# 技术报告 v1.0.0
在2024年3月,我们推出了Open-Sora-Plan,一个旨在复现OpenAI [Sora](https://openai.com/sora)的开源计划。它作为一个基础的开源框架,能够训练视频生成模型包括无条件视频生成,类别引导视频生成,文生视频。
**今天,我们兴奋地展示Open-Sora-Plan v1.0.0,极大地改进视频生成质量、文本控制能力。**
相比于之前的视频生成模型,Open-Sora-Plan v1.0.0 有以下的改进:
1. **CausalVideoVAE高效的训练与推理**。 我们用4×8×8的对视频进行时间和空间的压缩。
2. **图片视频联合训练提升视觉质量**。 CasualVideoVAE 将首帧看作图片,天然支持同时编码图片和视频。这允许扩散模型提取更多时空细节来改善质量。
### Open-Source Release
我们开源了Open-Sora-Plan去促进视频生成社区的进一步发展。公开代码、数据、模型。
- 在线演示:Hugging Face [](https://huggingface.co/spaces/LanguageBind/Open-Sora-Plan-v1.0.0), [](https://replicate.com/camenduru/open-sora-plan-512x512) 和 [](https://colab.research.google.com/github/camenduru/Open-Sora-Plan-jupyter/blob/main/Open_Sora_Plan_jupyter.ipynb), 感谢[@camenduru](https://github.com/camenduru)大力支持我们的工作!🤝
- 代码:所有训练脚本和采样代码。
- 模型:包括扩散模型和CausalVideoVAE [这里](https://huggingface.co/LanguageBind/Open-Sora-Plan-v1.0.0)。
- 数据:所有原视频和对应描述 [这里](https://huggingface.co/datasets/LanguageBind/Open-Sora-Plan-v1.0.0)。
## 效果
Open-Sora-Plan v1.0.0支持图片视频联合训练。我们在此展示视频和图片的重建以及生成:
720×1280**视频重建**。 因为github的限制,原视频放在: [1](https://streamable.com/gqojal), [2](https://streamable.com/6nu3j8).
https://github.com/PKU-YuanGroup/Open-Sora-Plan/assets/88202804/c100bb02-2420-48a3-9d7b-4608a41f14aa
https://github.com/PKU-YuanGroup/Open-Sora-Plan/assets/88202804/8aa8f587-d9f1-4e8b-8a82-d3bf9ba91d68
1536×1024**图片重建**

 65×1024×1024**文生视频**
https://github.com/PKU-YuanGroup/Open-Sora-Plan/assets/62638829/2641a8aa-66ac-4cda-8279-86b2e6a6e011
65×512×512**文生视频**
https://github.com/PKU-YuanGroup/Open-Sora-Plan/assets/62638829/37e3107e-56b3-4b09-8920-fa1d8d144b9e
512×512**文生视频**

## 详细技术报告
### CausalVideoVAE
#### 模型结构

因果VAE架构继承了[Stable-Diffusion Image VAE](https://github.com/CompVis/stable-diffusion/tree/main)。 为了保证图片VAE的预训练权重可以无缝运用到视频VAE中,模型结构采取如下设计:
1. **CausalConv3D**: 将Conv2D 转变成CausalConv3D可以实现图片和视频的联合训练. CausalConv3D 对第一帧进行特殊处理,因为它无法访问后续帧。对于更多细节,请参考https://github.com/PKU-YuanGroup/Open-Sora-Plan/pull/145
2. **初始化**:将Conv2D扩展到Conv3D常用的[方法](https://github.com/hassony2/inflated_convnets_pytorch/blob/master/src/inflate.py#L5)有两种:平均初始化和中心初始化。 但我们采用了特定的初始化方法(尾部初始化)。 这种初始化方法确保模型无需任何训练就能够直接重建图像,甚至视频。
#### 训练细节
65×1024×1024**文生视频**
https://github.com/PKU-YuanGroup/Open-Sora-Plan/assets/62638829/2641a8aa-66ac-4cda-8279-86b2e6a6e011
65×512×512**文生视频**
https://github.com/PKU-YuanGroup/Open-Sora-Plan/assets/62638829/37e3107e-56b3-4b09-8920-fa1d8d144b9e
512×512**文生视频**

## 详细技术报告
### CausalVideoVAE
#### 模型结构

因果VAE架构继承了[Stable-Diffusion Image VAE](https://github.com/CompVis/stable-diffusion/tree/main)。 为了保证图片VAE的预训练权重可以无缝运用到视频VAE中,模型结构采取如下设计:
1. **CausalConv3D**: 将Conv2D 转变成CausalConv3D可以实现图片和视频的联合训练. CausalConv3D 对第一帧进行特殊处理,因为它无法访问后续帧。对于更多细节,请参考https://github.com/PKU-YuanGroup/Open-Sora-Plan/pull/145
2. **初始化**:将Conv2D扩展到Conv3D常用的[方法](https://github.com/hassony2/inflated_convnets_pytorch/blob/master/src/inflate.py#L5)有两种:平均初始化和中心初始化。 但我们采用了特定的初始化方法(尾部初始化)。 这种初始化方法确保模型无需任何训练就能够直接重建图像,甚至视频。
#### 训练细节
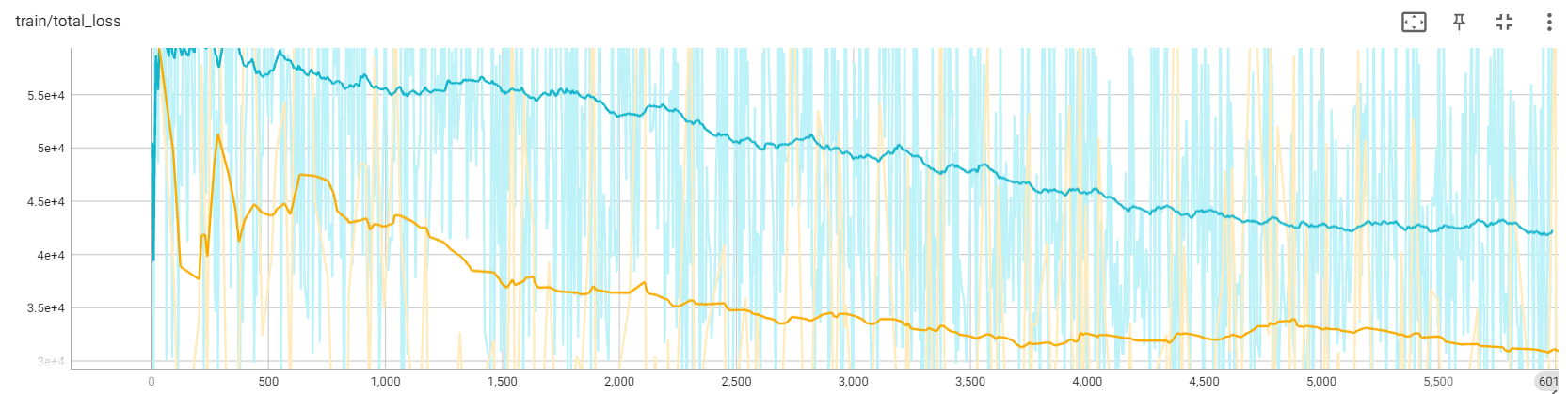 我们展示了 17×256×256 下两种不同初始化方法的损失曲线。黄色曲线代表使用尾部初始化的损失,而蓝色曲线对应中心初始化的损失。 如图所示,尾部初始化在损失曲线上表现出更好的性能。 此外,我们发现中心初始化会导致错误累积,导致长时间内崩溃。
#### 推理技巧
尽管训练Diffusion中VAE始终是冻住的,我们仍然无法负担CasualVideoVAE的花销。在我们的实验中, 80G的显存只能够在半精度下推理一个256×512×512或32×1024×1024的视频 ,这限制了我们扩展到更长更高清的视频。因此我们采用tile convolution,能够以几乎恒定的内存推理任意时长或任意分辨率的视频。
### 数据构建
我们定义高质量的视频数据集包括两个核心法则:(1) 没有与内容无关的水印。(2) 高质量的文本注释。
**对于法则1**,我们从开源网站(CC0协议)爬取了大约40k videos:1234个来自[mixkit](https://mixkit.co/),7408个来自[pexels](https://www.pexels.com/),31616个来自[pixabay](https://pixabay.com/)。我们根据[Panda70M](https://github.com/snap-research/Panda-70M/blob/main/splitting/README.md)提供的场景变换剪切script将这些视频切成大约434k video clips。事实上,根据我们的剪切结果,从这些网上上爬取的99%的视频都是单一的场景。另外,我们发现爬取的数据中超过60%为风景相关视频。更多细节可以在[这](https://github.com/PKU-YuanGroup/Open-Sora-Dataset)找到。
**对于法则2**,很难有大量的高质量的文本注释能够从网上直接爬取。因此我们用成熟的图片标注模型来获取高质量的稠密描述。我们对2个多模态大模型进行消融实验:[ShareGPT4V-Captioner-7B](https://github.com/InternLM/InternLM-XComposer/blob/main/projects/ShareGPT4V/README.md) 和 [LLaVA-1.6-34B](https://github.com/haotian-liu/LLaVA)。前者是专门用来制作文本注释的模型,而后者是一个通用的多模态大模型。经过我们的消融实验,他们在caption的表现差不多。然而他们的推理速度在A800上差距很大:40s/it of batch size of 12 for ShareGPT4V-Captioner-7B,15s/it of batch size of 1 for ShareGPT4V-Captioner-7B。我们开源所有的[文本注释和原视频](https://huggingface.co/datasets/LanguageBind/Open-Sora-Plan-v1.0.0)。
| 模型名字 | 平均长度 | 最大值 | 标准差 |
|---|---|---|---|
| ShareGPT4V-Captioner-7B | 170.0827524529121 | 467 | 53.689967539537776 |
| LLaVA-1.6-34B | 141.75851073472666 | 472 | 48.52492072346965 |
### 训练扩散模型
与之前的工作类似,我们采用多阶段的级联的训练方法,总共消耗了2048个A800 GPU 小时。我们发现联合图片训练能够显著加速模型的收敛并且增强视觉观感,这与[Latte](https://github.com/Vchitect/Latte)一致。以下是我们的训练花销。
| 名字 | Stage 1 | Stage 2 | Stage 3 | Stage 4 |
|---|---|---|---|---|
| 训练视频尺寸 | 17×256×256 | 65×256×256 | 65×512×512 | 65×1024×1024 |
| 计算资源 (#A800 GPU x #小时) | 32 × 40 | 32 × 18 | 32 × 6 | 训练中 |
| 权重 | [HF](https://huggingface.co/LanguageBind/Open-Sora-Plan-v1.0.0/tree/main/17x256x256) | [HF](https://huggingface.co/LanguageBind/Open-Sora-Plan-v1.0.0/tree/main/65x256x256) | [HF](https://huggingface.co/LanguageBind/Open-Sora-Plan-v1.0.0/tree/main/65x512x512) | 训练中 |
| 日志 | [wandb](https://api.wandb.ai/links/linbin/p6n3evym) | [wandb](https://api.wandb.ai/links/linbin/t2g53sew) | [wandb](https://api.wandb.ai/links/linbin/uomr0xzb) | 训练中 |
| 训练数据 | ~40k videos | ~40k videos | ~40k videos | ~40k videos |
## 下版本预览
### CausalVideoVAE
目前我们发布的CausalVideoVAE v1.0.0版本存在2个主要的缺陷:**运动模糊**以及**网格效应**。我们对CasualVideoVAE做了一系列的改进使它推理成本更低且性能更强大,我们暂时叫它为预览版本,将在下个版本发布。
**1分钟720×1280视频重建**。 受限于GitHub,我们将原视频放在这:[原视频](https://streamable.com/u4onbb),[重建视频](https://streamable.com/qt8ncc)。
https://github.com/PKU-YuanGroup/Open-Sora-Plan/assets/88202804/cdcfa9a3-4de0-42d4-94c0-0669710e407b
我们从kinetic 400的验证集中随机选取100个样本进行评估,结果表如下所示:
| | SSIM↑ | LPIPS↓ | PSNR↑ | FLOLPIPS↓ |
|---|---|---|---|---|
| v1.0.0 | 0.829 | 0.106 | 27.171 | 0.119 |
| Preview | 0.877 | 0.064 | 29.695 | 0.070 |
#### 运动模糊
| **v1.0.0** | **预览版本** |
| --- | --- |
|  |  |
#### 网格效应
| **v1.0.0** | **预览版本** |
| --- | --- |
|  |  |
### 数据构建
**数据源**:正如上文提到,我们的数据集中超过60%为风景视频。这意味着我们的开域视频生成能力有限。然而当前的大规模开源数据集大多从YouTube爬取,尽管视频的数量多,但我们担忧视频本身的质量是否达标。因此,我们将继续收集高质量的数据集,同时也欢迎开源社区的推荐。
**Caption生成流程**:当我们训练时长增加时,我们不得不考虑更有效的视频caption生成方法,而不是多模态图片大模型。我们正在开发一个新的视频注释生成管线,它能够很好的支持长视频,敬请期待。
### 训练扩散模型
尽管目前v1.0.0展现了可喜的结果,但我们仍然离Sora有一段距离。在接下来的工作中,我们主要围绕这三个方面:
1. **动态分辨率与时长的训练**: 我们的目标是开发出能够以不同分辨率和持续时间训练模型的技术,使训练过程更加灵活、适应性更强。
2. **更长的视频生成**: 我们将探索扩展模型生成能力的方法,使其能够制作更长的视频,超越目前的限制。
3. **更多条件控制**: 我们力求增强模型的条件控制能力,为用户提供更多的选项和对生成视频的控制能力。
另外,通过仔细观察生成的视频,我们发现存在一些不符合常理的斑点或异常的流动,这是由于CasualVideoVAE的性能不足导致的 如上面提到。在未来的实验中,我们将使用更强的VAE,重新训练一个扩散模型。
我们展示了 17×256×256 下两种不同初始化方法的损失曲线。黄色曲线代表使用尾部初始化的损失,而蓝色曲线对应中心初始化的损失。 如图所示,尾部初始化在损失曲线上表现出更好的性能。 此外,我们发现中心初始化会导致错误累积,导致长时间内崩溃。
#### 推理技巧
尽管训练Diffusion中VAE始终是冻住的,我们仍然无法负担CasualVideoVAE的花销。在我们的实验中, 80G的显存只能够在半精度下推理一个256×512×512或32×1024×1024的视频 ,这限制了我们扩展到更长更高清的视频。因此我们采用tile convolution,能够以几乎恒定的内存推理任意时长或任意分辨率的视频。
### 数据构建
我们定义高质量的视频数据集包括两个核心法则:(1) 没有与内容无关的水印。(2) 高质量的文本注释。
**对于法则1**,我们从开源网站(CC0协议)爬取了大约40k videos:1234个来自[mixkit](https://mixkit.co/),7408个来自[pexels](https://www.pexels.com/),31616个来自[pixabay](https://pixabay.com/)。我们根据[Panda70M](https://github.com/snap-research/Panda-70M/blob/main/splitting/README.md)提供的场景变换剪切script将这些视频切成大约434k video clips。事实上,根据我们的剪切结果,从这些网上上爬取的99%的视频都是单一的场景。另外,我们发现爬取的数据中超过60%为风景相关视频。更多细节可以在[这](https://github.com/PKU-YuanGroup/Open-Sora-Dataset)找到。
**对于法则2**,很难有大量的高质量的文本注释能够从网上直接爬取。因此我们用成熟的图片标注模型来获取高质量的稠密描述。我们对2个多模态大模型进行消融实验:[ShareGPT4V-Captioner-7B](https://github.com/InternLM/InternLM-XComposer/blob/main/projects/ShareGPT4V/README.md) 和 [LLaVA-1.6-34B](https://github.com/haotian-liu/LLaVA)。前者是专门用来制作文本注释的模型,而后者是一个通用的多模态大模型。经过我们的消融实验,他们在caption的表现差不多。然而他们的推理速度在A800上差距很大:40s/it of batch size of 12 for ShareGPT4V-Captioner-7B,15s/it of batch size of 1 for ShareGPT4V-Captioner-7B。我们开源所有的[文本注释和原视频](https://huggingface.co/datasets/LanguageBind/Open-Sora-Plan-v1.0.0)。
| 模型名字 | 平均长度 | 最大值 | 标准差 |
|---|---|---|---|
| ShareGPT4V-Captioner-7B | 170.0827524529121 | 467 | 53.689967539537776 |
| LLaVA-1.6-34B | 141.75851073472666 | 472 | 48.52492072346965 |
### 训练扩散模型
与之前的工作类似,我们采用多阶段的级联的训练方法,总共消耗了2048个A800 GPU 小时。我们发现联合图片训练能够显著加速模型的收敛并且增强视觉观感,这与[Latte](https://github.com/Vchitect/Latte)一致。以下是我们的训练花销。
| 名字 | Stage 1 | Stage 2 | Stage 3 | Stage 4 |
|---|---|---|---|---|
| 训练视频尺寸 | 17×256×256 | 65×256×256 | 65×512×512 | 65×1024×1024 |
| 计算资源 (#A800 GPU x #小时) | 32 × 40 | 32 × 18 | 32 × 6 | 训练中 |
| 权重 | [HF](https://huggingface.co/LanguageBind/Open-Sora-Plan-v1.0.0/tree/main/17x256x256) | [HF](https://huggingface.co/LanguageBind/Open-Sora-Plan-v1.0.0/tree/main/65x256x256) | [HF](https://huggingface.co/LanguageBind/Open-Sora-Plan-v1.0.0/tree/main/65x512x512) | 训练中 |
| 日志 | [wandb](https://api.wandb.ai/links/linbin/p6n3evym) | [wandb](https://api.wandb.ai/links/linbin/t2g53sew) | [wandb](https://api.wandb.ai/links/linbin/uomr0xzb) | 训练中 |
| 训练数据 | ~40k videos | ~40k videos | ~40k videos | ~40k videos |
## 下版本预览
### CausalVideoVAE
目前我们发布的CausalVideoVAE v1.0.0版本存在2个主要的缺陷:**运动模糊**以及**网格效应**。我们对CasualVideoVAE做了一系列的改进使它推理成本更低且性能更强大,我们暂时叫它为预览版本,将在下个版本发布。
**1分钟720×1280视频重建**。 受限于GitHub,我们将原视频放在这:[原视频](https://streamable.com/u4onbb),[重建视频](https://streamable.com/qt8ncc)。
https://github.com/PKU-YuanGroup/Open-Sora-Plan/assets/88202804/cdcfa9a3-4de0-42d4-94c0-0669710e407b
我们从kinetic 400的验证集中随机选取100个样本进行评估,结果表如下所示:
| | SSIM↑ | LPIPS↓ | PSNR↑ | FLOLPIPS↓ |
|---|---|---|---|---|
| v1.0.0 | 0.829 | 0.106 | 27.171 | 0.119 |
| Preview | 0.877 | 0.064 | 29.695 | 0.070 |
#### 运动模糊
| **v1.0.0** | **预览版本** |
| --- | --- |
|  |  |
#### 网格效应
| **v1.0.0** | **预览版本** |
| --- | --- |
|  |  |
### 数据构建
**数据源**:正如上文提到,我们的数据集中超过60%为风景视频。这意味着我们的开域视频生成能力有限。然而当前的大规模开源数据集大多从YouTube爬取,尽管视频的数量多,但我们担忧视频本身的质量是否达标。因此,我们将继续收集高质量的数据集,同时也欢迎开源社区的推荐。
**Caption生成流程**:当我们训练时长增加时,我们不得不考虑更有效的视频caption生成方法,而不是多模态图片大模型。我们正在开发一个新的视频注释生成管线,它能够很好的支持长视频,敬请期待。
### 训练扩散模型
尽管目前v1.0.0展现了可喜的结果,但我们仍然离Sora有一段距离。在接下来的工作中,我们主要围绕这三个方面:
1. **动态分辨率与时长的训练**: 我们的目标是开发出能够以不同分辨率和持续时间训练模型的技术,使训练过程更加灵活、适应性更强。
2. **更长的视频生成**: 我们将探索扩展模型生成能力的方法,使其能够制作更长的视频,超越目前的限制。
3. **更多条件控制**: 我们力求增强模型的条件控制能力,为用户提供更多的选项和对生成视频的控制能力。
另外,通过仔细观察生成的视频,我们发现存在一些不符合常理的斑点或异常的流动,这是由于CasualVideoVAE的性能不足导致的 如上面提到。在未来的实验中,我们将使用更强的VAE,重新训练一个扩散模型。