from dataclasses import dataclass
from enum import Enum
@dataclass
class Task:
benchmark: str
metric: str
col_name: str
# Init: to update with your specific keys
class Tasks(Enum):
# task_key in the json file, metric_key in the json file, name to display in the leaderboard
task0 = Task("SAS", "weighted_accuracy", "SAS")
task1 = Task("SPP", "weighted_accuracy", "SPP")
task2 = Task("EDP", "weighted_accuracy", "EDP")
task3 = Task("TSP_D", "weighted_accuracy", "TSP_D")
task4 = Task("GCP_D", "weighted_accuracy", "GCP_D")
task5 = Task("KSP", "weighted_accuracy", "KSP")
task6 = Task("TSP", "weighted_accuracy", "TSP")
task7 = Task("GCP", "weighted_accuracy", "GCP")
task8 = Task("MSP", "weighted_accuracy", "MSP")
# Your leaderboard name
TITLE = """NPHardEval leaderboard
"""
# What does your leaderboard evaluate?
INTRODUCTION_TEXT = """
NPHardEval serves as a comprehensive benchmark for assessing the reasoning abilities of large language models (LLMs) through the lens of computational complexity classes.
"""
# Which evaluations are you running? how can people reproduce what you have?
LLM_BENCHMARKS_TEXT = f"""
The paramount importance of complex reasoning in Large Language Models (LLMs) is well-recognized,
especially in their application to intricate decision-making tasks. This underscores the necessity
of thoroughly investigating LLMs' reasoning capabilities. To this end, various benchmarks have been
developed to evaluate these capabilities. However, existing benchmarks fall short in providing a
comprehensive assessment of LLMs' potential in reasoning. Additionally, there is a risk of overfitting,
as these benchmarks are static and publicly accessible, allowing models to tailor responses to specific
metrics, thus artificially boosting their performance.
In response, our research introduces 'NPHardEval,' a novel benchmark meticulously designed to
comprehensively evaluate LLMs' reasoning abilities. It comprises a diverse array of 900 algorithmic
questions, spanning the spectrum up to NP-Hard complexity. These questions are strategically selected
to cover a vast range of complexities, ensuring a thorough evaluation of LLMs' reasoning power. This
benchmark not only offers insights into the current state of reasoning in LLMs but also establishes
a benchmark for comparing LLMs' performance across various complexity classes.
[Our repository](https://github.com/casmlab/NPHardEval) contains datasets, data generation scripts, and experimental procedures designed to evaluate LLMs in various reasoning tasks.
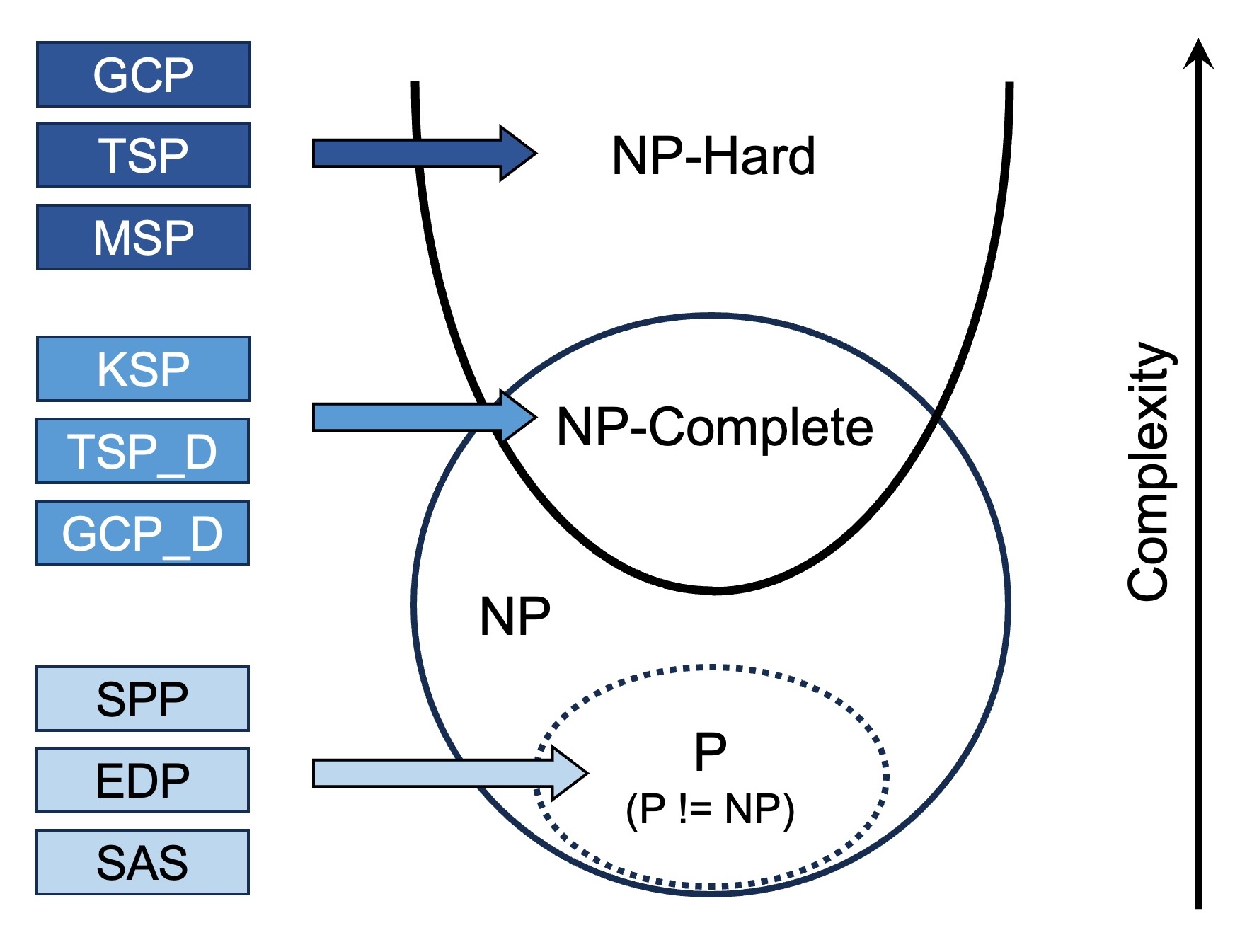
In particular, we use three complexity classes to define the task complexity in the benchmark, including P (polynomial time), NP-complete (nondeterministic polynomial-time complete),
and NP-hard, which are increasingly complex in both the intrinsic difficulty and the resources needed to solve them. The selected nine problems are:
1) P problems: Sorted Array Search (SAS), Edit Distance Problem (EDP), Shortest Path Problem (SPP);
2) NP-complete problems: Traveling Salesman Problem Decision Version (TSP-D), Graph Coloring Problem Decision Version (GCP-D), and Knapsack Problem (KSP);
3) NP-hard problems: Traveling Salesman Problem Optimization Version (TSP), Graph Coloring Problem Optimization Version (GCP), and Meeting Scheduling Problem (MSP).
The following figure shows their relation regarding computational complexity in an Euler diagram.
Our benchmark offers several advantages compared with current benchmarks:
- Data construction grounded in the established computational complexity hierarchy
- Automatic checking mechanisms
- Automatic generation of datapoints
- Complete focus on reasoning while exclude numerical computation
Our study marks a significant contribution to understanding LLMs' current reasoning capabilities
and paves the way for future enhancements. Furthermore, NPHardEval features a dynamic update mechanism,
refreshing data points monthly. This approach is crucial in reducing the risk of model overfitting,
leading to a more accurate and dependable evaluation of LLMs' reasoning skills. The benchmark dataset
and the associated code are accessible at [NPHardEval GitHub Repository]("https://github.com/casmlab/NPHardEval").
## Quick Start
### Environment setup
```bash
conda create --name llm_reason python=3.10
conda activate llm_reason
git clone https://github.com/casmlab/NPHardEval.git
pip install -r requirements.txt
```
### Set-up API keys
Please set up your API keys in `secrets.txt`. **Please don't directly upload your keys to any public repository.**
### Example Commands
Let's use the GPT 4 Turbo model (GPT-4-1106-preview) and the EDP for example.
For its zeroshot experiment, you can use:
```
cd run
cd run_close_zeroshot
python run_hard_GCP.py gpt-4-1106-preview
```
For its fewshot experiment,
```
cd run
cd run_close_fewshot
python run_close_fewshot/run_hard_GCP.py gpt-4-1106-preview self
```
"""
EVALUATION_QUEUE_TEXT = """
Currently, we don't support the submission of new evaluations.
"""
CITATION_BUTTON_LABEL = "Copy the following snippet to cite these results."
CITATION_BUTTON_TEXT = r"""
@misc{fan2023nphardeval,
title={NPHardEval: Dynamic Benchmark on Reasoning Ability of Large Language Models via Complexity Classes},
author={Lizhou Fan and Wenyue Hua and Lingyao Li and Haoyang Ling and Yongfeng Zhang and Libby Hemphill},
year={2023},
eprint={2312.14890},
archivePrefix={arXiv},
primaryClass={cs.AI}
}
"""
COMMENT_BUTTON_TEXT = """
We refer to the following links to mark the model parameters. Contact us if you find any issues.
- https://grabon.com/blog/claude-users-statistics/
- https://medium.com/@seanbetts/peering-inside-gpt-4-understanding-its-mixture-of-experts-moe-architecture-2a42eb8bdcb3
- https://www.cnbc.com/2023/05/16/googles-palm-2-uses-nearly-five-times-more-text-data-than-predecessor.html
"""