Spaces:
Runtime error

Runtime error
PR ENT
commited on
Commit
•
88d8172
1
Parent(s):
b5f706a
Push dashboard
Browse files- PR_ENT.py +165 -0
- README.md +4 -3
- helpers.py +234 -0
- pages/Actor_Target.py +107 -0
- pipeline_flow.png +0 -0
- pipeline_qa.png +0 -0
- requirements.txt +8 -0
PR_ENT.py
ADDED
|
@@ -0,0 +1,165 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
|
| 3 |
+
from PIL import Image
|
| 4 |
+
|
| 5 |
+
from transformers import pipeline
|
| 6 |
+
import nltk
|
| 7 |
+
import spacy
|
| 8 |
+
import en_core_web_lg
|
| 9 |
+
|
| 10 |
+
from helpers import prompt_to_nli, display_nli_pr_results_as_list
|
| 11 |
+
|
| 12 |
+
@st.cache()
|
| 13 |
+
def download_punkt():
|
| 14 |
+
nltk.download('punkt')
|
| 15 |
+
|
| 16 |
+
@st.cache(allow_output_mutation=True)
|
| 17 |
+
def load_spacy_pipeline():
|
| 18 |
+
return en_core_web_lg.load()
|
| 19 |
+
|
| 20 |
+
def choose_text_menu(text):
|
| 21 |
+
if 'text' not in st.session_state:
|
| 22 |
+
st.session_state.text = 'Several demonstrators were injured.'
|
| 23 |
+
text = st.text_area('Event description', st.session_state.text)
|
| 24 |
+
|
| 25 |
+
return text
|
| 26 |
+
|
| 27 |
+
# Load Models in cache
|
| 28 |
+
|
| 29 |
+
@st.cache(allow_output_mutation=True)
|
| 30 |
+
def load_model_prompting():
|
| 31 |
+
return pipeline("fill-mask", model="distilbert-base-uncased")
|
| 32 |
+
|
| 33 |
+
@st.cache(allow_output_mutation=True)
|
| 34 |
+
def load_model_nli():
|
| 35 |
+
return pipeline(task="sentiment-analysis", model="roberta-large-mnli")
|
| 36 |
+
|
| 37 |
+
download_punkt()
|
| 38 |
+
nlp = load_spacy_pipeline()
|
| 39 |
+
|
| 40 |
+
### App START
|
| 41 |
+
st.markdown("""# Rethinking the Event Coding Pipeline with Prompt Entailment
|
| 42 |
+
## Author: Anonymized for submission""")
|
| 43 |
+
st.markdown("""
|
| 44 |
+
### 1. PR-ENT summary
|
| 45 |
+
""")
|
| 46 |
+
|
| 47 |
+
@st.cache()
|
| 48 |
+
def load_prent_image():
|
| 49 |
+
return Image.open('pipeline_flow.png')
|
| 50 |
+
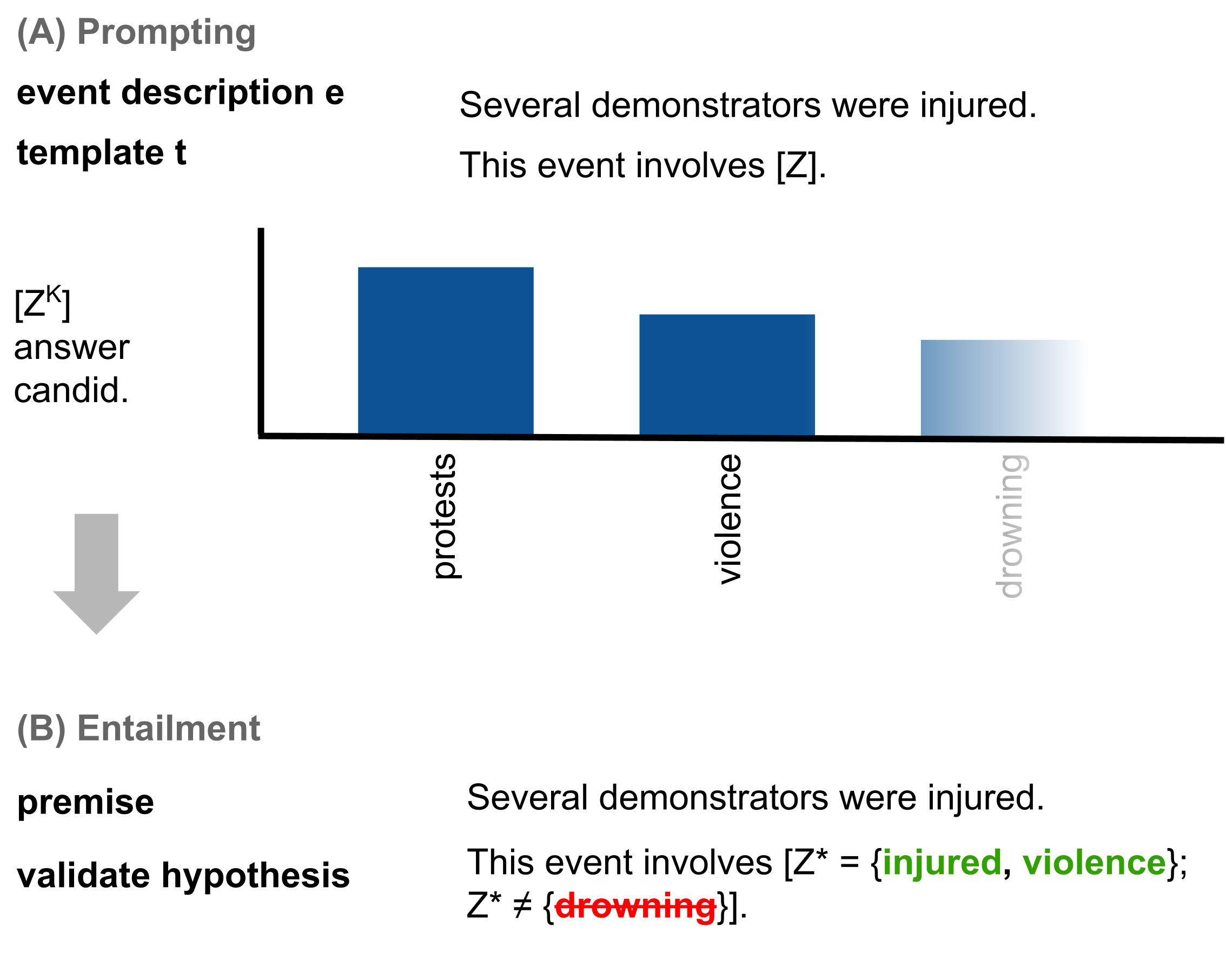
st.image(load_prent_image(), caption="""PR-ENT Flow. First, we concatenate the event description e and the template t. Then we feed them through a pretrained
|
| 51 |
+
prompting model to obtain a list of answer candidates. Then, for each answer candidate we build a
|
| 52 |
+
hypothesis by filling the template and check for entailment with the premise (the event description).
|
| 53 |
+
Finally, by filtering on the entailment score, we obtain a list of entailed answer candidates related to the event description.
|
| 54 |
+
""")
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
model_nli = load_model_nli()
|
| 59 |
+
model_prompting = load_model_prompting()
|
| 60 |
+
|
| 61 |
+
st.markdown("""
|
| 62 |
+
### 2. Write an event description:
|
| 63 |
+
The first step is to write an event description that will be fed to the pipeline. This can be any text in English.
|
| 64 |
+
""")
|
| 65 |
+
text = choose_text_menu('')
|
| 66 |
+
st.session_state.text = text
|
| 67 |
+
|
| 68 |
+
st.markdown("""
|
| 69 |
+
### 3. Template design:
|
| 70 |
+
The second step is to design a template while keeping in mind the objective of the classification.
|
| 71 |
+
- A good starting point is to use `This event involves [Z].`. This template will ideally be filled with a 1 word summary of the event.
|
| 72 |
+
- Another good example is `People were [Z].`. With this one we mostly expect a verb that describes the action.
|
| 73 |
+
You can also use any template you design. Keep in mind that if the masked slot `[Z]` is at the end of the sentence, to not forget punctuation,
|
| 74 |
+
otherwise the model may fill the template with punctuation signs.
|
| 75 |
+
""")
|
| 76 |
+
|
| 77 |
+
if 'prompt' not in st.session_state:
|
| 78 |
+
st.session_state.prompt = 'This event involves [Z].'
|
| 79 |
+
prompt = st.text_input('Template:',st.session_state.prompt)
|
| 80 |
+
st.session_state.prompt = prompt
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
st.markdown("""
|
| 84 |
+
### 4. Select the two parameters:
|
| 85 |
+
- The first parameter `top_k` is the maximum number of tokens that will be given by the prompting model.
|
| 86 |
+
It's also the number of tokens that will be tried for entailment. Ideally, you want a high enough number of tokens, otherwise you may miss critical information.
|
| 87 |
+
However, each additional token will increase the computation time as it needs to go through the entailment model.
|
| 88 |
+
From our experiments, a good choice is between `[10,50]`, lower and you miss information, higher and you start getting unrelated tokens and long computation time.
|
| 89 |
+
- The second parameter is the minimum entailment score to confirm that the token is entailed with the event description.
|
| 90 |
+
By default, we set it at `0.5` (more entailed than not) but it can be modified depending on needs.
|
| 91 |
+
""")
|
| 92 |
+
|
| 93 |
+
def select_top_k():
|
| 94 |
+
if 'top_k' not in st.session_state:
|
| 95 |
+
st.session_state.top_k = 10
|
| 96 |
+
|
| 97 |
+
return st.number_input('Number of max tokens to output (default: 10, min: 0, max: 50)? ',step = 100, min_value=0, max_value=50, value=int(st.session_state.top_k))
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
def select_nli_limit():
|
| 101 |
+
if 'nli_limit' not in st.session_state:
|
| 102 |
+
st.session_state.nli_limit = 0.5
|
| 103 |
+
|
| 104 |
+
return st.number_input('Minimum score of entailment (default: 0.5, min: 0, max: 1)? ',step = 100.0, min_value=0.0, max_value=1.0, value=st.session_state.nli_limit)
|
| 105 |
+
|
| 106 |
+
def update_session_state_callback(value, key):
|
| 107 |
+
st.session_state[value] = st.session_state[key]
|
| 108 |
+
|
| 109 |
+
top_k = select_top_k()
|
| 110 |
+
st.session_state.top_k = top_k
|
| 111 |
+
|
| 112 |
+
nli_limit = select_nli_limit()
|
| 113 |
+
st.session_state.nli_limit = nli_limit
|
| 114 |
+
|
| 115 |
+
st.markdown("""
|
| 116 |
+
### 5. Remove similar tokens from output:
|
| 117 |
+
An additional option is to remove similar tokens (e.g. `protest, protests`) from the output.
|
| 118 |
+
This computes the lemma of each word (based on the template) and removes duplicate lemmas.
|
| 119 |
+
""")
|
| 120 |
+
if 'remove_lemma' not in st.session_state:
|
| 121 |
+
st.session_state.remove_lemma = False
|
| 122 |
+
remove_lemma = st.checkbox('Remove similar lemma (e.g. protest, protests) from output?', value= st.session_state.remove_lemma)
|
| 123 |
+
st.session_state.remove_lemma = remove_lemma
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
# Save settings to display before the results
|
| 127 |
+
if "old_prompt" not in st.session_state:
|
| 128 |
+
st.session_state.old_text =st.session_state.text
|
| 129 |
+
st.session_state.old_prompt =st.session_state.prompt
|
| 130 |
+
st.session_state.old_top_k = st.session_state.top_k
|
| 131 |
+
st.session_state.old_nli_limit = st.session_state.nli_limit
|
| 132 |
+
|
| 133 |
+
st.markdown("""
|
| 134 |
+
### 6. Run the pipeline
|
| 135 |
+
""")
|
| 136 |
+
|
| 137 |
+
st.markdown("""The entailed tokens are given as a list of words associated with the probability of entailment.""")
|
| 138 |
+
|
| 139 |
+
if st.button("Run PR-ENT"):
|
| 140 |
+
computation_state_prent = st.text("PR-ENT Computation Running.")
|
| 141 |
+
st.session_state.old_text =st.session_state.text
|
| 142 |
+
st.session_state.old_prompt =st.session_state.prompt
|
| 143 |
+
st.session_state.old_top_k = st.session_state.top_k
|
| 144 |
+
st.session_state.old_nli_limit = st.session_state.nli_limit
|
| 145 |
+
|
| 146 |
+
# Replace the mask
|
| 147 |
+
prompt = prompt.replace('[Z]', '{}')
|
| 148 |
+
prompt = prompt.replace('[MASK]', '{}')
|
| 149 |
+
results = prompt_to_nli(text, prompt, model_prompting, model_nli, nlp, top_k, nli_limit, remove_lemma)
|
| 150 |
+
list_results = [x[0][0] + ' ' + str(int(x[1][1]*100)) + '%' for x in results]
|
| 151 |
+
st.session_state.list_results = list_results
|
| 152 |
+
|
| 153 |
+
computation_state_prent.text("PR-ENT Computation Done.")
|
| 154 |
+
|
| 155 |
+
if 'list_results' in st.session_state:
|
| 156 |
+
st.write('**Event Description**: {}'.format(st.session_state.old_text))
|
| 157 |
+
st.write('**Template**: "{}"; **Top K**: {}; **Entailment Threshold**: {}.'.format(st.session_state.old_prompt,st.session_state.old_top_k, st.session_state.old_nli_limit))
|
| 158 |
+
display_nli_pr_results_as_list('', st.session_state.list_results)
|
| 159 |
+
|
| 160 |
+
st.markdown("""
|
| 161 |
+
### 7. Actor-target coding (experimental)
|
| 162 |
+
|
| 163 |
+
Available in actor-target tab (on the left)
|
| 164 |
+
|
| 165 |
+
""")
|
README.md
CHANGED
|
@@ -1,11 +1,12 @@
|
|
| 1 |
---
|
| 2 |
title: PR-ENT Dashboard
|
| 3 |
-
emoji:
|
| 4 |
-
colorFrom:
|
| 5 |
colorTo: yellow
|
| 6 |
sdk: streamlit
|
|
|
|
| 7 |
sdk_version: 1.10.0
|
| 8 |
-
app_file:
|
| 9 |
pinned: false
|
| 10 |
---
|
| 11 |
|
| 1 |
---
|
| 2 |
title: PR-ENT Dashboard
|
| 3 |
+
emoji: ⚡
|
| 4 |
+
colorFrom: green
|
| 5 |
colorTo: yellow
|
| 6 |
sdk: streamlit
|
| 7 |
+
python_version: 3.8.9
|
| 8 |
sdk_version: 1.10.0
|
| 9 |
+
app_file: PR_ENT.py
|
| 10 |
pinned: false
|
| 11 |
---
|
| 12 |
|
helpers.py
ADDED
|
@@ -0,0 +1,234 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import pandas as pd
|
| 3 |
+
import numpy as np
|
| 4 |
+
|
| 5 |
+
from nltk.tokenize import sent_tokenize
|
| 6 |
+
|
| 7 |
+
# Split the text into sentences. Necessary for NLI models
|
| 8 |
+
def split_sentences(text):
|
| 9 |
+
return sent_tokenize(text)
|
| 10 |
+
|
| 11 |
+
###### Prompting
|
| 12 |
+
def query_model_prompting(model, text, prompt_with_mask, top_k, targets):
|
| 13 |
+
"""Query the prompting model
|
| 14 |
+
|
| 15 |
+
:param model: Prompting model object
|
| 16 |
+
:type model: Huggingface pipeline object
|
| 17 |
+
:param text: Event description (context)
|
| 18 |
+
:type text: str
|
| 19 |
+
:param prompt_with_mask: Prompt with a mask
|
| 20 |
+
:type prompt_with_mask: str
|
| 21 |
+
:param top_k: Number of tokens to output
|
| 22 |
+
:type top_k: integer
|
| 23 |
+
:param targets: Restrict the answer to these possible tokens
|
| 24 |
+
:type targets: list
|
| 25 |
+
:return: Results of the prompting model
|
| 26 |
+
:rtype: list of dict
|
| 27 |
+
"""
|
| 28 |
+
sequence = text + prompt_with_mask
|
| 29 |
+
output_tokens = model(sequence, top_k=top_k, targets=targets)
|
| 30 |
+
|
| 31 |
+
return output_tokens
|
| 32 |
+
|
| 33 |
+
def do_sentence_entailment(sentence, hypothesis, model):
|
| 34 |
+
"""Concatenate context and hypothesis then perform entailment
|
| 35 |
+
|
| 36 |
+
:param sentence: Event description (context), 1 sentence
|
| 37 |
+
:type sentence: str
|
| 38 |
+
:param hypothesis: Mask filled with a token
|
| 39 |
+
:type hypothesis: str
|
| 40 |
+
:param model: NLI Model
|
| 41 |
+
:type model: Huggingface pipeline
|
| 42 |
+
:return: DataFrame containing the result of the entailment
|
| 43 |
+
:rtype: pandas DataFrame
|
| 44 |
+
"""
|
| 45 |
+
text = sentence + '</s></s>' + hypothesis
|
| 46 |
+
res = model(text, return_all_scores=True)
|
| 47 |
+
df_res = pd.DataFrame(res[0])
|
| 48 |
+
df_res['label'] = df_res['label'].apply(lambda x: x.lower())
|
| 49 |
+
df_res.columns = ["Label", "Score"]
|
| 50 |
+
return df_res
|
| 51 |
+
|
| 52 |
+
def softmax(x):
|
| 53 |
+
"""Compute softmax values for each sets of scores in x."""
|
| 54 |
+
return np.exp(x) / np.sum(np.exp(x), axis=0)
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
######### NLI + PROMPTING
|
| 59 |
+
def do_text_entailment(text, hypothesis, model):
|
| 60 |
+
"""
|
| 61 |
+
Do entailment for each sentence of the event description as
|
| 62 |
+
model was trained on sentence pair
|
| 63 |
+
|
| 64 |
+
:param text: Event Description (context)
|
| 65 |
+
:type text: str
|
| 66 |
+
:param hypothesis: Mask filled with a token
|
| 67 |
+
:type hypothesis: str
|
| 68 |
+
:param model: Model NLI
|
| 69 |
+
:type model: Huggingface pipeline
|
| 70 |
+
:return: List of entailment results for each sentence of the text
|
| 71 |
+
:rtype: list
|
| 72 |
+
"""
|
| 73 |
+
text_entailment_results = []
|
| 74 |
+
for i, sentence in enumerate(split_sentences(text)):
|
| 75 |
+
df_score = do_sentence_entailment(sentence, hypothesis, model)
|
| 76 |
+
text_entailment_results.append((sentence, hypothesis, df_score))
|
| 77 |
+
return text_entailment_results
|
| 78 |
+
|
| 79 |
+
def get_true_entailment(text_entailment_results, nli_limit):
|
| 80 |
+
"""
|
| 81 |
+
From the result of each sentence entailment, extract the maximum entailment score and
|
| 82 |
+
check if it's higher than the entailment threshold.
|
| 83 |
+
"""
|
| 84 |
+
true_hypothesis_list = []
|
| 85 |
+
max_score = 0
|
| 86 |
+
for sentence_entailment in text_entailment_results:
|
| 87 |
+
df_score = sentence_entailment[2]
|
| 88 |
+
score = df_score[df_score["Label"] == 'entailment']["Score"].values.max()
|
| 89 |
+
if score > max_score:
|
| 90 |
+
max_score = score
|
| 91 |
+
if max_score > nli_limit:
|
| 92 |
+
true_hypothesis_list.append((sentence_entailment[1], np.round(max_score,2)))
|
| 93 |
+
return list(set(true_hypothesis_list))
|
| 94 |
+
|
| 95 |
+
def prompt_to_nli(text, prompt, model_prompting, nli_model, nlp, top_k=10, nli_limit=0.5, remove_lemma=False):
|
| 96 |
+
"""
|
| 97 |
+
Apply the PR-ENT pipeline
|
| 98 |
+
|
| 99 |
+
:param text: Event description
|
| 100 |
+
:type text: str
|
| 101 |
+
:param prompt: Prompt with mask
|
| 102 |
+
:type prompt: str
|
| 103 |
+
:param model_prompting: Prompting Model
|
| 104 |
+
:type model_prompting: Huggingface pipeline
|
| 105 |
+
:param nli_model: NLI Model
|
| 106 |
+
:type nli_model: Huggingface pipeline
|
| 107 |
+
:param top_k: Number of words output by the prompting model
|
| 108 |
+
:type top_k: int
|
| 109 |
+
:param nli_limit: Entailment threshold
|
| 110 |
+
:type nli_limit: float
|
| 111 |
+
|
| 112 |
+
:return: Results of the pipeline
|
| 113 |
+
:rtype: list
|
| 114 |
+
"""
|
| 115 |
+
prompt_masked = prompt.format(model_prompting.tokenizer.mask_token)
|
| 116 |
+
label = []
|
| 117 |
+
output_prompting = query_model_prompting(model_prompting, text, prompt_masked, top_k, targets=None)
|
| 118 |
+
if remove_lemma:
|
| 119 |
+
output_prompting = filter_prompt_output_by_lemma(prompt, output_prompting, nlp)
|
| 120 |
+
for token in output_prompting:
|
| 121 |
+
hypothesis = prompt.format(token['token_str'])
|
| 122 |
+
text_entailment_results = do_text_entailment(text, hypothesis, nli_model)
|
| 123 |
+
true_hypothesis_list = get_true_entailment(text_entailment_results, nli_limit)
|
| 124 |
+
if len(true_hypothesis_list) > 0:
|
| 125 |
+
label.append(((token['token_str'], token['score']), true_hypothesis_list[0]))
|
| 126 |
+
return label
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
def display_nli_pr_results_as_list(title, list_results):
|
| 130 |
+
"""
|
| 131 |
+
Display the list of entailment results as a streamlit choice list
|
| 132 |
+
"""
|
| 133 |
+
st.markdown(
|
| 134 |
+
"""
|
| 135 |
+
<style>
|
| 136 |
+
span[data-baseweb="tag"] {
|
| 137 |
+
background-color: red !important;
|
| 138 |
+
}
|
| 139 |
+
</style>
|
| 140 |
+
""",
|
| 141 |
+
unsafe_allow_html=True,
|
| 142 |
+
)
|
| 143 |
+
prompt_list = st.multiselect(
|
| 144 |
+
title,
|
| 145 |
+
list_results
|
| 146 |
+
,
|
| 147 |
+
list_results, key='results_mix')
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
##### QA
|
| 151 |
+
def question_answering(model, text, questions_list, to_print=True):
|
| 152 |
+
"""
|
| 153 |
+
Apply question answering model
|
| 154 |
+
|
| 155 |
+
:param model: QA Model
|
| 156 |
+
:type model: Huggingface pipeline
|
| 157 |
+
:param text: Event description (context)
|
| 158 |
+
:type text: str
|
| 159 |
+
:param question: Question to answer
|
| 160 |
+
:type question: str
|
| 161 |
+
:return: Tuple containing the answer and the confidence score
|
| 162 |
+
:rtype: tuple
|
| 163 |
+
"""
|
| 164 |
+
for question in questions_list:
|
| 165 |
+
QA_input = {
|
| 166 |
+
'question': question,
|
| 167 |
+
'context': text}
|
| 168 |
+
res = model(QA_input, handle_impossible_answer=False)
|
| 169 |
+
|
| 170 |
+
if to_print:
|
| 171 |
+
st.write("Question: {}".format(question))
|
| 172 |
+
st.write("Answer: {}".format(res["answer"]))
|
| 173 |
+
|
| 174 |
+
return res["answer"], res["score"]
|
| 175 |
+
|
| 176 |
+
|
| 177 |
+
### Prompt + NLI + QA
|
| 178 |
+
|
| 179 |
+
def get_who_what_whom_qa(text, tokens, model_qa):
|
| 180 |
+
who_what_whom = []
|
| 181 |
+
if not tokens:
|
| 182 |
+
res_dict = {"Actor":'', "Action":'', "Target": ''}
|
| 183 |
+
st.write("No entailed tokens.")
|
| 184 |
+
|
| 185 |
+
else:
|
| 186 |
+
for token in tokens:
|
| 187 |
+
# res_dict = {"who":'', "did_what":token, "to_whom": '', "qa_score": []}
|
| 188 |
+
res_dict = {"Actor":'', "Action":token, "Target": ''}
|
| 189 |
+
|
| 190 |
+
if token[-3:] == 'ing':
|
| 191 |
+
perp,score_p = question_answering(model_qa, text, ["Who was {}?".format(token)], to_print=False)
|
| 192 |
+
else:
|
| 193 |
+
perp,score_p = question_answering(model_qa, text, ["Who {} people?".format(token)], to_print=False)
|
| 194 |
+
if perp:
|
| 195 |
+
res_dict["Actor"] = perp + ' [' + str(np.round(score_p*100,1)) + '%]'
|
| 196 |
+
else:
|
| 197 |
+
res_dict["Actor"] = 'N/A' + ' [' + str(np.round(score_p*100,1)) + '%]'
|
| 198 |
+
|
| 199 |
+
victim,score_v = question_answering(model_qa, text, ["Who was {}?".format(token)], to_print=False)
|
| 200 |
+
|
| 201 |
+
if victim:
|
| 202 |
+
res_dict["Target"] = victim + ' [' + str(np.round(score_v*100,1)) + '%]'
|
| 203 |
+
else:
|
| 204 |
+
res_dict["Target"] = 'N/A' + ' [' + str(np.round(score_v*100,1)) + '%]'
|
| 205 |
+
|
| 206 |
+
who_what_whom.append(res_dict)
|
| 207 |
+
|
| 208 |
+
return who_what_whom
|
| 209 |
+
|
| 210 |
+
def remove_similar_lemma_from_list(prompt, list_words, nlp):
|
| 211 |
+
## Compute a dictionnary with the lemma for all tokens
|
| 212 |
+
## If there is a duplicate lemma then the dictionnary value will be a list of the corresponding tokens
|
| 213 |
+
lemma_dict = {}
|
| 214 |
+
for each in list_words:
|
| 215 |
+
mask_filled = nlp(prompt.strip('.').format(each))
|
| 216 |
+
lemma_dict.setdefault([x.lemma_ for x in mask_filled][-1],[]).append(each)
|
| 217 |
+
|
| 218 |
+
## Get back the list of tokens
|
| 219 |
+
## If multiple tokens available then take the shortest one
|
| 220 |
+
new_token_list = []
|
| 221 |
+
for key in lemma_dict.keys():
|
| 222 |
+
if len(lemma_dict[key]) >= 1:
|
| 223 |
+
new_token_list.append(min(lemma_dict[key], key=len))
|
| 224 |
+
else:
|
| 225 |
+
raise ValueError("Lemma dict has 0 corresponding words")
|
| 226 |
+
return new_token_list
|
| 227 |
+
|
| 228 |
+
def filter_prompt_output_by_lemma(prompt, output_prompting, nlp):
|
| 229 |
+
"""
|
| 230 |
+
Remove all similar lemmas from the prompt output (e.g. "protest", "protests")
|
| 231 |
+
"""
|
| 232 |
+
list_words = [x['token_str'] for x in output_prompting]
|
| 233 |
+
new_token_list = remove_similar_lemma_from_list(prompt, list_words, nlp)
|
| 234 |
+
return [x for x in output_prompting if x['token_str'] in new_token_list]
|
pages/Actor_Target.py
ADDED
|
@@ -0,0 +1,107 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
import os
|
| 3 |
+
|
| 4 |
+
import streamlit as st
|
| 5 |
+
|
| 6 |
+
from PIL import Image
|
| 7 |
+
import pandas as pd
|
| 8 |
+
|
| 9 |
+
from transformers import pipeline
|
| 10 |
+
import spacy
|
| 11 |
+
import en_core_web_lg
|
| 12 |
+
|
| 13 |
+
current = os.path.dirname(os.path.realpath(__file__))
|
| 14 |
+
parent = os.path.dirname(current)
|
| 15 |
+
sys.path.append(parent)
|
| 16 |
+
from helpers import display_nli_pr_results_as_list, prompt_to_nli, get_who_what_whom_qa
|
| 17 |
+
|
| 18 |
+
@st.cache(allow_output_mutation=True)
|
| 19 |
+
def load_spacy_pipeline():
|
| 20 |
+
return en_core_web_lg.load()
|
| 21 |
+
|
| 22 |
+
def choose_text_menu(text):
|
| 23 |
+
if 'text' not in st.session_state:
|
| 24 |
+
st.session_state.text = 'Several demonstrators were injured.'
|
| 25 |
+
text = st.text_area('Event description', st.session_state.text)
|
| 26 |
+
|
| 27 |
+
return text
|
| 28 |
+
|
| 29 |
+
# # Load Models in cache
|
| 30 |
+
@st.cache(allow_output_mutation=True)
|
| 31 |
+
def load_model_prompting():
|
| 32 |
+
return pipeline("fill-mask", model="distilbert-base-uncased")
|
| 33 |
+
|
| 34 |
+
@st.cache(allow_output_mutation=True)
|
| 35 |
+
def load_model_nli():
|
| 36 |
+
return pipeline(task="sentiment-analysis", model="roberta-large-mnli")
|
| 37 |
+
|
| 38 |
+
@st.cache(allow_output_mutation=True)
|
| 39 |
+
def load_model_qa():
|
| 40 |
+
model_name = "deepset/roberta-base-squad2"
|
| 41 |
+
model = pipeline(model=model_name, tokenizer=model_name, task="question-answering")
|
| 42 |
+
return model
|
| 43 |
+
|
| 44 |
+
nlp = load_spacy_pipeline()
|
| 45 |
+
|
| 46 |
+
### App START
|
| 47 |
+
st.markdown("""# Rethinking the Event Coding Pipeline with Prompt Entailment
|
| 48 |
+
## Author: Anonymized for submission""")
|
| 49 |
+
|
| 50 |
+
st.markdown("### 1. Actor-target coding (experimental):")
|
| 51 |
+
@st.cache()
|
| 52 |
+
def load_qa_image():
|
| 53 |
+
return Image.open('pipeline_qa.png')
|
| 54 |
+
st.image(load_qa_image(),caption="""Actor-target Coding Flow. First we get the entailed answer candidates through the PR-ENT pipeline.
|
| 55 |
+
Then we construct questions based on these tokens to extract actors and targets, 2 questions per verb.
|
| 56 |
+
Finally, we pass these questions and event description to a pre-trained extractive question answering model and fill a table of [Actor, Action, Target].""")
|
| 57 |
+
|
| 58 |
+
st.markdown("""
|
| 59 |
+
Here we use an extractive question answering model to find the actor and target of an event.
|
| 60 |
+
As this is still in experimental phase, there are some limitations:
|
| 61 |
+
- The only template possible is `People were [Z].`, this allows us to get a verb to construct the two questions:
|
| 62 |
+
- `Who was [Z]?` to find the target.
|
| 63 |
+
- `Who [Z] people?` to find the actor.
|
| 64 |
+
- `top_k = 10` and `entailment_threshold = 0.5`.
|
| 65 |
+
The results of the QA are given along the confidence score of the model in brackets `[xx.x%]`
|
| 66 |
+
""")
|
| 67 |
+
|
| 68 |
+
## Load Models
|
| 69 |
+
model_nli = load_model_nli()
|
| 70 |
+
model_prompting = load_model_prompting()
|
| 71 |
+
model_qa = load_model_qa()
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
st.markdown("""
|
| 76 |
+
### 2. Write an event description:
|
| 77 |
+
The first step is to write an event description that will be fed to the pipeline. This can be any text in English.
|
| 78 |
+
""")
|
| 79 |
+
text = choose_text_menu('')
|
| 80 |
+
st.session_state.text = text
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
st.markdown("""
|
| 84 |
+
### 3. Run actor-target coding:
|
| 85 |
+
""")
|
| 86 |
+
|
| 87 |
+
if "old_text_qa" not in st.session_state:
|
| 88 |
+
st.session_state.old_text_qa =st.session_state.text
|
| 89 |
+
|
| 90 |
+
qa_button = st.button("Run actor-target coding")
|
| 91 |
+
if qa_button:
|
| 92 |
+
computation_state_qa = st.text("Computation Running.")
|
| 93 |
+
st.session_state.old_text_qa =st.session_state.text
|
| 94 |
+
prompt = "People were {}."
|
| 95 |
+
results = prompt_to_nli(text, prompt, model_prompting, model_nli, nlp, 10, 0.5, True)
|
| 96 |
+
list_results = [x[0][0] + ' ' + str(int(x[1][1]*100)) + '%' for x in results]
|
| 97 |
+
st.session_state.list_results_prompt_qa = list_results
|
| 98 |
+
list_tokens = [x[0][0] for x in results]
|
| 99 |
+
who_what_whom = get_who_what_whom_qa(text, list_tokens, model_qa)
|
| 100 |
+
st.session_state.who_what_whom = who_what_whom
|
| 101 |
+
computation_state_qa.text("Computation Done.")
|
| 102 |
+
|
| 103 |
+
if 'who_what_whom' in st.session_state:
|
| 104 |
+
st.write('**Event Description**: {}'.format(st.session_state.old_text_qa))
|
| 105 |
+
st.write('**Template**: "{}"; **Top K**: {}; **Entailment Threshold**: {}.'.format("People were [Z]",10, 0.5))
|
| 106 |
+
display_nli_pr_results_as_list('', st.session_state.list_results_prompt_qa)
|
| 107 |
+
st.write(pd.DataFrame(st.session_state.who_what_whom))
|
pipeline_flow.png
ADDED
|
pipeline_qa.png
ADDED

|
requirements.txt
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# see environments.yml
|
| 2 |
+
numpy==1.22.3
|
| 3 |
+
pandas==1.4.2
|
| 4 |
+
spacy==3.2.3
|
| 5 |
+
https://github.com/explosion/spacy-models/releases/download/en_core_web_lg-3.2.0/en_core_web_lg-3.2.0-py3-none-any.whl
|
| 6 |
+
transformers[torch]==4.19.2
|
| 7 |
+
nltk==3.7
|
| 8 |
+
sentence_transformers==2.2.0
|