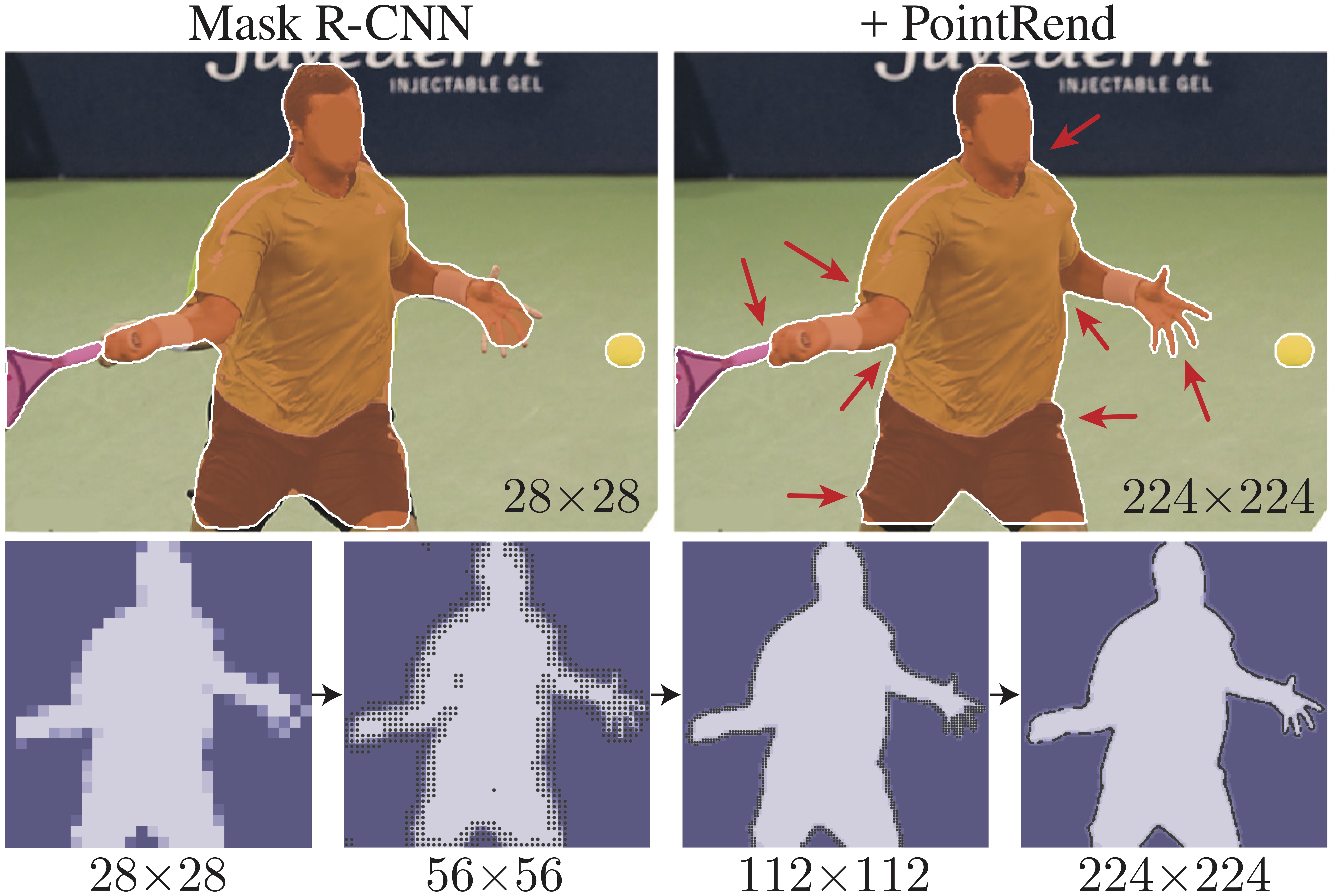
# PointRend: Image Segmentation as Rendering
Alexander Kirillov, Yuxin Wu, Kaiming He, Ross Girshick
[[`arXiv`](https://arxiv.org/abs/1912.08193)] [[`BibTeX`](#CitingPointRend)]
In this repository, we release code for PointRend in Detectron2. PointRend can be flexibly applied to both instance and semantic segmentation tasks by building on top of existing state-of-the-art models.
## Installation
Install Detectron 2 following [INSTALL.md](https://github.com/facebookresearch/detectron2/blob/master/INSTALL.md). You are ready to go!
## Quick start and visualization
This [Colab Notebook](https://colab.research.google.com/drive/1isGPL5h5_cKoPPhVL9XhMokRtHDvmMVL) tutorial contains examples of PointRend usage and visualizations of its point sampling stages.
## Training
To train a model with 8 GPUs run:
```bash
cd /path/to/detectron2/projects/PointRend
python train_net.py --config-file configs/InstanceSegmentation/pointrend_rcnn_R_50_FPN_1x_coco.yaml --num-gpus 8
```
## Evaluation
Model evaluation can be done similarly:
```bash
cd /path/to/detectron2/projects/PointRend
python train_net.py --config-file configs/InstanceSegmentation/pointrend_rcnn_R_50_FPN_1x_coco.yaml --eval-only MODEL.WEIGHTS /path/to/model_checkpoint
```
# Pretrained Models
## Instance Segmentation
#### COCO
AP* is COCO mask AP evaluated against the higher-quality LVIS annotations; see the paper for details. Run `python detectron2/datasets/prepare_cocofied_lvis.py` to prepare GT files for AP* evaluation. Since LVIS annotations are not exhaustive `lvis-api` and not `cocoapi` should be used to evaluate AP*.
#### Cityscapes
Cityscapes model is trained with ImageNet pretraining.
Mask
head |
Backbone |
lr
sched |
Output
resolution |
mask
AP |
model id |
download |
| PointRend |
R50-FPN |
1× |
224×224 |
35.9 |
164255101 |
model | metrics |
## Semantic Segmentation
#### Cityscapes
Cityscapes model is trained with ImageNet pretraining.
## Citing PointRend
If you use PointRend, please use the following BibTeX entry.
```BibTeX
@InProceedings{kirillov2019pointrend,
title={{PointRend}: Image Segmentation as Rendering},
author={Alexander Kirillov and Yuxin Wu and Kaiming He and Ross Girshick},
journal={ArXiv:1912.08193},
year={2019}
}
```