return, it allows your patented innovations to be more widely used and recognized, promoting innovation within the community.
+
+### What should I do if my contribution contains third-party content?
+
+If your contribution includes third-party content or you are aware of any third-party intellectual property rights, you must provide full details of such content and rights when submitting your contribution. This includes identifying the third-party content, its author, and the applicable license terms. For more information on third-party content, refer to the Third Party Content/Rights section of the Agreement.
+
+### What happens if Ultralytics does not use my contributions?
+
+Ultralytics is not obligated to use or incorporate your contributions into any projects. The decision to use or integrate contributions is at Ultralytics' sole discretion. This means that while your contributions are valuable, they may not always align with the project's current needs or directions. For further details, see the No Obligation section.
diff --git a/ultralytics/docs/en/help/FAQ.md b/ultralytics/docs/en/help/FAQ.md
new file mode 100644
index 0000000000000000000000000000000000000000..5ad7300a39a4528e9733160775680cad60d2e6b0
--- /dev/null
+++ b/ultralytics/docs/en/help/FAQ.md
@@ -0,0 +1,229 @@
+---
+comments: true
+description: Explore common questions and solutions related to Ultralytics YOLO, from hardware requirements to model fine-tuning and real-time detection.
+keywords: Ultralytics, YOLO, FAQ, object detection, hardware requirements, fine-tuning, ONNX, TensorFlow, real-time detection, model accuracy
+---
+
+# Ultralytics YOLO Frequently Asked Questions (FAQ)
+
+This FAQ section addresses common questions and issues users might encounter while working with [Ultralytics](https://ultralytics.com) YOLO repositories.
+
+## FAQ
+
+### What is Ultralytics and what does it offer?
+
+Ultralytics is a computer vision AI company specializing in state-of-the-art object detection and image segmentation models, with a focus on the YOLO (You Only Look Once) family. Their offerings include:
+
+- Open-source implementations of [YOLOv5](https://docs.ultralytics.com/models/yolov5/) and [YOLOv8](https://docs.ultralytics.com/models/yolov8/)
+- A wide range of [pre-trained models](https://docs.ultralytics.com/models/) for various computer vision tasks
+- A comprehensive [Python package](https://docs.ultralytics.com/usage/python/) for seamless integration of YOLO models into projects
+- Versatile [tools](https://docs.ultralytics.com/modes/) for training, testing, and deploying models
+- [Extensive documentation](https://docs.ultralytics.com/) and a supportive community
+
+### How do I install the Ultralytics package?
+
+Installing the Ultralytics package is straightforward using pip:
+
+```
+pip install ultralytics
+```
+
+For the latest development version, install directly from the GitHub repository:
+
+```
+pip install git+https://github.com/ultralytics/ultralytics.git
+```
+
+Detailed installation instructions can be found in the [quickstart guide](https://docs.ultralytics.com/quickstart/).
+
+### What are the system requirements for running Ultralytics models?
+
+Minimum requirements:
+
+- Python 3.7+
+- PyTorch 1.7+
+- CUDA-compatible GPU (for GPU acceleration)
+
+Recommended setup:
+
+- Python 3.8+
+- PyTorch 1.10+
+- NVIDIA GPU with CUDA 11.2+
+- 8GB+ RAM
+- 50GB+ free disk space (for dataset storage and model training)
+
+For troubleshooting common issues, visit the [YOLO Common Issues](https://docs.ultralytics.com/guides/yolo-common-issues/) page.
+
+### How can I train a custom YOLOv8 model on my own dataset?
+
+To train a custom YOLOv8 model:
+
+1. Prepare your dataset in YOLO format (images and corresponding label txt files).
+2. Create a YAML file describing your dataset structure and classes.
+3. Use the following Python code to start training:
+
+```python
+from ultralytics import YOLO
+
+# Load a model
+model = YOLO("yolov8n.yaml") # build a new model from scratch
+model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+
+# Train the model
+results = model.train(data="path/to/your/data.yaml", epochs=100, imgsz=640)
+```
+
+For a more in-depth guide, including data preparation and advanced training options, refer to the comprehensive [training guide](https://docs.ultralytics.com/modes/train/).
+
+### What pretrained models are available in Ultralytics?
+
+Ultralytics offers a diverse range of pretrained YOLOv8 models for various tasks:
+
+- Object Detection: YOLOv8n, YOLOv8s, YOLOv8m, YOLOv8l, YOLOv8x
+- Instance Segmentation: YOLOv8n-seg, YOLOv8s-seg, YOLOv8m-seg, YOLOv8l-seg, YOLOv8x-seg
+- Classification: YOLOv8n-cls, YOLOv8s-cls, YOLOv8m-cls, YOLOv8l-cls, YOLOv8x-cls
+
+These models vary in size and complexity, offering different trade-offs between speed and accuracy. Explore the full range of [pretrained models](https://docs.ultralytics.com/models/yolov8/) to find the best fit for your project.
+
+### How do I perform inference using a trained Ultralytics model?
+
+To perform inference with a trained model:
+
+```python
+from ultralytics import YOLO
+
+# Load a model
+model = YOLO("path/to/your/model.pt")
+
+# Perform inference
+results = model("path/to/image.jpg")
+
+# Process results
+for r in results:
+ print(r.boxes) # print bbox predictions
+ print(r.masks) # print mask predictions
+ print(r.probs) # print class probabilities
+```
+
+For advanced inference options, including batch processing and video inference, check out the detailed [prediction guide](https://docs.ultralytics.com/modes/predict/).
+
+### Can Ultralytics models be deployed on edge devices or in production environments?
+
+Absolutely! Ultralytics models are designed for versatile deployment across various platforms:
+
+- Edge devices: Optimize inference on devices like NVIDIA Jetson or Intel Neural Compute Stick using TensorRT, ONNX, or OpenVINO.
+- Mobile: Deploy on Android or iOS devices by converting models to TFLite or Core ML.
+- Cloud: Leverage frameworks like TensorFlow Serving or PyTorch Serve for scalable cloud deployments.
+- Web: Implement in-browser inference using ONNX.js or TensorFlow.js.
+
+Ultralytics provides export functions to convert models to various formats for deployment. Explore the wide range of [deployment options](https://docs.ultralytics.com/guides/model-deployment-options/) to find the best solution for your use case.
+
+### What's the difference between YOLOv5 and YOLOv8?
+
+Key distinctions include:
+
+- Architecture: YOLOv8 features an improved backbone and head design for enhanced performance.
+- Performance: YOLOv8 generally offers superior accuracy and speed compared to YOLOv5.
+- Tasks: YOLOv8 natively supports object detection, instance segmentation, and classification in a unified framework.
+- Codebase: YOLOv8 is implemented with a more modular and extensible architecture, facilitating easier customization and extension.
+- Training: YOLOv8 incorporates advanced training techniques like multi-dataset training and hyperparameter evolution for improved results.
+
+For an in-depth comparison of features and performance metrics, visit the [YOLOv5 vs YOLOv8](https://www.ultralytics.com/yolo) comparison page.
+
+### How can I contribute to the Ultralytics open-source project?
+
+Contributing to Ultralytics is a great way to improve the project and expand your skills. Here's how you can get involved:
+
+1. Fork the Ultralytics repository on GitHub.
+2. Create a new branch for your feature or bug fix.
+3. Make your changes and ensure all tests pass.
+4. Submit a pull request with a clear description of your changes.
+5. Participate in the code review process.
+
+You can also contribute by reporting bugs, suggesting features, or improving documentation. For detailed guidelines and best practices, refer to the [contributing guide](https://docs.ultralytics.com/help/contributing/).
+
+### How do I install the Ultralytics package in Python?
+
+Installing the Ultralytics package in Python is simple. Use pip by running the following command in your terminal or command prompt:
+
+```bash
+pip install ultralytics
+```
+
+For the cutting-edge development version, install directly from the GitHub repository:
+
+```bash
+pip install git+https://github.com/ultralytics/ultralytics.git
+```
+
+For environment-specific installation instructions and troubleshooting tips, consult the comprehensive [quickstart guide](https://docs.ultralytics.com/quickstart/).
+
+### What are the main features of Ultralytics YOLO?
+
+Ultralytics YOLO boasts a rich set of features for advanced object detection and image segmentation:
+
+- Real-Time Detection: Efficiently detect and classify objects in real-time scenarios.
+- Pre-Trained Models: Access a variety of [pretrained models](https://docs.ultralytics.com/models/yolov8/) that balance speed and accuracy for different use cases.
+- Custom Training: Easily fine-tune models on custom datasets with the flexible [training pipeline](https://docs.ultralytics.com/modes/train/).
+- Wide [Deployment Options](https://docs.ultralytics.com/guides/model-deployment-options/): Export models to various formats like TensorRT, ONNX, and CoreML for deployment across different platforms.
+- Extensive Documentation: Benefit from comprehensive [documentation](https://docs.ultralytics.com/) and a supportive community to guide you through your computer vision journey.
+
+Explore the [YOLO models page](https://docs.ultralytics.com/models/yolov8/) for an in-depth look at the capabilities and architectures of different YOLO versions.
+
+### How can I improve the performance of my YOLO model?
+
+Enhancing your YOLO model's performance can be achieved through several techniques:
+
+1. Hyperparameter Tuning: Experiment with different hyperparameters using the [Hyperparameter Tuning Guide](https://docs.ultralytics.com/guides/hyperparameter-tuning/) to optimize model performance.
+2. Data Augmentation: Implement techniques like flip, scale, rotate, and color adjustments to enhance your training dataset and improve model generalization.
+3. Transfer Learning: Leverage pre-trained models and fine-tune them on your specific dataset using the [Train YOLOv8](https://docs.ultralytics.com/modes/train/) guide.
+4. Export to Efficient Formats: Convert your model to optimized formats like TensorRT or ONNX for faster inference using the [Export guide](../modes/export.md).
+5. Benchmarking: Utilize the [Benchmark Mode](https://docs.ultralytics.com/modes/benchmark/) to measure and improve inference speed and accuracy systematically.
+
+### Can I deploy Ultralytics YOLO models on mobile and edge devices?
+
+Yes, Ultralytics YOLO models are designed for versatile deployment, including mobile and edge devices:
+
+- Mobile: Convert models to TFLite or CoreML for seamless integration into Android or iOS apps. Refer to the [TFLite Integration Guide](https://docs.ultralytics.com/integrations/tflite/) and [CoreML Integration Guide](https://docs.ultralytics.com/integrations/coreml/) for platform-specific instructions.
+- Edge Devices: Optimize inference on devices like NVIDIA Jetson or other edge hardware using TensorRT or ONNX. The [Edge TPU Integration Guide](https://docs.ultralytics.com/integrations/edge-tpu/) provides detailed steps for edge deployment.
+
+For a comprehensive overview of deployment strategies across various platforms, consult the [deployment options guide](https://docs.ultralytics.com/guides/model-deployment-options/).
+
+### How can I perform inference using a trained Ultralytics YOLO model?
+
+Performing inference with a trained Ultralytics YOLO model is straightforward:
+
+1. Load the Model:
+
+```python
+from ultralytics import YOLO
+
+model = YOLO("path/to/your/model.pt")
+```
+
+2. Run Inference:
+
+```python
+results = model("path/to/image.jpg")
+
+for r in results:
+ print(r.boxes) # print bounding box predictions
+ print(r.masks) # print mask predictions
+ print(r.probs) # print class probabilities
+```
+
+For advanced inference techniques, including batch processing, video inference, and custom preprocessing, refer to the detailed [prediction guide](https://docs.ultralytics.com/modes/predict/).
+
+### Where can I find examples and tutorials for using Ultralytics?
+
+Ultralytics provides a wealth of resources to help you get started and master their tools:
+
+- 📚 [Official documentation](https://docs.ultralytics.com/): Comprehensive guides, API references, and best practices.
+- 💻 [GitHub repository](https://github.com/ultralytics/ultralytics): Source code, example scripts, and community contributions.
+- ✍️ [Ultralytics blog](https://www.ultralytics.com/blog): In-depth articles, use cases, and technical insights.
+- 💬 [Community forums](https://community.ultralytics.com/): Connect with other users, ask questions, and share your experiences.
+- 🎥 [YouTube channel](https://youtube.com/ultralytics?sub_confirmation=1): Video tutorials, demos, and webinars on various Ultralytics topics.
+
+These resources provide code examples, real-world use cases, and step-by-step guides for various tasks using Ultralytics models.
+
+If you need further assistance, don't hesitate to consult the Ultralytics documentation or reach out to the community through [GitHub Issues](https://github.com/ultralytics/ultralytics/issues) or the official [discussion forum](https://github.com/orgs/ultralytics/discussions).
diff --git a/ultralytics/docs/en/help/code_of_conduct.md b/ultralytics/docs/en/help/code_of_conduct.md
new file mode 100644
index 0000000000000000000000000000000000000000..d1ab2c81462f757f71726311c5f4e11dcbadf9d1
--- /dev/null
+++ b/ultralytics/docs/en/help/code_of_conduct.md
@@ -0,0 +1,109 @@
+---
+comments: true
+description: Join our welcoming community! Learn about the Ultralytics Code of Conduct to ensure a harassment-free experience for all participants.
+keywords: Ultralytics, Contributor Covenant, Code of Conduct, community guidelines, harassment-free, inclusive community, diversity, enforcement policy
+---
+
+# Ultralytics Contributor Covenant Code of Conduct
+
+## Our Pledge
+
+We as members, contributors, and leaders pledge to make participation in our community a harassment-free experience for everyone, regardless of age, body size, visible or invisible disability, ethnicity, sex characteristics, gender identity and expression, level of experience, education, socioeconomic status, nationality, personal appearance, race, religion, or sexual identity and orientation.
+
+We pledge to act and interact in ways that contribute to an open, welcoming, diverse, inclusive, and healthy community.
+
+## Our Standards
+
+Examples of behavior that contributes to a positive environment for our community include:
+
+- Demonstrating empathy and kindness toward other people
+- Being respectful of differing opinions, viewpoints, and experiences
+- Giving and gracefully accepting constructive feedback
+- Accepting responsibility and apologizing to those affected by our mistakes, and learning from the experience
+- Focusing on what is best not just for us as individuals, but for the overall community
+
+Examples of unacceptable behavior include:
+
+- The use of sexualized language or imagery, and sexual attention or advances of any kind
+- Trolling, insulting or derogatory comments, and personal or political attacks
+- Public or private harassment
+- Publishing others' private information, such as a physical or email address, without their explicit permission
+- Other conduct which could reasonably be considered inappropriate in a professional setting
+
+## Enforcement Responsibilities
+
+Community leaders are responsible for clarifying and enforcing our standards of acceptable behavior and will take appropriate and fair corrective action in response to any behavior that they deem inappropriate, threatening, offensive, or harmful.
+
+Community leaders have the right and responsibility to remove, edit, or reject comments, commits, code, wiki edits, issues, and other contributions that are not aligned to this Code of Conduct, and will communicate reasons for moderation decisions when appropriate.
+
+## Scope
+
+This Code of Conduct applies within all community spaces, and also applies when an individual is officially representing the community in public spaces. Examples of representing our community include using an official e-mail address, posting via an official social media account, or acting as an appointed representative at an online or offline event.
+
+## Enforcement
+
+Instances of abusive, harassing, or otherwise unacceptable behavior may be reported to the community leaders responsible for enforcement at hello@ultralytics.com. All complaints will be reviewed and investigated promptly and fairly.
+
+All community leaders are obligated to respect the privacy and security of the reporter of any incident.
+
+## Enforcement Guidelines
+
+Community leaders will follow these Community Impact Guidelines in determining the consequences for any action they deem in violation of this Code of Conduct:
+
+### 1. Correction
+
+**Community Impact**: Use of inappropriate language or other behavior deemed unprofessional or unwelcome in the community.
+
+**Consequence**: A private, written warning from community leaders, providing clarity around the nature of the violation and an explanation of why the behavior was inappropriate. A public apology may be requested.
+
+### 2. Warning
+
+**Community Impact**: A violation through a single incident or series of actions.
+
+**Consequence**: A warning with consequences for continued behavior. No interaction with the people involved, including unsolicited interaction with those enforcing the Code of Conduct, for a specified period of time. This includes avoiding interactions in community spaces as well as external channels like social media. Violating these terms may lead to a temporary or permanent ban.
+
+### 3. Temporary Ban
+
+**Community Impact**: A serious violation of community standards, including sustained inappropriate behavior.
+
+**Consequence**: A temporary ban from any sort of interaction or public communication with the community for a specified period of time. No public or private interaction with the people involved, including unsolicited interaction with those enforcing the Code of Conduct, is allowed during this period. Violating these terms may lead to a permanent ban.
+
+### 4. Permanent Ban
+
+**Community Impact**: Demonstrating a pattern of violation of community standards, including sustained inappropriate behavior, harassment of an individual, or aggression toward or disparagement of classes of individuals.
+
+**Consequence**: A permanent ban from any sort of public interaction within the community.
+
+## Attribution
+
+This Code of Conduct is adapted from the [Contributor Covenant][homepage], version 2.0, available at https://www.contributor-covenant.org/version/2/0/code_of_conduct.html.
+
+Community Impact Guidelines were inspired by [Mozilla's code of conduct enforcement ladder](https://github.com/mozilla/diversity).
+
+For answers to common questions about this code of conduct, see the FAQ at https://www.contributor-covenant.org/faq. Translations are available at https://www.contributor-covenant.org/translations.
+
+[homepage]: https://www.contributor-covenant.org
+
+## FAQ
+
+### What is the Ultralytics Contributor Covenant Code of Conduct?
+
+The Ultralytics Contributor Covenant Code of Conduct aims to create a harassment-free experience for everyone participating in the Ultralytics community. It applies to all community interactions, including online and offline activities. The code details expected behaviors, unacceptable behaviors, and the enforcement responsibilities of community leaders. For more detailed information, see the [Enforcement Responsibilities](#enforcement-responsibilities) section.
+
+### How does the enforcement process work for the Ultralytics Code of Conduct?
+
+Enforcement of the Ultralytics Code of Conduct is managed by community leaders who can take appropriate action in response to any behavior deemed inappropriate. This could range from a private warning to a permanent ban, depending on the severity of the violation. Instances of misconduct can be reported to hello@ultralytics.com for investigation. Learn more about the enforcement steps in the [Enforcement Guidelines](#enforcement-guidelines) section.
+
+### Why is diversity and inclusion important in the Ultralytics community?
+
+Ultralytics values diversity and inclusion as fundamental aspects for fostering innovation and creativity within its community. A diverse and inclusive environment allows different perspectives and experiences to contribute to an open, welcoming, and healthy community. This commitment is reflected in our [Pledge](#our-pledge) to ensure a harassment-free experience for everyone regardless of their background.
+
+### How can I contribute to Ultralytics while adhering to the Code of Conduct?
+
+Contributing to Ultralytics means engaging positively and respectfully with other community members. You can contribute by demonstrating empathy, offering and accepting constructive feedback, and taking responsibility for any mistakes. Always aim to contribute in a way that benefits the entire community. For more details on acceptable behaviors, refer to the [Our Standards](#our-standards) section.
+
+### Where can I find additional information about the Ultralytics Code of Conduct?
+
+For more comprehensive details about the Ultralytics Code of Conduct, including reporting guidelines and enforcement policies, you can visit the [Contributor Covenant homepage](https://www.contributor-covenant.org/version/2/0/code_of_conduct.html) or check the [FAQ section of Contributor Covenant](https://www.contributor-covenant.org/faq). Learn more about Ultralytics' goals and initiatives on [our brand page](https://www.ultralytics.com/brand) and [about page](https://www.ultralytics.com/about).
+
+Should you have more questions or need further assistance, check our [Help Center](../help/FAQ.md) and [Contributing Guide](../help/contributing.md) for more information.
diff --git a/ultralytics/docs/en/help/contributing.md b/ultralytics/docs/en/help/contributing.md
new file mode 100644
index 0000000000000000000000000000000000000000..d585fb600dd5538d7f5eb767551a81284e3bbc0c
--- /dev/null
+++ b/ultralytics/docs/en/help/contributing.md
@@ -0,0 +1,168 @@
+---
+comments: true
+description: Learn how to contribute to Ultralytics YOLO open-source repositories. Follow guidelines for pull requests, code of conduct, and bug reporting.
+keywords: Ultralytics, YOLO, open-source, contribution, pull request, code of conduct, bug reporting, GitHub, CLA, Google-style docstrings
+---
+
+# Contributing to Ultralytics Open-Source Projects
+
+Welcome! We're thrilled that you're considering contributing to our [Ultralytics](https://ultralytics.com) [open-source](https://github.com/ultralytics) projects. Your involvement not only helps enhance the quality of our repositories but also benefits the entire community. This guide provides clear guidelines and best practices to help you get started.
+
+
+
+
+## Table of Contents
+
+1. [Code of Conduct](#code-of-conduct)
+2. [Contributing via Pull Requests](#contributing-via-pull-requests)
+ - [CLA Signing](#cla-signing)
+ - [Google-Style Docstrings](#google-style-docstrings)
+ - [GitHub Actions CI Tests](#github-actions-ci-tests)
+3. [Reporting Bugs](#reporting-bugs)
+4. [License](#license)
+5. [Conclusion](#conclusion)
+6. [FAQ](#faq)
+
+## Code of Conduct
+
+To ensure a welcoming and inclusive environment for everyone, all contributors must adhere to our [Code of Conduct](https://docs.ultralytics.com/help/code_of_conduct). Respect, kindness, and professionalism are at the heart of our community.
+
+## Contributing via Pull Requests
+
+We greatly appreciate contributions in the form of pull requests. To make the review process as smooth as possible, please follow these steps:
+
+1. **[Fork the repository](https://docs.github.com/en/pull-requests/collaborating-with-pull-requests/working-with-forks/fork-a-repo):** Start by forking the Ultralytics YOLO repository to your GitHub account.
+
+2. **[Create a branch](https://docs.github.com/en/desktop/making-changes-in-a-branch/managing-branches-in-github-desktop):** Create a new branch in your forked repository with a clear, descriptive name that reflects your changes.
+
+3. **Make your changes:** Ensure your code adheres to the project's style guidelines and does not introduce any new errors or warnings.
+
+4. **[Test your changes](https://github.com/ultralytics/ultralytics/tree/main/tests):** Before submitting, test your changes locally to confirm they work as expected and don't cause any new issues.
+
+5. **[Commit your changes](https://docs.github.com/en/desktop/making-changes-in-a-branch/committing-and-reviewing-changes-to-your-project-in-github-desktop):** Commit your changes with a concise and descriptive commit message. If your changes address a specific issue, include the issue number in your commit message.
+
+6. **[Create a pull request](https://docs.github.com/en/pull-requests/collaborating-with-pull-requests/proposing-changes-to-your-work-with-pull-requests/creating-a-pull-request):** Submit a pull request from your forked repository to the main Ultralytics YOLO repository. Provide a clear and detailed explanation of your changes and how they improve the project.
+
+### CLA Signing
+
+Before we can merge your pull request, you must sign our [Contributor License Agreement (CLA)](https://docs.ultralytics.com/help/CLA). This legal agreement ensures that your contributions are properly licensed, allowing the project to continue being distributed under the AGPL-3.0 license.
+
+After submitting your pull request, the CLA bot will guide you through the signing process. To sign the CLA, simply add a comment in your PR stating:
+
+```
+I have read the CLA Document and I sign the CLA
+```
+
+### Google-Style Docstrings
+
+When adding new functions or classes, please include [Google-style docstrings](https://google.github.io/styleguide/pyguide.html). These docstrings provide clear, standardized documentation that helps other developers understand and maintain your code.
+
+!!! Example "Example Docstrings"
+
+ === "Google-style"
+
+ This example illustrates a Google-style docstring. Ensure that both input and output `types` are always enclosed in parentheses, e.g., `(bool)`.
+
+ ```python
+ def example_function(arg1, arg2=4):
+ """
+ Example function demonstrating Google-style docstrings.
+
+ Args:
+ arg1 (int): The first argument.
+ arg2 (int): The second argument, with a default value of 4.
+
+ Returns:
+ (bool): True if successful, False otherwise.
+
+ Examples:
+ >>> result = example_function(1, 2) # returns False
+ """
+ if arg1 == arg2:
+ return True
+ return False
+ ```
+
+ === "Google-style with type hints"
+
+ This example includes both a Google-style docstring and type hints for arguments and returns, though using either independently is also acceptable.
+
+ ```python
+ def example_function(arg1: int, arg2: int = 4) -> bool:
+ """
+ Example function demonstrating Google-style docstrings.
+
+ Args:
+ arg1: The first argument.
+ arg2: The second argument, with a default value of 4.
+
+ Returns:
+ True if successful, False otherwise.
+
+ Examples:
+ >>> result = example_function(1, 2) # returns False
+ """
+ if arg1 == arg2:
+ return True
+ return False
+ ```
+
+ === "Single-line"
+
+ For smaller or simpler functions, a single-line docstring may be sufficient. The docstring must use three double-quotes, be a complete sentence, start with a capital letter, and end with a period.
+
+ ```python
+ def example_small_function(arg1: int, arg2: int = 4) -> bool:
+ """Example function with a single-line docstring."""
+ return arg1 == arg2
+ ```
+
+### GitHub Actions CI Tests
+
+All pull requests must pass the GitHub Actions [Continuous Integration](https://docs.ultralytics.com/help/CI) (CI) tests before they can be merged. These tests include linting, unit tests, and other checks to ensure that your changes meet the project's quality standards. Review the CI output and address any issues that arise.
+
+## Reporting Bugs
+
+We highly value bug reports as they help us maintain the quality of our projects. When reporting a bug, please provide a [Minimum Reproducible Example](https://docs.ultralytics.com/help/minimum_reproducible_example)—a simple, clear code example that consistently reproduces the issue. This allows us to quickly identify and resolve the problem.
+
+## License
+
+Ultralytics uses the [GNU Affero General Public License v3.0 (AGPL-3.0)](https://github.com/ultralytics/ultralytics/blob/main/LICENSE) for its repositories. This license promotes openness, transparency, and collaborative improvement in software development. It ensures that all users have the freedom to use, modify, and share the software, fostering a strong community of collaboration and innovation.
+
+We encourage all contributors to familiarize themselves with the terms of the AGPL-3.0 license to contribute effectively and ethically to the Ultralytics open-source community.
+
+## Conclusion
+
+Thank you for your interest in contributing to [Ultralytics](https://ultralytics.com) [open-source](https://github.com/ultralytics) YOLO projects. Your participation is essential in shaping the future of our software and building a vibrant community of innovation and collaboration. Whether you're enhancing code, reporting bugs, or suggesting new features, your contributions are invaluable.
+
+We're excited to see your ideas come to life and appreciate your commitment to advancing object detection technology. Together, let's continue to grow and innovate in this exciting open-source journey. Happy coding! 🚀🌟
+
+## FAQ
+
+### Why should I contribute to Ultralytics YOLO open-source repositories?
+
+Contributing to Ultralytics YOLO open-source repositories improves the software, making it more robust and feature-rich for the entire community. Contributions can include code enhancements, bug fixes, documentation improvements, and new feature implementations. Additionally, contributing allows you to collaborate with other skilled developers and experts in the field, enhancing your own skills and reputation. For details on how to get started, refer to the [Contributing via Pull Requests](#contributing-via-pull-requests) section.
+
+### How do I sign the Contributor License Agreement (CLA) for Ultralytics YOLO?
+
+To sign the Contributor License Agreement (CLA), follow the instructions provided by the CLA bot after submitting your pull request. This process ensures that your contributions are properly licensed under the AGPL-3.0 license, maintaining the legal integrity of the open-source project. Add a comment in your pull request stating:
+
+```
+I have read the CLA Document and I sign the CLA.
+```
+
+For more information, see the [CLA Signing](#cla-signing) section.
+
+### What are Google-style docstrings, and why are they required for Ultralytics YOLO contributions?
+
+Google-style docstrings provide clear, concise documentation for functions and classes, improving code readability and maintainability. These docstrings outline the function's purpose, arguments, and return values with specific formatting rules. When contributing to Ultralytics YOLO, following Google-style docstrings ensures that your additions are well-documented and easily understood. For examples and guidelines, visit the [Google-Style Docstrings](#google-style-docstrings) section.
+
+### How can I ensure my changes pass the GitHub Actions CI tests?
+
+Before your pull request can be merged, it must pass all GitHub Actions Continuous Integration (CI) tests. These tests include linting, unit tests, and other checks to ensure the code meets
+
+the project's quality standards. Review the CI output and fix any issues. For detailed information on the CI process and troubleshooting tips, see the [GitHub Actions CI Tests](#github-actions-ci-tests) section.
+
+### How do I report a bug in Ultralytics YOLO repositories?
+
+To report a bug, provide a clear and concise [Minimum Reproducible Example](https://docs.ultralytics.com/help/minimum_reproducible_example) along with your bug report. This helps developers quickly identify and fix the issue. Ensure your example is minimal yet sufficient to replicate the problem. For more detailed steps on reporting bugs, refer to the [Reporting Bugs](#reporting-bugs) section.
diff --git a/ultralytics/docs/en/help/environmental-health-safety.md b/ultralytics/docs/en/help/environmental-health-safety.md
new file mode 100644
index 0000000000000000000000000000000000000000..bdf6cfbd467270f78a920d9c53895fc55dc79b33
--- /dev/null
+++ b/ultralytics/docs/en/help/environmental-health-safety.md
@@ -0,0 +1,63 @@
+---
+comments: false
+description: Explore Ultralytics' commitment to Environmental, Health, and Safety (EHS) policies. Learn about our measures to ensure safety, compliance, and sustainability.
+keywords: Ultralytics, EHS policy, safety, sustainability, environmental impact, health and safety, risk management, compliance, continuous improvement
+---
+
+# Ultralytics Environmental, Health and Safety (EHS) Policy
+
+At Ultralytics, we recognize that the long-term success of our company relies not only on the products and services we offer, but also the manner in which we conduct our business. We are committed to ensuring the safety and well-being of our employees, stakeholders, and the environment, and we will continuously strive to mitigate our impact on the environment while promoting health and safety.
+
+## Policy Principles
+
+1. **Compliance**: We will comply with all applicable laws, regulations, and standards related to EHS, and we will strive to exceed these standards where possible.
+
+2. **Prevention**: We will work to prevent accidents, injuries, and environmental harm by implementing risk management measures and ensuring all our operations and procedures are safe.
+
+3. **Continuous Improvement**: We will continuously improve our EHS performance by setting measurable objectives, monitoring our performance, auditing our operations, and revising our policies and procedures as needed.
+
+4. **Communication**: We will communicate openly about our EHS performance and will engage with stakeholders to understand and address their concerns and expectations.
+
+5. **Education and Training**: We will educate and train our employees and contractors in appropriate EHS procedures and practices.
+
+## Implementation Measures
+
+1. **Responsibility and Accountability**: Every employee and contractor working at or with Ultralytics is responsible for adhering to this policy. Managers and supervisors are accountable for ensuring this policy is implemented within their areas of control.
+
+2. **Risk Management**: We will identify, assess, and manage EHS risks associated with our operations and activities to prevent accidents, injuries, and environmental harm.
+
+3. **Resource Allocation**: We will allocate the necessary resources to ensure the effective implementation of our EHS policy, including the necessary equipment, personnel, and training.
+
+4. **Emergency Preparedness and Response**: We will develop, maintain, and test emergency preparedness and response plans to ensure we can respond effectively to EHS incidents.
+
+5. **Monitoring and Review**: We will monitor and review our EHS performance regularly to identify opportunities for improvement and ensure we are meeting our objectives.
+
+This policy reflects our commitment to minimizing our environmental footprint, ensuring the safety and well-being of our employees, and continuously improving our performance.
+
+Please remember that the implementation of an effective EHS policy requires the involvement and commitment of everyone working at or with Ultralytics. We encourage you to take personal responsibility for your safety and the safety of others, and to take care of the environment in which we live and work.
+
+## FAQ
+
+### What is Ultralytics' Environmental, Health, and Safety (EHS) policy?
+
+Ultralytics' Environmental, Health, and Safety (EHS) policy is a comprehensive framework designed to ensure the safety and well-being of employees, stakeholders, and the environment. It emphasizes compliance with relevant laws, accident prevention through risk management, continuous improvement through measurable objectives, open communication, and education and training for employees. By following these principles, Ultralytics aims to minimize its environmental footprint and promote sustainable practices. [Learn more about Ultralytics' commitment to EHS](https://www.ultralytics.com/about).
+
+### How does Ultralytics ensure compliance with EHS regulations?
+
+Ultralytics ensures compliance with EHS regulations by adhering to all applicable laws, regulations, and standards. The company not only strives to meet these requirements but often exceeds them by implementing stringent internal policies. Regular audits, monitoring, and reviews are conducted to ensure ongoing compliance. Managers and supervisors are also accountable for ensuring these standards are maintained within their areas of control. For more details, refer to the [Policy Principles section](#policy-principles) on the documentation page.
+
+### Why is continuous improvement a key principle in Ultralytics' EHS policy?
+
+Continuous improvement is essential in Ultralytics' EHS policy because it ensures the company consistently enhances its performance in environmental, health, and safety areas. By setting measurable objectives, monitoring performance, and revising policies and procedures as needed, Ultralytics can adapt to new challenges and optimize its processes. This approach not only mitigates risks but also demonstrates Ultralytics' commitment to sustainability and excellence. For practical examples of continuous improvement, check the [Implementation Measures section](#implementation-measures).
+
+### What are the roles and responsibilities of employees in implementing the EHS policy at Ultralytics?
+
+Every employee and contractor at Ultralytics is responsible for adhering to the EHS policy. This includes following safety protocols, participating in necessary training, and taking personal responsibility for their safety and the safety of others. Managers and supervisors have an added responsibility of ensuring the EHS policy is effectively implemented within their areas of control, which involves risk assessments and resource allocation. For more information about responsibility and accountability, see the [Implementation Measures section](#implementation-measures).
+
+### How does Ultralytics handle emergency preparedness and response in its EHS policy?
+
+Ultralytics handles emergency preparedness and response by developing, maintaining, and regularly testing emergency plans to address potential EHS incidents effectively. These plans ensure that the company can respond swiftly and efficiently to minimize harm to employees, the environment, and property. Regular training and drills are conducted to keep the response teams prepared for various emergency scenarios. For additional context, refer to the [emergency preparedness and response measure](#implementation-measures).
+
+### How does Ultralytics engage with stakeholders regarding its EHS performance?
+
+Ultralytics communicates openly with stakeholders about its EHS performance by sharing relevant information and addressing any concerns or expectations. This engagement includes regular reporting on EHS activities, performance metrics, and improvement initiatives. Stakeholders are also encouraged to provide feedback, which helps Ultralytics to refine its policies and practices continually. Learn more about this commitment in the [Communication principle](#policy-principles) section.
diff --git a/ultralytics/docs/en/help/index.md b/ultralytics/docs/en/help/index.md
new file mode 100644
index 0000000000000000000000000000000000000000..67242bedcf911f564657e3f8a872d3041cff4fd4
--- /dev/null
+++ b/ultralytics/docs/en/help/index.md
@@ -0,0 +1,49 @@
+---
+comments: true
+description: Explore the Ultralytics Help Center with guides, FAQs, CI processes, and policies to support your YOLO model experience and contributions.
+keywords: Ultralytics, YOLO, help center, documentation, guides, FAQ, contributing, CI, MRE, CLA, code of conduct, security policy, privacy policy
+---
+
+Welcome to the Ultralytics Help page! We are dedicated to providing you with detailed resources to enhance your experience with the Ultralytics YOLO models and repositories. This page serves as your portal to guides and documentation designed to assist you with various tasks and answer questions you may encounter while engaging with our repositories.
+
+- [Frequently Asked Questions (FAQ)](FAQ.md): Find answers to common questions and issues encountered by the community of Ultralytics YOLO users and contributors.
+- [Contributing Guide](contributing.md): Discover the protocols for making contributions, including how to submit pull requests, report bugs, and more.
+- [Continuous Integration (CI) Guide](CI.md): Gain insights into the CI processes we employ, complete with status reports for each Ultralytics repository.
+- [Contributor License Agreement (CLA)](CLA.md): Review the CLA to understand the rights and responsibilities associated with contributing to Ultralytics projects.
+- [Minimum Reproducible Example (MRE) Guide](minimum_reproducible_example.md): Learn the process for creating an MRE, which is crucial for the timely and effective resolution of bug reports.
+- [Code of Conduct](code_of_conduct.md): Our community guidelines support a respectful and open atmosphere for all collaborators.
+- [Environmental, Health and Safety (EHS) Policy](environmental-health-safety.md): Delve into our commitment to sustainability and the well-being of all our stakeholders.
+- [Security Policy](security.md): Familiarize yourself with our security protocols and the procedure for reporting vulnerabilities.
+- [Privacy Policy](privacy.md): Read our privacy policy to understand how we protect your data and respect your privacy in all our services and operations.
+
+We encourage you to review these resources for a seamless and productive experience. Our aim is to foster a helpful and friendly environment for everyone in the Ultralytics community. Should you require additional support, please feel free to reach out via GitHub Issues or our official discussion forums. Happy coding!
+
+## FAQ
+
+### What is Ultralytics YOLO and how does it benefit my machine learning projects?
+
+Ultralytics YOLO (You Only Look Once) is a state-of-the-art, real-time object detection model. Its latest version, YOLOv8, enhances speed, accuracy, and versatility, making it ideal for a wide range of applications, from real-time video analytics to advanced machine learning research. YOLO's efficiency in detecting objects in images and videos has made it the go-to solution for businesses and researchers looking to integrate robust computer vision capabilities into their projects.
+
+For more details on YOLOv8, visit the [YOLOv8 documentation](../tasks/detect.md).
+
+### How do I contribute to Ultralytics YOLO repositories?
+
+Contributing to Ultralytics YOLO repositories is straightforward. Start by reviewing the [Contributing Guide](../help/contributing.md) to understand the protocols for submitting pull requests, reporting bugs, and more. You'll also need to sign the [Contributor License Agreement (CLA)](../help/CLA.md) to ensure your contributions are legally recognized. For effective bug reporting, refer to the [Minimum Reproducible Example (MRE) Guide](../help/minimum_reproducible_example.md).
+
+### Why should I use Ultralytics HUB for my machine learning projects?
+
+Ultralytics HUB offers a seamless, no-code solution for managing your machine learning projects. It enables you to generate, train, and deploy AI models like YOLOv8 effortlessly. Unique features include cloud training, real-time tracking, and intuitive dataset management. Ultralytics HUB simplifies the entire workflow, from data processing to model deployment, making it an indispensable tool for both beginners and advanced users.
+
+To get started, visit [Ultralytics HUB Quickstart](../hub/quickstart.md).
+
+### What is Continuous Integration (CI) in Ultralytics, and how does it ensure high-quality code?
+
+Continuous Integration (CI) in Ultralytics involves automated processes that ensure the integrity and quality of the codebase. Our CI setup includes Docker deployment, broken link checks, CodeQL analysis, and PyPI publishing. These processes help maintain stable and secure repositories by automatically running tests and checks on new code submissions.
+
+Learn more in the [Continuous Integration (CI) Guide](../help/CI.md).
+
+### How is data privacy handled by Ultralytics?
+
+Ultralytics takes data privacy seriously. Our [Privacy Policy](../help/privacy.md) outlines how we collect and use anonymized data to improve the YOLO package while prioritizing user privacy and control. We adhere to strict data protection regulations to ensure your information is secure at all times.
+
+For more information, review our [Privacy Policy](../help/privacy.md).
diff --git a/ultralytics/docs/en/help/minimum_reproducible_example.md b/ultralytics/docs/en/help/minimum_reproducible_example.md
new file mode 100644
index 0000000000000000000000000000000000000000..693560be45894bf5bbe54543709a69c9d369f589
--- /dev/null
+++ b/ultralytics/docs/en/help/minimum_reproducible_example.md
@@ -0,0 +1,139 @@
+---
+comments: true
+description: Learn how to create effective Minimum Reproducible Examples (MRE) for bug reports in Ultralytics YOLO repositories. Follow our guide for efficient issue resolution.
+keywords: Ultralytics, YOLO, Minimum Reproducible Example, MRE, bug report, issue resolution, machine learning, deep learning
+---
+
+# Creating a Minimum Reproducible Example for Bug Reports in Ultralytics YOLO Repositories
+
+When submitting a bug report for [Ultralytics](https://ultralytics.com) [YOLO](https://github.com/ultralytics) repositories, it's essential to provide a [Minimum Reproducible Example (MRE)](https://stackoverflow.com/help/minimal-reproducible-example). An MRE is a small, self-contained piece of code that demonstrates the problem you're experiencing. Providing an MRE helps maintainers and contributors understand the issue and work on a fix more efficiently. This guide explains how to create an MRE when submitting bug reports to Ultralytics YOLO repositories.
+
+## 1. Isolate the Problem
+
+The first step in creating an MRE is to isolate the problem. Remove any unnecessary code or dependencies that are not directly related to the issue. Focus on the specific part of the code that is causing the problem and eliminate any irrelevant sections.
+
+## 2. Use Public Models and Datasets
+
+When creating an MRE, use publicly available models and datasets to reproduce the issue. For example, use the `yolov8n.pt` model and the `coco8.yaml` dataset. This ensures that the maintainers and contributors can easily run your example and investigate the problem without needing access to proprietary data or custom models.
+
+## 3. Include All Necessary Dependencies
+
+Ensure all necessary dependencies are included in your MRE. If your code relies on external libraries, specify the required packages and their versions. Ideally, list the dependencies in your bug report using `yolo checks` if you have `ultralytics` installed or `pip list` for other tools.
+
+## 4. Write a Clear Description of the Issue
+
+Provide a clear and concise description of the issue you're experiencing. Explain the expected behavior and the actual behavior you're encountering. If applicable, include any relevant error messages or logs.
+
+## 5. Format Your Code Properly
+
+Format your code properly using code blocks in the issue description. This makes it easier for others to read and understand your code. In GitHub, you can create a code block by wrapping your code with triple backticks (\```) and specifying the language:
+
+````bash
+```python
+# Your Python code goes here
+```
+````
+
+## 6. Test Your MRE
+
+Before submitting your MRE, test it to ensure that it accurately reproduces the issue. Make sure that others can run your example without any issues or modifications.
+
+## Example of an MRE
+
+Here's an example of an MRE for a hypothetical bug report:
+
+**Bug description:**
+
+When running inference on a 0-channel image, I get an error related to the dimensions of the input tensor.
+
+**MRE:**
+
+```python
+import torch
+
+from ultralytics import YOLO
+
+# Load the model
+model = YOLO("yolov8n.pt")
+
+# Load a 0-channel image
+image = torch.rand(1, 0, 640, 640)
+
+# Run the model
+results = model(image)
+```
+
+**Error message:**
+
+```
+RuntimeError: Expected input[1, 0, 640, 640] to have 3 channels, but got 0 channels instead
+```
+
+**Dependencies:**
+
+- `torch==2.3.0`
+- `ultralytics==8.2.0`
+
+In this example, the MRE demonstrates the issue with a minimal amount of code, uses a public model (`"yolov8n.pt"`), includes all necessary dependencies, and provides a clear description of the problem along with the error message.
+
+By following these guidelines, you'll help the maintainers and [contributors](https://github.com/ultralytics/ultralytics/graphs/contributors) of Ultralytics YOLO repositories to understand and resolve your issue more efficiently.
+
+## FAQ
+
+### How do I create an effective Minimum Reproducible Example (MRE) for bug reports in Ultralytics YOLO repositories?
+
+To create an effective Minimum Reproducible Example (MRE) for bug reports in Ultralytics YOLO repositories, follow these steps:
+
+1. **Isolate the Problem**: Remove any code or dependencies that are not directly related to the issue.
+2. **Use Public Models and Datasets**: Utilize public resources like `yolov8n.pt` and `coco8.yaml` for easier reproducibility.
+3. **Include All Necessary Dependencies**: Specify required packages and their versions. You can list dependencies using `yolo checks` if you have `ultralytics` installed or `pip list`.
+4. **Write a Clear Description of the Issue**: Explain the expected and actual behavior, including any error messages or logs.
+5. **Format Your Code Properly**: Use code blocks to format your code, making it easier to read.
+6. **Test Your MRE**: Ensure your MRE reproduces the issue without modifications.
+
+For a detailed guide, see [Creating a Minimum Reproducible Example](#creating-a-minimum-reproducible-example-for-bug-reports-in-ultralytics-yolo-repositories).
+
+### Why should I use publicly available models and datasets in my MRE for Ultralytics YOLO bug reports?
+
+Using publicly available models and datasets in your MRE ensures that maintainers can easily run your example without needing access to proprietary data. This allows for quicker and more efficient issue resolution. For instance, using the `yolov8n.pt` model and `coco8.yaml` dataset helps standardize and simplify the debugging process. Learn more about public models and datasets in the [Use Public Models and Datasets](#2-use-public-models-and-datasets) section.
+
+### What information should I include in my bug report for Ultralytics YOLO?
+
+A comprehensive bug report for Ultralytics YOLO should include:
+
+- **Clear Description**: Explain the issue, expected behavior, and actual behavior.
+- **Error Messages**: Include any relevant error messages or logs.
+- **Dependencies**: List required dependencies and their versions.
+- **MRE**: Provide a Minimum Reproducible Example.
+- **Steps to Reproduce**: Outline the steps needed to reproduce the issue.
+
+For a complete checklist, refer to the [Write a Clear Description of the Issue](#4-write-a-clear-description-of-the-issue) section.
+
+### How can I format my code properly when submitting a bug report on GitHub?
+
+To format your code properly when submitting a bug report on GitHub:
+
+- Use triple backticks (\```) to create code blocks.
+- Specify the programming language for syntax highlighting, e.g., \```python.
+- Ensure your code is indented correctly for readability.
+
+Example:
+
+````bash
+```python
+# Your Python code goes here
+```
+````
+
+For more tips on code formatting, see [Format Your Code Properly](#5-format-your-code-properly).
+
+### What are some common errors to check before submitting my MRE for a bug report?
+
+Before submitting your MRE, make sure to:
+
+- Verify the issue is reproducible.
+- Ensure all dependencies are listed and correct.
+- Remove any unnecessary code.
+- Test the MRE to ensure it reproduces the issue without modifications.
+
+For a detailed checklist, visit the [Test Your MRE](#6-test-your-mre) section.
diff --git a/ultralytics/docs/en/help/privacy.md b/ultralytics/docs/en/help/privacy.md
new file mode 100644
index 0000000000000000000000000000000000000000..b3a6b3210babd18a37999189d298f6c11a90e198
--- /dev/null
+++ b/ultralytics/docs/en/help/privacy.md
@@ -0,0 +1,216 @@
+---
+description: Discover how Ultralytics collects and uses anonymized data to enhance the YOLO Python package while prioritizing user privacy and control.
+keywords: Ultralytics, data collection, YOLO, Python package, Google Analytics, Sentry, privacy, anonymized data, user control, crash reporting
+---
+
+# Data Collection for Ultralytics Python Package
+
+## Overview
+
+[Ultralytics](https://ultralytics.com) is dedicated to the continuous enhancement of the user experience and the capabilities of our Python package, including the advanced YOLO models we develop. Our approach involves the gathering of anonymized usage statistics and crash reports, helping us identify opportunities for improvement and ensuring the reliability of our software. This transparency document outlines what data we collect, its purpose, and the choice you have regarding this data collection.
+
+## Anonymized Google Analytics
+
+[Google Analytics](https://developers.google.com/analytics) is a web analytics service offered by Google that tracks and reports website traffic. It allows us to collect data about how our Python package is used, which is crucial for making informed decisions about design and functionality.
+
+### What We Collect
+
+- **Usage Metrics**: These metrics help us understand how frequently and in what ways the package is utilized, what features are favored, and the typical command-line arguments that are used.
+- **System Information**: We collect general non-identifiable information about your computing environment to ensure our package performs well across various systems.
+- **Performance Data**: Understanding the performance of our models during training, validation, and inference helps us in identifying optimization opportunities.
+
+For more information about Google Analytics and data privacy, visit [Google Analytics Privacy](https://support.google.com/analytics/answer/6004245).
+
+### How We Use This Data
+
+- **Feature Improvement**: Insights from usage metrics guide us in enhancing user satisfaction and interface design.
+- **Optimization**: Performance data assist us in fine-tuning our models for better efficiency and speed across diverse hardware and software configurations.
+- **Trend Analysis**: By studying usage trends, we can predict and respond to the evolving needs of our community.
+
+### Privacy Considerations
+
+We take several measures to ensure the privacy and security of the data you entrust to us:
+
+- **Anonymization**: We configure Google Analytics to anonymize the data collected, which means no personally identifiable information (PII) is gathered. You can use our services with the assurance that your personal details remain private.
+- **Aggregation**: Data is analyzed only in aggregate form. This practice ensures that patterns can be observed without revealing any individual user's activity.
+- **No Image Data Collection**: Ultralytics does not collect, process, or view any training or inference images.
+
+## Sentry Crash Reporting
+
+[Sentry](https://sentry.io/) is a developer-centric error tracking software that aids in identifying, diagnosing, and resolving issues in real-time, ensuring the robustness and reliability of applications. Within our package, it plays a crucial role by providing insights through crash reporting, significantly contributing to the stability and ongoing refinement of our software.
+
+!!! Note
+
+ Crash reporting via Sentry is activated only if the `sentry-sdk` Python package is pre-installed on your system. This package isn't included in the `ultralytics` prerequisites and won't be installed automatically by Ultralytics.
+
+### What We Collect
+
+If the `sentry-sdk` Python package is pre-installed on your system a crash event may send the following information:
+
+- **Crash Logs**: Detailed reports on the application's condition at the time of a crash, which are vital for our debugging efforts.
+- **Error Messages**: We record error messages generated during the operation of our package to understand and resolve potential issues quickly.
+
+To learn more about how Sentry handles data, please visit [Sentry's Privacy Policy](https://sentry.io/privacy/).
+
+### How We Use This Data
+
+- **Debugging**: Analyzing crash logs and error messages enables us to swiftly identify and correct software bugs.
+- **Stability Metrics**: By constantly monitoring for crashes, we aim to improve the stability and reliability of our package.
+
+### Privacy Considerations
+
+- **Sensitive Information**: We ensure that crash logs are scrubbed of any personally identifiable or sensitive user data, safeguarding the confidentiality of your information.
+- **Controlled Collection**: Our crash reporting mechanism is meticulously calibrated to gather only what is essential for troubleshooting while respecting user privacy.
+
+By detailing the tools used for data collection and offering additional background information with URLs to their respective privacy pages, users are provided with a comprehensive view of our practices, emphasizing transparency and respect for user privacy.
+
+## Disabling Data Collection
+
+We believe in providing our users with full control over their data. By default, our package is configured to collect analytics and crash reports to help improve the experience for all users. However, we respect that some users may prefer to opt out of this data collection.
+
+To opt out of sending analytics and crash reports, you can simply set `sync=False` in your YOLO settings. This ensures that no data is transmitted from your machine to our analytics tools.
+
+### Inspecting Settings
+
+To gain insight into the current configuration of your settings, you can view them directly:
+
+!!! Example "View settings"
+
+ === "Python"
+
+ You can use Python to view your settings. Start by importing the `settings` object from the `ultralytics` module. Print and return settings using the following commands:
+ ```python
+ from ultralytics import settings
+
+ # View all settings
+ print(settings)
+
+ # Return analytics and crash reporting setting
+ value = settings["sync"]
+ ```
+
+ === "CLI"
+
+ Alternatively, the command-line interface allows you to check your settings with a simple command:
+ ```bash
+ yolo settings
+ ```
+
+### Modifying Settings
+
+Ultralytics allows users to easily modify their settings. Changes can be performed in the following ways:
+
+!!! Example "Update settings"
+
+ === "Python"
+
+ Within the Python environment, call the `update` method on the `settings` object to change your settings:
+ ```python
+ from ultralytics import settings
+
+ # Disable analytics and crash reporting
+ settings.update({"sync": False})
+
+ # Reset settings to default values
+ settings.reset()
+ ```
+
+ === "CLI"
+
+ If you prefer using the command-line interface, the following commands will allow you to modify your settings:
+ ```bash
+ # Disable analytics and crash reporting
+ yolo settings sync=False
+
+ # Reset settings to default values
+ yolo settings reset
+ ```
+
+The `sync=False` setting will prevent any data from being sent to Google Analytics or Sentry. Your settings will be respected across all sessions using the Ultralytics package and saved to disk for future sessions.
+
+## Commitment to Privacy
+
+Ultralytics takes user privacy seriously. We design our data collection practices with the following principles:
+
+- **Transparency**: We are open about the data we collect and how it is used.
+- **Control**: We give users full control over their data.
+- **Security**: We employ industry-standard security measures to protect the data we collect.
+
+## Questions or Concerns
+
+If you have any questions or concerns about our data collection practices, please reach out to us via our [contact form](https://ultralytics.com/contact) or via [support@ultralytics.com](mailto:support@ultralytics.com). We are dedicated to ensuring our users feel informed and confident in their privacy when using our package.
+
+## FAQ
+
+### How does Ultralytics ensure the privacy of the data it collects?
+
+Ultralytics prioritizes user privacy through several key measures. First, all data collected via Google Analytics and Sentry is anonymized to ensure that no personally identifiable information (PII) is gathered. Secondly, data is analyzed in aggregate form, allowing us to observe patterns without identifying individual user activities. Finally, we do not collect any training or inference images, further protecting user data. These measures align with our commitment to transparency and privacy. For more details, visit our [Privacy Considerations](#privacy-considerations) section.
+
+### What types of data does Ultralytics collect with Google Analytics?
+
+Ultralytics collects three primary types of data using Google Analytics:
+
+- **Usage Metrics**: These include how often and in what ways the YOLO Python package is used, preferred features, and typical command-line arguments.
+- **System Information**: General non-identifiable information about the computing environments where the package is run.
+- **Performance Data**: Metrics related to the performance of models during training, validation, and inference.
+ This data helps us enhance user experience and optimize software performance. Learn more in the [Anonymized Google Analytics](#anonymized-google-analytics) section.
+
+### How can I disable data collection in the Ultralytics YOLO package?
+
+To opt out of data collection, you can simply set `sync=False` in your YOLO settings. This action stops the transmission of any analytics or crash reports. You can disable data collection using Python or CLI methods:
+
+!!! Example "Update settings"
+
+ === "Python"
+
+ ```python
+ from ultralytics import settings
+
+ # Disable analytics and crash reporting
+ settings.update({"sync": False})
+
+ # Reset settings to default values
+ settings.reset()
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Disable analytics and crash reporting
+ yolo settings sync=False
+
+ # Reset settings to default values
+ yolo settings reset
+ ```
+
+For more details on modifying your settings, refer to the [Modifying Settings](#modifying-settings) section.
+
+### How does crash reporting with Sentry work in Ultralytics YOLO?
+
+If the `sentry-sdk` package is pre-installed, Sentry collects detailed crash logs and error messages whenever a crash event occurs. This data helps us diagnose and resolve issues promptly, improving the robustness and reliability of the YOLO Python package. The collected crash logs are scrubbed of any personally identifiable information to protect user privacy. For more information, check the [Sentry Crash Reporting](#sentry-crash-reporting) section.
+
+### Can I inspect my current data collection settings in Ultralytics YOLO?
+
+Yes, you can easily view your current settings to understand the configuration of your data collection preferences. Use the following methods to inspect these settings:
+
+!!! Example "View settings"
+
+ === "Python"
+
+ ```python
+ from ultralytics import settings
+
+ # View all settings
+ print(settings)
+
+ # Return analytics and crash reporting setting
+ value = settings["sync"]
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo settings
+ ```
+
+For further details, refer to the [Inspecting Settings](#inspecting-settings) section.
diff --git a/ultralytics/docs/en/help/security.md b/ultralytics/docs/en/help/security.md
new file mode 100644
index 0000000000000000000000000000000000000000..517fedbc4b7c89ece6d8b39f5891ed91afbd6ffa
--- /dev/null
+++ b/ultralytics/docs/en/help/security.md
@@ -0,0 +1,74 @@
+---
+description: Learn about the security measures and tools used by Ultralytics to protect user data and systems. Discover how we address vulnerabilities with Snyk, CodeQL, Dependabot, and more.
+keywords: Ultralytics security policy, Snyk scanning, CodeQL scanning, Dependabot alerts, secret scanning, vulnerability reporting, GitHub security, open-source security
+---
+
+# Ultralytics Security Policy
+
+At [Ultralytics](https://ultralytics.com), the security of our users' data and systems is of utmost importance. To ensure the safety and security of our [open-source projects](https://github.com/ultralytics), we have implemented several measures to detect and prevent security vulnerabilities.
+
+## Snyk Scanning
+
+We utilize [Snyk](https://snyk.io/advisor/python/ultralytics) to conduct comprehensive security scans on Ultralytics repositories. Snyk's robust scanning capabilities extend beyond dependency checks; it also examines our code and Dockerfiles for various vulnerabilities. By identifying and addressing these issues proactively, we ensure a higher level of security and reliability for our users.
+
+[](https://snyk.io/advisor/python/ultralytics)
+
+## GitHub CodeQL Scanning
+
+Our security strategy includes GitHub's [CodeQL](https://docs.github.com/en/code-security/code-scanning/automatically-scanning-your-code-for-vulnerabilities-and-errors/about-code-scanning-with-codeql) scanning. CodeQL delves deep into our codebase, identifying complex vulnerabilities like SQL injection and XSS by analyzing the code's semantic structure. This advanced level of analysis ensures early detection and resolution of potential security risks.
+
+[](https://github.com/ultralytics/ultralytics/actions/workflows/codeql.yaml)
+
+## GitHub Dependabot Alerts
+
+[Dependabot](https://docs.github.com/en/code-security/dependabot) is integrated into our workflow to monitor dependencies for known vulnerabilities. When a vulnerability is identified in one of our dependencies, Dependabot alerts us, allowing for swift and informed remediation actions.
+
+## GitHub Secret Scanning Alerts
+
+We employ GitHub [secret scanning](https://docs.github.com/en/code-security/secret-scanning/managing-alerts-from-secret-scanning) alerts to detect sensitive data, such as credentials and private keys, accidentally pushed to our repositories. This early detection mechanism helps prevent potential security breaches and data exposures.
+
+## Private Vulnerability Reporting
+
+We enable private vulnerability reporting, allowing users to discreetly report potential security issues. This approach facilitates responsible disclosure, ensuring vulnerabilities are handled securely and efficiently.
+
+If you suspect or discover a security vulnerability in any of our repositories, please let us know immediately. You can reach out to us directly via our [contact form](https://ultralytics.com/contact) or via [security@ultralytics.com](mailto:security@ultralytics.com). Our security team will investigate and respond as soon as possible.
+
+We appreciate your help in keeping all Ultralytics open-source projects secure and safe for everyone 🙏.
+
+## FAQ
+
+### What are the security measures implemented by Ultralytics to protect user data?
+
+Ultralytics employs a comprehensive security strategy to protect user data and systems. Key measures include:
+
+- **Snyk Scanning**: Conducts security scans to detect vulnerabilities in code and Dockerfiles.
+- **GitHub CodeQL**: Analyzes code semantics to detect complex vulnerabilities such as SQL injection.
+- **Dependabot Alerts**: Monitors dependencies for known vulnerabilities and sends alerts for swift remediation.
+- **Secret Scanning**: Detects sensitive data like credentials or private keys in code repositories to prevent data breaches.
+- **Private Vulnerability Reporting**: Offers a secure channel for users to report potential security issues discreetly.
+
+These tools ensure proactive identification and resolution of security issues, enhancing overall system security. For more details, visit our [export documentation](../modes/export.md).
+
+### How does Ultralytics use Snyk for security scanning?
+
+Ultralytics utilizes [Snyk](https://snyk.io/advisor/python/ultralytics) to conduct thorough security scans on its repositories. Snyk extends beyond basic dependency checks, examining the code and Dockerfiles for various vulnerabilities. By proactively identifying and resolving potential security issues, Snyk helps ensure that Ultralytics' open-source projects remain secure and reliable.
+
+To see the Snyk badge and learn more about its deployment, check the [Snyk Scanning section](#snyk-scanning).
+
+### What is CodeQL and how does it enhance security for Ultralytics?
+
+[CodeQL](https://docs.github.com/en/code-security/code-scanning/automatically-scanning-your-code-for-vulnerabilities-and-errors/about-code-scanning-with-codeql) is a security analysis tool integrated into Ultralytics' workflow via GitHub. It delves deep into the codebase to identify complex vulnerabilities such as SQL injection and Cross-Site Scripting (XSS). CodeQL analyzes the semantic structure of the code to provide an advanced level of security, ensuring early detection and mitigation of potential risks.
+
+For more information on how CodeQL is used, visit the [GitHub CodeQL Scanning section](#github-codeql-scanning).
+
+### How does Dependabot help maintain Ultralytics' code security?
+
+[Dependabot](https://docs.github.com/en/code-security/dependabot) is an automated tool that monitors and manages dependencies for known vulnerabilities. When Dependabot detects a vulnerability in an Ultralytics project dependency, it sends an alert, allowing the team to quickly address and mitigate the issue. This ensures that dependencies are kept secure and up-to-date, minimizing potential security risks.
+
+For more details, explore the [GitHub Dependabot Alerts section](#github-dependabot-alerts).
+
+### How does Ultralytics handle private vulnerability reporting?
+
+Ultralytics encourages users to report potential security issues through private channels. Users can report vulnerabilities discreetly via the [contact form](https://ultralytics.com/contact) or by emailing [security@ultralytics.com](mailto:security@ultralytics.com). This ensures responsible disclosure and allows the security team to investigate and address vulnerabilities securely and efficiently.
+
+For more information on private vulnerability reporting, refer to the [Private Vulnerability Reporting section](#private-vulnerability-reporting).
diff --git a/ultralytics/docs/en/hub/api/index.md b/ultralytics/docs/en/hub/api/index.md
new file mode 100644
index 0000000000000000000000000000000000000000..aaead37950fd3dbbcfc976f41f45faa7c7a52b70
--- /dev/null
+++ b/ultralytics/docs/en/hub/api/index.md
@@ -0,0 +1,34 @@
+---
+description: Discover what's next for Ultralytics with our under-construction page, previewing new, groundbreaking AI and ML features coming soon.
+keywords: Ultralytics, coming soon, under construction, new features, AI updates, ML advancements, YOLO, technology preview
+---
+
+# Under Construction 🏗️🌟
+
+Welcome to the Ultralytics "Under Construction" page! Here, we're hard at work developing the next generation of AI and ML innovations. This page serves as a teaser for the exciting updates and new features we're eager to share with you!
+
+## Exciting New Features on the Way 🎉
+
+- **Innovative Breakthroughs:** Get ready for advanced features and services that will transform your AI and ML experience.
+- **New Horizons:** Anticipate novel products that redefine AI and ML capabilities.
+- **Enhanced Services:** We're upgrading our services for greater efficiency and user-friendliness.
+
+## Stay Updated 🚧
+
+This placeholder page is your first stop for upcoming developments. Keep an eye out for:
+
+- **Newsletter:** Subscribe [here](https://ultralytics.com/#newsletter) for the latest news.
+- **Social Media:** Follow us [here](https://www.linkedin.com/company/ultralytics) for updates and teasers.
+- **Blog:** Visit our [blog](https://ultralytics.com/blog) for detailed insights.
+
+## We Value Your Input 🗣️
+
+Your feedback shapes our future releases. Share your thoughts and suggestions [here](https://ultralytics.com/contact).
+
+## Thank You, Community! 🌍
+
+Your [contributions](../../help/contributing.md) inspire our continuous [innovation](https://github.com/ultralytics/ultralytics). Stay tuned for the big reveal of what's next in AI and ML at Ultralytics!
+
+---
+
+Excited for what's coming? Bookmark this page and get ready for a transformative AI and ML journey with Ultralytics! 🛠️🤖
diff --git a/ultralytics/docs/en/hub/app/android.md b/ultralytics/docs/en/hub/app/android.md
new file mode 100644
index 0000000000000000000000000000000000000000..89517929e0f403c0d42f8484f50053b676797030
--- /dev/null
+++ b/ultralytics/docs/en/hub/app/android.md
@@ -0,0 +1,100 @@
+---
+comments: true
+description: Experience real-time object detection on Android with Ultralytics. Leverage YOLO models for efficient and fast object identification. Download now!.
+keywords: Ultralytics, Android app, real-time object detection, YOLO models, TensorFlow Lite, FP16 quantization, INT8 quantization, hardware delegates, mobile AI, download app
+---
+
+# Ultralytics Android App: Real-time Object Detection with YOLO Models
+
+
+
+
+
+
+The Ultralytics Android App is a powerful tool that allows you to run YOLO models directly on your Android device for real-time object detection. This app utilizes TensorFlow Lite for model optimization and various hardware delegates for acceleration, enabling fast and efficient object detection.
+
+
+
+
+
+ Watch: Getting Started with the Ultralytics HUB App (IOS & Android)
+
+
+## Quantization and Acceleration
+
+To achieve real-time performance on your Android device, YOLO models are quantized to either FP16 or INT8 precision. Quantization is a process that reduces the numerical precision of the model's weights and biases, thus reducing the model's size and the amount of computation required. This results in faster inference times without significantly affecting the model's accuracy.
+
+### FP16 Quantization
+
+FP16 (or half-precision) quantization converts the model's 32-bit floating-point numbers to 16-bit floating-point numbers. This reduces the model's size by half and speeds up the inference process, while maintaining a good balance between accuracy and performance.
+
+### INT8 Quantization
+
+INT8 (or 8-bit integer) quantization further reduces the model's size and computation requirements by converting its 32-bit floating-point numbers to 8-bit integers. This quantization method can result in a significant speedup, but it may lead to a slight reduction in mean average precision (mAP) due to the lower numerical precision.
+
+!!! Tip "mAP Reduction in INT8 Models"
+
+ The reduced numerical precision in INT8 models can lead to some loss of information during the quantization process, which may result in a slight decrease in mAP. However, this trade-off is often acceptable considering the substantial performance gains offered by INT8 quantization.
+
+## Delegates and Performance Variability
+
+Different delegates are available on Android devices to accelerate model inference. These delegates include CPU, [GPU](https://www.tensorflow.org/lite/android/delegates/gpu), [Hexagon](https://www.tensorflow.org/lite/android/delegates/hexagon) and [NNAPI](https://www.tensorflow.org/lite/android/delegates/nnapi). The performance of these delegates varies depending on the device's hardware vendor, product line, and specific chipsets used in the device.
+
+1. **CPU**: The default option, with reasonable performance on most devices.
+2. **GPU**: Utilizes the device's GPU for faster inference. It can provide a significant performance boost on devices with powerful GPUs.
+3. **Hexagon**: Leverages Qualcomm's Hexagon DSP for faster and more efficient processing. This option is available on devices with Qualcomm Snapdragon processors.
+4. **NNAPI**: The Android Neural Networks API (NNAPI) serves as an abstraction layer for running ML models on Android devices. NNAPI can utilize various hardware accelerators, such as CPU, GPU, and dedicated AI chips (e.g., Google's Edge TPU, or the Pixel Neural Core).
+
+Here's a table showing the primary vendors, their product lines, popular devices, and supported delegates:
+
+| Vendor | Product Lines | Popular Devices | Delegates Supported |
+| --------------------------------------- | ------------------------------------------------------------------------------------ | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | ------------------------ |
+| [Qualcomm](https://www.qualcomm.com/) | [Snapdragon (e.g., 800 series)](https://www.qualcomm.com/snapdragon) | [Samsung Galaxy S21](https://www.samsung.com/global/galaxy/galaxy-s21-5g/), [OnePlus 9](https://www.oneplus.com/9), [Google Pixel 6](https://store.google.com/product/pixel_6) | CPU, GPU, Hexagon, NNAPI |
+| [Samsung](https://www.samsung.com/) | [Exynos (e.g., Exynos 2100)](https://www.samsung.com/semiconductor/minisite/exynos/) | [Samsung Galaxy S21 (Global version)](https://www.samsung.com/global/galaxy/galaxy-s21-5g/) | CPU, GPU, NNAPI |
+| [MediaTek](https://i.mediatek.com/) | [Dimensity (e.g., Dimensity 1200)](https://i.mediatek.com/dimensity-1200) | [Realme GT](https://www.realme.com/global/realme-gt), [Xiaomi Redmi Note](https://www.mi.com/en/phone/redmi/note-list) | CPU, GPU, NNAPI |
+| [HiSilicon](https://www.hisilicon.com/) | [Kirin (e.g., Kirin 990)](https://www.hisilicon.com/en/products/Kirin) | [Huawei P40 Pro](https://consumer.huawei.com/en/phones/p40-pro/), [Huawei Mate 30 Pro](https://consumer.huawei.com/en/phones/mate30-pro/) | CPU, GPU, NNAPI |
+| [NVIDIA](https://www.nvidia.com/) | [Tegra (e.g., Tegra X1)](https://developer.nvidia.com/content/tegra-x1) | [NVIDIA Shield TV](https://www.nvidia.com/en-us/shield/shield-tv/), [Nintendo Switch](https://www.nintendo.com/switch/) | CPU, GPU, NNAPI |
+
+Please note that the list of devices mentioned is not exhaustive and may vary depending on the specific chipsets and device models. Always test your models on your target devices to ensure compatibility and optimal performance.
+
+Keep in mind that the choice of delegate can affect performance and model compatibility. For example, some models may not work with certain delegates, or a delegate may not be available on a specific device. As such, it's essential to test your model and the chosen delegate on your target devices for the best results.
+
+## Getting Started with the Ultralytics Android App
+
+To get started with the Ultralytics Android App, follow these steps:
+
+1. Download the Ultralytics App from the [Google Play Store](https://play.google.com/store/apps/details?id=com.ultralytics.ultralytics_app).
+
+2. Launch the app on your Android device and sign in with your Ultralytics account. If you don't have an account yet, create one [here](https://hub.ultralytics.com/).
+
+3. Once signed in, you will see a list of your trained YOLO models. Select a model to use for object detection.
+
+4. Grant the app permission to access your device's camera.
+
+5. Point your device's camera at objects you want to detect. The app will display bounding boxes and class labels in real-time as it detects objects.
+
+6. Explore the app's settings to adjust the detection threshold, enable or disable specific object classes, and more.
+
+With the Ultralytics Android App, you now have the power of real-time object detection using YOLO models right at your fingertips. Enjoy exploring the app's features and optimizing its settings to suit your specific use cases.
diff --git a/ultralytics/docs/en/hub/app/index.md b/ultralytics/docs/en/hub/app/index.md
new file mode 100644
index 0000000000000000000000000000000000000000..35fd7aa4c7664d1c15a6b8c24ed8fc140bf3d506
--- /dev/null
+++ b/ultralytics/docs/en/hub/app/index.md
@@ -0,0 +1,48 @@
+---
+comments: true
+description: Discover the Ultralytics HUB App for running YOLOv5 and YOLOv8 models on iOS and Android devices with hardware acceleration.
+keywords: Ultralytics HUB, YOLO models, mobile app, iOS, Android, hardware acceleration, YOLOv5, YOLOv8, neural engine, GPU, NNAPI
+---
+
+# Ultralytics HUB App
+
+
+
+
+
+
+Welcome to the Ultralytics HUB App! We are excited to introduce this powerful mobile app that allows you to run YOLOv5 and YOLOv8 models directly on your [iOS](https://apps.apple.com/xk/app/ultralytics/id1583935240) and [Android](https://play.google.com/store/apps/details?id=com.ultralytics.ultralytics_app) devices. With the HUB App, you can utilize hardware acceleration features like Apple's Neural Engine (ANE) or Android GPU and Neural Network API (NNAPI) delegates to achieve impressive performance on your mobile device.
+
+## Features
+
+- **Run YOLOv5 and YOLOv8 models**: Experience the power of YOLO models on your mobile device for real-time object detection and image recognition tasks.
+- **Hardware Acceleration**: Benefit from Apple ANE on iOS devices or Android GPU and NNAPI delegates for optimized performance.
+- **Custom Model Training**: Train custom models with the Ultralytics HUB platform and preview them live using the HUB App.
+- **Mobile Compatibility**: The HUB App supports both iOS and Android devices, bringing the power of YOLO models to a wide range of users.
+
+## App Documentation
+
+- [**iOS**](ios.md): Learn about YOLO CoreML models accelerated on Apple's Neural Engine for iPhones and iPads.
+- [**Android**](android.md): Explore TFLite acceleration on Android mobile devices.
+
+Get started today by downloading the Ultralytics HUB App on your mobile device and unlock the potential of YOLOv5 and YOLOv8 models on-the-go. Don't forget to check out our comprehensive [HUB Docs](../index.md) for more information on training, deploying, and using your custom models with the Ultralytics HUB platform.
diff --git a/ultralytics/docs/en/hub/app/ios.md b/ultralytics/docs/en/hub/app/ios.md
new file mode 100644
index 0000000000000000000000000000000000000000..c4af56f1d4821d5168b1f4207bb10683bc6e0801
--- /dev/null
+++ b/ultralytics/docs/en/hub/app/ios.md
@@ -0,0 +1,90 @@
+---
+comments: true
+description: Discover the Ultralytics iOS App for running YOLO models on your iPhone or iPad. Achieve fast, real-time object detection with Apple Neural Engine.
+keywords: Ultralytics, iOS App, YOLO models, real-time object detection, Apple Neural Engine, Core ML, FP16 quantization, INT8 quantization, machine learning
+---
+
+# Ultralytics iOS App: Real-time Object Detection with YOLO Models
+
+
+
+
+
+
+The Ultralytics iOS App is a powerful tool that allows you to run YOLO models directly on your iPhone or iPad for real-time object detection. This app utilizes the Apple Neural Engine and Core ML for model optimization and acceleration, enabling fast and efficient object detection.
+
+
+
+
+
+ Watch: Getting Started with the Ultralytics HUB App (IOS & Android)
+
+
+## Quantization and Acceleration
+
+To achieve real-time performance on your iOS device, YOLO models are quantized to either FP16 or INT8 precision. Quantization is a process that reduces the numerical precision of the model's weights and biases, thus reducing the model's size and the amount of computation required. This results in faster inference times without significantly affecting the model's accuracy.
+
+### FP16 Quantization
+
+FP16 (or half-precision) quantization converts the model's 32-bit floating-point numbers to 16-bit floating-point numbers. This reduces the model's size by half and speeds up the inference process, while maintaining a good balance between accuracy and performance.
+
+### INT8 Quantization
+
+INT8 (or 8-bit integer) quantization further reduces the model's size and computation requirements by converting its 32-bit floating-point numbers to 8-bit integers. This quantization method can result in a significant speedup, but it may lead to a slight reduction in accuracy.
+
+## Apple Neural Engine
+
+The Apple Neural Engine (ANE) is a dedicated hardware component integrated into Apple's A-series and M-series chips. It's designed to accelerate machine learning tasks, particularly for neural networks, allowing for faster and more efficient execution of your YOLO models.
+
+By combining quantized YOLO models with the Apple Neural Engine, the Ultralytics iOS App achieves real-time object detection on your iOS device without compromising on accuracy or performance.
+
+| Release Year | iPhone Name | Chipset Name | Node Size | ANE TOPs |
+| ------------ | ---------------------------------------------------- | ----------------------------------------------------- | --------- | -------- |
+| 2017 | [iPhone X](https://en.wikipedia.org/wiki/IPhone_X) | [A11 Bionic](https://en.wikipedia.org/wiki/Apple_A11) | 10 nm | 0.6 |
+| 2018 | [iPhone XS](https://en.wikipedia.org/wiki/IPhone_XS) | [A12 Bionic](https://en.wikipedia.org/wiki/Apple_A12) | 7 nm | 5 |
+| 2019 | [iPhone 11](https://en.wikipedia.org/wiki/IPhone_11) | [A13 Bionic](https://en.wikipedia.org/wiki/Apple_A13) | 7 nm | 6 |
+| 2020 | [iPhone 12](https://en.wikipedia.org/wiki/IPhone_12) | [A14 Bionic](https://en.wikipedia.org/wiki/Apple_A14) | 5 nm | 11 |
+| 2021 | [iPhone 13](https://en.wikipedia.org/wiki/IPhone_13) | [A15 Bionic](https://en.wikipedia.org/wiki/Apple_A15) | 5 nm | 15.8 |
+| 2022 | [iPhone 14](https://en.wikipedia.org/wiki/IPhone_14) | [A16 Bionic](https://en.wikipedia.org/wiki/Apple_A16) | 4 nm | 17.0 |
+
+Please note that this list only includes iPhone models from 2017 onwards, and the ANE TOPs values are approximate.
+
+## Getting Started with the Ultralytics iOS App
+
+To get started with the Ultralytics iOS App, follow these steps:
+
+1. Download the Ultralytics App from the [App Store](https://apps.apple.com/xk/app/ultralytics/id1583935240).
+
+2. Launch the app on your iOS device and sign in with your Ultralytics account. If you don't have an account yet, create one [here](https://hub.ultralytics.com/).
+
+3. Once signed in, you will see a list of your trained YOLO models. Select a model to use for object detection.
+
+4. Grant the app permission to access your device's camera.
+
+5. Point your device's camera at objects you want to detect. The app will display bounding boxes and class labels in real-time as it detects objects.
+
+6. Explore the app's settings to adjust the detection threshold, enable or disable specific object classes, and more.
+
+With the Ultralytics iOS App, you can now leverage the power of YOLO models for real-time object detection on your iPhone or iPad, powered by the Apple Neural Engine and optimized with FP16 or INT8 quantization.
diff --git a/ultralytics/docs/en/hub/cloud-training.md b/ultralytics/docs/en/hub/cloud-training.md
new file mode 100644
index 0000000000000000000000000000000000000000..6110cbb3c497ec94fb0932fd01a7492671d9e7d9
--- /dev/null
+++ b/ultralytics/docs/en/hub/cloud-training.md
@@ -0,0 +1,103 @@
+---
+comments: true
+description: Discover Ultralytics HUB Cloud Training for easy model training. Upgrade to Pro and start training with a single click. Streamline your workflow now!.
+keywords: Ultralytics HUB, cloud training, model training, Pro Plan, easy AI setup
+---
+
+# Ultralytics HUB Cloud Training
+
+We've listened to the high demand and widespread interest and are thrilled to unveil [Ultralytics HUB](https://ultralytics.com/hub) Cloud Training, offering a single-click training experience for our [Pro](./pro.md) users!
+
+[Ultralytics HUB](https://ultralytics.com/hub) [Pro](./pro.md) users can finetune [Ultralytics HUB](https://ultralytics.com/hub) models on a custom dataset using our Cloud Training solution, making the model training process easy. Say goodbye to complex setups and hello to streamlined workflows with [Ultralytics HUB](https://ultralytics.com/hub)'s intuitive interface.
+
+
+
+
+ Watch: New Feature 🌟 Introducing Ultralytics HUB Cloud Training
+
+
+## Train Model
+
+In order to train models using Ultralytics Cloud Training, you need to [upgrade](./pro.md#upgrade) to the [Pro Plan](./pro.md).
+
+Follow the [Train Model](./models.md#train-model) instructions from the [Models](./models.md) page until you reach the third step ([Train](./models.md#3-train)) of the **Train Model** dialog. Once you are on this step, simply select the training duration (Epochs or Timed), the training instance, the payment method, and click the **Start Training** button. That's it!
+
+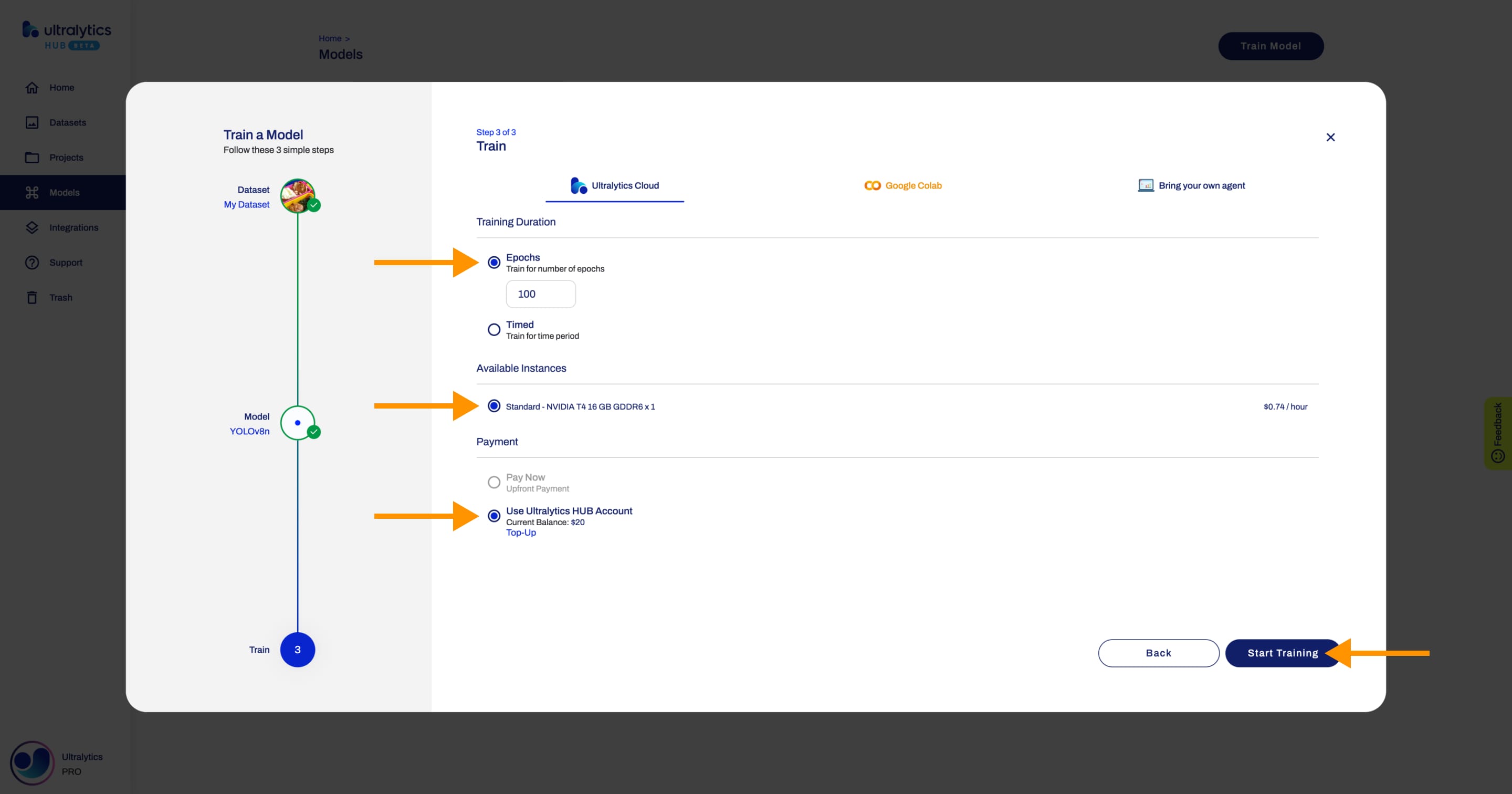
+
+??? note "Note"
+
+ When you are on this step, you have the option to close the **Train Model** dialog and start training your model from the Model page later.
+
+ 
+
+Most of the times, you will use the Epochs training. The number of epochs can be adjusted on this step (if the training didn't start yet) and represents the number of times your dataset needs to go through the cycle of train, label, and test. The exact pricing based on the number of epochs is hard to determine, reason why we only allow the [Account Balance](./pro.md#account-balance) payment method.
+
+!!! note "Note"
+
+ When using the Epochs training, your [account balance](./pro.md#account-balance) needs to be at least US$5.00 to start training. In case you have a low balance, you can top-up directly from this step.
+
+ 
+
+!!! note "Note"
+
+ When using the Epochs training, the [account balance](./pro.md#account-balance) is deducted after every epoch.
+
+ Also, after every epoch, we check if you have enough [account balance](./pro.md#account-balance) for the next epoch. In case you don't have enough [account balance](./pro.md#account-balance) for the next epoch, we will stop the training session, allowing you to resume training your model from the last checkpoint saved.
+
+ 
+
+Alternatively, you can use the Timed training. This option allows you to set the training duration. In this case, we can determine the exact pricing. You can pay upfront or using your [account balance](./pro.md#account-balance).
+
+If you have enough [account balance](./pro.md#account-balance), you can use the [Account Balance](./pro.md#account-balance) payment method.
+
+
+
+If you don't have enough [account balance](./pro.md#account-balance), you won't be able to use the [Account Balance](./pro.md#account-balance) payment method. You can pay upfront or top-up directly from this step.
+
+
+
+Before the training session starts, the initialization process spins up a dedicated instance equipped with GPU resources, which can sometimes take a while depending on the current demand and availability of GPU resources.
+
+
+
+!!! note "Note"
+
+ The account balance is not deducted during the initialization process (before the training session starts).
+
+After the training session starts, you can monitor each step of the progress.
+
+If needed, you can stop the training by clicking on the **Stop Training** button.
+
+
+
+!!! note "Note"
+
+ You can resume training your model from the last checkpoint saved.
+
+ 
+
+
+
+
+ Watch: Pause and Resume Model Training Using Ultralytics HUB
+
+
+!!! note "Note"
+
+ Unfortunately, at the moment, you can only train one model at a time using Ultralytics Cloud.
+
+ 
+
+## Billing
+
+During training or after training, you can check the cost of your model by clicking on the **Billing** tab. Furthermore, you can download the cost report by clicking on the **Download** button.
+
+
diff --git a/ultralytics/docs/en/hub/datasets.md b/ultralytics/docs/en/hub/datasets.md
new file mode 100644
index 0000000000000000000000000000000000000000..3b310a614a8da58158fd8d76237b8911fde1d368
--- /dev/null
+++ b/ultralytics/docs/en/hub/datasets.md
@@ -0,0 +1,179 @@
+---
+comments: true
+description: Effortlessly manage, upload, and share your custom datasets on Ultralytics HUB for seamless model training integration. Simplify your workflow today!.
+keywords: Ultralytics HUB, datasets, custom datasets, dataset management, model training, upload datasets, share datasets, dataset workflow
+---
+
+# Ultralytics HUB Datasets
+
+[Ultralytics HUB](https://ultralytics.com/hub) datasets are a practical solution for managing and leveraging your custom datasets.
+
+Once uploaded, datasets can be immediately utilized for model training. This integrated approach facilitates a seamless transition from dataset management to model training, significantly simplifying the entire process.
+
+
+
+
+ Watch: Watch: Upload Datasets to Ultralytics HUB | Complete Walkthrough of Dataset Upload Feature
+
+
+## Upload Dataset
+
+[Ultralytics HUB](https://ultralytics.com/hub) datasets are just like YOLOv5 and YOLOv8 🚀 datasets. They use the same structure and the same label formats to keep everything simple.
+
+Before you upload a dataset to [Ultralytics HUB](https://ultralytics.com/hub), make sure to **place your dataset YAML file inside the dataset root directory** and that **your dataset YAML, directory and ZIP have the same name**, as shown in the example below, and then zip the dataset directory.
+
+For example, if your dataset is called "coco8", as our [COCO8](https://docs.ultralytics.com/datasets/detect/coco8) example dataset, then you should have a `coco8.yaml` inside your `coco8/` directory, which will create a `coco8.zip` when zipped:
+
+```bash
+zip -r coco8.zip coco8
+```
+
+You can download our [COCO8](https://github.com/ultralytics/hub/blob/main/example_datasets/coco8.zip) example dataset and unzip it to see exactly how to structure your dataset.
+
+
+
+
+
+The dataset YAML is the same standard YOLOv5 and YOLOv8 YAML format.
+
+!!! Example "coco8.yaml"
+
+ ```yaml
+ --8<-- "ultralytics/cfg/datasets/coco8.yaml"
+ ```
+
+After zipping your dataset, you should [validate it](https://docs.ultralytics.com/reference/hub/__init__/#ultralytics.hub.check_dataset) before uploading it to [Ultralytics HUB](https://ultralytics.com/hub). [Ultralytics HUB](https://ultralytics.com/hub) conducts the dataset validation check post-upload, so by ensuring your dataset is correctly formatted and error-free ahead of time, you can forestall any setbacks due to dataset rejection.
+
+```py
+from ultralytics.hub import check_dataset
+
+check_dataset("path/to/dataset.zip", task="detect")
+```
+
+Once your dataset ZIP is ready, navigate to the [Datasets](https://hub.ultralytics.com/datasets) page by clicking on the **Datasets** button in the sidebar and click on the **Upload Dataset** button on the top right of the page.
+
+
+
+??? tip "Tip"
+
+ You can upload a dataset directly from the [Home](https://hub.ultralytics.com/home) page.
+
+ 
+
+This action will trigger the **Upload Dataset** dialog.
+
+Select the dataset task of your dataset and upload it in the _Dataset .zip file_ field.
+
+You have the additional option to set a custom name and description for your [Ultralytics HUB](https://ultralytics.com/hub) dataset.
+
+When you're happy with your dataset configuration, click **Upload**.
+
+
+
+After your dataset is uploaded and processed, you will be able to access it from the [Datasets](https://hub.ultralytics.com/datasets) page.
+
+
+
+You can view the images in your dataset grouped by splits (Train, Validation, Test).
+
+
+
+??? tip "Tip"
+
+ Each image can be enlarged for better visualization.
+
+ 
+
+ 
+
+Also, you can analyze your dataset by click on the **Overview** tab.
+
+
+
+Next, [train a model](./models.md#train-model) on your dataset.
+
+
+
+## Download Dataset
+
+Navigate to the Dataset page of the dataset you want to download, open the dataset actions dropdown and click on the **Download** option. This action will start downloading your dataset.
+
+
+
+??? tip "Tip"
+
+ You can download a dataset directly from the [Datasets](https://hub.ultralytics.com/datasets) page.
+
+ 
+
+## Share Dataset
+
+!!! info "Info"
+
+ [Ultralytics HUB](https://ultralytics.com/hub)'s sharing functionality provides a convenient way to share datasets with others. This feature is designed to accommodate both existing [Ultralytics HUB](https://ultralytics.com/hub) users and those who have yet to create an account.
+
+!!! note "Note"
+
+ You have control over the general access of your datasets.
+
+ You can choose to set the general access to "Private", in which case, only you will have access to it. Alternatively, you can set the general access to "Unlisted" which grants viewing access to anyone who has the direct link to the dataset, regardless of whether they have an [Ultralytics HUB](https://ultralytics.com/hub) account or not.
+
+Navigate to the Dataset page of the dataset you want to share, open the dataset actions dropdown and click on the **Share** option. This action will trigger the **Share Dataset** dialog.
+
+
+
+??? tip "Tip"
+
+ You can share a dataset directly from the [Datasets](https://hub.ultralytics.com/datasets) page.
+
+ 
+
+Set the general access to "Unlisted" and click **Save**.
+
+
+
+Now, anyone who has the direct link to your dataset can view it.
+
+??? tip "Tip"
+
+ You can easily click on the dataset's link shown in the **Share Dataset** dialog to copy it.
+
+ 
+
+## Edit Dataset
+
+Navigate to the Dataset page of the dataset you want to edit, open the dataset actions dropdown and click on the **Edit** option. This action will trigger the **Update Dataset** dialog.
+
+
+
+??? tip "Tip"
+
+ You can edit a dataset directly from the [Datasets](https://hub.ultralytics.com/datasets) page.
+
+ 
+
+Apply the desired modifications to your dataset and then confirm the changes by clicking **Save**.
+
+
+
+## Delete Dataset
+
+Navigate to the Dataset page of the dataset you want to delete, open the dataset actions dropdown and click on the **Delete** option. This action will delete the dataset.
+
+
+
+??? tip "Tip"
+
+ You can delete a dataset directly from the [Datasets](https://hub.ultralytics.com/datasets) page.
+
+ 
+
+!!! note "Note"
+
+ If you change your mind, you can restore the dataset from the [Trash](https://hub.ultralytics.com/trash) page.
+
+ 
diff --git a/ultralytics/docs/en/hub/index.md b/ultralytics/docs/en/hub/index.md
new file mode 100644
index 0000000000000000000000000000000000000000..ce7978236325fe7f775a1ebdbbb140877d3c1e72
--- /dev/null
+++ b/ultralytics/docs/en/hub/index.md
@@ -0,0 +1,126 @@
+---
+comments: true
+description: Discover Ultralytics HUB, the all-in-one web tool for training and deploying YOLOv5 and YOLOv8 models. Get started quickly with pre-trained models and user-friendly features.
+keywords: Ultralytics HUB, YOLO models, train YOLO, YOLOv5, YOLOv8, object detection, model deployment, machine learning, deep learning, AI tools, dataset upload, model training
+---
+
+# Ultralytics HUB
+
+
+
+👋 Hello from the [Ultralytics](https://ultralytics.com/) Team! We've been working hard these last few months to launch [Ultralytics HUB](https://ultralytics.com/hub), a new web tool for training and deploying all your YOLOv5 and YOLOv8 🚀 models from one spot!
+
+We hope that the resources here will help you get the most out of HUB. Please browse the HUB Docs for details, raise an issue on GitHub for support, and join our Discord community for questions and discussions!
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+## Introduction
+
+[Ultralytics HUB](https://ultralytics.com/hub) is designed to be user-friendly and intuitive, allowing users to quickly upload their datasets and train new YOLO models. It also offers a range of pre-trained models to choose from, making it extremely easy for users to get started. Once a model is trained, it can be effortlessly previewed in the [Ultralytics HUB App](app/index.md) before being deployed for real-time classification, object detection, and instance segmentation tasks.
+
+
+
+
+ Watch: Train Your Custom YOLO Models In A Few Clicks with Ultralytics HUB
+
+
+We hope that the resources here will help you get the most out of HUB. Please browse the HUB Docs for details, raise an issue on GitHub for support, and join our Discord community for questions and discussions!
+
+- [**Quickstart**](quickstart.md): Start training and deploying models in seconds.
+- [**Datasets**](datasets.md): Learn how to prepare and upload your datasets.
+- [**Projects**](projects.md): Group your models into projects for improved organization.
+- [**Models**](models.md): Train models and export them to various formats for deployment.
+- [**Pro**](pro.md): Level up your experience by becoming a Pro user.
+- [**Cloud Training**](cloud-training.md): Understand how to train models using our Cloud Training solution.
+- [**Inference API**](inference-api.md): Understand how to use our Inference API.
+- [**Teams**](teams.md): Collaborate effortlessly with your team.
+- [**Integrations**](integrations.md): Explore different integration options.
+- [**Ultralytics HUB App**](app/index.md): Learn about the Ultralytics HUB App, which allows you to run models directly on your mobile device.
+ - [**iOS**](app/ios.md): Explore CoreML acceleration on iPhones and iPads.
+ - [**Android**](app/android.md): Explore TFLite acceleration on Android devices.
+
+## FAQ
+
+### How do I get started with Ultralytics HUB for training YOLO models?
+
+To get started with [Ultralytics HUB](https://ultralytics.com/hub), follow these steps:
+
+1. **Sign Up:** Create an account on the [Ultralytics HUB](https://ultralytics.com/hub).
+2. **Upload Dataset:** Navigate to the [Datasets](datasets.md) section to upload your custom dataset.
+3. **Train Model:** Go to the [Models](models.md) section and select a pre-trained YOLOv5 or YOLOv8 model to start training.
+4. **Deploy Model:** Once trained, preview and deploy your model using the [Ultralytics HUB App](app/index.md) for real-time tasks.
+
+For a detailed guide, refer to the [Quickstart](quickstart.md) page.
+
+### What are the benefits of using Ultralytics HUB over other AI platforms?
+
+[Ultralytics HUB](https://ultralytics.com/hub) offers several unique benefits:
+
+- **User-Friendly Interface:** Intuitive design for easy dataset uploads and model training.
+- **Pre-Trained Models:** Access to a variety of pre-trained YOLOv5 and YOLOv8 models.
+- **Cloud Training:** Seamless cloud training capabilities, detailed on the [Cloud Training](cloud-training.md) page.
+- **Real-Time Deployment:** Effortlessly deploy models for real-time applications using the [Ultralytics HUB App](app/index.md).
+- **Team Collaboration:** Collaborate with your team efficiently through the [Teams](teams.md) feature.
+
+Explore more about the advantages in our [Ultralytics HUB Blog](https://www.ultralytics.com/blog/ultralytics-hub-a-game-changer-for-computer-vision).
+
+### Can I use Ultralytics HUB for object detection on mobile devices?
+
+Yes, Ultralytics HUB supports object detection on mobile devices. You can run YOLOv5 and YOLOv8 models on both iOS and Android devices using the Ultralytics HUB App. For more details:
+
+- **iOS:** Learn about CoreML acceleration on iPhones and iPads in the [iOS](app/ios.md) section.
+- **Android:** Explore TFLite acceleration on Android devices in the [Android](app/android.md) section.
+
+### How do I manage and organize my projects in Ultralytics HUB?
+
+Ultralytics HUB allows you to manage and organize your projects efficiently. You can group your models into projects for better organization. To learn more:
+
+- Visit the [Projects](projects.md) page for detailed instructions on creating, editing, and managing projects.
+- Use the [Teams](teams.md) feature to collaborate with team members and share resources.
+
+### What integrations are available with Ultralytics HUB?
+
+Ultralytics HUB offers seamless integrations with various platforms to enhance your machine learning workflows. Some key integrations include:
+
+- **Roboflow:** For dataset management and model training. Learn more on the [Integrations](integrations.md) page.
+- **Google Colab:** Efficiently train models using Google Colab's cloud-based environment. Detailed steps are available in the [Google Colab](https://docs.ultralytics.com/integrations/google-colab) section.
+- **Weights & Biases:** For enhanced experiment tracking and visualization. Explore the [Weights & Biases](https://docs.ultralytics.com/integrations/weights-biases) integration.
+
+For a complete list of integrations, refer to the [Integrations](integrations.md) page.
diff --git a/ultralytics/docs/en/hub/inference-api.md b/ultralytics/docs/en/hub/inference-api.md
new file mode 100644
index 0000000000000000000000000000000000000000..70dbb786a157dae1a36c040386629d4caf05d59e
--- /dev/null
+++ b/ultralytics/docs/en/hub/inference-api.md
@@ -0,0 +1,586 @@
+---
+comments: true
+description: Learn how to run inference using the Ultralytics HUB Inference API. Includes examples in Python and cURL for quick integration.
+keywords: Ultralytics, HUB, Inference API, Python, cURL, REST API, YOLO, image processing, machine learning, AI integration
+---
+
+# Ultralytics HUB Inference API
+
+After you [train a model](./models.md#train-model), you can use the [Shared Inference API](#shared-inference-api) for free. If you are a [Pro](./pro.md) user, you can access the [Dedicated Inference API](#dedicated-inference-api). The [Ultralytics HUB](https://ultralytics.com/hub) Inference API allows you to run inference through our REST API without the need to install and set up the Ultralytics YOLO environment locally.
+
+
+
+
+
+
+ Watch: Ultralytics HUB Inference API Walkthrough
+
+
+## Dedicated Inference API
+
+In response to high demand and widespread interest, we are thrilled to unveil the [Ultralytics HUB](https://ultralytics.com/hub) Dedicated Inference API, offering single-click deployment in a dedicated environment for our [Pro](./pro.md) users!
+
+!!! note "Note"
+
+ We are excited to offer this feature FREE during our public beta as part of the [Pro Plan](./pro.md), with paid tiers possible in the future.
+
+- **Global Coverage:** Deployed across 38 regions worldwide, ensuring low-latency access from any location. [See the full list of Google Cloud regions](https://cloud.google.com/about/locations).
+- **Google Cloud Run-Backed:** Backed by Google Cloud Run, providing infinitely scalable and highly reliable infrastructure.
+- **High Speed:** Sub-100ms latency is possible for YOLOv8n inference at 640 resolution from nearby regions based on Ultralytics testing.
+- **Enhanced Security:** Provides robust security features to protect your data and ensure compliance with industry standards. [Learn more about Google Cloud security](https://cloud.google.com/security).
+
+To use the [Ultralytics HUB](https://ultralytics.com/hub) Dedicated Inference API, click on the **Start Endpoint** button. Next, use the unique endpoint URL as described in the guides below.
+
+
+
+!!! tip "Tip"
+
+ Choose the region with the lowest latency for the best performance as described in the [documentation](https://docs.ultralytics.com/reference/hub/google/__init__).
+
+To shut down the dedicated endpoint, click on the **Stop Endpoint** button.
+
+
+
+## Shared Inference API
+
+To use the [Ultralytics HUB](https://ultralytics.com/hub) Shared Inference API, follow the guides below.
+
+Free users have the following usage limits:
+
+- 100 calls / hour
+- 1000 calls / month
+
+[Pro](./pro.md) users have the following usage limits:
+
+- 1000 calls / hour
+- 10000 calls / month
+
+## Python
+
+To access the [Ultralytics HUB](https://ultralytics.com/hub) Inference API using Python, use the following code:
+
+```python
+import requests
+
+# API URL, use actual MODEL_ID
+url = "https://api.ultralytics.com/v1/predict/MODEL_ID"
+
+# Headers, use actual API_KEY
+headers = {"x-api-key": "API_KEY"}
+
+# Inference arguments (optional)
+data = {"imgsz": 640, "conf": 0.25, "iou": 0.45}
+
+# Load image and send request
+with open("path/to/image.jpg", "rb") as image_file:
+ files = {"file": image_file}
+ response = requests.post(url, headers=headers, files=files, data=data)
+
+print(response.json())
+```
+
+!!! note "Note"
+
+ Replace `MODEL_ID` with the desired model ID, `API_KEY` with your actual API key, and `path/to/image.jpg` with the path to the image you want to run inference on.
+
+ If you are using our [Dedicated Inference API](#dedicated-inference-api), replace the `url` as well.
+
+## cURL
+
+To access the [Ultralytics HUB](https://ultralytics.com/hub) Inference API using cURL, use the following code:
+
+```bash
+curl -X POST "https://api.ultralytics.com/v1/predict/MODEL_ID" \
+ -H "x-api-key: API_KEY" \
+ -F "file=@/path/to/image.jpg" \
+ -F "imgsz=640" \
+ -F "conf=0.25" \
+ -F "iou=0.45"
+```
+
+!!! note "Note"
+
+ Replace `MODEL_ID` with the desired model ID, `API_KEY` with your actual API key, and `path/to/image.jpg` with the path to the image you want to run inference on.
+
+ If you are using our [Dedicated Inference API](#dedicated-inference-api), replace the `url` as well.
+
+## Arguments
+
+See the table below for a full list of available inference arguments.
+
+| Argument | Default | Type | Description |
+| -------- | ------- | ------- | -------------------------------------------------------------------- |
+| `file` | | `file` | Image or video file to be used for inference. |
+| `imgsz` | `640` | `int` | Size of the input image, valid range is `32` - `1280` pixels. |
+| `conf` | `0.25` | `float` | Confidence threshold for predictions, valid range `0.01` - `1.0`. |
+| `iou` | `0.45` | `float` | Intersection over Union (IoU) threshold, valid range `0.0` - `0.95`. |
+
+## Response
+
+The [Ultralytics HUB](https://ultralytics.com/hub) Inference API returns a JSON response.
+
+### Classification
+
+!!! Example "Classification Model"
+
+ === "`ultralytics`"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load model
+ model = YOLO("yolov8n-cls.pt")
+
+ # Run inference
+ results = model("image.jpg")
+
+ # Print image.jpg results in JSON format
+ print(results[0].tojson())
+ ```
+
+ === "cURL"
+
+ ```bash
+ curl -X POST "https://api.ultralytics.com/v1/predict/MODEL_ID" \
+ -H "x-api-key: API_KEY" \
+ -F "file=@/path/to/image.jpg" \
+ -F "imgsz=640" \
+ -F "conf=0.25" \
+ -F "iou=0.45"
+ ```
+
+ === "Python"
+
+ ```python
+ import requests
+
+ # API URL, use actual MODEL_ID
+ url = "https://api.ultralytics.com/v1/predict/MODEL_ID"
+
+ # Headers, use actual API_KEY
+ headers = {"x-api-key": "API_KEY"}
+
+ # Inference arguments (optional)
+ data = {"imgsz": 640, "conf": 0.25, "iou": 0.45}
+
+ # Load image and send request
+ with open("path/to/image.jpg", "rb") as image_file:
+ files = {"file": image_file}
+ response = requests.post(url, headers=headers, files=files, data=data)
+
+ print(response.json())
+ ```
+
+ === "Response"
+
+ ```json
+ {
+ "images": [
+ {
+ "results": [
+ {
+ "class": 0,
+ "name": "person",
+ "confidence": 0.92
+ }
+ ],
+ "shape": [
+ 750,
+ 600
+ ],
+ "speed": {
+ "inference": 200.8,
+ "postprocess": 0.8,
+ "preprocess": 2.8
+ }
+ }
+ ],
+ "metadata": ...
+ }
+ ```
+
+### Detection
+
+!!! Example "Detection Model"
+
+ === "`ultralytics`"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load model
+ model = YOLO("yolov8n.pt")
+
+ # Run inference
+ results = model("image.jpg")
+
+ # Print image.jpg results in JSON format
+ print(results[0].tojson())
+ ```
+
+ === "cURL"
+
+ ```bash
+ curl -X POST "https://api.ultralytics.com/v1/predict/MODEL_ID" \
+ -H "x-api-key: API_KEY" \
+ -F "file=@/path/to/image.jpg" \
+ -F "imgsz=640" \
+ -F "conf=0.25" \
+ -F "iou=0.45"
+ ```
+
+ === "Python"
+
+ ```python
+ import requests
+
+ # API URL, use actual MODEL_ID
+ url = "https://api.ultralytics.com/v1/predict/MODEL_ID"
+
+ # Headers, use actual API_KEY
+ headers = {"x-api-key": "API_KEY"}
+
+ # Inference arguments (optional)
+ data = {"imgsz": 640, "conf": 0.25, "iou": 0.45}
+
+ # Load image and send request
+ with open("path/to/image.jpg", "rb") as image_file:
+ files = {"file": image_file}
+ response = requests.post(url, headers=headers, files=files, data=data)
+
+ print(response.json())
+ ```
+
+ === "Response"
+
+ ```json
+ {
+ "images": [
+ {
+ "results": [
+ {
+ "class": 0,
+ "name": "person",
+ "confidence": 0.92,
+ "box": {
+ "x1": 118,
+ "x2": 416,
+ "y1": 112,
+ "y2": 660
+ }
+ }
+ ],
+ "shape": [
+ 750,
+ 600
+ ],
+ "speed": {
+ "inference": 200.8,
+ "postprocess": 0.8,
+ "preprocess": 2.8
+ }
+ }
+ ],
+ "metadata": ...
+ }
+ ```
+
+### OBB
+
+!!! Example "OBB Model"
+
+ === "`ultralytics`"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load model
+ model = YOLO("yolov8n-obb.pt")
+
+ # Run inference
+ results = model("image.jpg")
+
+ # Print image.jpg results in JSON format
+ print(results[0].tojson())
+ ```
+
+ === "cURL"
+
+ ```bash
+ curl -X POST "https://api.ultralytics.com/v1/predict/MODEL_ID" \
+ -H "x-api-key: API_KEY" \
+ -F "file=@/path/to/image.jpg" \
+ -F "imgsz=640" \
+ -F "conf=0.25" \
+ -F "iou=0.45"
+ ```
+
+ === "Python"
+
+ ```python
+ import requests
+
+ # API URL, use actual MODEL_ID
+ url = "https://api.ultralytics.com/v1/predict/MODEL_ID"
+
+ # Headers, use actual API_KEY
+ headers = {"x-api-key": "API_KEY"}
+
+ # Inference arguments (optional)
+ data = {"imgsz": 640, "conf": 0.25, "iou": 0.45}
+
+ # Load image and send request
+ with open("path/to/image.jpg", "rb") as image_file:
+ files = {"file": image_file}
+ response = requests.post(url, headers=headers, files=files, data=data)
+
+ print(response.json())
+ ```
+
+ === "Response"
+
+ ```json
+ {
+ "images": [
+ {
+ "results": [
+ {
+ "class": 0,
+ "name": "person",
+ "confidence": 0.92,
+ "box": {
+ "x1": 374.85565,
+ "x2": 392.31824,
+ "x3": 412.81805,
+ "x4": 395.35547,
+ "y1": 264.40704,
+ "y2": 267.45728,
+ "y3": 150.0966,
+ "y4": 147.04634
+ }
+ }
+ ],
+ "shape": [
+ 750,
+ 600
+ ],
+ "speed": {
+ "inference": 200.8,
+ "postprocess": 0.8,
+ "preprocess": 2.8
+ }
+ }
+ ],
+ "metadata": ...
+ }
+ ```
+
+### Segmentation
+
+!!! Example "Segmentation Model"
+
+ === "`ultralytics`"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load model
+ model = YOLO("yolov8n-seg.pt")
+
+ # Run inference
+ results = model("image.jpg")
+
+ # Print image.jpg results in JSON format
+ print(results[0].tojson())
+ ```
+
+ === "cURL"
+
+ ```bash
+ curl -X POST "https://api.ultralytics.com/v1/predict/MODEL_ID" \
+ -H "x-api-key: API_KEY" \
+ -F "file=@/path/to/image.jpg" \
+ -F "imgsz=640" \
+ -F "conf=0.25" \
+ -F "iou=0.45"
+ ```
+
+ === "Python"
+
+ ```python
+ import requests
+
+ # API URL, use actual MODEL_ID
+ url = "https://api.ultralytics.com/v1/predict/MODEL_ID"
+
+ # Headers, use actual API_KEY
+ headers = {"x-api-key": "API_KEY"}
+
+ # Inference arguments (optional)
+ data = {"imgsz": 640, "conf": 0.25, "iou": 0.45}
+
+ # Load image and send request
+ with open("path/to/image.jpg", "rb") as image_file:
+ files = {"file": image_file}
+ response = requests.post(url, headers=headers, files=files, data=data)
+
+ print(response.json())
+ ```
+
+ === "Response"
+
+ ```json
+ {
+ "images": [
+ {
+ "results": [
+ {
+ "class": 0,
+ "name": "person",
+ "confidence": 0.92,
+ "box": {
+ "x1": 118,
+ "x2": 416,
+ "y1": 112,
+ "y2": 660
+ },
+ "segments": {
+ "x": [
+ 266.015625,
+ 266.015625,
+ 258.984375,
+ ...
+ ],
+ "y": [
+ 110.15625,
+ 113.67188262939453,
+ 120.70311737060547,
+ ...
+ ]
+ }
+ }
+ ],
+ "shape": [
+ 750,
+ 600
+ ],
+ "speed": {
+ "inference": 200.8,
+ "postprocess": 0.8,
+ "preprocess": 2.8
+ }
+ }
+ ],
+ "metadata": ...
+ }
+ ```
+
+### Pose
+
+!!! Example "Pose Model"
+
+ === "`ultralytics`"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load model
+ model = YOLO("yolov8n-pose.pt")
+
+ # Run inference
+ results = model("image.jpg")
+
+ # Print image.jpg results in JSON format
+ print(results[0].tojson())
+ ```
+
+ === "cURL"
+
+ ```bash
+ curl -X POST "https://api.ultralytics.com/v1/predict/MODEL_ID" \
+ -H "x-api-key: API_KEY" \
+ -F "file=@/path/to/image.jpg" \
+ -F "imgsz=640" \
+ -F "conf=0.25" \
+ -F "iou=0.45"
+ ```
+
+ === "Python"
+
+ ```python
+ import requests
+
+ # API URL, use actual MODEL_ID
+ url = "https://api.ultralytics.com/v1/predict/MODEL_ID"
+
+ # Headers, use actual API_KEY
+ headers = {"x-api-key": "API_KEY"}
+
+ # Inference arguments (optional)
+ data = {"imgsz": 640, "conf": 0.25, "iou": 0.45}
+
+ # Load image and send request
+ with open("path/to/image.jpg", "rb") as image_file:
+ files = {"file": image_file}
+ response = requests.post(url, headers=headers, files=files, data=data)
+
+ print(response.json())
+ ```
+
+ === "Response"
+
+ ```json
+ {
+ "images": [
+ {
+ "results": [
+ {
+ "class": 0,
+ "name": "person",
+ "confidence": 0.92,
+ "box": {
+ "x1": 118,
+ "x2": 416,
+ "y1": 112,
+ "y2": 660
+ },
+ "keypoints": {
+ "visible": [
+ 0.9909399747848511,
+ 0.8162999749183655,
+ 0.9872099757194519,
+ ...
+ ],
+ "x": [
+ 316.3871765136719,
+ 315.9374694824219,
+ 304.878173828125,
+ ...
+ ],
+ "y": [
+ 156.4207763671875,
+ 148.05775451660156,
+ 144.93240356445312,
+ ...
+ ]
+ }
+ }
+ ],
+ "shape": [
+ 750,
+ 600
+ ],
+ "speed": {
+ "inference": 200.8,
+ "postprocess": 0.8,
+ "preprocess": 2.8
+ }
+ }
+ ],
+ "metadata": ...
+ }
+ ```
diff --git a/ultralytics/docs/en/hub/integrations.md b/ultralytics/docs/en/hub/integrations.md
new file mode 100644
index 0000000000000000000000000000000000000000..8ce87b60ab8f78bd7bb86124bf00970ab16b9879
--- /dev/null
+++ b/ultralytics/docs/en/hub/integrations.md
@@ -0,0 +1,127 @@
+---
+comments: true
+description: Explore seamless integrations between Ultralytics HUB and platforms like Roboflow. Learn how to import datasets, train models, and more.
+keywords: Ultralytics HUB, Roboflow integration, dataset import, model training, AI, machine learning
+---
+
+# Ultralytics HUB Integrations
+
+Learn about [Ultralytics HUB](https://ultralytics.com/hub) integrations with various platforms and formats.
+
+## Datasets
+
+Seamlessly import your datasets in [Ultralytics HUB](https://ultralytics.com/hub) for [model training](./models.md#train-model).
+
+After a dataset is imported in [Ultralytics HUB](https://ultralytics.com/hub), you can [train a model](./models.md#train-model) on your dataset just like you would using the [Ultralytics HUB](https://ultralytics.com/hub) datasets.
+
+### Roboflow
+
+You can easily filter the [Roboflow](https://roboflow.com/?ref=ultralytics) datasets on the [Ultralytics HUB](https://ultralytics.com/hub) [Datasets](https://hub.ultralytics.com/datasets) page.
+
+
+
+[Ultralytics HUB](https://ultralytics.com/hub) supports two types of integrations with [Roboflow](https://roboflow.com/?ref=ultralytics), [Universe](#universe) and [Workspace](#workspace).
+
+#### Universe
+
+The [Roboflow](https://roboflow.com/?ref=ultralytics) Universe integration allows you to import one dataset at a time into [Ultralytics HUB](https://ultralytics.com/hub) from [Roboflow](https://roboflow.com/?ref=ultralytics).
+
+##### Import
+
+When you export a [Roboflow](https://roboflow.com/?ref=ultralytics) dataset, select the [Ultralytics HUB](https://ultralytics.com/hub) format. This action will redirect you to [Ultralytics HUB](https://ultralytics.com/hub) and trigger the **Dataset Import** dialog.
+
+You can import your [Roboflow](https://roboflow.com/?ref=ultralytics) dataset by clicking on the **Import** button.
+
+
+
+Next, [train a model](./models.md#train-model) on your dataset.
+
+
+
+##### Remove
+
+Navigate to the Dataset page of the [Roboflow](https://roboflow.com/?ref=ultralytics) dataset you want to remove, open the dataset actions dropdown and click on the **Remove** option.
+
+
+
+??? tip "Tip"
+
+ You can remove an imported [Roboflow](https://roboflow.com/?ref=ultralytics) dataset directly from the [Datasets](https://hub.ultralytics.com/datasets) page.
+
+ 
+
+#### Workspace
+
+The [Roboflow](https://roboflow.com/?ref=ultralytics) Workspace integration allows you to import an entire [Roboflow](https://roboflow.com/?ref=ultralytics) Workspace at once into [Ultralytics HUB](https://ultralytics.com/hub).
+
+##### Import
+
+Navigate to the [Integrations](https://hub.ultralytics.com/settings?tab=integrations) page by clicking on the **Integrations** button in the sidebar.
+
+Type your [Roboflow](https://roboflow.com/?ref=ultralytics) Workspace private API key and click on the **Add** button.
+
+??? tip "Tip"
+
+ You can click on the **Get my API key** button which will redirect you to the settings of your [Roboflow](https://roboflow.com/?ref=ultralytics) Workspace from where you can obtain your private API key.
+
+
+
+This will connect your [Ultralytics HUB](https://ultralytics.com/hub) account with your [Roboflow](https://roboflow.com/?ref=ultralytics) Workspace and make your [Roboflow](https://roboflow.com/?ref=ultralytics) datasets available in [Ultralytics HUB](https://ultralytics.com/hub).
+
+
+
+Next, [train a model](./models.md#train-model) on your dataset.
+
+
+
+##### Remove
+
+Navigate to the [Integrations](https://hub.ultralytics.com/settings?tab=integrations) page by clicking on the **Integrations** button in the sidebar and click on the **Unlink** button of the [Roboflow](https://roboflow.com/?ref=ultralytics) Workspace you want to remove.
+
+
+
+??? tip "Tip"
+
+ You can remove a connected [Roboflow](https://roboflow.com/?ref=ultralytics) Workspace directly from the Dataset page of one of the datasets from your [Roboflow](https://roboflow.com/?ref=ultralytics) Workspace.
+
+ 
+
+??? tip "Tip"
+
+ You can remove a connected [Roboflow](https://roboflow.com/?ref=ultralytics) Workspace directly from the [Datasets](https://hub.ultralytics.com/datasets) page.
+
+ 
+
+## Models
+
+### Exports
+
+After you [train a model](./models.md#train-model), you can [export it](./models.md#deploy-model) to 13 different formats, including ONNX, OpenVINO, CoreML, TensorFlow, Paddle and many others.
+
+
+
+The available export formats are presented in the table below.
+
+{% include "macros/export-table.md" %}
+
+## Exciting New Features on the Way 🎉
+
+- Additional Dataset Integrations
+- Detailed Export Integration Guides
+- Step-by-Step Tutorials for Each Integration
+
+## Stay Updated 🚧
+
+This integrations page is your first stop for upcoming developments. Keep an eye out with our:
+
+- **Newsletter:** Subscribe [here](https://ultralytics.com/#newsletter) for the latest news.
+- **Social Media:** Follow us [here](https://www.linkedin.com/company/ultralytics) for updates and teasers.
+- **Blog:** Visit our [blog](https://ultralytics.com/blog) for detailed insights.
+
+## We Value Your Input 🗣️
+
+Your feedback shapes our future releases. Share your thoughts and suggestions [here](https://ultralytics.com/survey).
+
+## Thank You, Community! 🌍
+
+Your [contributions](https://docs.ultralytics.com/help/contributing) inspire our continuous [innovation](https://github.com/ultralytics/ultralytics). Stay tuned for the big reveal of what's next in AI and ML at Ultralytics!
diff --git a/ultralytics/docs/en/hub/models.md b/ultralytics/docs/en/hub/models.md
new file mode 100644
index 0000000000000000000000000000000000000000..e2e5e95271ae2b0db837257df61d5f84ed26f636
--- /dev/null
+++ b/ultralytics/docs/en/hub/models.md
@@ -0,0 +1,308 @@
+---
+comments: true
+description: Explore Ultralytics HUB for easy training, analysis, preview, deployment and sharing of custom vision AI models using YOLOv8. Start training today!.
+keywords: Ultralytics HUB, YOLOv8, custom AI models, model training, model deployment, model analysis, vision AI
+---
+
+# Ultralytics HUB Models
+
+[Ultralytics HUB](https://ultralytics.com/hub) models provide a streamlined solution for training vision AI models on custom datasets.
+
+The process is user-friendly and efficient, involving a simple three-step creation and accelerated training powered by Ultralytics YOLOv8. During training, real-time updates on model metrics are available so that you can monitor each step of the progress. Once training is completed, you can preview your model and easily deploy it to real-world applications. Therefore, [Ultralytics HUB](https://ultralytics.com/hub) offers a comprehensive yet straightforward system for model creation, training, evaluation, and deployment.
+
+
+
+
+ Watch: Ultralytics HUB Training and Validation Overview
+
+
+## Train Model
+
+Navigate to the [Models](https://hub.ultralytics.com/models) page by clicking on the **Models** button in the sidebar and click on the **Train Model** button on the top right of the page.
+
+
+
+??? tip "Tip"
+
+ You can train a model directly from the [Home](https://hub.ultralytics.com/home) page.
+
+ 
+
+This action will trigger the **Train Model** dialog which has three simple steps:
+
+### 1. Dataset
+
+In this step, you have to select the dataset you want to train your model on. After you selected a dataset, click **Continue**.
+
+
+
+??? tip "Tip"
+
+ You can skip this step if you train a model directly from the Dataset page.
+
+ 
+
+### 2. Model
+
+In this step, you have to choose the project in which you want to create your model, the name of your model and your model's architecture.
+
+
+
+??? note "Note"
+
+ Ultralytics HUB will try to pre-select the project.
+
+ If you opened the **Train Model** dialog as described above, [Ultralytics HUB](https://ultralytics.com/hub) will pre-select the last project you used.
+
+ If you opened the **Train Model** dialog from the Project page, [Ultralytics HUB](https://ultralytics.com/hub) will pre-select the project you were inside of.
+
+ 
+
+ In case you don't have a project created yet, you can set the name of your project in this step and it will be created together with your model.
+
+!!! Info "Info"
+
+ You can read more about the available [YOLOv8](https://docs.ultralytics.com/models/yolov8) (and [YOLOv5](https://docs.ultralytics.com/models/yolov5)) architectures in our documentation.
+
+By default, your model will use a pre-trained model (trained on the [COCO](https://docs.ultralytics.com/datasets/detect/coco) dataset) to reduce training time. You can change this behavior and tweak your model's configuration by opening the **Advanced Model Configuration** accordion.
+
+
+
+!!! note "Note"
+
+ You can easily change the most common model configuration options (such as the number of epochs) but you can also use the **Custom** option to access all [Train Settings](https://docs.ultralytics.com/modes/train/#train-settings) relevant to [Ultralytics HUB](https://ultralytics.com/hub).
+
+
+
+
+
+ Watch: How to Configure Ultralytics YOLOv8 Training Parameters in Ultralytics HUB
+
+
+Alternatively, you start training from one of your previously trained models by clicking on the **Custom** tab.
+
+
+
+When you're happy with your model configuration, click **Continue**.
+
+### 3. Train
+
+In this step, you will start training you model.
+
+??? note "Note"
+
+ When you are on this step, you have the option to close the **Train Model** dialog and start training your model from the Model page later.
+
+ 
+
+[Ultralytics HUB](https://ultralytics.com/hub) offers three training options:
+
+- [Ultralytics Cloud](./cloud-training.md)
+- Google Colab
+- Bring your own agent
+
+#### a. Ultralytics Cloud
+
+You need to [upgrade](./pro.md#upgrade) to the [Pro Plan](./pro.md) in order to access [Ultralytics Cloud](./cloud-training.md).
+
+
+
+To train models using our [Cloud Training](./cloud-training.md) solution, read the [Ultralytics Cloud Training](./cloud-training.md) documentation.
+
+#### b. Google Colab
+
+To start training your model using [Google Colab](https://colab.research.google.com/github/ultralytics/hub/blob/master/hub.ipynb), follow the instructions shown in the [Ultralytics HUB](https://ultralytics.com/hub) **Train Model** dialog or on the [Google Colab](https://colab.research.google.com/github/ultralytics/hub/blob/master/hub.ipynb) notebook.
+
+
+
+
+
+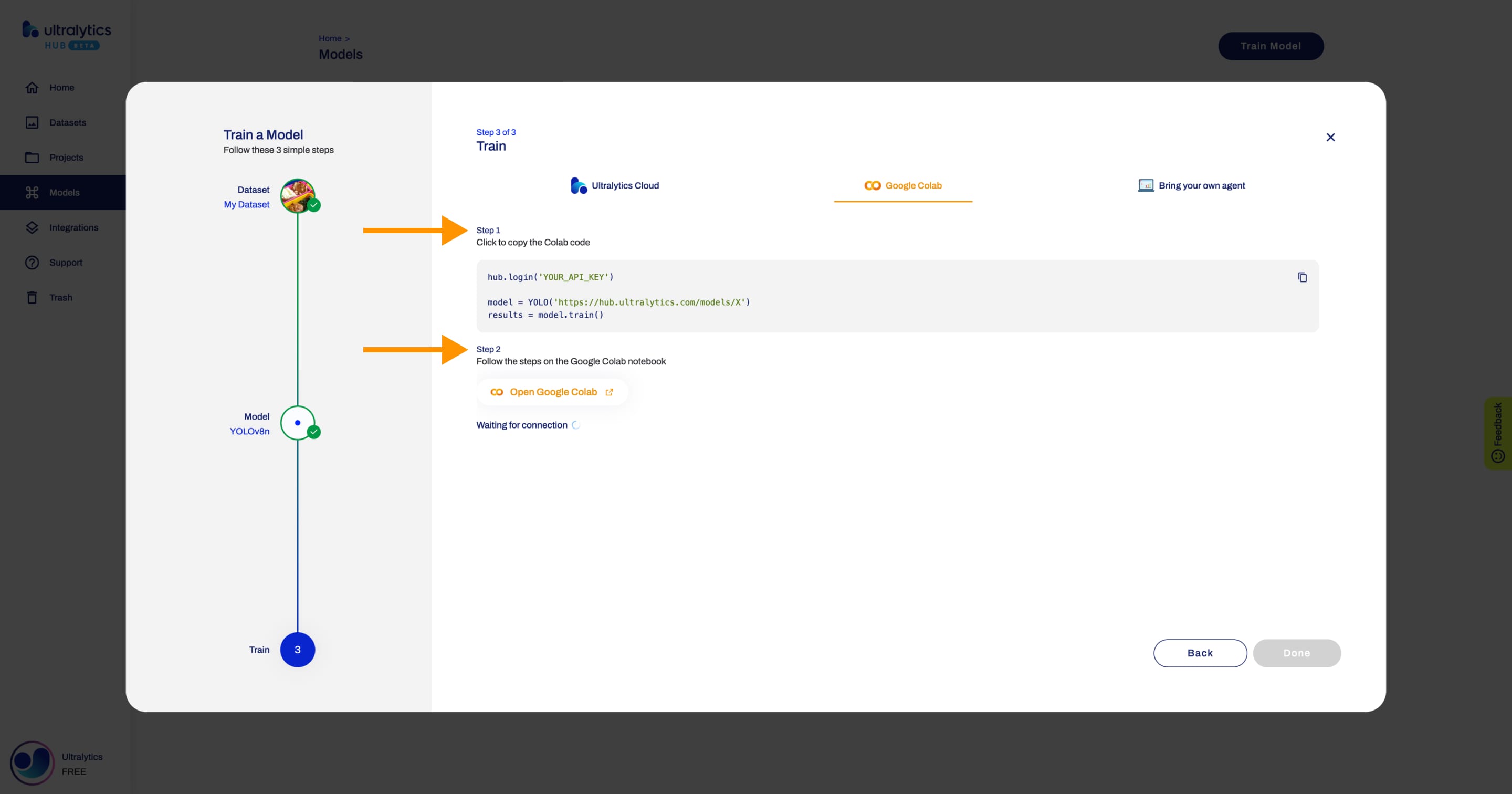
+
+When the training starts, you can click **Done** and monitor the training progress on the Model page.
+
+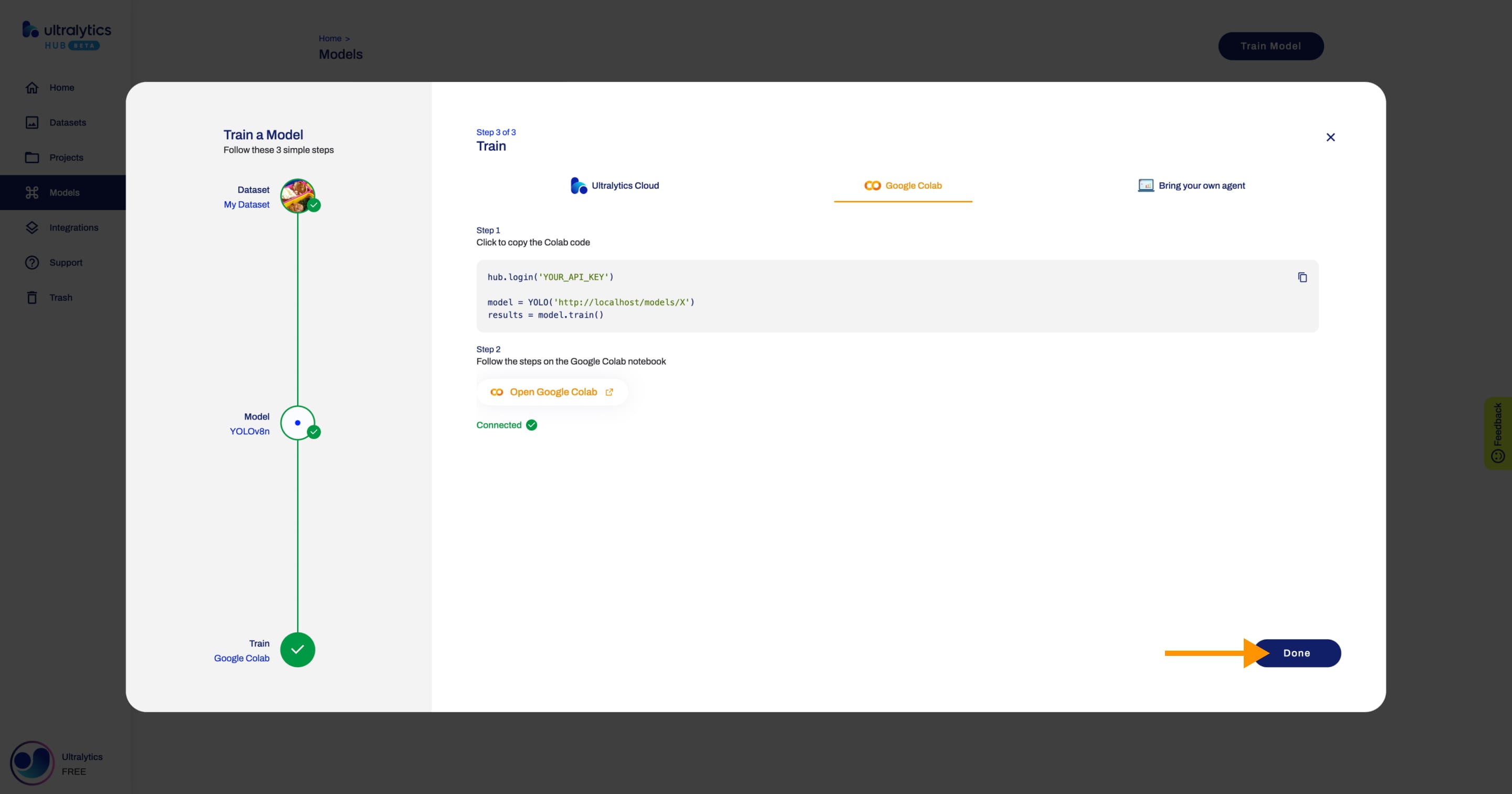
+
+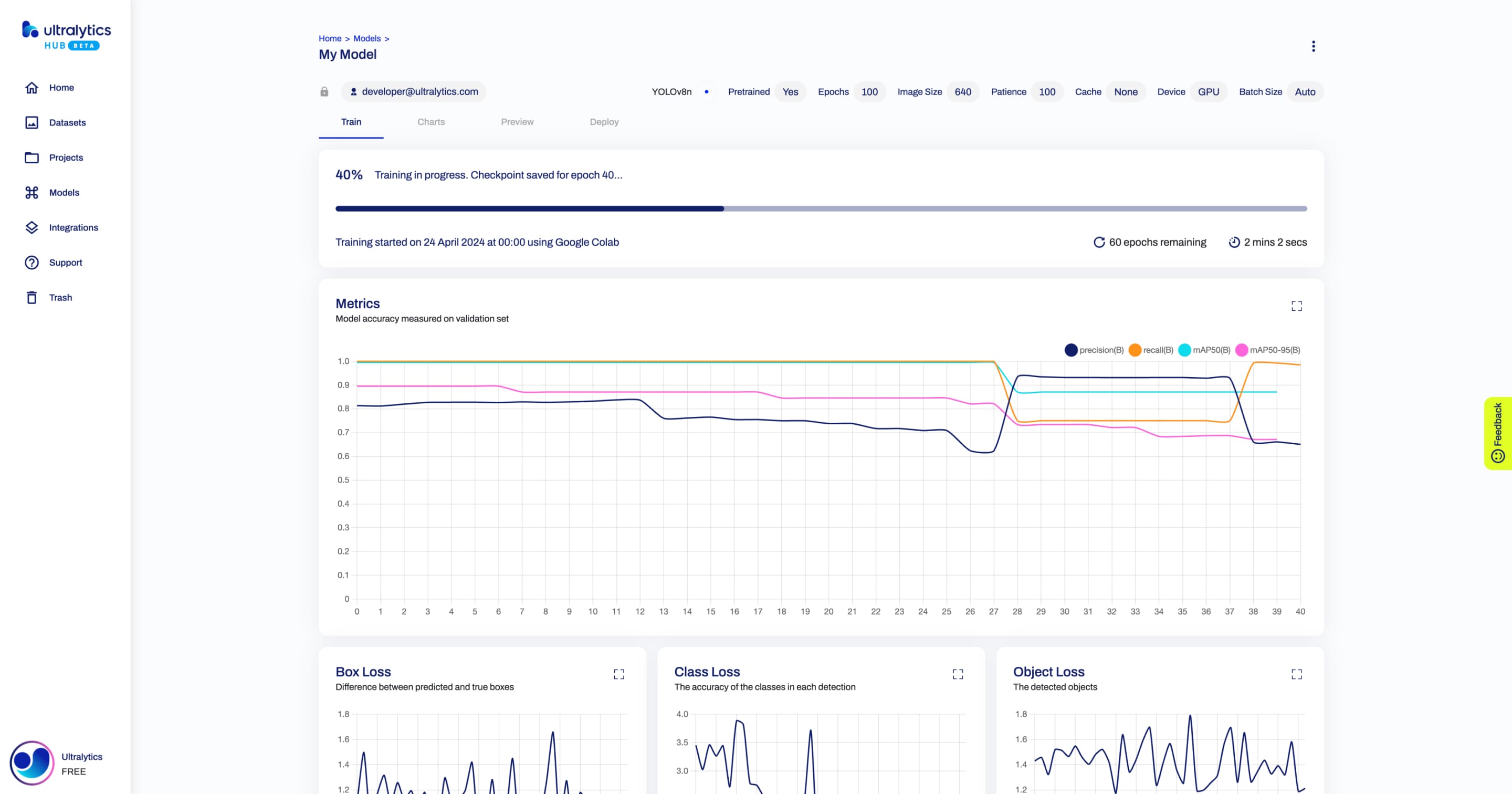
+
+!!! note "Note"
+
+ In case the training stops and a checkpoint was saved, you can resume training your model from the Model page.
+
+ 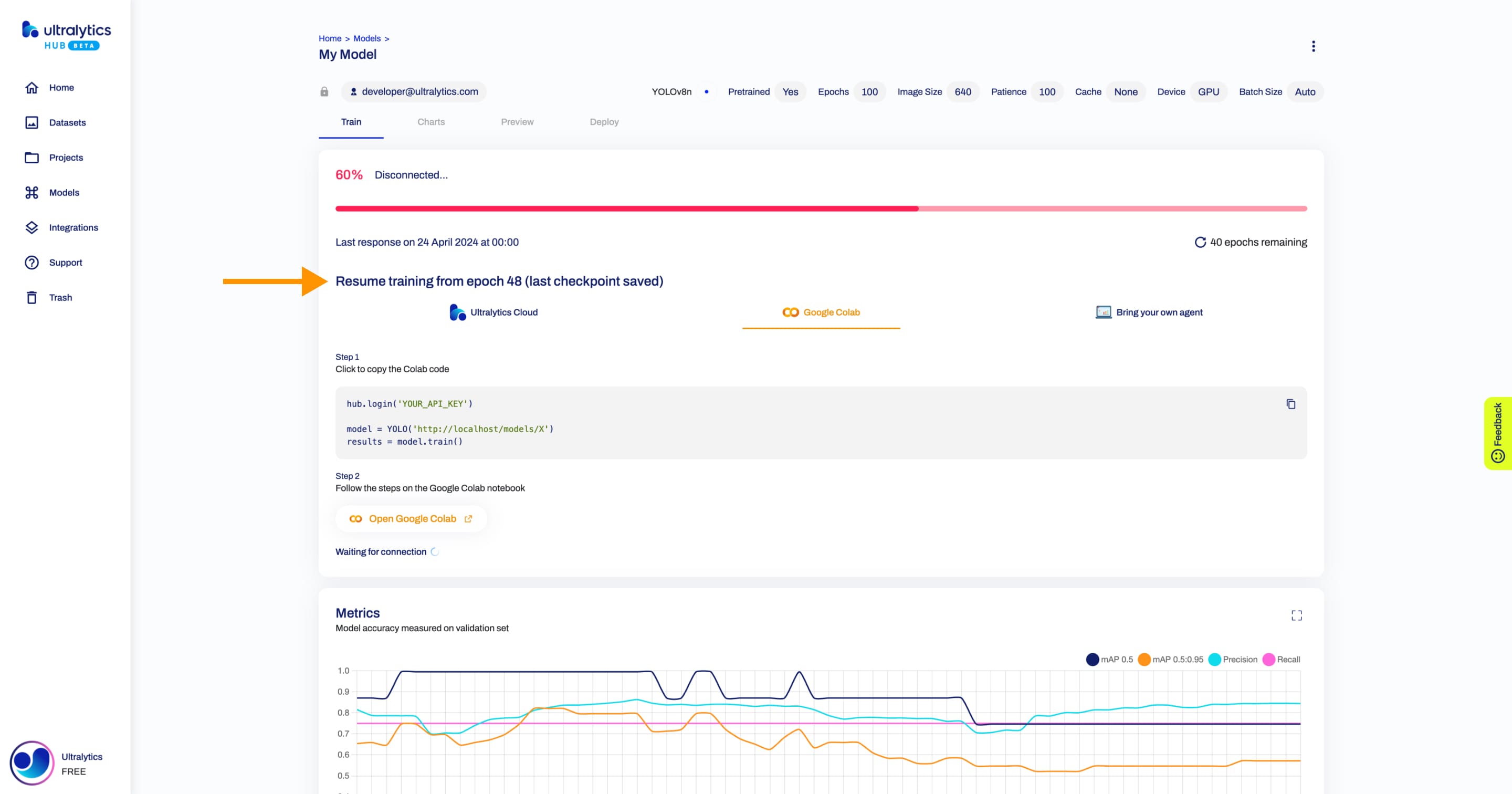
+
+#### c. Bring your own agent
+
+
+
+
+ Watch: Bring your Own Agent model training using Ultralytics HUB
+
+
+To start training your model using your own agent, follow the instructions shown in the [Ultralytics HUB](https://ultralytics.com/hub) **Train Model** dialog.
+
+
+
+Install the `ultralytics` package from [PyPI](https://pypi.org/project/ultralytics).
+
+```bash
+pip install -U ultralytics
+```
+
+Next, use the Python code provided to start training the model.
+
+When the training starts, you can click **Done** and monitor the training progress on the Model page.
+
+
+
+
+
+!!! note "Note"
+
+ In case the training stops and a checkpoint was saved, you can resume training your model from the Model page.
+
+ 
+
+## Analyze Model
+
+After you [train a model](#train-model), you can analyze the model metrics.
+
+The **Train** tab presents the most important metrics carefully grouped based on the task.
+
+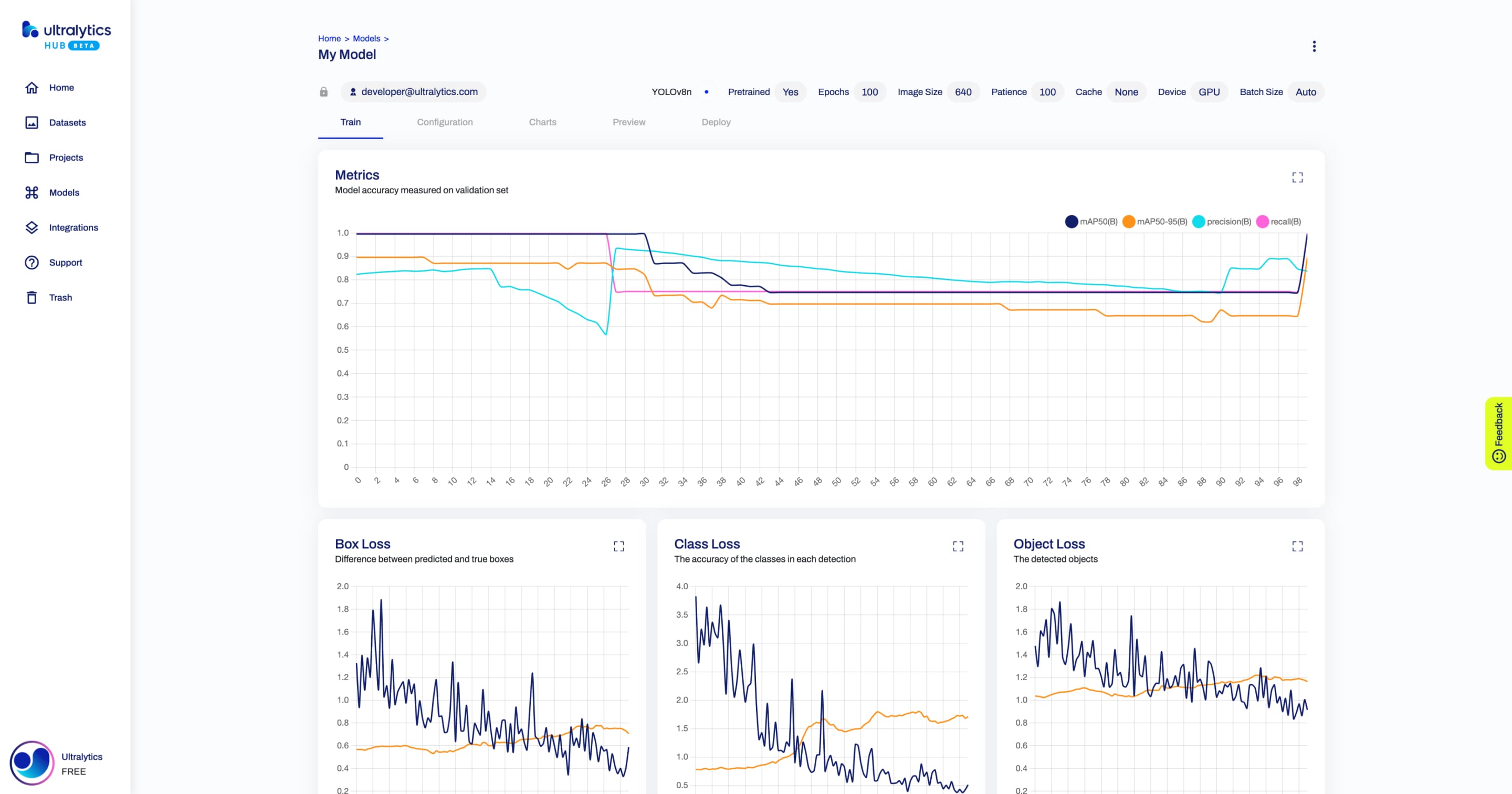
+
+To access all model metrics, click on the **Charts** tab.
+
+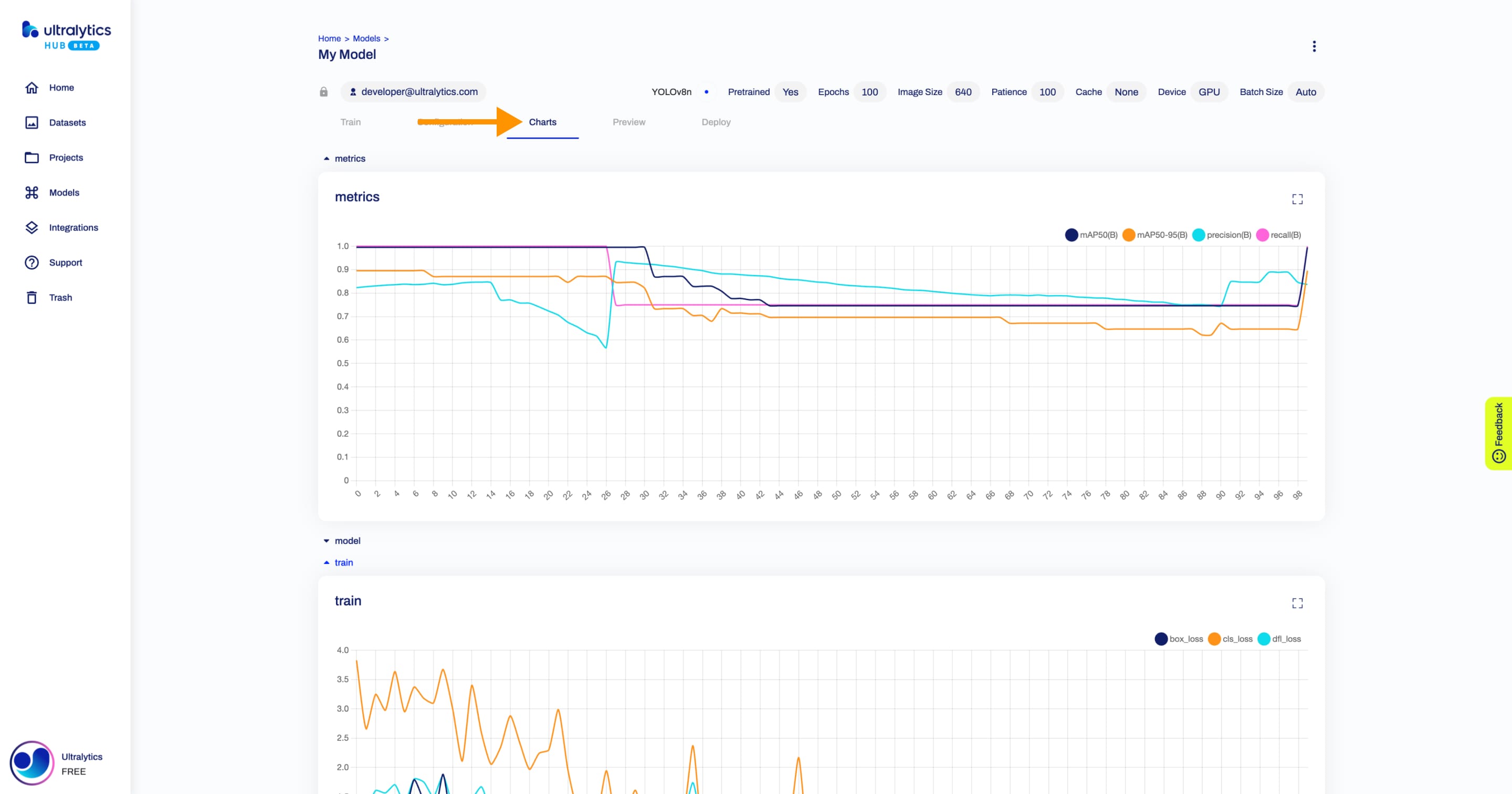
+
+??? tip "Tip"
+
+ Each chart can be enlarged for better visualization.
+
+ 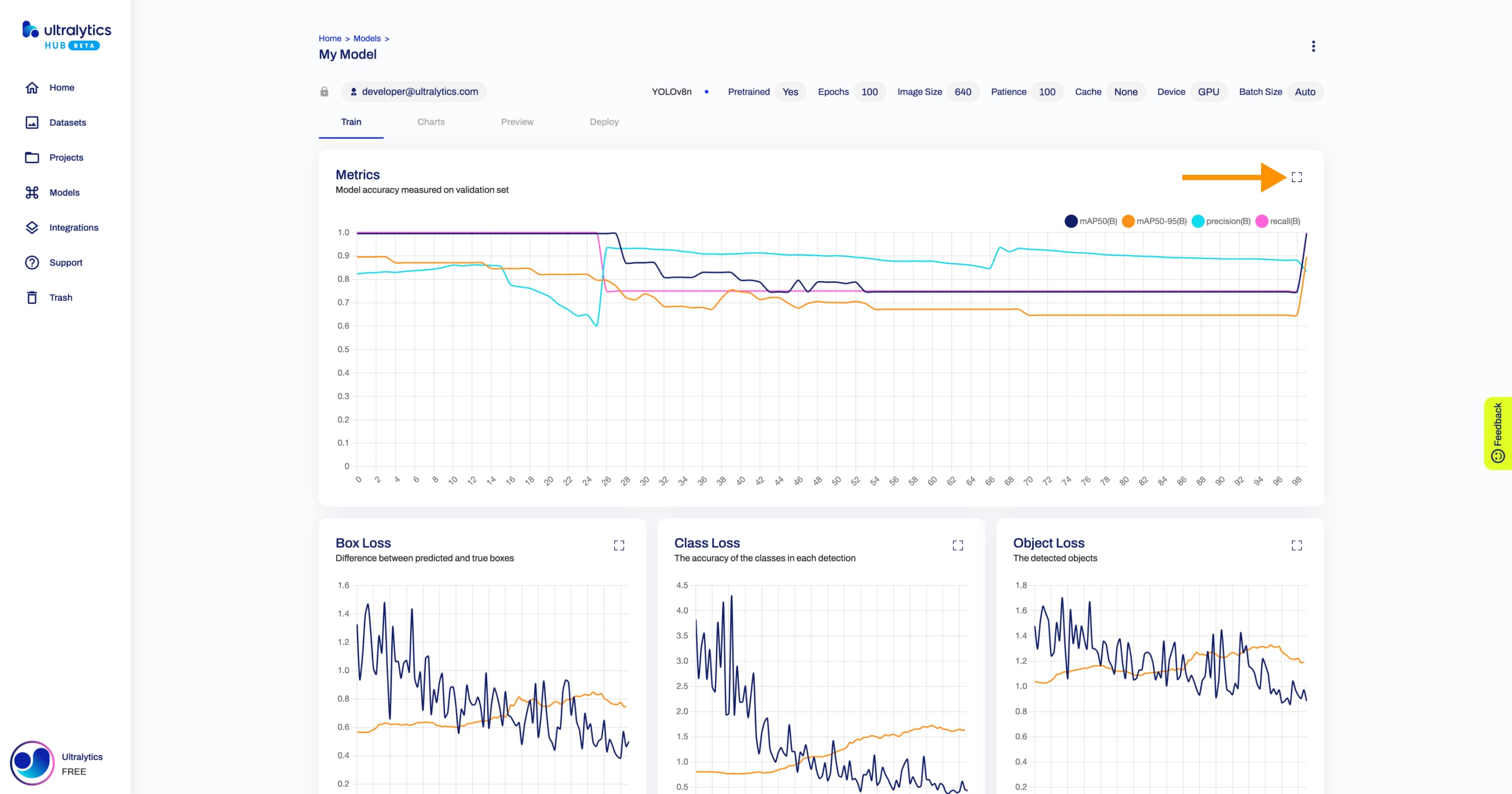
+
+ 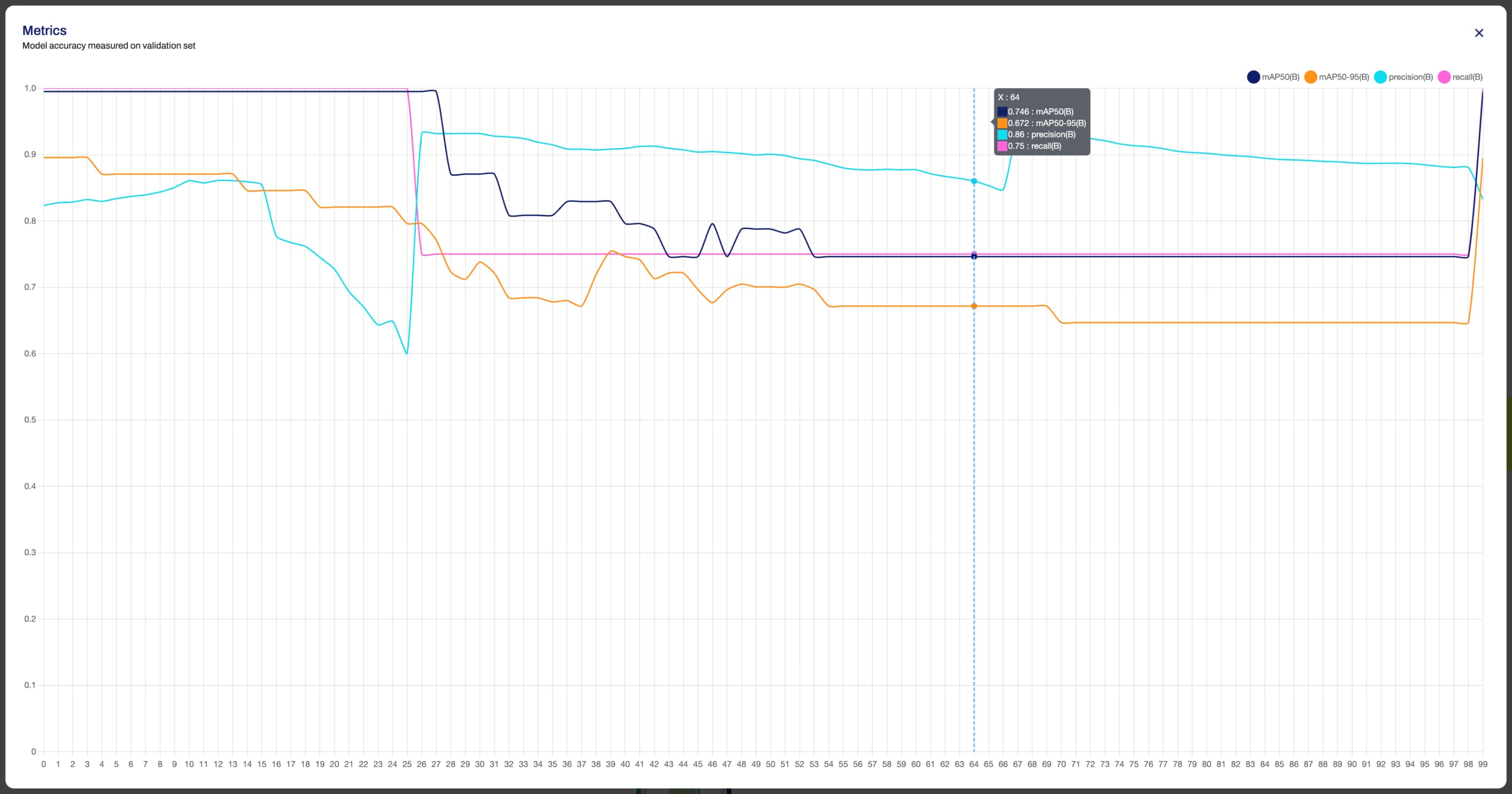
+
+ Furthermore, to properly analyze the data, you can utilize the zoom feature.
+
+ 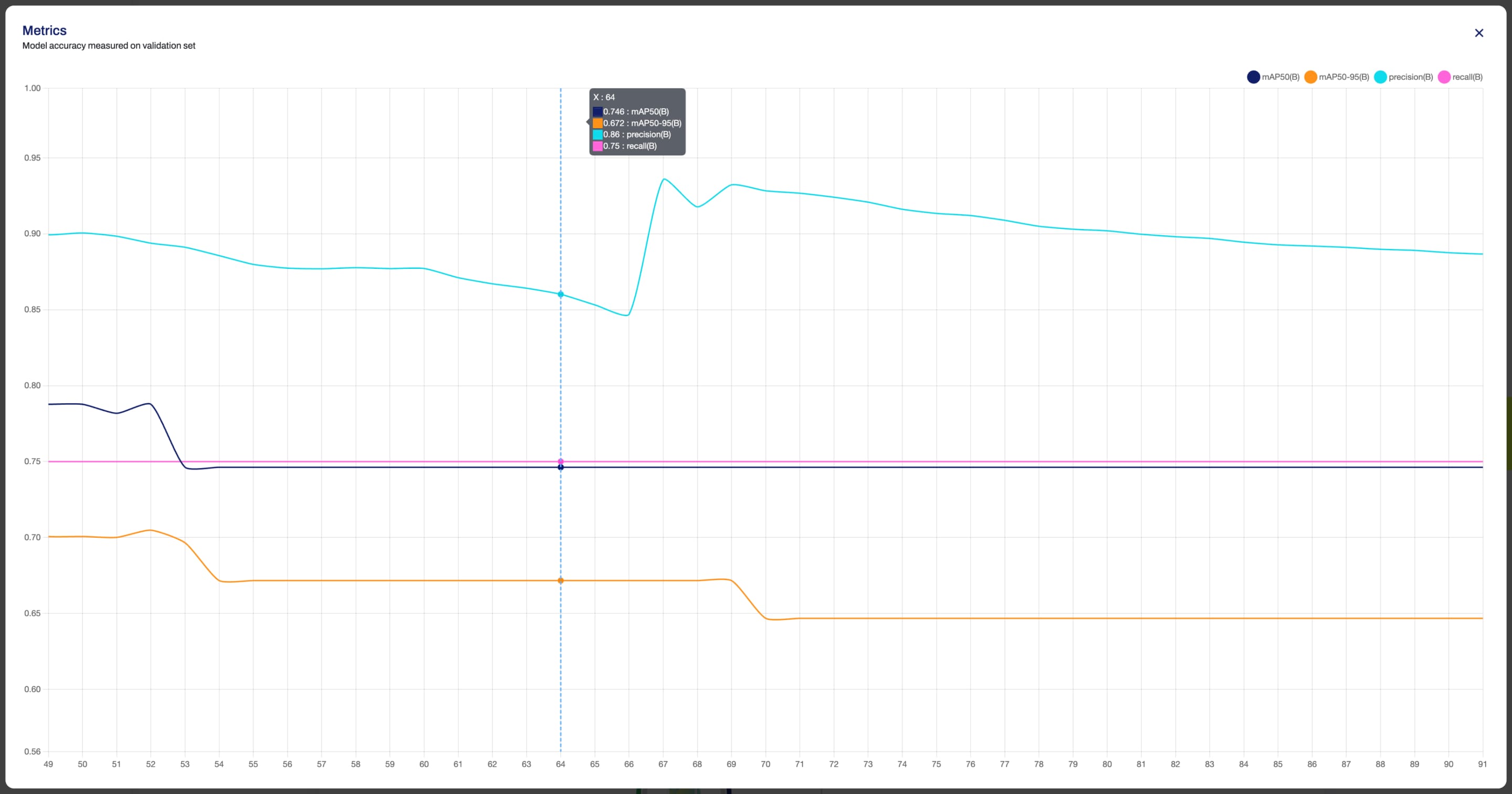
+
+## Preview Model
+
+After you [train a model](#train-model), you can preview it by clicking on the **Preview** tab.
+
+In the **Test** card, you can select a preview image from the dataset used during training or upload an image from your device.
+
+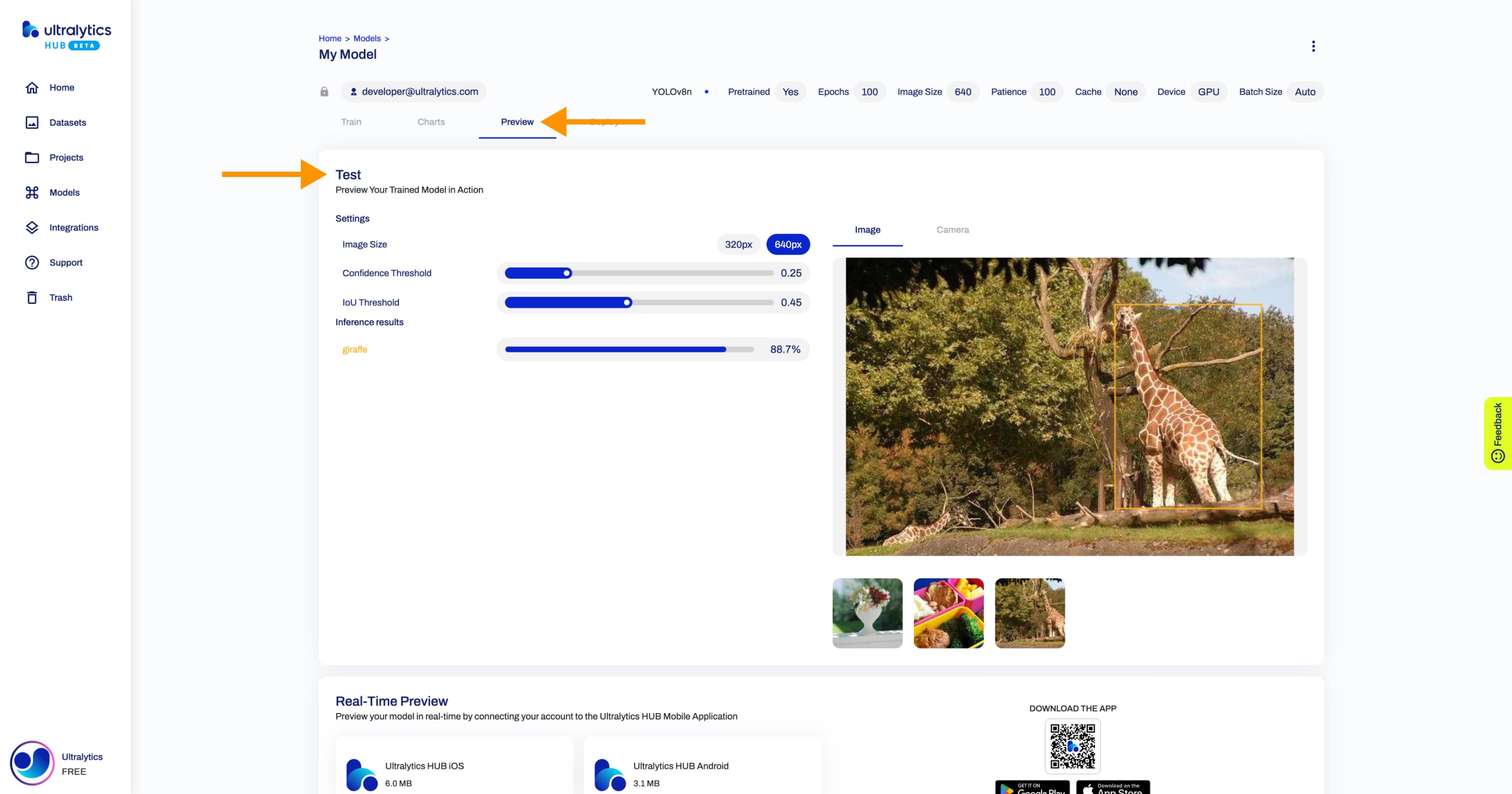
+
+!!! note "Note"
+
+ You can also use your camera to take a picture and run inference on it directly.
+
+ 
+
+Furthermore, you can preview your model in real-time directly on your [iOS](https://apps.apple.com/xk/app/ultralytics/id1583935240) or [Android](https://play.google.com/store/apps/details?id=com.ultralytics.ultralytics_app) mobile device by [downloading](https://ultralytics.com/app_install) our [Ultralytics HUB App](app/index.md).
+
+
+
+## Deploy Model
+
+After you [train a model](#train-model), you can export it to 13 different formats, including ONNX, OpenVINO, CoreML, TensorFlow, Paddle and many others.
+
+
+
+??? tip "Tip"
+
+ You can customize the export options of each format if you open the export actions dropdown and click on the **Advanced** option.
+
+ 
+
+!!! note "Note"
+
+ You can re-export each format if you open the export actions dropdown and click on the **Advanced** option.
+
+You can also use our [Inference API](./inference-api.md) in production.
+
+
+
+Read the [Ultralytics Inference API](./inference-api.md) documentation for more information.
+
+## Share Model
+
+!!! info "Info"
+
+ [Ultralytics HUB](https://ultralytics.com/hub)'s sharing functionality provides a convenient way to share models with others. This feature is designed to accommodate both existing [Ultralytics HUB](https://ultralytics.com/hub) users and those who have yet to create an account.
+
+??? note "Note"
+
+ You have control over the general access of your models.
+
+ You can choose to set the general access to "Private", in which case, only you will have access to it. Alternatively, you can set the general access to "Unlisted" which grants viewing access to anyone who has the direct link to the model, regardless of whether they have an [Ultralytics HUB](https://ultralytics.com/hub) account or not.
+
+Navigate to the Model page of the model you want to share, open the model actions dropdown and click on the **Share** option. This action will trigger the **Share Model** dialog.
+
+
+
+??? tip "Tip"
+
+ You can also share a model directly from the [Models](https://hub.ultralytics.com/models) page or from the Project page of the project where your model is located.
+
+ 
+
+Set the general access to "Unlisted" and click **Save**.
+
+
+
+Now, anyone who has the direct link to your model can view it.
+
+??? tip "Tip"
+
+ You can easily click on the model's link shown in the **Share Model** dialog to copy it.
+
+ 
+
+## Edit Model
+
+Navigate to the Model page of the model you want to edit, open the model actions dropdown and click on the **Edit** option. This action will trigger the **Update Model** dialog.
+
+
+
+??? tip "Tip"
+
+ You can also edit a model directly from the [Models](https://hub.ultralytics.com/models) page or from the Project page of the project where your model is located.
+
+ 
+
+Apply the desired modifications to your model and then confirm the changes by clicking **Save**.
+
+
+
+## Delete Model
+
+Navigate to the Model page of the model you want to delete, open the model actions dropdown and click on the **Delete** option. This action will delete the model.
+
+
+
+??? tip "Tip"
+
+ You can also delete a model directly from the [Models](https://hub.ultralytics.com/models) page or from the Project page of the project where your model is located.
+
+ 
+
+!!! note "Note"
+
+ If you change your mind, you can restore the model from the [Trash](https://hub.ultralytics.com/trash) page.
+
+ 
diff --git a/ultralytics/docs/en/hub/pro.md b/ultralytics/docs/en/hub/pro.md
new file mode 100644
index 0000000000000000000000000000000000000000..8e81e76ca1fc606c6df1666b48e8c2eb6d6f9d9e
--- /dev/null
+++ b/ultralytics/docs/en/hub/pro.md
@@ -0,0 +1,61 @@
+---
+comments: true
+description: Discover the enhanced features of Ultralytics HUB Pro Plan including 200GB storage, cloud training, and more. Learn how to upgrade and manage your account balance.
+keywords: Ultralytics HUB, Pro Plan, upgrade guide, cloud training, storage, inference API, team collaboration, account balance
+---
+
+# Ultralytics HUB Pro
+
+[Ultralytics HUB](https://ultralytics.com/hub) offers the Pro Plan as a monthly or annual subscription.
+
+The Pro Plan provides early access to upcoming features and includes enhanced benefits:
+
+- 200GB of storage, compared to the standard 20GB.
+- Access to our [Cloud Training](./cloud-training.md).
+- Access to our [Dedicated Inference API](./inference-api.md#dedicated-inference-api).
+- Increased rate limits for our [Shared Inference API](./inference-api.md#shared-inference-api).
+- Collaboration features for [teams](./teams.md).
+
+## Upgrade
+
+You can upgrade to the Pro Plan from the [Billing & License](https://hub.ultralytics.com/settings?tab=billing) tab on the [Settings](https://hub.ultralytics.com/settings) page by clicking on the **Upgrade** button.
+
+
+
+Next, select the Pro Plan.
+
+
+
+!!! tip "Tip"
+
+ You can save 20% if you choose the annual Pro Plan.
+
+ 
+
+Fill in your details during the checkout.
+
+
+
+!!! tip "Tip"
+
+ We recommend ticking the checkbox to save your payment information for future purchases, facilitating easier top-ups to your account balance.
+
+That's it!
+
+
+
+## Account Balance
+
+The account balance is used to pay for [Ultralytics Cloud Training](./cloud-training.md) resources.
+
+In order to top up your account balance, simply click on the **Top-Up** button.
+
+
+
+Next, set the amount you want to top-up.
+
+
+
+That's it!
+
+
diff --git a/ultralytics/docs/en/hub/projects.md b/ultralytics/docs/en/hub/projects.md
new file mode 100644
index 0000000000000000000000000000000000000000..fb9c54e599dd8c1a6ee61462016bedf534c02909
--- /dev/null
+++ b/ultralytics/docs/en/hub/projects.md
@@ -0,0 +1,181 @@
+---
+comments: true
+description: Optimize your model management with Ultralytics HUB Projects. Easily create, share, edit, and compare models for efficient development.
+keywords: Ultralytics HUB, model management, create project, share project, edit project, delete project, compare models, reorder models, transfer models
+---
+
+# Ultralytics HUB Projects
+
+[Ultralytics HUB](https://ultralytics.com/hub) projects provide an effective solution for consolidating and managing your models. If you are working with several models that perform similar tasks or have related purposes, [Ultralytics HUB](https://ultralytics.com/hub) projects allow you to group these models together.
+
+This creates a unified and organized workspace that facilitates easier model management, comparison and development. Having similar models or various iterations together can facilitate rapid benchmarking, as you can compare their effectiveness. This can lead to faster, more insightful iterative development and refinement of your models.
+
+
+
+
+ Watch: Train YOLOv8 Pose Model on Tiger-Pose Dataset Using Ultralytics HUB
+
+
+## Create Project
+
+Navigate to the [Projects](https://hub.ultralytics.com/projects) page by clicking on the **Projects** button in the sidebar and click on the **Create Project** button on the top right of the page.
+
+
+
+??? tip "Tip"
+
+ You can create a project directly from the [Home](https://hub.ultralytics.com/home) page.
+
+ 
+
+This action will trigger the **Create Project** dialog, opening up a suite of options for tailoring your project to your needs.
+
+Type the name of your project in the _Project name_ field or keep the default name and finalize the project creation with a single click.
+
+You have the additional option to enrich your project with a description and a unique image, enhancing its recognizability on the [Projects](https://hub.ultralytics.com/projects) page.
+
+When you're happy with your project configuration, click **Create**.
+
+
+
+After your project is created, you will be able to access it from the [Projects](https://hub.ultralytics.com/projects) page.
+
+
+
+Next, [train a model](./models.md#train-model) inside your project.
+
+
+
+## Share Project
+
+!!! info "Info"
+
+ [Ultralytics HUB](https://ultralytics.com/hub)'s sharing functionality provides a convenient way to share projects with others. This feature is designed to accommodate both existing [Ultralytics HUB](https://ultralytics.com/hub) users and those who have yet to create an account.
+
+??? note "Note"
+
+ You have control over the general access of your projects.
+
+ You can choose to set the general access to "Private", in which case, only you will have access to it. Alternatively, you can set the general access to "Unlisted" which grants viewing access to anyone who has the direct link to the project, regardless of whether they have an [Ultralytics HUB](https://ultralytics.com/hub) account or not.
+
+Navigate to the Project page of the project you want to share, open the project actions dropdown and click on the **Share** option. This action will trigger the **Share Project** dialog.
+
+
+
+??? tip "Tip"
+
+ You can share a project directly from the [Projects](https://hub.ultralytics.com/projects) page.
+
+ 
+
+Set the general access to "Unlisted" and click **Save**.
+
+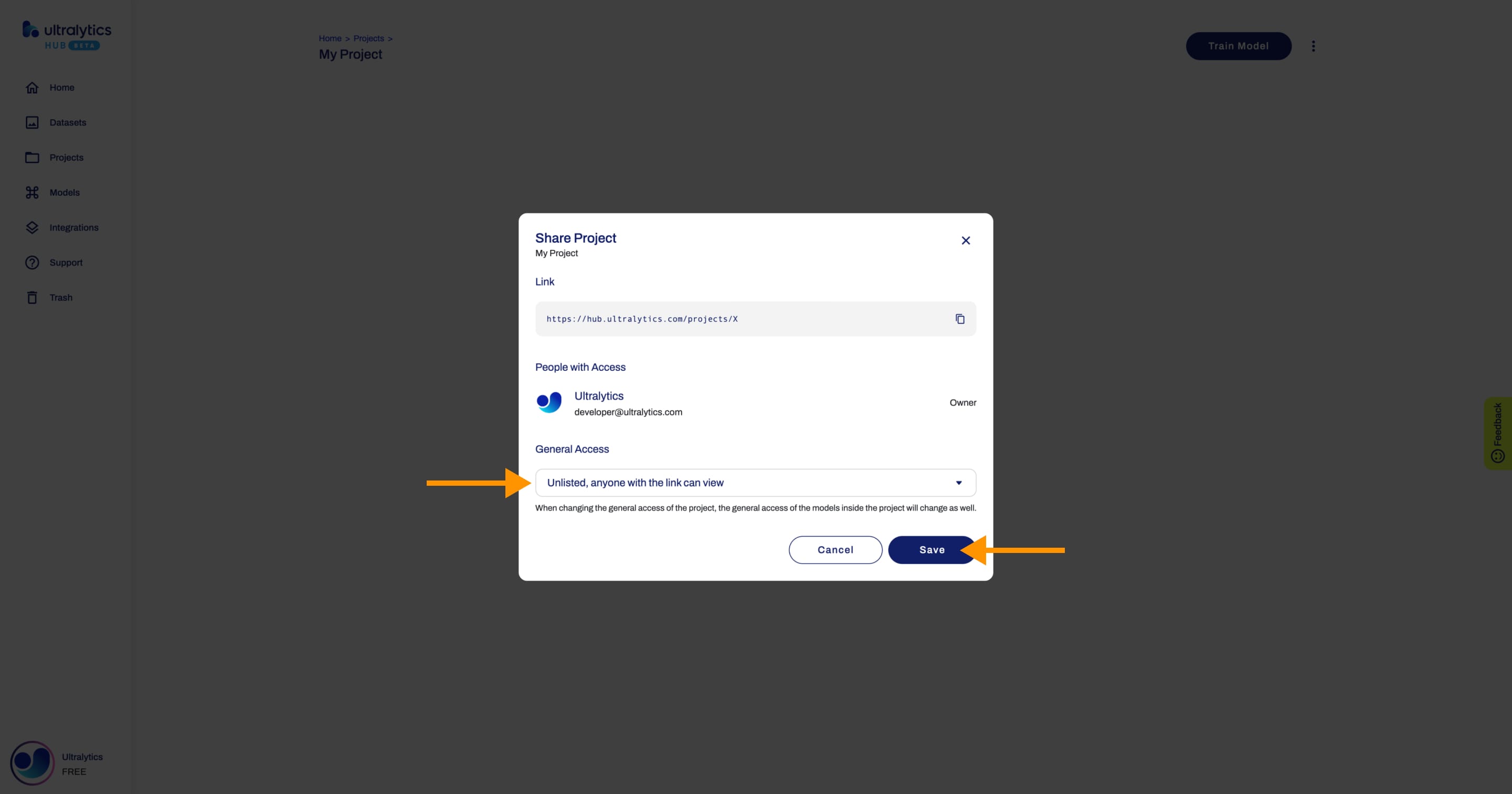
+
+!!! Warning "Warning"
+
+ When changing the general access of a project, the general access of the models inside the project will be changed as well.
+
+Now, anyone who has the direct link to your project can view it.
+
+??? tip "Tip"
+
+ You can easily click on the project's link shown in the **Share Project** dialog to copy it.
+
+ 
+
+## Edit Project
+
+Navigate to the Project page of the project you want to edit, open the project actions dropdown and click on the **Edit** option. This action will trigger the **Update Project** dialog.
+
+
+
+??? tip "Tip"
+
+ You can edit a project directly from the [Projects](https://hub.ultralytics.com/projects) page.
+
+ 
+
+Apply the desired modifications to your project and then confirm the changes by clicking **Save**.
+
+
+
+## Delete Project
+
+Navigate to the Project page of the project you want to delete, open the project actions dropdown and click on the **Delete** option. This action will delete the project.
+
+
+
+??? tip "Tip"
+
+ You can delete a project directly from the [Projects](https://hub.ultralytics.com/projects) page.
+
+ 
+
+!!! Warning "Warning"
+
+ When deleting a project, the models inside the project will be deleted as well.
+
+!!! note "Note"
+
+ If you change your mind, you can restore the project from the [Trash](https://hub.ultralytics.com/trash) page.
+
+ 
+
+## Compare Models
+
+Navigate to the Project page of the project where the models you want to compare are located. To use the model comparison feature, click on the **Charts** tab.
+
+
+
+This will display all the relevant charts. Each chart corresponds to a different metric and contains the performance of each model for that metric. The models are represented by different colors, and you can hover over each data point to get more information.
+
+
+
+??? tip "Tip"
+
+ Each chart can be enlarged for better visualization.
+
+ 
+
+ 
+
+ Furthermore, to properly analyze the data, you can utilize the zoom feature.
+
+ 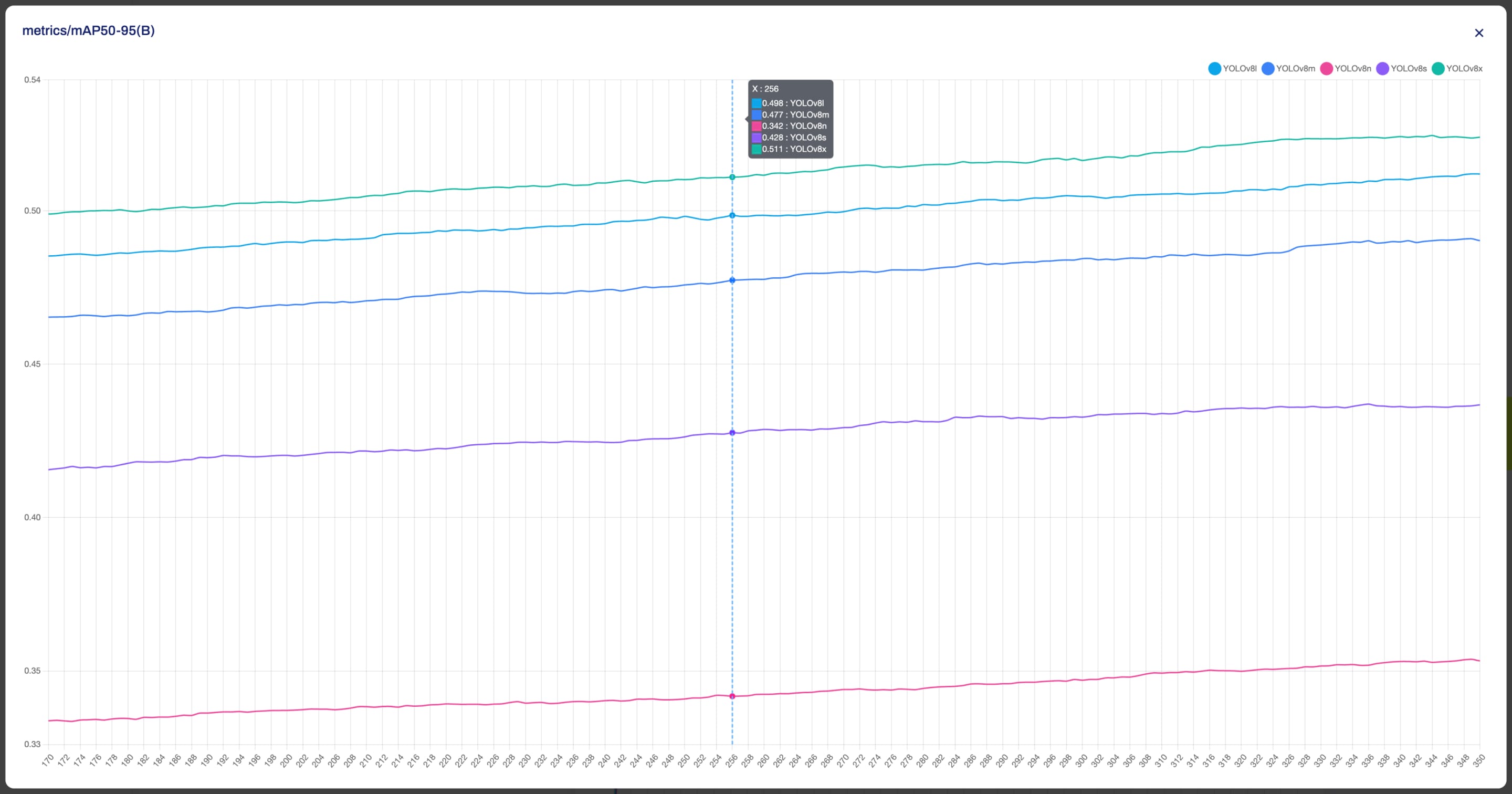
+
+??? tip "Tip"
+
+ You have the flexibility to customize your view by selectively hiding certain models. This feature allows you to concentrate on the models of interest.
+
+ 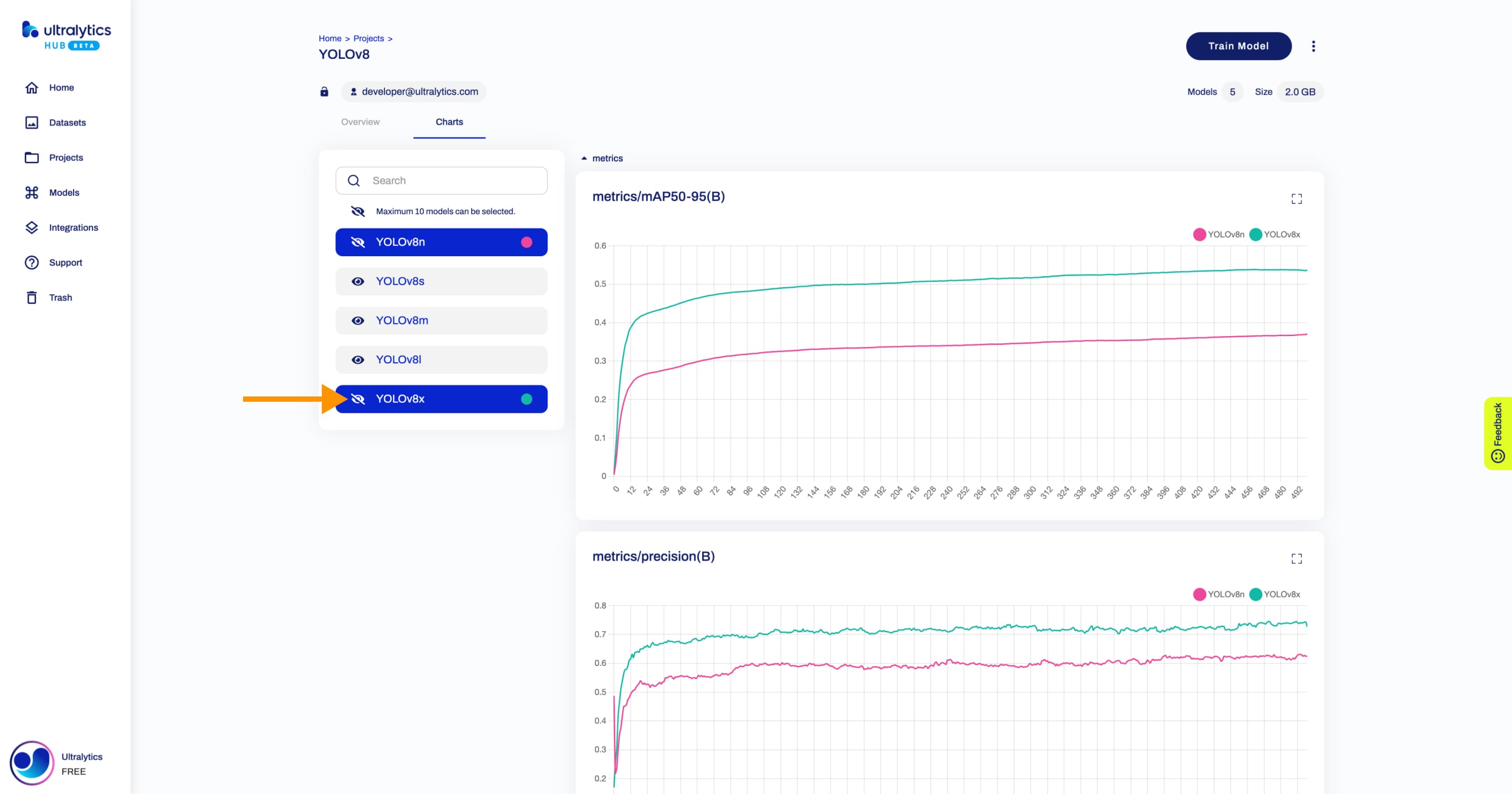
+
+## Reorder Models
+
+??? note "Note"
+
+ Ultralytics HUB's reordering functionality works only inside projects you own.
+
+Navigate to the Project page of the project where the models you want to reorder are located. Click on the designated reorder icon of the model you want to move and drag it to the desired location.
+
+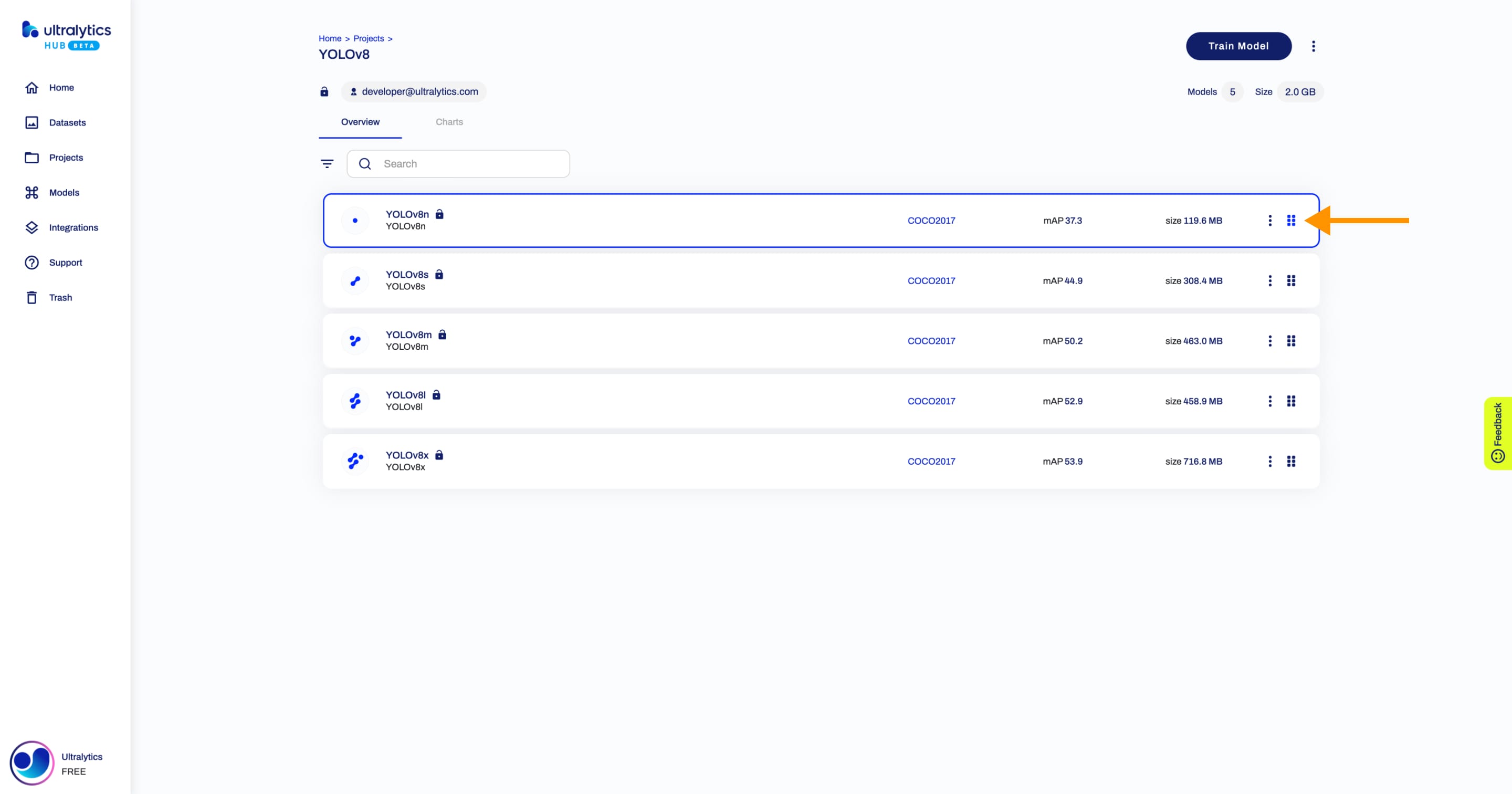
+
+## Transfer Models
+
+Navigate to the Project page of the project where the model you want to mode is located, open the project actions dropdown and click on the **Transfer** option. This action will trigger the **Transfer Model** dialog.
+
+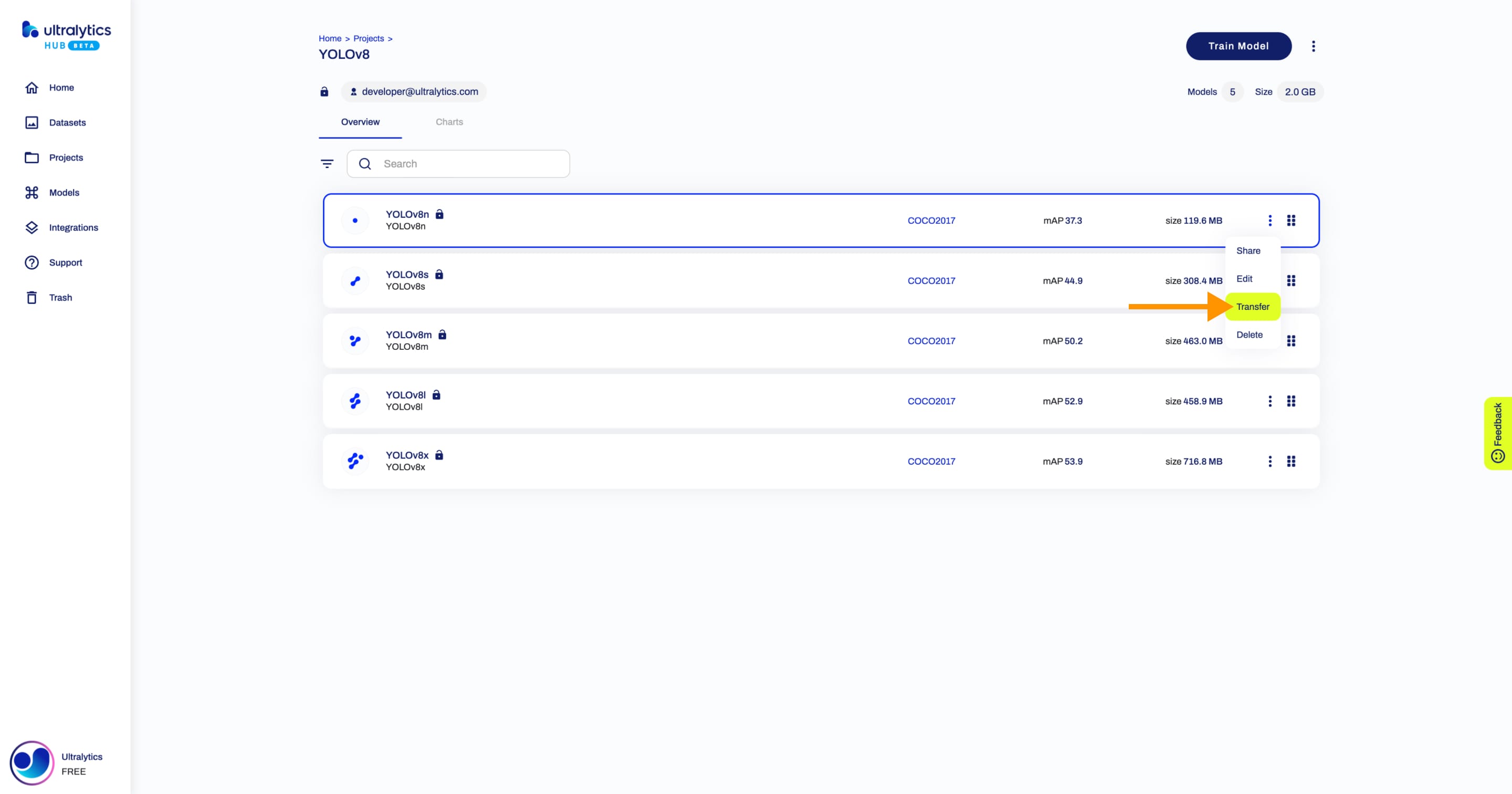
+
+??? tip "Tip"
+
+ You can also transfer a model directly from the [Models](https://hub.ultralytics.com/models) page.
+
+ 
+
+Select the project you want to transfer the model to and click **Save**.
+
+
diff --git a/ultralytics/docs/en/hub/quickstart.md b/ultralytics/docs/en/hub/quickstart.md
new file mode 100644
index 0000000000000000000000000000000000000000..ab3accfacb191aefd10c44865544ac2bec832123
--- /dev/null
+++ b/ultralytics/docs/en/hub/quickstart.md
@@ -0,0 +1,101 @@
+---
+comments: true
+description: Get started with Ultralytics HUB! Learn to upload datasets, train YOLO models, and manage projects easily with our user-friendly platform.
+keywords: Ultralytics HUB, Quickstart, YOLO models, dataset upload, project management, train models, machine learning
+---
+
+# Ultralytics HUB Quickstart
+
+[Ultralytics HUB](https://ultralytics.com/hub) is designed to be user-friendly and intuitive, allowing users to quickly upload their datasets and train new YOLO models. It also offers a range of pre-trained models to choose from, making it extremely easy for users to get started. Once a model is trained, it can be effortlessly previewed in the [Ultralytics HUB App](app/index.md) before being deployed for real-time classification, object detection, and instance segmentation tasks.
+
+
+
+
+ Watch: Train Your Custom YOLO Models In A Few Clicks with Ultralytics HUB
+
+
+## Get Started
+
+[Ultralytics HUB](https://ultralytics.com/hub) offers a variety easy of signup options. You can register and log in using your Google, Apple, or GitHub accounts, or simply with your email address.
+
+
+
+During the signup, you will be asked to complete your profile.
+
+
+
+??? tip "Tip"
+
+ You can update your profile from the [Account](https://hub.ultralytics.com/settings?tab=account) tab on the [Settings](https://hub.ultralytics.com/settings) page.
+
+ 
+
+## Home
+
+After signing in, you will be directed to the [Home](https://hub.ultralytics.com/home) page of [Ultralytics HUB](https://ultralytics.com/hub), which provides a comprehensive overview, quick links, and updates.
+
+The sidebar conveniently offers links to important modules of the platform, such as [Datasets](https://hub.ultralytics.com/datasets), [Projects](https://hub.ultralytics.com/projects), and [Models](https://hub.ultralytics.com/models).
+
+
+
+### Recent
+
+You can easily search globally or directly access your last updated [Datasets](https://hub.ultralytics.com/datasets), [Projects](https://hub.ultralytics.com/projects), or [Models](https://hub.ultralytics.com/models) using the Recent card on the [Home](https://hub.ultralytics.com/home) page.
+
+
+
+### Upload Dataset
+
+You can upload a dataset directly from the [Home](https://hub.ultralytics.com/home) page.
+
+
+
+Read more about [datasets](https://docs.ultralytics.com/hub/datasets).
+
+### Create Project
+
+You can create a project directly from the [Home](https://hub.ultralytics.com/home) page.
+
+
+
+Read more about [projects](https://docs.ultralytics.com/hub/projects).
+
+### Train Model
+
+You can train a model directly from the [Home](https://hub.ultralytics.com/home) page.
+
+
+
+Read more about [models](https://docs.ultralytics.com/hub/models).
+
+## Feedback
+
+We value your feedback! Feel free to leave a review at any time.
+
+
+
+
+
+??? info "Info"
+
+ Only our team will see your feedback, and we will use it to improve our platform.
+
+## Need Help?
+
+If you encounter any issues or have questions, we're here to assist you.
+
+You can report a bug, request a feature, or ask a question on GitHub.
+
+!!! note "Note"
+
+ When reporting a bug, please include your Environment Details from the [Support](https://hub.ultralytics.com/support) page.
+
+ 
+
+??? tip "Tip"
+
+ You can join our Discord community for questions and discussions!
diff --git a/ultralytics/docs/en/hub/teams.md b/ultralytics/docs/en/hub/teams.md
new file mode 100644
index 0000000000000000000000000000000000000000..8456f0df1e11acedd818dbfdcc064d858e96440e
--- /dev/null
+++ b/ultralytics/docs/en/hub/teams.md
@@ -0,0 +1,191 @@
+---
+comments: true
+description: Discover how to manage and collaborate with team members using Ultralytics HUB Teams. Learn to create, edit, and share resources efficiently.
+keywords: Ultralytics HUB, Teams, collaboration, team management, AI projects, resource sharing, Pro Plan, data sharing, project management
+---
+
+# Ultralytics HUB Teams
+
+We're excited to introduce you to the new Teams feature within [Ultralytics HUB](https://ultralytics.com/hub) for our [Pro](./pro.md) users!
+
+Here, you'll learn how to manage team members, share resources seamlessly, and collaborate efficiently on various projects.
+
+!!! note "Note"
+
+ As this is a new feature, we're still in the process of developing and refining it to ensure it meets your needs.
+
+## Create Team
+
+!!! note "Note"
+
+ You need to [upgrade](./pro.md#upgrade) to the [Pro Plan](./pro.md) in order to create a team.
+
+ 
+
+Navigate to the [Teams](https://hub.ultralytics.com/settings?tab=teams) page by clicking on the **Teams** tab in the [Settings](https://hub.ultralytics.com/settings) page and click on the **Create Team** button.
+
+
+
+This action will trigger the **Create Team** dialog.
+
+Type the name of your team in the _Team name_ field or keep the default name and finalize the team creation with a single click.
+
+You have the additional option to enrich your team with a description and a unique image, enhancing its recognizability on the [Teams](https://hub.ultralytics.com/settings?tab=teams) page.
+
+When you're happy with your team configuration, click **Create**.
+
+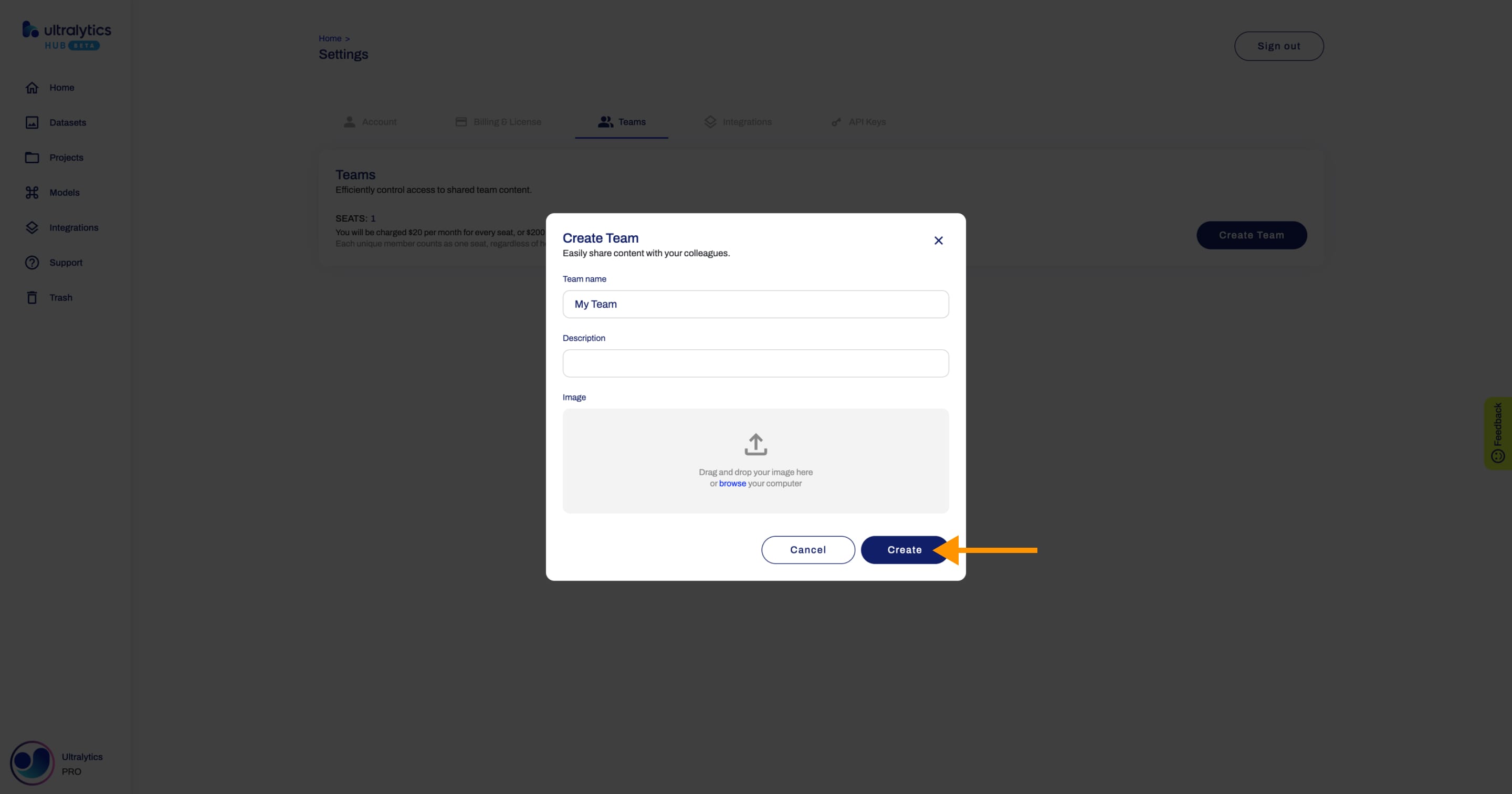
+
+After your team is created, you will be able to access it from the [Teams](https://hub.ultralytics.com/settings?tab=teams) page.
+
+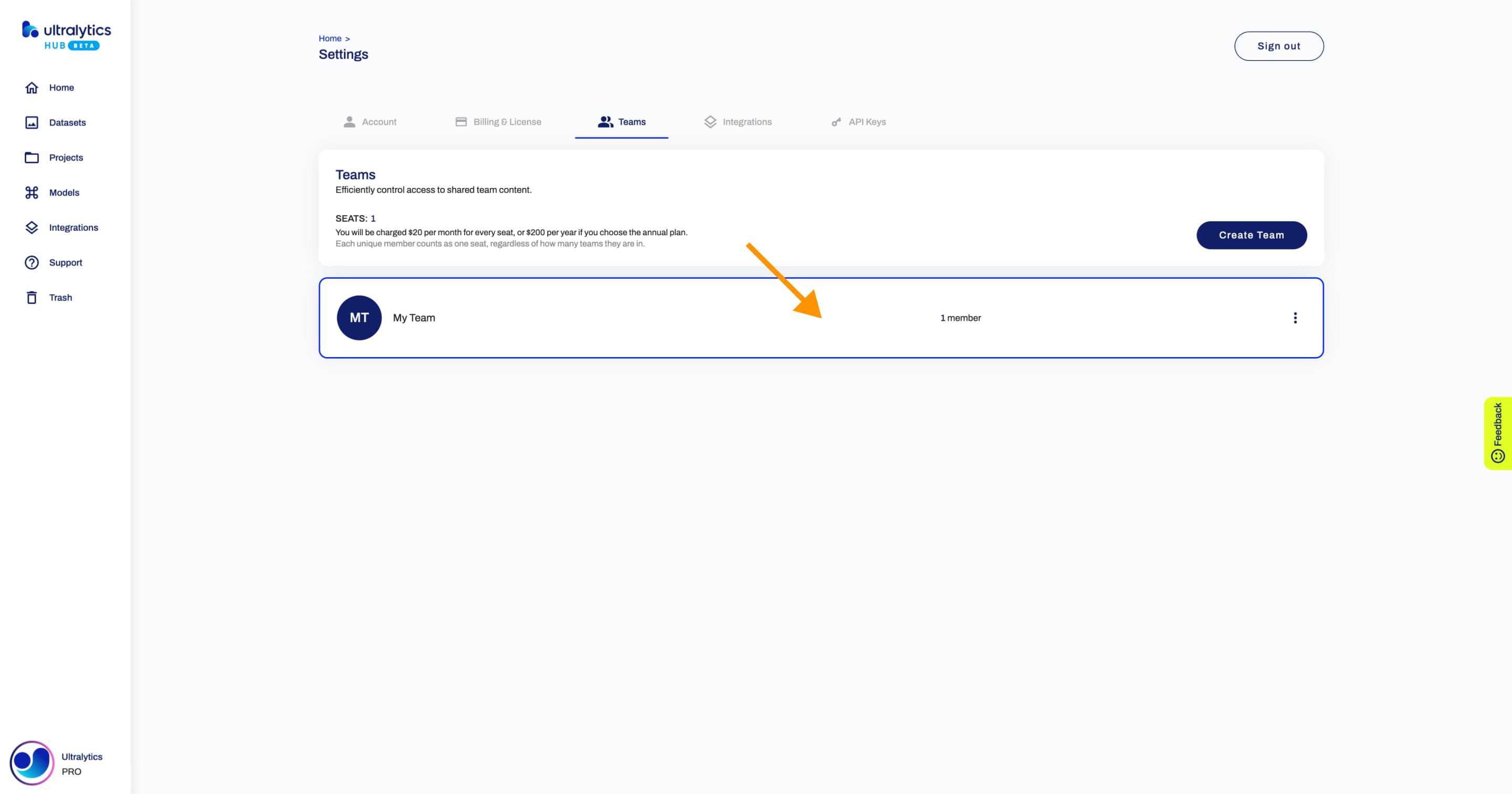
+
+## Edit Team
+
+Navigate to the [Teams](https://hub.ultralytics.com/settings?tab=teams) page, open the team actions dropdown of team you want to edit and click on the **Edit** option. This action will trigger the **Update Team** dialog.
+
+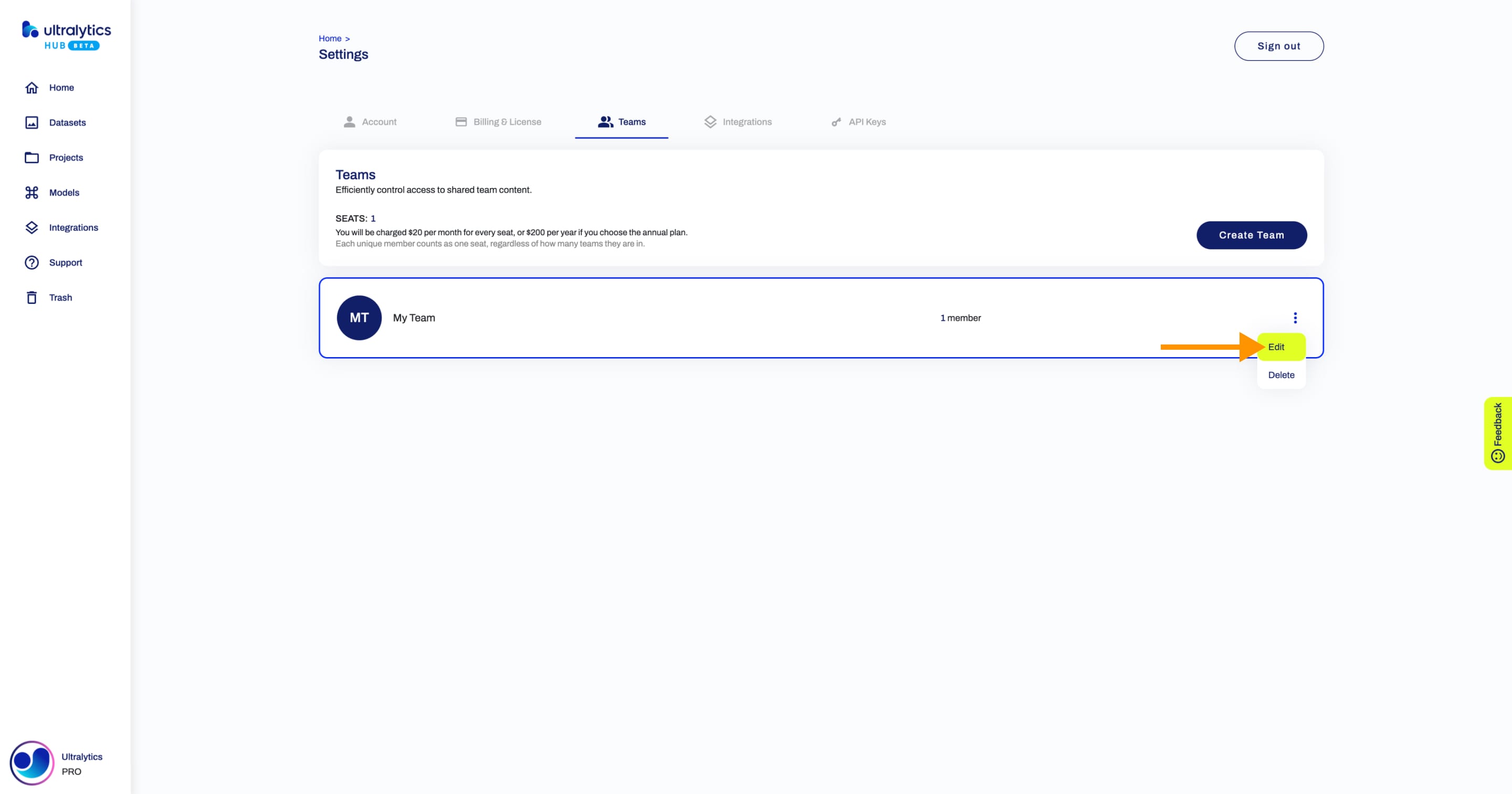
+
+Apply the desired modifications to your team and then confirm the changes by clicking **Save**.
+
+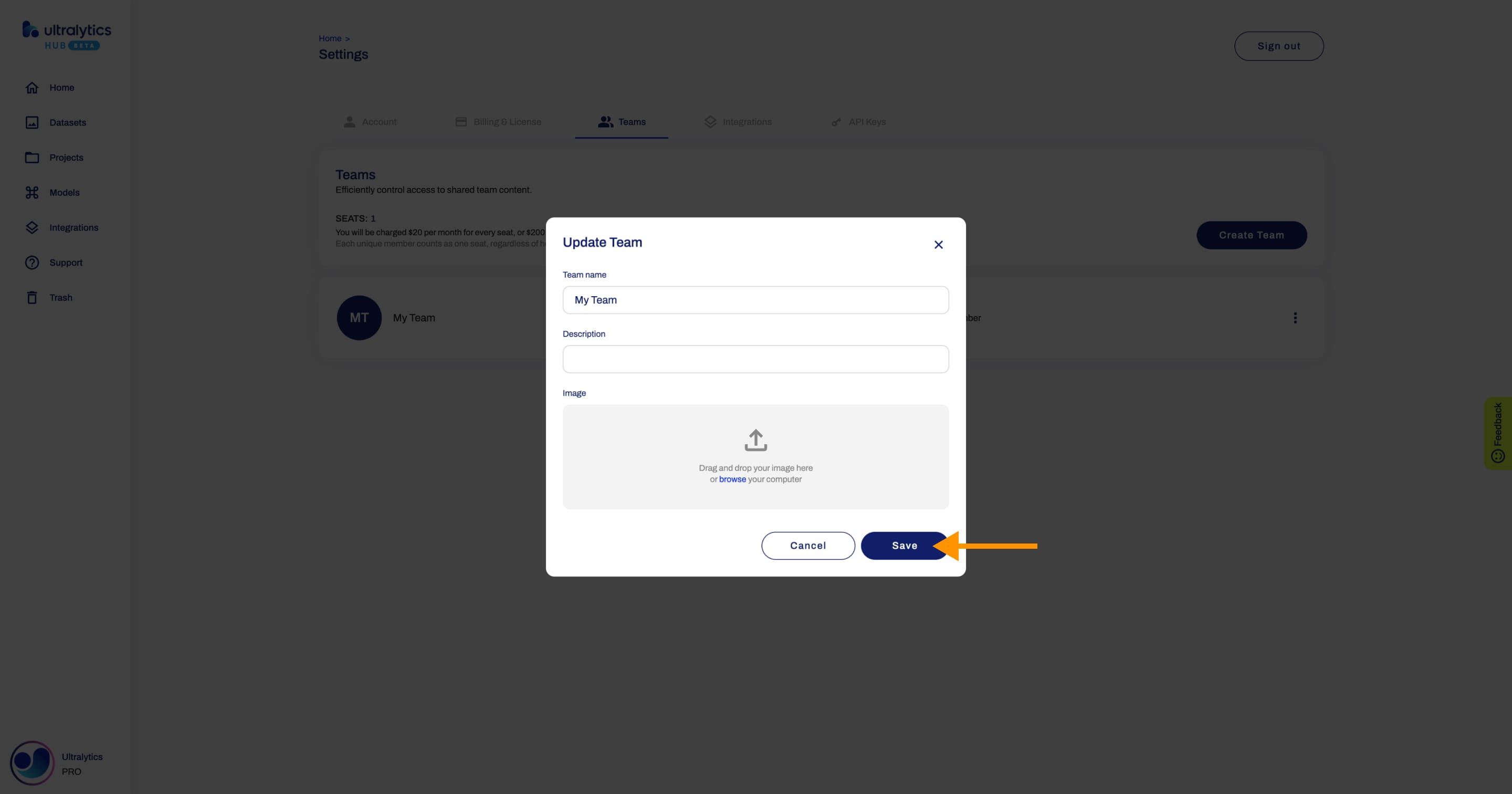
+
+## Delete Team
+
+Navigate to the [Teams](https://hub.ultralytics.com/settings?tab=teams) page, open the team actions dropdown of team you want to delete and click on the **Delete** option.
+
+
+
+!!! Warning "Warning"
+
+ When deleting a team, the team can't be restored.
+
+## Invite Member
+
+Navigate to the Team page of the team to which you want to add a new member and click on the **Invite Member** button. This action will trigger the **Invite Member** dialog.
+
+
+
+Type the email and select the role of the new member and click **Invite**.
+
+
+
+
+
+??? tip "Tip"
+
+ You can cancel the invite before the new member accepts it.
+
+ 
+
+The **Pending** status disappears after the new member accepts the invite.
+
+
+
+??? tip "Tip"
+
+ You can update a member's role at any time.
+
+ The **Admin** role allows inviting and removing members, as well as removing shared datasets or projects.
+
+ 
+
+### Seats
+
+The [Pro Plan](./pro.md) offers one free seat _(yours)_.
+
+When a new unique member joins one of your teams, the number of seats increases, and you will be charged **$20 per month** for each seat, or **$200 per year** if you choose the annual plan.
+
+Each unique member counts as one seat, regardless of how many teams they are in. For example, if John Doe is a member of 5 of your teams, he is using one seat.
+
+When you remove a unique member from the last team they are a member of, the number of seats decreases. The charge is prorated and can be applied to adding other unique members, paying for the [Pro Plan](./pro.md), or topping up your [account balance](./pro.md#account-balance).
+
+You can see the number of seats on the [Teams](https://hub.ultralytics.com/settings?tab=teams) page.
+
+
+
+## Remove Member
+
+Navigate to the Team page of the team from which you want to remove a member, open the member actions dropdown, and click on the **Remove** option.
+
+
+
+## Join Team
+
+When you are invited to a team, you receive an in-app notification.
+
+You can view your notifications by clicking on the **View** button on the **Notifications** card on the [Home](https://hub.ultralytics.com/home) page.
+
+
+
+Alternatively, you can view your notifications by accessing the [Notifications](https://hub.ultralytics.com/notifications) page directly.
+
+
+
+You can decide whether to join the team on the Team page of the team to which you were invited.
+
+If you want to join the team, click on the **Join Team** button.
+
+
+
+If you don't want to join the team, click on the **Reject Invitation** button.
+
+
+
+??? tip "Tip"
+
+ You can join the team directly from the [Teams](https://hub.ultralytics.com/settings?tab=teams) page.
+
+ 
+
+## Leave Team
+
+Navigate to the Team page of the team you want to leave and click on the **Leave Team** button.
+
+
+
+## Share Dataset
+
+Navigate to the Team page of the team you want to share your dataset with and click on the **Add Dataset** button.
+
+
+
+Select the dataset you want to share with your team and click on the **Add** button.
+
+
+
+That's it! Your team now has access to your dataset.
+
+
+
+??? tip "Tip"
+
+ As a team owner or team admin, you can remove a shared dataset.
+
+ 
+
+## Share Project
+
+Navigate to the Team page of the team you want to share your project with and click on the **Add Project** button.
+
+
+
+Select the project you want to share with your team and click on the **Add** button.
+
+
+
+That's it! Your team now has access to your project.
+
+
+
+??? tip "Tip"
+
+ As a team owner or team admin, you can remove a shared project.
+
+ 
+
+!!! note "Note"
+
+ When you share a project with your team, all models inside the project are shared as well.
+
+ 
diff --git a/ultralytics/docs/en/index.md b/ultralytics/docs/en/index.md
new file mode 100644
index 0000000000000000000000000000000000000000..10810ec738d4e29c7d6379b728f0b671f661e840
--- /dev/null
+++ b/ultralytics/docs/en/index.md
@@ -0,0 +1,145 @@
+---
+comments: true
+description: Discover Ultralytics YOLOv8 - the latest in real-time object detection and image segmentation. Learn its features and maximize its potential in your projects.
+keywords: Ultralytics, YOLOv8, object detection, image segmentation, deep learning, computer vision, AI, machine learning, documentation, tutorial
+---
+
+
+
+Introducing [Ultralytics](https://ultralytics.com) [YOLOv8](https://github.com/ultralytics/ultralytics), the latest version of the acclaimed real-time object detection and image segmentation model. YOLOv8 is built on cutting-edge advancements in deep learning and computer vision, offering unparalleled performance in terms of speed and accuracy. Its streamlined design makes it suitable for various applications and easily adaptable to different hardware platforms, from edge devices to cloud APIs.
+
+Explore the YOLOv8 Docs, a comprehensive resource designed to help you understand and utilize its features and capabilities. Whether you are a seasoned machine learning practitioner or new to the field, this hub aims to maximize YOLOv8's potential in your projects
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+## Where to Start
+
+- **Install** `ultralytics` with pip and get up and running in minutes [:material-clock-fast: Get Started](quickstart.md){ .md-button }
+- **Predict** new images and videos with YOLOv8 [:octicons-image-16: Predict on Images](modes/predict.md){ .md-button }
+- **Train** a new YOLOv8 model on your own custom dataset [:fontawesome-solid-brain: Train a Model](modes/train.md){ .md-button }
+- **Tasks** YOLOv8 tasks like segment, classify, pose and track [:material-magnify-expand: Explore Tasks](tasks/index.md){ .md-button }
+- **NEW 🚀 Explore** datasets with advanced semantic and SQL search [:material-magnify-expand: Explore a Dataset](datasets/explorer/index.md){ .md-button }
+
+
+
+
+
+ Watch: How to Train a YOLOv8 model on Your Custom Dataset in Google Colab.
+
+
+## YOLO: A Brief History
+
+[YOLO](https://arxiv.org/abs/1506.02640) (You Only Look Once), a popular object detection and image segmentation model, was developed by Joseph Redmon and Ali Farhadi at the University of Washington. Launched in 2015, YOLO quickly gained popularity for its high speed and accuracy.
+
+- [YOLOv2](https://arxiv.org/abs/1612.08242), released in 2016, improved the original model by incorporating batch normalization, anchor boxes, and dimension clusters.
+- [YOLOv3](https://pjreddie.com/media/files/papers/YOLOv3.pdf), launched in 2018, further enhanced the model's performance using a more efficient backbone network, multiple anchors and spatial pyramid pooling.
+- [YOLOv4](https://arxiv.org/abs/2004.10934) was released in 2020, introducing innovations like Mosaic data augmentation, a new anchor-free detection head, and a new loss function.
+- [YOLOv5](https://github.com/ultralytics/yolov5) further improved the model's performance and added new features such as hyperparameter optimization, integrated experiment tracking and automatic export to popular export formats.
+- [YOLOv6](https://github.com/meituan/YOLOv6) was open-sourced by [Meituan](https://about.meituan.com/) in 2022 and is in use in many of the company's autonomous delivery robots.
+- [YOLOv7](https://github.com/WongKinYiu/yolov7) added additional tasks such as pose estimation on the COCO keypoints dataset.
+- [YOLOv8](https://github.com/ultralytics/ultralytics) is the latest version of YOLO by Ultralytics. As a cutting-edge, state-of-the-art (SOTA) model, YOLOv8 builds on the success of previous versions, introducing new features and improvements for enhanced performance, flexibility, and efficiency. YOLOv8 supports a full range of vision AI tasks, including [detection](tasks/detect.md), [segmentation](tasks/segment.md), [pose estimation](tasks/pose.md), [tracking](modes/track.md), and [classification](tasks/classify.md). This versatility allows users to leverage YOLOv8's capabilities across diverse applications and domains.
+- [YOLOv9](models/yolov9.md) introduces innovative methods like Programmable Gradient Information (PGI) and the Generalized Efficient Layer Aggregation Network (GELAN).
+- [YOLOv10](models/yolov10.md) is created by researchers from [Tsinghua University](https://www.tsinghua.edu.cn/en/) using the [Ultralytics](https://ultralytics.com/) [Python package](https://pypi.org/project/ultralytics/). This version provides real-time [object detection](tasks/detect.md) advancements by introducing an End-to-End head that eliminates Non-Maximum Suppression (NMS) requirements.
+
+## YOLO Licenses: How is Ultralytics YOLO licensed?
+
+Ultralytics offers two licensing options to accommodate diverse use cases:
+
+- **AGPL-3.0 License**: This [OSI-approved](https://opensource.org/licenses/) open-source license is ideal for students and enthusiasts, promoting open collaboration and knowledge sharing. See the [LICENSE](https://github.com/ultralytics/ultralytics/blob/main/LICENSE) file for more details.
+- **Enterprise License**: Designed for commercial use, this license permits seamless integration of Ultralytics software and AI models into commercial goods and services, bypassing the open-source requirements of AGPL-3.0. If your scenario involves embedding our solutions into a commercial offering, reach out through [Ultralytics Licensing](https://ultralytics.com/license).
+
+Our licensing strategy is designed to ensure that any improvements to our open-source projects are returned to the community. We hold the principles of open source close to our hearts ❤️, and our mission is to guarantee that our contributions can be utilized and expanded upon in ways that are beneficial to all.
+
+## FAQ
+
+### What is Ultralytics YOLO and how does it improve object detection?
+
+Ultralytics YOLO is the latest advancement in the acclaimed YOLO (You Only Look Once) series for real-time object detection and image segmentation. It builds on previous versions by introducing new features and improvements for enhanced performance, flexibility, and efficiency. YOLOv8 supports various [vision AI tasks](tasks/index.md) such as detection, segmentation, pose estimation, tracking, and classification. Its state-of-the-art architecture ensures superior speed and accuracy, making it suitable for diverse applications, including edge devices and cloud APIs.
+
+### How can I get started with YOLO installation and setup?
+
+Getting started with YOLO is quick and straightforward. You can install the Ultralytics package using pip and get up and running in minutes. Here's a basic installation command:
+
+```bash
+pip install ultralytics
+```
+
+For a comprehensive step-by-step guide, visit our [quickstart guide](quickstart.md). This resource will help you with installation instructions, initial setup, and running your first model.
+
+### How can I train a custom YOLO model on my dataset?
+
+Training a custom YOLO model on your dataset involves a few detailed steps:
+
+1. Prepare your annotated dataset.
+2. Configure the training parameters in a YAML file.
+3. Use the `yolo train` command to start training.
+
+Here's an example command:
+
+```bash
+yolo train model=yolov8n.pt data=coco128.yaml epochs=100 imgsz=640
+```
+
+For a detailed walkthrough, check out our [Train a Model](modes/train.md) guide, which includes examples and tips for optimizing your training process.
+
+### What are the licensing options available for Ultralytics YOLO?
+
+Ultralytics offers two licensing options for YOLO:
+
+- **AGPL-3.0 License**: This open-source license is ideal for educational and non-commercial use, promoting open collaboration.
+- **Enterprise License**: This is designed for commercial applications, allowing seamless integration of Ultralytics software into commercial products without the restrictions of the AGPL-3.0 license.
+
+For more details, visit our [Licensing](https://ultralytics.com/license) page.
+
+### How can Ultralytics YOLO be used for real-time object tracking?
+
+Ultralytics YOLO supports efficient and customizable multi-object tracking. To utilize tracking capabilities, you can use the `yolo track` command as shown below:
+
+```bash
+yolo track model=yolov8n.pt source=video.mp4
+```
+
+For a detailed guide on setting up and running object tracking, check our [tracking mode](modes/track.md) documentation, which explains the configuration and practical applications in real-time scenarios.
diff --git a/ultralytics/docs/en/integrations/amazon-sagemaker.md b/ultralytics/docs/en/integrations/amazon-sagemaker.md
new file mode 100644
index 0000000000000000000000000000000000000000..dfaf727b8064d7426ad88acb5fd4d2780389fbe7
--- /dev/null
+++ b/ultralytics/docs/en/integrations/amazon-sagemaker.md
@@ -0,0 +1,256 @@
+---
+comments: true
+description: Learn step-by-step how to deploy Ultralytics' YOLOv8 on Amazon SageMaker Endpoints, from setup to testing, for powerful real-time inference with AWS services.
+keywords: YOLOv8, Amazon SageMaker, AWS, Ultralytics, machine learning, computer vision, model deployment, AWS CloudFormation, AWS CDK, real-time inference
+---
+
+# A Guide to Deploying YOLOv8 on Amazon SageMaker Endpoints
+
+Deploying advanced computer vision models like [Ultralytics' YOLOv8](https://github.com/ultralytics/ultralytics) on Amazon SageMaker Endpoints opens up a wide range of possibilities for various machine learning applications. The key to effectively using these models lies in understanding their setup, configuration, and deployment processes. YOLOv8 becomes even more powerful when integrated seamlessly with Amazon SageMaker, a robust and scalable machine learning service by AWS.
+
+This guide will take you through the process of deploying YOLOv8 PyTorch models on Amazon SageMaker Endpoints step by step. You'll learn the essentials of preparing your AWS environment, configuring the model appropriately, and using tools like AWS CloudFormation and the AWS Cloud Development Kit (CDK) for deployment.
+
+## Amazon SageMaker
+
+
+
+
+
+[Amazon SageMaker](https://aws.amazon.com/sagemaker/) is a machine learning service from Amazon Web Services (AWS) that simplifies the process of building, training, and deploying machine learning models. It provides a broad range of tools for handling various aspects of machine learning workflows. This includes automated features for tuning models, options for training models at scale, and straightforward methods for deploying models into production. SageMaker supports popular machine learning frameworks, offering the flexibility needed for diverse projects. Its features also cover data labeling, workflow management, and performance analysis.
+
+## Deploying YOLOv8 on Amazon SageMaker Endpoints
+
+Deploying YOLOv8 on Amazon SageMaker lets you use its managed environment for real-time inference and take advantage of features like autoscaling. Take a look at the AWS architecture below.
+
+
+
+
+
+### Step 1: Setup Your AWS Environment
+
+First, ensure you have the following prerequisites in place:
+
+- An AWS Account: If you don't already have one, sign up for an AWS account.
+
+- Configured IAM Roles: You'll need an IAM role with the necessary permissions for Amazon SageMaker, AWS CloudFormation, and Amazon S3. This role should have policies that allow it to access these services.
+
+- AWS CLI: If not already installed, download and install the AWS Command Line Interface (CLI) and configure it with your account details. Follow [the AWS CLI instructions](https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html) for installation.
+
+- AWS CDK: If not already installed, install the AWS Cloud Development Kit (CDK), which will be used for scripting the deployment. Follow [the AWS CDK instructions](https://docs.aws.amazon.com/cdk/v2/guide/getting_started.html#getting_started_install) for installation.
+
+- Adequate Service Quota: Confirm that you have sufficient quotas for two separate resources in Amazon SageMaker: one for `ml.m5.4xlarge` for endpoint usage and another for `ml.m5.4xlarge` for notebook instance usage. Each of these requires a minimum of one quota value. If your current quotas are below this requirement, it's important to request an increase for each. You can request a quota increase by following the detailed instructions in the [AWS Service Quotas documentation](https://docs.aws.amazon.com/servicequotas/latest/userguide/request-quota-increase.html#quota-console-increase).
+
+### Step 2: Clone the YOLOv8 SageMaker Repository
+
+The next step is to clone the specific AWS repository that contains the resources for deploying YOLOv8 on SageMaker. This repository, hosted on GitHub, includes the necessary CDK scripts and configuration files.
+
+- Clone the GitHub Repository: Execute the following command in your terminal to clone the host-yolov8-on-sagemaker-endpoint repository:
+
+```bash
+git clone https://github.com/aws-samples/host-yolov8-on-sagemaker-endpoint.git
+```
+
+- Navigate to the Cloned Directory: Change your directory to the cloned repository:
+
+```bash
+cd host-yolov8-on-sagemaker-endpoint/yolov8-pytorch-cdk
+```
+
+### Step 3: Set Up the CDK Environment
+
+Now that you have the necessary code, set up your environment for deploying with AWS CDK.
+
+- Create a Python Virtual Environment: This isolates your Python environment and dependencies. Run:
+
+```bash
+python3 -m venv .venv
+```
+
+- Activate the Virtual Environment:
+
+```bash
+source .venv/bin/activate
+```
+
+- Install Dependencies: Install the required Python dependencies for the project:
+
+```bash
+pip3 install -r requirements.txt
+```
+
+- Upgrade AWS CDK Library: Ensure you have the latest version of the AWS CDK library:
+
+```bash
+pip install --upgrade aws-cdk-lib
+```
+
+### Step 4: Create the AWS CloudFormation Stack
+
+- Synthesize the CDK Application: Generate the AWS CloudFormation template from your CDK code:
+
+```bash
+cdk synth
+```
+
+- Bootstrap the CDK Application: Prepare your AWS environment for CDK deployment:
+
+```bash
+cdk bootstrap
+```
+
+- Deploy the Stack: This will create the necessary AWS resources and deploy your model:
+
+```bash
+cdk deploy
+```
+
+### Step 5: Deploy the YOLOv8 Model
+
+Before diving into the deployment instructions, be sure to check out the range of [YOLOv8 models offered by Ultralytics](../models/index.md). This will help you choose the most appropriate model for your project requirements.
+
+After creating the AWS CloudFormation Stack, the next step is to deploy YOLOv8.
+
+- Open the Notebook Instance: Go to the AWS Console and navigate to the Amazon SageMaker service. Select "Notebook Instances" from the dashboard, then locate the notebook instance that was created by your CDK deployment script. Open the notebook instance to access the Jupyter environment.
+
+- Access and Modify inference.py: After opening the SageMaker notebook instance in Jupyter, locate the inference.py file. Edit the output_fn function in inference.py as shown below and save your changes to the script, ensuring that there are no syntax errors.
+
+```python
+import json
+
+
+def output_fn(prediction_output):
+ """Formats model outputs as JSON string, extracting attributes like boxes, masks, keypoints."""
+ print("Executing output_fn from inference.py ...")
+ infer = {}
+ for result in prediction_output:
+ if result.boxes is not None:
+ infer["boxes"] = result.boxes.numpy().data.tolist()
+ if result.masks is not None:
+ infer["masks"] = result.masks.numpy().data.tolist()
+ if result.keypoints is not None:
+ infer["keypoints"] = result.keypoints.numpy().data.tolist()
+ if result.obb is not None:
+ infer["obb"] = result.obb.numpy().data.tolist()
+ if result.probs is not None:
+ infer["probs"] = result.probs.numpy().data.tolist()
+ return json.dumps(infer)
+```
+
+- Deploy the Endpoint Using 1_DeployEndpoint.ipynb: In the Jupyter environment, open the 1_DeployEndpoint.ipynb notebook located in the sm-notebook directory. Follow the instructions in the notebook and run the cells to download the YOLOv8 model, package it with the updated inference code, and upload it to an Amazon S3 bucket. The notebook will guide you through creating and deploying a SageMaker endpoint for the YOLOv8 model.
+
+### Step 6: Testing Your Deployment
+
+Now that your YOLOv8 model is deployed, it's important to test its performance and functionality.
+
+- Open the Test Notebook: In the same Jupyter environment, locate and open the 2_TestEndpoint.ipynb notebook, also in the sm-notebook directory.
+
+- Run the Test Notebook: Follow the instructions within the notebook to test the deployed SageMaker endpoint. This includes sending an image to the endpoint and running inferences. Then, you'll plot the output to visualize the model's performance and accuracy, as shown below.
+
+
+
+
+
+- Clean-Up Resources: The test notebook will also guide you through the process of cleaning up the endpoint and the hosted model. This is an important step to manage costs and resources effectively, especially if you do not plan to use the deployed model immediately.
+
+### Step 7: Monitoring and Management
+
+After testing, continuous monitoring and management of your deployed model are essential.
+
+- Monitor with Amazon CloudWatch: Regularly check the performance and health of your SageMaker endpoint using [Amazon CloudWatch](https://aws.amazon.com/cloudwatch/).
+
+- Manage the Endpoint: Use the SageMaker console for ongoing management of the endpoint. This includes scaling, updating, or redeploying the model as required.
+
+By completing these steps, you will have successfully deployed and tested a YOLOv8 model on Amazon SageMaker Endpoints. This process not only equips you with practical experience in using AWS services for machine learning deployment but also lays the foundation for deploying other advanced models in the future.
+
+## Summary
+
+This guide took you step by step through deploying YOLOv8 on Amazon SageMaker Endpoints using AWS CloudFormation and the AWS Cloud Development Kit (CDK). The process includes cloning the necessary GitHub repository, setting up the CDK environment, deploying the model using AWS services, and testing its performance on SageMaker.
+
+For more technical details, refer to [this article](https://aws.amazon.com/blogs/machine-learning/hosting-yolov8-pytorch-model-on-amazon-sagemaker-endpoints/) on the AWS Machine Learning Blog. You can also check out the official [Amazon SageMaker Documentation](https://docs.aws.amazon.com/sagemaker/latest/dg/realtime-endpoints.html) for more insights into various features and functionalities.
+
+Are you interested in learning more about different YOLOv8 integrations? Visit the [Ultralytics integrations guide page](../integrations/index.md) to discover additional tools and capabilities that can enhance your machine-learning projects.
+
+## FAQ
+
+### How do I deploy the Ultralytics YOLOv8 model on Amazon SageMaker Endpoints?
+
+To deploy the Ultralytics YOLOv8 model on Amazon SageMaker Endpoints, follow these steps:
+
+1. **Set Up Your AWS Environment**: Ensure you have an AWS Account, IAM roles with necessary permissions, and the AWS CLI configured. Install AWS CDK if not already done (refer to the [AWS CDK instructions](https://docs.aws.amazon.com/cdk/v2/guide/getting_started.html#getting_started_install)).
+2. **Clone the YOLOv8 SageMaker Repository**:
+ ```bash
+ git clone https://github.com/aws-samples/host-yolov8-on-sagemaker-endpoint.git
+ cd host-yolov8-on-sagemaker-endpoint/yolov8-pytorch-cdk
+ ```
+3. **Set Up the CDK Environment**: Create a Python virtual environment, activate it, install dependencies, and upgrade AWS CDK library.
+ ```bash
+ python3 -m venv .venv
+ source .venv/bin/activate
+ pip3 install -r requirements.txt
+ pip install --upgrade aws-cdk-lib
+ ```
+4. **Deploy using AWS CDK**: Synthesize and deploy the CloudFormation stack, bootstrap the environment.
+ ```bash
+ cdk synth
+ cdk bootstrap
+ cdk deploy
+ ```
+
+For further details, review the [documentation section](#step-5-deploy-the-yolov8-model).
+
+### What are the prerequisites for deploying YOLOv8 on Amazon SageMaker?
+
+To deploy YOLOv8 on Amazon SageMaker, ensure you have the following prerequisites:
+
+1. **AWS Account**: Active AWS account ([sign up here](https://aws.amazon.com/)).
+2. **IAM Roles**: Configured IAM roles with permissions for SageMaker, CloudFormation, and Amazon S3.
+3. **AWS CLI**: Installed and configured AWS Command Line Interface ([AWS CLI installation guide](https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html)).
+4. **AWS CDK**: Installed AWS Cloud Development Kit ([CDK setup guide](https://docs.aws.amazon.com/cdk/v2/guide/getting_started.html#getting_started_install)).
+5. **Service Quotas**: Sufficient quotas for `ml.m5.4xlarge` instances for both endpoint and notebook usage ([request a quota increase](https://docs.aws.amazon.com/servicequotas/latest/userguide/request-quota-increase.html#quota-console-increase)).
+
+For detailed setup, refer to [this section](#step-1-setup-your-aws-environment).
+
+### Why should I use Ultralytics YOLOv8 on Amazon SageMaker?
+
+Using Ultralytics YOLOv8 on Amazon SageMaker offers several advantages:
+
+1. **Scalability and Management**: SageMaker provides a managed environment with features like autoscaling, which helps in real-time inference needs.
+2. **Integration with AWS Services**: Seamlessly integrate with other AWS services, such as S3 for data storage, CloudFormation for infrastructure as code, and CloudWatch for monitoring.
+3. **Ease of Deployment**: Simplified setup using AWS CDK scripts and streamlined deployment processes.
+4. **Performance**: Leverage Amazon SageMaker's high-performance infrastructure for running large scale inference tasks efficiently.
+
+Explore more about the advantages of using SageMaker in the [introduction section](#amazon-sagemaker).
+
+### Can I customize the inference logic for YOLOv8 on Amazon SageMaker?
+
+Yes, you can customize the inference logic for YOLOv8 on Amazon SageMaker:
+
+1. **Modify `inference.py`**: Locate and customize the `output_fn` function in the `inference.py` file to tailor output formats.
+
+ ```python
+ import json
+
+
+ def output_fn(prediction_output):
+ """Formats model outputs as JSON string, extracting attributes like boxes, masks, keypoints."""
+ infer = {}
+ for result in prediction_output:
+ if result.boxes is not None:
+ infer["boxes"] = result.boxes.numpy().data.tolist()
+ # Add more processing logic if necessary
+ return json.dumps(infer)
+ ```
+
+2. **Deploy Updated Model**: Ensure you redeploy the model using Jupyter notebooks provided (`1_DeployEndpoint.ipynb`) to include these changes.
+
+Refer to the [detailed steps](#step-5-deploy-the-yolov8-model) for deploying the modified model.
+
+### How can I test the deployed YOLOv8 model on Amazon SageMaker?
+
+To test the deployed YOLOv8 model on Amazon SageMaker:
+
+1. **Open the Test Notebook**: Locate the `2_TestEndpoint.ipynb` notebook in the SageMaker Jupyter environment.
+2. **Run the Notebook**: Follow the notebook's instructions to send an image to the endpoint, perform inference, and display results.
+3. **Visualize Results**: Use built-in plotting functionalities to visualize performance metrics, such as bounding boxes around detected objects.
+
+For comprehensive testing instructions, visit the [testing section](#step-6-testing-your-deployment).
diff --git a/ultralytics/docs/en/integrations/clearml.md b/ultralytics/docs/en/integrations/clearml.md
new file mode 100644
index 0000000000000000000000000000000000000000..139bac3778e438cbf43c900de3b0eb912efb77ee
--- /dev/null
+++ b/ultralytics/docs/en/integrations/clearml.md
@@ -0,0 +1,246 @@
+---
+comments: true
+description: Discover how to integrate YOLOv8 with ClearML to streamline your MLOps workflow, automate experiments, and enhance model management effortlessly.
+keywords: YOLOv8, ClearML, MLOps, Ultralytics, machine learning, object detection, model training, automation, experiment management
+---
+
+# Training YOLOv8 with ClearML: Streamlining Your MLOps Workflow
+
+MLOps bridges the gap between creating and deploying machine learning models in real-world settings. It focuses on efficient deployment, scalability, and ongoing management to ensure models perform well in practical applications.
+
+[Ultralytics YOLOv8](https://ultralytics.com) effortlessly integrates with ClearML, streamlining and enhancing your object detection model's training and management. This guide will walk you through the integration process, detailing how to set up ClearML, manage experiments, automate model management, and collaborate effectively.
+
+## ClearML
+
+
+
+
+
+[ClearML](https://clear.ml/) is an innovative open-source MLOps platform that is skillfully designed to automate, monitor, and orchestrate machine learning workflows. Its key features include automated logging of all training and inference data for full experiment reproducibility, an intuitive web UI for easy data visualization and analysis, advanced hyperparameter optimization algorithms, and robust model management for efficient deployment across various platforms.
+
+## YOLOv8 Training with ClearML
+
+You can bring automation and efficiency to your machine learning workflow by improving your training process by integrating YOLOv8 with ClearML.
+
+## Installation
+
+To install the required packages, run:
+
+!!! Tip "Installation"
+
+ === "CLI"
+
+ ```bash
+ # Install the required packages for YOLOv8 and ClearML
+ pip install ultralytics clearml
+ ```
+
+For detailed instructions and best practices related to the installation process, be sure to check our [YOLOv8 Installation guide](../quickstart.md). While installing the required packages for YOLOv8, if you encounter any difficulties, consult our [Common Issues guide](../guides/yolo-common-issues.md) for solutions and tips.
+
+## Configuring ClearML
+
+Once you have installed the necessary packages, the next step is to initialize and configure your ClearML SDK. This involves setting up your ClearML account and obtaining the necessary credentials for a seamless connection between your development environment and the ClearML server.
+
+Begin by initializing the ClearML SDK in your environment. The 'clearml-init' command starts the setup process and prompts you for the necessary credentials.
+
+!!! Tip "Initial SDK Setup"
+
+ === "CLI"
+
+ ```bash
+ # Initialize your ClearML SDK setup process
+ clearml-init
+ ```
+
+After executing this command, visit the [ClearML Settings page](https://app.clear.ml/settings/workspace-configuration). Navigate to the top right corner and select "Settings." Go to the "Workspace" section and click on "Create new credentials." Use the credentials provided in the "Create Credentials" pop-up to complete the setup as instructed, depending on whether you are configuring ClearML in a Jupyter Notebook or a local Python environment.
+
+## Usage
+
+Before diving into the usage instructions, be sure to check out the range of [YOLOv8 models offered by Ultralytics](../models/index.md). This will help you choose the most appropriate model for your project requirements.
+
+!!! Example "Usage"
+
+ === "Python"
+
+ ```python
+ from clearml import Task
+
+ from ultralytics import YOLO
+
+ # Step 1: Creating a ClearML Task
+ task = Task.init(project_name="my_project", task_name="my_yolov8_task")
+
+ # Step 2: Selecting the YOLOv8 Model
+ model_variant = "yolov8n"
+ task.set_parameter("model_variant", model_variant)
+
+ # Step 3: Loading the YOLOv8 Model
+ model = YOLO(f"{model_variant}.pt")
+
+ # Step 4: Setting Up Training Arguments
+ args = dict(data="coco8.yaml", epochs=16)
+ task.connect(args)
+
+ # Step 5: Initiating Model Training
+ results = model.train(**args)
+ ```
+
+### Understanding the Code
+
+Let's understand the steps showcased in the usage code snippet above.
+
+**Step 1: Creating a ClearML Task**: A new task is initialized in ClearML, specifying your project and task names. This task will track and manage your model's training.
+
+**Step 2: Selecting the YOLOv8 Model**: The `model_variant` variable is set to 'yolov8n', one of the YOLOv8 models. This variant is then logged in ClearML for tracking.
+
+**Step 3: Loading the YOLOv8 Model**: The selected YOLOv8 model is loaded using Ultralytics' YOLO class, preparing it for training.
+
+**Step 4: Setting Up Training Arguments**: Key training arguments like the dataset (`coco8.yaml`) and the number of epochs (`16`) are organized in a dictionary and connected to the ClearML task. This allows for tracking and potential modification via the ClearML UI. For a detailed understanding of the model training process and best practices, refer to our [YOLOv8 Model Training guide](../modes/train.md).
+
+**Step 5: Initiating Model Training**: The model training is started with the specified arguments. The results of the training process are captured in the `results` variable.
+
+### Understanding the Output
+
+Upon running the usage code snippet above, you can expect the following output:
+
+- A confirmation message indicating the creation of a new ClearML task, along with its unique ID.
+- An informational message about the script code being stored, indicating that the code execution is being tracked by ClearML.
+- A URL link to the ClearML results page where you can monitor the training progress and view detailed logs.
+- Download progress for the YOLOv8 model and the specified dataset, followed by a summary of the model architecture and training configuration.
+- Initialization messages for various training components like TensorBoard, Automatic Mixed Precision (AMP), and dataset preparation.
+- Finally, the training process starts, with progress updates as the model trains on the specified dataset. For an in-depth understanding of the performance metrics used during training, read [our guide on performance metrics](../guides/yolo-performance-metrics.md).
+
+### Viewing the ClearML Results Page
+
+By clicking on the URL link to the ClearML results page in the output of the usage code snippet, you can access a comprehensive view of your model's training process.
+
+#### Key Features of the ClearML Results Page
+
+- **Real-Time Metrics Tracking**
+
+ - Track critical metrics like loss, accuracy, and validation scores as they occur.
+ - Provides immediate feedback for timely model performance adjustments.
+
+- **Experiment Comparison**
+
+ - Compare different training runs side-by-side.
+ - Essential for hyperparameter tuning and identifying the most effective models.
+
+- **Detailed Logs and Outputs**
+
+ - Access comprehensive logs, graphical representations of metrics, and console outputs.
+ - Gain a deeper understanding of model behavior and issue resolution.
+
+- **Resource Utilization Monitoring**
+
+ - Monitor the utilization of computational resources, including CPU, GPU, and memory.
+ - Key to optimizing training efficiency and costs.
+
+- **Model Artifacts Management**
+
+ - View, download, and share model artifacts like trained models and checkpoints.
+ - Enhances collaboration and streamlines model deployment and sharing.
+
+For a visual walkthrough of what the ClearML Results Page looks like, watch the video below:
+
+
+
+### Advanced Features in ClearML
+
+ClearML offers several advanced features to enhance your MLOps experience.
+
+#### Remote Execution
+
+ClearML's remote execution feature facilitates the reproduction and manipulation of experiments on different machines. It logs essential details like installed packages and uncommitted changes. When a task is enqueued, the ClearML Agent pulls it, recreates the environment, and runs the experiment, reporting back with detailed results.
+
+Deploying a ClearML Agent is straightforward and can be done on various machines using the following command:
+
+```bash
+clearml-agent daemon --queue [--docker]
+```
+
+This setup is applicable to cloud VMs, local GPUs, or laptops. ClearML Autoscalers help manage cloud workloads on platforms like AWS, GCP, and Azure, automating the deployment of agents and adjusting resources based on your resource budget.
+
+### Cloning, Editing, and Enqueuing
+
+ClearML's user-friendly interface allows easy cloning, editing, and enqueuing of tasks. Users can clone an existing experiment, adjust parameters or other details through the UI, and enqueue the task for execution. This streamlined process ensures that the ClearML Agent executing the task uses updated configurations, making it ideal for iterative experimentation and model fine-tuning.
+
+
+
+
+
+## Summary
+
+This guide has led you through the process of integrating ClearML with Ultralytics' YOLOv8. Covering everything from initial setup to advanced model management, you've discovered how to leverage ClearML for efficient training, experiment tracking, and workflow optimization in your machine learning projects.
+
+For further details on usage, visit [ClearML's official documentation](https://clear.ml/docs/latest/docs/integrations/yolov8/).
+
+Additionally, explore more integrations and capabilities of Ultralytics by visiting the [Ultralytics integration guide page](../integrations/index.md), which is a treasure trove of resources and insights.
+
+## FAQ
+
+### What is the process for integrating Ultralytics YOLOv8 with ClearML?
+
+Integrating Ultralytics YOLOv8 with ClearML involves a series of steps to streamline your MLOps workflow. First, install the necessary packages:
+
+```bash
+pip install ultralytics clearml
+```
+
+Next, initialize the ClearML SDK in your environment using:
+
+```bash
+clearml-init
+```
+
+You then configure ClearML with your credentials from the [ClearML Settings page](https://app.clear.ml/settings/workspace-configuration). Detailed instructions on the entire setup process, including model selection and training configurations, can be found in our [YOLOv8 Model Training guide](../modes/train.md).
+
+### Why should I use ClearML with Ultralytics YOLOv8 for my machine learning projects?
+
+Using ClearML with Ultralytics YOLOv8 enhances your machine learning projects by automating experiment tracking, streamlining workflows, and enabling robust model management. ClearML offers real-time metrics tracking, resource utilization monitoring, and a user-friendly interface for comparing experiments. These features help optimize your model's performance and make the development process more efficient. Learn more about the benefits and procedures in our [MLOps Integration guide](../modes/train.md).
+
+### How do I troubleshoot common issues during YOLOv8 and ClearML integration?
+
+If you encounter issues during the integration of YOLOv8 with ClearML, consult our [Common Issues guide](../guides/yolo-common-issues.md) for solutions and tips. Typical problems might involve package installation errors, credential setup, or configuration issues. This guide provides step-by-step troubleshooting instructions to resolve these common issues efficiently.
+
+### How do I set up the ClearML task for YOLOv8 model training?
+
+Setting up a ClearML task for YOLOv8 training involves initializing a task, selecting the model variant, loading the model, setting up training arguments, and finally, starting the model training. Here's a simplified example:
+
+```python
+from clearml import Task
+
+from ultralytics import YOLO
+
+# Step 1: Creating a ClearML Task
+task = Task.init(project_name="my_project", task_name="my_yolov8_task")
+
+# Step 2: Selecting the YOLOv8 Model
+model_variant = "yolov8n"
+task.set_parameter("model_variant", model_variant)
+
+# Step 3: Loading the YOLOv8 Model
+model = YOLO(f"{model_variant}.pt")
+
+# Step 4: Setting Up Training Arguments
+args = dict(data="coco8.yaml", epochs=16)
+task.connect(args)
+
+# Step 5: Initiating Model Training
+results = model.train(**args)
+```
+
+Refer to our [Usage guide](#usage) for a detailed breakdown of these steps.
+
+### Where can I view the results of my YOLOv8 training in ClearML?
+
+After running your YOLOv8 training script with ClearML, you can view the results on the ClearML results page. The output will include a URL link to the ClearML dashboard, where you can track metrics, compare experiments, and monitor resource usage. For more details on how to view and interpret the results, check our section on [Viewing the ClearML Results Page](#viewing-the-clearml-results-page).
diff --git a/ultralytics/docs/en/integrations/comet.md b/ultralytics/docs/en/integrations/comet.md
new file mode 100644
index 0000000000000000000000000000000000000000..e668e4901530173102b65c6fdab6daacb2ff294f
--- /dev/null
+++ b/ultralytics/docs/en/integrations/comet.md
@@ -0,0 +1,286 @@
+---
+comments: true
+description: Learn to simplify the logging of YOLOv8 training with Comet ML. This guide covers installation, setup, real-time insights, and custom logging.
+keywords: YOLOv8, Comet ML, logging, machine learning, training, model checkpoints, metrics, installation, configuration, real-time insights, custom logging
+---
+
+# Elevating YOLOv8 Training: Simplify Your Logging Process with Comet ML
+
+Logging key training details such as parameters, metrics, image predictions, and model checkpoints is essential in machine learning—it keeps your project transparent, your progress measurable, and your results repeatable.
+
+[Ultralytics YOLOv8](https://ultralytics.com) seamlessly integrates with Comet ML, efficiently capturing and optimizing every aspect of your YOLOv8 object detection model's training process. In this guide, we'll cover the installation process, Comet ML setup, real-time insights, custom logging, and offline usage, ensuring that your YOLOv8 training is thoroughly documented and fine-tuned for outstanding results.
+
+## Comet ML
+
+
+
+
+
+[Comet ML](https://www.comet.ml/) is a platform for tracking, comparing, explaining, and optimizing machine learning models and experiments. It allows you to log metrics, parameters, media, and more during your model training and monitor your experiments through an aesthetically pleasing web interface. Comet ML helps data scientists iterate more rapidly, enhances transparency and reproducibility, and aids in the development of production models.
+
+## Harnessing the Power of YOLOv8 and Comet ML
+
+By combining Ultralytics YOLOv8 with Comet ML, you unlock a range of benefits. These include simplified experiment management, real-time insights for quick adjustments, flexible and tailored logging options, and the ability to log experiments offline when internet access is limited. This integration empowers you to make data-driven decisions, analyze performance metrics, and achieve exceptional results.
+
+## Installation
+
+To install the required packages, run:
+
+!!! Tip "Installation"
+
+ === "CLI"
+
+ ```bash
+ # Install the required packages for YOLOv8 and Comet ML
+ pip install ultralytics comet_ml torch torchvision
+ ```
+
+## Configuring Comet ML
+
+After installing the required packages, you'll need to sign up, get a [Comet API Key](https://www.comet.com/signup), and configure it.
+
+!!! Tip "Configuring Comet ML"
+
+ === "CLI"
+
+ ```bash
+ # Set your Comet Api Key
+ export COMET_API_KEY=
+ ```
+
+Then, you can initialize your Comet project. Comet will automatically detect the API key and proceed with the setup.
+
+```python
+import comet_ml
+
+comet_ml.login(project_name="comet-example-yolov8-coco128")
+```
+
+If you are using a Google Colab notebook, the code above will prompt you to enter your API key for initialization.
+
+## Usage
+
+Before diving into the usage instructions, be sure to check out the range of [YOLOv8 models offered by Ultralytics](../models/index.md). This will help you choose the most appropriate model for your project requirements.
+
+!!! Example "Usage"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt")
+
+ # Train the model
+ results = model.train(
+ data="coco8.yaml",
+ project="comet-example-yolov8-coco128",
+ batch=32,
+ save_period=1,
+ save_json=True,
+ epochs=3,
+ )
+ ```
+
+After running the training code, Comet ML will create an experiment in your Comet workspace to track the run automatically. You will then be provided with a link to view the detailed logging of your [YOLOv8 model's training](../modes/train.md) process.
+
+Comet automatically logs the following data with no additional configuration: metrics such as mAP and loss, hyperparameters, model checkpoints, interactive confusion matrix, and image bounding box predictions.
+
+## Understanding Your Model's Performance with Comet ML Visualizations
+
+Let's dive into what you'll see on the Comet ML dashboard once your YOLOv8 model begins training. The dashboard is where all the action happens, presenting a range of automatically logged information through visuals and statistics. Here's a quick tour:
+
+**Experiment Panels**
+
+The experiment panels section of the Comet ML dashboard organize and present the different runs and their metrics, such as segment mask loss, class loss, precision, and mean average precision.
+
+
+
+
+
+**Metrics**
+
+In the metrics section, you have the option to examine the metrics in a tabular format as well, which is displayed in a dedicated pane as illustrated here.
+
+
+
+
+
+**Interactive Confusion Matrix**
+
+The confusion matrix, found in the Confusion Matrix tab, provides an interactive way to assess the model's classification accuracy. It details the correct and incorrect predictions, allowing you to understand the model's strengths and weaknesses.
+
+
+
+
+
+**System Metrics**
+
+Comet ML logs system metrics to help identify any bottlenecks in the training process. It includes metrics such as GPU utilization, GPU memory usage, CPU utilization, and RAM usage. These are essential for monitoring the efficiency of resource usage during model training.
+
+
+
+
+
+## Customizing Comet ML Logging
+
+Comet ML offers the flexibility to customize its logging behavior by setting environment variables. These configurations allow you to tailor Comet ML to your specific needs and preferences. Here are some helpful customization options:
+
+### Logging Image Predictions
+
+You can control the number of image predictions that Comet ML logs during your experiments. By default, Comet ML logs 100 image predictions from the validation set. However, you can change this number to better suit your requirements. For example, to log 200 image predictions, use the following code:
+
+```python
+import os
+
+os.environ["COMET_MAX_IMAGE_PREDICTIONS"] = "200"
+```
+
+### Batch Logging Interval
+
+Comet ML allows you to specify how often batches of image predictions are logged. The `COMET_EVAL_BATCH_LOGGING_INTERVAL` environment variable controls this frequency. The default setting is 1, which logs predictions from every validation batch. You can adjust this value to log predictions at a different interval. For instance, setting it to 4 will log predictions from every fourth batch.
+
+```python
+import os
+
+os.environ["COMET_EVAL_BATCH_LOGGING_INTERVAL"] = "4"
+```
+
+### Disabling Confusion Matrix Logging
+
+In some cases, you may not want to log the confusion matrix from your validation set after every epoch. You can disable this feature by setting the `COMET_EVAL_LOG_CONFUSION_MATRIX` environment variable to "false." The confusion matrix will only be logged once, after the training is completed.
+
+```python
+import os
+
+os.environ["COMET_EVAL_LOG_CONFUSION_MATRIX"] = "false"
+```
+
+### Offline Logging
+
+If you find yourself in a situation where internet access is limited, Comet ML provides an offline logging option. You can set the `COMET_MODE` environment variable to "offline" to enable this feature. Your experiment data will be saved locally in a directory that you can later upload to Comet ML when internet connectivity is available.
+
+```python
+import os
+
+os.environ["COMET_MODE"] = "offline"
+```
+
+## Summary
+
+This guide has walked you through integrating Comet ML with Ultralytics' YOLOv8. From installation to customization, you've learned to streamline experiment management, gain real-time insights, and adapt logging to your project's needs.
+
+Explore [Comet ML's official documentation](https://www.comet.com/docs/v2/integrations/third-party-tools/yolov8/) for more insights on integrating with YOLOv8.
+
+Furthermore, if you're looking to dive deeper into the practical applications of YOLOv8, specifically for image segmentation tasks, this detailed guide on [fine-tuning YOLOv8 with Comet ML](https://www.comet.com/site/blog/fine-tuning-yolov8-for-image-segmentation-with-comet/) offers valuable insights and step-by-step instructions to enhance your model's performance.
+
+Additionally, to explore other exciting integrations with Ultralytics, check out the [integration guide page](../integrations/index.md), which offers a wealth of resources and information.
+
+## FAQ
+
+### How do I integrate Comet ML with Ultralytics YOLOv8 for training?
+
+To integrate Comet ML with Ultralytics YOLOv8, follow these steps:
+
+1. **Install the required packages**:
+
+ ```bash
+ pip install ultralytics comet_ml torch torchvision
+ ```
+
+2. **Set up your Comet API Key**:
+
+ ```bash
+ export COMET_API_KEY=
+ ```
+
+3. **Initialize your Comet project in your Python code**:
+
+ ```python
+ import comet_ml
+
+ comet_ml.login(project_name="comet-example-yolov8-coco128")
+ ```
+
+4. **Train your YOLOv8 model and log metrics**:
+
+ ```python
+ from ultralytics import YOLO
+
+ model = YOLO("yolov8n.pt")
+ results = model.train(
+ data="coco8.yaml",
+ project="comet-example-yolov8-coco128",
+ batch=32,
+ save_period=1,
+ save_json=True,
+ epochs=3,
+ )
+ ```
+
+For more detailed instructions, refer to the [Comet ML configuration section](#configuring-comet-ml).
+
+### What are the benefits of using Comet ML with YOLOv8?
+
+By integrating Ultralytics YOLOv8 with Comet ML, you can:
+
+- **Monitor real-time insights**: Get instant feedback on your training results, allowing for quick adjustments.
+- **Log extensive metrics**: Automatically capture essential metrics such as mAP, loss, hyperparameters, and model checkpoints.
+- **Track experiments offline**: Log your training runs locally when internet access is unavailable.
+- **Compare different training runs**: Use the interactive Comet ML dashboard to analyze and compare multiple experiments.
+
+By leveraging these features, you can optimize your machine learning workflows for better performance and reproducibility. For more information, visit the [Comet ML integration guide](../integrations/index.md).
+
+### How do I customize the logging behavior of Comet ML during YOLOv8 training?
+
+Comet ML allows for extensive customization of its logging behavior using environment variables:
+
+- **Change the number of image predictions logged**:
+
+ ```python
+ import os
+
+ os.environ["COMET_MAX_IMAGE_PREDICTIONS"] = "200"
+ ```
+
+- **Adjust batch logging interval**:
+
+ ```python
+ import os
+
+ os.environ["COMET_EVAL_BATCH_LOGGING_INTERVAL"] = "4"
+ ```
+
+- **Disable confusion matrix logging**:
+
+ ```python
+ import os
+
+ os.environ["COMET_EVAL_LOG_CONFUSION_MATRIX"] = "false"
+ ```
+
+Refer to the [Customizing Comet ML Logging](#customizing-comet-ml-logging) section for more customization options.
+
+### How do I view detailed metrics and visualizations of my YOLOv8 training on Comet ML?
+
+Once your YOLOv8 model starts training, you can access a wide range of metrics and visualizations on the Comet ML dashboard. Key features include:
+
+- **Experiment Panels**: View different runs and their metrics, including segment mask loss, class loss, and mean average precision.
+- **Metrics**: Examine metrics in tabular format for detailed analysis.
+- **Interactive Confusion Matrix**: Assess classification accuracy with an interactive confusion matrix.
+- **System Metrics**: Monitor GPU and CPU utilization, memory usage, and other system metrics.
+
+For a detailed overview of these features, visit the [Understanding Your Model's Performance with Comet ML Visualizations](#understanding-your-models-performance-with-comet-ml-visualizations) section.
+
+### Can I use Comet ML for offline logging when training YOLOv8 models?
+
+Yes, you can enable offline logging in Comet ML by setting the `COMET_MODE` environment variable to "offline":
+
+```python
+import os
+
+os.environ["COMET_MODE"] = "offline"
+```
+
+This feature allows you to log your experiment data locally, which can later be uploaded to Comet ML when internet connectivity is available. This is particularly useful when working in environments with limited internet access. For more details, refer to the [Offline Logging](#offline-logging) section.
diff --git a/ultralytics/docs/en/integrations/coreml.md b/ultralytics/docs/en/integrations/coreml.md
new file mode 100644
index 0000000000000000000000000000000000000000..0b3d3f79a250cdbb48ee4eb29c097b76745f29a4
--- /dev/null
+++ b/ultralytics/docs/en/integrations/coreml.md
@@ -0,0 +1,218 @@
+---
+comments: true
+description: Learn how to export YOLOv8 models to CoreML for optimized, on-device machine learning on iOS and macOS. Follow step-by-step instructions.
+keywords: CoreML export, YOLOv8 models, CoreML conversion, Ultralytics, iOS object detection, macOS machine learning, AI deployment, machine learning integration
+---
+
+# CoreML Export for YOLOv8 Models
+
+Deploying computer vision models on Apple devices like iPhones and Macs requires a format that ensures seamless performance.
+
+The CoreML export format allows you to optimize your [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics) models for efficient object detection in iOS and macOS applications. In this guide, we'll walk you through the steps for converting your models to the CoreML format, making it easier for your models to perform well on Apple devices.
+
+## CoreML
+
+
+
+
+
+[CoreML](https://developer.apple.com/documentation/coreml) is Apple's foundational machine learning framework that builds upon Accelerate, BNNS, and Metal Performance Shaders. It provides a machine-learning model format that seamlessly integrates into iOS applications and supports tasks such as image analysis, natural language processing, audio-to-text conversion, and sound analysis.
+
+Applications can take advantage of Core ML without the need to have a network connection or API calls because the Core ML framework works using on-device computing. This means model inference can be performed locally on the user's device.
+
+## Key Features of CoreML Models
+
+Apple's CoreML framework offers robust features for on-device machine learning. Here are the key features that make CoreML a powerful tool for developers:
+
+- **Comprehensive Model Support**: Converts and runs models from popular frameworks like TensorFlow, PyTorch, scikit-learn, XGBoost, and LibSVM.
+
+
+
+
+
+- **On-device Machine Learning**: Ensures data privacy and swift processing by executing models directly on the user's device, eliminating the need for network connectivity.
+
+- **Performance and Optimization**: Uses the device's CPU, GPU, and Neural Engine for optimal performance with minimal power and memory usage. Offers tools for model compression and optimization while maintaining accuracy.
+
+- **Ease of Integration**: Provides a unified format for various model types and a user-friendly API for seamless integration into apps. Supports domain-specific tasks through frameworks like Vision and Natural Language.
+
+- **Advanced Features**: Includes on-device training capabilities for personalized experiences, asynchronous predictions for interactive ML experiences, and model inspection and validation tools.
+
+## CoreML Deployment Options
+
+Before we look at the code for exporting YOLOv8 models to the CoreML format, let's understand where CoreML models are usually used.
+
+CoreML offers various deployment options for machine learning models, including:
+
+- **On-Device Deployment**: This method directly integrates CoreML models into your iOS app. It's particularly advantageous for ensuring low latency, enhanced privacy (since data remains on the device), and offline functionality. This approach, however, may be limited by the device's hardware capabilities, especially for larger and more complex models. On-device deployment can be executed in the following two ways.
+
+ - **Embedded Models**: These models are included in the app bundle and are immediately accessible. They are ideal for small models that do not require frequent updates.
+
+ - **Downloaded Models**: These models are fetched from a server as needed. This approach is suitable for larger models or those needing regular updates. It helps keep the app bundle size smaller.
+
+- **Cloud-Based Deployment**: CoreML models are hosted on servers and accessed by the iOS app through API requests. This scalable and flexible option enables easy model updates without app revisions. It's ideal for complex models or large-scale apps requiring regular updates. However, it does require an internet connection and may pose latency and security issues.
+
+## Exporting YOLOv8 Models to CoreML
+
+Exporting YOLOv8 to CoreML enables optimized, on-device machine learning performance within Apple's ecosystem, offering benefits in terms of efficiency, security, and seamless integration with iOS, macOS, watchOS, and tvOS platforms.
+
+### Installation
+
+To install the required package, run:
+
+!!! Tip "Installation"
+
+ === "CLI"
+
+ ```bash
+ # Install the required package for YOLOv8
+ pip install ultralytics
+ ```
+
+For detailed instructions and best practices related to the installation process, check our [YOLOv8 Installation guide](../quickstart.md). While installing the required packages for YOLOv8, if you encounter any difficulties, consult our [Common Issues guide](../guides/yolo-common-issues.md) for solutions and tips.
+
+### Usage
+
+Before diving into the usage instructions, be sure to check out the range of [YOLOv8 models offered by Ultralytics](../models/index.md). This will help you choose the most appropriate model for your project requirements.
+
+!!! Example "Usage"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load the YOLOv8 model
+ model = YOLO("yolov8n.pt")
+
+ # Export the model to CoreML format
+ model.export(format="coreml") # creates 'yolov8n.mlpackage'
+
+ # Load the exported CoreML model
+ coreml_model = YOLO("yolov8n.mlpackage")
+
+ # Run inference
+ results = coreml_model("https://ultralytics.com/images/bus.jpg")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Export a YOLOv8n PyTorch model to CoreML format
+ yolo export model=yolov8n.pt format=coreml # creates 'yolov8n.mlpackage''
+
+ # Run inference with the exported model
+ yolo predict model=yolov8n.mlpackage source='https://ultralytics.com/images/bus.jpg'
+ ```
+
+For more details about the export process, visit the [Ultralytics documentation page on exporting](../modes/export.md).
+
+## Deploying Exported YOLOv8 CoreML Models
+
+Having successfully exported your Ultralytics YOLOv8 models to CoreML, the next critical phase is deploying these models effectively. For detailed guidance on deploying CoreML models in various environments, check out these resources:
+
+- **[CoreML Tools](https://apple.github.io/coremltools/docs-guides/)**: This guide includes instructions and examples to convert models from TensorFlow, PyTorch, and other libraries to Core ML.
+
+- **[ML and Vision](https://developer.apple.com/videos/ml-vision)**: A collection of comprehensive videos that cover various aspects of using and implementing CoreML models.
+
+- **[Integrating a Core ML Model into Your App](https://developer.apple.com/documentation/coreml/integrating_a_core_ml_model_into_your_app)**: A comprehensive guide on integrating a CoreML model into an iOS application, detailing steps from preparing the model to implementing it in the app for various functionalities.
+
+## Summary
+
+In this guide, we went over how to export Ultralytics YOLOv8 models to CoreML format. By following the steps outlined in this guide, you can ensure maximum compatibility and performance when exporting YOLOv8 models to CoreML.
+
+For further details on usage, visit the [CoreML official documentation](https://developer.apple.com/documentation/coreml).
+
+Also, if you'd like to know more about other Ultralytics YOLOv8 integrations, visit our [integration guide page](../integrations/index.md). You'll find plenty of valuable resources and insights there.
+
+## FAQ
+
+### How do I export YOLOv8 models to CoreML format?
+
+To export your [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics) models to CoreML format, you'll first need to ensure you have the `ultralytics` package installed. You can install it using:
+
+!!! Example "Installation"
+
+ === "CLI"
+
+ ```bash
+ pip install ultralytics
+ ```
+
+Next, you can export the model using the following Python or CLI commands:
+
+!!! Example "Usage"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ model = YOLO("yolov8n.pt")
+ model.export(format="coreml")
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo export model=yolov8n.pt format=coreml
+ ```
+
+For further details, refer to the [Exporting YOLOv8 Models to CoreML](../modes/export.md) section of our documentation.
+
+### What are the benefits of using CoreML for deploying YOLOv8 models?
+
+CoreML provides numerous advantages for deploying [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics) models on Apple devices:
+
+- **On-device Processing**: Enables local model inference on devices, ensuring data privacy and minimizing latency.
+- **Performance Optimization**: Leverages the full potential of the device's CPU, GPU, and Neural Engine, optimizing both speed and efficiency.
+- **Ease of Integration**: Offers a seamless integration experience with Apple's ecosystems, including iOS, macOS, watchOS, and tvOS.
+- **Versatility**: Supports a wide range of machine learning tasks such as image analysis, audio processing, and natural language processing using the CoreML framework.
+
+For more details on integrating your CoreML model into an iOS app, check out the guide on [Integrating a Core ML Model into Your App](https://developer.apple.com/documentation/coreml/integrating_a_core_ml_model_into_your_app).
+
+### What are the deployment options for YOLOv8 models exported to CoreML?
+
+Once you export your YOLOv8 model to CoreML format, you have multiple deployment options:
+
+1. **On-Device Deployment**: Directly integrate CoreML models into your app for enhanced privacy and offline functionality. This can be done as:
+
+ - **Embedded Models**: Included in the app bundle, accessible immediately.
+ - **Downloaded Models**: Fetched from a server as needed, keeping the app bundle size smaller.
+
+2. **Cloud-Based Deployment**: Host CoreML models on servers and access them via API requests. This approach supports easier updates and can handle more complex models.
+
+For detailed guidance on deploying CoreML models, refer to [CoreML Deployment Options](#coreml-deployment-options).
+
+### How does CoreML ensure optimized performance for YOLOv8 models?
+
+CoreML ensures optimized performance for [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics) models by utilizing various optimization techniques:
+
+- **Hardware Acceleration**: Uses the device's CPU, GPU, and Neural Engine for efficient computation.
+- **Model Compression**: Provides tools for compressing models to reduce their footprint without compromising accuracy.
+- **Adaptive Inference**: Adjusts inference based on the device's capabilities to maintain a balance between speed and performance.
+
+For more information on performance optimization, visit the [CoreML official documentation](https://developer.apple.com/documentation/coreml).
+
+### Can I run inference directly with the exported CoreML model?
+
+Yes, you can run inference directly using the exported CoreML model. Below are the commands for Python and CLI:
+
+!!! Example "Running Inference"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ coreml_model = YOLO("yolov8n.mlpackage")
+ results = coreml_model("https://ultralytics.com/images/bus.jpg")
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo predict model=yolov8n.mlpackage source='https://ultralytics.com/images/bus.jpg'
+ ```
+
+For additional information, refer to the [Usage section](#usage) of the CoreML export guide.
diff --git a/ultralytics/docs/en/integrations/dvc.md b/ultralytics/docs/en/integrations/dvc.md
new file mode 100644
index 0000000000000000000000000000000000000000..0810220f70bbb1bc272ed0b8be48d9caac31aca8
--- /dev/null
+++ b/ultralytics/docs/en/integrations/dvc.md
@@ -0,0 +1,278 @@
+---
+comments: true
+description: Unlock seamless YOLOv8 tracking with DVCLive. Discover how to log, visualize, and analyze experiments for optimized ML model performance.
+keywords: YOLOv8, DVCLive, experiment tracking, machine learning, model training, data visualization, Git integration
+---
+
+# Advanced YOLOv8 Experiment Tracking with DVCLive
+
+Experiment tracking in machine learning is critical to model development and evaluation. It involves recording and analyzing various parameters, metrics, and outcomes from numerous training runs. This process is essential for understanding model performance and making data-driven decisions to refine and optimize models.
+
+Integrating DVCLive with [Ultralytics YOLOv8](https://ultralytics.com) transforms the way experiments are tracked and managed. This integration offers a seamless solution for automatically logging key experiment details, comparing results across different runs, and visualizing data for in-depth analysis. In this guide, we'll understand how DVCLive can be used to streamline the process.
+
+## DVCLive
+
+
+
+
+
+[DVCLive](https://dvc.org/doc/dvclive), developed by DVC, is an innovative open-source tool for experiment tracking in machine learning. Integrating seamlessly with Git and DVC, it automates the logging of crucial experiment data like model parameters and training metrics. Designed for simplicity, DVCLive enables effortless comparison and analysis of multiple runs, enhancing the efficiency of machine learning projects with intuitive data visualization and analysis tools.
+
+## YOLOv8 Training with DVCLive
+
+YOLOv8 training sessions can be effectively monitored with DVCLive. Additionally, DVC provides integral features for visualizing these experiments, including the generation of a report that enables the comparison of metric plots across all tracked experiments, offering a comprehensive view of the training process.
+
+## Installation
+
+To install the required packages, run:
+
+!!! Tip "Installation"
+
+ === "CLI"
+
+ ```bash
+ # Install the required packages for YOLOv8 and DVCLive
+ pip install ultralytics dvclive
+ ```
+
+For detailed instructions and best practices related to the installation process, be sure to check our [YOLOv8 Installation guide](../quickstart.md). While installing the required packages for YOLOv8, if you encounter any difficulties, consult our [Common Issues guide](../guides/yolo-common-issues.md) for solutions and tips.
+
+## Configuring DVCLive
+
+Once you have installed the necessary packages, the next step is to set up and configure your environment with the necessary credentials. This setup ensures a smooth integration of DVCLive into your existing workflow.
+
+Begin by initializing a Git repository, as Git plays a crucial role in version control for both your code and DVCLive configurations.
+
+!!! Tip "Initial Environment Setup"
+
+ === "CLI"
+
+ ```bash
+ # Initialize a Git repository
+ git init -q
+
+ # Configure Git with your details
+ git config --local user.email "you@example.com"
+ git config --local user.name "Your Name"
+
+ # Initialize DVCLive in your project
+ dvc init -q
+
+ # Commit the DVCLive setup to your Git repository
+ git commit -m "DVC init"
+ ```
+
+In these commands, ensure to replace "you@example.com" with the email address associated with your Git account, and "Your Name" with your Git account username.
+
+## Usage
+
+Before diving into the usage instructions, be sure to check out the range of [YOLOv8 models offered by Ultralytics](../models/index.md). This will help you choose the most appropriate model for your project requirements.
+
+### Training YOLOv8 Models with DVCLive
+
+Start by running your YOLOv8 training sessions. You can use different model configurations and training parameters to suit your project needs. For instance:
+
+```bash
+# Example training commands for YOLOv8 with varying configurations
+yolo train model=yolov8n.pt data=coco8.yaml epochs=5 imgsz=512
+yolo train model=yolov8n.pt data=coco8.yaml epochs=5 imgsz=640
+```
+
+Adjust the model, data, epochs, and imgsz parameters according to your specific requirements. For a detailed understanding of the model training process and best practices, refer to our [YOLOv8 Model Training guide](../modes/train.md).
+
+### Monitoring Experiments with DVCLive
+
+DVCLive enhances the training process by enabling the tracking and visualization of key metrics. When installed, Ultralytics YOLOv8 automatically integrates with DVCLive for experiment tracking, which you can later analyze for performance insights. For a comprehensive understanding of the specific performance metrics used during training, be sure to explore [our detailed guide on performance metrics](../guides/yolo-performance-metrics.md).
+
+### Analyzing Results
+
+After your YOLOv8 training sessions are complete, you can leverage DVCLive's powerful visualization tools for in-depth analysis of the results. DVCLive's integration ensures that all training metrics are systematically logged, facilitating a comprehensive evaluation of your model's performance.
+
+To start the analysis, you can extract the experiment data using DVC's API and process it with Pandas for easier handling and visualization:
+
+```python
+import dvc.api
+import pandas as pd
+
+# Define the columns of interest
+columns = ["Experiment", "epochs", "imgsz", "model", "metrics.mAP50-95(B)"]
+
+# Retrieve experiment data
+df = pd.DataFrame(dvc.api.exp_show(), columns=columns)
+
+# Clean the data
+df.dropna(inplace=True)
+df.reset_index(drop=True, inplace=True)
+
+# Display the DataFrame
+print(df)
+```
+
+The output of the code snippet above provides a clear tabular view of the different experiments conducted with YOLOv8 models. Each row represents a different training run, detailing the experiment's name, the number of epochs, image size (imgsz), the specific model used, and the mAP50-95(B) metric. This metric is crucial for evaluating the model's accuracy, with higher values indicating better performance.
+
+#### Visualizing Results with Plotly
+
+For a more interactive and visual analysis of your experiment results, you can use Plotly's parallel coordinates plot. This type of plot is particularly useful for understanding the relationships and trade-offs between different parameters and metrics.
+
+```python
+from plotly.express import parallel_coordinates
+
+# Create a parallel coordinates plot
+fig = parallel_coordinates(df, columns, color="metrics.mAP50-95(B)")
+
+# Display the plot
+fig.show()
+```
+
+The output of the code snippet above generates a plot that will visually represent the relationships between epochs, image size, model type, and their corresponding mAP50-95(B) scores, enabling you to spot trends and patterns in your experiment data.
+
+#### Generating Comparative Visualizations with DVC
+
+DVC provides a useful command to generate comparative plots for your experiments. This can be especially helpful to compare the performance of different models over various training runs.
+
+```bash
+# Generate DVC comparative plots
+dvc plots diff $(dvc exp list --names-only)
+```
+
+After executing this command, DVC generates plots comparing the metrics across different experiments, which are saved as HTML files. Below is an example image illustrating typical plots generated by this process. The image showcases various graphs, including those representing mAP, recall, precision, loss values, and more, providing a visual overview of key performance metrics:
+
+
+
+
+
+### Displaying DVC Plots
+
+If you are using a Jupyter Notebook and you want to display the generated DVC plots, you can use the IPython display functionality.
+
+```python
+from IPython.display import HTML
+
+# Display the DVC plots as HTML
+HTML(filename="./dvc_plots/index.html")
+```
+
+This code will render the HTML file containing the DVC plots directly in your Jupyter Notebook, providing an easy and convenient way to analyze the visualized experiment data.
+
+### Making Data-Driven Decisions
+
+Use the insights gained from these visualizations to make informed decisions about model optimizations, hyperparameter tuning, and other modifications to enhance your model's performance.
+
+### Iterating on Experiments
+
+Based on your analysis, iterate on your experiments. Adjust model configurations, training parameters, or even the data inputs, and repeat the training and analysis process. This iterative approach is key to refining your model for the best possible performance.
+
+## Summary
+
+This guide has led you through the process of integrating DVCLive with Ultralytics' YOLOv8. You have learned how to harness the power of DVCLive for detailed experiment monitoring, effective visualization, and insightful analysis in your machine learning endeavors.
+
+For further details on usage, visit [DVCLive's official documentation](https://dvc.org/doc/dvclive/ml-frameworks/yolo).
+
+Additionally, explore more integrations and capabilities of Ultralytics by visiting the [Ultralytics integration guide page](../integrations/index.md), which is a collection of great resources and insights.
+
+## FAQ
+
+### How do I integrate DVCLive with Ultralytics YOLOv8 for experiment tracking?
+
+Integrating DVCLive with Ultralytics YOLOv8 is straightforward. Start by installing the necessary packages:
+
+!!! Example "Installation"
+
+ === "CLI"
+
+ ```bash
+ pip install ultralytics dvclive
+ ```
+
+Next, initialize a Git repository and configure DVCLive in your project:
+
+!!! Example "Initial Environment Setup"
+
+ === "CLI"
+
+ ```bash
+ git init -q
+ git config --local user.email "you@example.com"
+ git config --local user.name "Your Name"
+ dvc init -q
+ git commit -m "DVC init"
+ ```
+
+Follow our [YOLOv8 Installation guide](../quickstart.md) for detailed setup instructions.
+
+### Why should I use DVCLive for tracking YOLOv8 experiments?
+
+Using DVCLive with YOLOv8 provides several advantages, such as:
+
+- **Automated Logging**: DVCLive automatically records key experiment details like model parameters and metrics.
+- **Easy Comparison**: Facilitates comparison of results across different runs.
+- **Visualization Tools**: Leverages DVCLive's robust data visualization capabilities for in-depth analysis.
+
+For further details, refer to our guide on [YOLOv8 Model Training](../modes/train.md) and [YOLO Performance Metrics](../guides/yolo-performance-metrics.md) to maximize your experiment tracking efficiency.
+
+### How can DVCLive improve my results analysis for YOLOv8 training sessions?
+
+After completing your YOLOv8 training sessions, DVCLive helps in visualizing and analyzing the results effectively. Example code for loading and displaying experiment data:
+
+```python
+import dvc.api
+import pandas as pd
+
+# Define columns of interest
+columns = ["Experiment", "epochs", "imgsz", "model", "metrics.mAP50-95(B)"]
+
+# Retrieve experiment data
+df = pd.DataFrame(dvc.api.exp_show(), columns=columns)
+
+# Clean data
+df.dropna(inplace=True)
+df.reset_index(drop=True, inplace=True)
+
+# Display DataFrame
+print(df)
+```
+
+To visualize results interactively, use Plotly's parallel coordinates plot:
+
+```python
+from plotly.express import parallel_coordinates
+
+fig = parallel_coordinates(df, columns, color="metrics.mAP50-95(B)")
+fig.show()
+```
+
+Refer to our guide on [YOLOv8 Training with DVCLive](#yolov8-training-with-dvclive) for more examples and best practices.
+
+### What are the steps to configure my environment for DVCLive and YOLOv8 integration?
+
+To configure your environment for a smooth integration of DVCLive and YOLOv8, follow these steps:
+
+1. **Install Required Packages**: Use `pip install ultralytics dvclive`.
+2. **Initialize Git Repository**: Run `git init -q`.
+3. **Setup DVCLive**: Execute `dvc init -q`.
+4. **Commit to Git**: Use `git commit -m "DVC init"`.
+
+These steps ensure proper version control and setup for experiment tracking. For in-depth configuration details, visit our [Configuration guide](../quickstart.md).
+
+### How do I visualize YOLOv8 experiment results using DVCLive?
+
+DVCLive offers powerful tools to visualize the results of YOLOv8 experiments. Here's how you can generate comparative plots:
+
+!!! Example "Generate Comparative Plots"
+
+ === "CLI"
+
+ ```bash
+ dvc plots diff $(dvc exp list --names-only)
+ ```
+
+To display these plots in a Jupyter Notebook, use:
+
+```python
+from IPython.display import HTML
+
+# Display plots as HTML
+HTML(filename="./dvc_plots/index.html")
+```
+
+These visualizations help identify trends and optimize model performance. Check our detailed guides on [YOLOv8 Experiment Analysis](#analyzing-results) for comprehensive steps and examples.
diff --git a/ultralytics/docs/en/integrations/edge-tpu.md b/ultralytics/docs/en/integrations/edge-tpu.md
new file mode 100644
index 0000000000000000000000000000000000000000..ef4dc84689aea997dd6cfb252d15fafdf5e1f859
--- /dev/null
+++ b/ultralytics/docs/en/integrations/edge-tpu.md
@@ -0,0 +1,185 @@
+---
+comments: true
+description: Learn how to export YOLOv8 models to TFLite Edge TPU format for high-speed, low-power inferencing on mobile and embedded devices.
+keywords: YOLOv8, TFLite Edge TPU, TensorFlow Lite, model export, machine learning, edge computing, neural networks, Ultralytics
+---
+
+# Learn to Export to TFLite Edge TPU Format From YOLOv8 Model
+
+Deploying computer vision models on devices with limited computational power, such as mobile or embedded systems, can be tricky. Using a model format that is optimized for faster performance simplifies the process. The [TensorFlow Lite](https://www.tensorflow.org/lite) [Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) or TFLite Edge TPU model format is designed to use minimal power while delivering fast performance for neural networks.
+
+The export to TFLite Edge TPU format feature allows you to optimize your [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics) models for high-speed and low-power inferencing. In this guide, we'll walk you through converting your models to the TFLite Edge TPU format, making it easier for your models to perform well on various mobile and embedded devices.
+
+## Why Should You Export to TFLite Edge TPU?
+
+Exporting models to TensorFlow Edge TPU makes machine learning tasks fast and efficient. This technology suits applications with limited power, computing resources, and connectivity. The Edge TPU is a hardware accelerator by Google. It speeds up TensorFlow Lite models on edge devices. The image below shows an example of the process involved.
+
+
+
+
+
+The Edge TPU works with quantized models. Quantization makes models smaller and faster without losing much accuracy. It is ideal for the limited resources of edge computing, allowing applications to respond quickly by reducing latency and allowing for quick data processing locally, without cloud dependency. Local processing also keeps user data private and secure since it's not sent to a remote server.
+
+## Key Features of TFLite Edge TPU
+
+Here are the key features that make TFLite Edge TPU a great model format choice for developers:
+
+- **Optimized Performance on Edge Devices**: The TFLite Edge TPU achieves high-speed neural networking performance through quantization, model optimization, hardware acceleration, and compiler optimization. Its minimalistic architecture contributes to its smaller size and cost-efficiency.
+
+- **High Computational Throughput**: TFLite Edge TPU combines specialized hardware acceleration and efficient runtime execution to achieve high computational throughput. It is well-suited for deploying machine learning models with stringent performance requirements on edge devices.
+
+- **Efficient Matrix Computations**: The TensorFlow Edge TPU is optimized for matrix operations, which are crucial for neural network computations. This efficiency is key in machine learning models, particularly those requiring numerous and complex matrix multiplications and transformations.
+
+## Deployment Options with TFLite Edge TPU
+
+Before we jump into how to export YOLOv8 models to the TFLite Edge TPU format, let's understand where TFLite Edge TPU models are usually used.
+
+TFLite Edge TPU offers various deployment options for machine learning models, including:
+
+- **On-Device Deployment**: TensorFlow Edge TPU models can be directly deployed on mobile and embedded devices. On-device deployment allows the models to execute directly on the hardware, eliminating the need for cloud connectivity.
+
+- **Edge Computing with Cloud TensorFlow TPUs**: In scenarios where edge devices have limited processing capabilities, TensorFlow Edge TPUs can offload inference tasks to cloud servers equipped with TPUs.
+
+- **Hybrid Deployment**: A hybrid approach combines on-device and cloud deployment and offers a versatile and scalable solution for deploying machine learning models. Advantages include on-device processing for quick responses and cloud computing for more complex computations.
+
+## Exporting YOLOv8 Models to TFLite Edge TPU
+
+You can expand model compatibility and deployment flexibility by converting YOLOv8 models to TensorFlow Edge TPU.
+
+### Installation
+
+To install the required package, run:
+
+!!! Tip "Installation"
+
+ === "CLI"
+
+ ```bash
+ # Install the required package for YOLOv8
+ pip install ultralytics
+ ```
+
+For detailed instructions and best practices related to the installation process, check our [Ultralytics Installation guide](../quickstart.md). While installing the required packages for YOLOv8, if you encounter any difficulties, consult our [Common Issues guide](../guides/yolo-common-issues.md) for solutions and tips.
+
+### Usage
+
+Before diving into the usage instructions, it's important to note that while all [Ultralytics YOLOv8 models](../models/index.md) are available for exporting, you can ensure that the model you select supports export functionality [here](../modes/export.md).
+
+!!! Example "Usage"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load the YOLOv8 model
+ model = YOLO("yolov8n.pt")
+
+ # Export the model to TFLite Edge TPU format
+ model.export(format="edgetpu") # creates 'yolov8n_full_integer_quant_edgetpu.tflite'
+
+ # Load the exported TFLite Edge TPU model
+ edgetpu_model = YOLO("yolov8n_full_integer_quant_edgetpu.tflite")
+
+ # Run inference
+ results = edgetpu_model("https://ultralytics.com/images/bus.jpg")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Export a YOLOv8n PyTorch model to TFLite Edge TPU format
+ yolo export model=yolov8n.pt format=edgetpu # creates 'yolov8n_full_integer_quant_edgetpu.tflite'
+
+ # Run inference with the exported model
+ yolo predict model=yolov8n_full_integer_quant_edgetpu.tflite source='https://ultralytics.com/images/bus.jpg'
+ ```
+
+For more details about supported export options, visit the [Ultralytics documentation page on deployment options](../guides/model-deployment-options.md).
+
+## Deploying Exported YOLOv8 TFLite Edge TPU Models
+
+After successfully exporting your Ultralytics YOLOv8 models to TFLite Edge TPU format, you can now deploy them. The primary and recommended first step for running a TFLite Edge TPU model is to use the YOLO("model_edgetpu.tflite") method, as outlined in the previous usage code snippet.
+
+However, for in-depth instructions on deploying your TFLite Edge TPU models, take a look at the following resources:
+
+- **[Coral Edge TPU on a Raspberry Pi with Ultralytics YOLOv8](../guides/coral-edge-tpu-on-raspberry-pi.md)**: Discover how to integrate Coral Edge TPUs with Raspberry Pi for enhanced machine learning capabilities.
+
+- **[Code Examples](https://coral.ai/docs/edgetpu/compiler/)**: Access practical TensorFlow Edge TPU deployment examples to kickstart your projects.
+
+- **[Run Inference on the Edge TPU with Python](https://coral.ai/docs/edgetpu/tflite-python/#overview)**: Explore how to use the TensorFlow Lite Python API for Edge TPU applications, including setup and usage guidelines.
+
+## Summary
+
+In this guide, we've learned how to export Ultralytics YOLOv8 models to TFLite Edge TPU format. By following the steps mentioned above, you can increase the speed and power of your computer vision applications.
+
+For further details on usage, visit the [Edge TPU official website](https://cloud.google.com/edge-tpu).
+
+Also, for more information on other Ultralytics YOLOv8 integrations, please visit our [integration guide page](index.md). There, you'll discover valuable resources and insights.
+
+## FAQ
+
+### How do I export a YOLOv8 model to TFLite Edge TPU format?
+
+To export a YOLOv8 model to TFLite Edge TPU format, you can follow these steps:
+
+!!! Example "Usage"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load the YOLOv8 model
+ model = YOLO("yolov8n.pt")
+
+ # Export the model to TFLite Edge TPU format
+ model.export(format="edgetpu") # creates 'yolov8n_full_integer_quant_edgetpu.tflite'
+
+ # Load the exported TFLite Edge TPU model
+ edgetpu_model = YOLO("yolov8n_full_integer_quant_edgetpu.tflite")
+
+ # Run inference
+ results = edgetpu_model("https://ultralytics.com/images/bus.jpg")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Export a YOLOv8n PyTorch model to TFLite Edge TPU format
+ yolo export model=yolov8n.pt format=edgetpu # creates 'yolov8n_full_integer_quant_edgetpu.tflite'
+
+ # Run inference with the exported model
+ yolo predict model=yolov8n_full_integer_quant_edgetpu.tflite source='https://ultralytics.com/images/bus.jpg'
+ ```
+
+For complete details on exporting models to other formats, refer to our [export guide](../modes/export.md).
+
+### What are the benefits of exporting YOLOv8 models to TFLite Edge TPU?
+
+Exporting YOLOv8 models to TFLite Edge TPU offers several benefits:
+
+- **Optimized Performance**: Achieve high-speed neural network performance with minimal power consumption.
+- **Reduced Latency**: Quick local data processing without the need for cloud dependency.
+- **Enhanced Privacy**: Local processing keeps user data private and secure.
+
+This makes it ideal for applications in edge computing, where devices have limited power and computational resources. Learn more about [why you should export](#why-should-you-export-to-tflite-edge-tpu).
+
+### Can I deploy TFLite Edge TPU models on mobile and embedded devices?
+
+Yes, TensorFlow Lite Edge TPU models can be deployed directly on mobile and embedded devices. This deployment approach allows models to execute directly on the hardware, offering faster and more efficient inferencing. For integration examples, check our [guide on deploying Coral Edge TPU on Raspberry Pi](../guides/coral-edge-tpu-on-raspberry-pi.md).
+
+### What are some common use cases for TFLite Edge TPU models?
+
+Common use cases for TFLite Edge TPU models include:
+
+- **Smart Cameras**: Enhancing real-time image and video analysis.
+- **IoT Devices**: Enabling smart home and industrial automation.
+- **Healthcare**: Accelerating medical imaging and diagnostics.
+- **Retail**: Improving inventory management and customer behavior analysis.
+
+These applications benefit from the high performance and low power consumption of TFLite Edge TPU models. Discover more about [usage scenarios](#deployment-options-with-tflite-edge-tpu).
+
+### How can I troubleshoot issues while exporting or deploying TFLite Edge TPU models?
+
+If you encounter issues while exporting or deploying TFLite Edge TPU models, refer to our [Common Issues guide](../guides/yolo-common-issues.md) for troubleshooting tips. This guide covers common problems and solutions to help you ensure smooth operation. For additional support, visit our [Help Center](https://docs.ultralytics.com/help/).
diff --git a/ultralytics/docs/en/integrations/google-colab.md b/ultralytics/docs/en/integrations/google-colab.md
new file mode 100644
index 0000000000000000000000000000000000000000..3f0919bcef9c65fc77f9ed965cc33c1d6ac5ecc8
--- /dev/null
+++ b/ultralytics/docs/en/integrations/google-colab.md
@@ -0,0 +1,151 @@
+---
+comments: true
+description: Learn how to efficiently train Ultralytics YOLOv8 models using Google Colab's powerful cloud-based environment. Start your project with ease.
+keywords: YOLOv8, Google Colab, machine learning, deep learning, model training, GPU, TPU, cloud computing, Jupyter Notebook, Ultralytics
+---
+
+# Accelerating YOLOv8 Projects with Google Colab
+
+Many developers lack the powerful computing resources needed to build deep learning models. Acquiring high-end hardware or renting a decent GPU can be expensive. Google Colab is a great solution to this. It's a browser-based platform that allows you to work with large datasets, develop complex models, and share your work with others without a huge cost.
+
+You can use Google Colab to work on projects related to [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics) models. Google Colab's user-friendly environment is well suited for efficient model development and experimentation. Let's learn more about Google Colab, its key features, and how you can use it to train YOLOv8 models.
+
+## Google Colaboratory
+
+Google Colaboratory, commonly known as Google Colab, was developed by Google Research in 2017. It is a free online cloud-based Jupyter Notebook environment that allows you to train your machine learning and deep learning models on CPUs, GPUs, and TPUs. The motivation behind developing Google Colab was Google's broader goals to advance AI technology and educational tools, and encourage the use of cloud services.
+
+You can use Google Colab regardless of the specifications and configurations of your local computer. All you need is a Google account and a web browser, and you're good to go.
+
+## Training YOLOv8 Using Google Colaboratory
+
+Training YOLOv8 models on Google Colab is pretty straightforward. Thanks to the integration, you can access the [Google Colab YOLOv8 Notebook](https://colab.research.google.com/github/ultralytics/ultralytics/blob/main/examples/tutorial.ipynb) and start training your model immediately. For a detailed understanding of the model training process and best practices, refer to our [YOLOv8 Model Training guide](../modes/train.md).
+
+Sign in to your Google account and run the notebook's cells to train your model.
+
+
+
+Learn how to train a YOLOv8 model with custom data on YouTube with Nicolai. Check out the guide below.
+
+
+
+
+
+ Watch: How to Train Ultralytics YOLOv8 models on Your Custom Dataset in Google Colab | Episode 3
+
+
+### Common Questions While Working with Google Colab
+
+When working with Google Colab, you might have a few common questions. Let's answer them.
+
+**Q: Why does my Google Colab session timeout?**
+A: Google Colab sessions can time out due to inactivity, especially for free users who have a limited session duration.
+
+**Q: Can I increase the session duration in Google Colab?**
+A: Free users face limits, but Google Colab Pro offers extended session durations.
+
+**Q: What should I do if my session closes unexpectedly?**
+A: Regularly save your work to Google Drive or GitHub to avoid losing unsaved progress.
+
+**Q: How can I check my session status and resource usage?**
+A: Colab provides 'RAM Usage' and 'Disk Usage' metrics in the interface to monitor your resources.
+
+**Q: Can I run multiple Colab sessions simultaneously?**
+A: Yes, but be cautious about resource usage to avoid performance issues.
+
+**Q: Does Google Colab have GPU access limitations?**
+A: Yes, free GPU access has limitations, but Google Colab Pro provides more substantial usage options.
+
+## Key Features of Google Colab
+
+Now, let's look at some of the standout features that make Google Colab a go-to platform for machine learning projects:
+
+- **Library Support:** Google Colab includes pre-installed libraries for data analysis and machine learning and allows additional libraries to be installed as needed. It also supports various libraries for creating interactive charts and visualizations.
+
+- **Hardware Resources:** Users also switch between different hardware options by modifying the runtime settings as shown below. Google Colab provides access to advanced hardware like Tesla K80 GPUs and TPUs, which are specialized circuits designed specifically for machine learning tasks.
+
+
+
+- **Collaboration:** Google Colab makes collaborating and working with other developers easy. You can easily share your notebooks with others and perform edits in real-time.
+
+- **Custom Environment:** Users can install dependencies, configure the system, and use shell commands directly in the notebook.
+
+- **Educational Resources:** Google Colab offers a range of tutorials and example notebooks to help users learn and explore various functionalities.
+
+## Why Should You Use Google Colab for Your YOLOv8 Projects?
+
+There are many options for training and evaluating YOLOv8 models, so what makes the integration with Google Colab unique? Let's explore the advantages of this integration:
+
+- **Zero Setup:** Since Colab runs in the cloud, users can start training models immediately without the need for complex environment setups. Just create an account and start coding.
+
+- **Form Support:** It allows users to create forms for parameter input, making it easier to experiment with different values.
+
+- **Integration with Google Drive:** Colab seamlessly integrates with Google Drive to make data storage, access, and management simple. Datasets and models can be stored and retrieved directly from Google Drive.
+
+- **Markdown Support:** You can use Markdown format for enhanced documentation within notebooks.
+
+- **Scheduled Execution:** Developers can set notebooks to run automatically at specified times.
+
+- **Extensions and Widgets:** Google Colab allows for adding functionality through third-party extensions and interactive widgets.
+
+## Keep Learning about Google Colab
+
+If you'd like to dive deeper into Google Colab, here are a few resources to guide you.
+
+- **[Training Custom Datasets with Ultralytics YOLOv8 in Google Colab](https://www.ultralytics.com/blog/training-custom-datasets-with-ultralytics-yolov8-in-google-colab)**: Learn how to train custom datasets with Ultralytics YOLOv8 on Google Colab. This comprehensive blog post will take you through the entire process, from initial setup to the training and evaluation stages.
+
+- **[Curated Notebooks](https://colab.google/notebooks/)**: Here you can explore a series of organized and educational notebooks, each grouped by specific topic areas.
+
+- **[Google Colab's Medium Page](https://medium.com/google-colab)**: You can find tutorials, updates, and community contributions here that can help you better understand and utilize this tool.
+
+## Summary
+
+We've discussed how you can easily experiment with Ultralytics YOLOv8 models on Google Colab. You can use Google Colab to train and evaluate your models on GPUs and TPUs with a few clicks.
+
+For more details, visit [Google Colab's FAQ page](https://research.google.com/colaboratory/intl/en-GB/faq.html).
+
+Interested in more YOLOv8 integrations? Visit the [Ultralytics integration guide page](index.md) to explore additional tools and capabilities that can improve your machine-learning projects.
+
+## FAQ
+
+### How do I start training Ultralytics YOLOv8 models on Google Colab?
+
+To start training Ultralytics YOLOv8 models on Google Colab, sign in to your Google account, then access the [Google Colab YOLOv8 Notebook](https://colab.research.google.com/github/ultralytics/ultralytics/blob/main/examples/tutorial.ipynb). This notebook guides you through the setup and training process. After launching the notebook, run the cells step-by-step to train your model. For a full guide, refer to the [YOLOv8 Model Training guide](../modes/train.md).
+
+### What are the advantages of using Google Colab for training YOLOv8 models?
+
+Google Colab offers several advantages for training YOLOv8 models:
+
+- **Zero Setup:** No initial environment setup is required; just log in and start coding.
+- **Free GPU Access:** Use powerful GPUs or TPUs without the need for expensive hardware.
+- **Integration with Google Drive:** Easily store and access datasets and models.
+- **Collaboration:** Share notebooks with others and collaborate in real-time.
+
+For more information on why you should use Google Colab, explore the [training guide](../modes/train.md) and visit the [Google Colab page](https://colab.google/notebooks/).
+
+### How can I handle Google Colab session timeouts during YOLOv8 training?
+
+Google Colab sessions timeout due to inactivity, especially for free users. To handle this:
+
+1. **Stay Active:** Regularly interact with your Colab notebook.
+2. **Save Progress:** Continuously save your work to Google Drive or GitHub.
+3. **Colab Pro:** Consider upgrading to Google Colab Pro for longer session durations.
+
+For more tips on managing your Colab session, visit the [Google Colab FAQ page](https://research.google.com/colaboratory/intl/en-GB/faq.html).
+
+### Can I use custom datasets for training YOLOv8 models in Google Colab?
+
+Yes, you can use custom datasets to train YOLOv8 models in Google Colab. Upload your dataset to Google Drive and load it directly into your Colab notebook. You can follow Nicolai's YouTube guide, [How to Train YOLOv8 Models on Your Custom Dataset](https://www.youtube.com/watch?v=LNwODJXcvt4), or refer to the [Custom Dataset Training guide](https://www.ultralytics.com/blog/training-custom-datasets-with-ultralytics-yolov8-in-google-colab) for detailed steps.
+
+### What should I do if my Google Colab training session is interrupted?
+
+If your Google Colab training session is interrupted:
+
+1. **Save Regularly:** Avoid losing unsaved progress by regularly saving your work to Google Drive or GitHub.
+2. **Resume Training:** Restart your session and re-run the cells from where the interruption occurred.
+3. **Use Checkpoints:** Incorporate checkpointing in your training script to save progress periodically.
+
+These practices help ensure your progress is secure. Learn more about session management on [Google Colab's FAQ page](https://research.google.com/colaboratory/intl/en-GB/faq.html).
diff --git a/ultralytics/docs/en/integrations/gradio.md b/ultralytics/docs/en/integrations/gradio.md
new file mode 100644
index 0000000000000000000000000000000000000000..123ef641d66190cc978e0e78c3a9d8e93e0afbba
--- /dev/null
+++ b/ultralytics/docs/en/integrations/gradio.md
@@ -0,0 +1,199 @@
+---
+comments: true
+description: Discover an interactive way to perform object detection with Ultralytics YOLOv8 using Gradio. Upload images and adjust settings for real-time results.
+keywords: Ultralytics, YOLOv8, Gradio, object detection, interactive, real-time, image processing, AI
+---
+
+# Interactive Object Detection: Gradio & Ultralytics YOLOv8 🚀
+
+## Introduction to Interactive Object Detection
+
+This Gradio interface provides an easy and interactive way to perform object detection using the [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) model. Users can upload images and adjust parameters like confidence threshold and intersection-over-union (IoU) threshold to get real-time detection results.
+
+
+
+## Why Use Gradio for Object Detection?
+
+- **User-Friendly Interface:** Gradio offers a straightforward platform for users to upload images and visualize detection results without any coding requirement.
+- **Real-Time Adjustments:** Parameters such as confidence and IoU thresholds can be adjusted on the fly, allowing for immediate feedback and optimization of detection results.
+- **Broad Accessibility:** The Gradio web interface can be accessed by anyone, making it an excellent tool for demonstrations, educational purposes, and quick experiments.
+
+
+
+
+
+## How to Install the Gradio
+
+```bash
+pip install gradio
+```
+
+## How to Use the Interface
+
+1. **Upload Image:** Click on 'Upload Image' to choose an image file for object detection.
+2. **Adjust Parameters:**
+ - **Confidence Threshold:** Slider to set the minimum confidence level for detecting objects.
+ - **IoU Threshold:** Slider to set the IoU threshold for distinguishing different objects.
+3. **View Results:** The processed image with detected objects and their labels will be displayed.
+
+## Example Use Cases
+
+- **Sample Image 1:** Bus detection with default thresholds.
+- **Sample Image 2:** Detection on a sports image with default thresholds.
+
+## Usage Example
+
+This section provides the Python code used to create the Gradio interface with the Ultralytics YOLOv8 model. Supports classification tasks, detection tasks, segmentation tasks, and key point tasks.
+
+```python
+import gradio as gr
+import PIL.Image as Image
+
+from ultralytics import ASSETS, YOLO
+
+model = YOLO("yolov8n.pt")
+
+
+def predict_image(img, conf_threshold, iou_threshold):
+ """Predicts objects in an image using a YOLOv8 model with adjustable confidence and IOU thresholds."""
+ results = model.predict(
+ source=img,
+ conf=conf_threshold,
+ iou=iou_threshold,
+ show_labels=True,
+ show_conf=True,
+ imgsz=640,
+ )
+
+ for r in results:
+ im_array = r.plot()
+ im = Image.fromarray(im_array[..., ::-1])
+
+ return im
+
+
+iface = gr.Interface(
+ fn=predict_image,
+ inputs=[
+ gr.Image(type="pil", label="Upload Image"),
+ gr.Slider(minimum=0, maximum=1, value=0.25, label="Confidence threshold"),
+ gr.Slider(minimum=0, maximum=1, value=0.45, label="IoU threshold"),
+ ],
+ outputs=gr.Image(type="pil", label="Result"),
+ title="Ultralytics Gradio",
+ description="Upload images for inference. The Ultralytics YOLOv8n model is used by default.",
+ examples=[
+ [ASSETS / "bus.jpg", 0.25, 0.45],
+ [ASSETS / "zidane.jpg", 0.25, 0.45],
+ ],
+)
+
+if __name__ == "__main__":
+ iface.launch()
+```
+
+## Parameters Explanation
+
+| Parameter Name | Type | Description |
+| ---------------- | ------- | -------------------------------------------------------- |
+| `img` | `Image` | The image on which object detection will be performed. |
+| `conf_threshold` | `float` | Confidence threshold for detecting objects. |
+| `iou_threshold` | `float` | Intersection-over-union threshold for object separation. |
+
+### Gradio Interface Components
+
+| Component | Description |
+| ------------ | ---------------------------------------- |
+| Image Input | To upload the image for detection. |
+| Sliders | To adjust confidence and IoU thresholds. |
+| Image Output | To display the detection results. |
+
+## FAQ
+
+### How do I use Gradio with Ultralytics YOLOv8 for object detection?
+
+To use Gradio with Ultralytics YOLOv8 for object detection, you can follow these steps:
+
+1. **Install Gradio:** Use the command `pip install gradio`.
+2. **Create Interface:** Write a Python script to initialize the Gradio interface. You can refer to the provided code example in the [documentation](#usage-example) for details.
+3. **Upload and Adjust:** Upload your image and adjust the confidence and IoU thresholds on the Gradio interface to get real-time object detection results.
+
+Here's a minimal code snippet for reference:
+
+```python
+import gradio as gr
+
+from ultralytics import YOLO
+
+model = YOLO("yolov8n.pt")
+
+
+def predict_image(img, conf_threshold, iou_threshold):
+ results = model.predict(
+ source=img,
+ conf=conf_threshold,
+ iou=iou_threshold,
+ show_labels=True,
+ show_conf=True,
+ )
+ return results[0].plot() if results else None
+
+
+iface = gr.Interface(
+ fn=predict_image,
+ inputs=[
+ gr.Image(type="pil", label="Upload Image"),
+ gr.Slider(minimum=0, maximum=1, value=0.25, label="Confidence threshold"),
+ gr.Slider(minimum=0, maximum=1, value=0.45, label="IoU threshold"),
+ ],
+ outputs=gr.Image(type="pil", label="Result"),
+ title="Ultralytics Gradio YOLOv8",
+ description="Upload images for YOLOv8 object detection.",
+)
+iface.launch()
+```
+
+### What are the benefits of using Gradio for Ultralytics YOLOv8 object detection?
+
+Using Gradio for Ultralytics YOLOv8 object detection offers several benefits:
+
+- **User-Friendly Interface:** Gradio provides an intuitive interface for users to upload images and visualize detection results without any coding effort.
+- **Real-Time Adjustments:** You can dynamically adjust detection parameters such as confidence and IoU thresholds and see the effects immediately.
+- **Accessibility:** The web interface is accessible to anyone, making it useful for quick experiments, educational purposes, and demonstrations.
+
+For more details, you can read this [blog post](https://www.ultralytics.com/blog/ai-and-radiology-a-new-era-of-precision-and-efficiency).
+
+### Can I use Gradio and Ultralytics YOLOv8 together for educational purposes?
+
+Yes, Gradio and Ultralytics YOLOv8 can be utilized together for educational purposes effectively. Gradio's intuitive web interface makes it easy for students and educators to interact with state-of-the-art deep learning models like Ultralytics YOLOv8 without needing advanced programming skills. This setup is ideal for demonstrating key concepts in object detection and computer vision, as Gradio provides immediate visual feedback which helps in understanding the impact of different parameters on the detection performance.
+
+### How do I adjust the confidence and IoU thresholds in the Gradio interface for YOLOv8?
+
+In the Gradio interface for YOLOv8, you can adjust the confidence and IoU thresholds using the sliders provided. These thresholds help control the prediction accuracy and object separation:
+
+- **Confidence Threshold:** Determines the minimum confidence level for detecting objects. Slide to increase or decrease the confidence required.
+- **IoU Threshold:** Sets the intersection-over-union threshold for distinguishing between overlapping objects. Adjust this value to refine object separation.
+
+For more information on these parameters, visit the [parameters explanation section](#parameters-explanation).
+
+### What are some practical applications of using Ultralytics YOLOv8 with Gradio?
+
+Practical applications of combining Ultralytics YOLOv8 with Gradio include:
+
+- **Real-Time Object Detection Demonstrations:** Ideal for showcasing how object detection works in real-time.
+- **Educational Tools:** Useful in academic settings to teach object detection and computer vision concepts.
+- **Prototype Development:** Efficient for developing and testing prototype object detection applications quickly.
+- **Community and Collaborations:** Making it easy to share models with the community for feedback and collaboration.
+
+For examples of similar use cases, check out the [Ultralytics blog](https://www.ultralytics.com/blog/monitoring-animal-behavior-using-ultralytics-yolov8).
+
+Providing this information within the documentation will help in enhancing the usability and accessibility of Ultralytics YOLOv8, making it more approachable for users at all levels of expertise.
diff --git a/ultralytics/docs/en/integrations/ibm-watsonx.md b/ultralytics/docs/en/integrations/ibm-watsonx.md
new file mode 100644
index 0000000000000000000000000000000000000000..d81c5bcf4bc73e6cc891acc395d5d71f85e166c3
--- /dev/null
+++ b/ultralytics/docs/en/integrations/ibm-watsonx.md
@@ -0,0 +1,410 @@
+---
+comments: true
+description: Dive into our detailed integration guide on using IBM Watson to train a YOLOv8 model. Uncover key features and step-by-step instructions on model training.
+keywords: IBM Watsonx, IBM Watsonx AI, What is Watson?, IBM Watson Integration, IBM Watson Features, YOLOv8, Ultralytics, Model Training, GPU, TPU, cloud computing
+---
+
+# A Step-by-Step Guide to Training YOLOv8 Models with IBM Watsonx
+
+Nowadays, scalable [computer vision solutions](../guides/steps-of-a-cv-project.md) are becoming more common and transforming the way we handle visual data. A great example is IBM Watsonx, an advanced AI and data platform that simplifies the development, deployment, and management of AI models. It offers a complete suite for the entire AI lifecycle and seamless integration with IBM Cloud services.
+
+You can train [Ultralytics YOLOv8 models](https://github.com/ultralytics/ultralytics) using IBM Watsonx. It's a good option for enterprises interested in efficient [model training](../modes/train.md), fine-tuning for specific tasks, and improving [model performance](../guides/model-evaluation-insights.md) with robust tools and a user-friendly setup. In this guide, we'll walk you through the process of training YOLOv8 with IBM Watsonx, covering everything from setting up your environment to evaluating your trained models. Let's get started!
+
+## What is IBM Watsonx?
+
+[Watsonx](https://www.ibm.com/watsonx) is IBM's cloud-based platform designed for commercial generative AI and scientific data. IBM Watsonx's three components - watsonx.ai, watsonx.data, and watsonx.governance - come together to create an end-to-end, trustworthy AI platform that can accelerate AI projects aimed at solving business problems. It provides powerful tools for building, training, and [deploying machine learning models](../guides/model-deployment-options.md) and makes it easy to connect with various data sources.
+
+
+
+
+
+Its user-friendly interface and collaborative capabilities streamline the development process and help with efficient model management and deployment. Whether for computer vision, predictive analytics, natural language processing, or other AI applications, IBM Watsonx provides the tools and support needed to drive innovation.
+
+## Key Features of IBM Watsonx
+
+IBM Watsonx is made of three main components: watsonx.ai, watsonx.data, and watsonx.governance. Each component offers features that cater to different aspects of AI and data management. Let's take a closer look at them.
+
+### [Watsonx.ai](https://www.ibm.com/products/watsonx-ai)
+
+Watsonx.ai provides powerful tools for AI development and offers access to IBM-supported custom models, third-party models like [Llama 3](https://www.ultralytics.com/blog/getting-to-know-metas-llama-3), and IBM's own Granite models. It includes the Prompt Lab for experimenting with AI prompts, the Tuning Studio for improving model performance with labeled data, and the Flows Engine for simplifying generative AI application development. Also, it offers comprehensive tools for automating the AI model lifecycle and connecting to various APIs and libraries.
+
+### [Watsonx.data](https://www.ibm.com/products/watsonx-data)
+
+Watsonx.data supports both cloud and on-premises deployments through the IBM Storage Fusion HCI integration. Its user-friendly console provides centralized access to data across environments and makes data exploration easy with common SQL. It optimizes workloads with efficient query engines like Presto and Spark, accelerates data insights with an AI-powered semantic layer, includes a vector database for AI relevance, and supports open data formats for easy sharing of analytics and AI data.
+
+### [Watsonx.governance](https://www.ibm.com/products/watsonx-governance)
+
+Watsonx.governance makes compliance easier by automatically identifying regulatory changes and enforcing policies. It links requirements to internal risk data and provides up-to-date AI factsheets. The platform helps manage risk with alerts and tools to detect issues such as [bias and drift](../guides/model-monitoring-and-maintenance.md). It also automates the monitoring and documentation of the AI lifecycle, organizes AI development with a model inventory, and enhances collaboration with user-friendly dashboards and reporting tools.
+
+## How to Train YOLOv8 Using IBM Watsonx
+
+You can use IBM Watsonx to accelerate your YOLOv8 model training workflow.
+
+### Prerequisites
+
+You need an [IBM Cloud account](https://cloud.ibm.com/registration) to create a [watsonx.ai](https://www.ibm.com/products/watsonx-ai) project, and you'll also need a [Kaggle](./kaggle.md) account to load the data set.
+
+### Step 1: Set Up Your Environment
+
+First, you'll need to set up an IBM account to use a Jupyter Notebook. Log in to [watsonx.ai](https://eu-de.dataplatform.cloud.ibm.com/registration/stepone?preselect_region=true) using your IBM Cloud account.
+
+Then, create a [watsonx.ai project](https://www.ibm.com/docs/en/watsonx/saas?topic=projects-creating-project), and a [Jupyter Notebook](https://www.ibm.com/docs/en/watsonx/saas?topic=editor-creating-managing-notebooks).
+
+Once you do so, a notebook environment will open for you to load your data set. You can use the code from this tutorial to tackle a simple object detection model training task.
+
+### Step 2: Install and Import Relevant Libraries
+
+Next, you can install and import the necessary Python libraries.
+
+!!! Tip "Installation"
+
+ === "CLI"
+
+ ```bash
+ # Install the required packages
+ pip install torch torchvision torchaudio
+ pip install opencv-contrib-python-headless
+ pip install ultralytics==8.0.196
+ ```
+
+For detailed instructions and best practices related to the installation process, check our [Ultralytics Installation guide](../quickstart.md). While installing the required packages for YOLOv8, if you encounter any difficulties, consult our [Common Issues guide](../guides/yolo-common-issues.md) for solutions and tips.
+
+Then, you can import the needed packages.
+
+!!! Example "Import Relevant Libraries"
+
+ === "Python"
+
+ ```python
+ # Import ultralytics
+ import ultralytics
+
+ ultralytics.checks()
+
+ # Import packages to retrieve and display image files
+ ```
+
+### Step 3: Load the Data
+
+For this tutorial, we will use a [marine litter dataset](https://www.kaggle.com/datasets/atiqishrak/trash-dataset-icra19) available on Kaggle. With this dataset, we will custom-train a YOLOv8 model to detect and classify litter and biological objects in underwater images.
+
+We can load the dataset directly into the notebook using the Kaggle API. First, create a free Kaggle account. Once you have created an account, you'll need to generate an API key. Directions for generating your key can be found in the [Kaggle API documentation](https://github.com/Kaggle/kaggle-api/blob/main/docs/README.md) under the section "API credentials".
+
+Copy and paste your Kaggle username and API key into the following code. Then run the code to install the API and load the dataset into Watsonx.
+
+!!! Tip "Installation"
+
+ === "CLI"
+
+ ```bash
+ # Install kaggle
+ pip install kaggle
+ ```
+
+After installing Kaggle, we can load the dataset into Watsonx.
+
+!!! Example "Load the Data"
+
+ === "Python"
+
+ ```python
+ # Replace "username" string with your username
+ os.environ["KAGGLE_USERNAME"] = "username"
+ # Replace "apiKey" string with your key
+ os.environ["KAGGLE_KEY"] = "apiKey"
+
+ # Load dataset
+ os.system("kaggle datasets download atiqishrak/trash-dataset-icra19 --unzip")
+
+ # Store working directory path as work_dir
+ work_dir = os.getcwd()
+
+ # Print work_dir path
+ print(os.getcwd())
+
+ # Print work_dir contents
+ print(os.listdir(f"{work_dir}"))
+
+ # Print trash_ICRA19 subdirectory contents
+ print(os.listdir(f"{work_dir}/trash_ICRA19"))
+ ```
+
+After loading the dataset, we printed and saved our working directory. We have also printed the contents of our working directory to confirm the "trash_ICRA19" data set was loaded properly.
+
+If you see "trash_ICRA19" among the directory's contents, then it has loaded successfully. You should see three files/folders: a `config.yaml` file, a `videos_for_testing` directory, and a `dataset` directory. We will ignore the `videos_for_testing` directory, so feel free to delete it.
+
+We will use the config.yaml file and the contents of the dataset directory to train our object detection model. Here is a sample image from our marine litter data set.
+
+
+
+
+
+### Step 4: Preprocess the Data
+
+Fortunately, all labels in the marine litter data set are already formatted as YOLO .txt files. However, we need to rearrange the structure of the image and label directories in order to help our model process the image and labels. Right now, our loaded data set directory follows this structure:
+
+
+
+
+
+But, YOLO models by default require separate images and labels in subdirectories within the train/val/test split. We need to reorganize the directory into the following structure:
+
+
+
+
+
+To reorganize the data set directory, we can run the following script:
+
+!!! Example "Preprocess the Data"
+
+ === "Python"
+
+ ```python
+ # Function to reorganize dir
+ def organize_files(directory):
+ for subdir in ["train", "test", "val"]:
+ subdir_path = os.path.join(directory, subdir)
+ if not os.path.exists(subdir_path):
+ continue
+
+ images_dir = os.path.join(subdir_path, "images")
+ labels_dir = os.path.join(subdir_path, "labels")
+
+ # Create image and label subdirs if non-existent
+ os.makedirs(images_dir, exist_ok=True)
+ os.makedirs(labels_dir, exist_ok=True)
+
+ # Move images and labels to respective subdirs
+ for filename in os.listdir(subdir_path):
+ if filename.endswith(".txt"):
+ shutil.move(os.path.join(subdir_path, filename), os.path.join(labels_dir, filename))
+ elif filename.endswith(".jpg") or filename.endswith(".png") or filename.endswith(".jpeg"):
+ shutil.move(os.path.join(subdir_path, filename), os.path.join(images_dir, filename))
+ # Delete .xml files
+ elif filename.endswith(".xml"):
+ os.remove(os.path.join(subdir_path, filename))
+
+
+ if __name__ == "__main__":
+ directory = f"{work_dir}/trash_ICRA19/dataset"
+ organize_files(directory)
+ ```
+
+Next, we need to modify the .yaml file for the data set. This is the setup we will use in our .yaml file. Class ID numbers start from 0:
+
+```yaml
+path: /path/to/dataset/directory # root directory for dataset
+train: train/images # train images subdirectory
+val: train/images # validation images subdirectory
+test: test/images # test images subdirectory
+
+# Classes
+names:
+ 0: plastic
+ 1: bio
+ 2: rov
+```
+
+Run the following script to delete the current contents of config.yaml and replace it with the above contents that reflect our new data set directory structure. Be certain to replace the work_dir portion of the root directory path in line 4 with your own working directory path we retrieved earlier. Leave the train, val, and test subdirectory definitions. Also, do not change {work_dir} in line 23 of the code.
+
+!!! Example "Edit the .yaml File"
+
+ === "Python"
+
+ ```python
+ # Contents of new confg.yaml file
+ def update_yaml_file(file_path):
+ data = {
+ "path": "work_dir/trash_ICRA19/dataset",
+ "train": "train/images",
+ "val": "train/images",
+ "test": "test/images",
+ "names": {0: "plastic", 1: "bio", 2: "rov"},
+ }
+
+ # Ensures the "names" list appears after the sub/directories
+ names_data = data.pop("names")
+ with open(file_path, "w") as yaml_file:
+ yaml.dump(data, yaml_file)
+ yaml_file.write("\n")
+ yaml.dump({"names": names_data}, yaml_file)
+
+
+ if __name__ == "__main__":
+ file_path = f"{work_dir}/trash_ICRA19/config.yaml" # .yaml file path
+ update_yaml_file(file_path)
+ print(f"{file_path} updated successfully.")
+ ```
+
+### Step 5: Train the YOLOv8 model
+
+Run the following command-line code to fine tune a pretrained default YOLOv8 model.
+
+!!! Example "Train the YOLOv8 model"
+
+ === "CLI"
+
+ ```bash
+ !yolo task=detect mode=train data={work_dir}/trash_ICRA19/config.yaml model=yolov8s.pt epochs=2 batch=32 lr0=.04 plots=True
+ ```
+
+Here's a closer look at the parameters in the model training command:
+
+- **task**: It specifies the computer vision task for which you are using the specified YOLO model and data set.
+- **mode**: Denotes the purpose for which you are loading the specified model and data. Since we are training a model, it is set to "train." Later, when we test our model's performance, we will set it to "predict."
+- **epochs**: This delimits the number of times YOLOv8 will pass through our entire data set.
+- **batch**: The numerical value stipulates the training batch sizes. Batches are the number of images a model processes before it updates its parameters.
+- **lr0**: Specifies the model's initial learning rate.
+- **plots**: Directs YOLO to generate and save plots of our model's training and evaluation metrics.
+
+For a detailed understanding of the model training process and best practices, refer to the [YOLOv8 Model Training guide](../modes/train.md). This guide will help you get the most out of your experiments and ensure you're using YOLOv8 effectively.
+
+### Step 6: Test the Model
+
+We can now run inference to test the performance of our fine-tuned model:
+
+!!! Example "Test the YOLOv8 model"
+
+ === "CLI"
+
+ ```bash
+ !yolo task=detect mode=predict source={work_dir}/trash_ICRA19/dataset/test/images model={work_dir}/runs/detect/train/weights/best.pt conf=0.5 iou=.5 save=True save_txt=True
+ ```
+
+This brief script generates predicted labels for each image in our test set, as well as new output image files that overlay the predicted bounding box atop the original image.
+
+Predicted .txt labels for each image are saved via the `save_txt=True` argument and the output images with bounding box overlays are generated through the `save=True` argument.
+The parameter `conf=0.5` informs the model to ignore all predictions with a confidence level of less than 50%.
+
+Lastly, `iou=.5` directs the model to ignore boxes in the same class with an overlap of 50% or greater. It helps to reduce potential duplicate boxes generated for the same object.
+we can load the images with predicted bounding box overlays to view how our model performs on a handful of images.
+
+!!! Example "Display Predictions"
+
+ === "Python"
+
+ ```python
+ # Show the first ten images from the preceding prediction task
+ for pred_dir in glob.glob(f"{work_dir}/runs/detect/predict/*.jpg")[:10]:
+ img = Image.open(pred_dir)
+ display(img)
+ ```
+
+The code above displays ten images from the test set with their predicted bounding boxes, accompanied by class name labels and confidence levels.
+
+### Step 7: Evaluate the Model
+
+We can produce visualizations of the model's precision and recall for each class. These visualizations are saved in the home directory, under the train folder. The precision score is displayed in the P_curve.png:
+
+
+
+
+
+The graph shows an exponential increase in precision as the model's confidence level for predictions increases. However, the model precision has not yet leveled out at a certain confidence level after two epochs.
+
+The recall graph (R_curve.png) displays an inverse trend:
+
+
+
+
+
+Unlike precision, recall moves in the opposite direction, showing greater recall with lower confidence instances and lower recall with higher confidence instances. This is an apt example of the trade-off in precision and recall for classification models.
+
+### Step 8: Calculating Intersection Over Union
+
+You can measure the prediction accuracy by calculating the IoU between a predicted bounding box and a ground truth bounding box for the same object. Check out [IBM's tutorial on training YOLOv8](https://developer.ibm.com/tutorials/awb-train-yolo-object-detection-model-in-python/) for more details.
+
+## Summary
+
+We explored IBM Watsonx key features, and how to train a YOLOv8 model using IBM Watsonx. We also saw how IBM Watsonx can enhance your AI workflows with advanced tools for model building, data management, and compliance.
+
+For further details on usage, visit [IBM Watsonx official documentation](https://www.ibm.com/watsonx).
+
+Also, be sure to check out the [Ultralytics integration guide page](./index.md), to learn more about different exciting integrations.
+
+## FAQ
+
+### How do I train a YOLOv8 model using IBM Watsonx?
+
+To train a YOLOv8 model using IBM Watsonx, follow these steps:
+
+1. **Set Up Your Environment**: Create an IBM Cloud account and set up a Watsonx.ai project. Use a Jupyter Notebook for your coding environment.
+2. **Install Libraries**: Install necessary libraries like `torch`, `opencv`, and `ultralytics`.
+3. **Load Data**: Use the Kaggle API to load your dataset into Watsonx.
+4. **Preprocess Data**: Organize your dataset into the required directory structure and update the `.yaml` configuration file.
+5. **Train the Model**: Use the YOLO command-line interface to train your model with specific parameters like `epochs`, `batch size`, and `learning rate`.
+6. **Test and Evaluate**: Run inference to test the model and evaluate its performance using metrics like precision and recall.
+
+For detailed instructions, refer to our [YOLOv8 Model Training guide](../modes/train.md).
+
+### What are the key features of IBM Watsonx for AI model training?
+
+IBM Watsonx offers several key features for AI model training:
+
+- **Watsonx.ai**: Provides tools for AI development, including access to IBM-supported custom models and third-party models like Llama 3. It includes the Prompt Lab, Tuning Studio, and Flows Engine for comprehensive AI lifecycle management.
+- **Watsonx.data**: Supports cloud and on-premises deployments, offering centralized data access, efficient query engines like Presto and Spark, and an AI-powered semantic layer.
+- **Watsonx.governance**: Automates compliance, manages risk with alerts, and provides tools for detecting issues like bias and drift. It also includes dashboards and reporting tools for collaboration.
+
+For more information, visit the [IBM Watsonx official documentation](https://www.ibm.com/watsonx).
+
+### Why should I use IBM Watsonx for training Ultralytics YOLOv8 models?
+
+IBM Watsonx is an excellent choice for training Ultralytics YOLOv8 models due to its comprehensive suite of tools that streamline the AI lifecycle. Key benefits include:
+
+- **Scalability**: Easily scale your model training with IBM Cloud services.
+- **Integration**: Seamlessly integrate with various data sources and APIs.
+- **User-Friendly Interface**: Simplifies the development process with a collaborative and intuitive interface.
+- **Advanced Tools**: Access to powerful tools like the Prompt Lab, Tuning Studio, and Flows Engine for enhancing model performance.
+
+Learn more about [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics) and how to train models using IBM Watsonx in our [integration guide](./index.md).
+
+### How can I preprocess my dataset for YOLOv8 training on IBM Watsonx?
+
+To preprocess your dataset for YOLOv8 training on IBM Watsonx:
+
+1. **Organize Directories**: Ensure your dataset follows the YOLO directory structure with separate subdirectories for images and labels within the train/val/test split.
+2. **Update .yaml File**: Modify the `.yaml` configuration file to reflect the new directory structure and class names.
+3. **Run Preprocessing Script**: Use a Python script to reorganize your dataset and update the `.yaml` file accordingly.
+
+Here's a sample script to organize your dataset:
+
+```python
+import os
+import shutil
+
+
+def organize_files(directory):
+ for subdir in ["train", "test", "val"]:
+ subdir_path = os.path.join(directory, subdir)
+ if not os.path.exists(subdir_path):
+ continue
+
+ images_dir = os.path.join(subdir_path, "images")
+ labels_dir = os.path.join(subdir_path, "labels")
+
+ os.makedirs(images_dir, exist_ok=True)
+ os.makedirs(labels_dir, exist_ok=True)
+
+ for filename in os.listdir(subdir_path):
+ if filename.endswith(".txt"):
+ shutil.move(os.path.join(subdir_path, filename), os.path.join(labels_dir, filename))
+ elif filename.endswith(".jpg") or filename.endswith(".png") or filename.endswith(".jpeg"):
+ shutil.move(os.path.join(subdir_path, filename), os.path.join(images_dir, filename))
+
+
+if __name__ == "__main__":
+ directory = f"{work_dir}/trash_ICRA19/dataset"
+ organize_files(directory)
+```
+
+For more details, refer to our [data preprocessing guide](../guides/preprocessing_annotated_data.md).
+
+### What are the prerequisites for training a YOLOv8 model on IBM Watsonx?
+
+Before you start training a YOLOv8 model on IBM Watsonx, ensure you have the following prerequisites:
+
+- **IBM Cloud Account**: Create an account on IBM Cloud to access Watsonx.ai.
+- **Kaggle Account**: For loading datasets, you'll need a Kaggle account and an API key.
+- **Jupyter Notebook**: Set up a Jupyter Notebook environment within Watsonx.ai for coding and model training.
+
+For more information on setting up your environment, visit our [Ultralytics Installation guide](../quickstart.md).
diff --git a/ultralytics/docs/en/integrations/index.md b/ultralytics/docs/en/integrations/index.md
new file mode 100644
index 0000000000000000000000000000000000000000..b3f6cb3655025d5aa965a7818b68ddf685b57764
--- /dev/null
+++ b/ultralytics/docs/en/integrations/index.md
@@ -0,0 +1,130 @@
+---
+comments: true
+description: Discover Ultralytics integrations for streamlined ML workflows, dataset management, optimized model training, and robust deployment solutions.
+keywords: Ultralytics, machine learning, ML workflows, dataset management, model training, model deployment, Roboflow, ClearML, Comet ML, DVC, MLFlow, Ultralytics HUB, Neptune, Ray Tune, TensorBoard, Weights & Biases, Amazon SageMaker, Paperspace Gradient, Google Colab, Neural Magic, Gradio, TorchScript, ONNX, OpenVINO, TensorRT, CoreML, TF SavedModel, TF GraphDef, TFLite, TFLite Edge TPU, TF.js, PaddlePaddle, NCNN
+---
+
+# Ultralytics Integrations
+
+Welcome to the Ultralytics Integrations page! This page provides an overview of our partnerships with various tools and platforms, designed to streamline your machine learning workflows, enhance dataset management, simplify model training, and facilitate efficient deployment.
+
+
+
+
+
+## Datasets Integrations
+
+- [Roboflow](roboflow.md): Facilitate seamless dataset management for Ultralytics models, offering robust annotation, preprocessing, and augmentation capabilities.
+
+## Training Integrations
+
+- [ClearML](clearml.md): Automate your Ultralytics ML workflows, monitor experiments, and foster team collaboration.
+
+- [Comet ML](comet.md): Enhance your model development with Ultralytics by tracking, comparing, and optimizing your machine learning experiments.
+
+- [DVC](dvc.md): Implement version control for your Ultralytics machine learning projects, synchronizing data, code, and models effectively.
+
+- [MLFlow](mlflow.md): Streamline the entire ML lifecycle of Ultralytics models, from experimentation and reproducibility to deployment.
+
+- [Ultralytics HUB](https://hub.ultralytics.com): Access and contribute to a community of pre-trained Ultralytics models.
+
+- [Neptune](https://neptune.ai/): Maintain a comprehensive log of your ML experiments with Ultralytics in this metadata store designed for MLOps.
+
+- [Ray Tune](ray-tune.md): Optimize the hyperparameters of your Ultralytics models at any scale.
+
+- [TensorBoard](tensorboard.md): Visualize your Ultralytics ML workflows, monitor model metrics, and foster team collaboration.
+
+- [Weights & Biases (W&B)](weights-biases.md): Monitor experiments, visualize metrics, and foster reproducibility and collaboration on Ultralytics projects.
+
+- [Amazon SageMaker](amazon-sagemaker.md): Leverage Amazon SageMaker to efficiently build, train, and deploy Ultralytics models, providing an all-in-one platform for the ML lifecycle.
+
+- [Paperspace Gradient](paperspace.md): Paperspace Gradient simplifies working on YOLOv8 projects by providing easy-to-use cloud tools for training, testing, and deploying your models quickly.
+
+- [Google Colab](google-colab.md): Use Google Colab to train and evaluate Ultralytics models in a cloud-based environment that supports collaboration and sharing.
+
+- [Kaggle](kaggle.md): Explore how you can use Kaggle to train and evaluate Ultralytics models in a cloud-based environment with pre-installed libraries, GPU support, and a vibrant community for collaboration and sharing.
+
+- [JupyterLab](jupyterlab.md): Find out how to use JupyterLab's interactive and customizable environment to train and evaluate Ultralytics models with ease and efficiency.
+
+- [IBM Watsonx](ibm-watsonx.md): See how IBM Watsonx simplifies the training and evaluation of Ultralytics models with its cutting-edge AI tools, effortless integration, and advanced model management system.
+
+## Deployment Integrations
+
+- [Neural Magic](neural-magic.md): Leverage Quantization Aware Training (QAT) and pruning techniques to optimize Ultralytics models for superior performance and leaner size.
+
+- [Gradio](gradio.md) 🚀 NEW: Deploy Ultralytics models with Gradio for real-time, interactive object detection demos.
+
+- [TorchScript](torchscript.md): Developed as part of the [PyTorch](https://pytorch.org/) framework, TorchScript enables efficient execution and deployment of machine learning models in various production environments without the need for Python dependencies.
+
+- [ONNX](onnx.md): An open-source format created by [Microsoft](https://www.microsoft.com) for facilitating the transfer of AI models between various frameworks, enhancing the versatility and deployment flexibility of Ultralytics models.
+
+- [OpenVINO](openvino.md): Intel's toolkit for optimizing and deploying computer vision models efficiently across various Intel CPU and GPU platforms.
+
+- [TensorRT](tensorrt.md): Developed by [NVIDIA](https://www.nvidia.com/), this high-performance deep learning inference framework and model format optimizes AI models for accelerated speed and efficiency on NVIDIA GPUs, ensuring streamlined deployment.
+
+- [CoreML](coreml.md): CoreML, developed by [Apple](https://www.apple.com/), is a framework designed for efficiently integrating machine learning models into applications across iOS, macOS, watchOS, and tvOS, using Apple's hardware for effective and secure model deployment.
+
+- [TF SavedModel](tf-savedmodel.md): Developed by [Google](https://www.google.com), TF SavedModel is a universal serialization format for TensorFlow models, enabling easy sharing and deployment across a wide range of platforms, from servers to edge devices.
+
+- [TF GraphDef](tf-graphdef.md): Developed by [Google](https://www.google.com), GraphDef is TensorFlow's format for representing computation graphs, enabling optimized execution of machine learning models across diverse hardware.
+
+- [TFLite](tflite.md): Developed by [Google](https://www.google.com), TFLite is a lightweight framework for deploying machine learning models on mobile and edge devices, ensuring fast, efficient inference with minimal memory footprint.
+
+- [TFLite Edge TPU](edge-tpu.md): Developed by [Google](https://www.google.com) for optimizing TensorFlow Lite models on Edge TPUs, this model format ensures high-speed, efficient edge computing.
+
+- [TF.js](tfjs.md): Developed by [Google](https://www.google.com) to facilitate machine learning in browsers and Node.js, TF.js allows JavaScript-based deployment of ML models.
+
+- [PaddlePaddle](paddlepaddle.md): An open-source deep learning platform by [Baidu](https://www.baidu.com/), PaddlePaddle enables the efficient deployment of AI models and focuses on the scalability of industrial applications.
+
+- [NCNN](ncnn.md): Developed by [Tencent](http://www.tencent.com/), NCNN is an efficient neural network inference framework tailored for mobile devices. It enables direct deployment of AI models into apps, optimizing performance across various mobile platforms.
+
+### Export Formats
+
+We also support a variety of model export formats for deployment in different environments. Here are the available formats:
+
+{% include "macros/export-table.md" %}
+
+Explore the links to learn more about each integration and how to get the most out of them with Ultralytics. See full `export` details in the [Export](../modes/export.md) page.
+
+## Contribute to Our Integrations
+
+We're always excited to see how the community integrates Ultralytics YOLO with other technologies, tools, and platforms! If you have successfully integrated YOLO with a new system or have valuable insights to share, consider contributing to our Integrations Docs.
+
+By writing a guide or tutorial, you can help expand our documentation and provide real-world examples that benefit the community. It's an excellent way to contribute to the growing ecosystem around Ultralytics YOLO.
+
+To contribute, please check out our [Contributing Guide](../help/contributing.md) for instructions on how to submit a Pull Request (PR) 🛠️. We eagerly await your contributions!
+
+Let's collaborate to make the Ultralytics YOLO ecosystem more expansive and feature-rich 🙏!
+
+## FAQ
+
+### What is Ultralytics HUB, and how does it streamline the ML workflow?
+
+Ultralytics HUB is a cloud-based platform designed to make machine learning (ML) workflows for Ultralytics models seamless and efficient. By using this tool, you can easily upload datasets, train models, perform real-time tracking, and deploy YOLOv8 models without needing extensive coding skills. You can explore the key features on the [Ultralytics HUB](https://hub.ultralytics.com) page and get started quickly with our [Quickstart](https://docs.ultralytics.com/hub/quickstart/) guide.
+
+### How do I integrate Ultralytics YOLO models with Roboflow for dataset management?
+
+Integrating Ultralytics YOLO models with Roboflow enhances dataset management by providing robust tools for annotation, preprocessing, and augmentation. To get started, follow the steps on the [Roboflow](roboflow.md) integration page. This partnership ensures efficient dataset handling, which is crucial for developing accurate and robust YOLO models.
+
+### Can I track the performance of my Ultralytics models using MLFlow?
+
+Yes, you can. Integrating MLFlow with Ultralytics models allows you to track experiments, improve reproducibility, and streamline the entire ML lifecycle. Detailed instructions for setting up this integration can be found on the [MLFlow](mlflow.md) integration page. This integration is particularly useful for monitoring model metrics and managing the ML workflow efficiently.
+
+### What are the benefits of using Neural Magic for YOLOv8 model optimization?
+
+Neural Magic optimizes YOLOv8 models by leveraging techniques like Quantization Aware Training (QAT) and pruning, resulting in highly efficient, smaller models that perform better on resource-limited hardware. Check out the [Neural Magic](neural-magic.md) integration page to learn how to implement these optimizations for superior performance and leaner models. This is especially beneficial for deployment on edge devices.
+
+### How do I deploy Ultralytics YOLO models with Gradio for interactive demos?
+
+To deploy Ultralytics YOLO models with Gradio for interactive object detection demos, you can follow the steps outlined on the [Gradio](gradio.md) integration page. Gradio allows you to create easy-to-use web interfaces for real-time model inference, making it an excellent tool for showcasing your YOLO model's capabilities in a user-friendly format suitable for both developers and end-users.
+
+By addressing these common questions, we aim to improve user experience and provide valuable insights into the powerful capabilities of Ultralytics products. Incorporating these FAQs will not only enhance the documentation but also drive more organic traffic to the Ultralytics website.
diff --git a/ultralytics/docs/en/integrations/jupyterlab.md b/ultralytics/docs/en/integrations/jupyterlab.md
new file mode 100644
index 0000000000000000000000000000000000000000..cb2ce59653dae44e480e188edd03bc4b6dc53839
--- /dev/null
+++ b/ultralytics/docs/en/integrations/jupyterlab.md
@@ -0,0 +1,210 @@
+---
+comments: true
+description: Explore our integration guide that explains how you can use JupyterLab to train a YOLOv8 model. We'll also cover key features and tips for common issues.
+keywords: JupyterLab, What is JupyterLab, How to Use JupyterLab, JupyterLab How to Use, YOLOv8, Ultralytics, Model Training, GPU, TPU, cloud computing
+---
+
+# A Guide on How to Use JupyterLab to Train Your YOLOv8 Models
+
+Building deep learning models can be tough, especially when you don't have the right tools or environment to work with. If you are facing this issue, JupyterLab might be the right solution for you. JupyterLab is a user-friendly, web-based platform that makes coding more flexible and interactive. You can use it to handle big datasets, create complex models, and even collaborate with others, all in one place.
+
+You can use JupyterLab to [work on projects](../guides/steps-of-a-cv-project.md) related to [Ultralytics YOLOv8 models](https://github.com/ultralytics/ultralytics). JupyterLab is a great option for efficient model development and experimentation. It makes it easy to start experimenting with and [training YOLOv8 models](../modes/train.md) right from your computer. Let's dive deeper into JupyterLab, its key features, and how you can use it to train YOLOv8 models.
+
+## What is JupyterLab?
+
+JupyterLab is an open-source web-based platform designed for working with Jupyter notebooks, code, and data. It's an upgrade from the traditional Jupyter Notebook interface that provides a more versatile and powerful user experience.
+
+JupyterLab allows you to work with notebooks, text editors, terminals, and other tools all in one place. Its flexible design lets you organize your workspace to fit your needs and makes it easier to perform tasks like data analysis, visualization, and machine learning. JupyterLab also supports real-time collaboration, making it ideal for team projects in research and data science.
+
+## Key Features of JupyterLab
+
+Here are some of the key features that make JupyterLab a great option for model development and experimentation:
+
+- **All-in-One Workspace**: JupyterLab is a one-stop shop for all your data science needs. Unlike the classic Jupyter Notebook, which had separate interfaces for text editing, terminal access, and notebooks, JupyterLab integrates all these features into a single, cohesive environment. You can view and edit various file formats, including JPEG, PDF, and CSV, directly within JupyterLab. An all-in-one workspace lets you access everything you need at your fingertips, streamlining your workflow and saving you time.
+- **Flexible Layouts**: One of JupyterLab's standout features is its flexible layout. You can drag, drop, and resize tabs to create a personalized layout that helps you work more efficiently. The collapsible left sidebar keeps essential tabs like the file browser, running kernels, and command palette within easy reach. You can have multiple windows open at once, allowing you to multitask and manage your projects more effectively.
+- **Interactive Code Consoles**: Code consoles in JupyterLab provide an interactive space to test out snippets of code or functions. They also serve as a log of computations made within a notebook. Creating a new console for a notebook and viewing all kernel activity is straightforward. This feature is especially useful when you're experimenting with new ideas or troubleshooting issues in your code.
+- **Markdown Preview**: Working with Markdown files is more efficient in JupyterLab, thanks to its simultaneous preview feature. As you write or edit your Markdown file, you can see the formatted output in real-time. It makes it easier to double-check that your documentation looks perfect, saving you from having to switch back and forth between editing and preview modes.
+- **Run Code from Text Files**: If you're sharing a text file with code, JupyterLab makes it easy to run it directly within the platform. You can highlight the code and press Shift + Enter to execute it. It is great for verifying code snippets quickly and helps guarantee that the code you share is functional and error-free.
+
+## Why Should You Use JupyterLab for Your YOLOv8 Projects?
+
+There are multiple platforms for developing and evaluating machine learning models, so what makes JupyterLab stand out? Let's explore some of the unique aspects that JupyterLab offers for your machine-learning projects:
+
+- **Easy Cell Management**: Managing cells in JupyterLab is a breeze. Instead of the cumbersome cut-and-paste method, you can simply drag and drop cells to rearrange them.
+- **Cross-Notebook Cell Copying**: JupyterLab makes it simple to copy cells between different notebooks. You can drag and drop cells from one notebook to another.
+- **Easy Switch to Classic Notebook View**: For those who miss the classic Jupyter Notebook interface, JupyterLab offers an easy switch back. Simply replace `/lab` in the URL with `/tree` to return to the familiar notebook view.
+- **Multiple Views**: JupyterLab supports multiple views of the same notebook, which is particularly useful for long notebooks. You can open different sections side-by-side for comparison or exploration, and any changes made in one view are reflected in the other.
+- **Customizable Themes**: JupyterLab includes a built-in Dark theme for the notebook, which is perfect for late-night coding sessions. There are also themes available for the text editor and terminal, allowing you to customize the appearance of your entire workspace.
+
+## Common Issues While Working with JupyterLab
+
+When working with Kaggle, you might come across some common issues. Here are some tips to help you navigate the platform smoothly:
+
+- **Managing Kernels**: Kernels are crucial because they manage the connection between the code you write in JupyterLab and the environment where it runs. They can also access and share data between notebooks. When you close a Jupyter Notebook, the kernel might still be running because other notebooks could be using it. If you want to completely shut down a kernel, you can select it, right-click, and choose "Shut Down Kernel" from the pop-up menu.
+- **Installing Python Packages**: Sometimes, you might need additional Python packages that aren't pre-installed on the server. You can easily install these packages in your home directory or a virtual environment by using the command `python -m pip install package-name`. To see all installed packages, use `python -m pip list`.
+- **Deploying Flask/FastAPI API to Posit Connect**: You can deploy your Flask and FastAPI APIs to Posit Connect using the [rsconnect-python](https://docs.posit.co/rsconnect-python/) package from the terminal. Doing so makes it easier to integrate your web applications with JupyterLab and share them with others.
+- **Installing JupyterLab Extensions**: JupyterLab supports various extensions to enhance functionality. You can install and customize these extensions to suit your needs. For detailed instructions, refer to [JupyterLab Extensions Guide](https://jupyterlab.readthedocs.io/en/latest/user/extensions.html) for more information.
+- **Using Multiple Versions of Python**: If you need to work with different versions of Python, you can use Jupyter kernels configured with different Python versions.
+
+## How to Use JupyterLab to Try Out YOLOv8
+
+JupyterLab makes it easy to experiment with YOLOv8. To get started, follow these simple steps.
+
+### Step 1: Install JupyterLab
+
+First, you need to install JupyterLab. Open your terminal and run the command:
+
+!!! Tip "Installation"
+
+ === "CLI"
+
+ ```bash
+ # Install the required package for JupyterLab
+ pip install jupyterlab
+ ```
+
+### Step 2: Download the YOLOv8 Tutorial Notebook
+
+Next, download the [tutorial.ipynb](https://github.com/ultralytics/ultralytics/blob/main/examples/tutorial.ipynb) file from the Ultralytics GitHub repository. Save this file to any directory on your local machine.
+
+### Step 3: Launch JupyterLab
+
+Navigate to the directory where you saved the notebook file using your terminal. Then, run the following command to launch JupyterLab:
+
+!!! Example "Usage"
+
+ === "CLI"
+
+ ```bash
+ jupyter lab
+ ```
+
+Once you've run this command, it will open JupyterLab in your default web browser, as shown below.
+
+
+
+### Step 4: Start Experimenting
+
+In JupyterLab, open the tutorial.ipynb notebook. You can now start running the cells to explore and experiment with YOLOv8.
+
+
+
+JupyterLab's interactive environment allows you to modify code, visualize outputs, and document your findings all in one place. You can try out different configurations and understand how YOLOv8 works.
+
+For a detailed understanding of the model training process and best practices, refer to the [YOLOv8 Model Training guide](../modes/train.md). This guide will help you get the most out of your experiments and ensure you're using YOLOv8 effectively.
+
+## Keep Learning about Jupyterlab
+
+If you're excited to learn more about JupyterLab, here are some great resources to get you started:
+
+- [**JupyterLab Documentation**](https://jupyterlab.readthedocs.io/en/stable/getting_started/starting.html): Dive into the official JupyterLab Documentation to explore its features and capabilities. It's a great way to understand how to use this powerful tool to its fullest potential.
+- [**Try It With Binder**](https://mybinder.org/v2/gh/jupyterlab/jupyterlab-demo/HEAD?urlpath=lab/tree/demo): Experiment with JupyterLab without installing anything by using Binder, which lets you launch a live JupyterLab instance directly in your browser. It's a great way to start experimenting immediately.
+- [**Installation Guide**](https://jupyterlab.readthedocs.io/en/stable/getting_started/installation.html): For a step-by-step guide on installing JupyterLab on your local machine, check out the installation guide.
+
+## Summary
+
+We've explored how JupyterLab can be a powerful tool for experimenting with Ultralytics YOLOv8 models. Using its flexible and interactive environment, you can easily set up JupyterLab on your local machine and start working with YOLOv8. JupyterLab makes it simple to [train](../guides/model-training-tips.md) and [evaluate](../guides/model-testing.md) your models, visualize outputs, and [document your findings](../guides/model-monitoring-and-maintenance.md) all in one place.
+
+For more details, visit the [JupyterLab FAQ Page](https://jupyterlab.readthedocs.io/en/stable/getting_started/faq.html).
+
+Interested in more YOLOv8 integrations? Check out the [Ultralytics integration guide](./index.md) to explore additional tools and capabilities for your machine learning projects.
+
+## FAQ
+
+### How do I use JupyterLab to train a YOLOv8 model?
+
+To train a YOLOv8 model using JupyterLab:
+
+1. Install JupyterLab and the Ultralytics package:
+
+ ```bash
+ pip install jupyterlab ultralytics
+ ```
+
+2. Launch JupyterLab and open a new notebook.
+
+3. Import the YOLO model and load a pretrained model:
+
+ ```python
+ from ultralytics import YOLO
+
+ model = YOLO("yolov8n.pt")
+ ```
+
+4. Train the model on your custom dataset:
+
+ ```python
+ results = model.train(data="path/to/your/data.yaml", epochs=100, imgsz=640)
+ ```
+
+5. Visualize training results using JupyterLab's built-in plotting capabilities:
+
+ ```ipython
+ %matplotlib inline
+ from ultralytics.utils.plotting import plot_results
+ plot_results(results)
+ ```
+
+JupyterLab's interactive environment allows you to easily modify parameters, visualize results, and iterate on your model training process.
+
+### What are the key features of JupyterLab that make it suitable for YOLOv8 projects?
+
+JupyterLab offers several features that make it ideal for YOLOv8 projects:
+
+1. Interactive code execution: Test and debug YOLOv8 code snippets in real-time.
+2. Integrated file browser: Easily manage datasets, model weights, and configuration files.
+3. Flexible layout: Arrange multiple notebooks, terminals, and output windows side-by-side for efficient workflow.
+4. Rich output display: Visualize YOLOv8 detection results, training curves, and model performance metrics inline.
+5. Markdown support: Document your YOLOv8 experiments and findings with rich text and images.
+6. Extension ecosystem: Enhance functionality with extensions for version control, [remote computing](google-colab.md), and more.
+
+These features allow for a seamless development experience when working with YOLOv8 models, from data preparation to model deployment.
+
+### How can I optimize YOLOv8 model performance using JupyterLab?
+
+To optimize YOLOv8 model performance in JupyterLab:
+
+1. Use the autobatch feature to determine the optimal batch size:
+
+ ```python
+ from ultralytics.utils.autobatch import autobatch
+
+ optimal_batch_size = autobatch(model)
+ ```
+
+2. Implement [hyperparameter tuning](../guides/hyperparameter-tuning.md) using libraries like Ray Tune:
+
+ ```python
+ from ultralytics.utils.tuner import run_ray_tune
+
+ best_results = run_ray_tune(model, data="path/to/data.yaml")
+ ```
+
+3. Visualize and analyze model metrics using JupyterLab's plotting capabilities:
+
+ ```python
+ from ultralytics.utils.plotting import plot_results
+
+ plot_results(results.results_dict)
+ ```
+
+4. Experiment with different model architectures and [export formats](../modes/export.md) to find the best balance of speed and accuracy for your specific use case.
+
+JupyterLab's interactive environment allows for quick iterations and real-time feedback, making it easier to optimize your YOLOv8 models efficiently.
+
+### How do I handle common issues when working with JupyterLab and YOLOv8?
+
+When working with JupyterLab and YOLOv8, you might encounter some common issues. Here's how to handle them:
+
+1. GPU memory issues:
+
+ - Use `torch.cuda.empty_cache()` to clear GPU memory between runs.
+ - Adjust batch size or image size to fit your GPU memory.
+
+2. Package conflicts:
+
+ - Create a separate conda environment for your YOLOv8 projects to avoid conflicts.
+ - Use `!pip install package_name` in a notebook cell to install missing packages.
+
+3. Kernel crashes:
+ - Restart the kernel and run cells one by one to identify the problematic code.
diff --git a/ultralytics/docs/en/integrations/kaggle.md b/ultralytics/docs/en/integrations/kaggle.md
new file mode 100644
index 0000000000000000000000000000000000000000..466d728c8c3f6eb499f5b6dbd3720134cff771d9
--- /dev/null
+++ b/ultralytics/docs/en/integrations/kaggle.md
@@ -0,0 +1,139 @@
+---
+comments: true
+description: Dive into our guide on YOLOv8's integration with Kaggle. Find out what Kaggle is, its key features, and how to train a YOLOv8 model using the integration.
+keywords: What is Kaggle, What is Kaggle Used For, YOLOv8, Kaggle Machine Learning, Model Training, GPU, TPU, cloud computing
+---
+
+# A Guide on Using Kaggle to Train Your YOLOv8 Models
+
+If you are learning about AI and working on [small projects](../solutions/index.md), you might not have access to powerful computing resources yet, and high-end hardware can be pretty expensive. Fortunately, Kaggle, a platform owned by Google, offers a great solution. Kaggle provides a free, cloud-based environment where you can access GPU resources, handle large datasets, and collaborate with a diverse community of data scientists and machine learning enthusiasts.
+
+Kaggle is a great choice for [training](../guides/model-training-tips.md) and experimenting with [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics?tab=readme-ov-file) models. Kaggle Notebooks make using popular machine-learning libraries and frameworks in your projects easy. Let's explore Kaggle's main features and learn how you can train YOLOv8 models on this platform!
+
+## What is Kaggle?
+
+Kaggle is a platform that brings together data scientists from around the world to collaborate, learn, and compete in solving real-world data science problems. Launched in 2010 by Anthony Goldbloom and Jeremy Howard and acquired by Google in 2017. Kaggle enables users to connect, discover and share datasets, use GPU-powered notebooks, and participate in data science competitions. The platform is designed to help both seasoned professionals and eager learners achieve their goals by offering robust tools and resources.
+
+With more than [10 million users](https://www.kaggle.com/discussions/general/332147) as of 2022, Kaggle provides a rich environment for developing and experimenting with machine learning models. You don't need to worry about your local machine's specs or setup; you can dive right in with just a Kaggle account and a web browser.
+
+## Training YOLOv8 Using Kaggle
+
+Training YOLOv8 models on Kaggle is simple and efficient, thanks to the platform's access to powerful GPUs.
+
+To get started, access the [Kaggle YOLOv8 Notebook](https://www.kaggle.com/code/ultralytics/yolov8). Kaggle's environment comes with pre-installed libraries like TensorFlow and PyTorch, making the setup process hassle-free.
+
+
+
+Once you sign in to your Kaggle account, you can click on the option to copy and edit the code, select a GPU under the accelerator settings, and run the notebook's cells to begin training your model. For a detailed understanding of the model training process and best practices, refer to our [YOLOv8 Model Training guide](../modes/train.md).
+
+
+
+On the [official YOLOv8 Kaggle notebook page](https://www.kaggle.com/code/ultralytics/yolov8), if you click on the three dots in the upper right-hand corner, you'll notice more options will pop up.
+
+
+
+These options include:
+
+- **View Versions**: Browse through different versions of the notebook to see changes over time and revert to previous versions if needed.
+- **Copy API Command**: Get an API command to programmatically interact with the notebook, which is useful for automation and integration into workflows.
+- **Open in Google Notebooks**: Open the notebook in Google's hosted notebook environment.
+- **Open in Colab**: Launch the notebook in [Google Colab](./google-colab.md) for further editing and execution.
+- **Follow Comments**: Subscribe to the comments section to get updates and engage with the community.
+- **Download Code**: Download the entire notebook as a Jupyter (.ipynb) file for offline use or version control in your local environment.
+- **Add to Collection**: Save the notebook to a collection within your Kaggle account for easy access and organization.
+- **Bookmark**: Bookmark the notebook for quick access in the future.
+- **Embed Notebook**: Get an embed link to include the notebook in blogs, websites, or documentation.
+
+### Common Issues While Working with Kaggle
+
+When working with Kaggle, you might come across some common issues. Here are some points to help you navigate the platform smoothly:
+
+- **Access to GPUs**: In your Kaggle notebooks, you can activate a GPU at any time, with usage allowed for up to 30 hours per week. Kaggle provides the Nvidia Tesla P100 GPU with 16GB of memory and also offers the option of using a Nvidia GPU T4 x2. Powerful hardware accelerates your machine-learning tasks, making model training and inference much faster.
+- **Kaggle Kernels**: Kaggle Kernels are free Jupyter notebook servers that can integrate GPUs, allowing you to perform machine learning operations on cloud computers. You don't have to rely on your own computer's CPU, avoiding overload and freeing up your local resources.
+- **Kaggle Datasets**: Kaggle datasets are free to download. However, it's important to check the license for each dataset to understand any usage restrictions. Some datasets may have limitations on academic publications or commercial use. You can download datasets directly to your Kaggle notebook or anywhere else via the Kaggle API.
+- **Saving and Committing Notebooks**: To save and commit a notebook on Kaggle, click "Save Version." This saves the current state of your notebook. Once the background kernel finishes generating the output files, you can access them from the Output tab on the main notebook page.
+- **Collaboration**: Kaggle supports collaboration, but multiple users cannot edit a notebook simultaneously. Collaboration on Kaggle is asynchronous, meaning users can share and work on the same notebook at different times.
+- **Reverting to a Previous Version**: If you need to revert to a previous version of your notebook, open the notebook and click on the three vertical dots in the top right corner to select "View Versions." Find the version you want to revert to, click on the "..." menu next to it, and select "Revert to Version." After the notebook reverts, click "Save Version" to commit the changes.
+
+## Key Features of Kaggle
+
+Next, let's understand the features Kaggle offers that make it an excellent platform for data science and machine learning enthusiasts. Here are some of the key highlights:
+
+- **Datasets**: Kaggle hosts a massive collection of datasets on various topics. You can easily search and use these datasets in your projects, which is particularly handy for training and testing your YOLOv8 models.
+- **Competitions**: Known for its exciting competitions, Kaggle allows data scientists and machine learning enthusiasts to solve real-world problems. Competing helps you improve your skills, learn new techniques, and gain recognition in the community.
+- **Free Access to TPUs**: Kaggle provides free access to powerful TPUs, which are essential for training complex machine learning models. This means you can speed up processing and boost the performance of your YOLOv8 projects without incurring extra costs.
+- **Integration with Github**: Kaggle allows you to easily connect your GitHub repository to upload notebooks and save your work. This integration makes it convenient to manage and access your files.
+- **Community and Discussions**: Kaggle boasts a strong community of data scientists and machine learning practitioners. The discussion forums and shared notebooks are fantastic resources for learning and troubleshooting. You can easily find help, share your knowledge, and collaborate with others.
+
+## Why Should You Use Kaggle for Your YOLOv8 Projects?
+
+There are multiple platforms for training and evaluating machine learning models, so what makes Kaggle stand out? Let's dive into the benefits of using Kaggle for your machine-learning projects:
+
+- **Public Notebooks**: You can make your Kaggle notebooks public, allowing other users to view, vote, fork, and discuss your work. Kaggle promotes collaboration, feedback, and the sharing of ideas, helping you improve your YOLOv8 models.
+- **Comprehensive History of Notebook Commits**: Kaggle creates a detailed history of your notebook commits. This allows you to review and track changes over time, making it easier to understand the evolution of your project and revert to previous versions if needed.
+- **Console Access**: Kaggle provides a console, giving you more control over your environment. This feature allows you to perform various tasks directly from the command line, enhancing your workflow and productivity.
+- **Resource Availability**: Each notebook editing session on Kaggle is provided with significant resources: 12 hours of execution time for CPU and GPU sessions, 9 hours of execution time for TPU sessions, and 20 gigabytes of auto-saved disk space.
+- **Notebook Scheduling**: Kaggle allows you to schedule your notebooks to run at specific times. You can automate repetitive tasks without manual intervention, such as training your model at regular intervals.
+
+## Keep Learning about Kaggle
+
+If you want to learn more about Kaggle, here are some helpful resources to guide you:
+
+- [**Kaggle Learn**](https://www.kaggle.com/learn): Discover a variety of free, interactive tutorials on Kaggle Learn. These courses cover essential data science topics and provide hands-on experience to help you master new skills.
+- [**Getting Started with Kaggle**](https://www.kaggle.com/code/alexisbcook/getting-started-with-kaggle): This comprehensive guide walks you through the basics of using Kaggle, from joining competitions to creating your first notebook. It's a great starting point for newcomers.
+- [**Kaggle Medium Page**](https://medium.com/@kaggleteam): Explore tutorials, updates, and community contributions on Kaggle's Medium page. It's an excellent source for staying up-to-date with the latest trends and gaining deeper insights into data science.
+
+## Summary
+
+We've seen how Kaggle can boost your YOLOv8 projects by providing free access to powerful GPUs, making model training and evaluation efficient. Kaggle's platform is user-friendly, with pre-installed libraries for quick setup.
+
+For more details, visit [Kaggle's documentation](https://www.kaggle.com/docs).
+
+Interested in more YOLOv8 integrations? Check out the[ Ultralytics integration guide](https://docs.ultralytics.com/integrations/) to explore additional tools and capabilities for your machine learning projects.
+
+## FAQ
+
+### How do I train a YOLOv8 model on Kaggle?
+
+Training a YOLOv8 model on Kaggle is straightforward. First, access the [Kaggle YOLOv8 Notebook](https://www.kaggle.com/ultralytics/yolov8). Sign in to your Kaggle account, copy and edit the notebook, and select a GPU under the accelerator settings. Run the notebook cells to start training. For more detailed steps, refer to our [YOLOv8 Model Training guide](../modes/train.md).
+
+### What are the benefits of using Kaggle for YOLOv8 model training?
+
+Kaggle offers several advantages for training YOLOv8 models:
+
+- **Free GPU Access**: Utilize powerful GPUs like Nvidia Tesla P100 or T4 x2 for up to 30 hours per week.
+- **Pre-installed Libraries**: Libraries like TensorFlow and PyTorch are pre-installed, simplifying the setup.
+- **Community Collaboration**: Engage with a vast community of data scientists and machine learning enthusiasts.
+- **Version Control**: Easily manage different versions of your notebooks and revert to previous versions if needed.
+
+For more details, visit our [Ultralytics integration guide](https://docs.ultralytics.com/integrations/).
+
+### What common issues might I encounter when using Kaggle for YOLOv8, and how can I resolve them?
+
+Common issues include:
+
+- **Access to GPUs**: Ensure you activate a GPU in your notebook settings. Kaggle allows up to 30 hours of GPU usage per week.
+- **Dataset Licenses**: Check the license of each dataset to understand usage restrictions.
+- **Saving and Committing Notebooks**: Click "Save Version" to save your notebook's state and access output files from the Output tab.
+- **Collaboration**: Kaggle supports asynchronous collaboration; multiple users cannot edit a notebook simultaneously.
+
+For more troubleshooting tips, see our [Common Issues guide](../guides/yolo-common-issues.md).
+
+### Why should I choose Kaggle over other platforms like Google Colab for training YOLOv8 models?
+
+Kaggle offers unique features that make it an excellent choice:
+
+- **Public Notebooks**: Share your work with the community for feedback and collaboration.
+- **Free Access to TPUs**: Speed up training with powerful TPUs without extra costs.
+- **Comprehensive History**: Track changes over time with a detailed history of notebook commits.
+- **Resource Availability**: Significant resources are provided for each notebook session, including 12 hours of execution time for CPU and GPU sessions.
+ For a comparison with Google Colab, refer to our [Google Colab guide](./google-colab.md).
+
+### How can I revert to a previous version of my Kaggle notebook?
+
+To revert to a previous version:
+
+1. Open the notebook and click on the three vertical dots in the top right corner.
+2. Select "View Versions."
+3. Find the version you want to revert to, click on the "..." menu next to it, and select "Revert to Version."
+4. Click "Save Version" to commit the changes.
diff --git a/ultralytics/docs/en/integrations/mlflow.md b/ultralytics/docs/en/integrations/mlflow.md
new file mode 100644
index 0000000000000000000000000000000000000000..acb09db92b11275009eec13f990a58629014957b
--- /dev/null
+++ b/ultralytics/docs/en/integrations/mlflow.md
@@ -0,0 +1,207 @@
+---
+comments: true
+description: Learn how to set up and use MLflow logging with Ultralytics YOLO for enhanced experiment tracking, model reproducibility, and performance improvements.
+keywords: MLflow, Ultralytics YOLO, machine learning, experiment tracking, metrics logging, parameter logging, artifact logging
+---
+
+# MLflow Integration for Ultralytics YOLO
+
+
+
+## Introduction
+
+Experiment logging is a crucial aspect of machine learning workflows that enables tracking of various metrics, parameters, and artifacts. It helps to enhance model reproducibility, debug issues, and improve model performance. [Ultralytics](https://ultralytics.com) YOLO, known for its real-time object detection capabilities, now offers integration with [MLflow](https://mlflow.org/), an open-source platform for complete machine learning lifecycle management.
+
+This documentation page is a comprehensive guide to setting up and utilizing the MLflow logging capabilities for your Ultralytics YOLO project.
+
+## What is MLflow?
+
+[MLflow](https://mlflow.org/) is an open-source platform developed by [Databricks](https://www.databricks.com/) for managing the end-to-end machine learning lifecycle. It includes tools for tracking experiments, packaging code into reproducible runs, and sharing and deploying models. MLflow is designed to work with any machine learning library and programming language.
+
+## Features
+
+- **Metrics Logging**: Logs metrics at the end of each epoch and at the end of the training.
+- **Parameter Logging**: Logs all the parameters used in the training.
+- **Artifacts Logging**: Logs model artifacts, including weights and configuration files, at the end of the training.
+
+## Setup and Prerequisites
+
+Ensure MLflow is installed. If not, install it using pip:
+
+```bash
+pip install mlflow
+```
+
+Make sure that MLflow logging is enabled in Ultralytics settings. Usually, this is controlled by the settings `mflow` key. See the [settings](../quickstart.md#ultralytics-settings) page for more info.
+
+!!! Example "Update Ultralytics MLflow Settings"
+
+ === "Python"
+
+ Within the Python environment, call the `update` method on the `settings` object to change your settings:
+ ```python
+ from ultralytics import settings
+
+ # Update a setting
+ settings.update({"mlflow": True})
+
+ # Reset settings to default values
+ settings.reset()
+ ```
+
+ === "CLI"
+
+ If you prefer using the command-line interface, the following commands will allow you to modify your settings:
+ ```bash
+ # Update a setting
+ yolo settings runs_dir='/path/to/runs'
+
+ # Reset settings to default values
+ yolo settings reset
+ ```
+
+## How to Use
+
+### Commands
+
+1. **Set a Project Name**: You can set the project name via an environment variable:
+
+ ```bash
+ export MLFLOW_EXPERIMENT_NAME=
+ ```
+
+ Or use the `project=` argument when training a YOLO model, i.e. `yolo train project=my_project`.
+
+2. **Set a Run Name**: Similar to setting a project name, you can set the run name via an environment variable:
+
+ ```bash
+ export MLFLOW_RUN=
+ ```
+
+ Or use the `name=` argument when training a YOLO model, i.e. `yolo train project=my_project name=my_name`.
+
+3. **Start Local MLflow Server**: To start tracking, use:
+
+ ```bash
+ mlflow server --backend-store-uri runs/mlflow'
+ ```
+
+ This will start a local server at http://127.0.0.1:5000 by default and save all mlflow logs to the 'runs/mlflow' directory. To specify a different URI, set the `MLFLOW_TRACKING_URI` environment variable.
+
+4. **Kill MLflow Server Instances**: To stop all running MLflow instances, run:
+
+ ```bash
+ ps aux | grep 'mlflow' | grep -v 'grep' | awk '{print $2}' | xargs kill -9
+ ```
+
+### Logging
+
+The logging is taken care of by the `on_pretrain_routine_end`, `on_fit_epoch_end`, and `on_train_end` callback functions. These functions are automatically called during the respective stages of the training process, and they handle the logging of parameters, metrics, and artifacts.
+
+## Examples
+
+1. **Logging Custom Metrics**: You can add custom metrics to be logged by modifying the `trainer.metrics` dictionary before `on_fit_epoch_end` is called.
+
+2. **View Experiment**: To view your logs, navigate to your MLflow server (usually http://127.0.0.1:5000) and select your experiment and run.
+
+3. **View Run**: Runs are individual models inside an experiment. Click on a Run and see the Run details, including uploaded artifacts and model weights.
+
+## Disabling MLflow
+
+To turn off MLflow logging:
+
+```bash
+yolo settings mlflow=False
+```
+
+## Conclusion
+
+MLflow logging integration with Ultralytics YOLO offers a streamlined way to keep track of your machine learning experiments. It empowers you to monitor performance metrics and manage artifacts effectively, thus aiding in robust model development and deployment. For further details please visit the MLflow [official documentation](https://mlflow.org/docs/latest/index.html).
+
+## FAQ
+
+### How do I set up MLflow logging with Ultralytics YOLO?
+
+To set up MLflow logging with Ultralytics YOLO, you first need to ensure MLflow is installed. You can install it using pip:
+
+```bash
+pip install mlflow
+```
+
+Next, enable MLflow logging in Ultralytics settings. This can be controlled using the `mlflow` key. For more information, see the [settings guide](../quickstart.md#ultralytics-settings).
+
+!!! Example "Update Ultralytics MLflow Settings"
+
+ === "Python"
+
+ ```python
+ from ultralytics import settings
+
+ # Update a setting
+ settings.update({"mlflow": True})
+
+ # Reset settings to default values
+ settings.reset()
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Update a setting
+ yolo settings runs_dir='/path/to/runs'
+
+ # Reset settings to default values
+ yolo settings reset
+ ```
+
+Finally, start a local MLflow server for tracking:
+
+```bash
+mlflow server --backend-store-uri runs/mlflow
+```
+
+### What metrics and parameters can I log using MLflow with Ultralytics YOLO?
+
+Ultralytics YOLO with MLflow supports logging various metrics, parameters, and artifacts throughout the training process:
+
+- **Metrics Logging**: Tracks metrics at the end of each epoch and upon training completion.
+- **Parameter Logging**: Logs all parameters used in the training process.
+- **Artifacts Logging**: Saves model artifacts like weights and configuration files after training.
+
+For more detailed information, visit the [Ultralytics YOLO tracking documentation](#features).
+
+### Can I disable MLflow logging once it is enabled?
+
+Yes, you can disable MLflow logging for Ultralytics YOLO by updating the settings. Here's how you can do it using the CLI:
+
+```bash
+yolo settings mlflow=False
+```
+
+For further customization and resetting settings, refer to the [settings guide](../quickstart.md#ultralytics-settings).
+
+### How can I start and stop an MLflow server for Ultralytics YOLO tracking?
+
+To start an MLflow server for tracking your experiments in Ultralytics YOLO, use the following command:
+
+```bash
+mlflow server --backend-store-uri runs/mlflow
+```
+
+This command starts a local server at http://127.0.0.1:5000 by default. If you need to stop running MLflow server instances, use the following bash command:
+
+```bash
+ps aux | grep 'mlflow' | grep -v 'grep' | awk '{print $2}' | xargs kill -9
+```
+
+Refer to the [commands section](#commands) for more command options.
+
+### What are the benefits of integrating MLflow with Ultralytics YOLO for experiment tracking?
+
+Integrating MLflow with Ultralytics YOLO offers several benefits for managing your machine learning experiments:
+
+- **Enhanced Experiment Tracking**: Easily track and compare different runs and their outcomes.
+- **Improved Model Reproducibility**: Ensure that your experiments are reproducible by logging all parameters and artifacts.
+- **Performance Monitoring**: Visualize performance metrics over time to make data-driven decisions for model improvements.
+
+For an in-depth look at setting up and leveraging MLflow with Ultralytics YOLO, explore the [MLflow Integration for Ultralytics YOLO](#introduction) documentation.
diff --git a/ultralytics/docs/en/integrations/ncnn.md b/ultralytics/docs/en/integrations/ncnn.md
new file mode 100644
index 0000000000000000000000000000000000000000..05da32280cdbc980847d39084891ac873012ff57
--- /dev/null
+++ b/ultralytics/docs/en/integrations/ncnn.md
@@ -0,0 +1,186 @@
+---
+comments: true
+description: Optimize YOLOv8 models for mobile and embedded devices by exporting to NCNN format. Enhance performance in resource-constrained environments.
+keywords: Ultralytics, YOLOv8, NCNN, model export, machine learning, deployment, mobile, embedded systems, deep learning, AI models
+---
+
+# How to Export to NCNN from YOLOv8 for Smooth Deployment
+
+Deploying computer vision models on devices with limited computational power, such as mobile or embedded systems, can be tricky. You need to make sure you use a format optimized for optimal performance. This makes sure that even devices with limited processing power can handle advanced computer vision tasks well.
+
+The export to NCNN format feature allows you to optimize your [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics) models for lightweight device-based applications. In this guide, we'll walk you through how to convert your models to the NCNN format, making it easier for your models to perform well on various mobile and embedded devices.
+
+## Why should you export to NCNN?
+
+
+
+
+
+The [NCNN](https://github.com/Tencent/ncnn) framework, developed by Tencent, is a high-performance neural network inference computing framework optimized specifically for mobile platforms, including mobile phones, embedded devices, and IoT devices. NCNN is compatible with a wide range of platforms, including Linux, Android, iOS, and macOS.
+
+NCNN is known for its fast processing speed on mobile CPUs and enables rapid deployment of deep learning models to mobile platforms. This makes it easier to build smart apps, putting the power of AI right at your fingertips.
+
+## Key Features of NCNN Models
+
+NCNN models offer a wide range of key features that enable on-device machine learning by helping developers run their models on mobile, embedded, and edge devices:
+
+- **Efficient and High-Performance**: NCNN models are made to be efficient and lightweight, optimized for running on mobile and embedded devices like Raspberry Pi with limited resources. They can also achieve high performance with high accuracy on various computer vision-based tasks.
+
+- **Quantization**: NCNN models often support quantization which is a technique that reduces the precision of the model's weights and activations. This leads to further improvements in performance and reduces memory footprint.
+
+- **Compatibility**: NCNN models are compatible with popular deep learning frameworks like [TensorFlow](https://www.tensorflow.org/), [Caffe](https://caffe.berkeleyvision.org/), and [ONNX](https://onnx.ai/). This compatibility allows developers to use existing models and workflows easily.
+
+- **Easy to Use**: NCNN models are designed for easy integration into various applications, thanks to their compatibility with popular deep learning frameworks. Additionally, NCNN offers user-friendly tools for converting models between different formats, ensuring smooth interoperability across the development landscape.
+
+## Deployment Options with NCNN
+
+Before we look at the code for exporting YOLOv8 models to the NCNN format, let's understand how NCNN models are normally used.
+
+NCNN models, designed for efficiency and performance, are compatible with a variety of deployment platforms:
+
+- **Mobile Deployment**: Specifically optimized for Android and iOS, allowing for seamless integration into mobile applications for efficient on-device inference.
+
+- **Embedded Systems and IoT Devices**: If you find that running inference on a Raspberry Pi with the [Ultralytics Guide](../guides/raspberry-pi.md) isn't fast enough, switching to an NCNN exported model could help speed things up. NCNN is great for devices like Raspberry Pi and NVIDIA Jetson, especially in situations where you need quick processing right on the device.
+
+- **Desktop and Server Deployment**: Capable of being deployed in desktop and server environments across Linux, Windows, and macOS, supporting development, training, and evaluation with higher computational capacities.
+
+## Export to NCNN: Converting Your YOLOv8 Model
+
+You can expand model compatibility and deployment flexibility by converting YOLOv8 models to NCNN format.
+
+### Installation
+
+To install the required packages, run:
+
+!!! Tip "Installation"
+
+ === "CLI"
+
+ ```bash
+ # Install the required package for YOLOv8
+ pip install ultralytics
+ ```
+
+For detailed instructions and best practices related to the installation process, check our [Ultralytics Installation guide](../quickstart.md). While installing the required packages for YOLOv8, if you encounter any difficulties, consult our [Common Issues guide](../guides/yolo-common-issues.md) for solutions and tips.
+
+### Usage
+
+Before diving into the usage instructions, it's important to note that while all [Ultralytics YOLOv8 models](../models/index.md) are available for exporting, you can ensure that the model you select supports export functionality [here](../modes/export.md).
+
+!!! Example "Usage"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load the YOLOv8 model
+ model = YOLO("yolov8n.pt")
+
+ # Export the model to NCNN format
+ model.export(format="ncnn") # creates '/yolov8n_ncnn_model'
+
+ # Load the exported NCNN model
+ ncnn_model = YOLO("./yolov8n_ncnn_model")
+
+ # Run inference
+ results = ncnn_model("https://ultralytics.com/images/bus.jpg")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Export a YOLOv8n PyTorch model to NCNN format
+ yolo export model=yolov8n.pt format=ncnn # creates '/yolov8n_ncnn_model'
+
+ # Run inference with the exported model
+ yolo predict model='./yolov8n_ncnn_model' source='https://ultralytics.com/images/bus.jpg'
+ ```
+
+For more details about supported export options, visit the [Ultralytics documentation page on deployment options](../guides/model-deployment-options.md).
+
+## Deploying Exported YOLOv8 NCNN Models
+
+After successfully exporting your Ultralytics YOLOv8 models to NCNN format, you can now deploy them. The primary and recommended first step for running a NCNN model is to utilize the YOLO("./model_ncnn_model") method, as outlined in the previous usage code snippet. However, for in-depth instructions on deploying your NCNN models in various other settings, take a look at the following resources:
+
+- **[Android](https://github.com/Tencent/ncnn/wiki/how-to-build#build-for-android)**: This blog explains how to use NCNN models for performing tasks like object detection through Android applications.
+
+- **[macOS](https://github.com/Tencent/ncnn/wiki/how-to-build#build-for-macos)**: Understand how to use NCNN models for performing tasks through macOS.
+
+- **[Linux](https://github.com/Tencent/ncnn/wiki/how-to-build#build-for-linux)**: Explore this page to learn how to deploy NCNN models on limited resource devices like Raspberry Pi and other similar devices.
+
+- **[Windows x64 using VS2017](https://github.com/Tencent/ncnn/wiki/how-to-build#build-for-windows-x64-using-visual-studio-community-2017)**: Explore this blog to learn how to deploy NCNN models on windows x64 using Visual Studio Community 2017.
+
+## Summary
+
+In this guide, we've gone over exporting Ultralytics YOLOv8 models to the NCNN format. This conversion step is crucial for improving the efficiency and speed of YOLOv8 models, making them more effective and suitable for limited-resource computing environments.
+
+For detailed instructions on usage, please refer to the [official NCNN documentation](https://ncnn.readthedocs.io/en/latest/index.html).
+
+Also, if you're interested in exploring other integration options for Ultralytics YOLOv8, be sure to visit our [integration guide page](index.md) for further insights and information.
+
+## FAQ
+
+### How do I export Ultralytics YOLOv8 models to NCNN format?
+
+To export your Ultralytics YOLOv8 model to NCNN format, follow these steps:
+
+- **Python**: Use the `export` function from the YOLO class.
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load the YOLOv8 model
+ model = YOLO("yolov8n.pt")
+
+ # Export to NCNN format
+ model.export(format="ncnn") # creates '/yolov8n_ncnn_model'
+ ```
+
+- **CLI**: Use the `yolo` command with the `export` argument.
+ ```bash
+ yolo export model=yolov8n.pt format=ncnn # creates '/yolov8n_ncnn_model'
+ ```
+
+For detailed export options, check the [Export](../modes/export.md) page in the documentation.
+
+### What are the advantages of exporting YOLOv8 models to NCNN?
+
+Exporting your Ultralytics YOLOv8 models to NCNN offers several benefits:
+
+- **Efficiency**: NCNN models are optimized for mobile and embedded devices, ensuring high performance even with limited computational resources.
+- **Quantization**: NCNN supports techniques like quantization that improve model speed and reduce memory usage.
+- **Broad Compatibility**: You can deploy NCNN models on multiple platforms, including Android, iOS, Linux, and macOS.
+
+For more details, see the [Export to NCNN](#why-should-you-export-to-ncnn) section in the documentation.
+
+### Why should I use NCNN for my mobile AI applications?
+
+NCNN, developed by Tencent, is specifically optimized for mobile platforms. Key reasons to use NCNN include:
+
+- **High Performance**: Designed for efficient and fast processing on mobile CPUs.
+- **Cross-Platform**: Compatible with popular frameworks such as TensorFlow and ONNX, making it easier to convert and deploy models across different platforms.
+- **Community Support**: Active community support ensures continual improvements and updates.
+
+To understand more, visit the [NCNN overview](#key-features-of-ncnn-models) in the documentation.
+
+### What platforms are supported for NCNN model deployment?
+
+NCNN is versatile and supports various platforms:
+
+- **Mobile**: Android, iOS.
+- **Embedded Systems and IoT Devices**: Devices like Raspberry Pi and NVIDIA Jetson.
+- **Desktop and Servers**: Linux, Windows, and macOS.
+
+If running models on a Raspberry Pi isn't fast enough, converting to the NCNN format could speed things up as detailed in our [Raspberry Pi Guide](../guides/raspberry-pi.md).
+
+### How can I deploy Ultralytics YOLOv8 NCNN models on Android?
+
+To deploy your YOLOv8 models on Android:
+
+1. **Build for Android**: Follow the [NCNN Build for Android](https://github.com/Tencent/ncnn/wiki/how-to-build#build-for-android) guide.
+2. **Integrate with Your App**: Use the NCNN Android SDK to integrate the exported model into your application for efficient on-device inference.
+
+For step-by-step instructions, refer to our guide on [Deploying YOLOv8 NCNN Models](#deploying-exported-yolov8-ncnn-models).
+
+For more advanced guides and use cases, visit the [Ultralytics documentation page](../guides/model-deployment-options.md).
diff --git a/ultralytics/docs/en/integrations/neural-magic.md b/ultralytics/docs/en/integrations/neural-magic.md
new file mode 100644
index 0000000000000000000000000000000000000000..1ae52e89974f3cb69c66b5d843aecae98494879a
--- /dev/null
+++ b/ultralytics/docs/en/integrations/neural-magic.md
@@ -0,0 +1,211 @@
+---
+comments: true
+description: Enhance YOLOv8 performance using Neural Magic's DeepSparse Engine. Learn how to deploy and benchmark YOLOv8 models on CPUs for efficient object detection.
+keywords: YOLOv8, DeepSparse, Neural Magic, model optimization, object detection, inference speed, CPU performance, sparsity, pruning, quantization
+---
+
+# Optimizing YOLOv8 Inferences with Neural Magic's DeepSparse Engine
+
+When deploying object detection models like [Ultralytics YOLOv8](https://ultralytics.com) on various hardware, you can bump into unique issues like optimization. This is where YOLOv8's integration with Neural Magic's DeepSparse Engine steps in. It transforms the way YOLOv8 models are executed and enables GPU-level performance directly on CPUs.
+
+This guide shows you how to deploy YOLOv8 using Neural Magic's DeepSparse, how to run inferences, and also how to benchmark performance to ensure it is optimized.
+
+## Neural Magic's DeepSparse
+
+
+
+
+
+[Neural Magic's DeepSparse](https://neuralmagic.com/deepsparse/) is an inference run-time designed to optimize the execution of neural networks on CPUs. It applies advanced techniques like sparsity, pruning, and quantization to dramatically reduce computational demands while maintaining accuracy. DeepSparse offers an agile solution for efficient and scalable neural network execution across various devices.
+
+## Benefits of Integrating Neural Magic's DeepSparse with YOLOv8
+
+Before diving into how to deploy YOLOV8 using DeepSparse, let's understand the benefits of using DeepSparse. Some key advantages include:
+
+- **Enhanced Inference Speed**: Achieves up to 525 FPS (on YOLOv8n), significantly speeding up YOLOv8's inference capabilities compared to traditional methods.
+
+
+
+
+
+- **Optimized Model Efficiency**: Uses pruning and quantization to enhance YOLOv8's efficiency, reducing model size and computational requirements while maintaining accuracy.
+
+
+
+
+
+- **High Performance on Standard CPUs**: Delivers GPU-like performance on CPUs, providing a more accessible and cost-effective option for various applications.
+
+- **Streamlined Integration and Deployment**: Offers user-friendly tools for easy integration of YOLOv8 into applications, including image and video annotation features.
+
+- **Support for Various Model Types**: Compatible with both standard and sparsity-optimized YOLOv8 models, adding deployment flexibility.
+
+- **Cost-Effective and Scalable Solution**: Reduces operational expenses and offers scalable deployment of advanced object detection models.
+
+## How Does Neural Magic's DeepSparse Technology Works?
+
+Neural Magic's Deep Sparse technology is inspired by the human brain's efficiency in neural network computation. It adopts two key principles from the brain as follows:
+
+- **Sparsity**: The process of sparsification involves pruning redundant information from deep learning networks, leading to smaller and faster models without compromising accuracy. This technique reduces the network's size and computational needs significantly.
+
+- **Locality of Reference**: DeepSparse uses a unique execution method, breaking the network into Tensor Columns. These columns are executed depth-wise, fitting entirely within the CPU's cache. This approach mimics the brain's efficiency, minimizing data movement and maximizing the CPU's cache use.
+
+
+
+
+
+For more details on how Neural Magic's DeepSparse technology work, check out [their blog post](https://neuralmagic.com/blog/how-neural-magics-deep-sparse-technology-works/).
+
+## Creating A Sparse Version of YOLOv8 Trained on a Custom Dataset
+
+SparseZoo, an open-source model repository by Neural Magic, offers [a collection of pre-sparsified YOLOv8 model checkpoints](https://sparsezoo.neuralmagic.com/?modelSet=computer_vision&searchModels=yolo). With SparseML, seamlessly integrated with Ultralytics, users can effortlessly fine-tune these sparse checkpoints on their specific datasets using a straightforward command-line interface.
+
+Checkout [Neural Magic's SparseML YOLOv8 documentation](https://github.com/neuralmagic/sparseml/tree/main/integrations/ultralytics-yolov8) for more details.
+
+## Usage: Deploying YOLOV8 using DeepSparse
+
+Deploying YOLOv8 with Neural Magic's DeepSparse involves a few straightforward steps. Before diving into the usage instructions, be sure to check out the range of [YOLOv8 models offered by Ultralytics](../models/index.md). This will help you choose the most appropriate model for your project requirements. Here's how you can get started.
+
+### Step 1: Installation
+
+To install the required packages, run:
+
+!!! Tip "Installation"
+
+ === "CLI"
+
+ ```bash
+ # Install the required packages
+ pip install deepsparse[yolov8]
+ ```
+
+### Step 2: Exporting YOLOv8 to ONNX Format
+
+DeepSparse Engine requires YOLOv8 models in ONNX format. Exporting your model to this format is essential for compatibility with DeepSparse. Use the following command to export YOLOv8 models:
+
+!!! Tip "Model Export"
+
+ === "CLI"
+
+ ```bash
+ # Export YOLOv8 model to ONNX format
+ yolo task=detect mode=export model=yolov8n.pt format=onnx opset=13
+ ```
+
+This command will save the `yolov8n.onnx` model to your disk.
+
+### Step 3: Deploying and Running Inferences
+
+With your YOLOv8 model in ONNX format, you can deploy and run inferences using DeepSparse. This can be done easily with their intuitive Python API:
+
+!!! Tip "Deploying and Running Inferences"
+
+ === "Python"
+
+ ```python
+ from deepsparse import Pipeline
+
+ # Specify the path to your YOLOv8 ONNX model
+ model_path = "path/to/yolov8n.onnx"
+
+ # Set up the DeepSparse Pipeline
+ yolo_pipeline = Pipeline.create(task="yolov8", model_path=model_path)
+
+ # Run the model on your images
+ images = ["path/to/image.jpg"]
+ pipeline_outputs = yolo_pipeline(images=images)
+ ```
+
+### Step 4: Benchmarking Performance
+
+It's important to check that your YOLOv8 model is performing optimally on DeepSparse. You can benchmark your model's performance to analyze throughput and latency:
+
+!!! Tip "Benchmarking"
+
+ === "CLI"
+
+ ```bash
+ # Benchmark performance
+ deepsparse.benchmark model_path="path/to/yolov8n.onnx" --scenario=sync --input_shapes="[1,3,640,640]"
+ ```
+
+### Step 5: Additional Features
+
+DeepSparse provides additional features for practical integration of YOLOv8 in applications, such as image annotation and dataset evaluation.
+
+!!! Tip "Additional Features"
+
+ === "CLI"
+
+ ```bash
+ # For image annotation
+ deepsparse.yolov8.annotate --source "path/to/image.jpg" --model_filepath "path/to/yolov8n.onnx"
+
+ # For evaluating model performance on a dataset
+ deepsparse.yolov8.eval --model_path "path/to/yolov8n.onnx"
+ ```
+
+Running the annotate command processes your specified image, detecting objects, and saving the annotated image with bounding boxes and classifications. The annotated image will be stored in an annotation-results folder. This helps provide a visual representation of the model's detection capabilities.
+
+
+
+
+
+After running the eval command, you will receive detailed output metrics such as precision, recall, and mAP (mean Average Precision). This provides a comprehensive view of your model's performance on the dataset. This functionality is particularly useful for fine-tuning and optimizing your YOLOv8 models for specific use cases, ensuring high accuracy and efficiency.
+
+## Summary
+
+This guide explored integrating Ultralytics' YOLOv8 with Neural Magic's DeepSparse Engine. It highlighted how this integration enhances YOLOv8's performance on CPU platforms, offering GPU-level efficiency and advanced neural network sparsity techniques.
+
+For more detailed information and advanced usage, visit [Neural Magic's DeepSparse documentation](https://docs.neuralmagic.com/products/deepsparse/). Also, check out Neural Magic's documentation on the integration with YOLOv8 [here](https://github.com/neuralmagic/deepsparse/tree/main/src/deepsparse/yolov8#yolov8-inference-pipelines) and watch a great session on it [here](https://www.youtube.com/watch?v=qtJ7bdt52x8).
+
+Additionally, for a broader understanding of various YOLOv8 integrations, visit the [Ultralytics integration guide page](../integrations/index.md), where you can discover a range of other exciting integration possibilities.
+
+## FAQ
+
+### What is Neural Magic's DeepSparse Engine and how does it optimize YOLOv8 performance?
+
+Neural Magic's DeepSparse Engine is an inference runtime designed to optimize the execution of neural networks on CPUs through advanced techniques such as sparsity, pruning, and quantization. By integrating DeepSparse with YOLOv8, you can achieve GPU-like performance on standard CPUs, significantly enhancing inference speed, model efficiency, and overall performance while maintaining accuracy. For more details, check out the [Neural Magic's DeepSparse section](#neural-magics-deepsparse).
+
+### How can I install the needed packages to deploy YOLOv8 using Neural Magic's DeepSparse?
+
+Installing the required packages for deploying YOLOv8 with Neural Magic's DeepSparse is straightforward. You can easily install them using the CLI. Here's the command you need to run:
+
+```bash
+pip install deepsparse[yolov8]
+```
+
+Once installed, follow the steps provided in the [Installation section](#step-1-installation) to set up your environment and start using DeepSparse with YOLOv8.
+
+### How do I convert YOLOv8 models to ONNX format for use with DeepSparse?
+
+To convert YOLOv8 models to the ONNX format, which is required for compatibility with DeepSparse, you can use the following CLI command:
+
+```bash
+yolo task=detect mode=export model=yolov8n.pt format=onnx opset=13
+```
+
+This command will export your YOLOv8 model (`yolov8n.pt`) to a format (`yolov8n.onnx`) that can be utilized by the DeepSparse Engine. More information about model export can be found in the [Model Export section](#step-2-exporting-yolov8-to-onnx-format).
+
+### How do I benchmark YOLOv8 performance on the DeepSparse Engine?
+
+Benchmarking YOLOv8 performance on DeepSparse helps you analyze throughput and latency to ensure your model is optimized. You can use the following CLI command to run a benchmark:
+
+```bash
+deepsparse.benchmark model_path="path/to/yolov8n.onnx" --scenario=sync --input_shapes="[1,3,640,640]"
+```
+
+This command will provide you with vital performance metrics. For more details, see the [Benchmarking Performance section](#step-4-benchmarking-performance).
+
+### Why should I use Neural Magic's DeepSparse with YOLOv8 for object detection tasks?
+
+Integrating Neural Magic's DeepSparse with YOLOv8 offers several benefits:
+
+- **Enhanced Inference Speed:** Achieves up to 525 FPS, significantly speeding up YOLOv8's capabilities.
+- **Optimized Model Efficiency:** Uses sparsity, pruning, and quantization techniques to reduce model size and computational needs while maintaining accuracy.
+- **High Performance on Standard CPUs:** Offers GPU-like performance on cost-effective CPU hardware.
+- **Streamlined Integration:** User-friendly tools for easy deployment and integration.
+- **Flexibility:** Supports both standard and sparsity-optimized YOLOv8 models.
+- **Cost-Effective:** Reduces operational expenses through efficient resource utilization.
+
+For a deeper dive into these advantages, visit the [Benefits of Integrating Neural Magic's DeepSparse with YOLOv8 section](#benefits-of-integrating-neural-magics-deepsparse-with-yolov8).
diff --git a/ultralytics/docs/en/integrations/onnx.md b/ultralytics/docs/en/integrations/onnx.md
new file mode 100644
index 0000000000000000000000000000000000000000..94865cba12bf6ee49ef33bbe104e55409d533442
--- /dev/null
+++ b/ultralytics/docs/en/integrations/onnx.md
@@ -0,0 +1,213 @@
+---
+comments: true
+description: Learn how to export YOLOv8 models to ONNX format for flexible deployment across various platforms with enhanced performance.
+keywords: YOLOv8, ONNX, model export, Ultralytics, ONNX Runtime, machine learning, model deployment, computer vision, deep learning
+---
+
+# ONNX Export for YOLOv8 Models
+
+Often, when deploying computer vision models, you'll need a model format that's both flexible and compatible with multiple platforms.
+
+Exporting [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics) models to ONNX format streamlines deployment and ensures optimal performance across various environments. This guide will show you how to easily convert your YOLOv8 models to ONNX and enhance their scalability and effectiveness in real-world applications.
+
+## ONNX and ONNX Runtime
+
+[ONNX](https://onnx.ai/), which stands for Open Neural Network Exchange, is a community project that Facebook and Microsoft initially developed. The ongoing development of ONNX is a collaborative effort supported by various organizations like IBM, Amazon (through AWS), and Google. The project aims to create an open file format designed to represent machine learning models in a way that allows them to be used across different AI frameworks and hardware.
+
+ONNX models can be used to transition between different frameworks seamlessly. For instance, a deep learning model trained in PyTorch can be exported to ONNX format and then easily imported into TensorFlow.
+
+
+
+
+
+Alternatively, ONNX models can be used with ONNX Runtime. [ONNX Runtime](https://onnxruntime.ai/) is a versatile cross-platform accelerator for machine learning models that is compatible with frameworks like PyTorch, TensorFlow, TFLite, scikit-learn, etc.
+
+ONNX Runtime optimizes the execution of ONNX models by leveraging hardware-specific capabilities. This optimization allows the models to run efficiently and with high performance on various hardware platforms, including CPUs, GPUs, and specialized accelerators.
+
+
+
+
+
+Whether used independently or in tandem with ONNX Runtime, ONNX provides a flexible solution for machine learning model deployment and compatibility.
+
+## Key Features of ONNX Models
+
+The ability of ONNX to handle various formats can be attributed to the following key features:
+
+- **Common Model Representation**: ONNX defines a common set of operators (like convolutions, layers, etc.) and a standard data format. When a model is converted to ONNX format, its architecture and weights are translated into this common representation. This uniformity ensures that the model can be understood by any framework that supports ONNX.
+
+- **Versioning and Backward Compatibility**: ONNX maintains a versioning system for its operators. This ensures that even as the standard evolves, models created in older versions remain usable. Backward compatibility is a crucial feature that prevents models from becoming obsolete quickly.
+
+- **Graph-based Model Representation**: ONNX represents models as computational graphs. This graph-based structure is a universal way of representing machine learning models, where nodes represent operations or computations, and edges represent the tensors flowing between them. This format is easily adaptable to various frameworks which also represent models as graphs.
+
+- **Tools and Ecosystem**: There is a rich ecosystem of tools around ONNX that assist in model conversion, visualization, and optimization. These tools make it easier for developers to work with ONNX models and to convert models between different frameworks seamlessly.
+
+## Common Usage of ONNX
+
+Before we jump into how to export YOLOv8 models to the ONNX format, let's take a look at where ONNX models are usually used.
+
+### CPU Deployment
+
+ONNX models are often deployed on CPUs due to their compatibility with ONNX Runtime. This runtime is optimized for CPU execution. It significantly improves inference speed and makes real-time CPU deployments feasible.
+
+### Supported Deployment Options
+
+While ONNX models are commonly used on CPUs, they can also be deployed on the following platforms:
+
+- **GPU Acceleration**: ONNX fully supports GPU acceleration, particularly NVIDIA CUDA. This enables efficient execution on NVIDIA GPUs for tasks that demand high computational power.
+
+- **Edge and Mobile Devices**: ONNX extends to edge and mobile devices, perfect for on-device and real-time inference scenarios. It's lightweight and compatible with edge hardware.
+
+- **Web Browsers**: ONNX can run directly in web browsers, powering interactive and dynamic web-based AI applications.
+
+## Exporting YOLOv8 Models to ONNX
+
+You can expand model compatibility and deployment flexibility by converting YOLOv8 models to ONNX format.
+
+### Installation
+
+To install the required package, run:
+
+!!! Tip "Installation"
+
+ === "CLI"
+
+ ```bash
+ # Install the required package for YOLOv8
+ pip install ultralytics
+ ```
+
+For detailed instructions and best practices related to the installation process, check our [YOLOv8 Installation guide](../quickstart.md). While installing the required packages for YOLOv8, if you encounter any difficulties, consult our [Common Issues guide](../guides/yolo-common-issues.md) for solutions and tips.
+
+### Usage
+
+Before diving into the usage instructions, be sure to check out the range of [YOLOv8 models offered by Ultralytics](../models/index.md). This will help you choose the most appropriate model for your project requirements.
+
+!!! Example "Usage"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load the YOLOv8 model
+ model = YOLO("yolov8n.pt")
+
+ # Export the model to ONNX format
+ model.export(format="onnx") # creates 'yolov8n.onnx'
+
+ # Load the exported ONNX model
+ onnx_model = YOLO("yolov8n.onnx")
+
+ # Run inference
+ results = onnx_model("https://ultralytics.com/images/bus.jpg")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Export a YOLOv8n PyTorch model to ONNX format
+ yolo export model=yolov8n.pt format=onnx # creates 'yolov8n.onnx'
+
+ # Run inference with the exported model
+ yolo predict model=yolov8n.onnx source='https://ultralytics.com/images/bus.jpg'
+ ```
+
+For more details about the export process, visit the [Ultralytics documentation page on exporting](../modes/export.md).
+
+## Deploying Exported YOLOv8 ONNX Models
+
+Once you've successfully exported your Ultralytics YOLOv8 models to ONNX format, the next step is deploying these models in various environments. For detailed instructions on deploying your ONNX models, take a look at the following resources:
+
+- **[ONNX Runtime Python API Documentation](https://onnxruntime.ai/docs/api/python/api_summary.html)**: This guide provides essential information for loading and running ONNX models using ONNX Runtime.
+
+- **[Deploying on Edge Devices](https://onnxruntime.ai/docs/tutorials/iot-edge/)**: Check out this docs page for different examples of deploying ONNX models on edge.
+
+- **[ONNX Tutorials on GitHub](https://github.com/onnx/tutorials)**: A collection of comprehensive tutorials that cover various aspects of using and implementing ONNX models in different scenarios.
+
+## Summary
+
+In this guide, you've learned how to export Ultralytics YOLOv8 models to ONNX format to increase their interoperability and performance across various platforms. You were also introduced to the ONNX Runtime and ONNX deployment options.
+
+For further details on usage, visit the [ONNX official documentation](https://onnx.ai/onnx/intro/).
+
+Also, if you'd like to know more about other Ultralytics YOLOv8 integrations, visit our [integration guide page](../integrations/index.md). You'll find plenty of useful resources and insights there.
+
+## FAQ
+
+### How do I export YOLOv8 models to ONNX format using Ultralytics?
+
+To export your YOLOv8 models to ONNX format using Ultralytics, follow these steps:
+
+!!! Example "Usage"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load the YOLOv8 model
+ model = YOLO("yolov8n.pt")
+
+ # Export the model to ONNX format
+ model.export(format="onnx") # creates 'yolov8n.onnx'
+
+ # Load the exported ONNX model
+ onnx_model = YOLO("yolov8n.onnx")
+
+ # Run inference
+ results = onnx_model("https://ultralytics.com/images/bus.jpg")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Export a YOLOv8n PyTorch model to ONNX format
+ yolo export model=yolov8n.pt format=onnx # creates 'yolov8n.onnx'
+
+ # Run inference with the exported model
+ yolo predict model=yolov8n.onnx source='https://ultralytics.com/images/bus.jpg'
+ ```
+
+For more details, visit the [export documentation](../modes/export.md).
+
+### What are the advantages of using ONNX Runtime for deploying YOLOv8 models?
+
+Using ONNX Runtime for deploying YOLOv8 models offers several advantages:
+
+- **Cross-platform compatibility**: ONNX Runtime supports various platforms, such as Windows, macOS, and Linux, ensuring your models run smoothly across different environments.
+- **Hardware acceleration**: ONNX Runtime can leverage hardware-specific optimizations for CPUs, GPUs, and dedicated accelerators, providing high-performance inference.
+- **Framework interoperability**: Models trained in popular frameworks like PyTorch or TensorFlow can be easily converted to ONNX format and run using ONNX Runtime.
+
+Learn more by checking the [ONNX Runtime documentation](https://onnxruntime.ai/docs/api/python/api_summary.html).
+
+### What deployment options are available for YOLOv8 models exported to ONNX?
+
+YOLOv8 models exported to ONNX can be deployed on various platforms including:
+
+- **CPUs**: Utilizing ONNX Runtime for optimized CPU inference.
+- **GPUs**: Leveraging NVIDIA CUDA for high-performance GPU acceleration.
+- **Edge devices**: Running lightweight models on edge and mobile devices for real-time, on-device inference.
+- **Web browsers**: Executing models directly within web browsers for interactive web-based applications.
+
+For more information, explore our guide on [model deployment options](../guides/model-deployment-options.md).
+
+### Why should I use ONNX format for Ultralytics YOLOv8 models?
+
+Using ONNX format for Ultralytics YOLOv8 models provides numerous benefits:
+
+- **Interoperability**: ONNX allows models to be transferred between different machine learning frameworks seamlessly.
+- **Performance Optimization**: ONNX Runtime can enhance model performance by utilizing hardware-specific optimizations.
+- **Flexibility**: ONNX supports various deployment environments, enabling you to use the same model on different platforms without modification.
+
+Refer to the comprehensive guide on [exporting YOLOv8 models to ONNX](https://www.ultralytics.com/blog/export-and-optimize-a-yolov8-model-for-inference-on-openvino).
+
+### How can I troubleshoot issues when exporting YOLOv8 models to ONNX?
+
+When exporting YOLOv8 models to ONNX, you might encounter common issues such as mismatched dependencies or unsupported operations. To troubleshoot these problems:
+
+1. Verify that you have the correct version of required dependencies installed.
+2. Check the official [ONNX documentation](https://onnx.ai/onnx/intro/) for supported operators and features.
+3. Review the error messages for clues and consult the [Ultralytics Common Issues guide](../guides/yolo-common-issues.md).
+
+If issues persist, contact Ultralytics support for further assistance.
diff --git a/ultralytics/docs/en/integrations/openvino.md b/ultralytics/docs/en/integrations/openvino.md
new file mode 100644
index 0000000000000000000000000000000000000000..0ab0aad7d3e4a540670aecb4616570d40c25bd7d
--- /dev/null
+++ b/ultralytics/docs/en/integrations/openvino.md
@@ -0,0 +1,393 @@
+---
+comments: true
+description: Learn to export YOLOv8 models to OpenVINO format for up to 3x CPU speedup and hardware acceleration on Intel GPU and NPU.
+keywords: YOLOv8, OpenVINO, model export, Intel, AI inference, CPU speedup, GPU acceleration, NPU, deep learning
+---
+
+# Intel OpenVINO Export
+
+
+
+In this guide, we cover exporting YOLOv8 models to the [OpenVINO](https://docs.openvino.ai/) format, which can provide up to 3x [CPU](https://docs.openvino.ai/2024/openvino-workflow/running-inference/inference-devices-and-modes/cpu-device.html) speedup, as well as accelerating YOLO inference on Intel [GPU](https://docs.openvino.ai/2024/openvino-workflow/running-inference/inference-devices-and-modes/gpu-device.html) and [NPU](https://docs.openvino.ai/2024/openvino-workflow/running-inference/inference-devices-and-modes/npu-device.html) hardware.
+
+OpenVINO, short for Open Visual Inference & Neural Network Optimization toolkit, is a comprehensive toolkit for optimizing and deploying AI inference models. Even though the name contains Visual, OpenVINO also supports various additional tasks including language, audio, time series, etc.
+
+
+
+
+
+ Watch: How To Export and Optimize an Ultralytics YOLOv8 Model for Inference with OpenVINO.
+
+
+## Usage Examples
+
+Export a YOLOv8n model to OpenVINO format and run inference with the exported model.
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a YOLOv8n PyTorch model
+ model = YOLO("yolov8n.pt")
+
+ # Export the model
+ model.export(format="openvino") # creates 'yolov8n_openvino_model/'
+
+ # Load the exported OpenVINO model
+ ov_model = YOLO("yolov8n_openvino_model/")
+
+ # Run inference
+ results = ov_model("https://ultralytics.com/images/bus.jpg")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Export a YOLOv8n PyTorch model to OpenVINO format
+ yolo export model=yolov8n.pt format=openvino # creates 'yolov8n_openvino_model/'
+
+ # Run inference with the exported model
+ yolo predict model=yolov8n_openvino_model source='https://ultralytics.com/images/bus.jpg'
+ ```
+
+## Arguments
+
+| Key | Value | Description |
+| --------- | ------------ | ---------------------------------------------------- |
+| `format` | `'openvino'` | format to export to |
+| `imgsz` | `640` | image size as scalar or (h, w) list, i.e. (640, 480) |
+| `half` | `False` | FP16 quantization |
+| `int8` | `False` | INT8 quantization |
+| `batch` | `1` | batch size for inference |
+| `dynamic` | `False` | allows dynamic input sizes |
+
+## Benefits of OpenVINO
+
+1. **Performance**: OpenVINO delivers high-performance inference by utilizing the power of Intel CPUs, integrated and discrete GPUs, and FPGAs.
+2. **Support for Heterogeneous Execution**: OpenVINO provides an API to write once and deploy on any supported Intel hardware (CPU, GPU, FPGA, VPU, etc.).
+3. **Model Optimizer**: OpenVINO provides a Model Optimizer that imports, converts, and optimizes models from popular deep learning frameworks such as PyTorch, TensorFlow, TensorFlow Lite, Keras, ONNX, PaddlePaddle, and Caffe.
+4. **Ease of Use**: The toolkit comes with more than [80 tutorial notebooks](https://github.com/openvinotoolkit/openvino_notebooks) (including [YOLOv8 optimization](https://github.com/openvinotoolkit/openvino_notebooks/tree/latest/notebooks/yolov8-optimization)) teaching different aspects of the toolkit.
+
+## OpenVINO Export Structure
+
+When you export a model to OpenVINO format, it results in a directory containing the following:
+
+1. **XML file**: Describes the network topology.
+2. **BIN file**: Contains the weights and biases binary data.
+3. **Mapping file**: Holds mapping of original model output tensors to OpenVINO tensor names.
+
+You can use these files to run inference with the OpenVINO Inference Engine.
+
+## Using OpenVINO Export in Deployment
+
+Once you have the OpenVINO files, you can use the OpenVINO Runtime to run the model. The Runtime provides a unified API to inference across all supported Intel hardware. It also provides advanced capabilities like load balancing across Intel hardware and asynchronous execution. For more information on running the inference, refer to the [Inference with OpenVINO Runtime Guide](https://docs.openvino.ai/2024/openvino-workflow/running-inference.html).
+
+Remember, you'll need the XML and BIN files as well as any application-specific settings like input size, scale factor for normalization, etc., to correctly set up and use the model with the Runtime.
+
+In your deployment application, you would typically do the following steps:
+
+1. Initialize OpenVINO by creating `core = Core()`.
+2. Load the model using the `core.read_model()` method.
+3. Compile the model using the `core.compile_model()` function.
+4. Prepare the input (image, text, audio, etc.).
+5. Run inference using `compiled_model(input_data)`.
+
+For more detailed steps and code snippets, refer to the [OpenVINO documentation](https://docs.openvino.ai/) or [API tutorial](https://github.com/openvinotoolkit/openvino_notebooks/blob/latest/notebooks/openvino-api/openvino-api.ipynb).
+
+## OpenVINO YOLOv8 Benchmarks
+
+YOLOv8 benchmarks below were run by the Ultralytics team on 4 different model formats measuring speed and accuracy: PyTorch, TorchScript, ONNX and OpenVINO. Benchmarks were run on Intel Flex and Arc GPUs, and on Intel Xeon CPUs at FP32 precision (with the `half=False` argument).
+
+!!! Note
+
+ The benchmarking results below are for reference and might vary based on the exact hardware and software configuration of a system, as well as the current workload of the system at the time the benchmarks are run.
+
+ All benchmarks run with `openvino` Python package version [2023.0.1](https://pypi.org/project/openvino/2023.0.1/).
+
+### Intel Flex GPU
+
+The Intel® Data Center GPU Flex Series is a versatile and robust solution designed for the intelligent visual cloud. This GPU supports a wide array of workloads including media streaming, cloud gaming, AI visual inference, and virtual desktop Infrastructure workloads. It stands out for its open architecture and built-in support for the AV1 encode, providing a standards-based software stack for high-performance, cross-architecture applications. The Flex Series GPU is optimized for density and quality, offering high reliability, availability, and scalability.
+
+Benchmarks below run on Intel® Data Center GPU Flex 170 at FP32 precision.
+
+
+
+
+
+| Model | Format | Status | Size (MB) | mAP50-95(B) | Inference time (ms/im) |
+| ------- | ----------- | ------ | --------- | ----------- | ---------------------- |
+| YOLOv8n | PyTorch | ✅ | 6.2 | 0.3709 | 21.79 |
+| YOLOv8n | TorchScript | ✅ | 12.4 | 0.3704 | 23.24 |
+| YOLOv8n | ONNX | ✅ | 12.2 | 0.3704 | 37.22 |
+| YOLOv8n | OpenVINO | ✅ | 12.3 | 0.3703 | 3.29 |
+| YOLOv8s | PyTorch | ✅ | 21.5 | 0.4471 | 31.89 |
+| YOLOv8s | TorchScript | ✅ | 42.9 | 0.4472 | 32.71 |
+| YOLOv8s | ONNX | ✅ | 42.8 | 0.4472 | 43.42 |
+| YOLOv8s | OpenVINO | ✅ | 42.9 | 0.4470 | 3.92 |
+| YOLOv8m | PyTorch | ✅ | 49.7 | 0.5013 | 50.75 |
+| YOLOv8m | TorchScript | ✅ | 99.2 | 0.4999 | 47.90 |
+| YOLOv8m | ONNX | ✅ | 99.0 | 0.4999 | 63.16 |
+| YOLOv8m | OpenVINO | ✅ | 49.8 | 0.4997 | 7.11 |
+| YOLOv8l | PyTorch | ✅ | 83.7 | 0.5293 | 77.45 |
+| YOLOv8l | TorchScript | ✅ | 167.2 | 0.5268 | 85.71 |
+| YOLOv8l | ONNX | ✅ | 166.8 | 0.5268 | 88.94 |
+| YOLOv8l | OpenVINO | ✅ | 167.0 | 0.5264 | 9.37 |
+| YOLOv8x | PyTorch | ✅ | 130.5 | 0.5404 | 100.09 |
+| YOLOv8x | TorchScript | ✅ | 260.7 | 0.5371 | 114.64 |
+| YOLOv8x | ONNX | ✅ | 260.4 | 0.5371 | 110.32 |
+| YOLOv8x | OpenVINO | ✅ | 260.6 | 0.5367 | 15.02 |
+
+This table represents the benchmark results for five different models (YOLOv8n, YOLOv8s, YOLOv8m, YOLOv8l, YOLOv8x) across four different formats (PyTorch, TorchScript, ONNX, OpenVINO), giving us the status, size, mAP50-95(B) metric, and inference time for each combination.
+
+### Intel Arc GPU
+
+Intel® Arc™ represents Intel's foray into the dedicated GPU market. The Arc™ series, designed to compete with leading GPU manufacturers like AMD and Nvidia, caters to both the laptop and desktop markets. The series includes mobile versions for compact devices like laptops, and larger, more powerful versions for desktop computers.
+
+The Arc™ series is divided into three categories: Arc™ 3, Arc™ 5, and Arc™ 7, with each number indicating the performance level. Each category includes several models, and the 'M' in the GPU model name signifies a mobile, integrated variant.
+
+Early reviews have praised the Arc™ series, particularly the integrated A770M GPU, for its impressive graphics performance. The availability of the Arc™ series varies by region, and additional models are expected to be released soon. Intel® Arc™ GPUs offer high-performance solutions for a range of computing needs, from gaming to content creation.
+
+Benchmarks below run on Intel® Arc 770 GPU at FP32 precision.
+
+
+
+
+
+| Model | Format | Status | Size (MB) | metrics/mAP50-95(B) | Inference time (ms/im) |
+| ------- | ----------- | ------ | --------- | ------------------- | ---------------------- |
+| YOLOv8n | PyTorch | ✅ | 6.2 | 0.3709 | 88.79 |
+| YOLOv8n | TorchScript | ✅ | 12.4 | 0.3704 | 102.66 |
+| YOLOv8n | ONNX | ✅ | 12.2 | 0.3704 | 57.98 |
+| YOLOv8n | OpenVINO | ✅ | 12.3 | 0.3703 | 8.52 |
+| YOLOv8s | PyTorch | ✅ | 21.5 | 0.4471 | 189.83 |
+| YOLOv8s | TorchScript | ✅ | 42.9 | 0.4472 | 227.58 |
+| YOLOv8s | ONNX | ✅ | 42.7 | 0.4472 | 142.03 |
+| YOLOv8s | OpenVINO | ✅ | 42.9 | 0.4469 | 9.19 |
+| YOLOv8m | PyTorch | ✅ | 49.7 | 0.5013 | 411.64 |
+| YOLOv8m | TorchScript | ✅ | 99.2 | 0.4999 | 517.12 |
+| YOLOv8m | ONNX | ✅ | 98.9 | 0.4999 | 298.68 |
+| YOLOv8m | OpenVINO | ✅ | 99.1 | 0.4996 | 12.55 |
+| YOLOv8l | PyTorch | ✅ | 83.7 | 0.5293 | 725.73 |
+| YOLOv8l | TorchScript | ✅ | 167.1 | 0.5268 | 892.83 |
+| YOLOv8l | ONNX | ✅ | 166.8 | 0.5268 | 576.11 |
+| YOLOv8l | OpenVINO | ✅ | 167.0 | 0.5262 | 17.62 |
+| YOLOv8x | PyTorch | ✅ | 130.5 | 0.5404 | 988.92 |
+| YOLOv8x | TorchScript | ✅ | 260.7 | 0.5371 | 1186.42 |
+| YOLOv8x | ONNX | ✅ | 260.4 | 0.5371 | 768.90 |
+| YOLOv8x | OpenVINO | ✅ | 260.6 | 0.5367 | 19 |
+
+### Intel Xeon CPU
+
+The Intel® Xeon® CPU is a high-performance, server-grade processor designed for complex and demanding workloads. From high-end cloud computing and virtualization to artificial intelligence and machine learning applications, Xeon® CPUs provide the power, reliability, and flexibility required for today's data centers.
+
+Notably, Xeon® CPUs deliver high compute density and scalability, making them ideal for both small businesses and large enterprises. By choosing Intel® Xeon® CPUs, organizations can confidently handle their most demanding computing tasks and foster innovation while maintaining cost-effectiveness and operational efficiency.
+
+Benchmarks below run on 4th Gen Intel® Xeon® Scalable CPU at FP32 precision.
+
+
+
+| Model | Format | Status | Size (MB) | metrics/mAP50-95(B) | Inference time (ms/im) |
+| ------- | ----------- | ------ | --------- | ------------------- | ---------------------- |
+| YOLOv8n | PyTorch | ✅ | 6.2 | 0.4478 | 104.61 |
+| YOLOv8n | TorchScript | ✅ | 12.4 | 0.4525 | 112.39 |
+| YOLOv8n | ONNX | ✅ | 12.2 | 0.4525 | 28.02 |
+| YOLOv8n | OpenVINO | ✅ | 12.3 | 0.4504 | 23.53 |
+| YOLOv8s | PyTorch | ✅ | 21.5 | 0.5885 | 194.83 |
+| YOLOv8s | TorchScript | ✅ | 43.0 | 0.5962 | 202.01 |
+| YOLOv8s | ONNX | ✅ | 42.8 | 0.5962 | 65.74 |
+| YOLOv8s | OpenVINO | ✅ | 42.9 | 0.5966 | 38.66 |
+| YOLOv8m | PyTorch | ✅ | 49.7 | 0.6101 | 355.23 |
+| YOLOv8m | TorchScript | ✅ | 99.2 | 0.6120 | 424.78 |
+| YOLOv8m | ONNX | ✅ | 99.0 | 0.6120 | 173.39 |
+| YOLOv8m | OpenVINO | ✅ | 99.1 | 0.6091 | 69.80 |
+| YOLOv8l | PyTorch | ✅ | 83.7 | 0.6591 | 593.00 |
+| YOLOv8l | TorchScript | ✅ | 167.2 | 0.6580 | 697.54 |
+| YOLOv8l | ONNX | ✅ | 166.8 | 0.6580 | 342.15 |
+| YOLOv8l | OpenVINO | ✅ | 167.0 | 0.0708 | 117.69 |
+| YOLOv8x | PyTorch | ✅ | 130.5 | 0.6651 | 804.65 |
+| YOLOv8x | TorchScript | ✅ | 260.8 | 0.6650 | 921.46 |
+| YOLOv8x | ONNX | ✅ | 260.4 | 0.6650 | 526.66 |
+| YOLOv8x | OpenVINO | ✅ | 260.6 | 0.6619 | 158.73 |
+
+## Reproduce Our Results
+
+To reproduce the Ultralytics benchmarks above on all export [formats](../modes/export.md) run this code:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a YOLOv8n PyTorch model
+ model = YOLO("yolov8n.pt")
+
+ # Benchmark YOLOv8n speed and accuracy on the COCO8 dataset for all export formats
+ results = model.benchmarks(data="coco8.yaml")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Benchmark YOLOv8n speed and accuracy on the COCO8 dataset for all export formats
+ yolo benchmark model=yolov8n.pt data=coco8.yaml
+ ```
+
+ Note that benchmarking results might vary based on the exact hardware and software configuration of a system, as well as the current workload of the system at the time the benchmarks are run. For the most reliable results use a dataset with a large number of images, i.e. `data='coco128.yaml' (128 val images), or `data='coco.yaml'` (5000 val images).
+
+## Conclusion
+
+The benchmarking results clearly demonstrate the benefits of exporting the YOLOv8 model to the OpenVINO format. Across different models and hardware platforms, the OpenVINO format consistently outperforms other formats in terms of inference speed while maintaining comparable accuracy.
+
+For the Intel® Data Center GPU Flex Series, the OpenVINO format was able to deliver inference speeds almost 10 times faster than the original PyTorch format. On the Xeon CPU, the OpenVINO format was twice as fast as the PyTorch format. The accuracy of the models remained nearly identical across the different formats.
+
+The benchmarks underline the effectiveness of OpenVINO as a tool for deploying deep learning models. By converting models to the OpenVINO format, developers can achieve significant performance improvements, making it easier to deploy these models in real-world applications.
+
+For more detailed information and instructions on using OpenVINO, refer to the [official OpenVINO documentation](https://docs.openvino.ai/).
+
+## FAQ
+
+### How do I export YOLOv8 models to OpenVINO format?
+
+Exporting YOLOv8 models to the OpenVINO format can significantly enhance CPU speed and enable GPU and NPU accelerations on Intel hardware. To export, you can use either Python or CLI as shown below:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a YOLOv8n PyTorch model
+ model = YOLO("yolov8n.pt")
+
+ # Export the model
+ model.export(format="openvino") # creates 'yolov8n_openvino_model/'
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Export a YOLOv8n PyTorch model to OpenVINO format
+ yolo export model=yolov8n.pt format=openvino # creates 'yolov8n_openvino_model/'
+ ```
+
+For more information, refer to the [export formats documentation](../modes/export.md).
+
+### What are the benefits of using OpenVINO with YOLOv8 models?
+
+Using Intel's OpenVINO toolkit with YOLOv8 models offers several benefits:
+
+1. **Performance**: Achieve up to 3x speedup on CPU inference and leverage Intel GPUs and NPUs for acceleration.
+2. **Model Optimizer**: Convert, optimize, and execute models from popular frameworks like PyTorch, TensorFlow, and ONNX.
+3. **Ease of Use**: Over 80 tutorial notebooks are available to help users get started, including ones for YOLOv8.
+4. **Heterogeneous Execution**: Deploy models on various Intel hardware with a unified API.
+
+For detailed performance comparisons, visit our [benchmarks section](#openvino-yolov8-benchmarks).
+
+### How can I run inference using a YOLOv8 model exported to OpenVINO?
+
+After exporting a YOLOv8 model to OpenVINO format, you can run inference using Python or CLI:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load the exported OpenVINO model
+ ov_model = YOLO("yolov8n_openvino_model/")
+
+ # Run inference
+ results = ov_model("https://ultralytics.com/images/bus.jpg")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Run inference with the exported model
+ yolo predict model=yolov8n_openvino_model source='https://ultralytics.com/images/bus.jpg'
+ ```
+
+Refer to our [predict mode documentation](../modes/predict.md) for more details.
+
+### Why should I choose Ultralytics YOLOv8 over other models for OpenVINO export?
+
+Ultralytics YOLOv8 is optimized for real-time object detection with high accuracy and speed. Specifically, when combined with OpenVINO, YOLOv8 provides:
+
+- Up to 3x speedup on Intel CPUs
+- Seamless deployment on Intel GPUs and NPUs
+- Consistent and comparable accuracy across various export formats
+
+For in-depth performance analysis, check our detailed [YOLOv8 benchmarks](#openvino-yolov8-benchmarks) on different hardware.
+
+### Can I benchmark YOLOv8 models on different formats such as PyTorch, ONNX, and OpenVINO?
+
+Yes, you can benchmark YOLOv8 models in various formats including PyTorch, TorchScript, ONNX, and OpenVINO. Use the following code snippet to run benchmarks on your chosen dataset:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a YOLOv8n PyTorch model
+ model = YOLO("yolov8n.pt")
+
+ # Benchmark YOLOv8n speed and accuracy on the COCO8 dataset for all export formats
+ results = model.benchmarks(data="coco8.yaml")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Benchmark YOLOv8n speed and accuracy on the COCO8 dataset for all export formats
+ yolo benchmark model=yolov8n.pt data=coco8.yaml
+ ```
+
+For detailed benchmark results, refer to our [benchmarks section](#openvino-yolov8-benchmarks) and [export formats](../modes/export.md) documentation.
diff --git a/ultralytics/docs/en/integrations/paddlepaddle.md b/ultralytics/docs/en/integrations/paddlepaddle.md
new file mode 100644
index 0000000000000000000000000000000000000000..af167b89a825f10308585015b512e4bc2146f580
--- /dev/null
+++ b/ultralytics/docs/en/integrations/paddlepaddle.md
@@ -0,0 +1,202 @@
+---
+comments: true
+description: Learn how to export YOLOv8 models to PaddlePaddle format for enhanced performance, flexibility, and deployment across various platforms and devices.
+keywords: YOLOv8, PaddlePaddle, export models, computer vision, deep learning, model deployment, performance optimization
+---
+
+# How to Export to PaddlePaddle Format from YOLOv8 Models
+
+Bridging the gap between developing and deploying computer vision models in real-world scenarios with varying conditions can be difficult. PaddlePaddle makes this process easier with its focus on flexibility, performance, and its capability for parallel processing in distributed environments. This means you can use your YOLOv8 computer vision models on a wide variety of devices and platforms, from smartphones to cloud-based servers.
+
+The ability to export to PaddlePaddle model format allows you to optimize your [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics) models for use within the PaddlePaddle framework. PaddlePaddle is known for facilitating industrial deployments and is a good choice for deploying computer vision applications in real-world settings across various domains.
+
+## Why should you export to PaddlePaddle?
+
+
+
+
+
+Developed by Baidu, [PaddlePaddle](https://www.paddlepaddle.org.cn/en) (**PA**rallel **D**istributed **D**eep **LE**arning) is China's first open-source deep learning platform. Unlike some frameworks built mainly for research, PaddlePaddle prioritizes ease of use and smooth integration across industries.
+
+It offers tools and resources similar to popular frameworks like TensorFlow and PyTorch, making it accessible for developers of all experience levels. From farming and factories to service businesses, PaddlePaddle's large developer community of over 4.77 million is helping create and deploy AI applications.
+
+By exporting your Ultralytics YOLOv8 models to PaddlePaddle format, you can tap into PaddlePaddle's strengths in performance optimization. PaddlePaddle prioritizes efficient model execution and reduced memory usage. As a result, your YOLOv8 models can potentially achieve even better performance, delivering top-notch results in practical scenarios.
+
+## Key Features of PaddlePaddle Models
+
+PaddlePaddle models offer a range of key features that contribute to their flexibility, performance, and scalability across diverse deployment scenarios:
+
+- **Dynamic-to-Static Graph**: PaddlePaddle supports [dynamic-to-static compilation](https://www.paddlepaddle.org.cn/documentation/docs/en/guides/jit/index_en.html), where models can be translated into a static computational graph. This enables optimizations that reduce runtime overhead and boost inference performance.
+
+- **Operator Fusion**: PaddlePaddle, like TensorRT, uses [operator fusion](https://developer.nvidia.com/gtc/2020/video/s21436-vid) to streamline computation and reduce overhead. The framework minimizes memory transfers and computational steps by merging compatible operations, resulting in faster inference.
+
+- **Quantization**: PaddlePaddle supports [quantization techniques](https://www.paddlepaddle.org.cn/documentation/docs/en/api/paddle/quantization/PTQ_en.html), including post-training quantization and quantization-aware training. These techniques allow for the use of lower-precision data representations, effectively boosting performance and reducing model size.
+
+## Deployment Options in PaddlePaddle
+
+Before diving into the code for exporting YOLOv8 models to PaddlePaddle, let's take a look at the different deployment scenarios in which PaddlePaddle models excel.
+
+PaddlePaddle provides a range of options, each offering a distinct balance of ease of use, flexibility, and performance:
+
+- **Paddle Serving**: This framework simplifies the deployment of PaddlePaddle models as high-performance RESTful APIs. Paddle Serving is ideal for production environments, providing features like model versioning, online A/B testing, and scalability for handling large volumes of requests.
+
+- **Paddle Inference API**: The Paddle Inference API gives you low-level control over model execution. This option is well-suited for scenarios where you need to integrate the model tightly within a custom application or optimize performance for specific hardware.
+
+- **Paddle Lite**: Paddle Lite is designed for deployment on mobile and embedded devices where resources are limited. It optimizes models for smaller sizes and faster inference on ARM CPUs, GPUs, and other specialized hardware.
+
+- **Paddle.js**: Paddle.js enables you to deploy PaddlePaddle models directly within web browsers. Paddle.js can either load a pre-trained model or transform a model from [paddle-hub](https://github.com/PaddlePaddle/PaddleHub) with model transforming tools provided by Paddle.js. It can run in browsers that support WebGL/WebGPU/WebAssembly.
+
+## Export to PaddlePaddle: Converting Your YOLOv8 Model
+
+Converting YOLOv8 models to the PaddlePaddle format can improve execution flexibility and optimize performance for various deployment scenarios.
+
+### Installation
+
+To install the required package, run:
+
+!!! Tip "Installation"
+
+ === "CLI"
+
+ ```bash
+ # Install the required package for YOLOv8
+ pip install ultralytics
+ ```
+
+For detailed instructions and best practices related to the installation process, check our [Ultralytics Installation guide](../quickstart.md). While installing the required packages for YOLOv8, if you encounter any difficulties, consult our [Common Issues guide](../guides/yolo-common-issues.md) for solutions and tips.
+
+### Usage
+
+Before diving into the usage instructions, it's important to note that while all [Ultralytics YOLOv8 models](../models/index.md) are available for exporting, you can ensure that the model you select supports export functionality [here](../modes/export.md).
+
+!!! Example "Usage"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load the YOLOv8 model
+ model = YOLO("yolov8n.pt")
+
+ # Export the model to PaddlePaddle format
+ model.export(format="paddle") # creates '/yolov8n_paddle_model'
+
+ # Load the exported PaddlePaddle model
+ paddle_model = YOLO("./yolov8n_paddle_model")
+
+ # Run inference
+ results = paddle_model("https://ultralytics.com/images/bus.jpg")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Export a YOLOv8n PyTorch model to PaddlePaddle format
+ yolo export model=yolov8n.pt format=paddle # creates '/yolov8n_paddle_model'
+
+ # Run inference with the exported model
+ yolo predict model='./yolov8n_paddle_model' source='https://ultralytics.com/images/bus.jpg'
+ ```
+
+For more details about supported export options, visit the [Ultralytics documentation page on deployment options](../guides/model-deployment-options.md).
+
+## Deploying Exported YOLOv8 PaddlePaddle Models
+
+After successfully exporting your Ultralytics YOLOv8 models to PaddlePaddle format, you can now deploy them. The primary and recommended first step for running a PaddlePaddle model is to use the YOLO("./model_paddle_model") method, as outlined in the previous usage code snippet.
+
+However, for in-depth instructions on deploying your PaddlePaddle models in various other settings, take a look at the following resources:
+
+- **[Paddle Serving](https://github.com/PaddlePaddle/Serving/blob/v0.9.0/README_CN.md)**: Learn how to deploy your PaddlePaddle models as performant services using Paddle Serving.
+
+- **[Paddle Lite](https://github.com/PaddlePaddle/Paddle-Lite/blob/develop/README_en.md)**: Explore how to optimize and deploy models on mobile and embedded devices using Paddle Lite.
+
+- **[Paddle.js](https://github.com/PaddlePaddle/Paddle.js)**: Discover how to run PaddlePaddle models in web browsers for client-side AI using Paddle.js.
+
+## Summary
+
+In this guide, we explored the process of exporting Ultralytics YOLOv8 models to the PaddlePaddle format. By following these steps, you can leverage PaddlePaddle's strengths in diverse deployment scenarios, optimizing your models for different hardware and software environments.
+
+For further details on usage, visit the [PaddlePaddle official documentation](https://www.paddlepaddle.org.cn/documentation/docs/en/guides/index_en.html)
+
+Want to explore more ways to integrate your Ultralytics YOLOv8 models? Our [integration guide page](index.md) explores various options, equipping you with valuable resources and insights.
+
+## FAQ
+
+### How do I export Ultralytics YOLOv8 models to PaddlePaddle format?
+
+Exporting Ultralytics YOLOv8 models to PaddlePaddle format is straightforward. You can use the `export` method of the YOLO class to perform this exportation. Here is an example using Python:
+
+!!! Example "Usage"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load the YOLOv8 model
+ model = YOLO("yolov8n.pt")
+
+ # Export the model to PaddlePaddle format
+ model.export(format="paddle") # creates '/yolov8n_paddle_model'
+
+ # Load the exported PaddlePaddle model
+ paddle_model = YOLO("./yolov8n_paddle_model")
+
+ # Run inference
+ results = paddle_model("https://ultralytics.com/images/bus.jpg")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Export a YOLOv8n PyTorch model to PaddlePaddle format
+ yolo export model=yolov8n.pt format=paddle # creates '/yolov8n_paddle_model'
+
+ # Run inference with the exported model
+ yolo predict model='./yolov8n_paddle_model' source='https://ultralytics.com/images/bus.jpg'
+ ```
+
+For more detailed setup and troubleshooting, check the [Ultralytics Installation Guide](../quickstart.md) and [Common Issues Guide](../guides/yolo-common-issues.md).
+
+### What are the advantages of using PaddlePaddle for model deployment?
+
+PaddlePaddle offers several key advantages for model deployment:
+
+- **Performance Optimization**: PaddlePaddle excels in efficient model execution and reduced memory usage.
+- **Dynamic-to-Static Graph Compilation**: It supports dynamic-to-static compilation, allowing for runtime optimizations.
+- **Operator Fusion**: By merging compatible operations, it reduces computational overhead.
+- **Quantization Techniques**: Supports both post-training and quantization-aware training, enabling lower-precision data representations for improved performance.
+
+You can achieve enhanced results by exporting your Ultralytics YOLOv8 models to PaddlePaddle, ensuring flexibility and high performance across various applications and hardware platforms. Learn more about PaddlePaddle's features [here](https://www.paddlepaddle.org.cn/en).
+
+### Why should I choose PaddlePaddle for deploying my YOLOv8 models?
+
+PaddlePaddle, developed by Baidu, is optimized for industrial and commercial AI deployments. Its large developer community and robust framework provide extensive tools similar to TensorFlow and PyTorch. By exporting your YOLOv8 models to PaddlePaddle, you leverage:
+
+- **Enhanced Performance**: Optimal execution speed and reduced memory footprint.
+- **Flexibility**: Wide compatibility with various devices from smartphones to cloud servers.
+- **Scalability**: Efficient parallel processing capabilities for distributed environments.
+
+These features make PaddlePaddle a compelling choice for deploying YOLOv8 models in production settings.
+
+### How does PaddlePaddle improve model performance over other frameworks?
+
+PaddlePaddle employs several advanced techniques to optimize model performance:
+
+- **Dynamic-to-Static Graph**: Converts models into a static computational graph for runtime optimizations.
+- **Operator Fusion**: Combines compatible operations to minimize memory transfer and increase inference speed.
+- **Quantization**: Reduces model size and increases efficiency using lower-precision data while maintaining accuracy.
+
+These techniques prioritize efficient model execution, making PaddlePaddle an excellent option for deploying high-performance YOLOv8 models. For more on optimization, see the [PaddlePaddle official documentation](https://www.paddlepaddle.org.cn/documentation/docs/en/guides/index_en.html).
+
+### What deployment options does PaddlePaddle offer for YOLOv8 models?
+
+PaddlePaddle provides flexible deployment options:
+
+- **Paddle Serving**: Deploys models as RESTful APIs, ideal for production with features like model versioning and online A/B testing.
+- **Paddle Inference API**: Gives low-level control over model execution for custom applications.
+- **Paddle Lite**: Optimizes models for mobile and embedded devices' limited resources.
+- **Paddle.js**: Enables deploying models directly within web browsers.
+
+These options cover a broad range of deployment scenarios, from on-device inference to scalable cloud services. Explore more deployment strategies on the [Ultralytics Model Deployment Options page](../guides/model-deployment-options.md).
diff --git a/ultralytics/docs/en/integrations/paperspace.md b/ultralytics/docs/en/integrations/paperspace.md
new file mode 100644
index 0000000000000000000000000000000000000000..346fb06c6f529190ce8defbade0c8d4fb56f868c
--- /dev/null
+++ b/ultralytics/docs/en/integrations/paperspace.md
@@ -0,0 +1,115 @@
+---
+comments: true
+description: Simplify YOLOv8 training with Paperspace Gradient's all-in-one MLOps platform. Access GPUs, automate workflows, and deploy with ease.
+keywords: YOLOv8, Paperspace Gradient, MLOps, machine learning, training, GPUs, Jupyter notebooks, model deployment, AI, cloud platform
+---
+
+# YOLOv8 Model Training Made Simple with Paperspace Gradient
+
+Training computer vision models like [YOLOv8](https://github.com/ultralytics/ultralytics) can be complicated. It involves managing large datasets, using different types of computer hardware like GPUs, TPUs, and CPUs, and making sure data flows smoothly during the training process. Typically, developers end up spending a lot of time managing their computer systems and environments. It can be frustrating when you just want to focus on building the best model.
+
+This is where a platform like Paperspace Gradient can make things simpler. Paperspace Gradient is a MLOps platform that lets you build, train, and deploy machine learning models all in one place. With Gradient, developers can focus on training their YOLOv8 models without the hassle of managing infrastructure and environments.
+
+## Paperspace
+
+
+
+
+
+[Paperspace](https://www.paperspace.com/), launched in 2014 by University of Michigan graduates and acquired by DigitalOcean in 2023, is a cloud platform specifically designed for machine learning. It provides users with powerful GPUs, collaborative Jupyter notebooks, a container service for deployments, automated workflows for machine learning tasks, and high-performance virtual machines. These features aim to streamline the entire machine learning development process, from coding to deployment.
+
+## Paperspace Gradient
+
+
+
+
+
+Paperspace Gradient is a suite of tools designed to make working with AI and machine learning in the cloud much faster and easier. Gradient addresses the entire machine learning development process, from building and training models to deploying them.
+
+Within its toolkit, it includes support for Google's TPUs via a job runner, comprehensive support for Jupyter notebooks and containers, and new programming language integrations. Its focus on language integration particularly stands out, allowing users to easily adapt their existing Python projects to use the most advanced GPU infrastructure available.
+
+## Training YOLOv8 Using Paperspace Gradient
+
+Paperspace Gradient makes training a YOLOv8 model possible with a few clicks. Thanks to the integration, you can access the [Paperspace console](https://console.paperspace.com/github/ultralytics/ultralytics) and start training your model immediately. For a detailed understanding of the model training process and best practices, refer to our [YOLOv8 Model Training guide](../modes/train.md).
+
+Sign in and then click on the “Start Machine” button shown in the image below. In a few seconds, a managed GPU environment will start up, and then you can run the notebook's cells.
+
+
+
+Explore more capabilities of YOLOv8 and Paperspace Gradient in a discussion with Glenn Jocher, Ultralytics founder, and James Skelton from Paperspace. Watch the discussion below.
+
+
+
+
+
+ Watch: Ultralytics Live Session 7: It's All About the Environment: Optimizing YOLOv8 Training With Gradient
+
+
+## Key Features of Paperspace Gradient
+
+As you explore the Paperspace console, you'll see how each step of the machine-learning workflow is supported and enhanced. Here are some things to look out for:
+
+- **One-Click Notebooks:** Gradient provides pre-configured Jupyter Notebooks specifically tailored for YOLOv8, eliminating the need for environment setup and dependency management. Simply choose the desired notebook and start experimenting immediately.
+
+- **Hardware Flexibility:** Choose from a range of machine types with varying CPU, GPU, and TPU configurations to suit your training needs and budget. Gradient handles all the backend setup, allowing you to focus on model development.
+
+- **Experiment Tracking:** Gradient automatically tracks your experiments, including hyperparameters, metrics, and code changes. This allows you to easily compare different training runs, identify optimal configurations, and reproduce successful results.
+
+- **Dataset Management:** Efficiently manage your datasets directly within Gradient. Upload, version, and pre-process data with ease, streamlining the data preparation phase of your project.
+
+- **Model Serving:** Deploy your trained YOLOv8 models as REST APIs with just a few clicks. Gradient handles the infrastructure, allowing you to easily integrate your object detection models into your applications.
+
+- **Real-time Monitoring:** Monitor the performance and health of your deployed models through Gradient's intuitive dashboard. Gain insights into inference speed, resource utilization, and potential errors.
+
+## Why Should You Use Gradient for Your YOLOv8 Projects?
+
+While many options are available for training, deploying, and evaluating YOLOv8 models, the integration with Paperspace Gradient offers a unique set of advantages that separates it from other solutions. Let's explore what makes this integration unique:
+
+- **Enhanced Collaboration:** Shared workspaces and version control facilitate seamless teamwork and ensure reproducibility, allowing your team to work together effectively and maintain a clear history of your project.
+
+- **Low-Cost GPUs:** Gradient provides access to high-performance GPUs at significantly lower costs than major cloud providers or on-premise solutions. With per-second billing, you only pay for the resources you actually use, optimizing your budget.
+
+- **Predictable Costs:** Gradient's on-demand pricing ensures cost transparency and predictability. You can scale your resources up or down as needed and only pay for the time you use, avoiding unnecessary expenses.
+
+- **No Commitments:** You can adjust your instance types anytime to adapt to changing project requirements and optimize the cost-performance balance. There are no lock-in periods or commitments, providing maximum flexibility.
+
+## Summary
+
+This guide explored the Paperspace Gradient integration for training YOLOv8 models. Gradient provides the tools and infrastructure to accelerate your AI development journey from effortless model training and evaluation to streamlined deployment options.
+
+For further exploration, visit [PaperSpace's official documentation](https://docs.digitalocean.com/products/paperspace/).
+
+Also, visit the [Ultralytics integration guide page](index.md) to learn more about different YOLOv8 integrations. It's full of insights and tips to take your computer vision projects to the next level.
+
+## FAQ
+
+### How do I train a YOLOv8 model using Paperspace Gradient?
+
+Training a YOLOv8 model with Paperspace Gradient is straightforward and efficient. First, sign in to the [Paperspace console](https://console.paperspace.com/github/ultralytics/ultralytics). Next, click the “Start Machine” button to initiate a managed GPU environment. Once the environment is ready, you can run the notebook's cells to start training your YOLOv8 model. For detailed instructions, refer to our [YOLOv8 Model Training guide](../modes/train.md).
+
+### What are the advantages of using Paperspace Gradient for YOLOv8 projects?
+
+Paperspace Gradient offers several unique advantages for training and deploying YOLOv8 models:
+
+- **Hardware Flexibility:** Choose from various CPU, GPU, and TPU configurations.
+- **One-Click Notebooks:** Use pre-configured Jupyter Notebooks for YOLOv8 without worrying about environment setup.
+- **Experiment Tracking:** Automatic tracking of hyperparameters, metrics, and code changes.
+- **Dataset Management:** Efficiently manage your datasets within Gradient.
+- **Model Serving:** Deploy models as REST APIs easily.
+- **Real-time Monitoring:** Monitor model performance and resource utilization through a dashboard.
+
+### Why should I choose Ultralytics YOLOv8 over other object detection models?
+
+Ultralytics YOLOv8 stands out for its real-time object detection capabilities and high accuracy. Its seamless integration with platforms like Paperspace Gradient enhances productivity by simplifying the training and deployment process. YOLOv8 supports various use cases, from security systems to retail inventory management. Explore more about YOLOv8's advantages [here](https://www.ultralytics.com/yolo).
+
+### Can I deploy my YOLOv8 model on edge devices using Paperspace Gradient?
+
+Yes, you can deploy YOLOv8 models on edge devices using Paperspace Gradient. The platform supports various deployment formats like TFLite and Edge TPU, which are optimized for edge devices. After training your model on Gradient, refer to our [export guide](../modes/export.md) for instructions on converting your model to the desired format.
+
+### How does experiment tracking in Paperspace Gradient help improve YOLOv8 training?
+
+Experiment tracking in Paperspace Gradient streamlines the model development process by automatically logging hyperparameters, metrics, and code changes. This allows you to easily compare different training runs, identify optimal configurations, and reproduce successful experiments.
diff --git a/ultralytics/docs/en/integrations/ray-tune.md b/ultralytics/docs/en/integrations/ray-tune.md
new file mode 100644
index 0000000000000000000000000000000000000000..95c24741a747b4564ab6bd22c1ef927fd5fd80ff
--- /dev/null
+++ b/ultralytics/docs/en/integrations/ray-tune.md
@@ -0,0 +1,284 @@
+---
+comments: true
+description: Optimize YOLOv8 model performance with Ray Tune. Learn efficient hyperparameter tuning using advanced search strategies, parallelism, and early stopping.
+keywords: YOLOv8, Ray Tune, hyperparameter tuning, model optimization, machine learning, deep learning, AI, Ultralytics, Weights & Biases
+---
+
+# Efficient Hyperparameter Tuning with Ray Tune and YOLOv8
+
+Hyperparameter tuning is vital in achieving peak model performance by discovering the optimal set of hyperparameters. This involves running trials with different hyperparameters and evaluating each trial's performance.
+
+## Accelerate Tuning with Ultralytics YOLOv8 and Ray Tune
+
+[Ultralytics YOLOv8](https://ultralytics.com) incorporates Ray Tune for hyperparameter tuning, streamlining the optimization of YOLOv8 model hyperparameters. With Ray Tune, you can utilize advanced search strategies, parallelism, and early stopping to expedite the tuning process.
+
+### Ray Tune
+
+
+
+
+
+[Ray Tune](https://docs.ray.io/en/latest/tune/index.html) is a hyperparameter tuning library designed for efficiency and flexibility. It supports various search strategies, parallelism, and early stopping strategies, and seamlessly integrates with popular machine learning frameworks, including Ultralytics YOLOv8.
+
+### Integration with Weights & Biases
+
+YOLOv8 also allows optional integration with [Weights & Biases](https://wandb.ai/site) for monitoring the tuning process.
+
+## Installation
+
+To install the required packages, run:
+
+!!! Tip "Installation"
+
+ === "CLI"
+
+ ```bash
+ # Install and update Ultralytics and Ray Tune packages
+ pip install -U ultralytics "ray[tune]"
+
+ # Optionally install W&B for logging
+ pip install wandb
+ ```
+
+## Usage
+
+!!! Example "Usage"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a YOLOv8n model
+ model = YOLO("yolov8n.pt")
+
+ # Start tuning hyperparameters for YOLOv8n training on the COCO8 dataset
+ result_grid = model.tune(data="coco8.yaml", use_ray=True)
+ ```
+
+## `tune()` Method Parameters
+
+The `tune()` method in YOLOv8 provides an easy-to-use interface for hyperparameter tuning with Ray Tune. It accepts several arguments that allow you to customize the tuning process. Below is a detailed explanation of each parameter:
+
+| Parameter | Type | Description | Default Value |
+| --------------- | ---------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------- |
+| `data` | `str` | The dataset configuration file (in YAML format) to run the tuner on. This file should specify the training and validation data paths, as well as other dataset-specific settings. | |
+| `space` | `dict, optional` | A dictionary defining the hyperparameter search space for Ray Tune. Each key corresponds to a hyperparameter name, and the value specifies the range of values to explore during tuning. If not provided, YOLOv8 uses a default search space with various hyperparameters. | |
+| `grace_period` | `int, optional` | The grace period in epochs for the [ASHA scheduler](https://docs.ray.io/en/latest/tune/api/schedulers.html) in Ray Tune. The scheduler will not terminate any trial before this number of epochs, allowing the model to have some minimum training before making a decision on early stopping. | 10 |
+| `gpu_per_trial` | `int, optional` | The number of GPUs to allocate per trial during tuning. This helps manage GPU usage, particularly in multi-GPU environments. If not provided, the tuner will use all available GPUs. | None |
+| `iterations` | `int, optional` | The maximum number of trials to run during tuning. This parameter helps control the total number of hyperparameter combinations tested, ensuring the tuning process does not run indefinitely. | 10 |
+| `**train_args` | `dict, optional` | Additional arguments to pass to the `train()` method during tuning. These arguments can include settings like the number of training epochs, batch size, and other training-specific configurations. | {} |
+
+By customizing these parameters, you can fine-tune the hyperparameter optimization process to suit your specific needs and available computational resources.
+
+## Default Search Space Description
+
+The following table lists the default search space parameters for hyperparameter tuning in YOLOv8 with Ray Tune. Each parameter has a specific value range defined by `tune.uniform()`.
+
+| Parameter | Value Range | Description |
+| ----------------- | -------------------------- | ---------------------------------------- |
+| `lr0` | `tune.uniform(1e-5, 1e-1)` | Initial learning rate |
+| `lrf` | `tune.uniform(0.01, 1.0)` | Final learning rate factor |
+| `momentum` | `tune.uniform(0.6, 0.98)` | Momentum |
+| `weight_decay` | `tune.uniform(0.0, 0.001)` | Weight decay |
+| `warmup_epochs` | `tune.uniform(0.0, 5.0)` | Warmup epochs |
+| `warmup_momentum` | `tune.uniform(0.0, 0.95)` | Warmup momentum |
+| `box` | `tune.uniform(0.02, 0.2)` | Box loss weight |
+| `cls` | `tune.uniform(0.2, 4.0)` | Class loss weight |
+| `hsv_h` | `tune.uniform(0.0, 0.1)` | Hue augmentation range |
+| `hsv_s` | `tune.uniform(0.0, 0.9)` | Saturation augmentation range |
+| `hsv_v` | `tune.uniform(0.0, 0.9)` | Value (brightness) augmentation range |
+| `degrees` | `tune.uniform(0.0, 45.0)` | Rotation augmentation range (degrees) |
+| `translate` | `tune.uniform(0.0, 0.9)` | Translation augmentation range |
+| `scale` | `tune.uniform(0.0, 0.9)` | Scaling augmentation range |
+| `shear` | `tune.uniform(0.0, 10.0)` | Shear augmentation range (degrees) |
+| `perspective` | `tune.uniform(0.0, 0.001)` | Perspective augmentation range |
+| `flipud` | `tune.uniform(0.0, 1.0)` | Vertical flip augmentation probability |
+| `fliplr` | `tune.uniform(0.0, 1.0)` | Horizontal flip augmentation probability |
+| `mosaic` | `tune.uniform(0.0, 1.0)` | Mosaic augmentation probability |
+| `mixup` | `tune.uniform(0.0, 1.0)` | Mixup augmentation probability |
+| `copy_paste` | `tune.uniform(0.0, 1.0)` | Copy-paste augmentation probability |
+
+## Custom Search Space Example
+
+In this example, we demonstrate how to use a custom search space for hyperparameter tuning with Ray Tune and YOLOv8. By providing a custom search space, you can focus the tuning process on specific hyperparameters of interest.
+
+!!! Example "Usage"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Define a YOLO model
+ model = YOLO("yolov8n.pt")
+
+ # Run Ray Tune on the model
+ result_grid = model.tune(
+ data="coco8.yaml",
+ space={"lr0": tune.uniform(1e-5, 1e-1)},
+ epochs=50,
+ use_ray=True,
+ )
+ ```
+
+In the code snippet above, we create a YOLO model with the "yolov8n.pt" pretrained weights. Then, we call the `tune()` method, specifying the dataset configuration with "coco8.yaml". We provide a custom search space for the initial learning rate `lr0` using a dictionary with the key "lr0" and the value `tune.uniform(1e-5, 1e-1)`. Finally, we pass additional training arguments, such as the number of epochs directly to the tune method as `epochs=50`.
+
+## Processing Ray Tune Results
+
+After running a hyperparameter tuning experiment with Ray Tune, you might want to perform various analyses on the obtained results. This guide will take you through common workflows for processing and analyzing these results.
+
+### Loading Tune Experiment Results from a Directory
+
+After running the tuning experiment with `tuner.fit()`, you can load the results from a directory. This is useful, especially if you're performing the analysis after the initial training script has exited.
+
+```python
+experiment_path = f"{storage_path}/{exp_name}"
+print(f"Loading results from {experiment_path}...")
+
+restored_tuner = tune.Tuner.restore(experiment_path, trainable=train_mnist)
+result_grid = restored_tuner.get_results()
+```
+
+### Basic Experiment-Level Analysis
+
+Get an overview of how trials performed. You can quickly check if there were any errors during the trials.
+
+```python
+if result_grid.errors:
+ print("One or more trials failed!")
+else:
+ print("No errors!")
+```
+
+### Basic Trial-Level Analysis
+
+Access individual trial hyperparameter configurations and the last reported metrics.
+
+```python
+for i, result in enumerate(result_grid):
+ print(f"Trial #{i}: Configuration: {result.config}, Last Reported Metrics: {result.metrics}")
+```
+
+### Plotting the Entire History of Reported Metrics for a Trial
+
+You can plot the history of reported metrics for each trial to see how the metrics evolved over time.
+
+```python
+import matplotlib.pyplot as plt
+
+for i, result in enumerate(result_grid):
+ plt.plot(
+ result.metrics_dataframe["training_iteration"],
+ result.metrics_dataframe["mean_accuracy"],
+ label=f"Trial {i}",
+ )
+
+plt.xlabel("Training Iterations")
+plt.ylabel("Mean Accuracy")
+plt.legend()
+plt.show()
+```
+
+## Summary
+
+In this documentation, we covered common workflows to analyze the results of experiments run with Ray Tune using Ultralytics. The key steps include loading the experiment results from a directory, performing basic experiment-level and trial-level analysis and plotting metrics.
+
+Explore further by looking into Ray Tune's [Analyze Results](https://docs.ray.io/en/latest/tune/examples/tune_analyze_results.html) docs page to get the most out of your hyperparameter tuning experiments.
+
+## FAQ
+
+### How do I tune the hyperparameters of my YOLOv8 model using Ray Tune?
+
+To tune the hyperparameters of your Ultralytics YOLOv8 model using Ray Tune, follow these steps:
+
+1. **Install the required packages:**
+
+ ```bash
+ pip install -U ultralytics "ray[tune]"
+ pip install wandb # optional for logging
+ ```
+
+2. **Load your YOLOv8 model and start tuning:**
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a YOLOv8 model
+ model = YOLO("yolov8n.pt")
+
+ # Start tuning with the COCO8 dataset
+ result_grid = model.tune(data="coco8.yaml", use_ray=True)
+ ```
+
+This utilizes Ray Tune's advanced search strategies and parallelism to efficiently optimize your model's hyperparameters. For more information, check out the [Ray Tune documentation](https://docs.ray.io/en/latest/tune/index.html).
+
+### What are the default hyperparameters for YOLOv8 tuning with Ray Tune?
+
+Ultralytics YOLOv8 uses the following default hyperparameters for tuning with Ray Tune:
+
+| Parameter | Value Range | Description |
+| --------------- | -------------------------- | ------------------------------ |
+| `lr0` | `tune.uniform(1e-5, 1e-1)` | Initial learning rate |
+| `lrf` | `tune.uniform(0.01, 1.0)` | Final learning rate factor |
+| `momentum` | `tune.uniform(0.6, 0.98)` | Momentum |
+| `weight_decay` | `tune.uniform(0.0, 0.001)` | Weight decay |
+| `warmup_epochs` | `tune.uniform(0.0, 5.0)` | Warmup epochs |
+| `box` | `tune.uniform(0.02, 0.2)` | Box loss weight |
+| `cls` | `tune.uniform(0.2, 4.0)` | Class loss weight |
+| `hsv_h` | `tune.uniform(0.0, 0.1)` | Hue augmentation range |
+| `translate` | `tune.uniform(0.0, 0.9)` | Translation augmentation range |
+
+These hyperparameters can be customized to suit your specific needs. For a complete list and more details, refer to the [Hyperparameter Tuning](../guides/hyperparameter-tuning.md) guide.
+
+### How can I integrate Weights & Biases with my YOLOv8 model tuning?
+
+To integrate Weights & Biases (W&B) with your Ultralytics YOLOv8 tuning process:
+
+1. **Install W&B:**
+
+ ```bash
+ pip install wandb
+ ```
+
+2. **Modify your tuning script:**
+
+ ```python
+ import wandb
+
+ from ultralytics import YOLO
+
+ wandb.init(project="YOLO-Tuning", entity="your-entity")
+
+ # Load YOLO model
+ model = YOLO("yolov8n.pt")
+
+ # Tune hyperparameters
+ result_grid = model.tune(data="coco8.yaml", use_ray=True)
+ ```
+
+This setup will allow you to monitor the tuning process, track hyperparameter configurations, and visualize results in W&B.
+
+### Why should I use Ray Tune for hyperparameter optimization with YOLOv8?
+
+Ray Tune offers numerous advantages for hyperparameter optimization:
+
+- **Advanced Search Strategies:** Utilizes algorithms like Bayesian Optimization and HyperOpt for efficient parameter search.
+- **Parallelism:** Supports parallel execution of multiple trials, significantly speeding up the tuning process.
+- **Early Stopping:** Employs strategies like ASHA to terminate under-performing trials early, saving computational resources.
+
+Ray Tune seamlessly integrates with Ultralytics YOLOv8, providing an easy-to-use interface for tuning hyperparameters effectively. To get started, check out the [Efficient Hyperparameter Tuning with Ray Tune and YOLOv8](../guides/hyperparameter-tuning.md) guide.
+
+### How can I define a custom search space for YOLOv8 hyperparameter tuning?
+
+To define a custom search space for your YOLOv8 hyperparameter tuning with Ray Tune:
+
+```python
+from ray import tune
+
+from ultralytics import YOLO
+
+model = YOLO("yolov8n.pt")
+search_space = {"lr0": tune.uniform(1e-5, 1e-1), "momentum": tune.uniform(0.6, 0.98)}
+result_grid = model.tune(data="coco8.yaml", space=search_space, use_ray=True)
+```
+
+This customizes the range of hyperparameters like initial learning rate and momentum to be explored during the tuning process. For advanced configurations, refer to the [Custom Search Space Example](#custom-search-space-example) section.
diff --git a/ultralytics/docs/en/integrations/roboflow.md b/ultralytics/docs/en/integrations/roboflow.md
new file mode 100644
index 0000000000000000000000000000000000000000..af3a0015a6df0fea82eff819d9960d2bfb1330c9
--- /dev/null
+++ b/ultralytics/docs/en/integrations/roboflow.md
@@ -0,0 +1,269 @@
+---
+comments: true
+description: Learn how to gather, label, and deploy data for custom YOLOv8 models using Roboflow's powerful tools. Optimize your computer vision pipeline effortlessly.
+keywords: Roboflow, YOLOv8, data labeling, computer vision, model training, model deployment, dataset management, automated image annotation, AI tools
+---
+
+# Roboflow
+
+[Roboflow](https://roboflow.com/?ref=ultralytics) has everything you need to build and deploy computer vision models. Connect Roboflow at any step in your pipeline with APIs and SDKs, or use the end-to-end interface to automate the entire process from image to inference. Whether you're in need of [data labeling](https://roboflow.com/annotate?ref=ultralytics), [model training](https://roboflow.com/train?ref=ultralytics), or [model deployment](https://roboflow.com/deploy?ref=ultralytics), Roboflow gives you building blocks to bring custom computer vision solutions to your project.
+
+!!! Question "Licensing"
+
+ Ultralytics offers two licensing options:
+
+ - The [AGPL-3.0 License](https://github.com/ultralytics/ultralytics/blob/main/LICENSE), an [OSI-approved](https://opensource.org/licenses/) open-source license ideal for students and enthusiasts.
+ - The [Enterprise License](https://ultralytics.com/license) for businesses seeking to incorporate our AI models into their products and services.
+
+ For more details see [Ultralytics Licensing](https://ultralytics.com/license).
+
+In this guide, we are going to showcase how to find, label, and organize data for use in training a custom Ultralytics YOLOv8 model. Use the table of contents below to jump directly to a specific section:
+
+- Gather data for training a custom YOLOv8 model
+- Upload, convert and label data for YOLOv8 format
+- Pre-process and augment data for model robustness
+- Dataset management for [YOLOv8](../models/yolov8.md)
+- Export data in 40+ formats for model training
+- Upload custom YOLOv8 model weights for testing and deployment
+- Gather Data for Training a Custom YOLOv8 Model
+
+Roboflow provides two services that can help you collect data for YOLOv8 models: [Universe](https://universe.roboflow.com/?ref=ultralytics) and [Collect](https://roboflow.com/collect?ref=ultralytics).
+
+Universe is an online repository with over 250,000 vision datasets totalling over 100 million images.
+
+
+
+
+
+With a [free Roboflow account](https://app.roboflow.com/?ref=ultralytics), you can export any dataset available on Universe. To export a dataset, click the "Download this Dataset" button on any dataset.
+
+
+
+
+
+For YOLOv8, select "YOLOv8" as the export format:
+
+
+
+
+
+Universe also has a page that aggregates all [public fine-tuned YOLOv8 models uploaded to Roboflow](https://universe.roboflow.com/search?q=model:yolov8). You can use this page to explore pre-trained models you can use for testing or [for automated data labeling](https://docs.roboflow.com/annotate/use-roboflow-annotate/model-assisted-labeling) or to prototype with [Roboflow inference](https://roboflow.com/inference?ref=ultralytics).
+
+If you want to gather images yourself, try [Collect](https://github.com/roboflow/roboflow-collect), an open source project that allows you to automatically gather images using a webcam on the edge. You can use text or image prompts with Collect to instruct what data should be collected, allowing you to capture only the useful data you need to build your vision model.
+
+## Upload, Convert and Label Data for YOLOv8 Format
+
+[Roboflow Annotate](https://docs.roboflow.com/annotate/use-roboflow-annotate) is an online annotation tool for use in labeling images for object detection, classification, and segmentation.
+
+To label data for a YOLOv8 object detection, instance segmentation, or classification model, first create a project in Roboflow.
+
+
+
+
+
+Next, upload your images, and any pre-existing annotations you have from other tools ([using one of the 40+ supported import formats](https://roboflow.com/formats?ref=ultralytics)), into Roboflow.
+
+
+
+
+
+Select the batch of images you have uploaded on the Annotate page to which you are taken after uploading images. Then, click "Start Annotating" to label images.
+
+To label with bounding boxes, press the `B` key on your keyboard or click the box icon in the sidebar. Click on a point where you want to start your bounding box, then drag to create the box:
+
+
+
+
+
+A pop-up will appear asking you to select a class for your annotation once you have created an annotation.
+
+To label with polygons, press the `P` key on your keyboard, or the polygon icon in the sidebar. With the polygon annotation tool enabled, click on individual points in the image to draw a polygon.
+
+Roboflow offers a SAM-based label assistant with which you can label images faster than ever. SAM (Segment Anything Model) is a state-of-the-art computer vision model that can precisely label images. With SAM, you can significantly speed up the image labeling process. Annotating images with polygons becomes as simple as a few clicks, rather than the tedious process of precisely clicking points around an object.
+
+To use the label assistant, click the cursor icon in the sidebar, SAM will be loaded for use in your project.
+
+
+
+
+
+Hover over any object in the image and SAM will recommend an annotation. You can hover to find the right place to annotate, then click to create your annotation. To amend your annotation to be more or less specific, you can click inside or outside the annotation SAM has created on the document.
+
+You can also add tags to images from the Tags panel in the sidebar. You can apply tags to data from a particular area, taken from a specific camera, and more. You can then use these tags to search through data for images matching a tag and generate versions of a dataset with images that contain a particular tag or set of tags.
+
+
+
+
+
+Models hosted on Roboflow can be used with Label Assist, an automated annotation tool that uses your YOLOv8 model to recommend annotations. To use Label Assist, first upload a YOLOv8 model to Roboflow (see instructions later in the guide). Then, click the magic wand icon in the left sidebar and select your model for use in Label Assist.
+
+Choose a model, then click "Continue" to enable Label Assist:
+
+
+
+
+
+When you open new images for annotation, Label Assist will trigger and recommend annotations.
+
+
+
+
+
+## Dataset Management for YOLOv8
+
+Roboflow provides a suite of tools for understanding computer vision datasets.
+
+First, you can use dataset search to find images that meet a semantic text description (i.e. find all images that contain people), or that meet a specified label (i.e. the image is associated with a specific tag). To use dataset search, click "Dataset" in the sidebar. Then, input a search query using the search bar and associated filters at the top of the page.
+
+For example, the following text query finds images that contain people in a dataset:
+
+
+
+
+
+You can narrow your search to images with a particular tag using the "Tags" selector:
+
+
+
+
+
+Before you start training a model with your dataset, we recommend using Roboflow [Health Check](https://docs.roboflow.com/datasets/dataset-health-check), a web tool that provides an insight into your dataset and how you can improve the dataset prior to training a vision model.
+
+To use Health Check, click the "Health Check" sidebar link. A list of statistics will appear that show the average size of images in your dataset, class balance, a heatmap of where annotations are in your images, and more.
+
+
+
+
+
+Health Check may recommend changes to help enhance dataset performance. For example, the class balance feature may show that there is an imbalance in labels that, if solved, may boost performance or your model.
+
+## Export Data in 40+ Formats for Model Training
+
+To export your data, you will need a dataset version. A version is a state of your dataset frozen-in-time. To create a version, first click "Versions" in the sidebar. Then, click the "Create New Version" button. On this page, you will be able to choose augmentations and preprocessing steps to apply to your dataset:
+
+
+
+
+
+For each augmentation you select, a pop-up will appear allowing you to tune the augmentation to your needs. Here is an example of tuning a brightness augmentation within specified parameters:
+
+
+
+
+
+When your dataset version has been generated, you can export your data into a range of formats. Click the "Export Dataset" button on your dataset version page to export your data:
+
+
+
+
+
+You are now ready to train YOLOv8 on a custom dataset. Follow this [written guide](https://blog.roboflow.com/how-to-train-yolov8-on-a-custom-dataset/) and [YouTube video](https://www.youtube.com/watch?v=wuZtUMEiKWY) for step-by-step instructions or refer to the [Ultralytics documentation](../modes/train.md).
+
+## Upload Custom YOLOv8 Model Weights for Testing and Deployment
+
+Roboflow offers an infinitely scalable API for deployed models and SDKs for use with NVIDIA Jetsons, Luxonis OAKs, Raspberry Pis, GPU-based devices, and more.
+
+You can deploy YOLOv8 models by uploading YOLOv8 weights to Roboflow. You can do this in a few lines of Python code. Create a new Python file and add the following code:
+
+```python
+import roboflow # install with 'pip install roboflow'
+
+roboflow.login()
+
+rf = roboflow.Roboflow()
+
+project = rf.workspace(WORKSPACE_ID).project("football-players-detection-3zvbc")
+dataset = project.version(VERSION).download("yolov8")
+
+project.version(dataset.version).deploy(model_type="yolov8", model_path=f"{HOME}/runs/detect/train/")
+```
+
+In this code, replace the project ID and version ID with the values for your account and project. [Learn how to retrieve your Roboflow API key](https://docs.roboflow.com/api-reference/authentication#retrieve-an-api-key).
+
+When you run the code above, you will be asked to authenticate. Then, your model will be uploaded and an API will be created for your project. This process can take up to 30 minutes to complete.
+
+To test your model and find deployment instructions for supported SDKs, go to the "Deploy" tab in the Roboflow sidebar. At the top of this page, a widget will appear with which you can test your model. You can use your webcam for live testing or upload images or videos.
+
+
+
+
+
+You can also use your uploaded model as a [labeling assistant](https://docs.roboflow.com/annotate/use-roboflow-annotate/model-assisted-labeling). This feature uses your trained model to recommend annotations on images uploaded to Roboflow.
+
+## How to Evaluate YOLOv8 Models
+
+Roboflow provides a range of features for use in evaluating models.
+
+Once you have uploaded a model to Roboflow, you can access our model evaluation tool, which provides a confusion matrix showing the performance of your model as well as an interactive vector analysis plot. These features can help you find opportunities to improve your model.
+
+To access a confusion matrix, go to your model page on the Roboflow dashboard, then click "View Detailed Evaluation":
+
+
+
+
+
+A pop-up will appear showing a confusion matrix:
+
+
+
+
+
+Hover over a box on the confusion matrix to see the value associated with the box. Click on a box to see images in the respective category. Click on an image to view the model predictions and ground truth data associated with that image.
+
+For more insights, click Vector Analysis. This will show a scatter plot of the images in your dataset, calculated using CLIP. The closer images are in the plot, the more similar they are, semantically. Each image is represented as a dot with a color between white and red. The more red the dot, the worse the model performed.
+
+
+
+
+
+You can use Vector Analysis to:
+
+- Find clusters of images;
+- Identify clusters where the model performs poorly, and;
+- Visualize commonalities between images on which the model performs poorly.
+
+## Learning Resources
+
+Want to learn more about using Roboflow for creating YOLOv8 models? The following resources may be helpful in your work.
+
+- [Train YOLOv8 on a Custom Dataset](https://github.com/roboflow/notebooks/blob/main/notebooks/train-yolov8-object-detection-on-custom-dataset.ipynb): Follow our interactive notebook that shows you how to train a YOLOv8 model on a custom dataset.
+- [Autodistill](https://autodistill.github.io/autodistill/): Use large foundation vision models to label data for specific models. You can label images for use in training YOLOv8 classification, detection, and segmentation models with Autodistill.
+- [Supervision](https://roboflow.github.io/supervision/): A Python package with helpful utilities for use in working with computer vision models. You can use supervision to filter detections, compute confusion matrices, and more, all in a few lines of Python code.
+- [Roboflow Blog](https://blog.roboflow.com/): The Roboflow Blog features over 500 articles on computer vision, covering topics from how to train a YOLOv8 model to annotation best practices.
+- [Roboflow YouTube channel](https://www.youtube.com/@Roboflow): Browse dozens of in-depth computer vision guides on our YouTube channel, covering topics from training YOLOv8 models to automated image labeling.
+
+## Project Showcase
+
+Below are a few of the many pieces of feedback we have received for using YOLOv8 and Roboflow together to create computer vision models.
+
+
+
+
+
+
+
+## FAQ
+
+### How do I label data for YOLOv8 models using Roboflow?
+
+Labeling data for YOLOv8 models using Roboflow is straightforward with Roboflow Annotate. First, create a project on Roboflow and upload your images. After uploading, select the batch of images and click "Start Annotating." You can use the `B` key for bounding boxes or the `P` key for polygons. For faster annotation, use the SAM-based label assistant by clicking the cursor icon in the sidebar. Detailed steps can be found [here](#upload-convert-and-label-data-for-yolov8-format).
+
+### What services does Roboflow offer for collecting YOLOv8 training data?
+
+Roboflow provides two key services for collecting YOLOv8 training data: [Universe](https://universe.roboflow.com/?ref=ultralytics) and [Collect](https://roboflow.com/collect?ref=ultralytics). Universe offers access to over 250,000 vision datasets, while Collect helps you gather images using a webcam and automated prompts.
+
+### How can I manage and analyze my YOLOv8 dataset using Roboflow?
+
+Roboflow offers robust dataset management tools, including dataset search, tagging, and Health Check. Use the search feature to find images based on text descriptions or tags. Health Check provides insights into dataset quality, showing class balance, image sizes, and annotation heatmaps. This helps optimize dataset performance before training YOLOv8 models. Detailed information can be found [here](#dataset-management-for-yolov8).
+
+### How do I export my YOLOv8 dataset from Roboflow?
+
+To export your YOLOv8 dataset from Roboflow, you need to create a dataset version. Click "Versions" in the sidebar, then "Create New Version" and apply any desired augmentations. Once the version is generated, click "Export Dataset" and choose the YOLOv8 format. Follow this process [here](#export-data-in-40-formats-for-model-training).
+
+### How can I integrate and deploy YOLOv8 models with Roboflow?
+
+Integrate and deploy YOLOv8 models on Roboflow by uploading your YOLOv8 weights through a few lines of Python code. Use the provided script to authenticate and upload your model, which will create an API for deployment. For details on the script and further instructions, see [this section](#upload-custom-yolov8-model-weights-for-testing-and-deployment).
+
+### What tools does Roboflow provide for evaluating YOLOv8 models?
+
+Roboflow offers model evaluation tools, including a confusion matrix and vector analysis plots. Access these tools from the "View Detailed Evaluation" button on your model page. These features help identify model performance issues and find areas for improvement. For more information, refer to [this section](#how-to-evaluate-yolov8-models).
diff --git a/ultralytics/docs/en/integrations/tensorboard.md b/ultralytics/docs/en/integrations/tensorboard.md
new file mode 100644
index 0000000000000000000000000000000000000000..752ad4e7f7fa52c8d83c6571166a690f8be65d88
--- /dev/null
+++ b/ultralytics/docs/en/integrations/tensorboard.md
@@ -0,0 +1,213 @@
+---
+comments: true
+description: Learn how to integrate YOLOv8 with TensorBoard for real-time visual insights into your model's training metrics, performance graphs, and debugging workflows.
+keywords: YOLOv8, TensorBoard, model training, visualization, machine learning, deep learning, Ultralytics, training metrics, performance analysis
+---
+
+# Gain Visual Insights with YOLOv8's Integration with TensorBoard
+
+Understanding and fine-tuning computer vision models like [Ultralytics' YOLOv8](https://ultralytics.com) becomes more straightforward when you take a closer look at their training processes. Model training visualization helps with getting insights into the model's learning patterns, performance metrics, and overall behavior. YOLOv8's integration with TensorBoard makes this process of visualization and analysis easier and enables more efficient and informed adjustments to the model.
+
+This guide covers how to use TensorBoard with YOLOv8. You'll learn about various visualizations, from tracking metrics to analyzing model graphs. These tools will help you understand your YOLOv8 model's performance better.
+
+## TensorBoard
+
+
+
+
+
+[TensorBoard](https://www.tensorflow.org/tensorboard), TensorFlow's visualization toolkit, is essential for machine learning experimentation. TensorBoard features a range of visualization tools, crucial for monitoring machine learning models. These tools include tracking key metrics like loss and accuracy, visualizing model graphs, and viewing histograms of weights and biases over time. It also provides capabilities for projecting embeddings to lower-dimensional spaces and displaying multimedia data.
+
+## YOLOv8 Training with TensorBoard
+
+Using TensorBoard while training YOLOv8 models is straightforward and offers significant benefits.
+
+## Installation
+
+To install the required package, run:
+
+!!! Tip "Installation"
+
+ === "CLI"
+
+ ```bash
+ # Install the required package for YOLOv8 and Tensorboard
+ pip install ultralytics
+ ```
+
+TensorBoard is conveniently pre-installed with YOLOv8, eliminating the need for additional setup for visualization purposes.
+
+For detailed instructions and best practices related to the installation process, be sure to check our [YOLOv8 Installation guide](../quickstart.md). While installing the required packages for YOLOv8, if you encounter any difficulties, consult our [Common Issues guide](../guides/yolo-common-issues.md) for solutions and tips.
+
+## Configuring TensorBoard for Google Colab
+
+When using Google Colab, it's important to set up TensorBoard before starting your training code:
+
+!!! Example "Configure TensorBoard for Google Colab"
+
+ === "Python"
+
+ ```ipython
+ %load_ext tensorboard
+ %tensorboard --logdir path/to/runs
+ ```
+
+## Usage
+
+Before diving into the usage instructions, be sure to check out the range of [YOLOv8 models offered by Ultralytics](../models/index.md). This will help you choose the most appropriate model for your project requirements.
+
+!!! Example "Usage"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a pre-trained model
+ model = YOLO("yolov8n.pt")
+
+ # Train the model
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
+ ```
+
+Upon running the usage code snippet above, you can expect the following output:
+
+```bash
+TensorBoard: Start with 'tensorboard --logdir path_to_your_tensorboard_logs', view at http://localhost:6006/
+```
+
+This output indicates that TensorBoard is now actively monitoring your YOLOv8 training session. You can access the TensorBoard dashboard by visiting the provided URL (http://localhost:6006/) to view real-time training metrics and model performance. For users working in Google Colab, the TensorBoard will be displayed in the same cell where you executed the TensorBoard configuration commands.
+
+For more information related to the model training process, be sure to check our [YOLOv8 Model Training guide](../modes/train.md). If you are interested in learning more about logging, checkpoints, plotting, and file management, read our [usage guide on configuration](../usage/cfg.md).
+
+## Understanding Your TensorBoard for YOLOv8 Training
+
+Now, let's focus on understanding the various features and components of TensorBoard in the context of YOLOv8 training. The three key sections of the TensorBoard are Time Series, Scalars, and Graphs.
+
+### Time Series
+
+The Time Series feature in the TensorBoard offers a dynamic and detailed perspective of various training metrics over time for YOLOv8 models. It focuses on the progression and trends of metrics across training epochs. Here's an example of what you can expect to see.
+
+
+
+#### Key Features of Time Series in TensorBoard
+
+- **Filter Tags and Pinned Cards**: This functionality allows users to filter specific metrics and pin cards for quick comparison and access. It's particularly useful for focusing on specific aspects of the training process.
+
+- **Detailed Metric Cards**: Time Series divides metrics into different categories like learning rate (lr), training (train), and validation (val) metrics, each represented by individual cards.
+
+- **Graphical Display**: Each card in the Time Series section shows a detailed graph of a specific metric over the course of training. This visual representation aids in identifying trends, patterns, or anomalies in the training process.
+
+- **In-Depth Analysis**: Time Series provides an in-depth analysis of each metric. For instance, different learning rate segments are shown, offering insights into how adjustments in learning rate impact the model's learning curve.
+
+#### Importance of Time Series in YOLOv8 Training
+
+The Time Series section is essential for a thorough analysis of the YOLOv8 model's training progress. It lets you track the metrics in real time to promptly identify and solve issues. It also offers a detailed view of each metrics progression, which is crucial for fine-tuning the model and enhancing its performance.
+
+### Scalars
+
+Scalars in the TensorBoard are crucial for plotting and analyzing simple metrics like loss and accuracy during the training of YOLOv8 models. They offer a clear and concise view of how these metrics evolve with each training epoch, providing insights into the model's learning effectiveness and stability. Here's an example of what you can expect to see.
+
+
+
+#### Key Features of Scalars in TensorBoard
+
+- **Learning Rate (lr) Tags**: These tags show the variations in the learning rate across different segments (e.g., `pg0`, `pg1`, `pg2`). This helps us understand the impact of learning rate adjustments on the training process.
+
+- **Metrics Tags**: Scalars include performance indicators such as:
+
+ - `mAP50 (B)`: Mean Average Precision at 50% Intersection over Union (IoU), crucial for assessing object detection accuracy.
+
+ - `mAP50-95 (B)`: Mean Average Precision calculated over a range of IoU thresholds, offering a more comprehensive evaluation of accuracy.
+
+ - `Precision (B)`: Indicates the ratio of correctly predicted positive observations, key to understanding prediction accuracy.
+
+ - `Recall (B)`: Important for models where missing a detection is significant, this metric measures the ability to detect all relevant instances.
+
+ - To learn more about the different metrics, read our guide on [performance metrics](../guides/yolo-performance-metrics.md).
+
+- **Training and Validation Tags (`train`, `val`)**: These tags display metrics specifically for the training and validation datasets, allowing for a comparative analysis of model performance across different data sets.
+
+#### Importance of Monitoring Scalars
+
+Observing scalar metrics is crucial for fine-tuning the YOLOv8 model. Variations in these metrics, such as spikes or irregular patterns in loss graphs, can highlight potential issues such as overfitting, underfitting, or inappropriate learning rate settings. By closely monitoring these scalars, you can make informed decisions to optimize the training process, ensuring that the model learns effectively and achieves the desired performance.
+
+### Difference Between Scalars and Time Series
+
+While both Scalars and Time Series in TensorBoard are used for tracking metrics, they serve slightly different purposes. Scalars focus on plotting simple metrics such as loss and accuracy as scalar values. They provide a high-level overview of how these metrics change with each training epoch. While, the time-series section of the TensorBoard offers a more detailed timeline view of various metrics. It is particularly useful for monitoring the progression and trends of metrics over time, providing a deeper dive into the specifics of the training process.
+
+### Graphs
+
+The Graphs section of the TensorBoard visualizes the computational graph of the YOLOv8 model, showing how operations and data flow within the model. It's a powerful tool for understanding the model's structure, ensuring that all layers are connected correctly, and for identifying any potential bottlenecks in data flow. Here's an example of what you can expect to see.
+
+
+
+Graphs are particularly useful for debugging the model, especially in complex architectures typical in deep learning models like YOLOv8. They help in verifying layer connections and the overall design of the model.
+
+## Summary
+
+This guide aims to help you use TensorBoard with YOLOv8 for visualization and analysis of machine learning model training. It focuses on explaining how key TensorBoard features can provide insights into training metrics and model performance during YOLOv8 training sessions.
+
+For a more detailed exploration of these features and effective utilization strategies, you can refer to TensorFlow's official [TensorBoard documentation](https://www.tensorflow.org/tensorboard/get_started) and their [GitHub repository](https://github.com/tensorflow/tensorboard).
+
+Want to learn more about the various integrations of Ultralytics? Check out the [Ultralytics integrations guide page](../integrations/index.md) to see what other exciting capabilities are waiting to be discovered!
+
+## FAQ
+
+### What benefits does using TensorBoard with YOLOv8 offer?
+
+Using TensorBoard with YOLOv8 provides several visualization tools essential for efficient model training:
+
+- **Real-Time Metrics Tracking:** Track key metrics such as loss, accuracy, precision, and recall live.
+- **Model Graph Visualization:** Understand and debug the model architecture by visualizing computational graphs.
+- **Embedding Visualization:** Project embeddings to lower-dimensional spaces for better insight.
+
+These tools enable you to make informed adjustments to enhance your YOLOv8 model's performance. For more details on TensorBoard features, check out the TensorFlow [TensorBoard guide](https://www.tensorflow.org/tensorboard/get_started).
+
+### How can I monitor training metrics using TensorBoard when training a YOLOv8 model?
+
+To monitor training metrics while training a YOLOv8 model with TensorBoard, follow these steps:
+
+1. **Install TensorBoard and YOLOv8:** Run `pip install ultralytics` which includes TensorBoard.
+2. **Configure TensorBoard Logging:** During the training process, YOLOv8 logs metrics to a specified log directory.
+3. **Start TensorBoard:** Launch TensorBoard using the command `tensorboard --logdir path/to/your/tensorboard/logs`.
+
+The TensorBoard dashboard, accessible via [http://localhost:6006/](http://localhost:6006/), provides real-time insights into various training metrics. For a deeper dive into training configurations, visit our [YOLOv8 Configuration guide](../usage/cfg.md).
+
+### What kind of metrics can I visualize with TensorBoard when training YOLOv8 models?
+
+When training YOLOv8 models, TensorBoard allows you to visualize an array of important metrics including:
+
+- **Loss (Training and Validation):** Indicates how well the model is performing during training and validation.
+- **Accuracy/Precision/Recall:** Key performance metrics to evaluate detection accuracy.
+- **Learning Rate:** Track learning rate changes to understand its impact on training dynamics.
+- **mAP (mean Average Precision):** For a comprehensive evaluation of object detection accuracy at various IoU thresholds.
+
+These visualizations are essential for tracking model performance and making necessary optimizations. For more information on these metrics, refer to our [Performance Metrics guide](../guides/yolo-performance-metrics.md).
+
+### Can I use TensorBoard in a Google Colab environment for training YOLOv8?
+
+Yes, you can use TensorBoard in a Google Colab environment to train YOLOv8 models. Here's a quick setup:
+
+!!! Example "Configure TensorBoard for Google Colab"
+
+ === "Python"
+
+ ```ipython
+ %load_ext tensorboard
+ %tensorboard --logdir path/to/runs
+ ```
+
+ Then, run the YOLOv8 training script:
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a pre-trained model
+ model = YOLO("yolov8n.pt")
+
+ # Train the model
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
+ ```
+
+TensorBoard will visualize the training progress within Colab, providing real-time insights into metrics like loss and accuracy. For additional details on configuring YOLOv8 training, see our detailed [YOLOv8 Installation guide](../quickstart.md).
diff --git a/ultralytics/docs/en/integrations/tensorrt.md b/ultralytics/docs/en/integrations/tensorrt.md
new file mode 100644
index 0000000000000000000000000000000000000000..d10ff69682e256842945854f5287612f3af601fa
--- /dev/null
+++ b/ultralytics/docs/en/integrations/tensorrt.md
@@ -0,0 +1,546 @@
+---
+comments: true
+description: Learn to convert YOLOv8 models to TensorRT for high-speed NVIDIA GPU inference. Boost efficiency and deploy optimized models with our step-by-step guide.
+keywords: YOLOv8, TensorRT, NVIDIA, GPU, deep learning, model optimization, high-speed inference, model export
+---
+
+# TensorRT Export for YOLOv8 Models
+
+Deploying computer vision models in high-performance environments can require a format that maximizes speed and efficiency. This is especially true when you are deploying your model on NVIDIA GPUs.
+
+By using the TensorRT export format, you can enhance your [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics) models for swift and efficient inference on NVIDIA hardware. This guide will give you easy-to-follow steps for the conversion process and help you make the most of NVIDIA's advanced technology in your deep learning projects.
+
+## TensorRT
+
+
+
+
+
+[TensorRT](https://developer.nvidia.com/tensorrt), developed by NVIDIA, is an advanced software development kit (SDK) designed for high-speed deep learning inference. It's well-suited for real-time applications like object detection.
+
+This toolkit optimizes deep learning models for NVIDIA GPUs and results in faster and more efficient operations. TensorRT models undergo TensorRT optimization, which includes techniques like layer fusion, precision calibration (INT8 and FP16), dynamic tensor memory management, and kernel auto-tuning. Converting deep learning models into the TensorRT format allows developers to realize the potential of NVIDIA GPUs fully.
+
+TensorRT is known for its compatibility with various model formats, including TensorFlow, PyTorch, and ONNX, providing developers with a flexible solution for integrating and optimizing models from different frameworks. This versatility enables efficient model deployment across diverse hardware and software environments.
+
+## Key Features of TensorRT Models
+
+TensorRT models offer a range of key features that contribute to their efficiency and effectiveness in high-speed deep learning inference:
+
+- **Precision Calibration**: TensorRT supports precision calibration, allowing models to be fine-tuned for specific accuracy requirements. This includes support for reduced precision formats like INT8 and FP16, which can further boost inference speed while maintaining acceptable accuracy levels.
+
+- **Layer Fusion**: The TensorRT optimization process includes layer fusion, where multiple layers of a neural network are combined into a single operation. This reduces computational overhead and improves inference speed by minimizing memory access and computation.
+
+
+
+
+
+- **Dynamic Tensor Memory Management**: TensorRT efficiently manages tensor memory usage during inference, reducing memory overhead and optimizing memory allocation. This results in more efficient GPU memory utilization.
+
+- **Automatic Kernel Tuning**: TensorRT applies automatic kernel tuning to select the most optimized GPU kernel for each layer of the model. This adaptive approach ensures that the model takes full advantage of the GPU's computational power.
+
+## Deployment Options in TensorRT
+
+Before we look at the code for exporting YOLOv8 models to the TensorRT format, let's understand where TensorRT models are normally used.
+
+TensorRT offers several deployment options, and each option balances ease of integration, performance optimization, and flexibility differently:
+
+- **Deploying within TensorFlow**: This method integrates TensorRT into TensorFlow, allowing optimized models to run in a familiar TensorFlow environment. It's useful for models with a mix of supported and unsupported layers, as TF-TRT can handle these efficiently.
+
+
+
+
+
+- **Standalone TensorRT Runtime API**: Offers granular control, ideal for performance-critical applications. It's more complex but allows for custom implementation of unsupported operators.
+
+- **NVIDIA Triton Inference Server**: An option that supports models from various frameworks. Particularly suited for cloud or edge inference, it provides features like concurrent model execution and model analysis.
+
+## Exporting YOLOv8 Models to TensorRT
+
+You can improve execution efficiency and optimize performance by converting YOLOv8 models to TensorRT format.
+
+### Installation
+
+To install the required package, run:
+
+!!! Tip "Installation"
+
+ === "CLI"
+
+ ```bash
+ # Install the required package for YOLOv8
+ pip install ultralytics
+ ```
+
+For detailed instructions and best practices related to the installation process, check our [YOLOv8 Installation guide](../quickstart.md). While installing the required packages for YOLOv8, if you encounter any difficulties, consult our [Common Issues guide](../guides/yolo-common-issues.md) for solutions and tips.
+
+### Usage
+
+Before diving into the usage instructions, be sure to check out the range of [YOLOv8 models offered by Ultralytics](../models/index.md). This will help you choose the most appropriate model for your project requirements.
+
+!!! Example "Usage"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load the YOLOv8 model
+ model = YOLO("yolov8n.pt")
+
+ # Export the model to TensorRT format
+ model.export(format="engine") # creates 'yolov8n.engine'
+
+ # Load the exported TensorRT model
+ tensorrt_model = YOLO("yolov8n.engine")
+
+ # Run inference
+ results = tensorrt_model("https://ultralytics.com/images/bus.jpg")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Export a YOLOv8n PyTorch model to TensorRT format
+ yolo export model=yolov8n.pt format=engine # creates 'yolov8n.engine''
+
+ # Run inference with the exported model
+ yolo predict model=yolov8n.engine source='https://ultralytics.com/images/bus.jpg'
+ ```
+
+For more details about the export process, visit the [Ultralytics documentation page on exporting](../modes/export.md).
+
+### Exporting TensorRT with INT8 Quantization
+
+Exporting Ultralytics YOLO models using TensorRT with INT8 precision executes post-training quantization (PTQ). TensorRT uses calibration for PTQ, which measures the distribution of activations within each activation tensor as the YOLO model processes inference on representative input data, and then uses that distribution to estimate scale values for each tensor. Each activation tensor that is a candidate for quantization has an associated scale that is deduced by a calibration process.
+
+When processing implicitly quantized networks TensorRT uses INT8 opportunistically to optimize layer execution time. If a layer runs faster in INT8 and has assigned quantization scales on its data inputs and outputs, then a kernel with INT8 precision is assigned to that layer, otherwise TensorRT selects a precision of either FP32 or FP16 for the kernel based on whichever results in faster execution time for that layer.
+
+!!! tip
+
+ It is **critical** to ensure that the same device that will use the TensorRT model weights for deployment is used for exporting with INT8 precision, as the calibration results can vary across devices.
+
+#### Configuring INT8 Export
+
+The arguments provided when using [export](../modes/export.md) for an Ultralytics YOLO model will **greatly** influence the performance of the exported model. They will also need to be selected based on the device resources available, however the default arguments _should_ work for most [Ampere (or newer) NVIDIA discrete GPUs](https://developer.nvidia.com/blog/nvidia-ampere-architecture-in-depth/). The calibration algorithm used is `"ENTROPY_CALIBRATION_2"` and you can read more details about the options available [in the TensorRT Developer Guide](https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#enable_int8_c). Ultralytics tests found that `"ENTROPY_CALIBRATION_2"` was the best choice and exports are fixed to using this algorithm.
+
+- `workspace` : Controls the size (in GiB) of the device memory allocation while converting the model weights.
+
+ - Adjust the `workspace` value according to your calibration needs and resource availability. While a larger `workspace` may increase calibration time, it allows TensorRT to explore a wider range of optimization tactics, potentially enhancing model performance and accuracy. Conversely, a smaller `workspace` can reduce calibration time but may limit the optimization strategies, affecting the quality of the quantized model.
+
+ - Default is `workspace=4` (GiB), this value may need to be increased if calibration crashes (exits without warning).
+
+ - TensorRT will report `UNSUPPORTED_STATE` during export if the value for `workspace` is larger than the memory available to the device, which means the value for `workspace` should be lowered.
+
+ - If `workspace` is set to max value and calibration fails/crashes, consider reducing the values for `imgsz` and `batch` to reduce memory requirements.
+
+ - Remember calibration for INT8 is specific to each device, borrowing a "high-end" GPU for calibration, might result in poor performance when inference is run on another device.
+
+- `batch` : The maximum batch-size that will be used for inference. During inference smaller batches can be used, but inference will not accept batches any larger than what is specified.
+
+!!! note
+
+ During calibration, twice the `batch` size provided will be used. Using small batches can lead to inaccurate scaling during calibration. This is because the process adjusts based on the data it sees. Small batches might not capture the full range of values, leading to issues with the final calibration, so the `batch` size is doubled automatically. If no batch size is specified `batch=1`, calibration will be run at `batch=1 * 2` to reduce calibration scaling errors.
+
+Experimentation by NVIDIA led them to recommend using at least 500 calibration images that are representative of the data for your model, with INT8 quantization calibration. This is a guideline and not a _hard_ requirement, and **you will need to experiment with what is required to perform well for your dataset**. Since the calibration data is required for INT8 calibration with TensorRT, make certain to use the `data` argument when `int8=True` for TensorRT and use `data="my_dataset.yaml"`, which will use the images from [validation](../modes/val.md) to calibrate with. When no value is passed for `data` with export to TensorRT with INT8 quantization, the default will be to use one of the ["small" example datasets based on the model task](../datasets/index.md) instead of throwing an error.
+
+!!! example
+
+ === "Python"
+
+ ```{ .py .annotate }
+ from ultralytics import YOLO
+
+ model = YOLO("yolov8n.pt")
+ model.export(
+ format="engine",
+ dynamic=True, # (1)!
+ batch=8, # (2)!
+ workspace=4, # (3)!
+ int8=True,
+ data="coco.yaml", # (4)!
+ )
+
+ # Load the exported TensorRT INT8 model
+ model = YOLO("yolov8n.engine", task="detect")
+
+ # Run inference
+ result = model.predict("https://ultralytics.com/images/bus.jpg")
+ ```
+
+ 1. Exports with dynamic axes, this will be enabled by default when exporting with `int8=True` even when not explicitly set. See [export arguments](../modes/export.md#arguments) for additional information.
+ 2. Sets max batch size of 8 for exported model, which calibrates with `batch = 2 * 8` to avoid scaling errors during calibration.
+ 3. Allocates 4 GiB of memory instead of allocating the entire device for conversion process.
+ 4. Uses [COCO dataset](../datasets/detect/coco.md) for calibration, specifically the images used for [validation](../modes/val.md) (5,000 total).
+
+
+ === "CLI"
+
+ ```bash
+ # Export a YOLOv8n PyTorch model to TensorRT format with INT8 quantization
+ yolo export model=yolov8n.pt format=engine batch=8 workspace=4 int8=True data=coco.yaml # creates 'yolov8n.engine''
+
+ # Run inference with the exported TensorRT quantized model
+ yolo predict model=yolov8n.engine source='https://ultralytics.com/images/bus.jpg'
+ ```
+
+???+ warning "Calibration Cache"
+
+ TensorRT will generate a calibration `.cache` which can be re-used to speed up export of future model weights using the same data, but this may result in poor calibration when the data is vastly different or if the `batch` value is changed drastically. In these circumstances, the existing `.cache` should be renamed and moved to a different directory or deleted entirely.
+
+#### Advantages of using YOLO with TensorRT INT8
+
+- **Reduced model size:** Quantization from FP32 to INT8 can reduce the model size by 4x (on disk or in memory), leading to faster download times. lower storage requirements, and reduced memory footprint when deploying a model.
+
+- **Lower power consumption:** Reduced precision operations for INT8 exported YOLO models can consume less power compared to FP32 models, especially for battery-powered devices.
+
+- **Improved inference speeds:** TensorRT optimizes the model for the target hardware, potentially leading to faster inference speeds on GPUs, embedded devices, and accelerators.
+
+??? note "Note on Inference Speeds"
+
+ The first few inference calls with a model exported to TensorRT INT8 can be expected to have longer than usual preprocessing, inference, and/or postprocessing times. This may also occur when changing `imgsz` during inference, especially when `imgsz` is not the same as what was specified during export (export `imgsz` is set as TensorRT "optimal" profile).
+
+#### Drawbacks of using YOLO with TensorRT INT8
+
+- **Decreases in evaluation metrics:** Using a lower precision will mean that `mAP`, `Precision`, `Recall` or any [other metric used to evaluate model performance](../guides/yolo-performance-metrics.md) is likely to be somewhat worse. See the [Performance results section](#ultralytics-yolo-tensorrt-export-performance) to compare the differences in `mAP50` and `mAP50-95` when exporting with INT8 on small sample of various devices.
+
+- **Increased development times:** Finding the "optimal" settings for INT8 calibration for dataset and device can take a significant amount of testing.
+
+- **Hardware dependency:** Calibration and performance gains could be highly hardware dependent and model weights are less transferable.
+
+## Ultralytics YOLO TensorRT Export Performance
+
+### NVIDIA A100
+
+!!! tip "Performance"
+
+ Tested with Ubuntu 22.04.3 LTS, `python 3.10.12`, `ultralytics==8.2.4`, `tensorrt==8.6.1.post1`
+
+ === "Detection (COCO)"
+
+ See [Detection Docs](../tasks/detect.md) for usage examples with these models trained on [COCO](../datasets/detect/coco.md), which include 80 pre-trained classes.
+
+ !!! note
+ Inference times shown for `mean`, `min` (fastest), and `max` (slowest) for each test using pre-trained weights `yolov8n.engine`
+
+ | Precision | Eval test | mean (ms) | min \| max (ms) | mAPval 50(B) | mAPval 50-95(B) | `batch` | size (pixels) |
+ |-----------|--------------|--------------|--------------------|----------------------|-------------------------|---------|-----------------------|
+ | FP32 | Predict | 0.52 | 0.51 \| 0.56 | | | 8 | 640 |
+ | FP32 | COCOval | 0.52 | | 0.52 | 0.37 | 1 | 640 |
+ | FP16 | Predict | 0.34 | 0.34 \| 0.41 | | | 8 | 640 |
+ | FP16 | COCOval | 0.33 | | 0.52 | 0.37 | 1 | 640 |
+ | INT8 | Predict | 0.28 | 0.27 \| 0.31 | | | 8 | 640 |
+ | INT8 | COCOval | 0.29 | | 0.47 | 0.33 | 1 | 640 |
+
+ === "Segmentation (COCO)"
+
+ See [Segmentation Docs](../tasks/segment.md) for usage examples with these models trained on [COCO](../datasets/segment/coco.md), which include 80 pre-trained classes.
+
+ !!! note
+ Inference times shown for `mean`, `min` (fastest), and `max` (slowest) for each test using pre-trained weights `yolov8n-seg.engine`
+
+ | Precision | Eval test | mean (ms) | min \| max (ms) | mAPval 50(B) | mAPval 50-95(B) | mAPval 50(M) | mAPval 50-95(M) | `batch` | size (pixels) |
+ |-----------|--------------|--------------|--------------------|----------------------|-------------------------|----------------------|-------------------------|---------|-----------------------|
+ | FP32 | Predict | 0.62 | 0.61 \| 0.68 | | | | | 8 | 640 |
+ | FP32 | COCOval | 0.63 | | 0.52 | 0.36 | 0.49 | 0.31 | 1 | 640 |
+ | FP16 | Predict | 0.40 | 0.39 \| 0.44 | | | | | 8 | 640 |
+ | FP16 | COCOval | 0.43 | | 0.52 | 0.36 | 0.49 | 0.30 | 1 | 640 |
+ | INT8 | Predict | 0.34 | 0.33 \| 0.37 | | | | | 8 | 640 |
+ | INT8 | COCOval | 0.36 | | 0.46 | 0.32 | 0.43 | 0.27 | 1 | 640 |
+
+ === "Classification (ImageNet)"
+
+ See [Classification Docs](../tasks/classify.md) for usage examples with these models trained on [ImageNet](../datasets/classify/imagenet.md), which include 1000 pre-trained classes.
+
+ !!! note
+ Inference times shown for `mean`, `min` (fastest), and `max` (slowest) for each test using pre-trained weights `yolov8n-cls.engine`
+
+ | Precision | Eval test | mean (ms) | min \| max (ms) | top-1 | top-5 | `batch` | size (pixels) |
+ |-----------|------------------|--------------|--------------------|-------|-------|---------|-----------------------|
+ | FP32 | Predict | 0.26 | 0.25 \| 0.28 | | | 8 | 640 |
+ | FP32 | ImageNetval | 0.26 | | 0.35 | 0.61 | 1 | 640 |
+ | FP16 | Predict | 0.18 | 0.17 \| 0.19 | | | 8 | 640 |
+ | FP16 | ImageNetval | 0.18 | | 0.35 | 0.61 | 1 | 640 |
+ | INT8 | Predict | 0.16 | 0.15 \| 0.57 | | | 8 | 640 |
+ | INT8 | ImageNetval | 0.15 | | 0.32 | 0.59 | 1 | 640 |
+
+ === "Pose (COCO)"
+
+ See [Pose Estimation Docs](../tasks/pose.md) for usage examples with these models trained on [COCO](../datasets/pose/coco.md), which include 1 pre-trained class, "person".
+
+ !!! note
+ Inference times shown for `mean`, `min` (fastest), and `max` (slowest) for each test using pre-trained weights `yolov8n-pose.engine`
+
+ | Precision | Eval test | mean (ms) | min \| max (ms) | mAPval 50(B) | mAPval 50-95(B) | mAPval 50(P) | mAPval 50-95(P) | `batch` | size (pixels) |
+ |-----------|--------------|--------------|--------------------|----------------------|-------------------------|----------------------|-------------------------|---------|-----------------------|
+ | FP32 | Predict | 0.54 | 0.53 \| 0.58 | | | | | 8 | 640 |
+ | FP32 | COCOval | 0.55 | | 0.91 | 0.69 | 0.80 | 0.51 | 1 | 640 |
+ | FP16 | Predict | 0.37 | 0.35 \| 0.41 | | | | | 8 | 640 |
+ | FP16 | COCOval | 0.36 | | 0.91 | 0.69 | 0.80 | 0.51 | 1 | 640 |
+ | INT8 | Predict | 0.29 | 0.28 \| 0.33 | | | | | 8 | 640 |
+ | INT8 | COCOval | 0.30 | | 0.90 | 0.68 | 0.78 | 0.47 | 1 | 640 |
+
+ === "OBB (DOTAv1)"
+
+ See [Oriented Detection Docs](../tasks/obb.md) for usage examples with these models trained on [DOTAv1](../datasets/obb/dota-v2.md#dota-v10), which include 15 pre-trained classes.
+
+ !!! note
+ Inference times shown for `mean`, `min` (fastest), and `max` (slowest) for each test using pre-trained weights `yolov8n-obb.engine`
+
+ | Precision | Eval test | mean (ms) | min \| max (ms) | mAPval 50(B) | mAPval 50-95(B) | `batch` | size (pixels) |
+ |-----------|----------------|--------------|--------------------|----------------------|-------------------------|---------|-----------------------|
+ | FP32 | Predict | 0.52 | 0.51 \| 0.59 | | | 8 | 640 |
+ | FP32 | DOTAv1val | 0.76 | | 0.50 | 0.36 | 1 | 640 |
+ | FP16 | Predict | 0.34 | 0.33 \| 0.42 | | | 8 | 640 |
+ | FP16 | DOTAv1val | 0.59 | | 0.50 | 0.36 | 1 | 640 |
+ | INT8 | Predict | 0.29 | 0.28 \| 0.33 | | | 8 | 640 |
+ | INT8 | DOTAv1val | 0.32 | | 0.45 | 0.32 | 1 | 640 |
+
+### Consumer GPUs
+
+!!! tip "Detection Performance (COCO)"
+
+ === "RTX 3080 12 GB"
+
+ Tested with Windows 10.0.19045, `python 3.10.9`, `ultralytics==8.2.4`, `tensorrt==10.0.0b6`
+
+ !!! note
+ Inference times shown for `mean`, `min` (fastest), and `max` (slowest) for each test using pre-trained weights `yolov8n.engine`
+
+ | Precision | Eval test | mean (ms) | min \| max (ms) | mAPval 50(B) | mAPval 50-95(B) | `batch` | size (pixels) |
+ |-----------|--------------|--------------|--------------------|----------------------|-------------------------|---------|-----------------------|
+ | FP32 | Predict | 1.06 | 0.75 \| 1.88 | | | 8 | 640 |
+ | FP32 | COCOval | 1.37 | | 0.52 | 0.37 | 1 | 640 |
+ | FP16 | Predict | 0.62 | 0.75 \| 1.13 | | | 8 | 640 |
+ | FP16 | COCOval | 0.85 | | 0.52 | 0.37 | 1 | 640 |
+ | INT8 | Predict | 0.52 | 0.38 \| 1.00 | | | 8 | 640 |
+ | INT8 | COCOval | 0.74 | | 0.47 | 0.33 | 1 | 640 |
+
+ === "RTX 3060 12 GB"
+
+ Tested with Windows 10.0.22631, `python 3.11.9`, `ultralytics==8.2.4`, `tensorrt==10.0.1`
+
+ !!! note
+ Inference times shown for `mean`, `min` (fastest), and `max` (slowest) for each test using pre-trained weights `yolov8n.engine`
+
+
+ | Precision | Eval test | mean (ms) | min \| max (ms) | mAPval 50(B) | mAPval 50-95(B) | `batch` | size (pixels) |
+ |-----------|--------------|--------------|--------------------|----------------------|-------------------------|---------|-----------------------|
+ | FP32 | Predict | 1.76 | 1.69 \| 1.87 | | | 8 | 640 |
+ | FP32 | COCOval | 1.94 | | 0.52 | 0.37 | 1 | 640 |
+ | FP16 | Predict | 0.86 | 0.75 \| 1.00 | | | 8 | 640 |
+ | FP16 | COCOval | 1.43 | | 0.52 | 0.37 | 1 | 640 |
+ | INT8 | Predict | 0.80 | 0.75 \| 1.00 | | | 8 | 640 |
+ | INT8 | COCOval | 1.35 | | 0.47 | 0.33 | 1 | 640 |
+
+ === "RTX 2060 6 GB"
+
+ Tested with Pop!_OS 22.04 LTS, `python 3.10.12`, `ultralytics==8.2.4`, `tensorrt==8.6.1.post1`
+
+ !!! note
+ Inference times shown for `mean`, `min` (fastest), and `max` (slowest) for each test using pre-trained weights `yolov8n.engine`
+
+ | Precision | Eval test | mean (ms) | min \| max (ms) | mAPval 50(B) | mAPval 50-95(B) | `batch` | size (pixels) |
+ |-----------|--------------|--------------|--------------------|----------------------|-------------------------|---------|-----------------------|
+ | FP32 | Predict | 2.84 | 2.84 \| 2.85 | | | 8 | 640 |
+ | FP32 | COCOval | 2.94 | | 0.52 | 0.37 | 1 | 640 |
+ | FP16 | Predict | 1.09 | 1.09 \| 1.10 | | | 8 | 640 |
+ | FP16 | COCOval | 1.20 | | 0.52 | 0.37 | 1 | 640 |
+ | INT8 | Predict | 0.75 | 0.74 \| 0.75 | | | 8 | 640 |
+ | INT8 | COCOval | 0.76 | | 0.47 | 0.33 | 1 | 640 |
+
+### Embedded Devices
+
+!!! tip "Detection Performance (COCO)"
+
+ === "Jetson Orin NX 16GB"
+
+ Tested with JetPack 6.0 (L4T 36.3) Ubuntu 22.04.4 LTS, `python 3.10.12`, `ultralytics==8.2.16`, `tensorrt==10.0.1`
+
+ !!! note
+ Inference times shown for `mean`, `min` (fastest), and `max` (slowest) for each test using pre-trained weights `yolov8n.engine`
+
+ | Precision | Eval test | mean (ms) | min \| max (ms) | mAPval 50(B) | mAPval 50-95(B) | `batch` | size (pixels) |
+ |-----------|--------------|--------------|--------------------|----------------------|-------------------------|---------|-----------------------|
+ | FP32 | Predict | 6.11 | 6.10 \| 6.29 | | | 8 | 640 |
+ | FP32 | COCOval | 6.17 | | 0.52 | 0.37 | 1 | 640 |
+ | FP16 | Predict | 3.18 | 3.18 \| 3.20 | | | 8 | 640 |
+ | FP16 | COCOval | 3.19 | | 0.52 | 0.37 | 1 | 640 |
+ | INT8 | Predict | 2.30 | 2.29 \| 2.35 | | | 8 | 640 |
+ | INT8 | COCOval | 2.32 | | 0.46 | 0.32 | 1 | 640 |
+
+!!! info
+
+ See our [quickstart guide on NVIDIA Jetson with Ultralytics YOLO](../guides/nvidia-jetson.md) to learn more about setup and configuration.
+
+#### Evaluation methods
+
+Expand sections below for information on how these models were exported and tested.
+
+??? example "Export configurations"
+
+ See [export mode](../modes/export.md) for details regarding export configuration arguments.
+
+ ```py
+ from ultralytics import YOLO
+
+ model = YOLO("yolov8n.pt")
+
+ # TensorRT FP32
+ out = model.export(format="engine", imgsz=640, dynamic=True, verbose=False, batch=8, workspace=2)
+
+ # TensorRT FP16
+ out = model.export(format="engine", imgsz=640, dynamic=True, verbose=False, batch=8, workspace=2, half=True)
+
+ # TensorRT INT8 with calibration `data` (i.e. COCO, ImageNet, or DOTAv1 for appropriate model task)
+ out = model.export(
+ format="engine", imgsz=640, dynamic=True, verbose=False, batch=8, workspace=2, int8=True, data="coco8.yaml"
+ )
+ ```
+
+??? example "Predict loop"
+
+ See [predict mode](../modes/predict.md) for additional information.
+
+ ```py
+ import cv2
+
+ from ultralytics import YOLO
+
+ model = YOLO("yolov8n.engine")
+ img = cv2.imread("path/to/image.jpg")
+
+ for _ in range(100):
+ result = model.predict(
+ [img] * 8, # batch=8 of the same image
+ verbose=False,
+ device="cuda",
+ )
+ ```
+
+??? example "Validation configuration"
+
+ See [`val` mode](../modes/val.md) to learn more about validation configuration arguments.
+
+ ```py
+ from ultralytics import YOLO
+
+ model = YOLO("yolov8n.engine")
+ results = model.val(
+ data="data.yaml", # COCO, ImageNet, or DOTAv1 for appropriate model task
+ batch=1,
+ imgsz=640,
+ verbose=False,
+ device="cuda",
+ )
+ ```
+
+## Deploying Exported YOLOv8 TensorRT Models
+
+Having successfully exported your Ultralytics YOLOv8 models to TensorRT format, you're now ready to deploy them. For in-depth instructions on deploying your TensorRT models in various settings, take a look at the following resources:
+
+- **[Deploy Ultralytics with a Triton Server](../guides/triton-inference-server.md)**: Our guide on how to use NVIDIA's Triton Inference (formerly TensorRT Inference) Server specifically for use with Ultralytics YOLO models.
+
+- **[Deploying Deep Neural Networks with NVIDIA TensorRT](https://developer.nvidia.com/blog/deploying-deep-learning-nvidia-tensorrt/)**: This article explains how to use NVIDIA TensorRT to deploy deep neural networks on GPU-based deployment platforms efficiently.
+
+- **[End-to-End AI for NVIDIA-Based PCs: NVIDIA TensorRT Deployment](https://developer.nvidia.com/blog/end-to-end-ai-for-nvidia-based-pcs-nvidia-tensorrt-deployment/)**: This blog post explains the use of NVIDIA TensorRT for optimizing and deploying AI models on NVIDIA-based PCs.
+
+- **[GitHub Repository for NVIDIA TensorRT:](https://github.com/NVIDIA/TensorRT)**: This is the official GitHub repository that contains the source code and documentation for NVIDIA TensorRT.
+
+## Summary
+
+In this guide, we focused on converting Ultralytics YOLOv8 models to NVIDIA's TensorRT model format. This conversion step is crucial for improving the efficiency and speed of YOLOv8 models, making them more effective and suitable for diverse deployment environments.
+
+For more information on usage details, take a look at the [TensorRT official documentation](https://docs.nvidia.com/deeplearning/tensorrt/).
+
+If you're curious about additional Ultralytics YOLOv8 integrations, our [integration guide page](../integrations/index.md) provides an extensive selection of informative resources and insights.
+
+## FAQ
+
+### How do I convert YOLOv8 models to TensorRT format?
+
+To convert your Ultralytics YOLOv8 models to TensorRT format for optimized NVIDIA GPU inference, follow these steps:
+
+1. **Install the required package**:
+
+ ```bash
+ pip install ultralytics
+ ```
+
+2. **Export your YOLOv8 model**:
+
+ ```python
+ from ultralytics import YOLO
+
+ model = YOLO("yolov8n.pt")
+ model.export(format="engine") # creates 'yolov8n.engine'
+
+ # Run inference
+ model = YOLO("yolov8n.engine")
+ results = model("https://ultralytics.com/images/bus.jpg")
+ ```
+
+For more details, visit the [YOLOv8 Installation guide](../quickstart.md) and the [export documentation](../modes/export.md).
+
+### What are the benefits of using TensorRT for YOLOv8 models?
+
+Using TensorRT to optimize YOLOv8 models offers several benefits:
+
+- **Faster Inference Speed**: TensorRT optimizes the model layers and uses precision calibration (INT8 and FP16) to speed up inference without significantly sacrificing accuracy.
+- **Memory Efficiency**: TensorRT manages tensor memory dynamically, reducing overhead and improving GPU memory utilization.
+- **Layer Fusion**: Combines multiple layers into single operations, reducing computational complexity.
+- **Kernel Auto-Tuning**: Automatically selects optimized GPU kernels for each model layer, ensuring maximum performance.
+
+For more information, explore the detailed features of TensorRT [here](https://developer.nvidia.com/tensorrt) and read our [TensorRT overview section](#tensorrt).
+
+### Can I use INT8 quantization with TensorRT for YOLOv8 models?
+
+Yes, you can export YOLOv8 models using TensorRT with INT8 quantization. This process involves post-training quantization (PTQ) and calibration:
+
+1. **Export with INT8**:
+
+ ```python
+ from ultralytics import YOLO
+
+ model = YOLO("yolov8n.pt")
+ model.export(format="engine", batch=8, workspace=4, int8=True, data="coco.yaml")
+ ```
+
+2. **Run inference**:
+
+ ```python
+ from ultralytics import YOLO
+
+ model = YOLO("yolov8n.engine", task="detect")
+ result = model.predict("https://ultralytics.com/images/bus.jpg")
+ ```
+
+For more details, refer to the [exporting TensorRT with INT8 quantization section](#exporting-tensorrt-with-int8-quantization).
+
+### How do I deploy YOLOv8 TensorRT models on an NVIDIA Triton Inference Server?
+
+Deploying YOLOv8 TensorRT models on an NVIDIA Triton Inference Server can be done using the following resources:
+
+- **[Deploy Ultralytics YOLOv8 with Triton Server](../guides/triton-inference-server.md)**: Step-by-step guidance on setting up and using Triton Inference Server.
+- **[NVIDIA Triton Inference Server Documentation](https://developer.nvidia.com/blog/deploying-deep-learning-nvidia-tensorrt/)**: Official NVIDIA documentation for detailed deployment options and configurations.
+
+These guides will help you integrate YOLOv8 models efficiently in various deployment environments.
+
+### What are the performance improvements observed with YOLOv8 models exported to TensorRT?
+
+Performance improvements with TensorRT can vary based on the hardware used. Here are some typical benchmarks:
+
+- **NVIDIA A100**:
+
+ - **FP32** Inference: ~0.52 ms / image
+ - **FP16** Inference: ~0.34 ms / image
+ - **INT8** Inference: ~0.28 ms / image
+ - Slight reduction in mAP with INT8 precision, but significant improvement in speed.
+
+- **Consumer GPUs (e.g., RTX 3080)**:
+ - **FP32** Inference: ~1.06 ms / image
+ - **FP16** Inference: ~0.62 ms / image
+ - **INT8** Inference: ~0.52 ms / image
+
+Detailed performance benchmarks for different hardware configurations can be found in the [performance section](#ultralytics-yolo-tensorrt-export-performance).
+
+For more comprehensive insights into TensorRT performance, refer to the [Ultralytics documentation](../modes/export.md) and our performance analysis reports.
diff --git a/ultralytics/docs/en/integrations/tf-graphdef.md b/ultralytics/docs/en/integrations/tf-graphdef.md
new file mode 100644
index 0000000000000000000000000000000000000000..c0f39667f57574115d498ed5806a40671798d610
--- /dev/null
+++ b/ultralytics/docs/en/integrations/tf-graphdef.md
@@ -0,0 +1,204 @@
+---
+comments: true
+description: Learn how to export YOLOv8 models to the TF GraphDef format for seamless deployment on various platforms, including mobile and web.
+keywords: YOLOv8, export, TensorFlow, GraphDef, model deployment, TensorFlow Serving, TensorFlow Lite, TensorFlow.js, machine learning, AI, computer vision
+---
+
+# How to Export to TF GraphDef from YOLOv8 for Deployment
+
+When you are deploying cutting-edge computer vision models, like YOLOv8, in different environments, you might run into compatibility issues. Google's TensorFlow GraphDef, or TF GraphDef, offers a solution by providing a serialized, platform-independent representation of your model. Using the TF GraphDef model format, you can deploy your YOLOv8 model in environments where the complete TensorFlow ecosystem may not be available, such as mobile devices or specialized hardware.
+
+In this guide, we'll walk you step by step through how to export your [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics) models to the TF GraphDef model format. By converting your model, you can streamline deployment and use YOLOv8's computer vision capabilities in a broader range of applications and platforms.
+
+
+
+
+
+## Why Should You Export to TF GraphDef?
+
+TF GraphDef is a powerful component of the TensorFlow ecosystem that was developed by Google. It can be used to optimize and deploy models like YOLOv8. Exporting to TF GraphDef lets us move models from research to real-world applications. It allows models to run in environments without the full TensorFlow framework.
+
+The GraphDef format represents the model as a serialized computation graph. This enables various optimization techniques like constant folding, quantization, and graph transformations. These optimizations ensure efficient execution, reduced memory usage, and faster inference speeds.
+
+GraphDef models can use hardware accelerators such as GPUs, TPUs, and AI chips, unlocking significant performance gains for the YOLOv8 inference pipeline. The TF GraphDef format creates a self-contained package with the model and its dependencies, simplifying deployment and integration into diverse systems.
+
+## Key Features of TF GraphDef Models
+
+TF GraphDef offers distinct features for streamlining model deployment and optimization.
+
+Here's a look at its key characteristics:
+
+- **Model Serialization**: TF GraphDef provides a way to serialize and store TensorFlow models in a platform-independent format. This serialized representation allows you to load and execute your models without the original Python codebase, making deployment easier.
+
+- **Graph Optimization**: TF GraphDef enables the optimization of computational graphs. These optimizations can boost performance by streamlining execution flow, reducing redundancies, and tailoring operations to suit specific hardware.
+
+- **Deployment Flexibility**: Models exported to the GraphDef format can be used in various environments, including resource-constrained devices, web browsers, and systems with specialized hardware. This opens up possibilities for wider deployment of your TensorFlow models.
+
+- **Production Focus**: GraphDef is designed for production deployment. It supports efficient execution, serialization features, and optimizations that align with real-world use cases.
+
+## Deployment Options with TF GraphDef
+
+Before we dive into the process of exporting YOLOv8 models to TF GraphDef, let's take a look at some typical deployment situations where this format is used.
+
+Here's how you can deploy with TF GraphDef efficiently across various platforms.
+
+- **TensorFlow Serving:** This framework is designed to deploy TensorFlow models in production environments. TensorFlow Serving offers model management, versioning, and the infrastructure for efficient model serving at scale. It's a seamless way to integrate your GraphDef-based models into production web services or APIs.
+
+- **Mobile and Embedded Devices:** With tools like TensorFlow Lite, you can convert TF GraphDef models into formats optimized for smartphones, tablets, and various embedded devices. Your models can then be used for on-device inference, where execution is done locally, often providing performance gains and offline capabilities.
+
+- **Web Browsers:** TensorFlow.js enables the deployment of TF GraphDef models directly within web browsers. It paves the way for real-time object detection applications running on the client side, using the capabilities of YOLOv8 through JavaScript.
+
+- **Specialized Hardware:** TF GraphDef's platform-agnostic nature allows it to target custom hardware, such as accelerators and TPUs (Tensor Processing Units). These devices can provide performance advantages for computationally intensive models.
+
+## Exporting YOLOv8 Models to TF GraphDef
+
+You can convert your YOLOv8 object detection model to the TF GraphDef format, which is compatible with various systems, to improve its performance across platforms.
+
+### Installation
+
+To install the required package, run:
+
+!!! Tip "Installation"
+
+ === "CLI"
+
+ ```bash
+ # Install the required package for YOLOv8
+ pip install ultralytics
+ ```
+
+For detailed instructions and best practices related to the installation process, check our [Ultralytics Installation guide](../quickstart.md). While installing the required packages for YOLOv8, if you encounter any difficulties, consult our [Common Issues guide](../guides/yolo-common-issues.md) for solutions and tips.
+
+### Usage
+
+Before diving into the usage instructions, it's important to note that while all [Ultralytics YOLOv8 models](../models/index.md) are available for exporting, you can ensure that the model you select supports export functionality [here](../modes/export.md).
+
+!!! Example "Usage"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load the YOLOv8 model
+ model = YOLO("yolov8n.pt")
+
+ # Export the model to TF GraphDef format
+ model.export(format="pb") # creates 'yolov8n.pb'
+
+ # Load the exported TF GraphDef model
+ tf_graphdef_model = YOLO("yolov8n.pb")
+
+ # Run inference
+ results = tf_graphdef_model("https://ultralytics.com/images/bus.jpg")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Export a YOLOv8n PyTorch model to TF GraphDef format
+ yolo export model=yolov8n.pt format=pb # creates 'yolov8n.pb'
+
+ # Run inference with the exported model
+ yolo predict model='yolov8n.pb' source='https://ultralytics.com/images/bus.jpg'
+ ```
+
+For more details about supported export options, visit the [Ultralytics documentation page on deployment options](../guides/model-deployment-options.md).
+
+## Deploying Exported YOLOv8 TF GraphDef Models
+
+Once you've exported your YOLOv8 model to the TF GraphDef format, the next step is deployment. The primary and recommended first step for running a TF GraphDef model is to use the YOLO("model.pb") method, as previously shown in the usage code snippet.
+
+However, for more information on deploying your TF GraphDef models, take a look at the following resources:
+
+- **[TensorFlow Serving](https://www.tensorflow.org/tfx/guide/serving)**: A guide on TensorFlow Serving that teaches how to deploy and serve machine learning models efficiently in production environments.
+
+- **[TensorFlow Lite](https://www.tensorflow.org/api_docs/python/tf/lite/TFLiteConverter)**: This page describes how to convert machine learning models into a format optimized for on-device inference with TensorFlow Lite.
+
+- **[TensorFlow.js](https://www.tensorflow.org/js/guide/conversion)**: A guide on model conversion that teaches how to convert TensorFlow or Keras models into TensorFlow.js format for use in web applications.
+
+## Summary
+
+In this guide, we explored how to export Ultralytics YOLOv8 models to the TF GraphDef format. By doing this, you can flexibly deploy your optimized YOLOv8 models in different environments.
+
+For further details on usage, visit the [TF GraphDef official documentation](https://www.tensorflow.org/api_docs/python/tf/Graph).
+
+For more information on integrating Ultralytics YOLOv8 with other platforms and frameworks, don't forget to check out our [integration guide page](index.md). It has great resources and insights to help you make the most of YOLOv8 in your projects.
+
+## FAQ
+
+### How do I export a YOLOv8 model to TF GraphDef format?
+
+Ultralytics YOLOv8 models can be exported to TensorFlow GraphDef (TF GraphDef) format seamlessly. This format provides a serialized, platform-independent representation of the model, ideal for deploying in varied environments like mobile and web. To export a YOLOv8 model to TF GraphDef, follow these steps:
+
+!!! Example "Usage"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load the YOLOv8 model
+ model = YOLO("yolov8n.pt")
+
+ # Export the model to TF GraphDef format
+ model.export(format="pb") # creates 'yolov8n.pb'
+
+ # Load the exported TF GraphDef model
+ tf_graphdef_model = YOLO("yolov8n.pb")
+
+ # Run inference
+ results = tf_graphdef_model("https://ultralytics.com/images/bus.jpg")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Export a YOLOv8n PyTorch model to TF GraphDef format
+ yolo export model="yolov8n.pt" format="pb" # creates 'yolov8n.pb'
+
+ # Run inference with the exported model
+ yolo predict model="yolov8n.pb" source="https://ultralytics.com/images/bus.jpg"
+ ```
+
+For more information on different export options, visit the [Ultralytics documentation on model export](../modes/export.md).
+
+### What are the benefits of using TF GraphDef for YOLOv8 model deployment?
+
+Exporting YOLOv8 models to the TF GraphDef format offers multiple advantages, including:
+
+1. **Platform Independence**: TF GraphDef provides a platform-independent format, allowing models to be deployed across various environments including mobile and web browsers.
+2. **Optimizations**: The format enables several optimizations, such as constant folding, quantization, and graph transformations, which enhance execution efficiency and reduce memory usage.
+3. **Hardware Acceleration**: Models in TF GraphDef format can leverage hardware accelerators like GPUs, TPUs, and AI chips for performance gains.
+
+Read more about the benefits in the [TF GraphDef section](#why-should-you-export-to-tf-graphdef) of our documentation.
+
+### Why should I use Ultralytics YOLOv8 over other object detection models?
+
+Ultralytics YOLOv8 offers numerous advantages compared to other models like YOLOv5 and YOLOv7. Some key benefits include:
+
+1. **State-of-the-Art Performance**: YOLOv8 provides exceptional speed and accuracy for real-time object detection, segmentation, and classification.
+2. **Ease of Use**: Features a user-friendly API for model training, validation, prediction, and export, making it accessible for both beginners and experts.
+3. **Broad Compatibility**: Supports multiple export formats including ONNX, TensorRT, CoreML, and TensorFlow, for versatile deployment options.
+
+Explore further details in our [introduction to YOLOv8](https://docs.ultralytics.com/models/yolov8/).
+
+### How can I deploy a YOLOv8 model on specialized hardware using TF GraphDef?
+
+Once a YOLOv8 model is exported to TF GraphDef format, you can deploy it across various specialized hardware platforms. Typical deployment scenarios include:
+
+- **TensorFlow Serving**: Use TensorFlow Serving for scalable model deployment in production environments. It supports model management and efficient serving.
+- **Mobile Devices**: Convert TF GraphDef models to TensorFlow Lite, optimized for mobile and embedded devices, enabling on-device inference.
+- **Web Browsers**: Deploy models using TensorFlow.js for client-side inference in web applications.
+- **AI Accelerators**: Leverage TPUs and custom AI chips for accelerated inference.
+
+Check the [deployment options](#deployment-options-with-tf-graphdef) section for detailed information.
+
+### Where can I find solutions for common issues while exporting YOLOv8 models?
+
+For troubleshooting common issues with exporting YOLOv8 models, Ultralytics provides comprehensive guides and resources. If you encounter problems during installation or model export, refer to:
+
+- **[Common Issues Guide](../guides/yolo-common-issues.md)**: Offers solutions to frequently faced problems.
+- **[Installation Guide](../quickstart.md)**: Step-by-step instructions for setting up the required packages.
+
+These resources should help you resolve most issues related to YOLOv8 model export and deployment.
diff --git a/ultralytics/docs/en/integrations/tf-savedmodel.md b/ultralytics/docs/en/integrations/tf-savedmodel.md
new file mode 100644
index 0000000000000000000000000000000000000000..223e713be0042971db2aa68ad8ecbdf09be28c23
--- /dev/null
+++ b/ultralytics/docs/en/integrations/tf-savedmodel.md
@@ -0,0 +1,197 @@
+---
+comments: true
+description: Learn how to export Ultralytics YOLOv8 models to TensorFlow SavedModel format for easy deployment across various platforms and environments.
+keywords: YOLOv8, TF SavedModel, Ultralytics, TensorFlow, model export, model deployment, machine learning, AI
+---
+
+# Understand How to Export to TF SavedModel Format From YOLOv8
+
+Deploying machine learning models can be challenging. However, using an efficient and flexible model format can make your job easier. TF SavedModel is an open-source machine-learning framework used by TensorFlow to load machine-learning models in a consistent way. It is like a suitcase for TensorFlow models, making them easy to carry and use on different devices and systems.
+
+Learning how to export to TF SavedModel from [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics) models can help you deploy models easily across different platforms and environments. In this guide, we'll walk through how to convert your models to the TF SavedModel format, simplifying the process of running inferences with your models on different devices.
+
+## Why Should You Export to TF SavedModel?
+
+The TensorFlow SavedModel format is a part of the TensorFlow ecosystem developed by Google as shown below. It is designed to save and serialize TensorFlow models seamlessly. It encapsulates the complete details of models like the architecture, weights, and even compilation information. This makes it straightforward to share, deploy, and continue training across different environments.
+
+
+
+
+
+The TF SavedModel has a key advantage: its compatibility. It works well with TensorFlow Serving, TensorFlow Lite, and TensorFlow.js. This compatibility makes it easier to share and deploy models across various platforms, including web and mobile applications. The TF SavedModel format is useful both for research and production. It provides a unified way to manage your models, ensuring they are ready for any application.
+
+## Key Features of TF SavedModels
+
+Here are the key features that make TF SavedModel a great option for AI developers:
+
+- **Portability**: TF SavedModel provides a language-neutral, recoverable, hermetic serialization format. They enable higher-level systems and tools to produce, consume, and transform TensorFlow models. SavedModels can be easily shared and deployed across different platforms and environments.
+
+- **Ease of Deployment**: TF SavedModel bundles the computational graph, trained parameters, and necessary metadata into a single package. They can be easily loaded and used for inference without requiring the original code that built the model. This makes the deployment of TensorFlow models straightforward and efficient in various production environments.
+
+- **Asset Management**: TF SavedModel supports the inclusion of external assets such as vocabularies, embeddings, or lookup tables. These assets are stored alongside the graph definition and variables, ensuring they are available when the model is loaded. This feature simplifies the management and distribution of models that rely on external resources.
+
+## Deployment Options with TF SavedModel
+
+Before we dive into the process of exporting YOLOv8 models to the TF SavedModel format, let's explore some typical deployment scenarios where this format is used.
+
+TF SavedModel provides a range of options to deploy your machine learning models:
+
+- **TensorFlow Serving:** TensorFlow Serving is a flexible, high-performance serving system designed for production environments. It natively supports TF SavedModels, making it easy to deploy and serve your models on cloud platforms, on-premises servers, or edge devices.
+
+- **Cloud Platforms:** Major cloud providers like Google Cloud Platform (GCP), Amazon Web Services (AWS), and Microsoft Azure offer services for deploying and running TensorFlow models, including TF SavedModels. These services provide scalable and managed infrastructure, allowing you to deploy and scale your models easily.
+
+- **Mobile and Embedded Devices:** TensorFlow Lite, a lightweight solution for running machine learning models on mobile, embedded, and IoT devices, supports converting TF SavedModels to the TensorFlow Lite format. This allows you to deploy your models on a wide range of devices, from smartphones and tablets to microcontrollers and edge devices.
+
+- **TensorFlow Runtime:** TensorFlow Runtime (`tfrt`) is a high-performance runtime for executing TensorFlow graphs. It provides lower-level APIs for loading and running TF SavedModels in C++ environments. TensorFlow Runtime offers better performance compared to the standard TensorFlow runtime. It is suitable for deployment scenarios that require low-latency inference and tight integration with existing C++ codebases.
+
+## Exporting YOLOv8 Models to TF SavedModel
+
+By exporting YOLOv8 models to the TF SavedModel format, you enhance their adaptability and ease of deployment across various platforms.
+
+### Installation
+
+To install the required package, run:
+
+!!! Tip "Installation"
+
+ === "CLI"
+
+ ```bash
+ # Install the required package for YOLOv8
+ pip install ultralytics
+ ```
+
+For detailed instructions and best practices related to the installation process, check our [Ultralytics Installation guide](../quickstart.md). While installing the required packages for YOLOv8, if you encounter any difficulties, consult our [Common Issues guide](../guides/yolo-common-issues.md) for solutions and tips.
+
+### Usage
+
+Before diving into the usage instructions, it's important to note that while all [Ultralytics YOLOv8 models](../models/index.md) are available for exporting, you can ensure that the model you select supports export functionality [here](../modes/export.md).
+
+!!! Example "Usage"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load the YOLOv8 model
+ model = YOLO("yolov8n.pt")
+
+ # Export the model to TF SavedModel format
+ model.export(format="saved_model") # creates '/yolov8n_saved_model'
+
+ # Load the exported TF SavedModel model
+ tf_savedmodel_model = YOLO("./yolov8n_saved_model")
+
+ # Run inference
+ results = tf_savedmodel_model("https://ultralytics.com/images/bus.jpg")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Export a YOLOv8n PyTorch model to TF SavedModel format
+ yolo export model=yolov8n.pt format=saved_model # creates '/yolov8n_saved_model'
+
+ # Run inference with the exported model
+ yolo predict model='./yolov8n_saved_model' source='https://ultralytics.com/images/bus.jpg'
+ ```
+
+For more details about supported export options, visit the [Ultralytics documentation page on deployment options](../guides/model-deployment-options.md).
+
+## Deploying Exported YOLOv8 TF SavedModel Models
+
+Now that you have exported your YOLOv8 model to the TF SavedModel format, the next step is to deploy it. The primary and recommended first step for running a TF GraphDef model is to use the YOLO("./yolov8n_saved_model") method, as previously shown in the usage code snippet.
+
+However, for in-depth instructions on deploying your TF SavedModel models, take a look at the following resources:
+
+- **[TensorFlow Serving](https://www.tensorflow.org/tfx/guide/serving)**: Here's the developer documentation for how to deploy your TF SavedModel models using TensorFlow Serving.
+
+- **[Run a TensorFlow SavedModel in Node.js](https://blog.tensorflow.org/2020/01/run-tensorflow-savedmodel-in-nodejs-directly-without-conversion.html)**: A TensorFlow blog post on running a TensorFlow SavedModel in Node.js directly without conversion.
+
+- **[Deploying on Cloud](https://blog.tensorflow.org/2020/04/how-to-deploy-tensorflow-2-models-on-cloud-ai-platform.html)**: A TensorFlow blog post on deploying a TensorFlow SavedModel model on the Cloud AI Platform.
+
+## Summary
+
+In this guide, we explored how to export Ultralytics YOLOv8 models to the TF SavedModel format. By exporting to TF SavedModel, you gain the flexibility to optimize, deploy, and scale your YOLOv8 models on a wide range of platforms.
+
+For further details on usage, visit the [TF SavedModel official documentation](https://www.tensorflow.org/guide/saved_model).
+
+For more information on integrating Ultralytics YOLOv8 with other platforms and frameworks, don't forget to check out our [integration guide page](index.md). It's packed with great resources to help you make the most of YOLOv8 in your projects.
+
+## FAQ
+
+### How do I export an Ultralytics YOLO model to TensorFlow SavedModel format?
+
+Exporting an Ultralytics YOLO model to the TensorFlow SavedModel format is straightforward. You can use either Python or CLI to achieve this:
+
+!!! Example "Exporting YOLOv8 to TF SavedModel"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load the YOLOv8 model
+ model = YOLO("yolov8n.pt")
+
+ # Export the model to TF SavedModel format
+ model.export(format="saved_model") # creates '/yolov8n_saved_model'
+
+ # Load the exported TF SavedModel for inference
+ tf_savedmodel_model = YOLO("./yolov8n_saved_model")
+ results = tf_savedmodel_model("https://ultralytics.com/images/bus.jpg")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Export the YOLOv8 model to TF SavedModel format
+ yolo export model=yolov8n.pt format=saved_model # creates '/yolov8n_saved_model'
+
+ # Run inference with the exported model
+ yolo predict model='./yolov8n_saved_model' source='https://ultralytics.com/images/bus.jpg'
+ ```
+
+Refer to the [Ultralytics Export documentation](../modes/export.md) for more details.
+
+### Why should I use the TensorFlow SavedModel format?
+
+The TensorFlow SavedModel format offers several advantages for model deployment:
+
+- **Portability:** It provides a language-neutral format, making it easy to share and deploy models across different environments.
+- **Compatibility:** Integrates seamlessly with tools like TensorFlow Serving, TensorFlow Lite, and TensorFlow.js, which are essential for deploying models on various platforms, including web and mobile applications.
+- **Complete encapsulation:** Encodes the model architecture, weights, and compilation information, allowing for straightforward sharing and training continuation.
+
+For more benefits and deployment options, check out the [Ultralytics YOLO model deployment options](../guides/model-deployment-options.md).
+
+### What are the typical deployment scenarios for TF SavedModel?
+
+TF SavedModel can be deployed in various environments, including:
+
+- **TensorFlow Serving:** Ideal for production environments requiring scalable and high-performance model serving.
+- **Cloud Platforms:** Supports major cloud services like Google Cloud Platform (GCP), Amazon Web Services (AWS), and Microsoft Azure for scalable model deployment.
+- **Mobile and Embedded Devices:** Using TensorFlow Lite to convert TF SavedModels allows for deployment on mobile devices, IoT devices, and microcontrollers.
+- **TensorFlow Runtime:** For C++ environments needing low-latency inference with better performance.
+
+For detailed deployment options, visit the official guides on [deploying TensorFlow models](https://www.tensorflow.org/tfx/guide/serving).
+
+### How can I install the necessary packages to export YOLOv8 models?
+
+To export YOLOv8 models, you need to install the `ultralytics` package. Run the following command in your terminal:
+
+```bash
+pip install ultralytics
+```
+
+For more detailed installation instructions and best practices, refer to our [Ultralytics Installation guide](../quickstart.md). If you encounter any issues, consult our [Common Issues guide](../guides/yolo-common-issues.md).
+
+### What are the key features of the TensorFlow SavedModel format?
+
+TF SavedModel format is beneficial for AI developers due to the following features:
+
+- **Portability:** Allows sharing and deployment across various environments effortlessly.
+- **Ease of Deployment:** Encapsulates the computational graph, trained parameters, and metadata into a single package, which simplifies loading and inference.
+- **Asset Management:** Supports external assets like vocabularies, ensuring they are available when the model loads.
+
+For further details, explore the [official TensorFlow documentation](https://www.tensorflow.org/guide/saved_model).
diff --git a/ultralytics/docs/en/integrations/tfjs.md b/ultralytics/docs/en/integrations/tfjs.md
new file mode 100644
index 0000000000000000000000000000000000000000..47504e4f3e7060a10cc335f3fee4d8bff712d423
--- /dev/null
+++ b/ultralytics/docs/en/integrations/tfjs.md
@@ -0,0 +1,194 @@
+---
+comments: true
+description: Convert your Ultralytics YOLOv8 models to TensorFlow.js for high-speed, local object detection. Learn how to optimize ML models for browser and Node.js apps.
+keywords: YOLOv8, TensorFlow.js, TF.js, model export, machine learning, object detection, browser ML, Node.js, Ultralytics, YOLO, export models
+---
+
+# Export to TF.js Model Format From a YOLOv8 Model Format
+
+Deploying machine learning models directly in the browser or on Node.js can be tricky. You'll need to make sure your model format is optimized for faster performance so that the model can be used to run interactive applications locally on the user's device. The TensorFlow.js, or TF.js, model format is designed to use minimal power while delivering fast performance.
+
+The 'export to TF.js model format' feature allows you to optimize your [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics) models for high-speed and locally-run object detection inference. In this guide, we'll walk you through converting your models to the TF.js format, making it easier for your models to perform well on various local browsers and Node.js applications.
+
+## Why Should You Export to TF.js?
+
+Exporting your machine learning models to TensorFlow.js, developed by the TensorFlow team as part of the broader TensorFlow ecosystem, offers numerous advantages for deploying machine learning applications. It helps enhance user privacy and security by keeping sensitive data on the device. The image below shows the TensorFlow.js architecture, and how machine learning models are converted and deployed on both web browsers and Node.js.
+
+
+
+
+
+Running models locally also reduces latency and provides a more responsive user experience. TensorFlow.js also comes with offline capabilities, allowing users to use your application even without an internet connection. TF.js is designed for efficient execution of complex models on devices with limited resources as it is engineered for scalability, with GPU acceleration support.
+
+## Key Features of TF.js
+
+Here are the key features that make TF.js a powerful tool for developers:
+
+- **Cross-Platform Support:** TensorFlow.js can be used in both browser and Node.js environments, providing flexibility in deployment across different platforms. It lets developers build and deploy applications more easily.
+
+- **Support for Multiple Backends:** TensorFlow.js supports various backends for computation including CPU, WebGL for GPU acceleration, WebAssembly (WASM) for near-native execution speed, and WebGPU for advanced browser-based machine learning capabilities.
+
+- **Offline Capabilities:** With TensorFlow.js, models can run in the browser without the need for an internet connection, making it possible to develop applications that are functional offline.
+
+## Deployment Options with TensorFlow.js
+
+Before we dive into the process of exporting YOLOv8 models to the TF.js format, let's explore some typical deployment scenarios where this format is used.
+
+TF.js provides a range of options to deploy your machine learning models:
+
+- **In-Browser ML Applications:** You can build web applications that run machine learning models directly in the browser. The need for server-side computation is eliminated and the server load is reduced.
+
+- **Node.js Applications::** TensorFlow.js also supports deployment in Node.js environments, enabling the development of server-side machine learning applications. It is particularly useful for applications that require the processing power of a server or access to server-side data.
+
+- **Chrome Extensions:** An interesting deployment scenario is the creation of Chrome extensions with TensorFlow.js. For instance, you can develop an extension that allows users to right-click on an image within any webpage to classify it using a pre-trained ML model. TensorFlow.js can be integrated into everyday web browsing experiences to provide immediate insights or augmentations based on machine learning.
+
+## Exporting YOLOv8 Models to TensorFlow.js
+
+You can expand model compatibility and deployment flexibility by converting YOLOv8 models to TF.js.
+
+### Installation
+
+To install the required package, run:
+
+!!! Tip "Installation"
+
+ === "CLI"
+
+ ```bash
+ # Install the required package for YOLOv8
+ pip install ultralytics
+ ```
+
+For detailed instructions and best practices related to the installation process, check our [Ultralytics Installation guide](../quickstart.md). While installing the required packages for YOLOv8, if you encounter any difficulties, consult our [Common Issues guide](../guides/yolo-common-issues.md) for solutions and tips.
+
+### Usage
+
+Before diving into the usage instructions, it's important to note that while all [Ultralytics YOLOv8 models](../models/index.md) are available for exporting, you can ensure that the model you select supports export functionality [here](../modes/export.md).
+
+!!! Example "Usage"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load the YOLOv8 model
+ model = YOLO("yolov8n.pt")
+
+ # Export the model to TF.js format
+ model.export(format="tfjs") # creates '/yolov8n_web_model'
+
+ # Load the exported TF.js model
+ tfjs_model = YOLO("./yolov8n_web_model")
+
+ # Run inference
+ results = tfjs_model("https://ultralytics.com/images/bus.jpg")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Export a YOLOv8n PyTorch model to TF.js format
+ yolo export model=yolov8n.pt format=tfjs # creates '/yolov8n_web_model'
+
+ # Run inference with the exported model
+ yolo predict model='./yolov8n_web_model' source='https://ultralytics.com/images/bus.jpg'
+ ```
+
+For more details about supported export options, visit the [Ultralytics documentation page on deployment options](../guides/model-deployment-options.md).
+
+## Deploying Exported YOLOv8 TensorFlow.js Models
+
+Now that you have exported your YOLOv8 model to the TF.js format, the next step is to deploy it. The primary and recommended first step for running a TF.js is to use the YOLO("./yolov8n_web_model") method, as previously shown in the usage code snippet.
+
+However, for in-depth instructions on deploying your TF.js models, take a look at the following resources:
+
+- **[Chrome Extension](https://www.tensorflow.org/js/tutorials/deployment/web_ml_in_chrome)**: Here's the developer documentation for how to deploy your TF.js models to a Chrome extension.
+
+- **[Run TensorFlow.js in Node.js](https://www.tensorflow.org/js/guide/nodejs)**: A TensorFlow blog post on running TensorFlow.js in Node.js directly.
+
+- **[Deploying TensorFlow.js - Node Project on Cloud Platform](https://www.tensorflow.org/js/guide/node_in_cloud)**: A TensorFlow blog post on deploying a TensorFlow.js model on a Cloud Platform.
+
+## Summary
+
+In this guide, we learned how to export Ultralytics YOLOv8 models to the TensorFlow.js format. By exporting to TF.js, you gain the flexibility to optimize, deploy, and scale your YOLOv8 models on a wide range of platforms.
+
+For further details on usage, visit the [TensorFlow.js official documentation](https://www.tensorflow.org/js/guide).
+
+For more information on integrating Ultralytics YOLOv8 with other platforms and frameworks, don't forget to check out our [integration guide page](index.md). It's packed with great resources to help you make the most of YOLOv8 in your projects.
+
+## FAQ
+
+### How do I export Ultralytics YOLOv8 models to TensorFlow.js format?
+
+Exporting Ultralytics YOLOv8 models to TensorFlow.js (TF.js) format is straightforward. You can follow these steps:
+
+!!! Example "Usage"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load the YOLOv8 model
+ model = YOLO("yolov8n.pt")
+
+ # Export the model to TF.js format
+ model.export(format="tfjs") # creates '/yolov8n_web_model'
+
+ # Load the exported TF.js model
+ tfjs_model = YOLO("./yolov8n_web_model")
+
+ # Run inference
+ results = tfjs_model("https://ultralytics.com/images/bus.jpg")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Export a YOLOv8n PyTorch model to TF.js format
+ yolo export model=yolov8n.pt format=tfjs # creates '/yolov8n_web_model'
+
+ # Run inference with the exported model
+ yolo predict model='./yolov8n_web_model' source='https://ultralytics.com/images/bus.jpg'
+ ```
+
+For more details about supported export options, visit the [Ultralytics documentation page on deployment options](../guides/model-deployment-options.md).
+
+### Why should I export my YOLOv8 models to TensorFlow.js?
+
+Exporting YOLOv8 models to TensorFlow.js offers several advantages, including:
+
+1. **Local Execution:** Models can run directly in the browser or Node.js, reducing latency and enhancing user experience.
+2. **Cross-Platform Support:** TF.js supports multiple environments, allowing flexibility in deployment.
+3. **Offline Capabilities:** Enables applications to function without an internet connection, ensuring reliability and privacy.
+4. **GPU Acceleration:** Leverages WebGL for GPU acceleration, optimizing performance on devices with limited resources.
+
+For a comprehensive overview, see our [Integrations with TensorFlow.js](../integrations/tf-graphdef.md).
+
+### How does TensorFlow.js benefit browser-based machine learning applications?
+
+TensorFlow.js is specifically designed for efficient execution of ML models in browsers and Node.js environments. Here's how it benefits browser-based applications:
+
+- **Reduces Latency:** Runs machine learning models locally, providing immediate results without relying on server-side computations.
+- **Improves Privacy:** Keeps sensitive data on the user's device, minimizing security risks.
+- **Enables Offline Use:** Models can operate without an internet connection, ensuring consistent functionality.
+- **Supports Multiple Backends:** Offers flexibility with backends like CPU, WebGL, WebAssembly (WASM), and WebGPU for varying computational needs.
+
+Interested in learning more about TF.js? Check out the [official TensorFlow.js guide](https://www.tensorflow.org/js/guide).
+
+### What are the key features of TensorFlow.js for deploying YOLOv8 models?
+
+Key features of TensorFlow.js include:
+
+- **Cross-Platform Support:** TF.js can be used in both web browsers and Node.js, providing extensive deployment flexibility.
+- **Multiple Backends:** Supports CPU, WebGL for GPU acceleration, WebAssembly (WASM), and WebGPU for advanced operations.
+- **Offline Capabilities:** Models can run directly in the browser without internet connectivity, making it ideal for developing responsive web applications.
+
+For deployment scenarios and more in-depth information, see our section on [Deployment Options with TensorFlow.js](#deploying-exported-yolov8-tensorflowjs-models).
+
+### Can I deploy a YOLOv8 model on server-side Node.js applications using TensorFlow.js?
+
+Yes, TensorFlow.js allows the deployment of YOLOv8 models on Node.js environments. This enables server-side machine learning applications that benefit from the processing power of a server and access to server-side data. Typical use cases include real-time data processing and machine learning pipelines on backend servers.
+
+To get started with Node.js deployment, refer to the [Run TensorFlow.js in Node.js](https://www.tensorflow.org/js/guide/nodejs) guide from TensorFlow.
diff --git a/ultralytics/docs/en/integrations/tflite.md b/ultralytics/docs/en/integrations/tflite.md
new file mode 100644
index 0000000000000000000000000000000000000000..332018ecc3fbf8e7b2b5c3cc2aa244e8eb06d3a1
--- /dev/null
+++ b/ultralytics/docs/en/integrations/tflite.md
@@ -0,0 +1,193 @@
+---
+comments: true
+description: Learn how to convert YOLOv8 models to TFLite for edge device deployment. Optimize performance and ensure seamless execution on various platforms.
+keywords: YOLOv8, TFLite, model export, TensorFlow Lite, edge devices, deployment, Ultralytics, machine learning, on-device inference, model optimization
+---
+
+# A Guide on YOLOv8 Model Export to TFLite for Deployment
+
+
+
+
+
+Deploying computer vision models on edge devices or embedded devices requires a format that can ensure seamless performance.
+
+The TensorFlow Lite or TFLite export format allows you to optimize your [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics) models for tasks like object detection and image classification in edge device-based applications. In this guide, we'll walk through the steps for converting your models to the TFLite format, making it easier for your models to perform well on various edge devices.
+
+## Why should you export to TFLite?
+
+Introduced by Google in May 2017 as part of their TensorFlow framework, [TensorFlow Lite](https://www.tensorflow.org/lite/guide), or TFLite for short, is an open-source deep learning framework designed for on-device inference, also known as edge computing. It gives developers the necessary tools to execute their trained models on mobile, embedded, and IoT devices, as well as traditional computers.
+
+TensorFlow Lite is compatible with a wide range of platforms, including embedded Linux, Android, iOS, and MCU. Exporting your model to TFLite makes your applications faster, more reliable, and capable of running offline.
+
+## Key Features of TFLite Models
+
+TFLite models offer a wide range of key features that enable on-device machine learning by helping developers run their models on mobile, embedded, and edge devices:
+
+- **On-device Optimization**: TFLite optimizes for on-device ML, reducing latency by processing data locally, enhancing privacy by not transmitting personal data, and minimizing model size to save space.
+
+- **Multiple Platform Support**: TFLite offers extensive platform compatibility, supporting Android, iOS, embedded Linux, and microcontrollers.
+
+- **Diverse Language Support**: TFLite is compatible with various programming languages, including Java, Swift, Objective-C, C++, and Python.
+
+- **High Performance**: Achieves superior performance through hardware acceleration and model optimization.
+
+## Deployment Options in TFLite
+
+Before we look at the code for exporting YOLOv8 models to the TFLite format, let's understand how TFLite models are normally used.
+
+TFLite offers various on-device deployment options for machine learning models, including:
+
+- **Deploying with Android and iOS**: Both Android and iOS applications with TFLite can analyze edge-based camera feeds and sensors to detect and identify objects. TFLite also offers native iOS libraries written in [Swift](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/swift) and [Objective-C](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/objc). The architecture diagram below shows the process of deploying a trained model onto Android and iOS platforms using TensorFlow Lite.
+
+
+
+
+
+- **Implementing with Embedded Linux**: If running inferences on a [Raspberry Pi](https://www.raspberrypi.org/) using the [Ultralytics Guide](../guides/raspberry-pi.md) does not meet the speed requirements for your use case, you can use an exported TFLite model to accelerate inference times. Additionally, it's possible to further improve performance by utilizing a [Coral Edge TPU device](https://coral.withgoogle.com/).
+
+- **Deploying with Microcontrollers**: TFLite models can also be deployed on microcontrollers and other devices with only a few kilobytes of memory. The core runtime just fits in 16 KB on an Arm Cortex M3 and can run many basic models. It doesn't require operating system support, any standard C or C++ libraries, or dynamic memory allocation.
+
+## Export to TFLite: Converting Your YOLOv8 Model
+
+You can improve on-device model execution efficiency and optimize performance by converting them to TFLite format.
+
+### Installation
+
+To install the required packages, run:
+
+!!! Tip "Installation"
+
+ === "CLI"
+
+ ```bash
+ # Install the required package for YOLOv8
+ pip install ultralytics
+ ```
+
+For detailed instructions and best practices related to the installation process, check our [Ultralytics Installation guide](../quickstart.md). While installing the required packages for YOLOv8, if you encounter any difficulties, consult our [Common Issues guide](../guides/yolo-common-issues.md) for solutions and tips.
+
+### Usage
+
+Before diving into the usage instructions, it's important to note that while all [Ultralytics YOLOv8 models](../models/index.md) are available for exporting, you can ensure that the model you select supports export functionality [here](../modes/export.md).
+
+!!! Example "Usage"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load the YOLOv8 model
+ model = YOLO("yolov8n.pt")
+
+ # Export the model to TFLite format
+ model.export(format="tflite") # creates 'yolov8n_float32.tflite'
+
+ # Load the exported TFLite model
+ tflite_model = YOLO("yolov8n_float32.tflite")
+
+ # Run inference
+ results = tflite_model("https://ultralytics.com/images/bus.jpg")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Export a YOLOv8n PyTorch model to TFLite format
+ yolo export model=yolov8n.pt format=tflite # creates 'yolov8n_float32.tflite'
+
+ # Run inference with the exported model
+ yolo predict model='yolov8n_float32.tflite' source='https://ultralytics.com/images/bus.jpg'
+ ```
+
+For more details about the export process, visit the [Ultralytics documentation page on exporting](../modes/export.md).
+
+## Deploying Exported YOLOv8 TFLite Models
+
+After successfully exporting your Ultralytics YOLOv8 models to TFLite format, you can now deploy them. The primary and recommended first step for running a TFLite model is to utilize the YOLO("model.tflite") method, as outlined in the previous usage code snippet. However, for in-depth instructions on deploying your TFLite models in various other settings, take a look at the following resources:
+
+- **[Android](https://www.tensorflow.org/lite/android/quickstart)**: A quick start guide for integrating TensorFlow Lite into Android applications, providing easy-to-follow steps for setting up and running machine learning models.
+
+- **[iOS](https://www.tensorflow.org/lite/guide/ios)**: Check out this detailed guide for developers on integrating and deploying TensorFlow Lite models in iOS applications, offering step-by-step instructions and resources.
+
+- **[End-To-End Examples](https://www.tensorflow.org/lite/examples)**: This page provides an overview of various TensorFlow Lite examples, showcasing practical applications and tutorials designed to help developers implement TensorFlow Lite in their machine learning projects on mobile and edge devices.
+
+## Summary
+
+In this guide, we focused on how to export to TFLite format. By converting your Ultralytics YOLOv8 models to TFLite model format, you can improve the efficiency and speed of YOLOv8 models, making them more effective and suitable for edge computing environments.
+
+For further details on usage, visit the [TFLite official documentation](https://www.tensorflow.org/lite/guide).
+
+Also, if you're curious about other Ultralytics YOLOv8 integrations, make sure to check out our [integration guide page](../integrations/index.md). You'll find tons of helpful info and insights waiting for you there.
+
+## FAQ
+
+### How do I export a YOLOv8 model to TFLite format?
+
+To export a YOLOv8 model to TFLite format, you can use the Ultralytics library. First, install the required package using:
+
+```bash
+pip install ultralytics
+```
+
+Then, use the following code snippet to export your model:
+
+```python
+from ultralytics import YOLO
+
+# Load the YOLOv8 model
+model = YOLO("yolov8n.pt")
+
+# Export the model to TFLite format
+model.export(format="tflite") # creates 'yolov8n_float32.tflite'
+```
+
+For CLI users, you can achieve this with:
+
+```bash
+yolo export model=yolov8n.pt format=tflite # creates 'yolov8n_float32.tflite'
+```
+
+For more details, visit the [Ultralytics export guide](../modes/export.md).
+
+### What are the benefits of using TensorFlow Lite for YOLOv8 model deployment?
+
+TensorFlow Lite (TFLite) is an open-source deep learning framework designed for on-device inference, making it ideal for deploying YOLOv8 models on mobile, embedded, and IoT devices. Key benefits include:
+
+- **On-device optimization**: Minimize latency and enhance privacy by processing data locally.
+- **Platform compatibility**: Supports Android, iOS, embedded Linux, and MCU.
+- **Performance**: Utilizes hardware acceleration to optimize model speed and efficiency.
+
+To learn more, check out the [TFLite guide](https://www.tensorflow.org/lite/guide).
+
+### Is it possible to run YOLOv8 TFLite models on Raspberry Pi?
+
+Yes, you can run YOLOv8 TFLite models on Raspberry Pi to improve inference speeds. First, export your model to TFLite format as explained [here](#how-do-i-export-a-yolov8-model-to-tflite-format). Then, use a tool like TensorFlow Lite Interpreter to execute the model on your Raspberry Pi.
+
+For further optimizations, you might consider using [Coral Edge TPU](https://coral.withgoogle.com/). For detailed steps, refer to our [Raspberry Pi deployment guide](../guides/raspberry-pi.md).
+
+### Can I use TFLite models on microcontrollers for YOLOv8 predictions?
+
+Yes, TFLite supports deployment on microcontrollers with limited resources. TFLite's core runtime requires only 16 KB of memory on an Arm Cortex M3 and can run basic YOLOv8 models. This makes it suitable for deployment on devices with minimal computational power and memory.
+
+To get started, visit the [TFLite Micro for Microcontrollers guide](https://www.tensorflow.org/lite/microcontrollers).
+
+### What platforms are compatible with TFLite exported YOLOv8 models?
+
+TensorFlow Lite provides extensive platform compatibility, allowing you to deploy YOLOv8 models on a wide range of devices, including:
+
+- **Android and iOS**: Native support through TFLite Android and iOS libraries.
+- **Embedded Linux**: Ideal for single-board computers such as Raspberry Pi.
+- **Microcontrollers**: Suitable for MCUs with constrained resources.
+
+For more information on deployment options, see our detailed [deployment guide](#deploying-exported-yolov8-tflite-models).
+
+### How do I troubleshoot common issues during YOLOv8 model export to TFLite?
+
+If you encounter errors while exporting YOLOv8 models to TFLite, common solutions include:
+
+- **Check package compatibility**: Ensure you're using compatible versions of Ultralytics and TensorFlow. Refer to our [installation guide](../quickstart.md).
+- **Model support**: Verify that the specific YOLOv8 model supports TFLite export by checking [here](../modes/export.md).
+
+For additional troubleshooting tips, visit our [Common Issues guide](../guides/yolo-common-issues.md).
diff --git a/ultralytics/docs/en/integrations/torchscript.md b/ultralytics/docs/en/integrations/torchscript.md
new file mode 100644
index 0000000000000000000000000000000000000000..ff7650f387172069a77252d54ac8e989bb0173d1
--- /dev/null
+++ b/ultralytics/docs/en/integrations/torchscript.md
@@ -0,0 +1,204 @@
+---
+comments: true
+description: Learn how to export Ultralytics YOLOv8 models to TorchScript for flexible, cross-platform deployment. Boost performance and utilize in various environments.
+keywords: YOLOv8, TorchScript, model export, Ultralytics, PyTorch, deep learning, AI deployment, cross-platform, performance optimization
+---
+
+# YOLOv8 Model Export to TorchScript for Quick Deployment
+
+Deploying computer vision models across different environments, including embedded systems, web browsers, or platforms with limited Python support, requires a flexible and portable solution. TorchScript focuses on portability and the ability to run models in environments where the entire Python framework is unavailable. This makes it ideal for scenarios where you need to deploy your computer vision capabilities across various devices or platforms.
+
+Export to Torchscript to serialize your [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics) models for cross-platform compatibility and streamlined deployment. In this guide, we'll show you how to export your YOLOv8 models to the TorchScript format, making it easier for you to use them across a wider range of applications.
+
+## Why should you export to TorchScript?
+
+
+
+Developed by the creators of PyTorch, TorchScript is a powerful tool for optimizing and deploying PyTorch models across a variety of platforms. Exporting YOLOv8 models to [TorchScript](https://pytorch.org/docs/stable/jit.html) is crucial for moving from research to real-world applications. TorchScript, part of the PyTorch framework, helps make this transition smoother by allowing PyTorch models to be used in environments that don't support Python.
+
+The process involves two techniques: tracing and scripting. Tracing records operations during model execution, while scripting allows for the definition of models using a subset of Python. These techniques ensure that models like YOLOv8 can still work their magic even outside their usual Python environment.
+
+
+
+TorchScript models can also be optimized through techniques such as operator fusion and refinements in memory usage, ensuring efficient execution. Another advantage of exporting to TorchScript is its potential to accelerate model execution across various hardware platforms. It creates a standalone, production-ready representation of your PyTorch model that can be integrated into C++ environments, embedded systems, or deployed in web or mobile applications.
+
+## Key Features of TorchScript Models
+
+TorchScript, a key part of the PyTorch ecosystem, provides powerful features for optimizing and deploying deep learning models.
+
+
+
+Here are the key features that make TorchScript a valuable tool for developers:
+
+- **Static Graph Execution**: TorchScript uses a static graph representation of the model's computation, which is different from PyTorch's dynamic graph execution. In static graph execution, the computational graph is defined and compiled once before the actual execution, resulting in improved performance during inference.
+
+- **Model Serialization**: TorchScript allows you to serialize PyTorch models into a platform-independent format. Serialized models can be loaded without requiring the original Python code, enabling deployment in different runtime environments.
+
+- **JIT Compilation**: TorchScript uses Just-In-Time (JIT) compilation to convert PyTorch models into an optimized intermediate representation. JIT compiles the model's computational graph, enabling efficient execution on target devices.
+
+- **Cross-Language Integration**: With TorchScript, you can export PyTorch models to other languages such as C++, Java, and JavaScript. This makes it easier to integrate PyTorch models into existing software systems written in different languages.
+
+- **Gradual Conversion**: TorchScript provides a gradual conversion approach, allowing you to incrementally convert parts of your PyTorch model into TorchScript. This flexibility is particularly useful when dealing with complex models or when you want to optimize specific portions of the code.
+
+## Deployment Options in TorchScript
+
+Before we look at the code for exporting YOLOv8 models to the TorchScript format, let's understand where TorchScript models are normally used.
+
+TorchScript offers various deployment options for machine learning models, such as:
+
+- **C++ API**: The most common use case for TorchScript is its C++ API, which allows you to load and execute optimized TorchScript models directly within C++ applications. This is ideal for production environments where Python may not be suitable or available. The C++ API offers low-overhead and efficient execution of TorchScript models, maximizing performance potential.
+
+- **Mobile Deployment**: TorchScript offers tools for converting models into formats readily deployable on mobile devices. PyTorch Mobile provides a runtime for executing these models within iOS and Android apps. This enables low-latency, offline inference capabilities, enhancing user experience and data privacy.
+
+- **Cloud Deployment**: TorchScript models can be deployed to cloud-based servers using solutions like TorchServe. It provides features like model versioning, batching, and metrics monitoring for scalable deployment in production environments. Cloud deployment with TorchScript can make your models accessible via APIs or other web services.
+
+## Export to TorchScript: Converting Your YOLOv8 Model
+
+Exporting YOLOv8 models to TorchScript makes it easier to use them in different places and helps them run faster and more efficiently. This is great for anyone looking to use deep learning models more effectively in real-world applications.
+
+### Installation
+
+To install the required package, run:
+
+!!! Tip "Installation"
+
+ === "CLI"
+
+ ```bash
+ # Install the required package for YOLOv8
+ pip install ultralytics
+ ```
+
+For detailed instructions and best practices related to the installation process, check our [Ultralytics Installation guide](../quickstart.md). While installing the required packages for YOLOv8, if you encounter any difficulties, consult our [Common Issues guide](../guides/yolo-common-issues.md) for solutions and tips.
+
+### Usage
+
+Before diving into the usage instructions, it's important to note that while all [Ultralytics YOLOv8 models](../models/index.md) are available for exporting, you can ensure that the model you select supports export functionality [here](../modes/export.md).
+
+!!! Example "Usage"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load the YOLOv8 model
+ model = YOLO("yolov8n.pt")
+
+ # Export the model to TorchScript format
+ model.export(format="torchscript") # creates 'yolov8n.torchscript'
+
+ # Load the exported TorchScript model
+ torchscript_model = YOLO("yolov8n.torchscript")
+
+ # Run inference
+ results = torchscript_model("https://ultralytics.com/images/bus.jpg")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Export a YOLOv8n PyTorch model to TorchScript format
+ yolo export model=yolov8n.pt format=torchscript # creates 'yolov8n.torchscript'
+
+ # Run inference with the exported model
+ yolo predict model=yolov8n.torchscript source='https://ultralytics.com/images/bus.jpg'
+ ```
+
+For more details about the export process, visit the [Ultralytics documentation page on exporting](../modes/export.md).
+
+## Deploying Exported YOLOv8 TorchScript Models
+
+After successfully exporting your Ultralytics YOLOv8 models to TorchScript format, you can now deploy them. The primary and recommended first step for running a TorchScript model is to utilize the YOLO("model.torchscript") method, as outlined in the previous usage code snippet. However, for in-depth instructions on deploying your TorchScript models in various other settings, take a look at the following resources:
+
+- **[Explore Mobile Deployment](https://pytorch.org/mobile/home/)**: The PyTorch Mobile Documentation provides comprehensive guidelines for deploying models on mobile devices, ensuring your applications are efficient and responsive.
+
+- **[Master Server-Side Deployment](https://pytorch.org/serve/getting_started.html)**: Learn how to deploy models server-side with TorchServe, offering a step-by-step tutorial for scalable, efficient model serving.
+
+- **[Implement C++ Deployment](https://pytorch.org/tutorials/advanced/cpp_export.html)**: Dive into the Tutorial on Loading a TorchScript Model in C++, facilitating the integration of your TorchScript models into C++ applications for enhanced performance and versatility.
+
+## Summary
+
+In this guide, we explored the process of exporting Ultralytics YOLOv8 models to the TorchScript format. By following the provided instructions, you can optimize YOLOv8 models for performance and gain the flexibility to deploy them across various platforms and environments.
+
+For further details on usage, visit [TorchScript's official documentation](https://pytorch.org/docs/stable/jit.html).
+
+Also, if you'd like to know more about other Ultralytics YOLOv8 integrations, visit our [integration guide page](../integrations/index.md). You'll find plenty of useful resources and insights there.
+
+## FAQ
+
+### What is Ultralytics YOLOv8 model export to TorchScript?
+
+Exporting an Ultralytics YOLOv8 model to TorchScript allows for flexible, cross-platform deployment. TorchScript, a part of the PyTorch ecosystem, facilitates the serialization of models, which can then be executed in environments that lack Python support. This makes it ideal for deploying models on embedded systems, C++ environments, mobile applications, and even web browsers. Exporting to TorchScript enables efficient performance and wider applicability of your YOLOv8 models across diverse platforms.
+
+### How can I export my YOLOv8 model to TorchScript using Ultralytics?
+
+To export a YOLOv8 model to TorchScript, you can use the following example code:
+
+!!! Example "Usage"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load the YOLOv8 model
+ model = YOLO("yolov8n.pt")
+
+ # Export the model to TorchScript format
+ model.export(format="torchscript") # creates 'yolov8n.torchscript'
+
+ # Load the exported TorchScript model
+ torchscript_model = YOLO("yolov8n.torchscript")
+
+ # Run inference
+ results = torchscript_model("https://ultralytics.com/images/bus.jpg")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Export a YOLOv8n PyTorch model to TorchScript format
+ yolo export model=yolov8n.pt format=torchscript # creates 'yolov8n.torchscript'
+
+ # Run inference with the exported model
+ yolo predict model=yolov8n.torchscript source='https://ultralytics.com/images/bus.jpg'
+ ```
+
+For more details about the export process, refer to the [Ultralytics documentation on exporting](../modes/export.md).
+
+### Why should I use TorchScript for deploying YOLOv8 models?
+
+Using TorchScript for deploying YOLOv8 models offers several advantages:
+
+- **Portability**: Exported models can run in environments without the need for Python, such as C++ applications, embedded systems, or mobile devices.
+- **Optimization**: TorchScript supports static graph execution and Just-In-Time (JIT) compilation, which can optimize model performance.
+- **Cross-Language Integration**: TorchScript models can be integrated into other programming languages, enhancing flexibility and expandability.
+- **Serialization**: Models can be serialized, allowing for platform-independent loading and inference.
+
+For more insights into deployment, visit the [PyTorch Mobile Documentation](https://pytorch.org/mobile/home/), [TorchServe Documentation](https://pytorch.org/serve/getting_started.html), and [C++ Deployment Guide](https://pytorch.org/tutorials/advanced/cpp_export.html).
+
+### What are the installation steps for exporting YOLOv8 models to TorchScript?
+
+To install the required package for exporting YOLOv8 models, use the following command:
+
+!!! Tip "Installation"
+
+ === "CLI"
+
+ ```bash
+ # Install the required package for YOLOv8
+ pip install ultralytics
+ ```
+
+For detailed instructions, visit the [Ultralytics Installation guide](../quickstart.md). If any issues arise during installation, consult the [Common Issues guide](../guides/yolo-common-issues.md).
+
+### How do I deploy my exported TorchScript YOLOv8 models?
+
+After exporting YOLOv8 models to the TorchScript format, you can deploy them across a variety of platforms:
+
+- **C++ API**: Ideal for low-overhead, highly efficient production environments.
+- **Mobile Deployment**: Use [PyTorch Mobile](https://pytorch.org/mobile/home/) for iOS and Android applications.
+- **Cloud Deployment**: Utilize services like [TorchServe](https://pytorch.org/serve/getting_started.html) for scalable server-side deployment.
+
+Explore comprehensive guidelines for deploying models in these settings to take full advantage of TorchScript's capabilities.
diff --git a/ultralytics/docs/en/integrations/weights-biases.md b/ultralytics/docs/en/integrations/weights-biases.md
new file mode 100644
index 0000000000000000000000000000000000000000..a8d36c943b5bcdd9f2847e9a1a9ea12bc1d734d3
--- /dev/null
+++ b/ultralytics/docs/en/integrations/weights-biases.md
@@ -0,0 +1,244 @@
+---
+comments: true
+description: Learn how to enhance YOLOv8 experiment tracking and visualization with Weights & Biases for better model performance and management.
+keywords: YOLOv8, Weights & Biases, model training, experiment tracking, Ultralytics, machine learning, computer vision, model visualization
+---
+
+# Enhancing YOLOv8 Experiment Tracking and Visualization with Weights & Biases
+
+Object detection models like [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics) have become integral to many computer vision applications. However, training, evaluating, and deploying these complex models introduces several challenges. Tracking key training metrics, comparing model variants, analyzing model behavior, and detecting issues require substantial instrumentation and experiment management.
+
+
+
+
+
+ Watch: How to use Ultralytics YOLOv8 with Weights and Biases
+
+
+This guide showcases Ultralytics YOLOv8 integration with Weights & Biases' for enhanced experiment tracking, model-checkpointing, and visualization of model performance. It also includes instructions for setting up the integration, training, fine-tuning, and visualizing results using Weights & Biases' interactive features.
+
+## Weights & Biases
+
+
+
+
+
+[Weights & Biases](https://wandb.ai/site) is a cutting-edge MLOps platform designed for tracking, visualizing, and managing machine learning experiments. It features automatic logging of training metrics for full experiment reproducibility, an interactive UI for streamlined data analysis, and efficient model management tools for deploying across various environments.
+
+## YOLOv8 Training with Weights & Biases
+
+You can use Weights & Biases to bring efficiency and automation to your YOLOv8 training process.
+
+## Installation
+
+To install the required packages, run:
+
+!!! Tip "Installation"
+
+ === "CLI"
+
+ ```bash
+ # Install the required packages for YOLOv8 and Weights & Biases
+ pip install --upgrade ultralytics==8.0.186 wandb
+ ```
+
+For detailed instructions and best practices related to the installation process, be sure to check our [YOLOv8 Installation guide](../quickstart.md). While installing the required packages for YOLOv8, if you encounter any difficulties, consult our [Common Issues guide](../guides/yolo-common-issues.md) for solutions and tips.
+
+## Configuring Weights & Biases
+
+After installing the necessary packages, the next step is to set up your Weights & Biases environment. This includes creating a Weights & Biases account and obtaining the necessary API key for a smooth connection between your development environment and the W&B platform.
+
+Start by initializing the Weights & Biases environment in your workspace. You can do this by running the following command and following the prompted instructions.
+
+!!! Tip "Initial SDK Setup"
+
+ === "CLI"
+
+ ```bash
+ # Initialize your Weights & Biases environment
+ import wandb
+ wandb.login()
+ ```
+
+Navigate to the Weights & Biases authorization page to create and retrieve your API key. Use this key to authenticate your environment with W&B.
+
+## Usage: Training YOLOv8 with Weights & Biases
+
+Before diving into the usage instructions for YOLOv8 model training with Weights & Biases, be sure to check out the range of [YOLOv8 models offered by Ultralytics](../models/index.md). This will help you choose the most appropriate model for your project requirements.
+
+!!! Example "Usage: Training YOLOv8 with Weights & Biases"
+
+ === "Python"
+
+ ```python
+ import wandb
+ from wandb.integration.ultralytics import add_wandb_callback
+
+ from ultralytics import YOLO
+
+ # Initialize a Weights & Biases run
+ wandb.init(project="ultralytics", job_type="training")
+
+ # Load a YOLO model
+ model = YOLO("yolov8n.pt")
+
+ # Add W&B Callback for Ultralytics
+ add_wandb_callback(model, enable_model_checkpointing=True)
+
+ # Train and Fine-Tune the Model
+ model.train(project="ultralytics", data="coco8.yaml", epochs=5, imgsz=640)
+
+ # Validate the Model
+ model.val()
+
+ # Perform Inference and Log Results
+ model(["path/to/image1", "path/to/image2"])
+
+ # Finalize the W&B Run
+ wandb.finish()
+ ```
+
+### Understanding the Code
+
+Let's understand the steps showcased in the usage code snippet above.
+
+- **Step 1: Initialize a Weights & Biases Run**: Start by initializing a Weights & Biases run, specifying the project name and the job type. This run will track and manage the training and validation processes of your model.
+
+- **Step 2: Define the YOLOv8 Model and Dataset**: Specify the model variant and the dataset you wish to use. The YOLO model is then initialized with the specified model file.
+
+- **Step 3: Add Weights & Biases Callback for Ultralytics**: This step is crucial as it enables the automatic logging of training metrics and validation results to Weights & Biases, providing a detailed view of the model's performance.
+
+- **Step 4: Train and Fine-Tune the Model**: Begin training the model with the specified dataset, number of epochs, and image size. The training process includes logging of metrics and predictions at the end of each epoch, offering a comprehensive view of the model's learning progress.
+
+- **Step 5: Validate the Model**: After training, the model is validated. This step is crucial for assessing the model's performance on unseen data and ensuring its generalizability.
+
+- **Step 6: Perform Inference and Log Results**: The model performs predictions on specified images. These predictions, along with visual overlays and insights, are automatically logged in a W&B Table for interactive exploration.
+
+- **Step 7: Finalize the W&B Run**: This step marks the end of data logging and saves the final state of your model's training and validation process in the W&B dashboard.
+
+### Understanding the Output
+
+Upon running the usage code snippet above, you can expect the following key outputs:
+
+- The setup of a new run with its unique ID, indicating the start of the training process.
+- A concise summary of the model's structure, including the number of layers and parameters.
+- Regular updates on important metrics such as box loss, cls loss, dfl loss, precision, recall, and mAP scores during each training epoch.
+- At the end of training, detailed metrics including the model's inference speed, and overall accuracy metrics are displayed.
+- Links to the Weights & Biases dashboard for in-depth analysis and visualization of the training process, along with information on local log file locations.
+
+### Viewing the Weights & Biases Dashboard
+
+After running the usage code snippet, you can access the Weights & Biases (W&B) dashboard through the provided link in the output. This dashboard offers a comprehensive view of your model's training process with YOLOv8.
+
+## Key Features of the Weights & Biases Dashboard
+
+- **Real-Time Metrics Tracking**: Observe metrics like loss, accuracy, and validation scores as they evolve during the training, offering immediate insights for model tuning. [See how experiments are tracked using Weights & Biases](https://imgur.com/D6NVnmN).
+
+- **Hyperparameter Optimization**: Weights & Biases aids in fine-tuning critical parameters such as learning rate, batch size, and more, enhancing the performance of YOLOv8.
+
+- **Comparative Analysis**: The platform allows side-by-side comparisons of different training runs, essential for assessing the impact of various model configurations.
+
+- **Visualization of Training Progress**: Graphical representations of key metrics provide an intuitive understanding of the model's performance across epochs. [See how Weights & Biases helps you visualize validation results](https://imgur.com/a/kU5h7W4).
+
+- **Resource Monitoring**: Keep track of CPU, GPU, and memory usage to optimize the efficiency of the training process.
+
+- **Model Artifacts Management**: Access and share model checkpoints, facilitating easy deployment and collaboration.
+
+- **Viewing Inference Results with Image Overlay**: Visualize the prediction results on images using interactive overlays in Weights & Biases, providing a clear and detailed view of model performance on real-world data. For more detailed information on Weights & Biases' image overlay capabilities, check out this [link](https://docs.wandb.ai/guides/track/log/media#image-overlays). [See how Weights & Biases' image overlays helps visualize model inferences](https://imgur.com/a/UTSiufs).
+
+By using these features, you can effectively track, analyze, and optimize your YOLOv8 model's training, ensuring the best possible performance and efficiency.
+
+## Summary
+
+This guide helped you explore Ultralytics' YOLOv8 integration with Weights & Biases. It illustrates the ability of this integration to efficiently track and visualize model training and prediction results.
+
+For further details on usage, visit [Weights & Biases' official documentation](https://docs.wandb.ai/guides/integrations/ultralytics).
+
+Also, be sure to check out the [Ultralytics integration guide page](../integrations/index.md), to learn more about different exciting integrations.
+
+## FAQ
+
+### How do I install the required packages for YOLOv8 and Weights & Biases?
+
+To install the required packages for YOLOv8 and Weights & Biases, open your command line interface and run:
+
+```bash
+pip install --upgrade ultralytics==8.0.186 wandb
+```
+
+For further guidance on installation steps, refer to our [YOLOv8 Installation guide](../quickstart.md). If you encounter issues, consult the [Common Issues guide](../guides/yolo-common-issues.md) for troubleshooting tips.
+
+### What are the benefits of integrating Ultralytics YOLOv8 with Weights & Biases?
+
+Integrating Ultralytics YOLOv8 with Weights & Biases offers several benefits including:
+
+- **Real-Time Metrics Tracking:** Observe metric changes during training for immediate insights.
+- **Hyperparameter Optimization:** Improve model performance by fine-tuning learning rate, batch size, etc.
+- **Comparative Analysis:** Side-by-side comparison of different training runs.
+- **Resource Monitoring:** Keep track of CPU, GPU, and memory usage.
+- **Model Artifacts Management:** Easy access and sharing of model checkpoints.
+
+Explore these features in detail in the Weights & Biases Dashboard section above.
+
+### How can I configure Weights & Biases for YOLOv8 training?
+
+To configure Weights & Biases for YOLOv8 training, follow these steps:
+
+1. Run the command to initialize Weights & Biases:
+ ```bash
+ import wandb
+ wandb.login()
+ ```
+2. Retrieve your API key from the Weights & Biases website.
+3. Use the API key to authenticate your development environment.
+
+Detailed setup instructions can be found in the Configuring Weights & Biases section above.
+
+### How do I train a YOLOv8 model using Weights & Biases?
+
+For training a YOLOv8 model using Weights & Biases, use the following steps in a Python script:
+
+```python
+import wandb
+from wandb.integration.ultralytics import add_wandb_callback
+
+from ultralytics import YOLO
+
+# Initialize a Weights & Biases run
+wandb.init(project="ultralytics", job_type="training")
+
+# Load a YOLO model
+model = YOLO("yolov8n.pt")
+
+# Add W&B Callback for Ultralytics
+add_wandb_callback(model, enable_model_checkpointing=True)
+
+# Train and Fine-Tune the Model
+model.train(project="ultralytics", data="coco8.yaml", epochs=5, imgsz=640)
+
+# Validate the Model
+model.val()
+
+# Perform Inference and Log Results
+model(["path/to/image1", "path/to/image2"])
+
+# Finalize the W&B Run
+wandb.finish()
+```
+
+This script initializes Weights & Biases, sets up the model, trains it, and logs results. For more details, visit the Usage section above.
+
+### Why should I use Ultralytics YOLOv8 with Weights & Biases over other platforms?
+
+Ultralytics YOLOv8 integrated with Weights & Biases offers several unique advantages:
+
+- **High Efficiency:** Real-time tracking of training metrics and performance optimization.
+- **Scalability:** Easily manage large-scale training jobs with robust resource monitoring and utilization tools.
+- **Interactivity:** A user-friendly interactive UI for data visualization and model management.
+- **Community and Support:** Strong integration documentation and community support with flexible customization and enhancement options.
+
+For comparisons with other platforms like Comet and ClearML, refer to [Ultralytics integrations](../integrations/index.md).
diff --git a/ultralytics/docs/en/macros/export-args.md b/ultralytics/docs/en/macros/export-args.md
new file mode 100644
index 0000000000000000000000000000000000000000..43fc6ff6604a711b5b61d8477d17251bb2270bf3
--- /dev/null
+++ b/ultralytics/docs/en/macros/export-args.md
@@ -0,0 +1,14 @@
+| Argument | Type | Default | Description |
+| ----------- | ---------------- | --------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| `format` | `str` | `'torchscript'` | Target format for the exported model, such as `'onnx'`, `'torchscript'`, `'tensorflow'`, or others, defining compatibility with various deployment environments. |
+| `imgsz` | `int` or `tuple` | `640` | Desired image size for the model input. Can be an integer for square images or a tuple `(height, width)` for specific dimensions. |
+| `keras` | `bool` | `False` | Enables export to Keras format for TensorFlow SavedModel, providing compatibility with TensorFlow serving and APIs. |
+| `optimize` | `bool` | `False` | Applies optimization for mobile devices when exporting to TorchScript, potentially reducing model size and improving performance. |
+| `half` | `bool` | `False` | Enables FP16 (half-precision) quantization, reducing model size and potentially speeding up inference on supported hardware. |
+| `int8` | `bool` | `False` | Activates INT8 quantization, further compressing the model and speeding up inference with minimal accuracy loss, primarily for edge devices. |
+| `dynamic` | `bool` | `False` | Allows dynamic input sizes for ONNX, TensorRT and OpenVINO exports, enhancing flexibility in handling varying image dimensions. |
+| `simplify` | `bool` | `False` | Simplifies the model graph for ONNX exports with `onnxslim`, potentially improving performance and compatibility. |
+| `opset` | `int` | `None` | Specifies the ONNX opset version for compatibility with different ONNX parsers and runtimes. If not set, uses the latest supported version. |
+| `workspace` | `float` | `4.0` | Sets the maximum workspace size in GiB for TensorRT optimizations, balancing memory usage and performance. |
+| `nms` | `bool` | `False` | Adds Non-Maximum Suppression (NMS) to the CoreML export, essential for accurate and efficient detection post-processing. |
+| `batch` | `int` | `1` | Specifies export model batch inference size or the max number of images the exported model will process concurrently in `predict` mode. |
diff --git a/ultralytics/docs/en/macros/export-table.md b/ultralytics/docs/en/macros/export-table.md
new file mode 100644
index 0000000000000000000000000000000000000000..829f378fb679ec53b83dca291417e7bfb3e5f07f
--- /dev/null
+++ b/ultralytics/docs/en/macros/export-table.md
@@ -0,0 +1,15 @@
+| Format | `format` Argument | Model | Metadata | Arguments |
+| ------------------------------------------------- | ----------------- | ----------------------------------------------- | -------- | -------------------------------------------------------------------- |
+| [PyTorch](https://pytorch.org/) | - | `{{ model_name or "yolov8n" }}.pt` | ✅ | - |
+| [TorchScript](../integrations/torchscript.md) | `torchscript` | `{{ model_name or "yolov8n" }}.torchscript` | ✅ | `imgsz`, `optimize`, `batch` |
+| [ONNX](../integrations/onnx.md) | `onnx` | `{{ model_name or "yolov8n" }}.onnx` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `opset`, `batch` |
+| [OpenVINO](../integrations/openvino.md) | `openvino` | `{{ model_name or "yolov8n" }}_openvino_model/` | ✅ | `imgsz`, `half`, `int8`, `batch` |
+| [TensorRT](../integrations/tensorrt.md) | `engine` | `{{ model_name or "yolov8n" }}.engine` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `workspace`, `int8`, `batch` |
+| [CoreML](../integrations/coreml.md) | `coreml` | `{{ model_name or "yolov8n" }}.mlpackage` | ✅ | `imgsz`, `half`, `int8`, `nms`, `batch` |
+| [TF SavedModel](../integrations/tf-savedmodel.md) | `saved_model` | `{{ model_name or "yolov8n" }}_saved_model/` | ✅ | `imgsz`, `keras`, `int8`, `batch` |
+| [TF GraphDef](../integrations/tf-graphdef.md) | `pb` | `{{ model_name or "yolov8n" }}.pb` | ❌ | `imgsz`, `batch` |
+| [TF Lite](../integrations/tflite.md) | `tflite` | `{{ model_name or "yolov8n" }}.tflite` | ✅ | `imgsz`, `half`, `int8`, `batch` |
+| [TF Edge TPU](../integrations/edge-tpu.md) | `edgetpu` | `{{ model_name or "yolov8n" }}_edgetpu.tflite` | ✅ | `imgsz` |
+| [TF.js](../integrations/tfjs.md) | `tfjs` | `{{ model_name or "yolov8n" }}_web_model/` | ✅ | `imgsz`, `half`, `int8`, `batch` |
+| [PaddlePaddle](../integrations/paddlepaddle.md) | `paddle` | `{{ model_name or "yolov8n" }}_paddle_model/` | ✅ | `imgsz`, `batch` |
+| [NCNN](../integrations/ncnn.md) | `ncnn` | `{{ model_name or "yolov8n" }}_ncnn_model/` | ✅ | `imgsz`, `half`, `batch` |
diff --git a/ultralytics/docs/en/models/fast-sam.md b/ultralytics/docs/en/models/fast-sam.md
new file mode 100644
index 0000000000000000000000000000000000000000..66cdb4d1bb29641f4e81619ef044a9da6fb223c2
--- /dev/null
+++ b/ultralytics/docs/en/models/fast-sam.md
@@ -0,0 +1,322 @@
+---
+comments: true
+description: Discover FastSAM, a real-time CNN-based solution for segmenting any object in an image. Efficient, competitive, and ideal for various vision tasks.
+keywords: FastSAM, Fast Segment Anything Model, Ultralytics, real-time segmentation, CNN, YOLOv8-seg, object segmentation, image processing, computer vision
+---
+
+# Fast Segment Anything Model (FastSAM)
+
+The Fast Segment Anything Model (FastSAM) is a novel, real-time CNN-based solution for the Segment Anything task. This task is designed to segment any object within an image based on various possible user interaction prompts. FastSAM significantly reduces computational demands while maintaining competitive performance, making it a practical choice for a variety of vision tasks.
+
+
+
+
+
+ Watch: Object Tracking using FastSAM with Ultralytics
+
+
+## Model Architecture
+
+
+
+## Overview
+
+FastSAM is designed to address the limitations of the [Segment Anything Model (SAM)](sam.md), a heavy Transformer model with substantial computational resource requirements. The FastSAM decouples the segment anything task into two sequential stages: all-instance segmentation and prompt-guided selection. The first stage uses [YOLOv8-seg](../tasks/segment.md) to produce the segmentation masks of all instances in the image. In the second stage, it outputs the region-of-interest corresponding to the prompt.
+
+## Key Features
+
+1. **Real-time Solution:** By leveraging the computational efficiency of CNNs, FastSAM provides a real-time solution for the segment anything task, making it valuable for industrial applications that require quick results.
+
+2. **Efficiency and Performance:** FastSAM offers a significant reduction in computational and resource demands without compromising on performance quality. It achieves comparable performance to SAM but with drastically reduced computational resources, enabling real-time application.
+
+3. **Prompt-guided Segmentation:** FastSAM can segment any object within an image guided by various possible user interaction prompts, providing flexibility and adaptability in different scenarios.
+
+4. **Based on YOLOv8-seg:** FastSAM is based on [YOLOv8-seg](../tasks/segment.md), an object detector equipped with an instance segmentation branch. This allows it to effectively produce the segmentation masks of all instances in an image.
+
+5. **Competitive Results on Benchmarks:** On the object proposal task on MS COCO, FastSAM achieves high scores at a significantly faster speed than [SAM](sam.md) on a single NVIDIA RTX 3090, demonstrating its efficiency and capability.
+
+6. **Practical Applications:** The proposed approach provides a new, practical solution for a large number of vision tasks at a really high speed, tens or hundreds of times faster than current methods.
+
+7. **Model Compression Feasibility:** FastSAM demonstrates the feasibility of a path that can significantly reduce the computational effort by introducing an artificial prior to the structure, thus opening new possibilities for large model architecture for general vision tasks.
+
+## Available Models, Supported Tasks, and Operating Modes
+
+This table presents the available models with their specific pre-trained weights, the tasks they support, and their compatibility with different operating modes like [Inference](../modes/predict.md), [Validation](../modes/val.md), [Training](../modes/train.md), and [Export](../modes/export.md), indicated by ✅ emojis for supported modes and ❌ emojis for unsupported modes.
+
+| Model Type | Pre-trained Weights | Tasks Supported | Inference | Validation | Training | Export |
+| ---------- | ------------------------------------------------------------------------------------------- | -------------------------------------------- | --------- | ---------- | -------- | ------ |
+| FastSAM-s | [FastSAM-s.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/FastSAM-s.pt) | [Instance Segmentation](../tasks/segment.md) | ✅ | ❌ | ❌ | ✅ |
+| FastSAM-x | [FastSAM-x.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/FastSAM-x.pt) | [Instance Segmentation](../tasks/segment.md) | ✅ | ❌ | ❌ | ✅ |
+
+## Usage Examples
+
+The FastSAM models are easy to integrate into your Python applications. Ultralytics provides user-friendly Python API and CLI commands to streamline development.
+
+### Predict Usage
+
+To perform object detection on an image, use the `predict` method as shown below:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import FastSAM
+
+ # Define an inference source
+ source = "path/to/bus.jpg"
+
+ # Create a FastSAM model
+ model = FastSAM("FastSAM-s.pt") # or FastSAM-x.pt
+
+ # Run inference on an image
+ everything_results = model(source, device="cpu", retina_masks=True, imgsz=1024, conf=0.4, iou=0.9)
+
+ # Run inference with bboxes prompt
+ results = model(source, bboxes=[439, 437, 524, 709])
+
+ # Run inference with points prompt
+ results = model(source, points=[[200, 200]], labels=[1])
+
+ # Run inference with texts prompt
+ results = model(source, texts="a photo of a dog")
+
+ # Run inference with bboxes and points and texts prompt at the same time
+ results = model(source, bboxes=[439, 437, 524, 709], points=[[200, 200]], labels=[1], texts="a photo of a dog")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Load a FastSAM model and segment everything with it
+ yolo segment predict model=FastSAM-s.pt source=path/to/bus.jpg imgsz=640
+ ```
+
+This snippet demonstrates the simplicity of loading a pre-trained model and running a prediction on an image.
+
+!!! Example "FastSAMPredictor example"
+
+ This way you can run inference on image and get all the segment `results` once and run prompts inference multiple times without running inference multiple times.
+
+ === "Prompt inference"
+
+ ```python
+ from ultralytics.models.fastsam import FastSAMPredictor
+
+ # Create FastSAMPredictor
+ overrides = dict(conf=0.25, task="segment", mode="predict", model="FastSAM-s.pt", save=False, imgsz=1024)
+ predictor = FastSAMPredictor(overrides=overrides)
+
+ # Segment everything
+ everything_results = predictor("ultralytics/assets/bus.jpg")
+
+ # Prompt inference
+ bbox_results = predictor.prompt(everything_results, bboxes=[[200, 200, 300, 300]])
+ point_results = predictor.prompt(everything_results, points=[200, 200])
+ text_results = predictor.prompt(everything_results, texts="a photo of a dog")
+ ```
+
+!!! Note
+
+ All the returned `results` in above examples are [Results](../modes/predict.md#working-with-results) object which allows access predicted masks and source image easily.
+
+### Val Usage
+
+Validation of the model on a dataset can be done as follows:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import FastSAM
+
+ # Create a FastSAM model
+ model = FastSAM("FastSAM-s.pt") # or FastSAM-x.pt
+
+ # Validate the model
+ results = model.val(data="coco8-seg.yaml")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Load a FastSAM model and validate it on the COCO8 example dataset at image size 640
+ yolo segment val model=FastSAM-s.pt data=coco8.yaml imgsz=640
+ ```
+
+Please note that FastSAM only supports detection and segmentation of a single class of object. This means it will recognize and segment all objects as the same class. Therefore, when preparing the dataset, you need to convert all object category IDs to 0.
+
+### Track Usage
+
+To perform object tracking on an image, use the `track` method as shown below:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import FastSAM
+
+ # Create a FastSAM model
+ model = FastSAM("FastSAM-s.pt") # or FastSAM-x.pt
+
+ # Track with a FastSAM model on a video
+ results = model.track(source="path/to/video.mp4", imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo segment track model=FastSAM-s.pt source="path/to/video/file.mp4" imgsz=640
+ ```
+
+## FastSAM official Usage
+
+FastSAM is also available directly from the [https://github.com/CASIA-IVA-Lab/FastSAM](https://github.com/CASIA-IVA-Lab/FastSAM) repository. Here is a brief overview of the typical steps you might take to use FastSAM:
+
+### Installation
+
+1. Clone the FastSAM repository:
+
+ ```shell
+ git clone https://github.com/CASIA-IVA-Lab/FastSAM.git
+ ```
+
+2. Create and activate a Conda environment with Python 3.9:
+
+ ```shell
+ conda create -n FastSAM python=3.9
+ conda activate FastSAM
+ ```
+
+3. Navigate to the cloned repository and install the required packages:
+
+ ```shell
+ cd FastSAM
+ pip install -r requirements.txt
+ ```
+
+4. Install the CLIP model:
+ ```shell
+ pip install git+https://github.com/ultralytics/CLIP.git
+ ```
+
+### Example Usage
+
+1. Download a [model checkpoint](https://drive.google.com/file/d/1m1sjY4ihXBU1fZXdQ-Xdj-mDltW-2Rqv/view?usp=sharing).
+
+2. Use FastSAM for inference. Example commands:
+
+ - Segment everything in an image:
+
+ ```shell
+ python Inference.py --model_path ./weights/FastSAM.pt --img_path ./images/dogs.jpg
+ ```
+
+ - Segment specific objects using text prompt:
+
+ ```shell
+ python Inference.py --model_path ./weights/FastSAM.pt --img_path ./images/dogs.jpg --text_prompt "the yellow dog"
+ ```
+
+ - Segment objects within a bounding box (provide box coordinates in xywh format):
+
+ ```shell
+ python Inference.py --model_path ./weights/FastSAM.pt --img_path ./images/dogs.jpg --box_prompt "[570,200,230,400]"
+ ```
+
+ - Segment objects near specific points:
+ ```shell
+ python Inference.py --model_path ./weights/FastSAM.pt --img_path ./images/dogs.jpg --point_prompt "[[520,360],[620,300]]" --point_label "[1,0]"
+ ```
+
+Additionally, you can try FastSAM through a [Colab demo](https://colab.research.google.com/drive/1oX14f6IneGGw612WgVlAiy91UHwFAvr9?usp=sharing) or on the [HuggingFace web demo](https://huggingface.co/spaces/An-619/FastSAM) for a visual experience.
+
+## Citations and Acknowledgements
+
+We would like to acknowledge the FastSAM authors for their significant contributions in the field of real-time instance segmentation:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @misc{zhao2023fast,
+ title={Fast Segment Anything},
+ author={Xu Zhao and Wenchao Ding and Yongqi An and Yinglong Du and Tao Yu and Min Li and Ming Tang and Jinqiao Wang},
+ year={2023},
+ eprint={2306.12156},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+ }
+ ```
+
+The original FastSAM paper can be found on [arXiv](https://arxiv.org/abs/2306.12156). The authors have made their work publicly available, and the codebase can be accessed on [GitHub](https://github.com/CASIA-IVA-Lab/FastSAM). We appreciate their efforts in advancing the field and making their work accessible to the broader community.
+
+## FAQ
+
+### What is FastSAM and how does it differ from SAM?
+
+FastSAM, short for Fast Segment Anything Model, is a real-time convolutional neural network (CNN)-based solution designed to reduce computational demands while maintaining high performance in object segmentation tasks. Unlike the Segment Anything Model (SAM), which uses a heavier Transformer-based architecture, FastSAM leverages [Ultralytics YOLOv8-seg](../tasks/segment.md) for efficient instance segmentation in two stages: all-instance segmentation followed by prompt-guided selection.
+
+### How does FastSAM achieve real-time segmentation performance?
+
+FastSAM achieves real-time segmentation by decoupling the segmentation task into all-instance segmentation with YOLOv8-seg and prompt-guided selection stages. By utilizing the computational efficiency of CNNs, FastSAM offers significant reductions in computational and resource demands while maintaining competitive performance. This dual-stage approach enables FastSAM to deliver fast and efficient segmentation suitable for applications requiring quick results.
+
+### What are the practical applications of FastSAM?
+
+FastSAM is practical for a variety of computer vision tasks that require real-time segmentation performance. Applications include:
+
+- Industrial automation for quality control and assurance
+- Real-time video analysis for security and surveillance
+- Autonomous vehicles for object detection and segmentation
+- Medical imaging for precise and quick segmentation tasks
+
+Its ability to handle various user interaction prompts makes FastSAM adaptable and flexible for diverse scenarios.
+
+### How do I use the FastSAM model for inference in Python?
+
+To use FastSAM for inference in Python, you can follow the example below:
+
+```python
+from ultralytics import FastSAM
+
+# Define an inference source
+source = "path/to/bus.jpg"
+
+# Create a FastSAM model
+model = FastSAM("FastSAM-s.pt") # or FastSAM-x.pt
+
+# Run inference on an image
+everything_results = model(source, device="cpu", retina_masks=True, imgsz=1024, conf=0.4, iou=0.9)
+
+# Run inference with bboxes prompt
+results = model(source, bboxes=[439, 437, 524, 709])
+
+# Run inference with points prompt
+results = model(source, points=[[200, 200]], labels=[1])
+
+# Run inference with texts prompt
+results = model(source, texts="a photo of a dog")
+
+# Run inference with bboxes and points and texts prompt at the same time
+results = model(source, bboxes=[439, 437, 524, 709], points=[[200, 200]], labels=[1], texts="a photo of a dog")
+```
+
+For more details on inference methods, check the [Predict Usage](#predict-usage) section of the documentation.
+
+### What types of prompts does FastSAM support for segmentation tasks?
+
+FastSAM supports multiple prompt types for guiding the segmentation tasks:
+
+- **Everything Prompt**: Generates segmentation for all visible objects.
+- **Bounding Box (BBox) Prompt**: Segments objects within a specified bounding box.
+- **Text Prompt**: Uses a descriptive text to segment objects matching the description.
+- **Point Prompt**: Segments objects near specific user-defined points.
+
+This flexibility allows FastSAM to adapt to a wide range of user interaction scenarios, enhancing its utility across different applications. For more information on using these prompts, refer to the [Key Features](#key-features) section.
diff --git a/ultralytics/docs/en/models/index.md b/ultralytics/docs/en/models/index.md
new file mode 100644
index 0000000000000000000000000000000000000000..6c1b4da12beb16489edbda5ddbb2fde6b855453b
--- /dev/null
+++ b/ultralytics/docs/en/models/index.md
@@ -0,0 +1,142 @@
+---
+comments: true
+description: Discover a variety of models supported by Ultralytics, including YOLOv3 to YOLOv10, NAS, SAM, and RT-DETR for detection, segmentation, and more.
+keywords: Ultralytics, supported models, YOLOv3, YOLOv4, YOLOv5, YOLOv6, YOLOv7, YOLOv8, YOLOv9, YOLOv10, SAM, NAS, RT-DETR, object detection, image segmentation, classification, pose estimation, multi-object tracking
+---
+
+# Models Supported by Ultralytics
+
+Welcome to Ultralytics' model documentation! We offer support for a wide range of models, each tailored to specific tasks like [object detection](../tasks/detect.md), [instance segmentation](../tasks/segment.md), [image classification](../tasks/classify.md), [pose estimation](../tasks/pose.md), and [multi-object tracking](../modes/track.md). If you're interested in contributing your model architecture to Ultralytics, check out our [Contributing Guide](../help/contributing.md).
+
+## Featured Models
+
+Here are some of the key models supported:
+
+1. **[YOLOv3](yolov3.md)**: The third iteration of the YOLO model family, originally by Joseph Redmon, known for its efficient real-time object detection capabilities.
+2. **[YOLOv4](yolov4.md)**: A darknet-native update to YOLOv3, released by Alexey Bochkovskiy in 2020.
+3. **[YOLOv5](yolov5.md)**: An improved version of the YOLO architecture by Ultralytics, offering better performance and speed trade-offs compared to previous versions.
+4. **[YOLOv6](yolov6.md)**: Released by [Meituan](https://about.meituan.com/) in 2022, and in use in many of the company's autonomous delivery robots.
+5. **[YOLOv7](yolov7.md)**: Updated YOLO models released in 2022 by the authors of YOLOv4.
+6. **[YOLOv8](yolov8.md) NEW 🚀**: The latest version of the YOLO family, featuring enhanced capabilities such as instance segmentation, pose/keypoints estimation, and classification.
+7. **[YOLOv9](yolov9.md)**: An experimental model trained on the Ultralytics [YOLOv5](yolov5.md) codebase implementing Programmable Gradient Information (PGI).
+8. **[YOLOv10](yolov10.md)**: By Tsinghua University, featuring NMS-free training and efficiency-accuracy driven architecture, delivering state-of-the-art performance and latency.
+9. **[Segment Anything Model (SAM)](sam.md)**: Meta's original Segment Anything Model (SAM).
+10. **[Segment Anything Model 2 (SAM2)](sam-2.md)**: The next generation of Meta's Segment Anything Model (SAM) for videos and images.
+11. **[Mobile Segment Anything Model (MobileSAM)](mobile-sam.md)**: MobileSAM for mobile applications, by Kyung Hee University.
+12. **[Fast Segment Anything Model (FastSAM)](fast-sam.md)**: FastSAM by Image & Video Analysis Group, Institute of Automation, Chinese Academy of Sciences.
+13. **[YOLO-NAS](yolo-nas.md)**: YOLO Neural Architecture Search (NAS) Models.
+14. **[Realtime Detection Transformers (RT-DETR)](rtdetr.md)**: Baidu's PaddlePaddle Realtime Detection Transformer (RT-DETR) models.
+15. **[YOLO-World](yolo-world.md)**: Real-time Open Vocabulary Object Detection models from Tencent AI Lab.
+
+
+
+
+
+ Watch: Run Ultralytics YOLO models in just a few lines of code.
+
+
+## Getting Started: Usage Examples
+
+This example provides simple YOLO training and inference examples. For full documentation on these and other [modes](../modes/index.md) see the [Predict](../modes/predict.md), [Train](../modes/train.md), [Val](../modes/val.md) and [Export](../modes/export.md) docs pages.
+
+Note the below example is for YOLOv8 [Detect](../tasks/detect.md) models for object detection. For additional supported tasks see the [Segment](../tasks/segment.md), [Classify](../tasks/classify.md) and [Pose](../tasks/pose.md) docs.
+
+!!! Example
+
+ === "Python"
+
+ PyTorch pretrained `*.pt` models as well as configuration `*.yaml` files can be passed to the `YOLO()`, `SAM()`, `NAS()` and `RTDETR()` classes to create a model instance in Python:
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a COCO-pretrained YOLOv8n model
+ model = YOLO("yolov8n.pt")
+
+ # Display model information (optional)
+ model.info()
+
+ # Train the model on the COCO8 example dataset for 100 epochs
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
+
+ # Run inference with the YOLOv8n model on the 'bus.jpg' image
+ results = model("path/to/bus.jpg")
+ ```
+
+ === "CLI"
+
+ CLI commands are available to directly run the models:
+
+ ```bash
+ # Load a COCO-pretrained YOLOv8n model and train it on the COCO8 example dataset for 100 epochs
+ yolo train model=yolov8n.pt data=coco8.yaml epochs=100 imgsz=640
+
+ # Load a COCO-pretrained YOLOv8n model and run inference on the 'bus.jpg' image
+ yolo predict model=yolov8n.pt source=path/to/bus.jpg
+ ```
+
+## Contributing New Models
+
+Interested in contributing your model to Ultralytics? Great! We're always open to expanding our model portfolio.
+
+1. **Fork the Repository**: Start by forking the [Ultralytics GitHub repository](https://github.com/ultralytics/ultralytics).
+
+2. **Clone Your Fork**: Clone your fork to your local machine and create a new branch to work on.
+
+3. **Implement Your Model**: Add your model following the coding standards and guidelines provided in our [Contributing Guide](../help/contributing.md).
+
+4. **Test Thoroughly**: Make sure to test your model rigorously, both in isolation and as part of the pipeline.
+
+5. **Create a Pull Request**: Once you're satisfied with your model, create a pull request to the main repository for review.
+
+6. **Code Review & Merging**: After review, if your model meets our criteria, it will be merged into the main repository.
+
+For detailed steps, consult our [Contributing Guide](../help/contributing.md).
+
+## FAQ
+
+### What are the key advantages of using Ultralytics YOLOv8 for object detection?
+
+Ultralytics YOLOv8 offers enhanced capabilities such as real-time object detection, instance segmentation, pose estimation, and classification. Its optimized architecture ensures high-speed performance without sacrificing accuracy, making it ideal for a variety of applications. YOLOv8 also includes built-in compatibility with popular datasets and models, as detailed on the [YOLOv8 documentation page](../models/yolov8.md).
+
+### How can I train a YOLOv8 model on custom data?
+
+Training a YOLOv8 model on custom data can be easily accomplished using Ultralytics' libraries. Here's a quick example:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a YOLOv8n model
+ model = YOLO("yolov8n.pt")
+
+ # Train the model on custom dataset
+ results = model.train(data="custom_data.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo train model=yolov8n.pt data='custom_data.yaml' epochs=100 imgsz=640
+ ```
+
+For more detailed instructions, visit the [Train](../modes/train.md) documentation page.
+
+### Which YOLO versions are supported by Ultralytics?
+
+Ultralytics supports a comprehensive range of YOLO (You Only Look Once) versions from YOLOv3 to YOLOv10, along with models like NAS, SAM, and RT-DETR. Each version is optimized for various tasks such as detection, segmentation, and classification. For detailed information on each model, refer to the [Models Supported by Ultralytics](../models/index.md) documentation.
+
+### Why should I use Ultralytics HUB for machine learning projects?
+
+Ultralytics HUB provides a no-code, end-to-end platform for training, deploying, and managing YOLO models. It simplifies complex workflows, enabling users to focus on model performance and application. The HUB also offers cloud training capabilities, comprehensive dataset management, and user-friendly interfaces. Learn more about it on the [Ultralytics HUB](../hub/index.md) documentation page.
+
+### What types of tasks can YOLOv8 perform, and how does it compare to other YOLO versions?
+
+YOLOv8 is a versatile model capable of performing tasks including object detection, instance segmentation, classification, and pose estimation. Compared to earlier versions like YOLOv3 and YOLOv4, YOLOv8 offers significant improvements in speed and accuracy due to its optimized architecture. For a deeper comparison, refer to the [YOLOv8 documentation](../models/yolov8.md) and the [Task pages](../tasks/index.md) for more details on specific tasks.
diff --git a/ultralytics/docs/en/models/mobile-sam.md b/ultralytics/docs/en/models/mobile-sam.md
new file mode 100644
index 0000000000000000000000000000000000000000..58b14418d8cab9a43acf0d0e1384cc8370572569
--- /dev/null
+++ b/ultralytics/docs/en/models/mobile-sam.md
@@ -0,0 +1,159 @@
+---
+comments: true
+description: Discover MobileSAM, a lightweight and fast image segmentation model for mobile applications. Compare its performance with the original SAM and explore its various modes.
+keywords: MobileSAM, image segmentation, lightweight model, fast segmentation, mobile applications, SAM, ViT encoder, Tiny-ViT, Ultralytics
+---
+
+
+
+# Mobile Segment Anything (MobileSAM)
+
+The MobileSAM paper is now available on [arXiv](https://arxiv.org/pdf/2306.14289.pdf).
+
+A demonstration of MobileSAM running on a CPU can be accessed at this [demo link](https://huggingface.co/spaces/dhkim2810/MobileSAM). The performance on a Mac i5 CPU takes approximately 3 seconds. On the Hugging Face demo, the interface and lower-performance CPUs contribute to a slower response, but it continues to function effectively.
+
+MobileSAM is implemented in various projects including [Grounding-SAM](https://github.com/IDEA-Research/Grounded-Segment-Anything), [AnyLabeling](https://github.com/vietanhdev/anylabeling), and [Segment Anything in 3D](https://github.com/Jumpat/SegmentAnythingin3D).
+
+MobileSAM is trained on a single GPU with a 100k dataset (1% of the original images) in less than a day. The code for this training will be made available in the future.
+
+## Available Models, Supported Tasks, and Operating Modes
+
+This table presents the available models with their specific pre-trained weights, the tasks they support, and their compatibility with different operating modes like [Inference](../modes/predict.md), [Validation](../modes/val.md), [Training](../modes/train.md), and [Export](../modes/export.md), indicated by ✅ emojis for supported modes and ❌ emojis for unsupported modes.
+
+| Model Type | Pre-trained Weights | Tasks Supported | Inference | Validation | Training | Export |
+| ---------- | --------------------------------------------------------------------------------------------- | -------------------------------------------- | --------- | ---------- | -------- | ------ |
+| MobileSAM | [mobile_sam.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/mobile_sam.pt) | [Instance Segmentation](../tasks/segment.md) | ✅ | ❌ | ❌ | ❌ |
+
+## Adapting from SAM to MobileSAM
+
+Since MobileSAM retains the same pipeline as the original SAM, we have incorporated the original's pre-processing, post-processing, and all other interfaces. Consequently, those currently using the original SAM can transition to MobileSAM with minimal effort.
+
+MobileSAM performs comparably to the original SAM and retains the same pipeline except for a change in the image encoder. Specifically, we replace the original heavyweight ViT-H encoder (632M) with a smaller Tiny-ViT (5M). On a single GPU, MobileSAM operates at about 12ms per image: 8ms on the image encoder and 4ms on the mask decoder.
+
+The following table provides a comparison of ViT-based image encoders:
+
+| Image Encoder | Original SAM | MobileSAM |
+| ------------- | ------------ | --------- |
+| Parameters | 611M | 5M |
+| Speed | 452ms | 8ms |
+
+Both the original SAM and MobileSAM utilize the same prompt-guided mask decoder:
+
+| Mask Decoder | Original SAM | MobileSAM |
+| ------------ | ------------ | --------- |
+| Parameters | 3.876M | 3.876M |
+| Speed | 4ms | 4ms |
+
+Here is the comparison of the whole pipeline:
+
+| Whole Pipeline (Enc+Dec) | Original SAM | MobileSAM |
+| ------------------------ | ------------ | --------- |
+| Parameters | 615M | 9.66M |
+| Speed | 456ms | 12ms |
+
+The performance of MobileSAM and the original SAM are demonstrated using both a point and a box as prompts.
+
+
+
+
+
+With its superior performance, MobileSAM is approximately 5 times smaller and 7 times faster than the current FastSAM. More details are available at the [MobileSAM project page](https://github.com/ChaoningZhang/MobileSAM).
+
+## Testing MobileSAM in Ultralytics
+
+Just like the original SAM, we offer a straightforward testing method in Ultralytics, including modes for both Point and Box prompts.
+
+### Model Download
+
+You can download the model [here](https://github.com/ChaoningZhang/MobileSAM/blob/master/weights/mobile_sam.pt).
+
+### Point Prompt
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import SAM
+
+ # Load the model
+ model = SAM("mobile_sam.pt")
+
+ # Predict a segment based on a point prompt
+ model.predict("ultralytics/assets/zidane.jpg", points=[900, 370], labels=[1])
+ ```
+
+### Box Prompt
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import SAM
+
+ # Load the model
+ model = SAM("mobile_sam.pt")
+
+ # Predict a segment based on a box prompt
+ model.predict("ultralytics/assets/zidane.jpg", bboxes=[439, 437, 524, 709])
+ ```
+
+We have implemented `MobileSAM` and `SAM` using the same API. For more usage information, please see the [SAM page](sam.md).
+
+## Citations and Acknowledgements
+
+If you find MobileSAM useful in your research or development work, please consider citing our paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @article{mobile_sam,
+ title={Faster Segment Anything: Towards Lightweight SAM for Mobile Applications},
+ author={Zhang, Chaoning and Han, Dongshen and Qiao, Yu and Kim, Jung Uk and Bae, Sung Ho and Lee, Seungkyu and Hong, Choong Seon},
+ journal={arXiv preprint arXiv:2306.14289},
+ year={2023}
+ }
+ ```
+
+## FAQ
+
+### What is MobileSAM and how does it differ from the original SAM model?
+
+MobileSAM is a lightweight, fast image segmentation model designed for mobile applications. It retains the same pipeline as the original SAM but replaces the heavyweight ViT-H encoder (632M parameters) with a smaller Tiny-ViT encoder (5M parameters). This change results in MobileSAM being approximately 5 times smaller and 7 times faster than the original SAM. For instance, MobileSAM operates at about 12ms per image, compared to the original SAM's 456ms. You can learn more about the MobileSAM implementation in various projects [here](https://github.com/ChaoningZhang/MobileSAM).
+
+### How can I test MobileSAM using Ultralytics?
+
+Testing MobileSAM in Ultralytics can be accomplished through straightforward methods. You can use Point and Box prompts to predict segments. Here's an example using a Point prompt:
+
+```python
+from ultralytics import SAM
+
+# Load the model
+model = SAM("mobile_sam.pt")
+
+# Predict a segment based on a point prompt
+model.predict("ultralytics/assets/zidane.jpg", points=[900, 370], labels=[1])
+```
+
+You can also refer to the [Testing MobileSAM](#testing-mobilesam-in-ultralytics) section for more details.
+
+### Why should I use MobileSAM for my mobile application?
+
+MobileSAM is ideal for mobile applications due to its lightweight architecture and fast inference speed. Compared to the original SAM, MobileSAM is approximately 5 times smaller and 7 times faster, making it suitable for environments where computational resources are limited. This efficiency ensures that mobile devices can perform real-time image segmentation without significant latency. Additionally, MobileSAM's models, such as [Inference](../modes/predict.md), are optimized for mobile performance.
+
+### How was MobileSAM trained, and is the training code available?
+
+MobileSAM was trained on a single GPU with a 100k dataset, which is 1% of the original images, in less than a day. While the training code will be made available in the future, you can currently explore other aspects of MobileSAM in the [MobileSAM GitHub repository](https://github.com/ultralytics/assets/releases/download/v8.2.0/mobile_sam.pt). This repository includes pre-trained weights and implementation details for various applications.
+
+### What are the primary use cases for MobileSAM?
+
+MobileSAM is designed for fast and efficient image segmentation in mobile environments. Primary use cases include:
+
+- **Real-time object detection and segmentation** for mobile applications.
+- **Low-latency image processing** in devices with limited computational resources.
+- **Integration in AI-driven mobile apps** for tasks such as augmented reality (AR) and real-time analytics.
+
+For more detailed use cases and performance comparisons, see the section on [Adapting from SAM to MobileSAM](#adapting-from-sam-to-mobilesam).
diff --git a/ultralytics/docs/en/models/rtdetr.md b/ultralytics/docs/en/models/rtdetr.md
new file mode 100644
index 0000000000000000000000000000000000000000..2199b9df1e536d4d6671c347f6ee2ca46d7e925b
--- /dev/null
+++ b/ultralytics/docs/en/models/rtdetr.md
@@ -0,0 +1,153 @@
+---
+comments: true
+description: Explore Baidu's RT-DETR, a Vision Transformer-based real-time object detector offering high accuracy and adaptable inference speed. Learn more with Ultralytics.
+keywords: RT-DETR, Baidu, Vision Transformer, real-time object detection, PaddlePaddle, Ultralytics, pre-trained models, AI, machine learning, computer vision
+---
+
+# Baidu's RT-DETR: A Vision Transformer-Based Real-Time Object Detector
+
+## Overview
+
+Real-Time Detection Transformer (RT-DETR), developed by Baidu, is a cutting-edge end-to-end object detector that provides real-time performance while maintaining high accuracy. It is based on the idea of DETR (the NMS-free framework), meanwhile introducing conv-based backbone and an efficient hybrid encoder to gain real-time speed. RT-DETR efficiently processes multiscale features by decoupling intra-scale interaction and cross-scale fusion. The model is highly adaptable, supporting flexible adjustment of inference speed using different decoder layers without retraining. RT-DETR excels on accelerated backends like CUDA with TensorRT, outperforming many other real-time object detectors.
+
+
+
+ **Overview of Baidu's RT-DETR.** The RT-DETR model architecture diagram shows the last three stages of the backbone {S3, S4, S5} as the input to the encoder. The efficient hybrid encoder transforms multiscale features into a sequence of image features through intrascale feature interaction (AIFI) and cross-scale feature-fusion module (CCFM). The IoU-aware query selection is employed to select a fixed number of image features to serve as initial object queries for the decoder. Finally, the decoder with auxiliary prediction heads iteratively optimizes object queries to generate boxes and confidence scores ([source](https://arxiv.org/pdf/2304.08069.pdf)).
+
+### Key Features
+
+- **Efficient Hybrid Encoder:** Baidu's RT-DETR uses an efficient hybrid encoder that processes multiscale features by decoupling intra-scale interaction and cross-scale fusion. This unique Vision Transformers-based design reduces computational costs and allows for real-time object detection.
+- **IoU-aware Query Selection:** Baidu's RT-DETR improves object query initialization by utilizing IoU-aware query selection. This allows the model to focus on the most relevant objects in the scene, enhancing the detection accuracy.
+- **Adaptable Inference Speed:** Baidu's RT-DETR supports flexible adjustments of inference speed by using different decoder layers without the need for retraining. This adaptability facilitates practical application in various real-time object detection scenarios.
+
+## Pre-trained Models
+
+The Ultralytics Python API provides pre-trained PaddlePaddle RT-DETR models with different scales:
+
+- RT-DETR-L: 53.0% AP on COCO val2017, 114 FPS on T4 GPU
+- RT-DETR-X: 54.8% AP on COCO val2017, 74 FPS on T4 GPU
+
+## Usage Examples
+
+This example provides simple RT-DETR training and inference examples. For full documentation on these and other [modes](../modes/index.md) see the [Predict](../modes/predict.md), [Train](../modes/train.md), [Val](../modes/val.md) and [Export](../modes/export.md) docs pages.
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import RTDETR
+
+ # Load a COCO-pretrained RT-DETR-l model
+ model = RTDETR("rtdetr-l.pt")
+
+ # Display model information (optional)
+ model.info()
+
+ # Train the model on the COCO8 example dataset for 100 epochs
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
+
+ # Run inference with the RT-DETR-l model on the 'bus.jpg' image
+ results = model("path/to/bus.jpg")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Load a COCO-pretrained RT-DETR-l model and train it on the COCO8 example dataset for 100 epochs
+ yolo train model=rtdetr-l.pt data=coco8.yaml epochs=100 imgsz=640
+
+ # Load a COCO-pretrained RT-DETR-l model and run inference on the 'bus.jpg' image
+ yolo predict model=rtdetr-l.pt source=path/to/bus.jpg
+ ```
+
+## Supported Tasks and Modes
+
+This table presents the model types, the specific pre-trained weights, the tasks supported by each model, and the various modes ([Train](../modes/train.md) , [Val](../modes/val.md), [Predict](../modes/predict.md), [Export](../modes/export.md)) that are supported, indicated by ✅ emojis.
+
+| Model Type | Pre-trained Weights | Tasks Supported | Inference | Validation | Training | Export |
+| ------------------- | ----------------------------------------------------------------------------------------- | -------------------------------------- | --------- | ---------- | -------- | ------ |
+| RT-DETR Large | [rtdetr-l.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/rtdetr-l.pt) | [Object Detection](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
+| RT-DETR Extra-Large | [rtdetr-x.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/rtdetr-x.pt) | [Object Detection](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
+
+## Citations and Acknowledgements
+
+If you use Baidu's RT-DETR in your research or development work, please cite the [original paper](https://arxiv.org/abs/2304.08069):
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @misc{lv2023detrs,
+ title={DETRs Beat YOLOs on Real-time Object Detection},
+ author={Wenyu Lv and Shangliang Xu and Yian Zhao and Guanzhong Wang and Jinman Wei and Cheng Cui and Yuning Du and Qingqing Dang and Yi Liu},
+ year={2023},
+ eprint={2304.08069},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+ }
+ ```
+
+We would like to acknowledge Baidu and the [PaddlePaddle](https://github.com/PaddlePaddle/PaddleDetection) team for creating and maintaining this valuable resource for the computer vision community. Their contribution to the field with the development of the Vision Transformers-based real-time object detector, RT-DETR, is greatly appreciated.
+
+## FAQ
+
+### What is Baidu's RT-DETR model and how does it work?
+
+Baidu's RT-DETR (Real-Time Detection Transformer) is an advanced real-time object detector built upon the Vision Transformer architecture. It efficiently processes multiscale features by decoupling intra-scale interaction and cross-scale fusion through its efficient hybrid encoder. By employing IoU-aware query selection, the model focuses on the most relevant objects, enhancing detection accuracy. Its adaptable inference speed, achieved by adjusting decoder layers without retraining, makes RT-DETR suitable for various real-time object detection scenarios. Learn more about RT-DETR features [here](https://arxiv.org/pdf/2304.08069.pdf).
+
+### How can I use the pre-trained RT-DETR models provided by Ultralytics?
+
+You can leverage Ultralytics Python API to use pre-trained PaddlePaddle RT-DETR models. For instance, to load an RT-DETR-l model pre-trained on COCO val2017 and achieve high FPS on T4 GPU, you can utilize the following example:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import RTDETR
+
+ # Load a COCO-pretrained RT-DETR-l model
+ model = RTDETR("rtdetr-l.pt")
+
+ # Display model information (optional)
+ model.info()
+
+ # Train the model on the COCO8 example dataset for 100 epochs
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
+
+ # Run inference with the RT-DETR-l model on the 'bus.jpg' image
+ results = model("path/to/bus.jpg")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Load a COCO-pretrained RT-DETR-l model and train it on the COCO8 example dataset for 100 epochs
+ yolo train model=rtdetr-l.pt data=coco8.yaml epochs=100 imgsz=640
+
+ # Load a COCO-pretrained RT-DETR-l model and run inference on the 'bus.jpg' image
+ yolo predict model=rtdetr-l.pt source=path/to/bus.jpg
+ ```
+
+### Why should I choose Baidu's RT-DETR over other real-time object detectors?
+
+Baidu's RT-DETR stands out due to its efficient hybrid encoder and IoU-aware query selection, which drastically reduce computational costs while maintaining high accuracy. Its unique ability to adjust inference speed by using different decoder layers without retraining adds significant flexibility. This makes it particularly advantageous for applications requiring real-time performance on accelerated backends like CUDA with TensorRT, outclassing many other real-time object detectors.
+
+### How does RT-DETR support adaptable inference speed for different real-time applications?
+
+Baidu's RT-DETR allows flexible adjustments of inference speed by using different decoder layers without requiring retraining. This adaptability is crucial for scaling performance across various real-time object detection tasks. Whether you need faster processing for lower precision needs or slower, more accurate detections, RT-DETR can be tailored to meet your specific requirements.
+
+### Can I use RT-DETR models with other Ultralytics modes, such as training, validation, and export?
+
+Yes, RT-DETR models are compatible with various Ultralytics modes including training, validation, prediction, and export. You can refer to the respective documentation for detailed instructions on how to utilize these modes: [Train](../modes/train.md), [Val](../modes/val.md), [Predict](../modes/predict.md), and [Export](../modes/export.md). This ensures a comprehensive workflow for developing and deploying your object detection solutions.
diff --git a/ultralytics/docs/en/models/sam-2.md b/ultralytics/docs/en/models/sam-2.md
new file mode 100644
index 0000000000000000000000000000000000000000..f3bcfd464fdfccfb2c4620c3f34a016a86e338fa
--- /dev/null
+++ b/ultralytics/docs/en/models/sam-2.md
@@ -0,0 +1,341 @@
+---
+comments: true
+description: Discover SAM 2, the next generation of Meta's Segment Anything Model, supporting real-time promptable segmentation in both images and videos with state-of-the-art performance. Learn about its key features, datasets, and how to use it.
+keywords: SAM 2, Segment Anything, video segmentation, image segmentation, promptable segmentation, zero-shot performance, SA-V dataset, Ultralytics, real-time segmentation, AI, machine learning
+---
+
+# SAM 2: Segment Anything Model 2
+
+SAM 2, the successor to Meta's [Segment Anything Model (SAM)](sam.md), is a cutting-edge tool designed for comprehensive object segmentation in both images and videos. It excels in handling complex visual data through a unified, promptable model architecture that supports real-time processing and zero-shot generalization.
+
+
+
+## Key Features
+
+### Unified Model Architecture
+
+SAM 2 combines the capabilities of image and video segmentation in a single model. This unification simplifies deployment and allows for consistent performance across different media types. It leverages a flexible prompt-based interface, enabling users to specify objects of interest through various prompt types, such as points, bounding boxes, or masks.
+
+### Real-Time Performance
+
+The model achieves real-time inference speeds, processing approximately 44 frames per second. This makes SAM 2 suitable for applications requiring immediate feedback, such as video editing and augmented reality.
+
+### Zero-Shot Generalization
+
+SAM 2 can segment objects it has never encountered before, demonstrating strong zero-shot generalization. This is particularly useful in diverse or evolving visual domains where pre-defined categories may not cover all possible objects.
+
+### Interactive Refinement
+
+Users can iteratively refine the segmentation results by providing additional prompts, allowing for precise control over the output. This interactivity is essential for fine-tuning results in applications like video annotation or medical imaging.
+
+### Advanced Handling of Visual Challenges
+
+SAM 2 includes mechanisms to manage common video segmentation challenges, such as object occlusion and reappearance. It uses a sophisticated memory mechanism to keep track of objects across frames, ensuring continuity even when objects are temporarily obscured or exit and re-enter the scene.
+
+For a deeper understanding of SAM 2's architecture and capabilities, explore the [SAM 2 research paper](https://arxiv.org/abs/2401.12741).
+
+## Performance and Technical Details
+
+SAM 2 sets a new benchmark in the field, outperforming previous models on various metrics:
+
+| Metric | SAM 2 | Previous SOTA |
+| ---------------------------------- | ------------- | ------------- |
+| **Interactive Video Segmentation** | **Best** | - |
+| **Human Interactions Required** | **3x fewer** | Baseline |
+| **Image Segmentation Accuracy** | **Improved** | SAM |
+| **Inference Speed** | **6x faster** | SAM |
+
+## Model Architecture
+
+### Core Components
+
+- **Image and Video Encoder**: Utilizes a transformer-based architecture to extract high-level features from both images and video frames. This component is responsible for understanding the visual content at each timestep.
+- **Prompt Encoder**: Processes user-provided prompts (points, boxes, masks) to guide the segmentation task. This allows SAM 2 to adapt to user input and target specific objects within a scene.
+- **Memory Mechanism**: Includes a memory encoder, memory bank, and memory attention module. These components collectively store and utilize information from past frames, enabling the model to maintain consistent object tracking over time.
+- **Mask Decoder**: Generates the final segmentation masks based on the encoded image features and prompts. In video, it also uses memory context to ensure accurate tracking across frames.
+
+
+
+### Memory Mechanism and Occlusion Handling
+
+The memory mechanism allows SAM 2 to handle temporal dependencies and occlusions in video data. As objects move and interact, SAM 2 records their features in a memory bank. When an object becomes occluded, the model can rely on this memory to predict its position and appearance when it reappears. The occlusion head specifically handles scenarios where objects are not visible, predicting the likelihood of an object being occluded.
+
+### Multi-Mask Ambiguity Resolution
+
+In situations with ambiguity (e.g., overlapping objects), SAM 2 can generate multiple mask predictions. This feature is crucial for accurately representing complex scenes where a single mask might not sufficiently describe the scene's nuances.
+
+## SA-V Dataset
+
+The SA-V dataset, developed for SAM 2's training, is one of the largest and most diverse video segmentation datasets available. It includes:
+
+- **51,000+ Videos**: Captured across 47 countries, providing a wide range of real-world scenarios.
+- **600,000+ Mask Annotations**: Detailed spatio-temporal mask annotations, referred to as "masklets," covering whole objects and parts.
+- **Dataset Scale**: It features 4.5 times more videos and 53 times more annotations than previous largest datasets, offering unprecedented diversity and complexity.
+
+## Benchmarks
+
+### Video Object Segmentation
+
+SAM 2 has demonstrated superior performance across major video segmentation benchmarks:
+
+| Dataset | J&F | J | F |
+| --------------- | ---- | ---- | ---- |
+| **DAVIS 2017** | 82.5 | 79.8 | 85.2 |
+| **YouTube-VOS** | 81.2 | 78.9 | 83.5 |
+
+### Interactive Segmentation
+
+In interactive segmentation tasks, SAM 2 shows significant efficiency and accuracy:
+
+| Dataset | NoC@90 | AUC |
+| --------------------- | ------ | ----- |
+| **DAVIS Interactive** | 1.54 | 0.872 |
+
+## Installation
+
+To install SAM 2, use the following command. All SAM 2 models will automatically download on first use.
+
+```bash
+pip install ultralytics
+```
+
+## How to Use SAM 2: Versatility in Image and Video Segmentation
+
+The following table details the available SAM 2 models, their pre-trained weights, supported tasks, and compatibility with different operating modes like [Inference](../modes/predict.md), [Validation](../modes/val.md), [Training](../modes/train.md), and [Export](../modes/export.md).
+
+| Model Type | Pre-trained Weights | Tasks Supported | Inference | Validation | Training | Export |
+| ----------- | ------------------------------------------------------------------------------------- | -------------------------------------------- | --------- | ---------- | -------- | ------ |
+| SAM 2 tiny | [sam2_t.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/sam2_t.pt) | [Instance Segmentation](../tasks/segment.md) | ✅ | ❌ | ❌ | ❌ |
+| SAM 2 small | [sam2_s.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/sam2_s.pt) | [Instance Segmentation](../tasks/segment.md) | ✅ | ❌ | ❌ | ❌ |
+| SAM 2 base | [sam2_b.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/sam2_b.pt) | [Instance Segmentation](../tasks/segment.md) | ✅ | ❌ | ❌ | ❌ |
+| SAM 2 large | [sam2_l.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/sam2_l.pt) | [Instance Segmentation](../tasks/segment.md) | ✅ | ❌ | ❌ | ❌ |
+
+### SAM 2 Prediction Examples
+
+SAM 2 can be utilized across a broad spectrum of tasks, including real-time video editing, medical imaging, and autonomous systems. Its ability to segment both static and dynamic visual data makes it a versatile tool for researchers and developers.
+
+#### Segment with Prompts
+
+!!! Example "Segment with Prompts"
+
+ Use prompts to segment specific objects in images or videos.
+
+ === "Python"
+
+ ```python
+ from ultralytics import SAM
+
+ # Load a model
+ model = SAM("sam2_b.pt")
+
+ # Display model information (optional)
+ model.info()
+
+ # Segment with bounding box prompt
+ results = model("path/to/image.jpg", bboxes=[100, 100, 200, 200])
+
+ # Segment with point prompt
+ results = model("path/to/image.jpg", points=[150, 150], labels=[1])
+ ```
+
+#### Segment Everything
+
+!!! Example "Segment Everything"
+
+ Segment the entire image or video content without specific prompts.
+
+ === "Python"
+
+ ```python
+ from ultralytics import SAM
+
+ # Load a model
+ model = SAM("sam2_b.pt")
+
+ # Display model information (optional)
+ model.info()
+
+ # Run inference
+ model("path/to/video.mp4")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Run inference with a SAM 2 model
+ yolo predict model=sam2_b.pt source=path/to/video.mp4
+ ```
+
+- This example demonstrates how SAM 2 can be used to segment the entire content of an image or video if no prompts (bboxes/points/masks) are provided.
+
+## SAM comparison vs YOLOv8
+
+Here we compare Meta's smallest SAM model, SAM-b, with Ultralytics smallest segmentation model, [YOLOv8n-seg](../tasks/segment.md):
+
+| Model | Size | Parameters | Speed (CPU) |
+| ---------------------------------------------- | -------------------------- | ---------------------- | -------------------------- |
+| Meta's SAM-b | 358 MB | 94.7 M | 51096 ms/im |
+| [MobileSAM](mobile-sam.md) | 40.7 MB | 10.1 M | 46122 ms/im |
+| [FastSAM-s](fast-sam.md) with YOLOv8 backbone | 23.7 MB | 11.8 M | 115 ms/im |
+| Ultralytics [YOLOv8n-seg](../tasks/segment.md) | **6.7 MB** (53.4x smaller) | **3.4 M** (27.9x less) | **59 ms/im** (866x faster) |
+
+This comparison shows the order-of-magnitude differences in the model sizes and speeds between models. Whereas SAM presents unique capabilities for automatic segmenting, it is not a direct competitor to YOLOv8 segment models, which are smaller, faster and more efficient.
+
+Tests run on a 2023 Apple M2 Macbook with 16GB of RAM. To reproduce this test:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import SAM, YOLO, FastSAM
+
+ # Profile SAM-b
+ model = SAM("sam_b.pt")
+ model.info()
+ model("ultralytics/assets")
+
+ # Profile MobileSAM
+ model = SAM("mobile_sam.pt")
+ model.info()
+ model("ultralytics/assets")
+
+ # Profile FastSAM-s
+ model = FastSAM("FastSAM-s.pt")
+ model.info()
+ model("ultralytics/assets")
+
+ # Profile YOLOv8n-seg
+ model = YOLO("yolov8n-seg.pt")
+ model.info()
+ model("ultralytics/assets")
+ ```
+
+## Auto-Annotation: Efficient Dataset Creation
+
+Auto-annotation is a powerful feature of SAM 2, enabling users to generate segmentation datasets quickly and accurately by leveraging pre-trained models. This capability is particularly useful for creating large, high-quality datasets without extensive manual effort.
+
+### How to Auto-Annotate with SAM 2
+
+To auto-annotate your dataset using SAM 2, follow this example:
+
+!!! Example "Auto-Annotation Example"
+
+ ```python
+ from ultralytics.data.annotator import auto_annotate
+
+ auto_annotate(data="path/to/images", det_model="yolov8x.pt", sam_model="sam2_b.pt")
+ ```
+
+| Argument | Type | Description | Default |
+| ------------ | ----------------------- | ------------------------------------------------------------------------------------------------------- | -------------- |
+| `data` | `str` | Path to a folder containing images to be annotated. | |
+| `det_model` | `str`, optional | Pre-trained YOLO detection model. Defaults to 'yolov8x.pt'. | `'yolov8x.pt'` |
+| `sam_model` | `str`, optional | Pre-trained SAM 2 segmentation model. Defaults to 'sam2_b.pt'. | `'sam2_b.pt'` |
+| `device` | `str`, optional | Device to run the models on. Defaults to an empty string (CPU or GPU, if available). | |
+| `output_dir` | `str`, `None`, optional | Directory to save the annotated results. Defaults to a 'labels' folder in the same directory as 'data'. | `None` |
+
+This function facilitates the rapid creation of high-quality segmentation datasets, ideal for researchers and developers aiming to accelerate their projects.
+
+## Limitations
+
+Despite its strengths, SAM 2 has certain limitations:
+
+- **Tracking Stability**: SAM 2 may lose track of objects during extended sequences or significant viewpoint changes.
+- **Object Confusion**: The model can sometimes confuse similar-looking objects, particularly in crowded scenes.
+- **Efficiency with Multiple Objects**: Segmentation efficiency decreases when processing multiple objects simultaneously due to the lack of inter-object communication.
+- **Detail Accuracy**: May miss fine details, especially with fast-moving objects. Additional prompts can partially address this issue, but temporal smoothness is not guaranteed.
+
+## Citations and Acknowledgements
+
+If SAM 2 is a crucial part of your research or development work, please cite it using the following reference:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @article{ravi2024sam2,
+ title={SAM 2: Segment Anything in Images and Videos},
+ author={Ravi, Nikhila and Gabeur, Valentin and Hu, Yuan-Ting and Hu, Ronghang and Ryali, Chaitanya and Ma, Tengyu and Khedr, Haitham and R{\"a}dle, Roman and Rolland, Chloe and Gustafson, Laura and Mintun, Eric and Pan, Junting and Alwala, Kalyan Vasudev and Carion, Nicolas and Wu, Chao-Yuan and Girshick, Ross and Doll{\'a}r, Piotr and Feichtenhofer, Christoph},
+ journal={arXiv preprint},
+ year={2024}
+ }
+ ```
+
+We extend our gratitude to Meta AI for their contributions to the AI community with this groundbreaking model and dataset.
+
+## FAQ
+
+### What is SAM 2 and how does it improve upon the original Segment Anything Model (SAM)?
+
+SAM 2, the successor to Meta's [Segment Anything Model (SAM)](sam.md), is a cutting-edge tool designed for comprehensive object segmentation in both images and videos. It excels in handling complex visual data through a unified, promptable model architecture that supports real-time processing and zero-shot generalization. SAM 2 offers several improvements over the original SAM, including:
+
+- **Unified Model Architecture**: Combines image and video segmentation capabilities in a single model.
+- **Real-Time Performance**: Processes approximately 44 frames per second, making it suitable for applications requiring immediate feedback.
+- **Zero-Shot Generalization**: Segments objects it has never encountered before, useful in diverse visual domains.
+- **Interactive Refinement**: Allows users to iteratively refine segmentation results by providing additional prompts.
+- **Advanced Handling of Visual Challenges**: Manages common video segmentation challenges like object occlusion and reappearance.
+
+For more details on SAM 2's architecture and capabilities, explore the [SAM 2 research paper](https://arxiv.org/abs/2401.12741).
+
+### How can I use SAM 2 for real-time video segmentation?
+
+SAM 2 can be utilized for real-time video segmentation by leveraging its promptable interface and real-time inference capabilities. Here's a basic example:
+
+!!! Example "Segment with Prompts"
+
+ Use prompts to segment specific objects in images or videos.
+
+ === "Python"
+
+ ```python
+ from ultralytics import SAM
+
+ # Load a model
+ model = SAM("sam2_b.pt")
+
+ # Display model information (optional)
+ model.info()
+
+ # Segment with bounding box prompt
+ results = model("path/to/image.jpg", bboxes=[100, 100, 200, 200])
+
+ # Segment with point prompt
+ results = model("path/to/image.jpg", points=[150, 150], labels=[1])
+ ```
+
+For more comprehensive usage, refer to the [How to Use SAM 2](#how-to-use-sam-2-versatility-in-image-and-video-segmentation) section.
+
+### What datasets are used to train SAM 2, and how do they enhance its performance?
+
+SAM 2 is trained on the SA-V dataset, one of the largest and most diverse video segmentation datasets available. The SA-V dataset includes:
+
+- **51,000+ Videos**: Captured across 47 countries, providing a wide range of real-world scenarios.
+- **600,000+ Mask Annotations**: Detailed spatio-temporal mask annotations, referred to as "masklets," covering whole objects and parts.
+- **Dataset Scale**: Features 4.5 times more videos and 53 times more annotations than previous largest datasets, offering unprecedented diversity and complexity.
+
+This extensive dataset allows SAM 2 to achieve superior performance across major video segmentation benchmarks and enhances its zero-shot generalization capabilities. For more information, see the [SA-V Dataset](#sa-v-dataset) section.
+
+### How does SAM 2 handle occlusions and object reappearances in video segmentation?
+
+SAM 2 includes a sophisticated memory mechanism to manage temporal dependencies and occlusions in video data. The memory mechanism consists of:
+
+- **Memory Encoder and Memory Bank**: Stores features from past frames.
+- **Memory Attention Module**: Utilizes stored information to maintain consistent object tracking over time.
+- **Occlusion Head**: Specifically handles scenarios where objects are not visible, predicting the likelihood of an object being occluded.
+
+This mechanism ensures continuity even when objects are temporarily obscured or exit and re-enter the scene. For more details, refer to the [Memory Mechanism and Occlusion Handling](#memory-mechanism-and-occlusion-handling) section.
+
+### How does SAM 2 compare to other segmentation models like YOLOv8?
+
+SAM 2 and Ultralytics YOLOv8 serve different purposes and excel in different areas. While SAM 2 is designed for comprehensive object segmentation with advanced features like zero-shot generalization and real-time performance, YOLOv8 is optimized for speed and efficiency in object detection and segmentation tasks. Here's a comparison:
+
+| Model | Size | Parameters | Speed (CPU) |
+| ---------------------------------------------- | -------------------------- | ---------------------- | -------------------------- |
+| Meta's SAM-b | 358 MB | 94.7 M | 51096 ms/im |
+| [MobileSAM](mobile-sam.md) | 40.7 MB | 10.1 M | 46122 ms/im |
+| [FastSAM-s](fast-sam.md) with YOLOv8 backbone | 23.7 MB | 11.8 M | 115 ms/im |
+| Ultralytics [YOLOv8n-seg](../tasks/segment.md) | **6.7 MB** (53.4x smaller) | **3.4 M** (27.9x less) | **59 ms/im** (866x faster) |
+
+For more details, see the [SAM comparison vs YOLOv8](#sam-comparison-vs-yolov8) section.
diff --git a/ultralytics/docs/en/models/sam.md b/ultralytics/docs/en/models/sam.md
new file mode 100644
index 0000000000000000000000000000000000000000..33f78b5ca2b2b47fa84ca919c5577bdec49416db
--- /dev/null
+++ b/ultralytics/docs/en/models/sam.md
@@ -0,0 +1,280 @@
+---
+comments: true
+description: Explore the revolutionary Segment Anything Model (SAM) for promptable image segmentation with zero-shot performance. Discover key features, datasets, and usage tips.
+keywords: Segment Anything, SAM, image segmentation, promptable segmentation, zero-shot performance, SA-1B dataset, advanced architecture, auto-annotation, Ultralytics, pre-trained models, instance segmentation, computer vision, AI, machine learning
+---
+
+# Segment Anything Model (SAM)
+
+Welcome to the frontier of image segmentation with the Segment Anything Model, or SAM. This revolutionary model has changed the game by introducing promptable image segmentation with real-time performance, setting new standards in the field.
+
+## Introduction to SAM: The Segment Anything Model
+
+The Segment Anything Model, or SAM, is a cutting-edge image segmentation model that allows for promptable segmentation, providing unparalleled versatility in image analysis tasks. SAM forms the heart of the Segment Anything initiative, a groundbreaking project that introduces a novel model, task, and dataset for image segmentation.
+
+SAM's advanced design allows it to adapt to new image distributions and tasks without prior knowledge, a feature known as zero-shot transfer. Trained on the expansive [SA-1B dataset](https://ai.facebook.com/datasets/segment-anything/), which contains more than 1 billion masks spread over 11 million carefully curated images, SAM has displayed impressive zero-shot performance, surpassing previous fully supervised results in many cases.
+
+ **SA-1B Example images.** Dataset images overlaid masks from the newly introduced SA-1B dataset. SA-1B contains 11M diverse, high-resolution, licensed, and privacy protecting images and 1.1B high-quality segmentation masks. These masks were annotated fully automatically by SAM, and as verified by human ratings and numerous experiments, are of high quality and diversity. Images are grouped by number of masks per image for visualization (there are ∼100 masks per image on average).
+
+## Key Features of the Segment Anything Model (SAM)
+
+- **Promptable Segmentation Task:** SAM was designed with a promptable segmentation task in mind, allowing it to generate valid segmentation masks from any given prompt, such as spatial or text clues identifying an object.
+- **Advanced Architecture:** The Segment Anything Model employs a powerful image encoder, a prompt encoder, and a lightweight mask decoder. This unique architecture enables flexible prompting, real-time mask computation, and ambiguity awareness in segmentation tasks.
+- **The SA-1B Dataset:** Introduced by the Segment Anything project, the SA-1B dataset features over 1 billion masks on 11 million images. As the largest segmentation dataset to date, it provides SAM with a diverse and large-scale training data source.
+- **Zero-Shot Performance:** SAM displays outstanding zero-shot performance across various segmentation tasks, making it a ready-to-use tool for diverse applications with minimal need for prompt engineering.
+
+For an in-depth look at the Segment Anything Model and the SA-1B dataset, please visit the [Segment Anything website](https://segment-anything.com) and check out the research paper [Segment Anything](https://arxiv.org/abs/2304.02643).
+
+## Available Models, Supported Tasks, and Operating Modes
+
+This table presents the available models with their specific pre-trained weights, the tasks they support, and their compatibility with different operating modes like [Inference](../modes/predict.md), [Validation](../modes/val.md), [Training](../modes/train.md), and [Export](../modes/export.md), indicated by ✅ emojis for supported modes and ❌ emojis for unsupported modes.
+
+| Model Type | Pre-trained Weights | Tasks Supported | Inference | Validation | Training | Export |
+| ---------- | ----------------------------------------------------------------------------------- | -------------------------------------------- | --------- | ---------- | -------- | ------ |
+| SAM base | [sam_b.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/sam_b.pt) | [Instance Segmentation](../tasks/segment.md) | ✅ | ❌ | ❌ | ❌ |
+| SAM large | [sam_l.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/sam_l.pt) | [Instance Segmentation](../tasks/segment.md) | ✅ | ❌ | ❌ | ❌ |
+
+## How to Use SAM: Versatility and Power in Image Segmentation
+
+The Segment Anything Model can be employed for a multitude of downstream tasks that go beyond its training data. This includes edge detection, object proposal generation, instance segmentation, and preliminary text-to-mask prediction. With prompt engineering, SAM can swiftly adapt to new tasks and data distributions in a zero-shot manner, establishing it as a versatile and potent tool for all your image segmentation needs.
+
+### SAM prediction example
+
+!!! Example "Segment with prompts"
+
+ Segment image with given prompts.
+
+ === "Python"
+
+ ```python
+ from ultralytics import SAM
+
+ # Load a model
+ model = SAM("sam_b.pt")
+
+ # Display model information (optional)
+ model.info()
+
+ # Run inference with bboxes prompt
+ results = model("ultralytics/assets/zidane.jpg", bboxes=[439, 437, 524, 709])
+
+ # Run inference with points prompt
+ results = model("ultralytics/assets/zidane.jpg", points=[900, 370], labels=[1])
+ ```
+
+!!! Example "Segment everything"
+
+ Segment the whole image.
+
+ === "Python"
+
+ ```python
+ from ultralytics import SAM
+
+ # Load a model
+ model = SAM("sam_b.pt")
+
+ # Display model information (optional)
+ model.info()
+
+ # Run inference
+ model("path/to/image.jpg")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Run inference with a SAM model
+ yolo predict model=sam_b.pt source=path/to/image.jpg
+ ```
+
+- The logic here is to segment the whole image if you don't pass any prompts(bboxes/points/masks).
+
+!!! Example "SAMPredictor example"
+
+ This way you can set image once and run prompts inference multiple times without running image encoder multiple times.
+
+ === "Prompt inference"
+
+ ```python
+ from ultralytics.models.sam import Predictor as SAMPredictor
+
+ # Create SAMPredictor
+ overrides = dict(conf=0.25, task="segment", mode="predict", imgsz=1024, model="mobile_sam.pt")
+ predictor = SAMPredictor(overrides=overrides)
+
+ # Set image
+ predictor.set_image("ultralytics/assets/zidane.jpg") # set with image file
+ predictor.set_image(cv2.imread("ultralytics/assets/zidane.jpg")) # set with np.ndarray
+ results = predictor(bboxes=[439, 437, 524, 709])
+ results = predictor(points=[900, 370], labels=[1])
+
+ # Reset image
+ predictor.reset_image()
+ ```
+
+ Segment everything with additional args.
+
+ === "Segment everything"
+
+ ```python
+ from ultralytics.models.sam import Predictor as SAMPredictor
+
+ # Create SAMPredictor
+ overrides = dict(conf=0.25, task="segment", mode="predict", imgsz=1024, model="mobile_sam.pt")
+ predictor = SAMPredictor(overrides=overrides)
+
+ # Segment with additional args
+ results = predictor(source="ultralytics/assets/zidane.jpg", crop_n_layers=1, points_stride=64)
+ ```
+
+!!! Note
+
+ All the returned `results` in above examples are [Results](../modes/predict.md#working-with-results) object which allows access predicted masks and source image easily.
+
+- More additional args for `Segment everything` see [`Predictor/generate` Reference](../reference/models/sam/predict.md).
+
+## SAM comparison vs YOLOv8
+
+Here we compare Meta's smallest SAM model, SAM-b, with Ultralytics smallest segmentation model, [YOLOv8n-seg](../tasks/segment.md):
+
+| Model | Size | Parameters | Speed (CPU) |
+| ---------------------------------------------- | -------------------------- | ---------------------- | -------------------------- |
+| Meta's SAM-b | 358 MB | 94.7 M | 51096 ms/im |
+| [MobileSAM](mobile-sam.md) | 40.7 MB | 10.1 M | 46122 ms/im |
+| [FastSAM-s](fast-sam.md) with YOLOv8 backbone | 23.7 MB | 11.8 M | 115 ms/im |
+| Ultralytics [YOLOv8n-seg](../tasks/segment.md) | **6.7 MB** (53.4x smaller) | **3.4 M** (27.9x less) | **59 ms/im** (866x faster) |
+
+This comparison shows the order-of-magnitude differences in the model sizes and speeds between models. Whereas SAM presents unique capabilities for automatic segmenting, it is not a direct competitor to YOLOv8 segment models, which are smaller, faster and more efficient.
+
+Tests run on a 2023 Apple M2 Macbook with 16GB of RAM. To reproduce this test:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import SAM, YOLO, FastSAM
+
+ # Profile SAM-b
+ model = SAM("sam_b.pt")
+ model.info()
+ model("ultralytics/assets")
+
+ # Profile MobileSAM
+ model = SAM("mobile_sam.pt")
+ model.info()
+ model("ultralytics/assets")
+
+ # Profile FastSAM-s
+ model = FastSAM("FastSAM-s.pt")
+ model.info()
+ model("ultralytics/assets")
+
+ # Profile YOLOv8n-seg
+ model = YOLO("yolov8n-seg.pt")
+ model.info()
+ model("ultralytics/assets")
+ ```
+
+## Auto-Annotation: A Quick Path to Segmentation Datasets
+
+Auto-annotation is a key feature of SAM, allowing users to generate a [segmentation dataset](../datasets/segment/index.md) using a pre-trained detection model. This feature enables rapid and accurate annotation of a large number of images, bypassing the need for time-consuming manual labeling.
+
+### Generate Your Segmentation Dataset Using a Detection Model
+
+To auto-annotate your dataset with the Ultralytics framework, use the `auto_annotate` function as shown below:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics.data.annotator import auto_annotate
+
+ auto_annotate(data="path/to/images", det_model="yolov8x.pt", sam_model="sam_b.pt")
+ ```
+
+| Argument | Type | Description | Default |
+| ------------ | --------------------- | ------------------------------------------------------------------------------------------------------- | -------------- |
+| `data` | `str` | Path to a folder containing images to be annotated. | |
+| `det_model` | `str`, optional | Pre-trained YOLO detection model. Defaults to 'yolov8x.pt'. | `'yolov8x.pt'` |
+| `sam_model` | `str`, optional | Pre-trained SAM segmentation model. Defaults to 'sam_b.pt'. | `'sam_b.pt'` |
+| `device` | `str`, optional | Device to run the models on. Defaults to an empty string (CPU or GPU, if available). | |
+| `output_dir` | `str`, None, optional | Directory to save the annotated results. Defaults to a 'labels' folder in the same directory as 'data'. | `None` |
+
+The `auto_annotate` function takes the path to your images, with optional arguments for specifying the pre-trained detection and SAM segmentation models, the device to run the models on, and the output directory for saving the annotated results.
+
+Auto-annotation with pre-trained models can dramatically cut down the time and effort required for creating high-quality segmentation datasets. This feature is especially beneficial for researchers and developers dealing with large image collections, as it allows them to focus on model development and evaluation rather than manual annotation.
+
+## Citations and Acknowledgements
+
+If you find SAM useful in your research or development work, please consider citing our paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @misc{kirillov2023segment,
+ title={Segment Anything},
+ author={Alexander Kirillov and Eric Mintun and Nikhila Ravi and Hanzi Mao and Chloe Rolland and Laura Gustafson and Tete Xiao and Spencer Whitehead and Alexander C. Berg and Wan-Yen Lo and Piotr Dollár and Ross Girshick},
+ year={2023},
+ eprint={2304.02643},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+ }
+ ```
+
+We would like to express our gratitude to Meta AI for creating and maintaining this valuable resource for the computer vision community.
+
+## FAQ
+
+### What is the Segment Anything Model (SAM) by Ultralytics?
+
+The Segment Anything Model (SAM) by Ultralytics is a revolutionary image segmentation model designed for promptable segmentation tasks. It leverages advanced architecture, including image and prompt encoders combined with a lightweight mask decoder, to generate high-quality segmentation masks from various prompts such as spatial or text cues. Trained on the expansive [SA-1B dataset](https://ai.facebook.com/datasets/segment-anything/), SAM excels in zero-shot performance, adapting to new image distributions and tasks without prior knowledge. Learn more [here](#introduction-to-sam-the-segment-anything-model).
+
+### How can I use the Segment Anything Model (SAM) for image segmentation?
+
+You can use the Segment Anything Model (SAM) for image segmentation by running inference with various prompts such as bounding boxes or points. Here's an example using Python:
+
+```python
+from ultralytics import SAM
+
+# Load a model
+model = SAM("sam_b.pt")
+
+# Segment with bounding box prompt
+model("ultralytics/assets/zidane.jpg", bboxes=[439, 437, 524, 709])
+
+# Segment with points prompt
+model("ultralytics/assets/zidane.jpg", points=[900, 370], labels=[1])
+```
+
+Alternatively, you can run inference with SAM in the command line interface (CLI):
+
+```bash
+yolo predict model=sam_b.pt source=path/to/image.jpg
+```
+
+For more detailed usage instructions, visit the [Segmentation section](#sam-prediction-example).
+
+### How do SAM and YOLOv8 compare in terms of performance?
+
+Compared to YOLOv8, SAM models like SAM-b and FastSAM-s are larger and slower but offer unique capabilities for automatic segmentation. For instance, Ultralytics [YOLOv8n-seg](../tasks/segment.md) is 53.4 times smaller and 866 times faster than SAM-b. However, SAM's zero-shot performance makes it highly flexible and efficient in diverse, untrained tasks. Learn more about performance comparisons between SAM and YOLOv8 [here](#sam-comparison-vs-yolov8).
+
+### How can I auto-annotate my dataset using SAM?
+
+Ultralytics' SAM offers an auto-annotation feature that allows generating segmentation datasets using a pre-trained detection model. Here's an example in Python:
+
+```python
+from ultralytics.data.annotator import auto_annotate
+
+auto_annotate(data="path/to/images", det_model="yolov8x.pt", sam_model="sam_b.pt")
+```
+
+This function takes the path to your images and optional arguments for pre-trained detection and SAM segmentation models, along with device and output directory specifications. For a complete guide, see [Auto-Annotation](#auto-annotation-a-quick-path-to-segmentation-datasets).
+
+### What datasets are used to train the Segment Anything Model (SAM)?
+
+SAM is trained on the extensive [SA-1B dataset](https://ai.facebook.com/datasets/segment-anything/) which comprises over 1 billion masks across 11 million images. SA-1B is the largest segmentation dataset to date, providing high-quality and diverse training data, ensuring impressive zero-shot performance in varied segmentation tasks. For more details, visit the [Dataset section](#key-features-of-the-segment-anything-model-sam).
diff --git a/ultralytics/docs/en/models/yolo-nas.md b/ultralytics/docs/en/models/yolo-nas.md
new file mode 100644
index 0000000000000000000000000000000000000000..3ba4f3297a9b4258ae8f73a8e7f373f65017a0f2
--- /dev/null
+++ b/ultralytics/docs/en/models/yolo-nas.md
@@ -0,0 +1,164 @@
+---
+comments: true
+description: Discover YOLO-NAS by Deci AI - a state-of-the-art object detection model with quantization support. Explore features, pretrained models, and implementation examples.
+keywords: YOLO-NAS, Deci AI, object detection, deep learning, Neural Architecture Search, Ultralytics, Python API, YOLO model, SuperGradients, pretrained models, quantization, AutoNAC
+---
+
+# YOLO-NAS
+
+## Overview
+
+Developed by Deci AI, YOLO-NAS is a groundbreaking object detection foundational model. It is the product of advanced Neural Architecture Search technology, meticulously designed to address the limitations of previous YOLO models. With significant improvements in quantization support and accuracy-latency trade-offs, YOLO-NAS represents a major leap in object detection.
+
+ **Overview of YOLO-NAS.** YOLO-NAS employs quantization-aware blocks and selective quantization for optimal performance. The model, when converted to its INT8 quantized version, experiences a minimal precision drop, a significant improvement over other models. These advancements culminate in a superior architecture with unprecedented object detection capabilities and outstanding performance.
+
+### Key Features
+
+- **Quantization-Friendly Basic Block:** YOLO-NAS introduces a new basic block that is friendly to quantization, addressing one of the significant limitations of previous YOLO models.
+- **Sophisticated Training and Quantization:** YOLO-NAS leverages advanced training schemes and post-training quantization to enhance performance.
+- **AutoNAC Optimization and Pre-training:** YOLO-NAS utilizes AutoNAC optimization and is pre-trained on prominent datasets such as COCO, Objects365, and Roboflow 100. This pre-training makes it extremely suitable for downstream object detection tasks in production environments.
+
+## Pre-trained Models
+
+Experience the power of next-generation object detection with the pre-trained YOLO-NAS models provided by Ultralytics. These models are designed to deliver top-notch performance in terms of both speed and accuracy. Choose from a variety of options tailored to your specific needs:
+
+| Model | mAP | Latency (ms) |
+| ---------------- | ----- | ------------ |
+| YOLO-NAS S | 47.5 | 3.21 |
+| YOLO-NAS M | 51.55 | 5.85 |
+| YOLO-NAS L | 52.22 | 7.87 |
+| YOLO-NAS S INT-8 | 47.03 | 2.36 |
+| YOLO-NAS M INT-8 | 51.0 | 3.78 |
+| YOLO-NAS L INT-8 | 52.1 | 4.78 |
+
+Each model variant is designed to offer a balance between Mean Average Precision (mAP) and latency, helping you optimize your object detection tasks for both performance and speed.
+
+## Usage Examples
+
+Ultralytics has made YOLO-NAS models easy to integrate into your Python applications via our `ultralytics` python package. The package provides a user-friendly Python API to streamline the process.
+
+The following examples show how to use YOLO-NAS models with the `ultralytics` package for inference and validation:
+
+### Inference and Validation Examples
+
+In this example we validate YOLO-NAS-s on the COCO8 dataset.
+
+!!! Example
+
+ This example provides simple inference and validation code for YOLO-NAS. For handling inference results see [Predict](../modes/predict.md) mode. For using YOLO-NAS with additional modes see [Val](../modes/val.md) and [Export](../modes/export.md). YOLO-NAS on the `ultralytics` package does not support training.
+
+ === "Python"
+
+ PyTorch pretrained `*.pt` models files can be passed to the `NAS()` class to create a model instance in python:
+
+ ```python
+ from ultralytics import NAS
+
+ # Load a COCO-pretrained YOLO-NAS-s model
+ model = NAS("yolo_nas_s.pt")
+
+ # Display model information (optional)
+ model.info()
+
+ # Validate the model on the COCO8 example dataset
+ results = model.val(data="coco8.yaml")
+
+ # Run inference with the YOLO-NAS-s model on the 'bus.jpg' image
+ results = model("path/to/bus.jpg")
+ ```
+
+ === "CLI"
+
+ CLI commands are available to directly run the models:
+
+ ```bash
+ # Load a COCO-pretrained YOLO-NAS-s model and validate it's performance on the COCO8 example dataset
+ yolo val model=yolo_nas_s.pt data=coco8.yaml
+
+ # Load a COCO-pretrained YOLO-NAS-s model and run inference on the 'bus.jpg' image
+ yolo predict model=yolo_nas_s.pt source=path/to/bus.jpg
+ ```
+
+## Supported Tasks and Modes
+
+We offer three variants of the YOLO-NAS models: Small (s), Medium (m), and Large (l). Each variant is designed to cater to different computational and performance needs:
+
+- **YOLO-NAS-s**: Optimized for environments where computational resources are limited but efficiency is key.
+- **YOLO-NAS-m**: Offers a balanced approach, suitable for general-purpose object detection with higher accuracy.
+- **YOLO-NAS-l**: Tailored for scenarios requiring the highest accuracy, where computational resources are less of a constraint.
+
+Below is a detailed overview of each model, including links to their pre-trained weights, the tasks they support, and their compatibility with different operating modes.
+
+| Model Type | Pre-trained Weights | Tasks Supported | Inference | Validation | Training | Export |
+| ---------- | --------------------------------------------------------------------------------------------- | -------------------------------------- | --------- | ---------- | -------- | ------ |
+| YOLO-NAS-s | [yolo_nas_s.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolo_nas_s.pt) | [Object Detection](../tasks/detect.md) | ✅ | ✅ | ❌ | ✅ |
+| YOLO-NAS-m | [yolo_nas_m.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolo_nas_m.pt) | [Object Detection](../tasks/detect.md) | ✅ | ✅ | ❌ | ✅ |
+| YOLO-NAS-l | [yolo_nas_l.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolo_nas_l.pt) | [Object Detection](../tasks/detect.md) | ✅ | ✅ | ❌ | ✅ |
+
+## Citations and Acknowledgements
+
+If you employ YOLO-NAS in your research or development work, please cite SuperGradients:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @misc{supergradients,
+ doi = {10.5281/ZENODO.7789328},
+ url = {https://zenodo.org/record/7789328},
+ author = {Aharon, Shay and {Louis-Dupont} and {Ofri Masad} and Yurkova, Kate and {Lotem Fridman} and {Lkdci} and Khvedchenya, Eugene and Rubin, Ran and Bagrov, Natan and Tymchenko, Borys and Keren, Tomer and Zhilko, Alexander and {Eran-Deci}},
+ title = {Super-Gradients},
+ publisher = {GitHub},
+ journal = {GitHub repository},
+ year = {2021},
+ }
+ ```
+
+We express our gratitude to Deci AI's [SuperGradients](https://github.com/Deci-AI/super-gradients/) team for their efforts in creating and maintaining this valuable resource for the computer vision community. We believe YOLO-NAS, with its innovative architecture and superior object detection capabilities, will become a critical tool for developers and researchers alike.
+
+## FAQ
+
+### What is YOLO-NAS and how does it improve over previous YOLO models?
+
+YOLO-NAS, developed by Deci AI, is a state-of-the-art object detection model leveraging advanced Neural Architecture Search (NAS) technology. It addresses the limitations of previous YOLO models by introducing features like quantization-friendly basic blocks and sophisticated training schemes. This results in significant improvements in performance, particularly in environments with limited computational resources. YOLO-NAS also supports quantization, maintaining high accuracy even when converted to its INT8 version, enhancing its suitability for production environments. For more details, see the [Overview](#overview) section.
+
+### How can I integrate YOLO-NAS models into my Python application?
+
+You can easily integrate YOLO-NAS models into your Python application using the `ultralytics` package. Here's a simple example of how to load a pre-trained YOLO-NAS model and perform inference:
+
+```python
+from ultralytics import NAS
+
+# Load a COCO-pretrained YOLO-NAS-s model
+model = NAS("yolo_nas_s.pt")
+
+# Validate the model on the COCO8 example dataset
+results = model.val(data="coco8.yaml")
+
+# Run inference with the YOLO-NAS-s model on the 'bus.jpg' image
+results = model("path/to/bus.jpg")
+```
+
+For more information, refer to the [Inference and Validation Examples](#inference-and-validation-examples).
+
+### What are the key features of YOLO-NAS and why should I consider using it?
+
+YOLO-NAS introduces several key features that make it a superior choice for object detection tasks:
+
+- **Quantization-Friendly Basic Block:** Enhanced architecture that improves model performance with minimal precision drop post quantization.
+- **Sophisticated Training and Quantization:** Employs advanced training schemes and post-training quantization techniques.
+- **AutoNAC Optimization and Pre-training:** Utilizes AutoNAC optimization and is pre-trained on prominent datasets like COCO, Objects365, and Roboflow 100.
+ These features contribute to its high accuracy, efficient performance, and suitability for deployment in production environments. Learn more in the [Key Features](#key-features) section.
+
+### Which tasks and modes are supported by YOLO-NAS models?
+
+YOLO-NAS models support various object detection tasks and modes such as inference, validation, and export. They do not support training. The supported models include YOLO-NAS-s, YOLO-NAS-m, and YOLO-NAS-l, each tailored to different computational capacities and performance needs. For a detailed overview, refer to the [Supported Tasks and Modes](#supported-tasks-and-modes) section.
+
+### Are there pre-trained YOLO-NAS models available and how do I access them?
+
+Yes, Ultralytics provides pre-trained YOLO-NAS models that you can access directly. These models are pre-trained on datasets like COCO, ensuring high performance in terms of both speed and accuracy. You can download these models using the links provided in the [Pre-trained Models](#pre-trained-models) section. Here are some examples:
+
+- [YOLO-NAS-s](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolo_nas_s.pt)
+- [YOLO-NAS-m](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolo_nas_m.pt)
+- [YOLO-NAS-l](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolo_nas_l.pt)
diff --git a/ultralytics/docs/en/models/yolo-world.md b/ultralytics/docs/en/models/yolo-world.md
new file mode 100644
index 0000000000000000000000000000000000000000..64162a957f5cfadb77311b81bb8812ffa8422377
--- /dev/null
+++ b/ultralytics/docs/en/models/yolo-world.md
@@ -0,0 +1,437 @@
+---
+comments: true
+description: Explore the YOLO-World Model for efficient, real-time open-vocabulary object detection using Ultralytics YOLOv8 advancements. Achieve top performance with minimal computation.
+keywords: YOLO-World, Ultralytics, open-vocabulary detection, YOLOv8, real-time object detection, machine learning, computer vision, AI, deep learning, model training
+---
+
+# YOLO-World Model
+
+The YOLO-World Model introduces an advanced, real-time [Ultralytics](https://ultralytics.com) [YOLOv8](yolov8.md)-based approach for Open-Vocabulary Detection tasks. This innovation enables the detection of any object within an image based on descriptive texts. By significantly lowering computational demands while preserving competitive performance, YOLO-World emerges as a versatile tool for numerous vision-based applications.
+
+
+
+
+
+ Watch: YOLO World training workflow on custom dataset
+
+
+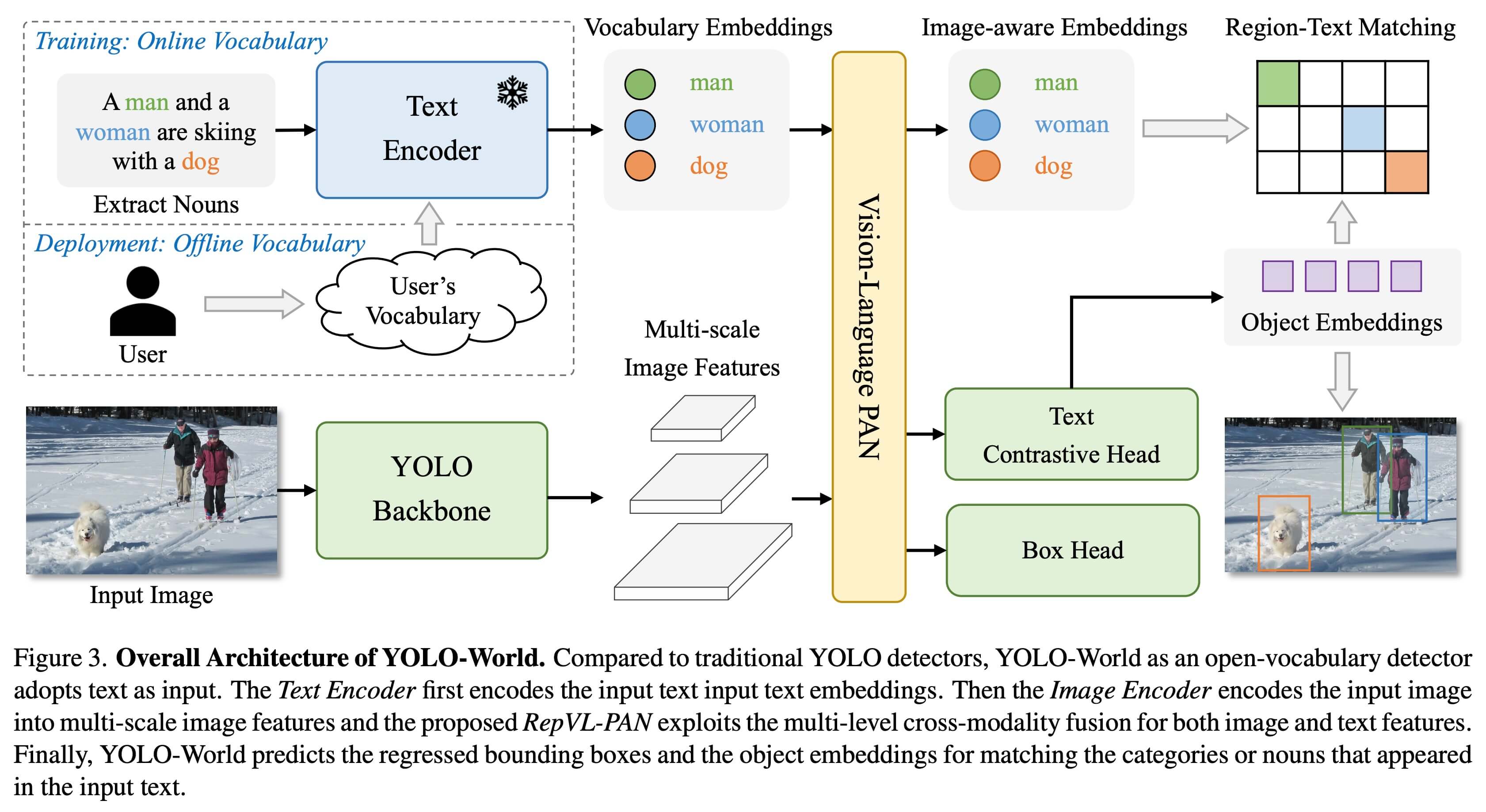
+
+## Overview
+
+YOLO-World tackles the challenges faced by traditional Open-Vocabulary detection models, which often rely on cumbersome Transformer models requiring extensive computational resources. These models' dependence on pre-defined object categories also restricts their utility in dynamic scenarios. YOLO-World revitalizes the YOLOv8 framework with open-vocabulary detection capabilities, employing vision-language modeling and pre-training on expansive datasets to excel at identifying a broad array of objects in zero-shot scenarios with unmatched efficiency.
+
+## Key Features
+
+1. **Real-time Solution:** Harnessing the computational speed of CNNs, YOLO-World delivers a swift open-vocabulary detection solution, catering to industries in need of immediate results.
+
+2. **Efficiency and Performance:** YOLO-World slashes computational and resource requirements without sacrificing performance, offering a robust alternative to models like SAM but at a fraction of the computational cost, enabling real-time applications.
+
+3. **Inference with Offline Vocabulary:** YOLO-World introduces a "prompt-then-detect" strategy, employing an offline vocabulary to enhance efficiency further. This approach enables the use of custom prompts computed apriori, including captions or categories, to be encoded and stored as offline vocabulary embeddings, streamlining the detection process.
+
+4. **Powered by YOLOv8:** Built upon [Ultralytics YOLOv8](yolov8.md), YOLO-World leverages the latest advancements in real-time object detection to facilitate open-vocabulary detection with unparalleled accuracy and speed.
+
+5. **Benchmark Excellence:** YOLO-World outperforms existing open-vocabulary detectors, including MDETR and GLIP series, in terms of speed and efficiency on standard benchmarks, showcasing YOLOv8's superior capability on a single NVIDIA V100 GPU.
+
+6. **Versatile Applications:** YOLO-World's innovative approach unlocks new possibilities for a multitude of vision tasks, delivering speed improvements by orders of magnitude over existing methods.
+
+## Available Models, Supported Tasks, and Operating Modes
+
+This section details the models available with their specific pre-trained weights, the tasks they support, and their compatibility with various operating modes such as [Inference](../modes/predict.md), [Validation](../modes/val.md), [Training](../modes/train.md), and [Export](../modes/export.md), denoted by ✅ for supported modes and ❌ for unsupported modes.
+
+!!! Note
+
+ All the YOLOv8-World weights have been directly migrated from the official [YOLO-World](https://github.com/AILab-CVC/YOLO-World) repository, highlighting their excellent contributions.
+
+| Model Type | Pre-trained Weights | Tasks Supported | Inference | Validation | Training | Export |
+| --------------- | ------------------------------------------------------------------------------------------------------- | -------------------------------------- | --------- | ---------- | -------- | ------ |
+| YOLOv8s-world | [yolov8s-world.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8s-world.pt) | [Object Detection](../tasks/detect.md) | ✅ | ✅ | ✅ | ❌ |
+| YOLOv8s-worldv2 | [yolov8s-worldv2.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8s-worldv2.pt) | [Object Detection](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
+| YOLOv8m-world | [yolov8m-world.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8m-world.pt) | [Object Detection](../tasks/detect.md) | ✅ | ✅ | ✅ | ❌ |
+| YOLOv8m-worldv2 | [yolov8m-worldv2.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8m-worldv2.pt) | [Object Detection](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
+| YOLOv8l-world | [yolov8l-world.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8l-world.pt) | [Object Detection](../tasks/detect.md) | ✅ | ✅ | ✅ | ❌ |
+| YOLOv8l-worldv2 | [yolov8l-worldv2.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8l-worldv2.pt) | [Object Detection](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
+| YOLOv8x-world | [yolov8x-world.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8x-world.pt) | [Object Detection](../tasks/detect.md) | ✅ | ✅ | ✅ | ❌ |
+| YOLOv8x-worldv2 | [yolov8x-worldv2.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8x-worldv2.pt) | [Object Detection](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
+
+## Zero-shot Transfer on COCO Dataset
+
+| Model Type | mAP | mAP50 | mAP75 |
+| --------------- | ---- | ----- | ----- |
+| yolov8s-world | 37.4 | 52.0 | 40.6 |
+| yolov8s-worldv2 | 37.7 | 52.2 | 41.0 |
+| yolov8m-world | 42.0 | 57.0 | 45.6 |
+| yolov8m-worldv2 | 43.0 | 58.4 | 46.8 |
+| yolov8l-world | 45.7 | 61.3 | 49.8 |
+| yolov8l-worldv2 | 45.8 | 61.3 | 49.8 |
+| yolov8x-world | 47.0 | 63.0 | 51.2 |
+| yolov8x-worldv2 | 47.1 | 62.8 | 51.4 |
+
+## Usage Examples
+
+The YOLO-World models are easy to integrate into your Python applications. Ultralytics provides user-friendly Python API and CLI commands to streamline development.
+
+### Train Usage
+
+!!! Tip "Tip"
+
+ We strongly recommend to use `yolov8-worldv2` model for custom training, because it supports deterministic training and also easy to export other formats i.e onnx/tensorrt.
+
+Object detection is straightforward with the `train` method, as illustrated below:
+
+!!! Example
+
+ === "Python"
+
+ PyTorch pretrained `*.pt` models as well as configuration `*.yaml` files can be passed to the `YOLOWorld()` class to create a model instance in python:
+
+ ```python
+ from ultralytics import YOLOWorld
+
+ # Load a pretrained YOLOv8s-worldv2 model
+ model = YOLOWorld("yolov8s-worldv2.pt")
+
+ # Train the model on the COCO8 example dataset for 100 epochs
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
+
+ # Run inference with the YOLOv8n model on the 'bus.jpg' image
+ results = model("path/to/bus.jpg")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Load a pretrained YOLOv8s-worldv2 model and train it on the COCO8 example dataset for 100 epochs
+ yolo train model=yolov8s-worldv2.yaml data=coco8.yaml epochs=100 imgsz=640
+ ```
+
+### Predict Usage
+
+Object detection is straightforward with the `predict` method, as illustrated below:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLOWorld
+
+ # Initialize a YOLO-World model
+ model = YOLOWorld("yolov8s-world.pt") # or select yolov8m/l-world.pt for different sizes
+
+ # Execute inference with the YOLOv8s-world model on the specified image
+ results = model.predict("path/to/image.jpg")
+
+ # Show results
+ results[0].show()
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Perform object detection using a YOLO-World model
+ yolo predict model=yolov8s-world.pt source=path/to/image.jpg imgsz=640
+ ```
+
+This snippet demonstrates the simplicity of loading a pre-trained model and running a prediction on an image.
+
+### Val Usage
+
+Model validation on a dataset is streamlined as follows:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Create a YOLO-World model
+ model = YOLO("yolov8s-world.pt") # or select yolov8m/l-world.pt for different sizes
+
+ # Conduct model validation on the COCO8 example dataset
+ metrics = model.val(data="coco8.yaml")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Validate a YOLO-World model on the COCO8 dataset with a specified image size
+ yolo val model=yolov8s-world.pt data=coco8.yaml imgsz=640
+ ```
+
+### Track Usage
+
+Object tracking with YOLO-World model on a video/images is streamlined as follows:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Create a YOLO-World model
+ model = YOLO("yolov8s-world.pt") # or select yolov8m/l-world.pt for different sizes
+
+ # Track with a YOLO-World model on a video
+ results = model.track(source="path/to/video.mp4")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Track with a YOLO-World model on the video with a specified image size
+ yolo track model=yolov8s-world.pt imgsz=640 source="path/to/video/file.mp4"
+ ```
+
+!!! Note
+
+ The YOLO-World models provided by Ultralytics come pre-configured with [COCO dataset](../datasets/detect/coco.md) categories as part of their offline vocabulary, enhancing efficiency for immediate application. This integration allows the YOLOv8-World models to directly recognize and predict the 80 standard categories defined in the COCO dataset without requiring additional setup or customization.
+
+### Set prompts
+
+
+
+The YOLO-World framework allows for the dynamic specification of classes through custom prompts, empowering users to tailor the model to their specific needs **without retraining**. This feature is particularly useful for adapting the model to new domains or specific tasks that were not originally part of the training data. By setting custom prompts, users can essentially guide the model's focus towards objects of interest, enhancing the relevance and accuracy of the detection results.
+
+For instance, if your application only requires detecting 'person' and 'bus' objects, you can specify these classes directly:
+
+!!! Example
+
+ === "Custom Inference Prompts"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Initialize a YOLO-World model
+ model = YOLO("yolov8s-world.pt") # or choose yolov8m/l-world.pt
+
+ # Define custom classes
+ model.set_classes(["person", "bus"])
+
+ # Execute prediction for specified categories on an image
+ results = model.predict("path/to/image.jpg")
+
+ # Show results
+ results[0].show()
+ ```
+
+You can also save a model after setting custom classes. By doing this you create a version of the YOLO-World model that is specialized for your specific use case. This process embeds your custom class definitions directly into the model file, making the model ready to use with your specified classes without further adjustments. Follow these steps to save and load your custom YOLOv8 model:
+
+!!! Example
+
+ === "Persisting Models with Custom Vocabulary"
+
+ First load a YOLO-World model, set custom classes for it and save it:
+
+ ```python
+ from ultralytics import YOLO
+
+ # Initialize a YOLO-World model
+ model = YOLO("yolov8s-world.pt") # or select yolov8m/l-world.pt
+
+ # Define custom classes
+ model.set_classes(["person", "bus"])
+
+ # Save the model with the defined offline vocabulary
+ model.save("custom_yolov8s.pt")
+ ```
+
+ After saving, the custom_yolov8s.pt model behaves like any other pre-trained YOLOv8 model but with a key difference: it is now optimized to detect only the classes you have defined. This customization can significantly improve detection performance and efficiency for your specific application scenarios.
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load your custom model
+ model = YOLO("custom_yolov8s.pt")
+
+ # Run inference to detect your custom classes
+ results = model.predict("path/to/image.jpg")
+
+ # Show results
+ results[0].show()
+ ```
+
+### Benefits of Saving with Custom Vocabulary
+
+- **Efficiency**: Streamlines the detection process by focusing on relevant objects, reducing computational overhead and speeding up inference.
+- **Flexibility**: Allows for easy adaptation of the model to new or niche detection tasks without the need for extensive retraining or data collection.
+- **Simplicity**: Simplifies deployment by eliminating the need to repeatedly specify custom classes at runtime, making the model directly usable with its embedded vocabulary.
+- **Performance**: Enhances detection accuracy for specified classes by focusing the model's attention and resources on recognizing the defined objects.
+
+This approach provides a powerful means of customizing state-of-the-art object detection models for specific tasks, making advanced AI more accessible and applicable to a broader range of practical applications.
+
+## Reproduce official results from scratch(Experimental)
+
+### Prepare datasets
+
+- Train data
+
+| Dataset | Type | Samples | Boxes | Annotation Files |
+| ----------------------------------------------------------------- | --------- | ------- | ----- | ------------------------------------------------------------------------------------------------------------------------------------------ |
+| [Objects365v1](https://opendatalab.com/OpenDataLab/Objects365_v1) | Detection | 609k | 9621k | [objects365_train.json](https://opendatalab.com/OpenDataLab/Objects365_v1) |
+| [GQA](https://nlp.stanford.edu/data/gqa/images.zip) | Grounding | 621k | 3681k | [final_mixed_train_no_coco.json](https://huggingface.co/GLIPModel/GLIP/blob/main/mdetr_annotations/final_mixed_train_no_coco.json) |
+| [Flickr30k](https://shannon.cs.illinois.edu/DenotationGraph/) | Grounding | 149k | 641k | [final_flickr_separateGT_train.json](https://huggingface.co/GLIPModel/GLIP/blob/main/mdetr_annotations/final_flickr_separateGT_train.json) |
+
+- Val data
+
+| Dataset | Type | Annotation Files |
+| ------------------------------------------------------------------------------------------------------- | --------- | ------------------------------------------------------------------------------------------------------ |
+| [LVIS minival](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/lvis.yaml) | Detection | [minival.txt](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/lvis.yaml) |
+
+### Launch training from scratch
+
+!!! Note
+
+ `WorldTrainerFromScratch` is highly customized to allow training yolo-world models on both detection datasets and grounding datasets simultaneously. More details please checkout [ultralytics.model.yolo.world.train_world.py](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/models/yolo/world/train_world.py).
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLOWorld
+ from ultralytics.models.yolo.world.train_world import WorldTrainerFromScratch
+
+ data = dict(
+ train=dict(
+ yolo_data=["Objects365.yaml"],
+ grounding_data=[
+ dict(
+ img_path="../datasets/flickr30k/images",
+ json_file="../datasets/flickr30k/final_flickr_separateGT_train.json",
+ ),
+ dict(
+ img_path="../datasets/GQA/images",
+ json_file="../datasets/GQA/final_mixed_train_no_coco.json",
+ ),
+ ],
+ ),
+ val=dict(yolo_data=["lvis.yaml"]),
+ )
+ model = YOLOWorld("yolov8s-worldv2.yaml")
+ model.train(data=data, batch=128, epochs=100, trainer=WorldTrainerFromScratch)
+ ```
+
+## Citations and Acknowledgements
+
+We extend our gratitude to the [Tencent AILab Computer Vision Center](https://ai.tencent.com/) for their pioneering work in real-time open-vocabulary object detection with YOLO-World:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @article{cheng2024yolow,
+ title={YOLO-World: Real-Time Open-Vocabulary Object Detection},
+ author={Cheng, Tianheng and Song, Lin and Ge, Yixiao and Liu, Wenyu and Wang, Xinggang and Shan, Ying},
+ journal={arXiv preprint arXiv:2401.17270},
+ year={2024}
+ }
+ ```
+
+For further reading, the original YOLO-World paper is available on [arXiv](https://arxiv.org/pdf/2401.17270v2.pdf). The project's source code and additional resources can be accessed via their [GitHub repository](https://github.com/AILab-CVC/YOLO-World). We appreciate their commitment to advancing the field and sharing their valuable insights with the community.
+
+## FAQ
+
+### What is the YOLO-World model and how does it work?
+
+The YOLO-World model is an advanced, real-time object detection approach based on the [Ultralytics YOLOv8](yolov8.md) framework. It excels in Open-Vocabulary Detection tasks by identifying objects within an image based on descriptive texts. Using vision-language modeling and pre-training on large datasets, YOLO-World achieves high efficiency and performance with significantly reduced computational demands, making it ideal for real-time applications across various industries.
+
+### How does YOLO-World handle inference with custom prompts?
+
+YOLO-World supports a "prompt-then-detect" strategy, which utilizes an offline vocabulary to enhance efficiency. Custom prompts like captions or specific object categories are pre-encoded and stored as offline vocabulary embeddings. This approach streamlines the detection process without the need for retraining. You can dynamically set these prompts within the model to tailor it to specific detection tasks, as shown below:
+
+```python
+from ultralytics import YOLOWorld
+
+# Initialize a YOLO-World model
+model = YOLOWorld("yolov8s-world.pt")
+
+# Define custom classes
+model.set_classes(["person", "bus"])
+
+# Execute prediction on an image
+results = model.predict("path/to/image.jpg")
+
+# Show results
+results[0].show()
+```
+
+### Why should I choose YOLO-World over traditional Open-Vocabulary detection models?
+
+YOLO-World provides several advantages over traditional Open-Vocabulary detection models:
+
+- **Real-Time Performance:** It leverages the computational speed of CNNs to offer quick, efficient detection.
+- **Efficiency and Low Resource Requirement:** YOLO-World maintains high performance while significantly reducing computational and resource demands.
+- **Customizable Prompts:** The model supports dynamic prompt setting, allowing users to specify custom detection classes without retraining.
+- **Benchmark Excellence:** It outperforms other open-vocabulary detectors like MDETR and GLIP in both speed and efficiency on standard benchmarks.
+
+### How do I train a YOLO-World model on my dataset?
+
+Training a YOLO-World model on your dataset is straightforward through the provided Python API or CLI commands. Here's how to start training using Python:
+
+```python
+from ultralytics import YOLOWorld
+
+# Load a pretrained YOLOv8s-worldv2 model
+model = YOLOWorld("yolov8s-worldv2.pt")
+
+# Train the model on the COCO8 dataset for 100 epochs
+results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
+```
+
+Or using CLI:
+
+```bash
+yolo train model=yolov8s-worldv2.yaml data=coco8.yaml epochs=100 imgsz=640
+```
+
+### What are the available pre-trained YOLO-World models and their supported tasks?
+
+Ultralytics offers multiple pre-trained YOLO-World models supporting various tasks and operating modes:
+
+| Model Type | Pre-trained Weights | Tasks Supported | Inference | Validation | Training | Export |
+| --------------- | ------------------------------------------------------------------------------------------------------- | -------------------------------------- | --------- | ---------- | -------- | ------ |
+| YOLOv8s-world | [yolov8s-world.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8s-world.pt) | [Object Detection](../tasks/detect.md) | ✅ | ✅ | ✅ | ❌ |
+| YOLOv8s-worldv2 | [yolov8s-worldv2.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8s-worldv2.pt) | [Object Detection](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
+| YOLOv8m-world | [yolov8m-world.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8m-world.pt) | [Object Detection](../tasks/detect.md) | ✅ | ✅ | ✅ | ❌ |
+| YOLOv8m-worldv2 | [yolov8m-worldv2.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8m-worldv2.pt) | [Object Detection](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
+| YOLOv8l-world | [yolov8l-world.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8l-world.pt) | [Object Detection](../tasks/detect.md) | ✅ | ✅ | ✅ | ❌ |
+| YOLOv8l-worldv2 | [yolov8l-worldv2.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8l-worldv2.pt) | [Object Detection](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
+| YOLOv8x-world | [yolov8x-world.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8x-world.pt) | [Object Detection](../tasks/detect.md) | ✅ | ✅ | ✅ | ❌ |
+| YOLOv8x-worldv2 | [yolov8x-worldv2.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8x-worldv2.pt) | [Object Detection](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
+
+### How do I reproduce the official results of YOLO-World from scratch?
+
+To reproduce the official results from scratch, you need to prepare the datasets and launch the training using the provided code. The training procedure involves creating a data dictionary and running the `train` method with a custom trainer:
+
+```python
+from ultralytics import YOLOWorld
+from ultralytics.models.yolo.world.train_world import WorldTrainerFromScratch
+
+data = {
+ "train": {
+ "yolo_data": ["Objects365.yaml"],
+ "grounding_data": [
+ {
+ "img_path": "../datasets/flickr30k/images",
+ "json_file": "../datasets/flickr30k/final_flickr_separateGT_train.json",
+ },
+ {
+ "img_path": "../datasets/GQA/images",
+ "json_file": "../datasets/GQA/final_mixed_train_no_coco.json",
+ },
+ ],
+ },
+ "val": {"yolo_data": ["lvis.yaml"]},
+}
+
+model = YOLOWorld("yolov8s-worldv2.yaml")
+model.train(data=data, batch=128, epochs=100, trainer=WorldTrainerFromScratch)
+```
diff --git a/ultralytics/docs/en/models/yolov10.md b/ultralytics/docs/en/models/yolov10.md
new file mode 100644
index 0000000000000000000000000000000000000000..09c3d3414206c19ec1e6072486bbf0af0f6407ba
--- /dev/null
+++ b/ultralytics/docs/en/models/yolov10.md
@@ -0,0 +1,299 @@
+---
+comments: true
+description: Discover YOLOv10, the latest in real-time object detection, eliminating NMS and boosting efficiency. Achieve top performance with a low computational cost.
+keywords: YOLOv10, real-time object detection, NMS-free, deep learning, Tsinghua University, Ultralytics, machine learning, neural networks, performance optimization
+---
+
+# YOLOv10: Real-Time End-to-End Object Detection
+
+YOLOv10, built on the [Ultralytics](https://ultralytics.com) [Python package](https://pypi.org/project/ultralytics/) by researchers at [Tsinghua University](https://www.tsinghua.edu.cn/en/), introduces a new approach to real-time object detection, addressing both the post-processing and model architecture deficiencies found in previous YOLO versions. By eliminating non-maximum suppression (NMS) and optimizing various model components, YOLOv10 achieves state-of-the-art performance with significantly reduced computational overhead. Extensive experiments demonstrate its superior accuracy-latency trade-offs across multiple model scales.
+
+
+
+
+
+
+
+ Watch: How to Train YOLOv10 on SKU-110k Dataset using Ultralytics | Retail Dataset
+
+
+## Overview
+
+Real-time object detection aims to accurately predict object categories and positions in images with low latency. The YOLO series has been at the forefront of this research due to its balance between performance and efficiency. However, reliance on NMS and architectural inefficiencies have hindered optimal performance. YOLOv10 addresses these issues by introducing consistent dual assignments for NMS-free training and a holistic efficiency-accuracy driven model design strategy.
+
+### Architecture
+
+The architecture of YOLOv10 builds upon the strengths of previous YOLO models while introducing several key innovations. The model architecture consists of the following components:
+
+1. **Backbone**: Responsible for feature extraction, the backbone in YOLOv10 uses an enhanced version of CSPNet (Cross Stage Partial Network) to improve gradient flow and reduce computational redundancy.
+2. **Neck**: The neck is designed to aggregate features from different scales and passes them to the head. It includes PAN (Path Aggregation Network) layers for effective multiscale feature fusion.
+3. **One-to-Many Head**: Generates multiple predictions per object during training to provide rich supervisory signals and improve learning accuracy.
+4. **One-to-One Head**: Generates a single best prediction per object during inference to eliminate the need for NMS, thereby reducing latency and improving efficiency.
+
+## Key Features
+
+1. **NMS-Free Training**: Utilizes consistent dual assignments to eliminate the need for NMS, reducing inference latency.
+2. **Holistic Model Design**: Comprehensive optimization of various components from both efficiency and accuracy perspectives, including lightweight classification heads, spatial-channel decoupled down sampling, and rank-guided block design.
+3. **Enhanced Model Capabilities**: Incorporates large-kernel convolutions and partial self-attention modules to improve performance without significant computational cost.
+
+## Model Variants
+
+YOLOv10 comes in various model scales to cater to different application needs:
+
+- **YOLOv10-N**: Nano version for extremely resource-constrained environments.
+- **YOLOv10-S**: Small version balancing speed and accuracy.
+- **YOLOv10-M**: Medium version for general-purpose use.
+- **YOLOv10-B**: Balanced version with increased width for higher accuracy.
+- **YOLOv10-L**: Large version for higher accuracy at the cost of increased computational resources.
+- **YOLOv10-X**: Extra-large version for maximum accuracy and performance.
+
+## Performance
+
+YOLOv10 outperforms previous YOLO versions and other state-of-the-art models in terms of accuracy and efficiency. For example, YOLOv10-S is 1.8x faster than RT-DETR-R18 with similar AP on the COCO dataset, and YOLOv10-B has 46% less latency and 25% fewer parameters than YOLOv9-C with the same performance.
+
+| Model | Input Size | APval | FLOPs (G) | Latency (ms) |
+| -------------- | ---------- | ---------------- | --------- | ------------ |
+| [YOLOv10-N][1] | 640 | 38.5 | **6.7** | **1.84** |
+| [YOLOv10-S][2] | 640 | 46.3 | 21.6 | 2.49 |
+| [YOLOv10-M][3] | 640 | 51.1 | 59.1 | 4.74 |
+| [YOLOv10-B][4] | 640 | 52.5 | 92.0 | 5.74 |
+| [YOLOv10-L][5] | 640 | 53.2 | 120.3 | 7.28 |
+| [YOLOv10-X][6] | 640 | **54.4** | 160.4 | 10.70 |
+
+Latency measured with TensorRT FP16 on T4 GPU.
+
+## Methodology
+
+### Consistent Dual Assignments for NMS-Free Training
+
+YOLOv10 employs dual label assignments, combining one-to-many and one-to-one strategies during training to ensure rich supervision and efficient end-to-end deployment. The consistent matching metric aligns the supervision between both strategies, enhancing the quality of predictions during inference.
+
+### Holistic Efficiency-Accuracy Driven Model Design
+
+#### Efficiency Enhancements
+
+1. **Lightweight Classification Head**: Reduces the computational overhead of the classification head by using depth-wise separable convolutions.
+2. **Spatial-Channel Decoupled Down sampling**: Decouples spatial reduction and channel modulation to minimize information loss and computational cost.
+3. **Rank-Guided Block Design**: Adapts block design based on intrinsic stage redundancy, ensuring optimal parameter utilization.
+
+#### Accuracy Enhancements
+
+1. **Large-Kernel Convolution**: Enlarges the receptive field to enhance feature extraction capability.
+2. **Partial Self-Attention (PSA)**: Incorporates self-attention modules to improve global representation learning with minimal overhead.
+
+## Experiments and Results
+
+YOLOv10 has been extensively tested on standard benchmarks like COCO, demonstrating superior performance and efficiency. The model achieves state-of-the-art results across different variants, showcasing significant improvements in latency and accuracy compared to previous versions and other contemporary detectors.
+
+## Comparisons
+
+
+
+Compared to other state-of-the-art detectors:
+
+- YOLOv10-S / X are 1.8× / 1.3× faster than RT-DETR-R18 / R101 with similar accuracy
+- YOLOv10-B has 25% fewer parameters and 46% lower latency than YOLOv9-C at same accuracy
+- YOLOv10-L / X outperform YOLOv8-L / X by 0.3 AP / 0.5 AP with 1.8× / 2.3× fewer parameters
+
+Here is a detailed comparison of YOLOv10 variants with other state-of-the-art models:
+
+| Model | Params (M) | FLOPs (G) | mAPval 50-95 | Latency (ms) | Latency-forward (ms) |
+| ------------------ | ------------------ | ----------------- | -------------------- | -------------------- | ---------------------------- |
+| YOLOv6-3.0-N | 4.7 | 11.4 | 37.0 | 2.69 | **1.76** |
+| Gold-YOLO-N | 5.6 | 12.1 | **39.6** | 2.92 | 1.82 |
+| YOLOv8-N | 3.2 | 8.7 | 37.3 | 6.16 | 1.77 |
+| **[YOLOv10-N][1]** | **2.3** | **6.7** | 39.5 | **1.84** | 1.79 |
+| | | | | | |
+| YOLOv6-3.0-S | 18.5 | 45.3 | 44.3 | 3.42 | 2.35 |
+| Gold-YOLO-S | 21.5 | 46.0 | 45.4 | 3.82 | 2.73 |
+| YOLOv8-S | 11.2 | 28.6 | 44.9 | 7.07 | **2.33** |
+| **[YOLOv10-S][2]** | **7.2** | **21.6** | **46.8** | **2.49** | 2.39 |
+| | | | | | |
+| RT-DETR-R18 | 20.0 | 60.0 | 46.5 | **4.58** | **4.49** |
+| YOLOv6-3.0-M | 34.9 | 85.8 | 49.1 | 5.63 | 4.56 |
+| Gold-YOLO-M | 41.3 | 87.5 | 49.8 | 6.38 | 5.45 |
+| YOLOv8-M | 25.9 | 78.9 | 50.6 | 9.50 | 5.09 |
+| **[YOLOv10-M][3]** | **15.4** | **59.1** | **51.3** | 4.74 | 4.63 |
+| | | | | | |
+| YOLOv6-3.0-L | 59.6 | 150.7 | 51.8 | 9.02 | 7.90 |
+| Gold-YOLO-L | 75.1 | 151.7 | 51.8 | 10.65 | 9.78 |
+| YOLOv8-L | 43.7 | 165.2 | 52.9 | 12.39 | 8.06 |
+| RT-DETR-R50 | 42.0 | 136.0 | 53.1 | 9.20 | 9.07 |
+| **[YOLOv10-L][5]** | **24.4** | **120.3** | **53.4** | **7.28** | **7.21** |
+| | | | | | |
+| YOLOv8-X | 68.2 | 257.8 | 53.9 | 16.86 | 12.83 |
+| RT-DETR-R101 | 76.0 | 259.0 | 54.3 | 13.71 | 13.58 |
+| **[YOLOv10-X][6]** | **29.5** | **160.4** | **54.4** | **10.70** | **10.60** |
+
+[1]: https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov10n.pt
+[2]: https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov10s.pt
+[3]: https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov10m.pt
+[4]: https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov10b.pt
+[5]: https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov10l.pt
+[6]: https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov10x.pt
+
+## Usage Examples
+
+For predicting new images with YOLOv10:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a pre-trained YOLOv10n model
+ model = YOLO("yolov10n.pt")
+
+ # Perform object detection on an image
+ results = model("image.jpg")
+
+ # Display the results
+ results[0].show()
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Load a COCO-pretrained YOLOv10n model and run inference on the 'bus.jpg' image
+ yolo detect predict model=yolov10n.pt source=path/to/bus.jpg
+ ```
+
+For training YOLOv10 on a custom dataset:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load YOLOv10n model from scratch
+ model = YOLO("yolov10n.yaml")
+
+ # Train the model
+ model.train(data="coco8.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Build a YOLOv10n model from scratch and train it on the COCO8 example dataset for 100 epochs
+ yolo train model=yolov10n.yaml data=coco8.yaml epochs=100 imgsz=640
+
+ # Build a YOLOv10n model from scratch and run inference on the 'bus.jpg' image
+ yolo predict model=yolov10n.yaml source=path/to/bus.jpg
+ ```
+
+## Supported Tasks and Modes
+
+The YOLOv10 models series offers a range of models, each optimized for high-performance [Object Detection](../tasks/detect.md). These models cater to varying computational needs and accuracy requirements, making them versatile for a wide array of applications.
+
+| Model | Filenames | Tasks | Inference | Validation | Training | Export |
+| ------- | --------------------------------------------------------------------- | -------------------------------------- | --------- | ---------- | -------- | ------ |
+| YOLOv10 | `yolov10n.pt` `yolov10s.pt` `yolov10m.pt` `yolov10l.pt` `yolov10x.pt` | [Object Detection](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
+
+## Exporting YOLOv10
+
+Due to the new operations introduced with YOLOv10, not all export formats provided by Ultralytics are currently supported. The following table outlines which formats have been successfully converted using Ultralytics for YOLOv10. Feel free to open a pull request if you're able to [provide a contribution change](../help/contributing.md) for adding export support of additional formats for YOLOv10.
+
+| Export Format | Export Support | Exported Model Inference | Notes |
+| ------------------------------------------------- | -------------- | ------------------------ | ------------------------------------------- |
+| [TorchScript](../integrations/torchscript.md) | ✅ | ✅ | Standard PyTorch model format. |
+| [ONNX](../integrations/onnx.md) | ✅ | ✅ | Widely supported for deployment. |
+| [OpenVINO](../integrations/openvino.md) | ✅ | ✅ | Optimized for Intel hardware. |
+| [TensorRT](../integrations/tensorrt.md) | ✅ | ✅ | Optimized for NVIDIA GPUs. |
+| [CoreML](../integrations/coreml.md) | ✅ | ✅ | Limited to Apple devices. |
+| [TF SavedModel](../integrations/tf-savedmodel.md) | ✅ | ✅ | TensorFlow's standard model format. |
+| [TF GraphDef](../integrations/tf-graphdef.md) | ✅ | ✅ | Legacy TensorFlow format. |
+| [TF Lite](../integrations/tflite.md) | ✅ | ✅ | Optimized for mobile and embedded. |
+| [TF Edge TPU](../integrations/edge-tpu.md) | ✅ | ✅ | Specific to Google's Edge TPU devices. |
+| [TF.js](../integrations/tfjs.md) | ✅ | ✅ | JavaScript environment for browser use. |
+| [PaddlePaddle](../integrations/paddlepaddle.md) | ❌ | ❌ | Popular in China; less global support. |
+| [NCNN](../integrations/ncnn.md) | ✅ | ❌ | Layer `torch.topk` not exists or registered |
+
+## Conclusion
+
+YOLOv10 sets a new standard in real-time object detection by addressing the shortcomings of previous YOLO versions and incorporating innovative design strategies. Its ability to deliver high accuracy with low computational cost makes it an ideal choice for a wide range of real-world applications.
+
+## Citations and Acknowledgements
+
+We would like to acknowledge the YOLOv10 authors from [Tsinghua University](https://www.tsinghua.edu.cn/en/) for their extensive research and significant contributions to the [Ultralytics](https://ultralytics.com) framework:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @article{THU-MIGyolov10,
+ title={YOLOv10: Real-Time End-to-End Object Detection},
+ author={Ao Wang, Hui Chen, Lihao Liu, et al.},
+ journal={arXiv preprint arXiv:2405.14458},
+ year={2024},
+ institution={Tsinghua University},
+ license = {AGPL-3.0}
+ }
+ ```
+
+For detailed implementation, architectural innovations, and experimental results, please refer to the YOLOv10 [research paper](https://arxiv.org/pdf/2405.14458) and [GitHub repository](https://github.com/THU-MIG/yolov10) by the Tsinghua University team.
+
+## FAQ
+
+### What is YOLOv10 and how does it differ from previous YOLO versions?
+
+YOLOv10, developed by researchers at [Tsinghua University](https://www.tsinghua.edu.cn/en/), introduces several key innovations to real-time object detection. It eliminates the need for non-maximum suppression (NMS) by employing consistent dual assignments during training and optimized model components for superior performance with reduced computational overhead. For more details on its architecture and key features, check out the [YOLOv10 overview](#overview) section.
+
+### How can I get started with running inference using YOLOv10?
+
+For easy inference, you can use the Ultralytics YOLO Python library or the command line interface (CLI). Below are examples of predicting new images using YOLOv10:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load the pre-trained YOLOv10-N model
+ model = YOLO("yolov10n.pt")
+ results = model("image.jpg")
+ results[0].show()
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo detect predict model=yolov10n.pt source=path/to/image.jpg
+ ```
+
+For more usage examples, visit our [Usage Examples](#usage-examples) section.
+
+### Which model variants does YOLOv10 offer and what are their use cases?
+
+YOLOv10 offers several model variants to cater to different use cases:
+
+- **YOLOv10-N**: Suitable for extremely resource-constrained environments
+- **YOLOv10-S**: Balances speed and accuracy
+- **YOLOv10-M**: General-purpose use
+- **YOLOv10-B**: Higher accuracy with increased width
+- **YOLOv10-L**: High accuracy at the cost of computational resources
+- **YOLOv10-X**: Maximum accuracy and performance
+
+Each variant is designed for different computational needs and accuracy requirements, making them versatile for a variety of applications. Explore the [Model Variants](#model-variants) section for more information.
+
+### How does the NMS-free approach in YOLOv10 improve performance?
+
+YOLOv10 eliminates the need for non-maximum suppression (NMS) during inference by employing consistent dual assignments for training. This approach reduces inference latency and enhances prediction efficiency. The architecture also includes a one-to-one head for inference, ensuring that each object gets a single best prediction. For a detailed explanation, see the [Consistent Dual Assignments for NMS-Free Training](#consistent-dual-assignments-for-nms-free-training) section.
+
+### Where can I find the export options for YOLOv10 models?
+
+YOLOv10 supports several export formats, including TorchScript, ONNX, OpenVINO, and TensorRT. However, not all export formats provided by Ultralytics are currently supported for YOLOv10 due to its new operations. For details on the supported formats and instructions on exporting, visit the [Exporting YOLOv10](#exporting-yolov10) section.
+
+### What are the performance benchmarks for YOLOv10 models?
+
+YOLOv10 outperforms previous YOLO versions and other state-of-the-art models in both accuracy and efficiency. For example, YOLOv10-S is 1.8x faster than RT-DETR-R18 with a similar AP on the COCO dataset. YOLOv10-B shows 46% less latency and 25% fewer parameters than YOLOv9-C with the same performance. Detailed benchmarks can be found in the [Comparisons](#comparisons) section.
diff --git a/ultralytics/docs/en/models/yolov3.md b/ultralytics/docs/en/models/yolov3.md
new file mode 100644
index 0000000000000000000000000000000000000000..23530e7f34fd301aba8594c2203a56e93166dd76
--- /dev/null
+++ b/ultralytics/docs/en/models/yolov3.md
@@ -0,0 +1,185 @@
+---
+comments: true
+description: Discover YOLOv3 and its variants YOLOv3-Ultralytics and YOLOv3u. Learn about their features, implementations, and support for object detection tasks.
+keywords: YOLOv3, YOLOv3-Ultralytics, YOLOv3u, object detection, Ultralytics, computer vision, AI models, deep learning
+---
+
+# YOLOv3, YOLOv3-Ultralytics, and YOLOv3u
+
+## Overview
+
+This document presents an overview of three closely related object detection models, namely [YOLOv3](https://pjreddie.com/darknet/yolo/), [YOLOv3-Ultralytics](https://github.com/ultralytics/yolov3), and [YOLOv3u](https://github.com/ultralytics/ultralytics).
+
+1. **YOLOv3:** This is the third version of the You Only Look Once (YOLO) object detection algorithm. Originally developed by Joseph Redmon, YOLOv3 improved on its predecessors by introducing features such as multiscale predictions and three different sizes of detection kernels.
+
+2. **YOLOv3-Ultralytics:** This is Ultralytics' implementation of the YOLOv3 model. It reproduces the original YOLOv3 architecture and offers additional functionalities, such as support for more pre-trained models and easier customization options.
+
+3. **YOLOv3u:** This is an updated version of YOLOv3-Ultralytics that incorporates the anchor-free, objectness-free split head used in YOLOv8 models. YOLOv3u maintains the same backbone and neck architecture as YOLOv3 but with the updated detection head from YOLOv8.
+
+
+
+## Key Features
+
+- **YOLOv3:** Introduced the use of three different scales for detection, leveraging three different sizes of detection kernels: 13x13, 26x26, and 52x52. This significantly improved detection accuracy for objects of different sizes. Additionally, YOLOv3 added features such as multi-label predictions for each bounding box and a better feature extractor network.
+
+- **YOLOv3-Ultralytics:** Ultralytics' implementation of YOLOv3 provides the same performance as the original model but comes with added support for more pre-trained models, additional training methods, and easier customization options. This makes it more versatile and user-friendly for practical applications.
+
+- **YOLOv3u:** This updated model incorporates the anchor-free, objectness-free split head from YOLOv8. By eliminating the need for pre-defined anchor boxes and objectness scores, this detection head design can improve the model's ability to detect objects of varying sizes and shapes. This makes YOLOv3u more robust and accurate for object detection tasks.
+
+## Supported Tasks and Modes
+
+The YOLOv3 series, including YOLOv3, YOLOv3-Ultralytics, and YOLOv3u, are designed specifically for object detection tasks. These models are renowned for their effectiveness in various real-world scenarios, balancing accuracy and speed. Each variant offers unique features and optimizations, making them suitable for a range of applications.
+
+All three models support a comprehensive set of modes, ensuring versatility in various stages of model deployment and development. These modes include [Inference](../modes/predict.md), [Validation](../modes/val.md), [Training](../modes/train.md), and [Export](../modes/export.md), providing users with a complete toolkit for effective object detection.
+
+| Model Type | Tasks Supported | Inference | Validation | Training | Export |
+| ------------------ | -------------------------------------- | --------- | ---------- | -------- | ------ |
+| YOLOv3 | [Object Detection](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
+| YOLOv3-Ultralytics | [Object Detection](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
+| YOLOv3u | [Object Detection](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
+
+This table provides an at-a-glance view of the capabilities of each YOLOv3 variant, highlighting their versatility and suitability for various tasks and operational modes in object detection workflows.
+
+## Usage Examples
+
+This example provides simple YOLOv3 training and inference examples. For full documentation on these and other [modes](../modes/index.md) see the [Predict](../modes/predict.md), [Train](../modes/train.md), [Val](../modes/val.md) and [Export](../modes/export.md) docs pages.
+
+!!! Example
+
+ === "Python"
+
+ PyTorch pretrained `*.pt` models as well as configuration `*.yaml` files can be passed to the `YOLO()` class to create a model instance in python:
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a COCO-pretrained YOLOv3n model
+ model = YOLO("yolov3n.pt")
+
+ # Display model information (optional)
+ model.info()
+
+ # Train the model on the COCO8 example dataset for 100 epochs
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
+
+ # Run inference with the YOLOv3n model on the 'bus.jpg' image
+ results = model("path/to/bus.jpg")
+ ```
+
+ === "CLI"
+
+ CLI commands are available to directly run the models:
+
+ ```bash
+ # Load a COCO-pretrained YOLOv3n model and train it on the COCO8 example dataset for 100 epochs
+ yolo train model=yolov3n.pt data=coco8.yaml epochs=100 imgsz=640
+
+ # Load a COCO-pretrained YOLOv3n model and run inference on the 'bus.jpg' image
+ yolo predict model=yolov3n.pt source=path/to/bus.jpg
+ ```
+
+## Citations and Acknowledgements
+
+If you use YOLOv3 in your research, please cite the original YOLO papers and the Ultralytics YOLOv3 repository:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @article{redmon2018yolov3,
+ title={YOLOv3: An Incremental Improvement},
+ author={Redmon, Joseph and Farhadi, Ali},
+ journal={arXiv preprint arXiv:1804.02767},
+ year={2018}
+ }
+ ```
+
+Thank you to Joseph Redmon and Ali Farhadi for developing the original YOLOv3.
+
+## FAQ
+
+### What are the differences between YOLOv3, YOLOv3-Ultralytics, and YOLOv3u?
+
+YOLOv3 is the third iteration of the YOLO (You Only Look Once) object detection algorithm developed by Joseph Redmon, known for its balance of accuracy and speed, utilizing three different scales (13x13, 26x26, and 52x52) for detections. YOLOv3-Ultralytics is Ultralytics' adaptation of YOLOv3 that adds support for more pre-trained models and facilitates easier model customization. YOLOv3u is an upgraded variant of YOLOv3-Ultralytics, integrating the anchor-free, objectness-free split head from YOLOv8, improving detection robustness and accuracy for various object sizes. For more details on the variants, refer to the [YOLOv3 series](https://github.com/ultralytics/yolov3).
+
+### How can I train a YOLOv3 model using Ultralytics?
+
+Training a YOLOv3 model with Ultralytics is straightforward. You can train the model using either Python or CLI:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a COCO-pretrained YOLOv3n model
+ model = YOLO("yolov3n.pt")
+
+ # Train the model on the COCO8 example dataset for 100 epochs
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Load a COCO-pretrained YOLOv3n model and train it on the COCO8 example dataset for 100 epochs
+ yolo train model=yolov3n.pt data=coco8.yaml epochs=100 imgsz=640
+ ```
+
+For more comprehensive training options and guidelines, visit our [Train mode documentation](../modes/train.md).
+
+### What makes YOLOv3u more accurate for object detection tasks?
+
+YOLOv3u improves upon YOLOv3 and YOLOv3-Ultralytics by incorporating the anchor-free, objectness-free split head used in YOLOv8 models. This upgrade eliminates the need for pre-defined anchor boxes and objectness scores, enhancing its capability to detect objects of varying sizes and shapes more precisely. This makes YOLOv3u a better choice for complex and diverse object detection tasks. For more information, refer to the [Why YOLOv3u](#overview) section.
+
+### How can I use YOLOv3 models for inference?
+
+You can perform inference using YOLOv3 models by either Python scripts or CLI commands:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a COCO-pretrained YOLOv3n model
+ model = YOLO("yolov3n.pt")
+
+ # Run inference with the YOLOv3n model on the 'bus.jpg' image
+ results = model("path/to/bus.jpg")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Load a COCO-pretrained YOLOv3n model and run inference on the 'bus.jpg' image
+ yolo predict model=yolov3n.pt source=path/to/bus.jpg
+ ```
+
+Refer to the [Inference mode documentation](../modes/predict.md) for more details on running YOLO models.
+
+### What tasks are supported by YOLOv3 and its variants?
+
+YOLOv3, YOLOv3-Ultralytics, and YOLOv3u primarily support object detection tasks. These models can be used for various stages of model deployment and development, such as Inference, Validation, Training, and Export. For a comprehensive set of tasks supported and more in-depth details, visit our [Object Detection tasks documentation](../tasks/detect.md).
+
+### Where can I find resources to cite YOLOv3 in my research?
+
+If you use YOLOv3 in your research, please cite the original YOLO papers and the Ultralytics YOLOv3 repository. Example BibTeX citation:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @article{redmon2018yolov3,
+ title={YOLOv3: An Incremental Improvement},
+ author={Redmon, Joseph and Farhadi, Ali},
+ journal={arXiv preprint arXiv:1804.02767},
+ year={2018}
+ }
+ ```
+
+For more citation details, refer to the [Citations and Acknowledgements](#citations-and-acknowledgements) section.
diff --git a/ultralytics/docs/en/models/yolov4.md b/ultralytics/docs/en/models/yolov4.md
new file mode 100644
index 0000000000000000000000000000000000000000..d5a145f3f3170a1eaa1e28f0d0d1ffd8fac4f6c2
--- /dev/null
+++ b/ultralytics/docs/en/models/yolov4.md
@@ -0,0 +1,92 @@
+---
+comments: true
+description: Explore YOLOv4, a state-of-the-art real-time object detection model by Alexey Bochkovskiy. Discover its architecture, features, and performance.
+keywords: YOLOv4, object detection, real-time detection, Alexey Bochkovskiy, neural networks, machine learning, computer vision
+---
+
+# YOLOv4: High-Speed and Precise Object Detection
+
+Welcome to the Ultralytics documentation page for YOLOv4, a state-of-the-art, real-time object detector launched in 2020 by Alexey Bochkovskiy at [https://github.com/AlexeyAB/darknet](https://github.com/AlexeyAB/darknet). YOLOv4 is designed to provide the optimal balance between speed and accuracy, making it an excellent choice for many applications.
+
+ **YOLOv4 architecture diagram**. Showcasing the intricate network design of YOLOv4, including the backbone, neck, and head components, and their interconnected layers for optimal real-time object detection.
+
+## Introduction
+
+YOLOv4 stands for You Only Look Once version 4. It is a real-time object detection model developed to address the limitations of previous YOLO versions like [YOLOv3](yolov3.md) and other object detection models. Unlike other convolutional neural network (CNN) based object detectors, YOLOv4 is not only applicable for recommendation systems but also for standalone process management and human input reduction. Its operation on conventional graphics processing units (GPUs) allows for mass usage at an affordable price, and it is designed to work in real-time on a conventional GPU while requiring only one such GPU for training.
+
+## Architecture
+
+YOLOv4 makes use of several innovative features that work together to optimize its performance. These include Weighted-Residual-Connections (WRC), Cross-Stage-Partial-connections (CSP), Cross mini-Batch Normalization (CmBN), Self-adversarial-training (SAT), Mish-activation, Mosaic data augmentation, DropBlock regularization, and CIoU loss. These features are combined to achieve state-of-the-art results.
+
+A typical object detector is composed of several parts including the input, the backbone, the neck, and the head. The backbone of YOLOv4 is pre-trained on ImageNet and is used to predict classes and bounding boxes of objects. The backbone could be from several models including VGG, ResNet, ResNeXt, or DenseNet. The neck part of the detector is used to collect feature maps from different stages and usually includes several bottom-up paths and several top-down paths. The head part is what is used to make the final object detections and classifications.
+
+## Bag of Freebies
+
+YOLOv4 also makes use of methods known as "bag of freebies," which are techniques that improve the accuracy of the model during training without increasing the cost of inference. Data augmentation is a common bag of freebies technique used in object detection, which increases the variability of the input images to improve the robustness of the model. Some examples of data augmentation include photometric distortions (adjusting the brightness, contrast, hue, saturation, and noise of an image) and geometric distortions (adding random scaling, cropping, flipping, and rotating). These techniques help the model to generalize better to different types of images.
+
+## Features and Performance
+
+YOLOv4 is designed for optimal speed and accuracy in object detection. The architecture of YOLOv4 includes CSPDarknet53 as the backbone, PANet as the neck, and YOLOv3 as the detection head. This design allows YOLOv4 to perform object detection at an impressive speed, making it suitable for real-time applications. YOLOv4 also excels in accuracy, achieving state-of-the-art results in object detection benchmarks.
+
+## Usage Examples
+
+As of the time of writing, Ultralytics does not currently support YOLOv4 models. Therefore, any users interested in using YOLOv4 will need to refer directly to the YOLOv4 GitHub repository for installation and usage instructions.
+
+Here is a brief overview of the typical steps you might take to use YOLOv4:
+
+1. Visit the YOLOv4 GitHub repository: [https://github.com/AlexeyAB/darknet](https://github.com/AlexeyAB/darknet).
+
+2. Follow the instructions provided in the README file for installation. This typically involves cloning the repository, installing necessary dependencies, and setting up any necessary environment variables.
+
+3. Once installation is complete, you can train and use the model as per the usage instructions provided in the repository. This usually involves preparing your dataset, configuring the model parameters, training the model, and then using the trained model to perform object detection.
+
+Please note that the specific steps may vary depending on your specific use case and the current state of the YOLOv4 repository. Therefore, it is strongly recommended to refer directly to the instructions provided in the YOLOv4 GitHub repository.
+
+We regret any inconvenience this may cause and will strive to update this document with usage examples for Ultralytics once support for YOLOv4 is implemented.
+
+## Conclusion
+
+YOLOv4 is a powerful and efficient object detection model that strikes a balance between speed and accuracy. Its use of unique features and bag of freebies techniques during training allows it to perform excellently in real-time object detection tasks. YOLOv4 can be trained and used by anyone with a conventional GPU, making it accessible and practical for a wide range of applications.
+
+## Citations and Acknowledgements
+
+We would like to acknowledge the YOLOv4 authors for their significant contributions in the field of real-time object detection:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @misc{bochkovskiy2020yolov4,
+ title={YOLOv4: Optimal Speed and Accuracy of Object Detection},
+ author={Alexey Bochkovskiy and Chien-Yao Wang and Hong-Yuan Mark Liao},
+ year={2020},
+ eprint={2004.10934},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+ }
+ ```
+
+The original YOLOv4 paper can be found on [arXiv](https://arxiv.org/abs/2004.10934). The authors have made their work publicly available, and the codebase can be accessed on [GitHub](https://github.com/AlexeyAB/darknet). We appreciate their efforts in advancing the field and making their work accessible to the broader community.
+
+## FAQ
+
+### What is YOLOv4 and why should I use it for object detection?
+
+YOLOv4, which stands for "You Only Look Once version 4," is a state-of-the-art real-time object detection model developed by Alexey Bochkovskiy in 2020. It achieves an optimal balance between speed and accuracy, making it highly suitable for real-time applications. YOLOv4's architecture incorporates several innovative features like Weighted-Residual-Connections (WRC), Cross-Stage-Partial-connections (CSP), and Self-adversarial-training (SAT), among others, to achieve state-of-the-art results. If you're looking for a high-performance model that operates efficiently on conventional GPUs, YOLOv4 is an excellent choice.
+
+### How does the architecture of YOLOv4 enhance its performance?
+
+The architecture of YOLOv4 includes several key components: the backbone, the neck, and the head. The backbone, which can be models like VGG, ResNet, or CSPDarknet53, is pre-trained to predict classes and bounding boxes. The neck, utilizing PANet, connects feature maps from different stages for comprehensive data extraction. Finally, the head, which uses configurations from YOLOv3, makes the final object detections. YOLOv4 also employs "bag of freebies" techniques like mosaic data augmentation and DropBlock regularization, further optimizing its speed and accuracy.
+
+### What are "bag of freebies" in the context of YOLOv4?
+
+"Bag of freebies" refers to methods that improve the training accuracy of YOLOv4 without increasing the cost of inference. These techniques include various forms of data augmentation like photometric distortions (adjusting brightness, contrast, etc.) and geometric distortions (scaling, cropping, flipping, rotating). By increasing the variability of the input images, these augmentations help YOLOv4 generalize better to different types of images, thereby improving its robustness and accuracy without compromising its real-time performance.
+
+### Why is YOLOv4 considered suitable for real-time object detection on conventional GPUs?
+
+YOLOv4 is designed to optimize both speed and accuracy, making it ideal for real-time object detection tasks that require quick and reliable performance. It operates efficiently on conventional GPUs, needing only one for both training and inference. This makes it accessible and practical for various applications ranging from recommendation systems to standalone process management, thereby reducing the need for extensive hardware setups and making it a cost-effective solution for real-time object detection.
+
+### How can I get started with YOLOv4 if Ultralytics does not currently support it?
+
+To get started with YOLOv4, you should visit the official [YOLOv4 GitHub repository](https://github.com/AlexeyAB/darknet). Follow the installation instructions provided in the README file, which typically include cloning the repository, installing dependencies, and setting up environment variables. Once installed, you can train the model by preparing your dataset, configuring the model parameters, and following the usage instructions provided. Since Ultralytics does not currently support YOLOv4, it is recommended to refer directly to the YOLOv4 GitHub for the most up-to-date and detailed guidance.
diff --git a/ultralytics/docs/en/models/yolov5.md b/ultralytics/docs/en/models/yolov5.md
new file mode 100644
index 0000000000000000000000000000000000000000..764dfb1e8fff8ce99fb17f92416e0ae8e5d58374
--- /dev/null
+++ b/ultralytics/docs/en/models/yolov5.md
@@ -0,0 +1,162 @@
+---
+comments: true
+description: Explore YOLOv5u, an advanced object detection model with optimized accuracy-speed tradeoff, featuring anchor-free Ultralytics head and various pre-trained models.
+keywords: YOLOv5, YOLOv5u, object detection, Ultralytics, anchor-free, pre-trained models, accuracy, speed, real-time detection
+---
+
+# YOLOv5
+
+## Overview
+
+YOLOv5u represents an advancement in object detection methodologies. Originating from the foundational architecture of the [YOLOv5](https://github.com/ultralytics/yolov5) model developed by Ultralytics, YOLOv5u integrates the anchor-free, objectness-free split head, a feature previously introduced in the [YOLOv8](yolov8.md) models. This adaptation refines the model's architecture, leading to an improved accuracy-speed tradeoff in object detection tasks. Given the empirical results and its derived features, YOLOv5u provides an efficient alternative for those seeking robust solutions in both research and practical applications.
+
+
+
+## Key Features
+
+- **Anchor-free Split Ultralytics Head:** Traditional object detection models rely on predefined anchor boxes to predict object locations. However, YOLOv5u modernizes this approach. By adopting an anchor-free split Ultralytics head, it ensures a more flexible and adaptive detection mechanism, consequently enhancing the performance in diverse scenarios.
+
+- **Optimized Accuracy-Speed Tradeoff:** Speed and accuracy often pull in opposite directions. But YOLOv5u challenges this tradeoff. It offers a calibrated balance, ensuring real-time detections without compromising on accuracy. This feature is particularly invaluable for applications that demand swift responses, such as autonomous vehicles, robotics, and real-time video analytics.
+
+- **Variety of Pre-trained Models:** Understanding that different tasks require different toolsets, YOLOv5u provides a plethora of pre-trained models. Whether you're focusing on Inference, Validation, or Training, there's a tailor-made model awaiting you. This variety ensures you're not just using a one-size-fits-all solution, but a model specifically fine-tuned for your unique challenge.
+
+## Supported Tasks and Modes
+
+The YOLOv5u models, with various pre-trained weights, excel in [Object Detection](../tasks/detect.md) tasks. They support a comprehensive range of modes, making them suitable for diverse applications, from development to deployment.
+
+| Model Type | Pre-trained Weights | Task | Inference | Validation | Training | Export |
+| ---------- | --------------------------------------------------------------------------------------------------------------------------- | -------------------------------------- | --------- | ---------- | -------- | ------ |
+| YOLOv5u | `yolov5nu`, `yolov5su`, `yolov5mu`, `yolov5lu`, `yolov5xu`, `yolov5n6u`, `yolov5s6u`, `yolov5m6u`, `yolov5l6u`, `yolov5x6u` | [Object Detection](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
+
+This table provides a detailed overview of the YOLOv5u model variants, highlighting their applicability in object detection tasks and support for various operational modes such as [Inference](../modes/predict.md), [Validation](../modes/val.md), [Training](../modes/train.md), and [Export](../modes/export.md). This comprehensive support ensures that users can fully leverage the capabilities of YOLOv5u models in a wide range of object detection scenarios.
+
+## Performance Metrics
+
+!!! Performance
+
+ === "Detection"
+
+ See [Detection Docs](../tasks/detect.md) for usage examples with these models trained on [COCO](../datasets/detect/coco.md), which include 80 pre-trained classes.
+
+ | Model | YAML | size (pixels) | mAPval 50-95 | Speed CPU ONNX (ms) | Speed A100 TensorRT (ms) | params (M) | FLOPs (B) |
+ |---------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------|-----------------------|----------------------|--------------------------------|-------------------------------------|--------------------|-------------------|
+ | [yolov5nu.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov5nu.pt) | [yolov5n.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5.yaml) | 640 | 34.3 | 73.6 | 1.06 | 2.6 | 7.7 |
+ | [yolov5su.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov5su.pt) | [yolov5s.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5.yaml) | 640 | 43.0 | 120.7 | 1.27 | 9.1 | 24.0 |
+ | [yolov5mu.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov5mu.pt) | [yolov5m.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5.yaml) | 640 | 49.0 | 233.9 | 1.86 | 25.1 | 64.2 |
+ | [yolov5lu.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov5lu.pt) | [yolov5l.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5.yaml) | 640 | 52.2 | 408.4 | 2.50 | 53.2 | 135.0 |
+ | [yolov5xu.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov5xu.pt) | [yolov5x.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5.yaml) | 640 | 53.2 | 763.2 | 3.81 | 97.2 | 246.4 |
+ | | | | | | | | |
+ | [yolov5n6u.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov5n6u.pt) | [yolov5n6.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5-p6.yaml) | 1280 | 42.1 | 211.0 | 1.83 | 4.3 | 7.8 |
+ | [yolov5s6u.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov5s6u.pt) | [yolov5s6.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5-p6.yaml) | 1280 | 48.6 | 422.6 | 2.34 | 15.3 | 24.6 |
+ | [yolov5m6u.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov5m6u.pt) | [yolov5m6.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5-p6.yaml) | 1280 | 53.6 | 810.9 | 4.36 | 41.2 | 65.7 |
+ | [yolov5l6u.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov5l6u.pt) | [yolov5l6.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5-p6.yaml) | 1280 | 55.7 | 1470.9 | 5.47 | 86.1 | 137.4 |
+ | [yolov5x6u.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov5x6u.pt) | [yolov5x6.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/models/v5/yolov5-p6.yaml) | 1280 | 56.8 | 2436.5 | 8.98 | 155.4 | 250.7 |
+
+## Usage Examples
+
+This example provides simple YOLOv5 training and inference examples. For full documentation on these and other [modes](../modes/index.md) see the [Predict](../modes/predict.md), [Train](../modes/train.md), [Val](../modes/val.md) and [Export](../modes/export.md) docs pages.
+
+!!! Example
+
+ === "Python"
+
+ PyTorch pretrained `*.pt` models as well as configuration `*.yaml` files can be passed to the `YOLO()` class to create a model instance in python:
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a COCO-pretrained YOLOv5n model
+ model = YOLO("yolov5n.pt")
+
+ # Display model information (optional)
+ model.info()
+
+ # Train the model on the COCO8 example dataset for 100 epochs
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
+
+ # Run inference with the YOLOv5n model on the 'bus.jpg' image
+ results = model("path/to/bus.jpg")
+ ```
+
+ === "CLI"
+
+ CLI commands are available to directly run the models:
+
+ ```bash
+ # Load a COCO-pretrained YOLOv5n model and train it on the COCO8 example dataset for 100 epochs
+ yolo train model=yolov5n.pt data=coco8.yaml epochs=100 imgsz=640
+
+ # Load a COCO-pretrained YOLOv5n model and run inference on the 'bus.jpg' image
+ yolo predict model=yolov5n.pt source=path/to/bus.jpg
+ ```
+
+## Citations and Acknowledgements
+
+If you use YOLOv5 or YOLOv5u in your research, please cite the Ultralytics YOLOv5 repository as follows:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @software{yolov5,
+ title = {Ultralytics YOLOv5},
+ author = {Glenn Jocher},
+ year = {2020},
+ version = {7.0},
+ license = {AGPL-3.0},
+ url = {https://github.com/ultralytics/yolov5},
+ doi = {10.5281/zenodo.3908559},
+ orcid = {0000-0001-5950-6979}
+ }
+ ```
+
+Please note that YOLOv5 models are provided under [AGPL-3.0](https://github.com/ultralytics/ultralytics/blob/main/LICENSE) and [Enterprise](https://ultralytics.com/license) licenses.
+
+## FAQ
+
+### What is Ultralytics YOLOv5u and how does it differ from YOLOv5?
+
+Ultralytics YOLOv5u is an advanced version of YOLOv5, integrating the anchor-free, objectness-free split head that enhances the accuracy-speed tradeoff for real-time object detection tasks. Unlike the traditional YOLOv5, YOLOv5u adopts an anchor-free detection mechanism, making it more flexible and adaptive in diverse scenarios. For more detailed information on its features, you can refer to the [YOLOv5 Overview](#overview).
+
+### How does the anchor-free Ultralytics head improve object detection performance in YOLOv5u?
+
+The anchor-free Ultralytics head in YOLOv5u improves object detection performance by eliminating the dependency on predefined anchor boxes. This results in a more flexible and adaptive detection mechanism that can handle various object sizes and shapes with greater efficiency. This enhancement directly contributes to a balanced tradeoff between accuracy and speed, making YOLOv5u suitable for real-time applications. Learn more about its architecture in the [Key Features](#key-features) section.
+
+### Can I use pre-trained YOLOv5u models for different tasks and modes?
+
+Yes, you can use pre-trained YOLOv5u models for various tasks such as [Object Detection](../tasks/detect.md). These models support multiple modes, including [Inference](../modes/predict.md), [Validation](../modes/val.md), [Training](../modes/train.md), and [Export](../modes/export.md). This flexibility allows users to leverage the capabilities of YOLOv5u models across different operational requirements. For a detailed overview, check the [Supported Tasks and Modes](#supported-tasks-and-modes) section.
+
+### How do the performance metrics of YOLOv5u models compare on different platforms?
+
+The performance metrics of YOLOv5u models vary depending on the platform and hardware used. For example, the YOLOv5nu model achieves a 34.3 mAP on COCO dataset with a speed of 73.6 ms on CPU (ONNX) and 1.06 ms on A100 TensorRT. Detailed performance metrics for different YOLOv5u models can be found in the [Performance Metrics](#performance-metrics) section, which provides a comprehensive comparison across various devices.
+
+### How can I train a YOLOv5u model using the Ultralytics Python API?
+
+You can train a YOLOv5u model by loading a pre-trained model and running the training command with your dataset. Here's a quick example:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a COCO-pretrained YOLOv5n model
+ model = YOLO("yolov5n.pt")
+
+ # Display model information (optional)
+ model.info()
+
+ # Train the model on the COCO8 example dataset for 100 epochs
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Load a COCO-pretrained YOLOv5n model and train it on the COCO8 example dataset for 100 epochs
+ yolo train model=yolov5n.pt data=coco8.yaml epochs=100 imgsz=640
+ ```
+
+For more detailed instructions, visit the [Usage Examples](#usage-examples) section.
diff --git a/ultralytics/docs/en/models/yolov6.md b/ultralytics/docs/en/models/yolov6.md
new file mode 100644
index 0000000000000000000000000000000000000000..26320250c57423b6a25fedc86f9b2f5666ebb064
--- /dev/null
+++ b/ultralytics/docs/en/models/yolov6.md
@@ -0,0 +1,162 @@
+---
+comments: true
+description: Explore Meituan YOLOv6, a top-tier object detector balancing speed and accuracy. Learn about its unique features and performance metrics on Ultralytics Docs.
+keywords: Meituan YOLOv6, object detection, real-time applications, BiC module, Anchor-Aided Training, COCO dataset, high-performance models, Ultralytics Docs
+---
+
+# Meituan YOLOv6
+
+## Overview
+
+[Meituan](https://about.meituan.com/) YOLOv6 is a cutting-edge object detector that offers remarkable balance between speed and accuracy, making it a popular choice for real-time applications. This model introduces several notable enhancements on its architecture and training scheme, including the implementation of a Bi-directional Concatenation (BiC) module, an anchor-aided training (AAT) strategy, and an improved backbone and neck design for state-of-the-art accuracy on the COCO dataset.
+
+
+ **Overview of YOLOv6.** Model architecture diagram showing the redesigned network components and training strategies that have led to significant performance improvements. (a) The neck of YOLOv6 (N and S are shown). Note for M/L, RepBlocks is replaced with CSPStackRep. (b) The structure of a BiC module. (c) A SimCSPSPPF block. ([source](https://arxiv.org/pdf/2301.05586.pdf)).
+
+### Key Features
+
+- **Bidirectional Concatenation (BiC) Module:** YOLOv6 introduces a BiC module in the neck of the detector, enhancing localization signals and delivering performance gains with negligible speed degradation.
+- **Anchor-Aided Training (AAT) Strategy:** This model proposes AAT to enjoy the benefits of both anchor-based and anchor-free paradigms without compromising inference efficiency.
+- **Enhanced Backbone and Neck Design:** By deepening YOLOv6 to include another stage in the backbone and neck, this model achieves state-of-the-art performance on the COCO dataset at high-resolution input.
+- **Self-Distillation Strategy:** A new self-distillation strategy is implemented to boost the performance of smaller models of YOLOv6, enhancing the auxiliary regression branch during training and removing it at inference to avoid a marked speed decline.
+
+## Performance Metrics
+
+YOLOv6 provides various pre-trained models with different scales:
+
+- YOLOv6-N: 37.5% AP on COCO val2017 at 1187 FPS with NVIDIA Tesla T4 GPU.
+- YOLOv6-S: 45.0% AP at 484 FPS.
+- YOLOv6-M: 50.0% AP at 226 FPS.
+- YOLOv6-L: 52.8% AP at 116 FPS.
+- YOLOv6-L6: State-of-the-art accuracy in real-time.
+
+YOLOv6 also provides quantized models for different precisions and models optimized for mobile platforms.
+
+## Usage Examples
+
+This example provides simple YOLOv6 training and inference examples. For full documentation on these and other [modes](../modes/index.md) see the [Predict](../modes/predict.md), [Train](../modes/train.md), [Val](../modes/val.md) and [Export](../modes/export.md) docs pages.
+
+!!! Example
+
+ === "Python"
+
+ PyTorch pretrained `*.pt` models as well as configuration `*.yaml` files can be passed to the `YOLO()` class to create a model instance in python:
+
+ ```python
+ from ultralytics import YOLO
+
+ # Build a YOLOv6n model from scratch
+ model = YOLO("yolov6n.yaml")
+
+ # Display model information (optional)
+ model.info()
+
+ # Train the model on the COCO8 example dataset for 100 epochs
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
+
+ # Run inference with the YOLOv6n model on the 'bus.jpg' image
+ results = model("path/to/bus.jpg")
+ ```
+
+ === "CLI"
+
+ CLI commands are available to directly run the models:
+
+ ```bash
+ # Build a YOLOv6n model from scratch and train it on the COCO8 example dataset for 100 epochs
+ yolo train model=yolov6n.yaml data=coco8.yaml epochs=100 imgsz=640
+
+ # Build a YOLOv6n model from scratch and run inference on the 'bus.jpg' image
+ yolo predict model=yolov6n.yaml source=path/to/bus.jpg
+ ```
+
+## Supported Tasks and Modes
+
+The YOLOv6 series offers a range of models, each optimized for high-performance [Object Detection](../tasks/detect.md). These models cater to varying computational needs and accuracy requirements, making them versatile for a wide array of applications.
+
+| Model Type | Pre-trained Weights | Tasks Supported | Inference | Validation | Training | Export |
+| ---------- | ------------------- | -------------------------------------- | --------- | ---------- | -------- | ------ |
+| YOLOv6-N | `yolov6-n.pt` | [Object Detection](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
+| YOLOv6-S | `yolov6-s.pt` | [Object Detection](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
+| YOLOv6-M | `yolov6-m.pt` | [Object Detection](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
+| YOLOv6-L | `yolov6-l.pt` | [Object Detection](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
+| YOLOv6-L6 | `yolov6-l6.pt` | [Object Detection](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
+
+This table provides a detailed overview of the YOLOv6 model variants, highlighting their capabilities in object detection tasks and their compatibility with various operational modes such as [Inference](../modes/predict.md), [Validation](../modes/val.md), [Training](../modes/train.md), and [Export](../modes/export.md). This comprehensive support ensures that users can fully leverage the capabilities of YOLOv6 models in a broad range of object detection scenarios.
+
+## Citations and Acknowledgements
+
+We would like to acknowledge the authors for their significant contributions in the field of real-time object detection:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @misc{li2023yolov6,
+ title={YOLOv6 v3.0: A Full-Scale Reloading},
+ author={Chuyi Li and Lulu Li and Yifei Geng and Hongliang Jiang and Meng Cheng and Bo Zhang and Zaidan Ke and Xiaoming Xu and Xiangxiang Chu},
+ year={2023},
+ eprint={2301.05586},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+ }
+ ```
+
+The original YOLOv6 paper can be found on [arXiv](https://arxiv.org/abs/2301.05586). The authors have made their work publicly available, and the codebase can be accessed on [GitHub](https://github.com/meituan/YOLOv6). We appreciate their efforts in advancing the field and making their work accessible to the broader community.
+
+## FAQ
+
+### What is Meituan YOLOv6 and what makes it unique?
+
+Meituan YOLOv6 is a state-of-the-art object detector that balances speed and accuracy, ideal for real-time applications. It features notable architectural enhancements like the Bi-directional Concatenation (BiC) module and an Anchor-Aided Training (AAT) strategy. These innovations provide substantial performance gains with minimal speed degradation, making YOLOv6 a competitive choice for object detection tasks.
+
+### How does the Bi-directional Concatenation (BiC) Module in YOLOv6 improve performance?
+
+The Bi-directional Concatenation (BiC) module in YOLOv6 enhances localization signals in the detector's neck, delivering performance improvements with negligible speed impact. This module effectively combines different feature maps, increasing the model's ability to detect objects accurately. For more details on YOLOv6's features, refer to the [Key Features](#key-features) section.
+
+### How can I train a YOLOv6 model using Ultralytics?
+
+You can train a YOLOv6 model using Ultralytics with simple Python or CLI commands. For instance:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Build a YOLOv6n model from scratch
+ model = YOLO("yolov6n.yaml")
+
+ # Train the model on the COCO8 example dataset for 100 epochs
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo train model=yolov6n.yaml data=coco8.yaml epochs=100 imgsz=640
+ ```
+
+For more information, visit the [Train](../modes/train.md) page.
+
+### What are the different versions of YOLOv6 and their performance metrics?
+
+YOLOv6 offers multiple versions, each optimized for different performance requirements:
+
+- YOLOv6-N: 37.5% AP at 1187 FPS
+- YOLOv6-S: 45.0% AP at 484 FPS
+- YOLOv6-M: 50.0% AP at 226 FPS
+- YOLOv6-L: 52.8% AP at 116 FPS
+- YOLOv6-L6: State-of-the-art accuracy in real-time scenarios
+
+These models are evaluated on the COCO dataset using an NVIDIA Tesla T4 GPU. For more on performance metrics, see the [Performance Metrics](#performance-metrics) section.
+
+### How does the Anchor-Aided Training (AAT) strategy benefit YOLOv6?
+
+Anchor-Aided Training (AAT) in YOLOv6 combines elements of anchor-based and anchor-free approaches, enhancing the model's detection capabilities without compromising inference efficiency. This strategy leverages anchors during training to improve bounding box predictions, making YOLOv6 effective in diverse object detection tasks.
+
+### Which operational modes are supported by YOLOv6 models in Ultralytics?
+
+YOLOv6 supports various operational modes including Inference, Validation, Training, and Export. This flexibility allows users to fully exploit the model's capabilities in different scenarios. Check out the [Supported Tasks and Modes](#supported-tasks-and-modes) section for a detailed overview of each mode.
diff --git a/ultralytics/docs/en/models/yolov7.md b/ultralytics/docs/en/models/yolov7.md
new file mode 100644
index 0000000000000000000000000000000000000000..361892253dac3787f594a4d066407c3073ced948
--- /dev/null
+++ b/ultralytics/docs/en/models/yolov7.md
@@ -0,0 +1,154 @@
+---
+comments: true
+description: Discover YOLOv7, the breakthrough real-time object detector with top speed and accuracy. Learn about key features, usage, and performance metrics.
+keywords: YOLOv7, real-time object detection, Ultralytics, AI, computer vision, model training, object detector
+---
+
+# YOLOv7: Trainable Bag-of-Freebies
+
+YOLOv7 is a state-of-the-art real-time object detector that surpasses all known object detectors in both speed and accuracy in the range from 5 FPS to 160 FPS. It has the highest accuracy (56.8% AP) among all known real-time object detectors with 30 FPS or higher on GPU V100. Moreover, YOLOv7 outperforms other object detectors such as YOLOR, YOLOX, Scaled-YOLOv4, YOLOv5, and many others in speed and accuracy. The model is trained on the MS COCO dataset from scratch without using any other datasets or pre-trained weights. Source code for YOLOv7 is available on GitHub.
+
+
+
+## Comparison of SOTA object detectors
+
+From the results in the YOLO comparison table we know that the proposed method has the best speed-accuracy trade-off comprehensively. If we compare YOLOv7-tiny-SiLU with YOLOv5-N (r6.1), our method is 127 fps faster and 10.7% more accurate on AP. In addition, YOLOv7 has 51.4% AP at frame rate of 161 fps, while PPYOLOE-L with the same AP has only 78 fps frame rate. In terms of parameter usage, YOLOv7 is 41% less than PPYOLOE-L. If we compare YOLOv7-X with 114 fps inference speed to YOLOv5-L (r6.1) with 99 fps inference speed, YOLOv7-X can improve AP by 3.9%. If YOLOv7-X is compared with YOLOv5-X (r6.1) of similar scale, the inference speed of YOLOv7-X is 31 fps faster. In addition, in terms the amount of parameters and computation, YOLOv7-X reduces 22% of parameters and 8% of computation compared to YOLOv5-X (r6.1), but improves AP by 2.2% ([Source](https://arxiv.org/pdf/2207.02696.pdf)).
+
+| Model | Params (M) | FLOPs (G) | Size (pixels) | FPS | APtest / val 50-95 | APtest 50 | APtest 75 | APtest S | APtest M | APtest L |
+| --------------------- | ------------------ | ----------------- | --------------------- | ------- | -------------------------- | ----------------- | ----------------- | ---------------- | ---------------- | ---------------- |
+| [YOLOX-S][1] | **9.0M** | **26.8G** | 640 | **102** | 40.5% / 40.5% | - | - | - | - | - |
+| [YOLOX-M][1] | 25.3M | 73.8G | 640 | 81 | 47.2% / 46.9% | - | - | - | - | - |
+| [YOLOX-L][1] | 54.2M | 155.6G | 640 | 69 | 50.1% / 49.7% | - | - | - | - | - |
+| [YOLOX-X][1] | 99.1M | 281.9G | 640 | 58 | **51.5% / 51.1%** | - | - | - | - | - |
+| | | | | | | | | | | |
+| [PPYOLOE-S][2] | **7.9M** | **17.4G** | 640 | **208** | 43.1% / 42.7% | 60.5% | 46.6% | 23.2% | 46.4% | 56.9% |
+| [PPYOLOE-M][2] | 23.4M | 49.9G | 640 | 123 | 48.9% / 48.6% | 66.5% | 53.0% | 28.6% | 52.9% | 63.8% |
+| [PPYOLOE-L][2] | 52.2M | 110.1G | 640 | 78 | 51.4% / 50.9% | 68.9% | 55.6% | 31.4% | 55.3% | 66.1% |
+| [PPYOLOE-X][2] | 98.4M | 206.6G | 640 | 45 | **52.2% / 51.9%** | **69.9%** | **56.5%** | **33.3%** | **56.3%** | **66.4%** |
+| | | | | | | | | | | |
+| [YOLOv5-N (r6.1)][3] | **1.9M** | **4.5G** | 640 | **159** | - / 28.0% | - | - | - | - | - |
+| [YOLOv5-S (r6.1)][3] | 7.2M | 16.5G | 640 | 156 | - / 37.4% | - | - | - | - | - |
+| [YOLOv5-M (r6.1)][3] | 21.2M | 49.0G | 640 | 122 | - / 45.4% | - | - | - | - | - |
+| [YOLOv5-L (r6.1)][3] | 46.5M | 109.1G | 640 | 99 | - / 49.0% | - | - | - | - | - |
+| [YOLOv5-X (r6.1)][3] | 86.7M | 205.7G | 640 | 83 | - / **50.7%** | - | - | - | - | - |
+| | | | | | | | | | | |
+| [YOLOR-CSP][4] | 52.9M | 120.4G | 640 | 106 | 51.1% / 50.8% | 69.6% | 55.7% | 31.7% | 55.3% | 64.7% |
+| [YOLOR-CSP-X][4] | 96.9M | 226.8G | 640 | 87 | 53.0% / 52.7% | 71.4% | 57.9% | 33.7% | 57.1% | 66.8% |
+| [YOLOv7-tiny-SiLU][5] | **6.2M** | **13.8G** | 640 | **286** | 38.7% / 38.7% | 56.7% | 41.7% | 18.8% | 42.4% | 51.9% |
+| [YOLOv7][5] | 36.9M | 104.7G | 640 | 161 | 51.4% / 51.2% | 69.7% | 55.9% | 31.8% | 55.5% | 65.0% |
+| [YOLOv7-X][5] | 71.3M | 189.9G | 640 | 114 | **53.1% / 52.9%** | **71.2%** | **57.8%** | **33.8%** | **57.1%** | **67.4%** |
+| | | | | | | | | | | |
+| [YOLOv5-N6 (r6.1)][3] | **3.2M** | **18.4G** | 1280 | **123** | - / 36.0% | - | - | - | - | - |
+| [YOLOv5-S6 (r6.1)][3] | 12.6M | 67.2G | 1280 | 122 | - / 44.8% | - | - | - | - | - |
+| [YOLOv5-M6 (r6.1)][3] | 35.7M | 200.0G | 1280 | 90 | - / 51.3% | - | - | - | - | - |
+| [YOLOv5-L6 (r6.1)][3] | 76.8M | 445.6G | 1280 | 63 | - / 53.7% | - | - | - | - | - |
+| [YOLOv5-X6 (r6.1)][3] | 140.7M | 839.2G | 1280 | 38 | - / **55.0%** | - | - | - | - | - |
+| | | | | | | | | | | |
+| [YOLOR-P6][4] | **37.2M** | **325.6G** | 1280 | **76** | 53.9% / 53.5% | 71.4% | 58.9% | 36.1% | 57.7% | 65.6% |
+| [YOLOR-W6][4] | 79.8G | 453.2G | 1280 | 66 | 55.2% / 54.8% | 72.7% | 60.5% | 37.7% | 59.1% | 67.1% |
+| [YOLOR-E6][4] | 115.8M | 683.2G | 1280 | 45 | 55.8% / 55.7% | 73.4% | 61.1% | 38.4% | 59.7% | 67.7% |
+| [YOLOR-D6][4] | 151.7M | 935.6G | 1280 | 34 | **56.5% / 56.1%** | **74.1%** | **61.9%** | **38.9%** | **60.4%** | **68.7%** |
+| | | | | | | | | | | |
+| [YOLOv7-W6][5] | **70.4M** | **360.0G** | 1280 | **84** | 54.9% / 54.6% | 72.6% | 60.1% | 37.3% | 58.7% | 67.1% |
+| [YOLOv7-E6][5] | 97.2M | 515.2G | 1280 | 56 | 56.0% / 55.9% | 73.5% | 61.2% | 38.0% | 59.9% | 68.4% |
+| [YOLOv7-D6][5] | 154.7M | 806.8G | 1280 | 44 | 56.6% / 56.3% | 74.0% | 61.8% | 38.8% | 60.1% | 69.5% |
+| [YOLOv7-E6E][5] | 151.7M | 843.2G | 1280 | 36 | **56.8% / 56.8%** | **74.4%** | **62.1%** | **39.3%** | **60.5%** | **69.0%** |
+
+[1]: https://github.com/Megvii-BaseDetection/YOLOX
+[2]: https://github.com/PaddlePaddle/PaddleDetection
+[3]: https://github.com/ultralytics/yolov5
+[4]: https://github.com/WongKinYiu/yolor
+[5]: https://github.com/WongKinYiu/yolov7
+
+## Overview
+
+Real-time object detection is an important component in many computer vision systems, including multi-object tracking, autonomous driving, robotics, and medical image analysis. In recent years, real-time object detection development has focused on designing efficient architectures and improving the inference speed of various CPUs, GPUs, and neural processing units (NPUs). YOLOv7 supports both mobile GPU and GPU devices, from the edge to the cloud.
+
+Unlike traditional real-time object detectors that focus on architecture optimization, YOLOv7 introduces a focus on the optimization of the training process. This includes modules and optimization methods designed to improve the accuracy of object detection without increasing the inference cost, a concept known as the "trainable bag-of-freebies".
+
+## Key Features
+
+YOLOv7 introduces several key features:
+
+1. **Model Re-parameterization**: YOLOv7 proposes a planned re-parameterized model, which is a strategy applicable to layers in different networks with the concept of gradient propagation path.
+
+2. **Dynamic Label Assignment**: The training of the model with multiple output layers presents a new issue: "How to assign dynamic targets for the outputs of different branches?" To solve this problem, YOLOv7 introduces a new label assignment method called coarse-to-fine lead guided label assignment.
+
+3. **Extended and Compound Scaling**: YOLOv7 proposes "extend" and "compound scaling" methods for the real-time object detector that can effectively utilize parameters and computation.
+
+4. **Efficiency**: The method proposed by YOLOv7 can effectively reduce about 40% parameters and 50% computation of state-of-the-art real-time object detector, and has faster inference speed and higher detection accuracy.
+
+## Usage Examples
+
+As of the time of writing, Ultralytics does not currently support YOLOv7 models. Therefore, any users interested in using YOLOv7 will need to refer directly to the YOLOv7 GitHub repository for installation and usage instructions.
+
+Here is a brief overview of the typical steps you might take to use YOLOv7:
+
+1. Visit the YOLOv7 GitHub repository: [https://github.com/WongKinYiu/yolov7](https://github.com/WongKinYiu/yolov7).
+
+2. Follow the instructions provided in the README file for installation. This typically involves cloning the repository, installing necessary dependencies, and setting up any necessary environment variables.
+
+3. Once installation is complete, you can train and use the model as per the usage instructions provided in the repository. This usually involves preparing your dataset, configuring the model parameters, training the model, and then using the trained model to perform object detection.
+
+Please note that the specific steps may vary depending on your specific use case and the current state of the YOLOv7 repository. Therefore, it is strongly recommended to refer directly to the instructions provided in the YOLOv7 GitHub repository.
+
+We regret any inconvenience this may cause and will strive to update this document with usage examples for Ultralytics once support for YOLOv7 is implemented.
+
+## Citations and Acknowledgements
+
+We would like to acknowledge the YOLOv7 authors for their significant contributions in the field of real-time object detection:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @article{wang2022yolov7,
+ title={YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors},
+ author={Wang, Chien-Yao and Bochkovskiy, Alexey and Liao, Hong-Yuan Mark},
+ journal={arXiv preprint arXiv:2207.02696},
+ year={2022}
+ }
+ ```
+
+The original YOLOv7 paper can be found on [arXiv](https://arxiv.org/pdf/2207.02696.pdf). The authors have made their work publicly available, and the codebase can be accessed on [GitHub](https://github.com/WongKinYiu/yolov7). We appreciate their efforts in advancing the field and making their work accessible to the broader community.
+
+## FAQ
+
+### What is YOLOv7 and why is it considered a breakthrough in real-time object detection?
+
+YOLOv7 is a cutting-edge real-time object detection model that achieves unparalleled speed and accuracy. It surpasses other models, such as YOLOX, YOLOv5, and PPYOLOE, in both parameters usage and inference speed. YOLOv7's distinguishing features include its model re-parameterization and dynamic label assignment, which optimize its performance without increasing inference costs. For more technical details about its architecture and comparison metrics with other state-of-the-art object detectors, refer to the [YOLOv7 paper](https://arxiv.org/pdf/2207.02696.pdf).
+
+### How does YOLOv7 improve on previous YOLO models like YOLOv4 and YOLOv5?
+
+YOLOv7 introduces several innovations, including model re-parameterization and dynamic label assignment, which enhance the training process and improve inference accuracy. Compared to YOLOv5, YOLOv7 significantly boosts speed and accuracy. For instance, YOLOv7-X improves accuracy by 2.2% and reduces parameters by 22% compared to YOLOv5-X. Detailed comparisons can be found in the performance table [YOLOv7 comparison with SOTA object detectors](#comparison-of-sota-object-detectors).
+
+### Can I use YOLOv7 with Ultralytics tools and platforms?
+
+As of now, Ultralytics does not directly support YOLOv7 in its tools and platforms. Users interested in using YOLOv7 need to follow the installation and usage instructions provided in the [YOLOv7 GitHub repository](https://github.com/WongKinYiu/yolov7). For other state-of-the-art models, you can explore and train using Ultralytics tools like [Ultralytics HUB](../hub/quickstart.md).
+
+### How do I install and run YOLOv7 for a custom object detection project?
+
+To install and run YOLOv7, follow these steps:
+
+1. Clone the YOLOv7 repository:
+ ```bash
+ git clone https://github.com/WongKinYiu/yolov7
+ ```
+2. Navigate to the cloned directory and install dependencies:
+ ```bash
+ cd yolov7
+ pip install -r requirements.txt
+ ```
+3. Prepare your dataset and configure the model parameters according to the [usage instructions](https://github.com/WongKinYiu/yolov7) provided in the repository.
+ For further guidance, visit the YOLOv7 GitHub repository for the latest information and updates.
+
+### What are the key features and optimizations introduced in YOLOv7?
+
+YOLOv7 offers several key features that revolutionize real-time object detection:
+
+- **Model Re-parameterization**: Enhances the model's performance by optimizing gradient propagation paths.
+- **Dynamic Label Assignment**: Uses a coarse-to-fine lead guided method to assign dynamic targets for outputs across different branches, improving accuracy.
+- **Extended and Compound Scaling**: Efficiently utilizes parameters and computation to scale the model for various real-time applications.
+- **Efficiency**: Reduces parameter count by 40% and computation by 50% compared to other state-of-the-art models while achieving faster inference speeds.
+ For further details on these features, see the [YOLOv7 Overview](#overview) section.
diff --git a/ultralytics/docs/en/models/yolov8.md b/ultralytics/docs/en/models/yolov8.md
new file mode 100644
index 0000000000000000000000000000000000000000..8d527b7c0f2fda00d9d204ee40e29dd62ca2c323
--- /dev/null
+++ b/ultralytics/docs/en/models/yolov8.md
@@ -0,0 +1,249 @@
+---
+comments: true
+description: Discover YOLOv8, the latest advancement in real-time object detection, optimizing performance with an array of pre-trained models for diverse tasks.
+keywords: YOLOv8, real-time object detection, YOLO series, Ultralytics, computer vision, advanced object detection, AI, machine learning, deep learning
+---
+
+# YOLOv8
+
+## Overview
+
+YOLOv8 is the latest iteration in the YOLO series of real-time object detectors, offering cutting-edge performance in terms of accuracy and speed. Building upon the advancements of previous YOLO versions, YOLOv8 introduces new features and optimizations that make it an ideal choice for various object detection tasks in a wide range of applications.
+
+
+
+
+
+
+
+ Watch: Ultralytics YOLOv8 Model Overview
+
+
+## Key Features
+
+- **Advanced Backbone and Neck Architectures:** YOLOv8 employs state-of-the-art backbone and neck architectures, resulting in improved feature extraction and object detection performance.
+- **Anchor-free Split Ultralytics Head:** YOLOv8 adopts an anchor-free split Ultralytics head, which contributes to better accuracy and a more efficient detection process compared to anchor-based approaches.
+- **Optimized Accuracy-Speed Tradeoff:** With a focus on maintaining an optimal balance between accuracy and speed, YOLOv8 is suitable for real-time object detection tasks in diverse application areas.
+- **Variety of Pre-trained Models:** YOLOv8 offers a range of pre-trained models to cater to various tasks and performance requirements, making it easier to find the right model for your specific use case.
+
+## Supported Tasks and Modes
+
+The YOLOv8 series offers a diverse range of models, each specialized for specific tasks in computer vision. These models are designed to cater to various requirements, from object detection to more complex tasks like instance segmentation, pose/keypoints detection, oriented object detection, and classification.
+
+Each variant of the YOLOv8 series is optimized for its respective task, ensuring high performance and accuracy. Additionally, these models are compatible with various operational modes including [Inference](../modes/predict.md), [Validation](../modes/val.md), [Training](../modes/train.md), and [Export](../modes/export.md), facilitating their use in different stages of deployment and development.
+
+| Model | Filenames | Task | Inference | Validation | Training | Export |
+| ----------- | -------------------------------------------------------------------------------------------------------------- | -------------------------------------------- | --------- | ---------- | -------- | ------ |
+| YOLOv8 | `yolov8n.pt` `yolov8s.pt` `yolov8m.pt` `yolov8l.pt` `yolov8x.pt` | [Detection](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
+| YOLOv8-seg | `yolov8n-seg.pt` `yolov8s-seg.pt` `yolov8m-seg.pt` `yolov8l-seg.pt` `yolov8x-seg.pt` | [Instance Segmentation](../tasks/segment.md) | ✅ | ✅ | ✅ | ✅ |
+| YOLOv8-pose | `yolov8n-pose.pt` `yolov8s-pose.pt` `yolov8m-pose.pt` `yolov8l-pose.pt` `yolov8x-pose.pt` `yolov8x-pose-p6.pt` | [Pose/Keypoints](../tasks/pose.md) | ✅ | ✅ | ✅ | ✅ |
+| YOLOv8-obb | `yolov8n-obb.pt` `yolov8s-obb.pt` `yolov8m-obb.pt` `yolov8l-obb.pt` `yolov8x-obb.pt` | [Oriented Detection](../tasks/obb.md) | ✅ | ✅ | ✅ | ✅ |
+| YOLOv8-cls | `yolov8n-cls.pt` `yolov8s-cls.pt` `yolov8m-cls.pt` `yolov8l-cls.pt` `yolov8x-cls.pt` | [Classification](../tasks/classify.md) | ✅ | ✅ | ✅ | ✅ |
+
+This table provides an overview of the YOLOv8 model variants, highlighting their applicability in specific tasks and their compatibility with various operational modes such as Inference, Validation, Training, and Export. It showcases the versatility and robustness of the YOLOv8 series, making them suitable for a variety of applications in computer vision.
+
+## Performance Metrics
+
+!!! Performance
+
+ === "Detection (COCO)"
+
+ See [Detection Docs](../tasks/detect.md) for usage examples with these models trained on [COCO](../datasets/detect/coco.md), which include 80 pre-trained classes.
+
+ | Model | size (pixels) | mAPval 50-95 | Speed CPU ONNX (ms) | Speed A100 TensorRT (ms) | params (M) | FLOPs (B) |
+ | ------------------------------------------------------------------------------------ | --------------------- | -------------------- | ------------------------------ | ----------------------------------- | ------------------ | ----------------- |
+ | [YOLOv8n](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n.pt) | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
+ | [YOLOv8s](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8s.pt) | 640 | 44.9 | 128.4 | 1.20 | 11.2 | 28.6 |
+ | [YOLOv8m](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8m.pt) | 640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 |
+ | [YOLOv8l](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8l.pt) | 640 | 52.9 | 375.2 | 2.39 | 43.7 | 165.2 |
+ | [YOLOv8x](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8x.pt) | 640 | 53.9 | 479.1 | 3.53 | 68.2 | 257.8 |
+
+ === "Detection (Open Images V7)"
+
+ See [Detection Docs](../tasks/detect.md) for usage examples with these models trained on [Open Image V7](../datasets/detect/open-images-v7.md), which include 600 pre-trained classes.
+
+ | Model | size (pixels) | mAPval 50-95 | Speed CPU ONNX (ms) | Speed A100 TensorRT (ms) | params (M) | FLOPs (B) |
+ | ----------------------------------------------------------------------------------------- | --------------------- | -------------------- | ------------------------------ | ----------------------------------- | ------------------ | ----------------- |
+ | [YOLOv8n](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n-oiv7.pt) | 640 | 18.4 | 142.4 | 1.21 | 3.5 | 10.5 |
+ | [YOLOv8s](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8s-oiv7.pt) | 640 | 27.7 | 183.1 | 1.40 | 11.4 | 29.7 |
+ | [YOLOv8m](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8m-oiv7.pt) | 640 | 33.6 | 408.5 | 2.26 | 26.2 | 80.6 |
+ | [YOLOv8l](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8l-oiv7.pt) | 640 | 34.9 | 596.9 | 2.43 | 44.1 | 167.4 |
+ | [YOLOv8x](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8x-oiv7.pt) | 640 | 36.3 | 860.6 | 3.56 | 68.7 | 260.6 |
+
+ === "Segmentation (COCO)"
+
+ See [Segmentation Docs](../tasks/segment.md) for usage examples with these models trained on [COCO](../datasets/segment/coco.md), which include 80 pre-trained classes.
+
+ | Model | size (pixels) | mAPbox 50-95 | mAPmask 50-95 | Speed CPU ONNX (ms) | Speed A100 TensorRT (ms) | params (M) | FLOPs (B) |
+ | -------------------------------------------------------------------------------------------- | --------------------- | -------------------- | --------------------- | ------------------------------ | ----------------------------------- | ------------------ | ----------------- |
+ | [YOLOv8n-seg](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n-seg.pt) | 640 | 36.7 | 30.5 | 96.1 | 1.21 | 3.4 | 12.6 |
+ | [YOLOv8s-seg](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8s-seg.pt) | 640 | 44.6 | 36.8 | 155.7 | 1.47 | 11.8 | 42.6 |
+ | [YOLOv8m-seg](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8m-seg.pt) | 640 | 49.9 | 40.8 | 317.0 | 2.18 | 27.3 | 110.2 |
+ | [YOLOv8l-seg](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8l-seg.pt) | 640 | 52.3 | 42.6 | 572.4 | 2.79 | 46.0 | 220.5 |
+ | [YOLOv8x-seg](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8x-seg.pt) | 640 | 53.4 | 43.4 | 712.1 | 4.02 | 71.8 | 344.1 |
+
+ === "Classification (ImageNet)"
+
+ See [Classification Docs](../tasks/classify.md) for usage examples with these models trained on [ImageNet](../datasets/classify/imagenet.md), which include 1000 pre-trained classes.
+
+ | Model | size (pixels) | acc top1 | acc top5 | Speed CPU ONNX (ms) | Speed A100 TensorRT (ms) | params (M) | FLOPs (B) at 640 |
+ | -------------------------------------------------------------------------------------------- | --------------------- | ---------------- | ---------------- | ------------------------------ | ----------------------------------- | ------------------ | ------------------------ |
+ | [YOLOv8n-cls](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n-cls.pt) | 224 | 69.0 | 88.3 | 12.9 | 0.31 | 2.7 | 4.3 |
+ | [YOLOv8s-cls](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8s-cls.pt) | 224 | 73.8 | 91.7 | 23.4 | 0.35 | 6.4 | 13.5 |
+ | [YOLOv8m-cls](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8m-cls.pt) | 224 | 76.8 | 93.5 | 85.4 | 0.62 | 17.0 | 42.7 |
+ | [YOLOv8l-cls](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8l-cls.pt) | 224 | 76.8 | 93.5 | 163.0 | 0.87 | 37.5 | 99.7 |
+ | [YOLOv8x-cls](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8x-cls.pt) | 224 | 79.0 | 94.6 | 232.0 | 1.01 | 57.4 | 154.8 |
+
+ === "Pose (COCO)"
+
+ See [Pose Estimation Docs](../tasks/pose.md) for usage examples with these models trained on [COCO](../datasets/pose/coco.md), which include 1 pre-trained class, 'person'.
+
+ | Model | size (pixels) | mAPpose 50-95 | mAPpose 50 | Speed CPU ONNX (ms) | Speed A100 TensorRT (ms) | params (M) | FLOPs (B) |
+ | ---------------------------------------------------------------------------------------------------- | --------------------- | --------------------- | ------------------ | ------------------------------ | ----------------------------------- | ------------------ | ----------------- |
+ | [YOLOv8n-pose](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n-pose.pt) | 640 | 50.4 | 80.1 | 131.8 | 1.18 | 3.3 | 9.2 |
+ | [YOLOv8s-pose](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8s-pose.pt) | 640 | 60.0 | 86.2 | 233.2 | 1.42 | 11.6 | 30.2 |
+ | [YOLOv8m-pose](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8m-pose.pt) | 640 | 65.0 | 88.8 | 456.3 | 2.00 | 26.4 | 81.0 |
+ | [YOLOv8l-pose](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8l-pose.pt) | 640 | 67.6 | 90.0 | 784.5 | 2.59 | 44.4 | 168.6 |
+ | [YOLOv8x-pose](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8x-pose.pt) | 640 | 69.2 | 90.2 | 1607.1 | 3.73 | 69.4 | 263.2 |
+ | [YOLOv8x-pose-p6](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8x-pose-p6.pt) | 1280 | 71.6 | 91.2 | 4088.7 | 10.04 | 99.1 | 1066.4 |
+
+ === "OBB (DOTAv1)"
+
+ See [Oriented Detection Docs](../tasks/obb.md) for usage examples with these models trained on [DOTAv1](../datasets/obb/dota-v2.md#dota-v10), which include 15 pre-trained classes.
+
+ | Model | size (pixels) | mAPtest 50 | Speed CPU ONNX (ms) | Speed A100 TensorRT (ms) | params (M) | FLOPs (B) |
+ |----------------------------------------------------------------------------------------------|-----------------------| -------------------- | -------------------------------- | ------------------------------------- | -------------------- | ----------------- |
+ | [YOLOv8n-obb](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n-obb.pt) | 1024 | 78.0 | 204.77 | 3.57 | 3.1 | 23.3 |
+ | [YOLOv8s-obb](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8s-obb.pt) | 1024 | 79.5 | 424.88 | 4.07 | 11.4 | 76.3 |
+ | [YOLOv8m-obb](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8m-obb.pt) | 1024 | 80.5 | 763.48 | 7.61 | 26.4 | 208.6 |
+ | [YOLOv8l-obb](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8l-obb.pt) | 1024 | 80.7 | 1278.42 | 11.83 | 44.5 | 433.8 |
+ | [YOLOv8x-obb](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8x-obb.pt) | 1024 | 81.36 | 1759.10 | 13.23 | 69.5 | 676.7 |
+
+## Usage Examples
+
+This example provides simple YOLOv8 training and inference examples. For full documentation on these and other [modes](../modes/index.md) see the [Predict](../modes/predict.md), [Train](../modes/train.md), [Val](../modes/val.md) and [Export](../modes/export.md) docs pages.
+
+Note the below example is for YOLOv8 [Detect](../tasks/detect.md) models for object detection. For additional supported tasks see the [Segment](../tasks/segment.md), [Classify](../tasks/classify.md), [OBB](../tasks/obb.md) docs and [Pose](../tasks/pose.md) docs.
+
+!!! Example
+
+ === "Python"
+
+ PyTorch pretrained `*.pt` models as well as configuration `*.yaml` files can be passed to the `YOLO()` class to create a model instance in python:
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a COCO-pretrained YOLOv8n model
+ model = YOLO("yolov8n.pt")
+
+ # Display model information (optional)
+ model.info()
+
+ # Train the model on the COCO8 example dataset for 100 epochs
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
+
+ # Run inference with the YOLOv8n model on the 'bus.jpg' image
+ results = model("path/to/bus.jpg")
+ ```
+
+ === "CLI"
+
+ CLI commands are available to directly run the models:
+
+ ```bash
+ # Load a COCO-pretrained YOLOv8n model and train it on the COCO8 example dataset for 100 epochs
+ yolo train model=yolov8n.pt data=coco8.yaml epochs=100 imgsz=640
+
+ # Load a COCO-pretrained YOLOv8n model and run inference on the 'bus.jpg' image
+ yolo predict model=yolov8n.pt source=path/to/bus.jpg
+ ```
+
+## Citations and Acknowledgements
+
+If you use the YOLOv8 model or any other software from this repository in your work, please cite it using the following format:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @software{yolov8_ultralytics,
+ author = {Glenn Jocher and Ayush Chaurasia and Jing Qiu},
+ title = {Ultralytics YOLOv8},
+ version = {8.0.0},
+ year = {2023},
+ url = {https://github.com/ultralytics/ultralytics},
+ orcid = {0000-0001-5950-6979, 0000-0002-7603-6750, 0000-0003-3783-7069},
+ license = {AGPL-3.0}
+ }
+ ```
+
+Please note that the DOI is pending and will be added to the citation once it is available. YOLOv8 models are provided under [AGPL-3.0](https://github.com/ultralytics/ultralytics/blob/main/LICENSE) and [Enterprise](https://ultralytics.com/license) licenses.
+
+## FAQ
+
+### What is YOLOv8 and how does it differ from previous YOLO versions?
+
+YOLOv8 is the latest iteration in the Ultralytics YOLO series, designed to improve real-time object detection performance with advanced features. Unlike earlier versions, YOLOv8 incorporates an **anchor-free split Ultralytics head**, state-of-the-art backbone and neck architectures, and offers optimized accuracy-speed tradeoff, making it ideal for diverse applications. For more details, check the [Overview](#overview) and [Key Features](#key-features) sections.
+
+### How can I use YOLOv8 for different computer vision tasks?
+
+YOLOv8 supports a wide range of computer vision tasks, including object detection, instance segmentation, pose/keypoints detection, oriented object detection, and classification. Each model variant is optimized for its specific task and compatible with various operational modes like [Inference](../modes/predict.md), [Validation](../modes/val.md), [Training](../modes/train.md), and [Export](../modes/export.md). Refer to the [Supported Tasks and Modes](#supported-tasks-and-modes) section for more information.
+
+### What are the performance metrics for YOLOv8 models?
+
+YOLOv8 models achieve state-of-the-art performance across various benchmarking datasets. For instance, the YOLOv8n model achieves a mAP (mean Average Precision) of 37.3 on the COCO dataset and a speed of 0.99 ms on A100 TensorRT. Detailed performance metrics for each model variant across different tasks and datasets can be found in the [Performance Metrics](#performance-metrics) section.
+
+### How do I train a YOLOv8 model?
+
+Training a YOLOv8 model can be done using either Python or CLI. Below are examples for training a model using a COCO-pretrained YOLOv8 model on the COCO8 dataset for 100 epochs:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a COCO-pretrained YOLOv8n model
+ model = YOLO("yolov8n.pt")
+
+ # Train the model on the COCO8 example dataset for 100 epochs
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo train model=yolov8n.pt data=coco8.yaml epochs=100 imgsz=640
+ ```
+
+For further details, visit the [Training](../modes/train.md) documentation.
+
+### Can I benchmark YOLOv8 models for performance?
+
+Yes, YOLOv8 models can be benchmarked for performance in terms of speed and accuracy across various export formats. You can use PyTorch, ONNX, TensorRT, and more for benchmarking. Below are example commands for benchmarking using Python and CLI:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics.utils.benchmarks import benchmark
+
+ # Benchmark on GPU
+ benchmark(model="yolov8n.pt", data="coco8.yaml", imgsz=640, half=False, device=0)
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo benchmark model=yolov8n.pt data='coco8.yaml' imgsz=640 half=False device=0
+ ```
+
+For additional information, check the [Performance Metrics](#performance-metrics) section.
diff --git a/ultralytics/docs/en/models/yolov9.md b/ultralytics/docs/en/models/yolov9.md
new file mode 100644
index 0000000000000000000000000000000000000000..97c1e164da49a47316cbec3010754c77e4988d16
--- /dev/null
+++ b/ultralytics/docs/en/models/yolov9.md
@@ -0,0 +1,238 @@
+---
+comments: true
+description: Explore YOLOv9, the latest leap in real-time object detection, featuring innovations like PGI and GELAN, and achieving new benchmarks in efficiency and accuracy.
+keywords: YOLOv9, object detection, real-time, PGI, GELAN, deep learning, MS COCO, AI, neural networks, model efficiency, accuracy, Ultralytics
+---
+
+# YOLOv9: A Leap Forward in Object Detection Technology
+
+YOLOv9 marks a significant advancement in real-time object detection, introducing groundbreaking techniques such as Programmable Gradient Information (PGI) and the Generalized Efficient Layer Aggregation Network (GELAN). This model demonstrates remarkable improvements in efficiency, accuracy, and adaptability, setting new benchmarks on the MS COCO dataset. The YOLOv9 project, while developed by a separate open-source team, builds upon the robust codebase provided by [Ultralytics](https://ultralytics.com) [YOLOv5](yolov5.md), showcasing the collaborative spirit of the AI research community.
+
+
+
+
+
+ Watch: YOLOv9 Training on Custom Data using Ultralytics | Industrial Package Dataset
+
+
+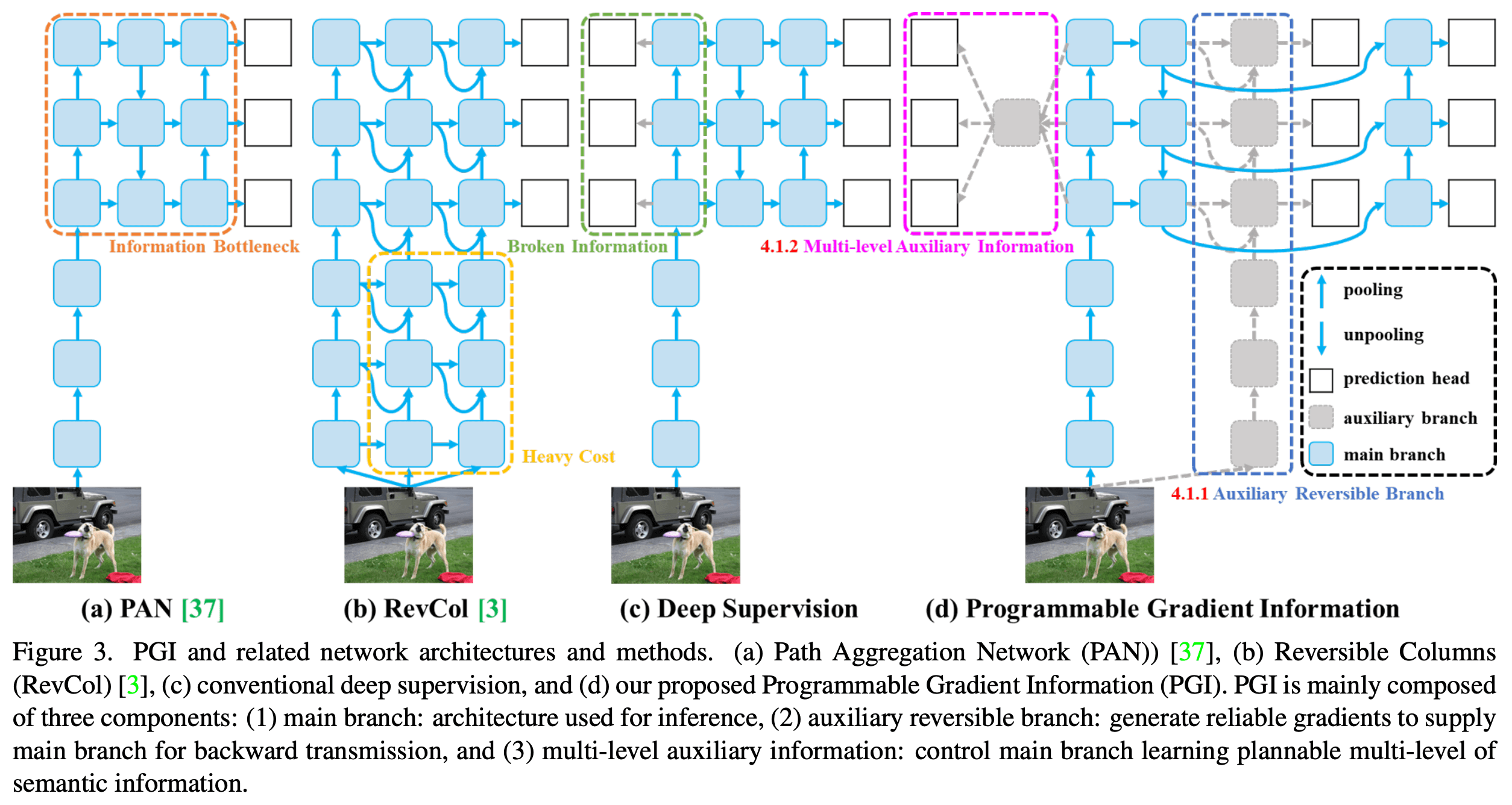
+
+## Introduction to YOLOv9
+
+In the quest for optimal real-time object detection, YOLOv9 stands out with its innovative approach to overcoming information loss challenges inherent in deep neural networks. By integrating PGI and the versatile GELAN architecture, YOLOv9 not only enhances the model's learning capacity but also ensures the retention of crucial information throughout the detection process, thereby achieving exceptional accuracy and performance.
+
+## Core Innovations of YOLOv9
+
+YOLOv9's advancements are deeply rooted in addressing the challenges posed by information loss in deep neural networks. The Information Bottleneck Principle and the innovative use of Reversible Functions are central to its design, ensuring YOLOv9 maintains high efficiency and accuracy.
+
+### Information Bottleneck Principle
+
+The Information Bottleneck Principle reveals a fundamental challenge in deep learning: as data passes through successive layers of a network, the potential for information loss increases. This phenomenon is mathematically represented as:
+
+```python
+I(X, X) >= I(X, f_theta(X)) >= I(X, g_phi(f_theta(X)))
+```
+
+where `I` denotes mutual information, and `f` and `g` represent transformation functions with parameters `theta` and `phi`, respectively. YOLOv9 counters this challenge by implementing Programmable Gradient Information (PGI), which aids in preserving essential data across the network's depth, ensuring more reliable gradient generation and, consequently, better model convergence and performance.
+
+### Reversible Functions
+
+The concept of Reversible Functions is another cornerstone of YOLOv9's design. A function is deemed reversible if it can be inverted without any loss of information, as expressed by:
+
+```python
+X = v_zeta(r_psi(X))
+```
+
+with `psi` and `zeta` as parameters for the reversible and its inverse function, respectively. This property is crucial for deep learning architectures, as it allows the network to retain a complete information flow, thereby enabling more accurate updates to the model's parameters. YOLOv9 incorporates reversible functions within its architecture to mitigate the risk of information degradation, especially in deeper layers, ensuring the preservation of critical data for object detection tasks.
+
+### Impact on Lightweight Models
+
+Addressing information loss is particularly vital for lightweight models, which are often under-parameterized and prone to losing significant information during the feedforward process. YOLOv9's architecture, through the use of PGI and reversible functions, ensures that even with a streamlined model, the essential information required for accurate object detection is retained and effectively utilized.
+
+### Programmable Gradient Information (PGI)
+
+PGI is a novel concept introduced in YOLOv9 to combat the information bottleneck problem, ensuring the preservation of essential data across deep network layers. This allows for the generation of reliable gradients, facilitating accurate model updates and improving the overall detection performance.
+
+### Generalized Efficient Layer Aggregation Network (GELAN)
+
+GELAN represents a strategic architectural advancement, enabling YOLOv9 to achieve superior parameter utilization and computational efficiency. Its design allows for flexible integration of various computational blocks, making YOLOv9 adaptable to a wide range of applications without sacrificing speed or accuracy.
+
+
+
+## YOLOv9 Benchmarks
+
+Benchmarking in YOLOv9 using [Ultralytics](https://docs.ultralytics.com/modes/benchmark/) involves evaluating the performance of your trained and validated model in real-world scenarios. This process includes:
+
+- **Performance Evaluation:** Assessing the model's speed and accuracy.
+- **Export Formats:** Testing the model across different export formats to ensure it meets the necessary standards and performs well in various environments.
+- **Framework Support:** Providing a comprehensive framework within Ultralytics YOLOv8 to facilitate these assessments and ensure consistent and reliable results.
+
+By benchmarking, you can ensure that your model not only performs well in controlled testing environments but also maintains high performance in practical, real-world applications.
+
+
+
+
+
+ Watch: How to Benchmark the YOLOv9 Model Using the Ultralytics Python Package
+
+
+## Performance on MS COCO Dataset
+
+The performance of YOLOv9 on the [COCO dataset](../datasets/detect/coco.md) exemplifies its significant advancements in real-time object detection, setting new benchmarks across various model sizes. Table 1 presents a comprehensive comparison of state-of-the-art real-time object detectors, illustrating YOLOv9's superior efficiency and accuracy.
+
+**Table 1. Comparison of State-of-the-Art Real-Time Object Detectors**
+
+!!! tip "Performance"
+
+ === "Detection (COCO)"
+
+ | Model | size (pixels) | mAPval 50-95 | mAPval 50 | params (M) | FLOPs (B) |
+ |---------------------------------------------------------------------------------------|-----------------------|----------------------|-------------------|--------------------|-------------------|
+ | [YOLOv9t](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov9t.pt) | 640 | 38.3 | 53.1 | 2.0 | 7.7 |
+ | [YOLOv9s](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov9s.pt) | 640 | 46.8 | 63.4 | 7.2 | 26.7 |
+ | [YOLOv9m](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov9m.pt) | 640 | 51.4 | 68.1 | 20.1 | 76.8 |
+ | [YOLOv9c](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov9c.pt) | 640 | 53.0 | 70.2 | 25.5 | 102.8 |
+ | [YOLOv9e](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov9e.pt) | 640 | 55.6 | 72.8 | 58.1 | 192.5 |
+
+ === "Segmentation (COCO)"
+
+ | Model | size (pixels) | mAPbox 50-95 | mAPmask 50-95 | params (M) | FLOPs (B) |
+ |-----------------------------------------------------------------------------------------------|-----------------------|----------------------|-----------------------|--------------------|-------------------|
+ | [YOLOv9c-seg](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov9c-seg.pt) | 640 | 52.4 | 42.2 | 27.9 | 159.4 |
+ | [YOLOv9e-seg](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov9e-seg.pt) | 640 | 55.1 | 44.3 | 60.5 | 248.4 |
+
+YOLOv9's iterations, ranging from the tiny `t` variant to the extensive `e` model, demonstrate improvements not only in accuracy (mAP metrics) but also in efficiency with a reduced number of parameters and computational needs (FLOPs). This table underscores YOLOv9's ability to deliver high precision while maintaining or reducing the computational overhead compared to prior versions and competing models.
+
+Comparatively, YOLOv9 exhibits remarkable gains:
+
+- **Lightweight Models**: YOLOv9s surpasses the YOLO MS-S in parameter efficiency and computational load while achieving an improvement of 0.4∼0.6% in AP.
+- **Medium to Large Models**: YOLOv9m and YOLOv9e show notable advancements in balancing the trade-off between model complexity and detection performance, offering significant reductions in parameters and computations against the backdrop of improved accuracy.
+
+The YOLOv9c model, in particular, highlights the effectiveness of the architecture's optimizations. It operates with 42% fewer parameters and 21% less computational demand than YOLOv7 AF, yet it achieves comparable accuracy, demonstrating YOLOv9's significant efficiency improvements. Furthermore, the YOLOv9e model sets a new standard for large models, with 15% fewer parameters and 25% less computational need than [YOLOv8x](yolov8.md), alongside an incremental 1.7% improvement in AP.
+
+These results showcase YOLOv9's strategic advancements in model design, emphasizing its enhanced efficiency without compromising on the precision essential for real-time object detection tasks. The model not only pushes the boundaries of performance metrics but also emphasizes the importance of computational efficiency, making it a pivotal development in the field of computer vision.
+
+## Conclusion
+
+YOLOv9 represents a pivotal development in real-time object detection, offering significant improvements in terms of efficiency, accuracy, and adaptability. By addressing critical challenges through innovative solutions like PGI and GELAN, YOLOv9 sets a new precedent for future research and application in the field. As the AI community continues to evolve, YOLOv9 stands as a testament to the power of collaboration and innovation in driving technological progress.
+
+## Usage Examples
+
+This example provides simple YOLOv9 training and inference examples. For full documentation on these and other [modes](../modes/index.md) see the [Predict](../modes/predict.md), [Train](../modes/train.md), [Val](../modes/val.md) and [Export](../modes/export.md) docs pages.
+
+!!! Example
+
+ === "Python"
+
+ PyTorch pretrained `*.pt` models as well as configuration `*.yaml` files can be passed to the `YOLO()` class to create a model instance in python:
+
+ ```python
+ from ultralytics import YOLO
+
+ # Build a YOLOv9c model from scratch
+ model = YOLO("yolov9c.yaml")
+
+ # Build a YOLOv9c model from pretrained weight
+ model = YOLO("yolov9c.pt")
+
+ # Display model information (optional)
+ model.info()
+
+ # Train the model on the COCO8 example dataset for 100 epochs
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
+
+ # Run inference with the YOLOv9c model on the 'bus.jpg' image
+ results = model("path/to/bus.jpg")
+ ```
+
+ === "CLI"
+
+ CLI commands are available to directly run the models:
+
+ ```bash
+ # Build a YOLOv9c model from scratch and train it on the COCO8 example dataset for 100 epochs
+ yolo train model=yolov9c.yaml data=coco8.yaml epochs=100 imgsz=640
+
+ # Build a YOLOv9c model from scratch and run inference on the 'bus.jpg' image
+ yolo predict model=yolov9c.yaml source=path/to/bus.jpg
+ ```
+
+## Supported Tasks and Modes
+
+The YOLOv9 series offers a range of models, each optimized for high-performance [Object Detection](../tasks/detect.md). These models cater to varying computational needs and accuracy requirements, making them versatile for a wide array of applications.
+
+| Model | Filenames | Tasks | Inference | Validation | Training | Export |
+| ---------- | ------------------------------------------------------- | -------------------------------------------- | --------- | ---------- | -------- | ------ |
+| YOLOv9 | `yolov9t` `yolov9s` `yolov9m` `yolov9c.pt` `yolov9e.pt` | [Object Detection](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
+| YOLOv9-seg | `yolov9c-seg.pt` `yolov9e-seg.pt` | [Instance Segmentation](../tasks/segment.md) | ✅ | ✅ | ✅ | ✅ |
+
+This table provides a detailed overview of the YOLOv9 model variants, highlighting their capabilities in object detection tasks and their compatibility with various operational modes such as [Inference](../modes/predict.md), [Validation](../modes/val.md), [Training](../modes/train.md), and [Export](../modes/export.md). This comprehensive support ensures that users can fully leverage the capabilities of YOLOv9 models in a broad range of object detection scenarios.
+
+!!! note
+
+ Training YOLOv9 models will require _more_ resources **and** take longer than the equivalent sized [YOLOv8 model](yolov8.md).
+
+## Citations and Acknowledgements
+
+We would like to acknowledge the YOLOv9 authors for their significant contributions in the field of real-time object detection:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @article{wang2024yolov9,
+ title={YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information},
+ author={Wang, Chien-Yao and Liao, Hong-Yuan Mark},
+ booktitle={arXiv preprint arXiv:2402.13616},
+ year={2024}
+ }
+ ```
+
+The original YOLOv9 paper can be found on [arXiv](https://arxiv.org/pdf/2402.13616.pdf). The authors have made their work publicly available, and the codebase can be accessed on [GitHub](https://github.com/WongKinYiu/yolov9). We appreciate their efforts in advancing the field and making their work accessible to the broader community.
+
+## FAQ
+
+### What innovations does YOLOv9 introduce for real-time object detection?
+
+YOLOv9 introduces groundbreaking techniques such as Programmable Gradient Information (PGI) and the Generalized Efficient Layer Aggregation Network (GELAN). These innovations address information loss challenges in deep neural networks, ensuring high efficiency, accuracy, and adaptability. PGI preserves essential data across network layers, while GELAN optimizes parameter utilization and computational efficiency. Learn more about [YOLOv9's core innovations](#core-innovations-of-yolov9) that set new benchmarks on the MS COCO dataset.
+
+### How does YOLOv9 perform on the MS COCO dataset compared to other models?
+
+YOLOv9 outperforms state-of-the-art real-time object detectors by achieving higher accuracy and efficiency. On the [COCO dataset](../datasets/detect/coco.md), YOLOv9 models exhibit superior mAP scores across various sizes while maintaining or reducing computational overhead. For instance, YOLOv9c achieves comparable accuracy with 42% fewer parameters and 21% less computational demand than YOLOv7 AF. Explore [performance comparisons](#performance-on-ms-coco-dataset) for detailed metrics.
+
+### How can I train a YOLOv9 model using Python and CLI?
+
+You can train a YOLOv9 model using both Python and CLI commands. For Python, instantiate a model using the `YOLO` class and call the `train` method:
+
+```python
+from ultralytics import YOLO
+
+# Build a YOLOv9c model from pretrained weights and train
+model = YOLO("yolov9c.pt")
+results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
+```
+
+For CLI training, execute:
+
+```bash
+yolo train model=yolov9c.yaml data=coco8.yaml epochs=100 imgsz=640
+```
+
+Learn more about [usage examples](#usage-examples) for training and inference.
+
+### What are the advantages of using Ultralytics YOLOv9 for lightweight models?
+
+YOLOv9 is designed to mitigate information loss, which is particularly important for lightweight models often prone to losing significant information. By integrating Programmable Gradient Information (PGI) and reversible functions, YOLOv9 ensures essential data retention, enhancing the model's accuracy and efficiency. This makes it highly suitable for applications requiring compact models with high performance. For more details, explore the section on [YOLOv9's impact on lightweight models](#impact-on-lightweight-models).
+
+### What tasks and modes does YOLOv9 support?
+
+YOLOv9 supports various tasks including object detection and instance segmentation. It is compatible with multiple operational modes such as inference, validation, training, and export. This versatility makes YOLOv9 adaptable to diverse real-time computer vision applications. Refer to the [supported tasks and modes](#supported-tasks-and-modes) section for more information.
diff --git a/ultralytics/docs/en/modes/benchmark.md b/ultralytics/docs/en/modes/benchmark.md
new file mode 100644
index 0000000000000000000000000000000000000000..55a94eead80c31b5364f9c05679968216ea9f2f4
--- /dev/null
+++ b/ultralytics/docs/en/modes/benchmark.md
@@ -0,0 +1,159 @@
+---
+comments: true
+description: Learn how to evaluate your YOLOv8 model's performance in real-world scenarios using benchmark mode. Optimize speed, accuracy, and resource allocation across export formats.
+keywords: model benchmarking, YOLOv8, Ultralytics, performance evaluation, export formats, ONNX, TensorRT, OpenVINO, CoreML, TensorFlow, optimization, mAP50-95, inference time
+---
+
+# Model Benchmarking with Ultralytics YOLO
+
+
+
+## Introduction
+
+Once your model is trained and validated, the next logical step is to evaluate its performance in various real-world scenarios. Benchmark mode in Ultralytics YOLOv8 serves this purpose by providing a robust framework for assessing the speed and accuracy of your model across a range of export formats.
+
+
+
+## Why Is Benchmarking Crucial?
+
+- **Informed Decisions:** Gain insights into the trade-offs between speed and accuracy.
+- **Resource Allocation:** Understand how different export formats perform on different hardware.
+- **Optimization:** Learn which export format offers the best performance for your specific use case.
+- **Cost Efficiency:** Make more efficient use of hardware resources based on benchmark results.
+
+### Key Metrics in Benchmark Mode
+
+- **mAP50-95:** For object detection, segmentation, and pose estimation.
+- **accuracy_top5:** For image classification.
+- **Inference Time:** Time taken for each image in milliseconds.
+
+### Supported Export Formats
+
+- **ONNX:** For optimal CPU performance
+- **TensorRT:** For maximal GPU efficiency
+- **OpenVINO:** For Intel hardware optimization
+- **CoreML, TensorFlow SavedModel, and More:** For diverse deployment needs.
+
+!!! Tip "Tip"
+
+ * Export to ONNX or OpenVINO for up to 3x CPU speedup.
+ * Export to TensorRT for up to 5x GPU speedup.
+
+## Usage Examples
+
+Run YOLOv8n benchmarks on all supported export formats including ONNX, TensorRT etc. See Arguments section below for a full list of export arguments.
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics.utils.benchmarks import benchmark
+
+ # Benchmark on GPU
+ benchmark(model="yolov8n.pt", data="coco8.yaml", imgsz=640, half=False, device=0)
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo benchmark model=yolov8n.pt data='coco8.yaml' imgsz=640 half=False device=0
+ ```
+
+## Arguments
+
+Arguments such as `model`, `data`, `imgsz`, `half`, `device`, and `verbose` provide users with the flexibility to fine-tune the benchmarks to their specific needs and compare the performance of different export formats with ease.
+
+| Key | Default Value | Description |
+| --------- | ------------- | ------------------------------------------------------------------------------------------------------------------------------------------------- |
+| `model` | `None` | Specifies the path to the model file. Accepts both `.pt` and `.yaml` formats, e.g., `"yolov8n.pt"` for pre-trained models or configuration files. |
+| `data` | `None` | Path to a YAML file defining the dataset for benchmarking, typically including paths and settings for validation data. Example: `"coco8.yaml"`. |
+| `imgsz` | `640` | The input image size for the model. Can be a single integer for square images or a tuple `(width, height)` for non-square, e.g., `(640, 480)`. |
+| `half` | `False` | Enables FP16 (half-precision) inference, reducing memory usage and possibly increasing speed on compatible hardware. Use `half=True` to enable. |
+| `int8` | `False` | Activates INT8 quantization for further optimized performance on supported devices, especially useful for edge devices. Set `int8=True` to use. |
+| `device` | `None` | Defines the computation device(s) for benchmarking, such as `"cpu"`, `"cuda:0"`, or a list of devices like `"cuda:0,1"` for multi-GPU setups. |
+| `verbose` | `False` | Controls the level of detail in logging output. A boolean value; set `verbose=True` for detailed logs or a float for thresholding errors. |
+
+## Export Formats
+
+Benchmarks will attempt to run automatically on all possible export formats below.
+
+{% include "macros/export-table.md" %}
+
+See full `export` details in the [Export](../modes/export.md) page.
+
+## FAQ
+
+### How do I benchmark my YOLOv8 model's performance using Ultralytics?
+
+Ultralytics YOLOv8 offers a Benchmark mode to assess your model's performance across different export formats. This mode provides insights into key metrics such as mean Average Precision (mAP50-95), accuracy, and inference time in milliseconds. To run benchmarks, you can use either Python or CLI commands. For example, to benchmark on a GPU:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics.utils.benchmarks import benchmark
+
+ # Benchmark on GPU
+ benchmark(model="yolov8n.pt", data="coco8.yaml", imgsz=640, half=False, device=0)
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo benchmark model=yolov8n.pt data='coco8.yaml' imgsz=640 half=False device=0
+ ```
+
+For more details on benchmark arguments, visit the [Arguments](#arguments) section.
+
+### What are the benefits of exporting YOLOv8 models to different formats?
+
+Exporting YOLOv8 models to different formats such as ONNX, TensorRT, and OpenVINO allows you to optimize performance based on your deployment environment. For instance:
+
+- **ONNX:** Provides up to 3x CPU speedup.
+- **TensorRT:** Offers up to 5x GPU speedup.
+- **OpenVINO:** Specifically optimized for Intel hardware.
+ These formats enhance both the speed and accuracy of your models, making them more efficient for various real-world applications. Visit the [Export](../modes/export.md) page for complete details.
+
+### Why is benchmarking crucial in evaluating YOLOv8 models?
+
+Benchmarking your YOLOv8 models is essential for several reasons:
+
+- **Informed Decisions:** Understand the trade-offs between speed and accuracy.
+- **Resource Allocation:** Gauge the performance across different hardware options.
+- **Optimization:** Determine which export format offers the best performance for specific use cases.
+- **Cost Efficiency:** Optimize hardware usage based on benchmark results.
+ Key metrics such as mAP50-95, Top-5 accuracy, and inference time help in making these evaluations. Refer to the [Key Metrics](#key-metrics-in-benchmark-mode) section for more information.
+
+### Which export formats are supported by YOLOv8, and what are their advantages?
+
+YOLOv8 supports a variety of export formats, each tailored for specific hardware and use cases:
+
+- **ONNX:** Best for CPU performance.
+- **TensorRT:** Ideal for GPU efficiency.
+- **OpenVINO:** Optimized for Intel hardware.
+- **CoreML & TensorFlow:** Useful for iOS and general ML applications.
+ For a complete list of supported formats and their respective advantages, check out the [Supported Export Formats](#supported-export-formats) section.
+
+### What arguments can I use to fine-tune my YOLOv8 benchmarks?
+
+When running benchmarks, several arguments can be customized to suit specific needs:
+
+- **model:** Path to the model file (e.g., "yolov8n.pt").
+- **data:** Path to a YAML file defining the dataset (e.g., "coco8.yaml").
+- **imgsz:** The input image size, either as a single integer or a tuple.
+- **half:** Enable FP16 inference for better performance.
+- **int8:** Activate INT8 quantization for edge devices.
+- **device:** Specify the computation device (e.g., "cpu", "cuda:0").
+- **verbose:** Control the level of logging detail.
+ For a full list of arguments, refer to the [Arguments](#arguments) section.
diff --git a/ultralytics/docs/en/modes/export.md b/ultralytics/docs/en/modes/export.md
new file mode 100644
index 0000000000000000000000000000000000000000..99d1ba1f2614dbbf75a0477e8366fd5f11ab712a
--- /dev/null
+++ b/ultralytics/docs/en/modes/export.md
@@ -0,0 +1,185 @@
+---
+comments: true
+description: Learn how to export your YOLOv8 model to various formats like ONNX, TensorRT, and CoreML. Achieve maximum compatibility and performance.
+keywords: YOLOv8, Model Export, ONNX, TensorRT, CoreML, Ultralytics, AI, Machine Learning, Inference, Deployment
+---
+
+# Model Export with Ultralytics YOLO
+
+
+
+## Introduction
+
+The ultimate goal of training a model is to deploy it for real-world applications. Export mode in Ultralytics YOLOv8 offers a versatile range of options for exporting your trained model to different formats, making it deployable across various platforms and devices. This comprehensive guide aims to walk you through the nuances of model exporting, showcasing how to achieve maximum compatibility and performance.
+
+
+
+
+
+ Watch: How To Export Custom Trained Ultralytics YOLOv8 Model and Run Live Inference on Webcam.
+
+
+## Why Choose YOLOv8's Export Mode?
+
+- **Versatility:** Export to multiple formats including ONNX, TensorRT, CoreML, and more.
+- **Performance:** Gain up to 5x GPU speedup with TensorRT and 3x CPU speedup with ONNX or OpenVINO.
+- **Compatibility:** Make your model universally deployable across numerous hardware and software environments.
+- **Ease of Use:** Simple CLI and Python API for quick and straightforward model exporting.
+
+### Key Features of Export Mode
+
+Here are some of the standout functionalities:
+
+- **One-Click Export:** Simple commands for exporting to different formats.
+- **Batch Export:** Export batched-inference capable models.
+- **Optimized Inference:** Exported models are optimized for quicker inference times.
+- **Tutorial Videos:** In-depth guides and tutorials for a smooth exporting experience.
+
+!!! Tip "Tip"
+
+ * Export to [ONNX](../integrations/onnx.md) or [OpenVINO](../integrations/openvino.md) for up to 3x CPU speedup.
+ * Export to [TensorRT](../integrations/tensorrt.md) for up to 5x GPU speedup.
+
+## Usage Examples
+
+Export a YOLOv8n model to a different format like ONNX or TensorRT. See Arguments section below for a full list of export arguments.
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt") # load an official model
+ model = YOLO("path/to/best.pt") # load a custom trained model
+
+ # Export the model
+ model.export(format="onnx")
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo export model=yolov8n.pt format=onnx # export official model
+ yolo export model=path/to/best.pt format=onnx # export custom trained model
+ ```
+
+## Arguments
+
+This table details the configurations and options available for exporting YOLO models to different formats. These settings are critical for optimizing the exported model's performance, size, and compatibility across various platforms and environments. Proper configuration ensures that the model is ready for deployment in the intended application with optimal efficiency.
+
+{% include "macros/export-args.md" %}
+
+Adjusting these parameters allows for customization of the export process to fit specific requirements, such as deployment environment, hardware constraints, and performance targets. Selecting the appropriate format and settings is essential for achieving the best balance between model size, speed, and accuracy.
+
+## Export Formats
+
+Available YOLOv8 export formats are in the table below. You can export to any format using the `format` argument, i.e. `format='onnx'` or `format='engine'`. You can predict or validate directly on exported models, i.e. `yolo predict model=yolov8n.onnx`. Usage examples are shown for your model after export completes.
+
+{% include "macros/export-table.md" %}
+
+## FAQ
+
+### How do I export a YOLOv8 model to ONNX format?
+
+Exporting a YOLOv8 model to ONNX format is straightforward with Ultralytics. It provides both Python and CLI methods for exporting models.
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt") # load an official model
+ model = YOLO("path/to/best.pt") # load a custom trained model
+
+ # Export the model
+ model.export(format="onnx")
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo export model=yolov8n.pt format=onnx # export official model
+ yolo export model=path/to/best.pt format=onnx # export custom trained model
+ ```
+
+For more details on the process, including advanced options like handling different input sizes, refer to the [ONNX](../integrations/onnx.md) section.
+
+### What are the benefits of using TensorRT for model export?
+
+Using TensorRT for model export offers significant performance improvements. YOLOv8 models exported to TensorRT can achieve up to a 5x GPU speedup, making it ideal for real-time inference applications.
+
+- **Versatility:** Optimize models for a specific hardware setup.
+- **Speed:** Achieve faster inference through advanced optimizations.
+- **Compatibility:** Integrate smoothly with NVIDIA hardware.
+
+To learn more about integrating TensorRT, see the [TensorRT](../integrations/tensorrt.md) integration guide.
+
+### How do I enable INT8 quantization when exporting my YOLOv8 model?
+
+INT8 quantization is an excellent way to compress the model and speed up inference, especially on edge devices. Here's how you can enable INT8 quantization:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ model = YOLO("yolov8n.pt") # Load a model
+ model.export(format="onnx", int8=True)
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo export model=yolov8n.pt format=onnx int8=True # export model with INT8 quantization
+ ```
+
+INT8 quantization can be applied to various formats, such as TensorRT and CoreML. More details can be found in the [Export](../modes/export.md) section.
+
+### Why is dynamic input size important when exporting models?
+
+Dynamic input size allows the exported model to handle varying image dimensions, providing flexibility and optimizing processing efficiency for different use cases. When exporting to formats like ONNX or TensorRT, enabling dynamic input size ensures that the model can adapt to different input shapes seamlessly.
+
+To enable this feature, use the `dynamic=True` flag during export:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ model = YOLO("yolov8n.pt")
+ model.export(format="onnx", dynamic=True)
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo export model=yolov8n.pt format=onnx dynamic=True
+ ```
+
+For additional context, refer to the [dynamic input size configuration](#arguments).
+
+### What are the key export arguments to consider for optimizing model performance?
+
+Understanding and configuring export arguments is crucial for optimizing model performance:
+
+- **`format:`** The target format for the exported model (e.g., `onnx`, `torchscript`, `tensorflow`).
+- **`imgsz:`** Desired image size for the model input (e.g., `640` or `(height, width)`).
+- **`half:`** Enables FP16 quantization, reducing model size and potentially speeding up inference.
+- **`optimize:`** Applies specific optimizations for mobile or constrained environments.
+- **`int8:`** Enables INT8 quantization, highly beneficial for edge deployments.
+
+For a detailed list and explanations of all the export arguments, visit the [Export Arguments](#arguments) section.
diff --git a/ultralytics/docs/en/modes/index.md b/ultralytics/docs/en/modes/index.md
new file mode 100644
index 0000000000000000000000000000000000000000..e5a68a2892bac37edfb32b868d93ed6970b452ec
--- /dev/null
+++ b/ultralytics/docs/en/modes/index.md
@@ -0,0 +1,200 @@
+---
+comments: true
+description: Discover the diverse modes of Ultralytics YOLOv8, including training, validation, prediction, export, tracking, and benchmarking. Maximize model performance and efficiency.
+keywords: Ultralytics, YOLOv8, machine learning, model training, validation, prediction, export, tracking, benchmarking, object detection
+---
+
+# Ultralytics YOLOv8 Modes
+
+
+
+## Introduction
+
+Ultralytics YOLOv8 is not just another object detection model; it's a versatile framework designed to cover the entire lifecycle of machine learning models—from data ingestion and model training to validation, deployment, and real-world tracking. Each mode serves a specific purpose and is engineered to offer you the flexibility and efficiency required for different tasks and use-cases.
+
+
+
+### Modes at a Glance
+
+Understanding the different **modes** that Ultralytics YOLOv8 supports is critical to getting the most out of your models:
+
+- **Train** mode: Fine-tune your model on custom or preloaded datasets.
+- **Val** mode: A post-training checkpoint to validate model performance.
+- **Predict** mode: Unleash the predictive power of your model on real-world data.
+- **Export** mode: Make your model deployment-ready in various formats.
+- **Track** mode: Extend your object detection model into real-time tracking applications.
+- **Benchmark** mode: Analyze the speed and accuracy of your model in diverse deployment environments.
+
+This comprehensive guide aims to give you an overview and practical insights into each mode, helping you harness the full potential of YOLOv8.
+
+## [Train](train.md)
+
+Train mode is used for training a YOLOv8 model on a custom dataset. In this mode, the model is trained using the specified dataset and hyperparameters. The training process involves optimizing the model's parameters so that it can accurately predict the classes and locations of objects in an image.
+
+[Train Examples](train.md){ .md-button }
+
+## [Val](val.md)
+
+Val mode is used for validating a YOLOv8 model after it has been trained. In this mode, the model is evaluated on a validation set to measure its accuracy and generalization performance. This mode can be used to tune the hyperparameters of the model to improve its performance.
+
+[Val Examples](val.md){ .md-button }
+
+## [Predict](predict.md)
+
+Predict mode is used for making predictions using a trained YOLOv8 model on new images or videos. In this mode, the model is loaded from a checkpoint file, and the user can provide images or videos to perform inference. The model predicts the classes and locations of objects in the input images or videos.
+
+[Predict Examples](predict.md){ .md-button }
+
+## [Export](export.md)
+
+Export mode is used for exporting a YOLOv8 model to a format that can be used for deployment. In this mode, the model is converted to a format that can be used by other software applications or hardware devices. This mode is useful when deploying the model to production environments.
+
+[Export Examples](export.md){ .md-button }
+
+## [Track](track.md)
+
+Track mode is used for tracking objects in real-time using a YOLOv8 model. In this mode, the model is loaded from a checkpoint file, and the user can provide a live video stream to perform real-time object tracking. This mode is useful for applications such as surveillance systems or self-driving cars.
+
+[Track Examples](track.md){ .md-button }
+
+## [Benchmark](benchmark.md)
+
+Benchmark mode is used to profile the speed and accuracy of various export formats for YOLOv8. The benchmarks provide information on the size of the exported format, its `mAP50-95` metrics (for object detection, segmentation and pose) or `accuracy_top5` metrics (for classification), and the inference time in milliseconds per image across various export formats like ONNX, OpenVINO, TensorRT and others. This information can help users choose the optimal export format for their specific use case based on their requirements for speed and accuracy.
+
+[Benchmark Examples](benchmark.md){ .md-button }
+
+## FAQ
+
+### How do I train a custom object detection model with Ultralytics YOLOv8?
+
+Training a custom object detection model with Ultralytics YOLOv8 involves using the train mode. You need a dataset formatted in YOLO format, containing images and corresponding annotation files. Use the following command to start the training process:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Train a custom model
+ model = YOLO("yolov8n.pt")
+ model.train(data="path/to/dataset.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo train data=path/to/dataset.yaml epochs=100 imgsz=640
+ ```
+
+For more detailed instructions, you can refer to the [Ultralytics Train Guide](../modes/train.md).
+
+### What metrics does Ultralytics YOLOv8 use to validate the model's performance?
+
+Ultralytics YOLOv8 uses various metrics during the validation process to assess model performance. These include:
+
+- **mAP (mean Average Precision)**: This evaluates the accuracy of object detection.
+- **IOU (Intersection over Union)**: Measures the overlap between predicted and ground truth bounding boxes.
+- **Precision and Recall**: Precision measures the ratio of true positive detections to the total detected positives, while recall measures the ratio of true positive detections to the total actual positives.
+
+You can run the following command to start the validation:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Validate the model
+ model = YOLO("yolov8n.pt")
+ model.val(data="path/to/validation.yaml")
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo val data=path/to/validation.yaml
+ ```
+
+Refer to the [Validation Guide](../modes/val.md) for further details.
+
+### How can I export my YOLOv8 model for deployment?
+
+Ultralytics YOLOv8 offers export functionality to convert your trained model into various deployment formats such as ONNX, TensorRT, CoreML, and more. Use the following example to export your model:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Export the model
+ model = YOLO("yolov8n.pt")
+ model.export(format="onnx")
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo export model=yolov8n.pt format=onnx
+ ```
+
+Detailed steps for each export format can be found in the [Export Guide](../modes/export.md).
+
+### What is the purpose of the benchmark mode in Ultralytics YOLOv8?
+
+Benchmark mode in Ultralytics YOLOv8 is used to analyze the speed and accuracy of various export formats such as ONNX, TensorRT, and OpenVINO. It provides metrics like model size, `mAP50-95` for object detection, and inference time across different hardware setups, helping you choose the most suitable format for your deployment needs.
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics.utils.benchmarks import benchmark
+
+ # Benchmark on GPU
+ benchmark(model="yolov8n.pt", data="coco8.yaml", imgsz=640, half=False, device=0)
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo benchmark model=yolov8n.pt data='coco8.yaml' imgsz=640 half=False device=0
+ ```
+
+For more details, refer to the [Benchmark Guide](../modes/benchmark.md).
+
+### How can I perform real-time object tracking using Ultralytics YOLOv8?
+
+Real-time object tracking can be achieved using the track mode in Ultralytics YOLOv8. This mode extends object detection capabilities to track objects across video frames or live feeds. Use the following example to enable tracking:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Track objects in a video
+ model = YOLO("yolov8n.pt")
+ model.track(source="path/to/video.mp4")
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo track source=path/to/video.mp4
+ ```
+
+For in-depth instructions, visit the [Track Guide](../modes/track.md).
diff --git a/ultralytics/docs/en/modes/predict.md b/ultralytics/docs/en/modes/predict.md
new file mode 100644
index 0000000000000000000000000000000000000000..d765b0ec2ee0f2bcc6561f25002799d2126decfb
--- /dev/null
+++ b/ultralytics/docs/en/modes/predict.md
@@ -0,0 +1,825 @@
+---
+comments: true
+description: Harness the power of Ultralytics YOLOv8 for real-time, high-speed inference on various data sources. Learn about predict mode, key features, and practical applications.
+keywords: Ultralytics, YOLOv8, model prediction, inference, predict mode, real-time inference, computer vision, machine learning, streaming, high performance
+---
+
+# Model Prediction with Ultralytics YOLO
+
+
+
+## Introduction
+
+In the world of machine learning and computer vision, the process of making sense out of visual data is called 'inference' or 'prediction'. Ultralytics YOLOv8 offers a powerful feature known as **predict mode** that is tailored for high-performance, real-time inference on a wide range of data sources.
+
+
+
+
+
+ Watch: How to Extract the Outputs from Ultralytics YOLOv8 Model for Custom Projects.
+
+
+## Real-world Applications
+
+| Manufacturing | Sports | Safety |
+| :-----------------------------------------------: | :--------------------------------------------------: | :-----------------------------------------: |
+| ![Vehicle Spare Parts Detection][car spare parts] | ![Football Player Detection][football player detect] | ![People Fall Detection][human fall detect] |
+| Vehicle Spare Parts Detection | Football Player Detection | People Fall Detection |
+
+## Why Use Ultralytics YOLO for Inference?
+
+Here's why you should consider YOLOv8's predict mode for your various inference needs:
+
+- **Versatility:** Capable of making inferences on images, videos, and even live streams.
+- **Performance:** Engineered for real-time, high-speed processing without sacrificing accuracy.
+- **Ease of Use:** Intuitive Python and CLI interfaces for rapid deployment and testing.
+- **Highly Customizable:** Various settings and parameters to tune the model's inference behavior according to your specific requirements.
+
+### Key Features of Predict Mode
+
+YOLOv8's predict mode is designed to be robust and versatile, featuring:
+
+- **Multiple Data Source Compatibility:** Whether your data is in the form of individual images, a collection of images, video files, or real-time video streams, predict mode has you covered.
+- **Streaming Mode:** Use the streaming feature to generate a memory-efficient generator of `Results` objects. Enable this by setting `stream=True` in the predictor's call method.
+- **Batch Processing:** The ability to process multiple images or video frames in a single batch, further speeding up inference time.
+- **Integration Friendly:** Easily integrate with existing data pipelines and other software components, thanks to its flexible API.
+
+Ultralytics YOLO models return either a Python list of `Results` objects, or a memory-efficient Python generator of `Results` objects when `stream=True` is passed to the model during inference:
+
+!!! Example "Predict"
+
+ === "Return a list with `stream=False`"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt") # pretrained YOLOv8n model
+
+ # Run batched inference on a list of images
+ results = model(["im1.jpg", "im2.jpg"]) # return a list of Results objects
+
+ # Process results list
+ for result in results:
+ boxes = result.boxes # Boxes object for bounding box outputs
+ masks = result.masks # Masks object for segmentation masks outputs
+ keypoints = result.keypoints # Keypoints object for pose outputs
+ probs = result.probs # Probs object for classification outputs
+ obb = result.obb # Oriented boxes object for OBB outputs
+ result.show() # display to screen
+ result.save(filename="result.jpg") # save to disk
+ ```
+
+ === "Return a generator with `stream=True`"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt") # pretrained YOLOv8n model
+
+ # Run batched inference on a list of images
+ results = model(["im1.jpg", "im2.jpg"], stream=True) # return a generator of Results objects
+
+ # Process results generator
+ for result in results:
+ boxes = result.boxes # Boxes object for bounding box outputs
+ masks = result.masks # Masks object for segmentation masks outputs
+ keypoints = result.keypoints # Keypoints object for pose outputs
+ probs = result.probs # Probs object for classification outputs
+ obb = result.obb # Oriented boxes object for OBB outputs
+ result.show() # display to screen
+ result.save(filename="result.jpg") # save to disk
+ ```
+
+## Inference Sources
+
+YOLOv8 can process different types of input sources for inference, as shown in the table below. The sources include static images, video streams, and various data formats. The table also indicates whether each source can be used in streaming mode with the argument `stream=True` ✅. Streaming mode is beneficial for processing videos or live streams as it creates a generator of results instead of loading all frames into memory.
+
+!!! Tip "Tip"
+
+ Use `stream=True` for processing long videos or large datasets to efficiently manage memory. When `stream=False`, the results for all frames or data points are stored in memory, which can quickly add up and cause out-of-memory errors for large inputs. In contrast, `stream=True` utilizes a generator, which only keeps the results of the current frame or data point in memory, significantly reducing memory consumption and preventing out-of-memory issues.
+
+| Source | Example | Type | Notes |
+| --------------- | ------------------------------------------ | --------------- | ------------------------------------------------------------------------------------------- |
+| image | `'image.jpg'` | `str` or `Path` | Single image file. |
+| URL | `'https://ultralytics.com/images/bus.jpg'` | `str` | URL to an image. |
+| screenshot | `'screen'` | `str` | Capture a screenshot. |
+| PIL | `Image.open('im.jpg')` | `PIL.Image` | HWC format with RGB channels. |
+| OpenCV | `cv2.imread('im.jpg')` | `np.ndarray` | HWC format with BGR channels `uint8 (0-255)`. |
+| numpy | `np.zeros((640,1280,3))` | `np.ndarray` | HWC format with BGR channels `uint8 (0-255)`. |
+| torch | `torch.zeros(16,3,320,640)` | `torch.Tensor` | BCHW format with RGB channels `float32 (0.0-1.0)`. |
+| CSV | `'sources.csv'` | `str` or `Path` | CSV file containing paths to images, videos, or directories. |
+| video ✅ | `'video.mp4'` | `str` or `Path` | Video file in formats like MP4, AVI, etc. |
+| directory ✅ | `'path/'` | `str` or `Path` | Path to a directory containing images or videos. |
+| glob ✅ | `'path/*.jpg'` | `str` | Glob pattern to match multiple files. Use the `*` character as a wildcard. |
+| YouTube ✅ | `'https://youtu.be/LNwODJXcvt4'` | `str` | URL to a YouTube video. |
+| stream ✅ | `'rtsp://example.com/media.mp4'` | `str` | URL for streaming protocols such as RTSP, RTMP, TCP, or an IP address. |
+| multi-stream ✅ | `'list.streams'` | `str` or `Path` | `*.streams` text file with one stream URL per row, i.e. 8 streams will run at batch-size 8. |
+
+Below are code examples for using each source type:
+
+!!! Example "Prediction sources"
+
+ === "image"
+
+ Run inference on an image file.
+ ```python
+ from ultralytics import YOLO
+
+ # Load a pretrained YOLOv8n model
+ model = YOLO("yolov8n.pt")
+
+ # Define path to the image file
+ source = "path/to/image.jpg"
+
+ # Run inference on the source
+ results = model(source) # list of Results objects
+ ```
+
+ === "screenshot"
+
+ Run inference on the current screen content as a screenshot.
+ ```python
+ from ultralytics import YOLO
+
+ # Load a pretrained YOLOv8n model
+ model = YOLO("yolov8n.pt")
+
+ # Define current screenshot as source
+ source = "screen"
+
+ # Run inference on the source
+ results = model(source) # list of Results objects
+ ```
+
+ === "URL"
+
+ Run inference on an image or video hosted remotely via URL.
+ ```python
+ from ultralytics import YOLO
+
+ # Load a pretrained YOLOv8n model
+ model = YOLO("yolov8n.pt")
+
+ # Define remote image or video URL
+ source = "https://ultralytics.com/images/bus.jpg"
+
+ # Run inference on the source
+ results = model(source) # list of Results objects
+ ```
+
+ === "PIL"
+
+ Run inference on an image opened with Python Imaging Library (PIL).
+ ```python
+ from PIL import Image
+
+ from ultralytics import YOLO
+
+ # Load a pretrained YOLOv8n model
+ model = YOLO("yolov8n.pt")
+
+ # Open an image using PIL
+ source = Image.open("path/to/image.jpg")
+
+ # Run inference on the source
+ results = model(source) # list of Results objects
+ ```
+
+ === "OpenCV"
+
+ Run inference on an image read with OpenCV.
+ ```python
+ import cv2
+
+ from ultralytics import YOLO
+
+ # Load a pretrained YOLOv8n model
+ model = YOLO("yolov8n.pt")
+
+ # Read an image using OpenCV
+ source = cv2.imread("path/to/image.jpg")
+
+ # Run inference on the source
+ results = model(source) # list of Results objects
+ ```
+
+ === "numpy"
+
+ Run inference on an image represented as a numpy array.
+ ```python
+ import numpy as np
+
+ from ultralytics import YOLO
+
+ # Load a pretrained YOLOv8n model
+ model = YOLO("yolov8n.pt")
+
+ # Create a random numpy array of HWC shape (640, 640, 3) with values in range [0, 255] and type uint8
+ source = np.random.randint(low=0, high=255, size=(640, 640, 3), dtype="uint8")
+
+ # Run inference on the source
+ results = model(source) # list of Results objects
+ ```
+
+ === "torch"
+
+ Run inference on an image represented as a PyTorch tensor.
+ ```python
+ import torch
+
+ from ultralytics import YOLO
+
+ # Load a pretrained YOLOv8n model
+ model = YOLO("yolov8n.pt")
+
+ # Create a random torch tensor of BCHW shape (1, 3, 640, 640) with values in range [0, 1] and type float32
+ source = torch.rand(1, 3, 640, 640, dtype=torch.float32)
+
+ # Run inference on the source
+ results = model(source) # list of Results objects
+ ```
+
+ === "CSV"
+
+ Run inference on a collection of images, URLs, videos and directories listed in a CSV file.
+ ```python
+ from ultralytics import YOLO
+
+ # Load a pretrained YOLOv8n model
+ model = YOLO("yolov8n.pt")
+
+ # Define a path to a CSV file with images, URLs, videos and directories
+ source = "path/to/file.csv"
+
+ # Run inference on the source
+ results = model(source) # list of Results objects
+ ```
+
+ === "video"
+
+ Run inference on a video file. By using `stream=True`, you can create a generator of Results objects to reduce memory usage.
+ ```python
+ from ultralytics import YOLO
+
+ # Load a pretrained YOLOv8n model
+ model = YOLO("yolov8n.pt")
+
+ # Define path to video file
+ source = "path/to/video.mp4"
+
+ # Run inference on the source
+ results = model(source, stream=True) # generator of Results objects
+ ```
+
+ === "directory"
+
+ Run inference on all images and videos in a directory. To also capture images and videos in subdirectories use a glob pattern, i.e. `path/to/dir/**/*`.
+ ```python
+ from ultralytics import YOLO
+
+ # Load a pretrained YOLOv8n model
+ model = YOLO("yolov8n.pt")
+
+ # Define path to directory containing images and videos for inference
+ source = "path/to/dir"
+
+ # Run inference on the source
+ results = model(source, stream=True) # generator of Results objects
+ ```
+
+ === "glob"
+
+ Run inference on all images and videos that match a glob expression with `*` characters.
+ ```python
+ from ultralytics import YOLO
+
+ # Load a pretrained YOLOv8n model
+ model = YOLO("yolov8n.pt")
+
+ # Define a glob search for all JPG files in a directory
+ source = "path/to/dir/*.jpg"
+
+ # OR define a recursive glob search for all JPG files including subdirectories
+ source = "path/to/dir/**/*.jpg"
+
+ # Run inference on the source
+ results = model(source, stream=True) # generator of Results objects
+ ```
+
+ === "YouTube"
+
+ Run inference on a YouTube video. By using `stream=True`, you can create a generator of Results objects to reduce memory usage for long videos.
+ ```python
+ from ultralytics import YOLO
+
+ # Load a pretrained YOLOv8n model
+ model = YOLO("yolov8n.pt")
+
+ # Define source as YouTube video URL
+ source = "https://youtu.be/LNwODJXcvt4"
+
+ # Run inference on the source
+ results = model(source, stream=True) # generator of Results objects
+ ```
+
+ === "Streams"
+
+ Run inference on remote streaming sources using RTSP, RTMP, TCP and IP address protocols. If multiple streams are provided in a `*.streams` text file then batched inference will run, i.e. 8 streams will run at batch-size 8, otherwise single streams will run at batch-size 1.
+ ```python
+ from ultralytics import YOLO
+
+ # Load a pretrained YOLOv8n model
+ model = YOLO("yolov8n.pt")
+
+ # Single stream with batch-size 1 inference
+ source = "rtsp://example.com/media.mp4" # RTSP, RTMP, TCP or IP streaming address
+
+ # Multiple streams with batched inference (i.e. batch-size 8 for 8 streams)
+ source = "path/to/list.streams" # *.streams text file with one streaming address per row
+
+ # Run inference on the source
+ results = model(source, stream=True) # generator of Results objects
+ ```
+
+## Inference Arguments
+
+`model.predict()` accepts multiple arguments that can be passed at inference time to override defaults:
+
+!!! Example
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a pretrained YOLOv8n model
+ model = YOLO("yolov8n.pt")
+
+ # Run inference on 'bus.jpg' with arguments
+ model.predict("bus.jpg", save=True, imgsz=320, conf=0.5)
+ ```
+
+Inference arguments:
+
+| Argument | Type | Default | Description |
+| --------------- | -------------- | ---------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
+| `source` | `str` | `'ultralytics/assets'` | Specifies the data source for inference. Can be an image path, video file, directory, URL, or device ID for live feeds. Supports a wide range of formats and sources, enabling flexible application across different types of input. |
+| `conf` | `float` | `0.25` | Sets the minimum confidence threshold for detections. Objects detected with confidence below this threshold will be disregarded. Adjusting this value can help reduce false positives. |
+| `iou` | `float` | `0.7` | Intersection Over Union (IoU) threshold for Non-Maximum Suppression (NMS). Lower values result in fewer detections by eliminating overlapping boxes, useful for reducing duplicates. |
+| `imgsz` | `int or tuple` | `640` | Defines the image size for inference. Can be a single integer `640` for square resizing or a (height, width) tuple. Proper sizing can improve detection accuracy and processing speed. |
+| `half` | `bool` | `False` | Enables half-precision (FP16) inference, which can speed up model inference on supported GPUs with minimal impact on accuracy. |
+| `device` | `str` | `None` | Specifies the device for inference (e.g., `cpu`, `cuda:0` or `0`). Allows users to select between CPU, a specific GPU, or other compute devices for model execution. |
+| `max_det` | `int` | `300` | Maximum number of detections allowed per image. Limits the total number of objects the model can detect in a single inference, preventing excessive outputs in dense scenes. |
+| `vid_stride` | `int` | `1` | Frame stride for video inputs. Allows skipping frames in videos to speed up processing at the cost of temporal resolution. A value of 1 processes every frame, higher values skip frames. |
+| `stream_buffer` | `bool` | `False` | Determines if all frames should be buffered when processing video streams (`True`), or if the model should return the most recent frame (`False`). Useful for real-time applications. |
+| `visualize` | `bool` | `False` | Activates visualization of model features during inference, providing insights into what the model is "seeing". Useful for debugging and model interpretation. |
+| `augment` | `bool` | `False` | Enables test-time augmentation (TTA) for predictions, potentially improving detection robustness at the cost of inference speed. |
+| `agnostic_nms` | `bool` | `False` | Enables class-agnostic Non-Maximum Suppression (NMS), which merges overlapping boxes of different classes. Useful in multi-class detection scenarios where class overlap is common. |
+| `classes` | `list[int]` | `None` | Filters predictions to a set of class IDs. Only detections belonging to the specified classes will be returned. Useful for focusing on relevant objects in multi-class detection tasks. |
+| `retina_masks` | `bool` | `False` | Uses high-resolution segmentation masks if available in the model. This can enhance mask quality for segmentation tasks, providing finer detail. |
+| `embed` | `list[int]` | `None` | Specifies the layers from which to extract feature vectors or embeddings. Useful for downstream tasks like clustering or similarity search. |
+
+Visualization arguments:
+
+| Argument | Type | Default | Description |
+| ------------- | ------------- | ------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| `show` | `bool` | `False` | If `True`, displays the annotated images or videos in a window. Useful for immediate visual feedback during development or testing. |
+| `save` | `bool` | `False` | Enables saving of the annotated images or videos to file. Useful for documentation, further analysis, or sharing results. |
+| `save_frames` | `bool` | `False` | When processing videos, saves individual frames as images. Useful for extracting specific frames or for detailed frame-by-frame analysis. |
+| `save_txt` | `bool` | `False` | Saves detection results in a text file, following the format `[class] [x_center] [y_center] [width] [height] [confidence]`. Useful for integration with other analysis tools. |
+| `save_conf` | `bool` | `False` | Includes confidence scores in the saved text files. Enhances the detail available for post-processing and analysis. |
+| `save_crop` | `bool` | `False` | Saves cropped images of detections. Useful for dataset augmentation, analysis, or creating focused datasets for specific objects. |
+| `show_labels` | `bool` | `True` | Displays labels for each detection in the visual output. Provides immediate understanding of detected objects. |
+| `show_conf` | `bool` | `True` | Displays the confidence score for each detection alongside the label. Gives insight into the model's certainty for each detection. |
+| `show_boxes` | `bool` | `True` | Draws bounding boxes around detected objects. Essential for visual identification and location of objects in images or video frames. |
+| `line_width` | `None or int` | `None` | Specifies the line width of bounding boxes. If `None`, the line width is automatically adjusted based on the image size. Provides visual customization for clarity. |
+
+## Image and Video Formats
+
+YOLOv8 supports various image and video formats, as specified in [ultralytics/data/utils.py](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/data/utils.py). See the tables below for the valid suffixes and example predict commands.
+
+### Images
+
+The below table contains valid Ultralytics image formats.
+
+| Image Suffixes | Example Predict Command | Reference |
+| -------------- | -------------------------------- | -------------------------------------------------------------------------- |
+| `.bmp` | `yolo predict source=image.bmp` | [Microsoft BMP File Format](https://en.wikipedia.org/wiki/BMP_file_format) |
+| `.dng` | `yolo predict source=image.dng` | [Adobe DNG](https://en.wikipedia.org/wiki/Digital_Negative) |
+| `.jpeg` | `yolo predict source=image.jpeg` | [JPEG](https://en.wikipedia.org/wiki/JPEG) |
+| `.jpg` | `yolo predict source=image.jpg` | [JPEG](https://en.wikipedia.org/wiki/JPEG) |
+| `.mpo` | `yolo predict source=image.mpo` | [Multi Picture Object](https://fileinfo.com/extension/mpo) |
+| `.png` | `yolo predict source=image.png` | [Portable Network Graphics](https://en.wikipedia.org/wiki/PNG) |
+| `.tif` | `yolo predict source=image.tif` | [Tag Image File Format](https://en.wikipedia.org/wiki/TIFF) |
+| `.tiff` | `yolo predict source=image.tiff` | [Tag Image File Format](https://en.wikipedia.org/wiki/TIFF) |
+| `.webp` | `yolo predict source=image.webp` | [WebP](https://en.wikipedia.org/wiki/WebP) |
+| `.pfm` | `yolo predict source=image.pfm` | [Portable FloatMap](https://en.wikipedia.org/wiki/Netpbm#File_formats) |
+
+### Videos
+
+The below table contains valid Ultralytics video formats.
+
+| Video Suffixes | Example Predict Command | Reference |
+| -------------- | -------------------------------- | -------------------------------------------------------------------------------- |
+| `.asf` | `yolo predict source=video.asf` | [Advanced Systems Format](https://en.wikipedia.org/wiki/Advanced_Systems_Format) |
+| `.avi` | `yolo predict source=video.avi` | [Audio Video Interleave](https://en.wikipedia.org/wiki/Audio_Video_Interleave) |
+| `.gif` | `yolo predict source=video.gif` | [Graphics Interchange Format](https://en.wikipedia.org/wiki/GIF) |
+| `.m4v` | `yolo predict source=video.m4v` | [MPEG-4 Part 14](https://en.wikipedia.org/wiki/M4V) |
+| `.mkv` | `yolo predict source=video.mkv` | [Matroska](https://en.wikipedia.org/wiki/Matroska) |
+| `.mov` | `yolo predict source=video.mov` | [QuickTime File Format](https://en.wikipedia.org/wiki/QuickTime_File_Format) |
+| `.mp4` | `yolo predict source=video.mp4` | [MPEG-4 Part 14 - Wikipedia](https://en.wikipedia.org/wiki/MPEG-4_Part_14) |
+| `.mpeg` | `yolo predict source=video.mpeg` | [MPEG-1 Part 2](https://en.wikipedia.org/wiki/MPEG-1) |
+| `.mpg` | `yolo predict source=video.mpg` | [MPEG-1 Part 2](https://en.wikipedia.org/wiki/MPEG-1) |
+| `.ts` | `yolo predict source=video.ts` | [MPEG Transport Stream](https://en.wikipedia.org/wiki/MPEG_transport_stream) |
+| `.wmv` | `yolo predict source=video.wmv` | [Windows Media Video](https://en.wikipedia.org/wiki/Windows_Media_Video) |
+| `.webm` | `yolo predict source=video.webm` | [WebM Project](https://en.wikipedia.org/wiki/WebM) |
+
+## Working with Results
+
+All Ultralytics `predict()` calls will return a list of `Results` objects:
+
+!!! Example "Results"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a pretrained YOLOv8n model
+ model = YOLO("yolov8n.pt")
+
+ # Run inference on an image
+ results = model("bus.jpg") # list of 1 Results object
+ results = model(["bus.jpg", "zidane.jpg"]) # list of 2 Results objects
+ ```
+
+`Results` objects have the following attributes:
+
+| Attribute | Type | Description |
+| ------------ | --------------------- | ---------------------------------------------------------------------------------------- |
+| `orig_img` | `numpy.ndarray` | The original image as a numpy array. |
+| `orig_shape` | `tuple` | The original image shape in (height, width) format. |
+| `boxes` | `Boxes, optional` | A Boxes object containing the detection bounding boxes. |
+| `masks` | `Masks, optional` | A Masks object containing the detection masks. |
+| `probs` | `Probs, optional` | A Probs object containing probabilities of each class for classification task. |
+| `keypoints` | `Keypoints, optional` | A Keypoints object containing detected keypoints for each object. |
+| `obb` | `OBB, optional` | An OBB object containing oriented bounding boxes. |
+| `speed` | `dict` | A dictionary of preprocess, inference, and postprocess speeds in milliseconds per image. |
+| `names` | `dict` | A dictionary of class names. |
+| `path` | `str` | The path to the image file. |
+
+`Results` objects have the following methods:
+
+| Method | Return Type | Description |
+| ------------- | --------------- | ----------------------------------------------------------------------------------- |
+| `update()` | `None` | Update the boxes, masks, and probs attributes of the Results object. |
+| `cpu()` | `Results` | Return a copy of the Results object with all tensors on CPU memory. |
+| `numpy()` | `Results` | Return a copy of the Results object with all tensors as numpy arrays. |
+| `cuda()` | `Results` | Return a copy of the Results object with all tensors on GPU memory. |
+| `to()` | `Results` | Return a copy of the Results object with tensors on the specified device and dtype. |
+| `new()` | `Results` | Return a new Results object with the same image, path, and names. |
+| `plot()` | `numpy.ndarray` | Plots the detection results. Returns a numpy array of the annotated image. |
+| `show()` | `None` | Show annotated results to screen. |
+| `save()` | `None` | Save annotated results to file. |
+| `verbose()` | `str` | Return log string for each task. |
+| `save_txt()` | `None` | Save predictions into a txt file. |
+| `save_crop()` | `None` | Save cropped predictions to `save_dir/cls/file_name.jpg`. |
+| `tojson()` | `str` | Convert the object to JSON format. |
+
+For more details see the [`Results` class documentation](../reference/engine/results.md).
+
+### Boxes
+
+`Boxes` object can be used to index, manipulate, and convert bounding boxes to different formats.
+
+!!! Example "Boxes"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a pretrained YOLOv8n model
+ model = YOLO("yolov8n.pt")
+
+ # Run inference on an image
+ results = model("bus.jpg") # results list
+
+ # View results
+ for r in results:
+ print(r.boxes) # print the Boxes object containing the detection bounding boxes
+ ```
+
+Here is a table for the `Boxes` class methods and properties, including their name, type, and description:
+
+| Name | Type | Description |
+| --------- | ------------------------- | ------------------------------------------------------------------ |
+| `cpu()` | Method | Move the object to CPU memory. |
+| `numpy()` | Method | Convert the object to a numpy array. |
+| `cuda()` | Method | Move the object to CUDA memory. |
+| `to()` | Method | Move the object to the specified device. |
+| `xyxy` | Property (`torch.Tensor`) | Return the boxes in xyxy format. |
+| `conf` | Property (`torch.Tensor`) | Return the confidence values of the boxes. |
+| `cls` | Property (`torch.Tensor`) | Return the class values of the boxes. |
+| `id` | Property (`torch.Tensor`) | Return the track IDs of the boxes (if available). |
+| `xywh` | Property (`torch.Tensor`) | Return the boxes in xywh format. |
+| `xyxyn` | Property (`torch.Tensor`) | Return the boxes in xyxy format normalized by original image size. |
+| `xywhn` | Property (`torch.Tensor`) | Return the boxes in xywh format normalized by original image size. |
+
+For more details see the [`Boxes` class documentation](../reference/engine/results.md#ultralytics.engine.results.Boxes).
+
+### Masks
+
+`Masks` object can be used index, manipulate and convert masks to segments.
+
+!!! Example "Masks"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a pretrained YOLOv8n-seg Segment model
+ model = YOLO("yolov8n-seg.pt")
+
+ # Run inference on an image
+ results = model("bus.jpg") # results list
+
+ # View results
+ for r in results:
+ print(r.masks) # print the Masks object containing the detected instance masks
+ ```
+
+Here is a table for the `Masks` class methods and properties, including their name, type, and description:
+
+| Name | Type | Description |
+| --------- | ------------------------- | --------------------------------------------------------------- |
+| `cpu()` | Method | Returns the masks tensor on CPU memory. |
+| `numpy()` | Method | Returns the masks tensor as a numpy array. |
+| `cuda()` | Method | Returns the masks tensor on GPU memory. |
+| `to()` | Method | Returns the masks tensor with the specified device and dtype. |
+| `xyn` | Property (`torch.Tensor`) | A list of normalized segments represented as tensors. |
+| `xy` | Property (`torch.Tensor`) | A list of segments in pixel coordinates represented as tensors. |
+
+For more details see the [`Masks` class documentation](../reference/engine/results.md#ultralytics.engine.results.Masks).
+
+### Keypoints
+
+`Keypoints` object can be used index, manipulate and normalize coordinates.
+
+!!! Example "Keypoints"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a pretrained YOLOv8n-pose Pose model
+ model = YOLO("yolov8n-pose.pt")
+
+ # Run inference on an image
+ results = model("bus.jpg") # results list
+
+ # View results
+ for r in results:
+ print(r.keypoints) # print the Keypoints object containing the detected keypoints
+ ```
+
+Here is a table for the `Keypoints` class methods and properties, including their name, type, and description:
+
+| Name | Type | Description |
+| --------- | ------------------------- | ----------------------------------------------------------------- |
+| `cpu()` | Method | Returns the keypoints tensor on CPU memory. |
+| `numpy()` | Method | Returns the keypoints tensor as a numpy array. |
+| `cuda()` | Method | Returns the keypoints tensor on GPU memory. |
+| `to()` | Method | Returns the keypoints tensor with the specified device and dtype. |
+| `xyn` | Property (`torch.Tensor`) | A list of normalized keypoints represented as tensors. |
+| `xy` | Property (`torch.Tensor`) | A list of keypoints in pixel coordinates represented as tensors. |
+| `conf` | Property (`torch.Tensor`) | Returns confidence values of keypoints if available, else None. |
+
+For more details see the [`Keypoints` class documentation](../reference/engine/results.md#ultralytics.engine.results.Keypoints).
+
+### Probs
+
+`Probs` object can be used index, get `top1` and `top5` indices and scores of classification.
+
+!!! Example "Probs"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a pretrained YOLOv8n-cls Classify model
+ model = YOLO("yolov8n-cls.pt")
+
+ # Run inference on an image
+ results = model("bus.jpg") # results list
+
+ # View results
+ for r in results:
+ print(r.probs) # print the Probs object containing the detected class probabilities
+ ```
+
+Here's a table summarizing the methods and properties for the `Probs` class:
+
+| Name | Type | Description |
+| ---------- | ------------------------- | ----------------------------------------------------------------------- |
+| `cpu()` | Method | Returns a copy of the probs tensor on CPU memory. |
+| `numpy()` | Method | Returns a copy of the probs tensor as a numpy array. |
+| `cuda()` | Method | Returns a copy of the probs tensor on GPU memory. |
+| `to()` | Method | Returns a copy of the probs tensor with the specified device and dtype. |
+| `top1` | Property (`int`) | Index of the top 1 class. |
+| `top5` | Property (`list[int]`) | Indices of the top 5 classes. |
+| `top1conf` | Property (`torch.Tensor`) | Confidence of the top 1 class. |
+| `top5conf` | Property (`torch.Tensor`) | Confidences of the top 5 classes. |
+
+For more details see the [`Probs` class documentation](../reference/engine/results.md#ultralytics.engine.results.Probs).
+
+### OBB
+
+`OBB` object can be used to index, manipulate, and convert oriented bounding boxes to different formats.
+
+!!! Example "OBB"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a pretrained YOLOv8n model
+ model = YOLO("yolov8n-obb.pt")
+
+ # Run inference on an image
+ results = model("bus.jpg") # results list
+
+ # View results
+ for r in results:
+ print(r.obb) # print the OBB object containing the oriented detection bounding boxes
+ ```
+
+Here is a table for the `OBB` class methods and properties, including their name, type, and description:
+
+| Name | Type | Description |
+| ----------- | ------------------------- | --------------------------------------------------------------------- |
+| `cpu()` | Method | Move the object to CPU memory. |
+| `numpy()` | Method | Convert the object to a numpy array. |
+| `cuda()` | Method | Move the object to CUDA memory. |
+| `to()` | Method | Move the object to the specified device. |
+| `conf` | Property (`torch.Tensor`) | Return the confidence values of the boxes. |
+| `cls` | Property (`torch.Tensor`) | Return the class values of the boxes. |
+| `id` | Property (`torch.Tensor`) | Return the track IDs of the boxes (if available). |
+| `xyxy` | Property (`torch.Tensor`) | Return the horizontal boxes in xyxy format. |
+| `xywhr` | Property (`torch.Tensor`) | Return the rotated boxes in xywhr format. |
+| `xyxyxyxy` | Property (`torch.Tensor`) | Return the rotated boxes in xyxyxyxy format. |
+| `xyxyxyxyn` | Property (`torch.Tensor`) | Return the rotated boxes in xyxyxyxy format normalized by image size. |
+
+For more details see the [`OBB` class documentation](../reference/engine/results.md#ultralytics.engine.results.OBB).
+
+## Plotting Results
+
+The `plot()` method in `Results` objects facilitates visualization of predictions by overlaying detected objects (such as bounding boxes, masks, keypoints, and probabilities) onto the original image. This method returns the annotated image as a NumPy array, allowing for easy display or saving.
+
+!!! Example "Plotting"
+
+ ```python
+ from PIL import Image
+
+ from ultralytics import YOLO
+
+ # Load a pretrained YOLOv8n model
+ model = YOLO("yolov8n.pt")
+
+ # Run inference on 'bus.jpg'
+ results = model(["bus.jpg", "zidane.jpg"]) # results list
+
+ # Visualize the results
+ for i, r in enumerate(results):
+ # Plot results image
+ im_bgr = r.plot() # BGR-order numpy array
+ im_rgb = Image.fromarray(im_bgr[..., ::-1]) # RGB-order PIL image
+
+ # Show results to screen (in supported environments)
+ r.show()
+
+ # Save results to disk
+ r.save(filename=f"results{i}.jpg")
+ ```
+
+### `plot()` Method Parameters
+
+The `plot()` method supports various arguments to customize the output:
+
+| Argument | Type | Description | Default |
+| ------------ | --------------- | -------------------------------------------------------------------------- | ------------- |
+| `conf` | `bool` | Include detection confidence scores. | `True` |
+| `line_width` | `float` | Line width of bounding boxes. Scales with image size if `None`. | `None` |
+| `font_size` | `float` | Text font size. Scales with image size if `None`. | `None` |
+| `font` | `str` | Font name for text annotations. | `'Arial.ttf'` |
+| `pil` | `bool` | Return image as a PIL Image object. | `False` |
+| `img` | `numpy.ndarray` | Alternative image for plotting. Uses the original image if `None`. | `None` |
+| `im_gpu` | `torch.Tensor` | GPU-accelerated image for faster mask plotting. Shape: (1, 3, 640, 640). | `None` |
+| `kpt_radius` | `int` | Radius for drawn keypoints. | `5` |
+| `kpt_line` | `bool` | Connect keypoints with lines. | `True` |
+| `labels` | `bool` | Include class labels in annotations. | `True` |
+| `boxes` | `bool` | Overlay bounding boxes on the image. | `True` |
+| `masks` | `bool` | Overlay masks on the image. | `True` |
+| `probs` | `bool` | Include classification probabilities. | `True` |
+| `show` | `bool` | Display the annotated image directly using the default image viewer. | `False` |
+| `save` | `bool` | Save the annotated image to a file specified by `filename`. | `False` |
+| `filename` | `str` | Path and name of the file to save the annotated image if `save` is `True`. | `None` |
+| `color_mode` | `str` | Specify the color mode, e.g., 'instance' or 'class'. | `'class'` |
+
+## Thread-Safe Inference
+
+Ensuring thread safety during inference is crucial when you are running multiple YOLO models in parallel across different threads. Thread-safe inference guarantees that each thread's predictions are isolated and do not interfere with one another, avoiding race conditions and ensuring consistent and reliable outputs.
+
+When using YOLO models in a multi-threaded application, it's important to instantiate separate model objects for each thread or employ thread-local storage to prevent conflicts:
+
+!!! Example "Thread-Safe Inference"
+
+ Instantiate a single model inside each thread for thread-safe inference:
+ ```python
+ from threading import Thread
+
+ from ultralytics import YOLO
+
+
+ def thread_safe_predict(image_path):
+ """Performs thread-safe prediction on an image using a locally instantiated YOLO model."""
+ local_model = YOLO("yolov8n.pt")
+ results = local_model.predict(image_path)
+ # Process results
+
+
+ # Starting threads that each have their own model instance
+ Thread(target=thread_safe_predict, args=("image1.jpg",)).start()
+ Thread(target=thread_safe_predict, args=("image2.jpg",)).start()
+ ```
+
+For an in-depth look at thread-safe inference with YOLO models and step-by-step instructions, please refer to our [YOLO Thread-Safe Inference Guide](../guides/yolo-thread-safe-inference.md). This guide will provide you with all the necessary information to avoid common pitfalls and ensure that your multi-threaded inference runs smoothly.
+
+## Streaming Source `for`-loop
+
+Here's a Python script using OpenCV (`cv2`) and YOLOv8 to run inference on video frames. This script assumes you have already installed the necessary packages (`opencv-python` and `ultralytics`).
+
+!!! Example "Streaming for-loop"
+
+ ```python
+ import cv2
+
+ from ultralytics import YOLO
+
+ # Load the YOLOv8 model
+ model = YOLO("yolov8n.pt")
+
+ # Open the video file
+ video_path = "path/to/your/video/file.mp4"
+ cap = cv2.VideoCapture(video_path)
+
+ # Loop through the video frames
+ while cap.isOpened():
+ # Read a frame from the video
+ success, frame = cap.read()
+
+ if success:
+ # Run YOLOv8 inference on the frame
+ results = model(frame)
+
+ # Visualize the results on the frame
+ annotated_frame = results[0].plot()
+
+ # Display the annotated frame
+ cv2.imshow("YOLOv8 Inference", annotated_frame)
+
+ # Break the loop if 'q' is pressed
+ if cv2.waitKey(1) & 0xFF == ord("q"):
+ break
+ else:
+ # Break the loop if the end of the video is reached
+ break
+
+ # Release the video capture object and close the display window
+ cap.release()
+ cv2.destroyAllWindows()
+ ```
+
+This script will run predictions on each frame of the video, visualize the results, and display them in a window. The loop can be exited by pressing 'q'.
+
+[car spare parts]: https://github.com/RizwanMunawar/ultralytics/assets/62513924/a0f802a8-0776-44cf-8f17-93974a4a28a1
+[football player detect]: https://github.com/RizwanMunawar/ultralytics/assets/62513924/7d320e1f-fc57-4d7f-a691-78ee579c3442
+[human fall detect]: https://github.com/RizwanMunawar/ultralytics/assets/62513924/86437c4a-3227-4eee-90ef-9efb697bdb43
+
+## FAQ
+
+### What is Ultralytics YOLOv8 and its predict mode for real-time inference?
+
+Ultralytics YOLOv8 is a state-of-the-art model for real-time object detection, segmentation, and classification. Its **predict mode** allows users to perform high-speed inference on various data sources such as images, videos, and live streams. Designed for performance and versatility, it also offers batch processing and streaming modes. For more details on its features, check out the [Ultralytics YOLOv8 predict mode](#key-features-of-predict-mode).
+
+### How can I run inference using Ultralytics YOLOv8 on different data sources?
+
+Ultralytics YOLOv8 can process a wide range of data sources, including individual images, videos, directories, URLs, and streams. You can specify the data source in the `model.predict()` call. For example, use `'image.jpg'` for a local image or `'https://ultralytics.com/images/bus.jpg'` for a URL. Check out the detailed examples for various [inference sources](#inference-sources) in the documentation.
+
+### How do I optimize YOLOv8 inference speed and memory usage?
+
+To optimize inference speed and manage memory efficiently, you can use the streaming mode by setting `stream=True` in the predictor's call method. The streaming mode generates a memory-efficient generator of `Results` objects instead of loading all frames into memory. For processing long videos or large datasets, streaming mode is particularly useful. Learn more about [streaming mode](#key-features-of-predict-mode).
+
+### What inference arguments does Ultralytics YOLOv8 support?
+
+The `model.predict()` method in YOLOv8 supports various arguments such as `conf`, `iou`, `imgsz`, `device`, and more. These arguments allow you to customize the inference process, setting parameters like confidence thresholds, image size, and the device used for computation. Detailed descriptions of these arguments can be found in the [inference arguments](#inference-arguments) section.
+
+### How can I visualize and save the results of YOLOv8 predictions?
+
+After running inference with YOLOv8, the `Results` objects contain methods for displaying and saving annotated images. You can use methods like `result.show()` and `result.save(filename="result.jpg")` to visualize and save the results. For a comprehensive list of these methods, refer to the [working with results](#working-with-results) section.
diff --git a/ultralytics/docs/en/modes/track.md b/ultralytics/docs/en/modes/track.md
new file mode 100644
index 0000000000000000000000000000000000000000..262f9ce284bf34612a979ade9b35dc6065e1d36f
--- /dev/null
+++ b/ultralytics/docs/en/modes/track.md
@@ -0,0 +1,496 @@
+---
+comments: true
+description: Discover efficient, flexible, and customizable multi-object tracking with Ultralytics YOLO. Learn to track real-time video streams with ease.
+keywords: multi-object tracking, Ultralytics YOLO, video analytics, real-time tracking, object detection, AI, machine learning
+---
+
+# Multi-Object Tracking with Ultralytics YOLO
+
+
+
+Object tracking in the realm of video analytics is a critical task that not only identifies the location and class of objects within the frame but also maintains a unique ID for each detected object as the video progresses. The applications are limitless—ranging from surveillance and security to real-time sports analytics.
+
+## Why Choose Ultralytics YOLO for Object Tracking?
+
+The output from Ultralytics trackers is consistent with standard object detection but has the added value of object IDs. This makes it easy to track objects in video streams and perform subsequent analytics. Here's why you should consider using Ultralytics YOLO for your object tracking needs:
+
+- **Efficiency:** Process video streams in real-time without compromising accuracy.
+- **Flexibility:** Supports multiple tracking algorithms and configurations.
+- **Ease of Use:** Simple Python API and CLI options for quick integration and deployment.
+- **Customizability:** Easy to use with custom trained YOLO models, allowing integration into domain-specific applications.
+
+
+
+
+
+ Watch: Object Detection and Tracking with Ultralytics YOLOv8.
+
+
+## Real-world Applications
+
+| Transportation | Retail | Aquaculture |
+| :--------------------------------: | :------------------------------: | :--------------------------: |
+| ![Vehicle Tracking][vehicle track] | ![People Tracking][people track] | ![Fish Tracking][fish track] |
+| Vehicle Tracking | People Tracking | Fish Tracking |
+
+## Features at a Glance
+
+Ultralytics YOLO extends its object detection features to provide robust and versatile object tracking:
+
+- **Real-Time Tracking:** Seamlessly track objects in high-frame-rate videos.
+- **Multiple Tracker Support:** Choose from a variety of established tracking algorithms.
+- **Customizable Tracker Configurations:** Tailor the tracking algorithm to meet specific requirements by adjusting various parameters.
+
+## Available Trackers
+
+Ultralytics YOLO supports the following tracking algorithms. They can be enabled by passing the relevant YAML configuration file such as `tracker=tracker_type.yaml`:
+
+- [BoT-SORT](https://github.com/NirAharon/BoT-SORT) - Use `botsort.yaml` to enable this tracker.
+- [ByteTrack](https://github.com/ifzhang/ByteTrack) - Use `bytetrack.yaml` to enable this tracker.
+
+The default tracker is BoT-SORT.
+
+## Tracking
+
+!!! Warning "Tracker Threshold Information"
+
+ If object confidence score will be low, i.e lower than [`track_high_thresh`](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/trackers/bytetrack.yaml#L5), then there will be no tracks successfully returned and updated.
+
+To run the tracker on video streams, use a trained Detect, Segment or Pose model such as YOLOv8n, YOLOv8n-seg and YOLOv8n-pose.
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load an official or custom model
+ model = YOLO("yolov8n.pt") # Load an official Detect model
+ model = YOLO("yolov8n-seg.pt") # Load an official Segment model
+ model = YOLO("yolov8n-pose.pt") # Load an official Pose model
+ model = YOLO("path/to/best.pt") # Load a custom trained model
+
+ # Perform tracking with the model
+ results = model.track("https://youtu.be/LNwODJXcvt4", show=True) # Tracking with default tracker
+ results = model.track("https://youtu.be/LNwODJXcvt4", show=True, tracker="bytetrack.yaml") # with ByteTrack
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Perform tracking with various models using the command line interface
+ yolo track model=yolov8n.pt source="https://youtu.be/LNwODJXcvt4" # Official Detect model
+ yolo track model=yolov8n-seg.pt source="https://youtu.be/LNwODJXcvt4" # Official Segment model
+ yolo track model=yolov8n-pose.pt source="https://youtu.be/LNwODJXcvt4" # Official Pose model
+ yolo track model=path/to/best.pt source="https://youtu.be/LNwODJXcvt4" # Custom trained model
+
+ # Track using ByteTrack tracker
+ yolo track model=path/to/best.pt tracker="bytetrack.yaml"
+ ```
+
+As can be seen in the above usage, tracking is available for all Detect, Segment and Pose models run on videos or streaming sources.
+
+## Configuration
+
+!!! Warning "Tracker Threshold Information"
+
+ If object confidence score will be low, i.e lower than [`track_high_thresh`](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/trackers/bytetrack.yaml#L5), then there will be no tracks successfully returned and updated.
+
+### Tracking Arguments
+
+Tracking configuration shares properties with Predict mode, such as `conf`, `iou`, and `show`. For further configurations, refer to the [Predict](../modes/predict.md#inference-arguments) model page.
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Configure the tracking parameters and run the tracker
+ model = YOLO("yolov8n.pt")
+ results = model.track(source="https://youtu.be/LNwODJXcvt4", conf=0.3, iou=0.5, show=True)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Configure tracking parameters and run the tracker using the command line interface
+ yolo track model=yolov8n.pt source="https://youtu.be/LNwODJXcvt4" conf=0.3, iou=0.5 show
+ ```
+
+### Tracker Selection
+
+Ultralytics also allows you to use a modified tracker configuration file. To do this, simply make a copy of a tracker config file (for example, `custom_tracker.yaml`) from [ultralytics/cfg/trackers](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/trackers) and modify any configurations (except the `tracker_type`) as per your needs.
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load the model and run the tracker with a custom configuration file
+ model = YOLO("yolov8n.pt")
+ results = model.track(source="https://youtu.be/LNwODJXcvt4", tracker="custom_tracker.yaml")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Load the model and run the tracker with a custom configuration file using the command line interface
+ yolo track model=yolov8n.pt source="https://youtu.be/LNwODJXcvt4" tracker='custom_tracker.yaml'
+ ```
+
+For a comprehensive list of tracking arguments, refer to the [ultralytics/cfg/trackers](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/trackers) page.
+
+## Python Examples
+
+### Persisting Tracks Loop
+
+Here is a Python script using OpenCV (`cv2`) and YOLOv8 to run object tracking on video frames. This script still assumes you have already installed the necessary packages (`opencv-python` and `ultralytics`). The `persist=True` argument tells the tracker that the current image or frame is the next in a sequence and to expect tracks from the previous image in the current image.
+
+!!! Example "Streaming for-loop with tracking"
+
+ ```python
+ import cv2
+
+ from ultralytics import YOLO
+
+ # Load the YOLOv8 model
+ model = YOLO("yolov8n.pt")
+
+ # Open the video file
+ video_path = "path/to/video.mp4"
+ cap = cv2.VideoCapture(video_path)
+
+ # Loop through the video frames
+ while cap.isOpened():
+ # Read a frame from the video
+ success, frame = cap.read()
+
+ if success:
+ # Run YOLOv8 tracking on the frame, persisting tracks between frames
+ results = model.track(frame, persist=True)
+
+ # Visualize the results on the frame
+ annotated_frame = results[0].plot()
+
+ # Display the annotated frame
+ cv2.imshow("YOLOv8 Tracking", annotated_frame)
+
+ # Break the loop if 'q' is pressed
+ if cv2.waitKey(1) & 0xFF == ord("q"):
+ break
+ else:
+ # Break the loop if the end of the video is reached
+ break
+
+ # Release the video capture object and close the display window
+ cap.release()
+ cv2.destroyAllWindows()
+ ```
+
+Please note the change from `model(frame)` to `model.track(frame)`, which enables object tracking instead of simple detection. This modified script will run the tracker on each frame of the video, visualize the results, and display them in a window. The loop can be exited by pressing 'q'.
+
+### Plotting Tracks Over Time
+
+Visualizing object tracks over consecutive frames can provide valuable insights into the movement patterns and behavior of detected objects within a video. With Ultralytics YOLOv8, plotting these tracks is a seamless and efficient process.
+
+In the following example, we demonstrate how to utilize YOLOv8's tracking capabilities to plot the movement of detected objects across multiple video frames. This script involves opening a video file, reading it frame by frame, and utilizing the YOLO model to identify and track various objects. By retaining the center points of the detected bounding boxes and connecting them, we can draw lines that represent the paths followed by the tracked objects.
+
+!!! Example "Plotting tracks over multiple video frames"
+
+ ```python
+ from collections import defaultdict
+
+ import cv2
+ import numpy as np
+
+ from ultralytics import YOLO
+
+ # Load the YOLOv8 model
+ model = YOLO("yolov8n.pt")
+
+ # Open the video file
+ video_path = "path/to/video.mp4"
+ cap = cv2.VideoCapture(video_path)
+
+ # Store the track history
+ track_history = defaultdict(lambda: [])
+
+ # Loop through the video frames
+ while cap.isOpened():
+ # Read a frame from the video
+ success, frame = cap.read()
+
+ if success:
+ # Run YOLOv8 tracking on the frame, persisting tracks between frames
+ results = model.track(frame, persist=True)
+
+ # Get the boxes and track IDs
+ boxes = results[0].boxes.xywh.cpu()
+ track_ids = results[0].boxes.id.int().cpu().tolist()
+
+ # Visualize the results on the frame
+ annotated_frame = results[0].plot()
+
+ # Plot the tracks
+ for box, track_id in zip(boxes, track_ids):
+ x, y, w, h = box
+ track = track_history[track_id]
+ track.append((float(x), float(y))) # x, y center point
+ if len(track) > 30: # retain 90 tracks for 90 frames
+ track.pop(0)
+
+ # Draw the tracking lines
+ points = np.hstack(track).astype(np.int32).reshape((-1, 1, 2))
+ cv2.polylines(annotated_frame, [points], isClosed=False, color=(230, 230, 230), thickness=10)
+
+ # Display the annotated frame
+ cv2.imshow("YOLOv8 Tracking", annotated_frame)
+
+ # Break the loop if 'q' is pressed
+ if cv2.waitKey(1) & 0xFF == ord("q"):
+ break
+ else:
+ # Break the loop if the end of the video is reached
+ break
+
+ # Release the video capture object and close the display window
+ cap.release()
+ cv2.destroyAllWindows()
+ ```
+
+### Multithreaded Tracking
+
+Multithreaded tracking provides the capability to run object tracking on multiple video streams simultaneously. This is particularly useful when handling multiple video inputs, such as from multiple surveillance cameras, where concurrent processing can greatly enhance efficiency and performance.
+
+In the provided Python script, we make use of Python's `threading` module to run multiple instances of the tracker concurrently. Each thread is responsible for running the tracker on one video file, and all the threads run simultaneously in the background.
+
+To ensure that each thread receives the correct parameters (the video file, the model to use and the file index), we define a function `run_tracker_in_thread` that accepts these parameters and contains the main tracking loop. This function reads the video frame by frame, runs the tracker, and displays the results.
+
+Two different models are used in this example: `yolov8n.pt` and `yolov8n-seg.pt`, each tracking objects in a different video file. The video files are specified in `video_file1` and `video_file2`.
+
+The `daemon=True` parameter in `threading.Thread` means that these threads will be closed as soon as the main program finishes. We then start the threads with `start()` and use `join()` to make the main thread wait until both tracker threads have finished.
+
+Finally, after all threads have completed their task, the windows displaying the results are closed using `cv2.destroyAllWindows()`.
+
+!!! Example "Streaming for-loop with tracking"
+
+ ```python
+ import threading
+
+ import cv2
+
+ from ultralytics import YOLO
+
+
+ def run_tracker_in_thread(filename, model, file_index):
+ """
+ Runs a video file or webcam stream concurrently with the YOLOv8 model using threading.
+
+ This function captures video frames from a given file or camera source and utilizes the YOLOv8 model for object
+ tracking. The function runs in its own thread for concurrent processing.
+
+ Args:
+ filename (str): The path to the video file or the identifier for the webcam/external camera source.
+ model (obj): The YOLOv8 model object.
+ file_index (int): An index to uniquely identify the file being processed, used for display purposes.
+
+ Note:
+ Press 'q' to quit the video display window.
+ """
+ video = cv2.VideoCapture(filename) # Read the video file
+
+ while True:
+ ret, frame = video.read() # Read the video frames
+
+ # Exit the loop if no more frames in either video
+ if not ret:
+ break
+
+ # Track objects in frames if available
+ results = model.track(frame, persist=True)
+ res_plotted = results[0].plot()
+ cv2.imshow(f"Tracking_Stream_{file_index}", res_plotted)
+
+ key = cv2.waitKey(1)
+ if key == ord("q"):
+ break
+
+ # Release video sources
+ video.release()
+
+
+ # Load the models
+ model1 = YOLO("yolov8n.pt")
+ model2 = YOLO("yolov8n-seg.pt")
+
+ # Define the video files for the trackers
+ video_file1 = "path/to/video1.mp4" # Path to video file, 0 for webcam
+ video_file2 = 0 # Path to video file, 0 for webcam, 1 for external camera
+
+ # Create the tracker threads
+ tracker_thread1 = threading.Thread(target=run_tracker_in_thread, args=(video_file1, model1, 1), daemon=True)
+ tracker_thread2 = threading.Thread(target=run_tracker_in_thread, args=(video_file2, model2, 2), daemon=True)
+
+ # Start the tracker threads
+ tracker_thread1.start()
+ tracker_thread2.start()
+
+ # Wait for the tracker threads to finish
+ tracker_thread1.join()
+ tracker_thread2.join()
+
+ # Clean up and close windows
+ cv2.destroyAllWindows()
+ ```
+
+This example can easily be extended to handle more video files and models by creating more threads and applying the same methodology.
+
+## Contribute New Trackers
+
+Are you proficient in multi-object tracking and have successfully implemented or adapted a tracking algorithm with Ultralytics YOLO? We invite you to contribute to our Trackers section in [ultralytics/cfg/trackers](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/trackers)! Your real-world applications and solutions could be invaluable for users working on tracking tasks.
+
+By contributing to this section, you help expand the scope of tracking solutions available within the Ultralytics YOLO framework, adding another layer of functionality and utility for the community.
+
+To initiate your contribution, please refer to our [Contributing Guide](../help/contributing.md) for comprehensive instructions on submitting a Pull Request (PR) 🛠️. We are excited to see what you bring to the table!
+
+Together, let's enhance the tracking capabilities of the Ultralytics YOLO ecosystem 🙏!
+
+[fish track]: https://github.com/RizwanMunawar/ultralytics/assets/62513924/a5146d0f-bfa8-4e0a-b7df-3c1446cd8142
+[people track]: https://github.com/RizwanMunawar/ultralytics/assets/62513924/93bb4ee2-77a0-4e4e-8eb6-eb8f527f0527
+[vehicle track]: https://github.com/RizwanMunawar/ultralytics/assets/62513924/ee6e6038-383b-4f21-ac29-b2a1c7d386ab
+
+## FAQ
+
+### What is Multi-Object Tracking and how does Ultralytics YOLO support it?
+
+Multi-object tracking in video analytics involves both identifying objects and maintaining a unique ID for each detected object across video frames. Ultralytics YOLO supports this by providing real-time tracking along with object IDs, facilitating tasks such as security surveillance and sports analytics. The system uses trackers like BoT-SORT and ByteTrack, which can be configured via YAML files.
+
+### How do I configure a custom tracker for Ultralytics YOLO?
+
+You can configure a custom tracker by copying an existing tracker configuration file (e.g., `custom_tracker.yaml`) from the [Ultralytics tracker configuration directory](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/trackers) and modifying parameters as needed, except for the `tracker_type`. Use this file in your tracking model like so:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ model = YOLO("yolov8n.pt")
+ results = model.track(source="https://youtu.be/LNwODJXcvt4", tracker="custom_tracker.yaml")
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo track model=yolov8n.pt source="https://youtu.be/LNwODJXcvt4" tracker='custom_tracker.yaml'
+ ```
+
+### How can I run object tracking on multiple video streams simultaneously?
+
+To run object tracking on multiple video streams simultaneously, you can use Python's `threading` module. Each thread will handle a separate video stream. Here's an example of how you can set this up:
+
+!!! Example "Multithreaded Tracking"
+
+ ```python
+ import threading
+
+ import cv2
+
+ from ultralytics import YOLO
+
+
+ def run_tracker_in_thread(filename, model, file_index):
+ video = cv2.VideoCapture(filename)
+ while True:
+ ret, frame = video.read()
+ if not ret:
+ break
+ results = model.track(frame, persist=True)
+ res_plotted = results[0].plot()
+ cv2.imshow(f"Tracking_Stream_{file_index}", res_plotted)
+ if cv2.waitKey(1) & 0xFF == ord("q"):
+ break
+ video.release()
+
+
+ model1 = YOLO("yolov8n.pt")
+ model2 = YOLO("yolov8n-seg.pt")
+ video_file1 = "path/to/video1.mp4"
+ video_file2 = 0 # Path to a second video file, or 0 for a webcam
+
+ tracker_thread1 = threading.Thread(target=run_tracker_in_thread, args=(video_file1, model1, 1), daemon=True)
+ tracker_thread2 = threading.Thread(target=run_tracker_in_thread, args=(video_file2, model2, 2), daemon=True)
+
+ tracker_thread1.start()
+ tracker_thread2.start()
+
+ tracker_thread1.join()
+ tracker_thread2.join()
+
+ cv2.destroyAllWindows()
+ ```
+
+### What are the real-world applications of multi-object tracking with Ultralytics YOLO?
+
+Multi-object tracking with Ultralytics YOLO has numerous applications, including:
+
+- **Transportation:** Vehicle tracking for traffic management and autonomous driving.
+- **Retail:** People tracking for in-store analytics and security.
+- **Aquaculture:** Fish tracking for monitoring aquatic environments.
+
+These applications benefit from Ultralytics YOLO's ability to process high-frame-rate videos in real time.
+
+### How can I visualize object tracks over multiple video frames with Ultralytics YOLO?
+
+To visualize object tracks over multiple video frames, you can use the YOLO model's tracking features along with OpenCV to draw the paths of detected objects. Here's an example script that demonstrates this:
+
+!!! Example "Plotting tracks over multiple video frames"
+
+ ```python
+ from collections import defaultdict
+
+ import cv2
+ import numpy as np
+
+ from ultralytics import YOLO
+
+ model = YOLO("yolov8n.pt")
+ video_path = "path/to/video.mp4"
+ cap = cv2.VideoCapture(video_path)
+ track_history = defaultdict(lambda: [])
+
+ while cap.isOpened():
+ success, frame = cap.read()
+ if success:
+ results = model.track(frame, persist=True)
+ boxes = results[0].boxes.xywh.cpu()
+ track_ids = results[0].boxes.id.int().cpu().tolist()
+ annotated_frame = results[0].plot()
+ for box, track_id in zip(boxes, track_ids):
+ x, y, w, h = box
+ track = track_history[track_id]
+ track.append((float(x), float(y)))
+ if len(track) > 30:
+ track.pop(0)
+ points = np.hstack(track).astype(np.int32).reshape((-1, 1, 2))
+ cv2.polylines(annotated_frame, [points], isClosed=False, color=(230, 230, 230), thickness=10)
+ cv2.imshow("YOLOv8 Tracking", annotated_frame)
+ if cv2.waitKey(1) & 0xFF == ord("q"):
+ break
+ else:
+ break
+ cap.release()
+ cv2.destroyAllWindows()
+ ```
+
+This script will plot the tracking lines showing the movement paths of the tracked objects over time.
diff --git a/ultralytics/docs/en/modes/train.md b/ultralytics/docs/en/modes/train.md
new file mode 100644
index 0000000000000000000000000000000000000000..ccbe003d79a7dc47c036fdac605aa0c727c11ee6
--- /dev/null
+++ b/ultralytics/docs/en/modes/train.md
@@ -0,0 +1,445 @@
+---
+comments: true
+description: Learn how to efficiently train object detection models using YOLOv8 with comprehensive instructions on settings, augmentation, and hardware utilization.
+keywords: Ultralytics, YOLOv8, model training, deep learning, object detection, GPU training, dataset augmentation, hyperparameter tuning, model performance, M1 M2 training
+---
+
+# Model Training with Ultralytics YOLO
+
+
+
+## Introduction
+
+Training a deep learning model involves feeding it data and adjusting its parameters so that it can make accurate predictions. Train mode in Ultralytics YOLOv8 is engineered for effective and efficient training of object detection models, fully utilizing modern hardware capabilities. This guide aims to cover all the details you need to get started with training your own models using YOLOv8's robust set of features.
+
+
+
+
+
+ Watch: How to Train a YOLOv8 model on Your Custom Dataset in Google Colab.
+
+
+## Why Choose Ultralytics YOLO for Training?
+
+Here are some compelling reasons to opt for YOLOv8's Train mode:
+
+- **Efficiency:** Make the most out of your hardware, whether you're on a single-GPU setup or scaling across multiple GPUs.
+- **Versatility:** Train on custom datasets in addition to readily available ones like COCO, VOC, and ImageNet.
+- **User-Friendly:** Simple yet powerful CLI and Python interfaces for a straightforward training experience.
+- **Hyperparameter Flexibility:** A broad range of customizable hyperparameters to fine-tune model performance.
+
+### Key Features of Train Mode
+
+The following are some notable features of YOLOv8's Train mode:
+
+- **Automatic Dataset Download:** Standard datasets like COCO, VOC, and ImageNet are downloaded automatically on first use.
+- **Multi-GPU Support:** Scale your training efforts seamlessly across multiple GPUs to expedite the process.
+- **Hyperparameter Configuration:** The option to modify hyperparameters through YAML configuration files or CLI arguments.
+- **Visualization and Monitoring:** Real-time tracking of training metrics and visualization of the learning process for better insights.
+
+!!! Tip "Tip"
+
+ * YOLOv8 datasets like COCO, VOC, ImageNet and many others automatically download on first use, i.e. `yolo train data=coco.yaml`
+
+## Usage Examples
+
+Train YOLOv8n on the COCO8 dataset for 100 epochs at image size 640. The training device can be specified using the `device` argument. If no argument is passed GPU `device=0` will be used if available, otherwise `device='cpu'` will be used. See Arguments section below for a full list of training arguments.
+
+!!! Example "Single-GPU and CPU Training Example"
+
+ Device is determined automatically. If a GPU is available then it will be used, otherwise training will start on CPU.
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.yaml") # build a new model from YAML
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n.yaml").load("yolov8n.pt") # build from YAML and transfer weights
+
+ # Train the model
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Build a new model from YAML and start training from scratch
+ yolo detect train data=coco8.yaml model=yolov8n.yaml epochs=100 imgsz=640
+
+ # Start training from a pretrained *.pt model
+ yolo detect train data=coco8.yaml model=yolov8n.pt epochs=100 imgsz=640
+
+ # Build a new model from YAML, transfer pretrained weights to it and start training
+ yolo detect train data=coco8.yaml model=yolov8n.yaml pretrained=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+### Multi-GPU Training
+
+Multi-GPU training allows for more efficient utilization of available hardware resources by distributing the training load across multiple GPUs. This feature is available through both the Python API and the command-line interface. To enable multi-GPU training, specify the GPU device IDs you wish to use.
+
+!!! Example "Multi-GPU Training Example"
+
+ To train with 2 GPUs, CUDA devices 0 and 1 use the following commands. Expand to additional GPUs as required.
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+
+ # Train the model with 2 GPUs
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640, device=[0, 1])
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model using GPUs 0 and 1
+ yolo detect train data=coco8.yaml model=yolov8n.pt epochs=100 imgsz=640 device=0,1
+ ```
+
+### Apple M1 and M2 MPS Training
+
+With the support for Apple M1 and M2 chips integrated in the Ultralytics YOLO models, it's now possible to train your models on devices utilizing the powerful Metal Performance Shaders (MPS) framework. The MPS offers a high-performance way of executing computation and image processing tasks on Apple's custom silicon.
+
+To enable training on Apple M1 and M2 chips, you should specify 'mps' as your device when initiating the training process. Below is an example of how you could do this in Python and via the command line:
+
+!!! Example "MPS Training Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+
+ # Train the model with 2 GPUs
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640, device="mps")
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model using GPUs 0 and 1
+ yolo detect train data=coco8.yaml model=yolov8n.pt epochs=100 imgsz=640 device=mps
+ ```
+
+While leveraging the computational power of the M1/M2 chips, this enables more efficient processing of the training tasks. For more detailed guidance and advanced configuration options, please refer to the [PyTorch MPS documentation](https://pytorch.org/docs/stable/notes/mps.html).
+
+### Resuming Interrupted Trainings
+
+Resuming training from a previously saved state is a crucial feature when working with deep learning models. This can come in handy in various scenarios, like when the training process has been unexpectedly interrupted, or when you wish to continue training a model with new data or for more epochs.
+
+When training is resumed, Ultralytics YOLO loads the weights from the last saved model and also restores the optimizer state, learning rate scheduler, and the epoch number. This allows you to continue the training process seamlessly from where it was left off.
+
+You can easily resume training in Ultralytics YOLO by setting the `resume` argument to `True` when calling the `train` method, and specifying the path to the `.pt` file containing the partially trained model weights.
+
+Below is an example of how to resume an interrupted training using Python and via the command line:
+
+!!! Example "Resume Training Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("path/to/last.pt") # load a partially trained model
+
+ # Resume training
+ results = model.train(resume=True)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Resume an interrupted training
+ yolo train resume model=path/to/last.pt
+ ```
+
+By setting `resume=True`, the `train` function will continue training from where it left off, using the state stored in the 'path/to/last.pt' file. If the `resume` argument is omitted or set to `False`, the `train` function will start a new training session.
+
+Remember that checkpoints are saved at the end of every epoch by default, or at fixed interval using the `save_period` argument, so you must complete at least 1 epoch to resume a training run.
+
+## Train Settings
+
+The training settings for YOLO models encompass various hyperparameters and configurations used during the training process. These settings influence the model's performance, speed, and accuracy. Key training settings include batch size, learning rate, momentum, and weight decay. Additionally, the choice of optimizer, loss function, and training dataset composition can impact the training process. Careful tuning and experimentation with these settings are crucial for optimizing performance.
+
+| Argument | Default | Description |
+| ----------------- | -------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| `model` | `None` | Specifies the model file for training. Accepts a path to either a `.pt` pretrained model or a `.yaml` configuration file. Essential for defining the model structure or initializing weights. |
+| `data` | `None` | Path to the dataset configuration file (e.g., `coco8.yaml`). This file contains dataset-specific parameters, including paths to training and validation data, class names, and number of classes. |
+| `epochs` | `100` | Total number of training epochs. Each epoch represents a full pass over the entire dataset. Adjusting this value can affect training duration and model performance. |
+| `time` | `None` | Maximum training time in hours. If set, this overrides the `epochs` argument, allowing training to automatically stop after the specified duration. Useful for time-constrained training scenarios. |
+| `patience` | `100` | Number of epochs to wait without improvement in validation metrics before early stopping the training. Helps prevent overfitting by stopping training when performance plateaus. |
+| `batch` | `16` | Batch size, with three modes: set as an integer (e.g., `batch=16`), auto mode for 60% GPU memory utilization (`batch=-1`), or auto mode with specified utilization fraction (`batch=0.70`). |
+| `imgsz` | `640` | Target image size for training. All images are resized to this dimension before being fed into the model. Affects model accuracy and computational complexity. |
+| `save` | `True` | Enables saving of training checkpoints and final model weights. Useful for resuming training or model deployment. |
+| `save_period` | `-1` | Frequency of saving model checkpoints, specified in epochs. A value of -1 disables this feature. Useful for saving interim models during long training sessions. |
+| `cache` | `False` | Enables caching of dataset images in memory (`True`/`ram`), on disk (`disk`), or disables it (`False`). Improves training speed by reducing disk I/O at the cost of increased memory usage. |
+| `device` | `None` | Specifies the computational device(s) for training: a single GPU (`device=0`), multiple GPUs (`device=0,1`), CPU (`device=cpu`), or MPS for Apple silicon (`device=mps`). |
+| `workers` | `8` | Number of worker threads for data loading (per `RANK` if Multi-GPU training). Influences the speed of data preprocessing and feeding into the model, especially useful in multi-GPU setups. |
+| `project` | `None` | Name of the project directory where training outputs are saved. Allows for organized storage of different experiments. |
+| `name` | `None` | Name of the training run. Used for creating a subdirectory within the project folder, where training logs and outputs are stored. |
+| `exist_ok` | `False` | If True, allows overwriting of an existing project/name directory. Useful for iterative experimentation without needing to manually clear previous outputs. |
+| `pretrained` | `True` | Determines whether to start training from a pretrained model. Can be a boolean value or a string path to a specific model from which to load weights. Enhances training efficiency and model performance. |
+| `optimizer` | `'auto'` | Choice of optimizer for training. Options include `SGD`, `Adam`, `AdamW`, `NAdam`, `RAdam`, `RMSProp` etc., or `auto` for automatic selection based on model configuration. Affects convergence speed and stability. |
+| `verbose` | `False` | Enables verbose output during training, providing detailed logs and progress updates. Useful for debugging and closely monitoring the training process. |
+| `seed` | `0` | Sets the random seed for training, ensuring reproducibility of results across runs with the same configurations. |
+| `deterministic` | `True` | Forces deterministic algorithm use, ensuring reproducibility but may affect performance and speed due to the restriction on non-deterministic algorithms. |
+| `single_cls` | `False` | Treats all classes in multi-class datasets as a single class during training. Useful for binary classification tasks or when focusing on object presence rather than classification. |
+| `rect` | `False` | Enables rectangular training, optimizing batch composition for minimal padding. Can improve efficiency and speed but may affect model accuracy. |
+| `cos_lr` | `False` | Utilizes a cosine learning rate scheduler, adjusting the learning rate following a cosine curve over epochs. Helps in managing learning rate for better convergence. |
+| `close_mosaic` | `10` | Disables mosaic data augmentation in the last N epochs to stabilize training before completion. Setting to 0 disables this feature. |
+| `resume` | `False` | Resumes training from the last saved checkpoint. Automatically loads model weights, optimizer state, and epoch count, continuing training seamlessly. |
+| `amp` | `True` | Enables Automatic Mixed Precision (AMP) training, reducing memory usage and possibly speeding up training with minimal impact on accuracy. |
+| `fraction` | `1.0` | Specifies the fraction of the dataset to use for training. Allows for training on a subset of the full dataset, useful for experiments or when resources are limited. |
+| `profile` | `False` | Enables profiling of ONNX and TensorRT speeds during training, useful for optimizing model deployment. |
+| `freeze` | `None` | Freezes the first N layers of the model or specified layers by index, reducing the number of trainable parameters. Useful for fine-tuning or transfer learning. |
+| `lr0` | `0.01` | Initial learning rate (i.e. `SGD=1E-2`, `Adam=1E-3`) . Adjusting this value is crucial for the optimization process, influencing how rapidly model weights are updated. |
+| `lrf` | `0.01` | Final learning rate as a fraction of the initial rate = (`lr0 * lrf`), used in conjunction with schedulers to adjust the learning rate over time. |
+| `momentum` | `0.937` | Momentum factor for SGD or beta1 for Adam optimizers, influencing the incorporation of past gradients in the current update. |
+| `weight_decay` | `0.0005` | L2 regularization term, penalizing large weights to prevent overfitting. |
+| `warmup_epochs` | `3.0` | Number of epochs for learning rate warmup, gradually increasing the learning rate from a low value to the initial learning rate to stabilize training early on. |
+| `warmup_momentum` | `0.8` | Initial momentum for warmup phase, gradually adjusting to the set momentum over the warmup period. |
+| `warmup_bias_lr` | `0.1` | Learning rate for bias parameters during the warmup phase, helping stabilize model training in the initial epochs. |
+| `box` | `7.5` | Weight of the box loss component in the loss function, influencing how much emphasis is placed on accurately predicting bounding box coordinates. |
+| `cls` | `0.5` | Weight of the classification loss in the total loss function, affecting the importance of correct class prediction relative to other components. |
+| `dfl` | `1.5` | Weight of the distribution focal loss, used in certain YOLO versions for fine-grained classification. |
+| `pose` | `12.0` | Weight of the pose loss in models trained for pose estimation, influencing the emphasis on accurately predicting pose keypoints. |
+| `kobj` | `2.0` | Weight of the keypoint objectness loss in pose estimation models, balancing detection confidence with pose accuracy. |
+| `label_smoothing` | `0.0` | Applies label smoothing, softening hard labels to a mix of the target label and a uniform distribution over labels, can improve generalization. |
+| `nbs` | `64` | Nominal batch size for normalization of loss. |
+| `overlap_mask` | `True` | Determines whether segmentation masks should overlap during training, applicable in instance segmentation tasks. |
+| `mask_ratio` | `4` | Downsample ratio for segmentation masks, affecting the resolution of masks used during training. |
+| `dropout` | `0.0` | Dropout rate for regularization in classification tasks, preventing overfitting by randomly omitting units during training. |
+| `val` | `True` | Enables validation during training, allowing for periodic evaluation of model performance on a separate dataset. |
+| `plots` | `False` | Generates and saves plots of training and validation metrics, as well as prediction examples, providing visual insights into model performance and learning progression. |
+
+!!! info "Note on Batch-size Settings"
+
+ The `batch` argument can be configured in three ways:
+
+ - **Fixed Batch Size**: Set an integer value (e.g., `batch=16`), specifying the number of images per batch directly.
+ - **Auto Mode (60% GPU Memory)**: Use `batch=-1` to automatically adjust batch size for approximately 60% CUDA memory utilization.
+ - **Auto Mode with Utilization Fraction**: Set a fraction value (e.g., `batch=0.70`) to adjust batch size based on the specified fraction of GPU memory usage.
+
+## Augmentation Settings and Hyperparameters
+
+Augmentation techniques are essential for improving the robustness and performance of YOLO models by introducing variability into the training data, helping the model generalize better to unseen data. The following table outlines the purpose and effect of each augmentation argument:
+
+| Argument | Type | Default | Range | Description |
+| --------------- | ------- | ------------- | ------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| `hsv_h` | `float` | `0.015` | `0.0 - 1.0` | Adjusts the hue of the image by a fraction of the color wheel, introducing color variability. Helps the model generalize across different lighting conditions. |
+| `hsv_s` | `float` | `0.7` | `0.0 - 1.0` | Alters the saturation of the image by a fraction, affecting the intensity of colors. Useful for simulating different environmental conditions. |
+| `hsv_v` | `float` | `0.4` | `0.0 - 1.0` | Modifies the value (brightness) of the image by a fraction, helping the model to perform well under various lighting conditions. |
+| `degrees` | `float` | `0.0` | `-180 - +180` | Rotates the image randomly within the specified degree range, improving the model's ability to recognize objects at various orientations. |
+| `translate` | `float` | `0.1` | `0.0 - 1.0` | Translates the image horizontally and vertically by a fraction of the image size, aiding in learning to detect partially visible objects. |
+| `scale` | `float` | `0.5` | `>=0.0` | Scales the image by a gain factor, simulating objects at different distances from the camera. |
+| `shear` | `float` | `0.0` | `-180 - +180` | Shears the image by a specified degree, mimicking the effect of objects being viewed from different angles. |
+| `perspective` | `float` | `0.0` | `0.0 - 0.001` | Applies a random perspective transformation to the image, enhancing the model's ability to understand objects in 3D space. |
+| `flipud` | `float` | `0.0` | `0.0 - 1.0` | Flips the image upside down with the specified probability, increasing the data variability without affecting the object's characteristics. |
+| `fliplr` | `float` | `0.5` | `0.0 - 1.0` | Flips the image left to right with the specified probability, useful for learning symmetrical objects and increasing dataset diversity. |
+| `bgr` | `float` | `0.0` | `0.0 - 1.0` | Flips the image channels from RGB to BGR with the specified probability, useful for increasing robustness to incorrect channel ordering. |
+| `mosaic` | `float` | `1.0` | `0.0 - 1.0` | Combines four training images into one, simulating different scene compositions and object interactions. Highly effective for complex scene understanding. |
+| `mixup` | `float` | `0.0` | `0.0 - 1.0` | Blends two images and their labels, creating a composite image. Enhances the model's ability to generalize by introducing label noise and visual variability. |
+| `copy_paste` | `float` | `0.0` | `0.0 - 1.0` | Copies objects from one image and pastes them onto another, useful for increasing object instances and learning object occlusion. |
+| `auto_augment` | `str` | `randaugment` | - | Automatically applies a predefined augmentation policy (`randaugment`, `autoaugment`, `augmix`), optimizing for classification tasks by diversifying the visual features. |
+| `erasing` | `float` | `0.4` | `0.0 - 0.9` | Randomly erases a portion of the image during classification training, encouraging the model to focus on less obvious features for recognition. |
+| `crop_fraction` | `float` | `1.0` | `0.1 - 1.0` | Crops the classification image to a fraction of its size to emphasize central features and adapt to object scales, reducing background distractions. |
+
+These settings can be adjusted to meet the specific requirements of the dataset and task at hand. Experimenting with different values can help find the optimal augmentation strategy that leads to the best model performance.
+
+!!! info
+
+ For more information about training augmentation operations, see the [reference section](../reference/data/augment.md).
+
+## Logging
+
+In training a YOLOv8 model, you might find it valuable to keep track of the model's performance over time. This is where logging comes into play. Ultralytics' YOLO provides support for three types of loggers - Comet, ClearML, and TensorBoard.
+
+To use a logger, select it from the dropdown menu in the code snippet above and run it. The chosen logger will be installed and initialized.
+
+### Comet
+
+[Comet](../integrations/comet.md) is a platform that allows data scientists and developers to track, compare, explain and optimize experiments and models. It provides functionalities such as real-time metrics, code diffs, and hyperparameters tracking.
+
+To use Comet:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ # pip install comet_ml
+ import comet_ml
+
+ comet_ml.init()
+ ```
+
+Remember to sign in to your Comet account on their website and get your API key. You will need to add this to your environment variables or your script to log your experiments.
+
+### ClearML
+
+[ClearML](https://www.clear.ml/) is an open-source platform that automates tracking of experiments and helps with efficient sharing of resources. It is designed to help teams manage, execute, and reproduce their ML work more efficiently.
+
+To use ClearML:
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ # pip install clearml
+ import clearml
+
+ clearml.browser_login()
+ ```
+
+After running this script, you will need to sign in to your ClearML account on the browser and authenticate your session.
+
+### TensorBoard
+
+[TensorBoard](https://www.tensorflow.org/tensorboard) is a visualization toolkit for TensorFlow. It allows you to visualize your TensorFlow graph, plot quantitative metrics about the execution of your graph, and show additional data like images that pass through it.
+
+To use TensorBoard in [Google Colab](https://colab.research.google.com/github/ultralytics/ultralytics/blob/main/examples/tutorial.ipynb):
+
+!!! Example
+
+ === "CLI"
+
+ ```bash
+ load_ext tensorboard
+ tensorboard --logdir ultralytics/runs # replace with 'runs' directory
+ ```
+
+To use TensorBoard locally run the below command and view results at http://localhost:6006/.
+
+!!! Example
+
+ === "CLI"
+
+ ```bash
+ tensorboard --logdir ultralytics/runs # replace with 'runs' directory
+ ```
+
+This will load TensorBoard and direct it to the directory where your training logs are saved.
+
+After setting up your logger, you can then proceed with your model training. All training metrics will be automatically logged in your chosen platform, and you can access these logs to monitor your model's performance over time, compare different models, and identify areas for improvement.
+
+## FAQ
+
+### How do I train an object detection model using Ultralytics YOLOv8?
+
+To train an object detection model using Ultralytics YOLOv8, you can either use the Python API or the CLI. Below is an example for both:
+
+!!! Example "Single-GPU and CPU Training Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo detect train data=coco8.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+For more details, refer to the [Train Settings](#train-settings) section.
+
+### What are the key features of Ultralytics YOLOv8's Train mode?
+
+The key features of Ultralytics YOLOv8's Train mode include:
+
+- **Automatic Dataset Download:** Automatically downloads standard datasets like COCO, VOC, and ImageNet.
+- **Multi-GPU Support:** Scale training across multiple GPUs for faster processing.
+- **Hyperparameter Configuration:** Customize hyperparameters through YAML files or CLI arguments.
+- **Visualization and Monitoring:** Real-time tracking of training metrics for better insights.
+
+These features make training efficient and customizable to your needs. For more details, see the [Key Features of Train Mode](#key-features-of-train-mode) section.
+
+### How do I resume training from an interrupted session in Ultralytics YOLOv8?
+
+To resume training from an interrupted session, set the `resume` argument to `True` and specify the path to the last saved checkpoint.
+
+!!! Example "Resume Training Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load the partially trained model
+ model = YOLO("path/to/last.pt")
+
+ # Resume training
+ results = model.train(resume=True)
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo train resume model=path/to/last.pt
+ ```
+
+Check the section on [Resuming Interrupted Trainings](#resuming-interrupted-trainings) for more information.
+
+### Can I train YOLOv8 models on Apple M1 and M2 chips?
+
+Yes, Ultralytics YOLOv8 supports training on Apple M1 and M2 chips utilizing the Metal Performance Shaders (MPS) framework. Specify 'mps' as your training device.
+
+!!! Example "MPS Training Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a pretrained model
+ model = YOLO("yolov8n.pt")
+
+ # Train the model on M1/M2 chip
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640, device="mps")
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo detect train data=coco8.yaml model=yolov8n.pt epochs=100 imgsz=640 device=mps
+ ```
+
+For more details, refer to the [Apple M1 and M2 MPS Training](#apple-m1-and-m2-mps-training) section.
+
+### What are the common training settings, and how do I configure them?
+
+Ultralytics YOLOv8 allows you to configure a variety of training settings such as batch size, learning rate, epochs, and more through arguments. Here's a brief overview:
+
+| Argument | Default | Description |
+| -------- | ------- | ---------------------------------------------------------------------- |
+| `model` | `None` | Path to the model file for training. |
+| `data` | `None` | Path to the dataset configuration file (e.g., `coco8.yaml`). |
+| `epochs` | `100` | Total number of training epochs. |
+| `batch` | `16` | Batch size, adjustable as integer or auto mode. |
+| `imgsz` | `640` | Target image size for training. |
+| `device` | `None` | Computational device(s) for training like `cpu`, `0`, `0,1`, or `mps`. |
+| `save` | `True` | Enables saving of training checkpoints and final model weights. |
+
+For an in-depth guide on training settings, check the [Train Settings](#train-settings) section.
diff --git a/ultralytics/docs/en/modes/val.md b/ultralytics/docs/en/modes/val.md
new file mode 100644
index 0000000000000000000000000000000000000000..1010df14a4292d27d68b158281a6a851e9cc0df3
--- /dev/null
+++ b/ultralytics/docs/en/modes/val.md
@@ -0,0 +1,228 @@
+---
+comments: true
+description: Learn how to validate your YOLOv8 model with precise metrics, easy-to-use tools, and custom settings for optimal performance.
+keywords: Ultralytics, YOLOv8, model validation, machine learning, object detection, mAP metrics, Python API, CLI
+---
+
+# Model Validation with Ultralytics YOLO
+
+
+
+## Introduction
+
+Validation is a critical step in the machine learning pipeline, allowing you to assess the quality of your trained models. Val mode in Ultralytics YOLOv8 provides a robust suite of tools and metrics for evaluating the performance of your object detection models. This guide serves as a complete resource for understanding how to effectively use the Val mode to ensure that your models are both accurate and reliable.
+
+
+
+## Why Validate with Ultralytics YOLO?
+
+Here's why using YOLOv8's Val mode is advantageous:
+
+- **Precision:** Get accurate metrics like mAP50, mAP75, and mAP50-95 to comprehensively evaluate your model.
+- **Convenience:** Utilize built-in features that remember training settings, simplifying the validation process.
+- **Flexibility:** Validate your model with the same or different datasets and image sizes.
+- **Hyperparameter Tuning:** Use validation metrics to fine-tune your model for better performance.
+
+### Key Features of Val Mode
+
+These are the notable functionalities offered by YOLOv8's Val mode:
+
+- **Automated Settings:** Models remember their training configurations for straightforward validation.
+- **Multi-Metric Support:** Evaluate your model based on a range of accuracy metrics.
+- **CLI and Python API:** Choose from command-line interface or Python API based on your preference for validation.
+- **Data Compatibility:** Works seamlessly with datasets used during the training phase as well as custom datasets.
+
+!!! Tip "Tip"
+
+ * YOLOv8 models automatically remember their training settings, so you can validate a model at the same image size and on the original dataset easily with just `yolo val model=yolov8n.pt` or `model('yolov8n.pt').val()`
+
+## Usage Examples
+
+Validate trained YOLOv8n model accuracy on the COCO8 dataset. No argument need to passed as the `model` retains its training `data` and arguments as model attributes. See Arguments section below for a full list of export arguments.
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt") # load an official model
+ model = YOLO("path/to/best.pt") # load a custom model
+
+ # Validate the model
+ metrics = model.val() # no arguments needed, dataset and settings remembered
+ metrics.box.map # map50-95
+ metrics.box.map50 # map50
+ metrics.box.map75 # map75
+ metrics.box.maps # a list contains map50-95 of each category
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo detect val model=yolov8n.pt # val official model
+ yolo detect val model=path/to/best.pt # val custom model
+ ```
+
+## Arguments for YOLO Model Validation
+
+When validating YOLO models, several arguments can be fine-tuned to optimize the evaluation process. These arguments control aspects such as input image size, batch processing, and performance thresholds. Below is a detailed breakdown of each argument to help you customize your validation settings effectively.
+
+| Argument | Type | Default | Description |
+| ------------- | ------- | ------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| `data` | `str` | `None` | Specifies the path to the dataset configuration file (e.g., `coco8.yaml`). This file includes paths to validation data, class names, and number of classes. |
+| `imgsz` | `int` | `640` | Defines the size of input images. All images are resized to this dimension before processing. |
+| `batch` | `int` | `16` | Sets the number of images per batch. Use `-1` for AutoBatch, which automatically adjusts based on GPU memory availability. |
+| `save_json` | `bool` | `False` | If `True`, saves the results to a JSON file for further analysis or integration with other tools. |
+| `save_hybrid` | `bool` | `False` | If `True`, saves a hybrid version of labels that combines original annotations with additional model predictions. |
+| `conf` | `float` | `0.001` | Sets the minimum confidence threshold for detections. Detections with confidence below this threshold are discarded. |
+| `iou` | `float` | `0.6` | Sets the Intersection Over Union (IoU) threshold for Non-Maximum Suppression (NMS). Helps in reducing duplicate detections. |
+| `max_det` | `int` | `300` | Limits the maximum number of detections per image. Useful in dense scenes to prevent excessive detections. |
+| `half` | `bool` | `True` | Enables half-precision (FP16) computation, reducing memory usage and potentially increasing speed with minimal impact on accuracy. |
+| `device` | `str` | `None` | Specifies the device for validation (`cpu`, `cuda:0`, etc.). Allows flexibility in utilizing CPU or GPU resources. |
+| `dnn` | `bool` | `False` | If `True`, uses the OpenCV DNN module for ONNX model inference, offering an alternative to PyTorch inference methods. |
+| `plots` | `bool` | `False` | When set to `True`, generates and saves plots of predictions versus ground truth for visual evaluation of the model's performance. |
+| `rect` | `bool` | `False` | If `True`, uses rectangular inference for batching, reducing padding and potentially increasing speed and efficiency. |
+| `split` | `str` | `val` | Determines the dataset split to use for validation (`val`, `test`, or `train`). Allows flexibility in choosing the data segment for performance evaluation. |
+
+Each of these settings plays a vital role in the validation process, allowing for a customizable and efficient evaluation of YOLO models. Adjusting these parameters according to your specific needs and resources can help achieve the best balance between accuracy and performance.
+
+### Example Validation with Arguments
+
+The below examples showcase YOLO model validation with custom arguments in Python and CLI.
+
+!!! Example
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt")
+
+ # Customize validation settings
+ validation_results = model.val(data="coco8.yaml", imgsz=640, batch=16, conf=0.25, iou=0.6, device="0")
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo val model=yolov8n.pt data=coco8.yaml imgsz=640 batch=16 conf=0.25 iou=0.6 device=0
+ ```
+
+## FAQ
+
+### How do I validate my YOLOv8 model with Ultralytics?
+
+To validate your YOLOv8 model, you can use the Val mode provided by Ultralytics. For example, using the Python API, you can load a model and run validation with:
+
+```python
+from ultralytics import YOLO
+
+# Load a model
+model = YOLO("yolov8n.pt")
+
+# Validate the model
+metrics = model.val()
+print(metrics.box.map) # map50-95
+```
+
+Alternatively, you can use the command-line interface (CLI):
+
+```bash
+yolo val model=yolov8n.pt
+```
+
+For further customization, you can adjust various arguments like `imgsz`, `batch`, and `conf` in both Python and CLI modes. Check the [Arguments for YOLO Model Validation](#arguments-for-yolo-model-validation) section for the full list of parameters.
+
+### What metrics can I get from YOLOv8 model validation?
+
+YOLOv8 model validation provides several key metrics to assess model performance. These include:
+
+- mAP50 (mean Average Precision at IoU threshold 0.5)
+- mAP75 (mean Average Precision at IoU threshold 0.75)
+- mAP50-95 (mean Average Precision across multiple IoU thresholds from 0.5 to 0.95)
+
+Using the Python API, you can access these metrics as follows:
+
+```python
+metrics = model.val() # assumes `model` has been loaded
+print(metrics.box.map) # mAP50-95
+print(metrics.box.map50) # mAP50
+print(metrics.box.map75) # mAP75
+print(metrics.box.maps) # list of mAP50-95 for each category
+```
+
+For a complete performance evaluation, it's crucial to review all these metrics. For more details, refer to the [Key Features of Val Mode](#key-features-of-val-mode).
+
+### What are the advantages of using Ultralytics YOLO for validation?
+
+Using Ultralytics YOLO for validation provides several advantages:
+
+- **Precision:** YOLOv8 offers accurate performance metrics including mAP50, mAP75, and mAP50-95.
+- **Convenience:** The models remember their training settings, making validation straightforward.
+- **Flexibility:** You can validate against the same or different datasets and image sizes.
+- **Hyperparameter Tuning:** Validation metrics help in fine-tuning models for better performance.
+
+These benefits ensure that your models are evaluated thoroughly and can be optimized for superior results. Learn more about these advantages in the [Why Validate with Ultralytics YOLO](#why-validate-with-ultralytics-yolo) section.
+
+### Can I validate my YOLOv8 model using a custom dataset?
+
+Yes, you can validate your YOLOv8 model using a custom dataset. Specify the `data` argument with the path to your dataset configuration file. This file should include paths to the validation data, class names, and other relevant details.
+
+Example in Python:
+
+```python
+from ultralytics import YOLO
+
+# Load a model
+model = YOLO("yolov8n.pt")
+
+# Validate with a custom dataset
+metrics = model.val(data="path/to/your/custom_dataset.yaml")
+print(metrics.box.map) # map50-95
+```
+
+Example using CLI:
+
+```bash
+yolo val model=yolov8n.pt data=path/to/your/custom_dataset.yaml
+```
+
+For more customizable options during validation, see the [Example Validation with Arguments](#example-validation-with-arguments) section.
+
+### How do I save validation results to a JSON file in YOLOv8?
+
+To save the validation results to a JSON file, you can set the `save_json` argument to `True` when running validation. This can be done in both the Python API and CLI.
+
+Example in Python:
+
+```python
+from ultralytics import YOLO
+
+# Load a model
+model = YOLO("yolov8n.pt")
+
+# Save validation results to JSON
+metrics = model.val(save_json=True)
+```
+
+Example using CLI:
+
+```bash
+yolo val model=yolov8n.pt save_json=True
+```
+
+This functionality is particularly useful for further analysis or integration with other tools. Check the [Arguments for YOLO Model Validation](#arguments-for-yolo-model-validation) for more details.
diff --git a/ultralytics/docs/en/quickstart.md b/ultralytics/docs/en/quickstart.md
new file mode 100644
index 0000000000000000000000000000000000000000..32e09c46b4d030bb4d3e32d22d9452e529c9f224
--- /dev/null
+++ b/ultralytics/docs/en/quickstart.md
@@ -0,0 +1,426 @@
+---
+comments: true
+description: Learn how to install Ultralytics using pip, conda, or Docker. Follow our step-by-step guide for a seamless setup of YOLOv8 with thorough instructions.
+keywords: Ultralytics, YOLOv8, Install Ultralytics, pip, conda, Docker, GitHub, machine learning, object detection
+---
+
+## Install Ultralytics
+
+Ultralytics provides various installation methods including pip, conda, and Docker. Install YOLOv8 via the `ultralytics` pip package for the latest stable release or by cloning the [Ultralytics GitHub repository](https://github.com/ultralytics/ultralytics) for the most up-to-date version. Docker can be used to execute the package in an isolated container, avoiding local installation.
+
+
+
+ === "Pip install (recommended)"
+
+ Install the `ultralytics` package using pip, or update an existing installation by running `pip install -U ultralytics`. Visit the Python Package Index (PyPI) for more details on the `ultralytics` package: [https://pypi.org/project/ultralytics/](https://pypi.org/project/ultralytics/).
+
+ [](https://pypi.org/project/ultralytics/)
+ [](https://pepy.tech/project/ultralytics)
+
+ ```bash
+ # Install the ultralytics package from PyPI
+ pip install ultralytics
+ ```
+
+ You can also install the `ultralytics` package directly from the GitHub [repository](https://github.com/ultralytics/ultralytics). This might be useful if you want the latest development version. Make sure to have the Git command-line tool installed on your system. The `@main` command installs the `main` branch and may be modified to another branch, i.e. `@my-branch`, or removed entirely to default to `main` branch.
+
+ ```bash
+ # Install the ultralytics package from GitHub
+ pip install git+https://github.com/ultralytics/ultralytics.git@main
+ ```
+
+ === "Conda install"
+
+ Conda is an alternative package manager to pip which may also be used for installation. Visit Anaconda for more details at [https://anaconda.org/conda-forge/ultralytics](https://anaconda.org/conda-forge/ultralytics). Ultralytics feedstock repository for updating the conda package is at [https://github.com/conda-forge/ultralytics-feedstock/](https://github.com/conda-forge/ultralytics-feedstock/).
+
+ [](https://anaconda.org/conda-forge/ultralytics)
+ [](https://anaconda.org/conda-forge/ultralytics)
+ [](https://anaconda.org/conda-forge/ultralytics)
+ [](https://anaconda.org/conda-forge/ultralytics)
+
+ ```bash
+ # Install the ultralytics package using conda
+ conda install -c conda-forge ultralytics
+ ```
+
+ !!! Note
+
+ If you are installing in a CUDA environment best practice is to install `ultralytics`, `pytorch` and `pytorch-cuda` in the same command to allow the conda package manager to resolve any conflicts, or else to install `pytorch-cuda` last to allow it override the CPU-specific `pytorch` package if necessary.
+ ```bash
+ # Install all packages together using conda
+ conda install -c pytorch -c nvidia -c conda-forge pytorch torchvision pytorch-cuda=11.8 ultralytics
+ ```
+
+ ### Conda Docker Image
+
+ Ultralytics Conda Docker images are also available from [DockerHub](https://hub.docker.com/r/ultralytics/ultralytics). These images are based on [Miniconda3](https://docs.conda.io/projects/miniconda/en/latest/) and are an simple way to start using `ultralytics` in a Conda environment.
+
+ ```bash
+ # Set image name as a variable
+ t=ultralytics/ultralytics:latest-conda
+
+ # Pull the latest ultralytics image from Docker Hub
+ sudo docker pull $t
+
+ # Run the ultralytics image in a container with GPU support
+ sudo docker run -it --ipc=host --gpus all $t # all GPUs
+ sudo docker run -it --ipc=host --gpus '"device=2,3"' $t # specify GPUs
+ ```
+
+ === "Git clone"
+
+ Clone the `ultralytics` repository if you are interested in contributing to the development or wish to experiment with the latest source code. After cloning, navigate into the directory and install the package in editable mode `-e` using pip.
+
+ [](https://github.com/ultralytics/ultralytics)
+ [](https://github.com/ultralytics/ultralytics)
+
+ ```bash
+ # Clone the ultralytics repository
+ git clone https://github.com/ultralytics/ultralytics
+
+ # Navigate to the cloned directory
+ cd ultralytics
+
+ # Install the package in editable mode for development
+ pip install -e .
+ ```
+
+ === "Docker"
+
+ Utilize Docker to effortlessly execute the `ultralytics` package in an isolated container, ensuring consistent and smooth performance across various environments. By choosing one of the official `ultralytics` images from [Docker Hub](https://hub.docker.com/r/ultralytics/ultralytics), you not only avoid the complexity of local installation but also benefit from access to a verified working environment. Ultralytics offers 5 main supported Docker images, each designed to provide high compatibility and efficiency for different platforms and use cases:
+
+ [](https://hub.docker.com/r/ultralytics/ultralytics)
+ [](https://hub.docker.com/r/ultralytics/ultralytics)
+
+ - **Dockerfile:** GPU image recommended for training.
+ - **Dockerfile-arm64:** Optimized for ARM64 architecture, allowing deployment on devices like Raspberry Pi and other ARM64-based platforms.
+ - **Dockerfile-cpu:** Ubuntu-based CPU-only version suitable for inference and environments without GPUs.
+ - **Dockerfile-jetson:** Tailored for NVIDIA Jetson devices, integrating GPU support optimized for these platforms.
+ - **Dockerfile-python:** Minimal image with just Python and necessary dependencies, ideal for lightweight applications and development.
+ - **Dockerfile-conda:** Based on Miniconda3 with conda installation of ultralytics package.
+
+ Below are the commands to get the latest image and execute it:
+
+ ```bash
+ # Set image name as a variable
+ t=ultralytics/ultralytics:latest
+
+ # Pull the latest ultralytics image from Docker Hub
+ sudo docker pull $t
+
+ # Run the ultralytics image in a container with GPU support
+ sudo docker run -it --ipc=host --gpus all $t # all GPUs
+ sudo docker run -it --ipc=host --gpus '"device=2,3"' $t # specify GPUs
+ ```
+
+ The above command initializes a Docker container with the latest `ultralytics` image. The `-it` flag assigns a pseudo-TTY and maintains stdin open, enabling you to interact with the container. The `--ipc=host` flag sets the IPC (Inter-Process Communication) namespace to the host, which is essential for sharing memory between processes. The `--gpus all` flag enables access to all available GPUs inside the container, which is crucial for tasks that require GPU computation.
+
+ Note: To work with files on your local machine within the container, use Docker volumes for mounting a local directory into the container:
+
+ ```bash
+ # Mount local directory to a directory inside the container
+ sudo docker run -it --ipc=host --gpus all -v /path/on/host:/path/in/container $t
+ ```
+
+ Alter `/path/on/host` with the directory path on your local machine, and `/path/in/container` with the desired path inside the Docker container for accessibility.
+
+ For advanced Docker usage, feel free to explore the [Ultralytics Docker Guide](./guides/docker-quickstart.md).
+
+See the `ultralytics` [pyproject.toml](https://github.com/ultralytics/ultralytics/blob/main/pyproject.toml) file for a list of dependencies. Note that all examples above install all required dependencies.
+
+!!! Tip "Tip"
+
+ PyTorch requirements vary by operating system and CUDA requirements, so it's recommended to install PyTorch first following instructions at [https://pytorch.org/get-started/locally](https://pytorch.org/get-started/locally).
+
+
+
 + - **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)
+ - **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)
+ - **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/)
+ - **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)
+ - **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)
+ - **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/)  +
+ ## Status
+
+
+
+ ## Status
+
+  +
+## Table of Contents
+
+1. [Code of Conduct](#code-of-conduct)
+2. [Contributing via Pull Requests](#contributing-via-pull-requests)
+ - [CLA Signing](#cla-signing)
+ - [Google-Style Docstrings](#google-style-docstrings)
+ - [GitHub Actions CI Tests](#github-actions-ci-tests)
+3. [Reporting Bugs](#reporting-bugs)
+4. [License](#license)
+5. [Conclusion](#conclusion)
+6. [FAQ](#faq)
+
+## Code of Conduct
+
+To ensure a welcoming and inclusive environment for everyone, all contributors must adhere to our [Code of Conduct](https://docs.ultralytics.com/help/code_of_conduct). Respect, kindness, and professionalism are at the heart of our community.
+
+## Contributing via Pull Requests
+
+We greatly appreciate contributions in the form of pull requests. To make the review process as smooth as possible, please follow these steps:
+
+1. **[Fork the repository](https://docs.github.com/en/pull-requests/collaborating-with-pull-requests/working-with-forks/fork-a-repo):** Start by forking the Ultralytics YOLO repository to your GitHub account.
+
+2. **[Create a branch](https://docs.github.com/en/desktop/making-changes-in-a-branch/managing-branches-in-github-desktop):** Create a new branch in your forked repository with a clear, descriptive name that reflects your changes.
+
+3. **Make your changes:** Ensure your code adheres to the project's style guidelines and does not introduce any new errors or warnings.
+
+4. **[Test your changes](https://github.com/ultralytics/ultralytics/tree/main/tests):** Before submitting, test your changes locally to confirm they work as expected and don't cause any new issues.
+
+5. **[Commit your changes](https://docs.github.com/en/desktop/making-changes-in-a-branch/committing-and-reviewing-changes-to-your-project-in-github-desktop):** Commit your changes with a concise and descriptive commit message. If your changes address a specific issue, include the issue number in your commit message.
+
+6. **[Create a pull request](https://docs.github.com/en/pull-requests/collaborating-with-pull-requests/proposing-changes-to-your-work-with-pull-requests/creating-a-pull-request):** Submit a pull request from your forked repository to the main Ultralytics YOLO repository. Provide a clear and detailed explanation of your changes and how they improve the project.
+
+### CLA Signing
+
+Before we can merge your pull request, you must sign our [Contributor License Agreement (CLA)](https://docs.ultralytics.com/help/CLA). This legal agreement ensures that your contributions are properly licensed, allowing the project to continue being distributed under the AGPL-3.0 license.
+
+After submitting your pull request, the CLA bot will guide you through the signing process. To sign the CLA, simply add a comment in your PR stating:
+
+```
+I have read the CLA Document and I sign the CLA
+```
+
+### Google-Style Docstrings
+
+When adding new functions or classes, please include [Google-style docstrings](https://google.github.io/styleguide/pyguide.html). These docstrings provide clear, standardized documentation that helps other developers understand and maintain your code.
+
+#### Example
+
+This example illustrates a Google-style docstring. Ensure that both input and output `types` are always enclosed in parentheses, e.g., `(bool)`.
+
+```python
+def example_function(arg1, arg2=4):
+ """
+ Example function demonstrating Google-style docstrings.
+
+ Args:
+ arg1 (int): The first argument.
+ arg2 (int): The second argument, with a default value of 4.
+
+ Returns:
+ (bool): True if successful, False otherwise.
+
+ Examples:
+ >>> result = example_function(1, 2) # returns False
+ """
+ if arg1 == arg2:
+ return True
+ return False
+```
+
+#### Example with type hints
+
+This example includes both a Google-style docstring and type hints for arguments and returns, though using either independently is also acceptable.
+
+```python
+def example_function(arg1: int, arg2: int = 4) -> bool:
+ """
+ Example function demonstrating Google-style docstrings.
+
+ Args:
+ arg1: The first argument.
+ arg2: The second argument, with a default value of 4.
+
+ Returns:
+ True if successful, False otherwise.
+
+ Examples:
+ >>> result = example_function(1, 2) # returns False
+ """
+ if arg1 == arg2:
+ return True
+ return False
+```
+
+#### Example Single-line
+
+For smaller or simpler functions, a single-line docstring may be sufficient. The docstring must use three double-quotes, be a complete sentence, start with a capital letter, and end with a period.
+
+```python
+def example_small_function(arg1: int, arg2: int = 4) -> bool:
+ """Example function with a single-line docstring."""
+ return arg1 == arg2
+```
+
+### GitHub Actions CI Tests
+
+All pull requests must pass the GitHub Actions [Continuous Integration](https://docs.ultralytics.com/help/CI) (CI) tests before they can be merged. These tests include linting, unit tests, and other checks to ensure that your changes meet the project's quality standards. Review the CI output and address any issues that arise.
+
+## Reporting Bugs
+
+We highly value bug reports as they help us maintain the quality of our projects. When reporting a bug, please provide a [Minimum Reproducible Example](https://docs.ultralytics.com/help/minimum_reproducible_example)—a simple, clear code example that consistently reproduces the issue. This allows us to quickly identify and resolve the problem.
+
+## License
+
+Ultralytics uses the [GNU Affero General Public License v3.0 (AGPL-3.0)](https://github.com/ultralytics/ultralytics/blob/main/LICENSE) for its repositories. This license promotes openness, transparency, and collaborative improvement in software development. It ensures that all users have the freedom to use, modify, and share the software, fostering a strong community of collaboration and innovation.
+
+We encourage all contributors to familiarize themselves with the terms of the AGPL-3.0 license to contribute effectively and ethically to the Ultralytics open-source community.
+
+## Conclusion
+
+Thank you for your interest in contributing to [Ultralytics](https://ultralytics.com) [open-source](https://github.com/ultralytics) YOLO projects. Your participation is essential in shaping the future of our software and building a vibrant community of innovation and collaboration. Whether you're enhancing code, reporting bugs, or suggesting new features, your contributions are invaluable.
+
+We're excited to see your ideas come to life and appreciate your commitment to advancing object detection technology. Together, let's continue to grow and innovate in this exciting open-source journey. Happy coding! 🚀🌟
+
+## FAQ
+
+### Why should I contribute to Ultralytics YOLO open-source repositories?
+
+Contributing to Ultralytics YOLO open-source repositories improves the software, making it more robust and feature-rich for the entire community. Contributions can include code enhancements, bug fixes, documentation improvements, and new feature implementations. Additionally, contributing allows you to collaborate with other skilled developers and experts in the field, enhancing your own skills and reputation. For details on how to get started, refer to the [Contributing via Pull Requests](#contributing-via-pull-requests) section.
+
+### How do I sign the Contributor License Agreement (CLA) for Ultralytics YOLO?
+
+To sign the Contributor License Agreement (CLA), follow the instructions provided by the CLA bot after submitting your pull request. This process ensures that your contributions are properly licensed under the AGPL-3.0 license, maintaining the legal integrity of the open-source project. Add a comment in your pull request stating:
+
+```
+I have read the CLA Document and I sign the CLA.
+```
+
+For more information, see the [CLA Signing](#cla-signing) section.
+
+### What are Google-style docstrings, and why are they required for Ultralytics YOLO contributions?
+
+Google-style docstrings provide clear, concise documentation for functions and classes, improving code readability and maintainability. These docstrings outline the function's purpose, arguments, and return values with specific formatting rules. When contributing to Ultralytics YOLO, following Google-style docstrings ensures that your additions are well-documented and easily understood. For examples and guidelines, visit the [Google-Style Docstrings](#google-style-docstrings) section.
+
+### How can I ensure my changes pass the GitHub Actions CI tests?
+
+Before your pull request can be merged, it must pass all GitHub Actions Continuous Integration (CI) tests. These tests include linting, unit tests, and other checks to ensure the code meets
+
+the project's quality standards. Review the CI output and fix any issues. For detailed information on the CI process and troubleshooting tips, see the [GitHub Actions CI Tests](#github-actions-ci-tests) section.
+
+### How do I report a bug in Ultralytics YOLO repositories?
+
+To report a bug, provide a clear and concise [Minimum Reproducible Example](https://docs.ultralytics.com/help/minimum_reproducible_example) along with your bug report. This helps developers quickly identify and fix the issue. Ensure your example is minimal yet sufficient to replicate the problem. For more detailed steps on reporting bugs, refer to the [Reporting Bugs](#reporting-bugs) section.
diff --git a/ultralytics/LICENSE b/ultralytics/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..1468d07c88d6a48dae9360ed0094955b54370224
--- /dev/null
+++ b/ultralytics/LICENSE
@@ -0,0 +1,661 @@
+ GNU AFFERO GENERAL PUBLIC LICENSE
+ Version 3, 19 November 2007
+
+ Copyright (C) 2007 Free Software Foundation, Inc.
+
+## Table of Contents
+
+1. [Code of Conduct](#code-of-conduct)
+2. [Contributing via Pull Requests](#contributing-via-pull-requests)
+ - [CLA Signing](#cla-signing)
+ - [Google-Style Docstrings](#google-style-docstrings)
+ - [GitHub Actions CI Tests](#github-actions-ci-tests)
+3. [Reporting Bugs](#reporting-bugs)
+4. [License](#license)
+5. [Conclusion](#conclusion)
+6. [FAQ](#faq)
+
+## Code of Conduct
+
+To ensure a welcoming and inclusive environment for everyone, all contributors must adhere to our [Code of Conduct](https://docs.ultralytics.com/help/code_of_conduct). Respect, kindness, and professionalism are at the heart of our community.
+
+## Contributing via Pull Requests
+
+We greatly appreciate contributions in the form of pull requests. To make the review process as smooth as possible, please follow these steps:
+
+1. **[Fork the repository](https://docs.github.com/en/pull-requests/collaborating-with-pull-requests/working-with-forks/fork-a-repo):** Start by forking the Ultralytics YOLO repository to your GitHub account.
+
+2. **[Create a branch](https://docs.github.com/en/desktop/making-changes-in-a-branch/managing-branches-in-github-desktop):** Create a new branch in your forked repository with a clear, descriptive name that reflects your changes.
+
+3. **Make your changes:** Ensure your code adheres to the project's style guidelines and does not introduce any new errors or warnings.
+
+4. **[Test your changes](https://github.com/ultralytics/ultralytics/tree/main/tests):** Before submitting, test your changes locally to confirm they work as expected and don't cause any new issues.
+
+5. **[Commit your changes](https://docs.github.com/en/desktop/making-changes-in-a-branch/committing-and-reviewing-changes-to-your-project-in-github-desktop):** Commit your changes with a concise and descriptive commit message. If your changes address a specific issue, include the issue number in your commit message.
+
+6. **[Create a pull request](https://docs.github.com/en/pull-requests/collaborating-with-pull-requests/proposing-changes-to-your-work-with-pull-requests/creating-a-pull-request):** Submit a pull request from your forked repository to the main Ultralytics YOLO repository. Provide a clear and detailed explanation of your changes and how they improve the project.
+
+### CLA Signing
+
+Before we can merge your pull request, you must sign our [Contributor License Agreement (CLA)](https://docs.ultralytics.com/help/CLA). This legal agreement ensures that your contributions are properly licensed, allowing the project to continue being distributed under the AGPL-3.0 license.
+
+After submitting your pull request, the CLA bot will guide you through the signing process. To sign the CLA, simply add a comment in your PR stating:
+
+```
+I have read the CLA Document and I sign the CLA
+```
+
+### Google-Style Docstrings
+
+When adding new functions or classes, please include [Google-style docstrings](https://google.github.io/styleguide/pyguide.html). These docstrings provide clear, standardized documentation that helps other developers understand and maintain your code.
+
+#### Example
+
+This example illustrates a Google-style docstring. Ensure that both input and output `types` are always enclosed in parentheses, e.g., `(bool)`.
+
+```python
+def example_function(arg1, arg2=4):
+ """
+ Example function demonstrating Google-style docstrings.
+
+ Args:
+ arg1 (int): The first argument.
+ arg2 (int): The second argument, with a default value of 4.
+
+ Returns:
+ (bool): True if successful, False otherwise.
+
+ Examples:
+ >>> result = example_function(1, 2) # returns False
+ """
+ if arg1 == arg2:
+ return True
+ return False
+```
+
+#### Example with type hints
+
+This example includes both a Google-style docstring and type hints for arguments and returns, though using either independently is also acceptable.
+
+```python
+def example_function(arg1: int, arg2: int = 4) -> bool:
+ """
+ Example function demonstrating Google-style docstrings.
+
+ Args:
+ arg1: The first argument.
+ arg2: The second argument, with a default value of 4.
+
+ Returns:
+ True if successful, False otherwise.
+
+ Examples:
+ >>> result = example_function(1, 2) # returns False
+ """
+ if arg1 == arg2:
+ return True
+ return False
+```
+
+#### Example Single-line
+
+For smaller or simpler functions, a single-line docstring may be sufficient. The docstring must use three double-quotes, be a complete sentence, start with a capital letter, and end with a period.
+
+```python
+def example_small_function(arg1: int, arg2: int = 4) -> bool:
+ """Example function with a single-line docstring."""
+ return arg1 == arg2
+```
+
+### GitHub Actions CI Tests
+
+All pull requests must pass the GitHub Actions [Continuous Integration](https://docs.ultralytics.com/help/CI) (CI) tests before they can be merged. These tests include linting, unit tests, and other checks to ensure that your changes meet the project's quality standards. Review the CI output and address any issues that arise.
+
+## Reporting Bugs
+
+We highly value bug reports as they help us maintain the quality of our projects. When reporting a bug, please provide a [Minimum Reproducible Example](https://docs.ultralytics.com/help/minimum_reproducible_example)—a simple, clear code example that consistently reproduces the issue. This allows us to quickly identify and resolve the problem.
+
+## License
+
+Ultralytics uses the [GNU Affero General Public License v3.0 (AGPL-3.0)](https://github.com/ultralytics/ultralytics/blob/main/LICENSE) for its repositories. This license promotes openness, transparency, and collaborative improvement in software development. It ensures that all users have the freedom to use, modify, and share the software, fostering a strong community of collaboration and innovation.
+
+We encourage all contributors to familiarize themselves with the terms of the AGPL-3.0 license to contribute effectively and ethically to the Ultralytics open-source community.
+
+## Conclusion
+
+Thank you for your interest in contributing to [Ultralytics](https://ultralytics.com) [open-source](https://github.com/ultralytics) YOLO projects. Your participation is essential in shaping the future of our software and building a vibrant community of innovation and collaboration. Whether you're enhancing code, reporting bugs, or suggesting new features, your contributions are invaluable.
+
+We're excited to see your ideas come to life and appreciate your commitment to advancing object detection technology. Together, let's continue to grow and innovate in this exciting open-source journey. Happy coding! 🚀🌟
+
+## FAQ
+
+### Why should I contribute to Ultralytics YOLO open-source repositories?
+
+Contributing to Ultralytics YOLO open-source repositories improves the software, making it more robust and feature-rich for the entire community. Contributions can include code enhancements, bug fixes, documentation improvements, and new feature implementations. Additionally, contributing allows you to collaborate with other skilled developers and experts in the field, enhancing your own skills and reputation. For details on how to get started, refer to the [Contributing via Pull Requests](#contributing-via-pull-requests) section.
+
+### How do I sign the Contributor License Agreement (CLA) for Ultralytics YOLO?
+
+To sign the Contributor License Agreement (CLA), follow the instructions provided by the CLA bot after submitting your pull request. This process ensures that your contributions are properly licensed under the AGPL-3.0 license, maintaining the legal integrity of the open-source project. Add a comment in your pull request stating:
+
+```
+I have read the CLA Document and I sign the CLA.
+```
+
+For more information, see the [CLA Signing](#cla-signing) section.
+
+### What are Google-style docstrings, and why are they required for Ultralytics YOLO contributions?
+
+Google-style docstrings provide clear, concise documentation for functions and classes, improving code readability and maintainability. These docstrings outline the function's purpose, arguments, and return values with specific formatting rules. When contributing to Ultralytics YOLO, following Google-style docstrings ensures that your additions are well-documented and easily understood. For examples and guidelines, visit the [Google-Style Docstrings](#google-style-docstrings) section.
+
+### How can I ensure my changes pass the GitHub Actions CI tests?
+
+Before your pull request can be merged, it must pass all GitHub Actions Continuous Integration (CI) tests. These tests include linting, unit tests, and other checks to ensure the code meets
+
+the project's quality standards. Review the CI output and fix any issues. For detailed information on the CI process and troubleshooting tips, see the [GitHub Actions CI Tests](#github-actions-ci-tests) section.
+
+### How do I report a bug in Ultralytics YOLO repositories?
+
+To report a bug, provide a clear and concise [Minimum Reproducible Example](https://docs.ultralytics.com/help/minimum_reproducible_example) along with your bug report. This helps developers quickly identify and fix the issue. Ensure your example is minimal yet sufficient to replicate the problem. For more detailed steps on reporting bugs, refer to the [Reporting Bugs](#reporting-bugs) section.
diff --git a/ultralytics/LICENSE b/ultralytics/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..1468d07c88d6a48dae9360ed0094955b54370224
--- /dev/null
+++ b/ultralytics/LICENSE
@@ -0,0 +1,661 @@
+ GNU AFFERO GENERAL PUBLIC LICENSE
+ Version 3, 19 November 2007
+
+ Copyright (C) 2007 Free Software Foundation, Inc.  +
+  +
+  +
+  +
+
+
+ +
+All [Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models) download automatically from the latest Ultralytics [release](https://github.com/ultralytics/assets/releases) on first use.
+
+
+
+All [Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models) download automatically from the latest Ultralytics [release](https://github.com/ultralytics/assets/releases) on first use.
+
+ +
+ +
+##
+
+##  +
+- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
+
+The example showcases the variety and complexity of the images in the COCO8 dataset and the benefits of using mosaicing during the training process.
+
+## Citations and Acknowledgments
+
+If you use the COCO dataset in your research or development work, please cite the following paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @misc{lin2015microsoft,
+ title={Microsoft COCO: Common Objects in Context},
+ author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
+ year={2015},
+ eprint={1405.0312},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+ }
+ ```
+
+We would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
+
+## FAQ
+
+### What is the Ultralytics COCO8 dataset used for?
+
+The Ultralytics COCO8 dataset is a compact yet versatile object detection dataset consisting of the first 8 images from the COCO train 2017 set, with 4 images for training and 4 for validation. It is designed for testing and debugging object detection models and experimentation with new detection approaches. Despite its small size, COCO8 offers enough diversity to act as a sanity check for your training pipelines before deploying larger datasets. For more details, view the [COCO8 dataset](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco8.yaml).
+
+### How do I train a YOLOv8 model using the COCO8 dataset?
+
+To train a YOLOv8 model using the COCO8 dataset, you can employ either Python or CLI commands. Here's how you can start:
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo detect train data=coco8.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+### Why should I use Ultralytics HUB for managing my COCO8 training?
+
+Ultralytics HUB is an all-in-one web tool designed to simplify the training and deployment of YOLO models, including the Ultralytics YOLOv8 models on the COCO8 dataset. It offers cloud training, real-time tracking, and seamless dataset management. HUB allows you to start training with a single click and avoids the complexities of manual setups. Discover more about [Ultralytics HUB](https://hub.ultralytics.com) and its benefits.
+
+### What are the benefits of using mosaic augmentation in training with the COCO8 dataset?
+
+Mosaic augmentation, demonstrated in the COCO8 dataset, combines multiple images into a single image during training. This technique increases the variety of objects and scenes in each training batch, improving the model's ability to generalize across different object sizes, aspect ratios, and contexts. This results in a more robust object detection model. For more details, refer to the [training guide](#usage).
+
+### How can I validate my YOLOv8 model trained on the COCO8 dataset?
+
+Validation of your YOLOv8 model trained on the COCO8 dataset can be performed using the model's validation commands. You can invoke the validation mode via CLI or Python script to evaluate the model's performance using precise metrics. For detailed instructions, visit the [Validation](../../modes/val.md) page.
diff --git a/ultralytics/docs/en/datasets/detect/globalwheat2020.md b/ultralytics/docs/en/datasets/detect/globalwheat2020.md
new file mode 100644
index 0000000000000000000000000000000000000000..ca77f862e2896617311e73383f78f3affa27ff53
--- /dev/null
+++ b/ultralytics/docs/en/datasets/detect/globalwheat2020.md
@@ -0,0 +1,145 @@
+---
+comments: true
+description: Explore the Global Wheat Head Dataset to develop accurate wheat head detection models. Includes training images, annotations, and usage for crop management.
+keywords: Global Wheat Head Dataset, wheat head detection, wheat phenotyping, crop management, deep learning, object detection, training datasets
+---
+
+# Global Wheat Head Dataset
+
+The [Global Wheat Head Dataset](https://www.global-wheat.com/) is a collection of images designed to support the development of accurate wheat head detection models for applications in wheat phenotyping and crop management. Wheat heads, also known as spikes, are the grain-bearing parts of the wheat plant. Accurate estimation of wheat head density and size is essential for assessing crop health, maturity, and yield potential. The dataset, created by a collaboration of nine research institutes from seven countries, covers multiple growing regions to ensure models generalize well across different environments.
+
+## Key Features
+
+- The dataset contains over 3,000 training images from Europe (France, UK, Switzerland) and North America (Canada).
+- It includes approximately 1,000 test images from Australia, Japan, and China.
+- Images are outdoor field images, capturing the natural variability in wheat head appearances.
+- Annotations include wheat head bounding boxes to support object detection tasks.
+
+## Dataset Structure
+
+The Global Wheat Head Dataset is organized into two main subsets:
+
+1. **Training Set**: This subset contains over 3,000 images from Europe and North America. The images are labeled with wheat head bounding boxes, providing ground truth for training object detection models.
+2. **Test Set**: This subset consists of approximately 1,000 images from Australia, Japan, and China. These images are used for evaluating the performance of trained models on unseen genotypes, environments, and observational conditions.
+
+## Applications
+
+The Global Wheat Head Dataset is widely used for training and evaluating deep learning models in wheat head detection tasks. The dataset's diverse set of images, capturing a wide range of appearances, environments, and conditions, make it a valuable resource for researchers and practitioners in the field of plant phenotyping and crop management.
+
+## Dataset YAML
+
+A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. For the case of the Global Wheat Head Dataset, the `GlobalWheat2020.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/GlobalWheat2020.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/GlobalWheat2020.yaml).
+
+!!! Example "ultralytics/cfg/datasets/GlobalWheat2020.yaml"
+
+ ```yaml
+ --8<-- "ultralytics/cfg/datasets/GlobalWheat2020.yaml"
+ ```
+
+## Usage
+
+To train a YOLOv8n model on the Global Wheat Head Dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="GlobalWheat2020.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo detect train data=GlobalWheat2020.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+## Sample Data and Annotations
+
+The Global Wheat Head Dataset contains a diverse set of outdoor field images, capturing the natural variability in wheat head appearances, environments, and conditions. Here are some examples of data from the dataset, along with their corresponding annotations:
+
+
+
+- **Wheat Head Detection**: This image demonstrates an example of wheat head detection, where wheat heads are annotated with bounding boxes. The dataset provides a variety of images to facilitate the development of models for this task.
+
+The example showcases the variety and complexity of the data in the Global Wheat Head Dataset and highlights the importance of accurate wheat head detection for applications in wheat phenotyping and crop management.
+
+## Citations and Acknowledgments
+
+If you use the Global Wheat Head Dataset in your research or development work, please cite the following paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @article{david2020global,
+ title={Global Wheat Head Detection (GWHD) Dataset: A Large and Diverse Dataset of High-Resolution RGB-Labelled Images to Develop and Benchmark Wheat Head Detection Methods},
+ author={David, Etienne and Madec, Simon and Sadeghi-Tehran, Pouria and Aasen, Helge and Zheng, Bangyou and Liu, Shouyang and Kirchgessner, Norbert and Ishikawa, Goro and Nagasawa, Koichi and Badhon, Minhajul and others},
+ journal={arXiv preprint arXiv:2005.02162},
+ year={2020}
+ }
+ ```
+
+We would like to acknowledge the researchers and institutions that contributed to the creation and maintenance of the Global Wheat Head Dataset as a valuable resource for the plant phenotyping and crop management research community. For more information about the dataset and its creators, visit the [Global Wheat Head Dataset website](https://www.global-wheat.com/).
+
+## FAQ
+
+### What is the Global Wheat Head Dataset used for?
+
+The Global Wheat Head Dataset is primarily used for developing and training deep learning models aimed at wheat head detection. This is crucial for applications in wheat phenotyping and crop management, allowing for more accurate estimations of wheat head density, size, and overall crop yield potential. Accurate detection methods help in assessing crop health and maturity, essential for efficient crop management.
+
+### How do I train a YOLOv8n model on the Global Wheat Head Dataset?
+
+To train a YOLOv8n model on the Global Wheat Head Dataset, you can use the following code snippets. Make sure you have the `GlobalWheat2020.yaml` configuration file specifying dataset paths and classes:
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a pre-trained model (recommended for training)
+ model = YOLO("yolov8n.pt")
+
+ # Train the model
+ results = model.train(data="GlobalWheat2020.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo detect train data=GlobalWheat2020.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+### What are the key features of the Global Wheat Head Dataset?
+
+Key features of the Global Wheat Head Dataset include:
+
+- Over 3,000 training images from Europe (France, UK, Switzerland) and North America (Canada).
+- Approximately 1,000 test images from Australia, Japan, and China.
+- High variability in wheat head appearances due to different growing environments.
+- Detailed annotations with wheat head bounding boxes to aid object detection models.
+
+These features facilitate the development of robust models capable of generalization across multiple regions.
+
+### Where can I find the configuration YAML file for the Global Wheat Head Dataset?
+
+The configuration YAML file for the Global Wheat Head Dataset, named `GlobalWheat2020.yaml`, is available on GitHub. You can access it at this [link](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/GlobalWheat2020.yaml). This file contains necessary information about dataset paths, classes, and other configuration details needed for model training in Ultralytics YOLO.
+
+### Why is wheat head detection important in crop management?
+
+Wheat head detection is critical in crop management because it enables accurate estimation of wheat head density and size, which are essential for evaluating crop health, maturity, and yield potential. By leveraging deep learning models trained on datasets like the Global Wheat Head Dataset, farmers and researchers can better monitor and manage crops, leading to improved productivity and optimized resource use in agricultural practices. This technological advancement supports sustainable agriculture and food security initiatives.
+
+For more information on applications of AI in agriculture, visit [AI in Agriculture](https://www.ultralytics.com/solutions/ai-in-agriculture).
diff --git a/ultralytics/docs/en/datasets/detect/index.md b/ultralytics/docs/en/datasets/detect/index.md
new file mode 100644
index 0000000000000000000000000000000000000000..dd6658bd159196a7ae0ef8f4440ffc92b9ccd27b
--- /dev/null
+++ b/ultralytics/docs/en/datasets/detect/index.md
@@ -0,0 +1,187 @@
+---
+comments: true
+description: Learn about dataset formats compatible with Ultralytics YOLO for robust object detection. Explore supported datasets and learn how to convert formats.
+keywords: Ultralytics, YOLO, object detection datasets, dataset formats, COCO, dataset conversion, training datasets
+---
+
+# Object Detection Datasets Overview
+
+Training a robust and accurate object detection model requires a comprehensive dataset. This guide introduces various formats of datasets that are compatible with the Ultralytics YOLO model and provides insights into their structure, usage, and how to convert between different formats.
+
+## Supported Dataset Formats
+
+### Ultralytics YOLO format
+
+The Ultralytics YOLO format is a dataset configuration format that allows you to define the dataset root directory, the relative paths to training/validation/testing image directories or `*.txt` files containing image paths, and a dictionary of class names. Here is an example:
+
+```yaml
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/coco8 # dataset root dir
+train: images/train # train images (relative to 'path') 4 images
+val: images/val # val images (relative to 'path') 4 images
+test: # test images (optional)
+
+# Classes (80 COCO classes)
+names:
+ 0: person
+ 1: bicycle
+ 2: car
+ # ...
+ 77: teddy bear
+ 78: hair drier
+ 79: toothbrush
+```
+
+Labels for this format should be exported to YOLO format with one `*.txt` file per image. If there are no objects in an image, no `*.txt` file is required. The `*.txt` file should be formatted with one row per object in `class x_center y_center width height` format. Box coordinates must be in **normalized xywh** format (from 0 to 1). If your boxes are in pixels, you should divide `x_center` and `width` by image width, and `y_center` and `height` by image height. Class numbers should be zero-indexed (start with 0).
+
+
+
+- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
+
+The example showcases the variety and complexity of the images in the COCO8 dataset and the benefits of using mosaicing during the training process.
+
+## Citations and Acknowledgments
+
+If you use the COCO dataset in your research or development work, please cite the following paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @misc{lin2015microsoft,
+ title={Microsoft COCO: Common Objects in Context},
+ author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
+ year={2015},
+ eprint={1405.0312},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+ }
+ ```
+
+We would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
+
+## FAQ
+
+### What is the Ultralytics COCO8 dataset used for?
+
+The Ultralytics COCO8 dataset is a compact yet versatile object detection dataset consisting of the first 8 images from the COCO train 2017 set, with 4 images for training and 4 for validation. It is designed for testing and debugging object detection models and experimentation with new detection approaches. Despite its small size, COCO8 offers enough diversity to act as a sanity check for your training pipelines before deploying larger datasets. For more details, view the [COCO8 dataset](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco8.yaml).
+
+### How do I train a YOLOv8 model using the COCO8 dataset?
+
+To train a YOLOv8 model using the COCO8 dataset, you can employ either Python or CLI commands. Here's how you can start:
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo detect train data=coco8.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+### Why should I use Ultralytics HUB for managing my COCO8 training?
+
+Ultralytics HUB is an all-in-one web tool designed to simplify the training and deployment of YOLO models, including the Ultralytics YOLOv8 models on the COCO8 dataset. It offers cloud training, real-time tracking, and seamless dataset management. HUB allows you to start training with a single click and avoids the complexities of manual setups. Discover more about [Ultralytics HUB](https://hub.ultralytics.com) and its benefits.
+
+### What are the benefits of using mosaic augmentation in training with the COCO8 dataset?
+
+Mosaic augmentation, demonstrated in the COCO8 dataset, combines multiple images into a single image during training. This technique increases the variety of objects and scenes in each training batch, improving the model's ability to generalize across different object sizes, aspect ratios, and contexts. This results in a more robust object detection model. For more details, refer to the [training guide](#usage).
+
+### How can I validate my YOLOv8 model trained on the COCO8 dataset?
+
+Validation of your YOLOv8 model trained on the COCO8 dataset can be performed using the model's validation commands. You can invoke the validation mode via CLI or Python script to evaluate the model's performance using precise metrics. For detailed instructions, visit the [Validation](../../modes/val.md) page.
diff --git a/ultralytics/docs/en/datasets/detect/globalwheat2020.md b/ultralytics/docs/en/datasets/detect/globalwheat2020.md
new file mode 100644
index 0000000000000000000000000000000000000000..ca77f862e2896617311e73383f78f3affa27ff53
--- /dev/null
+++ b/ultralytics/docs/en/datasets/detect/globalwheat2020.md
@@ -0,0 +1,145 @@
+---
+comments: true
+description: Explore the Global Wheat Head Dataset to develop accurate wheat head detection models. Includes training images, annotations, and usage for crop management.
+keywords: Global Wheat Head Dataset, wheat head detection, wheat phenotyping, crop management, deep learning, object detection, training datasets
+---
+
+# Global Wheat Head Dataset
+
+The [Global Wheat Head Dataset](https://www.global-wheat.com/) is a collection of images designed to support the development of accurate wheat head detection models for applications in wheat phenotyping and crop management. Wheat heads, also known as spikes, are the grain-bearing parts of the wheat plant. Accurate estimation of wheat head density and size is essential for assessing crop health, maturity, and yield potential. The dataset, created by a collaboration of nine research institutes from seven countries, covers multiple growing regions to ensure models generalize well across different environments.
+
+## Key Features
+
+- The dataset contains over 3,000 training images from Europe (France, UK, Switzerland) and North America (Canada).
+- It includes approximately 1,000 test images from Australia, Japan, and China.
+- Images are outdoor field images, capturing the natural variability in wheat head appearances.
+- Annotations include wheat head bounding boxes to support object detection tasks.
+
+## Dataset Structure
+
+The Global Wheat Head Dataset is organized into two main subsets:
+
+1. **Training Set**: This subset contains over 3,000 images from Europe and North America. The images are labeled with wheat head bounding boxes, providing ground truth for training object detection models.
+2. **Test Set**: This subset consists of approximately 1,000 images from Australia, Japan, and China. These images are used for evaluating the performance of trained models on unseen genotypes, environments, and observational conditions.
+
+## Applications
+
+The Global Wheat Head Dataset is widely used for training and evaluating deep learning models in wheat head detection tasks. The dataset's diverse set of images, capturing a wide range of appearances, environments, and conditions, make it a valuable resource for researchers and practitioners in the field of plant phenotyping and crop management.
+
+## Dataset YAML
+
+A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. For the case of the Global Wheat Head Dataset, the `GlobalWheat2020.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/GlobalWheat2020.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/GlobalWheat2020.yaml).
+
+!!! Example "ultralytics/cfg/datasets/GlobalWheat2020.yaml"
+
+ ```yaml
+ --8<-- "ultralytics/cfg/datasets/GlobalWheat2020.yaml"
+ ```
+
+## Usage
+
+To train a YOLOv8n model on the Global Wheat Head Dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="GlobalWheat2020.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo detect train data=GlobalWheat2020.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+## Sample Data and Annotations
+
+The Global Wheat Head Dataset contains a diverse set of outdoor field images, capturing the natural variability in wheat head appearances, environments, and conditions. Here are some examples of data from the dataset, along with their corresponding annotations:
+
+
+
+- **Wheat Head Detection**: This image demonstrates an example of wheat head detection, where wheat heads are annotated with bounding boxes. The dataset provides a variety of images to facilitate the development of models for this task.
+
+The example showcases the variety and complexity of the data in the Global Wheat Head Dataset and highlights the importance of accurate wheat head detection for applications in wheat phenotyping and crop management.
+
+## Citations and Acknowledgments
+
+If you use the Global Wheat Head Dataset in your research or development work, please cite the following paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @article{david2020global,
+ title={Global Wheat Head Detection (GWHD) Dataset: A Large and Diverse Dataset of High-Resolution RGB-Labelled Images to Develop and Benchmark Wheat Head Detection Methods},
+ author={David, Etienne and Madec, Simon and Sadeghi-Tehran, Pouria and Aasen, Helge and Zheng, Bangyou and Liu, Shouyang and Kirchgessner, Norbert and Ishikawa, Goro and Nagasawa, Koichi and Badhon, Minhajul and others},
+ journal={arXiv preprint arXiv:2005.02162},
+ year={2020}
+ }
+ ```
+
+We would like to acknowledge the researchers and institutions that contributed to the creation and maintenance of the Global Wheat Head Dataset as a valuable resource for the plant phenotyping and crop management research community. For more information about the dataset and its creators, visit the [Global Wheat Head Dataset website](https://www.global-wheat.com/).
+
+## FAQ
+
+### What is the Global Wheat Head Dataset used for?
+
+The Global Wheat Head Dataset is primarily used for developing and training deep learning models aimed at wheat head detection. This is crucial for applications in wheat phenotyping and crop management, allowing for more accurate estimations of wheat head density, size, and overall crop yield potential. Accurate detection methods help in assessing crop health and maturity, essential for efficient crop management.
+
+### How do I train a YOLOv8n model on the Global Wheat Head Dataset?
+
+To train a YOLOv8n model on the Global Wheat Head Dataset, you can use the following code snippets. Make sure you have the `GlobalWheat2020.yaml` configuration file specifying dataset paths and classes:
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a pre-trained model (recommended for training)
+ model = YOLO("yolov8n.pt")
+
+ # Train the model
+ results = model.train(data="GlobalWheat2020.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo detect train data=GlobalWheat2020.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+### What are the key features of the Global Wheat Head Dataset?
+
+Key features of the Global Wheat Head Dataset include:
+
+- Over 3,000 training images from Europe (France, UK, Switzerland) and North America (Canada).
+- Approximately 1,000 test images from Australia, Japan, and China.
+- High variability in wheat head appearances due to different growing environments.
+- Detailed annotations with wheat head bounding boxes to aid object detection models.
+
+These features facilitate the development of robust models capable of generalization across multiple regions.
+
+### Where can I find the configuration YAML file for the Global Wheat Head Dataset?
+
+The configuration YAML file for the Global Wheat Head Dataset, named `GlobalWheat2020.yaml`, is available on GitHub. You can access it at this [link](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/GlobalWheat2020.yaml). This file contains necessary information about dataset paths, classes, and other configuration details needed for model training in Ultralytics YOLO.
+
+### Why is wheat head detection important in crop management?
+
+Wheat head detection is critical in crop management because it enables accurate estimation of wheat head density and size, which are essential for evaluating crop health, maturity, and yield potential. By leveraging deep learning models trained on datasets like the Global Wheat Head Dataset, farmers and researchers can better monitor and manage crops, leading to improved productivity and optimized resource use in agricultural practices. This technological advancement supports sustainable agriculture and food security initiatives.
+
+For more information on applications of AI in agriculture, visit [AI in Agriculture](https://www.ultralytics.com/solutions/ai-in-agriculture).
diff --git a/ultralytics/docs/en/datasets/detect/index.md b/ultralytics/docs/en/datasets/detect/index.md
new file mode 100644
index 0000000000000000000000000000000000000000..dd6658bd159196a7ae0ef8f4440ffc92b9ccd27b
--- /dev/null
+++ b/ultralytics/docs/en/datasets/detect/index.md
@@ -0,0 +1,187 @@
+---
+comments: true
+description: Learn about dataset formats compatible with Ultralytics YOLO for robust object detection. Explore supported datasets and learn how to convert formats.
+keywords: Ultralytics, YOLO, object detection datasets, dataset formats, COCO, dataset conversion, training datasets
+---
+
+# Object Detection Datasets Overview
+
+Training a robust and accurate object detection model requires a comprehensive dataset. This guide introduces various formats of datasets that are compatible with the Ultralytics YOLO model and provides insights into their structure, usage, and how to convert between different formats.
+
+## Supported Dataset Formats
+
+### Ultralytics YOLO format
+
+The Ultralytics YOLO format is a dataset configuration format that allows you to define the dataset root directory, the relative paths to training/validation/testing image directories or `*.txt` files containing image paths, and a dictionary of class names. Here is an example:
+
+```yaml
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/coco8 # dataset root dir
+train: images/train # train images (relative to 'path') 4 images
+val: images/val # val images (relative to 'path') 4 images
+test: # test images (optional)
+
+# Classes (80 COCO classes)
+names:
+ 0: person
+ 1: bicycle
+ 2: car
+ # ...
+ 77: teddy bear
+ 78: hair drier
+ 79: toothbrush
+```
+
+Labels for this format should be exported to YOLO format with one `*.txt` file per image. If there are no objects in an image, no `*.txt` file is required. The `*.txt` file should be formatted with one row per object in `class x_center y_center width height` format. Box coordinates must be in **normalized xywh** format (from 0 to 1). If your boxes are in pixels, you should divide `x_center` and `width` by image width, and `y_center` and `height` by image height. Class numbers should be zero-indexed (start with 0).
+
+

 +
+ +
+ \n",
+ "\n",
+ " [中文](https://docs.ultralytics.com/zh/) | [한국어](https://docs.ultralytics.com/ko/) | [日本語](https://docs.ultralytics.com/ja/) | [Русский](https://docs.ultralytics.com/ru/) | [Deutsch](https://docs.ultralytics.com/de/) | [Français](https://docs.ultralytics.com/fr/) | [Español](https://docs.ultralytics.com/es/) | [Português](https://docs.ultralytics.com/pt/) | [Türkçe](https://docs.ultralytics.com/tr/) | [Tiếng Việt](https://docs.ultralytics.com/vi/) | [العربية](https://docs.ultralytics.com/ar/)\n",
+ "\n",
+ "
\n",
+ "\n",
+ " [中文](https://docs.ultralytics.com/zh/) | [한국어](https://docs.ultralytics.com/ko/) | [日本語](https://docs.ultralytics.com/ja/) | [Русский](https://docs.ultralytics.com/ru/) | [Deutsch](https://docs.ultralytics.com/de/) | [Français](https://docs.ultralytics.com/fr/) | [Español](https://docs.ultralytics.com/es/) | [Português](https://docs.ultralytics.com/pt/) | [Türkçe](https://docs.ultralytics.com/tr/) | [Tiếng Việt](https://docs.ultralytics.com/vi/) | [العربية](https://docs.ultralytics.com/ar/)\n",
+ "\n",
+ "  \n",
+ "\n",
+ "Welcome to the Ultralytics Explorer API notebook! This notebook serves as the starting point for exploring the various resources available to help you get started with using Ultralytics to explore your datasets using with the power of semantic search. You can utilities out of the box that allow you to examine specific types of labels using vector search or even SQL queries.\n",
+ "\n",
+ "We hope that the resources in this notebook will help you get the most out of Ultralytics. Please browse the Explorer Docs for details, raise an issue on GitHub for support, and join our Discord community for questions and discussions!\n",
+ "\n",
+ "Try `yolo explorer` powered by Exlorer API\n",
+ "\n",
+ "Simply `pip install ultralytics` and run `yolo explorer` in your terminal to run custom queries and semantic search on your datasets right inside your browser!\n",
+ "\n",
+ "
\n",
+ "\n",
+ "Welcome to the Ultralytics Explorer API notebook! This notebook serves as the starting point for exploring the various resources available to help you get started with using Ultralytics to explore your datasets using with the power of semantic search. You can utilities out of the box that allow you to examine specific types of labels using vector search or even SQL queries.\n",
+ "\n",
+ "We hope that the resources in this notebook will help you get the most out of Ultralytics. Please browse the Explorer Docs for details, raise an issue on GitHub for support, and join our Discord community for questions and discussions!\n",
+ "\n",
+ "Try `yolo explorer` powered by Exlorer API\n",
+ "\n",
+ "Simply `pip install ultralytics` and run `yolo explorer` in your terminal to run custom queries and semantic search on your datasets right inside your browser!\n",
+ "\n",
+ "
 +
+- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
+
+The example showcases the variety and complexity of the images in the COCO8-Pose dataset and the benefits of using mosaicing during the training process.
+
+## Citations and Acknowledgments
+
+If you use the COCO dataset in your research or development work, please cite the following paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @misc{lin2015microsoft,
+ title={Microsoft COCO: Common Objects in Context},
+ author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
+ year={2015},
+ eprint={1405.0312},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+ }
+ ```
+
+We would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
+
+## FAQ
+
+### What is the COCO8-Pose dataset, and how is it used with Ultralytics YOLOv8?
+
+The COCO8-Pose dataset is a small, versatile pose detection dataset that includes the first 8 images from the COCO train 2017 set, with 4 images for training and 4 for validation. It's designed for testing and debugging object detection models and experimenting with new detection approaches. This dataset is ideal for quick experiments with [Ultralytics YOLOv8](https://docs.ultralytics.com/models/yolov8/). For more details on dataset configuration, check out the dataset YAML file [here](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco8-pose.yaml).
+
+### How do I train a YOLOv8 model using the COCO8-Pose dataset in Ultralytics?
+
+To train a YOLOv8n-pose model on the COCO8-Pose dataset for 100 epochs with an image size of 640, follow these examples:
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-pose.pt")
+
+ # Train the model
+ results = model.train(data="coco8-pose.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo pose train data=coco8-pose.yaml model=yolov8n-pose.pt epochs=100 imgsz=640
+ ```
+
+For a comprehensive list of training arguments, refer to the model [Training](../../modes/train.md) page.
+
+### What are the benefits of using the COCO8-Pose dataset?
+
+The COCO8-Pose dataset offers several benefits:
+
+- **Compact Size**: With only 8 images, it is easy to manage and perfect for quick experiments.
+- **Diverse Data**: Despite its small size, it includes a variety of scenes, useful for thorough pipeline testing.
+- **Error Debugging**: Ideal for identifying training errors and performing sanity checks before scaling up to larger datasets.
+
+For more about its features and usage, see the [Dataset Introduction](#introduction) section.
+
+### How does mosaicing benefit the YOLOv8 training process using the COCO8-Pose dataset?
+
+Mosaicing, demonstrated in the sample images of the COCO8-Pose dataset, combines multiple images into one, increasing the variety of objects and scenes within each training batch. This technique helps improve the model's ability to generalize across various object sizes, aspect ratios, and contexts, ultimately enhancing model performance. See the [Sample Images and Annotations](#sample-images-and-annotations) section for example images.
+
+### Where can I find the COCO8-Pose dataset YAML file and how do I use it?
+
+The COCO8-Pose dataset YAML file can be found [here](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco8-pose.yaml). This file defines the dataset configuration, including paths, classes, and other relevant information. Use this file with the YOLOv8 training scripts as mentioned in the [Train Example](#how-do-i-train-a-yolov8-model-using-the-coco8-pose-dataset-in-ultralytics) section.
+
+For more FAQs and detailed documentation, visit the [Ultralytics Documentation](https://docs.ultralytics.com/).
diff --git a/ultralytics/docs/en/datasets/pose/index.md b/ultralytics/docs/en/datasets/pose/index.md
new file mode 100644
index 0000000000000000000000000000000000000000..7386a8e207d604c9b7348985b84ac1a89acb8bc9
--- /dev/null
+++ b/ultralytics/docs/en/datasets/pose/index.md
@@ -0,0 +1,210 @@
+---
+comments: true
+description: Learn about Ultralytics YOLO format for pose estimation datasets, supported formats, COCO-Pose, COCO8-Pose, Tiger-Pose, and how to add your own dataset.
+keywords: pose estimation, Ultralytics, YOLO format, COCO-Pose, COCO8-Pose, Tiger-Pose, dataset conversion, keypoints
+---
+
+# Pose Estimation Datasets Overview
+
+## Supported Dataset Formats
+
+### Ultralytics YOLO format
+
+The dataset label format used for training YOLO pose models is as follows:
+
+1. One text file per image: Each image in the dataset has a corresponding text file with the same name as the image file and the ".txt" extension.
+2. One row per object: Each row in the text file corresponds to one object instance in the image.
+3. Object information per row: Each row contains the following information about the object instance:
+ - Object class index: An integer representing the class of the object (e.g., 0 for person, 1 for car, etc.).
+ - Object center coordinates: The x and y coordinates of the center of the object, normalized to be between 0 and 1.
+ - Object width and height: The width and height of the object, normalized to be between 0 and 1.
+ - Object keypoint coordinates: The keypoints of the object, normalized to be between 0 and 1.
+
+Here is an example of the label format for pose estimation task:
+
+Format with Dim = 2
+
+```
+
+
+- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
+
+The example showcases the variety and complexity of the images in the COCO8-Pose dataset and the benefits of using mosaicing during the training process.
+
+## Citations and Acknowledgments
+
+If you use the COCO dataset in your research or development work, please cite the following paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @misc{lin2015microsoft,
+ title={Microsoft COCO: Common Objects in Context},
+ author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
+ year={2015},
+ eprint={1405.0312},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+ }
+ ```
+
+We would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
+
+## FAQ
+
+### What is the COCO8-Pose dataset, and how is it used with Ultralytics YOLOv8?
+
+The COCO8-Pose dataset is a small, versatile pose detection dataset that includes the first 8 images from the COCO train 2017 set, with 4 images for training and 4 for validation. It's designed for testing and debugging object detection models and experimenting with new detection approaches. This dataset is ideal for quick experiments with [Ultralytics YOLOv8](https://docs.ultralytics.com/models/yolov8/). For more details on dataset configuration, check out the dataset YAML file [here](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco8-pose.yaml).
+
+### How do I train a YOLOv8 model using the COCO8-Pose dataset in Ultralytics?
+
+To train a YOLOv8n-pose model on the COCO8-Pose dataset for 100 epochs with an image size of 640, follow these examples:
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-pose.pt")
+
+ # Train the model
+ results = model.train(data="coco8-pose.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ yolo pose train data=coco8-pose.yaml model=yolov8n-pose.pt epochs=100 imgsz=640
+ ```
+
+For a comprehensive list of training arguments, refer to the model [Training](../../modes/train.md) page.
+
+### What are the benefits of using the COCO8-Pose dataset?
+
+The COCO8-Pose dataset offers several benefits:
+
+- **Compact Size**: With only 8 images, it is easy to manage and perfect for quick experiments.
+- **Diverse Data**: Despite its small size, it includes a variety of scenes, useful for thorough pipeline testing.
+- **Error Debugging**: Ideal for identifying training errors and performing sanity checks before scaling up to larger datasets.
+
+For more about its features and usage, see the [Dataset Introduction](#introduction) section.
+
+### How does mosaicing benefit the YOLOv8 training process using the COCO8-Pose dataset?
+
+Mosaicing, demonstrated in the sample images of the COCO8-Pose dataset, combines multiple images into one, increasing the variety of objects and scenes within each training batch. This technique helps improve the model's ability to generalize across various object sizes, aspect ratios, and contexts, ultimately enhancing model performance. See the [Sample Images and Annotations](#sample-images-and-annotations) section for example images.
+
+### Where can I find the COCO8-Pose dataset YAML file and how do I use it?
+
+The COCO8-Pose dataset YAML file can be found [here](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco8-pose.yaml). This file defines the dataset configuration, including paths, classes, and other relevant information. Use this file with the YOLOv8 training scripts as mentioned in the [Train Example](#how-do-i-train-a-yolov8-model-using-the-coco8-pose-dataset-in-ultralytics) section.
+
+For more FAQs and detailed documentation, visit the [Ultralytics Documentation](https://docs.ultralytics.com/).
diff --git a/ultralytics/docs/en/datasets/pose/index.md b/ultralytics/docs/en/datasets/pose/index.md
new file mode 100644
index 0000000000000000000000000000000000000000..7386a8e207d604c9b7348985b84ac1a89acb8bc9
--- /dev/null
+++ b/ultralytics/docs/en/datasets/pose/index.md
@@ -0,0 +1,210 @@
+---
+comments: true
+description: Learn about Ultralytics YOLO format for pose estimation datasets, supported formats, COCO-Pose, COCO8-Pose, Tiger-Pose, and how to add your own dataset.
+keywords: pose estimation, Ultralytics, YOLO format, COCO-Pose, COCO8-Pose, Tiger-Pose, dataset conversion, keypoints
+---
+
+# Pose Estimation Datasets Overview
+
+## Supported Dataset Formats
+
+### Ultralytics YOLO format
+
+The dataset label format used for training YOLO pose models is as follows:
+
+1. One text file per image: Each image in the dataset has a corresponding text file with the same name as the image file and the ".txt" extension.
+2. One row per object: Each row in the text file corresponds to one object instance in the image.
+3. Object information per row: Each row contains the following information about the object instance:
+ - Object class index: An integer representing the class of the object (e.g., 0 for person, 1 for car, etc.).
+ - Object center coordinates: The x and y coordinates of the center of the object, normalized to be between 0 and 1.
+ - Object width and height: The width and height of the object, normalized to be between 0 and 1.
+ - Object keypoint coordinates: The keypoints of the object, normalized to be between 0 and 1.
+
+Here is an example of the label format for pose estimation task:
+
+Format with Dim = 2
+
+```
+ +
+- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
+
+The example showcases the variety and complexity of the images in the Tiger-Pose dataset and the benefits of using mosaicing during the training process.
+
+## Inference Example
+
+!!! Example "Inference Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("path/to/best.pt") # load a tiger-pose trained model
+
+ # Run inference
+ results = model.predict(source="https://youtu.be/MIBAT6BGE6U", show=True)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Run inference using a tiger-pose trained model
+ yolo task=pose mode=predict source="https://youtu.be/MIBAT6BGE6U" show=True model="path/to/best.pt"
+ ```
+
+## Citations and Acknowledgments
+
+The dataset has been released available under the [AGPL-3.0 License](https://github.com/ultralytics/ultralytics/blob/main/LICENSE).
+
+## FAQ
+
+### What is the Ultralytics Tiger-Pose dataset used for?
+
+The Ultralytics Tiger-Pose dataset is designed for pose estimation tasks, consisting of 263 images sourced from a [YouTube video](https://www.youtube.com/watch?v=MIBAT6BGE6U&pp=ygUbVGlnZXIgd2Fsa2luZyByZWZlcmVuY2UubXA0). The dataset is divided into 210 training images and 53 validation images. It is particularly useful for testing, training, and refining pose estimation algorithms using [Ultralytics HUB](https://hub.ultralytics.com) and [YOLOv8](https://github.com/ultralytics/ultralytics).
+
+### How do I train a YOLOv8 model on the Tiger-Pose dataset?
+
+To train a YOLOv8n-pose model on the Tiger-Pose dataset for 100 epochs with an image size of 640, use the following code snippets. For more details, visit the [Training](../../modes/train.md) page:
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-pose.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="tiger-pose.yaml", epochs=100, imgsz=640)
+ ```
+
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo task=pose mode=train data=tiger-pose.yaml model=yolov8n-pose.pt epochs=100 imgsz=640
+ ```
+
+### What configurations does the `tiger-pose.yaml` file include?
+
+The `tiger-pose.yaml` file is used to specify the configuration details of the Tiger-Pose dataset. It includes crucial data such as file paths and class definitions. To see the exact configuration, you can check out the [Ultralytics Tiger-Pose Dataset Configuration File](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/tiger-pose.yaml).
+
+### How can I run inference using a YOLOv8 model trained on the Tiger-Pose dataset?
+
+To perform inference using a YOLOv8 model trained on the Tiger-Pose dataset, you can use the following code snippets. For a detailed guide, visit the [Prediction](../../modes/predict.md) page:
+
+!!! Example "Inference Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("path/to/best.pt") # load a tiger-pose trained model
+
+ # Run inference
+ results = model.predict(source="https://youtu.be/MIBAT6BGE6U", show=True)
+ ```
+
+
+ === "CLI"
+
+ ```bash
+ # Run inference using a tiger-pose trained model
+ yolo task=pose mode=predict source="https://youtu.be/MIBAT6BGE6U" show=True model="path/to/best.pt"
+ ```
+
+### What are the benefits of using the Tiger-Pose dataset for pose estimation?
+
+The Tiger-Pose dataset, despite its manageable size of 210 images for training, provides a diverse collection of images that are ideal for testing pose estimation pipelines. The dataset helps identify potential errors and acts as a preliminary step before working with larger datasets. Additionally, the dataset supports the training and refinement of pose estimation algorithms using advanced tools like [Ultralytics HUB](https://hub.ultralytics.com) and [YOLOv8](https://github.com/ultralytics/ultralytics), enhancing model performance and accuracy.
diff --git a/ultralytics/docs/en/datasets/segment/carparts-seg.md b/ultralytics/docs/en/datasets/segment/carparts-seg.md
new file mode 100644
index 0000000000000000000000000000000000000000..03064d95a8e415c54ccee62d2c4a57b80fc23e22
--- /dev/null
+++ b/ultralytics/docs/en/datasets/segment/carparts-seg.md
@@ -0,0 +1,160 @@
+---
+comments: true
+description: Explore the Roboflow Carparts Segmentation Dataset for automotive AI applications. Enhance your segmentation models with rich, annotated data.
+keywords: Carparts Segmentation Dataset, Roboflow, computer vision, automotive AI, vehicle maintenance, Ultralytics
+---
+
+# Roboflow Universe Carparts Segmentation Dataset
+
+The [Roboflow](https://roboflow.com/?ref=ultralytics) [Carparts Segmentation Dataset](https://universe.roboflow.com/gianmarco-russo-vt9xr/car-seg-un1pm) is a curated collection of images and videos designed for computer vision applications, specifically focusing on segmentation tasks related to car parts. This dataset provides a diverse set of visuals captured from multiple perspectives, offering valuable annotated examples for training and testing segmentation models.
+
+Whether you're working on automotive research, developing AI solutions for vehicle maintenance, or exploring computer vision applications, the Carparts Segmentation Dataset serves as a valuable resource for enhancing accuracy and efficiency in your projects.
+
+
+
+- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
+
+The example showcases the variety and complexity of the images in the Tiger-Pose dataset and the benefits of using mosaicing during the training process.
+
+## Inference Example
+
+!!! Example "Inference Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("path/to/best.pt") # load a tiger-pose trained model
+
+ # Run inference
+ results = model.predict(source="https://youtu.be/MIBAT6BGE6U", show=True)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Run inference using a tiger-pose trained model
+ yolo task=pose mode=predict source="https://youtu.be/MIBAT6BGE6U" show=True model="path/to/best.pt"
+ ```
+
+## Citations and Acknowledgments
+
+The dataset has been released available under the [AGPL-3.0 License](https://github.com/ultralytics/ultralytics/blob/main/LICENSE).
+
+## FAQ
+
+### What is the Ultralytics Tiger-Pose dataset used for?
+
+The Ultralytics Tiger-Pose dataset is designed for pose estimation tasks, consisting of 263 images sourced from a [YouTube video](https://www.youtube.com/watch?v=MIBAT6BGE6U&pp=ygUbVGlnZXIgd2Fsa2luZyByZWZlcmVuY2UubXA0). The dataset is divided into 210 training images and 53 validation images. It is particularly useful for testing, training, and refining pose estimation algorithms using [Ultralytics HUB](https://hub.ultralytics.com) and [YOLOv8](https://github.com/ultralytics/ultralytics).
+
+### How do I train a YOLOv8 model on the Tiger-Pose dataset?
+
+To train a YOLOv8n-pose model on the Tiger-Pose dataset for 100 epochs with an image size of 640, use the following code snippets. For more details, visit the [Training](../../modes/train.md) page:
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-pose.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="tiger-pose.yaml", epochs=100, imgsz=640)
+ ```
+
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo task=pose mode=train data=tiger-pose.yaml model=yolov8n-pose.pt epochs=100 imgsz=640
+ ```
+
+### What configurations does the `tiger-pose.yaml` file include?
+
+The `tiger-pose.yaml` file is used to specify the configuration details of the Tiger-Pose dataset. It includes crucial data such as file paths and class definitions. To see the exact configuration, you can check out the [Ultralytics Tiger-Pose Dataset Configuration File](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/tiger-pose.yaml).
+
+### How can I run inference using a YOLOv8 model trained on the Tiger-Pose dataset?
+
+To perform inference using a YOLOv8 model trained on the Tiger-Pose dataset, you can use the following code snippets. For a detailed guide, visit the [Prediction](../../modes/predict.md) page:
+
+!!! Example "Inference Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("path/to/best.pt") # load a tiger-pose trained model
+
+ # Run inference
+ results = model.predict(source="https://youtu.be/MIBAT6BGE6U", show=True)
+ ```
+
+
+ === "CLI"
+
+ ```bash
+ # Run inference using a tiger-pose trained model
+ yolo task=pose mode=predict source="https://youtu.be/MIBAT6BGE6U" show=True model="path/to/best.pt"
+ ```
+
+### What are the benefits of using the Tiger-Pose dataset for pose estimation?
+
+The Tiger-Pose dataset, despite its manageable size of 210 images for training, provides a diverse collection of images that are ideal for testing pose estimation pipelines. The dataset helps identify potential errors and acts as a preliminary step before working with larger datasets. Additionally, the dataset supports the training and refinement of pose estimation algorithms using advanced tools like [Ultralytics HUB](https://hub.ultralytics.com) and [YOLOv8](https://github.com/ultralytics/ultralytics), enhancing model performance and accuracy.
diff --git a/ultralytics/docs/en/datasets/segment/carparts-seg.md b/ultralytics/docs/en/datasets/segment/carparts-seg.md
new file mode 100644
index 0000000000000000000000000000000000000000..03064d95a8e415c54ccee62d2c4a57b80fc23e22
--- /dev/null
+++ b/ultralytics/docs/en/datasets/segment/carparts-seg.md
@@ -0,0 +1,160 @@
+---
+comments: true
+description: Explore the Roboflow Carparts Segmentation Dataset for automotive AI applications. Enhance your segmentation models with rich, annotated data.
+keywords: Carparts Segmentation Dataset, Roboflow, computer vision, automotive AI, vehicle maintenance, Ultralytics
+---
+
+# Roboflow Universe Carparts Segmentation Dataset
+
+The [Roboflow](https://roboflow.com/?ref=ultralytics) [Carparts Segmentation Dataset](https://universe.roboflow.com/gianmarco-russo-vt9xr/car-seg-un1pm) is a curated collection of images and videos designed for computer vision applications, specifically focusing on segmentation tasks related to car parts. This dataset provides a diverse set of visuals captured from multiple perspectives, offering valuable annotated examples for training and testing segmentation models.
+
+Whether you're working on automotive research, developing AI solutions for vehicle maintenance, or exploring computer vision applications, the Carparts Segmentation Dataset serves as a valuable resource for enhancing accuracy and efficiency in your projects.
+
+ +
+- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
+
+The example showcases the variety and complexity of the images in the COCO8-Seg dataset and the benefits of using mosaicing during the training process.
+
+## Citations and Acknowledgments
+
+If you use the COCO dataset in your research or development work, please cite the following paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @misc{lin2015microsoft,
+ title={Microsoft COCO: Common Objects in Context},
+ author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
+ year={2015},
+ eprint={1405.0312},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+ }
+ ```
+
+We would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
+
+## FAQ
+
+### What is the COCO8-Seg dataset, and how is it used in Ultralytics YOLOv8?
+
+The **COCO8-Seg dataset** is a compact instance segmentation dataset by Ultralytics, consisting of the first 8 images from the COCO train 2017 set—4 images for training and 4 for validation. This dataset is tailored for testing and debugging segmentation models or experimenting with new detection methods. It is particularly useful with Ultralytics [YOLOv8](https://github.com/ultralytics/ultralytics) and [HUB](https://hub.ultralytics.com) for rapid iteration and pipeline error-checking before scaling to larger datasets. For detailed usage, refer to the model [Training](../../modes/train.md) page.
+
+### How can I train a YOLOv8n-seg model using the COCO8-Seg dataset?
+
+To train a **YOLOv8n-seg** model on the COCO8-Seg dataset for 100 epochs with an image size of 640, you can use Python or CLI commands. Here's a quick example:
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-seg.pt") # Load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="coco8-seg.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo segment train data=coco8-seg.yaml model=yolov8n-seg.pt epochs=100 imgsz=640
+ ```
+
+For a thorough explanation of available arguments and configuration options, you can check the [Training](../../modes/train.md) documentation.
+
+### Why is the COCO8-Seg dataset important for model development and debugging?
+
+The **COCO8-Seg dataset** is ideal for its manageability and diversity within a small size. It consists of only 8 images, providing a quick way to test and debug segmentation models or new detection approaches without the overhead of larger datasets. This makes it an efficient tool for sanity checks and pipeline error identification before committing to extensive training on large datasets. Learn more about dataset formats [here](https://docs.ultralytics.com/datasets/segment).
+
+### Where can I find the YAML configuration file for the COCO8-Seg dataset?
+
+The YAML configuration file for the **COCO8-Seg dataset** is available in the Ultralytics repository. You can access the file directly [here](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco8-seg.yaml). The YAML file includes essential information about dataset paths, classes, and configuration settings required for model training and validation.
+
+### What are some benefits of using mosaicing during training with the COCO8-Seg dataset?
+
+Using **mosaicing** during training helps increase the diversity and variety of objects and scenes in each training batch. This technique combines multiple images into a single composite image, enhancing the model's ability to generalize to different object sizes, aspect ratios, and contexts within the scene. Mosaicing is beneficial for improving a model's robustness and accuracy, especially when working with small datasets like COCO8-Seg. For an example of mosaiced images, see the [Sample Images and Annotations](#sample-images-and-annotations) section.
diff --git a/ultralytics/docs/en/datasets/segment/crack-seg.md b/ultralytics/docs/en/datasets/segment/crack-seg.md
new file mode 100644
index 0000000000000000000000000000000000000000..b274d077453f29eb5b30c13a3e0e8e6ce87fe5a0
--- /dev/null
+++ b/ultralytics/docs/en/datasets/segment/crack-seg.md
@@ -0,0 +1,157 @@
+---
+comments: true
+description: Explore the extensive Roboflow Crack Segmentation Dataset, perfect for transportation and public safety studies or self-driving car model development.
+keywords: Roboflow, Crack Segmentation Dataset, Ultralytics, transportation safety, public safety, self-driving cars, computer vision, road safety, infrastructure maintenance, dataset
+---
+
+# Roboflow Universe Crack Segmentation Dataset
+
+The [Roboflow](https://roboflow.com/?ref=ultralytics) [Crack Segmentation Dataset](https://universe.roboflow.com/university-bswxt/crack-bphdr) stands out as an extensive resource designed specifically for individuals involved in transportation and public safety studies. It is equally beneficial for those working on the development of self-driving car models or simply exploring computer vision applications for recreational purposes.
+
+Comprising a total of 4029 static images captured from diverse road and wall scenarios, this dataset emerges as a valuable asset for tasks related to crack segmentation. Whether you are delving into the intricacies of transportation research or seeking to enhance the accuracy of your self-driving car models, this dataset provides a rich and varied collection of images to support your endeavors.
+
+## Dataset Structure
+
+The division of data within the Crack Segmentation Dataset is outlined as follows:
+
+- **Training set**: Consists of 3717 images with corresponding annotations.
+- **Testing set**: Comprises 112 images along with their respective annotations.
+- **Validation set**: Includes 200 images with their corresponding annotations.
+
+## Applications
+
+Crack segmentation finds practical applications in infrastructure maintenance, aiding in the identification and assessment of structural damage. It also plays a crucial role in enhancing road safety by enabling automated systems to detect and address pavement cracks for timely repairs.
+
+## Dataset YAML
+
+A YAML (Yet Another Markup Language) file is employed to outline the configuration of the dataset, encompassing details about paths, classes, and other pertinent information. Specifically, for the Crack Segmentation dataset, the `crack-seg.yaml` file is managed and accessible at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/crack-seg.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/crack-seg.yaml).
+
+!!! Example "ultralytics/cfg/datasets/crack-seg.yaml"
+
+ ```yaml
+ --8<-- "ultralytics/cfg/datasets/crack-seg.yaml"
+ ```
+
+## Usage
+
+To train Ultralytics YOLOv8n model on the Crack Segmentation dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-seg.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="crack-seg.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo segment train data=crack-seg.yaml model=yolov8n-seg.pt epochs=100 imgsz=640
+ ```
+
+## Sample Data and Annotations
+
+The Crack Segmentation dataset comprises a varied collection of images and videos captured from multiple perspectives. Below are instances of data from the dataset, accompanied by their respective annotations:
+
+
+
+- This image presents an example of image object segmentation, featuring annotated bounding boxes with masks outlining identified objects. The dataset includes a diverse array of images taken in different locations, environments, and densities, making it a comprehensive resource for developing models designed for this particular task.
+
+- The example underscores the diversity and complexity found in the Crack segmentation dataset, emphasizing the crucial role of high-quality data in computer vision tasks.
+
+## Citations and Acknowledgments
+
+If you incorporate the crack segmentation dataset into your research or development endeavors, kindly reference the following paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @misc{ crack-bphdr_dataset,
+ title = { crack Dataset },
+ type = { Open Source Dataset },
+ author = { University },
+ howpublished = { \url{ https://universe.roboflow.com/university-bswxt/crack-bphdr } },
+ url = { https://universe.roboflow.com/university-bswxt/crack-bphdr },
+ journal = { Roboflow Universe },
+ publisher = { Roboflow },
+ year = { 2022 },
+ month = { dec },
+ note = { visited on 2024-01-23 },
+ }
+ ```
+
+We would like to acknowledge the Roboflow team for creating and maintaining the Crack Segmentation dataset as a valuable resource for the road safety and research projects. For more information about the Crack segmentation dataset and its creators, visit the [Crack Segmentation Dataset Page](https://universe.roboflow.com/university-bswxt/crack-bphdr).
+
+## FAQ
+
+### What is the Roboflow Crack Segmentation Dataset?
+
+The [Roboflow Crack Segmentation Dataset](https://universe.roboflow.com/university-bswxt/crack-bphdr) is a comprehensive collection of 4029 static images designed specifically for transportation and public safety studies. It is ideal for tasks such as self-driving car model development and infrastructure maintenance. The dataset includes training, testing, and validation sets, aiding in accurate crack detection and segmentation.
+
+### How do I train a model using the Crack Segmentation Dataset with Ultralytics YOLOv8?
+
+To train an Ultralytics YOLOv8 model on the Crack Segmentation dataset, use the following code snippets. Detailed instructions and further parameters can be found on the model [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-seg.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="crack-seg.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo segment train data=crack-seg.yaml model=yolov8n-seg.pt epochs=100 imgsz=640
+ ```
+
+### Why should I use the Crack Segmentation Dataset for my self-driving car project?
+
+The Crack Segmentation Dataset is exceptionally suited for self-driving car projects due to its diverse collection of 4029 road and wall images, which provide a varied range of scenarios. This diversity enhances the accuracy and robustness of models trained for crack detection, crucial for maintaining road safety and ensuring timely infrastructure repairs.
+
+### What unique features does Ultralytics YOLO offer for crack segmentation?
+
+Ultralytics YOLO offers advanced real-time object detection, segmentation, and classification capabilities that make it ideal for crack segmentation tasks. Its ability to handle large datasets and complex scenarios ensures high accuracy and efficiency. For example, the model [Training](../../modes/train.md), [Predict](../../modes/predict.md), and [Export](../../modes/export.md) modes cover comprehensive functionalities from training to deployment.
+
+### How do I cite the Roboflow Crack Segmentation Dataset in my research paper?
+
+If you incorporate the Crack Segmentation Dataset into your research, please use the following BibTeX reference:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @misc{ crack-bphdr_dataset,
+ title = { crack Dataset },
+ type = { Open Source Dataset },
+ author = { University },
+ howpublished = { \url{ https://universe.roboflow.com/university-bswxt/crack-bphdr } },
+ url = { https://universe.roboflow.com/university-bswxt/crack-bphdr },
+ journal = { Roboflow Universe },
+ publisher = { Roboflow },
+ year = { 2022 },
+ month = { dec },
+ note = { visited on 2024-01-23 },
+ }
+ ```
+
+This citation format ensures proper accreditation to the creators of the dataset and acknowledges its use in your research.
diff --git a/ultralytics/docs/en/datasets/segment/index.md b/ultralytics/docs/en/datasets/segment/index.md
new file mode 100644
index 0000000000000000000000000000000000000000..86617704fa6d9bf5873068ce1dd755fe5e57e995
--- /dev/null
+++ b/ultralytics/docs/en/datasets/segment/index.md
@@ -0,0 +1,200 @@
+---
+comments: true
+description: Explore the supported dataset formats for Ultralytics YOLO and learn how to prepare and use datasets for training object segmentation models.
+keywords: Ultralytics, YOLO, instance segmentation, dataset formats, auto-annotation, COCO, segmentation models, training data
+---
+
+# Instance Segmentation Datasets Overview
+
+## Supported Dataset Formats
+
+### Ultralytics YOLO format
+
+The dataset label format used for training YOLO segmentation models is as follows:
+
+1. One text file per image: Each image in the dataset has a corresponding text file with the same name as the image file and the ".txt" extension.
+2. One row per object: Each row in the text file corresponds to one object instance in the image.
+3. Object information per row: Each row contains the following information about the object instance:
+ - Object class index: An integer representing the class of the object (e.g., 0 for person, 1 for car, etc.).
+ - Object bounding coordinates: The bounding coordinates around the mask area, normalized to be between 0 and 1.
+
+The format for a single row in the segmentation dataset file is as follows:
+
+```
+
+
+- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
+
+The example showcases the variety and complexity of the images in the COCO8-Seg dataset and the benefits of using mosaicing during the training process.
+
+## Citations and Acknowledgments
+
+If you use the COCO dataset in your research or development work, please cite the following paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @misc{lin2015microsoft,
+ title={Microsoft COCO: Common Objects in Context},
+ author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
+ year={2015},
+ eprint={1405.0312},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+ }
+ ```
+
+We would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
+
+## FAQ
+
+### What is the COCO8-Seg dataset, and how is it used in Ultralytics YOLOv8?
+
+The **COCO8-Seg dataset** is a compact instance segmentation dataset by Ultralytics, consisting of the first 8 images from the COCO train 2017 set—4 images for training and 4 for validation. This dataset is tailored for testing and debugging segmentation models or experimenting with new detection methods. It is particularly useful with Ultralytics [YOLOv8](https://github.com/ultralytics/ultralytics) and [HUB](https://hub.ultralytics.com) for rapid iteration and pipeline error-checking before scaling to larger datasets. For detailed usage, refer to the model [Training](../../modes/train.md) page.
+
+### How can I train a YOLOv8n-seg model using the COCO8-Seg dataset?
+
+To train a **YOLOv8n-seg** model on the COCO8-Seg dataset for 100 epochs with an image size of 640, you can use Python or CLI commands. Here's a quick example:
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-seg.pt") # Load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="coco8-seg.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo segment train data=coco8-seg.yaml model=yolov8n-seg.pt epochs=100 imgsz=640
+ ```
+
+For a thorough explanation of available arguments and configuration options, you can check the [Training](../../modes/train.md) documentation.
+
+### Why is the COCO8-Seg dataset important for model development and debugging?
+
+The **COCO8-Seg dataset** is ideal for its manageability and diversity within a small size. It consists of only 8 images, providing a quick way to test and debug segmentation models or new detection approaches without the overhead of larger datasets. This makes it an efficient tool for sanity checks and pipeline error identification before committing to extensive training on large datasets. Learn more about dataset formats [here](https://docs.ultralytics.com/datasets/segment).
+
+### Where can I find the YAML configuration file for the COCO8-Seg dataset?
+
+The YAML configuration file for the **COCO8-Seg dataset** is available in the Ultralytics repository. You can access the file directly [here](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco8-seg.yaml). The YAML file includes essential information about dataset paths, classes, and configuration settings required for model training and validation.
+
+### What are some benefits of using mosaicing during training with the COCO8-Seg dataset?
+
+Using **mosaicing** during training helps increase the diversity and variety of objects and scenes in each training batch. This technique combines multiple images into a single composite image, enhancing the model's ability to generalize to different object sizes, aspect ratios, and contexts within the scene. Mosaicing is beneficial for improving a model's robustness and accuracy, especially when working with small datasets like COCO8-Seg. For an example of mosaiced images, see the [Sample Images and Annotations](#sample-images-and-annotations) section.
diff --git a/ultralytics/docs/en/datasets/segment/crack-seg.md b/ultralytics/docs/en/datasets/segment/crack-seg.md
new file mode 100644
index 0000000000000000000000000000000000000000..b274d077453f29eb5b30c13a3e0e8e6ce87fe5a0
--- /dev/null
+++ b/ultralytics/docs/en/datasets/segment/crack-seg.md
@@ -0,0 +1,157 @@
+---
+comments: true
+description: Explore the extensive Roboflow Crack Segmentation Dataset, perfect for transportation and public safety studies or self-driving car model development.
+keywords: Roboflow, Crack Segmentation Dataset, Ultralytics, transportation safety, public safety, self-driving cars, computer vision, road safety, infrastructure maintenance, dataset
+---
+
+# Roboflow Universe Crack Segmentation Dataset
+
+The [Roboflow](https://roboflow.com/?ref=ultralytics) [Crack Segmentation Dataset](https://universe.roboflow.com/university-bswxt/crack-bphdr) stands out as an extensive resource designed specifically for individuals involved in transportation and public safety studies. It is equally beneficial for those working on the development of self-driving car models or simply exploring computer vision applications for recreational purposes.
+
+Comprising a total of 4029 static images captured from diverse road and wall scenarios, this dataset emerges as a valuable asset for tasks related to crack segmentation. Whether you are delving into the intricacies of transportation research or seeking to enhance the accuracy of your self-driving car models, this dataset provides a rich and varied collection of images to support your endeavors.
+
+## Dataset Structure
+
+The division of data within the Crack Segmentation Dataset is outlined as follows:
+
+- **Training set**: Consists of 3717 images with corresponding annotations.
+- **Testing set**: Comprises 112 images along with their respective annotations.
+- **Validation set**: Includes 200 images with their corresponding annotations.
+
+## Applications
+
+Crack segmentation finds practical applications in infrastructure maintenance, aiding in the identification and assessment of structural damage. It also plays a crucial role in enhancing road safety by enabling automated systems to detect and address pavement cracks for timely repairs.
+
+## Dataset YAML
+
+A YAML (Yet Another Markup Language) file is employed to outline the configuration of the dataset, encompassing details about paths, classes, and other pertinent information. Specifically, for the Crack Segmentation dataset, the `crack-seg.yaml` file is managed and accessible at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/crack-seg.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/crack-seg.yaml).
+
+!!! Example "ultralytics/cfg/datasets/crack-seg.yaml"
+
+ ```yaml
+ --8<-- "ultralytics/cfg/datasets/crack-seg.yaml"
+ ```
+
+## Usage
+
+To train Ultralytics YOLOv8n model on the Crack Segmentation dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-seg.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="crack-seg.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo segment train data=crack-seg.yaml model=yolov8n-seg.pt epochs=100 imgsz=640
+ ```
+
+## Sample Data and Annotations
+
+The Crack Segmentation dataset comprises a varied collection of images and videos captured from multiple perspectives. Below are instances of data from the dataset, accompanied by their respective annotations:
+
+
+
+- This image presents an example of image object segmentation, featuring annotated bounding boxes with masks outlining identified objects. The dataset includes a diverse array of images taken in different locations, environments, and densities, making it a comprehensive resource for developing models designed for this particular task.
+
+- The example underscores the diversity and complexity found in the Crack segmentation dataset, emphasizing the crucial role of high-quality data in computer vision tasks.
+
+## Citations and Acknowledgments
+
+If you incorporate the crack segmentation dataset into your research or development endeavors, kindly reference the following paper:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @misc{ crack-bphdr_dataset,
+ title = { crack Dataset },
+ type = { Open Source Dataset },
+ author = { University },
+ howpublished = { \url{ https://universe.roboflow.com/university-bswxt/crack-bphdr } },
+ url = { https://universe.roboflow.com/university-bswxt/crack-bphdr },
+ journal = { Roboflow Universe },
+ publisher = { Roboflow },
+ year = { 2022 },
+ month = { dec },
+ note = { visited on 2024-01-23 },
+ }
+ ```
+
+We would like to acknowledge the Roboflow team for creating and maintaining the Crack Segmentation dataset as a valuable resource for the road safety and research projects. For more information about the Crack segmentation dataset and its creators, visit the [Crack Segmentation Dataset Page](https://universe.roboflow.com/university-bswxt/crack-bphdr).
+
+## FAQ
+
+### What is the Roboflow Crack Segmentation Dataset?
+
+The [Roboflow Crack Segmentation Dataset](https://universe.roboflow.com/university-bswxt/crack-bphdr) is a comprehensive collection of 4029 static images designed specifically for transportation and public safety studies. It is ideal for tasks such as self-driving car model development and infrastructure maintenance. The dataset includes training, testing, and validation sets, aiding in accurate crack detection and segmentation.
+
+### How do I train a model using the Crack Segmentation Dataset with Ultralytics YOLOv8?
+
+To train an Ultralytics YOLOv8 model on the Crack Segmentation dataset, use the following code snippets. Detailed instructions and further parameters can be found on the model [Training](../../modes/train.md) page.
+
+!!! Example "Train Example"
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO("yolov8n-seg.pt") # load a pretrained model (recommended for training)
+
+ # Train the model
+ results = model.train(data="crack-seg.yaml", epochs=100, imgsz=640)
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo segment train data=crack-seg.yaml model=yolov8n-seg.pt epochs=100 imgsz=640
+ ```
+
+### Why should I use the Crack Segmentation Dataset for my self-driving car project?
+
+The Crack Segmentation Dataset is exceptionally suited for self-driving car projects due to its diverse collection of 4029 road and wall images, which provide a varied range of scenarios. This diversity enhances the accuracy and robustness of models trained for crack detection, crucial for maintaining road safety and ensuring timely infrastructure repairs.
+
+### What unique features does Ultralytics YOLO offer for crack segmentation?
+
+Ultralytics YOLO offers advanced real-time object detection, segmentation, and classification capabilities that make it ideal for crack segmentation tasks. Its ability to handle large datasets and complex scenarios ensures high accuracy and efficiency. For example, the model [Training](../../modes/train.md), [Predict](../../modes/predict.md), and [Export](../../modes/export.md) modes cover comprehensive functionalities from training to deployment.
+
+### How do I cite the Roboflow Crack Segmentation Dataset in my research paper?
+
+If you incorporate the Crack Segmentation Dataset into your research, please use the following BibTeX reference:
+
+!!! Quote ""
+
+ === "BibTeX"
+
+ ```bibtex
+ @misc{ crack-bphdr_dataset,
+ title = { crack Dataset },
+ type = { Open Source Dataset },
+ author = { University },
+ howpublished = { \url{ https://universe.roboflow.com/university-bswxt/crack-bphdr } },
+ url = { https://universe.roboflow.com/university-bswxt/crack-bphdr },
+ journal = { Roboflow Universe },
+ publisher = { Roboflow },
+ year = { 2022 },
+ month = { dec },
+ note = { visited on 2024-01-23 },
+ }
+ ```
+
+This citation format ensures proper accreditation to the creators of the dataset and acknowledges its use in your research.
diff --git a/ultralytics/docs/en/datasets/segment/index.md b/ultralytics/docs/en/datasets/segment/index.md
new file mode 100644
index 0000000000000000000000000000000000000000..86617704fa6d9bf5873068ce1dd755fe5e57e995
--- /dev/null
+++ b/ultralytics/docs/en/datasets/segment/index.md
@@ -0,0 +1,200 @@
+---
+comments: true
+description: Explore the supported dataset formats for Ultralytics YOLO and learn how to prepare and use datasets for training object segmentation models.
+keywords: Ultralytics, YOLO, instance segmentation, dataset formats, auto-annotation, COCO, segmentation models, training data
+---
+
+# Instance Segmentation Datasets Overview
+
+## Supported Dataset Formats
+
+### Ultralytics YOLO format
+
+The dataset label format used for training YOLO segmentation models is as follows:
+
+1. One text file per image: Each image in the dataset has a corresponding text file with the same name as the image file and the ".txt" extension.
+2. One row per object: Each row in the text file corresponds to one object instance in the image.
+3. Object information per row: Each row contains the following information about the object instance:
+ - Object class index: An integer representing the class of the object (e.g., 0 for person, 1 for car, etc.).
+ - Object bounding coordinates: The bounding coordinates around the mask area, normalized to be between 0 and 1.
+
+The format for a single row in the segmentation dataset file is as follows:
+
+```
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+
 +
+ +
+ +
+ +
+ +
+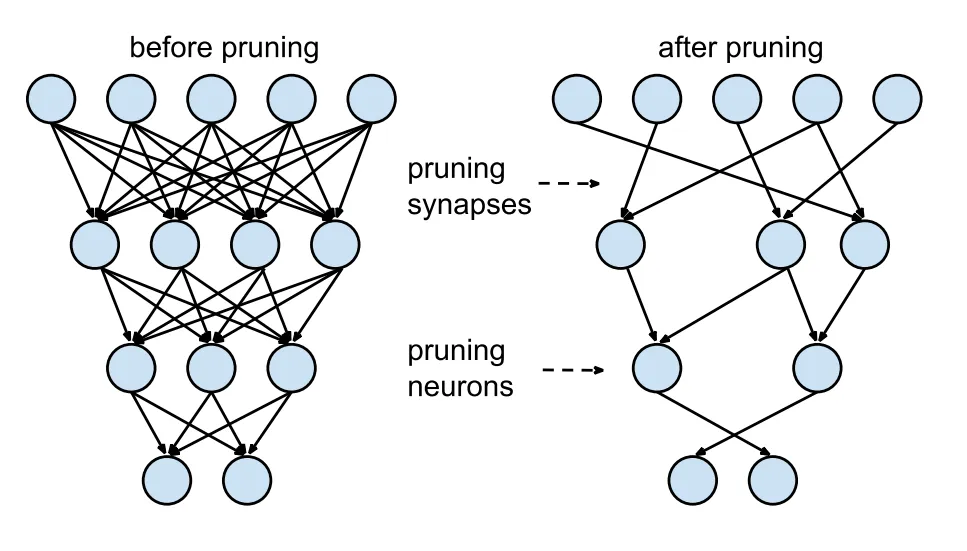 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+


.jpeg) +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+
+## FAQ
+
+### What is Continuous Integration (CI) in Ultralytics?
+
+Continuous Integration (CI) in Ultralytics involves automatically integrating and testing code changes to ensure high-quality standards. Our CI setup includes running [unit tests, linting checks, and comprehensive tests](https://github.com/ultralytics/ultralytics/actions/workflows/ci.yaml). Additionally, we perform [Docker deployment](https://github.com/ultralytics/ultralytics/actions/workflows/docker.yaml), [broken link checks](https://github.com/ultralytics/ultralytics/actions/workflows/links.yml), [CodeQL analysis](https://github.com/ultralytics/ultralytics/actions/workflows/codeql.yaml) for security vulnerabilities, and [PyPI publishing](https://github.com/ultralytics/ultralytics/actions/workflows/publish.yml) to package and distribute our software.
+
+### How does Ultralytics check for broken links in documentation and code?
+
+Ultralytics uses a specific CI action to [check for broken links](https://github.com/ultralytics/ultralytics/actions/workflows/links.yml) within our markdown and HTML files. This helps maintain the integrity of our documentation by scanning and identifying dead or broken links, ensuring that users always have access to accurate and live resources.
+
+### Why is CodeQL analysis important for Ultralytics' codebase?
+
+[CodeQL analysis](https://github.com/ultralytics/ultralytics/actions/workflows/codeql.yaml) is crucial for Ultralytics as it performs semantic code analysis to find potential security vulnerabilities and maintain high-quality standards. With CodeQL, we can proactively identify and mitigate risks in our code, helping us deliver robust and secure software solutions.
+
+### How does Ultralytics utilize Docker for deployment?
+
+Ultralytics employs Docker to validate the deployment of our projects through a dedicated CI action. This process ensures that our [Dockerfile and associated scripts](https://github.com/ultralytics/ultralytics/actions/workflows/docker.yaml) are functioning correctly, allowing for consistent and reproducible deployment environments which are critical for scalable and reliable AI solutions.
+
+### What is the role of automated PyPI publishing in Ultralytics?
+
+Automated [PyPI publishing](https://github.com/ultralytics/ultralytics/actions/workflows/publish.yml) ensures that our projects can be packaged and published without errors. This step is essential for distributing Ultralytics' Python packages, allowing users to easily install and use our tools via the Python Package Index (PyPI).
+
+### How does Ultralytics measure code coverage and why is it important?
+
+Ultralytics measures code coverage by integrating with [Codecov](https://codecov.io/github/ultralytics/ultralytics), providing insights into how much of the codebase is executed during tests. High code coverage can indicate well-tested code, helping to uncover untested areas that might be prone to bugs. Detailed code coverage metrics can be explored via badges displayed on our main repositories or directly on [Codecov](https://codecov.io/gh/ultralytics/ultralytics).
diff --git a/ultralytics/docs/en/help/CLA.md b/ultralytics/docs/en/help/CLA.md
new file mode 100644
index 0000000000000000000000000000000000000000..2b317aef5af1400d5c4fe8a238bb7764e7f54795
--- /dev/null
+++ b/ultralytics/docs/en/help/CLA.md
@@ -0,0 +1,50 @@
+---
+description: Review the terms for contributing to Ultralytics projects. Learn about copyright, patent licenses, and moral rights for your contributions.
+keywords: Ultralytics, Contributor License Agreement, open source, contributions, copyright license, patent license, moral rights
+---
+
+# Ultralytics Individual Contributor License Agreement
+
+Thank you for your interest in contributing to open source software projects (“Projects”) made available by Ultralytics Inc. (“Ultralytics”). This Individual Contributor License Agreement (“Agreement”) sets out the terms governing any source code, object code, bug fixes, configuration changes, tools, specifications, documentation, data, materials, feedback, information or other works of authorship that you submit or have submitted, in any form and in any manner, to Ultralytics in respect of any Projects (collectively “Contributions”). If you have any questions respecting this Agreement, please contact hello@ultralytics.com.
+
+You agree that the following terms apply to all of your past, present and future Contributions. Except for the licenses granted in this Agreement, you retain all of your right, title and interest in and to your Contributions.
+
+**Copyright License.** You hereby grant, and agree to grant, to Ultralytics a non-exclusive, perpetual, irrevocable, worldwide, fully-paid, royalty-free, transferable copyright license to reproduce, prepare derivative works of, publicly display, publicly perform, and distribute your Contributions and such derivative works, with the right to sublicense the foregoing rights through multiple tiers of sublicensees.
+
+**Patent License.** You hereby grant, and agree to grant, to Ultralytics a non-exclusive, perpetual, irrevocable, worldwide, fully-paid, royalty-free, transferable patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer your Contributions, where such license applies only to those patent claims licensable by you that are necessarily infringed by your Contributions alone or by combination of your Contributions with the Project to which such Contributions were submitted, with the right to sublicense the foregoing rights through multiple tiers of sublicensees.
+
+**Moral Rights.** To the fullest extent permitted under applicable law, you hereby waive, and agree not to assert, all of your “moral rights” in or relating to your Contributions for the benefit of Ultralytics, its assigns, and their respective direct and indirect sublicensees.
+
+**Third Party Content/Rights.** If your Contribution includes or is based on any source code, object code, bug fixes, configuration changes, tools, specifications, documentation, data, materials, feedback, information or other works of authorship that were not authored by you (“Third Party Content”) or if you are aware of any third party intellectual property or proprietary rights associated with your Contribution (“Third Party Rights”), then you agree to include with the submission of your Contribution full details respecting such Third Party Content and Third Party Rights, including, without limitation, identification of which aspects of your Contribution contain Third Party Content or are associated with Third Party Rights, the owner/author of the Third Party Content and Third Party Rights, where you obtained the Third Party Content, and any applicable third party license terms or restrictions respecting the Third Party Content and Third Party Rights. For greater certainty, the foregoing obligations respecting the identification of Third Party Content and Third Party Rights do not apply to any portion of a Project that is incorporated into your Contribution to that same Project.
+
+**Representations.** You represent that, other than the Third Party Content and Third Party Rights identified by you in accordance with this Agreement, you are the sole author of your Contributions and are legally entitled to grant the foregoing licenses and waivers in respect of your Contributions. If your Contributions were created in the course of your employment with your past or present employer(s), you represent that such employer(s) has authorized you to make your Contributions on behalf of such employer(s) or such employer(s) has waived all of their right, title or interest in or to your Contributions.
+
+**Disclaimer.** To the fullest extent permitted under applicable law, your Contributions are provided on an "asis" basis, without any warranties or conditions, express or implied, including, without limitation, any implied warranties or conditions of non-infringement, merchantability or fitness for a particular purpose. You are not required to provide support for your Contributions, except to the extent you desire to provide support.
+
+**No Obligation.** You acknowledge that Ultralytics is under no obligation to use or incorporate your Contributions into any of the Projects. The decision to use or incorporate your Contributions into any of the Projects will be made at the sole discretion of Ultralytics or its authorized delegates.
+
+**Disputes.** This Agreement shall be governed by and construed in accordance with the laws of the State of New York, United States of America, without giving effect to its principles or rules regarding conflicts of laws, other than such principles directing application of New York law. The parties hereby submit to venue in, and jurisdiction of the courts located in New York, New York for purposes relating to this Agreement. In the event that any of the provisions of this Agreement shall be held by a court or other tribunal of competent jurisdiction to be unenforceable, the remaining portions hereof shall remain in full force and effect.
+
+**Assignment.** You agree that Ultralytics may assign this Agreement, and all of its rights, obligations and licenses hereunder.
+
+## FAQ
+
+### What is the purpose of the Ultralytics Individual Contributor License Agreement?
+
+The Ultralytics Individual Contributor License Agreement (ICLA) governs the terms under which you contribute to Ultralytics' open-source projects. It sets out the rights and obligations related to your contributions, including granting copyright and patent licenses, waiving moral rights, and disclosing any third-party content.
+
+### Why do I need to agree to the Copyright License in the ICLA?
+
+Agreeing to the Copyright License allows Ultralytics to use and distribute your contributions, including making derivative works. This ensures that your contributions can be integrated into Ultralytics projects and shared with the community, fostering collaboration and software development.
+
+### How does the Patent License benefit both contributors and Ultralytics?
+
+The Patent License grants Ultralytics the rights to use, make, and sell contributions covered by your patents, which is crucial for product development and commercialization. In return, it allows your patented innovations to be more widely used and recognized, promoting innovation within the community.
+
+### What should I do if my contribution contains third-party content?
+
+If your contribution includes third-party content or you are aware of any third-party intellectual property rights, you must provide full details of such content and rights when submitting your contribution. This includes identifying the third-party content, its author, and the applicable license terms. For more information on third-party content, refer to the Third Party Content/Rights section of the Agreement.
+
+### What happens if Ultralytics does not use my contributions?
+
+Ultralytics is not obligated to use or incorporate your contributions into any projects. The decision to use or integrate contributions is at Ultralytics' sole discretion. This means that while your contributions are valuable, they may not always align with the project's current needs or directions. For further details, see the No Obligation section.
diff --git a/ultralytics/docs/en/help/FAQ.md b/ultralytics/docs/en/help/FAQ.md
new file mode 100644
index 0000000000000000000000000000000000000000..5ad7300a39a4528e9733160775680cad60d2e6b0
--- /dev/null
+++ b/ultralytics/docs/en/help/FAQ.md
@@ -0,0 +1,229 @@
+---
+comments: true
+description: Explore common questions and solutions related to Ultralytics YOLO, from hardware requirements to model fine-tuning and real-time detection.
+keywords: Ultralytics, YOLO, FAQ, object detection, hardware requirements, fine-tuning, ONNX, TensorFlow, real-time detection, model accuracy
+---
+
+# Ultralytics YOLO Frequently Asked Questions (FAQ)
+
+This FAQ section addresses common questions and issues users might encounter while working with [Ultralytics](https://ultralytics.com) YOLO repositories.
+
+## FAQ
+
+### What is Ultralytics and what does it offer?
+
+Ultralytics is a computer vision AI company specializing in state-of-the-art object detection and image segmentation models, with a focus on the YOLO (You Only Look Once) family. Their offerings include:
+
+- Open-source implementations of [YOLOv5](https://docs.ultralytics.com/models/yolov5/) and [YOLOv8](https://docs.ultralytics.com/models/yolov8/)
+- A wide range of [pre-trained models](https://docs.ultralytics.com/models/) for various computer vision tasks
+- A comprehensive [Python package](https://docs.ultralytics.com/usage/python/) for seamless integration of YOLO models into projects
+- Versatile [tools](https://docs.ultralytics.com/modes/) for training, testing, and deploying models
+- [Extensive documentation](https://docs.ultralytics.com/) and a supportive community
+
+### How do I install the Ultralytics package?
+
+Installing the Ultralytics package is straightforward using pip:
+
+```
+pip install ultralytics
+```
+
+For the latest development version, install directly from the GitHub repository:
+
+```
+pip install git+https://github.com/ultralytics/ultralytics.git
+```
+
+Detailed installation instructions can be found in the [quickstart guide](https://docs.ultralytics.com/quickstart/).
+
+### What are the system requirements for running Ultralytics models?
+
+Minimum requirements:
+
+- Python 3.7+
+- PyTorch 1.7+
+- CUDA-compatible GPU (for GPU acceleration)
+
+Recommended setup:
+
+- Python 3.8+
+- PyTorch 1.10+
+- NVIDIA GPU with CUDA 11.2+
+- 8GB+ RAM
+- 50GB+ free disk space (for dataset storage and model training)
+
+For troubleshooting common issues, visit the [YOLO Common Issues](https://docs.ultralytics.com/guides/yolo-common-issues/) page.
+
+### How can I train a custom YOLOv8 model on my own dataset?
+
+To train a custom YOLOv8 model:
+
+1. Prepare your dataset in YOLO format (images and corresponding label txt files).
+2. Create a YAML file describing your dataset structure and classes.
+3. Use the following Python code to start training:
+
+```python
+from ultralytics import YOLO
+
+# Load a model
+model = YOLO("yolov8n.yaml") # build a new model from scratch
+model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+
+# Train the model
+results = model.train(data="path/to/your/data.yaml", epochs=100, imgsz=640)
+```
+
+For a more in-depth guide, including data preparation and advanced training options, refer to the comprehensive [training guide](https://docs.ultralytics.com/modes/train/).
+
+### What pretrained models are available in Ultralytics?
+
+Ultralytics offers a diverse range of pretrained YOLOv8 models for various tasks:
+
+- Object Detection: YOLOv8n, YOLOv8s, YOLOv8m, YOLOv8l, YOLOv8x
+- Instance Segmentation: YOLOv8n-seg, YOLOv8s-seg, YOLOv8m-seg, YOLOv8l-seg, YOLOv8x-seg
+- Classification: YOLOv8n-cls, YOLOv8s-cls, YOLOv8m-cls, YOLOv8l-cls, YOLOv8x-cls
+
+These models vary in size and complexity, offering different trade-offs between speed and accuracy. Explore the full range of [pretrained models](https://docs.ultralytics.com/models/yolov8/) to find the best fit for your project.
+
+### How do I perform inference using a trained Ultralytics model?
+
+To perform inference with a trained model:
+
+```python
+from ultralytics import YOLO
+
+# Load a model
+model = YOLO("path/to/your/model.pt")
+
+# Perform inference
+results = model("path/to/image.jpg")
+
+# Process results
+for r in results:
+ print(r.boxes) # print bbox predictions
+ print(r.masks) # print mask predictions
+ print(r.probs) # print class probabilities
+```
+
+For advanced inference options, including batch processing and video inference, check out the detailed [prediction guide](https://docs.ultralytics.com/modes/predict/).
+
+### Can Ultralytics models be deployed on edge devices or in production environments?
+
+Absolutely! Ultralytics models are designed for versatile deployment across various platforms:
+
+- Edge devices: Optimize inference on devices like NVIDIA Jetson or Intel Neural Compute Stick using TensorRT, ONNX, or OpenVINO.
+- Mobile: Deploy on Android or iOS devices by converting models to TFLite or Core ML.
+- Cloud: Leverage frameworks like TensorFlow Serving or PyTorch Serve for scalable cloud deployments.
+- Web: Implement in-browser inference using ONNX.js or TensorFlow.js.
+
+Ultralytics provides export functions to convert models to various formats for deployment. Explore the wide range of [deployment options](https://docs.ultralytics.com/guides/model-deployment-options/) to find the best solution for your use case.
+
+### What's the difference between YOLOv5 and YOLOv8?
+
+Key distinctions include:
+
+- Architecture: YOLOv8 features an improved backbone and head design for enhanced performance.
+- Performance: YOLOv8 generally offers superior accuracy and speed compared to YOLOv5.
+- Tasks: YOLOv8 natively supports object detection, instance segmentation, and classification in a unified framework.
+- Codebase: YOLOv8 is implemented with a more modular and extensible architecture, facilitating easier customization and extension.
+- Training: YOLOv8 incorporates advanced training techniques like multi-dataset training and hyperparameter evolution for improved results.
+
+For an in-depth comparison of features and performance metrics, visit the [YOLOv5 vs YOLOv8](https://www.ultralytics.com/yolo) comparison page.
+
+### How can I contribute to the Ultralytics open-source project?
+
+Contributing to Ultralytics is a great way to improve the project and expand your skills. Here's how you can get involved:
+
+1. Fork the Ultralytics repository on GitHub.
+2. Create a new branch for your feature or bug fix.
+3. Make your changes and ensure all tests pass.
+4. Submit a pull request with a clear description of your changes.
+5. Participate in the code review process.
+
+You can also contribute by reporting bugs, suggesting features, or improving documentation. For detailed guidelines and best practices, refer to the [contributing guide](https://docs.ultralytics.com/help/contributing/).
+
+### How do I install the Ultralytics package in Python?
+
+Installing the Ultralytics package in Python is simple. Use pip by running the following command in your terminal or command prompt:
+
+```bash
+pip install ultralytics
+```
+
+For the cutting-edge development version, install directly from the GitHub repository:
+
+```bash
+pip install git+https://github.com/ultralytics/ultralytics.git
+```
+
+For environment-specific installation instructions and troubleshooting tips, consult the comprehensive [quickstart guide](https://docs.ultralytics.com/quickstart/).
+
+### What are the main features of Ultralytics YOLO?
+
+Ultralytics YOLO boasts a rich set of features for advanced object detection and image segmentation:
+
+- Real-Time Detection: Efficiently detect and classify objects in real-time scenarios.
+- Pre-Trained Models: Access a variety of [pretrained models](https://docs.ultralytics.com/models/yolov8/) that balance speed and accuracy for different use cases.
+- Custom Training: Easily fine-tune models on custom datasets with the flexible [training pipeline](https://docs.ultralytics.com/modes/train/).
+- Wide [Deployment Options](https://docs.ultralytics.com/guides/model-deployment-options/): Export models to various formats like TensorRT, ONNX, and CoreML for deployment across different platforms.
+- Extensive Documentation: Benefit from comprehensive [documentation](https://docs.ultralytics.com/) and a supportive community to guide you through your computer vision journey.
+
+Explore the [YOLO models page](https://docs.ultralytics.com/models/yolov8/) for an in-depth look at the capabilities and architectures of different YOLO versions.
+
+### How can I improve the performance of my YOLO model?
+
+Enhancing your YOLO model's performance can be achieved through several techniques:
+
+1. Hyperparameter Tuning: Experiment with different hyperparameters using the [Hyperparameter Tuning Guide](https://docs.ultralytics.com/guides/hyperparameter-tuning/) to optimize model performance.
+2. Data Augmentation: Implement techniques like flip, scale, rotate, and color adjustments to enhance your training dataset and improve model generalization.
+3. Transfer Learning: Leverage pre-trained models and fine-tune them on your specific dataset using the [Train YOLOv8](https://docs.ultralytics.com/modes/train/) guide.
+4. Export to Efficient Formats: Convert your model to optimized formats like TensorRT or ONNX for faster inference using the [Export guide](../modes/export.md).
+5. Benchmarking: Utilize the [Benchmark Mode](https://docs.ultralytics.com/modes/benchmark/) to measure and improve inference speed and accuracy systematically.
+
+### Can I deploy Ultralytics YOLO models on mobile and edge devices?
+
+Yes, Ultralytics YOLO models are designed for versatile deployment, including mobile and edge devices:
+
+- Mobile: Convert models to TFLite or CoreML for seamless integration into Android or iOS apps. Refer to the [TFLite Integration Guide](https://docs.ultralytics.com/integrations/tflite/) and [CoreML Integration Guide](https://docs.ultralytics.com/integrations/coreml/) for platform-specific instructions.
+- Edge Devices: Optimize inference on devices like NVIDIA Jetson or other edge hardware using TensorRT or ONNX. The [Edge TPU Integration Guide](https://docs.ultralytics.com/integrations/edge-tpu/) provides detailed steps for edge deployment.
+
+For a comprehensive overview of deployment strategies across various platforms, consult the [deployment options guide](https://docs.ultralytics.com/guides/model-deployment-options/).
+
+### How can I perform inference using a trained Ultralytics YOLO model?
+
+Performing inference with a trained Ultralytics YOLO model is straightforward:
+
+1. Load the Model:
+
+```python
+from ultralytics import YOLO
+
+model = YOLO("path/to/your/model.pt")
+```
+
+2. Run Inference:
+
+```python
+results = model("path/to/image.jpg")
+
+for r in results:
+ print(r.boxes) # print bounding box predictions
+ print(r.masks) # print mask predictions
+ print(r.probs) # print class probabilities
+```
+
+For advanced inference techniques, including batch processing, video inference, and custom preprocessing, refer to the detailed [prediction guide](https://docs.ultralytics.com/modes/predict/).
+
+### Where can I find examples and tutorials for using Ultralytics?
+
+Ultralytics provides a wealth of resources to help you get started and master their tools:
+
+- 📚 [Official documentation](https://docs.ultralytics.com/): Comprehensive guides, API references, and best practices.
+- 💻 [GitHub repository](https://github.com/ultralytics/ultralytics): Source code, example scripts, and community contributions.
+- ✍️ [Ultralytics blog](https://www.ultralytics.com/blog): In-depth articles, use cases, and technical insights.
+- 💬 [Community forums](https://community.ultralytics.com/): Connect with other users, ask questions, and share your experiences.
+- 🎥 [YouTube channel](https://youtube.com/ultralytics?sub_confirmation=1): Video tutorials, demos, and webinars on various Ultralytics topics.
+
+These resources provide code examples, real-world use cases, and step-by-step guides for various tasks using Ultralytics models.
+
+If you need further assistance, don't hesitate to consult the Ultralytics documentation or reach out to the community through [GitHub Issues](https://github.com/ultralytics/ultralytics/issues) or the official [discussion forum](https://github.com/orgs/ultralytics/discussions).
diff --git a/ultralytics/docs/en/help/code_of_conduct.md b/ultralytics/docs/en/help/code_of_conduct.md
new file mode 100644
index 0000000000000000000000000000000000000000..d1ab2c81462f757f71726311c5f4e11dcbadf9d1
--- /dev/null
+++ b/ultralytics/docs/en/help/code_of_conduct.md
@@ -0,0 +1,109 @@
+---
+comments: true
+description: Join our welcoming community! Learn about the Ultralytics Code of Conduct to ensure a harassment-free experience for all participants.
+keywords: Ultralytics, Contributor Covenant, Code of Conduct, community guidelines, harassment-free, inclusive community, diversity, enforcement policy
+---
+
+# Ultralytics Contributor Covenant Code of Conduct
+
+## Our Pledge
+
+We as members, contributors, and leaders pledge to make participation in our community a harassment-free experience for everyone, regardless of age, body size, visible or invisible disability, ethnicity, sex characteristics, gender identity and expression, level of experience, education, socioeconomic status, nationality, personal appearance, race, religion, or sexual identity and orientation.
+
+We pledge to act and interact in ways that contribute to an open, welcoming, diverse, inclusive, and healthy community.
+
+## Our Standards
+
+Examples of behavior that contributes to a positive environment for our community include:
+
+- Demonstrating empathy and kindness toward other people
+- Being respectful of differing opinions, viewpoints, and experiences
+- Giving and gracefully accepting constructive feedback
+- Accepting responsibility and apologizing to those affected by our mistakes, and learning from the experience
+- Focusing on what is best not just for us as individuals, but for the overall community
+
+Examples of unacceptable behavior include:
+
+- The use of sexualized language or imagery, and sexual attention or advances of any kind
+- Trolling, insulting or derogatory comments, and personal or political attacks
+- Public or private harassment
+- Publishing others' private information, such as a physical or email address, without their explicit permission
+- Other conduct which could reasonably be considered inappropriate in a professional setting
+
+## Enforcement Responsibilities
+
+Community leaders are responsible for clarifying and enforcing our standards of acceptable behavior and will take appropriate and fair corrective action in response to any behavior that they deem inappropriate, threatening, offensive, or harmful.
+
+Community leaders have the right and responsibility to remove, edit, or reject comments, commits, code, wiki edits, issues, and other contributions that are not aligned to this Code of Conduct, and will communicate reasons for moderation decisions when appropriate.
+
+## Scope
+
+This Code of Conduct applies within all community spaces, and also applies when an individual is officially representing the community in public spaces. Examples of representing our community include using an official e-mail address, posting via an official social media account, or acting as an appointed representative at an online or offline event.
+
+## Enforcement
+
+Instances of abusive, harassing, or otherwise unacceptable behavior may be reported to the community leaders responsible for enforcement at hello@ultralytics.com. All complaints will be reviewed and investigated promptly and fairly.
+
+All community leaders are obligated to respect the privacy and security of the reporter of any incident.
+
+## Enforcement Guidelines
+
+Community leaders will follow these Community Impact Guidelines in determining the consequences for any action they deem in violation of this Code of Conduct:
+
+### 1. Correction
+
+**Community Impact**: Use of inappropriate language or other behavior deemed unprofessional or unwelcome in the community.
+
+**Consequence**: A private, written warning from community leaders, providing clarity around the nature of the violation and an explanation of why the behavior was inappropriate. A public apology may be requested.
+
+### 2. Warning
+
+**Community Impact**: A violation through a single incident or series of actions.
+
+**Consequence**: A warning with consequences for continued behavior. No interaction with the people involved, including unsolicited interaction with those enforcing the Code of Conduct, for a specified period of time. This includes avoiding interactions in community spaces as well as external channels like social media. Violating these terms may lead to a temporary or permanent ban.
+
+### 3. Temporary Ban
+
+**Community Impact**: A serious violation of community standards, including sustained inappropriate behavior.
+
+**Consequence**: A temporary ban from any sort of interaction or public communication with the community for a specified period of time. No public or private interaction with the people involved, including unsolicited interaction with those enforcing the Code of Conduct, is allowed during this period. Violating these terms may lead to a permanent ban.
+
+### 4. Permanent Ban
+
+**Community Impact**: Demonstrating a pattern of violation of community standards, including sustained inappropriate behavior, harassment of an individual, or aggression toward or disparagement of classes of individuals.
+
+**Consequence**: A permanent ban from any sort of public interaction within the community.
+
+## Attribution
+
+This Code of Conduct is adapted from the [Contributor Covenant][homepage], version 2.0, available at https://www.contributor-covenant.org/version/2/0/code_of_conduct.html.
+
+Community Impact Guidelines were inspired by [Mozilla's code of conduct enforcement ladder](https://github.com/mozilla/diversity).
+
+For answers to common questions about this code of conduct, see the FAQ at https://www.contributor-covenant.org/faq. Translations are available at https://www.contributor-covenant.org/translations.
+
+[homepage]: https://www.contributor-covenant.org
+
+## FAQ
+
+### What is the Ultralytics Contributor Covenant Code of Conduct?
+
+The Ultralytics Contributor Covenant Code of Conduct aims to create a harassment-free experience for everyone participating in the Ultralytics community. It applies to all community interactions, including online and offline activities. The code details expected behaviors, unacceptable behaviors, and the enforcement responsibilities of community leaders. For more detailed information, see the [Enforcement Responsibilities](#enforcement-responsibilities) section.
+
+### How does the enforcement process work for the Ultralytics Code of Conduct?
+
+Enforcement of the Ultralytics Code of Conduct is managed by community leaders who can take appropriate action in response to any behavior deemed inappropriate. This could range from a private warning to a permanent ban, depending on the severity of the violation. Instances of misconduct can be reported to hello@ultralytics.com for investigation. Learn more about the enforcement steps in the [Enforcement Guidelines](#enforcement-guidelines) section.
+
+### Why is diversity and inclusion important in the Ultralytics community?
+
+Ultralytics values diversity and inclusion as fundamental aspects for fostering innovation and creativity within its community. A diverse and inclusive environment allows different perspectives and experiences to contribute to an open, welcoming, and healthy community. This commitment is reflected in our [Pledge](#our-pledge) to ensure a harassment-free experience for everyone regardless of their background.
+
+### How can I contribute to Ultralytics while adhering to the Code of Conduct?
+
+Contributing to Ultralytics means engaging positively and respectfully with other community members. You can contribute by demonstrating empathy, offering and accepting constructive feedback, and taking responsibility for any mistakes. Always aim to contribute in a way that benefits the entire community. For more details on acceptable behaviors, refer to the [Our Standards](#our-standards) section.
+
+### Where can I find additional information about the Ultralytics Code of Conduct?
+
+For more comprehensive details about the Ultralytics Code of Conduct, including reporting guidelines and enforcement policies, you can visit the [Contributor Covenant homepage](https://www.contributor-covenant.org/version/2/0/code_of_conduct.html) or check the [FAQ section of Contributor Covenant](https://www.contributor-covenant.org/faq). Learn more about Ultralytics' goals and initiatives on [our brand page](https://www.ultralytics.com/brand) and [about page](https://www.ultralytics.com/about).
+
+Should you have more questions or need further assistance, check our [Help Center](../help/FAQ.md) and [Contributing Guide](../help/contributing.md) for more information.
diff --git a/ultralytics/docs/en/help/contributing.md b/ultralytics/docs/en/help/contributing.md
new file mode 100644
index 0000000000000000000000000000000000000000..d585fb600dd5538d7f5eb767551a81284e3bbc0c
--- /dev/null
+++ b/ultralytics/docs/en/help/contributing.md
@@ -0,0 +1,168 @@
+---
+comments: true
+description: Learn how to contribute to Ultralytics YOLO open-source repositories. Follow guidelines for pull requests, code of conduct, and bug reporting.
+keywords: Ultralytics, YOLO, open-source, contribution, pull request, code of conduct, bug reporting, GitHub, CLA, Google-style docstrings
+---
+
+# Contributing to Ultralytics Open-Source Projects
+
+Welcome! We're thrilled that you're considering contributing to our [Ultralytics](https://ultralytics.com) [open-source](https://github.com/ultralytics) projects. Your involvement not only helps enhance the quality of our repositories but also benefits the entire community. This guide provides clear guidelines and best practices to help you get started.
+
+
+
+
+
+## FAQ
+
+### What is Continuous Integration (CI) in Ultralytics?
+
+Continuous Integration (CI) in Ultralytics involves automatically integrating and testing code changes to ensure high-quality standards. Our CI setup includes running [unit tests, linting checks, and comprehensive tests](https://github.com/ultralytics/ultralytics/actions/workflows/ci.yaml). Additionally, we perform [Docker deployment](https://github.com/ultralytics/ultralytics/actions/workflows/docker.yaml), [broken link checks](https://github.com/ultralytics/ultralytics/actions/workflows/links.yml), [CodeQL analysis](https://github.com/ultralytics/ultralytics/actions/workflows/codeql.yaml) for security vulnerabilities, and [PyPI publishing](https://github.com/ultralytics/ultralytics/actions/workflows/publish.yml) to package and distribute our software.
+
+### How does Ultralytics check for broken links in documentation and code?
+
+Ultralytics uses a specific CI action to [check for broken links](https://github.com/ultralytics/ultralytics/actions/workflows/links.yml) within our markdown and HTML files. This helps maintain the integrity of our documentation by scanning and identifying dead or broken links, ensuring that users always have access to accurate and live resources.
+
+### Why is CodeQL analysis important for Ultralytics' codebase?
+
+[CodeQL analysis](https://github.com/ultralytics/ultralytics/actions/workflows/codeql.yaml) is crucial for Ultralytics as it performs semantic code analysis to find potential security vulnerabilities and maintain high-quality standards. With CodeQL, we can proactively identify and mitigate risks in our code, helping us deliver robust and secure software solutions.
+
+### How does Ultralytics utilize Docker for deployment?
+
+Ultralytics employs Docker to validate the deployment of our projects through a dedicated CI action. This process ensures that our [Dockerfile and associated scripts](https://github.com/ultralytics/ultralytics/actions/workflows/docker.yaml) are functioning correctly, allowing for consistent and reproducible deployment environments which are critical for scalable and reliable AI solutions.
+
+### What is the role of automated PyPI publishing in Ultralytics?
+
+Automated [PyPI publishing](https://github.com/ultralytics/ultralytics/actions/workflows/publish.yml) ensures that our projects can be packaged and published without errors. This step is essential for distributing Ultralytics' Python packages, allowing users to easily install and use our tools via the Python Package Index (PyPI).
+
+### How does Ultralytics measure code coverage and why is it important?
+
+Ultralytics measures code coverage by integrating with [Codecov](https://codecov.io/github/ultralytics/ultralytics), providing insights into how much of the codebase is executed during tests. High code coverage can indicate well-tested code, helping to uncover untested areas that might be prone to bugs. Detailed code coverage metrics can be explored via badges displayed on our main repositories or directly on [Codecov](https://codecov.io/gh/ultralytics/ultralytics).
diff --git a/ultralytics/docs/en/help/CLA.md b/ultralytics/docs/en/help/CLA.md
new file mode 100644
index 0000000000000000000000000000000000000000..2b317aef5af1400d5c4fe8a238bb7764e7f54795
--- /dev/null
+++ b/ultralytics/docs/en/help/CLA.md
@@ -0,0 +1,50 @@
+---
+description: Review the terms for contributing to Ultralytics projects. Learn about copyright, patent licenses, and moral rights for your contributions.
+keywords: Ultralytics, Contributor License Agreement, open source, contributions, copyright license, patent license, moral rights
+---
+
+# Ultralytics Individual Contributor License Agreement
+
+Thank you for your interest in contributing to open source software projects (“Projects”) made available by Ultralytics Inc. (“Ultralytics”). This Individual Contributor License Agreement (“Agreement”) sets out the terms governing any source code, object code, bug fixes, configuration changes, tools, specifications, documentation, data, materials, feedback, information or other works of authorship that you submit or have submitted, in any form and in any manner, to Ultralytics in respect of any Projects (collectively “Contributions”). If you have any questions respecting this Agreement, please contact hello@ultralytics.com.
+
+You agree that the following terms apply to all of your past, present and future Contributions. Except for the licenses granted in this Agreement, you retain all of your right, title and interest in and to your Contributions.
+
+**Copyright License.** You hereby grant, and agree to grant, to Ultralytics a non-exclusive, perpetual, irrevocable, worldwide, fully-paid, royalty-free, transferable copyright license to reproduce, prepare derivative works of, publicly display, publicly perform, and distribute your Contributions and such derivative works, with the right to sublicense the foregoing rights through multiple tiers of sublicensees.
+
+**Patent License.** You hereby grant, and agree to grant, to Ultralytics a non-exclusive, perpetual, irrevocable, worldwide, fully-paid, royalty-free, transferable patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer your Contributions, where such license applies only to those patent claims licensable by you that are necessarily infringed by your Contributions alone or by combination of your Contributions with the Project to which such Contributions were submitted, with the right to sublicense the foregoing rights through multiple tiers of sublicensees.
+
+**Moral Rights.** To the fullest extent permitted under applicable law, you hereby waive, and agree not to assert, all of your “moral rights” in or relating to your Contributions for the benefit of Ultralytics, its assigns, and their respective direct and indirect sublicensees.
+
+**Third Party Content/Rights.** If your Contribution includes or is based on any source code, object code, bug fixes, configuration changes, tools, specifications, documentation, data, materials, feedback, information or other works of authorship that were not authored by you (“Third Party Content”) or if you are aware of any third party intellectual property or proprietary rights associated with your Contribution (“Third Party Rights”), then you agree to include with the submission of your Contribution full details respecting such Third Party Content and Third Party Rights, including, without limitation, identification of which aspects of your Contribution contain Third Party Content or are associated with Third Party Rights, the owner/author of the Third Party Content and Third Party Rights, where you obtained the Third Party Content, and any applicable third party license terms or restrictions respecting the Third Party Content and Third Party Rights. For greater certainty, the foregoing obligations respecting the identification of Third Party Content and Third Party Rights do not apply to any portion of a Project that is incorporated into your Contribution to that same Project.
+
+**Representations.** You represent that, other than the Third Party Content and Third Party Rights identified by you in accordance with this Agreement, you are the sole author of your Contributions and are legally entitled to grant the foregoing licenses and waivers in respect of your Contributions. If your Contributions were created in the course of your employment with your past or present employer(s), you represent that such employer(s) has authorized you to make your Contributions on behalf of such employer(s) or such employer(s) has waived all of their right, title or interest in or to your Contributions.
+
+**Disclaimer.** To the fullest extent permitted under applicable law, your Contributions are provided on an "asis" basis, without any warranties or conditions, express or implied, including, without limitation, any implied warranties or conditions of non-infringement, merchantability or fitness for a particular purpose. You are not required to provide support for your Contributions, except to the extent you desire to provide support.
+
+**No Obligation.** You acknowledge that Ultralytics is under no obligation to use or incorporate your Contributions into any of the Projects. The decision to use or incorporate your Contributions into any of the Projects will be made at the sole discretion of Ultralytics or its authorized delegates.
+
+**Disputes.** This Agreement shall be governed by and construed in accordance with the laws of the State of New York, United States of America, without giving effect to its principles or rules regarding conflicts of laws, other than such principles directing application of New York law. The parties hereby submit to venue in, and jurisdiction of the courts located in New York, New York for purposes relating to this Agreement. In the event that any of the provisions of this Agreement shall be held by a court or other tribunal of competent jurisdiction to be unenforceable, the remaining portions hereof shall remain in full force and effect.
+
+**Assignment.** You agree that Ultralytics may assign this Agreement, and all of its rights, obligations and licenses hereunder.
+
+## FAQ
+
+### What is the purpose of the Ultralytics Individual Contributor License Agreement?
+
+The Ultralytics Individual Contributor License Agreement (ICLA) governs the terms under which you contribute to Ultralytics' open-source projects. It sets out the rights and obligations related to your contributions, including granting copyright and patent licenses, waiving moral rights, and disclosing any third-party content.
+
+### Why do I need to agree to the Copyright License in the ICLA?
+
+Agreeing to the Copyright License allows Ultralytics to use and distribute your contributions, including making derivative works. This ensures that your contributions can be integrated into Ultralytics projects and shared with the community, fostering collaboration and software development.
+
+### How does the Patent License benefit both contributors and Ultralytics?
+
+The Patent License grants Ultralytics the rights to use, make, and sell contributions covered by your patents, which is crucial for product development and commercialization. In return, it allows your patented innovations to be more widely used and recognized, promoting innovation within the community.
+
+### What should I do if my contribution contains third-party content?
+
+If your contribution includes third-party content or you are aware of any third-party intellectual property rights, you must provide full details of such content and rights when submitting your contribution. This includes identifying the third-party content, its author, and the applicable license terms. For more information on third-party content, refer to the Third Party Content/Rights section of the Agreement.
+
+### What happens if Ultralytics does not use my contributions?
+
+Ultralytics is not obligated to use or incorporate your contributions into any projects. The decision to use or integrate contributions is at Ultralytics' sole discretion. This means that while your contributions are valuable, they may not always align with the project's current needs or directions. For further details, see the No Obligation section.
diff --git a/ultralytics/docs/en/help/FAQ.md b/ultralytics/docs/en/help/FAQ.md
new file mode 100644
index 0000000000000000000000000000000000000000..5ad7300a39a4528e9733160775680cad60d2e6b0
--- /dev/null
+++ b/ultralytics/docs/en/help/FAQ.md
@@ -0,0 +1,229 @@
+---
+comments: true
+description: Explore common questions and solutions related to Ultralytics YOLO, from hardware requirements to model fine-tuning and real-time detection.
+keywords: Ultralytics, YOLO, FAQ, object detection, hardware requirements, fine-tuning, ONNX, TensorFlow, real-time detection, model accuracy
+---
+
+# Ultralytics YOLO Frequently Asked Questions (FAQ)
+
+This FAQ section addresses common questions and issues users might encounter while working with [Ultralytics](https://ultralytics.com) YOLO repositories.
+
+## FAQ
+
+### What is Ultralytics and what does it offer?
+
+Ultralytics is a computer vision AI company specializing in state-of-the-art object detection and image segmentation models, with a focus on the YOLO (You Only Look Once) family. Their offerings include:
+
+- Open-source implementations of [YOLOv5](https://docs.ultralytics.com/models/yolov5/) and [YOLOv8](https://docs.ultralytics.com/models/yolov8/)
+- A wide range of [pre-trained models](https://docs.ultralytics.com/models/) for various computer vision tasks
+- A comprehensive [Python package](https://docs.ultralytics.com/usage/python/) for seamless integration of YOLO models into projects
+- Versatile [tools](https://docs.ultralytics.com/modes/) for training, testing, and deploying models
+- [Extensive documentation](https://docs.ultralytics.com/) and a supportive community
+
+### How do I install the Ultralytics package?
+
+Installing the Ultralytics package is straightforward using pip:
+
+```
+pip install ultralytics
+```
+
+For the latest development version, install directly from the GitHub repository:
+
+```
+pip install git+https://github.com/ultralytics/ultralytics.git
+```
+
+Detailed installation instructions can be found in the [quickstart guide](https://docs.ultralytics.com/quickstart/).
+
+### What are the system requirements for running Ultralytics models?
+
+Minimum requirements:
+
+- Python 3.7+
+- PyTorch 1.7+
+- CUDA-compatible GPU (for GPU acceleration)
+
+Recommended setup:
+
+- Python 3.8+
+- PyTorch 1.10+
+- NVIDIA GPU with CUDA 11.2+
+- 8GB+ RAM
+- 50GB+ free disk space (for dataset storage and model training)
+
+For troubleshooting common issues, visit the [YOLO Common Issues](https://docs.ultralytics.com/guides/yolo-common-issues/) page.
+
+### How can I train a custom YOLOv8 model on my own dataset?
+
+To train a custom YOLOv8 model:
+
+1. Prepare your dataset in YOLO format (images and corresponding label txt files).
+2. Create a YAML file describing your dataset structure and classes.
+3. Use the following Python code to start training:
+
+```python
+from ultralytics import YOLO
+
+# Load a model
+model = YOLO("yolov8n.yaml") # build a new model from scratch
+model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+
+# Train the model
+results = model.train(data="path/to/your/data.yaml", epochs=100, imgsz=640)
+```
+
+For a more in-depth guide, including data preparation and advanced training options, refer to the comprehensive [training guide](https://docs.ultralytics.com/modes/train/).
+
+### What pretrained models are available in Ultralytics?
+
+Ultralytics offers a diverse range of pretrained YOLOv8 models for various tasks:
+
+- Object Detection: YOLOv8n, YOLOv8s, YOLOv8m, YOLOv8l, YOLOv8x
+- Instance Segmentation: YOLOv8n-seg, YOLOv8s-seg, YOLOv8m-seg, YOLOv8l-seg, YOLOv8x-seg
+- Classification: YOLOv8n-cls, YOLOv8s-cls, YOLOv8m-cls, YOLOv8l-cls, YOLOv8x-cls
+
+These models vary in size and complexity, offering different trade-offs between speed and accuracy. Explore the full range of [pretrained models](https://docs.ultralytics.com/models/yolov8/) to find the best fit for your project.
+
+### How do I perform inference using a trained Ultralytics model?
+
+To perform inference with a trained model:
+
+```python
+from ultralytics import YOLO
+
+# Load a model
+model = YOLO("path/to/your/model.pt")
+
+# Perform inference
+results = model("path/to/image.jpg")
+
+# Process results
+for r in results:
+ print(r.boxes) # print bbox predictions
+ print(r.masks) # print mask predictions
+ print(r.probs) # print class probabilities
+```
+
+For advanced inference options, including batch processing and video inference, check out the detailed [prediction guide](https://docs.ultralytics.com/modes/predict/).
+
+### Can Ultralytics models be deployed on edge devices or in production environments?
+
+Absolutely! Ultralytics models are designed for versatile deployment across various platforms:
+
+- Edge devices: Optimize inference on devices like NVIDIA Jetson or Intel Neural Compute Stick using TensorRT, ONNX, or OpenVINO.
+- Mobile: Deploy on Android or iOS devices by converting models to TFLite or Core ML.
+- Cloud: Leverage frameworks like TensorFlow Serving or PyTorch Serve for scalable cloud deployments.
+- Web: Implement in-browser inference using ONNX.js or TensorFlow.js.
+
+Ultralytics provides export functions to convert models to various formats for deployment. Explore the wide range of [deployment options](https://docs.ultralytics.com/guides/model-deployment-options/) to find the best solution for your use case.
+
+### What's the difference between YOLOv5 and YOLOv8?
+
+Key distinctions include:
+
+- Architecture: YOLOv8 features an improved backbone and head design for enhanced performance.
+- Performance: YOLOv8 generally offers superior accuracy and speed compared to YOLOv5.
+- Tasks: YOLOv8 natively supports object detection, instance segmentation, and classification in a unified framework.
+- Codebase: YOLOv8 is implemented with a more modular and extensible architecture, facilitating easier customization and extension.
+- Training: YOLOv8 incorporates advanced training techniques like multi-dataset training and hyperparameter evolution for improved results.
+
+For an in-depth comparison of features and performance metrics, visit the [YOLOv5 vs YOLOv8](https://www.ultralytics.com/yolo) comparison page.
+
+### How can I contribute to the Ultralytics open-source project?
+
+Contributing to Ultralytics is a great way to improve the project and expand your skills. Here's how you can get involved:
+
+1. Fork the Ultralytics repository on GitHub.
+2. Create a new branch for your feature or bug fix.
+3. Make your changes and ensure all tests pass.
+4. Submit a pull request with a clear description of your changes.
+5. Participate in the code review process.
+
+You can also contribute by reporting bugs, suggesting features, or improving documentation. For detailed guidelines and best practices, refer to the [contributing guide](https://docs.ultralytics.com/help/contributing/).
+
+### How do I install the Ultralytics package in Python?
+
+Installing the Ultralytics package in Python is simple. Use pip by running the following command in your terminal or command prompt:
+
+```bash
+pip install ultralytics
+```
+
+For the cutting-edge development version, install directly from the GitHub repository:
+
+```bash
+pip install git+https://github.com/ultralytics/ultralytics.git
+```
+
+For environment-specific installation instructions and troubleshooting tips, consult the comprehensive [quickstart guide](https://docs.ultralytics.com/quickstart/).
+
+### What are the main features of Ultralytics YOLO?
+
+Ultralytics YOLO boasts a rich set of features for advanced object detection and image segmentation:
+
+- Real-Time Detection: Efficiently detect and classify objects in real-time scenarios.
+- Pre-Trained Models: Access a variety of [pretrained models](https://docs.ultralytics.com/models/yolov8/) that balance speed and accuracy for different use cases.
+- Custom Training: Easily fine-tune models on custom datasets with the flexible [training pipeline](https://docs.ultralytics.com/modes/train/).
+- Wide [Deployment Options](https://docs.ultralytics.com/guides/model-deployment-options/): Export models to various formats like TensorRT, ONNX, and CoreML for deployment across different platforms.
+- Extensive Documentation: Benefit from comprehensive [documentation](https://docs.ultralytics.com/) and a supportive community to guide you through your computer vision journey.
+
+Explore the [YOLO models page](https://docs.ultralytics.com/models/yolov8/) for an in-depth look at the capabilities and architectures of different YOLO versions.
+
+### How can I improve the performance of my YOLO model?
+
+Enhancing your YOLO model's performance can be achieved through several techniques:
+
+1. Hyperparameter Tuning: Experiment with different hyperparameters using the [Hyperparameter Tuning Guide](https://docs.ultralytics.com/guides/hyperparameter-tuning/) to optimize model performance.
+2. Data Augmentation: Implement techniques like flip, scale, rotate, and color adjustments to enhance your training dataset and improve model generalization.
+3. Transfer Learning: Leverage pre-trained models and fine-tune them on your specific dataset using the [Train YOLOv8](https://docs.ultralytics.com/modes/train/) guide.
+4. Export to Efficient Formats: Convert your model to optimized formats like TensorRT or ONNX for faster inference using the [Export guide](../modes/export.md).
+5. Benchmarking: Utilize the [Benchmark Mode](https://docs.ultralytics.com/modes/benchmark/) to measure and improve inference speed and accuracy systematically.
+
+### Can I deploy Ultralytics YOLO models on mobile and edge devices?
+
+Yes, Ultralytics YOLO models are designed for versatile deployment, including mobile and edge devices:
+
+- Mobile: Convert models to TFLite or CoreML for seamless integration into Android or iOS apps. Refer to the [TFLite Integration Guide](https://docs.ultralytics.com/integrations/tflite/) and [CoreML Integration Guide](https://docs.ultralytics.com/integrations/coreml/) for platform-specific instructions.
+- Edge Devices: Optimize inference on devices like NVIDIA Jetson or other edge hardware using TensorRT or ONNX. The [Edge TPU Integration Guide](https://docs.ultralytics.com/integrations/edge-tpu/) provides detailed steps for edge deployment.
+
+For a comprehensive overview of deployment strategies across various platforms, consult the [deployment options guide](https://docs.ultralytics.com/guides/model-deployment-options/).
+
+### How can I perform inference using a trained Ultralytics YOLO model?
+
+Performing inference with a trained Ultralytics YOLO model is straightforward:
+
+1. Load the Model:
+
+```python
+from ultralytics import YOLO
+
+model = YOLO("path/to/your/model.pt")
+```
+
+2. Run Inference:
+
+```python
+results = model("path/to/image.jpg")
+
+for r in results:
+ print(r.boxes) # print bounding box predictions
+ print(r.masks) # print mask predictions
+ print(r.probs) # print class probabilities
+```
+
+For advanced inference techniques, including batch processing, video inference, and custom preprocessing, refer to the detailed [prediction guide](https://docs.ultralytics.com/modes/predict/).
+
+### Where can I find examples and tutorials for using Ultralytics?
+
+Ultralytics provides a wealth of resources to help you get started and master their tools:
+
+- 📚 [Official documentation](https://docs.ultralytics.com/): Comprehensive guides, API references, and best practices.
+- 💻 [GitHub repository](https://github.com/ultralytics/ultralytics): Source code, example scripts, and community contributions.
+- ✍️ [Ultralytics blog](https://www.ultralytics.com/blog): In-depth articles, use cases, and technical insights.
+- 💬 [Community forums](https://community.ultralytics.com/): Connect with other users, ask questions, and share your experiences.
+- 🎥 [YouTube channel](https://youtube.com/ultralytics?sub_confirmation=1): Video tutorials, demos, and webinars on various Ultralytics topics.
+
+These resources provide code examples, real-world use cases, and step-by-step guides for various tasks using Ultralytics models.
+
+If you need further assistance, don't hesitate to consult the Ultralytics documentation or reach out to the community through [GitHub Issues](https://github.com/ultralytics/ultralytics/issues) or the official [discussion forum](https://github.com/orgs/ultralytics/discussions).
diff --git a/ultralytics/docs/en/help/code_of_conduct.md b/ultralytics/docs/en/help/code_of_conduct.md
new file mode 100644
index 0000000000000000000000000000000000000000..d1ab2c81462f757f71726311c5f4e11dcbadf9d1
--- /dev/null
+++ b/ultralytics/docs/en/help/code_of_conduct.md
@@ -0,0 +1,109 @@
+---
+comments: true
+description: Join our welcoming community! Learn about the Ultralytics Code of Conduct to ensure a harassment-free experience for all participants.
+keywords: Ultralytics, Contributor Covenant, Code of Conduct, community guidelines, harassment-free, inclusive community, diversity, enforcement policy
+---
+
+# Ultralytics Contributor Covenant Code of Conduct
+
+## Our Pledge
+
+We as members, contributors, and leaders pledge to make participation in our community a harassment-free experience for everyone, regardless of age, body size, visible or invisible disability, ethnicity, sex characteristics, gender identity and expression, level of experience, education, socioeconomic status, nationality, personal appearance, race, religion, or sexual identity and orientation.
+
+We pledge to act and interact in ways that contribute to an open, welcoming, diverse, inclusive, and healthy community.
+
+## Our Standards
+
+Examples of behavior that contributes to a positive environment for our community include:
+
+- Demonstrating empathy and kindness toward other people
+- Being respectful of differing opinions, viewpoints, and experiences
+- Giving and gracefully accepting constructive feedback
+- Accepting responsibility and apologizing to those affected by our mistakes, and learning from the experience
+- Focusing on what is best not just for us as individuals, but for the overall community
+
+Examples of unacceptable behavior include:
+
+- The use of sexualized language or imagery, and sexual attention or advances of any kind
+- Trolling, insulting or derogatory comments, and personal or political attacks
+- Public or private harassment
+- Publishing others' private information, such as a physical or email address, without their explicit permission
+- Other conduct which could reasonably be considered inappropriate in a professional setting
+
+## Enforcement Responsibilities
+
+Community leaders are responsible for clarifying and enforcing our standards of acceptable behavior and will take appropriate and fair corrective action in response to any behavior that they deem inappropriate, threatening, offensive, or harmful.
+
+Community leaders have the right and responsibility to remove, edit, or reject comments, commits, code, wiki edits, issues, and other contributions that are not aligned to this Code of Conduct, and will communicate reasons for moderation decisions when appropriate.
+
+## Scope
+
+This Code of Conduct applies within all community spaces, and also applies when an individual is officially representing the community in public spaces. Examples of representing our community include using an official e-mail address, posting via an official social media account, or acting as an appointed representative at an online or offline event.
+
+## Enforcement
+
+Instances of abusive, harassing, or otherwise unacceptable behavior may be reported to the community leaders responsible for enforcement at hello@ultralytics.com. All complaints will be reviewed and investigated promptly and fairly.
+
+All community leaders are obligated to respect the privacy and security of the reporter of any incident.
+
+## Enforcement Guidelines
+
+Community leaders will follow these Community Impact Guidelines in determining the consequences for any action they deem in violation of this Code of Conduct:
+
+### 1. Correction
+
+**Community Impact**: Use of inappropriate language or other behavior deemed unprofessional or unwelcome in the community.
+
+**Consequence**: A private, written warning from community leaders, providing clarity around the nature of the violation and an explanation of why the behavior was inappropriate. A public apology may be requested.
+
+### 2. Warning
+
+**Community Impact**: A violation through a single incident or series of actions.
+
+**Consequence**: A warning with consequences for continued behavior. No interaction with the people involved, including unsolicited interaction with those enforcing the Code of Conduct, for a specified period of time. This includes avoiding interactions in community spaces as well as external channels like social media. Violating these terms may lead to a temporary or permanent ban.
+
+### 3. Temporary Ban
+
+**Community Impact**: A serious violation of community standards, including sustained inappropriate behavior.
+
+**Consequence**: A temporary ban from any sort of interaction or public communication with the community for a specified period of time. No public or private interaction with the people involved, including unsolicited interaction with those enforcing the Code of Conduct, is allowed during this period. Violating these terms may lead to a permanent ban.
+
+### 4. Permanent Ban
+
+**Community Impact**: Demonstrating a pattern of violation of community standards, including sustained inappropriate behavior, harassment of an individual, or aggression toward or disparagement of classes of individuals.
+
+**Consequence**: A permanent ban from any sort of public interaction within the community.
+
+## Attribution
+
+This Code of Conduct is adapted from the [Contributor Covenant][homepage], version 2.0, available at https://www.contributor-covenant.org/version/2/0/code_of_conduct.html.
+
+Community Impact Guidelines were inspired by [Mozilla's code of conduct enforcement ladder](https://github.com/mozilla/diversity).
+
+For answers to common questions about this code of conduct, see the FAQ at https://www.contributor-covenant.org/faq. Translations are available at https://www.contributor-covenant.org/translations.
+
+[homepage]: https://www.contributor-covenant.org
+
+## FAQ
+
+### What is the Ultralytics Contributor Covenant Code of Conduct?
+
+The Ultralytics Contributor Covenant Code of Conduct aims to create a harassment-free experience for everyone participating in the Ultralytics community. It applies to all community interactions, including online and offline activities. The code details expected behaviors, unacceptable behaviors, and the enforcement responsibilities of community leaders. For more detailed information, see the [Enforcement Responsibilities](#enforcement-responsibilities) section.
+
+### How does the enforcement process work for the Ultralytics Code of Conduct?
+
+Enforcement of the Ultralytics Code of Conduct is managed by community leaders who can take appropriate action in response to any behavior deemed inappropriate. This could range from a private warning to a permanent ban, depending on the severity of the violation. Instances of misconduct can be reported to hello@ultralytics.com for investigation. Learn more about the enforcement steps in the [Enforcement Guidelines](#enforcement-guidelines) section.
+
+### Why is diversity and inclusion important in the Ultralytics community?
+
+Ultralytics values diversity and inclusion as fundamental aspects for fostering innovation and creativity within its community. A diverse and inclusive environment allows different perspectives and experiences to contribute to an open, welcoming, and healthy community. This commitment is reflected in our [Pledge](#our-pledge) to ensure a harassment-free experience for everyone regardless of their background.
+
+### How can I contribute to Ultralytics while adhering to the Code of Conduct?
+
+Contributing to Ultralytics means engaging positively and respectfully with other community members. You can contribute by demonstrating empathy, offering and accepting constructive feedback, and taking responsibility for any mistakes. Always aim to contribute in a way that benefits the entire community. For more details on acceptable behaviors, refer to the [Our Standards](#our-standards) section.
+
+### Where can I find additional information about the Ultralytics Code of Conduct?
+
+For more comprehensive details about the Ultralytics Code of Conduct, including reporting guidelines and enforcement policies, you can visit the [Contributor Covenant homepage](https://www.contributor-covenant.org/version/2/0/code_of_conduct.html) or check the [FAQ section of Contributor Covenant](https://www.contributor-covenant.org/faq). Learn more about Ultralytics' goals and initiatives on [our brand page](https://www.ultralytics.com/brand) and [about page](https://www.ultralytics.com/about).
+
+Should you have more questions or need further assistance, check our [Help Center](../help/FAQ.md) and [Contributing Guide](../help/contributing.md) for more information.
diff --git a/ultralytics/docs/en/help/contributing.md b/ultralytics/docs/en/help/contributing.md
new file mode 100644
index 0000000000000000000000000000000000000000..d585fb600dd5538d7f5eb767551a81284e3bbc0c
--- /dev/null
+++ b/ultralytics/docs/en/help/contributing.md
@@ -0,0 +1,168 @@
+---
+comments: true
+description: Learn how to contribute to Ultralytics YOLO open-source repositories. Follow guidelines for pull requests, code of conduct, and bug reporting.
+keywords: Ultralytics, YOLO, open-source, contribution, pull request, code of conduct, bug reporting, GitHub, CLA, Google-style docstrings
+---
+
+# Contributing to Ultralytics Open-Source Projects
+
+Welcome! We're thrilled that you're considering contributing to our [Ultralytics](https://ultralytics.com) [open-source](https://github.com/ultralytics) projects. Your involvement not only helps enhance the quality of our repositories but also benefits the entire community. This guide provides clear guidelines and best practices to help you get started.
+
+
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+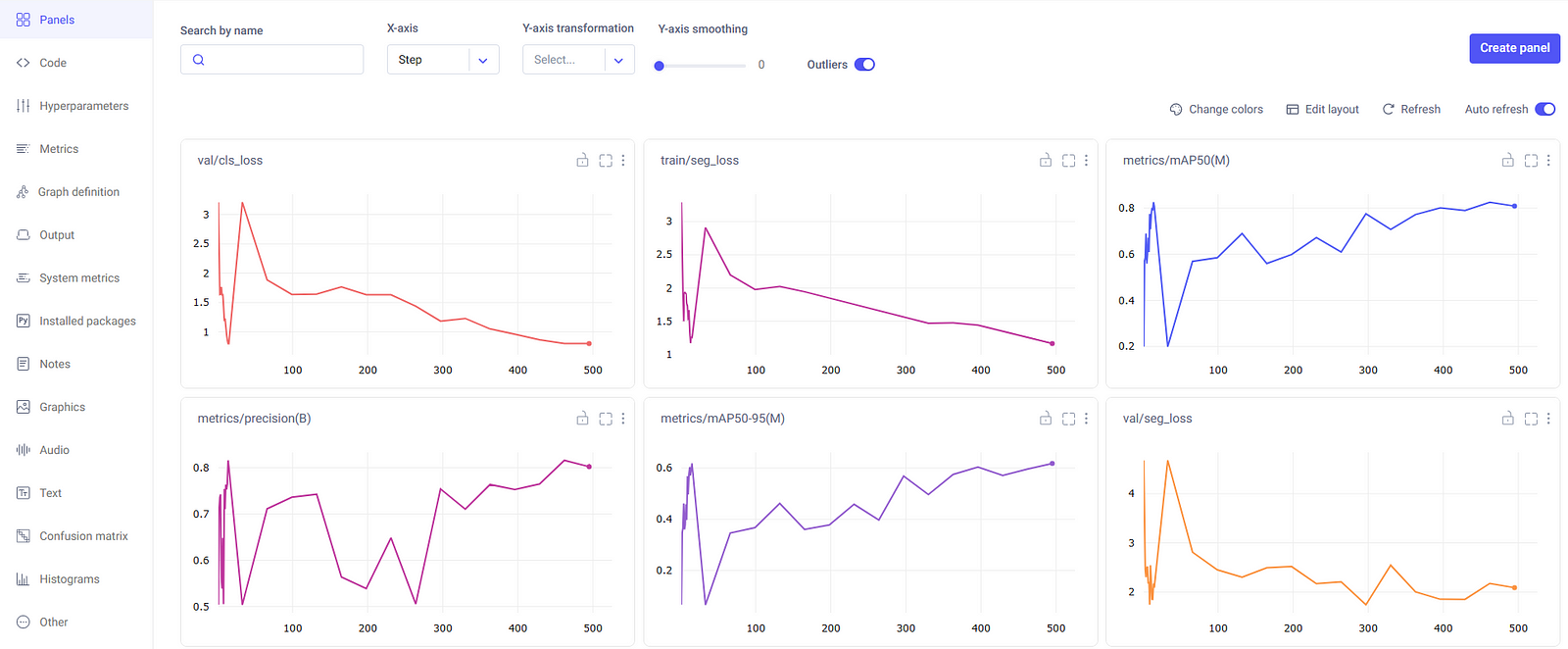 +
+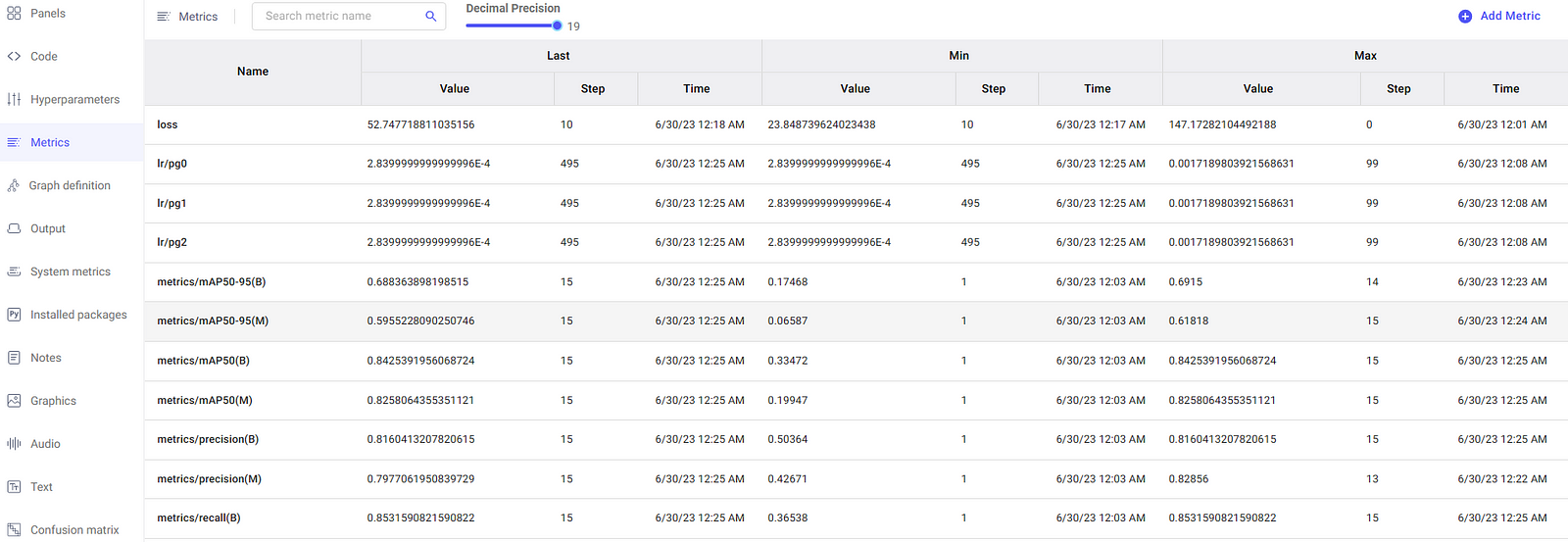 +
+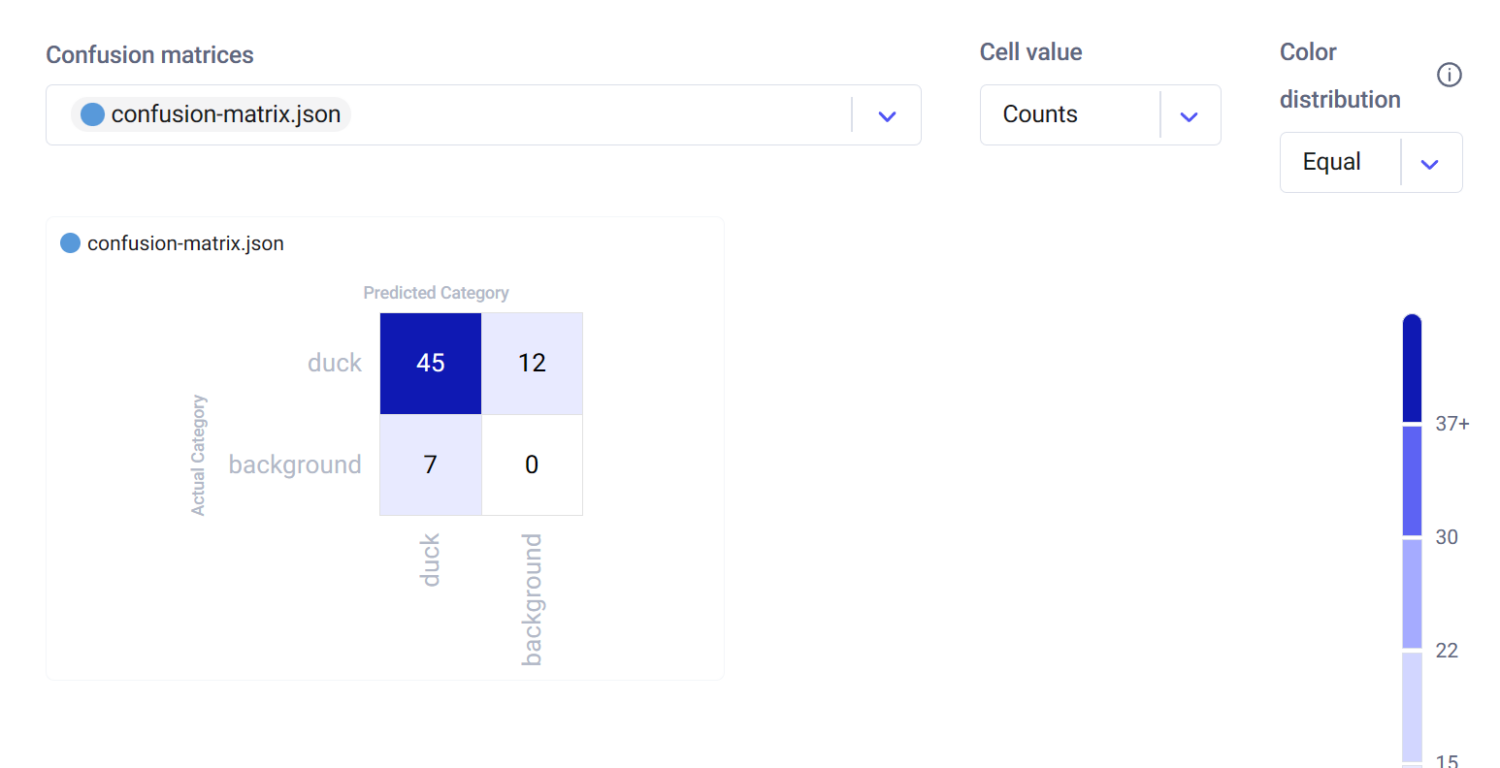 +
+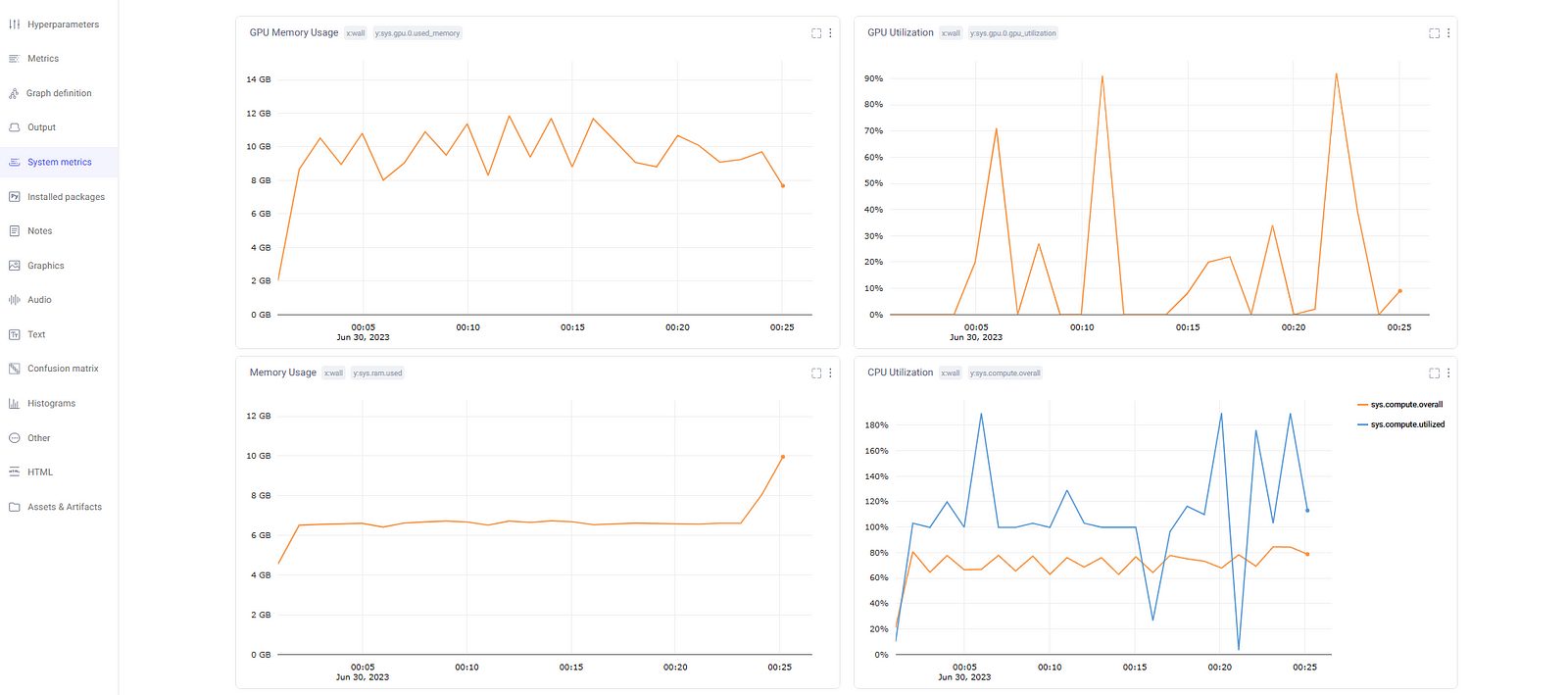 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+## Introduction
+
+Experiment logging is a crucial aspect of machine learning workflows that enables tracking of various metrics, parameters, and artifacts. It helps to enhance model reproducibility, debug issues, and improve model performance. [Ultralytics](https://ultralytics.com) YOLO, known for its real-time object detection capabilities, now offers integration with [MLflow](https://mlflow.org/), an open-source platform for complete machine learning lifecycle management.
+
+This documentation page is a comprehensive guide to setting up and utilizing the MLflow logging capabilities for your Ultralytics YOLO project.
+
+## What is MLflow?
+
+[MLflow](https://mlflow.org/) is an open-source platform developed by [Databricks](https://www.databricks.com/) for managing the end-to-end machine learning lifecycle. It includes tools for tracking experiments, packaging code into reproducible runs, and sharing and deploying models. MLflow is designed to work with any machine learning library and programming language.
+
+## Features
+
+- **Metrics Logging**: Logs metrics at the end of each epoch and at the end of the training.
+- **Parameter Logging**: Logs all the parameters used in the training.
+- **Artifacts Logging**: Logs model artifacts, including weights and configuration files, at the end of the training.
+
+## Setup and Prerequisites
+
+Ensure MLflow is installed. If not, install it using pip:
+
+```bash
+pip install mlflow
+```
+
+Make sure that MLflow logging is enabled in Ultralytics settings. Usually, this is controlled by the settings `mflow` key. See the [settings](../quickstart.md#ultralytics-settings) page for more info.
+
+!!! Example "Update Ultralytics MLflow Settings"
+
+ === "Python"
+
+ Within the Python environment, call the `update` method on the `settings` object to change your settings:
+ ```python
+ from ultralytics import settings
+
+ # Update a setting
+ settings.update({"mlflow": True})
+
+ # Reset settings to default values
+ settings.reset()
+ ```
+
+ === "CLI"
+
+ If you prefer using the command-line interface, the following commands will allow you to modify your settings:
+ ```bash
+ # Update a setting
+ yolo settings runs_dir='/path/to/runs'
+
+ # Reset settings to default values
+ yolo settings reset
+ ```
+
+## How to Use
+
+### Commands
+
+1. **Set a Project Name**: You can set the project name via an environment variable:
+
+ ```bash
+ export MLFLOW_EXPERIMENT_NAME=
+
+## Introduction
+
+Experiment logging is a crucial aspect of machine learning workflows that enables tracking of various metrics, parameters, and artifacts. It helps to enhance model reproducibility, debug issues, and improve model performance. [Ultralytics](https://ultralytics.com) YOLO, known for its real-time object detection capabilities, now offers integration with [MLflow](https://mlflow.org/), an open-source platform for complete machine learning lifecycle management.
+
+This documentation page is a comprehensive guide to setting up and utilizing the MLflow logging capabilities for your Ultralytics YOLO project.
+
+## What is MLflow?
+
+[MLflow](https://mlflow.org/) is an open-source platform developed by [Databricks](https://www.databricks.com/) for managing the end-to-end machine learning lifecycle. It includes tools for tracking experiments, packaging code into reproducible runs, and sharing and deploying models. MLflow is designed to work with any machine learning library and programming language.
+
+## Features
+
+- **Metrics Logging**: Logs metrics at the end of each epoch and at the end of the training.
+- **Parameter Logging**: Logs all the parameters used in the training.
+- **Artifacts Logging**: Logs model artifacts, including weights and configuration files, at the end of the training.
+
+## Setup and Prerequisites
+
+Ensure MLflow is installed. If not, install it using pip:
+
+```bash
+pip install mlflow
+```
+
+Make sure that MLflow logging is enabled in Ultralytics settings. Usually, this is controlled by the settings `mflow` key. See the [settings](../quickstart.md#ultralytics-settings) page for more info.
+
+!!! Example "Update Ultralytics MLflow Settings"
+
+ === "Python"
+
+ Within the Python environment, call the `update` method on the `settings` object to change your settings:
+ ```python
+ from ultralytics import settings
+
+ # Update a setting
+ settings.update({"mlflow": True})
+
+ # Reset settings to default values
+ settings.reset()
+ ```
+
+ === "CLI"
+
+ If you prefer using the command-line interface, the following commands will allow you to modify your settings:
+ ```bash
+ # Update a setting
+ yolo settings runs_dir='/path/to/runs'
+
+ # Reset settings to default values
+ yolo settings reset
+ ```
+
+## How to Use
+
+### Commands
+
+1. **Set a Project Name**: You can set the project name via an environment variable:
+
+ ```bash
+ export MLFLOW_EXPERIMENT_NAME= +
+3. **View Run**: Runs are individual models inside an experiment. Click on a Run and see the Run details, including uploaded artifacts and model weights.
+
+3. **View Run**: Runs are individual models inside an experiment. Click on a Run and see the Run details, including uploaded artifacts and model weights.  +
+## Disabling MLflow
+
+To turn off MLflow logging:
+
+```bash
+yolo settings mlflow=False
+```
+
+## Conclusion
+
+MLflow logging integration with Ultralytics YOLO offers a streamlined way to keep track of your machine learning experiments. It empowers you to monitor performance metrics and manage artifacts effectively, thus aiding in robust model development and deployment. For further details please visit the MLflow [official documentation](https://mlflow.org/docs/latest/index.html).
+
+## FAQ
+
+### How do I set up MLflow logging with Ultralytics YOLO?
+
+To set up MLflow logging with Ultralytics YOLO, you first need to ensure MLflow is installed. You can install it using pip:
+
+```bash
+pip install mlflow
+```
+
+Next, enable MLflow logging in Ultralytics settings. This can be controlled using the `mlflow` key. For more information, see the [settings guide](../quickstart.md#ultralytics-settings).
+
+!!! Example "Update Ultralytics MLflow Settings"
+
+ === "Python"
+
+ ```python
+ from ultralytics import settings
+
+ # Update a setting
+ settings.update({"mlflow": True})
+
+ # Reset settings to default values
+ settings.reset()
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Update a setting
+ yolo settings runs_dir='/path/to/runs'
+
+ # Reset settings to default values
+ yolo settings reset
+ ```
+
+Finally, start a local MLflow server for tracking:
+
+```bash
+mlflow server --backend-store-uri runs/mlflow
+```
+
+### What metrics and parameters can I log using MLflow with Ultralytics YOLO?
+
+Ultralytics YOLO with MLflow supports logging various metrics, parameters, and artifacts throughout the training process:
+
+- **Metrics Logging**: Tracks metrics at the end of each epoch and upon training completion.
+- **Parameter Logging**: Logs all parameters used in the training process.
+- **Artifacts Logging**: Saves model artifacts like weights and configuration files after training.
+
+For more detailed information, visit the [Ultralytics YOLO tracking documentation](#features).
+
+### Can I disable MLflow logging once it is enabled?
+
+Yes, you can disable MLflow logging for Ultralytics YOLO by updating the settings. Here's how you can do it using the CLI:
+
+```bash
+yolo settings mlflow=False
+```
+
+For further customization and resetting settings, refer to the [settings guide](../quickstart.md#ultralytics-settings).
+
+### How can I start and stop an MLflow server for Ultralytics YOLO tracking?
+
+To start an MLflow server for tracking your experiments in Ultralytics YOLO, use the following command:
+
+```bash
+mlflow server --backend-store-uri runs/mlflow
+```
+
+This command starts a local server at http://127.0.0.1:5000 by default. If you need to stop running MLflow server instances, use the following bash command:
+
+```bash
+ps aux | grep 'mlflow' | grep -v 'grep' | awk '{print $2}' | xargs kill -9
+```
+
+Refer to the [commands section](#commands) for more command options.
+
+### What are the benefits of integrating MLflow with Ultralytics YOLO for experiment tracking?
+
+Integrating MLflow with Ultralytics YOLO offers several benefits for managing your machine learning experiments:
+
+- **Enhanced Experiment Tracking**: Easily track and compare different runs and their outcomes.
+- **Improved Model Reproducibility**: Ensure that your experiments are reproducible by logging all parameters and artifacts.
+- **Performance Monitoring**: Visualize performance metrics over time to make data-driven decisions for model improvements.
+
+For an in-depth look at setting up and leveraging MLflow with Ultralytics YOLO, explore the [MLflow Integration for Ultralytics YOLO](#introduction) documentation.
diff --git a/ultralytics/docs/en/integrations/ncnn.md b/ultralytics/docs/en/integrations/ncnn.md
new file mode 100644
index 0000000000000000000000000000000000000000..05da32280cdbc980847d39084891ac873012ff57
--- /dev/null
+++ b/ultralytics/docs/en/integrations/ncnn.md
@@ -0,0 +1,186 @@
+---
+comments: true
+description: Optimize YOLOv8 models for mobile and embedded devices by exporting to NCNN format. Enhance performance in resource-constrained environments.
+keywords: Ultralytics, YOLOv8, NCNN, model export, machine learning, deployment, mobile, embedded systems, deep learning, AI models
+---
+
+# How to Export to NCNN from YOLOv8 for Smooth Deployment
+
+Deploying computer vision models on devices with limited computational power, such as mobile or embedded systems, can be tricky. You need to make sure you use a format optimized for optimal performance. This makes sure that even devices with limited processing power can handle advanced computer vision tasks well.
+
+The export to NCNN format feature allows you to optimize your [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics) models for lightweight device-based applications. In this guide, we'll walk you through how to convert your models to the NCNN format, making it easier for your models to perform well on various mobile and embedded devices.
+
+## Why should you export to NCNN?
+
+
+
+## Disabling MLflow
+
+To turn off MLflow logging:
+
+```bash
+yolo settings mlflow=False
+```
+
+## Conclusion
+
+MLflow logging integration with Ultralytics YOLO offers a streamlined way to keep track of your machine learning experiments. It empowers you to monitor performance metrics and manage artifacts effectively, thus aiding in robust model development and deployment. For further details please visit the MLflow [official documentation](https://mlflow.org/docs/latest/index.html).
+
+## FAQ
+
+### How do I set up MLflow logging with Ultralytics YOLO?
+
+To set up MLflow logging with Ultralytics YOLO, you first need to ensure MLflow is installed. You can install it using pip:
+
+```bash
+pip install mlflow
+```
+
+Next, enable MLflow logging in Ultralytics settings. This can be controlled using the `mlflow` key. For more information, see the [settings guide](../quickstart.md#ultralytics-settings).
+
+!!! Example "Update Ultralytics MLflow Settings"
+
+ === "Python"
+
+ ```python
+ from ultralytics import settings
+
+ # Update a setting
+ settings.update({"mlflow": True})
+
+ # Reset settings to default values
+ settings.reset()
+ ```
+
+ === "CLI"
+
+ ```bash
+ # Update a setting
+ yolo settings runs_dir='/path/to/runs'
+
+ # Reset settings to default values
+ yolo settings reset
+ ```
+
+Finally, start a local MLflow server for tracking:
+
+```bash
+mlflow server --backend-store-uri runs/mlflow
+```
+
+### What metrics and parameters can I log using MLflow with Ultralytics YOLO?
+
+Ultralytics YOLO with MLflow supports logging various metrics, parameters, and artifacts throughout the training process:
+
+- **Metrics Logging**: Tracks metrics at the end of each epoch and upon training completion.
+- **Parameter Logging**: Logs all parameters used in the training process.
+- **Artifacts Logging**: Saves model artifacts like weights and configuration files after training.
+
+For more detailed information, visit the [Ultralytics YOLO tracking documentation](#features).
+
+### Can I disable MLflow logging once it is enabled?
+
+Yes, you can disable MLflow logging for Ultralytics YOLO by updating the settings. Here's how you can do it using the CLI:
+
+```bash
+yolo settings mlflow=False
+```
+
+For further customization and resetting settings, refer to the [settings guide](../quickstart.md#ultralytics-settings).
+
+### How can I start and stop an MLflow server for Ultralytics YOLO tracking?
+
+To start an MLflow server for tracking your experiments in Ultralytics YOLO, use the following command:
+
+```bash
+mlflow server --backend-store-uri runs/mlflow
+```
+
+This command starts a local server at http://127.0.0.1:5000 by default. If you need to stop running MLflow server instances, use the following bash command:
+
+```bash
+ps aux | grep 'mlflow' | grep -v 'grep' | awk '{print $2}' | xargs kill -9
+```
+
+Refer to the [commands section](#commands) for more command options.
+
+### What are the benefits of integrating MLflow with Ultralytics YOLO for experiment tracking?
+
+Integrating MLflow with Ultralytics YOLO offers several benefits for managing your machine learning experiments:
+
+- **Enhanced Experiment Tracking**: Easily track and compare different runs and their outcomes.
+- **Improved Model Reproducibility**: Ensure that your experiments are reproducible by logging all parameters and artifacts.
+- **Performance Monitoring**: Visualize performance metrics over time to make data-driven decisions for model improvements.
+
+For an in-depth look at setting up and leveraging MLflow with Ultralytics YOLO, explore the [MLflow Integration for Ultralytics YOLO](#introduction) documentation.
diff --git a/ultralytics/docs/en/integrations/ncnn.md b/ultralytics/docs/en/integrations/ncnn.md
new file mode 100644
index 0000000000000000000000000000000000000000..05da32280cdbc980847d39084891ac873012ff57
--- /dev/null
+++ b/ultralytics/docs/en/integrations/ncnn.md
@@ -0,0 +1,186 @@
+---
+comments: true
+description: Optimize YOLOv8 models for mobile and embedded devices by exporting to NCNN format. Enhance performance in resource-constrained environments.
+keywords: Ultralytics, YOLOv8, NCNN, model export, machine learning, deployment, mobile, embedded systems, deep learning, AI models
+---
+
+# How to Export to NCNN from YOLOv8 for Smooth Deployment
+
+Deploying computer vision models on devices with limited computational power, such as mobile or embedded systems, can be tricky. You need to make sure you use a format optimized for optimal performance. This makes sure that even devices with limited processing power can handle advanced computer vision tasks well.
+
+The export to NCNN format feature allows you to optimize your [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics) models for lightweight device-based applications. In this guide, we'll walk you through how to convert your models to the NCNN format, making it easier for your models to perform well on various mobile and embedded devices.
+
+## Why should you export to NCNN?
+
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+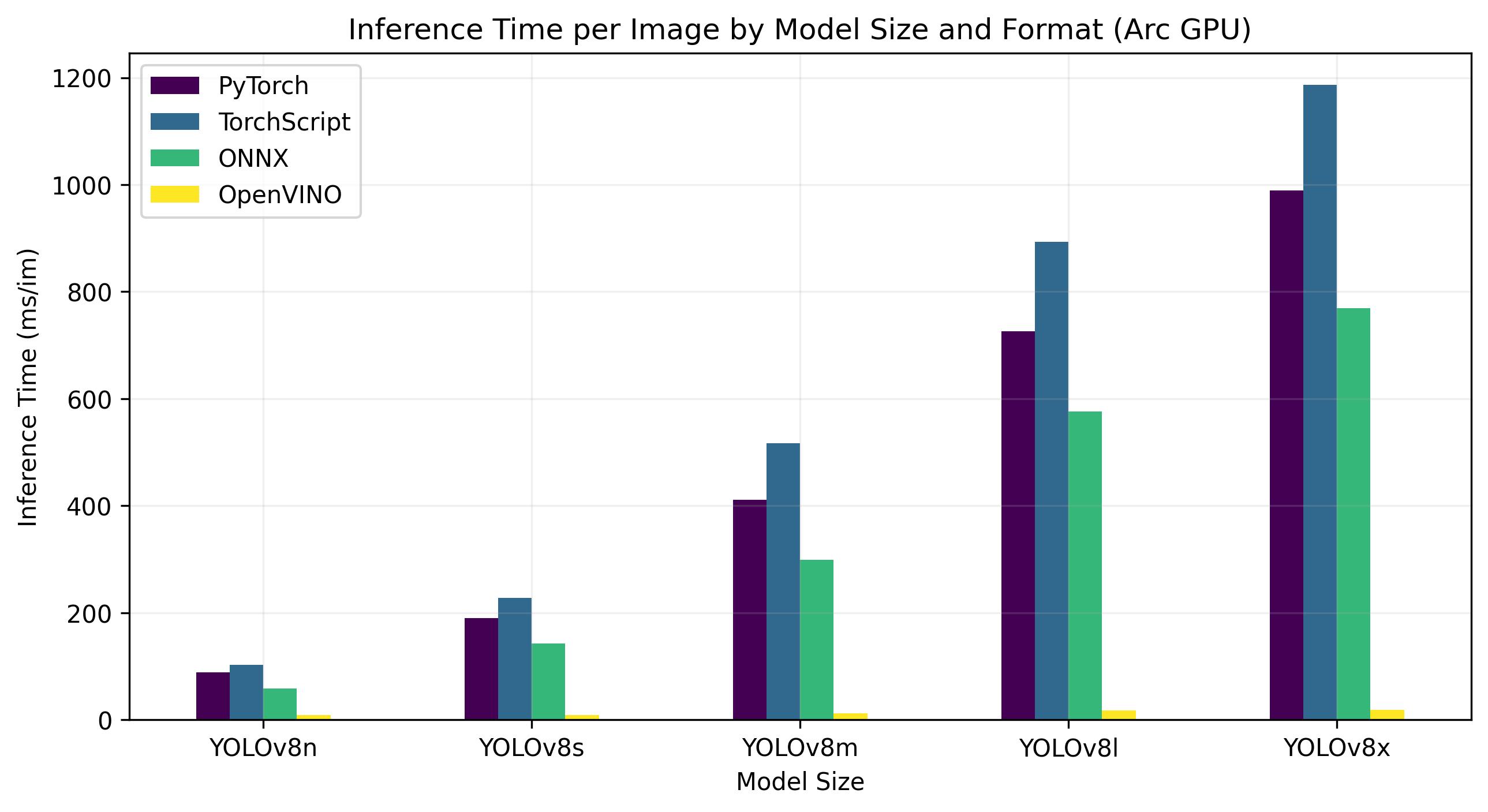 +
+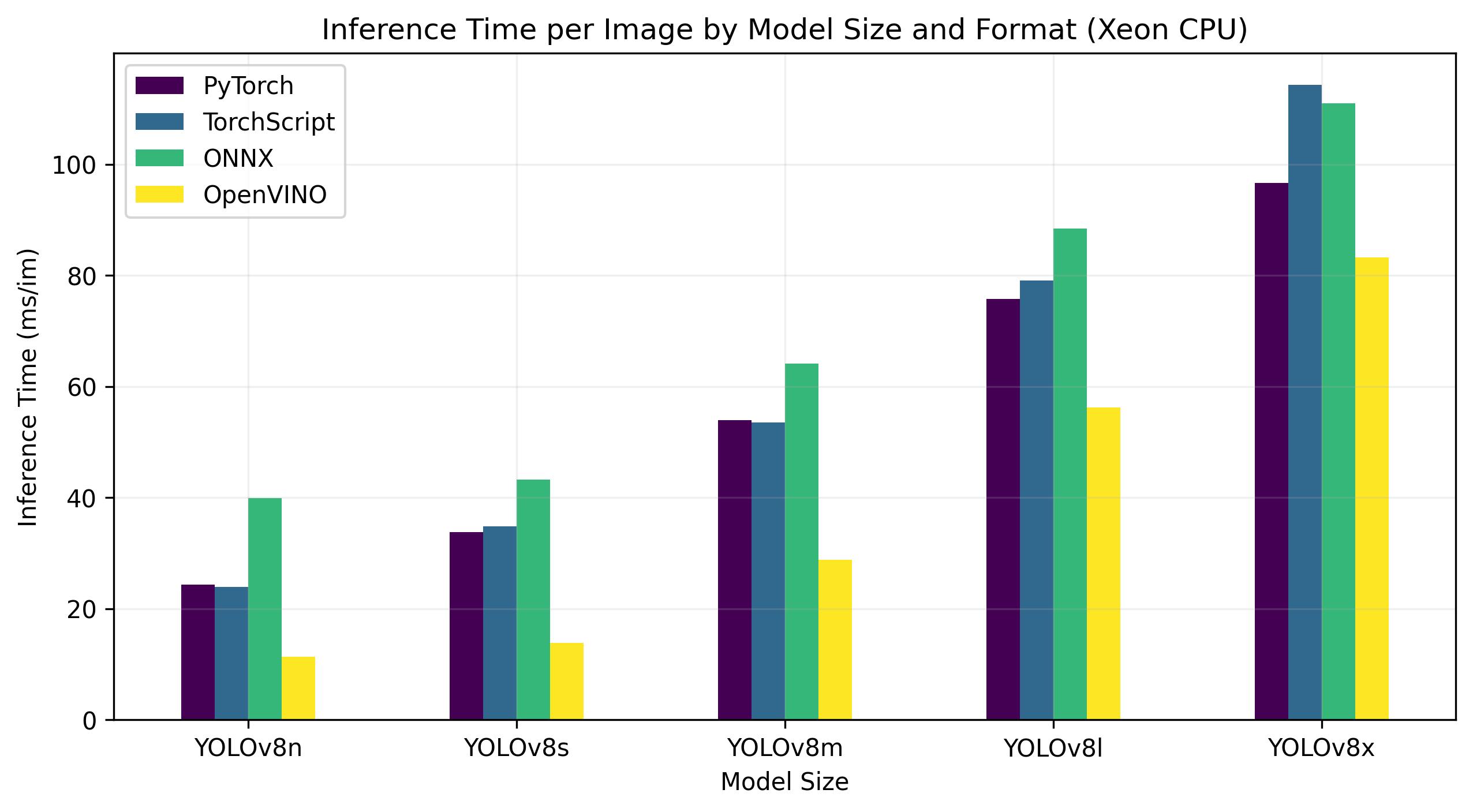 +
+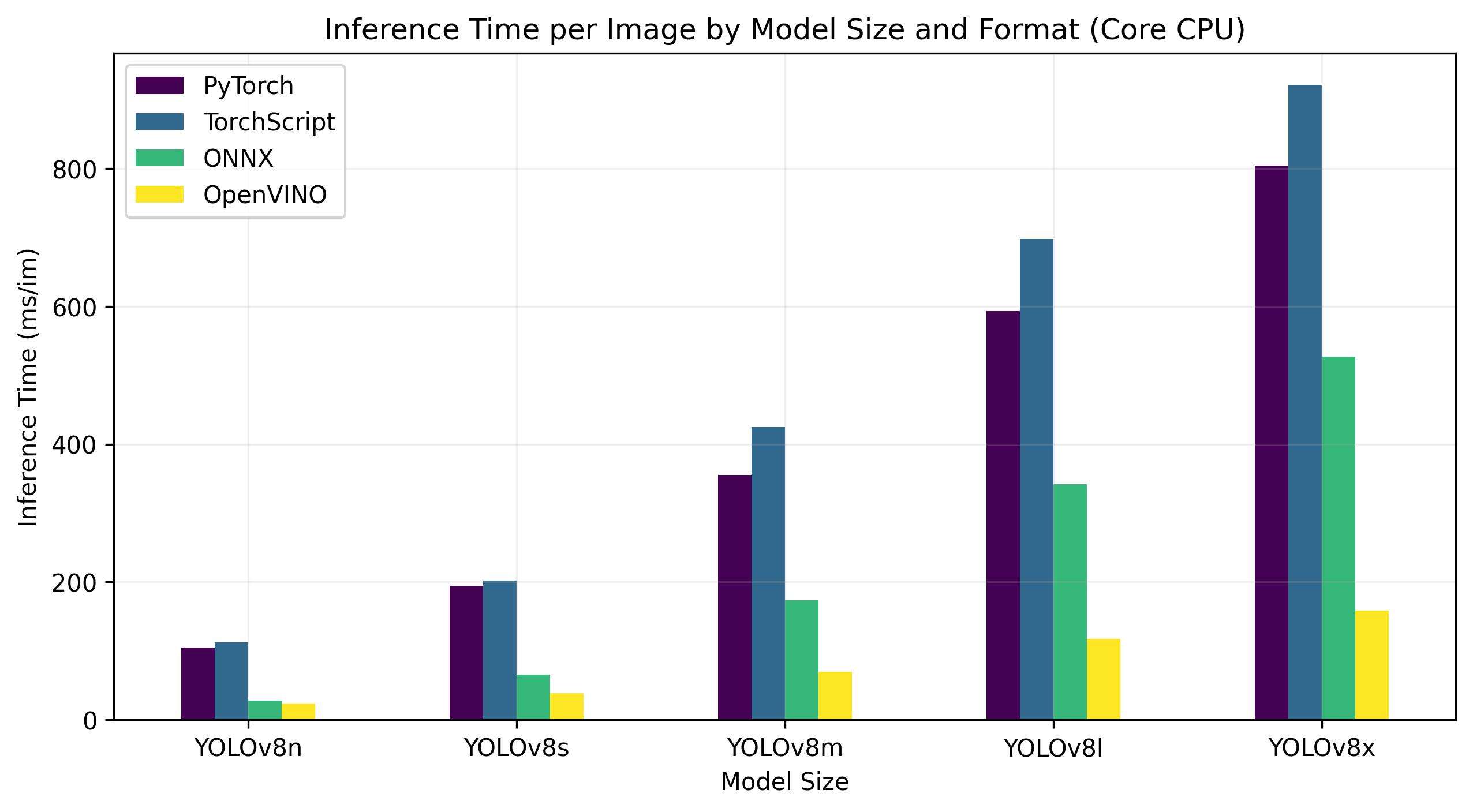 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+Object tracking in the realm of video analytics is a critical task that not only identifies the location and class of objects within the frame but also maintains a unique ID for each detected object as the video progresses. The applications are limitless—ranging from surveillance and security to real-time sports analytics.
+
+## Why Choose Ultralytics YOLO for Object Tracking?
+
+The output from Ultralytics trackers is consistent with standard object detection but has the added value of object IDs. This makes it easy to track objects in video streams and perform subsequent analytics. Here's why you should consider using Ultralytics YOLO for your object tracking needs:
+
+- **Efficiency:** Process video streams in real-time without compromising accuracy.
+- **Flexibility:** Supports multiple tracking algorithms and configurations.
+- **Ease of Use:** Simple Python API and CLI options for quick integration and deployment.
+- **Customizability:** Easy to use with custom trained YOLO models, allowing integration into domain-specific applications.
+
+
+
+Object tracking in the realm of video analytics is a critical task that not only identifies the location and class of objects within the frame but also maintains a unique ID for each detected object as the video progresses. The applications are limitless—ranging from surveillance and security to real-time sports analytics.
+
+## Why Choose Ultralytics YOLO for Object Tracking?
+
+The output from Ultralytics trackers is consistent with standard object detection but has the added value of object IDs. This makes it easy to track objects in video streams and perform subsequent analytics. Here's why you should consider using Ultralytics YOLO for your object tracking needs:
+
+- **Efficiency:** Process video streams in real-time without compromising accuracy.
+- **Flexibility:** Supports multiple tracking algorithms and configurations.
+- **Ease of Use:** Simple Python API and CLI options for quick integration and deployment.
+- **Customizability:** Easy to use with custom trained YOLO models, allowing integration into domain-specific applications.
+
+
