# Amphion Text-to-Audio (TTA) Recipe
## Quick Start
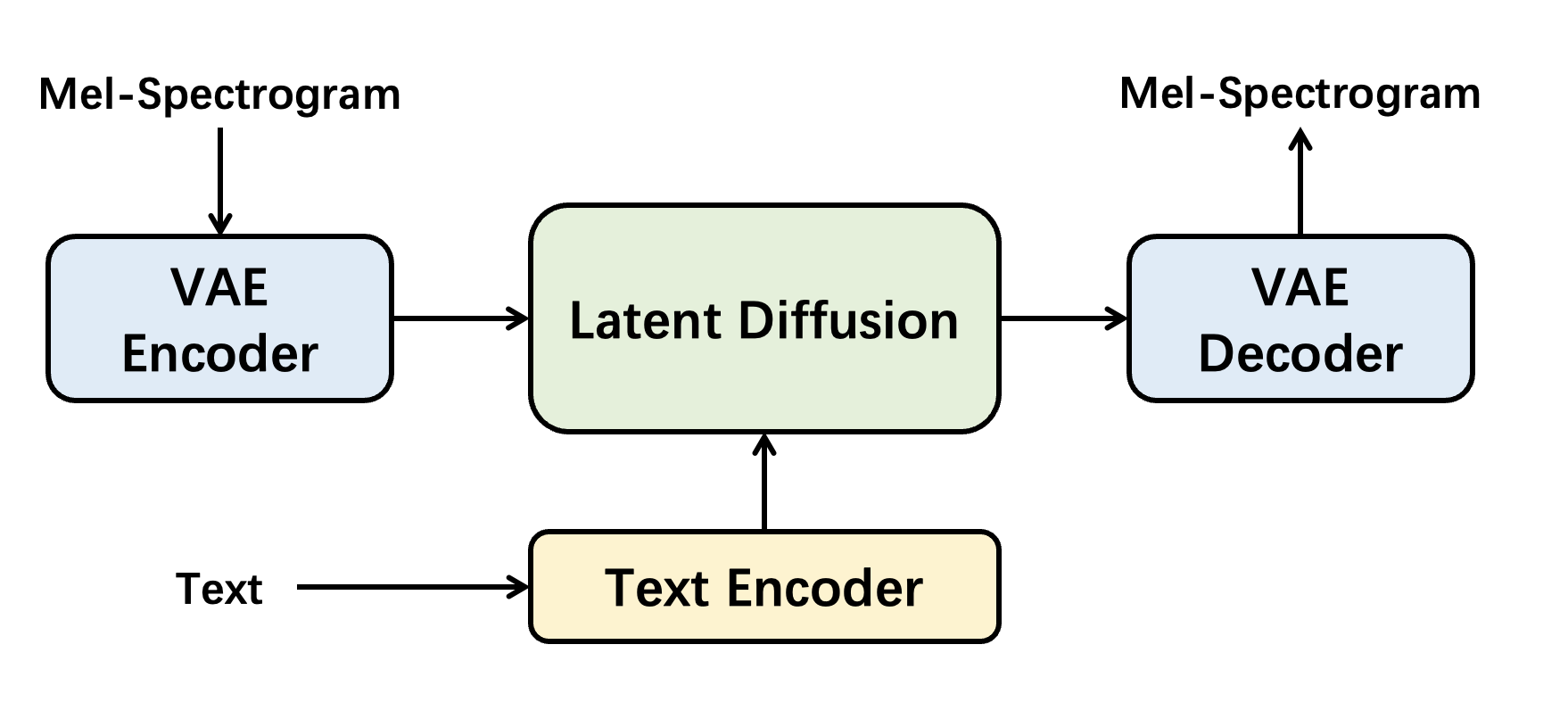
We provide a **[beginner recipe](RECIPE.md)** to demonstrate how to train a cutting edge TTA model. Specifically, it is designed as a latent diffusion model like [AudioLDM](https://arxiv.org/abs/2301.12503), [Make-an-Audio](https://arxiv.org/abs/2301.12661), and [AUDIT](https://arxiv.org/abs/2304.00830).
## Supported Model Architectures
Until now, Amphion has supported a latent diffusion based text-to-audio model:
Similar to [AUDIT](https://arxiv.org/abs/2304.00830), we implement it in two-stage training:
1. Training the VAE which is called `AutoencoderKL` in Amphion.
2. Training the conditional latent diffusion model which is called `AudioLDM` in Amphion.