\n",
"
\n",
"
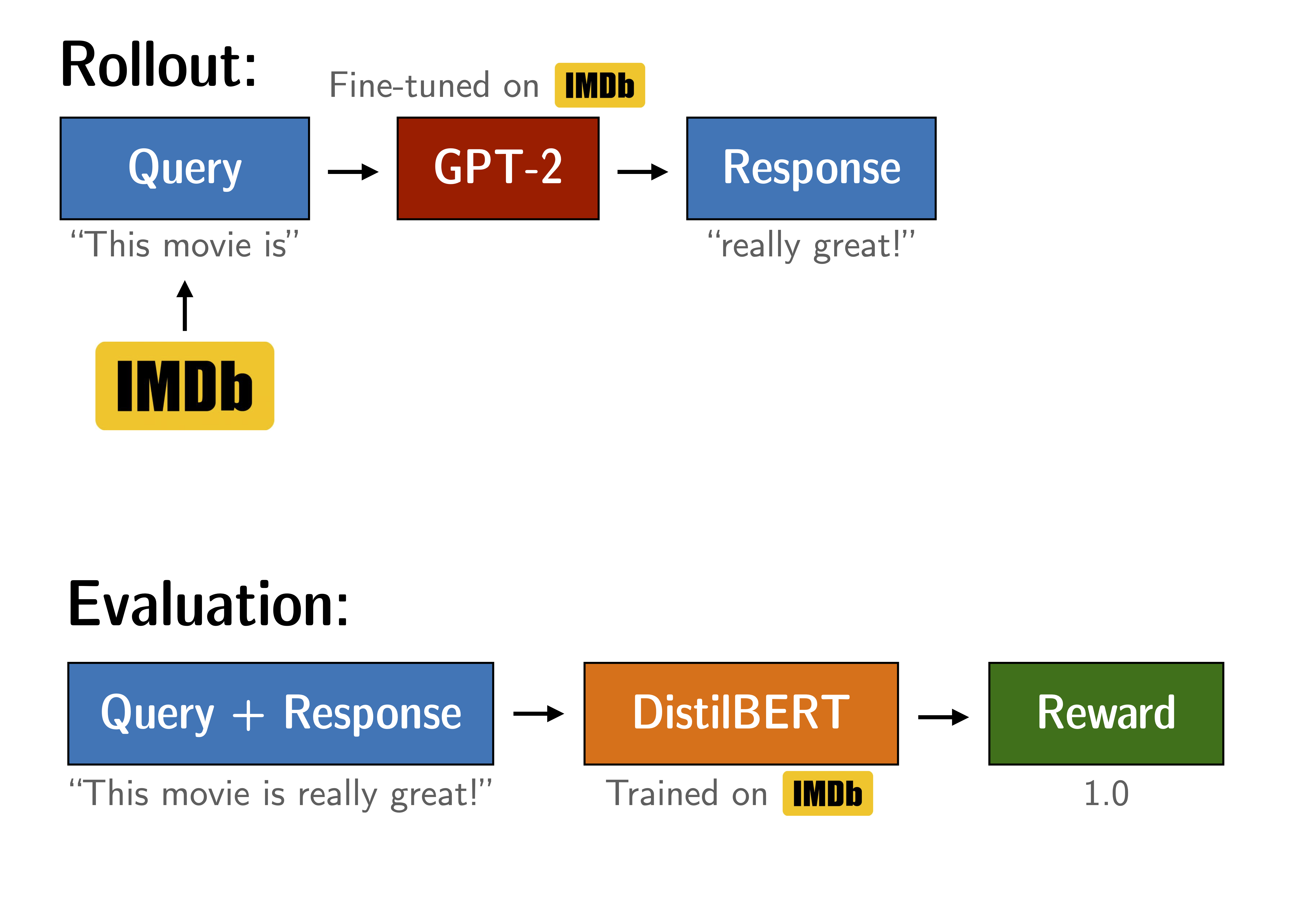
Figure: Experiment setup to tune GPT2. The yellow arrows are outside the scope of this notebook, but the trained models are available through Hugging Face.
\n",
"
 \n",
"
\n",
"