diff --git a/CITATION.cff b/CITATION.cff
new file mode 100644
index 0000000000000000000000000000000000000000..7d1d93a7c68daf442bc6540b197b401e7a38b91c
--- /dev/null
+++ b/CITATION.cff
@@ -0,0 +1,9 @@
+cff-version: 1.2.0
+message: "If you use this software, please cite it as below."
+title: "OpenMMLab Text Detection, Recognition and Understanding Toolbox"
+authors:
+ - name: "MMOCR Contributors"
+version: 0.3.0
+date-released: 2020-08-15
+repository-code: "https://github.com/open-mmlab/mmocr"
+license: Apache-2.0
diff --git a/configs/backbone/oclip/README.md b/configs/backbone/oclip/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..e29cf971f6f8e6ba6c4fc640e6d06c5583d2909d
--- /dev/null
+++ b/configs/backbone/oclip/README.md
@@ -0,0 +1,41 @@
+# oCLIP
+
+> [Language Matters: A Weakly Supervised Vision-Language Pre-training Approach for Scene Text Detection and Spotting](https://www.ecva.net/papers/eccv_2022/papers_ECCV/papers/136880282.pdf)
+
+
+
+## Abstract
+
+Recently, Vision-Language Pre-training (VLP) techniques have greatly benefited various vision-language tasks by jointly learning visual and textual representations, which intuitively helps in Optical Character Recognition (OCR) tasks due to the rich visual and textual information in scene text images. However, these methods cannot well cope with OCR tasks because of the difficulty in both instance-level text encoding and image-text pair acquisition (i.e. images and captured texts in them). This paper presents a weakly supervised pre-training method, oCLIP, which can acquire effective scene text representations by jointly learning and aligning visual and textual information. Our network consists of an image encoder and a character-aware text encoder that extract visual and textual features, respectively, as well as a visual-textual decoder that models the interaction among textual and visual features for learning effective scene text representations. With the learning of textual features, the pre-trained model can attend texts in images well with character awareness. Besides, these designs enable the learning from weakly annotated texts (i.e. partial texts in images without text bounding boxes) which mitigates the data annotation constraint greatly. Experiments over the weakly annotated images in ICDAR2019-LSVT show that our pre-trained model improves F-score by +2.5% and +4.8% while transferring its weights to other text detection and spotting networks, respectively. In addition, the proposed method outperforms existing pre-training techniques consistently across multiple public datasets (e.g., +3.2% and +1.3% for Total-Text and CTW1500).
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
[ASTER: An Attentional Scene Text Recognizer with Flexible Rectification](https://ieeexplore.ieee.org/abstract/document/8395027/)
+
+
+
+## Abstract
+
+A challenging aspect of scene text recognition is to handle text with distortions or irregular layout. In particular, perspective text and curved text are common in natural scenes and are difficult to recognize. In this work, we introduce ASTER, an end-to-end neural network model that comprises a rectification network and a recognition network. The rectification network adaptively transforms an input image into a new one, rectifying the text in it. It is powered by a flexible Thin-Plate Spline transformation which handles a variety of text irregularities and is trained without human annotations. The recognition network is an attentional sequence-to-sequence model that predicts a character sequence directly from the rectified image. The whole model is trained end to end, requiring only images and their groundtruth text. Through extensive experiments, we verify the effectiveness of the rectification and demonstrate the state-of-the-art recognition performance of ASTER. Furthermore, we demonstrate that ASTER is a powerful component in end-to-end recognition systems, for its ability to enhance the detector.
+
+
+
+
[An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition](https://arxiv.org/abs/1507.05717)
+
+
+
+## Abstract
+
+Image-based sequence recognition has been a long-standing research topic in computer vision. In this paper, we investigate the problem of scene text recognition, which is among the most important and challenging tasks in image-based sequence recognition. A novel neural network architecture, which integrates feature extraction, sequence modeling and transcription into a unified framework, is proposed. Compared with previous systems for scene text recognition, the proposed architecture possesses four distinctive properties: (1) It is end-to-end trainable, in contrast to most of the existing algorithms whose components are separately trained and tuned. (2) It naturally handles sequences in arbitrary lengths, involving no character segmentation or horizontal scale normalization. (3) It is not confined to any predefined lexicon and achieves remarkable performances in both lexicon-free and lexicon-based scene text recognition tasks. (4) It generates an effective yet much smaller model, which is more practical for real-world application scenarios. The experiments on standard benchmarks, including the IIIT-5K, Street View Text and ICDAR datasets, demonstrate the superiority of the proposed algorithm over the prior arts. Moreover, the proposed algorithm performs well in the task of image-based music score recognition, which evidently verifies the generality of it.
+
+
+
+
[MASTER: Multi-aspect non-local network for scene text recognition](https://arxiv.org/abs/1910.02562)
+
+
+
+## Abstract
+
+Attention-based scene text recognizers have gained huge success, which leverages a more compact intermediate representation to learn 1d- or 2d- attention by a RNN-based encoder-decoder architecture. However, such methods suffer from attention-drift problem because high similarity among encoded features leads to attention confusion under the RNN-based local attention mechanism. Moreover, RNN-based methods have low efficiency due to poor parallelization. To overcome these problems, we propose the MASTER, a self-attention based scene text recognizer that (1) not only encodes the input-output attention but also learns self-attention which encodes feature-feature and target-target relationships inside the encoder and decoder and (2) learns a more powerful and robust intermediate representation to spatial distortion, and (3) owns a great training efficiency because of high training parallelization and a high-speed inference because of an efficient memory-cache mechanism. Extensive experiments on various benchmarks demonstrate the superior performance of our MASTER on both regular and irregular scene text.
+
+
+
+
[NRTR: A No-Recurrence Sequence-to-Sequence Model For Scene Text Recognition](https://arxiv.org/abs/1806.00926)
+
+
+
+## Abstract
+
+Scene text recognition has attracted a great many researches due to its importance to various applications. Existing methods mainly adopt recurrence or convolution based networks. Though have obtained good performance, these methods still suffer from two limitations: slow training speed due to the internal recurrence of RNNs, and high complexity due to stacked convolutional layers for long-term feature extraction. This paper, for the first time, proposes a no-recurrence sequence-to-sequence text recognizer, named NRTR, that dispenses with recurrences and convolutions entirely. NRTR follows the encoder-decoder paradigm, where the encoder uses stacked self-attention to extract image features, and the decoder applies stacked self-attention to recognize texts based on encoder output. NRTR relies solely on self-attention mechanism thus could be trained with more parallelization and less complexity. Considering scene image has large variation in text and background, we further design a modality-transform block to effectively transform 2D input images to 1D sequences, combined with the encoder to extract more discriminative features. NRTR achieves state-of-the-art or highly competitive performance on both regular and irregular benchmarks, while requires only a small fraction of training time compared to the best model from the literature (at least 8 times faster).
+
+
+
+
[RobustScanner: Dynamically Enhancing Positional Clues for Robust Text Recognition](https://arxiv.org/abs/2007.07542)
+
+
+
+## Abstract
+
+The attention-based encoder-decoder framework has recently achieved impressive results for scene text recognition, and many variants have emerged with improvements in recognition quality. However, it performs poorly on contextless texts (e.g., random character sequences) which is unacceptable in most of real application scenarios. In this paper, we first deeply investigate the decoding process of the decoder. We empirically find that a representative character-level sequence decoder utilizes not only context information but also positional information. Contextual information, which the existing approaches heavily rely on, causes the problem of attention drift. To suppress such side-effect, we propose a novel position enhancement branch, and dynamically fuse its outputs with those of the decoder attention module for scene text recognition. Specifically, it contains a position aware module to enable the encoder to output feature vectors encoding their own spatial positions, and an attention module to estimate glimpses using the positional clue (i.e., the current decoding time step) only. The dynamic fusion is conducted for more robust feature via an element-wise gate mechanism. Theoretically, our proposed method, dubbed \\emph{RobustScanner}, decodes individual characters with dynamic ratio between context and positional clues, and utilizes more positional ones when the decoding sequences with scarce context, and thus is robust and practical. Empirically, it has achieved new state-of-the-art results on popular regular and irregular text recognition benchmarks while without much performance drop on contextless benchmarks, validating its robustness in both contextual and contextless application scenarios.
+
+
+
+
\[1\] Li, Hui and Wang, Peng and Shen, Chunhua and Zhang, Guyu. Show, attend and read: A simple and strong baseline for irregular text recognition. In AAAI 2019.
+
+## Citation
+
+```bibtex
+@inproceedings{yue2020robustscanner,
+ title={RobustScanner: Dynamically Enhancing Positional Clues for Robust Text Recognition},
+ author={Yue, Xiaoyu and Kuang, Zhanghui and Lin, Chenhao and Sun, Hongbin and Zhang, Wayne},
+ booktitle={European Conference on Computer Vision},
+ year={2020}
+}
+```
diff --git a/configs/textrecog/robust_scanner/_base_robustscanner_resnet31.py b/configs/textrecog/robust_scanner/_base_robustscanner_resnet31.py
new file mode 100644
index 0000000000000000000000000000000000000000..357794016f7891234d0e54bfd5fad96a09eed76c
--- /dev/null
+++ b/configs/textrecog/robust_scanner/_base_robustscanner_resnet31.py
@@ -0,0 +1,117 @@
+dictionary = dict(
+ type='Dictionary',
+ dict_file='{{ fileDirname }}/../../../dicts/english_digits_symbols.txt',
+ with_start=True,
+ with_end=True,
+ same_start_end=True,
+ with_padding=True,
+ with_unknown=True)
+
+model = dict(
+ type='RobustScanner',
+ data_preprocessor=dict(
+ type='TextRecogDataPreprocessor',
+ mean=[127, 127, 127],
+ std=[127, 127, 127]),
+ backbone=dict(type='ResNet31OCR'),
+ encoder=dict(
+ type='ChannelReductionEncoder', in_channels=512, out_channels=128),
+ decoder=dict(
+ type='RobustScannerFuser',
+ hybrid_decoder=dict(
+ type='SequenceAttentionDecoder', dim_input=512, dim_model=128),
+ position_decoder=dict(
+ type='PositionAttentionDecoder', dim_input=512, dim_model=128),
+ in_channels=[512, 512],
+ postprocessor=dict(type='AttentionPostprocessor'),
+ module_loss=dict(
+ type='CEModuleLoss', ignore_first_char=True, reduction='mean'),
+ dictionary=dictionary,
+ max_seq_len=30))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile', ignore_empty=True, min_size=2),
+ dict(type='LoadOCRAnnotations', with_text=True),
+ dict(
+ type='RescaleToHeight',
+ height=48,
+ min_width=48,
+ max_width=160,
+ width_divisor=4),
+ dict(type='PadToWidth', width=160),
+ dict(
+ type='PackTextRecogInputs',
+ meta_keys=('img_path', 'ori_shape', 'img_shape', 'valid_ratio'))
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='RescaleToHeight',
+ height=48,
+ min_width=48,
+ max_width=160,
+ width_divisor=4),
+ dict(type='PadToWidth', width=160),
+ # add loading annotation after ``Resize`` because ground truth
+ # does not need to do resize data transform
+ dict(type='LoadOCRAnnotations', with_text=True),
+ dict(
+ type='PackTextRecogInputs',
+ meta_keys=('img_path', 'ori_shape', 'img_shape', 'valid_ratio'))
+]
+
+tta_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='TestTimeAug',
+ transforms=[
+ [
+ dict(
+ type='ConditionApply',
+ true_transforms=[
+ dict(
+ type='ImgAugWrapper',
+ args=[dict(cls='Rot90', k=0, keep_size=False)])
+ ],
+ condition="results['img_shape'][1] [Show, Attend and Read: A Simple and Strong Baseline for Irregular Text Recognition](https://arxiv.org/abs/1811.00751)
+
+
+
+## Abstract
+
+Recognizing irregular text in natural scene images is challenging due to the large variance in text appearance, such as curvature, orientation and distortion. Most existing approaches rely heavily on sophisticated model designs and/or extra fine-grained annotations, which, to some extent, increase the difficulty in algorithm implementation and data collection. In this work, we propose an easy-to-implement strong baseline for irregular scene text recognition, using off-the-shelf neural network components and only word-level annotations. It is composed of a 31-layer ResNet, an LSTM-based encoder-decoder framework and a 2-dimensional attention module. Despite its simplicity, the proposed method is robust and achieves state-of-the-art performance on both regular and irregular scene text recognition benchmarks.
+
+
+
+
[On Recognizing Texts of Arbitrary Shapes with 2D Self-Attention](https://arxiv.org/abs/1910.04396)
+
+
+
+## Abstract
+
+Scene text recognition (STR) is the task of recognizing character sequences in natural scenes. While there have been great advances in STR methods, current methods still fail to recognize texts in arbitrary shapes, such as heavily curved or rotated texts, which are abundant in daily life (e.g. restaurant signs, product labels, company logos, etc). This paper introduces a novel architecture to recognizing texts of arbitrary shapes, named Self-Attention Text Recognition Network (SATRN), which is inspired by the Transformer. SATRN utilizes the self-attention mechanism to describe two-dimensional (2D) spatial dependencies of characters in a scene text image. Exploiting the full-graph propagation of self-attention, SATRN can recognize texts with arbitrary arrangements and large inter-character spacing. As a result, SATRN outperforms existing STR models by a large margin of 5.7 pp on average in "irregular text" benchmarks. We provide empirical analyses that illustrate the inner mechanisms and the extent to which the model is applicable (e.g. rotated and multi-line text). We will open-source the code.
+
+
+
+
[SVTR: Scene Text Recognition with a Single Visual Model](https://arxiv.org/abs/2205.00159)
+
+
+
+## Abstract
+
+Dominant scene text recognition models commonly contain two building blocks, a visual model for feature extraction and a sequence model for text transcription. This hybrid architecture, although accurate, is complex and less efficient. In this study, we propose a Single Visual model for Scene Text recognition within the patch-wise image tokenization framework, which dispenses with the sequential modeling entirely. The method, termed SVTR, firstly decomposes an image text into small patches named character components. Afterward, hierarchical stages are recurrently carried out by component-level mixing, merging and/or combining. Global and local mixing blocks are devised to perceive the inter-character and intra-character patterns, leading to a multi-grained character component perception. Thus, characters are recognized by a simple linear prediction. Experimental results on both English and Chinese scene text recognition tasks demonstrate the effectiveness of SVTR. SVTR-L (Large) achieves highly competitive accuracy in English and outperforms existing methods by a large margin in Chinese, while running faster. In addition, SVTR-T (Tiny) is an effective and much smaller model, which shows appealing speed at inference.
+
+
+
+
+?
+@
+A
+B
+C
+D
+E
+F
+G
+H
+I
+J
+K
+L
+M
+N
+O
+P
+Q
+R
+S
+T
+U
+V
+W
+X
+Y
+Z
+[
+\
+]
+^
+_
+`
+a
+b
+c
+d
+e
+f
+g
+h
+i
+j
+k
+l
+m
+n
+o
+p
+q
+r
+s
+t
+u
+v
+w
+x
+y
+z
+{
+|
+}
+~
+®
+°
+±
+³
+´
+·
+Â
+Ä
+Ç
+È
+É
+Ê
+Ô
+×
+Ü
+ß
+à
+ä
+è
+é
+ì
+ò
+ó
+ô
+ö
+÷
+ü
+ō
+ɑ
+˙
+Ω
+β
+δ
+ο
+Д
+з
+ـ
+–
+—
+―
+‖
+‘
+’
+“
+”
+•
+‥
+…
+‰
+′
+※
+€
+℃
+™
+Ⅰ
+Ⅱ
+Ⅲ
+Ⅳ
+Ⅴ
+Ⅵ
+→
+∅
+∈
+−
+√
+∞
+∶
+≠
+≤
+①
+─
+━
+┌
+■
+□
+▪
+▲
+△
+▶
+▸
+▼
+▽
+◆
+◇
+○
+◎
+◥
+★
+☆
+☑
+♀
+♥
+♪
+♭
+✕
+❤
+、
+。
+々
+〇
+〈
+〉
+《
+》
+「
+」
+『
+』
+【
+】
+〔
+〕
+〖
+〗
+〜
+ぁ
+あ
+ぃ
+い
+ぅ
+う
+ぇ
+え
+お
+か
+が
+き
+ぎ
+く
+ぐ
+け
+げ
+こ
+ご
+さ
+ざ
+し
+じ
+す
+ず
+せ
+ぜ
+そ
+ぞ
+た
+だ
+ち
+ぢ
+っ
+つ
+づ
+て
+で
+と
+ど
+な
+に
+ぬ
+ね
+の
+は
+ば
+ぱ
+ひ
+び
+ぴ
+ふ
+ぶ
+ぷ
+へ
+べ
+ぺ
+ほ
+ぼ
+ぽ
+ま
+み
+む
+め
+も
+ゃ
+や
+ゅ
+ゆ
+ょ
+よ
+ら
+り
+る
+れ
+ろ
+わ
+ゑ
+を
+ん
+゜
+ァ
+ア
+ィ
+イ
+ゥ
+ウ
+ェ
+エ
+ォ
+オ
+カ
+ガ
+キ
+ギ
+ク
+グ
+ケ
+ゲ
+コ
+ゴ
+サ
+ザ
+シ
+ジ
+ス
+ズ
+セ
+ゼ
+ソ
+ゾ
+タ
+ダ
+チ
+ッ
+ツ
+ヅ
+テ
+デ
+ト
+ド
+ナ
+ニ
+ヌ
+ネ
+ノ
+ハ
+バ
+パ
+ヒ
+ビ
+ピ
+フ
+ブ
+プ
+ヘ
+ベ
+ペ
+ホ
+ボ
+ポ
+マ
+ミ
+ム
+メ
+モ
+ャ
+ヤ
+ュ
+ユ
+ョ
+ヨ
+ラ
+リ
+ル
+レ
+ロ
+ワ
+ヱ
+ヲ
+ン
+ヴ
+ヵ
+ヶ
+ー
+㎝
+㎡
+㓥
+㔉
+㖞
+㧑
+㶉
+㺍
+䁖
+䇲
+䌷
+䌸
+䌹
+䌽
+䍁
+䓕
+䗖
+䜣
+䝙
+䠙
+䯄
+䴕
+䴖
+䴗
+䴙
+一
+丁
+七
+万
+丈
+三
+上
+下
+不
+与
+丐
+丑
+专
+且
+丕
+世
+丘
+丙
+业
+丛
+东
+丝
+丞
+両
+丢
+丣
+两
+严
+丧
+丨
+个
+丫
+丬
+中
+丰
+丱
+串
+临
+丶
+丸
+丹
+为
+主
+丼
+丽
+举
+丿
+乂
+乃
+乄
+久
+么
+义
+之
+乌
+乍
+乎
+乏
+乐
+乒
+乓
+乔
+乖
+乗
+乘
+乙
+乜
+九
+乞
+也
+习
+乡
+书
+乩
+买
+乱
+乳
+乸
+乾
+亀
+亁
+亂
+了
+予
+争
+事
+二
+亍
+于
+亏
+云
+互
+亓
+五
+井
+亘
+亚
+些
+亜
+亟
+亡
+亢
+交
+亥
+亦
+产
+亨
+亩
+享
+京
+亭
+亮
+亲
+亳
+亵
+亶
+亸
+亹
+人
+亻
+亿
+什
+仁
+仂
+仃
+仄
+仅
+仆
+仇
+仉
+今
+介
+仍
+从
+仏
+仑
+仓
+仔
+仕
+他
+仗
+付
+仙
+仝
+仞
+仟
+仠
+仡
+代
+令
+以
+仨
+仪
+仫
+们
+仭
+仮
+仰
+仱
+仲
+仳
+仵
+件
+价
+任
+份
+仿
+企
+伃
+伈
+伉
+伊
+伋
+伍
+伎
+伏
+伐
+休
+伓
+伖
+众
+优
+伙
+会
+伛
+伝
+伞
+伟
+传
+伢
+伣
+伤
+伥
+伦
+伧
+伩
+伪
+伫
+伬
+伯
+估
+伱
+伲
+伴
+伶
+伷
+伸
+伺
+伻
+似
+伽
+伾
+佃
+但
+佈
+佉
+佌
+位
+低
+住
+佐
+佑
+体
+佔
+何
+佗
+佘
+余
+佚
+佛
+作
+佝
+佞
+佟
+你
+佢
+佣
+佤
+佥
+佧
+佩
+佬
+佮
+佯
+佰
+佳
+佴
+併
+佶
+佷
+佸
+佹
+佺
+佻
+佼
+佽
+佾
+使
+侁
+侂
+侃
+侄
+來
+侈
+侉
+例
+侍
+侏
+侑
+侔
+侗
+侘
+供
+侜
+依
+侠
+価
+侣
+侥
+侦
+侧
+侨
+侩
+侪
+侬
+侭
+侮
+侯
+侲
+侵
+侹
+侼
+便
+俀
+係
+促
+俄
+俅
+俆
+俉
+俊
+俎
+俏
+俐
+俑
+俗
+俘
+俙
+俚
+俛
+俜
+保
+俞
+俟
+信
+俣
+俤
+俦
+俧
+俨
+俩
+俪
+俫
+俬
+俭
+修
+俯
+俱
+俳
+俴
+俵
+俶
+俷
+俸
+俺
+俾
+倅
+倉
+個
+倌
+倍
+倏
+倐
+們
+倒
+倓
+倔
+倕
+倖
+倘
+候
+倚
+倛
+倜
+倞
+借
+倡
+倢
+値
+倥
+倦
+倨
+倩
+倪
+倫
+倬
+倭
+倮
+倳
+倴
+倶
+倷
+倸
+倹
+债
+值
+倾
+偀
+偁
+偃
+偄
+假
+偈
+偌
+偎
+偏
+偓
+偕
+偘
+做
+停
+偢
+健
+偪
+偬
+偭
+偰
+偱
+偲
+側
+偶
+偷
+偻
+偾
+偿
+傀
+傃
+傅
+傈
+傍
+傎
+傒
+傕
+備
+傜
+傞
+傣
+傥
+傦
+傧
+储
+傩
+傪
+傫
+催
+傯
+傲
+傳
+債
+傷
+傺
+傻
+傾
+僁
+僄
+僆
+僇
+僊
+働
+僎
+像
+僔
+僖
+僚
+僛
+僜
+僝
+僡
+僤
+僦
+僧
+僪
+僬
+僭
+僮
+僰
+僱
+僳
+僴
+僵
+僶
+僸
+價
+僻
+僽
+僾
+僿
+儀
+儁
+儆
+儇
+儋
+儌
+儏
+儒
+儓
+儗
+儙
+儛
+償
+儡
+儣
+儦
+儲
+儴
+儵
+儽
+儾
+儿
+兀
+允
+元
+兄
+充
+兆
+先
+光
+克
+兌
+免
+児
+兑
+兒
+兔
+兕
+兖
+党
+兜
+兟
+兢
+入
+內
+全
+兩
+八
+公
+六
+兮
+兰
+共
+关
+兴
+兵
+其
+具
+典
+兹
+养
+兼
+兽
+兿
+冀
+冁
+内
+円
+冇
+冈
+冉
+冊
+册
+再
+冏
+冑
+冒
+冓
+冔
+冕
+冗
+写
+冚
+军
+农
+冞
+冠
+冢
+冤
+冥
+冧
+冨
+冬
+冯
+冰
+冱
+冲
+决
+冴
+况
+冶
+冷
+冻
+冼
+冽
+冿
+净
+凃
+凄
+准
+凇
+凈
+凉
+凊
+凋
+凌
+减
+凑
+凘
+凛
+凝
+几
+凡
+凤
+処
+凧
+凪
+凫
+凭
+凯
+凰
+凱
+凳
+凶
+凸
+凹
+出
+击
+凼
+函
+凿
+刀
+刁
+刃
+分
+切
+刈
+刊
+刌
+刍
+刎
+刑
+划
+刓
+刖
+列
+刘
+则
+刚
+创
+刜
+初
+删
+判
+別
+刨
+利
+别
+刬
+刭
+刮
+到
+刲
+刳
+刵
+制
+刷
+券
+刹
+刺
+刻
+刽
+刿
+剀
+剁
+剂
+剃
+剅
+則
+剉
+削
+剌
+前
+剎
+剐
+剑
+剔
+剖
+剚
+剜
+剞
+剟
+剡
+剣
+剤
+剥
+剧
+剨
+剩
+剪
+副
+剰
+割
+剸
+剺
+剽
+剿
+劂
+劄
+劈
+劓
+劖
+劘
+劙
+劚
+力
+劝
+办
+功
+加
+务
+劢
+劣
+动
+助
+努
+劫
+劬
+劭
+励
+劲
+劳
+労
+劵
+劷
+効
+劻
+劼
+劾
+势
+勃
+勇
+勉
+勋
+勍
+勐
+勑
+勒
+勔
+動
+勖
+勘
+務
+勚
+勝
+募
+勢
+勤
+勧
+勩
+勮
+勰
+勲
+勷
+勸
+勺
+勼
+勾
+勿
+匀
+匁
+匂
+匄
+包
+匆
+匈
+匊
+匌
+匍
+匏
+匐
+匕
+化
+北
+匙
+匜
+匝
+匠
+匡
+匣
+匤
+匦
+匪
+匮
+匯
+匳
+匹
+区
+医
+匼
+匽
+匾
+匿
+區
+十
+千
+卅
+升
+午
+卉
+半
+卍
+华
+协
+卑
+卒
+卓
+協
+单
+卖
+南
+単
+博
+卜
+卞
+卟
+占
+卡
+卢
+卣
+卤
+卦
+卧
+卨
+卫
+卬
+卭
+卮
+卯
+印
+危
+卲
+即
+却
+卵
+卷
+卸
+卺
+卻
+卼
+卿
+厂
+厄
+厅
+历
+厉
+压
+厌
+厍
+厎
+厐
+厓
+厔
+厕
+厖
+厘
+厚
+厝
+原
+厢
+厣
+厥
+厦
+厨
+厩
+厭
+厮
+厲
+厳
+厹
+去
+厾
+县
+叁
+参
+叄
+叆
+叇
+又
+叉
+及
+友
+双
+反
+収
+发
+叔
+取
+受
+变
+叙
+叛
+叞
+叟
+叠
+叡
+口
+古
+句
+另
+叨
+叩
+只
+叫
+召
+叭
+叮
+可
+台
+叱
+史
+右
+叵
+叶
+号
+司
+叹
+叻
+叼
+叽
+吁
+吃
+各
+吆
+合
+吉
+吊
+吋
+同
+名
+后
+吏
+吐
+向
+吒
+吓
+吔
+吕
+吖
+吗
+君
+吝
+吞
+吟
+吠
+吡
+否
+吧
+吨
+吩
+吪
+含
+听
+吭
+吮
+启
+吰
+吱
+吲
+吳
+吴
+吵
+吷
+吸
+吹
+吺
+吻
+吼
+吽
+吾
+吿
+呀
+呃
+呆
+呈
+呉
+告
+呋
+呎
+呐
+呒
+呓
+呔
+呕
+呖
+呗
+员
+呙
+呚
+呛
+呜
+呢
+呣
+呤
+呥
+呦
+周
+呪
+呫
+呰
+呱
+呲
+味
+呴
+呵
+呶
+呷
+呸
+呺
+呻
+呼
+命
+呿
+咀
+咁
+咂
+咄
+咆
+咇
+咈
+咉
+咋
+和
+咍
+咎
+咏
+咐
+咑
+咒
+咔
+咕
+咖
+咗
+咘
+咙
+咚
+咛
+咝
+咢
+咣
+咤
+咥
+咦
+咧
+咨
+咩
+咪
+咫
+咬
+咭
+咮
+咯
+咱
+咲
+咳
+咶
+咷
+咸
+咺
+咻
+咽
+咾
+咿
+哀
+品
+哂
+哃
+哄
+哆
+哇
+哈
+哉
+哋
+哌
+响
+哎
+哏
+哐
+哑
+哒
+哓
+哔
+哕
+哗
+哙
+哚
+哜
+哝
+哞
+哟
+員
+哢
+哣
+哤
+哥
+哦
+哧
+哨
+哩
+哪
+哭
+哮
+哲
+哳
+哺
+哼
+哽
+哿
+唁
+唅
+唆
+唇
+唈
+唉
+唊
+唎
+唏
+唐
+唑
+唔
+唛
+唝
+唞
+唠
+唡
+唢
+唣
+唤
+唥
+唦
+唧
+唪
+唫
+唬
+唭
+售
+唯
+唰
+唱
+唲
+唳
+唵
+唶
+唷
+唸
+唻
+唼
+唽
+唾
+唿
+啀
+啁
+啃
+啄
+啅
+商
+啈
+啉
+啊
+啋
+啍
+問
+啐
+啑
+啒
+啕
+啖
+啗
+啛
+啜
+啝
+啟
+啡
+啤
+啥
+啦
+啧
+啩
+啪
+啫
+啬
+啭
+啮
+啰
+啱
+啲
+啳
+啴
+啵
+啶
+啷
+啸
+啻
+啼
+啾
+喀
+喁
+喂
+喃
+善
+喆
+喇
+喈
+喉
+喊
+喋
+喏
+喐
+喑
+喓
+喔
+喘
+喙
+喜
+喝
+喞
+喟
+喢
+喣
+喤
+喦
+喧
+喨
+喪
+喫
+喬
+喭
+單
+喯
+喰
+喱
+喳
+喵
+営
+喷
+喹
+喺
+喻
+喼
+喽
+喾
+嗄
+嗅
+嗈
+嗉
+嗋
+嗌
+嗍
+嗐
+嗑
+嗒
+嗓
+嗔
+嗖
+嗗
+嗙
+嗛
+嗜
+嗝
+嗞
+嗟
+嗡
+嗢
+嗣
+嗤
+嗥
+嗦
+嗨
+嗪
+嗫
+嗬
+嗮
+嗯
+嗰
+嗱
+嗲
+嗳
+嗵
+嗷
+嗻
+嗽
+嗾
+嗿
+嘀
+嘁
+嘄
+嘅
+嘆
+嘈
+嘉
+嘌
+嘎
+嘏
+嘐
+嘒
+嘗
+嘘
+嘚
+嘛
+嘞
+嘟
+嘠
+嘡
+嘢
+嘣
+嘤
+嘥
+嘧
+嘬
+嘭
+嘱
+嘲
+嘴
+嘶
+嘷
+嘹
+嘻
+嘿
+噀
+噁
+噂
+噃
+噆
+噇
+噉
+噌
+噍
+噎
+噏
+噔
+噗
+噘
+噙
+噛
+噜
+噞
+噢
+噣
+噤
+器
+噩
+噪
+噫
+噬
+噭
+噱
+噳
+噶
+噷
+噻
+噼
+嚄
+嚅
+嚆
+嚋
+嚎
+嚏
+嚒
+嚓
+嚘
+嚚
+嚜
+嚟
+嚡
+嚢
+嚣
+嚤
+嚥
+嚬
+嚭
+嚯
+嚰
+嚱
+嚴
+嚵
+嚷
+嚺
+嚼
+嚿
+囂
+囄
+囊
+囋
+囍
+囏
+囐
+囓
+囔
+囗
+囚
+四
+囝
+回
+囟
+因
+囡
+团
+団
+囤
+囦
+囧
+囨
+囫
+园
+囮
+囯
+困
+囱
+囲
+図
+围
+囵
+囷
+囹
+固
+国
+图
+囿
+圂
+圃
+圄
+圆
+圈
+圉
+圊
+國
+圌
+圍
+圏
+圐
+園
+圖
+團
+圙
+圛
+圜
+圞
+土
+圠
+圣
+圥
+圧
+在
+圩
+圪
+圬
+圭
+圮
+圯
+地
+圳
+圴
+圹
+场
+圻
+圾
+圿
+址
+坂
+均
+坊
+坌
+坍
+坎
+坏
+坐
+坑
+块
+坚
+坛
+坜
+坝
+坞
+坟
+坠
+坡
+坣
+坤
+坦
+坨
+坩
+坪
+坫
+坬
+坭
+坯
+坰
+坱
+坳
+坵
+坷
+坺
+坻
+坼
+坾
+垂
+垃
+垄
+垅
+垆
+垇
+垊
+型
+垌
+垍
+垎
+垐
+垒
+垓
+垔
+垕
+垚
+垛
+垝
+垞
+垟
+垠
+垡
+垢
+垣
+垤
+垦
+垧
+垨
+垩
+垫
+垭
+垮
+垯
+垱
+垲
+垴
+垵
+垸
+垺
+垾
+垿
+埂
+埃
+埆
+埇
+埈
+埋
+埌
+城
+埏
+埒
+埔
+埕
+埗
+埘
+埙
+埚
+埜
+埝
+埞
+域
+埠
+埤
+埥
+埧
+埨
+埩
+埪
+埫
+埭
+埮
+埯
+埳
+埴
+埵
+埶
+執
+埸
+培
+基
+埼
+埽
+埿
+堀
+堂
+堃
+堆
+堇
+堉
+堋
+堌
+堍
+堎
+堑
+堕
+堙
+堛
+堞
+堠
+堡
+堣
+堤
+堦
+堧
+堨
+堪
+堭
+堮
+堰
+報
+堳
+場
+堵
+堶
+堺
+堼
+堽
+塀
+塁
+塄
+塅
+塆
+塇
+塈
+塉
+塌
+塍
+塑
+塔
+塘
+塙
+塚
+塝
+塞
+塠
+塨
+塩
+填
+塬
+塭
+塯
+塱
+塸
+塼
+塽
+塾
+塿
+墀
+墁
+境
+墄
+墅
+墈
+墉
+墊
+墋
+墍
+墐
+墒
+墓
+墕
+増
+墘
+墙
+增
+墟
+墠
+墡
+墦
+墨
+墩
+墹
+墺
+壁
+壅
+壆
+壇
+壈
+壊
+壌
+壑
+壒
+壓
+壕
+壖
+壝
+壞
+壡
+壤
+壩
+士
+壬
+壮
+声
+壱
+売
+壳
+壶
+壸
+壹
+壺
+壼
+壽
+夀
+处
+夅
+备
+変
+复
+夏
+夐
+夔
+夕
+外
+夙
+多
+夜
+够
+夠
+夡
+夢
+夤
+夥
+大
+天
+太
+夫
+夬
+夭
+央
+夯
+夰
+失
+头
+夷
+夸
+夹
+夺
+夼
+夾
+夿
+奀
+奁
+奂
+奄
+奅
+奇
+奈
+奉
+奋
+奌
+奎
+奏
+契
+奓
+奔
+奕
+奖
+套
+奘
+奚
+奠
+奡
+奢
+奣
+奤
+奥
+奧
+奨
+奫
+奭
+奰
+女
+奴
+奶
+奸
+她
+好
+妁
+如
+妃
+妄
+妆
+妇
+妈
+妉
+妊
+妍
+妒
+妓
+妖
+妗
+妘
+妙
+妞
+妣
+妤
+妥
+妨
+妩
+妪
+妫
+妬
+妮
+妯
+妲
+妳
+妹
+妻
+妼
+妾
+姁
+姅
+姆
+姉
+姊
+始
+姌
+姐
+姑
+姒
+姓
+委
+姗
+姘
+姚
+姜
+姝
+姞
+姣
+姤
+姥
+姨
+姪
+姫
+姬
+姮
+姱
+姵
+姹
+姺
+姻
+姿
+娀
+威
+娃
+娄
+娅
+娆
+娇
+娈
+娉
+娌
+娑
+娓
+娖
+娘
+娙
+娚
+娜
+娝
+娟
+娠
+娡
+娣
+娥
+娩
+娭
+娯
+娱
+娲
+娴
+娵
+娶
+娼
+婀
+婄
+婆
+婉
+婊
+婑
+婕
+婗
+婘
+婚
+婛
+婞
+婢
+婣
+婥
+婦
+婧
+婨
+婪
+婲
+婴
+婵
+婶
+婷
+婺
+婼
+婿
+媉
+媒
+媕
+媖
+媚
+媛
+媞
+媟
+媠
+媢
+媥
+媪
+媭
+媮
+媲
+媳
+媵
+媸
+媻
+媽
+媾
+媿
+嫁
+嫂
+嫄
+嫈
+嫉
+嫋
+嫌
+嫑
+嫒
+嫔
+嫖
+嫘
+嫚
+嫛
+嫜
+嫠
+嫡
+嫣
+嫦
+嫧
+嫩
+嫪
+嫫
+嫭
+嫮
+嫰
+嫱
+嫲
+嫳
+嫶
+嫽
+嬁
+嬃
+嬅
+嬇
+嬉
+嬐
+嬓
+嬖
+嬗
+嬛
+嬢
+嬬
+嬲
+嬴
+嬷
+嬾
+嬿
+孀
+孃
+孅
+子
+孑
+孓
+孔
+孕
+孖
+字
+存
+孙
+孚
+孛
+孜
+孝
+孟
+孢
+季
+孤
+孥
+学
+孩
+孪
+孬
+孭
+孰
+孱
+孲
+孳
+孵
+學
+孺
+孻
+孽
+宀
+宁
+它
+宄
+宅
+宇
+守
+安
+宋
+完
+宍
+宎
+宏
+宓
+宕
+宗
+官
+宙
+定
+宛
+宜
+宝
+实
+実
+宠
+审
+客
+宣
+室
+宥
+宦
+宪
+宫
+宬
+宮
+宰
+害
+宴
+宵
+家
+宸
+容
+宼
+宽
+宾
+宿
+寀
+寂
+寄
+寅
+密
+寇
+富
+寐
+寑
+寒
+寓
+寔
+寕
+寖
+寗
+寘
+寙
+寛
+寝
+寞
+察
+寡
+寢
+寤
+寥
+實
+寧
+寨
+審
+寮
+寯
+寰
+寶
+寸
+对
+寺
+寻
+导
+対
+寿
+封
+専
+尃
+射
+尅
+将
+將
+尉
+尊
+尋
+對
+小
+尐
+少
+尓
+尔
+尕
+尖
+尘
+尙
+尚
+尝
+尟
+尤
+尥
+尧
+尨
+尪
+尫
+尬
+尭
+尰
+就
+尴
+尸
+尹
+尺
+尻
+尼
+尽
+尾
+尿
+局
+屁
+层
+屃
+屄
+居
+屈
+屉
+届
+屋
+屌
+屍
+屎
+屏
+屐
+屑
+展
+屘
+屙
+屝
+属
+屟
+屠
+屡
+屣
+履
+屦
+屧
+屩
+屭
+屮
+屯
+山
+屳
+屴
+屹
+屺
+屼
+屾
+屿
+岁
+岂
+岈
+岊
+岌
+岍
+岏
+岐
+岑
+岔
+岕
+岖
+岗
+岘
+岙
+岚
+岛
+岜
+岝
+岞
+岡
+岢
+岣
+岧
+岨
+岩
+岫
+岬
+岭
+岱
+岳
+岵
+岷
+岸
+岽
+岿
+峁
+峃
+峄
+峇
+峋
+峒
+峘
+峙
+峛
+峞
+峠
+峡
+峣
+峤
+峥
+峦
+峧
+峨
+峩
+峪
+峭
+峯
+峰
+峻
+峿
+崀
+崁
+崂
+崃
+崄
+崆
+崇
+崈
+崋
+崌
+崎
+崐
+崑
+崒
+崔
+崕
+崖
+崙
+崚
+崛
+崞
+崟
+崠
+崣
+崤
+崦
+崧
+崩
+崭
+崮
+崱
+崴
+崶
+崷
+崽
+崾
+崿
+嵁
+嵂
+嵇
+嵊
+嵋
+嵌
+嵎
+嵒
+嵓
+嵔
+嵕
+嵖
+嵘
+嵙
+嵚
+嵛
+嵝
+嵡
+嵥
+嵦
+嵩
+嵫
+嵬
+嵯
+嵰
+嵲
+嵴
+嵷
+嵸
+嵺
+嵽
+嵾
+嶂
+嶅
+嶋
+嶌
+嶒
+嶓
+嶔
+嶘
+嶙
+嶛
+嶝
+嶞
+嶟
+嶨
+嶪
+嶭
+嶮
+嶰
+嶱
+嶲
+嶶
+嶷
+嶽
+嶾
+巁
+巂
+巃
+巅
+巇
+巉
+巌
+巍
+巏
+巑
+巖
+巘
+巛
+川
+州
+巡
+巢
+巣
+工
+左
+巧
+巨
+巩
+巫
+差
+巯
+己
+已
+巳
+巴
+巵
+巷
+巻
+巽
+巾
+巿
+币
+市
+布
+帅
+帆
+帇
+师
+帊
+希
+帏
+帐
+帑
+帔
+帕
+帖
+帘
+帙
+帚
+帛
+帜
+帝
+帟
+帡
+帢
+帣
+带
+帧
+帨
+師
+席
+帮
+帯
+帰
+帱
+帳
+帶
+帷
+常
+帻
+帼
+帽
+帿
+幂
+幄
+幅
+幌
+幓
+幔
+幕
+幙
+幛
+幝
+幞
+幠
+幡
+幢
+幣
+幤
+幥
+幨
+幩
+幪
+幭
+幮
+幰
+干
+平
+年
+幵
+并
+幷
+幸
+幹
+幺
+幻
+幼
+幽
+幾
+广
+庀
+庁
+広
+庄
+庆
+庇
+床
+庋
+序
+庐
+庑
+库
+应
+底
+庖
+店
+庙
+庚
+府
+庞
+废
+庠
+庤
+庥
+度
+座
+庪
+庭
+庳
+庵
+庶
+康
+庸
+庹
+庾
+廃
+廉
+廊
+廋
+廌
+廐
+廓
+廖
+廙
+廛
+廞
+廢
+廣
+廥
+廦
+廧
+廨
+廪
+廭
+延
+廷
+廸
+建
+廻
+廼
+廿
+开
+弁
+异
+弃
+弄
+弇
+弈
+弊
+弋
+弎
+式
+弐
+弑
+弒
+弓
+弔
+引
+弗
+弘
+弛
+弝
+弟
+张
+弢
+弥
+弦
+弧
+弨
+弩
+弪
+弭
+弮
+弯
+弰
+弱
+張
+弶
+強
+弸
+弹
+强
+弼
+弾
+彀
+彁
+彊
+彍
+彐
+归
+当
+彔
+录
+彖
+彗
+彘
+彝
+彟
+彡
+形
+彤
+彦
+彧
+彩
+彪
+彫
+彬
+彭
+彯
+彰
+影
+彳
+彴
+彷
+役
+彻
+彼
+彿
+往
+征
+徂
+径
+待
+徇
+很
+徉
+徊
+律
+後
+徐
+徒
+従
+徕
+得
+徘
+徙
+徚
+徜
+從
+御
+徧
+徨
+循
+徬
+徭
+微
+徯
+徳
+徴
+徵
+徶
+德
+徹
+徼
+徽
+心
+必
+忆
+忉
+忌
+忍
+忏
+忐
+忑
+忒
+忔
+忕
+忖
+志
+忘
+忙
+応
+忝
+忞
+忠
+忡
+忤
+忧
+忪
+快
+忭
+忮
+忱
+忳
+念
+忸
+忺
+忻
+忼
+忽
+忾
+忿
+怀
+态
+怂
+怃
+怄
+怅
+怆
+怊
+怍
+怎
+怏
+怐
+怑
+怒
+怓
+怔
+怕
+怖
+怗
+怙
+怚
+怛
+怜
+思
+怠
+怡
+急
+怦
+性
+怨
+怩
+怪
+怫
+怯
+怱
+怲
+怳
+怵
+总
+怼
+怿
+恁
+恂
+恃
+恄
+恇
+恈
+恋
+恌
+恍
+恐
+恑
+恒
+恓
+恕
+恙
+恚
+恛
+恝
+恟
+恠
+恢
+恣
+恤
+恧
+恨
+恩
+恪
+恫
+恬
+恭
+息
+恰
+恳
+恵
+恶
+恸
+恹
+恺
+恻
+恼
+恽
+恿
+悁
+悃
+悄
+悅
+悆
+悉
+悊
+悌
+悍
+悒
+悔
+悖
+悚
+悛
+悝
+悞
+悟
+悠
+悢
+患
+悦
+您
+悩
+悪
+悫
+悬
+悭
+悮
+悯
+悰
+悱
+悲
+悴
+悸
+悻
+悼
+惃
+惄
+情
+惆
+惇
+惉
+惊
+惋
+惏
+惑
+惓
+惔
+惕
+惘
+惙
+惚
+惛
+惜
+惝
+惟
+惠
+惡
+惦
+惧
+惨
+惩
+惫
+惬
+惭
+惮
+惯
+惰
+想
+惴
+惵
+惶
+惸
+惹
+惺
+愀
+愁
+愆
+愈
+愉
+愊
+愍
+愎
+意
+愒
+愓
+愔
+愕
+愗
+愚
+愛
+感
+愠
+愣
+愤
+愥
+愦
+愧
+愫
+愬
+愵
+愿
+慅
+慆
+慈
+慊
+態
+慌
+慎
+慐
+慑
+慒
+慓
+慕
+慙
+慜
+慝
+慞
+慠
+慢
+慥
+慧
+慨
+慬
+慭
+慰
+慱
+慴
+慵
+慶
+慷
+慽
+慾
+憀
+憁
+憂
+憋
+憍
+憎
+憔
+憕
+憖
+憘
+憚
+憝
+憧
+憨
+憩
+憬
+憭
+憯
+憰
+憲
+憷
+憸
+憹
+憺
+憾
+懁
+懂
+懃
+懆
+懈
+應
+懊
+懋
+懌
+懐
+懑
+懒
+懔
+懘
+懜
+懟
+懠
+懡
+懦
+懭
+懰
+懲
+懵
+懹
+懻
+懽
+懿
+戀
+戁
+戃
+戄
+戆
+戈
+戊
+戋
+戌
+戍
+戎
+戏
+成
+我
+戒
+戕
+或
+戗
+战
+戙
+戚
+戛
+戟
+戡
+戢
+戥
+戦
+截
+戫
+戬
+戭
+戮
+戲
+戳
+戴
+戶
+户
+戸
+戺
+戻
+戽
+戾
+房
+所
+扁
+扂
+扃
+扅
+扆
+扇
+扈
+扉
+扊
+手
+扌
+才
+扎
+扐
+扑
+扒
+打
+扔
+払
+托
+扙
+扚
+扛
+扜
+扞
+扠
+扡
+扢
+扣
+扤
+扥
+扦
+执
+扩
+扪
+扫
+扬
+扭
+扮
+扯
+扰
+扱
+扳
+扶
+批
+扼
+扽
+找
+承
+技
+抂
+抃
+抄
+抆
+抉
+把
+抌
+抏
+抑
+抒
+抓
+抔
+投
+抖
+抗
+折
+抚
+抛
+抜
+択
+抟
+抠
+抡
+抢
+护
+报
+抨
+披
+抬
+抱
+抵
+抶
+抹
+抻
+押
+抽
+抿
+拀
+拂
+拃
+拄
+担
+拆
+拇
+拈
+拉
+拊
+拌
+拍
+拎
+拏
+拐
+拑
+拒
+拓
+拔
+拖
+拗
+拘
+拙
+拚
+招
+拜
+拝
+拟
+拠
+拡
+拢
+拣
+拥
+拦
+拧
+拨
+择
+拫
+括
+拭
+拮
+拯
+拱
+拳
+拴
+拶
+拷
+拼
+拽
+拾
+拿
+持
+挂
+挃
+指
+挈
+按
+挎
+挐
+挑
+挒
+挓
+挖
+挙
+挚
+挛
+挜
+挝
+挞
+挟
+挠
+挡
+挢
+挣
+挤
+挥
+挦
+挨
+挪
+挫
+挭
+振
+挱
+挲
+挵
+挹
+挺
+挼
+挽
+挿
+捂
+捃
+捄
+捅
+捆
+捉
+捋
+捌
+捍
+捎
+捏
+捐
+捕
+捗
+捘
+捜
+捞
+损
+捡
+换
+捣
+捧
+捨
+捩
+捭
+据
+捰
+捱
+捲
+捴
+捶
+捷
+捺
+捻
+捽
+掀
+掁
+掂
+掅
+掇
+授
+掉
+掊
+掌
+掎
+掏
+掐
+排
+掕
+掖
+掘
+掞
+掟
+掠
+採
+探
+掣
+掤
+接
+控
+推
+掩
+措
+掬
+掮
+掯
+掰
+掱
+掲
+掳
+掴
+掷
+掸
+掹
+掺
+掻
+掼
+掾
+掿
+揃
+揄
+揆
+揈
+揉
+揌
+揍
+揎
+描
+提
+插
+揕
+揖
+揗
+揜
+揝
+揞
+揟
+揠
+握
+揣
+揥
+揦
+揩
+揪
+揫
+揭
+揰
+揲
+援
+揵
+揶
+揸
+揺
+揼
+揽
+揾
+揿
+搀
+搁
+搂
+搅
+搉
+搊
+搋
+搌
+損
+搎
+搏
+搐
+搒
+搓
+搔
+搕
+搘
+搚
+搜
+搞
+搠
+搡
+搢
+搣
+搤
+搥
+搦
+搧
+搨
+搪
+搬
+搭
+搯
+搰
+搴
+搵
+携
+搽
+搾
+摁
+摂
+摄
+摅
+摆
+摇
+摈
+摊
+摋
+摌
+摍
+摎
+摐
+摒
+摔
+摘
+摛
+摞
+摠
+摧
+摩
+摭
+摴
+摵
+摸
+摹
+摺
+摽
+撂
+撃
+撄
+撅
+撇
+撍
+撑
+撒
+撕
+撖
+撙
+撚
+撝
+撞
+撤
+撥
+撦
+撧
+撩
+撬
+播
+撮
+撰
+撱
+撴
+撵
+撶
+撷
+撸
+撺
+撼
+擀
+擂
+擅
+擉
+操
+擎
+擏
+擐
+擒
+擔
+擖
+擗
+擘
+據
+擞
+擢
+擤
+擦
+擩
+擫
+擷
+擸
+擿
+攀
+攃
+攉
+攋
+攒
+攕
+攘
+攚
+攝
+攞
+攥
+攧
+攩
+攫
+攮
+支
+攰
+攲
+收
+攸
+改
+攻
+攽
+放
+政
+故
+效
+敌
+敏
+救
+敔
+敕
+敖
+教
+敛
+敝
+敞
+敢
+散
+敦
+敧
+敩
+敫
+敬
+数
+敱
+敲
+整
+敷
+數
+敺
+敻
+斁
+斄
+斅
+文
+斉
+斋
+斌
+斎
+斐
+斑
+斒
+斓
+斗
+料
+斛
+斜
+斝
+斟
+斠
+斡
+斤
+斥
+斧
+斨
+斩
+斫
+断
+斮
+斯
+新
+斲
+斴
+斶
+斸
+方
+於
+施
+斿
+旁
+旂
+旃
+旄
+旅
+旆
+旋
+旌
+旍
+旎
+族
+旐
+旒
+旓
+旖
+旗
+旘
+旛
+旜
+旟
+无
+旡
+既
+日
+旦
+旧
+旨
+早
+旬
+旭
+旮
+旯
+旰
+旱
+旳
+旴
+旵
+时
+旷
+旸
+旺
+旻
+旼
+旿
+昀
+昂
+昃
+昄
+昆
+昇
+昈
+昉
+昊
+昌
+明
+昏
+昒
+易
+昔
+昕
+昙
+昚
+昝
+昞
+星
+映
+昣
+昤
+春
+昧
+昨
+昪
+昫
+昬
+昭
+是
+昰
+昱
+昳
+昴
+昵
+昶
+昺
+昼
+昽
+显
+晁
+時
+晃
+晅
+晊
+晋
+晌
+晏
+晒
+晓
+晔
+晕
+晖
+晗
+晙
+晚
+晛
+晞
+晟
+晡
+晢
+晣
+晤
+晥
+晦
+晧
+晨
+晩
+晫
+晬
+普
+景
+晰
+晳
+晴
+晶
+晷
+晹
+智
+晻
+晼
+晾
+暁
+暂
+暄
+暇
+暌
+暍
+暎
+暐
+暑
+暕
+暖
+暗
+暝
+暞
+暠
+暣
+暦
+暧
+暨
+暬
+暮
+暱
+暲
+暴
+暵
+暶
+暹
+暻
+暾
+曀
+曈
+曌
+曒
+曙
+曚
+曛
+曜
+曝
+曢
+曦
+曧
+曨
+曩
+曪
+曭
+曰
+曱
+曲
+曳
+更
+曵
+曷
+書
+曹
+曼
+曽
+曾
+替
+最
+朂
+會
+朅
+朆
+月
+有
+朊
+朋
+服
+朏
+朐
+朒
+朓
+朔
+朕
+朗
+朘
+望
+朝
+期
+朣
+朦
+木
+未
+末
+本
+札
+朮
+术
+朱
+朳
+朴
+朵
+朶
+机
+朽
+朿
+杀
+杂
+权
+杅
+杆
+杈
+杉
+杌
+李
+杏
+材
+村
+杓
+杕
+杖
+杙
+杜
+杞
+束
+杠
+条
+杢
+来
+杧
+杨
+杩
+杪
+杬
+杭
+杯
+杰
+東
+杲
+杳
+杵
+杷
+杻
+杼
+松
+板
+极
+构
+枅
+枇
+枉
+枋
+枌
+枍
+枎
+析
+枑
+枒
+枕
+林
+枘
+枚
+果
+枝
+枞
+枟
+枠
+枡
+枢
+枣
+枥
+枦
+枧
+枨
+枪
+枫
+枬
+枭
+枮
+枯
+枰
+枲
+枳
+枵
+架
+枷
+枸
+枹
+枻
+枿
+柁
+柂
+柃
+柄
+柅
+柈
+柊
+柎
+柏
+某
+柑
+柒
+染
+柔
+柖
+柘
+柙
+柚
+柜
+柝
+柞
+柟
+柠
+柢
+柣
+柤
+查
+柩
+柬
+柮
+柯
+柰
+柱
+柳
+柴
+柷
+柹
+柺
+査
+柽
+柿
+栀
+栂
+栃
+栄
+栅
+栆
+标
+栈
+栉
+栊
+栋
+栌
+栎
+栏
+栐
+树
+栒
+栓
+栖
+栗
+栘
+栜
+栝
+栟
+校
+栢
+栩
+株
+栯
+栱
+栲
+栳
+栴
+栵
+样
+核
+根
+栻
+格
+栽
+栾
+栿
+桀
+桁
+桂
+桃
+桄
+桅
+框
+案
+桉
+桊
+桋
+桌
+桎
+桐
+桑
+桓
+桔
+桕
+桚
+桜
+桝
+桞
+桠
+桡
+桢
+档
+桤
+桥
+桦
+桧
+桨
+桩
+桫
+桮
+桯
+桲
+桴
+桶
+桷
+桹
+桻
+梀
+梁
+梃
+梅
+梆
+梏
+梐
+梓
+梗
+條
+梠
+梡
+梢
+梣
+梦
+梧
+梨
+梩
+梪
+梫
+梬
+梭
+梯
+械
+梱
+梲
+梳
+梴
+梵
+梶
+梼
+梽
+梾
+梿
+检
+棁
+棂
+棃
+棄
+棅
+棆
+棉
+棊
+棋
+棍
+棐
+棑
+棒
+棓
+棕
+棘
+棙
+棚
+棝
+棠
+棡
+棣
+棨
+棪
+棫
+棬
+森
+棯
+棰
+棱
+棲
+棵
+棸
+棹
+棺
+棻
+棼
+棽
+椀
+椁
+椅
+椆
+椇
+椋
+植
+椎
+椐
+椑
+椒
+椓
+椗
+椙
+検
+椟
+椠
+椤
+椩
+椫
+椭
+椮
+椰
+椲
+椴
+椸
+椹
+椽
+椿
+楂
+楅
+楇
+楍
+楎
+楔
+楕
+楗
+楘
+楙
+楚
+楛
+楝
+楞
+楟
+楠
+楢
+楣
+楤
+楥
+楦
+楨
+楩
+楪
+楫
+業
+楮
+楯
+楰
+楱
+極
+楶
+楷
+楸
+楹
+楺
+楼
+楽
+榀
+概
+榃
+榄
+榅
+榆
+榇
+榈
+榉
+榊
+榍
+榔
+榕
+榖
+榘
+榛
+榜
+榞
+榠
+榥
+榧
+榨
+榫
+榭
+榰
+榱
+榴
+榷
+榺
+榻
+榼
+榾
+槁
+槃
+槅
+槇
+槊
+構
+槌
+槎
+槐
+槑
+槓
+槔
+槖
+様
+槙
+槚
+槛
+槟
+槠
+槢
+槥
+槩
+槬
+槭
+槱
+槲
+槵
+槻
+槽
+槾
+槿
+樀
+樂
+樊
+樋
+樏
+樓
+樕
+樗
+樘
+標
+樛
+樝
+樟
+模
+樣
+樨
+権
+横
+樫
+樭
+樯
+樱
+樵
+樹
+樽
+樾
+橄
+橅
+橇
+橉
+橌
+橎
+橐
+橑
+橘
+橙
+橚
+橛
+橞
+機
+橡
+橦
+橪
+橱
+橹
+橺
+橼
+橿
+檀
+檄
+檇
+檉
+檊
+檋
+檍
+檎
+檐
+檑
+檔
+檖
+檗
+檛
+檝
+檞
+檠
+檥
+檧
+檨
+檩
+檫
+檬
+檰
+檵
+檻
+檿
+櫁
+櫂
+櫆
+櫈
+櫌
+櫐
+櫑
+櫜
+櫞
+櫡
+櫰
+櫻
+櫼
+欃
+欉
+權
+欌
+欎
+欓
+欕
+欝
+欠
+次
+欢
+欣
+欤
+欦
+欧
+欬
+欱
+欲
+欷
+欸
+欹
+欺
+欻
+款
+欿
+歃
+歆
+歇
+歈
+歉
+歊
+歌
+歓
+歔
+歕
+歗
+歘
+歙
+歛
+歜
+歠
+止
+正
+此
+步
+武
+歧
+歩
+歪
+歯
+歳
+歴
+歸
+歹
+死
+歼
+殁
+殂
+殃
+殄
+殆
+殇
+殉
+殊
+残
+殍
+殑
+殒
+殓
+殖
+殘
+殚
+殛
+殡
+殢
+殣
+殪
+殭
+殳
+殴
+段
+殷
+殽
+殿
+毁
+毂
+毅
+毈
+毉
+毋
+母
+毎
+每
+毐
+毒
+毓
+比
+毕
+毖
+毗
+毘
+毙
+毚
+毛
+毡
+毨
+毫
+毬
+毯
+毰
+毳
+毵
+毶
+毸
+毹
+毻
+毽
+氄
+氅
+氆
+氇
+氍
+氎
+氏
+氐
+民
+氓
+气
+氕
+氖
+気
+氘
+氙
+氚
+氛
+氟
+氡
+氢
+氣
+氤
+氦
+氧
+氨
+氩
+氪
+氮
+氯
+氰
+氲
+水
+氵
+氷
+永
+氹
+氽
+氾
+氿
+汀
+汁
+求
+汃
+汆
+汇
+汉
+汊
+汍
+汎
+汏
+汐
+汔
+汕
+汗
+汚
+汛
+汜
+汝
+汞
+江
+池
+污
+汣
+汤
+汧
+汨
+汩
+汪
+汫
+汭
+汯
+汰
+汲
+汴
+汶
+汸
+汹
+決
+汽
+汾
+沁
+沂
+沃
+沄
+沅
+沆
+沇
+沈
+沉
+沋
+沌
+沍
+沏
+沐
+沒
+沓
+沔
+沕
+沙
+沚
+沛
+沜
+沟
+没
+沢
+沣
+沤
+沥
+沦
+沧
+沨
+沩
+沪
+沫
+沬
+沭
+沮
+沱
+沲
+河
+沴
+沵
+沶
+沸
+油
+治
+沼
+沽
+沾
+沿
+泂
+泃
+泄
+泅
+泆
+泇
+泉
+泊
+泌
+泐
+泓
+泔
+法
+泖
+泗
+泘
+泚
+泛
+泜
+泝
+泞
+泟
+泠
+泡
+波
+泣
+泥
+注
+泪
+泫
+泬
+泮
+泯
+泰
+泱
+泲
+泳
+泵
+泷
+泸
+泺
+泻
+泼
+泽
+泾
+洁
+洄
+洇
+洈
+洊
+洋
+洌
+洎
+洏
+洑
+洒
+洗
+洙
+洚
+洛
+洞
+洟
+洣
+洤
+津
+洧
+洨
+洩
+洪
+洫
+洭
+洮
+洱
+洲
+洳
+洴
+洵
+洸
+洹
+洺
+活
+洼
+洽
+派
+洿
+流
+浃
+浄
+浅
+浆
+浇
+浈
+浉
+浊
+测
+浍
+济
+浏
+浐
+浑
+浒
+浓
+浔
+浕
+浘
+浙
+浚
+浛
+浜
+浞
+浠
+浡
+浣
+浤
+浥
+浦
+浩
+浪
+浬
+浮
+浯
+浰
+浱
+浲
+浴
+海
+浸
+浼
+浿
+涂
+涅
+消
+涉
+涌
+涎
+涑
+涒
+涓
+涔
+涕
+涖
+涘
+涙
+涚
+涛
+涜
+涝
+涞
+涟
+涠
+涡
+涢
+涣
+涤
+涥
+润
+涧
+涨
+涩
+涪
+涫
+涬
+涮
+涯
+液
+涴
+涵
+涷
+涸
+涼
+涿
+淀
+淄
+淅
+淆
+淇
+淈
+淋
+淌
+淏
+淐
+淑
+淓
+淕
+淖
+淘
+淙
+淛
+淜
+淝
+淞
+淠
+淡
+淢
+淤
+淦
+淨
+淫
+淬
+淮
+淯
+淰
+深
+淳
+混
+淹
+添
+淼
+渀
+清
+渇
+済
+渉
+渊
+渋
+渌
+渍
+渎
+渏
+渐
+渑
+渓
+渔
+渕
+渖
+渗
+渙
+渚
+減
+渝
+渟
+渠
+渡
+渢
+渣
+渤
+渥
+渧
+温
+渫
+測
+渭
+港
+渰
+渱
+渲
+渴
+渶
+游
+渺
+渻
+渼
+湁
+湃
+湄
+湆
+湉
+湋
+湍
+湎
+湑
+湓
+湔
+湖
+湘
+湛
+湜
+湝
+湟
+湡
+湢
+湣
+湦
+湧
+湩
+湫
+湮
+湲
+湳
+湴
+湼
+湾
+湿
+満
+溁
+溂
+溃
+溅
+溆
+溇
+溉
+溊
+溋
+溍
+溎
+溏
+源
+溓
+溔
+準
+溘
+溜
+溞
+溟
+溠
+溡
+溢
+溥
+溦
+溧
+溪
+溫
+溯
+溱
+溲
+溳
+溴
+溵
+溶
+溷
+溺
+溻
+溽
+滁
+滂
+滃
+滆
+滇
+滈
+滉
+滋
+滍
+滏
+滑
+滓
+滔
+滕
+滗
+滘
+滙
+滚
+滜
+滝
+滞
+滟
+滠
+满
+滢
+滤
+滥
+滦
+滧
+滨
+滩
+滪
+滫
+滮
+滴
+滹
+滺
+滽
+漂
+漆
+漈
+漉
+漋
+漍
+漎
+漏
+漓
+演
+漕
+漖
+漘
+漙
+漠
+漢
+漤
+漦
+漩
+漪
+漫
+漭
+漯
+漰
+漱
+漳
+漴
+漶
+漷
+漹
+漻
+漼
+漾
+潀
+潄
+潆
+潇
+潈
+潋
+潍
+潎
+潏
+潒
+潓
+潕
+潘
+潜
+潝
+潞
+潟
+潠
+潢
+潤
+潦
+潩
+潬
+潭
+潮
+潲
+潴
+潵
+潸
+潺
+潼
+潽
+潾
+澂
+澄
+澈
+澉
+澌
+澍
+澎
+澒
+澔
+澗
+澘
+澙
+澛
+澜
+澡
+澣
+澤
+澥
+澧
+澨
+澪
+澫
+澭
+澳
+澴
+澶
+澹
+澼
+澾
+激
+濂
+濅
+濆
+濈
+濉
+濊
+濋
+濎
+濑
+濒
+濙
+濛
+濞
+濟
+濠
+濡
+濦
+濩
+濫
+濬
+濮
+濯
+濸
+瀁
+瀄
+瀌
+瀍
+瀎
+瀑
+瀔
+瀖
+瀚
+瀛
+瀜
+瀞
+瀡
+瀣
+瀩
+瀬
+瀰
+瀱
+瀴
+瀵
+瀹
+瀺
+瀼
+瀽
+灂
+灈
+灉
+灊
+灌
+灏
+灑
+灒
+灞
+灩
+火
+灬
+灭
+灯
+灰
+灵
+灶
+灸
+灺
+灼
+灾
+灿
+炀
+炅
+炆
+炉
+炊
+炌
+炎
+炒
+炓
+炔
+炕
+炖
+炘
+炙
+炜
+炝
+炟
+炡
+炤
+炧
+炫
+炬
+炭
+炮
+炯
+炰
+炱
+炳
+炵
+炷
+炸
+点
+為
+炼
+炽
+炿
+烀
+烁
+烂
+烃
+烈
+烊
+烋
+烓
+烔
+烘
+烙
+烚
+烛
+烜
+烝
+烟
+烤
+烦
+烧
+烨
+烩
+烫
+烬
+热
+烯
+烷
+烹
+烺
+烻
+烽
+焄
+焉
+焊
+焌
+焏
+焐
+焒
+焓
+焕
+焖
+焗
+焘
+焙
+焚
+焜
+焞
+焟
+焠
+無
+焦
+焩
+焫
+焮
+焯
+焰
+焱
+焲
+焴
+然
+焹
+焻
+焼
+煀
+煁
+煃
+煅
+煊
+煌
+煍
+煎
+煐
+煓
+煕
+煚
+煜
+煞
+煟
+煠
+煤
+煦
+照
+煨
+煮
+煲
+煳
+煴
+煵
+煶
+煸
+煹
+煺
+煽
+煿
+熂
+熄
+熇
+熉
+熊
+熏
+熔
+熕
+熘
+熙
+熛
+熜
+熝
+熟
+熠
+熤
+熨
+熬
+熭
+熯
+熱
+熳
+熴
+熵
+熸
+熹
+熿
+燀
+燂
+燃
+燅
+燈
+燊
+燋
+燎
+燏
+燐
+燑
+燔
+燕
+燖
+燚
+燝
+營
+燠
+燢
+燥
+燧
+燬
+燮
+燹
+燿
+爆
+爇
+爊
+爋
+爎
+爔
+爘
+爚
+爝
+爞
+爟
+爢
+爧
+爨
+爪
+爬
+爭
+爰
+爱
+爵
+父
+爷
+爸
+爹
+爻
+爽
+爿
+牁
+牂
+片
+版
+牋
+牌
+牍
+牏
+牒
+牖
+牙
+牛
+牝
+牟
+牡
+牢
+牣
+牤
+牥
+牦
+牧
+物
+牮
+牯
+牲
+牴
+牵
+牷
+牸
+特
+牺
+牻
+牾
+牿
+犀
+犁
+犄
+犇
+犉
+犊
+犋
+犍
+犏
+犒
+犘
+犜
+犟
+犨
+犬
+犭
+犯
+犰
+犴
+状
+犷
+犸
+犹
+犺
+犼
+犽
+狁
+狂
+狃
+狄
+狈
+狌
+狍
+狎
+狐
+狒
+狖
+狗
+狘
+狙
+狛
+狝
+狞
+狟
+狠
+狡
+狢
+狥
+狧
+狨
+狩
+独
+狭
+狮
+狯
+狰
+狱
+狲
+狳
+狴
+狶
+狷
+狸
+狺
+狻
+狼
+猁
+猃
+猄
+猇
+猊
+猋
+猎
+猕
+猖
+猗
+猘
+猛
+猜
+猝
+猞
+猟
+猡
+猢
+猥
+猧
+猩
+猪
+猫
+猬
+献
+猰
+猱
+猲
+猳
+猴
+猵
+猶
+猷
+猸
+猾
+猿
+獂
+獈
+獍
+獏
+獐
+獒
+獗
+獘
+獚
+獜
+獝
+獠
+獣
+獦
+獨
+獬
+獭
+獮
+獯
+獲
+獴
+獶
+獻
+獾
+玁
+玃
+玄
+率
+玈
+玉
+玊
+王
+玍
+玎
+玑
+玒
+玓
+玕
+玖
+玗
+玘
+玙
+玚
+玛
+玟
+玠
+玡
+玢
+玥
+玦
+玩
+玫
+玭
+玮
+环
+现
+玱
+玲
+玳
+玶
+玷
+玺
+玻
+玼
+珀
+珂
+珅
+珈
+珉
+珊
+珌
+珍
+珎
+珏
+珐
+珑
+珓
+珔
+珖
+珙
+珝
+珞
+珠
+珣
+珥
+珦
+珧
+珩
+珪
+班
+珮
+珰
+珲
+珵
+珸
+珹
+珺
+珽
+現
+球
+琅
+理
+琇
+琉
+琊
+琍
+琎
+琏
+琐
+琖
+琚
+琛
+琠
+琢
+琣
+琤
+琥
+琦
+琨
+琪
+琫
+琬
+琭
+琮
+琯
+琰
+琱
+琲
+琳
+琴
+琵
+琶
+琻
+琼
+瑀
+瑁
+瑂
+瑃
+瑄
+瑅
+瑆
+瑊
+瑌
+瑍
+瑑
+瑔
+瑕
+瑗
+瑙
+瑚
+瑛
+瑜
+瑞
+瑟
+瑠
+瑢
+瑧
+瑨
+瑪
+瑭
+瑮
+瑰
+瑱
+瑳
+瑴
+瑶
+瑷
+瑸
+瑽
+瑾
+瑿
+璀
+璁
+璂
+璃
+璅
+璆
+璇
+璈
+璊
+璋
+璎
+璐
+璕
+璘
+璙
+璚
+璜
+璝
+璞
+璟
+璠
+璤
+璥
+璧
+璨
+璩
+璪
+璲
+璵
+璷
+璸
+璹
+璺
+璿
+瓀
+瓅
+瓈
+瓊
+瓎
+瓒
+瓖
+瓘
+瓚
+瓛
+瓜
+瓞
+瓟
+瓠
+瓢
+瓣
+瓤
+瓦
+瓨
+瓬
+瓮
+瓯
+瓴
+瓶
+瓷
+瓹
+瓻
+瓿
+甀
+甂
+甃
+甄
+甈
+甋
+甍
+甑
+甒
+甓
+甔
+甕
+甖
+甗
+甘
+甙
+甚
+甜
+生
+甡
+產
+甥
+甦
+用
+甩
+甪
+甫
+甬
+甭
+甯
+田
+由
+甲
+申
+甴
+电
+男
+甸
+町
+画
+甽
+甾
+甿
+畀
+畅
+畇
+畈
+畊
+畋
+界
+畎
+畏
+畑
+畓
+畔
+留
+畚
+畛
+畜
+畝
+畟
+畠
+畤
+略
+畦
+畧
+番
+畫
+畬
+畯
+畲
+畳
+畴
+當
+畷
+畸
+畹
+畼
+畽
+畿
+疁
+疃
+疆
+疈
+疋
+疍
+疎
+疏
+疐
+疑
+疔
+疖
+疗
+疙
+疚
+疝
+疟
+疠
+疡
+疢
+疣
+疤
+疥
+疧
+疫
+疬
+疭
+疮
+疯
+疰
+疱
+疲
+疳
+疴
+疵
+疸
+疹
+疻
+疼
+疽
+疾
+痁
+痂
+痃
+痄
+病
+症
+痈
+痉
+痊
+痌
+痍
+痎
+痏
+痒
+痔
+痕
+痖
+痗
+痘
+痛
+痞
+痟
+痠
+痡
+痢
+痣
+痤
+痦
+痧
+痨
+痩
+痪
+痫
+痯
+痰
+痱
+痲
+痴
+痹
+痺
+痻
+痼
+痾
+痿
+瘀
+瘁
+瘅
+瘆
+瘈
+瘉
+瘊
+瘌
+瘏
+瘐
+瘕
+瘖
+瘗
+瘘
+瘙
+瘛
+瘝
+瘟
+瘠
+瘢
+瘣
+瘤
+瘥
+瘦
+瘨
+瘩
+瘪
+瘫
+瘭
+瘰
+瘱
+瘳
+瘴
+瘵
+瘸
+瘼
+瘾
+瘿
+癀
+癃
+癌
+癏
+癒
+癔
+癖
+癙
+癜
+癞
+癢
+癣
+癥
+癦
+癨
+癪
+癫
+癯
+癴
+癶
+癸
+癹
+発
+登
+發
+白
+百
+癿
+皁
+皂
+的
+皆
+皇
+皈
+皋
+皎
+皑
+皓
+皖
+皙
+皛
+皝
+皞
+皤
+皦
+皪
+皮
+皱
+皲
+皴
+皿
+盂
+盅
+盆
+盈
+益
+盍
+盎
+盏
+盐
+监
+盒
+盔
+盖
+盗
+盘
+盛
+盜
+盝
+盟
+盡
+盢
+監
+盥
+盩
+盬
+盭
+目
+盯
+盱
+盲
+直
+盵
+相
+盹
+盻
+盼
+盾
+眀
+省
+眄
+眆
+眇
+眈
+眉
+眊
+看
+県
+眎
+眐
+眙
+眚
+眛
+眞
+真
+眠
+眢
+眦
+眨
+眩
+眬
+眭
+眯
+眴
+眵
+眶
+眷
+眸
+眹
+眺
+眼
+眽
+着
+睁
+睃
+睅
+睆
+睇
+睍
+睎
+睐
+睑
+睒
+睖
+睗
+睚
+睛
+睟
+睠
+睡
+睢
+督
+睥
+睦
+睨
+睩
+睪
+睫
+睬
+睭
+睰
+睳
+睷
+睹
+睺
+睽
+睾
+睿
+瞀
+瞂
+瞄
+瞅
+瞆
+瞋
+瞌
+瞍
+瞎
+瞑
+瞒
+瞓
+瞚
+瞟
+瞠
+瞢
+瞤
+瞥
+瞧
+瞩
+瞪
+瞬
+瞭
+瞯
+瞰
+瞳
+瞵
+瞻
+瞽
+瞾
+瞿
+矂
+矇
+矋
+矍
+矐
+矑
+矖
+矗
+矛
+矜
+矞
+矟
+矢
+矣
+知
+矧
+矨
+矩
+矫
+矬
+短
+矮
+矰
+矱
+矲
+石
+矶
+矸
+矻
+矼
+矽
+矾
+矿
+砀
+码
+砂
+砃
+砅
+砆
+砉
+砌
+砍
+砏
+砑
+砒
+研
+砖
+砗
+砘
+砚
+砜
+砝
+砟
+砠
+砢
+砣
+砥
+砦
+砧
+砬
+砭
+砮
+砯
+砰
+砲
+破
+砷
+砸
+砹
+砺
+砻
+砼
+砾
+础
+硁
+硅
+硇
+硉
+硊
+硌
+硍
+硎
+硏
+硐
+硒
+硕
+硖
+硗
+硙
+硚
+硝
+硡
+硪
+硫
+硬
+确
+硰
+硵
+硷
+硼
+硾
+硿
+碁
+碃
+碆
+碇
+碉
+碌
+碍
+碎
+碏
+碐
+碑
+碓
+碔
+碕
+碗
+碘
+碚
+碛
+碜
+碟
+碡
+碣
+碥
+碧
+碨
+碪
+碫
+碰
+碱
+碲
+碳
+碴
+碶
+確
+碻
+碾
+磁
+磂
+磅
+磈
+磉
+磊
+磋
+磎
+磏
+磐
+磑
+磒
+磔
+磕
+磖
+磙
+磛
+磜
+磝
+磡
+磢
+磨
+磬
+磲
+磳
+磴
+磵
+磷
+磹
+磺
+磻
+磾
+磿
+礁
+礅
+礉
+礌
+礐
+礒
+礓
+礜
+礞
+礡
+礤
+礧
+礨
+礮
+礲
+礴
+礶
+示
+礼
+礽
+社
+礿
+祀
+祁
+祃
+祄
+祅
+祆
+祇
+祈
+祉
+祊
+祋
+祎
+祏
+祐
+祓
+祔
+祕
+祖
+祗
+祚
+祛
+祜
+祝
+神
+祟
+祠
+祢
+祤
+祥
+祧
+票
+祫
+祭
+祯
+祱
+祲
+祴
+祶
+祷
+祸
+祺
+祼
+祾
+祿
+禀
+禁
+禂
+禄
+禅
+禇
+禊
+禋
+禎
+福
+禑
+禔
+禖
+禗
+禘
+禚
+禛
+禜
+禟
+禤
+禥
+禧
+禨
+禩
+禫
+禮
+禳
+禴
+禵
+禷
+禹
+禺
+离
+禽
+禾
+秀
+私
+秃
+秄
+秅
+秆
+秇
+秉
+秋
+种
+秏
+科
+秒
+秔
+秕
+秖
+秘
+秛
+秞
+租
+秠
+秣
+秤
+秦
+秧
+秩
+秪
+秫
+秬
+秭
+积
+称
+秴
+秸
+移
+秽
+秾
+秿
+稀
+稂
+稃
+稅
+稆
+稊
+程
+稌
+稍
+税
+稔
+稖
+稗
+稙
+稚
+稛
+稞
+稠
+稣
+稭
+種
+稱
+稲
+稳
+稷
+稹
+稺
+稻
+稼
+稽
+稾
+稿
+穀
+穂
+穅
+穆
+穇
+穈
+穉
+穊
+穋
+積
+穏
+穑
+穗
+穞
+穟
+穠
+穡
+穧
+穨
+穬
+穰
+穴
+穵
+究
+穷
+穸
+穹
+空
+穼
+穽
+穾
+穿
+窀
+突
+窃
+窄
+窅
+窆
+窈
+窊
+窋
+窌
+窍
+窎
+窑
+窒
+窓
+窕
+窖
+窗
+窘
+窙
+窜
+窝
+窞
+窟
+窠
+窡
+窣
+窥
+窦
+窨
+窩
+窫
+窬
+窭
+窰
+窱
+窳
+窴
+窸
+窹
+窺
+窻
+窽
+窾
+窿
+竂
+竉
+立
+竑
+竖
+竘
+站
+竛
+竜
+竝
+竞
+竟
+章
+竣
+童
+竦
+竭
+竮
+端
+竹
+竺
+竻
+竽
+竿
+笃
+笄
+笆
+笈
+笉
+笊
+笋
+笏
+笐
+笑
+笔
+笕
+笙
+笛
+笞
+笠
+笡
+笤
+笥
+符
+笨
+笪
+笫
+第
+笭
+笮
+笯
+笱
+笲
+笳
+笴
+笵
+笸
+笹
+笺
+笼
+笾
+筇
+筈
+等
+筋
+筌
+筏
+筐
+筑
+筒
+筓
+答
+策
+筚
+筛
+筜
+筝
+筠
+筢
+筤
+筥
+筦
+筩
+筭
+筮
+筯
+筰
+筱
+筲
+筳
+筴
+筵
+筷
+筹
+筻
+筼
+签
+简
+箄
+箅
+箇
+箊
+箍
+箎
+箐
+箑
+箒
+箓
+箔
+箕
+算
+箘
+箜
+箝
+箠
+管
+箢
+箣
+箦
+箧
+箨
+箩
+箪
+箫
+箬
+箭
+箯
+箱
+箴
+箵
+箸
+箻
+箼
+箾
+篁
+篃
+篆
+篇
+篌
+篑
+篓
+篘
+篙
+篚
+篛
+篝
+篡
+篢
+篥
+篦
+篨
+篪
+篭
+篮
+篯
+篱
+篲
+篷
+篸
+篹
+篻
+篼
+篾
+簁
+簃
+簄
+簇
+簈
+簉
+簋
+簌
+簏
+簕
+簖
+簜
+簟
+簠
+簡
+簦
+簧
+簨
+簪
+簬
+簰
+簳
+簴
+簵
+簸
+簿
+籀
+籁
+籊
+籋
+籌
+籍
+籏
+籐
+籓
+籛
+籝
+籞
+籢
+籣
+籤
+籥
+籧
+籯
+米
+籴
+籹
+籺
+类
+籼
+籽
+籾
+粃
+粆
+粉
+粊
+粋
+粐
+粑
+粒
+粔
+粕
+粗
+粘
+粜
+粝
+粞
+粟
+粢
+粤
+粥
+粧
+粩
+粪
+粮
+粱
+粲
+粳
+粶
+粹
+粺
+粻
+粼
+粽
+精
+粿
+糀
+糁
+糅
+糇
+糈
+糊
+糌
+糍
+糒
+糕
+糖
+糗
+糙
+糜
+糟
+糠
+糦
+糧
+糨
+糯
+糵
+糸
+系
+紀
+紃
+約
+紅
+紊
+納
+紑
+純
+級
+紞
+素
+索
+紧
+紫
+累
+紵
+紽
+紾
+絁
+終
+組
+絆
+絇
+経
+絏
+絓
+絕
+絖
+絙
+絜
+絠
+絣
+給
+絩
+絪
+絫
+絮
+絵
+絷
+絺
+絻
+絿
+綀
+綅
+綈
+綌
+綍
+經
+綖
+継
+続
+綝
+綟
+綦
+綪
+綮
+綯
+綴
+綷
+緃
+緊
+緌
+緎
+総
+緒
+線
+緝
+緣
+緩
+緺
+緼
+縁
+縄
+縆
+縓
+縕
+縠
+縢
+縦
+縩
+縮
+縯
+縺
+縻
+縿
+繁
+繂
+繄
+繇
+繊
+繋
+繍
+繐
+繑
+織
+繖
+繙
+繟
+繣
+繳
+繸
+繻
+纁
+纂
+纆
+纇
+纑
+纔
+纕
+纚
+纛
+纟
+纠
+纡
+红
+纣
+纤
+纥
+约
+级
+纨
+纩
+纪
+纫
+纬
+纭
+纮
+纯
+纰
+纱
+纲
+纳
+纴
+纵
+纶
+纷
+纸
+纹
+纺
+纻
+纼
+纽
+纾
+线
+绀
+绁
+绂
+练
+组
+绅
+细
+织
+终
+绉
+绊
+绋
+绌
+绍
+绎
+经
+绐
+绑
+绒
+结
+绔
+绕
+绖
+绗
+绘
+给
+绚
+绛
+络
+绝
+绞
+统
+绠
+绡
+绢
+绣
+绤
+绥
+绦
+继
+绨
+绩
+绪
+绫
+续
+绮
+绯
+绰
+绱
+绲
+绳
+维
+绵
+绶
+绷
+绸
+绹
+绺
+绻
+综
+绽
+绾
+绿
+缀
+缁
+缃
+缄
+缅
+缆
+缇
+缈
+缉
+缊
+缋
+缌
+缍
+缎
+缏
+缐
+缑
+缒
+缓
+缔
+缕
+编
+缗
+缘
+缙
+缚
+缛
+缜
+缝
+缞
+缟
+缠
+缡
+缢
+缣
+缤
+缥
+缦
+缧
+缨
+缩
+缪
+缫
+缬
+缭
+缮
+缯
+缰
+缱
+缲
+缳
+缴
+缵
+缶
+缸
+缺
+缼
+缾
+罂
+罃
+罄
+罅
+罈
+罉
+罍
+罐
+网
+罔
+罕
+罗
+罘
+罙
+罚
+罛
+罝
+罟
+罠
+罡
+罢
+罣
+罥
+罦
+罨
+罩
+罪
+罭
+置
+罯
+署
+罳
+罴
+罶
+罹
+罻
+罽
+罾
+罿
+羀
+羁
+羂
+羅
+羆
+羇
+羉
+羊
+羌
+美
+羑
+羒
+羔
+羕
+羖
+羗
+羚
+羜
+羝
+羞
+羟
+羠
+羡
+羣
+群
+羧
+羨
+義
+羫
+羭
+羯
+羰
+羱
+羲
+羴
+羵
+羶
+羸
+羹
+羼
+羽
+羾
+羿
+翀
+翁
+翂
+翃
+翅
+翈
+翊
+翌
+翎
+翏
+習
+翔
+翕
+翖
+翘
+翙
+翚
+翛
+翟
+翠
+翡
+翣
+翥
+翦
+翩
+翫
+翬
+翮
+翯
+翰
+翱
+翲
+翳
+翶
+翻
+翼
+翾
+翿
+耀
+老
+考
+耄
+者
+耆
+耇
+耈
+耋
+而
+耍
+耎
+耐
+耒
+耔
+耕
+耖
+耗
+耘
+耙
+耜
+耡
+耢
+耤
+耥
+耦
+耧
+耨
+耩
+耭
+耰
+耱
+耳
+耵
+耶
+耷
+耸
+耻
+耽
+耿
+聂
+聃
+聆
+聊
+聋
+职
+聍
+聒
+联
+聖
+聘
+聚
+聛
+聡
+聩
+聪
+聰
+聱
+聲
+聴
+聻
+聽
+聿
+肃
+肄
+肆
+肇
+肉
+肋
+肌
+肏
+肐
+肓
+肖
+肘
+肚
+肛
+肜
+肝
+肞
+肟
+肠
+股
+肢
+肣
+肤
+肥
+肦
+肩
+肪
+肫
+肬
+肭
+肮
+肯
+肱
+育
+肳
+肴
+肶
+肸
+肺
+肼
+肽
+肾
+肿
+胀
+胁
+胂
+胃
+胄
+胆
+胈
+背
+胍
+胎
+胐
+胔
+胖
+胗
+胘
+胙
+胚
+胛
+胜
+胝
+胞
+胠
+胡
+胤
+胥
+胧
+胨
+胩
+胪
+胫
+胬
+胭
+胮
+胯
+胰
+胱
+胲
+胳
+胴
+胶
+胸
+胹
+胺
+胻
+胼
+能
+胾
+脁
+脂
+脃
+脆
+脇
+脉
+脊
+脍
+脎
+脏
+脐
+脑
+脒
+脓
+脔
+脖
+脘
+脙
+脚
+脝
+脞
+脟
+脡
+脢
+脣
+脤
+脩
+脬
+脯
+脰
+脱
+脲
+脳
+脶
+脷
+脸
+脹
+脽
+脾
+脿
+腄
+腆
+腈
+腊
+腋
+腌
+腍
+腐
+腑
+腒
+腓
+腔
+腕
+腘
+腙
+腚
+腠
+腥
+腧
+腩
+腬
+腭
+腮
+腯
+腰
+腱
+腲
+腴
+腷
+腹
+腺
+腻
+腼
+腽
+腾
+腿
+膀
+膂
+膄
+膇
+膈
+膊
+膋
+膍
+膏
+膑
+膘
+膚
+膛
+膜
+膝
+膣
+膦
+膨
+膪
+膫
+膰
+膳
+膴
+膶
+膺
+膻
+臀
+臁
+臂
+臃
+臄
+臆
+臊
+臋
+臌
+臎
+臑
+臓
+臙
+臛
+臜
+臝
+臞
+臡
+臣
+臧
+臨
+臩
+自
+臬
+臭
+臯
+臱
+臲
+至
+致
+臺
+臻
+臼
+臾
+臿
+舀
+舁
+舂
+舄
+舅
+舆
+與
+興
+舉
+舊
+舋
+舌
+舍
+舎
+舐
+舒
+舔
+舕
+舗
+舘
+舛
+舜
+舝
+舞
+舟
+舠
+舡
+舢
+舣
+舥
+舦
+舨
+航
+舫
+般
+舰
+舱
+舲
+舳
+舴
+舵
+舶
+舷
+舸
+船
+舺
+舻
+舼
+艄
+艅
+艇
+艋
+艎
+艏
+艐
+艑
+艓
+艔
+艘
+艚
+艛
+艟
+艨
+艮
+良
+艰
+色
+艳
+艴
+艹
+艺
+艻
+艽
+艾
+艿
+节
+芃
+芄
+芈
+芊
+芋
+芍
+芎
+芏
+芐
+芑
+芒
+芔
+芗
+芘
+芙
+芛
+芜
+芝
+芟
+芡
+芣
+芤
+芥
+芦
+芧
+芨
+芩
+芪
+芫
+芬
+芭
+芮
+芯
+芰
+花
+芳
+芴
+芶
+芷
+芸
+芹
+芺
+芼
+芽
+芾
+苁
+苄
+苅
+苇
+苈
+苊
+苋
+苌
+苍
+苎
+苏
+苑
+苒
+苓
+苔
+苕
+苖
+苗
+苘
+苙
+苛
+苜
+苝
+苞
+苟
+苠
+苡
+苣
+苤
+若
+苦
+苧
+苨
+苫
+苯
+英
+苳
+苴
+苶
+苷
+苹
+苺
+苻
+苾
+茀
+茁
+茂
+范
+茄
+茅
+茆
+茇
+茈
+茉
+茌
+茍
+茎
+茏
+茐
+茑
+茔
+茕
+茖
+茗
+茙
+茚
+茛
+茜
+茝
+茞
+茧
+茨
+茫
+茬
+茭
+茯
+茱
+茲
+茳
+茴
+茵
+茶
+茷
+茸
+茹
+茺
+茼
+荀
+荂
+荃
+荄
+荅
+荆
+荇
+荈
+草
+荊
+荍
+荎
+荏
+荐
+荑
+荒
+荓
+荔
+荘
+荙
+荚
+荛
+荜
+荞
+荟
+荠
+荡
+荣
+荤
+荥
+荦
+荧
+荨
+荩
+荪
+荫
+荬
+荭
+荮
+药
+荴
+荵
+荷
+荸
+荻
+荼
+荽
+莅
+莆
+莉
+莊
+莋
+莎
+莐
+莒
+莓
+莕
+莘
+莙
+莛
+莜
+莞
+莠
+莨
+莩
+莪
+莫
+莰
+莱
+莲
+莳
+莴
+莶
+获
+莸
+莹
+莺
+莼
+莽
+莿
+菀
+菁
+菂
+菅
+菇
+菈
+菉
+菊
+菌
+菍
+菏
+菑
+菓
+菔
+菖
+菘
+菙
+菜
+菝
+菟
+菠
+菡
+菢
+菥
+菧
+菩
+菪
+菫
+菭
+華
+菰
+菱
+菲
+菴
+菵
+菶
+菷
+菸
+菹
+菺
+菼
+菽
+菾
+萁
+萃
+萄
+萆
+萋
+萌
+萍
+萎
+萏
+萐
+萑
+萘
+萚
+萜
+萝
+萣
+萤
+营
+萦
+萧
+萨
+萩
+萬
+萮
+萯
+萱
+萶
+萷
+萸
+萹
+萼
+落
+葅
+葆
+葇
+葉
+葊
+葍
+葎
+葐
+葑
+葓
+葖
+著
+葙
+葚
+葛
+葜
+葡
+董
+葨
+葩
+葫
+葬
+葭
+葰
+葱
+葳
+葴
+葵
+葶
+葸
+葹
+葺
+葽
+蒀
+蒂
+蒈
+蒉
+蒊
+蒋
+蒌
+蒍
+蒎
+蒐
+蒔
+蒗
+蒙
+蒜
+蒟
+蒡
+蒢
+蒧
+蒨
+蒮
+蒯
+蒱
+蒲
+蒴
+蒶
+蒸
+蒹
+蒺
+蒻
+蒼
+蒽
+蒾
+蒿
+蓁
+蓂
+蓄
+蓇
+蓉
+蓊
+蓍
+蓏
+蓐
+蓑
+蓓
+蓖
+蓗
+蓝
+蓞
+蓟
+蓠
+蓢
+蓣
+蓥
+蓦
+蓧
+蓪
+蓫
+蓬
+蓮
+蓰
+蓱
+蓳
+蓴
+蓵
+蓷
+蓺
+蓼
+蓿
+蔀
+蔂
+蔃
+蔇
+蔊
+蔌
+蔑
+蔓
+蔕
+蔗
+蔘
+蔚
+蔞
+蔟
+蔡
+蔪
+蔫
+蔬
+蔯
+蔵
+蔷
+蔸
+蔹
+蔺
+蔻
+蔼
+蔽
+蕃
+蕅
+蕈
+蕉
+蕊
+蕑
+蕖
+蕗
+蕙
+蕝
+蕞
+蕟
+蕡
+蕣
+蕤
+蕨
+蕫
+蕰
+蕲
+蕳
+蕴
+蕹
+蕺
+蕻
+蕾
+薁
+薄
+薅
+薆
+薇
+薍
+薏
+薖
+薗
+薙
+薛
+薜
+薝
+薡
+薢
+薤
+薦
+薨
+薪
+薫
+薬
+薮
+薯
+薰
+薶
+薷
+薸
+薹
+薿
+藁
+藂
+藇
+藉
+藊
+藋
+藏
+藐
+藓
+藕
+藖
+藘
+藙
+藚
+藜
+藞
+藟
+藠
+藢
+藤
+藥
+藦
+藨
+藩
+藫
+藭
+藳
+藹
+藻
+藾
+藿
+蘂
+蘅
+蘋
+蘎
+蘑
+蘖
+蘗
+蘘
+蘙
+蘡
+蘤
+蘧
+蘩
+蘭
+蘵
+蘸
+蘼
+蘽
+虀
+虉
+虌
+虎
+虏
+虐
+虑
+虒
+虓
+虔
+處
+虖
+虙
+虚
+虜
+虞
+號
+虡
+虢
+虥
+虧
+虫
+虬
+虮
+虱
+虵
+虹
+虺
+虻
+虼
+虽
+虾
+虿
+蚀
+蚁
+蚂
+蚃
+蚊
+蚋
+蚌
+蚍
+蚏
+蚑
+蚓
+蚕
+蚖
+蚗
+蚘
+蚜
+蚝
+蚡
+蚢
+蚣
+蚤
+蚧
+蚨
+蚩
+蚪
+蚬
+蚯
+蚰
+蚱
+蚳
+蚴
+蚵
+蚶
+蚷
+蚹
+蚺
+蚻
+蚾
+蚿
+蛀
+蛁
+蛃
+蛄
+蛆
+蛇
+蛉
+蛊
+蛋
+蛎
+蛏
+蛐
+蛑
+蛔
+蛕
+蛙
+蛚
+蛛
+蛜
+蛞
+蛟
+蛣
+蛤
+蛦
+蛩
+蛪
+蛫
+蛭
+蛮
+蛰
+蛱
+蛲
+蛳
+蛴
+蛸
+蛹
+蛾
+蜀
+蜂
+蜃
+蜄
+蜇
+蜈
+蜉
+蜊
+蜋
+蜍
+蜎
+蜐
+蜑
+蜒
+蜓
+蜔
+蜕
+蜗
+蜘
+蜚
+蜜
+蜞
+蜡
+蜢
+蜣
+蜤
+蜥
+蜨
+蜩
+蜮
+蜰
+蜱
+蜴
+蜷
+蜺
+蜻
+蜼
+蜾
+蜿
+蝀
+蝃
+蝄
+蝇
+蝈
+蝉
+蝋
+蝌
+蝍
+蝎
+蝓
+蝗
+蝘
+蝙
+蝚
+蝛
+蝝
+蝠
+蝡
+蝣
+蝤
+蝥
+蝮
+蝯
+蝰
+蝱
+蝲
+蝴
+蝶
+蝻
+蝼
+蝽
+蝾
+螀
+螂
+螃
+螅
+螆
+螈
+螉
+螋
+螌
+融
+螓
+螕
+螗
+螘
+螟
+螣
+螨
+螩
+螫
+螬
+螭
+螮
+螯
+螳
+螵
+螹
+螺
+螽
+螾
+螿
+蟀
+蟅
+蟆
+蟉
+蟊
+蟋
+蟏
+蟑
+蟒
+蟚
+蟛
+蟜
+蟝
+蟟
+蟠
+蟢
+蟥
+蟦
+蟧
+蟩
+蟪
+蟫
+蟭
+蟮
+蟳
+蟹
+蟺
+蟾
+蠀
+蠂
+蠃
+蠄
+蠊
+蠋
+蠍
+蠓
+蠔
+蠕
+蠖
+蠗
+蠙
+蠛
+蠡
+蠢
+蠨
+蠪
+蠭
+蠲
+蠹
+蠻
+蠼
+血
+衄
+衅
+衉
+行
+衍
+衎
+衏
+衒
+衔
+衖
+街
+衙
+衠
+衡
+衢
+衣
+衤
+补
+表
+衩
+衫
+衬
+衮
+衰
+衱
+衲
+衵
+衷
+衹
+衽
+衾
+衿
+袁
+袂
+袄
+袅
+袆
+袈
+袋
+袍
+袑
+袒
+袓
+袖
+袗
+袚
+袛
+袜
+袞
+袢
+袤
+袨
+袩
+袪
+被
+袭
+袯
+袱
+袴
+袷
+袸
+袺
+袼
+袿
+裀
+裁
+裂
+裄
+装
+裆
+裇
+裈
+裋
+裌
+裎
+裒
+裓
+裔
+裕
+裖
+裘
+裙
+裛
+補
+裟
+裢
+裤
+裥
+裨
+裪
+裯
+裰
+裱
+裳
+裴
+裸
+裹
+裼
+製
+裾
+褂
+褆
+褊
+褎
+褐
+褒
+褓
+褔
+褕
+褙
+褚
+褛
+褡
+褣
+褥
+褦
+褧
+褪
+褫
+褭
+褯
+褰
+褱
+褴
+褵
+褶
+褷
+褾
+襀
+襁
+襄
+襆
+襋
+襌
+襕
+襚
+襛
+襜
+襞
+襟
+襦
+襪
+襫
+襭
+襮
+襰
+襵
+襶
+襻
+襼
+西
+要
+覃
+覆
+覇
+覈
+見
+覌
+規
+視
+覗
+覙
+覚
+覧
+親
+観
+觀
+见
+观
+规
+觅
+视
+觇
+览
+觉
+觊
+觋
+觌
+觎
+觏
+觐
+觑
+角
+觖
+觘
+觚
+觜
+觞
+解
+觥
+触
+觩
+觫
+觭
+觯
+觱
+觳
+觺
+觼
+觽
+觿
+言
+訂
+訇
+計
+訍
+討
+訏
+託
+記
+訚
+訜
+訦
+訧
+訪
+設
+許
+訳
+訴
+訹
+註
+証
+訾
+訿
+詀
+詈
+詝
+詞
+詟
+詠
+詢
+詧
+詰
+話
+詹
+誉
+誊
+誌
+認
+誓
+誕
+誠
+誨
+読
+誰
+課
+誷
+誾
+調
+諄
+請
+諐
+論
+諟
+諠
+諡
+諮
+諲
+諴
+諵
+諾
+謇
+謏
+謔
+謥
+謦
+謷
+譄
+譆
+證
+譊
+譓
+譖
+識
+譞
+警
+譩
+譬
+議
+譲
+譳
+譶
+譺
+譾
+變
+讎
+讓
+讙
+讟
+讠
+计
+订
+讣
+认
+讥
+讦
+讧
+讨
+让
+讪
+讫
+讬
+训
+议
+讯
+记
+讱
+讲
+讳
+讴
+讵
+讶
+讷
+许
+讹
+论
+讻
+讼
+讽
+设
+访
+诀
+证
+诂
+诃
+评
+诅
+识
+诇
+诈
+诉
+诊
+诋
+诌
+词
+诎
+诏
+诐
+译
+诒
+诓
+诔
+试
+诖
+诗
+诘
+诙
+诚
+诛
+诜
+话
+诞
+诟
+诠
+诡
+询
+诣
+诤
+该
+详
+诧
+诨
+诩
+诪
+诫
+诬
+语
+诮
+误
+诰
+诱
+诲
+诳
+说
+诵
+诶
+请
+诸
+诹
+诺
+读
+诼
+诽
+课
+诿
+谀
+谁
+谂
+调
+谄
+谅
+谆
+谇
+谈
+谊
+谋
+谌
+谍
+谎
+谏
+谐
+谑
+谒
+谓
+谔
+谕
+谖
+谗
+谘
+谙
+谚
+谛
+谜
+谝
+谞
+谟
+谠
+谡
+谢
+谣
+谤
+谥
+谦
+谧
+谨
+谩
+谪
+谫
+谬
+谭
+谮
+谯
+谰
+谱
+谲
+谳
+谴
+谵
+谶
+谷
+谹
+谺
+谼
+谽
+谾
+谿
+豀
+豁
+豄
+豆
+豇
+豉
+豊
+豌
+豏
+豐
+豕
+豗
+豚
+豜
+豝
+象
+豢
+豨
+豩
+豪
+豫
+豭
+豯
+豰
+豳
+豵
+豸
+豹
+豺
+豿
+貂
+貅
+貆
+貉
+貊
+貋
+貌
+貍
+貎
+貐
+貑
+貒
+貔
+貕
+貘
+貝
+貞
+負
+財
+貤
+貨
+責
+貮
+貳
+貴
+買
+貸
+費
+貼
+貿
+賀
+資
+賚
+賛
+賝
+賠
+賣
+賦
+賨
+賸
+購
+贁
+贇
+贈
+贔
+贝
+贞
+负
+贠
+贡
+财
+责
+贤
+败
+账
+货
+质
+贩
+贪
+贫
+贬
+购
+贮
+贯
+贰
+贱
+贲
+贳
+贴
+贵
+贶
+贷
+贸
+费
+贺
+贻
+贼
+贽
+贾
+贿
+赀
+赁
+赂
+赃
+资
+赅
+赆
+赇
+赈
+赉
+赊
+赋
+赌
+赍
+赎
+赏
+赐
+赑
+赒
+赓
+赔
+赖
+赗
+赘
+赙
+赚
+赛
+赜
+赝
+赞
+赟
+赠
+赡
+赢
+赣
+赤
+赥
+赦
+赧
+赩
+赪
+赫
+赭
+走
+赳
+赴
+赵
+赶
+起
+赺
+趁
+趄
+超
+越
+趋
+趍
+趐
+趑
+趔
+趖
+趗
+趟
+趠
+趢
+趣
+趨
+趫
+趮
+趯
+趱
+足
+趴
+趵
+趷
+趸
+趹
+趺
+趼
+趾
+趿
+跂
+跃
+跄
+跅
+跆
+跇
+跋
+跌
+跍
+跎
+跏
+跐
+跑
+跕
+跖
+跗
+跙
+跚
+跛
+跜
+距
+跟
+跡
+跣
+跤
+跧
+跨
+跩
+跪
+跫
+跬
+路
+跱
+跳
+践
+跶
+跷
+跸
+跹
+跺
+跻
+跼
+跽
+跿
+踄
+踅
+踆
+踇
+踉
+踊
+踌
+踎
+踏
+踔
+踕
+踖
+踘
+踝
+踞
+踟
+踠
+踡
+踢
+踣
+踦
+踧
+踩
+踪
+踬
+踭
+踮
+踯
+踰
+踱
+踵
+踶
+踸
+踹
+踺
+踼
+踽
+蹀
+蹁
+蹂
+蹄
+蹅
+蹇
+蹈
+蹉
+蹊
+蹋
+蹏
+蹐
+蹑
+蹒
+蹓
+蹔
+蹙
+蹚
+蹛
+蹜
+蹟
+蹠
+蹡
+蹢
+蹦
+蹩
+蹬
+蹭
+蹮
+蹯
+蹰
+蹱
+蹲
+蹳
+蹴
+蹶
+蹸
+蹻
+蹼
+蹿
+躁
+躃
+躄
+躅
+躇
+躏
+躐
+躔
+躜
+躝
+躞
+躠
+躧
+躨
+躩
+身
+躬
+躭
+躯
+躲
+躴
+躺
+躿
+軃
+車
+軍
+軏
+軜
+転
+軥
+軧
+軨
+軱
+軵
+軶
+軷
+軽
+軿
+輀
+輈
+輋
+輗
+輠
+輣
+輤
+輧
+輮
+輴
+輵
+輶
+輷
+輸
+輼
+轉
+轑
+轒
+轓
+轗
+轘
+轝
+轣
+轥
+车
+轧
+轨
+轩
+轪
+轫
+转
+轭
+轮
+软
+轰
+轱
+轲
+轳
+轴
+轵
+轶
+轸
+轹
+轺
+轻
+轼
+载
+轾
+轿
+辀
+辁
+辂
+较
+辄
+辅
+辆
+辇
+辈
+辉
+辊
+辋
+辍
+辎
+辏
+辐
+辑
+输
+辔
+辕
+辖
+辗
+辘
+辙
+辚
+辛
+辜
+辞
+辟
+辣
+辦
+辨
+辩
+辫
+辰
+辱
+辴
+辶
+辷
+边
+辺
+辻
+込
+辽
+达
+辿
+迁
+迂
+迄
+迅
+过
+迈
+迋
+迍
+迎
+运
+近
+迒
+迓
+返
+迕
+还
+这
+进
+远
+违
+连
+迟
+迢
+迤
+迥
+迦
+迨
+迩
+迪
+迫
+迭
+迮
+述
+迳
+迴
+迵
+迷
+迸
+迹
+迺
+追
+迾
+退
+送
+适
+逃
+逄
+逅
+逆
+逈
+选
+逊
+逋
+逍
+透
+逐
+逑
+递
+途
+逖
+逗
+這
+通
+逛
+逝
+逞
+速
+造
+逡
+逢
+連
+逤
+逥
+逦
+逭
+逮
+逯
+進
+逴
+逵
+逶
+逷
+逸
+逻
+逼
+逾
+逿
+遁
+遂
+遄
+遅
+遆
+遇
+遍
+遏
+遐
+遑
+遒
+道
+違
+遗
+遘
+遛
+遝
+遞
+遠
+遡
+遢
+遣
+遥
+遨
+適
+遫
+遭
+遮
+遯
+遱
+遴
+遵
+遶
+遹
+遺
+遽
+避
+邀
+邂
+邃
+還
+邅
+邈
+邊
+邋
+邍
+邑
+邓
+邕
+邗
+邘
+邙
+邛
+邝
+邞
+邠
+邡
+邢
+那
+邤
+邥
+邦
+邨
+邪
+邬
+邮
+邯
+邰
+邱
+邲
+邳
+邴
+邵
+邶
+邷
+邸
+邹
+邺
+邻
+邽
+邾
+郁
+郃
+郄
+郅
+郇
+郈
+郉
+郊
+郎
+郏
+郐
+郑
+郓
+郕
+郗
+郚
+郛
+郜
+郝
+郞
+郡
+郢
+郤
+郦
+郧
+部
+郩
+郪
+郫
+郭
+郯
+郴
+郷
+郸
+都
+郾
+郿
+鄀
+鄂
+鄄
+鄋
+鄌
+鄏
+鄑
+鄗
+鄘
+鄙
+鄚
+鄛
+鄜
+鄞
+鄠
+鄡
+鄢
+鄣
+鄤
+鄦
+鄨
+鄩
+鄪
+鄬
+鄮
+鄯
+鄰
+鄱
+鄳
+鄹
+鄼
+鄽
+酂
+酃
+酄
+酅
+酆
+酇
+酉
+酊
+酋
+酌
+配
+酎
+酏
+酐
+酑
+酒
+酔
+酕
+酖
+酗
+酘
+酚
+酝
+酞
+酡
+酢
+酣
+酤
+酥
+酦
+酧
+酩
+酪
+酬
+酭
+酮
+酯
+酰
+酱
+酲
+酴
+酵
+酶
+酷
+酸
+酹
+酺
+酽
+酾
+酿
+醁
+醃
+醄
+醅
+醆
+醇
+醉
+醋
+醌
+醍
+醎
+醐
+醑
+醒
+醓
+醘
+醚
+醛
+醜
+醡
+醢
+醤
+醥
+醦
+醨
+醪
+醫
+醭
+醮
+醯
+醲
+醳
+醴
+醵
+醸
+醹
+醺
+醻
+醽
+醾
+醿
+釂
+釆
+采
+釈
+釉
+释
+里
+重
+野
+量
+釐
+金
+釚
+釜
+釭
+釱
+釴
+鈇
+鈋
+鈌
+鈖
+鈚
+鈜
+鈟
+鈡
+鈣
+鈴
+鈵
+鉁
+鉄
+鉊
+鉌
+鉏
+鉝
+鉞
+鉟
+鉢
+鉤
+鉥
+鉧
+鉨
+鉱
+鉲
+鉴
+鉼
+鉽
+銀
+銁
+銍
+銙
+銛
+銭
+銮
+銶
+銺
+鋂
+鋆
+鋈
+鋋
+鋐
+鋕
+鋗
+鋘
+鋣
+鋪
+鋹
+錏
+錔
+錞
+錢
+錤
+錧
+錫
+錬
+錯
+錱
+錺
+錻
+錽
+錾
+鍑
+鍜
+鍟
+鍧
+鍪
+鍭
+鍮
+鍱
+鍼
+鎈
+鎌
+鎎
+鎏
+鎓
+鎕
+鎗
+鎛
+鎝
+鎞
+鎬
+鎶
+鎷
+鎹
+鏁
+鏊
+鏖
+鏣
+鏦
+鏸
+鐀
+鐈
+鐍
+鐖
+鐘
+鐻
+鑑
+鑙
+鑛
+鑨
+鑫
+鑯
+鑴
+钀
+钅
+钆
+钇
+针
+钉
+钊
+钌
+钍
+钎
+钏
+钐
+钑
+钒
+钓
+钕
+钖
+钗
+钘
+钙
+钚
+钛
+钜
+钝
+钞
+钟
+钠
+钡
+钢
+钣
+钤
+钥
+钦
+钧
+钨
+钩
+钪
+钫
+钬
+钭
+钮
+钯
+钰
+钱
+钲
+钳
+钴
+钵
+钸
+钹
+钺
+钻
+钼
+钽
+钾
+钿
+铀
+铁
+铂
+铃
+铄
+铅
+铆
+铇
+铈
+铉
+铊
+铋
+铌
+铍
+铎
+铏
+铐
+铑
+铒
+铓
+铔
+铕
+铖
+铗
+铘
+铙
+铚
+铛
+铜
+铝
+铟
+铠
+铡
+铢
+铣
+铤
+铥
+铦
+铧
+铨
+铩
+铪
+铫
+铬
+铭
+铮
+铯
+铰
+铱
+铲
+铳
+铴
+铵
+银
+铷
+铸
+铺
+铻
+铼
+铽
+链
+铿
+销
+锁
+锂
+锃
+锄
+锅
+锆
+锇
+锈
+锉
+锋
+锌
+锍
+锏
+锐
+锑
+锒
+锓
+锔
+锕
+锖
+锗
+锘
+错
+锚
+锛
+锜
+锝
+锞
+锟
+锠
+锡
+锢
+锣
+锤
+锥
+锦
+锧
+锨
+锪
+锭
+键
+锯
+锰
+锱
+锲
+锴
+锵
+锶
+锷
+锸
+锹
+锺
+锻
+锼
+锽
+锾
+镀
+镁
+镂
+镃
+镆
+镇
+镈
+镉
+镊
+镋
+镌
+镍
+镎
+镏
+镐
+镑
+镒
+镓
+镔
+镕
+镖
+镗
+镘
+镚
+镛
+镜
+镝
+镞
+镠
+镡
+镢
+镣
+镤
+镥
+镦
+镧
+镨
+镩
+镪
+镫
+镬
+镭
+镮
+镯
+镰
+镱
+镲
+镳
+镴
+镵
+镶
+長
+长
+門
+閁
+閈
+開
+閑
+閒
+間
+閛
+閜
+閞
+閟
+関
+閤
+閦
+閧
+閪
+閴
+闇
+闉
+闍
+闕
+闘
+闙
+闚
+關
+闟
+闢
+门
+闩
+闪
+闫
+闬
+闭
+问
+闯
+闰
+闱
+闲
+闳
+间
+闵
+闷
+闸
+闹
+闺
+闻
+闼
+闽
+闾
+闿
+阀
+阁
+阂
+阃
+阄
+阅
+阆
+阇
+阈
+阉
+阊
+阋
+阌
+阍
+阎
+阏
+阐
+阑
+阒
+阓
+阔
+阕
+阖
+阗
+阘
+阙
+阚
+阛
+阜
+阝
+队
+阠
+阡
+阨
+阪
+阬
+阮
+阯
+阱
+防
+阳
+阴
+阵
+阶
+阻
+阼
+阽
+阿
+陀
+陁
+陂
+附
+际
+陆
+陇
+陈
+陉
+陋
+陌
+降
+限
+陑
+陔
+陕
+陛
+陜
+陟
+陡
+院
+除
+陥
+陧
+陨
+险
+陪
+陬
+陭
+陲
+陴
+陵
+陶
+陷
+険
+陻
+陼
+陽
+陾
+隃
+隅
+隆
+隈
+隊
+隋
+隍
+階
+随
+隐
+隑
+隔
+隕
+隗
+隘
+隙
+際
+障
+隞
+隠
+隣
+隤
+隥
+隦
+隧
+隨
+隩
+險
+隮
+隰
+隳
+隶
+隷
+隹
+隻
+隼
+隽
+难
+雀
+雁
+雄
+雅
+集
+雇
+雉
+雊
+雌
+雍
+雎
+雏
+雑
+雒
+雕
+雘
+雙
+雜
+雝
+雠
+難
+雨
+雩
+雪
+雫
+雯
+雰
+雱
+雲
+雳
+零
+雷
+雹
+電
+雾
+需
+霁
+霂
+霃
+霄
+霅
+霆
+震
+霈
+霉
+霊
+霍
+霎
+霏
+霑
+霓
+霔
+霖
+霙
+霜
+霞
+霠
+霡
+霢
+霣
+霤
+霨
+霪
+霭
+霮
+霰
+露
+霳
+霸
+霹
+霾
+霿
+靂
+靃
+青
+靓
+靖
+靗
+静
+靛
+非
+靠
+靡
+面
+靥
+靦
+靧
+革
+靫
+靮
+靰
+靳
+靴
+靶
+靷
+靸
+靺
+靼
+靿
+鞀
+鞃
+鞄
+鞅
+鞉
+鞋
+鞍
+鞑
+鞒
+鞓
+鞔
+鞕
+鞗
+鞘
+鞙
+鞚
+鞞
+鞟
+鞠
+鞣
+鞨
+鞫
+鞬
+鞭
+鞮
+鞯
+鞲
+鞳
+鞴
+鞵
+鞶
+鞸
+鞹
+鞺
+鞾
+鞿
+韂
+韅
+韍
+韎
+韐
+韓
+韔
+韘
+韝
+韠
+韡
+韦
+韧
+韨
+韩
+韪
+韫
+韬
+韭
+韮
+音
+韵
+韶
+韹
+韻
+頂
+項
+須
+頉
+頋
+頍
+預
+頔
+頚
+頞
+頠
+頣
+頩
+頫
+頬
+頭
+頯
+頳
+頵
+頼
+顇
+顉
+額
+顏
+顒
+顕
+顗
+顜
+類
+顡
+顦
+页
+顶
+顷
+顸
+项
+顺
+须
+顼
+顽
+顾
+顿
+颀
+颁
+颂
+颃
+预
+颅
+领
+颇
+颈
+颉
+颊
+颋
+颌
+颍
+颎
+颏
+颐
+频
+颒
+颓
+颔
+颕
+颖
+颗
+题
+颙
+颚
+颛
+颜
+额
+颞
+颟
+颠
+颡
+颢
+颣
+颤
+颥
+颦
+颧
+風
+颾
+颿
+飁
+飉
+飋
+飍
+风
+飏
+飐
+飑
+飒
+飓
+飔
+飕
+飖
+飗
+飘
+飙
+飚
+飛
+飞
+食
+飡
+飣
+飧
+飨
+飯
+飰
+飱
+飶
+飽
+餂
+養
+餍
+餐
+餔
+餗
+餘
+餠
+餤
+餧
+館
+餬
+餮
+餲
+餴
+餸
+餽
+饁
+饇
+饉
+饎
+饐
+饑
+饔
+饕
+饗
+饘
+饙
+饛
+饟
+饣
+饤
+饥
+饦
+饧
+饨
+饩
+饪
+饫
+饬
+饭
+饮
+饯
+饰
+饱
+饲
+饴
+饵
+饶
+饷
+饸
+饹
+饺
+饼
+饽
+饾
+饿
+馀
+馁
+馃
+馄
+馅
+馆
+馇
+馈
+馉
+馊
+馋
+馌
+馍
+馎
+馏
+馐
+馑
+馒
+馓
+馔
+馕
+首
+馗
+馘
+香
+馛
+馞
+馠
+馡
+馤
+馥
+馧
+馨
+馬
+馯
+馹
+馺
+馽
+駃
+駄
+駅
+駆
+駉
+駊
+駓
+駖
+駜
+駠
+駪
+駬
+駮
+駰
+駱
+駷
+駸
+駹
+駻
+駼
+駽
+駾
+駿
+騀
+騂
+騃
+騄
+騅
+騊
+騋
+騏
+騑
+騒
+験
+騕
+騞
+騠
+騡
+騢
+騣
+騧
+騪
+騰
+騱
+騳
+騵
+騹
+騺
+驈
+驎
+驒
+驔
+驖
+驚
+驛
+驩
+马
+驭
+驮
+驯
+驰
+驱
+驲
+驳
+驴
+驵
+驶
+驷
+驸
+驹
+驺
+驻
+驼
+驽
+驾
+驿
+骀
+骁
+骂
+骃
+骄
+骅
+骆
+骇
+骈
+骉
+骊
+骋
+验
+骍
+骎
+骏
+骐
+骑
+骒
+骓
+骕
+骖
+骗
+骘
+骙
+骚
+骛
+骜
+骝
+骞
+骟
+骠
+骡
+骢
+骣
+骤
+骥
+骦
+骧
+骨
+骫
+骭
+骰
+骱
+骶
+骷
+骸
+骹
+骺
+骼
+髀
+髁
+髂
+髃
+髅
+髆
+髇
+髋
+髌
+髎
+髐
+髑
+髓
+體
+高
+髙
+髟
+髠
+髡
+髢
+髤
+髦
+髧
+髪
+髫
+髭
+髮
+髯
+髲
+髳
+髵
+髹
+髻
+髽
+髾
+鬃
+鬅
+鬇
+鬈
+鬋
+鬐
+鬑
+鬒
+鬓
+鬖
+鬘
+鬙
+鬝
+鬟
+鬡
+鬣
+鬬
+鬯
+鬱
+鬲
+鬵
+鬷
+鬺
+鬻
+鬼
+鬽
+魀
+魁
+魂
+魃
+魄
+魅
+魆
+魇
+魈
+魉
+魋
+魍
+魏
+魑
+魔
+魖
+魗
+魟
+魠
+魣
+魭
+魮
+魯
+魶
+魼
+魾
+魿
+鮀
+鮄
+鮅
+鮆
+鮇
+鮈
+鮍
+鮖
+鮗
+鮟
+鮠
+鮡
+鮣
+鮧
+鮨
+鮮
+鮰
+鮸
+鮹
+鮻
+鮼
+鯄
+鯈
+鯏
+鯙
+鯥
+鯮
+鯵
+鯶
+鯺
+鯻
+鯾
+鰅
+鰆
+鰋
+鰔
+鰕
+鰞
+鰟
+鰤
+鰧
+鰬
+鰶
+鰽
+鱄
+鱇
+鱊
+鱋
+鱍
+鱎
+鱏
+鱗
+鱚
+鱠
+鱥
+鱮
+鱲
+鱳
+鱵
+鱻
+鱼
+鱾
+鱿
+鲀
+鲁
+鲂
+鲃
+鲅
+鲆
+鲇
+鲈
+鲉
+鲊
+鲋
+鲌
+鲍
+鲎
+鲏
+鲐
+鲑
+鲒
+鲓
+鲔
+鲕
+鲖
+鲘
+鲙
+鲚
+鲛
+鲜
+鲞
+鲟
+鲠
+鲡
+鲢
+鲣
+鲤
+鲥
+鲦
+鲧
+鲨
+鲩
+鲪
+鲫
+鲬
+鲭
+鲮
+鲯
+鲰
+鲱
+鲲
+鲳
+鲴
+鲵
+鲶
+鲷
+鲸
+鲹
+鲺
+鲻
+鲼
+鲽
+鲾
+鲿
+鳀
+鳁
+鳂
+鳃
+鳄
+鳅
+鳆
+鳇
+鳈
+鳉
+鳊
+鳋
+鳌
+鳍
+鳎
+鳏
+鳐
+鳑
+鳒
+鳓
+鳔
+鳕
+鳖
+鳗
+鳙
+鳚
+鳜
+鳝
+鳞
+鳟
+鳠
+鳡
+鳢
+鳣
+鳤
+鳥
+鳦
+鳧
+鳩
+鳲
+鳳
+鳴
+鳶
+鳷
+鳸
+鳺
+鳼
+鳽
+鴂
+鴃
+鴇
+鴈
+鴋
+鴐
+鴒
+鴜
+鴥
+鴳
+鴹
+鴽
+鵉
+鵊
+鵕
+鵙
+鵝
+鵞
+鵟
+鵩
+鵰
+鵱
+鵻
+鶀
+鶂
+鶃
+鶋
+鶏
+鶒
+鶖
+鶗
+鶡
+鶢
+鶤
+鶬
+鶱
+鶵
+鶹
+鶺
+鷃
+鷇
+鷉
+鷊
+鷕
+鷛
+鷞
+鷟
+鷠
+鷢
+鷣
+鷤
+鷩
+鷫
+鷮
+鷾
+鷿
+鸂
+鸃
+鸄
+鸊
+鸐
+鸑
+鸒
+鸓
+鸘
+鸜
+鸝
+鸟
+鸠
+鸡
+鸢
+鸣
+鸤
+鸥
+鸦
+鸧
+鸨
+鸩
+鸪
+鸫
+鸬
+鸭
+鸮
+鸯
+鸰
+鸱
+鸲
+鸳
+鸴
+鸵
+鸶
+鸷
+鸸
+鸹
+鸺
+鸻
+鸽
+鸾
+鸿
+鹀
+鹁
+鹂
+鹃
+鹄
+鹅
+鹆
+鹇
+鹈
+鹉
+鹊
+鹋
+鹌
+鹍
+鹎
+鹏
+鹐
+鹑
+鹒
+鹓
+鹔
+鹕
+鹖
+鹗
+鹘
+鹙
+鹚
+鹛
+鹜
+鹝
+鹞
+鹟
+鹠
+鹡
+鹢
+鹣
+鹤
+鹥
+鹦
+鹧
+鹨
+鹩
+鹪
+鹫
+鹬
+鹭
+鹮
+鹯
+鹰
+鹱
+鹲
+鹳
+鹴
+鹾
+鹿
+麀
+麂
+麃
+麇
+麈
+麋
+麌
+麏
+麐
+麑
+麒
+麓
+麕
+麖
+麗
+麚
+麛
+麝
+麞
+麟
+麤
+麦
+麧
+麨
+麯
+麰
+麴
+麸
+麹
+麺
+麻
+麼
+麽
+麾
+麿
+黁
+黃
+黄
+黈
+黉
+黍
+黎
+黏
+黐
+黑
+黒
+黓
+黔
+黕
+黖
+默
+黙
+黛
+黜
+黝
+點
+黟
+黠
+黡
+黢
+黤
+黥
+黦
+黧
+黨
+黩
+黪
+黫
+黬
+黮
+黯
+黳
+黸
+黻
+黼
+黾
+鼆
+鼋
+鼍
+鼎
+鼐
+鼒
+鼓
+鼗
+鼙
+鼛
+鼟
+鼠
+鼢
+鼩
+鼪
+鼫
+鼬
+鼮
+鼯
+鼷
+鼹
+鼺
+鼻
+鼽
+鼾
+鼿
+齁
+齃
+齄
+齅
+齊
+齎
+齐
+齑
+齚
+齢
+齧
+齨
+齮
+齰
+齾
+齿
+龀
+龁
+龂
+龃
+龄
+龅
+龆
+龇
+龈
+龉
+龊
+龋
+龌
+龍
+龏
+龑
+龙
+龚
+龛
+龜
+龟
+龠
+거
+나
+났
+다
+딜
+또
+리
+맥
+버
+요
+워
+타
+
+
+凉
+︰
+﹐
+﹒
+﹖
+!
+&
+(
+)
+,
+-
+.
+/
+2
+:
+;
+<
+>
+?
+@
+_
+`
+|
+~
+¥
+𡒄
+𨱏
\ No newline at end of file
diff --git a/dicts/english_digits_symbols.txt b/dicts/english_digits_symbols.txt
new file mode 100644
index 0000000000000000000000000000000000000000..a945ae9c526e4faa68852eb3fb47d078a2f3f6ce
--- /dev/null
+++ b/dicts/english_digits_symbols.txt
@@ -0,0 +1,90 @@
+0
+1
+2
+3
+4
+5
+6
+7
+8
+9
+a
+b
+c
+d
+e
+f
+g
+h
+i
+j
+k
+l
+m
+n
+o
+p
+q
+r
+s
+t
+u
+v
+w
+x
+y
+z
+A
+B
+C
+D
+E
+F
+G
+H
+I
+J
+K
+L
+M
+N
+O
+P
+Q
+R
+S
+T
+U
+V
+W
+X
+Y
+Z
+!
+"
+#
+$
+%
+&
+'
+(
+)
+*
++
+,
+-
+.
+/
+:
+;
+<
+=
+>
+?
+@
+[
+\
+]
+_
+`
+~
\ No newline at end of file
diff --git a/dicts/english_digits_symbols_space.txt b/dicts/english_digits_symbols_space.txt
new file mode 100644
index 0000000000000000000000000000000000000000..5bd66a185eeeb64e39b78f33ba96c8120ca28112
--- /dev/null
+++ b/dicts/english_digits_symbols_space.txt
@@ -0,0 +1,91 @@
+0
+1
+2
+3
+4
+5
+6
+7
+8
+9
+a
+b
+c
+d
+e
+f
+g
+h
+i
+j
+k
+l
+m
+n
+o
+p
+q
+r
+s
+t
+u
+v
+w
+x
+y
+z
+A
+B
+C
+D
+E
+F
+G
+H
+I
+J
+K
+L
+M
+N
+O
+P
+Q
+R
+S
+T
+U
+V
+W
+X
+Y
+Z
+!
+"
+#
+$
+%
+&
+'
+(
+)
+*
++
+,
+-
+.
+/
+:
+;
+<
+=
+>
+?
+@
+[
+\
+]
+_
+`
+~
+
\ No newline at end of file
diff --git a/dicts/korean_english_digits_symbols.txt b/dicts/korean_english_digits_symbols.txt
new file mode 100644
index 0000000000000000000000000000000000000000..764080d5486ebd77cb7b5db26ac82022eb84cc4e
--- /dev/null
+++ b/dicts/korean_english_digits_symbols.txt
@@ -0,0 +1,1803 @@
+0
+1
+2
+3
+4
+5
+6
+7
+8
+9
+!
+"
+#
+$
+%
+&
+\
+'
+(
+)
+*
++
+,
+-
+.
+/
+:
+;
+<
+=
+>
+?
+@
+[
+]
+^
+_
+`
+{
+|
+}
+~
+
+a
+b
+c
+d
+e
+f
+g
+h
+i
+j
+k
+l
+m
+n
+o
+p
+q
+r
+s
+t
+u
+v
+w
+x
+y
+z
+A
+B
+C
+D
+E
+F
+G
+H
+I
+J
+K
+L
+M
+N
+O
+P
+Q
+R
+S
+T
+U
+V
+W
+X
+Y
+Z
+ㆍ
+가
+각
+간
+갇
+갈
+갉
+감
+갑
+값
+갓
+갔
+강
+갖
+같
+갚
+갛
+개
+객
+갤
+갬
+갭
+갯
+갱
+갸
+걀
+거
+걱
+건
+걷
+걸
+검
+겁
+것
+겅
+겉
+게
+겐
+겔
+겟
+겠
+겨
+격
+겪
+견
+결
+겸
+겹
+겼
+경
+곁
+계
+고
+곡
+곤
+곧
+골
+곰
+곱
+곳
+공
+곶
+과
+곽
+관
+괄
+괌
+광
+괘
+괜
+괭
+괴
+괼
+굉
+교
+굘
+구
+국
+군
+굳
+굴
+굵
+굶
+굼
+굽
+굿
+궁
+궂
+궈
+권
+궐
+궤
+귀
+귄
+귈
+규
+균
+귤
+그
+극
+근
+글
+긁
+금
+급
+긋
+긍
+기
+긴
+길
+김
+깁
+깃
+깅
+깊
+까
+깍
+깎
+깐
+깔
+깜
+깝
+깡
+깥
+깨
+깬
+깻
+깽
+꺠
+꺵
+꺼
+꺽
+꺾
+껄
+껌
+껍
+껏
+껐
+껑
+께
+껴
+꼈
+꼬
+꼭
+꼴
+꼼
+꼽
+꽁
+꽂
+꽃
+꽈
+꽉
+꽐
+꽝
+꽤
+꽥
+꾀
+꾸
+꾹
+꾼
+꿀
+꿇
+꿈
+꿉
+꿍
+꿔
+꿨
+꿩
+꿰
+뀌
+뀐
+뀔
+끄
+끈
+끊
+끌
+끓
+끔
+끗
+끙
+끝
+끼
+낀
+낄
+낌
+나
+낙
+낚
+난
+날
+낡
+낢
+남
+납
+낫
+났
+낭
+낮
+낯
+낱
+낳
+내
+낵
+낸
+낼
+냄
+냅
+냇
+냈
+냉
+냐
+냑
+냠
+냥
+너
+넉
+넌
+널
+넓
+넘
+넙
+넛
+넝
+넣
+네
+넥
+넨
+넬
+넴
+넵
+넷
+녀
+녁
+년
+념
+녔
+녕
+녘
+녜
+녠
+노
+녹
+논
+놀
+놈
+놉
+놋
+농
+높
+놓
+놔
+놨
+뇌
+뇨
+뇰
+뇸
+뇽
+누
+눅
+눈
+눌
+눔
+눕
+눙
+눠
+뉘
+뉜
+뉴
+뉼
+늄
+느
+늑
+는
+늘
+늙
+늠
+능
+늦
+늪
+늬
+니
+닉
+닌
+닐
+님
+닙
+닛
+닝
+다
+닥
+닦
+단
+닫
+달
+닭
+닮
+닳
+담
+답
+닷
+당
+닻
+닿
+대
+댁
+댄
+댈
+댐
+댑
+댓
+댕
+더
+덕
+덖
+던
+덜
+덟
+덤
+덥
+덧
+덩
+덫
+덮
+데
+덱
+덴
+델
+뎀
+뎅
+뎌
+뎬
+도
+독
+돈
+돋
+돌
+돔
+돕
+돗
+동
+돛
+돼
+됐
+되
+된
+될
+됨
+됩
+두
+둑
+둔
+둘
+둠
+둡
+둣
+둥
+둬
+뒀
+뒤
+뒷
+뒹
+듀
+듈
+듐
+드
+득
+든
+듣
+들
+듦
+듬
+듭
+듯
+등
+듸
+딍
+디
+딕
+딘
+딛
+딜
+딝
+딤
+딥
+딧
+딩
+딪
+따
+딱
+딴
+딸
+땀
+땃
+땄
+땅
+때
+땐
+땜
+땡
+떠
+떡
+떤
+떨
+떴
+떻
+떼
+뗴
+또
+똑
+똔
+똘
+똣
+똥
+뚜
+뚝
+뚫
+뚱
+뛰
+뛴
+뛸
+뜀
+뜨
+뜩
+뜬
+뜯
+뜰
+뜸
+뜻
+띄
+띈
+띠
+띤
+띵
+라
+락
+란
+랄
+람
+랍
+랏
+랐
+랑
+랗
+래
+랙
+랜
+랠
+램
+랩
+랫
+랬
+랭
+랲
+랴
+략
+랸
+량
+러
+럭
+런
+럴
+럼
+럽
+럿
+렀
+렁
+렇
+레
+렉
+렌
+렐
+렘
+렙
+렛
+렝
+려
+력
+련
+렬
+렴
+렵
+렷
+렸
+령
+례
+롄
+로
+록
+론
+롤
+롬
+롭
+롯
+롱
+롸
+뢰
+룀
+료
+룡
+루
+룩
+룬
+룰
+룸
+룹
+룻
+룽
+뤄
+뤘
+뤼
+뤽
+륀
+륄
+류
+륙
+륜
+률
+륨
+륫
+륭
+르
+륵
+른
+를
+름
+릅
+릇
+릉
+릎
+리
+릭
+린
+릳
+릴
+림
+립
+릿
+링
+마
+막
+만
+많
+맏
+말
+맑
+맘
+맙
+맛
+망
+맞
+맡
+맣
+매
+맥
+맨
+맬
+맴
+맵
+맷
+맹
+맺
+먀
+머
+먹
+먼
+멀
+멈
+멋
+멍
+메
+멕
+멘
+멜
+멤
+멥
+멧
+멩
+며
+멱
+면
+멸
+몄
+명
+몇
+모
+목
+몫
+몬
+몰
+몸
+몹
+못
+몽
+뫼
+묀
+묘
+무
+묵
+묶
+문
+묻
+물
+뭄
+뭇
+뭉
+뭐
+뭔
+뭘
+뮈
+뮌
+뮐
+뮤
+뮬
+므
+믄
+믈
+믐
+미
+믹
+민
+믿
+밀
+밈
+밋
+밌
+밍
+및
+밑
+바
+박
+밖
+반
+받
+발
+밝
+밟
+밤
+밥
+밧
+방
+밭
+배
+백
+밴
+밸
+뱀
+뱃
+뱅
+뱉
+뱌
+버
+벅
+번
+벌
+범
+법
+벗
+벙
+벚
+베
+벡
+벤
+벧
+벨
+벰
+벳
+벵
+벼
+벽
+변
+별
+볍
+병
+볕
+보
+복
+볶
+본
+볼
+봄
+봅
+봇
+봉
+봐
+봤
+뵈
+뵙
+뵤
+부
+북
+분
+붇
+불
+붉
+붐
+붓
+붕
+붙
+뷔
+뷘
+뷰
+브
+븐
+블
+븟
+븨
+비
+빅
+빈
+빌
+빔
+빕
+빗
+빙
+빚
+빛
+빠
+빡
+빤
+빨
+빵
+빻
+빼
+빽
+뺀
+뺄
+뺌
+뺏
+뺑
+뺨
+뺴
+뺵
+뻐
+뻑
+뻔
+뻗
+뻘
+뻤
+뻥
+뻬
+뼈
+뼛
+뽀
+뽁
+뽈
+뽐
+뽑
+뽕
+뾰
+뿅
+뿌
+뿍
+뿐
+뿔
+뿜
+쁘
+쁜
+쁠
+쁨
+삐
+삔
+삘
+사
+삭
+산
+살
+삶
+삼
+삽
+삿
+샀
+상
+새
+색
+샌
+샐
+샘
+샛
+생
+샤
+샥
+샨
+샬
+샴
+샵
+샷
+샹
+샾
+섀
+서
+석
+섞
+선
+섣
+설
+섬
+섭
+섯
+섰
+성
+세
+섹
+센
+셀
+셈
+셉
+셋
+셍
+셔
+션
+셜
+셤
+셧
+셨
+셰
+셴
+셸
+소
+속
+손
+솔
+솜
+솝
+솟
+송
+솥
+솽
+쇄
+쇠
+쇳
+쇼
+숀
+숄
+숍
+숏
+숑
+숖
+수
+숙
+순
+숟
+술
+숨
+숫
+숭
+숮
+숯
+숱
+숲
+숴
+쉐
+쉘
+쉬
+쉴
+쉼
+쉽
+쉿
+슈
+슐
+슘
+슛
+슝
+스
+슨
+슬
+슭
+슴
+습
+슷
+승
+시
+식
+신
+싣
+실
+싫
+심
+십
+싯
+싰
+싱
+싶
+싸
+싹
+싼
+쌀
+쌈
+쌉
+쌌
+쌍
+쌓
+쌘
+쌤
+쌩
+썜
+써
+썩
+썬
+썰
+썸
+썹
+썼
+썽
+쎄
+쎈
+쎌
+쎴
+쏘
+쏙
+쏜
+쏟
+쏠
+쏩
+쏭
+쏴
+쐈
+쐐
+쑈
+쑝
+쑤
+쑥
+쑨
+쑬
+쑹
+쒰
+쓔
+쓰
+쓱
+쓴
+쓸
+씀
+씅
+씌
+씨
+씩
+씬
+씰
+씷
+씹
+씻
+씽
+아
+악
+안
+앉
+않
+알
+앓
+암
+압
+앗
+았
+앙
+앞
+애
+액
+앤
+앨
+앰
+앱
+앳
+앴
+앵
+야
+약
+얀
+얄
+얇
+얌
+얏
+양
+얕
+얗
+얘
+어
+억
+언
+얹
+얻
+얼
+얽
+엄
+업
+없
+엇
+었
+엉
+엌
+엎
+에
+엑
+엔
+엘
+엠
+엡
+엣
+엥
+여
+역
+엮
+연
+열
+엷
+염
+엽
+엿
+였
+영
+옅
+옆
+예
+옌
+옐
+옙
+옛
+오
+옥
+온
+올
+옭
+옮
+옳
+옴
+옵
+옷
+옹
+옻
+와
+왁
+완
+왈
+왑
+왓
+왔
+왕
+왜
+외
+왼
+요
+욕
+욘
+욜
+욤
+용
+우
+욱
+운
+울
+움
+웁
+웃
+웅
+워
+웍
+원
+월
+웜
+웠
+웨
+웩
+웬
+웰
+웸
+웹
+위
+윅
+윈
+윌
+윔
+윗
+윙
+유
+육
+윤
+율
+윰
+윳
+융
+으
+윽
+은
+을
+음
+읍
+응
+읗
+의
+이
+익
+인
+일
+읽
+잃
+임
+입
+잇
+있
+잉
+잊
+잌
+잎
+자
+작
+잔
+잖
+잘
+잠
+잡
+잣
+장
+잦
+재
+잭
+잼
+잿
+쟁
+쟈
+쟉
+쟌
+쟝
+저
+적
+전
+절
+젊
+젋
+점
+접
+젓
+정
+젖
+제
+젝
+젠
+젤
+젬
+젭
+젯
+젱
+져
+젼
+졌
+조
+족
+존
+졸
+좀
+좁
+종
+좇
+좋
+좌
+좡
+죄
+죠
+죤
+주
+죽
+준
+줄
+줌
+줍
+줏
+중
+줘
+줬
+쥐
+쥔
+쥘
+쥬
+쥰
+쥴
+즈
+즉
+즌
+즐
+즘
+즙
+증
+지
+직
+진
+짇
+질
+짊
+짐
+집
+짓
+징
+짖
+짙
+짚
+짜
+짝
+짠
+짤
+짧
+짬
+짭
+짱
+째
+쨈
+쨌
+쨍
+쨰
+쩌
+쩍
+쩐
+쩔
+쩜
+쩡
+쩰
+쪄
+쪼
+쪽
+쫀
+쫄
+쫑
+쫓
+쬐
+쬘
+쭈
+쭉
+쭝
+쭤
+쮸
+쯔
+쯤
+찌
+찍
+찐
+찔
+찜
+찝
+찡
+찢
+찧
+차
+착
+찬
+찮
+찰
+참
+찹
+찻
+창
+찾
+챂
+채
+책
+챈
+챌
+챔
+챗
+챙
+챠
+챤
+처
+척
+천
+철
+첨
+첩
+첫
+청
+체
+첵
+첸
+첼
+쳇
+쳐
+쳤
+초
+촉
+촌
+촐
+촘
+촛
+총
+촨
+촬
+최
+쵸
+쵹
+추
+축
+춘
+출
+춤
+춥
+춧
+충
+춰
+췄
+췌
+취
+츄
+츠
+측
+츨
+츰
+츳
+층
+치
+칙
+친
+칠
+칡
+침
+칩
+칫
+칭
+칲
+카
+칵
+칸
+칼
+캄
+캅
+캇
+캉
+캐
+캔
+캘
+캠
+캡
+캣
+캥
+캬
+커
+컥
+컨
+컫
+컬
+컴
+컵
+컷
+컸
+컹
+케
+켁
+켄
+켈
+켐
+켓
+켜
+켰
+코
+콕
+콘
+콜
+콤
+콥
+콧
+콩
+콰
+콴
+콸
+쾅
+쾌
+쾨
+쾰
+쿄
+쿠
+쿡
+쿤
+쿨
+쿰
+쿵
+쿼
+퀀
+퀄
+퀘
+퀴
+퀵
+퀸
+퀼
+큐
+큔
+큘
+큠
+크
+큰
+클
+큼
+키
+킥
+킨
+킬
+킴
+킵
+킷
+킹
+타
+탁
+탄
+탈
+탉
+탐
+탑
+탓
+탔
+탕
+태
+택
+탠
+탤
+탬
+탭
+탱
+탸
+터
+턱
+턴
+털
+텀
+텁
+텃
+텅
+테
+텍
+텐
+텔
+템
+텝
+텟
+텡
+텨
+톈
+토
+톡
+톤
+톨
+톰
+톱
+톳
+통
+톺
+퇘
+퇴
+투
+툭
+툰
+툴
+툼
+퉁
+튀
+튕
+튜
+튠
+튬
+트
+특
+튼
+튿
+틀
+틈
+틔
+티
+틱
+틴
+틸
+팀
+팁
+팃
+팅
+파
+팍
+팎
+판
+팔
+팜
+팝
+팟
+팡
+팥
+패
+팩
+팬
+팰
+팸
+팹
+팻
+팽
+퍼
+퍽
+펀
+펄
+펌
+펍
+펑
+펖
+페
+펙
+펜
+펠
+펨
+펩
+펫
+펭
+펴
+편
+펼
+폄
+폈
+평
+폐
+포
+폭
+폰
+폴
+폼
+퐁
+푀
+표
+푸
+푹
+푼
+풀
+품
+풋
+풍
+퓌
+퓨
+퓰
+퓸
+프
+픈
+플
+픔
+피
+픽
+핀
+필
+핌
+핍
+핏
+핑
+하
+학
+한
+할
+핥
+함
+합
+핫
+항
+해
+핵
+핸
+핼
+햄
+햅
+햇
+했
+행
+햐
+향
+허
+헉
+헌
+헐
+험
+헛
+헝
+헤
+헥
+헨
+헬
+헴
+헵
+헸
+헹
+혀
+혁
+현
+혈
+혐
+협
+혓
+혔
+형
+혜
+호
+혹
+혼
+홀
+홈
+홉
+홋
+홍
+화
+확
+환
+활
+황
+홰
+횃
+회
+획
+횐
+횟
+횡
+효
+후
+훅
+훈
+훌
+훑
+훔
+훗
+훙
+훠
+훤
+훨
+훼
+휀
+휘
+휙
+휜
+휠
+휩
+휴
+흄
+흉
+흐
+흑
+흔
+흘
+흙
+흠
+흡
+흥
+흩
+희
+흰
+히
+힉
+힌
+힐
+힘
+힙
+곹
+뗌
+쏨
+똠
+챱
+쬬
+햬
+촤
+튤
+갠
+먄
+뀰
+걍
+삥
+뽄
+귓
+끽
+촙
+쿱
+슉
+켙
+좔
+뽂
+삑
+릐
+웡
+쨔
+잽
+볽
+떢
+꼰
+볏
+잰
+뷜
+셑
+쉡
+쏸
+썅
+쌥
+쎕
+뚤
+뚠
+뼘
+쎼
+긱
+삣
+쉰
+텬
+쌰
+뤠
+뤨
+땋
+뷸
+뗄
+됀
+뚬
+쉑
+쩨
+빳
+꺳
+쌔
+떙
+깟
+뒥
+솬
+숩
\ No newline at end of file
diff --git a/dicts/lower_english_digits.txt b/dicts/lower_english_digits.txt
new file mode 100644
index 0000000000000000000000000000000000000000..474060366f8a2a00c108d5c743821c0a61867cd5
--- /dev/null
+++ b/dicts/lower_english_digits.txt
@@ -0,0 +1,36 @@
+0
+1
+2
+3
+4
+5
+6
+7
+8
+9
+a
+b
+c
+d
+e
+f
+g
+h
+i
+j
+k
+l
+m
+n
+o
+p
+q
+r
+s
+t
+u
+v
+w
+x
+y
+z
\ No newline at end of file
diff --git a/dicts/lower_english_digits_space.txt b/dicts/lower_english_digits_space.txt
new file mode 100644
index 0000000000000000000000000000000000000000..a80a4a20b6f47e0338d5cccb9b71504eb38f62bb
--- /dev/null
+++ b/dicts/lower_english_digits_space.txt
@@ -0,0 +1,37 @@
+0
+1
+2
+3
+4
+5
+6
+7
+8
+9
+a
+b
+c
+d
+e
+f
+g
+h
+i
+j
+k
+l
+m
+n
+o
+p
+q
+r
+s
+t
+u
+v
+w
+x
+y
+z
+
\ No newline at end of file
diff --git a/dicts/sdmgr_dict.txt b/dicts/sdmgr_dict.txt
new file mode 100644
index 0000000000000000000000000000000000000000..b68274119a13962dc989c7330edd371d5c43ced4
--- /dev/null
+++ b/dicts/sdmgr_dict.txt
@@ -0,0 +1,91 @@
+/
+\
+.
+$
+£
+€
+¥
+:
+-
+,
+*
+#
+(
+)
+%
+@
+!
+'
+&
+=
+>
++
+"
+×
+?
+<
+[
+]
+_
+0
+1
+2
+3
+4
+5
+6
+7
+8
+9
+a
+b
+c
+d
+e
+f
+g
+h
+i
+j
+k
+l
+m
+n
+o
+p
+q
+r
+s
+t
+u
+v
+w
+x
+y
+z
+A
+B
+C
+D
+E
+F
+G
+H
+I
+J
+K
+L
+M
+N
+O
+P
+Q
+R
+S
+T
+U
+V
+W
+X
+Y
+Z
\ No newline at end of file
diff --git a/mmocr/__init__.py b/mmocr/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..335bfd04b961b96d2fcf6bdc0ea235d98066094f
--- /dev/null
+++ b/mmocr/__init__.py
@@ -0,0 +1,56 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+
+import mmcv
+import mmdet
+
+try:
+ import mmengine
+ from mmengine.utils import digit_version
+except ImportError:
+ mmengine = None
+ from mmcv import digit_version
+
+from .version import __version__, short_version
+
+mmcv_minimum_version = '2.0.0rc4'
+mmcv_maximum_version = '2.1.0'
+mmcv_version = digit_version(mmcv.__version__)
+if mmengine is not None:
+ mmengine_minimum_version = '0.7.1'
+ mmengine_maximum_version = '1.0.0'
+ mmengine_version = digit_version(mmengine.__version__)
+
+if not mmengine or mmcv_version < digit_version('2.0.0rc0') or digit_version(
+ mmdet.__version__) < digit_version('3.0.0rc0'):
+ raise RuntimeError(
+ 'MMOCR 1.0 only runs with MMEngine, MMCV 2.0.0rc0+ and '
+ 'MMDetection 3.0.0rc0+, but got MMCV '
+ f'{mmcv.__version__} and MMDetection '
+ f'{mmdet.__version__}. For more information, please refer to '
+ 'https://mmocr.readthedocs.io/en/dev-1.x/migration/overview.html'
+ ) # noqa
+
+assert (mmcv_version >= digit_version(mmcv_minimum_version)
+ and mmcv_version < digit_version(mmcv_maximum_version)), \
+ f'MMCV {mmcv.__version__} is incompatible with MMOCR {__version__}. ' \
+ f'Please use MMCV >= {mmcv_minimum_version}, ' \
+ f'< {mmcv_maximum_version} instead.'
+
+assert (mmengine_version >= digit_version(mmengine_minimum_version)
+ and mmengine_version < digit_version(mmengine_maximum_version)), \
+ f'MMEngine=={mmengine.__version__} is used but incompatible. ' \
+ f'Please install mmengine>={mmengine_minimum_version}, ' \
+ f'<{mmengine_maximum_version}.'
+
+mmdet_minimum_version = '3.0.0rc5'
+mmdet_maximum_version = '3.1.0'
+mmdet_version = digit_version(mmdet.__version__)
+
+assert (mmdet_version >= digit_version(mmdet_minimum_version)
+ and mmdet_version < digit_version(mmdet_maximum_version)), \
+ f'MMDetection {mmdet.__version__} is incompatible ' \
+ f'with MMOCR {__version__}. ' \
+ f'Please use MMDetection >= {mmdet_minimum_version}, ' \
+ f'< {mmdet_maximum_version} instead.'
+
+__all__ = ['__version__', 'short_version', 'digit_version']
diff --git a/mmocr/__pycache__/__init__.cpython-38.pyc b/mmocr/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..eeb91089560b1e2f413834fc8d5534f2fbc0b8ae
Binary files /dev/null and b/mmocr/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/__pycache__/registry.cpython-38.pyc b/mmocr/__pycache__/registry.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1eac5f6473141318de52948c8a05957f5ff77e44
Binary files /dev/null and b/mmocr/__pycache__/registry.cpython-38.pyc differ
diff --git a/mmocr/__pycache__/version.cpython-38.pyc b/mmocr/__pycache__/version.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1a281b156be9304c2c6d63bcb5bf50adae43e1ed
Binary files /dev/null and b/mmocr/__pycache__/version.cpython-38.pyc differ
diff --git a/mmocr/apis/__init__.py b/mmocr/apis/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..71141fb7a5962d851b250a5ad71877ef5f80fd4a
--- /dev/null
+++ b/mmocr/apis/__init__.py
@@ -0,0 +1,2 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .inferencers import * # NOQA
diff --git a/mmocr/apis/__pycache__/__init__.cpython-38.pyc b/mmocr/apis/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b7548a6a250d2f931c13d40c2c016bf81e0647f6
Binary files /dev/null and b/mmocr/apis/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/apis/inferencers/__init__.py b/mmocr/apis/inferencers/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..deb4950150fdf68a7dcbb5dcfd4cc5b33e324b41
--- /dev/null
+++ b/mmocr/apis/inferencers/__init__.py
@@ -0,0 +1,11 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .kie_inferencer import KIEInferencer
+from .mmocr_inferencer import MMOCRInferencer
+from .textdet_inferencer import TextDetInferencer
+from .textrec_inferencer import TextRecInferencer
+from .textspot_inferencer import TextSpotInferencer
+
+__all__ = [
+ 'TextDetInferencer', 'TextRecInferencer', 'KIEInferencer',
+ 'MMOCRInferencer', 'TextSpotInferencer'
+]
diff --git a/mmocr/apis/inferencers/__pycache__/__init__.cpython-38.pyc b/mmocr/apis/inferencers/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..7b2ad5e5c8c79088eb22de5e343b444fbb47107d
Binary files /dev/null and b/mmocr/apis/inferencers/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/apis/inferencers/__pycache__/base_mmocr_inferencer.cpython-38.pyc b/mmocr/apis/inferencers/__pycache__/base_mmocr_inferencer.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..73bbb81069f605bcc86be6f5f5f24ff068b246c9
Binary files /dev/null and b/mmocr/apis/inferencers/__pycache__/base_mmocr_inferencer.cpython-38.pyc differ
diff --git a/mmocr/apis/inferencers/__pycache__/kie_inferencer.cpython-38.pyc b/mmocr/apis/inferencers/__pycache__/kie_inferencer.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b3e9d233e1d386ad1de3c38024a0cf3b00f19031
Binary files /dev/null and b/mmocr/apis/inferencers/__pycache__/kie_inferencer.cpython-38.pyc differ
diff --git a/mmocr/apis/inferencers/__pycache__/mmocr_inferencer.cpython-38.pyc b/mmocr/apis/inferencers/__pycache__/mmocr_inferencer.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5e2728bb7c6edf45faf1f754dba05d38e75c5399
Binary files /dev/null and b/mmocr/apis/inferencers/__pycache__/mmocr_inferencer.cpython-38.pyc differ
diff --git a/mmocr/apis/inferencers/__pycache__/textdet_inferencer.cpython-38.pyc b/mmocr/apis/inferencers/__pycache__/textdet_inferencer.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1957d7352ceee8bcbf01e658a7ac1ebdb00de5b0
Binary files /dev/null and b/mmocr/apis/inferencers/__pycache__/textdet_inferencer.cpython-38.pyc differ
diff --git a/mmocr/apis/inferencers/__pycache__/textrec_inferencer.cpython-38.pyc b/mmocr/apis/inferencers/__pycache__/textrec_inferencer.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..601165bc8ff4986a55d3ac859331ef17acc11cf1
Binary files /dev/null and b/mmocr/apis/inferencers/__pycache__/textrec_inferencer.cpython-38.pyc differ
diff --git a/mmocr/apis/inferencers/__pycache__/textspot_inferencer.cpython-38.pyc b/mmocr/apis/inferencers/__pycache__/textspot_inferencer.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5e59132d4df56cab211f3e6d88a364c5c6d0c67c
Binary files /dev/null and b/mmocr/apis/inferencers/__pycache__/textspot_inferencer.cpython-38.pyc differ
diff --git a/mmocr/apis/inferencers/base_mmocr_inferencer.py b/mmocr/apis/inferencers/base_mmocr_inferencer.py
new file mode 100644
index 0000000000000000000000000000000000000000..02ac643d9ffea8dddde098aa02038ebfdc1cce25
--- /dev/null
+++ b/mmocr/apis/inferencers/base_mmocr_inferencer.py
@@ -0,0 +1,405 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from typing import Dict, Iterable, List, Optional, Sequence, Tuple, Union
+
+import mmcv
+import mmengine
+import numpy as np
+from mmengine.dataset import Compose
+from mmengine.infer.infer import BaseInferencer, ModelType
+from mmengine.model.utils import revert_sync_batchnorm
+from mmengine.registry import init_default_scope
+from mmengine.structures import InstanceData
+from rich.progress import track
+from torch import Tensor
+
+from mmocr.utils import ConfigType
+
+InstanceList = List[InstanceData]
+InputType = Union[str, np.ndarray]
+InputsType = Union[InputType, Sequence[InputType]]
+PredType = Union[InstanceData, InstanceList]
+ImgType = Union[np.ndarray, Sequence[np.ndarray]]
+ResType = Union[Dict, List[Dict], InstanceData, List[InstanceData]]
+
+
+class BaseMMOCRInferencer(BaseInferencer):
+ """Base inferencer.
+
+ Args:
+ model (str, optional): Path to the config file or the model name
+ defined in metafile. For example, it could be
+ "dbnet_resnet18_fpnc_1200e_icdar2015" or
+ "configs/textdet/dbnet/dbnet_resnet18_fpnc_1200e_icdar2015.py".
+ If model is not specified, user must provide the
+ `weights` saved by MMEngine which contains the config string.
+ Defaults to None.
+ weights (str, optional): Path to the checkpoint. If it is not specified
+ and model is a model name of metafile, the weights will be loaded
+ from metafile. Defaults to None.
+ device (str, optional): Device to run inference. If None, the available
+ device will be automatically used. Defaults to None.
+ scope (str, optional): The scope of the model. Defaults to "mmocr".
+ """
+
+ preprocess_kwargs: set = set()
+ forward_kwargs: set = set()
+ visualize_kwargs: set = {
+ 'return_vis', 'show', 'wait_time', 'draw_pred', 'pred_score_thr',
+ 'save_vis'
+ }
+ postprocess_kwargs: set = {
+ 'print_result', 'return_datasample', 'save_pred'
+ }
+ loading_transforms: list = ['LoadImageFromFile', 'LoadImageFromNDArray']
+
+ def __init__(self,
+ model: Union[ModelType, str, None] = None,
+ weights: Optional[str] = None,
+ device: Optional[str] = None,
+ scope: str = 'mmocr') -> None:
+ # A global counter tracking the number of images given in the form
+ # of ndarray, for naming the output images
+ self.num_unnamed_imgs = 0
+ init_default_scope(scope)
+ super().__init__(
+ model=model, weights=weights, device=device, scope=scope)
+ self.model = revert_sync_batchnorm(self.model)
+
+ def preprocess(self, inputs: InputsType, batch_size: int = 1, **kwargs):
+ """Process the inputs into a model-feedable format.
+
+ Args:
+ inputs (InputsType): Inputs given by user.
+ batch_size (int): batch size. Defaults to 1.
+
+ Yields:
+ Any: Data processed by the ``pipeline`` and ``collate_fn``.
+ """
+ chunked_data = self._get_chunk_data(inputs, batch_size)
+ yield from map(self.collate_fn, chunked_data)
+
+ def _get_chunk_data(self, inputs: Iterable, chunk_size: int):
+ """Get batch data from inputs.
+
+ Args:
+ inputs (Iterable): An iterable dataset.
+ chunk_size (int): Equivalent to batch size.
+
+ Yields:
+ list: batch data.
+ """
+ inputs_iter = iter(inputs)
+ while True:
+ try:
+ chunk_data = []
+ for _ in range(chunk_size):
+ inputs_ = next(inputs_iter)
+ pipe_out = self.pipeline(inputs_)
+ if pipe_out['data_samples'].get('img_path') is None:
+ pipe_out['data_samples'].set_metainfo(
+ dict(img_path=f'{self.num_unnamed_imgs}.jpg'))
+ self.num_unnamed_imgs += 1
+ chunk_data.append((inputs_, pipe_out))
+ yield chunk_data
+ except StopIteration:
+ if chunk_data:
+ yield chunk_data
+ break
+
+ def __call__(self,
+ inputs: InputsType,
+ return_datasamples: bool = False,
+ batch_size: int = 1,
+ progress_bar: bool = True,
+ return_vis: bool = False,
+ show: bool = False,
+ wait_time: int = 0,
+ draw_pred: bool = True,
+ pred_score_thr: float = 0.3,
+ out_dir: str = 'results/',
+ save_vis: bool = False,
+ save_pred: bool = False,
+ print_result: bool = False,
+ **kwargs) -> dict:
+ """Call the inferencer.
+
+ Args:
+ inputs (InputsType): Inputs for the inferencer. It can be a path
+ to image / image directory, or an array, or a list of these.
+ Note: If it's an numpy array, it should be in BGR order.
+ return_datasamples (bool): Whether to return results as
+ :obj:`BaseDataElement`. Defaults to False.
+ batch_size (int): Inference batch size. Defaults to 1.
+ progress_bar (bool): Whether to show a progress bar. Defaults to
+ True.
+ return_vis (bool): Whether to return the visualization result.
+ Defaults to False.
+ show (bool): Whether to display the visualization results in a
+ popup window. Defaults to False.
+ wait_time (float): The interval of show (s). Defaults to 0.
+ draw_pred (bool): Whether to draw predicted bounding boxes.
+ Defaults to True.
+ pred_score_thr (float): Minimum score of bboxes to draw.
+ Defaults to 0.3.
+ out_dir (str): Output directory of results. Defaults to 'results/'.
+ save_vis (bool): Whether to save the visualization results to
+ "out_dir". Defaults to False.
+ save_pred (bool): Whether to save the inference results to
+ "out_dir". Defaults to False.
+ print_result (bool): Whether to print the inference result w/o
+ visualization to the console. Defaults to False.
+
+ **kwargs: Other keyword arguments passed to :meth:`preprocess`,
+ :meth:`forward`, :meth:`visualize` and :meth:`postprocess`.
+ Each key in kwargs should be in the corresponding set of
+ ``preprocess_kwargs``, ``forward_kwargs``, ``visualize_kwargs``
+ and ``postprocess_kwargs``.
+
+ Returns:
+ dict: Inference and visualization results, mapped from
+ "predictions" and "visualization".
+ """
+ if (save_vis or save_pred) and not out_dir:
+ raise ValueError('out_dir must be specified when save_vis or '
+ 'save_pred is True!')
+ if out_dir:
+ img_out_dir = osp.join(out_dir, 'vis')
+ pred_out_dir = osp.join(out_dir, 'preds')
+ else:
+ img_out_dir, pred_out_dir = '', ''
+ (
+ preprocess_kwargs,
+ forward_kwargs,
+ visualize_kwargs,
+ postprocess_kwargs,
+ ) = self._dispatch_kwargs(
+ return_vis=return_vis,
+ show=show,
+ wait_time=wait_time,
+ draw_pred=draw_pred,
+ pred_score_thr=pred_score_thr,
+ save_vis=save_vis,
+ save_pred=save_pred,
+ print_result=print_result,
+ **kwargs)
+
+ ori_inputs = self._inputs_to_list(inputs)
+ inputs = self.preprocess(
+ ori_inputs, batch_size=batch_size, **preprocess_kwargs)
+ results = {'predictions': [], 'visualization': []}
+ for ori_inputs, data in track(
+ inputs, description='Inference', disable=not progress_bar):
+ preds = self.forward(data, **forward_kwargs)
+ visualization = self.visualize(
+ ori_inputs, preds, img_out_dir=img_out_dir, **visualize_kwargs)
+ batch_res = self.postprocess(
+ preds,
+ visualization,
+ return_datasamples,
+ pred_out_dir=pred_out_dir,
+ **postprocess_kwargs)
+ results['predictions'].extend(batch_res['predictions'])
+ if return_vis and batch_res['visualization'] is not None:
+ results['visualization'].extend(batch_res['visualization'])
+ return results
+
+ def _init_pipeline(self, cfg: ConfigType) -> Compose:
+ """Initialize the test pipeline."""
+ pipeline_cfg = cfg.test_dataloader.dataset.pipeline
+
+ # For inference, the key of ``instances`` is not used.
+ if 'meta_keys' in pipeline_cfg[-1]:
+ pipeline_cfg[-1]['meta_keys'] = tuple(
+ meta_key for meta_key in pipeline_cfg[-1]['meta_keys']
+ if meta_key != 'instances')
+
+ # Loading annotations is also not applicable
+ idx = self._get_transform_idx(pipeline_cfg, 'LoadOCRAnnotations')
+ if idx != -1:
+ del pipeline_cfg[idx]
+
+ for transform in self.loading_transforms:
+ load_img_idx = self._get_transform_idx(pipeline_cfg, transform)
+ if load_img_idx != -1:
+ pipeline_cfg[load_img_idx]['type'] = 'InferencerLoader'
+ break
+ if load_img_idx == -1:
+ raise ValueError(
+ f'None of {self.loading_transforms} is found in the test '
+ 'pipeline')
+
+ return Compose(pipeline_cfg)
+
+ def _get_transform_idx(self, pipeline_cfg: ConfigType, name: str) -> int:
+ """Returns the index of the transform in a pipeline.
+
+ If the transform is not found, returns -1.
+ """
+ for i, transform in enumerate(pipeline_cfg):
+ if transform['type'] == name:
+ return i
+ return -1
+
+ def visualize(self,
+ inputs: InputsType,
+ preds: PredType,
+ return_vis: bool = False,
+ show: bool = False,
+ wait_time: int = 0,
+ draw_pred: bool = True,
+ pred_score_thr: float = 0.3,
+ save_vis: bool = False,
+ img_out_dir: str = '') -> Union[List[np.ndarray], None]:
+ """Visualize predictions.
+
+ Args:
+ inputs (List[Union[str, np.ndarray]]): Inputs for the inferencer.
+ preds (List[Dict]): Predictions of the model.
+ return_vis (bool): Whether to return the visualization result.
+ Defaults to False.
+ show (bool): Whether to display the image in a popup window.
+ Defaults to False.
+ wait_time (float): The interval of show (s). Defaults to 0.
+ draw_pred (bool): Whether to draw predicted bounding boxes.
+ Defaults to True.
+ pred_score_thr (float): Minimum score of bboxes to draw.
+ Defaults to 0.3.
+ save_vis (bool): Whether to save the visualization result. Defaults
+ to False.
+ img_out_dir (str): Output directory of visualization results.
+ If left as empty, no file will be saved. Defaults to ''.
+
+ Returns:
+ List[np.ndarray] or None: Returns visualization results only if
+ applicable.
+ """
+ if self.visualizer is None or not (show or save_vis or return_vis):
+ return None
+
+ if getattr(self, 'visualizer') is None:
+ raise ValueError('Visualization needs the "visualizer" term'
+ 'defined in the config, but got None.')
+
+ results = []
+
+ for single_input, pred in zip(inputs, preds):
+ if isinstance(single_input, str):
+ img_bytes = mmengine.fileio.get(single_input)
+ img = mmcv.imfrombytes(img_bytes, channel_order='rgb')
+ elif isinstance(single_input, np.ndarray):
+ img = single_input.copy()[:, :, ::-1] # to RGB
+ else:
+ raise ValueError('Unsupported input type: '
+ f'{type(single_input)}')
+ img_name = osp.splitext(osp.basename(pred.img_path))[0]
+
+ if save_vis and img_out_dir:
+ out_file = osp.splitext(img_name)[0]
+ out_file = f'{out_file}.jpg'
+ out_file = osp.join(img_out_dir, out_file)
+ else:
+ out_file = None
+
+ visualization = self.visualizer.add_datasample(
+ img_name,
+ img,
+ pred,
+ show=show,
+ wait_time=wait_time,
+ draw_gt=False,
+ draw_pred=draw_pred,
+ pred_score_thr=pred_score_thr,
+ out_file=out_file,
+ )
+ results.append(visualization)
+
+ return results
+
+ def postprocess(
+ self,
+ preds: PredType,
+ visualization: Optional[List[np.ndarray]] = None,
+ return_datasample: bool = False,
+ print_result: bool = False,
+ save_pred: bool = False,
+ pred_out_dir: str = '',
+ ) -> Union[ResType, Tuple[ResType, np.ndarray]]:
+ """Process the predictions and visualization results from ``forward``
+ and ``visualize``.
+
+ This method should be responsible for the following tasks:
+
+ 1. Convert datasamples into a json-serializable dict if needed.
+ 2. Pack the predictions and visualization results and return them.
+ 3. Dump or log the predictions.
+
+ Args:
+ preds (List[Dict]): Predictions of the model.
+ visualization (Optional[np.ndarray]): Visualized predictions.
+ return_datasample (bool): Whether to use Datasample to store
+ inference results. If False, dict will be used.
+ print_result (bool): Whether to print the inference result w/o
+ visualization to the console. Defaults to False.
+ save_pred (bool): Whether to save the inference result. Defaults to
+ False.
+ pred_out_dir: File to save the inference results w/o
+ visualization. If left as empty, no file will be saved.
+ Defaults to ''.
+
+ Returns:
+ dict: Inference and visualization results with key ``predictions``
+ and ``visualization``.
+
+ - ``visualization`` (Any): Returned by :meth:`visualize`.
+ - ``predictions`` (dict or DataSample): Returned by
+ :meth:`forward` and processed in :meth:`postprocess`.
+ If ``return_datasample=False``, it usually should be a
+ json-serializable dict containing only basic data elements such
+ as strings and numbers.
+ """
+ result_dict = {}
+ results = preds
+ if not return_datasample:
+ results = []
+ for pred in preds:
+ result = self.pred2dict(pred)
+ if save_pred and pred_out_dir:
+ pred_name = osp.splitext(osp.basename(pred.img_path))[0]
+ pred_name = f'{pred_name}.json'
+ pred_out_file = osp.join(pred_out_dir, pred_name)
+ mmengine.dump(result, pred_out_file)
+ results.append(result)
+ # Add img to the results after printing and dumping
+ result_dict['predictions'] = results
+ if print_result:
+ print(result_dict)
+ result_dict['visualization'] = visualization
+ return result_dict
+
+ def pred2dict(self, data_sample: InstanceData) -> Dict:
+ """Extract elements necessary to represent a prediction into a
+ dictionary.
+
+ It's better to contain only basic data elements such as strings and
+ numbers in order to guarantee it's json-serializable.
+ """
+ raise NotImplementedError
+
+ def _array2list(self, array: Union[Tensor, np.ndarray,
+ List]) -> List[float]:
+ """Convert a tensor or numpy array to a list.
+
+ Args:
+ array (Union[Tensor, np.ndarray]): The array to be converted.
+
+ Returns:
+ List[float]: The converted list.
+ """
+ if isinstance(array, Tensor):
+ return array.detach().cpu().numpy().tolist()
+ if isinstance(array, np.ndarray):
+ return array.tolist()
+ if isinstance(array, list):
+ array = [self._array2list(arr) for arr in array]
+ return array
diff --git a/mmocr/apis/inferencers/kie_inferencer.py b/mmocr/apis/inferencers/kie_inferencer.py
new file mode 100644
index 0000000000000000000000000000000000000000..c7865d5c9b756d3556538304023039a6648b07db
--- /dev/null
+++ b/mmocr/apis/inferencers/kie_inferencer.py
@@ -0,0 +1,285 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import os.path as osp
+from typing import Any, Dict, List, Optional, Sequence, Union
+
+import mmcv
+import mmengine
+import numpy as np
+from mmengine.dataset import Compose, pseudo_collate
+from mmengine.runner.checkpoint import _load_checkpoint
+
+from mmocr.registry import DATASETS
+from mmocr.structures import KIEDataSample
+from mmocr.utils import ConfigType
+from .base_mmocr_inferencer import BaseMMOCRInferencer, ModelType, PredType
+
+InputType = Dict
+InputsType = Sequence[Dict]
+
+
+class KIEInferencer(BaseMMOCRInferencer):
+ """Key Information Extraction Inferencer.
+
+ Args:
+ model (str, optional): Path to the config file or the model name
+ defined in metafile. For example, it could be
+ "sdmgr_unet16_60e_wildreceipt" or
+ "configs/kie/sdmgr/sdmgr_unet16_60e_wildreceipt.py".
+ If model is not specified, user must provide the
+ `weights` saved by MMEngine which contains the config string.
+ Defaults to None.
+ weights (str, optional): Path to the checkpoint. If it is not specified
+ and model is a model name of metafile, the weights will be loaded
+ from metafile. Defaults to None.
+ device (str, optional): Device to run inference. If None, the available
+ device will be automatically used. Defaults to None.
+ scope (str, optional): The scope of the model. Defaults to "mmocr".
+ """
+
+ def __init__(self,
+ model: Union[ModelType, str, None] = None,
+ weights: Optional[str] = None,
+ device: Optional[str] = None,
+ scope: Optional[str] = 'mmocr') -> None:
+ super().__init__(
+ model=model, weights=weights, device=device, scope=scope)
+ self._load_metainfo_to_visualizer(weights, self.cfg)
+ self.collate_fn = self.kie_collate
+
+ def _load_metainfo_to_visualizer(self, weights: Optional[str],
+ cfg: ConfigType) -> None:
+ """Load meta information to visualizer."""
+ if hasattr(self, 'visualizer'):
+ if weights is not None:
+ w = _load_checkpoint(weights, map_location='cpu')
+ if w and 'meta' in w and 'dataset_meta' in w['meta']:
+ self.visualizer.dataset_meta = w['meta']['dataset_meta']
+ return
+ if 'test_dataloader' in cfg:
+ dataset_cfg = copy.deepcopy(cfg.test_dataloader.dataset)
+ dataset_cfg['lazy_init'] = True
+ dataset_cfg['metainfo'] = None
+ dataset = DATASETS.build(dataset_cfg)
+ self.visualizer.dataset_meta = dataset.metainfo
+ else:
+ raise ValueError(
+ 'KIEVisualizer requires meta information from weights or '
+ 'test dataset, but none of them is provided.')
+
+ def _init_pipeline(self, cfg: ConfigType) -> None:
+ """Initialize the test pipeline."""
+ pipeline_cfg = cfg.test_dataloader.dataset.pipeline
+ idx = self._get_transform_idx(pipeline_cfg, 'LoadKIEAnnotations')
+ if idx == -1:
+ raise ValueError(
+ 'LoadKIEAnnotations is not found in the test pipeline')
+ pipeline_cfg[idx]['with_label'] = False
+ self.novisual = all(
+ self._get_transform_idx(pipeline_cfg, t) == -1
+ for t in self.loading_transforms)
+ # Remove Resize from test_pipeline, since SDMGR requires bbox
+ # annotations to be resized together with pictures, but visualization
+ # loads the original image from the disk.
+ # TODO: find a more elegant way to fix this
+ idx = self._get_transform_idx(pipeline_cfg, 'Resize')
+ if idx != -1:
+ pipeline_cfg.pop(idx)
+ # If it's in non-visual mode, self.pipeline will be specified.
+ # Otherwise, file_pipeline and ndarray_pipeline will be specified.
+ if self.novisual:
+ return Compose(pipeline_cfg)
+ return super()._init_pipeline(cfg)
+
+ @staticmethod
+ def kie_collate(data_batch: Sequence) -> Any:
+ """A collate function designed for KIE, where the first element (input)
+ is a dict and we only want to keep it as-is instead of batching
+ elements inside.
+
+ Returns:
+ Any: Transversed Data in the same format as the data_itement of
+ ``data_batch``.
+ """ # noqa: E501
+ transposed = list(zip(*data_batch))
+ for i in range(1, len(transposed)):
+ transposed[i] = pseudo_collate(transposed[i])
+ return transposed
+
+ def _inputs_to_list(self, inputs: InputsType) -> list:
+ """Preprocess the inputs to a list.
+
+ Preprocess inputs to a list according to its type.
+
+ The inputs can be a dict or list[dict], where each dictionary contains
+ following keys:
+
+ - img (str or ndarray): Path to the image or the image itself. If KIE
+ Inferencer is used in no-visual mode, this key is not required.
+ Note: If it's an numpy array, it should be in BGR order.
+ - img_shape (tuple(int, int)): Image shape in (H, W). In
+ - instances (list[dict]): A list of instances.
+ - bbox (ndarray(dtype=np.float32)): Shape (4, ). Bounding box.
+ - text (str): Annotation text.
+
+ Each ``instance`` looks like the following:
+
+ .. code-block:: python
+
+ {
+ # A nested list of 4 numbers representing the bounding box of
+ # the instance, in (x1, y1, x2, y2) order.
+ 'bbox': np.array([[x1, y1, x2, y2], [x1, y1, x2, y2], ...],
+ dtype=np.int32),
+
+ # List of texts.
+ "texts": ['text1', 'text2', ...],
+ }
+
+ Args:
+ inputs (InputsType): Inputs for the inferencer.
+
+ Returns:
+ list: List of input for the :meth:`preprocess`.
+ """
+
+ processed_inputs = []
+
+ if not isinstance(inputs, (list, tuple)):
+ inputs = [inputs]
+
+ for single_input in inputs:
+ if self.novisual:
+ processed_input = copy.deepcopy(single_input)
+ if 'img' not in single_input and \
+ 'img_shape' not in single_input:
+ raise ValueError(
+ 'KIEInferencer in no-visual mode '
+ 'requires input has "img" or "img_shape", but both are'
+ ' not found.')
+ if 'img' in single_input:
+ img = single_input['img']
+ if isinstance(img, str):
+ img_bytes = mmengine.fileio.get(img)
+ img = mmcv.imfrombytes(img_bytes)
+ processed_input['img'] = img
+ processed_input['img_shape'] = img.shape[:2]
+ processed_inputs.append(processed_input)
+ else:
+ if 'img' not in single_input:
+ raise ValueError(
+ 'This inferencer is constructed to '
+ 'accept image inputs, but the input does not contain '
+ '"img" key.')
+ if isinstance(single_input['img'], str):
+ processed_input = {
+ k: v
+ for k, v in single_input.items() if k != 'img'
+ }
+ processed_input['img_path'] = single_input['img']
+ processed_inputs.append(processed_input)
+ elif isinstance(single_input['img'], np.ndarray):
+ processed_inputs.append(copy.deepcopy(single_input))
+ else:
+ atype = type(single_input['img'])
+ raise ValueError(f'Unsupported input type: {atype}')
+
+ return processed_inputs
+
+ def visualize(self,
+ inputs: InputsType,
+ preds: PredType,
+ return_vis: bool = False,
+ show: bool = False,
+ wait_time: int = 0,
+ draw_pred: bool = True,
+ pred_score_thr: float = 0.3,
+ save_vis: bool = False,
+ img_out_dir: str = '') -> Union[List[np.ndarray], None]:
+ """Visualize predictions.
+
+ Args:
+ inputs (List[Union[str, np.ndarray]]): Inputs for the inferencer.
+ preds (List[Dict]): Predictions of the model.
+ return_vis (bool): Whether to return the visualization result.
+ Defaults to False.
+ show (bool): Whether to display the image in a popup window.
+ Defaults to False.
+ wait_time (float): The interval of show (s). Defaults to 0.
+ draw_pred (bool): Whether to draw predicted bounding boxes.
+ Defaults to True.
+ pred_score_thr (float): Minimum score of bboxes to draw.
+ Defaults to 0.3.
+ save_vis (bool): Whether to save the visualization result. Defaults
+ to False.
+ img_out_dir (str): Output directory of visualization results.
+ If left as empty, no file will be saved. Defaults to ''.
+
+ Returns:
+ List[np.ndarray] or None: Returns visualization results only if
+ applicable.
+ """
+ if self.visualizer is None or not (show or save_vis or return_vis):
+ return None
+
+ if getattr(self, 'visualizer') is None:
+ raise ValueError('Visualization needs the "visualizer" term'
+ 'defined in the config, but got None.')
+
+ results = []
+
+ for single_input, pred in zip(inputs, preds):
+ assert 'img' in single_input or 'img_shape' in single_input
+ if 'img' in single_input:
+ if isinstance(single_input['img'], str):
+ img_bytes = mmengine.fileio.get(single_input['img'])
+ img = mmcv.imfrombytes(img_bytes, channel_order='rgb')
+ elif isinstance(single_input['img'], np.ndarray):
+ img = single_input['img'].copy()[:, :, ::-1] # To RGB
+ elif 'img_shape' in single_input:
+ img = np.zeros(single_input['img_shape'], dtype=np.uint8)
+ else:
+ raise ValueError('Input does not contain either "img" or '
+ '"img_shape"')
+ img_name = osp.splitext(osp.basename(pred.img_path))[0]
+
+ if save_vis and img_out_dir:
+ out_file = osp.splitext(img_name)[0]
+ out_file = f'{out_file}.jpg'
+ out_file = osp.join(img_out_dir, out_file)
+ else:
+ out_file = None
+
+ visualization = self.visualizer.add_datasample(
+ img_name,
+ img,
+ pred,
+ show=show,
+ wait_time=wait_time,
+ draw_gt=False,
+ draw_pred=draw_pred,
+ pred_score_thr=pred_score_thr,
+ out_file=out_file,
+ )
+ results.append(visualization)
+
+ return results
+
+ def pred2dict(self, data_sample: KIEDataSample) -> Dict:
+ """Extract elements necessary to represent a prediction into a
+ dictionary. It's better to contain only basic data elements such as
+ strings and numbers in order to guarantee it's json-serializable.
+
+ Args:
+ data_sample (TextRecogDataSample): The data sample to be converted.
+
+ Returns:
+ dict: The output dictionary.
+ """
+ result = {}
+ pred = data_sample.pred_instances
+ result['scores'] = pred.scores.cpu().numpy().tolist()
+ result['edge_scores'] = pred.edge_scores.cpu().numpy().tolist()
+ result['edge_labels'] = pred.edge_labels.cpu().numpy().tolist()
+ result['labels'] = pred.labels.cpu().numpy().tolist()
+ return result
diff --git a/mmocr/apis/inferencers/mmocr_inferencer.py b/mmocr/apis/inferencers/mmocr_inferencer.py
new file mode 100644
index 0000000000000000000000000000000000000000..be7f74237875ed42ef5cb099957662c8a125d94c
--- /dev/null
+++ b/mmocr/apis/inferencers/mmocr_inferencer.py
@@ -0,0 +1,422 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from datetime import datetime
+from typing import Dict, List, Optional, Tuple, Union
+
+import mmcv
+import mmengine
+import numpy as np
+from rich.progress import track
+
+from mmocr.registry import VISUALIZERS
+from mmocr.structures import TextSpottingDataSample
+from mmocr.utils import ConfigType, bbox2poly, crop_img, poly2bbox
+from .base_mmocr_inferencer import (BaseMMOCRInferencer, InputsType, PredType,
+ ResType)
+from .kie_inferencer import KIEInferencer
+from .textdet_inferencer import TextDetInferencer
+from .textrec_inferencer import TextRecInferencer
+
+
+class MMOCRInferencer(BaseMMOCRInferencer):
+ """MMOCR Inferencer. It's a wrapper around three base task
+ inferenecers: TextDetInferencer, TextRecInferencer and KIEInferencer,
+ and it can be used to perform end-to-end OCR or KIE inference.
+
+ Args:
+ det (Optional[Union[ConfigType, str]]): Pretrained text detection
+ algorithm. It's the path to the config file or the model name
+ defined in metafile. Defaults to None.
+ det_weights (Optional[str]): Path to the custom checkpoint file of
+ the selected det model. If it is not specified and "det" is a model
+ name of metafile, the weights will be loaded from metafile.
+ Defaults to None.
+ rec (Optional[Union[ConfigType, str]]): Pretrained text recognition
+ algorithm. It's the path to the config file or the model name
+ defined in metafile. Defaults to None.
+ rec_weights (Optional[str]): Path to the custom checkpoint file of
+ the selected rec model. If it is not specified and "rec" is a model
+ name of metafile, the weights will be loaded from metafile.
+ Defaults to None.
+ kie (Optional[Union[ConfigType, str]]): Pretrained key information
+ extraction algorithm. It's the path to the config file or the model
+ name defined in metafile. Defaults to None.
+ kie_weights (Optional[str]): Path to the custom checkpoint file of
+ the selected kie model. If it is not specified and "kie" is a model
+ name of metafile, the weights will be loaded from metafile.
+ Defaults to None.
+ device (Optional[str]): Device to run inference. If None, the available
+ device will be automatically used. Defaults to None.
+
+ """
+
+ def __init__(self,
+ det: Optional[Union[ConfigType, str]] = None,
+ det_weights: Optional[str] = None,
+ rec: Optional[Union[ConfigType, str]] = None,
+ rec_weights: Optional[str] = None,
+ kie: Optional[Union[ConfigType, str]] = None,
+ kie_weights: Optional[str] = None,
+ device: Optional[str] = None) -> None:
+
+ if det is None and rec is None and kie is None:
+ raise ValueError('At least one of det, rec and kie should be '
+ 'provided.')
+
+ self.visualizer = None
+
+ if det is not None:
+ self.textdet_inferencer = TextDetInferencer(
+ det, det_weights, device)
+ self.mode = 'det'
+ if rec is not None:
+ self.textrec_inferencer = TextRecInferencer(
+ rec, rec_weights, device)
+ if getattr(self, 'mode', None) == 'det':
+ self.mode = 'det_rec'
+ ts = str(datetime.timestamp(datetime.now()))
+ self.visualizer = VISUALIZERS.build(
+ dict(
+ type='TextSpottingLocalVisualizer',
+ name=f'inferencer{ts}',
+ font_families=self.textrec_inferencer.visualizer.
+ font_families))
+ else:
+ self.mode = 'rec'
+ if kie is not None:
+ if det is None or rec is None:
+ raise ValueError(
+ 'kie_config is only applicable when det_config and '
+ 'rec_config are both provided')
+ self.kie_inferencer = KIEInferencer(kie, kie_weights, device)
+ self.mode = 'det_rec_kie'
+
+ def _inputs2ndarrray(self, inputs: List[InputsType]) -> List[np.ndarray]:
+ """Preprocess the inputs to a list of numpy arrays."""
+ new_inputs = []
+ for item in inputs:
+ if isinstance(item, np.ndarray):
+ new_inputs.append(item)
+ elif isinstance(item, str):
+ img_bytes = mmengine.fileio.get(item)
+ new_inputs.append(mmcv.imfrombytes(img_bytes))
+ else:
+ raise NotImplementedError(f'The input type {type(item)} is not'
+ 'supported yet.')
+ return new_inputs
+
+ def forward(self,
+ inputs: InputsType,
+ batch_size: int = 1,
+ det_batch_size: Optional[int] = None,
+ rec_batch_size: Optional[int] = None,
+ kie_batch_size: Optional[int] = None,
+ **forward_kwargs) -> PredType:
+ """Forward the inputs to the model.
+
+ Args:
+ inputs (InputsType): The inputs to be forwarded.
+ batch_size (int): Batch size. Defaults to 1.
+ det_batch_size (Optional[int]): Batch size for text detection
+ model. Overwrite batch_size if it is not None.
+ Defaults to None.
+ rec_batch_size (Optional[int]): Batch size for text recognition
+ model. Overwrite batch_size if it is not None.
+ Defaults to None.
+ kie_batch_size (Optional[int]): Batch size for KIE model.
+ Overwrite batch_size if it is not None.
+ Defaults to None.
+
+ Returns:
+ Dict: The prediction results. Possibly with keys "det", "rec", and
+ "kie"..
+ """
+ result = {}
+ forward_kwargs['progress_bar'] = False
+ if det_batch_size is None:
+ det_batch_size = batch_size
+ if rec_batch_size is None:
+ rec_batch_size = batch_size
+ if kie_batch_size is None:
+ kie_batch_size = batch_size
+ if self.mode == 'rec':
+ # The extra list wrapper here is for the ease of postprocessing
+ self.rec_inputs = inputs
+ predictions = self.textrec_inferencer(
+ self.rec_inputs,
+ return_datasamples=True,
+ batch_size=rec_batch_size,
+ **forward_kwargs)['predictions']
+ result['rec'] = [[p] for p in predictions]
+ elif self.mode.startswith('det'): # 'det'/'det_rec'/'det_rec_kie'
+ result['det'] = self.textdet_inferencer(
+ inputs,
+ return_datasamples=True,
+ batch_size=det_batch_size,
+ **forward_kwargs)['predictions']
+ if self.mode.startswith('det_rec'): # 'det_rec'/'det_rec_kie'
+ result['rec'] = []
+ for img, det_data_sample in zip(
+ self._inputs2ndarrray(inputs), result['det']):
+ det_pred = det_data_sample.pred_instances
+ self.rec_inputs = []
+ for polygon in det_pred['polygons']:
+ # Roughly convert the polygon to a quadangle with
+ # 4 points
+ quad = bbox2poly(poly2bbox(polygon)).tolist()
+ self.rec_inputs.append(crop_img(img, quad))
+ result['rec'].append(
+ self.textrec_inferencer(
+ self.rec_inputs,
+ return_datasamples=True,
+ batch_size=rec_batch_size,
+ **forward_kwargs)['predictions'])
+ if self.mode == 'det_rec_kie':
+ self.kie_inputs = []
+ # TODO: when the det output is empty, kie will fail
+ # as no gt-instances can be provided. It's a known
+ # issue but cannot be solved elegantly since we support
+ # batch inference.
+ for img, det_data_sample, rec_data_samples in zip(
+ inputs, result['det'], result['rec']):
+ det_pred = det_data_sample.pred_instances
+ kie_input = dict(img=img)
+ kie_input['instances'] = []
+ for polygon, rec_data_sample in zip(
+ det_pred['polygons'], rec_data_samples):
+ kie_input['instances'].append(
+ dict(
+ bbox=poly2bbox(polygon),
+ text=rec_data_sample.pred_text.item))
+ self.kie_inputs.append(kie_input)
+ result['kie'] = self.kie_inferencer(
+ self.kie_inputs,
+ return_datasamples=True,
+ batch_size=kie_batch_size,
+ **forward_kwargs)['predictions']
+ return result
+
+ def visualize(self, inputs: InputsType, preds: PredType,
+ **kwargs) -> Union[List[np.ndarray], None]:
+ """Visualize predictions.
+
+ Args:
+ inputs (List[Union[str, np.ndarray]]): Inputs for the inferencer.
+ preds (List[Dict]): Predictions of the model.
+ show (bool): Whether to display the image in a popup window.
+ Defaults to False.
+ wait_time (float): The interval of show (s). Defaults to 0.
+ draw_pred (bool): Whether to draw predicted bounding boxes.
+ Defaults to True.
+ pred_score_thr (float): Minimum score of bboxes to draw.
+ Defaults to 0.3.
+ save_vis (bool): Whether to save the visualization result. Defaults
+ to False.
+ img_out_dir (str): Output directory of visualization results.
+ If left as empty, no file will be saved. Defaults to ''.
+
+ Returns:
+ List[np.ndarray] or None: Returns visualization results only if
+ applicable.
+ """
+
+ if 'kie' in self.mode:
+ return self.kie_inferencer.visualize(self.kie_inputs, preds['kie'],
+ **kwargs)
+ elif 'rec' in self.mode:
+ if 'det' in self.mode:
+ return super().visualize(inputs,
+ self._pack_e2e_datasamples(preds),
+ **kwargs)
+ else:
+ return self.textrec_inferencer.visualize(
+ self.rec_inputs, preds['rec'][0], **kwargs)
+ else:
+ return self.textdet_inferencer.visualize(inputs, preds['det'],
+ **kwargs)
+
+ def __call__(
+ self,
+ inputs: InputsType,
+ batch_size: int = 1,
+ det_batch_size: Optional[int] = None,
+ rec_batch_size: Optional[int] = None,
+ kie_batch_size: Optional[int] = None,
+ out_dir: str = 'results/',
+ return_vis: bool = False,
+ save_vis: bool = False,
+ save_pred: bool = False,
+ **kwargs,
+ ) -> dict:
+ """Call the inferencer.
+
+ Args:
+ inputs (InputsType): Inputs for the inferencer. It can be a path
+ to image / image directory, or an array, or a list of these.
+ batch_size (int): Batch size. Defaults to 1.
+ det_batch_size (Optional[int]): Batch size for text detection
+ model. Overwrite batch_size if it is not None.
+ Defaults to None.
+ rec_batch_size (Optional[int]): Batch size for text recognition
+ model. Overwrite batch_size if it is not None.
+ Defaults to None.
+ kie_batch_size (Optional[int]): Batch size for KIE model.
+ Overwrite batch_size if it is not None.
+ Defaults to None.
+ out_dir (str): Output directory of results. Defaults to 'results/'.
+ return_vis (bool): Whether to return the visualization result.
+ Defaults to False.
+ save_vis (bool): Whether to save the visualization results to
+ "out_dir". Defaults to False.
+ save_pred (bool): Whether to save the inference results to
+ "out_dir". Defaults to False.
+ **kwargs: Key words arguments passed to :meth:`preprocess`,
+ :meth:`forward`, :meth:`visualize` and :meth:`postprocess`.
+ Each key in kwargs should be in the corresponding set of
+ ``preprocess_kwargs``, ``forward_kwargs``, ``visualize_kwargs``
+ and ``postprocess_kwargs``.
+
+ Returns:
+ dict: Inference and visualization results, mapped from
+ "predictions" and "visualization".
+ """
+ if (save_vis or save_pred) and not out_dir:
+ raise ValueError('out_dir must be specified when save_vis or '
+ 'save_pred is True!')
+ if out_dir:
+ img_out_dir = osp.join(out_dir, 'vis')
+ pred_out_dir = osp.join(out_dir, 'preds')
+ else:
+ img_out_dir, pred_out_dir = '', ''
+
+ (
+ preprocess_kwargs,
+ forward_kwargs,
+ visualize_kwargs,
+ postprocess_kwargs,
+ ) = self._dispatch_kwargs(
+ save_vis=save_vis,
+ save_pred=save_pred,
+ return_vis=return_vis,
+ **kwargs)
+
+ ori_inputs = self._inputs_to_list(inputs)
+ if det_batch_size is None:
+ det_batch_size = batch_size
+ if rec_batch_size is None:
+ rec_batch_size = batch_size
+ if kie_batch_size is None:
+ kie_batch_size = batch_size
+
+ chunked_inputs = super(BaseMMOCRInferencer,
+ self)._get_chunk_data(ori_inputs, batch_size)
+ results = {'predictions': [], 'visualization': []}
+ for ori_input in track(chunked_inputs, description='Inference'):
+ preds = self.forward(
+ ori_input,
+ det_batch_size=det_batch_size,
+ rec_batch_size=rec_batch_size,
+ kie_batch_size=kie_batch_size,
+ **forward_kwargs)
+ visualization = self.visualize(
+ ori_input, preds, img_out_dir=img_out_dir, **visualize_kwargs)
+ batch_res = self.postprocess(
+ preds,
+ visualization,
+ pred_out_dir=pred_out_dir,
+ **postprocess_kwargs)
+ results['predictions'].extend(batch_res['predictions'])
+ if return_vis and batch_res['visualization'] is not None:
+ results['visualization'].extend(batch_res['visualization'])
+ return results
+
+ def postprocess(self,
+ preds: PredType,
+ visualization: Optional[List[np.ndarray]] = None,
+ print_result: bool = False,
+ save_pred: bool = False,
+ pred_out_dir: str = ''
+ ) -> Union[ResType, Tuple[ResType, np.ndarray]]:
+ """Process the predictions and visualization results from ``forward``
+ and ``visualize``.
+
+ This method should be responsible for the following tasks:
+
+ 1. Convert datasamples into a json-serializable dict if needed.
+ 2. Pack the predictions and visualization results and return them.
+ 3. Dump or log the predictions.
+
+ Args:
+ preds (PredType): Predictions of the model.
+ visualization (Optional[np.ndarray]): Visualized predictions.
+ print_result (bool): Whether to print the result.
+ Defaults to False.
+ save_pred (bool): Whether to save the inference result. Defaults to
+ False.
+ pred_out_dir: File to save the inference results w/o
+ visualization. If left as empty, no file will be saved.
+ Defaults to ''.
+
+ Returns:
+ Dict: Inference and visualization results, mapped from
+ "predictions" and "visualization".
+ """
+
+ result_dict = {}
+ pred_results = [{} for _ in range(len(next(iter(preds.values()))))]
+ if 'rec' in self.mode:
+ for i, rec_pred in enumerate(preds['rec']):
+ result = dict(rec_texts=[], rec_scores=[])
+ for rec_pred_instance in rec_pred:
+ rec_dict_res = self.textrec_inferencer.pred2dict(
+ rec_pred_instance)
+ result['rec_texts'].append(rec_dict_res['text'])
+ result['rec_scores'].append(rec_dict_res['scores'])
+ pred_results[i].update(result)
+ if 'det' in self.mode:
+ for i, det_pred in enumerate(preds['det']):
+ det_dict_res = self.textdet_inferencer.pred2dict(det_pred)
+ pred_results[i].update(
+ dict(
+ det_polygons=det_dict_res['polygons'],
+ det_scores=det_dict_res['scores']))
+ if 'kie' in self.mode:
+ for i, kie_pred in enumerate(preds['kie']):
+ kie_dict_res = self.kie_inferencer.pred2dict(kie_pred)
+ pred_results[i].update(
+ dict(
+ kie_labels=kie_dict_res['labels'],
+ kie_scores=kie_dict_res['scores']),
+ kie_edge_scores=kie_dict_res['edge_scores'],
+ kie_edge_labels=kie_dict_res['edge_labels'])
+
+ if save_pred and pred_out_dir:
+ pred_key = 'det' if 'det' in self.mode else 'rec'
+ for pred, pred_result in zip(preds[pred_key], pred_results):
+ img_path = (
+ pred.img_path if pred_key == 'det' else pred[0].img_path)
+ pred_name = osp.splitext(osp.basename(img_path))[0]
+ pred_name = f'{pred_name}.json'
+ pred_out_file = osp.join(pred_out_dir, pred_name)
+ mmengine.dump(pred_result, pred_out_file)
+
+ result_dict['predictions'] = pred_results
+ if print_result:
+ print(result_dict)
+ result_dict['visualization'] = visualization
+ return result_dict
+
+ def _pack_e2e_datasamples(self,
+ preds: Dict) -> List[TextSpottingDataSample]:
+ """Pack text detection and recognition results into a list of
+ TextSpottingDataSample."""
+ results = []
+
+ for det_data_sample, rec_data_samples in zip(preds['det'],
+ preds['rec']):
+ texts = []
+ for rec_data_sample in rec_data_samples:
+ texts.append(rec_data_sample.pred_text.item)
+ det_data_sample.pred_instances.texts = texts
+ results.append(det_data_sample)
+ return results
diff --git a/mmocr/apis/inferencers/textdet_inferencer.py b/mmocr/apis/inferencers/textdet_inferencer.py
new file mode 100644
index 0000000000000000000000000000000000000000..8c526d91a648f9117b5b59c51bd404a3534e5097
--- /dev/null
+++ b/mmocr/apis/inferencers/textdet_inferencer.py
@@ -0,0 +1,45 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict
+
+from mmocr.structures import TextDetDataSample
+from .base_mmocr_inferencer import BaseMMOCRInferencer
+
+
+class TextDetInferencer(BaseMMOCRInferencer):
+ """Text Detection inferencer.
+
+ Args:
+ model (str, optional): Path to the config file or the model name
+ defined in metafile. For example, it could be
+ "dbnet_resnet18_fpnc_1200e_icdar2015" or
+ "configs/textdet/dbnet/dbnet_resnet18_fpnc_1200e_icdar2015.py".
+ If model is not specified, user must provide the
+ `weights` saved by MMEngine which contains the config string.
+ Defaults to None.
+ weights (str, optional): Path to the checkpoint. If it is not specified
+ and model is a model name of metafile, the weights will be loaded
+ from metafile. Defaults to None.
+ device (str, optional): Device to run inference. If None, the available
+ device will be automatically used. Defaults to None.
+ scope (str, optional): The scope of the model. Defaults to "mmocr".
+ """
+
+ def pred2dict(self, data_sample: TextDetDataSample) -> Dict:
+ """Extract elements necessary to represent a prediction into a
+ dictionary. It's better to contain only basic data elements such as
+ strings and numbers in order to guarantee it's json-serializable.
+
+ Args:
+ data_sample (TextDetDataSample): The data sample to be converted.
+
+ Returns:
+ dict: The output dictionary.
+ """
+ result = {}
+ pred_instances = data_sample.pred_instances
+ if 'polygons' in pred_instances:
+ result['polygons'] = self._array2list(pred_instances.polygons)
+ if 'bboxes' in pred_instances:
+ result['bboxes'] = self._array2list(pred_instances.bboxes)
+ result['scores'] = self._array2list(pred_instances.scores)
+ return result
diff --git a/mmocr/apis/inferencers/textrec_inferencer.py b/mmocr/apis/inferencers/textrec_inferencer.py
new file mode 100644
index 0000000000000000000000000000000000000000..cc78a8fe6a165500fac31cf993c63868862a8954
--- /dev/null
+++ b/mmocr/apis/inferencers/textrec_inferencer.py
@@ -0,0 +1,44 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict
+
+import numpy as np
+
+from mmocr.structures import TextRecogDataSample
+from .base_mmocr_inferencer import BaseMMOCRInferencer
+
+
+class TextRecInferencer(BaseMMOCRInferencer):
+ """Text Recognition inferencer.
+
+ Args:
+ model (str, optional): Path to the config file or the model name
+ defined in metafile. For example, it could be
+ "crnn_mini-vgg_5e_mj" or
+ "configs/textrecog/crnn/crnn_mini-vgg_5e_mj.py".
+ If model is not specified, user must provide the
+ `weights` saved by MMEngine which contains the config string.
+ Defaults to None.
+ weights (str, optional): Path to the checkpoint. If it is not specified
+ and model is a model name of metafile, the weights will be loaded
+ from metafile. Defaults to None.
+ device (str, optional): Device to run inference. If None, the available
+ device will be automatically used. Defaults to None.
+ scope (str, optional): The scope of the model. Defaults to "mmocr".
+ """
+
+ def pred2dict(self, data_sample: TextRecogDataSample) -> Dict:
+ """Extract elements necessary to represent a prediction into a
+ dictionary. It's better to contain only basic data elements such as
+ strings and numbers in order to guarantee it's json-serializable.
+
+ Args:
+ data_sample (TextRecogDataSample): The data sample to be converted.
+
+ Returns:
+ dict: The output dictionary.
+ """
+ result = {}
+ result['text'] = data_sample.pred_text.item
+ score = self._array2list(data_sample.pred_text.score)
+ result['scores'] = float(np.mean(score))
+ return result
diff --git a/mmocr/apis/inferencers/textspot_inferencer.py b/mmocr/apis/inferencers/textspot_inferencer.py
new file mode 100644
index 0000000000000000000000000000000000000000..374894cbe37f0d6a90d04f772710a5d0a278a3a6
--- /dev/null
+++ b/mmocr/apis/inferencers/textspot_inferencer.py
@@ -0,0 +1,47 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict
+
+from mmocr.structures import TextSpottingDataSample
+from .base_mmocr_inferencer import BaseMMOCRInferencer
+
+
+class TextSpotInferencer(BaseMMOCRInferencer):
+ """Text Spotting inferencer.
+
+ Args:
+ model (str, optional): Path to the config file or the model name
+ defined in metafile. For example, it could be
+ "dbnet_resnet18_fpnc_1200e_icdar2015" or
+ "configs/textdet/dbnet/dbnet_resnet18_fpnc_1200e_icdar2015.py".
+ If model is not specified, user must provide the
+ `weights` saved by MMEngine which contains the config string.
+ Defaults to None.
+ weights (str, optional): Path to the checkpoint. If it is not specified
+ and model is a model name of metafile, the weights will be loaded
+ from metafile. Defaults to None.
+ device (str, optional): Device to run inference. If None, the available
+ device will be automatically used. Defaults to None.
+ scope (str, optional): The scope of the model. Defaults to "mmocr".
+ """
+
+ def pred2dict(self, data_sample: TextSpottingDataSample) -> Dict:
+ """Extract elements necessary to represent a prediction into a
+ dictionary. It's better to contain only basic data elements such as
+ strings and numbers in order to guarantee it's json-serializable.
+
+ Args:
+ data_sample (TextSpottingDataSample): The data sample to be
+ converted.
+
+ Returns:
+ dict: The output dictionary.
+ """
+ result = {}
+ pred_instances = data_sample.pred_instances
+ if 'polygons' in pred_instances:
+ result['polygons'] = self._array2list(pred_instances.polygons)
+ if 'bboxes' in pred_instances:
+ result['bboxes'] = self._array2list(pred_instances.bboxes)
+ result['scores'] = self._array2list(pred_instances.scores)
+ result['texts'] = pred_instances.texts
+ return result
diff --git a/mmocr/datasets/__init__.py b/mmocr/datasets/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..54a9ea7f02824c517d2529ce3ae0ff4a607ca70f
--- /dev/null
+++ b/mmocr/datasets/__init__.py
@@ -0,0 +1,14 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .dataset_wrapper import ConcatDataset
+from .icdar_dataset import IcdarDataset
+from .ocr_dataset import OCRDataset
+from .recog_lmdb_dataset import RecogLMDBDataset
+from .recog_text_dataset import RecogTextDataset
+from .samplers import * # NOQA
+from .transforms import * # NOQA
+from .wildreceipt_dataset import WildReceiptDataset
+
+__all__ = [
+ 'IcdarDataset', 'OCRDataset', 'RecogLMDBDataset', 'RecogTextDataset',
+ 'WildReceiptDataset', 'ConcatDataset'
+]
diff --git a/mmocr/datasets/__pycache__/__init__.cpython-38.pyc b/mmocr/datasets/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..49f2353607b5982db272bdb1170d962091e89cea
Binary files /dev/null and b/mmocr/datasets/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/datasets/__pycache__/dataset_wrapper.cpython-38.pyc b/mmocr/datasets/__pycache__/dataset_wrapper.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..bc0b1c724370822b5ff6c5f544a0049fbe632282
Binary files /dev/null and b/mmocr/datasets/__pycache__/dataset_wrapper.cpython-38.pyc differ
diff --git a/mmocr/datasets/__pycache__/icdar_dataset.cpython-38.pyc b/mmocr/datasets/__pycache__/icdar_dataset.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..02b557c7d3dbad9e9b6e9b01e1bfbde5ea904820
Binary files /dev/null and b/mmocr/datasets/__pycache__/icdar_dataset.cpython-38.pyc differ
diff --git a/mmocr/datasets/__pycache__/ocr_dataset.cpython-38.pyc b/mmocr/datasets/__pycache__/ocr_dataset.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2e956cfdb57974e44ec97f93c3477626552df9df
Binary files /dev/null and b/mmocr/datasets/__pycache__/ocr_dataset.cpython-38.pyc differ
diff --git a/mmocr/datasets/__pycache__/recog_lmdb_dataset.cpython-38.pyc b/mmocr/datasets/__pycache__/recog_lmdb_dataset.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1e48c5d78a78154565c92cdeeedbb248f571e3cc
Binary files /dev/null and b/mmocr/datasets/__pycache__/recog_lmdb_dataset.cpython-38.pyc differ
diff --git a/mmocr/datasets/__pycache__/recog_text_dataset.cpython-38.pyc b/mmocr/datasets/__pycache__/recog_text_dataset.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5f5a2ac990a8a3c27b804f95acb348b0bc6e1306
Binary files /dev/null and b/mmocr/datasets/__pycache__/recog_text_dataset.cpython-38.pyc differ
diff --git a/mmocr/datasets/__pycache__/wildreceipt_dataset.cpython-38.pyc b/mmocr/datasets/__pycache__/wildreceipt_dataset.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d2571529296f2bc17f4e0e0eb73a36e4ac114ecf
Binary files /dev/null and b/mmocr/datasets/__pycache__/wildreceipt_dataset.cpython-38.pyc differ
diff --git a/mmocr/datasets/dataset_wrapper.py b/mmocr/datasets/dataset_wrapper.py
new file mode 100644
index 0000000000000000000000000000000000000000..c1b8bc5cfe9836e18d5166bfb53ee86799e02cf1
--- /dev/null
+++ b/mmocr/datasets/dataset_wrapper.py
@@ -0,0 +1,77 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Callable, List, Sequence, Union
+
+from mmengine.dataset import BaseDataset, Compose
+from mmengine.dataset import ConcatDataset as MMENGINE_CONCATDATASET
+
+from mmocr.registry import DATASETS
+
+
+@DATASETS.register_module()
+class ConcatDataset(MMENGINE_CONCATDATASET):
+ """A wrapper of concatenated dataset.
+
+ Same as ``torch.utils.data.dataset.ConcatDataset`` and support lazy_init.
+
+ Note:
+ ``ConcatDataset`` should not inherit from ``BaseDataset`` since
+ ``get_subset`` and ``get_subset_`` could produce ambiguous meaning
+ sub-dataset which conflicts with original dataset. If you want to use
+ a sub-dataset of ``ConcatDataset``, you should set ``indices``
+ arguments for wrapped dataset which inherit from ``BaseDataset``.
+
+ Args:
+ datasets (Sequence[BaseDataset] or Sequence[dict]): A list of datasets
+ which will be concatenated.
+ pipeline (list, optional): Processing pipeline to be applied to all
+ of the concatenated datasets. Defaults to [].
+ verify_meta (bool): Whether to verify the consistency of meta
+ information of the concatenated datasets. Defaults to True.
+ force_apply (bool): Whether to force apply pipeline to all datasets if
+ any of them already has the pipeline configured. Defaults to False.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. Defaults to False.
+ """
+
+ def __init__(self,
+ datasets: Sequence[Union[BaseDataset, dict]],
+ pipeline: List[Union[dict, Callable]] = [],
+ verify_meta: bool = True,
+ force_apply: bool = False,
+ lazy_init: bool = False):
+ self.datasets: List[BaseDataset] = []
+
+ # Compose dataset
+ pipeline = Compose(pipeline)
+
+ for i, dataset in enumerate(datasets):
+ if isinstance(dataset, dict):
+ self.datasets.append(DATASETS.build(dataset))
+ elif isinstance(dataset, BaseDataset):
+ self.datasets.append(dataset)
+ else:
+ raise TypeError(
+ 'elements in datasets sequence should be config or '
+ f'`BaseDataset` instance, but got {type(dataset)}')
+ if len(pipeline.transforms) > 0:
+ if len(self.datasets[-1].pipeline.transforms
+ ) > 0 and not force_apply:
+ raise ValueError(
+ f'The pipeline of dataset {i} is not empty, '
+ 'please set `force_apply` to True.')
+ self.datasets[-1].pipeline = pipeline
+
+ self._metainfo = self.datasets[0].metainfo
+
+ if verify_meta:
+ # Only use metainfo of first dataset.
+ for i, dataset in enumerate(self.datasets, 1):
+ if self._metainfo != dataset.metainfo:
+ raise ValueError(
+ f'The meta information of the {i}-th dataset does not '
+ 'match meta information of the first dataset')
+
+ self._fully_initialized = False
+ if not lazy_init:
+ self.full_init()
+ self._metainfo.update(dict(cumulative_sizes=self.cumulative_sizes))
diff --git a/mmocr/datasets/icdar_dataset.py b/mmocr/datasets/icdar_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..68fd911adf5dac4ca5c97421260cd12962fb3428
--- /dev/null
+++ b/mmocr/datasets/icdar_dataset.py
@@ -0,0 +1,93 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from typing import List, Union
+
+from mmdet.datasets.coco import CocoDataset
+
+from mmocr.registry import DATASETS
+
+
+@DATASETS.register_module()
+class IcdarDataset(CocoDataset):
+ """Dataset for text detection while ann_file in coco format.
+
+ Args:
+ ann_file (str): Annotation file path. Defaults to ''.
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Defaults to None.
+ data_root (str): The root directory for ``data_prefix`` and
+ ``ann_file``. Defaults to ''.
+ data_prefix (dict): Prefix for training data. Defaults to
+ dict(img_path='').
+ filter_cfg (dict, optional): Config for filter data. Defaults to None.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Defaults to None which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy. Defaults
+ to True.
+ pipeline (list, optional): Processing pipeline. Defaults to [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Defaults to False.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Defaults to False.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Defaults to 1000.
+ """
+ METAINFO = {'classes': ('text', )}
+
+ def parse_data_info(self, raw_data_info: dict) -> Union[dict, List[dict]]:
+ """Parse raw annotation to target format.
+
+ Args:
+ raw_data_info (dict): Raw data information loaded from ``ann_file``
+
+ Returns:
+ Union[dict, List[dict]]: Parsed annotation.
+ """
+ img_info = raw_data_info['raw_img_info']
+ ann_info = raw_data_info['raw_ann_info']
+
+ data_info = {}
+
+ img_path = osp.join(self.data_prefix['img_path'],
+ img_info['file_name'])
+ data_info['img_path'] = img_path
+ data_info['img_id'] = img_info['img_id']
+ data_info['height'] = img_info['height']
+ data_info['width'] = img_info['width']
+
+ instances = []
+ for ann in ann_info:
+ instance = {}
+
+ if ann.get('ignore', False):
+ continue
+ x1, y1, w, h = ann['bbox']
+ inter_w = max(0, min(x1 + w, img_info['width']) - max(x1, 0))
+ inter_h = max(0, min(y1 + h, img_info['height']) - max(y1, 0))
+ if inter_w * inter_h == 0:
+ continue
+ if ann['area'] <= 0 or w < 1 or h < 1:
+ continue
+ if ann['category_id'] not in self.cat_ids:
+ continue
+ bbox = [x1, y1, x1 + w, y1 + h]
+
+ if ann.get('iscrowd', False):
+ instance['ignore'] = 1
+ else:
+ instance['ignore'] = 0
+ instance['bbox'] = bbox
+ instance['bbox_label'] = self.cat2label[ann['category_id']]
+ if ann.get('segmentation', None):
+ instance['polygon'] = ann['segmentation'][0]
+
+ instances.append(instance)
+ data_info['instances'] = instances
+ return data_info
diff --git a/mmocr/datasets/ocr_dataset.py b/mmocr/datasets/ocr_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..826c3fe9892daa41bf24eaa565a4b11c8d3bc9d6
--- /dev/null
+++ b/mmocr/datasets/ocr_dataset.py
@@ -0,0 +1,94 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmengine.dataset import BaseDataset
+
+from mmocr.registry import DATASETS
+
+
+@DATASETS.register_module()
+class OCRDataset(BaseDataset):
+ r"""OCRDataset for text detection and text recognition.
+
+ The annotation format is shown as follows.
+
+ .. code-block:: none
+
+ {
+ "metainfo":
+ {
+ "dataset_type": "test_dataset",
+ "task_name": "test_task"
+ },
+ "data_list":
+ [
+ {
+ "img_path": "test_img.jpg",
+ "height": 604,
+ "width": 640,
+ "instances":
+ [
+ {
+ "bbox": [0, 0, 10, 20],
+ "bbox_label": 1,
+ "mask": [0,0,0,10,10,20,20,0],
+ "text": '123'
+ },
+ {
+ "bbox": [10, 10, 110, 120],
+ "bbox_label": 2,
+ "mask": [10,10],10,110,110,120,120,10]],
+ "extra_anns": '456'
+ }
+ ]
+ },
+ ]
+ }
+
+ Args:
+ ann_file (str): Annotation file path. Defaults to ''.
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Defaults to None.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Defaults to None.
+ data_prefix (dict): Prefix for training data. Defaults to
+ dict(img_path='').
+ filter_cfg (dict, optional): Config for filter data. Defaults to None.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Defaults to None which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy. Defaults
+ to True.
+ pipeline (list, optional): Processing pipeline. Defaults to [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Defaults to False.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``OCRdataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Defaults to False.
+ max_refetch (int, optional): If ``OCRdataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Defaults to 1000.
+
+ Note:
+ OCRDataset collects meta information from `annotation file` (the
+ lowest priority), ``OCRDataset.METAINFO``(medium) and `metainfo
+ parameter` (highest) passed to constructors. The lower priority meta
+ information will be overwritten by higher one.
+
+ Examples:
+ Assume the annotation file is given above.
+ >>> class CustomDataset(OCRDataset):
+ >>> METAINFO: dict = dict(task_name='custom_task',
+ >>> dataset_type='custom_type')
+ >>> metainfo=dict(task_name='custom_task_name')
+ >>> custom_dataset = CustomDataset(
+ >>> 'path/to/ann_file',
+ >>> metainfo=metainfo)
+ >>> # meta information of annotation file will be overwritten by
+ >>> # `CustomDataset.METAINFO`. The merged meta information will
+ >>> # further be overwritten by argument `metainfo`.
+ >>> custom_dataset.metainfo
+ {'task_name': custom_task_name, dataset_type: custom_type}
+ """
diff --git a/mmocr/datasets/preparers/__init__.py b/mmocr/datasets/preparers/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e2323e3273d988c4e26443567a77dbd328e4f329
--- /dev/null
+++ b/mmocr/datasets/preparers/__init__.py
@@ -0,0 +1,10 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .config_generators import * # noqa
+from .data_preparer import DatasetPreparer
+from .dumpers import * # noqa
+from .gatherers import * # noqa
+from .obtainers import * # noqa
+from .packers import * # noqa
+from .parsers import * # noqa
+
+__all__ = ['DatasetPreparer']
diff --git a/mmocr/datasets/preparers/config_generators/__init__.py b/mmocr/datasets/preparers/config_generators/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..8e884c6d9d4cbd71e2e7c9625a87a7993839b75e
--- /dev/null
+++ b/mmocr/datasets/preparers/config_generators/__init__.py
@@ -0,0 +1,10 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .base import BaseDatasetConfigGenerator
+from .textdet_config_generator import TextDetConfigGenerator
+from .textrecog_config_generator import TextRecogConfigGenerator
+from .textspotting_config_generator import TextSpottingConfigGenerator
+
+__all__ = [
+ 'BaseDatasetConfigGenerator', 'TextDetConfigGenerator',
+ 'TextRecogConfigGenerator', 'TextSpottingConfigGenerator'
+]
diff --git a/mmocr/datasets/preparers/config_generators/base.py b/mmocr/datasets/preparers/config_generators/base.py
new file mode 100644
index 0000000000000000000000000000000000000000..ba3811a425f203d2e5a810dc6e57a0934fb13a93
--- /dev/null
+++ b/mmocr/datasets/preparers/config_generators/base.py
@@ -0,0 +1,131 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from abc import abstractmethod
+from typing import Dict, List, Optional
+
+from mmengine import mkdir_or_exist
+
+
+class BaseDatasetConfigGenerator:
+ """Base class for dataset config generator.
+
+ Args:
+ data_root (str): The root path of the dataset.
+ task (str): The task of the dataset.
+ dataset_name (str): The name of the dataset.
+ overwrite_cfg (bool): Whether to overwrite the dataset config file if
+ it already exists. If False, config generator will not generate new
+ config for datasets whose configs are already in base.
+ train_anns (List[Dict], optional): A list of train annotation files
+ to appear in the base configs. Defaults to None.
+ Each element is typically a dict with the following fields:
+ - ann_file (str): The path to the annotation file relative to
+ data_root.
+ - dataset_postfix (str, optional): Affects the postfix of the
+ resulting variable in the generated config. If specified, the
+ dataset variable will be named in the form of
+ ``{dataset_name}_{dataset_postfix}_{task}_{split}``. Defaults to
+ None.
+ val_anns (List[Dict], optional): A list of val annotation files
+ to appear in the base configs, similar to ``train_anns``. Defaults
+ to None.
+ test_anns (List[Dict], optional): A list of test annotation files
+ to appear in the base configs, similar to ``train_anns``. Defaults
+ to None.
+ config_path (str): Path to the configs. Defaults to 'configs/'.
+ """
+
+ def __init__(
+ self,
+ data_root: str,
+ task: str,
+ dataset_name: str,
+ overwrite_cfg: bool = False,
+ train_anns: Optional[List[Dict]] = None,
+ val_anns: Optional[List[Dict]] = None,
+ test_anns: Optional[List[Dict]] = None,
+ config_path: str = 'configs/',
+ ) -> None:
+ self.config_path = config_path
+ self.data_root = data_root
+ self.task = task
+ self.dataset_name = dataset_name
+ self.overwrite_cfg = overwrite_cfg
+ self._prepare_anns(train_anns, val_anns, test_anns)
+
+ def _prepare_anns(self, train_anns: Optional[List[Dict]],
+ val_anns: Optional[List[Dict]],
+ test_anns: Optional[List[Dict]]) -> None:
+ """Preprocess input arguments and stores these information into
+ ``self.anns``.
+
+ ``self.anns`` is a dict that maps the name of a dataset config variable
+ to a dict, which contains the following fields:
+ - ann_file (str): The path to the annotation file relative to
+ data_root.
+ - split (str): The split the annotation belongs to. Usually
+ it can be 'train', 'val' and 'test'.
+ - dataset_postfix (str, optional): Affects the postfix of the
+ resulting variable in the generated config. If specified, the
+ dataset variable will be named in the form of
+ ``{dataset_name}_{dataset_postfix}_{task}_{split}``. Defaults to
+ None.
+ """
+ self.anns = {}
+ for split, ann_list in zip(('train', 'val', 'test'),
+ (train_anns, val_anns, test_anns)):
+ if ann_list is None:
+ continue
+ if not isinstance(ann_list, list):
+ raise ValueError(f'{split}_anns must be either a list or'
+ ' None!')
+ for ann_dict in ann_list:
+ assert 'ann_file' in ann_dict
+ suffix = ann_dict['ann_file'].split('.')[-1]
+ if suffix == 'json':
+ dataset_type = 'OCRDataset'
+ elif suffix == 'lmdb':
+ assert self.task == 'textrecog', \
+ 'LMDB format only works for textrecog now.'
+ dataset_type = 'RecogLMDBDataset'
+ else:
+ raise NotImplementedError(
+ 'ann file only supports JSON file or LMDB file')
+ ann_dict['dataset_type'] = dataset_type
+ if ann_dict.get('dataset_postfix', ''):
+ key = f'{self.dataset_name}_{ann_dict["dataset_postfix"]}_{self.task}_{split}' # noqa
+ else:
+ key = f'{self.dataset_name}_{self.task}_{split}'
+ ann_dict['split'] = split
+ if key in self.anns:
+ raise ValueError(
+ f'Duplicate dataset variable {key} found! '
+ 'Please use different dataset_postfix to avoid '
+ 'conflict.')
+ self.anns[key] = ann_dict
+
+ def __call__(self) -> None:
+ """Generates the base dataset config."""
+
+ dataset_config = self._gen_dataset_config()
+
+ cfg_path = osp.join(self.config_path, self.task, '_base_', 'datasets',
+ f'{self.dataset_name}.py')
+ if osp.exists(cfg_path) and not self.overwrite_cfg:
+ print(f'{cfg_path} found, skipping.')
+ return
+ mkdir_or_exist(osp.dirname(cfg_path))
+ with open(cfg_path, 'w') as f:
+ f.write(
+ f'{self.dataset_name}_{self.task}_data_root = \'{self.data_root}\'\n' # noqa: E501
+ )
+ f.write(dataset_config)
+
+ @abstractmethod
+ def _gen_dataset_config(self) -> str:
+ """Generate a full dataset config based on the annotation file
+ dictionary.
+
+ Returns:
+ str: The generated dataset config.
+ """
diff --git a/mmocr/datasets/preparers/config_generators/textdet_config_generator.py b/mmocr/datasets/preparers/config_generators/textdet_config_generator.py
new file mode 100644
index 0000000000000000000000000000000000000000..fcb8af4fb0e0fc031e81acf51ebe9526c0192439
--- /dev/null
+++ b/mmocr/datasets/preparers/config_generators/textdet_config_generator.py
@@ -0,0 +1,96 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional
+
+from mmocr.registry import CFG_GENERATORS
+from .base import BaseDatasetConfigGenerator
+
+
+@CFG_GENERATORS.register_module()
+class TextDetConfigGenerator(BaseDatasetConfigGenerator):
+ """Text detection config generator.
+
+ Args:
+ data_root (str): The root path of the dataset.
+ dataset_name (str): The name of the dataset.
+ overwrite_cfg (bool): Whether to overwrite the dataset config file if
+ it already exists. If False, config generator will not generate new
+ config for datasets whose configs are already in base.
+ train_anns (List[Dict], optional): A list of train annotation files
+ to appear in the base configs. Defaults to
+ ``[dict(file='textdet_train.json', dataset_postfix='')]``.
+ Each element is typically a dict with the following fields:
+ - ann_file (str): The path to the annotation file relative to
+ data_root.
+ - dataset_postfix (str, optional): Affects the postfix of the
+ resulting variable in the generated config. If specified, the
+ dataset variable will be named in the form of
+ ``{dataset_name}_{dataset_postfix}_{task}_{split}``. Defaults to
+ None.
+ val_anns (List[Dict], optional): A list of val annotation files
+ to appear in the base configs, similar to ``train_anns``. Defaults
+ to [].
+ test_anns (List[Dict], optional): A list of test annotation files
+ to appear in the base configs, similar to ``train_anns``. Defaults
+ to ``[dict(file='textdet_test.json')]``.
+ config_path (str): Path to the configs. Defaults to 'configs/'.
+ """
+
+ def __init__(
+ self,
+ data_root: str,
+ dataset_name: str,
+ overwrite_cfg: bool = False,
+ train_anns: Optional[List[Dict]] = [
+ dict(ann_file='textdet_train.json', dataset_postfix='')
+ ],
+ val_anns: Optional[List[Dict]] = [],
+ test_anns: Optional[List[Dict]] = [
+ dict(ann_file='textdet_test.json', dataset_postfix='')
+ ],
+ config_path: str = 'configs/',
+ ) -> None:
+ super().__init__(
+ data_root=data_root,
+ task='textdet',
+ overwrite_cfg=overwrite_cfg,
+ dataset_name=dataset_name,
+ train_anns=train_anns,
+ val_anns=val_anns,
+ test_anns=test_anns,
+ config_path=config_path,
+ )
+
+ def _gen_dataset_config(self) -> str:
+ """Generate a full dataset config based on the annotation file
+ dictionary.
+
+ Args:
+ ann_dict (dict[str, dict(str, str)]): A nested dictionary that maps
+ a config variable name (such as icdar2015_textrecog_train) to
+ its corresponding annotation information dict. Each dict
+ contains following keys:
+ - ann_file (str): The path to the annotation file relative to
+ data_root.
+ - dataset_postfix (str, optional): Affects the postfix of the
+ resulting variable in the generated config. If specified, the
+ dataset variable will be named in the form of
+ ``{dataset_name}_{dataset_postfix}_{task}_{split}``. Defaults
+ to None.
+ - split (str): The split the annotation belongs to. Usually
+ it can be 'train', 'val' and 'test'.
+
+ Returns:
+ str: The generated dataset config.
+ """
+ cfg = ''
+ for key_name, ann_dict in self.anns.items():
+ cfg += f'\n{key_name} = dict(\n'
+ cfg += ' type=\'OCRDataset\',\n'
+ cfg += ' data_root=' + f'{self.dataset_name}_{self.task}_data_root,\n' # noqa: E501
+ cfg += f' ann_file=\'{ann_dict["ann_file"]}\',\n'
+ if ann_dict['split'] == 'train':
+ cfg += ' filter_cfg=dict(filter_empty_gt=True, min_size=32),\n' # noqa: E501
+ elif ann_dict['split'] in ['test', 'val']:
+ cfg += ' test_mode=True,\n'
+ cfg += ' pipeline=None)\n'
+ return cfg
diff --git a/mmocr/datasets/preparers/config_generators/textrecog_config_generator.py b/mmocr/datasets/preparers/config_generators/textrecog_config_generator.py
new file mode 100644
index 0000000000000000000000000000000000000000..bb8b62625884e0d135fbcf4c61abe8162b9f7df5
--- /dev/null
+++ b/mmocr/datasets/preparers/config_generators/textrecog_config_generator.py
@@ -0,0 +1,128 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional
+
+from mmocr.registry import CFG_GENERATORS
+from .base import BaseDatasetConfigGenerator
+
+
+@CFG_GENERATORS.register_module()
+class TextRecogConfigGenerator(BaseDatasetConfigGenerator):
+ """Text recognition config generator.
+
+ Args:
+ data_root (str): The root path of the dataset.
+ dataset_name (str): The name of the dataset.
+ overwrite_cfg (bool): Whether to overwrite the dataset config file if
+ it already exists. If False, config generator will not generate new
+ config for datasets whose configs are already in base.
+ train_anns (List[Dict], optional): A list of train annotation files
+ to appear in the base configs. Defaults to
+ ``[dict(file='textrecog_train.json'), dataset_postfix='']``.
+ Each element is typically a dict with the following fields:
+ - ann_file (str): The path to the annotation file relative to
+ data_root.
+ - dataset_postfix (str, optional): Affects the postfix of the
+ resulting variable in the generated config. If specified, the
+ dataset variable will be named in the form of
+ ``{dataset_name}_{dataset_postfix}_{task}_{split}``. Defaults to
+ None.
+ val_anns (List[Dict], optional): A list of val annotation files
+ to appear in the base configs, similar to ``train_anns``. Defaults
+ to [].
+ test_anns (List[Dict], optional): A list of test annotation files
+ to appear in the base configs, similar to ``train_anns``. Defaults
+ to ``[dict(file='textrecog_test.json')]``.
+ config_path (str): Path to the configs. Defaults to 'configs/'.
+
+ Example:
+ It generates a dataset config like:
+ >>> icdar2015_textrecog_data_root = 'data/icdar2015/'
+ >>> icdar2015_textrecog_train = dict(
+ >>> type='OCRDataset',
+ >>> data_root=icdar2015_textrecog_data_root,
+ >>> ann_file='textrecog_train.json',
+ >>> pipeline=None)
+ >>> icdar2015_textrecog_test = dict(
+ >>> type='OCRDataset',
+ >>> data_root=icdar2015_textrecog_data_root,
+ >>> ann_file='textrecog_test.json',
+ >>> test_mode=True,
+ >>> pipeline=None)
+
+ It generates a lmdb format dataset config like:
+ >>> icdar2015_lmdb_textrecog_data_root = 'data/icdar2015'
+ >>> icdar2015_lmdb_textrecog_train = dict(
+ >>> type='RecogLMDBDataset',
+ >>> data_root=icdar2015_lmdb_textrecog_data_root,
+ >>> ann_file='textrecog_train.lmdb',
+ >>> pipeline=None)
+ >>> icdar2015_lmdb_textrecog_test = dict(
+ >>> type='RecogLMDBDataset',
+ >>> data_root=icdar2015_lmdb_textrecog_data_root,
+ >>> ann_file='textrecog_test.lmdb',
+ >>> test_mode=True,
+ >>> pipeline=None)
+ >>> icdar2015_lmdb_1811_textrecog_test = dict(
+ >>> type='RecogLMDBDataset',
+ >>> data_root=icdar2015_lmdb_textrecog_data_root,
+ >>> ann_file='textrecog_test_1811.lmdb',
+ >>> test_mode=True,
+ >>> pipeline=None)
+ """
+
+ def __init__(
+ self,
+ data_root: str,
+ dataset_name: str,
+ overwrite_cfg: bool = False,
+ train_anns: Optional[List[Dict]] = [
+ dict(ann_file='textrecog_train.json', dataset_postfix='')
+ ],
+ val_anns: Optional[List[Dict]] = [],
+ test_anns: Optional[List[Dict]] = [
+ dict(ann_file='textrecog_test.json', dataset_postfix='')
+ ],
+ config_path: str = 'configs/',
+ ) -> None:
+ super().__init__(
+ data_root=data_root,
+ task='textrecog',
+ overwrite_cfg=overwrite_cfg,
+ dataset_name=dataset_name,
+ train_anns=train_anns,
+ val_anns=val_anns,
+ test_anns=test_anns,
+ config_path=config_path)
+
+ def _gen_dataset_config(self) -> str:
+ """Generate a full dataset config based on the annotation file
+ dictionary.
+
+ Args:
+ ann_dict (dict[str, dict(str, str)]): A nested dictionary that maps
+ a config variable name (such as icdar2015_textrecog_train) to
+ its corresponding annotation information dict. Each dict
+ contains following keys:
+ - ann_file (str): The path to the annotation file relative to
+ data_root.
+ - dataset_postfix (str, optional): Affects the postfix of the
+ resulting variable in the generated config. If specified, the
+ dataset variable will be named in the form of
+ ``{dataset_name}_{dataset_postfix}_{task}_{split}``. Defaults
+ to None.
+ - split (str): The split the annotation belongs to. Usually
+ it can be 'train', 'val' and 'test'.
+
+ Returns:
+ str: The generated dataset config.
+ """
+ cfg = ''
+ for key_name, ann_dict in self.anns.items():
+ cfg += f'\n{key_name} = dict(\n'
+ cfg += f' type=\'{ann_dict["dataset_type"]}\',\n'
+ cfg += f' data_root={self.dataset_name}_{self.task}_data_root,\n' # noqa: E501
+ cfg += f' ann_file=\'{ann_dict["ann_file"]}\',\n'
+ if ann_dict['split'] in ['test', 'val']:
+ cfg += ' test_mode=True,\n'
+ cfg += ' pipeline=None)\n'
+ return cfg
diff --git a/mmocr/datasets/preparers/config_generators/textspotting_config_generator.py b/mmocr/datasets/preparers/config_generators/textspotting_config_generator.py
new file mode 100644
index 0000000000000000000000000000000000000000..b4c1db7b642d6b1fd56354a87508baf09dede64f
--- /dev/null
+++ b/mmocr/datasets/preparers/config_generators/textspotting_config_generator.py
@@ -0,0 +1,63 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional
+
+from mmocr.registry import CFG_GENERATORS
+from .base import BaseDatasetConfigGenerator
+from .textdet_config_generator import TextDetConfigGenerator
+
+
+@CFG_GENERATORS.register_module()
+class TextSpottingConfigGenerator(TextDetConfigGenerator):
+ """Text spotting config generator.
+
+ Args:
+ data_root (str): The root path of the dataset.
+ dataset_name (str): The name of the dataset.
+ overwrite_cfg (bool): Whether to overwrite the dataset config file if
+ it already exists. If False, config generator will not generate new
+ config for datasets whose configs are already in base.
+ train_anns (List[Dict], optional): A list of train annotation files
+ to appear in the base configs. Defaults to
+ ``[dict(file='textspotting_train.json', dataset_postfix='')]``.
+ Each element is typically a dict with the following fields:
+ - ann_file (str): The path to the annotation file relative to
+ data_root.
+ - dataset_postfix (str, optional): Affects the postfix of the
+ resulting variable in the generated config. If specified, the
+ dataset variable will be named in the form of
+ ``{dataset_name}_{dataset_postfix}_{task}_{split}``. Defaults to
+ None.
+ val_anns (List[Dict], optional): A list of val annotation files
+ to appear in the base configs, similar to ``train_anns``. Defaults
+ to [].
+ test_anns (List[Dict], optional): A list of test annotation files
+ to appear in the base configs, similar to ``train_anns``. Defaults
+ to ``[dict(file='textspotting_test.json')]``.
+ config_path (str): Path to the configs. Defaults to 'configs/'.
+ """
+
+ def __init__(
+ self,
+ data_root: str,
+ dataset_name: str,
+ overwrite_cfg: bool = False,
+ train_anns: Optional[List[Dict]] = [
+ dict(ann_file='textspotting_train.json', dataset_postfix='')
+ ],
+ val_anns: Optional[List[Dict]] = [],
+ test_anns: Optional[List[Dict]] = [
+ dict(ann_file='textspotting_test.json', dataset_postfix='')
+ ],
+ config_path: str = 'configs/',
+ ) -> None:
+ BaseDatasetConfigGenerator.__init__(
+ self,
+ data_root=data_root,
+ task='textspotting',
+ overwrite_cfg=overwrite_cfg,
+ dataset_name=dataset_name,
+ train_anns=train_anns,
+ val_anns=val_anns,
+ test_anns=test_anns,
+ config_path=config_path,
+ )
diff --git a/mmocr/datasets/preparers/data_preparer.py b/mmocr/datasets/preparers/data_preparer.py
new file mode 100644
index 0000000000000000000000000000000000000000..7e64856254194d91ac03e2c43aaa5161151b0564
--- /dev/null
+++ b/mmocr/datasets/preparers/data_preparer.py
@@ -0,0 +1,200 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import os
+import os.path as osp
+import shutil
+from typing import List, Optional, Union
+
+from mmocr.registry import (CFG_GENERATORS, DATA_DUMPERS, DATA_GATHERERS,
+ DATA_OBTAINERS, DATA_PACKERS, DATA_PARSERS)
+from mmocr.utils.typing_utils import ConfigType, OptConfigType
+
+
+class DatasetPreparer:
+ """Base class of dataset preparer.
+
+ Dataset preparer is used to prepare dataset for MMOCR. It mainly consists
+ of three steps:
+ 1. For each split:
+ - Obtain the dataset
+ - Download
+ - Extract
+ - Move/Rename
+ - Gather the dataset
+ - Parse the dataset
+ - Pack the dataset to MMOCR format
+ - Dump the dataset
+ 2. Delete useless files
+ 3. Generate the base config for this dataset
+
+ After all these steps, the original datasets have been prepared for
+ usage in MMOCR. Check out the dataset format used in MMOCR here:
+ https://mmocr.readthedocs.io/en/dev-1.x/user_guides/dataset_prepare.html
+
+ Args:
+ data_root (str): Root directory of data.
+ dataset_name (str): Dataset name.
+ task (str): Task type. Options are 'textdet', 'textrecog',
+ 'textspotter', and 'kie'. Defaults to 'textdet'.
+ nproc (int): Number of parallel processes. Defaults to 4.
+ train_preparer (OptConfigType): cfg for train data prepare. It contains
+ the following keys:
+ - obtainer: cfg for data obtainer.
+ - gatherer: cfg for data gatherer.
+ - parser: cfg for data parser.
+ - packer: cfg for data packer.
+ - dumper: cfg for data dumper.
+ Defaults to None.
+ test_preparer (OptConfigType): cfg for test data prepare. Defaults to
+ None.
+ val_preparer (OptConfigType): cfg for val data prepare. Defaults to
+ None.
+ config_generator (OptConfigType): cfg for config generator. Defaults to
+ None.
+ delete (list[str], optional): List of files to be deleted.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ data_root: str,
+ dataset_name: str = '',
+ task: str = 'textdet',
+ nproc: int = 4,
+ train_preparer: OptConfigType = None,
+ test_preparer: OptConfigType = None,
+ val_preparer: OptConfigType = None,
+ config_generator: OptConfigType = None,
+ delete: Optional[List[str]] = None) -> None:
+ self.data_root = data_root
+ self.nproc = nproc
+ self.task = task
+ self.dataset_name = dataset_name
+ self.train_preparer = train_preparer
+ self.test_preparer = test_preparer
+ self.val_preparer = val_preparer
+ self.config_generator = config_generator
+ self.delete = delete
+
+ def run(self, splits: Union[str, List] = ['train', 'test', 'val']) -> None:
+ """Prepare the dataset."""
+ if isinstance(splits, str):
+ splits = [splits]
+ assert set(splits).issubset(set(['train', 'test',
+ 'val'])), 'Invalid split name'
+ for split in splits:
+ self.loop(split, getattr(self, f'{split}_preparer'))
+ self.clean()
+ self.generate_config()
+
+ @classmethod
+ def from_file(cls, cfg: ConfigType) -> 'DatasetPreparer':
+ """Create a DataPreparer from config file.
+
+ Args:
+ cfg (ConfigType): A config used for building runner. Keys of
+ ``cfg`` can see :meth:`__init__`.
+
+ Returns:
+ Runner: A DatasetPreparer build from ``cfg``.
+ """
+
+ cfg = copy.deepcopy(cfg)
+ data_preparer = cls(
+ data_root=cfg['data_root'],
+ dataset_name=cfg.get('dataset_name', ''),
+ task=cfg.get('task', 'textdet'),
+ nproc=cfg.get('nproc', 4),
+ train_preparer=cfg.get('train_preparer', None),
+ test_preparer=cfg.get('test_preparer', None),
+ val_preparer=cfg.get('val_preparer', None),
+ delete=cfg.get('delete', None),
+ config_generator=cfg.get('config_generator', None))
+ return data_preparer
+
+ def loop(self, split: str, cfg: ConfigType) -> None:
+ """Loop over the dataset.
+
+ Args:
+ split (str): The split of the dataset.
+ cfg (ConfigType): A config used for building obtainer, gatherer,
+ parser, packer and dumper.
+ """
+ if cfg is None:
+ return
+
+ # build obtainer and run
+ obtainer = cfg.get('obtainer', None)
+ if obtainer:
+ print(f'Obtaining {split} Dataset...')
+ obtainer.setdefault('task', default=self.task)
+ obtainer.setdefault('data_root', default=self.data_root)
+ obtainer = DATA_OBTAINERS.build(obtainer)
+ obtainer()
+
+ # build gatherer
+ gatherer = cfg.get('gatherer', None)
+ parser = cfg.get('parser', None)
+ packer = cfg.get('packer', None)
+ dumper = cfg.get('dumper', None)
+ related = [gatherer, parser, packer, dumper]
+ if all(item is None for item in related): # no data process
+ return
+ if not all(item is not None for item in related):
+ raise ValueError('gatherer, parser, packer and dumper should be '
+ 'either all None or not None')
+
+ print(f'Gathering {split} Dataset...')
+ gatherer.setdefault('split', default=split)
+ gatherer.setdefault('data_root', default=self.data_root)
+ gatherer.setdefault('ann_dir', default='annotations')
+ gatherer.setdefault(
+ 'img_dir', default=osp.join(f'{self.task}_imgs', split))
+
+ gatherer = DATA_GATHERERS.build(gatherer)
+ img_paths, ann_paths = gatherer()
+
+ # build parser
+ print(f'Parsing {split} Images and Annotations...')
+ parser.setdefault('split', default=split)
+ parser.setdefault('nproc', default=self.nproc)
+ parser = DATA_PARSERS.build(parser)
+ # Convert dataset annotations to MMOCR format
+ samples = parser(img_paths, ann_paths)
+
+ # build packer
+ print(f'Packing {split} Annotations...')
+ packer.setdefault('split', default=split)
+ packer.setdefault('nproc', default=self.nproc)
+ packer.setdefault('data_root', default=self.data_root)
+ packer = DATA_PACKERS.build(packer)
+ samples = packer(samples)
+
+ # build dumper
+ print(f'Dumping {split} Annotations...')
+ # Dump annotation files
+ dumper.setdefault('task', default=self.task)
+ dumper.setdefault('split', default=split)
+ dumper.setdefault('data_root', default=self.data_root)
+ dumper = DATA_DUMPERS.build(dumper)
+ dumper(samples)
+
+ def generate_config(self):
+ if self.config_generator is None:
+ return
+ self.config_generator.setdefault(
+ 'dataset_name', default=self.dataset_name)
+ self.config_generator.setdefault('data_root', default=self.data_root)
+ config_generator = CFG_GENERATORS.build(self.config_generator)
+ print('Generating base configs...')
+ config_generator()
+
+ def clean(self) -> None:
+ if self.delete is None:
+ return
+ for d in self.delete:
+ delete_file = osp.join(self.data_root, d)
+ if osp.exists(delete_file):
+ if osp.isdir(delete_file):
+ shutil.rmtree(delete_file)
+ else:
+ os.remove(delete_file)
diff --git a/mmocr/datasets/preparers/dumpers/__init__.py b/mmocr/datasets/preparers/dumpers/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..ed3dda486b568ea5b4c7f48100b2c32c0b8ec987
--- /dev/null
+++ b/mmocr/datasets/preparers/dumpers/__init__.py
@@ -0,0 +1,10 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .base import BaseDumper
+from .json_dumper import JsonDumper
+from .lmdb_dumper import TextRecogLMDBDumper
+from .wild_receipt_openset_dumper import WildreceiptOpensetDumper
+
+__all__ = [
+ 'BaseDumper', 'JsonDumper', 'WildreceiptOpensetDumper',
+ 'TextRecogLMDBDumper'
+]
diff --git a/mmocr/datasets/preparers/dumpers/base.py b/mmocr/datasets/preparers/dumpers/base.py
new file mode 100644
index 0000000000000000000000000000000000000000..3b4416a8d9adb4352a4426e834ac87841fc12c9b
--- /dev/null
+++ b/mmocr/datasets/preparers/dumpers/base.py
@@ -0,0 +1,35 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Any
+
+
+class BaseDumper:
+ """Base class for data dumpers.
+
+ Args:
+ task (str): Task type. Options are 'textdet', 'textrecog',
+ 'textspotter', and 'kie'. It is usually set automatically and users
+ do not need to set it manually in config file in most cases.
+ split (str): It' s the partition of the datasets. Options are 'train',
+ 'val' or 'test'. It is usually set automatically and users do not
+ need to set it manually in config file in most cases. Defaults to
+ None.
+ data_root (str): The root directory of the image and
+ annotation. It is usually set automatically and users do not need
+ to set it manually in config file in most cases. Defaults to None.
+ """
+
+ def __init__(self, task: str, split: str, data_root: str) -> None:
+ self.task = task
+ self.split = split
+ self.data_root = data_root
+
+ def __call__(self, data: Any) -> None:
+ """Call function.
+
+ Args:
+ data (Any): Data to be dumped.
+ """
+ self.dump(data)
+
+ def dump(self, data: Any) -> None:
+ raise NotImplementedError
diff --git a/mmocr/datasets/preparers/dumpers/json_dumper.py b/mmocr/datasets/preparers/dumpers/json_dumper.py
new file mode 100644
index 0000000000000000000000000000000000000000..e1c8ab026df3b03231e2edd6e9bf39de7cf27e38
--- /dev/null
+++ b/mmocr/datasets/preparers/dumpers/json_dumper.py
@@ -0,0 +1,24 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from typing import Dict
+
+import mmengine
+
+from mmocr.registry import DATA_DUMPERS
+from .base import BaseDumper
+
+
+@DATA_DUMPERS.register_module()
+class JsonDumper(BaseDumper):
+ """Dumper for json file."""
+
+ def dump(self, data: Dict) -> None:
+ """Dump data to json file.
+
+ Args:
+ data (Dict): Data to be dumped.
+ """
+
+ filename = f'{self.task}_{self.split}.json'
+ dst_file = osp.join(self.data_root, filename)
+ mmengine.dump(data, dst_file)
diff --git a/mmocr/datasets/preparers/dumpers/lmdb_dumper.py b/mmocr/datasets/preparers/dumpers/lmdb_dumper.py
new file mode 100644
index 0000000000000000000000000000000000000000..9cd49d17ff17a8224e16284669e3d1206e0463ca
--- /dev/null
+++ b/mmocr/datasets/preparers/dumpers/lmdb_dumper.py
@@ -0,0 +1,140 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+import warnings
+from typing import Dict, List
+
+import cv2
+import lmdb
+import mmengine
+import numpy as np
+
+from mmocr.registry import DATA_DUMPERS
+from .base import BaseDumper
+
+
+@DATA_DUMPERS.register_module()
+class TextRecogLMDBDumper(BaseDumper):
+ """Text recognition LMDB format dataset dumper.
+
+ Args:
+ task (str): Task type. Options are 'textdet', 'textrecog',
+ 'textspotter', and 'kie'. It is usually set automatically and users
+ do not need to set it manually in config file in most cases.
+ split (str): It' s the partition of the datasets. Options are 'train',
+ 'val' or 'test'. It is usually set automatically and users do not
+ need to set it manually in config file in most cases. Defaults to
+ None.
+ data_root (str): The root directory of the image and
+ annotation. It is usually set automatically and users do not need
+ to set it manually in config file in most cases. Defaults to None.
+ batch_size (int): Number of files written to the cache each time.
+ Defaults to 1000.
+ encoding (str): Label encoding method. Defaults to 'utf-8'.
+ lmdb_map_size (int): Maximum size database may grow to. Defaults to
+ 1099511627776.
+ verify (bool): Whether to check the validity of every image. Defaults
+ to True.
+ """
+
+ def __init__(self,
+ task: str,
+ split: str,
+ data_root: str,
+ batch_size: int = 1000,
+ encoding: str = 'utf-8',
+ lmdb_map_size: int = 1099511627776,
+ verify: bool = True) -> None:
+ assert task == 'textrecog', \
+ f'TextRecogLMDBDumper only works with textrecog, but got {task}'
+ super().__init__(task=task, split=split, data_root=data_root)
+ self.batch_size = batch_size
+ self.encoding = encoding
+ self.lmdb_map_size = lmdb_map_size
+ self.verify = verify
+
+ def check_image_is_valid(self, imageBin):
+ if imageBin is None:
+ return False
+ imageBuf = np.frombuffer(imageBin, dtype=np.uint8)
+ img = cv2.imdecode(imageBuf, cv2.IMREAD_GRAYSCALE)
+ imgH, imgW = img.shape[0], img.shape[1]
+ if imgH * imgW == 0:
+ return False
+ return True
+
+ def write_cache(self, env, cache):
+ with env.begin(write=True) as txn:
+ cursor = txn.cursor()
+ cursor.putmulti(cache, dupdata=False, overwrite=True)
+
+ def parser_pack_instance(self, instance: Dict):
+ """parser an packed MMOCR format textrecog instance.
+ Args:
+ instance (Dict): An packed MMOCR format textrecog instance.
+ For example,
+ {
+ "instance": [
+ {
+ "text": "Hello"
+ }
+ ],
+ "img_path": "img1.jpg"
+ }
+ """
+ assert isinstance(instance,
+ Dict), 'Element of data_list must be a dict'
+ assert 'img_path' in instance and 'instances' in instance, \
+ 'Element of data_list must have the following keys: ' \
+ f'img_path and instances, but got {instance.keys()}'
+ assert isinstance(instance['instances'], List) and len(
+ instance['instances']) == 1
+ assert 'text' in instance['instances'][0]
+
+ img_path = instance['img_path']
+ text = instance['instances'][0]['text']
+ return img_path, text
+
+ def dump(self, data: Dict) -> None:
+ """Dump data to LMDB format."""
+
+ # create lmdb env
+ output_dirname = f'{self.task}_{self.split}.lmdb'
+ output = osp.join(self.data_root, output_dirname)
+ mmengine.mkdir_or_exist(output)
+ env = lmdb.open(output, map_size=self.lmdb_map_size)
+ # load data
+ if 'data_list' not in data:
+ raise ValueError('Dump data must have data_list key')
+ data_list = data['data_list']
+ cache = []
+ # index start from 1
+ cnt = 1
+ n_samples = len(data_list)
+ for d in data_list:
+ # convert both images and labels to lmdb
+ label_key = 'label-%09d'.encode(self.encoding) % cnt
+ img_name, text = self.parser_pack_instance(d)
+ img_path = osp.join(self.data_root, img_name)
+ if not osp.exists(img_path):
+ warnings.warn('%s does not exist' % img_path)
+ continue
+ with open(img_path, 'rb') as f:
+ image_bin = f.read()
+ if self.verify:
+ if not self.check_image_is_valid(image_bin):
+ warnings.warn('%s is not a valid image' % img_path)
+ continue
+ image_key = 'image-%09d'.encode(self.encoding) % cnt
+ cache.append((image_key, image_bin))
+ cache.append((label_key, text.encode(self.encoding)))
+
+ if cnt % self.batch_size == 0:
+ self.write_cache(env, cache)
+ cache = []
+ print('Written %d / %d' % (cnt, n_samples))
+ cnt += 1
+ n_samples = cnt - 1
+ cache.append(('num-samples'.encode(self.encoding),
+ str(n_samples).encode(self.encoding)))
+ self.write_cache(env, cache)
+ print('Created lmdb dataset with %d samples' % n_samples)
diff --git a/mmocr/datasets/preparers/dumpers/wild_receipt_openset_dumper.py b/mmocr/datasets/preparers/dumpers/wild_receipt_openset_dumper.py
new file mode 100644
index 0000000000000000000000000000000000000000..df6a462c8e29b04a877698ca96c9739579484874
--- /dev/null
+++ b/mmocr/datasets/preparers/dumpers/wild_receipt_openset_dumper.py
@@ -0,0 +1,22 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from typing import List
+
+from mmocr.registry import DATA_DUMPERS
+from mmocr.utils import list_to_file
+from .base import BaseDumper
+
+
+@DATA_DUMPERS.register_module()
+class WildreceiptOpensetDumper(BaseDumper):
+
+ def dump(self, data: List):
+ """Dump data to txt file.
+
+ Args:
+ data (List): Data to be dumped.
+ """
+
+ filename = f'openset_{self.split}.txt'
+ dst_file = osp.join(self.data_root, filename)
+ list_to_file(dst_file, data)
diff --git a/mmocr/datasets/preparers/gatherers/__init__.py b/mmocr/datasets/preparers/gatherers/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..9a05c79754e6a6392c97b1e7937b725d2d9df752
--- /dev/null
+++ b/mmocr/datasets/preparers/gatherers/__init__.py
@@ -0,0 +1,8 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+
+from .base import BaseGatherer
+from .mono_gatherer import MonoGatherer
+from .naf_gatherer import NAFGatherer
+from .pair_gatherer import PairGatherer
+
+__all__ = ['BaseGatherer', 'MonoGatherer', 'PairGatherer', 'NAFGatherer']
diff --git a/mmocr/datasets/preparers/gatherers/base.py b/mmocr/datasets/preparers/gatherers/base.py
new file mode 100644
index 0000000000000000000000000000000000000000..f982a1a5d62e5071646d621865e6e9fd1dad674f
--- /dev/null
+++ b/mmocr/datasets/preparers/gatherers/base.py
@@ -0,0 +1,49 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from typing import List, Optional, Tuple, Union
+
+
+class BaseGatherer:
+ """Base class for gatherer.
+
+ Note: Gatherer assumes that all the annotation file is in the same
+ directory and all the image files are in the same directory.
+
+ Args:
+ img_dir(str): The directory of the images. It is usually set
+ automatically to f'text{task}_imgs/split' and users do not need to
+ set it manually in config file in most cases. When the image files
+ is not in 'text{task}_imgs/split' directory, users should set it.
+ Defaults to ''.
+ ann_dir (str): The directory of the annotation files. It is usually set
+ automatically to 'annotations' and users do not need to set it
+ manually in config file in most cases. When the annotation files
+ is not in 'annotations' directory, users should set it. Defaults to
+ 'annotations'.
+ split (str, optional): List of splits to gather. It' s the partition of
+ the datasets. Options are 'train', 'val' or 'test'. It is usually
+ set automatically and users do not need to set it manually in
+ config file in most cases. Defaults to None.
+ data_root (str, optional): The root directory of the image and
+ annotation. It is usually set automatically and users do not need
+ to set it manually in config file in most cases. Defaults to None.
+ """
+
+ def __init__(self,
+ img_dir: str = '',
+ ann_dir: str = 'annotations',
+ split: Optional[str] = None,
+ data_root: Optional[str] = None) -> None:
+ self.split = split
+ self.data_root = data_root
+ self.ann_dir = osp.join(data_root, ann_dir)
+ self.img_dir = osp.join(data_root, img_dir)
+
+ def __call__(self) -> Union[Tuple[List[str], List[str]], Tuple[str, str]]:
+ """The return value of the gatherer is a tuple of two lists or strings.
+
+ The first element is the list of image paths or the directory of the
+ images. The second element is the list of annotation paths or the path
+ of the annotation file which contains all the annotations.
+ """
+ raise NotImplementedError
diff --git a/mmocr/datasets/preparers/gatherers/mono_gatherer.py b/mmocr/datasets/preparers/gatherers/mono_gatherer.py
new file mode 100644
index 0000000000000000000000000000000000000000..bad35fa2f1a46362ac3e515fbe5281621143118a
--- /dev/null
+++ b/mmocr/datasets/preparers/gatherers/mono_gatherer.py
@@ -0,0 +1,34 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from typing import Tuple
+
+from mmocr.registry import DATA_GATHERERS
+from .base import BaseGatherer
+
+
+@DATA_GATHERERS.register_module()
+class MonoGatherer(BaseGatherer):
+ """Gather the dataset file. Specifically for the case that only one
+ annotation file is needed. For example,
+
+ img_001.jpg \
+ img_002.jpg ---> train.json
+ img_003.jpg /
+
+ Args:
+ ann_name (str): The name of the annotation file.
+ """
+
+ def __init__(self, ann_name: str, **kwargs) -> None:
+ super().__init__(**kwargs)
+
+ self.ann_name = ann_name
+
+ def __call__(self) -> Tuple[str, str]:
+ """
+ Returns:
+ tuple(str, str): The directory of the image and the path of
+ annotation file.
+ """
+
+ return (self.img_dir, osp.join(self.ann_dir, self.ann_name))
diff --git a/mmocr/datasets/preparers/gatherers/naf_gatherer.py b/mmocr/datasets/preparers/gatherers/naf_gatherer.py
new file mode 100644
index 0000000000000000000000000000000000000000..3251bde40ddd01885ee45c4ad21911156a3ecf07
--- /dev/null
+++ b/mmocr/datasets/preparers/gatherers/naf_gatherer.py
@@ -0,0 +1,66 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import json
+import os
+import os.path as osp
+import shutil
+from typing import List, Tuple
+
+from mmocr.registry import DATA_GATHERERS
+from .base import BaseGatherer
+
+
+@DATA_GATHERERS.register_module()
+class NAFGatherer(BaseGatherer):
+ """Gather the dataset file from NAF dataset. Specifically for the case that
+ there is a split file that contains the names of different splits. For
+ example,
+
+ img_001.jpg train: img_001.jpg
+ img_002.jpg ---> split_file ---> test: img_002.jpg
+ img_003.jpg val: img_003.jpg
+
+ Args:
+ split_file (str, optional): The name of the split file. Defaults to
+ "data_split.json".
+ temp_dir (str, optional): The directory of the temporary images.
+ Defaults to "temp_images".
+ """
+
+ def __init__(self,
+ split_file='data_split.json',
+ temp_dir: str = 'temp_images',
+ **kwargs) -> None:
+ super().__init__(**kwargs)
+ self.temp_dir = temp_dir
+ self.split_file = split_file
+
+ def __call__(self) -> Tuple[List[str], List[str]]:
+ """
+ Returns:
+ tuple(list[str], list[str]): The list of image paths and the list
+ of annotation paths.
+ """
+
+ split_file = osp.join(self.data_root, self.split_file)
+ with open(split_file, 'r') as f:
+ split_data = json.load(f)
+ img_list = list()
+ ann_list = list()
+ # Rename the key
+ split_data['val'] = split_data.pop('valid')
+ if not osp.exists(self.img_dir):
+ os.makedirs(self.img_dir)
+ current_split_data = split_data[self.split]
+ for groups in current_split_data:
+ for img_name in current_split_data[groups]:
+ src_img = osp.join(self.data_root, self.temp_dir, img_name)
+ dst_img = osp.join(self.img_dir, img_name)
+ if not osp.exists(src_img):
+ Warning(f'{src_img} does not exist!')
+ continue
+ # move the image to the new path
+ shutil.move(src_img, dst_img)
+ ann = osp.join(self.ann_dir, img_name.replace('.jpg', '.json'))
+ img_list.append(dst_img)
+ ann_list.append(ann)
+ return img_list, ann_list
diff --git a/mmocr/datasets/preparers/gatherers/pair_gatherer.py b/mmocr/datasets/preparers/gatherers/pair_gatherer.py
new file mode 100644
index 0000000000000000000000000000000000000000..63c11e0c121a6608a7a39769f8a9f09bdf3ba076
--- /dev/null
+++ b/mmocr/datasets/preparers/gatherers/pair_gatherer.py
@@ -0,0 +1,59 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+import re
+from typing import List, Optional, Tuple
+
+from mmocr.registry import DATA_GATHERERS
+from mmocr.utils import list_files
+from .base import BaseGatherer
+
+
+@DATA_GATHERERS.register_module()
+class PairGatherer(BaseGatherer):
+ """Gather the dataset files. Specifically for the paired annotations. That
+ is to say, each image has a corresponding annotation file. For example,
+
+ img_1.jpg <---> gt_img_1.txt
+ img_2.jpg <---> gt_img_2.txt
+ img_3.jpg <---> gt_img_3.txt
+
+ Args:
+ img_suffixes (List[str]): File suffixes that used for searching.
+ rule (Sequence): The rule for pairing the files. The first element is
+ the matching pattern for the file, and the second element is the
+ replacement pattern, which should be a regular expression. For
+ example, to map the image name img_1.jpg to the annotation name
+ gt_img_1.txt, the rule is
+ [r'img_(\d+)\.([jJ][pP][gG])', r'gt_img_\1.txt'] # noqa: W605 E501
+
+ Note: PairGatherer assumes that each split annotation file is in the
+ correspond split directory. For example, all the train annotation files are
+ in {ann_dir}/train.
+ """
+
+ def __init__(self,
+ img_suffixes: Optional[List[str]] = None,
+ rule: Optional[List[str]] = None,
+ **kwargs) -> None:
+ super().__init__(**kwargs)
+ self.rule = rule
+ self.img_suffixes = img_suffixes
+ # ann_dir = {ann_root}/{ann_dir}/{split}
+ self.ann_dir = osp.join(self.ann_dir, self.split)
+
+ def __call__(self) -> Tuple[List[str], List[str]]:
+ """tuple(list, list): The list of image paths and the list of
+ annotation paths."""
+
+ img_list = list()
+ ann_list = list()
+ for img_path in list_files(self.img_dir, self.img_suffixes):
+ if not re.match(self.rule[0], osp.basename(img_path)):
+ continue
+ ann_name = re.sub(self.rule[0], self.rule[1],
+ osp.basename(img_path))
+ ann_path = osp.join(self.ann_dir, ann_name)
+ img_list.append(img_path)
+ ann_list.append(ann_path)
+
+ return img_list, ann_list
diff --git a/mmocr/datasets/preparers/obtainers/__init__.py b/mmocr/datasets/preparers/obtainers/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..55d484d981deb70e7a557ee310a36ab9f2c45d64
--- /dev/null
+++ b/mmocr/datasets/preparers/obtainers/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .naive_data_obtainer import NaiveDataObtainer
+
+__all__ = ['NaiveDataObtainer']
diff --git a/mmocr/datasets/preparers/obtainers/naive_data_obtainer.py b/mmocr/datasets/preparers/obtainers/naive_data_obtainer.py
new file mode 100644
index 0000000000000000000000000000000000000000..51b0d266c847771b403dea62de3b2d81d4d71b02
--- /dev/null
+++ b/mmocr/datasets/preparers/obtainers/naive_data_obtainer.py
@@ -0,0 +1,201 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import glob
+import os
+import os.path as osp
+import shutil
+import ssl
+import urllib.request as request
+from typing import Dict, List, Optional, Tuple
+
+from mmengine import mkdir_or_exist
+
+from mmocr.registry import DATA_OBTAINERS
+from mmocr.utils import check_integrity, is_archive
+
+ssl._create_default_https_context = ssl._create_unverified_context
+
+
+@DATA_OBTAINERS.register_module()
+class NaiveDataObtainer:
+ """A naive pipeline for obtaining dataset.
+
+ download -> extract -> move
+
+ Args:
+ files (list[dict]): A list of file information.
+ cache_path (str): The path to cache the downloaded files.
+ data_root (str): The root path of the dataset. It is usually set auto-
+ matically and users do not need to set it manually in config file
+ in most cases.
+ task (str): The task of the dataset. It is usually set automatically
+ and users do not need to set it manually in config file
+ in most cases.
+ """
+
+ def __init__(self, files: List[Dict], cache_path: str, data_root: str,
+ task: str) -> None:
+ self.files = files
+ self.cache_path = cache_path
+ self.data_root = data_root
+ self.task = task
+ mkdir_or_exist(self.data_root)
+ mkdir_or_exist(osp.join(self.data_root, f'{task}_imgs'))
+ mkdir_or_exist(osp.join(self.data_root, 'annotations'))
+ mkdir_or_exist(self.cache_path)
+
+ def __call__(self):
+ for file in self.files:
+ save_name = file.get('save_name', None)
+ url = file.get('url', None)
+ md5 = file.get('md5', None)
+ download_path = osp.join(
+ self.cache_path,
+ osp.basename(url) if save_name is None else save_name)
+ # Download required files
+ if not check_integrity(download_path, md5):
+ self.download(url=url, dst_path=download_path)
+ # Extract downloaded zip files to data root
+ self.extract(src_path=download_path, dst_path=self.data_root)
+ # Move & Rename dataset files
+ if 'mapping' in file:
+ self.move(mapping=file['mapping'])
+ self.clean()
+
+ def download(self, url: Optional[str], dst_path: str) -> None:
+ """Download file from given url with progress bar.
+
+ Args:
+ url (str): The url to download the file.
+ dst_path (str): The destination path to save the file.
+ """
+
+ def progress(down: float, block: float, size: float) -> None:
+ """Show download progress.
+
+ Args:
+ down (float): Downloaded size.
+ block (float): Block size.
+ size (float): Total size of the file.
+ """
+
+ percent = min(100. * down * block / size, 100)
+ file_name = osp.basename(dst_path)
+ print(f'\rDownloading {file_name}: {percent:.2f}%', end='')
+
+ if url is None and not osp.exists(dst_path):
+ raise FileNotFoundError(
+ 'Direct url is not available for this dataset.'
+ ' Please manually download the required files'
+ ' following the guides.')
+
+ if url.startswith('magnet'):
+ raise NotImplementedError('Please use any BitTorrent client to '
+ 'download the following magnet link to '
+ f'{osp.abspath(dst_path)} and '
+ f'try again.\nLink: {url}')
+
+ print('Downloading...')
+ print(f'URL: {url}')
+ print(f'Destination: {osp.abspath(dst_path)}')
+ print('If you stuck here for a long time, please check your network, '
+ 'or manually download the file to the destination path and '
+ 'run the script again.')
+ request.urlretrieve(url, dst_path, progress)
+ print('')
+
+ def extract(self,
+ src_path: str,
+ dst_path: str,
+ delete: bool = False) -> None:
+ """Extract zip/tar.gz files.
+
+ Args:
+ src_path (str): Path to the zip file.
+ dst_path (str): Path to the destination folder.
+ delete (bool, optional): Whether to delete the zip file. Defaults
+ to False.
+ """
+ if not is_archive(src_path):
+ # Copy the file to the destination folder if it is not a zip
+ if osp.isfile(src_path):
+ shutil.copy(src_path, dst_path)
+ else:
+ shutil.copytree(src_path, dst_path)
+ return
+
+ zip_name = osp.basename(src_path).split('.')[0]
+ if dst_path is None:
+ dst_path = osp.join(osp.dirname(src_path), zip_name)
+ else:
+ dst_path = osp.join(dst_path, zip_name)
+
+ extracted = False
+ if osp.exists(dst_path):
+ name = set(os.listdir(dst_path))
+ if '.finish' in name:
+ extracted = True
+ elif '.finish' not in name and len(name) > 0:
+ while True:
+ c = input(f'{dst_path} already exists when extracting '
+ '{zip_name}, unzip again? (y/N) ') or 'N'
+ if c.lower() in ['y', 'n']:
+ extracted = c == 'n'
+ break
+ if extracted:
+ open(osp.join(dst_path, '.finish'), 'w').close()
+ print(f'{zip_name} has been extracted. Skip')
+ return
+ mkdir_or_exist(dst_path)
+ print(f'Extracting: {osp.basename(src_path)}')
+ if src_path.endswith('.zip'):
+ try:
+ import zipfile
+ except ImportError:
+ raise ImportError(
+ 'Please install zipfile by running "pip install zipfile".')
+ with zipfile.ZipFile(src_path, 'r') as zip_ref:
+ zip_ref.extractall(dst_path)
+ elif src_path.endswith('.tar.gz') or src_path.endswith('.tar'):
+ if src_path.endswith('.tar.gz'):
+ mode = 'r:gz'
+ elif src_path.endswith('.tar'):
+ mode = 'r:'
+ try:
+ import tarfile
+ except ImportError:
+ raise ImportError(
+ 'Please install tarfile by running "pip install tarfile".')
+ with tarfile.open(src_path, mode) as tar_ref:
+ tar_ref.extractall(dst_path)
+
+ open(osp.join(dst_path, '.finish'), 'w').close()
+ if delete:
+ os.remove(src_path)
+
+ def move(self, mapping: List[Tuple[str, str]]) -> None:
+ """Rename and move dataset files one by one.
+
+ Args:
+ mapping (List[Tuple[str, str]]): A list of tuples, each
+ tuple contains the source file name and the destination file name.
+ """
+ for src, dst in mapping:
+ src = osp.join(self.data_root, src)
+ dst = osp.join(self.data_root, dst)
+
+ if '*' in src:
+ mkdir_or_exist(dst)
+ for f in glob.glob(src):
+ if not osp.exists(
+ osp.join(dst, osp.relpath(f, self.data_root))):
+ shutil.move(f, dst)
+
+ elif osp.exists(src) and not osp.exists(dst):
+ mkdir_or_exist(osp.dirname(dst))
+ shutil.move(src, dst)
+
+ def clean(self) -> None:
+ """Remove empty dirs."""
+ for root, dirs, files in os.walk(self.data_root, topdown=False):
+ if not files and not dirs:
+ os.rmdir(root)
diff --git a/mmocr/datasets/preparers/packers/__init__.py b/mmocr/datasets/preparers/packers/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..78eb55dc4e16e34b69dc0fa784e9c1120d912d07
--- /dev/null
+++ b/mmocr/datasets/preparers/packers/__init__.py
@@ -0,0 +1,11 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .base import BasePacker
+from .textdet_packer import TextDetPacker
+from .textrecog_packer import TextRecogCropPacker, TextRecogPacker
+from .textspotting_packer import TextSpottingPacker
+from .wildreceipt_packer import WildReceiptPacker
+
+__all__ = [
+ 'BasePacker', 'TextDetPacker', 'TextRecogPacker', 'TextRecogCropPacker',
+ 'TextSpottingPacker', 'WildReceiptPacker'
+]
diff --git a/mmocr/datasets/preparers/packers/base.py b/mmocr/datasets/preparers/packers/base.py
new file mode 100644
index 0000000000000000000000000000000000000000..4826fd32225b9445ff868a0c9774ee01ae3849e5
--- /dev/null
+++ b/mmocr/datasets/preparers/packers/base.py
@@ -0,0 +1,57 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import abstractmethod
+from typing import Dict, List, Tuple
+
+from mmengine import track_parallel_progress
+
+
+class BasePacker:
+ """Base class for packing the parsed annotation info to MMOCR format.
+
+ Args:
+ data_root (str): The root path of the dataset. It is usually set auto-
+ matically and users do not need to set it manually in config file
+ in most cases.
+ split (str): The split of the dataset. It is usually set automatically
+ and users do not need to set it manually in config file in most
+ cases.
+ nproc (int): Number of processes to process the data. Defaults to 1.
+ It is usually set automatically and users do not need to set it
+ manually in config file in most cases.
+ """
+
+ def __init__(self, data_root: str, split: str, nproc: int = 1) -> None:
+ self.data_root = data_root
+ self.split = split
+ self.nproc = nproc
+
+ @abstractmethod
+ def pack_instance(self, sample: Tuple, split: str) -> Dict:
+ """Pack the parsed annotation info to an MMOCR format instance.
+
+ Args:
+ sample (Tuple): A tuple of (img_file, ann_file).
+ - img_path (str): Path to image file.
+ - instances (Sequence[Dict]): A list of converted annos.
+ split (str): The split of the instance.
+
+ Returns:
+ Dict: An MMOCR format instance.
+ """
+
+ @abstractmethod
+ def add_meta(self, sample: List) -> Dict:
+ """Add meta information to the sample.
+
+ Args:
+ sample (List): A list of samples of the dataset.
+
+ Returns:
+ Dict: A dict contains the meta information and samples.
+ """
+
+ def __call__(self, samples) -> Dict:
+ samples = track_parallel_progress(
+ self.pack_instance, samples, nproc=self.nproc)
+ samples = self.add_meta(samples)
+ return samples
diff --git a/mmocr/datasets/preparers/packers/textdet_packer.py b/mmocr/datasets/preparers/packers/textdet_packer.py
new file mode 100644
index 0000000000000000000000000000000000000000..b9d4c230945fefaca9d6c90a1b99ed05b3956269
--- /dev/null
+++ b/mmocr/datasets/preparers/packers/textdet_packer.py
@@ -0,0 +1,110 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from typing import Dict, List, Tuple
+
+import mmcv
+
+from mmocr.registry import DATA_PACKERS
+from mmocr.utils import bbox2poly, poly2bbox
+from .base import BasePacker
+
+
+@DATA_PACKERS.register_module()
+class TextDetPacker(BasePacker):
+ """Text detection packer. It is used to pack the parsed annotation info to.
+
+ .. code-block:: python
+
+ {
+ "metainfo":
+ {
+ "dataset_type": "TextDetDataset",
+ "task_name": "textdet",
+ "category": [{"id": 0, "name": "text"}]
+ },
+ "data_list":
+ [
+ {
+ "img_path": "test_img.jpg",
+ "height": 640,
+ "width": 640,
+ "instances":
+ [
+ {
+ "polygon": [0, 0, 0, 10, 10, 20, 20, 0],
+ "bbox": [0, 0, 10, 20],
+ "bbox_label": 0,
+ "ignore": False
+ },
+ // ...
+ ]
+ }
+ ]
+ }
+ """
+
+ def pack_instance(self, sample: Tuple, bbox_label: int = 0) -> Dict:
+ """Pack the parsed annotation info to an MMOCR format instance.
+
+ Args:
+ sample (Tuple): A tuple of (img_file, instances).
+ - img_path (str): Path to the image file.
+ - instances (Sequence[Dict]): A list of converted annos. Each
+ element should be a dict with the following keys:
+
+ - 'poly' or 'box'
+ - 'ignore'
+ - 'bbox_label' (optional)
+ split (str): The split of the instance.
+
+ Returns:
+ Dict: An MMOCR format instance.
+ """
+
+ img_path, instances = sample
+
+ img = mmcv.imread(img_path)
+ h, w = img.shape[:2]
+
+ packed_instances = list()
+ for instance in instances:
+ poly = instance.get('poly', None)
+ box = instance.get('box', None)
+ assert box or poly
+ packed_sample = dict(
+ polygon=poly if poly else list(
+ bbox2poly(box).astype('float64')),
+ bbox=box if box else list(poly2bbox(poly).astype('float64')),
+ bbox_label=bbox_label,
+ ignore=instance['ignore'])
+ packed_instances.append(packed_sample)
+
+ packed_instances = dict(
+ instances=packed_instances,
+ img_path=osp.relpath(img_path, self.data_root),
+ height=h,
+ width=w)
+
+ return packed_instances
+
+ def add_meta(self, sample: List) -> Dict:
+ """Add meta information to the sample.
+
+ Args:
+ sample (List): A list of samples of the dataset.
+
+ Returns:
+ Dict: A dict contains the meta information and samples.
+ """
+ meta = {
+ 'metainfo': {
+ 'dataset_type': 'TextDetDataset',
+ 'task_name': 'textdet',
+ 'category': [{
+ 'id': 0,
+ 'name': 'text'
+ }]
+ },
+ 'data_list': sample
+ }
+ return meta
diff --git a/mmocr/datasets/preparers/packers/textrecog_packer.py b/mmocr/datasets/preparers/packers/textrecog_packer.py
new file mode 100644
index 0000000000000000000000000000000000000000..6af70064aa7303d494c6d51121ece8c6e4cd06da
--- /dev/null
+++ b/mmocr/datasets/preparers/packers/textrecog_packer.py
@@ -0,0 +1,175 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from typing import Dict, List, Tuple
+
+import mmcv
+from mmengine import mkdir_or_exist
+
+from mmocr.registry import DATA_PACKERS
+from mmocr.utils import bbox2poly, crop_img, poly2bbox, warp_img
+from .base import BasePacker
+
+
+@DATA_PACKERS.register_module()
+class TextRecogPacker(BasePacker):
+ """Text recogntion packer. It is used to pack the parsed annotation info
+ to:
+
+ .. code-block:: python
+
+ {
+ "metainfo":
+ {
+ "dataset_type": "TextRecogDataset",
+ "task_name": "textrecog",
+ },
+ "data_list":
+ [
+ {
+ "img_path": "textrecog_imgs/train/test_img.jpg",
+ "instances":
+ [
+ {
+ "text": "GRAND"
+ }
+ ]
+ }
+ ]
+ }
+ """
+
+ def pack_instance(self, sample: Tuple) -> Dict:
+ """Pack the text info to a recognition instance.
+
+ Args:
+ samples (Tuple): A tuple of (img_name, text).
+ split (str): The split of the instance.
+
+ Returns:
+ Dict: The packed instance.
+ """
+
+ img_name, text = sample
+ img_name = osp.relpath(img_name, self.data_root)
+ packed_instance = dict(instances=[dict(text=text)], img_path=img_name)
+
+ return packed_instance
+
+ def add_meta(self, sample: List) -> Dict:
+ """Add meta information to the sample.
+
+ Args:
+ sample (List): A list of samples of the dataset.
+
+ Returns:
+ Dict: A dict contains the meta information and samples.
+ """
+ meta = {
+ 'metainfo': {
+ 'dataset_type': 'TextRecogDataset',
+ 'task_name': 'textrecog'
+ },
+ 'data_list': sample
+ }
+ return meta
+
+
+@DATA_PACKERS.register_module()
+class TextRecogCropPacker(TextRecogPacker):
+ """Text recognition packer with image cropper. It is used to pack the
+ parsed annotation info and crop out the word images from the full-size
+ ones.
+
+ Args:
+ crop_with_warp (bool): Whether to crop the text from the original
+ image using opencv warpPerspective.
+ jitter (bool): (Applicable when crop_with_warp=True)
+ Whether to jitter the box.
+ jitter_ratio_x (float): (Applicable when crop_with_warp=True)
+ Horizontal jitter ratio relative to the height.
+ jitter_ratio_y (float): (Applicable when crop_with_warp=True)
+ Vertical jitter ratio relative to the height.
+ long_edge_pad_ratio (float): (Applicable when crop_with_warp=False)
+ The ratio of padding the long edge of the cropped image.
+ Defaults to 0.1.
+ short_edge_pad_ratio (float): (Applicable when crop_with_warp=False)
+ The ratio of padding the short edge of the cropped image.
+ Defaults to 0.05.
+ """
+
+ def __init__(self,
+ crop_with_warp: bool = False,
+ jitter: bool = False,
+ jitter_ratio_x: float = 0.0,
+ jitter_ratio_y: float = 0.0,
+ long_edge_pad_ratio: float = 0.0,
+ short_edge_pad_ratio: float = 0.0,
+ **kwargs):
+ super().__init__(**kwargs)
+ self.crop_with_warp = crop_with_warp
+ self.jitter = jitter
+ self.jrx = jitter_ratio_x
+ self.jry = jitter_ratio_y
+ self.lepr = long_edge_pad_ratio
+ self.sepr = short_edge_pad_ratio
+ # Crop converter crops the images of textdet to patches
+ self.cropped_img_dir = 'textrecog_imgs'
+ self.crop_save_path = osp.join(self.data_root, self.cropped_img_dir)
+ mkdir_or_exist(self.crop_save_path)
+ mkdir_or_exist(osp.join(self.crop_save_path, self.split))
+
+ def pack_instance(self, sample: Tuple) -> List:
+ """Crop patches from image.
+
+ Args:
+ samples (Tuple): A tuple of (img_name, text).
+
+ Return:
+ List: The list of cropped patches.
+ """
+
+ def get_box(instance: Dict) -> List:
+ if 'box' in instance:
+ return bbox2poly(instance['box']).tolist()
+ if 'poly' in instance:
+ return bbox2poly(poly2bbox(instance['poly'])).tolist()
+
+ def get_poly(instance: Dict) -> List:
+ if 'poly' in instance:
+ return instance['poly']
+ if 'box' in instance:
+ return bbox2poly(instance['box']).tolist()
+
+ data_list = []
+ img_path, instances = sample
+ img = mmcv.imread(img_path)
+ for i, instance in enumerate(instances):
+ if instance['ignore']:
+ continue
+ if self.crop_with_warp:
+ poly = get_poly(instance)
+ patch = warp_img(img, poly, self.jitter, self.jrx, self.jry)
+ else:
+ box = get_box(instance)
+ patch = crop_img(img, box, self.lepr, self.sepr)
+ if patch.shape[0] == 0 or patch.shape[1] == 0:
+ continue
+ text = instance['text']
+ patch_name = osp.splitext(
+ osp.basename(img_path))[0] + f'_{i}' + osp.splitext(
+ osp.basename(img_path))[1]
+ dst_path = osp.join(self.crop_save_path, self.split, patch_name)
+ mmcv.imwrite(patch, dst_path)
+ rec_instance = dict(
+ instances=[dict(text=text)],
+ img_path=osp.join(self.cropped_img_dir, self.split,
+ patch_name))
+ data_list.append(rec_instance)
+
+ return data_list
+
+ def add_meta(self, sample: List) -> Dict:
+ # Since the TextRecogCropConverter packs all of the patches in a single
+ # image into a list, we need to flatten the list.
+ sample = [item for sublist in sample for item in sublist]
+ return super().add_meta(sample)
diff --git a/mmocr/datasets/preparers/packers/textspotting_packer.py b/mmocr/datasets/preparers/packers/textspotting_packer.py
new file mode 100644
index 0000000000000000000000000000000000000000..ee5467169a66f727d9052905f8a4c0d1731003fe
--- /dev/null
+++ b/mmocr/datasets/preparers/packers/textspotting_packer.py
@@ -0,0 +1,113 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from typing import Dict, List, Tuple
+
+import mmcv
+
+from mmocr.registry import DATA_PACKERS
+from mmocr.utils import bbox2poly, poly2bbox
+from .base import BasePacker
+
+
+@DATA_PACKERS.register_module()
+class TextSpottingPacker(BasePacker):
+ """Text spotting packer. It is used to pack the parsed annotation info to:
+
+ .. code-block:: python
+
+ {
+ "metainfo":
+ {
+ "dataset_type": "TextDetDataset",
+ "task_name": "textdet",
+ "category": [{"id": 0, "name": "text"}]
+ },
+ "data_list":
+ [
+ {
+ "img_path": "test_img.jpg",
+ "height": 640,
+ "width": 640,
+ "instances":
+ [
+ {
+ "polygon": [0, 0, 0, 10, 10, 20, 20, 0],
+ "bbox": [0, 0, 10, 20],
+ "bbox_label": 0,
+ "ignore": False,
+ "text": "mmocr"
+ },
+ // ...
+ ]
+ }
+ ]
+ }
+ """
+
+ def pack_instance(self, sample: Tuple, bbox_label: int = 0) -> Dict:
+ """Pack the parsed annotation info to an MMOCR format instance.
+
+ Args:
+ sample (Tuple): A tuple of (img_file, ann_file).
+ - img_path (str): Path to image file.
+ - instances (Sequence[Dict]): A list of converted annos. Each
+ element should be a dict with the following keys:
+ - 'poly' or 'box'
+ - 'text'
+ - 'ignore'
+ - 'bbox_label' (optional)
+ split (str): The split of the instance.
+
+ Returns:
+ Dict: An MMOCR format instance.
+ """
+
+ img_path, instances = sample
+
+ img = mmcv.imread(img_path)
+ h, w = img.shape[:2]
+
+ packed_instances = list()
+ for instance in instances:
+ assert 'text' in instance, 'Text is not found in the instance.'
+ poly = instance.get('poly', None)
+ box = instance.get('box', None)
+ assert box or poly
+ packed_sample = dict(
+ polygon=poly if poly else list(
+ bbox2poly(box).astype('float64')),
+ bbox=box if box else list(poly2bbox(poly).astype('float64')),
+ bbox_label=bbox_label,
+ ignore=instance['ignore'],
+ text=instance['text'])
+ packed_instances.append(packed_sample)
+
+ packed_instances = dict(
+ instances=packed_instances,
+ img_path=osp.relpath(img_path, self.data_root),
+ height=h,
+ width=w)
+
+ return packed_instances
+
+ def add_meta(self, sample: List) -> Dict:
+ """Add meta information to the sample.
+
+ Args:
+ sample (List): A list of samples of the dataset.
+
+ Returns:
+ Dict: A dict contains the meta information and samples.
+ """
+ meta = {
+ 'metainfo': {
+ 'dataset_type': 'TextSpottingDataset',
+ 'task_name': 'textspotting',
+ 'category': [{
+ 'id': 0,
+ 'name': 'text'
+ }]
+ },
+ 'data_list': sample
+ }
+ return meta
diff --git a/mmocr/datasets/preparers/packers/wildreceipt_packer.py b/mmocr/datasets/preparers/packers/wildreceipt_packer.py
new file mode 100644
index 0000000000000000000000000000000000000000..df13bc66a3dd5c188d3fa093651521955b4e1630
--- /dev/null
+++ b/mmocr/datasets/preparers/packers/wildreceipt_packer.py
@@ -0,0 +1,112 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import json
+from typing import List
+
+from mmocr.registry import DATA_PACKERS
+from .base import BasePacker
+
+
+@DATA_PACKERS.register_module()
+class WildReceiptPacker(BasePacker):
+ """Pack the wildreceipt annotation to MMOCR format.
+
+ Args:
+ merge_bg_others (bool): If True, give the same label to "background"
+ class and "others" class. Defaults to True.
+ ignore_idx (int): Index for ``ignore`` class. Defaults to 0.
+ others_idx (int): Index for ``others`` class. Defaults to 25.
+ """
+
+ def __init__(self,
+ merge_bg_others: bool = False,
+ ignore_idx: int = 0,
+ others_idx: int = 25,
+ **kwargs) -> None:
+ super().__init__(**kwargs)
+
+ self.ignore_idx = ignore_idx
+ self.others_idx = others_idx
+ self.merge_bg_others = merge_bg_others
+
+ def add_meta(self, samples: List) -> List:
+ """No meta info is required for the wildreceipt dataset."""
+ return samples
+
+ def pack_instance(self, sample: str):
+ """Pack line-json str of close set to line-json str of open set.
+
+ Args:
+ sample (str): The string to be deserialized to
+ the close set dictionary object.
+ split (str): The split of the instance.
+ """
+ # Two labels at the same index of the following two lists
+ # make up a key-value pair. For example, in wildreceipt,
+ # closeset_key_inds[0] maps to "Store_name_key"
+ # and closeset_value_inds[0] maps to "Store_addr_value".
+ closeset_key_inds = list(range(2, self.others_idx, 2))
+ closeset_value_inds = list(range(1, self.others_idx, 2))
+
+ openset_node_label_mapping = {
+ 'bg': 0,
+ 'key': 1,
+ 'value': 2,
+ 'others': 3
+ }
+ if self.merge_bg_others:
+ openset_node_label_mapping['others'] = openset_node_label_mapping[
+ 'bg']
+
+ closeset_obj = json.loads(sample)
+ openset_obj = {
+ 'file_name':
+ closeset_obj['file_name'].replace(self.data_root + '/', ''),
+ 'height':
+ closeset_obj['height'],
+ 'width':
+ closeset_obj['width'],
+ 'annotations': []
+ }
+
+ edge_idx = 1
+ label_to_edge = {}
+ for anno in closeset_obj['annotations']:
+ label = anno['label']
+ if label == self.ignore_idx:
+ anno['label'] = openset_node_label_mapping['bg']
+ anno['edge'] = edge_idx
+ edge_idx += 1
+ elif label == self.others_idx:
+ anno['label'] = openset_node_label_mapping['others']
+ anno['edge'] = edge_idx
+ edge_idx += 1
+ else:
+ edge = label_to_edge.get(label, None)
+ if edge is not None:
+ anno['edge'] = edge
+ if label in closeset_key_inds:
+ anno['label'] = openset_node_label_mapping['key']
+ elif label in closeset_value_inds:
+ anno['label'] = openset_node_label_mapping['value']
+ else:
+ tmp_key = 'key'
+ if label in closeset_key_inds:
+ label_with_same_edge = closeset_value_inds[
+ closeset_key_inds.index(label)]
+ elif label in closeset_value_inds:
+ label_with_same_edge = closeset_key_inds[
+ closeset_value_inds.index(label)]
+ tmp_key = 'value'
+ edge_counterpart = label_to_edge.get(
+ label_with_same_edge, None)
+ if edge_counterpart is not None:
+ anno['edge'] = edge_counterpart
+ else:
+ anno['edge'] = edge_idx
+ edge_idx += 1
+ anno['label'] = openset_node_label_mapping[tmp_key]
+ label_to_edge[label] = anno['edge']
+
+ openset_obj['annotations'] = closeset_obj['annotations']
+
+ return json.dumps(openset_obj, ensure_ascii=False)
diff --git a/mmocr/datasets/preparers/parsers/__init__.py b/mmocr/datasets/preparers/parsers/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..fd37947107eba2d2cd54630f5d44360a046d7d32
--- /dev/null
+++ b/mmocr/datasets/preparers/parsers/__init__.py
@@ -0,0 +1,22 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .base import BaseParser
+from .coco_parser import COCOTextDetAnnParser
+from .ctw1500_parser import CTW1500AnnParser
+from .funsd_parser import FUNSDTextDetAnnParser
+from .icdar_txt_parser import (ICDARTxtTextDetAnnParser,
+ ICDARTxtTextRecogAnnParser)
+from .mjsynth_parser import MJSynthAnnParser
+from .naf_parser import NAFAnnParser
+from .sroie_parser import SROIETextDetAnnParser
+from .svt_parser import SVTTextDetAnnParser
+from .synthtext_parser import SynthTextAnnParser
+from .totaltext_parser import TotaltextTextDetAnnParser
+from .wildreceipt_parser import WildreceiptKIEAnnParser
+
+__all__ = [
+ 'BaseParser', 'ICDARTxtTextDetAnnParser', 'ICDARTxtTextRecogAnnParser',
+ 'TotaltextTextDetAnnParser', 'WildreceiptKIEAnnParser',
+ 'COCOTextDetAnnParser', 'SVTTextDetAnnParser', 'FUNSDTextDetAnnParser',
+ 'SROIETextDetAnnParser', 'NAFAnnParser', 'CTW1500AnnParser',
+ 'SynthTextAnnParser', 'MJSynthAnnParser'
+]
diff --git a/mmocr/datasets/preparers/parsers/base.py b/mmocr/datasets/preparers/parsers/base.py
new file mode 100644
index 0000000000000000000000000000000000000000..dfe79e1549320e22ce9a631a6b2fe81d192917e3
--- /dev/null
+++ b/mmocr/datasets/preparers/parsers/base.py
@@ -0,0 +1,124 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import abstractmethod
+from typing import Dict, List, Tuple, Union
+
+from mmocr.utils import track_parallel_progress_multi_args
+
+
+class BaseParser:
+ """Base class for parsing annotations.
+
+ Args:
+ split (str): The split of the dataset. It is usually set automatically
+ and users do not need to set it manually in config file in most
+ cases.
+ nproc (int): Number of processes to process the data. Defaults to 1.
+ It is usually set automatically and users do not need to set it
+ manually in config file in most cases.
+ """
+
+ def __init__(self, split: str, nproc: int = 1) -> None:
+ self.nproc = nproc
+ self.split = split
+
+ def __call__(self, img_paths: Union[List[str], str],
+ ann_paths: Union[List[str], str]) -> List[Tuple]:
+ """Parse annotations.
+
+ Args:
+ img_paths (str or list[str]): the list of image paths or the
+ directory of the images.
+ ann_paths (str or list[str]): the list of annotation paths or the
+ path of the annotation file which contains all the annotations.
+
+ Returns:
+ List: A list of a tuple of (image_path, instances)
+ """
+ samples = self.parse_files(img_paths, ann_paths)
+ return samples
+
+ def parse_files(self, img_paths: Union[List[str], str],
+ ann_paths: Union[List[str], str]) -> List[Tuple]:
+ """Convert annotations to MMOCR format.
+
+ Args:
+ img_paths (str or list[str]): the list of image paths or the
+ directory of the images.
+ ann_paths (str or list[str]): the list of annotation paths or the
+ path of the annotation file which contains all the annotations.
+
+ Returns:
+ List[Tuple]: A list of a tuple of (image_path, instances).
+
+ - img_path (str): The path of image file, which can be read
+ directly by opencv.
+ - instance: instance is a list of dict containing parsed
+ annotations, which should contain the following keys:
+
+ - 'poly' or 'box' (textdet or textspotting)
+ - 'text' (textspotting or textrecog)
+ - 'ignore' (all task)
+ """
+ samples = track_parallel_progress_multi_args(
+ self.parse_file, (img_paths, ann_paths), nproc=self.nproc)
+ return samples
+
+ @abstractmethod
+ def parse_file(self, img_path: str, ann_path: str) -> Tuple:
+ """Convert annotation for a single image.
+
+ Args:
+ img_path (str): The path of image.
+ ann_path (str): The path of annotation.
+
+ Returns:
+ Tuple: A tuple of (img_path, instance).
+
+ - img_path (str): The path of image file, which can be read
+ directly by opencv.
+ - instance: instance is a list of dict containing parsed
+ annotations, which should contain the following keys:
+
+ - 'poly' or 'box' (textdet or textspotting)
+ - 'text' (textspotting or textrecog)
+ - 'ignore' (all task)
+
+ Examples:
+ An example of returned values:
+ >>> ('imgs/train/xxx.jpg',
+ >>> dict(
+ >>> poly=[[[0, 1], [1, 1], [1, 0], [0, 0]]],
+ >>> text='hello',
+ >>> ignore=False)
+ >>> )
+ """
+ raise NotImplementedError
+
+ def loader(self,
+ file_path: str,
+ separator: str = ',',
+ format: str = 'x1,y1,x2,y2,x3,y3,x4,y4,trans',
+ encoding='utf-8') -> Union[Dict, str]:
+ """A basic loader designed for .txt format annotation. It greedily
+ extracts information separated by separators.
+
+ Args:
+ file_path (str): Path to the txt file.
+ separator (str, optional): Separator of data. Defaults to ','.
+ format (str, optional): Annotation format.
+ Defaults to 'x1,y1,x2,y2,x3,y3,x4,y4,trans'.
+ encoding (str, optional): Encoding format. Defaults to 'utf-8'.
+
+ Yields:
+ Iterator[Union[Dict, str]]: Original text line or a dict containing
+ the information of the text line.
+ """
+ keys = format.split(separator)
+ with open(file_path, 'r', encoding=encoding) as f:
+ for line in f.readlines():
+ line = line.strip()
+ values = line.split(separator)
+ values = values[:len(keys) -
+ 1] + [separator.join(values[len(keys) - 1:])]
+ if line:
+ yield dict(zip(keys, values))
diff --git a/mmocr/datasets/preparers/parsers/coco_parser.py b/mmocr/datasets/preparers/parsers/coco_parser.py
new file mode 100644
index 0000000000000000000000000000000000000000..0d23bd00e523d3212ea1387bef7b30338adb2e45
--- /dev/null
+++ b/mmocr/datasets/preparers/parsers/coco_parser.py
@@ -0,0 +1,99 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from typing import List
+
+from mmdet.datasets.api_wrappers import COCO
+
+from mmocr.datasets.preparers.parsers.base import BaseParser
+from mmocr.registry import DATA_PARSERS
+
+
+@DATA_PARSERS.register_module()
+class COCOTextDetAnnParser(BaseParser):
+ """COCO-like Format Text Detection Parser.
+
+ Args:
+ data_root (str): The root path of the dataset. Defaults to None.
+ nproc (int): The number of processes to parse the annotation. Defaults
+ to 1.
+ variant (str): Variant of COCO dataset, options are ['standard',
+ 'cocotext', 'textocr']. Defaults to 'standard'.
+ """
+
+ def __init__(self,
+ split: str,
+ nproc: int = 1,
+ variant: str = 'standard') -> None:
+
+ super().__init__(nproc=nproc, split=split)
+ assert variant in ['standard', 'cocotext', 'textocr'], \
+ f'variant {variant} is not supported'
+ self.variant = variant
+
+ def parse_files(self, img_dir: str, ann_path: str) -> List:
+ """Parse single annotation."""
+ samples = list()
+ coco = COCO(ann_path)
+ if self.variant == 'cocotext' or self.variant == 'textocr':
+ # cocotext stores both 'train' and 'val' split in one annotation
+ # file, and uses the 'set' field to distinguish them.
+ if self.variant == 'cocotext':
+ for img in coco.dataset['imgs']:
+ if self.split == coco.dataset['imgs'][img]['set']:
+ coco.imgs[img] = coco.dataset['imgs'][img]
+ # textocr stores 'train' and 'val'split separately
+ elif self.variant == 'textocr':
+ coco.imgs = coco.dataset['imgs']
+ # both cocotext and textocr stores the annotation ID in the
+ # 'imgToAnns' field, so we need to convert it to the 'anns' field
+ for img in coco.dataset['imgToAnns']:
+ ann_ids = coco.dataset['imgToAnns'][img]
+ anns = [
+ coco.dataset['anns'][str(ann_id)] for ann_id in ann_ids
+ ]
+ coco.dataset['imgToAnns'][img] = anns
+ coco.imgToAnns = coco.dataset['imgToAnns']
+ coco.anns = coco.dataset['anns']
+ img_ids = coco.get_img_ids()
+ total_ann_ids = []
+ for img_id in img_ids:
+ img_info = coco.load_imgs([img_id])[0]
+ img_info['img_id'] = img_id
+ img_path = img_info['file_name']
+ ann_ids = coco.get_ann_ids(img_ids=[img_id])
+ if len(ann_ids) == 0:
+ continue
+ ann_ids = [str(ann_id) for ann_id in ann_ids]
+ ann_info = coco.load_anns(ann_ids)
+ total_ann_ids.extend(ann_ids)
+ instances = list()
+ for ann in ann_info:
+ if self.variant == 'standard':
+ # standard coco format use 'segmentation' field to store
+ # the polygon and 'iscrowd' field to store the ignore flag,
+ # and the 'text' field to store the text content.
+ instances.append(
+ dict(
+ poly=ann['segmentation'][0],
+ text=ann.get('text', None),
+ ignore=ann.get('iscrowd', False)))
+ elif self.variant == 'cocotext':
+ # cocotext use 'utf8_string' field to store the text and
+ # 'legibility' field to store the ignore flag, and the
+ # 'mask' field to store the polygon.
+ instances.append(
+ dict(
+ poly=ann['mask'],
+ text=ann.get('utf8_string', None),
+ ignore=ann['legibility'] == 'illegible'))
+ elif self.variant == 'textocr':
+ # textocr use 'utf8_string' field to store the text and
+ # the 'points' field to store the polygon, '.' is used to
+ # represent the ignored text.
+ text = ann.get('utf8_string', None)
+ instances.append(
+ dict(
+ poly=ann['points'], text=text, ignore=text == '.'))
+ samples.append((osp.join(img_dir,
+ osp.basename(img_path)), instances))
+ return samples
diff --git a/mmocr/datasets/preparers/parsers/ctw1500_parser.py b/mmocr/datasets/preparers/parsers/ctw1500_parser.py
new file mode 100644
index 0000000000000000000000000000000000000000..4c6bdbc59a82c485b6f62142b3cb31ae5874a795
--- /dev/null
+++ b/mmocr/datasets/preparers/parsers/ctw1500_parser.py
@@ -0,0 +1,102 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import xml.etree.ElementTree as ET
+from typing import List, Tuple
+
+import numpy as np
+
+from mmocr.datasets.preparers.data_preparer import DATA_PARSERS
+from mmocr.datasets.preparers.parsers.base import BaseParser
+from mmocr.utils import list_from_file
+
+
+@DATA_PARSERS.register_module()
+class CTW1500AnnParser(BaseParser):
+ """SCUT-CTW1500 dataset parser.
+
+ Args:
+ ignore (str): The text of the ignored instances. Defaults to
+ '###'.
+ """
+
+ def __init__(self, ignore: str = '###', **kwargs) -> None:
+ self.ignore = ignore
+ super().__init__(**kwargs)
+
+ def parse_file(self, img_path: str, ann_path: str) -> Tuple:
+ """Convert annotation for a single image.
+
+ Args:
+ img_path (str): The path of image.
+ ann_path (str): The path of annotation.
+
+ Returns:
+ Tuple: A tuple of (img_path, instance).
+
+ - img_path (str): The path of image file, which can be read
+ directly by opencv.
+ - instance: instance is a list of dict containing parsed
+ annotations, which should contain the following keys:
+
+ - 'poly' or 'box' (textdet or textspotting)
+ - 'text' (textspotting or textrecog)
+ - 'ignore' (all task)
+
+ Examples:
+ An example of returned values:
+ >>> ('imgs/train/xxx.jpg',
+ >>> dict(
+ >>> poly=[[[0, 1], [1, 1], [1, 0], [0, 0]]],
+ >>> text='hello',
+ >>> ignore=False)
+ >>> )
+ """
+
+ if self.split == 'train':
+ instances = self.load_xml_info(ann_path)
+ elif self.split == 'test':
+ instances = self.load_txt_info(ann_path)
+ return img_path, instances
+
+ def load_txt_info(self, anno_dir: str) -> List:
+ """Load the annotation of the SCUT-CTW dataset (test split).
+ Args:
+ anno_dir (str): Path to the annotation file.
+
+ Returns:
+ list[Dict]: List of instances.
+ """
+ instances = list()
+ for line in list_from_file(anno_dir):
+ # each line has one ploygen (n vetices), and one text.
+ # e.g., 695,885,866,888,867,1146,696,1143,####Latin 9
+ line = line.strip()
+ strs = line.split(',')
+ assert strs[28][0] == '#'
+ xy = [int(x) for x in strs[0:28]]
+ assert len(xy) == 28
+ poly = np.array(xy).reshape(-1).tolist()
+ text = strs[28][4:]
+ instances.append(
+ dict(poly=poly, text=text, ignore=text == self.ignore))
+ return instances
+
+ def load_xml_info(self, anno_dir: str) -> List:
+ """Load the annotation of the SCUT-CTW dataset (train split).
+ Args:
+ anno_dir (str): Path to the annotation file.
+
+ Returns:
+ list[Dict]: List of instances.
+ """
+ obj = ET.parse(anno_dir)
+ instances = list()
+ for image in obj.getroot(): # image
+ for box in image: # image
+ text = box[0].text
+ segs = box[1].text
+ pts = segs.strip().split(',')
+ pts = [int(x) for x in pts]
+ assert len(pts) == 28
+ poly = np.array(pts).reshape(-1).tolist()
+ instances.append(dict(poly=poly, text=text, ignore=0))
+ return instances
diff --git a/mmocr/datasets/preparers/parsers/funsd_parser.py b/mmocr/datasets/preparers/parsers/funsd_parser.py
new file mode 100644
index 0000000000000000000000000000000000000000..bf6d2cd5f636b0c12ae0d4fc1744b128b302528f
--- /dev/null
+++ b/mmocr/datasets/preparers/parsers/funsd_parser.py
@@ -0,0 +1,36 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import json
+from typing import Tuple
+
+from mmocr.registry import DATA_PARSERS
+from mmocr.utils import bbox2poly
+from .base import BaseParser
+
+
+@DATA_PARSERS.register_module()
+class FUNSDTextDetAnnParser(BaseParser):
+ """FUNSD Text Detection Annotation Parser. See
+ dataset_zoo/funsd/sample_anno.md for annotation example.
+
+ Args:
+ nproc (int): The number of processes to parse the annotation. Defaults
+ to 1.
+ """
+
+ def parse_file(self, img_path: str, ann_path: str) -> Tuple:
+ """Parse single annotation."""
+ instances = list()
+ for poly, text, ignore in self.loader(ann_path):
+ instances.append(dict(poly=poly, text=text, ignore=ignore))
+
+ return img_path, instances
+
+ def loader(self, file_path: str):
+ with open(file_path, 'r') as f:
+ data = json.load(f)
+ for form in data['form']:
+ for word in form['words']:
+ poly = bbox2poly(word['box']).tolist()
+ text = word['text']
+ ignore = len(text) == 0
+ yield poly, text, ignore
diff --git a/mmocr/datasets/preparers/parsers/icdar_txt_parser.py b/mmocr/datasets/preparers/parsers/icdar_txt_parser.py
new file mode 100644
index 0000000000000000000000000000000000000000..e90d5d7b94a2345fbe803d254428326215de4fea
--- /dev/null
+++ b/mmocr/datasets/preparers/parsers/icdar_txt_parser.py
@@ -0,0 +1,127 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from typing import List, Optional, Tuple
+
+from mmocr.registry import DATA_PARSERS
+from mmocr.utils import bbox2poly
+from .base import BaseParser
+
+
+@DATA_PARSERS.register_module()
+class ICDARTxtTextDetAnnParser(BaseParser):
+ """ICDAR Txt Format Text Detection Annotation Parser.
+
+ The original annotation format of this dataset is stored in txt files,
+ which is formed as the following format:
+ x1, y1, x2, y2, x3, y3, x4, y4, transcription
+
+ Args:
+ separator (str): The separator between each element in a line. Defaults
+ to ','.
+ ignore (str): The text to be ignored. Defaults to '###'.
+ format (str): The format of the annotation. Defaults to
+ 'x1,y1,x2,y2,x3,y3,x4,trans'.
+ encoding (str): The encoding of the annotation file. Defaults to
+ 'utf-8-sig'.
+ nproc (int): The number of processes to parse the annotation. Defaults
+ to 1.
+ remove_strs (List[str], Optional): Used to remove redundant strings in
+ the transcription. Defaults to None.
+ mode (str, optional): The mode of the box converter. Supported modes
+ are 'xywh' and 'xyxy'. Defaults to None.
+ """
+
+ def __init__(self,
+ separator: str = ',',
+ ignore: str = '###',
+ format: str = 'x1,y1,x2,y2,x3,y3,x4,y4,trans',
+ encoding: str = 'utf-8',
+ remove_strs: Optional[List[str]] = None,
+ mode: str = None,
+ **kwargs) -> None:
+ self.sep = separator
+ self.format = format
+ self.encoding = encoding
+ self.ignore = ignore
+ self.mode = mode
+ self.remove_strs = remove_strs
+ super().__init__(**kwargs)
+
+ def parse_file(self, img_path: str, ann_path: str) -> Tuple:
+ """Parse single annotation."""
+ instances = list()
+ for anno in self.loader(ann_path, self.sep, self.format,
+ self.encoding):
+ anno = list(anno.values())
+ if self.remove_strs is not None:
+ for strs in self.remove_strs:
+ for i in range(len(anno)):
+ if strs in anno[i]:
+ anno[i] = anno[i].replace(strs, '')
+ poly = list(map(float, anno[0:-1]))
+ if self.mode is not None:
+ poly = bbox2poly(poly, self.mode)
+ poly = poly.tolist()
+ text = anno[-1]
+ instances.append(
+ dict(poly=poly, text=text, ignore=text == self.ignore))
+
+ return img_path, instances
+
+
+@DATA_PARSERS.register_module()
+class ICDARTxtTextRecogAnnParser(BaseParser):
+ """ICDAR Txt Format Text Recognition Annotation Parser.
+
+ The original annotation format of this dataset is stored in txt files,
+ which is formed as the following format:
+ img_path, transcription
+
+ Args:
+ separator (str): The separator between each element in a line. Defaults
+ to ','.
+ ignore (str): The text to be ignored. Defaults to '#'.
+ format (str): The format of the annotation. Defaults to 'img, text'.
+ encoding (str): The encoding of the annotation file. Defaults to
+ 'utf-8-sig'.
+ nproc (int): The number of processes to parse the annotation. Defaults
+ to 1.
+ base_name (bool): Whether to use the basename of the image path as the
+ image name. Defaults to False.
+ remove_strs (List[str], Optional): Used to remove redundant strings in
+ the transcription. Defaults to ['"'].
+ """
+
+ def __init__(self,
+ separator: str = ',',
+ ignore: str = '#',
+ format: str = 'img,text',
+ encoding: str = 'utf-8',
+ remove_strs: Optional[List[str]] = ['"'],
+ **kwargs) -> None:
+ self.sep = separator
+ self.format = format
+ self.encoding = encoding
+ self.ignore = ignore
+ self.remove_strs = remove_strs
+ super().__init__(**kwargs)
+
+ def parse_files(self, img_dir: str, ann_path: str) -> List:
+ """Parse annotations."""
+ assert isinstance(ann_path, str)
+ samples = list()
+ for anno in self.loader(
+ file_path=ann_path,
+ format=self.format,
+ encoding=self.encoding,
+ separator=self.sep):
+ text = anno['text'].strip()
+ if self.remove_strs is not None:
+ for strs in self.remove_strs:
+ text = text.replace(strs, '')
+ if text == self.ignore:
+ continue
+ img_name = anno['img']
+ samples.append((osp.join(img_dir, img_name), text))
+
+ return samples
diff --git a/mmocr/datasets/preparers/parsers/mjsynth_parser.py b/mmocr/datasets/preparers/parsers/mjsynth_parser.py
new file mode 100644
index 0000000000000000000000000000000000000000..3eee6e29a373bfb9689de1845f7a22587750816c
--- /dev/null
+++ b/mmocr/datasets/preparers/parsers/mjsynth_parser.py
@@ -0,0 +1,50 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from typing import List
+
+from mmocr.registry import DATA_PARSERS
+from .icdar_txt_parser import ICDARTxtTextRecogAnnParser
+
+
+@DATA_PARSERS.register_module()
+class MJSynthAnnParser(ICDARTxtTextRecogAnnParser):
+ """MJSynth Text Recognition Annotation Parser.
+
+ The original annotation format of this dataset is stored in txt files,
+ which is formed as the following format:
+ img_path, transcription
+
+ Args:
+ separator (str): The separator between each element in a line. Defaults
+ to ','.
+ ignore (str): The text to be ignored. Defaults to '#'.
+ format (str): The format of the annotation. Defaults to 'img, text'.
+ encoding (str): The encoding of the annotation file. Defaults to
+ 'utf-8-sig'.
+ nproc (int): The number of processes to parse the annotation. Defaults
+ to 1.
+ base_name (bool): Whether to use the basename of the image path as the
+ image name. Defaults to False.
+ remove_strs (List[str], Optional): Used to remove redundant strings in
+ the transcription. Defaults to ['"'].
+ """
+
+ def parse_files(self, img_dir: str, ann_path: str) -> List:
+ """Parse annotations."""
+ assert isinstance(ann_path, str)
+ samples = list()
+ for anno in self.loader(
+ file_path=ann_path,
+ format=self.format,
+ encoding=self.encoding,
+ separator=self.sep):
+ text = osp.basename(anno['img']).split('_')[1]
+ if self.remove_strs is not None:
+ for strs in self.remove_strs:
+ text = text.replace(strs, '')
+ if text == self.ignore:
+ continue
+ img_name = anno['img']
+ samples.append((osp.join(img_dir, img_name), text))
+
+ return samples
diff --git a/mmocr/datasets/preparers/parsers/naf_parser.py b/mmocr/datasets/preparers/parsers/naf_parser.py
new file mode 100644
index 0000000000000000000000000000000000000000..988b4b453b1aba44dca342a4be1f0258f583ca08
--- /dev/null
+++ b/mmocr/datasets/preparers/parsers/naf_parser.py
@@ -0,0 +1,106 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import json
+from typing import List, Tuple
+
+import numpy as np
+
+from mmocr.registry import DATA_PARSERS
+from .base import BaseParser
+
+
+@DATA_PARSERS.register_module()
+class NAFAnnParser(BaseParser):
+ """NAF dataset parser.
+
+ The original annotation format of this dataset is stored in json files,
+ which has the following keys that will be used here:
+ - 'textBBs': List of text bounding box objects
+ - 'poly_points': list of [x,y] pairs, the box corners going
+ top-left,top-right,bottom-right,bottom-left
+ - 'id': id of the textBB, used to match with the text
+ - 'transcriptions': Dict of transcription objects, use the 'id' key
+ to match with the textBB.
+
+ Some special characters are used in the transcription:
+ "«text»" indicates that "text" had a strikethrough
+ "¿" indicates the transcriber could not read a character
+ "§" indicates the whole line or word was illegible
+ "" (empty string) is if the field was blank
+
+ Args:
+ ignore (list(str)): The text of the ignored instances. Default: ['#'].
+ det (bool): Whether to parse the detection annotation. Default: True.
+ If False, the parser will consider special case in NAF dataset
+ where the transcription is not available.
+ """
+
+ def __init__(self,
+ ignore: List[str] = ['#'],
+ det: bool = True,
+ **kwargs) -> None:
+ self.ignore = ignore
+ self.det = det
+ super().__init__(**kwargs)
+
+ def parse_file(self, img_path: str, ann_path: str) -> Tuple:
+ """Convert single annotation."""
+ instances = list()
+ for poly, text in self.loader(ann_path):
+ instances.append(
+ dict(poly=poly, text=text, ignore=text in self.ignore))
+
+ return img_path, instances
+
+ def loader(self, file_path: str) -> str:
+ """Load the annotation of the NAF dataset.
+
+ Args:
+ file_path (str): Path to the json file
+
+ Retyrb:
+ str: Complete annotation of the json file
+ """
+ with open(file_path, 'r') as f:
+ data = json.load(f)
+
+ # 'textBBs' contains the printed texts of the table while 'fieldBBs'
+ # contains the text filled by human.
+ for box_type in ['textBBs', 'fieldBBs']:
+ if not self.det:
+ # 'textBBs' is only used for detection task.
+ if box_type == 'textBBs':
+ continue
+ for anno in data[box_type]:
+ # Skip blanks
+ if self.det:
+ if box_type == 'fieldBBs':
+ if anno['type'] == 'blank':
+ continue
+ poly = np.array(anno['poly_points']).reshape(
+ 1, 8)[0].tolist()
+ # Since detection task only need poly, we can skip the
+ # transcription part that can be empty.
+ text = None
+ else:
+ # For tasks that need transcription, NAF dataset has
+ # serval special cases:
+ # 1. The transcription for the whole image is not
+ # available.
+ # 2. The transcription for the certain text is not
+ # available.
+ # 3. If the length of the transcription is 0, it should
+ # be ignored.
+ if 'transcriptions' not in data.keys():
+ break
+ if anno['id'] not in data['transcriptions'].keys():
+ continue
+ text = data['transcriptions'][anno['id']]
+ text = text.strip(
+ '\u202a') # Remove unicode control character
+ text = text.replace('»', '').replace(
+ '«', '') # Remove strikethrough flag
+ if len(text) == 0:
+ continue
+ poly = np.array(anno['poly_points']).reshape(
+ 1, 8)[0].tolist()
+ yield poly, text
diff --git a/mmocr/datasets/preparers/parsers/sroie_parser.py b/mmocr/datasets/preparers/parsers/sroie_parser.py
new file mode 100644
index 0000000000000000000000000000000000000000..f89793e8c4aeed43d1cf462e8041cf38c8b08af3
--- /dev/null
+++ b/mmocr/datasets/preparers/parsers/sroie_parser.py
@@ -0,0 +1,74 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Tuple
+
+from mmocr.registry import DATA_PARSERS
+from mmocr.utils import bbox2poly
+from .base import BaseParser
+
+
+@DATA_PARSERS.register_module()
+class SROIETextDetAnnParser(BaseParser):
+ """SROIE Txt Format Text Detection Annotation Parser.
+
+ The original annotation format of this dataset is stored in txt files,
+ which is formed as the following format:
+ x1, y1, x2, y2, x3, y3, x4, y4, transcription
+
+ Args:
+ separator (str): The separator between each element in a line. Defaults
+ to ','.
+ ignore (str): The text to be ignored. Defaults to '###'.
+ format (str): The format of the annotation. Defaults to
+ 'x1,y1,x2,y2,x3,y3,x4,trans'.
+ encoding (str): The encoding of the annotation file. Defaults to
+ 'utf-8-sig'.
+ nproc (int): The number of processes to parse the annotation. Defaults
+ to 1.
+ remove_strs (List[str], Optional): Used to remove redundant strings in
+ the transcription. Defaults to None.
+ mode (str, optional): The mode of the box converter. Supported modes
+ are 'xywh' and 'xyxy'. Defaults to None.
+ """
+
+ def __init__(self,
+ split: str,
+ separator: str = ',',
+ ignore: str = '###',
+ format: str = 'x1,y1,x2,y2,x3,y3,x4,y4,trans',
+ encoding: str = 'utf-8-sig',
+ nproc: int = 1,
+ remove_strs: Optional[List[str]] = None,
+ mode: str = None) -> None:
+ self.sep = separator
+ self.format = format
+ self.encoding = encoding
+ self.ignore = ignore
+ self.mode = mode
+ self.remove_strs = remove_strs
+ super().__init__(nproc=nproc, split=split)
+
+ def parse_file(self, img_path: str, ann_path: str) -> Tuple:
+ """Parse single annotation."""
+ instances = list()
+ try:
+ # there might be some illegal symbols in the annotation
+ # which cannot be parsed by loader
+ for anno in self.loader(ann_path, self.sep, self.format,
+ self.encoding):
+ anno = list(anno.values())
+ if self.remove_strs is not None:
+ for strs in self.remove_strs:
+ for i in range(len(anno)):
+ if strs in anno[i]:
+ anno[i] = anno[i].replace(strs, '')
+ poly = list(map(float, anno[0:-1]))
+ if self.mode is not None:
+ poly = bbox2poly(poly, self.mode)
+ poly = poly.tolist()
+ text = anno[-1]
+ instances.append(
+ dict(poly=poly, text=text, ignore=text == self.ignore))
+ except Exception:
+ pass
+
+ return img_path, instances
diff --git a/mmocr/datasets/preparers/parsers/svt_parser.py b/mmocr/datasets/preparers/parsers/svt_parser.py
new file mode 100644
index 0000000000000000000000000000000000000000..553f46fb0f83c6b0b8d65479de6c2f6d597c64a3
--- /dev/null
+++ b/mmocr/datasets/preparers/parsers/svt_parser.py
@@ -0,0 +1,62 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+import xml.etree.ElementTree as ET
+from typing import List, Tuple
+
+from mmocr.registry import DATA_PARSERS
+from .base import BaseParser
+
+
+@DATA_PARSERS.register_module()
+class SVTTextDetAnnParser(BaseParser):
+ """SVT Text Detection Parser.
+
+ Args:
+ data_root (str): The root of the dataset. Defaults to None.
+ nproc (int): The number of processes to parse the annotation. Defaults
+ to 1.
+ """
+
+ def parse_files(self, img_dir: str, ann_path: str) -> List:
+ """Parse annotations."""
+ assert isinstance(ann_path, str)
+ samples = list()
+ for img_name, instance in self.loader(ann_path):
+ samples.append((osp.join(img_dir,
+ osp.basename(img_name)), instance))
+
+ return samples
+
+ def loader(self, file_path: str) -> Tuple[str, List]:
+ """Load annotation from SVT xml format file. See annotation example in
+ dataset_zoo/svt/sample_anno.md.
+
+ Args:
+ file_path (str): The path of the annotation file.
+
+ Returns:
+ Tuple[str, List]: The image name and the annotation list.
+
+ Yields:
+ Iterator[Tuple[str, List]]: The image name and the annotation list.
+ """
+ tree = ET.parse(file_path)
+ root = tree.getroot()
+ for image in root.findall('image'):
+ image_name = image.find('imageName').text
+ instances = list()
+ for rectangle in image.find('taggedRectangles'):
+ x = int(rectangle.get('x'))
+ y = int(rectangle.get('y'))
+ w = int(rectangle.get('width'))
+ h = int(rectangle.get('height'))
+ # The text annotation of this dataset is not case sensitive.
+ # All of the texts were labeled as upper case. We convert them
+ # to lower case for convenience.
+ text = rectangle.find('tag').text.lower()
+ instances.append(
+ dict(
+ poly=[x, y, x + w, y, x + w, y + h, x, y + h],
+ text=text,
+ ignore=False))
+ yield image_name, instances
diff --git a/mmocr/datasets/preparers/parsers/synthtext_parser.py b/mmocr/datasets/preparers/parsers/synthtext_parser.py
new file mode 100644
index 0000000000000000000000000000000000000000..0764e0d8f1f5b00bdc7d2c8210b24d8bb2b87a53
--- /dev/null
+++ b/mmocr/datasets/preparers/parsers/synthtext_parser.py
@@ -0,0 +1,172 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from typing import List, Optional, Tuple, Union
+
+import numpy as np
+from mmengine import track_parallel_progress
+from scipy.io import loadmat
+
+from mmocr.utils import is_type_list
+from ..data_preparer import DATA_PARSERS
+from .base import BaseParser
+
+
+@DATA_PARSERS.register_module()
+class SynthTextAnnParser(BaseParser):
+ """SynthText Text Detection Annotation Parser.
+
+ Args:
+ split (str): The split of the dataset. It is usually set automatically
+ and users do not need to set it manually in config file in most
+ cases.
+ nproc (int): Number of processes to process the data. Defaults to 1.
+ It is usually set automatically and users do not need to set it
+ manually in config file in most cases.
+ separator (str): The separator between each element in a line. Defaults
+ to ','.
+ ignore (str): The text to be ignored. Defaults to '###'.
+ format (str): The format of the annotation. Defaults to
+ 'x1,y1,x2,y2,x3,y3,x4,trans'.
+ encoding (str): The encoding of the annotation file. Defaults to
+ 'utf-8-sig'.
+ remove_strs (List[str], Optional): Used to remove redundant strings in
+ the transcription. Defaults to None.
+ mode (str, optional): The mode of the box converter. Supported modes
+ are 'xywh' and 'xyxy'. Defaults to None.
+ """
+
+ def __init__(self,
+ split: str,
+ nproc: int,
+ separator: str = ',',
+ ignore: str = '###',
+ format: str = 'x1,y1,x2,y2,x3,y3,x4,y4,trans',
+ encoding: str = 'utf-8',
+ remove_strs: Optional[List[str]] = None,
+ mode: str = None) -> None:
+ self.sep = separator
+ self.format = format
+ self.encoding = encoding
+ self.ignore = ignore
+ self.mode = mode
+ self.remove_strs = remove_strs
+ super().__init__(split=split, nproc=nproc)
+
+ def _trace_boundary(self, char_boxes: List[np.ndarray]) -> np.ndarray:
+ """Trace the boundary point of text.
+
+ Args:
+ char_boxes (list[ndarray]): The char boxes for one text. Each
+ element is 4x2 ndarray.
+
+ Returns:
+ ndarray: The boundary point sets with size nx2.
+ """
+ assert is_type_list(char_boxes, np.ndarray)
+
+ # from top left to to right
+ p_top = [box[0:2] for box in char_boxes]
+ # from bottom right to bottom left
+ p_bottom = [
+ char_boxes[idx][[2, 3], :]
+ for idx in range(len(char_boxes) - 1, -1, -1)
+ ]
+
+ p = p_top + p_bottom
+
+ boundary = np.concatenate(p).astype(int)
+
+ return boundary
+
+ def _match_bbox_char_str(self, bboxes: np.ndarray, char_bboxes: np.ndarray,
+ strs: np.ndarray
+ ) -> Tuple[List[np.ndarray], List[str]]:
+ """Match the bboxes, char bboxes, and strs.
+
+ Args:
+ bboxes (ndarray): The text boxes of size (2, 4, num_box).
+ char_bboxes (ndarray): The char boxes of size (2, 4, num_char_box).
+ strs (ndarray): The string of size (num_strs,)
+
+ Returns:
+ Tuple(List[ndarray], List[str]): Polygon & word list.
+ """
+ assert isinstance(bboxes, np.ndarray)
+ assert isinstance(char_bboxes, np.ndarray)
+ assert isinstance(strs, np.ndarray)
+ # bboxes = bboxes.astype(np.int32)
+ char_bboxes = char_bboxes.astype(np.int32)
+
+ if len(char_bboxes.shape) == 2:
+ char_bboxes = np.expand_dims(char_bboxes, axis=2)
+ char_bboxes = np.transpose(char_bboxes, (2, 1, 0))
+ num_boxes = 1 if len(bboxes.shape) == 2 else bboxes.shape[-1]
+
+ poly_charbox_list = [[] for _ in range(num_boxes)]
+
+ words = []
+ for line in strs:
+ words += line.split()
+ words_len = [len(w) for w in words]
+ words_end_inx = np.cumsum(words_len)
+ start_inx = 0
+ for word_inx, end_inx in enumerate(words_end_inx):
+ for char_inx in range(start_inx, end_inx):
+ poly_charbox_list[word_inx].append(char_bboxes[char_inx])
+ start_inx = end_inx
+
+ for box_inx in range(num_boxes):
+ assert len(poly_charbox_list[box_inx]) > 0
+
+ poly_boundary_list = []
+ for item in poly_charbox_list:
+ boundary = np.ndarray((0, 2))
+ if len(item) > 0:
+ boundary = self._trace_boundary(item)
+ poly_boundary_list.append(boundary)
+
+ return poly_boundary_list, words
+
+ def parse_files(self, img_paths: Union[List[str], str],
+ ann_paths: Union[List[str], str]) -> List[Tuple]:
+ """Convert annotations to MMOCR format.
+
+ Args:
+ img_paths (str or list[str]): the list of image paths or the
+ directory of the images.
+ ann_paths (str or list[str]): the list of annotation paths or the
+ path of the annotation file which contains all the annotations.
+
+ Returns:
+ List[Tuple]: A list of a tuple of (image_path, instances).
+
+ - img_path (str): The path of image file, which can be read
+ directly by opencv.
+ - instance: instance is a list of dict containing parsed
+ annotations, which should contain the following keys:
+
+ - 'poly' or 'box' (textdet or textspotting)
+ - 'text' (textspotting or textrecog)
+ - 'ignore' (all task)
+ """
+ assert isinstance(ann_paths, str)
+ gt = loadmat(ann_paths)
+ self.img_dir = img_paths
+ samples = track_parallel_progress(
+ self.parse_file,
+ list(
+ zip(gt['imnames'][0], gt['wordBB'][0], gt['charBB'][0],
+ gt['txt'][0])),
+ nproc=self.nproc)
+ return samples
+
+ def parse_file(self, annotation: Tuple) -> Tuple:
+ """Parse single annotation."""
+ img_file, wordBB, charBB, txt = annotation
+ polys_list, word_list = self._match_bbox_char_str(wordBB, charBB, txt)
+
+ instances = list()
+ for poly, word in zip(polys_list, word_list):
+ instances.append(
+ dict(poly=poly.flatten().tolist(), text=word, ignore=False))
+ return osp.join(self.img_dir, img_file[0]), instances
diff --git a/mmocr/datasets/preparers/parsers/totaltext_parser.py b/mmocr/datasets/preparers/parsers/totaltext_parser.py
new file mode 100644
index 0000000000000000000000000000000000000000..2255f2f1b1abb01601dde8c33af8cf4732340938
--- /dev/null
+++ b/mmocr/datasets/preparers/parsers/totaltext_parser.py
@@ -0,0 +1,99 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import re
+from typing import Dict, Tuple
+
+import yaml
+
+from mmocr.registry import DATA_PARSERS
+from .base import BaseParser
+
+
+@DATA_PARSERS.register_module()
+class TotaltextTextDetAnnParser(BaseParser):
+ """TotalText Text Detection Parser.
+
+ The original annotation format of this dataset is stored in txt files,
+ which is formed as the following format:
+ x: [[x1 x2 x3 ... xn]], y: [[y1 y2 y3 ... yn]],
+ ornt: [u'c'], transcriptions: [u'transcription']
+
+ Args:
+ data_root (str): Path to the dataset root.
+ ignore (str): The text of the ignored instances. Default: '#'.
+ nproc (int): Number of processes to load the data. Default: 1.
+ """
+
+ def __init__(self, ignore: str = '#', **kwargs) -> None:
+ self.ignore = ignore
+ super().__init__(**kwargs)
+
+ def parse_file(self, img_path: str, ann_path: str) -> Dict:
+ """Convert single annotation."""
+ instances = list()
+ for poly, text in self.loader(ann_path):
+ instances.append(
+ dict(poly=poly, text=text, ignore=text == self.ignore))
+
+ return img_path, instances
+
+ def loader(self, file_path: str) -> str:
+ """The annotation of the totaltext dataset may be stored in multiple
+ lines, this loader is designed for this special case.
+
+ Args:
+ file_path (str): Path to the txt file
+
+ Yield:
+ str: Complete annotation of the txt file
+ """
+
+ def parsing_line(line: str) -> Tuple:
+ """Parsing a line of the annotation.
+
+ Args:
+ line (str): A line of the annotation.
+
+ Returns:
+ Tuple: A tuple of (polygon, transcription).
+ """
+ line = '{' + line.replace('[[', '[').replace(']]', ']') + '}'
+ ann_dict = re.sub('([0-9]) +([0-9])', r'\1,\2', line)
+ ann_dict = re.sub('([0-9]) +([ 0-9])', r'\1,\2', ann_dict)
+ ann_dict = re.sub('([0-9]) -([0-9])', r'\1,-\2', ann_dict)
+ ann_dict = ann_dict.replace("[u',']", "[u'#']")
+ ann_dict = yaml.safe_load(ann_dict)
+
+ # polygon
+ xs, ys = ann_dict['x'], ann_dict['y']
+ poly = []
+ for x, y in zip(xs, ys):
+ poly.append(x)
+ poly.append(y)
+ # text
+ text = ann_dict['transcriptions']
+ if len(text) == 0:
+ text = '#'
+ else:
+ word = text[0]
+ if len(text) > 1:
+ for ann_word in text[1:]:
+ word += ',' + ann_word
+ text = str(eval(word))
+
+ return poly, text
+
+ with open(file_path, 'r') as f:
+ for idx, line in enumerate(f):
+ line = line.strip()
+ if idx == 0:
+ tmp_line = line
+ continue
+ if not line.startswith('x:'):
+ tmp_line += ' ' + line
+ continue
+ complete_line = tmp_line
+ tmp_line = line
+ yield parsing_line(complete_line)
+
+ if tmp_line != '':
+ yield parsing_line(tmp_line)
diff --git a/mmocr/datasets/preparers/parsers/wildreceipt_parser.py b/mmocr/datasets/preparers/parsers/wildreceipt_parser.py
new file mode 100644
index 0000000000000000000000000000000000000000..22a131888d06db41d095c27b0ab1fe434957188b
--- /dev/null
+++ b/mmocr/datasets/preparers/parsers/wildreceipt_parser.py
@@ -0,0 +1,91 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import json
+import os.path as osp
+from typing import Dict
+
+from mmocr.registry import DATA_PARSERS
+from mmocr.utils import list_from_file
+from .base import BaseParser
+
+
+@DATA_PARSERS.register_module()
+class WildreceiptTextDetAnnParser(BaseParser):
+ """Wildreceipt Text Detection Parser.
+
+ The original annotation format of this dataset is stored in txt files,
+ which is formed as the following json line format:
+ {"file_name": "xxx/xxx/xx/xxxx.jpeg",
+ "height": 1200,
+ "width": 1600,
+ "annotations": [
+ "box": [x1, y1, x2, y2, x3, y3, x4, y4],
+ "text": "xxx",
+ "label": 25,
+ ]}
+
+ Args:
+ data_root (str): The root path of the dataset.
+ ignore (int): The label to be ignored. Defaults to 0.
+ nproc (int): The number of processes to parse the annotation. Defaults
+ to 1.
+ """
+
+ def __init__(self, ignore: int = 0, **kwargs) -> None:
+ self.ignore = ignore
+ super().__init__(**kwargs)
+
+ def parse_files(self, img_dir: str, ann_path) -> Dict:
+ """Convert single annotation."""
+ closeset_lines = list_from_file(ann_path)
+ samples = list()
+ for line in closeset_lines:
+ instances = list()
+ line = json.loads(line)
+ img_file = osp.join(img_dir, osp.basename(line['file_name']))
+ for anno in line['annotations']:
+ poly = anno['box']
+ text = anno['text']
+ label = anno['label']
+ instances.append(
+ dict(poly=poly, text=text, ignore=label == self.ignore))
+ samples.append((img_file, instances))
+
+ return samples
+
+
+@DATA_PARSERS.register_module()
+class WildreceiptKIEAnnParser(BaseParser):
+ """Wildreceipt KIE Parser.
+
+ The original annotation format of this dataset is stored in txt files,
+ which is formed as the following json line format:
+ {"file_name": "xxx/xxx/xx/xxxx.jpeg",
+ "height": 1200,
+ "width": 1600,
+ "annotations": [
+ "box": [x1, y1, x2, y2, x3, y3, x4, y4],
+ "text": "xxx",
+ "label": 25,
+ ]}
+
+ Args:
+ ignore (int): The label to be ignored. Defaults to 0.
+ nproc (int): The number of processes to parse the annotation. Defaults
+ to 1.
+ """
+
+ def __init__(self, ignore: int = 0, **kwargs) -> None:
+ self.ignore = ignore
+ super().__init__(**kwargs)
+
+ def parse_files(self, img_dir: str, ann_path: str) -> Dict:
+ """Convert single annotation."""
+ closeset_lines = list_from_file(ann_path)
+ samples = list()
+ for line in closeset_lines:
+ json_line = json.loads(line)
+ img_file = osp.join(img_dir, osp.basename(json_line['file_name']))
+ json_line['file_name'] = img_file
+ samples.append(json.dumps(json_line))
+
+ return samples
diff --git a/mmocr/datasets/recog_lmdb_dataset.py b/mmocr/datasets/recog_lmdb_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..88512c62a7674cc61804e6b420d38a2173a5af51
--- /dev/null
+++ b/mmocr/datasets/recog_lmdb_dataset.py
@@ -0,0 +1,179 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Any, Callable, List, Optional, Sequence, Tuple, Union
+
+import mmcv
+from mmengine.dataset import BaseDataset
+
+from mmocr.registry import DATASETS
+
+
+@DATASETS.register_module()
+class RecogLMDBDataset(BaseDataset):
+ r"""RecogLMDBDataset for text recognition.
+
+ The annotation format should be in lmdb format. The lmdb file should
+ contain three keys: 'num-samples', 'label-xxxxxxxxx' and 'image-xxxxxxxxx',
+ where 'xxxxxxxxx' is the index of the image. The value of 'num-samples' is
+ the total number of images. The value of 'label-xxxxxxx' is the text label
+ of the image, and the value of 'image-xxxxxxx' is the image data.
+
+ following keys:
+ Each item fetched from this dataset will be a dict containing the
+ following keys:
+
+ - img (ndarray): The loaded image.
+ - img_path (str): The image key.
+ - instances (list[dict]): The list of annotations for the image.
+
+ Args:
+ ann_file (str): Annotation file path. Defaults to ''.
+ img_color_type (str): The flag argument for :func:``mmcv.imfrombytes``,
+ which determines how the image bytes will be parsed. Defaults to
+ 'color'.
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Defaults to None.
+ data_root (str): The root directory for ``data_prefix`` and
+ ``ann_file``. Defaults to ''.
+ data_prefix (dict): Prefix for training data. Defaults to
+ ``dict(img_path='')``.
+ filter_cfg (dict, optional): Config for filter data. Defaults to None.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Defaults to None which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy. Defaults
+ to True.
+ pipeline (list, optional): Processing pipeline. Defaults to [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Defaults to False.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``RecogLMDBDataset`` can skip load
+ annotations to save time by set ``lazy_init=False``.
+ Defaults to False.
+ max_refetch (int, optional): If ``RecogLMDBdataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Defaults to 1000.
+ """
+
+ def __init__(
+ self,
+ ann_file: str = '',
+ img_color_type: str = 'color',
+ metainfo: Optional[dict] = None,
+ data_root: Optional[str] = '',
+ data_prefix: dict = dict(img_path=''),
+ filter_cfg: Optional[dict] = None,
+ indices: Optional[Union[int, Sequence[int]]] = None,
+ serialize_data: bool = True,
+ pipeline: List[Union[dict, Callable]] = [],
+ test_mode: bool = False,
+ lazy_init: bool = False,
+ max_refetch: int = 1000,
+ ) -> None:
+
+ super().__init__(
+ ann_file=ann_file,
+ metainfo=metainfo,
+ data_root=data_root,
+ data_prefix=data_prefix,
+ filter_cfg=filter_cfg,
+ indices=indices,
+ serialize_data=serialize_data,
+ pipeline=pipeline,
+ test_mode=test_mode,
+ lazy_init=lazy_init,
+ max_refetch=max_refetch)
+
+ self.color_type = img_color_type
+
+ def load_data_list(self) -> List[dict]:
+ """Load annotations from an annotation file named as ``self.ann_file``
+
+ Returns:
+ List[dict]: A list of annotation.
+ """
+ if not hasattr(self, 'env'):
+ self._make_env()
+ with self.env.begin(write=False) as txn:
+ self.total_number = int(
+ txn.get(b'num-samples').decode('utf-8'))
+
+ data_list = []
+ with self.env.begin(write=False) as txn:
+ for i in range(self.total_number):
+ idx = i + 1
+ label_key = f'label-{idx:09d}'
+ img_key = f'image-{idx:09d}'
+ text = txn.get(label_key.encode('utf-8')).decode('utf-8')
+ line = [img_key, text]
+ data_list.append(self.parse_data_info(line))
+ return data_list
+
+ def parse_data_info(self,
+ raw_anno_info: Tuple[Optional[str],
+ str]) -> Union[dict, List[dict]]:
+ """Parse raw annotation to target format.
+
+ Args:
+ raw_anno_info (str): One raw data information loaded
+ from ``ann_file``.
+
+ Returns:
+ (dict): Parsed annotation.
+ """
+ data_info = {}
+ img_key, text = raw_anno_info
+ data_info['img_key'] = img_key
+ data_info['instances'] = [dict(text=text)]
+ return data_info
+
+ def prepare_data(self, idx) -> Any:
+ """Get data processed by ``self.pipeline``.
+
+ Args:
+ idx (int): The index of ``data_info``.
+
+ Returns:
+ Any: Depends on ``self.pipeline``.
+ """
+ data_info = self.get_data_info(idx)
+ with self.env.begin(write=False) as txn:
+ img_bytes = txn.get(data_info['img_key'].encode('utf-8'))
+ if img_bytes is None:
+ return None
+ data_info['img'] = mmcv.imfrombytes(
+ img_bytes, flag=self.color_type)
+ return self.pipeline(data_info)
+
+ def _make_env(self):
+ """Create lmdb environment from self.ann_file and save it to
+ ``self.env``.
+
+ Returns:
+ Lmdb environment.
+ """
+ try:
+ import lmdb
+ except ImportError:
+ raise ImportError(
+ 'Please install lmdb to enable RecogLMDBDataset.')
+ if hasattr(self, 'env'):
+ return
+
+ self.env = lmdb.open(
+ self.ann_file,
+ max_readers=1,
+ readonly=True,
+ lock=False,
+ readahead=False,
+ meminit=False,
+ )
+
+ def close(self):
+ """Close lmdb environment."""
+ if hasattr(self, 'env'):
+ self.env.close()
+ del self.env
diff --git a/mmocr/datasets/recog_text_dataset.py b/mmocr/datasets/recog_text_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..25cc54ff8e3639fc5a3ba3182749d0920bfc0a8b
--- /dev/null
+++ b/mmocr/datasets/recog_text_dataset.py
@@ -0,0 +1,134 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from typing import Callable, List, Optional, Sequence, Union
+
+from mmengine.dataset import BaseDataset
+from mmengine.fileio import list_from_file
+
+from mmocr.registry import DATASETS, TASK_UTILS
+
+
+@DATASETS.register_module()
+class RecogTextDataset(BaseDataset):
+ r"""RecogTextDataset for text recognition.
+
+ The annotation format can be both in jsonl and txt. If the annotation file
+ is in jsonl format, it should be a list of dicts. If the annotation file
+ is in txt format, it should be a list of lines.
+
+ The annotation formats are shown as follows.
+ - txt format
+ .. code-block:: none
+
+ ``test_img1.jpg OpenMMLab``
+ ``test_img2.jpg MMOCR``
+
+ - jsonl format
+ .. code-block:: none
+
+ ``{"filename": "test_img1.jpg", "text": "OpenMMLab"}``
+ ``{"filename": "test_img2.jpg", "text": "MMOCR"}``
+
+ Args:
+ ann_file (str): Annotation file path. Defaults to ''.
+ backend_args (dict, optional): Arguments to instantiate the
+ prefix of uri corresponding backend. Defaults to None.
+ parse_cfg (dict, optional): Config of parser for parsing annotations.
+ Use ``LineJsonParser`` when the annotation file is in jsonl format
+ with keys of ``filename`` and ``text``. The keys in parse_cfg
+ should be consistent with the keys in jsonl annotations. The first
+ key in parse_cfg should be the key of the path in jsonl
+ annotations. The second key in parse_cfg should be the key of the
+ text in jsonl Use ``LineStrParser`` when the annotation file is in
+ txt format. Defaults to
+ ``dict(type='LineJsonParser', keys=['filename', 'text'])``.
+ metainfo (dict, optional): Meta information for dataset, such as class
+ information. Defaults to None.
+ data_root (str): The root directory for ``data_prefix`` and
+ ``ann_file``. Defaults to ''.
+ data_prefix (dict): Prefix for training data. Defaults to
+ ``dict(img_path='')``.
+ filter_cfg (dict, optional): Config for filter data. Defaults to None.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Defaults to None which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy. Defaults
+ to True.
+ pipeline (list, optional): Processing pipeline. Defaults to [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Defaults to False.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``RecogTextDataset`` can skip load
+ annotations to save time by set ``lazy_init=False``. Defaults to
+ False.
+ max_refetch (int, optional): If ``RecogTextDataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Defaults to 1000.
+ """
+
+ def __init__(self,
+ ann_file: str = '',
+ backend_args=None,
+ parser_cfg: Optional[dict] = dict(
+ type='LineJsonParser', keys=['filename', 'text']),
+ metainfo: Optional[dict] = None,
+ data_root: Optional[str] = '',
+ data_prefix: dict = dict(img_path=''),
+ filter_cfg: Optional[dict] = None,
+ indices: Optional[Union[int, Sequence[int]]] = None,
+ serialize_data: bool = True,
+ pipeline: List[Union[dict, Callable]] = [],
+ test_mode: bool = False,
+ lazy_init: bool = False,
+ max_refetch: int = 1000) -> None:
+
+ self.parser = TASK_UTILS.build(parser_cfg)
+ self.backend_args = backend_args
+ super().__init__(
+ ann_file=ann_file,
+ metainfo=metainfo,
+ data_root=data_root,
+ data_prefix=data_prefix,
+ filter_cfg=filter_cfg,
+ indices=indices,
+ serialize_data=serialize_data,
+ pipeline=pipeline,
+ test_mode=test_mode,
+ lazy_init=lazy_init,
+ max_refetch=max_refetch)
+
+ def load_data_list(self) -> List[dict]:
+ """Load annotations from an annotation file named as ``self.ann_file``
+
+ Returns:
+ List[dict]: A list of annotation.
+ """
+ data_list = []
+ raw_anno_infos = list_from_file(
+ self.ann_file, backend_args=self.backend_args)
+ for raw_anno_info in raw_anno_infos:
+ data_list.append(self.parse_data_info(raw_anno_info))
+ return data_list
+
+ def parse_data_info(self, raw_anno_info: str) -> dict:
+ """Parse raw annotation to target format.
+
+ Args:
+ raw_anno_info (str): One raw data information loaded
+ from ``ann_file``.
+
+ Returns:
+ (dict): Parsed annotation.
+ """
+ data_info = {}
+ parsed_anno = self.parser(raw_anno_info)
+ img_path = osp.join(self.data_prefix['img_path'],
+ parsed_anno[self.parser.keys[0]])
+
+ data_info['img_path'] = img_path
+ data_info['instances'] = [dict(text=parsed_anno[self.parser.keys[1]])]
+ return data_info
diff --git a/mmocr/datasets/samplers/__init__.py b/mmocr/datasets/samplers/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..063a79cb1286282712d8530b87cdfa50ae06f71a
--- /dev/null
+++ b/mmocr/datasets/samplers/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .batch_aug import BatchAugSampler
+
+__all__ = ['BatchAugSampler']
diff --git a/mmocr/datasets/samplers/__pycache__/__init__.cpython-38.pyc b/mmocr/datasets/samplers/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..39e8b91380b6eae3c97e0c0c729724bfdcd0d6ac
Binary files /dev/null and b/mmocr/datasets/samplers/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/datasets/samplers/__pycache__/batch_aug.cpython-38.pyc b/mmocr/datasets/samplers/__pycache__/batch_aug.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ead7a97abbd5c112d0acdd718e6ee99f23eb65a6
Binary files /dev/null and b/mmocr/datasets/samplers/__pycache__/batch_aug.cpython-38.pyc differ
diff --git a/mmocr/datasets/samplers/batch_aug.py b/mmocr/datasets/samplers/batch_aug.py
new file mode 100644
index 0000000000000000000000000000000000000000..852fbc67fbbb5dc4a0c3c202a71a0b84f9c3832b
--- /dev/null
+++ b/mmocr/datasets/samplers/batch_aug.py
@@ -0,0 +1,98 @@
+import math
+from typing import Iterator, Optional, Sized
+
+import torch
+from mmengine.dist import get_dist_info, sync_random_seed
+from torch.utils.data import Sampler
+
+from mmocr.registry import DATA_SAMPLERS
+
+
+@DATA_SAMPLERS.register_module()
+class BatchAugSampler(Sampler):
+ """Sampler that repeats the same data elements for num_repeats times. The
+ batch size should be divisible by num_repeats.
+
+ It ensures that different each
+ augmented version of a sample will be visible to a different process (GPU).
+ Heavily based on torch.utils.data.DistributedSampler.
+
+ This sampler was modified from
+ https://github.com/facebookresearch/deit/blob/0c4b8f60/samplers.py
+ Used in
+ Copyright (c) 2015-present, Facebook, Inc.
+
+ Args:
+ dataset (Sized): The dataset.
+ shuffle (bool): Whether shuffle the dataset or not. Defaults to True.
+ num_repeats (int): The repeat times of every sample. Defaults to 3.
+ seed (int, optional): Random seed used to shuffle the sampler if
+ :attr:`shuffle=True`. This number should be identical across all
+ processes in the distributed group. Defaults to None.
+ """
+
+ def __init__(self,
+ dataset: Sized,
+ shuffle: bool = True,
+ num_repeats: int = 3,
+ seed: Optional[int] = None):
+ rank, world_size = get_dist_info()
+ self.rank = rank
+ self.world_size = world_size
+
+ self.dataset = dataset
+ self.shuffle = shuffle
+
+ if seed is None:
+ seed = sync_random_seed()
+ self.seed = seed
+ self.epoch = 0
+ self.num_repeats = num_repeats
+
+ # The number of repeated samples in the rank
+ self.num_samples = math.ceil(
+ len(self.dataset) * num_repeats / world_size)
+ # The total number of repeated samples in all ranks.
+ self.total_size = self.num_samples * world_size
+ # The number of selected samples in the rank
+ self.num_selected_samples = math.ceil(len(self.dataset) / world_size)
+
+ def __iter__(self) -> Iterator[int]:
+ """Iterate the indices."""
+ # deterministically shuffle based on epoch and seed
+ if self.shuffle:
+ g = torch.Generator()
+ g.manual_seed(self.seed + self.epoch)
+ indices = torch.randperm(len(self.dataset), generator=g).tolist()
+ else:
+ indices = list(range(len(self.dataset)))
+
+ # produce repeats e.g. [0, 0, 0, 1, 1, 1, 2, 2, 2....]
+ indices = [x for x in indices for _ in range(self.num_repeats)]
+ # add extra samples to make it evenly divisible
+ indices = (indices *
+ int(self.total_size / len(indices) + 1))[:self.total_size]
+ assert len(indices) == self.total_size
+
+ # subsample per rank
+ indices = indices[self.rank:self.total_size:self.world_size]
+ assert len(indices) == self.num_samples
+
+ # return up to num selected samples
+ return iter(indices)
+
+ def __len__(self) -> int:
+ """The number of samples in this rank."""
+ return self.num_selected_samples
+
+ def set_epoch(self, epoch: int) -> None:
+ """Sets the epoch for this sampler.
+
+ When :attr:`shuffle=True`, this ensures all replicas use a different
+ random ordering for each epoch. Otherwise, the next iteration of this
+ sampler will yield the same ordering.
+
+ Args:
+ epoch (int): Epoch number.
+ """
+ self.epoch = epoch
diff --git a/mmocr/datasets/transforms/__init__.py b/mmocr/datasets/transforms/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..61a15ec9609c65edee438679ff7c68ff33aabcf6
--- /dev/null
+++ b/mmocr/datasets/transforms/__init__.py
@@ -0,0 +1,27 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .adapters import MMDet2MMOCR, MMOCR2MMDet
+from .formatting import PackKIEInputs, PackTextDetInputs, PackTextRecogInputs
+from .loading import (InferencerLoader, LoadImageFromFile,
+ LoadImageFromNDArray, LoadKIEAnnotations,
+ LoadOCRAnnotations)
+from .ocr_transforms import (FixInvalidPolygon, RandomCrop, RandomRotate,
+ RemoveIgnored, Resize)
+from .textdet_transforms import (BoundedScaleAspectJitter, RandomFlip,
+ ShortScaleAspectJitter, SourceImagePad,
+ TextDetRandomCrop, TextDetRandomCropFlip)
+from .textrecog_transforms import (CropHeight, ImageContentJitter, PadToWidth,
+ PyramidRescale, RescaleToHeight,
+ ReversePixels, TextRecogGeneralAug)
+from .wrappers import ConditionApply, ImgAugWrapper, TorchVisionWrapper
+
+__all__ = [
+ 'LoadOCRAnnotations', 'RandomRotate', 'ImgAugWrapper', 'SourceImagePad',
+ 'TextDetRandomCropFlip', 'PyramidRescale', 'TorchVisionWrapper', 'Resize',
+ 'RandomCrop', 'TextDetRandomCrop', 'RandomCrop', 'PackTextDetInputs',
+ 'PackTextRecogInputs', 'RescaleToHeight', 'PadToWidth',
+ 'ShortScaleAspectJitter', 'RandomFlip', 'BoundedScaleAspectJitter',
+ 'PackKIEInputs', 'LoadKIEAnnotations', 'FixInvalidPolygon', 'MMDet2MMOCR',
+ 'MMOCR2MMDet', 'LoadImageFromFile', 'LoadImageFromNDArray', 'CropHeight',
+ 'InferencerLoader', 'RemoveIgnored', 'ConditionApply', 'CropHeight',
+ 'TextRecogGeneralAug', 'ImageContentJitter', 'ReversePixels'
+]
diff --git a/mmocr/datasets/transforms/__pycache__/__init__.cpython-38.pyc b/mmocr/datasets/transforms/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..834e3921c641a95b14f5b242d65f97d266c86d76
Binary files /dev/null and b/mmocr/datasets/transforms/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/datasets/transforms/__pycache__/adapters.cpython-38.pyc b/mmocr/datasets/transforms/__pycache__/adapters.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..066aa46fc67a6287738883836793b0fa8b5e3c62
Binary files /dev/null and b/mmocr/datasets/transforms/__pycache__/adapters.cpython-38.pyc differ
diff --git a/mmocr/datasets/transforms/__pycache__/formatting.cpython-38.pyc b/mmocr/datasets/transforms/__pycache__/formatting.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..03d13fa439d3879393c4dfef82f3267fa9428bfa
Binary files /dev/null and b/mmocr/datasets/transforms/__pycache__/formatting.cpython-38.pyc differ
diff --git a/mmocr/datasets/transforms/__pycache__/loading.cpython-38.pyc b/mmocr/datasets/transforms/__pycache__/loading.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..305450b9fd5dba69cb5281f82000fb11a0c77929
Binary files /dev/null and b/mmocr/datasets/transforms/__pycache__/loading.cpython-38.pyc differ
diff --git a/mmocr/datasets/transforms/__pycache__/ocr_transforms.cpython-38.pyc b/mmocr/datasets/transforms/__pycache__/ocr_transforms.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..68642d9736e278601e104023d80e59e1559863d2
Binary files /dev/null and b/mmocr/datasets/transforms/__pycache__/ocr_transforms.cpython-38.pyc differ
diff --git a/mmocr/datasets/transforms/__pycache__/textdet_transforms.cpython-38.pyc b/mmocr/datasets/transforms/__pycache__/textdet_transforms.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..3b7d7ac0b4c0f4a5194f6b91d97ed30b855e4b36
Binary files /dev/null and b/mmocr/datasets/transforms/__pycache__/textdet_transforms.cpython-38.pyc differ
diff --git a/mmocr/datasets/transforms/__pycache__/textrecog_transforms.cpython-38.pyc b/mmocr/datasets/transforms/__pycache__/textrecog_transforms.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..4fb7db2bf2015d9922ced371de38e1bc65a878b5
Binary files /dev/null and b/mmocr/datasets/transforms/__pycache__/textrecog_transforms.cpython-38.pyc differ
diff --git a/mmocr/datasets/transforms/__pycache__/wrappers.cpython-38.pyc b/mmocr/datasets/transforms/__pycache__/wrappers.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..622085ffa0b580894e369a90e5af4715c30914e0
Binary files /dev/null and b/mmocr/datasets/transforms/__pycache__/wrappers.cpython-38.pyc differ
diff --git a/mmocr/datasets/transforms/adapters.py b/mmocr/datasets/transforms/adapters.py
new file mode 100644
index 0000000000000000000000000000000000000000..370174727ade4117a4857e8ec72a8c70c7a8950e
--- /dev/null
+++ b/mmocr/datasets/transforms/adapters.py
@@ -0,0 +1,121 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict
+
+from mmcv.transforms.base import BaseTransform
+from mmdet.structures.mask import PolygonMasks, bitmap_to_polygon
+
+from mmocr.registry import TRANSFORMS
+
+
+@TRANSFORMS.register_module()
+class MMDet2MMOCR(BaseTransform):
+ """Convert transforms's data format from MMDet to MMOCR.
+
+ Required Keys:
+
+ - gt_masks (PolygonMasks | BitmapMasks) (optional)
+ - gt_ignore_flags (np.bool) (optional)
+
+ Added Keys:
+
+ - gt_polygons (list[np.ndarray])
+ - gt_ignored (np.ndarray)
+ """
+
+ def transform(self, results: Dict) -> Dict:
+ """Convert MMDet's data format to MMOCR's data format.
+
+ Args:
+ results (Dict): Result dict containing the data to transform.
+
+ Returns:
+ (Dict): The transformed data.
+ """
+ # gt_masks -> gt_polygons
+ if 'gt_masks' in results.keys():
+ gt_polygons = []
+ gt_masks = results.pop('gt_masks')
+ if len(gt_masks) > 0:
+ # PolygonMasks
+ if isinstance(gt_masks[0], PolygonMasks):
+ gt_polygons = [mask[0] for mask in gt_masks.masks]
+ # BitmapMasks
+ else:
+ polygons = []
+ for mask in gt_masks.masks:
+ contours, _ = bitmap_to_polygon(mask)
+ polygons += [
+ contour.reshape(-1) for contour in contours
+ ]
+ # filter invalid polygons
+ gt_polygons = []
+ for polygon in polygons:
+ if len(polygon) < 6:
+ continue
+ gt_polygons.append(polygon)
+
+ results['gt_polygons'] = gt_polygons
+ # gt_ignore_flags -> gt_ignored
+ if 'gt_ignore_flags' in results.keys():
+ gt_ignored = results.pop('gt_ignore_flags')
+ results['gt_ignored'] = gt_ignored
+
+ return results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class MMOCR2MMDet(BaseTransform):
+ """Convert transforms's data format from MMOCR to MMDet.
+
+ Required Keys:
+
+ - img_shape
+ - gt_polygons (List[ndarray]) (optional)
+ - gt_ignored (np.bool) (optional)
+
+ Added Keys:
+
+ - gt_masks (PolygonMasks | BitmapMasks) (optional)
+ - gt_ignore_flags (np.bool) (optional)
+
+ Args:
+ poly2mask (bool): Whether to convert mask to bitmap. Default: True.
+ """
+
+ def __init__(self, poly2mask: bool = False) -> None:
+ self.poly2mask = poly2mask
+
+ def transform(self, results: Dict) -> Dict:
+ """Convert MMOCR's data format to MMDet's data format.
+
+ Args:
+ results (Dict): Result dict containing the data to transform.
+
+ Returns:
+ (Dict): The transformed data.
+ """
+ # gt_polygons -> gt_masks
+ if 'gt_polygons' in results.keys():
+ gt_polygons = results.pop('gt_polygons')
+ gt_polygons = [[gt_polygon] for gt_polygon in gt_polygons]
+ gt_masks = PolygonMasks(gt_polygons, *results['img_shape'])
+
+ if self.poly2mask:
+ gt_masks = gt_masks.to_bitmap()
+
+ results['gt_masks'] = gt_masks
+ # gt_ignore_flags -> gt_ignored
+ if 'gt_ignored' in results.keys():
+ gt_ignored = results.pop('gt_ignored')
+ results['gt_ignore_flags'] = gt_ignored
+
+ return results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(poly2mask = {self.poly2mask})'
+ return repr_str
diff --git a/mmocr/datasets/transforms/formatting.py b/mmocr/datasets/transforms/formatting.py
new file mode 100644
index 0000000000000000000000000000000000000000..b9b71437a6cc1de2396b17fe5c04909855f2ed86
--- /dev/null
+++ b/mmocr/datasets/transforms/formatting.py
@@ -0,0 +1,330 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+import torch
+from mmcv.transforms import to_tensor
+from mmcv.transforms.base import BaseTransform
+from mmengine.structures import InstanceData, LabelData
+
+from mmocr.registry import TRANSFORMS
+from mmocr.structures import (KIEDataSample, TextDetDataSample,
+ TextRecogDataSample)
+
+
+@TRANSFORMS.register_module()
+class PackTextDetInputs(BaseTransform):
+ """Pack the inputs data for text detection.
+
+ The type of outputs is `dict`:
+
+ - inputs: image converted to tensor, whose shape is (C, H, W).
+ - data_samples: Two components of ``TextDetDataSample`` will be updated:
+
+ - gt_instances (InstanceData): Depending on annotations, a subset of the
+ following keys will be updated:
+
+ - bboxes (torch.Tensor((N, 4), dtype=torch.float32)): The groundtruth
+ of bounding boxes in the form of [x1, y1, x2, y2]. Renamed from
+ 'gt_bboxes'.
+ - labels (torch.LongTensor(N)): The labels of instances.
+ Renamed from 'gt_bboxes_labels'.
+ - polygons(list[np.array((2k,), dtype=np.float32)]): The
+ groundtruth of polygons in the form of [x1, y1,..., xk, yk]. Each
+ element in polygons may have different number of points. Renamed from
+ 'gt_polygons'. Using numpy instead of tensor is that polygon usually
+ is not the output of model and operated on cpu.
+ - ignored (torch.BoolTensor((N,))): The flag indicating whether the
+ corresponding instance should be ignored. Renamed from
+ 'gt_ignored'.
+ - texts (list[str]): The groundtruth texts. Renamed from 'gt_texts'.
+
+ - metainfo (dict): 'metainfo' is always populated. The contents of the
+ 'metainfo' depends on ``meta_keys``. By default it includes:
+
+ - "img_path": Path to the image file.
+ - "img_shape": Shape of the image input to the network as a tuple
+ (h, w). Note that the image may be zero-padded afterward on the
+ bottom/right if the batch tensor is larger than this shape.
+ - "scale_factor": A tuple indicating the ratio of width and height
+ of the preprocessed image to the original one.
+ - "ori_shape": Shape of the preprocessed image as a tuple
+ (h, w).
+ - "pad_shape": Image shape after padding (if any Pad-related
+ transform involved) as a tuple (h, w).
+ - "flip": A boolean indicating if the image has been flipped.
+ - ``flip_direction``: the flipping direction.
+
+ Args:
+ meta_keys (Sequence[str], optional): Meta keys to be converted to
+ the metainfo of ``TextDetSample``. Defaults to ``('img_path',
+ 'ori_shape', 'img_shape', 'scale_factor', 'flip',
+ 'flip_direction')``.
+ """
+ mapping_table = {
+ 'gt_bboxes': 'bboxes',
+ 'gt_bboxes_labels': 'labels',
+ 'gt_polygons': 'polygons',
+ 'gt_texts': 'texts',
+ 'gt_ignored': 'ignored'
+ }
+
+ def __init__(self,
+ meta_keys=('img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'flip', 'flip_direction')):
+ self.meta_keys = meta_keys
+
+ def transform(self, results: dict) -> dict:
+ """Method to pack the input data.
+
+ Args:
+ results (dict): Result dict from the data pipeline.
+
+ Returns:
+ dict:
+
+ - 'inputs' (obj:`torch.Tensor`): Data for model forwarding.
+ - 'data_samples' (obj:`DetDataSample`): The annotation info of the
+ sample.
+ """
+ packed_results = dict()
+ if 'img' in results:
+ img = results['img']
+ if len(img.shape) < 3:
+ img = np.expand_dims(img, -1)
+ # A simple trick to speedup formatting by 3-5 times when
+ # OMP_NUM_THREADS != 1
+ # Refer to https://github.com/open-mmlab/mmdetection/pull/9533
+ # for more details
+ if img.flags.c_contiguous:
+ img = to_tensor(img)
+ img = img.permute(2, 0, 1).contiguous()
+ else:
+ img = np.ascontiguousarray(img.transpose(2, 0, 1))
+ img = to_tensor(img)
+ packed_results['inputs'] = img
+
+ data_sample = TextDetDataSample()
+ instance_data = InstanceData()
+ for key in self.mapping_table.keys():
+ if key not in results:
+ continue
+ if key in ['gt_bboxes', 'gt_bboxes_labels', 'gt_ignored']:
+ instance_data[self.mapping_table[key]] = to_tensor(
+ results[key])
+ else:
+ instance_data[self.mapping_table[key]] = results[key]
+ data_sample.gt_instances = instance_data
+
+ img_meta = {}
+ for key in self.meta_keys:
+ img_meta[key] = results[key]
+ data_sample.set_metainfo(img_meta)
+ packed_results['data_samples'] = data_sample
+
+ return packed_results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(meta_keys={self.meta_keys})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class PackTextRecogInputs(BaseTransform):
+ """Pack the inputs data for text recognition.
+
+ The type of outputs is `dict`:
+
+ - inputs: Image as a tensor, whose shape is (C, H, W).
+ - data_samples: Two components of ``TextRecogDataSample`` will be updated:
+
+ - gt_text (LabelData):
+
+ - item(str): The groundtruth of text. Rename from 'gt_texts'.
+
+ - metainfo (dict): 'metainfo' is always populated. The contents of the
+ 'metainfo' depends on ``meta_keys``. By default it includes:
+
+ - "img_path": Path to the image file.
+ - "ori_shape": Shape of the preprocessed image as a tuple
+ (h, w).
+ - "img_shape": Shape of the image input to the network as a tuple
+ (h, w). Note that the image may be zero-padded afterward on the
+ bottom/right if the batch tensor is larger than this shape.
+ - "valid_ratio": The proportion of valid (unpadded) content of image
+ on the x-axis. It defaults to 1 if not set in pipeline.
+
+ Args:
+ meta_keys (Sequence[str], optional): Meta keys to be converted to
+ the metainfo of ``TextRecogDataSampel``. Defaults to
+ ``('img_path', 'ori_shape', 'img_shape', 'pad_shape',
+ 'valid_ratio')``.
+ """
+
+ def __init__(self,
+ meta_keys=('img_path', 'ori_shape', 'img_shape', 'pad_shape',
+ 'valid_ratio')):
+ self.meta_keys = meta_keys
+
+ def transform(self, results: dict) -> dict:
+ """Method to pack the input data.
+
+ Args:
+ results (dict): Result dict from the data pipeline.
+
+ Returns:
+ dict:
+
+ - 'inputs' (obj:`torch.Tensor`): Data for model forwarding.
+ - 'data_samples' (obj:`TextRecogDataSample`): The annotation info
+ of the sample.
+ """
+ packed_results = dict()
+ if 'img' in results:
+ img = results['img']
+ if len(img.shape) < 3:
+ img = np.expand_dims(img, -1)
+ # A simple trick to speedup formatting by 3-5 times when
+ # OMP_NUM_THREADS != 1
+ # Refer to https://github.com/open-mmlab/mmdetection/pull/9533
+ # for more details
+ if img.flags.c_contiguous:
+ img = to_tensor(img)
+ img = img.permute(2, 0, 1).contiguous()
+ else:
+ img = np.ascontiguousarray(img.transpose(2, 0, 1))
+ img = to_tensor(img)
+ packed_results['inputs'] = img
+
+ data_sample = TextRecogDataSample()
+ gt_text = LabelData()
+
+ if results.get('gt_texts', None):
+ assert len(
+ results['gt_texts']
+ ) == 1, 'Each image sample should have one text annotation only'
+ gt_text.item = results['gt_texts'][0]
+ data_sample.gt_text = gt_text
+
+ img_meta = {}
+ for key in self.meta_keys:
+ if key == 'valid_ratio':
+ img_meta[key] = results.get('valid_ratio', 1)
+ else:
+ img_meta[key] = results[key]
+ data_sample.set_metainfo(img_meta)
+
+ packed_results['data_samples'] = data_sample
+
+ return packed_results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(meta_keys={self.meta_keys})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class PackKIEInputs(BaseTransform):
+ """Pack the inputs data for key information extraction.
+
+ The type of outputs is `dict`:
+
+ - inputs: image converted to tensor, whose shape is (C, H, W).
+ - data_samples: Two components of ``TextDetDataSample`` will be updated:
+
+ - gt_instances (InstanceData): Depending on annotations, a subset of the
+ following keys will be updated:
+
+ - bboxes (torch.Tensor((N, 4), dtype=torch.float32)): The groundtruth
+ of bounding boxes in the form of [x1, y1, x2, y2]. Renamed from
+ 'gt_bboxes'.
+ - labels (torch.LongTensor(N)): The labels of instances.
+ Renamed from 'gt_bboxes_labels'.
+ - edge_labels (torch.LongTensor(N, N)): The edge labels.
+ Renamed from 'gt_edges_labels'.
+ - texts (list[str]): The groundtruth texts. Renamed from 'gt_texts'.
+
+ - metainfo (dict): 'metainfo' is always populated. The contents of the
+ 'metainfo' depends on ``meta_keys``. By default it includes:
+
+ - "img_path": Path to the image file.
+ - "img_shape": Shape of the image input to the network as a tuple
+ (h, w). Note that the image may be zero-padded afterward on the
+ bottom/right if the batch tensor is larger than this shape.
+ - "scale_factor": A tuple indicating the ratio of width and height
+ of the preprocessed image to the original one.
+ - "ori_shape": Shape of the preprocessed image as a tuple
+ (h, w).
+
+ Args:
+ meta_keys (Sequence[str], optional): Meta keys to be converted to
+ the metainfo of ``TextDetSample``. Defaults to ``('img_path',
+ 'ori_shape', 'img_shape', 'scale_factor', 'flip',
+ 'flip_direction')``.
+ """
+ mapping_table = {
+ 'gt_bboxes': 'bboxes',
+ 'gt_bboxes_labels': 'labels',
+ 'gt_edges_labels': 'edge_labels',
+ 'gt_texts': 'texts',
+ }
+
+ def __init__(self, meta_keys=()):
+ self.meta_keys = meta_keys
+
+ def transform(self, results: dict) -> dict:
+ """Method to pack the input data.
+
+ Args:
+ results (dict): Result dict from the data pipeline.
+
+ Returns:
+ dict:
+
+ - 'inputs' (obj:`torch.Tensor`): Data for model forwarding.
+ - 'data_samples' (obj:`DetDataSample`): The annotation info of the
+ sample.
+ """
+ packed_results = dict()
+ if 'img' in results:
+ img = results['img']
+ if len(img.shape) < 3:
+ img = np.expand_dims(img, -1)
+ # A simple trick to speedup formatting by 3-5 times when
+ # OMP_NUM_THREADS != 1
+ # Refer to https://github.com/open-mmlab/mmdetection/pull/9533
+ # for more details
+ if img.flags.c_contiguous:
+ img = to_tensor(img)
+ img = img.permute(2, 0, 1).contiguous()
+ else:
+ img = np.ascontiguousarray(img.transpose(2, 0, 1))
+ img = to_tensor(img)
+ packed_results['inputs'] = img
+ else:
+ packed_results['inputs'] = torch.FloatTensor().reshape(0, 0, 0)
+
+ data_sample = KIEDataSample()
+ instance_data = InstanceData()
+ for key in self.mapping_table.keys():
+ if key not in results:
+ continue
+ if key in ['gt_bboxes', 'gt_bboxes_labels', 'gt_edges_labels']:
+ instance_data[self.mapping_table[key]] = to_tensor(
+ results[key])
+ else:
+ instance_data[self.mapping_table[key]] = results[key]
+ data_sample.gt_instances = instance_data
+
+ img_meta = {}
+ for key in self.meta_keys:
+ img_meta[key] = results[key]
+ data_sample.set_metainfo(img_meta)
+ packed_results['data_samples'] = data_sample
+
+ return packed_results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(meta_keys={self.meta_keys})'
+ return repr_str
diff --git a/mmocr/datasets/transforms/loading.py b/mmocr/datasets/transforms/loading.py
new file mode 100644
index 0000000000000000000000000000000000000000..e9a3af8189edb4159a4676c6401a0364981bc4d7
--- /dev/null
+++ b/mmocr/datasets/transforms/loading.py
@@ -0,0 +1,572 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import warnings
+from typing import Optional, Union
+
+import mmcv
+import mmengine.fileio as fileio
+import numpy as np
+from mmcv.transforms import BaseTransform
+from mmcv.transforms import LoadAnnotations as MMCV_LoadAnnotations
+from mmcv.transforms import LoadImageFromFile as MMCV_LoadImageFromFile
+
+from mmocr.registry import TRANSFORMS
+
+
+@TRANSFORMS.register_module()
+class LoadImageFromFile(MMCV_LoadImageFromFile):
+ """Load an image from file.
+
+ Required Keys:
+
+ - img_path
+
+ Modified Keys:
+
+ - img
+ - img_shape
+ - ori_shape
+
+ Args:
+ to_float32 (bool): Whether to convert the loaded image to a float32
+ numpy array. If set to False, the loaded image is an uint8 array.
+ Defaults to False.
+ color_type (str): The flag argument for :func:``mmcv.imfrombytes``.
+ Defaults to 'color'.
+ imdecode_backend (str): The image decoding backend type. The backend
+ argument for :func:``mmcv.imfrombytes``.
+ See :func:``mmcv.imfrombytes`` for details.
+ Defaults to 'cv2'.
+ file_client_args (dict): Arguments to instantiate a FileClient.
+ See :class:`mmengine.fileio.FileClient` for details.
+ Defaults to None. It will be deprecated in future. Please use
+ ``backend_args`` instead.
+ Deprecated in version 1.0.0rc6.
+ backend_args (dict, optional): Instantiates the corresponding file
+ backend. It may contain `backend` key to specify the file
+ backend. If it contains, the file backend corresponding to this
+ value will be used and initialized with the remaining values,
+ otherwise the corresponding file backend will be selected
+ based on the prefix of the file path. Defaults to None.
+ New in version 1.0.0rc6.
+ ignore_empty (bool): Whether to allow loading empty image or file path
+ not existent. Defaults to False.
+ min_size (int): The minimum size of the image to be loaded. If the
+ image is smaller than the minimum size, it will be regarded as a
+ broken image. Defaults to 0.
+ """
+
+ def __init__(
+ self,
+ to_float32: bool = False,
+ color_type: str = 'color',
+ imdecode_backend: str = 'cv2',
+ file_client_args: Optional[dict] = None,
+ min_size: int = 0,
+ ignore_empty: bool = False,
+ *,
+ backend_args: Optional[dict] = None,
+ ) -> None:
+ self.ignore_empty = ignore_empty
+ self.to_float32 = to_float32
+ self.color_type = color_type
+ self.imdecode_backend = imdecode_backend
+ self.min_size = min_size
+ self.file_client_args = file_client_args
+ self.backend_args = backend_args
+ if file_client_args is not None:
+ warnings.warn(
+ '"file_client_args" will be deprecated in future. '
+ 'Please use "backend_args" instead', DeprecationWarning)
+ if backend_args is not None:
+ raise ValueError(
+ '"file_client_args" and "backend_args" cannot be set '
+ 'at the same time.')
+
+ self.file_client_args = file_client_args.copy()
+ if backend_args is not None:
+ self.backend_args = backend_args.copy()
+
+ def transform(self, results: dict) -> Optional[dict]:
+ """Functions to load image.
+
+ Args:
+ results (dict): Result dict from :obj:``mmcv.BaseDataset``.
+
+ Returns:
+ dict: The dict contains loaded image and meta information.
+ """
+
+ filename = results['img_path']
+ try:
+ if getattr(self, 'file_client_args', None) is not None:
+ file_client = fileio.FileClient.infer_client(
+ self.file_client_args, filename)
+ img_bytes = file_client.get(filename)
+ else:
+ img_bytes = fileio.get(
+ filename, backend_args=self.backend_args)
+ img = mmcv.imfrombytes(
+ img_bytes, flag=self.color_type, backend=self.imdecode_backend)
+ except Exception as e:
+ if self.ignore_empty:
+ warnings.warn(f'Failed to load {filename} due to {e}')
+ return None
+ else:
+ raise e
+ if img is None or min(img.shape[:2]) < self.min_size:
+ if self.ignore_empty:
+ warnings.warn(f'Ignore broken image: {filename}')
+ return None
+ raise IOError(f'{filename} is broken')
+
+ if self.to_float32:
+ img = img.astype(np.float32)
+
+ results['img'] = img
+ results['img_shape'] = img.shape[:2]
+ results['ori_shape'] = img.shape[:2]
+ return results
+
+ def __repr__(self):
+ repr_str = (f'{self.__class__.__name__}('
+ f'ignore_empty={self.ignore_empty}, '
+ f'min_size={self.min_size}, '
+ f'to_float32={self.to_float32}, '
+ f"color_type='{self.color_type}', "
+ f"imdecode_backend='{self.imdecode_backend}', ")
+
+ if self.file_client_args is not None:
+ repr_str += f'file_client_args={self.file_client_args})'
+ else:
+ repr_str += f'backend_args={self.backend_args})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class LoadImageFromNDArray(LoadImageFromFile):
+ """Load an image from ``results['img']``.
+
+ Similar with :obj:`LoadImageFromFile`, but the image has been loaded as
+ :obj:`np.ndarray` in ``results['img']``. Can be used when loading image
+ from webcam.
+
+ Required Keys:
+
+ - img
+
+ Modified Keys:
+
+ - img
+ - img_path
+ - img_shape
+ - ori_shape
+
+ Args:
+ to_float32 (bool): Whether to convert the loaded image to a float32
+ numpy array. If set to False, the loaded image is an uint8 array.
+ Defaults to False.
+ """
+
+ def transform(self, results: dict) -> dict:
+ """Transform function to add image meta information.
+
+ Args:
+ results (dict): Result dict with Webcam read image in
+ ``results['img']``.
+
+ Returns:
+ dict: The dict contains loaded image and meta information.
+ """
+
+ img = results['img']
+ if self.to_float32:
+ img = img.astype(np.float32)
+ if self.color_type == 'grayscale':
+ img = mmcv.image.rgb2gray(img)
+ results['img'] = img
+ if results.get('img_path', None) is None:
+ results['img_path'] = None
+ results['img_shape'] = img.shape[:2]
+ results['ori_shape'] = img.shape[:2]
+ return results
+
+
+@TRANSFORMS.register_module()
+class InferencerLoader(BaseTransform):
+ """Load the image in Inferencer's pipeline.
+
+ Modified Keys:
+
+ - img
+ - img_path
+ - img_shape
+ - ori_shape
+
+ Args:
+ to_float32 (bool): Whether to convert the loaded image to a float32
+ numpy array. If set to False, the loaded image is an uint8 array.
+ Defaults to False.
+ """
+
+ def __init__(self, **kwargs) -> None:
+ super().__init__()
+ self.from_file = TRANSFORMS.build(
+ dict(type='LoadImageFromFile', **kwargs))
+ self.from_ndarray = TRANSFORMS.build(
+ dict(type='LoadImageFromNDArray', **kwargs))
+
+ def transform(self, single_input: Union[str, np.ndarray, dict]) -> dict:
+ """Transform function to add image meta information.
+
+ Args:
+ single_input (str or dict or np.ndarray): The raw input from
+ inferencer.
+
+ Returns:
+ dict: The dict contains loaded image and meta information.
+ """
+ if isinstance(single_input, str):
+ inputs = dict(img_path=single_input)
+ elif isinstance(single_input, np.ndarray):
+ inputs = dict(img=single_input)
+ elif isinstance(single_input, dict):
+ inputs = single_input
+ else:
+ raise NotImplementedError
+
+ if 'img' in inputs:
+ return self.from_ndarray(inputs)
+
+ return self.from_file(inputs)
+
+
+@TRANSFORMS.register_module()
+class LoadOCRAnnotations(MMCV_LoadAnnotations):
+ """Load and process the ``instances`` annotation provided by dataset.
+
+ The annotation format is as the following:
+
+ .. code-block:: python
+
+ {
+ 'instances':
+ [
+ {
+ # List of 4 numbers representing the bounding box of the
+ # instance, in (x1, y1, x2, y2) order.
+ # used in text detection or text spotting tasks.
+ 'bbox': [x1, y1, x2, y2],
+
+ # Label of instance, usually it's 0.
+ # used in text detection or text spotting tasks.
+ 'bbox_label': 0,
+
+ # List of n numbers representing the polygon of the
+ # instance, in (xn, yn) order.
+ # used in text detection/ textspotter.
+ "polygon": [x1, y1, x2, y2, ... xn, yn],
+
+ # The flag indicating whether the instance should be ignored.
+ # used in text detection or text spotting tasks.
+ "ignore": False,
+
+ # The groundtruth of text.
+ # used in text recognition or text spotting tasks.
+ "text": 'tmp',
+ }
+ ]
+ }
+
+ After this module, the annotation has been changed to the format below:
+
+ .. code-block:: python
+
+ {
+ # In (x1, y1, x2, y2) order, float type. N is the number of bboxes
+ # in np.float32
+ 'gt_bboxes': np.ndarray(N, 4)
+ # In np.int64 type.
+ 'gt_bboxes_labels': np.ndarray(N, )
+ # In (x1, y1,..., xk, yk) order, float type.
+ # in list[np.float32]
+ 'gt_polygons': list[np.ndarray(2k, )]
+ # In np.bool_ type.
+ 'gt_ignored': np.ndarray(N, )
+ # In list[str]
+ 'gt_texts': list[str]
+ }
+
+ Required Keys:
+
+ - instances
+
+ - bbox (optional)
+ - bbox_label (optional)
+ - polygon (optional)
+ - ignore (optional)
+ - text (optional)
+
+ Added Keys:
+
+ - gt_bboxes (np.float32)
+ - gt_bboxes_labels (np.int64)
+ - gt_polygons (list[np.float32])
+ - gt_ignored (np.bool_)
+ - gt_texts (list[str])
+
+ Args:
+ with_bbox (bool): Whether to parse and load the bbox annotation.
+ Defaults to False.
+ with_label (bool): Whether to parse and load the label annotation.
+ Defaults to False.
+ with_polygon (bool): Whether to parse and load the polygon annotation.
+ Defaults to False.
+ with_text (bool): Whether to parse and load the text annotation.
+ Defaults to False.
+ """
+
+ def __init__(self,
+ with_bbox: bool = False,
+ with_label: bool = False,
+ with_polygon: bool = False,
+ with_text: bool = False,
+ **kwargs) -> None:
+ super().__init__(with_bbox=with_bbox, with_label=with_label, **kwargs)
+ self.with_polygon = with_polygon
+ self.with_text = with_text
+ self.with_ignore = with_bbox or with_polygon
+
+ def _load_ignore_flags(self, results: dict) -> None:
+ """Private function to load ignore annotations.
+
+ Args:
+ results (dict): Result dict from :obj:``OCRDataset``.
+
+ Returns:
+ dict: The dict contains loaded ignore annotations.
+ """
+ gt_ignored = []
+ for instance in results['instances']:
+ gt_ignored.append(instance['ignore'])
+ results['gt_ignored'] = np.array(gt_ignored, dtype=np.bool_)
+
+ def _load_polygons(self, results: dict) -> None:
+ """Private function to load polygon annotations.
+
+ Args:
+ results (dict): Result dict from :obj:``OCRDataset``.
+
+ Returns:
+ dict: The dict contains loaded polygon annotations.
+ """
+
+ gt_polygons = []
+ for instance in results['instances']:
+ gt_polygons.append(np.array(instance['polygon'], dtype=np.float32))
+ results['gt_polygons'] = gt_polygons
+
+ def _load_texts(self, results: dict) -> None:
+ """Private function to load text annotations.
+
+ Args:
+ results (dict): Result dict from :obj:``OCRDataset``.
+
+ Returns:
+ dict: The dict contains loaded text annotations.
+ """
+ gt_texts = []
+ for instance in results['instances']:
+ gt_texts.append(instance['text'])
+ results['gt_texts'] = gt_texts
+
+ def transform(self, results: dict) -> dict:
+ """Function to load multiple types annotations.
+
+ Args:
+ results (dict): Result dict from :obj:``OCRDataset``.
+
+ Returns:
+ dict: The dict contains loaded bounding box, label polygon and
+ text annotations.
+ """
+ results = super().transform(results)
+ if self.with_polygon:
+ self._load_polygons(results)
+ if self.with_text:
+ self._load_texts(results)
+ if self.with_ignore:
+ self._load_ignore_flags(results)
+ return results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(with_bbox={self.with_bbox}, '
+ repr_str += f'with_label={self.with_label}, '
+ repr_str += f'with_polygon={self.with_polygon}, '
+ repr_str += f'with_text={self.with_text}, '
+ repr_str += f"imdecode_backend='{self.imdecode_backend}', "
+
+ if self.file_client_args is not None:
+ repr_str += f'file_client_args={self.file_client_args})'
+ else:
+ repr_str += f'backend_args={self.backend_args})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class LoadKIEAnnotations(MMCV_LoadAnnotations):
+ """Load and process the ``instances`` annotation provided by dataset.
+
+ The annotation format is as the following:
+
+ .. code-block:: python
+
+ {
+ # A nested list of 4 numbers representing the bounding box of the
+ # instance, in (x1, y1, x2, y2) order.
+ 'bbox': np.array([[x1, y1, x2, y2], [x1, y1, x2, y2], ...],
+ dtype=np.int32),
+
+ # Labels of boxes. Shape is (N,).
+ 'bbox_labels': np.array([0, 2, ...], dtype=np.int32),
+
+ # Labels of edges. Shape (N, N).
+ 'edge_labels': np.array([0, 2, ...], dtype=np.int32),
+
+ # List of texts.
+ "texts": ['text1', 'text2', ...],
+ }
+
+ After this module, the annotation has been changed to the format below:
+
+ .. code-block:: python
+
+ {
+ # In (x1, y1, x2, y2) order, float type. N is the number of bboxes
+ # in np.float32
+ 'gt_bboxes': np.ndarray(N, 4),
+ # In np.int64 type.
+ 'gt_bboxes_labels': np.ndarray(N, ),
+ # In np.int32 type.
+ 'gt_edges_labels': np.ndarray(N, N),
+ # In list[str]
+ 'gt_texts': list[str],
+ # tuple(int)
+ 'ori_shape': (H, W)
+ }
+
+ Required Keys:
+
+ - bboxes
+ - bbox_labels
+ - edge_labels
+ - texts
+
+ Added Keys:
+
+ - gt_bboxes (np.float32)
+ - gt_bboxes_labels (np.int64)
+ - gt_edges_labels (np.int64)
+ - gt_texts (list[str])
+ - ori_shape (tuple[int])
+
+ Args:
+ with_bbox (bool): Whether to parse and load the bbox annotation.
+ Defaults to True.
+ with_label (bool): Whether to parse and load the label annotation.
+ Defaults to True.
+ with_text (bool): Whether to parse and load the text annotation.
+ Defaults to True.
+ directed (bool): Whether build edges as a directed graph.
+ Defaults to False.
+ key_node_idx (int, optional): Key node label, used to mask out edges
+ that are not connected from key nodes to value nodes. It has to be
+ specified together with ``value_node_idx``. Defaults to None.
+ value_node_idx (int, optional): Value node label, used to mask out
+ edges that are not connected from key nodes to value nodes. It has
+ to be specified together with ``key_node_idx``. Defaults to None.
+ """
+
+ def __init__(self,
+ with_bbox: bool = True,
+ with_label: bool = True,
+ with_text: bool = True,
+ directed: bool = False,
+ key_node_idx: Optional[int] = None,
+ value_node_idx: Optional[int] = None,
+ **kwargs) -> None:
+ super().__init__(with_bbox=with_bbox, with_label=with_label, **kwargs)
+ self.with_text = with_text
+ self.directed = directed
+ if key_node_idx is not None or value_node_idx is not None:
+ assert key_node_idx is not None and value_node_idx is not None
+ self.key_node_idx = key_node_idx
+ self.value_node_idx = value_node_idx
+
+ def _load_texts(self, results: dict) -> None:
+ """Private function to load text annotations.
+
+ Args:
+ results (dict): Result dict from :obj:``OCRDataset``.
+ """
+ gt_texts = []
+ for instance in results['instances']:
+ gt_texts.append(instance['text'])
+ results['gt_texts'] = gt_texts
+
+ def _load_labels(self, results: dict) -> None:
+ """Private function to load label annotations.
+
+ Args:
+ results (dict): Result dict from :obj:``WildReceiptDataset``.
+ """
+ bbox_labels = []
+ edge_labels = []
+ for instance in results['instances']:
+ bbox_labels.append(instance['bbox_label'])
+ edge_labels.append(instance['edge_label'])
+
+ bbox_labels = np.array(bbox_labels, np.int32)
+ edge_labels = np.array(edge_labels)
+ edge_labels = (edge_labels[:, None] == edge_labels[None, :]).astype(
+ np.int32)
+
+ if self.directed:
+ edge_labels = (edge_labels & bbox_labels == 1).astype(np.int32)
+
+ if hasattr(self, 'key_node_idx'):
+ key_nodes_mask = bbox_labels == self.key_node_idx
+ value_nodes_mask = bbox_labels == self.value_node_idx
+ key2value_mask = key_nodes_mask[:,
+ None] * value_nodes_mask[None, :]
+ edge_labels[~key2value_mask] = -1
+
+ np.fill_diagonal(edge_labels, -1)
+
+ results['gt_edges_labels'] = edge_labels.astype(np.int64)
+ results['gt_bboxes_labels'] = bbox_labels.astype(np.int64)
+
+ def transform(self, results: dict) -> dict:
+ """Function to load multiple types annotations.
+
+ Args:
+ results (dict): Result dict from :obj:``OCRDataset``.
+
+ Returns:
+ dict: The dict contains loaded bounding box, label polygon and
+ text annotations.
+ """
+ if 'ori_shape' not in results:
+ results['ori_shape'] = copy.deepcopy(results['img_shape'])
+ results = super().transform(results)
+ if self.with_text:
+ self._load_texts(results)
+ return results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(with_bbox={self.with_bbox}, '
+ repr_str += f'with_label={self.with_label}, '
+ repr_str += f'with_text={self.with_text})'
+ return repr_str
diff --git a/mmocr/datasets/transforms/ocr_transforms.py b/mmocr/datasets/transforms/ocr_transforms.py
new file mode 100644
index 0000000000000000000000000000000000000000..a05984a78935a99de2c7eed92edf5f1f764c3997
--- /dev/null
+++ b/mmocr/datasets/transforms/ocr_transforms.py
@@ -0,0 +1,758 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from typing import Dict, Tuple
+
+import cv2
+import mmcv
+import numpy as np
+from mmcv.transforms import Resize as MMCV_Resize
+from mmcv.transforms.base import BaseTransform
+from mmcv.transforms.utils import avoid_cache_randomness, cache_randomness
+
+from mmocr.registry import TRANSFORMS
+from mmocr.utils import (bbox2poly, crop_polygon, is_poly_inside_rect,
+ poly2bbox, poly2shapely, poly_make_valid,
+ remove_pipeline_elements, rescale_polygon,
+ shapely2poly)
+from .wrappers import ImgAugWrapper
+
+
+@TRANSFORMS.register_module()
+@avoid_cache_randomness
+class RandomCrop(BaseTransform):
+ """Randomly crop images and make sure to contain at least one intact
+ instance.
+
+ Required Keys:
+
+ - img
+ - gt_polygons
+ - gt_bboxes
+ - gt_bboxes_labels
+ - gt_ignored
+ - gt_texts (optional)
+
+ Modified Keys:
+
+ - img
+ - img_shape
+ - gt_polygons
+ - gt_bboxes
+ - gt_bboxes_labels
+ - gt_ignored
+ - gt_texts (optional)
+
+ Args:
+ min_side_ratio (float): The ratio of the shortest edge of the cropped
+ image to the original image size.
+ """
+
+ def __init__(self, min_side_ratio: float = 0.4) -> None:
+ if not 0. <= min_side_ratio <= 1.:
+ raise ValueError('`min_side_ratio` should be in range [0, 1],')
+ self.min_side_ratio = min_side_ratio
+
+ def _sample_valid_start_end(self, valid_array: np.ndarray, min_len: int,
+ max_start_idx: int,
+ min_end_idx: int) -> Tuple[int, int]:
+ """Sample a start and end idx on a given axis that contains at least
+ one polygon. There should be at least one intact polygon bounded by
+ max_start_idx and min_end_idx.
+
+ Args:
+ valid_array (ndarray): A 0-1 mask 1D array indicating valid regions
+ on the axis. 0 indicates text regions which are not allowed to
+ be sampled from.
+ min_len (int): Minimum distance between two start and end points.
+ max_start_idx (int): The maximum start index.
+ min_end_idx (int): The minimum end index.
+
+ Returns:
+ tuple(int, int): Start and end index on a given axis, where
+ 0 <= start < max_start_idx and
+ min_end_idx <= end < len(valid_array).
+ """
+ assert isinstance(min_len, int)
+ assert len(valid_array) > min_len
+
+ start_array = valid_array.copy()
+ max_start_idx = min(len(start_array) - min_len, max_start_idx)
+ start_array[max_start_idx:] = 0
+ start_array[0] = 1
+ diff_array = np.hstack([0, start_array]) - np.hstack([start_array, 0])
+ region_starts = np.where(diff_array < 0)[0]
+ region_ends = np.where(diff_array > 0)[0]
+ region_ind = np.random.randint(0, len(region_starts))
+ start = np.random.randint(region_starts[region_ind],
+ region_ends[region_ind])
+
+ end_array = valid_array.copy()
+ min_end_idx = max(start + min_len, min_end_idx)
+ end_array[:min_end_idx] = 0
+ end_array[-1] = 1
+ diff_array = np.hstack([0, end_array]) - np.hstack([end_array, 0])
+ region_starts = np.where(diff_array < 0)[0]
+ region_ends = np.where(diff_array > 0)[0]
+ region_ind = np.random.randint(0, len(region_starts))
+ # Note that end index will never be region_ends[region_ind]
+ # and therefore end index is always in range [0, w+1]
+ end = np.random.randint(region_starts[region_ind],
+ region_ends[region_ind])
+ return start, end
+
+ def _sample_crop_box(self, img_size: Tuple[int, int],
+ results: Dict) -> np.ndarray:
+ """Generate crop box which only contains intact polygon instances with
+ the number >= 1.
+
+ Args:
+ img_size (tuple(int, int)): The image size (h, w).
+ results (dict): The results dict.
+
+ Returns:
+ ndarray: Crop area in shape (4, ).
+ """
+ assert isinstance(img_size, tuple)
+ h, w = img_size[:2]
+
+ # Crop box can be represented by any integer numbers in
+ # range [0, w] and [0, h]
+ x_valid_array = np.ones(w + 1, dtype=np.int32)
+ y_valid_array = np.ones(h + 1, dtype=np.int32)
+
+ polygons = results['gt_polygons']
+
+ # Randomly select a polygon that must be inside
+ # the cropped region
+ kept_poly_idx = np.random.randint(0, len(polygons))
+ for i, polygon in enumerate(polygons):
+ polygon = polygon.reshape((-1, 2))
+
+ clip_x = np.clip(polygon[:, 0], 0, w)
+ clip_y = np.clip(polygon[:, 1], 0, h)
+ min_x = np.floor(np.min(clip_x)).astype(np.int32)
+ min_y = np.floor(np.min(clip_y)).astype(np.int32)
+ max_x = np.ceil(np.max(clip_x)).astype(np.int32)
+ max_y = np.ceil(np.max(clip_y)).astype(np.int32)
+
+ x_valid_array[min_x:max_x] = 0
+ y_valid_array[min_y:max_y] = 0
+
+ if i == kept_poly_idx:
+ max_x_start = min_x
+ min_x_end = max_x
+ max_y_start = min_y
+ min_y_end = max_y
+
+ min_w = int(w * self.min_side_ratio)
+ min_h = int(h * self.min_side_ratio)
+
+ x1, x2 = self._sample_valid_start_end(x_valid_array, min_w,
+ max_x_start, min_x_end)
+ y1, y2 = self._sample_valid_start_end(y_valid_array, min_h,
+ max_y_start, min_y_end)
+
+ return np.array([x1, y1, x2, y2])
+
+ def _crop_img(self, img: np.ndarray, bbox: np.ndarray) -> np.ndarray:
+ """Crop image given a bbox region.
+ Args:
+ img (ndarray): Image.
+ bbox (ndarray): Cropping region in shape (4, )
+
+ Returns:
+ ndarray: Cropped image.
+ """
+ assert img.ndim == 3
+ h, w, _ = img.shape
+ assert 0 <= bbox[1] < bbox[3] <= h
+ assert 0 <= bbox[0] < bbox[2] <= w
+ return img[bbox[1]:bbox[3], bbox[0]:bbox[2]]
+
+ def transform(self, results: Dict) -> Dict:
+ """Applying random crop on results.
+ Args:
+ results (dict): Result dict contains the data to transform.
+
+ Returns:
+ dict: The transformed data.
+ """
+ if len(results['gt_polygons']) < 1:
+ return results
+
+ crop_box = self._sample_crop_box(results['img'].shape, results)
+ img = self._crop_img(results['img'], crop_box)
+ results['img'] = img
+ results['img_shape'] = img.shape[:2]
+ crop_x = crop_box[0]
+ crop_y = crop_box[1]
+ crop_w = crop_box[2] - crop_box[0]
+ crop_h = crop_box[3] - crop_box[1]
+
+ labels = results['gt_bboxes_labels']
+ valid_labels = []
+ ignored = results['gt_ignored']
+ valid_ignored = []
+ if 'gt_texts' in results:
+ valid_texts = []
+ texts = results['gt_texts']
+
+ polys = results['gt_polygons']
+ valid_polys = []
+ for idx, poly in enumerate(polys):
+ poly = poly.reshape(-1, 2)
+ poly = (poly - (crop_x, crop_y)).flatten()
+ if is_poly_inside_rect(poly, [0, 0, crop_w, crop_h]):
+ valid_polys.append(poly)
+ valid_labels.append(labels[idx])
+ valid_ignored.append(ignored[idx])
+ if 'gt_texts' in results:
+ valid_texts.append(texts[idx])
+ results['gt_polygons'] = valid_polys
+ results['gt_bboxes_labels'] = np.array(valid_labels, dtype=np.int64)
+ results['gt_ignored'] = np.array(valid_ignored, dtype=bool)
+ if 'gt_texts' in results:
+ results['gt_texts'] = valid_texts
+ valid_bboxes = [poly2bbox(poly) for poly in results['gt_polygons']]
+ results['gt_bboxes'] = np.array(valid_bboxes).astype(
+ np.float32).reshape(-1, 4)
+
+ return results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(min_side_ratio = {self.min_side_ratio})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class RandomRotate(BaseTransform):
+ """Randomly rotate the image, boxes, and polygons. For recognition task,
+ only the image will be rotated. If set ``use_canvas`` as True, the shape of
+ rotated image might be modified based on the rotated angle size, otherwise,
+ the image will keep the shape before rotation.
+
+ Required Keys:
+
+ - img
+ - img_shape
+ - gt_bboxes (optional)
+ - gt_polygons (optional)
+
+ Modified Keys:
+
+ - img
+ - img_shape (optional)
+ - gt_bboxes (optional)
+ - gt_polygons (optional)
+
+ Added Keys:
+
+ - rotated_angle
+
+ Args:
+ max_angle (int): The maximum rotation angle (can be bigger than 180 or
+ a negative). Defaults to 10.
+ pad_with_fixed_color (bool): The flag for whether to pad rotated
+ image with fixed value. Defaults to False.
+ pad_value (tuple[int, int, int]): The color value for padding rotated
+ image. Defaults to (0, 0, 0).
+ use_canvas (bool): Whether to create a canvas for rotated image.
+ Defaults to False. If set true, the image shape may be modified.
+ """
+
+ def __init__(
+ self,
+ max_angle: int = 10,
+ pad_with_fixed_color: bool = False,
+ pad_value: Tuple[int, int, int] = (0, 0, 0),
+ use_canvas: bool = False,
+ ) -> None:
+ if not isinstance(max_angle, int):
+ raise TypeError('`max_angle` should be an integer'
+ f', but got {type(max_angle)} instead')
+ if not isinstance(pad_with_fixed_color, bool):
+ raise TypeError('`pad_with_fixed_color` should be a bool, '
+ f'but got {type(pad_with_fixed_color)} instead')
+ if not isinstance(pad_value, (list, tuple)):
+ raise TypeError('`pad_value` should be a list or tuple, '
+ f'but got {type(pad_value)} instead')
+ if len(pad_value) != 3:
+ raise ValueError('`pad_value` should contain three integers')
+ if not isinstance(pad_value[0], int) or not isinstance(
+ pad_value[1], int) or not isinstance(pad_value[2], int):
+ raise ValueError('`pad_value` should contain three integers')
+
+ self.max_angle = max_angle
+ self.pad_with_fixed_color = pad_with_fixed_color
+ self.pad_value = pad_value
+ self.use_canvas = use_canvas
+
+ @cache_randomness
+ def _sample_angle(self, max_angle: int) -> float:
+ """Sampling a random angle for rotation.
+
+ Args:
+ max_angle (int): Maximum rotation angle
+
+ Returns:
+ float: The random angle used for rotation
+ """
+ angle = np.random.random_sample() * 2 * max_angle - max_angle
+ return angle
+
+ @staticmethod
+ def _cal_canvas_size(ori_size: Tuple[int, int],
+ degree: int) -> Tuple[int, int]:
+ """Calculate the canvas size.
+
+ Args:
+ ori_size (Tuple[int, int]): The original image size (height, width)
+ degree (int): The rotation angle
+
+ Returns:
+ Tuple[int, int]: The size of the canvas
+ """
+ assert isinstance(ori_size, tuple)
+ angle = degree * math.pi / 180.0
+ h, w = ori_size[:2]
+
+ cos = math.cos(angle)
+ sin = math.sin(angle)
+ canvas_h = int(w * math.fabs(sin) + h * math.fabs(cos))
+ canvas_w = int(w * math.fabs(cos) + h * math.fabs(sin))
+
+ canvas_size = (canvas_h, canvas_w)
+ return canvas_size
+
+ @staticmethod
+ def _rotate_points(center: Tuple[float, float],
+ points: np.array,
+ theta: float,
+ center_shift: Tuple[int, int] = (0, 0)) -> np.array:
+ """Rotating a set of points according to the given theta.
+
+ Args:
+ center (Tuple[float, float]): The coordinate of the canvas center
+ points (np.array): A set of points needed to be rotated
+ theta (float): Rotation angle
+ center_shift (Tuple[int, int]): The shifting offset of the center
+ coordinate
+
+ Returns:
+ np.array: The rotated coordinates of the input points
+ """
+ (center_x, center_y) = center
+ center_y = -center_y
+ x, y = points[::2], points[1::2]
+ y = -y
+
+ theta = theta / 180 * math.pi
+ cos = math.cos(theta)
+ sin = math.sin(theta)
+
+ x = (x - center_x)
+ y = (y - center_y)
+
+ _x = center_x + x * cos - y * sin + center_shift[0]
+ _y = -(center_y + x * sin + y * cos) + center_shift[1]
+
+ points[::2], points[1::2] = _x, _y
+ return points
+
+ def _rotate_img(self, results: Dict) -> Tuple[int, int]:
+ """Rotating the input image based on the given angle.
+
+ Args:
+ results (dict): Result dict containing the data to transform.
+
+ Returns:
+ Tuple[int, int]: The shifting offset of the center point.
+ """
+ if results.get('img', None) is not None:
+ h = results['img'].shape[0]
+ w = results['img'].shape[1]
+ rotation_matrix = cv2.getRotationMatrix2D(
+ (w / 2, h / 2), results['rotated_angle'], 1)
+
+ canvas_size = self._cal_canvas_size((h, w),
+ results['rotated_angle'])
+ center_shift = (int(
+ (canvas_size[1] - w) / 2), int((canvas_size[0] - h) / 2))
+ rotation_matrix[0, 2] += int((canvas_size[1] - w) / 2)
+ rotation_matrix[1, 2] += int((canvas_size[0] - h) / 2)
+ if self.pad_with_fixed_color:
+ rotated_img = cv2.warpAffine(
+ results['img'],
+ rotation_matrix, (canvas_size[1], canvas_size[0]),
+ flags=cv2.INTER_NEAREST,
+ borderValue=self.pad_value)
+ else:
+ mask = np.zeros_like(results['img'])
+ (h_ind, w_ind) = (np.random.randint(0, h * 7 // 8),
+ np.random.randint(0, w * 7 // 8))
+ img_cut = results['img'][h_ind:(h_ind + h // 9),
+ w_ind:(w_ind + w // 9)]
+ img_cut = mmcv.imresize(img_cut,
+ (canvas_size[1], canvas_size[0]))
+ mask = cv2.warpAffine(
+ mask,
+ rotation_matrix, (canvas_size[1], canvas_size[0]),
+ borderValue=[1, 1, 1])
+ rotated_img = cv2.warpAffine(
+ results['img'],
+ rotation_matrix, (canvas_size[1], canvas_size[0]),
+ borderValue=[0, 0, 0])
+ rotated_img = rotated_img + img_cut * mask
+
+ results['img'] = rotated_img
+ else:
+ raise ValueError('`img` is not found in results')
+
+ return center_shift
+
+ def _rotate_bboxes(self, results: Dict, center_shift: Tuple[int,
+ int]) -> None:
+ """Rotating the bounding boxes based on the given angle.
+
+ Args:
+ results (dict): Result dict containing the data to transform.
+ center_shift (Tuple[int, int]): The shifting offset of the
+ center point
+ """
+ if results.get('gt_bboxes', None) is not None:
+ height, width = results['img_shape']
+ box_list = []
+ for box in results['gt_bboxes']:
+ rotated_box = self._rotate_points((width / 2, height / 2),
+ bbox2poly(box),
+ results['rotated_angle'],
+ center_shift)
+ rotated_box = poly2bbox(rotated_box)
+ box_list.append(rotated_box)
+
+ results['gt_bboxes'] = np.array(
+ box_list, dtype=np.float32).reshape(-1, 4)
+
+ def _rotate_polygons(self, results: Dict,
+ center_shift: Tuple[int, int]) -> None:
+ """Rotating the polygons based on the given angle.
+
+ Args:
+ results (dict): Result dict containing the data to transform.
+ center_shift (Tuple[int, int]): The shifting offset of the
+ center point
+ """
+ if results.get('gt_polygons', None) is not None:
+ height, width = results['img_shape']
+ polygon_list = []
+ for poly in results['gt_polygons']:
+ rotated_poly = self._rotate_points(
+ (width / 2, height / 2), poly, results['rotated_angle'],
+ center_shift)
+ polygon_list.append(rotated_poly)
+ results['gt_polygons'] = polygon_list
+
+ def transform(self, results: Dict) -> Dict:
+ """Applying random rotate on results.
+
+ Args:
+ results (Dict): Result dict containing the data to transform.
+ center_shift (Tuple[int, int]): The shifting offset of the
+ center point
+
+ Returns:
+ dict: The transformed data
+ """
+ # TODO rotate char_quads & char_rects for SegOCR
+ if self.use_canvas:
+ results['rotated_angle'] = self._sample_angle(self.max_angle)
+ # rotate image
+ center_shift = self._rotate_img(results)
+ # rotate gt_bboxes
+ self._rotate_bboxes(results, center_shift)
+ # rotate gt_polygons
+ self._rotate_polygons(results, center_shift)
+
+ results['img_shape'] = (results['img'].shape[0],
+ results['img'].shape[1])
+ else:
+ args = [
+ dict(
+ cls='Affine',
+ rotate=[-self.max_angle, self.max_angle],
+ backend='cv2',
+ order=0) # order=0 -> cv2.INTER_NEAREST
+ ]
+ imgaug_transform = ImgAugWrapper(args)
+ results = imgaug_transform(results)
+ return results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(max_angle = {self.max_angle}'
+ repr_str += f', pad_with_fixed_color = {self.pad_with_fixed_color}'
+ repr_str += f', pad_value = {self.pad_value}'
+ repr_str += f', use_canvas = {self.use_canvas})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class Resize(MMCV_Resize):
+ """Resize image & bboxes & polygons.
+
+ This transform resizes the input image according to ``scale`` or
+ ``scale_factor``. Bboxes and polygons are then resized with the same
+ scale factor. if ``scale`` and ``scale_factor`` are both set, it will use
+ ``scale`` to resize.
+
+ Required Keys:
+
+ - img
+ - img_shape
+ - gt_bboxes
+ - gt_polygons
+
+
+ Modified Keys:
+
+ - img
+ - img_shape
+ - gt_bboxes
+ - gt_polygons
+
+ Added Keys:
+
+ - scale
+ - scale_factor
+ - keep_ratio
+
+ Args:
+ scale (int or tuple): Image scales for resizing. Defaults to None.
+ scale_factor (float or tuple[float, float]): Scale factors for
+ resizing. It's either a factor applicable to both dimensions or
+ in the form of (scale_w, scale_h). Defaults to None.
+ keep_ratio (bool): Whether to keep the aspect ratio when resizing the
+ image. Defaults to False.
+ clip_object_border (bool): Whether to clip the objects outside the
+ border of the image. Defaults to True.
+ backend (str): Image resize backend, choices are 'cv2' and 'pillow'.
+ These two backends generates slightly different results. Defaults
+ to 'cv2'.
+ interpolation (str): Interpolation method, accepted values are
+ "nearest", "bilinear", "bicubic", "area", "lanczos" for 'cv2'
+ backend, "nearest", "bilinear" for 'pillow' backend. Defaults
+ to 'bilinear'.
+ """
+
+ def _resize_img(self, results: dict) -> None:
+ """Resize images with ``results['scale']``.
+
+ If no image is provided, only resize ``results['img_shape']``.
+ """
+ if results.get('img', None) is not None:
+ return super()._resize_img(results)
+ h, w = results['img_shape']
+ if self.keep_ratio:
+ new_w, new_h = mmcv.rescale_size((w, h),
+ results['scale'],
+ return_scale=False)
+ else:
+ new_w, new_h = results['scale']
+ w_scale = new_w / w
+ h_scale = new_h / h
+ results['img_shape'] = (new_h, new_w)
+ results['scale'] = (new_w, new_h)
+ results['scale_factor'] = (w_scale, h_scale)
+ results['keep_ratio'] = self.keep_ratio
+
+ def _resize_bboxes(self, results: dict) -> None:
+ """Resize bounding boxes."""
+ super()._resize_bboxes(results)
+ if results.get('gt_bboxes', None) is not None:
+ results['gt_bboxes'] = results['gt_bboxes'].astype(np.float32)
+
+ def _resize_polygons(self, results: dict) -> None:
+ """Resize polygons with ``results['scale_factor']``."""
+ if results.get('gt_polygons', None) is not None:
+ polygons = results['gt_polygons']
+ polygons_resize = []
+ for idx, polygon in enumerate(polygons):
+ polygon = rescale_polygon(polygon, results['scale_factor'])
+ if self.clip_object_border:
+ crop_bbox = np.array([
+ 0, 0, results['img_shape'][1], results['img_shape'][0]
+ ])
+ polygon = crop_polygon(polygon, crop_bbox)
+ if polygon is not None:
+ polygons_resize.append(polygon.astype(np.float32))
+ else:
+ polygons_resize.append(
+ np.zeros_like(polygons[idx], dtype=np.float32))
+ results['gt_polygons'] = polygons_resize
+
+ def transform(self, results: dict) -> dict:
+ """Transform function to resize images, bounding boxes and polygons.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Resized results, 'img', 'gt_bboxes', 'gt_polygons',
+ 'scale', 'scale_factor', 'height', 'width', and 'keep_ratio' keys
+ are updated in result dict.
+ """
+ results = super().transform(results)
+ self._resize_polygons(results)
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(scale={self.scale}, '
+ repr_str += f'scale_factor={self.scale_factor}, '
+ repr_str += f'keep_ratio={self.keep_ratio}, '
+ repr_str += f'clip_object_border={self.clip_object_border}), '
+ repr_str += f'backend={self.backend}), '
+ repr_str += f'interpolation={self.interpolation})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class RemoveIgnored(BaseTransform):
+ """Removed ignored elements from the pipeline.
+
+ Required Keys:
+
+ - gt_ignored
+ - gt_polygons (optional)
+ - gt_bboxes (optional)
+ - gt_bboxes_labels (optional)
+ - gt_texts (optional)
+
+ Modified Keys:
+
+ - gt_ignored
+ - gt_polygons (optional)
+ - gt_bboxes (optional)
+ - gt_bboxes_labels (optional)
+ - gt_texts (optional)
+ """
+
+ def transform(self, results: Dict) -> Dict:
+ remove_inds = np.where(results['gt_ignored'])[0]
+ if len(remove_inds) == len(results['gt_ignored']):
+ return None
+ return remove_pipeline_elements(results, remove_inds)
+
+
+@TRANSFORMS.register_module()
+class FixInvalidPolygon(BaseTransform):
+ """Fix invalid polygons in the dataset.
+
+ Required Keys:
+
+ - gt_polygons
+ - gt_ignored (optional)
+ - gt_bboxes (optional)
+ - gt_bboxes_labels (optional)
+ - gt_texts (optional)
+
+ Modified Keys:
+
+ - gt_polygons
+ - gt_ignored (optional)
+ - gt_bboxes (optional)
+ - gt_bboxes_labels (optional)
+ - gt_texts (optional)
+
+ Args:
+ mode (str): The mode of fixing invalid polygons. Options are 'fix' and
+ 'ignore'.
+ For the 'fix' mode, the transform will try to fix
+ the invalid polygons to a valid one by eliminating the
+ self-intersection or converting the bboxes to polygons. If
+ it can't be fixed by any means (e.g. the polygon contains less
+ than 3 points or it's actually a line/point), the annotation will
+ be removed.
+ For the 'ignore' mode, the invalid polygons
+ will be set to "ignored" during training.
+ Defaults to 'fix'.
+ min_poly_points (int): Minimum number of the coordinate points in a
+ polygon. Defaults to 4.
+ fix_from_bbox (bool): Whether to convert the bboxes to polygons when
+ the polygon is invalid and not directly fixable. Defaults to True.
+ """
+
+ def __init__(self,
+ mode: str = 'fix',
+ min_poly_points: int = 4,
+ fix_from_bbox: bool = True) -> None:
+ super().__init__()
+ self.mode = mode
+ assert min_poly_points >= 3, 'min_poly_points must be greater than 3.'
+ self.min_poly_points = min_poly_points
+ self.fix_from_bbox = fix_from_bbox
+ assert self.mode in [
+ 'fix', 'ignore'
+ ], f"Supported modes are 'fix' and 'ignore', but got {self.mode}"
+
+ def transform(self, results: Dict) -> Dict:
+ """Fix invalid polygons.
+
+ Args:
+ results (dict): Result dict containing the data to transform.
+
+ Returns:
+ Optional[dict]: The transformed data. If all the polygons are
+ unfixable, return None.
+ """
+ if results.get('gt_polygons', None) is not None:
+ remove_inds = []
+ for idx, polygon in enumerate(results['gt_polygons']):
+ if self.mode == 'ignore':
+ if results['gt_ignored'][idx]:
+ continue
+ if not (len(polygon) >= self.min_poly_points * 2
+ and len(polygon) % 2
+ == 0) or not poly2shapely(polygon).is_valid:
+ results['gt_ignored'][idx] = True
+ else:
+ # If "polygon" contains less than 3 points
+ if len(polygon) < 6:
+ remove_inds.append(idx)
+ continue
+ try:
+ shapely_polygon = poly2shapely(polygon)
+ if shapely_polygon.is_valid and len(
+ polygon) >= self.min_poly_points * 2:
+ continue
+ results['gt_polygons'][idx] = shapely2poly(
+ poly_make_valid(shapely_polygon))
+ # If an empty polygon is generated, it's still a bad
+ # fix
+ if len(results['gt_polygons'][idx]) == 0:
+ raise ValueError
+ # It's hard to fix, e.g. the "polygon" is a line or
+ # a point
+ except Exception:
+ if self.fix_from_bbox and 'gt_bboxes' in results:
+ bbox = results['gt_bboxes'][idx]
+ bbox_polygon = bbox2poly(bbox)
+ results['gt_polygons'][idx] = bbox_polygon
+ shapely_polygon = poly2shapely(bbox_polygon)
+ if (not shapely_polygon.is_valid
+ or shapely_polygon.is_empty):
+ remove_inds.append(idx)
+ else:
+ remove_inds.append(idx)
+ if len(remove_inds) == len(results['gt_polygons']):
+ return None
+ results = remove_pipeline_elements(results, remove_inds)
+ return results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(mode = "{self.mode}", '
+ repr_str += f'min_poly_points = {self.min_poly_points}, '
+ repr_str += f'fix_from_bbox = {self.fix_from_bbox})'
+ return repr_str
diff --git a/mmocr/datasets/transforms/textdet_transforms.py b/mmocr/datasets/transforms/textdet_transforms.py
new file mode 100644
index 0000000000000000000000000000000000000000..537c9bd323888e8906e287ce72a77d1af4d48582
--- /dev/null
+++ b/mmocr/datasets/transforms/textdet_transforms.py
@@ -0,0 +1,854 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+import random
+from typing import Dict, List, Sequence, Tuple, Union
+
+import cv2
+import mmcv
+import numpy as np
+from mmcv.transforms import RandomFlip as MMCV_RandomFlip
+from mmcv.transforms.base import BaseTransform
+from mmcv.transforms.utils import avoid_cache_randomness, cache_randomness
+from shapely.geometry import Polygon as plg
+
+from mmocr.registry import TRANSFORMS
+from mmocr.utils import crop_polygon, poly2bbox, poly_intersection
+
+
+@TRANSFORMS.register_module()
+@avoid_cache_randomness
+class BoundedScaleAspectJitter(BaseTransform):
+ """First randomly rescale the image so that the longside and shortside of
+ the image are around the bound; then jitter its aspect ratio.
+
+ Required Keys:
+
+ - img
+ - img_shape
+ - gt_bboxes (optional)
+ - gt_polygons (optional)
+
+ Modified Keys:
+
+ - img
+ - img_shape
+ - gt_bboxes (optional)
+ - gt_polygons (optional)
+
+ Added Keys:
+
+ - scale
+ - scale_factor
+ - keep_ratio
+
+ Args:
+ long_size_bound (int): The approximate bound for long size.
+ short_size_bound (int): The approximate bound for short size.
+ size_jitter_range (tuple(float, float)): Range of the ratio used
+ to jitter the size. Defaults to (0.7, 1.3).
+ aspect_ratio_jitter_range (tuple(float, float)): Range of the ratio
+ used to jitter its aspect ratio. Defaults to (0.9, 1.1).
+ resize_type (str): The type of resize class to use. Defaults to
+ "Resize".
+ **resize_kwargs: Other keyword arguments for the ``resize_type``.
+ """
+
+ def __init__(
+ self,
+ long_size_bound: int,
+ short_size_bound: int,
+ ratio_range: Tuple[float, float] = (0.7, 1.3),
+ aspect_ratio_range: Tuple[float, float] = (0.9, 1.1),
+ resize_type: str = 'Resize',
+ **resize_kwargs,
+ ) -> None:
+ super().__init__()
+ self.ratio_range = ratio_range
+ self.aspect_ratio_range = aspect_ratio_range
+ self.long_size_bound = long_size_bound
+ self.short_size_bound = short_size_bound
+ self.resize_cfg = dict(type=resize_type, **resize_kwargs)
+ # create an empty Reisize object
+ self.resize_cfg.update(dict(scale=0))
+ self.resize = TRANSFORMS.build(self.resize_cfg)
+
+ def _sample_from_range(self, range: Tuple[float, float]) -> float:
+ """A ratio will be randomly sampled from the range specified by
+ ``range``.
+
+ Args:
+ ratio_range (tuple[float]): The minimum and maximum ratio.
+
+ Returns:
+ float: A ratio randomly sampled from the range.
+ """
+ min_value, max_value = min(range), max(range)
+ value = np.random.random_sample() * (max_value - min_value) + min_value
+ return value
+
+ def transform(self, results: Dict) -> Dict:
+ h, w = results['img'].shape[:2]
+ new_scale = 1
+ if max(h, w) > self.long_size_bound:
+ new_scale = self.long_size_bound / max(h, w)
+ jitter_ratio = self._sample_from_range(self.ratio_range)
+ jitter_ratio = new_scale * jitter_ratio
+ if min(h, w) * jitter_ratio <= self.short_size_bound:
+ jitter_ratio = (self.short_size_bound + 10) * 1.0 / min(h, w)
+ aspect = self._sample_from_range(self.aspect_ratio_range)
+ h_scale = jitter_ratio * math.sqrt(aspect)
+ w_scale = jitter_ratio / math.sqrt(aspect)
+ new_h = int(h * h_scale)
+ new_w = int(w * w_scale)
+
+ self.resize.scale = (new_w, new_h)
+ return self.resize(results)
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(long_size_bound = {self.long_size_bound}, '
+ repr_str += f'short_size_bound = {self.short_size_bound}, '
+ repr_str += f'ratio_range = {self.ratio_range}, '
+ repr_str += f'aspect_ratio_range = {self.aspect_ratio_range}, '
+ repr_str += f'resize_cfg = {self.resize_cfg})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class RandomFlip(MMCV_RandomFlip):
+ """Flip the image & bbox polygon.
+
+ There are 3 flip modes:
+
+ - ``prob`` is float, ``direction`` is string: the image will be
+ ``direction``ly flipped with probability of ``prob`` .
+ E.g., ``prob=0.5``, ``direction='horizontal'``,
+ then image will be horizontally flipped with probability of 0.5.
+ - ``prob`` is float, ``direction`` is list of string: the image will
+ be ``direction[i]``ly flipped with probability of
+ ``prob/len(direction)``.
+ E.g., ``prob=0.5``, ``direction=['horizontal', 'vertical']``,
+ then image will be horizontally flipped with probability of 0.25,
+ vertically with probability of 0.25.
+ - ``prob`` is list of float, ``direction`` is list of string:
+ given ``len(prob) == len(direction)``, the image will
+ be ``direction[i]``ly flipped with probability of ``prob[i]``.
+ E.g., ``prob=[0.3, 0.5]``, ``direction=['horizontal',
+ 'vertical']``, then image will be horizontally flipped with
+ probability of 0.3, vertically with probability of 0.5.
+
+ Required Keys:
+ - img
+ - gt_bboxes (optional)
+ - gt_polygons (optional)
+
+ Modified Keys:
+ - img
+ - gt_bboxes (optional)
+ - gt_polygons (optional)
+
+ Added Keys:
+ - flip
+ - flip_direction
+ Args:
+ prob (float | list[float], optional): The flipping probability.
+ Defaults to None.
+ direction(str | list[str]): The flipping direction. Options
+ If input is a list, the length must equal ``prob``. Each
+ element in ``prob`` indicates the flip probability of
+ corresponding direction. Defaults to 'horizontal'.
+ """
+
+ def flip_polygons(self, polygons: Sequence[np.ndarray],
+ img_shape: Tuple[int, int],
+ direction: str) -> Sequence[np.ndarray]:
+ """Flip polygons horizontally, vertically or diagonally.
+
+ Args:
+ polygons (list[numpy.ndarray): polygons.
+ img_shape (tuple[int]): Image shape (height, width)
+ direction (str): Flip direction. Options are 'horizontal',
+ 'vertical' and 'diagonal'.
+ Returns:
+ list[numpy.ndarray]: Flipped polygons.
+ """
+
+ h, w = img_shape
+ flipped_polygons = []
+ if direction == 'horizontal':
+ for polygon in polygons:
+ flipped_polygon = polygon.copy()
+ flipped_polygon[0::2] = w - polygon[0::2]
+ flipped_polygons.append(flipped_polygon)
+ elif direction == 'vertical':
+ for polygon in polygons:
+ flipped_polygon = polygon.copy()
+ flipped_polygon[1::2] = h - polygon[1::2]
+ flipped_polygons.append(flipped_polygon)
+ elif direction == 'diagonal':
+ for polygon in polygons:
+ flipped_polygon = polygon.copy()
+ flipped_polygon[0::2] = w - polygon[0::2]
+ flipped_polygon[1::2] = h - polygon[1::2]
+ flipped_polygons.append(flipped_polygon)
+ else:
+ raise ValueError(
+ f"Flipping direction must be 'horizontal', 'vertical', \
+ or 'diagnal', but got '{direction}'")
+ return flipped_polygons
+
+ def _flip(self, results: dict) -> None:
+ """Flip images, bounding boxes and polygons.
+
+ Args:
+ results (dict): Result dict containing the data to transform.
+ """
+ super()._flip(results)
+ # flip polygons
+ if results.get('gt_polygons', None) is not None:
+ results['gt_polygons'] = self.flip_polygons(
+ results['gt_polygons'], results['img'].shape[:2],
+ results['flip_direction'])
+
+
+@TRANSFORMS.register_module()
+class SourceImagePad(BaseTransform):
+ """Pad Image to target size. It will randomly crop an area from the
+ original image and resize it to the target size, then paste the original
+ image to its top left corner.
+
+ Required Keys:
+
+ - img
+
+ Modified Keys:
+
+ - img
+ - img_shape
+
+ Added Keys:
+ - pad_shape
+ - pad_fixed_size
+
+ Args:
+ target_scale (int or tuple[int, int]]): The target size of padded
+ image. If it's an integer, then the padding size would be
+ (target_size, target_size). If it's tuple, then ``target_scale[0]``
+ should be the width and ``target_scale[1]`` should be the height.
+ The size of the padded image will be (target_scale[1],
+ target_scale[0])
+ crop_ratio (float or Tuple[float, float]): Relative size for the
+ crop region. If ``crop_ratio`` is a float, then the initial crop
+ size would be
+ ``(crop_ratio * img.shape[0], crop_ratio * img.shape[1])`` . If
+ ``crop_ratio`` is a tuple, then ``crop_ratio[0]`` is for the width
+ and ``crop_ratio[1]`` is for the height. The initial crop size
+ would be
+ ``(crop_ratio[1] * img.shape[0], crop_ratio[0] * img.shape[1])``.
+ Defaults to 1./9.
+ """
+
+ def __init__(self,
+ target_scale: Union[int, Tuple[int, int]],
+ crop_ratio: Union[float, Tuple[float,
+ float]] = 1. / 9) -> None:
+ self.target_scale = target_scale if isinstance(
+ target_scale, tuple) else (target_scale, target_scale)
+ self.crop_ratio = crop_ratio if isinstance(
+ crop_ratio, tuple) else (crop_ratio, crop_ratio)
+
+ def transform(self, results: Dict) -> Dict:
+ """Pad Image to target size. It will randomly select a small area from
+ the original image and resize it to the target size, then paste the
+ original image to its top left corner.
+
+ Args:
+ results (Dict): Result dict containing the data to transform.
+
+ Returns:
+ (Dict): The transformed data.
+ """
+ img = results['img']
+ h, w = img.shape[:2]
+ assert h <= self.target_scale[1] and w <= self.target_scale[
+ 0], 'image size should be smaller that the target size'
+ h_ind = np.random.randint(0, int(h - h * self.crop_ratio[1]) + 1)
+ w_ind = np.random.randint(0, int(w - w * self.crop_ratio[0]) + 1)
+ img_cut = img[h_ind:int(h_ind + h * self.crop_ratio[1]),
+ w_ind:int(w_ind + w * self.crop_ratio[1])]
+ expand_img = mmcv.imresize(img_cut, self.target_scale)
+ # paste img to the top left corner of the padding region
+ expand_img[0:h, 0:w] = img
+ results['img'] = expand_img
+ results['img_shape'] = expand_img.shape[:2]
+ results['pad_shape'] = expand_img.shape
+ results['pad_fixed_size'] = self.target_scale
+ return results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(target_scale = {self.target_scale}, '
+ repr_str += f'crop_ratio = {self.crop_ratio})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+@avoid_cache_randomness
+class ShortScaleAspectJitter(BaseTransform):
+ """First rescale the image for its shorter side to reach the short_size and
+ then jitter its aspect ratio, final rescale the shape guaranteed to be
+ divided by scale_divisor.
+
+ Required Keys:
+
+ - img
+ - img_shape
+ - gt_bboxes (optional)
+ - gt_polygons (optional)
+
+
+ Modified Keys:
+
+ - img
+ - img_shape
+ - gt_bboxes (optional)
+ - gt_polygons (optional)
+
+ Added Keys:
+
+ - scale
+ - scale_factor
+ - keep_ratio
+
+ Args:
+ short_size (int): Target shorter size before jittering the aspect
+ ratio. Defaults to 736.
+ short_size_jitter_range (tuple(float, float)): Range of the ratio used
+ to jitter the target shorter size. Defaults to (0.7, 1.3).
+ aspect_ratio_jitter_range (tuple(float, float)): Range of the ratio
+ used to jitter its aspect ratio. Defaults to (0.9, 1.1).
+ scale_divisor (int): The scale divisor. Defaults to 1.
+ resize_type (str): The type of resize class to use. Defaults to
+ "Resize".
+ **resize_kwargs: Other keyword arguments for the ``resize_type``.
+ """
+
+ def __init__(self,
+ short_size: int = 736,
+ ratio_range: Tuple[float, float] = (0.7, 1.3),
+ aspect_ratio_range: Tuple[float, float] = (0.9, 1.1),
+ scale_divisor: int = 1,
+ resize_type: str = 'Resize',
+ **resize_kwargs) -> None:
+
+ super().__init__()
+ self.short_size = short_size
+ self.ratio_range = ratio_range
+ self.aspect_ratio_range = aspect_ratio_range
+ self.resize_cfg = dict(type=resize_type, **resize_kwargs)
+
+ # create a empty Reisize object
+ self.resize_cfg.update(dict(scale=0))
+ self.resize = TRANSFORMS.build(self.resize_cfg)
+ self.scale_divisor = scale_divisor
+
+ def _sample_from_range(self, range: Tuple[float, float]) -> float:
+ """A ratio will be randomly sampled from the range specified by
+ ``range``.
+
+ Args:
+ ratio_range (tuple[float]): The minimum and maximum ratio.
+
+ Returns:
+ float: A ratio randomly sampled from the range.
+ """
+ min_value, max_value = min(range), max(range)
+ value = np.random.random_sample() * (max_value - min_value) + min_value
+ return value
+
+ def transform(self, results: Dict) -> Dict:
+ """Short Scale Aspect Jitter.
+ Args:
+ results (dict): Result dict containing the data to transform.
+
+ Returns:
+ dict: The transformed data.
+ """
+ h, w = results['img'].shape[:2]
+ ratio = self._sample_from_range(self.ratio_range)
+ scale = (ratio * self.short_size) / min(h, w)
+
+ aspect = self._sample_from_range(self.aspect_ratio_range)
+ h_scale = scale * math.sqrt(aspect)
+ w_scale = scale / math.sqrt(aspect)
+ new_h = round(h * h_scale)
+ new_w = round(w * w_scale)
+
+ new_h = math.ceil(new_h / self.scale_divisor) * self.scale_divisor
+ new_w = math.ceil(new_w / self.scale_divisor) * self.scale_divisor
+ self.resize.scale = (new_w, new_h)
+ return self.resize(results)
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(short_size = {self.short_size}, '
+ repr_str += f'ratio_range = {self.ratio_range}, '
+ repr_str += f'aspect_ratio_range = {self.aspect_ratio_range}, '
+ repr_str += f'scale_divisor = {self.scale_divisor}, '
+ repr_str += f'resize_cfg = {self.resize_cfg})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class TextDetRandomCropFlip(BaseTransform):
+ # TODO Rename this transformer; Refactor the redundant code.
+ """Random crop and flip a patch in the image. Only used in text detection
+ task.
+
+ Required Keys:
+
+ - img
+ - gt_bboxes
+ - gt_polygons
+
+ Modified Keys:
+
+ - img
+ - gt_bboxes
+ - gt_polygons
+
+ Args:
+ pad_ratio (float): The ratio of padding. Defaults to 0.1.
+ crop_ratio (float): The ratio of cropping. Defaults to 0.5.
+ iter_num (int): Number of operations. Defaults to 1.
+ min_area_ratio (float): Minimal area ratio between cropped patch
+ and original image. Defaults to 0.2.
+ epsilon (float): The threshold of polygon IoU between cropped area
+ and polygon, which is used to avoid cropping text instances.
+ Defaults to 0.01.
+ """
+
+ def __init__(self,
+ pad_ratio: float = 0.1,
+ crop_ratio: float = 0.5,
+ iter_num: int = 1,
+ min_area_ratio: float = 0.2,
+ epsilon: float = 1e-2) -> None:
+ if not isinstance(pad_ratio, float):
+ raise TypeError('`pad_ratio` should be an float, '
+ f'but got {type(pad_ratio)} instead')
+ if not isinstance(crop_ratio, float):
+ raise TypeError('`crop_ratio` should be a float, '
+ f'but got {type(crop_ratio)} instead')
+ if not isinstance(iter_num, int):
+ raise TypeError('`iter_num` should be an integer, '
+ f'but got {type(iter_num)} instead')
+ if not isinstance(min_area_ratio, float):
+ raise TypeError('`min_area_ratio` should be a float, '
+ f'but got {type(min_area_ratio)} instead')
+ if not isinstance(epsilon, float):
+ raise TypeError('`epsilon` should be a float, '
+ f'but got {type(epsilon)} instead')
+
+ self.pad_ratio = pad_ratio
+ self.epsilon = epsilon
+ self.crop_ratio = crop_ratio
+ self.iter_num = iter_num
+ self.min_area_ratio = min_area_ratio
+
+ @cache_randomness
+ def _random_prob(self) -> float:
+ """Get the random prob to decide whether apply the transform.
+
+ Returns:
+ float: The probability
+ """
+ return random.random()
+
+ @cache_randomness
+ def _random_flip_type(self) -> int:
+ """Get the random flip type.
+
+ Returns:
+ int: The flip type index. (0: horizontal; 1: vertical; 2: both)
+ """
+ return np.random.randint(3)
+
+ @cache_randomness
+ def _random_choice(self, axis: np.ndarray) -> np.ndarray:
+ """Randomly select two coordinates from the axis.
+
+ Args:
+ axis (np.ndarray): Result dict containing the data to transform
+
+ Returns:
+ np.ndarray: The selected coordinates
+ """
+ return np.random.choice(axis, size=2)
+
+ def transform(self, results: Dict) -> Dict:
+ """Applying random crop flip on results.
+
+ Args:
+ results (dict): Result dict containing the data to transform
+
+ Returns:
+ dict: The transformed data
+ """
+ assert 'img' in results, '`img` is not found in results'
+ for _ in range(self.iter_num):
+ results = self._random_crop_flip_polygons(results)
+ bboxes = [poly2bbox(poly) for poly in results['gt_polygons']]
+ results['gt_bboxes'] = np.array(
+ bboxes, dtype=np.float32).reshape(-1, 4)
+ return results
+
+ def _random_crop_flip_polygons(self, results: Dict) -> Dict:
+ """Applying random crop flip on polygons.
+
+ Args:
+ results (dict): Result dict containing the data to transform
+
+ Returns:
+ dict: The transformed data
+ """
+ if results.get('gt_polygons', None) is None:
+ return results
+
+ image = results['img']
+ polygons = results['gt_polygons']
+ if len(polygons) == 0 or self._random_prob() > self.crop_ratio:
+ return results
+
+ h, w = results['img_shape']
+ area = h * w
+ pad_h = int(h * self.pad_ratio)
+ pad_w = int(w * self.pad_ratio)
+ h_axis, w_axis = self._generate_crop_target(image, polygons, pad_h,
+ pad_w)
+ if len(h_axis) == 0 or len(w_axis) == 0:
+ return results
+
+ # At most 10 attempts
+ for _ in range(10):
+ polys_keep = []
+ polys_new = []
+ kept_idxs = []
+ xx = self._random_choice(w_axis)
+ yy = self._random_choice(h_axis)
+ xmin = np.clip(np.min(xx) - pad_w, 0, w - 1)
+ xmax = np.clip(np.max(xx) - pad_w, 0, w - 1)
+ ymin = np.clip(np.min(yy) - pad_h, 0, h - 1)
+ ymax = np.clip(np.max(yy) - pad_h, 0, h - 1)
+ if (xmax - xmin) * (ymax - ymin) < area * self.min_area_ratio:
+ # Skip when cropped area is too small
+ continue
+
+ pts = np.stack([[xmin, xmax, xmax, xmin],
+ [ymin, ymin, ymax, ymax]]).T.astype(np.int32)
+ pp = plg(pts)
+ success_flag = True
+ for poly_idx, polygon in enumerate(polygons):
+ ppi = plg(polygon.reshape(-1, 2))
+ ppiou = poly_intersection(ppi, pp)
+ if np.abs(ppiou - float(ppi.area)) > self.epsilon and \
+ np.abs(ppiou) > self.epsilon:
+ success_flag = False
+ break
+ kept_idxs.append(poly_idx)
+ if np.abs(ppiou - float(ppi.area)) < self.epsilon:
+ polys_new.append(polygon)
+ else:
+ polys_keep.append(polygon)
+
+ if success_flag:
+ break
+
+ cropped = image[ymin:ymax, xmin:xmax, :]
+ select_type = self._random_flip_type()
+ if select_type == 0:
+ img = np.ascontiguousarray(cropped[:, ::-1])
+ elif select_type == 1:
+ img = np.ascontiguousarray(cropped[::-1, :])
+ else:
+ img = np.ascontiguousarray(cropped[::-1, ::-1])
+ image[ymin:ymax, xmin:xmax, :] = img
+ results['img'] = image
+
+ if len(polys_new) != 0:
+ height, width, _ = cropped.shape
+ if select_type == 0:
+ for idx, polygon in enumerate(polys_new):
+ poly = polygon.reshape(-1, 2)
+ poly[:, 0] = width - poly[:, 0] + 2 * xmin
+ polys_new[idx] = poly.reshape(-1, )
+ elif select_type == 1:
+ for idx, polygon in enumerate(polys_new):
+ poly = polygon.reshape(-1, 2)
+ poly[:, 1] = height - poly[:, 1] + 2 * ymin
+ polys_new[idx] = poly.reshape(-1, )
+ else:
+ for idx, polygon in enumerate(polys_new):
+ poly = polygon.reshape(-1, 2)
+ poly[:, 0] = width - poly[:, 0] + 2 * xmin
+ poly[:, 1] = height - poly[:, 1] + 2 * ymin
+ polys_new[idx] = poly.reshape(-1, )
+ polygons = polys_keep + polys_new
+ # ignored = polys_keep_ignore_idx + polys_new_ignore_idx
+ results['gt_polygons'] = polygons
+ results['gt_ignored'] = results['gt_ignored'][kept_idxs]
+ results['gt_bboxes_labels'] = results['gt_bboxes_labels'][
+ kept_idxs]
+ return results
+
+ def _generate_crop_target(self, image: np.ndarray,
+ all_polys: List[np.ndarray], pad_h: int,
+ pad_w: int) -> Tuple[np.ndarray, np.ndarray]:
+ """Generate cropping target and make sure not to crop the polygon
+ instances.
+
+ Args:
+ image (np.ndarray): The image waited to be crop.
+ all_polys (list[np.ndarray]): Ground-truth polygons.
+ pad_h (int): Padding length of height.
+ pad_w (int): Padding length of width.
+
+ Returns:
+ (np.ndarray, np.ndarray): Returns a tuple ``(h_axis, w_axis)``,
+ where ``h_axis`` is the vertical cropping range and ``w_axis``
+ is the horizontal cropping range.
+ """
+ h, w, _ = image.shape
+ h_array = np.zeros((h + pad_h * 2), dtype=np.int32)
+ w_array = np.zeros((w + pad_w * 2), dtype=np.int32)
+
+ text_polys = []
+ for polygon in all_polys:
+ rect = cv2.minAreaRect(polygon.astype(np.int32).reshape(-1, 2))
+ box = cv2.boxPoints(rect)
+ box = np.int0(box)
+ text_polys.append([box[0], box[1], box[2], box[3]])
+
+ polys = np.array(text_polys, dtype=np.int32)
+ for poly in polys:
+ poly = np.round(poly, decimals=0).astype(np.int32)
+ minx, maxx = np.min(poly[:, 0]), np.max(poly[:, 0])
+ miny, maxy = np.min(poly[:, 1]), np.max(poly[:, 1])
+ w_array[minx + pad_w:maxx + pad_w] = 1
+ h_array[miny + pad_h:maxy + pad_h] = 1
+
+ h_axis = np.where(h_array == 0)[0]
+ w_axis = np.where(w_array == 0)[0]
+ return h_axis, w_axis
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(pad_ratio = {self.pad_ratio}'
+ repr_str += f', crop_ratio = {self.crop_ratio}'
+ repr_str += f', iter_num = {self.iter_num}'
+ repr_str += f', min_area_ratio = {self.min_area_ratio}'
+ repr_str += f', epsilon = {self.epsilon})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+@avoid_cache_randomness
+class TextDetRandomCrop(BaseTransform):
+ """Randomly select a region and crop images to a target size and make sure
+ to contain text region. This transform may break up text instances, and for
+ broken text instances, we will crop it's bbox and polygon coordinates. This
+ transform is recommend to be used in segmentation-based network.
+
+ Required Keys:
+
+ - img
+ - gt_polygons
+ - gt_bboxes
+ - gt_bboxes_labels
+ - gt_ignored
+
+ Modified Keys:
+
+ - img
+ - img_shape
+ - gt_polygons
+ - gt_bboxes
+ - gt_bboxes_labels
+ - gt_ignored
+
+ Args:
+ target_size (tuple(int, int) or int): Target size for the cropped
+ image. If it's a tuple, then target width and target height will be
+ ``target_size[0]`` and ``target_size[1]``, respectively. If it's an
+ integer, them both target width and target height will be
+ ``target_size``.
+ positive_sample_ratio (float): The probability of sampling regions
+ that go through text regions. Defaults to 5. / 8.
+ """
+
+ def __init__(self,
+ target_size: Tuple[int, int] or int,
+ positive_sample_ratio: float = 5.0 / 8.0) -> None:
+ self.target_size = target_size if isinstance(
+ target_size, tuple) else (target_size, target_size)
+ self.positive_sample_ratio = positive_sample_ratio
+
+ def _get_postive_prob(self) -> float:
+ """Get the probability to do positive sample.
+
+ Returns:
+ float: The probability to do positive sample.
+ """
+ return np.random.random_sample()
+
+ def _sample_num(self, start, end):
+ """Sample a number in range [start, end].
+
+ Args:
+ start (int): Starting point.
+ end (int): Ending point.
+
+ Returns:
+ (int): Sampled number.
+ """
+ return random.randint(start, end)
+
+ def _sample_offset(self, gt_polygons: Sequence[np.ndarray],
+ img_size: Tuple[int, int]) -> Tuple[int, int]:
+ """Samples the top-left coordinate of a crop region, ensuring that the
+ cropped region contains at least one polygon.
+
+ Args:
+ gt_polygons (list(ndarray)) : Polygons.
+ img_size (tuple(int, int)) : Image size in the format of
+ (height, width).
+
+ Returns:
+ tuple(int, int): Top-left coordinate of the cropped region.
+ """
+ h, w = img_size
+ t_w, t_h = self.target_size
+
+ # target size is bigger than origin size
+ t_h = t_h if t_h < h else h
+ t_w = t_w if t_w < w else w
+ if (gt_polygons is not None and len(gt_polygons) > 0
+ and self._get_postive_prob() < self.positive_sample_ratio):
+
+ # make sure to crop the positive region
+
+ # the minimum top left to crop positive region (h,w)
+ tl = np.array([h + 1, w + 1], dtype=np.int32)
+ for gt_polygon in gt_polygons:
+ temp_point = np.min(gt_polygon.reshape(2, -1), axis=1)
+ if temp_point[0] <= tl[0]:
+ tl[0] = temp_point[0]
+ if temp_point[1] <= tl[1]:
+ tl[1] = temp_point[1]
+ tl = tl - (t_h, t_w)
+ tl[tl < 0] = 0
+ # the maximum bottum right to crop positive region
+ br = np.array([0, 0], dtype=np.int32)
+ for gt_polygon in gt_polygons:
+ temp_point = np.max(gt_polygon.reshape(2, -1), axis=1)
+ if temp_point[0] > br[0]:
+ br[0] = temp_point[0]
+ if temp_point[1] > br[1]:
+ br[1] = temp_point[1]
+ br = br - (t_h, t_w)
+ br[br < 0] = 0
+
+ # if br is too big so that crop the outside region of img
+ br[0] = min(br[0], h - t_h)
+ br[1] = min(br[1], w - t_w)
+ #
+ h = self._sample_num(tl[0], br[0]) if tl[0] < br[0] else 0
+ w = self._sample_num(tl[1], br[1]) if tl[1] < br[1] else 0
+ else:
+ # make sure not to crop outside of img
+
+ h = self._sample_num(0, h - t_h) if h - t_h > 0 else 0
+ w = self._sample_num(0, w - t_w) if w - t_w > 0 else 0
+
+ return (h, w)
+
+ def _crop_img(self, img: np.ndarray, offset: Tuple[int, int],
+ target_size: Tuple[int, int]) -> np.ndarray:
+ """Crop the image given an offset and a target size.
+
+ Args:
+ img (ndarray): Image.
+ offset (Tuple[int. int]): Coordinates of the starting point.
+ target_size: Target image size.
+ """
+ h, w = img.shape[:2]
+ target_size = target_size[::-1]
+ br = np.min(
+ np.stack((np.array(offset) + np.array(target_size), np.array(
+ (h, w)))),
+ axis=0)
+ return img[offset[0]:br[0], offset[1]:br[1]], np.array(
+ [offset[1], offset[0], br[1], br[0]])
+
+ def _crop_polygons(self, polygons: Sequence[np.ndarray],
+ crop_bbox: np.ndarray) -> Sequence[np.ndarray]:
+ """Crop polygons to be within a crop region. If polygon crosses the
+ crop_bbox, we will keep the part left in crop_bbox by cropping its
+ boardline.
+
+ Args:
+ polygons (list(ndarray)): List of polygons [(N1, ), (N2, ), ...].
+ crop_bbox (ndarray): Cropping region. [x1, y1, x2, y1].
+
+ Returns
+ tuple(List(ArrayLike), list[int]):
+ - (List(ArrayLike)): The rest of the polygons located in the
+ crop region.
+ - (list[int]): Index list of the reserved polygons.
+ """
+ polygons_cropped = []
+ kept_idx = []
+ for idx, polygon in enumerate(polygons):
+ if polygon.size < 6:
+ continue
+ poly = crop_polygon(polygon, crop_bbox)
+ if poly is not None:
+ poly = poly.reshape(-1, 2) - (crop_bbox[0], crop_bbox[1])
+ polygons_cropped.append(poly.reshape(-1))
+ kept_idx.append(idx)
+ return (polygons_cropped, kept_idx)
+
+ def transform(self, results: Dict) -> Dict:
+ """Applying random crop on results.
+ Args:
+ results (dict): Result dict contains the data to transform.
+
+ Returns:
+ dict: The transformed data
+ """
+ if self.target_size == results['img'].shape[:2][::-1]:
+ return results
+ gt_polygons = results['gt_polygons']
+ crop_offset = self._sample_offset(gt_polygons,
+ results['img'].shape[:2])
+ img, crop_bbox = self._crop_img(results['img'], crop_offset,
+ self.target_size)
+ results['img'] = img
+ results['img_shape'] = img.shape[:2]
+ gt_polygons, polygon_kept_idx = self._crop_polygons(
+ gt_polygons, crop_bbox)
+ bboxes = [poly2bbox(poly) for poly in gt_polygons]
+ results['gt_bboxes'] = np.array(
+ bboxes, dtype=np.float32).reshape(-1, 4)
+
+ results['gt_polygons'] = gt_polygons
+ results['gt_bboxes_labels'] = results['gt_bboxes_labels'][
+ polygon_kept_idx]
+ results['gt_ignored'] = results['gt_ignored'][polygon_kept_idx]
+ return results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(target_size = {self.target_size}, '
+ repr_str += f'positive_sample_ratio = {self.positive_sample_ratio})'
+ return repr_str
diff --git a/mmocr/datasets/transforms/textrecog_transforms.py b/mmocr/datasets/transforms/textrecog_transforms.py
new file mode 100644
index 0000000000000000000000000000000000000000..abb094c316cc88b4f288de84aba281f9cabc4dd8
--- /dev/null
+++ b/mmocr/datasets/transforms/textrecog_transforms.py
@@ -0,0 +1,724 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+import random
+from typing import Dict, List, Optional, Tuple
+
+import cv2
+import mmcv
+import numpy as np
+from mmcv.transforms.base import BaseTransform
+from mmcv.transforms.utils import cache_randomness
+
+from mmocr.registry import TRANSFORMS
+
+
+@TRANSFORMS.register_module()
+class PyramidRescale(BaseTransform):
+ """Resize the image to the base shape, downsample it with gaussian pyramid,
+ and rescale it back to original size.
+
+ Adapted from https://github.com/FangShancheng/ABINet.
+
+ Required Keys:
+
+ - img (ndarray)
+
+ Modified Keys:
+
+ - img (ndarray)
+
+ Args:
+ factor (int): The decay factor from base size, or the number of
+ downsampling operations from the base layer.
+ base_shape (tuple[int, int]): The shape (width, height) of the base
+ layer of the pyramid.
+ randomize_factor (bool): If True, the final factor would be a random
+ integer in [0, factor].
+ """
+
+ def __init__(self,
+ factor: int = 4,
+ base_shape: Tuple[int, int] = (128, 512),
+ randomize_factor: bool = True) -> None:
+ if not isinstance(factor, int):
+ raise TypeError('`factor` should be an integer, '
+ f'but got {type(factor)} instead')
+ if not isinstance(base_shape, (list, tuple)):
+ raise TypeError('`base_shape` should be a list or tuple, '
+ f'but got {type(base_shape)} instead')
+ if not len(base_shape) == 2:
+ raise ValueError('`base_shape` should contain two integers')
+ if not isinstance(base_shape[0], int) or not isinstance(
+ base_shape[1], int):
+ raise ValueError('`base_shape` should contain two integers')
+ if not isinstance(randomize_factor, bool):
+ raise TypeError('`randomize_factor` should be a bool, '
+ f'but got {type(randomize_factor)} instead')
+
+ self.factor = factor
+ self.randomize_factor = randomize_factor
+ self.base_w, self.base_h = base_shape
+
+ @cache_randomness
+ def get_random_factor(self) -> float:
+ """Get the randomized factor.
+
+ Returns:
+ float: The randomized factor.
+ """
+ return np.random.randint(0, self.factor + 1)
+
+ def transform(self, results: Dict) -> Dict:
+ """Applying pyramid rescale on results.
+
+ Args:
+ results (dict): Result dict containing the data to transform.
+
+ Returns:
+ Dict: The transformed data.
+ """
+
+ assert 'img' in results, '`img` is not found in results'
+ if self.randomize_factor:
+ self.factor = self.get_random_factor()
+ if self.factor == 0:
+ return results
+ img = results['img']
+ src_h, src_w = img.shape[:2]
+ scale_img = mmcv.imresize(img, (self.base_w, self.base_h))
+ for _ in range(self.factor):
+ scale_img = cv2.pyrDown(scale_img)
+ scale_img = mmcv.imresize(scale_img, (src_w, src_h))
+ results['img'] = scale_img
+ return results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(factor = {self.factor}'
+ repr_str += f', randomize_factor = {self.randomize_factor}'
+ repr_str += f', base_w = {self.base_w}'
+ repr_str += f', base_h = {self.base_h})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class RescaleToHeight(BaseTransform):
+ """Rescale the image to the height according to setting and keep the aspect
+ ratio unchanged if possible. However, if any of ``min_width``,
+ ``max_width`` or ``width_divisor`` are specified, aspect ratio may still be
+ changed to ensure the width meets these constraints.
+
+ Required Keys:
+
+ - img
+
+ Modified Keys:
+
+ - img
+ - img_shape
+
+ Added Keys:
+
+ - scale
+ - scale_factor
+ - keep_ratio
+
+ Args:
+ height (int): Height of rescaled image.
+ min_width (int, optional): Minimum width of rescaled image. Defaults
+ to None.
+ max_width (int, optional): Maximum width of rescaled image. Defaults
+ to None.
+ width_divisor (int): The divisor of width size. Defaults to 1.
+ resize_type (str): The type of resize class to use. Defaults to
+ "Resize".
+ **resize_kwargs: Other keyword arguments for the ``resize_type``.
+ """
+
+ def __init__(self,
+ height: int,
+ min_width: Optional[int] = None,
+ max_width: Optional[int] = None,
+ width_divisor: int = 1,
+ resize_type: str = 'Resize',
+ **resize_kwargs) -> None:
+
+ super().__init__()
+ assert isinstance(height, int)
+ assert isinstance(width_divisor, int)
+ if min_width is not None:
+ assert isinstance(min_width, int)
+ if max_width is not None:
+ assert isinstance(max_width, int)
+ self.width_divisor = width_divisor
+ self.height = height
+ self.min_width = min_width
+ self.max_width = max_width
+ self.resize_cfg = dict(type=resize_type, **resize_kwargs)
+ self.resize_cfg.update(dict(scale=0))
+ self.resize = TRANSFORMS.build(self.resize_cfg)
+
+ def transform(self, results: Dict) -> Dict:
+ """Transform function to resize images, bounding boxes and polygons.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Resized results.
+ """
+ ori_height, ori_width = results['img'].shape[:2]
+ new_width = math.ceil(float(self.height) / ori_height * ori_width)
+ if self.min_width is not None:
+ new_width = max(self.min_width, new_width)
+ if self.max_width is not None:
+ new_width = min(self.max_width, new_width)
+
+ if new_width % self.width_divisor != 0:
+ new_width = round(
+ new_width / self.width_divisor) * self.width_divisor
+ # TODO replace up code after testing precision.
+ # new_width = math.ceil(
+ # new_width / self.width_divisor) * self.width_divisor
+ scale = (new_width, self.height)
+ self.resize.scale = scale
+ results = self.resize(results)
+ return results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(height={self.height}, '
+ repr_str += f'min_width={self.min_width}, '
+ repr_str += f'max_width={self.max_width}, '
+ repr_str += f'width_divisor={self.width_divisor}, '
+ repr_str += f'resize_cfg={self.resize_cfg})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class PadToWidth(BaseTransform):
+ """Only pad the image's width.
+
+ Required Keys:
+
+ - img
+
+ Modified Keys:
+
+ - img
+ - img_shape
+
+ Added Keys:
+
+ - pad_shape
+ - pad_fixed_size
+ - pad_size_divisor
+ - valid_ratio
+
+ Args:
+ width (int): Target width of padded image. Defaults to None.
+ pad_cfg (dict): Config to construct the Resize transform. Refer to
+ ``Pad`` for detail. Defaults to ``dict(type='Pad')``.
+ """
+
+ def __init__(self, width: int, pad_cfg: dict = dict(type='Pad')) -> None:
+ super().__init__()
+ assert isinstance(width, int)
+ self.width = width
+ self.pad_cfg = pad_cfg
+ _pad_cfg = self.pad_cfg.copy()
+ _pad_cfg.update(dict(size=0))
+ self.pad = TRANSFORMS.build(_pad_cfg)
+
+ def transform(self, results: Dict) -> Dict:
+ """Call function to pad images.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Updated result dict.
+ """
+ ori_height, ori_width = results['img'].shape[:2]
+ valid_ratio = min(1.0, 1.0 * ori_width / self.width)
+ size = (self.width, ori_height)
+ self.pad.size = size
+ results = self.pad(results)
+ results['valid_ratio'] = valid_ratio
+ return results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(width={self.width}, '
+ repr_str += f'pad_cfg={self.pad_cfg})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class TextRecogGeneralAug(BaseTransform):
+ """A general geometric augmentation tool for text images in the CVPR 2020
+ paper "Learn to Augment: Joint Data Augmentation and Network Optimization
+ for Text Recognition". It applies distortion, stretching, and perspective
+ transforms to an image.
+
+ This implementation is adapted from
+ https://github.com/RubanSeven/Text-Image-Augmentation-python/blob/master/augment.py # noqa
+
+ TODO: Split this transform into three transforms.
+
+ Required Keys:
+
+ - img
+
+ Modified Keys:
+
+ - img
+ - img_shape
+ """ # noqa
+
+ def transform(self, results: Dict) -> Dict:
+ """Call function to pad images.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Updated result dict.
+ """
+ h, w = results['img'].shape[:2]
+ if h >= 20 and w >= 20:
+ results['img'] = self.tia_distort(results['img'],
+ random.randint(3, 6))
+ results['img'] = self.tia_stretch(results['img'],
+ random.randint(3, 6))
+ h, w = results['img'].shape[:2]
+ if h >= 5 and w >= 5:
+ results['img'] = self.tia_perspective(results['img'])
+ results['img_shape'] = results['img'].shape[:2]
+ return results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += '()'
+ return repr_str
+
+ def tia_distort(self, img: np.ndarray, segment: int = 4) -> np.ndarray:
+ """Image distortion.
+
+ Args:
+ img (np.ndarray): The image.
+ segment (int): The number of segments to divide the image along
+ the width. Defaults to 4.
+ """
+ img_h, img_w = img.shape[:2]
+
+ cut = img_w // segment
+ thresh = cut // 3
+
+ src_pts = list()
+ dst_pts = list()
+
+ src_pts.append([0, 0])
+ src_pts.append([img_w, 0])
+ src_pts.append([img_w, img_h])
+ src_pts.append([0, img_h])
+
+ dst_pts.append([np.random.randint(thresh), np.random.randint(thresh)])
+ dst_pts.append(
+ [img_w - np.random.randint(thresh),
+ np.random.randint(thresh)])
+ dst_pts.append([
+ img_w - np.random.randint(thresh),
+ img_h - np.random.randint(thresh)
+ ])
+ dst_pts.append(
+ [np.random.randint(thresh), img_h - np.random.randint(thresh)])
+
+ half_thresh = thresh * 0.5
+
+ for cut_idx in np.arange(1, segment, 1):
+ src_pts.append([cut * cut_idx, 0])
+ src_pts.append([cut * cut_idx, img_h])
+ dst_pts.append([
+ cut * cut_idx + np.random.randint(thresh) - half_thresh,
+ np.random.randint(thresh) - half_thresh
+ ])
+ dst_pts.append([
+ cut * cut_idx + np.random.randint(thresh) - half_thresh,
+ img_h + np.random.randint(thresh) - half_thresh
+ ])
+
+ dst = self.warp_mls(img, src_pts, dst_pts, img_w, img_h)
+
+ return dst
+
+ def tia_stretch(self, img: np.ndarray, segment: int = 4) -> np.ndarray:
+ """Image stretching.
+
+ Args:
+ img (np.ndarray): The image.
+ segment (int): The number of segments to divide the image along
+ the width. Defaults to 4.
+ """
+ img_h, img_w = img.shape[:2]
+
+ cut = img_w // segment
+ thresh = cut * 4 // 5
+
+ src_pts = list()
+ dst_pts = list()
+
+ src_pts.append([0, 0])
+ src_pts.append([img_w, 0])
+ src_pts.append([img_w, img_h])
+ src_pts.append([0, img_h])
+
+ dst_pts.append([0, 0])
+ dst_pts.append([img_w, 0])
+ dst_pts.append([img_w, img_h])
+ dst_pts.append([0, img_h])
+
+ half_thresh = thresh * 0.5
+
+ for cut_idx in np.arange(1, segment, 1):
+ move = np.random.randint(thresh) - half_thresh
+ src_pts.append([cut * cut_idx, 0])
+ src_pts.append([cut * cut_idx, img_h])
+ dst_pts.append([cut * cut_idx + move, 0])
+ dst_pts.append([cut * cut_idx + move, img_h])
+
+ dst = self.warp_mls(img, src_pts, dst_pts, img_w, img_h)
+
+ return dst
+
+ def tia_perspective(self, img: np.ndarray) -> np.ndarray:
+ """Image perspective transformation.
+
+ Args:
+ img (np.ndarray): The image.
+ segment (int): The number of segments to divide the image along
+ the width. Defaults to 4.
+ """
+ img_h, img_w = img.shape[:2]
+
+ thresh = img_h // 2
+
+ src_pts = list()
+ dst_pts = list()
+
+ src_pts.append([0, 0])
+ src_pts.append([img_w, 0])
+ src_pts.append([img_w, img_h])
+ src_pts.append([0, img_h])
+
+ dst_pts.append([0, np.random.randint(thresh)])
+ dst_pts.append([img_w, np.random.randint(thresh)])
+ dst_pts.append([img_w, img_h - np.random.randint(thresh)])
+ dst_pts.append([0, img_h - np.random.randint(thresh)])
+
+ dst = self.warp_mls(img, src_pts, dst_pts, img_w, img_h)
+
+ return dst
+
+ def warp_mls(self,
+ src: np.ndarray,
+ src_pts: List[int],
+ dst_pts: List[int],
+ dst_w: int,
+ dst_h: int,
+ trans_ratio: float = 1.) -> np.ndarray:
+ """Warp the image."""
+ rdx, rdy = self._calc_delta(dst_w, dst_h, src_pts, dst_pts, 100)
+ return self._gen_img(src, rdx, rdy, dst_w, dst_h, 100, trans_ratio)
+
+ def _calc_delta(self, dst_w: int, dst_h: int, src_pts: List[int],
+ dst_pts: List[int],
+ grid_size: int) -> Tuple[np.ndarray, np.ndarray]:
+ """Compute delta."""
+
+ pt_count = len(dst_pts)
+ rdx = np.zeros((dst_h, dst_w))
+ rdy = np.zeros((dst_h, dst_w))
+ w = np.zeros(pt_count, dtype=np.float32)
+
+ if pt_count < 2:
+ return
+
+ i = 0
+ while True:
+ if dst_w <= i < dst_w + grid_size - 1:
+ i = dst_w - 1
+ elif i >= dst_w:
+ break
+
+ j = 0
+ while True:
+ if dst_h <= j < dst_h + grid_size - 1:
+ j = dst_h - 1
+ elif j >= dst_h:
+ break
+
+ sw = 0
+ swp = np.zeros(2, dtype=np.float32)
+ swq = np.zeros(2, dtype=np.float32)
+ new_pt = np.zeros(2, dtype=np.float32)
+ cur_pt = np.array([i, j], dtype=np.float32)
+
+ k = 0
+ for k in range(pt_count):
+ if i == dst_pts[k][0] and j == dst_pts[k][1]:
+ break
+
+ w[k] = 1. / ((i - dst_pts[k][0]) * (i - dst_pts[k][0]) +
+ (j - dst_pts[k][1]) * (j - dst_pts[k][1]))
+
+ sw += w[k]
+ swp = swp + w[k] * np.array(dst_pts[k])
+ swq = swq + w[k] * np.array(src_pts[k])
+
+ if k == pt_count - 1:
+ pstar = 1 / sw * swp
+ qstar = 1 / sw * swq
+
+ miu_s = 0
+ for k in range(pt_count):
+ if i == dst_pts[k][0] and j == dst_pts[k][1]:
+ continue
+ pt_i = dst_pts[k] - pstar
+ miu_s += w[k] * np.sum(pt_i * pt_i)
+
+ cur_pt -= pstar
+ cur_pt_j = np.array([-cur_pt[1], cur_pt[0]])
+
+ for k in range(pt_count):
+ if i == dst_pts[k][0] and j == dst_pts[k][1]:
+ continue
+
+ pt_i = dst_pts[k] - pstar
+ pt_j = np.array([-pt_i[1], pt_i[0]])
+
+ tmp_pt = np.zeros(2, dtype=np.float32)
+ tmp_pt[0] = (
+ np.sum(pt_i * cur_pt) * src_pts[k][0] -
+ np.sum(pt_j * cur_pt) * src_pts[k][1])
+ tmp_pt[1] = (-np.sum(pt_i * cur_pt_j) * src_pts[k][0] +
+ np.sum(pt_j * cur_pt_j) * src_pts[k][1])
+ tmp_pt *= (w[k] / miu_s)
+ new_pt += tmp_pt
+
+ new_pt += qstar
+ else:
+ new_pt = src_pts[k]
+
+ rdx[j, i] = new_pt[0] - i
+ rdy[j, i] = new_pt[1] - j
+
+ j += grid_size
+ i += grid_size
+ return rdx, rdy
+
+ def _gen_img(self, src: np.ndarray, rdx: np.ndarray, rdy: np.ndarray,
+ dst_w: int, dst_h: int, grid_size: int,
+ trans_ratio: float) -> np.ndarray:
+ """Generate the image based on delta."""
+
+ src_h, src_w = src.shape[:2]
+ dst = np.zeros_like(src, dtype=np.float32)
+
+ for i in np.arange(0, dst_h, grid_size):
+ for j in np.arange(0, dst_w, grid_size):
+ ni = i + grid_size
+ nj = j + grid_size
+ w = h = grid_size
+ if ni >= dst_h:
+ ni = dst_h - 1
+ h = ni - i + 1
+ if nj >= dst_w:
+ nj = dst_w - 1
+ w = nj - j + 1
+
+ di = np.reshape(np.arange(h), (-1, 1))
+ dj = np.reshape(np.arange(w), (1, -1))
+ delta_x = self._bilinear_interp(di / h, dj / w, rdx[i, j],
+ rdx[i, nj], rdx[ni, j],
+ rdx[ni, nj])
+ delta_y = self._bilinear_interp(di / h, dj / w, rdy[i, j],
+ rdy[i, nj], rdy[ni, j],
+ rdy[ni, nj])
+ nx = j + dj + delta_x * trans_ratio
+ ny = i + di + delta_y * trans_ratio
+ nx = np.clip(nx, 0, src_w - 1)
+ ny = np.clip(ny, 0, src_h - 1)
+ nxi = np.array(np.floor(nx), dtype=np.int32)
+ nyi = np.array(np.floor(ny), dtype=np.int32)
+ nxi1 = np.array(np.ceil(nx), dtype=np.int32)
+ nyi1 = np.array(np.ceil(ny), dtype=np.int32)
+
+ if len(src.shape) == 3:
+ x = np.tile(np.expand_dims(ny - nyi, axis=-1), (1, 1, 3))
+ y = np.tile(np.expand_dims(nx - nxi, axis=-1), (1, 1, 3))
+ else:
+ x = ny - nyi
+ y = nx - nxi
+ dst[i:i + h,
+ j:j + w] = self._bilinear_interp(x, y, src[nyi, nxi],
+ src[nyi, nxi1],
+ src[nyi1, nxi], src[nyi1,
+ nxi1])
+
+ dst = np.clip(dst, 0, 255)
+ dst = np.array(dst, dtype=np.uint8)
+
+ return dst
+
+ @staticmethod
+ def _bilinear_interp(x, y, v11, v12, v21, v22):
+ """Bilinear interpolation.
+
+ TODO: Docs for args and put it into utils.
+ """
+ return (v11 * (1 - y) + v12 * y) * (1 - x) + (v21 *
+ (1 - y) + v22 * y) * x
+
+
+@TRANSFORMS.register_module()
+class CropHeight(BaseTransform):
+ """Randomly crop the image's height, either from top or bottom.
+
+ Adapted from
+ https://github.com/PaddlePaddle/PaddleOCR/blob/release%2F2.6/ppocr/data/imaug/rec_img_aug.py # noqa
+
+ Required Keys:
+
+ - img
+
+ Modified Keys:
+
+ - img
+ - img_shape
+
+ Args:
+ crop_min (int): Minimum pixel(s) to crop. Defaults to 1.
+ crop_max (int): Maximum pixel(s) to crop. Defaults to 8.
+ """
+
+ def __init__(
+ self,
+ min_pixels: int = 1,
+ max_pixels: int = 8,
+ ) -> None:
+ super().__init__()
+ assert max_pixels >= min_pixels
+ self.min_pixels = min_pixels
+ self.max_pixels = max_pixels
+
+ @cache_randomness
+ def get_random_vars(self):
+ """Get all the random values used in this transform."""
+ crop_pixels = int(random.randint(self.min_pixels, self.max_pixels))
+ crop_top = random.randint(0, 1)
+ return crop_pixels, crop_top
+
+ def transform(self, results: Dict) -> Dict:
+ """Transform function to crop images.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Cropped results.
+ """
+ h = results['img'].shape[0]
+ crop_pixels, crop_top = self.get_random_vars()
+ crop_pixels = min(crop_pixels, h - 1)
+ img = results['img'].copy()
+ if crop_top:
+ img = img[crop_pixels:h, :, :]
+ else:
+ img = img[0:h - crop_pixels, :, :]
+ results['img_shape'] = img.shape[:2]
+ results['img'] = img
+ return results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(min_pixels = {self.min_pixels}, '
+ repr_str += f'max_pixels = {self.max_pixels})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class ImageContentJitter(BaseTransform):
+ """Jitter the image contents.
+
+ Adapted from
+ https://github.com/PaddlePaddle/PaddleOCR/blob/release%2F2.6/ppocr/data/imaug/rec_img_aug.py # noqa
+
+ Required Keys:
+
+ - img
+
+ Modified Keys:
+
+ - img
+ """
+
+ def transform(self, results: Dict, jitter_ratio: float = 0.01) -> Dict:
+ """Transform function to jitter images.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+ jitter_ratio (float): Controls the strength of jittering.
+ Defaults to 0.01.
+
+ Returns:
+ dict: Jittered results.
+ """
+ h, w = results['img'].shape[:2]
+ img = results['img'].copy()
+ if h > 10 and w > 10:
+ thres = min(h, w)
+ jitter_range = int(random.random() * thres * 0.01)
+ for i in range(jitter_range):
+ img[i:, i:, :] = img[:h - i, :w - i, :]
+ results['img'] = img
+ return results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += '()'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class ReversePixels(BaseTransform):
+ """Reverse image pixels.
+
+ Adapted from
+ https://github.com/PaddlePaddle/PaddleOCR/blob/release%2F2.6/ppocr/data/imaug/rec_img_aug.py # noqa
+
+ Required Keys:
+
+ - img
+
+ Modified Keys:
+
+ - img
+ """
+
+ def transform(self, results: Dict) -> Dict:
+ """Transform function to reverse image pixels.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Reversed results.
+ """
+ results['img'] = 255. - results['img'].copy()
+ return results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += '()'
+ return repr_str
diff --git a/mmocr/datasets/transforms/wrappers.py b/mmocr/datasets/transforms/wrappers.py
new file mode 100644
index 0000000000000000000000000000000000000000..086edb759b20c20a94fe8d7139350ba22a636c03
--- /dev/null
+++ b/mmocr/datasets/transforms/wrappers.py
@@ -0,0 +1,343 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from typing import Any, Dict, List, Optional, Tuple, Union
+
+import imgaug
+import imgaug.augmenters as iaa
+import numpy as np
+import torchvision.transforms as torchvision_transforms
+from mmcv.transforms import Compose
+from mmcv.transforms.base import BaseTransform
+from PIL import Image
+
+from mmocr.registry import TRANSFORMS
+from mmocr.utils import poly2bbox
+
+
+@TRANSFORMS.register_module()
+class ImgAugWrapper(BaseTransform):
+ """A wrapper around imgaug https://github.com/aleju/imgaug.
+
+ Find available augmenters at
+ https://imgaug.readthedocs.io/en/latest/source/overview_of_augmenters.html.
+
+ Required Keys:
+
+ - img
+ - gt_polygons (optional for text recognition)
+ - gt_bboxes (optional for text recognition)
+ - gt_bboxes_labels (optional for text recognition)
+ - gt_ignored (optional for text recognition)
+ - gt_texts (optional)
+
+ Modified Keys:
+
+ - img
+ - gt_polygons (optional for text recognition)
+ - gt_bboxes (optional for text recognition)
+ - gt_bboxes_labels (optional for text recognition)
+ - gt_ignored (optional for text recognition)
+ - img_shape (optional)
+ - gt_texts (optional)
+
+ Args:
+ args (list[list or dict]], optional): The argumentation list. For
+ details, please refer to imgaug document. Take
+ args=[['Fliplr', 0.5], dict(cls='Affine', rotate=[-10, 10]),
+ ['Resize', [0.5, 3.0]]] as an example. The args horizontally flip
+ images with probability 0.5, followed by random rotation with
+ angles in range [-10, 10], and resize with an independent scale in
+ range [0.5, 3.0] for each side of images. Defaults to None.
+ fix_poly_trans (dict): The transform configuration to fix invalid
+ polygons. Set it to None if no fixing is needed.
+ Defaults to dict(type='FixInvalidPolygon').
+ """
+
+ def __init__(
+ self,
+ args: Optional[List[Union[List, Dict]]] = None,
+ fix_poly_trans: Optional[dict] = dict(type='FixInvalidPolygon')
+ ) -> None:
+ assert args is None or isinstance(args, list) and len(args) > 0
+ if args is not None:
+ for arg in args:
+ assert isinstance(arg, (list, dict)), \
+ 'args should be a list of list or dict'
+ self.args = args
+ self.augmenter = self._build_augmentation(args)
+ self.fix_poly_trans = fix_poly_trans
+ if fix_poly_trans is not None:
+ self.fix = TRANSFORMS.build(fix_poly_trans)
+
+ def transform(self, results: Dict) -> Dict:
+ """Transform the image and annotation data.
+
+ Args:
+ results (dict): Result dict containing the data to transform.
+
+ Returns:
+ dict: The transformed data.
+ """
+ # img is bgr
+ image = results['img']
+ aug = None
+ ori_shape = image.shape
+
+ if self.augmenter:
+ aug = self.augmenter.to_deterministic()
+ if not self._augment_annotations(aug, ori_shape, results):
+ return None
+ results['img'] = aug.augment_image(image)
+ results['img_shape'] = (results['img'].shape[0],
+ results['img'].shape[1])
+ if getattr(self, 'fix', None) is not None:
+ results = self.fix(results)
+ return results
+
+ def _augment_annotations(self, aug: imgaug.augmenters.meta.Augmenter,
+ ori_shape: Tuple[int,
+ int], results: Dict) -> Dict:
+ """Augment annotations following the pre-defined augmentation sequence.
+
+ Args:
+ aug (imgaug.augmenters.meta.Augmenter): The imgaug augmenter.
+ ori_shape (tuple[int, int]): The ori_shape of the original image.
+ results (dict): Result dict containing annotations to transform.
+
+ Returns:
+ bool: Whether the transformation has been successfully applied. If
+ the transform results in empty polygon/bbox annotations, return
+ False.
+ """
+ # Assume co-existence of `gt_polygons`, `gt_bboxes` and `gt_ignored`
+ # for text detection
+ if 'gt_polygons' in results:
+
+ # augment polygons
+ transformed_polygons, removed_poly_inds = self._augment_polygons(
+ aug, ori_shape, results['gt_polygons'])
+ if len(transformed_polygons) == 0:
+ return False
+ results['gt_polygons'] = transformed_polygons
+
+ # remove instances that are no longer inside the augmented image
+ results['gt_bboxes_labels'] = np.delete(
+ results['gt_bboxes_labels'], removed_poly_inds, axis=0)
+ results['gt_ignored'] = np.delete(
+ results['gt_ignored'], removed_poly_inds, axis=0)
+ # TODO: deal with gt_texts corresponding to clipped polygons
+ if 'gt_texts' in results:
+ results['gt_texts'] = [
+ text for i, text in enumerate(results['gt_texts'])
+ if i not in removed_poly_inds
+ ]
+
+ # Generate new bboxes
+ bboxes = [poly2bbox(poly) for poly in transformed_polygons]
+ results['gt_bboxes'] = np.zeros((0, 4), dtype=np.float32)
+ if len(bboxes) > 0:
+ results['gt_bboxes'] = np.stack(bboxes)
+
+ return True
+
+ def _augment_polygons(self, aug: imgaug.augmenters.meta.Augmenter,
+ ori_shape: Tuple[int, int], polys: List[np.ndarray]
+ ) -> Tuple[List[np.ndarray], List[int]]:
+ """Augment polygons.
+
+ Args:
+ aug (imgaug.augmenters.meta.Augmenter): The imgaug augmenter.
+ ori_shape (tuple[int, int]): The shape of the original image.
+ polys (list[np.ndarray]): The polygons to be augmented.
+
+ Returns:
+ tuple(list[np.ndarray], list[int]): The augmented polygons, and the
+ indices of polygons removed as they are out of the augmented image.
+ """
+ imgaug_polys = []
+ for poly in polys:
+ poly = poly.reshape(-1, 2)
+ imgaug_polys.append(imgaug.Polygon(poly))
+ imgaug_polys = aug.augment_polygons(
+ [imgaug.PolygonsOnImage(imgaug_polys, shape=ori_shape)])[0]
+
+ new_polys = []
+ removed_poly_inds = []
+ for i, poly in enumerate(imgaug_polys.polygons):
+ # Sometimes imgaug may produce some invalid polygons with no points
+ if not poly.is_valid or poly.is_out_of_image(imgaug_polys.shape):
+ removed_poly_inds.append(i)
+ continue
+ new_poly = []
+ try:
+ poly = poly.clip_out_of_image(imgaug_polys.shape)[0]
+ except Exception as e:
+ warnings.warn(f'Failed to clip polygon out of image: {e}')
+ for point in poly:
+ new_poly.append(np.array(point, dtype=np.float32))
+ new_poly = np.array(new_poly, dtype=np.float32).flatten()
+ # Under some conditions, imgaug can generate "polygon" with only
+ # two points, which is not a valid polygon.
+ if len(new_poly) <= 4:
+ removed_poly_inds.append(i)
+ continue
+ new_polys.append(new_poly)
+
+ return new_polys, removed_poly_inds
+
+ def _build_augmentation(self, args, root=True):
+ """Build ImgAugWrapper augmentations.
+
+ Args:
+ args (dict): Arguments to be passed to imgaug.
+ root (bool): Whether it's building the root augmenter.
+
+ Returns:
+ imgaug.augmenters.meta.Augmenter: The built augmenter.
+ """
+ if args is None:
+ return None
+ if isinstance(args, (int, float, str)):
+ return args
+ if isinstance(args, list):
+ if root:
+ sequence = [
+ self._build_augmentation(value, root=False)
+ for value in args
+ ]
+ return iaa.Sequential(sequence)
+ arg_list = [self._to_tuple_if_list(a) for a in args[1:]]
+ return getattr(iaa, args[0])(*arg_list)
+ if isinstance(args, dict):
+ if 'cls' in args:
+ cls = getattr(iaa, args['cls'])
+ return cls(
+ **{
+ k: self._to_tuple_if_list(v)
+ for k, v in args.items() if not k == 'cls'
+ })
+ else:
+ return {
+ key: self._build_augmentation(value, root=False)
+ for key, value in args.items()
+ }
+ raise RuntimeError('unknown augmenter arg: ' + str(args))
+
+ def _to_tuple_if_list(self, obj: Any) -> Any:
+ """Convert an object into a tuple if it is a list."""
+ if isinstance(obj, list):
+ return tuple(obj)
+ return obj
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(args = {self.args}, '
+ repr_str += f'fix_poly_trans = {self.fix_poly_trans})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class TorchVisionWrapper(BaseTransform):
+ """A wrapper around torchvision transforms. It applies specific transform
+ to ``img`` and updates ``height`` and ``width`` accordingly.
+
+ Required Keys:
+
+ - img (ndarray): The input image.
+
+ Modified Keys:
+
+ - img (ndarray): The modified image.
+ - img_shape (tuple(int, int)): The shape of the image in (height, width).
+
+
+ Warning:
+ This transform only affects the image but not its associated
+ annotations, such as word bounding boxes and polygons. Therefore,
+ it may only be applicable to text recognition tasks.
+
+ Args:
+ op (str): The name of any transform class in
+ :func:`torchvision.transforms`.
+ **kwargs: Arguments that will be passed to initializer of torchvision
+ transform.
+ """
+
+ def __init__(self, op: str, **kwargs) -> None:
+ assert isinstance(op, str)
+ obj_cls = getattr(torchvision_transforms, op)
+ self.torchvision = obj_cls(**kwargs)
+ self.op = op
+ self.kwargs = kwargs
+
+ def transform(self, results):
+ """Transform the image.
+
+ Args:
+ results (dict): Result dict from the data loader.
+
+ Returns:
+ dict: Transformed results.
+ """
+ assert 'img' in results
+ # BGR -> RGB
+ img = results['img'][..., ::-1]
+ img = Image.fromarray(img)
+ img = self.torchvision(img)
+ img = np.asarray(img)
+ img = img[..., ::-1]
+ results['img'] = img
+ results['img_shape'] = img.shape[:2]
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(op = {self.op}'
+ for k, v in self.kwargs.items():
+ repr_str += f', {k} = {v}'
+ repr_str += ')'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class ConditionApply(BaseTransform):
+ """Apply transforms according to the condition. If the condition is met,
+ true_transforms will be applied, otherwise false_transforms will be
+ applied.
+
+ Args:
+ condition (str): The string that can be evaluated to a boolean value.
+ true_transforms (list[dict]): Transforms to be applied if the condition
+ is met. Defaults to [].
+ false_transforms (list[dict]): Transforms to be applied if the
+ condition is not met. Defaults to [].
+ """
+
+ def __init__(self,
+ condition: str,
+ true_transforms: Union[Dict, List[Dict]] = [],
+ false_transforms: Union[Dict, List[Dict]] = []):
+ self.condition = condition
+ self.true_transforms = Compose(true_transforms)
+ self.false_transforms = Compose(false_transforms)
+
+ def transform(self, results: Dict) -> Optional[Dict]:
+ """Transform the image.
+
+ Args:
+ results (dict):Result dict containing the data to transform.
+
+ Returns:
+ dict: Transformed results.
+ """
+ if eval(self.condition):
+ return self.true_transforms(results) # type: ignore
+ else:
+ return self.false_transforms(results)
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(condition = {self.condition}, '
+ repr_str += f'true_transforms = {self.true_transforms}, '
+ repr_str += f'false_transforms = {self.false_transforms})'
+ return repr_str
diff --git a/mmocr/datasets/wildreceipt_dataset.py b/mmocr/datasets/wildreceipt_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..5f8699a043b893be2f826a760b81e8d939719a99
--- /dev/null
+++ b/mmocr/datasets/wildreceipt_dataset.py
@@ -0,0 +1,286 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+from typing import Callable, List, Optional, Sequence, Union
+
+import numpy as np
+from mmengine.dataset import BaseDataset
+from mmengine.fileio import list_from_file
+
+from mmocr.registry import DATASETS
+from mmocr.utils.parsers import LineJsonParser
+from mmocr.utils.polygon_utils import sort_vertex8
+
+
+@DATASETS.register_module()
+class WildReceiptDataset(BaseDataset):
+ """WildReceipt Dataset for key information extraction. There are two files
+ to be loaded: metainfo and annotation. The metainfo file contains the
+ mapping between classes and labels. The annotation file contains the all
+ necessary information about the image, such as bounding boxes, texts, and
+ labels etc.
+
+ The metainfo file is a text file with the following format:
+
+ .. code-block:: none
+
+ 0 Ignore
+ 1 Store_name_value
+ 2 Store_name_key
+
+ The annotation format is shown as follows.
+
+ .. code-block:: json
+
+ {
+ "file_name": "a.jpeg",
+ "height": 348,
+ "width": 348,
+ "annotations": [
+ {
+ "box": [
+ 114.0,
+ 19.0,
+ 230.0,
+ 19.0,
+ 230.0,
+ 1.0,
+ 114.0,
+ 1.0
+ ],
+ "text": "CHOEUN",
+ "label": 1
+ },
+ {
+ "box": [
+ 97.0,
+ 35.0,
+ 236.0,
+ 35.0,
+ 236.0,
+ 19.0,
+ 97.0,
+ 19.0
+ ],
+ "text": "KOREANRESTAURANT",
+ "label": 2
+ }
+ ]
+ }
+
+ Args:
+ directed (bool): Whether to use directed graph. Defaults to False.
+ ann_file (str): Annotation file path. Defaults to ''.
+ metainfo (str or dict, optional): Meta information for dataset, such as
+ class information. If it's a string, it will be treated as a path
+ to the class file from which the class information will be loaded.
+ Defaults to None.
+ data_root (str, optional): The root directory for ``data_prefix`` and
+ ``ann_file``. Defaults to ''.
+ data_prefix (dict, optional): Prefix for training data. Defaults to
+ dict(img_path='').
+ filter_cfg (dict, optional): Config for filter data. Defaults to None.
+ indices (int or Sequence[int], optional): Support using first few
+ data in annotation file to facilitate training/testing on a smaller
+ dataset. Defaults to None which means using all ``data_infos``.
+ serialize_data (bool, optional): Whether to hold memory using
+ serialized objects, when enabled, data loader workers can use
+ shared RAM from master process instead of making a copy. Defaults
+ to True.
+ pipeline (list, optional): Processing pipeline. Defaults to [].
+ test_mode (bool, optional): ``test_mode=True`` means in test phase.
+ Defaults to False.
+ lazy_init (bool, optional): Whether to load annotation during
+ instantiation. In some cases, such as visualization, only the meta
+ information of the dataset is needed, which is not necessary to
+ load annotation file. ``Basedataset`` can skip load annotations to
+ save time by set ``lazy_init=False``. Defaults to False.
+ max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
+ None img. The maximum extra number of cycles to get a valid
+ image. Defaults to 1000.
+ """
+ METAINFO = {
+ 'category': [{
+ 'id': '0',
+ 'name': 'Ignore'
+ }, {
+ 'id': '1',
+ 'name': 'Store_name_value'
+ }, {
+ 'id': '2',
+ 'name': 'Store_name_key'
+ }, {
+ 'id': '3',
+ 'name': 'Store_addr_value'
+ }, {
+ 'id': '4',
+ 'name': 'Store_addr_key'
+ }, {
+ 'id': '5',
+ 'name': 'Tel_value'
+ }, {
+ 'id': '6',
+ 'name': 'Tel_key'
+ }, {
+ 'id': '7',
+ 'name': 'Date_value'
+ }, {
+ 'id': '8',
+ 'name': 'Date_key'
+ }, {
+ 'id': '9',
+ 'name': 'Time_value'
+ }, {
+ 'id': '10',
+ 'name': 'Time_key'
+ }, {
+ 'id': '11',
+ 'name': 'Prod_item_value'
+ }, {
+ 'id': '12',
+ 'name': 'Prod_item_key'
+ }, {
+ 'id': '13',
+ 'name': 'Prod_quantity_value'
+ }, {
+ 'id': '14',
+ 'name': 'Prod_quantity_key'
+ }, {
+ 'id': '15',
+ 'name': 'Prod_price_value'
+ }, {
+ 'id': '16',
+ 'name': 'Prod_price_key'
+ }, {
+ 'id': '17',
+ 'name': 'Subtotal_value'
+ }, {
+ 'id': '18',
+ 'name': 'Subtotal_key'
+ }, {
+ 'id': '19',
+ 'name': 'Tax_value'
+ }, {
+ 'id': '20',
+ 'name': 'Tax_key'
+ }, {
+ 'id': '21',
+ 'name': 'Tips_value'
+ }, {
+ 'id': '22',
+ 'name': 'Tips_key'
+ }, {
+ 'id': '23',
+ 'name': 'Total_value'
+ }, {
+ 'id': '24',
+ 'name': 'Total_key'
+ }, {
+ 'id': '25',
+ 'name': 'Others'
+ }]
+ }
+
+ def __init__(self,
+ directed: bool = False,
+ ann_file: str = '',
+ metainfo: Optional[Union[dict, str]] = None,
+ data_root: str = '',
+ data_prefix: dict = dict(img_path=''),
+ filter_cfg: Optional[dict] = None,
+ indices: Optional[Union[int, Sequence[int]]] = None,
+ serialize_data: bool = True,
+ pipeline: List[Union[dict, Callable]] = ...,
+ test_mode: bool = False,
+ lazy_init: bool = False,
+ max_refetch: int = 1000):
+ self.directed = directed
+ super().__init__(ann_file, metainfo, data_root, data_prefix,
+ filter_cfg, indices, serialize_data, pipeline,
+ test_mode, lazy_init, max_refetch)
+ self._metainfo['dataset_type'] = 'WildReceiptDataset'
+ self._metainfo['task_name'] = 'KIE'
+
+ @classmethod
+ def _load_metainfo(cls, metainfo: Union[str, dict] = None) -> dict:
+ """Collect meta information from path to the class list or the
+ dictionary of meta.
+
+ Args:
+ metainfo (str or dict): Path to the class list, or a meta
+ information dict. If ``metainfo`` contains existed filename, it
+ will be parsed by ``list_from_file``.
+
+ Returns:
+ dict: Parsed meta information.
+ """
+ cls_metainfo = copy.deepcopy(cls.METAINFO)
+ if isinstance(metainfo, str):
+ cls_metainfo['category'] = []
+ for line in list_from_file(metainfo):
+ k, v = line.split()
+ cls_metainfo['category'].append({'id': k, 'name': v})
+ return cls_metainfo
+ else:
+ return super()._load_metainfo(metainfo)
+
+ def load_data_list(self) -> List[dict]:
+ """Load data list from annotation file.
+
+ Returns:
+ List[dict]: A list of annotation dict.
+ """
+ parser = LineJsonParser(
+ keys=['file_name', 'height', 'width', 'annotations'])
+ data_list = []
+ for line in list_from_file(self.ann_file):
+ data_info = parser(line)
+ data_info = self.parse_data_info(data_info)
+ data_list.append(data_info)
+ return data_list
+
+ def parse_data_info(self, raw_data_info: dict) -> dict:
+ """Parse data info from raw data info.
+
+ Args:
+ raw_data_info (dict): Raw data info.
+
+ Returns:
+ dict: Parsed data info.
+
+ - img_path (str): Path to the image.
+ - img_shape (tuple(int, int)): Image shape in (H, W).
+ - instances (list[dict]): A list of instances.
+ - bbox (ndarray(dtype=np.float32)): Shape (4, ). Bounding box.
+ - text (str): Annotation text.
+ - edge_label (int): Edge label.
+ - bbox_label (int): Bounding box label.
+ """
+
+ raw_data_info['img_path'] = raw_data_info['file_name']
+ data_info = super().parse_data_info(raw_data_info)
+ annotations = data_info['annotations']
+
+ assert 'box' in annotations[0]
+ assert 'text' in annotations[0]
+
+ instances = []
+
+ for ann in annotations:
+ instance = {}
+ bbox = np.array(sort_vertex8(ann['box']), dtype=np.int32)
+ bbox = np.array([
+ bbox[0::2].min(), bbox[1::2].min(), bbox[0::2].max(),
+ bbox[1::2].max()
+ ],
+ dtype=np.int32)
+
+ instance['bbox'] = bbox
+ instance['text'] = ann['text']
+ instance['bbox_label'] = ann.get('label', 0)
+ instance['edge_label'] = ann.get('edge', 0)
+ instances.append(instance)
+
+ return dict(
+ instances=instances,
+ img_path=data_info['img_path'],
+ img_shape=(data_info['height'], data_info['width']))
diff --git a/mmocr/engine/__init__.py b/mmocr/engine/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..1944bc1e57726ec1922b1e97fb69a75df9c384fe
--- /dev/null
+++ b/mmocr/engine/__init__.py
@@ -0,0 +1,2 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .hooks import * # NOQA
diff --git a/mmocr/engine/__pycache__/__init__.cpython-38.pyc b/mmocr/engine/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e8bdc18bc6775c42c0db22688f90c2051b0fc9ff
Binary files /dev/null and b/mmocr/engine/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/engine/hooks/__init__.py b/mmocr/engine/hooks/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..62d8c9e56449a003b0b8ad186c4c18e4743c0906
--- /dev/null
+++ b/mmocr/engine/hooks/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .visualization_hook import VisualizationHook
+
+__all__ = ['VisualizationHook']
diff --git a/mmocr/engine/hooks/__pycache__/__init__.cpython-38.pyc b/mmocr/engine/hooks/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..47a28006bf24149f231036768c81aa635e6c30df
Binary files /dev/null and b/mmocr/engine/hooks/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/engine/hooks/__pycache__/visualization_hook.cpython-38.pyc b/mmocr/engine/hooks/__pycache__/visualization_hook.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..586510756c59ffdef8696974ab9d1172db6a51cd
Binary files /dev/null and b/mmocr/engine/hooks/__pycache__/visualization_hook.cpython-38.pyc differ
diff --git a/mmocr/engine/hooks/visualization_hook.py b/mmocr/engine/hooks/visualization_hook.py
new file mode 100644
index 0000000000000000000000000000000000000000..2bbc6aaf490b1a1804afe54dd078a1f63224d391
--- /dev/null
+++ b/mmocr/engine/hooks/visualization_hook.py
@@ -0,0 +1,130 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from typing import Optional, Sequence, Union
+
+import mmcv
+import mmengine.fileio as fileio
+from mmengine.hooks import Hook
+from mmengine.runner import Runner
+from mmengine.visualization import Visualizer
+
+from mmocr.registry import HOOKS
+from mmocr.structures import TextDetDataSample, TextRecogDataSample
+
+
+# TODO Files with the same name will be overwritten for multi datasets
+@HOOKS.register_module()
+class VisualizationHook(Hook):
+ """Detection Visualization Hook. Used to visualize validation and testing
+ process prediction results.
+
+ Args:
+ enable (bool): Whether to enable this hook. Defaults to False.
+ interval (int): The interval of visualization. Defaults to 50.
+ score_thr (float): The threshold to visualize the bboxes
+ and masks. It's only useful for text detection. Defaults to 0.3.
+ show (bool): Whether to display the drawn image. Defaults to False.
+ wait_time (float): The interval of show in seconds. Defaults
+ to 0.
+ backend_args (dict, optional): Instantiates the corresponding file
+ backend. It may contain `backend` key to specify the file
+ backend. If it contains, the file backend corresponding to this
+ value will be used and initialized with the remaining values,
+ otherwise the corresponding file backend will be selected
+ based on the prefix of the file path. Defaults to None.
+ """
+
+ def __init__(
+ self,
+ enable: bool = False,
+ interval: int = 50,
+ score_thr: float = 0.3,
+ show: bool = False,
+ draw_pred: bool = False,
+ draw_gt: bool = False,
+ wait_time: float = 0.,
+ backend_args: Optional[dict] = None,
+ ) -> None:
+ self._visualizer: Visualizer = Visualizer.get_current_instance()
+ self.interval = interval
+ self.score_thr = score_thr
+ self.show = show
+ self.draw_pred = draw_pred
+ self.draw_gt = draw_gt
+ self.wait_time = wait_time
+ self.backend_args = backend_args
+ self.enable = enable
+
+ # TODO after MultiDatasetWrapper, rewrites this function and try to merge
+ # with after_val_iter and after_test_iter
+ def after_val_iter(self, runner: Runner, batch_idx: int,
+ data_batch: Sequence[dict],
+ outputs: Sequence[Union[TextDetDataSample,
+ TextRecogDataSample]]) -> None:
+ """Run after every ``self.interval`` validation iterations.
+
+ Args:
+ runner (:obj:`Runner`): The runner of the validation process.
+ batch_idx (int): The index of the current batch in the val loop.
+ data_batch (Sequence[dict]): Data from dataloader.
+ outputs (Sequence[:obj:`TextDetDataSample` or
+ :obj:`TextRecogDataSample`]): Outputs from model.
+ """
+ # TODO: data_batch does not include annotation information
+ if self.enable is False:
+ return
+
+ # There is no guarantee that the same batch of images
+ # is visualized for each evaluation.
+ total_curr_iter = runner.iter + batch_idx
+
+ # Visualize only the first data
+ if total_curr_iter % self.interval == 0:
+ for output in outputs:
+ img_path = output.img_path
+ img_bytes = fileio.get(
+ img_path, backend_args=self.backend_args)
+ img = mmcv.imfrombytes(img_bytes, channel_order='rgb')
+ self._visualizer.add_datasample(
+ osp.splitext(osp.basename(img_path))[0],
+ img,
+ data_sample=output,
+ draw_gt=self.draw_gt,
+ draw_pred=self.draw_pred,
+ show=self.show,
+ wait_time=self.wait_time,
+ pred_score_thr=self.score_thr,
+ step=total_curr_iter)
+
+ def after_test_iter(self, runner: Runner, batch_idx: int,
+ data_batch: Sequence[dict],
+ outputs: Sequence[Union[TextDetDataSample,
+ TextRecogDataSample]]) -> None:
+ """Run after every testing iterations.
+
+ Args:
+ runner (:obj:`Runner`): The runner of the testing process.
+ batch_idx (int): The index of the current batch in the val loop.
+ data_batch (Sequence[dict]): Data from dataloader.
+ outputs (Sequence[:obj:`TextDetDataSample` or
+ :obj:`TextRecogDataSample`]): Outputs from model.
+ """
+
+ if self.enable is False:
+ return
+
+ for output in outputs:
+ img_path = output.img_path
+ img_bytes = fileio.get(img_path, backend_args=self.backend_args)
+ img = mmcv.imfrombytes(img_bytes, channel_order='rgb')
+
+ self._visualizer.add_datasample(
+ osp.splitext(osp.basename(img_path))[0],
+ img,
+ data_sample=output,
+ show=self.show,
+ draw_gt=self.draw_gt,
+ draw_pred=self.draw_pred,
+ wait_time=self.wait_time,
+ pred_score_thr=self.score_thr,
+ step=batch_idx)
diff --git a/mmocr/evaluation/__init__.py b/mmocr/evaluation/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..40cd21686174fe2831ab8bc0693e283297955125
--- /dev/null
+++ b/mmocr/evaluation/__init__.py
@@ -0,0 +1,3 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .evaluator import * # NOQA
+from .metrics import * # NOQA
diff --git a/mmocr/evaluation/__pycache__/__init__.cpython-38.pyc b/mmocr/evaluation/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a98f9c3bd6ab75d798203e76f5068c7199f9e107
Binary files /dev/null and b/mmocr/evaluation/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/evaluation/evaluator/__init__.py b/mmocr/evaluation/evaluator/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..6b13fe99548e7e2e4c6e196a2da22b9c8cbec8a3
--- /dev/null
+++ b/mmocr/evaluation/evaluator/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .multi_datasets_evaluator import MultiDatasetsEvaluator
+
+__all__ = ['MultiDatasetsEvaluator']
diff --git a/mmocr/evaluation/evaluator/__pycache__/__init__.cpython-38.pyc b/mmocr/evaluation/evaluator/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a29ea970a00ed044f6711c763117b848d48cc33d
Binary files /dev/null and b/mmocr/evaluation/evaluator/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/evaluation/evaluator/__pycache__/multi_datasets_evaluator.cpython-38.pyc b/mmocr/evaluation/evaluator/__pycache__/multi_datasets_evaluator.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1c40c92b6224f46e38ce2bb31daa3641f3cbe1db
Binary files /dev/null and b/mmocr/evaluation/evaluator/__pycache__/multi_datasets_evaluator.cpython-38.pyc differ
diff --git a/mmocr/evaluation/evaluator/multi_datasets_evaluator.py b/mmocr/evaluation/evaluator/multi_datasets_evaluator.py
new file mode 100644
index 0000000000000000000000000000000000000000..f01aa70f645d5a9f61fe02386ff214dc72bcffb4
--- /dev/null
+++ b/mmocr/evaluation/evaluator/multi_datasets_evaluator.py
@@ -0,0 +1,100 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from collections import OrderedDict
+from typing import Sequence, Union
+
+from mmengine.dist import (broadcast_object_list, collect_results,
+ is_main_process)
+from mmengine.evaluator import BaseMetric, Evaluator
+from mmengine.evaluator.metric import _to_cpu
+
+from mmocr.registry import EVALUATOR
+from mmocr.utils.typing_utils import ConfigType
+
+
+@EVALUATOR.register_module()
+class MultiDatasetsEvaluator(Evaluator):
+ """Wrapper class to compose class: `ConcatDataset` and multiple
+ :class:`BaseMetric` instances.
+ The metrics will be evaluated on each dataset slice separately. The name of
+ the each metric is the concatenation of the dataset prefix, the metric
+ prefix and the key of metric - e.g.
+ `dataset_prefix/metric_prefix/accuracy`.
+
+ Args:
+ metrics (dict or BaseMetric or Sequence): The config of metrics.
+ dataset_prefixes (Sequence[str]): The prefix of each dataset. The
+ length of this sequence should be the same as the length of the
+ datasets.
+ """
+
+ def __init__(self, metrics: Union[ConfigType, BaseMetric, Sequence],
+ dataset_prefixes: Sequence[str]) -> None:
+ super().__init__(metrics)
+ self.dataset_prefixes = dataset_prefixes
+
+ def evaluate(self, size: int) -> dict:
+ """Invoke ``evaluate`` method of each metric and collect the metrics
+ dictionary.
+
+ Args:
+ size (int): Length of the entire validation dataset. When batch
+ size > 1, the dataloader may pad some data samples to make
+ sure all ranks have the same length of dataset slice. The
+ ``collect_results`` function will drop the padded data based on
+ this size.
+
+ Returns:
+ dict: Evaluation results of all metrics. The keys are the names
+ of the metrics, and the values are corresponding results.
+ """
+ metrics_results = OrderedDict()
+ dataset_slices = self.dataset_meta.get('cumulative_sizes', [size])
+ assert len(dataset_slices) == len(self.dataset_prefixes)
+ for metric in self.metrics:
+ if len(metric.results) == 0:
+ warnings.warn(
+ f'{metric.__class__.__name__} got empty `self.results`.'
+ 'Please ensure that the processed results are properly '
+ 'added into `self.results` in `process` method.')
+
+ results = collect_results(metric.results, size,
+ metric.collect_device)
+
+ if is_main_process():
+ # cast all tensors in results list to cpu
+ results = _to_cpu(results)
+ for start, end, dataset_prefix in zip([0] +
+ dataset_slices[:-1],
+ dataset_slices,
+ self.dataset_prefixes):
+ metric_results = metric.compute_metrics(
+ results[start:end]) # type: ignore
+ # Add prefix to metric names
+
+ if metric.prefix:
+ final_prefix = '/'.join(
+ (dataset_prefix, metric.prefix))
+ else:
+ final_prefix = dataset_prefix
+ metric_results = {
+ '/'.join((final_prefix, k)): v
+ for k, v in metric_results.items()
+ }
+
+ # Check metric name conflicts
+ for name in metric_results.keys():
+ if name in metrics_results:
+ raise ValueError(
+ 'There are multiple evaluation results with '
+ f'the same metric name {name}. Please make '
+ 'sure all metrics have different prefixes.')
+ metrics_results.update(metric_results)
+ metric.results.clear()
+ if is_main_process():
+ metrics_results = [metrics_results]
+ else:
+ metrics_results = [None] # type: ignore
+ broadcast_object_list(metrics_results)
+
+ return metrics_results[0]
diff --git a/mmocr/evaluation/functional/__init__.py b/mmocr/evaluation/functional/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..6aaf75768924bef3e7ad6dc1c9d6d0161aab9879
--- /dev/null
+++ b/mmocr/evaluation/functional/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .hmean import compute_hmean
+
+__all__ = ['compute_hmean']
diff --git a/mmocr/evaluation/functional/__pycache__/__init__.cpython-38.pyc b/mmocr/evaluation/functional/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..359f0f93fadf4583824a16e0803001c6f2493a48
Binary files /dev/null and b/mmocr/evaluation/functional/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/evaluation/functional/__pycache__/hmean.cpython-38.pyc b/mmocr/evaluation/functional/__pycache__/hmean.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a0e975ff3e83589b7404dbccc84d235180323f80
Binary files /dev/null and b/mmocr/evaluation/functional/__pycache__/hmean.cpython-38.pyc differ
diff --git a/mmocr/evaluation/functional/hmean.py b/mmocr/evaluation/functional/hmean.py
new file mode 100644
index 0000000000000000000000000000000000000000..d3aabf4c2804ca4d6df43e2699890e682f4f713c
--- /dev/null
+++ b/mmocr/evaluation/functional/hmean.py
@@ -0,0 +1,42 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+
+
+def compute_hmean(accum_hit_recall, accum_hit_prec, gt_num, pred_num):
+ # TODO Add typehints
+ """Compute hmean given hit number, ground truth number and prediction
+ number.
+
+ Args:
+ accum_hit_recall (int|float): Accumulated hits for computing recall.
+ accum_hit_prec (int|float): Accumulated hits for computing precision.
+ gt_num (int): Ground truth number.
+ pred_num (int): Prediction number.
+
+ Returns:
+ recall (float): The recall value.
+ precision (float): The precision value.
+ hmean (float): The hmean value.
+ """
+
+ assert isinstance(accum_hit_recall, (float, int))
+ assert isinstance(accum_hit_prec, (float, int))
+
+ assert isinstance(gt_num, int)
+ assert isinstance(pred_num, int)
+ assert accum_hit_recall >= 0.0
+ assert accum_hit_prec >= 0.0
+ assert gt_num >= 0.0
+ assert pred_num >= 0.0
+
+ if gt_num == 0:
+ recall = 1.0
+ precision = 0.0 if pred_num > 0 else 1.0
+ else:
+ recall = float(accum_hit_recall) / gt_num
+ precision = 0.0 if pred_num == 0 else float(accum_hit_prec) / pred_num
+
+ denom = recall + precision
+
+ hmean = 0.0 if denom == 0 else (2.0 * precision * recall / denom)
+
+ return recall, precision, hmean
diff --git a/mmocr/evaluation/metrics/__init__.py b/mmocr/evaluation/metrics/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..3b10f4b2ac720e096db27b7e54dcc75611f92dfa
--- /dev/null
+++ b/mmocr/evaluation/metrics/__init__.py
@@ -0,0 +1,9 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .f_metric import F1Metric
+from .hmean_iou_metric import HmeanIOUMetric
+from .recog_metric import CharMetric, OneMinusNEDMetric, WordMetric
+
+__all__ = [
+ 'WordMetric', 'CharMetric', 'OneMinusNEDMetric', 'HmeanIOUMetric',
+ 'F1Metric'
+]
diff --git a/mmocr/evaluation/metrics/__pycache__/__init__.cpython-38.pyc b/mmocr/evaluation/metrics/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e09d0e79116557cb255998adda6e26b6fc470490
Binary files /dev/null and b/mmocr/evaluation/metrics/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/evaluation/metrics/__pycache__/f_metric.cpython-38.pyc b/mmocr/evaluation/metrics/__pycache__/f_metric.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..19fc48d98bf03cf506ce8a23e2292ecf5a9c557e
Binary files /dev/null and b/mmocr/evaluation/metrics/__pycache__/f_metric.cpython-38.pyc differ
diff --git a/mmocr/evaluation/metrics/__pycache__/hmean_iou_metric.cpython-38.pyc b/mmocr/evaluation/metrics/__pycache__/hmean_iou_metric.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..610e21762c2fdc1dca05b012c31a81aec4e2c5fa
Binary files /dev/null and b/mmocr/evaluation/metrics/__pycache__/hmean_iou_metric.cpython-38.pyc differ
diff --git a/mmocr/evaluation/metrics/__pycache__/recog_metric.cpython-38.pyc b/mmocr/evaluation/metrics/__pycache__/recog_metric.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..47d1eaeae64fa7c443119c48e5110f6a74889b0d
Binary files /dev/null and b/mmocr/evaluation/metrics/__pycache__/recog_metric.cpython-38.pyc differ
diff --git a/mmocr/evaluation/metrics/f_metric.py b/mmocr/evaluation/metrics/f_metric.py
new file mode 100644
index 0000000000000000000000000000000000000000..e021ed6b73d059cc15c5255e947c1ff0a5d895ea
--- /dev/null
+++ b/mmocr/evaluation/metrics/f_metric.py
@@ -0,0 +1,164 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, Optional, Sequence, Union
+
+import torch
+from mmengine.evaluator import BaseMetric
+
+from mmocr.registry import METRICS
+
+
+@METRICS.register_module()
+class F1Metric(BaseMetric):
+ """Compute F1 scores.
+
+ Args:
+ num_classes (int): Number of labels.
+ key (str): The key name of the predicted and ground truth labels.
+ Defaults to 'labels'.
+ mode (str or list[str]): Options are:
+ - 'micro': Calculate metrics globally by counting the total true
+ positives, false negatives and false positives.
+ - 'macro': Calculate metrics for each label, and find their
+ unweighted mean.
+ If mode is a list, then metrics in mode will be calculated
+ separately. Defaults to 'micro'.
+ cared_classes (list[int]): The indices of the labels particpated in
+ the metirc computing. If both ``cared_classes`` and
+ ``ignored_classes`` are empty, all classes will be taken into
+ account. Defaults to []. Note: ``cared_classes`` and
+ ``ignored_classes`` cannot be specified together.
+ ignored_classes (list[int]): The index set of labels that are ignored
+ when computing metrics. If both ``cared_classes`` and
+ ``ignored_classes`` are empty, all classes will be taken into
+ account. Defaults to []. Note: ``cared_classes`` and
+ ``ignored_classes`` cannot be specified together.
+ collect_device (str): Device name used for collecting results from
+ different ranks during distributed training. Must be 'cpu' or
+ 'gpu'. Defaults to 'cpu'.
+ prefix (str, optional): The prefix that will be added in the metric
+ names to disambiguate homonymous metrics of different evaluators.
+ If prefix is not provided in the argument, self.default_prefix
+ will be used instead. Defaults to None.
+
+ Warning:
+ Only non-negative integer labels are involved in computing. All
+ negative ground truth labels will be ignored.
+ """
+
+ default_prefix: Optional[str] = 'kie'
+
+ def __init__(self,
+ num_classes: int,
+ key: str = 'labels',
+ mode: Union[str, Sequence[str]] = 'micro',
+ cared_classes: Sequence[int] = [],
+ ignored_classes: Sequence[int] = [],
+ collect_device: str = 'cpu',
+ prefix: Optional[str] = None) -> None:
+ super().__init__(collect_device, prefix)
+ assert isinstance(num_classes, int)
+ assert isinstance(cared_classes, (list, tuple))
+ assert isinstance(ignored_classes, (list, tuple))
+ assert isinstance(mode, (list, str))
+ assert not (len(cared_classes) > 0 and len(ignored_classes) > 0), \
+ 'cared_classes and ignored_classes cannot be both non-empty'
+
+ if isinstance(mode, str):
+ mode = [mode]
+ assert set(mode).issubset({'micro', 'macro'})
+ self.mode = mode
+
+ if len(cared_classes) > 0:
+ assert min(cared_classes) >= 0 and \
+ max(cared_classes) < num_classes, \
+ 'cared_classes must be a subset of [0, num_classes)'
+ self.cared_labels = sorted(cared_classes)
+ elif len(ignored_classes) > 0:
+ assert min(ignored_classes) >= 0 and \
+ max(ignored_classes) < num_classes, \
+ 'ignored_classes must be a subset of [0, num_classes)'
+ self.cared_labels = sorted(
+ set(range(num_classes)) - set(ignored_classes))
+ else:
+ self.cared_labels = list(range(num_classes))
+ self.num_classes = num_classes
+ self.key = key
+
+ def process(self, data_batch: Sequence[Dict],
+ data_samples: Sequence[Dict]) -> None:
+ """Process one batch of data_samples. The processed results should be
+ stored in ``self.results``, which will be used to compute the metrics
+ when all batches have been processed.
+
+ Args:
+ data_batch (Sequence[Dict]): A batch of gts.
+ data_samples (Sequence[Dict]): A batch of outputs from the model.
+ """
+ for data_sample in data_samples:
+ pred_labels = data_sample.get('pred_instances').get(self.key).cpu()
+ gt_labels = data_sample.get('gt_instances').get(self.key).cpu()
+
+ result = dict(
+ pred_labels=pred_labels.flatten(),
+ gt_labels=gt_labels.flatten())
+ self.results.append(result)
+
+ def compute_metrics(self, results: Sequence[Dict]) -> Dict:
+ """Compute the metrics from processed results.
+
+ Args:
+ results (list[Dict]): The processed results of each batch.
+
+ Returns:
+ dict[str, float]: The f1 scores. The keys are the names of the
+ metrics, and the values are corresponding results. Possible
+ keys are 'micro_f1' and 'macro_f1'.
+ """
+
+ preds = []
+ gts = []
+ for result in results:
+ preds.append(result['pred_labels'])
+ gts.append(result['gt_labels'])
+ preds = torch.cat(preds)
+ gts = torch.cat(gts)
+
+ assert preds.max() < self.num_classes
+ assert gts.max() < self.num_classes
+
+ cared_labels = preds.new_tensor(self.cared_labels, dtype=torch.long)
+
+ hits = (preds == gts)[None, :]
+ preds_per_label = cared_labels[:, None] == preds[None, :]
+ gts_per_label = cared_labels[:, None] == gts[None, :]
+
+ tp = (hits * preds_per_label).float()
+ fp = (~hits * preds_per_label).float()
+ fn = (~hits * gts_per_label).float()
+
+ result = {}
+ if 'macro' in self.mode:
+ result['macro_f1'] = self._compute_f1(
+ tp.sum(-1), fp.sum(-1), fn.sum(-1))
+ if 'micro' in self.mode:
+ result['micro_f1'] = self._compute_f1(tp.sum(), fp.sum(), fn.sum())
+
+ return result
+
+ def _compute_f1(self, tp: torch.Tensor, fp: torch.Tensor,
+ fn: torch.Tensor) -> float:
+ """Compute the F1-score based on the true positives, false positives
+ and false negatives.
+
+ Args:
+ tp (Tensor): The true positives.
+ fp (Tensor): The false positives.
+ fn (Tensor): The false negatives.
+
+ Returns:
+ float: The F1-score.
+ """
+ precision = tp / (tp + fp).clamp(min=1e-8)
+ recall = tp / (tp + fn).clamp(min=1e-8)
+ f1 = 2 * precision * recall / (precision + recall).clamp(min=1e-8)
+ return float(f1.mean())
diff --git a/mmocr/evaluation/metrics/hmean_iou_metric.py b/mmocr/evaluation/metrics/hmean_iou_metric.py
new file mode 100644
index 0000000000000000000000000000000000000000..c5d40971cd965d0f8fcac2247e4859c40bc1760e
--- /dev/null
+++ b/mmocr/evaluation/metrics/hmean_iou_metric.py
@@ -0,0 +1,225 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Sequence
+
+import numpy as np
+import torch
+from mmengine.evaluator import BaseMetric
+from mmengine.logging import MMLogger
+from scipy.sparse import csr_matrix
+from scipy.sparse.csgraph import maximum_bipartite_matching
+from shapely.geometry import Polygon
+
+from mmocr.evaluation.functional import compute_hmean
+from mmocr.registry import METRICS
+from mmocr.utils import poly_intersection, poly_iou, polys2shapely
+
+
+@METRICS.register_module()
+class HmeanIOUMetric(BaseMetric):
+ """HmeanIOU metric.
+
+ This method computes the hmean iou metric, which is done in the
+ following steps:
+
+ - Filter the prediction polygon:
+
+ - Scores is smaller than minimum prediction score threshold.
+ - The proportion of the area that intersects with gt ignored polygon is
+ greater than ignore_precision_thr.
+
+ - Computing an M x N IoU matrix, where each element indexing
+ E_mn represents the IoU between the m-th valid GT and n-th valid
+ prediction.
+ - Based on different prediction score threshold:
+ - Obtain the ignored predictions according to prediction score.
+ The filtered predictions will not be involved in the later metric
+ computations.
+ - Based on the IoU matrix, get the match metric according to
+ ``match_iou_thr``.
+ - Based on different `strategy`, accumulate the match number.
+ - calculate H-mean under different prediction score threshold.
+
+ Args:
+ match_iou_thr (float): IoU threshold for a match. Defaults to 0.5.
+ ignore_precision_thr (float): Precision threshold when prediction and\
+ gt ignored polygons are matched. Defaults to 0.5.
+ pred_score_thrs (dict): Best prediction score threshold searching
+ space. Defaults to dict(start=0.3, stop=0.9, step=0.1).
+ strategy (str): Polygon matching strategy. Options are 'max_matching'
+ and 'vanilla'. 'max_matching' refers to the optimum strategy that
+ maximizes the number of matches. Vanilla strategy matches gt and
+ pred polygons if both of them are never matched before. It was used
+ in MMOCR 0.x and and academia. Defaults to 'vanilla'.
+ collect_device (str): Device name used for collecting results from
+ different ranks during distributed training. Must be 'cpu' or
+ 'gpu'. Defaults to 'cpu'.
+ prefix (str, optional): The prefix that will be added in the metric
+ names to disambiguate homonymous metrics of different evaluators.
+ If prefix is not provided in the argument, self.default_prefix
+ will be used instead. Defaults to None
+ """
+ default_prefix: Optional[str] = 'icdar'
+
+ def __init__(self,
+ match_iou_thr: float = 0.5,
+ ignore_precision_thr: float = 0.5,
+ pred_score_thrs: Dict = dict(start=0.3, stop=0.9, step=0.1),
+ strategy: str = 'vanilla',
+ collect_device: str = 'cpu',
+ prefix: Optional[str] = None) -> None:
+ super().__init__(collect_device=collect_device, prefix=prefix)
+ self.match_iou_thr = match_iou_thr
+ self.ignore_precision_thr = ignore_precision_thr
+ self.pred_score_thrs = np.arange(**pred_score_thrs)
+ assert strategy in ['max_matching', 'vanilla']
+ self.strategy = strategy
+
+ def process(self, data_batch: Sequence[Dict],
+ data_samples: Sequence[Dict]) -> None:
+ """Process one batch of data samples and predictions. The processed
+ results should be stored in ``self.results``, which will be used to
+ compute the metrics when all batches have been processed.
+
+ Args:
+ data_batch (Sequence[Dict]): A batch of data from dataloader.
+ data_samples (Sequence[Dict]): A batch of outputs from
+ the model.
+ """
+ for data_sample in data_samples:
+
+ pred_instances = data_sample.get('pred_instances')
+ pred_polygons = pred_instances.get('polygons')
+ pred_scores = pred_instances.get('scores')
+ if isinstance(pred_scores, torch.Tensor):
+ pred_scores = pred_scores.cpu().numpy()
+ pred_scores = np.array(pred_scores, dtype=np.float32)
+
+ gt_instances = data_sample.get('gt_instances')
+ gt_polys = gt_instances.get('polygons')
+ gt_ignore_flags = gt_instances.get('ignored')
+ if isinstance(gt_ignore_flags, torch.Tensor):
+ gt_ignore_flags = gt_ignore_flags.cpu().numpy()
+ gt_polys = polys2shapely(gt_polys)
+ pred_polys = polys2shapely(pred_polygons)
+
+ pred_ignore_flags = self._filter_preds(pred_polys, gt_polys,
+ pred_scores,
+ gt_ignore_flags)
+
+ gt_num = np.sum(~gt_ignore_flags)
+ pred_num = np.sum(~pred_ignore_flags)
+ iou_metric = np.zeros([gt_num, pred_num])
+
+ # Compute IoU scores amongst kept pred and gt polygons
+ for pred_mat_id, pred_poly_id in enumerate(
+ self._true_indexes(~pred_ignore_flags)):
+ for gt_mat_id, gt_poly_id in enumerate(
+ self._true_indexes(~gt_ignore_flags)):
+ iou_metric[gt_mat_id, pred_mat_id] = poly_iou(
+ gt_polys[gt_poly_id], pred_polys[pred_poly_id])
+
+ result = dict(
+ iou_metric=iou_metric,
+ pred_scores=pred_scores[~pred_ignore_flags])
+ self.results.append(result)
+
+ def compute_metrics(self, results: List[Dict]) -> Dict:
+ """Compute the metrics from processed results.
+
+ Args:
+ results (list[dict]): The processed results of each batch.
+
+ Returns:
+ dict: The computed metrics. The keys are the names of the metrics,
+ and the values are corresponding results.
+ """
+ logger: MMLogger = MMLogger.get_current_instance()
+
+ best_eval_results = dict(hmean=-1)
+ logger.info('Evaluating hmean-iou...')
+
+ dataset_pred_num = np.zeros_like(self.pred_score_thrs)
+ dataset_hit_num = np.zeros_like(self.pred_score_thrs)
+ dataset_gt_num = 0
+
+ for result in results:
+ iou_metric = result['iou_metric'] # (gt_num, pred_num)
+ pred_scores = result['pred_scores'] # (pred_num)
+ dataset_gt_num += iou_metric.shape[0]
+
+ # Filter out predictions by IoU threshold
+ for i, pred_score_thr in enumerate(self.pred_score_thrs):
+ pred_ignore_flags = pred_scores < pred_score_thr
+ # get the number of matched boxes
+ matched_metric = iou_metric[:, ~pred_ignore_flags] \
+ > self.match_iou_thr
+ if self.strategy == 'max_matching':
+ csr_matched_metric = csr_matrix(matched_metric)
+ matched_preds = maximum_bipartite_matching(
+ csr_matched_metric, perm_type='row')
+ # -1 denotes unmatched pred polygons
+ dataset_hit_num[i] += np.sum(matched_preds != -1)
+ else:
+ # first come first matched
+ matched_gt_indexes = set()
+ matched_pred_indexes = set()
+ for gt_idx, pred_idx in zip(*np.nonzero(matched_metric)):
+ if gt_idx in matched_gt_indexes or \
+ pred_idx in matched_pred_indexes:
+ continue
+ matched_gt_indexes.add(gt_idx)
+ matched_pred_indexes.add(pred_idx)
+ dataset_hit_num[i] += len(matched_gt_indexes)
+ dataset_pred_num[i] += np.sum(~pred_ignore_flags)
+
+ for i, pred_score_thr in enumerate(self.pred_score_thrs):
+ recall, precision, hmean = compute_hmean(
+ int(dataset_hit_num[i]), int(dataset_hit_num[i]),
+ int(dataset_gt_num), int(dataset_pred_num[i]))
+ eval_results = dict(
+ precision=precision, recall=recall, hmean=hmean)
+ logger.info(f'prediction score threshold: {pred_score_thr:.2f}, '
+ f'recall: {eval_results["recall"]:.4f}, '
+ f'precision: {eval_results["precision"]:.4f}, '
+ f'hmean: {eval_results["hmean"]:.4f}\n')
+ if eval_results['hmean'] > best_eval_results['hmean']:
+ best_eval_results = eval_results
+ return best_eval_results
+
+ def _filter_preds(self, pred_polys: List[Polygon], gt_polys: List[Polygon],
+ pred_scores: List[float],
+ gt_ignore_flags: np.ndarray) -> np.ndarray:
+ """Filter out the predictions by score threshold and whether it
+ overlaps ignored gt polygons.
+
+ Args:
+ pred_polys (list[Polygon]): Pred polygons.
+ gt_polys (list[Polygon]): GT polygons.
+ pred_scores (list[float]): Pred scores of polygons.
+ gt_ignore_flags (np.ndarray): 1D boolean array indicating
+ the positions of ignored gt polygons.
+
+ Returns:
+ np.ndarray: 1D boolean array indicating the positions of ignored
+ pred polygons.
+ """
+
+ # Filter out predictions based on the minimum score threshold
+ pred_ignore_flags = pred_scores < self.pred_score_thrs.min()
+
+ # Filter out pred polygons which overlaps any ignored gt polygons
+ for pred_id in self._true_indexes(~pred_ignore_flags):
+ for gt_id in self._true_indexes(gt_ignore_flags):
+ # Match pred with ignored gt
+ precision = poly_intersection(
+ gt_polys[gt_id], pred_polys[pred_id]) / (
+ pred_polys[pred_id].area + 1e-5)
+ if precision > self.ignore_precision_thr:
+ pred_ignore_flags[pred_id] = True
+ break
+
+ return pred_ignore_flags
+
+ def _true_indexes(self, array: np.ndarray) -> np.ndarray:
+ """Get indexes of True elements from a 1D boolean array."""
+ return np.where(array)[0]
diff --git a/mmocr/evaluation/metrics/recog_metric.py b/mmocr/evaluation/metrics/recog_metric.py
new file mode 100644
index 0000000000000000000000000000000000000000..a046951211c1c1b7027dce83f9b7b3b7428e2b02
--- /dev/null
+++ b/mmocr/evaluation/metrics/recog_metric.py
@@ -0,0 +1,292 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import re
+from difflib import SequenceMatcher
+from typing import Dict, Optional, Sequence, Union
+
+import mmengine
+from mmengine.evaluator import BaseMetric
+from rapidfuzz.distance import Levenshtein
+
+from mmocr.registry import METRICS
+
+
+@METRICS.register_module()
+class WordMetric(BaseMetric):
+ """Word metrics for text recognition task.
+
+ Args:
+ mode (str or list[str]): Options are:
+ - 'exact': Accuracy at word level.
+ - 'ignore_case': Accuracy at word level, ignoring letter
+ case.
+ - 'ignore_case_symbol': Accuracy at word level, ignoring
+ letter case and symbol. (Default metric for academic evaluation)
+ If mode is a list, then metrics in mode will be calculated
+ separately. Defaults to 'ignore_case_symbol'
+ valid_symbol (str): Valid characters. Defaults to
+ '[^A-Z^a-z^0-9^\u4e00-\u9fa5]'
+ collect_device (str): Device name used for collecting results from
+ different ranks during distributed training. Must be 'cpu' or
+ 'gpu'. Defaults to 'cpu'.
+ prefix (str, optional): The prefix that will be added in the metric
+ names to disambiguate homonymous metrics of different evaluators.
+ If prefix is not provided in the argument, self.default_prefix
+ will be used instead. Defaults to None.
+ """
+
+ default_prefix: Optional[str] = 'recog'
+
+ def __init__(self,
+ mode: Union[str, Sequence[str]] = 'ignore_case_symbol',
+ valid_symbol: str = '[^A-Z^a-z^0-9^\u4e00-\u9fa5]',
+ collect_device: str = 'cpu',
+ prefix: Optional[str] = None) -> None:
+ super().__init__(collect_device, prefix)
+ self.valid_symbol = re.compile(valid_symbol)
+ if isinstance(mode, str):
+ mode = [mode]
+ assert mmengine.is_seq_of(mode, str)
+ assert set(mode).issubset(
+ {'exact', 'ignore_case', 'ignore_case_symbol'})
+ self.mode = set(mode)
+
+ def process(self, data_batch: Sequence[Dict],
+ data_samples: Sequence[Dict]) -> None:
+ """Process one batch of data_samples. The processed results should be
+ stored in ``self.results``, which will be used to compute the metrics
+ when all batches have been processed.
+
+ Args:
+ data_batch (Sequence[Dict]): A batch of gts.
+ data_samples (Sequence[Dict]): A batch of outputs from the model.
+ """
+ for data_sample in data_samples:
+ match_num = 0
+ match_ignore_case_num = 0
+ match_ignore_case_symbol_num = 0
+ pred_text = data_sample.get('pred_text').get('item')
+ gt_text = data_sample.get('gt_text').get('item')
+ if 'ignore_case' in self.mode or 'ignore_case_symbol' in self.mode:
+ pred_text_lower = pred_text.lower()
+ gt_text_lower = gt_text.lower()
+ if 'ignore_case_symbol' in self.mode:
+ gt_text_lower_ignore = self.valid_symbol.sub('', gt_text_lower)
+ pred_text_lower_ignore = self.valid_symbol.sub(
+ '', pred_text_lower)
+ match_ignore_case_symbol_num =\
+ gt_text_lower_ignore == pred_text_lower_ignore
+ if 'ignore_case' in self.mode:
+ match_ignore_case_num = pred_text_lower == gt_text_lower
+ if 'exact' in self.mode:
+ match_num = pred_text == gt_text
+ result = dict(
+ match_num=match_num,
+ match_ignore_case_num=match_ignore_case_num,
+ match_ignore_case_symbol_num=match_ignore_case_symbol_num)
+ self.results.append(result)
+
+ def compute_metrics(self, results: Sequence[Dict]) -> Dict:
+ """Compute the metrics from processed results.
+
+ Args:
+ results (list[Dict]): The processed results of each batch.
+
+ Returns:
+ Dict: The computed metrics. The keys are the names of the metrics,
+ and the values are corresponding results.
+ """
+
+ eps = 1e-8
+ eval_res = {}
+ gt_word_num = len(results)
+ if 'exact' in self.mode:
+ match_nums = [result['match_num'] for result in results]
+ match_nums = sum(match_nums)
+ eval_res['word_acc'] = 1.0 * match_nums / (eps + gt_word_num)
+ if 'ignore_case' in self.mode:
+ match_ignore_case_num = [
+ result['match_ignore_case_num'] for result in results
+ ]
+ match_ignore_case_num = sum(match_ignore_case_num)
+ eval_res['word_acc_ignore_case'] = 1.0 *\
+ match_ignore_case_num / (eps + gt_word_num)
+ if 'ignore_case_symbol' in self.mode:
+ match_ignore_case_symbol_num = [
+ result['match_ignore_case_symbol_num'] for result in results
+ ]
+ match_ignore_case_symbol_num = sum(match_ignore_case_symbol_num)
+ eval_res['word_acc_ignore_case_symbol'] = 1.0 *\
+ match_ignore_case_symbol_num / (eps + gt_word_num)
+
+ for key, value in eval_res.items():
+ eval_res[key] = float(f'{value:.4f}')
+ return eval_res
+
+
+@METRICS.register_module()
+class CharMetric(BaseMetric):
+ """Character metrics for text recognition task.
+
+ Args:
+ valid_symbol (str): Valid characters.
+ Defaults to '[^A-Z^a-z^0-9^\u4e00-\u9fa5]'
+ collect_device (str): Device name used for collecting results from
+ different ranks during distributed training. Must be 'cpu' or
+ 'gpu'. Defaults to 'cpu'.
+ prefix (str, optional): The prefix that will be added in the metric
+ names to disambiguate homonymous metrics of different evaluators.
+ If prefix is not provided in the argument, self.default_prefix
+ will be used instead. Defaults to None.
+ """
+
+ default_prefix: Optional[str] = 'recog'
+
+ def __init__(self,
+ valid_symbol: str = '[^A-Z^a-z^0-9^\u4e00-\u9fa5]',
+ collect_device: str = 'cpu',
+ prefix: Optional[str] = None) -> None:
+ super().__init__(collect_device, prefix)
+ self.valid_symbol = re.compile(valid_symbol)
+
+ def process(self, data_batch: Sequence[Dict],
+ data_samples: Sequence[Dict]) -> None:
+ """Process one batch of data_samples. The processed results should be
+ stored in ``self.results``, which will be used to compute the metrics
+ when all batches have been processed.
+
+ Args:
+ data_batch (Sequence[Dict]): A batch of gts.
+ data_samples (Sequence[Dict]): A batch of outputs from the model.
+ """
+ for data_sample in data_samples:
+ pred_text = data_sample.get('pred_text').get('item')
+ gt_text = data_sample.get('gt_text').get('item')
+ gt_text_lower = gt_text.lower()
+ pred_text_lower = pred_text.lower()
+ gt_text_lower_ignore = self.valid_symbol.sub('', gt_text_lower)
+ pred_text_lower_ignore = self.valid_symbol.sub('', pred_text_lower)
+ # number to calculate char level recall & precision
+ result = dict(
+ gt_char_num=len(gt_text_lower_ignore),
+ pred_char_num=len(pred_text_lower_ignore),
+ true_positive_char_num=self._cal_true_positive_char(
+ pred_text_lower_ignore, gt_text_lower_ignore))
+ self.results.append(result)
+
+ def compute_metrics(self, results: Sequence[Dict]) -> Dict:
+ """Compute the metrics from processed results.
+
+ Args:
+ results (list[Dict]): The processed results of each batch.
+
+ Returns:
+ Dict: The computed metrics. The keys are the names of the
+ metrics, and the values are corresponding results.
+ """
+ gt_char_num = [result['gt_char_num'] for result in results]
+ pred_char_num = [result['pred_char_num'] for result in results]
+ true_positive_char_num = [
+ result['true_positive_char_num'] for result in results
+ ]
+ gt_char_num = sum(gt_char_num)
+ pred_char_num = sum(pred_char_num)
+ true_positive_char_num = sum(true_positive_char_num)
+
+ eps = 1e-8
+ char_recall = 1.0 * true_positive_char_num / (eps + gt_char_num)
+ char_precision = 1.0 * true_positive_char_num / (eps + pred_char_num)
+ eval_res = {}
+ eval_res['char_recall'] = char_recall
+ eval_res['char_precision'] = char_precision
+
+ for key, value in eval_res.items():
+ eval_res[key] = float(f'{value:.4f}')
+ return eval_res
+
+ def _cal_true_positive_char(self, pred: str, gt: str) -> int:
+ """Calculate correct character number in prediction.
+
+ Args:
+ pred (str): Prediction text.
+ gt (str): Ground truth text.
+
+ Returns:
+ true_positive_char_num (int): The true positive number.
+ """
+
+ all_opt = SequenceMatcher(None, pred, gt)
+ true_positive_char_num = 0
+ for opt, _, _, s2, e2 in all_opt.get_opcodes():
+ if opt == 'equal':
+ true_positive_char_num += (e2 - s2)
+ else:
+ pass
+ return true_positive_char_num
+
+
+@METRICS.register_module()
+class OneMinusNEDMetric(BaseMetric):
+ """One minus NED metric for text recognition task.
+
+ Args:
+ valid_symbol (str): Valid characters. Defaults to
+ '[^A-Z^a-z^0-9^\u4e00-\u9fa5]'
+ collect_device (str): Device name used for collecting results from
+ different ranks during distributed training. Must be 'cpu' or
+ 'gpu'. Defaults to 'cpu'.
+ prefix (str, optional): The prefix that will be added in the metric
+ names to disambiguate homonymous metrics of different evaluators.
+ If prefix is not provided in the argument, self.default_prefix
+ will be used instead. Defaults to None
+ """
+ default_prefix: Optional[str] = 'recog'
+
+ def __init__(self,
+ valid_symbol: str = '[^A-Z^a-z^0-9^\u4e00-\u9fa5]',
+ collect_device: str = 'cpu',
+ prefix: Optional[str] = None) -> None:
+ super().__init__(collect_device, prefix)
+ self.valid_symbol = re.compile(valid_symbol)
+
+ def process(self, data_batch: Sequence[Dict],
+ data_samples: Sequence[Dict]) -> None:
+ """Process one batch of data_samples. The processed results should be
+ stored in ``self.results``, which will be used to compute the metrics
+ when all batches have been processed.
+
+ Args:
+ data_batch (Sequence[Dict]): A batch of gts.
+ data_samples (Sequence[Dict]): A batch of outputs from the model.
+ """
+ for data_sample in data_samples:
+ pred_text = data_sample.get('pred_text').get('item')
+ gt_text = data_sample.get('gt_text').get('item')
+ gt_text_lower = gt_text.lower()
+ pred_text_lower = pred_text.lower()
+ gt_text_lower_ignore = self.valid_symbol.sub('', gt_text_lower)
+ pred_text_lower_ignore = self.valid_symbol.sub('', pred_text_lower)
+ norm_ed = Levenshtein.normalized_distance(pred_text_lower_ignore,
+ gt_text_lower_ignore)
+ result = dict(norm_ed=norm_ed)
+ self.results.append(result)
+
+ def compute_metrics(self, results: Sequence[Dict]) -> Dict:
+ """Compute the metrics from processed results.
+
+ Args:
+ results (list[Dict]): The processed results of each batch.
+
+ Returns:
+ Dict: The computed metrics. The keys are the names of the
+ metrics, and the values are corresponding results.
+ """
+
+ gt_word_num = len(results)
+ norm_ed = [result['norm_ed'] for result in results]
+ norm_ed_sum = sum(norm_ed)
+ normalized_edit_distance = norm_ed_sum / max(1, gt_word_num)
+ eval_res = {}
+ eval_res['1-N.E.D'] = 1.0 - normalized_edit_distance
+ for key, value in eval_res.items():
+ eval_res[key] = float(f'{value:.4f}')
+ return eval_res
diff --git a/mmocr/models/__init__.py b/mmocr/models/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..abea668b3d52be16b5fe41ab20e3494885bba297
--- /dev/null
+++ b/mmocr/models/__init__.py
@@ -0,0 +1,5 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .common import * # NOQA
+from .kie import * # NOQA
+from .textdet import * # NOQA
+from .textrecog import * # NOQA
diff --git a/mmocr/models/__pycache__/__init__.cpython-38.pyc b/mmocr/models/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..9e32bef6b322da92c7e6a55cff3d96576f39d0c2
Binary files /dev/null and b/mmocr/models/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/models/common/__init__.py b/mmocr/models/common/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..30fe928ceced2064bc4adabc5d36291872df4b29
--- /dev/null
+++ b/mmocr/models/common/__init__.py
@@ -0,0 +1,7 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .backbones import * # NOQA
+from .dictionary import * # NOQA
+from .layers import * # NOQA
+from .losses import * # NOQA
+from .modules import * # NOQA
+from .plugins import * # NOQA
diff --git a/mmocr/models/common/__pycache__/__init__.cpython-38.pyc b/mmocr/models/common/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1ee8e6d4f14313ad542346a04078b4ff02349df3
Binary files /dev/null and b/mmocr/models/common/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/models/common/backbones/__init__.py b/mmocr/models/common/backbones/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..053ed524657ebf335ea622776687291931df2358
--- /dev/null
+++ b/mmocr/models/common/backbones/__init__.py
@@ -0,0 +1,5 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .clip_resnet import CLIPResNet
+from .unet import UNet
+from .vit import VisionTransformer, VisionTransformer_LoRA
+__all__ = ['UNet', 'CLIPResNet', 'VisionTransformer', 'VisionTransformer_LoRA']
diff --git a/mmocr/models/common/backbones/__pycache__/__init__.cpython-38.pyc b/mmocr/models/common/backbones/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..43004d340554f84746c7232c91f31d8902be5491
Binary files /dev/null and b/mmocr/models/common/backbones/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/models/common/backbones/__pycache__/clip_resnet.cpython-38.pyc b/mmocr/models/common/backbones/__pycache__/clip_resnet.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..fb1b1437bd5586b5d78610d72230325ca4388c5e
Binary files /dev/null and b/mmocr/models/common/backbones/__pycache__/clip_resnet.cpython-38.pyc differ
diff --git a/mmocr/models/common/backbones/__pycache__/unet.cpython-38.pyc b/mmocr/models/common/backbones/__pycache__/unet.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..3b4bc3d011324af67cca913685507ff5b02e2dac
Binary files /dev/null and b/mmocr/models/common/backbones/__pycache__/unet.cpython-38.pyc differ
diff --git a/mmocr/models/common/backbones/__pycache__/vit.cpython-38.pyc b/mmocr/models/common/backbones/__pycache__/vit.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f54d89abbd81a16ab72259a6ca7e016c9dffea06
Binary files /dev/null and b/mmocr/models/common/backbones/__pycache__/vit.cpython-38.pyc differ
diff --git a/mmocr/models/common/backbones/clip_resnet.py b/mmocr/models/common/backbones/clip_resnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..4de20986b7e4ab3031c20d7d1660c3fb5b6894df
--- /dev/null
+++ b/mmocr/models/common/backbones/clip_resnet.py
@@ -0,0 +1,100 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+
+import torch.nn as nn
+from mmdet.models.backbones import ResNet
+from mmdet.models.backbones.resnet import Bottleneck
+
+from mmocr.registry import MODELS
+
+
+class CLIPBottleneck(Bottleneck):
+ """Bottleneck for CLIPResNet.
+
+ It is a Bottleneck variant used in the ResNet variant of CLIP. After the
+ second convolution layer, there is an additional average pooling layer with
+ kernel_size 2 and stride 2, which is added as a plugin when the
+ input stride > 1. The stride of each convolution layer is always set to 1.
+
+ Args:
+ **kwargs: Keyword arguments for
+ :class:``mmdet.models.backbones.resnet.Bottleneck``.
+ """
+
+ def __init__(self, **kwargs):
+ stride = kwargs.get('stride', 1)
+ kwargs['stride'] = 1
+ plugins = kwargs.get('plugins', None)
+ if stride > 1:
+ if plugins is None:
+ plugins = []
+
+ plugins.insert(
+ 0,
+ dict(
+ cfg=dict(type='mmocr.AvgPool2d', kernel_size=2),
+ position='after_conv2'))
+ kwargs['plugins'] = plugins
+ super().__init__(**kwargs)
+
+
+@MODELS.register_module()
+class CLIPResNet(ResNet):
+ """Implement the ResNet variant used in `oCLIP.
+
+ `_.
+
+ It is also the official structure in
+ `CLIP `_.
+
+ Compared with ResNetV1d structure, CLIPResNet replaces the
+ max pooling layer with an average pooling layer at the end
+ of the input stem.
+
+ In the Bottleneck of CLIPResNet, after the second convolution
+ layer, there is an additional average pooling layer with
+ kernel_size 2 and stride 2, which is added as a plugin
+ when the input stride > 1.
+ The stride of each convolution layer is always set to 1.
+
+ Args:
+ depth (int): Depth of resnet, options are [50]. Defaults to 50.
+ strides (sequence(int)): Strides of the first block of each stage.
+ Defaults to (1, 2, 2, 2).
+ deep_stem (bool): Replace 7x7 conv in input stem with 3 3x3 conv.
+ Defaults to True.
+ avg_down (bool): Use AvgPool instead of stride conv at
+ the downsampling stage in the bottleneck. Defaults to True.
+ **kwargs: Keyword arguments for
+ :class:``mmdet.models.backbones.resnet.ResNet``.
+ """
+ arch_settings = {
+ 50: (CLIPBottleneck, (3, 4, 6, 3)),
+ }
+
+ def __init__(self,
+ depth=50,
+ strides=(1, 2, 2, 2),
+ deep_stem=True,
+ avg_down=True,
+ **kwargs):
+ super().__init__(
+ depth=depth,
+ strides=strides,
+ deep_stem=deep_stem,
+ avg_down=avg_down,
+ **kwargs)
+
+ def _make_stem_layer(self, in_channels: int, stem_channels: int):
+ """Build stem layer for CLIPResNet used in `CLIP
+ https://github.com/openai/CLIP>`_.
+
+ It uses an average pooling layer rather than a max pooling
+ layer at the end of the input stem.
+
+ Args:
+ in_channels (int): Number of input channels.
+ stem_channels (int): Number of output channels.
+ """
+ super()._make_stem_layer(in_channels, stem_channels)
+ if self.deep_stem:
+ self.maxpool = nn.AvgPool2d(kernel_size=2)
diff --git a/mmocr/models/common/backbones/unet.py b/mmocr/models/common/backbones/unet.py
new file mode 100644
index 0000000000000000000000000000000000000000..d582551715fc20353d26745b9d1bb55892b7a10d
--- /dev/null
+++ b/mmocr/models/common/backbones/unet.py
@@ -0,0 +1,516 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.utils.checkpoint as cp
+from mmcv.cnn import ConvModule, build_norm_layer
+from mmengine.model import BaseModule
+from mmengine.utils.dl_utils.parrots_wrapper import _BatchNorm
+
+from mmocr.registry import MODELS
+
+
+class UpConvBlock(nn.Module):
+ """Upsample convolution block in decoder for UNet.
+
+ This upsample convolution block consists of one upsample module
+ followed by one convolution block. The upsample module expands the
+ high-level low-resolution feature map and the convolution block fuses
+ the upsampled high-level low-resolution feature map and the low-level
+ high-resolution feature map from encoder.
+
+ Args:
+ conv_block (nn.Sequential): Sequential of convolutional layers.
+ in_channels (int): Number of input channels of the high-level
+ skip_channels (int): Number of input channels of the low-level
+ high-resolution feature map from encoder.
+ out_channels (int): Number of output channels.
+ num_convs (int): Number of convolutional layers in the conv_block.
+ Default: 2.
+ stride (int): Stride of convolutional layer in conv_block. Default: 1.
+ dilation (int): Dilation rate of convolutional layer in conv_block.
+ Default: 1.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ conv_cfg (dict | None): Config dict for convolution layer.
+ Default: None.
+ norm_cfg (dict | None): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict | None): Config dict for activation layer in ConvModule.
+ Default: dict(type='ReLU').
+ upsample_cfg (dict): The upsample config of the upsample module in
+ decoder. Default: dict(type='InterpConv'). If the size of
+ high-level feature map is the same as that of skip feature map
+ (low-level feature map from encoder), it does not need upsample the
+ high-level feature map and the upsample_cfg is None.
+ dcn (bool): Use deformable convolution in convolutional layer or not.
+ Default: None.
+ plugins (dict): plugins for convolutional layers. Default: None.
+ """
+
+ def __init__(self,
+ conv_block,
+ in_channels,
+ skip_channels,
+ out_channels,
+ num_convs=2,
+ stride=1,
+ dilation=1,
+ with_cp=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ upsample_cfg=dict(type='InterpConv'),
+ dcn=None,
+ plugins=None):
+ super().__init__()
+ assert dcn is None, 'Not implemented yet.'
+ assert plugins is None, 'Not implemented yet.'
+
+ self.conv_block = conv_block(
+ in_channels=2 * skip_channels,
+ out_channels=out_channels,
+ num_convs=num_convs,
+ stride=stride,
+ dilation=dilation,
+ with_cp=with_cp,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ dcn=None,
+ plugins=None)
+ if upsample_cfg is not None:
+ upsample_cfg.update(
+ dict(
+ in_channels=in_channels,
+ out_channels=skip_channels,
+ with_cp=with_cp,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ self.upsample = MODELS.build(upsample_cfg)
+ else:
+ self.upsample = ConvModule(
+ in_channels,
+ skip_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ def forward(self, skip, x):
+ """Forward function."""
+
+ x = self.upsample(x)
+ out = torch.cat([skip, x], dim=1)
+ out = self.conv_block(out)
+
+ return out
+
+
+class BasicConvBlock(nn.Module):
+ """Basic convolutional block for UNet.
+
+ This module consists of several plain convolutional layers.
+
+ Args:
+ in_channels (int): Number of input channels.
+ out_channels (int): Number of output channels.
+ num_convs (int): Number of convolutional layers. Default: 2.
+ stride (int): Whether use stride convolution to downsample
+ the input feature map. If stride=2, it only uses stride convolution
+ in the first convolutional layer to downsample the input feature
+ map. Options are 1 or 2. Default: 1.
+ dilation (int): Whether use dilated convolution to expand the
+ receptive field. Set dilation rate of each convolutional layer and
+ the dilation rate of the first convolutional layer is always 1.
+ Default: 1.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ conv_cfg (dict | None): Config dict for convolution layer.
+ Default: None.
+ norm_cfg (dict | None): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict | None): Config dict for activation layer in ConvModule.
+ Default: dict(type='ReLU').
+ dcn (bool): Use deformable convolution in convolutional layer or not.
+ Default: None.
+ plugins (dict): plugins for convolutional layers. Default: None.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ num_convs=2,
+ stride=1,
+ dilation=1,
+ with_cp=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ dcn=None,
+ plugins=None):
+ super().__init__()
+ assert dcn is None, 'Not implemented yet.'
+ assert plugins is None, 'Not implemented yet.'
+
+ self.with_cp = with_cp
+ convs = []
+ for i in range(num_convs):
+ convs.append(
+ ConvModule(
+ in_channels=in_channels if i == 0 else out_channels,
+ out_channels=out_channels,
+ kernel_size=3,
+ stride=stride if i == 0 else 1,
+ dilation=1 if i == 0 else dilation,
+ padding=1 if i == 0 else dilation,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+
+ self.convs = nn.Sequential(*convs)
+
+ def forward(self, x):
+ """Forward function."""
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(self.convs, x)
+ else:
+ out = self.convs(x)
+ return out
+
+
+@MODELS.register_module()
+class DeconvModule(nn.Module):
+ """Deconvolution upsample module in decoder for UNet (2X upsample).
+
+ This module uses deconvolution to upsample feature map in the decoder
+ of UNet.
+
+ Args:
+ in_channels (int): Number of input channels.
+ out_channels (int): Number of output channels.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ norm_cfg (dict | None): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict | None): Config dict for activation layer in ConvModule.
+ Default: dict(type='ReLU').
+ kernel_size (int): Kernel size of the convolutional layer. Default: 4.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ with_cp=False,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ *,
+ kernel_size=4,
+ scale_factor=2):
+ super().__init__()
+
+ assert (
+ kernel_size - scale_factor >= 0
+ and (kernel_size - scale_factor) % 2 == 0), (
+ f'kernel_size should be greater than or equal to scale_factor '
+ f'and (kernel_size - scale_factor) should be even numbers, '
+ f'while the kernel size is {kernel_size} and scale_factor is '
+ f'{scale_factor}.')
+
+ stride = scale_factor
+ padding = (kernel_size - scale_factor) // 2
+ self.with_cp = with_cp
+ deconv = nn.ConvTranspose2d(
+ in_channels,
+ out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding)
+
+ _, norm = build_norm_layer(norm_cfg, out_channels)
+ activate = MODELS.build(act_cfg)
+ self.deconv_upsamping = nn.Sequential(deconv, norm, activate)
+
+ def forward(self, x):
+ """Forward function."""
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(self.deconv_upsamping, x)
+ else:
+ out = self.deconv_upsamping(x)
+ return out
+
+
+@MODELS.register_module()
+class InterpConv(nn.Module):
+ """Interpolation upsample module in decoder for UNet.
+
+ This module uses interpolation to upsample feature map in the decoder
+ of UNet. It consists of one interpolation upsample layer and one
+ convolutional layer. It can be one interpolation upsample layer followed
+ by one convolutional layer (conv_first=False) or one convolutional layer
+ followed by one interpolation upsample layer (conv_first=True).
+
+ Args:
+ in_channels (int): Number of input channels.
+ out_channels (int): Number of output channels.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ norm_cfg (dict | None): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict | None): Config dict for activation layer in ConvModule.
+ Default: dict(type='ReLU').
+ conv_cfg (dict | None): Config dict for convolution layer.
+ Default: None.
+ conv_first (bool): Whether convolutional layer or interpolation
+ upsample layer first. Default: False. It means interpolation
+ upsample layer followed by one convolutional layer.
+ kernel_size (int): Kernel size of the convolutional layer. Default: 1.
+ stride (int): Stride of the convolutional layer. Default: 1.
+ padding (int): Padding of the convolutional layer. Default: 1.
+ upsample_cfg (dict): Interpolation config of the upsample layer.
+ Default: dict(
+ scale_factor=2, mode='bilinear', align_corners=False).
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ with_cp=False,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ *,
+ conv_cfg=None,
+ conv_first=False,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ upsample_cfg=dict(
+ scale_factor=2, mode='bilinear', align_corners=False)):
+ super().__init__()
+
+ self.with_cp = with_cp
+ conv = ConvModule(
+ in_channels,
+ out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ upsample = nn.Upsample(**upsample_cfg)
+ if conv_first:
+ self.interp_upsample = nn.Sequential(conv, upsample)
+ else:
+ self.interp_upsample = nn.Sequential(upsample, conv)
+
+ def forward(self, x):
+ """Forward function."""
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(self.interp_upsample, x)
+ else:
+ out = self.interp_upsample(x)
+ return out
+
+
+@MODELS.register_module()
+class UNet(BaseModule):
+ """UNet backbone.
+ U-Net: Convolutional Networks for Biomedical Image Segmentation.
+ https://arxiv.org/pdf/1505.04597.pdf
+
+ Args:
+ in_channels (int): Number of input image channels. Default" 3.
+ base_channels (int): Number of base channels of each stage.
+ The output channels of the first stage. Default: 64.
+ num_stages (int): Number of stages in encoder, normally 5. Default: 5.
+ strides (Sequence[int 1 | 2]): Strides of each stage in encoder.
+ len(strides) is equal to num_stages. Normally the stride of the
+ first stage in encoder is 1. If strides[i]=2, it uses stride
+ convolution to downsample in the correspondence encoder stage.
+ Default: (1, 1, 1, 1, 1).
+ enc_num_convs (Sequence[int]): Number of convolutional layers in the
+ convolution block of the correspondence encoder stage.
+ Default: (2, 2, 2, 2, 2).
+ dec_num_convs (Sequence[int]): Number of convolutional layers in the
+ convolution block of the correspondence decoder stage.
+ Default: (2, 2, 2, 2).
+ downsamples (Sequence[int]): Whether use MaxPool to downsample the
+ feature map after the first stage of encoder
+ (stages: [1, num_stages)). If the correspondence encoder stage use
+ stride convolution (strides[i]=2), it will never use MaxPool to
+ downsample, even downsamples[i-1]=True.
+ Default: (True, True, True, True).
+ enc_dilations (Sequence[int]): Dilation rate of each stage in encoder.
+ Default: (1, 1, 1, 1, 1).
+ dec_dilations (Sequence[int]): Dilation rate of each stage in decoder.
+ Default: (1, 1, 1, 1).
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ conv_cfg (dict | None): Config dict for convolution layer.
+ Default: None.
+ norm_cfg (dict | None): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict | None): Config dict for activation layer in ConvModule.
+ Default: dict(type='ReLU').
+ upsample_cfg (dict): The upsample config of the upsample module in
+ decoder. Default: dict(type='InterpConv').
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: False.
+ dcn (bool): Use deformable convolution in convolutional layer or not.
+ Default: None.
+ plugins (dict): plugins for convolutional layers. Default: None.
+
+ Notice:
+ The input image size should be divisible by the whole downsample rate
+ of the encoder. More detail of the whole downsample rate can be found
+ in UNet._check_input_divisible.
+
+ """
+
+ def __init__(self,
+ in_channels=3,
+ base_channels=64,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, True),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1),
+ with_cp=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ upsample_cfg=dict(type='InterpConv'),
+ norm_eval=False,
+ dcn=None,
+ plugins=None,
+ init_cfg=[
+ dict(type='Kaiming', layer='Conv2d'),
+ dict(
+ type='Constant',
+ layer=['_BatchNorm', 'GroupNorm'],
+ val=1)
+ ]):
+ super().__init__(init_cfg=init_cfg)
+ assert dcn is None, 'Not implemented yet.'
+ assert plugins is None, 'Not implemented yet.'
+ assert len(strides) == num_stages, (
+ 'The length of strides should be equal to num_stages, '
+ f'while the strides is {strides}, the length of '
+ f'strides is {len(strides)}, and the num_stages is '
+ f'{num_stages}.')
+ assert len(enc_num_convs) == num_stages, (
+ 'The length of enc_num_convs should be equal to num_stages, '
+ f'while the enc_num_convs is {enc_num_convs}, the length of '
+ f'enc_num_convs is {len(enc_num_convs)}, and the num_stages is '
+ f'{num_stages}.')
+ assert len(dec_num_convs) == (num_stages - 1), (
+ 'The length of dec_num_convs should be equal to (num_stages-1), '
+ f'while the dec_num_convs is {dec_num_convs}, the length of '
+ f'dec_num_convs is {len(dec_num_convs)}, and the num_stages is '
+ f'{num_stages}.')
+ assert len(downsamples) == (num_stages - 1), (
+ 'The length of downsamples should be equal to (num_stages-1), '
+ f'while the downsamples is {downsamples}, the length of '
+ f'downsamples is {len(downsamples)}, and the num_stages is '
+ f'{num_stages}.')
+ assert len(enc_dilations) == num_stages, (
+ 'The length of enc_dilations should be equal to num_stages, '
+ f'while the enc_dilations is {enc_dilations}, the length of '
+ f'enc_dilations is {len(enc_dilations)}, and the num_stages is '
+ f'{num_stages}.')
+ assert len(dec_dilations) == (num_stages - 1), (
+ 'The length of dec_dilations should be equal to (num_stages-1), '
+ f'while the dec_dilations is {dec_dilations}, the length of '
+ f'dec_dilations is {len(dec_dilations)}, and the num_stages is '
+ f'{num_stages}.')
+ self.num_stages = num_stages
+ self.strides = strides
+ self.downsamples = downsamples
+ self.norm_eval = norm_eval
+ self.base_channels = base_channels
+
+ self.encoder = nn.ModuleList()
+ self.decoder = nn.ModuleList()
+
+ for i in range(num_stages):
+ enc_conv_block = []
+ if i != 0:
+ if strides[i] == 1 and downsamples[i - 1]:
+ enc_conv_block.append(nn.MaxPool2d(kernel_size=2))
+ upsample = (strides[i] != 1 or downsamples[i - 1])
+ self.decoder.append(
+ UpConvBlock(
+ conv_block=BasicConvBlock,
+ in_channels=base_channels * 2**i,
+ skip_channels=base_channels * 2**(i - 1),
+ out_channels=base_channels * 2**(i - 1),
+ num_convs=dec_num_convs[i - 1],
+ stride=1,
+ dilation=dec_dilations[i - 1],
+ with_cp=with_cp,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ upsample_cfg=upsample_cfg if upsample else None,
+ dcn=None,
+ plugins=None))
+
+ enc_conv_block.append(
+ BasicConvBlock(
+ in_channels=in_channels,
+ out_channels=base_channels * 2**i,
+ num_convs=enc_num_convs[i],
+ stride=strides[i],
+ dilation=enc_dilations[i],
+ with_cp=with_cp,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ dcn=None,
+ plugins=None))
+ self.encoder.append(nn.Sequential(*enc_conv_block))
+ in_channels = base_channels * 2**i
+
+ def forward(self, x):
+ self._check_input_divisible(x)
+ enc_outs = []
+ for enc in self.encoder:
+ x = enc(x)
+ enc_outs.append(x)
+ dec_outs = [x]
+ for i in reversed(range(len(self.decoder))):
+ x = self.decoder[i](enc_outs[i], x)
+ dec_outs.append(x)
+
+ return dec_outs
+
+ def train(self, mode=True):
+ """Convert the model into training mode while keep normalization layer
+ freezed."""
+ super().train(mode)
+ if mode and self.norm_eval:
+ for m in self.modules():
+ # trick: eval have effect on BatchNorm only
+ if isinstance(m, _BatchNorm):
+ m.eval()
+
+ def _check_input_divisible(self, x):
+ h, w = x.shape[-2:]
+ whole_downsample_rate = 1
+ for i in range(1, self.num_stages):
+ if self.strides[i] == 2 or self.downsamples[i - 1]:
+ whole_downsample_rate *= 2
+ assert (
+ h % whole_downsample_rate == 0 and w % whole_downsample_rate == 0
+ ), (f'The input image size {(h, w)} should be divisible by the whole '
+ f'downsample rate {whole_downsample_rate}, when num_stages is '
+ f'{self.num_stages}, strides is {self.strides}, and downsamples '
+ f'is {self.downsamples}.')
diff --git a/mmocr/models/common/backbones/vit.py b/mmocr/models/common/backbones/vit.py
new file mode 100644
index 0000000000000000000000000000000000000000..745c185b8918a890e1cb76a06d37bdbdf267e33c
--- /dev/null
+++ b/mmocr/models/common/backbones/vit.py
@@ -0,0 +1,284 @@
+# Copyright (c) Meta Platforms, Inc. and affiliates.
+# All rights reserved.
+
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+# --------------------------------------------------------
+# References:
+# timm: https://github.com/rwightman/pytorch-image-models/tree/master/timm
+# DeiT: https://github.com/facebookresearch/deit
+# --------------------------------------------------------
+
+from functools import partial
+from typing import Tuple
+import timm.models.vision_transformer
+from safetensors import safe_open
+from safetensors.torch import save_file
+import torch
+import torch.nn as nn
+import math
+from mmocr.registry import MODELS
+
+
+@MODELS.register_module()
+class VisionTransformer(timm.models.vision_transformer.VisionTransformer):
+ """ Vision Transformer.
+
+ Args:
+ global_pool (bool): If True, apply global pooling to the output
+ of the last stage. Default: False.
+ patch_size (int): Patch token size. Default: 8.
+ img_size (tuple[int]): Input image size. Default: (32, 128).
+ embed_dim (int): Number of linear projection output channels.
+ Default: 192.
+ depth (int): Number of blocks. Default: 12.
+ num_heads (int): Number of attention heads. Default: 3.
+ mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
+ Default: 4.
+ qkv_bias (bool): If True, add a learnable bias to query, key,
+ value. Default: True.
+ norm_layer (nn.Module): Normalization layer. Default:
+ partial(nn.LayerNorm, eps=1e-6).
+ pretrained (str): Path to pre-trained checkpoint. Default: None.
+ """
+
+ def __init__(self,
+ global_pool: bool = False,
+ patch_size: int = 8,
+ img_size: Tuple[int, int] = (32, 128),
+ embed_dim: int = 192,
+ depth: int = 12,
+ num_heads: int = 3,
+ mlp_ratio: int = 4.,
+ qkv_bias: bool = True,
+ norm_layer=partial(nn.LayerNorm, eps=1e-6),
+ pretrained: bool = None,
+ **kwargs):
+ super(VisionTransformer, self).__init__(
+ patch_size=patch_size,
+ img_size=img_size,
+ embed_dim=embed_dim,
+ depth=depth,
+ num_heads=num_heads,
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias,
+ norm_layer=norm_layer,
+ **kwargs)
+
+ self.global_pool = global_pool
+ if self.global_pool:
+ norm_layer = kwargs['norm_layer']
+ embed_dim = kwargs['embed_dim']
+ self.fc_norm = norm_layer(embed_dim)
+
+ del self.norm # remove the original norm
+ self.reset_classifier(0)
+
+ if pretrained:
+ checkpoint = torch.load(pretrained, map_location='cpu')
+
+ print("Load pre-trained checkpoint from: %s" % pretrained)
+ checkpoint_model = checkpoint['model']
+ state_dict = self.state_dict()
+ for k in ['head.weight', 'head.bias']:
+ if k in checkpoint_model and checkpoint_model[
+ k].shape != state_dict[k].shape:
+ print(f"Removing key {k} from pretrained checkpoint")
+ del checkpoint_model[k]
+ # remove key with decoder
+ for k in list(checkpoint_model.keys()):
+ if 'decoder' in k:
+ del checkpoint_model[k]
+ msg = self.load_state_dict(checkpoint_model, strict=False)
+ print(msg)
+
+ def forward_features(self, x: torch.Tensor):
+ B = x.shape[0]
+ x = self.patch_embed(x)
+
+ cls_tokens = self.cls_token.expand(
+ B, -1, -1) # stole cls_tokens impl from Phil Wang, thanks
+ x = torch.cat((cls_tokens, x), dim=1)
+ x = x + self.pos_embed
+ x = self.pos_drop(x)
+
+ for blk in self.blocks:
+ x = blk(x)
+
+ x = self.norm(x)
+ return x
+
+ def forward(self, x):
+ return self.forward_features(x)
+
+
+class _LoRA_qkv_timm(nn.Module):
+ """LoRA layer for query and value projection in Vision Transformer of timm.
+
+ Args:
+ qkv (nn.Module): qkv projection layer in Vision Transformer of timm.
+ linear_a_q (nn.Module): Linear layer for query projection.
+ linear_b_q (nn.Module): Linear layer for query projection.
+ linear_a_v (nn.Module): Linear layer for value projection.
+ linear_b_v (nn.Module): Linear layer for value projection.
+ """
+
+ def __init__(
+ self,
+ qkv: nn.Module,
+ linear_a_q: nn.Module,
+ linear_b_q: nn.Module,
+ linear_a_v: nn.Module,
+ linear_b_v: nn.Module,
+ ):
+ super().__init__()
+ self.qkv = qkv
+ self.linear_a_q = linear_a_q
+ self.linear_b_q = linear_b_q
+ self.linear_a_v = linear_a_v
+ self.linear_b_v = linear_b_v
+ self.dim = qkv.in_features
+
+ def forward(self, x):
+ qkv = self.qkv(x) # B, N, 3*dim
+ new_q = self.linear_b_q(self.linear_a_q(x))
+ new_v = self.linear_b_v(self.linear_a_v(x))
+ qkv[:, :, :self.dim] += new_q
+ qkv[:, :, -self.dim:] += new_v
+ return qkv
+
+
+@MODELS.register_module()
+class VisionTransformer_LoRA(nn.Module):
+ """Vision Transformer with LoRA. For each block, we add a LoRA layer for
+ the linear projection of query and value.
+
+ Args:
+ vit_config (dict): Config dict for VisionTransformer.
+ rank (int): Rank of LoRA layer. Default: 4.
+ lora_layers (int): Stages to add LoRA layer. Defaults None means
+ add LoRA layer to all stages.
+ pretrained_lora (str): Path to pre-trained checkpoint of LoRA layer.
+ """
+
+ def __init__(self,
+ vit_config: dict,
+ rank: int = 4,
+ lora_layers: int = None,
+ pretrained_lora: str = None):
+ super(VisionTransformer_LoRA, self).__init__()
+ self.vit = MODELS.build(vit_config)
+ assert rank > 0
+ if lora_layers:
+ self.lora_layers = lora_layers
+ else:
+ self.lora_layers = list(range(len(self.vit.blocks)))
+ # creat list of LoRA layers
+ self.query_As = nn.Sequential() # matrix A for query linear projection
+ self.query_Bs = nn.Sequential()
+ self.value_As = nn.Sequential() # matrix B for value linear projection
+ self.value_Bs = nn.Sequential()
+
+ # freeze the original vit
+ for param in self.vit.parameters():
+ param.requires_grad = False
+
+ # compose LoRA layers
+ for block_idx, block in enumerate(self.vit.blocks):
+ if block_idx not in self.lora_layers:
+ continue
+ # create LoRA layer
+ w_qkv_linear = block.attn.qkv
+ self.dim = w_qkv_linear.in_features
+ w_a_linear_q = nn.Linear(self.dim, rank, bias=False)
+ w_b_linear_q = nn.Linear(rank, self.dim, bias=False)
+ w_a_linear_v = nn.Linear(self.dim, rank, bias=False)
+ w_b_linear_v = nn.Linear(rank, self.dim, bias=False)
+ self.query_As.append(w_a_linear_q)
+ self.query_Bs.append(w_b_linear_q)
+ self.value_As.append(w_a_linear_v)
+ self.value_Bs.append(w_b_linear_v)
+ # replace the original qkv layer with LoRA layer
+ block.attn.qkv = _LoRA_qkv_timm(
+ w_qkv_linear,
+ w_a_linear_q,
+ w_b_linear_q,
+ w_a_linear_v,
+ w_b_linear_v,
+ )
+ self._init_lora()
+ if pretrained_lora is not None:
+ self._load_lora(pretrained_lora)
+
+ def _init_lora(self):
+ """Initialize the LoRA layers to be identity mapping."""
+ for query_A, query_B, value_A, value_B in zip(self.query_As,
+ self.query_Bs,
+ self.value_As,
+ self.value_Bs):
+ nn.init.kaiming_uniform_(query_A.weight, a=math.sqrt(5))
+ nn.init.kaiming_uniform_(value_A.weight, a=math.sqrt(5))
+ nn.init.zeros_(query_B.weight)
+ nn.init.zeros_(value_B.weight)
+
+ def _load_lora(self, checkpoint_lora: str):
+ """Load pre-trained LoRA checkpoint.
+
+ Args:
+ checkpoint_lora (str): Path to pre-trained LoRA checkpoint.
+ """
+ assert checkpoint_lora.endswith(".safetensors")
+ with safe_open(checkpoint_lora, framework="pt") as f:
+ for i, q_A, q_B, v_A, v_B in zip(
+ range(len(self.query_As)),
+ self.query_As,
+ self.query_Bs,
+ self.value_As,
+ self.value_Bs,
+ ):
+ q_A.weight = nn.Parameter(f.get_tensor(f"q_a_{i:03d}"))
+ q_B.weight = nn.Parameter(f.get_tensor(f"q_b_{i:03d}"))
+ v_A.weight = nn.Parameter(f.get_tensor(f"v_a_{i:03d}"))
+ v_B.weight = nn.Parameter(f.get_tensor(f"v_b_{i:03d}"))
+
+ def forward(self, x):
+ x = self.vit(x)
+ return x
+
+
+def extract_lora_from_vit(checkpoint_path: str,
+ save_path: str,
+ ckpt_key: str = None):
+ """Given a checkpoint of VisionTransformer_LoRA, extract the LoRA weights
+ and save them to a new checkpoint.
+
+ Args:
+ checkpoint_path (str): Path to checkpoint of VisionTransformer_LoRA.
+ ckpt_key (str): Key of model in the checkpoint.
+ save_path (str): Path to save the extracted LoRA checkpoint.
+ """
+ assert save_path.endswith(".safetensors")
+ ckpt = torch.load(checkpoint_path, map_location="cpu")
+ # travel throung the ckpt to find the LoRA layers
+ query_As = []
+ query_Bs = []
+ value_As = []
+ value_Bs = []
+ ckpt = ckpt if ckpt_key is None else ckpt[ckpt_key]
+ for k, v in ckpt.items():
+ if k.startswith("query_As"):
+ query_As.append(v)
+ elif k.startswith("query_Bs"):
+ query_Bs.append(v)
+ elif k.startswith("value_As"):
+ value_As.append(v)
+ elif k.startswith("value_Bs"):
+ value_Bs.append(v)
+ # save the LoRA layers to a new checkpoint
+ ckpt_dict = {}
+ for i in range(len(query_As)):
+ ckpt_dict[f"q_a_{i:03d}"] = query_As[i]
+ ckpt_dict[f"q_b_{i:03d}"] = query_Bs[i]
+ ckpt_dict[f"v_a_{i:03d}"] = value_As[i]
+ ckpt_dict[f"v_b_{i:03d}"] = value_Bs[i]
+ save_file(ckpt_dict, save_path)
diff --git a/mmocr/models/common/dictionary/__init__.py b/mmocr/models/common/dictionary/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..9ad0ab306f183192aa5c8464eee5947e13d294e6
--- /dev/null
+++ b/mmocr/models/common/dictionary/__init__.py
@@ -0,0 +1,5 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+
+from .dictionary import Dictionary
+
+__all__ = ['Dictionary']
diff --git a/mmocr/models/common/dictionary/__pycache__/__init__.cpython-38.pyc b/mmocr/models/common/dictionary/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..834ad6bcf01b485233f0e0142abdc928c6c56581
Binary files /dev/null and b/mmocr/models/common/dictionary/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/models/common/dictionary/__pycache__/dictionary.cpython-38.pyc b/mmocr/models/common/dictionary/__pycache__/dictionary.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..38d95a0d68396f8bf064b2e43c241ca5fd83be27
Binary files /dev/null and b/mmocr/models/common/dictionary/__pycache__/dictionary.cpython-38.pyc differ
diff --git a/mmocr/models/common/dictionary/dictionary.py b/mmocr/models/common/dictionary/dictionary.py
new file mode 100644
index 0000000000000000000000000000000000000000..d16dc87582da52f0179fb2188646bf5e07a3df6d
--- /dev/null
+++ b/mmocr/models/common/dictionary/dictionary.py
@@ -0,0 +1,188 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Sequence
+
+from mmocr.registry import TASK_UTILS
+from mmocr.utils import list_from_file
+
+
+@TASK_UTILS.register_module()
+class Dictionary:
+ """The class generates a dictionary for recognition. It pre-defines four
+ special tokens: ``start_token``, ``end_token``, ``pad_token``, and
+ ``unknown_token``, which will be sequentially placed at the end of the
+ dictionary when their corresponding flags are True.
+
+ Args:
+ dict_file (str): The path of Character dict file which a single
+ character must occupies a line.
+ with_start (bool): The flag to control whether to include the start
+ token. Defaults to False.
+ with_end (bool): The flag to control whether to include the end token.
+ Defaults to False.
+ same_start_end (bool): The flag to control whether the start token and
+ end token are the same. It only works when both ``with_start`` and
+ ``with_end`` are True. Defaults to False.
+ with_padding (bool):The padding token may represent more than a
+ padding. It can also represent tokens like the blank token in CTC
+ or the background token in SegOCR. Defaults to False.
+ with_unknown (bool): The flag to control whether to include the
+ unknown token. Defaults to False.
+ start_token (str): The start token as a string. Defaults to ''.
+ end_token (str): The end token as a string. Defaults to ''.
+ start_end_token (str): The start/end token as a string. if start and
+ end is the same. Defaults to ''.
+ padding_token (str): The padding token as a string.
+ Defaults to ''.
+ unknown_token (str, optional): The unknown token as a string. If it's
+ set to None and ``with_unknown`` is True, the unknown token will be
+ skipped when converting string to index. Defaults to ''.
+ """
+
+ def __init__(self,
+ dict_file: str,
+ with_start: bool = False,
+ with_end: bool = False,
+ same_start_end: bool = False,
+ with_padding: bool = False,
+ with_unknown: bool = False,
+ start_token: str = '',
+ end_token: str = '',
+ start_end_token: str = '',
+ padding_token: str = '',
+ unknown_token: str = '') -> None:
+ self.with_start = with_start
+ self.with_end = with_end
+ self.same_start_end = same_start_end
+ self.with_padding = with_padding
+ self.with_unknown = with_unknown
+ self.start_end_token = start_end_token
+ self.start_token = start_token
+ self.end_token = end_token
+ self.padding_token = padding_token
+ self.unknown_token = unknown_token
+
+ assert isinstance(dict_file, str)
+ self._dict = []
+ for line_num, line in enumerate(list_from_file(dict_file)):
+ line = line.strip('\r\n')
+ if len(line) > 1:
+ raise ValueError('Expect each line has 0 or 1 character, '
+ f'got {len(line)} characters '
+ f'at line {line_num + 1}')
+ if line != '':
+ self._dict.append(line)
+
+ self._char2idx = {char: idx for idx, char in enumerate(self._dict)}
+
+ self._update_dict()
+ assert len(set(self._dict)) == len(self._dict), \
+ 'Invalid dictionary: Has duplicated characters.'
+
+ @property
+ def num_classes(self) -> int:
+ """int: Number of output classes. Special tokens are counted.
+ """
+ return len(self._dict)
+
+ @property
+ def dict(self) -> list:
+ """list: Returns a list of characters to recognize, where special
+ tokens are counted."""
+ return self._dict
+
+ def char2idx(self, char: str, strict: bool = True) -> int:
+ """Convert a character to an index via ``Dictionary.dict``.
+
+ Args:
+ char (str): The character to convert to index.
+ strict (bool): The flag to control whether to raise an exception
+ when the character is not in the dictionary. Defaults to True.
+
+ Return:
+ int: The index of the character.
+ """
+ char_idx = self._char2idx.get(char, None)
+ if char_idx is None:
+ if self.with_unknown:
+ return self.unknown_idx
+ elif not strict:
+ return None
+ else:
+ raise Exception(f'Chararcter: {char} not in dict,'
+ ' please check gt_label and use'
+ ' custom dict file,'
+ ' or set "with_unknown=True"')
+ return char_idx
+
+ def str2idx(self, string: str) -> List:
+ """Convert a string to a list of indexes via ``Dictionary.dict``.
+
+ Args:
+ string (str): The string to convert to indexes.
+
+ Return:
+ list: The list of indexes of the string.
+ """
+ idx = list()
+ for s in string:
+ char_idx = self.char2idx(s)
+ if char_idx is None:
+ if self.with_unknown:
+ continue
+ raise Exception(f'Chararcter: {s} not in dict,'
+ ' please check gt_label and use'
+ ' custom dict file,'
+ ' or set "with_unknown=True"')
+ idx.append(char_idx)
+ return idx
+
+ def idx2str(self, index: Sequence[int]) -> str:
+ """Convert a list of index to string.
+
+ Args:
+ index (list[int]): The list of indexes to convert to string.
+
+ Return:
+ str: The converted string.
+ """
+ assert isinstance(index, (list, tuple))
+ string = ''
+ for i in index:
+ assert i < len(self._dict), f'Index: {i} out of range! Index ' \
+ f'must be less than {len(self._dict)}'
+ string += self._dict[i]
+ return string
+
+ def _update_dict(self):
+ """Update the dict with tokens according to parameters."""
+ # BOS/EOS
+ self.start_idx = None
+ self.end_idx = None
+ if self.with_start and self.with_end and self.same_start_end:
+ self._dict.append(self.start_end_token)
+ self.start_idx = len(self._dict) - 1
+ self.end_idx = self.start_idx
+ else:
+ if self.with_start:
+ self._dict.append(self.start_token)
+ self.start_idx = len(self._dict) - 1
+ if self.with_end:
+ self._dict.append(self.end_token)
+ self.end_idx = len(self._dict) - 1
+
+ # padding
+ self.padding_idx = None
+ if self.with_padding:
+ self._dict.append(self.padding_token)
+ self.padding_idx = len(self._dict) - 1
+
+ # unknown
+ self.unknown_idx = None
+ if self.with_unknown and self.unknown_token is not None:
+ self._dict.append(self.unknown_token)
+ self.unknown_idx = len(self._dict) - 1
+
+ # update char2idx
+ self._char2idx = {}
+ for idx, char in enumerate(self._dict):
+ self._char2idx[char] = idx
diff --git a/mmocr/models/common/layers/__init__.py b/mmocr/models/common/layers/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..1d1a921fdc8b57e2de15cedd6a214df77d9bdb42
--- /dev/null
+++ b/mmocr/models/common/layers/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .transformer_layers import TFDecoderLayer, TFEncoderLayer
+
+__all__ = ['TFEncoderLayer', 'TFDecoderLayer']
diff --git a/mmocr/models/common/layers/__pycache__/__init__.cpython-38.pyc b/mmocr/models/common/layers/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..33927d0f8d31f9fe28a52d05744692db136476cc
Binary files /dev/null and b/mmocr/models/common/layers/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/models/common/layers/__pycache__/transformer_layers.cpython-38.pyc b/mmocr/models/common/layers/__pycache__/transformer_layers.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d4d8c6fb12fad9549957dc5691646506e83beb52
Binary files /dev/null and b/mmocr/models/common/layers/__pycache__/transformer_layers.cpython-38.pyc differ
diff --git a/mmocr/models/common/layers/transformer_layers.py b/mmocr/models/common/layers/transformer_layers.py
new file mode 100644
index 0000000000000000000000000000000000000000..8be138d5c5af89b96f27f3646b14a60302659105
--- /dev/null
+++ b/mmocr/models/common/layers/transformer_layers.py
@@ -0,0 +1,167 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+from mmengine.model import BaseModule
+
+from mmocr.models.common.modules import (MultiHeadAttention,
+ PositionwiseFeedForward)
+
+
+class TFEncoderLayer(BaseModule):
+ """Transformer Encoder Layer.
+
+ Args:
+ d_model (int): The number of expected features
+ in the decoder inputs (default=512).
+ d_inner (int): The dimension of the feedforward
+ network model (default=256).
+ n_head (int): The number of heads in the
+ multiheadattention models (default=8).
+ d_k (int): Total number of features in key.
+ d_v (int): Total number of features in value.
+ dropout (float): Dropout layer on attn_output_weights.
+ qkv_bias (bool): Add bias in projection layer. Default: False.
+ act_cfg (dict): Activation cfg for feedforward module.
+ operation_order (tuple[str]): The execution order of operation
+ in transformer. Such as ('self_attn', 'norm', 'ffn', 'norm')
+ or ('norm', 'self_attn', 'norm', 'ffn').
+ Default:None.
+ """
+
+ def __init__(self,
+ d_model=512,
+ d_inner=256,
+ n_head=8,
+ d_k=64,
+ d_v=64,
+ dropout=0.1,
+ qkv_bias=False,
+ act_cfg=dict(type='mmengine.GELU'),
+ operation_order=None):
+ super().__init__()
+ self.attn = MultiHeadAttention(
+ n_head, d_model, d_k, d_v, qkv_bias=qkv_bias, dropout=dropout)
+ self.norm1 = nn.LayerNorm(d_model)
+ self.mlp = PositionwiseFeedForward(
+ d_model, d_inner, dropout=dropout, act_cfg=act_cfg)
+ self.norm2 = nn.LayerNorm(d_model)
+
+ self.operation_order = operation_order
+ if self.operation_order is None:
+ self.operation_order = ('norm', 'self_attn', 'norm', 'ffn')
+
+ assert self.operation_order in [('norm', 'self_attn', 'norm', 'ffn'),
+ ('self_attn', 'norm', 'ffn', 'norm')]
+
+ def forward(self, x, mask=None):
+ if self.operation_order == ('self_attn', 'norm', 'ffn', 'norm'):
+ residual = x
+ x = residual + self.attn(x, x, x, mask)
+ x = self.norm1(x)
+
+ residual = x
+ x = residual + self.mlp(x)
+ x = self.norm2(x)
+ elif self.operation_order == ('norm', 'self_attn', 'norm', 'ffn'):
+ residual = x
+ x = self.norm1(x)
+ x = residual + self.attn(x, x, x, mask)
+
+ residual = x
+ x = self.norm2(x)
+ x = residual + self.mlp(x)
+
+ return x
+
+
+class TFDecoderLayer(nn.Module):
+ """Transformer Decoder Layer.
+
+ Args:
+ d_model (int): The number of expected features
+ in the decoder inputs (default=512).
+ d_inner (int): The dimension of the feedforward
+ network model (default=256).
+ n_head (int): The number of heads in the
+ multiheadattention models (default=8).
+ d_k (int): Total number of features in key.
+ d_v (int): Total number of features in value.
+ dropout (float): Dropout layer on attn_output_weights.
+ qkv_bias (bool): Add bias in projection layer. Default: False.
+ act_cfg (dict): Activation cfg for feedforward module.
+ operation_order (tuple[str]): The execution order of operation
+ in transformer. Such as ('self_attn', 'norm', 'enc_dec_attn',
+ 'norm', 'ffn', 'norm') or ('norm', 'self_attn', 'norm',
+ 'enc_dec_attn', 'norm', 'ffn').
+ Default:None.
+ """
+
+ def __init__(self,
+ d_model=512,
+ d_inner=256,
+ n_head=8,
+ d_k=64,
+ d_v=64,
+ dropout=0.1,
+ qkv_bias=False,
+ act_cfg=dict(type='mmengine.GELU'),
+ operation_order=None):
+ super().__init__()
+
+ self.norm1 = nn.LayerNorm(d_model)
+ self.norm2 = nn.LayerNorm(d_model)
+ self.norm3 = nn.LayerNorm(d_model)
+
+ self.self_attn = MultiHeadAttention(
+ n_head, d_model, d_k, d_v, dropout=dropout, qkv_bias=qkv_bias)
+
+ self.enc_attn = MultiHeadAttention(
+ n_head, d_model, d_k, d_v, dropout=dropout, qkv_bias=qkv_bias)
+
+ self.mlp = PositionwiseFeedForward(
+ d_model, d_inner, dropout=dropout, act_cfg=act_cfg)
+
+ self.operation_order = operation_order
+ if self.operation_order is None:
+ self.operation_order = ('norm', 'self_attn', 'norm',
+ 'enc_dec_attn', 'norm', 'ffn')
+ assert self.operation_order in [
+ ('norm', 'self_attn', 'norm', 'enc_dec_attn', 'norm', 'ffn'),
+ ('self_attn', 'norm', 'enc_dec_attn', 'norm', 'ffn', 'norm')
+ ]
+
+ def forward(self,
+ dec_input,
+ enc_output,
+ self_attn_mask=None,
+ dec_enc_attn_mask=None):
+ if self.operation_order == ('self_attn', 'norm', 'enc_dec_attn',
+ 'norm', 'ffn', 'norm'):
+ dec_attn_out = self.self_attn(dec_input, dec_input, dec_input,
+ self_attn_mask)
+ dec_attn_out += dec_input
+ dec_attn_out = self.norm1(dec_attn_out)
+
+ enc_dec_attn_out = self.enc_attn(dec_attn_out, enc_output,
+ enc_output, dec_enc_attn_mask)
+ enc_dec_attn_out += dec_attn_out
+ enc_dec_attn_out = self.norm2(enc_dec_attn_out)
+
+ mlp_out = self.mlp(enc_dec_attn_out)
+ mlp_out += enc_dec_attn_out
+ mlp_out = self.norm3(mlp_out)
+ elif self.operation_order == ('norm', 'self_attn', 'norm',
+ 'enc_dec_attn', 'norm', 'ffn'):
+ dec_input_norm = self.norm1(dec_input)
+ dec_attn_out = self.self_attn(dec_input_norm, dec_input_norm,
+ dec_input_norm, self_attn_mask)
+ dec_attn_out += dec_input
+
+ enc_dec_attn_in = self.norm2(dec_attn_out)
+ enc_dec_attn_out = self.enc_attn(enc_dec_attn_in, enc_output,
+ enc_output, dec_enc_attn_mask)
+ enc_dec_attn_out += dec_attn_out
+
+ mlp_out = self.mlp(self.norm3(enc_dec_attn_out))
+ mlp_out += enc_dec_attn_out
+
+ return mlp_out
diff --git a/mmocr/models/common/losses/__init__.py b/mmocr/models/common/losses/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..336d2ed81e35a886ace8c54046abe13e1685b1ec
--- /dev/null
+++ b/mmocr/models/common/losses/__init__.py
@@ -0,0 +1,12 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .bce_loss import (MaskedBalancedBCELoss, MaskedBalancedBCEWithLogitsLoss,
+ MaskedBCELoss, MaskedBCEWithLogitsLoss)
+from .ce_loss import CrossEntropyLoss
+from .dice_loss import MaskedDiceLoss, MaskedSquareDiceLoss
+from .l1_loss import MaskedSmoothL1Loss, SmoothL1Loss
+
+__all__ = [
+ 'MaskedBalancedBCEWithLogitsLoss', 'MaskedDiceLoss', 'MaskedSmoothL1Loss',
+ 'MaskedSquareDiceLoss', 'MaskedBCEWithLogitsLoss', 'SmoothL1Loss',
+ 'CrossEntropyLoss', 'MaskedBalancedBCELoss', 'MaskedBCELoss'
+]
diff --git a/mmocr/models/common/losses/__pycache__/__init__.cpython-38.pyc b/mmocr/models/common/losses/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..16784a46c6477b998537bfff4794a12453dec414
Binary files /dev/null and b/mmocr/models/common/losses/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/models/common/losses/__pycache__/bce_loss.cpython-38.pyc b/mmocr/models/common/losses/__pycache__/bce_loss.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..02e9117c6b70b244910cb968fafc91b598659795
Binary files /dev/null and b/mmocr/models/common/losses/__pycache__/bce_loss.cpython-38.pyc differ
diff --git a/mmocr/models/common/losses/__pycache__/ce_loss.cpython-38.pyc b/mmocr/models/common/losses/__pycache__/ce_loss.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..72d342a316d20dec9fc7d4f766f244f4e56c8b64
Binary files /dev/null and b/mmocr/models/common/losses/__pycache__/ce_loss.cpython-38.pyc differ
diff --git a/mmocr/models/common/losses/__pycache__/dice_loss.cpython-38.pyc b/mmocr/models/common/losses/__pycache__/dice_loss.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..6b04515509abf7e952329ac9812bb10e4069a10c
Binary files /dev/null and b/mmocr/models/common/losses/__pycache__/dice_loss.cpython-38.pyc differ
diff --git a/mmocr/models/common/losses/__pycache__/l1_loss.cpython-38.pyc b/mmocr/models/common/losses/__pycache__/l1_loss.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8e51d36f5fbc3ed540638e72ebabdba7980ca49b
Binary files /dev/null and b/mmocr/models/common/losses/__pycache__/l1_loss.cpython-38.pyc differ
diff --git a/mmocr/models/common/losses/bce_loss.py b/mmocr/models/common/losses/bce_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..df4ce140dc6adb84c42dc4533dc2240dd6ca34bb
--- /dev/null
+++ b/mmocr/models/common/losses/bce_loss.py
@@ -0,0 +1,227 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Union
+
+import torch
+import torch.nn as nn
+
+from mmocr.registry import MODELS
+
+
+@MODELS.register_module()
+class MaskedBalancedBCEWithLogitsLoss(nn.Module):
+ """This loss combines a Sigmoid layers and a masked balanced BCE loss in
+ one single class. It's AMP-eligible.
+
+ Args:
+ reduction (str, optional): The method to reduce the loss.
+ Options are 'none', 'mean' and 'sum'. Defaults to 'none'.
+ negative_ratio (float or int, optional): Maximum ratio of negative
+ samples to positive ones. Defaults to 3.
+ fallback_negative_num (int, optional): When the mask contains no
+ positive samples, the number of negative samples to be sampled.
+ Defaults to 0.
+ eps (float, optional): Eps to avoid zero-division error. Defaults to
+ 1e-6.
+ """
+
+ def __init__(self,
+ reduction: str = 'none',
+ negative_ratio: Union[float, int] = 3,
+ fallback_negative_num: int = 0,
+ eps: float = 1e-6) -> None:
+ super().__init__()
+ assert reduction in ['none', 'mean', 'sum']
+ assert isinstance(negative_ratio, (float, int))
+ assert isinstance(fallback_negative_num, int)
+ assert isinstance(eps, float)
+ self.eps = eps
+ self.negative_ratio = negative_ratio
+ self.reduction = reduction
+ self.fallback_negative_num = fallback_negative_num
+ self.loss = nn.BCEWithLogitsLoss(reduction=reduction)
+
+ def forward(self,
+ pred: torch.Tensor,
+ gt: torch.Tensor,
+ mask: Optional[torch.Tensor] = None) -> torch.Tensor:
+ """Forward function.
+
+ Args:
+ pred (torch.Tensor): The prediction in any shape.
+ gt (torch.Tensor): The learning target of the prediction in the
+ same shape as pred.
+ mask (torch.Tensor, optional): Binary mask in the same shape of
+ pred, indicating positive regions to calculate the loss. Whole
+ region will be taken into account if not provided. Defaults to
+ None.
+
+ Returns:
+ torch.Tensor: The loss value.
+ """
+
+ assert pred.size() == gt.size() and gt.numel() > 0
+ if mask is None:
+ mask = torch.ones_like(gt)
+ assert mask.size() == gt.size()
+
+ positive = (gt * mask).float()
+ negative = ((1 - gt) * mask).float()
+ positive_count = int(positive.sum())
+ if positive_count == 0:
+ negative_count = min(
+ int(negative.sum()), self.fallback_negative_num)
+ else:
+ negative_count = min(
+ int(negative.sum()), int(positive_count * self.negative_ratio))
+
+ assert gt.max() <= 1 and gt.min() >= 0
+ loss = self.loss(pred, gt)
+ positive_loss = loss * positive
+ negative_loss = loss * negative
+
+ negative_loss, _ = torch.topk(negative_loss.view(-1), negative_count)
+
+ balance_loss = (positive_loss.sum() + negative_loss.sum()) / (
+ positive_count + negative_count + self.eps)
+
+ return balance_loss
+
+
+@MODELS.register_module()
+class MaskedBalancedBCELoss(MaskedBalancedBCEWithLogitsLoss):
+ """Masked Balanced BCE loss.
+
+ Args:
+ reduction (str, optional): The method to reduce the loss.
+ Options are 'none', 'mean' and 'sum'. Defaults to 'none'.
+ negative_ratio (float or int): Maximum ratio of negative
+ samples to positive ones. Defaults to 3.
+ fallback_negative_num (int): When the mask contains no
+ positive samples, the number of negative samples to be sampled.
+ Defaults to 0.
+ eps (float): Eps to avoid zero-division error. Defaults to
+ 1e-6.
+ """
+
+ def __init__(self,
+ reduction: str = 'none',
+ negative_ratio: Union[float, int] = 3,
+ fallback_negative_num: int = 0,
+ eps: float = 1e-6) -> None:
+ super().__init__()
+ assert reduction in ['none', 'mean', 'sum']
+ assert isinstance(negative_ratio, (float, int))
+ assert isinstance(fallback_negative_num, int)
+ assert isinstance(eps, float)
+ self.eps = eps
+ self.negative_ratio = negative_ratio
+ self.reduction = reduction
+ self.fallback_negative_num = fallback_negative_num
+ self.loss = nn.BCELoss(reduction=reduction)
+
+ def forward(self,
+ pred: torch.Tensor,
+ gt: torch.Tensor,
+ mask: Optional[torch.Tensor] = None) -> torch.Tensor:
+ """Forward function.
+
+ Args:
+ pred (torch.Tensor): The prediction in any shape.
+ gt (torch.Tensor): The learning target of the prediction in the
+ same shape as pred.
+ mask (torch.Tensor, optional): Binary mask in the same shape of
+ pred, indicating positive regions to calculate the loss. Whole
+ region will be taken into account if not provided. Defaults to
+ None.
+
+ Returns:
+ torch.Tensor: The loss value.
+ """
+
+ assert pred.max() <= 1 and pred.min() >= 0
+ return super().forward(pred, gt, mask)
+
+
+@MODELS.register_module()
+class MaskedBCEWithLogitsLoss(nn.Module):
+ """This loss combines a Sigmoid layers and a masked BCE loss in one single
+ class. It's AMP-eligible.
+
+ Args:
+ eps (float): Eps to avoid zero-division error. Defaults to
+ 1e-6.
+ """
+
+ def __init__(self, eps: float = 1e-6) -> None:
+ super().__init__()
+ assert isinstance(eps, float)
+ self.eps = eps
+ self.loss = nn.BCEWithLogitsLoss(reduction='none')
+
+ def forward(self,
+ pred: torch.Tensor,
+ gt: torch.Tensor,
+ mask: Optional[torch.Tensor] = None) -> torch.Tensor:
+ """Forward function.
+
+ Args:
+ pred (torch.Tensor): The prediction in any shape.
+ gt (torch.Tensor): The learning target of the prediction in the
+ same shape as pred.
+ mask (torch.Tensor, optional): Binary mask in the same shape of
+ pred, indicating positive regions to calculate the loss. Whole
+ region will be taken into account if not provided. Defaults to
+ None.
+
+ Returns:
+ torch.Tensor: The loss value.
+ """
+
+ assert pred.size() == gt.size() and gt.numel() > 0
+ if mask is None:
+ mask = torch.ones_like(gt)
+ assert mask.size() == gt.size()
+
+ assert gt.max() <= 1 and gt.min() >= 0
+ loss = self.loss(pred, gt)
+
+ return (loss * mask).sum() / (mask.sum() + self.eps)
+
+
+@MODELS.register_module()
+class MaskedBCELoss(MaskedBCEWithLogitsLoss):
+ """Masked BCE loss.
+
+ Args:
+ eps (float): Eps to avoid zero-division error. Defaults to
+ 1e-6.
+ """
+
+ def __init__(self, eps: float = 1e-6) -> None:
+ super().__init__()
+ assert isinstance(eps, float)
+ self.eps = eps
+ self.loss = nn.BCELoss(reduction='none')
+
+ def forward(self,
+ pred: torch.Tensor,
+ gt: torch.Tensor,
+ mask: Optional[torch.Tensor] = None) -> torch.Tensor:
+ """Forward function.
+
+ Args:
+ pred (torch.Tensor): The prediction in any shape.
+ gt (torch.Tensor): The learning target of the prediction in the
+ same shape as pred.
+ mask (torch.Tensor, optional): Binary mask in the same shape of
+ pred, indicating positive regions to calculate the loss. Whole
+ region will be taken into account if not provided. Defaults to
+ None.
+
+ Returns:
+ torch.Tensor: The loss value.
+ """
+
+ assert pred.max() <= 1 and pred.min() >= 0
+
+ return super().forward(pred, gt, mask)
diff --git a/mmocr/models/common/losses/ce_loss.py b/mmocr/models/common/losses/ce_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..9ff498723d9cbae1d71808ab028cd870da86b3b1
--- /dev/null
+++ b/mmocr/models/common/losses/ce_loss.py
@@ -0,0 +1,9 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+
+from mmocr.registry import MODELS
+
+
+@MODELS.register_module()
+class CrossEntropyLoss(nn.CrossEntropyLoss):
+ """Cross entropy loss."""
diff --git a/mmocr/models/common/losses/dice_loss.py b/mmocr/models/common/losses/dice_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..37d2d3d1926263e85c4fd4b98c8f98087405686e
--- /dev/null
+++ b/mmocr/models/common/losses/dice_loss.py
@@ -0,0 +1,112 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional
+
+import torch
+import torch.nn as nn
+
+from mmocr.registry import MODELS
+
+
+@MODELS.register_module()
+class MaskedDiceLoss(nn.Module):
+ """Masked dice loss.
+
+ Args:
+ eps (float, optional): Eps to avoid zero-divison error. Defaults to
+ 1e-6.
+ """
+
+ def __init__(self, eps: float = 1e-6) -> None:
+ super().__init__()
+ assert isinstance(eps, float)
+ self.eps = eps
+
+ def forward(self,
+ pred: torch.Tensor,
+ gt: torch.Tensor,
+ mask: Optional[torch.Tensor] = None) -> torch.Tensor:
+ """Forward function.
+
+ Args:
+ pred (torch.Tensor): The prediction in any shape.
+ gt (torch.Tensor): The learning target of the prediction in the
+ same shape as pred.
+ mask (torch.Tensor, optional): Binary mask in the same shape of
+ pred, indicating positive regions to calculate the loss. Whole
+ region will be taken into account if not provided. Defaults to
+ None.
+
+ Returns:
+ torch.Tensor: The loss value.
+ """
+
+ assert pred.size() == gt.size() and gt.numel() > 0
+ if mask is None:
+ mask = torch.ones_like(gt)
+ assert mask.size() == gt.size()
+
+ pred = pred.contiguous().view(pred.size(0), -1)
+ gt = gt.contiguous().view(gt.size(0), -1)
+
+ mask = mask.contiguous().view(mask.size(0), -1)
+ pred = pred * mask
+ gt = gt * mask
+
+ dice_coeff = (2 * (pred * gt).sum()) / (
+ pred.sum() + gt.sum() + self.eps)
+
+ return 1 - dice_coeff
+
+
+@MODELS.register_module()
+class MaskedSquareDiceLoss(nn.Module):
+ """Masked square dice loss.
+
+ Args:
+ eps (float, optional): Eps to avoid zero-divison error. Defaults to
+ 1e-3.
+ """
+
+ def __init__(self, eps: float = 1e-3) -> None:
+ super().__init__()
+ assert isinstance(eps, float)
+ self.eps = eps
+
+ def forward(self,
+ pred: torch.Tensor,
+ gt: torch.Tensor,
+ mask: Optional[torch.Tensor] = None) -> torch.Tensor:
+ """Forward function.
+
+ Args:
+ pred (torch.Tensor): The prediction in any shape.
+ gt (torch.Tensor): The learning target of the prediction in the
+ same shape as pred.
+ mask (torch.Tensor, optional): Binary mask in the same shape of
+ pred, indicating positive regions to calculate the loss. Whole
+ region will be taken into account if not provided. Defaults to
+ None.
+
+ Returns:
+ torch.Tensor: The loss value.
+ """
+ assert pred.size() == gt.size() and gt.numel() > 0
+ if mask is None:
+ mask = torch.ones_like(gt)
+ assert mask.size() == gt.size()
+ batch_size = pred.size(0)
+ pred = pred.contiguous().view(batch_size, -1)
+ gt = gt.contiguous().view(batch_size, -1).float()
+ mask = mask.contiguous().view(batch_size, -1).float()
+
+ pred = pred * mask
+ gt = gt * mask
+
+ a = torch.sum(pred * gt, dim=1)
+ b = torch.sum(pred * pred, dim=1) + self.eps
+ c = torch.sum(gt * gt, dim=1) + self.eps
+ d = (2 * a) / (b + c)
+ loss = 1 - d
+
+ loss = torch.mean(loss)
+ return loss
diff --git a/mmocr/models/common/losses/l1_loss.py b/mmocr/models/common/losses/l1_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..68771a328ddedb4d0d4b925626a3abbb17ab9a7c
--- /dev/null
+++ b/mmocr/models/common/losses/l1_loss.py
@@ -0,0 +1,70 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Union
+
+import torch
+import torch.nn as nn
+
+from mmocr import digit_version
+from mmocr.registry import MODELS
+
+
+@MODELS.register_module()
+class SmoothL1Loss(nn.SmoothL1Loss):
+ """Smooth L1 loss."""
+
+
+@MODELS.register_module()
+class MaskedSmoothL1Loss(nn.Module):
+ """Masked Smooth L1 loss.
+
+ Args:
+ beta (float, optional): The threshold in the piecewise function.
+ Defaults to 1.
+ eps (float, optional): Eps to avoid zero-division error. Defaults to
+ 1e-6.
+ """
+
+ def __init__(self, beta: Union[float, int] = 1, eps: float = 1e-6) -> None:
+ super().__init__()
+ if digit_version(torch.__version__) > digit_version('1.6.0'):
+ if digit_version(torch.__version__) >= digit_version(
+ '1.13.0') and beta == 0:
+ beta = beta + eps
+ self.smooth_l1_loss = nn.SmoothL1Loss(beta=beta, reduction='none')
+ self.eps = eps
+ self.beta = beta
+
+ def forward(self,
+ pred: torch.Tensor,
+ gt: torch.Tensor,
+ mask: Optional[torch.Tensor] = None) -> torch.Tensor:
+ """Forward function.
+
+ Args:
+ pred (torch.Tensor): The prediction in any shape.
+ gt (torch.Tensor): The learning target of the prediction in the
+ same shape as pred.
+ mask (torch.Tensor, optional): Binary mask in the same shape of
+ pred, indicating positive regions to calculate the loss. Whole
+ region will be taken into account if not provided. Defaults to
+ None.
+
+ Returns:
+ torch.Tensor: The loss value.
+ """
+
+ assert pred.size() == gt.size() and gt.numel() > 0
+ if mask is None:
+ mask = torch.ones_like(gt).bool()
+ assert mask.size() == gt.size()
+ x = pred * mask
+ y = gt * mask
+ if digit_version(torch.__version__) > digit_version('1.6.0'):
+ loss = self.smooth_l1_loss(x, y)
+ else:
+ loss = torch.zeros_like(gt)
+ diff = torch.abs(x - y)
+ mask_beta = diff < self.beta
+ loss[mask_beta] = 0.5 * torch.square(diff)[mask_beta] / self.beta
+ loss[~mask_beta] = diff[~mask_beta] - 0.5 * self.beta
+ return loss.sum() / (mask.sum() + self.eps)
diff --git a/mmocr/models/common/modules/__init__.py b/mmocr/models/common/modules/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..30960fd5dd45f069c4ae2f6c74ec66d5eecb13b8
--- /dev/null
+++ b/mmocr/models/common/modules/__init__.py
@@ -0,0 +1,9 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .transformer_module import (MultiHeadAttention, PositionalEncoding,
+ PositionwiseFeedForward,
+ ScaledDotProductAttention)
+
+__all__ = [
+ 'ScaledDotProductAttention', 'MultiHeadAttention',
+ 'PositionwiseFeedForward', 'PositionalEncoding'
+]
diff --git a/mmocr/models/common/modules/__pycache__/__init__.cpython-38.pyc b/mmocr/models/common/modules/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..9cd6b126855932486523efacc231c2ce1c053d35
Binary files /dev/null and b/mmocr/models/common/modules/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/models/common/modules/__pycache__/transformer_module.cpython-38.pyc b/mmocr/models/common/modules/__pycache__/transformer_module.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..3011a49227e346ecf3ecba0d7f2899716fd1f616
Binary files /dev/null and b/mmocr/models/common/modules/__pycache__/transformer_module.cpython-38.pyc differ
diff --git a/mmocr/models/common/modules/transformer_module.py b/mmocr/models/common/modules/transformer_module.py
new file mode 100644
index 0000000000000000000000000000000000000000..89dde388ae98e6da736b874746ac722992e6d0b1
--- /dev/null
+++ b/mmocr/models/common/modules/transformer_module.py
@@ -0,0 +1,164 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from mmocr.registry import MODELS
+
+
+class ScaledDotProductAttention(nn.Module):
+ """Scaled Dot-Product Attention Module. This code is adopted from
+ https://github.com/jadore801120/attention-is-all-you-need-pytorch.
+
+ Args:
+ temperature (float): The scale factor for softmax input.
+ attn_dropout (float): Dropout layer on attn_output_weights.
+ """
+
+ def __init__(self, temperature, attn_dropout=0.1):
+ super().__init__()
+ self.temperature = temperature
+ self.dropout = nn.Dropout(attn_dropout)
+
+ def forward(self, q, k, v, mask=None):
+
+ attn = torch.matmul(q / self.temperature, k.transpose(2, 3))
+
+ if mask is not None:
+ attn = attn.masked_fill(mask == 0, float('-inf'))
+
+ attn = self.dropout(F.softmax(attn, dim=-1))
+ output = torch.matmul(attn, v)
+
+ return output, attn
+
+
+class MultiHeadAttention(nn.Module):
+ """Multi-Head Attention module.
+
+ Args:
+ n_head (int): The number of heads in the
+ multiheadattention models (default=8).
+ d_model (int): The number of expected features
+ in the decoder inputs (default=512).
+ d_k (int): Total number of features in key.
+ d_v (int): Total number of features in value.
+ dropout (float): Dropout layer on attn_output_weights.
+ qkv_bias (bool): Add bias in projection layer. Default: False.
+ """
+
+ def __init__(self,
+ n_head=8,
+ d_model=512,
+ d_k=64,
+ d_v=64,
+ dropout=0.1,
+ qkv_bias=False):
+ super().__init__()
+ self.n_head = n_head
+ self.d_k = d_k
+ self.d_v = d_v
+
+ self.dim_k = n_head * d_k
+ self.dim_v = n_head * d_v
+
+ self.linear_q = nn.Linear(self.dim_k, self.dim_k, bias=qkv_bias)
+ self.linear_k = nn.Linear(self.dim_k, self.dim_k, bias=qkv_bias)
+ self.linear_v = nn.Linear(self.dim_v, self.dim_v, bias=qkv_bias)
+
+ self.attention = ScaledDotProductAttention(d_k**0.5, dropout)
+
+ self.fc = nn.Linear(self.dim_v, d_model, bias=qkv_bias)
+ self.proj_drop = nn.Dropout(dropout)
+
+ def forward(self, q, k, v, mask=None):
+ batch_size, len_q, _ = q.size()
+ _, len_k, _ = k.size()
+
+ q = self.linear_q(q).view(batch_size, len_q, self.n_head, self.d_k)
+ k = self.linear_k(k).view(batch_size, len_k, self.n_head, self.d_k)
+ v = self.linear_v(v).view(batch_size, len_k, self.n_head, self.d_v)
+
+ q, k, v = q.transpose(1, 2), k.transpose(1, 2), v.transpose(1, 2)
+
+ if mask is not None:
+ if mask.dim() == 3:
+ mask = mask.unsqueeze(1)
+ elif mask.dim() == 2:
+ mask = mask.unsqueeze(1).unsqueeze(1)
+
+ attn_out, _ = self.attention(q, k, v, mask=mask)
+
+ attn_out = attn_out.transpose(1, 2).contiguous().view(
+ batch_size, len_q, self.dim_v)
+
+ attn_out = self.fc(attn_out)
+ attn_out = self.proj_drop(attn_out)
+
+ return attn_out
+
+
+class PositionwiseFeedForward(nn.Module):
+ """Two-layer feed-forward module.
+
+ Args:
+ d_in (int): The dimension of the input for feedforward
+ network model.
+ d_hid (int): The dimension of the feedforward
+ network model.
+ dropout (float): Dropout layer on feedforward output.
+ act_cfg (dict): Activation cfg for feedforward module.
+ """
+
+ def __init__(self, d_in, d_hid, dropout=0.1, act_cfg=dict(type='Relu')):
+ super().__init__()
+ self.w_1 = nn.Linear(d_in, d_hid)
+ self.w_2 = nn.Linear(d_hid, d_in)
+ self.act = MODELS.build(act_cfg)
+ self.dropout = nn.Dropout(dropout)
+
+ def forward(self, x):
+ x = self.w_1(x)
+ x = self.act(x)
+ x = self.w_2(x)
+ x = self.dropout(x)
+
+ return x
+
+
+class PositionalEncoding(nn.Module):
+ """Fixed positional encoding with sine and cosine functions."""
+
+ def __init__(self, d_hid=512, n_position=200, dropout=0):
+ super().__init__()
+ self.dropout = nn.Dropout(p=dropout)
+
+ # Not a parameter
+ # Position table of shape (1, n_position, d_hid)
+ self.register_buffer(
+ 'position_table',
+ self._get_sinusoid_encoding_table(n_position, d_hid))
+
+ def _get_sinusoid_encoding_table(self, n_position, d_hid):
+ """Sinusoid position encoding table."""
+ denominator = torch.Tensor([
+ 1.0 / np.power(10000, 2 * (hid_j // 2) / d_hid)
+ for hid_j in range(d_hid)
+ ])
+ denominator = denominator.view(1, -1)
+ pos_tensor = torch.arange(n_position).unsqueeze(-1).float()
+ sinusoid_table = pos_tensor * denominator
+ sinusoid_table[:, 0::2] = torch.sin(sinusoid_table[:, 0::2])
+ sinusoid_table[:, 1::2] = torch.cos(sinusoid_table[:, 1::2])
+
+ return sinusoid_table.unsqueeze(0)
+
+ def forward(self, x):
+ """
+ Args:
+ x (Tensor): Tensor of shape (batch_size, pos_len, d_hid, ...)
+ """
+ self.device = x.device
+ x = x + self.position_table[:, :x.size(1)].clone().detach()
+ return self.dropout(x)
diff --git a/mmocr/models/common/plugins/__init__.py b/mmocr/models/common/plugins/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..1ad4c93c0dbdc9f95d23df30413c495261970bfd
--- /dev/null
+++ b/mmocr/models/common/plugins/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .common import AvgPool2d
+
+__all__ = ['AvgPool2d']
diff --git a/mmocr/models/common/plugins/__pycache__/__init__.cpython-38.pyc b/mmocr/models/common/plugins/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e8310977e1fe5f12bc93fdc8f56f6ed9e785478b
Binary files /dev/null and b/mmocr/models/common/plugins/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/models/common/plugins/__pycache__/common.cpython-38.pyc b/mmocr/models/common/plugins/__pycache__/common.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..03dc58cddcd66b832c82f5c401cb60f3fa1c5c87
Binary files /dev/null and b/mmocr/models/common/plugins/__pycache__/common.cpython-38.pyc differ
diff --git a/mmocr/models/common/plugins/common.py b/mmocr/models/common/plugins/common.py
new file mode 100644
index 0000000000000000000000000000000000000000..722b53f568002720f28c1683a2304d335b94b883
--- /dev/null
+++ b/mmocr/models/common/plugins/common.py
@@ -0,0 +1,40 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Tuple, Union
+
+import torch
+import torch.nn as nn
+
+from mmocr.registry import MODELS
+
+
+@MODELS.register_module()
+class AvgPool2d(nn.Module):
+ """Applies a 2D average pooling over an input signal composed of several
+ input planes.
+
+ It can also be used as a network plugin.
+
+ Args:
+ kernel_size (int or tuple(int)): the size of the window.
+ stride (int or tuple(int), optional): the stride of the window.
+ Defaults to None.
+ padding (int or tuple(int)): implicit zero padding. Defaults to 0.
+ """
+
+ def __init__(self,
+ kernel_size: Union[int, Tuple[int]],
+ stride: Optional[Union[int, Tuple[int]]] = None,
+ padding: Union[int, Tuple[int]] = 0,
+ **kwargs) -> None:
+ super().__init__()
+ self.model = nn.AvgPool2d(kernel_size, stride, padding)
+
+ def forward(self, x: torch.Tensor) -> torch.Tensor:
+ """Forward function.
+ Args:
+ x (Tensor): Input feature map.
+
+ Returns:
+ Tensor: Output tensor after Avgpooling layer.
+ """
+ return self.model(x)
diff --git a/mmocr/models/kie/__init__.py b/mmocr/models/kie/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..82660bae2c780c0150eee06df55f80a416ca3104
--- /dev/null
+++ b/mmocr/models/kie/__init__.py
@@ -0,0 +1,5 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .extractors import * # NOQA
+from .heads import * # NOQA
+from .module_losses import * # NOQA
+from .postprocessors import * # NOQA
diff --git a/mmocr/models/kie/__pycache__/__init__.cpython-38.pyc b/mmocr/models/kie/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d02ba7dfd0a98757332de572ec19bf98f659b27e
Binary files /dev/null and b/mmocr/models/kie/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/models/kie/extractors/__init__.py b/mmocr/models/kie/extractors/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..914d0f6903cefec1236107346e59901ac9d64fd4
--- /dev/null
+++ b/mmocr/models/kie/extractors/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .sdmgr import SDMGR
+
+__all__ = ['SDMGR']
diff --git a/mmocr/models/kie/extractors/__pycache__/__init__.cpython-38.pyc b/mmocr/models/kie/extractors/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..16f178eabd8de7bcf0d1c701141bfd76f2ec3a62
Binary files /dev/null and b/mmocr/models/kie/extractors/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/models/kie/extractors/__pycache__/sdmgr.cpython-38.pyc b/mmocr/models/kie/extractors/__pycache__/sdmgr.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ae8ef1001e0d4789f166b994ce8b380fa81237ba
Binary files /dev/null and b/mmocr/models/kie/extractors/__pycache__/sdmgr.cpython-38.pyc differ
diff --git a/mmocr/models/kie/extractors/sdmgr.py b/mmocr/models/kie/extractors/sdmgr.py
new file mode 100644
index 0000000000000000000000000000000000000000..670dcdf59827ffb2ea3926474cddbdef76bdb105
--- /dev/null
+++ b/mmocr/models/kie/extractors/sdmgr.py
@@ -0,0 +1,191 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from typing import Dict, List, Optional, Sequence, Tuple
+
+import torch
+from mmdet.structures.bbox import bbox2roi
+from mmengine.model import BaseModel
+from torch import nn
+
+from mmocr.registry import MODELS, TASK_UTILS
+from mmocr.structures import KIEDataSample
+
+
+@MODELS.register_module()
+class SDMGR(BaseModel):
+ """The implementation of the paper: Spatial Dual-Modality Graph Reasoning
+ for Key Information Extraction. https://arxiv.org/abs/2103.14470.
+
+ Args:
+ backbone (dict, optional): Config of backbone. If None, None will be
+ passed to kie_head during training and testing. Defaults to None.
+ roi_extractor (dict, optional): Config of roi extractor. Only
+ applicable when backbone is not None. Defaults to None.
+ neck (dict, optional): Config of neck. Defaults to None.
+ kie_head (dict): Config of KIE head. Defaults to None.
+ dictionary (dict, optional): Config of dictionary. Defaults to None.
+ data_preprocessor (dict or ConfigDict, optional): The pre-process
+ config of :class:`BaseDataPreprocessor`. it usually includes,
+ ``pad_size_divisor``, ``pad_value``, ``mean`` and ``std``. It has
+ to be None when working in non-visual mode. Defaults to None.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ backbone: Optional[Dict] = None,
+ roi_extractor: Optional[Dict] = None,
+ neck: Optional[Dict] = None,
+ kie_head: Dict = None,
+ dictionary: Optional[Dict] = None,
+ data_preprocessor: Optional[Dict] = None,
+ init_cfg: Optional[Dict] = None) -> None:
+ super().__init__(
+ data_preprocessor=data_preprocessor, init_cfg=init_cfg)
+ if dictionary is not None:
+ self.dictionary = TASK_UTILS.build(dictionary)
+ if kie_head.get('dictionary', None) is None:
+ kie_head.update(dictionary=self.dictionary)
+ else:
+ warnings.warn(f"Using dictionary {kie_head['dictionary']} "
+ "in kie_head's config.")
+ if backbone is not None:
+ self.backbone = MODELS.build(backbone)
+ self.extractor = MODELS.build({
+ **roi_extractor, 'out_channels':
+ self.backbone.base_channels
+ })
+ self.maxpool = nn.MaxPool2d(
+ roi_extractor['roi_layer']['output_size'])
+ if neck is not None:
+ self.neck = MODELS.build(neck)
+ self.kie_head = MODELS.build(kie_head)
+
+ def extract_feat(self, img: torch.Tensor,
+ gt_bboxes: List[torch.Tensor]) -> torch.Tensor:
+ """Extract features from images if self.backbone is not None. It
+ returns None otherwise.
+
+ Args:
+ img (torch.Tensor): The input image with shape (N, C, H, W).
+ gt_bboxes (list[torch.Tensor)): A list of ground truth bounding
+ boxes, each of shape :math:`(N_i, 4)`.
+
+ Returns:
+ torch.Tensor: The extracted features with shape (N, E).
+ """
+ if not hasattr(self, 'backbone'):
+ return None
+ x = self.backbone(img)
+ if hasattr(self, 'neck'):
+ x = self.neck(x)
+ x = x[-1]
+ feats = self.maxpool(self.extractor([x], bbox2roi(gt_bboxes)))
+ return feats.view(feats.size(0), -1)
+
+ def forward(self,
+ inputs: torch.Tensor,
+ data_samples: Sequence[KIEDataSample] = None,
+ mode: str = 'tensor',
+ **kwargs) -> torch.Tensor:
+ """The unified entry for a forward process in both training and test.
+
+ The method should accept three modes: "tensor", "predict" and "loss":
+
+ - "tensor": Forward the whole network and return tensor or tuple of
+ tensor without any post-processing, same as a common nn.Module.
+ - "predict": Forward and return the predictions, which are fully
+ processed to a list of :obj:`DetDataSample`.
+ - "loss": Forward and return a dict of losses according to the given
+ inputs and data samples.
+
+ Note that this method doesn't handle neither back propagation nor
+ optimizer updating, which are done in the :meth:`train_step`.
+
+ Args:
+ inputs (torch.Tensor): The input tensor with shape
+ (N, C, ...) in general.
+ data_samples (list[:obj:`DetDataSample`], optional): The
+ annotation data of every samples. Defaults to None.
+ mode (str): Return what kind of value. Defaults to 'tensor'.
+
+ Returns:
+ The return type depends on ``mode``.
+
+ - If ``mode="tensor"``, return a tensor or a tuple of tensor.
+ - If ``mode="predict"``, return a list of :obj:`DetDataSample`.
+ - If ``mode="loss"``, return a dict of tensor.
+ """
+ if mode == 'loss':
+ return self.loss(inputs, data_samples, **kwargs)
+ elif mode == 'predict':
+ return self.predict(inputs, data_samples, **kwargs)
+ elif mode == 'tensor':
+ return self._forward(inputs, data_samples, **kwargs)
+ else:
+ raise RuntimeError(f'Invalid mode "{mode}". '
+ 'Only supports loss, predict and tensor mode')
+
+ def loss(self, inputs: torch.Tensor, data_samples: Sequence[KIEDataSample],
+ **kwargs) -> dict:
+ """Calculate losses from a batch of inputs and data samples.
+
+ Args:
+ inputs (torch.Tensor): Input images of shape (N, C, H, W).
+ Typically these should be mean centered and std scaled.
+ data_samples (list[KIEDataSample]): A list of N datasamples,
+ containing meta information and gold annotations for each of
+ the images.
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ x = self.extract_feat(
+ inputs,
+ [data_sample.gt_instances.bboxes for data_sample in data_samples])
+ return self.kie_head.loss(x, data_samples)
+
+ def predict(self, inputs: torch.Tensor,
+ data_samples: Sequence[KIEDataSample],
+ **kwargs) -> List[KIEDataSample]:
+ """Predict results from a batch of inputs and data samples with post-
+ processing.
+ Args:
+ inputs (torch.Tensor): Input images of shape (N, C, H, W).
+ Typically these should be mean centered and std scaled.
+ data_samples (list[KIEDataSample]): A list of N datasamples,
+ containing meta information and gold annotations for each of
+ the images.
+
+ Returns:
+ List[KIEDataSample]: A list of datasamples of prediction results.
+ Results are stored in ``pred_instances.labels`` and
+ ``pred_instances.edge_labels``.
+ """
+ x = self.extract_feat(
+ inputs,
+ [data_sample.gt_instances.bboxes for data_sample in data_samples])
+ return self.kie_head.predict(x, data_samples)
+
+ def _forward(self, inputs: torch.Tensor,
+ data_samples: Sequence[KIEDataSample],
+ **kwargs) -> Tuple[torch.Tensor, torch.Tensor]:
+ """Get the raw tensor outputs from backbone and head without any post-
+ processing.
+
+ Args:
+ inputs (torch.Tensor): Input images of shape (N, C, H, W).
+ Typically these should be mean centered and std scaled.
+ data_samples (list[KIEDataSample]): A list of N datasamples,
+ containing meta information and gold annotations for each of
+ the images.
+
+ Returns:
+ tuple(torch.Tensor, torch.Tensor): Tensor output from head.
+
+ - node_cls (torch.Tensor): Node classification output.
+ - edge_cls (torch.Tensor): Edge classification output.
+ """
+ x = self.extract_feat(
+ inputs,
+ [data_sample.gt_instances.bboxes for data_sample in data_samples])
+ return self.kie_head(x, data_samples)
diff --git a/mmocr/models/kie/heads/__init__.py b/mmocr/models/kie/heads/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..1c08ed6ffa4f8b177c56a947da9b49980ab0a2c2
--- /dev/null
+++ b/mmocr/models/kie/heads/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .sdmgr_head import SDMGRHead
+
+__all__ = ['SDMGRHead']
diff --git a/mmocr/models/kie/heads/__pycache__/__init__.cpython-38.pyc b/mmocr/models/kie/heads/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a2eb85076ec9385059d99c694d96d7a70f047669
Binary files /dev/null and b/mmocr/models/kie/heads/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/models/kie/heads/__pycache__/sdmgr_head.cpython-38.pyc b/mmocr/models/kie/heads/__pycache__/sdmgr_head.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..99819d3d72990ce460a76c1c63a7cf25ea271374
Binary files /dev/null and b/mmocr/models/kie/heads/__pycache__/sdmgr_head.cpython-38.pyc differ
diff --git a/mmocr/models/kie/heads/sdmgr_head.py b/mmocr/models/kie/heads/sdmgr_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..311e870941f212f26a504afd4b6c30ccc0d9cc7e
--- /dev/null
+++ b/mmocr/models/kie/heads/sdmgr_head.py
@@ -0,0 +1,377 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Tuple, Union
+
+import torch
+from mmengine.model import BaseModule
+from torch import Tensor, nn
+from torch.nn import functional as F
+
+from mmocr.models.common.dictionary import Dictionary
+from mmocr.registry import MODELS, TASK_UTILS
+from mmocr.structures import KIEDataSample
+
+
+@MODELS.register_module()
+class SDMGRHead(BaseModule):
+ """SDMGR Head.
+
+ Args:
+ dictionary (dict or :obj:`Dictionary`): The config for `Dictionary` or
+ the instance of `Dictionary`.
+ num_classes (int): Number of class labels. Defaults to 26.
+ visual_dim (int): Dimension of visual features :math:`E`. Defaults to
+ 64.
+ fusion_dim (int): Dimension of fusion layer. Defaults to 1024.
+ node_input (int): Dimension of raw node embedding. Defaults to 32.
+ node_embed (int): Dimension of node embedding. Defaults to 256.
+ edge_input (int): Dimension of raw edge embedding. Defaults to 5.
+ edge_embed (int): Dimension of edge embedding. Defaults to 256.
+ num_gnn (int): Number of GNN layers. Defaults to 2.
+ bidirectional (bool): Whether to use bidirectional RNN to embed nodes.
+ Defaults to False.
+ relation_norm (float): Norm to map value from one range to another.=
+ Defaults to 10.
+ module_loss (dict): Module Loss config. Defaults to
+ ``dict(type='SDMGRModuleLoss')``.
+ postprocessor (dict): Postprocessor config. Defaults to
+ ``dict(type='SDMGRPostProcessor')``.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ """
+
+ def __init__(
+ self,
+ dictionary: Union[Dictionary, Dict],
+ num_classes: int = 26,
+ visual_dim: int = 64,
+ fusion_dim: int = 1024,
+ node_input: int = 32,
+ node_embed: int = 256,
+ edge_input: int = 5,
+ edge_embed: int = 256,
+ num_gnn: int = 2,
+ bidirectional: bool = False,
+ relation_norm: float = 10.,
+ module_loss: Dict = dict(type='SDMGRModuleLoss'),
+ postprocessor: Dict = dict(type='SDMGRPostProcessor'),
+ init_cfg: Optional[Union[Dict, List[Dict]]] = dict(
+ type='Normal', override=dict(name='edge_embed'), mean=0, std=0.01)
+ ) -> None:
+ super().__init__(init_cfg=init_cfg)
+ assert isinstance(dictionary, (dict, Dictionary))
+ if isinstance(dictionary, dict):
+ self.dictionary = TASK_UTILS.build(dictionary)
+ elif isinstance(dictionary, Dictionary):
+ self.dictionary = dictionary
+
+ self.fusion = FusionBlock([visual_dim, node_embed], node_embed,
+ fusion_dim)
+ self.node_embed = nn.Embedding(self.dictionary.num_classes, node_input,
+ self.dictionary.padding_idx)
+ hidden = node_embed // 2 if bidirectional else node_embed
+ self.rnn = nn.LSTM(
+ input_size=node_input,
+ hidden_size=hidden,
+ num_layers=1,
+ batch_first=True,
+ bidirectional=bidirectional)
+ self.edge_embed = nn.Linear(edge_input, edge_embed)
+ self.gnn_layers = nn.ModuleList(
+ [GNNLayer(node_embed, edge_embed) for _ in range(num_gnn)])
+ self.node_cls = nn.Linear(node_embed, num_classes)
+ self.edge_cls = nn.Linear(edge_embed, 2)
+ self.module_loss = MODELS.build(module_loss)
+ self.postprocessor = MODELS.build(postprocessor)
+ self.relation_norm = relation_norm
+
+ def loss(self, inputs: Tensor, data_samples: List[KIEDataSample]) -> Dict:
+ """Calculate losses from a batch of inputs and data samples.
+ Args:
+ inputs (torch.Tensor): Shape :math:`(N, E)`.
+ data_samples (List[KIEDataSample]): List of data samples.
+
+ Returns:
+ dict[str, tensor]: A dictionary of loss components.
+ """
+ preds = self.forward(inputs, data_samples)
+ return self.module_loss(preds, data_samples)
+
+ def predict(self, inputs: Tensor,
+ data_samples: List[KIEDataSample]) -> List[KIEDataSample]:
+ """Predict results from a batch of inputs and data samples with post-
+ processing.
+
+ Args:
+ inputs (torch.Tensor): Shape :math:`(N, E)`.
+ data_samples (List[KIEDataSample]): List of data samples.
+
+ Returns:
+ List[KIEDataSample]: A list of datasamples of prediction results.
+ Results are stored in ``pred_instances.labels``,
+ ``pred_instances.scores``, ``pred_instances.edge_labels`` and
+ ``pred_instances.edge_scores``.
+
+ - labels (Tensor): An integer tensor of shape (N, ) indicating bbox
+ labels for each image.
+ - scores (Tensor): A float tensor of shape (N, ), indicating the
+ confidence scores for node label predictions.
+ - edge_labels (Tensor): An integer tensor of shape (N, N)
+ indicating the connection between nodes. Options are 0, 1.
+ - edge_scores (Tensor): A float tensor of shape (N, ), indicating
+ the confidence scores for edge predictions.
+ """
+ preds = self.forward(inputs, data_samples)
+ return self.postprocessor(preds, data_samples)
+
+ def forward(self, inputs: Tensor,
+ data_samples: List[KIEDataSample]) -> Tuple[Tensor, Tensor]:
+ """
+ Args:
+ inputs (torch.Tensor): Shape :math:`(N, E)`.
+ data_samples (List[KIEDataSample]): List of data samples.
+
+ Returns:
+ tuple(Tensor, Tensor):
+
+ - node_cls (Tensor): Raw logits scores for nodes. Shape
+ :math:`(N, C_{l})` where :math:`C_{l}` is number of classes.
+ - edge_cls (Tensor): Raw logits scores for edges. Shape
+ :math:`(N * N, 2)`.
+ """
+
+ device = self.node_embed.weight.device
+
+ node_nums, char_nums, all_nodes = self.convert_texts(data_samples)
+
+ embed_nodes = self.node_embed(all_nodes.to(device).long())
+ rnn_nodes, _ = self.rnn(embed_nodes)
+
+ nodes = rnn_nodes.new_zeros(*rnn_nodes.shape[::2])
+ all_nums = torch.cat(char_nums).to(device)
+ valid = all_nums > 0
+ nodes[valid] = rnn_nodes[valid].gather(
+ 1, (all_nums[valid] - 1).unsqueeze(-1).unsqueeze(-1).expand(
+ -1, -1, rnn_nodes.size(-1))).squeeze(1)
+
+ if inputs is not None:
+ nodes = self.fusion([inputs, nodes])
+
+ relations = self.compute_relations(data_samples)
+ all_edges = torch.cat(
+ [relation.view(-1, relation.size(-1)) for relation in relations],
+ dim=0)
+ embed_edges = self.edge_embed(all_edges.float())
+ embed_edges = F.normalize(embed_edges)
+
+ for gnn_layer in self.gnn_layers:
+ nodes, embed_edges = gnn_layer(nodes, embed_edges, node_nums)
+
+ node_cls, edge_cls = self.node_cls(nodes), self.edge_cls(embed_edges)
+ return node_cls, edge_cls
+
+ def convert_texts(
+ self, data_samples: List[KIEDataSample]
+ ) -> Tuple[List[Tensor], List[Tensor], Tensor]:
+ """Extract texts in datasamples and pack them into a batch.
+
+ Args:
+ data_samples (List[KIEDataSample]): List of data samples.
+
+ Returns:
+ tuple(List[int], List[Tensor], Tensor):
+
+ - node_nums (List[int]): A list of node numbers for each
+ sample.
+ - char_nums (List[Tensor]): A list of character numbers for each
+ sample.
+ - nodes (Tensor): A tensor of shape :math:`(N, C)` where
+ :math:`C` is the maximum number of characters in a sample.
+ """
+ node_nums, char_nums = [], []
+ max_len = -1
+ text_idxs = []
+ for data_sample in data_samples:
+ node_nums.append(len(data_sample.gt_instances.texts))
+ for text in data_sample.gt_instances.texts:
+ text_idxs.append(self.dictionary.str2idx(text))
+ max_len = max(max_len, len(text))
+
+ nodes = torch.zeros((sum(node_nums), max_len),
+ dtype=torch.long) + self.dictionary.padding_idx
+ for i, text_idx in enumerate(text_idxs):
+ nodes[i, :len(text_idx)] = torch.LongTensor(text_idx)
+ char_nums = (nodes != self.dictionary.padding_idx).sum(-1).split(
+ node_nums, dim=0)
+ return node_nums, char_nums, nodes
+
+ def compute_relations(self, data_samples: List[KIEDataSample]) -> Tensor:
+ """Compute the relations between every two boxes for each datasample,
+ then return the concatenated relations."""
+
+ relations = []
+ for data_sample in data_samples:
+ bboxes = data_sample.gt_instances.bboxes
+ x1, y1 = bboxes[:, 0:1], bboxes[:, 1:2]
+ x2, y2 = bboxes[:, 2:3], bboxes[:, 3:4]
+ w, h = torch.clamp(
+ x2 - x1 + 1, min=1), torch.clamp(
+ y2 - y1 + 1, min=1)
+ dx = (x1.t() - x1) / self.relation_norm
+ dy = (y1.t() - y1) / self.relation_norm
+ xhh, xwh = h.T / h, w.T / h
+ whs = w / h + torch.zeros_like(xhh)
+ relation = torch.stack([dx, dy, whs, xhh, xwh], -1).float()
+ relations.append(relation)
+ return relations
+
+
+class GNNLayer(nn.Module):
+ """GNN layer for SDMGR.
+
+ Args:
+ node_dim (int): Dimension of node embedding. Defaults to 256.
+ edge_dim (int): Dimension of edge embedding. Defaults to 256.
+ """
+
+ def __init__(self, node_dim: int = 256, edge_dim: int = 256) -> None:
+ super().__init__()
+ self.in_fc = nn.Linear(node_dim * 2 + edge_dim, node_dim)
+ self.coef_fc = nn.Linear(node_dim, 1)
+ self.out_fc = nn.Linear(node_dim, node_dim)
+ self.relu = nn.ReLU()
+
+ def forward(self, nodes: Tensor, edges: Tensor,
+ nums: List[int]) -> Tuple[Tensor, Tensor]:
+ """Forward function.
+
+ Args:
+ nodes (Tensor): Concatenated node embeddings.
+ edges (Tensor): Concatenated edge embeddings.
+ nums (List[int]): List of number of nodes in each batch.
+
+ Returns:
+ tuple(Tensor, Tensor):
+
+ - nodes (Tensor): New node embeddings.
+ - edges (Tensor): New edge embeddings.
+ """
+ start, cat_nodes = 0, []
+ for num in nums:
+ sample_nodes = nodes[start:start + num]
+ cat_nodes.append(
+ torch.cat([
+ sample_nodes.unsqueeze(1).expand(-1, num, -1),
+ sample_nodes.unsqueeze(0).expand(num, -1, -1)
+ ], -1).view(num**2, -1))
+ start += num
+ cat_nodes = torch.cat([torch.cat(cat_nodes), edges], -1)
+ cat_nodes = self.relu(self.in_fc(cat_nodes))
+ coefs = self.coef_fc(cat_nodes)
+
+ start, residuals = 0, []
+ for num in nums:
+ residual = F.softmax(
+ -torch.eye(num).to(coefs.device).unsqueeze(-1) * 1e9 +
+ coefs[start:start + num**2].view(num, num, -1), 1)
+ residuals.append(
+ (residual *
+ cat_nodes[start:start + num**2].view(num, num, -1)).sum(1))
+ start += num**2
+
+ nodes += self.relu(self.out_fc(torch.cat(residuals)))
+ return nodes, cat_nodes
+
+
+class FusionBlock(nn.Module):
+ """Fusion block of SDMGR.
+
+ Args:
+ input_dims (tuple(int, int)): Visual dimension and node embedding
+ dimension.
+ output_dim (int): Output dimension.
+ mm_dim (int): Model dimension. Defaults to 1600.
+ chunks (int): Number of chunks. Defaults to 20.
+ rank (int): Rank number. Defaults to 15.
+ shared (bool): Whether to share the project layer between visual and
+ node embedding features. Defaults to False.
+ dropout_input (float): Dropout rate after the first projection layer.
+ Defaults to 0.
+ dropout_pre_lin (float): Dropout rate before the final project layer.
+ Defaults to 0.
+ dropout_pre_lin (float): Dropout rate after the final project layer.
+ Defaults to 0.
+ pos_norm (str): The normalization position. Options are 'before_cat'
+ and 'after_cat'. Defaults to 'before_cat'.
+ """
+
+ def __init__(self,
+ input_dims: Tuple[int, int],
+ output_dim: int,
+ mm_dim: int = 1600,
+ chunks: int = 20,
+ rank: int = 15,
+ shared: bool = False,
+ dropout_input: float = 0.,
+ dropout_pre_lin: float = 0.,
+ dropout_output: float = 0.,
+ pos_norm: str = 'before_cat') -> None:
+ super().__init__()
+ self.rank = rank
+ self.dropout_input = dropout_input
+ self.dropout_pre_lin = dropout_pre_lin
+ self.dropout_output = dropout_output
+ assert (pos_norm in ['before_cat', 'after_cat'])
+ self.pos_norm = pos_norm
+ # Modules
+ self.linear0 = nn.Linear(input_dims[0], mm_dim)
+ self.linear1 = (
+ self.linear0 if shared else nn.Linear(input_dims[1], mm_dim))
+ self.merge_linears0 = nn.ModuleList()
+ self.merge_linears1 = nn.ModuleList()
+ self.chunks = self.chunk_sizes(mm_dim, chunks)
+ for size in self.chunks:
+ ml0 = nn.Linear(size, size * rank)
+ self.merge_linears0.append(ml0)
+ ml1 = ml0 if shared else nn.Linear(size, size * rank)
+ self.merge_linears1.append(ml1)
+ self.linear_out = nn.Linear(mm_dim, output_dim)
+
+ def forward(self, x: Tensor) -> Tensor:
+ """Forward function."""
+ x0 = self.linear0(x[0])
+ x1 = self.linear1(x[1])
+ bs = x1.size(0)
+ if self.dropout_input > 0:
+ x0 = F.dropout(x0, p=self.dropout_input, training=self.training)
+ x1 = F.dropout(x1, p=self.dropout_input, training=self.training)
+ x0_chunks = torch.split(x0, self.chunks, -1)
+ x1_chunks = torch.split(x1, self.chunks, -1)
+ zs = []
+ for x0_c, x1_c, m0, m1 in zip(x0_chunks, x1_chunks,
+ self.merge_linears0,
+ self.merge_linears1):
+ m = m0(x0_c) * m1(x1_c) # bs x split_size*rank
+ m = m.view(bs, self.rank, -1)
+ z = torch.sum(m, 1)
+ if self.pos_norm == 'before_cat':
+ z = torch.sqrt(F.relu(z)) - torch.sqrt(F.relu(-z))
+ z = F.normalize(z)
+ zs.append(z)
+ z = torch.cat(zs, 1)
+ if self.pos_norm == 'after_cat':
+ z = torch.sqrt(F.relu(z)) - torch.sqrt(F.relu(-z))
+ z = F.normalize(z)
+
+ if self.dropout_pre_lin > 0:
+ z = F.dropout(z, p=self.dropout_pre_lin, training=self.training)
+ z = self.linear_out(z)
+ if self.dropout_output > 0:
+ z = F.dropout(z, p=self.dropout_output, training=self.training)
+ return z
+
+ @staticmethod
+ def chunk_sizes(dim: int, chunks: int) -> List[int]:
+ """Compute chunk sizes."""
+ split_size = (dim + chunks - 1) // chunks
+ sizes_list = [split_size] * chunks
+ sizes_list[-1] = sizes_list[-1] - (sum(sizes_list) - dim)
+ return sizes_list
diff --git a/mmocr/models/kie/module_losses/__init__.py b/mmocr/models/kie/module_losses/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..9af5550ae843622d0fa2ff81a23d7c825c3c43fd
--- /dev/null
+++ b/mmocr/models/kie/module_losses/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .sdmgr_module_loss import SDMGRModuleLoss
+
+__all__ = ['SDMGRModuleLoss']
diff --git a/mmocr/models/kie/module_losses/__pycache__/__init__.cpython-38.pyc b/mmocr/models/kie/module_losses/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..08e7507c607dd43ac5eececd3146a490eb606718
Binary files /dev/null and b/mmocr/models/kie/module_losses/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/models/kie/module_losses/__pycache__/sdmgr_module_loss.cpython-38.pyc b/mmocr/models/kie/module_losses/__pycache__/sdmgr_module_loss.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..532e92ac08d910b86a7e52d5209ee0d6444e1593
Binary files /dev/null and b/mmocr/models/kie/module_losses/__pycache__/sdmgr_module_loss.cpython-38.pyc differ
diff --git a/mmocr/models/kie/module_losses/sdmgr_module_loss.py b/mmocr/models/kie/module_losses/sdmgr_module_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..5dc87ea32c28d3d4fdc411e35cda79e82eb3b676
--- /dev/null
+++ b/mmocr/models/kie/module_losses/sdmgr_module_loss.py
@@ -0,0 +1,65 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Tuple
+
+import torch
+from mmdet.models.losses import accuracy
+from torch import Tensor, nn
+
+from mmocr.registry import MODELS
+from mmocr.structures import KIEDataSample
+
+
+@MODELS.register_module()
+class SDMGRModuleLoss(nn.Module):
+ """The implementation the loss of key information extraction proposed in
+ the paper: `Spatial Dual-Modality Graph Reasoning for Key Information
+ Extraction `_.
+
+ Args:
+ weight_node (float): Weight of node loss. Defaults to 1.0.
+ weight_edge (float): Weight of edge loss. Defaults to 1.0.
+ ignore_idx (int): Node label to ignore. Defaults to -100.
+ """
+
+ def __init__(self,
+ weight_node: float = 1.0,
+ weight_edge: float = 1.0,
+ ignore_idx: int = -100) -> None:
+ super().__init__()
+ # TODO: Use MODELS.build after DRRG loss has been merged
+ self.loss_node = nn.CrossEntropyLoss(ignore_index=ignore_idx)
+ self.loss_edge = nn.CrossEntropyLoss(ignore_index=-1)
+ self.weight_node = weight_node
+ self.weight_edge = weight_edge
+ self.ignore_idx = ignore_idx
+
+ def forward(self, preds: Tuple[Tensor, Tensor],
+ data_samples: List[KIEDataSample]) -> Dict:
+ """Forward function.
+
+ Args:
+ preds (tuple(Tensor, Tensor)):
+ data_samples (list[KIEDataSample]): A list of datasamples
+ containing ``gt_instances.labels`` and
+ ``gt_instances.edge_labels``.
+
+ Returns:
+ dict(str, Tensor): Loss dict, containing ``loss_node``,
+ ``loss_edge``, ``acc_node`` and ``acc_edge``.
+ """
+ node_preds, edge_preds = preds
+ node_gts, edge_gts = [], []
+ for data_sample in data_samples:
+ node_gts.append(data_sample.gt_instances.labels)
+ edge_gts.append(data_sample.gt_instances.edge_labels.reshape(-1))
+ node_gts = torch.cat(node_gts).long()
+ edge_gts = torch.cat(edge_gts).long()
+
+ node_valids = torch.nonzero(
+ node_gts != self.ignore_idx, as_tuple=False).reshape(-1)
+ edge_valids = torch.nonzero(edge_gts != -1, as_tuple=False).reshape(-1)
+ return dict(
+ loss_node=self.weight_node * self.loss_node(node_preds, node_gts),
+ loss_edge=self.weight_edge * self.loss_edge(edge_preds, edge_gts),
+ acc_node=accuracy(node_preds[node_valids], node_gts[node_valids]),
+ acc_edge=accuracy(edge_preds[edge_valids], edge_gts[edge_valids]))
diff --git a/mmocr/models/kie/postprocessors/__init__.py b/mmocr/models/kie/postprocessors/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..645904bc1beb0b8e1b4f169a8b5344de55e41f8f
--- /dev/null
+++ b/mmocr/models/kie/postprocessors/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .sdmgr_postprocessor import SDMGRPostProcessor
+
+__all__ = ['SDMGRPostProcessor']
diff --git a/mmocr/models/kie/postprocessors/__pycache__/__init__.cpython-38.pyc b/mmocr/models/kie/postprocessors/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0b5f5cbd3501741c956add2bd69d25db04728162
Binary files /dev/null and b/mmocr/models/kie/postprocessors/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/models/kie/postprocessors/__pycache__/sdmgr_postprocessor.cpython-38.pyc b/mmocr/models/kie/postprocessors/__pycache__/sdmgr_postprocessor.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e8cc824aa9e4929b13ff97398c7beb1abd8f0e6b
Binary files /dev/null and b/mmocr/models/kie/postprocessors/__pycache__/sdmgr_postprocessor.cpython-38.pyc differ
diff --git a/mmocr/models/kie/postprocessors/sdmgr_postprocessor.py b/mmocr/models/kie/postprocessors/sdmgr_postprocessor.py
new file mode 100644
index 0000000000000000000000000000000000000000..977c4f94ad087f244c8648ccd1081494e8a38d6c
--- /dev/null
+++ b/mmocr/models/kie/postprocessors/sdmgr_postprocessor.py
@@ -0,0 +1,170 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Tuple
+
+import numpy as np
+import torch
+from mmengine.structures import InstanceData
+from torch import Tensor, nn
+
+from mmocr.registry import MODELS
+from mmocr.structures import KIEDataSample
+
+
+@MODELS.register_module()
+class SDMGRPostProcessor:
+ """Postprocessor for SDMGR. It converts the node and edge scores into
+ labels and edge labels. If the link_type is not "none", it reconstructs the
+ edge labels with different strategies specified by ``link_type``, which is
+ generally known as the "openset" mode. In "openset" mode, only the edges
+ connecting from "key" to "value" nodes will be constructed.
+
+ Args:
+ link_type (str): The type of link to be constructed.
+ Defaults to 'none'. Options are:
+
+ - 'none': The simplest link type involving no edge
+ postprocessing. The edge prediction will be returned as-is.
+ - 'one-to-one': One key node can be connected to one value node.
+ - 'one-to-many': One key node can be connected to multiple value
+ nodes.
+ - 'many-to-one': Multiple key nodes can be connected to one value
+ node.
+ - 'many-to-many': No restrictions on the number of edges that a
+ key/value node can have.
+ key_node_idx (int, optional): The label index of the key node. It must
+ be specified if ``link_type`` is not "none". Defaults to None.
+ value_node_idx (int, optional): The index of the value node. It must be
+ specified if ``link_type`` is not "none". Defaults to None.
+ """
+
+ def __init__(self,
+ link_type: str = 'none',
+ key_node_idx: Optional[int] = None,
+ value_node_idx: Optional[int] = None):
+ assert link_type in [
+ 'one-to-one', 'one-to-many', 'many-to-one', 'many-to-many', 'none'
+ ]
+ self.link_type = link_type
+ if link_type != 'none':
+ assert key_node_idx is not None and value_node_idx is not None
+ self.key_node_idx = key_node_idx
+ self.value_node_idx = value_node_idx
+ self.softmax = nn.Softmax(dim=-1)
+
+ def __call__(self, preds: Tuple[Tensor, Tensor],
+ data_samples: List[KIEDataSample]) -> List[KIEDataSample]:
+ """Postprocess raw outputs from SDMGR heads and pack the results into a
+ list of KIEDataSample.
+
+ Args:
+ preds (tuple[Tensor]): A tuple of raw outputs from SDMGR heads.
+ data_samples (list[KIEDataSample]): A list of N datasamples,
+ containing meta information and gold annotations for each of
+ the images.
+
+ Returns:
+ List[KIEDataSample]: A list of datasamples of prediction results.
+ Results are stored in ``pred_instances.labels``,
+ ``pred_instances.scores``, ``pred_instances.edge_labels`` and
+ ``pred_instances.edge_scores``.
+
+ - labels (Tensor): An integer tensor of shape (N, ) indicating bbox
+ labels for each image.
+ - scores (Tensor): A float tensor of shape (N, ), indicating the
+ confidence scores for node label predictions.
+ - edge_labels (Tensor): An integer tensor of shape (N, N)
+ indicating the connection between nodes. Options are 0, 1.
+ - edge_scores (Tensor): A float tensor of shape (N, ), indicating
+ the confidence scores for edge predictions.
+ """
+ node_preds, edge_preds = preds
+ all_node_scores = self.softmax(node_preds)
+ all_edge_scores = self.softmax(edge_preds)
+ chunk_size = [
+ data_sample.gt_instances.bboxes.shape[0]
+ for data_sample in data_samples
+ ]
+ node_scores, node_preds = torch.max(all_node_scores, dim=-1)
+ edge_scores, edge_preds = torch.max(all_edge_scores, dim=-1)
+ node_preds = node_preds.split(chunk_size, dim=0)
+ node_scores = node_scores.split(chunk_size, dim=0)
+
+ sq_chunks = [chunk**2 for chunk in chunk_size]
+ edge_preds = list(edge_preds.split(sq_chunks, dim=0))
+ edge_scores = list(edge_scores.split(sq_chunks, dim=0))
+ for i, chunk in enumerate(chunk_size):
+ edge_preds[i] = edge_preds[i].reshape((chunk, chunk))
+ edge_scores[i] = edge_scores[i].reshape((chunk, chunk))
+
+ for i in range(len(data_samples)):
+ data_samples[i].pred_instances = InstanceData()
+ data_samples[i].pred_instances.labels = node_preds[i].cpu()
+ data_samples[i].pred_instances.scores = node_scores[i].cpu()
+ if self.link_type != 'none':
+ edge_scores[i], edge_preds[i] = self.decode_edges(
+ node_preds[i], edge_scores[i], edge_preds[i])
+ data_samples[i].pred_instances.edge_labels = edge_preds[i].cpu()
+ data_samples[i].pred_instances.edge_scores = edge_scores[i].cpu()
+
+ return data_samples
+
+ def decode_edges(self, node_labels: Tensor, edge_scores: Tensor,
+ edge_labels: Tensor) -> Tuple[Tensor, Tensor]:
+ """Reconstruct the edges and update edge scores according to
+ ``link_type``.
+
+ Args:
+ data_sample (KIEDataSample): A datasample containing prediction
+ results.
+
+ Returns:
+ tuple(Tensor, Tensor):
+
+ - edge_scores (Tensor): A float tensor of shape (N, N)
+ indicating the confidence scores for edge predictions.
+ - edge_labels (Tensor): An integer tensor of shape (N, N)
+ indicating the connection between nodes. Options are 0, 1.
+ """
+ # Obtain the scores of the existence of edges.
+ pos_edges_scores = edge_scores.clone()
+ edge_labels_mask = edge_labels.bool()
+ pos_edges_scores[
+ ~edge_labels_mask] = 1 - pos_edges_scores[~edge_labels_mask]
+
+ # Temporarily convert the directed graph to undirected by adding
+ # reversed edges to every pair of nodes if they were already connected
+ # by an directed edge before.
+ edge_labels = torch.max(edge_labels, edge_labels.T)
+
+ # Maximize edge scores
+ edge_labels_mask = edge_labels.bool()
+ edge_scores[~edge_labels_mask] = pos_edges_scores[~edge_labels_mask]
+ new_edge_scores = torch.max(edge_scores, edge_scores.T)
+
+ # Only reconstruct the edges from key nodes to value nodes.
+ key_nodes_mask = node_labels == self.key_node_idx
+ value_nodes_mask = node_labels == self.value_node_idx
+ key2value_mask = key_nodes_mask[:, None] * value_nodes_mask[None, :]
+
+ if self.link_type == 'many-to-many':
+ new_edge_labels = (key2value_mask * edge_labels).int()
+ else:
+ new_edge_labels = torch.zeros_like(edge_labels).int()
+
+ tmp_edge_scores = new_edge_scores.clone().cpu()
+ tmp_edge_scores[~edge_labels_mask] = -1
+ tmp_edge_scores[~key2value_mask] = -1
+ # Greedily extract valid edges
+ while (tmp_edge_scores > -1).any():
+ i, j = np.unravel_index(
+ torch.argmax(tmp_edge_scores), tmp_edge_scores.shape)
+ new_edge_labels[i, j] = 1
+ if self.link_type == 'one-to-one':
+ tmp_edge_scores[i, :] = -1
+ tmp_edge_scores[:, j] = -1
+ elif self.link_type == 'one-to-many':
+ tmp_edge_scores[:, j] = -1
+ elif self.link_type == 'many-to-one':
+ tmp_edge_scores[i, :] = -1
+
+ return new_edge_scores.cpu(), new_edge_labels.cpu()
diff --git a/mmocr/models/textdet/__init__.py b/mmocr/models/textdet/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..b803a0d22e93cdfde7986b5fe111d2b061d9d9fb
--- /dev/null
+++ b/mmocr/models/textdet/__init__.py
@@ -0,0 +1,7 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .data_preprocessors import * # NOQA
+from .detectors import * # NOQA
+from .heads import * # NOQA
+from .module_losses import * # NOQA
+from .necks import * # NOQA
+from .postprocessors import * # NOQA
diff --git a/mmocr/models/textdet/__pycache__/__init__.cpython-38.pyc b/mmocr/models/textdet/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..11de01763ae74d614c1d9e24acad5ca7bdb02241
Binary files /dev/null and b/mmocr/models/textdet/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/data_preprocessors/__init__.py b/mmocr/models/textdet/data_preprocessors/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..056e8b6d5a06aff8502c0a36712f6d2a5f4ac4b5
--- /dev/null
+++ b/mmocr/models/textdet/data_preprocessors/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .data_preprocessor import TextDetDataPreprocessor
+
+__all__ = ['TextDetDataPreprocessor']
diff --git a/mmocr/models/textdet/data_preprocessors/__pycache__/__init__.cpython-38.pyc b/mmocr/models/textdet/data_preprocessors/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..266e7dce293615d4ee6a148956ed4b64e95dcc22
Binary files /dev/null and b/mmocr/models/textdet/data_preprocessors/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/data_preprocessors/__pycache__/data_preprocessor.cpython-38.pyc b/mmocr/models/textdet/data_preprocessors/__pycache__/data_preprocessor.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d5a3ed4d7972c2ce69673095410f10f1c9573b0b
Binary files /dev/null and b/mmocr/models/textdet/data_preprocessors/__pycache__/data_preprocessor.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/data_preprocessors/data_preprocessor.py b/mmocr/models/textdet/data_preprocessors/data_preprocessor.py
new file mode 100644
index 0000000000000000000000000000000000000000..990f0b146455cbf315d8f12f8f25915caa112f11
--- /dev/null
+++ b/mmocr/models/textdet/data_preprocessors/data_preprocessor.py
@@ -0,0 +1,99 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from numbers import Number
+from typing import Dict, List, Optional, Sequence, Union
+
+import torch.nn as nn
+from mmengine.model import ImgDataPreprocessor
+
+from mmocr.registry import MODELS
+
+
+@MODELS.register_module()
+class TextDetDataPreprocessor(ImgDataPreprocessor):
+ """Image pre-processor for detection tasks.
+
+ Comparing with the :class:`mmengine.ImgDataPreprocessor`,
+
+ 1. It supports batch augmentations.
+ 2. It will additionally append batch_input_shape and pad_shape
+ to data_samples considering the object detection task.
+
+ It provides the data pre-processing as follows
+
+ - Collate and move data to the target device.
+ - Pad inputs to the maximum size of current batch with defined
+ ``pad_value``. The padding size can be divisible by a defined
+ ``pad_size_divisor``
+ - Stack inputs to batch_inputs.
+ - Convert inputs from bgr to rgb if the shape of input is (3, H, W).
+ - Normalize image with defined std and mean.
+ - Do batch augmentations during training.
+
+ Args:
+ mean (Sequence[Number], optional): The pixel mean of R, G, B channels.
+ Defaults to None.
+ std (Sequence[Number], optional): The pixel standard deviation of
+ R, G, B channels. Defaults to None.
+ pad_size_divisor (int): The size of padded image should be
+ divisible by ``pad_size_divisor``. Defaults to 1.
+ pad_value (Number): The padded pixel value. Defaults to 0.
+ pad_mask (bool): Whether to pad instance masks. Defaults to False.
+ mask_pad_value (int): The padded pixel value for instance masks.
+ Defaults to 0.
+ pad_seg (bool): Whether to pad semantic segmentation maps.
+ Defaults to False.
+ seg_pad_value (int): The padded pixel value for semantic
+ segmentation maps. Defaults to 255.
+ bgr_to_rgb (bool): whether to convert image from BGR to RGB.
+ Defaults to False.
+ rgb_to_bgr (bool): whether to convert image from RGB to RGB.
+ Defaults to False.
+ batch_augments (list[dict], optional): Batch-level augmentations
+ """
+
+ def __init__(self,
+ mean: Sequence[Number] = None,
+ std: Sequence[Number] = None,
+ pad_size_divisor: int = 1,
+ pad_value: Union[float, int] = 0,
+ bgr_to_rgb: bool = False,
+ rgb_to_bgr: bool = False,
+ batch_augments: Optional[List[Dict]] = None) -> None:
+ super().__init__(
+ mean=mean,
+ std=std,
+ pad_size_divisor=pad_size_divisor,
+ pad_value=pad_value,
+ bgr_to_rgb=bgr_to_rgb,
+ rgb_to_bgr=rgb_to_bgr)
+ if batch_augments is not None:
+ self.batch_augments = nn.ModuleList(
+ [MODELS.build(aug) for aug in batch_augments])
+ else:
+ self.batch_augments = None
+
+ def forward(self, data: Dict, training: bool = False) -> Dict:
+ """Perform normalization、padding and bgr2rgb conversion based on
+ ``BaseDataPreprocessor``.
+
+ Args:
+ data (dict): data sampled from dataloader.
+ training (bool): Whether to enable training time augmentation.
+
+ Returns:
+ dict: Data in the same format as the model input.
+ """
+ data = super().forward(data=data, training=training)
+ inputs, data_samples = data['inputs'], data['data_samples']
+
+ if data_samples is not None:
+ batch_input_shape = tuple(inputs[0].size()[-2:])
+ for data_sample in data_samples:
+ data_sample.set_metainfo(
+ {'batch_input_shape': batch_input_shape})
+
+ if training and self.batch_augments is not None:
+ for batch_aug in self.batch_augments:
+ inputs, data_samples = batch_aug(inputs, data_samples)
+
+ return data
diff --git a/mmocr/models/textdet/detectors/__init__.py b/mmocr/models/textdet/detectors/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..00b95bdb9aaf708a96fb4afb6a44f8b89bf489a5
--- /dev/null
+++ b/mmocr/models/textdet/detectors/__init__.py
@@ -0,0 +1,14 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .dbnet import DBNet
+from .drrg import DRRG
+from .fcenet import FCENet
+from .mmdet_wrapper import MMDetWrapper
+from .panet import PANet
+from .psenet import PSENet
+from .single_stage_text_detector import SingleStageTextDetector
+from .textsnake import TextSnake
+
+__all__ = [
+ 'SingleStageTextDetector', 'DBNet', 'PANet', 'PSENet', 'TextSnake',
+ 'FCENet', 'DRRG', 'MMDetWrapper'
+]
diff --git a/mmocr/models/textdet/detectors/__pycache__/__init__.cpython-38.pyc b/mmocr/models/textdet/detectors/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..64da40f872a95cbd0b7ba0a45c2a167d152f84b2
Binary files /dev/null and b/mmocr/models/textdet/detectors/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/detectors/__pycache__/base.cpython-38.pyc b/mmocr/models/textdet/detectors/__pycache__/base.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..9e8f18f15e7e48e62201352b5ed83727ee427ab7
Binary files /dev/null and b/mmocr/models/textdet/detectors/__pycache__/base.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/detectors/__pycache__/dbnet.cpython-38.pyc b/mmocr/models/textdet/detectors/__pycache__/dbnet.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e01ce95613bcf595c8539e79006cd1b16ae903a8
Binary files /dev/null and b/mmocr/models/textdet/detectors/__pycache__/dbnet.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/detectors/__pycache__/drrg.cpython-38.pyc b/mmocr/models/textdet/detectors/__pycache__/drrg.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5727def93da18d4bcdaac1c6b366c00a52d8667f
Binary files /dev/null and b/mmocr/models/textdet/detectors/__pycache__/drrg.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/detectors/__pycache__/fcenet.cpython-38.pyc b/mmocr/models/textdet/detectors/__pycache__/fcenet.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..04e24ea00650a71c94aada0d8f13412eb565780c
Binary files /dev/null and b/mmocr/models/textdet/detectors/__pycache__/fcenet.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/detectors/__pycache__/mmdet_wrapper.cpython-38.pyc b/mmocr/models/textdet/detectors/__pycache__/mmdet_wrapper.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f9653e6666aaa2467fc969da7842fd814a311c9c
Binary files /dev/null and b/mmocr/models/textdet/detectors/__pycache__/mmdet_wrapper.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/detectors/__pycache__/panet.cpython-38.pyc b/mmocr/models/textdet/detectors/__pycache__/panet.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..4ca62a95cf91d62b634778c9a750141bd8c2e4b8
Binary files /dev/null and b/mmocr/models/textdet/detectors/__pycache__/panet.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/detectors/__pycache__/psenet.cpython-38.pyc b/mmocr/models/textdet/detectors/__pycache__/psenet.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..834407e1db01fb06ccc217e0304a2061b3b087e8
Binary files /dev/null and b/mmocr/models/textdet/detectors/__pycache__/psenet.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/detectors/__pycache__/single_stage_text_detector.cpython-38.pyc b/mmocr/models/textdet/detectors/__pycache__/single_stage_text_detector.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a719a5b707684ddaef33f499006c1a72c5045741
Binary files /dev/null and b/mmocr/models/textdet/detectors/__pycache__/single_stage_text_detector.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/detectors/__pycache__/textsnake.cpython-38.pyc b/mmocr/models/textdet/detectors/__pycache__/textsnake.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0d5c5877e891698fd97b8ce65b7ffb90512fcbe4
Binary files /dev/null and b/mmocr/models/textdet/detectors/__pycache__/textsnake.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/detectors/base.py b/mmocr/models/textdet/detectors/base.py
new file mode 100644
index 0000000000000000000000000000000000000000..a81ba0214d6bec28c0807e8a60d6ff376a6727ec
--- /dev/null
+++ b/mmocr/models/textdet/detectors/base.py
@@ -0,0 +1,106 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import ABCMeta, abstractmethod
+from typing import Dict, Tuple, Union
+
+import torch
+from mmengine.model import BaseModel
+from torch import Tensor
+
+from mmocr.utils.typing_utils import (DetSampleList, OptConfigType,
+ OptDetSampleList, OptMultiConfig)
+
+ForwardResults = Union[Dict[str, torch.Tensor], DetSampleList,
+ Tuple[torch.Tensor], torch.Tensor]
+
+
+class BaseTextDetector(BaseModel, metaclass=ABCMeta):
+ """Base class for detectors.
+
+ Args:
+ data_preprocessor (dict or ConfigDict, optional): The pre-process
+ config of :class:`BaseDataPreprocessor`. it usually includes,
+ ``pad_size_divisor``, ``pad_value``, ``mean`` and ``std``.
+ init_cfg (dict or ConfigDict, optional): the config to control the
+ initialization. Defaults to None.
+ """
+
+ def __init__(self,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None):
+ super().__init__(
+ data_preprocessor=data_preprocessor, init_cfg=init_cfg)
+
+ @property
+ def with_neck(self) -> bool:
+ """bool: whether the detector has a neck"""
+ return hasattr(self, 'neck') and self.neck is not None
+
+ def forward(self,
+ inputs: torch.Tensor,
+ data_samples: OptDetSampleList = None,
+ mode: str = 'tensor') -> ForwardResults:
+ """The unified entry for a forward process in both training and test.
+
+ The method should accept three modes: "tensor", "predict" and "loss":
+
+ - "tensor": Forward the whole network and return tensor or tuple of
+ tensor without any post-processing, same as a common nn.Module.
+ - "predict": Forward and return the predictions, which are fully
+ processed to a list of :obj:`TextDetDataSample`.
+ - "loss": Forward and return a dict of losses according to the given
+ inputs and data samples.
+
+ Note that this method doesn't handle either back propagation or
+ parameter update, which are supposed to be done in :meth:`train_step`.
+
+ Args:
+ inputs (torch.Tensor): The input tensor with shape
+ (N, C, ...) in general.
+ data_samples (list[:obj:`TextDetDataSample`], optional): A batch of
+ data samples that contain annotations and predictions.
+ Defaults to None.
+ mode (str): Return what kind of value. Defaults to 'tensor'.
+
+ Returns:
+ The return type depends on ``mode``.
+
+ - If ``mode="tensor"``, return a tensor or a tuple of tensor.
+ - If ``mode="predict"``, return a list of :obj:`TextDetDataSample`.
+ - If ``mode="loss"``, return a dict of tensor.
+ """
+ if mode == 'loss':
+ return self.loss(inputs, data_samples)
+ elif mode == 'predict':
+ return self.predict(inputs, data_samples)
+ elif mode == 'tensor':
+ return self._forward(inputs, data_samples)
+ else:
+ raise RuntimeError(f'Invalid mode "{mode}". '
+ 'Only supports loss, predict and tensor mode')
+
+ @abstractmethod
+ def loss(self, inputs: Tensor,
+ data_samples: DetSampleList) -> Union[dict, tuple]:
+ """Calculate losses from a batch of inputs and data samples."""
+ pass
+
+ @abstractmethod
+ def predict(self, inputs: Tensor,
+ data_samples: DetSampleList) -> DetSampleList:
+ """Predict results from a batch of inputs and data samples with post-
+ processing."""
+ pass
+
+ @abstractmethod
+ def _forward(self, inputs: Tensor, data_samples: OptDetSampleList = None):
+ """Network forward process.
+
+ Usually includes backbone, neck and head forward without any post-
+ processing.
+ """
+ pass
+
+ @abstractmethod
+ def extract_feat(self, inputs: Tensor):
+ """Extract features from images."""
+ pass
diff --git a/mmocr/models/textdet/detectors/dbnet.py b/mmocr/models/textdet/detectors/dbnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..eed95b9fabd24ff17ffcba05fb814c0f1cdc9b42
--- /dev/null
+++ b/mmocr/models/textdet/detectors/dbnet.py
@@ -0,0 +1,12 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmocr.registry import MODELS
+from .single_stage_text_detector import SingleStageTextDetector
+
+
+@MODELS.register_module()
+class DBNet(SingleStageTextDetector):
+ """The class for implementing DBNet text detector: Real-time Scene Text
+ Detection with Differentiable Binarization.
+
+ [https://arxiv.org/abs/1911.08947].
+ """
diff --git a/mmocr/models/textdet/detectors/drrg.py b/mmocr/models/textdet/detectors/drrg.py
new file mode 100644
index 0000000000000000000000000000000000000000..04ea2da5fef75c7b2bbb51a9a7361332534f816c
--- /dev/null
+++ b/mmocr/models/textdet/detectors/drrg.py
@@ -0,0 +1,12 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmocr.registry import MODELS
+from .single_stage_text_detector import SingleStageTextDetector
+
+
+@MODELS.register_module()
+class DRRG(SingleStageTextDetector):
+ """The class for implementing DRRG text detector. Deep Relational Reasoning
+ Graph Network for Arbitrary Shape Text Detection.
+
+ [https://arxiv.org/abs/2003.07493]
+ """
diff --git a/mmocr/models/textdet/detectors/fcenet.py b/mmocr/models/textdet/detectors/fcenet.py
new file mode 100644
index 0000000000000000000000000000000000000000..9b99f491ff8eedaeb37d64990f0c1dd8dc3c5e89
--- /dev/null
+++ b/mmocr/models/textdet/detectors/fcenet.py
@@ -0,0 +1,13 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmocr.registry import MODELS
+from .single_stage_text_detector import SingleStageTextDetector
+
+
+@MODELS.register_module()
+class FCENet(SingleStageTextDetector):
+ """The class for implementing FCENet text detector
+ FCENet(CVPR2021): Fourier Contour Embedding for Arbitrary-shaped Text
+ Detection
+
+ [https://arxiv.org/abs/2104.10442]
+ """
diff --git a/mmocr/models/textdet/detectors/mmdet_wrapper.py b/mmocr/models/textdet/detectors/mmdet_wrapper.py
new file mode 100644
index 0000000000000000000000000000000000000000..1d6be8caa6469ab2da2e55eb1f645f9129037490
--- /dev/null
+++ b/mmocr/models/textdet/detectors/mmdet_wrapper.py
@@ -0,0 +1,156 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Tuple, Union
+
+import cv2
+import torch
+from mmdet.structures import DetDataSample
+from mmdet.structures import SampleList as MMDET_SampleList
+from mmdet.structures.mask import bitmap_to_polygon
+from mmengine.model import BaseModel
+from mmengine.structures import InstanceData
+
+from mmocr.registry import MODELS
+from mmocr.utils.bbox_utils import bbox2poly
+from mmocr.utils.typing_utils import DetSampleList
+
+ForwardResults = Union[Dict[str, torch.Tensor], List[DetDataSample],
+ Tuple[torch.Tensor], torch.Tensor]
+
+
+@MODELS.register_module()
+class MMDetWrapper(BaseModel):
+ """A wrapper of MMDet's model.
+
+ Args:
+ cfg (dict): The config of the model.
+ text_repr_type (str): The boundary encoding type 'poly' or 'quad'.
+ Defaults to 'poly'.
+ """
+
+ def __init__(self, cfg: Dict, text_repr_type: str = 'poly') -> None:
+ data_preprocessor = cfg.pop('data_preprocessor')
+ data_preprocessor.update(_scope_='mmdet')
+ super().__init__(data_preprocessor=data_preprocessor, init_cfg=None)
+ cfg['_scope_'] = 'mmdet'
+ self.wrapped_model = MODELS.build(cfg)
+ self.text_repr_type = text_repr_type
+
+ def forward(self,
+ inputs: torch.Tensor,
+ data_samples: Optional[Union[DetSampleList,
+ MMDET_SampleList]] = None,
+ mode: str = 'tensor',
+ **kwargs) -> ForwardResults:
+ """The unified entry for a forward process in both training and test.
+
+ The method works in three modes: "tensor", "predict" and "loss":
+
+ - "tensor": Forward the whole network and return tensor or tuple of
+ tensor without any post-processing, same as a common nn.Module.
+ - "predict": Forward and return the predictions, which are fully
+ processed to a list of :obj:`DetDataSample`.
+ - "loss": Forward and return a dict of losses according to the given
+ inputs and data samples.
+
+ Note that this method doesn't handle either back propagation or
+ parameter update, which are supposed to be done in :meth:`train_step`.
+
+ Args:
+ inputs (torch.Tensor): The input tensor with shape
+ (N, C, ...) in general.
+ data_samples (list[:obj:`DetDataSample`] or
+ list[:obj:`TextDetDataSample`]): The annotation data of every
+ sample. When in "predict" mode, it should be a list of
+ :obj:`TextDetDataSample`. Otherwise they are
+ :obj:`DetDataSample`s. Defaults to None.
+ mode (str): Running mode. Defaults to 'tensor'.
+
+ Returns:
+ The return type depends on ``mode``.
+
+ - If ``mode="tensor"``, return a tensor or a tuple of tensor.
+ - If ``mode="predict"``, return a list of :obj:`TextDetDataSample`.
+ - If ``mode="loss"``, return a dict of tensor.
+ """
+ if mode == 'predict':
+ ocr_data_samples = data_samples
+ data_samples = []
+ for i in range(len(ocr_data_samples)):
+ data_samples.append(
+ DetDataSample(metainfo=ocr_data_samples[i].metainfo))
+
+ results = self.wrapped_model.forward(inputs, data_samples, mode,
+ **kwargs)
+
+ if mode == 'predict':
+ results = self.adapt_predictions(results, ocr_data_samples)
+
+ return results
+
+ def adapt_predictions(self, data: MMDET_SampleList,
+ data_samples: DetSampleList) -> DetSampleList:
+ """Convert Instance datas from MMDet into MMOCR's format.
+
+ Args:
+ data: (list[DetDataSample]): Detection results of the
+ input images. Each DetDataSample usually contain
+ 'pred_instances'. And the ``pred_instances`` usually
+ contains following keys.
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ - masks (Tensor, Optional): Has a shape (num_instances, H, W).
+ data_samples (list[:obj:`TextDetDataSample`]): The annotation data
+ of every samples.
+
+ Returns:
+ list[TextDetDataSample]: A list of N datasamples containing ground
+ truth and prediction results.
+ The polygon results are saved in
+ ``TextDetDataSample.pred_instances.polygons``
+ The confidence scores are saved in
+ ``TextDetDataSample.pred_instances.scores``.
+ """
+ for i, det_data_sample in enumerate(data):
+ data_samples[i].pred_instances = InstanceData()
+ # convert mask to polygons if mask exists
+ if 'masks' in det_data_sample.pred_instances.keys():
+ masks = det_data_sample.pred_instances.masks.cpu().numpy()
+ polygons = []
+ scores = []
+ for mask_idx, mask in enumerate(masks):
+ contours, _ = bitmap_to_polygon(mask)
+ polygons += [contour.reshape(-1) for contour in contours]
+ scores += [
+ det_data_sample.pred_instances.scores[mask_idx].cpu()
+ ] * len(contours)
+ # filter invalid polygons
+ filterd_polygons = []
+ keep_idx = []
+ for poly_idx, polygon in enumerate(polygons):
+ if len(polygon) < 6:
+ continue
+ filterd_polygons.append(polygon)
+ keep_idx.append(poly_idx)
+ # convert by text_repr_type
+ if self.text_repr_type == 'quad':
+ for j, poly in enumerate(filterd_polygons):
+ rect = cv2.minAreaRect(poly)
+ vertices = cv2.boxPoints(rect)
+ poly = vertices.flatten()
+ filterd_polygons[j] = poly
+
+ data_samples[i].pred_instances.polygons = filterd_polygons
+ data_samples[i].pred_instances.scores = torch.FloatTensor(
+ scores)[keep_idx]
+ else:
+ bboxes = det_data_sample.pred_instances.bboxes.cpu().numpy()
+ polygons = [bbox2poly(bbox) for bbox in bboxes]
+ data_samples[i].pred_instances.polygons = polygons
+ data_samples[i].pred_instances.scores = torch.FloatTensor(
+ det_data_sample.pred_instances.scores.cpu())
+
+ return data_samples
diff --git a/mmocr/models/textdet/detectors/panet.py b/mmocr/models/textdet/detectors/panet.py
new file mode 100644
index 0000000000000000000000000000000000000000..135ee1e9af33e8207286d4990bd513dfd441176e
--- /dev/null
+++ b/mmocr/models/textdet/detectors/panet.py
@@ -0,0 +1,12 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmocr.registry import MODELS
+from .single_stage_text_detector import SingleStageTextDetector
+
+
+@MODELS.register_module()
+class PANet(SingleStageTextDetector):
+ """The class for implementing PANet text detector:
+
+ Efficient and Accurate Arbitrary-Shaped Text Detection with Pixel
+ Aggregation Network [https://arxiv.org/abs/1908.05900].
+ """
diff --git a/mmocr/models/textdet/detectors/psenet.py b/mmocr/models/textdet/detectors/psenet.py
new file mode 100644
index 0000000000000000000000000000000000000000..0ccf10a13a50e04610b6022552139c8c1ebc0a17
--- /dev/null
+++ b/mmocr/models/textdet/detectors/psenet.py
@@ -0,0 +1,12 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmocr.registry import MODELS
+from .single_stage_text_detector import SingleStageTextDetector
+
+
+@MODELS.register_module()
+class PSENet(SingleStageTextDetector):
+ """The class for implementing PSENet text detector: Shape Robust Text
+ Detection with Progressive Scale Expansion Network.
+
+ [https://arxiv.org/abs/1806.02559].
+ """
diff --git a/mmocr/models/textdet/detectors/single_stage_text_detector.py b/mmocr/models/textdet/detectors/single_stage_text_detector.py
new file mode 100644
index 0000000000000000000000000000000000000000..5617e26ae0507da3ee4a23475325c4ea11f94ffd
--- /dev/null
+++ b/mmocr/models/textdet/detectors/single_stage_text_detector.py
@@ -0,0 +1,127 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, Optional, Sequence
+
+import torch
+
+from mmocr.registry import MODELS
+from mmocr.structures import TextDetDataSample
+from .base import BaseTextDetector
+
+
+@MODELS.register_module()
+class SingleStageTextDetector(BaseTextDetector):
+ """The class for implementing single stage text detector.
+
+ Single-stage text detectors directly and densely predict bounding boxes or
+ polygons on the output features of the backbone + neck (optional).
+
+ Args:
+ backbone (dict): Backbone config.
+ neck (dict, optional): Neck config. If None, the output from backbone
+ will be directly fed into ``det_head``.
+ det_head (dict): Head config.
+ data_preprocessor (dict, optional): Model preprocessing config
+ for processing the input image data. Keys allowed are
+ ``to_rgb``(bool), ``pad_size_divisor``(int), ``pad_value``(int or
+ float), ``mean``(int or float) and ``std``(int or float).
+ Preprcessing order: 1. to rgb; 2. normalization 3. pad.
+ Defaults to None.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ backbone: Dict,
+ det_head: Dict,
+ neck: Optional[Dict] = None,
+ data_preprocessor: Optional[Dict] = None,
+ init_cfg: Optional[Dict] = None) -> None:
+ super().__init__(
+ data_preprocessor=data_preprocessor, init_cfg=init_cfg)
+ assert det_head is not None, 'det_head cannot be None!'
+ self.backbone = MODELS.build(backbone)
+ if neck is not None:
+ self.neck = MODELS.build(neck)
+ self.det_head = MODELS.build(det_head)
+
+ def extract_feat(self, inputs: torch.Tensor) -> torch.Tensor:
+ """Extract features.
+
+ Args:
+ inputs (Tensor): Image tensor with shape (N, C, H ,W).
+
+ Returns:
+ Tensor or tuple[Tensor]: Multi-level features that may have
+ different resolutions.
+ """
+ inputs = self.backbone(inputs)
+ if self.with_neck:
+ inputs = self.neck(inputs)
+ return inputs
+
+ def loss(self, inputs: torch.Tensor,
+ data_samples: Sequence[TextDetDataSample]) -> Dict:
+ """Calculate losses from a batch of inputs and data samples.
+
+ Args:
+ inputs (torch.Tensor): Input images of shape (N, C, H, W).
+ Typically these should be mean centered and std scaled.
+ data_samples (list[TextDetDataSample]): A list of N
+ datasamples, containing meta information and gold annotations
+ for each of the images.
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ inputs = self.extract_feat(inputs)
+ return self.det_head.loss(inputs, data_samples)
+
+ def predict(self, inputs: torch.Tensor,
+ data_samples: Sequence[TextDetDataSample]
+ ) -> Sequence[TextDetDataSample]:
+ """Predict results from a batch of inputs and data samples with post-
+ processing.
+
+ Args:
+ inputs (torch.Tensor): Images of shape (N, C, H, W).
+ data_samples (list[TextDetDataSample]): A list of N
+ datasamples, containing meta information and gold annotations
+ for each of the images.
+
+ Returns:
+ list[TextDetDataSample]: A list of N datasamples of prediction
+ results. Each DetDataSample usually contain
+ 'pred_instances'. And the ``pred_instances`` usually
+ contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ - polygons (list[np.ndarray]): The length is num_instances.
+ Each element represents the polygon of the
+ instance, in (xn, yn) order.
+ """
+ x = self.extract_feat(inputs)
+ return self.det_head.predict(x, data_samples)
+
+ def _forward(self,
+ inputs: torch.Tensor,
+ data_samples: Optional[Sequence[TextDetDataSample]] = None,
+ **kwargs) -> torch.Tensor:
+ """Network forward process. Usually includes backbone, neck and head
+ forward without any post-processing.
+
+ Args:
+ inputs (Tensor): Inputs with shape (N, C, H, W).
+ data_samples (list[TextDetDataSample]): A list of N
+ datasamples, containing meta information and gold annotations
+ for each of the images.
+
+ Returns:
+ Tensor or tuple[Tensor]: A tuple of features from ``det_head``
+ forward.
+ """
+ x = self.extract_feat(inputs)
+ return self.det_head(x, data_samples)
diff --git a/mmocr/models/textdet/detectors/textsnake.py b/mmocr/models/textdet/detectors/textsnake.py
new file mode 100644
index 0000000000000000000000000000000000000000..6a001806cb9fe7d3003cfb8c728b5d72254d6726
--- /dev/null
+++ b/mmocr/models/textdet/detectors/textsnake.py
@@ -0,0 +1,12 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmocr.registry import MODELS
+from .single_stage_text_detector import SingleStageTextDetector
+
+
+@MODELS.register_module()
+class TextSnake(SingleStageTextDetector):
+ """The class for implementing TextSnake text detector: TextSnake: A
+ Flexible Representation for Detecting Text of Arbitrary Shapes.
+
+ [https://arxiv.org/abs/1807.01544]
+ """
diff --git a/mmocr/models/textdet/heads/__init__.py b/mmocr/models/textdet/heads/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..5663ebebb88ab2ef0cf41e8beee86f0253288972
--- /dev/null
+++ b/mmocr/models/textdet/heads/__init__.py
@@ -0,0 +1,13 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .base import BaseTextDetHead
+from .db_head import DBHead
+from .drrg_head import DRRGHead
+from .fce_head import FCEHead
+from .pan_head import PANHead
+from .pse_head import PSEHead
+from .textsnake_head import TextSnakeHead
+
+__all__ = [
+ 'PSEHead', 'PANHead', 'DBHead', 'FCEHead', 'TextSnakeHead', 'DRRGHead',
+ 'BaseTextDetHead'
+]
diff --git a/mmocr/models/textdet/heads/__pycache__/__init__.cpython-38.pyc b/mmocr/models/textdet/heads/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..bdb01126d7efd493ff76361e6213febb4a6059c0
Binary files /dev/null and b/mmocr/models/textdet/heads/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/heads/__pycache__/base.cpython-38.pyc b/mmocr/models/textdet/heads/__pycache__/base.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c447bf04cd721e602cc88868e68ccaef66b065db
Binary files /dev/null and b/mmocr/models/textdet/heads/__pycache__/base.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/heads/__pycache__/db_head.cpython-38.pyc b/mmocr/models/textdet/heads/__pycache__/db_head.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..314dafddd2601ee353aba98cfab414df448e89b6
Binary files /dev/null and b/mmocr/models/textdet/heads/__pycache__/db_head.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/heads/__pycache__/drrg_head.cpython-38.pyc b/mmocr/models/textdet/heads/__pycache__/drrg_head.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b99f5d2113ae885c0dc6cf5afbab4cfe1b690957
Binary files /dev/null and b/mmocr/models/textdet/heads/__pycache__/drrg_head.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/heads/__pycache__/fce_head.cpython-38.pyc b/mmocr/models/textdet/heads/__pycache__/fce_head.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..aa86530185af68508ea57db1b3197e7f2efeed4b
Binary files /dev/null and b/mmocr/models/textdet/heads/__pycache__/fce_head.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/heads/__pycache__/pan_head.cpython-38.pyc b/mmocr/models/textdet/heads/__pycache__/pan_head.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..81ecdd2b019a474edcaf4853fa1022ffd4804025
Binary files /dev/null and b/mmocr/models/textdet/heads/__pycache__/pan_head.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/heads/__pycache__/pse_head.cpython-38.pyc b/mmocr/models/textdet/heads/__pycache__/pse_head.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b3d6f2aa78ed6a61f112a3e1e912a7bc12092c56
Binary files /dev/null and b/mmocr/models/textdet/heads/__pycache__/pse_head.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/heads/__pycache__/textsnake_head.cpython-38.pyc b/mmocr/models/textdet/heads/__pycache__/textsnake_head.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1e206bf36f88189378a9410d088d724a7910d186
Binary files /dev/null and b/mmocr/models/textdet/heads/__pycache__/textsnake_head.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/heads/base.py b/mmocr/models/textdet/heads/base.py
new file mode 100644
index 0000000000000000000000000000000000000000..82dee4dfc23702e5948d2ebf2e8ee8ae12560397
--- /dev/null
+++ b/mmocr/models/textdet/heads/base.py
@@ -0,0 +1,133 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Tuple, Union
+
+import torch
+from mmengine.model import BaseModule
+from torch import Tensor
+
+from mmocr.registry import MODELS
+from mmocr.utils.typing_utils import DetSampleList
+
+
+@MODELS.register_module()
+class BaseTextDetHead(BaseModule):
+ """Base head for text detection, build the loss and postprocessor.
+
+ 1. The ``init_weights`` method is used to initialize head's
+ model parameters. After detector initialization, ``init_weights``
+ is triggered when ``detector.init_weights()`` is called externally.
+
+ 2. The ``loss`` method is used to calculate the loss of head,
+ which includes two steps: (1) the head model performs forward
+ propagation to obtain the feature maps (2) The ``module_loss`` method
+ is called based on the feature maps to calculate the loss.
+
+ .. code:: text
+
+ loss(): forward() -> module_loss()
+
+ 3. The ``predict`` method is used to predict detection results,
+ which includes two steps: (1) the head model performs forward
+ propagation to obtain the feature maps (2) The ``postprocessor`` method
+ is called based on the feature maps to predict detection results including
+ post-processing.
+
+ .. code:: text
+
+ predict(): forward() -> postprocessor()
+
+ 4. The ``loss_and_predict`` method is used to return loss and detection
+ results at the same time. It will call head's ``forward``,
+ ``module_loss`` and ``postprocessor`` methods in order.
+
+ .. code:: text
+
+ loss_and_predict(): forward() -> module_loss() -> postprocessor()
+
+
+ Args:
+ loss (dict, optional): Config to build loss. Defaults to None.
+ postprocessor (dict, optional): Config to build postprocessor. Defaults
+ to None.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ module_loss: Optional[Dict] = None,
+ postprocessor: Optional[Dict] = None,
+ init_cfg: Optional[Union[Dict, List[Dict]]] = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+ if module_loss is not None:
+ assert isinstance(module_loss, dict)
+ self.module_loss = MODELS.build(module_loss)
+ else:
+ self.module_loss = module_loss
+ if postprocessor is not None:
+ assert isinstance(postprocessor, dict)
+ self.postprocessor = MODELS.build(postprocessor)
+ else:
+ self.postprocessor = postprocessor
+
+ def loss(self, x: Tuple[Tensor], data_samples: DetSampleList) -> dict:
+ """Perform forward propagation and loss calculation of the detection
+ head on the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+ data_samples (List[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ outs = self(x, data_samples)
+ losses = self.module_loss(outs, data_samples)
+ return losses
+
+ def loss_and_predict(self, x: Tuple[Tensor], data_samples: DetSampleList
+ ) -> Tuple[dict, DetSampleList]:
+ """Perform forward propagation of the head, then calculate loss and
+ predictions from the features and data samples.
+
+ Args:
+ x (tuple[Tensor]): Features from FPN.
+ data_samples (list[:obj:`DetDataSample`]): Each item contains
+ the meta information of each image and corresponding
+ annotations.
+
+ Returns:
+ tuple: the return value is a tuple contains:
+
+ - losses: (dict[str, Tensor]): A dictionary of loss components.
+ - predictions (list[:obj:`InstanceData`]): Detection
+ results of each image after the post process.
+ """
+ outs = self(x, data_samples)
+ losses = self.module_loss(outs, data_samples)
+
+ predictions = self.postprocessor(outs, data_samples, self.training)
+ return losses, predictions
+
+ def predict(self, x: torch.Tensor,
+ data_samples: DetSampleList) -> DetSampleList:
+ """Perform forward propagation of the detection head and predict
+ detection results on the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Multi-level features from the
+ upstream network, each is a 4D-tensor.
+ data_samples (List[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+
+ Returns:
+ SampleList: Detection results of each image
+ after the post process.
+ """
+ outs = self(x, data_samples)
+
+ predictions = self.postprocessor(outs, data_samples)
+ return predictions
diff --git a/mmocr/models/textdet/heads/db_head.py b/mmocr/models/textdet/heads/db_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..848843e87fb2d99d44a915f8929893d218fa7d1f
--- /dev/null
+++ b/mmocr/models/textdet/heads/db_head.py
@@ -0,0 +1,184 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Tuple, Union
+
+import torch
+import torch.nn as nn
+from mmengine.model import Sequential
+from torch import Tensor
+
+from mmocr.models.textdet.heads import BaseTextDetHead
+from mmocr.registry import MODELS
+from mmocr.structures import TextDetDataSample
+from mmocr.utils.typing_utils import DetSampleList
+
+
+@MODELS.register_module()
+class DBHead(BaseTextDetHead):
+ """The class for DBNet head.
+
+ This was partially adapted from https://github.com/MhLiao/DB
+
+ Args:
+ in_channels (int): The number of input channels.
+ with_bias (bool): Whether add bias in Conv2d layer. Defaults to False.
+ module_loss (dict): Config of loss for dbnet. Defaults to
+ ``dict(type='DBModuleLoss')``
+ postprocessor (dict): Config of postprocessor for dbnet.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ """
+
+ def __init__(
+ self,
+ in_channels: int,
+ with_bias: bool = False,
+ module_loss: Dict = dict(type='DBModuleLoss'),
+ postprocessor: Dict = dict(
+ type='DBPostprocessor', text_repr_type='quad'),
+ init_cfg: Optional[Union[Dict, List[Dict]]] = [
+ dict(type='Kaiming', layer='Conv'),
+ dict(type='Constant', layer='BatchNorm', val=1., bias=1e-4)
+ ]
+ ) -> None:
+ super().__init__(
+ module_loss=module_loss,
+ postprocessor=postprocessor,
+ init_cfg=init_cfg)
+
+ assert isinstance(in_channels, int)
+ assert isinstance(with_bias, bool)
+
+ self.in_channels = in_channels
+ self.binarize = Sequential(
+ nn.Conv2d(
+ in_channels, in_channels // 4, 3, bias=with_bias, padding=1),
+ nn.BatchNorm2d(in_channels // 4), nn.ReLU(inplace=True),
+ nn.ConvTranspose2d(in_channels // 4, in_channels // 4, 2, 2),
+ nn.BatchNorm2d(in_channels // 4), nn.ReLU(inplace=True),
+ nn.ConvTranspose2d(in_channels // 4, 1, 2, 2))
+ self.threshold = self._init_thr(in_channels)
+ self.sigmoid = nn.Sigmoid()
+
+ def _diff_binarize(self, prob_map: Tensor, thr_map: Tensor,
+ k: int) -> Tensor:
+ """Differential binarization.
+
+ Args:
+ prob_map (Tensor): Probability map.
+ thr_map (Tensor): Threshold map.
+ k (int): Amplification factor.
+
+ Returns:
+ Tensor: Binary map.
+ """
+ return torch.reciprocal(1.0 + torch.exp(-k * (prob_map - thr_map)))
+
+ def _init_thr(self,
+ inner_channels: int,
+ bias: bool = False) -> nn.ModuleList:
+ """Initialize threshold branch."""
+ in_channels = inner_channels
+ seq = Sequential(
+ nn.Conv2d(
+ in_channels, inner_channels // 4, 3, padding=1, bias=bias),
+ nn.BatchNorm2d(inner_channels // 4), nn.ReLU(inplace=True),
+ nn.ConvTranspose2d(inner_channels // 4, inner_channels // 4, 2, 2),
+ nn.BatchNorm2d(inner_channels // 4), nn.ReLU(inplace=True),
+ nn.ConvTranspose2d(inner_channels // 4, 1, 2, 2), nn.Sigmoid())
+ return seq
+
+ def forward(self,
+ img: Tensor,
+ data_samples: Optional[List[TextDetDataSample]] = None,
+ mode: str = 'predict') -> Tuple[Tensor, Tensor, Tensor]:
+ """
+ Args:
+ img (Tensor): Shape :math:`(N, C, H, W)`.
+ data_samples (list[TextDetDataSample], optional): A list of data
+ samples. Defaults to None.
+ mode (str): Forward mode. It affects the return values. Options are
+ "loss", "predict" and "both". Defaults to "predict".
+
+ - ``loss``: Run the full network and return the prob
+ logits, threshold map and binary map.
+ - ``predict``: Run the binarzation part and return the prob
+ map only.
+ - ``both``: Run the full network and return prob logits,
+ threshold map, binary map and prob map.
+
+ Returns:
+ Tensor or tuple(Tensor): Its type depends on ``mode``, read its
+ docstring for details. Each has the shape of
+ :math:`(N, 4H, 4W)`.
+ """
+ prob_logits = self.binarize(img).squeeze(1)
+ prob_map = self.sigmoid(prob_logits)
+ if mode == 'predict':
+ return prob_map
+ thr_map = self.threshold(img).squeeze(1)
+ binary_map = self._diff_binarize(prob_map, thr_map, k=50).squeeze(1)
+ if mode == 'loss':
+ return prob_logits, thr_map, binary_map
+ return prob_logits, thr_map, binary_map, prob_map
+
+ def loss(self, x: Tuple[Tensor],
+ batch_data_samples: DetSampleList) -> Dict:
+ """Perform forward propagation and loss calculation of the detection
+ head on the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+ batch_data_samples (List[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ outs = self(x, batch_data_samples, mode='loss')
+ losses = self.module_loss(outs, batch_data_samples)
+ return losses
+
+ def loss_and_predict(self, x: Tuple[Tensor],
+ batch_data_samples: DetSampleList
+ ) -> Tuple[dict, DetSampleList]:
+ """Perform forward propagation of the head, then calculate loss and
+ predictions from the features and data samples.
+
+ Args:
+ x (tuple[Tensor]): Features from FPN.
+ batch_data_samples (list[:obj:`DetDataSample`]): Each item contains
+ the meta information of each image and corresponding
+ annotations.
+
+ Returns:
+ tuple: the return value is a tuple contains:
+
+ - losses: (dict[str, Tensor]): A dictionary of loss components.
+ - predictions (list[:obj:`InstanceData`]): Detection
+ results of each image after the post process.
+ """
+ outs = self(x, batch_data_samples, mode='both')
+ losses = self.module_loss(outs[:3], batch_data_samples)
+ predictions = self.postprocessor(outs[3], batch_data_samples)
+ return losses, predictions
+
+ def predict(self, x: torch.Tensor,
+ batch_data_samples: DetSampleList) -> DetSampleList:
+ """Perform forward propagation of the detection head and predict
+ detection results on the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Multi-level features from the
+ upstream network, each is a 4D-tensor.
+ batch_data_samples (List[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+
+ Returns:
+ SampleList: Detection results of each image
+ after the post process.
+ """
+ outs = self(x, batch_data_samples, mode='predict')
+ predictions = self.postprocessor(outs, batch_data_samples)
+ return predictions
diff --git a/mmocr/models/textdet/heads/drrg_head.py b/mmocr/models/textdet/heads/drrg_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..14f70858a7a80e6fa1f2ee2964b40ad3b6d2a935
--- /dev/null
+++ b/mmocr/models/textdet/heads/drrg_head.py
@@ -0,0 +1,1181 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Sequence, Tuple, Union
+
+import cv2
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+try:
+ from lanms import merge_quadrangle_n9 as la_nms
+except ImportError:
+ la_nms = None
+from mmcv.ops import RoIAlignRotated
+from mmengine.model import BaseModule
+from numpy import ndarray
+from torch import Tensor
+from torch.nn import init
+
+from mmocr.models.textdet.heads import BaseTextDetHead
+from mmocr.registry import MODELS
+from mmocr.structures import TextDetDataSample
+from mmocr.utils import fill_hole
+
+
+def normalize_adjacent_matrix(mat: ndarray) -> ndarray:
+ """Normalize adjacent matrix for GCN. This code was partially adapted from
+ https://github.com/GXYM/DRRG licensed under the MIT license.
+
+ Args:
+ mat (ndarray): The adjacent matrix.
+
+ returns:
+ ndarray: The normalized adjacent matrix.
+ """
+ assert mat.ndim == 2
+ assert mat.shape[0] == mat.shape[1]
+
+ mat = mat + np.eye(mat.shape[0])
+ d = np.sum(mat, axis=0)
+ d = np.clip(d, 0, None)
+ d_inv = np.power(d, -0.5).flatten()
+ d_inv[np.isinf(d_inv)] = 0.0
+ d_inv = np.diag(d_inv)
+ norm_mat = mat.dot(d_inv).transpose().dot(d_inv)
+ return norm_mat
+
+
+def euclidean_distance_matrix(mat_a: ndarray, mat_b: ndarray) -> ndarray:
+ """Calculate the Euclidean distance matrix.
+
+ Args:
+ mat_a (ndarray): The point sequence.
+ mat_b (ndarray): The point sequence with the same dimensions as mat_a.
+
+ returns:
+ ndarray: The Euclidean distance matrix.
+ """
+ assert mat_a.ndim == 2
+ assert mat_b.ndim == 2
+ assert mat_a.shape[1] == mat_b.shape[1]
+
+ m = mat_a.shape[0]
+ n = mat_b.shape[0]
+
+ mat_a_dots = (mat_a * mat_a).sum(axis=1).reshape(
+ (m, 1)) * np.ones(shape=(1, n))
+ mat_b_dots = (mat_b * mat_b).sum(axis=1) * np.ones(shape=(m, 1))
+ mat_d_squared = mat_a_dots + mat_b_dots - 2 * mat_a.dot(mat_b.T)
+
+ zero_mask = np.less(mat_d_squared, 0.0)
+ mat_d_squared[zero_mask] = 0.0
+ mat_d = np.sqrt(mat_d_squared)
+ return mat_d
+
+
+def feature_embedding(input_feats: ndarray, out_feat_len: int) -> ndarray:
+ """Embed features. This code was partially adapted from
+ https://github.com/GXYM/DRRG licensed under the MIT license.
+
+ Args:
+ input_feats (ndarray): The input features of shape (N, d), where N is
+ the number of nodes in graph, d is the input feature vector length.
+ out_feat_len (int): The length of output feature vector.
+
+ Returns:
+ ndarray: The embedded features.
+ """
+ assert input_feats.ndim == 2
+ assert isinstance(out_feat_len, int)
+ assert out_feat_len >= input_feats.shape[1]
+
+ num_nodes = input_feats.shape[0]
+ feat_dim = input_feats.shape[1]
+ feat_repeat_times = out_feat_len // feat_dim
+ residue_dim = out_feat_len % feat_dim
+
+ if residue_dim > 0:
+ embed_wave = np.array([
+ np.power(1000, 2.0 * (j // 2) / feat_repeat_times + 1)
+ for j in range(feat_repeat_times + 1)
+ ]).reshape((feat_repeat_times + 1, 1, 1))
+ repeat_feats = np.repeat(
+ np.expand_dims(input_feats, axis=0), feat_repeat_times, axis=0)
+ residue_feats = np.hstack([
+ input_feats[:, 0:residue_dim],
+ np.zeros((num_nodes, feat_dim - residue_dim))
+ ])
+ residue_feats = np.expand_dims(residue_feats, axis=0)
+ repeat_feats = np.concatenate([repeat_feats, residue_feats], axis=0)
+ embedded_feats = repeat_feats / embed_wave
+ embedded_feats[:, 0::2] = np.sin(embedded_feats[:, 0::2])
+ embedded_feats[:, 1::2] = np.cos(embedded_feats[:, 1::2])
+ embedded_feats = np.transpose(embedded_feats, (1, 0, 2)).reshape(
+ (num_nodes, -1))[:, 0:out_feat_len]
+ else:
+ embed_wave = np.array([
+ np.power(1000, 2.0 * (j // 2) / feat_repeat_times)
+ for j in range(feat_repeat_times)
+ ]).reshape((feat_repeat_times, 1, 1))
+ repeat_feats = np.repeat(
+ np.expand_dims(input_feats, axis=0), feat_repeat_times, axis=0)
+ embedded_feats = repeat_feats / embed_wave
+ embedded_feats[:, 0::2] = np.sin(embedded_feats[:, 0::2])
+ embedded_feats[:, 1::2] = np.cos(embedded_feats[:, 1::2])
+ embedded_feats = np.transpose(embedded_feats, (1, 0, 2)).reshape(
+ (num_nodes, -1)).astype(np.float32)
+
+ return embedded_feats
+
+
+@MODELS.register_module()
+class DRRGHead(BaseTextDetHead):
+ """The class for DRRG head: `Deep Relational Reasoning Graph Network for
+ Arbitrary Shape Text Detection `_.
+
+ Args:
+ in_channels (int): The number of input channels.
+ k_at_hops (tuple(int)): The number of i-hop neighbors, i = 1, 2.
+ Defaults to (8, 4).
+ num_adjacent_linkages (int): The number of linkages when constructing
+ adjacent matrix. Defaults to 3.
+ node_geo_feat_len (int): The length of embedded geometric feature
+ vector of a component. Defaults to 120.
+ pooling_scale (float): The spatial scale of rotated RoI-Align. Defaults
+ to 1.0.
+ pooling_output_size (tuple(int)): The output size of RRoI-Aligning.
+ Defaults to (4, 3).
+ nms_thr (float): The locality-aware NMS threshold of text components.
+ Defaults to 0.3.
+ min_width (float): The minimum width of text components. Defaults to
+ 8.0.
+ max_width (float): The maximum width of text components. Defaults to
+ 24.0.
+ comp_shrink_ratio (float): The shrink ratio of text components.
+ Defaults to 1.03.
+ comp_ratio (float): The reciprocal of aspect ratio of text components.
+ Defaults to 0.4.
+ comp_score_thr (float): The score threshold of text components.
+ Defaults to 0.3.
+ text_region_thr (float): The threshold for text region probability map.
+ Defaults to 0.2.
+ center_region_thr (float): The threshold for text center region
+ probability map. Defaults to 0.2.
+ center_region_area_thr (int): The threshold for filtering small-sized
+ text center region. Defaults to 50.
+ local_graph_thr (float): The threshold to filter identical local
+ graphs. Defaults to 0.7.
+ module_loss (dict): The config of loss that DRRGHead uses. Defaults to
+ ``dict(type='DRRGModuleLoss')``.
+ postprocessor (dict): Config of postprocessor for Drrg. Defaults to
+ ``dict(type='DrrgPostProcessor', link_thr=0.85)``.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ Defaults to ``dict(type='Normal',
+ override=dict(name='out_conv'), mean=0, std=0.01)``.
+ """
+
+ def __init__(
+ self,
+ in_channels: int,
+ k_at_hops: Tuple[int, int] = (8, 4),
+ num_adjacent_linkages: int = 3,
+ node_geo_feat_len: int = 120,
+ pooling_scale: float = 1.0,
+ pooling_output_size: Tuple[int, int] = (4, 3),
+ nms_thr: float = 0.3,
+ min_width: float = 8.0,
+ max_width: float = 24.0,
+ comp_shrink_ratio: float = 1.03,
+ comp_ratio: float = 0.4,
+ comp_score_thr: float = 0.3,
+ text_region_thr: float = 0.2,
+ center_region_thr: float = 0.2,
+ center_region_area_thr: int = 50,
+ local_graph_thr: float = 0.7,
+ module_loss: Dict = dict(type='DRRGModuleLoss'),
+ postprocessor: Dict = dict(type='DRRGPostprocessor', link_thr=0.85),
+ init_cfg: Optional[Union[Dict, List[Dict]]] = dict(
+ type='Normal', override=dict(name='out_conv'), mean=0, std=0.01)
+ ) -> None:
+ super().__init__(
+ module_loss=module_loss,
+ postprocessor=postprocessor,
+ init_cfg=init_cfg)
+
+ assert isinstance(in_channels, int)
+ assert isinstance(k_at_hops, tuple)
+ assert isinstance(num_adjacent_linkages, int)
+ assert isinstance(node_geo_feat_len, int)
+ assert isinstance(pooling_scale, float)
+ assert isinstance(pooling_output_size, tuple)
+ assert isinstance(comp_shrink_ratio, float)
+ assert isinstance(nms_thr, float)
+ assert isinstance(min_width, float)
+ assert isinstance(max_width, float)
+ assert isinstance(comp_ratio, float)
+ assert isinstance(comp_score_thr, float)
+ assert isinstance(text_region_thr, float)
+ assert isinstance(center_region_thr, float)
+ assert isinstance(center_region_area_thr, int)
+ assert isinstance(local_graph_thr, float)
+
+ self.in_channels = in_channels
+ self.out_channels = 6
+ self.downsample_ratio = 1.0
+ self.k_at_hops = k_at_hops
+ self.num_adjacent_linkages = num_adjacent_linkages
+ self.node_geo_feat_len = node_geo_feat_len
+ self.pooling_scale = pooling_scale
+ self.pooling_output_size = pooling_output_size
+ self.comp_shrink_ratio = comp_shrink_ratio
+ self.nms_thr = nms_thr
+ self.min_width = min_width
+ self.max_width = max_width
+ self.comp_ratio = comp_ratio
+ self.comp_score_thr = comp_score_thr
+ self.text_region_thr = text_region_thr
+ self.center_region_thr = center_region_thr
+ self.center_region_area_thr = center_region_area_thr
+ self.local_graph_thr = local_graph_thr
+
+ self.out_conv = nn.Conv2d(
+ in_channels=self.in_channels,
+ out_channels=self.out_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0)
+
+ self.graph_train = LocalGraphs(self.k_at_hops,
+ self.num_adjacent_linkages,
+ self.node_geo_feat_len,
+ self.pooling_scale,
+ self.pooling_output_size,
+ self.local_graph_thr)
+
+ self.graph_test = ProposalLocalGraphs(
+ self.k_at_hops, self.num_adjacent_linkages, self.node_geo_feat_len,
+ self.pooling_scale, self.pooling_output_size, self.nms_thr,
+ self.min_width, self.max_width, self.comp_shrink_ratio,
+ self.comp_ratio, self.comp_score_thr, self.text_region_thr,
+ self.center_region_thr, self.center_region_area_thr)
+
+ pool_w, pool_h = self.pooling_output_size
+ node_feat_len = (pool_w * pool_h) * (
+ self.in_channels + self.out_channels) + self.node_geo_feat_len
+ self.gcn = GCN(node_feat_len)
+
+ def loss(self, inputs: torch.Tensor, data_samples: List[TextDetDataSample]
+ ) -> Tuple[Tensor, Tensor, Tensor]:
+ """Loss function.
+
+ Args:
+ inputs (Tensor): Shape of :math:`(N, C, H, W)`.
+ data_samples (List[TextDetDataSample]): List of data samples.
+
+ Returns:
+ tuple(pred_maps, gcn_pred, gt_labels):
+
+ - pred_maps (Tensor): Prediction map with shape
+ :math:`(N, 6, H, W)`.
+ - gcn_pred (Tensor): Prediction from GCN module, with
+ shape :math:`(N, 2)`.
+ - gt_labels (Tensor): Ground-truth label of shape
+ :math:`(m, n)` where :math:`m * n = N`.
+ """
+ targets = self.module_loss.get_targets(data_samples)
+ gt_comp_attribs = targets[-1]
+
+ pred_maps = self.out_conv(inputs)
+ feat_maps = torch.cat([inputs, pred_maps], dim=1)
+ node_feats, adjacent_matrices, knn_inds, gt_labels = self.graph_train(
+ feat_maps, np.stack(gt_comp_attribs))
+
+ gcn_pred = self.gcn(node_feats, adjacent_matrices, knn_inds)
+
+ return self.module_loss((pred_maps, gcn_pred, gt_labels), data_samples)
+
+ def forward(
+ self,
+ inputs: Tensor,
+ data_samples: Optional[List[TextDetDataSample]] = None
+ ) -> Tuple[Tensor, Tensor, Tensor]:
+ r"""Run DRRG head in prediction mode, and return the raw tensors only.
+ Args:
+ inputs (Tensor): Shape of :math:`(1, C, H, W)`.
+ data_samples (list[TextDetDataSample], optional): A list of data
+ samples. Defaults to None.
+
+ Returns:
+ tuple: Returns (edge, score, text_comps).
+
+ - edge (ndarray): The edge array of shape :math:`(N_{edges}, 2)`
+ where each row is a pair of text component indices
+ that makes up an edge in graph.
+ - score (ndarray): The score array of shape :math:`(N_{edges},)`,
+ corresponding to the edge above.
+ - text_comps (ndarray): The text components of shape
+ :math:`(M, 9)` where each row corresponds to one box and
+ its score: (x1, y1, x2, y2, x3, y3, x4, y4, score).
+ """
+ pred_maps = self.out_conv(inputs)
+ inputs = torch.cat([inputs, pred_maps], dim=1)
+
+ none_flag, graph_data = self.graph_test(pred_maps, inputs)
+
+ (local_graphs_node_feat, adjacent_matrices, pivots_knn_inds,
+ pivot_local_graphs, text_comps) = graph_data
+
+ if none_flag:
+ return None, None, None
+
+ gcn_pred = self.gcn(local_graphs_node_feat, adjacent_matrices,
+ pivots_knn_inds)
+ pred_labels = F.softmax(gcn_pred, dim=1)
+
+ edges = []
+ scores = []
+ pivot_local_graphs = pivot_local_graphs.long().squeeze().cpu().numpy()
+
+ for pivot_ind, pivot_local_graph in enumerate(pivot_local_graphs):
+ pivot = pivot_local_graph[0]
+ for k_ind, neighbor_ind in enumerate(pivots_knn_inds[pivot_ind]):
+ neighbor = pivot_local_graph[neighbor_ind.item()]
+ edges.append([pivot, neighbor])
+ scores.append(
+ pred_labels[pivot_ind * pivots_knn_inds.shape[1] + k_ind,
+ 1].item())
+
+ edges = np.asarray(edges)
+ scores = np.asarray(scores)
+
+ return edges, scores, text_comps
+
+
+class LocalGraphs:
+ """Generate local graphs for GCN to classify the neighbors of a pivot for
+ `DRRG: Deep Relational Reasoning Graph Network for Arbitrary Shape Text
+ Detection <[https://arxiv.org/abs/2003.07493]>`_.
+
+ This code was partially adapted from
+ https://github.com/GXYM/DRRG licensed under the MIT license.
+
+ Args:
+ k_at_hops (tuple(int)): The number of i-hop neighbors, i = 1, 2.
+ num_adjacent_linkages (int): The number of linkages when constructing
+ adjacent matrix.
+ node_geo_feat_len (int): The length of embedded geometric feature
+ vector of a text component.
+ pooling_scale (float): The spatial scale of rotated RoI-Align.
+ pooling_output_size (tuple(int)): The output size of rotated RoI-Align.
+ local_graph_thr(float): The threshold for filtering out identical local
+ graphs.
+ """
+
+ def __init__(self, k_at_hops: Tuple[int, int], num_adjacent_linkages: int,
+ node_geo_feat_len: int, pooling_scale: float,
+ pooling_output_size: Sequence[int],
+ local_graph_thr: float) -> None:
+
+ assert len(k_at_hops) == 2
+ assert all(isinstance(n, int) for n in k_at_hops)
+ assert isinstance(num_adjacent_linkages, int)
+ assert isinstance(node_geo_feat_len, int)
+ assert isinstance(pooling_scale, float)
+ assert all(isinstance(n, int) for n in pooling_output_size)
+ assert isinstance(local_graph_thr, float)
+
+ self.k_at_hops = k_at_hops
+ self.num_adjacent_linkages = num_adjacent_linkages
+ self.node_geo_feat_dim = node_geo_feat_len
+ self.pooling = RoIAlignRotated(pooling_output_size, pooling_scale)
+ self.local_graph_thr = local_graph_thr
+
+ def generate_local_graphs(self, sorted_dist_inds: ndarray,
+ gt_comp_labels: ndarray
+ ) -> Tuple[List[List[int]], List[List[int]]]:
+ """Generate local graphs for GCN to predict which instance a text
+ component belongs to.
+
+ Args:
+ sorted_dist_inds (ndarray): The complete graph node indices, which
+ is sorted according to the Euclidean distance.
+ gt_comp_labels(ndarray): The ground truth labels define the
+ instance to which the text components (nodes in graphs) belong.
+
+ Returns:
+ Tuple(pivot_local_graphs, pivot_knns):
+
+ - pivot_local_graphs (list[list[int]]): The list of local graph
+ neighbor indices of pivots.
+ - pivot_knns (list[list[int]]): The list of k-nearest neighbor
+ indices of pivots.
+ """
+
+ assert sorted_dist_inds.ndim == 2
+ assert (sorted_dist_inds.shape[0] == sorted_dist_inds.shape[1] ==
+ gt_comp_labels.shape[0])
+
+ knn_graph = sorted_dist_inds[:, 1:self.k_at_hops[0] + 1]
+ pivot_local_graphs = []
+ pivot_knns = []
+ for pivot_ind, knn in enumerate(knn_graph):
+
+ local_graph_neighbors = set(knn)
+
+ for neighbor_ind in knn:
+ local_graph_neighbors.update(
+ set(sorted_dist_inds[neighbor_ind,
+ 1:self.k_at_hops[1] + 1]))
+
+ local_graph_neighbors.discard(pivot_ind)
+ pivot_local_graph = list(local_graph_neighbors)
+ pivot_local_graph.insert(0, pivot_ind)
+ pivot_knn = [pivot_ind] + list(knn)
+
+ if pivot_ind < 1:
+ pivot_local_graphs.append(pivot_local_graph)
+ pivot_knns.append(pivot_knn)
+ else:
+ add_flag = True
+ for graph_ind, added_knn in enumerate(pivot_knns):
+ added_pivot_ind = added_knn[0]
+ added_local_graph = pivot_local_graphs[graph_ind]
+
+ union = len(
+ set(pivot_local_graph[1:]).union(
+ set(added_local_graph[1:])))
+ intersect = len(
+ set(pivot_local_graph[1:]).intersection(
+ set(added_local_graph[1:])))
+ local_graph_iou = intersect / (union + 1e-8)
+
+ if (local_graph_iou > self.local_graph_thr
+ and pivot_ind in added_knn
+ and gt_comp_labels[added_pivot_ind]
+ == gt_comp_labels[pivot_ind]
+ and gt_comp_labels[pivot_ind] != 0):
+ add_flag = False
+ break
+ if add_flag:
+ pivot_local_graphs.append(pivot_local_graph)
+ pivot_knns.append(pivot_knn)
+
+ return pivot_local_graphs, pivot_knns
+
+ def generate_gcn_input(
+ self, node_feat_batch: List[Tensor], node_label_batch: List[ndarray],
+ local_graph_batch: List[List[List[int]]],
+ knn_batch: List[List[List[int]]], sorted_dist_ind_batch: List[ndarray]
+ ) -> Tuple[Tensor, Tensor, Tensor, Tensor]:
+ """Generate graph convolution network input data.
+
+ Args:
+ node_feat_batch (List[Tensor]): The batched graph node features.
+ node_label_batch (List[ndarray]): The batched text component
+ labels.
+ local_graph_batch (List[List[List[int]]]): The local graph node
+ indices of image batch.
+ knn_batch (List[List[List[int]]]): The knn graph node indices of
+ image batch.
+ sorted_dist_ind_batch (List[ndarray]): The node indices sorted
+ according to the Euclidean distance.
+
+ Returns:
+ Tuple(local_graphs_node_feat, adjacent_matrices, pivots_knn_inds,
+ gt_linkage):
+
+ - local_graphs_node_feat (Tensor): The node features of graph.
+ - adjacent_matrices (Tensor): The adjacent matrices of local
+ graphs.
+ - pivots_knn_inds (Tensor): The k-nearest neighbor indices in
+ local graph.
+ - gt_linkage (Tensor): The surpervision signal of GCN for linkage
+ prediction.
+ """
+ assert isinstance(node_feat_batch, list)
+ assert isinstance(node_label_batch, list)
+ assert isinstance(local_graph_batch, list)
+ assert isinstance(knn_batch, list)
+ assert isinstance(sorted_dist_ind_batch, list)
+
+ num_max_nodes = max(
+ len(pivot_local_graph) for pivot_local_graphs in local_graph_batch
+ for pivot_local_graph in pivot_local_graphs)
+
+ local_graphs_node_feat = []
+ adjacent_matrices = []
+ pivots_knn_inds = []
+ pivots_gt_linkage = []
+
+ for batch_ind, sorted_dist_inds in enumerate(sorted_dist_ind_batch):
+ node_feats = node_feat_batch[batch_ind]
+ pivot_local_graphs = local_graph_batch[batch_ind]
+ pivot_knns = knn_batch[batch_ind]
+ node_labels = node_label_batch[batch_ind]
+ device = node_feats.device
+
+ for graph_ind, pivot_knn in enumerate(pivot_knns):
+ pivot_local_graph = pivot_local_graphs[graph_ind]
+ num_nodes = len(pivot_local_graph)
+ pivot_ind = pivot_local_graph[0]
+ node2ind_map = {j: i for i, j in enumerate(pivot_local_graph)}
+
+ knn_inds = torch.tensor(
+ [node2ind_map[i] for i in pivot_knn[1:]])
+ pivot_feats = node_feats[pivot_ind]
+ normalized_feats = node_feats[pivot_local_graph] - pivot_feats
+
+ adjacent_matrix = np.zeros((num_nodes, num_nodes),
+ dtype=np.float32)
+ for node in pivot_local_graph:
+ neighbors = sorted_dist_inds[node,
+ 1:self.num_adjacent_linkages +
+ 1]
+ for neighbor in neighbors:
+ if neighbor in pivot_local_graph:
+
+ adjacent_matrix[node2ind_map[node],
+ node2ind_map[neighbor]] = 1
+ adjacent_matrix[node2ind_map[neighbor],
+ node2ind_map[node]] = 1
+
+ adjacent_matrix = normalize_adjacent_matrix(adjacent_matrix)
+ pad_adjacent_matrix = torch.zeros(
+ (num_max_nodes, num_max_nodes),
+ dtype=torch.float,
+ device=device)
+ pad_adjacent_matrix[:num_nodes, :num_nodes] = torch.from_numpy(
+ adjacent_matrix)
+
+ pad_normalized_feats = torch.cat([
+ normalized_feats,
+ torch.zeros(
+ (num_max_nodes - num_nodes, normalized_feats.shape[1]),
+ dtype=torch.float,
+ device=device)
+ ],
+ dim=0)
+
+ local_graph_labels = node_labels[pivot_local_graph]
+ knn_labels = local_graph_labels[knn_inds]
+ link_labels = ((node_labels[pivot_ind] == knn_labels) &
+ (node_labels[pivot_ind] > 0)).astype(np.int64)
+ link_labels = torch.from_numpy(link_labels)
+
+ local_graphs_node_feat.append(pad_normalized_feats)
+ adjacent_matrices.append(pad_adjacent_matrix)
+ pivots_knn_inds.append(knn_inds)
+ pivots_gt_linkage.append(link_labels)
+
+ local_graphs_node_feat = torch.stack(local_graphs_node_feat, 0)
+ adjacent_matrices = torch.stack(adjacent_matrices, 0)
+ pivots_knn_inds = torch.stack(pivots_knn_inds, 0)
+ pivots_gt_linkage = torch.stack(pivots_gt_linkage, 0)
+
+ return (local_graphs_node_feat, adjacent_matrices, pivots_knn_inds,
+ pivots_gt_linkage)
+
+ def __call__(self, feat_maps: Tensor, comp_attribs: ndarray
+ ) -> Tuple[Tensor, Tensor, Tensor, Tensor]:
+ """Generate local graphs as GCN input.
+
+ Args:
+ feat_maps (Tensor): The feature maps to extract the content
+ features of text components.
+ comp_attribs (ndarray): The text component attributes.
+
+ Returns:
+ Tuple(local_graphs_node_feat, adjacent_matrices, pivots_knn_inds,
+ gt_linkage):
+
+ - local_graphs_node_feat (Tensor): The node features of graph.
+ - adjacent_matrices (Tensor): The adjacent matrices of local
+ graphs.
+ - pivots_knn_inds (Tensor): The k-nearest neighbor indices in local
+ graph.
+ - gt_linkage (Tensor): The surpervision signal of GCN for linkage
+ prediction.
+ """
+
+ assert isinstance(feat_maps, Tensor)
+ assert comp_attribs.ndim == 3
+ assert comp_attribs.shape[2] == 8
+
+ sorted_dist_inds_batch = []
+ local_graph_batch = []
+ knn_batch = []
+ node_feat_batch = []
+ node_label_batch = []
+ device = feat_maps.device
+
+ for batch_ind in range(comp_attribs.shape[0]):
+ num_comps = int(comp_attribs[batch_ind, 0, 0])
+ comp_geo_attribs = comp_attribs[batch_ind, :num_comps, 1:7]
+ node_labels = comp_attribs[batch_ind, :num_comps,
+ 7].astype(np.int32)
+
+ comp_centers = comp_geo_attribs[:, 0:2]
+ distance_matrix = euclidean_distance_matrix(
+ comp_centers, comp_centers)
+
+ batch_id = np.zeros(
+ (comp_geo_attribs.shape[0], 1), dtype=np.float32) * batch_ind
+ comp_geo_attribs[:, -2] = np.clip(comp_geo_attribs[:, -2], -1, 1)
+ angle = np.arccos(comp_geo_attribs[:, -2]) * np.sign(
+ comp_geo_attribs[:, -1])
+ angle = angle.reshape((-1, 1))
+ rotated_rois = np.hstack(
+ [batch_id, comp_geo_attribs[:, :-2], angle])
+ rois = torch.from_numpy(rotated_rois).to(device)
+ content_feats = self.pooling(feat_maps[batch_ind].unsqueeze(0),
+ rois)
+
+ content_feats = content_feats.view(content_feats.shape[0],
+ -1).to(feat_maps.device)
+ geo_feats = feature_embedding(comp_geo_attribs,
+ self.node_geo_feat_dim)
+ geo_feats = torch.from_numpy(geo_feats).to(device)
+ node_feats = torch.cat([content_feats, geo_feats], dim=-1)
+
+ sorted_dist_inds = np.argsort(distance_matrix, axis=1)
+ pivot_local_graphs, pivot_knns = self.generate_local_graphs(
+ sorted_dist_inds, node_labels)
+
+ node_feat_batch.append(node_feats)
+ node_label_batch.append(node_labels)
+ local_graph_batch.append(pivot_local_graphs)
+ knn_batch.append(pivot_knns)
+ sorted_dist_inds_batch.append(sorted_dist_inds)
+
+ (node_feats, adjacent_matrices, knn_inds, gt_linkage) = \
+ self.generate_gcn_input(node_feat_batch,
+ node_label_batch,
+ local_graph_batch,
+ knn_batch,
+ sorted_dist_inds_batch)
+
+ return node_feats, adjacent_matrices, knn_inds, gt_linkage
+
+
+class ProposalLocalGraphs:
+ """Propose text components and generate local graphs for GCN to classify
+ the k-nearest neighbors of a pivot in `DRRG: Deep Relational Reasoning
+ Graph Network for Arbitrary Shape Text Detection.
+
+ `_.
+
+ This code was partially adapted from https://github.com/GXYM/DRRG licensed
+ under the MIT license.
+
+ Args:
+ k_at_hops (tuple(int)): The number of i-hop neighbors, i = 1, 2.
+ num_adjacent_linkages (int): The number of linkages when constructing
+ adjacent matrix.
+ node_geo_feat_len (int): The length of embedded geometric feature
+ vector of a text component.
+ pooling_scale (float): The spatial scale of rotated RoI-Align.
+ pooling_output_size (tuple(int)): The output size of rotated RoI-Align.
+ nms_thr (float): The locality-aware NMS threshold for text components.
+ min_width (float): The minimum width of text components.
+ max_width (float): The maximum width of text components.
+ comp_shrink_ratio (float): The shrink ratio of text components.
+ comp_w_h_ratio (float): The width to height ratio of text components.
+ comp_score_thr (float): The score threshold of text component.
+ text_region_thr (float): The threshold for text region probability map.
+ center_region_thr (float): The threshold for text center region
+ probability map.
+ center_region_area_thr (int): The threshold for filtering small-sized
+ text center region.
+ """
+
+ def __init__(self, k_at_hops: Tuple[int, int], num_adjacent_linkages: int,
+ node_geo_feat_len: int, pooling_scale: float,
+ pooling_output_size: Sequence[int], nms_thr: float,
+ min_width: float, max_width: float, comp_shrink_ratio: float,
+ comp_w_h_ratio: float, comp_score_thr: float,
+ text_region_thr: float, center_region_thr: float,
+ center_region_area_thr: int) -> None:
+
+ assert len(k_at_hops) == 2
+ assert isinstance(k_at_hops, tuple)
+ assert isinstance(num_adjacent_linkages, int)
+ assert isinstance(node_geo_feat_len, int)
+ assert isinstance(pooling_scale, float)
+ assert isinstance(pooling_output_size, tuple)
+ assert isinstance(nms_thr, float)
+ assert isinstance(min_width, float)
+ assert isinstance(max_width, float)
+ assert isinstance(comp_shrink_ratio, float)
+ assert isinstance(comp_w_h_ratio, float)
+ assert isinstance(comp_score_thr, float)
+ assert isinstance(text_region_thr, float)
+ assert isinstance(center_region_thr, float)
+ assert isinstance(center_region_area_thr, int)
+
+ self.k_at_hops = k_at_hops
+ self.active_connection = num_adjacent_linkages
+ self.local_graph_depth = len(self.k_at_hops)
+ self.node_geo_feat_dim = node_geo_feat_len
+ self.pooling = RoIAlignRotated(pooling_output_size, pooling_scale)
+ self.nms_thr = nms_thr
+ self.min_width = min_width
+ self.max_width = max_width
+ self.comp_shrink_ratio = comp_shrink_ratio
+ self.comp_w_h_ratio = comp_w_h_ratio
+ self.comp_score_thr = comp_score_thr
+ self.text_region_thr = text_region_thr
+ self.center_region_thr = center_region_thr
+ self.center_region_area_thr = center_region_area_thr
+
+ def propose_comps(self, score_map: ndarray, top_height_map: ndarray,
+ bot_height_map: ndarray, sin_map: ndarray,
+ cos_map: ndarray, comp_score_thr: float,
+ min_width: float, max_width: float,
+ comp_shrink_ratio: float,
+ comp_w_h_ratio: float) -> ndarray:
+ """Propose text components.
+
+ Args:
+ score_map (ndarray): The score map for NMS.
+ top_height_map (ndarray): The predicted text height map from each
+ pixel in text center region to top sideline.
+ bot_height_map (ndarray): The predicted text height map from each
+ pixel in text center region to bottom sideline.
+ sin_map (ndarray): The predicted sin(theta) map.
+ cos_map (ndarray): The predicted cos(theta) map.
+ comp_score_thr (float): The score threshold of text component.
+ min_width (float): The minimum width of text components.
+ max_width (float): The maximum width of text components.
+ comp_shrink_ratio (float): The shrink ratio of text components.
+ comp_w_h_ratio (float): The width to height ratio of text
+ components.
+
+ Returns:
+ ndarray: The text components.
+ """
+
+ comp_centers = np.argwhere(score_map > comp_score_thr)
+ comp_centers = comp_centers[np.argsort(comp_centers[:, 0])]
+ y = comp_centers[:, 0]
+ x = comp_centers[:, 1]
+
+ top_height = top_height_map[y, x].reshape((-1, 1)) * comp_shrink_ratio
+ bot_height = bot_height_map[y, x].reshape((-1, 1)) * comp_shrink_ratio
+ sin = sin_map[y, x].reshape((-1, 1))
+ cos = cos_map[y, x].reshape((-1, 1))
+
+ top_mid_pts = comp_centers + np.hstack(
+ [top_height * sin, top_height * cos])
+ bot_mid_pts = comp_centers - np.hstack(
+ [bot_height * sin, bot_height * cos])
+
+ width = (top_height + bot_height) * comp_w_h_ratio
+ width = np.clip(width, min_width, max_width)
+ r = width / 2
+
+ tl = top_mid_pts[:, ::-1] - np.hstack([-r * sin, r * cos])
+ tr = top_mid_pts[:, ::-1] + np.hstack([-r * sin, r * cos])
+ br = bot_mid_pts[:, ::-1] + np.hstack([-r * sin, r * cos])
+ bl = bot_mid_pts[:, ::-1] - np.hstack([-r * sin, r * cos])
+ text_comps = np.hstack([tl, tr, br, bl]).astype(np.float32)
+
+ score = score_map[y, x].reshape((-1, 1))
+ text_comps = np.hstack([text_comps, score])
+
+ return text_comps
+
+ def propose_comps_and_attribs(self, text_region_map: ndarray,
+ center_region_map: ndarray,
+ top_height_map: ndarray,
+ bot_height_map: ndarray, sin_map: ndarray,
+ cos_map: ndarray) -> Tuple[ndarray, ndarray]:
+ """Generate text components and attributes.
+
+ Args:
+ text_region_map (ndarray): The predicted text region probability
+ map.
+ center_region_map (ndarray): The predicted text center region
+ probability map.
+ top_height_map (ndarray): The predicted text height map from each
+ pixel in text center region to top sideline.
+ bot_height_map (ndarray): The predicted text height map from each
+ pixel in text center region to bottom sideline.
+ sin_map (ndarray): The predicted sin(theta) map.
+ cos_map (ndarray): The predicted cos(theta) map.
+
+ Returns:
+ tuple(ndarray, ndarray):
+
+ - comp_attribs (ndarray): The text component attributes.
+ - text_comps (ndarray): The text components.
+ """
+
+ assert (text_region_map.shape == center_region_map.shape ==
+ top_height_map.shape == bot_height_map.shape == sin_map.shape
+ == cos_map.shape)
+ text_mask = text_region_map > self.text_region_thr
+ center_region_mask = (center_region_map >
+ self.center_region_thr) * text_mask
+
+ scale = np.sqrt(1.0 / (sin_map**2 + cos_map**2 + 1e-8))
+ sin_map, cos_map = sin_map * scale, cos_map * scale
+
+ center_region_mask = fill_hole(center_region_mask)
+ center_region_contours, _ = cv2.findContours(
+ center_region_mask.astype(np.uint8), cv2.RETR_TREE,
+ cv2.CHAIN_APPROX_SIMPLE)
+
+ mask_sz = center_region_map.shape
+ comp_list = []
+ for contour in center_region_contours:
+ current_center_mask = np.zeros(mask_sz)
+ cv2.drawContours(current_center_mask, [contour], -1, 1, -1)
+ if current_center_mask.sum() <= self.center_region_area_thr:
+ continue
+ score_map = text_region_map * current_center_mask
+
+ text_comps = self.propose_comps(score_map, top_height_map,
+ bot_height_map, sin_map, cos_map,
+ self.comp_score_thr,
+ self.min_width, self.max_width,
+ self.comp_shrink_ratio,
+ self.comp_w_h_ratio)
+
+ if la_nms is None:
+ raise ImportError('lanms-neo is not installed, '
+ 'please run "pip install lanms-neo==1.0.2".')
+ text_comps = la_nms(text_comps, self.nms_thr)
+ text_comp_mask = np.zeros(mask_sz)
+ text_comp_boxes = text_comps[:, :8].reshape(
+ (-1, 4, 2)).astype(np.int32)
+
+ cv2.drawContours(text_comp_mask, text_comp_boxes, -1, 1, -1)
+ if (text_comp_mask * text_mask).sum() < text_comp_mask.sum() * 0.5:
+ continue
+ if text_comps.shape[-1] > 0:
+ comp_list.append(text_comps)
+
+ if len(comp_list) <= 0:
+ return None, None
+
+ text_comps = np.vstack(comp_list)
+ text_comp_boxes = text_comps[:, :8].reshape((-1, 4, 2))
+ centers = np.mean(text_comp_boxes, axis=1).astype(np.int32)
+ x = centers[:, 0]
+ y = centers[:, 1]
+
+ scores = []
+ for text_comp_box in text_comp_boxes:
+ text_comp_box[:, 0] = np.clip(text_comp_box[:, 0], 0,
+ mask_sz[1] - 1)
+ text_comp_box[:, 1] = np.clip(text_comp_box[:, 1], 0,
+ mask_sz[0] - 1)
+ min_coord = np.min(text_comp_box, axis=0).astype(np.int32)
+ max_coord = np.max(text_comp_box, axis=0).astype(np.int32)
+ text_comp_box = text_comp_box - min_coord
+ box_sz = (max_coord - min_coord + 1)
+ temp_comp_mask = np.zeros((box_sz[1], box_sz[0]), dtype=np.uint8)
+ cv2.fillPoly(temp_comp_mask, [text_comp_box.astype(np.int32)], 1)
+ temp_region_patch = text_region_map[min_coord[1]:(max_coord[1] +
+ 1),
+ min_coord[0]:(max_coord[0] +
+ 1)]
+ score = cv2.mean(temp_region_patch, temp_comp_mask)[0]
+ scores.append(score)
+ scores = np.array(scores).reshape((-1, 1))
+ text_comps = np.hstack([text_comps[:, :-1], scores])
+
+ h = top_height_map[y, x].reshape(
+ (-1, 1)) + bot_height_map[y, x].reshape((-1, 1))
+ w = np.clip(h * self.comp_w_h_ratio, self.min_width, self.max_width)
+ sin = sin_map[y, x].reshape((-1, 1))
+ cos = cos_map[y, x].reshape((-1, 1))
+
+ x = x.reshape((-1, 1))
+ y = y.reshape((-1, 1))
+ comp_attribs = np.hstack([x, y, h, w, cos, sin])
+
+ return comp_attribs, text_comps
+
+ def generate_local_graphs(self, sorted_dist_inds: ndarray,
+ node_feats: Tensor
+ ) -> Tuple[Tensor, Tensor, Tensor, Tensor]:
+ """Generate local graphs and graph convolution network input data.
+
+ Args:
+ sorted_dist_inds (ndarray): The node indices sorted according to
+ the Euclidean distance.
+ node_feats (tensor): The features of nodes in graph.
+
+ Returns:
+ Tuple(local_graphs_node_feat, adjacent_matrices, pivots_knn_inds,
+ pivots_local_graphs):
+
+ - local_graphs_node_feats (tensor): The features of nodes in local
+ graphs.
+ - adjacent_matrices (tensor): The adjacent matrices.
+ - pivots_knn_inds (tensor): The k-nearest neighbor indices in
+ local graphs.
+ - pivots_local_graphs (tensor): The indices of nodes in local
+ graphs.
+ """
+
+ assert sorted_dist_inds.ndim == 2
+ assert (sorted_dist_inds.shape[0] == sorted_dist_inds.shape[1] ==
+ node_feats.shape[0])
+
+ knn_graph = sorted_dist_inds[:, 1:self.k_at_hops[0] + 1]
+ pivot_local_graphs = []
+ pivot_knns = []
+ device = node_feats.device
+
+ for pivot_ind, knn in enumerate(knn_graph):
+
+ local_graph_neighbors = set(knn)
+
+ for neighbor_ind in knn:
+ local_graph_neighbors.update(
+ set(sorted_dist_inds[neighbor_ind,
+ 1:self.k_at_hops[1] + 1]))
+
+ local_graph_neighbors.discard(pivot_ind)
+ pivot_local_graph = list(local_graph_neighbors)
+ pivot_local_graph.insert(0, pivot_ind)
+ pivot_knn = [pivot_ind] + list(knn)
+
+ pivot_local_graphs.append(pivot_local_graph)
+ pivot_knns.append(pivot_knn)
+
+ num_max_nodes = max(
+ len(pivot_local_graph) for pivot_local_graph in pivot_local_graphs)
+
+ local_graphs_node_feat = []
+ adjacent_matrices = []
+ pivots_knn_inds = []
+ pivots_local_graphs = []
+
+ for graph_ind, pivot_knn in enumerate(pivot_knns):
+ pivot_local_graph = pivot_local_graphs[graph_ind]
+ num_nodes = len(pivot_local_graph)
+ pivot_ind = pivot_local_graph[0]
+ node2ind_map = {j: i for i, j in enumerate(pivot_local_graph)}
+
+ knn_inds = torch.tensor([node2ind_map[i]
+ for i in pivot_knn[1:]]).long().to(device)
+ pivot_feats = node_feats[pivot_ind]
+ normalized_feats = node_feats[pivot_local_graph] - pivot_feats
+
+ adjacent_matrix = np.zeros((num_nodes, num_nodes))
+ for node in pivot_local_graph:
+ neighbors = sorted_dist_inds[node,
+ 1:self.active_connection + 1]
+ for neighbor in neighbors:
+ if neighbor in pivot_local_graph:
+ adjacent_matrix[node2ind_map[node],
+ node2ind_map[neighbor]] = 1
+ adjacent_matrix[node2ind_map[neighbor],
+ node2ind_map[node]] = 1
+
+ adjacent_matrix = normalize_adjacent_matrix(adjacent_matrix)
+ pad_adjacent_matrix = torch.zeros((num_max_nodes, num_max_nodes),
+ dtype=torch.float,
+ device=device)
+ pad_adjacent_matrix[:num_nodes, :num_nodes] = torch.from_numpy(
+ adjacent_matrix)
+
+ pad_normalized_feats = torch.cat([
+ normalized_feats,
+ torch.zeros(
+ (num_max_nodes - num_nodes, normalized_feats.shape[1]),
+ dtype=torch.float,
+ device=device)
+ ],
+ dim=0)
+
+ local_graph_nodes = torch.tensor(pivot_local_graph)
+ local_graph_nodes = torch.cat([
+ local_graph_nodes,
+ torch.zeros(num_max_nodes - num_nodes, dtype=torch.long)
+ ],
+ dim=-1)
+
+ local_graphs_node_feat.append(pad_normalized_feats)
+ adjacent_matrices.append(pad_adjacent_matrix)
+ pivots_knn_inds.append(knn_inds)
+ pivots_local_graphs.append(local_graph_nodes)
+
+ local_graphs_node_feat = torch.stack(local_graphs_node_feat, 0)
+ adjacent_matrices = torch.stack(adjacent_matrices, 0)
+ pivots_knn_inds = torch.stack(pivots_knn_inds, 0)
+ pivots_local_graphs = torch.stack(pivots_local_graphs, 0)
+
+ return (local_graphs_node_feat, adjacent_matrices, pivots_knn_inds,
+ pivots_local_graphs)
+
+ def __call__(self, preds: Tensor, feat_maps: Tensor
+ ) -> Tuple[bool, Tensor, Tensor, Tensor, Tensor, ndarray]:
+ """Generate local graphs and graph convolutional network input data.
+
+ Args:
+ preds (tensor): The predicted maps.
+ feat_maps (tensor): The feature maps to extract content feature of
+ text components.
+
+ Returns:
+ Tuple(none_flag, local_graphs_node_feat, adjacent_matrices,
+ pivots_knn_inds, pivots_local_graphs, text_comps):
+
+ - none_flag (bool): The flag showing whether the number of proposed
+ text components is 0.
+ - local_graphs_node_feats (tensor): The features of nodes in local
+ graphs.
+ - adjacent_matrices (tensor): The adjacent matrices.
+ - pivots_knn_inds (tensor): The k-nearest neighbor indices in
+ local graphs.
+ - pivots_local_graphs (tensor): The indices of nodes in local
+ graphs.
+ - text_comps (ndarray): The predicted text components.
+ """
+
+ if preds.ndim == 4:
+ assert preds.shape[0] == 1
+ preds = torch.squeeze(preds)
+ pred_text_region = torch.sigmoid(preds[0]).data.cpu().numpy()
+ pred_center_region = torch.sigmoid(preds[1]).data.cpu().numpy()
+ pred_sin_map = preds[2].data.cpu().numpy()
+ pred_cos_map = preds[3].data.cpu().numpy()
+ pred_top_height_map = preds[4].data.cpu().numpy()
+ pred_bot_height_map = preds[5].data.cpu().numpy()
+ device = preds.device
+
+ comp_attribs, text_comps = self.propose_comps_and_attribs(
+ pred_text_region, pred_center_region, pred_top_height_map,
+ pred_bot_height_map, pred_sin_map, pred_cos_map)
+
+ if comp_attribs is None or len(comp_attribs) < 2:
+ none_flag = True
+ return none_flag, (0, 0, 0, 0, 0)
+
+ comp_centers = comp_attribs[:, 0:2]
+ distance_matrix = euclidean_distance_matrix(comp_centers, comp_centers)
+
+ geo_feats = feature_embedding(comp_attribs, self.node_geo_feat_dim)
+ geo_feats = torch.from_numpy(geo_feats).to(preds.device)
+
+ batch_id = np.zeros((comp_attribs.shape[0], 1), dtype=np.float32)
+ comp_attribs = comp_attribs.astype(np.float32)
+ angle = np.arccos(comp_attribs[:, -2]) * np.sign(comp_attribs[:, -1])
+ angle = angle.reshape((-1, 1))
+ rotated_rois = np.hstack([batch_id, comp_attribs[:, :-2], angle])
+ rois = torch.from_numpy(rotated_rois).to(device)
+
+ content_feats = self.pooling(feat_maps, rois)
+ content_feats = content_feats.view(content_feats.shape[0],
+ -1).to(device)
+ node_feats = torch.cat([content_feats, geo_feats], dim=-1)
+
+ sorted_dist_inds = np.argsort(distance_matrix, axis=1)
+ (local_graphs_node_feat, adjacent_matrices, pivots_knn_inds,
+ pivots_local_graphs) = self.generate_local_graphs(
+ sorted_dist_inds, node_feats)
+
+ none_flag = False
+ return none_flag, (local_graphs_node_feat, adjacent_matrices,
+ pivots_knn_inds, pivots_local_graphs, text_comps)
+
+
+class GraphConv(BaseModule):
+ """Graph convolutional neural network.
+
+ Args:
+ in_dim (int): The number of input channels.
+ out_dim (int): The number of output channels.
+ """
+
+ class MeanAggregator(BaseModule):
+ """Mean aggregator for graph convolutional network."""
+
+ def forward(self, features: Tensor, A: Tensor) -> Tensor:
+ """Forward function."""
+ x = torch.bmm(A, features)
+ return x
+
+ def __init__(self, in_dim: int, out_dim: int) -> None:
+ super().__init__()
+ self.in_dim = in_dim
+ self.out_dim = out_dim
+ self.weight = nn.Parameter(torch.FloatTensor(in_dim * 2, out_dim))
+ self.bias = nn.Parameter(torch.FloatTensor(out_dim))
+ init.xavier_uniform_(self.weight)
+ init.constant_(self.bias, 0)
+ self.aggregator = self.MeanAggregator()
+
+ def forward(self, features: Tensor, A: Tensor) -> Tensor:
+ """Forward function."""
+ _, _, d = features.shape
+ assert d == self.in_dim
+ agg_feats = self.aggregator(features, A)
+ cat_feats = torch.cat([features, agg_feats], dim=2)
+ out = torch.einsum('bnd,df->bnf', cat_feats, self.weight)
+ out = F.relu(out + self.bias)
+ return out
+
+
+class GCN(BaseModule):
+ """Graph convolutional network for clustering. This was from repo
+ https://github.com/Zhongdao/gcn_clustering licensed under the MIT license.
+
+ Args:
+ feat_len (int): The input node feature length.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ """
+
+ def __init__(self,
+ feat_len: int,
+ init_cfg: Optional[Union[Dict, List[Dict]]] = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.bn0 = nn.BatchNorm1d(feat_len, affine=False).float()
+ self.conv1 = GraphConv(feat_len, 512)
+ self.conv2 = GraphConv(512, 256)
+ self.conv3 = GraphConv(256, 128)
+ self.conv4 = GraphConv(128, 64)
+ self.classifier = nn.Sequential(
+ nn.Linear(64, 32), nn.PReLU(32), nn.Linear(32, 2))
+
+ def forward(self, node_feats: Tensor, adj_mats: Tensor,
+ knn_inds: Tensor) -> Tensor:
+ """Forward function.
+
+ Args:
+ local_graphs_node_feat (Tensor): The node features of graph.
+ adjacent_matrices (Tensor): The adjacent matrices of local
+ graphs.
+ pivots_knn_inds (Tensor): The k-nearest neighbor indices in
+ local graph.
+
+ Returns:
+ Tensor: The output feature.
+ """
+
+ num_local_graphs, num_max_nodes, feat_len = node_feats.shape
+
+ node_feats = node_feats.view(-1, feat_len)
+ node_feats = self.bn0(node_feats)
+ node_feats = node_feats.view(num_local_graphs, num_max_nodes, feat_len)
+
+ node_feats = self.conv1(node_feats, adj_mats)
+ node_feats = self.conv2(node_feats, adj_mats)
+ node_feats = self.conv3(node_feats, adj_mats)
+ node_feats = self.conv4(node_feats, adj_mats)
+ k = knn_inds.size(-1)
+ mid_feat_len = node_feats.size(-1)
+ edge_feat = torch.zeros((num_local_graphs, k, mid_feat_len),
+ device=node_feats.device)
+ for graph_ind in range(num_local_graphs):
+ edge_feat[graph_ind, :, :] = node_feats[graph_ind,
+ knn_inds[graph_ind]]
+ edge_feat = edge_feat.view(-1, mid_feat_len)
+ pred = self.classifier(edge_feat)
+
+ return pred
diff --git a/mmocr/models/textdet/heads/fce_head.py b/mmocr/models/textdet/heads/fce_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..949a2835a8aa08ffb1d32f18d480efb1c62260e3
--- /dev/null
+++ b/mmocr/models/textdet/heads/fce_head.py
@@ -0,0 +1,117 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional
+
+import torch
+import torch.nn as nn
+from mmdet.models.utils import multi_apply
+
+from mmocr.models.textdet.heads import BaseTextDetHead
+from mmocr.registry import MODELS
+from mmocr.structures import TextDetDataSample
+
+
+@MODELS.register_module()
+class FCEHead(BaseTextDetHead):
+ """The class for implementing FCENet head.
+
+ FCENet(CVPR2021): `Fourier Contour Embedding for Arbitrary-shaped Text
+ Detection `_
+
+ Args:
+ in_channels (int): The number of input channels.
+ fourier_degree (int) : The maximum Fourier transform degree k. Defaults
+ to 5.
+ module_loss (dict): Config of loss for FCENet. Defaults to
+ ``dict(type='FCEModuleLoss', num_sample=50)``.
+ postprocessor (dict): Config of postprocessor for FCENet.
+ init_cfg (dict, optional): Initialization configs.
+ """
+
+ def __init__(
+ self,
+ in_channels: int,
+ fourier_degree: int = 5,
+ module_loss: Dict = dict(type='FCEModuleLoss', num_sample=50),
+ postprocessor: Dict = dict(
+ type='FCEPostprocessor',
+ text_repr_type='poly',
+ num_reconstr_points=50,
+ alpha=1.0,
+ beta=2.0,
+ score_thr=0.3),
+ init_cfg: Optional[Dict] = dict(
+ type='Normal',
+ mean=0,
+ std=0.01,
+ override=[dict(name='out_conv_cls'),
+ dict(name='out_conv_reg')])
+ ) -> None:
+ module_loss['fourier_degree'] = fourier_degree
+ postprocessor['fourier_degree'] = fourier_degree
+ super().__init__(
+ module_loss=module_loss,
+ postprocessor=postprocessor,
+ init_cfg=init_cfg)
+
+ assert isinstance(in_channels, int)
+ assert isinstance(fourier_degree, int)
+
+ self.in_channels = in_channels
+ self.fourier_degree = fourier_degree
+ self.out_channels_cls = 4
+ self.out_channels_reg = (2 * self.fourier_degree + 1) * 2
+
+ self.out_conv_cls = nn.Conv2d(
+ self.in_channels,
+ self.out_channels_cls,
+ kernel_size=3,
+ stride=1,
+ padding=1)
+ self.out_conv_reg = nn.Conv2d(
+ self.in_channels,
+ self.out_channels_reg,
+ kernel_size=3,
+ stride=1,
+ padding=1)
+
+ def forward(self,
+ inputs: List[torch.Tensor],
+ data_samples: Optional[List[TextDetDataSample]] = None
+ ) -> Dict:
+ """
+ Args:
+ inputs (List[Tensor]): Each tensor has the shape of :math:`(N, C_i,
+ H_i, W_i)`.
+ data_samples (list[TextDetDataSample], optional): A list of data
+ samples. Defaults to None.
+
+ Returns:
+ list[dict]: A list of dict with keys of ``cls_res``, ``reg_res``
+ corresponds to the classification result and regression result
+ computed from the input tensor with the same index. They have
+ the shapes of :math:`(N, C_{cls,i}, H_i, W_i)` and :math:`(N,
+ C_{out,i}, H_i, W_i)`.
+ """
+ cls_res, reg_res = multi_apply(self.forward_single, inputs)
+ level_num = len(cls_res)
+ preds = [
+ dict(cls_res=cls_res[i], reg_res=reg_res[i])
+ for i in range(level_num)
+ ]
+ return preds
+
+ def forward_single(self, x: torch.Tensor) -> torch.Tensor:
+ """Forward function for a single feature level.
+
+ Args:
+ x (Tensor): The input tensor with the shape of :math:`(N, C_i,
+ H_i, W_i)`.
+
+ Returns:
+ Tensor: The classification and regression result with the shape of
+ :math:`(N, C_{cls,i}, H_i, W_i)` and :math:`(N, C_{out,i}, H_i,
+ W_i)`.
+ """
+ cls_predict = self.out_conv_cls(x)
+ reg_predict = self.out_conv_reg(x)
+ return cls_predict, reg_predict
diff --git a/mmocr/models/textdet/heads/pan_head.py b/mmocr/models/textdet/heads/pan_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..a7d4f053d09049c21442d357f631c51ac2f3e41d
--- /dev/null
+++ b/mmocr/models/textdet/heads/pan_head.py
@@ -0,0 +1,83 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional
+
+import torch
+import torch.nn as nn
+
+from mmocr.registry import MODELS
+from mmocr.structures import TextDetDataSample
+from mmocr.utils import check_argument
+from .base import BaseTextDetHead
+
+
+@MODELS.register_module()
+class PANHead(BaseTextDetHead):
+ """The class for PANet head.
+
+ Args:
+ in_channels (list[int]): A list of 4 numbers of input channels.
+ hidden_dim (int): The hidden dimension of the first convolutional
+ layer.
+ out_channel (int): Number of output channels.
+ module_loss (dict): Configuration dictionary for loss type. Defaults
+ to dict(type='PANModuleLoss')
+ postprocessor (dict): Config of postprocessor for PANet. Defaults to
+ dict(type='PANPostprocessor', text_repr_type='poly').
+ init_cfg (list[dict]): Initialization configs. Defaults to
+ [dict(type='Normal', mean=0, std=0.01, layer='Conv2d'),
+ dict(type='Constant', val=1, bias=0, layer='BN')]
+ """
+
+ def __init__(
+ self,
+ in_channels: List[int],
+ hidden_dim: int,
+ out_channel: int,
+ module_loss=dict(type='PANModuleLoss'),
+ postprocessor=dict(type='PANPostprocessor', text_repr_type='poly'),
+ init_cfg=[
+ dict(type='Normal', mean=0, std=0.01, layer='Conv2d'),
+ dict(type='Constant', val=1, bias=0, layer='BN')
+ ]
+ ) -> None:
+ super().__init__(
+ module_loss=module_loss,
+ postprocessor=postprocessor,
+ init_cfg=init_cfg)
+
+ assert check_argument.is_type_list(in_channels, int)
+ assert isinstance(out_channel, int)
+ assert isinstance(hidden_dim, int)
+
+ in_channels = sum(in_channels)
+ self.conv1 = nn.Conv2d(
+ in_channels, hidden_dim, kernel_size=3, stride=1, padding=1)
+ self.bn1 = nn.BatchNorm2d(hidden_dim)
+ self.relu1 = nn.ReLU(inplace=True)
+ self.conv2 = nn.Conv2d(
+ hidden_dim, out_channel, kernel_size=1, stride=1, padding=0)
+
+ def forward(self,
+ inputs: torch.Tensor,
+ data_samples: Optional[List[TextDetDataSample]] = None
+ ) -> torch.Tensor:
+ r"""PAN head forward.
+ Args:
+ inputs (list[Tensor] | Tensor): Each tensor has the shape of
+ :math:`(N, C_i, W, H)`, where :math:`\sum_iC_i=C_{in}` and
+ :math:`C_{in}` is ``input_channels``.
+ data_samples (list[TextDetDataSample], optional): A list of data
+ samples. Defaults to None.
+
+ Returns:
+ Tensor: A tensor of shape :math:`(N, C_{out}, W, H)` where
+ :math:`C_{out}` is ``output_channels``.
+ """
+ if isinstance(inputs, tuple):
+ outputs = torch.cat(inputs, dim=1)
+ else:
+ outputs = inputs
+ outputs = self.conv1(outputs)
+ outputs = self.relu1(self.bn1(outputs))
+ outputs = self.conv2(outputs)
+ return outputs
diff --git a/mmocr/models/textdet/heads/pse_head.py b/mmocr/models/textdet/heads/pse_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..0aee6a07b4d6325d22a14dc76c2796391ce62eab
--- /dev/null
+++ b/mmocr/models/textdet/heads/pse_head.py
@@ -0,0 +1,39 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Union
+
+from mmocr.registry import MODELS
+from . import PANHead
+
+
+@MODELS.register_module()
+class PSEHead(PANHead):
+ """The class for PSENet head.
+
+ Args:
+ in_channels (list[int]): A list of numbers of input channels.
+ hidden_dim (int): The hidden dimension of the first convolutional
+ layer.
+ out_channel (int): Number of output channels.
+ module_loss (dict): Configuration dictionary for loss type. Supported
+ loss types are "PANModuleLoss" and "PSEModuleLoss". Defaults to
+ PSEModuleLoss.
+ postprocessor (dict): Config of postprocessor for PSENet.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ """
+
+ def __init__(self,
+ in_channels: List[int],
+ hidden_dim: int,
+ out_channel: int,
+ module_loss: Dict = dict(type='PSEModuleLoss'),
+ postprocessor: Dict = dict(
+ type='PSEPostprocessor', text_repr_type='poly'),
+ init_cfg: Optional[Union[Dict, List[Dict]]] = None) -> None:
+
+ super().__init__(
+ in_channels=in_channels,
+ hidden_dim=hidden_dim,
+ out_channel=out_channel,
+ module_loss=module_loss,
+ postprocessor=postprocessor,
+ init_cfg=init_cfg)
diff --git a/mmocr/models/textdet/heads/textsnake_head.py b/mmocr/models/textdet/heads/textsnake_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..6cda55e10f445ed77771eabcde6a8dc91986550d
--- /dev/null
+++ b/mmocr/models/textdet/heads/textsnake_head.py
@@ -0,0 +1,76 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Union
+
+import torch
+import torch.nn as nn
+
+from mmocr.models.textdet.heads import BaseTextDetHead
+from mmocr.registry import MODELS
+from mmocr.structures import TextDetDataSample
+
+
+@MODELS.register_module()
+class TextSnakeHead(BaseTextDetHead):
+ """The class for TextSnake head: TextSnake: A Flexible Representation for
+ Detecting Text of Arbitrary Shapes.
+
+ TextSnake: `A Flexible Representation for Detecting Text of Arbitrary
+ Shapes `_.
+
+ Args:
+ in_channels (int): Number of input channels.
+ out_channels (int): Number of output channels.
+ downsample_ratio (float): Downsample ratio.
+ module_loss (dict): Configuration dictionary for loss type.
+ Defaults to ``dict(type='TextSnakeModuleLoss')``.
+ postprocessor (dict): Config of postprocessor for TextSnake.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ """
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int = 5,
+ downsample_ratio: float = 1.0,
+ module_loss: Dict = dict(type='TextSnakeModuleLoss'),
+ postprocessor: Dict = dict(
+ type='TextSnakePostprocessor', text_repr_type='poly'),
+ init_cfg: Optional[Union[Dict, List[Dict]]] = dict(
+ type='Normal', override=dict(name='out_conv'), mean=0, std=0.01)
+ ) -> None:
+ super().__init__(
+ module_loss=module_loss,
+ postprocessor=postprocessor,
+ init_cfg=init_cfg)
+ assert isinstance(in_channels, int)
+ assert isinstance(out_channels, int)
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.downsample_ratio = downsample_ratio
+
+ self.out_conv = nn.Conv2d(
+ in_channels=self.in_channels,
+ out_channels=self.out_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0)
+
+ def forward(self,
+ inputs: torch.Tensor,
+ data_samples: Optional[List[TextDetDataSample]] = None
+ ) -> Dict:
+ """
+ Args:
+ inputs (torch.Tensor): Shape :math:`(N, C_{in}, H, W)`, where
+ :math:`C_{in}` is ``in_channels``. :math:`H` and :math:`W`
+ should be the same as the input of backbone.
+ data_samples (list[TextDetDataSample], optional): A list of data
+ samples. Defaults to None.
+
+ Returns:
+ Tensor: A tensor of shape :math:`(N, 5, H, W)`, where the five
+ channels represent [0]: text score, [1]: center score,
+ [2]: sin, [3] cos, [4] radius, respectively.
+ """
+ outputs = self.out_conv(inputs)
+ return outputs
diff --git a/mmocr/models/textdet/module_losses/__init__.py b/mmocr/models/textdet/module_losses/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..111c47990143147a8acaf6fdf75a36749042af0c
--- /dev/null
+++ b/mmocr/models/textdet/module_losses/__init__.py
@@ -0,0 +1,13 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .db_module_loss import DBModuleLoss
+from .drrg_module_loss import DRRGModuleLoss
+from .fce_module_loss import FCEModuleLoss
+from .pan_module_loss import PANModuleLoss
+from .pse_module_loss import PSEModuleLoss
+from .seg_based_module_loss import SegBasedModuleLoss
+from .textsnake_module_loss import TextSnakeModuleLoss
+
+__all__ = [
+ 'PANModuleLoss', 'PSEModuleLoss', 'DBModuleLoss', 'TextSnakeModuleLoss',
+ 'FCEModuleLoss', 'DRRGModuleLoss', 'SegBasedModuleLoss'
+]
diff --git a/mmocr/models/textdet/module_losses/__pycache__/__init__.cpython-38.pyc b/mmocr/models/textdet/module_losses/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..25f7793dc8d89b97dffae283b5fa662ebe8ecd35
Binary files /dev/null and b/mmocr/models/textdet/module_losses/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/module_losses/__pycache__/base.cpython-38.pyc b/mmocr/models/textdet/module_losses/__pycache__/base.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..bd70c745f077c7691bae6d7b2e719f4f4c338e91
Binary files /dev/null and b/mmocr/models/textdet/module_losses/__pycache__/base.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/module_losses/__pycache__/db_module_loss.cpython-38.pyc b/mmocr/models/textdet/module_losses/__pycache__/db_module_loss.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..23d43c60ccfd48f497631788e928ef0bb800e11c
Binary files /dev/null and b/mmocr/models/textdet/module_losses/__pycache__/db_module_loss.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/module_losses/__pycache__/drrg_module_loss.cpython-38.pyc b/mmocr/models/textdet/module_losses/__pycache__/drrg_module_loss.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d82174804504c669b27161aaa94fec47f2991e12
Binary files /dev/null and b/mmocr/models/textdet/module_losses/__pycache__/drrg_module_loss.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/module_losses/__pycache__/fce_module_loss.cpython-38.pyc b/mmocr/models/textdet/module_losses/__pycache__/fce_module_loss.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..dca516b94a3ed29954bc12bd29348c38eef283a5
Binary files /dev/null and b/mmocr/models/textdet/module_losses/__pycache__/fce_module_loss.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/module_losses/__pycache__/pan_module_loss.cpython-38.pyc b/mmocr/models/textdet/module_losses/__pycache__/pan_module_loss.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ba620f55668e36dd64a9f643b591bc859e79c166
Binary files /dev/null and b/mmocr/models/textdet/module_losses/__pycache__/pan_module_loss.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/module_losses/__pycache__/pse_module_loss.cpython-38.pyc b/mmocr/models/textdet/module_losses/__pycache__/pse_module_loss.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..327ccac93fb53af51e17ee333b7196a0783600f7
Binary files /dev/null and b/mmocr/models/textdet/module_losses/__pycache__/pse_module_loss.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/module_losses/__pycache__/seg_based_module_loss.cpython-38.pyc b/mmocr/models/textdet/module_losses/__pycache__/seg_based_module_loss.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..7995881ce5394a495259701870ff7e24af202556
Binary files /dev/null and b/mmocr/models/textdet/module_losses/__pycache__/seg_based_module_loss.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/module_losses/__pycache__/textsnake_module_loss.cpython-38.pyc b/mmocr/models/textdet/module_losses/__pycache__/textsnake_module_loss.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..014d39a5c72f2fe8d2e4f0a2a397156aa95a340f
Binary files /dev/null and b/mmocr/models/textdet/module_losses/__pycache__/textsnake_module_loss.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/module_losses/base.py b/mmocr/models/textdet/module_losses/base.py
new file mode 100644
index 0000000000000000000000000000000000000000..b65c5c5ec77f683ca8feaad28f8a6931458c816a
--- /dev/null
+++ b/mmocr/models/textdet/module_losses/base.py
@@ -0,0 +1,51 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import ABCMeta, abstractmethod
+from typing import Dict, Sequence, Tuple, Union
+
+import torch
+from torch import nn
+
+from mmocr.registry import MODELS
+from mmocr.utils.typing_utils import DetSampleList
+
+INPUT_TYPES = Union[torch.Tensor, Sequence[torch.Tensor], Dict]
+
+
+@MODELS.register_module()
+class BaseTextDetModuleLoss(nn.Module, metaclass=ABCMeta):
+ r"""Base class for text detection module loss.
+ """
+
+ def __init__(self) -> None:
+ super().__init__()
+
+ @abstractmethod
+ def forward(self,
+ inputs: INPUT_TYPES,
+ data_samples: DetSampleList = None) -> Dict:
+ """Calculates losses from a batch of inputs and data samples. Returns a
+ dict of losses.
+
+ Args:
+ inputs (Tensor or list[Tensor] or dict): The raw tensor outputs
+ from the model.
+ data_samples (list(TextDetDataSample)): Datasamples containing
+ ground truth data.
+
+ Returns:
+ dict: A dict of losses.
+ """
+ pass
+
+ @abstractmethod
+ def get_targets(self, data_samples: DetSampleList) -> Tuple:
+ """Generates loss targets from data samples. Returns a tuple of target
+ tensors.
+
+ Args:
+ data_samples (list(TextDetDataSample)): Ground truth data samples.
+
+ Returns:
+ tuple: A tuple of target tensors.
+ """
+ pass
diff --git a/mmocr/models/textdet/module_losses/db_module_loss.py b/mmocr/models/textdet/module_losses/db_module_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..ba8487310f2ce9592a2fa5b8b20621b870a9fe05
--- /dev/null
+++ b/mmocr/models/textdet/module_losses/db_module_loss.py
@@ -0,0 +1,300 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Sequence, Tuple, Union
+
+import cv2
+import numpy as np
+import torch
+from mmdet.models.utils import multi_apply
+from shapely.geometry import Polygon
+from torch import Tensor
+
+from mmocr.registry import MODELS
+from mmocr.structures import TextDetDataSample
+from mmocr.utils import offset_polygon
+from mmocr.utils.typing_utils import ArrayLike
+from .seg_based_module_loss import SegBasedModuleLoss
+
+
+@MODELS.register_module()
+class DBModuleLoss(SegBasedModuleLoss):
+ r"""The class for implementing DBNet loss.
+
+ This is partially adapted from https://github.com/MhLiao/DB.
+
+ Args:
+ loss_prob (dict): The loss config for probability map. Defaults to
+ dict(type='MaskedBalancedBCEWithLogitsLoss').
+ loss_thr (dict): The loss config for threshold map. Defaults to
+ dict(type='MaskedSmoothL1Loss', beta=0).
+ loss_db (dict): The loss config for binary map. Defaults to
+ dict(type='MaskedDiceLoss').
+ weight_prob (float): The weight of probability map loss.
+ Denoted as :math:`\alpha` in paper. Defaults to 5.
+ weight_thr (float): The weight of threshold map loss.
+ Denoted as :math:`\beta` in paper. Defaults to 10.
+ shrink_ratio (float): The ratio of shrunk text region. Defaults to 0.4.
+ thr_min (float): The minimum threshold map value. Defaults to 0.3.
+ thr_max (float): The maximum threshold map value. Defaults to 0.7.
+ min_sidelength (int or float): The minimum sidelength of the
+ minimum rotated rectangle around any text region. Defaults to 8.
+ """
+
+ def __init__(self,
+ loss_prob: Dict = dict(
+ type='MaskedBalancedBCEWithLogitsLoss'),
+ loss_thr: Dict = dict(type='MaskedSmoothL1Loss', beta=0),
+ loss_db: Dict = dict(type='MaskedDiceLoss'),
+ weight_prob: float = 5.,
+ weight_thr: float = 10.,
+ shrink_ratio: float = 0.4,
+ thr_min: float = 0.3,
+ thr_max: float = 0.7,
+ min_sidelength: Union[int, float] = 8) -> None:
+ super().__init__()
+ self.loss_prob = MODELS.build(loss_prob)
+ self.loss_thr = MODELS.build(loss_thr)
+ self.loss_db = MODELS.build(loss_db)
+ self.weight_prob = weight_prob
+ self.weight_thr = weight_thr
+ self.shrink_ratio = shrink_ratio
+ self.thr_min = thr_min
+ self.thr_max = thr_max
+ self.min_sidelength = min_sidelength
+
+ def forward(self, preds: Tuple[Tensor, Tensor, Tensor],
+ data_samples: Sequence[TextDetDataSample]) -> Dict:
+ """Compute DBNet loss.
+
+ Args:
+ preds (tuple(tensor)): Raw predictions from model, containing
+ ``prob_logits``, ``thr_map`` and ``binary_map``.
+ Each is a tensor of shape :math:`(N, H, W)`.
+ data_samples (list[TextDetDataSample]): The data samples.
+
+ Returns:
+ results(dict): The dict for dbnet losses with loss_prob, \
+ loss_db and loss_thr.
+ """
+ prob_logits, thr_map, binary_map = preds
+ gt_shrinks, gt_shrink_masks, gt_thrs, gt_thr_masks = self.get_targets(
+ data_samples)
+ gt_shrinks = gt_shrinks.to(prob_logits.device)
+ gt_shrink_masks = gt_shrink_masks.to(prob_logits.device)
+ gt_thrs = gt_thrs.to(thr_map.device)
+ gt_thr_masks = gt_thr_masks.to(thr_map.device)
+ loss_prob = self.loss_prob(prob_logits, gt_shrinks, gt_shrink_masks)
+
+ loss_thr = self.loss_thr(thr_map, gt_thrs, gt_thr_masks)
+ loss_db = self.loss_db(binary_map, gt_shrinks, gt_shrink_masks)
+
+ results = dict(
+ loss_prob=self.weight_prob * loss_prob,
+ loss_thr=self.weight_thr * loss_thr,
+ loss_db=loss_db)
+
+ return results
+
+ def _is_poly_invalid(self, poly: np.ndarray) -> bool:
+ """Check if the input polygon is invalid or not. It is invalid if its
+ area is smaller than 1 or the shorter side of its minimum bounding box
+ is smaller than min_sidelength.
+
+ Args:
+ poly (ndarray): The polygon.
+
+ Returns:
+ bool: Whether the polygon is invalid.
+ """
+ poly = poly.reshape(-1, 2)
+ area = Polygon(poly).area
+ if abs(area) < 1:
+ return True
+ rect_size = cv2.minAreaRect(poly)[1]
+ len_shortest_side = min(rect_size)
+ if len_shortest_side < self.min_sidelength:
+ return True
+
+ return False
+
+ def _generate_thr_map(self, img_size: Tuple[int, int],
+ polygons: ArrayLike) -> np.ndarray:
+ """Generate threshold map.
+
+ Args:
+ img_size (tuple(int)): The image size (h, w)
+ polygons (Sequence[ndarray]): 2-d array, representing all the
+ polygons of the text region.
+
+ Returns:
+ tuple:
+
+ - thr_map (ndarray): The generated threshold map.
+ - thr_mask (ndarray): The effective mask of threshold map.
+ """
+ thr_map = np.zeros(img_size, dtype=np.float32)
+ thr_mask = np.zeros(img_size, dtype=np.uint8)
+
+ for polygon in polygons:
+ self._draw_border_map(polygon, thr_map, mask=thr_mask)
+ thr_map = thr_map * (self.thr_max - self.thr_min) + self.thr_min
+
+ return thr_map, thr_mask
+
+ def _draw_border_map(self, polygon: np.ndarray, canvas: np.ndarray,
+ mask: np.ndarray) -> None:
+ """Generate threshold map for one polygon.
+
+ Args:
+ polygon (np.ndarray): The polygon.
+ canvas (np.ndarray): The generated threshold map.
+ mask (np.ndarray): The generated threshold mask.
+ """
+
+ polygon = polygon.reshape(-1, 2)
+ polygon_obj = Polygon(polygon)
+ distance = (
+ polygon_obj.area * (1 - np.power(self.shrink_ratio, 2)) /
+ polygon_obj.length)
+ expanded_polygon = offset_polygon(polygon, distance)
+ if len(expanded_polygon) == 0:
+ print(f'Padding {polygon} with {distance} gets {expanded_polygon}')
+ expanded_polygon = polygon.copy().astype(np.int32)
+ else:
+ expanded_polygon = expanded_polygon.reshape(-1, 2).astype(np.int32)
+
+ x_min = expanded_polygon[:, 0].min()
+ x_max = expanded_polygon[:, 0].max()
+ y_min = expanded_polygon[:, 1].min()
+ y_max = expanded_polygon[:, 1].max()
+
+ width = x_max - x_min + 1
+ height = y_max - y_min + 1
+
+ polygon[:, 0] = polygon[:, 0] - x_min
+ polygon[:, 1] = polygon[:, 1] - y_min
+
+ xs = np.broadcast_to(
+ np.linspace(0, width - 1, num=width).reshape(1, width),
+ (height, width))
+ ys = np.broadcast_to(
+ np.linspace(0, height - 1, num=height).reshape(height, 1),
+ (height, width))
+
+ distance_map = np.zeros((polygon.shape[0], height, width),
+ dtype=np.float32)
+ for i in range(polygon.shape[0]):
+ j = (i + 1) % polygon.shape[0]
+ absolute_distance = self._dist_points2line(xs, ys, polygon[i],
+ polygon[j])
+ distance_map[i] = np.clip(absolute_distance / distance, 0, 1)
+ distance_map = distance_map.min(axis=0)
+
+ x_min_valid = min(max(0, x_min), canvas.shape[1] - 1)
+ x_max_valid = min(max(0, x_max), canvas.shape[1] - 1)
+ y_min_valid = min(max(0, y_min), canvas.shape[0] - 1)
+ y_max_valid = min(max(0, y_max), canvas.shape[0] - 1)
+
+ if x_min_valid - x_min >= width or y_min_valid - y_min >= height:
+ return
+
+ cv2.fillPoly(mask, [expanded_polygon.astype(np.int32)], 1.0)
+ canvas[y_min_valid:y_max_valid + 1,
+ x_min_valid:x_max_valid + 1] = np.fmax(
+ 1 - distance_map[y_min_valid - y_min:y_max_valid - y_max +
+ height, x_min_valid - x_min:x_max_valid -
+ x_max + width],
+ canvas[y_min_valid:y_max_valid + 1,
+ x_min_valid:x_max_valid + 1])
+
+ def get_targets(self, data_samples: List[TextDetDataSample]) -> Tuple:
+ """Generate loss targets from data samples.
+
+ Args:
+ data_samples (list(TextDetDataSample)): Ground truth data samples.
+
+ Returns:
+ tuple: A tuple of four tensors as DBNet targets.
+ """
+
+ gt_shrinks, gt_shrink_masks, gt_thrs, gt_thr_masks = multi_apply(
+ self._get_target_single, data_samples)
+ gt_shrinks = torch.cat(gt_shrinks)
+ gt_shrink_masks = torch.cat(gt_shrink_masks)
+ gt_thrs = torch.cat(gt_thrs)
+ gt_thr_masks = torch.cat(gt_thr_masks)
+ return gt_shrinks, gt_shrink_masks, gt_thrs, gt_thr_masks
+
+ def _get_target_single(self, data_sample: TextDetDataSample) -> Tuple:
+ """Generate loss target from a data sample.
+
+ Args:
+ data_sample (TextDetDataSample): The data sample.
+
+ Returns:
+ tuple: A tuple of four tensors as the targets of one prediction.
+ """
+
+ gt_instances = data_sample.gt_instances
+ ignore_flags = gt_instances.ignored
+ for idx, polygon in enumerate(gt_instances.polygons):
+ if self._is_poly_invalid(polygon):
+ ignore_flags[idx] = True
+ gt_shrink, ignore_flags = self._generate_kernels(
+ data_sample.img_shape,
+ gt_instances.polygons,
+ self.shrink_ratio,
+ ignore_flags=ignore_flags)
+
+ # Get boolean mask where Trues indicate text instance pixels
+ gt_shrink = gt_shrink > 0
+
+ gt_shrink_mask = self._generate_effective_mask(
+ data_sample.img_shape, gt_instances[ignore_flags].polygons)
+ gt_thr, gt_thr_mask = self._generate_thr_map(
+ data_sample.img_shape, gt_instances[~ignore_flags].polygons)
+
+ # to_tensor
+ gt_shrink = torch.from_numpy(gt_shrink).unsqueeze(0).float()
+ gt_shrink_mask = torch.from_numpy(gt_shrink_mask).unsqueeze(0).float()
+ gt_thr = torch.from_numpy(gt_thr).unsqueeze(0).float()
+ gt_thr_mask = torch.from_numpy(gt_thr_mask).unsqueeze(0).float()
+ return gt_shrink, gt_shrink_mask, gt_thr, gt_thr_mask
+
+ @staticmethod
+ def _dist_points2line(xs: np.ndarray, ys: np.ndarray, pt1: np.ndarray,
+ pt2: np.ndarray) -> np.ndarray:
+ """Compute distances from points to a line. This is adapted from
+ https://github.com/MhLiao/DB.
+
+ Args:
+ xs (ndarray): The x coordinates of points of size :math:`(N, )`.
+ ys (ndarray): The y coordinates of size :math:`(N, )`.
+ pt1 (ndarray): The first point on the line of size :math:`(2, )`.
+ pt2 (ndarray): The second point on the line of size :math:`(2, )`.
+
+ Returns:
+ ndarray: The distance matrix of size :math:`(N, )`.
+ """
+ # suppose a triangle with three edge abc with c=point_1 point_2
+ # a^2
+ a_square = np.square(xs - pt1[0]) + np.square(ys - pt1[1])
+ # b^2
+ b_square = np.square(xs - pt2[0]) + np.square(ys - pt2[1])
+ # c^2
+ c_square = np.square(pt1[0] - pt2[0]) + np.square(pt1[1] - pt2[1])
+ # -cosC=(c^2-a^2-b^2)/2(ab)
+ neg_cos_c = (
+ (c_square - a_square - b_square) /
+ (np.finfo(np.float32).eps + 2 * np.sqrt(a_square * b_square)))
+ # clip -cosC value to [-1, 1]
+ neg_cos_c = np.clip(neg_cos_c, -1.0, 1.0)
+ # sinC^2=1-cosC^2
+ square_sin = 1 - np.square(neg_cos_c)
+ square_sin = np.nan_to_num(square_sin)
+ # distance=a*b*sinC/c=a*h/c=2*area/c
+ result = np.sqrt(a_square * b_square * square_sin /
+ (np.finfo(np.float32).eps + c_square))
+ # set result to minimum edge if C`_.
+
+ Args:
+ ohem_ratio (float): The negative/positive ratio in ohem. Defaults to
+ 3.0.
+ downsample_ratio (float): Downsample ratio. Defaults to 1.0. TODO:
+ remove it.
+ orientation_thr (float): The threshold for distinguishing between
+ head edge and tail edge among the horizontal and vertical edges
+ of a quadrangle. Defaults to 2.0.
+ resample_step (float): The step size for resampling the text center
+ line. Defaults to 8.0.
+ num_min_comps (int): The minimum number of text components, which
+ should be larger than k_hop1 mentioned in paper. Defaults to 9.
+ num_max_comps (int): The maximum number of text components. Defaults
+ to 600.
+ min_width (float): The minimum width of text components. Defaults to
+ 8.0.
+ max_width (float): The maximum width of text components. Defaults to
+ 24.0.
+ center_region_shrink_ratio (float): The shrink ratio of text center
+ regions. Defaults to 0.3.
+ comp_shrink_ratio (float): The shrink ratio of text components.
+ Defaults to 1.0.
+ comp_w_h_ratio (float): The width to height ratio of text components.
+ Defaults to 0.3.
+ min_rand_half_height(float): The minimum half-height of random text
+ components. Defaults to 8.0.
+ max_rand_half_height (float): The maximum half-height of random
+ text components. Defaults to 24.0.
+ jitter_level (float): The jitter level of text component geometric
+ features. Defaults to 0.2.
+ loss_text (dict): The loss config used to calculate the text loss.
+ Defaults to ``dict(type='MaskedBalancedBCEWithLogitsLoss',
+ fallback_negative_num=100, eps=1e-5)``.
+ loss_center (dict): The loss config used to calculate the center loss.
+ Defaults to ``dict(type='MaskedBCEWithLogitsLoss')``.
+ loss_top (dict): The loss config used to calculate the top loss, which
+ is a part of the height loss. Defaults to
+ ``dict(type='SmoothL1Loss', reduction='none')``.
+ loss_btm (dict): The loss config used to calculate the bottom loss,
+ which is a part of the height loss. Defaults to
+ ``dict(type='SmoothL1Loss', reduction='none')``.
+ loss_sin (dict): The loss config used to calculate the sin loss.
+ Defaults to ``dict(type='MaskedSmoothL1Loss')``.
+ loss_cos (dict): The loss config used to calculate the cos loss.
+ Defaults to ``dict(type='MaskedSmoothL1Loss')``.
+ loss_gcn (dict): The loss config used to calculate the GCN loss.
+ Defaults to ``dict(type='CrossEntropyLoss')``.
+ """
+
+ def __init__(
+ self,
+ ohem_ratio: float = 3.0,
+ downsample_ratio: float = 1.0,
+ orientation_thr: float = 2.0,
+ resample_step: float = 8.0,
+ num_min_comps: int = 9,
+ num_max_comps: int = 600,
+ min_width: float = 8.0,
+ max_width: float = 24.0,
+ center_region_shrink_ratio: float = 0.3,
+ comp_shrink_ratio: float = 1.0,
+ comp_w_h_ratio: float = 0.3,
+ text_comp_nms_thr: float = 0.25,
+ min_rand_half_height: float = 8.0,
+ max_rand_half_height: float = 24.0,
+ jitter_level: float = 0.2,
+ loss_text: Dict = dict(
+ type='MaskedBalancedBCEWithLogitsLoss',
+ fallback_negative_num=100,
+ eps=1e-5),
+ loss_center: Dict = dict(type='MaskedBCEWithLogitsLoss'),
+ loss_top: Dict = dict(type='SmoothL1Loss', reduction='none'),
+ loss_btm: Dict = dict(type='SmoothL1Loss', reduction='none'),
+ loss_sin: Dict = dict(type='MaskedSmoothL1Loss'),
+ loss_cos: Dict = dict(type='MaskedSmoothL1Loss'),
+ loss_gcn: Dict = dict(type='CrossEntropyLoss')
+ ) -> None:
+ super().__init__()
+ self.ohem_ratio = ohem_ratio
+ self.downsample_ratio = downsample_ratio
+ self.orientation_thr = orientation_thr
+ self.resample_step = resample_step
+ self.num_max_comps = num_max_comps
+ self.num_min_comps = num_min_comps
+ self.min_width = min_width
+ self.max_width = max_width
+ self.center_region_shrink_ratio = center_region_shrink_ratio
+ self.comp_shrink_ratio = comp_shrink_ratio
+ self.comp_w_h_ratio = comp_w_h_ratio
+ self.text_comp_nms_thr = text_comp_nms_thr
+ self.min_rand_half_height = min_rand_half_height
+ self.max_rand_half_height = max_rand_half_height
+ self.jitter_level = jitter_level
+ self.loss_text = MODELS.build(loss_text)
+ self.loss_center = MODELS.build(loss_center)
+ self.loss_top = MODELS.build(loss_top)
+ self.loss_btm = MODELS.build(loss_btm)
+ self.loss_sin = MODELS.build(loss_sin)
+ self.loss_cos = MODELS.build(loss_cos)
+ self.loss_gcn = MODELS.build(loss_gcn)
+
+ def forward(self, preds: Tuple[Tensor, Tensor, Tensor],
+ data_samples: Sequence[TextDetDataSample]) -> Dict:
+ """Compute Drrg loss.
+
+ Args:
+ preds (tuple): The prediction
+ tuple(pred_maps, gcn_pred, gt_labels), each of shape
+ :math:`(N, 6, H, W)`, :math:`(N, 2)` and :math:`(m ,n)`, where
+ :math:`m * n = N`.
+ data_samples (list[TextDetDataSample]): The data samples.
+
+ Returns:
+ dict: A loss dict with ``loss_text``, ``loss_center``,
+ ``loss_height``, ``loss_sin``, ``loss_cos``, and ``loss_gcn``.
+ """
+ assert isinstance(preds, tuple)
+
+ (gt_text_masks, gt_center_region_masks, gt_masks, gt_top_height_maps,
+ gt_bot_height_maps, gt_sin_maps, gt_cos_maps,
+ _) = self.get_targets(data_samples)
+ pred_maps, gcn_pred, gt_labels = preds
+ pred_text_region = pred_maps[:, 0, :, :]
+ pred_center_region = pred_maps[:, 1, :, :]
+ pred_sin_map = pred_maps[:, 2, :, :]
+ pred_cos_map = pred_maps[:, 3, :, :]
+ pred_top_height_map = pred_maps[:, 4, :, :]
+ pred_bot_height_map = pred_maps[:, 5, :, :]
+ feature_sz = pred_maps.size()
+ device = pred_maps.device
+
+ # bitmask 2 tensor
+ mapping = {
+ 'gt_text_masks': gt_text_masks,
+ 'gt_center_region_masks': gt_center_region_masks,
+ 'gt_masks': gt_masks,
+ 'gt_top_height_maps': gt_top_height_maps,
+ 'gt_bot_height_maps': gt_bot_height_maps,
+ 'gt_sin_maps': gt_sin_maps,
+ 'gt_cos_maps': gt_cos_maps
+ }
+ gt = {}
+ for key, value in mapping.items():
+ gt[key] = value
+ if abs(self.downsample_ratio - 1.0) < 1e-2:
+ gt[key] = self._batch_pad(gt[key], feature_sz[2:])
+ else:
+ gt[key] = [
+ imrescale(
+ mask,
+ scale=self.downsample_ratio,
+ interpolation='nearest') for mask in gt[key]
+ ]
+ gt[key] = self._batch_pad(gt[key], feature_sz[2:])
+ if key in ['gt_top_height_maps', 'gt_bot_height_maps']:
+ gt[key] *= self.downsample_ratio
+ gt[key] = torch.from_numpy(gt[key]).float().to(device)
+
+ scale = torch.sqrt(1.0 / (pred_sin_map**2 + pred_cos_map**2 + 1e-8))
+ pred_sin_map = pred_sin_map * scale
+ pred_cos_map = pred_cos_map * scale
+
+ loss_text = self.loss_text(pred_text_region, gt['gt_text_masks'],
+ gt['gt_masks'])
+
+ text_mask = (gt['gt_text_masks'] * gt['gt_masks']).float()
+ negative_text_mask = ((1 - gt['gt_text_masks']) *
+ gt['gt_masks']).float()
+ loss_center_positive = self.loss_center(pred_center_region,
+ gt['gt_center_region_masks'],
+ text_mask)
+ loss_center_negative = self.loss_center(pred_center_region,
+ gt['gt_center_region_masks'],
+ negative_text_mask)
+ loss_center = loss_center_positive + 0.5 * loss_center_negative
+
+ center_mask = (gt['gt_center_region_masks'] * gt['gt_masks']).float()
+ map_sz = pred_top_height_map.size()
+ ones = torch.ones(map_sz, dtype=torch.float, device=device)
+ loss_top = self.loss_top(
+ pred_top_height_map / (gt['gt_top_height_maps'] + 1e-2), ones)
+ loss_btm = self.loss_btm(
+ pred_bot_height_map / (gt['gt_bot_height_maps'] + 1e-2), ones)
+ gt_height = gt['gt_top_height_maps'] + gt['gt_bot_height_maps']
+ loss_height = torch.sum((torch.log(gt_height + 1) *
+ (loss_top + loss_btm)) * center_mask) / (
+ torch.sum(center_mask) + 1e-6)
+
+ loss_sin = self.loss_sin(pred_sin_map, gt['gt_sin_maps'], center_mask)
+ loss_cos = self.loss_cos(pred_cos_map, gt['gt_cos_maps'], center_mask)
+
+ loss_gcn = self.loss_gcn(gcn_pred,
+ gt_labels.view(-1).to(gcn_pred.device))
+
+ results = dict(
+ loss_text=loss_text,
+ loss_center=loss_center,
+ loss_height=loss_height,
+ loss_sin=loss_sin,
+ loss_cos=loss_cos,
+ loss_gcn=loss_gcn)
+
+ return results
+
+ def get_targets(self, data_samples: List[TextDetDataSample]) -> Tuple:
+ """Generate loss targets from data samples.
+
+ Args:
+ data_samples (list(TextDetDataSample)): Ground truth data samples.
+
+ Returns:
+ tuple: A tuple of 8 lists of tensors as DRRG targets. Read
+ docstring of ``_get_target_single`` for more details.
+ """
+
+ # If data_samples points to same object as self.cached_data_samples, it
+ # means that get_targets is called more than once in the same train
+ # iteration, and pre-computed targets can be reused.
+ if hasattr(self, 'targets') and \
+ self.cache_data_samples is data_samples:
+ return self.targets
+
+ self.cache_data_samples = data_samples
+ self.targets = multi_apply(self._get_target_single, data_samples)
+ return self.targets
+
+ def _get_target_single(self, data_sample: TextDetDataSample) -> Tuple:
+ """Generate loss target from a data sample.
+
+ Args:
+ data_sample (TextDetDataSample): The data sample.
+
+ Returns:
+ tuple: A tuple of 8 tensors as DRRG targets.
+
+ - gt_text_mask (ndarray): The text region mask.
+ - gt_center_region_mask (ndarray): The text center region mask.
+ - gt_mask (ndarray): The effective mask.
+ - gt_top_height_map (ndarray): The map on which the distance from
+ points to top side lines will be drawn for each pixel in text
+ center regions.
+ - gt_bot_height_map (ndarray): The map on which the distance from
+ points to bottom side lines will be drawn for each pixel in text
+ center regions.
+ - gt_sin_map (ndarray): The sin(theta) map where theta is the angle
+ between vector (top point - bottom point) and vector (1, 0).
+ - gt_cos_map (ndarray): The cos(theta) map where theta is the angle
+ between vector (top point - bottom point) and vector (1, 0).
+ - gt_comp_attribs (ndarray): The padded text component attributes
+ of a fixed size. Shape: (num_component, 8).
+ """
+
+ gt_instances = data_sample.gt_instances
+ ignore_flags = gt_instances.ignored
+
+ polygons = gt_instances[~ignore_flags].polygons
+ ignored_polygons = gt_instances[ignore_flags].polygons
+ h, w = data_sample.img_shape
+
+ gt_text_mask = self._generate_text_region_mask((h, w), polygons)
+ gt_mask = self._generate_effective_mask((h, w), ignored_polygons)
+ (center_lines, gt_center_region_mask, gt_top_height_map,
+ gt_bot_height_map, gt_sin_map,
+ gt_cos_map) = self._generate_center_mask_attrib_maps((h, w), polygons)
+
+ gt_comp_attribs = self._generate_comp_attribs(center_lines,
+ gt_text_mask,
+ gt_center_region_mask,
+ gt_top_height_map,
+ gt_bot_height_map,
+ gt_sin_map, gt_cos_map)
+
+ return (gt_text_mask, gt_center_region_mask, gt_mask,
+ gt_top_height_map, gt_bot_height_map, gt_sin_map, gt_cos_map,
+ gt_comp_attribs)
+
+ def _generate_center_mask_attrib_maps(self, img_size: Tuple[int, int],
+ text_polys: List[ndarray]) -> Tuple:
+ """Generate text center region masks and geometric attribute maps.
+
+ Args:
+ img_size (tuple(int, int)): The image size (height, width).
+ text_polys (list[ndarray]): The list of text polygons.
+
+ Returns:
+ tuple(center_lines, center_region_mask, top_height_map,
+ bot_height_map,sin_map, cos_map):
+
+ center_lines (list[ndarray]): The list of text center lines.
+ center_region_mask (ndarray): The text center region mask.
+ top_height_map (ndarray): The map on which the distance from points
+ to top side lines will be drawn for each pixel in text center
+ regions.
+ bot_height_map (ndarray): The map on which the distance from points
+ to bottom side lines will be drawn for each pixel in text
+ center regions.
+ sin_map (ndarray): The sin(theta) map where theta is the angle
+ between vector (top point - bottom point) and vector (1, 0).
+ cos_map (ndarray): The cos(theta) map where theta is the angle
+ between vector (top point - bottom point) and vector (1, 0).
+ """
+
+ assert isinstance(img_size, tuple)
+ assert check_argument.is_type_list(text_polys, ndarray)
+
+ h, w = img_size
+
+ center_lines = []
+ center_region_mask = np.zeros((h, w), np.uint8)
+ top_height_map = np.zeros((h, w), dtype=np.float32)
+ bot_height_map = np.zeros((h, w), dtype=np.float32)
+ sin_map = np.zeros((h, w), dtype=np.float32)
+ cos_map = np.zeros((h, w), dtype=np.float32)
+
+ for poly in text_polys:
+ polygon_points = poly.reshape(-1, 2)
+ _, _, top_line, bot_line = self._reorder_poly_edge(polygon_points)
+ resampled_top_line, resampled_bot_line = self._resample_sidelines(
+ top_line, bot_line, self.resample_step)
+ resampled_bot_line = resampled_bot_line[::-1]
+ center_line = (resampled_top_line + resampled_bot_line) / 2
+
+ if self.vector_slope(center_line[-1] - center_line[0]) > 2:
+ if (center_line[-1] - center_line[0])[1] < 0:
+ center_line = center_line[::-1]
+ resampled_top_line = resampled_top_line[::-1]
+ resampled_bot_line = resampled_bot_line[::-1]
+ else:
+ if (center_line[-1] - center_line[0])[0] < 0:
+ center_line = center_line[::-1]
+ resampled_top_line = resampled_top_line[::-1]
+ resampled_bot_line = resampled_bot_line[::-1]
+
+ line_head_shrink_len = np.clip(
+ (norm(top_line[0] - bot_line[0]) * self.comp_w_h_ratio),
+ self.min_width, self.max_width) / 2
+ line_tail_shrink_len = np.clip(
+ (norm(top_line[-1] - bot_line[-1]) * self.comp_w_h_ratio),
+ self.min_width, self.max_width) / 2
+ num_head_shrink = int(line_head_shrink_len // self.resample_step)
+ num_tail_shrink = int(line_tail_shrink_len // self.resample_step)
+ if len(center_line) > num_head_shrink + num_tail_shrink + 2:
+ center_line = center_line[num_head_shrink:len(center_line) -
+ num_tail_shrink]
+ resampled_top_line = resampled_top_line[
+ num_head_shrink:len(resampled_top_line) - num_tail_shrink]
+ resampled_bot_line = resampled_bot_line[
+ num_head_shrink:len(resampled_bot_line) - num_tail_shrink]
+ center_lines.append(center_line.astype(np.int32))
+
+ self._draw_center_region_maps(resampled_top_line,
+ resampled_bot_line, center_line,
+ center_region_mask, top_height_map,
+ bot_height_map, sin_map, cos_map,
+ self.center_region_shrink_ratio)
+
+ return (center_lines, center_region_mask, top_height_map,
+ bot_height_map, sin_map, cos_map)
+
+ def _generate_comp_attribs(self, center_lines: List[ndarray],
+ text_mask: ndarray, center_region_mask: ndarray,
+ top_height_map: ndarray,
+ bot_height_map: ndarray, sin_map: ndarray,
+ cos_map: ndarray) -> ndarray:
+ """Generate text component attributes.
+
+ Args:
+ center_lines (list[ndarray]): The list of text center lines .
+ text_mask (ndarray): The text region mask.
+ center_region_mask (ndarray): The text center region mask.
+ top_height_map (ndarray): The map on which the distance from points
+ to top side lines will be drawn for each pixel in text center
+ regions.
+ bot_height_map (ndarray): The map on which the distance from points
+ to bottom side lines will be drawn for each pixel in text
+ center regions.
+ sin_map (ndarray): The sin(theta) map where theta is the angle
+ between vector (top point - bottom point) and vector (1, 0).
+ cos_map (ndarray): The cos(theta) map where theta is the angle
+ between vector (top point - bottom point) and vector (1, 0).
+
+ Returns:
+ ndarray: The padded text component attributes of a fixed size.
+ """
+
+ assert isinstance(center_lines, list)
+ assert (text_mask.shape == center_region_mask.shape ==
+ top_height_map.shape == bot_height_map.shape == sin_map.shape
+ == cos_map.shape)
+
+ center_lines_mask = np.zeros_like(center_region_mask)
+ cv2.polylines(center_lines_mask, center_lines, 0, 1, 1)
+ center_lines_mask = center_lines_mask * center_region_mask
+ comp_centers = np.argwhere(center_lines_mask > 0)
+
+ y = comp_centers[:, 0]
+ x = comp_centers[:, 1]
+
+ top_height = top_height_map[y, x].reshape(
+ (-1, 1)) * self.comp_shrink_ratio
+ bot_height = bot_height_map[y, x].reshape(
+ (-1, 1)) * self.comp_shrink_ratio
+ sin = sin_map[y, x].reshape((-1, 1))
+ cos = cos_map[y, x].reshape((-1, 1))
+
+ top_mid_points = comp_centers + np.hstack(
+ [top_height * sin, top_height * cos])
+ bot_mid_points = comp_centers - np.hstack(
+ [bot_height * sin, bot_height * cos])
+
+ width = (top_height + bot_height) * self.comp_w_h_ratio
+ width = np.clip(width, self.min_width, self.max_width)
+ r = width / 2
+
+ tl = top_mid_points[:, ::-1] - np.hstack([-r * sin, r * cos])
+ tr = top_mid_points[:, ::-1] + np.hstack([-r * sin, r * cos])
+ br = bot_mid_points[:, ::-1] + np.hstack([-r * sin, r * cos])
+ bl = bot_mid_points[:, ::-1] - np.hstack([-r * sin, r * cos])
+ text_comps = np.hstack([tl, tr, br, bl]).astype(np.float32)
+
+ score = np.ones((text_comps.shape[0], 1), dtype=np.float32)
+ text_comps = np.hstack([text_comps, score])
+ if la_nms is None:
+ raise ImportError('lanms-neo is not installed, '
+ 'please run "pip install lanms-neo==1.0.2".')
+ text_comps = la_nms(text_comps, self.text_comp_nms_thr)
+
+ if text_comps.shape[0] >= 1:
+ img_h, img_w = center_region_mask.shape
+ text_comps[:, 0:8:2] = np.clip(text_comps[:, 0:8:2], 0, img_w - 1)
+ text_comps[:, 1:8:2] = np.clip(text_comps[:, 1:8:2], 0, img_h - 1)
+
+ comp_centers = np.mean(
+ text_comps[:, 0:8].reshape((-1, 4, 2)),
+ axis=1).astype(np.int32)
+ x = comp_centers[:, 0]
+ y = comp_centers[:, 1]
+
+ height = (top_height_map[y, x] + bot_height_map[y, x]).reshape(
+ (-1, 1))
+ width = np.clip(height * self.comp_w_h_ratio, self.min_width,
+ self.max_width)
+
+ cos = cos_map[y, x].reshape((-1, 1))
+ sin = sin_map[y, x].reshape((-1, 1))
+
+ _, comp_label_mask = cv2.connectedComponents(
+ center_region_mask, connectivity=8)
+ comp_labels = comp_label_mask[y, x].reshape(
+ (-1, 1)).astype(np.float32)
+
+ x = x.reshape((-1, 1)).astype(np.float32)
+ y = y.reshape((-1, 1)).astype(np.float32)
+ comp_attribs = np.hstack(
+ [x, y, height, width, cos, sin, comp_labels])
+ comp_attribs = self._jitter_comp_attribs(comp_attribs,
+ self.jitter_level)
+
+ if comp_attribs.shape[0] < self.num_min_comps:
+ num_rand_comps = self.num_min_comps - comp_attribs.shape[0]
+ rand_comp_attribs = self._generate_rand_comp_attribs(
+ num_rand_comps, 1 - text_mask)
+ comp_attribs = np.vstack([comp_attribs, rand_comp_attribs])
+ else:
+ comp_attribs = self._generate_rand_comp_attribs(
+ self.num_min_comps, 1 - text_mask)
+
+ num_comps = (
+ np.ones((comp_attribs.shape[0], 1), dtype=np.float32) *
+ comp_attribs.shape[0])
+ comp_attribs = np.hstack([num_comps, comp_attribs])
+
+ if comp_attribs.shape[0] > self.num_max_comps:
+ comp_attribs = comp_attribs[:self.num_max_comps, :]
+ comp_attribs[:, 0] = self.num_max_comps
+
+ pad_comp_attribs = np.zeros(
+ (self.num_max_comps, comp_attribs.shape[1]), dtype=np.float32)
+ pad_comp_attribs[:comp_attribs.shape[0], :] = comp_attribs
+
+ return pad_comp_attribs
+
+ def _generate_rand_comp_attribs(self, num_rand_comps: int,
+ center_sample_mask: ndarray) -> ndarray:
+ """Generate random text components and their attributes to ensure the
+ the number of text components in an image is larger than k_hop1, which
+ is the number of one hop neighbors in KNN graph.
+
+ Args:
+ num_rand_comps (int): The number of random text components.
+ center_sample_mask (ndarray): The region mask for sampling text
+ component centers .
+
+ Returns:
+ ndarray: The random text component attributes
+ (x, y, h, w, cos, sin, comp_label=0).
+ """
+
+ assert isinstance(num_rand_comps, int)
+ assert num_rand_comps > 0
+ assert center_sample_mask.ndim == 2
+
+ h, w = center_sample_mask.shape
+
+ max_rand_half_height = self.max_rand_half_height
+ min_rand_half_height = self.min_rand_half_height
+ max_rand_height = max_rand_half_height * 2
+ max_rand_width = np.clip(max_rand_height * self.comp_w_h_ratio,
+ self.min_width, self.max_width)
+ margin = int(
+ np.sqrt((max_rand_height / 2)**2 + (max_rand_width / 2)**2)) + 1
+
+ if 2 * margin + 1 > min(h, w):
+
+ assert min(h, w) > (np.sqrt(2) * (self.min_width + 1))
+ max_rand_half_height = max(min(h, w) / 4, self.min_width / 2 + 1)
+ min_rand_half_height = max(max_rand_half_height / 4,
+ self.min_width / 2)
+
+ max_rand_height = max_rand_half_height * 2
+ max_rand_width = np.clip(max_rand_height * self.comp_w_h_ratio,
+ self.min_width, self.max_width)
+ margin = int(
+ np.sqrt((max_rand_height / 2)**2 +
+ (max_rand_width / 2)**2)) + 1
+
+ inner_center_sample_mask = np.zeros_like(center_sample_mask)
+ inner_center_sample_mask[margin:h - margin, margin:w - margin] = \
+ center_sample_mask[margin:h - margin, margin:w - margin]
+ kernel_size = int(np.clip(max_rand_half_height, 7, 21))
+ inner_center_sample_mask = cv2.erode(
+ inner_center_sample_mask,
+ np.ones((kernel_size, kernel_size), np.uint8))
+
+ center_candidates = np.argwhere(inner_center_sample_mask > 0)
+ num_center_candidates = len(center_candidates)
+ sample_inds = np.random.choice(num_center_candidates, num_rand_comps)
+ rand_centers = center_candidates[sample_inds]
+
+ rand_top_height = np.random.randint(
+ min_rand_half_height,
+ max_rand_half_height,
+ size=(len(rand_centers), 1))
+ rand_bot_height = np.random.randint(
+ min_rand_half_height,
+ max_rand_half_height,
+ size=(len(rand_centers), 1))
+
+ rand_cos = 2 * np.random.random(size=(len(rand_centers), 1)) - 1
+ rand_sin = 2 * np.random.random(size=(len(rand_centers), 1)) - 1
+ scale = np.sqrt(1.0 / (rand_cos**2 + rand_sin**2 + 1e-8))
+ rand_cos = rand_cos * scale
+ rand_sin = rand_sin * scale
+
+ height = (rand_top_height + rand_bot_height)
+ width = np.clip(height * self.comp_w_h_ratio, self.min_width,
+ self.max_width)
+
+ rand_comp_attribs = np.hstack([
+ rand_centers[:, ::-1], height, width, rand_cos, rand_sin,
+ np.zeros_like(rand_sin)
+ ]).astype(np.float32)
+
+ return rand_comp_attribs
+
+ def _jitter_comp_attribs(self, comp_attribs: ndarray,
+ jitter_level: float) -> ndarray:
+ """Jitter text components attributes.
+
+ Args:
+ comp_attribs (ndarray): The text component attributes.
+ jitter_level (float): The jitter level of text components
+ attributes.
+
+ Returns:
+ ndarray: The jittered text component
+ attributes (x, y, h, w, cos, sin, comp_label).
+ """
+
+ assert comp_attribs.shape[1] == 7
+ assert comp_attribs.shape[0] > 0
+ assert isinstance(jitter_level, float)
+
+ x = comp_attribs[:, 0].reshape((-1, 1))
+ y = comp_attribs[:, 1].reshape((-1, 1))
+ h = comp_attribs[:, 2].reshape((-1, 1))
+ w = comp_attribs[:, 3].reshape((-1, 1))
+ cos = comp_attribs[:, 4].reshape((-1, 1))
+ sin = comp_attribs[:, 5].reshape((-1, 1))
+ comp_labels = comp_attribs[:, 6].reshape((-1, 1))
+
+ x += (np.random.random(size=(len(comp_attribs), 1)) -
+ 0.5) * (h * np.abs(cos) + w * np.abs(sin)) * jitter_level
+ y += (np.random.random(size=(len(comp_attribs), 1)) -
+ 0.5) * (h * np.abs(sin) + w * np.abs(cos)) * jitter_level
+
+ h += (np.random.random(size=(len(comp_attribs), 1)) -
+ 0.5) * h * jitter_level
+ w += (np.random.random(size=(len(comp_attribs), 1)) -
+ 0.5) * w * jitter_level
+
+ cos += (np.random.random(size=(len(comp_attribs), 1)) -
+ 0.5) * 2 * jitter_level
+ sin += (np.random.random(size=(len(comp_attribs), 1)) -
+ 0.5) * 2 * jitter_level
+
+ scale = np.sqrt(1.0 / (cos**2 + sin**2 + 1e-8))
+ cos = cos * scale
+ sin = sin * scale
+
+ jittered_comp_attribs = np.hstack([x, y, h, w, cos, sin, comp_labels])
+
+ return jittered_comp_attribs
+
+ def _draw_center_region_maps(self, top_line: ndarray, bot_line: ndarray,
+ center_line: ndarray,
+ center_region_mask: ndarray,
+ top_height_map: ndarray,
+ bot_height_map: ndarray, sin_map: ndarray,
+ cos_map: ndarray,
+ region_shrink_ratio: float) -> None:
+ """Draw attributes of text components on text center regions.
+
+ Args:
+ top_line (ndarray): The points composing the top side lines of text
+ polygons.
+ bot_line (ndarray): The points composing bottom side lines of text
+ polygons.
+ center_line (ndarray): The points composing the center lines of
+ text instances.
+ center_region_mask (ndarray): The text center region mask.
+ top_height_map (ndarray): The map on which the distance from points
+ to top side lines will be drawn for each pixel in text center
+ regions.
+ bot_height_map (ndarray): The map on which the distance from points
+ to bottom side lines will be drawn for each pixel in text
+ center regions.
+ sin_map (ndarray): The map of vector_sin(top_point - bot_point)
+ that will be drawn on text center regions.
+ cos_map (ndarray): The map of vector_cos(top_point - bot_point)
+ will be drawn on text center regions.
+ region_shrink_ratio (float): The shrink ratio of text center
+ regions.
+ """
+
+ assert top_line.shape == bot_line.shape == center_line.shape
+ assert (center_region_mask.shape == top_height_map.shape ==
+ bot_height_map.shape == sin_map.shape == cos_map.shape)
+ assert isinstance(region_shrink_ratio, float)
+
+ h, w = center_region_mask.shape
+ for i in range(0, len(center_line) - 1):
+
+ top_mid_point = (top_line[i] + top_line[i + 1]) / 2
+ bot_mid_point = (bot_line[i] + bot_line[i + 1]) / 2
+
+ sin_theta = self.vector_sin(top_mid_point - bot_mid_point)
+ cos_theta = self.vector_cos(top_mid_point - bot_mid_point)
+
+ tl = center_line[i] + (top_line[i] -
+ center_line[i]) * region_shrink_ratio
+ tr = center_line[i + 1] + (
+ top_line[i + 1] - center_line[i + 1]) * region_shrink_ratio
+ br = center_line[i + 1] + (
+ bot_line[i + 1] - center_line[i + 1]) * region_shrink_ratio
+ bl = center_line[i] + (bot_line[i] -
+ center_line[i]) * region_shrink_ratio
+ current_center_box = np.vstack([tl, tr, br, bl]).astype(np.int32)
+
+ cv2.fillPoly(center_region_mask, [current_center_box], color=1)
+ cv2.fillPoly(sin_map, [current_center_box], color=sin_theta)
+ cv2.fillPoly(cos_map, [current_center_box], color=cos_theta)
+
+ current_center_box[:, 0] = np.clip(current_center_box[:, 0], 0,
+ w - 1)
+ current_center_box[:, 1] = np.clip(current_center_box[:, 1], 0,
+ h - 1)
+ min_coord = np.min(current_center_box, axis=0).astype(np.int32)
+ max_coord = np.max(current_center_box, axis=0).astype(np.int32)
+ current_center_box = current_center_box - min_coord
+ box_sz = (max_coord - min_coord + 1)
+
+ center_box_mask = np.zeros((box_sz[1], box_sz[0]), dtype=np.uint8)
+ cv2.fillPoly(center_box_mask, [current_center_box], color=1)
+
+ inds = np.argwhere(center_box_mask > 0)
+ inds = inds + (min_coord[1], min_coord[0])
+ inds_xy = np.fliplr(inds)
+ top_height_map[(inds[:, 0], inds[:, 1])] = self._dist_point2line(
+ inds_xy, (top_line[i], top_line[i + 1]))
+ bot_height_map[(inds[:, 0], inds[:, 1])] = self._dist_point2line(
+ inds_xy, (bot_line[i], bot_line[i + 1]))
+
+ def _dist_point2line(self, point: ndarray,
+ line: Tuple[ndarray, ndarray]) -> ndarray:
+ """Calculate the distance from points to a line.
+
+ TODO: Check its mergibility with the one in mmocr.utils.point_utils.
+ """
+
+ assert isinstance(line, tuple)
+ point1, point2 = line
+ d = abs(np.cross(point2 - point1, point - point1)) / (
+ norm(point2 - point1) + 1e-8)
+ return d
diff --git a/mmocr/models/textdet/module_losses/fce_module_loss.py b/mmocr/models/textdet/module_losses/fce_module_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..c833c17787c3584605f83b04b0394e10ac7f14d5
--- /dev/null
+++ b/mmocr/models/textdet/module_losses/fce_module_loss.py
@@ -0,0 +1,563 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Sequence, Tuple, Union
+
+import cv2
+import numpy as np
+import torch
+from mmdet.models.utils import multi_apply
+from numpy.fft import fft
+from numpy.linalg import norm
+
+from mmocr.registry import MODELS
+from mmocr.structures import TextDetDataSample
+from mmocr.utils.typing_utils import ArrayLike
+from .textsnake_module_loss import TextSnakeModuleLoss
+
+
+@MODELS.register_module()
+class FCEModuleLoss(TextSnakeModuleLoss):
+ """The class for implementing FCENet loss.
+
+ FCENet(CVPR2021): `Fourier Contour Embedding for Arbitrary-shaped Text
+ Detection `_
+
+ Args:
+ fourier_degree (int) : The maximum Fourier transform degree k.
+ num_sample (int) : The sampling points number of regression
+ loss. If it is too small, fcenet tends to be overfitting.
+ negative_ratio (float or int): Maximum ratio of negative
+ samples to positive ones in OHEM. Defaults to 3.
+ resample_step (float): The step size for resampling the text center
+ line (TCL). It's better not to exceed half of the minimum width.
+ center_region_shrink_ratio (float): The shrink ratio of text center
+ region.
+ level_size_divisors (tuple(int)): The downsample ratio on each level.
+ level_proportion_range (tuple(tuple(int))): The range of text sizes
+ assigned to each level.
+ loss_tr (dict) : The loss config used to calculate the text region
+ loss. Defaults to dict(type='MaskedBalancedBCELoss').
+ loss_tcl (dict) : The loss config used to calculate the text center
+ line loss. Defaults to dict(type='MaskedBCELoss').
+ loss_reg_x (dict) : The loss config used to calculate the regression
+ loss on x axis. Defaults to dict(type='MaskedSmoothL1Loss').
+ loss_reg_y (dict) : The loss config used to calculate the regression
+ loss on y axis. Defaults to dict(type='MaskedSmoothL1Loss').
+ """
+
+ def __init__(
+ self,
+ fourier_degree: int,
+ num_sample: int,
+ negative_ratio: Union[float, int] = 3.,
+ resample_step: float = 4.0,
+ center_region_shrink_ratio: float = 0.3,
+ level_size_divisors: Tuple[int] = (8, 16, 32),
+ level_proportion_range: Tuple[Tuple[int]] = ((0, 0.4), (0.3, 0.7),
+ (0.6, 1.0)),
+ loss_tr: Dict = dict(type='MaskedBalancedBCELoss'),
+ loss_tcl: Dict = dict(type='MaskedBCELoss'),
+ loss_reg_x: Dict = dict(type='SmoothL1Loss', reduction='none'),
+ loss_reg_y: Dict = dict(type='SmoothL1Loss', reduction='none'),
+ ) -> None:
+ super().__init__()
+ self.fourier_degree = fourier_degree
+ self.num_sample = num_sample
+ self.resample_step = resample_step
+ self.center_region_shrink_ratio = center_region_shrink_ratio
+ self.level_size_divisors = level_size_divisors
+ self.level_proportion_range = level_proportion_range
+
+ loss_tr.update(negative_ratio=negative_ratio)
+ self.loss_tr = MODELS.build(loss_tr)
+ self.loss_tcl = MODELS.build(loss_tcl)
+ self.loss_reg_x = MODELS.build(loss_reg_x)
+ self.loss_reg_y = MODELS.build(loss_reg_y)
+
+ def forward(self, preds: Sequence[Dict],
+ data_samples: Sequence[TextDetDataSample]) -> Dict:
+ """Compute FCENet loss.
+
+ Args:
+ preds (list[dict]): A list of dict with keys of ``cls_res``,
+ ``reg_res`` corresponds to the classification result and
+ regression result computed from the input tensor with the
+ same index. They have the shapes of :math:`(N, C_{cls,i}, H_i,
+ W_i)` and :math: `(N, C_{out,i}, H_i, W_i)`.
+ data_samples (list[TextDetDataSample]): The data samples.
+
+ Returns:
+ dict: The dict for fcenet losses with loss_text, loss_center,
+ loss_reg_x and loss_reg_y.
+ """
+ assert isinstance(preds, list) and len(preds) == 3
+ p3_maps, p4_maps, p5_maps = self.get_targets(data_samples)
+ device = preds[0]['cls_res'].device
+ # to device
+ gts = [p3_maps.to(device), p4_maps.to(device), p5_maps.to(device)]
+
+ losses = multi_apply(self.forward_single, preds, gts)
+
+ loss_tr = torch.tensor(0., device=device).float()
+ loss_tcl = torch.tensor(0., device=device).float()
+ loss_reg_x = torch.tensor(0., device=device).float()
+ loss_reg_y = torch.tensor(0., device=device).float()
+
+ for idx, loss in enumerate(losses):
+ if idx == 0:
+ loss_tr += sum(loss)
+ elif idx == 1:
+ loss_tcl += sum(loss)
+ elif idx == 2:
+ loss_reg_x += sum(loss)
+ else:
+ loss_reg_y += sum(loss)
+
+ results = dict(
+ loss_text=loss_tr,
+ loss_center=loss_tcl,
+ loss_reg_x=loss_reg_x,
+ loss_reg_y=loss_reg_y,
+ )
+
+ return results
+
+ def forward_single(self, pred: torch.Tensor,
+ gt: torch.Tensor) -> Sequence[torch.Tensor]:
+ """Compute loss for one feature level.
+
+ Args:
+ pred (dict): A dict with keys ``cls_res`` and ``reg_res``
+ corresponds to the classification result and regression result
+ from one feature level.
+ gt (Tensor): Ground truth for one feature level. Cls and reg
+ targets are concatenated along the channel dimension.
+
+ Returns:
+ list[Tensor]: A list of losses for each feature level.
+ """
+ assert isinstance(pred, dict) and isinstance(gt, torch.Tensor)
+ cls_pred = pred['cls_res'].permute(0, 2, 3, 1).contiguous()
+ reg_pred = pred['reg_res'].permute(0, 2, 3, 1).contiguous()
+
+ gt = gt.permute(0, 2, 3, 1).contiguous()
+
+ k = 2 * self.fourier_degree + 1
+ tr_pred = cls_pred[:, :, :, :2].view(-1, 2)
+ tcl_pred = cls_pred[:, :, :, 2:].view(-1, 2)
+ x_pred = reg_pred[:, :, :, 0:k].view(-1, k)
+ y_pred = reg_pred[:, :, :, k:2 * k].view(-1, k)
+
+ tr_mask = gt[:, :, :, :1].view(-1)
+ tcl_mask = gt[:, :, :, 1:2].view(-1)
+ train_mask = gt[:, :, :, 2:3].view(-1)
+ x_map = gt[:, :, :, 3:3 + k].view(-1, k)
+ y_map = gt[:, :, :, 3 + k:].view(-1, k)
+
+ tr_train_mask = (train_mask * tr_mask).float()
+ # text region loss
+ loss_tr = self.loss_tr(tr_pred.softmax(-1)[:, 1], tr_mask, train_mask)
+
+ # text center line loss
+ tr_neg_mask = 1 - tr_train_mask
+ loss_tcl_positive = self.loss_center(
+ tcl_pred.softmax(-1)[:, 1], tcl_mask, tr_train_mask)
+ loss_tcl_negative = self.loss_center(
+ tcl_pred.softmax(-1)[:, 1], tcl_mask, tr_neg_mask)
+ loss_tcl = loss_tcl_positive + 0.5 * loss_tcl_negative
+
+ # regression loss
+ loss_reg_x = torch.tensor(0.).float().to(x_pred.device)
+ loss_reg_y = torch.tensor(0.).float().to(x_pred.device)
+ if tr_train_mask.sum().item() > 0:
+ weight = (tr_mask[tr_train_mask.bool()].float() +
+ tcl_mask[tr_train_mask.bool()].float()) / 2
+ weight = weight.contiguous().view(-1, 1)
+
+ ft_x, ft_y = self._fourier2poly(x_map, y_map)
+ ft_x_pre, ft_y_pre = self._fourier2poly(x_pred, y_pred)
+
+ loss_reg_x = torch.mean(weight * self.loss_reg_x(
+ ft_x_pre[tr_train_mask.bool()], ft_x[tr_train_mask.bool()]))
+ loss_reg_y = torch.mean(weight * self.loss_reg_x(
+ ft_y_pre[tr_train_mask.bool()], ft_y[tr_train_mask.bool()]))
+
+ return loss_tr, loss_tcl, loss_reg_x, loss_reg_y
+
+ def get_targets(self, data_samples: List[TextDetDataSample]) -> Tuple:
+ """Generate loss targets for fcenet from data samples.
+
+ Args:
+ data_samples (list(TextDetDataSample)): Ground truth data samples.
+
+ Returns:
+ tuple[Tensor]: A tuple of three tensors from three different
+ feature level as FCENet targets.
+ """
+ p3_maps, p4_maps, p5_maps = multi_apply(self._get_target_single,
+ data_samples)
+ p3_maps = torch.cat(p3_maps, 0)
+ p4_maps = torch.cat(p4_maps, 0)
+ p5_maps = torch.cat(p5_maps, 0)
+
+ return p3_maps, p4_maps, p5_maps
+
+ def _get_target_single(self, data_sample: TextDetDataSample) -> Tuple:
+ """Generate loss target for fcenet from a data sample.
+
+ Args:
+ data_sample (TextDetDataSample): The data sample.
+
+ Returns:
+ tuple[Tensor]: A tuple of three tensors from three different
+ feature level as the targets of one prediction.
+ """
+ img_size = data_sample.img_shape[:2]
+ text_polys = data_sample.gt_instances.polygons
+ ignore_flags = data_sample.gt_instances.ignored
+
+ p3_map, p4_map, p5_map = self._generate_level_targets(
+ img_size, text_polys, ignore_flags)
+ # to tesnor
+ p3_map = torch.from_numpy(p3_map).unsqueeze(0).float()
+ p4_map = torch.from_numpy(p4_map).unsqueeze(0).float()
+ p5_map = torch.from_numpy(p5_map).unsqueeze(0).float()
+ return p3_map, p4_map, p5_map
+
+ def _generate_level_targets(self,
+ img_size: Tuple[int, int],
+ text_polys: List[ArrayLike],
+ ignore_flags: Optional[torch.BoolTensor] = None
+ ) -> Tuple[torch.Tensor]:
+ """Generate targets for one feature level.
+
+ Args:
+ img_size (tuple(int, int)): The image size of (height, width).
+ text_polys (List[ndarray]): 2D array of text polygons.
+ ignore_flags (torch.BoolTensor, optional): Indicate whether the
+ corresponding text polygon is ignored. Defaults to None.
+
+ Returns:
+ tuple[Tensor]: A tuple of three tensors from one feature level
+ as the targets.
+ """
+ h, w = img_size
+ lv_size_divs = self.level_size_divisors
+ lv_proportion_range = self.level_proportion_range
+
+ lv_size_divs = self.level_size_divisors
+ lv_proportion_range = self.level_proportion_range
+ lv_text_polys = [[] for i in range(len(lv_size_divs))]
+ lv_ignore_polys = [[] for i in range(len(lv_size_divs))]
+ level_maps = []
+
+ for poly_ind, poly in enumerate(text_polys):
+ poly = np.array(poly, dtype=np.int_).reshape((1, -1, 2))
+ _, _, box_w, box_h = cv2.boundingRect(poly)
+ proportion = max(box_h, box_w) / (h + 1e-8)
+
+ for ind, proportion_range in enumerate(lv_proportion_range):
+ if proportion_range[0] < proportion < proportion_range[1]:
+ if ignore_flags is not None and ignore_flags[poly_ind]:
+ lv_ignore_polys[ind].append(poly[0] /
+ lv_size_divs[ind])
+ else:
+ lv_text_polys[ind].append(poly[0] / lv_size_divs[ind])
+
+ for ind, size_divisor in enumerate(lv_size_divs):
+ current_level_maps = []
+ level_img_size = (h // size_divisor, w // size_divisor)
+
+ text_region = self._generate_text_region_mask(
+ level_img_size, lv_text_polys[ind])[None]
+ current_level_maps.append(text_region)
+
+ center_region = self._generate_center_region_mask(
+ level_img_size, lv_text_polys[ind])[None]
+ current_level_maps.append(center_region)
+
+ effective_mask = self._generate_effective_mask(
+ level_img_size, lv_ignore_polys[ind])[None]
+ current_level_maps.append(effective_mask)
+
+ fourier_real_map, fourier_image_maps = self._generate_fourier_maps(
+ level_img_size, lv_text_polys[ind])
+ current_level_maps.append(fourier_real_map)
+ current_level_maps.append(fourier_image_maps)
+
+ level_maps.append(np.concatenate(current_level_maps))
+
+ return level_maps
+
+ def _generate_center_region_mask(self, img_size: Tuple[int, int],
+ text_polys: ArrayLike) -> np.ndarray:
+ """Generate text center region mask.
+
+ Args:
+ img_size (tuple): The image size of (height, width).
+ text_polys (list[ndarray]): The list of text polygons.
+
+ Returns:
+ ndarray: The text center region mask.
+ """
+
+ assert isinstance(img_size, tuple)
+
+ h, w = img_size
+
+ center_region_mask = np.zeros((h, w), np.uint8)
+
+ center_region_boxes = []
+ for poly in text_polys:
+ polygon_points = poly.reshape(-1, 2)
+ _, _, top_line, bot_line = self._reorder_poly_edge(polygon_points)
+ resampled_top_line, resampled_bot_line = self._resample_sidelines(
+ top_line, bot_line, self.resample_step)
+ resampled_bot_line = resampled_bot_line[::-1]
+ center_line = (resampled_top_line + resampled_bot_line) / 2
+
+ line_head_shrink_len = norm(resampled_top_line[0] -
+ resampled_bot_line[0]) / 4.0
+ line_tail_shrink_len = norm(resampled_top_line[-1] -
+ resampled_bot_line[-1]) / 4.0
+ head_shrink_num = int(line_head_shrink_len // self.resample_step)
+ tail_shrink_num = int(line_tail_shrink_len // self.resample_step)
+ if len(center_line) > head_shrink_num + tail_shrink_num + 2:
+ center_line = center_line[head_shrink_num:len(center_line) -
+ tail_shrink_num]
+ resampled_top_line = resampled_top_line[
+ head_shrink_num:len(resampled_top_line) - tail_shrink_num]
+ resampled_bot_line = resampled_bot_line[
+ head_shrink_num:len(resampled_bot_line) - tail_shrink_num]
+
+ for i in range(0, len(center_line) - 1):
+ tl = center_line[i] + (resampled_top_line[i] - center_line[i]
+ ) * self.center_region_shrink_ratio
+ tr = center_line[i + 1] + (
+ resampled_top_line[i + 1] -
+ center_line[i + 1]) * self.center_region_shrink_ratio
+ br = center_line[i + 1] + (
+ resampled_bot_line[i + 1] -
+ center_line[i + 1]) * self.center_region_shrink_ratio
+ bl = center_line[i] + (resampled_bot_line[i] - center_line[i]
+ ) * self.center_region_shrink_ratio
+ current_center_box = np.vstack([tl, tr, br,
+ bl]).astype(np.int32)
+ center_region_boxes.append(current_center_box)
+
+ cv2.fillPoly(center_region_mask, center_region_boxes, 1)
+ return center_region_mask
+
+ def _generate_fourier_maps(self, img_size: Tuple[int, int],
+ text_polys: ArrayLike
+ ) -> Tuple[np.ndarray, np.ndarray]:
+ """Generate Fourier coefficient maps.
+
+ Args:
+ img_size (tuple): The image size of (height, width).
+ text_polys (list[ndarray]): The list of text polygons.
+
+ Returns:
+ tuple(ndarray, ndarray):
+
+ - fourier_real_map (ndarray): The Fourier coefficient real part
+ maps.
+ - fourier_image_map (ndarray): The Fourier coefficient image part
+ maps.
+ """
+
+ assert isinstance(img_size, tuple)
+
+ h, w = img_size
+ k = self.fourier_degree
+ real_map = np.zeros((k * 2 + 1, h, w), dtype=np.float32)
+ imag_map = np.zeros((k * 2 + 1, h, w), dtype=np.float32)
+
+ for poly in text_polys:
+ mask = np.zeros((h, w), dtype=np.uint8)
+ polygon = np.array(poly).reshape((1, -1, 2))
+ cv2.fillPoly(mask, polygon.astype(np.int32), 1)
+ fourier_coeff = self._cal_fourier_signature(polygon[0], k)
+ for i in range(-k, k + 1):
+ if i != 0:
+ real_map[i + k, :, :] = mask * fourier_coeff[i + k, 0] + (
+ 1 - mask) * real_map[i + k, :, :]
+ imag_map[i + k, :, :] = mask * fourier_coeff[i + k, 1] + (
+ 1 - mask) * imag_map[i + k, :, :]
+ else:
+ yx = np.argwhere(mask > 0.5)
+ k_ind = np.ones((len(yx)), dtype=np.int64) * k
+ y, x = yx[:, 0], yx[:, 1]
+ real_map[k_ind, y, x] = fourier_coeff[k, 0] - x
+ imag_map[k_ind, y, x] = fourier_coeff[k, 1] - y
+
+ return real_map, imag_map
+
+ def _cal_fourier_signature(self, polygon: ArrayLike,
+ fourier_degree: int) -> np.ndarray:
+ """Calculate Fourier signature from input polygon.
+
+ Args:
+ polygon (list[ndarray]): The input polygon.
+ fourier_degree (int): The maximum Fourier degree K.
+ Returns:
+ ndarray: An array shaped (2k+1, 2) containing
+ real part and image part of 2k+1 Fourier coefficients.
+ """
+ resampled_polygon = self._resample_polygon(polygon)
+ resampled_polygon = self._normalize_polygon(resampled_polygon)
+
+ fourier_coeff = self._poly2fourier(resampled_polygon, fourier_degree)
+ fourier_coeff = self._clockwise(fourier_coeff, fourier_degree)
+
+ real_part = np.real(fourier_coeff).reshape((-1, 1))
+ image_part = np.imag(fourier_coeff).reshape((-1, 1))
+ fourier_signature = np.hstack([real_part, image_part])
+
+ return fourier_signature
+
+ def _resample_polygon(self,
+ polygon: ArrayLike,
+ n: int = 400) -> np.ndarray:
+ """Resample one polygon with n points on its boundary.
+
+ Args:
+ polygon (list[ndarray]): The input polygon.
+ n (int): The number of resampled points. Defaults to 400.
+ Returns:
+ ndarray: The resampled polygon.
+ """
+ length = []
+
+ for i in range(len(polygon)):
+ p1 = polygon[i]
+ if i == len(polygon) - 1:
+ p2 = polygon[0]
+ else:
+ p2 = polygon[i + 1]
+ length.append(((p1[0] - p2[0])**2 + (p1[1] - p2[1])**2)**0.5)
+
+ total_length = sum(length)
+ n_on_each_line = (np.array(length) / (total_length + 1e-8)) * n
+ n_on_each_line = n_on_each_line.astype(np.int32)
+ new_polygon = []
+
+ for i in range(len(polygon)):
+ num = n_on_each_line[i]
+ p1 = polygon[i]
+ if i == len(polygon) - 1:
+ p2 = polygon[0]
+ else:
+ p2 = polygon[i + 1]
+
+ if num == 0:
+ continue
+
+ dxdy = (p2 - p1) / num
+ for j in range(num):
+ point = p1 + dxdy * j
+ new_polygon.append(point)
+
+ return np.array(new_polygon)
+
+ def _normalize_polygon(self, polygon: ArrayLike) -> np.ndarray:
+ """Normalize one polygon so that its start point is at right most.
+
+ Args:
+ polygon (list[ndarray]): The origin polygon.
+ Returns:
+ ndarray: The polygon with start point at right.
+ """
+ temp_polygon = polygon - polygon.mean(axis=0)
+ x = np.abs(temp_polygon[:, 0])
+ y = temp_polygon[:, 1]
+ index_x = np.argsort(x)
+ index_y = np.argmin(y[index_x[:8]])
+ index = index_x[index_y]
+ new_polygon = np.concatenate([polygon[index:], polygon[:index]])
+ return new_polygon
+
+ def _clockwise(self, fourier_coeff: np.ndarray,
+ fourier_degree: int) -> np.ndarray:
+ """Make sure the polygon reconstructed from Fourier coefficients c in
+ the clockwise direction.
+
+ Args:
+ fourier_coeff (ndarray[complex]): The Fourier coefficients.
+ fourier_degree: The maximum Fourier degree K.
+ Returns:
+ lost[float]: The polygon in clockwise point order.
+ """
+ if np.abs(fourier_coeff[fourier_degree + 1]) > np.abs(
+ fourier_coeff[fourier_degree - 1]):
+ return fourier_coeff
+ elif np.abs(fourier_coeff[fourier_degree + 1]) < np.abs(
+ fourier_coeff[fourier_degree - 1]):
+ return fourier_coeff[::-1]
+ else:
+ if np.abs(fourier_coeff[fourier_degree + 2]) > np.abs(
+ fourier_coeff[fourier_degree - 2]):
+ return fourier_coeff
+ else:
+ return fourier_coeff[::-1]
+
+ def _poly2fourier(self, polygon: ArrayLike,
+ fourier_degree: int) -> np.ndarray:
+ """Perform Fourier transformation to generate Fourier coefficients ck
+ from polygon.
+
+ Args:
+ polygon (list[ndarray]): An input polygon.
+ fourier_degree (int): The maximum Fourier degree K.
+ Returns:
+ ndarray: Fourier coefficients.
+ """
+ points = polygon[:, 0] + polygon[:, 1] * 1j
+ c_fft = fft(points) / len(points)
+ c = np.hstack((c_fft[-fourier_degree:], c_fft[:fourier_degree + 1]))
+ return c
+
+ def _fourier2poly(self, real_maps: torch.Tensor,
+ imag_maps: torch.Tensor) -> Sequence[torch.Tensor]:
+ """Transform Fourier coefficient maps to polygon maps.
+
+ Args:
+ real_maps (tensor): A map composed of the real parts of the
+ Fourier coefficients, whose shape is (-1, 2k+1)
+ imag_maps (tensor):A map composed of the imag parts of the
+ Fourier coefficients, whose shape is (-1, 2k+1)
+
+ Returns
+ tuple(tensor, tensor):
+
+ - x_maps (tensor): A map composed of the x value of the polygon
+ represented by n sample points (xn, yn), whose shape is (-1, n)
+ - y_maps (tensor): A map composed of the y value of the polygon
+ represented by n sample points (xn, yn), whose shape is (-1, n)
+ """
+
+ device = real_maps.device
+
+ k_vect = torch.arange(
+ -self.fourier_degree,
+ self.fourier_degree + 1,
+ dtype=torch.float,
+ device=device).view(-1, 1)
+ i_vect = torch.arange(
+ 0, self.num_sample, dtype=torch.float, device=device).view(1, -1)
+
+ transform_matrix = 2 * np.pi / self.num_sample * torch.mm(
+ k_vect, i_vect)
+
+ x1 = torch.einsum('ak, kn-> an', real_maps,
+ torch.cos(transform_matrix))
+ x2 = torch.einsum('ak, kn-> an', imag_maps,
+ torch.sin(transform_matrix))
+ y1 = torch.einsum('ak, kn-> an', real_maps,
+ torch.sin(transform_matrix))
+ y2 = torch.einsum('ak, kn-> an', imag_maps,
+ torch.cos(transform_matrix))
+
+ x_maps = x1 - x2
+ y_maps = y1 + y2
+
+ return x_maps, y_maps
diff --git a/mmocr/models/textdet/module_losses/pan_module_loss.py b/mmocr/models/textdet/module_losses/pan_module_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..6a5a6685aa9514f5d9afbfbe9b5a7fe4029ab96d
--- /dev/null
+++ b/mmocr/models/textdet/module_losses/pan_module_loss.py
@@ -0,0 +1,347 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from typing import Dict, Sequence, Tuple, Union
+
+import numpy as np
+import torch
+import torch.nn.functional as F
+from mmdet.models.utils import multi_apply
+from torch import nn
+
+from mmocr.registry import MODELS
+from mmocr.structures import TextDetDataSample
+from .seg_based_module_loss import SegBasedModuleLoss
+
+
+@MODELS.register_module()
+class PANModuleLoss(SegBasedModuleLoss):
+ """The class for implementing PANet loss. This was partially adapted from
+ https://github.com/whai362/pan_pp.pytorch and
+ https://github.com/WenmuZhou/PAN.pytorch.
+
+ PANet: `Efficient and Accurate Arbitrary-
+ Shaped Text Detection with Pixel Aggregation Network
+ `_.
+
+ Args:
+ loss_text (dict) The loss config for text map. Defaults to
+ dict(type='MaskedSquareDiceLoss').
+ loss_kernel (dict) The loss config for kernel map. Defaults to
+ dict(type='MaskedSquareDiceLoss').
+ loss_embedding (dict) The loss config for embedding map. Defaults to
+ dict(type='PANEmbLossV1').
+ weight_text (float): The weight of text loss. Defaults to 1.
+ weight_kernel (float): The weight of kernel loss. Defaults to 0.5.
+ weight_embedding (float): The weight of embedding loss.
+ Defaults to 0.25.
+ ohem_ratio (float): The negative/positive ratio in ohem. Defaults to 3.
+ shrink_ratio (tuple[float]) : The ratio of shrinking kernel. Defaults
+ to (1.0, 0.5).
+ max_shrink_dist (int or float): The maximum shrinking distance.
+ Defaults to 20.
+ reduction (str): The way to reduce the loss. Available options are
+ "mean" and "sum". Defaults to 'mean'.
+ """
+
+ def __init__(
+ self,
+ loss_text: Dict = dict(type='MaskedSquareDiceLoss'),
+ loss_kernel: Dict = dict(type='MaskedSquareDiceLoss'),
+ loss_embedding: Dict = dict(type='PANEmbLossV1'),
+ weight_text: float = 1.0,
+ weight_kernel: float = 0.5,
+ weight_embedding: float = 0.25,
+ ohem_ratio: Union[int, float] = 3, # TODO Find a better name
+ shrink_ratio: Sequence[Union[int, float]] = (1.0, 0.5),
+ max_shrink_dist: Union[int, float] = 20,
+ reduction: str = 'mean') -> None:
+ super().__init__()
+ assert reduction in ['mean', 'sum'], "reduction must in ['mean','sum']"
+ self.weight_text = weight_text
+ self.weight_kernel = weight_kernel
+ self.weight_embedding = weight_embedding
+ self.shrink_ratio = shrink_ratio
+ self.ohem_ratio = ohem_ratio
+ self.reduction = reduction
+ self.max_shrink_dist = max_shrink_dist
+ self.loss_text = MODELS.build(loss_text)
+ self.loss_kernel = MODELS.build(loss_kernel)
+ self.loss_embedding = MODELS.build(loss_embedding)
+
+ def forward(self, preds: torch.Tensor,
+ data_samples: Sequence[TextDetDataSample]) -> Dict:
+ """Compute PAN loss.
+
+ Args:
+ preds (dict): Raw predictions from model with
+ shape :math:`(N, C, H, W)`.
+ data_samples (list[TextDetDataSample]): The data samples.
+
+ Returns:
+ dict: The dict for pan losses with loss_text, loss_kernel,
+ loss_aggregation and loss_discrimination.
+ """
+
+ gt_kernels, gt_masks = self.get_targets(data_samples)
+ target_size = gt_kernels.size()[2:]
+ preds = F.interpolate(preds, size=target_size, mode='bilinear')
+ pred_texts = preds[:, 0, :, :]
+ pred_kernels = preds[:, 1, :, :]
+ inst_embed = preds[:, 2:, :, :]
+ gt_kernels = gt_kernels.to(preds.device)
+ gt_masks = gt_masks.to(preds.device)
+
+ # compute embedding loss
+ loss_emb = self.loss_embedding(inst_embed, gt_kernels[0],
+ gt_kernels[1], gt_masks)
+ gt_kernels[gt_kernels <= 0.5] = 0
+ gt_kernels[gt_kernels > 0.5] = 1
+ # compute text loss
+ sampled_mask = self._ohem_batch(pred_texts.detach(), gt_kernels[0],
+ gt_masks)
+ pred_texts = torch.sigmoid(pred_texts)
+ loss_texts = self.loss_text(pred_texts, gt_kernels[0], sampled_mask)
+
+ # compute kernel loss
+ pred_kernels = torch.sigmoid(pred_kernels)
+ sampled_masks_kernel = (gt_kernels[0] > 0.5).float() * gt_masks
+ loss_kernels = self.loss_kernel(pred_kernels, gt_kernels[1],
+ sampled_masks_kernel)
+
+ losses = [loss_texts, loss_kernels, loss_emb]
+ if self.reduction == 'mean':
+ losses = [item.mean() for item in losses]
+ else:
+ losses = [item.sum() for item in losses]
+
+ results = dict()
+ results.update(
+ loss_text=self.weight_text * losses[0],
+ loss_kernel=self.weight_kernel * losses[1],
+ loss_embedding=self.weight_embedding * losses[2])
+ return results
+
+ def get_targets(
+ self,
+ data_samples: Sequence[TextDetDataSample],
+ ) -> Tuple[torch.Tensor, torch.Tensor]:
+ """Generate the gt targets for PANet.
+
+ Args:
+ results (dict): The input result dictionary.
+
+ Returns:
+ results (dict): The output result dictionary.
+ """
+ gt_kernels, gt_masks = multi_apply(self._get_target_single,
+ data_samples)
+ # gt_kernels: (N, kernel_number, H, W)->(kernel_number, N, H, W)
+ gt_kernels = torch.stack(gt_kernels, dim=0).permute(1, 0, 2, 3)
+ gt_masks = torch.stack(gt_masks, dim=0)
+ return gt_kernels, gt_masks
+
+ def _get_target_single(self, data_sample: TextDetDataSample
+ ) -> Tuple[torch.Tensor, torch.Tensor]:
+ """Generate loss target from a data sample.
+
+ Args:
+ data_sample (TextDetDataSample): The data sample.
+
+ Returns:
+ tuple: A tuple of four tensors as the targets of one prediction.
+ """
+ gt_polygons = data_sample.gt_instances.polygons
+ gt_ignored = data_sample.gt_instances.ignored
+
+ gt_kernels = []
+ for ratio in self.shrink_ratio:
+ # TODO pass `gt_ignored` to `_generate_kernels`
+ gt_kernel, _ = self._generate_kernels(
+ data_sample.img_shape,
+ gt_polygons,
+ ratio,
+ ignore_flags=None,
+ max_shrink_dist=self.max_shrink_dist)
+ gt_kernels.append(gt_kernel)
+ gt_polygons_ignored = data_sample.gt_instances[gt_ignored].polygons
+ gt_mask = self._generate_effective_mask(data_sample.img_shape,
+ gt_polygons_ignored)
+
+ gt_kernels = np.stack(gt_kernels, axis=0)
+ gt_kernels = torch.from_numpy(gt_kernels).float()
+ gt_mask = torch.from_numpy(gt_mask).float()
+ return gt_kernels, gt_mask
+
+ def _ohem_batch(self, text_scores: torch.Tensor, gt_texts: torch.Tensor,
+ gt_mask: torch.Tensor) -> torch.Tensor:
+ """OHEM sampling for a batch of imgs.
+
+ Args:
+ text_scores (Tensor): The text scores of size :math:`(H, W)`.
+ gt_texts (Tensor): The gt text masks of size :math:`(H, W)`.
+ gt_mask (Tensor): The gt effective mask of size :math:`(H, W)`.
+
+ Returns:
+ Tensor: The sampled mask of size :math:`(H, W)`.
+ """
+ assert isinstance(text_scores, torch.Tensor)
+ assert isinstance(gt_texts, torch.Tensor)
+ assert isinstance(gt_mask, torch.Tensor)
+ assert len(text_scores.shape) == 3
+ assert text_scores.shape == gt_texts.shape
+ assert gt_texts.shape == gt_mask.shape
+
+ sampled_masks = []
+ for i in range(text_scores.shape[0]):
+ sampled_masks.append(
+ self._ohem_single(text_scores[i], gt_texts[i], gt_mask[i]))
+
+ sampled_masks = torch.stack(sampled_masks)
+
+ return sampled_masks
+
+ def _ohem_single(self, text_score: torch.Tensor, gt_text: torch.Tensor,
+ gt_mask: torch.Tensor) -> torch.Tensor:
+ """Sample the top-k maximal negative samples and all positive samples.
+
+ Args:
+ text_score (Tensor): The text score of size :math:`(H, W)`.
+ gt_text (Tensor): The ground truth text mask of size
+ :math:`(H, W)`.
+ gt_mask (Tensor): The effective region mask of size :math:`(H, W)`.
+
+ Returns:
+ Tensor: The sampled pixel mask of size :math:`(H, W)`.
+ """
+ assert isinstance(text_score, torch.Tensor)
+ assert isinstance(gt_text, torch.Tensor)
+ assert isinstance(gt_mask, torch.Tensor)
+ assert len(text_score.shape) == 2
+ assert text_score.shape == gt_text.shape
+ assert gt_text.shape == gt_mask.shape
+
+ pos_num = (int)(torch.sum(gt_text > 0.5).item()) - (int)(
+ torch.sum((gt_text > 0.5) * (gt_mask <= 0.5)).item())
+ neg_num = (int)(torch.sum(gt_text <= 0.5).item())
+ neg_num = (int)(min(pos_num * self.ohem_ratio, neg_num))
+
+ if pos_num == 0 or neg_num == 0:
+ warnings.warn('pos_num = 0 or neg_num = 0')
+ return gt_mask.bool()
+
+ neg_score = text_score[gt_text <= 0.5]
+ neg_score_sorted, _ = torch.sort(neg_score, descending=True)
+ threshold = neg_score_sorted[neg_num - 1]
+ sampled_mask = (((text_score >= threshold) + (gt_text > 0.5)) > 0) * (
+ gt_mask > 0.5)
+ return sampled_mask
+
+
+@MODELS.register_module()
+class PANEmbLossV1(nn.Module):
+ """The class for implementing EmbLossV1. This was partially adapted from
+ https://github.com/whai362/pan_pp.pytorch.
+
+ Args:
+ feature_dim (int): The dimension of the feature. Defaults to 4.
+ delta_aggregation (float): The delta for aggregation. Defaults to 0.5.
+ delta_discrimination (float): The delta for discrimination.
+ Defaults to 1.5.
+ """
+
+ def __init__(self,
+ feature_dim: int = 4,
+ delta_aggregation: float = 0.5,
+ delta_discrimination: float = 1.5) -> None:
+ super().__init__()
+ self.feature_dim = feature_dim
+ self.delta_aggregation = delta_aggregation
+ self.delta_discrimination = delta_discrimination
+ self.weights = (1.0, 1.0)
+
+ def _forward_single(self, emb: torch.Tensor, instance: torch.Tensor,
+ kernel: torch.Tensor,
+ training_mask: torch.Tensor) -> torch.Tensor:
+ """Compute the loss for a single image.
+
+ Args:
+ emb (torch.Tensor): The embedding feature.
+ instance (torch.Tensor): The instance feature.
+ kernel (torch.Tensor): The kernel feature.
+ training_mask (torch.Tensor): The effective mask.
+ """
+ training_mask = (training_mask > 0.5).float()
+ kernel = (kernel > 0.5).float()
+ instance = instance * training_mask
+ instance_kernel = (instance * kernel).view(-1)
+ instance = instance.view(-1)
+ emb = emb.view(self.feature_dim, -1)
+
+ unique_labels, unique_ids = torch.unique(
+ instance_kernel, sorted=True, return_inverse=True)
+ num_instance = unique_labels.size(0)
+ if num_instance <= 1:
+ return 0
+
+ emb_mean = emb.new_zeros((self.feature_dim, num_instance),
+ dtype=torch.float32)
+ for i, lb in enumerate(unique_labels):
+ if lb == 0:
+ continue
+ ind_k = instance_kernel == lb
+ emb_mean[:, i] = torch.mean(emb[:, ind_k], dim=1)
+
+ l_agg = emb.new_zeros(num_instance, dtype=torch.float32)
+ for i, lb in enumerate(unique_labels):
+ if lb == 0:
+ continue
+ ind = instance == lb
+ emb_ = emb[:, ind]
+ dist = (emb_ - emb_mean[:, i:i + 1]).norm(p=2, dim=0)
+ dist = F.relu(dist - self.delta_aggregation)**2
+ l_agg[i] = torch.mean(torch.log(dist + 1.0))
+ l_agg = torch.mean(l_agg[1:])
+
+ if num_instance > 2:
+ emb_interleave = emb_mean.permute(1, 0).repeat(num_instance, 1)
+ emb_band = emb_mean.permute(1, 0).repeat(1, num_instance).view(
+ -1, self.feature_dim)
+
+ mask = (1 - torch.eye(num_instance, dtype=torch.int8)).view(
+ -1, 1).repeat(1, self.feature_dim)
+ mask = mask.view(num_instance, num_instance, -1)
+ mask[0, :, :] = 0
+ mask[:, 0, :] = 0
+ mask = mask.view(num_instance * num_instance, -1)
+
+ dist = emb_interleave - emb_band
+ dist = dist[mask > 0].view(-1, self.feature_dim).norm(p=2, dim=1)
+ dist = F.relu(2 * self.delta_discrimination - dist)**2
+ l_dis = torch.mean(torch.log(dist + 1.0))
+ else:
+ l_dis = 0
+
+ l_agg = self.weights[0] * l_agg
+ l_dis = self.weights[1] * l_dis
+ l_reg = torch.mean(torch.log(torch.norm(emb_mean, 2, 0) + 1.0)) * 0.001
+ loss = l_agg + l_dis + l_reg
+ return loss
+
+ def forward(self, emb: torch.Tensor, instance: torch.Tensor,
+ kernel: torch.Tensor,
+ training_mask: torch.Tensor) -> torch.Tensor:
+ """Compute the loss for a batch image.
+
+ Args:
+ emb (torch.Tensor): The embedding feature.
+ instance (torch.Tensor): The instance feature.
+ kernel (torch.Tensor): The kernel feature.
+ training_mask (torch.Tensor): The effective mask.
+ """
+ loss_batch = emb.new_zeros((emb.size(0)), dtype=torch.float32)
+
+ for i in range(loss_batch.size(0)):
+ loss_batch[i] = self._forward_single(emb[i], instance[i],
+ kernel[i], training_mask[i])
+
+ return loss_batch
diff --git a/mmocr/models/textdet/module_losses/pse_module_loss.py b/mmocr/models/textdet/module_losses/pse_module_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..902588c49cc642c059e86dc1a76c08658349295d
--- /dev/null
+++ b/mmocr/models/textdet/module_losses/pse_module_loss.py
@@ -0,0 +1,129 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, Sequence, Tuple, Union
+
+import torch
+import torch.nn.functional as F
+
+from mmocr.registry import MODELS
+from mmocr.structures import TextDetDataSample
+from . import PANModuleLoss
+
+
+@MODELS.register_module()
+class PSEModuleLoss(PANModuleLoss):
+ """The class for implementing PSENet loss. This is partially adapted from
+ https://github.com/whai362/PSENet.
+
+ PSENet: `Shape Robust Text Detection with
+ Progressive Scale Expansion Network `_.
+
+ Args:
+ weight_text (float): The weight of text loss. Defaults to 0.7.
+ weight_kernel (float): The weight of text kernel. Defaults to 0.3.
+ loss_text (dict): Loss type for text. Defaults to
+ dict('MaskedSquareDiceLoss').
+ loss_kernel (dict): Loss type for kernel. Defaults to
+ dict('MaskedSquareDiceLoss').
+ ohem_ratio (int or float): The negative/positive ratio in ohem.
+ Defaults to 3.
+ reduction (str): The way to reduce the loss. Defaults to 'mean'.
+ Options are 'mean' and 'sum'.
+ kernel_sample_type (str): The way to sample kernel. Defaults to
+ adaptive. Options are 'adaptive' and 'hard'.
+ shrink_ratio (tuple): The ratio for shirinking text instances.
+ Defaults to (1.0, 0.9, 0.8, 0.7, 0.6, 0.5, 0.4).
+ max_shrink_dist (int or float): The maximum shrinking distance.
+ Defaults to 20.
+ """
+
+ def __init__(
+ self,
+ weight_text: float = 0.7,
+ weight_kernel: float = 0.3,
+ loss_text: Dict = dict(type='MaskedSquareDiceLoss'),
+ loss_kernel: Dict = dict(type='MaskedSquareDiceLoss'),
+ ohem_ratio: Union[int, float] = 3,
+ reduction: str = 'mean',
+ kernel_sample_type: str = 'adaptive',
+ shrink_ratio: Tuple[float] = (1.0, 0.9, 0.8, 0.7, 0.6, 0.5, 0.4),
+ max_shrink_dist: Union[int, float] = 20,
+ ) -> None:
+ super().__init__()
+ assert reduction in ['mean', 'sum'
+ ], "reduction must be either of ['mean','sum']"
+ assert kernel_sample_type in [
+ 'adaptive', 'hard'
+ ], "kernel_sample_type must be either of ['hard', 'adaptive']"
+ self.weight_text = weight_text
+ self.weight_kernel = weight_kernel
+ self.ohem_ratio = ohem_ratio
+ self.reduction = reduction
+ self.shrink_ratio = shrink_ratio
+ self.kernel_sample_type = kernel_sample_type
+ self.max_shrink_dist = max_shrink_dist
+ self.loss_text = MODELS.build(loss_text)
+ self.loss_kernel = MODELS.build(loss_kernel)
+
+ def forward(self, preds: torch.Tensor,
+ data_samples: Sequence[TextDetDataSample]) -> Dict:
+ """Compute PSENet loss.
+
+ Args:
+ preds (torch.Tensor): Raw predictions from model with
+ shape :math:`(N, C, H, W)`.
+ data_samples (list[TextDetDataSample]): The data samples.
+
+ Returns:
+ dict: The dict for pse losses with loss_text, loss_kernel,
+ loss_aggregation and loss_discrimination.
+ """
+ losses = []
+
+ gt_kernels, gt_masks = self.get_targets(data_samples)
+ target_size = gt_kernels.size()[2:]
+ preds = F.interpolate(preds, size=target_size, mode='bilinear')
+ pred_texts = preds[:, 0, :, :]
+ pred_kernels = preds[:, 1:, :, :]
+
+ gt_kernels = gt_kernels.to(preds.device)
+ gt_kernels[gt_kernels <= 0.5] = 0
+ gt_kernels[gt_kernels > 0.5] = 1
+ gt_masks = gt_masks.to(preds.device)
+
+ # compute text loss
+ sampled_mask = self._ohem_batch(pred_texts.detach(), gt_kernels[0],
+ gt_masks)
+ loss_texts = self.loss_text(pred_texts.sigmoid(), gt_kernels[0],
+ sampled_mask)
+ losses.append(self.weight_text * loss_texts)
+
+ # compute kernel loss
+ if self.kernel_sample_type == 'hard':
+ sampled_masks_kernel = (gt_kernels[0] >
+ 0.5).float() * gt_masks.float()
+ elif self.kernel_sample_type == 'adaptive':
+ sampled_masks_kernel = (pred_texts > 0).float() * (
+ gt_masks.float())
+ else:
+ raise NotImplementedError
+
+ num_kernel = pred_kernels.shape[1]
+ assert num_kernel == len(gt_kernels) - 1
+ loss_list = []
+ for idx in range(num_kernel):
+ loss_kernels = self.loss_kernel(
+ pred_kernels[:, idx, :, :].sigmoid(), gt_kernels[1 + idx],
+ sampled_masks_kernel)
+ loss_list.append(loss_kernels)
+
+ losses.append(self.weight_kernel * sum(loss_list) / len(loss_list))
+
+ if self.reduction == 'mean':
+ losses = [item.mean() for item in losses]
+ elif self.reduction == 'sum':
+ losses = [item.sum() for item in losses]
+ else:
+ raise NotImplementedError
+
+ results = dict(loss_text=losses[0], loss_kernel=losses[1])
+ return results
diff --git a/mmocr/models/textdet/module_losses/seg_based_module_loss.py b/mmocr/models/textdet/module_losses/seg_based_module_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..2f2166921a1a31e9cbe1bfb0be7b8a9d2252b3d4
--- /dev/null
+++ b/mmocr/models/textdet/module_losses/seg_based_module_loss.py
@@ -0,0 +1,100 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import sys
+from typing import Optional, Sequence, Tuple, Union
+
+import cv2
+import numpy as np
+import torch
+from mmengine.logging import MMLogger
+from shapely.geometry import Polygon
+
+from mmocr.utils.polygon_utils import offset_polygon
+from .base import BaseTextDetModuleLoss
+
+
+class SegBasedModuleLoss(BaseTextDetModuleLoss):
+ """Base class for the module loss of segmentation-based text detection
+ algorithms with some handy utilities."""
+
+ def _generate_kernels(
+ self,
+ img_size: Tuple[int, int],
+ text_polys: Sequence[np.ndarray],
+ shrink_ratio: float,
+ max_shrink_dist: Union[float, int] = sys.maxsize,
+ ignore_flags: Optional[torch.Tensor] = None
+ ) -> Tuple[np.ndarray, np.ndarray]:
+ """Generate text instance kernels according to a shrink ratio.
+
+ Args:
+ img_size (tuple(int, int)): The image size of (height, width).
+ text_polys (Sequence[np.ndarray]): 2D array of text polygons.
+ shrink_ratio (float or int): The shrink ratio of kernel.
+ max_shrink_dist (float or int): The maximum shrinking distance.
+ ignore_flags (torch.BoolTensor, optional): Indicate whether the
+ corresponding text polygon is ignored. Defaults to None.
+
+ Returns:
+ tuple(ndarray, ndarray): The text instance kernels of shape
+ (height, width) and updated ignorance flags.
+ """
+ assert isinstance(img_size, tuple)
+ assert isinstance(shrink_ratio, (float, int))
+
+ logger: MMLogger = MMLogger.get_current_instance()
+
+ h, w = img_size
+ text_kernel = np.zeros((h, w), dtype=np.float32)
+
+ for text_ind, poly in enumerate(text_polys):
+ if ignore_flags is not None and ignore_flags[text_ind]:
+ continue
+ poly = poly.reshape(-1, 2).astype(np.int32)
+ poly_obj = Polygon(poly)
+ area = poly_obj.area
+ peri = poly_obj.length
+ distance = min(
+ int(area * (1 - shrink_ratio * shrink_ratio) / (peri + 0.001) +
+ 0.5), max_shrink_dist)
+ shrunk_poly = offset_polygon(poly, -distance)
+
+ if len(shrunk_poly) == 0:
+ if ignore_flags is not None:
+ ignore_flags[text_ind] = True
+ continue
+
+ try:
+ shrunk_poly = shrunk_poly.reshape(-1, 2)
+ except Exception as e:
+ logger.info(f'{shrunk_poly} with error {e}')
+ if ignore_flags is not None:
+ ignore_flags[text_ind] = True
+ continue
+
+ cv2.fillPoly(text_kernel, [shrunk_poly.astype(np.int32)],
+ text_ind + 1)
+
+ return text_kernel, ignore_flags
+
+ def _generate_effective_mask(self, mask_size: Tuple[int, int],
+ ignored_polygons: Sequence[np.ndarray]
+ ) -> np.ndarray:
+ """Generate effective mask by setting the invalid regions to 0 and 1
+ otherwise.
+
+ Args:
+ mask_size (tuple(int, int)): The mask size.
+ ignored_polygons (Sequence[ndarray]): 2-d array, representing all
+ the ignored polygons of the text region.
+
+ Returns:
+ mask (ndarray): The effective mask of shape (height, width).
+ """
+
+ mask = np.ones(mask_size, dtype=np.uint8)
+
+ for poly in ignored_polygons:
+ instance = poly.astype(np.int32).reshape(1, -1, 2)
+ cv2.fillPoly(mask, instance, 0)
+
+ return mask
diff --git a/mmocr/models/textdet/module_losses/textsnake_module_loss.py b/mmocr/models/textdet/module_losses/textsnake_module_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..651a74755cf44e4103721b7416c6455bf0438f05
--- /dev/null
+++ b/mmocr/models/textdet/module_losses/textsnake_module_loss.py
@@ -0,0 +1,648 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Sequence, Tuple
+
+import cv2
+import numpy as np
+import torch
+from mmcv.image import impad, imrescale
+from mmdet.models.utils import multi_apply
+from numpy import ndarray
+from numpy.linalg import norm
+from torch import Tensor
+
+from mmocr.registry import MODELS
+from mmocr.structures import TextDetDataSample
+from .seg_based_module_loss import SegBasedModuleLoss
+
+
+@MODELS.register_module()
+class TextSnakeModuleLoss(SegBasedModuleLoss):
+ """The class for implementing TextSnake loss. This is partially adapted
+ from https://github.com/princewang1994/TextSnake.pytorch.
+
+ TextSnake: `A Flexible Representation for Detecting Text of Arbitrary
+ Shapes `_.
+
+ Args:
+ ohem_ratio (float): The negative/positive ratio in ohem.
+ downsample_ratio (float): Downsample ratio. Defaults to 1.0. TODO:
+ remove it.
+ orientation_thr (float): The threshold for distinguishing between
+ head edge and tail edge among the horizontal and vertical edges
+ of a quadrangle.
+ resample_step (float): The step of resampling.
+ center_region_shrink_ratio (float): The shrink ratio of text center.
+ loss_text (dict): The loss config used to calculate the text loss.
+ loss_center (dict): The loss config used to calculate the center loss.
+ loss_radius (dict): The loss config used to calculate the radius loss.
+ loss_sin (dict): The loss config used to calculate the sin loss.
+ loss_cos (dict): The loss config used to calculate the cos loss.
+ """
+
+ def __init__(
+ self,
+ ohem_ratio: float = 3.0,
+ downsample_ratio: float = 1.0,
+ orientation_thr: float = 2.0,
+ resample_step: float = 4.0,
+ center_region_shrink_ratio: float = 0.3,
+ loss_text: Dict = dict(
+ type='MaskedBalancedBCEWithLogitsLoss',
+ fallback_negative_num=100,
+ eps=1e-5),
+ loss_center: Dict = dict(type='MaskedBCEWithLogitsLoss'),
+ loss_radius: Dict = dict(type='MaskedSmoothL1Loss'),
+ loss_sin: Dict = dict(type='MaskedSmoothL1Loss'),
+ loss_cos: Dict = dict(type='MaskedSmoothL1Loss')
+ ) -> None:
+ super().__init__()
+ self.ohem_ratio = ohem_ratio
+ self.downsample_ratio = downsample_ratio
+ self.orientation_thr = orientation_thr
+ self.resample_step = resample_step
+ self.center_region_shrink_ratio = center_region_shrink_ratio
+ self.eps = 1e-8
+ self.loss_text = MODELS.build(loss_text)
+ self.loss_center = MODELS.build(loss_center)
+ self.loss_radius = MODELS.build(loss_radius)
+ self.loss_sin = MODELS.build(loss_sin)
+ self.loss_cos = MODELS.build(loss_cos)
+
+ def _batch_pad(self, masks: List[ndarray],
+ target_sz: Tuple[int, int]) -> ndarray:
+ """Pad the masks to the right and bottom side to the target size and
+ pack them into a batch.
+
+ Args:
+ mask (list[ndarray]): The masks to be padded.
+ target_sz (tuple(int, int)): The target tensor of size
+ :math:`(H, W)`.
+
+ Returns:
+ ndarray: A batch of padded mask.
+ """
+ batch = []
+ for mask in masks:
+ # H x W
+ mask_sz = mask.shape
+ # left, top, right, bottom
+ padding = (0, 0, target_sz[1] - mask_sz[1],
+ target_sz[0] - mask_sz[0])
+ padded_mask = impad(
+ mask, padding=padding, padding_mode='constant', pad_val=0)
+ batch.append(np.expand_dims(padded_mask, axis=0))
+ return np.concatenate(batch)
+
+ def forward(self, preds: Tensor,
+ data_samples: Sequence[TextDetDataSample]) -> Dict:
+ """
+ Args:
+ preds (Tensor): The prediction map of shape
+ :math:`(N, 5, H, W)`, where each dimension is the map of
+ "text_region", "center_region", "sin_map", "cos_map", and
+ "radius_map" respectively.
+ data_samples (list[TextDetDataSample]): The data samples.
+
+ Returns:
+ dict: A loss dict with ``loss_text``, ``loss_center``,
+ ``loss_radius``, ``loss_sin`` and ``loss_cos``.
+ """
+
+ (gt_text_masks, gt_masks, gt_center_region_masks, gt_radius_maps,
+ gt_sin_maps, gt_cos_maps) = self.get_targets(data_samples)
+
+ pred_text_region = preds[:, 0, :, :]
+ pred_center_region = preds[:, 1, :, :]
+ pred_sin_map = preds[:, 2, :, :]
+ pred_cos_map = preds[:, 3, :, :]
+ pred_radius_map = preds[:, 4, :, :]
+ feature_sz = preds.size()
+ device = preds.device
+
+ mapping = {
+ 'gt_text_masks': gt_text_masks,
+ 'gt_center_region_masks': gt_center_region_masks,
+ 'gt_masks': gt_masks,
+ 'gt_radius_maps': gt_radius_maps,
+ 'gt_sin_maps': gt_sin_maps,
+ 'gt_cos_maps': gt_cos_maps
+ }
+ gt = {}
+ for key, value in mapping.items():
+ gt[key] = value
+ if abs(self.downsample_ratio - 1.0) < 1e-2:
+ gt[key] = self._batch_pad(gt[key], feature_sz[2:])
+ else:
+ gt[key] = [
+ imrescale(
+ mask,
+ scale=self.downsample_ratio,
+ interpolation='nearest') for mask in gt[key]
+ ]
+ gt[key] = self._batch_pad(gt[key], feature_sz[2:])
+ if key == 'gt_radius_maps':
+ gt[key] *= self.downsample_ratio
+ gt[key] = torch.from_numpy(gt[key]).float().to(device)
+
+ scale = torch.sqrt(1.0 / (pred_sin_map**2 + pred_cos_map**2 + 1e-8))
+ pred_sin_map = pred_sin_map * scale
+ pred_cos_map = pred_cos_map * scale
+
+ loss_text = self.loss_text(pred_text_region, gt['gt_text_masks'],
+ gt['gt_masks'])
+
+ text_mask = (gt['gt_text_masks'] * gt['gt_masks']).float()
+ loss_center = self.loss_center(pred_center_region,
+ gt['gt_center_region_masks'], text_mask)
+
+ center_mask = (gt['gt_center_region_masks'] * gt['gt_masks']).float()
+ map_sz = pred_radius_map.size()
+ ones = torch.ones(map_sz, dtype=torch.float, device=device)
+ loss_radius = self.loss_radius(
+ pred_radius_map / (gt['gt_radius_maps'] + 1e-2), ones, center_mask)
+ loss_sin = self.loss_sin(pred_sin_map, gt['gt_sin_maps'], center_mask)
+ loss_cos = self.loss_cos(pred_cos_map, gt['gt_cos_maps'], center_mask)
+
+ results = dict(
+ loss_text=loss_text,
+ loss_center=loss_center,
+ loss_radius=loss_radius,
+ loss_sin=loss_sin,
+ loss_cos=loss_cos)
+
+ return results
+
+ def get_targets(self, data_samples: List[TextDetDataSample]) -> Tuple:
+ """Generate loss targets from data samples.
+
+ Args:
+ data_samples (list(TextDetDataSample)): Ground truth data samples.
+
+ Returns:
+ tuple(gt_text_masks, gt_masks, gt_center_region_masks,
+ gt_radius_maps, gt_sin_maps, gt_cos_maps):
+ A tuple of six lists of ndarrays as the targets.
+ """
+ return multi_apply(self._get_target_single, data_samples)
+
+ def _get_target_single(self, data_sample: TextDetDataSample) -> Tuple:
+ """Generate loss target from a data sample.
+
+ Args:
+ data_sample (TextDetDataSample): The data sample.
+
+ Returns:
+ tuple(gt_text_mask, gt_mask, gt_center_region_mask, gt_radius_map,
+ gt_sin_map, gt_cos_map):
+ A tuple of six ndarrays as the targets of one prediction.
+ """
+
+ gt_instances = data_sample.gt_instances
+ ignore_flags = gt_instances.ignored
+
+ polygons = gt_instances[~ignore_flags].polygons
+ ignored_polygons = gt_instances[ignore_flags].polygons
+
+ gt_text_mask = self._generate_text_region_mask(data_sample.img_shape,
+ polygons)
+ gt_mask = self._generate_effective_mask(data_sample.img_shape,
+ ignored_polygons)
+
+ (gt_center_region_mask, gt_radius_map, gt_sin_map,
+ gt_cos_map) = self._generate_center_mask_attrib_maps(
+ data_sample.img_shape, polygons)
+
+ return (gt_text_mask, gt_mask, gt_center_region_mask, gt_radius_map,
+ gt_sin_map, gt_cos_map)
+
+ def _generate_text_region_mask(self, img_size: Tuple[int, int],
+ text_polys: List[ndarray]) -> ndarray:
+ """Generate text center region mask and geometry attribute maps.
+
+ Args:
+ img_size (tuple): The image size (height, width).
+ text_polys (list[ndarray]): The list of text polygons.
+
+ Returns:
+ text_region_mask (ndarray): The text region mask.
+ """
+
+ assert isinstance(img_size, tuple)
+
+ text_region_mask = np.zeros(img_size, dtype=np.uint8)
+
+ for poly in text_polys:
+ polygon = np.array(poly, dtype=np.int32).reshape((1, -1, 2))
+ cv2.fillPoly(text_region_mask, polygon, 1)
+
+ return text_region_mask
+
+ def _generate_center_mask_attrib_maps(
+ self, img_size: Tuple[int, int], text_polys: List[ndarray]
+ ) -> Tuple[ndarray, ndarray, ndarray, ndarray]:
+ """Generate text center region mask and geometric attribute maps.
+
+ Args:
+ img_size (tuple(int, int)): The image size of (height, width).
+ text_polys (list[ndarray]): The list of text polygons.
+
+ Returns:
+ Tuple(center_region_mask, radius_map, sin_map, cos_map):
+
+ - center_region_mask (ndarray): The text center region mask.
+ - radius_map (ndarray): The distance map from each pixel in text
+ center region to top sideline.
+ - sin_map (ndarray): The sin(theta) map where theta is the angle
+ between vector (top point - bottom point) and vector (1, 0).
+ - cos_map (ndarray): The cos(theta) map where theta is the angle
+ between vector (top point - bottom point) and vector (1, 0).
+ """
+
+ assert isinstance(img_size, tuple)
+
+ center_region_mask = np.zeros(img_size, np.uint8)
+ radius_map = np.zeros(img_size, dtype=np.float32)
+ sin_map = np.zeros(img_size, dtype=np.float32)
+ cos_map = np.zeros(img_size, dtype=np.float32)
+
+ for poly in text_polys:
+ polygon_points = np.array(poly).reshape(-1, 2)
+
+ n = len(polygon_points)
+ keep_inds = []
+ for i in range(n):
+ if norm(polygon_points[i] -
+ polygon_points[(i + 1) % n]) > 1e-5:
+ keep_inds.append(i)
+ polygon_points = polygon_points[keep_inds]
+
+ _, _, top_line, bot_line = self._reorder_poly_edge(polygon_points)
+ resampled_top_line, resampled_bot_line = self._resample_sidelines(
+ top_line, bot_line, self.resample_step)
+ resampled_bot_line = resampled_bot_line[::-1]
+ center_line = (resampled_top_line + resampled_bot_line) / 2
+
+ if self.vector_slope(center_line[-1] - center_line[0]) > 0.9:
+ if (center_line[-1] - center_line[0])[1] < 0:
+ center_line = center_line[::-1]
+ resampled_top_line = resampled_top_line[::-1]
+ resampled_bot_line = resampled_bot_line[::-1]
+ else:
+ if (center_line[-1] - center_line[0])[0] < 0:
+ center_line = center_line[::-1]
+ resampled_top_line = resampled_top_line[::-1]
+ resampled_bot_line = resampled_bot_line[::-1]
+
+ line_head_shrink_len = norm(resampled_top_line[0] -
+ resampled_bot_line[0]) / 4.0
+ line_tail_shrink_len = norm(resampled_top_line[-1] -
+ resampled_bot_line[-1]) / 4.0
+ head_shrink_num = int(line_head_shrink_len // self.resample_step)
+ tail_shrink_num = int(line_tail_shrink_len // self.resample_step)
+
+ if len(center_line) > head_shrink_num + tail_shrink_num + 2:
+ center_line = center_line[head_shrink_num:len(center_line) -
+ tail_shrink_num]
+ resampled_top_line = resampled_top_line[
+ head_shrink_num:len(resampled_top_line) - tail_shrink_num]
+ resampled_bot_line = resampled_bot_line[
+ head_shrink_num:len(resampled_bot_line) - tail_shrink_num]
+
+ self._draw_center_region_maps(resampled_top_line,
+ resampled_bot_line, center_line,
+ center_region_mask, radius_map,
+ sin_map, cos_map,
+ self.center_region_shrink_ratio)
+
+ return center_region_mask, radius_map, sin_map, cos_map
+
+ def _reorder_poly_edge(self, points: ndarray
+ ) -> Tuple[ndarray, ndarray, ndarray, ndarray]:
+ """Get the respective points composing head edge, tail edge, top
+ sideline and bottom sideline.
+
+ Args:
+ points (ndarray): The points composing a text polygon.
+
+ Returns:
+ Tuple(center_region_mask, radius_map, sin_map, cos_map):
+
+ - head_edge (ndarray): The two points composing the head edge of
+ text polygon.
+ - tail_edge (ndarray): The two points composing the tail edge of
+ text polygon.
+ - top_sideline (ndarray): The points composing top curved sideline
+ of text polygon.
+ - bot_sideline (ndarray): The points composing bottom curved
+ sideline of text polygon.
+ """
+
+ assert points.ndim == 2
+ assert points.shape[0] >= 4
+ assert points.shape[1] == 2
+
+ head_inds, tail_inds = self._find_head_tail(points,
+ self.orientation_thr)
+ head_edge, tail_edge = points[head_inds], points[tail_inds]
+
+ pad_points = np.vstack([points, points])
+ if tail_inds[1] < 1:
+ tail_inds[1] = len(points)
+ sideline1 = pad_points[head_inds[1]:tail_inds[1]]
+ sideline2 = pad_points[tail_inds[1]:(head_inds[1] + len(points))]
+ sideline_mean_shift = np.mean(
+ sideline1, axis=0) - np.mean(
+ sideline2, axis=0)
+
+ if sideline_mean_shift[1] > 0:
+ top_sideline, bot_sideline = sideline2, sideline1
+ else:
+ top_sideline, bot_sideline = sideline1, sideline2
+
+ return head_edge, tail_edge, top_sideline, bot_sideline
+
+ def _find_head_tail(self, points: ndarray,
+ orientation_thr: float) -> Tuple[List[int], List[int]]:
+ """Find the head edge and tail edge of a text polygon.
+
+ Args:
+ points (ndarray): The points composing a text polygon.
+ orientation_thr (float): The threshold for distinguishing between
+ head edge and tail edge among the horizontal and vertical edges
+ of a quadrangle.
+
+ Returns:
+ Tuple(head_inds, tail_inds):
+
+ - head_inds (list[int]): The indexes of two points composing head
+ edge.
+ - tail_inds (list[int]): The indexes of two points composing tail
+ edge.
+ """
+
+ assert points.ndim == 2
+ assert points.shape[0] >= 4
+ assert points.shape[1] == 2
+ assert isinstance(orientation_thr, float)
+
+ if len(points) > 4:
+ pad_points = np.vstack([points, points[0]])
+ edge_vec = pad_points[1:] - pad_points[:-1]
+
+ theta_sum = []
+ adjacent_vec_theta = []
+ for i, edge_vec1 in enumerate(edge_vec):
+ adjacent_ind = [x % len(edge_vec) for x in [i - 1, i + 1]]
+ adjacent_edge_vec = edge_vec[adjacent_ind]
+ temp_theta_sum = np.sum(
+ self.vector_angle(edge_vec1, adjacent_edge_vec))
+ temp_adjacent_theta = self.vector_angle(
+ adjacent_edge_vec[0], adjacent_edge_vec[1])
+ theta_sum.append(temp_theta_sum)
+ adjacent_vec_theta.append(temp_adjacent_theta)
+ theta_sum_score = np.array(theta_sum) / np.pi
+ adjacent_theta_score = np.array(adjacent_vec_theta) / np.pi
+ poly_center = np.mean(points, axis=0)
+ edge_dist = np.maximum(
+ norm(pad_points[1:] - poly_center, axis=-1),
+ norm(pad_points[:-1] - poly_center, axis=-1))
+ dist_score = edge_dist / (np.max(edge_dist) + self.eps)
+ position_score = np.zeros(len(edge_vec))
+ score = 0.5 * theta_sum_score + 0.15 * adjacent_theta_score
+ score += 0.35 * dist_score
+ if len(points) % 2 == 0:
+ position_score[(len(score) // 2 - 1)] += 1
+ position_score[-1] += 1
+ score += 0.1 * position_score
+ pad_score = np.concatenate([score, score])
+ score_matrix = np.zeros((len(score), len(score) - 3))
+ x = np.arange(len(score) - 3) / float(len(score) - 4)
+ gaussian = 1. / (np.sqrt(2. * np.pi) * 0.5) * np.exp(-np.power(
+ (x - 0.5) / 0.5, 2.) / 2)
+ gaussian = gaussian / np.max(gaussian)
+ for i in range(len(score)):
+ score_matrix[i, :] = score[i] + pad_score[
+ (i + 2):(i + len(score) - 1)] * gaussian * 0.3
+
+ head_start, tail_increment = np.unravel_index(
+ score_matrix.argmax(), score_matrix.shape)
+ tail_start = (head_start + tail_increment + 2) % len(points)
+ head_end = (head_start + 1) % len(points)
+ tail_end = (tail_start + 1) % len(points)
+
+ if head_end > tail_end:
+ head_start, tail_start = tail_start, head_start
+ head_end, tail_end = tail_end, head_end
+ head_inds = [head_start, head_end]
+ tail_inds = [tail_start, tail_end]
+ else:
+ if self.vector_slope(points[1] - points[0]) + self.vector_slope(
+ points[3] - points[2]) < self.vector_slope(
+ points[2] - points[1]) + self.vector_slope(points[0] -
+ points[3]):
+ horizontal_edge_inds = [[0, 1], [2, 3]]
+ vertical_edge_inds = [[3, 0], [1, 2]]
+ else:
+ horizontal_edge_inds = [[3, 0], [1, 2]]
+ vertical_edge_inds = [[0, 1], [2, 3]]
+
+ vertical_len_sum = norm(points[vertical_edge_inds[0][0]] -
+ points[vertical_edge_inds[0][1]]) + norm(
+ points[vertical_edge_inds[1][0]] -
+ points[vertical_edge_inds[1][1]])
+ horizontal_len_sum = norm(
+ points[horizontal_edge_inds[0][0]] -
+ points[horizontal_edge_inds[0][1]]) + norm(
+ points[horizontal_edge_inds[1][0]] -
+ points[horizontal_edge_inds[1][1]])
+
+ if vertical_len_sum > horizontal_len_sum * orientation_thr:
+ head_inds = horizontal_edge_inds[0]
+ tail_inds = horizontal_edge_inds[1]
+ else:
+ head_inds = vertical_edge_inds[0]
+ tail_inds = vertical_edge_inds[1]
+
+ return head_inds, tail_inds
+
+ def _resample_line(self, line: ndarray, n: int) -> ndarray:
+ """Resample n points on a line.
+
+ Args:
+ line (ndarray): The points composing a line.
+ n (int): The resampled points number.
+
+ Returns:
+ resampled_line (ndarray): The points composing the resampled line.
+ """
+
+ assert line.ndim == 2
+ assert line.shape[0] >= 2
+ assert line.shape[1] == 2
+ assert isinstance(n, int)
+ assert n > 2
+
+ edges_length, total_length = self._cal_curve_length(line)
+ t_org = np.insert(np.cumsum(edges_length), 0, 0)
+ unit_t = total_length / (n - 1)
+ t_equidistant = np.arange(1, n - 1, dtype=np.float32) * unit_t
+ edge_ind = 0
+ points = [line[0]]
+ for t in t_equidistant:
+ while edge_ind < len(edges_length) - 1 and t > t_org[edge_ind + 1]:
+ edge_ind += 1
+ t_l, t_r = t_org[edge_ind], t_org[edge_ind + 1]
+ weight = np.array([t_r - t, t - t_l], dtype=np.float32) / (
+ t_r - t_l + self.eps)
+ p_coords = np.dot(weight, line[[edge_ind, edge_ind + 1]])
+ points.append(p_coords)
+ points.append(line[-1])
+ resampled_line = np.vstack(points)
+
+ return resampled_line
+
+ def _resample_sidelines(self, sideline1: ndarray, sideline2: ndarray,
+ resample_step: float) -> Tuple[ndarray, ndarray]:
+ """Resample two sidelines to be of the same points number according to
+ step size.
+
+ Args:
+ sideline1 (ndarray): The points composing a sideline of a text
+ polygon.
+ sideline2 (ndarray): The points composing another sideline of a
+ text polygon.
+ resample_step (float): The resampled step size.
+
+ Returns:
+ Tuple(resampled_line1, resampled_line2):
+
+ - resampled_line1 (ndarray): The resampled line 1.
+ - resampled_line2 (ndarray): The resampled line 2.
+ """
+
+ assert sideline1.ndim == sideline2.ndim == 2
+ assert sideline1.shape[1] == sideline2.shape[1] == 2
+ assert sideline1.shape[0] >= 2
+ assert sideline2.shape[0] >= 2
+ assert isinstance(resample_step, float)
+
+ _, length1 = self._cal_curve_length(sideline1)
+ _, length2 = self._cal_curve_length(sideline2)
+
+ avg_length = (length1 + length2) / 2
+ resample_point_num = max(int(float(avg_length) / resample_step) + 1, 3)
+
+ resampled_line1 = self._resample_line(sideline1, resample_point_num)
+ resampled_line2 = self._resample_line(sideline2, resample_point_num)
+
+ return resampled_line1, resampled_line2
+
+ def _cal_curve_length(self, line: ndarray) -> Tuple[ndarray, float]:
+ """Calculate the length of each edge on the discrete curve and the sum.
+
+ Args:
+ line (ndarray): The points composing a discrete curve.
+
+ Returns:
+ Tuple(edges_length, total_length):
+
+ - edge_length (ndarray): The length of each edge on the
+ discrete curve.
+ - total_length (float): The total length of the discrete
+ curve.
+ """
+
+ assert line.ndim == 2
+ assert len(line) >= 2
+
+ edges_length = np.sqrt((line[1:, 0] - line[:-1, 0])**2 +
+ (line[1:, 1] - line[:-1, 1])**2)
+ total_length = np.sum(edges_length)
+ return edges_length, total_length
+
+ def _draw_center_region_maps(self, top_line: ndarray, bot_line: ndarray,
+ center_line: ndarray,
+ center_region_mask: ndarray,
+ radius_map: ndarray, sin_map: ndarray,
+ cos_map: ndarray,
+ region_shrink_ratio: float) -> None:
+ """Draw attributes on text center region.
+
+ Args:
+ top_line (ndarray): The points composing top curved sideline of
+ text polygon.
+ bot_line (ndarray): The points composing bottom curved sideline
+ of text polygon.
+ center_line (ndarray): The points composing the center line of text
+ instance.
+ center_region_mask (ndarray): The text center region mask.
+ radius_map (ndarray): The map where the distance from point to
+ sidelines will be drawn on for each pixel in text center
+ region.
+ sin_map (ndarray): The map where vector_sin(theta) will be drawn
+ on text center regions. Theta is the angle between tangent
+ line and vector (1, 0).
+ cos_map (ndarray): The map where vector_cos(theta) will be drawn on
+ text center regions. Theta is the angle between tangent line
+ and vector (1, 0).
+ region_shrink_ratio (float): The shrink ratio of text center.
+ """
+
+ assert top_line.shape == bot_line.shape == center_line.shape
+ assert (center_region_mask.shape == radius_map.shape == sin_map.shape
+ == cos_map.shape)
+ assert isinstance(region_shrink_ratio, float)
+ for i in range(0, len(center_line) - 1):
+
+ top_mid_point = (top_line[i] + top_line[i + 1]) / 2
+ bot_mid_point = (bot_line[i] + bot_line[i + 1]) / 2
+ radius = norm(top_mid_point - bot_mid_point) / 2
+
+ text_direction = center_line[i + 1] - center_line[i]
+ sin_theta = self.vector_sin(text_direction)
+ cos_theta = self.vector_cos(text_direction)
+
+ tl = center_line[i] + (top_line[i] -
+ center_line[i]) * region_shrink_ratio
+ tr = center_line[i + 1] + (
+ top_line[i + 1] - center_line[i + 1]) * region_shrink_ratio
+ br = center_line[i + 1] + (
+ bot_line[i + 1] - center_line[i + 1]) * region_shrink_ratio
+ bl = center_line[i] + (bot_line[i] -
+ center_line[i]) * region_shrink_ratio
+ current_center_box = np.vstack([tl, tr, br, bl]).astype(np.int32)
+
+ cv2.fillPoly(center_region_mask, [current_center_box], color=1)
+ cv2.fillPoly(sin_map, [current_center_box], color=sin_theta)
+ cv2.fillPoly(cos_map, [current_center_box], color=cos_theta)
+ cv2.fillPoly(radius_map, [current_center_box], color=radius)
+
+ def vector_angle(self, vec1: ndarray, vec2: ndarray) -> ndarray:
+ """Compute the angle between two vectors."""
+ if vec1.ndim > 1:
+ unit_vec1 = vec1 / (norm(vec1, axis=-1) + self.eps).reshape(
+ (-1, 1))
+ else:
+ unit_vec1 = vec1 / (norm(vec1, axis=-1) + self.eps)
+ if vec2.ndim > 1:
+ unit_vec2 = vec2 / (norm(vec2, axis=-1) + self.eps).reshape(
+ (-1, 1))
+ else:
+ unit_vec2 = vec2 / (norm(vec2, axis=-1) + self.eps)
+ return np.arccos(
+ np.clip(np.sum(unit_vec1 * unit_vec2, axis=-1), -1.0, 1.0))
+
+ def vector_slope(self, vec: ndarray) -> float:
+ """Compute the slope of a vector."""
+ assert len(vec) == 2
+ return abs(vec[1] / (vec[0] + self.eps))
+
+ def vector_sin(self, vec: ndarray) -> float:
+ """Compute the sin of the angle between vector and x-axis."""
+ assert len(vec) == 2
+ return vec[1] / (norm(vec) + self.eps)
+
+ def vector_cos(self, vec: ndarray) -> float:
+ """Compute the cos of the angle between vector and x-axis."""
+ assert len(vec) == 2
+ return vec[0] / (norm(vec) + self.eps)
diff --git a/mmocr/models/textdet/necks/__init__.py b/mmocr/models/textdet/necks/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..0b21bf192b93f8a09278989837f8b9b762052f7e
--- /dev/null
+++ b/mmocr/models/textdet/necks/__init__.py
@@ -0,0 +1,7 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .fpem_ffm import FPEM_FFM
+from .fpn_cat import FPNC
+from .fpn_unet import FPN_UNet
+from .fpnf import FPNF
+
+__all__ = ['FPEM_FFM', 'FPNF', 'FPNC', 'FPN_UNet']
diff --git a/mmocr/models/textdet/necks/__pycache__/__init__.cpython-38.pyc b/mmocr/models/textdet/necks/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ae870dd9b28eede76cf1c6a31ae815646b18c73a
Binary files /dev/null and b/mmocr/models/textdet/necks/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/necks/__pycache__/fpem_ffm.cpython-38.pyc b/mmocr/models/textdet/necks/__pycache__/fpem_ffm.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5eff203287b09f6fa60c0ec1533b47a7b66945c0
Binary files /dev/null and b/mmocr/models/textdet/necks/__pycache__/fpem_ffm.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/necks/__pycache__/fpn_cat.cpython-38.pyc b/mmocr/models/textdet/necks/__pycache__/fpn_cat.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f39f41e8f3063dc5274e4c72e088be3ce90c6294
Binary files /dev/null and b/mmocr/models/textdet/necks/__pycache__/fpn_cat.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/necks/__pycache__/fpn_unet.cpython-38.pyc b/mmocr/models/textdet/necks/__pycache__/fpn_unet.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..44aa800e8bb48a8e147e4d7a7ce6148276416e0f
Binary files /dev/null and b/mmocr/models/textdet/necks/__pycache__/fpn_unet.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/necks/__pycache__/fpnf.cpython-38.pyc b/mmocr/models/textdet/necks/__pycache__/fpnf.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..6947f49c2598ef085a7d632f7d6cf18f913fbaf9
Binary files /dev/null and b/mmocr/models/textdet/necks/__pycache__/fpnf.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/necks/fpem_ffm.py b/mmocr/models/textdet/necks/fpem_ffm.py
new file mode 100644
index 0000000000000000000000000000000000000000..265fdaab674b29bba294a368e2a8683d1aa42da0
--- /dev/null
+++ b/mmocr/models/textdet/necks/fpem_ffm.py
@@ -0,0 +1,202 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Tuple, Union
+
+import torch
+import torch.nn.functional as F
+from mmengine.model import BaseModule, ModuleList
+from torch import nn
+
+from mmocr.registry import MODELS
+
+
+class FPEM(BaseModule):
+ """FPN-like feature fusion module in PANet.
+
+ Args:
+ in_channels (int): Number of input channels.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ """
+
+ def __init__(self,
+ in_channels: int = 128,
+ init_cfg: Optional[Union[Dict, List[Dict]]] = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.up_add1 = SeparableConv2d(in_channels, in_channels, 1)
+ self.up_add2 = SeparableConv2d(in_channels, in_channels, 1)
+ self.up_add3 = SeparableConv2d(in_channels, in_channels, 1)
+ self.down_add1 = SeparableConv2d(in_channels, in_channels, 2)
+ self.down_add2 = SeparableConv2d(in_channels, in_channels, 2)
+ self.down_add3 = SeparableConv2d(in_channels, in_channels, 2)
+
+ def forward(self, c2: torch.Tensor, c3: torch.Tensor, c4: torch.Tensor,
+ c5: torch.Tensor) -> List[torch.Tensor]:
+ """
+ Args:
+ c2, c3, c4, c5 (Tensor): Each has the shape of
+ :math:`(N, C_i, H_i, W_i)`.
+
+ Returns:
+ list[Tensor]: A list of 4 tensors of the same shape as input.
+ """
+ # upsample
+ c4 = self.up_add1(self._upsample_add(c5, c4)) # c4 shape
+ c3 = self.up_add2(self._upsample_add(c4, c3))
+ c2 = self.up_add3(self._upsample_add(c3, c2))
+
+ # downsample
+ c3 = self.down_add1(self._upsample_add(c3, c2))
+ c4 = self.down_add2(self._upsample_add(c4, c3))
+ c5 = self.down_add3(self._upsample_add(c5, c4)) # c4 / 2
+ return c2, c3, c4, c5
+
+ def _upsample_add(self, x, y):
+ return F.interpolate(x, size=y.size()[2:]) + y
+
+
+class SeparableConv2d(BaseModule):
+ """Implementation of separable convolution, which is consisted of depthwise
+ convolution and pointwise convolution.
+
+ Args:
+ in_channels (int): Number of input channels.
+ out_channels (int): Number of output channels.
+ stride (int): Stride of the depthwise convolution.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ """
+
+ def __init__(self,
+ in_channels: int,
+ out_channels: int,
+ stride: int = 1,
+ init_cfg: Optional[Union[Dict, List[Dict]]] = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+
+ self.depthwise_conv = nn.Conv2d(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ kernel_size=3,
+ padding=1,
+ stride=stride,
+ groups=in_channels)
+ self.pointwise_conv = nn.Conv2d(
+ in_channels=in_channels, out_channels=out_channels, kernel_size=1)
+ self.bn = nn.BatchNorm2d(out_channels)
+ self.relu = nn.ReLU()
+
+ def forward(self, x: torch.Tensor) -> torch.Tensor:
+ """Forward function.
+
+ Args:
+ x (Tensor): Input tensor.
+
+ Returns:
+ Tensor: Output tensor.
+ """
+ x = self.depthwise_conv(x)
+ x = self.pointwise_conv(x)
+ x = self.bn(x)
+ x = self.relu(x)
+ return x
+
+
+@MODELS.register_module()
+class FPEM_FFM(BaseModule):
+ """This code is from https://github.com/WenmuZhou/PAN.pytorch.
+
+ Args:
+ in_channels (list[int]): A list of 4 numbers of input channels.
+ conv_out (int): Number of output channels.
+ fpem_repeat (int): Number of FPEM layers before FFM operations.
+ align_corners (bool): The interpolation behaviour in FFM operation,
+ used in :func:`torch.nn.functional.interpolate`.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ """
+
+ def __init__(
+ self,
+ in_channels: List[int],
+ conv_out: int = 128,
+ fpem_repeat: int = 2,
+ align_corners: bool = False,
+ init_cfg: Optional[Union[Dict, List[Dict]]] = dict(
+ type='Xavier', layer='Conv2d', distribution='uniform')
+ ) -> None:
+ super().__init__(init_cfg=init_cfg)
+ # reduce layers
+ self.reduce_conv_c2 = nn.Sequential(
+ nn.Conv2d(
+ in_channels=in_channels[0],
+ out_channels=conv_out,
+ kernel_size=1), nn.BatchNorm2d(conv_out), nn.ReLU())
+ self.reduce_conv_c3 = nn.Sequential(
+ nn.Conv2d(
+ in_channels=in_channels[1],
+ out_channels=conv_out,
+ kernel_size=1), nn.BatchNorm2d(conv_out), nn.ReLU())
+ self.reduce_conv_c4 = nn.Sequential(
+ nn.Conv2d(
+ in_channels=in_channels[2],
+ out_channels=conv_out,
+ kernel_size=1), nn.BatchNorm2d(conv_out), nn.ReLU())
+ self.reduce_conv_c5 = nn.Sequential(
+ nn.Conv2d(
+ in_channels=in_channels[3],
+ out_channels=conv_out,
+ kernel_size=1), nn.BatchNorm2d(conv_out), nn.ReLU())
+ self.align_corners = align_corners
+ self.fpems = ModuleList()
+ for _ in range(fpem_repeat):
+ self.fpems.append(FPEM(conv_out))
+
+ def forward(self, x: List[torch.Tensor]) -> Tuple[torch.Tensor]:
+ """
+ Args:
+ x (list[Tensor]): A list of four tensors of shape
+ :math:`(N, C_i, H_i, W_i)`, representing C2, C3, C4, C5
+ features respectively. :math:`C_i` should matches the number in
+ ``in_channels``.
+
+ Returns:
+ tuple[Tensor]: Four tensors of shape
+ :math:`(N, C_{out}, H_0, W_0)` where :math:`C_{out}` is
+ ``conv_out``.
+ """
+ c2, c3, c4, c5 = x
+ # reduce channel
+ c2 = self.reduce_conv_c2(c2)
+ c3 = self.reduce_conv_c3(c3)
+ c4 = self.reduce_conv_c4(c4)
+ c5 = self.reduce_conv_c5(c5)
+
+ # FPEM
+ for i, fpem in enumerate(self.fpems):
+ c2, c3, c4, c5 = fpem(c2, c3, c4, c5)
+ if i == 0:
+ c2_ffm = c2
+ c3_ffm = c3
+ c4_ffm = c4
+ c5_ffm = c5
+ else:
+ c2_ffm = c2_ffm + c2
+ c3_ffm = c3_ffm + c3
+ c4_ffm = c4_ffm + c4
+ c5_ffm = c5_ffm + c5
+
+ # FFM
+ c5 = F.interpolate(
+ c5_ffm,
+ c2_ffm.size()[-2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+ c4 = F.interpolate(
+ c4_ffm,
+ c2_ffm.size()[-2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+ c3 = F.interpolate(
+ c3_ffm,
+ c2_ffm.size()[-2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+ outs = [c2_ffm, c3, c4, c5]
+ return tuple(outs)
diff --git a/mmocr/models/textdet/necks/fpn_cat.py b/mmocr/models/textdet/necks/fpn_cat.py
new file mode 100644
index 0000000000000000000000000000000000000000..c1c8efb354b3ca5598db76e785fdbe620ef147e6
--- /dev/null
+++ b/mmocr/models/textdet/necks/fpn_cat.py
@@ -0,0 +1,276 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Union
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+from mmengine.model import BaseModule, ModuleList, Sequential
+
+from mmocr.registry import MODELS
+
+
+@MODELS.register_module()
+class FPNC(BaseModule):
+ """FPN-like fusion module in Real-time Scene Text Detection with
+ Differentiable Binarization.
+
+ This was partially adapted from https://github.com/MhLiao/DB and
+ https://github.com/WenmuZhou/DBNet.pytorch.
+
+ Args:
+ in_channels (list[int]): A list of numbers of input channels.
+ lateral_channels (int): Number of channels for lateral layers.
+ out_channels (int): Number of output channels.
+ bias_on_lateral (bool): Whether to use bias on lateral convolutional
+ layers.
+ bn_re_on_lateral (bool): Whether to use BatchNorm and ReLU
+ on lateral convolutional layers.
+ bias_on_smooth (bool): Whether to use bias on smoothing layer.
+ bn_re_on_smooth (bool): Whether to use BatchNorm and ReLU on smoothing
+ layer.
+ asf_cfg (dict, optional): Adaptive Scale Fusion module configs. The
+ attention_type can be 'ScaleChannelSpatial'.
+ conv_after_concat (bool): Whether to add a convolution layer after
+ the concatenation of predictions.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ """
+
+ def __init__(
+ self,
+ in_channels: List[int],
+ lateral_channels: int = 256,
+ out_channels: int = 64,
+ bias_on_lateral: bool = False,
+ bn_re_on_lateral: bool = False,
+ bias_on_smooth: bool = False,
+ bn_re_on_smooth: bool = False,
+ asf_cfg: Optional[Dict] = None,
+ conv_after_concat: bool = False,
+ init_cfg: Optional[Union[Dict, List[Dict]]] = [
+ dict(type='Kaiming', layer='Conv'),
+ dict(type='Constant', layer='BatchNorm', val=1., bias=1e-4)
+ ]
+ ) -> None:
+ super().__init__(init_cfg=init_cfg)
+ assert isinstance(in_channels, list)
+ self.in_channels = in_channels
+ self.lateral_channels = lateral_channels
+ self.out_channels = out_channels
+ self.num_ins = len(in_channels)
+ self.bn_re_on_lateral = bn_re_on_lateral
+ self.bn_re_on_smooth = bn_re_on_smooth
+ self.asf_cfg = asf_cfg
+ self.conv_after_concat = conv_after_concat
+ self.lateral_convs = ModuleList()
+ self.smooth_convs = ModuleList()
+ self.num_outs = self.num_ins
+
+ for i in range(self.num_ins):
+ norm_cfg = None
+ act_cfg = None
+ if self.bn_re_on_lateral:
+ norm_cfg = dict(type='BN')
+ act_cfg = dict(type='ReLU')
+ l_conv = ConvModule(
+ in_channels[i],
+ lateral_channels,
+ 1,
+ bias=bias_on_lateral,
+ conv_cfg=None,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ inplace=False)
+ norm_cfg = None
+ act_cfg = None
+ if self.bn_re_on_smooth:
+ norm_cfg = dict(type='BN')
+ act_cfg = dict(type='ReLU')
+
+ smooth_conv = ConvModule(
+ lateral_channels,
+ out_channels,
+ 3,
+ bias=bias_on_smooth,
+ padding=1,
+ conv_cfg=None,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ inplace=False)
+
+ self.lateral_convs.append(l_conv)
+ self.smooth_convs.append(smooth_conv)
+
+ if self.asf_cfg is not None:
+ self.asf_conv = ConvModule(
+ out_channels * self.num_outs,
+ out_channels * self.num_outs,
+ 3,
+ padding=1,
+ conv_cfg=None,
+ norm_cfg=None,
+ act_cfg=None,
+ inplace=False)
+ if self.asf_cfg['attention_type'] == 'ScaleChannelSpatial':
+ self.asf_attn = ScaleChannelSpatialAttention(
+ self.out_channels * self.num_outs,
+ (self.out_channels * self.num_outs) // 4, self.num_outs)
+ else:
+ raise NotImplementedError
+
+ if self.conv_after_concat:
+ norm_cfg = dict(type='BN')
+ act_cfg = dict(type='ReLU')
+ self.out_conv = ConvModule(
+ out_channels * self.num_outs,
+ out_channels * self.num_outs,
+ 3,
+ padding=1,
+ conv_cfg=None,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ inplace=False)
+
+ def forward(self, inputs: List[torch.Tensor]) -> torch.Tensor:
+ """
+ Args:
+ inputs (list[Tensor]): Each tensor has the shape of
+ :math:`(N, C_i, H_i, W_i)`. It usually expects 4 tensors
+ (C2-C5 features) from ResNet.
+
+ Returns:
+ Tensor: A tensor of shape :math:`(N, C_{out}, H_0, W_0)` where
+ :math:`C_{out}` is ``out_channels``.
+ """
+ assert len(inputs) == len(self.in_channels)
+ # build laterals
+ laterals = [
+ lateral_conv(inputs[i])
+ for i, lateral_conv in enumerate(self.lateral_convs)
+ ]
+ used_backbone_levels = len(laterals)
+ # build top-down path
+ for i in range(used_backbone_levels - 1, 0, -1):
+ prev_shape = laterals[i - 1].shape[2:]
+ laterals[i - 1] = laterals[i - 1] + F.interpolate(
+ laterals[i], size=prev_shape, mode='nearest')
+ # build outputs
+ # part 1: from original levels
+ outs = [
+ self.smooth_convs[i](laterals[i])
+ for i in range(used_backbone_levels)
+ ]
+
+ for i, out in enumerate(outs):
+ outs[i] = F.interpolate(
+ outs[i], size=outs[0].shape[2:], mode='nearest')
+
+ out = torch.cat(outs, dim=1)
+ if self.asf_cfg is not None:
+ asf_feature = self.asf_conv(out)
+ attention = self.asf_attn(asf_feature)
+ enhanced_feature = []
+ for i, out in enumerate(outs):
+ enhanced_feature.append(attention[:, i:i + 1] * outs[i])
+ out = torch.cat(enhanced_feature, dim=1)
+
+ if self.conv_after_concat:
+ out = self.out_conv(out)
+
+ return out
+
+
+class ScaleChannelSpatialAttention(BaseModule):
+ """Spatial Attention module in Real-Time Scene Text Detection with
+ Differentiable Binarization and Adaptive Scale Fusion.
+
+ This was partially adapted from https://github.com/MhLiao/DB
+
+ Args:
+ in_channels (int): A numbers of input channels.
+ c_wise_channels (int): Number of channel-wise attention channels.
+ out_channels (int): Number of output channels.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ """
+
+ def __init__(
+ self,
+ in_channels: int,
+ c_wise_channels: int,
+ out_channels: int,
+ init_cfg: Optional[Union[Dict, List[Dict]]] = [
+ dict(type='Kaiming', layer='Conv', bias=0)
+ ]
+ ) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.avg_pool = nn.AdaptiveAvgPool2d(1)
+ # Channel Wise
+ self.channel_wise = Sequential(
+ ConvModule(
+ in_channels,
+ c_wise_channels,
+ 1,
+ bias=False,
+ conv_cfg=None,
+ norm_cfg=None,
+ act_cfg=dict(type='ReLU'),
+ inplace=False),
+ ConvModule(
+ c_wise_channels,
+ in_channels,
+ 1,
+ bias=False,
+ conv_cfg=None,
+ norm_cfg=None,
+ act_cfg=dict(type='Sigmoid'),
+ inplace=False))
+ # Spatial Wise
+ self.spatial_wise = Sequential(
+ ConvModule(
+ 1,
+ 1,
+ 3,
+ padding=1,
+ bias=False,
+ conv_cfg=None,
+ norm_cfg=None,
+ act_cfg=dict(type='ReLU'),
+ inplace=False),
+ ConvModule(
+ 1,
+ 1,
+ 1,
+ bias=False,
+ conv_cfg=None,
+ norm_cfg=None,
+ act_cfg=dict(type='Sigmoid'),
+ inplace=False))
+ # Attention Wise
+ self.attention_wise = ConvModule(
+ in_channels,
+ out_channels,
+ 1,
+ bias=False,
+ conv_cfg=None,
+ norm_cfg=None,
+ act_cfg=dict(type='Sigmoid'),
+ inplace=False)
+
+ def forward(self, inputs: torch.Tensor) -> torch.Tensor:
+ """
+ Args:
+ inputs (Tensor): A concat FPN feature tensor that has the shape of
+ :math:`(N, C, H, W)`.
+
+ Returns:
+ Tensor: An attention map of shape :math:`(N, C_{out}, H, W)`
+ where :math:`C_{out}` is ``out_channels``.
+ """
+ out = self.avg_pool(inputs)
+ out = self.channel_wise(out)
+ out = out + inputs
+ inputs = torch.mean(out, dim=1, keepdim=True)
+ out = self.spatial_wise(inputs) + out
+ out = self.attention_wise(out)
+
+ return out
diff --git a/mmocr/models/textdet/necks/fpn_unet.py b/mmocr/models/textdet/necks/fpn_unet.py
new file mode 100644
index 0000000000000000000000000000000000000000..63e0d7fc794773263f97024d0392883022079858
--- /dev/null
+++ b/mmocr/models/textdet/necks/fpn_unet.py
@@ -0,0 +1,136 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Tuple, Union
+
+import torch
+import torch.nn.functional as F
+from mmengine.model import BaseModule
+from torch import nn
+
+from mmocr.registry import MODELS
+
+
+class UpBlock(BaseModule):
+ """Upsample block for DRRG and TextSnake.
+
+ DRRG: `Deep Relational Reasoning Graph Network for Arbitrary Shape
+ Text Detection `_.
+
+ TextSnake: `A Flexible Representation for Detecting Text of Arbitrary
+ Shapes `_.
+
+ Args:
+ in_channels (list[int]): Number of input channels at each scale. The
+ length of the list should be 4.
+ out_channels (int): The number of output channels.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ in_channels: int,
+ out_channels: int,
+ init_cfg: Optional[Union[Dict, List[Dict]]] = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+
+ assert isinstance(in_channels, int)
+ assert isinstance(out_channels, int)
+
+ self.conv1x1 = nn.Conv2d(
+ in_channels, in_channels, kernel_size=1, stride=1, padding=0)
+ self.conv3x3 = nn.Conv2d(
+ in_channels, out_channels, kernel_size=3, stride=1, padding=1)
+ self.deconv = nn.ConvTranspose2d(
+ out_channels, out_channels, kernel_size=4, stride=2, padding=1)
+
+ def forward(self, x: torch.Tensor) -> torch.Tensor:
+ """Forward propagation."""
+ x = F.relu(self.conv1x1(x))
+ x = F.relu(self.conv3x3(x))
+ x = self.deconv(x)
+ return x
+
+
+@MODELS.register_module()
+class FPN_UNet(BaseModule):
+ """The class for implementing DRRG and TextSnake U-Net-like FPN.
+
+ DRRG: `Deep Relational Reasoning Graph Network for Arbitrary Shape
+ Text Detection `_.
+
+ TextSnake: `A Flexible Representation for Detecting Text of Arbitrary
+ Shapes `_.
+
+ Args:
+ in_channels (list[int]): Number of input channels at each scale. The
+ length of the list should be 4.
+ out_channels (int): The number of output channels.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ """
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ init_cfg: Optional[Union[Dict, List[Dict]]] = dict(
+ type='Xavier',
+ layer=['Conv2d', 'ConvTranspose2d'],
+ distribution='uniform')
+ ) -> None:
+ super().__init__(init_cfg=init_cfg)
+
+ assert len(in_channels) == 4
+ assert isinstance(out_channels, int)
+
+ blocks_out_channels = [out_channels] + [
+ min(out_channels * 2**i, 256) for i in range(4)
+ ]
+ blocks_in_channels = [blocks_out_channels[1]] + [
+ in_channels[i] + blocks_out_channels[i + 2] for i in range(3)
+ ] + [in_channels[3]]
+
+ self.up4 = nn.ConvTranspose2d(
+ blocks_in_channels[4],
+ blocks_out_channels[4],
+ kernel_size=4,
+ stride=2,
+ padding=1)
+ self.up_block3 = UpBlock(blocks_in_channels[3], blocks_out_channels[3])
+ self.up_block2 = UpBlock(blocks_in_channels[2], blocks_out_channels[2])
+ self.up_block1 = UpBlock(blocks_in_channels[1], blocks_out_channels[1])
+ self.up_block0 = UpBlock(blocks_in_channels[0], blocks_out_channels[0])
+
+ def forward(self, x: List[Union[torch.Tensor,
+ Tuple[torch.Tensor]]]) -> torch.Tensor:
+ """
+ Args:
+ x (list[Tensor] | tuple[Tensor]): A list of four tensors of shape
+ :math:`(N, C_i, H_i, W_i)`, representing C2, C3, C4, C5
+ features respectively. :math:`C_i` should matches the number in
+ ``in_channels``.
+
+ Returns:
+ Tensor: Shape :math:`(N, C, H, W)` where :math:`H=4H_0` and
+ :math:`W=4W_0`.
+ """
+ c2, c3, c4, c5 = x
+
+ x = F.relu(self.up4(c5))
+
+ c4 = F.interpolate(
+ c4, size=x.shape[2:], mode='bilinear', align_corners=True)
+ x = torch.cat([x, c4], dim=1)
+ x = F.relu(self.up_block3(x))
+
+ c3 = F.interpolate(
+ c3, size=x.shape[2:], mode='bilinear', align_corners=True)
+ x = torch.cat([x, c3], dim=1)
+ x = F.relu(self.up_block2(x))
+
+ c2 = F.interpolate(
+ c2, size=x.shape[2:], mode='bilinear', align_corners=True)
+ x = torch.cat([x, c2], dim=1)
+ x = F.relu(self.up_block1(x))
+
+ x = self.up_block0(x)
+ # the output should be of the same height and width as backbone input
+ return x
diff --git a/mmocr/models/textdet/necks/fpnf.py b/mmocr/models/textdet/necks/fpnf.py
new file mode 100644
index 0000000000000000000000000000000000000000..17887e66b8c74b1f60383479e5df8f01b528a40b
--- /dev/null
+++ b/mmocr/models/textdet/necks/fpnf.py
@@ -0,0 +1,136 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Union
+
+import torch
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+from mmengine.model import BaseModule, ModuleList
+from torch import Tensor
+
+from mmocr.registry import MODELS
+
+
+@MODELS.register_module()
+class FPNF(BaseModule):
+ """FPN-like fusion module in Shape Robust Text Detection with Progressive
+ Scale Expansion Network.
+
+ Args:
+ in_channels (list[int]): A list of number of input channels.
+ Defaults to [256, 512, 1024, 2048].
+ out_channels (int): The number of output channels.
+ Defaults to 256.
+ fusion_type (str): Type of the final feature fusion layer. Available
+ options are "concat" and "add". Defaults to "concat".
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ Defaults to
+ dict(type='Xavier', layer='Conv2d', distribution='uniform')
+ """
+
+ def __init__(
+ self,
+ in_channels: List[int] = [256, 512, 1024, 2048],
+ out_channels: int = 256,
+ fusion_type: str = 'concat',
+ init_cfg: Optional[Union[Dict, List[Dict]]] = dict(
+ type='Xavier', layer='Conv2d', distribution='uniform')
+ ) -> None:
+ super().__init__(init_cfg=init_cfg)
+ conv_cfg = None
+ norm_cfg = dict(type='BN')
+ act_cfg = dict(type='ReLU')
+
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+
+ self.lateral_convs = ModuleList()
+ self.fpn_convs = ModuleList()
+ self.backbone_end_level = len(in_channels)
+ for i in range(self.backbone_end_level):
+ l_conv = ConvModule(
+ in_channels[i],
+ out_channels,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ inplace=False)
+ self.lateral_convs.append(l_conv)
+
+ if i < self.backbone_end_level - 1:
+ fpn_conv = ConvModule(
+ out_channels,
+ out_channels,
+ 3,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ inplace=False)
+ self.fpn_convs.append(fpn_conv)
+
+ self.fusion_type = fusion_type
+
+ if self.fusion_type == 'concat':
+ feature_channels = 1024
+ elif self.fusion_type == 'add':
+ feature_channels = 256
+ else:
+ raise NotImplementedError
+
+ self.output_convs = ConvModule(
+ feature_channels,
+ out_channels,
+ 3,
+ padding=1,
+ conv_cfg=None,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ inplace=False)
+
+ def forward(self, inputs: List[Tensor]) -> Tensor:
+ """
+ Args:
+ inputs (list[Tensor]): Each tensor has the shape of
+ :math:`(N, C_i, H_i, W_i)`. It usually expects 4 tensors
+ (C2-C5 features) from ResNet.
+
+ Returns:
+ Tensor: A tensor of shape :math:`(N, C_{out}, H_0, W_0)` where
+ :math:`C_{out}` is ``out_channels``.
+ """
+ assert len(inputs) == len(self.in_channels)
+
+ # build laterals
+ laterals = [
+ lateral_conv(inputs[i])
+ for i, lateral_conv in enumerate(self.lateral_convs)
+ ]
+
+ # build top-down path
+ used_backbone_levels = len(laterals)
+ for i in range(used_backbone_levels - 1, 0, -1):
+ # step 1: upsample to level i-1 size and add level i-1
+ prev_shape = laterals[i - 1].shape[2:]
+ laterals[i - 1] = laterals[i - 1] + F.interpolate(
+ laterals[i], size=prev_shape, mode='nearest')
+ # step 2: smooth level i-1
+ laterals[i - 1] = self.fpn_convs[i - 1](laterals[i - 1])
+
+ # upsample and cat
+ bottom_shape = laterals[0].shape[2:]
+ for i in range(1, used_backbone_levels):
+ laterals[i] = F.interpolate(
+ laterals[i], size=bottom_shape, mode='nearest')
+
+ if self.fusion_type == 'concat':
+ out = torch.cat(laterals, 1)
+ elif self.fusion_type == 'add':
+ out = laterals[0]
+ for i in range(1, used_backbone_levels):
+ out += laterals[i]
+ else:
+ raise NotImplementedError
+ out = self.output_convs(out)
+
+ return out
diff --git a/mmocr/models/textdet/postprocessors/__init__.py b/mmocr/models/textdet/postprocessors/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..783958e518b3707736aef40be7c7720ad447424c
--- /dev/null
+++ b/mmocr/models/textdet/postprocessors/__init__.py
@@ -0,0 +1,14 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .base import BaseTextDetPostProcessor
+from .db_postprocessor import DBPostprocessor
+from .drrg_postprocessor import DRRGPostprocessor
+from .fce_postprocessor import FCEPostprocessor
+from .pan_postprocessor import PANPostprocessor
+from .pse_postprocessor import PSEPostprocessor
+from .textsnake_postprocessor import TextSnakePostprocessor
+
+__all__ = [
+ 'PSEPostprocessor', 'PANPostprocessor', 'DBPostprocessor',
+ 'DRRGPostprocessor', 'FCEPostprocessor', 'TextSnakePostprocessor',
+ 'BaseTextDetPostProcessor'
+]
diff --git a/mmocr/models/textdet/postprocessors/__pycache__/__init__.cpython-38.pyc b/mmocr/models/textdet/postprocessors/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..3fff0de0802d73b9a89dd5de804af8d68b44abb7
Binary files /dev/null and b/mmocr/models/textdet/postprocessors/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/postprocessors/__pycache__/base.cpython-38.pyc b/mmocr/models/textdet/postprocessors/__pycache__/base.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2f7cd31edf9698978882555f05182a73e61d6a30
Binary files /dev/null and b/mmocr/models/textdet/postprocessors/__pycache__/base.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/postprocessors/__pycache__/db_postprocessor.cpython-38.pyc b/mmocr/models/textdet/postprocessors/__pycache__/db_postprocessor.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..7db28939f59881d3000750ef88b8003ce8392692
Binary files /dev/null and b/mmocr/models/textdet/postprocessors/__pycache__/db_postprocessor.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/postprocessors/__pycache__/drrg_postprocessor.cpython-38.pyc b/mmocr/models/textdet/postprocessors/__pycache__/drrg_postprocessor.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..371b2cd0a4a52fc87cf2dd89bb5425547c5a1aa2
Binary files /dev/null and b/mmocr/models/textdet/postprocessors/__pycache__/drrg_postprocessor.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/postprocessors/__pycache__/fce_postprocessor.cpython-38.pyc b/mmocr/models/textdet/postprocessors/__pycache__/fce_postprocessor.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..85a54e0d205042e8142294a62511b147b1e6d207
Binary files /dev/null and b/mmocr/models/textdet/postprocessors/__pycache__/fce_postprocessor.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/postprocessors/__pycache__/pan_postprocessor.cpython-38.pyc b/mmocr/models/textdet/postprocessors/__pycache__/pan_postprocessor.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..593761fe6fd9da1f895583054fc7eeec75c35239
Binary files /dev/null and b/mmocr/models/textdet/postprocessors/__pycache__/pan_postprocessor.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/postprocessors/__pycache__/pse_postprocessor.cpython-38.pyc b/mmocr/models/textdet/postprocessors/__pycache__/pse_postprocessor.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..198c5eb26134cf3fdb4618928024ac50ee756784
Binary files /dev/null and b/mmocr/models/textdet/postprocessors/__pycache__/pse_postprocessor.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/postprocessors/__pycache__/textsnake_postprocessor.cpython-38.pyc b/mmocr/models/textdet/postprocessors/__pycache__/textsnake_postprocessor.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ef4d9e8cf02ce84e7cfb566679ea909614e4d4e0
Binary files /dev/null and b/mmocr/models/textdet/postprocessors/__pycache__/textsnake_postprocessor.cpython-38.pyc differ
diff --git a/mmocr/models/textdet/postprocessors/base.py b/mmocr/models/textdet/postprocessors/base.py
new file mode 100644
index 0000000000000000000000000000000000000000..706b152672665c9500aeda5bab4cc5bd156fe678
--- /dev/null
+++ b/mmocr/models/textdet/postprocessors/base.py
@@ -0,0 +1,204 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from functools import partial
+from typing import Dict, List, Optional, Sequence, Tuple, Union
+
+import mmengine
+import numpy as np
+from torch import Tensor
+
+from mmocr.structures import TextDetDataSample
+from mmocr.utils import boundary_iou, rescale_polygons
+
+
+class BaseTextDetPostProcessor:
+ """Base postprocessor for text detection models.
+
+ Args:
+ text_repr_type (str): The boundary encoding type, 'poly' or 'quad'.
+ Defaults to 'poly'.
+ rescale_fields (list[str], optional): The bbox/polygon field names to
+ be rescaled. If None, no rescaling will be performed.
+ train_cfg (dict, optional): The parameters to be passed to
+ ``self.get_text_instances`` in training. Defaults to None.
+ test_cfg (dict, optional): The parameters to be passed to
+ ``self.get_text_instances`` in testing. Defaults to None.
+ """
+
+ def __init__(self,
+ text_repr_type: str = 'poly',
+ rescale_fields: Optional[Sequence[str]] = None,
+ train_cfg: Optional[Dict] = None,
+ test_cfg: Optional[Dict] = None) -> None:
+ assert text_repr_type in ['poly', 'quad']
+ assert rescale_fields is None or isinstance(rescale_fields, list)
+ assert train_cfg is None or isinstance(train_cfg, dict)
+ assert test_cfg is None or isinstance(test_cfg, dict)
+ self.text_repr_type = text_repr_type
+ self.rescale_fields = rescale_fields
+ self.train_cfg = train_cfg
+ self.test_cfg = test_cfg
+
+ def __call__(self,
+ pred_results: Union[Tensor, List[Tensor]],
+ data_samples: Sequence[TextDetDataSample],
+ training: bool = False) -> Sequence[TextDetDataSample]:
+ """Postprocess pred_results according to metainfos in data_samples.
+
+ Args:
+ pred_results (Union[Tensor, List[Tensor]]): The prediction results
+ stored in a tensor or a list of tensor. Usually each item to
+ be post-processed is expected to be a batched tensor.
+ data_samples (list[TextDetDataSample]): Batch of data_samples,
+ each corresponding to a prediction result.
+ training (bool): Whether the model is in training mode. Defaults to
+ False.
+
+ Returns:
+ list[TextDetDataSample]: Batch of post-processed datasamples.
+ """
+ cfg = self.train_cfg if training else self.test_cfg
+ if cfg is None:
+ cfg = {}
+ pred_results = self.split_results(pred_results)
+ process_single = partial(self._process_single, **cfg)
+ results = list(map(process_single, pred_results, data_samples))
+
+ return results
+
+ def _process_single(self, pred_result: Union[Tensor, List[Tensor]],
+ data_sample: TextDetDataSample,
+ **kwargs) -> TextDetDataSample:
+ """Process prediction results from one image.
+
+ Args:
+ pred_result (Union[Tensor, List[Tensor]]): Prediction results of an
+ image.
+ data_sample (TextDetDataSample): Datasample of an image.
+ """
+
+ results = self.get_text_instances(pred_result, data_sample, **kwargs)
+
+ if self.rescale_fields and len(self.rescale_fields) > 0:
+ assert isinstance(self.rescale_fields, list)
+ assert set(self.rescale_fields).issubset(
+ set(results.pred_instances.keys()))
+ results = self.rescale(results, data_sample.scale_factor)
+ return results
+
+ def rescale(self, results: TextDetDataSample,
+ scale_factor: Sequence[int]) -> TextDetDataSample:
+ """Rescale results in ``results.pred_instances`` according to
+ ``scale_factor``, whose keys are defined in ``self.rescale_fields``.
+ Usually used to rescale bboxes and/or polygons.
+
+ Args:
+ results (TextDetDataSample): The post-processed prediction results.
+ scale_factor (tuple(int)): (w_scale, h_scale)
+
+ Returns:
+ TextDetDataSample: Prediction results with rescaled results.
+ """
+ scale_factor = np.asarray(scale_factor)
+ for key in self.rescale_fields:
+ results.pred_instances[key] = rescale_polygons(
+ results.pred_instances[key], scale_factor, mode='div')
+ return results
+
+ def get_text_instances(self, pred_results: Union[Tensor, List[Tensor]],
+ data_sample: TextDetDataSample,
+ **kwargs) -> TextDetDataSample:
+ """Get text instance predictions of one image.
+
+ Args:
+ pred_result (tuple(Tensor)): Prediction results of an image.
+ data_sample (TextDetDataSample): Datasample of an image.
+ **kwargs: Other parameters. Configurable via ``__init__.train_cfg``
+ and ``__init__.test_cfg``.
+
+ Returns:
+ TextDetDataSample: A new DataSample with predictions filled in.
+ The polygon/bbox results are usually saved in
+ ``TextDetDataSample.pred_instances.polygons`` or
+ ``TextDetDataSample.pred_instances.bboxes``. The confidence scores
+ are saved in ``TextDetDataSample.pred_instances.scores``.
+ """
+ raise NotImplementedError
+
+ def split_results(
+ self, pred_results: Union[Tensor, List[Tensor]]
+ ) -> Union[List[Tensor], List[List[Tensor]]]:
+ """Split batched tensor(s) along the first dimension pack split tensors
+ into a list.
+
+ Args:
+ pred_results (tensor or list[tensor]): Raw result tensor(s) from
+ detection head. Each tensor usually has the shape of (N, ...)
+
+ Returns:
+ list[tensor] or list[list[tensor]]: N tensors if ``pred_results``
+ is a tensor, or a list of N lists of tensors if
+ ``pred_results`` is a list of tensors.
+ """
+ assert isinstance(pred_results, Tensor) or mmengine.is_seq_of(
+ pred_results, Tensor)
+
+ if mmengine.is_seq_of(pred_results, Tensor):
+ for i in range(1, len(pred_results)):
+ assert pred_results[0].shape[0] == pred_results[i].shape[0], \
+ 'The first dimension of all tensors should be the same'
+
+ batch_num = len(pred_results) if isinstance(pred_results, Tensor) else\
+ len(pred_results[0])
+ results = []
+ for i in range(batch_num):
+ if isinstance(pred_results, Tensor):
+ results.append(pred_results[i])
+ else:
+ results.append([])
+ for tensor in pred_results:
+ results[i].append(tensor[i])
+ return results
+
+ def poly_nms(self, polygons: List[np.ndarray], scores: List[float],
+ threshold: float) -> Tuple[List[np.ndarray], List[float]]:
+ """Non-maximum suppression for text detection.
+
+ Args:
+ polygons (list[ndarray]): List of polygons.
+ scores (list[float]): List of scores.
+ threshold (float): Threshold for NMS.
+
+ Returns:
+ tuple(keep_polys, keep_scores):
+
+ - keep_polys (list[ndarray]): List of preserved polygons after NMS.
+ - keep_scores (list[float]): List of preserved scores after NMS.
+ """
+ assert isinstance(polygons, list)
+ assert isinstance(scores, list)
+ assert len(polygons) == len(scores)
+
+ polygons = [
+ np.hstack((polygon, score))
+ for polygon, score in zip(polygons, scores)
+ ]
+ polygons = np.array(sorted(polygons, key=lambda x: x[-1]))
+ keep_polys = []
+ keep_scores = []
+ index = [i for i in range(len(polygons))]
+
+ while len(index) > 0:
+ keep_polys.append(polygons[index[-1]][:-1].tolist())
+ keep_scores.append(polygons[index[-1]][-1])
+ A = polygons[index[-1]][:-1]
+ index = np.delete(index, -1)
+
+ iou_list = np.zeros((len(index), ))
+ for i in range(len(index)):
+ B = polygons[index[i]][:-1]
+
+ iou_list[i] = boundary_iou(A, B, 1)
+ remove_index = np.where(iou_list > threshold)
+ index = np.delete(index, remove_index)
+
+ return keep_polys, keep_scores
diff --git a/mmocr/models/textdet/postprocessors/db_postprocessor.py b/mmocr/models/textdet/postprocessors/db_postprocessor.py
new file mode 100644
index 0000000000000000000000000000000000000000..7ae3290e8645942a601d16ede54c6ba7146b8430
--- /dev/null
+++ b/mmocr/models/textdet/postprocessors/db_postprocessor.py
@@ -0,0 +1,169 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Sequence
+
+import cv2
+import numpy as np
+import torch
+from mmengine.structures import InstanceData
+from shapely.geometry import Polygon
+from torch import Tensor
+
+from mmocr.registry import MODELS
+from mmocr.structures import TextDetDataSample
+from mmocr.utils import offset_polygon
+from .base import BaseTextDetPostProcessor
+
+
+@MODELS.register_module()
+class DBPostprocessor(BaseTextDetPostProcessor):
+ """Decoding predictions of DbNet to instances. This is partially adapted
+ from https://github.com/MhLiao/DB.
+
+ Args:
+ text_repr_type (str): The boundary encoding type 'poly' or 'quad'.
+ Defaults to 'poly'.
+ rescale_fields (list[str]): The bbox/polygon field names to
+ be rescaled. If None, no rescaling will be performed. Defaults to
+ ['polygons'].
+ mask_thr (float): The mask threshold value for binarization. Defaults
+ to 0.3.
+ min_text_score (float): The threshold value for converting binary map
+ to shrink text regions. Defaults to 0.3.
+ min_text_width (int): The minimum width of boundary polygon/box
+ predicted. Defaults to 5.
+ unclip_ratio (float): The unclip ratio for text regions dilation.
+ Defaults to 1.5.
+ epsilon_ratio (float): The epsilon ratio for approximation accuracy.
+ Defaults to 0.01.
+ max_candidates (int): The maximum candidate number. Defaults to 3000.
+ """
+
+ def __init__(self,
+ text_repr_type: str = 'poly',
+ rescale_fields: Sequence[str] = ['polygons'],
+ mask_thr: float = 0.3,
+ min_text_score: float = 0.3,
+ min_text_width: int = 5,
+ unclip_ratio: float = 1.5,
+ epsilon_ratio: float = 0.01,
+ max_candidates: int = 3000,
+ **kwargs) -> None:
+ super().__init__(
+ text_repr_type=text_repr_type,
+ rescale_fields=rescale_fields,
+ **kwargs)
+ self.mask_thr = mask_thr
+ self.min_text_score = min_text_score
+ self.min_text_width = min_text_width
+ self.unclip_ratio = unclip_ratio
+ self.epsilon_ratio = epsilon_ratio
+ self.max_candidates = max_candidates
+
+ def get_text_instances(self, prob_map: Tensor,
+ data_sample: TextDetDataSample
+ ) -> TextDetDataSample:
+ """Get text instance predictions of one image.
+
+ Args:
+ pred_result (Tensor): DBNet's output ``prob_map`` of shape
+ :math:`(H, W)`.
+ data_sample (TextDetDataSample): Datasample of an image.
+
+ Returns:
+ TextDetDataSample: A new DataSample with predictions filled in.
+ Polygons and results are saved in
+ ``TextDetDataSample.pred_instances.polygons``. The confidence
+ scores are saved in ``TextDetDataSample.pred_instances.scores``.
+ """
+
+ data_sample.pred_instances = InstanceData()
+ data_sample.pred_instances.polygons = []
+ data_sample.pred_instances.scores = []
+
+ text_mask = prob_map > self.mask_thr
+
+ score_map = prob_map.data.cpu().numpy().astype(np.float32)
+ text_mask = text_mask.data.cpu().numpy().astype(np.uint8) # to numpy
+
+ contours, _ = cv2.findContours((text_mask * 255).astype(np.uint8),
+ cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
+
+ for i, poly in enumerate(contours):
+ if i > self.max_candidates:
+ break
+ epsilon = self.epsilon_ratio * cv2.arcLength(poly, True)
+ approx = cv2.approxPolyDP(poly, epsilon, True)
+ poly_pts = approx.reshape((-1, 2))
+ if poly_pts.shape[0] < 4:
+ continue
+ score = self._get_bbox_score(score_map, poly_pts)
+ if score < self.min_text_score:
+ continue
+ poly = self._unclip(poly_pts)
+ # If the result polygon does not exist, or it is split into
+ # multiple polygons, skip it.
+ if len(poly) == 0:
+ continue
+ poly = poly.reshape(-1, 2)
+
+ if self.text_repr_type == 'quad':
+ rect = cv2.minAreaRect(poly)
+ vertices = cv2.boxPoints(rect)
+ poly = vertices.flatten() if min(
+ rect[1]) >= self.min_text_width else []
+ elif self.text_repr_type == 'poly':
+ poly = poly.flatten()
+
+ if len(poly) < 8:
+ poly = np.array([], dtype=np.float32)
+
+ if len(poly) > 0:
+ data_sample.pred_instances.polygons.append(poly)
+ data_sample.pred_instances.scores.append(score)
+
+ data_sample.pred_instances.scores = torch.FloatTensor(
+ data_sample.pred_instances.scores)
+
+ return data_sample
+
+ def _get_bbox_score(self, score_map: np.ndarray,
+ poly_pts: np.ndarray) -> float:
+ """Compute the average score over the area of the bounding box of the
+ polygon.
+
+ Args:
+ score_map (np.ndarray): The score map.
+ poly_pts (np.ndarray): The polygon points.
+
+ Returns:
+ float: The average score.
+ """
+ h, w = score_map.shape[:2]
+ poly_pts = poly_pts.copy()
+ xmin = np.clip(
+ np.floor(poly_pts[:, 0].min()).astype(np.int32), 0, w - 1)
+ xmax = np.clip(
+ np.ceil(poly_pts[:, 0].max()).astype(np.int32), 0, w - 1)
+ ymin = np.clip(
+ np.floor(poly_pts[:, 1].min()).astype(np.int32), 0, h - 1)
+ ymax = np.clip(
+ np.ceil(poly_pts[:, 1].max()).astype(np.int32), 0, h - 1)
+
+ mask = np.zeros((ymax - ymin + 1, xmax - xmin + 1), dtype=np.uint8)
+ poly_pts[:, 0] = poly_pts[:, 0] - xmin
+ poly_pts[:, 1] = poly_pts[:, 1] - ymin
+ cv2.fillPoly(mask, poly_pts.reshape(1, -1, 2).astype(np.int32), 1)
+ return cv2.mean(score_map[ymin:ymax + 1, xmin:xmax + 1], mask)[0]
+
+ def _unclip(self, poly_pts: np.ndarray) -> np.ndarray:
+ """Unclip a polygon.
+
+ Args:
+ poly_pts (np.ndarray): The polygon points.
+
+ Returns:
+ np.ndarray: The expanded polygon points.
+ """
+ poly = Polygon(poly_pts)
+ distance = poly.area * self.unclip_ratio / poly.length
+ return offset_polygon(poly_pts, distance)
diff --git a/mmocr/models/textdet/postprocessors/drrg_postprocessor.py b/mmocr/models/textdet/postprocessors/drrg_postprocessor.py
new file mode 100644
index 0000000000000000000000000000000000000000..1bf3dacdfa0ceaefddd7c946af2f2cbf862ac3d6
--- /dev/null
+++ b/mmocr/models/textdet/postprocessors/drrg_postprocessor.py
@@ -0,0 +1,447 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import functools
+import operator
+from typing import Dict, List, Tuple, Union
+
+import cv2
+import numpy as np
+import torch
+from mmengine.structures import InstanceData
+from numpy import ndarray
+
+from mmocr.registry import MODELS
+from mmocr.structures import TextDetDataSample
+from .base import BaseTextDetPostProcessor
+
+
+class Node:
+ """A simple graph node.
+
+ Args:
+ ind (int): The index of the node.
+ """
+
+ def __init__(self, ind: int) -> None:
+ self.__ind = ind
+ self.__links = set()
+
+ @property
+ def ind(self) -> int:
+ """Current node index."""
+ return self.__ind
+
+ @property
+ def links(self) -> set:
+ """A set of links."""
+ return set(self.__links)
+
+ def add_link(self, link_node: 'Node') -> None:
+ """Add a link to the node.
+
+ Args:
+ link_node (Node): The link node.
+ """
+ self.__links.add(link_node)
+ link_node.__links.add(self)
+
+
+@MODELS.register_module()
+class DRRGPostprocessor(BaseTextDetPostProcessor):
+ """Merge text components and construct boundaries of text instances.
+
+ Args:
+ link_thr (float): The edge score threshold. Defaults to 0.8.
+ edge_len_thr (int or float): The edge length threshold. Defaults to 50.
+ rescale_fields (list[str]): The bbox/polygon field names to
+ be rescaled. If None, no rescaling will be performed. Defaults to
+ [polygons'].
+ """
+
+ def __init__(self,
+ link_thr: float = 0.8,
+ edge_len_thr: Union[int, float] = 50.,
+ rescale_fields=['polygons'],
+ **kwargs) -> None:
+ super().__init__(rescale_fields=rescale_fields)
+ assert isinstance(link_thr, float)
+ assert isinstance(edge_len_thr, (int, float))
+ self.link_thr = link_thr
+ self.edge_len_thr = edge_len_thr
+
+ def get_text_instances(self, pred_results: Tuple[ndarray, ndarray,
+ ndarray],
+ data_sample: TextDetDataSample
+ ) -> TextDetDataSample:
+ """Get text instance predictions of one image.
+
+ Args:
+ pred_result (tuple(ndarray, ndarray, ndarray)): Prediction results
+ edge, score and text_comps. Each of shape
+ :math:`(N_{edges}, 2)`, :math:`(N_{edges},)` and
+ :math:`(M, 9)`, respectively.
+ data_sample (TextDetDataSample): Datasample of an image.
+
+ Returns:
+ TextDetDataSample: The original dataSample with predictions filled
+ in. Polygons and results are saved in
+ ``TextDetDataSample.pred_instances.polygons``. The confidence
+ scores are saved in ``TextDetDataSample.pred_instances.scores``.
+ """
+
+ data_sample.pred_instances = InstanceData()
+ polys = []
+ scores = []
+
+ pred_edges, pred_scores, text_comps = pred_results
+
+ if pred_edges is not None:
+ assert len(pred_edges) == len(pred_scores)
+ assert text_comps.ndim == 2
+ assert text_comps.shape[1] == 9
+
+ vertices, score_dict = self._graph_propagation(
+ pred_edges, pred_scores, text_comps)
+ clusters = self._connected_components(vertices, score_dict)
+ pred_labels = self._clusters2labels(clusters, text_comps.shape[0])
+ text_comps, pred_labels = self._remove_single(
+ text_comps, pred_labels)
+ polys, scores = self._comps2polys(text_comps, pred_labels)
+
+ data_sample.pred_instances.polygons = polys
+ data_sample.pred_instances.scores = torch.FloatTensor(scores)
+
+ return data_sample
+
+ def split_results(self, pred_results: Tuple[ndarray, ndarray,
+ ndarray]) -> List[Tuple]:
+ """Split batched elements in pred_results along the first dimension
+ into ``batch_num`` sub-elements and regather them into a list of dicts.
+
+ However, DRRG only outputs one batch at inference time, so this
+ function is a no-op.
+ """
+ return [pred_results]
+
+ def _graph_propagation(self, edges: ndarray, scores: ndarray,
+ text_comps: ndarray) -> Tuple[List[Node], Dict]:
+ """Propagate edge score information and construct graph. This code was
+ partially adapted from https://github.com/GXYM/DRRG licensed under the
+ MIT license.
+
+ Args:
+ edges (ndarray): The edge array of shape N * 2, each row is a node
+ index pair that makes up an edge in graph.
+ scores (ndarray): The edge score array.
+ text_comps (ndarray): The text components.
+
+ Returns:
+ tuple(vertices, score_dict):
+
+ - vertices (list[Node]): The Nodes in graph.
+ - score_dict (dict): The edge score dict.
+ """
+ assert edges.ndim == 2
+ assert edges.shape[1] == 2
+ assert edges.shape[0] == scores.shape[0]
+ assert text_comps.ndim == 2
+
+ edges = np.sort(edges, axis=1)
+ score_dict = {}
+ for i, edge in enumerate(edges):
+ if text_comps is not None:
+ box1 = text_comps[edge[0], :8].reshape(4, 2)
+ box2 = text_comps[edge[1], :8].reshape(4, 2)
+ center1 = np.mean(box1, axis=0)
+ center2 = np.mean(box2, axis=0)
+ distance = np.linalg.norm(center1 - center2)
+ if distance > self.edge_len_thr:
+ scores[i] = 0
+ if (edge[0], edge[1]) in score_dict:
+ score_dict[edge[0], edge[1]] = 0.5 * (
+ score_dict[edge[0], edge[1]] + scores[i])
+ else:
+ score_dict[edge[0], edge[1]] = scores[i]
+
+ nodes = np.sort(np.unique(edges.flatten()))
+ mapping = -1 * np.ones((np.max(nodes) + 1), dtype=int)
+ mapping[nodes] = np.arange(nodes.shape[0])
+ order_inds = mapping[edges]
+ vertices = [Node(node) for node in nodes]
+ for ind in order_inds:
+ vertices[ind[0]].add_link(vertices[ind[1]])
+
+ return vertices, score_dict
+
+ def _connected_components(self, nodes: List[Node],
+ score_dict: Dict) -> List[List[Node]]:
+ """Conventional connected components searching. This code was partially
+ adapted from https://github.com/GXYM/DRRG licensed under the MIT
+ license.
+
+ Args:
+ nodes (list[Node]): The list of Node objects.
+ score_dict (dict): The edge score dict.
+
+ Returns:
+ List[list[Node]]: The clustered Node objects.
+ """
+ assert isinstance(nodes, list)
+ assert all([isinstance(node, Node) for node in nodes])
+ assert isinstance(score_dict, dict)
+
+ clusters = []
+ nodes = set(nodes)
+ while nodes:
+ node = nodes.pop()
+ cluster = {node}
+ node_queue = [node]
+ while node_queue:
+ node = node_queue.pop(0)
+ neighbors = {
+ neighbor
+ for neighbor in node.links if score_dict[tuple(
+ sorted([node.ind, neighbor.ind]))] >= self.link_thr
+ }
+ neighbors.difference_update(cluster)
+ nodes.difference_update(neighbors)
+ cluster.update(neighbors)
+ node_queue.extend(neighbors)
+ clusters.append(list(cluster))
+ return clusters
+
+ def _clusters2labels(self, clusters: List[List[Node]],
+ num_nodes: int) -> ndarray:
+ """Convert clusters of Node to text component labels. This code was
+ partially adapted from https://github.com/GXYM/DRRG licensed under the
+ MIT license.
+
+ Args:
+ clusters (List[list[Node]]): The clusters of Node objects.
+ num_nodes (int): The total node number of graphs in an image.
+
+ Returns:
+ ndarray: The node label array.
+ """
+ assert isinstance(clusters, list)
+ assert all([isinstance(cluster, list) for cluster in clusters])
+ assert all([
+ isinstance(node, Node) for cluster in clusters for node in cluster
+ ])
+ assert isinstance(num_nodes, int)
+
+ node_labels = np.zeros(num_nodes)
+ for cluster_ind, cluster in enumerate(clusters):
+ for node in cluster:
+ node_labels[node.ind] = cluster_ind
+ return node_labels
+
+ def _remove_single(self, text_comps: ndarray,
+ comp_pred_labels: ndarray) -> Tuple[ndarray, ndarray]:
+ """Remove isolated text components. This code was partially adapted
+ from https://github.com/GXYM/DRRG licensed under the MIT license.
+
+ Args:
+ text_comps (ndarray): The text components.
+ comp_pred_labels (ndarray): The clustering labels of text
+ components.
+
+ Returns:
+ tuple(filtered_text_comps, comp_pred_labels):
+
+ - filtered_text_comps (ndarray): The text components with isolated
+ ones removed.
+ - comp_pred_labels (ndarray): The clustering labels with labels of
+ isolated text components removed.
+ """
+ assert text_comps.ndim == 2
+ assert text_comps.shape[0] == comp_pred_labels.shape[0]
+
+ single_flags = np.zeros_like(comp_pred_labels)
+ pred_labels = np.unique(comp_pred_labels)
+ for label in pred_labels:
+ current_label_flag = (comp_pred_labels == label)
+ if np.sum(current_label_flag) == 1:
+ single_flags[np.where(current_label_flag)[0][0]] = 1
+ keep_ind = [
+ i for i in range(len(comp_pred_labels)) if not single_flags[i]
+ ]
+ filtered_text_comps = text_comps[keep_ind, :]
+ filtered_labels = comp_pred_labels[keep_ind]
+
+ return filtered_text_comps, filtered_labels
+
+ def _comps2polys(self, text_comps: ndarray, comp_pred_labels: ndarray
+ ) -> Tuple[List[ndarray], List[float]]:
+ """Construct text instance boundaries from clustered text components.
+ This code was partially adapted from https://github.com/GXYM/DRRG
+ licensed under the MIT license.
+
+ Args:
+ text_comps (ndarray): The text components.
+ comp_pred_labels (ndarray): The clustering labels of text
+ components.
+
+ Returns:
+ tuple(boundaries, scores):
+
+ - boundaries (list[ndarray]): The predicted boundaries of text
+ instances.
+ - scores (list[float]): The boundary scores.
+ """
+ assert text_comps.ndim == 2
+ assert len(text_comps) == len(comp_pred_labels)
+ boundaries = []
+ scores = []
+ if len(text_comps) < 1:
+ return boundaries, scores
+ for cluster_ind in range(0, int(np.max(comp_pred_labels)) + 1):
+ cluster_comp_inds = np.where(comp_pred_labels == cluster_ind)
+ text_comp_boxes = text_comps[cluster_comp_inds, :8].reshape(
+ (-1, 4, 2)).astype(np.int32)
+ score = np.mean(text_comps[cluster_comp_inds, -1])
+
+ if text_comp_boxes.shape[0] < 1:
+ continue
+
+ elif text_comp_boxes.shape[0] > 1:
+ centers = np.mean(
+ text_comp_boxes, axis=1).astype(np.int32).tolist()
+ shortest_path = self._min_connect_path(centers)
+ text_comp_boxes = text_comp_boxes[shortest_path]
+ top_line = np.mean(
+ text_comp_boxes[:, 0:2, :],
+ axis=1).astype(np.int32).tolist()
+ bot_line = np.mean(
+ text_comp_boxes[:, 2:4, :],
+ axis=1).astype(np.int32).tolist()
+ top_line, bot_line = self._fix_corner(top_line, bot_line,
+ text_comp_boxes[0],
+ text_comp_boxes[-1])
+ boundary_points = top_line + bot_line[::-1]
+
+ else:
+ top_line = text_comp_boxes[0, 0:2, :].astype(np.int32).tolist()
+ bot_line = text_comp_boxes[0, 2:4:-1, :].astype(
+ np.int32).tolist()
+ boundary_points = top_line + bot_line
+
+ boundary = [p for coord in boundary_points for p in coord]
+ boundaries.append(np.array(boundary, dtype=np.float32))
+ scores.append(score)
+
+ return boundaries, scores
+
+ def _norm2(self, point1: List[int], point2: List[int]) -> float:
+ """Calculate the norm of two points."""
+ return ((point1[0] - point2[0])**2 + (point1[1] - point2[1])**2)**0.5
+
+ def _min_connect_path(self, points: List[List[int]]) -> List[List[int]]:
+ """Find the shortest path to traverse all points. This code was
+ partially adapted from https://github.com/GXYM/DRRG licensed under the
+ MIT license.
+
+ Args:
+ points(List[list[int]]): The point sequence
+ [[x0, y0], [x1, y1], ...].
+
+ Returns:
+ List[list[int]]: The shortest index path.
+ """
+ assert isinstance(points, list)
+ assert all([isinstance(point, list) for point in points])
+ assert all(
+ [isinstance(coord, int) for point in points for coord in point])
+
+ points_queue = points.copy()
+ shortest_path = []
+ current_edge = [[], []]
+
+ edge_dict0 = {}
+ edge_dict1 = {}
+ current_edge[0] = points_queue[0]
+ current_edge[1] = points_queue[0]
+ points_queue.remove(points_queue[0])
+ while points_queue:
+ for point in points_queue:
+ length0 = self._norm2(point, current_edge[0])
+ edge_dict0[length0] = [point, current_edge[0]]
+ length1 = self._norm2(current_edge[1], point)
+ edge_dict1[length1] = [current_edge[1], point]
+ key0 = min(edge_dict0.keys())
+ key1 = min(edge_dict1.keys())
+
+ if key0 <= key1:
+ start = edge_dict0[key0][0]
+ end = edge_dict0[key0][1]
+ shortest_path.insert(0,
+ [points.index(start),
+ points.index(end)])
+ points_queue.remove(start)
+ current_edge[0] = start
+ else:
+ start = edge_dict1[key1][0]
+ end = edge_dict1[key1][1]
+ shortest_path.append([points.index(start), points.index(end)])
+ points_queue.remove(end)
+ current_edge[1] = end
+
+ edge_dict0 = {}
+ edge_dict1 = {}
+
+ shortest_path = functools.reduce(operator.concat, shortest_path)
+ shortest_path = sorted(set(shortest_path), key=shortest_path.index)
+
+ return shortest_path
+
+ def _in_contour(self, contour: ndarray, point: ndarray) -> bool:
+ """Whether a point is in a contour."""
+ x, y = point
+ return cv2.pointPolygonTest(contour, (int(x), int(y)), False) > 0.5
+
+ def _fix_corner(self, top_line: List[List[int]], btm_line: List[List[int]],
+ start_box: ndarray, end_box: ndarray
+ ) -> Tuple[List[List[int]], List[List[int]]]:
+ """Add corner points to predicted side lines. This code was partially
+ adapted from https://github.com/GXYM/DRRG licensed under the MIT
+ license.
+
+ Args:
+ top_line (List[list[int]]): The predicted top sidelines of text
+ instance.
+ btm_line (List[list[int]]): The predicted bottom sidelines of text
+ instance.
+ start_box (ndarray): The first text component box.
+ end_box (ndarray): The last text component box.
+
+ Returns:
+ tuple(top_line, bot_line):
+
+ - top_line (List[list[int]]): The top sidelines with corner point
+ added.
+ - bot_line (List[list[int]]): The bottom sidelines with corner
+ point added.
+ """
+ assert isinstance(top_line, list)
+ assert all(isinstance(point, list) for point in top_line)
+ assert isinstance(btm_line, list)
+ assert all(isinstance(point, list) for point in btm_line)
+ assert start_box.shape == end_box.shape == (4, 2)
+
+ contour = np.array(top_line + btm_line[::-1])
+ start_left_mid = (start_box[0] + start_box[3]) / 2
+ start_right_mid = (start_box[1] + start_box[2]) / 2
+ end_left_mid = (end_box[0] + end_box[3]) / 2
+ end_right_mid = (end_box[1] + end_box[2]) / 2
+ if not self._in_contour(contour, start_left_mid):
+ top_line.insert(0, start_box[0].tolist())
+ btm_line.insert(0, start_box[3].tolist())
+ elif not self._in_contour(contour, start_right_mid):
+ top_line.insert(0, start_box[1].tolist())
+ btm_line.insert(0, start_box[2].tolist())
+ if not self._in_contour(contour, end_left_mid):
+ top_line.append(end_box[0].tolist())
+ btm_line.append(end_box[3].tolist())
+ elif not self._in_contour(contour, end_right_mid):
+ top_line.append(end_box[1].tolist())
+ btm_line.append(end_box[2].tolist())
+ return top_line, btm_line
diff --git a/mmocr/models/textdet/postprocessors/fce_postprocessor.py b/mmocr/models/textdet/postprocessors/fce_postprocessor.py
new file mode 100644
index 0000000000000000000000000000000000000000..b6c49bf433224284da715c1589a3041fe445bb97
--- /dev/null
+++ b/mmocr/models/textdet/postprocessors/fce_postprocessor.py
@@ -0,0 +1,239 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Sequence
+
+import cv2
+import numpy as np
+import torch
+from mmengine.structures import InstanceData
+from numpy.fft import ifft
+
+from mmocr.registry import MODELS
+from mmocr.structures import TextDetDataSample
+from mmocr.utils import fill_hole
+from .base import BaseTextDetPostProcessor
+
+
+@MODELS.register_module()
+class FCEPostprocessor(BaseTextDetPostProcessor):
+ """Decoding predictions of FCENet to instances.
+
+ Args:
+ fourier_degree (int): The maximum Fourier transform degree k.
+ num_reconstr_points (int): The points number of the polygon
+ reconstructed from predicted Fourier coefficients.
+ rescale_fields (list[str]): The bbox/polygon field names to
+ be rescaled. If None, no rescaling will be performed. Defaults to
+ ['polygons'].
+ scales (list[int]) : The down-sample scale of each layer. Defaults
+ to [8, 16, 32].
+ text_repr_type (str): Boundary encoding type 'poly' or 'quad'. Defaults
+ to 'poly'.
+ alpha (float): The parameter to calculate final scores
+ :math:`Score_{final} = (Score_{text region} ^ alpha)
+ * (Score_{text center_region}^ beta)`. Defaults to 1.0.
+ beta (float): The parameter to calculate final score. Defaults to 2.0.
+ score_thr (float): The threshold used to filter out the final
+ candidates.Defaults to 0.3.
+ nms_thr (float): The threshold of nms. Defaults to 0.1.
+ """
+
+ def __init__(self,
+ fourier_degree: int,
+ num_reconstr_points: int,
+ rescale_fields: Sequence[str] = ['polygons'],
+ scales: Sequence[int] = [8, 16, 32],
+ text_repr_type: str = 'poly',
+ alpha: float = 1.0,
+ beta: float = 2.0,
+ score_thr: float = 0.3,
+ nms_thr: float = 0.1,
+ **kwargs) -> None:
+ super().__init__(
+ text_repr_type=text_repr_type,
+ rescale_fields=rescale_fields,
+ **kwargs)
+ self.fourier_degree = fourier_degree
+ self.num_reconstr_points = num_reconstr_points
+ self.scales = scales
+ self.alpha = alpha
+ self.beta = beta
+ self.score_thr = score_thr
+ self.nms_thr = nms_thr
+
+ def split_results(self, pred_results: List[Dict]) -> List[List[Dict]]:
+ """Split batched elements in pred_results along the first dimension
+ into ``batch_num`` sub-elements and regather them into a list of dicts.
+
+ Args:
+ pred_results (list[dict]): A list of dict with keys of ``cls_res``,
+ ``reg_res`` corresponding to the classification result and
+ regression result computed from the input tensor with the
+ same index. They have the shapes of :math:`(N, C_{cls,i},
+ H_i, W_i)` and :math:`(N, C_{out,i}, H_i, W_i)`.
+
+ Returns:
+ list[list[dict]]: N lists. Each list contains three dicts from
+ different feature level.
+ """
+ assert isinstance(pred_results, list) and len(pred_results) == len(
+ self.scales)
+
+ fields = list(pred_results[0].keys())
+ batch_num = len(pred_results[0][fields[0]])
+ level_num = len(pred_results)
+ results = []
+ for i in range(batch_num):
+ batch_list = []
+ for level in range(level_num):
+ feat_dict = {}
+ for field in fields:
+ feat_dict[field] = pred_results[level][field][i]
+ batch_list.append(feat_dict)
+ results.append(batch_list)
+ return results
+
+ def get_text_instances(self, pred_results: Sequence[Dict],
+ data_sample: TextDetDataSample
+ ) -> TextDetDataSample:
+ """Get text instance predictions of one image.
+
+ Args:
+ pred_results (List[dict]): A list of dict with keys of ``cls_res``,
+ ``reg_res`` corresponding to the classification result and
+ regression result computed from the input tensor with the
+ same index. They have the shapes of :math:`(N, C_{cls,i}, H_i,
+ W_i)` and :math:`(N, C_{out,i}, H_i, W_i)`.
+ data_sample (TextDetDataSample): Datasample of an image.
+
+ Returns:
+ TextDetDataSample: A new DataSample with predictions filled in.
+ Polygons and results are saved in
+ ``TextDetDataSample.pred_instances.polygons``. The confidence
+ scores are saved in ``TextDetDataSample.pred_instances.scores``.
+ """
+ assert len(pred_results) == len(self.scales)
+ data_sample.pred_instances = InstanceData()
+ data_sample.pred_instances.polygons = []
+ data_sample.pred_instances.scores = []
+
+ result_polys = []
+ result_scores = []
+ for idx, pred_result in enumerate(pred_results):
+ # TODO: Scale can be calculated given image shape and feature
+ # shape. This param can be removed in the future.
+ polygons, scores = self._get_text_instances_single(
+ pred_result, self.scales[idx])
+ result_polys += polygons
+ result_scores += scores
+ result_polys, result_scores = self.poly_nms(result_polys,
+ result_scores,
+ self.nms_thr)
+ for result_poly, result_score in zip(result_polys, result_scores):
+ result_poly = np.array(result_poly, dtype=np.float32)
+ data_sample.pred_instances.polygons.append(result_poly)
+ data_sample.pred_instances.scores.append(result_score)
+ data_sample.pred_instances.scores = torch.FloatTensor(
+ data_sample.pred_instances.scores)
+
+ return data_sample
+
+ def _get_text_instances_single(self, pred_result: Dict, scale: int):
+ """Get text instance predictions from one feature level.
+
+ Args:
+ pred_result (dict): A dict with keys of ``cls_res``, ``reg_res``
+ corresponding to the classification result and regression
+ result computed from the input tensor with the same index.
+ They have the shapes of :math:`(1, C_{cls,i}, H_i, W_i)` and
+ :math:`(1, C_{out,i}, H_i, W_i)`.
+ scale (int): Scale of current feature map which equals to
+ img_size / feat_size.
+
+ Returns:
+ result_polys (list[ndarray]): A list of polygons after postprocess.
+ result_scores (list[ndarray]): A list of scores after postprocess.
+ """
+
+ cls_pred = pred_result['cls_res']
+ tr_pred = cls_pred[0:2].softmax(dim=0).data.cpu().numpy()
+ tcl_pred = cls_pred[2:].softmax(dim=0).data.cpu().numpy()
+
+ reg_pred = pred_result['reg_res'].permute(1, 2, 0).data.cpu().numpy()
+ x_pred = reg_pred[:, :, :2 * self.fourier_degree + 1]
+ y_pred = reg_pred[:, :, 2 * self.fourier_degree + 1:]
+
+ score_pred = (tr_pred[1]**self.alpha) * (tcl_pred[1]**self.beta)
+ tr_pred_mask = (score_pred) > self.score_thr
+ tr_mask = fill_hole(tr_pred_mask)
+
+ tr_contours, _ = cv2.findContours(
+ tr_mask.astype(np.uint8), cv2.RETR_TREE,
+ cv2.CHAIN_APPROX_SIMPLE) # opencv4
+
+ mask = np.zeros_like(tr_mask)
+
+ result_polys = []
+ result_scores = []
+ for cont in tr_contours:
+ deal_map = mask.copy().astype(np.int8)
+ cv2.drawContours(deal_map, [cont], -1, 1, -1)
+
+ score_map = score_pred * deal_map
+ score_mask = score_map > 0
+ xy_text = np.argwhere(score_mask)
+ dxy = xy_text[:, 1] + xy_text[:, 0] * 1j
+
+ x, y = x_pred[score_mask], y_pred[score_mask]
+ c = x + y * 1j
+ c[:, self.fourier_degree] = c[:, self.fourier_degree] + dxy
+ c *= scale
+
+ polygons = self._fourier2poly(c, self.num_reconstr_points)
+ scores = score_map[score_mask].reshape(-1, 1).tolist()
+ polygons, scores = self.poly_nms(polygons, scores, self.nms_thr)
+ result_polys += polygons
+ result_scores += scores
+
+ result_polys, result_scores = self.poly_nms(result_polys,
+ result_scores,
+ self.nms_thr)
+
+ if self.text_repr_type == 'quad':
+ new_polys = []
+ for poly in result_polys:
+ poly = np.array(poly).reshape(-1, 2).astype(np.float32)
+ points = cv2.boxPoints(cv2.minAreaRect(poly))
+ points = np.int0(points)
+ new_polys.append(points.reshape(-1))
+
+ return new_polys, result_scores
+ return result_polys, result_scores
+
+ def _fourier2poly(self,
+ fourier_coeff: np.ndarray,
+ num_reconstr_points: int = 50):
+ """ Inverse Fourier transform
+ Args:
+ fourier_coeff (ndarray): Fourier coefficients shaped (n, 2k+1),
+ with n and k being candidates number and Fourier degree
+ respectively.
+ num_reconstr_points (int): Number of reconstructed polygon
+ points. Defaults to 50.
+
+ Returns:
+ List[ndarray]: The reconstructed polygons.
+ """
+
+ a = np.zeros((len(fourier_coeff), num_reconstr_points),
+ dtype='complex')
+ k = (len(fourier_coeff[0]) - 1) // 2
+
+ a[:, 0:k + 1] = fourier_coeff[:, k:]
+ a[:, -k:] = fourier_coeff[:, :k]
+
+ poly_complex = ifft(a) * num_reconstr_points
+ polygon = np.zeros((len(fourier_coeff), num_reconstr_points, 2))
+ polygon[:, :, 0] = poly_complex.real
+ polygon[:, :, 1] = poly_complex.imag
+ return polygon.astype('int32').reshape(
+ (len(fourier_coeff), -1)).tolist()
diff --git a/mmocr/models/textdet/postprocessors/pan_postprocessor.py b/mmocr/models/textdet/postprocessors/pan_postprocessor.py
new file mode 100644
index 0000000000000000000000000000000000000000..63676856bebd78dfc97156739a2745e51cb272da
--- /dev/null
+++ b/mmocr/models/textdet/postprocessors/pan_postprocessor.py
@@ -0,0 +1,159 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Sequence
+
+import cv2
+import numpy as np
+import torch
+from mmcv.ops import pixel_group
+from mmengine.structures import InstanceData
+
+from mmocr.registry import MODELS
+from mmocr.structures import TextDetDataSample
+from .base import BaseTextDetPostProcessor
+
+
+@MODELS.register_module()
+class PANPostprocessor(BaseTextDetPostProcessor):
+ """Convert scores to quadrangles via post processing in PANet. This is
+ partially adapted from https://github.com/WenmuZhou/PAN.pytorch.
+
+ Args:
+ text_repr_type (str): The boundary encoding type 'poly' or 'quad'.
+ Defaults to 'poly'.
+ score_threshold (float): The minimal text score.
+ Defaults to 0.3.
+ rescale_fields (list[str]): The bbox/polygon field names to
+ be rescaled. If None, no rescaling will be performed. Defaults to
+ ['polygons'].
+ min_text_confidence (float): The minimal text confidence.
+ Defaults to 0.5.
+ min_kernel_confidence (float): The minimal kernel confidence.
+ Defaults to 0.5.
+ distance_threshold (float): The minimal distance between the point to
+ mean of text kernel. Defaults to 3.0.
+ min_text_area (int): The minimal text instance region area.
+ Defaults to 16.
+ downsample_ratio (float): Downsample ratio. Defaults to 0.25.
+ """
+
+ def __init__(self,
+ text_repr_type: str = 'poly',
+ score_threshold: float = 0.3,
+ rescale_fields: Sequence[str] = ['polygons'],
+ min_text_confidence: float = 0.5,
+ min_kernel_confidence: float = 0.5,
+ distance_threshold: float = 3.0,
+ min_text_area: int = 16,
+ downsample_ratio: float = 0.25) -> None:
+ super().__init__(text_repr_type, rescale_fields)
+
+ self.min_text_confidence = min_text_confidence
+ self.min_kernel_confidence = min_kernel_confidence
+ self.score_threshold = score_threshold
+ self.min_text_area = min_text_area
+ self.distance_threshold = distance_threshold
+ self.downsample_ratio = downsample_ratio
+
+ def get_text_instances(self, pred_results: torch.Tensor,
+ data_sample: TextDetDataSample,
+ **kwargs) -> TextDetDataSample:
+ """Get text instance predictions of one image.
+
+ Args:
+ pred_result (torch.Tensor): Prediction results of an image which
+ is a tensor of shape :math:`(N, H, W)`.
+ data_sample (TextDetDataSample): Datasample of an image.
+
+ Returns:
+ TextDetDataSample: A new DataSample with predictions filled in.
+ Polygons and results are saved in
+ ``TextDetDataSample.pred_instances.polygons``. The confidence
+ scores are saved in ``TextDetDataSample.pred_instances.scores``.
+ """
+ assert pred_results.dim() == 3
+
+ pred_results[:2, :, :] = torch.sigmoid(pred_results[:2, :, :])
+ pred_results = pred_results.detach().cpu().numpy()
+
+ text_score = pred_results[0].astype(np.float32)
+ text = pred_results[0] > self.min_text_confidence
+ kernel = (pred_results[1] > self.min_kernel_confidence) * text
+ embeddings = pred_results[2:] * text.astype(np.float32)
+ embeddings = embeddings.transpose((1, 2, 0)) # (h, w, 4)
+
+ region_num, labels = cv2.connectedComponents(
+ kernel.astype(np.uint8), connectivity=4)
+ contours, _ = cv2.findContours((kernel * 255).astype(np.uint8),
+ cv2.RETR_LIST, cv2.CHAIN_APPROX_NONE)
+ kernel_contours = np.zeros(text.shape, dtype='uint8')
+ cv2.drawContours(kernel_contours, contours, -1, 255)
+ text_points = pixel_group(text_score, text, embeddings, labels,
+ kernel_contours, region_num,
+ self.distance_threshold)
+
+ polygons = []
+ scores = []
+ for text_point in text_points:
+ text_confidence = text_point[0]
+ text_point = text_point[2:]
+ text_point = np.array(text_point, dtype=int).reshape(-1, 2)
+ area = text_point.shape[0]
+ if (area < self.min_text_area
+ or text_confidence <= self.score_threshold):
+ continue
+
+ polygon = self._points2boundary(text_point)
+ if len(polygon) > 0:
+ polygons.append(polygon)
+ scores.append(text_confidence)
+ pred_instances = InstanceData()
+ pred_instances.polygons = polygons
+ pred_instances.scores = torch.FloatTensor(scores)
+ data_sample.pred_instances = pred_instances
+ scale_factor = data_sample.scale_factor
+ scale_factor = tuple(factor * self.downsample_ratio
+ for factor in scale_factor)
+ data_sample.set_metainfo(dict(scale_factor=scale_factor))
+ return data_sample
+
+ def _points2boundary(self,
+ points: np.ndarray,
+ min_width: int = 0) -> List[float]:
+ """Convert a text mask represented by point coordinates sequence into a
+ text boundary.
+
+ Args:
+ points (ndarray): Mask index of size (n, 2).
+ min_width (int): Minimum bounding box width to be converted. Only
+ applicable to 'quad' type. Defaults to 0.
+
+ Returns:
+ list[float]: The text boundary point coordinates (x, y) list.
+ Return [] if no text boundary found.
+ """
+ assert isinstance(points, np.ndarray)
+ assert points.shape[1] == 2
+ assert self.text_repr_type in ['quad', 'poly']
+
+ if self.text_repr_type == 'quad':
+ rect = cv2.minAreaRect(points)
+ vertices = cv2.boxPoints(rect)
+ boundary = []
+ if min(rect[1]) >= min_width:
+ boundary = [p for p in vertices.flatten().tolist()]
+ elif self.text_repr_type == 'poly':
+
+ height = np.max(points[:, 1]) + 10
+ width = np.max(points[:, 0]) + 10
+
+ mask = np.zeros((height, width), np.uint8)
+ mask[points[:, 1], points[:, 0]] = 255
+
+ contours, _ = cv2.findContours(mask, cv2.RETR_EXTERNAL,
+ cv2.CHAIN_APPROX_SIMPLE)
+ boundary = list(contours[0].flatten().tolist())
+
+ if len(boundary) < 8:
+ return []
+
+ return boundary
diff --git a/mmocr/models/textdet/postprocessors/pse_postprocessor.py b/mmocr/models/textdet/postprocessors/pse_postprocessor.py
new file mode 100644
index 0000000000000000000000000000000000000000..b0a1fb9f8a2dde54dfa71e0d531f0e85fb74d1c6
--- /dev/null
+++ b/mmocr/models/textdet/postprocessors/pse_postprocessor.py
@@ -0,0 +1,113 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+
+from typing import List
+
+import cv2
+import numpy as np
+import torch
+from mmcv.ops import contour_expand
+from mmengine.structures import InstanceData
+
+from mmocr.registry import MODELS
+from mmocr.structures import TextDetDataSample
+from .pan_postprocessor import PANPostprocessor
+
+
+@MODELS.register_module()
+class PSEPostprocessor(PANPostprocessor):
+ """Decoding predictions of PSENet to instances. This is partially adapted
+ from https://github.com/whai362/PSENet.
+
+ Args:
+ text_repr_type (str): The boundary encoding type 'poly' or 'quad'.
+ Defaults to 'poly'.
+ rescale_fields (list[str]): The bbox/polygon field names to
+ be rescaled. If None, no rescaling will be performed. Defaults to
+ ['polygons'].
+ min_kernel_confidence (float): The minimal kernel confidence.
+ Defaults to 0.5.
+ score_threshold (float): The minimal text average confidence.
+ Defaults to 0.3.
+ min_kernel_area (int): The minimal text kernel area. Defaults to 0.
+ min_text_area (int): The minimal text instance region area.
+ Defaults to 16.
+ downsample_ratio (float): Downsample ratio. Defaults to 0.25.
+ """
+
+ def __init__(self,
+ text_repr_type: str = 'poly',
+ rescale_fields: List[str] = ['polygons'],
+ min_kernel_confidence: float = 0.5,
+ score_threshold: float = 0.3,
+ min_kernel_area: int = 0,
+ min_text_area: int = 16,
+ downsample_ratio: float = 0.25) -> None:
+ super().__init__(
+ text_repr_type=text_repr_type,
+ rescale_fields=rescale_fields,
+ min_kernel_confidence=min_kernel_confidence,
+ score_threshold=score_threshold,
+ min_text_area=min_text_area,
+ downsample_ratio=downsample_ratio)
+ self.min_kernel_area = min_kernel_area
+
+ def get_text_instances(self, pred_results: torch.Tensor,
+ data_sample: TextDetDataSample,
+ **kwargs) -> TextDetDataSample:
+ """
+ Args:
+ pred_result (torch.Tensor): Prediction results of an image which
+ is a tensor of shape :math:`(N, H, W)`.
+ data_sample (TextDetDataSample): Datasample of an image.
+
+ Returns:
+ TextDetDataSample: A new DataSample with predictions filled in.
+ Polygons and results are saved in
+ ``TextDetDataSample.pred_instances.polygons``. The confidence
+ scores are saved in ``TextDetDataSample.pred_instances.scores``.
+ """
+ assert pred_results.dim() == 3
+
+ pred_results = torch.sigmoid(pred_results) # text confidence
+
+ masks = pred_results > self.min_kernel_confidence
+ text_mask = masks[0, :, :]
+ kernel_masks = masks[0:, :, :] * text_mask
+ kernel_masks = kernel_masks.data.cpu().numpy().astype(np.uint8)
+
+ score = pred_results[0, :, :]
+ score = score.data.cpu().numpy().astype(np.float32)
+
+ region_num, labels = cv2.connectedComponents(
+ kernel_masks[-1], connectivity=4)
+
+ labels = contour_expand(kernel_masks, labels, self.min_kernel_area,
+ region_num)
+ labels = np.array(labels)
+ label_num = np.max(labels)
+
+ polygons = []
+ scores = []
+ for i in range(1, label_num + 1):
+ points = np.array(np.where(labels == i)).transpose((1, 0))[:, ::-1]
+ area = points.shape[0]
+ score_instance = np.mean(score[labels == i])
+ if not (area >= self.min_text_area
+ or score_instance > self.score_threshold):
+ continue
+
+ polygon = self._points2boundary(points)
+ if polygon:
+ polygons.append(polygon)
+ scores.append(score_instance)
+
+ pred_instances = InstanceData()
+ pred_instances.polygons = polygons
+ pred_instances.scores = torch.FloatTensor(scores)
+ data_sample.pred_instances = pred_instances
+ scale_factor = data_sample.scale_factor
+ scale_factor = tuple(factor * self.downsample_ratio
+ for factor in scale_factor)
+ data_sample.set_metainfo(dict(scale_factor=scale_factor))
+
+ return data_sample
diff --git a/mmocr/models/textdet/postprocessors/textsnake_postprocessor.py b/mmocr/models/textdet/postprocessors/textsnake_postprocessor.py
new file mode 100644
index 0000000000000000000000000000000000000000..a4f7ae02ee33688925d799df6ed303b61be59bd1
--- /dev/null
+++ b/mmocr/models/textdet/postprocessors/textsnake_postprocessor.py
@@ -0,0 +1,234 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+
+from typing import List, Sequence
+
+import cv2
+import numpy as np
+import torch
+from mmengine.structures import InstanceData
+from numpy.linalg import norm
+from skimage.morphology import skeletonize
+
+from mmocr.registry import MODELS
+from mmocr.structures import TextDetDataSample
+from mmocr.utils import fill_hole
+from .base import BaseTextDetPostProcessor
+
+
+@MODELS.register_module()
+class TextSnakePostprocessor(BaseTextDetPostProcessor):
+ """Decoding predictions of TextSnake to instances. This was partially
+ adapted from https://github.com/princewang1994/TextSnake.pytorch.
+
+ Args:
+ text_repr_type (str): The boundary encoding type 'poly' or 'quad'.
+ min_text_region_confidence (float): The confidence threshold of text
+ region in TextSnake.
+ min_center_region_confidence (float): The confidence threshold of text
+ center region in TextSnake.
+ min_center_area (int): The minimal text center region area.
+ disk_overlap_thr (float): The radius overlap threshold for merging
+ disks.
+ radius_shrink_ratio (float): The shrink ratio of ordered disks radii.
+ rescale_fields (list[str], optional): The bbox/polygon field names to
+ be rescaled. If None, no rescaling will be performed.
+ """
+
+ def __init__(self,
+ text_repr_type: str = 'poly',
+ min_text_region_confidence: float = 0.6,
+ min_center_region_confidence: float = 0.2,
+ min_center_area: int = 30,
+ disk_overlap_thr: float = 0.03,
+ radius_shrink_ratio: float = 1.03,
+ rescale_fields: Sequence[str] = ['polygons'],
+ **kwargs) -> None:
+ super().__init__(
+ text_repr_type=text_repr_type,
+ rescale_fields=rescale_fields,
+ **kwargs)
+ assert text_repr_type == 'poly'
+ self.min_text_region_confidence = min_text_region_confidence
+ self.min_center_region_confidence = min_center_region_confidence
+ self.min_center_area = min_center_area
+ self.disk_overlap_thr = disk_overlap_thr
+ self.radius_shrink_ratio = radius_shrink_ratio
+
+ def get_text_instances(self, pred_results: torch.Tensor,
+ data_sample: TextDetDataSample
+ ) -> TextDetDataSample:
+ """
+ Args:
+ pred_results (torch.Tensor): Prediction map with
+ shape :math:`(C, H, W)`.
+ data_sample (TextDetDataSample): Datasample of an image.
+
+ Returns:
+ list[list[float]]: The instance boundary and its confidence.
+ """
+ assert pred_results.dim() == 3
+ data_sample.pred_instances = InstanceData()
+ data_sample.pred_instances.polygons = []
+ data_sample.pred_instances.scores = []
+
+ pred_results[:2, :, :] = torch.sigmoid(pred_results[:2, :, :])
+ pred_results = pred_results.detach().cpu().numpy()
+
+ pred_text_score = pred_results[0]
+ pred_text_mask = pred_text_score > self.min_text_region_confidence
+ pred_center_score = pred_results[1] * pred_text_score
+ pred_center_mask = \
+ pred_center_score > self.min_center_region_confidence
+ pred_sin = pred_results[2]
+ pred_cos = pred_results[3]
+ pred_radius = pred_results[4]
+ mask_sz = pred_text_mask.shape
+
+ scale = np.sqrt(1.0 / (pred_sin**2 + pred_cos**2 + 1e-8))
+ pred_sin = pred_sin * scale
+ pred_cos = pred_cos * scale
+
+ pred_center_mask = fill_hole(pred_center_mask).astype(np.uint8)
+ center_contours, _ = cv2.findContours(pred_center_mask, cv2.RETR_TREE,
+ cv2.CHAIN_APPROX_SIMPLE)
+
+ for contour in center_contours:
+ if cv2.contourArea(contour) < self.min_center_area:
+ continue
+ instance_center_mask = np.zeros(mask_sz, dtype=np.uint8)
+ cv2.drawContours(instance_center_mask, [contour], -1, 1, -1)
+ skeleton = skeletonize(instance_center_mask)
+ skeleton_yx = np.argwhere(skeleton > 0)
+ y, x = skeleton_yx[:, 0], skeleton_yx[:, 1]
+ cos = pred_cos[y, x].reshape((-1, 1))
+ sin = pred_sin[y, x].reshape((-1, 1))
+ radius = pred_radius[y, x].reshape((-1, 1))
+
+ center_line_yx = self._centralize(skeleton_yx, cos, -sin, radius,
+ instance_center_mask)
+ y, x = center_line_yx[:, 0], center_line_yx[:, 1]
+ radius = (pred_radius[y, x] * self.radius_shrink_ratio).reshape(
+ (-1, 1))
+ score = pred_center_score[y, x].reshape((-1, 1))
+ instance_disks = np.hstack(
+ [np.fliplr(center_line_yx), radius, score])
+ instance_disks = self._merge_disks(instance_disks,
+ self.disk_overlap_thr)
+
+ instance_mask = np.zeros(mask_sz, dtype=np.uint8)
+ for x, y, radius, score in instance_disks:
+ if radius > 1:
+ cv2.circle(instance_mask, (int(x), int(y)), int(radius), 1,
+ -1)
+ contours, _ = cv2.findContours(instance_mask, cv2.RETR_TREE,
+ cv2.CHAIN_APPROX_SIMPLE)
+
+ score = np.sum(instance_mask * pred_text_score) / (
+ np.sum(instance_mask) + 1e-8)
+ if (len(contours) > 0 and cv2.contourArea(contours[0]) > 0
+ and contours[0].size > 8):
+ polygon = contours[0].flatten().tolist()
+ data_sample.pred_instances.polygons.append(polygon)
+ data_sample.pred_instances.scores.append(score)
+
+ data_sample.pred_instances.scores = torch.FloatTensor(
+ data_sample.pred_instances.scores)
+
+ return data_sample
+
+ def split_results(self, pred_results: torch.Tensor) -> List[torch.Tensor]:
+ """Split the prediction results into text score and kernel score.
+
+ Args:
+ pred_results (torch.Tensor): The prediction results.
+
+ Returns:
+ List[torch.Tensor]: The text score and kernel score.
+ """
+ pred_results = [pred_result for pred_result in pred_results]
+ return pred_results
+
+ @staticmethod
+ def _centralize(points_yx: np.ndarray,
+ normal_cos: torch.Tensor,
+ normal_sin: torch.Tensor,
+ radius: torch.Tensor,
+ contour_mask: np.ndarray,
+ step_ratio: float = 0.03) -> np.ndarray:
+ """Centralize the points.
+
+ Args:
+ points_yx (np.array): The points in yx order.
+ normal_cos (torch.Tensor): The normal cosine of the points.
+ normal_sin (torch.Tensor): The normal sine of the points.
+ radius (torch.Tensor): The radius of the points.
+ contour_mask (np.array): The contour mask of the points.
+ step_ratio (float): The step ratio of the centralization.
+ Defaults to 0.03.
+
+ Returns:
+ np.ndarray: The centralized points.
+ """
+
+ h, w = contour_mask.shape
+ top_yx = bot_yx = points_yx
+ step_flags = np.ones((len(points_yx), 1), dtype=np.bool_)
+ step = step_ratio * radius * np.hstack([normal_cos, normal_sin])
+ while np.any(step_flags):
+ next_yx = np.array(top_yx + step, dtype=np.int32)
+ next_y, next_x = next_yx[:, 0], next_yx[:, 1]
+ step_flags = (next_y >= 0) & (next_y < h) & (next_x > 0) & (
+ next_x < w) & contour_mask[np.clip(next_y, 0, h - 1),
+ np.clip(next_x, 0, w - 1)]
+ top_yx = top_yx + step_flags.reshape((-1, 1)) * step
+ step_flags = np.ones((len(points_yx), 1), dtype=np.bool_)
+ while np.any(step_flags):
+ next_yx = np.array(bot_yx - step, dtype=np.int32)
+ next_y, next_x = next_yx[:, 0], next_yx[:, 1]
+ step_flags = (next_y >= 0) & (next_y < h) & (next_x > 0) & (
+ next_x < w) & contour_mask[np.clip(next_y, 0, h - 1),
+ np.clip(next_x, 0, w - 1)]
+ bot_yx = bot_yx - step_flags.reshape((-1, 1)) * step
+ centers = np.array((top_yx + bot_yx) * 0.5, dtype=np.int32)
+ return centers
+
+ @staticmethod
+ def _merge_disks(disks: np.ndarray, disk_overlap_thr: float) -> np.ndarray:
+ """Merging overlapped disks.
+
+ Args:
+ disks (np.ndarray): The predicted disks.
+ disk_overlap_thr (float): The radius overlap threshold for merging
+ disks.
+
+ Returns:
+ np.ndarray: The merged disks.
+ """
+ xy = disks[:, 0:2]
+ radius = disks[:, 2]
+ scores = disks[:, 3]
+ order = scores.argsort()[::-1]
+
+ merged_disks = []
+ while order.size > 0:
+ if order.size == 1:
+ merged_disks.append(disks[order])
+ break
+ i = order[0]
+ d = norm(xy[i] - xy[order[1:]], axis=1)
+ ri = radius[i]
+ r = radius[order[1:]]
+ d_thr = (ri + r) * disk_overlap_thr
+
+ merge_inds = np.where(d <= d_thr)[0] + 1
+ if merge_inds.size > 0:
+ merge_order = np.hstack([i, order[merge_inds]])
+ merged_disks.append(np.mean(disks[merge_order], axis=0))
+ else:
+ merged_disks.append(disks[i])
+
+ inds = np.where(d > d_thr)[0] + 1
+ order = order[inds]
+ merged_disks = np.vstack(merged_disks)
+
+ return merged_disks
diff --git a/mmocr/models/textrecog/__init__.py b/mmocr/models/textrecog/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e573c71efd65c3c94fe7e10c2031bae88cb9fc90
--- /dev/null
+++ b/mmocr/models/textrecog/__init__.py
@@ -0,0 +1,11 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .backbones import * # NOQA
+from .data_preprocessors import * # NOQA
+from .decoders import * # NOQA
+from .encoders import * # NOQA
+from .layers import * # NOQA
+from .module_losses import * # NOQA
+from .plugins import * # NOQA
+from .postprocessors import * # NOQA
+from .preprocessors import * # NOQA
+from .recognizers import * # NOQA
diff --git a/mmocr/models/textrecog/__pycache__/__init__.cpython-38.pyc b/mmocr/models/textrecog/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d01cabd7bdda5adb7914ec5fc48407f03996796f
Binary files /dev/null and b/mmocr/models/textrecog/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/backbones/__init__.py b/mmocr/models/textrecog/backbones/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..3201de3884b6582bd466daee1d0e8721075f5bac
--- /dev/null
+++ b/mmocr/models/textrecog/backbones/__init__.py
@@ -0,0 +1,13 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .mini_vgg import MiniVGG
+from .mobilenet_v2 import MobileNetV2
+from .nrtr_modality_transformer import NRTRModalityTransform
+from .resnet import ResNet
+from .resnet31_ocr import ResNet31OCR
+from .resnet_abi import ResNetABI
+from .shallow_cnn import ShallowCNN
+
+__all__ = [
+ 'ResNet31OCR', 'MiniVGG', 'NRTRModalityTransform', 'ShallowCNN',
+ 'ResNetABI', 'ResNet', 'MobileNetV2'
+]
diff --git a/mmocr/models/textrecog/backbones/__pycache__/__init__.cpython-38.pyc b/mmocr/models/textrecog/backbones/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..9ef600cbe83ac1647c68c6292e5981bc8a2f347b
Binary files /dev/null and b/mmocr/models/textrecog/backbones/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/backbones/__pycache__/mini_vgg.cpython-38.pyc b/mmocr/models/textrecog/backbones/__pycache__/mini_vgg.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..9eaecbb7fc7ce229202d9192f1e36791ce6162a4
Binary files /dev/null and b/mmocr/models/textrecog/backbones/__pycache__/mini_vgg.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/backbones/__pycache__/mobilenet_v2.cpython-38.pyc b/mmocr/models/textrecog/backbones/__pycache__/mobilenet_v2.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..26ccf5ecca5a9de0810db4d49831866779078508
Binary files /dev/null and b/mmocr/models/textrecog/backbones/__pycache__/mobilenet_v2.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/backbones/__pycache__/nrtr_modality_transformer.cpython-38.pyc b/mmocr/models/textrecog/backbones/__pycache__/nrtr_modality_transformer.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c01b048020369f8a2d16ce242b008cee8a35ce4c
Binary files /dev/null and b/mmocr/models/textrecog/backbones/__pycache__/nrtr_modality_transformer.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/backbones/__pycache__/resnet.cpython-38.pyc b/mmocr/models/textrecog/backbones/__pycache__/resnet.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..25fed6e7b048e767ba3d791f68043a963c9f18ad
Binary files /dev/null and b/mmocr/models/textrecog/backbones/__pycache__/resnet.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/backbones/__pycache__/resnet31_ocr.cpython-38.pyc b/mmocr/models/textrecog/backbones/__pycache__/resnet31_ocr.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a34ea02a3f5ff2fbd3437baeb78b887d431c8e22
Binary files /dev/null and b/mmocr/models/textrecog/backbones/__pycache__/resnet31_ocr.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/backbones/__pycache__/resnet_abi.cpython-38.pyc b/mmocr/models/textrecog/backbones/__pycache__/resnet_abi.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..cbd53fcd5f613b8f2992f178abd6cf203567944e
Binary files /dev/null and b/mmocr/models/textrecog/backbones/__pycache__/resnet_abi.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/backbones/__pycache__/shallow_cnn.cpython-38.pyc b/mmocr/models/textrecog/backbones/__pycache__/shallow_cnn.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..92d63917f3e14f9671192496eed63072e8a9856f
Binary files /dev/null and b/mmocr/models/textrecog/backbones/__pycache__/shallow_cnn.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/backbones/mini_vgg.py b/mmocr/models/textrecog/backbones/mini_vgg.py
new file mode 100644
index 0000000000000000000000000000000000000000..ed3601c1b4936cea459c6f0ac67042907fbc846c
--- /dev/null
+++ b/mmocr/models/textrecog/backbones/mini_vgg.py
@@ -0,0 +1,79 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+from mmengine.model import BaseModule, Sequential
+
+from mmocr.registry import MODELS
+
+
+@MODELS.register_module()
+class MiniVGG(BaseModule):
+ """A mini VGG backbone for text recognition, modified from `VGG-VeryDeep.
+
+ `_
+
+ Args:
+ leaky_relu (bool): Use leakyRelu or not.
+ input_channels (int): Number of channels of input image tensor.
+ """
+
+ def __init__(self,
+ leaky_relu=True,
+ input_channels=3,
+ init_cfg=[
+ dict(type='Xavier', layer='Conv2d'),
+ dict(type='Uniform', layer='BatchNorm2d')
+ ]):
+ super().__init__(init_cfg=init_cfg)
+
+ ks = [3, 3, 3, 3, 3, 3, 2]
+ ps = [1, 1, 1, 1, 1, 1, 0]
+ ss = [1, 1, 1, 1, 1, 1, 1]
+ nm = [64, 128, 256, 256, 512, 512, 512]
+
+ self.channels = nm
+
+ # cnn = nn.Sequential()
+ cnn = Sequential()
+
+ def conv_relu(i, batch_normalization=False):
+ n_in = input_channels if i == 0 else nm[i - 1]
+ n_out = nm[i]
+ cnn.add_module(f'conv{i}',
+ nn.Conv2d(n_in, n_out, ks[i], ss[i], ps[i]))
+ if batch_normalization:
+ cnn.add_module(f'batchnorm{i}', nn.BatchNorm2d(n_out))
+ if leaky_relu:
+ cnn.add_module(f'relu{i}', nn.LeakyReLU(0.2, inplace=True))
+ else:
+ cnn.add_module(f'relu{i}', nn.ReLU(True))
+
+ conv_relu(0)
+ cnn.add_module(f'pooling{0}', nn.MaxPool2d(2, 2)) # 64x16x64
+ conv_relu(1)
+ cnn.add_module(f'pooling{1}', nn.MaxPool2d(2, 2)) # 128x8x32
+ conv_relu(2, True)
+ conv_relu(3)
+ cnn.add_module(f'pooling{2}', nn.MaxPool2d((2, 2), (2, 1),
+ (0, 1))) # 256x4x16
+ conv_relu(4, True)
+ conv_relu(5)
+ cnn.add_module(f'pooling{3}', nn.MaxPool2d((2, 2), (2, 1),
+ (0, 1))) # 512x2x16
+ conv_relu(6, True) # 512x1x16
+
+ self.cnn = cnn
+
+ def out_channels(self):
+ return self.channels[-1]
+
+ def forward(self, x):
+ """
+ Args:
+ x (Tensor): Images of shape :math:`(N, C, H, W)`.
+
+ Returns:
+ Tensor: The feature Tensor of shape :math:`(N, 512, H/32, (W/4+1)`.
+ """
+ output = self.cnn(x)
+
+ return output
diff --git a/mmocr/models/textrecog/backbones/mobilenet_v2.py b/mmocr/models/textrecog/backbones/mobilenet_v2.py
new file mode 100644
index 0000000000000000000000000000000000000000..b0c671645f48773baa3df75a3ed868ca31c56a83
--- /dev/null
+++ b/mmocr/models/textrecog/backbones/mobilenet_v2.py
@@ -0,0 +1,43 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List
+
+import torch.nn as nn
+from mmdet.models.backbones import MobileNetV2 as MMDet_MobileNetV2
+from torch import Tensor
+
+from mmocr.registry import MODELS
+from mmocr.utils.typing_utils import InitConfigType
+
+
+@MODELS.register_module()
+class MobileNetV2(MMDet_MobileNetV2):
+ """See mmdet.models.backbones.MobileNetV2 for details.
+
+ Args:
+ pooling_layers (list): List of indices of pooling layers.
+ init_cfg (InitConfigType, optional): Initialization config dict.
+ """
+ # Parameters to build layers. 4 parameters are needed to construct a
+ # layer, from left to right: expand_ratio, channel, num_blocks, stride.
+ arch_settings = [[1, 16, 1, 1], [6, 24, 2, 2], [6, 32, 3, 1],
+ [6, 64, 4, 1], [6, 96, 3, 1], [6, 160, 3, 1],
+ [6, 320, 1, 1]]
+
+ def __init__(self,
+ pooling_layers: List = [3, 4, 5],
+ init_cfg: InitConfigType = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.pooling = nn.MaxPool2d((2, 2), (2, 1), (0, 1))
+ self.pooling_layers = pooling_layers
+
+ def forward(self, x: Tensor) -> Tensor:
+ """Forward function."""
+
+ x = self.conv1(x)
+ for i, layer_name in enumerate(self.layers):
+ layer = getattr(self, layer_name)
+ x = layer(x)
+ if i in self.pooling_layers:
+ x = self.pooling(x)
+
+ return x
diff --git a/mmocr/models/textrecog/backbones/nrtr_modality_transformer.py b/mmocr/models/textrecog/backbones/nrtr_modality_transformer.py
new file mode 100644
index 0000000000000000000000000000000000000000..35f4f9c3f2e0e7f874620cfad643bfcbcb5cd0c5
--- /dev/null
+++ b/mmocr/models/textrecog/backbones/nrtr_modality_transformer.py
@@ -0,0 +1,75 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, Optional, Sequence, Union
+
+import torch
+import torch.nn as nn
+from mmengine.model import BaseModule
+
+from mmocr.registry import MODELS
+
+
+@MODELS.register_module()
+class NRTRModalityTransform(BaseModule):
+ """Modality transform in NRTR.
+
+ Args:
+ in_channels (int): Input channel of image. Defaults to 3.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ """
+
+ def __init__(
+ self,
+ in_channels: int = 3,
+ init_cfg: Optional[Union[Dict, Sequence[Dict]]] = [
+ dict(type='Kaiming', layer='Conv2d'),
+ dict(type='Uniform', layer='BatchNorm2d')
+ ]
+ ) -> None:
+ super().__init__(init_cfg=init_cfg)
+
+ self.conv_1 = nn.Conv2d(
+ in_channels=in_channels,
+ out_channels=32,
+ kernel_size=3,
+ stride=2,
+ padding=1)
+ self.relu_1 = nn.ReLU(True)
+ self.bn_1 = nn.BatchNorm2d(32)
+
+ self.conv_2 = nn.Conv2d(
+ in_channels=32,
+ out_channels=64,
+ kernel_size=3,
+ stride=2,
+ padding=1)
+ self.relu_2 = nn.ReLU(True)
+ self.bn_2 = nn.BatchNorm2d(64)
+
+ self.linear = nn.Linear(512, 512)
+
+ def forward(self, x: torch.Tensor) -> torch.Tensor:
+ """Backbone forward.
+
+ Args:
+ x (torch.Tensor): Image tensor of shape :math:`(N, C, W, H)`. W, H
+ is the width and height of image.
+ Return:
+ Tensor: Output tensor.
+ """
+ x = self.conv_1(x)
+ x = self.relu_1(x)
+ x = self.bn_1(x)
+
+ x = self.conv_2(x)
+ x = self.relu_2(x)
+ x = self.bn_2(x)
+
+ n, c, h, w = x.size()
+
+ x = x.permute(0, 3, 2, 1).contiguous().view(n, w, h * c)
+
+ x = self.linear(x)
+
+ x = x.permute(0, 2, 1).contiguous().view(n, -1, 1, w)
+
+ return x
diff --git a/mmocr/models/textrecog/backbones/resnet.py b/mmocr/models/textrecog/backbones/resnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..bb17a8cdcbb732cc04674106fc043560555bec2e
--- /dev/null
+++ b/mmocr/models/textrecog/backbones/resnet.py
@@ -0,0 +1,264 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Tuple, Union
+
+import torch
+from mmcv.cnn import ConvModule, build_plugin_layer
+from mmengine.model import BaseModule, Sequential
+
+import mmocr.utils as utils
+from mmocr.models.textrecog.layers import BasicBlock
+from mmocr.registry import MODELS
+
+
+@MODELS.register_module()
+class ResNet(BaseModule):
+ """
+ Args:
+ in_channels (int): Number of channels of input image tensor.
+ stem_channels (list[int]): List of channels in each stem layer. E.g.,
+ [64, 128] stands for 64 and 128 channels in the first and second
+ stem layers.
+ block_cfgs (dict): Configs of block
+ arch_layers (list[int]): List of Block number for each stage.
+ arch_channels (list[int]): List of channels for each stage.
+ strides (Sequence[int] or Sequence[tuple]): Strides of the first block
+ of each stage.
+ out_indices (Sequence[int], optional): Indices of output stages. If not
+ specified, only the last stage will be returned.
+ plugins (dict, optional): Configs of stage plugins
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ """
+
+ def __init__(self,
+ in_channels: int,
+ stem_channels: List[int],
+ block_cfgs: dict,
+ arch_layers: List[int],
+ arch_channels: List[int],
+ strides: Union[List[int], List[Tuple]],
+ out_indices: Optional[List[int]] = None,
+ plugins: Optional[Dict] = None,
+ init_cfg: Optional[Union[Dict, List[Dict]]] = [
+ dict(type='Xavier', layer='Conv2d'),
+ dict(type='Constant', val=1, layer='BatchNorm2d'),
+ ]):
+ super().__init__(init_cfg=init_cfg)
+ assert isinstance(in_channels, int)
+ assert isinstance(stem_channels, int) or utils.is_type_list(
+ stem_channels, int)
+ assert utils.is_type_list(arch_layers, int)
+ assert utils.is_type_list(arch_channels, int)
+ assert utils.is_type_list(strides, tuple) or utils.is_type_list(
+ strides, int)
+ assert len(arch_layers) == len(arch_channels) == len(strides)
+ assert out_indices is None or isinstance(out_indices, (list, tuple))
+
+ self.out_indices = out_indices
+ self._make_stem_layer(in_channels, stem_channels)
+ self.num_stages = len(arch_layers)
+ self.use_plugins = False
+ self.arch_channels = arch_channels
+ self.res_layers = []
+ if plugins is not None:
+ self.plugin_ahead_names = []
+ self.plugin_after_names = []
+ self.use_plugins = True
+ for i, num_blocks in enumerate(arch_layers):
+ stride = strides[i]
+ channel = arch_channels[i]
+
+ if self.use_plugins:
+ self._make_stage_plugins(plugins, stage_idx=i)
+
+ res_layer = self._make_layer(
+ block_cfgs=block_cfgs,
+ inplanes=self.inplanes,
+ planes=channel,
+ blocks=num_blocks,
+ stride=stride,
+ )
+ self.inplanes = channel
+ layer_name = f'layer{i + 1}'
+ self.add_module(layer_name, res_layer)
+ self.res_layers.append(layer_name)
+
+ def _make_layer(self, block_cfgs: Dict, inplanes: int, planes: int,
+ blocks: int, stride: int) -> Sequential:
+ """Build resnet layer.
+
+ Args:
+ block_cfgs (dict): Configs of blocks.
+ inplanes (int): Number of input channels.
+ planes (int): Number of output channels.
+ blocks (int): Number of blocks.
+ stride (int): Stride of the first block.
+
+ Returns:
+ Sequential: A sequence of blocks.
+ """
+ layers = []
+ downsample = None
+ block_cfgs_ = block_cfgs.copy()
+ if isinstance(stride, int):
+ stride = (stride, stride)
+
+ if stride[0] != 1 or stride[1] != 1 or inplanes != planes:
+ downsample = ConvModule(
+ inplanes,
+ planes,
+ 1,
+ stride,
+ norm_cfg=dict(type='BN'),
+ act_cfg=None)
+
+ if block_cfgs_['type'] == 'BasicBlock':
+ block = BasicBlock
+ block_cfgs_.pop('type')
+ else:
+ raise ValueError('{} not implement yet'.format(block['type']))
+
+ layers.append(
+ block(
+ inplanes,
+ planes,
+ stride=stride,
+ downsample=downsample,
+ **block_cfgs_))
+ inplanes = planes
+ for _ in range(1, blocks):
+ layers.append(block(inplanes, planes, **block_cfgs_))
+
+ return Sequential(*layers)
+
+ def _make_stem_layer(self, in_channels: int,
+ stem_channels: Union[int, List[int]]) -> None:
+ """Make stem layers.
+
+ Args:
+ in_channels (int): Number of input channels.
+ stem_channels (list[int] or int): List of channels in each stem
+ layer. If int, only one stem layer will be created.
+ """
+ if isinstance(stem_channels, int):
+ stem_channels = [stem_channels]
+ stem_layers = []
+ for _, channels in enumerate(stem_channels):
+ stem_layer = ConvModule(
+ in_channels,
+ channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=False,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'))
+ in_channels = channels
+ stem_layers.append(stem_layer)
+ self.stem_layers = Sequential(*stem_layers)
+ self.inplanes = stem_channels[-1]
+
+ def _make_stage_plugins(self, plugins: List[Dict], stage_idx: int) -> None:
+ """Make plugins for ResNet ``stage_idx``th stage.
+
+ Currently we support inserting ``nn.Maxpooling``,
+ ``mmcv.cnn.Convmodule``into the backbone. Originally designed
+ for ResNet31-like architectures.
+
+ Examples:
+ >>> plugins=[
+ ... dict(cfg=dict(type="Maxpooling", arg=(2,2)),
+ ... stages=(True, True, False, False),
+ ... position='before_stage'),
+ ... dict(cfg=dict(type="Maxpooling", arg=(2,1)),
+ ... stages=(False, False, True, Flase),
+ ... position='before_stage'),
+ ... dict(cfg=dict(
+ ... type='ConvModule',
+ ... kernel_size=3,
+ ... stride=1,
+ ... padding=1,
+ ... norm_cfg=dict(type='BN'),
+ ... act_cfg=dict(type='ReLU')),
+ ... stages=(True, True, True, True),
+ ... position='after_stage')]
+
+ Suppose ``stage_idx=1``, the structure of stage would be:
+
+ .. code-block:: none
+
+ Maxpooling -> A set of Basicblocks -> ConvModule
+
+ Args:
+ plugins (list[dict]): List of plugin configs to build.
+ stage_idx (int): Index of stage to build
+ """
+ in_channels = self.arch_channels[stage_idx]
+ self.plugin_ahead_names.append([])
+ self.plugin_after_names.append([])
+ for plugin in plugins:
+ plugin = plugin.copy()
+ stages = plugin.pop('stages', None)
+ position = plugin.pop('position', None)
+ assert stages is None or len(stages) == self.num_stages
+ if stages[stage_idx]:
+ if position == 'before_stage':
+ name, layer = build_plugin_layer(
+ plugin['cfg'],
+ f'_before_stage_{stage_idx+1}',
+ in_channels=in_channels,
+ out_channels=in_channels)
+ self.plugin_ahead_names[stage_idx].append(name)
+ self.add_module(name, layer)
+ elif position == 'after_stage':
+ name, layer = build_plugin_layer(
+ plugin['cfg'],
+ f'_after_stage_{stage_idx+1}',
+ in_channels=in_channels,
+ out_channels=in_channels)
+ self.plugin_after_names[stage_idx].append(name)
+ self.add_module(name, layer)
+ else:
+ raise ValueError('uncorrect plugin position')
+
+ def forward_plugin(self, x: torch.Tensor,
+ plugin_name: List[str]) -> torch.Tensor:
+ """Forward tensor through plugin.
+
+ Args:
+ x (torch.Tensor): Input tensor.
+ plugin_name (list[str]): Name of plugins.
+
+ Returns:
+ torch.Tensor: Output tensor.
+ """
+ out = x
+ for name in plugin_name:
+ out = getattr(self, name)(out)
+ return out
+
+ def forward(self,
+ x: torch.Tensor) -> Union[torch.Tensor, List[torch.Tensor]]:
+ """
+ Args: x (Tensor): Image tensor of shape :math:`(N, 3, H, W)`.
+
+ Returns:
+ Tensor or list[Tensor]: Feature tensor. It can be a list of
+ feature outputs at specific layers if ``out_indices`` is specified.
+ """
+ x = self.stem_layers(x)
+
+ outs = []
+ for i, layer_name in enumerate(self.res_layers):
+ res_layer = getattr(self, layer_name)
+ if not self.use_plugins:
+ x = res_layer(x)
+ if self.out_indices and i in self.out_indices:
+ outs.append(x)
+ else:
+ x = self.forward_plugin(x, self.plugin_ahead_names[i])
+ x = res_layer(x)
+ x = self.forward_plugin(x, self.plugin_after_names[i])
+ if self.out_indices and i in self.out_indices:
+ outs.append(x)
+
+ return tuple(outs) if self.out_indices else x
diff --git a/mmocr/models/textrecog/backbones/resnet31_ocr.py b/mmocr/models/textrecog/backbones/resnet31_ocr.py
new file mode 100644
index 0000000000000000000000000000000000000000..96ca7b7af7ae9b1ed724d9ae783cf39df5aa6f57
--- /dev/null
+++ b/mmocr/models/textrecog/backbones/resnet31_ocr.py
@@ -0,0 +1,145 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+from mmengine.model import BaseModule, Sequential
+
+import mmocr.utils as utils
+from mmocr.models.textrecog.layers import BasicBlock
+from mmocr.registry import MODELS
+
+
+@MODELS.register_module()
+class ResNet31OCR(BaseModule):
+ """Implement ResNet backbone for text recognition, modified from
+ `ResNet `_
+ Args:
+ base_channels (int): Number of channels of input image tensor.
+ layers (list[int]): List of BasicBlock number for each stage.
+ channels (list[int]): List of out_channels of Conv2d layer.
+ out_indices (None | Sequence[int]): Indices of output stages.
+ stage4_pool_cfg (dict): Dictionary to construct and configure
+ pooling layer in stage 4.
+ last_stage_pool (bool): If True, add `MaxPool2d` layer to last stage.
+ """
+
+ def __init__(self,
+ base_channels=3,
+ layers=[1, 2, 5, 3],
+ channels=[64, 128, 256, 256, 512, 512, 512],
+ out_indices=None,
+ stage4_pool_cfg=dict(kernel_size=(2, 1), stride=(2, 1)),
+ last_stage_pool=False,
+ init_cfg=[
+ dict(type='Kaiming', layer='Conv2d'),
+ dict(type='Uniform', layer='BatchNorm2d')
+ ]):
+ super().__init__(init_cfg=init_cfg)
+ assert isinstance(base_channels, int)
+ assert utils.is_type_list(layers, int)
+ assert utils.is_type_list(channels, int)
+ assert out_indices is None or isinstance(out_indices, (list, tuple))
+ assert isinstance(last_stage_pool, bool)
+
+ self.out_indices = out_indices
+ self.last_stage_pool = last_stage_pool
+
+ # conv 1 (Conv, Conv)
+ self.conv1_1 = nn.Conv2d(
+ base_channels, channels[0], kernel_size=3, stride=1, padding=1)
+ self.bn1_1 = nn.BatchNorm2d(channels[0])
+ self.relu1_1 = nn.ReLU(inplace=True)
+
+ self.conv1_2 = nn.Conv2d(
+ channels[0], channels[1], kernel_size=3, stride=1, padding=1)
+ self.bn1_2 = nn.BatchNorm2d(channels[1])
+ self.relu1_2 = nn.ReLU(inplace=True)
+
+ # conv 2 (Max-pooling, Residual block, Conv)
+ self.pool2 = nn.MaxPool2d(
+ kernel_size=2, stride=2, padding=0, ceil_mode=True)
+ self.block2 = self._make_layer(channels[1], channels[2], layers[0])
+ self.conv2 = nn.Conv2d(
+ channels[2], channels[2], kernel_size=3, stride=1, padding=1)
+ self.bn2 = nn.BatchNorm2d(channels[2])
+ self.relu2 = nn.ReLU(inplace=True)
+
+ # conv 3 (Max-pooling, Residual block, Conv)
+ self.pool3 = nn.MaxPool2d(
+ kernel_size=2, stride=2, padding=0, ceil_mode=True)
+ self.block3 = self._make_layer(channels[2], channels[3], layers[1])
+ self.conv3 = nn.Conv2d(
+ channels[3], channels[3], kernel_size=3, stride=1, padding=1)
+ self.bn3 = nn.BatchNorm2d(channels[3])
+ self.relu3 = nn.ReLU(inplace=True)
+
+ # conv 4 (Max-pooling, Residual block, Conv)
+ self.pool4 = nn.MaxPool2d(padding=0, ceil_mode=True, **stage4_pool_cfg)
+ self.block4 = self._make_layer(channels[3], channels[4], layers[2])
+ self.conv4 = nn.Conv2d(
+ channels[4], channels[4], kernel_size=3, stride=1, padding=1)
+ self.bn4 = nn.BatchNorm2d(channels[4])
+ self.relu4 = nn.ReLU(inplace=True)
+
+ # conv 5 ((Max-pooling), Residual block, Conv)
+ self.pool5 = None
+ if self.last_stage_pool:
+ self.pool5 = nn.MaxPool2d(
+ kernel_size=2, stride=2, padding=0, ceil_mode=True) # 1/16
+ self.block5 = self._make_layer(channels[4], channels[5], layers[3])
+ self.conv5 = nn.Conv2d(
+ channels[5], channels[5], kernel_size=3, stride=1, padding=1)
+ self.bn5 = nn.BatchNorm2d(channels[5])
+ self.relu5 = nn.ReLU(inplace=True)
+
+ def _make_layer(self, input_channels, output_channels, blocks):
+ layers = []
+ for _ in range(blocks):
+ downsample = None
+ if input_channels != output_channels:
+ downsample = Sequential(
+ nn.Conv2d(
+ input_channels,
+ output_channels,
+ kernel_size=1,
+ stride=1,
+ bias=False),
+ nn.BatchNorm2d(output_channels),
+ )
+ layers.append(
+ BasicBlock(
+ input_channels, output_channels, downsample=downsample))
+ input_channels = output_channels
+
+ return Sequential(*layers)
+
+ def forward(self, x):
+
+ x = self.conv1_1(x)
+ x = self.bn1_1(x)
+ x = self.relu1_1(x)
+
+ x = self.conv1_2(x)
+ x = self.bn1_2(x)
+ x = self.relu1_2(x)
+
+ outs = []
+ for i in range(4):
+ layer_index = i + 2
+ pool_layer = getattr(self, f'pool{layer_index}')
+ block_layer = getattr(self, f'block{layer_index}')
+ conv_layer = getattr(self, f'conv{layer_index}')
+ bn_layer = getattr(self, f'bn{layer_index}')
+ relu_layer = getattr(self, f'relu{layer_index}')
+
+ if pool_layer is not None:
+ x = pool_layer(x)
+ x = block_layer(x)
+ x = conv_layer(x)
+ x = bn_layer(x)
+ x = relu_layer(x)
+
+ outs.append(x)
+
+ if self.out_indices is not None:
+ return tuple(outs[i] for i in self.out_indices)
+
+ return x
diff --git a/mmocr/models/textrecog/backbones/resnet_abi.py b/mmocr/models/textrecog/backbones/resnet_abi.py
new file mode 100644
index 0000000000000000000000000000000000000000..ce79758501a34696e14005f0cf8b2cad68c6d7bb
--- /dev/null
+++ b/mmocr/models/textrecog/backbones/resnet_abi.py
@@ -0,0 +1,121 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+from mmengine.model import BaseModule, Sequential
+
+import mmocr.utils as utils
+from mmocr.models.textrecog.layers import BasicBlock
+from mmocr.registry import MODELS
+
+
+@MODELS.register_module()
+class ResNetABI(BaseModule):
+ """Implement ResNet backbone for text recognition, modified from `ResNet.
+
+ `_ and
+ ``_
+
+ Args:
+ in_channels (int): Number of channels of input image tensor.
+ stem_channels (int): Number of stem channels.
+ base_channels (int): Number of base channels.
+ arch_settings (list[int]): List of BasicBlock number for each stage.
+ strides (Sequence[int]): Strides of the first block of each stage.
+ out_indices (None | Sequence[int]): Indices of output stages. If not
+ specified, only the last stage will be returned.
+ last_stage_pool (bool): If True, add `MaxPool2d` layer to last stage.
+ """
+
+ def __init__(self,
+ in_channels=3,
+ stem_channels=32,
+ base_channels=32,
+ arch_settings=[3, 4, 6, 6, 3],
+ strides=[2, 1, 2, 1, 1],
+ out_indices=None,
+ last_stage_pool=False,
+ init_cfg=[
+ dict(type='Xavier', layer='Conv2d'),
+ dict(type='Constant', val=1, layer='BatchNorm2d')
+ ]):
+ super().__init__(init_cfg=init_cfg)
+ assert isinstance(in_channels, int)
+ assert isinstance(stem_channels, int)
+ assert utils.is_type_list(arch_settings, int)
+ assert utils.is_type_list(strides, int)
+ assert len(arch_settings) == len(strides)
+ assert out_indices is None or isinstance(out_indices, (list, tuple))
+ assert isinstance(last_stage_pool, bool)
+
+ self.out_indices = out_indices
+ self.last_stage_pool = last_stage_pool
+ self.block = BasicBlock
+ self.inplanes = stem_channels
+
+ self._make_stem_layer(in_channels, stem_channels)
+
+ self.res_layers = []
+ planes = base_channels
+ for i, num_blocks in enumerate(arch_settings):
+ stride = strides[i]
+ res_layer = self._make_layer(
+ block=self.block,
+ inplanes=self.inplanes,
+ planes=planes,
+ blocks=num_blocks,
+ stride=stride)
+ self.inplanes = planes * self.block.expansion
+ planes *= 2
+ layer_name = f'layer{i + 1}'
+ self.add_module(layer_name, res_layer)
+ self.res_layers.append(layer_name)
+
+ def _make_layer(self, block, inplanes, planes, blocks, stride=1):
+ layers = []
+ downsample = None
+ if stride != 1 or inplanes != planes:
+ downsample = nn.Sequential(
+ nn.Conv2d(inplanes, planes, 1, stride, bias=False),
+ nn.BatchNorm2d(planes),
+ )
+ layers.append(
+ block(
+ inplanes,
+ planes,
+ use_conv1x1=True,
+ stride=stride,
+ downsample=downsample))
+ inplanes = planes
+ for _ in range(1, blocks):
+ layers.append(block(inplanes, planes, use_conv1x1=True))
+
+ return Sequential(*layers)
+
+ def _make_stem_layer(self, in_channels, stem_channels):
+ self.conv1 = nn.Conv2d(
+ in_channels, stem_channels, kernel_size=3, stride=1, padding=1)
+ self.bn1 = nn.BatchNorm2d(stem_channels)
+ self.relu1 = nn.ReLU(inplace=True)
+
+ def forward(self, x):
+ """
+ Args:
+ x (Tensor): Image tensor of shape :math:`(N, 3, H, W)`.
+
+ Returns:
+ Tensor or list[Tensor]: Feature tensor. Its shape depends on
+ ResNetABI's config. It can be a list of feature outputs at specific
+ layers if ``out_indices`` is specified.
+ """
+
+ x = self.conv1(x)
+ x = self.bn1(x)
+ x = self.relu1(x)
+
+ outs = []
+ for i, layer_name in enumerate(self.res_layers):
+ res_layer = getattr(self, layer_name)
+ x = res_layer(x)
+ if self.out_indices and i in self.out_indices:
+ outs.append(x)
+
+ return tuple(outs) if self.out_indices else x
diff --git a/mmocr/models/textrecog/backbones/shallow_cnn.py b/mmocr/models/textrecog/backbones/shallow_cnn.py
new file mode 100644
index 0000000000000000000000000000000000000000..542b37bbc893c3bb0a01840a01ea81e6e259136a
--- /dev/null
+++ b/mmocr/models/textrecog/backbones/shallow_cnn.py
@@ -0,0 +1,75 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Union
+
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+from mmengine.model import BaseModule
+from torch import Tensor
+
+from mmocr.registry import MODELS
+
+
+@MODELS.register_module()
+class ShallowCNN(BaseModule):
+ """Implement Shallow CNN block for SATRN.
+
+ SATRN: `On Recognizing Texts of Arbitrary Shapes with 2D Self-Attention
+ `_.
+
+ Args:
+ input_channels (int): Number of channels of input image tensor
+ :math:`D_i`. Defaults to 1.
+ hidden_dim (int): Size of hidden layers of the model :math:`D_m`.
+ Defaults to 512.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ """
+
+ def __init__(
+ self,
+ input_channels: int = 1,
+ hidden_dim: int = 512,
+ init_cfg: Optional[Union[Dict, List[Dict]]] = [
+ dict(type='Kaiming', layer='Conv2d'),
+ dict(type='Uniform', layer='BatchNorm2d')
+ ]
+ ) -> None:
+ super().__init__(init_cfg=init_cfg)
+ assert isinstance(input_channels, int)
+ assert isinstance(hidden_dim, int)
+
+ self.conv1 = ConvModule(
+ input_channels,
+ hidden_dim // 2,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=False,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'))
+ self.conv2 = ConvModule(
+ hidden_dim // 2,
+ hidden_dim,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=False,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'))
+ self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
+
+ def forward(self, x: Tensor) -> Tensor:
+ """
+ Args:
+ x (Tensor): Input image feature :math:`(N, D_i, H, W)`.
+
+ Returns:
+ Tensor: A tensor of shape :math:`(N, D_m, H/4, W/4)`.
+ """
+
+ x = self.conv1(x)
+ x = self.pool(x)
+
+ x = self.conv2(x)
+ x = self.pool(x)
+
+ return x
diff --git a/mmocr/models/textrecog/data_preprocessors/__init__.py b/mmocr/models/textrecog/data_preprocessors/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..43b65323c6baf512d358772df06b15dc1bf802da
--- /dev/null
+++ b/mmocr/models/textrecog/data_preprocessors/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .data_preprocessor import TextRecogDataPreprocessor
+
+__all__ = ['TextRecogDataPreprocessor']
diff --git a/mmocr/models/textrecog/data_preprocessors/__pycache__/__init__.cpython-38.pyc b/mmocr/models/textrecog/data_preprocessors/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..61de5785d89a0a730a2362e655f349fa6579830a
Binary files /dev/null and b/mmocr/models/textrecog/data_preprocessors/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/data_preprocessors/__pycache__/data_preprocessor.cpython-38.pyc b/mmocr/models/textrecog/data_preprocessors/__pycache__/data_preprocessor.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..cc460f23de726cce366e35cf9a8e385db68ec96d
Binary files /dev/null and b/mmocr/models/textrecog/data_preprocessors/__pycache__/data_preprocessor.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/data_preprocessors/data_preprocessor.py b/mmocr/models/textrecog/data_preprocessors/data_preprocessor.py
new file mode 100644
index 0000000000000000000000000000000000000000..99ae1719ca9fcc722c0c4f2f8d01e14bdbfed13d
--- /dev/null
+++ b/mmocr/models/textrecog/data_preprocessors/data_preprocessor.py
@@ -0,0 +1,97 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from numbers import Number
+from typing import Dict, List, Optional, Sequence, Union
+
+import torch.nn as nn
+from mmengine.model import ImgDataPreprocessor
+
+from mmocr.registry import MODELS
+
+
+@MODELS.register_module()
+class TextRecogDataPreprocessor(ImgDataPreprocessor):
+ """Image pre-processor for recognition tasks.
+
+ Comparing with the :class:`mmengine.ImgDataPreprocessor`,
+
+ 1. It supports batch augmentations.
+ 2. It will additionally append batch_input_shape and valid_ratio
+ to data_samples considering the object recognition task.
+
+ It provides the data pre-processing as follows
+
+ - Collate and move data to the target device.
+ - Pad inputs to the maximum size of current batch with defined
+ ``pad_value``. The padding size can be divisible by a defined
+ ``pad_size_divisor``
+ - Stack inputs to inputs.
+ - Convert inputs from bgr to rgb if the shape of input is (3, H, W).
+ - Normalize image with defined std and mean.
+ - Do batch augmentations during training.
+
+ Args:
+ mean (Sequence[Number], optional): The pixel mean of R, G, B channels.
+ Defaults to None.
+ std (Sequence[Number], optional): The pixel standard deviation of
+ R, G, B channels. Defaults to None.
+ pad_size_divisor (int): The size of padded image should be
+ divisible by ``pad_size_divisor``. Defaults to 1.
+ pad_value (Number): The padded pixel value. Defaults to 0.
+ bgr_to_rgb (bool): whether to convert image from BGR to RGB.
+ Defaults to False.
+ rgb_to_bgr (bool): whether to convert image from RGB to RGB.
+ Defaults to False.
+ batch_augments (list[dict], optional): Batch-level augmentations
+ """
+
+ def __init__(self,
+ mean: Sequence[Number] = None,
+ std: Sequence[Number] = None,
+ pad_size_divisor: int = 1,
+ pad_value: Union[float, int] = 0,
+ bgr_to_rgb: bool = False,
+ rgb_to_bgr: bool = False,
+ batch_augments: Optional[List[Dict]] = None) -> None:
+ super().__init__(
+ mean=mean,
+ std=std,
+ pad_size_divisor=pad_size_divisor,
+ pad_value=pad_value,
+ bgr_to_rgb=bgr_to_rgb,
+ rgb_to_bgr=rgb_to_bgr)
+ if batch_augments is not None:
+ self.batch_augments = nn.ModuleList(
+ [MODELS.build(aug) for aug in batch_augments])
+ else:
+ self.batch_augments = None
+
+ def forward(self, data: Dict, training: bool = False) -> Dict:
+ """Perform normalization、padding and bgr2rgb conversion based on
+ ``BaseDataPreprocessor``.
+
+ Args:
+ data (dict): Data sampled from dataloader.
+ training (bool): Whether to enable training time augmentation.
+
+ Returns:
+ dict: Data in the same format as the model input.
+ """
+ data = super().forward(data=data, training=training)
+ inputs, data_samples = data['inputs'], data['data_samples']
+
+ if data_samples is not None:
+ batch_input_shape = tuple(inputs[0].size()[-2:])
+ for data_sample in data_samples:
+
+ valid_ratio = data_sample.valid_ratio * \
+ data_sample.img_shape[1] / batch_input_shape[1]
+ data_sample.set_metainfo(
+ dict(
+ valid_ratio=valid_ratio,
+ batch_input_shape=batch_input_shape))
+
+ if training and self.batch_augments is not None:
+ for batch_aug in self.batch_augments:
+ inputs, data_samples = batch_aug(inputs, data_samples)
+
+ return data
diff --git a/mmocr/models/textrecog/decoders/__init__.py b/mmocr/models/textrecog/decoders/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..ec4981fe891baebb6c623de124a7308192272abb
--- /dev/null
+++ b/mmocr/models/textrecog/decoders/__init__.py
@@ -0,0 +1,24 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .abi_fuser import ABIFuser
+from .abi_language_decoder import ABILanguageDecoder
+from .abi_vision_decoder import ABIVisionDecoder
+from .aster_decoder import ASTERDecoder
+from .base import BaseDecoder
+from .crnn_decoder import CRNNDecoder
+from .master_decoder import MasterDecoder
+from .nrtr_decoder import NRTRDecoder
+from .position_attention_decoder import PositionAttentionDecoder
+from .robust_scanner_fuser import RobustScannerFuser
+from .sar_decoder import ParallelSARDecoder, SequentialSARDecoder
+from .sar_decoder_with_bs import ParallelSARDecoderWithBS
+from .sequence_attention_decoder import SequenceAttentionDecoder
+from .svtr_decoder import SVTRDecoder
+from .maerec_decoder import MAERecDecoder
+__all__ = [
+ 'CRNNDecoder', 'ParallelSARDecoder', 'SequentialSARDecoder',
+ 'ParallelSARDecoderWithBS', 'NRTRDecoder', 'BaseDecoder',
+ 'SequenceAttentionDecoder', 'PositionAttentionDecoder',
+ 'ABILanguageDecoder', 'ABIVisionDecoder', 'MasterDecoder',
+ 'RobustScannerFuser', 'ABIFuser', 'SVTRDecoder', 'ASTERDecoder',
+ 'MAERecDecoder'
+]
diff --git a/mmocr/models/textrecog/decoders/__pycache__/__init__.cpython-38.pyc b/mmocr/models/textrecog/decoders/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..faf5bb9f53fd64878f45e3431d3a4b346b975ca4
Binary files /dev/null and b/mmocr/models/textrecog/decoders/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/decoders/__pycache__/abi_fuser.cpython-38.pyc b/mmocr/models/textrecog/decoders/__pycache__/abi_fuser.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..00a7d8f43a133389443653028faa4c16bd167b29
Binary files /dev/null and b/mmocr/models/textrecog/decoders/__pycache__/abi_fuser.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/decoders/__pycache__/abi_language_decoder.cpython-38.pyc b/mmocr/models/textrecog/decoders/__pycache__/abi_language_decoder.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..bcdf11f901218daba1c9a115489457ac978ba0af
Binary files /dev/null and b/mmocr/models/textrecog/decoders/__pycache__/abi_language_decoder.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/decoders/__pycache__/abi_vision_decoder.cpython-38.pyc b/mmocr/models/textrecog/decoders/__pycache__/abi_vision_decoder.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..7bd598219bae8bd7a9b10e9470736d64bf93be04
Binary files /dev/null and b/mmocr/models/textrecog/decoders/__pycache__/abi_vision_decoder.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/decoders/__pycache__/aster_decoder.cpython-38.pyc b/mmocr/models/textrecog/decoders/__pycache__/aster_decoder.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..bbe45c8d90fa8da3450b998c96f8ba5577899995
Binary files /dev/null and b/mmocr/models/textrecog/decoders/__pycache__/aster_decoder.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/decoders/__pycache__/base.cpython-38.pyc b/mmocr/models/textrecog/decoders/__pycache__/base.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a22b05031c9481d68e3c6e08427d5855648e5637
Binary files /dev/null and b/mmocr/models/textrecog/decoders/__pycache__/base.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/decoders/__pycache__/crnn_decoder.cpython-38.pyc b/mmocr/models/textrecog/decoders/__pycache__/crnn_decoder.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5bbd31204e68aefa1f2d0545518e9384b0813f71
Binary files /dev/null and b/mmocr/models/textrecog/decoders/__pycache__/crnn_decoder.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/decoders/__pycache__/maerec_decoder.cpython-38.pyc b/mmocr/models/textrecog/decoders/__pycache__/maerec_decoder.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..56495a2d7c13526336ed6978368cc4e65414cc9a
Binary files /dev/null and b/mmocr/models/textrecog/decoders/__pycache__/maerec_decoder.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/decoders/__pycache__/master_decoder.cpython-38.pyc b/mmocr/models/textrecog/decoders/__pycache__/master_decoder.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..4ad2f6cc55885746ac4cffda2f9cdfe5c945dc96
Binary files /dev/null and b/mmocr/models/textrecog/decoders/__pycache__/master_decoder.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/decoders/__pycache__/nrtr_decoder.cpython-38.pyc b/mmocr/models/textrecog/decoders/__pycache__/nrtr_decoder.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..43be895eabe66d96854dd047810ab953b81a0062
Binary files /dev/null and b/mmocr/models/textrecog/decoders/__pycache__/nrtr_decoder.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/decoders/__pycache__/position_attention_decoder.cpython-38.pyc b/mmocr/models/textrecog/decoders/__pycache__/position_attention_decoder.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..fed0ffd26ce2e577cad6f9a5a57110782be70bfd
Binary files /dev/null and b/mmocr/models/textrecog/decoders/__pycache__/position_attention_decoder.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/decoders/__pycache__/robust_scanner_fuser.cpython-38.pyc b/mmocr/models/textrecog/decoders/__pycache__/robust_scanner_fuser.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f8f76776128fa6da7e6d92a5348085263109e550
Binary files /dev/null and b/mmocr/models/textrecog/decoders/__pycache__/robust_scanner_fuser.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/decoders/__pycache__/sar_decoder.cpython-38.pyc b/mmocr/models/textrecog/decoders/__pycache__/sar_decoder.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..02f554dee2a0c16dbe52558ec1eb7367800711be
Binary files /dev/null and b/mmocr/models/textrecog/decoders/__pycache__/sar_decoder.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/decoders/__pycache__/sar_decoder_with_bs.cpython-38.pyc b/mmocr/models/textrecog/decoders/__pycache__/sar_decoder_with_bs.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b44e538d5131a05e20002ed96fe553c874f31993
Binary files /dev/null and b/mmocr/models/textrecog/decoders/__pycache__/sar_decoder_with_bs.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/decoders/__pycache__/sequence_attention_decoder.cpython-38.pyc b/mmocr/models/textrecog/decoders/__pycache__/sequence_attention_decoder.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..cdedc15a08e664c04ad35e3a0601005f00db8299
Binary files /dev/null and b/mmocr/models/textrecog/decoders/__pycache__/sequence_attention_decoder.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/decoders/__pycache__/svtr_decoder.cpython-38.pyc b/mmocr/models/textrecog/decoders/__pycache__/svtr_decoder.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..bc6a07ce189edd56a08eb801eec0f8632f4b9d68
Binary files /dev/null and b/mmocr/models/textrecog/decoders/__pycache__/svtr_decoder.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/decoders/abi_fuser.py b/mmocr/models/textrecog/decoders/abi_fuser.py
new file mode 100644
index 0000000000000000000000000000000000000000..43ecba41e87e72803525b38cf2c019bc1d2d7bba
--- /dev/null
+++ b/mmocr/models/textrecog/decoders/abi_fuser.py
@@ -0,0 +1,174 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from typing import Dict, List, Optional, Sequence, Union
+
+import torch
+import torch.nn as nn
+
+from mmocr.models.common.dictionary import Dictionary
+from mmocr.registry import MODELS
+from mmocr.structures import TextRecogDataSample
+from .base import BaseDecoder
+
+
+@MODELS.register_module()
+class ABIFuser(BaseDecoder):
+ r"""A special decoder responsible for mixing and aligning visual feature
+ and linguistic feature. `ABINet `_
+
+ Args:
+ dictionary (dict or :obj:`Dictionary`): The config for `Dictionary` or
+ the instance of `Dictionary`. The dictionary must have an end
+ token.
+ vision_decoder (dict): The config for vision decoder.
+ language_decoder (dict, optional): The config for language decoder.
+ num_iters (int): Rounds of iterative correction. Defaults to 1.
+ d_model (int): Hidden size :math:`E` of model. Defaults to 512.
+ max_seq_len (int): Maximum sequence length :math:`T`. The
+ sequence is usually generated from decoder. Defaults to 40.
+ module_loss (dict, optional): Config to build loss. Defaults to None.
+ postprocessor (dict, optional): Config to build postprocessor.
+ Defaults to None.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ dictionary: Union[Dict, Dictionary],
+ vision_decoder: Dict,
+ language_decoder: Optional[Dict] = None,
+ d_model: int = 512,
+ num_iters: int = 1,
+ max_seq_len: int = 40,
+ module_loss: Optional[Dict] = None,
+ postprocessor: Optional[Dict] = None,
+ init_cfg: Optional[Union[Dict, List[Dict]]] = None,
+ **kwargs) -> None:
+ super().__init__(
+ dictionary=dictionary,
+ module_loss=module_loss,
+ postprocessor=postprocessor,
+ max_seq_len=max_seq_len,
+ init_cfg=init_cfg)
+
+ assert self.dictionary.end_idx is not None,\
+ 'Dictionary must contain an end token! (with_end=True)'
+
+ self.d_model = d_model
+ self.num_iters = num_iters
+ if language_decoder is not None:
+ self.w_att = nn.Linear(2 * d_model, d_model)
+ self.cls = nn.Linear(d_model, self.dictionary.num_classes)
+
+ self.vision_decoder = vision_decoder
+ self.language_decoder = language_decoder
+ for cfg_name in ['vision_decoder', 'language_decoder']:
+ if getattr(self, cfg_name, None) is not None:
+ cfg = getattr(self, cfg_name)
+ if cfg.get('dictionary', None) is None:
+ cfg.update(dictionary=self.dictionary)
+ else:
+ warnings.warn(f"Using dictionary {cfg['dictionary']} "
+ "in decoder's config.")
+ if cfg.get('max_seq_len', None) is None:
+ cfg.update(max_seq_len=max_seq_len)
+ else:
+ warnings.warn(f"Using max_seq_len {cfg['max_seq_len']} "
+ "in decoder's config.")
+ setattr(self, cfg_name, MODELS.build(cfg))
+ self.softmax = nn.Softmax(dim=-1)
+
+ def forward_train(
+ self,
+ feat: Optional[torch.Tensor] = None,
+ out_enc: torch.Tensor = None,
+ data_samples: Optional[Sequence[TextRecogDataSample]] = None
+ ) -> Dict:
+ """
+ Args:
+ feat (torch.Tensor, optional): Not required. Feature map
+ placeholder. Defaults to None.
+ out_enc (Tensor): Raw language logitis. Shape :math:`(N, T, C)`.
+ Defaults to None.
+ data_samples (list[TextRecogDataSample], optional): Not required.
+ DataSample placeholder. Defaults to None.
+
+ Returns:
+ A dict with keys ``out_enc``, ``out_decs`` and ``out_fusers``.
+
+ - out_vis (dict): Dict from ``self.vision_decoder`` with keys
+ ``feature``, ``logits`` and ``attn_scores``.
+ - out_langs (dict or list): Dict from ``self.vision_decoder`` with
+ keys ``feature``, ``logits`` if applicable, or an empty list
+ otherwise.
+ - out_fusers (dict or list): Dict of fused visual and language
+ features with keys ``feature``, ``logits`` if applicable, or
+ an empty list otherwise.
+ """
+ out_vis = self.vision_decoder(feat, out_enc, data_samples)
+ out_langs = []
+ out_fusers = []
+ if self.language_decoder is not None:
+ text_logits = out_vis['logits']
+ for _ in range(self.num_iters):
+ out_dec = self.language_decoder(feat, text_logits,
+ data_samples)
+ out_langs.append(out_dec)
+ out_fuser = self.fuse(out_vis['feature'], out_dec['feature'])
+ text_logits = out_fuser['logits']
+ out_fusers.append(out_fuser)
+
+ outputs = dict(
+ out_vis=out_vis, out_langs=out_langs, out_fusers=out_fusers)
+
+ return outputs
+
+ def forward_test(
+ self,
+ feat: Optional[torch.Tensor],
+ logits: torch.Tensor,
+ data_samples: Optional[Sequence[TextRecogDataSample]] = None
+ ) -> torch.Tensor:
+ """
+ Args:
+ feat (torch.Tensor, optional): Not required. Feature map
+ placeholder. Defaults to None.
+ logits (Tensor): Raw language logitis. Shape :math:`(N, T, C)`.
+ data_samples (list[TextRecogDataSample], optional): Not required.
+ DataSample placeholder. Defaults to None.
+
+ Returns:
+ Tensor: Character probabilities. of shape
+ :math:`(N, self.max_seq_len, C)` where :math:`C` is
+ ``num_classes``.
+ """
+ raw_result = self.forward_train(feat, logits, data_samples)
+
+ if 'out_fusers' in raw_result and len(raw_result['out_fusers']) > 0:
+ ret = raw_result['out_fusers'][-1]['logits']
+ elif 'out_langs' in raw_result and len(raw_result['out_langs']) > 0:
+ ret = raw_result['out_langs'][-1]['logits']
+ else:
+ ret = raw_result['out_vis']['logits']
+
+ return self.softmax(ret)
+
+ def fuse(self, l_feature: torch.Tensor, v_feature: torch.Tensor) -> Dict:
+ """Mix and align visual feature and linguistic feature.
+
+ Args:
+ l_feature (torch.Tensor): (N, T, E) where T is length, N is batch
+ size and E is dim of model.
+ v_feature (torch.Tensor): (N, T, E) shape the same as l_feature.
+
+ Returns:
+ dict: A dict with key ``logits``. of shape :math:`(N, T, C)` where
+ N is batch size, T is length and C is the number of characters.
+ """
+ f = torch.cat((l_feature, v_feature), dim=2)
+ f_att = torch.sigmoid(self.w_att(f))
+ output = f_att * v_feature + (1 - f_att) * l_feature
+
+ logits = self.cls(output) # (N, T, C)
+
+ return {'logits': logits}
diff --git a/mmocr/models/textrecog/decoders/abi_language_decoder.py b/mmocr/models/textrecog/decoders/abi_language_decoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..03492200fd1abb9ad9386f9578bae435a04bc6d0
--- /dev/null
+++ b/mmocr/models/textrecog/decoders/abi_language_decoder.py
@@ -0,0 +1,230 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+from typing import Dict, List, Optional, Sequence, Union
+
+import torch
+import torch.nn as nn
+from mmcv.cnn.bricks.transformer import BaseTransformerLayer
+from mmengine.model import ModuleList
+
+from mmocr.models.common.dictionary import Dictionary
+from mmocr.models.common.modules import PositionalEncoding
+from mmocr.registry import MODELS
+from mmocr.structures import TextRecogDataSample
+from .base import BaseDecoder
+
+
+@MODELS.register_module()
+class ABILanguageDecoder(BaseDecoder):
+ r"""Transformer-based language model responsible for spell correction.
+ Implementation of language model of \
+ `ABINet `_.
+
+ Args:
+ dictionary (dict or :obj:`Dictionary`): The config for `Dictionary` or
+ the instance of `Dictionary`. The dictionary must have an end
+ token.
+ d_model (int): Hidden size :math:`E` of model. Defaults to 512.
+ n_head (int): Number of multi-attention heads.
+ d_inner (int): Hidden size of feedforward network model.
+ n_layers (int): The number of similar decoding layers.
+ dropout (float): Dropout rate.
+ detach_tokens (bool): Whether to block the gradient flow at input
+ tokens.
+ use_self_attn (bool): If True, use self attention in decoder layers,
+ otherwise cross attention will be used.
+ max_seq_len (int): Maximum sequence length :math:`T`. The
+ sequence is usually generated from decoder. Defaults to 40.
+ module_loss (dict, optional): Config to build loss. Defaults to None.
+ postprocessor (dict, optional): Config to build postprocessor.
+ Defaults to None.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ dictionary: Union[Dict, Dictionary],
+ d_model: int = 512,
+ n_head: int = 8,
+ d_inner: int = 2048,
+ n_layers: int = 4,
+ dropout: float = 0.1,
+ detach_tokens: bool = True,
+ use_self_attn: bool = False,
+ max_seq_len: int = 40,
+ module_loss: Optional[Dict] = None,
+ postprocessor: Optional[Dict] = None,
+ init_cfg: Optional[Union[Dict, List[Dict]]] = None,
+ **kwargs) -> None:
+ super().__init__(
+ dictionary=dictionary,
+ module_loss=module_loss,
+ postprocessor=postprocessor,
+ max_seq_len=max_seq_len,
+ init_cfg=init_cfg)
+
+ assert self.dictionary.end_idx is not None,\
+ 'Dictionary must contain an end token! (with_end=True)'
+
+ self.detach_tokens = detach_tokens
+ self.d_model = d_model
+
+ self.proj = nn.Linear(self.dictionary.num_classes, d_model, False)
+ self.token_encoder = PositionalEncoding(
+ d_model, n_position=self.max_seq_len, dropout=0.1)
+ self.pos_encoder = PositionalEncoding(
+ d_model, n_position=self.max_seq_len)
+
+ if use_self_attn:
+ operation_order = ('self_attn', 'norm', 'cross_attn', 'norm',
+ 'ffn', 'norm')
+ else:
+ operation_order = ('cross_attn', 'norm', 'ffn', 'norm')
+
+ decoder_layer = BaseTransformerLayer(
+ operation_order=operation_order,
+ attn_cfgs=dict(
+ type='MultiheadAttention',
+ embed_dims=d_model,
+ num_heads=n_head,
+ attn_drop=dropout,
+ dropout_layer=dict(type='Dropout', drop_prob=dropout),
+ ),
+ ffn_cfgs=dict(
+ type='FFN',
+ embed_dims=d_model,
+ feedforward_channels=d_inner,
+ ffn_drop=dropout,
+ ),
+ norm_cfg=dict(type='LN'),
+ )
+ self.decoder_layers = ModuleList(
+ [copy.deepcopy(decoder_layer) for _ in range(n_layers)])
+
+ self.cls = nn.Linear(d_model, self.dictionary.num_classes)
+
+ def forward_train(
+ self,
+ feat: Optional[torch.Tensor] = None,
+ out_enc: torch.Tensor = None,
+ data_samples: Optional[Sequence[TextRecogDataSample]] = None
+ ) -> Dict:
+ """
+ Args:
+ feat (torch.Tensor, optional): Not required. Feature map
+ placeholder. Defaults to None.
+ out_enc (torch.Tensor): Logits with shape :math:`(N, T, C)`.
+ Defaults to None.
+ data_samples (list[TextRecogDataSample], optional): Not required.
+ DataSample placeholder. Defaults to None.
+
+ Returns:
+ A dict with keys ``feature`` and ``logits``.
+
+ - feature (Tensor): Shape :math:`(N, T, E)`. Raw textual features
+ for vision language aligner.
+ - logits (Tensor): Shape :math:`(N, T, C)`. The raw logits for
+ characters after spell correction.
+ """
+ lengths = self._get_length(out_enc)
+ lengths.clamp_(2, self.max_seq_len)
+ tokens = torch.softmax(out_enc, dim=-1)
+ if self.detach_tokens:
+ tokens = tokens.detach()
+ embed = self.proj(tokens) # (N, T, E)
+ embed = self.token_encoder(embed) # (N, T, E)
+ padding_mask = self._get_padding_mask(lengths, self.max_seq_len)
+
+ zeros = embed.new_zeros(*embed.shape)
+ query = self.pos_encoder(zeros)
+ query = query.permute(1, 0, 2) # (T, N, E)
+ embed = embed.permute(1, 0, 2)
+ location_mask = self._get_location_mask(self.max_seq_len,
+ tokens.device)
+ output = query
+ for m in self.decoder_layers:
+ output = m(
+ query=output,
+ key=embed,
+ value=embed,
+ attn_masks=location_mask,
+ key_padding_mask=padding_mask)
+ output = output.permute(1, 0, 2) # (N, T, E)
+
+ out_enc = self.cls(output) # (N, T, C)
+ return {'feature': output, 'logits': out_enc}
+
+ def forward_test(
+ self,
+ feat: Optional[torch.Tensor] = None,
+ logits: torch.Tensor = None,
+ data_samples: Optional[Sequence[TextRecogDataSample]] = None
+ ) -> Dict:
+ """
+ Args:
+ feat (torch.Tensor, optional): Not required. Feature map
+ placeholder. Defaults to None.
+ logits (Tensor): Raw language logitis. Shape :math:`(N, T, C)`.
+ Defaults to None.
+ data_samples (list[TextRecogDataSample], optional): Not required.
+ DataSample placeholder. Defaults to None.
+
+ Returns:
+ A dict with keys ``feature`` and ``logits``.
+
+ - feature (Tensor): Shape :math:`(N, T, E)`. Raw textual features
+ for vision language aligner.
+ - logits (Tensor): Shape :math:`(N, T, C)`. The raw logits for
+ characters after spell correction.
+ """
+ return self.forward_train(feat, logits, data_samples)
+
+ def _get_length(self, logit: torch.Tensor, dim: int = -1) -> torch.Tensor:
+ """Greedy decoder to obtain length from logit.
+
+ Returns the first location of padding index or the length of the entire
+ tensor otherwise.
+ """
+ # out as a boolean vector indicating the existence of end token(s)
+ out = (logit.argmax(dim=-1) == self.dictionary.end_idx)
+ abn = out.any(dim)
+ # Get the first index of end token
+ out = ((out.cumsum(dim) == 1) & out).max(dim)[1]
+ out = out + 1
+ out = torch.where(abn, out, out.new_tensor(logit.shape[1]))
+ return out
+
+ @staticmethod
+ def _get_location_mask(seq_len: int,
+ device: Union[Optional[torch.device],
+ str] = None) -> torch.Tensor:
+ """Generate location masks given input sequence length.
+
+ Args:
+ seq_len (int): The length of input sequence to transformer.
+ device (torch.device or str, optional): The device on which the
+ masks will be placed.
+
+ Returns:
+ Tensor: A mask tensor of shape (seq_len, seq_len) with -infs on
+ diagonal and zeros elsewhere.
+ """
+ mask = torch.eye(seq_len, device=device)
+ mask = mask.float().masked_fill(mask == 1, float('-inf'))
+ return mask
+
+ @staticmethod
+ def _get_padding_mask(length: int, max_length: int) -> torch.Tensor:
+ """Generate padding masks.
+
+ Args:
+ length (Tensor): Shape :math:`(N,)`.
+ max_length (int): The maximum sequence length :math:`T`.
+
+ Returns:
+ Tensor: A bool tensor of shape :math:`(N, T)` with Trues on
+ elements located over the length, or Falses elsewhere.
+ """
+ length = length.unsqueeze(-1)
+ grid = torch.arange(0, max_length, device=length.device).unsqueeze(0)
+ return grid >= length
diff --git a/mmocr/models/textrecog/decoders/abi_vision_decoder.py b/mmocr/models/textrecog/decoders/abi_vision_decoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..7095e82209f24f9d30f68c979b504401ea514c05
--- /dev/null
+++ b/mmocr/models/textrecog/decoders/abi_vision_decoder.py
@@ -0,0 +1,238 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Sequence, Tuple, Union
+
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+
+from mmocr.models.common.dictionary import Dictionary
+from mmocr.models.common.modules import PositionalEncoding
+from mmocr.registry import MODELS
+from mmocr.structures import TextRecogDataSample
+from .base import BaseDecoder
+
+
+@MODELS.register_module()
+class ABIVisionDecoder(BaseDecoder):
+ """Converts visual features into text characters.
+
+ Implementation of VisionEncoder in
+ `ABINet `_.
+
+ Args:
+ dictionary (dict or :obj:`Dictionary`): The config for `Dictionary` or
+ the instance of `Dictionary`.
+ in_channels (int): Number of channels :math:`E` of input vector.
+ Defaults to 512.
+ num_channels (int): Number of channels of hidden vectors in mini U-Net.
+ Defaults to 64.
+ attn_height (int): Height :math:`H` of input image features. Defaults
+ to 8.
+ attn_width (int): Width :math:`W` of input image features. Defaults to
+ 32.
+ attn_mode (str): Upsampling mode for :obj:`torch.nn.Upsample` in mini
+ U-Net. Defaults to 'nearest'.
+ module_loss (dict, optional): Config to build loss. Defaults to None.
+ postprocessor (dict, optional): Config to build postprocessor.
+ Defaults to None.
+ max_seq_len (int): Maximum sequence length. The
+ sequence is usually generated from decoder. Defaults to 40.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ Defaults to dict(type='Xavier', layer='Conv2d').
+ """
+
+ def __init__(self,
+ dictionary: Union[Dict, Dictionary],
+ in_channels: int = 512,
+ num_channels: int = 64,
+ attn_height: int = 8,
+ attn_width: int = 32,
+ attn_mode: str = 'nearest',
+ module_loss: Optional[Dict] = None,
+ postprocessor: Optional[Dict] = None,
+ max_seq_len: int = 40,
+ init_cfg: Optional[Union[Dict, List[Dict]]] = dict(
+ type='Xavier', layer='Conv2d'),
+ **kwargs) -> None:
+
+ super().__init__(
+ dictionary=dictionary,
+ module_loss=module_loss,
+ postprocessor=postprocessor,
+ max_seq_len=max_seq_len,
+ init_cfg=init_cfg)
+
+ # For mini-Unet
+ self.k_encoder = nn.Sequential(
+ self._encoder_layer(in_channels, num_channels, stride=(1, 2)),
+ self._encoder_layer(num_channels, num_channels, stride=(2, 2)),
+ self._encoder_layer(num_channels, num_channels, stride=(2, 2)),
+ self._encoder_layer(num_channels, num_channels, stride=(2, 2)))
+
+ self.k_decoder = nn.Sequential(
+ self._decoder_layer(
+ num_channels, num_channels, scale_factor=2, mode=attn_mode),
+ self._decoder_layer(
+ num_channels, num_channels, scale_factor=2, mode=attn_mode),
+ self._decoder_layer(
+ num_channels, num_channels, scale_factor=2, mode=attn_mode),
+ self._decoder_layer(
+ num_channels,
+ in_channels,
+ size=(attn_height, attn_width),
+ mode=attn_mode))
+
+ self.pos_encoder = PositionalEncoding(in_channels, max_seq_len)
+ self.project = nn.Linear(in_channels, in_channels)
+ self.cls = nn.Linear(in_channels, self.dictionary.num_classes)
+
+ def forward_train(
+ self,
+ feat: Optional[torch.Tensor] = None,
+ out_enc: torch.Tensor = None,
+ data_samples: Optional[Sequence[TextRecogDataSample]] = None
+ ) -> Dict:
+ """
+ Args:
+ feat (Tensor, optional): Image features of shape (N, E, H, W).
+ Defaults to None.
+ out_enc (torch.Tensor): Encoder output. Defaults to None.
+ data_samples (list[TextRecogDataSample], optional): Batch of
+ TextRecogDataSample, containing gt_text information. Defaults
+ to None.
+
+ Returns:
+ dict: A dict with keys ``feature``, ``logits`` and ``attn_scores``.
+
+ - feature (Tensor): Shape (N, T, E). Raw visual features for
+ language decoder.
+ - logits (Tensor): Shape (N, T, C). The raw logits for
+ characters.
+ - attn_scores (Tensor): Shape (N, T, H, W). Intermediate result
+ for vision-language aligner.
+ """
+ # Position Attention
+ N, E, H, W = out_enc.size()
+ k, v = out_enc, out_enc # (N, E, H, W)
+
+ # Apply mini U-Net on k
+ features = []
+ for i in range(len(self.k_encoder)):
+ k = self.k_encoder[i](k)
+ features.append(k)
+ for i in range(len(self.k_decoder) - 1):
+ k = self.k_decoder[i](k)
+ k = k + features[len(self.k_decoder) - 2 - i]
+ k = self.k_decoder[-1](k)
+
+ # q = positional encoding
+ zeros = out_enc.new_zeros((N, self.max_seq_len, E)) # (N, T, E)
+ q = self.pos_encoder(zeros) # (N, T, E)
+ q = self.project(q) # (N, T, E)
+
+ # Attention encoding
+ attn_scores = torch.bmm(q, k.flatten(2, 3)) # (N, T, (H*W))
+ attn_scores = attn_scores / (E**0.5)
+ attn_scores = torch.softmax(attn_scores, dim=-1)
+ v = v.permute(0, 2, 3, 1).view(N, -1, E) # (N, (H*W), E)
+ attn_vecs = torch.bmm(attn_scores, v) # (N, T, E)
+
+ out_enc = self.cls(attn_vecs)
+ result = {
+ 'feature': attn_vecs,
+ 'logits': out_enc,
+ 'attn_scores': attn_scores.view(N, -1, H, W)
+ }
+ return result
+
+ def forward_test(
+ self,
+ feat: Optional[torch.Tensor] = None,
+ out_enc: torch.Tensor = None,
+ data_samples: Optional[Sequence[TextRecogDataSample]] = None
+ ) -> Dict:
+ """
+ Args:
+ feat (torch.Tensor, optional): Image features of shape
+ (N, E, H, W). Defaults to None.
+ out_enc (torch.Tensor): Encoder output. Defaults to None.
+ data_samples (list[TextRecogDataSample], optional): Batch of
+ TextRecogDataSample, containing gt_text information. Defaults
+ to None.
+
+ Returns:
+ dict: A dict with keys ``feature``, ``logits`` and ``attn_scores``.
+
+ - feature (Tensor): Shape (N, T, E). Raw visual features for
+ language decoder.
+ - logits (Tensor): Shape (N, T, C). The raw logits for
+ characters.
+ - attn_scores (Tensor): Shape (N, T, H, W). Intermediate result
+ for vision-language aligner.
+ """
+ return self.forward_train(
+ feat, out_enc=out_enc, data_samples=data_samples)
+
+ def _encoder_layer(self,
+ in_channels: int,
+ out_channels: int,
+ kernel_size: int = 3,
+ stride: int = 2,
+ padding: int = 1) -> nn.Sequential:
+ """Generate encoder layer.
+
+ Args:
+ in_channels (int): Input channels.
+ out_channels (int): Output channels.
+ kernel_size (int, optional): Kernel size. Defaults to 3.
+ stride (int, optional): Stride. Defaults to 2.
+ padding (int, optional): Padding. Defaults to 1.
+
+ Returns:
+ nn.Sequential: Encoder layer.
+ """
+ return ConvModule(
+ in_channels,
+ out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'))
+
+ def _decoder_layer(self,
+ in_channels: int,
+ out_channels: int,
+ kernel_size: int = 3,
+ stride: int = 1,
+ padding: int = 1,
+ mode: str = 'nearest',
+ scale_factor: Optional[int] = None,
+ size: Optional[Tuple[int, int]] = None):
+ """Generate decoder layer.
+
+ Args:
+ in_channels (int): Input channels.
+ out_channels (int): Output channels.
+ kernel_size (int): Kernel size. Defaults to 3.
+ stride (int): Stride. Defaults to 1.
+ padding (int): Padding. Defaults to 1.
+ mode (str): Interpolation mode. Defaults to 'nearest'.
+ scale_factor (int, optional): Scale factor for upsampling.
+ size (Tuple[int, int], optional): Output size. Defaults to None.
+ """
+ align_corners = None if mode == 'nearest' else True
+ return nn.Sequential(
+ nn.Upsample(
+ size=size,
+ scale_factor=scale_factor,
+ mode=mode,
+ align_corners=align_corners),
+ ConvModule(
+ in_channels,
+ out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU')))
diff --git a/mmocr/models/textrecog/decoders/aster_decoder.py b/mmocr/models/textrecog/decoders/aster_decoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..83e249b08c00acc06a7a31a5b5e44ba70ff3b712
--- /dev/null
+++ b/mmocr/models/textrecog/decoders/aster_decoder.py
@@ -0,0 +1,181 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, Optional, Sequence, Tuple, Union
+
+import torch
+import torch.nn as nn
+
+from mmocr.models.common.dictionary import Dictionary
+from mmocr.registry import MODELS
+from mmocr.structures import TextRecogDataSample
+from .base import BaseDecoder
+
+
+@MODELS.register_module()
+class ASTERDecoder(BaseDecoder):
+ """Implement attention decoder.
+
+ Args:
+ in_channels (int): Number of input channels.
+ emb_dims (int): Dims of char embedding. Defaults to 512.
+ attn_dims (int): Dims of attention. Both hidden states and features
+ will be projected to this dims. Defaults to 512.
+ hidden_size (int): Dims of hidden state for GRU. Defaults to 512.
+ dictionary (dict or :obj:`Dictionary`): The config for `Dictionary` or
+ the instance of `Dictionary`. Defaults to None.
+ max_seq_len (int): Maximum output sequence length :math:`T`. Defaults
+ to 25.
+ module_loss (dict, optional): Config to build loss. Defaults to None.
+ postprocessor (dict, optional): Config to build postprocessor.
+ Defaults to None.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ in_channels: int,
+ emb_dims: int = 512,
+ attn_dims: int = 512,
+ hidden_size: int = 512,
+ dictionary: Union[Dictionary, Dict] = None,
+ max_seq_len: int = 25,
+ module_loss: Dict = None,
+ postprocessor: Dict = None,
+ init_cfg=dict(type='Xavier', layer='Conv2d')):
+ super().__init__(
+ init_cfg=init_cfg,
+ dictionary=dictionary,
+ module_loss=module_loss,
+ postprocessor=postprocessor,
+ max_seq_len=max_seq_len)
+
+ self.start_idx = self.dictionary.start_idx
+ self.num_classes = self.dictionary.num_classes
+ self.in_channels = in_channels
+ self.embedding_dim = emb_dims
+ self.att_dims = attn_dims
+ self.hidden_size = hidden_size
+
+ # Projection layers
+ self.proj_feat = nn.Linear(in_channels, attn_dims)
+ self.proj_hidden = nn.Linear(hidden_size, attn_dims)
+ self.proj_sum = nn.Linear(attn_dims, 1)
+
+ # Decoder input embedding
+ self.embedding = nn.Embedding(self.num_classes, self.att_dims)
+
+ # GRU
+ self.gru = nn.GRU(
+ input_size=self.in_channels + self.embedding_dim,
+ hidden_size=self.hidden_size,
+ batch_first=True)
+
+ # Prediction layer
+ self.fc = nn.Linear(hidden_size, self.dictionary.num_classes)
+ self.softmax = nn.Softmax(dim=-1)
+
+ def _attention(self, feat: torch.Tensor, prev_hidden: torch.Tensor,
+ prev_char: torch.Tensor
+ ) -> Tuple[torch.Tensor, torch.Tensor]:
+ """Implement the attention mechanism.
+
+ Args:
+ feat (Tensor): Feature map from encoder of shape :math:`(N, T, C)`.
+ prev_hidden (Tensor): Previous hidden state from GRU of shape
+ :math:`(1, N, self.hidden_size)`.
+ prev_char (Tensor): Previous predicted character of shape
+ :math:`(N, )`.
+
+ Returns:
+ tuple(Tensor, Tensor):
+ - output (Tensor): Predicted character of current time step of
+ shape :math:`(N, 1)`.
+ - state (Tensor): Hidden state from GRU of current time step of
+ shape :math:`(N, self.hidden_size)`.
+ """
+ # Calculate the attention weights
+ B, T, _ = feat.size()
+ feat_proj = self.proj_feat(feat) # [N, T, attn_dims]
+ hidden_proj = self.proj_hidden(prev_hidden) # [1, N, attn_dims]
+ hidden_proj = hidden_proj.squeeze(0).unsqueeze(1) # [N, 1, attn_dims]
+ hidden_proj = hidden_proj.expand(B, T,
+ self.att_dims) # [N, T, attn_dims]
+
+ sum_tanh = torch.tanh(feat_proj + hidden_proj) # [N, T, attn_dims]
+ sum_proj = self.proj_sum(sum_tanh).squeeze(-1) # [N, T]
+ attn_weights = torch.softmax(sum_proj, dim=1) # [N, T]
+
+ # GRU forward
+ context = torch.bmm(attn_weights.unsqueeze(1), feat).squeeze(1)
+ char_embed = self.embedding(prev_char.long()) # [N, emb_dims]
+ output, state = self.gru(
+ torch.cat([char_embed, context], 1).unsqueeze(1), prev_hidden)
+ output = output.squeeze(1)
+ output = self.fc(output)
+ return output, state
+
+ def forward_train(
+ self,
+ feat: torch.Tensor = None,
+ out_enc: Optional[torch.Tensor] = None,
+ data_samples: Optional[Sequence[TextRecogDataSample]] = None
+ ) -> torch.Tensor:
+ """
+ Args:
+ feat (Tensor): Feature from backbone. Unused in this decoder.
+ out_enc (torch.Tensor, optional): Encoder output. Defaults to None.
+ data_samples (list[TextRecogDataSample], optional): Batch of
+ TextRecogDataSample, containing gt_text information. Defaults
+ to None.
+
+ Returns:
+ Tensor: The raw logit tensor. Shape :math:`(N, T, C)` where
+ :math:`C` is ``num_classes``.
+ """
+ B = out_enc.shape[0]
+ state = torch.zeros(1, B, self.hidden_size).to(out_enc.device)
+ padded_targets = [
+ data_sample.gt_text.padded_indexes for data_sample in data_samples
+ ]
+ padded_targets = torch.stack(padded_targets, dim=0).to(out_enc.device)
+ outputs = []
+ for i in range(self.max_seq_len):
+ prev_char = padded_targets[:, i].to(out_enc.device)
+ output, state = self._attention(out_enc, state, prev_char)
+ outputs.append(output)
+ outputs = torch.cat([_.unsqueeze(1) for _ in outputs], 1)
+ return outputs
+
+ def forward_test(
+ self,
+ feat: Optional[torch.Tensor] = None,
+ out_enc: Optional[torch.Tensor] = None,
+ data_samples: Optional[Sequence[TextRecogDataSample]] = None
+ ) -> torch.Tensor:
+ """
+ Args:
+ feat (Tensor): Feature from backbone. Unused in this decoder.
+ out_enc (torch.Tensor, optional): Encoder output. Defaults to None.
+ data_samples (list[TextRecogDataSample], optional): Batch of
+ TextRecogDataSample, containing gt_text information. Defaults
+ to None. Unused in this decoder.
+
+ Returns:
+ Tensor: The raw logit tensor. Shape :math:`(N, T, C)` where
+ :math:`C` is ``num_classes``.
+ """
+ B = out_enc.shape[0]
+ predicted = []
+ state = torch.zeros(1, B, self.hidden_size).to(out_enc.device)
+ outputs = []
+ for i in range(self.max_seq_len):
+ if i == 0:
+ prev_char = torch.zeros(B).fill_(self.start_idx).to(
+ out_enc.device)
+ else:
+ prev_char = predicted
+
+ output, state = self._attention(out_enc, state, prev_char)
+ outputs.append(output)
+ _, predicted = output.max(-1)
+ outputs = torch.cat([_.unsqueeze(1) for _ in outputs], 1)
+ return self.softmax(outputs)
diff --git a/mmocr/models/textrecog/decoders/base.py b/mmocr/models/textrecog/decoders/base.py
new file mode 100644
index 0000000000000000000000000000000000000000..2c990ca0c1c9c1b6a2878ca05cb764b20e3d8fb1
--- /dev/null
+++ b/mmocr/models/textrecog/decoders/base.py
@@ -0,0 +1,166 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Sequence, Union
+
+import torch
+from mmengine.model import BaseModule
+
+from mmocr.models.common.dictionary import Dictionary
+from mmocr.registry import MODELS, TASK_UTILS
+from mmocr.structures import TextRecogDataSample
+
+
+@MODELS.register_module()
+class BaseDecoder(BaseModule):
+ """Base decoder for text recognition, build the loss and postprocessor.
+
+ Args:
+ dictionary (dict or :obj:`Dictionary`): The config for `Dictionary` or
+ the instance of `Dictionary`.
+ loss (dict, optional): Config to build loss. Defaults to None.
+ postprocessor (dict, optional): Config to build postprocessor.
+ Defaults to None.
+ max_seq_len (int): Maximum sequence length. The
+ sequence is usually generated from decoder. Defaults to 40.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ dictionary: Union[Dict, Dictionary],
+ module_loss: Optional[Dict] = None,
+ postprocessor: Optional[Dict] = None,
+ max_seq_len: int = 40,
+ init_cfg: Optional[Union[Dict, List[Dict]]] = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+ if isinstance(dictionary, dict):
+ self.dictionary = TASK_UTILS.build(dictionary)
+ elif isinstance(dictionary, Dictionary):
+ self.dictionary = dictionary
+ else:
+ raise TypeError(
+ 'The type of dictionary should be `Dictionary` or dict, '
+ f'but got {type(dictionary)}')
+ self.module_loss = None
+ self.postprocessor = None
+ self.max_seq_len = max_seq_len
+
+ if module_loss is not None:
+ assert isinstance(module_loss, dict)
+ module_loss.update(dictionary=dictionary)
+ module_loss.update(max_seq_len=max_seq_len)
+ self.module_loss = MODELS.build(module_loss)
+
+ if postprocessor is not None:
+ assert isinstance(postprocessor, dict)
+ postprocessor.update(dictionary=dictionary)
+ postprocessor.update(max_seq_len=max_seq_len)
+ self.postprocessor = MODELS.build(postprocessor)
+
+ def forward_train(
+ self,
+ feat: Optional[torch.Tensor] = None,
+ out_enc: Optional[torch.Tensor] = None,
+ data_samples: Optional[Sequence[TextRecogDataSample]] = None
+ ) -> torch.Tensor:
+ """Forward for training.
+
+ Args:
+ feat (torch.Tensor, optional): The feature map from backbone of
+ shape :math:`(N, E, H, W)`. Defaults to None.
+ out_enc (torch.Tensor, optional): Encoder output. Defaults to None.
+ data_samples (Sequence[TextRecogDataSample]): Batch of
+ TextRecogDataSample, containing gt_text information. Defaults
+ to None.
+ """
+ raise NotImplementedError
+
+ def forward_test(
+ self,
+ feat: Optional[torch.Tensor] = None,
+ out_enc: Optional[torch.Tensor] = None,
+ data_samples: Optional[Sequence[TextRecogDataSample]] = None
+ ) -> torch.Tensor:
+ """Forward for testing.
+
+ Args:
+ feat (torch.Tensor, optional): The feature map from backbone of
+ shape :math:`(N, E, H, W)`. Defaults to None.
+ out_enc (torch.Tensor, optional): Encoder output. Defaults to None.
+ data_samples (Sequence[TextRecogDataSample]): Batch of
+ TextRecogDataSample, containing gt_text information. Defaults
+ to None.
+ """
+ raise NotImplementedError
+
+ def loss(self,
+ feat: Optional[torch.Tensor] = None,
+ out_enc: Optional[torch.Tensor] = None,
+ data_samples: Optional[Sequence[TextRecogDataSample]] = None
+ ) -> Dict:
+ """Calculate losses from a batch of inputs and data samples.
+
+ Args:
+ feat (Tensor, optional): Features from the backbone. Defaults
+ to None.
+ out_enc (Tensor, optional): Features from the encoder.
+ Defaults to None.
+ data_samples (list[TextRecogDataSample], optional): A list of
+ N datasamples, containing meta information and gold
+ annotations for each of the images. Defaults to None.
+
+ Returns:
+ dict[str, tensor]: A dictionary of loss components.
+ """
+ out_dec = self(feat, out_enc, data_samples)
+ return self.module_loss(out_dec, data_samples)
+
+ def predict(
+ self,
+ feat: Optional[torch.Tensor] = None,
+ out_enc: Optional[torch.Tensor] = None,
+ data_samples: Optional[Sequence[TextRecogDataSample]] = None
+ ) -> Sequence[TextRecogDataSample]:
+ """Perform forward propagation of the decoder and postprocessor.
+
+ Args:
+ feat (Tensor, optional): Features from the backbone. Defaults
+ to None.
+ out_enc (Tensor, optional): Features from the encoder. Defaults
+ to None.
+ data_samples (list[TextRecogDataSample]): A list of N datasamples,
+ containing meta information and gold annotations for each of
+ the images. Defaults to None.
+
+ Returns:
+ list[TextRecogDataSample]: A list of N datasamples of prediction
+ results. Results are stored in ``pred_text``.
+ """
+ out_dec = self(feat, out_enc, data_samples)
+ return self.postprocessor(out_dec, data_samples)
+
+ def forward(
+ self,
+ feat: Optional[torch.Tensor] = None,
+ out_enc: Optional[torch.Tensor] = None,
+ data_samples: Optional[Sequence[TextRecogDataSample]] = None
+ ) -> torch.Tensor:
+ """Decoder forward.
+
+ Args:
+ feat (Tensor, optional): Features from the backbone. Defaults
+ to None.
+ out_enc (Tensor, optional): Features from the encoder.
+ Defaults to None.
+ data_samples (list[TextRecogDataSample]): A list of N datasamples,
+ containing meta information and gold annotations for each of
+ the images. Defaults to None.
+
+ Returns:
+ Tensor: Features from ``decoder`` forward.
+ """
+ if self.training:
+ if getattr(self, 'module_loss') is not None:
+ data_samples = self.module_loss.get_targets(data_samples)
+ return self.forward_train(feat, out_enc, data_samples)
+ else:
+ return self.forward_test(feat, out_enc, data_samples)
diff --git a/mmocr/models/textrecog/decoders/crnn_decoder.py b/mmocr/models/textrecog/decoders/crnn_decoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..7d29abbd86a9c5bd2cafe633efd1514eb1c97b96
--- /dev/null
+++ b/mmocr/models/textrecog/decoders/crnn_decoder.py
@@ -0,0 +1,109 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, Optional, Sequence, Union
+
+import torch
+import torch.nn as nn
+from mmengine.model import Sequential
+
+from mmocr.models.common.dictionary import Dictionary
+from mmocr.models.textrecog.layers import BidirectionalLSTM
+from mmocr.registry import MODELS
+from mmocr.structures import TextRecogDataSample
+from .base import BaseDecoder
+
+
+@MODELS.register_module()
+class CRNNDecoder(BaseDecoder):
+ """Decoder for CRNN.
+
+ Args:
+ in_channels (int): Number of input channels.
+ dictionary (dict or :obj:`Dictionary`): The config for `Dictionary` or
+ the instance of `Dictionary`.
+ rnn_flag (bool): Use RNN or CNN as the decoder. Defaults to False.
+ module_loss (dict, optional): Config to build module_loss. Defaults
+ to None.
+ postprocessor (dict, optional): Config to build postprocessor.
+ Defaults to None.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ in_channels: int,
+ dictionary: Union[Dictionary, Dict],
+ rnn_flag: bool = False,
+ module_loss: Dict = None,
+ postprocessor: Dict = None,
+ init_cfg=dict(type='Xavier', layer='Conv2d'),
+ **kwargs):
+ super().__init__(
+ init_cfg=init_cfg,
+ dictionary=dictionary,
+ module_loss=module_loss,
+ postprocessor=postprocessor)
+ self.rnn_flag = rnn_flag
+
+ if rnn_flag:
+ self.decoder = Sequential(
+ BidirectionalLSTM(in_channels, 256, 256),
+ BidirectionalLSTM(256, 256, self.dictionary.num_classes))
+ else:
+ self.decoder = nn.Conv2d(
+ in_channels,
+ self.dictionary.num_classes,
+ kernel_size=1,
+ stride=1)
+ self.softmax = nn.Softmax(dim=-1)
+
+ def forward_train(
+ self,
+ feat: torch.Tensor,
+ out_enc: Optional[torch.Tensor] = None,
+ data_samples: Optional[Sequence[TextRecogDataSample]] = None
+ ) -> torch.Tensor:
+ """
+ Args:
+ feat (Tensor): A Tensor of shape :math:`(N, C, 1, W)`.
+ out_enc (torch.Tensor, optional): Encoder output. Defaults to None.
+ data_samples (list[TextRecogDataSample], optional): Batch of
+ TextRecogDataSample, containing gt_text information. Defaults
+ to None.
+
+ Returns:
+ Tensor: The raw logit tensor. Shape :math:`(N, W, C)` where
+ :math:`C` is ``num_classes``.
+ """
+ assert feat.size(2) == 1, 'feature height must be 1'
+ if self.rnn_flag:
+ x = feat.squeeze(2) # [N, C, W]
+ x = x.permute(2, 0, 1) # [W, N, C]
+ x = self.decoder(x) # [W, N, C]
+ outputs = x.permute(1, 0, 2).contiguous()
+ else:
+ x = self.decoder(feat)
+ x = x.permute(0, 3, 1, 2).contiguous()
+ n, w, c, h = x.size()
+ outputs = x.view(n, w, c * h)
+ return outputs
+
+ def forward_test(
+ self,
+ feat: Optional[torch.Tensor] = None,
+ out_enc: Optional[torch.Tensor] = None,
+ data_samples: Optional[Sequence[TextRecogDataSample]] = None
+ ) -> torch.Tensor:
+ """
+ Args:
+ feat (Tensor): A Tensor of shape :math:`(N, C, 1, W)`.
+ out_enc (torch.Tensor, optional): Encoder output. Defaults to None.
+ data_samples (list[TextRecogDataSample]): Batch of
+ TextRecogDataSample, containing ``gt_text`` information.
+ Defaults to None.
+
+ Returns:
+ Tensor: Character probabilities. of shape
+ :math:`(N, self.max_seq_len, C)` where :math:`C` is
+ ``num_classes``.
+ """
+ return self.softmax(self.forward_train(feat, out_enc, data_samples))
diff --git a/mmocr/models/textrecog/decoders/maerec_decoder.py b/mmocr/models/textrecog/decoders/maerec_decoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..e569b06f371769e32cb729e72ea65be64e4ecc5f
--- /dev/null
+++ b/mmocr/models/textrecog/decoders/maerec_decoder.py
@@ -0,0 +1,258 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from typing import Dict, List, Optional, Sequence, Union
+
+import torch
+import torch.nn as nn
+from mmengine.model import ModuleList
+
+from mmocr.models.common import PositionalEncoding, TFDecoderLayer
+from mmocr.models.common.dictionary import Dictionary
+from mmocr.registry import MODELS
+from mmocr.structures import TextRecogDataSample
+from .base import BaseDecoder
+
+
+@MODELS.register_module()
+class MAERecDecoder(BaseDecoder):
+ """Transformer Decoder block with self attention mechanism.
+
+ Args:
+ n_layers (int): Number of attention layers. Defaults to 6.
+ d_embedding (int): Language embedding dimension. Defaults to 512.
+ n_head (int): Number of parallel attention heads. Defaults to 8.
+ d_k (int): Dimension of the key vector. Defaults to 64.
+ d_v (int): Dimension of the value vector. Defaults to 64
+ d_model (int): Dimension :math:`D_m` of the input from previous model.
+ Defaults to 512.
+ d_inner (int): Hidden dimension of feedforward layers. Defaults to 256.
+ n_position (int): Length of the positional encoding vector. Must be
+ greater than ``max_seq_len``. Defaults to 200.
+ dropout (float): Dropout rate for text embedding, MHSA, FFN. Defaults
+ to 0.1.
+ module_loss (dict, optional): Config to build module_loss. Defaults
+ to None.
+ postprocessor (dict, optional): Config to build postprocessor.
+ Defaults to None.
+ dictionary (dict or :obj:`Dictionary`): The config for `Dictionary` or
+ the instance of `Dictionary`.
+ max_seq_len (int): Maximum output sequence length :math:`T`. Defaults
+ to 30.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ """
+
+ def __init__(self,
+ n_layers: int = 6,
+ d_embedding: int = 512,
+ n_head: int = 8,
+ d_k: int = 64,
+ d_v: int = 64,
+ d_model: int = 512,
+ d_inner: int = 256,
+ n_position: int = 200,
+ dropout: float = 0.1,
+ module_loss: Optional[Dict] = None,
+ postprocessor: Optional[Dict] = None,
+ dictionary: Optional[Union[Dict, Dictionary]] = None,
+ max_seq_len: int = 30,
+ init_cfg: Optional[Union[Dict, List[Dict]]] = None) -> None:
+ super().__init__(
+ module_loss=module_loss,
+ postprocessor=postprocessor,
+ dictionary=dictionary,
+ init_cfg=init_cfg,
+ max_seq_len=max_seq_len)
+
+ self.padding_idx = self.dictionary.padding_idx
+ self.start_idx = self.dictionary.start_idx
+ self.max_seq_len = max_seq_len
+
+ self.trg_word_emb = nn.Embedding(
+ self.dictionary.num_classes,
+ d_embedding,
+ padding_idx=self.padding_idx)
+
+ self.position_enc = PositionalEncoding(
+ d_embedding, n_position=n_position)
+ self.dropout = nn.Dropout(p=dropout)
+
+ self.layer_stack = ModuleList([
+ TFDecoderLayer(
+ d_model, d_inner, n_head, d_k, d_v, dropout=dropout)
+ for _ in range(n_layers)
+ ])
+ self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
+
+ pred_num_class = self.dictionary.num_classes
+ self.classifier = nn.Linear(d_model, pred_num_class)
+ self.softmax = nn.Softmax(dim=-1)
+
+ def _get_target_mask(self, trg_seq: torch.Tensor) -> torch.Tensor:
+ """Generate mask for target sequence.
+
+ Args:
+ trg_seq (torch.Tensor): Input text sequence. Shape :math:`(N, T)`.
+
+ Returns:
+ Tensor: Target mask. Shape :math:`(N, T, T)`.
+ E.g.:
+ seq = torch.Tensor([[1, 2, 0, 0]]), pad_idx = 0, then
+ target_mask =
+ torch.Tensor([[[True, False, False, False],
+ [True, True, False, False],
+ [True, True, False, False],
+ [True, True, False, False]]])
+ """
+
+ pad_mask = (trg_seq != self.padding_idx).unsqueeze(-2)
+
+ len_s = trg_seq.size(1)
+ subsequent_mask = 1 - torch.triu(
+ torch.ones((len_s, len_s), device=trg_seq.device), diagonal=1)
+ subsequent_mask = subsequent_mask.unsqueeze(0).bool()
+
+ return pad_mask & subsequent_mask
+
+ def _get_source_mask(self, src_seq: torch.Tensor,
+ valid_ratios: Sequence[float]) -> torch.Tensor:
+ """Generate mask for source sequence.
+
+ Args:
+ src_seq (torch.Tensor): Image sequence. Shape :math:`(N, T, C)`.
+ valid_ratios (list[float]): The valid ratio of input image. For
+ example, if the width of the original image is w1 and the width
+ after padding is w2, then valid_ratio = w1/w2. Source mask is
+ used to cover the area of the padding region.
+
+ Returns:
+ Tensor or None: Source mask. Shape :math:`(N, T)`. The region of
+ padding area are False, and the rest are True.
+ """
+
+ N, T, _ = src_seq.size()
+ mask = None
+ if len(valid_ratios) > 0:
+ mask = src_seq.new_zeros((N, T), device=src_seq.device)
+ for i, valid_ratio in enumerate(valid_ratios):
+ valid_width = min(T, math.ceil(T * valid_ratio))
+ mask[i, :valid_width] = 1
+
+ return mask
+
+ def _attention(self,
+ trg_seq: torch.Tensor,
+ src: torch.Tensor,
+ src_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
+ """A wrapped process for transformer based decoder including text
+ embedding, position embedding, N x transformer decoder and a LayerNorm
+ operation.
+
+ Args:
+ trg_seq (Tensor): Target sequence in. Shape :math:`(N, T)`.
+ src (Tensor): Source sequence from encoder in shape
+ Shape :math:`(N, T, D_m)` where :math:`D_m` is ``d_model``.
+ src_mask (Tensor, Optional): Mask for source sequence.
+ Shape :math:`(N, T)`. Defaults to None.
+
+ Returns:
+ Tensor: Output sequence from transformer decoder.
+ Shape :math:`(N, T, D_m)` where :math:`D_m` is ``d_model``.
+ """
+
+ trg_embedding = self.trg_word_emb(trg_seq)
+ trg_pos_encoded = self.position_enc(trg_embedding)
+ trg_mask = self._get_target_mask(trg_seq)
+ tgt_seq = self.dropout(trg_pos_encoded)
+
+ output = tgt_seq
+ for dec_layer in self.layer_stack:
+ output = dec_layer(
+ output,
+ src,
+ self_attn_mask=trg_mask,
+ dec_enc_attn_mask=src_mask)
+ output = self.layer_norm(output)
+
+ return output
+
+ def forward_train(
+ self,
+ feat: Optional[torch.Tensor] = None,
+ out_enc: torch.Tensor = None,
+ data_samples: Sequence[TextRecogDataSample] = None
+ ) -> torch.Tensor:
+ """Forward for training. Source mask will be used here.
+
+ Args:
+ feat (Tensor, optional): Unused.
+ out_enc (Tensor): Encoder output of shape : math:`(N, T, D_m)`
+ where :math:`D_m` is ``d_model``. Defaults to None.
+ data_samples (list[TextRecogDataSample]): Batch of
+ TextRecogDataSample, containing gt_text and valid_ratio
+ information. Defaults to None.
+
+ Returns:
+ Tensor: The raw logit tensor. Shape :math:`(N, T, C)` where
+ :math:`C` is ``num_classes``.
+ """
+ valid_ratios = []
+ for data_sample in data_samples:
+ valid_ratios.append(data_sample.get('valid_ratio'))
+ src_mask = self._get_source_mask(feat, valid_ratios)
+ trg_seq = []
+ for data_sample in data_samples:
+ trg_seq.append(data_sample.gt_text.padded_indexes.to(feat.device))
+ trg_seq = torch.stack(trg_seq, dim=0)
+ attn_output = self._attention(trg_seq, feat, src_mask=src_mask)
+ outputs = self.classifier(attn_output)
+
+ return outputs
+
+ def forward_test(
+ self,
+ feat: Optional[torch.Tensor] = None,
+ out_enc: torch.Tensor = None,
+ data_samples: Sequence[TextRecogDataSample] = None
+ ) -> torch.Tensor:
+ """Forward for testing.
+
+ Args:
+ feat (Tensor, optional): Unused.
+ out_enc (Tensor): Encoder output of shape:
+ math:`(N, T, D_m)` where :math:`D_m` is ``d_model``.
+ Defaults to None.
+ data_samples (list[TextRecogDataSample]): Batch of
+ TextRecogDataSample, containing gt_text and valid_ratio
+ information. Defaults to None.
+
+ Returns:
+ Tensor: Character probabilities. of shape
+ :math:`(N, self.max_seq_len, C)` where :math:`C` is
+ ``num_classes``.
+ """
+ valid_ratios = []
+ for data_sample in data_samples:
+ valid_ratios.append(data_sample.get('valid_ratio'))
+ src_mask = self._get_source_mask(feat, valid_ratios)
+ N = feat.size(0)
+ init_target_seq = torch.full((N, self.max_seq_len + 1),
+ self.padding_idx,
+ device=feat.device,
+ dtype=torch.long)
+ # bsz * seq_len
+ init_target_seq[:, 0] = self.start_idx
+
+ outputs = []
+ for step in range(0, self.max_seq_len):
+ decoder_output = self._attention(
+ init_target_seq, feat, src_mask=src_mask)
+ # bsz * seq_len * C
+ step_result = self.classifier(decoder_output[:, step, :])
+ # bsz * num_classes
+ outputs.append(step_result)
+ _, step_max_index = torch.max(step_result, dim=-1)
+ init_target_seq[:, step + 1] = step_max_index
+
+ outputs = torch.stack(outputs, dim=1)
+
+ return self.softmax(outputs)
diff --git a/mmocr/models/textrecog/decoders/master_decoder.py b/mmocr/models/textrecog/decoders/master_decoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..b92b4fc8f4538e1dd9f2485509e27f7036532ce7
--- /dev/null
+++ b/mmocr/models/textrecog/decoders/master_decoder.py
@@ -0,0 +1,275 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import math
+from typing import Dict, Optional, Sequence, Union
+
+import torch
+import torch.nn as nn
+from mmcv.cnn.bricks.transformer import BaseTransformerLayer
+from mmengine.model import ModuleList
+
+from mmocr.models.common.dictionary import Dictionary
+from mmocr.models.common.modules import PositionalEncoding
+from mmocr.registry import MODELS
+from mmocr.structures import TextRecogDataSample
+from .base import BaseDecoder
+
+
+def clones(module: nn.Module, N: int) -> nn.ModuleList:
+ """Produce N identical layers.
+
+ Args:
+ module (nn.Module): A pytorch nn.module.
+ N (int): Number of copies.
+
+ Returns:
+ nn.ModuleList: A pytorch nn.ModuleList with the copies.
+ """
+ return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
+
+
+class Embeddings(nn.Module):
+ """Construct the word embeddings given vocab size and embed dim.
+
+ Args:
+ d_model (int): The embedding dimension.
+ vocab (int): Vocablury size.
+ """
+
+ def __init__(self, d_model: int, vocab: int):
+ super().__init__()
+ self.lut = nn.Embedding(vocab, d_model)
+ self.d_model = d_model
+
+ def forward(self, *input: torch.Tensor) -> torch.Tensor:
+ """Forward the embeddings.
+
+ Args:
+ input (torch.Tensor): The input tensors.
+
+ Returns:
+ torch.Tensor: The embeddings.
+ """
+ x = input[0]
+ return self.lut(x) * math.sqrt(self.d_model)
+
+
+@MODELS.register_module()
+class MasterDecoder(BaseDecoder):
+ """Decoder module in `MASTER `_.
+
+ Code is partially modified from https://github.com/wenwenyu/MASTER-pytorch.
+
+ Args:
+ n_layers (int): Number of attention layers. Defaults to 3.
+ n_head (int): Number of parallel attention heads. Defaults to 8.
+ d_model (int): Dimension :math:`E` of the input from previous model.
+ Defaults to 512.
+ feat_size (int): The size of the input feature from previous model,
+ usually :math:`H * W`. Defaults to 6 * 40.
+ d_inner (int): Hidden dimension of feedforward layers.
+ Defaults to 2048.
+ attn_drop (float): Dropout rate of the attention layer. Defaults to 0.
+ ffn_drop (float): Dropout rate of the feedforward layer. Defaults to 0.
+ feat_pe_drop (float): Dropout rate of the feature positional encoding
+ layer. Defaults to 0.2.
+ dictionary (dict or :obj:`Dictionary`): The config for `Dictionary` or
+ the instance of `Dictionary`. Defaults to None.
+ module_loss (dict, optional): Config to build module_loss. Defaults
+ to None.
+ postprocessor (dict, optional): Config to build postprocessor.
+ Defaults to None.
+ max_seq_len (int): Maximum output sequence length :math:`T`. Defaults
+ to 30.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ """
+
+ def __init__(
+ self,
+ n_layers: int = 3,
+ n_head: int = 8,
+ d_model: int = 512,
+ feat_size: int = 6 * 40,
+ d_inner: int = 2048,
+ attn_drop: float = 0.,
+ ffn_drop: float = 0.,
+ feat_pe_drop: float = 0.2,
+ module_loss: Optional[Dict] = None,
+ postprocessor: Optional[Dict] = None,
+ dictionary: Optional[Union[Dict, Dictionary]] = None,
+ max_seq_len: int = 30,
+ init_cfg: Optional[Union[Dict, Sequence[Dict]]] = None,
+ ):
+ super().__init__(
+ module_loss=module_loss,
+ postprocessor=postprocessor,
+ dictionary=dictionary,
+ init_cfg=init_cfg,
+ max_seq_len=max_seq_len)
+ operation_order = ('norm', 'self_attn', 'norm', 'cross_attn', 'norm',
+ 'ffn')
+ decoder_layer = BaseTransformerLayer(
+ operation_order=operation_order,
+ attn_cfgs=dict(
+ type='MultiheadAttention',
+ embed_dims=d_model,
+ num_heads=n_head,
+ attn_drop=attn_drop,
+ dropout_layer=dict(type='Dropout', drop_prob=attn_drop),
+ ),
+ ffn_cfgs=dict(
+ type='FFN',
+ embed_dims=d_model,
+ feedforward_channels=d_inner,
+ ffn_drop=ffn_drop,
+ dropout_layer=dict(type='Dropout', drop_prob=ffn_drop),
+ ),
+ norm_cfg=dict(type='LN'),
+ batch_first=True,
+ )
+ self.decoder_layers = ModuleList(
+ [copy.deepcopy(decoder_layer) for _ in range(n_layers)])
+
+ self.cls = nn.Linear(d_model, self.dictionary.num_classes)
+
+ self.SOS = self.dictionary.start_idx
+ self.PAD = self.dictionary.padding_idx
+ self.max_seq_len = max_seq_len
+ self.feat_size = feat_size
+ self.n_head = n_head
+
+ self.embedding = Embeddings(
+ d_model=d_model, vocab=self.dictionary.num_classes)
+
+ # TODO:
+ self.positional_encoding = PositionalEncoding(
+ d_hid=d_model, n_position=self.max_seq_len + 1)
+ self.feat_positional_encoding = PositionalEncoding(
+ d_hid=d_model, n_position=self.feat_size, dropout=feat_pe_drop)
+ self.norm = nn.LayerNorm(d_model)
+ self.softmax = nn.Softmax(dim=-1)
+
+ def make_target_mask(self, tgt: torch.Tensor,
+ device: torch.device) -> torch.Tensor:
+ """Make target mask for self attention.
+
+ Args:
+ tgt (Tensor): Shape [N, l_tgt]
+ device (torch.device): Mask device.
+
+ Returns:
+ Tensor: Mask of shape [N * self.n_head, l_tgt, l_tgt]
+ """
+
+ trg_pad_mask = (tgt != self.PAD).unsqueeze(1).unsqueeze(3).bool()
+ tgt_len = tgt.size(1)
+ trg_sub_mask = torch.tril(
+ torch.ones((tgt_len, tgt_len), dtype=torch.bool, device=device))
+ tgt_mask = trg_pad_mask & trg_sub_mask
+
+ # inverse for mmcv's BaseTransformerLayer
+ tril_mask = tgt_mask.clone()
+ tgt_mask = tgt_mask.float().masked_fill_(tril_mask == 0, -1e9)
+ tgt_mask = tgt_mask.masked_fill_(tril_mask, 0)
+ tgt_mask = tgt_mask.repeat(1, self.n_head, 1, 1)
+ tgt_mask = tgt_mask.view(-1, tgt_len, tgt_len)
+ return tgt_mask
+
+ def decode(self, tgt_seq: torch.Tensor, feature: torch.Tensor,
+ src_mask: torch.BoolTensor,
+ tgt_mask: torch.BoolTensor) -> torch.Tensor:
+ """Decode the input sequence.
+
+ Args:
+ tgt_seq (Tensor): Target sequence of shape: math: `(N, T, C)`.
+ feature (Tensor): Input feature map from encoder of
+ shape: math: `(N, C, H, W)`
+ src_mask (BoolTensor): The source mask of shape: math: `(N, H*W)`.
+ tgt_mask (BoolTensor): The target mask of shape: math: `(N, T, T)`.
+
+ Return:
+ Tensor: The decoded sequence.
+ """
+ tgt_seq = self.embedding(tgt_seq)
+ x = self.positional_encoding(tgt_seq)
+ attn_masks = [tgt_mask, src_mask]
+ for layer in self.decoder_layers:
+ x = layer(
+ query=x, key=feature, value=feature, attn_masks=attn_masks)
+ x = self.norm(x)
+ return self.cls(x)
+
+ def forward_train(self,
+ feat: Optional[torch.Tensor] = None,
+ out_enc: torch.Tensor = None,
+ data_samples: Sequence[TextRecogDataSample] = None
+ ) -> torch.Tensor:
+ """Forward for training. Source mask will not be used here.
+
+ Args:
+ feat (Tensor, optional): Input feature map from backbone.
+ out_enc (Tensor): Unused.
+ data_samples (list[TextRecogDataSample]): Batch of
+ TextRecogDataSample, containing gt_text and valid_ratio
+ information.
+
+ Returns:
+ Tensor: The raw logit tensor. Shape :math:`(N, T, C)` where
+ :math:`C` is ``num_classes``.
+ """
+
+ # flatten 2D feature map
+ if len(feat.shape) > 3:
+ b, c, h, w = feat.shape
+ feat = feat.view(b, c, h * w)
+ feat = feat.permute((0, 2, 1))
+ feat = self.feat_positional_encoding(feat)
+
+ trg_seq = []
+ for target in data_samples:
+ trg_seq.append(target.gt_text.padded_indexes.to(feat.device))
+
+ trg_seq = torch.stack(trg_seq, dim=0)
+
+ src_mask = None
+ tgt_mask = self.make_target_mask(trg_seq, device=feat.device)
+ return self.decode(trg_seq, feat, src_mask, tgt_mask)
+
+ def forward_test(self,
+ feat: Optional[torch.Tensor] = None,
+ out_enc: torch.Tensor = None,
+ data_samples: Sequence[TextRecogDataSample] = None
+ ) -> torch.Tensor:
+ """Forward for testing.
+
+ Args:
+ feat (Tensor, optional): Input feature map from backbone.
+ out_enc (Tensor): Unused.
+ data_samples (list[TextRecogDataSample]): Unused.
+
+ Returns:
+ Tensor: Character probabilities. of shape
+ :math:`(N, self.max_seq_len, C)` where :math:`C` is
+ ``num_classes``.
+ """
+
+ # flatten 2D feature map
+ if len(feat.shape) > 3:
+ b, c, h, w = feat.shape
+ feat = feat.view(b, c, h * w)
+ feat = feat.permute((0, 2, 1))
+ feat = self.feat_positional_encoding(feat)
+
+ N = feat.shape[0]
+ input = torch.full((N, 1),
+ self.SOS,
+ device=feat.device,
+ dtype=torch.long)
+ output = None
+ for _ in range(self.max_seq_len):
+ target_mask = self.make_target_mask(input, device=feat.device)
+ out = self.decode(input, feat, None, target_mask)
+ output = out
+ _, next_word = torch.max(out, dim=-1)
+ input = torch.cat([input, next_word[:, -1].unsqueeze(-1)], dim=1)
+ return self.softmax(output)
diff --git a/mmocr/models/textrecog/decoders/nrtr_decoder.py b/mmocr/models/textrecog/decoders/nrtr_decoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..dc986c48807e696b2001d3d91ae33a0312ae9044
--- /dev/null
+++ b/mmocr/models/textrecog/decoders/nrtr_decoder.py
@@ -0,0 +1,257 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from typing import Dict, List, Optional, Sequence, Union
+
+import torch
+import torch.nn as nn
+from mmengine.model import ModuleList
+
+from mmocr.models.common import PositionalEncoding, TFDecoderLayer
+from mmocr.models.common.dictionary import Dictionary
+from mmocr.registry import MODELS
+from mmocr.structures import TextRecogDataSample
+from .base import BaseDecoder
+
+
+@MODELS.register_module()
+class NRTRDecoder(BaseDecoder):
+ """Transformer Decoder block with self attention mechanism.
+
+ Args:
+ n_layers (int): Number of attention layers. Defaults to 6.
+ d_embedding (int): Language embedding dimension. Defaults to 512.
+ n_head (int): Number of parallel attention heads. Defaults to 8.
+ d_k (int): Dimension of the key vector. Defaults to 64.
+ d_v (int): Dimension of the value vector. Defaults to 64
+ d_model (int): Dimension :math:`D_m` of the input from previous model.
+ Defaults to 512.
+ d_inner (int): Hidden dimension of feedforward layers. Defaults to 256.
+ n_position (int): Length of the positional encoding vector. Must be
+ greater than ``max_seq_len``. Defaults to 200.
+ dropout (float): Dropout rate for text embedding, MHSA, FFN. Defaults
+ to 0.1.
+ module_loss (dict, optional): Config to build module_loss. Defaults
+ to None.
+ postprocessor (dict, optional): Config to build postprocessor.
+ Defaults to None.
+ dictionary (dict or :obj:`Dictionary`): The config for `Dictionary` or
+ the instance of `Dictionary`.
+ max_seq_len (int): Maximum output sequence length :math:`T`. Defaults
+ to 30.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ """
+
+ def __init__(self,
+ n_layers: int = 6,
+ d_embedding: int = 512,
+ n_head: int = 8,
+ d_k: int = 64,
+ d_v: int = 64,
+ d_model: int = 512,
+ d_inner: int = 256,
+ n_position: int = 200,
+ dropout: float = 0.1,
+ module_loss: Optional[Dict] = None,
+ postprocessor: Optional[Dict] = None,
+ dictionary: Optional[Union[Dict, Dictionary]] = None,
+ max_seq_len: int = 30,
+ init_cfg: Optional[Union[Dict, List[Dict]]] = None) -> None:
+ super().__init__(
+ module_loss=module_loss,
+ postprocessor=postprocessor,
+ dictionary=dictionary,
+ init_cfg=init_cfg,
+ max_seq_len=max_seq_len)
+
+ self.padding_idx = self.dictionary.padding_idx
+ self.start_idx = self.dictionary.start_idx
+ self.max_seq_len = max_seq_len
+
+ self.trg_word_emb = nn.Embedding(
+ self.dictionary.num_classes,
+ d_embedding,
+ padding_idx=self.padding_idx)
+
+ self.position_enc = PositionalEncoding(
+ d_embedding, n_position=n_position)
+ self.dropout = nn.Dropout(p=dropout)
+
+ self.layer_stack = ModuleList([
+ TFDecoderLayer(
+ d_model, d_inner, n_head, d_k, d_v, dropout=dropout)
+ for _ in range(n_layers)
+ ])
+ self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
+
+ pred_num_class = self.dictionary.num_classes
+ self.classifier = nn.Linear(d_model, pred_num_class)
+ self.softmax = nn.Softmax(dim=-1)
+
+ def _get_target_mask(self, trg_seq: torch.Tensor) -> torch.Tensor:
+ """Generate mask for target sequence.
+
+ Args:
+ trg_seq (torch.Tensor): Input text sequence. Shape :math:`(N, T)`.
+
+ Returns:
+ Tensor: Target mask. Shape :math:`(N, T, T)`.
+ E.g.:
+ seq = torch.Tensor([[1, 2, 0, 0]]), pad_idx = 0, then
+ target_mask =
+ torch.Tensor([[[True, False, False, False],
+ [True, True, False, False],
+ [True, True, False, False],
+ [True, True, False, False]]])
+ """
+
+ pad_mask = (trg_seq != self.padding_idx).unsqueeze(-2)
+
+ len_s = trg_seq.size(1)
+ subsequent_mask = 1 - torch.triu(
+ torch.ones((len_s, len_s), device=trg_seq.device), diagonal=1)
+ subsequent_mask = subsequent_mask.unsqueeze(0).bool()
+
+ return pad_mask & subsequent_mask
+
+ def _get_source_mask(self, src_seq: torch.Tensor,
+ valid_ratios: Sequence[float]) -> torch.Tensor:
+ """Generate mask for source sequence.
+
+ Args:
+ src_seq (torch.Tensor): Image sequence. Shape :math:`(N, T, C)`.
+ valid_ratios (list[float]): The valid ratio of input image. For
+ example, if the width of the original image is w1 and the width
+ after padding is w2, then valid_ratio = w1/w2. Source mask is
+ used to cover the area of the padding region.
+
+ Returns:
+ Tensor or None: Source mask. Shape :math:`(N, T)`. The region of
+ padding area are False, and the rest are True.
+ """
+
+ N, T, _ = src_seq.size()
+ mask = None
+ if len(valid_ratios) > 0:
+ mask = src_seq.new_zeros((N, T), device=src_seq.device)
+ for i, valid_ratio in enumerate(valid_ratios):
+ valid_width = min(T, math.ceil(T * valid_ratio))
+ mask[i, :valid_width] = 1
+
+ return mask
+
+ def _attention(self,
+ trg_seq: torch.Tensor,
+ src: torch.Tensor,
+ src_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
+ """A wrapped process for transformer based decoder including text
+ embedding, position embedding, N x transformer decoder and a LayerNorm
+ operation.
+
+ Args:
+ trg_seq (Tensor): Target sequence in. Shape :math:`(N, T)`.
+ src (Tensor): Source sequence from encoder in shape
+ Shape :math:`(N, T, D_m)` where :math:`D_m` is ``d_model``.
+ src_mask (Tensor, Optional): Mask for source sequence.
+ Shape :math:`(N, T)`. Defaults to None.
+
+ Returns:
+ Tensor: Output sequence from transformer decoder.
+ Shape :math:`(N, T, D_m)` where :math:`D_m` is ``d_model``.
+ """
+
+ trg_embedding = self.trg_word_emb(trg_seq)
+ trg_pos_encoded = self.position_enc(trg_embedding)
+ trg_mask = self._get_target_mask(trg_seq)
+ tgt_seq = self.dropout(trg_pos_encoded)
+
+ output = tgt_seq
+ for dec_layer in self.layer_stack:
+ output = dec_layer(
+ output,
+ src,
+ self_attn_mask=trg_mask,
+ dec_enc_attn_mask=src_mask)
+ output = self.layer_norm(output)
+
+ return output
+
+ def forward_train(self,
+ feat: Optional[torch.Tensor] = None,
+ out_enc: torch.Tensor = None,
+ data_samples: Sequence[TextRecogDataSample] = None
+ ) -> torch.Tensor:
+ """Forward for training. Source mask will be used here.
+
+ Args:
+ feat (Tensor, optional): Unused.
+ out_enc (Tensor): Encoder output of shape : math:`(N, T, D_m)`
+ where :math:`D_m` is ``d_model``. Defaults to None.
+ data_samples (list[TextRecogDataSample]): Batch of
+ TextRecogDataSample, containing gt_text and valid_ratio
+ information. Defaults to None.
+
+ Returns:
+ Tensor: The raw logit tensor. Shape :math:`(N, T, C)` where
+ :math:`C` is ``num_classes``.
+ """
+ valid_ratios = []
+ for data_sample in data_samples:
+ valid_ratios.append(data_sample.get('valid_ratio'))
+ src_mask = self._get_source_mask(out_enc, valid_ratios)
+ trg_seq = []
+ for data_sample in data_samples:
+ trg_seq.append(
+ data_sample.gt_text.padded_indexes.to(out_enc.device))
+ trg_seq = torch.stack(trg_seq, dim=0)
+ attn_output = self._attention(trg_seq, out_enc, src_mask=src_mask)
+ outputs = self.classifier(attn_output)
+
+ return outputs
+
+ def forward_test(self,
+ feat: Optional[torch.Tensor] = None,
+ out_enc: torch.Tensor = None,
+ data_samples: Sequence[TextRecogDataSample] = None
+ ) -> torch.Tensor:
+ """Forward for testing.
+
+ Args:
+ feat (Tensor, optional): Unused.
+ out_enc (Tensor): Encoder output of shape:
+ math:`(N, T, D_m)` where :math:`D_m` is ``d_model``.
+ Defaults to None.
+ data_samples (list[TextRecogDataSample]): Batch of
+ TextRecogDataSample, containing gt_text and valid_ratio
+ information. Defaults to None.
+
+ Returns:
+ Tensor: Character probabilities. of shape
+ :math:`(N, self.max_seq_len, C)` where :math:`C` is
+ ``num_classes``.
+ """
+ valid_ratios = []
+ for data_sample in data_samples:
+ valid_ratios.append(data_sample.get('valid_ratio'))
+ src_mask = self._get_source_mask(out_enc, valid_ratios)
+ N = out_enc.size(0)
+ init_target_seq = torch.full((N, self.max_seq_len + 1),
+ self.padding_idx,
+ device=out_enc.device,
+ dtype=torch.long)
+ # bsz * seq_len
+ init_target_seq[:, 0] = self.start_idx
+
+ outputs = []
+ for step in range(0, self.max_seq_len):
+ decoder_output = self._attention(
+ init_target_seq, out_enc, src_mask=src_mask)
+ # bsz * seq_len * C
+ step_result = self.classifier(decoder_output[:, step, :])
+ # bsz * num_classes
+ outputs.append(step_result)
+ _, step_max_index = torch.max(step_result, dim=-1)
+ init_target_seq[:, step + 1] = step_max_index
+
+ outputs = torch.stack(outputs, dim=1)
+
+ return self.softmax(outputs)
diff --git a/mmocr/models/textrecog/decoders/position_attention_decoder.py b/mmocr/models/textrecog/decoders/position_attention_decoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..7543c2b199814143fab916d811cc419c1163274a
--- /dev/null
+++ b/mmocr/models/textrecog/decoders/position_attention_decoder.py
@@ -0,0 +1,220 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from typing import Dict, Optional, Sequence, Union
+
+import torch
+import torch.nn as nn
+
+from mmocr.models.common.dictionary import Dictionary
+from mmocr.models.textrecog.layers import (DotProductAttentionLayer,
+ PositionAwareLayer)
+from mmocr.registry import MODELS
+from mmocr.structures import TextRecogDataSample
+from .base import BaseDecoder
+
+
+@MODELS.register_module()
+class PositionAttentionDecoder(BaseDecoder):
+ """Position attention decoder for RobustScanner.
+
+ RobustScanner: `RobustScanner: Dynamically Enhancing Positional Clues for
+ Robust Text Recognition `_
+
+ Args:
+ dictionary (dict or :obj:`Dictionary`): The config for `Dictionary` or
+ the instance of `Dictionary`.
+ module_loss (dict, optional): Config to build module_loss. Defaults
+ to None.
+ postprocessor (dict, optional): Config to build postprocessor.
+ Defaults to None.
+ rnn_layers (int): Number of RNN layers. Defaults to 2.
+ dim_input (int): Dimension :math:`D_i` of input vector ``feat``.
+ Defaults to 512.
+ dim_model (int): Dimension :math:`D_m` of the model. Should also be the
+ same as encoder output vector ``out_enc``. Defaults to 128.
+ max_seq_len (int): Maximum output sequence length :math:`T`. Defaults
+ to 40.
+ mask (bool): Whether to mask input features according to
+ ``img_meta['valid_ratio']``. Defaults to True.
+ return_feature (bool): Return feature or logits as the result. Defaults
+ to True.
+ encode_value (bool): Whether to use the output of encoder ``out_enc``
+ as `value` of attention layer. If False, the original feature
+ ``feat`` will be used. Defaults to False.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ dictionary: Union[Dictionary, Dict],
+ module_loss: Optional[Dict] = None,
+ postprocessor: Optional[Dict] = None,
+ rnn_layers: int = 2,
+ dim_input: int = 512,
+ dim_model: int = 128,
+ max_seq_len: int = 40,
+ mask: bool = True,
+ return_feature: bool = True,
+ encode_value: bool = False,
+ init_cfg: Optional[Union[Dict,
+ Sequence[Dict]]] = None) -> None:
+ super().__init__(
+ dictionary=dictionary,
+ module_loss=module_loss,
+ postprocessor=postprocessor,
+ max_seq_len=max_seq_len,
+ init_cfg=init_cfg)
+
+ self.dim_input = dim_input
+ self.dim_model = dim_model
+ self.return_feature = return_feature
+ self.encode_value = encode_value
+ self.mask = mask
+
+ self.embedding = nn.Embedding(self.max_seq_len + 1, self.dim_model)
+
+ self.position_aware_module = PositionAwareLayer(
+ self.dim_model, rnn_layers)
+
+ self.attention_layer = DotProductAttentionLayer()
+
+ self.prediction = None
+ if not self.return_feature:
+ self.prediction = nn.Linear(
+ dim_model if encode_value else dim_input,
+ self.dictionary.num_classes)
+ self.softmax = nn.Softmax(dim=-1)
+
+ def _get_position_index(self,
+ length: int,
+ batch_size: int,
+ device: Optional[torch.device] = None
+ ) -> torch.Tensor:
+ """Get position index for position attention.
+
+ Args:
+ length (int): Length of the sequence.
+ batch_size (int): Batch size.
+ device (torch.device, optional): Device. Defaults to None.
+
+ Returns:
+ torch.Tensor: Position index.
+ """
+ position_index = torch.arange(0, length, device=device)
+ position_index = position_index.repeat([batch_size, 1])
+ position_index = position_index.long()
+ return position_index
+
+ def forward_train(self, feat: torch.Tensor, out_enc: torch.Tensor,
+ data_samples: Sequence[TextRecogDataSample]
+ ) -> torch.Tensor:
+ """
+ Args:
+ feat (Tensor): Tensor of shape :math:`(N, D_i, H, W)`.
+ out_enc (Tensor): Encoder output of shape
+ :math:`(N, D_m, H, W)`.
+ data_samples (list[TextRecogDataSample], optional): Batch of
+ TextRecogDataSample, containing gt_text information. Defaults
+ to None.
+
+ Returns:
+ Tensor: A raw logit tensor of shape :math:`(N, T, C)` if
+ ``return_feature=False``. Otherwise it will be the hidden feature
+ before the prediction projection layer, whose shape is
+ :math:`(N, T, D_m)`.
+ """
+ valid_ratios = [
+ data_sample.get('valid_ratio', 1.0) for data_sample in data_samples
+ ] if self.mask else None
+
+ #
+ n, c_enc, h, w = out_enc.size()
+ assert c_enc == self.dim_model
+ _, c_feat, _, _ = feat.size()
+ assert c_feat == self.dim_input
+ position_index = self._get_position_index(self.max_seq_len, n,
+ feat.device)
+
+ position_out_enc = self.position_aware_module(out_enc)
+
+ query = self.embedding(position_index)
+ query = query.permute(0, 2, 1).contiguous()
+ key = position_out_enc.view(n, c_enc, h * w)
+ if self.encode_value:
+ value = out_enc.view(n, c_enc, h * w)
+ else:
+ value = feat.view(n, c_feat, h * w)
+
+ mask = None
+ if valid_ratios is not None:
+ mask = query.new_zeros((n, h, w))
+ for i, valid_ratio in enumerate(valid_ratios):
+ valid_width = min(w, math.ceil(w * valid_ratio))
+ mask[i, :, valid_width:] = 1
+ mask = mask.bool()
+ mask = mask.view(n, h * w)
+
+ attn_out = self.attention_layer(query, key, value, mask)
+ attn_out = attn_out.permute(0, 2,
+ 1).contiguous() # [n, max_seq_len, dim_v]
+
+ if self.return_feature:
+ return attn_out
+
+ return self.prediction(attn_out)
+
+ def forward_test(self, feat: torch.Tensor, out_enc: torch.Tensor,
+ img_metas: Sequence[TextRecogDataSample]) -> torch.Tensor:
+ """
+ Args:
+ feat (Tensor): Tensor of shape :math:`(N, D_i, H, W)`.
+ out_enc (Tensor): Encoder output of shape
+ :math:`(N, D_m, H, W)`.
+ data_samples (list[TextRecogDataSample], optional): Batch of
+ TextRecogDataSample, containing gt_text information. Defaults
+ to None.
+
+ Returns:
+ Tensor: Character probabilities of shape :math:`(N, T, C)` if
+ ``return_feature=False``. Otherwise it would be the hidden feature
+ before the prediction projection layer, whose shape is
+ :math:`(N, T, D_m)`.
+ """
+ valid_ratios = [
+ img_meta.get('valid_ratio', 1.0) for img_meta in img_metas
+ ] if self.mask else None
+
+ seq_len = self.max_seq_len
+ n, c_enc, h, w = out_enc.size()
+ assert c_enc == self.dim_model
+ _, c_feat, _, _ = feat.size()
+ assert c_feat == self.dim_input
+
+ position_index = self._get_position_index(seq_len, n, feat.device)
+
+ position_out_enc = self.position_aware_module(out_enc)
+
+ query = self.embedding(position_index)
+ query = query.permute(0, 2, 1).contiguous()
+ key = position_out_enc.view(n, c_enc, h * w)
+ if self.encode_value:
+ value = out_enc.view(n, c_enc, h * w)
+ else:
+ value = feat.view(n, c_feat, h * w)
+
+ mask = None
+ if valid_ratios is not None:
+ mask = query.new_zeros((n, h, w))
+ for i, valid_ratio in enumerate(valid_ratios):
+ valid_width = min(w, math.ceil(w * valid_ratio))
+ mask[i, :, valid_width:] = 1
+ mask = mask.bool()
+ mask = mask.view(n, h * w)
+
+ attn_out = self.attention_layer(query, key, value, mask)
+ attn_out = attn_out.permute(0, 2, 1).contiguous()
+
+ if self.return_feature:
+ return attn_out
+
+ return self.softmax(self.prediction(attn_out))
diff --git a/mmocr/models/textrecog/decoders/robust_scanner_fuser.py b/mmocr/models/textrecog/decoders/robust_scanner_fuser.py
new file mode 100644
index 0000000000000000000000000000000000000000..be954e53fcfd13af59395ea911cb91f67c378c3f
--- /dev/null
+++ b/mmocr/models/textrecog/decoders/robust_scanner_fuser.py
@@ -0,0 +1,146 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from typing import Dict, List, Optional, Sequence, Union
+
+import torch
+import torch.nn as nn
+
+from mmocr.models.common.dictionary import Dictionary
+from mmocr.registry import MODELS
+from mmocr.structures import TextRecogDataSample
+from .base import BaseDecoder
+
+
+@MODELS.register_module()
+class RobustScannerFuser(BaseDecoder):
+ """Decoder for RobustScanner.
+
+ Args:
+ dictionary (dict or :obj:`Dictionary`): The config for `Dictionary` or
+ the instance of `Dictionary`.
+ module_loss (dict, optional): Config to build module_loss. Defaults
+ to None.
+ postprocessor (dict, optional): Config to build postprocessor.
+ Defaults to None.
+ hybrid_decoder (dict): Config to build hybrid_decoder. Defaults to
+ dict(type='SequenceAttentionDecoder').
+ position_decoder (dict): Config to build position_decoder. Defaults to
+ dict(type='PositionAttentionDecoder').
+ fuser (dict): Config to build fuser. Defaults to
+ dict(type='RobustScannerFuser').
+ max_seq_len (int): Maximum sequence length. The
+ sequence is usually generated from decoder. Defaults to 30.
+ in_channels (list[int]): List of input channels.
+ Defaults to [512, 512].
+ dim (int): The dimension on which to split the input. Defaults to -1.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ dictionary: Union[Dict, Dictionary],
+ module_loss: Optional[Dict] = None,
+ postprocessor: Optional[Dict] = None,
+ hybrid_decoder: Dict = dict(type='SequenceAttentionDecoder'),
+ position_decoder: Dict = dict(
+ type='PositionAttentionDecoder'),
+ max_seq_len: int = 30,
+ in_channels: List[int] = [512, 512],
+ dim: int = -1,
+ init_cfg: Optional[Union[Dict, List[Dict]]] = None) -> None:
+ super().__init__(
+ dictionary=dictionary,
+ module_loss=module_loss,
+ postprocessor=postprocessor,
+ max_seq_len=max_seq_len,
+ init_cfg=init_cfg)
+
+ for cfg_name in ['hybrid_decoder', 'position_decoder']:
+ cfg = eval(cfg_name)
+ if cfg is not None:
+ if cfg.get('dictionary', None) is None:
+ cfg.update(dictionary=self.dictionary)
+ else:
+ warnings.warn(f"Using dictionary {cfg['dictionary']} "
+ "in decoder's config.")
+ if cfg.get('max_seq_len', None) is None:
+ cfg.update(max_seq_len=max_seq_len)
+ else:
+ warnings.warn(f"Using max_seq_len {cfg['max_seq_len']} "
+ "in decoder's config.")
+ setattr(self, cfg_name, MODELS.build(cfg))
+
+ in_channels = sum(in_channels)
+ self.dim = dim
+
+ self.linear_layer = nn.Linear(in_channels, in_channels)
+ self.glu_layer = nn.GLU(dim=dim)
+ self.prediction = nn.Linear(
+ int(in_channels / 2), self.dictionary.num_classes)
+ self.softmax = nn.Softmax(dim=-1)
+
+ def forward_train(
+ self,
+ feat: Optional[torch.Tensor] = None,
+ out_enc: Optional[torch.Tensor] = None,
+ data_samples: Optional[Sequence[TextRecogDataSample]] = None
+ ) -> torch.Tensor:
+ """Forward for training.
+
+ Args:
+ feat (torch.Tensor, optional): The feature map from backbone of
+ shape :math:`(N, E, H, W)`. Defaults to None.
+ out_enc (torch.Tensor, optional): Encoder output. Defaults to None.
+ data_samples (Sequence[TextRecogDataSample]): Batch of
+ TextRecogDataSample, containing gt_text information. Defaults
+ to None.
+ """
+ hybrid_glimpse = self.hybrid_decoder(feat, out_enc, data_samples)
+ position_glimpse = self.position_decoder(feat, out_enc, data_samples)
+ fusion_input = torch.cat([hybrid_glimpse, position_glimpse], self.dim)
+ outputs = self.linear_layer(fusion_input)
+ outputs = self.glu_layer(outputs)
+ return self.prediction(outputs)
+
+ def forward_test(
+ self,
+ feat: Optional[torch.Tensor] = None,
+ out_enc: Optional[torch.Tensor] = None,
+ data_samples: Optional[Sequence[TextRecogDataSample]] = None
+ ) -> torch.Tensor:
+ """Forward for testing.
+
+ Args:
+ feat (torch.Tensor, optional): The feature map from backbone of
+ shape :math:`(N, E, H, W)`. Defaults to None.
+ out_enc (torch.Tensor, optional): Encoder output. Defaults to None.
+ data_samples (Sequence[TextRecogDataSample]): Batch of
+ TextRecogDataSample, containing vaild_ratio information.
+ Defaults to None.
+
+ Returns:
+ Tensor: Character probabilities. of shape
+ :math:`(N, self.max_seq_len, C)` where :math:`C` is
+ ``num_classes``.
+ """
+ position_glimpse = self.position_decoder(feat, out_enc, data_samples)
+
+ batch_size = feat.size(0)
+ decode_sequence = (feat.new_ones((batch_size, self.max_seq_len)) *
+ self.dictionary.start_idx).long()
+ outputs = []
+ for step in range(self.max_seq_len):
+ hybrid_glimpse_step = self.hybrid_decoder.forward_test_step(
+ feat, out_enc, decode_sequence, step, data_samples)
+
+ fusion_input = torch.cat(
+ [hybrid_glimpse_step, position_glimpse[:, step, :]], self.dim)
+ output = self.linear_layer(fusion_input)
+ output = self.glu_layer(output)
+ output = self.prediction(output)
+ _, max_idx = torch.max(output, dim=1, keepdim=False)
+ if step < self.max_seq_len - 1:
+ decode_sequence[:, step + 1] = max_idx
+ outputs.append(output)
+ outputs = torch.stack(outputs, 1)
+ return self.softmax(outputs)
diff --git a/mmocr/models/textrecog/decoders/sar_decoder.py b/mmocr/models/textrecog/decoders/sar_decoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..d156c30fd144a5256965c7bc376ab5645c925792
--- /dev/null
+++ b/mmocr/models/textrecog/decoders/sar_decoder.py
@@ -0,0 +1,574 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from typing import Dict, List, Optional, Sequence, Union
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from mmocr.models.common.dictionary import Dictionary
+from mmocr.registry import MODELS
+from mmocr.structures import TextRecogDataSample
+from .base import BaseDecoder
+
+
+@MODELS.register_module()
+class ParallelSARDecoder(BaseDecoder):
+ """Implementation Parallel Decoder module in `SAR.
+
+ `_.
+
+ Args:
+ dictionary (dict or :obj:`Dictionary`): The config for `Dictionary` or
+ the instance of `Dictionary`.
+ module_loss (dict, optional): Config to build module_loss. Defaults
+ to None.
+ postprocessor (dict, optional): Config to build postprocessor.
+ Defaults to None.
+ enc_bi_rnn (bool): If True, use bidirectional RNN in encoder.
+ Defaults to False.
+ dec_bi_rnn (bool): If True, use bidirectional RNN in decoder.
+ Defaults to False.
+ dec_rnn_dropout (float): Dropout of RNN layer in decoder.
+ Defaults to 0.0.
+ dec_gru (bool): If True, use GRU, else LSTM in decoder. Defaults to
+ False.
+ d_model (int): Dim of channels from backbone :math:`D_i`. Defaults
+ to 512.
+ d_enc (int): Dim of encoder RNN layer :math:`D_m`. Defaults to 512.
+ d_k (int): Dim of channels of attention module. Defaults to 64.
+ pred_dropout (float): Dropout probability of prediction layer. Defaults
+ to 0.0.
+ max_seq_len (int): Maximum sequence length for decoding. Defaults to
+ 30.
+ mask (bool): If True, mask padding in feature map. Defaults to True.
+ pred_concat (bool): If True, concat glimpse feature from
+ attention with holistic feature and hidden state. Defaults to
+ False.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ dictionary: Union[Dict, Dictionary],
+ module_loss: Optional[Dict] = None,
+ postprocessor: Optional[Dict] = None,
+ enc_bi_rnn: bool = False,
+ dec_bi_rnn: bool = False,
+ dec_rnn_dropout: Union[int, float] = 0.0,
+ dec_gru: bool = False,
+ d_model: int = 512,
+ d_enc: int = 512,
+ d_k: int = 64,
+ pred_dropout: float = 0.0,
+ max_seq_len: int = 30,
+ mask: bool = True,
+ pred_concat: bool = False,
+ init_cfg: Optional[Union[Dict, List[Dict]]] = None,
+ **kwargs) -> None:
+ super().__init__(
+ dictionary=dictionary,
+ module_loss=module_loss,
+ max_seq_len=max_seq_len,
+ postprocessor=postprocessor,
+ init_cfg=init_cfg)
+
+ self.num_classes = self.dictionary.num_classes
+ self.enc_bi_rnn = enc_bi_rnn
+ self.d_k = d_k
+ self.start_idx = self.dictionary.start_idx
+ self.mask = mask
+ self.pred_concat = pred_concat
+
+ encoder_rnn_out_size = d_enc * (int(enc_bi_rnn) + 1)
+ decoder_rnn_out_size = encoder_rnn_out_size * (int(dec_bi_rnn) + 1)
+ # 2D attention layer
+ self.conv1x1_1 = nn.Linear(decoder_rnn_out_size, d_k)
+ self.conv3x3_1 = nn.Conv2d(
+ d_model, d_k, kernel_size=3, stride=1, padding=1)
+ self.conv1x1_2 = nn.Linear(d_k, 1)
+
+ # Decoder RNN layer
+ kwargs = dict(
+ input_size=encoder_rnn_out_size,
+ hidden_size=encoder_rnn_out_size,
+ num_layers=2,
+ batch_first=True,
+ dropout=dec_rnn_dropout,
+ bidirectional=dec_bi_rnn)
+ if dec_gru:
+ self.rnn_decoder = nn.GRU(**kwargs)
+ else:
+ self.rnn_decoder = nn.LSTM(**kwargs)
+
+ # Decoder input embedding
+ self.embedding = nn.Embedding(
+ self.num_classes,
+ encoder_rnn_out_size,
+ padding_idx=self.dictionary.padding_idx)
+
+ # Prediction layer
+ self.pred_dropout = nn.Dropout(pred_dropout)
+ if pred_concat:
+ fc_in_channel = decoder_rnn_out_size + d_model + \
+ encoder_rnn_out_size
+ else:
+ fc_in_channel = d_model
+ self.prediction = nn.Linear(fc_in_channel, self.num_classes)
+ self.softmax = nn.Softmax(dim=-1)
+
+ def _2d_attention(self,
+ decoder_input: torch.Tensor,
+ feat: torch.Tensor,
+ holistic_feat: torch.Tensor,
+ valid_ratios: Optional[Sequence[float]] = None
+ ) -> torch.Tensor:
+ """2D attention layer.
+
+ Args:
+ decoder_input (torch.Tensor): Input of decoder RNN.
+ feat (torch.Tensor): Feature map of encoder.
+ holistic_feat (torch.Tensor): Feature map of holistic encoder.
+ valid_ratios (Sequence[float]): Valid ratios of attention.
+ Defaults to None.
+
+ Returns:
+ torch.Tensor: Output of 2D attention layer.
+ """
+ y = self.rnn_decoder(decoder_input)[0]
+ # y: bsz * (seq_len + 1) * hidden_size
+
+ attn_query = self.conv1x1_1(y) # bsz * (seq_len + 1) * attn_size
+ bsz, seq_len, attn_size = attn_query.size()
+ attn_query = attn_query.view(bsz, seq_len, attn_size, 1, 1)
+
+ attn_key = self.conv3x3_1(feat)
+ # bsz * attn_size * h * w
+ attn_key = attn_key.unsqueeze(1)
+ # bsz * 1 * attn_size * h * w
+
+ attn_weight = torch.tanh(torch.add(attn_key, attn_query, alpha=1))
+ # bsz * (seq_len + 1) * attn_size * h * w
+ attn_weight = attn_weight.permute(0, 1, 3, 4, 2).contiguous()
+ # bsz * (seq_len + 1) * h * w * attn_size
+ attn_weight = self.conv1x1_2(attn_weight)
+ # bsz * (seq_len + 1) * h * w * 1
+ bsz, T, h, w, c = attn_weight.size()
+ assert c == 1
+
+ if valid_ratios is not None:
+ # cal mask of attention weight
+ attn_mask = torch.zeros_like(attn_weight)
+ for i, valid_ratio in enumerate(valid_ratios):
+ valid_width = min(w, math.ceil(w * valid_ratio))
+ attn_mask[i, :, :, valid_width:, :] = 1
+ attn_weight = attn_weight.masked_fill(attn_mask.bool(),
+ float('-inf'))
+
+ attn_weight = attn_weight.view(bsz, T, -1)
+ attn_weight = F.softmax(attn_weight, dim=-1)
+ attn_weight = attn_weight.view(bsz, T, h, w,
+ c).permute(0, 1, 4, 2, 3).contiguous()
+
+ attn_feat = torch.sum(
+ torch.mul(feat.unsqueeze(1), attn_weight), (3, 4), keepdim=False)
+ # bsz * (seq_len + 1) * C
+
+ # linear transformation
+ if self.pred_concat:
+ hf_c = holistic_feat.size(-1)
+ holistic_feat = holistic_feat.expand(bsz, seq_len, hf_c)
+ y = self.prediction(torch.cat((y, attn_feat, holistic_feat), 2))
+ else:
+ y = self.prediction(attn_feat)
+ # bsz * (seq_len + 1) * num_classes
+ y = self.pred_dropout(y)
+
+ return y
+
+ def forward_train(self, feat: torch.Tensor, out_enc: torch.Tensor,
+ data_samples: Sequence[TextRecogDataSample]
+ ) -> torch.Tensor:
+ """
+ Args:
+ feat (Tensor): Tensor of shape :math:`(N, D_i, H, W)`.
+ out_enc (Tensor): Encoder output of shape
+ :math:`(N, D_m, H, W)`.
+ data_samples (list[TextRecogDataSample]): Batch of
+ TextRecogDataSample, containing gt_text and valid_ratio
+ information.
+
+ Returns:
+ Tensor: A raw logit tensor of shape :math:`(N, T, C)`.
+ """
+ if data_samples is not None:
+ assert len(data_samples) == feat.size(0)
+
+ valid_ratios = [
+ img_meta.get('valid_ratio', 1.0) for img_meta in data_samples
+ ] if self.mask else None
+
+ padded_targets = [
+ data_sample.gt_text.padded_indexes for data_sample in data_samples
+ ]
+ padded_targets = torch.stack(padded_targets, dim=0).to(feat.device)
+ tgt_embedding = self.embedding(padded_targets)
+ # bsz * seq_len * emb_dim
+ out_enc = out_enc.unsqueeze(1)
+ # bsz * 1 * emb_dim
+ in_dec = torch.cat((out_enc, tgt_embedding), dim=1)
+ # bsz * (seq_len + 1) * C
+ out_dec = self._2d_attention(
+ in_dec, feat, out_enc, valid_ratios=valid_ratios)
+ # bsz * (seq_len + 1) * num_classes
+
+ return out_dec[:, 1:, :] # bsz * seq_len * num_classes
+
+ def forward_test(
+ self,
+ feat: torch.Tensor,
+ out_enc: torch.Tensor,
+ data_samples: Optional[Sequence[TextRecogDataSample]] = None
+ ) -> torch.Tensor:
+ """
+ Args:
+ feat (Tensor): Tensor of shape :math:`(N, D_i, H, W)`.
+ out_enc (Tensor): Encoder output of shape
+ :math:`(N, D_m, H, W)`.
+ data_samples (list[TextRecogDataSample], optional): Batch of
+ TextRecogDataSample, containing valid_ratio
+ information. Defaults to None.
+
+ Returns:
+ Tensor: Character probabilities. of shape
+ :math:`(N, self.max_seq_len, C)` where :math:`C` is
+ ``num_classes``.
+ """
+ if data_samples is not None:
+ assert len(data_samples) == feat.size(0)
+
+ valid_ratios = None
+ if data_samples is not None:
+ valid_ratios = [
+ data_sample.get('valid_ratio', 1.0)
+ for data_sample in data_samples
+ ] if self.mask else None
+
+ seq_len = self.max_seq_len
+
+ bsz = feat.size(0)
+ start_token = torch.full((bsz, ),
+ self.start_idx,
+ device=feat.device,
+ dtype=torch.long)
+ # bsz
+ start_token = self.embedding(start_token)
+ # bsz * emb_dim
+ start_token = start_token.unsqueeze(1).expand(-1, seq_len, -1)
+ # bsz * seq_len * emb_dim
+ out_enc = out_enc.unsqueeze(1)
+ # bsz * 1 * emb_dim
+ decoder_input = torch.cat((out_enc, start_token), dim=1)
+ # bsz * (seq_len + 1) * emb_dim
+
+ outputs = []
+ for i in range(1, seq_len + 1):
+ decoder_output = self._2d_attention(
+ decoder_input, feat, out_enc, valid_ratios=valid_ratios)
+ char_output = decoder_output[:, i, :] # bsz * num_classes
+ outputs.append(char_output)
+ _, max_idx = torch.max(char_output, dim=1, keepdim=False)
+ char_embedding = self.embedding(max_idx) # bsz * emb_dim
+ if i < seq_len:
+ decoder_input[:, i + 1, :] = char_embedding
+
+ outputs = torch.stack(outputs, 1) # bsz * seq_len * num_classes
+
+ return self.softmax(outputs)
+
+
+@MODELS.register_module()
+class SequentialSARDecoder(BaseDecoder):
+ """Implementation Sequential Decoder module in `SAR.
+
+ `_.
+
+ Args:
+ dictionary (dict or :obj:`Dictionary`): The config for `Dictionary` or
+ the instance of `Dictionary`.
+ module_loss (dict, optional): Config to build module_loss. Defaults
+ to None.
+ postprocessor (dict, optional): Config to build postprocessor.
+ Defaults to None.
+ enc_bi_rnn (bool): If True, use bidirectional RNN in encoder. Defaults
+ to False.
+ dec_bi_rnn (bool): If True, use bidirectional RNN in decoder. Defaults
+ to False.
+ dec_do_rnn (float): Dropout of RNN layer in decoder. Defaults to 0.
+ dec_gru (bool): If True, use GRU, else LSTM in decoder. Defaults to
+ False.
+ d_k (int): Dim of conv layers in attention module. Defaults to 64.
+ d_model (int): Dim of channels from backbone :math:`D_i`. Defaults to
+ 512.
+ d_enc (int): Dim of encoder RNN layer :math:`D_m`. Defaults to 512.
+ pred_dropout (float): Dropout probability of prediction layer. Defaults
+ to 0.
+ max_seq_len (int): Maximum sequence length during decoding. Defaults to
+ 40.
+ mask (bool): If True, mask padding in feature map. Defaults to False.
+ pred_concat (bool): If True, concat glimpse feature from
+ attention with holistic feature and hidden state. Defaults to
+ False.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ dictionary: Optional[Union[Dict, Dictionary]] = None,
+ module_loss: Optional[Dict] = None,
+ postprocessor: Optional[Dict] = None,
+ enc_bi_rnn: bool = False,
+ dec_bi_rnn: bool = False,
+ dec_gru: bool = False,
+ d_k: int = 64,
+ d_model: int = 512,
+ d_enc: int = 512,
+ pred_dropout: float = 0.0,
+ mask: bool = True,
+ max_seq_len: int = 40,
+ pred_concat: bool = False,
+ init_cfg: Optional[Union[Dict, List[Dict]]] = None,
+ **kwargs):
+ super().__init__(
+ dictionary=dictionary,
+ module_loss=module_loss,
+ postprocessor=postprocessor,
+ max_seq_len=max_seq_len,
+ init_cfg=init_cfg)
+
+ self.num_classes = self.dictionary.num_classes
+ self.enc_bi_rnn = enc_bi_rnn
+ self.d_k = d_k
+ self.start_idx = self.dictionary.start_idx
+ self.dec_gru = dec_gru
+ self.mask = mask
+ self.pred_concat = pred_concat
+
+ encoder_rnn_out_size = d_enc * (int(enc_bi_rnn) + 1)
+ decoder_rnn_out_size = encoder_rnn_out_size * (int(dec_bi_rnn) + 1)
+ # 2D attention layer
+ self.conv1x1_1 = nn.Conv2d(
+ decoder_rnn_out_size, d_k, kernel_size=1, stride=1)
+ self.conv3x3_1 = nn.Conv2d(
+ d_model, d_k, kernel_size=3, stride=1, padding=1)
+ self.conv1x1_2 = nn.Conv2d(d_k, 1, kernel_size=1, stride=1)
+
+ # Decoder rnn layer
+ if dec_gru:
+ self.rnn_decoder_layer1 = nn.GRUCell(encoder_rnn_out_size,
+ encoder_rnn_out_size)
+ self.rnn_decoder_layer2 = nn.GRUCell(encoder_rnn_out_size,
+ encoder_rnn_out_size)
+ else:
+ self.rnn_decoder_layer1 = nn.LSTMCell(encoder_rnn_out_size,
+ encoder_rnn_out_size)
+ self.rnn_decoder_layer2 = nn.LSTMCell(encoder_rnn_out_size,
+ encoder_rnn_out_size)
+
+ # Decoder input embedding
+ self.embedding = nn.Embedding(
+ self.num_classes,
+ encoder_rnn_out_size,
+ padding_idx=self.dictionary.padding_idx)
+
+ # Prediction layer
+ self.pred_dropout = nn.Dropout(pred_dropout)
+ if pred_concat:
+ fc_in_channel = decoder_rnn_out_size + d_model + d_enc
+ else:
+ fc_in_channel = d_model
+ self.prediction = nn.Linear(fc_in_channel, self.num_classes)
+ self.softmax = nn.Softmax(dim=-1)
+
+ def _2d_attention(self,
+ y_prev: torch.Tensor,
+ feat: torch.Tensor,
+ holistic_feat: torch.Tensor,
+ hx1: torch.Tensor,
+ cx1: torch.Tensor,
+ hx2: torch.Tensor,
+ cx2: torch.Tensor,
+ valid_ratios: Optional[Sequence[float]] = None
+ ) -> torch.Tensor:
+ """2D attention layer.
+
+ Args:
+ y_prev (torch.Tensor): Previous decoder hidden state.
+ feat (torch.Tensor): Feature map.
+ holistic_feat (torch.Tensor): Holistic feature map.
+ hx1 (torch.Tensor): rnn decoder layer 1 hidden state.
+ cx1 (torch.Tensor): rnn decoder layer 1 cell state.
+ hx2 (torch.Tensor): rnn decoder layer 2 hidden state.
+ cx2 (torch.Tensor): rnn decoder layer 2 cell state.
+ valid_ratios (Optional[Sequence[float]]): Valid ratios of
+ attention. Defaults to None.
+ """
+ _, _, h_feat, w_feat = feat.size()
+ if self.dec_gru:
+ hx1 = cx1 = self.rnn_decoder_layer1(y_prev, hx1)
+ hx2 = cx2 = self.rnn_decoder_layer2(hx1, hx2)
+ else:
+ hx1, cx1 = self.rnn_decoder_layer1(y_prev, (hx1, cx1))
+ hx2, cx2 = self.rnn_decoder_layer2(hx1, (hx2, cx2))
+
+ tile_hx2 = hx2.view(hx2.size(0), hx2.size(1), 1, 1)
+ attn_query = self.conv1x1_1(tile_hx2) # bsz * attn_size * 1 * 1
+ attn_query = attn_query.expand(-1, -1, h_feat, w_feat)
+ attn_key = self.conv3x3_1(feat)
+ attn_weight = torch.tanh(torch.add(attn_key, attn_query, alpha=1))
+ attn_weight = self.conv1x1_2(attn_weight)
+ bsz, c, h, w = attn_weight.size()
+ assert c == 1
+
+ if valid_ratios is not None:
+ # cal mask of attention weight
+ attn_mask = torch.zeros_like(attn_weight)
+ for i, valid_ratio in enumerate(valid_ratios):
+ valid_width = min(w, math.ceil(w * valid_ratio))
+ attn_mask[i, :, :, valid_width:] = 1
+ attn_weight = attn_weight.masked_fill(attn_mask.bool(),
+ float('-inf'))
+
+ attn_weight = F.softmax(attn_weight.view(bsz, -1), dim=-1)
+ attn_weight = attn_weight.view(bsz, c, h, w)
+
+ attn_feat = torch.sum(
+ torch.mul(feat, attn_weight), (2, 3), keepdim=False) # n * c
+
+ # linear transformation
+ if self.pred_concat:
+ y = self.prediction(torch.cat((hx2, attn_feat, holistic_feat), 1))
+ else:
+ y = self.prediction(attn_feat)
+
+ return y, hx1, hx1, hx2, hx2
+
+ def forward_train(
+ self,
+ feat: torch.Tensor,
+ out_enc: torch.Tensor,
+ data_samples: Optional[Sequence[TextRecogDataSample]] = None
+ ) -> torch.Tensor:
+ """
+ Args:
+ feat (Tensor): Tensor of shape :math:`(N, D_i, H, W)`.
+ out_enc (Tensor): Encoder output of shape
+ :math:`(N, D_m, H, W)`.
+ data_samples (list[TextRecogDataSample]): Batch of
+ TextRecogDataSample, containing gt_text and valid_ratio
+ information.
+
+ Returns:
+ Tensor: A raw logit tensor of shape :math:`(N, T, C)`.
+ """
+ valid_ratios = None
+ if data_samples is not None:
+ valid_ratios = [
+ data_sample.get('valid_ratio', 1.0)
+ for data_sample in data_samples
+ ] if self.mask else None
+
+ padded_targets = [
+ data_sample.gt_text.padded_indexes for data_sample in data_samples
+ ]
+ padded_targets = torch.stack(padded_targets, dim=0).to(feat.device)
+ tgt_embedding = self.embedding(padded_targets)
+
+ outputs = []
+ for i in range(-1, self.max_seq_len):
+ if i == -1:
+ if self.dec_gru:
+ hx1 = cx1 = self.rnn_decoder_layer1(out_enc)
+ hx2 = cx2 = self.rnn_decoder_layer2(hx1)
+ else:
+ hx1, cx1 = self.rnn_decoder_layer1(out_enc)
+ hx2, cx2 = self.rnn_decoder_layer2(hx1)
+ else:
+ y_prev = tgt_embedding[:, i, :]
+ y, hx1, cx1, hx2, cx2 = self._2d_attention(
+ y_prev,
+ feat,
+ out_enc,
+ hx1,
+ cx1,
+ hx2,
+ cx2,
+ valid_ratios=valid_ratios)
+ y = self.pred_dropout(y)
+
+ outputs.append(y)
+
+ outputs = torch.stack(outputs, 1)
+
+ return outputs
+
+ def forward_test(
+ self,
+ feat: torch.Tensor,
+ out_enc: torch.Tensor,
+ data_samples: Optional[Sequence[TextRecogDataSample]] = None
+ ) -> torch.Tensor:
+ """
+ Args:
+ feat (Tensor): Tensor of shape :math:`(N, D_i, H, W)`.
+ out_enc (Tensor): Encoder output of shape
+ :math:`(N, D_m, H, W)`.
+ data_samples (list[TextRecogDataSample]): Batch of
+ TextRecogDataSample, containing valid_ratio
+ information.
+
+ Returns:
+ Tensor: Character probabilities. of shape
+ :math:`(N, self.max_seq_len, C)` where :math:`C` is
+ ``num_classes``.
+ """
+ valid_ratios = None
+ if data_samples is not None:
+ valid_ratios = [
+ data_sample.get('valid_ratio', 1.0)
+ for data_sample in data_samples
+ ] if self.mask else None
+
+ outputs = []
+ start_token = torch.full((feat.size(0), ),
+ self.start_idx,
+ device=feat.device,
+ dtype=torch.long)
+ start_token = self.embedding(start_token)
+ for i in range(-1, self.max_seq_len):
+ if i == -1:
+ if self.dec_gru:
+ hx1 = cx1 = self.rnn_decoder_layer1(out_enc)
+ hx2 = cx2 = self.rnn_decoder_layer2(hx1)
+ else:
+ hx1, cx1 = self.rnn_decoder_layer1(out_enc)
+ hx2, cx2 = self.rnn_decoder_layer2(hx1)
+ y_prev = start_token
+ else:
+ y, hx1, cx1, hx2, cx2 = self._2d_attention(
+ y_prev,
+ feat,
+ out_enc,
+ hx1,
+ cx1,
+ hx2,
+ cx2,
+ valid_ratios=valid_ratios)
+ _, max_idx = torch.max(y, dim=1, keepdim=False)
+ char_embedding = self.embedding(max_idx)
+ y_prev = char_embedding
+ outputs.append(y)
+
+ outputs = torch.stack(outputs, 1)
+
+ return self.softmax(outputs)
diff --git a/mmocr/models/textrecog/decoders/sar_decoder_with_bs.py b/mmocr/models/textrecog/decoders/sar_decoder_with_bs.py
new file mode 100644
index 0000000000000000000000000000000000000000..495b72fb1881f340b7cca7c70571bd669fd6a81b
--- /dev/null
+++ b/mmocr/models/textrecog/decoders/sar_decoder_with_bs.py
@@ -0,0 +1,162 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from queue import PriorityQueue
+
+import torch
+import torch.nn.functional as F
+
+import mmocr.utils as utils
+from mmocr.registry import MODELS
+from . import ParallelSARDecoder
+
+
+class DecodeNode:
+ """Node class to save decoded char indices and scores.
+
+ Args:
+ indexes (list[int]): Char indices that decoded yes.
+ scores (list[float]): Char scores that decoded yes.
+ """
+
+ def __init__(self, indexes=[1], scores=[0.9]):
+ assert utils.is_type_list(indexes, int)
+ assert utils.is_type_list(scores, float)
+ assert utils.equal_len(indexes, scores)
+
+ self.indexes = indexes
+ self.scores = scores
+
+ def eval(self):
+ """Calculate accumulated score."""
+ accu_score = sum(self.scores)
+ return accu_score
+
+
+@MODELS.register_module()
+class ParallelSARDecoderWithBS(ParallelSARDecoder):
+ """Parallel Decoder module with beam-search in SAR.
+
+ Args:
+ beam_width (int): Width for beam search.
+ """
+
+ def __init__(self,
+ beam_width=5,
+ num_classes=37,
+ enc_bi_rnn=False,
+ dec_bi_rnn=False,
+ dec_do_rnn=0,
+ dec_gru=False,
+ d_model=512,
+ d_enc=512,
+ d_k=64,
+ pred_dropout=0.0,
+ max_seq_len=40,
+ mask=True,
+ start_idx=0,
+ padding_idx=0,
+ pred_concat=False,
+ init_cfg=None,
+ **kwargs):
+ super().__init__(
+ num_classes,
+ enc_bi_rnn,
+ dec_bi_rnn,
+ dec_do_rnn,
+ dec_gru,
+ d_model,
+ d_enc,
+ d_k,
+ pred_dropout,
+ max_seq_len,
+ mask,
+ start_idx,
+ padding_idx,
+ pred_concat,
+ init_cfg=init_cfg)
+ assert isinstance(beam_width, int)
+ assert beam_width > 0
+
+ self.beam_width = beam_width
+
+ def forward_test(self, feat, out_enc, img_metas):
+ assert utils.is_type_list(img_metas, dict)
+ assert len(img_metas) == feat.size(0)
+
+ valid_ratios = [
+ img_meta.get('valid_ratio', 1.0) for img_meta in img_metas
+ ] if self.mask else None
+
+ seq_len = self.max_seq_len
+ bsz = feat.size(0)
+ assert bsz == 1, 'batch size must be 1 for beam search.'
+
+ start_token = torch.full((bsz, ),
+ self.start_idx,
+ device=feat.device,
+ dtype=torch.long)
+ # bsz
+ start_token = self.embedding(start_token)
+ # bsz * emb_dim
+ start_token = start_token.unsqueeze(1).expand(-1, seq_len, -1)
+ # bsz * seq_len * emb_dim
+ out_enc = out_enc.unsqueeze(1)
+ # bsz * 1 * emb_dim
+ decoder_input = torch.cat((out_enc, start_token), dim=1)
+ # bsz * (seq_len + 1) * emb_dim
+
+ # Initialize beam-search queue
+ q = PriorityQueue()
+ init_node = DecodeNode([self.start_idx], [0.0])
+ q.put((-init_node.eval(), init_node))
+
+ for i in range(1, seq_len + 1):
+ next_nodes = []
+ beam_width = self.beam_width if i > 1 else 1
+ for _ in range(beam_width):
+ _, node = q.get()
+
+ input_seq = torch.clone(decoder_input) # bsz * T * emb_dim
+ # fill previous input tokens (step 1...i) in input_seq
+ for t, index in enumerate(node.indexes):
+ input_token = torch.full((bsz, ),
+ index,
+ device=input_seq.device,
+ dtype=torch.long)
+ input_token = self.embedding(input_token) # bsz * emb_dim
+ input_seq[:, t + 1, :] = input_token
+
+ output_seq = self._2d_attention(
+ input_seq, feat, out_enc, valid_ratios=valid_ratios)
+
+ output_char = output_seq[:, i, :] # bsz * num_classes
+ output_char = F.softmax(output_char, -1)
+ topk_value, topk_idx = output_char.topk(self.beam_width, dim=1)
+ topk_value, topk_idx = topk_value.squeeze(0), topk_idx.squeeze(
+ 0)
+
+ for k in range(self.beam_width):
+ kth_score = topk_value[k].item()
+ kth_idx = topk_idx[k].item()
+ next_node = DecodeNode(node.indexes + [kth_idx],
+ node.scores + [kth_score])
+ delta = k * 1e-6
+ next_nodes.append(
+ (-node.eval() - kth_score - delta, next_node))
+ # Use minus since priority queue sort
+ # with ascending order
+
+ while not q.empty():
+ q.get()
+
+ # Put all candidates to queue
+ for next_node in next_nodes:
+ q.put(next_node)
+
+ best_node = q.get()
+ num_classes = self.num_classes - 1 # ignore padding index
+ outputs = torch.zeros(bsz, seq_len, num_classes)
+ for i in range(seq_len):
+ idx = best_node[1].indexes[i + 1]
+ outputs[0, i, idx] = best_node[1].scores[i + 1]
+
+ return outputs
diff --git a/mmocr/models/textrecog/decoders/sequence_attention_decoder.py b/mmocr/models/textrecog/decoders/sequence_attention_decoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..dfbf293f730e7c729511afa6ea24d494b86fe1b2
--- /dev/null
+++ b/mmocr/models/textrecog/decoders/sequence_attention_decoder.py
@@ -0,0 +1,260 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from typing import Dict, Optional, Sequence, Union
+
+import torch
+import torch.nn as nn
+
+from mmocr.models.common.dictionary import Dictionary
+from mmocr.models.textrecog.layers import DotProductAttentionLayer
+from mmocr.registry import MODELS
+from mmocr.structures import TextRecogDataSample
+from .base import BaseDecoder
+
+
+@MODELS.register_module()
+class SequenceAttentionDecoder(BaseDecoder):
+ """Sequence attention decoder for RobustScanner.
+
+ RobustScanner: `RobustScanner: Dynamically Enhancing Positional Clues for
+ Robust Text Recognition `_
+
+ Args:
+ dictionary (dict or :obj:`Dictionary`): The config for `Dictionary` or
+ the instance of `Dictionary`.
+ module_loss (dict, optional): Config to build module_loss. Defaults
+ to None.
+ postprocessor (dict, optional): Config to build postprocessor.
+ Defaults to None.
+ rnn_layers (int): Number of RNN layers. Defaults to 2.
+ dim_input (int): Dimension :math:`D_i` of input vector ``feat``.
+ Defaults to 512.
+ dim_model (int): Dimension :math:`D_m` of the model. Should also be the
+ same as encoder output vector ``out_enc``. Defaults to 128.
+ max_seq_len (int): Maximum output sequence length :math:`T`.
+ Defaults to 40.
+ mask (bool): Whether to mask input features according to
+ ``data_sample.valid_ratio``. Defaults to True.
+ dropout (float): Dropout rate for LSTM layer. Defaults to 0.
+ return_feature (bool): Return feature or logic as the result.
+ Defaults to True.
+ encode_value (bool): Whether to use the output of encoder ``out_enc``
+ as `value` of attention layer. If False, the original feature
+ ``feat`` will be used. Defaults to False.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ dictionary: Union[Dictionary, Dict],
+ module_loss: Optional[Dict] = None,
+ postprocessor: Optional[Dict] = None,
+ rnn_layers: int = 2,
+ dim_input: int = 512,
+ dim_model: int = 128,
+ max_seq_len: int = 40,
+ mask: bool = True,
+ dropout: int = 0,
+ return_feature: bool = True,
+ encode_value: bool = False,
+ init_cfg: Optional[Union[Dict,
+ Sequence[Dict]]] = None) -> None:
+ super().__init__(
+ dictionary=dictionary,
+ module_loss=module_loss,
+ postprocessor=postprocessor,
+ max_seq_len=max_seq_len,
+ init_cfg=init_cfg)
+
+ self.dim_input = dim_input
+ self.dim_model = dim_model
+ self.return_feature = return_feature
+ self.encode_value = encode_value
+ self.mask = mask
+
+ self.embedding = nn.Embedding(
+ self.dictionary.num_classes,
+ self.dim_model,
+ padding_idx=self.dictionary.padding_idx)
+
+ self.sequence_layer = nn.LSTM(
+ input_size=dim_model,
+ hidden_size=dim_model,
+ num_layers=rnn_layers,
+ batch_first=True,
+ dropout=dropout)
+
+ self.attention_layer = DotProductAttentionLayer()
+
+ self.prediction = None
+ if not self.return_feature:
+ self.prediction = nn.Linear(
+ dim_model if encode_value else dim_input,
+ self.dictionary.num_classes)
+ self.softmax = nn.Softmax(dim=-1)
+
+ def forward_train(
+ self,
+ feat: torch.Tensor,
+ out_enc: torch.Tensor,
+ data_samples: Optional[Sequence[TextRecogDataSample]] = None
+ ) -> torch.Tensor:
+ """
+ Args:
+ feat (Tensor): Tensor of shape :math:`(N, D_i, H, W)`.
+ out_enc (Tensor): Encoder output of shape
+ :math:`(N, D_m, H, W)`.
+ targets_dict (dict): A dict with the key ``padded_targets``, a
+ tensor of shape :math:`(N, T)`. Each element is the index of a
+ character.
+ data_samples (list[TextRecogDataSample], optional): Batch of
+ TextRecogDataSample, containing gt_text information. Defaults
+ to None.
+
+ Returns:
+ Tensor: A raw logit tensor of shape :math:`(N, T, C)` if
+ ``return_feature=False``. Otherwise it would be the hidden feature
+ before the prediction projection layer, whose shape is
+ :math:`(N, T, D_m)`.
+ """
+
+ valid_ratios = [
+ data_sample.get('valid_ratio', 1.0) for data_sample in data_samples
+ ] if self.mask else None
+
+ padded_targets = [
+ data_sample.gt_text.padded_indexes for data_sample in data_samples
+ ]
+ padded_targets = torch.stack(padded_targets, dim=0).to(feat.device)
+ tgt_embedding = self.embedding(padded_targets)
+
+ n, c_enc, h, w = out_enc.size()
+ assert c_enc == self.dim_model
+ _, c_feat, _, _ = feat.size()
+ assert c_feat == self.dim_input
+ _, len_q, c_q = tgt_embedding.size()
+ assert c_q == self.dim_model
+ assert len_q <= self.max_seq_len
+
+ query, _ = self.sequence_layer(tgt_embedding)
+ query = query.permute(0, 2, 1).contiguous()
+ key = out_enc.view(n, c_enc, h * w)
+ if self.encode_value:
+ value = key
+ else:
+ value = feat.view(n, c_feat, h * w)
+
+ mask = None
+ if valid_ratios is not None:
+ mask = query.new_zeros((n, h, w))
+ for i, valid_ratio in enumerate(valid_ratios):
+ valid_width = min(w, math.ceil(w * valid_ratio))
+ mask[i, :, valid_width:] = 1
+ mask = mask.bool()
+ mask = mask.view(n, h * w)
+
+ attn_out = self.attention_layer(query, key, value, mask)
+ attn_out = attn_out.permute(0, 2, 1).contiguous()
+
+ if self.return_feature:
+ return attn_out
+
+ out = self.prediction(attn_out)
+
+ return out
+
+ def forward_test(self, feat: torch.Tensor, out_enc: torch.Tensor,
+ data_samples: Optional[Sequence[TextRecogDataSample]]
+ ) -> torch.Tensor:
+ """
+ Args:
+ feat (Tensor): Tensor of shape :math:`(N, D_i, H, W)`.
+ out_enc (Tensor): Encoder output of shape
+ :math:`(N, D_m, H, W)`.
+ data_samples (list[TextRecogDataSample], optional): Batch of
+ TextRecogDataSample, containing gt_text information. Defaults
+ to None.
+
+ Returns:
+ Tensor: Character probabilities. of shape
+ :math:`(N, self.max_seq_len, C)` where :math:`C` is
+ ``num_classes``.
+ """
+ seq_len = self.max_seq_len
+ batch_size = feat.size(0)
+
+ decode_sequence = (feat.new_ones(
+ (batch_size, seq_len)) * self.dictionary.start_idx).long()
+ assert not self.return_feature
+ outputs = []
+ for i in range(seq_len):
+ step_out = self.forward_test_step(feat, out_enc, decode_sequence,
+ i, data_samples)
+ outputs.append(step_out)
+ _, max_idx = torch.max(step_out, dim=1, keepdim=False)
+ if i < seq_len - 1:
+ decode_sequence[:, i + 1] = max_idx
+
+ outputs = torch.stack(outputs, 1)
+
+ return self.softmax(outputs)
+
+ def forward_test_step(self, feat: torch.Tensor, out_enc: torch.Tensor,
+ decode_sequence: torch.Tensor, current_step: int,
+ data_samples: Sequence[TextRecogDataSample]
+ ) -> torch.Tensor:
+ """
+ Args:
+ feat (Tensor): Tensor of shape :math:`(N, D_i, H, W)`.
+ out_enc (Tensor): Encoder output of shape
+ :math:`(N, D_m, H, W)`.
+ decode_sequence (Tensor): Shape :math:`(N, T)`. The tensor that
+ stores history decoding result.
+ current_step (int): Current decoding step.
+ data_samples (list[TextRecogDataSample], optional): Batch of
+ TextRecogDataSample, containing gt_text information. Defaults
+ to None.
+
+ Returns:
+ Tensor: Shape :math:`(N, C)`. The logit tensor of predicted
+ tokens at current time step.
+ """
+ valid_ratios = [
+ img_meta.get('valid_ratio', 1.0) for img_meta in data_samples
+ ] if self.mask else None
+
+ embed = self.embedding(decode_sequence)
+
+ n, c_enc, h, w = out_enc.size()
+ assert c_enc == self.dim_model
+ _, c_feat, _, _ = feat.size()
+ assert c_feat == self.dim_input
+ _, _, c_q = embed.size()
+ assert c_q == self.dim_model
+
+ query, _ = self.sequence_layer(embed)
+ query = query.permute(0, 2, 1).contiguous()
+ key = out_enc.view(n, c_enc, h * w)
+ if self.encode_value:
+ value = key
+ else:
+ value = feat.view(n, c_feat, h * w)
+
+ mask = None
+ if valid_ratios is not None:
+ mask = query.new_zeros((n, h, w))
+ for i, valid_ratio in enumerate(valid_ratios):
+ valid_width = min(w, math.ceil(w * valid_ratio))
+ mask[i, :, valid_width:] = 1
+ mask = mask.bool()
+ mask = mask.view(n, h * w)
+
+ # [n, c, l]
+ attn_out = self.attention_layer(query, key, value, mask)
+
+ out = attn_out[:, :, current_step]
+
+ if not self.return_feature:
+ out = self.prediction(out)
+
+ return out
diff --git a/mmocr/models/textrecog/decoders/svtr_decoder.py b/mmocr/models/textrecog/decoders/svtr_decoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..122a51dc09b6c55d25ad80f3c763135317c6aca3
--- /dev/null
+++ b/mmocr/models/textrecog/decoders/svtr_decoder.py
@@ -0,0 +1,96 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Sequence, Union
+
+import torch
+import torch.nn as nn
+
+from mmocr.models.common.dictionary import Dictionary
+from mmocr.registry import MODELS
+from mmocr.structures import TextRecogDataSample
+from .base import BaseDecoder
+
+
+@MODELS.register_module()
+class SVTRDecoder(BaseDecoder):
+ """Decoder module in `SVTR `_.
+
+ Args:
+ in_channels (int): The num of input channels.
+ dictionary (Union[Dict, Dictionary]): The config for `Dictionary` or
+ the instance of `Dictionary`. Defaults to None.
+ module_loss (Optional[Dict], optional): Cfg to build module_loss.
+ Defaults to None.
+ postprocessor (Optional[Dict], optional): Cfg to build postprocessor.
+ Defaults to None.
+ max_seq_len (int, optional): Maximum output sequence length :math:`T`.
+ Defaults to 25.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ in_channels: int,
+ dictionary: Union[Dict, Dictionary] = None,
+ module_loss: Optional[Dict] = None,
+ postprocessor: Optional[Dict] = None,
+ max_seq_len: int = 25,
+ init_cfg: Optional[Union[Dict, List[Dict]]] = None) -> None:
+
+ super().__init__(
+ dictionary=dictionary,
+ module_loss=module_loss,
+ postprocessor=postprocessor,
+ max_seq_len=max_seq_len,
+ init_cfg=init_cfg)
+
+ self.decoder = nn.Linear(
+ in_features=in_channels, out_features=self.dictionary.num_classes)
+ self.softmax = nn.Softmax(dim=-1)
+
+ def forward_train(
+ self,
+ feat: Optional[torch.Tensor] = None,
+ out_enc: Optional[torch.Tensor] = None,
+ data_samples: Optional[Sequence[TextRecogDataSample]] = None
+ ) -> torch.Tensor:
+ """Forward for training.
+
+ Args:
+ feat (torch.Tensor, optional): The feature map. Defaults to None.
+ out_enc (torch.Tensor, optional): Encoder output from encoder of
+ shape :math:`(N, 1, H, W)`. Defaults to None.
+ data_samples (Sequence[TextRecogDataSample]): Batch of
+ TextRecogDataSample, containing gt_text information. Defaults
+ to None.
+
+ Returns:
+ Tensor: The raw logit tensor. Shape :math:`(N, T, C)` where
+ :math:`C` is ``num_classes``.
+ """
+ assert out_enc.size(2) == 1, 'feature height must be 1'
+ x = out_enc.squeeze(2)
+ x = x.permute(0, 2, 1)
+ predicts = self.decoder(x)
+ return predicts
+
+ def forward_test(
+ self,
+ feat: Optional[torch.Tensor] = None,
+ out_enc: Optional[torch.Tensor] = None,
+ data_samples: Optional[Sequence[TextRecogDataSample]] = None
+ ) -> torch.Tensor:
+ """Forward for testing.
+
+ Args:
+ feat (torch.Tensor, optional): The feature map. Defaults to None.
+ out_enc (torch.Tensor, optional): Encoder output from encoder of
+ shape :math:`(N, 1, H, W)`. Defaults to None.
+ data_samples (Sequence[TextRecogDataSample]): Batch of
+ TextRecogDataSample, containing gt_text information. Defaults
+ to None.
+ Returns:
+ Tensor: Character probabilities. of shape
+ :math:`(N, self.max_seq_len, C)` where :math:`C` is
+ ``num_classes``.
+ """
+ return self.softmax(self.forward_train(feat, out_enc, data_samples))
diff --git a/mmocr/models/textrecog/encoders/__init__.py b/mmocr/models/textrecog/encoders/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..ceef10116baf4bf1bec14613af0bfbd1f28e86d0
--- /dev/null
+++ b/mmocr/models/textrecog/encoders/__init__.py
@@ -0,0 +1,14 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .abi_encoder import ABIEncoder
+from .aster_encoder import ASTEREncoder
+from .base import BaseEncoder
+from .channel_reduction_encoder import ChannelReductionEncoder
+from .nrtr_encoder import NRTREncoder
+from .sar_encoder import SAREncoder
+from .satrn_encoder import SATRNEncoder
+from .svtr_encoder import SVTREncoder
+
+__all__ = [
+ 'SAREncoder', 'NRTREncoder', 'BaseEncoder', 'ChannelReductionEncoder',
+ 'SATRNEncoder', 'ABIEncoder', 'SVTREncoder', 'ASTEREncoder'
+]
diff --git a/mmocr/models/textrecog/encoders/__pycache__/__init__.cpython-38.pyc b/mmocr/models/textrecog/encoders/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..daff8479d6ac89d2d0bd02ab9358728dee97eec6
Binary files /dev/null and b/mmocr/models/textrecog/encoders/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/encoders/__pycache__/abi_encoder.cpython-38.pyc b/mmocr/models/textrecog/encoders/__pycache__/abi_encoder.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..7c3f30e4f89016931d68ef2f22a22c953e01c550
Binary files /dev/null and b/mmocr/models/textrecog/encoders/__pycache__/abi_encoder.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/encoders/__pycache__/aster_encoder.cpython-38.pyc b/mmocr/models/textrecog/encoders/__pycache__/aster_encoder.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c7040e64253a3ad86e9040d182a4e66d83ca752d
Binary files /dev/null and b/mmocr/models/textrecog/encoders/__pycache__/aster_encoder.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/encoders/__pycache__/base.cpython-38.pyc b/mmocr/models/textrecog/encoders/__pycache__/base.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ddef9dc94232b32f35f076d181f5da011d1ca568
Binary files /dev/null and b/mmocr/models/textrecog/encoders/__pycache__/base.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/encoders/__pycache__/channel_reduction_encoder.cpython-38.pyc b/mmocr/models/textrecog/encoders/__pycache__/channel_reduction_encoder.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b036f6e05e41855fc4f7fae11773e997fe9a3d0d
Binary files /dev/null and b/mmocr/models/textrecog/encoders/__pycache__/channel_reduction_encoder.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/encoders/__pycache__/nrtr_encoder.cpython-38.pyc b/mmocr/models/textrecog/encoders/__pycache__/nrtr_encoder.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..100163af91124ac4e89ede4e9e888c06b9f3320f
Binary files /dev/null and b/mmocr/models/textrecog/encoders/__pycache__/nrtr_encoder.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/encoders/__pycache__/sar_encoder.cpython-38.pyc b/mmocr/models/textrecog/encoders/__pycache__/sar_encoder.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2dedf7bc49f93519a60cbc134d139f4d9679391f
Binary files /dev/null and b/mmocr/models/textrecog/encoders/__pycache__/sar_encoder.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/encoders/__pycache__/satrn_encoder.cpython-38.pyc b/mmocr/models/textrecog/encoders/__pycache__/satrn_encoder.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c85f594a42ea9661d521a292ca53f4ec3e4064ad
Binary files /dev/null and b/mmocr/models/textrecog/encoders/__pycache__/satrn_encoder.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/encoders/__pycache__/svtr_encoder.cpython-38.pyc b/mmocr/models/textrecog/encoders/__pycache__/svtr_encoder.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f6a55f021f12770b81f71d863ecaa8d310c6ef68
Binary files /dev/null and b/mmocr/models/textrecog/encoders/__pycache__/svtr_encoder.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/encoders/abi_encoder.py b/mmocr/models/textrecog/encoders/abi_encoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..a5f6a85c71bfe84c09fdc3d6d2eb560804f7564e
--- /dev/null
+++ b/mmocr/models/textrecog/encoders/abi_encoder.py
@@ -0,0 +1,83 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+from typing import Dict, List, Optional, Union
+
+import torch
+from mmcv.cnn.bricks.transformer import BaseTransformerLayer
+from mmengine.model import BaseModule, ModuleList
+
+from mmocr.models.common.modules import PositionalEncoding
+from mmocr.registry import MODELS
+from mmocr.structures import TextRecogDataSample
+
+
+@MODELS.register_module()
+class ABIEncoder(BaseModule):
+ """Implement transformer encoder for text recognition, modified from
+ ``.
+
+ Args:
+ n_layers (int): Number of attention layers. Defaults to 2.
+ n_head (int): Number of parallel attention heads. Defaults to 8.
+ d_model (int): Dimension :math:`D_m` of the input from previous model.
+ Defaults to 512.
+ d_inner (int): Hidden dimension of feedforward layers. Defaults to
+ 2048.
+ dropout (float): Dropout rate. Defaults to 0.1.
+ max_len (int): Maximum output sequence length :math:`T`. Defaults to
+ 8 * 32.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ n_layers: int = 2,
+ n_head: int = 8,
+ d_model: int = 512,
+ d_inner: int = 2048,
+ dropout: float = 0.1,
+ max_len: int = 8 * 32,
+ init_cfg: Optional[Union[Dict, List[Dict]]] = None):
+ super().__init__(init_cfg=init_cfg)
+
+ assert d_model % n_head == 0, 'd_model must be divisible by n_head'
+
+ self.pos_encoder = PositionalEncoding(d_model, n_position=max_len)
+ encoder_layer = BaseTransformerLayer(
+ operation_order=('self_attn', 'norm', 'ffn', 'norm'),
+ attn_cfgs=dict(
+ type='MultiheadAttention',
+ embed_dims=d_model,
+ num_heads=n_head,
+ attn_drop=dropout,
+ dropout_layer=dict(type='Dropout', drop_prob=dropout),
+ ),
+ ffn_cfgs=dict(
+ type='FFN',
+ embed_dims=d_model,
+ feedforward_channels=d_inner,
+ ffn_drop=dropout,
+ ),
+ norm_cfg=dict(type='LN'),
+ )
+ self.transformer = ModuleList(
+ [copy.deepcopy(encoder_layer) for _ in range(n_layers)])
+
+ def forward(self, feature: torch.Tensor,
+ data_samples: List[TextRecogDataSample]) -> torch.Tensor:
+ """
+ Args:
+ feature (Tensor): Feature tensor of shape :math:`(N, D_m, H, W)`.
+ data_samples (List[TextRecogDataSample]): List of data samples.
+
+ Returns:
+ Tensor: Features of shape :math:`(N, D_m, H, W)`.
+ """
+ n, c, h, w = feature.shape
+ feature = feature.view(n, c, -1).transpose(1, 2) # (n, h*w, c)
+ feature = self.pos_encoder(feature) # (n, h*w, c)
+ feature = feature.transpose(0, 1) # (h*w, n, c)
+ for m in self.transformer:
+ feature = m(feature)
+ feature = feature.permute(1, 2, 0).view(n, c, h, w)
+ return feature
diff --git a/mmocr/models/textrecog/encoders/aster_encoder.py b/mmocr/models/textrecog/encoders/aster_encoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..521218153701c510478b1e4ac3912c89f8eecfd4
--- /dev/null
+++ b/mmocr/models/textrecog/encoders/aster_encoder.py
@@ -0,0 +1,43 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+
+from mmocr.registry import MODELS
+from .base import BaseEncoder
+
+
+@MODELS.register_module()
+class ASTEREncoder(BaseEncoder):
+ """Implement BiLSTM encoder module in `ASTER: An Attentional Scene Text
+ Recognizer with Flexible Rectification.
+
+ None:
+ super().__init__(init_cfg=init_cfg)
+ self.bilstm = nn.LSTM(
+ in_channels,
+ in_channels // 2,
+ num_layers=num_layers,
+ bidirectional=True,
+ batch_first=True)
+
+ def forward(self, feat: torch.Tensor, img_metas=None) -> torch.Tensor:
+ """
+ Args:
+ feat (Tensor): Feature of shape (N, C, 1, W).
+ Returns:
+ Tensor: Output of BiLSTM.
+ """
+ assert feat.dim() == 4
+ assert feat.size(2) == 1, 'height must be 1'
+ feat = feat.squeeze(2).permute(0, 2, 1)
+ feat, _ = self.bilstm(feat)
+ return feat.contiguous()
diff --git a/mmocr/models/textrecog/encoders/base.py b/mmocr/models/textrecog/encoders/base.py
new file mode 100644
index 0000000000000000000000000000000000000000..26edafb79869c840ec9362faef7a871759d15d3b
--- /dev/null
+++ b/mmocr/models/textrecog/encoders/base.py
@@ -0,0 +1,12 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmengine.model import BaseModule
+
+from mmocr.registry import MODELS
+
+
+@MODELS.register_module()
+class BaseEncoder(BaseModule):
+ """Base Encoder class for text recognition."""
+
+ def forward(self, feat, **kwargs):
+ return feat
diff --git a/mmocr/models/textrecog/encoders/channel_reduction_encoder.py b/mmocr/models/textrecog/encoders/channel_reduction_encoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..49b40bf27406c0c1d1b46d4f7232bdeca50776f7
--- /dev/null
+++ b/mmocr/models/textrecog/encoders/channel_reduction_encoder.py
@@ -0,0 +1,50 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, Optional, Sequence
+
+import torch
+import torch.nn as nn
+
+from mmocr.registry import MODELS
+from mmocr.structures import TextRecogDataSample
+from .base import BaseEncoder
+
+
+@MODELS.register_module()
+class ChannelReductionEncoder(BaseEncoder):
+ """Change the channel number with a one by one convoluational layer.
+
+ Args:
+ in_channels (int): Number of input channels.
+ out_channels (int): Number of output channels.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ Defaults to dict(type='Xavier', layer='Conv2d').
+ """
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ init_cfg: Dict = dict(type='Xavier', layer='Conv2d')
+ ) -> None:
+ super().__init__(init_cfg=init_cfg)
+
+ self.layer = nn.Conv2d(
+ in_channels, out_channels, kernel_size=1, stride=1, padding=0)
+
+ def forward(
+ self,
+ feat: torch.Tensor,
+ data_samples: Optional[Sequence[TextRecogDataSample]] = None
+ ) -> torch.Tensor:
+ """
+ Args:
+ feat (Tensor): Image features with the shape of
+ :math:`(N, C_{in}, H, W)`.
+ data_samples (list[TextRecogDataSample], optional): Batch of
+ TextRecogDataSample, containing valid_ratio information.
+ Defaults to None.
+
+ Returns:
+ Tensor: A tensor of shape :math:`(N, C_{out}, H, W)`.
+ """
+ return self.layer(feat)
diff --git a/mmocr/models/textrecog/encoders/nrtr_encoder.py b/mmocr/models/textrecog/encoders/nrtr_encoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..e7d80778990dce9bd8f22eff9a32b6fc5b64fb5d
--- /dev/null
+++ b/mmocr/models/textrecog/encoders/nrtr_encoder.py
@@ -0,0 +1,108 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from typing import Dict, Optional, Sequence, Union
+
+import torch
+import torch.nn as nn
+from mmengine.model import ModuleList
+
+from mmocr.models.common import TFEncoderLayer
+from mmocr.registry import MODELS
+from mmocr.structures import TextRecogDataSample
+from .base import BaseEncoder
+
+
+@MODELS.register_module()
+class NRTREncoder(BaseEncoder):
+ """Transformer Encoder block with self attention mechanism.
+
+ Args:
+ n_layers (int): The number of sub-encoder-layers in the encoder.
+ Defaults to 6.
+ n_head (int): The number of heads in the multiheadattention models
+ Defaults to 8.
+ d_k (int): Total number of features in key. Defaults to 64.
+ d_v (int): Total number of features in value. Defaults to 64.
+ d_model (int): The number of expected features in the decoder inputs.
+ Defaults to 512.
+ d_inner (int): The dimension of the feedforward network model.
+ Defaults to 256.
+ dropout (float): Dropout rate for MHSA and FFN. Defaults to 0.1.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ """
+
+ def __init__(self,
+ n_layers: int = 6,
+ n_head: int = 8,
+ d_k: int = 64,
+ d_v: int = 64,
+ d_model: int = 512,
+ d_inner: int = 256,
+ dropout: float = 0.1,
+ init_cfg: Optional[Union[Dict,
+ Sequence[Dict]]] = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.d_model = d_model
+ self.layer_stack = ModuleList([
+ TFEncoderLayer(
+ d_model, d_inner, n_head, d_k, d_v, dropout=dropout)
+ for _ in range(n_layers)
+ ])
+ self.layer_norm = nn.LayerNorm(d_model)
+
+ def _get_source_mask(self, src_seq: torch.Tensor,
+ valid_ratios: Sequence[float]) -> torch.Tensor:
+ """Generate mask for source sequence.
+
+ Args:
+ src_seq (torch.Tensor): Image sequence. Shape :math:`(N, T, C)`.
+ valid_ratios (list[float]): The valid ratio of input image. For
+ example, if the width of the original image is w1 and the width
+ after pad is w2, then valid_ratio = w1/w2. source mask is used
+ to cover the area of the pad region.
+
+ Returns:
+ Tensor or None: Source mask. Shape :math:`(N, T)`. The region of
+ pad area are False, and the rest are True.
+ """
+
+ N, T, _ = src_seq.size()
+ mask = None
+ if len(valid_ratios) > 0:
+ mask = src_seq.new_zeros((N, T), device=src_seq.device)
+ for i, valid_ratio in enumerate(valid_ratios):
+ valid_width = min(T, math.ceil(T * valid_ratio))
+ mask[i, :valid_width] = 1
+
+ return mask
+
+ def forward(self,
+ feat: torch.Tensor,
+ data_samples: Sequence[TextRecogDataSample] = None
+ ) -> torch.Tensor:
+ """
+ Args:
+ feat (Tensor): Backbone output of shape :math:`(N, C, H, W)`.
+ data_samples (list[TextRecogDataSample]): Batch of
+ TextRecogDataSample, containing valid_ratio information.
+ Defaults to None.
+
+
+ Returns:
+ Tensor: The encoder output tensor. Shape :math:`(N, T, C)`.
+ """
+ n, c, h, w = feat.size()
+
+ feat = feat.view(n, c, h * w).permute(0, 2, 1).contiguous()
+
+ valid_ratios = []
+ for data_sample in data_samples:
+ valid_ratios.append(data_sample.get('valid_ratio'))
+ mask = self._get_source_mask(feat, valid_ratios)
+
+ output = feat
+ for enc_layer in self.layer_stack:
+ output = enc_layer(output, mask)
+ output = self.layer_norm(output)
+
+ return output
diff --git a/mmocr/models/textrecog/encoders/sar_encoder.py b/mmocr/models/textrecog/encoders/sar_encoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..33d8c1ef8f5b8f57c5762d4449bc8baf06f8a380
--- /dev/null
+++ b/mmocr/models/textrecog/encoders/sar_encoder.py
@@ -0,0 +1,124 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from typing import Dict, Optional, Sequence, Union
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from mmocr.registry import MODELS
+from mmocr.structures import TextRecogDataSample
+from .base import BaseEncoder
+
+
+@MODELS.register_module()
+class SAREncoder(BaseEncoder):
+ """Implementation of encoder module in `SAR.
+
+ `_.
+
+ Args:
+ enc_bi_rnn (bool): If True, use bidirectional RNN in encoder.
+ Defaults to False.
+ rnn_dropout (float): Dropout probability of RNN layer in encoder.
+ Defaults to 0.0.
+ enc_gru (bool): If True, use GRU, else LSTM in encoder. Defaults
+ to False.
+ d_model (int): Dim :math:`D_i` of channels from backbone. Defaults
+ to 512.
+ d_enc (int): Dim :math:`D_m` of encoder RNN layer. Defaults to 512.
+ mask (bool): If True, mask padding in RNN sequence. Defaults to
+ True.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ Defaults to [dict(type='Xavier', layer='Conv2d'),
+ dict(type='Uniform', layer='BatchNorm2d')].
+ """
+
+ def __init__(self,
+ enc_bi_rnn: bool = False,
+ rnn_dropout: Union[int, float] = 0.0,
+ enc_gru: bool = False,
+ d_model: int = 512,
+ d_enc: int = 512,
+ mask: bool = True,
+ init_cfg: Sequence[Dict] = [
+ dict(type='Xavier', layer='Conv2d'),
+ dict(type='Uniform', layer='BatchNorm2d')
+ ],
+ **kwargs) -> None:
+ super().__init__(init_cfg=init_cfg)
+ assert isinstance(enc_bi_rnn, bool)
+ assert isinstance(rnn_dropout, (int, float))
+ assert 0 <= rnn_dropout < 1.0
+ assert isinstance(enc_gru, bool)
+ assert isinstance(d_model, int)
+ assert isinstance(d_enc, int)
+ assert isinstance(mask, bool)
+
+ self.enc_bi_rnn = enc_bi_rnn
+ self.rnn_dropout = rnn_dropout
+ self.mask = mask
+
+ # LSTM Encoder
+ kwargs = dict(
+ input_size=d_model,
+ hidden_size=d_enc,
+ num_layers=2,
+ batch_first=True,
+ dropout=rnn_dropout,
+ bidirectional=enc_bi_rnn)
+ if enc_gru:
+ self.rnn_encoder = nn.GRU(**kwargs)
+ else:
+ self.rnn_encoder = nn.LSTM(**kwargs)
+
+ # global feature transformation
+ encoder_rnn_out_size = d_enc * (int(enc_bi_rnn) + 1)
+ self.linear = nn.Linear(encoder_rnn_out_size, encoder_rnn_out_size)
+
+ def forward(
+ self,
+ feat: torch.Tensor,
+ data_samples: Optional[Sequence[TextRecogDataSample]] = None
+ ) -> torch.Tensor:
+ """
+ Args:
+ feat (Tensor): Tensor of shape :math:`(N, D_i, H, W)`.
+ data_samples (list[TextRecogDataSample], optional): Batch of
+ TextRecogDataSample, containing valid_ratio information.
+ Defaults to None.
+
+ Returns:
+ Tensor: A tensor of shape :math:`(N, D_m)`.
+ """
+ if data_samples is not None:
+ assert len(data_samples) == feat.size(0)
+
+ valid_ratios = None
+ if data_samples is not None:
+ valid_ratios = [
+ data_sample.get('valid_ratio', 1.0)
+ for data_sample in data_samples
+ ] if self.mask else None
+
+ h_feat = feat.size(2)
+ feat_v = F.max_pool2d(
+ feat, kernel_size=(h_feat, 1), stride=1, padding=0)
+ feat_v = feat_v.squeeze(2) # bsz * C * W
+ feat_v = feat_v.permute(0, 2, 1).contiguous() # bsz * W * C
+
+ holistic_feat = self.rnn_encoder(feat_v)[0] # bsz * T * C
+
+ if valid_ratios is not None:
+ valid_hf = []
+ T = holistic_feat.size(1)
+ for i, valid_ratio in enumerate(valid_ratios):
+ valid_step = min(T, math.ceil(T * valid_ratio)) - 1
+ valid_hf.append(holistic_feat[i, valid_step, :])
+ valid_hf = torch.stack(valid_hf, dim=0)
+ else:
+ valid_hf = holistic_feat[:, -1, :] # bsz * C
+
+ holistic_feat = self.linear(valid_hf) # bsz * C
+
+ return holistic_feat
diff --git a/mmocr/models/textrecog/encoders/satrn_encoder.py b/mmocr/models/textrecog/encoders/satrn_encoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..ec6613535f99ca233196adbeb9fec5cdfe2531c6
--- /dev/null
+++ b/mmocr/models/textrecog/encoders/satrn_encoder.py
@@ -0,0 +1,95 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from typing import Dict, List, Optional, Union
+
+import torch.nn as nn
+from mmengine.model import ModuleList
+from torch import Tensor
+
+from mmocr.models.textrecog.layers import (Adaptive2DPositionalEncoding,
+ SATRNEncoderLayer)
+from mmocr.registry import MODELS
+from mmocr.structures import TextRecogDataSample
+from .base import BaseEncoder
+
+
+@MODELS.register_module()
+class SATRNEncoder(BaseEncoder):
+ """Implement encoder for SATRN, see `SATRN.
+
+ `_.
+
+ Args:
+ n_layers (int): Number of attention layers. Defaults to 12.
+ n_head (int): Number of parallel attention heads. Defaults to 8.
+ d_k (int): Dimension of the key vector. Defaults to 64.
+ d_v (int): Dimension of the value vector. Defaults to 64.
+ d_model (int): Dimension :math:`D_m` of the input from previous model.
+ Defaults to 512.
+ n_position (int): Length of the positional encoding vector. Must be
+ greater than ``max_seq_len``. Defaults to 100.
+ d_inner (int): Hidden dimension of feedforward layers. Defaults to 256.
+ dropout (float): Dropout rate. Defaults to 0.1.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ n_layers: int = 12,
+ n_head: int = 8,
+ d_k: int = 64,
+ d_v: int = 64,
+ d_model: int = 512,
+ n_position: int = 100,
+ d_inner: int = 256,
+ dropout: float = 0.1,
+ init_cfg: Optional[Union[Dict, List[Dict]]] = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.d_model = d_model
+ self.position_enc = Adaptive2DPositionalEncoding(
+ d_hid=d_model,
+ n_height=n_position,
+ n_width=n_position,
+ dropout=dropout)
+ self.layer_stack = ModuleList([
+ SATRNEncoderLayer(
+ d_model, d_inner, n_head, d_k, d_v, dropout=dropout)
+ for _ in range(n_layers)
+ ])
+ self.layer_norm = nn.LayerNorm(d_model)
+
+ def forward(self,
+ feat: Tensor,
+ data_samples: List[TextRecogDataSample] = None) -> Tensor:
+ """Forward propagation of encoder.
+
+ Args:
+ feat (Tensor): Feature tensor of shape :math:`(N, D_m, H, W)`.
+ data_samples (list[TextRecogDataSample]): Batch of
+ TextRecogDataSample, containing `valid_ratio` information.
+ Defaults to None.
+
+ Returns:
+ Tensor: A tensor of shape :math:`(N, T, D_m)`.
+ """
+ valid_ratios = [1.0 for _ in range(feat.size(0))]
+ if data_samples is not None:
+ valid_ratios = [
+ data_sample.get('valid_ratio', 1.0)
+ for data_sample in data_samples
+ ]
+ feat = self.position_enc(feat)
+ n, c, h, w = feat.size()
+ mask = feat.new_zeros((n, h, w))
+ for i, valid_ratio in enumerate(valid_ratios):
+ valid_width = min(w, math.ceil(w * valid_ratio))
+ mask[i, :, :valid_width] = 1
+ mask = mask.view(n, h * w)
+ feat = feat.view(n, c, h * w)
+
+ output = feat.permute(0, 2, 1).contiguous()
+ for enc_layer in self.layer_stack:
+ output = enc_layer(output, h, w, mask)
+ output = self.layer_norm(output)
+
+ return output
diff --git a/mmocr/models/textrecog/encoders/svtr_encoder.py b/mmocr/models/textrecog/encoders/svtr_encoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..aa27f42209c80fca9fdd58e1fae4566cbea9cc76
--- /dev/null
+++ b/mmocr/models/textrecog/encoders/svtr_encoder.py
@@ -0,0 +1,639 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+from mmcv.cnn.bricks import DropPath
+from mmengine.model import BaseModule
+from mmengine.model.weight_init import trunc_normal_init
+
+from mmocr.registry import MODELS
+from mmocr.structures import TextRecogDataSample
+
+
+class OverlapPatchEmbed(BaseModule):
+ """Image to the progressive overlapping Patch Embedding.
+
+ Args:
+ in_channels (int): Number of input channels. Defaults to 3.
+ embed_dims (int): The dimensions of embedding. Defaults to 768.
+ num_layers (int, optional): Number of Conv_BN_Layer. Defaults to 2 and
+ limit to [2, 3].
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ in_channels: int = 3,
+ embed_dims: int = 768,
+ num_layers: int = 2,
+ init_cfg: Optional[Union[Dict, List[Dict]]] = None):
+
+ super().__init__(init_cfg=init_cfg)
+
+ assert num_layers in [2, 3], \
+ 'The number of layers must belong to [2, 3]'
+ self.net = nn.Sequential()
+ for num in range(num_layers, 0, -1):
+ if (num == num_layers):
+ _input = in_channels
+ _output = embed_dims // (2**(num - 1))
+ self.net.add_module(
+ f'ConvModule{str(num_layers - num)}',
+ ConvModule(
+ in_channels=_input,
+ out_channels=_output,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='GELU')))
+ _input = _output
+
+ def forward(self, x: torch.Tensor) -> torch.Tensor:
+ """Forward function.
+
+ Args:
+ x (Tensor): A Tensor of shape :math:`(N, C, H, W)`.
+
+ Returns:
+ Tensor: A tensor of shape math:`(N, HW//16, C)`.
+ """
+ x = self.net(x).flatten(2).permute(0, 2, 1)
+ return x
+
+
+class ConvMixer(BaseModule):
+ """The conv Mixer.
+
+ Args:
+ embed_dims (int): Number of character components.
+ num_heads (int, optional): Number of heads. Defaults to 8.
+ input_shape (Tuple[int, int], optional): The shape of input [H, W].
+ Defaults to [8, 25].
+ local_k (Tuple[int, int], optional): Window size. Defaults to [3, 3].
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ embed_dims: int,
+ num_heads: int = 8,
+ input_shape: Tuple[int, int] = [8, 25],
+ local_k: Tuple[int, int] = [3, 3],
+ init_cfg: Optional[Union[Dict, List[Dict]]] = None):
+ super().__init__(init_cfg)
+ self.input_shape = input_shape
+ self.embed_dims = embed_dims
+ self.local_mixer = nn.Conv2d(
+ in_channels=embed_dims,
+ out_channels=embed_dims,
+ kernel_size=local_k,
+ stride=1,
+ padding=(local_k[0] // 2, local_k[1] // 2),
+ groups=num_heads)
+
+ def forward(self, x: torch.Tensor) -> torch.Tensor:
+ """Forward function.
+
+ Args:
+ x (torch.Tensor): A Tensor of shape :math:`(N, HW, C)`.
+
+ Returns:
+ torch.Tensor: Tensor: A tensor of shape math:`(N, HW, C)`.
+ """
+ h, w = self.input_shape
+ x = x.permute(0, 2, 1).reshape([-1, self.embed_dims, h, w])
+ x = self.local_mixer(x)
+ x = x.flatten(2).permute(0, 2, 1)
+ return x
+
+
+class AttnMixer(BaseModule):
+ """One of mixer of {'Global', 'Local'}. Defaults to Global Mixer.
+
+ Args:
+ embed_dims (int): Number of character components.
+ num_heads (int, optional): Number of heads. Defaults to 8.
+ mixer (str, optional): The mixer type, choices are 'Global' and
+ 'Local'. Defaults to 'Global'.
+ input_shape (Tuple[int, int], optional): The shape of input [H, W].
+ Defaults to [8, 25].
+ local_k (Tuple[int, int], optional): Window size. Defaults to [7, 11].
+ qkv_bias (bool, optional): Whether a additive bias is required.
+ Defaults to False.
+ qk_scale (float, optional): A scaling factor. Defaults to None.
+ attn_drop (float, optional): Attn dropout probability. Defaults to 0.0.
+ proj_drop (float, optional): Proj dropout layer. Defaults to 0.0.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ embed_dims: int,
+ num_heads: int = 8,
+ mixer: str = 'Global',
+ input_shape: Tuple[int, int] = [8, 25],
+ local_k: Tuple[int, int] = [7, 11],
+ qkv_bias: bool = False,
+ qk_scale: float = None,
+ attn_drop: float = 0.,
+ proj_drop: float = 0.,
+ init_cfg: Optional[Union[Dict, List[Dict]]] = None):
+ super().__init__(init_cfg)
+ assert mixer in {'Global', 'Local'}, \
+ "The type of mixer must belong to {'Global', 'Local'}"
+ self.num_heads = num_heads
+ head_dim = embed_dims // num_heads
+ self.scale = qk_scale or head_dim**-0.5
+ self.qkv = nn.Linear(embed_dims, embed_dims * 3, bias=qkv_bias)
+ self.attn_drop = nn.Dropout(attn_drop)
+ self.proj = nn.Linear(embed_dims, embed_dims)
+ self.proj_drop = nn.Dropout(proj_drop)
+ self.input_shape = input_shape
+ if input_shape is not None:
+ height, width = input_shape
+ self.input_size = height * width
+ self.embed_dims = embed_dims
+ if mixer == 'Local' and input_shape is not None:
+ hk = local_k[0]
+ wk = local_k[1]
+ mask = torch.ones(
+ [height * width, height + hk - 1, width + wk - 1],
+ dtype=torch.float32)
+ for h in range(0, height):
+ for w in range(0, width):
+ mask[h * width + w, h:h + hk, w:w + wk] = 0.
+ mask = mask[:, hk // 2:height + hk // 2,
+ wk // 2:width + wk // 2].flatten(1)
+ mask[mask >= 1] = -np.inf
+ self.register_buffer('mask', mask[None, None, :, :])
+ self.mixer = mixer
+
+ def forward(self, x: torch.Tensor) -> torch.Tensor:
+ """Forward function.
+
+ Args:
+ x (torch.Tensor): A Tensor of shape :math:`(N, H, W, C)`.
+
+ Returns:
+ torch.Tensor: A Tensor of shape :math:`(N, H, W, C)`.
+ """
+ if self.input_shape is not None:
+ input_size, embed_dims = self.input_size, self.embed_dims
+ else:
+ _, input_size, embed_dims = x.shape
+ qkv = self.qkv(x).reshape((-1, input_size, 3, self.num_heads,
+ embed_dims // self.num_heads)).permute(
+ (2, 0, 3, 1, 4))
+ q, k, v = qkv[0] * self.scale, qkv[1], qkv[2]
+ attn = q.matmul(k.permute(0, 1, 3, 2))
+ if self.mixer == 'Local':
+ attn += self.mask
+ attn = F.softmax(attn, dim=-1)
+ attn = self.attn_drop(attn)
+
+ x = attn.matmul(v).permute(0, 2, 1, 3).reshape(-1, input_size,
+ embed_dims)
+ x = self.proj(x)
+ x = self.proj_drop(x)
+ return x
+
+
+class MLP(BaseModule):
+ """The MLP block.
+
+ Args:
+ in_features (int): The input features.
+ hidden_features (int, optional): The hidden features.
+ Defaults to None.
+ out_features (int, optional): The output features.
+ Defaults to None.
+ drop (float, optional): cfg of dropout function. Defaults to 0.0.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ in_features: int,
+ hidden_features: int = None,
+ out_features: int = None,
+ drop: float = 0.,
+ init_cfg: Optional[Union[Dict, List[Dict]]] = None):
+ super().__init__(init_cfg)
+ hidden_features = hidden_features or in_features
+ out_features = out_features or in_features
+ self.fc1 = nn.Linear(in_features, hidden_features)
+ self.act = nn.GELU()
+ self.fc2 = nn.Linear(hidden_features, out_features)
+ self.drop = nn.Dropout(drop)
+
+ def forward(self, x: torch.Tensor) -> torch.Tensor:
+ """Forward function.
+
+ Args:
+ x (torch.Tensor): A Tensor of shape :math:`(N, H, W, C)`.
+
+ Returns:
+ torch.Tensor: A Tensor of shape :math:`(N, H, W, C)`.
+ """
+ x = self.fc1(x)
+ x = self.act(x)
+ x = self.drop(x)
+ x = self.fc2(x)
+ x = self.drop(x)
+ return x
+
+
+class MixingBlock(BaseModule):
+ """The Mixing block.
+
+ Args:
+ embed_dims (int): Number of character components.
+ num_heads (int): Number of heads
+ mixer (str, optional): The mixer type. Defaults to 'Global'.
+ window_size (Tuple[int ,int], optional): Local window size.
+ Defaults to [7, 11].
+ input_shape (Tuple[int, int], optional): The shape of input [H, W].
+ Defaults to [8, 25].
+ mlp_ratio (float, optional): The ratio of hidden features to input.
+ Defaults to 4.0.
+ qkv_bias (bool, optional): Whether a additive bias is required.
+ Defaults to False.
+ qk_scale (float, optional): A scaling factor. Defaults to None.
+ drop (float, optional): cfg of Dropout. Defaults to 0..
+ attn_drop (float, optional): cfg of Dropout. Defaults to 0.0.
+ drop_path (float, optional): The probability of drop path.
+ Defaults to 0.0.
+ pernorm (bool, optional): Whether to place the MxingBlock before norm.
+ Defaults to True.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ embed_dims: int,
+ num_heads: int,
+ mixer: str = 'Global',
+ window_size: Tuple[int, int] = [7, 11],
+ input_shape: Tuple[int, int] = [8, 25],
+ mlp_ratio: float = 4.,
+ qkv_bias: bool = False,
+ qk_scale: float = None,
+ drop: float = 0.,
+ attn_drop: float = 0.,
+ drop_path=0.,
+ prenorm: bool = True,
+ init_cfg: Optional[Union[Dict, List[Dict]]] = None):
+ super().__init__(init_cfg)
+ self.norm1 = nn.LayerNorm(embed_dims, eps=1e-6)
+ if mixer in {'Global', 'Local'}:
+ self.mixer = AttnMixer(
+ embed_dims,
+ num_heads=num_heads,
+ mixer=mixer,
+ input_shape=input_shape,
+ local_k=window_size,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ attn_drop=attn_drop,
+ proj_drop=drop)
+ elif mixer == 'Conv':
+ self.mixer = ConvMixer(
+ embed_dims,
+ num_heads=num_heads,
+ input_shape=input_shape,
+ local_k=window_size)
+ else:
+ raise TypeError('The mixer must be one of [Global, Local, Conv]')
+ self.drop_path = DropPath(
+ drop_path) if drop_path > 0. else nn.Identity()
+ self.norm2 = nn.LayerNorm(embed_dims, eps=1e-6)
+ mlp_hidden_dim = int(embed_dims * mlp_ratio)
+ self.mlp_ratio = mlp_ratio
+ self.mlp = MLP(
+ in_features=embed_dims, hidden_features=mlp_hidden_dim, drop=drop)
+ self.prenorm = prenorm
+
+ def forward(self, x: torch.Tensor) -> torch.Tensor:
+ """Forward function.
+
+ Args:
+ x (torch.Tensor): A Tensor of shape :math:`(N, H*W, C)`.
+
+ Returns:
+ torch.Tensor: A Tensor of shape :math:`(N, H*W, C)`.
+ """
+ if self.prenorm:
+ x = self.norm1(x + self.drop_path(self.mixer(x)))
+ x = self.norm2(x + self.drop_path(self.mlp(x)))
+ else:
+ x = x + self.drop_path(self.mixer(self.norm1(x)))
+ x = x + self.drop_path(self.mlp(self.norm2(x)))
+ return x
+
+
+class MerigingBlock(BaseModule):
+ """The last block of any stage, except for the last stage.
+
+ Args:
+ in_channels (int): The channels of input.
+ out_channels (int): The channels of output.
+ types (str, optional): Which downsample operation of ['Pool', 'Conv'].
+ Defaults to 'Pool'.
+ stride (Union[int, Tuple[int, int]], optional): Stride of the Conv.
+ Defaults to [2, 1].
+ act (bool, optional): activation function. Defaults to None.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ in_channels: int,
+ out_channels: int,
+ types: str = 'Pool',
+ stride: Union[int, Tuple[int, int]] = [2, 1],
+ act: bool = None,
+ init_cfg: Optional[Union[Dict, List[Dict]]] = None):
+ super().__init__(init_cfg)
+ self.types = types
+ if types == 'Pool':
+ self.avgpool = nn.AvgPool2d(
+ kernel_size=[3, 5], stride=stride, padding=[1, 2])
+ self.maxpool = nn.MaxPool2d(
+ kernel_size=[3, 5], stride=stride, padding=[1, 2])
+ self.proj = nn.Linear(in_channels, out_channels)
+ else:
+ self.conv = nn.Conv2d(
+ in_channels,
+ out_channels,
+ kernel_size=3,
+ stride=stride,
+ padding=1)
+ self.norm = nn.LayerNorm(out_channels)
+ if act is not None:
+ self.act = act()
+ else:
+ self.act = None
+
+ def forward(self, x: torch.Tensor) -> torch.Tensor:
+ """Forward function.
+
+ Args:
+ x (torch.Tensor): A Tensor of shape :math:`(N, H, W, C)`.
+
+ Returns:
+ torch.Tensor: A Tensor of shape :math:`(N, H/2, W, 2C)`.
+ """
+ if self.types == 'Pool':
+ x = (self.avgpool(x) + self.maxpool(x)) * 0.5
+ out = self.proj(x.flatten(2).permute(0, 2, 1))
+
+ else:
+ x = self.conv(x)
+ out = x.flatten(2).permute(0, 2, 1)
+ out = self.norm(out)
+ if self.act is not None:
+ out = self.act(out)
+
+ return out
+
+
+@MODELS.register_module()
+class SVTREncoder(BaseModule):
+ """A PyTorch implementation of `SVTR: Scene Text Recognition with a Single
+ Visual Model `_
+
+ Code is partially modified from https://github.com/PaddlePaddle/PaddleOCR.
+
+ Args:
+ img_size (Tuple[int, int], optional): The expected input image shape.
+ Defaults to [32, 100].
+ in_channels (int, optional): The num of input channels. Defaults to 3.
+ embed_dims (Tuple[int, int, int], optional): Number of input channels.
+ Defaults to [64, 128, 256].
+ depth (Tuple[int, int, int], optional):
+ The number of MixingBlock at each stage. Defaults to [3, 6, 3].
+ num_heads (Tuple[int, int, int], optional): Number of attention heads.
+ Defaults to [2, 4, 8].
+ mixer_types (Tuple[str], optional): Mixing type in a MixingBlock.
+ Defaults to ['Local']*6+['Global']*6.
+ window_size (Tuple[Tuple[int, int]], optional):
+ The height and width of the window at eeach stage.
+ Defaults to [[7, 11], [7, 11], [7, 11]].
+ merging_types (str, optional): The way of downsample in MergingBlock.
+ Defaults to 'Conv'.
+ mlp_ratio (int, optional): Ratio of hidden features to input in MLP.
+ Defaults to 4.
+ qkv_bias (bool, optional):
+ Whether to add bias for qkv in attention modules. Defaults to True.
+ qk_scale (float, optional): A scaling factor. Defaults to None.
+ drop_rate (float, optional): Probability of an element to be zeroed.
+ Defaults to 0.0.
+ last_drop (float, optional): cfg of dropout at last stage.
+ Defaults to 0.1.
+ attn_drop_rate (float, optional): _description_. Defaults to 0..
+ drop_path_rate (float, optional): stochastic depth rate.
+ Defaults to 0.1.
+ out_channels (int, optional): The num of output channels in backone.
+ Defaults to 192.
+ max_seq_len (int, optional): Maximum output sequence length :math:`T`.
+ Defaults to 25.
+ num_layers (int, optional): The num of conv in PatchEmbedding.
+ Defaults to 2.
+ prenorm (bool, optional): Whether to place the MixingBlock before norm.
+ Defaults to True.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ img_size: Tuple[int, int] = [32, 100],
+ in_channels: int = 3,
+ embed_dims: Tuple[int, int, int] = [64, 128, 256],
+ depth: Tuple[int, int, int] = [3, 6, 3],
+ num_heads: Tuple[int, int, int] = [2, 4, 8],
+ mixer_types: Tuple[str] = ['Local'] * 6 + ['Global'] * 6,
+ window_size: Tuple[Tuple[int, int]] = [[7, 11], [7, 11],
+ [7, 11]],
+ merging_types: str = 'Conv',
+ mlp_ratio: int = 4,
+ qkv_bias: bool = True,
+ qk_scale: float = None,
+ drop_rate: float = 0.,
+ last_drop: float = 0.1,
+ attn_drop_rate: float = 0.,
+ drop_path_rate: float = 0.1,
+ out_channels: int = 192,
+ max_seq_len: int = 25,
+ num_layers: int = 2,
+ prenorm: bool = True,
+ init_cfg: Optional[Union[Dict, List[Dict]]] = None):
+ super().__init__(init_cfg)
+ self.img_size = img_size
+ self.embed_dims = embed_dims
+ self.out_channels = out_channels
+ self.prenorm = prenorm
+ self.patch_embed = OverlapPatchEmbed(
+ in_channels=in_channels,
+ embed_dims=embed_dims[0],
+ num_layers=num_layers)
+ num_patches = (img_size[1] // (2**num_layers)) * (
+ img_size[0] // (2**num_layers))
+ self.input_shape = [
+ img_size[0] // (2**num_layers), img_size[1] // (2**num_layers)
+ ]
+ self.absolute_pos_embed = nn.Parameter(
+ torch.zeros([1, num_patches, embed_dims[0]], dtype=torch.float32),
+ requires_grad=True)
+ self.pos_drop = nn.Dropout(drop_rate)
+ dpr = np.linspace(0, drop_path_rate, sum(depth))
+
+ self.blocks1 = nn.ModuleList([
+ MixingBlock(
+ embed_dims=embed_dims[0],
+ num_heads=num_heads[0],
+ mixer=mixer_types[0:depth[0]][i],
+ window_size=window_size[0],
+ input_shape=self.input_shape,
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop=drop_rate,
+ attn_drop=attn_drop_rate,
+ drop_path=dpr[0:depth[0]][i],
+ prenorm=prenorm) for i in range(depth[0])
+ ])
+ self.downsample1 = MerigingBlock(
+ in_channels=embed_dims[0],
+ out_channels=embed_dims[1],
+ types=merging_types,
+ stride=[2, 1])
+ input_shape = [self.input_shape[0] // 2, self.input_shape[1]]
+ self.merging_types = merging_types
+
+ self.blocks2 = nn.ModuleList([
+ MixingBlock(
+ embed_dims=embed_dims[1],
+ num_heads=num_heads[1],
+ mixer=mixer_types[depth[0]:depth[0] + depth[1]][i],
+ window_size=window_size[1],
+ input_shape=input_shape,
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop=drop_rate,
+ attn_drop=attn_drop_rate,
+ drop_path=dpr[depth[0]:depth[0] + depth[1]][i],
+ prenorm=prenorm) for i in range(depth[1])
+ ])
+ self.downsample2 = MerigingBlock(
+ in_channels=embed_dims[1],
+ out_channels=embed_dims[2],
+ types=merging_types,
+ stride=[2, 1])
+ input_shape = [self.input_shape[0] // 4, self.input_shape[1]]
+
+ self.blocks3 = nn.ModuleList([
+ MixingBlock(
+ embed_dims=embed_dims[2],
+ num_heads=num_heads[2],
+ mixer=mixer_types[depth[0] + depth[1]:][i],
+ window_size=window_size[2],
+ input_shape=input_shape,
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop=drop_rate,
+ attn_drop=attn_drop_rate,
+ drop_path=dpr[depth[0] + depth[1]:][i],
+ prenorm=prenorm) for i in range(depth[2])
+ ])
+ self.layer_norm = nn.LayerNorm(self.embed_dims[-1], eps=1e-6)
+ self.avgpool = nn.AdaptiveAvgPool2d([1, max_seq_len])
+ self.last_conv = nn.Conv2d(
+ in_channels=embed_dims[2],
+ out_channels=self.out_channels,
+ kernel_size=1,
+ bias=False,
+ stride=1,
+ padding=0)
+ self.hardwish = nn.Hardswish()
+ self.dropout = nn.Dropout(p=last_drop)
+
+ trunc_normal_init(self.absolute_pos_embed, mean=0, std=0.02)
+ self.apply(self._init_weights)
+
+ def _init_weights(self, m):
+ if isinstance(m, nn.Linear):
+ trunc_normal_init(m.weight, mean=0, std=0.02)
+ if isinstance(m, nn.Linear) and m.bias is not None:
+ nn.init.zeros_(m.bias)
+ if isinstance(m, nn.LayerNorm):
+ nn.init.zeros_(m.bias)
+ nn.init.ones_(m.weight)
+ if isinstance(m, nn.Conv2d):
+ nn.init.kaiming_normal_(
+ m.weight, mode='fan_out', nonlinearity='relu')
+
+ def forward_features(self, x: torch.Tensor) -> torch.Tensor:
+ """Forward function except the last combing operation.
+
+ Args:
+ x (torch.Tensor): A Tensor of shape :math:`(N, H, W, C)`.
+
+ Returns:
+ torch.Tensor: A Tensor of shape :math:`(N, H/16, W/4, 256)`.
+ """
+ x = self.patch_embed(x)
+ x = x + self.absolute_pos_embed
+ x = self.pos_drop(x)
+ for blk in self.blocks1:
+ x = blk(x)
+ x = self.downsample1(
+ x.permute(0, 2, 1).reshape([
+ -1, self.embed_dims[0], self.input_shape[0],
+ self.input_shape[1]
+ ]))
+
+ for blk in self.blocks2:
+ x = blk(x)
+ x = self.downsample2(
+ x.permute(0, 2, 1).reshape([
+ -1, self.embed_dims[1], self.input_shape[0] // 2,
+ self.input_shape[1]
+ ]))
+
+ for blk in self.blocks3:
+ x = blk(x)
+ if not self.prenorm:
+ x = self.layer_norm(x)
+ return x
+
+ def forward(self,
+ x: torch.Tensor,
+ data_samples: List[TextRecogDataSample] = None
+ ) -> torch.Tensor:
+ """Forward function.
+
+ Args:
+ x (torch.Tensor): A Tensor of shape :math:`(N, H/16, W/4, 256)`.
+ data_samples (list[TextRecogDataSample]): Batch of
+ TextRecogDataSample. Defaults to None.
+
+ Returns:
+ torch.Tensor: A Tensor of shape :math:`(N, 1, W/4, 192)`.
+ """
+ x = self.forward_features(x)
+ x = self.avgpool(
+ x.permute(0, 2, 1).reshape([
+ -1, self.embed_dims[2], self.input_shape[0] // 4,
+ self.input_shape[1]
+ ]))
+ x = self.last_conv(x)
+ x = self.hardwish(x)
+ x = self.dropout(x)
+ return x
diff --git a/mmocr/models/textrecog/layers/__init__.py b/mmocr/models/textrecog/layers/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..a1fa8af5586145c8e31c463e6d0620c9f1af2e3b
--- /dev/null
+++ b/mmocr/models/textrecog/layers/__init__.py
@@ -0,0 +1,13 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .conv_layer import BasicBlock, Bottleneck
+from .dot_product_attention_layer import DotProductAttentionLayer
+from .lstm_layer import BidirectionalLSTM
+from .position_aware_layer import PositionAwareLayer
+from .robust_scanner_fusion_layer import RobustScannerFusionLayer
+from .satrn_layers import Adaptive2DPositionalEncoding, SATRNEncoderLayer
+
+__all__ = [
+ 'BidirectionalLSTM', 'Adaptive2DPositionalEncoding', 'BasicBlock',
+ 'Bottleneck', 'RobustScannerFusionLayer', 'DotProductAttentionLayer',
+ 'PositionAwareLayer', 'SATRNEncoderLayer'
+]
diff --git a/mmocr/models/textrecog/layers/__pycache__/__init__.cpython-38.pyc b/mmocr/models/textrecog/layers/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0ecc84158017df8996d8ab3a1ee7407af4a59766
Binary files /dev/null and b/mmocr/models/textrecog/layers/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/layers/__pycache__/conv_layer.cpython-38.pyc b/mmocr/models/textrecog/layers/__pycache__/conv_layer.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..705dd491cf32e7a3689d278d2dec3049174842ca
Binary files /dev/null and b/mmocr/models/textrecog/layers/__pycache__/conv_layer.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/layers/__pycache__/dot_product_attention_layer.cpython-38.pyc b/mmocr/models/textrecog/layers/__pycache__/dot_product_attention_layer.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..84b19664e6843e26d208c8e02ba49d8d9b6c6076
Binary files /dev/null and b/mmocr/models/textrecog/layers/__pycache__/dot_product_attention_layer.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/layers/__pycache__/lstm_layer.cpython-38.pyc b/mmocr/models/textrecog/layers/__pycache__/lstm_layer.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..9c4d9180c20c4ed39d01ff2e6a5f666cab6feaa3
Binary files /dev/null and b/mmocr/models/textrecog/layers/__pycache__/lstm_layer.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/layers/__pycache__/position_aware_layer.cpython-38.pyc b/mmocr/models/textrecog/layers/__pycache__/position_aware_layer.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1200a11dba936f475c0c6742a546fd9258a34a55
Binary files /dev/null and b/mmocr/models/textrecog/layers/__pycache__/position_aware_layer.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/layers/__pycache__/robust_scanner_fusion_layer.cpython-38.pyc b/mmocr/models/textrecog/layers/__pycache__/robust_scanner_fusion_layer.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..23ba9a3828e159fa7c405c94b61937e9e7e96afd
Binary files /dev/null and b/mmocr/models/textrecog/layers/__pycache__/robust_scanner_fusion_layer.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/layers/__pycache__/satrn_layers.cpython-38.pyc b/mmocr/models/textrecog/layers/__pycache__/satrn_layers.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8cc8abf974588fde52e763b63d4e39cd0be87ad0
Binary files /dev/null and b/mmocr/models/textrecog/layers/__pycache__/satrn_layers.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/layers/conv_layer.py b/mmocr/models/textrecog/layers/conv_layer.py
new file mode 100644
index 0000000000000000000000000000000000000000..a60f2f5599318e29fd3e97b6079fa6db388a507e
--- /dev/null
+++ b/mmocr/models/textrecog/layers/conv_layer.py
@@ -0,0 +1,182 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+from mmcv.cnn import build_plugin_layer
+
+
+def conv3x3(in_planes, out_planes, stride=1):
+ """3x3 convolution with padding."""
+ return nn.Conv2d(
+ in_planes,
+ out_planes,
+ kernel_size=3,
+ stride=stride,
+ padding=1,
+ bias=False)
+
+
+def conv1x1(in_planes, out_planes):
+ """1x1 convolution with padding."""
+ return nn.Conv2d(
+ in_planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False)
+
+
+class BasicBlock(nn.Module):
+
+ expansion = 1
+
+ def __init__(self,
+ inplanes,
+ planes,
+ stride=1,
+ downsample=None,
+ use_conv1x1=False,
+ plugins=None):
+ super().__init__()
+
+ if use_conv1x1:
+ self.conv1 = conv1x1(inplanes, planes)
+ self.conv2 = conv3x3(planes, planes * self.expansion, stride)
+ else:
+ self.conv1 = conv3x3(inplanes, planes, stride)
+ self.conv2 = conv3x3(planes, planes * self.expansion)
+
+ self.with_plugins = False
+ if plugins:
+ if isinstance(plugins, dict):
+ plugins = [plugins]
+ self.with_plugins = True
+ # collect plugins for conv1/conv2/
+ self.before_conv1_plugin = [
+ plugin['cfg'] for plugin in plugins
+ if plugin['position'] == 'before_conv1'
+ ]
+ self.after_conv1_plugin = [
+ plugin['cfg'] for plugin in plugins
+ if plugin['position'] == 'after_conv1'
+ ]
+ self.after_conv2_plugin = [
+ plugin['cfg'] for plugin in plugins
+ if plugin['position'] == 'after_conv2'
+ ]
+ self.after_shortcut_plugin = [
+ plugin['cfg'] for plugin in plugins
+ if plugin['position'] == 'after_shortcut'
+ ]
+
+ self.planes = planes
+ self.bn1 = nn.BatchNorm2d(planes)
+ self.relu = nn.ReLU(inplace=True)
+ self.bn2 = nn.BatchNorm2d(planes * self.expansion)
+ self.downsample = downsample
+ self.stride = stride
+
+ if self.with_plugins:
+ self.before_conv1_plugin_names = self.make_block_plugins(
+ inplanes, self.before_conv1_plugin)
+ self.after_conv1_plugin_names = self.make_block_plugins(
+ planes, self.after_conv1_plugin)
+ self.after_conv2_plugin_names = self.make_block_plugins(
+ planes, self.after_conv2_plugin)
+ self.after_shortcut_plugin_names = self.make_block_plugins(
+ planes, self.after_shortcut_plugin)
+
+ def make_block_plugins(self, in_channels, plugins):
+ """make plugins for block.
+
+ Args:
+ in_channels (int): Input channels of plugin.
+ plugins (list[dict]): List of plugins cfg to build.
+
+ Returns:
+ list[str]: List of the names of plugin.
+ """
+ assert isinstance(plugins, list)
+ plugin_names = []
+ for plugin in plugins:
+ plugin = plugin.copy()
+ name, layer = build_plugin_layer(
+ plugin,
+ in_channels=in_channels,
+ out_channels=in_channels,
+ postfix=plugin.pop('postfix', ''))
+ assert not hasattr(self, name), f'duplicate plugin {name}'
+ self.add_module(name, layer)
+ plugin_names.append(name)
+ return plugin_names
+
+ def forward_plugin(self, x, plugin_names):
+ out = x
+ for name in plugin_names:
+ out = getattr(self, name)(x)
+ return out
+
+ def forward(self, x):
+ if self.with_plugins:
+ x = self.forward_plugin(x, self.before_conv1_plugin_names)
+ residual = x
+
+ out = self.conv1(x)
+ out = self.bn1(out)
+ out = self.relu(out)
+
+ if self.with_plugins:
+ out = self.forward_plugin(out, self.after_conv1_plugin_names)
+
+ out = self.conv2(out)
+ out = self.bn2(out)
+
+ if self.with_plugins:
+ out = self.forward_plugin(out, self.after_conv2_plugin_names)
+
+ if self.downsample is not None:
+ residual = self.downsample(x)
+
+ out += residual
+ out = self.relu(out)
+
+ if self.with_plugins:
+ out = self.forward_plugin(out, self.after_shortcut_plugin_names)
+
+ return out
+
+
+class Bottleneck(nn.Module):
+ expansion = 4
+
+ def __init__(self, inplanes, planes, stride=1, downsample=False):
+ super().__init__()
+ self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
+ self.bn1 = nn.BatchNorm2d(planes)
+ self.conv2 = nn.Conv2d(planes, planes, 3, stride, 1, bias=False)
+ self.bn2 = nn.BatchNorm2d(planes)
+ self.conv3 = nn.Conv2d(
+ planes, planes * self.expansion, kernel_size=1, bias=False)
+ self.bn3 = nn.BatchNorm2d(planes * self.expansion)
+ self.relu = nn.ReLU(inplace=True)
+ if downsample:
+ self.downsample = nn.Sequential(
+ nn.Conv2d(
+ inplanes, planes * self.expansion, 1, stride, bias=False),
+ nn.BatchNorm2d(planes * self.expansion),
+ )
+ else:
+ self.downsample = nn.Sequential()
+
+ def forward(self, x):
+ residual = self.downsample(x)
+
+ out = self.conv1(x)
+ out = self.bn1(out)
+ out = self.relu(out)
+
+ out = self.conv2(out)
+ out = self.bn2(out)
+ out = self.relu(out)
+
+ out = self.conv3(out)
+ out = self.bn3(out)
+
+ out += residual
+ out = self.relu(out)
+
+ return out
diff --git a/mmocr/models/textrecog/layers/dot_product_attention_layer.py b/mmocr/models/textrecog/layers/dot_product_attention_layer.py
new file mode 100644
index 0000000000000000000000000000000000000000..6d9cdb6528d90d9ec6e0bf0ac2a2343bd7227cc2
--- /dev/null
+++ b/mmocr/models/textrecog/layers/dot_product_attention_layer.py
@@ -0,0 +1,28 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+
+class DotProductAttentionLayer(nn.Module):
+
+ def __init__(self, dim_model=None):
+ super().__init__()
+
+ self.scale = dim_model**-0.5 if dim_model is not None else 1.
+
+ def forward(self, query, key, value, mask=None):
+ n, seq_len = mask.size()
+ logits = torch.matmul(query.permute(0, 2, 1), key) * self.scale
+
+ if mask is not None:
+ mask = mask.view(n, 1, seq_len)
+ logits = logits.masked_fill(mask, float('-inf'))
+
+ weights = F.softmax(logits, dim=2)
+
+ glimpse = torch.matmul(weights, value.transpose(1, 2))
+
+ glimpse = glimpse.permute(0, 2, 1).contiguous()
+
+ return glimpse
diff --git a/mmocr/models/textrecog/layers/lstm_layer.py b/mmocr/models/textrecog/layers/lstm_layer.py
new file mode 100644
index 0000000000000000000000000000000000000000..16d3c1a4e5285c238176d2e0be76463657f282e5
--- /dev/null
+++ b/mmocr/models/textrecog/layers/lstm_layer.py
@@ -0,0 +1,21 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+
+
+class BidirectionalLSTM(nn.Module):
+
+ def __init__(self, nIn, nHidden, nOut):
+ super().__init__()
+
+ self.rnn = nn.LSTM(nIn, nHidden, bidirectional=True)
+ self.embedding = nn.Linear(nHidden * 2, nOut)
+
+ def forward(self, input):
+ recurrent, _ = self.rnn(input)
+ T, b, h = recurrent.size()
+ t_rec = recurrent.view(T * b, h)
+
+ output = self.embedding(t_rec) # [T * b, nOut]
+ output = output.view(T, b, -1)
+
+ return output
diff --git a/mmocr/models/textrecog/layers/position_aware_layer.py b/mmocr/models/textrecog/layers/position_aware_layer.py
new file mode 100644
index 0000000000000000000000000000000000000000..2c994e372782aa882e9c3a32cec4e9bf733008ae
--- /dev/null
+++ b/mmocr/models/textrecog/layers/position_aware_layer.py
@@ -0,0 +1,36 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+
+
+class PositionAwareLayer(nn.Module):
+
+ def __init__(self, dim_model, rnn_layers=2):
+ super().__init__()
+
+ self.dim_model = dim_model
+
+ self.rnn = nn.LSTM(
+ input_size=dim_model,
+ hidden_size=dim_model,
+ num_layers=rnn_layers,
+ batch_first=True)
+
+ self.mixer = nn.Sequential(
+ nn.Conv2d(
+ dim_model, dim_model, kernel_size=3, stride=1, padding=1),
+ nn.ReLU(True),
+ nn.Conv2d(
+ dim_model, dim_model, kernel_size=3, stride=1, padding=1))
+
+ def forward(self, img_feature):
+ n, c, h, w = img_feature.size()
+
+ rnn_input = img_feature.permute(0, 2, 3, 1).contiguous()
+ rnn_input = rnn_input.view(n * h, w, c)
+ rnn_output, _ = self.rnn(rnn_input)
+ rnn_output = rnn_output.view(n, h, w, c)
+ rnn_output = rnn_output.permute(0, 3, 1, 2).contiguous()
+
+ out = self.mixer(rnn_output)
+
+ return out
diff --git a/mmocr/models/textrecog/layers/robust_scanner_fusion_layer.py b/mmocr/models/textrecog/layers/robust_scanner_fusion_layer.py
new file mode 100644
index 0000000000000000000000000000000000000000..126d119f3e3853c53d1a0a584c6cfbc0197ca90c
--- /dev/null
+++ b/mmocr/models/textrecog/layers/robust_scanner_fusion_layer.py
@@ -0,0 +1,24 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmengine.model import BaseModule
+
+
+class RobustScannerFusionLayer(BaseModule):
+
+ def __init__(self, dim_model, dim=-1, init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+
+ self.dim_model = dim_model
+ self.dim = dim
+
+ self.linear_layer = nn.Linear(dim_model * 2, dim_model * 2)
+ self.glu_layer = nn.GLU(dim=dim)
+
+ def forward(self, x0, x1):
+ assert x0.size() == x1.size()
+ fusion_input = torch.cat([x0, x1], self.dim)
+ output = self.linear_layer(fusion_input)
+ output = self.glu_layer(output)
+
+ return output
diff --git a/mmocr/models/textrecog/layers/satrn_layers.py b/mmocr/models/textrecog/layers/satrn_layers.py
new file mode 100644
index 0000000000000000000000000000000000000000..a8441c1bcf0f98c10ff35ce270578016e003d1e6
--- /dev/null
+++ b/mmocr/models/textrecog/layers/satrn_layers.py
@@ -0,0 +1,230 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Union
+
+import numpy as np
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+from mmengine.model import BaseModule
+from torch import Tensor
+
+from mmocr.models.common import MultiHeadAttention
+
+
+class SATRNEncoderLayer(BaseModule):
+ """Implement encoder layer for SATRN, see `SATRN.
+
+ `_.
+
+ Args:
+ d_model (int): Dimension :math:`D_m` of the input from previous model.
+ Defaults to 512.
+ d_inner (int): Hidden dimension of feedforward layers. Defaults to 256.
+ n_head (int): Number of parallel attention heads. Defaults to 8.
+ d_k (int): Dimension of the key vector. Defaults to 64.
+ d_v (int): Dimension of the value vector. Defaults to 64.
+ dropout (float): Dropout rate. Defaults to 0.1.
+ qkv_bias (bool): Whether to use bias. Defaults to False.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ d_model: int = 512,
+ d_inner: int = 512,
+ n_head: int = 8,
+ d_k: int = 64,
+ d_v: int = 64,
+ dropout: float = 0.1,
+ qkv_bias: bool = False,
+ init_cfg: Optional[Union[Dict, List[Dict]]] = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.norm1 = nn.LayerNorm(d_model)
+ self.attn = MultiHeadAttention(
+ n_head, d_model, d_k, d_v, qkv_bias=qkv_bias, dropout=dropout)
+ self.norm2 = nn.LayerNorm(d_model)
+ self.feed_forward = LocalityAwareFeedforward(d_model, d_inner)
+
+ def forward(self,
+ x: Tensor,
+ h: int,
+ w: int,
+ mask: Optional[Tensor] = None) -> Tensor:
+ """Forward propagation of encoder.
+
+ Args:
+ x (Tensor): Feature tensor of shape :math:`(N, h*w, D_m)`.
+ h (int): Height of the original feature.
+ w (int): Width of the original feature.
+ mask (Tensor, optional): Mask used for masked multi-head attention.
+ Defaults to None.
+
+ Returns:
+ Tensor: A tensor of shape :math:`(N, h*w, D_m)`.
+ """
+ n, hw, c = x.size()
+ residual = x
+ x = self.norm1(x)
+ x = residual + self.attn(x, x, x, mask)
+ residual = x
+ x = self.norm2(x)
+ x = x.transpose(1, 2).contiguous().view(n, c, h, w)
+ x = self.feed_forward(x)
+ x = x.view(n, c, hw).transpose(1, 2)
+ x = residual + x
+ return x
+
+
+class LocalityAwareFeedforward(BaseModule):
+ """Locality-aware feedforward layer in SATRN, see `SATRN.
+
+ `_
+
+ Args:
+ d_in (int): Dimension of the input features.
+ d_hid (int): Hidden dimension of feedforward layers.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ Defaults to [dict(type='Xavier', layer='Conv2d'),
+ dict(type='Constant', layer='BatchNorm2d', val=1, bias=0)].
+ """
+
+ def __init__(
+ self,
+ d_in: int,
+ d_hid: int,
+ init_cfg: Optional[Union[Dict, List[Dict]]] = [
+ dict(type='Xavier', layer='Conv2d'),
+ dict(type='Constant', layer='BatchNorm2d', val=1, bias=0)
+ ]
+ ) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.conv1 = ConvModule(
+ d_in,
+ d_hid,
+ kernel_size=1,
+ padding=0,
+ bias=False,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'))
+
+ self.depthwise_conv = ConvModule(
+ d_hid,
+ d_hid,
+ kernel_size=3,
+ padding=1,
+ bias=False,
+ groups=d_hid,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'))
+
+ self.conv2 = ConvModule(
+ d_hid,
+ d_in,
+ kernel_size=1,
+ padding=0,
+ bias=False,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'))
+
+ def forward(self, x: Tensor) -> Tensor:
+ """Forward propagation of Locality Aware Feedforward module.
+
+ Args:
+ x (Tensor): Feature tensor.
+
+ Returns:
+ Tensor: Feature tensor after Locality Aware Feedforward.
+ """
+ x = self.conv1(x)
+ x = self.depthwise_conv(x)
+ x = self.conv2(x)
+ return x
+
+
+class Adaptive2DPositionalEncoding(BaseModule):
+ """Implement Adaptive 2D positional encoder for SATRN, see `SATRN.
+
+ `_ Modified from
+ https://github.com/Media-Smart/vedastr Licensed under the Apache License,
+ Version 2.0 (the "License");
+
+ Args:
+ d_hid (int): Dimensions of hidden layer. Defaults to 512.
+ n_height (int): Max height of the 2D feature output. Defaults to 100.
+ n_width (int): Max width of the 2D feature output. Defaults to 100.
+ dropout (float): Dropout rate. Defaults to 0.1.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ Defaults to [dict(type='Xavier', layer='Conv2d')]
+ """
+
+ def __init__(
+ self,
+ d_hid: int = 512,
+ n_height: int = 100,
+ n_width: int = 100,
+ dropout: float = 0.1,
+ init_cfg: Optional[Union[Dict, List[Dict]]] = [
+ dict(type='Xavier', layer='Conv2d')
+ ]
+ ) -> None:
+ super().__init__(init_cfg=init_cfg)
+
+ h_position_encoder = self._get_sinusoid_encoding_table(n_height, d_hid)
+ h_position_encoder = h_position_encoder.transpose(0, 1)
+ h_position_encoder = h_position_encoder.view(1, d_hid, n_height, 1)
+
+ w_position_encoder = self._get_sinusoid_encoding_table(n_width, d_hid)
+ w_position_encoder = w_position_encoder.transpose(0, 1)
+ w_position_encoder = w_position_encoder.view(1, d_hid, 1, n_width)
+
+ self.register_buffer('h_position_encoder', h_position_encoder)
+ self.register_buffer('w_position_encoder', w_position_encoder)
+
+ self.h_scale = self._scale_factor_generate(d_hid)
+ self.w_scale = self._scale_factor_generate(d_hid)
+ self.pool = nn.AdaptiveAvgPool2d(1)
+ self.dropout = nn.Dropout(p=dropout)
+
+ @staticmethod
+ def _get_sinusoid_encoding_table(n_position: int, d_hid: int) -> Tensor:
+ """Generate sinusoid position encoding table."""
+ denominator = torch.Tensor([
+ 1.0 / np.power(10000, 2 * (hid_j // 2) / d_hid)
+ for hid_j in range(d_hid)
+ ])
+ denominator = denominator.view(1, -1)
+ pos_tensor = torch.arange(n_position).unsqueeze(-1).float()
+ sinusoid_table = pos_tensor * denominator
+ sinusoid_table[:, 0::2] = torch.sin(sinusoid_table[:, 0::2])
+ sinusoid_table[:, 1::2] = torch.cos(sinusoid_table[:, 1::2])
+
+ return sinusoid_table
+
+ @staticmethod
+ def _scale_factor_generate(d_hid: int) -> nn.Sequential:
+ """Generate scale factor layers."""
+ scale_factor = nn.Sequential(
+ nn.Conv2d(d_hid, d_hid, kernel_size=1), nn.ReLU(inplace=True),
+ nn.Conv2d(d_hid, d_hid, kernel_size=1), nn.Sigmoid())
+
+ return scale_factor
+
+ def forward(self, x: Tensor) -> Tensor:
+ """Forward propagation of Locality Aware Feedforward module.
+
+ Args:
+ x (Tensor): Feature tensor.
+
+ Returns:
+ Tensor: Feature tensor after Locality Aware Feedforward.
+ """
+ _, _, h, w = x.size()
+ avg_pool = self.pool(x)
+ h_pos_encoding = \
+ self.h_scale(avg_pool) * self.h_position_encoder[:, :, :h, :]
+ w_pos_encoding = \
+ self.w_scale(avg_pool) * self.w_position_encoder[:, :, :, :w]
+ out = x + h_pos_encoding + w_pos_encoding
+ out = self.dropout(out)
+
+ return out
diff --git a/mmocr/models/textrecog/module_losses/__init__.py b/mmocr/models/textrecog/module_losses/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..f5a81305d4fc345d6ce4c73a806aad551fac85b4
--- /dev/null
+++ b/mmocr/models/textrecog/module_losses/__init__.py
@@ -0,0 +1,9 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .abi_module_loss import ABIModuleLoss
+from .base import BaseTextRecogModuleLoss
+from .ce_module_loss import CEModuleLoss
+from .ctc_module_loss import CTCModuleLoss
+
+__all__ = [
+ 'BaseTextRecogModuleLoss', 'CEModuleLoss', 'CTCModuleLoss', 'ABIModuleLoss'
+]
diff --git a/mmocr/models/textrecog/module_losses/__pycache__/__init__.cpython-38.pyc b/mmocr/models/textrecog/module_losses/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..681d6ce8a37dda97e58c706d6fae522bcb95b2c3
Binary files /dev/null and b/mmocr/models/textrecog/module_losses/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/module_losses/__pycache__/abi_module_loss.cpython-38.pyc b/mmocr/models/textrecog/module_losses/__pycache__/abi_module_loss.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..02eef3cae30960c35cc59cb71e98ca4244263695
Binary files /dev/null and b/mmocr/models/textrecog/module_losses/__pycache__/abi_module_loss.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/module_losses/__pycache__/base.cpython-38.pyc b/mmocr/models/textrecog/module_losses/__pycache__/base.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..190d707ae7505c7e1598b5ce9fa63d7df09ca6c6
Binary files /dev/null and b/mmocr/models/textrecog/module_losses/__pycache__/base.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/module_losses/__pycache__/ce_module_loss.cpython-38.pyc b/mmocr/models/textrecog/module_losses/__pycache__/ce_module_loss.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c1da8e5936c0d3e757ff9650631456950755b8b8
Binary files /dev/null and b/mmocr/models/textrecog/module_losses/__pycache__/ce_module_loss.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/module_losses/__pycache__/ctc_module_loss.cpython-38.pyc b/mmocr/models/textrecog/module_losses/__pycache__/ctc_module_loss.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1cde402884d85a0371c584a60601d7d10cef510e
Binary files /dev/null and b/mmocr/models/textrecog/module_losses/__pycache__/ctc_module_loss.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/module_losses/abi_module_loss.py b/mmocr/models/textrecog/module_losses/abi_module_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..918847b9d02bcb7f5e9de9abbb2b0d0837dfe47c
--- /dev/null
+++ b/mmocr/models/textrecog/module_losses/abi_module_loss.py
@@ -0,0 +1,99 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, Sequence, Union
+
+import torch
+
+from mmocr.models.common.dictionary import Dictionary
+from mmocr.registry import MODELS
+from mmocr.structures import TextRecogDataSample
+from .base import BaseTextRecogModuleLoss
+from .ce_module_loss import CEModuleLoss
+
+
+@MODELS.register_module()
+class ABIModuleLoss(BaseTextRecogModuleLoss):
+ """Implementation of ABINet multiloss that allows mixing different types of
+ losses with weights.
+
+ Args:
+ dictionary (dict or :obj:`Dictionary`): The config for `Dictionary` or
+ the instance of `Dictionary`.
+ max_seq_len (int): Maximum sequence length. The sequence is usually
+ generated from decoder. Defaults to 40.
+ letter_case (str): There are three options to alter the letter cases
+ of gt texts:
+ - unchanged: Do not change gt texts.
+ - upper: Convert gt texts into uppercase characters.
+ - lower: Convert gt texts into lowercase characters.
+ Usually, it only works for English characters. Defaults to
+ 'unchanged'.
+ weight_vis (float or int): The weight of vision decoder loss. Defaults
+ to 1.0.
+ weight_dec (float or int): The weight of language decoder loss.
+ Defaults to 1.0.
+ weight_fusion (float or int): The weight of fuser (aligner) loss.
+ Defaults to 1.0.
+ """
+
+ def __init__(self,
+ dictionary: Union[Dict, Dictionary],
+ max_seq_len: int = 40,
+ letter_case: str = 'unchanged',
+ weight_vis: Union[float, int] = 1.0,
+ weight_lang: Union[float, int] = 1.0,
+ weight_fusion: Union[float, int] = 1.0,
+ **kwargs) -> None:
+ assert isinstance(weight_vis, (float, int))
+ assert isinstance(weight_lang, (float, int))
+ assert isinstance(weight_fusion, (float, int))
+ super().__init__(
+ dictionary=dictionary,
+ max_seq_len=max_seq_len,
+ letter_case=letter_case)
+ self.weight_vis = weight_vis
+ self.weight_lang = weight_lang
+ self.weight_fusion = weight_fusion
+ self._ce_loss = CEModuleLoss(
+ self.dictionary,
+ max_seq_len,
+ letter_case,
+ reduction='mean',
+ ignore_first_char=True)
+
+ def forward(self, outputs: Dict,
+ data_samples: Sequence[TextRecogDataSample]) -> Dict:
+ """
+ Args:
+ outputs (dict): The output dictionary with at least one of
+ ``out_vis``, ``out_langs`` and ``out_fusers`` specified.
+ data_samples (list[TextRecogDataSample]): List of
+ ``TextRecogDataSample`` which are processed by ``get_target``.
+
+ Returns:
+ dict: A loss dictionary with ``loss_visual``, ``loss_lang`` and
+ ``loss_fusion``. Each should either be the loss tensor or None if
+ the output of its corresponding module is not given.
+ """
+ assert 'out_vis' in outputs or \
+ 'out_langs' in outputs or 'out_fusers' in outputs
+ losses = {}
+
+ if outputs.get('out_vis', None):
+ losses['loss_visual'] = self.weight_vis * self._ce_loss(
+ outputs['out_vis']['logits'], data_samples)['loss_ce']
+ if outputs.get('out_langs', None):
+ lang_losses = []
+ for out_lang in outputs['out_langs']:
+ lang_losses.append(
+ self._ce_loss(out_lang['logits'], data_samples)['loss_ce'])
+ losses['loss_lang'] = self.weight_lang * torch.mean(
+ torch.stack(lang_losses))
+ if outputs.get('out_fusers', None):
+ fuser_losses = []
+ for out_fuser in outputs['out_fusers']:
+ fuser_losses.append(
+ self._ce_loss(out_fuser['logits'],
+ data_samples)['loss_ce'])
+ losses['loss_fusion'] = self.weight_fusion * torch.mean(
+ torch.stack(fuser_losses))
+ return losses
diff --git a/mmocr/models/textrecog/module_losses/base.py b/mmocr/models/textrecog/module_losses/base.py
new file mode 100644
index 0000000000000000000000000000000000000000..5fbf83df9dbfe9d962d2e37af7edde7c833b603a
--- /dev/null
+++ b/mmocr/models/textrecog/module_losses/base.py
@@ -0,0 +1,132 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+
+from typing import Dict, Sequence, Union
+
+import torch
+import torch.nn as nn
+
+from mmocr.models.common.dictionary import Dictionary
+from mmocr.registry import TASK_UTILS
+from mmocr.structures import TextRecogDataSample
+
+
+class BaseTextRecogModuleLoss(nn.Module):
+ """Base recognition loss.
+
+ Args:
+ dictionary (dict or :obj:`Dictionary`): The config for `Dictionary` or
+ the instance of `Dictionary`.
+ max_seq_len (int): Maximum sequence length. The sequence is usually
+ generated from decoder. Defaults to 40.
+ letter_case (str): There are three options to alter the letter cases
+ of gt texts:
+ - unchanged: Do not change gt texts.
+ - upper: Convert gt texts into uppercase characters.
+ - lower: Convert gt texts into lowercase characters.
+ Usually, it only works for English characters. Defaults to
+ 'unchanged'.
+ pad_with (str): The padding strategy for ``gt_text.padded_indexes``.
+ Defaults to 'auto'. Options are:
+ - 'auto': Use dictionary.padding_idx to pad gt texts, or
+ dictionary.end_idx if dictionary.padding_idx
+ is None.
+ - 'padding': Always use dictionary.padding_idx to pad gt texts.
+ - 'end': Always use dictionary.end_idx to pad gt texts.
+ - 'none': Do not pad gt texts.
+ """
+
+ def __init__(self,
+ dictionary: Union[Dict, Dictionary],
+ max_seq_len: int = 40,
+ letter_case: str = 'unchanged',
+ pad_with: str = 'auto',
+ **kwargs) -> None:
+ super().__init__()
+ if isinstance(dictionary, dict):
+ self.dictionary = TASK_UTILS.build(dictionary)
+ elif isinstance(dictionary, Dictionary):
+ self.dictionary = dictionary
+ else:
+ raise TypeError(
+ 'The type of dictionary should be `Dictionary` or dict, '
+ f'but got {type(dictionary)}')
+ self.max_seq_len = max_seq_len
+ assert letter_case in ['unchanged', 'upper', 'lower']
+ self.letter_case = letter_case
+
+ assert pad_with in ['auto', 'padding', 'end', 'none']
+ if pad_with == 'auto':
+ self.pad_idx = self.dictionary.padding_idx or \
+ self.dictionary.end_idx
+ elif pad_with == 'padding':
+ self.pad_idx = self.dictionary.padding_idx
+ elif pad_with == 'end':
+ self.pad_idx = self.dictionary.end_idx
+ else:
+ self.pad_idx = None
+ if self.pad_idx is None and pad_with != 'none':
+ if pad_with == 'auto':
+ raise ValueError('pad_with="auto", but dictionary.end_idx'
+ ' and dictionary.padding_idx are both None')
+ else:
+ raise ValueError(
+ f'pad_with="{pad_with}", but dictionary.{pad_with}_idx is'
+ ' None')
+
+ def get_targets(
+ self, data_samples: Sequence[TextRecogDataSample]
+ ) -> Sequence[TextRecogDataSample]:
+ """Target generator.
+
+ Args:
+ data_samples (list[TextRecogDataSample]): It usually includes
+ ``gt_text`` information.
+
+ Returns:
+ list[TextRecogDataSample]: Updated data_samples. Two keys will be
+ added to data_sample:
+
+ - indexes (torch.LongTensor): Character indexes representing gt
+ texts. All special tokens are excluded, except for UKN.
+ - padded_indexes (torch.LongTensor): Character indexes
+ representing gt texts with BOS and EOS if applicable, following
+ several padding indexes until the length reaches ``max_seq_len``.
+ In particular, if ``pad_with='none'``, no padding will be
+ applied.
+ """
+
+ for data_sample in data_samples:
+ if data_sample.get('have_target', False):
+ continue
+ text = data_sample.gt_text.item
+ if self.letter_case in ['upper', 'lower']:
+ text = getattr(text, self.letter_case)()
+ indexes = self.dictionary.str2idx(text)
+ indexes = torch.LongTensor(indexes)
+
+ # target indexes for loss
+ src_target = torch.LongTensor(indexes.size(0) + 2).fill_(0)
+ src_target[1:-1] = indexes
+ if self.dictionary.start_idx is not None:
+ src_target[0] = self.dictionary.start_idx
+ slice_start = 0
+ else:
+ slice_start = 1
+ if self.dictionary.end_idx is not None:
+ src_target[-1] = self.dictionary.end_idx
+ slice_end = src_target.size(0)
+ else:
+ slice_end = src_target.size(0) - 1
+ src_target = src_target[slice_start:slice_end]
+ if self.pad_idx is not None:
+ padded_indexes = (torch.ones(self.max_seq_len) *
+ self.pad_idx).long()
+ char_num = min(src_target.size(0), self.max_seq_len)
+ padded_indexes[:char_num] = src_target[:char_num]
+ else:
+ padded_indexes = src_target
+ # put in DataSample
+ data_sample.gt_text.indexes = indexes
+ data_sample.gt_text.padded_indexes = padded_indexes
+ data_sample.set_metainfo(dict(have_target=True))
+ return data_samples
diff --git a/mmocr/models/textrecog/module_losses/ce_module_loss.py b/mmocr/models/textrecog/module_losses/ce_module_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..a351ea0c553bf1e1c7c9534630178904ba0f1a30
--- /dev/null
+++ b/mmocr/models/textrecog/module_losses/ce_module_loss.py
@@ -0,0 +1,138 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from typing import Dict, Sequence, Union
+
+import torch
+import torch.nn as nn
+
+from mmocr.models.common.dictionary import Dictionary
+from mmocr.registry import MODELS
+from mmocr.structures import TextRecogDataSample
+from .base import BaseTextRecogModuleLoss
+
+
+@MODELS.register_module()
+class CEModuleLoss(BaseTextRecogModuleLoss):
+ """Implementation of loss module for encoder-decoder based text recognition
+ method with CrossEntropy loss.
+
+ Args:
+ dictionary (dict or :obj:`Dictionary`): The config for `Dictionary` or
+ the instance of `Dictionary`.
+ max_seq_len (int): Maximum sequence length. The sequence is usually
+ generated from decoder. Defaults to 40.
+ letter_case (str): There are three options to alter the letter cases
+ of gt texts:
+ - unchanged: Do not change gt texts.
+ - upper: Convert gt texts into uppercase characters.
+ - lower: Convert gt texts into lowercase characters.
+ Usually, it only works for English characters. Defaults to
+ 'unchanged'.
+ pad_with (str): The padding strategy for ``gt_text.padded_indexes``.
+ Defaults to 'auto'. Options are:
+ - 'auto': Use dictionary.padding_idx to pad gt texts, or
+ dictionary.end_idx if dictionary.padding_idx
+ is None.
+ - 'padding': Always use dictionary.padding_idx to pad gt texts.
+ - 'end': Always use dictionary.end_idx to pad gt texts.
+ - 'none': Do not pad gt texts.
+ ignore_char (int or str): Specifies a target value that is
+ ignored and does not contribute to the input gradient.
+ ignore_char can be int or str. If int, it is the index of
+ the ignored char. If str, it is the character to ignore.
+ Apart from single characters, each item can be one of the
+ following reversed keywords: 'padding', 'start', 'end',
+ and 'unknown', which refer to their corresponding special
+ tokens in the dictionary. It will not ignore any special
+ tokens when ignore_char == -1 or 'none'. Defaults to 'padding'.
+ flatten (bool): Whether to flatten the output and target before
+ computing CE loss. Defaults to False.
+ reduction (str): Specifies the reduction to apply to the output,
+ should be one of the following: ('none', 'mean', 'sum'). Defaults
+ to 'none'.
+ ignore_first_char (bool): Whether to ignore the first token in target (
+ usually the start token). If ``True``, the last token of the output
+ sequence will also be removed to be aligned with the target length.
+ Defaults to ``False``.
+ flatten (bool): Whether to flatten the vectors for loss computation.
+ Defaults to False.
+ """
+
+ def __init__(self,
+ dictionary: Union[Dict, Dictionary],
+ max_seq_len: int = 40,
+ letter_case: str = 'unchanged',
+ pad_with: str = 'auto',
+ ignore_char: Union[int, str] = 'padding',
+ flatten: bool = False,
+ reduction: str = 'none',
+ ignore_first_char: bool = False):
+ super().__init__(
+ dictionary=dictionary,
+ max_seq_len=max_seq_len,
+ letter_case=letter_case,
+ pad_with=pad_with)
+ assert isinstance(ignore_char, (int, str))
+ assert isinstance(reduction, str)
+ assert reduction in ['none', 'mean', 'sum']
+ assert isinstance(ignore_first_char, bool)
+ assert isinstance(flatten, bool)
+ self.flatten = flatten
+
+ self.ignore_first_char = ignore_first_char
+
+ if isinstance(ignore_char, int):
+ ignore_index = ignore_char
+ else:
+ mapping_table = {
+ 'none': -1,
+ 'start': self.dictionary.start_idx,
+ 'padding': self.dictionary.padding_idx,
+ 'end': self.dictionary.end_idx,
+ 'unknown': self.dictionary.unknown_idx,
+ }
+
+ ignore_index = mapping_table.get(
+ ignore_char,
+ self.dictionary.char2idx(ignore_char, strict=False))
+ if ignore_index is None or (ignore_index
+ == self.dictionary.unknown_idx
+ and ignore_char != 'unknown'):
+ warnings.warn(
+ f'{ignore_char} does not exist in the dictionary',
+ UserWarning)
+ ignore_index = -1
+
+ self.ignore_char = ignore_char
+ self.ignore_index = ignore_index
+ self.loss_ce = nn.CrossEntropyLoss(
+ ignore_index=ignore_index, reduction=reduction)
+
+ def forward(self, outputs: torch.Tensor,
+ data_samples: Sequence[TextRecogDataSample]) -> Dict:
+ """
+ Args:
+ outputs (Tensor): A raw logit tensor of shape :math:`(N, T, C)`.
+ data_samples (list[TextRecogDataSample]): List of
+ ``TextRecogDataSample`` which are processed by ``get_target``.
+
+ Returns:
+ dict: A loss dict with the key ``loss_ce``.
+ """
+ targets = list()
+ for data_sample in data_samples:
+ targets.append(data_sample.gt_text.padded_indexes)
+ targets = torch.stack(targets, dim=0).long()
+ if self.ignore_first_char:
+ targets = targets[:, 1:].contiguous()
+ outputs = outputs[:, :-1, :].contiguous()
+ if self.flatten:
+ outputs = outputs.view(-1, outputs.size(-1))
+ targets = targets.view(-1)
+ else:
+ outputs = outputs.permute(0, 2, 1).contiguous()
+
+ loss_ce = self.loss_ce(outputs, targets.to(outputs.device))
+ losses = dict(loss_ce=loss_ce)
+
+ return losses
diff --git a/mmocr/models/textrecog/module_losses/ctc_module_loss.py b/mmocr/models/textrecog/module_losses/ctc_module_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..e98d7b4c905487d1158402dd00d82570207513b5
--- /dev/null
+++ b/mmocr/models/textrecog/module_losses/ctc_module_loss.py
@@ -0,0 +1,130 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from typing import Dict, Sequence, Union
+
+import torch
+import torch.nn as nn
+
+from mmocr.models.common.dictionary import Dictionary
+from mmocr.registry import MODELS
+from mmocr.structures import TextRecogDataSample
+from .base import BaseTextRecogModuleLoss
+
+
+@MODELS.register_module()
+class CTCModuleLoss(BaseTextRecogModuleLoss):
+ """Implementation of loss module for CTC-loss based text recognition.
+
+ Args:
+ dictionary (dict or :obj:`Dictionary`): The config for `Dictionary` or
+ the instance of `Dictionary`.
+ letter_case (str): There are three options to alter the letter cases
+ of gt texts:
+ - unchanged: Do not change gt texts.
+ - upper: Convert gt texts into uppercase characters.
+ - lower: Convert gt texts into lowercase characters.
+ Usually, it only works for English characters. Defaults to
+ 'unchanged'.
+ flatten (bool): If True, use flattened targets, else padded targets.
+ reduction (str): Specifies the reduction to apply to the output,
+ should be one of the following: ('none', 'mean', 'sum').
+ zero_infinity (bool): Whether to zero infinite losses and
+ the associated gradients. Default: False.
+ Infinite losses mainly occur when the inputs
+ are too short to be aligned to the targets.
+ """
+
+ def __init__(self,
+ dictionary: Union[Dict, Dictionary],
+ letter_case: str = 'unchanged',
+ flatten: bool = True,
+ reduction: str = 'mean',
+ zero_infinity: bool = False,
+ **kwargs) -> None:
+ super().__init__(dictionary=dictionary, letter_case=letter_case)
+ assert isinstance(flatten, bool)
+ assert isinstance(reduction, str)
+ assert isinstance(zero_infinity, bool)
+
+ self.flatten = flatten
+ self.ctc_loss = nn.CTCLoss(
+ blank=self.dictionary.padding_idx,
+ reduction=reduction,
+ zero_infinity=zero_infinity)
+
+ def forward(self, outputs: torch.Tensor,
+ data_samples: Sequence[TextRecogDataSample]) -> Dict:
+ """
+ Args:
+ outputs (Tensor): A raw logit tensor of shape :math:`(N, T, C)`.
+ data_samples (list[TextRecogDataSample]): List of
+ ``TextRecogDataSample`` which are processed by ``get_target``.
+
+ Returns:
+ dict: The loss dict with key ``loss_ctc``.
+ """
+ valid_ratios = None
+ if data_samples is not None:
+ valid_ratios = [
+ img_meta.get('valid_ratio', 1.0) for img_meta in data_samples
+ ]
+
+ outputs = torch.log_softmax(outputs, dim=2)
+ bsz, seq_len = outputs.size(0), outputs.size(1)
+ outputs_for_loss = outputs.permute(1, 0, 2).contiguous() # T * N * C
+ targets = [
+ data_sample.gt_text.indexes[:seq_len]
+ for data_sample in data_samples
+ ]
+ target_lengths = torch.IntTensor([len(t) for t in targets])
+ target_lengths = torch.clamp(target_lengths, max=seq_len).long()
+ input_lengths = torch.full(
+ size=(bsz, ), fill_value=seq_len, dtype=torch.long)
+ if self.flatten:
+ targets = torch.cat(targets)
+ else:
+ padded_targets = torch.full(
+ size=(bsz, seq_len),
+ fill_value=self.dictionary.padding_idx,
+ dtype=torch.long)
+ for idx, valid_len in enumerate(target_lengths):
+ padded_targets[idx, :valid_len] = targets[idx][:valid_len]
+ targets = padded_targets
+
+ if valid_ratios is not None:
+ input_lengths = [
+ math.ceil(valid_ratio * seq_len)
+ for valid_ratio in valid_ratios
+ ]
+ input_lengths = torch.Tensor(input_lengths).long()
+ loss_ctc = self.ctc_loss(outputs_for_loss, targets, input_lengths,
+ target_lengths)
+ losses = dict(loss_ctc=loss_ctc)
+
+ return losses
+
+ def get_targets(
+ self, data_samples: Sequence[TextRecogDataSample]
+ ) -> Sequence[TextRecogDataSample]:
+ """Target generator.
+
+ Args:
+ data_samples (list[TextRecogDataSample]): It usually includes
+ ``gt_text`` information.
+
+ Returns:
+
+ list[TextRecogDataSample]: updated data_samples. It will add two
+ key in data_sample:
+
+ - indexes (torch.LongTensor): The index corresponding to the item.
+ """
+
+ for data_sample in data_samples:
+ text = data_sample.gt_text.item
+ if self.letter_case in ['upper', 'lower']:
+ text = getattr(text, self.letter_case)()
+ indexes = self.dictionary.str2idx(text)
+ indexes = torch.IntTensor(indexes)
+ data_sample.gt_text.indexes = indexes
+ return data_samples
diff --git a/mmocr/models/textrecog/plugins/__init__.py b/mmocr/models/textrecog/plugins/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..053a33e2d647128fc7dcc60e85aea0b560103984
--- /dev/null
+++ b/mmocr/models/textrecog/plugins/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .common import GCAModule, Maxpool2d
+
+__all__ = ['Maxpool2d', 'GCAModule']
diff --git a/mmocr/models/textrecog/plugins/__pycache__/__init__.cpython-38.pyc b/mmocr/models/textrecog/plugins/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..78dafbda75dbdd24e26a738811c1566c2f2ba047
Binary files /dev/null and b/mmocr/models/textrecog/plugins/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/plugins/__pycache__/common.cpython-38.pyc b/mmocr/models/textrecog/plugins/__pycache__/common.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..fbc7ca6168926d78d1a25b19761b3363753c06a4
Binary files /dev/null and b/mmocr/models/textrecog/plugins/__pycache__/common.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/plugins/common.py b/mmocr/models/textrecog/plugins/common.py
new file mode 100644
index 0000000000000000000000000000000000000000..7a6e8c6de712978c571224b9e20ea881d1116211
--- /dev/null
+++ b/mmocr/models/textrecog/plugins/common.py
@@ -0,0 +1,194 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Tuple, Union
+
+import torch
+import torch.nn as nn
+
+from mmocr.registry import MODELS
+
+
+@MODELS.register_module()
+class Maxpool2d(nn.Module):
+ """A wrapper around nn.Maxpool2d().
+
+ Args:
+ kernel_size (int or tuple(int)): Kernel size for max pooling layer
+ stride (int or tuple(int)): Stride for max pooling layer
+ padding (int or tuple(int)): Padding for pooling layer
+ """
+
+ def __init__(self,
+ kernel_size: Union[int, Tuple[int]],
+ stride: Union[int, Tuple[int]],
+ padding: Union[int, Tuple[int]] = 0,
+ **kwargs) -> None:
+ super().__init__()
+ self.model = nn.MaxPool2d(kernel_size, stride, padding)
+
+ def forward(self, x) -> torch.Tensor:
+ """Forward function.
+ Args:
+ x (Tensor): Input feature map.
+
+ Returns:
+ Tensor: Output tensor after Maxpooling layer.
+ """
+ return self.model(x)
+
+
+@MODELS.register_module()
+class GCAModule(nn.Module):
+ """GCAModule in MASTER.
+
+ Args:
+ in_channels (int): Channels of input tensor.
+ ratio (float): Scale ratio of in_channels.
+ n_head (int): Numbers of attention head.
+ pooling_type (str): Spatial pooling type. Options are [``avg``,
+ ``att``].
+ scale_attn (bool): Whether to scale the attention map. Defaults to
+ False.
+ fusion_type (str): Fusion type of input and context. Options are
+ [``channel_add``, ``channel_mul``, ``channel_concat``].
+ """
+
+ def __init__(self,
+ in_channels: int,
+ ratio: float,
+ n_head: int,
+ pooling_type: str = 'att',
+ scale_attn: bool = False,
+ fusion_type: str = 'channel_add',
+ **kwargs) -> None:
+ super().__init__()
+
+ assert pooling_type in ['avg', 'att']
+ assert fusion_type in ['channel_add', 'channel_mul', 'channel_concat']
+
+ # in_channels must be divided by headers evenly
+ assert in_channels % n_head == 0 and in_channels >= 8
+
+ self.n_head = n_head
+ self.in_channels = in_channels
+ self.ratio = ratio
+ self.planes = int(in_channels * ratio)
+ self.pooling_type = pooling_type
+ self.fusion_type = fusion_type
+ self.scale_attn = scale_attn
+ self.single_header_inplanes = int(in_channels / n_head)
+
+ if pooling_type == 'att':
+ self.conv_mask = nn.Conv2d(
+ self.single_header_inplanes, 1, kernel_size=1)
+ self.softmax = nn.Softmax(dim=2)
+ else:
+ self.avg_pool = nn.AdaptiveAvgPool2d(1)
+
+ if fusion_type == 'channel_add':
+ self.channel_add_conv = nn.Sequential(
+ nn.Conv2d(self.in_channels, self.planes, kernel_size=1),
+ nn.LayerNorm([self.planes, 1, 1]), nn.ReLU(inplace=True),
+ nn.Conv2d(self.planes, self.in_channels, kernel_size=1))
+ elif fusion_type == 'channel_concat':
+ self.channel_concat_conv = nn.Sequential(
+ nn.Conv2d(self.in_channels, self.planes, kernel_size=1),
+ nn.LayerNorm([self.planes, 1, 1]), nn.ReLU(inplace=True),
+ nn.Conv2d(self.planes, self.in_channels, kernel_size=1))
+ # for concat
+ self.cat_conv = nn.Conv2d(
+ 2 * self.in_channels, self.in_channels, kernel_size=1)
+ elif fusion_type == 'channel_mul':
+ self.channel_mul_conv = nn.Sequential(
+ nn.Conv2d(self.in_channels, self.planes, kernel_size=1),
+ nn.LayerNorm([self.planes, 1, 1]), nn.ReLU(inplace=True),
+ nn.Conv2d(self.planes, self.in_channels, kernel_size=1))
+
+ def spatial_pool(self, x: torch.Tensor) -> torch.Tensor:
+ """Spatial pooling function.
+
+ Args:
+ x (Tensor): Input feature map.
+
+ Returns:
+ Tensor: Output tensor after spatial pooling.
+ """
+ batch, channel, height, width = x.size()
+ if self.pooling_type == 'att':
+ # [N*headers, C', H , W] C = headers * C'
+ x = x.view(batch * self.n_head, self.single_header_inplanes,
+ height, width)
+ input_x = x
+
+ # [N*headers, C', H * W] C = headers * C'
+ input_x = input_x.view(batch * self.n_head,
+ self.single_header_inplanes, height * width)
+
+ # [N*headers, 1, C', H * W]
+ input_x = input_x.unsqueeze(1)
+ # [N*headers, 1, H, W]
+ context_mask = self.conv_mask(x)
+ # [N*headers, 1, H * W]
+ context_mask = context_mask.view(batch * self.n_head, 1,
+ height * width)
+
+ # scale variance
+ if self.scale_attn and self.n_head > 1:
+ context_mask = context_mask / \
+ torch.sqrt(self.single_header_inplanes)
+
+ # [N*headers, 1, H * W]
+ context_mask = self.softmax(context_mask)
+
+ # [N*headers, 1, H * W, 1]
+ context_mask = context_mask.unsqueeze(-1)
+ # [N*headers, 1, C', 1] =
+ # [N*headers, 1, C', H * W] * [N*headers, 1, H * W, 1]
+ context = torch.matmul(input_x, context_mask)
+
+ # [N, headers * C', 1, 1]
+ context = context.view(batch,
+ self.n_head * self.single_header_inplanes,
+ 1, 1)
+ else:
+ # [N, C, 1, 1]
+ context = self.avg_pool(x)
+
+ return context
+
+ def forward(self, x: torch.Tensor) -> torch.Tensor:
+ """Forward function.
+
+ Args:
+ x (Tensor): Input feature map.
+
+ Returns:
+ Tensor: Output tensor after GCAModule.
+ """
+ # [N, C, 1, 1]
+ context = self.spatial_pool(x)
+ out = x
+
+ if self.fusion_type == 'channel_mul':
+ # [N, C, 1, 1]
+ channel_mul_term = torch.sigmoid(self.channel_mul_conv(context))
+ out = out * channel_mul_term
+ elif self.fusion_type == 'channel_add':
+ # [N, C, 1, 1]
+ channel_add_term = self.channel_add_conv(context)
+ out = out + channel_add_term
+ else:
+ # [N, C, 1, 1]
+ channel_concat_term = self.channel_concat_conv(context)
+
+ # use concat
+ _, C1, _, _ = channel_concat_term.shape
+ N, C2, H, W = out.shape
+
+ out = torch.cat([out,
+ channel_concat_term.expand(-1, -1, H, W)],
+ dim=1)
+ out = self.cat_conv(out)
+ out = nn.functional.layer_norm(out, [self.in_channels, H, W])
+ out = nn.functional.relu(out)
+
+ return out
diff --git a/mmocr/models/textrecog/postprocessors/__init__.py b/mmocr/models/textrecog/postprocessors/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..14b51daebd7dc398915ea733c7e257fd66313d80
--- /dev/null
+++ b/mmocr/models/textrecog/postprocessors/__init__.py
@@ -0,0 +1,8 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .attn_postprocessor import AttentionPostprocessor
+from .base import BaseTextRecogPostprocessor
+from .ctc_postprocessor import CTCPostProcessor
+
+__all__ = [
+ 'BaseTextRecogPostprocessor', 'AttentionPostprocessor', 'CTCPostProcessor'
+]
diff --git a/mmocr/models/textrecog/postprocessors/__pycache__/__init__.cpython-38.pyc b/mmocr/models/textrecog/postprocessors/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f6a694a97661cb1434e12adbb4df841cb59707f6
Binary files /dev/null and b/mmocr/models/textrecog/postprocessors/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/postprocessors/__pycache__/attn_postprocessor.cpython-38.pyc b/mmocr/models/textrecog/postprocessors/__pycache__/attn_postprocessor.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1ba134667a9c947cd873196e9d623fbd5e7e405b
Binary files /dev/null and b/mmocr/models/textrecog/postprocessors/__pycache__/attn_postprocessor.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/postprocessors/__pycache__/base.cpython-38.pyc b/mmocr/models/textrecog/postprocessors/__pycache__/base.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..af2dbfdca9f10892b0cd1e17eb58527c97bf2fac
Binary files /dev/null and b/mmocr/models/textrecog/postprocessors/__pycache__/base.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/postprocessors/__pycache__/ctc_postprocessor.cpython-38.pyc b/mmocr/models/textrecog/postprocessors/__pycache__/ctc_postprocessor.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8efc66e04e9dc7eb177c0802d8570ff14df4cb72
Binary files /dev/null and b/mmocr/models/textrecog/postprocessors/__pycache__/ctc_postprocessor.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/postprocessors/attn_postprocessor.py b/mmocr/models/textrecog/postprocessors/attn_postprocessor.py
new file mode 100644
index 0000000000000000000000000000000000000000..e047a6a341ca90b874d993c0def6aed9a3af114e
--- /dev/null
+++ b/mmocr/models/textrecog/postprocessors/attn_postprocessor.py
@@ -0,0 +1,43 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Sequence, Tuple
+
+import torch
+
+from mmocr.registry import MODELS
+from mmocr.structures import TextRecogDataSample
+from .base import BaseTextRecogPostprocessor
+
+
+@MODELS.register_module()
+class AttentionPostprocessor(BaseTextRecogPostprocessor):
+ """PostProcessor for seq2seq."""
+
+ def get_single_prediction(
+ self,
+ probs: torch.Tensor,
+ data_sample: Optional[TextRecogDataSample] = None,
+ ) -> Tuple[Sequence[int], Sequence[float]]:
+ """Convert the output probabilities of a single image to index and
+ score.
+
+ Args:
+ probs (torch.Tensor): Character probabilities with shape
+ :math:`(T, C)`.
+ data_sample (TextRecogDataSample, optional): Datasample of an
+ image. Defaults to None.
+
+ Returns:
+ tuple(list[int], list[float]): index and score.
+ """
+ max_value, max_idx = torch.max(probs, -1)
+ index, score = [], []
+ output_index = max_idx.cpu().detach().numpy().tolist()
+ output_score = max_value.cpu().detach().numpy().tolist()
+ for char_index, char_score in zip(output_index, output_score):
+ if char_index in self.ignore_indexes:
+ continue
+ if char_index == self.dictionary.end_idx:
+ break
+ index.append(char_index)
+ score.append(char_score)
+ return index, score
diff --git a/mmocr/models/textrecog/postprocessors/base.py b/mmocr/models/textrecog/postprocessors/base.py
new file mode 100644
index 0000000000000000000000000000000000000000..818640a8ca572f55e8c819a14c496dd47a6b4e93
--- /dev/null
+++ b/mmocr/models/textrecog/postprocessors/base.py
@@ -0,0 +1,110 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from typing import Dict, Optional, Sequence, Tuple, Union
+
+import mmengine
+import torch
+from mmengine.structures import LabelData
+
+from mmocr.models.common.dictionary import Dictionary
+from mmocr.registry import TASK_UTILS
+from mmocr.structures import TextRecogDataSample
+
+
+class BaseTextRecogPostprocessor:
+ """Base text recognition postprocessor.
+
+ Args:
+ dictionary (dict or :obj:`Dictionary`): The config for `Dictionary` or
+ the instance of `Dictionary`.
+ max_seq_len (int): max_seq_len (int): Maximum sequence length. The
+ sequence is usually generated from decoder. Defaults to 40.
+ ignore_chars (list[str]): A list of characters to be ignored from the
+ final results. Postprocessor will skip over these characters when
+ converting raw indexes to characters. Apart from single characters,
+ each item can be one of the following reversed keywords: 'padding',
+ 'end' and 'unknown', which refer to their corresponding special
+ tokens in the dictionary.
+ """
+
+ def __init__(self,
+ dictionary: Union[Dictionary, Dict],
+ max_seq_len: int = 40,
+ ignore_chars: Sequence[str] = ['padding'],
+ **kwargs) -> None:
+
+ if isinstance(dictionary, dict):
+ self.dictionary = TASK_UTILS.build(dictionary)
+ elif isinstance(dictionary, Dictionary):
+ self.dictionary = dictionary
+ else:
+ raise TypeError(
+ 'The type of dictionary should be `Dictionary` or dict, '
+ f'but got {type(dictionary)}')
+ self.max_seq_len = max_seq_len
+
+ mapping_table = {
+ 'padding': self.dictionary.padding_idx,
+ 'end': self.dictionary.end_idx,
+ 'unknown': self.dictionary.unknown_idx,
+ }
+ if not mmengine.is_list_of(ignore_chars, str):
+ raise TypeError('ignore_chars must be list of str')
+ ignore_indexes = list()
+ for ignore_char in ignore_chars:
+ index = mapping_table.get(
+ ignore_char,
+ self.dictionary.char2idx(ignore_char, strict=False))
+ if index is None or (index == self.dictionary.unknown_idx
+ and ignore_char != 'unknown'):
+ warnings.warn(
+ f'{ignore_char} does not exist in the dictionary',
+ UserWarning)
+ continue
+ ignore_indexes.append(index)
+ self.ignore_indexes = ignore_indexes
+
+ def get_single_prediction(
+ self,
+ probs: torch.Tensor,
+ data_sample: Optional[TextRecogDataSample] = None,
+ ) -> Tuple[Sequence[int], Sequence[float]]:
+ """Convert the output probabilities of a single image to index and
+ score.
+
+ Args:
+ probs (torch.Tensor): Character probabilities with shape
+ :math:`(T, C)`.
+ data_sample (TextRecogDataSample): Datasample of an image.
+
+ Returns:
+ tuple(list[int], list[float]): Index and scores per-character.
+ """
+ raise NotImplementedError
+
+ def __call__(
+ self, probs: torch.Tensor, data_samples: Sequence[TextRecogDataSample]
+ ) -> Sequence[TextRecogDataSample]:
+ """Convert outputs to strings and scores.
+
+ Args:
+ probs (torch.Tensor): Batched character probabilities, the model's
+ softmaxed output in size: :math:`(N, T, C)`.
+ data_samples (list[TextRecogDataSample]): The list of
+ TextRecogDataSample.
+
+ Returns:
+ list(TextRecogDataSample): The list of TextRecogDataSample. It
+ usually contain ``pred_text`` information.
+ """
+ batch_size = probs.size(0)
+
+ for idx in range(batch_size):
+ index, score = self.get_single_prediction(probs[idx, :, :],
+ data_samples[idx])
+ text = self.dictionary.idx2str(index)
+ pred_text = LabelData()
+ pred_text.score = score
+ pred_text.item = text
+ data_samples[idx].pred_text = pred_text
+ return data_samples
diff --git a/mmocr/models/textrecog/postprocessors/ctc_postprocessor.py b/mmocr/models/textrecog/postprocessors/ctc_postprocessor.py
new file mode 100644
index 0000000000000000000000000000000000000000..0fa28779abaf64e1d964ae05b4296e81308aab13
--- /dev/null
+++ b/mmocr/models/textrecog/postprocessors/ctc_postprocessor.py
@@ -0,0 +1,52 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from typing import Sequence, Tuple
+
+import torch
+
+from mmocr.registry import MODELS
+from mmocr.structures import TextRecogDataSample
+from .base import BaseTextRecogPostprocessor
+
+
+# TODO support beam search
+@MODELS.register_module()
+class CTCPostProcessor(BaseTextRecogPostprocessor):
+ """PostProcessor for CTC."""
+
+ def get_single_prediction(self, probs: torch.Tensor,
+ data_sample: TextRecogDataSample
+ ) -> Tuple[Sequence[int], Sequence[float]]:
+ """Convert the output probabilities of a single image to index and
+ score.
+
+ Args:
+ probs (torch.Tensor): Character probabilities with shape
+ :math:`(T, C)`.
+ data_sample (TextRecogDataSample): Datasample of an image.
+
+ Returns:
+ tuple(list[int], list[float]): index and score.
+ """
+ feat_len = probs.size(0)
+ max_value, max_idx = torch.max(probs, -1)
+ valid_ratio = data_sample.get('valid_ratio', 1)
+ decode_len = min(feat_len, math.ceil(feat_len * valid_ratio))
+ index = []
+ score = []
+
+ prev_idx = self.dictionary.padding_idx
+ for t in range(decode_len):
+ tmp_value = max_idx[t].item()
+ if tmp_value not in (prev_idx, *self.ignore_indexes):
+ index.append(tmp_value)
+ score.append(max_value[t].item())
+ prev_idx = tmp_value
+ return index, score
+
+ def __call__(
+ self, outputs: torch.Tensor,
+ data_samples: Sequence[TextRecogDataSample]
+ ) -> Sequence[TextRecogDataSample]:
+ outputs = outputs.cpu().detach()
+ return super().__call__(outputs, data_samples)
diff --git a/mmocr/models/textrecog/preprocessors/__init__.py b/mmocr/models/textrecog/preprocessors/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..15825f25fe22be1eb6d32a1555277d50ad5c5383
--- /dev/null
+++ b/mmocr/models/textrecog/preprocessors/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .tps_preprocessor import STN, TPStransform
+
+__all__ = ['TPStransform', 'STN']
diff --git a/mmocr/models/textrecog/preprocessors/__pycache__/__init__.cpython-38.pyc b/mmocr/models/textrecog/preprocessors/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..6a670ad17c435f79783c1bdcaed4c7da4f05c8c8
Binary files /dev/null and b/mmocr/models/textrecog/preprocessors/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/preprocessors/__pycache__/base.cpython-38.pyc b/mmocr/models/textrecog/preprocessors/__pycache__/base.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0289f3abc1ba7ff39063ed6bbbd7eb6cb7009720
Binary files /dev/null and b/mmocr/models/textrecog/preprocessors/__pycache__/base.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/preprocessors/__pycache__/tps_preprocessor.cpython-38.pyc b/mmocr/models/textrecog/preprocessors/__pycache__/tps_preprocessor.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..589a562f113bcaf4ec982ad4beb62346a0c52bd5
Binary files /dev/null and b/mmocr/models/textrecog/preprocessors/__pycache__/tps_preprocessor.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/preprocessors/base.py b/mmocr/models/textrecog/preprocessors/base.py
new file mode 100644
index 0000000000000000000000000000000000000000..a1f138bed0eef9517f3e4b1e9f5e33c382a77292
--- /dev/null
+++ b/mmocr/models/textrecog/preprocessors/base.py
@@ -0,0 +1,12 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmengine.model import BaseModule
+
+from mmocr.registry import MODELS
+
+
+@MODELS.register_module()
+class BasePreprocessor(BaseModule):
+ """Base Preprocessor class for text recognition."""
+
+ def forward(self, x, **kwargs):
+ return x
diff --git a/mmocr/models/textrecog/preprocessors/tps_preprocessor.py b/mmocr/models/textrecog/preprocessors/tps_preprocessor.py
new file mode 100644
index 0000000000000000000000000000000000000000..6a9e0ccc6b0d077b2e66a3e9d9df944b5f862d86
--- /dev/null
+++ b/mmocr/models/textrecog/preprocessors/tps_preprocessor.py
@@ -0,0 +1,272 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import itertools
+from typing import Dict, List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+
+from mmocr.registry import MODELS
+from .base import BasePreprocessor
+
+
+class TPStransform(nn.Module):
+ """Implement TPS transform.
+
+ This was partially adapted from https://github.com/ayumiymk/aster.pytorch
+
+ Args:
+ output_image_size (tuple[int, int]): The size of the output image.
+ Defaults to (32, 128).
+ num_control_points (int): The number of control points. Defaults to 20.
+ margins (tuple[float, float]): The margins for control points to the
+ top and down side of the image. Defaults to [0.05, 0.05].
+ """
+
+ def __init__(self,
+ output_image_size: Tuple[int, int] = (32, 100),
+ num_control_points: int = 20,
+ margins: Tuple[float, float] = [0.05, 0.05]) -> None:
+ super().__init__()
+ self.output_image_size = output_image_size
+ self.num_control_points = num_control_points
+ self.margins = margins
+ self.target_height, self.target_width = output_image_size
+
+ # build output control points
+ target_control_points = self._build_output_control_points(
+ num_control_points, margins)
+ N = num_control_points
+
+ # create padded kernel matrix
+ forward_kernel = torch.zeros(N + 3, N + 3)
+ target_control_partial_repr = self._compute_partial_repr(
+ target_control_points, target_control_points)
+ forward_kernel[:N, :N].copy_(target_control_partial_repr)
+ forward_kernel[:N, -3].fill_(1)
+ forward_kernel[-3, :N].fill_(1)
+ forward_kernel[:N, -2:].copy_(target_control_points)
+ forward_kernel[-2:, :N].copy_(target_control_points.transpose(0, 1))
+
+ # compute inverse matrix
+ inverse_kernel = torch.inverse(forward_kernel).contiguous()
+
+ # create target coordinate matrix
+ HW = self.target_height * self.target_width
+ tgt_coord = list(
+ itertools.product(
+ range(self.target_height), range(self.target_width)))
+ tgt_coord = torch.Tensor(tgt_coord)
+ Y, X = tgt_coord.split(1, dim=1)
+ Y = Y / (self.target_height - 1)
+ X = X / (self.target_width - 1)
+ tgt_coord = torch.cat([X, Y], dim=1)
+ tgt_coord_partial_repr = self._compute_partial_repr(
+ tgt_coord, target_control_points)
+ tgt_coord_repr = torch.cat(
+ [tgt_coord_partial_repr,
+ torch.ones(HW, 1), tgt_coord], dim=1)
+
+ # register precomputed matrices
+ self.register_buffer('inverse_kernel', inverse_kernel)
+ self.register_buffer('padding_matrix', torch.zeros(3, 2))
+ self.register_buffer('target_coordinate_repr', tgt_coord_repr)
+ self.register_buffer('target_control_points', target_control_points)
+
+ def forward(self, input: torch.Tensor,
+ source_control_points: torch.Tensor) -> torch.Tensor:
+ """Forward function of the TPS block.
+
+ Args:
+ input (Tensor): The input image.
+ source_control_points (Tensor): The control points of the source
+ image of shape (N, self.num_control_points, 2).
+ Returns:
+ Tensor: The output image after TPS transform.
+ """
+ assert source_control_points.ndimension() == 3
+ assert source_control_points.size(1) == self.num_control_points
+ assert source_control_points.size(2) == 2
+ batch_size = source_control_points.size(0)
+
+ Y = torch.cat([
+ source_control_points,
+ self.padding_matrix.expand(batch_size, 3, 2)
+ ], 1)
+ mapping_matrix = torch.matmul(self.inverse_kernel, Y)
+ source_coordinate = torch.matmul(self.target_coordinate_repr,
+ mapping_matrix)
+
+ grid = source_coordinate.view(-1, self.target_height,
+ self.target_width, 2)
+ grid = torch.clamp(grid, 0, 1)
+ grid = 2.0 * grid - 1.0
+ output_maps = self._grid_sample(input, grid, canvas=None)
+ return output_maps
+
+ def _grid_sample(self,
+ input: torch.Tensor,
+ grid: torch.Tensor,
+ canvas: Optional[torch.Tensor] = None) -> torch.Tensor:
+ """Sample the input image at the given grid.
+
+ Args:
+ input (Tensor): The input image.
+ grid (Tensor): The grid to sample the input image.
+ canvas (Optional[Tensor]): The canvas to store the output image.
+ Returns:
+ Tensor: The sampled image.
+ """
+ output = F.grid_sample(input, grid, align_corners=True)
+ if canvas is None:
+ return output
+ else:
+ input_mask = input.data.new(input.size()).fill_(1)
+ output_mask = F.grid_sample(input_mask, grid, align_corners=True)
+ padded_output = output * output_mask + canvas * (1 - output_mask)
+ return padded_output
+
+ def _compute_partial_repr(self, input_points: torch.Tensor,
+ control_points: torch.Tensor) -> torch.Tensor:
+ """Compute the partial representation matrix.
+
+ Args:
+ input_points (Tensor): The input points.
+ control_points (Tensor): The control points.
+ Returns:
+ Tensor: The partial representation matrix.
+ """
+ N = input_points.size(0)
+ M = control_points.size(0)
+ pairwise_diff = input_points.view(N, 1, 2) - control_points.view(
+ 1, M, 2)
+ pairwise_diff_square = pairwise_diff * pairwise_diff
+ pairwise_dist = pairwise_diff_square[:, :,
+ 0] + pairwise_diff_square[:, :, 1]
+ repr_matrix = 0.5 * pairwise_dist * torch.log(pairwise_dist)
+ mask = repr_matrix != repr_matrix
+ repr_matrix.masked_fill_(mask, 0)
+ return repr_matrix
+
+ # output_ctrl_pts are specified, according to our task.
+ def _build_output_control_points(self, num_control_points: torch.Tensor,
+ margins: Tuple[float,
+ float]) -> torch.Tensor:
+ """Build the output control points.
+
+ The output points will be fix at
+ top and down side of the image.
+ Args:
+ num_control_points (Tensor): The number of control points.
+ margins (Tuple[float, float]): The margins for control points to
+ the top and down side of the image.
+ Returns:
+ Tensor: The output control points.
+ """
+ margin_x, margin_y = margins
+ num_ctrl_pts_per_side = num_control_points // 2
+ ctrl_pts_x = np.linspace(margin_x, 1.0 - margin_x,
+ num_ctrl_pts_per_side)
+ ctrl_pts_y_top = np.ones(num_ctrl_pts_per_side) * margin_y
+ ctrl_pts_y_bottom = np.ones(num_ctrl_pts_per_side) * (1.0 - margin_y)
+ ctrl_pts_top = np.stack([ctrl_pts_x, ctrl_pts_y_top], axis=1)
+ ctrl_pts_bottom = np.stack([ctrl_pts_x, ctrl_pts_y_bottom], axis=1)
+ output_ctrl_pts_arr = np.concatenate([ctrl_pts_top, ctrl_pts_bottom],
+ axis=0)
+ output_ctrl_pts = torch.Tensor(output_ctrl_pts_arr)
+ return output_ctrl_pts
+
+
+@MODELS.register_module()
+class STN(BasePreprocessor):
+ """Implement STN module in ASTER: An Attentional Scene Text Recognizer with
+ Flexible Rectification
+ (https://ieeexplore.ieee.org/abstract/document/8395027/)
+
+ Args:
+ in_channels (int): The number of input channels.
+ resized_image_size (Tuple[int, int]): The resized image size. The input
+ image will be downsampled to have a better recitified result.
+ output_image_size: The size of the output image for TPS. Defaults to
+ (32, 100).
+ num_control_points: The number of control points. Defaults to 20.
+ margins: The margins for control points to the top and down side of the
+ image for TPS. Defaults to [0.05, 0.05].
+ """
+
+ def __init__(self,
+ in_channels: int,
+ resized_image_size: Tuple[int, int] = (32, 64),
+ output_image_size: Tuple[int, int] = (32, 100),
+ num_control_points: int = 20,
+ margins: Tuple[float, float] = [0.05, 0.05],
+ init_cfg: Optional[Union[Dict, List[Dict]]] = [
+ dict(type='Xavier', layer='Conv2d'),
+ dict(type='Constant', val=1, layer='BatchNorm2d'),
+ ]):
+ super().__init__(init_cfg=init_cfg)
+ self.resized_image_size = resized_image_size
+ self.num_control_points = num_control_points
+ self.tps = TPStransform(output_image_size, num_control_points, margins)
+ self.stn_convnet = nn.Sequential(
+ ConvModule(in_channels, 32, 3, 1, 1, norm_cfg=dict(type='BN')),
+ nn.MaxPool2d(kernel_size=2, stride=2),
+ ConvModule(32, 64, 3, 1, 1, norm_cfg=dict(type='BN')),
+ nn.MaxPool2d(kernel_size=2, stride=2),
+ ConvModule(64, 128, 3, 1, 1, norm_cfg=dict(type='BN')),
+ nn.MaxPool2d(kernel_size=2, stride=2),
+ ConvModule(128, 256, 3, 1, 1, norm_cfg=dict(type='BN')),
+ nn.MaxPool2d(kernel_size=2, stride=2),
+ ConvModule(256, 256, 3, 1, 1, norm_cfg=dict(type='BN')),
+ nn.MaxPool2d(kernel_size=2, stride=2),
+ ConvModule(256, 256, 3, 1, 1, norm_cfg=dict(type='BN')),
+ )
+
+ self.stn_fc1 = nn.Sequential(
+ nn.Linear(2 * 256, 512), nn.BatchNorm1d(512),
+ nn.ReLU(inplace=True))
+ self.stn_fc2 = nn.Linear(512, num_control_points * 2)
+ self.init_stn(self.stn_fc2)
+
+ def init_stn(self, stn_fc2: nn.Linear) -> None:
+ """Initialize the output linear layer of stn, so that the initial
+ source point will be at the top and down side of the image, which will
+ help to optimize.
+
+ Args:
+ stn_fc2 (nn.Linear): The output linear layer of stn.
+ """
+ margin = 0.01
+ sampling_num_per_side = int(self.num_control_points / 2)
+ ctrl_pts_x = np.linspace(margin, 1. - margin, sampling_num_per_side)
+ ctrl_pts_y_top = np.ones(sampling_num_per_side) * margin
+ ctrl_pts_y_bottom = np.ones(sampling_num_per_side) * (1 - margin)
+ ctrl_pts_top = np.stack([ctrl_pts_x, ctrl_pts_y_top], axis=1)
+ ctrl_pts_bottom = np.stack([ctrl_pts_x, ctrl_pts_y_bottom], axis=1)
+ ctrl_points = np.concatenate([ctrl_pts_top, ctrl_pts_bottom],
+ axis=0).astype(np.float32)
+ stn_fc2.weight.data.zero_()
+ stn_fc2.bias.data = torch.Tensor(ctrl_points).view(-1)
+
+ def forward(self, img: torch.Tensor) -> torch.Tensor:
+ """Forward function of STN.
+
+ Args:
+ img (Tensor): The input image tensor.
+
+ Returns:
+ Tensor: The rectified image tensor.
+ """
+ resize_img = F.interpolate(
+ img, self.resized_image_size, mode='bilinear', align_corners=True)
+ points = self.stn_convnet(resize_img)
+ batch_size, _, _, _ = points.size()
+ points = points.view(batch_size, -1)
+ img_feat = self.stn_fc1(points)
+ points = self.stn_fc2(0.1 * img_feat)
+ points = points.view(-1, self.num_control_points, 2)
+
+ transformd_image = self.tps(img, points)
+ return transformd_image
diff --git a/mmocr/models/textrecog/recognizers/__init__.py b/mmocr/models/textrecog/recognizers/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..f590e60dc695b21da4ed859e25a5dbecc0551601
--- /dev/null
+++ b/mmocr/models/textrecog/recognizers/__init__.py
@@ -0,0 +1,20 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .abinet import ABINet
+from .aster import ASTER
+from .base import BaseRecognizer
+from .crnn import CRNN
+from .encoder_decoder_recognizer import EncoderDecoderRecognizer
+from .encoder_decoder_recognizer_tta import EncoderDecoderRecognizerTTAModel
+from .master import MASTER
+from .nrtr import NRTR
+from .robust_scanner import RobustScanner
+from .sar import SARNet
+from .satrn import SATRN
+from .svtr import SVTR
+from .maerec import MAERec
+
+__all__ = [
+ 'BaseRecognizer', 'EncoderDecoderRecognizer', 'CRNN', 'SARNet', 'NRTR',
+ 'RobustScanner', 'SATRN', 'ABINet', 'MASTER', 'SVTR', 'ASTER',
+ 'EncoderDecoderRecognizerTTAModel', 'MAERec'
+]
diff --git a/mmocr/models/textrecog/recognizers/__pycache__/__init__.cpython-38.pyc b/mmocr/models/textrecog/recognizers/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e1b3471a7eebfaf954fb4b0e0182eac2d03d9d88
Binary files /dev/null and b/mmocr/models/textrecog/recognizers/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/recognizers/__pycache__/abinet.cpython-38.pyc b/mmocr/models/textrecog/recognizers/__pycache__/abinet.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..23f2c3cdecb57194d661d126f8add38bf64508d9
Binary files /dev/null and b/mmocr/models/textrecog/recognizers/__pycache__/abinet.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/recognizers/__pycache__/aster.cpython-38.pyc b/mmocr/models/textrecog/recognizers/__pycache__/aster.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..dbbbe58d56321882f6694197028badc99df8858e
Binary files /dev/null and b/mmocr/models/textrecog/recognizers/__pycache__/aster.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/recognizers/__pycache__/base.cpython-38.pyc b/mmocr/models/textrecog/recognizers/__pycache__/base.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..9aed2a0ad03dca45d10c7722eab75e0ff43faf5b
Binary files /dev/null and b/mmocr/models/textrecog/recognizers/__pycache__/base.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/recognizers/__pycache__/crnn.cpython-38.pyc b/mmocr/models/textrecog/recognizers/__pycache__/crnn.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f682908b5564d83e261a267f50e39767e84f785d
Binary files /dev/null and b/mmocr/models/textrecog/recognizers/__pycache__/crnn.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/recognizers/__pycache__/encoder_decoder_recognizer.cpython-38.pyc b/mmocr/models/textrecog/recognizers/__pycache__/encoder_decoder_recognizer.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b7a065cbc5a34ebb097dfaa57f9d79ac7b480ce8
Binary files /dev/null and b/mmocr/models/textrecog/recognizers/__pycache__/encoder_decoder_recognizer.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/recognizers/__pycache__/encoder_decoder_recognizer_tta.cpython-38.pyc b/mmocr/models/textrecog/recognizers/__pycache__/encoder_decoder_recognizer_tta.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c5eb238d68fd753ae36f565798cd2226dfc28666
Binary files /dev/null and b/mmocr/models/textrecog/recognizers/__pycache__/encoder_decoder_recognizer_tta.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/recognizers/__pycache__/maerec.cpython-38.pyc b/mmocr/models/textrecog/recognizers/__pycache__/maerec.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ded73bde37dc6f4852149e71a818f1d200335b5f
Binary files /dev/null and b/mmocr/models/textrecog/recognizers/__pycache__/maerec.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/recognizers/__pycache__/master.cpython-38.pyc b/mmocr/models/textrecog/recognizers/__pycache__/master.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..fbdbe2671b8c17768de7201e90210cfb59063eb7
Binary files /dev/null and b/mmocr/models/textrecog/recognizers/__pycache__/master.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/recognizers/__pycache__/nrtr.cpython-38.pyc b/mmocr/models/textrecog/recognizers/__pycache__/nrtr.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..6fafc029ecbe9826bc739498651eefa5e55ef840
Binary files /dev/null and b/mmocr/models/textrecog/recognizers/__pycache__/nrtr.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/recognizers/__pycache__/robust_scanner.cpython-38.pyc b/mmocr/models/textrecog/recognizers/__pycache__/robust_scanner.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..00771f020d8870aa4da3750858a6682eceb72bad
Binary files /dev/null and b/mmocr/models/textrecog/recognizers/__pycache__/robust_scanner.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/recognizers/__pycache__/sar.cpython-38.pyc b/mmocr/models/textrecog/recognizers/__pycache__/sar.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..7cf1c8fd609e88d541481456652956bf04b051f0
Binary files /dev/null and b/mmocr/models/textrecog/recognizers/__pycache__/sar.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/recognizers/__pycache__/satrn.cpython-38.pyc b/mmocr/models/textrecog/recognizers/__pycache__/satrn.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f59f5621a54b38a7f2b5f24e8f2161a02285f586
Binary files /dev/null and b/mmocr/models/textrecog/recognizers/__pycache__/satrn.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/recognizers/__pycache__/svtr.cpython-38.pyc b/mmocr/models/textrecog/recognizers/__pycache__/svtr.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ae8dcb493cbce3291f29f7d2c1eaa61e8ff27200
Binary files /dev/null and b/mmocr/models/textrecog/recognizers/__pycache__/svtr.cpython-38.pyc differ
diff --git a/mmocr/models/textrecog/recognizers/abinet.py b/mmocr/models/textrecog/recognizers/abinet.py
new file mode 100644
index 0000000000000000000000000000000000000000..f8ee3a5cafd021d6072d33b1648a9722a91bcf10
--- /dev/null
+++ b/mmocr/models/textrecog/recognizers/abinet.py
@@ -0,0 +1,12 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmocr.registry import MODELS
+from .encoder_decoder_recognizer import EncoderDecoderRecognizer
+
+
+@MODELS.register_module()
+class ABINet(EncoderDecoderRecognizer):
+ """Implementation of `Read Like Humans: Autonomous, Bidirectional and
+ Iterative LanguageModeling for Scene Text Recognition.
+
+ `_
+ """
diff --git a/mmocr/models/textrecog/recognizers/aster.py b/mmocr/models/textrecog/recognizers/aster.py
new file mode 100644
index 0000000000000000000000000000000000000000..ce6535448af0473fefee4d4289c88df36bf16707
--- /dev/null
+++ b/mmocr/models/textrecog/recognizers/aster.py
@@ -0,0 +1,12 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmocr.registry import MODELS
+from .encoder_decoder_recognizer import EncoderDecoderRecognizer
+
+
+@MODELS.register_module()
+class ASTER(EncoderDecoderRecognizer):
+ """Implement `ASTER: An Attentional Scene Text Recognizer with Flexible
+ Rectification.
+
+ torch.Tensor:
+ """Extract features from images."""
+ pass
+
+ def forward(self,
+ inputs: torch.Tensor,
+ data_samples: OptRecSampleList = None,
+ mode: str = 'tensor',
+ **kwargs) -> RecForwardResults:
+ """The unified entry for a forward process in both training and test.
+
+ The method should accept three modes: "tensor", "predict" and "loss":
+
+ - "tensor": Forward the whole network and return tensor or tuple of
+ tensor without any post-processing, same as a common nn.Module.
+ - "predict": Forward and return the predictions, which are fully
+ processed to a list of :obj:`DetDataSample`.
+ - "loss": Forward and return a dict of losses according to the given
+ inputs and data samples.
+
+ Note that this method doesn't handle neither back propagation nor
+ optimizer updating, which are done in the :meth:`train_step`.
+
+ Args:
+ inputs (torch.Tensor): The input tensor with shape
+ (N, C, ...) in general.
+ data_samples (list[:obj:`DetDataSample`], optional): The
+ annotation data of every samples. Defaults to None.
+ mode (str): Return what kind of value. Defaults to 'tensor'.
+
+ Returns:
+ The return type depends on ``mode``.
+
+ - If ``mode="tensor"``, return a tensor or a tuple of tensor.
+ - If ``mode="predict"``, return a list of :obj:`DetDataSample`.
+ - If ``mode="loss"``, return a dict of tensor.
+ """
+ if mode == 'loss':
+ return self.loss(inputs, data_samples, **kwargs)
+ elif mode == 'predict':
+ return self.predict(inputs, data_samples, **kwargs)
+ elif mode == 'tensor':
+ return self._forward(inputs, data_samples, **kwargs)
+ else:
+ raise RuntimeError(f'Invalid mode "{mode}". '
+ 'Only supports loss, predict and tensor mode')
+
+ @abstractmethod
+ def loss(self, inputs: torch.Tensor, data_samples: RecSampleList,
+ **kwargs) -> Union[dict, tuple]:
+ """Calculate losses from a batch of inputs and data samples."""
+ pass
+
+ @abstractmethod
+ def predict(self, inputs: torch.Tensor, data_samples: RecSampleList,
+ **kwargs) -> RecSampleList:
+ """Predict results from a batch of inputs and data samples with post-
+ processing."""
+ pass
+
+ @abstractmethod
+ def _forward(self,
+ inputs: torch.Tensor,
+ data_samples: OptRecSampleList = None,
+ **kwargs):
+ """Network forward process.
+
+ Usually includes backbone, neck and head forward without any post-
+ processing.
+ """
+ pass
diff --git a/mmocr/models/textrecog/recognizers/crnn.py b/mmocr/models/textrecog/recognizers/crnn.py
new file mode 100644
index 0000000000000000000000000000000000000000..61d6853d10c6fb1909b8b8cde2421b302cd8f52a
--- /dev/null
+++ b/mmocr/models/textrecog/recognizers/crnn.py
@@ -0,0 +1,8 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmocr.registry import MODELS
+from .encoder_decoder_recognizer import EncoderDecoderRecognizer
+
+
+@MODELS.register_module()
+class CRNN(EncoderDecoderRecognizer):
+ """CTC-loss based recognizer."""
diff --git a/mmocr/models/textrecog/recognizers/encoder_decoder_recognizer.py b/mmocr/models/textrecog/recognizers/encoder_decoder_recognizer.py
new file mode 100644
index 0000000000000000000000000000000000000000..2696ac70ef3553e867d3be5a2a62b02923d3e3d3
--- /dev/null
+++ b/mmocr/models/textrecog/recognizers/encoder_decoder_recognizer.py
@@ -0,0 +1,130 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+
+from typing import Dict
+
+import torch
+
+from mmocr.registry import MODELS
+from mmocr.utils.typing_utils import (ConfigType, InitConfigType,
+ OptConfigType, OptRecSampleList,
+ RecForwardResults, RecSampleList)
+from .base import BaseRecognizer
+
+
+@MODELS.register_module()
+class EncoderDecoderRecognizer(BaseRecognizer):
+ """Base class for encode-decode recognizer.
+
+ Args:
+ preprocessor (dict, optional): Config dict for preprocessor. Defaults
+ to None.
+ backbone (dict, optional): Backbone config. Defaults to None.
+ encoder (dict, optional): Encoder config. If None, the output from
+ backbone will be directly fed into ``decoder``. Defaults to None.
+ decoder (dict, optional): Decoder config. Defaults to None.
+ data_preprocessor (dict, optional): Model preprocessing config
+ for processing the input image data. Keys allowed are
+ ``to_rgb``(bool), ``pad_size_divisor``(int), ``pad_value``(int or
+ float), ``mean``(int or float) and ``std``(int or float).
+ Preprcessing order: 1. to rgb; 2. normalization 3. pad.
+ Defaults to None.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ preprocessor: OptConfigType = None,
+ backbone: OptConfigType = None,
+ encoder: OptConfigType = None,
+ decoder: OptConfigType = None,
+ data_preprocessor: ConfigType = None,
+ init_cfg: InitConfigType = None) -> None:
+
+ super().__init__(
+ init_cfg=init_cfg, data_preprocessor=data_preprocessor)
+
+ # Preprocessor module, e.g., TPS
+ if preprocessor is not None:
+ self.preprocessor = MODELS.build(preprocessor)
+
+ # Backbone
+ if backbone is not None:
+ self.backbone = MODELS.build(backbone)
+
+ # Encoder module
+ if encoder is not None:
+ self.encoder = MODELS.build(encoder)
+
+ # Decoder module
+ assert decoder is not None
+ self.decoder = MODELS.build(decoder)
+
+ def extract_feat(self, inputs: torch.Tensor) -> torch.Tensor:
+ """Directly extract features from the backbone."""
+ if self.with_preprocessor:
+ inputs = self.preprocessor(inputs)
+ if self.with_backbone:
+ inputs = self.backbone(inputs)
+ return inputs
+
+ def loss(self, inputs: torch.Tensor, data_samples: RecSampleList,
+ **kwargs) -> Dict:
+ """Calculate losses from a batch of inputs and data samples.
+ Args:
+ inputs (tensor): Input images of shape (N, C, H, W).
+ Typically these should be mean centered and std scaled.
+ data_samples (list[TextRecogDataSample]): A list of N
+ datasamples, containing meta information and gold
+ annotations for each of the images.
+
+ Returns:
+ dict[str, tensor]: A dictionary of loss components.
+ """
+ feat = self.extract_feat(inputs)
+ out_enc = None
+ if self.with_encoder:
+ out_enc = self.encoder(feat, data_samples)
+ return self.decoder.loss(feat, out_enc, data_samples)
+
+ def predict(self, inputs: torch.Tensor, data_samples: RecSampleList,
+ **kwargs) -> RecSampleList:
+ """Predict results from a batch of inputs and data samples with post-
+ processing.
+
+ Args:
+ inputs (torch.Tensor): Image input tensor.
+ data_samples (list[TextRecogDataSample]): A list of N datasamples,
+ containing meta information and gold annotations for each of
+ the images.
+
+ Returns:
+ list[TextRecogDataSample]: A list of N datasamples of prediction
+ results. Results are stored in ``pred_text``.
+ """
+ feat = self.extract_feat(inputs)
+ out_enc = None
+ if self.with_encoder:
+ out_enc = self.encoder(feat, data_samples)
+ return self.decoder.predict(feat, out_enc, data_samples)
+
+ def _forward(self,
+ inputs: torch.Tensor,
+ data_samples: OptRecSampleList = None,
+ **kwargs) -> RecForwardResults:
+ """Network forward process. Usually includes backbone, encoder and
+ decoder forward without any post-processing.
+
+ Args:
+ inputs (Tensor): Inputs with shape (N, C, H, W).
+ data_samples (list[TextRecogDataSample]): A list of N
+ datasamples, containing meta information and gold
+ annotations for each of the images.
+
+ Returns:
+ Tensor: A tuple of features from ``decoder`` forward.
+ """
+ feat = self.extract_feat(inputs)
+ out_enc = None
+ if self.with_encoder:
+ out_enc = self.encoder(feat, data_samples)
+ return self.decoder(feat, out_enc, data_samples)
diff --git a/mmocr/models/textrecog/recognizers/encoder_decoder_recognizer_tta.py b/mmocr/models/textrecog/recognizers/encoder_decoder_recognizer_tta.py
new file mode 100644
index 0000000000000000000000000000000000000000..6ee7aa1c464e2d9efefd8d8cd50a3d4cf4c2ed50
--- /dev/null
+++ b/mmocr/models/textrecog/recognizers/encoder_decoder_recognizer_tta.py
@@ -0,0 +1,99 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List
+
+import numpy as np
+from mmengine.model import BaseTTAModel
+
+from mmocr.registry import MODELS
+from mmocr.utils.typing_utils import RecSampleList
+
+
+@MODELS.register_module()
+class EncoderDecoderRecognizerTTAModel(BaseTTAModel):
+ """Merge augmented recognition results. It will select the best result
+ according average scores from all augmented results.
+
+ Examples:
+ >>> tta_model = dict(
+ >>> type='EncoderDecoderRecognizerTTAModel')
+ >>>
+ >>> tta_pipeline = [
+ >>> dict(
+ >>> type='LoadImageFromFile',
+ >>> color_type='grayscale'),
+ >>> dict(
+ >>> type='TestTimeAug',
+ >>> transforms=[
+ >>> [
+ >>> dict(
+ >>> type='ConditionApply',
+ >>> true_transforms=[
+ >>> dict(
+ >>> type='ImgAugWrapper',
+ >>> args=[dict(cls='Rot90', k=0, keep_size=False)]) # noqa: E501
+ >>> ],
+ >>> condition="results['img_shape'][1]>> ),
+ >>> dict(
+ >>> type='ConditionApply',
+ >>> true_transforms=[
+ >>> dict(
+ >>> type='ImgAugWrapper',
+ >>> args=[dict(cls='Rot90', k=1, keep_size=False)]) # noqa: E501
+ >>> ],
+ >>> condition="results['img_shape'][1]>> ),
+ >>> dict(
+ >>> type='ConditionApply',
+ >>> true_transforms=[
+ >>> dict(
+ >>> type='ImgAugWrapper',
+ >>> args=[dict(cls='Rot90', k=3, keep_size=False)])
+ >>> ],
+ >>> condition="results['img_shape'][1]>> ),
+ >>> ],
+ >>> [
+ >>> dict(
+ >>> type='RescaleToHeight',
+ >>> height=32,
+ >>> min_width=32,
+ >>> max_width=None,
+ >>> width_divisor=16)
+ >>> ],
+ >>> # add loading annotation after ``Resize`` because ground truth
+ >>> # does not need to do resize data transform
+ >>> [dict(type='LoadOCRAnnotations', with_text=True)],
+ >>> [
+ >>> dict(
+ >>> type='PackTextRecogInputs',
+ >>> meta_keys=('img_path', 'ori_shape', 'img_shape',
+ >>> 'valid_ratio'))
+ >>> ]
+ >>> ])
+ >>> ]
+ """
+
+ def merge_preds(self,
+ data_samples_list: List[RecSampleList]) -> RecSampleList:
+ """Merge predictions of enhanced data to one prediction.
+
+ Args:
+ data_samples_list (List[RecSampleList]): List of predictions of
+ all enhanced data. The shape of data_samples_list is (B, M),
+ where B is the batch size and M is the number of augmented
+ data.
+
+ Returns:
+ RecSampleList: Merged prediction.
+ """
+ predictions = list()
+ for data_samples in data_samples_list:
+ scores = [
+ data_sample.pred_text.score for data_sample in data_samples
+ ]
+ average_scores = np.array(
+ [sum(score) / max(1, len(score)) for score in scores])
+ max_idx = np.argmax(average_scores)
+ predictions.append(data_samples[max_idx])
+ return predictions
diff --git a/mmocr/models/textrecog/recognizers/maerec.py b/mmocr/models/textrecog/recognizers/maerec.py
new file mode 100644
index 0000000000000000000000000000000000000000..6fdbfa246ce0d850a48af435359bbc54699c8ba3
--- /dev/null
+++ b/mmocr/models/textrecog/recognizers/maerec.py
@@ -0,0 +1,8 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmocr.registry import MODELS
+from .encoder_decoder_recognizer import EncoderDecoderRecognizer
+
+
+@MODELS.register_module()
+class MAERec(EncoderDecoderRecognizer):
+ """Implementation of MAERec"""
diff --git a/mmocr/models/textrecog/recognizers/master.py b/mmocr/models/textrecog/recognizers/master.py
new file mode 100644
index 0000000000000000000000000000000000000000..dbc059caadeb379e9d9514880187b5ee06367721
--- /dev/null
+++ b/mmocr/models/textrecog/recognizers/master.py
@@ -0,0 +1,8 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmocr.registry import MODELS
+from .encoder_decoder_recognizer import EncoderDecoderRecognizer
+
+
+@MODELS.register_module()
+class MASTER(EncoderDecoderRecognizer):
+ """Implementation of `MASTER `_"""
diff --git a/mmocr/models/textrecog/recognizers/nrtr.py b/mmocr/models/textrecog/recognizers/nrtr.py
new file mode 100644
index 0000000000000000000000000000000000000000..9c57e02c0f828674cb47abc1b32bd870e6268c62
--- /dev/null
+++ b/mmocr/models/textrecog/recognizers/nrtr.py
@@ -0,0 +1,8 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmocr.registry import MODELS
+from .encoder_decoder_recognizer import EncoderDecoderRecognizer
+
+
+@MODELS.register_module()
+class NRTR(EncoderDecoderRecognizer):
+ """Implementation of `NRTR `_"""
diff --git a/mmocr/models/textrecog/recognizers/robust_scanner.py b/mmocr/models/textrecog/recognizers/robust_scanner.py
new file mode 100644
index 0000000000000000000000000000000000000000..987ac965046ff14a5c6d1299dda3e394c1374a5f
--- /dev/null
+++ b/mmocr/models/textrecog/recognizers/robust_scanner.py
@@ -0,0 +1,11 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmocr.registry import MODELS
+from .encoder_decoder_recognizer import EncoderDecoderRecognizer
+
+
+@MODELS.register_module()
+class RobustScanner(EncoderDecoderRecognizer):
+ """Implementation of `RobustScanner.
+
+
+ """
diff --git a/mmocr/models/textrecog/recognizers/sar.py b/mmocr/models/textrecog/recognizers/sar.py
new file mode 100644
index 0000000000000000000000000000000000000000..8ba8306232b2598416c0149c8baf786338b07ab4
--- /dev/null
+++ b/mmocr/models/textrecog/recognizers/sar.py
@@ -0,0 +1,8 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmocr.registry import MODELS
+from .encoder_decoder_recognizer import EncoderDecoderRecognizer
+
+
+@MODELS.register_module()
+class SARNet(EncoderDecoderRecognizer):
+ """Implementation of `SAR `_"""
diff --git a/mmocr/models/textrecog/recognizers/satrn.py b/mmocr/models/textrecog/recognizers/satrn.py
new file mode 100644
index 0000000000000000000000000000000000000000..9182d8bea829b5453dc8228d842b91c6d9915a9e
--- /dev/null
+++ b/mmocr/models/textrecog/recognizers/satrn.py
@@ -0,0 +1,8 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmocr.registry import MODELS
+from .encoder_decoder_recognizer import EncoderDecoderRecognizer
+
+
+@MODELS.register_module()
+class SATRN(EncoderDecoderRecognizer):
+ """Implementation of `SATRN `_"""
diff --git a/mmocr/models/textrecog/recognizers/svtr.py b/mmocr/models/textrecog/recognizers/svtr.py
new file mode 100644
index 0000000000000000000000000000000000000000..6fc42b85d0beea3062e06f16ee3265c0763d32c6
--- /dev/null
+++ b/mmocr/models/textrecog/recognizers/svtr.py
@@ -0,0 +1,9 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmocr.registry import MODELS
+from .encoder_decoder_recognizer import EncoderDecoderRecognizer
+
+
+@MODELS.register_module()
+class SVTR(EncoderDecoderRecognizer):
+ """A PyTorch implementation of : `SVTR: Scene Text Recognition with a
+ Single Visual Model `_"""
diff --git a/mmocr/registry.py b/mmocr/registry.py
new file mode 100644
index 0000000000000000000000000000000000000000..d1ed33552881316ab4dc151650243456e06e1c4f
--- /dev/null
+++ b/mmocr/registry.py
@@ -0,0 +1,157 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+"""MMOCR provides 20 registry nodes to support using modules across projects.
+Each node is a child of the root registry in MMEngine.
+
+More details can be found at
+https://mmengine.readthedocs.io/en/latest/tutorials/registry.html.
+"""
+
+from mmengine.registry import DATA_SAMPLERS as MMENGINE_DATA_SAMPLERS
+from mmengine.registry import DATASETS as MMENGINE_DATASETS
+from mmengine.registry import EVALUATOR as MMENGINE_EVALUATOR
+from mmengine.registry import HOOKS as MMENGINE_HOOKS
+from mmengine.registry import LOG_PROCESSORS as MMENGINE_LOG_PROCESSORS
+from mmengine.registry import LOOPS as MMENGINE_LOOPS
+from mmengine.registry import METRICS as MMENGINE_METRICS
+from mmengine.registry import MODEL_WRAPPERS as MMENGINE_MODEL_WRAPPERS
+from mmengine.registry import MODELS as MMENGINE_MODELS
+from mmengine.registry import \
+ OPTIM_WRAPPER_CONSTRUCTORS as MMENGINE_OPTIM_WRAPPER_CONSTRUCTORS
+from mmengine.registry import OPTIM_WRAPPERS as MMENGINE_OPTIM_WRAPPERS
+from mmengine.registry import OPTIMIZERS as MMENGINE_OPTIMIZERS
+from mmengine.registry import PARAM_SCHEDULERS as MMENGINE_PARAM_SCHEDULERS
+from mmengine.registry import \
+ RUNNER_CONSTRUCTORS as MMENGINE_RUNNER_CONSTRUCTORS
+from mmengine.registry import RUNNERS as MMENGINE_RUNNERS
+from mmengine.registry import TASK_UTILS as MMENGINE_TASK_UTILS
+from mmengine.registry import TRANSFORMS as MMENGINE_TRANSFORMS
+from mmengine.registry import VISBACKENDS as MMENGINE_VISBACKENDS
+from mmengine.registry import VISUALIZERS as MMENGINE_VISUALIZERS
+from mmengine.registry import \
+ WEIGHT_INITIALIZERS as MMENGINE_WEIGHT_INITIALIZERS
+from mmengine.registry import Registry
+
+# manage all kinds of runners like `EpochBasedRunner` and `IterBasedRunner`
+RUNNERS = Registry(
+ 'runner',
+ parent=MMENGINE_RUNNERS,
+ # TODO: update the location when mmocr has its own runner
+ locations=['mmocr.engine'])
+# manage runner constructors that define how to initialize runners
+RUNNER_CONSTRUCTORS = Registry(
+ 'runner constructor',
+ parent=MMENGINE_RUNNER_CONSTRUCTORS,
+ # TODO: update the location when mmocr has its own runner constructor
+ locations=['mmocr.engine'])
+# manage all kinds of loops like `EpochBasedTrainLoop`
+LOOPS = Registry(
+ 'loop',
+ parent=MMENGINE_LOOPS,
+ # TODO: update the location when mmocr has its own loop
+ locations=['mmocr.engine'])
+# manage all kinds of hooks like `CheckpointHook`
+HOOKS = Registry(
+ 'hook', parent=MMENGINE_HOOKS, locations=['mmocr.engine.hooks'])
+
+# manage data-related modules
+DATASETS = Registry(
+ 'dataset', parent=MMENGINE_DATASETS, locations=['mmocr.datasets'])
+DATA_SAMPLERS = Registry(
+ 'data sampler',
+ parent=MMENGINE_DATA_SAMPLERS,
+ locations=['mmocr.datasets.samplers'])
+TRANSFORMS = Registry(
+ 'transform',
+ parent=MMENGINE_TRANSFORMS,
+ locations=['mmocr.datasets.transforms'])
+
+# manage all kinds of modules inheriting `nn.Module`
+MODELS = Registry('model', parent=MMENGINE_MODELS, locations=['mmocr.models'])
+# manage all kinds of model wrappers like 'MMDistributedDataParallel'
+MODEL_WRAPPERS = Registry(
+ 'model wrapper',
+ parent=MMENGINE_MODEL_WRAPPERS,
+ locations=['mmocr.models'])
+# manage all kinds of weight initialization modules like `Uniform`
+WEIGHT_INITIALIZERS = Registry(
+ 'weight initializer',
+ parent=MMENGINE_WEIGHT_INITIALIZERS,
+ locations=['mmocr.models'])
+
+# manage all kinds of optimizers like `SGD` and `Adam`
+OPTIMIZERS = Registry(
+ 'optimizer',
+ parent=MMENGINE_OPTIMIZERS,
+ # TODO: update the location when mmocr has its own optimizer
+ locations=['mmocr.engine'])
+# manage optimizer wrapper
+OPTIM_WRAPPERS = Registry(
+ 'optimizer wrapper',
+ parent=MMENGINE_OPTIM_WRAPPERS,
+ # TODO: update the location when mmocr has its own optimizer wrapper
+ locations=['mmocr.engine'])
+# manage constructors that customize the optimization hyperparameters.
+OPTIM_WRAPPER_CONSTRUCTORS = Registry(
+ 'optimizer constructor',
+ parent=MMENGINE_OPTIM_WRAPPER_CONSTRUCTORS,
+ # TODO: update the location when mmocr has its own optimizer constructor
+ locations=['mmocr.engine'])
+# manage all kinds of parameter schedulers like `MultiStepLR`
+PARAM_SCHEDULERS = Registry(
+ 'parameter scheduler',
+ parent=MMENGINE_PARAM_SCHEDULERS,
+ # TODO: update the location when mmocr has its own parameter scheduler
+ locations=['mmocr.engine'])
+# manage all kinds of metrics
+METRICS = Registry(
+ 'metric', parent=MMENGINE_METRICS, locations=['mmocr.evaluation.metrics'])
+# manage evaluator
+EVALUATOR = Registry(
+ 'evaluator',
+ parent=MMENGINE_EVALUATOR,
+ locations=['mmocr.evaluation.evaluator'])
+
+# manage task-specific modules like anchor generators and box coders
+TASK_UTILS = Registry(
+ 'task util', parent=MMENGINE_TASK_UTILS, locations=['mmocr.models'])
+
+# manage visualizer
+VISUALIZERS = Registry(
+ 'visualizer',
+ parent=MMENGINE_VISUALIZERS,
+ locations=['mmocr.visualization'])
+# manage visualizer backend
+VISBACKENDS = Registry(
+ 'visualizer backend',
+ parent=MMENGINE_VISBACKENDS,
+ locations=['mmocr.visualization'])
+
+# manage logprocessor
+LOG_PROCESSORS = Registry(
+ 'logger processor',
+ parent=MMENGINE_LOG_PROCESSORS,
+ # TODO: update the location when mmocr has its own log processor
+ locations=['mmocr.engine'])
+# manage data obtainer
+DATA_OBTAINERS = Registry(
+ 'data obtainer', locations=['mmocr.datasets.preparers.obtainers'])
+
+# manage data gatherer
+DATA_GATHERERS = Registry(
+ 'data gatherer', locations=['mmocr.datasets.preparers.gatherers'])
+
+# manage data parser
+DATA_PARSERS = Registry(
+ 'data parser', locations=['mmocr.datasets.preparers.parsers'])
+
+# manage data packer
+DATA_PACKERS = Registry(
+ 'data packer', locations=['mmocr.datasets.preparers.packers'])
+
+# manage data dumper
+DATA_DUMPERS = Registry(
+ 'data dumper', locations=['mmocr.datasets.preparers.dumpers'])
+
+# manage dataset config generator
+CFG_GENERATORS = Registry(
+ 'cfg generator', locations=['mmocr.datasets.preparers.config_generators'])
diff --git a/mmocr/structures/__init__.py b/mmocr/structures/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..2b71ac262a07022d63faee8766a555933793da5e
--- /dev/null
+++ b/mmocr/structures/__init__.py
@@ -0,0 +1,10 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .kie_data_sample import KIEDataSample
+from .textdet_data_sample import TextDetDataSample
+from .textrecog_data_sample import TextRecogDataSample
+from .textspotting_data_sample import TextSpottingDataSample
+
+__all__ = [
+ 'TextDetDataSample', 'TextRecogDataSample', 'KIEDataSample',
+ 'TextSpottingDataSample'
+]
diff --git a/mmocr/structures/__pycache__/__init__.cpython-38.pyc b/mmocr/structures/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b4ea2c2fde3b9c19c4b69b4dba25006ba8d86f68
Binary files /dev/null and b/mmocr/structures/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/structures/__pycache__/kie_data_sample.cpython-38.pyc b/mmocr/structures/__pycache__/kie_data_sample.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..bbcb39ed51a32d1c562099c480250f8cc9558111
Binary files /dev/null and b/mmocr/structures/__pycache__/kie_data_sample.cpython-38.pyc differ
diff --git a/mmocr/structures/__pycache__/textdet_data_sample.cpython-38.pyc b/mmocr/structures/__pycache__/textdet_data_sample.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..66bbc0a0acf32deb4818df520cffc29b8bf0322a
Binary files /dev/null and b/mmocr/structures/__pycache__/textdet_data_sample.cpython-38.pyc differ
diff --git a/mmocr/structures/__pycache__/textrecog_data_sample.cpython-38.pyc b/mmocr/structures/__pycache__/textrecog_data_sample.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..cd17a2508a048000c3a00de6a19a970615310eda
Binary files /dev/null and b/mmocr/structures/__pycache__/textrecog_data_sample.cpython-38.pyc differ
diff --git a/mmocr/structures/__pycache__/textspotting_data_sample.cpython-38.pyc b/mmocr/structures/__pycache__/textspotting_data_sample.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e1b05b03acd82e337b2fd738675ee4aaca4a0369
Binary files /dev/null and b/mmocr/structures/__pycache__/textspotting_data_sample.cpython-38.pyc differ
diff --git a/mmocr/structures/kie_data_sample.py b/mmocr/structures/kie_data_sample.py
new file mode 100644
index 0000000000000000000000000000000000000000..c681e5b2fd30a6f8cc52db90a4d3fe70df28fe1a
--- /dev/null
+++ b/mmocr/structures/kie_data_sample.py
@@ -0,0 +1,91 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmengine.structures import BaseDataElement, InstanceData
+
+
+class KIEDataSample(BaseDataElement):
+ """A data structure interface of MMOCR. They are used as interfaces between
+ different components.
+
+ The attributes in ``KIEDataSample`` are divided into two parts:
+
+ - ``gt_instances``(InstanceData): Ground truth of instance annotations.
+ - ``pred_instances``(InstanceData): Instances of model predictions.
+
+ Examples:
+ >>> import torch
+ >>> import numpy as np
+ >>> from mmengine.structures import InstanceData
+ >>> from mmocr.data import KIEDataSample
+ >>> # gt_instances
+ >>> data_sample = KIEDataSample()
+ >>> img_meta = dict(img_shape=(800, 1196, 3),
+ ... pad_shape=(800, 1216, 3))
+ >>> gt_instances = InstanceData(metainfo=img_meta)
+ >>> gt_instances.bboxes = torch.rand((5, 4))
+ >>> gt_instances.labels = torch.rand((5,))
+ >>> data_sample.gt_instances = gt_instances
+ >>> assert 'img_shape' in data_sample.gt_instances.metainfo_keys()
+ >>> len(data_sample.gt_instances)
+ 5
+ >>> print(data_sample)
+
+ ) at 0x7f21fb1b9880>
+ >>> # pred_instances
+ >>> pred_instances = InstanceData(metainfo=img_meta)
+ >>> pred_instances.bboxes = torch.rand((5, 4))
+ >>> pred_instances.scores = torch.rand((5,))
+ >>> data_sample = KIEDataSample(pred_instances=pred_instances)
+ >>> assert 'pred_instances' in data_sample
+ >>> data_sample = KIEDataSample()
+ >>> gt_instances_data = dict(
+ ... bboxes=torch.rand(2, 4),
+ ... labels=torch.rand(2))
+ >>> gt_instances = InstanceData(**gt_instances_data)
+ >>> data_sample.gt_instances = gt_instances
+ >>> assert 'gt_instances' in data_sample
+ """
+
+ @property
+ def gt_instances(self) -> InstanceData:
+ """InstanceData: groundtruth instances."""
+ return self._gt_instances
+
+ @gt_instances.setter
+ def gt_instances(self, value: InstanceData):
+ """gt_instances setter."""
+ self.set_field(value, '_gt_instances', dtype=InstanceData)
+
+ @gt_instances.deleter
+ def gt_instances(self):
+ """gt_instances deleter."""
+ del self._gt_instances
+
+ @property
+ def pred_instances(self) -> InstanceData:
+ """InstanceData: prediction instances."""
+ return self._pred_instances
+
+ @pred_instances.setter
+ def pred_instances(self, value: InstanceData):
+ """pred_instances setter."""
+ self.set_field(value, '_pred_instances', dtype=InstanceData)
+
+ @pred_instances.deleter
+ def pred_instances(self):
+ """pred_instances deleter."""
+ del self._pred_instances
diff --git a/mmocr/structures/textdet_data_sample.py b/mmocr/structures/textdet_data_sample.py
new file mode 100644
index 0000000000000000000000000000000000000000..465967064b7b4038423b56cf7be49497663e7feb
--- /dev/null
+++ b/mmocr/structures/textdet_data_sample.py
@@ -0,0 +1,93 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmengine.structures import BaseDataElement, InstanceData
+
+
+class TextDetDataSample(BaseDataElement):
+ """A data structure interface of MMOCR. They are used as interfaces between
+ different components.
+
+ The attributes in ``TextDetDataSample`` are divided into two parts:
+
+ - ``gt_instances``(InstanceData): Ground truth of instance annotations.
+ - ``pred_instances``(InstanceData): Instances of model predictions.
+
+ Examples:
+ >>> import torch
+ >>> import numpy as np
+ >>> from mmengine.structures import InstanceData
+ >>> from mmocr.data import TextDetDataSample
+ >>> # gt_instances
+ >>> data_sample = TextDetDataSample()
+ >>> img_meta = dict(img_shape=(800, 1196, 3),
+ ... pad_shape=(800, 1216, 3))
+ >>> gt_instances = InstanceData(metainfo=img_meta)
+ >>> gt_instances.bboxes = torch.rand((5, 4))
+ >>> gt_instances.labels = torch.rand((5,))
+ >>> data_sample.gt_instances = gt_instances
+ >>> assert 'img_shape' in data_sample.gt_instances.metainfo_keys()
+ >>> len(data_sample.gt_instances)
+ 5
+ >>> print(data_sample)
+
+ ) at 0x7f21fb1b9880>
+ >>> # pred_instances
+ >>> pred_instances = InstanceData(metainfo=img_meta)
+ >>> pred_instances.bboxes = torch.rand((5, 4))
+ >>> pred_instances.scores = torch.rand((5,))
+ >>> data_sample = TextDetDataSample(pred_instances=pred_instances)
+ >>> assert 'pred_instances' in data_sample
+ >>> data_sample = TextDetDataSample()
+ >>> gt_instances_data = dict(
+ ... bboxes=torch.rand(2, 4),
+ ... labels=torch.rand(2),
+ ... masks=np.random.rand(2, 2, 2))
+ >>> gt_instances = InstanceData(**gt_instances_data)
+ >>> data_sample.gt_instances = gt_instances
+ >>> assert 'gt_instances' in data_sample
+ >>> assert 'masks' in data_sample.gt_instances
+ """
+
+ @property
+ def gt_instances(self) -> InstanceData:
+ """InstanceData: groundtruth instances."""
+ return self._gt_instances
+
+ @gt_instances.setter
+ def gt_instances(self, value: InstanceData):
+ """gt_instances setter."""
+ self.set_field(value, '_gt_instances', dtype=InstanceData)
+
+ @gt_instances.deleter
+ def gt_instances(self):
+ """gt_instances deleter."""
+ del self._gt_instances
+
+ @property
+ def pred_instances(self) -> InstanceData:
+ """InstanceData: prediction instances."""
+ return self._pred_instances
+
+ @pred_instances.setter
+ def pred_instances(self, value: InstanceData):
+ """pred_instances setter."""
+ self.set_field(value, '_pred_instances', dtype=InstanceData)
+
+ @pred_instances.deleter
+ def pred_instances(self):
+ """pred_instances deleter."""
+ del self._pred_instances
diff --git a/mmocr/structures/textrecog_data_sample.py b/mmocr/structures/textrecog_data_sample.py
new file mode 100644
index 0000000000000000000000000000000000000000..f40572b0282dd82d1bc67734dcfe52c0073fe5d4
--- /dev/null
+++ b/mmocr/structures/textrecog_data_sample.py
@@ -0,0 +1,82 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmengine.structures import BaseDataElement, LabelData
+
+
+class TextRecogDataSample(BaseDataElement):
+ """A data structure interface of MMOCR for text recognition. They are used
+ as interfaces between different components.
+
+ The attributes in ``TextRecogDataSample`` are divided into two parts:
+
+ - ``gt_text``(LabelData): Ground truth text.
+ - ``pred_text``(LabelData): predictions text.
+
+ Examples:
+ >>> import torch
+ >>> import numpy as np
+ >>> from mmengine.structures import LabelData
+ >>> from mmocr.data import TextRecogDataSample
+ >>> # gt_text
+ >>> data_sample = TextRecogDataSample()
+ >>> img_meta = dict(img_shape=(800, 1196, 3),
+ ... pad_shape=(800, 1216, 3))
+ >>> gt_text = LabelData(metainfo=img_meta)
+ >>> gt_text.item = 'mmocr'
+ >>> data_sample.gt_text = gt_text
+ >>> assert 'img_shape' in data_sample.gt_text.metainfo_keys()
+ >>> print(data_sample)
+
+ ) at 0x7f21fb1b9880>
+ >>> # pred_text
+ >>> pred_text = LabelData(metainfo=img_meta)
+ >>> pred_text.item = 'mmocr'
+ >>> data_sample = TextRecogDataSample(pred_text=pred_text)
+ >>> assert 'pred_text' in data_sample
+ >>> data_sample = TextRecogDataSample()
+ >>> gt_text_data = dict(item='mmocr')
+ >>> gt_text = LabelData(**gt_text_data)
+ >>> data_sample.gt_text = gt_text
+ >>> assert 'gt_text' in data_sample
+ >>> assert 'item' in data_sample.gt_text
+ """
+
+ @property
+ def gt_text(self) -> LabelData:
+ """LabelData: ground truth text.
+ """
+ return self._gt_text
+
+ @gt_text.setter
+ def gt_text(self, value: LabelData) -> None:
+ """gt_text setter."""
+ self.set_field(value, '_gt_text', dtype=LabelData)
+
+ @gt_text.deleter
+ def gt_text(self) -> None:
+ """gt_text deleter."""
+ del self._gt_text
+
+ @property
+ def pred_text(self) -> LabelData:
+ """LabelData: prediction text.
+ """
+ return self._pred_text
+
+ @pred_text.setter
+ def pred_text(self, value: LabelData) -> None:
+ """pred_text setter."""
+ self.set_field(value, '_pred_text', dtype=LabelData)
+
+ @pred_text.deleter
+ def pred_text(self) -> None:
+ """pred_text deleter."""
+ del self._pred_text
diff --git a/mmocr/structures/textspotting_data_sample.py b/mmocr/structures/textspotting_data_sample.py
new file mode 100644
index 0000000000000000000000000000000000000000..28478f516f96651d2e49c180cea4a97336fc5c97
--- /dev/null
+++ b/mmocr/structures/textspotting_data_sample.py
@@ -0,0 +1,64 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmocr.structures import TextDetDataSample
+
+
+class TextSpottingDataSample(TextDetDataSample):
+ """A data structure interface of MMOCR. They are used as interfaces between
+ different components.
+
+ The attributes in ``TextSpottingDataSample`` are divided into two parts:
+
+ - ``gt_instances``(InstanceData): Ground truth of instance annotations.
+ - ``pred_instances``(InstanceData): Instances of model predictions.
+
+ Examples:
+ >>> import torch
+ >>> import numpy as np
+ >>> from mmengine.structures import InstanceData
+ >>> from mmocr.data import TextSpottingDataSample
+ >>> # gt_instances
+ >>> data_sample = TextSpottingDataSample()
+ >>> img_meta = dict(img_shape=(800, 1196, 3),
+ ... pad_shape=(800, 1216, 3))
+ >>> gt_instances = InstanceData(metainfo=img_meta)
+ >>> gt_instances.bboxes = torch.rand((5, 4))
+ >>> gt_instances.labels = torch.rand((5,))
+ >>> data_sample.gt_instances = gt_instances
+ >>> assert 'img_shape' in data_sample.gt_instances.metainfo_keys()
+ >>> len(data_sample.gt_instances)
+ 5
+ >>> print(data_sample)
+
+ ) at 0x7f21fb1b9880>
+ >>> # pred_instances
+ >>> pred_instances = InstanceData(metainfo=img_meta)
+ >>> pred_instances.bboxes = torch.rand((5, 4))
+ >>> pred_instances.scores = torch.rand((5,))
+ >>> data_sample = TextSpottingDataSample(
+ ... pred_instances=pred_instances)
+ >>> assert 'pred_instances' in data_sample
+ >>> data_sample = TextSpottingDataSample()
+ >>> gt_instances_data = dict(
+ ... bboxes=torch.rand(2, 4),
+ ... labels=torch.rand(2),
+ ... masks=np.random.rand(2, 2, 2))
+ >>> gt_instances = InstanceData(**gt_instances_data)
+ >>> data_sample.gt_instances = gt_instances
+ >>> assert 'gt_instances' in data_sample
+ >>> assert 'masks' in data_sample.gt_instances
+ """
diff --git a/mmocr/testing/__init__.py b/mmocr/testing/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..3000419b8fd971c4b05d87893e4d23df7459caf8
--- /dev/null
+++ b/mmocr/testing/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .data import create_dummy_dict_file, create_dummy_textdet_inputs
+
+__all__ = ['create_dummy_dict_file', 'create_dummy_textdet_inputs']
diff --git a/mmocr/testing/data.py b/mmocr/testing/data.py
new file mode 100644
index 0000000000000000000000000000000000000000..fc0b4d2cddcda3e9200855853e58a8d2213c4194
--- /dev/null
+++ b/mmocr/testing/data.py
@@ -0,0 +1,110 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Any, Dict, List, Optional, Sequence
+
+import numpy as np
+import torch
+from mmengine.structures import InstanceData
+
+from mmocr.structures import TextDetDataSample
+
+
+def create_dummy_textdet_inputs(input_shape: Sequence[int] = (1, 3, 300, 300),
+ num_items: Optional[Sequence[int]] = None
+ ) -> Dict[str, Any]:
+ """Create dummy inputs to test text detectors.
+
+ Args:
+ input_shape (tuple(int)): 4-d shape of the input image. Defaults to
+ (1, 3, 300, 300).
+ num_items (list[int], optional): Number of bboxes to create for each
+ image. If None, they will be randomly generated. Defaults to None.
+
+ Returns:
+ Dict[str, Any]: A dictionary of demo inputs.
+ """
+ (N, C, H, W) = input_shape
+
+ rng = np.random.RandomState(0)
+
+ imgs = rng.rand(*input_shape)
+
+ metainfo = dict(
+ img_shape=(H, W, C),
+ ori_shape=(H, W, C),
+ pad_shape=(H, W, C),
+ filename='test.jpg',
+ scale_factor=(1, 1),
+ flip=False)
+
+ gt_masks = []
+ gt_kernels = []
+ gt_effective_mask = []
+
+ data_samples = []
+
+ for batch_idx in range(N):
+ if num_items is None:
+ num_boxes = rng.randint(1, 10)
+ else:
+ num_boxes = num_items[batch_idx]
+
+ data_sample = TextDetDataSample(
+ metainfo=metainfo, gt_instances=InstanceData())
+
+ cx, cy, bw, bh = rng.rand(num_boxes, 4).T
+
+ tl_x = ((cx * W) - (W * bw / 2)).clip(0, W)
+ tl_y = ((cy * H) - (H * bh / 2)).clip(0, H)
+ br_x = ((cx * W) + (W * bw / 2)).clip(0, W)
+ br_y = ((cy * H) + (H * bh / 2)).clip(0, H)
+
+ boxes = np.vstack([tl_x, tl_y, br_x, br_y]).T
+ class_idxs = [0] * num_boxes
+
+ data_sample.gt_instances.bboxes = torch.FloatTensor(boxes)
+ data_sample.gt_instances.labels = torch.LongTensor(class_idxs)
+ data_sample.gt_instances.ignored = torch.BoolTensor([False] *
+ num_boxes)
+ data_samples.append(data_sample)
+
+ # kernels = []
+ # TODO: add support for multiple kernels (if necessary)
+ # for _ in range(num_kernels):
+ # kernel = np.random.rand(H, W)
+ # kernels.append(kernel)
+ gt_kernels.append(np.random.rand(H, W))
+ gt_effective_mask.append(np.ones((H, W)))
+
+ mask = np.random.randint(0, 2, (len(boxes), H, W), dtype=np.uint8)
+ gt_masks.append(mask)
+
+ mm_inputs = {
+ 'imgs': torch.FloatTensor(imgs).requires_grad_(True),
+ 'data_samples': data_samples,
+ 'gt_masks': gt_masks,
+ 'gt_kernels': gt_kernels,
+ 'gt_mask': gt_effective_mask,
+ 'gt_thr_mask': gt_effective_mask,
+ 'gt_text_mask': gt_effective_mask,
+ 'gt_center_region_mask': gt_effective_mask,
+ 'gt_radius_map': gt_kernels,
+ 'gt_sin_map': gt_kernels,
+ 'gt_cos_map': gt_kernels,
+ }
+ return mm_inputs
+
+
+def create_dummy_dict_file(
+ dict_file: str,
+ chars: List[str] = list('0123456789abcdefghijklmnopqrstuvwxyz')
+) -> None: # NOQA
+ """Create a dummy dictionary file.
+
+ Args:
+ dict_file (str): Path to the dummy dictionary file.
+ chars (list[str]): List of characters in dictionary. Defaults to
+ ``list('0123456789abcdefghijklmnopqrstuvwxyz')``.
+ """
+ with open(dict_file, 'w') as f:
+ for char in chars:
+ f.write(char + '\n')
diff --git a/mmocr/utils/__init__.py b/mmocr/utils/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..3e4fb6fb22fec6e35eb563547ff03b50354f4f2f
--- /dev/null
+++ b/mmocr/utils/__init__.py
@@ -0,0 +1,54 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .bbox_utils import (bbox2poly, bbox_center_distance, bbox_diag_distance,
+ bezier2polygon, is_on_same_line, rescale_bbox,
+ rescale_bboxes, stitch_boxes_into_lines)
+from .bezier_utils import bezier2poly, poly2bezier
+from .check_argument import (equal_len, is_2dlist, is_3dlist, is_none_or_type,
+ is_type_list, valid_boundary)
+from .collect_env import collect_env
+from .data_converter_utils import dump_ocr_data, recog_anno_to_imginfo
+from .fileio import (check_integrity, get_md5, is_archive, list_files,
+ list_from_file, list_to_file)
+from .img_utils import crop_img, warp_img
+from .mask_utils import fill_hole
+from .parsers import LineJsonParser, LineStrParser
+from .point_utils import point_distance, points_center
+from .polygon_utils import (boundary_iou, crop_polygon, is_poly_inside_rect,
+ offset_polygon, poly2bbox, poly2shapely,
+ poly_intersection, poly_iou, poly_make_valid,
+ poly_union, polys2shapely, rescale_polygon,
+ rescale_polygons, shapely2poly, sort_points,
+ sort_vertex, sort_vertex8)
+from .processing import track_parallel_progress_multi_args
+from .setup_env import register_all_modules
+from .string_utils import StringStripper
+from .transform_utils import remove_pipeline_elements
+from .typing_utils import (ColorType, ConfigType, DetSampleList,
+ InitConfigType, InstanceList, KIESampleList,
+ LabelList, MultiConfig, OptConfigType,
+ OptDetSampleList, OptInitConfigType,
+ OptInstanceList, OptKIESampleList, OptLabelList,
+ OptMultiConfig, OptRecSampleList, OptTensor,
+ RangeType, RecForwardResults, RecSampleList)
+
+__all__ = [
+ 'collect_env', 'is_3dlist', 'is_type_list', 'is_none_or_type', 'equal_len',
+ 'is_2dlist', 'valid_boundary', 'list_to_file', 'list_from_file',
+ 'is_on_same_line', 'stitch_boxes_into_lines', 'StringStripper',
+ 'bezier2polygon', 'sort_points', 'dump_ocr_data', 'recog_anno_to_imginfo',
+ 'rescale_polygons', 'rescale_polygon', 'rescale_bbox', 'rescale_bboxes',
+ 'bbox2poly', 'crop_polygon', 'is_poly_inside_rect', 'poly2bbox',
+ 'poly_intersection', 'poly_iou', 'poly_make_valid', 'poly_union',
+ 'poly2shapely', 'polys2shapely', 'register_all_modules', 'offset_polygon',
+ 'sort_vertex8', 'sort_vertex', 'bbox_center_distance',
+ 'bbox_diag_distance', 'boundary_iou', 'point_distance', 'points_center',
+ 'fill_hole', 'LineJsonParser', 'LineStrParser', 'shapely2poly', 'crop_img',
+ 'warp_img', 'ConfigType', 'DetSampleList', 'RecForwardResults',
+ 'InitConfigType', 'OptConfigType', 'OptDetSampleList', 'OptInitConfigType',
+ 'OptMultiConfig', 'OptRecSampleList', 'RecSampleList', 'MultiConfig',
+ 'OptTensor', 'ColorType', 'OptKIESampleList', 'KIESampleList',
+ 'is_archive', 'check_integrity', 'list_files', 'get_md5', 'InstanceList',
+ 'LabelList', 'OptInstanceList', 'OptLabelList', 'RangeType',
+ 'remove_pipeline_elements', 'bezier2poly', 'poly2bezier',
+ 'track_parallel_progress_multi_args'
+]
diff --git a/mmocr/utils/__pycache__/__init__.cpython-38.pyc b/mmocr/utils/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e2efca87dacd308c95dfba47d8f7b767b204336d
Binary files /dev/null and b/mmocr/utils/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/utils/__pycache__/bbox_utils.cpython-38.pyc b/mmocr/utils/__pycache__/bbox_utils.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..bd20a3ac3bcebd67aaee2e129b0b9a9f7fdd5001
Binary files /dev/null and b/mmocr/utils/__pycache__/bbox_utils.cpython-38.pyc differ
diff --git a/mmocr/utils/__pycache__/bezier_utils.cpython-38.pyc b/mmocr/utils/__pycache__/bezier_utils.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..fbac05ba24598d21d9579c5d0f97dfc71fd197a1
Binary files /dev/null and b/mmocr/utils/__pycache__/bezier_utils.cpython-38.pyc differ
diff --git a/mmocr/utils/__pycache__/check_argument.cpython-38.pyc b/mmocr/utils/__pycache__/check_argument.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0a7cbfe596b7ba061a061ddbbbc76d65697003dd
Binary files /dev/null and b/mmocr/utils/__pycache__/check_argument.cpython-38.pyc differ
diff --git a/mmocr/utils/__pycache__/collect_env.cpython-38.pyc b/mmocr/utils/__pycache__/collect_env.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..dfec1cb43c60d5db01ef34b2f3777ad664b2f72f
Binary files /dev/null and b/mmocr/utils/__pycache__/collect_env.cpython-38.pyc differ
diff --git a/mmocr/utils/__pycache__/data_converter_utils.cpython-38.pyc b/mmocr/utils/__pycache__/data_converter_utils.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..02111a8d3b47af979ec17dcbee93f5201409e746
Binary files /dev/null and b/mmocr/utils/__pycache__/data_converter_utils.cpython-38.pyc differ
diff --git a/mmocr/utils/__pycache__/fileio.cpython-38.pyc b/mmocr/utils/__pycache__/fileio.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ca7d41ffe2ba9f81124f2b11a0e591923fd0611f
Binary files /dev/null and b/mmocr/utils/__pycache__/fileio.cpython-38.pyc differ
diff --git a/mmocr/utils/__pycache__/img_utils.cpython-38.pyc b/mmocr/utils/__pycache__/img_utils.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ce2532da56328808538fe5572943d4217d2b6aad
Binary files /dev/null and b/mmocr/utils/__pycache__/img_utils.cpython-38.pyc differ
diff --git a/mmocr/utils/__pycache__/mask_utils.cpython-38.pyc b/mmocr/utils/__pycache__/mask_utils.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..7baf153ba3411ae05d5b7d30616d19df7897c366
Binary files /dev/null and b/mmocr/utils/__pycache__/mask_utils.cpython-38.pyc differ
diff --git a/mmocr/utils/__pycache__/parsers.cpython-38.pyc b/mmocr/utils/__pycache__/parsers.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d96b5475d3fa5e23799d71d908f2640550027842
Binary files /dev/null and b/mmocr/utils/__pycache__/parsers.cpython-38.pyc differ
diff --git a/mmocr/utils/__pycache__/point_utils.cpython-38.pyc b/mmocr/utils/__pycache__/point_utils.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d94b60ff0ded5e8b3769e3f42a80ea46df9030f6
Binary files /dev/null and b/mmocr/utils/__pycache__/point_utils.cpython-38.pyc differ
diff --git a/mmocr/utils/__pycache__/polygon_utils.cpython-38.pyc b/mmocr/utils/__pycache__/polygon_utils.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..18ae00fc29fbc5892a4f50718da906fe9841db54
Binary files /dev/null and b/mmocr/utils/__pycache__/polygon_utils.cpython-38.pyc differ
diff --git a/mmocr/utils/__pycache__/processing.cpython-38.pyc b/mmocr/utils/__pycache__/processing.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c8dd64f090730b657177ac2091fd407f2e7caa62
Binary files /dev/null and b/mmocr/utils/__pycache__/processing.cpython-38.pyc differ
diff --git a/mmocr/utils/__pycache__/setup_env.cpython-38.pyc b/mmocr/utils/__pycache__/setup_env.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..3ab0f025d43de3dca6f5182967fe56cbaf45e31d
Binary files /dev/null and b/mmocr/utils/__pycache__/setup_env.cpython-38.pyc differ
diff --git a/mmocr/utils/__pycache__/string_utils.cpython-38.pyc b/mmocr/utils/__pycache__/string_utils.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c4369b15965caf9cddb878d0d219c71dbb264f34
Binary files /dev/null and b/mmocr/utils/__pycache__/string_utils.cpython-38.pyc differ
diff --git a/mmocr/utils/__pycache__/transform_utils.cpython-38.pyc b/mmocr/utils/__pycache__/transform_utils.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2e8ab6b9007379096aa93dfabc08793807419d19
Binary files /dev/null and b/mmocr/utils/__pycache__/transform_utils.cpython-38.pyc differ
diff --git a/mmocr/utils/__pycache__/typing_utils.cpython-38.pyc b/mmocr/utils/__pycache__/typing_utils.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..fa0de5ada9f8b5d45188738a807e0a869e65d60a
Binary files /dev/null and b/mmocr/utils/__pycache__/typing_utils.cpython-38.pyc differ
diff --git a/mmocr/utils/bbox_utils.py b/mmocr/utils/bbox_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..a91df91d79916c151c399b0489ae4662f6149ee7
--- /dev/null
+++ b/mmocr/utils/bbox_utils.py
@@ -0,0 +1,368 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Tuple
+
+import numpy as np
+from shapely.geometry import LineString, Point
+
+from mmocr.utils.check_argument import is_type_list
+from mmocr.utils.point_utils import point_distance, points_center
+from mmocr.utils.typing_utils import ArrayLike
+
+
+def rescale_bbox(bbox: np.ndarray,
+ scale_factor: Tuple[int, int],
+ mode: str = 'mul') -> np.ndarray:
+ """Rescale a bounding box according to scale_factor.
+
+ The behavior is different depending on the mode. When mode is 'mul', the
+ coordinates will be multiplied by scale_factor, which is usually used in
+ preprocessing transforms such as :func:`Resize`.
+ The coordinates will be divided by scale_factor if mode is 'div'. It can be
+ used in postprocessors to recover the bbox in the original image size.
+
+ Args:
+ bbox (ndarray): A bounding box [x1, y1, x2, y2].
+ scale_factor (tuple(int, int)): (w_scale, h_scale).
+ model (str): Rescale mode. Can be 'mul' or 'div'. Defaults to 'mul'.
+
+ Returns:
+ np.ndarray: Rescaled bbox.
+ """
+ assert mode in ['mul', 'div']
+ bbox = np.array(bbox, dtype=np.float32)
+ bbox_shape = bbox.shape
+ reshape_bbox = bbox.reshape(-1, 2)
+ scale_factor = np.array(scale_factor, dtype=float)
+ if mode == 'div':
+ scale_factor = 1 / scale_factor
+ bbox = (reshape_bbox * scale_factor[None]).reshape(bbox_shape)
+ return bbox
+
+
+def rescale_bboxes(bboxes: np.ndarray,
+ scale_factor: Tuple[int, int],
+ mode: str = 'mul') -> np.ndarray:
+ """Rescale bboxes according to scale_factor.
+
+ The behavior is different depending on the mode. When mode is 'mul', the
+ coordinates will be multiplied by scale_factor, which is usually used in
+ preprocessing transforms such as :func:`Resize`.
+ The coordinates will be divided by scale_factor if mode is 'div'. It can be
+ used in postprocessors to recover the bboxes in the original
+ image size.
+
+ Args:
+ bboxes (np.ndarray]): Bounding bboxes in shape (N, 4)
+ scale_factor (tuple(int, int)): (w_scale, h_scale).
+ model (str): Rescale mode. Can be 'mul' or 'div'. Defaults to 'mul'.
+
+ Returns:
+ list[np.ndarray]: Rescaled bboxes.
+ """
+ bboxes = rescale_bbox(bboxes, scale_factor, mode)
+ return bboxes
+
+
+def bbox2poly(bbox: ArrayLike, mode: str = 'xyxy') -> np.array:
+ """Converting a bounding box to a polygon.
+
+ Args:
+ bbox (ArrayLike): A bbox. In any form can be accessed by 1-D indices.
+ E.g. list[float], np.ndarray, or torch.Tensor. bbox is written in
+ [x1, y1, x2, y2].
+ mode (str): Specify the format of bbox. Can be 'xyxy' or 'xywh'.
+ Defaults to 'xyxy'.
+
+ Returns:
+ np.array: The converted polygon [x1, y1, x2, y1, x2, y2, x1, y2].
+ """
+ assert len(bbox) == 4
+ if mode == 'xyxy':
+ x1, y1, x2, y2 = bbox
+ poly = np.array([x1, y1, x2, y1, x2, y2, x1, y2])
+ elif mode == 'xywh':
+ x, y, w, h = bbox
+ poly = np.array([x, y, x + w, y, x + w, y + h, x, y + h])
+ else:
+ raise NotImplementedError('Not supported mode.')
+
+ return poly
+
+
+def is_on_same_line(box_a, box_b, min_y_overlap_ratio=0.8):
+ # TODO Check if it should be deleted after ocr.py refactored
+ """Check if two boxes are on the same line by their y-axis coordinates.
+
+ Two boxes are on the same line if they overlap vertically, and the length
+ of the overlapping line segment is greater than min_y_overlap_ratio * the
+ height of either of the boxes.
+
+ Args:
+ box_a (list), box_b (list): Two bounding boxes to be checked
+ min_y_overlap_ratio (float): The minimum vertical overlapping ratio
+ allowed for boxes in the same line
+
+ Returns:
+ The bool flag indicating if they are on the same line
+ """
+ a_y_min = np.min(box_a[1::2])
+ b_y_min = np.min(box_b[1::2])
+ a_y_max = np.max(box_a[1::2])
+ b_y_max = np.max(box_b[1::2])
+
+ # Make sure that box a is always the box above another
+ if a_y_min > b_y_min:
+ a_y_min, b_y_min = b_y_min, a_y_min
+ a_y_max, b_y_max = b_y_max, a_y_max
+
+ if b_y_min <= a_y_max:
+ if min_y_overlap_ratio is not None:
+ sorted_y = sorted([b_y_min, b_y_max, a_y_max])
+ overlap = sorted_y[1] - sorted_y[0]
+ min_a_overlap = (a_y_max - a_y_min) * min_y_overlap_ratio
+ min_b_overlap = (b_y_max - b_y_min) * min_y_overlap_ratio
+ return overlap >= min_a_overlap or \
+ overlap >= min_b_overlap
+ else:
+ return True
+ return False
+
+
+def stitch_boxes_into_lines(boxes, max_x_dist=10, min_y_overlap_ratio=0.8):
+ # TODO Check if it should be deleted after ocr.py refactored
+ """Stitch fragmented boxes of words into lines.
+
+ Note: part of its logic is inspired by @Johndirr
+ (https://github.com/faustomorales/keras-ocr/issues/22)
+
+ Args:
+ boxes (list): List of ocr results to be stitched
+ max_x_dist (int): The maximum horizontal distance between the closest
+ edges of neighboring boxes in the same line
+ min_y_overlap_ratio (float): The minimum vertical overlapping ratio
+ allowed for any pairs of neighboring boxes in the same line
+
+ Returns:
+ merged_boxes(list[dict]): List of merged boxes and texts
+ """
+
+ if len(boxes) <= 1:
+ return boxes
+
+ merged_boxes = []
+
+ # sort groups based on the x_min coordinate of boxes
+ x_sorted_boxes = sorted(boxes, key=lambda x: np.min(x['box'][::2]))
+ # store indexes of boxes which are already parts of other lines
+ skip_idxs = set()
+
+ i = 0
+ # locate lines of boxes starting from the leftmost one
+ for i in range(len(x_sorted_boxes)):
+ if i in skip_idxs:
+ continue
+ # the rightmost box in the current line
+ rightmost_box_idx = i
+ line = [rightmost_box_idx]
+ for j in range(i + 1, len(x_sorted_boxes)):
+ if j in skip_idxs:
+ continue
+ if is_on_same_line(x_sorted_boxes[rightmost_box_idx]['box'],
+ x_sorted_boxes[j]['box'], min_y_overlap_ratio):
+ line.append(j)
+ skip_idxs.add(j)
+ rightmost_box_idx = j
+
+ # split line into lines if the distance between two neighboring
+ # sub-lines' is greater than max_x_dist
+ lines = []
+ line_idx = 0
+ lines.append([line[0]])
+ rightmost = np.max(x_sorted_boxes[line[0]]['box'][::2])
+ for k in range(1, len(line)):
+ curr_box = x_sorted_boxes[line[k]]
+ dist = np.min(curr_box['box'][::2]) - rightmost
+ if dist > max_x_dist:
+ line_idx += 1
+ lines.append([])
+ lines[line_idx].append(line[k])
+ rightmost = max(rightmost, np.max(curr_box['box'][::2]))
+
+ # Get merged boxes
+ for box_group in lines:
+ merged_box = {}
+ merged_box['text'] = ' '.join(
+ [x_sorted_boxes[idx]['text'] for idx in box_group])
+ x_min, y_min = float('inf'), float('inf')
+ x_max, y_max = float('-inf'), float('-inf')
+ for idx in box_group:
+ x_max = max(np.max(x_sorted_boxes[idx]['box'][::2]), x_max)
+ x_min = min(np.min(x_sorted_boxes[idx]['box'][::2]), x_min)
+ y_max = max(np.max(x_sorted_boxes[idx]['box'][1::2]), y_max)
+ y_min = min(np.min(x_sorted_boxes[idx]['box'][1::2]), y_min)
+ merged_box['box'] = [
+ x_min, y_min, x_max, y_min, x_max, y_max, x_min, y_max
+ ]
+ merged_boxes.append(merged_box)
+
+ return merged_boxes
+
+
+def bezier2polygon(bezier_points: np.ndarray,
+ num_sample: int = 20) -> List[np.ndarray]:
+ # TODO check test later
+ """Sample points from the boundary of a polygon enclosed by two Bezier
+ curves, which are controlled by ``bezier_points``.
+
+ Args:
+ bezier_points (ndarray): A :math:`(2, 4, 2)` array of 8 Bezeir points
+ or its equalivance. The first 4 points control the curve at one
+ side and the last four control the other side.
+ num_sample (int): The number of sample points at each Bezeir curve.
+ Defaults to 20.
+
+ Returns:
+ list[ndarray]: A list of 2*num_sample points representing the polygon
+ extracted from Bezier curves.
+
+ Warning:
+ The points are not guaranteed to be ordered. Please use
+ :func:`mmocr.utils.sort_points` to sort points if necessary.
+ """
+ assert num_sample > 0, 'The sampling number should greater than 0'
+
+ bezier_points = np.asarray(bezier_points)
+ assert np.prod(
+ bezier_points.shape) == 16, 'Need 8 Bezier control points to continue!'
+
+ bezier = bezier_points.reshape(2, 4, 2).transpose(0, 2, 1).reshape(4, 4)
+ u = np.linspace(0, 1, num_sample)
+
+ points = np.outer((1 - u) ** 3, bezier[:, 0]) \
+ + np.outer(3 * u * ((1 - u) ** 2), bezier[:, 1]) \
+ + np.outer(3 * (u ** 2) * (1 - u), bezier[:, 2]) \
+ + np.outer(u ** 3, bezier[:, 3])
+
+ # Convert points to polygon
+ points = np.concatenate((points[:, :2], points[:, 2:]), axis=0)
+ return points.tolist()
+
+
+def sort_vertex(points_x, points_y):
+ # TODO Add typehints & docstring & test
+ """Sort box vertices in clockwise order from left-top first.
+
+ Args:
+ points_x (list[float]): x of four vertices.
+ points_y (list[float]): y of four vertices.
+ Returns:
+ sorted_points_x (list[float]): x of sorted four vertices.
+ sorted_points_y (list[float]): y of sorted four vertices.
+ """
+ assert is_type_list(points_x, (float, int))
+ assert is_type_list(points_y, (float, int))
+ assert len(points_x) == 4
+ assert len(points_y) == 4
+ vertices = np.stack((points_x, points_y), axis=-1).astype(np.float32)
+ vertices = _sort_vertex(vertices)
+ sorted_points_x = list(vertices[:, 0])
+ sorted_points_y = list(vertices[:, 1])
+ return sorted_points_x, sorted_points_y
+
+
+def _sort_vertex(vertices):
+ # TODO Add typehints & docstring & test
+ assert vertices.ndim == 2
+ assert vertices.shape[-1] == 2
+ N = vertices.shape[0]
+ if N == 0:
+ return vertices
+
+ center = np.mean(vertices, axis=0)
+ directions = vertices - center
+ angles = np.arctan2(directions[:, 1], directions[:, 0])
+ sort_idx = np.argsort(angles)
+ vertices = vertices[sort_idx]
+
+ left_top = np.min(vertices, axis=0)
+ dists = np.linalg.norm(left_top - vertices, axis=-1, ord=2)
+ lefttop_idx = np.argmin(dists)
+ indexes = (np.arange(N, dtype=np.int_) + lefttop_idx) % N
+ return vertices[indexes]
+
+
+def sort_vertex8(points):
+ # TODO Add typehints & docstring & test
+ """Sort vertex with 8 points [x1 y1 x2 y2 x3 y3 x4 y4]"""
+ assert len(points) == 8
+ vertices = _sort_vertex(np.array(points, dtype=np.float32).reshape(-1, 2))
+ sorted_box = list(vertices.flatten())
+ return sorted_box
+
+
+def bbox_center_distance(box1: ArrayLike, box2: ArrayLike) -> float:
+ """Calculate the distance between the center points of two bounding boxes.
+
+ Args:
+ box1 (ArrayLike): The first bounding box
+ represented in [x1, y1, x2, y2].
+ box2 (ArrayLike): The second bounding box
+ represented in [x1, y1, x2, y2].
+
+ Returns:
+ float: The distance between the center points of two bounding boxes.
+ """
+ return point_distance(points_center(box1), points_center(box2))
+
+
+def bbox_diag_distance(box: ArrayLike) -> float:
+ """Calculate the diagonal length of a bounding box (distance between the
+ top-left and bottom-right).
+
+ Args:
+ box (ArrayLike): The bounding box represented in
+ [x1, y1, x2, y2, x3, y3, x4, y4] or [x1, y1, x2, y2].
+
+ Returns:
+ float: The diagonal length of the bounding box.
+ """
+ box = np.array(box, dtype=np.float32)
+ assert (box.size == 8 or box.size == 4)
+
+ if box.size == 8:
+ diag = point_distance(box[0:2], box[4:6])
+ elif box.size == 4:
+ diag = point_distance(box[0:2], box[2:4])
+
+ return diag
+
+
+def bbox_jitter(points_x, points_y, jitter_ratio_x=0.5, jitter_ratio_y=0.1):
+ """Jitter on the coordinates of bounding box.
+
+ Args:
+ points_x (list[float | int]): List of y for four vertices.
+ points_y (list[float | int]): List of x for four vertices.
+ jitter_ratio_x (float): Horizontal jitter ratio relative to the height.
+ jitter_ratio_y (float): Vertical jitter ratio relative to the height.
+ """
+ assert len(points_x) == 4
+ assert len(points_y) == 4
+ assert isinstance(jitter_ratio_x, float)
+ assert isinstance(jitter_ratio_y, float)
+ assert 0 <= jitter_ratio_x < 1
+ assert 0 <= jitter_ratio_y < 1
+
+ points = [Point(points_x[i], points_y[i]) for i in range(4)]
+ line_list = [
+ LineString([points[i], points[i + 1 if i < 3 else 0]])
+ for i in range(4)
+ ]
+
+ tmp_h = max(line_list[1].length, line_list[3].length)
+
+ for i in range(4):
+ jitter_pixel_x = (np.random.rand() - 0.5) * 2 * jitter_ratio_x * tmp_h
+ jitter_pixel_y = (np.random.rand() - 0.5) * 2 * jitter_ratio_y * tmp_h
+ points_x[i] += jitter_pixel_x
+ points_y[i] += jitter_pixel_y
diff --git a/mmocr/utils/bezier_utils.py b/mmocr/utils/bezier_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..d93a6293926e2d807eb089bf92835e39a4ef5d84
--- /dev/null
+++ b/mmocr/utils/bezier_utils.py
@@ -0,0 +1,62 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+from scipy.special import comb as n_over_k
+
+from mmocr.utils.typing_utils import ArrayLike
+
+
+def bezier_coefficient(n, t, k):
+ return t**k * (1 - t)**(n - k) * n_over_k(n, k)
+
+
+def bezier_coefficients(time, point_num, ratios):
+ return [[bezier_coefficient(time, ratio, num) for num in range(point_num)]
+ for ratio in ratios]
+
+
+def linear_interpolation(point1: np.ndarray,
+ point2: np.ndarray,
+ number: int = 2) -> np.ndarray:
+ t = np.linspace(0, 1, number + 2).reshape(-1, 1)
+ return point1 + (point2 - point1) * t
+
+
+def curve2bezier(curve: ArrayLike):
+ curve = np.array(curve).reshape(-1, 2)
+ if len(curve) == 2:
+ return linear_interpolation(curve[0], curve[1])
+ diff = curve[1:] - curve[:-1]
+ distance = np.linalg.norm(diff, axis=-1)
+ norm_distance = distance / distance.sum()
+ norm_distance = np.hstack(([0], norm_distance))
+ cum_norm_dis = norm_distance.cumsum()
+ pseudo_inv = np.linalg.pinv(bezier_coefficients(3, 4, cum_norm_dis))
+ control_points = pseudo_inv.dot(curve)
+ return control_points
+
+
+def bezier2curve(bezier: np.ndarray, num_sample: int = 10):
+ bezier = np.asarray(bezier)
+ t = np.linspace(0, 1, num_sample)
+ return np.array(bezier_coefficients(3, 4, t)).dot(bezier)
+
+
+def poly2bezier(poly):
+ poly = np.array(poly).reshape(-1, 2)
+ points_num = len(poly)
+ up_curve = poly[:points_num // 2]
+ down_curve = poly[points_num // 2:]
+ up_bezier = curve2bezier(up_curve)
+ down_bezier = curve2bezier(down_curve)
+ up_bezier[0] = up_curve[0]
+ up_bezier[-1] = up_curve[-1]
+ down_bezier[0] = down_curve[0]
+ down_bezier[-1] = down_curve[-1]
+ return np.vstack((up_bezier, down_bezier)).flatten().tolist()
+
+
+def bezier2poly(bezier, num_sample=20):
+ bezier = bezier.reshape(2, 4, 2)
+ curve_top = bezier2curve(bezier[0], num_sample)
+ curve_bottom = bezier2curve(bezier[1], num_sample)
+ return np.vstack((curve_top, curve_bottom)).flatten().tolist()
diff --git a/mmocr/utils/check_argument.py b/mmocr/utils/check_argument.py
new file mode 100644
index 0000000000000000000000000000000000000000..34cbe8dc2658d725c328eb5cd98652633a22aa24
--- /dev/null
+++ b/mmocr/utils/check_argument.py
@@ -0,0 +1,72 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+
+
+def is_3dlist(x):
+ """check x is 3d-list([[[1], []]]) or 2d empty list([[], []]) or 1d empty
+ list([]).
+
+ Notice:
+ The reason that it contains 1d or 2d empty list is because
+ some arguments from gt annotation file or model prediction
+ may be empty, but usually, it should be 3d-list.
+ """
+ if not isinstance(x, list):
+ return False
+ if len(x) == 0:
+ return True
+ for sub_x in x:
+ if not is_2dlist(sub_x):
+ return False
+
+ return True
+
+
+def is_2dlist(x):
+ """check x is 2d-list([[1], []]) or 1d empty list([]).
+
+ Notice:
+ The reason that it contains 1d empty list is because
+ some arguments from gt annotation file or model prediction
+ may be empty, but usually, it should be 2d-list.
+ """
+ if not isinstance(x, list):
+ return False
+ if len(x) == 0:
+ return True
+
+ return all(isinstance(item, list) for item in x)
+
+
+def is_type_list(x, type):
+
+ if not isinstance(x, list):
+ return False
+
+ return all(isinstance(item, type) for item in x)
+
+
+def is_none_or_type(x, type):
+
+ return isinstance(x, type) or x is None
+
+
+def equal_len(*argv):
+ assert len(argv) > 0
+
+ num_arg = len(argv[0])
+ for arg in argv:
+ if len(arg) != num_arg:
+ return False
+ return True
+
+
+def valid_boundary(x, with_score=True):
+ num = len(x)
+ if num < 8:
+ return False
+ if num % 2 == 0 and (not with_score):
+ return True
+ if num % 2 == 1 and with_score:
+ return True
+
+ return False
diff --git a/mmocr/utils/collect_env.py b/mmocr/utils/collect_env.py
new file mode 100644
index 0000000000000000000000000000000000000000..cf56ecc77902841220cb3e9040033de82fe81e2c
--- /dev/null
+++ b/mmocr/utils/collect_env.py
@@ -0,0 +1,17 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmengine.utils import get_git_hash
+from mmengine.utils.dl_utils import collect_env as collect_base_env
+
+import mmocr
+
+
+def collect_env():
+ """Collect the information of the running environments."""
+ env_info = collect_base_env()
+ env_info['MMOCR'] = mmocr.__version__ + '+' + get_git_hash()[:7]
+ return env_info
+
+
+if __name__ == '__main__':
+ for name, val in collect_env().items():
+ print(f'{name}: {val}')
diff --git a/mmocr/utils/data_converter_utils.py b/mmocr/utils/data_converter_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..bbc4ad090a143c4acd705fdce8d45d2e3e73bf0d
--- /dev/null
+++ b/mmocr/utils/data_converter_utils.py
@@ -0,0 +1,189 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from typing import Dict, Sequence
+
+import mmengine
+
+from mmocr.utils import is_type_list
+
+
+def dump_ocr_data(image_infos: Sequence[Dict], out_json_name: str,
+ task_name: str, **kwargs) -> Dict:
+ """Dump the annotation in openmmlab style.
+
+ Args:
+ image_infos (list): List of image information dicts. Read the example
+ section for the format illustration.
+ out_json_name (str): Output json filename.
+ task_name (str): Task name. Options are 'textdet', 'textrecog' and
+ 'textspotter'.
+
+ Examples:
+ Here is the general structure of image_infos for textdet/textspotter
+ tasks:
+
+ .. code-block:: python
+
+ [ # A list of dicts. Each dict stands for a single image.
+ {
+ "file_name": "1.jpg",
+ "height": 100,
+ "width": 200,
+ "segm_file": "seg.txt" # (optional) path to segmap
+ "anno_info": [ # a list of dicts. Each dict
+ # stands for a single text instance.
+ {
+ "iscrowd": 0, # 0: don't ignore this instance
+ # 1: ignore
+ "category_id": 0, # Instance class id. Must be 0
+ # for OCR tasks to permanently
+ # be mapped to 'text' category
+ "bbox": [x, y, w, h],
+ "segmentation": [x1, y1, x2, y2, ...],
+ "text": "demo_text" # for textspotter only.
+ }
+ ]
+ },
+ ]
+
+ The input for textrecog task is much simpler:
+
+ .. code-block:: python
+
+ [ # A list of dicts. Each dict stands for a single image.
+ {
+ "file_name": "1.jpg",
+ "anno_info": [ # a list of dicts. Each dict
+ # stands for a single text instance.
+ # However, in textrecog, usually each
+ # image only has one text instance.
+ {
+ "text": "demo_text"
+ }
+ ]
+ },
+ ]
+
+
+ Returns:
+ out_json(dict): The openmmlab-style annotation.
+ """
+
+ task2dataset = {
+ 'textspotter': 'TextSpotterDataset',
+ 'textdet': 'TextDetDataset',
+ 'textrecog': 'TextRecogDataset'
+ }
+
+ assert isinstance(image_infos, list)
+ assert isinstance(out_json_name, str)
+ assert task_name in task2dataset.keys()
+
+ dataset_type = task2dataset[task_name]
+
+ out_json = dict(
+ metainfo=dict(dataset_type=dataset_type, task_name=task_name),
+ data_list=list())
+ if task_name in ['textdet', 'textspotter']:
+ out_json['metainfo']['category'] = [dict(id=0, name='text')]
+
+ for image_info in image_infos:
+
+ single_info = dict(instances=list())
+ single_info['img_path'] = image_info['file_name']
+ if task_name in ['textdet', 'textspotter']:
+ single_info['height'] = image_info['height']
+ single_info['width'] = image_info['width']
+ if 'segm_file' in image_info:
+ single_info['seg_map'] = image_info['segm_file']
+
+ anno_infos = image_info['anno_info']
+
+ for anno_info in anno_infos:
+ instance = {}
+ if task_name in ['textrecog', 'textspotter']:
+ instance['text'] = anno_info['text']
+ if task_name in ['textdet', 'textspotter']:
+ mask = anno_info['segmentation']
+ # TODO: remove this if-branch when all converters have been
+ # verified
+ if len(mask) == 1 and len(mask[0]) > 1:
+ mask = mask[0]
+ warnings.warn(
+ 'Detected nested segmentation for a single'
+ 'text instance, which should be a 1-d array now.'
+ 'Please fix input accordingly.')
+ instance['polygon'] = mask
+ x, y, w, h = anno_info['bbox']
+ instance['bbox'] = [x, y, x + w, y + h]
+ instance['bbox_label'] = anno_info['category_id']
+ instance['ignore'] = anno_info['iscrowd'] == 1
+ single_info['instances'].append(instance)
+
+ out_json['data_list'].append(single_info)
+
+ mmengine.dump(out_json, out_json_name, **kwargs)
+
+ return out_json
+
+
+def recog_anno_to_imginfo(
+ file_paths: Sequence[str],
+ labels: Sequence[str],
+) -> Sequence[Dict]:
+ """Convert a list of file_paths and labels for recognition tasks into the
+ format of image_infos acceptable by :func:`dump_ocr_data()`. It's meant to
+ maintain compatibility with the legacy annotation format in MMOCR 0.x.
+
+ In MMOCR 0.x, data converters for recognition usually converts the
+ annotations into a list of file paths and a list of labels, which look
+ like the following:
+
+ .. code-block:: python
+
+ file_paths = ['1.jpg', '2.jpg', ...]
+ labels = ['aaa', 'bbb', ...]
+
+ This utility merges them into a list of dictionaries parsable by
+ :func:`dump_ocr_data()`:
+
+ .. code-block:: python
+
+ [ # A list of dicts. Each dict stands for a single image.
+ {
+ "file_name": "1.jpg",
+ "anno_info": [
+ {
+ "text": "aaa"
+ }
+ ]
+ },
+ {
+ "file_name": "2.jpg",
+ "anno_info": [
+ {
+ "text": "bbb"
+ }
+ ]
+ },
+ ...
+ ]
+
+ Args:
+ file_paths (list[str]): A list of file paths to images.
+ labels (list[str]): A list of text labels.
+
+ Returns:
+ list[dict]: Annotations parsable by :func:`dump_ocr_data()`.
+ """
+ assert is_type_list(file_paths, str)
+ assert is_type_list(labels, str)
+ assert len(file_paths) == len(labels)
+
+ results = []
+ for i in range(len(file_paths)):
+ result = dict(
+ file_name=file_paths[i], anno_info=[dict(text=labels[i])])
+ results.append(result)
+
+ return results
diff --git a/mmocr/utils/fileio.py b/mmocr/utils/fileio.py
new file mode 100644
index 0000000000000000000000000000000000000000..cae4e58571c29a1f3573dc8053b7daf5b04c07cd
--- /dev/null
+++ b/mmocr/utils/fileio.py
@@ -0,0 +1,125 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import hashlib
+import os.path as osp
+import sys
+import warnings
+from glob import glob
+from typing import List
+
+from mmengine import mkdir_or_exist
+
+
+def list_to_file(filename, lines):
+ """Write a list of strings to a text file.
+
+ Args:
+ filename (str): The output filename. It will be created/overwritten.
+ lines (list(str)): Data to be written.
+ """
+ mkdir_or_exist(osp.dirname(filename))
+ with open(filename, 'w', encoding='utf-8') as fw:
+ for line in lines:
+ fw.write(f'{line}\n')
+
+
+def list_from_file(filename, encoding='utf-8'):
+ """Load a text file and parse the content as a list of strings. The
+ trailing "\\r" and "\\n" of each line will be removed.
+
+ Note:
+ This will be replaced by mmcv's version after it supports encoding.
+
+ Args:
+ filename (str): Filename.
+ encoding (str): Encoding used to open the file. Default utf-8.
+
+ Returns:
+ list[str]: A list of strings.
+ """
+ item_list = []
+ with open(filename, encoding=encoding) as f:
+ for line in f:
+ item_list.append(line.rstrip('\n\r'))
+ return item_list
+
+
+def is_archive(file_path: str) -> bool:
+ """Check whether the file is a supported archive format.
+
+ Args:
+ file_path (str): Path to the file.
+
+ Returns:
+ bool: Whether the file is an archive.
+ """
+
+ suffixes = ['zip', 'tar', 'tar.gz']
+
+ for suffix in suffixes:
+ if file_path.endswith(suffix):
+ return True
+ return False
+
+
+def check_integrity(file_path: str,
+ md5: str,
+ chunk_size: int = 1024 * 1024) -> bool:
+ """Check if the file exist and match to the given md5 code.
+
+ Args:
+ file_path (str): Path to the file.
+ md5 (str): MD5 to be matched.
+ chunk_size (int, optional): Chunk size. Defaults to 1024*1024.
+
+ Returns:
+ bool: Whether the md5 is matched.
+ """
+ if md5 is None:
+ warnings.warn('MD5 is None, skip the integrity check.')
+ return True
+ if not osp.exists(file_path):
+ return False
+
+ return get_md5(file_path=file_path, chunk_size=chunk_size) == md5
+
+
+def get_md5(file_path: str, chunk_size: int = 1024 * 1024) -> str:
+ """Get the md5 of the file.
+
+ Args:
+ file_path (str): Path to the file.
+ chunk_size (int, optional): Chunk size. Defaults to 1024*1024.
+
+ Returns:
+ str: MD5 of the file.
+ """
+ if not osp.exists(file_path):
+ raise FileNotFoundError(f'{file_path} does not exist.')
+
+ if sys.version_info >= (3, 9):
+ hash = hashlib.md5(usedforsecurity=False)
+ else:
+ hash = hashlib.md5()
+ with open(file_path, 'rb') as f:
+ for chunk in iter(lambda: f.read(chunk_size), b''):
+ hash.update(chunk)
+
+ return hash.hexdigest()
+
+
+def list_files(path: str, suffixes: List) -> List:
+ """Retrieve file list from the path.
+
+ Args:
+ path (str): Path to the directory.
+ suffixes (list[str], optional): Suffixes to be retrieved.
+
+ Returns:
+ List: List of the files.
+ """
+
+ file_list = []
+ for suffix in suffixes:
+ file_list.extend(glob(osp.join(path, '*' + suffix)))
+
+ return file_list
diff --git a/mmocr/utils/img_utils.py b/mmocr/utils/img_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..c96a05d2578ffc165d6323b37e3a7955b8ce68cf
--- /dev/null
+++ b/mmocr/utils/img_utils.py
@@ -0,0 +1,108 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import cv2
+import numpy as np
+from mmengine.utils import is_seq_of
+from shapely.geometry import LineString, Point
+
+from .bbox_utils import bbox_jitter
+from .polygon_utils import sort_vertex
+
+
+def warp_img(src_img,
+ box,
+ jitter=False,
+ jitter_ratio_x=0.5,
+ jitter_ratio_y=0.1):
+ """Crop box area from image using opencv warpPerspective.
+
+ Args:
+ src_img (np.array): Image before cropping.
+ box (list[float | int]): Coordinates of quadrangle.
+ jitter (bool): Whether to jitter the box.
+ jitter_ratio_x (float): Horizontal jitter ratio relative to the height.
+ jitter_ratio_y (float): Vertical jitter ratio relative to the height.
+
+ Returns:
+ np.array: The warped image.
+ """
+ assert is_seq_of(box, (float, int))
+ assert len(box) == 8
+
+ h, w = src_img.shape[:2]
+ points_x = [min(max(x, 0), w) for x in box[0:8:2]]
+ points_y = [min(max(y, 0), h) for y in box[1:9:2]]
+
+ points_x, points_y = sort_vertex(points_x, points_y)
+
+ if jitter:
+ bbox_jitter(
+ points_x,
+ points_y,
+ jitter_ratio_x=jitter_ratio_x,
+ jitter_ratio_y=jitter_ratio_y)
+
+ points = [Point(points_x[i], points_y[i]) for i in range(4)]
+ edges = [
+ LineString([points[i], points[i + 1 if i < 3 else 0]])
+ for i in range(4)
+ ]
+
+ pts1 = np.float32([[points[i].x, points[i].y] for i in range(4)])
+ box_width = max(edges[0].length, edges[2].length)
+ box_height = max(edges[1].length, edges[3].length)
+
+ pts2 = np.float32([[0, 0], [box_width, 0], [box_width, box_height],
+ [0, box_height]])
+ M = cv2.getPerspectiveTransform(pts1, pts2)
+ dst_img = cv2.warpPerspective(src_img, M,
+ (int(box_width), int(box_height)))
+
+ return dst_img
+
+
+def crop_img(src_img, box, long_edge_pad_ratio=0.4, short_edge_pad_ratio=0.2):
+ """Crop text region given the bounding box which might be slightly padded.
+ The bounding box is assumed to be a quadrangle and tightly bound the text
+ region.
+
+ Args:
+ src_img (np.array): The original image.
+ box (list[float | int]): Points of quadrangle.
+ long_edge_pad_ratio (float): The ratio of padding to the long edge. The
+ padding will be the length of the short edge * long_edge_pad_ratio.
+ Defaults to 0.4.
+ short_edge_pad_ratio (float): The ratio of padding to the short edge.
+ The padding will be the length of the long edge *
+ short_edge_pad_ratio. Defaults to 0.2.
+
+ Returns:
+ np.array: The cropped image.
+ """
+ assert is_seq_of(box, (float, int))
+ assert len(box) == 8
+ assert 0. <= long_edge_pad_ratio < 1.0
+ assert 0. <= short_edge_pad_ratio < 1.0
+
+ h, w = src_img.shape[:2]
+ points_x = np.clip(np.array(box[0::2]), 0, w)
+ points_y = np.clip(np.array(box[1::2]), 0, h)
+
+ box_width = np.max(points_x) - np.min(points_x)
+ box_height = np.max(points_y) - np.min(points_y)
+ shorter_size = min(box_height, box_width)
+
+ if box_height < box_width:
+ horizontal_pad = long_edge_pad_ratio * shorter_size
+ vertical_pad = short_edge_pad_ratio * shorter_size
+ else:
+ horizontal_pad = short_edge_pad_ratio * shorter_size
+ vertical_pad = long_edge_pad_ratio * shorter_size
+
+ left = np.clip(int(np.min(points_x) - horizontal_pad), 0, w)
+ top = np.clip(int(np.min(points_y) - vertical_pad), 0, h)
+ right = np.clip(int(np.max(points_x) + horizontal_pad), 0, w)
+ bottom = np.clip(int(np.max(points_y) + vertical_pad), 0, h)
+
+ dst_img = src_img[top:bottom, left:right]
+
+ return dst_img
diff --git a/mmocr/utils/mask_utils.py b/mmocr/utils/mask_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..a6903072f250766b876f1518be7c613e8c60cebc
--- /dev/null
+++ b/mmocr/utils/mask_utils.py
@@ -0,0 +1,40 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import cv2
+import numpy as np
+
+from mmocr.utils.typing_utils import ArrayLike
+
+
+def fill_hole(input_mask: ArrayLike) -> np.array:
+ """Fill holes in matrix.
+
+ Input:
+ [[0, 0, 0, 0, 0, 0, 0],
+ [0, 1, 1, 1, 1, 1, 0],
+ [0, 1, 0, 0, 0, 1, 0],
+ [0, 1, 1, 1, 1, 1, 0],
+ [0, 0, 0, 0, 0, 0, 0]]
+ Output:
+ [[0, 0, 0, 0, 0, 0, 0],
+ [0, 1, 1, 1, 1, 1, 0],
+ [0, 1, 1, 1, 1, 1, 0],
+ [0, 1, 1, 1, 1, 1, 0],
+ [0, 0, 0, 0, 0, 0, 0]]
+
+ Args:
+ input_mask (ArrayLike): The input mask.
+
+ Returns:
+ np.array: The output mask that has been filled.
+ """
+ input_mask = np.array(input_mask)
+ h, w = input_mask.shape
+ canvas = np.zeros((h + 2, w + 2), np.uint8)
+ canvas[1:h + 1, 1:w + 1] = input_mask.copy()
+
+ mask = np.zeros((h + 4, w + 4), np.uint8)
+
+ cv2.floodFill(canvas, mask, (0, 0), 1)
+ canvas = canvas[1:h + 1, 1:w + 1].astype(np.bool_)
+
+ return ~canvas | input_mask
diff --git a/mmocr/utils/parsers.py b/mmocr/utils/parsers.py
new file mode 100644
index 0000000000000000000000000000000000000000..87cc063de1252611cf662b5b62c312bbdcfca0c0
--- /dev/null
+++ b/mmocr/utils/parsers.py
@@ -0,0 +1,82 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import json
+import warnings
+from typing import Dict, Tuple
+
+from mmocr.registry import TASK_UTILS
+from mmocr.utils.string_utils import StringStripper
+
+
+@TASK_UTILS.register_module()
+class LineStrParser:
+ """Parse string of one line in annotation file to dict format.
+
+ Args:
+ keys (list[str]): Keys in result dict. Defaults to
+ ['filename', 'text'].
+ keys_idx (list[int]): Value index in sub-string list for each key
+ above. Defaults to [0, 1].
+ separator (str): Separator to separate string to list of sub-string.
+ Defaults to ' '.
+ """
+
+ def __init__(self,
+ keys: Tuple[str, str] = ['filename', 'text'],
+ keys_idx: Tuple[int, int] = [0, 1],
+ separator: str = ' ',
+ **kwargs):
+ assert isinstance(keys, list)
+ assert isinstance(keys_idx, list)
+ assert isinstance(separator, str)
+ assert len(keys) > 0
+ assert len(keys) == len(keys_idx)
+ self.keys = keys
+ self.keys_idx = keys_idx
+ self.separator = separator
+ self.strip_cls = StringStripper(**kwargs)
+
+ def __call__(self, in_str: str) -> Dict:
+ line_str = self.strip_cls(in_str)
+ if len(line_str.split(' ')) > 2:
+ msg = 'More than two blank spaces were detected. '
+ msg += 'Please use LineJsonParser to handle '
+ msg += 'annotations with blanks. '
+ msg += 'Check Doc '
+ msg += 'https://mmocr.readthedocs.io/en/latest/'
+ msg += 'tutorials/blank_recog.html '
+ msg += 'for details.'
+ warnings.warn(msg, UserWarning)
+ line_str = line_str.split(self.separator)
+ if len(line_str) <= max(self.keys_idx):
+ raise ValueError(
+ f'key index: {max(self.keys_idx)} out of range: {line_str}')
+
+ line_info = {}
+ for i, key in enumerate(self.keys):
+ line_info[key] = line_str[self.keys_idx[i]]
+ return line_info
+
+
+@TASK_UTILS.register_module()
+class LineJsonParser:
+ """Parse json-string of one line in annotation file to dict format.
+
+ Args:
+ keys (list[str]): Keys in both json-string and result dict. Defaults
+ to ['filename', 'text'].
+ """
+
+ def __init__(self, keys: Tuple[str, str] = ['filename', 'text']) -> None:
+ assert isinstance(keys, list)
+ assert len(keys) > 0
+ self.keys = keys
+
+ def __call__(self, in_str: str) -> Dict:
+ line_json_obj = json.loads(in_str)
+ line_info = {}
+ for key in self.keys:
+ if key not in line_json_obj:
+ raise Exception(f'key {key} not in line json {line_json_obj}')
+ line_info[key] = line_json_obj[key]
+
+ return line_info
diff --git a/mmocr/utils/point_utils.py b/mmocr/utils/point_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..809805f2eaf44337c184216375428f07e99899b9
--- /dev/null
+++ b/mmocr/utils/point_utils.py
@@ -0,0 +1,40 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+
+from mmocr.utils.typing_utils import ArrayLike
+
+
+def points_center(points: ArrayLike) -> np.ndarray:
+ """Calculate the center of a set of points.
+
+ Args:
+ points (ArrayLike): A set of points.
+
+ Returns:
+ np.ndarray: The coordinate of center point.
+ """
+ points = np.array(points, dtype=np.float32)
+ assert points.size % 2 == 0
+
+ points = points.reshape([-1, 2])
+ return np.mean(points, axis=0)
+
+
+def point_distance(pt1: ArrayLike, pt2: ArrayLike) -> float:
+ """Calculate the distance between two points.
+
+ Args:
+ pt1 (ArrayLike): The first point.
+ pt2 (ArrayLike): The second point.
+
+ Returns:
+ float: The distance between two points.
+ """
+ pt1 = np.array(pt1)
+ pt2 = np.array(pt2)
+
+ assert (pt1.size == 2 and pt2.size == 2)
+
+ dist = np.square(pt2 - pt1).sum()
+ dist = np.sqrt(dist)
+ return dist
diff --git a/mmocr/utils/polygon_utils.py b/mmocr/utils/polygon_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..805404a6f49cdc26129cdad4197bab28a4da5556
--- /dev/null
+++ b/mmocr/utils/polygon_utils.py
@@ -0,0 +1,457 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+import operator
+from functools import reduce
+from typing import List, Optional, Sequence, Tuple, Union
+
+import numpy as np
+import pyclipper
+import shapely
+from mmengine.utils import is_list_of
+from shapely.geometry import MultiPolygon, Polygon
+
+from mmocr.utils import bbox2poly, valid_boundary
+from mmocr.utils.check_argument import is_2dlist
+from mmocr.utils.typing_utils import ArrayLike
+
+
+def rescale_polygon(polygon: ArrayLike,
+ scale_factor: Tuple[int, int],
+ mode: str = 'mul') -> np.ndarray:
+ """Rescale a polygon according to scale_factor.
+
+ The behavior is different depending on the mode. When mode is 'mul', the
+ coordinates will be multiplied by scale_factor, which is usually used in
+ preprocessing transforms such as :func:`Resize`.
+ The coordinates will be divided by scale_factor if mode is 'div'. It can be
+ used in postprocessors to recover the polygon in the original
+ image size.
+
+ Args:
+ polygon (ArrayLike): A polygon. In any form can be converted
+ to an 1-D numpy array. E.g. list[float], np.ndarray,
+ or torch.Tensor. Polygon is written in
+ [x1, y1, x2, y2, ...].
+ scale_factor (tuple(int, int)): (w_scale, h_scale).
+ model (str): Rescale mode. Can be 'mul' or 'div'. Defaults to 'mul'.
+
+ Returns:
+ np.ndarray: Rescaled polygon.
+ """
+ assert len(polygon) % 2 == 0
+ assert mode in ['mul', 'div']
+ polygon = np.array(polygon, dtype=np.float32)
+ poly_shape = polygon.shape
+ reshape_polygon = polygon.reshape(-1, 2)
+ scale_factor = np.array(scale_factor, dtype=float)
+ if mode == 'div':
+ scale_factor = 1 / scale_factor
+ polygon = (reshape_polygon * scale_factor[None]).reshape(poly_shape)
+ return polygon
+
+
+def rescale_polygons(polygons: Union[ArrayLike, Sequence[ArrayLike]],
+ scale_factor: Tuple[int, int],
+ mode: str = 'mul'
+ ) -> Union[ArrayLike, Sequence[np.ndarray]]:
+ """Rescale polygons according to scale_factor.
+
+ The behavior is different depending on the mode. When mode is 'mul', the
+ coordinates will be multiplied by scale_factor, which is usually used in
+ preprocessing transforms such as :func:`Resize`.
+ The coordinates will be divided by scale_factor if mode is 'div'. It can be
+ used in postprocessors to recover the polygon in the original
+ image size.
+
+ Args:
+ polygons (list[ArrayLike] or ArrayLike): A list of polygons, each
+ written in [x1, y1, x2, y2, ...] and in any form can be converted
+ to an 1-D numpy array. E.g. list[list[float]],
+ list[np.ndarray], or list[torch.Tensor].
+ scale_factor (tuple(int, int)): (w_scale, h_scale).
+ model (str): Rescale mode. Can be 'mul' or 'div'. Defaults to 'mul'.
+
+ Returns:
+ list[np.ndarray] or np.ndarray: Rescaled polygons. The type of the
+ return value depends on the type of the input polygons.
+ """
+ results = []
+ for polygon in polygons:
+ results.append(rescale_polygon(polygon, scale_factor, mode))
+ if isinstance(polygons, np.ndarray):
+ results = np.array(results)
+ return results
+
+
+def poly2bbox(polygon: ArrayLike) -> np.array:
+ """Converting a polygon to a bounding box.
+
+ Args:
+ polygon (ArrayLike): A polygon. In any form can be converted
+ to an 1-D numpy array. E.g. list[float], np.ndarray,
+ or torch.Tensor. Polygon is written in
+ [x1, y1, x2, y2, ...].
+
+ Returns:
+ np.array: The converted bounding box [x1, y1, x2, y2]
+ """
+ assert len(polygon) % 2 == 0
+ polygon = np.array(polygon, dtype=np.float32)
+ x = polygon[::2]
+ y = polygon[1::2]
+ return np.array([min(x), min(y), max(x), max(y)])
+
+
+def poly2shapely(polygon: ArrayLike) -> Polygon:
+ """Convert a polygon to shapely.geometry.Polygon.
+
+ Args:
+ polygon (ArrayLike): A set of points of 2k shape.
+
+ Returns:
+ polygon (Polygon): A polygon object.
+ """
+ polygon = np.array(polygon, dtype=np.float32)
+ assert polygon.size % 2 == 0 and polygon.size >= 6
+
+ polygon = polygon.reshape([-1, 2])
+ return Polygon(polygon)
+
+
+def polys2shapely(polygons: Sequence[ArrayLike]) -> Sequence[Polygon]:
+ """Convert a nested list of boundaries to a list of Polygons.
+
+ Args:
+ polygons (list): The point coordinates of the instance boundary.
+
+ Returns:
+ list: Converted shapely.Polygon.
+ """
+ return [poly2shapely(polygon) for polygon in polygons]
+
+
+def shapely2poly(polygon: Polygon) -> np.array:
+ """Convert a nested list of boundaries to a list of Polygons.
+
+ Args:
+ polygon (Polygon): A polygon represented by shapely.Polygon.
+
+ Returns:
+ np.array: Converted numpy array
+ """
+ return np.array(polygon.exterior.coords).reshape(-1, )
+
+
+def crop_polygon(polygon: ArrayLike,
+ crop_box: np.ndarray) -> Union[np.ndarray, None]:
+ """Crop polygon to be within a box region.
+
+ Args:
+ polygon (ndarray): polygon in shape (N, ).
+ crop_box (ndarray): target box region in shape (4, ).
+
+ Returns:
+ np.array or None: Cropped polygon. If the polygon is not within the
+ crop box, return None.
+ """
+ poly = poly_make_valid(poly2shapely(polygon))
+ crop_poly = poly_make_valid(poly2shapely(bbox2poly(crop_box)))
+ area, poly_cropped = poly_intersection(poly, crop_poly, return_poly=True)
+ if area == 0 or area is None or not isinstance(
+ poly_cropped, shapely.geometry.polygon.Polygon):
+ return None
+ else:
+ poly_cropped = poly_make_valid(poly_cropped)
+ poly_cropped = np.array(poly_cropped.boundary.xy, dtype=np.float32)
+ poly_cropped = poly_cropped.T
+ # reverse poly_cropped to have clockwise order
+ poly_cropped = poly_cropped[::-1, :].reshape(-1)
+ return poly_cropped
+
+
+def poly_make_valid(poly: Polygon) -> Polygon:
+ """Convert a potentially invalid polygon to a valid one by eliminating
+ self-crossing or self-touching parts. Note that if the input is a line, the
+ returned polygon could be an empty one.
+
+ Args:
+ poly (Polygon): A polygon needed to be converted.
+
+ Returns:
+ Polygon: A valid polygon, which might be empty.
+ """
+ assert isinstance(poly, Polygon)
+ fixed_poly = poly if poly.is_valid else poly.buffer(0)
+ # Sometimes the fixed_poly is still a MultiPolygon,
+ # so we need to find the convex hull of the MultiPolygon, which should
+ # always be a Polygon (but could be empty).
+ if not isinstance(fixed_poly, Polygon):
+ fixed_poly = fixed_poly.convex_hull
+ return fixed_poly
+
+
+def poly_intersection(poly_a: Polygon,
+ poly_b: Polygon,
+ invalid_ret: Optional[Union[float, int]] = None,
+ return_poly: bool = False
+ ) -> Tuple[float, Optional[Polygon]]:
+ """Calculate the intersection area between two polygons.
+
+ Args:
+ poly_a (Polygon): Polygon a.
+ poly_b (Polygon): Polygon b.
+ invalid_ret (float or int, optional): The return value when the
+ invalid polygon exists. If it is not specified, the function
+ allows the computation to proceed with invalid polygons by
+ cleaning the their self-touching or self-crossing parts.
+ Defaults to None.
+ return_poly (bool): Whether to return the polygon of the intersection
+ Defaults to False.
+
+ Returns:
+ float or tuple(float, Polygon): Returns the intersection area or
+ a tuple ``(area, Optional[poly_obj])``, where the `area` is the
+ intersection area between two polygons and `poly_obj` is The Polygon
+ object of the intersection area, which will be `None` if the input is
+ invalid. `poly_obj` will be returned only if `return_poly` is `True`.
+ """
+ assert isinstance(poly_a, Polygon)
+ assert isinstance(poly_b, Polygon)
+ assert invalid_ret is None or isinstance(invalid_ret, (float, int))
+
+ if invalid_ret is None:
+ poly_a = poly_make_valid(poly_a)
+ poly_b = poly_make_valid(poly_b)
+
+ poly_obj = None
+ area = invalid_ret
+ if poly_a.is_valid and poly_b.is_valid:
+ if poly_a.intersects(poly_b):
+ poly_obj = poly_a.intersection(poly_b)
+ area = poly_obj.area
+ else:
+ poly_obj = Polygon()
+ area = 0.0
+ return (area, poly_obj) if return_poly else area
+
+
+def poly_union(
+ poly_a: Polygon,
+ poly_b: Polygon,
+ invalid_ret: Optional[Union[float, int]] = None,
+ return_poly: bool = False
+) -> Tuple[float, Optional[Union[Polygon, MultiPolygon]]]:
+ """Calculate the union area between two polygons.
+
+ Args:
+ poly_a (Polygon): Polygon a.
+ poly_b (Polygon): Polygon b.
+ invalid_ret (float or int, optional): The return value when the
+ invalid polygon exists. If it is not specified, the function
+ allows the computation to proceed with invalid polygons by
+ cleaning the their self-touching or self-crossing parts.
+ Defaults to False.
+ return_poly (bool): Whether to return the polygon of the union.
+ Defaults to False.
+
+ Returns:
+ tuple: Returns a tuple ``(area, Optional[poly_obj])``, where
+ the `area` is the union between two polygons and `poly_obj` is the
+ Polygon or MultiPolygon object of the union of the inputs. The type
+ of object depends on whether they intersect or not. Set as `None`
+ if the input is invalid. `poly_obj` will be returned only if
+ `return_poly` is `True`.
+ """
+ assert isinstance(poly_a, Polygon)
+ assert isinstance(poly_b, Polygon)
+ assert invalid_ret is None or isinstance(invalid_ret, (float, int))
+
+ if invalid_ret is None:
+ poly_a = poly_make_valid(poly_a)
+ poly_b = poly_make_valid(poly_b)
+
+ poly_obj = None
+ area = invalid_ret
+ if poly_a.is_valid and poly_b.is_valid:
+ poly_obj = poly_a.union(poly_b)
+ area = poly_obj.area
+ return (area, poly_obj) if return_poly else area
+
+
+def poly_iou(poly_a: Polygon,
+ poly_b: Polygon,
+ zero_division: float = 0.) -> float:
+ """Calculate the IOU between two polygons.
+
+ Args:
+ poly_a (Polygon): Polygon a.
+ poly_b (Polygon): Polygon b.
+ zero_division (float): The return value when invalid polygon exists.
+
+ Returns:
+ float: The IoU between two polygons.
+ """
+ assert isinstance(poly_a, Polygon)
+ assert isinstance(poly_b, Polygon)
+ area_inters = poly_intersection(poly_a, poly_b)
+ area_union = poly_union(poly_a, poly_b)
+ return area_inters / area_union if area_union != 0 else zero_division
+
+
+def is_poly_inside_rect(poly: ArrayLike, rect: np.ndarray) -> bool:
+ """Check if the polygon is inside the target region.
+ Args:
+ poly (ArrayLike): Polygon in shape (N, ).
+ rect (ndarray): Target region [x1, y1, x2, y2].
+
+ Returns:
+ bool: Whether the polygon is inside the cropping region.
+ """
+
+ poly = poly2shapely(poly)
+ rect = poly2shapely(bbox2poly(rect))
+ return rect.contains(poly)
+
+
+def offset_polygon(poly: ArrayLike, distance: float) -> ArrayLike:
+ """Offset (expand/shrink) the polygon by the target distance. It's a
+ wrapper around pyclipper based on Vatti clipping algorithm.
+
+ Warning:
+ Polygon coordinates will be casted to int type in PyClipper. Mind the
+ potential precision loss caused by the casting.
+
+ Args:
+ poly (ArrayLike): A polygon. In any form can be converted
+ to an 1-D numpy array. E.g. list[float], np.ndarray,
+ or torch.Tensor. Polygon is written in
+ [x1, y1, x2, y2, ...].
+ distance (float): The offset distance. Positive value means expanding,
+ negative value means shrinking.
+
+ Returns:
+ np.array: 1-D Offsetted polygon ndarray in float32 type. If the
+ result polygon is invalid or has been split into several parts,
+ return an empty array.
+ """
+ poly = np.array(poly).reshape(-1, 2)
+ pco = pyclipper.PyclipperOffset()
+ pco.AddPath(poly, pyclipper.JT_ROUND, pyclipper.ET_CLOSEDPOLYGON)
+ # Returned result will be in type of int32, convert it back to float32
+ # following MMOCR's convention
+ result = np.array(pco.Execute(distance), dtype=object)
+ if len(result) > 0 and isinstance(result[0], list):
+ # The processed polygon has been split into several parts
+ result = np.array([])
+ result = result.astype(np.float32)
+ # Always use the first polygon since only one polygon is expected
+ # But when the resulting polygon is invalid, return the empty array
+ # as it is
+ return result if len(result) == 0 else result[0].flatten()
+
+
+def boundary_iou(src: List,
+ target: List,
+ zero_division: Union[int, float] = 0) -> float:
+ """Calculate the IOU between two boundaries.
+
+ Args:
+ src (list): Source boundary.
+ target (list): Target boundary.
+ zero_division (int or float): The return value when invalid
+ boundary exists.
+
+ Returns:
+ float: The iou between two boundaries.
+ """
+ assert valid_boundary(src, False)
+ assert valid_boundary(target, False)
+ src_poly = poly2shapely(src)
+ target_poly = poly2shapely(target)
+
+ return poly_iou(src_poly, target_poly, zero_division=zero_division)
+
+
+def sort_points(points):
+ # TODO Add typehints & test & docstring
+ """Sort arbitrary points in clockwise order in Cartesian coordinate, you
+ may need to reverse the output sequence if you are using OpenCV's image
+ coordinate.
+
+ Reference:
+ https://github.com/novioleo/Savior/blob/master/Utils/GeometryUtils.py.
+
+ Warning: This function can only sort convex polygons.
+
+ Args:
+ points (list[ndarray] or ndarray or list[list]): A list of unsorted
+ boundary points.
+
+ Returns:
+ list[ndarray]: A list of points sorted in clockwise order.
+ """
+ assert is_list_of(points, np.ndarray) or isinstance(points, np.ndarray) \
+ or is_2dlist(points)
+ center_point = tuple(
+ map(operator.truediv,
+ reduce(lambda x, y: map(operator.add, x, y), points),
+ [len(points)] * 2))
+ return sorted(
+ points,
+ key=lambda coord: (180 + math.degrees(
+ math.atan2(*tuple(map(operator.sub, coord, center_point))))) % 360)
+
+
+def sort_vertex(points_x, points_y):
+ # TODO Add typehints & test
+ """Sort box vertices in clockwise order from left-top first.
+
+ Args:
+ points_x (list[float]): x of four vertices.
+ points_y (list[float]): y of four vertices.
+
+ Returns:
+ tuple[list[float], list[float]]: Sorted x and y of four vertices.
+
+ - sorted_points_x (list[float]): x of sorted four vertices.
+ - sorted_points_y (list[float]): y of sorted four vertices.
+ """
+ assert is_list_of(points_x, (float, int))
+ assert is_list_of(points_y, (float, int))
+ assert len(points_x) == 4
+ assert len(points_y) == 4
+ vertices = np.stack((points_x, points_y), axis=-1).astype(np.float32)
+ vertices = _sort_vertex(vertices)
+ sorted_points_x = list(vertices[:, 0])
+ sorted_points_y = list(vertices[:, 1])
+ return sorted_points_x, sorted_points_y
+
+
+def _sort_vertex(vertices):
+ # TODO Add typehints & docstring & test
+ assert vertices.ndim == 2
+ assert vertices.shape[-1] == 2
+ N = vertices.shape[0]
+ if N == 0:
+ return vertices
+
+ center = np.mean(vertices, axis=0)
+ directions = vertices - center
+ angles = np.arctan2(directions[:, 1], directions[:, 0])
+ sort_idx = np.argsort(angles)
+ vertices = vertices[sort_idx]
+
+ left_top = np.min(vertices, axis=0)
+ dists = np.linalg.norm(left_top - vertices, axis=-1, ord=2)
+ lefttop_idx = np.argmin(dists)
+ indexes = (np.arange(N, dtype=np.int_) + lefttop_idx) % N
+ return vertices[indexes]
+
+
+def sort_vertex8(points):
+ # TODO Add typehints & docstring & test
+ """Sort vertex with 8 points [x1 y1 x2 y2 x3 y3 x4 y4]"""
+ assert len(points) == 8
+ vertices = _sort_vertex(np.array(points, dtype=np.float32).reshape(-1, 2))
+ sorted_box = list(vertices.flatten())
+ return sorted_box
diff --git a/mmocr/utils/processing.py b/mmocr/utils/processing.py
new file mode 100644
index 0000000000000000000000000000000000000000..2da6ff2c90d746c67c18fd1f22e6bd8d1f2bf887
--- /dev/null
+++ b/mmocr/utils/processing.py
@@ -0,0 +1,67 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import sys
+from collections.abc import Iterable
+
+from mmengine.utils.progressbar import ProgressBar, init_pool
+
+
+def track_parallel_progress_multi_args(func,
+ args,
+ nproc,
+ initializer=None,
+ initargs=None,
+ bar_width=50,
+ chunksize=1,
+ skip_first=False,
+ file=sys.stdout):
+ """Track the progress of parallel task execution with a progress bar.
+
+ The built-in :mod:`multiprocessing` module is used for process pools and
+ tasks are done with :func:`Pool.map` or :func:`Pool.imap_unordered`.
+
+ Args:
+ func (callable): The function to be applied to each task.
+ tasks (tuple[Iterable]): A tuple of tasks.
+ nproc (int): Process (worker) number.
+ initializer (None or callable): Refer to :class:`multiprocessing.Pool`
+ for details.
+ initargs (None or tuple): Refer to :class:`multiprocessing.Pool` for
+ details.
+ chunksize (int): Refer to :class:`multiprocessing.Pool` for details.
+ bar_width (int): Width of progress bar.
+ skip_first (bool): Whether to skip the first sample for each worker
+ when estimating fps, since the initialization step may takes
+ longer.
+ keep_order (bool): If True, :func:`Pool.imap` is used, otherwise
+ :func:`Pool.imap_unordered` is used.
+
+ Returns:
+ list: The task results.
+ """
+ assert isinstance(args, tuple)
+ for arg in args:
+ assert isinstance(arg, Iterable)
+ assert len(set([len(arg)
+ for arg in args])) == 1, 'args must have same length'
+ task_num = len(args[0])
+ tasks = zip(*args)
+
+ pool = init_pool(nproc, initializer, initargs)
+ start = not skip_first
+ task_num -= nproc * chunksize * int(skip_first)
+ prog_bar = ProgressBar(task_num, bar_width, start, file=file)
+ results = []
+ gen = pool.starmap(func, tasks, chunksize)
+ for result in gen:
+ results.append(result)
+ if skip_first:
+ if len(results) < nproc * chunksize:
+ continue
+ elif len(results) == nproc * chunksize:
+ prog_bar.start()
+ continue
+ prog_bar.update()
+ prog_bar.file.write('\n')
+ pool.close()
+ pool.join()
+ return results
diff --git a/mmocr/utils/setup_env.py b/mmocr/utils/setup_env.py
new file mode 100644
index 0000000000000000000000000000000000000000..32206ecfa3fd847d37750411e3329af8a3a4703d
--- /dev/null
+++ b/mmocr/utils/setup_env.py
@@ -0,0 +1,41 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import datetime
+import warnings
+
+from mmengine.registry import DefaultScope
+
+
+def register_all_modules(init_default_scope: bool = True) -> None:
+ """Register all modules in mmocr into the registries.
+
+ Args:
+ init_default_scope (bool): Whether initialize the mmocr default scope.
+ When `init_default_scope=True`, the global default scope will be
+ set to `mmocr`, and all registries will build modules from mmocr's
+ registry node. To understand more about the registry, please refer
+ to https://github.com/open-mmlab/mmengine/blob/main/docs/en/tutorials/registry.md
+ Defaults to True.
+ """ # noqa
+ import mmocr.apis # noqa: F401,F403
+ import mmocr.datasets # noqa: F401,F403
+ import mmocr.engine # noqa: F401,F403
+ import mmocr.evaluation # noqa: F401,F403
+ import mmocr.models # noqa: F401,F403
+ import mmocr.structures # noqa: F401,F403
+ import mmocr.visualization # noqa: F401,F403
+ if init_default_scope:
+ never_created = DefaultScope.get_current_instance() is None \
+ or not DefaultScope.check_instance_created('mmocr')
+ if never_created:
+ DefaultScope.get_instance('mmocr', scope_name='mmocr')
+ return
+ current_scope = DefaultScope.get_current_instance()
+ if current_scope.scope_name != 'mmocr':
+ warnings.warn('The current default scope '
+ f'"{current_scope.scope_name}" is not "mmocr", '
+ '`register_all_modules` will force the current'
+ 'default scope to be "mmocr". If this is not '
+ 'expected, please set `init_default_scope=False`.')
+ # avoid name conflict
+ new_instance_name = f'mmocr-{datetime.datetime.now()}'
+ DefaultScope.get_instance(new_instance_name, scope_name='mmocr')
diff --git a/mmocr/utils/string_utils.py b/mmocr/utils/string_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..4c59740872dc9e086f7f672f9b0f58250d6512c6
--- /dev/null
+++ b/mmocr/utils/string_utils.py
@@ -0,0 +1,36 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+class StringStripper:
+ """Removing the leading and/or the trailing characters based on the string
+ argument passed.
+
+ Args:
+ strip (bool): Whether remove characters from both left and right of
+ the string. Default: True.
+ strip_pos (str): Which position for removing, can be one of
+ ('both', 'left', 'right'), Default: 'both'.
+ strip_str (str|None): A string specifying the set of characters
+ to be removed from the left and right part of the string.
+ If None, all leading and trailing whitespaces
+ are removed from the string. Default: None.
+ """
+
+ def __init__(self, strip=True, strip_pos='both', strip_str=None):
+ assert isinstance(strip, bool)
+ assert strip_pos in ('both', 'left', 'right')
+ assert strip_str is None or isinstance(strip_str, str)
+
+ self.strip = strip
+ self.strip_pos = strip_pos
+ self.strip_str = strip_str
+
+ def __call__(self, in_str):
+
+ if not self.strip:
+ return in_str
+
+ if self.strip_pos == 'left':
+ return in_str.lstrip(self.strip_str)
+ elif self.strip_pos == 'right':
+ return in_str.rstrip(self.strip_str)
+ else:
+ return in_str.strip(self.strip_str)
diff --git a/mmocr/utils/transform_utils.py b/mmocr/utils/transform_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..4b45a82517212a67228eaad905d04bdf77d49afe
--- /dev/null
+++ b/mmocr/utils/transform_utils.py
@@ -0,0 +1,58 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Union
+
+import numpy as np
+
+
+def remove_pipeline_elements(results: Dict,
+ remove_inds: Union[List[int],
+ np.ndarray]) -> Dict:
+ """Remove elements in the pipeline given target indexes.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+ remove_inds (list(int) or np.ndarray): The element indexes to be
+ removed.
+
+ Required Keys:
+
+ - gt_polygons (optional)
+ - gt_bboxes (optional)
+ - gt_bboxes_labels (optional)
+ - gt_ignored (optional)
+ - gt_texts (optional)
+
+ Modified Keys:
+
+ - gt_polygons (optional)
+ - gt_bboxes (optional)
+ - gt_bboxes_labels (optional)
+ - gt_ignored (optional)
+ - gt_texts (optional)
+
+ Returns:
+ dict: The results with element removed.
+ """
+ keys = [
+ 'gt_polygons', 'gt_bboxes', 'gt_bboxes_labels', 'gt_ignored',
+ 'gt_texts'
+ ]
+ num_elements = -1
+ for key in keys:
+ if key in results:
+ num_elements = len(results[key])
+ break
+ if num_elements == -1:
+ return results
+ kept_inds = np.array(
+ [i for i in range(num_elements) if i not in remove_inds])
+ for key in keys:
+ if key in results:
+ if isinstance(results[key], np.ndarray):
+ results[key] = results[key][kept_inds]
+ elif isinstance(results[key], list):
+ results[key] = [results[key][i] for i in kept_inds]
+ else:
+ raise TypeError(
+ f'Unsupported type {type(results[key])} for key {key}')
+ return results
diff --git a/mmocr/utils/typing_utils.py b/mmocr/utils/typing_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..592fb36e75ad17d282fe4fce70000227d7bcfa58
--- /dev/null
+++ b/mmocr/utils/typing_utils.py
@@ -0,0 +1,50 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+"""Collecting some commonly used type hint in MMOCR."""
+
+from typing import Dict, List, Optional, Sequence, Tuple, Union
+
+import numpy as np
+import torch
+from mmengine.config import ConfigDict
+from mmengine.structures import InstanceData, LabelData
+
+from mmocr import digit_version
+from mmocr.structures import (KIEDataSample, TextDetDataSample,
+ TextRecogDataSample, TextSpottingDataSample)
+
+# Config
+ConfigType = Union[ConfigDict, Dict]
+OptConfigType = Optional[ConfigType]
+MultiConfig = Union[ConfigType, List[ConfigType]]
+OptMultiConfig = Optional[MultiConfig]
+InitConfigType = Union[Dict, List[Dict]]
+OptInitConfigType = Optional[InitConfigType]
+
+# Data
+InstanceList = List[InstanceData]
+OptInstanceList = Optional[InstanceList]
+LabelList = List[LabelData]
+OptLabelList = Optional[LabelList]
+E2ESampleList = List[TextSpottingDataSample]
+RecSampleList = List[TextRecogDataSample]
+DetSampleList = List[TextDetDataSample]
+KIESampleList = List[KIEDataSample]
+OptRecSampleList = Optional[RecSampleList]
+OptDetSampleList = Optional[DetSampleList]
+OptKIESampleList = Optional[KIESampleList]
+OptE2ESampleList = Optional[E2ESampleList]
+
+OptTensor = Optional[torch.Tensor]
+
+RecForwardResults = Union[Dict[str, torch.Tensor], List[TextRecogDataSample],
+ Tuple[torch.Tensor], torch.Tensor]
+
+# Visualization
+ColorType = Union[str, Tuple, List[str], List[Tuple]]
+
+ArrayLike = 'ArrayLike'
+if digit_version(np.__version__) >= digit_version('1.20.0'):
+ from numpy.typing import ArrayLike as NP_ARRAY_LIKE
+ ArrayLike = NP_ARRAY_LIKE
+
+RangeType = Sequence[Tuple[int, int]]
diff --git a/mmocr/version.py b/mmocr/version.py
new file mode 100644
index 0000000000000000000000000000000000000000..e83928324b12ac13d2e2318fbcdb6b0935b354ec
--- /dev/null
+++ b/mmocr/version.py
@@ -0,0 +1,4 @@
+# Copyright (c) Open-MMLab. All rights reserved.
+
+__version__ = '1.0.0'
+short_version = __version__
diff --git a/mmocr/visualization/__init__.py b/mmocr/visualization/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..b070794bbd486e295520ba7bd141488e0574f92b
--- /dev/null
+++ b/mmocr/visualization/__init__.py
@@ -0,0 +1,11 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .base_visualizer import BaseLocalVisualizer
+from .kie_visualizer import KIELocalVisualizer
+from .textdet_visualizer import TextDetLocalVisualizer
+from .textrecog_visualizer import TextRecogLocalVisualizer
+from .textspotting_visualizer import TextSpottingLocalVisualizer
+
+__all__ = [
+ 'BaseLocalVisualizer', 'KIELocalVisualizer', 'TextDetLocalVisualizer',
+ 'TextRecogLocalVisualizer', 'TextSpottingLocalVisualizer'
+]
diff --git a/mmocr/visualization/__pycache__/__init__.cpython-38.pyc b/mmocr/visualization/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..dbaed3ed0b23fdc2fb6b916d287f19ce7725c343
Binary files /dev/null and b/mmocr/visualization/__pycache__/__init__.cpython-38.pyc differ
diff --git a/mmocr/visualization/__pycache__/base_visualizer.cpython-38.pyc b/mmocr/visualization/__pycache__/base_visualizer.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b5cc3dea87377435cbc5dc52d452f98729902e83
Binary files /dev/null and b/mmocr/visualization/__pycache__/base_visualizer.cpython-38.pyc differ
diff --git a/mmocr/visualization/__pycache__/kie_visualizer.cpython-38.pyc b/mmocr/visualization/__pycache__/kie_visualizer.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5c4f03d24bc04b53c1e88df57eab691e7061f9d1
Binary files /dev/null and b/mmocr/visualization/__pycache__/kie_visualizer.cpython-38.pyc differ
diff --git a/mmocr/visualization/__pycache__/textdet_visualizer.cpython-38.pyc b/mmocr/visualization/__pycache__/textdet_visualizer.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c945368283308d3fc80eb6cede78239940dc8622
Binary files /dev/null and b/mmocr/visualization/__pycache__/textdet_visualizer.cpython-38.pyc differ
diff --git a/mmocr/visualization/__pycache__/textrecog_visualizer.cpython-38.pyc b/mmocr/visualization/__pycache__/textrecog_visualizer.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..adfa6a9df798fa88c3504dedce968193d162d77c
Binary files /dev/null and b/mmocr/visualization/__pycache__/textrecog_visualizer.cpython-38.pyc differ
diff --git a/mmocr/visualization/__pycache__/textspotting_visualizer.cpython-38.pyc b/mmocr/visualization/__pycache__/textspotting_visualizer.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0f450e0e6294f887d68c7fcfc0dda364cee3cbca
Binary files /dev/null and b/mmocr/visualization/__pycache__/textspotting_visualizer.cpython-38.pyc differ
diff --git a/mmocr/visualization/base_visualizer.py b/mmocr/visualization/base_visualizer.py
new file mode 100644
index 0000000000000000000000000000000000000000..38b4479d330bc7700ba8d66615719e76e7a1d8d0
--- /dev/null
+++ b/mmocr/visualization/base_visualizer.py
@@ -0,0 +1,261 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from typing import List, Optional, Sequence, Union
+
+import numpy as np
+import torch
+from matplotlib.font_manager import FontProperties
+from mmengine.visualization import Visualizer
+
+from mmocr.registry import VISUALIZERS
+
+
+@VISUALIZERS.register_module()
+class BaseLocalVisualizer(Visualizer):
+ """The MMOCR Text Detection Local Visualizer.
+
+ Args:
+ name (str): Name of the instance. Defaults to 'visualizer'.
+ image (np.ndarray, optional): the origin image to draw. The format
+ should be RGB. Defaults to None.
+ vis_backends (list, optional): Visual backend config list.
+ Default to None.
+ save_dir (str, optional): Save file dir for all storage backends.
+ If it is None, the backend storage will not save any data.
+ fig_save_cfg (dict): Keyword parameters of figure for saving.
+ Defaults to empty dict.
+ fig_show_cfg (dict): Keyword parameters of figure for showing.
+ Defaults to empty dict.
+ is_openset (bool, optional): Whether the visualizer is used in
+ OpenSet. Defaults to False.
+ font_families (Union[str, List[str]]): The font families of labels.
+ Defaults to 'sans-serif'.
+ font_properties (Union[str, FontProperties], optional):
+ The font properties of texts. The format should be a path str
+ to font file or a `font_manager.FontProperties()` object.
+ If you want to draw Chinese texts, you need to prepare
+ a font file that can show Chinese characters properly.
+ For example: `simhei.ttf`,`simsun.ttc`,`simkai.ttf` and so on.
+ Then set font_properties=matplotlib.font_manager.FontProperties
+ (fname='path/to/font_file') or font_properties='path/to/font_file'
+ This function need mmengine version >=0.6.0.
+ Defaults to None.
+ """
+ PALETTE = [(220, 20, 60), (119, 11, 32), (0, 0, 142), (0, 0, 230),
+ (106, 0, 228), (0, 60, 100), (0, 80, 100), (0, 0, 70),
+ (0, 0, 192), (250, 170, 30), (100, 170, 30), (220, 220, 0),
+ (175, 116, 175), (250, 0, 30), (165, 42, 42), (255, 77, 255),
+ (0, 226, 252), (182, 182, 255), (0, 82, 0), (120, 166, 157),
+ (110, 76, 0), (174, 57, 255), (199, 100, 0), (72, 0, 118),
+ (255, 179, 240), (0, 125, 92), (209, 0, 151), (188, 208, 182),
+ (0, 220, 176), (255, 99, 164), (92, 0, 73), (133, 129, 255),
+ (78, 180, 255), (0, 228, 0), (174, 255, 243), (45, 89, 255),
+ (134, 134, 103), (145, 148, 174), (255, 208, 186),
+ (197, 226, 255), (171, 134, 1), (109, 63, 54), (207, 138, 255),
+ (151, 0, 95), (9, 80, 61), (84, 105, 51), (74, 65, 105),
+ (166, 196, 102), (208, 195, 210), (255, 109, 65), (0, 143, 149),
+ (179, 0, 194), (209, 99, 106), (5, 121, 0), (227, 255, 205),
+ (147, 186, 208), (153, 69, 1), (3, 95, 161), (163, 255, 0),
+ (119, 0, 170), (0, 182, 199), (0, 165, 120), (183, 130, 88),
+ (95, 32, 0), (130, 114, 135), (110, 129, 133), (166, 74, 118),
+ (219, 142, 185), (79, 210, 114), (178, 90, 62), (65, 70, 15),
+ (127, 167, 115), (59, 105, 106), (142, 108, 45), (196, 172, 0),
+ (95, 54, 80), (128, 76, 255), (201, 57, 1), (246, 0, 122),
+ (191, 162, 208)]
+
+ def __init__(self,
+ name: str = 'visualizer',
+ font_families: Union[str, List[str]] = 'sans-serif',
+ font_properties: Optional[Union[str, FontProperties]] = None,
+ **kwargs) -> None:
+ super().__init__(name=name, **kwargs)
+ self.font_families = font_families
+ self.font_properties = self._set_font_properties(font_properties)
+
+ def _set_font_properties(self,
+ fp: Optional[Union[str, FontProperties]] = None):
+ if fp is None:
+ return None
+ elif isinstance(fp, str):
+ return FontProperties(fname=fp)
+ elif isinstance(fp, FontProperties):
+ return fp
+ else:
+ raise ValueError(
+ 'font_properties argument type should be'
+ ' `str` or `matplotlib.font_manager.FontProperties`')
+
+ def get_labels_image(
+ self,
+ image: np.ndarray,
+ labels: Union[np.ndarray, torch.Tensor],
+ bboxes: Union[np.ndarray, torch.Tensor],
+ colors: Union[str, Sequence[str]] = 'k',
+ font_size: Union[int, float] = 10,
+ auto_font_size: bool = False,
+ font_families: Union[str, List[str]] = 'sans-serif',
+ font_properties: Optional[Union[str, FontProperties]] = None
+ ) -> np.ndarray:
+ """Draw labels on image.
+
+ Args:
+ image (np.ndarray): The origin image to draw. The format
+ should be RGB.
+ labels (Union[np.ndarray, torch.Tensor]): The labels to draw.
+ bboxes (Union[np.ndarray, torch.Tensor]): The bboxes to draw.
+ colors (Union[str, Sequence[str]]): The colors of labels.
+ ``colors`` can have the same length with labels or just single
+ value. If ``colors`` is single value, all the labels will have
+ the same colors. Refer to `matplotlib.colors` for full list of
+ formats that are accepted. Defaults to 'k'.
+ font_size (Union[int, float]): The font size of labels. Defaults
+ to 10.
+ auto_font_size (bool): Whether to automatically adjust font size.
+ Defaults to False.
+ font_families (Union[str, List[str]]): The font families of labels.
+ Defaults to 'sans-serif'.
+ font_properties (Union[str, FontProperties], optional):
+ The font properties of texts. The format should be a path str
+ to font file or a `font_manager.FontProperties()` object.
+ If you want to draw Chinese texts, you need to prepare
+ a font file that can show Chinese characters properly.
+ For example: `simhei.ttf`,`simsun.ttc`,`simkai.ttf` and so on.
+ Then set font_properties=matplotlib.font_manager.FontProperties
+ (fname='path/to/font_file') or
+ font_properties='path/to/font_file'.
+ This function need mmengine version >=0.6.0.
+ Defaults to None.
+ """
+ if not labels and not bboxes:
+ return image
+ if colors is not None and isinstance(colors, (list, tuple)):
+ size = math.ceil(len(labels) / len(colors))
+ colors = (colors * size)[:len(labels)]
+ if auto_font_size:
+ assert font_size is not None and isinstance(
+ font_size, (int, float))
+ font_size = (bboxes[:, 2:] - bboxes[:, :2]).min(-1) * font_size
+ font_size = font_size.tolist()
+ self.set_image(image)
+ self.draw_texts(
+ labels, (bboxes[:, :2] + bboxes[:, 2:]) / 2,
+ vertical_alignments='center',
+ horizontal_alignments='center',
+ colors='k',
+ font_sizes=font_size,
+ font_families=font_families,
+ font_properties=font_properties)
+ return self.get_image()
+
+ def get_polygons_image(self,
+ image: np.ndarray,
+ polygons: Sequence[np.ndarray],
+ colors: Union[str, Sequence[str]] = 'g',
+ filling: bool = False,
+ line_width: Union[int, float] = 0.5,
+ alpha: float = 0.5) -> np.ndarray:
+ """Draw polygons on image.
+
+ Args:
+ image (np.ndarray): The origin image to draw. The format
+ should be RGB.
+ polygons (Sequence[np.ndarray]): The polygons to draw. The shape
+ should be (N, 2).
+ colors (Union[str, Sequence[str]]): The colors of polygons.
+ ``colors`` can have the same length with polygons or just
+ single value. If ``colors`` is single value, all the polygons
+ will have the same colors. Refer to `matplotlib.colors` for
+ full list of formats that are accepted. Defaults to 'g'.
+ filling (bool): Whether to fill the polygons. Defaults to False.
+ line_width (Union[int, float]): The line width of polygons.
+ Defaults to 0.5.
+ alpha (float): The alpha of polygons. Defaults to 0.5.
+
+ Returns:
+ np.ndarray: The image with polygons drawn.
+ """
+ if colors is not None and isinstance(colors, (list, tuple)):
+ size = math.ceil(len(polygons) / len(colors))
+ colors = (colors * size)[:len(polygons)]
+ self.set_image(image)
+ if filling:
+ self.draw_polygons(
+ polygons,
+ face_colors=colors,
+ edge_colors=colors,
+ line_widths=line_width,
+ alpha=alpha)
+ else:
+ self.draw_polygons(
+ polygons,
+ edge_colors=colors,
+ line_widths=line_width,
+ alpha=alpha)
+ return self.get_image()
+
+ def get_bboxes_image(self: Visualizer,
+ image: np.ndarray,
+ bboxes: Union[np.ndarray, torch.Tensor],
+ colors: Union[str, Sequence[str]] = 'g',
+ filling: bool = False,
+ line_width: Union[int, float] = 0.5,
+ alpha: float = 0.5) -> np.ndarray:
+ """Draw bboxes on image.
+
+ Args:
+ image (np.ndarray): The origin image to draw. The format
+ should be RGB.
+ bboxes (Union[np.ndarray, torch.Tensor]): The bboxes to draw.
+ colors (Union[str, Sequence[str]]): The colors of bboxes.
+ ``colors`` can have the same length with bboxes or just single
+ value. If ``colors`` is single value, all the bboxes will have
+ the same colors. Refer to `matplotlib.colors` for full list of
+ formats that are accepted. Defaults to 'g'.
+ filling (bool): Whether to fill the bboxes. Defaults to False.
+ line_width (Union[int, float]): The line width of bboxes.
+ Defaults to 0.5.
+ alpha (float): The alpha of bboxes. Defaults to 0.5.
+
+ Returns:
+ np.ndarray: The image with bboxes drawn.
+ """
+ if colors is not None and isinstance(colors, (list, tuple)):
+ size = math.ceil(len(bboxes) / len(colors))
+ colors = (colors * size)[:len(bboxes)]
+ self.set_image(image)
+ if filling:
+ self.draw_bboxes(
+ bboxes,
+ face_colors=colors,
+ edge_colors=colors,
+ line_widths=line_width,
+ alpha=alpha)
+ else:
+ self.draw_bboxes(
+ bboxes,
+ edge_colors=colors,
+ line_widths=line_width,
+ alpha=alpha)
+ return self.get_image()
+
+ def _draw_instances(self) -> np.ndarray:
+ raise NotImplementedError
+
+ def _cat_image(self, imgs: Sequence[np.ndarray], axis: int) -> np.ndarray:
+ """Concatenate images.
+
+ Args:
+ imgs (Sequence[np.ndarray]): The images to concatenate.
+ axis (int): The axis to concatenate.
+
+ Returns:
+ np.ndarray: The concatenated image.
+ """
+ cat_image = list()
+ for img in imgs:
+ if img is not None:
+ cat_image.append(img)
+ if len(cat_image):
+ return np.concatenate(cat_image, axis=axis)
+ else:
+ return None
diff --git a/mmocr/visualization/kie_visualizer.py b/mmocr/visualization/kie_visualizer.py
new file mode 100644
index 0000000000000000000000000000000000000000..753bac2e9b6387cf5c9908f19d4d15389269eb22
--- /dev/null
+++ b/mmocr/visualization/kie_visualizer.py
@@ -0,0 +1,402 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from typing import Dict, List, Optional, Sequence, Union
+
+import mmcv
+import numpy as np
+import torch
+from matplotlib.collections import PatchCollection
+from matplotlib.patches import FancyArrow
+from mmengine.visualization import Visualizer
+from mmengine.visualization.utils import (check_type, check_type_and_length,
+ color_val_matplotlib, tensor2ndarray,
+ value2list)
+
+from mmocr.registry import VISUALIZERS
+from mmocr.structures import KIEDataSample
+from .base_visualizer import BaseLocalVisualizer
+
+
+@VISUALIZERS.register_module()
+class KIELocalVisualizer(BaseLocalVisualizer):
+ """The MMOCR Text Detection Local Visualizer.
+
+ Args:
+ name (str): Name of the instance. Defaults to 'visualizer'.
+ image (np.ndarray, optional): the origin image to draw. The format
+ should be RGB. Defaults to None.
+ vis_backends (list, optional): Visual backend config list.
+ Default to None.
+ save_dir (str, optional): Save file dir for all storage backends.
+ If it is None, the backend storage will not save any data.
+ fig_save_cfg (dict): Keyword parameters of figure for saving.
+ Defaults to empty dict.
+ fig_show_cfg (dict): Keyword parameters of figure for showing.
+ Defaults to empty dict.
+ is_openset (bool, optional): Whether the visualizer is used in
+ OpenSet. Defaults to False.
+ """
+
+ def __init__(self,
+ name: str = 'kie_visualizer',
+ is_openset: bool = False,
+ **kwargs) -> None:
+ super().__init__(name=name, **kwargs)
+ self.is_openset = is_openset
+
+ def _draw_edge_label(self,
+ image: np.ndarray,
+ edge_labels: Union[np.ndarray, torch.Tensor],
+ bboxes: Union[np.ndarray, torch.Tensor],
+ texts: Sequence[str],
+ arrow_colors: str = 'g') -> np.ndarray:
+ """Draw edge labels on image.
+
+ Args:
+ image (np.ndarray): The origin image to draw. The format
+ should be RGB.
+ edge_labels (np.ndarray or torch.Tensor): The edge labels to draw.
+ The shape of edge_labels should be (N, N), where N is the
+ number of texts.
+ bboxes (np.ndarray or torch.Tensor): The bboxes to draw. The shape
+ of bboxes should be (N, 4), where N is the number of texts.
+ texts (Sequence[str]): The texts to draw. The length of texts
+ should be the same as the number of bboxes.
+ arrow_colors (str, optional): The colors of arrows. Refer to
+ `matplotlib.colors` for full list of formats that are accepted.
+ Defaults to 'g'.
+
+ Returns:
+ np.ndarray: The image with edge labels drawn.
+ """
+ pairs = np.where(edge_labels > 0)
+ if torch.is_tensor(pairs):
+ pairs = pairs.cpu()
+ key_bboxes = bboxes[pairs[0]]
+ value_bboxes = bboxes[pairs[1]]
+ x_data = np.stack([(key_bboxes[:, 2] + key_bboxes[:, 0]) / 2,
+ (value_bboxes[:, 0] + value_bboxes[:, 2]) / 2],
+ axis=-1)
+ y_data = np.stack([(key_bboxes[:, 1] + key_bboxes[:, 3]) / 2,
+ (value_bboxes[:, 1] + value_bboxes[:, 3]) / 2],
+ axis=-1)
+ key_index = np.array(list(set(pairs[0])))
+ val_index = np.array(list(set(pairs[1])))
+ key_texts = [texts[i] for i in key_index]
+ val_texts = [texts[i] for i in val_index]
+
+ self.set_image(image)
+ if key_texts:
+ self.draw_texts(
+ key_texts, (bboxes[key_index, :2] + bboxes[key_index, 2:]) / 2,
+ colors='k',
+ horizontal_alignments='center',
+ vertical_alignments='center',
+ font_families=self.font_families,
+ font_properties=self.font_properties)
+ if val_texts:
+ self.draw_texts(
+ val_texts, (bboxes[val_index, :2] + bboxes[val_index, 2:]) / 2,
+ colors='k',
+ horizontal_alignments='center',
+ vertical_alignments='center',
+ font_families=self.font_families,
+ font_properties=self.font_properties)
+ self.draw_arrows(
+ x_data,
+ y_data,
+ colors=arrow_colors,
+ line_widths=0.3,
+ arrow_tail_widths=0.05,
+ arrow_head_widths=5,
+ overhangs=1,
+ arrow_shapes='full')
+ return self.get_image()
+
+ def _draw_instances(
+ self,
+ image: np.ndarray,
+ bbox_labels: Union[np.ndarray, torch.Tensor],
+ bboxes: Union[np.ndarray, torch.Tensor],
+ polygons: Sequence[np.ndarray],
+ edge_labels: Union[np.ndarray, torch.Tensor],
+ texts: Sequence[str],
+ class_names: Dict,
+ is_openset: bool = False,
+ arrow_colors: str = 'g',
+ ) -> np.ndarray:
+ """Draw instances on image.
+
+ Args:
+ image (np.ndarray): The origin image to draw. The format
+ should be RGB.
+ bbox_labels (np.ndarray or torch.Tensor): The bbox labels to draw.
+ The shape of bbox_labels should be (N,), where N is the
+ number of texts.
+ bboxes (np.ndarray or torch.Tensor): The bboxes to draw. The shape
+ of bboxes should be (N, 4), where N is the number of texts.
+ polygons (Sequence[np.ndarray]): The polygons to draw. The length
+ of polygons should be the same as the number of bboxes.
+ edge_labels (np.ndarray or torch.Tensor): The edge labels to draw.
+ The shape of edge_labels should be (N, N), where N is the
+ number of texts.
+ texts (Sequence[str]): The texts to draw. The length of texts
+ should be the same as the number of bboxes.
+ class_names (dict): The class names for bbox labels.
+ is_openset (bool): Whether the dataset is openset. Defaults to
+ False.
+ arrow_colors (str, optional): The colors of arrows. Refer to
+ `matplotlib.colors` for full list of formats that are accepted.
+ Defaults to 'g'.
+
+ Returns:
+ np.ndarray: The image with instances drawn.
+ """
+ img_shape = image.shape[:2]
+ empty_shape = (img_shape[0], img_shape[1], 3)
+
+ text_image = np.full(empty_shape, 255, dtype=np.uint8)
+ text_image = self.get_labels_image(
+ text_image,
+ texts,
+ bboxes,
+ font_families=self.font_families,
+ font_properties=self.font_properties)
+
+ classes_image = np.full(empty_shape, 255, dtype=np.uint8)
+ bbox_classes = [class_names[int(i)]['name'] for i in bbox_labels]
+ classes_image = self.get_labels_image(
+ classes_image,
+ bbox_classes,
+ bboxes,
+ font_families=self.font_families,
+ font_properties=self.font_properties)
+ if polygons:
+ polygons = [polygon.reshape(-1, 2) for polygon in polygons]
+ image = self.get_polygons_image(
+ image, polygons, filling=True, colors=self.PALETTE)
+ text_image = self.get_polygons_image(
+ text_image, polygons, colors=self.PALETTE)
+ classes_image = self.get_polygons_image(
+ classes_image, polygons, colors=self.PALETTE)
+ else:
+ image = self.get_bboxes_image(
+ image, bboxes, filling=True, colors=self.PALETTE)
+ text_image = self.get_bboxes_image(
+ text_image, bboxes, colors=self.PALETTE)
+ classes_image = self.get_bboxes_image(
+ classes_image, bboxes, colors=self.PALETTE)
+ cat_image = [image, text_image, classes_image]
+ if is_openset:
+ edge_image = np.full(empty_shape, 255, dtype=np.uint8)
+ edge_image = self._draw_edge_label(edge_image, edge_labels, bboxes,
+ texts, arrow_colors)
+ cat_image.append(edge_image)
+ return self._cat_image(cat_image, axis=1)
+
+ def add_datasample(self,
+ name: str,
+ image: np.ndarray,
+ data_sample: Optional['KIEDataSample'] = None,
+ draw_gt: bool = True,
+ draw_pred: bool = True,
+ show: bool = False,
+ wait_time: int = 0,
+ pred_score_thr: float = None,
+ out_file: Optional[str] = None,
+ step: int = 0) -> None:
+ """Draw datasample and save to all backends.
+
+ - If GT and prediction are plotted at the same time, they are
+ displayed in a stitched image where the left image is the
+ ground truth and the right image is the prediction.
+ - If ``show`` is True, all storage backends are ignored, and
+ the images will be displayed in a local window.
+ - If ``out_file`` is specified, the drawn image will be
+ saved to ``out_file``. This is usually used when the display
+ is not available.
+
+ Args:
+ name (str): The image identifier.
+ image (np.ndarray): The image to draw.
+ data_sample (:obj:`KIEDataSample`, optional):
+ KIEDataSample which contains gt and prediction. Defaults
+ to None.
+ draw_gt (bool): Whether to draw GT KIEDataSample.
+ Defaults to True.
+ draw_pred (bool): Whether to draw Predicted KIEDataSample.
+ Defaults to True.
+ show (bool): Whether to display the drawn image. Default to False.
+ wait_time (float): The interval of show (s). Defaults to 0.
+ pred_score_thr (float): The threshold to visualize the bboxes
+ and masks. Defaults to 0.3.
+ out_file (str): Path to output file. Defaults to None.
+ step (int): Global step value to record. Defaults to 0.
+ """
+ cat_images = list()
+
+ if draw_gt:
+ gt_bboxes = data_sample.gt_instances.bboxes
+ gt_labels = data_sample.gt_instances.labels
+ gt_texts = data_sample.gt_instances.texts
+ gt_polygons = data_sample.gt_instances.get('polygons', None)
+ gt_edge_labels = data_sample.gt_instances.get('edge_labels', None)
+ gt_img_data = self._draw_instances(image, gt_labels, gt_bboxes,
+ gt_polygons, gt_edge_labels,
+ gt_texts,
+ self.dataset_meta['category'],
+ self.is_openset, 'g')
+ cat_images.append(gt_img_data)
+ if draw_pred:
+ gt_bboxes = data_sample.gt_instances.bboxes
+ pred_labels = data_sample.pred_instances.labels
+ gt_texts = data_sample.gt_instances.texts
+ gt_polygons = data_sample.gt_instances.get('polygons', None)
+ pred_edge_labels = data_sample.pred_instances.get(
+ 'edge_labels', None)
+ pred_img_data = self._draw_instances(image, pred_labels, gt_bboxes,
+ gt_polygons, pred_edge_labels,
+ gt_texts,
+ self.dataset_meta['category'],
+ self.is_openset, 'r')
+ cat_images.append(pred_img_data)
+
+ cat_images = self._cat_image(cat_images, axis=0)
+ if cat_images is None:
+ cat_images = image
+
+ if show:
+ self.show(cat_images, win_name=name, wait_time=wait_time)
+ else:
+ self.add_image(name, cat_images, step)
+
+ if out_file is not None:
+ mmcv.imwrite(cat_images[..., ::-1], out_file)
+
+ self.set_image(cat_images)
+ return self.get_image()
+
+ def draw_arrows(self,
+ x_data: Union[np.ndarray, torch.Tensor],
+ y_data: Union[np.ndarray, torch.Tensor],
+ colors: Union[str, tuple, List[str], List[tuple]] = 'C1',
+ line_widths: Union[Union[int, float],
+ List[Union[int, float]]] = 1,
+ line_styles: Union[str, List[str]] = '-',
+ arrow_tail_widths: Union[Union[int, float],
+ List[Union[int, float]]] = 0.001,
+ arrow_head_widths: Union[Union[int, float],
+ List[Union[int, float]]] = None,
+ arrow_head_lengths: Union[Union[int, float],
+ List[Union[int, float]]] = None,
+ arrow_shapes: Union[str, List[str]] = 'full',
+ overhangs: Union[int, List[int]] = 0) -> 'Visualizer':
+ """Draw single or multiple arrows.
+
+ Args:
+ x_data (np.ndarray or torch.Tensor): The x coordinate of
+ each line' start and end points.
+ y_data (np.ndarray, torch.Tensor): The y coordinate of
+ each line' start and end points.
+ colors (str or tuple or list[str or tuple]): The colors of
+ lines. ``colors`` can have the same length with lines or just
+ single value. If ``colors`` is single value, all the lines
+ will have the same colors. Reference to
+ https://matplotlib.org/stable/gallery/color/named_colors.html
+ for more details. Defaults to 'g'.
+ line_widths (int or float or list[int or float]):
+ The linewidth of lines. ``line_widths`` can have
+ the same length with lines or just single value.
+ If ``line_widths`` is single value, all the lines will
+ have the same linewidth. Defaults to 2.
+ line_styles (str or list[str]]): The linestyle of lines.
+ ``line_styles`` can have the same length with lines or just
+ single value. If ``line_styles`` is single value, all the
+ lines will have the same linestyle. Defaults to '-'.
+ arrow_tail_widths (int or float or list[int, float]):
+ The width of arrow tails. ``arrow_tail_widths`` can have
+ the same length with lines or just single value. If
+ ``arrow_tail_widths`` is single value, all the lines will
+ have the same width. Defaults to 0.001.
+ arrow_head_widths (int or float or list[int, float]):
+ The width of arrow heads. ``arrow_head_widths`` can have
+ the same length with lines or just single value. If
+ ``arrow_head_widths`` is single value, all the lines will
+ have the same width. Defaults to None.
+ arrow_head_lengths (int or float or list[int, float]):
+ The length of arrow heads. ``arrow_head_lengths`` can have
+ the same length with lines or just single value. If
+ ``arrow_head_lengths`` is single value, all the lines will
+ have the same length. Defaults to None.
+ arrow_shapes (str or list[str]]): The shapes of arrow heads.
+ ``arrow_shapes`` can have the same length with lines or just
+ single value. If ``arrow_shapes`` is single value, all the
+ lines will have the same shape. Defaults to 'full'.
+ overhangs (int or list[int]]): The overhangs of arrow heads.
+ ``overhangs`` can have the same length with lines or just
+ single value. If ``overhangs`` is single value, all the lines
+ will have the same overhangs. Defaults to 0.
+ """
+ check_type('x_data', x_data, (np.ndarray, torch.Tensor))
+ x_data = tensor2ndarray(x_data)
+ check_type('y_data', y_data, (np.ndarray, torch.Tensor))
+ y_data = tensor2ndarray(y_data)
+ assert x_data.shape == y_data.shape, (
+ '`x_data` and `y_data` should have the same shape')
+ assert x_data.shape[-1] == 2, (
+ f'The shape of `x_data` should be (N, 2), but got {x_data.shape}')
+ if len(x_data.shape) == 1:
+ x_data = x_data[None]
+ y_data = y_data[None]
+ number_arrow = x_data.shape[0]
+ check_type_and_length('colors', colors, (str, tuple, list),
+ number_arrow)
+ colors = value2list(colors, (str, tuple), number_arrow)
+ colors = color_val_matplotlib(colors) # type: ignore
+ check_type_and_length('line_widths', line_widths, (int, float),
+ number_arrow)
+ line_widths = value2list(line_widths, (int, float), number_arrow)
+ check_type_and_length('arrow_tail_widths', arrow_tail_widths,
+ (int, float), number_arrow)
+ check_type_and_length('line_styles', line_styles, str, number_arrow)
+ line_styles = value2list(line_styles, str, number_arrow)
+ arrow_tail_widths = value2list(arrow_tail_widths, (int, float),
+ number_arrow)
+ check_type_and_length('arrow_head_widths', arrow_head_widths,
+ (int, float, type(None)), number_arrow)
+ arrow_head_widths = value2list(arrow_head_widths,
+ (int, float, type(None)), number_arrow)
+ check_type_and_length('arrow_head_lengths', arrow_head_lengths,
+ (int, float, type(None)), number_arrow)
+ arrow_head_lengths = value2list(arrow_head_lengths,
+ (int, float, type(None)), number_arrow)
+ check_type_and_length('arrow_shapes', arrow_shapes, (str, list),
+ number_arrow)
+ arrow_shapes = value2list(arrow_shapes, (str, list), number_arrow)
+ check_type('overhang', overhangs, int)
+ overhangs = value2list(overhangs, int, number_arrow)
+
+ lines = np.concatenate(
+ (x_data.reshape(-1, 2, 1), y_data.reshape(-1, 2, 1)), axis=-1)
+ if not self._is_posion_valid(lines):
+ warnings.warn(
+ 'Warning: The line is out of bounds,'
+ ' the drawn line may not be in the image', UserWarning)
+ arrows = []
+ for i in range(number_arrow):
+ arrows.append(
+ FancyArrow(
+ *tuple(lines[i, 0]),
+ *tuple(lines[i, 1] - lines[i, 0]),
+ linestyle=line_styles[i],
+ color=colors[i],
+ length_includes_head=True,
+ width=arrow_tail_widths[i],
+ head_width=arrow_head_widths[i],
+ head_length=arrow_head_lengths[i],
+ overhang=overhangs[i],
+ shape=arrow_shapes[i],
+ linewidth=line_widths[i]))
+ p = PatchCollection(arrows, match_original=True)
+ self.ax_save.add_collection(p)
+ return self
diff --git a/mmocr/visualization/textdet_visualizer.py b/mmocr/visualization/textdet_visualizer.py
new file mode 100644
index 0000000000000000000000000000000000000000..8b3f54da13984a77ec7ed7a13f3773bed00fc8e3
--- /dev/null
+++ b/mmocr/visualization/textdet_visualizer.py
@@ -0,0 +1,194 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Sequence, Tuple, Union
+
+import mmcv
+import numpy as np
+import torch
+
+from mmocr.registry import VISUALIZERS
+from mmocr.structures import TextDetDataSample
+from .base_visualizer import BaseLocalVisualizer
+
+
+@VISUALIZERS.register_module()
+class TextDetLocalVisualizer(BaseLocalVisualizer):
+ """The MMOCR Text Detection Local Visualizer.
+
+ Args:
+ name (str): Name of the instance. Defaults to 'visualizer'.
+ image (np.ndarray, optional): The origin image to draw. The format
+ should be RGB. Defaults to None.
+ with_poly (bool): Whether to draw polygons. Defaults to True.
+ with_bbox (bool): Whether to draw bboxes. Defaults to False.
+ vis_backends (list, optional): Visual backend config list.
+ Defaults to None.
+ save_dir (str, optional): Save file dir for all storage backends.
+ If it is None, the backend storage will not save any data.
+ gt_color (Union[str, tuple, list[str], list[tuple]]): The
+ colors of GT polygons and bboxes. ``colors`` can have the same
+ length with lines or just single value. If ``colors`` is single
+ value, all the lines will have the same colors. Refer to
+ `matplotlib.colors` for full list of formats that are accepted.
+ Defaults to 'g'.
+ gt_ignored_color (Union[str, tuple, list[str], list[tuple]]): The
+ colors of ignored GT polygons and bboxes. ``colors`` can have
+ the same length with lines or just single value. If ``colors``
+ is single value, all the lines will have the same colors. Refer
+ to `matplotlib.colors` for full list of formats that are accepted.
+ Defaults to 'b'.
+ pred_color (Union[str, tuple, list[str], list[tuple]]): The
+ colors of pred polygons and bboxes. ``colors`` can have the same
+ length with lines or just single value. If ``colors`` is single
+ value, all the lines will have the same colors. Refer to
+ `matplotlib.colors` for full list of formats that are accepted.
+ Defaults to 'r'.
+ line_width (int, float): The linewidth of lines. Defaults to 2.
+ alpha (float): The transparency of bboxes or polygons. Defaults to 0.8.
+ """
+
+ def __init__(self,
+ name: str = 'visualizer',
+ image: Optional[np.ndarray] = None,
+ with_poly: bool = True,
+ with_bbox: bool = False,
+ vis_backends: Optional[Dict] = None,
+ save_dir: Optional[str] = None,
+ gt_color: Union[str, Tuple, List[str], List[Tuple]] = 'g',
+ gt_ignored_color: Union[str, Tuple, List[str],
+ List[Tuple]] = 'b',
+ pred_color: Union[str, Tuple, List[str], List[Tuple]] = 'r',
+ line_width: Union[int, float] = 2,
+ alpha: float = 0.8) -> None:
+ super().__init__(
+ name=name,
+ image=image,
+ vis_backends=vis_backends,
+ save_dir=save_dir)
+ self.with_poly = with_poly
+ self.with_bbox = with_bbox
+ self.gt_color = gt_color
+ self.gt_ignored_color = gt_ignored_color
+ self.pred_color = pred_color
+ self.line_width = line_width
+ self.alpha = alpha
+
+ def _draw_instances(
+ self,
+ image: np.ndarray,
+ bboxes: Union[np.ndarray, torch.Tensor],
+ polygons: Sequence[np.ndarray],
+ color: Union[str, Tuple, List[str], List[Tuple]] = 'g',
+ ) -> np.ndarray:
+ """Draw bboxes and polygons on image.
+
+ Args:
+ image (np.ndarray): The origin image to draw.
+ bboxes (Union[np.ndarray, torch.Tensor]): The bboxes to draw.
+ polygons (Sequence[np.ndarray]): The polygons to draw.
+ color (Union[str, tuple, list[str], list[tuple]]): The
+ colors of polygons and bboxes. ``colors`` can have the same
+ length with lines or just single value. If ``colors`` is
+ single value, all the lines will have the same colors. Refer
+ to `matplotlib.colors` for full list of formats that are
+ accepted. Defaults to 'g'.
+
+ Returns:
+ np.ndarray: The image with bboxes and polygons drawn.
+ """
+ if polygons is not None and self.with_poly:
+ polygons = [polygon.reshape(-1, 2) for polygon in polygons]
+ image = self.get_polygons_image(
+ image, polygons, filling=True, colors=color, alpha=self.alpha)
+ if bboxes is not None and self.with_bbox:
+ image = self.get_bboxes_image(
+ image,
+ bboxes,
+ colors=color,
+ line_width=self.line_width,
+ alpha=self.alpha)
+ return image
+
+ def add_datasample(self,
+ name: str,
+ image: np.ndarray,
+ data_sample: Optional['TextDetDataSample'] = None,
+ draw_gt: bool = True,
+ draw_pred: bool = True,
+ show: bool = False,
+ wait_time: int = 0,
+ out_file: Optional[str] = None,
+ pred_score_thr: float = 0.3,
+ step: int = 0) -> None:
+ """Draw datasample and save to all backends.
+
+ - If GT and prediction are plotted at the same time, they are
+ displayed in a stitched image where the left image is the
+ ground truth and the right image is the prediction.
+ - If ``show`` is True, all storage backends are ignored, and
+ the images will be displayed in a local window.
+ - If ``out_file`` is specified, the drawn image will be
+ saved to ``out_file``. This is usually used when the display
+ is not available.
+
+ Args:
+ name (str): The image identifier.
+ image (np.ndarray): The image to draw.
+ data_sample (:obj:`TextDetDataSample`, optional):
+ TextDetDataSample which contains gt and prediction. Defaults
+ to None.
+ draw_gt (bool): Whether to draw GT TextDetDataSample.
+ Defaults to True.
+ draw_pred (bool): Whether to draw Predicted TextDetDataSample.
+ Defaults to True.
+ show (bool): Whether to display the drawn image. Default to False.
+ wait_time (float): The interval of show (s). Defaults to 0.
+ out_file (str): Path to output file. Defaults to None.
+ pred_score_thr (float): The threshold to visualize the bboxes
+ and masks. Defaults to 0.3.
+ step (int): Global step value to record. Defaults to 0.
+ """
+ cat_images = []
+ if data_sample is not None:
+ if draw_gt and 'gt_instances' in data_sample:
+ gt_instances = data_sample.gt_instances
+ gt_img_data = image.copy()
+ if gt_instances.get('ignored', None) is not None:
+ ignore_flags = gt_instances.ignored
+ gt_ignored_instances = gt_instances[ignore_flags]
+ gt_ignored_polygons = gt_ignored_instances.get(
+ 'polygons', None)
+ gt_ignored_bboxes = gt_ignored_instances.get(
+ 'bboxes', None)
+ gt_img_data = self._draw_instances(gt_img_data,
+ gt_ignored_bboxes,
+ gt_ignored_polygons,
+ self.gt_ignored_color)
+ gt_instances = gt_instances[~ignore_flags]
+ gt_polygons = gt_instances.get('polygons', None)
+ gt_bboxes = gt_instances.get('bboxes', None)
+ gt_img_data = self._draw_instances(gt_img_data, gt_bboxes,
+ gt_polygons, self.gt_color)
+ cat_images.append(gt_img_data)
+ if draw_pred and 'pred_instances' in data_sample:
+ pred_instances = data_sample.pred_instances
+ pred_instances = pred_instances[
+ pred_instances.scores > pred_score_thr].cpu()
+ pred_polygons = pred_instances.get('polygons', None)
+ pred_bboxes = pred_instances.get('bboxes', None)
+ pred_img_data = self._draw_instances(image.copy(), pred_bboxes,
+ pred_polygons,
+ self.pred_color)
+ cat_images.append(pred_img_data)
+ cat_images = self._cat_image(cat_images, axis=1)
+ if cat_images is None:
+ cat_images = image
+ if show:
+ self.show(cat_images, win_name=name, wait_time=wait_time)
+ else:
+ self.add_image(name, cat_images, step)
+
+ if out_file is not None:
+ mmcv.imwrite(cat_images[..., ::-1], out_file)
+
+ self.set_image(cat_images)
+ return self.get_image()
diff --git a/mmocr/visualization/textrecog_visualizer.py b/mmocr/visualization/textrecog_visualizer.py
new file mode 100644
index 0000000000000000000000000000000000000000..d2f529b47f40b97d46ffdd73ee467da46e2e92c4
--- /dev/null
+++ b/mmocr/visualization/textrecog_visualizer.py
@@ -0,0 +1,144 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, Optional, Tuple, Union
+
+import cv2
+import mmcv
+import numpy as np
+
+from mmocr.registry import VISUALIZERS
+from mmocr.structures import TextRecogDataSample
+from .base_visualizer import BaseLocalVisualizer
+
+
+@VISUALIZERS.register_module()
+class TextRecogLocalVisualizer(BaseLocalVisualizer):
+ """MMOCR Text Detection Local Visualizer.
+
+ Args:
+ name (str): Name of the instance. Defaults to 'visualizer'.
+ image (np.ndarray, optional): The origin image to draw. The format
+ should be RGB. Defaults to None.
+ vis_backends (list, optional): Visual backend config list.
+ Defaults to None.
+ save_dir (str, optional): Save file dir for all storage backends.
+ If it is None, the backend storage will not save any data.
+ gt_color (str or tuple[int, int, int]): Colors of GT text. The tuple of
+ color should be in RGB order. Or using an abbreviation of color,
+ such as `'g'` for `'green'`. Defaults to 'g'.
+ pred_color (str or tuple[int, int, int]): Colors of Predicted text.
+ The tuple of color should be in RGB order. Or using an abbreviation
+ of color, such as `'r'` for `'red'`. Defaults to 'r'.
+ """
+
+ def __init__(self,
+ name: str = 'visualizer',
+ image: Optional[np.ndarray] = None,
+ vis_backends: Optional[Dict] = None,
+ save_dir: Optional[str] = None,
+ gt_color: Optional[Union[str, Tuple[int, int, int]]] = 'g',
+ pred_color: Optional[Union[str, Tuple[int, int, int]]] = 'r',
+ **kwargs) -> None:
+ super().__init__(
+ name=name,
+ image=image,
+ vis_backends=vis_backends,
+ save_dir=save_dir,
+ **kwargs)
+ self.gt_color = gt_color
+ self.pred_color = pred_color
+
+ def _draw_instances(self, image: np.ndarray, text: str) -> np.ndarray:
+ """Draw text on image.
+
+ Args:
+ image (np.ndarray): The image to draw.
+ text (str): The text to draw.
+
+ Returns:
+ np.ndarray: The image with text drawn.
+ """
+ height, width = image.shape[:2]
+ empty_img = np.full_like(image, 255)
+ self.set_image(empty_img)
+ font_size = min(0.5 * width / (len(text) + 1), 0.5 * height)
+ self.draw_texts(
+ text,
+ np.array([width / 2, height / 2]),
+ colors=self.gt_color,
+ font_sizes=font_size,
+ vertical_alignments='center',
+ horizontal_alignments='center',
+ font_families=self.font_families,
+ font_properties=self.font_properties)
+ text_image = self.get_image()
+ return text_image
+
+ def add_datasample(self,
+ name: str,
+ image: np.ndarray,
+ data_sample: Optional['TextRecogDataSample'] = None,
+ draw_gt: bool = True,
+ draw_pred: bool = True,
+ show: bool = False,
+ wait_time: int = 0,
+ pred_score_thr: float = None,
+ out_file: Optional[str] = None,
+ step=0) -> None:
+ """Visualize datasample and save to all backends.
+
+ - If GT and prediction are plotted at the same time, they are
+ displayed in a stitched image where the left image is the
+ ground truth and the right image is the prediction.
+ - If ``show`` is True, all storage backends are ignored, and
+ the images will be displayed in a local window.
+ - If ``out_file`` is specified, the drawn image will be
+ saved to ``out_file``. This is usually used when the display
+ is not available.
+
+ Args:
+ name (str): The image title. Defaults to 'image'.
+ image (np.ndarray): The image to draw.
+ data_sample (:obj:`TextRecogDataSample`, optional):
+ TextRecogDataSample which contains gt and prediction.
+ Defaults to None.
+ draw_gt (bool): Whether to draw GT TextRecogDataSample.
+ Defaults to True.
+ draw_pred (bool): Whether to draw Predicted TextRecogDataSample.
+ Defaults to True.
+ show (bool): Whether to display the drawn image. Defaults to False.
+ wait_time (float): The interval of show (s). Defaults to 0.
+ out_file (str): Path to output file. Defaults to None.
+ step (int): Global step value to record. Defaults to 0.
+ pred_score_thr (float): Threshold of prediction score. It's not
+ used in this function. Defaults to None.
+ """
+ height, width = image.shape[:2]
+ resize_height = 64
+ resize_width = int(1.0 * width / height * resize_height)
+ image = cv2.resize(image, (resize_width, resize_height))
+
+ if image.ndim == 2:
+ image = cv2.cvtColor(image, cv2.COLOR_GRAY2RGB)
+
+ cat_images = [image]
+ if (draw_gt and data_sample is not None and 'gt_text' in data_sample
+ and 'item' in data_sample.gt_text):
+ gt_text = data_sample.gt_text.item
+ cat_images.append(self._draw_instances(image, gt_text))
+ if (draw_pred and data_sample is not None
+ and 'pred_text' in data_sample
+ and 'item' in data_sample.pred_text):
+ pred_text = data_sample.pred_text.item
+ cat_images.append(self._draw_instances(image, pred_text))
+ cat_images = self._cat_image(cat_images, axis=0)
+
+ if show:
+ self.show(cat_images, win_name=name, wait_time=wait_time)
+ else:
+ self.add_image(name, cat_images, step)
+
+ if out_file is not None:
+ mmcv.imwrite(cat_images[..., ::-1], out_file)
+
+ self.set_image(cat_images)
+ return self.get_image()
diff --git a/mmocr/visualization/textspotting_visualizer.py b/mmocr/visualization/textspotting_visualizer.py
new file mode 100644
index 0000000000000000000000000000000000000000..bd4038c35aadfc346e2b370d5a361462acdaf326
--- /dev/null
+++ b/mmocr/visualization/textspotting_visualizer.py
@@ -0,0 +1,144 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Sequence, Union
+
+import mmcv
+import numpy as np
+import torch
+
+from mmocr.registry import VISUALIZERS
+from mmocr.structures import TextDetDataSample
+from mmocr.utils.polygon_utils import poly2bbox
+from .base_visualizer import BaseLocalVisualizer
+
+
+@VISUALIZERS.register_module()
+class TextSpottingLocalVisualizer(BaseLocalVisualizer):
+
+ def _draw_instances(
+ self,
+ image: np.ndarray,
+ bboxes: Union[np.ndarray, torch.Tensor],
+ polygons: Sequence[np.ndarray],
+ texts: Sequence[str],
+ ) -> np.ndarray:
+ """Draw instances on image.
+
+ Args:
+ image (np.ndarray): The origin image to draw. The format
+ should be RGB.
+ bboxes (np.ndarray, torch.Tensor): The bboxes to draw. The shape of
+ bboxes should be (N, 4), where N is the number of texts.
+ polygons (Sequence[np.ndarray]): The polygons to draw. The length
+ of polygons should be the same as the number of bboxes.
+ edge_labels (np.ndarray, torch.Tensor): The edge labels to draw.
+ The shape of edge_labels should be (N, N), where N is the
+ number of texts.
+ texts (Sequence[str]): The texts to draw. The length of texts
+ should be the same as the number of bboxes.
+ class_names (dict): The class names for bbox labels.
+ is_openset (bool): Whether the dataset is openset. Default: False.
+
+ Returns:
+ np.ndarray: The image with instances drawn.
+ """
+ img_shape = image.shape[:2]
+ empty_shape = (img_shape[0], img_shape[1], 3)
+ text_image = np.full(empty_shape, 255, dtype=np.uint8)
+ if texts:
+ text_image = self.get_labels_image(
+ text_image,
+ labels=texts,
+ bboxes=bboxes,
+ font_families=self.font_families,
+ font_properties=self.font_properties)
+ if polygons:
+ polygons = [polygon.reshape(-1, 2) for polygon in polygons]
+ image = self.get_polygons_image(
+ image, polygons, filling=True, colors=self.PALETTE)
+ text_image = self.get_polygons_image(
+ text_image, polygons, colors=self.PALETTE)
+ elif len(bboxes) > 0:
+ image = self.get_bboxes_image(
+ image, bboxes, filling=True, colors=self.PALETTE)
+ text_image = self.get_bboxes_image(
+ text_image, bboxes, colors=self.PALETTE)
+ return np.concatenate([image, text_image], axis=1)
+
+ def add_datasample(self,
+ name: str,
+ image: np.ndarray,
+ data_sample: Optional['TextDetDataSample'] = None,
+ draw_gt: bool = True,
+ draw_pred: bool = True,
+ show: bool = False,
+ wait_time: int = 0,
+ pred_score_thr: float = 0.5,
+ out_file: Optional[str] = None,
+ step: int = 0) -> None:
+ """Draw datasample and save to all backends.
+
+ - If GT and prediction are plotted at the same time, they are
+ displayed in a stitched image where the left image is the
+ ground truth and the right image is the prediction.
+ - If ``show`` is True, all storage backends are ignored, and
+ the images will be displayed in a local window.
+ - If ``out_file`` is specified, the drawn image will be
+ saved to ``out_file``. This is usually used when the display
+ is not available.
+
+ Args:
+ name (str): The image identifier.
+ image (np.ndarray): The image to draw.
+ data_sample (:obj:`TextSpottingDataSample`, optional):
+ TextDetDataSample which contains gt and prediction. Defaults
+ to None.
+ draw_gt (bool): Whether to draw GT TextDetDataSample.
+ Defaults to True.
+ draw_pred (bool): Whether to draw Predicted TextDetDataSample.
+ Defaults to True.
+ show (bool): Whether to display the drawn image. Default to False.
+ wait_time (float): The interval of show (s). Defaults to 0.
+ out_file (str): Path to output file. Defaults to None.
+ pred_score_thr (float): The threshold to visualize the bboxes
+ and masks. Defaults to 0.3.
+ step (int): Global step value to record. Defaults to 0.
+ """
+ cat_images = []
+
+ if data_sample is not None:
+ if draw_gt and 'gt_instances' in data_sample:
+ gt_bboxes = data_sample.gt_instances.get('bboxes', None)
+ gt_texts = data_sample.gt_instances.texts
+ gt_polygons = data_sample.gt_instances.get('polygons', None)
+ gt_img_data = self._draw_instances(image, gt_bboxes,
+ gt_polygons, gt_texts)
+ cat_images.append(gt_img_data)
+
+ if draw_pred and 'pred_instances' in data_sample:
+ pred_instances = data_sample.pred_instances
+ pred_instances = pred_instances[
+ pred_instances.scores > pred_score_thr].cpu().numpy()
+ pred_bboxes = pred_instances.get('bboxes', None)
+ pred_texts = pred_instances.texts
+ pred_polygons = pred_instances.get('polygons', None)
+ if pred_bboxes is None:
+ pred_bboxes = [poly2bbox(poly) for poly in pred_polygons]
+ pred_bboxes = np.array(pred_bboxes)
+ pred_img_data = self._draw_instances(image, pred_bboxes,
+ pred_polygons, pred_texts)
+ cat_images.append(pred_img_data)
+
+ cat_images = self._cat_image(cat_images, axis=0)
+ if cat_images is None:
+ cat_images = image
+
+ if show:
+ self.show(cat_images, win_name=name, wait_time=wait_time)
+ else:
+ self.add_image(name, cat_images, step)
+
+ if out_file is not None:
+ mmcv.imwrite(cat_images[..., ::-1], out_file)
+
+ self.set_image(cat_images)
+ return self.get_image()
diff --git a/model-index.yml b/model-index.yml
new file mode 100644
index 0000000000000000000000000000000000000000..563372c2623fe797281a4a3d0b80ad8c559ea2ef
--- /dev/null
+++ b/model-index.yml
@@ -0,0 +1,19 @@
+Import:
+ - configs/textdet/dbnet/metafile.yml
+ - configs/textdet/dbnetpp/metafile.yml
+ - configs/textdet/maskrcnn/metafile.yml
+ - configs/textdet/drrg/metafile.yml
+ - configs/textdet/fcenet/metafile.yml
+ - configs/textdet/panet/metafile.yml
+ - configs/textdet/psenet/metafile.yml
+ - configs/textdet/textsnake/metafile.yml
+ - configs/textrecog/abinet/metafile.yml
+ - configs/textrecog/aster/metafile.yml
+ - configs/textrecog/crnn/metafile.yml
+ - configs/textrecog/master/metafile.yml
+ - configs/textrecog/nrtr/metafile.yml
+ - configs/textrecog/svtr/metafile.yml
+ - configs/textrecog/robust_scanner/metafile.yml
+ - configs/textrecog/sar/metafile.yml
+ - configs/textrecog/satrn/metafile.yml
+ - configs/kie/sdmgr/metafile.yml
diff --git a/requirements/albu.txt b/requirements/albu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..ddcc3fb3b271dcad3526ef130e1267be3fc20b5b
--- /dev/null
+++ b/requirements/albu.txt
@@ -0,0 +1 @@
+albumentations>=1.1.0 --no-binary qudida,albumentations
diff --git a/requirements/build.txt b/requirements/build.txt
new file mode 100644
index 0000000000000000000000000000000000000000..e06b090722e0079badeb07d094d39571754995e4
--- /dev/null
+++ b/requirements/build.txt
@@ -0,0 +1,4 @@
+# These must be installed before building mmocr
+numpy
+pyclipper
+torch>=1.1
diff --git a/requirements/docs.txt b/requirements/docs.txt
new file mode 100644
index 0000000000000000000000000000000000000000..16ddccda5db65197434a6c1b543f6c87395465a8
--- /dev/null
+++ b/requirements/docs.txt
@@ -0,0 +1,9 @@
+docutils==0.16.0
+markdown>=3.4.0
+myst-parser
+-e git+https://github.com/open-mmlab/pytorch_sphinx_theme.git#egg=pytorch_sphinx_theme
+sphinx==4.0.2
+sphinx-tabs
+sphinx_copybutton
+sphinx_markdown_tables>=0.0.16
+tabulate
diff --git a/requirements/mminstall.txt b/requirements/mminstall.txt
new file mode 100644
index 0000000000000000000000000000000000000000..fe6b6d945dd1e5593a2d3569a33f848aed864ec7
--- /dev/null
+++ b/requirements/mminstall.txt
@@ -0,0 +1,3 @@
+mmcv>=2.0.0rc4,<2.1.0
+mmdet>=3.0.0rc5,<3.1.0
+mmengine>=0.7.0, <1.0.0
diff --git a/requirements/optional.txt b/requirements/optional.txt
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/requirements/readthedocs.txt b/requirements/readthedocs.txt
new file mode 100644
index 0000000000000000000000000000000000000000..45edbc15ff0f9496f452c4d94764806640d0dc8c
--- /dev/null
+++ b/requirements/readthedocs.txt
@@ -0,0 +1,16 @@
+imgaug
+kwarray
+lmdb
+matplotlib
+mmcv>=2.0.0rc1
+mmdet>=3.0.0rc0
+mmengine>=0.1.0
+pyclipper
+rapidfuzz>=2.0.0
+regex
+scikit-image
+scipy
+shapely
+titlecase
+torch
+torchvision
diff --git a/requirements/runtime.txt b/requirements/runtime.txt
new file mode 100644
index 0000000000000000000000000000000000000000..52a9eec3c3bb54d6ae96d1293923c56c2399d690
--- /dev/null
+++ b/requirements/runtime.txt
@@ -0,0 +1,9 @@
+imgaug
+lmdb
+matplotlib
+numpy
+opencv-python >=4.2.0.32, != 4.5.5.* # avoid Github security alert
+pyclipper
+pycocotools
+rapidfuzz>=2.0.0
+scikit-image
diff --git a/requirements/tests.txt b/requirements/tests.txt
new file mode 100644
index 0000000000000000000000000000000000000000..19711e108cae25ce6e65f5493d3a4fe2646bc51c
--- /dev/null
+++ b/requirements/tests.txt
@@ -0,0 +1,15 @@
+asynctest
+codecov
+flake8
+interrogate
+isort
+# Note: used for kwarray.group_items, this may be ported to mmcv in the future.
+kwarray
+lanms-neo==1.0.2
+parameterized
+pytest
+pytest-cov
+pytest-runner
+ubelt
+xdoctest >= 0.10.0
+yapf
diff --git a/setup.cfg b/setup.cfg
new file mode 100644
index 0000000000000000000000000000000000000000..e54ab9ea76642e8e4bbf5c8a7895d14d9ef9b637
--- /dev/null
+++ b/setup.cfg
@@ -0,0 +1,23 @@
+[bdist_wheel]
+universal=1
+
+[yapf]
+based_on_style = pep8
+blank_line_before_nested_class_or_def = true
+split_before_expression_after_opening_paren = true
+split_penalty_import_names=0
+SPLIT_PENALTY_AFTER_OPENING_BRACKET=800
+
+[isort]
+line_length = 79
+multi_line_output = 0
+extra_standard_library = setuptools
+known_first_party = mmocr
+known_third_party = PIL,cv2,imgaug,lanms,lmdb,matplotlib,mmcv,mmdet,numpy,packaging,pyclipper,pytest,pytorch_sphinx_theme,rapidfuzz,requests,scipy,shapely,skimage,titlecase,torch,torchvision,ts,yaml,mmengine
+no_lines_before = STDLIB,LOCALFOLDER
+default_section = THIRDPARTY
+
+[style]
+BASED_ON_STYLE = pep8
+BLANK_LINE_BEFORE_NESTED_CLASS_OR_DEF = true
+SPLIT_BEFORE_EXPRESSION_AFTER_OPENING_PAREN = true
diff --git a/setup.py b/setup.py
new file mode 100644
index 0000000000000000000000000000000000000000..edc22512aacd3095bc0d7fb6c79e9c596b687320
--- /dev/null
+++ b/setup.py
@@ -0,0 +1,201 @@
+import os
+import os.path as osp
+import shutil
+import sys
+import warnings
+from setuptools import find_packages, setup
+
+
+def readme():
+ with open('README.md', encoding='utf-8') as f:
+ content = f.read()
+ return content
+
+
+version_file = 'mmocr/version.py'
+is_windows = sys.platform == 'win32'
+
+
+def add_mim_extension():
+ """Add extra files that are required to support MIM into the package.
+
+ These files will be added by creating a symlink to the originals if the
+ package is installed in `editable` mode (e.g. pip install -e .), or by
+ copying from the originals otherwise.
+ """
+
+ # parse installment mode
+ if 'develop' in sys.argv:
+ # installed by `pip install -e .`
+ mode = 'symlink'
+ elif 'sdist' in sys.argv or 'bdist_wheel' in sys.argv:
+ # installed by `pip install .`
+ # or create source distribution by `python setup.py sdist`
+ mode = 'copy'
+ else:
+ return
+
+ filenames = ['tools', 'configs', 'model-index.yml', 'dicts']
+ repo_path = osp.dirname(__file__)
+ mim_path = osp.join(repo_path, 'mmocr', '.mim')
+ os.makedirs(mim_path, exist_ok=True)
+
+ for filename in filenames:
+ if osp.exists(filename):
+ src_path = osp.join(repo_path, filename)
+ tar_path = osp.join(mim_path, filename)
+
+ if osp.isfile(tar_path) or osp.islink(tar_path):
+ os.remove(tar_path)
+ elif osp.isdir(tar_path):
+ shutil.rmtree(tar_path)
+
+ if mode == 'symlink':
+ src_relpath = osp.relpath(src_path, osp.dirname(tar_path))
+ try:
+ os.symlink(src_relpath, tar_path)
+ except OSError:
+ # Creating a symbolic link on windows may raise an
+ # `OSError: [WinError 1314]` due to privilege. If
+ # the error happens, the src file will be copied
+ mode = 'copy'
+ warnings.warn(
+ f'Failed to create a symbolic link for {src_relpath}, '
+ f'and it will be copied to {tar_path}')
+ else:
+ continue
+
+ if mode == 'copy':
+ if osp.isfile(src_path):
+ shutil.copyfile(src_path, tar_path)
+ elif osp.isdir(src_path):
+ shutil.copytree(src_path, tar_path)
+ else:
+ warnings.warn(f'Cannot copy file {src_path}.')
+ else:
+ raise ValueError(f'Invalid mode {mode}')
+
+
+def get_version():
+ with open(version_file) as f:
+ exec(compile(f.read(), version_file, 'exec'))
+ import sys
+
+ # return short version for sdist
+ if 'sdist' in sys.argv or 'bdist_wheel' in sys.argv:
+ return locals()['short_version']
+ else:
+ return locals()['__version__']
+
+
+def parse_requirements(fname='requirements.txt', with_version=True):
+ """Parse the package dependencies listed in a requirements file but strip
+ specific version information.
+
+ Args:
+ fname (str): Path to requirements file.
+ with_version (bool, default=False): If True, include version specs.
+ Returns:
+ info (list[str]): List of requirements items.
+ CommandLine:
+ python -c "import setup; print(setup.parse_requirements())"
+ """
+ import re
+ import sys
+ from os.path import exists
+ require_fpath = fname
+
+ def parse_line(line):
+ """Parse information from a line in a requirements text file."""
+ if line.startswith('-r '):
+ # Allow specifying requirements in other files
+ target = line.split(' ')[1]
+ for info in parse_require_file(target):
+ yield info
+ else:
+ info = {'line': line}
+ if line.startswith('-e '):
+ info['package'] = line.split('#egg=')[1]
+ else:
+ # Remove versioning from the package
+ pat = '(' + '|'.join(['>=', '==', '>']) + ')'
+ parts = re.split(pat, line, maxsplit=1)
+ parts = [p.strip() for p in parts]
+
+ info['package'] = parts[0]
+ if len(parts) > 1:
+ op, rest = parts[1:]
+ if ';' in rest:
+ # Handle platform specific dependencies
+ # http://setuptools.readthedocs.io/en/latest/setuptools.html#declaring-platform-specific-dependencies
+ version, platform_deps = map(str.strip,
+ rest.split(';'))
+ info['platform_deps'] = platform_deps
+ else:
+ version = rest # NOQA
+ info['version'] = (op, version)
+ yield info
+
+ def parse_require_file(fpath):
+ with open(fpath) as f:
+ for line in f.readlines():
+ line = line.strip()
+ if line and not line.startswith('#'):
+ yield from parse_line(line)
+
+ def gen_packages_items():
+ if exists(require_fpath):
+ for info in parse_require_file(require_fpath):
+ parts = [info['package']]
+ if with_version and 'version' in info:
+ parts.extend(info['version'])
+ if not sys.version.startswith('3.4'):
+ # apparently package_deps are broken in 3.4
+ platform_deps = info.get('platform_deps')
+ if platform_deps is not None:
+ parts.append(';' + platform_deps)
+ item = ''.join(parts)
+ yield item
+
+ packages = list(gen_packages_items())
+ return packages
+
+
+if __name__ == '__main__':
+ add_mim_extension()
+ library_dirs = [
+ lp for lp in os.environ.get('LD_LIBRARY_PATH', '').split(':')
+ if len(lp) > 1
+ ]
+ setup(
+ name='mmocr',
+ version=get_version(),
+ description='OpenMMLab Text Detection, OCR, and NLP Toolbox',
+ long_description=readme(),
+ long_description_content_type='text/markdown',
+ maintainer='MMOCR Authors',
+ maintainer_email='openmmlab@gmail.com',
+ keywords='Text Detection, OCR, KIE, NLP',
+ packages=find_packages(exclude=('configs', 'tools', 'demo')),
+ include_package_data=True,
+ url='https://github.com/open-mmlab/mmocr',
+ classifiers=[
+ 'Development Status :: 4 - Beta',
+ 'License :: OSI Approved :: Apache Software License',
+ 'Operating System :: OS Independent',
+ 'Programming Language :: Python :: 3',
+ 'Programming Language :: Python :: 3.6',
+ 'Programming Language :: Python :: 3.7',
+ 'Programming Language :: Python :: 3.8',
+ 'Programming Language :: Python :: 3.9',
+ ],
+ license='Apache License 2.0',
+ install_requires=parse_requirements('requirements/runtime.txt'),
+ extras_require={
+ 'all': parse_requirements('requirements.txt'),
+ 'tests': parse_requirements('requirements/tests.txt'),
+ 'build': parse_requirements('requirements/build.txt'),
+ 'optional': parse_requirements('requirements/optional.txt'),
+ 'mim': parse_requirements('requirements/mminstall.txt'),
+ },
+ zip_safe=False)
diff --git a/tools/analysis_tools/get_flops.py b/tools/analysis_tools/get_flops.py
new file mode 100644
index 0000000000000000000000000000000000000000..caa97203aa1e077bd266ab64aa02c1d59f88ec7f
--- /dev/null
+++ b/tools/analysis_tools/get_flops.py
@@ -0,0 +1,55 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+
+import torch
+from fvcore.nn import FlopCountAnalysis, flop_count_table
+from mmengine import Config
+from mmengine.registry import init_default_scope
+
+from mmocr.registry import MODELS
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Train a detector')
+ parser.add_argument('config', help='train config file path')
+ parser.add_argument(
+ '--shape',
+ type=int,
+ nargs='+',
+ default=[640, 640],
+ help='input image size')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+
+ args = parse_args()
+
+ if len(args.shape) == 1:
+ h = w = args.shape[0]
+ elif len(args.shape) == 2:
+ h, w = args.shape
+ else:
+ raise ValueError('invalid input shape, please use --shape h w')
+
+ input_shape = (1, 3, h, w)
+
+ cfg = Config.fromfile(args.config)
+ init_default_scope(cfg.get('default_scope', 'mmocr'))
+ model = MODELS.build(cfg.model)
+
+ flops = FlopCountAnalysis(model, torch.ones(input_shape))
+
+ # params = parameter_count_table(model)
+ flops_data = flop_count_table(flops)
+
+ print(flops_data)
+
+ print('!!!Please be cautious if you use the results in papers. '
+ 'You may need to check if all ops are supported and verify that the '
+ 'flops computation is correct.')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/analysis_tools/offline_eval.py b/tools/analysis_tools/offline_eval.py
new file mode 100644
index 0000000000000000000000000000000000000000..b454942238d59d4f07067896ca9f9742094d0d59
--- /dev/null
+++ b/tools/analysis_tools/offline_eval.py
@@ -0,0 +1,49 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import json
+
+import mmengine
+from mmengine.config import Config, DictAction
+from mmengine.evaluator import Evaluator
+from mmengine.registry import init_default_scope
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Offline evaluation of the '
+ 'prediction saved in pkl format')
+ parser.add_argument('config', help='Config of the model')
+ parser.add_argument(
+ 'pkl_results', help='Path to the predictions in '
+ 'pickle format')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='Override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+
+ # load config
+ cfg = Config.fromfile(args.config)
+ init_default_scope(cfg.get('default_scope', 'mmocr'))
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+
+ predictions = mmengine.load(args.pkl_results)
+
+ evaluator = Evaluator(cfg.test_evaluator)
+ eval_results = evaluator.offline_evaluate(predictions)
+ print(json.dumps(eval_results))
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/analysis_tools/print_config.py b/tools/analysis_tools/print_config.py
new file mode 100644
index 0000000000000000000000000000000000000000..770bb6da216bd382751a8b20c323e87119afe4e6
--- /dev/null
+++ b/tools/analysis_tools/print_config.py
@@ -0,0 +1,36 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+
+from mmengine import Config, DictAction
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Print the whole config')
+ parser.add_argument('config', help='config file path')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ args = parser.parse_args()
+
+ return args
+
+
+def main():
+ args = parse_args()
+
+ cfg = Config.fromfile(args.config)
+
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+ print(f'Config:\n{cfg.pretty_text}')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/common/curvedsyntext_converter.py b/tools/dataset_converters/common/curvedsyntext_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..5fd8784a708c45591c00b97fc1e0c4fe96c88df7
--- /dev/null
+++ b/tools/dataset_converters/common/curvedsyntext_converter.py
@@ -0,0 +1,129 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+from functools import partial
+
+import mmengine
+import numpy as np
+
+from mmocr.utils import bezier2polygon, sort_points
+
+# The default dictionary used by CurvedSynthText
+dict95 = [
+ ' ', '!', '"', '#', '$', '%', '&', '\'', '(', ')', '*', '+', ',', '-', '.',
+ '/', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ':', ';', '<', '=',
+ '>', '?', '@', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L',
+ 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', '[',
+ '\\', ']', '^', '_', '`', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j',
+ 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y',
+ 'z', '{', '|', '}', '~'
+]
+UNK = len(dict95)
+EOS = UNK + 1
+
+
+def digit2text(rec):
+ res = []
+ for d in rec:
+ assert d <= EOS
+ if d == EOS:
+ break
+ if d == UNK:
+ print('Warning: Has a UNK character')
+ res.append('口') # Or any special character not in the target dict
+ res.append(dict95[d])
+ return ''.join(res)
+
+
+def modify_annotation(ann, num_sample, start_img_id=0, start_ann_id=0):
+ ann['text'] = digit2text(ann.pop('rec'))
+ # Get hide egmentation points
+ polygon_pts = bezier2polygon(ann['bezier_pts'], num_sample=num_sample)
+ ann['segmentation'] = np.asarray(sort_points(polygon_pts)).reshape(
+ 1, -1).tolist()
+ ann['image_id'] += start_img_id
+ ann['id'] += start_ann_id
+ return ann
+
+
+def modify_image_info(image_info, path_prefix, start_img_id=0):
+ image_info['file_name'] = osp.join(path_prefix, image_info['file_name'])
+ image_info['id'] += start_img_id
+ return image_info
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert CurvedSynText150k to COCO format')
+ parser.add_argument('root_path', help='CurvedSynText150k root path')
+ parser.add_argument('-o', '--out-dir', help='Output path')
+ parser.add_argument(
+ '-n',
+ '--num-sample',
+ type=int,
+ default=4,
+ help='Number of sample points at each Bezier curve.')
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='Number of processes')
+ args = parser.parse_args()
+ return args
+
+
+def convert_annotations(data,
+ path_prefix,
+ num_sample,
+ nproc,
+ start_img_id=0,
+ start_ann_id=0):
+ modify_image_info_with_params = partial(
+ modify_image_info, path_prefix=path_prefix, start_img_id=start_img_id)
+ modify_annotation_with_params = partial(
+ modify_annotation,
+ num_sample=num_sample,
+ start_img_id=start_img_id,
+ start_ann_id=start_ann_id)
+ if nproc > 1:
+ data['annotations'] = mmengine.track_parallel_progress(
+ modify_annotation_with_params, data['annotations'], nproc=nproc)
+ data['images'] = mmengine.track_parallel_progress(
+ modify_image_info_with_params, data['images'], nproc=nproc)
+ else:
+ data['annotations'] = mmengine.track_progress(
+ modify_annotation_with_params, data['annotations'])
+ data['images'] = mmengine.track_progress(
+ modify_image_info_with_params,
+ data['images'],
+ )
+ data['categories'] = [{'id': 1, 'name': 'text'}]
+ return data
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+ out_dir = args.out_dir if args.out_dir else root_path
+ mmengine.mkdir_or_exist(out_dir)
+
+ anns = mmengine.load(osp.join(root_path, 'train1.json'))
+ data1 = convert_annotations(anns, 'syntext_word_eng', args.num_sample,
+ args.nproc)
+
+ # Get the maximum image id from data1
+ start_img_id = max(data1['images'], key=lambda x: x['id'])['id'] + 1
+ start_ann_id = max(data1['annotations'], key=lambda x: x['id'])['id'] + 1
+ anns = mmengine.load(osp.join(root_path, 'train2.json'))
+ data2 = convert_annotations(
+ anns,
+ 'emcs_imgs',
+ args.num_sample,
+ args.nproc,
+ start_img_id=start_img_id,
+ start_ann_id=start_ann_id)
+
+ data1['images'] += data2['images']
+ data1['annotations'] += data2['annotations']
+ mmengine.dump(data1, osp.join(out_dir, 'instances_training.json'))
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/common/extract_kaist.py b/tools/dataset_converters/common/extract_kaist.py
new file mode 100644
index 0000000000000000000000000000000000000000..76d2579ccbb59f9addc60bbbe9df9037fd543665
--- /dev/null
+++ b/tools/dataset_converters/common/extract_kaist.py
@@ -0,0 +1,75 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+import shutil
+import xml.etree.ElementTree as ET
+import zipfile
+from xml.etree.ElementTree import ParseError
+
+
+def extract(root_path):
+ idx = 0
+ for language in ['English', 'Korean', 'Mixed']:
+ for camera in ['Digital_Camera', 'Mobile_Phone']:
+ crt_path = osp.join(root_path, 'KAIST', language, camera)
+ zips = os.listdir(crt_path)
+ for zip in zips:
+ extracted_path = osp.join(root_path, 'tmp', zip)
+ extract_zipfile(osp.join(crt_path, zip), extracted_path)
+ for file in os.listdir(extracted_path):
+ if file.endswith('xml'):
+ src_ann = os.path.join(extracted_path, file)
+ # Filtering broken annotations
+ try:
+ ET.parse(src_ann)
+ except ParseError:
+ continue
+ src_img = None
+ img_names = [
+ file.replace('xml', suffix)
+ for suffix in ['jpg', 'JPG']
+ ]
+ for im in img_names:
+ img_path = osp.join(extracted_path, im)
+ if osp.exists(img_path):
+ src_img = img_path
+ if src_img:
+ shutil.move(
+ src_ann,
+ osp.join(root_path, 'annotations',
+ str(idx).zfill(5) + '.xml'))
+ shutil.move(
+ src_img,
+ osp.join(root_path, 'imgs',
+ str(idx).zfill(5) + '.jpg'))
+ idx += 1
+
+
+def extract_zipfile(zip_path, dst_dir, delete=True):
+
+ files = zipfile.ZipFile(zip_path)
+ for file in files.namelist():
+ files.extract(file, dst_dir)
+ if delete:
+ os.remove(zip_path)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Extract KAIST zips')
+ parser.add_argument('root_path', help='Root path of KAIST')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+ assert osp.exists(root_path)
+ extract(root_path)
+ shutil.rmtree(osp.join(args.root_path, 'tmp'))
+ shutil.rmtree(osp.join(args.root_path, 'KAIST'))
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/kie/closeset_to_openset.py b/tools/dataset_converters/kie/closeset_to_openset.py
new file mode 100644
index 0000000000000000000000000000000000000000..2057e9797bd0586fd8820ef3ae161486bea22d32
--- /dev/null
+++ b/tools/dataset_converters/kie/closeset_to_openset.py
@@ -0,0 +1,122 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import json
+from functools import partial
+
+import mmengine
+
+from mmocr.utils import list_from_file, list_to_file
+
+
+def convert(closeset_line, merge_bg_others=False, ignore_idx=0, others_idx=25):
+ """Convert line-json str of closeset to line-json str of openset. Note that
+ this function is designed for closeset-wildreceipt to openset-wildreceipt.
+ It may not be suitable to your own dataset.
+
+ Args:
+ closeset_line (str): The string to be deserialized to
+ the closeset dictionary object.
+ merge_bg_others (bool): If True, give the same label to "background"
+ class and "others" class.
+ ignore_idx (int): Index for ``ignore`` class.
+ others_idx (int): Index for ``others`` class.
+ """
+ # Two labels at the same index of the following two lists
+ # make up a key-value pair. For example, in wildreceipt,
+ # closeset_key_inds[0] maps to "Store_name_key"
+ # and closeset_value_inds[0] maps to "Store_addr_value".
+ closeset_key_inds = list(range(2, others_idx, 2))
+ closeset_value_inds = list(range(1, others_idx, 2))
+
+ openset_node_label_mapping = {'bg': 0, 'key': 1, 'value': 2, 'others': 3}
+ if merge_bg_others:
+ openset_node_label_mapping['others'] = openset_node_label_mapping['bg']
+
+ closeset_obj = json.loads(closeset_line)
+ openset_obj = {
+ 'file_name': closeset_obj['file_name'],
+ 'height': closeset_obj['height'],
+ 'width': closeset_obj['width'],
+ 'annotations': []
+ }
+
+ edge_idx = 1
+ label_to_edge = {}
+ for anno in closeset_obj['annotations']:
+ label = anno['label']
+ if label == ignore_idx:
+ anno['label'] = openset_node_label_mapping['bg']
+ anno['edge'] = edge_idx
+ edge_idx += 1
+ elif label == others_idx:
+ anno['label'] = openset_node_label_mapping['others']
+ anno['edge'] = edge_idx
+ edge_idx += 1
+ else:
+ edge = label_to_edge.get(label, None)
+ if edge is not None:
+ anno['edge'] = edge
+ if label in closeset_key_inds:
+ anno['label'] = openset_node_label_mapping['key']
+ elif label in closeset_value_inds:
+ anno['label'] = openset_node_label_mapping['value']
+ else:
+ tmp_key = 'key'
+ if label in closeset_key_inds:
+ label_with_same_edge = closeset_value_inds[
+ closeset_key_inds.index(label)]
+ elif label in closeset_value_inds:
+ label_with_same_edge = closeset_key_inds[
+ closeset_value_inds.index(label)]
+ tmp_key = 'value'
+ edge_counterpart = label_to_edge.get(label_with_same_edge,
+ None)
+ if edge_counterpart is not None:
+ anno['edge'] = edge_counterpart
+ else:
+ anno['edge'] = edge_idx
+ edge_idx += 1
+ anno['label'] = openset_node_label_mapping[tmp_key]
+ label_to_edge[label] = anno['edge']
+
+ openset_obj['annotations'] = closeset_obj['annotations']
+
+ return json.dumps(openset_obj, ensure_ascii=False)
+
+
+def process(closeset_file, openset_file, merge_bg_others=False, n_proc=10):
+ closeset_lines = list_from_file(closeset_file)
+
+ convert_func = partial(convert, merge_bg_others=merge_bg_others)
+
+ openset_lines = mmengine.track_parallel_progress(
+ convert_func, closeset_lines, nproc=n_proc)
+
+ list_to_file(openset_file, openset_lines)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('in_file', help='Annotation file for closeset.')
+ parser.add_argument('out_file', help='Annotation file for openset.')
+ parser.add_argument(
+ '--merge',
+ action='store_true',
+ help='Merge two classes: "background" and "others" in closeset '
+ 'to one class in openset.')
+ parser.add_argument(
+ '--n_proc', type=int, default=10, help='Number of process.')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+
+ process(args.in_file, args.out_file, args.merge, args.n_proc)
+
+ print('finish')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/prepare_dataset.py b/tools/dataset_converters/prepare_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..84b8a0353c420adc696a628baa54829d28367020
--- /dev/null
+++ b/tools/dataset_converters/prepare_dataset.py
@@ -0,0 +1,153 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+import time
+import warnings
+
+from mmengine import Config
+
+from mmocr.datasets.preparers import DatasetPreparer
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Preparing datasets used in MMOCR.')
+ parser.add_argument(
+ 'datasets',
+ help='A list of the dataset names that would like to prepare.',
+ nargs='+')
+ parser.add_argument(
+ '--nproc', help='Number of processes to run', default=4, type=int)
+ parser.add_argument(
+ '--task',
+ default='textdet',
+ choices=['textdet', 'textrecog', 'textspotting', 'kie'],
+ help='Task type. Options are "textdet", "textrecog", "textspotting"'
+ ' and "kie".')
+ parser.add_argument(
+ '--splits',
+ default=['train', 'test', 'val'],
+ help='A list of the split that would like to prepare.',
+ nargs='+')
+ parser.add_argument(
+ '--lmdb',
+ action='store_true',
+ default=False,
+ help='Whether to dump the textrecog dataset to LMDB format, It\'s a '
+ 'shortcut to force the dataset to be dumped in lmdb format. '
+ 'Applicable when --task=textrecog')
+ parser.add_argument(
+ '--overwrite-cfg',
+ action='store_true',
+ default=False,
+ help='Whether to overwrite the dataset config file if it already'
+ ' exists. If not specified, Dataset Preparer will not generate'
+ ' new config for datasets whose configs are already in base.')
+ parser.add_argument(
+ '--dataset-zoo-path',
+ default='./dataset_zoo',
+ help='Path to dataset zoo config files.')
+ args = parser.parse_args()
+ return args
+
+
+def parse_meta(task: str, meta_path: str) -> None:
+ """Parse meta file.
+
+ Args:
+ cfg_path (str): Path to meta file.
+ """
+ try:
+ meta = Config.fromfile(meta_path)
+ except FileNotFoundError:
+ return
+ assert task in meta['Data']['Tasks'], \
+ f'Task {task} not supported!'
+ # License related
+ if meta['Data']['License']['Type']:
+ print(f"\033[1;33;40mDataset Name: {meta['Name']}")
+ print(f"License Type: {meta['Data']['License']['Type']}")
+ print(f"License Link: {meta['Data']['License']['Link']}")
+ print(f"BibTeX: {meta['Paper']['BibTeX']}\033[0m")
+ print('\033[1;31;43mMMOCR does not own the dataset. Using this '
+ 'dataset you must accept the license provided by the owners, '
+ 'and cite the corresponding papers appropriately.')
+ print('If you do not agree with the above license, please cancel '
+ 'the progress immediately by pressing ctrl+c. Otherwise, '
+ 'you are deemed to accept the terms and conditions.\033[0m')
+ for i in range(5):
+ print(f'{5-i}...')
+ time.sleep(1)
+
+
+def force_lmdb(cfg):
+ """Force the dataset to be dumped in lmdb format.
+
+ Args:
+ cfg (Config): Config object.
+
+ Returns:
+ Config: Config object.
+ """
+ for split in ['train', 'val', 'test']:
+ preparer_cfg = cfg.get(f'{split}_preparer')
+ if preparer_cfg:
+ if preparer_cfg.get('dumper') is None:
+ raise ValueError(
+ f'{split} split does not come with a dumper, '
+ 'so most likely the annotations are MMOCR-ready and do '
+ 'not need any adaptation, and it '
+ 'cannot be dumped in LMDB format.')
+ preparer_cfg.dumper['type'] = 'TextRecogLMDBDumper'
+
+ cfg.config_generator['dataset_name'] = f'{cfg.dataset_name}_lmdb'
+
+ for split in ['train_anns', 'val_anns', 'test_anns']:
+ if split in cfg.config_generator:
+ # It can be None when users want to clear out the default
+ # value
+ if not cfg.config_generator[split]:
+ continue
+ ann_list = cfg.config_generator[split]
+ for ann_dict in ann_list:
+ ann_dict['ann_file'] = (
+ osp.splitext(ann_dict['ann_file'])[0] + '.lmdb')
+ else:
+ if split == 'train_anns':
+ ann_list = [dict(ann_file='textrecog_train.lmdb')]
+ elif split == 'test_anns':
+ ann_list = [dict(ann_file='textrecog_test.lmdb')]
+ else:
+ ann_list = []
+ cfg.config_generator[split] = ann_list
+
+ return cfg
+
+
+def main():
+ args = parse_args()
+ if args.lmdb and args.task != 'textrecog':
+ raise ValueError('--lmdb only works with --task=textrecog')
+ for dataset in args.datasets:
+ if not osp.isdir(osp.join(args.dataset_zoo_path, dataset)):
+ warnings.warn(f'{dataset} is not supported yet. Please check '
+ 'dataset zoo for supported datasets.')
+ continue
+ meta_path = osp.join(args.dataset_zoo_path, dataset, 'metafile.yml')
+ parse_meta(args.task, meta_path)
+ cfg_path = osp.join(args.dataset_zoo_path, dataset, args.task + '.py')
+ cfg = Config.fromfile(cfg_path)
+ if args.overwrite_cfg and cfg.get('config_generator',
+ None) is not None:
+ cfg.config_generator.overwrite_cfg = args.overwrite_cfg
+ cfg.nproc = args.nproc
+ cfg.task = args.task
+ cfg.dataset_name = dataset
+ if args.lmdb:
+ cfg = force_lmdb(cfg)
+ preparer = DatasetPreparer.from_file(cfg)
+ preparer.run(args.splits)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textdet/art_converter.py b/tools/dataset_converters/textdet/art_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..9d3b6a25132752887cd3beaf82d515c53d4cc083
--- /dev/null
+++ b/tools/dataset_converters/textdet/art_converter.py
@@ -0,0 +1,145 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import math
+import os.path as osp
+
+import mmcv
+import mmengine
+
+from mmocr.utils import convert_annotations
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training and validation set of ArT ')
+ parser.add_argument('root_path', help='Root dir path of ArT')
+ parser.add_argument(
+ '--val-ratio', help='Split ratio for val set', default=0.0, type=float)
+ args = parser.parse_args()
+ return args
+
+
+def collect_art_info(root_path, split, ratio, print_every=1000):
+ """Collect the annotation information.
+
+ The annotation format is as the following:
+ {
+ 'gt_1726': # 'gt_1726' is file name
+ [
+ {
+ 'transcription': '燎申集团',
+ 'points': [
+ [141, 199],
+ [237, 201],
+ [313, 236],
+ [357, 283],
+ [359, 300],
+ [309, 261],
+ [233, 230],
+ [140, 231]
+ ],
+ 'language': 'Chinese',
+ 'illegibility': False
+ },
+ ...
+ ],
+ ...
+ }
+
+
+ Args:
+ root_path (str): Root path to the dataset
+ split (str): Dataset split, which should be 'train' or 'val'
+ ratio (float): Split ratio for val set
+ print_every (int): Print log info per iteration
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+
+ annotation_path = osp.join(root_path, 'annotations/train_labels.json')
+ if not osp.exists(annotation_path):
+ raise Exception(
+ f'{annotation_path} not exists, please check and try again.')
+
+ annotation = mmengine.load(annotation_path)
+ img_prefixes = annotation.keys()
+
+ trn_files, val_files = [], []
+ if ratio > 0:
+ for i, file in enumerate(img_prefixes):
+ if i % math.floor(1 / ratio):
+ trn_files.append(file)
+ else:
+ val_files.append(file)
+ else:
+ trn_files, val_files = img_prefixes, []
+ print(f'training #{len(trn_files)}, val #{len(val_files)}')
+
+ if split == 'train':
+ img_prefixes = trn_files
+ elif split == 'val':
+ img_prefixes = val_files
+ else:
+ raise NotImplementedError
+
+ img_infos = []
+ for i, prefix in enumerate(img_prefixes):
+ if i > 0 and i % print_every == 0:
+ print(f'{i}/{len(img_prefixes)}')
+ img_file = osp.join(root_path, 'imgs', prefix + '.jpg')
+ # Skip not exist images
+ if not osp.exists(img_file):
+ continue
+ img = mmcv.imread(img_file)
+
+ img_info = dict(
+ file_name=osp.join(osp.basename(img_file)),
+ height=img.shape[0],
+ width=img.shape[1],
+ segm_file=osp.join(osp.basename(annotation_path)))
+
+ anno_info = []
+ for ann in annotation[prefix]:
+ segmentation = []
+ for x, y in ann['points']:
+ segmentation.append(max(0, x))
+ segmentation.append(max(0, y))
+ xs, ys = segmentation[::2], segmentation[1::2]
+ x, y = min(xs), min(ys)
+ w, h = max(xs) - x, max(ys) - y
+ bbox = [x, y, w, h]
+ if ann['transcription'] == '###' or ann['illegibility']:
+ iscrowd = 1
+ else:
+ iscrowd = 0
+ anno = dict(
+ iscrowd=iscrowd,
+ category_id=1,
+ bbox=bbox,
+ area=w * h,
+ segmentation=[segmentation])
+ anno_info.append(anno)
+ img_info.update(anno_info=anno_info)
+ img_infos.append(img_info)
+
+ return img_infos
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+ print('Processing training set...')
+ training_infos = collect_art_info(root_path, 'train', args.val_ratio)
+ convert_annotations(training_infos,
+ osp.join(root_path, 'instances_training.json'))
+ if args.val_ratio > 0:
+ print('Processing validation set...')
+ val_infos = collect_art_info(root_path, 'val', args.val_ratio)
+ convert_annotations(val_infos, osp.join(root_path,
+ 'instances_val.json'))
+ print('Finish')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textdet/bid_converter.py b/tools/dataset_converters/textdet/bid_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..a16a3439e5cf1802e24505d97b1e94a790010698
--- /dev/null
+++ b/tools/dataset_converters/textdet/bid_converter.py
@@ -0,0 +1,185 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+
+import mmcv
+import mmengine
+
+from mmocr.utils import dump_ocr_data
+
+
+def collect_files(img_dir, gt_dir):
+ """Collect all images and their corresponding groundtruth files.
+
+ Args:
+ img_dir (str): The image directory
+ gt_dir (str): The groundtruth directory
+
+ Returns:
+ files (list): The list of tuples (img_file, groundtruth_file)
+ """
+ assert isinstance(img_dir, str)
+ assert img_dir
+ assert isinstance(gt_dir, str)
+ assert gt_dir
+
+ ann_list, imgs_list = [], []
+ for img_file in os.listdir(img_dir):
+ ann_file = img_file.split('_')[0] + '_gt_ocr.txt'
+ ann_list.append(osp.join(gt_dir, ann_file))
+ imgs_list.append(osp.join(img_dir, img_file))
+
+ files = list(zip(imgs_list, ann_list))
+ assert len(files), f'No images found in {img_dir}'
+ print(f'Loaded {len(files)} images from {img_dir}')
+
+ return files
+
+
+def collect_annotations(files, nproc=1):
+ """Collect the annotation information.
+
+ Args:
+ files (list): The list of tuples (image_file, groundtruth_file)
+ nproc (int): The number of process to collect annotations
+
+ Returns:
+ images (list): The list of image information dicts
+ """
+ assert isinstance(files, list)
+ assert isinstance(nproc, int)
+
+ if nproc > 1:
+ images = mmengine.track_parallel_progress(
+ load_img_info, files, nproc=nproc)
+ else:
+ images = mmengine.track_progress(load_img_info, files)
+
+ return images
+
+
+def load_img_info(files):
+ """Load the information of one image.
+
+ Args:
+ files (tuple): The tuple of (img_file, groundtruth_file)
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+ assert isinstance(files, tuple)
+
+ img_file, gt_file = files
+ assert osp.basename(gt_file).split('_')[0] == osp.basename(gt_file).split(
+ '_')[0]
+ # read imgs while ignoring orientations
+ img = mmcv.imread(img_file, 'unchanged')
+
+ img_info = dict(
+ file_name=osp.basename(img_file),
+ height=img.shape[0],
+ width=img.shape[1],
+ segm_file=osp.basename(gt_file))
+
+ if osp.splitext(gt_file)[1] == '.txt':
+ img_info = load_txt_info(gt_file, img_info)
+ else:
+ raise NotImplementedError
+
+ return img_info
+
+
+def load_txt_info(gt_file, img_info):
+ """Collect the annotation information.
+
+ The annotation format is as the following:
+ x, y, w, h, text
+ 977, 152, 16, 49, NOME
+ 962, 143, 12, 323, APPINHANESI BLAZEK PASSOTTO
+ 906, 446, 12, 94, 206940361
+ 905, 641, 12, 44, SPTC
+
+ Args:
+ gt_file (str): The path to ground-truth
+ img_info (dict): The dict of the img and annotation information
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+ with open(gt_file, encoding='latin1') as f:
+ anno_info = []
+ for line in f:
+ line = line.strip('\n')
+ if line[0] == '[' or line[0] == 'x':
+ continue
+ ann = line.split(',')
+ bbox = ann[0:4]
+ bbox = [int(coord) for coord in bbox]
+ x, y, w, h = bbox
+ segmentation = [x, y, x + w, y, x + w, y + h, x, y + h]
+ anno = dict(
+ iscrowd=0,
+ category_id=1,
+ bbox=bbox,
+ area=w * h,
+ segmentation=[segmentation])
+ anno_info.append(anno)
+
+ img_info.update(anno_info=anno_info)
+
+ return img_info
+
+
+def split_train_val_list(full_list, val_ratio):
+ """Split list by val_ratio.
+
+ Args:
+ full_list (list): list to be split
+ val_ratio (float): split ratio for val set
+
+ return:
+ list(list, list): train_list and val_list
+ """
+ n_total = len(full_list)
+ offset = int(n_total * val_ratio)
+ if n_total == 0 or offset < 1:
+ return [], full_list
+ val_list = full_list[:offset]
+ train_list = full_list[offset:]
+ return [train_list, val_list]
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training and val set of BID ')
+ parser.add_argument('root_path', help='Root dir path of BID')
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='Number of processes')
+ parser.add_argument(
+ '--val-ratio', help='Split ratio for val set', default=0., type=float)
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+ with mmengine.Timer(print_tmpl='It takes {}s to convert BID annotation'):
+ files = collect_files(
+ osp.join(root_path, 'imgs'), osp.join(root_path, 'annotations'))
+ image_infos = collect_annotations(files, nproc=args.nproc)
+ if args.val_ratio:
+ image_infos = split_train_val_list(image_infos, args.val_ratio)
+ splits = ['training', 'val']
+ else:
+ image_infos = [image_infos]
+ splits = ['training']
+ for i, split in enumerate(splits):
+ dump_ocr_data(image_infos[i],
+ osp.join(root_path, 'instances_' + split + '.json'),
+ 'textdet')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textdet/coco_to_line_dict.py b/tools/dataset_converters/textdet/coco_to_line_dict.py
new file mode 100644
index 0000000000000000000000000000000000000000..7dcb5edb453edbc7904478de6d636b241a29336e
--- /dev/null
+++ b/tools/dataset_converters/textdet/coco_to_line_dict.py
@@ -0,0 +1,67 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import json
+
+import mmengine
+
+from mmocr.utils import list_to_file
+
+
+def parse_coco_json(in_path):
+ json_obj = mmengine.load(in_path)
+ image_infos = json_obj['images']
+ annotations = json_obj['annotations']
+ imgid2imgname = {}
+ img_ids = []
+ for image_info in image_infos:
+ imgid2imgname[image_info['id']] = image_info
+ img_ids.append(image_info['id'])
+ imgid2anno = {}
+ for img_id in img_ids:
+ imgid2anno[img_id] = []
+ for anno in annotations:
+ img_id = anno['image_id']
+ new_anno = {}
+ new_anno['iscrowd'] = anno['iscrowd']
+ new_anno['category_id'] = anno['category_id']
+ new_anno['bbox'] = anno['bbox']
+ new_anno['segmentation'] = anno['segmentation']
+ if img_id in imgid2anno.keys():
+ imgid2anno[img_id].append(new_anno)
+
+ return imgid2imgname, imgid2anno
+
+
+def gen_line_dict_file(out_path, imgid2imgname, imgid2anno):
+ lines = []
+ for key, value in imgid2imgname.items():
+ if key in imgid2anno:
+ anno = imgid2anno[key]
+ line_dict = {}
+ line_dict['file_name'] = value['file_name']
+ line_dict['height'] = value['height']
+ line_dict['width'] = value['width']
+ line_dict['annotations'] = anno
+ lines.append(json.dumps(line_dict))
+ list_to_file(out_path, lines)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--in-path', help='input json path with coco format')
+ parser.add_argument(
+ '--out-path', help='output txt path with line-json format')
+
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ imgid2imgname, imgid2anno = parse_coco_json(args.in_path)
+ gen_line_dict_file(args.out_path, imgid2imgname, imgid2anno)
+ print('finish')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textdet/cocotext_converter.py b/tools/dataset_converters/textdet/cocotext_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..e4ef78ee39ffe945e1a7e5cf3eba87b19c0fd002
--- /dev/null
+++ b/tools/dataset_converters/textdet/cocotext_converter.py
@@ -0,0 +1,124 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import math
+import os.path as osp
+
+import mmengine
+
+from mmocr.utils import dump_ocr_data
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training and validation set of COCO Text v2 ')
+ parser.add_argument('root_path', help='Root dir path of COCO Text v2')
+ args = parser.parse_args()
+ return args
+
+
+def collect_cocotext_info(root_path, split, print_every=1000):
+ """Collect the annotation information.
+
+ The annotation format is as the following:
+ {
+ 'anns':{
+ '45346':{
+ 'mask': [468.9,286.7,468.9,295.2,493.0,295.8,493.0,287.2],
+ 'class': 'machine printed',
+ 'bbox': [468.9, 286.7, 24.1, 9.1], # x, y, w, h
+ 'image_id': 217925,
+ 'id': 45346,
+ 'language': 'english', # 'english' or 'not english'
+ 'area': 206.06,
+ 'utf8_string': 'New',
+ 'legibility': 'legible', # 'legible' or 'illegible'
+ },
+ ...
+ }
+ 'imgs':{
+ '540965':{
+ 'id': 540965,
+ 'set': 'train', # 'train' or 'val'
+ 'width': 640,
+ 'height': 360,
+ 'file_name': 'COCO_train2014_000000540965.jpg'
+ },
+ ...
+ }
+ 'imgToAnns':{
+ '540965': [],
+ '260932': [63993, 63994, 63995, 63996, 63997, 63998, 63999],
+ ...
+ }
+ }
+
+ Args:
+ root_path (str): Root path to the dataset
+ split (str): Dataset split, which should be 'train' or 'val'
+ print_every (int): Print log information per iter
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+
+ annotation_path = osp.join(root_path, 'annotations/cocotext.v2.json')
+ if not osp.exists(annotation_path):
+ raise Exception(
+ f'{annotation_path} not exists, please check and try again.')
+
+ annotation = mmengine.load(annotation_path)
+
+ img_infos = []
+ for i, img_info in enumerate(annotation['imgs'].values()):
+ if i > 0 and i % print_every == 0:
+ print(f'{i}/{len(annotation["imgs"].values())}')
+
+ if img_info['set'] == split:
+ img_info['segm_file'] = annotation_path
+ ann_ids = annotation['imgToAnns'][str(img_info['id'])]
+ # Filter out images without text
+ if len(ann_ids) == 0:
+ continue
+ anno_info = []
+ for ann_id in ann_ids:
+ ann = annotation['anns'][str(ann_id)]
+
+ # Ignore illegible or non-English words
+ iscrowd = 1 if ann['language'] == 'not english' or ann[
+ 'legibility'] == 'illegible' else 0
+
+ x, y, w, h = ann['bbox']
+ x, y = max(0, math.floor(x)), max(0, math.floor(y))
+ w, h = math.ceil(w), math.ceil(h)
+ bbox = [x, y, w, h]
+ segmentation = [max(0, int(x)) for x in ann['mask']]
+ if len(segmentation) < 8 or len(segmentation) % 2 != 0:
+ segmentation = [x, y, x + w, y, x + w, y + h, x, y + h]
+ anno = dict(
+ iscrowd=iscrowd,
+ category_id=1,
+ bbox=bbox,
+ area=ann['area'],
+ segmentation=[segmentation])
+ anno_info.append(anno)
+ img_info.update(anno_info=anno_info)
+ img_infos.append(img_info)
+ return img_infos
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+ print('Processing training set...')
+ training_infos = collect_cocotext_info(root_path, 'train')
+ dump_ocr_data(training_infos,
+ osp.join(root_path, 'instances_training.json'), 'textdet')
+ print('Processing validation set...')
+ val_infos = collect_cocotext_info(root_path, 'val')
+ dump_ocr_data(val_infos, osp.join(root_path, 'instances_val.json'),
+ 'textdet')
+ print('Finish')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textdet/data_migrator.py b/tools/dataset_converters/textdet/data_migrator.py
new file mode 100644
index 0000000000000000000000000000000000000000..38da8a04861aa5d4f80dbeb65a6be5fdcd55acaf
--- /dev/null
+++ b/tools/dataset_converters/textdet/data_migrator.py
@@ -0,0 +1,70 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+from collections import defaultdict
+from copy import deepcopy
+from typing import Dict, List
+
+import mmengine
+
+from mmocr.utils import dump_ocr_data
+
+
+def parse_coco_json(in_path: str) -> List[Dict]:
+ """Load coco annotations into image_infos parsable by dump_ocr_data().
+
+ Args:
+ in_path (str): COCO text annotation path.
+
+ Returns:
+ list[dict]: List of image information dicts. To be used by
+ dump_ocr_data().
+ """
+ json_obj = mmengine.load(in_path)
+ image_infos = json_obj['images']
+ annotations = json_obj['annotations']
+ imgid2annos = defaultdict(list)
+ for anno in annotations:
+ new_anno = deepcopy(anno)
+ new_anno['category_id'] = 0 # Must be 0 for OCR tasks which stands
+ # for "text" category
+ imgid2annos[anno['image_id']].append(new_anno)
+
+ results = []
+ for image_info in image_infos:
+ image_info['anno_info'] = imgid2annos[image_info['id']]
+ results.append(image_info)
+
+ return results
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('in_path', help='Input json path in coco format.')
+ parser.add_argument(
+ 'out_path', help='Output json path in openmmlab format.')
+ parser.add_argument(
+ '--task',
+ type=str,
+ default='auto',
+ choices=['auto', 'textdet', 'textspotter'],
+ help='Output annotation type, defaults to "auto", which decides the'
+ 'best task type based on whether "text" is annotated. Other options'
+ 'are "textdet" and "textspotter".')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ image_infos = parse_coco_json(args.in_path)
+ task_name = args.task
+ if task_name == 'auto':
+ task_name = 'textdet'
+ if 'text' in image_infos[0]['anno_info'][0]:
+ task_name = 'textspotter'
+ dump_ocr_data(image_infos, args.out_path, task_name)
+ print('finish')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textdet/detext_converter.py b/tools/dataset_converters/textdet/detext_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..d99378e44559222d0d32f1cccd4ccf673a33b6df
--- /dev/null
+++ b/tools/dataset_converters/textdet/detext_converter.py
@@ -0,0 +1,162 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+
+import mmcv
+import mmengine
+import numpy as np
+
+from mmocr.utils import dump_ocr_data
+
+
+def collect_files(img_dir, gt_dir):
+ """Collect all images and their corresponding groundtruth files.
+
+ Args:
+ img_dir (str): The image directory
+ gt_dir (str): The groundtruth directory
+
+ Returns:
+ files (list): The list of tuples (img_file, groundtruth_file)
+ """
+ assert isinstance(img_dir, str)
+ assert img_dir
+ assert isinstance(gt_dir, str)
+ assert gt_dir
+
+ ann_list, imgs_list = [], []
+ for img in os.listdir(img_dir):
+ imgs_list.append(osp.join(img_dir, img))
+ ann_list.append(osp.join(gt_dir, 'gt_' + img.replace('jpg', 'txt')))
+
+ files = list(zip(imgs_list, ann_list))
+ assert len(files), f'No images found in {img_dir}'
+ print(f'Loaded {len(files)} images from {img_dir}')
+
+ return files
+
+
+def collect_annotations(files, nproc=1):
+ """Collect the annotation information.
+
+ Args:
+ files (list): The list of tuples (image_file, groundtruth_file)
+ nproc (int): The number of process to collect annotations
+
+ Returns:
+ images (list): The list of image information dicts
+ """
+ assert isinstance(files, list)
+ assert isinstance(nproc, int)
+
+ if nproc > 1:
+ images = mmengine.track_parallel_progress(
+ load_img_info, files, nproc=nproc)
+ else:
+ images = mmengine.track_progress(load_img_info, files)
+
+ return images
+
+
+def load_img_info(files):
+ """Load the information of one image.
+
+ Args:
+ files (tuple): The tuple of (img_file, groundtruth_file)
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+ assert isinstance(files, tuple)
+
+ img_file, gt_file = files
+ # read imgs while ignoring orientations
+ img = mmcv.imread(img_file, 'unchanged')
+
+ img_info = dict(
+ file_name=osp.join(osp.basename(img_file)),
+ height=img.shape[0],
+ width=img.shape[1],
+ segm_file=osp.join(osp.basename(gt_file)))
+
+ if osp.splitext(gt_file)[1] == '.txt':
+ img_info = load_txt_info(gt_file, img_info)
+ else:
+ raise NotImplementedError
+
+ return img_info
+
+
+def load_txt_info(gt_file, img_info):
+ """Collect the annotation information.
+
+ # Annotation Format
+ # x1, y1, x2, y2, x3, y3, x4, y4, transcript
+
+ Args:
+ gt_file (str): The path to ground-truth
+ img_info (dict): The dict of the img and annotation information
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+
+ with open(gt_file) as f:
+ anno_info = []
+ annotations = f.readlines()
+ for ann in annotations:
+ try:
+ ann_box = np.array(ann.split(',')[0:8]).astype(int).tolist()
+ except ValueError:
+ # skip invalid annotation line
+ continue
+ x = max(0, min(ann_box[0::2]))
+ y = max(0, min(ann_box[1::2]))
+ w, h = max(ann_box[0::2]) - x, max(ann_box[1::2]) - y
+ bbox = [x, y, w, h]
+ segmentation = ann_box
+ word = ann.split(',')[-1].replace('\n', '').strip()
+
+ anno = dict(
+ iscrowd=0 if word != '###' else 1,
+ category_id=1,
+ bbox=bbox,
+ area=w * h,
+ segmentation=[segmentation])
+ anno_info.append(anno)
+
+ img_info.update(anno_info=anno_info)
+
+ return img_info
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training and val set of DeText ')
+ parser.add_argument('root_path', help='Root dir path of DeText')
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='Number of process')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+
+ for split in ['training', 'val']:
+ print(f'Processing {split} set...')
+ with mmengine.Timer(
+ print_tmpl='It takes {}s to convert DeText annotation'):
+ files = collect_files(
+ osp.join(root_path, 'imgs', split),
+ osp.join(root_path, 'annotations', split))
+ image_infos = collect_annotations(files, nproc=args.nproc)
+ dump_ocr_data(image_infos,
+ osp.join(root_path, 'instances_' + split + '.json'),
+ 'textdet')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textdet/funsd_converter.py b/tools/dataset_converters/textdet/funsd_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..7be887d2637b99f0113f99f06a05f7591c061f39
--- /dev/null
+++ b/tools/dataset_converters/textdet/funsd_converter.py
@@ -0,0 +1,159 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import math
+import os
+import os.path as osp
+
+import mmcv
+import mmengine
+
+from mmocr.utils import dump_ocr_data
+
+
+def collect_files(img_dir, gt_dir):
+ """Collect all images and their corresponding groundtruth files.
+
+ Args:
+ img_dir (str): The image directory
+ gt_dir (str): The groundtruth directory
+
+ Returns:
+ files (list): The list of tuples (img_file, groundtruth_file)
+ """
+ assert isinstance(img_dir, str)
+ assert img_dir
+ assert isinstance(gt_dir, str)
+ assert gt_dir
+
+ ann_list, imgs_list = [], []
+ for gt_file in os.listdir(gt_dir):
+ ann_list.append(osp.join(gt_dir, gt_file))
+ imgs_list.append(osp.join(img_dir, gt_file.replace('.json', '.png')))
+
+ files = list(zip(sorted(imgs_list), sorted(ann_list)))
+ assert len(files), f'No images found in {img_dir}'
+ print(f'Loaded {len(files)} images from {img_dir}')
+
+ return files
+
+
+def collect_annotations(files, nproc=1):
+ """Collect the annotation information.
+
+ Args:
+ files (list): The list of tuples (image_file, groundtruth_file)
+ nproc (int): The number of process to collect annotations
+
+ Returns:
+ images (list): The list of image information dicts
+ """
+ assert isinstance(files, list)
+ assert isinstance(nproc, int)
+
+ if nproc > 1:
+ images = mmengine.track_parallel_progress(
+ load_img_info, files, nproc=nproc)
+ else:
+ images = mmengine.track_progress(load_img_info, files)
+
+ return images
+
+
+def load_img_info(files):
+ """Load the information of one image.
+
+ Args:
+ files (tuple): The tuple of (img_file, groundtruth_file)
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+ assert isinstance(files, tuple)
+
+ img_file, gt_file = files
+ assert osp.basename(gt_file).split('.')[0] == osp.basename(img_file).split(
+ '.')[0]
+ # read imgs while ignoring orientations
+ img = mmcv.imread(img_file, 'unchanged')
+
+ img_info = dict(
+ file_name=osp.join(osp.basename(img_file)),
+ height=img.shape[0],
+ width=img.shape[1],
+ segm_file=osp.join(osp.basename(gt_file)))
+
+ if osp.splitext(gt_file)[1] == '.json':
+ img_info = load_json_info(gt_file, img_info)
+ else:
+ raise NotImplementedError
+
+ return img_info
+
+
+def load_json_info(gt_file, img_info):
+ """Collect the annotation information.
+
+ Args:
+ gt_file (str): The path to ground-truth
+ img_info (dict): The dict of the img and annotation information
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+
+ annotation = mmengine.load(gt_file)
+ anno_info = []
+ for form in annotation['form']:
+ for ann in form['words']:
+
+ iscrowd = 1 if len(ann['text']) == 0 else 0
+
+ x1, y1, x2, y2 = ann['box']
+ x = max(0, min(math.floor(x1), math.floor(x2)))
+ y = max(0, min(math.floor(y1), math.floor(y2)))
+ w, h = math.ceil(abs(x2 - x1)), math.ceil(abs(y2 - y1))
+ bbox = [x, y, w, h]
+ segmentation = [x, y, x + w, y, x + w, y + h, x, y + h]
+
+ anno = dict(
+ iscrowd=iscrowd,
+ category_id=1,
+ bbox=bbox,
+ area=w * h,
+ segmentation=[segmentation])
+ anno_info.append(anno)
+
+ img_info.update(anno_info=anno_info)
+
+ return img_info
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training and test set of FUNSD ')
+ parser.add_argument('root_path', help='Root dir path of FUNSD')
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='Number of process')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+
+ for split in ['training', 'test']:
+ print(f'Processing {split} set...')
+ with mmengine.Timer(
+ print_tmpl='It takes {}s to convert FUNSD annotation'):
+ files = collect_files(
+ osp.join(root_path, 'imgs'),
+ osp.join(root_path, 'annotations', split))
+ image_infos = collect_annotations(files, nproc=args.nproc)
+ dump_ocr_data(image_infos,
+ osp.join(root_path, 'instances_' + split + '.json'),
+ 'textdet')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textdet/hiertext_converter.py b/tools/dataset_converters/textdet/hiertext_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..9ca0163099c815382fe3362da1b0525d109bc23f
--- /dev/null
+++ b/tools/dataset_converters/textdet/hiertext_converter.py
@@ -0,0 +1,152 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import json
+import os.path as osp
+
+import numpy as np
+from shapely.geometry import Polygon
+
+from mmocr.utils import dump_ocr_data
+
+
+def collect_level_info(annotation):
+ """Collect information from any level in HierText.
+
+ Args:
+ annotation (dict): dict at each level
+
+ Return:
+ anno (dict): dict containing annotations
+ """
+ iscrowd = 0 if annotation['legible'] else 1
+ vertices = np.array(annotation['vertices'])
+ polygon = Polygon(vertices)
+ area = polygon.area
+ min_x, min_y, max_x, max_y = polygon.bounds
+ bbox = [min_x, min_y, max_x - min_x, max_y - min_y]
+ segmentation = [i for j in vertices for i in j]
+ anno = dict(
+ iscrowd=iscrowd,
+ category_id=1,
+ bbox=bbox,
+ area=area,
+ segmentation=[segmentation])
+ return anno
+
+
+def collect_hiertext_info(root_path, level, split, print_every=1000):
+ """Collect the annotation information.
+
+ The annotation format is as the following:
+ {
+ "info": {
+ "date": "release date",
+ "version": "current version"
+ },
+ "annotations": [ // List of dictionaries, one for each image.
+ {
+ "image_id": "the filename of corresponding image.",
+ "image_width": image_width, // (int) The image width.
+ "image_height": image_height, // (int) The image height.
+ "paragraphs": [ // List of paragraphs.
+ {
+ "vertices": [[x1, y1], [x2, y2],...,[xn, yn]]
+ "legible": true
+ "lines": [
+ {
+ "vertices": [[x1, y1], [x2, y2],...,[x4, y4]]
+ "text": L
+ "legible": true,
+ "handwritten": false
+ "vertical": false,
+ "words": [
+ {
+ "vertices": [[x1, y1], [x2, y2],...,[xm, ym]]
+ "text": "the text content of this word",
+ "legible": true
+ "handwritten": false,
+ "vertical": false,
+ }, ...
+ ]
+ }, ...
+ ]
+ }, ...
+ ]
+ }, ...
+ ]
+ }
+
+ Args:
+ root_path (str): Root path to the dataset
+ level (str): Level of annotations, which should be 'word', 'line',
+ or 'paragraphs'
+ split (str): Dataset split, which should be 'train' or 'validation'
+ print_every (int): Print log information per iter
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+
+ annotation_path = osp.join(root_path, 'annotations/' + split + '.jsonl')
+ if not osp.exists(annotation_path):
+ raise Exception(
+ f'{annotation_path} not exists, please check and try again.')
+
+ annotation = json.load(open(annotation_path))['annotations']
+ img_infos = []
+ for i, img_annos in enumerate(annotation):
+ if i > 0 and i % print_every == 0:
+ print(f'{i}/{len(annotation)}')
+ img_info = {}
+ img_info['file_name'] = img_annos['image_id'] + '.jpg'
+ img_info['height'] = img_annos['image_height']
+ img_info['width'] = img_annos['image_width']
+ img_info['segm_file'] = annotation_path
+ anno_info = []
+ for paragraph in img_annos['paragraphs']:
+ if level == 'paragraph':
+ anno = collect_level_info(paragraph)
+ anno_info.append(anno)
+ elif level == 'line':
+ for line in paragraph['lines']:
+ anno = collect_level_info(line)
+ anno_info.append(anno)
+ elif level == 'word':
+ for line in paragraph['lines']:
+ for word in line['words']:
+ anno = collect_level_info(line)
+ anno_info.append(anno)
+ img_info.update(anno_info=anno_info)
+ img_infos.append(img_info)
+ return img_infos
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training and validation set of HierText ')
+ parser.add_argument('root_path', help='Root dir path of HierText')
+ parser.add_argument(
+ '--level',
+ default='word',
+ help='HierText provides three levels of annotation',
+ choices=['word', 'line', 'paragraph'])
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+ print('Processing training set...')
+ training_infos = collect_hiertext_info(root_path, args.level, 'train')
+ dump_ocr_data(training_infos,
+ osp.join(root_path, 'instances_training.json'), 'textdet')
+ print('Processing validation set...')
+ val_infos = collect_hiertext_info(root_path, args.level, 'val')
+ dump_ocr_data(val_infos, osp.join(root_path, 'instances_val.json'),
+ 'textdet')
+ print('Finish')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textdet/ic11_converter.py b/tools/dataset_converters/textdet/ic11_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..1a5683f4ae17e52fa8f13fc542a8424ae6cb488f
--- /dev/null
+++ b/tools/dataset_converters/textdet/ic11_converter.py
@@ -0,0 +1,173 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+
+import mmcv
+import mmengine
+from PIL import Image
+
+from mmocr.utils import dump_ocr_data
+
+
+def convert_gif(img_path):
+ """Convert the gif image to png format.
+
+ Args:
+ img_path (str): The path to the gif image
+ """
+ img = Image.open(img_path)
+ dst_path = img_path.replace('gif', 'png')
+ img.save(dst_path)
+ os.remove(img_path)
+ print(f'Convert {img_path} to {dst_path}')
+
+
+def collect_files(img_dir, gt_dir):
+ """Collect all images and their corresponding groundtruth files.
+
+ Args:
+ img_dir (str): The image directory
+ gt_dir (str): The groundtruth directory
+
+ Returns:
+ files (list): The list of tuples (img_file, groundtruth_file)
+ """
+ assert isinstance(img_dir, str)
+ assert img_dir
+ assert isinstance(gt_dir, str)
+ assert gt_dir
+
+ ann_list, imgs_list = [], []
+ for img in os.listdir(img_dir):
+ img_path = osp.join(img_dir, img)
+ # mmcv cannot read gif images, so convert them to png
+ if img.endswith('gif'):
+ convert_gif(img_path)
+ img_path = img_path.replace('gif', 'png')
+ imgs_list.append(img_path)
+ ann_list.append(osp.join(gt_dir, 'gt_' + img.split('.')[0] + '.txt'))
+
+ files = list(zip(sorted(imgs_list), sorted(ann_list)))
+ assert len(files), f'No images found in {img_dir}'
+ print(f'Loaded {len(files)} images from {img_dir}')
+
+ return files
+
+
+def collect_annotations(files, nproc=1):
+ """Collect the annotation information.
+
+ Args:
+ files (list): The list of tuples (image_file, groundtruth_file)
+ nproc (int): The number of process to collect annotations
+
+ Returns:
+ images (list): The list of image information dicts
+ """
+ assert isinstance(files, list)
+ assert isinstance(nproc, int)
+
+ if nproc > 1:
+ images = mmengine.track_parallel_progress(
+ load_img_info, files, nproc=nproc)
+ else:
+ images = mmengine.track_progress(load_img_info, files)
+
+ return images
+
+
+def load_img_info(files):
+ """Load the information of one image.
+
+ Args:
+ files (tuple): The tuple of (img_file, groundtruth_file)
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+ assert isinstance(files, tuple)
+
+ img_file, gt_file = files
+ # read imgs while ignoring orientations
+ img = mmcv.imread(img_file, 'unchanged')
+
+ img_info = dict(
+ file_name=osp.join(osp.basename(img_file)),
+ height=img.shape[0],
+ width=img.shape[1],
+ segm_file=osp.join(osp.basename(gt_file)))
+
+ if osp.splitext(gt_file)[1] == '.txt':
+ img_info = load_txt_info(gt_file, img_info)
+ else:
+ raise NotImplementedError
+
+ return img_info
+
+
+def load_txt_info(gt_file, img_info):
+ """Collect the annotation information.
+
+ The annotation format is as the following:
+ left, top, right, bottom, "transcription"
+
+ Args:
+ gt_file (str): The path to ground-truth
+ img_info (dict): The dict of the img and annotation information
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+ anno_info = []
+ with open(gt_file) as f:
+ lines = f.readlines()
+ for line in lines:
+ xmin, ymin, xmax, ymax = line.split(',')[0:4]
+ x = max(0, int(xmin))
+ y = max(0, int(ymin))
+ w = int(xmax) - x
+ h = int(ymax) - y
+ bbox = [x, y, w, h]
+ segmentation = [x, y, x + w, y, x + w, y + h, x, y + h]
+
+ anno = dict(
+ iscrowd=0,
+ category_id=1,
+ bbox=bbox,
+ area=w * h,
+ segmentation=[segmentation])
+ anno_info.append(anno)
+ img_info.update(anno_info=anno_info)
+
+ return img_info
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training and test set of IC11')
+ parser.add_argument('root_path', help='Root dir path of IC11')
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='Number of process')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+
+ for split in ['training', 'test']:
+ print(f'Processing {split} set...')
+ with mmengine.Timer(print_tmpl='It takes {}s to convert annotation'):
+ files = collect_files(
+ osp.join(root_path, 'imgs', split),
+ osp.join(root_path, 'annotations', split))
+ image_infos = collect_annotations(files, nproc=args.nproc)
+ dump_ocr_data(image_infos,
+ osp.join(root_path, 'instances_' + split + '.json'),
+ 'textdet')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textdet/ilst_converter.py b/tools/dataset_converters/textdet/ilst_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..56ac54e3e30ed95159b25bee69afe39c47896a2a
--- /dev/null
+++ b/tools/dataset_converters/textdet/ilst_converter.py
@@ -0,0 +1,206 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+import xml.etree.ElementTree as ET
+
+import mmcv
+import mmengine
+
+from mmocr.utils import dump_ocr_data
+
+
+def collect_files(img_dir, gt_dir):
+ """Collect all images and their corresponding groundtruth files.
+
+ Args:
+ img_dir (str): The image directory
+ gt_dir (str): The groundtruth directory
+
+ Returns:
+ files (list): The list of tuples (img_file, groundtruth_file)
+ """
+ assert isinstance(img_dir, str)
+ assert img_dir
+ assert isinstance(gt_dir, str)
+ assert gt_dir
+
+ ann_list, imgs_list = [], []
+ for img_file in os.listdir(img_dir):
+ ann_path = osp.join(gt_dir, img_file.split('.')[0] + '.xml')
+ if os.path.exists(ann_path):
+ ann_list.append(ann_path)
+ imgs_list.append(osp.join(img_dir, img_file))
+
+ files = list(zip(imgs_list, ann_list))
+ assert len(files), f'No images found in {img_dir}'
+ print(f'Loaded {len(files)} images from {img_dir}')
+
+ return files
+
+
+def collect_annotations(files, nproc=1):
+ """Collect the annotation information.
+
+ Args:
+ files (list): The list of tuples (image_file, groundtruth_file)
+ nproc (int): The number of process to collect annotations
+
+ Returns:
+ images (list): The list of image information dicts
+ """
+ assert isinstance(files, list)
+ assert isinstance(nproc, int)
+
+ if nproc > 1:
+ images = mmengine.track_parallel_progress(
+ load_img_info, files, nproc=nproc)
+ else:
+ images = mmengine.track_progress(load_img_info, files)
+
+ return images
+
+
+def load_img_info(files):
+ """Load the information of one image.
+
+ Args:
+ files (tuple): The tuple of (img_file, groundtruth_file)
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+ assert isinstance(files, tuple)
+
+ img_file, gt_file = files
+ assert osp.basename(gt_file).split('.')[0] == osp.basename(img_file).split(
+ '.')[0]
+ # read imgs while ignoring orientations
+ img = mmcv.imread(img_file, 'unchanged')
+
+ try:
+ img_info = dict(
+ file_name=osp.join(osp.basename(img_file)),
+ height=img.shape[0],
+ width=img.shape[1],
+ segm_file=osp.join(osp.basename(gt_file)))
+ except AttributeError:
+ print(f'Skip broken img {img_file}')
+ return None
+
+ if osp.splitext(gt_file)[1] == '.xml':
+ img_info = load_xml_info(gt_file, img_info)
+ else:
+ raise NotImplementedError
+
+ return img_info
+
+
+def load_xml_info(gt_file, img_info):
+ """Collect the annotation information.
+
+ The annotation format is as the following:
+
+ ...
+
+ SMT
+ Unspecified
+ 0
+ 0
+
+ 157
+ 294
+ 237
+ 357
+
+
+
+ Args:
+ gt_file (str): The path to ground-truth
+ img_info (dict): The dict of the img and annotation information
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+ obj = ET.parse(gt_file)
+ root = obj.getroot()
+ anno_info = []
+ for object in root.iter('object'):
+ word = object.find('name').text
+ iscrowd = 1 if len(word) == 0 else 0
+ x1 = int(object.find('bndbox').find('xmin').text)
+ y1 = int(object.find('bndbox').find('ymin').text)
+ x2 = int(object.find('bndbox').find('xmax').text)
+ y2 = int(object.find('bndbox').find('ymax').text)
+
+ x = max(0, min(x1, x2))
+ y = max(0, min(y1, y2))
+ w, h = abs(x2 - x1), abs(y2 - y1)
+ bbox = [x1, y1, w, h]
+ segmentation = [x, y, x + w, y, x + w, y + h, x, y + h]
+ anno = dict(
+ iscrowd=iscrowd,
+ category_id=1,
+ bbox=bbox,
+ area=w * h,
+ segmentation=[segmentation])
+ anno_info.append(anno)
+
+ img_info.update(anno_info=anno_info)
+
+ return img_info
+
+
+def split_train_val_list(full_list, val_ratio):
+ """Split list by val_ratio.
+
+ Args:
+ full_list (list): List to be split
+ val_ratio (float): Split ratio for val set
+
+ return:
+ list(list, list): Train_list and val_list
+ """
+
+ n_total = len(full_list)
+ offset = int(n_total * val_ratio)
+ if n_total == 0 or offset < 1:
+ return [], full_list
+ val_list = full_list[:offset]
+ train_list = full_list[offset:]
+ return [train_list, val_list]
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training and val set of ILST ')
+ parser.add_argument('root_path', help='Root dir path of ILST')
+ parser.add_argument(
+ '--val-ratio', help='Split ratio for val set', default=0., type=float)
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='Number of processes')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+ with mmengine.Timer(print_tmpl='It takes {}s to convert ILST annotation'):
+ files = collect_files(
+ osp.join(root_path, 'imgs'), osp.join(root_path, 'annotations'))
+ image_infos = collect_annotations(files, nproc=args.nproc)
+ if args.val_ratio:
+ image_infos = split_train_val_list(image_infos, args.val_ratio)
+ splits = ['training', 'val']
+ else:
+ image_infos = [image_infos]
+ splits = ['training']
+ for i, split in enumerate(splits):
+ dump_ocr_data(
+ list(filter(None, image_infos[i])),
+ osp.join(root_path, 'instances_' + split + '.json'), 'textdet')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textdet/imgur_converter.py b/tools/dataset_converters/textdet/imgur_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..f6c19cd33cdf27bc085563992a126aa02028c43e
--- /dev/null
+++ b/tools/dataset_converters/textdet/imgur_converter.py
@@ -0,0 +1,152 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import math
+import os.path as osp
+
+import mmcv
+import mmengine
+import numpy as np
+
+from mmocr.utils import dump_ocr_data
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training, validation and test set of IMGUR ')
+ parser.add_argument('root_path', help='Root dir path of IMGUR')
+ args = parser.parse_args()
+
+ return args
+
+
+def collect_imgur_info(root_path, annotation_filename, print_every=1000):
+
+ annotation_path = osp.join(root_path, 'annotations', annotation_filename)
+ if not osp.exists(annotation_path):
+ raise Exception(
+ f'{annotation_path} not exists, please check and try again.')
+
+ annotation = mmengine.load(annotation_path)
+ images = annotation['index_to_ann_map'].keys()
+ img_infos = []
+ for i, img_name in enumerate(images):
+ if i >= 0 and i % print_every == 0:
+ print(f'{i}/{len(images)}')
+
+ img_path = osp.join(root_path, 'imgs', img_name + '.jpg')
+
+ # Skip not exist images
+ if not osp.exists(img_path):
+ continue
+
+ img = mmcv.imread(img_path, 'unchanged')
+
+ # Skip broken images
+ if img is None:
+ continue
+
+ img_info = dict(
+ file_name=img_name + '.jpg',
+ height=img.shape[0],
+ width=img.shape[1])
+
+ anno_info = []
+ for ann_id in annotation['index_to_ann_map'][img_name]:
+ ann = annotation['ann_id'][ann_id]
+
+ # The original annotation is oriented rects [x, y, w, h, a]
+ box = np.fromstring(
+ ann['bounding_box'][1:-2], sep=',', dtype=float)
+ quadrilateral = convert_oriented_box(box)
+
+ xs, ys = quadrilateral[::2], quadrilateral[1::2]
+ x = max(0, math.floor(min(xs)))
+ y = max(0, math.floor(min(ys)))
+ w = math.floor(max(xs)) - x
+ h = math.floor(max(ys)) - y
+ bbox = [x, y, w, h]
+ segmentation = quadrilateral
+
+ anno = dict(
+ iscrowd=0,
+ category_id=1,
+ bbox=bbox,
+ area=w * h,
+ segmentation=[segmentation])
+ anno_info.append(anno)
+ img_info.update(anno_info=anno_info)
+ img_infos.append(img_info)
+
+ return img_infos
+
+
+def convert_oriented_box(box):
+
+ x_ctr, y_ctr, width, height, angle = box[:5]
+ angle = -angle * math.pi / 180
+
+ tl_x, tl_y, br_x, br_y = -width / 2, -height / 2, width / 2, height / 2
+ rect = np.array([[tl_x, br_x, br_x, tl_x], [tl_y, tl_y, br_y, br_y]])
+ R = np.array([[np.cos(angle), -np.sin(angle)],
+ [np.sin(angle), np.cos(angle)]])
+ poly = R.dot(rect)
+ x0, x1, x2, x3 = poly[0, :4] + x_ctr
+ y0, y1, y2, y3 = poly[1, :4] + y_ctr
+ poly = np.array([x0, y0, x1, y1, x2, y2, x3, y3], dtype=np.float32)
+ poly = get_best_begin_point_single(poly)
+
+ return poly.tolist()
+
+
+def get_best_begin_point_single(coordinate):
+
+ x1, y1, x2, y2, x3, y3, x4, y4 = coordinate
+ xmin = min(x1, x2, x3, x4)
+ ymin = min(y1, y2, y3, y4)
+ xmax = max(x1, x2, x3, x4)
+ ymax = max(y1, y2, y3, y4)
+ combine = [[[x1, y1], [x2, y2], [x3, y3], [x4, y4]],
+ [[x2, y2], [x3, y3], [x4, y4], [x1, y1]],
+ [[x3, y3], [x4, y4], [x1, y1], [x2, y2]],
+ [[x4, y4], [x1, y1], [x2, y2], [x3, y3]]]
+ dst_coordinate = [[xmin, ymin], [xmax, ymin], [xmax, ymax], [xmin, ymax]]
+ force = 100000000.0
+ force_flag = 0
+ for i in range(4):
+ temp_force = cal_line_length(combine[i][0], dst_coordinate[0]) \
+ + cal_line_length(combine[i][1], dst_coordinate[1]) \
+ + cal_line_length(combine[i][2], dst_coordinate[2]) \
+ + cal_line_length(combine[i][3], dst_coordinate[3])
+ if temp_force < force:
+ force = temp_force
+ force_flag = i
+ if force_flag != 0:
+ pass
+
+ return np.array(combine[force_flag]).reshape(8)
+
+
+def cal_line_length(point1, point2):
+
+ return math.sqrt(
+ math.pow(point1[0] - point2[0], 2) +
+ math.pow(point1[1] - point2[1], 2))
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+
+ for split in ['train', 'val', 'test']:
+ print(f'Processing {split} set...')
+ with mmengine.Timer(
+ print_tmpl='It takes {}s to convert IMGUR annotation'):
+ anno_infos = collect_imgur_info(
+ root_path, f'imgur5k_annotations_{split}.json')
+ dump_ocr_data(anno_infos,
+ osp.join(root_path, f'instances_{split}.json'),
+ 'textdet')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textdet/kaist_converter.py b/tools/dataset_converters/textdet/kaist_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..3f95804d1dda27a88db247e177c3f7522361faf5
--- /dev/null
+++ b/tools/dataset_converters/textdet/kaist_converter.py
@@ -0,0 +1,201 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import math
+import os
+import os.path as osp
+import xml.etree.ElementTree as ET
+
+import mmcv
+import mmengine
+
+from mmocr.utils import dump_ocr_data
+
+
+def collect_files(img_dir, gt_dir, ratio):
+ """Collect all images and their corresponding groundtruth files.
+
+ Args:
+ img_dir (str): The image directory
+ gt_dir (str): The groundtruth directory
+ ratio (float): Split ratio for val set
+
+ Returns:
+ files (list): The list of tuples (img_file, groundtruth_file)
+ """
+ assert isinstance(img_dir, str)
+ assert img_dir
+ assert isinstance(gt_dir, str)
+ assert gt_dir
+ assert isinstance(ratio, float)
+ assert ratio < 1.0, 'val_ratio should be a float between 0.0 to 1.0'
+
+ ann_list, imgs_list = [], []
+ for img_file in os.listdir(img_dir):
+ ann_list.append(osp.join(gt_dir, img_file.split('.')[0] + '.xml'))
+ imgs_list.append(osp.join(img_dir, img_file))
+
+ all_files = list(zip(sorted(imgs_list), sorted(ann_list)))
+ assert len(all_files), f'No images found in {img_dir}'
+ print(f'Loaded {len(all_files)} images from {img_dir}')
+
+ trn_files, val_files = [], []
+ if ratio > 0:
+ for i, file in enumerate(all_files):
+ if i % math.floor(1 / ratio):
+ trn_files.append(file)
+ else:
+ val_files.append(file)
+ else:
+ trn_files, val_files = all_files, []
+
+ print(f'training #{len(trn_files)}, val #{len(val_files)}')
+
+ return trn_files, val_files
+
+
+def collect_annotations(files, nproc=1):
+ """Collect the annotation information.
+
+ Args:
+ files (list): The list of tuples (image_file, groundtruth_file)
+ nproc (int): The number of process to collect annotations
+
+ Returns:
+ images (list): The list of image information dicts
+ """
+ assert isinstance(files, list)
+ assert isinstance(nproc, int)
+
+ if nproc > 1:
+ images = mmengine.track_parallel_progress(
+ load_img_info, files, nproc=nproc)
+ else:
+ images = mmengine.track_progress(load_img_info, files)
+
+ return images
+
+
+def load_img_info(files):
+ """Load the information of one image.
+
+ Args:
+ files (tuple): The tuple of (img_file, groundtruth_file)
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+ assert isinstance(files, tuple)
+
+ img_file, gt_file = files
+ assert osp.basename(gt_file).split('.')[0] == osp.basename(img_file).split(
+ '.')[0]
+ # read imgs while ignoring orientations
+ img = mmcv.imread(img_file, 'unchanged')
+
+ img_info = dict(
+ file_name=osp.join(osp.basename(img_file)),
+ height=img.shape[0],
+ width=img.shape[1],
+ segm_file=osp.join(osp.basename(gt_file)))
+
+ if osp.splitext(gt_file)[1] == '.xml':
+ img_info = load_xml_info(gt_file, img_info)
+ else:
+ raise NotImplementedError
+
+ return img_info
+
+
+def load_xml_info(gt_file, img_info):
+ """Collect the annotation information.
+
+ Annotation Format
+
+ DSC02306.JPG
+
+
+
+
+ no
+ 2
+
+
+
+
+ Args:
+ gt_file (str): The path to ground-truth
+ img_info (dict): The dict of the img and annotation information
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+
+ obj = ET.parse(gt_file)
+ root = obj.getroot()
+ anno_info = []
+ for word in root.iter('word'):
+ x, y = max(0, int(word.attrib['x'])), max(0, int(word.attrib['y']))
+ w, h = int(word.attrib['width']), int(word.attrib['height'])
+ bbox = [x, y, w, h]
+ segmentation = [x, y, x + w, y, x + w, y + h, x, y + h]
+
+ anno = dict(
+ iscrowd=0,
+ category_id=1,
+ bbox=bbox,
+ area=w * h,
+ segmentation=[segmentation])
+ anno_info.append(anno)
+
+ img_info.update(anno_info=anno_info)
+
+ return img_info
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training and val set of KAIST ')
+ parser.add_argument('root_path', help='Root dir path of KAIST')
+ parser.add_argument(
+ '--val-ratio', help='Split ratio for val set', default=0.0, type=float)
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='Number of process')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+ ratio = args.val_ratio
+
+ trn_files, val_files = collect_files(
+ osp.join(root_path, 'imgs'), osp.join(root_path, 'annotations'), ratio)
+
+ # Train set
+ trn_infos = collect_annotations(trn_files, nproc=args.nproc)
+ with mmengine.Timer(
+ print_tmpl='It takes {}s to convert KAIST Training annotation'):
+ dump_ocr_data(trn_infos, osp.join(root_path,
+ 'instances_training.json'),
+ 'textdet')
+
+ # Val set
+ if len(val_files) > 0:
+ val_infos = collect_annotations(val_files, nproc=args.nproc)
+ with mmengine.Timer(
+ print_tmpl='It takes {}s to convert KAIST Val annotation'):
+ dump_ocr_data(val_infos, osp.join(root_path, 'instances_val.json'),
+ 'textdet')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textdet/lsvt_converter.py b/tools/dataset_converters/textdet/lsvt_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..aa44d10663e762ddbcccb354b65cfd349634a6ce
--- /dev/null
+++ b/tools/dataset_converters/textdet/lsvt_converter.py
@@ -0,0 +1,130 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import math
+import os.path as osp
+
+import mmcv
+import mmengine
+
+from mmocr.utils import dump_ocr_data
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training and validation set of LSVT ')
+ parser.add_argument('root_path', help='Root dir path of LSVT')
+ parser.add_argument(
+ '--val-ratio', help='Split ratio for val set', default=0.0, type=float)
+ args = parser.parse_args()
+ return args
+
+
+def collect_lsvt_info(root_path, split, ratio, print_every=1000):
+ """Collect the annotation information.
+
+ The annotation format is as the following:
+ [
+ {'gt_1234': # 'gt_1234' is file name
+ [
+ {
+ 'transcription': '一站式购物中心',
+ 'points': [[45, 272], [215, 273], [212, 296], [45, 290]]
+ 'illegibility': False
+ }, ...
+ ]
+ }
+ ]
+
+
+ Args:
+ root_path (str): Root path to the dataset
+ split (str): Dataset split, which should be 'train' or 'val'
+ ratio (float): Split ratio for val set
+ print_every (int): Print log info per iteration
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+
+ annotation_path = osp.join(root_path, 'annotations/train_full_labels.json')
+ if not osp.exists(annotation_path):
+ raise Exception(
+ f'{annotation_path} not exists, please check and try again.')
+
+ annotation = mmengine.load(annotation_path)
+ img_prefixes = annotation.keys()
+
+ trn_files, val_files = [], []
+ if ratio > 0:
+ for i, file in enumerate(img_prefixes):
+ if i % math.floor(1 / ratio):
+ trn_files.append(file)
+ else:
+ val_files.append(file)
+ else:
+ trn_files, val_files = img_prefixes, []
+ print(f'training #{len(trn_files)}, val #{len(val_files)}')
+
+ if split == 'train':
+ img_prefixes = trn_files
+ elif split == 'val':
+ img_prefixes = val_files
+ else:
+ raise NotImplementedError
+
+ img_infos = []
+ for i, prefix in enumerate(img_prefixes):
+ if i > 0 and i % print_every == 0:
+ print(f'{i}/{len(img_prefixes)}')
+ img_file = osp.join(root_path, 'imgs', prefix + '.jpg')
+ # Skip not exist images
+ if not osp.exists(img_file):
+ continue
+ img = mmcv.imread(img_file)
+
+ img_info = dict(
+ file_name=osp.join(osp.basename(img_file)),
+ height=img.shape[0],
+ width=img.shape[1],
+ segm_file=osp.join(osp.basename(annotation_path)))
+
+ anno_info = []
+ for ann in annotation[prefix]:
+ segmentation = []
+ for x, y in ann['points']:
+ segmentation.append(max(0, x))
+ segmentation.append(max(0, y))
+ xs, ys = segmentation[::2], segmentation[1::2]
+ x, y = min(xs), min(ys)
+ w, h = max(xs) - x, max(ys) - y
+ bbox = [x, y, w, h]
+ anno = dict(
+ iscrowd=1 if ann['illegibility'] else 0,
+ category_id=1,
+ bbox=bbox,
+ area=w * h,
+ segmentation=[segmentation])
+ anno_info.append(anno)
+ img_info.update(anno_info=anno_info)
+ img_infos.append(img_info)
+
+ return img_infos
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+ print('Processing training set...')
+ training_infos = collect_lsvt_info(root_path, 'train', args.val_ratio)
+ dump_ocr_data(training_infos,
+ osp.join(root_path, 'instances_training.json'), 'textdet')
+ if args.val_ratio > 0:
+ print('Processing validation set...')
+ val_infos = collect_lsvt_info(root_path, 'val', args.val_ratio)
+ dump_ocr_data(val_infos, osp.join(root_path, 'instances_val.json'),
+ 'textdet')
+ print('Finish')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textdet/lv_converter.py b/tools/dataset_converters/textdet/lv_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..6efcc14317da87adc655f4096f5a4db3cbfb7558
--- /dev/null
+++ b/tools/dataset_converters/textdet/lv_converter.py
@@ -0,0 +1,182 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+import xml.etree.ElementTree as ET
+
+import mmcv
+import mmengine
+
+from mmocr.utils import dump_ocr_data
+
+
+def collect_files(data_dir):
+ """Collect all images and their corresponding groundtruth files.
+
+ Args:
+ data_dir (str): The directory to dataset
+
+ Returns:
+ files (list): The list of tuples (img_file, groundtruth_file)
+ """
+ assert isinstance(data_dir, str)
+ assert data_dir
+
+ ann_list, imgs_list = [], []
+ for video_dir in os.listdir(data_dir):
+ for frame_dir in os.listdir(osp.join(data_dir, video_dir)):
+ crt_dir = osp.join(data_dir, video_dir, frame_dir)
+ if not osp.isdir(crt_dir):
+ continue
+ for crt_file in os.listdir(crt_dir):
+ if crt_file.endswith('xml'):
+ ann_path = osp.join(crt_dir, crt_file)
+ img_path = osp.join(crt_dir,
+ crt_file.replace('xml', 'png'))
+ if os.path.exists(img_path):
+ ann_list.append(ann_path)
+ imgs_list.append(img_path)
+ else:
+ continue
+
+ files = list(zip(imgs_list, ann_list))
+ assert len(files), f'No images found in {data_dir}'
+ print(f'Loaded {len(files)} images from {data_dir}')
+
+ return files
+
+
+def collect_annotations(files, nproc=1):
+ """Collect the annotation information.
+
+ Args:
+ files (list): The list of tuples (image_file, groundtruth_file)
+ nproc (int): The number of process to collect annotations
+
+ Returns:
+ images (list): The list of image information dicts
+ """
+ assert isinstance(files, list)
+ assert isinstance(nproc, int)
+
+ if nproc > 1:
+ images = mmengine.track_parallel_progress(
+ load_img_info, files, nproc=nproc)
+ else:
+ images = mmengine.track_progress(load_img_info, files)
+
+ return images
+
+
+def load_img_info(files):
+ """Load the information of one image.
+
+ Args:
+ files (tuple): The tuple of (img_file, groundtruth_file)
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+ assert isinstance(files, tuple)
+
+ img_file, gt_file = files
+ assert osp.basename(gt_file).split('.')[0] == osp.basename(img_file).split(
+ '.')[0]
+ # read imgs while ignoring orientations
+ img = mmcv.imread(img_file, 'unchanged')
+ img_file = os.path.split(img_file)[-1]
+
+ img_info = dict(
+ file_name=img_file,
+ height=img.shape[0],
+ width=img.shape[1],
+ segm_file=osp.join(osp.basename(gt_file)))
+
+ if osp.splitext(gt_file)[1] == '.xml':
+ img_info = load_xml_info(gt_file, img_info)
+ else:
+ raise NotImplementedError
+
+ return img_info
+
+
+def load_xml_info(gt_file, img_info):
+ """Collect the annotation information.
+
+ The annotation format is as the following:
+
+
+ hierarchy
+ Unspecified
+ 0
+ 0
+
+ 657
+ 467
+ 839
+ 557
+
+
+
+
+ Args:
+ gt_file (str): The path to ground-truth
+ img_info (dict): The dict of the img and annotation information
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+
+ obj = ET.parse(gt_file)
+ root = obj.getroot()
+ anno_info = []
+ for obj in root.iter('object'):
+ x = max(0, int(obj.find('bndbox').find('xmin').text))
+ y = max(0, int(obj.find('bndbox').find('ymin').text))
+ xmax = int(obj.find('bndbox').find('xmax').text)
+ ymax = int(obj.find('bndbox').find('ymax').text)
+
+ w, h = abs(xmax - x), abs(ymax - y)
+ bbox = [x, y, w, h]
+ segmentation = [x, y, x + w, y, x + w, y + h, x, y + h]
+
+ anno = dict(
+ iscrowd=0,
+ category_id=1,
+ bbox=bbox,
+ area=w * h,
+ segmentation=[segmentation])
+ anno_info.append(anno)
+
+ img_info.update(anno_info=anno_info)
+
+ return img_info
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training, val and test set of Lecture Video DB ')
+ parser.add_argument('root_path', help='Root dir path of Lecture Video DB')
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='number of process')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+
+ for split in ['train', 'val', 'test']:
+ print(f'Processing {split} set...')
+ with mmengine.Timer(
+ print_tmpl='It takes {}s to convert LV annotation'):
+ files = collect_files(osp.join(root_path, 'imgs', split))
+ image_infos = collect_annotations(files, nproc=args.nproc)
+ dump_ocr_data(image_infos,
+ osp.join(root_path, 'instances_' + split + '.json'),
+ 'textdet')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textdet/mtwi_converter.py b/tools/dataset_converters/textdet/mtwi_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..1c9fde3bf870ffcd1ea482e3d73bfc138f51a381
--- /dev/null
+++ b/tools/dataset_converters/textdet/mtwi_converter.py
@@ -0,0 +1,203 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import math
+import os
+import os.path as osp
+
+import cv2
+import mmcv
+import mmengine
+from PIL import Image
+
+from mmocr.utils import dump_ocr_data
+
+
+def collect_files(img_dir, gt_dir, ratio):
+ """Collect all images and their corresponding groundtruth files.
+ Args:
+ img_dir (str): The image directory
+ gt_dir (str): The groundtruth directory
+ ratio (float): Split ratio for val set
+
+ Returns:
+ files (list): The list of tuples (img_file, groundtruth_file)
+ """
+ assert isinstance(img_dir, str)
+ assert img_dir
+ assert isinstance(gt_dir, str)
+ assert gt_dir
+ assert isinstance(ratio, float)
+ assert ratio < 1.0, 'val_ratio should be a float between 0.0 to 1.0'
+
+ ann_list, imgs_list = [], []
+ for ann_file in os.listdir(gt_dir):
+ img_file = osp.join(img_dir, ann_file.replace('txt', 'jpg'))
+ # This dataset contains some images obtained from .gif,
+ # which cannot be loaded by mmcv.imread(), convert them
+ # to RGB mode.
+ try:
+ if mmcv.imread(img_file) is None:
+ print(f'Convert {img_file} to RGB mode.')
+ img = Image.open(img_file)
+ img = img.convert('RGB')
+ img.save(img_file)
+ except cv2.error:
+ print(f'Skip broken img {img_file}')
+ continue
+
+ ann_list.append(osp.join(gt_dir, ann_file))
+ imgs_list.append(img_file)
+
+ all_files = list(zip(imgs_list, ann_list))
+ assert len(all_files), f'No images found in {img_dir}'
+ print(f'Loaded {len(all_files)} images from {img_dir}')
+
+ trn_files, val_files = [], []
+ if ratio > 0:
+ for i, file in enumerate(all_files):
+ if i % math.floor(1 / ratio):
+ trn_files.append(file)
+ else:
+ val_files.append(file)
+ else:
+ trn_files, val_files = all_files, []
+
+ print(f'training #{len(trn_files)}, val #{len(val_files)}')
+
+ return trn_files, val_files
+
+
+def collect_annotations(files, nproc=1):
+ """Collect the annotation information.
+ Args:
+ files (list): The list of tuples (image_file, groundtruth_file)
+ nproc (int): The number of process to collect annotations
+
+ Returns:
+ images (list): The list of image information dicts
+ """
+ assert isinstance(files, list)
+ assert isinstance(nproc, int)
+
+ if nproc > 1:
+ images = mmengine.track_parallel_progress(
+ load_img_info, files, nproc=nproc)
+ else:
+ images = mmengine.track_progress(load_img_info, files)
+
+ return images
+
+
+def load_img_info(files):
+ """Load the information of one image.
+ Args:
+ files (tuple): The tuple of (img_file, groundtruth_file)
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+ assert isinstance(files, tuple)
+
+ img_file, gt_file = files
+ assert osp.basename(gt_file).split('.')[0] == osp.basename(img_file).split(
+ '.')[0]
+ # read imgs while ignoring orientations
+ img = mmcv.imread(img_file)
+
+ img_info = dict(
+ file_name=osp.join(osp.basename(img_file)),
+ height=img.shape[0],
+ width=img.shape[1],
+ segm_file=osp.join(osp.basename(gt_file)))
+
+ if osp.splitext(gt_file)[1] == '.txt':
+ img_info = load_txt_info(gt_file, img_info)
+ else:
+ raise NotImplementedError
+
+ return img_info
+
+
+def load_txt_info(gt_file, img_info):
+ """Collect the annotation information.
+
+ The annotation format is as the following:
+ x1,y1,x2,y2,x3,y3,x4,y4,text
+
+ 45.45,226.83,11.87,181.79,183.84,13.1,233.79,49.95,时尚袋袋
+ 345.98,311.18,345.98,347.21,462.26,347.21,462.26,311.18,73774
+ 462.26,292.34,461.44,299.71,502.39,299.71,502.39,292.34,73/74/737
+
+ Args:
+ gt_file (str): The path to ground-truth
+ img_info (dict): The dict of the img and annotation information
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+
+ anno_info = []
+ with open(gt_file) as f:
+ lines = f.readlines()
+ for line in lines:
+ points = line.split(',')[0:8]
+ word = line.split(',')[8].rstrip('\n')
+ segmentation = [math.floor(float(pt)) for pt in points]
+ x = max(0, min(segmentation[0::2]))
+ y = max(0, min(segmentation[1::2]))
+ w = abs(max(segmentation[0::2]) - x)
+ h = abs(max(segmentation[1::2]) - y)
+ bbox = [x, y, w, h]
+
+ anno = dict(
+ iscrowd=1 if word == '###' else 0,
+ category_id=1,
+ bbox=bbox,
+ area=w * h,
+ segmentation=[segmentation])
+ anno_info.append(anno)
+
+ img_info.update(anno_info=anno_info)
+
+ return img_info
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training and val set of MTWI.')
+ parser.add_argument('root_path', help='Root dir path of MTWI')
+ parser.add_argument(
+ '--val-ratio', help='Split ratio for val set', default=0.0, type=float)
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='Number of process')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+ ratio = args.val_ratio
+
+ trn_files, val_files = collect_files(
+ osp.join(root_path, 'imgs'), osp.join(root_path, 'annotations'), ratio)
+
+ # Train set
+ trn_infos = collect_annotations(trn_files, nproc=args.nproc)
+ with mmengine.Timer(
+ print_tmpl='It takes {}s to convert MTWI Training annotation'):
+ dump_ocr_data(trn_infos, osp.join(root_path,
+ 'instances_training.json'),
+ 'textdet')
+
+ # Val set
+ if len(val_files) > 0:
+ val_infos = collect_annotations(val_files, nproc=args.nproc)
+ with mmengine.Timer(
+ print_tmpl='It takes {}s to convert MTWI Val annotation'):
+ dump_ocr_data(val_infos, osp.join(root_path, 'instances_val.json'),
+ 'textdet')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textdet/naf_converter.py b/tools/dataset_converters/textdet/naf_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..2e43c8fba909723edd55f7b13b2a9cfa0b6c2e15
--- /dev/null
+++ b/tools/dataset_converters/textdet/naf_converter.py
@@ -0,0 +1,197 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+
+import mmcv
+import mmengine
+
+from mmocr.utils import dump_ocr_data
+
+
+def collect_files(img_dir, gt_dir, split_info):
+ """Collect all images and their corresponding groundtruth files.
+
+ Args:
+ img_dir (str): The image directory
+ gt_dir (str): The groundtruth directory
+ split_info (dict): The split information for train/val/test
+
+ Returns:
+ files (list): The list of tuples (img_file, groundtruth_file)
+ """
+ assert isinstance(img_dir, str)
+ assert img_dir
+ assert isinstance(gt_dir, str)
+ assert gt_dir
+ assert isinstance(split_info, dict)
+ assert split_info
+
+ ann_list, imgs_list = [], []
+ for group in split_info:
+ for img in split_info[group]:
+ image_path = osp.join(img_dir, img)
+ anno_path = osp.join(gt_dir, 'groups', group,
+ img.replace('jpg', 'json'))
+
+ # Filtering out the missing images
+ if not osp.exists(image_path) or not osp.exists(anno_path):
+ continue
+
+ imgs_list.append(image_path)
+ ann_list.append(anno_path)
+
+ files = list(zip(imgs_list, ann_list))
+ assert len(files), f'No images found in {img_dir}'
+ print(f'Loaded {len(files)} images from {img_dir}')
+
+ return files
+
+
+def collect_annotations(files, nproc=1):
+ """Collect the annotation information.
+
+ Args:
+ files (list): The list of tuples (image_file, groundtruth_file)
+ nproc (int): The number of process to collect annotations
+
+ Returns:
+ images (list): The list of image information dicts
+ """
+ assert isinstance(files, list)
+ assert isinstance(nproc, int)
+
+ if nproc > 1:
+ images = mmengine.track_parallel_progress(
+ load_img_info, files, nproc=nproc)
+ else:
+ images = mmengine.track_progress(load_img_info, files)
+
+ return images
+
+
+def load_img_info(files):
+ """Load the information of one image.
+
+ Args:
+ files (tuple): The tuple of (img_file, groundtruth_file)
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+ assert isinstance(files, tuple)
+
+ img_file, gt_file = files
+ assert osp.basename(gt_file).split('.')[0] == osp.basename(img_file).split(
+ '.')[0]
+ # Read imgs while ignoring orientations
+ img = mmcv.imread(img_file, 'unchanged')
+
+ img_info = dict(
+ file_name=osp.join(osp.basename(img_file)),
+ height=img.shape[0],
+ width=img.shape[1],
+ segm_file=osp.join(osp.basename(gt_file)))
+
+ if osp.splitext(gt_file)[1] == '.json':
+ img_info = load_json_info(gt_file, img_info)
+ else:
+ raise NotImplementedError
+
+ return img_info
+
+
+def load_json_info(gt_file, img_info):
+ """Collect the annotation information.
+
+ Annotation Format
+ {
+ 'textBBs': [{
+ 'poly_points': [[435,1406], [466,1406], [466,1439], [435,1439]],
+ "type": "text",
+ "id": "t1",
+ }], ...
+ }
+
+ Some special characters are used in the transcription:
+ "«text»" indicates that "text" had a strikethrough
+ "¿" indicates the transcriber could not read a character
+ "§" indicates the whole line or word was illegible
+ "" (empty string) is if the field was blank
+
+ Args:
+ gt_file (str): The path to ground-truth
+ img_info (dict): The dict of the img and annotation information
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+ assert isinstance(gt_file, str)
+ assert isinstance(img_info, dict)
+
+ annotation = mmengine.load(gt_file)
+ anno_info = []
+
+ # 'textBBs' contains the printed texts of the table while 'fieldBBs'
+ # contains the text filled by human.
+ for box_type in ['textBBs', 'fieldBBs']:
+ for anno in annotation[box_type]:
+ # Skip blanks
+ if box_type == 'fieldBBs':
+ if anno['type'] == 'blank':
+ continue
+
+ xs, ys, segmentation = [], [], []
+ for p in anno['poly_points']:
+ xs.append(p[0])
+ ys.append(p[1])
+ segmentation.append(p[0])
+ segmentation.append(p[1])
+ x, y = max(0, min(xs)), max(0, min(ys))
+ w, h = max(xs) - x, max(ys) - y
+ bbox = [x, y, w, h]
+
+ anno = dict(
+ iscrowd=0,
+ category_id=1,
+ bbox=bbox,
+ area=w * h,
+ segmentation=[segmentation])
+ anno_info.append(anno)
+
+ img_info.update(anno_info=anno_info)
+
+ return img_info
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training, val, and test set of NAF ')
+ parser.add_argument('root_path', help='Root dir path of NAF')
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='Number of process')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+ split_info = mmengine.load(
+ osp.join(root_path, 'annotations', 'train_valid_test_split.json'))
+ split_info['training'] = split_info.pop('train')
+ split_info['val'] = split_info.pop('valid')
+ for split in ['training', 'val', 'test']:
+ print(f'Processing {split} set...')
+ with mmengine.Timer(
+ print_tmpl='It takes {}s to convert NAF annotation'):
+ files = collect_files(
+ osp.join(root_path, 'imgs'),
+ osp.join(root_path, 'annotations'), split_info[split])
+ image_infos = collect_annotations(files, nproc=args.nproc)
+ dump_ocr_data(image_infos,
+ osp.join(root_path, 'instances_' + split + '.json'),
+ 'textdet')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textdet/rctw_converter.py b/tools/dataset_converters/textdet/rctw_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..cc46dd85999c616a89167a56de27ccf2f306ec4a
--- /dev/null
+++ b/tools/dataset_converters/textdet/rctw_converter.py
@@ -0,0 +1,193 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import math
+import os
+import os.path as osp
+
+import mmcv
+import mmengine
+
+from mmocr.utils import dump_ocr_data
+
+
+def collect_files(img_dir, gt_dir, ratio):
+ """Collect all images and their corresponding groundtruth files.
+ Args:
+ img_dir (str): The image directory
+ gt_dir (str): The groundtruth directory
+ ratio (float): Split ratio for val set
+
+ Returns:
+ files (list): The list of tuples (img_file, groundtruth_file)
+ """
+ assert isinstance(img_dir, str)
+ assert img_dir
+ assert isinstance(gt_dir, str)
+ assert gt_dir
+ assert isinstance(ratio, float)
+ assert ratio < 1.0, 'val_ratio should be a float between 0.0 to 1.0'
+
+ ann_list, imgs_list = [], []
+ for ann_file in os.listdir(gt_dir):
+ ann_list.append(osp.join(gt_dir, ann_file))
+ imgs_list.append(osp.join(img_dir, ann_file.replace('txt', 'jpg')))
+
+ all_files = list(zip(imgs_list, ann_list))
+ assert len(all_files), f'No images found in {img_dir}'
+ print(f'Loaded {len(all_files)} images from {img_dir}')
+
+ trn_files, val_files = [], []
+ if ratio > 0:
+ for i, file in enumerate(all_files):
+ if i % math.floor(1 / ratio):
+ trn_files.append(file)
+ else:
+ val_files.append(file)
+ else:
+ trn_files, val_files = all_files, []
+
+ print(f'training #{len(trn_files)}, val #{len(val_files)}')
+
+ return trn_files, val_files
+
+
+def collect_annotations(files, nproc=1):
+ """Collect the annotation information.
+ Args:
+ files (list): The list of tuples (image_file, groundtruth_file)
+ nproc (int): The number of process to collect annotations
+
+ Returns:
+ images (list): The list of image information dicts
+ """
+ assert isinstance(files, list)
+ assert isinstance(nproc, int)
+
+ if nproc > 1:
+ images = mmengine.track_parallel_progress(
+ load_img_info, files, nproc=nproc)
+ else:
+ images = mmengine.track_progress(load_img_info, files)
+
+ return images
+
+
+def load_img_info(files):
+ """Load the information of one image.
+ Args:
+ files (tuple): The tuple of (img_file, groundtruth_file)
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+ assert isinstance(files, tuple)
+
+ img_file, gt_file = files
+ assert osp.basename(gt_file).split('.')[0] == osp.basename(img_file).split(
+ '.')[0]
+ # read imgs while ignoring orientations
+ img = mmcv.imread(img_file)
+
+ img_info = dict(
+ file_name=osp.join(osp.basename(img_file)),
+ height=img.shape[0],
+ width=img.shape[1],
+ segm_file=osp.join(osp.basename(gt_file)))
+
+ if osp.splitext(gt_file)[1] == '.txt':
+ img_info = load_txt_info(gt_file, img_info)
+ else:
+ raise NotImplementedError
+
+ return img_info
+
+
+def load_txt_info(gt_file, img_info):
+ """Collect the annotation information.
+
+ The annotation format is as the following:
+ x1, y1, x2, y2, x3, y3, x4, y4, difficult, text
+
+ 390,902,1856,902,1856,1225,390,1225,0,"金氏眼镜"
+ 1875,1170,2149,1170,2149,1245,1875,1245,0,"创于1989"
+ 2054,1277,2190,1277,2190,1323,2054,1323,0,"城建店"
+
+ Args:
+ gt_file (str): The path to ground-truth
+ img_info (dict): The dict of the img and annotation information
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+
+ anno_info = []
+ with open(gt_file, encoding='utf-8-sig') as f:
+ lines = f.readlines()
+ for line in lines:
+ points = line.split(',')[0:8]
+ word = line.split(',')[9].rstrip('\n').strip('"')
+ difficult = 1 if line.split(',')[8] != '0' else 0
+ segmentation = [int(pt) for pt in points]
+ x = max(0, min(segmentation[0::2]))
+ y = max(0, min(segmentation[1::2]))
+ w = abs(max(segmentation[0::2]) - x)
+ h = abs(max(segmentation[1::2]) - y)
+ bbox = [x, y, w, h]
+
+ if word == '###' or difficult == 1:
+ iscrowd = 1
+ else:
+ iscrowd = 0
+
+ anno = dict(
+ iscrowd=iscrowd,
+ category_id=1,
+ bbox=bbox,
+ area=w * h,
+ segmentation=[segmentation])
+ anno_info.append(anno)
+
+ img_info.update(anno_info=anno_info)
+
+ return img_info
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training and val set of RCTW.')
+ parser.add_argument('root_path', help='Root dir path of RCTW')
+ parser.add_argument(
+ '--val-ratio', help='Split ratio for val set', default=0.0, type=float)
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='Number of process')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+ ratio = args.val_ratio
+
+ trn_files, val_files = collect_files(
+ osp.join(root_path, 'imgs'), osp.join(root_path, 'annotations'), ratio)
+
+ # Train set
+ with mmengine.Timer(
+ print_tmpl='It takes {}s to convert RCTW Training annotation'):
+ trn_infos = collect_annotations(trn_files, nproc=args.nproc)
+ dump_ocr_data(trn_infos, osp.join(root_path,
+ 'instances_training.json'),
+ 'textdet')
+
+ # Val set
+ if len(val_files) > 0:
+ with mmengine.Timer(
+ print_tmpl='It takes {}s to convert RCTW Val annotation'):
+ val_infos = collect_annotations(val_files, nproc=args.nproc)
+ dump_ocr_data(val_infos, osp.join(root_path, 'instances_val.json'),
+ 'textdet')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textdet/rects_converter.py b/tools/dataset_converters/textdet/rects_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..75f3b734607af2c44b78273df3401457166432c2
--- /dev/null
+++ b/tools/dataset_converters/textdet/rects_converter.py
@@ -0,0 +1,207 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import math
+import os
+import os.path as osp
+
+import mmcv
+import mmengine
+
+from mmocr.utils import dump_ocr_data
+
+
+def collect_files(img_dir, gt_dir, ratio):
+ """Collect all images and their corresponding groundtruth files.
+ Args:
+ img_dir (str): The image directory
+ gt_dir (str): The groundtruth directory
+ ratio (float): Split ratio for val set
+
+ Returns:
+ files (list): The list of tuples (img_file, groundtruth_file)
+ """
+ assert isinstance(img_dir, str)
+ assert img_dir
+ assert isinstance(gt_dir, str)
+ assert gt_dir
+ assert isinstance(ratio, float)
+ assert ratio < 1.0, 'val_ratio should be a float between 0.0 to 1.0'
+
+ ann_list, imgs_list = [], []
+ for ann_file in os.listdir(gt_dir):
+ ann_list.append(osp.join(gt_dir, ann_file))
+ imgs_list.append(osp.join(img_dir, ann_file.replace('json', 'jpg')))
+
+ all_files = list(zip(imgs_list, ann_list))
+ assert len(all_files), f'No images found in {img_dir}'
+ print(f'Loaded {len(all_files)} images from {img_dir}')
+
+ trn_files, val_files = [], []
+ if ratio > 0:
+ for i, file in enumerate(all_files):
+ if i % math.floor(1 / ratio):
+ trn_files.append(file)
+ else:
+ val_files.append(file)
+ else:
+ trn_files, val_files = all_files, []
+
+ print(f'training #{len(trn_files)}, val #{len(val_files)}')
+
+ return trn_files, val_files
+
+
+def collect_annotations(files, nproc=1):
+ """Collect the annotation information.
+ Args:
+ files (list): The list of tuples (image_file, groundtruth_file)
+ nproc (int): The number of process to collect annotations
+
+ Returns:
+ images (list): The list of image information dicts
+ """
+ assert isinstance(files, list)
+ assert isinstance(nproc, int)
+
+ if nproc > 1:
+ images = mmengine.track_parallel_progress(
+ load_img_info, files, nproc=nproc)
+ else:
+ images = mmengine.track_progress(load_img_info, files)
+
+ return images
+
+
+def load_img_info(files):
+ """Load the information of one image.
+ Args:
+ files (tuple): The tuple of (img_file, groundtruth_file)
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+ assert isinstance(files, tuple)
+
+ img_file, gt_file = files
+ assert osp.basename(gt_file).split('.')[0] == osp.basename(img_file).split(
+ '.')[0]
+ # read imgs while ignoring orientations
+ img = mmcv.imread(img_file)
+
+ img_info = dict(
+ file_name=osp.join(osp.basename(img_file)),
+ height=img.shape[0],
+ width=img.shape[1],
+ segm_file=osp.join(osp.basename(gt_file)))
+
+ if osp.splitext(gt_file)[1] == '.json':
+ img_info = load_json_info(gt_file, img_info)
+ else:
+ raise NotImplementedError
+
+ return img_info
+
+
+def load_json_info(gt_file, img_info):
+ """Collect the annotation information.
+
+ The annotation format is as the following:
+
+ {
+ "chars": [
+ {
+ "ignore": 0,
+ "transcription": "H",
+ "points": [25, 175, 112, 175, 112, 286, 25, 286]
+ },
+ {
+ "ignore": 0,
+ "transcription": "O",
+ "points": [102, 182, 210, 182, 210, 273, 102, 273]
+ }, ...
+ ]
+ "lines": [
+ {
+ "ignore": 0,
+ "transcription": "HOKI",
+ "points": [23, 173, 327, 180, 327, 290, 23, 283]
+ },
+ {
+ "ignore": 0,
+ "transcription": "TEA",
+ "points": [368, 180, 621, 180, 621, 294, 368, 294]
+ }, ...
+ ]
+ }
+
+
+ Args:
+ gt_file (str): The path to ground-truth
+ img_info (dict): The dict of the img and annotation information
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+
+ annotation = mmengine.load(gt_file)
+ anno_info = []
+ for line in annotation['lines']:
+ segmentation = line['points']
+ x = max(0, min(segmentation[0::2]))
+ y = max(0, min(segmentation[1::2]))
+ w = abs(max(segmentation[0::2]) - x)
+ h = abs(max(segmentation[1::2]) - y)
+ bbox = [x, y, w, h]
+
+ anno = dict(
+ iscrowd=line['ignore'],
+ category_id=1,
+ bbox=bbox,
+ area=w * h,
+ segmentation=[segmentation])
+ anno_info.append(anno)
+
+ img_info.update(anno_info=anno_info)
+
+ return img_info
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training and val set of ReCTS.')
+ parser.add_argument('root_path', help='Root dir path of ReCTS')
+ parser.add_argument(
+ '--val-ratio', help='Split ratio for val set', default=0.0, type=float)
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='Number of process')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+ ratio = args.val_ratio
+
+ trn_files, val_files = collect_files(
+ osp.join(root_path, 'imgs'), osp.join(root_path, 'annotations'), ratio)
+
+ # Train set
+ trn_infos = collect_annotations(trn_files, nproc=args.nproc)
+ with mmengine.Timer(
+ print_tmpl='It takes {}s to convert ReCTS Training annotation'):
+ dump_ocr_data(trn_infos, osp.join(root_path,
+ 'instances_training.json'),
+ 'textdet')
+
+ # Val set
+ if len(val_files) > 0:
+ val_infos = collect_annotations(val_files, nproc=args.nproc)
+ with mmengine.Timer(
+ print_tmpl='It takes {}s to convert ReCTS Val annotation'):
+ dump_ocr_data(val_infos, osp.join(root_path, 'instances_val.json'),
+ 'textdet')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textdet/sroie_converter.py b/tools/dataset_converters/textdet/sroie_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..7ee0725e2fde0533248ed584c290377416bd5b46
--- /dev/null
+++ b/tools/dataset_converters/textdet/sroie_converter.py
@@ -0,0 +1,168 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+
+import mmcv
+import mmengine
+import numpy as np
+
+from mmocr.utils import dump_ocr_data
+
+
+def collect_files(img_dir, gt_dir):
+ """Collect all images and their corresponding groundtruth files.
+
+ Args:
+ img_dir (str): The image directory
+ gt_dir (str): The groundtruth directory
+
+ Returns:
+ files (list): The list of tuples (img_file, groundtruth_file)
+ """
+
+ assert isinstance(img_dir, str)
+ assert img_dir
+ assert isinstance(gt_dir, str)
+ assert gt_dir
+
+ ann_list, imgs_list = [], []
+ for gt_file in os.listdir(gt_dir):
+ # Filtering repeated and missing images
+ if '(' in gt_file or gt_file == 'X51006619570.txt':
+ continue
+ ann_list.append(osp.join(gt_dir, gt_file))
+ imgs_list.append(osp.join(img_dir, gt_file.replace('.txt', '.jpg')))
+
+ files = list(zip(sorted(imgs_list), sorted(ann_list)))
+ assert len(files), f'No images found in {img_dir}'
+
+ print(f'Loaded {len(files)} images from {img_dir}')
+
+ return files
+
+
+def collect_annotations(files, nproc=1):
+ """Collect the annotation information.
+
+ Args:
+ files (list): The list of tuples (image_file, groundtruth_file)
+ nproc (int): The number of process to collect annotations
+
+ Returns:
+ images (list): The list of image information dicts
+ """
+
+ assert isinstance(files, list)
+ assert isinstance(nproc, int)
+
+ if nproc > 1:
+ images = mmengine.track_parallel_progress(
+ load_img_info, files, nproc=nproc)
+ else:
+ images = mmengine.track_progress(load_img_info, files)
+
+ return images
+
+
+def load_img_info(files):
+ """Load the information of one image.
+
+ Args:
+ files (tuple): The tuple of (img_file, groundtruth_file)
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+
+ assert isinstance(files, tuple)
+
+ img_file, gt_file = files
+ assert osp.basename(gt_file).split('.')[0] == osp.basename(img_file).split(
+ '.')[0]
+ # read imgs while ignoring orientations
+ img = mmcv.imread(img_file, 'unchanged')
+
+ img_info = dict(
+ file_name=osp.join(osp.basename(img_file)),
+ height=img.shape[0],
+ width=img.shape[1],
+ segm_file=osp.join(osp.basename(gt_file)))
+
+ if osp.splitext(gt_file)[1] == '.txt':
+ img_info = load_txt_info(gt_file, img_info)
+ else:
+ raise NotImplementedError
+
+ return img_info
+
+
+def load_txt_info(gt_file, img_info):
+ """Collect the annotation information.
+
+ Args:
+ gt_file (list): The list of tuples (image_file, groundtruth_file)
+ img_info (int): The dict of the img and annotation information
+
+ Returns:
+ img_info (list): The dict of the img and annotation information
+ """
+
+ with open(gt_file, encoding='unicode_escape') as f:
+ anno_info = []
+ for ann in f.readlines():
+
+ # annotation format [x1, y1, x2, y2, x3, y3, x4, y4, transcript]
+ try:
+ ann_box = np.array(ann.split(',')[0:8]).astype(int).tolist()
+ except ValueError:
+ # skip invalid annotation line
+ continue
+ x = max(0, min(ann_box[0::2]))
+ y = max(0, min(ann_box[1::2]))
+ w, h = max(ann_box[0::2]) - x, max(ann_box[1::2]) - y
+ bbox = [x, y, w, h]
+ segmentation = ann_box
+
+ anno = dict(
+ iscrowd=0,
+ category_id=1,
+ bbox=bbox,
+ area=w * h,
+ segmentation=[segmentation])
+ anno_info.append(anno)
+
+ img_info.update(anno_info=anno_info)
+
+ return img_info
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training and test set of SROIE')
+ parser.add_argument('root_path', help='Root dir path of SROIE')
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='Number of process')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+
+ for split in ['training', 'test']:
+ print(f'Processing {split} set...')
+ with mmengine.Timer(
+ print_tmpl='It takes {}s to convert SROIE annotation'):
+ files = collect_files(
+ osp.join(root_path, 'imgs', split),
+ osp.join(root_path, 'annotations', split))
+ image_infos = collect_annotations(files, nproc=args.nproc)
+ dump_ocr_data(image_infos,
+ osp.join(root_path, 'instances_' + split + '.json'),
+ 'textdet')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textdet/vintext_converter.py b/tools/dataset_converters/textdet/vintext_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..fb7a364d9591bec7785a73d571670121bb985978
--- /dev/null
+++ b/tools/dataset_converters/textdet/vintext_converter.py
@@ -0,0 +1,171 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+
+import mmcv
+import mmengine
+
+from mmocr.utils import dump_ocr_data
+
+
+def collect_files(img_dir, gt_dir):
+ """Collect all images and their corresponding groundtruth files.
+
+ Args:
+ img_dir (str): The image directory
+ gt_dir (str): The groundtruth directory
+
+ Returns:
+ files (list): The list of tuples (img_file, groundtruth_file)
+ """
+ assert isinstance(img_dir, str)
+ assert img_dir
+ assert isinstance(gt_dir, str)
+ assert gt_dir
+
+ ann_list, imgs_list = [], []
+ for img_file in os.listdir(img_dir):
+ ann_file = 'gt_' + str(int(img_file[2:6])) + '.txt'
+ ann_list.append(osp.join(gt_dir, ann_file))
+ imgs_list.append(osp.join(img_dir, img_file))
+
+ files = list(zip(imgs_list, ann_list))
+ assert len(files), f'No images found in {img_dir}'
+ print(f'Loaded {len(files)} images from {img_dir}')
+
+ return files
+
+
+def collect_annotations(files, nproc=1):
+ """Collect the annotation information.
+
+ Args:
+ files (list): The list of tuples (image_file, groundtruth_file)
+ nproc (int): The number of process to collect annotations
+
+ Returns:
+ images (list): The list of image information dicts
+ """
+ assert isinstance(files, list)
+ assert isinstance(nproc, int)
+
+ if nproc > 1:
+ images = mmengine.track_parallel_progress(
+ load_img_info, files, nproc=nproc)
+ else:
+ images = mmengine.track_progress(load_img_info, files)
+
+ return images
+
+
+def load_img_info(files):
+ """Load the information of one image.
+
+ Args:
+ files (tuple): The tuple of (img_file, groundtruth_file)
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+ assert isinstance(files, tuple)
+
+ img_file, gt_file = files
+ assert int(osp.basename(gt_file)[3:-4]) == int(
+ osp.basename(img_file)[2:-4])
+ # read imgs while ignoring orientations
+ img = mmcv.imread(img_file, 'unchanged')
+
+ img_info = dict(
+ file_name=osp.basename(img_file),
+ height=img.shape[0],
+ width=img.shape[1],
+ segm_file=osp.basename(gt_file))
+
+ if osp.splitext(gt_file)[1] == '.txt':
+ img_info = load_txt_info(gt_file, img_info)
+ else:
+ raise NotImplementedError
+
+ return img_info
+
+
+def load_txt_info(gt_file, img_info):
+ """Collect the annotation information.
+
+ The annotation format is as the following:
+ x1,y1,x2,y2,x3,y3,x4,y4,text
+ 118,15,147,15,148,46,118,46,LƯỢNG
+ 149,9,165,9,165,43,150,43,TỐT
+ 167,9,180,9,179,43,167,42,ĐỂ
+ 181,12,193,12,193,43,181,43,CÓ
+ 195,13,215,14,215,46,196,46,VIỆC
+ 217,13,237,14,239,47,217,46,LÀM,
+
+ Args:
+ gt_file (str): The path to ground-truth
+ img_info (dict): The dict of the img and annotation information
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+
+ with open(gt_file, encoding='utf-8') as f:
+ anno_info = []
+ for line in f:
+ line = line.strip('\n')
+ ann = line.split(',')
+ bbox = ann[0:8]
+ word = line[len(','.join(bbox)) + 1:]
+ bbox = [int(coord) for coord in bbox]
+ segmentation = bbox
+ x_min = min(bbox[0], bbox[2], bbox[4], bbox[6])
+ x_max = max(bbox[0], bbox[2], bbox[4], bbox[6])
+ y_min = min(bbox[1], bbox[3], bbox[5], bbox[7])
+ y_max = max(bbox[1], bbox[3], bbox[5], bbox[7])
+ w = x_max - x_min
+ h = y_max - y_min
+ bbox = [x_min, y_min, w, h]
+ iscrowd = 1 if word == '###' else 0
+
+ anno = dict(
+ iscrowd=iscrowd,
+ category_id=1,
+ bbox=bbox,
+ area=w * h,
+ segmentation=[segmentation])
+ anno_info.append(anno)
+
+ img_info.update(anno_info=anno_info)
+
+ return img_info
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training and test set of VinText ')
+ parser.add_argument('root_path', help='Root dir path of VinText')
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='Number of processes')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+ for split in ['training', 'test', 'unseen_test']:
+ print(f'Processing {split} set...')
+ with mmengine.Timer(
+ print_tmpl='It takes {}s to convert VinText annotation'):
+ files = collect_files(
+ osp.join(root_path, 'imgs', split),
+ osp.join(root_path, 'annotations'))
+ image_infos = collect_annotations(files, nproc=args.nproc)
+ dump_ocr_data(image_infos,
+ osp.join(root_path, 'instances_' + split + '.json'),
+ 'textdet')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textrecog/art_converter.py b/tools/dataset_converters/textrecog/art_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..24acaad289be221558701d19a95ea7ce24a7e0f9
--- /dev/null
+++ b/tools/dataset_converters/textrecog/art_converter.py
@@ -0,0 +1,108 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import math
+import os.path as osp
+
+import mmengine
+
+from mmocr.utils import dump_ocr_data
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training and validation set of ArT ')
+ parser.add_argument('root_path', help='Root dir path of ArT')
+ parser.add_argument(
+ '--val-ratio', help='Split ratio for val set', default=0.0, type=float)
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='Number of processes')
+ args = parser.parse_args()
+ return args
+
+
+def convert_art(root_path, split, ratio):
+ """Collect the annotation information and crop the images.
+
+ The annotation format is as the following:
+ {
+ "gt_2836_0": [
+ {
+ "transcription": "URDER",
+ "points": [
+ [25, 51],
+ [0, 2],
+ [21, 0],
+ [42, 43]
+ ],
+ "language": "Latin",
+ "illegibility": false
+ }
+ ], ...
+ }
+
+ Args:
+ root_path (str): The root path of the dataset
+ split (str): The split of dataset. Namely: training or val
+ ratio (float): Split ratio for val set
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+
+ annotation_path = osp.join(root_path,
+ 'annotations/train_task2_labels.json')
+ if not osp.exists(annotation_path):
+ raise Exception(
+ f'{annotation_path} not exists, please check and try again.')
+
+ annotation = mmengine.load(annotation_path)
+ img_prefixes = annotation.keys()
+
+ trn_files, val_files = [], []
+ if ratio > 0:
+ for i, file in enumerate(img_prefixes):
+ if i % math.floor(1 / ratio):
+ trn_files.append(file)
+ else:
+ val_files.append(file)
+ else:
+ trn_files, val_files = img_prefixes, []
+ print(f'training #{len(trn_files)}, val #{len(val_files)}')
+
+ if split == 'train':
+ img_prefixes = trn_files
+ elif split == 'val':
+ img_prefixes = val_files
+ else:
+ raise NotImplementedError
+
+ img_info = []
+ for prefix in img_prefixes:
+ text_label = annotation[prefix][0]['transcription']
+ dst_img_name = prefix + '.jpg'
+
+ img_info.append({
+ 'file_name': dst_img_name,
+ 'anno_info': [{
+ 'text': text_label
+ }]
+ })
+
+ ensure_ascii = dict(ensure_ascii=False)
+ dump_ocr_data(img_info, osp.join(root_path, f'{split.lower()}_label.json'),
+ 'textrecog', **ensure_ascii)
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+ print('Processing training set...')
+ convert_art(root_path=root_path, split='train', ratio=args.val_ratio)
+ if args.val_ratio > 0:
+ print('Processing validation set...')
+ convert_art(root_path=root_path, split='val', ratio=args.val_ratio)
+ print('Finish')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textrecog/bid_converter.py b/tools/dataset_converters/textrecog/bid_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..ec61b64bb42effc6194e1661a819224fa02b2c13
--- /dev/null
+++ b/tools/dataset_converters/textrecog/bid_converter.py
@@ -0,0 +1,247 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+
+import mmcv
+import mmengine
+
+from mmocr.utils import crop_img, dump_ocr_data
+
+
+def collect_files(img_dir, gt_dir):
+ """Collect all images and their corresponding groundtruth files.
+
+ Args:
+ img_dir (str): The image directory
+ gt_dir (str): The groundtruth directory
+
+ Returns:
+ files (list): The list of tuples (img_file, groundtruth_file)
+ """
+ assert isinstance(img_dir, str)
+ assert img_dir
+ assert isinstance(gt_dir, str)
+ assert gt_dir
+
+ ann_list, imgs_list = [], []
+ for img_file in os.listdir(img_dir):
+ ann_file = img_file.split('_')[0] + '_gt_ocr.txt'
+ ann_list.append(osp.join(gt_dir, ann_file))
+ imgs_list.append(osp.join(img_dir, img_file))
+
+ files = list(zip(imgs_list, ann_list))
+ assert len(files), f'No images found in {img_dir}'
+ print(f'Loaded {len(files)} images from {img_dir}')
+
+ return files
+
+
+def collect_annotations(files, nproc=1):
+ """Collect the annotation information.
+
+ Args:
+ files (list): The list of tuples (image_file, groundtruth_file)
+ nproc (int): The number of process to collect annotations
+
+ Returns:
+ images (list): The list of image information dicts
+ """
+ assert isinstance(files, list)
+ assert isinstance(nproc, int)
+
+ if nproc > 1:
+ images = mmengine.track_parallel_progress(
+ load_img_info, files, nproc=nproc)
+ else:
+ images = mmengine.track_progress(load_img_info, files)
+
+ return images
+
+
+def load_img_info(files):
+ """Load the information of one image.
+
+ Args:
+ files (tuple): The tuple of (img_file, groundtruth_file)
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+ assert isinstance(files, tuple)
+
+ img_file, gt_file = files
+ assert osp.basename(gt_file).split('_')[0] == osp.basename(gt_file).split(
+ '_')[0]
+ # read imgs while ignoring orientations
+ img = mmcv.imread(img_file, 'unchanged')
+
+ img_info = dict(
+ file_name=osp.basename(img_file),
+ height=img.shape[0],
+ width=img.shape[1],
+ segm_file=osp.basename(gt_file))
+
+ if osp.splitext(gt_file)[1] == '.txt':
+ img_info = load_txt_info(gt_file, img_info)
+ else:
+ raise NotImplementedError
+
+ return img_info
+
+
+def load_txt_info(gt_file, img_info):
+ """Collect the annotation information.
+
+ The annotation format is as the following:
+ x, y, w, h, text
+ 977, 152, 16, 49, NOME
+ 962, 143, 12, 323, APPINHANESI BLAZEK PASSOTTO
+ 906, 446, 12, 94, 206940361
+ 905, 641, 12, 44, SPTC
+
+ Args:
+ gt_file (str): The path to ground-truth
+ img_info (dict): The dict of the img and annotation information
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+ with open(gt_file, encoding='latin1') as f:
+ anno_info = []
+ for line in f:
+ line = line.strip('\n')
+ # Ignore hard samples
+ if line[0] == '[' or line[0] == 'x':
+ continue
+ ann = line.split(',')
+ bbox = ann[0:4]
+ bbox = [int(coord) for coord in bbox]
+ x, y, w, h = bbox
+ # in case ',' exists in label
+ word = ','.join(ann[4:]) if len(ann[4:]) > 1 else ann[4]
+ # remove the initial space
+ word = word.strip()
+ bbox = [x, y, x + w, y, x + w, y + h, x, y + h]
+
+ anno = dict(bbox=bbox, word=word)
+ anno_info.append(anno)
+
+ img_info.update(anno_info=anno_info)
+
+ return img_info
+
+
+def split_train_val_list(full_list, val_ratio):
+ """Split list by val_ratio.
+
+ Args:
+ full_list (list): List to be splited
+ val_ratio (float): Split ratio for val set
+
+ return:
+ list(list, list): Train_list and val_list
+ """
+ n_total = len(full_list)
+ offset = int(n_total * val_ratio)
+ if n_total == 0 or offset < 1:
+ return [], full_list
+ val_list = full_list[:offset]
+ train_list = full_list[offset:]
+ return [train_list, val_list]
+
+
+def generate_ann(root_path, image_infos, preserve_vertical, val_ratio, format):
+ """Generate cropped annotations and label txt file.
+
+ Args:
+ root_path (str): The root path of the dataset
+ image_infos (list[dict]): A list of dicts of the img and
+ annotation information
+ preserve_vertical (bool): Whether to preserve vertical texts
+ val_ratio (float): Split ratio for val set
+ format (str): Using jsonl(dict) or str to format annotations
+ """
+
+ assert val_ratio <= 1.
+
+ if val_ratio:
+ image_infos = split_train_val_list(image_infos, val_ratio)
+ splits = ['training', 'val']
+
+ else:
+ image_infos = [image_infos]
+ splits = ['training']
+
+ for i, split in enumerate(splits):
+ dst_image_root = osp.join(root_path, 'crops', split)
+ ignore_image_root = osp.join(root_path, 'ignores', split)
+ os.makedirs(dst_image_root, exist_ok=True)
+
+ img_info = []
+ for image_info in image_infos[i]:
+ index = 1
+ src_img_path = osp.join(root_path, 'imgs', image_info['file_name'])
+ image = mmcv.imread(src_img_path)
+ src_img_root = image_info['file_name'].split('.')[0]
+
+ for anno in image_info['anno_info']:
+ word = anno['word']
+ dst_img = crop_img(image, anno['bbox'], 0, 0)
+ h, w, _ = dst_img.shape
+
+ dst_img_name = f'{src_img_root}_{index}.png'
+ index += 1
+ # Skip invalid annotations
+ if min(dst_img.shape) == 0:
+ continue
+ # Skip vertical texts
+ if not preserve_vertical and h / w > 2 and split == 'training':
+ dst_img_path = osp.join(ignore_image_root, dst_img_name)
+ mmcv.imwrite(dst_img, dst_img_path)
+ continue
+
+ dst_img_path = osp.join(dst_image_root, dst_img_name)
+ mmcv.imwrite(dst_img, dst_img_path)
+
+ img_info.append({
+ 'file_name': dst_img_name,
+ 'anno_info': [{
+ 'text': word
+ }]
+ })
+
+ dump_ocr_data(img_info,
+ osp.join(root_path, f'{split.lower()}_label.json'),
+ 'textrecog')
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training and val set of BID ')
+ parser.add_argument('root_path', help='Root dir path of BID')
+ parser.add_argument(
+ '--preserve-vertical',
+ help='Preserve samples containing vertical texts',
+ action='store_true')
+ parser.add_argument(
+ '--val-ratio', help='Split ratio for val set', default=0., type=float)
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='Number of processes')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+ with mmengine.Timer(print_tmpl='It takes {}s to convert BID annotation'):
+ files = collect_files(
+ osp.join(root_path, 'imgs'), osp.join(root_path, 'annotations'))
+ image_infos = collect_annotations(files, nproc=args.nproc)
+ generate_ann(root_path, image_infos, args.preserve_vertical,
+ args.val_ratio, args.format)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textrecog/cocotext_converter.py b/tools/dataset_converters/textrecog/cocotext_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..413c09b6c32c7f31ec86fe46c42d69809986bbf9
--- /dev/null
+++ b/tools/dataset_converters/textrecog/cocotext_converter.py
@@ -0,0 +1,174 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import math
+import os.path as osp
+from functools import partial
+
+import mmcv
+import mmengine
+
+from mmocr.utils import dump_ocr_data
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training and validation set of COCO Text v2 ')
+ parser.add_argument('root_path', help='Root dir path of COCO Text v2')
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='Number of processes')
+ parser.add_argument(
+ '--preserve-vertical',
+ help='Preserve samples containing vertical texts',
+ action='store_true')
+ args = parser.parse_args()
+ return args
+
+
+def process_img(args, src_image_root, dst_image_root, ignore_image_root,
+ preserve_vertical, split):
+ # Dirty hack for multi-processing
+ img_idx, img_info, anns = args
+ src_img = mmcv.imread(osp.join(src_image_root, img_info['file_name']))
+ label = []
+ for ann_idx, ann in enumerate(anns):
+ text_label = ann['utf8_string']
+
+ # Ignore illegible or non-English words
+ if ann['language'] == 'not english':
+ continue
+ if ann['legibility'] == 'illegible':
+ continue
+
+ x, y, w, h = ann['bbox']
+ x, y = max(0, math.floor(x)), max(0, math.floor(y))
+ w, h = math.ceil(w), math.ceil(h)
+ dst_img = src_img[y:y + h, x:x + w]
+ dst_img_name = f'img_{img_idx}_{ann_idx}.jpg'
+
+ if not preserve_vertical and h / w > 2 and split == 'train':
+ dst_img_path = osp.join(ignore_image_root, dst_img_name)
+ mmcv.imwrite(dst_img, dst_img_path)
+ continue
+
+ dst_img_path = osp.join(dst_image_root, dst_img_name)
+ mmcv.imwrite(dst_img, dst_img_path)
+
+ label.append({
+ 'file_name': dst_img_name,
+ 'anno_info': [{
+ 'text': text_label
+ }]
+ })
+
+ return label
+
+
+def convert_cocotext(root_path,
+ split,
+ preserve_vertical,
+ nproc,
+ img_start_idx=0):
+ """Collect the annotation information and crop the images.
+
+ The annotation format is as the following:
+ {
+ 'anns':{
+ '45346':{
+ 'mask': [468.9,286.7,468.9,295.2,493.0,295.8,493.0,287.2],
+ 'class': 'machine printed',
+ 'bbox': [468.9, 286.7, 24.1, 9.1], # x, y, w, h
+ 'image_id': 217925,
+ 'id': 45346,
+ 'language': 'english', # 'english' or 'not english'
+ 'area': 206.06,
+ 'utf8_string': 'New',
+ 'legibility': 'legible', # 'legible' or 'illegible'
+ },
+ ...
+ }
+ 'imgs':{
+ '540965':{
+ 'id': 540965,
+ 'set': 'train', # 'train' or 'val'
+ 'width': 640,
+ 'height': 360,
+ 'file_name': 'COCO_train2014_000000540965.jpg'
+ },
+ ...
+ }
+ 'imgToAnns':{
+ '540965': [],
+ '260932': [63993, 63994, 63995, 63996, 63997, 63998, 63999],
+ ...
+ }
+ }
+
+ Args:
+ root_path (str): Root path to the dataset
+ split (str): Dataset split, which should be 'train' or 'val'
+ preserve_vertical (bool): Whether to preserve vertical texts
+ nproc (int): Number of processes
+ img_start_idx (int): Index of start image
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+
+ annotation_path = osp.join(root_path, 'annotations/cocotext.v2.json')
+ if not osp.exists(annotation_path):
+ raise Exception(
+ f'{annotation_path} not exists, please check and try again.')
+
+ annotation = mmengine.load(annotation_path)
+ # outputs
+ dst_label_file = osp.join(root_path, f'{split}_label.json')
+ dst_image_root = osp.join(root_path, 'crops', split)
+ ignore_image_root = osp.join(root_path, 'ignores', split)
+ src_image_root = osp.join(root_path, 'imgs')
+ mmengine.mkdir_or_exist(dst_image_root)
+ mmengine.mkdir_or_exist(ignore_image_root)
+
+ process_img_with_path = partial(
+ process_img,
+ src_image_root=src_image_root,
+ dst_image_root=dst_image_root,
+ ignore_image_root=ignore_image_root,
+ preserve_vertical=preserve_vertical,
+ split=split)
+ tasks = []
+ for img_idx, img_info in enumerate(annotation['imgs'].values()):
+ if img_info['set'] == split:
+ ann_ids = annotation['imgToAnns'][str(img_info['id'])]
+ anns = [annotation['anns'][str(ann_id)] for ann_id in ann_ids]
+ tasks.append((img_idx + img_start_idx, img_info, anns))
+ labels_list = mmengine.track_parallel_progress(
+ process_img_with_path, tasks, keep_order=True, nproc=nproc)
+ final_labels = []
+ for label_list in labels_list:
+ final_labels += label_list
+ dump_ocr_data(final_labels, dst_label_file, 'textrecog')
+
+ return len(annotation['imgs'])
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+ print('Processing training set...')
+ num_train_imgs = convert_cocotext(
+ root_path=root_path,
+ split='train',
+ preserve_vertical=args.preserve_vertical,
+ nproc=args.nproc)
+ print('Processing validation set...')
+ convert_cocotext(
+ root_path=root_path,
+ split='val',
+ preserve_vertical=args.preserve_vertical,
+ nproc=args.nproc,
+ img_start_idx=num_train_imgs)
+ print('Finish')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textrecog/data_migrator.py b/tools/dataset_converters/textrecog/data_migrator.py
new file mode 100644
index 0000000000000000000000000000000000000000..9fb0f205b67a4d55bb1208feba4e4db65c0b78e8
--- /dev/null
+++ b/tools/dataset_converters/textrecog/data_migrator.py
@@ -0,0 +1,98 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import json
+from typing import List, Tuple
+
+from mmocr.datasets import RecogLMDBDataset
+from mmocr.utils import StringStripper, dump_ocr_data, recog_anno_to_imginfo
+
+
+def parse_legacy_data(in_path: str,
+ format: str) -> Tuple[List[str], List[str]]:
+ """Load legacy data and return a list of file paths and labels.
+
+ Args:
+ in_path (str): Path to annotation file.
+ format (str): Annotation format. Choices are 'txt', 'json' and 'lmdb'.
+ For 'lmdb' format, the lmdb file should only contains labels. For
+ lmdb file with labels and images, the conversion is unnecessary.
+ Returns:
+ tuple(list[str], list[str]): File paths and labels.
+ """
+ file_paths = []
+ labels = []
+ strip_cls = StringStripper()
+ if format == 'lmdb':
+ dataset = RecogLMDBDataset(
+ in_path,
+ parser_cfg=dict(type='LineJsonParser', keys=['filename', 'text']))
+ for data_info in dataset:
+ file_path = data_info['img_path']
+ label = data_info['instances'][0]['text']
+ file_path = strip_cls(file_path)
+ label = strip_cls(label)
+ # MJ's file_path starts with './'
+ if file_path.startswith('./'):
+ file_path = file_path[2:]
+
+ file_paths.append(file_path)
+ labels.append(label)
+ return file_paths, labels
+ else:
+ with open(in_path) as f:
+ if format == 'txt':
+ for line in f:
+ line = strip_cls(line)
+ file_path, label = line.split()[:2]
+ # MJ's file_path starts with './'
+ if file_path.startswith('./'):
+ file_path = file_path[2:]
+
+ file_paths.append(file_path)
+ labels.append(label)
+ elif format == 'jsonl':
+ for line in f:
+ datum = json.loads(line)
+ file_path = datum['filename']
+ # MJ's file_path starts with './'
+ if file_path.startswith('./'):
+ file_path = file_path[2:]
+
+ file_paths.append(file_path)
+ labels.append(datum['text'])
+
+ return file_paths, labels
+
+
+def parse_args():
+ """Parse input arguments."""
+ parser = argparse.ArgumentParser(
+ description='Convert annotations for'
+ 'text recognition tasks in MMOCR 0.x into the latest openmmlab format.'
+ )
+ parser.add_argument(
+ 'in_path', help='The path to legacy recognition data file')
+ parser.add_argument(
+ 'out_path', help='The output json path in openmmlab format')
+ parser.add_argument(
+ '--format',
+ choices=['txt', 'jsonl', 'lmdb'],
+ type=str,
+ default='txt',
+ help='Legacy data format')
+ args = parser.parse_args()
+ if args.out_path.split('.')[-1] != 'json':
+ raise ValueError('The output path must be a json file.')
+ return args
+
+
+def main():
+ args = parse_args()
+ file_paths, labels = parse_legacy_data(args.in_path, args.format)
+ img_infos = recog_anno_to_imginfo(file_paths, labels)
+ dump_ocr_data(img_infos, args.out_path, 'textrecog')
+ print('finish')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textrecog/detext_converter.py b/tools/dataset_converters/textrecog/detext_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..360dc5a6f4555d45fb69533f033710eb58e12cad
--- /dev/null
+++ b/tools/dataset_converters/textrecog/detext_converter.py
@@ -0,0 +1,212 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+
+import mmcv
+import mmengine
+import numpy as np
+
+from mmocr.utils import crop_img, dump_ocr_data
+
+
+def collect_files(img_dir, gt_dir):
+ """Collect all images and their corresponding groundtruth files.
+
+ Args:
+ img_dir (str): The image directory
+ gt_dir (str): The groundtruth directory
+
+ Returns:
+ files (list): The list of tuples (img_file, groundtruth_file)
+ """
+ assert isinstance(img_dir, str)
+ assert img_dir
+ assert isinstance(gt_dir, str)
+ assert gt_dir
+
+ ann_list, imgs_list = [], []
+ for img in os.listdir(img_dir):
+ imgs_list.append(osp.join(img_dir, img))
+ ann_list.append(osp.join(gt_dir, 'gt_' + img.replace('jpg', 'txt')))
+
+ files = list(zip(imgs_list, ann_list))
+ assert len(files), f'No images found in {img_dir}'
+ print(f'Loaded {len(files)} images from {img_dir}')
+
+ return files
+
+
+def collect_annotations(files, nproc=1):
+ """Collect the annotation information.
+
+ Args:
+ files (list): The list of tuples (image_file, groundtruth_file)
+ nproc (int): The number of process to collect annotations
+
+ Returns:
+ images (list): The list of image information dicts
+ """
+ assert isinstance(files, list)
+ assert isinstance(nproc, int)
+
+ if nproc > 1:
+ images = mmengine.track_parallel_progress(
+ load_img_info, files, nproc=nproc)
+ else:
+ images = mmengine.track_progress(load_img_info, files)
+
+ return images
+
+
+def load_img_info(files):
+ """Load the information of one image.
+
+ Args:
+ files (tuple): The tuple of (img_file, groundtruth_file)
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+ assert isinstance(files, tuple)
+
+ img_file, gt_file = files
+ # read imgs while ignoring orientations
+ img = mmcv.imread(img_file, 'unchanged')
+
+ img_info = dict(
+ file_name=osp.join(osp.basename(img_file)),
+ height=img.shape[0],
+ width=img.shape[1],
+ segm_file=osp.join(osp.basename(gt_file)))
+
+ if osp.splitext(gt_file)[1] == '.txt':
+ img_info = load_txt_info(gt_file, img_info)
+ else:
+ raise NotImplementedError
+
+ return img_info
+
+
+def load_txt_info(gt_file, img_info):
+ """Collect the annotation information.
+
+ Args:
+ gt_file (str): The path to ground-truth
+ img_info (dict): The dict of the img and annotation information
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+
+ with open(gt_file) as f:
+ anno_info = []
+ annotations = f.readlines()
+ for ann in annotations:
+ # Annotation format [x1, y1, x2, y2, x3, y3, x4, y4, transcript]
+ try:
+ bbox = np.array(ann.split(',')[0:8]).astype(int).tolist()
+ except ValueError:
+ # Skip invalid annotation line
+ continue
+ word = ann.split(',')[-1].replace('\n', '').strip()
+
+ # Skip samples without recog gt
+ if word == '###':
+ continue
+ anno = dict(bbox=bbox, word=word)
+ anno_info.append(anno)
+
+ img_info.update(anno_info=anno_info)
+
+ return img_info
+
+
+def generate_ann(root_path, split, image_infos, preserve_vertical):
+ """Generate cropped annotations and label txt file.
+
+ Args:
+ root_path (str): The root path of the dataset
+ split (str): The split of dataset. Namely: training or test
+ image_infos (list[dict]): A list of dicts of the img and
+ annotation information
+ preserve_vertical (bool): Whether to preserve vertical texts
+ """
+
+ dst_image_root = osp.join(root_path, 'crops', split)
+ ignore_image_root = osp.join(root_path, 'ignores', split)
+ if split == 'training':
+ dst_label_file = osp.join(root_path, 'train_label.json')
+ elif split == 'val':
+ dst_label_file = osp.join(root_path, 'val_label.json')
+ mmengine.mkdir_or_exist(dst_image_root)
+ mmengine.mkdir_or_exist(ignore_image_root)
+
+ img_info = []
+ for image_info in image_infos:
+ index = 1
+ src_img_path = osp.join(root_path, 'imgs', split,
+ image_info['file_name'])
+ image = mmcv.imread(src_img_path)
+ src_img_root = image_info['file_name'].split('.')[0]
+
+ for anno in image_info['anno_info']:
+ word = anno['word']
+ dst_img = crop_img(image, anno['bbox'], 0, 0)
+ h, w, _ = dst_img.shape
+
+ dst_img_name = f'{src_img_root}_{index}.png'
+ index += 1
+ # Skip invalid annotations
+ if min(dst_img.shape) == 0 or len(word) == 0:
+ continue
+ # Filter out vertical texts
+ if not preserve_vertical and h / w > 2 and split == 'training':
+ dst_img_path = osp.join(ignore_image_root, dst_img_name)
+ mmcv.imwrite(dst_img, dst_img_path)
+ continue
+
+ dst_img_path = osp.join(dst_image_root, dst_img_name)
+ mmcv.imwrite(dst_img, dst_img_path)
+
+ img_info.append({
+ 'file_name': dst_img_name,
+ 'anno_info': [{
+ 'text': word
+ }]
+ })
+
+ dump_ocr_data(img_info, dst_label_file, 'textrecog')
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training and val set of DeText ')
+ parser.add_argument('root_path', help='Root dir path of DeText')
+ parser.add_argument(
+ '--preserve-vertical',
+ help='Preserve samples containing vertical texts',
+ action='store_true')
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='Number of process')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+
+ for split in ['training', 'val']:
+ print(f'Processing {split} set...')
+ with mmengine.Timer(
+ print_tmpl='It takes {}s to convert DeText annotation'):
+ files = collect_files(
+ osp.join(root_path, 'imgs', split),
+ osp.join(root_path, 'annotations', split))
+ image_infos = collect_annotations(files, nproc=args.nproc)
+ generate_ann(root_path, split, image_infos, args.preserve_vertical)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textrecog/funsd_converter.py b/tools/dataset_converters/textrecog/funsd_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..a8da8ab00183f20ec749585bde1bb6958a48f9d0
--- /dev/null
+++ b/tools/dataset_converters/textrecog/funsd_converter.py
@@ -0,0 +1,210 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import math
+import os
+import os.path as osp
+
+import mmcv
+import mmengine
+
+from mmocr.utils import crop_img, dump_ocr_data
+
+
+def collect_files(img_dir, gt_dir):
+ """Collect all images and their corresponding groundtruth files.
+
+ Args:
+ img_dir (str): The image directory
+ gt_dir (str): The groundtruth directory
+
+ Returns:
+ files (list): The list of tuples (img_file, groundtruth_file)
+ """
+ assert isinstance(img_dir, str)
+ assert img_dir
+ assert isinstance(gt_dir, str)
+ assert gt_dir
+
+ ann_list, imgs_list = [], []
+ for gt_file in os.listdir(gt_dir):
+ ann_list.append(osp.join(gt_dir, gt_file))
+ imgs_list.append(osp.join(img_dir, gt_file.replace('.json', '.png')))
+
+ files = list(zip(sorted(imgs_list), sorted(ann_list)))
+ assert len(files), f'No images found in {img_dir}'
+ print(f'Loaded {len(files)} images from {img_dir}')
+
+ return files
+
+
+def collect_annotations(files, nproc=1):
+ """Collect the annotation information.
+
+ Args:
+ files (list): The list of tuples (image_file, groundtruth_file)
+ nproc (int): The number of process to collect annotations
+
+ Returns:
+ images (list): The list of image information dicts
+ """
+ assert isinstance(files, list)
+ assert isinstance(nproc, int)
+
+ if nproc > 1:
+ images = mmengine.track_parallel_progress(
+ load_img_info, files, nproc=nproc)
+ else:
+ images = mmengine.track_progress(load_img_info, files)
+
+ return images
+
+
+def load_img_info(files):
+ """Load the information of one image.
+
+ Args:
+ files (tuple): The tuple of (img_file, groundtruth_file)
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+ assert isinstance(files, tuple)
+
+ img_file, gt_file = files
+ assert osp.basename(gt_file).split('.')[0] == osp.basename(img_file).split(
+ '.')[0]
+ # read imgs while ignoring orientations
+ img = mmcv.imread(img_file, 'unchanged')
+
+ img_info = dict(
+ file_name=osp.join(osp.basename(img_file)),
+ height=img.shape[0],
+ width=img.shape[1],
+ segm_file=osp.join(osp.basename(gt_file)))
+
+ if osp.splitext(gt_file)[1] == '.json':
+ img_info = load_json_info(gt_file, img_info)
+ else:
+ raise NotImplementedError
+
+ return img_info
+
+
+def load_json_info(gt_file, img_info):
+ """Collect the annotation information.
+
+ Args:
+ gt_file (str): The path to ground-truth
+ img_info (dict): The dict of the img and annotation information
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+
+ annotation = mmengine.load(gt_file)
+ anno_info = []
+ for form in annotation['form']:
+ for ann in form['words']:
+
+ # Ignore illegible samples
+ if len(ann['text']) == 0:
+ continue
+
+ x1, y1, x2, y2 = ann['box']
+ x = max(0, min(math.floor(x1), math.floor(x2)))
+ y = max(0, min(math.floor(y1), math.floor(y2)))
+ w, h = math.ceil(abs(x2 - x1)), math.ceil(abs(y2 - y1))
+ bbox = [x, y, x + w, y, x + w, y + h, x, y + h]
+ word = ann['text']
+
+ anno = dict(bbox=bbox, word=word)
+ anno_info.append(anno)
+
+ img_info.update(anno_info=anno_info)
+
+ return img_info
+
+
+def generate_ann(root_path, split, image_infos, preserve_vertical):
+ """Generate cropped annotations and label txt file.
+
+ Args:
+ root_path (str): The root path of the dataset
+ split (str): The split of dataset. Namely: training or test
+ image_infos (list[dict]): A list of dicts of the img and
+ annotation information
+ preserve_vertical (bool): Whether to preserve vertical texts
+ """
+
+ dst_image_root = osp.join(root_path, 'crops', split)
+ if split == 'training':
+ dst_label_file = osp.join(root_path, 'train_label.json')
+ elif split == 'test':
+ dst_label_file = osp.join(root_path, 'test_label.json')
+ os.makedirs(dst_image_root, exist_ok=True)
+
+ img_info = []
+ for image_info in image_infos:
+ index = 1
+ src_img_path = osp.join(root_path, 'imgs', image_info['file_name'])
+ image = mmcv.imread(src_img_path)
+ src_img_root = image_info['file_name'].split('.')[0]
+
+ for anno in image_info['anno_info']:
+ word = anno['word']
+ dst_img = crop_img(image, anno['bbox'])
+ h, w, _ = dst_img.shape
+
+ # Skip invalid annotations
+ if min(dst_img.shape) == 0:
+ continue
+ # Skip vertical texts
+ if not preserve_vertical and h / w > 2:
+ continue
+
+ dst_img_name = f'{src_img_root}_{index}.png'
+ index += 1
+ dst_img_path = osp.join(dst_image_root, dst_img_name)
+ mmcv.imwrite(dst_img, dst_img_path)
+
+ img_info.append({
+ 'file_name': dst_img_name,
+ 'anno_info': [{
+ 'text': word
+ }]
+ })
+
+ dump_ocr_data(img_info, dst_label_file, 'textrecog')
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training and test set of FUNSD ')
+ parser.add_argument('root_path', help='Root dir path of FUNSD')
+ parser.add_argument(
+ '--preserve_vertical',
+ help='Preserve samples containing vertical texts',
+ action='store_true')
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='Number of processes')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+
+ for split in ['training', 'test']:
+ print(f'Processing {split} set...')
+ with mmengine.Timer(
+ print_tmpl='It takes {}s to convert FUNSD annotation'):
+ files = collect_files(
+ osp.join(root_path, 'imgs'),
+ osp.join(root_path, 'annotations', split))
+ image_infos = collect_annotations(files, nproc=args.nproc)
+ generate_ann(root_path, split, image_infos, args.preserve_vertical)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textrecog/hiertext_converter.py b/tools/dataset_converters/textrecog/hiertext_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..948142446e30ceea2c1b58cbcd7aec930a982482
--- /dev/null
+++ b/tools/dataset_converters/textrecog/hiertext_converter.py
@@ -0,0 +1,236 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import json
+import math
+import os.path as osp
+from functools import partial
+
+import mmcv
+import mmengine
+import numpy as np
+from shapely.geometry import Polygon
+
+from mmocr.utils import dump_ocr_data
+
+
+def seg2bbox(seg):
+ """Convert segmentation to bbox.
+
+ Args:
+ seg (list(int | float)): A set of coordinates
+ """
+ if len(seg) == 4:
+ min_x = min(seg[0], seg[2], seg[4], seg[6])
+ max_x = max(seg[0], seg[2], seg[4], seg[6])
+ min_y = min(seg[1], seg[3], seg[5], seg[7])
+ max_y = max(seg[1], seg[3], seg[5], seg[7])
+ else:
+ seg = np.array(seg).reshape(-1, 2)
+ polygon = Polygon(seg)
+ min_x, min_y, max_x, max_y = polygon.bounds
+ bbox = [min_x, min_y, max_x - min_x, max_y - min_y]
+ return bbox
+
+
+def process_level(
+ src_img,
+ annotation,
+ dst_image_root,
+ ignore_image_root,
+ preserve_vertical,
+ split,
+ para_idx,
+ img_idx,
+ line_idx,
+ word_idx=None,
+):
+ vertices = annotation['vertices']
+ text_label = annotation['text']
+ segmentation = [i for j in vertices for i in j]
+ x, y, w, h = seg2bbox(segmentation)
+ x, y = max(0, math.floor(x)), max(0, math.floor(y))
+ w, h = math.ceil(w), math.ceil(h)
+ dst_img = src_img[y:y + h, x:x + w]
+ if word_idx:
+ dst_img_name = f'img_{img_idx}_{para_idx}_{line_idx}_{word_idx}.jpg'
+ else:
+ dst_img_name = f'img_{img_idx}_{para_idx}_{line_idx}.jpg'
+ if not preserve_vertical and h / w > 2 and split == 'train':
+ dst_img_path = osp.join(ignore_image_root, dst_img_name)
+ mmcv.imwrite(dst_img, dst_img_path)
+ return None
+
+ dst_img_path = osp.join(dst_image_root, dst_img_name)
+ mmcv.imwrite(dst_img, dst_img_path)
+
+ label = {'file_name': dst_img_name, 'anno_info': [{'text': text_label}]}
+
+ return label
+
+
+def process_img(args, src_image_root, dst_image_root, ignore_image_root, level,
+ preserve_vertical, split):
+ # Dirty hack for multi-processing
+ img_idx, img_annos = args
+ src_img = mmcv.imread(
+ osp.join(src_image_root, img_annos['image_id'] + '.jpg'))
+ labels = []
+ for para_idx, paragraph in enumerate(img_annos['paragraphs']):
+ for line_idx, line in enumerate(paragraph['lines']):
+ if level == 'line':
+ # Ignore illegible words
+ if line['legible']:
+
+ label = process_level(src_img, line, dst_image_root,
+ ignore_image_root, preserve_vertical,
+ split, para_idx, img_idx, line_idx)
+ if label is not None:
+ labels.append(label)
+ elif level == 'word':
+ for word_idx, word in enumerate(line['words']):
+ if not word['legible']:
+ continue
+ label = process_level(src_img, word, dst_image_root,
+ ignore_image_root, preserve_vertical,
+ split, para_idx, img_idx, line_idx,
+ word_idx)
+ if label is not None:
+ labels.append(label)
+ return labels
+
+
+def convert_hiertext(
+ root_path,
+ split,
+ level,
+ preserve_vertical,
+ nproc,
+):
+ """Collect the annotation information and crop the images.
+
+ The annotation format is as the following:
+ {
+ "info": {
+ "date": "release date",
+ "version": "current version"
+ },
+ "annotations": [ // List of dictionaries, one for each image.
+ {
+ "image_id": "the filename of corresponding image.",
+ "image_width": image_width, // (int) The image width.
+ "image_height": image_height, // (int) The image height.
+ "paragraphs": [ // List of paragraphs.
+ {
+ "vertices": [[x1, y1], [x2, y2],...,[xn, yn]]
+ "legible": true
+ "lines": [
+ {
+ "vertices": [[x1, y1], [x2, y2],...,[x4, y4]]
+ "text": L
+ "legible": true,
+ "handwritten": false
+ "vertical": false,
+ "words": [
+ {
+ "vertices": [[x1, y1], [x2, y2],...,[xm, ym]]
+ "text": "the text content of this word",
+ "legible": true
+ "handwritten": false,
+ "vertical": false,
+ }, ...
+ ]
+ }, ...
+ ]
+ }, ...
+ ]
+ }, ...
+ ]
+ }
+
+ Args:
+ root_path (str): Root path to the dataset
+ split (str): Dataset split, which should be 'train' or 'val'
+ level (str): Crop word or line level instances
+ preserve_vertical (bool): Whether to preserve vertical texts
+ nproc (int): Number of processes
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+
+ annotation_path = osp.join(root_path, 'annotations/' + split + '.jsonl')
+ if not osp.exists(annotation_path):
+ raise Exception(
+ f'{annotation_path} not exists, please check and try again.')
+
+ annotation = json.load(open(annotation_path))['annotations']
+ # outputs
+ dst_label_file = osp.join(root_path, f'{split}_label.json')
+ dst_image_root = osp.join(root_path, 'crops', split)
+ ignore_image_root = osp.join(root_path, 'ignores', split)
+ src_image_root = osp.join(root_path, 'imgs', split)
+ mmengine.mkdir_or_exist(dst_image_root)
+ mmengine.mkdir_or_exist(ignore_image_root)
+
+ process_img_with_path = partial(
+ process_img,
+ src_image_root=src_image_root,
+ dst_image_root=dst_image_root,
+ ignore_image_root=ignore_image_root,
+ level=level,
+ preserve_vertical=preserve_vertical,
+ split=split)
+ tasks = []
+ for img_idx, img_info in enumerate(annotation):
+ tasks.append((img_idx, img_info))
+ labels_list = mmengine.track_parallel_progress(
+ process_img_with_path, tasks, keep_order=True, nproc=nproc)
+
+ final_labels = []
+ for label_list in labels_list:
+ final_labels += label_list
+
+ dump_ocr_data(final_labels, dst_label_file, 'textrecog')
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training and validation set of HierText')
+ parser.add_argument('root_path', help='Root dir path of HierText')
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='Number of processes')
+ parser.add_argument(
+ '--preserve-vertical',
+ help='Preserve samples containing vertical texts',
+ action='store_true')
+ parser.add_argument(
+ '--level',
+ default='word',
+ help='Crop word or line level instance',
+ choices=['word', 'line'])
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+ print('Processing training set...')
+ convert_hiertext(
+ root_path=root_path,
+ split='train',
+ level=args.level,
+ preserve_vertical=args.preserve_vertical,
+ nproc=args.nproc)
+ print('Processing validation set...')
+ convert_hiertext(
+ root_path=root_path,
+ split='val',
+ level=args.level,
+ preserve_vertical=args.preserve_vertical,
+ nproc=args.nproc)
+ print('Finish')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textrecog/ic11_converter.py b/tools/dataset_converters/textrecog/ic11_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..3de125d39bd87c137b2ed1d470fa6bcfd19836ba
--- /dev/null
+++ b/tools/dataset_converters/textrecog/ic11_converter.py
@@ -0,0 +1,66 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+
+from mmocr.utils import dump_ocr_data
+
+
+def convert_annotations(root_path, split):
+ """Convert original annotations to mmocr format.
+
+ The annotation format of this dataset is as the following:
+ word_1.png, "flying"
+ word_2.png, "today"
+ word_3.png, "means"
+ See the format of converted annotation in mmocr.utils.dump_ocr_data.
+
+ Args:
+ root_path (str): The root path of the dataset
+ split (str): The split of dataset. Namely: Train or Test
+ """
+ assert isinstance(root_path, str)
+ assert isinstance(split, str)
+
+ img_info = []
+ with open(
+ osp.join(root_path, 'annotations',
+ f'Challenge1_{split}_Task3_GT.txt'),
+ encoding='"utf-8-sig') as f:
+ annos = f.readlines()
+ for anno in annos:
+ # text may contain comma ','
+ dst_img_name, word = anno.split(', "')
+ word = word.replace('"\n', '')
+
+ img_info.append({
+ 'file_name': dst_img_name,
+ 'anno_info': [{
+ 'text': word
+ }]
+ })
+
+ return img_info
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training and test set of IC11')
+ parser.add_argument('root_path', help='Root dir path of IC11')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+
+ for split in ['Train', 'Test']:
+ img_info = convert_annotations(root_path, split)
+ dump_ocr_data(img_info,
+ osp.join(root_path, f'{split.lower()}_label.json'),
+ 'textrecog')
+ print(f'{split} split converted.')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textrecog/ilst_converter.py b/tools/dataset_converters/textrecog/ilst_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..01ce4bd17f57bf1281fe3b254e39d37c0f92c7a7
--- /dev/null
+++ b/tools/dataset_converters/textrecog/ilst_converter.py
@@ -0,0 +1,260 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+import xml.etree.ElementTree as ET
+
+import mmcv
+import mmengine
+
+from mmocr.utils import crop_img, dump_ocr_data
+
+
+def collect_files(img_dir, gt_dir):
+ """Collect all images and their corresponding groundtruth files.
+
+ Args:
+ img_dir (str): The image directory
+ gt_dir (str): The groundtruth directory
+
+ Returns:
+ files (list): The list of tuples (img_file, groundtruth_file)
+ """
+ assert isinstance(img_dir, str)
+ assert img_dir
+ assert isinstance(gt_dir, str)
+ assert gt_dir
+
+ ann_list, imgs_list = [], []
+ for img_file in os.listdir(img_dir):
+ ann_path = osp.join(gt_dir, img_file.split('.')[0] + '.xml')
+ if os.path.exists(ann_path):
+ ann_list.append(ann_path)
+ imgs_list.append(osp.join(img_dir, img_file))
+
+ files = list(zip(imgs_list, ann_list))
+ assert len(files), f'No images found in {img_dir}'
+ print(f'Loaded {len(files)} images from {img_dir}')
+
+ return files
+
+
+def collect_annotations(files, nproc=1):
+ """Collect the annotation information.
+
+ Args:
+ files (list): The list of tuples (image_file, groundtruth_file)
+ nproc (int): The number of process to collect annotations
+
+ Returns:
+ images (list): The list of image information dicts
+ """
+ assert isinstance(files, list)
+ assert isinstance(nproc, int)
+
+ if nproc > 1:
+ images = mmengine.track_parallel_progress(
+ load_img_info, files, nproc=nproc)
+ else:
+ images = mmengine.track_progress(load_img_info, files)
+
+ return images
+
+
+def load_img_info(files):
+ """Load the information of one image.
+
+ Args:
+ files (tuple): The tuple of (img_file, groundtruth_file)
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+ assert isinstance(files, tuple)
+
+ img_file, gt_file = files
+ assert osp.basename(gt_file).split('.')[0] == osp.basename(img_file).split(
+ '.')[0]
+ # read imgs while ignoring orientations
+ img = mmcv.imread(img_file, 'unchanged')
+
+ try:
+ img_info = dict(
+ file_name=osp.join(osp.basename(img_file)),
+ height=img.shape[0],
+ width=img.shape[1],
+ segm_file=osp.join(osp.basename(gt_file)))
+ except AttributeError:
+ print(f'Skip broken img {img_file}')
+ return None
+
+ if osp.splitext(gt_file)[1] == '.xml':
+ img_info = load_xml_info(gt_file, img_info)
+ else:
+ raise NotImplementedError
+
+ return img_info
+
+
+def load_xml_info(gt_file, img_info):
+ """Collect the annotation information.
+
+ The annotation format is as the following:
+
+ ...
+
+ SMT
+ Unspecified
+ 0
+ 0
+
+ 157
+ 294
+ 237
+ 357
+
+
+
+ Args:
+ gt_file (str): The path to ground-truth
+ img_info (dict): The dict of the img and annotation information
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+ obj = ET.parse(gt_file)
+ root = obj.getroot()
+ anno_info = []
+ for object in root.iter('object'):
+ word = object.find('name').text
+ x1 = int(object.find('bndbox').find('xmin').text)
+ y1 = int(object.find('bndbox').find('ymin').text)
+ x2 = int(object.find('bndbox').find('xmax').text)
+ y2 = int(object.find('bndbox').find('ymax').text)
+
+ x = max(0, min(x1, x2))
+ y = max(0, min(y1, y2))
+ w, h = abs(x2 - x1), abs(y2 - y1)
+ bbox = [x, y, x + w, y, x + w, y + h, x, y + h]
+ anno = dict(bbox=bbox, word=word)
+ anno_info.append(anno)
+
+ img_info.update(anno_info=anno_info)
+
+ return img_info
+
+
+def split_train_val_list(full_list, val_ratio):
+ """Split list by val_ratio.
+
+ Args:
+ full_list (list): List to be splited
+ val_ratio (float): Split ratio for val set
+
+ return:
+ list(list, list): Train_list and val_list
+ """
+ n_total = len(full_list)
+ offset = int(n_total * val_ratio)
+ if n_total == 0 or offset < 1:
+ return [], full_list
+ val_list = full_list[:offset]
+ train_list = full_list[offset:]
+ return [train_list, val_list]
+
+
+def generate_ann(root_path, image_infos, preserve_vertical, val_ratio):
+ """Generate cropped annotations and label txt file.
+
+ Args:
+ root_path (str): The root path of the dataset
+ split (str): The split of dataset. Namely: training or test
+ image_infos (list[dict]): A list of dicts of the img and
+ annotation information
+ preserve_vertical (bool): Whether to preserve vertical texts
+ val_ratio (float): Split ratio for val set
+ """
+
+ assert val_ratio <= 1.
+
+ if val_ratio:
+ image_infos = split_train_val_list(image_infos, val_ratio)
+ splits = ['training', 'val']
+
+ else:
+ image_infos = [image_infos]
+ splits = ['training']
+
+ for i, split in enumerate(splits):
+ dst_image_root = osp.join(root_path, 'crops', split)
+ ignore_image_root = osp.join(root_path, 'ignores', split)
+ dst_label_file = osp.join(root_path, f'{split}_label.json')
+ os.makedirs(dst_image_root, exist_ok=True)
+
+ img_info = []
+ for image_info in image_infos[i]:
+ index = 1
+ src_img_path = osp.join(root_path, 'imgs', image_info['file_name'])
+ image = mmcv.imread(src_img_path)
+ src_img_root = image_info['file_name'].split('.')[0]
+
+ for anno in image_info['anno_info']:
+ word = anno['word']
+ dst_img = crop_img(image, anno['bbox'], 0, 0)
+ h, w, _ = dst_img.shape
+
+ dst_img_name = f'{src_img_root}_{index}.png'
+ index += 1
+ # Skip invalid annotations
+ if min(dst_img.shape) == 0:
+ continue
+ # Skip vertical texts
+ if not preserve_vertical and h / w > 2 and split == 'training':
+ dst_img_path = osp.join(ignore_image_root, dst_img_name)
+ mmcv.imwrite(dst_img, dst_img_path)
+ continue
+
+ dst_img_path = osp.join(dst_image_root, dst_img_name)
+ mmcv.imwrite(dst_img, dst_img_path)
+ img_info.append({
+ 'file_name': dst_img_name,
+ 'anno_info': [{
+ 'text': word
+ }]
+ })
+
+ ensure_ascii = dict(ensure_ascii=False)
+ dump_ocr_data(img_info, dst_label_file, 'textrecog', **ensure_ascii)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training and val set of ILST ')
+ parser.add_argument('root_path', help='Root dir path of ILST')
+ parser.add_argument(
+ '--preserve-vertical',
+ help='Preserve samples containing vertical texts',
+ action='store_true')
+ parser.add_argument(
+ '--val-ratio', help='Split ratio for val set', default=0., type=float)
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='Number of processes')
+ args = parser.parse_args(['data/IIIT-ILST'])
+ return args
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+ with mmengine.Timer(print_tmpl='It takes {}s to convert ILST annotation'):
+ files = collect_files(
+ osp.join(root_path, 'imgs'), osp.join(root_path, 'annotations'))
+ image_infos = collect_annotations(files, nproc=args.nproc)
+ # filter broken images
+ image_infos = list(filter(None, image_infos))
+ generate_ann(root_path, image_infos, args.preserve_vertical,
+ args.val_ratio)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textrecog/imgur_converter.py b/tools/dataset_converters/textrecog/imgur_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..34d161eb3d39674dc5a64d98248e00d8760e0c42
--- /dev/null
+++ b/tools/dataset_converters/textrecog/imgur_converter.py
@@ -0,0 +1,175 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import math
+import os
+import os.path as osp
+
+import mmcv
+import mmengine
+import numpy as np
+
+from mmocr.utils import crop_img, dump_ocr_data
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training, validation and test set of IMGUR ')
+ parser.add_argument('root_path', help='Root dir path of IMGUR')
+ args = parser.parse_args()
+
+ return args
+
+
+def collect_imgur_info(root_path, annotation_filename, print_every=1000):
+
+ annotation_path = osp.join(root_path, 'annotations', annotation_filename)
+ if not osp.exists(annotation_path):
+ raise Exception(
+ f'{annotation_path} not exists, please check and try again.')
+
+ annotation = mmengine.load(annotation_path)
+ images = annotation['index_to_ann_map'].keys()
+ img_infos = []
+ for i, img_name in enumerate(images):
+ if i >= 0 and i % print_every == 0:
+ print(f'{i}/{len(images)}')
+
+ img_path = osp.join(root_path, 'imgs', img_name + '.jpg')
+
+ # Skip not exist images
+ if not osp.exists(img_path):
+ continue
+
+ img = mmcv.imread(img_path, 'unchanged')
+
+ # Skip broken images
+ if img is None:
+ continue
+
+ img_info = dict(
+ file_name=img_name + '.jpg',
+ height=img.shape[0],
+ width=img.shape[1])
+
+ anno_info = []
+ for ann_id in annotation['index_to_ann_map'][img_name]:
+ ann = annotation['ann_id'][ann_id]
+
+ # The original annotation is oriented rects [x, y, w, h, a]
+ box = np.fromstring(
+ ann['bounding_box'][1:-2], sep=',', dtype=float)
+ bbox = convert_oriented_box(box)
+ word = ann['word']
+
+ anno = dict(bbox=bbox, word=word)
+ anno_info.append(anno)
+ img_info.update(anno_info=anno_info)
+ img_infos.append(img_info)
+
+ return img_infos
+
+
+def convert_oriented_box(box):
+
+ x_ctr, y_ctr, width, height, angle = box[:5]
+ angle = -angle * math.pi / 180
+
+ tl_x, tl_y, br_x, br_y = -width / 2, -height / 2, width / 2, height / 2
+ rect = np.array([[tl_x, br_x, br_x, tl_x], [tl_y, tl_y, br_y, br_y]])
+ R = np.array([[np.cos(angle), -np.sin(angle)],
+ [np.sin(angle), np.cos(angle)]])
+ poly = R.dot(rect)
+ x0, x1, x2, x3 = poly[0, :4] + x_ctr
+ y0, y1, y2, y3 = poly[1, :4] + y_ctr
+ poly = np.array([x0, y0, x1, y1, x2, y2, x3, y3], dtype=np.float32)
+ poly = get_best_begin_point_single(poly)
+
+ return poly.tolist()
+
+
+def get_best_begin_point_single(coordinate):
+
+ x1, y1, x2, y2, x3, y3, x4, y4 = coordinate
+ xmin = min(x1, x2, x3, x4)
+ ymin = min(y1, y2, y3, y4)
+ xmax = max(x1, x2, x3, x4)
+ ymax = max(y1, y2, y3, y4)
+ combine = [[[x1, y1], [x2, y2], [x3, y3], [x4, y4]],
+ [[x2, y2], [x3, y3], [x4, y4], [x1, y1]],
+ [[x3, y3], [x4, y4], [x1, y1], [x2, y2]],
+ [[x4, y4], [x1, y1], [x2, y2], [x3, y3]]]
+ dst_coordinate = [[xmin, ymin], [xmax, ymin], [xmax, ymax], [xmin, ymax]]
+ force = 100000000.0
+ force_flag = 0
+ for i in range(4):
+ temp_force = cal_line_length(combine[i][0], dst_coordinate[0]) \
+ + cal_line_length(combine[i][1], dst_coordinate[1]) \
+ + cal_line_length(combine[i][2], dst_coordinate[2]) \
+ + cal_line_length(combine[i][3], dst_coordinate[3])
+ if temp_force < force:
+ force = temp_force
+ force_flag = i
+ if force_flag != 0:
+ pass
+
+ return np.array(combine[force_flag]).reshape(8)
+
+
+def cal_line_length(point1, point2):
+
+ return math.sqrt(
+ math.pow(point1[0] - point2[0], 2) +
+ math.pow(point1[1] - point2[1], 2))
+
+
+def generate_ann(root_path, split, image_infos):
+
+ dst_image_root = osp.join(root_path, 'crops', split)
+ dst_label_file = osp.join(root_path, f'{split}_label.json')
+ os.makedirs(dst_image_root, exist_ok=True)
+
+ img_info = []
+ for image_info in image_infos:
+ index = 1
+ src_img_path = osp.join(root_path, 'imgs', image_info['file_name'])
+ image = mmcv.imread(src_img_path)
+ src_img_root = image_info['file_name'].split('.')[0]
+
+ for anno in image_info['anno_info']:
+ word = anno['word']
+ dst_img = crop_img(image, anno['bbox'], 0, 0)
+
+ # Skip invalid annotations
+ if min(dst_img.shape) == 0:
+ continue
+
+ dst_img_name = f'{src_img_root}_{index}.png'
+ index += 1
+ dst_img_path = osp.join(dst_image_root, dst_img_name)
+ mmcv.imwrite(dst_img, dst_img_path)
+
+ img_info.append({
+ 'file_name': dst_img_name,
+ 'anno_info': [{
+ 'text': word
+ }]
+ })
+
+ dump_ocr_data(img_info, dst_label_file, 'textrecog')
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+
+ for split in ['train', 'val', 'test']:
+ print(f'Processing {split} set...')
+ with mmengine.Timer(
+ print_tmpl='It takes {}s to convert IMGUR annotation'):
+ anno_infos = collect_imgur_info(
+ root_path, f'imgur5k_annotations_{split}.json')
+ generate_ann(root_path, split, anno_infos)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textrecog/kaist_converter.py b/tools/dataset_converters/textrecog/kaist_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..525e9be96d3652746d074bb2e924c62e7bb5b421
--- /dev/null
+++ b/tools/dataset_converters/textrecog/kaist_converter.py
@@ -0,0 +1,259 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import math
+import os
+import os.path as osp
+import xml.etree.ElementTree as ET
+
+import mmcv
+import mmengine
+
+from mmocr.utils import crop_img, dump_ocr_data
+
+
+def collect_files(img_dir, gt_dir, ratio):
+ """Collect all images and their corresponding groundtruth files.
+
+ Args:
+ img_dir (str): The image directory
+ gt_dir (str): The groundtruth directory
+ ratio (float): Split ratio for val set
+
+ Returns:
+ files (list): The list of tuples (img_file, groundtruth_file)
+ """
+ assert isinstance(img_dir, str)
+ assert img_dir
+ assert isinstance(gt_dir, str)
+ assert gt_dir
+ assert isinstance(ratio, float)
+ assert ratio < 1.0, 'val_ratio should be a float between 0.0 to 1.0'
+
+ ann_list, imgs_list = [], []
+ for img_file in os.listdir(img_dir):
+ ann_list.append(osp.join(gt_dir, img_file.split('.')[0] + '.xml'))
+ imgs_list.append(osp.join(img_dir, img_file))
+
+ all_files = list(zip(sorted(imgs_list), sorted(ann_list)))
+ assert len(all_files), f'No images found in {img_dir}'
+ print(f'Loaded {len(all_files)} images from {img_dir}')
+
+ trn_files, val_files = [], []
+ if ratio > 0:
+ for i, file in enumerate(all_files):
+ if i % math.floor(1 / ratio):
+ trn_files.append(file)
+ else:
+ val_files.append(file)
+ else:
+ trn_files, val_files = all_files, []
+
+ print(f'training #{len(trn_files)}, val #{len(val_files)}')
+
+ return trn_files, val_files
+
+
+def collect_annotations(files, nproc=1):
+ """Collect the annotation information.
+
+ Args:
+ files (list): The list of tuples (image_file, groundtruth_file)
+ nproc (int): The number of process to collect annotations
+
+ Returns:
+ images (list): The list of image information dicts
+ """
+ assert isinstance(files, list)
+ assert isinstance(nproc, int)
+
+ if nproc > 1:
+ images = mmengine.track_parallel_progress(
+ load_img_info, files, nproc=nproc)
+ else:
+ images = mmengine.track_progress(load_img_info, files)
+
+ return images
+
+
+def load_img_info(files):
+ """Load the information of one image.
+
+ Args:
+ files (tuple): The tuple of (img_file, groundtruth_file)
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+ assert isinstance(files, tuple)
+
+ img_file, gt_file = files
+ assert osp.basename(gt_file).split('.')[0] == osp.basename(img_file).split(
+ '.')[0]
+ # read imgs while ignoring orientations
+ img = mmcv.imread(img_file, 'unchanged')
+
+ img_info = dict(
+ file_name=osp.join(osp.basename(img_file)),
+ height=img.shape[0],
+ width=img.shape[1],
+ segm_file=osp.join(osp.basename(gt_file)))
+
+ if osp.splitext(gt_file)[1] == '.xml':
+ img_info = load_xml_info(gt_file, img_info)
+ else:
+ raise NotImplementedError
+
+ return img_info
+
+
+def load_xml_info(gt_file, img_info):
+ """Collect the annotation information.
+
+ Annotation Format
+
+ DSC02306.JPG
+
+
+
+
+ no
+ 2
+
+
+
+
+ Args:
+ gt_file (str): The path to ground-truth
+ img_info (dict): The dict of the img and annotation information
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+
+ obj = ET.parse(gt_file)
+ root = obj.getroot()
+ anno_info = []
+ for word in root.iter('word'):
+ x, y = max(0, int(word.attrib['x'])), max(0, int(word.attrib['y']))
+ w, h = int(word.attrib['width']), int(word.attrib['height'])
+ bbox = [x, y, x + w, y, x + w, y + h, x, y + h]
+ chars = []
+ for character in word.iter('character'):
+ chars.append(character.attrib['char'])
+ word = ''.join(chars)
+ if len(word) == 0:
+ continue
+ anno = dict(bbox=bbox, word=word)
+ anno_info.append(anno)
+
+ img_info.update(anno_info=anno_info)
+
+ return img_info
+
+
+def generate_ann(root_path, split, image_infos, preserve_vertical):
+ """Generate cropped annotations and label txt file.
+
+ Args:
+ root_path (str): The root path of the dataset
+ split (str): The split of dataset. Namely: training or test
+ image_infos (list[dict]): A list of dicts of the img and
+ annotation information
+ preserve_vertical (bool): Whether to preserve vertical texts
+ format (str): Annotation format, should be either 'txt' or 'jsonl'
+ """
+
+ dst_image_root = osp.join(root_path, 'crops', split)
+ ignore_image_root = osp.join(root_path, 'ignores', split)
+ if split == 'training':
+ dst_label_file = osp.join(root_path, 'train_label.json')
+ elif split == 'val':
+ dst_label_file = osp.join(root_path, 'val_label.json')
+ mmengine.mkdir_or_exist(dst_image_root)
+ mmengine.mkdir_or_exist(ignore_image_root)
+
+ img_info = []
+ for image_info in image_infos:
+ index = 1
+ src_img_path = osp.join(root_path, 'imgs', image_info['file_name'])
+ image = mmcv.imread(src_img_path)
+ src_img_root = image_info['file_name'].split('.')[0]
+
+ for anno in image_info['anno_info']:
+ word = anno['word']
+ dst_img = crop_img(image, anno['bbox'], 0, 0)
+ h, w, _ = dst_img.shape
+
+ dst_img_name = f'{src_img_root}_{index}.png'
+ index += 1
+ # Skip invalid annotations
+ if min(dst_img.shape) == 0:
+ continue
+ # Filter out vertical texts
+ if not preserve_vertical and h / w > 2:
+ dst_img_path = osp.join(ignore_image_root, dst_img_name)
+ mmcv.imwrite(dst_img, dst_img_path)
+ continue
+
+ dst_img_path = osp.join(dst_image_root, dst_img_name)
+ mmcv.imwrite(dst_img, dst_img_path)
+
+ img_info.append({
+ 'file_name': dst_img_name,
+ 'anno_info': [{
+ 'text': word
+ }]
+ })
+
+ ensure_ascii = dict(ensure_ascii=False)
+ dump_ocr_data(img_info, dst_label_file, 'textrecog', **ensure_ascii)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training and val set of KAIST ')
+ parser.add_argument('root_path', help='Root dir path of KAIST')
+ parser.add_argument(
+ '--val-ratio', help='Split ratio for val set', default=0.0, type=float)
+ parser.add_argument(
+ '--preserve-vertical',
+ help='Preserve samples containing vertical texts',
+ action='store_true')
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='Number of process')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+ ratio = args.val_ratio
+
+ trn_files, val_files = collect_files(
+ osp.join(root_path, 'imgs'), osp.join(root_path, 'annotations'), ratio)
+
+ # Train set
+ trn_infos = collect_annotations(trn_files, nproc=args.nproc)
+ with mmengine.Timer(
+ print_tmpl='It takes {}s to convert KAIST Training annotation'):
+ generate_ann(root_path, 'training', trn_infos, args.preserve_vertical)
+
+ # Val set
+ if len(val_files) > 0:
+ val_infos = collect_annotations(val_files, nproc=args.nproc)
+ with mmengine.Timer(
+ print_tmpl='It takes {}s to convert KAIST Val annotation'):
+ generate_ann(root_path, 'val', val_infos, args.preserve_vertical)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textrecog/lmdb_converter.py b/tools/dataset_converters/textrecog/lmdb_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..68afd28f3cc41ad819faf478e5068e787c4fb32b
--- /dev/null
+++ b/tools/dataset_converters/textrecog/lmdb_converter.py
@@ -0,0 +1,175 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import json
+import os
+import os.path as osp
+
+import cv2
+import lmdb
+import numpy as np
+
+from mmocr.utils import list_from_file
+
+
+def parse_line(line, format):
+ if format == 'txt':
+ img_name, text = line.split(' ')
+ else:
+ line = json.loads(line)
+ img_name = line['filename']
+ text = line['text']
+ return img_name, text
+
+
+def check_image_is_valid(imageBin):
+ if imageBin is None:
+ return False
+ imageBuf = np.frombuffer(imageBin, dtype=np.uint8)
+ img = cv2.imdecode(imageBuf, cv2.IMREAD_GRAYSCALE)
+ imgH, imgW = img.shape[0], img.shape[1]
+ if imgH * imgW == 0:
+ return False
+ return True
+
+
+def write_cache(env, cache):
+ with env.begin(write=True) as txn:
+ cursor = txn.cursor()
+ cursor.putmulti(cache, dupdata=False, overwrite=True)
+
+
+def recog2lmdb(img_root,
+ label_path,
+ output,
+ label_format='txt',
+ label_only=False,
+ batch_size=1000,
+ encoding='utf-8',
+ lmdb_map_size=1099511627776,
+ verify=True):
+ """Create text recognition dataset to LMDB format.
+
+ Args:
+ img_root (str): Path to images.
+ label_path (str): Path to label file.
+ output (str): LMDB output path.
+ label_format (str): Format of the label file, either txt or jsonl.
+ label_only (bool): Only convert label to lmdb format.
+ batch_size (int): Number of files written to the cache each time.
+ encoding (str): Label encoding method.
+ lmdb_map_size (int): Maximum size database may grow to.
+ verify (bool): If true, check the validity of
+ every image.Defaults to True.
+
+ E.g.
+ This function supports MMOCR's recognition data format and the label file
+ can be txt or jsonl, as follows:
+
+ ├──img_root
+ | |—— img1.jpg
+ | |—— img2.jpg
+ | |—— ...
+ |——label.txt (or label.jsonl)
+
+ label.txt: img1.jpg HELLO
+ img2.jpg WORLD
+ ...
+
+ label.jsonl: {'filename':'img1.jpg', 'text':'HELLO'}
+ {'filename':'img2.jpg', 'text':'WORLD'}
+ ...
+ """
+ # check label format
+ assert osp.basename(label_path).split('.')[-1] == label_format
+ # create lmdb env
+ os.makedirs(output, exist_ok=True)
+ env = lmdb.open(output, map_size=lmdb_map_size)
+ # load label file
+ anno_list = list_from_file(label_path, encoding=encoding)
+ cache = []
+ # index start from 1
+ cnt = 1
+ n_samples = len(anno_list)
+ for anno in anno_list:
+ label_key = 'label-%09d'.encode(encoding) % cnt
+ img_name, text = parse_line(anno, label_format)
+ if label_only:
+ # convert only labels to lmdb
+ line = json.dumps(
+ dict(filename=img_name, text=text), ensure_ascii=False)
+ cache.append((label_key, line.encode(encoding)))
+ else:
+ # convert both images and labels to lmdb
+ img_path = osp.join(img_root, img_name)
+ if not osp.exists(img_path):
+ print('%s does not exist' % img_path)
+ continue
+ with open(img_path, 'rb') as f:
+ image_bin = f.read()
+ if verify:
+ try:
+ if not check_image_is_valid(image_bin):
+ print('%s is not a valid image' % img_path)
+ continue
+ except Exception:
+ print('error occurred at ', img_name)
+ image_key = 'image-%09d'.encode(encoding) % cnt
+ cache.append((image_key, image_bin))
+ cache.append((label_key, text.encode(encoding)))
+
+ if cnt % batch_size == 0:
+ write_cache(env, cache)
+ cache = []
+ print('Written %d / %d' % (cnt, n_samples))
+ cnt += 1
+ n_samples = cnt - 1
+ cache.append(
+ ('num-samples'.encode(encoding), str(n_samples).encode(encoding)))
+ write_cache(env, cache)
+ print('Created lmdb dataset with %d samples' % n_samples)
+
+
+def main():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('label_path', type=str, help='Path to label file')
+ parser.add_argument('output', type=str, help='Output lmdb path')
+ parser.add_argument(
+ '--img-root', '-i', type=str, help='Input imglist path')
+ parser.add_argument(
+ '--label-only',
+ action='store_true',
+ help='Only converter label to lmdb')
+ parser.add_argument(
+ '--label-format',
+ '-f',
+ default='txt',
+ choices=['txt', 'jsonl'],
+ help='The format of the label file, either txt or jsonl')
+ parser.add_argument(
+ '--batch-size',
+ '-b',
+ type=int,
+ default=1000,
+ help='Processing batch size, defaults to 1000')
+ parser.add_argument(
+ '--encoding',
+ '-e',
+ type=str,
+ default='utf8',
+ help='Bytes coding scheme, defaults to utf8')
+ parser.add_argument(
+ '--lmdb-map-size',
+ '-m',
+ type=int,
+ default=1099511627776,
+ help='Maximum size database may grow to, '
+ 'defaults to 1099511627776 bytes (1TB)')
+ opt = parser.parse_args()
+
+ assert opt.img_root or opt.label_only
+ recog2lmdb(opt.img_root, opt.label_path, opt.output, opt.label_format,
+ opt.label_only, opt.batch_size, opt.encoding, opt.lmdb_map_size)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textrecog/lsvt_converter.py b/tools/dataset_converters/textrecog/lsvt_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..b1f581974967cc6eebb8491fd163bd026e925fbb
--- /dev/null
+++ b/tools/dataset_converters/textrecog/lsvt_converter.py
@@ -0,0 +1,186 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import math
+import os.path as osp
+from functools import partial
+
+import mmcv
+import mmengine
+
+from mmocr.utils import dump_ocr_data
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training and validation set of LSVT ')
+ parser.add_argument('root_path', help='Root dir path of LSVT')
+ parser.add_argument(
+ '--val-ratio', help='Split ratio for val set', default=0.0, type=float)
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='Number of processes')
+ parser.add_argument(
+ '--preserve-vertical',
+ help='Preserve samples containing vertical texts',
+ action='store_true')
+ args = parser.parse_args()
+ return args
+
+
+def process_img(args, dst_image_root, ignore_image_root, preserve_vertical,
+ split):
+ # Dirty hack for multi-processing
+ img_idx, img_info, anns = args
+ src_img = mmcv.imread(img_info['file_name'])
+ img_info = []
+ for ann_idx, ann in enumerate(anns):
+ segmentation = []
+ for x, y in ann['points']:
+ segmentation.append(max(0, x))
+ segmentation.append(max(0, y))
+ xs, ys = segmentation[::2], segmentation[1::2]
+ x, y = min(xs), min(ys)
+ w, h = max(xs) - x, max(ys) - y
+ text_label = ann['transcription']
+
+ dst_img = src_img[y:y + h, x:x + w]
+ dst_img_name = f'img_{img_idx}_{ann_idx}.jpg'
+
+ if not preserve_vertical and h / w > 2 and split == 'train':
+ dst_img_path = osp.join(ignore_image_root, dst_img_name)
+ mmcv.imwrite(dst_img, dst_img_path)
+ continue
+
+ dst_img_path = osp.join(dst_image_root, dst_img_name)
+ mmcv.imwrite(dst_img, dst_img_path)
+
+ img_info.append({
+ 'file_name': dst_img_name,
+ 'anno_info': [{
+ 'text': text_label
+ }]
+ })
+
+ return img_info
+
+
+def convert_lsvt(root_path,
+ split,
+ ratio,
+ preserve_vertical,
+ nproc,
+ img_start_idx=0):
+ """Collect the annotation information and crop the images.
+
+ The annotation format is as the following:
+ [
+ {'gt_1234': # 'gt_1234' is file name
+ [
+ {
+ 'transcription': '一站式购物中心',
+ 'points': [[45, 272], [215, 273], [212, 296], [45, 290]]
+ 'illegibility': False
+ }, ...
+ ]
+ }
+ ]
+
+
+ Args:
+ root_path (str): The root path of the dataset
+ split (str): The split of dataset. Namely: training or val
+ ratio (float): Split ratio for val set
+ preserve_vertical (bool): Whether to preserve vertical texts
+ nproc (int): The number of process to collect annotations
+ img_start_idx (int): Index of start image
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+
+ annotation_path = osp.join(root_path, 'annotations/train_full_labels.json')
+ if not osp.exists(annotation_path):
+ raise Exception(
+ f'{annotation_path} not exists, please check and try again.')
+
+ annotation = mmengine.load(annotation_path)
+ # outputs
+ dst_label_file = osp.join(root_path, f'{split}_label.json')
+ dst_image_root = osp.join(root_path, 'crops', split)
+ ignore_image_root = osp.join(root_path, 'ignores', split)
+ src_image_root = osp.join(root_path, 'imgs')
+ mmengine.mkdir_or_exist(dst_image_root)
+ mmengine.mkdir_or_exist(ignore_image_root)
+
+ process_img_with_path = partial(
+ process_img,
+ dst_image_root=dst_image_root,
+ ignore_image_root=ignore_image_root,
+ preserve_vertical=preserve_vertical,
+ split=split)
+
+ img_prefixes = annotation.keys()
+
+ trn_files, val_files = [], []
+ if ratio > 0:
+ for i, file in enumerate(img_prefixes):
+ if i % math.floor(1 / ratio):
+ trn_files.append(file)
+ else:
+ val_files.append(file)
+ else:
+ trn_files, val_files = img_prefixes, []
+ print(f'training #{len(trn_files)}, val #{len(val_files)}')
+
+ if split == 'train':
+ img_prefixes = trn_files
+ elif split == 'val':
+ img_prefixes = val_files
+ else:
+ raise NotImplementedError
+
+ tasks = []
+ idx = 0
+ for img_idx, prefix in enumerate(img_prefixes):
+ img_file = osp.join(src_image_root, prefix + '.jpg')
+ img_info = {'file_name': img_file}
+ # Skip not exist images
+ if not osp.exists(img_file):
+ continue
+ tasks.append((img_idx + img_start_idx, img_info, annotation[prefix]))
+ idx = idx + 1
+
+ labels_list = mmengine.track_parallel_progress(
+ process_img_with_path, tasks, keep_order=True, nproc=nproc)
+ final_labels = []
+ for label_list in labels_list:
+ final_labels += label_list
+
+ dump_ocr_data(final_labels, dst_label_file, 'textrecog')
+
+ return idx
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+ print('Processing training set...')
+ num_train_imgs = convert_lsvt(
+ root_path=root_path,
+ split='train',
+ ratio=args.val_ratio,
+ preserve_vertical=args.preserve_vertical,
+ nproc=args.nproc)
+ if args.val_ratio > 0:
+ print('Processing validation set...')
+ convert_lsvt(
+ root_path=root_path,
+ split='val',
+ ratio=args.val_ratio,
+ preserve_vertical=args.preserve_vertical,
+ nproc=args.nproc,
+ img_start_idx=num_train_imgs)
+ print('Finish')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textrecog/lv_converter.py b/tools/dataset_converters/textrecog/lv_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..d22c60b224d7fb122ebe26b2729650a961aac992
--- /dev/null
+++ b/tools/dataset_converters/textrecog/lv_converter.py
@@ -0,0 +1,68 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+
+from mmocr.utils import dump_ocr_data
+
+
+def convert_annotations(root_path, split):
+ """Convert original annotations to mmocr format.
+
+ The annotation format is as the following:
+ Crops/val/11/1/1.png weighted
+ Crops/val/11/1/2.png 26
+ Crops/val/11/1/3.png casting
+ Crops/val/11/1/4.png 28
+ After this module, the annotation has been changed to the format below:
+ jsonl:
+ {'filename': 'Crops/val/11/1/1.png', 'text': 'weighted'}
+ {'filename': 'Crops/val/11/1/1.png', 'text': '26'}
+ {'filename': 'Crops/val/11/1/1.png', 'text': 'casting'}
+ {'filename': 'Crops/val/11/1/1.png', 'text': '28'}
+
+ Args:
+ root_path (str): The root path of the dataset
+ split (str): The split of dataset. Namely: training or test
+ """
+ assert isinstance(root_path, str)
+ assert isinstance(split, str)
+
+ img_info = []
+ with open(
+ osp.join(root_path, f'{split}_label.txt'),
+ encoding='"utf-8-sig') as f:
+ annos = f.readlines()
+ for anno in annos:
+ if anno:
+ # Text may contain spaces
+ dst_img_name, word = anno.split('png ')
+ word = word.strip('\n')
+ img_info.append({
+ 'file_name': dst_img_name + 'png',
+ 'anno_info': [{
+ 'text': word
+ }]
+ })
+ dump_ocr_data(img_info, osp.join(root_path, f'{split.lower()}_label.json'),
+ 'textrecog')
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training and test set of Lecture Video DB')
+ parser.add_argument('root_path', help='Root dir path of Lecture Video DB')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+
+ for split in ['train', 'val', 'test']:
+ convert_annotations(root_path, split)
+ print(f'{split} split converted.')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textrecog/mtwi_converter.py b/tools/dataset_converters/textrecog/mtwi_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..86d4e4e895b36a225fd2e916b675dcdf3abe8d17
--- /dev/null
+++ b/tools/dataset_converters/textrecog/mtwi_converter.py
@@ -0,0 +1,251 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import math
+import os
+import os.path as osp
+
+import cv2
+import mmcv
+import mmengine
+from PIL import Image
+
+from mmocr.utils import crop_img, dump_ocr_data
+
+
+def collect_files(img_dir, gt_dir, ratio):
+ """Collect all images and their corresponding groundtruth files.
+ Args:
+ img_dir (str): The image directory
+ gt_dir (str): The groundtruth directory
+ ratio (float): Split ratio for val set
+
+ Returns:
+ files (list): The list of tuples (img_file, groundtruth_file)
+ """
+ assert isinstance(img_dir, str)
+ assert img_dir
+ assert isinstance(gt_dir, str)
+ assert gt_dir
+ assert isinstance(ratio, float)
+ assert ratio < 1.0, 'val_ratio should be a float between 0.0 to 1.0'
+
+ ann_list, imgs_list = [], []
+ for ann_file in os.listdir(gt_dir):
+ img_file = osp.join(img_dir, ann_file.replace('txt', 'jpg'))
+ # This dataset contains some images obtained from .gif,
+ # which cannot be loaded by mmcv.imread(), convert them
+ # to RGB mode.
+ try:
+ if mmcv.imread(img_file) is None:
+ print(f'Convert {img_file} to RGB mode.')
+ img = Image.open(img_file)
+ img = img.convert('RGB')
+ img.save(img_file)
+ except cv2.error:
+ print(f'Skip broken img {img_file}')
+ continue
+
+ ann_list.append(osp.join(gt_dir, ann_file))
+ imgs_list.append(img_file)
+
+ all_files = list(zip(imgs_list, ann_list))
+ assert len(all_files), f'No images found in {img_dir}'
+ print(f'Loaded {len(all_files)} images from {img_dir}')
+
+ trn_files, val_files = [], []
+ if ratio > 0:
+ for i, file in enumerate(all_files):
+ if i % math.floor(1 / ratio):
+ trn_files.append(file)
+ else:
+ val_files.append(file)
+ else:
+ trn_files, val_files = all_files, []
+
+ print(f'training #{len(trn_files)}, val #{len(val_files)}')
+
+ return trn_files, val_files
+
+
+def collect_annotations(files, nproc=1):
+ """Collect the annotation information.
+ Args:
+ files (list): The list of tuples (image_file, groundtruth_file)
+ nproc (int): The number of process to collect annotations
+
+ Returns:
+ images (list): The list of image information dicts
+ """
+ assert isinstance(files, list)
+ assert isinstance(nproc, int)
+
+ if nproc > 1:
+ images = mmengine.track_parallel_progress(
+ load_img_info, files, nproc=nproc)
+ else:
+ images = mmengine.track_progress(load_img_info, files)
+
+ return images
+
+
+def load_img_info(files):
+ """Load the information of one image.
+ Args:
+ files (tuple): The tuple of (img_file, groundtruth_file)
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+ assert isinstance(files, tuple)
+
+ img_file, gt_file = files
+ assert osp.basename(gt_file).split('.')[0] == osp.basename(img_file).split(
+ '.')[0]
+ # read imgs while ignoring orientations
+ img = mmcv.imread(img_file)
+
+ img_info = dict(
+ file_name=osp.join(osp.basename(img_file)),
+ height=img.shape[0],
+ width=img.shape[1],
+ segm_file=osp.join(osp.basename(gt_file)))
+
+ if osp.splitext(gt_file)[1] == '.txt':
+ img_info = load_txt_info(gt_file, img_info)
+ else:
+ raise NotImplementedError
+
+ return img_info
+
+
+def load_txt_info(gt_file, img_info):
+ """Collect the annotation information.
+
+ The annotation format is as the following:
+ x1,y1,x2,y2,x3,y3,x4,y4,text
+
+ 45.45,226.83,11.87,181.79,183.84,13.1,233.79,49.95,时尚袋袋
+ 345.98,311.18,345.98,347.21,462.26,347.21,462.26,311.18,73774
+ 462.26,292.34,461.44,299.71,502.39,299.71,502.39,292.34,73/74/737
+
+ Args:
+ gt_file (str): The path to ground-truth
+ img_info (dict): The dict of the img and annotation information
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+
+ anno_info = []
+ with open(gt_file) as f:
+ lines = f.readlines()
+ for line in lines:
+ points = line.split(',')[0:8]
+ word = line.split(',')[8].rstrip('\n')
+ if word == '###':
+ continue
+ bbox = [math.floor(float(pt)) for pt in points]
+ anno = dict(bbox=bbox, word=word)
+ anno_info.append(anno)
+
+ img_info.update(anno_info=anno_info)
+
+ return img_info
+
+
+def generate_ann(root_path, split, image_infos, preserve_vertical):
+ """Generate cropped annotations and label txt file.
+
+ Args:
+ root_path (str): The root path of the dataset
+ split (str): The split of dataset. Namely: training or test
+ image_infos (list[dict]): A list of dicts of the img and
+ annotation information
+ preserve_vertical (bool): Whether to preserve vertical texts
+ """
+ print('Cropping images...')
+ dst_image_root = osp.join(root_path, 'crops', split)
+ ignore_image_root = osp.join(root_path, 'ignores', split)
+ if split == 'training':
+ dst_label_file = osp.join(root_path, 'train_label.json')
+ elif split == 'val':
+ dst_label_file = osp.join(root_path, 'val_label.json')
+ mmengine.mkdir_or_exist(dst_image_root)
+ mmengine.mkdir_or_exist(ignore_image_root)
+
+ img_info = []
+ for image_info in image_infos:
+ index = 1
+ src_img_path = osp.join(root_path, 'imgs', image_info['file_name'])
+ image = mmcv.imread(src_img_path)
+ src_img_root = image_info['file_name'].split('.')[0]
+
+ for anno in image_info['anno_info']:
+ word = anno['word']
+ dst_img = crop_img(image, anno['bbox'], 0, 0)
+ h, w, _ = dst_img.shape
+
+ dst_img_name = f'{src_img_root}_{index}.png'
+ index += 1
+ # Skip invalid annotations
+ if min(dst_img.shape) == 0:
+ continue
+ # Skip vertical texts
+ if not preserve_vertical and h / w > 2 and split == 'training':
+ dst_img_path = osp.join(ignore_image_root, dst_img_name)
+ mmcv.imwrite(dst_img, dst_img_path)
+ continue
+
+ dst_img_path = osp.join(dst_image_root, dst_img_name)
+ mmcv.imwrite(dst_img, dst_img_path)
+
+ img_info.append({
+ 'file_name': dst_img_name,
+ 'anno_info': [{
+ 'text': word
+ }]
+ })
+
+ dump_ocr_data(img_info, dst_label_file, 'textrecog')
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training and val set of MTWI.')
+ parser.add_argument('root_path', help='Root dir path of MTWI')
+ parser.add_argument(
+ '--val-ratio', help='Split ratio for val set', default=0.0, type=float)
+ parser.add_argument(
+ '--preserve-vertical',
+ help='Preserve samples containing vertical texts',
+ action='store_true')
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='Number of process')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+ ratio = args.val_ratio
+
+ trn_files, val_files = collect_files(
+ osp.join(root_path, 'imgs'), osp.join(root_path, 'annotations'), ratio)
+
+ # Train set
+ trn_infos = collect_annotations(trn_files, nproc=args.nproc)
+ with mmengine.Timer(
+ print_tmpl='It takes {}s to convert MTWI Training annotation'):
+ generate_ann(root_path, 'training', trn_infos, args.preserve_vertical)
+
+ # Val set
+ if len(val_files) > 0:
+ val_infos = collect_annotations(val_files, nproc=args.nproc)
+ with mmengine.Timer(
+ print_tmpl='It takes {}s to convert MTWI Val annotation'):
+ generate_ann(root_path, 'val', val_infos, args.preserve_vertical)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textrecog/naf_converter.py b/tools/dataset_converters/textrecog/naf_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..3c6d84ad2d9613606e767bdd67793f65ae0e5239
--- /dev/null
+++ b/tools/dataset_converters/textrecog/naf_converter.py
@@ -0,0 +1,272 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+
+import mmcv
+import mmengine
+import numpy as np
+
+from mmocr.utils import crop_img, dump_ocr_data
+
+
+def collect_files(img_dir, gt_dir, split_info):
+ """Collect all images and their corresponding groundtruth files.
+
+ Args:
+ img_dir (str): The image directory
+ gt_dir (str): The groundtruth directory
+ split_info (dict): The split information for train/val/test
+
+ Returns:
+ files (list): The list of tuples (img_file, groundtruth_file)
+ """
+ assert isinstance(img_dir, str)
+ assert img_dir
+ assert isinstance(gt_dir, str)
+ assert gt_dir
+ assert isinstance(split_info, dict)
+ assert split_info
+
+ ann_list, imgs_list = [], []
+ for group in split_info:
+ for img in split_info[group]:
+ image_path = osp.join(img_dir, img)
+ anno_path = osp.join(gt_dir, 'groups', group,
+ img.replace('jpg', 'json'))
+
+ # Filtering out the missing images
+ if not osp.exists(image_path) or not osp.exists(anno_path):
+ continue
+
+ imgs_list.append(image_path)
+ ann_list.append(anno_path)
+
+ files = list(zip(imgs_list, ann_list))
+ assert len(files), f'No images found in {img_dir}'
+ print(f'Loaded {len(files)} images from {img_dir}')
+
+ return files
+
+
+def collect_annotations(files, nproc=1):
+ """Collect the annotation information.
+
+ Args:
+ files (list): The list of tuples (image_file, groundtruth_file)
+ nproc (int): The number of process to collect annotations
+
+ Returns:
+ images (list): The list of image information dicts
+ """
+ assert isinstance(files, list)
+ assert isinstance(nproc, int)
+
+ if nproc > 1:
+ images = mmengine.track_parallel_progress(
+ load_img_info, files, nproc=nproc)
+ else:
+ images = mmengine.track_progress(load_img_info, files)
+
+ return images
+
+
+def load_img_info(files):
+ """Load the information of one image.
+
+ Args:
+ files (tuple): The tuple of (img_file, groundtruth_file)
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+ assert isinstance(files, tuple)
+
+ img_file, gt_file = files
+ assert osp.basename(gt_file).split('.')[0] == osp.basename(img_file).split(
+ '.')[0]
+ # Read imgs while ignoring orientations
+ img = mmcv.imread(img_file, 'unchanged')
+
+ img_info = dict(
+ file_name=osp.join(osp.basename(img_file)),
+ height=img.shape[0],
+ width=img.shape[1],
+ segm_file=osp.join(osp.basename(gt_file)))
+
+ if osp.splitext(gt_file)[1] == '.json':
+ img_info = load_json_info(gt_file, img_info)
+ else:
+ raise NotImplementedError
+
+ return img_info
+
+
+def load_json_info(gt_file, img_info):
+ """Collect the annotation information.
+
+ Annotation Format
+ {
+ 'filedBBs': [{
+ 'poly_points': [[435,1406], [466,1406], [466,1439], [435,1439]],
+ "type": "fieldCheckBox",
+ "id": "f0",
+ "isBlank": 1, # 0:text,1:handwriting,2:print,3:blank,4:signature,
+ }], ...
+ "transcriptions":{
+ "f38": "CASE NUMBER",
+ "f29": "July 1, 1949",
+ "t20": "RANK",
+ "t19": "COMPANY",
+ ...
+ }
+ }
+
+ Some special characters are used in the transcription:
+ "«text»" indicates that "text" had a strikethrough
+ "¿" indicates the transcriber could not read a character
+ "§" indicates the whole line or word was illegible
+ "" (empty string) is if the field was blank
+
+ Args:
+ gt_file (str): The path to ground-truth
+ img_info (dict): The dict of the img and annotation information
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+ assert isinstance(gt_file, str)
+ assert isinstance(img_info, dict)
+
+ annotation = mmengine.load(gt_file)
+ anno_info = []
+
+ # 'textBBs' contains the printed texts of the table while 'fieldBBs'
+ # contains the text filled by human.
+ for box_type in ['textBBs', 'fieldBBs']:
+ # NAF dataset only provides transcription GT for 'filedBBs', the
+ # 'textBBs' is only used for detection task.
+ if box_type == 'textBBs':
+ continue
+ for anno in annotation[box_type]:
+ # Skip images containing detection annotations only
+ if 'transcriptions' not in annotation.keys():
+ continue
+ # Skip boxes without recognition GT
+ if anno['id'] not in annotation['transcriptions'].keys():
+ continue
+
+ word = annotation['transcriptions'][anno['id']]
+ # Skip blank boxes
+ if len(word) == 0:
+ continue
+
+ bbox = np.array(anno['poly_points']).reshape(1, 8)[0].tolist()
+
+ anno = dict(bbox=bbox, word=word)
+ anno_info.append(anno)
+
+ img_info.update(anno_info=anno_info)
+
+ return img_info
+
+
+def generate_ann(root_path, split, image_infos, preserve_vertical):
+ """Generate cropped annotations and label txt file.
+
+ Args:
+ root_path (str): The root path of the dataset
+ split (str): The split of dataset. Namely: training or test
+ image_infos (list[dict]): A list of dicts of the img and
+ annotation information
+ preserve_vertical (bool): Whether to preserve vertical texts
+ """
+
+ dst_image_root = osp.join(root_path, 'crops', split)
+ ignore_image_root = osp.join(root_path, 'ignores', split)
+ if split == 'training':
+ dst_label_file = osp.join(root_path, 'train_label.json')
+ elif split == 'val':
+ dst_label_file = osp.join(root_path, 'val_label.json')
+ elif split == 'test':
+ dst_label_file = osp.join(root_path, 'test_label.json')
+ else:
+ raise NotImplementedError
+ mmengine.mkdir_or_exist(dst_image_root)
+ mmengine.mkdir_or_exist(ignore_image_root)
+
+ img_info = []
+ for image_info in image_infos:
+ index = 1
+ src_img_path = osp.join(root_path, 'imgs', image_info['file_name'])
+ image = mmcv.imread(src_img_path)
+ src_img_root = image_info['file_name'].split('.')[0]
+
+ for anno in image_info['anno_info']:
+ word = anno['word']
+ word = word.strip('\u202a') # Remove unicode control character
+ word = word.replace('»',
+ '').replace('«',
+ '') # Remove strikethrough flag
+ dst_img = crop_img(image, anno['bbox'], 0, 0)
+ h, w, _ = dst_img.shape
+
+ dst_img_name = f'{src_img_root}_{index}.png'
+ index += 1
+ # Skip invalid and illegible annotations
+ if min(dst_img.shape) == 0 or '§' in word or '¿' in word or len(
+ word) == 0:
+ continue
+ # Skip vertical texts
+ # (Do Not Filter For Val and Test Split)
+ if (not preserve_vertical and h / w > 2) and split == 'training':
+ dst_img_path = osp.join(ignore_image_root, dst_img_name)
+ mmcv.imwrite(dst_img, dst_img_path)
+ continue
+
+ dst_img_path = osp.join(dst_image_root, dst_img_name)
+ mmcv.imwrite(dst_img, dst_img_path)
+
+ img_info.append({
+ 'file_name': dst_img_name,
+ 'anno_info': [{
+ 'text': word
+ }]
+ })
+
+ dump_ocr_data(img_info, dst_label_file, 'textrecog')
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training, val, and test set of NAF ')
+ parser.add_argument('root_path', help='Root dir path of NAF')
+ parser.add_argument(
+ '--preserve-vertical',
+ help='Preserve samples containing vertical texts',
+ action='store_true')
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='Number of process')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+ split_info = mmengine.load(
+ osp.join(root_path, 'annotations', 'train_valid_test_split.json'))
+ split_info['training'] = split_info.pop('train')
+ split_info['val'] = split_info.pop('valid')
+ for split in ['training', 'val', 'test']:
+ print(f'Processing {split} set...')
+ with mmengine.Timer(
+ print_tmpl='It takes {}s to convert NAF annotation'):
+ files = collect_files(
+ osp.join(root_path, 'imgs'),
+ osp.join(root_path, 'annotations'), split_info[split])
+ image_infos = collect_annotations(files, nproc=args.nproc)
+ generate_ann(root_path, split, image_infos, args.preserve_vertical)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textrecog/openvino_converter.py b/tools/dataset_converters/textrecog/openvino_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..79b962bbdaa9ff35e8f726234fdd2c007fb8f105
--- /dev/null
+++ b/tools/dataset_converters/textrecog/openvino_converter.py
@@ -0,0 +1,120 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+import os
+import os.path as osp
+from argparse import ArgumentParser
+from functools import partial
+
+import mmengine
+from PIL import Image
+
+from mmocr.utils import dump_ocr_data
+
+
+def parse_args():
+ parser = ArgumentParser(description='Generate training and validation set '
+ 'of OpenVINO annotations for Open '
+ 'Images by cropping box image.')
+ parser.add_argument(
+ 'root_path', help='Root dir containing images and annotations')
+ parser.add_argument(
+ 'n_proc', default=1, type=int, help='Number of processes to run')
+ args = parser.parse_args()
+ return args
+
+
+def process_img(args, src_image_root, dst_image_root):
+ # Dirty hack for multi-processing
+ img_idx, img_info, anns = args
+ src_img = Image.open(osp.join(src_image_root, img_info['file_name']))
+ labels = []
+ for ann_idx, ann in enumerate(anns):
+ attrs = ann['attributes']
+ text_label = attrs['transcription']
+
+ # Ignore illegible or non-English words
+ if not attrs['legible'] or attrs['language'] != 'english':
+ continue
+
+ x, y, w, h = ann['bbox']
+ x, y = max(0, math.floor(x)), max(0, math.floor(y))
+ w, h = math.ceil(w), math.ceil(h)
+ dst_img = src_img.crop((x, y, x + w, y + h))
+ dst_img_name = f'img_{img_idx}_{ann_idx}.jpg'
+ dst_img_path = osp.join(dst_image_root, dst_img_name)
+ # Preserve JPEG quality
+ dst_img.save(dst_img_path, qtables=src_img.quantization)
+ labels.append({
+ 'file_name': dst_img_name,
+ 'anno_info': [{
+ 'text': text_label
+ }]
+ })
+ src_img.close()
+ return labels
+
+
+def convert_openimages(root_path,
+ dst_image_path,
+ dst_label_filename,
+ annotation_filename,
+ img_start_idx=0,
+ nproc=1):
+ annotation_path = osp.join(root_path, annotation_filename)
+ if not osp.exists(annotation_path):
+ raise Exception(
+ f'{annotation_path} not exists, please check and try again.')
+ src_image_root = root_path
+
+ # outputs
+ dst_label_file = osp.join(root_path, dst_label_filename)
+ dst_image_root = osp.join(root_path, dst_image_path)
+ os.makedirs(dst_image_root, exist_ok=True)
+
+ annotation = mmengine.load(annotation_path)
+
+ process_img_with_path = partial(
+ process_img,
+ src_image_root=src_image_root,
+ dst_image_root=dst_image_root)
+ tasks = []
+ anns = {}
+ for ann in annotation['annotations']:
+ anns.setdefault(ann['image_id'], []).append(ann)
+ for img_idx, img_info in enumerate(annotation['images']):
+ tasks.append((img_idx + img_start_idx, img_info, anns[img_info['id']]))
+ labels_list = mmengine.track_parallel_progress(
+ process_img_with_path, tasks, keep_order=True, nproc=nproc)
+ final_labels = []
+ for label_list in labels_list:
+ final_labels += label_list
+ dump_ocr_data(final_labels, dst_label_file, 'textrecog')
+ return len(annotation['images'])
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+ print('Processing training set...')
+ num_train_imgs = 0
+ for s in '125f':
+ num_train_imgs = convert_openimages(
+ root_path=root_path,
+ dst_image_path=f'image_{s}',
+ dst_label_filename=f'train_{s}_label.json',
+ annotation_filename=f'text_spotting_openimages_v5_train_{s}.json',
+ img_start_idx=num_train_imgs,
+ nproc=args.n_proc)
+ print('Processing validation set...')
+ convert_openimages(
+ root_path=root_path,
+ dst_image_path='image_val',
+ dst_label_filename='val_label.json',
+ annotation_filename='text_spotting_openimages_v5_validation.json',
+ img_start_idx=num_train_imgs,
+ nproc=args.n_proc)
+ print('Finish')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textrecog/rctw_converter.py b/tools/dataset_converters/textrecog/rctw_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..e3bfd2baa2a31594850ae2cae82040fb6e8e0362
--- /dev/null
+++ b/tools/dataset_converters/textrecog/rctw_converter.py
@@ -0,0 +1,238 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import math
+import os
+import os.path as osp
+
+import mmcv
+import mmengine
+
+from mmocr.utils import crop_img, dump_ocr_data
+
+
+def collect_files(img_dir, gt_dir, ratio):
+ """Collect all images and their corresponding groundtruth files.
+ Args:
+ img_dir (str): The image directory
+ gt_dir (str): The groundtruth directory
+ ratio (float): Split ratio for val set
+
+ Returns:
+ files (list): The list of tuples (img_file, groundtruth_file)
+ """
+ assert isinstance(img_dir, str)
+ assert img_dir
+ assert isinstance(gt_dir, str)
+ assert gt_dir
+ assert isinstance(ratio, float)
+ assert ratio < 1.0, 'val_ratio should be a float between 0.0 to 1.0'
+
+ ann_list, imgs_list = [], []
+ for ann_file in os.listdir(gt_dir):
+ ann_list.append(osp.join(gt_dir, ann_file))
+ imgs_list.append(osp.join(img_dir, ann_file.replace('txt', 'jpg')))
+
+ all_files = list(zip(imgs_list, ann_list))
+ assert len(all_files), f'No images found in {img_dir}'
+ print(f'Loaded {len(all_files)} images from {img_dir}')
+
+ trn_files, val_files = [], []
+ if ratio > 0:
+ for i, file in enumerate(all_files):
+ if i % math.floor(1 / ratio):
+ trn_files.append(file)
+ else:
+ val_files.append(file)
+ else:
+ trn_files, val_files = all_files, []
+
+ print(f'training #{len(trn_files)}, val #{len(val_files)}')
+
+ return trn_files, val_files
+
+
+def collect_annotations(files, nproc=1):
+ """Collect the annotation information.
+ Args:
+ files (list): The list of tuples (image_file, groundtruth_file)
+ nproc (int): The number of process to collect annotations
+
+ Returns:
+ images (list): The list of image information dicts
+ """
+ assert isinstance(files, list)
+ assert isinstance(nproc, int)
+
+ if nproc > 1:
+ images = mmengine.track_parallel_progress(
+ load_img_info, files, nproc=nproc)
+ else:
+ images = mmengine.track_progress(load_img_info, files)
+
+ return images
+
+
+def load_img_info(files):
+ """Load the information of one image.
+ Args:
+ files (tuple): The tuple of (img_file, groundtruth_file)
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+ assert isinstance(files, tuple)
+
+ img_file, gt_file = files
+ assert osp.basename(gt_file).split('.')[0] == osp.basename(img_file).split(
+ '.')[0]
+ # read imgs while ignoring orientations
+ img = mmcv.imread(img_file)
+
+ img_info = dict(
+ file_name=osp.join(osp.basename(img_file)),
+ height=img.shape[0],
+ width=img.shape[1],
+ segm_file=osp.join(osp.basename(gt_file)))
+
+ if osp.splitext(gt_file)[1] == '.txt':
+ img_info = load_txt_info(gt_file, img_info)
+ else:
+ raise NotImplementedError
+
+ return img_info
+
+
+def load_txt_info(gt_file, img_info):
+ """Collect the annotation information.
+
+ The annotation format is as the following:
+ x1, y1, x2, y2, x3, y3, x4, y4, difficult, text
+
+ 390,902,1856,902,1856,1225,390,1225,0,"金氏眼镜"
+ 1875,1170,2149,1170,2149,1245,1875,1245,0,"创于1989"
+ 2054,1277,2190,1277,2190,1323,2054,1323,0,"城建店"
+
+ Args:
+ gt_file (str): The path to ground-truth
+ img_info (dict): The dict of the img and annotation information
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+
+ anno_info = []
+ with open(gt_file, encoding='utf-8-sig') as f:
+ lines = f.readlines()
+ for line in lines:
+ points = line.split(',')[0:8]
+ word = line.split(',')[9].rstrip('\n').strip('"')
+ difficult = 1 if line.split(',')[8] != '0' else 0
+ bbox = [int(pt) for pt in points]
+
+ if word == '###' or difficult == 1:
+ continue
+
+ anno = dict(bbox=bbox, word=word)
+ anno_info.append(anno)
+
+ img_info.update(anno_info=anno_info)
+
+ return img_info
+
+
+def generate_ann(root_path, split, image_infos, preserve_vertical):
+ """Generate cropped annotations and label txt file.
+
+ Args:
+ root_path (str): The root path of the dataset
+ split (str): The split of dataset. Namely: training or val
+ image_infos (list[dict]): A list of dicts of the img and
+ annotation information
+ preserve_vertical (bool): Whether to preserve vertical texts
+ """
+
+ dst_image_root = osp.join(root_path, 'crops', split)
+ ignore_image_root = osp.join(root_path, 'ignores', split)
+ if split == 'training':
+ dst_label_file = osp.join(root_path, 'train_label.json')
+ elif split == 'val':
+ dst_label_file = osp.join(root_path, 'val_label.json')
+ mmengine.mkdir_or_exist(dst_image_root)
+ mmengine.mkdir_or_exist(ignore_image_root)
+
+ img_info = []
+ for image_info in image_infos:
+ index = 1
+ src_img_path = osp.join(root_path, 'imgs', image_info['file_name'])
+ image = mmcv.imread(src_img_path)
+ src_img_root = image_info['file_name'].split('.')[0]
+
+ for anno in image_info['anno_info']:
+ word = anno['word']
+ dst_img = crop_img(image, anno['bbox'], 0, 0)
+ h, w, _ = dst_img.shape
+
+ dst_img_name = f'{src_img_root}_{index}.png'
+ index += 1
+ # Skip invalid annotations
+ if min(dst_img.shape) == 0:
+ continue
+ # Filter out vertical texts
+ if not preserve_vertical and h / w > 2:
+ dst_img_path = osp.join(ignore_image_root, dst_img_name)
+ mmcv.imwrite(dst_img, dst_img_path)
+ continue
+
+ dst_img_path = osp.join(dst_image_root, dst_img_name)
+ mmcv.imwrite(dst_img, dst_img_path)
+
+ img_info.append({
+ 'file_name': dst_img_name,
+ 'anno_info': [{
+ 'text': word
+ }]
+ })
+
+ dump_ocr_data(img_info, dst_label_file, 'textrecog')
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training and val set of RCTW.')
+ parser.add_argument('root_path', help='Root dir path of RCTW')
+ parser.add_argument(
+ '--val-ratio', help='Split ratio for val set', default=0.0, type=float)
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='Number of process')
+ parser.add_argument(
+ '--preserve-vertical',
+ help='Preserve samples containing vertical texts',
+ action='store_true')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+ ratio = args.val_ratio
+
+ trn_files, val_files = collect_files(
+ osp.join(root_path, 'imgs'), osp.join(root_path, 'annotations'), ratio)
+
+ # Train set
+ with mmengine.Timer(
+ print_tmpl='It takes {}s to convert RCTW Training annotation'):
+ trn_infos = collect_annotations(trn_files, nproc=args.nproc)
+ generate_ann(root_path, 'training', trn_infos, args.preserve_vertical)
+
+ # Val set
+ if len(val_files) > 0:
+ with mmengine.Timer(
+ print_tmpl='It takes {}s to convert RCTW Val annotation'):
+ val_infos = collect_annotations(val_files, nproc=args.nproc)
+ generate_ann(root_path, 'val', val_infos, args.preserve_vertical)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textrecog/rects_converter.py b/tools/dataset_converters/textrecog/rects_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..630e81509715ef67edcb7dbf77542b399962d551
--- /dev/null
+++ b/tools/dataset_converters/textrecog/rects_converter.py
@@ -0,0 +1,256 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import math
+import os
+import os.path as osp
+
+import mmcv
+import mmengine
+
+from mmocr.utils import crop_img, dump_ocr_data
+
+
+def collect_files(img_dir, gt_dir, ratio):
+ """Collect all images and their corresponding groundtruth files.
+ Args:
+ img_dir (str): The image directory
+ gt_dir (str): The groundtruth directory
+ ratio (float): Split ratio for val set
+
+ Returns:
+ files (list): The list of tuples (img_file, groundtruth_file)
+ """
+ assert isinstance(img_dir, str)
+ assert img_dir
+ assert isinstance(gt_dir, str)
+ assert gt_dir
+ assert isinstance(ratio, float)
+ assert ratio < 1.0, 'val_ratio should be a float between 0.0 to 1.0'
+
+ ann_list, imgs_list = [], []
+ for ann_file in os.listdir(gt_dir):
+ ann_list.append(osp.join(gt_dir, ann_file))
+ imgs_list.append(osp.join(img_dir, ann_file.replace('json', 'jpg')))
+
+ all_files = list(zip(imgs_list, ann_list))
+ assert len(all_files), f'No images found in {img_dir}'
+ print(f'Loaded {len(all_files)} images from {img_dir}')
+
+ trn_files, val_files = [], []
+ if ratio > 0:
+ for i, file in enumerate(all_files):
+ if i % math.floor(1 / ratio):
+ trn_files.append(file)
+ else:
+ val_files.append(file)
+ else:
+ trn_files, val_files = all_files, []
+
+ print(f'training #{len(trn_files)}, val #{len(val_files)}')
+
+ return trn_files, val_files
+
+
+def collect_annotations(files, nproc=1):
+ """Collect the annotation information.
+ Args:
+ files (list): The list of tuples (image_file, groundtruth_file)
+ nproc (int): The number of process to collect annotations
+
+ Returns:
+ images (list): The list of image information dicts
+ """
+ assert isinstance(files, list)
+ assert isinstance(nproc, int)
+
+ if nproc > 1:
+ images = mmengine.track_parallel_progress(
+ load_img_info, files, nproc=nproc)
+ else:
+ images = mmengine.track_progress(load_img_info, files)
+
+ return images
+
+
+def load_img_info(files):
+ """Load the information of one image.
+ Args:
+ files (tuple): The tuple of (img_file, groundtruth_file)
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+ assert isinstance(files, tuple)
+
+ img_file, gt_file = files
+ assert osp.basename(gt_file).split('.')[0] == osp.basename(img_file).split(
+ '.')[0]
+ # read imgs while ignoring orientations
+ img = mmcv.imread(img_file)
+
+ img_info = dict(
+ file_name=osp.join(osp.basename(img_file)),
+ height=img.shape[0],
+ width=img.shape[1],
+ segm_file=osp.join(osp.basename(gt_file)))
+
+ if osp.splitext(gt_file)[1] == '.json':
+ img_info = load_json_info(gt_file, img_info)
+ else:
+ raise NotImplementedError
+
+ return img_info
+
+
+def load_json_info(gt_file, img_info):
+ """Collect the annotation information.
+
+ The annotation format is as the following:
+
+ {
+ "chars": [
+ {
+ "ignore": 0,
+ "transcription": "H",
+ "points": [25, 175, 112, 175, 112, 286, 25, 286]
+ },
+ {
+ "ignore": 0,
+ "transcription": "O",
+ "points": [102, 182, 210, 182, 210, 273, 102, 273]
+ }, ...
+ ]
+ "lines": [
+ {
+ "ignore": 0,
+ "transcription": "HOKI",
+ "points": [23, 173, 327, 180, 327, 290, 23, 283]
+ },
+ {
+ "ignore": 0,
+ "transcription": "TEA",
+ "points": [368, 180, 621, 180, 621, 294, 368, 294]
+ }, ...
+ ]
+ }
+
+
+ Args:
+ gt_file (str): The path to ground-truth
+ img_info (dict): The dict of the img and annotation information
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+
+ annotation = mmengine.load(gt_file)
+ anno_info = []
+ for line in annotation['lines']:
+ if line['ignore'] == 1:
+ continue
+ segmentation = line['points']
+ word = line['transcription']
+ anno = dict(bbox=segmentation, word=word)
+ anno_info.append(anno)
+
+ img_info.update(anno_info=anno_info)
+
+ return img_info
+
+
+def generate_ann(root_path, split, image_infos, preserve_vertical):
+ """Generate cropped annotations and label txt file.
+
+ Args:
+ root_path (str): The root path of the dataset
+ split (str): The split of dataset. Namely: training or test
+ image_infos (list[dict]): A list of dicts of the img and
+ annotation information
+ preserve_vertical (bool): Whether to preserve vertical texts
+ """
+ print('Cropping images...')
+ dst_image_root = osp.join(root_path, 'crops', split)
+ ignore_image_root = osp.join(root_path, 'ignores', split)
+ if split == 'training':
+ dst_label_file = osp.join(root_path, 'train_label.json')
+ elif split == 'val':
+ dst_label_file = osp.join(root_path, 'val_label.json')
+ mmengine.mkdir_or_exist(dst_image_root)
+ mmengine.mkdir_or_exist(ignore_image_root)
+
+ img_info = []
+ for image_info in image_infos:
+ index = 1
+ src_img_path = osp.join(root_path, 'imgs', image_info['file_name'])
+ image = mmcv.imread(src_img_path)
+ src_img_root = image_info['file_name'].split('.')[0]
+
+ for anno in image_info['anno_info']:
+ word = anno['word']
+ dst_img = crop_img(image, anno['bbox'], 0, 0)
+ h, w, _ = dst_img.shape
+
+ dst_img_name = f'{src_img_root}_{index}.png'
+ index += 1
+ # Skip invalid annotations
+ if min(dst_img.shape) == 0:
+ continue
+ # Skip vertical texts
+ if not preserve_vertical and h / w > 2 and split == 'training':
+ dst_img_path = osp.join(ignore_image_root, dst_img_name)
+ mmcv.imwrite(dst_img, dst_img_path)
+ continue
+
+ dst_img_path = osp.join(dst_image_root, dst_img_name)
+ mmcv.imwrite(dst_img, dst_img_path)
+
+ img_info.append({
+ 'file_name': dst_img_name,
+ 'anno_info': [{
+ 'text': word
+ }]
+ })
+
+ dump_ocr_data(img_info, dst_label_file, 'textrecog')
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training and val set of ReCTS.')
+ parser.add_argument('root_path', help='Root dir path of ReCTS')
+ parser.add_argument(
+ '--val-ratio', help='Split ratio for val set', default=0.0, type=float)
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='Number of process')
+ parser.add_argument(
+ '--preserve-vertical',
+ help='Preserve samples containing vertical texts',
+ action='store_true')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+ ratio = args.val_ratio
+
+ trn_files, val_files = collect_files(
+ osp.join(root_path, 'imgs'), osp.join(root_path, 'annotations'), ratio)
+
+ # Train set
+ trn_infos = collect_annotations(trn_files, nproc=args.nproc)
+ with mmengine.Timer(
+ print_tmpl='It takes {}s to convert ReCTS Training annotation'):
+ generate_ann(root_path, 'training', trn_infos, args.preserve_vertical)
+
+ # Val set
+ if len(val_files) > 0:
+ val_infos = collect_annotations(val_files, nproc=args.nproc)
+ with mmengine.Timer(
+ print_tmpl='It takes {}s to convert ReCTS Val annotation'):
+ generate_ann(root_path, 'val', val_infos, args.preserve_vertical)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textrecog/sroie_converter.py b/tools/dataset_converters/textrecog/sroie_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..1c380e49d42d7c09907f5c1642baa172e5dff1ed
--- /dev/null
+++ b/tools/dataset_converters/textrecog/sroie_converter.py
@@ -0,0 +1,207 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+
+import mmcv
+import mmengine
+import numpy as np
+
+from mmocr.utils import crop_img, dump_ocr_data
+
+
+def collect_files(img_dir, gt_dir):
+ """Collect all images and their corresponding groundtruth files.
+
+ Args:
+ img_dir (str): The image directory
+ gt_dir (str): The groundtruth directory
+
+ Returns:
+ files (list): The list of tuples (img_file, groundtruth_file)
+ """
+
+ assert isinstance(img_dir, str)
+ assert img_dir
+ assert isinstance(gt_dir, str)
+ assert gt_dir
+
+ ann_list, imgs_list = [], []
+ for gt_file in os.listdir(gt_dir):
+ # Filtering repeated and missing images
+ if '(' in gt_file or gt_file == 'X51006619570.txt':
+ continue
+ ann_list.append(osp.join(gt_dir, gt_file))
+ imgs_list.append(osp.join(img_dir, gt_file.replace('.txt', '.jpg')))
+
+ files = list(zip(sorted(imgs_list), sorted(ann_list)))
+ assert len(files), f'No images found in {img_dir}'
+
+ print(f'Loaded {len(files)} images from {img_dir}')
+
+ return files
+
+
+def collect_annotations(files, nproc=1):
+ """Collect the annotation information.
+
+ Args:
+ files (list): The list of tuples (image_file, groundtruth_file)
+ nproc (int): The number of process to collect annotations
+
+ Returns:
+ images (list): The list of image information dicts
+ """
+
+ assert isinstance(files, list)
+ assert isinstance(nproc, int)
+
+ if nproc > 1:
+ images = mmengine.track_parallel_progress(
+ load_img_info, files, nproc=nproc)
+ else:
+ images = mmengine.track_progress(load_img_info, files)
+
+ return images
+
+
+def load_img_info(files):
+ """Load the information of one image.
+
+ Args:
+ files (tuple): The tuple of (img_file, groundtruth_file)
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+
+ assert isinstance(files, tuple)
+
+ img_file, gt_file = files
+ assert osp.basename(gt_file).split('.')[0] == osp.basename(img_file).split(
+ '.')[0]
+ # read imgs while ignoring orientations
+ img = mmcv.imread(img_file, 'unchanged')
+
+ img_info = dict(
+ file_name=osp.join(osp.basename(img_file)),
+ height=img.shape[0],
+ width=img.shape[1],
+ segm_file=osp.join(osp.basename(gt_file)))
+
+ if osp.splitext(gt_file)[1] == '.txt':
+ img_info = load_txt_info(gt_file, img_info)
+ else:
+ raise NotImplementedError
+
+ return img_info
+
+
+def load_txt_info(gt_file, img_info):
+ """Collect the annotation information.
+
+ Annotation Format
+ x1, y1, x2, y2, x3, y3, x4, y4, transcript
+
+ Args:
+ gt_file (list): The list of tuples (image_file, groundtruth_file)
+ img_info (int): The dict of the img and annotation information
+
+ Returns:
+ img_info (list): The dict of the img and annotation information
+ """
+
+ with open(gt_file, encoding='unicode_escape') as f:
+ anno_info = []
+ for ann in f.readlines():
+ # skip invalid annotation line
+ try:
+ bbox = np.array(ann.split(',')[0:8]).astype(int).tolist()
+ except ValueError:
+
+ continue
+ word = ann.split(',')[-1].replace('\n', '').strip()
+
+ anno = dict(bbox=bbox, word=word)
+ anno_info.append(anno)
+
+ img_info.update(anno_info=anno_info)
+
+ return img_info
+
+
+def generate_ann(root_path, split, image_infos):
+ """Generate cropped annotations and label txt file.
+
+ Args:
+ root_path (str): The root path of the dataset
+ split (str): The split of dataset. Namely: training or test
+ image_infos (list[dict]): A list of dicts of the img and
+ annotation information
+ """
+
+ dst_image_root = osp.join(root_path, 'crops', split)
+ if split == 'training':
+ dst_label_file = osp.join(root_path, 'train_label.json')
+ elif split == 'test':
+ dst_label_file = osp.join(root_path, 'test_label.json')
+ os.makedirs(dst_image_root, exist_ok=True)
+
+ img_info = []
+ for image_info in image_infos:
+ index = 1
+ src_img_path = osp.join(root_path, 'imgs', split,
+ image_info['file_name'])
+ image = mmcv.imread(src_img_path)
+ src_img_root = image_info['file_name'].split('.')[0]
+
+ for anno in image_info['anno_info']:
+ word = anno['word']
+ dst_img = crop_img(image, anno['bbox'], 0, 0)
+
+ # Skip invalid annotations
+ if min(dst_img.shape) == 0 or len(word) == 0:
+ continue
+
+ dst_img_name = f'{src_img_root}_{index}.png'
+ index += 1
+ dst_img_path = osp.join(dst_image_root, dst_img_name)
+ mmcv.imwrite(dst_img, dst_img_path)
+
+ img_info.append({
+ 'file_name': dst_img_name,
+ 'anno_info': [{
+ 'text': word
+ }]
+ })
+
+ dump_ocr_data(img_info, dst_label_file, 'textrecog')
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training and test set of SROIE')
+ parser.add_argument('root_path', help='Root dir path of SROIE')
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='Number of process')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+
+ for split in ['training', 'test']:
+ print(f'Processing {split} set...')
+ with mmengine.Timer(
+ print_tmpl='It takes {}s to convert SROIE annotation'):
+ files = collect_files(
+ osp.join(root_path, 'imgs', split),
+ osp.join(root_path, 'annotations', split))
+ image_infos = collect_annotations(files, nproc=args.nproc)
+ generate_ann(root_path, split, image_infos)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/textrecog/vintext_converter.py b/tools/dataset_converters/textrecog/vintext_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..ea9103da033c2d4bdbba3855f78a88d32aec9553
--- /dev/null
+++ b/tools/dataset_converters/textrecog/vintext_converter.py
@@ -0,0 +1,217 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+
+import mmcv
+import mmengine
+
+from mmocr.utils import crop_img, dump_ocr_data
+
+
+def collect_files(img_dir, gt_dir):
+ """Collect all images and their corresponding groundtruth files.
+
+ Args:
+ img_dir (str): The image directory
+ gt_dir (str): The groundtruth directory
+
+ Returns:
+ files (list): The list of tuples (img_file, groundtruth_file)
+ """
+ assert isinstance(img_dir, str)
+ assert img_dir
+ assert isinstance(gt_dir, str)
+ assert gt_dir
+
+ ann_list, imgs_list = [], []
+ for img_file in os.listdir(img_dir):
+ ann_file = 'gt_' + str(int(img_file[2:6])) + '.txt'
+ ann_list.append(osp.join(gt_dir, ann_file))
+ imgs_list.append(osp.join(img_dir, img_file))
+
+ files = list(zip(imgs_list, ann_list))
+ assert len(files), f'No images found in {img_dir}'
+ print(f'Loaded {len(files)} images from {img_dir}')
+
+ return files
+
+
+def collect_annotations(files, nproc=1):
+ """Collect the annotation information.
+
+ Args:
+ files (list): The list of tuples (image_file, groundtruth_file)
+ nproc (int): The number of process to collect annotations
+
+ Returns:
+ images (list): The list of image information dicts
+ """
+ assert isinstance(files, list)
+ assert isinstance(nproc, int)
+
+ if nproc > 1:
+ images = mmengine.track_parallel_progress(
+ load_img_info, files, nproc=nproc)
+ else:
+ images = mmengine.track_progress(load_img_info, files)
+
+ return images
+
+
+def load_img_info(files):
+ """Load the information of one image.
+
+ Args:
+ files (tuple): The tuple of (img_file, groundtruth_file)
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+ assert isinstance(files, tuple)
+
+ img_file, gt_file = files
+ assert int(osp.basename(gt_file)[3:-4]) == int(
+ osp.basename(img_file)[2:-4])
+ # read imgs while ignoring orientations
+ img = mmcv.imread(img_file, 'unchanged')
+
+ img_info = dict(
+ file_name=osp.join(osp.basename(img_file)),
+ height=img.shape[0],
+ width=img.shape[1],
+ segm_file=osp.join(osp.basename(gt_file)))
+
+ if osp.splitext(gt_file)[1] == '.txt':
+ img_info = load_txt_info(gt_file, img_info)
+ else:
+ raise NotImplementedError
+
+ return img_info
+
+
+def load_txt_info(gt_file, img_info):
+ """Collect the annotation information.
+
+ The annotation format is as the following:
+ x1,y1,x2,y2,x3,y3,x4,y4,text
+ 118,15,147,15,148,46,118,46,LƯỢNG
+ 149,9,165,9,165,43,150,43,TỐT
+ 167,9,180,9,179,43,167,42,ĐỂ
+ 181,12,193,12,193,43,181,43,CÓ
+ 195,13,215,14,215,46,196,46,VIỆC
+ 217,13,237,14,239,47,217,46,LÀM,
+
+ Args:
+ gt_file (str): The path to ground-truth
+ img_info (dict): The dict of the img and annotation information
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+
+ with open(gt_file, encoding='utf-8') as f:
+ anno_info = []
+ for line in f:
+ line = line.strip('\n')
+ ann = line.split(',')
+ bbox = ann[0:8]
+ word = line[len(','.join(bbox)) + 1:]
+ bbox = [int(coord) for coord in bbox]
+ # Ignore hard samples
+ if word == '###':
+ continue
+ assert len(bbox) == 8
+ anno = dict(bbox=bbox, word=word)
+ anno_info.append(anno)
+
+ img_info.update(anno_info=anno_info)
+
+ return img_info
+
+
+def generate_ann(root_path, split, image_infos, preserve_vertical):
+ """Generate cropped annotations and label txt file.
+
+ Args:
+ root_path (str): The root path of the dataset
+ split (str): The split of dataset. Namely: training or test
+ image_infos (list[dict]): A list of dicts of the img and
+ annotation information
+ preserve_vertical (bool): Whether to preserve vertical texts
+ """
+ dst_image_root = osp.join(root_path, 'crops', split)
+ ignore_image_root = osp.join(root_path, 'ignores', split)
+ if split == 'training':
+ dst_label_file = osp.join(root_path, 'train_label.json')
+ elif split == 'test':
+ dst_label_file = osp.join(root_path, 'test_label.json')
+ elif split == 'unseen_test':
+ dst_label_file = osp.join(root_path, 'unseen_test_label.json')
+ os.makedirs(dst_image_root, exist_ok=True)
+
+ img_info = []
+ for image_info in image_infos:
+ index = 1
+ src_img_path = osp.join(root_path, 'imgs', split,
+ image_info['file_name'])
+ image = mmcv.imread(src_img_path)
+ src_img_root = image_info['file_name'].split('.')[0]
+
+ for anno in image_info['anno_info']:
+ word = anno['word']
+ dst_img = crop_img(image, anno['bbox'], 0, 0)
+ h, w, _ = dst_img.shape
+
+ dst_img_name = f'{src_img_root}_{index}.png'
+ index += 1
+ # Skip invalid annotations
+ if min(dst_img.shape) == 0:
+ continue
+ # Skip vertical texts
+ if not preserve_vertical and h / w > 2 and split == 'training':
+ dst_img_path = osp.join(ignore_image_root, dst_img_name)
+ mmcv.imwrite(dst_img, dst_img_path)
+ continue
+
+ dst_img_path = osp.join(dst_image_root, dst_img_name)
+ mmcv.imwrite(dst_img, dst_img_path)
+ img_info.append({
+ 'file_name': dst_img_name,
+ 'anno_info': [{
+ 'text': word
+ }]
+ })
+ dump_ocr_data(img_info, dst_label_file, 'textrecog')
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training and test set of VinText ')
+ parser.add_argument('root_path', help='Root dir path of VinText')
+ parser.add_argument(
+ '--preserve-vertical',
+ help='Preserve samples containing vertical texts',
+ action='store_true')
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='Number of processes')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+ for split in ['training', 'test', 'unseen_test']:
+ print(f'Processing {split} set...')
+ with mmengine.Timer(
+ print_tmpl='It takes {}s to convert VinText annotation'):
+ files = collect_files(
+ osp.join(root_path, 'imgs', split),
+ osp.join(root_path, 'annotations'))
+ image_infos = collect_annotations(files, nproc=args.nproc)
+ generate_ann(root_path, split, image_infos, args.preserve_vertical)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dist_test.sh b/tools/dist_test.sh
new file mode 100644
index 0000000000000000000000000000000000000000..dea131b43ea8f1222661d20603d40c18ea7f28a1
--- /dev/null
+++ b/tools/dist_test.sh
@@ -0,0 +1,22 @@
+#!/usr/bin/env bash
+
+CONFIG=$1
+CHECKPOINT=$2
+GPUS=$3
+NNODES=${NNODES:-1}
+NODE_RANK=${NODE_RANK:-0}
+PORT=${PORT:-29500}
+MASTER_ADDR=${MASTER_ADDR:-"127.0.0.1"}
+
+PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
+python -m torch.distributed.launch \
+ --nnodes=$NNODES \
+ --node_rank=$NODE_RANK \
+ --master_addr=$MASTER_ADDR \
+ --nproc_per_node=$GPUS \
+ --master_port=$PORT \
+ $(dirname "$0")/test.py \
+ $CONFIG \
+ $CHECKPOINT \
+ --launcher pytorch \
+ ${@:4}
diff --git a/tools/dist_train.sh b/tools/dist_train.sh
new file mode 100644
index 0000000000000000000000000000000000000000..3f5b40b2318c6bd58504d9e570b90adf21825376
--- /dev/null
+++ b/tools/dist_train.sh
@@ -0,0 +1,20 @@
+
+#!/usr/bin/env bash
+
+CONFIG=$1
+GPUS=$2
+NNODES=${NNODES:-1}
+NODE_RANK=${NODE_RANK:-0}
+PORT=${PORT:-29500}
+MASTER_ADDR=${MASTER_ADDR:-"127.0.0.1"}
+
+PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
+python -m torch.distributed.launch \
+ --nnodes=$NNODES \
+ --node_rank=$NODE_RANK \
+ --master_addr=$MASTER_ADDR \
+ --nproc_per_node=$GPUS \
+ --master_port=$PORT \
+ $(dirname "$0")/train.py \
+ $CONFIG \
+ --launcher pytorch ${@:3}
diff --git a/tools/infer.py b/tools/infer.py
new file mode 100644
index 0000000000000000000000000000000000000000..74ff9099e2727910ecffa0ff47f28f3c4208bed3
--- /dev/null
+++ b/tools/infer.py
@@ -0,0 +1,100 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from argparse import ArgumentParser
+
+from mmocr.apis.inferencers import MMOCRInferencer
+
+
+def parse_args():
+ parser = ArgumentParser()
+ parser.add_argument(
+ 'inputs', type=str, help='Input image file or folder path.')
+ parser.add_argument(
+ '--out-dir',
+ type=str,
+ default='results/',
+ help='Output directory of results.')
+ parser.add_argument(
+ '--det',
+ type=str,
+ default=None,
+ help='Pretrained text detection algorithm. It\'s the path to the '
+ 'config file or the model name defined in metafile.')
+ parser.add_argument(
+ '--det-weights',
+ type=str,
+ default=None,
+ help='Path to the custom checkpoint file of the selected det model. '
+ 'If it is not specified and "det" is a model name of metafile, the '
+ 'weights will be loaded from metafile.')
+ parser.add_argument(
+ '--rec',
+ type=str,
+ default=None,
+ help='Pretrained text recognition algorithm. It\'s the path to the '
+ 'config file or the model name defined in metafile.')
+ parser.add_argument(
+ '--rec-weights',
+ type=str,
+ default=None,
+ help='Path to the custom checkpoint file of the selected recog model. '
+ 'If it is not specified and "rec" is a model name of metafile, the '
+ 'weights will be loaded from metafile.')
+ parser.add_argument(
+ '--kie',
+ type=str,
+ default=None,
+ help='Pretrained key information extraction algorithm. It\'s the path'
+ 'to the config file or the model name defined in metafile.')
+ parser.add_argument(
+ '--kie-weights',
+ type=str,
+ default=None,
+ help='Path to the custom checkpoint file of the selected kie model. '
+ 'If it is not specified and "kie" is a model name of metafile, the '
+ 'weights will be loaded from metafile.')
+ parser.add_argument(
+ '--device',
+ type=str,
+ default=None,
+ help='Device used for inference. '
+ 'If not specified, the available device will be automatically used.')
+ parser.add_argument(
+ '--batch-size', type=int, default=1, help='Inference batch size.')
+ parser.add_argument(
+ '--show',
+ action='store_true',
+ help='Display the image in a popup window.')
+ parser.add_argument(
+ '--print-result',
+ action='store_true',
+ help='Whether to print the results.')
+ parser.add_argument(
+ '--save_pred',
+ action='store_true',
+ help='Save the inference results to out_dir.')
+ parser.add_argument(
+ '--save_vis',
+ action='store_true',
+ help='Save the visualization results to out_dir.')
+
+ call_args = vars(parser.parse_args())
+
+ init_kws = [
+ 'det', 'det_weights', 'rec', 'rec_weights', 'kie', 'kie_weights',
+ 'device'
+ ]
+ init_args = {}
+ for init_kw in init_kws:
+ init_args[init_kw] = call_args.pop(init_kw)
+
+ return init_args, call_args
+
+
+def main():
+ init_args, call_args = parse_args()
+ ocr = MMOCRInferencer(**init_args)
+ ocr(**call_args)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/model_converters/publish_model.py b/tools/model_converters/publish_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..18fc3e15045dea63a74ed1a7727a388e9031ac8c
--- /dev/null
+++ b/tools/model_converters/publish_model.py
@@ -0,0 +1,57 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import subprocess
+
+import torch
+from mmengine.logging import print_log
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Process a checkpoint to be published')
+ parser.add_argument('in_file', help='input checkpoint filename')
+ parser.add_argument('out_file', help='output checkpoint filename')
+ parser.add_argument(
+ '--save-keys',
+ nargs='+',
+ type=str,
+ default=['meta', 'state_dict'],
+ help='keys to save in the published checkpoint')
+ args = parser.parse_args()
+ return args
+
+
+def process_checkpoint(in_file, out_file, save_keys=['meta', 'state_dict']):
+ checkpoint = torch.load(in_file, map_location='cpu')
+
+ # only keep `meta` and `state_dict` for smaller file size
+ ckpt_keys = list(checkpoint.keys())
+ for k in ckpt_keys:
+ if k not in save_keys:
+ print_log(
+ f'Key `{k}` will be removed because it is not in '
+ f'save_keys. If you want to keep it, '
+ f'please set --save-keys.',
+ logger='current')
+ checkpoint.pop(k, None)
+
+ # if it is necessary to remove some sensitive data in checkpoint['meta'],
+ # add the code here.
+ if torch.__version__ >= '1.6':
+ torch.save(checkpoint, out_file, _use_new_zipfile_serialization=False)
+ else:
+ torch.save(checkpoint, out_file)
+ sha = subprocess.check_output(['sha256sum', out_file]).decode()
+ final_file = out_file.rstrip('.pth') + f'-{sha[:8]}.pth'
+ subprocess.Popen(['mv', out_file, final_file])
+ print_log(
+ f'The published model is saved at {final_file}.', logger='current')
+
+
+def main():
+ args = parse_args()
+ process_checkpoint(args.in_file, args.out_file, args.save_keys)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/slurm_test.sh b/tools/slurm_test.sh
new file mode 100644
index 0000000000000000000000000000000000000000..865f45599ad883d216f0df0248a3815700615c17
--- /dev/null
+++ b/tools/slurm_test.sh
@@ -0,0 +1,22 @@
+#!/usr/bin/env bash
+
+set -x
+export PYTHONPATH=`pwd`:$PYTHONPATH
+
+PARTITION=$1
+JOB_NAME=$2
+CONFIG=$3
+CHECKPOINT=$4
+GPUS=${GPUS:-8}
+GPUS_PER_NODE=${GPUS_PER_NODE:-8}
+PY_ARGS=${@:5}
+SRUN_ARGS=${SRUN_ARGS:-""}
+
+srun -p ${PARTITION} \
+ --job-name=${JOB_NAME} \
+ --gres=gpu:${GPUS_PER_NODE} \
+ --ntasks=${GPUS} \
+ --ntasks-per-node=${GPUS_PER_NODE} \
+ --kill-on-bad-exit=1 \
+ ${SRUN_ARGS} \
+ python -u tools/test.py ${CONFIG} ${CHECKPOINT} --launcher="slurm" ${PY_ARGS}
diff --git a/tools/slurm_train.sh b/tools/slurm_train.sh
new file mode 100644
index 0000000000000000000000000000000000000000..452b09454a08ac522a9df2304c3039487ea517bd
--- /dev/null
+++ b/tools/slurm_train.sh
@@ -0,0 +1,25 @@
+#!/usr/bin/env bash
+export MASTER_PORT=$((12000 + $RANDOM % 20000))
+
+set -x
+
+PARTITION=$1
+JOB_NAME=$2
+CONFIG=$3
+WORK_DIR=$4
+GPUS=${GPUS:-8}
+GPUS_PER_NODE=${GPUS_PER_NODE:-8}
+CPUS_PER_TASK=${CPUS_PER_TASK:-5}
+PY_ARGS=${@:5}
+SRUN_ARGS=${SRUN_ARGS:-""}
+
+PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
+srun -p ${PARTITION} \
+ --job-name=${JOB_NAME} \
+ --gres=gpu:${GPUS_PER_NODE} \
+ --ntasks=${GPUS} \
+ --ntasks-per-node=${GPUS_PER_NODE} \
+ --cpus-per-task=${CPUS_PER_TASK} \
+ --kill-on-bad-exit=1 \
+ ${SRUN_ARGS} \
+ python -u tools/train.py ${CONFIG} --work-dir=${WORK_DIR} --launcher="slurm" ${PY_ARGS}
diff --git a/tools/test.py b/tools/test.py
new file mode 100644
index 0000000000000000000000000000000000000000..15645f2207ebdb61fd70293f2b2c9602e99b2c61
--- /dev/null
+++ b/tools/test.py
@@ -0,0 +1,141 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+
+from mmengine.config import Config, DictAction
+from mmengine.registry import RUNNERS
+from mmengine.runner import Runner
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Test (and eval) a model')
+ parser.add_argument('config', help='Test config file path')
+ parser.add_argument('checkpoint', help='Checkpoint file')
+ parser.add_argument(
+ '--work-dir',
+ help='The directory to save the file containing evaluation metrics')
+ parser.add_argument(
+ '--save-preds',
+ action='store_true',
+ help='Dump predictions to a pickle file for offline evaluation')
+ parser.add_argument(
+ '--show', action='store_true', help='Show prediction results')
+ parser.add_argument(
+ '--show-dir',
+ help='Directory where painted images will be saved. '
+ 'If specified, it will be automatically saved '
+ 'to the work_dir/timestamp/show_dir')
+ parser.add_argument(
+ '--wait-time', type=float, default=2, help='The interval of show (s)')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='Override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ parser.add_argument(
+ '--launcher',
+ choices=['none', 'pytorch', 'slurm', 'mpi'],
+ default='none',
+ help='Job launcher')
+ parser.add_argument(
+ '--tta', action='store_true', help='Test time augmentation')
+ # When using PyTorch version >= 2.0.0, the `torch.distributed.launch`
+ # will pass the `--local-rank` parameter to `tools/test.py` instead
+ # of `--local_rank`.
+ parser.add_argument('--local_rank', '--local-rank', type=int, default=0)
+ args = parser.parse_args()
+ if 'LOCAL_RANK' not in os.environ:
+ os.environ['LOCAL_RANK'] = str(args.local_rank)
+ return args
+
+
+def trigger_visualization_hook(cfg, args):
+ default_hooks = cfg.default_hooks
+ if 'visualization' in default_hooks:
+ visualization_hook = default_hooks['visualization']
+ # Turn on visualization
+ visualization_hook['enable'] = True
+ visualization_hook['draw_gt'] = True
+ visualization_hook['draw_pred'] = True
+ if args.show:
+ visualization_hook['show'] = True
+ visualization_hook['wait_time'] = args.wait_time
+ if args.show_dir:
+ cfg.visualizer['save_dir'] = args.show_dir
+ cfg.visualizer['vis_backends'] = [dict(type='LocalVisBackend')]
+ else:
+ raise RuntimeError(
+ 'VisualizationHook must be included in default_hooks.'
+ 'refer to usage '
+ '"visualization=dict(type=\'VisualizationHook\')"')
+
+ return cfg
+
+
+def main():
+ args = parse_args()
+
+ # load config
+ cfg = Config.fromfile(args.config)
+ cfg.launcher = args.launcher
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+
+ # work_dir is determined in this priority: CLI > segment in file > filename
+ if args.work_dir is not None:
+ # update configs according to CLI args if args.work_dir is not None
+ cfg.work_dir = args.work_dir
+ elif cfg.get('work_dir', None) is None:
+ # use config filename as default work_dir if cfg.work_dir is None
+ cfg.work_dir = osp.join('./work_dirs',
+ osp.splitext(osp.basename(args.config))[0])
+
+ cfg.load_from = args.checkpoint
+
+ # TODO: It will be supported after refactoring the visualizer
+ if args.show and args.show_dir:
+ raise NotImplementedError('--show and --show-dir cannot be set '
+ 'at the same time')
+
+ if args.show or args.show_dir:
+ cfg = trigger_visualization_hook(cfg, args)
+
+ if args.tta:
+ cfg.test_dataloader.dataset.pipeline = cfg.tta_pipeline
+ cfg.tta_model.module = cfg.model
+ cfg.model = cfg.tta_model
+
+ # save predictions
+ if args.save_preds:
+ dump_metric = dict(
+ type='DumpResults',
+ out_file_path=osp.join(
+ cfg.work_dir,
+ f'{osp.basename(args.checkpoint)}_predictions.pkl'))
+ if isinstance(cfg.test_evaluator, (list, tuple)):
+ cfg.test_evaluator = list(cfg.test_evaluator)
+ cfg.test_evaluator.append(dump_metric)
+ else:
+ cfg.test_evaluator = [cfg.test_evaluator, dump_metric]
+
+ # build the runner from config
+ if 'runner_type' not in cfg:
+ # build the default runner
+ runner = Runner.from_cfg(cfg)
+ else:
+ # build customized runner from the registry
+ # if 'runner_type' is set in the cfg
+ runner = RUNNERS.build(cfg)
+
+ # start testing
+ runner.test()
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/train.py b/tools/train.py
new file mode 100644
index 0000000000000000000000000000000000000000..349cbb3ef4fc74c821c9bd4266ecacdd6acd8cc2
--- /dev/null
+++ b/tools/train.py
@@ -0,0 +1,113 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import logging
+import os
+import os.path as osp
+
+from mmengine.config import Config, DictAction
+from mmengine.logging import print_log
+from mmengine.registry import RUNNERS
+from mmengine.runner import Runner
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Train a model')
+ parser.add_argument('config', help='Train config file path')
+ parser.add_argument('--work-dir', help='The dir to save logs and models')
+ parser.add_argument(
+ '--resume', action='store_true', help='Whether to resume checkpoint.')
+ parser.add_argument(
+ '--amp',
+ action='store_true',
+ default=False,
+ help='Enable automatic-mixed-precision training')
+ parser.add_argument(
+ '--auto-scale-lr',
+ action='store_true',
+ help='Whether to scale the learning rate automatically. It requires '
+ '`auto_scale_lr` in config, and `base_batch_size` in `auto_scale_lr`')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='Override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ parser.add_argument(
+ '--launcher',
+ choices=['none', 'pytorch', 'slurm', 'mpi'],
+ default='none',
+ help='Job launcher')
+ # When using PyTorch version >= 2.0.0, the `torch.distributed.launch`
+ # will pass the `--local-rank` parameter to `tools/train.py` instead
+ # of `--local_rank`.
+ parser.add_argument('--local_rank', '--local-rank', type=int, default=0)
+ args = parser.parse_args()
+ if 'LOCAL_RANK' not in os.environ:
+ os.environ['LOCAL_RANK'] = str(args.local_rank)
+
+ return args
+
+
+def main():
+ args = parse_args()
+ # load config
+ cfg = Config.fromfile(args.config)
+ cfg.launcher = args.launcher
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+
+ # work_dir is determined in this priority: CLI > segment in file > filename
+ if args.work_dir is not None:
+ # update configs according to CLI args if args.work_dir is not None
+ cfg.work_dir = args.work_dir
+ elif cfg.get('work_dir', None) is None:
+ # use config filename as default work_dir if cfg.work_dir is None
+ cfg.work_dir = osp.join('./work_dirs',
+ osp.splitext(osp.basename(args.config))[0])
+ # enable automatic-mixed-precision training
+ if args.amp:
+ optim_wrapper = cfg.optim_wrapper.type
+ if optim_wrapper == 'AmpOptimWrapper':
+ print_log(
+ 'AMP training is already enabled in your config.',
+ logger='current',
+ level=logging.WARNING)
+ else:
+ assert optim_wrapper == 'OptimWrapper', (
+ '`--amp` is only supported when the optimizer wrapper type is '
+ f'`OptimWrapper` but got {optim_wrapper}.')
+ cfg.optim_wrapper.type = 'AmpOptimWrapper'
+ cfg.optim_wrapper.loss_scale = 'dynamic'
+
+ if args.resume:
+ cfg.resume = True
+
+ # enable automatically scaling LR
+ if args.auto_scale_lr:
+ if 'auto_scale_lr' in cfg and \
+ 'base_batch_size' in cfg.auto_scale_lr:
+ cfg.auto_scale_lr.enable = True
+ else:
+ raise RuntimeError('Can not find "auto_scale_lr" or '
+ '"auto_scale_lr.base_batch_size" in your'
+ ' configuration file.')
+
+ # build the runner from config
+ if 'runner_type' not in cfg:
+ # build the default runner
+ runner = Runner.from_cfg(cfg)
+ else:
+ # build customized runner from the registry
+ # if 'runner_type' is set in the cfg
+ runner = RUNNERS.build(cfg)
+
+ # start training
+ runner.train()
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/visualizations/browse_dataset.py b/tools/visualizations/browse_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..d92ee83f586005de5b14ed95066c778547baa0d4
--- /dev/null
+++ b/tools/visualizations/browse_dataset.py
@@ -0,0 +1,415 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+import sys
+from typing import Optional, Tuple
+
+import cv2
+import mmcv
+import numpy as np
+from mmengine.config import Config, DictAction
+from mmengine.dataset import Compose
+from mmengine.registry import init_default_scope
+from mmengine.utils import ProgressBar
+from mmengine.visualization import Visualizer
+
+from mmocr.registry import DATASETS, VISUALIZERS
+
+
+# TODO: Support for printing the change in key of results
+def parse_args():
+ parser = argparse.ArgumentParser(description='Browse a dataset')
+ parser.add_argument('config', help='Path to model or dataset config.')
+ parser.add_argument(
+ '--phase',
+ '-p',
+ default='train',
+ type=str,
+ help='Phase of dataset to visualize. Use "train", "test" or "val" if '
+ "you just want to visualize the default split. It's also possible to "
+ 'be a dataset variable name, which might be useful when a dataset '
+ 'split has multiple variants in the config.')
+ parser.add_argument(
+ '--mode',
+ '-m',
+ default='transformed',
+ type=str,
+ choices=['original', 'transformed', 'pipeline'],
+ help='Display mode: display original pictures or '
+ 'transformed pictures or comparison pictures. "original" '
+ 'only visualizes the original dataset & annotations; '
+ '"transformed" shows the resulting images processed through all the '
+ 'transforms; "pipeline" shows all the intermediate images. '
+ 'Defaults to "transformed".')
+ parser.add_argument(
+ '--output-dir',
+ '-o',
+ default=None,
+ type=str,
+ help='If there is no display interface, you can save it.')
+ parser.add_argument(
+ '--task',
+ '-t',
+ default='auto',
+ choices=['auto', 'textdet', 'textrecog'],
+ type=str,
+ help='Specify the task type of the dataset. If "auto", the task type '
+ 'will be inferred from the config. If the script is unable to infer '
+ 'the task type, you need to specify it manually. Defaults to "auto".')
+ parser.add_argument('--not-show', default=False, action='store_true')
+ parser.add_argument(
+ '--show-number',
+ '-n',
+ type=int,
+ default=sys.maxsize,
+ help='number of images selected to visualize, '
+ 'must bigger than 0. if the number is bigger than length '
+ 'of dataset, show all the images in dataset; '
+ 'default "sys.maxsize", show all images in dataset')
+ parser.add_argument(
+ '--show-interval',
+ '-i',
+ type=float,
+ default=3,
+ help='the interval of show (s)')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ args = parser.parse_args()
+ return args
+
+
+def _get_adaptive_scale(img_shape: Tuple[int, int],
+ min_scale: float = 0.3,
+ max_scale: float = 3.0) -> float:
+ """Get adaptive scale according to image shape.
+
+ The target scale depends on the the short edge length of the image. If the
+ short edge length equals 224, the output is 1.0. And output linear
+ scales according the short edge length. You can also specify the minimum
+ scale and the maximum scale to limit the linear scale.
+
+ Args:
+ img_shape (Tuple[int, int]): The shape of the canvas image.
+ min_scale (int): The minimum scale. Defaults to 0.3.
+ max_scale (int): The maximum scale. Defaults to 3.0.
+
+ Returns:
+ int: The adaptive scale.
+ """
+ short_edge_length = min(img_shape)
+ scale = short_edge_length / 224.
+ return min(max(scale, min_scale), max_scale)
+
+
+def make_grid(imgs, infos):
+ """Concat list of pictures into a single big picture, align height here."""
+ visualizer = Visualizer.get_current_instance()
+ names = [info['name'] for info in infos]
+ ori_shapes = [
+ info['dataset_sample'].metainfo['img_shape'] for info in infos
+ ]
+ max_height = int(max(img.shape[0] for img in imgs) * 1.1)
+ min_width = min(img.shape[1] for img in imgs)
+ horizontal_gap = min_width // 10
+ img_scale = _get_adaptive_scale((max_height, min_width))
+
+ texts = []
+ text_positions = []
+ start_x = 0
+ for i, img in enumerate(imgs):
+ pad_height = (max_height - img.shape[0]) // 2
+ pad_width = horizontal_gap // 2
+ # make border
+ imgs[i] = cv2.copyMakeBorder(
+ img,
+ pad_height,
+ max_height - img.shape[0] - pad_height + int(img_scale * 30 * 2),
+ pad_width,
+ pad_width,
+ cv2.BORDER_CONSTANT,
+ value=(255, 255, 255))
+ texts.append(f'{"execution: "}{i}\n{names[i]}\n{ori_shapes[i]}')
+ text_positions.append(
+ [start_x + img.shape[1] // 2 + pad_width, max_height])
+ start_x += img.shape[1] + horizontal_gap
+
+ display_img = np.concatenate(imgs, axis=1)
+ visualizer.set_image(display_img)
+ img_scale = _get_adaptive_scale(display_img.shape[:2])
+ visualizer.draw_texts(
+ texts,
+ positions=np.array(text_positions),
+ font_sizes=img_scale * 7,
+ colors='black',
+ horizontal_alignments='center',
+ font_families='monospace')
+ return visualizer.get_image()
+
+
+class InspectCompose(Compose):
+ """Compose multiple transforms sequentially.
+
+ And record "img" field of all results in one list.
+ """
+
+ def __init__(self, transforms, intermediate_imgs):
+ super().__init__(transforms=transforms)
+ self.intermediate_imgs = intermediate_imgs
+
+ def __call__(self, data):
+ self.ptransforms = [
+ self.transforms[i] for i in range(len(self.transforms) - 1)
+ ]
+ for t in self.ptransforms:
+ data = t(data)
+ # Keep the same meta_keys in the PackTextDetInputs
+ # or PackTextRecogInputs
+ self.transforms[-1].meta_keys = [key for key in data]
+ data_sample = self.transforms[-1](data)
+ if data is None:
+ return None
+ if 'img' in data:
+ self.intermediate_imgs.append({
+ 'name':
+ t.__class__.__name__,
+ 'dataset_sample':
+ data_sample['data_samples']
+ })
+ return data
+
+
+def infer_dataset_task(task: str,
+ dataset_cfg: Config,
+ var_name: Optional[str] = None) -> str:
+ """Try to infer the dataset's task type from the config and the variable
+ name."""
+ if task != 'auto':
+ return task
+
+ if dataset_cfg.pipeline is not None:
+ if dataset_cfg.pipeline[-1].type == 'PackTextDetInputs':
+ return 'textdet'
+ elif dataset_cfg.pipeline[-1].type == 'PackTextRecogInputs':
+ return 'textrecog'
+
+ if var_name is not None:
+ if 'det' in var_name:
+ return 'textdet'
+ elif 'rec' in var_name:
+ return 'textrecog'
+
+ raise ValueError(
+ 'Unable to infer the task type from dataset pipeline '
+ 'or variable name. Please specify the task type with --task argument '
+ 'explicitly.')
+
+
+def obtain_dataset_cfg(cfg: Config, phase: str, mode: str, task: str) -> Tuple:
+ """Obtain dataset and visualizer from config. Two modes are supported:
+ 1. Model Config Mode:
+ In this mode, the input config should be a complete model config, which
+ includes a dataset within pipeline and a visualizer.
+ 2. Dataset Config Mode:
+ In this mode, the input config should be a complete dataset config,
+ which only includes basic dataset information, and it may does not
+ contain a visualizer and dataset pipeline.
+
+ Examples:
+ Typically, the model config files are stored in
+ `configs/textdet/dbnet/xxx.py` and should look like:
+ >>> train_dataloader = dict(
+ >>> batch_size=16,
+ >>> num_workers=8,
+ >>> persistent_workers=True,
+ >>> sampler=dict(type='DefaultSampler', shuffle=True),
+ >>> dataset=icdar2015_textdet_train)
+
+ while the dataset config files are stored in
+ `configs/textdet/_base_/datasets/xxx.py` and should be like:
+ >>> icdar2015_textdet_train = dict(
+ >>> type='OCRDataset',
+ >>> data_root=ic15_det_data_root,
+ >>> ann_file='textdet_train.json',
+ >>> filter_cfg=dict(filter_empty_gt=True, min_size=32),
+ >>> pipeline=None)
+
+ Args:
+ cfg (Config): Config object.
+ phase (str): The dataset phase to visualize.
+ mode (str): Script mode.
+ task (str): The current task type.
+
+ Returns:
+ Tuple: Tuple of (dataset, visualizer).
+ """
+ default_cfgs = dict(
+ textdet=dict(
+ visualizer=dict(
+ type='TextDetLocalVisualizer',
+ name='visualizer',
+ vis_backends=[dict(type='LocalVisBackend')]),
+ pipeline=[
+ dict(
+ type='LoadImageFromFile',
+ color_type='color_ignore_orientation'),
+ dict(
+ type='LoadOCRAnnotations',
+ with_polygon=True,
+ with_bbox=True,
+ with_label=True,
+ ),
+ dict(
+ type='PackTextDetInputs',
+ meta_keys=('img_path', 'ori_shape', 'img_shape'))
+ ]),
+ textrecog=dict(
+ visualizer=dict(
+ type='TextRecogLocalVisualizer',
+ name='visualizer',
+ vis_backends=[dict(type='LocalVisBackend')]),
+ pipeline=[
+ dict(type='LoadImageFromFile', ignore_empty=True, min_size=2),
+ dict(type='LoadOCRAnnotations', with_text=True),
+ dict(
+ type='PackTextRecogInputs',
+ meta_keys=('img_path', 'ori_shape', 'img_shape',
+ 'valid_ratio'))
+ ]),
+ )
+
+ # Model config mode
+ dataloader_name = f'{phase}_dataloader'
+ if dataloader_name in cfg:
+ dataset = cfg.get(dataloader_name).dataset
+ visualizer = cfg.visualizer
+
+ if mode == 'original':
+ default_cfg = default_cfgs[infer_dataset_task(task, dataset)]
+ # Image can be stored in other methods, like LMDB,
+ # which LoadImageFromFile can not handle
+ if dataset.pipeline is not None:
+ all_transform_types = [tfm['type'] for tfm in dataset.pipeline]
+ if any([
+ tfm_type.startswith('LoadImageFrom')
+ for tfm_type in all_transform_types
+ ]):
+ for tfm in dataset.pipeline:
+ if tfm['type'].startswith('LoadImageFrom'):
+ # update LoadImageFrom** transform
+ default_cfg['pipeline'][0] = tfm
+ dataset.pipeline = default_cfg['pipeline']
+ else:
+ # In test_pipeline LoadOCRAnnotations is placed behind
+ # other transforms. Transform will not be applied on
+ # gt annotation.
+ if phase == 'test':
+ all_transform_types = [tfm['type'] for tfm in dataset.pipeline]
+ load_ocr_ann_tfm_index = all_transform_types.index(
+ 'LoadOCRAnnotations')
+ load_ocr_ann_tfm = dataset.pipeline.pop(load_ocr_ann_tfm_index)
+ dataset.pipeline.insert(1, load_ocr_ann_tfm)
+
+ return dataset, visualizer
+
+ # Dataset config mode
+
+ for key in cfg.keys():
+ if key.endswith(phase) and cfg[key]['type'].endswith('Dataset'):
+ dataset = cfg[key]
+ default_cfg = default_cfgs[infer_dataset_task(
+ task, dataset, key.lower())]
+ visualizer = default_cfg['visualizer']
+ dataset['pipeline'] = default_cfg['pipeline'] if dataset[
+ 'pipeline'] is None else dataset['pipeline']
+
+ return dataset, visualizer
+
+ raise ValueError(
+ f'Unable to find "{phase}_dataloader" or any dataset variable ending '
+ f'with "{phase}". Please check your config file or --phase argument '
+ 'and try again. More details can be found in the docstring of '
+ 'obtain_dataset_cfg function. Or, you may visit the documentation via '
+ 'https://mmocr.readthedocs.io/en/dev-1.x/user_guides/useful_tools.html#dataset-visualization-tool' # noqa: E501
+ )
+
+
+def main():
+ args = parse_args()
+ cfg = Config.fromfile(args.config)
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+
+ init_default_scope(cfg.get('default_scope', 'mmocr'))
+
+ dataset_cfg, visualizer_cfg = obtain_dataset_cfg(cfg, args.phase,
+ args.mode, args.task)
+ dataset = DATASETS.build(dataset_cfg)
+ visualizer = VISUALIZERS.build(visualizer_cfg)
+ visualizer.dataset_meta = dataset.metainfo
+
+ intermediate_imgs = []
+
+ if dataset_cfg.type == 'ConcatDataset':
+ for sub_dataset in dataset.datasets:
+ sub_dataset.pipeline = InspectCompose(
+ sub_dataset.pipeline.transforms, intermediate_imgs)
+ else:
+ dataset.pipeline = InspectCompose(dataset.pipeline.transforms,
+ intermediate_imgs)
+
+ # init visualization image number
+ assert args.show_number > 0
+ display_number = min(args.show_number, len(dataset))
+
+ progress_bar = ProgressBar(display_number)
+ # fetching items from dataset is a must for visualization
+ for i, _ in zip(range(display_number), dataset):
+ image_i = []
+ result_i = [result['dataset_sample'] for result in intermediate_imgs]
+ for k, datasample in enumerate(result_i):
+ image = datasample.img
+ if len(image.shape) == 3:
+ image = image[..., [2, 1, 0]] # bgr to rgb
+ image_show = visualizer.add_datasample(
+ 'result',
+ image,
+ datasample,
+ draw_pred=False,
+ draw_gt=True,
+ show=False)
+ image_i.append(image_show)
+
+ if args.mode == 'pipeline':
+ image = make_grid(image_i, intermediate_imgs)
+ else:
+ image = image_i[-1]
+
+ if hasattr(datasample, 'img_path'):
+ filename = osp.basename(datasample.img_path)
+ else:
+ # some dataset have not image path
+ filename = f'{i}.jpg'
+ out_file = osp.join(args.output_dir,
+ filename) if args.output_dir is not None else None
+
+ if out_file is not None:
+ mmcv.imwrite(image[..., ::-1], out_file)
+
+ if not args.not_show:
+ visualizer.show(
+ image, win_name=filename, wait_time=args.show_interval)
+
+ intermediate_imgs.clear()
+ progress_bar.update()
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/visualizations/vis_scheduler.py b/tools/visualizations/vis_scheduler.py
new file mode 100644
index 0000000000000000000000000000000000000000..4a2d4a3c7e75f9cba0b82456ec009acef214f5fc
--- /dev/null
+++ b/tools/visualizations/vis_scheduler.py
@@ -0,0 +1,286 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import json
+import os.path as osp
+import re
+from pathlib import Path
+from unittest.mock import MagicMock
+
+import matplotlib.pyplot as plt
+import rich
+import torch.nn as nn
+from mmengine.config import Config, DictAction
+from mmengine.hooks import Hook
+from mmengine.model import BaseModel
+from mmengine.registry import init_default_scope
+from mmengine.runner import Runner
+from mmengine.visualization import Visualizer
+from rich.progress import BarColumn, MofNCompleteColumn, Progress, TextColumn
+
+from mmocr.registry import DATASETS
+
+
+class SimpleModel(BaseModel):
+ """simple model that do nothing in train_step."""
+
+ def __init__(self):
+ super(SimpleModel, self).__init__()
+ self.data_preprocessor = nn.Identity()
+ self.conv = nn.Conv2d(1, 1, 1)
+
+ def forward(self, inputs, data_samples, mode='tensor'):
+ pass
+
+ def train_step(self, data, optim_wrapper):
+ pass
+
+
+class ParamRecordHook(Hook):
+
+ def __init__(self, by_epoch):
+ super().__init__()
+ self.by_epoch = by_epoch
+ self.lr_list = []
+ self.momentum_list = []
+ self.wd_list = []
+ self.task_id = 0
+ self.progress = Progress(BarColumn(), MofNCompleteColumn(),
+ TextColumn('{task.description}'))
+
+ def before_train(self, runner):
+ if self.by_epoch:
+ total = runner.train_loop.max_epochs
+ self.task_id = self.progress.add_task(
+ 'epochs', start=True, total=total)
+ else:
+ total = runner.train_loop.max_iters
+ self.task_id = self.progress.add_task(
+ 'iters', start=True, total=total)
+ self.progress.start()
+
+ def after_train_epoch(self, runner):
+ if self.by_epoch:
+ self.progress.update(self.task_id, advance=1)
+
+ def after_train_iter(self, runner, batch_idx, data_batch, outputs):
+ if not self.by_epoch:
+ self.progress.update(self.task_id, advance=1)
+ self.lr_list.append(runner.optim_wrapper.get_lr()['lr'][0])
+ self.momentum_list.append(
+ runner.optim_wrapper.get_momentum()['momentum'][0])
+ self.wd_list.append(
+ runner.optim_wrapper.param_groups[0]['weight_decay'])
+
+ def after_train(self, runner):
+ self.progress.stop()
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Visualize a Dataset Pipeline')
+ parser.add_argument('config', help='config file path')
+ parser.add_argument(
+ '-p',
+ '--parameter',
+ type=str,
+ default='lr',
+ choices=['lr', 'momentum', 'wd'],
+ help='The parameter to visualize its change curve, choose from'
+ '"lr", "wd" and "momentum". Defaults to "lr".')
+ parser.add_argument(
+ '-d',
+ '--dataset-size',
+ type=int,
+ help='The size of the dataset. If specify, `build_dataset` will '
+ 'be skipped and use this size as the dataset size.')
+ parser.add_argument(
+ '-n',
+ '--ngpus',
+ type=int,
+ default=1,
+ help='The number of GPUs used in training.')
+ parser.add_argument(
+ '-s',
+ '--save-path',
+ type=Path,
+ help='The learning rate curve plot save path')
+ parser.add_argument(
+ '--log-level',
+ default='WARNING',
+ help='The log level of the handler and logger. Defaults to '
+ 'WARNING.')
+ parser.add_argument('--title', type=str, help='title of figure')
+ parser.add_argument(
+ '--style', type=str, default='whitegrid', help='style of plt')
+ parser.add_argument('--not-show', default=False, action='store_true')
+ parser.add_argument(
+ '--window-size',
+ default='12*7',
+ help='Size of the window to display images, in format of "$W*$H".')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ args = parser.parse_args()
+ if args.window_size != '':
+ assert re.match(r'\d+\*\d+', args.window_size), \
+ "'window-size' must be in format 'W*H'."
+
+ return args
+
+
+def plot_curve(lr_list, args, param_name, iters_per_epoch, by_epoch=True):
+ """Plot learning rate vs iter graph."""
+ try:
+ import seaborn as sns
+ sns.set_style(args.style)
+ except ImportError:
+ pass
+
+ wind_w, wind_h = args.window_size.split('*')
+ wind_w, wind_h = int(wind_w), int(wind_h)
+ plt.figure(figsize=(wind_w, wind_h))
+
+ ax: plt.Axes = plt.subplot()
+ ax.plot(lr_list, linewidth=1)
+
+ if by_epoch:
+ ax.xaxis.tick_top()
+ ax.set_xlabel('Iters')
+ ax.xaxis.set_label_position('top')
+ sec_ax = ax.secondary_xaxis(
+ 'bottom',
+ functions=(lambda x: x / iters_per_epoch,
+ lambda y: y * iters_per_epoch))
+ sec_ax.set_xlabel('Epochs')
+ else:
+ plt.xlabel('Iters')
+ plt.ylabel(param_name)
+
+ if args.title is None:
+ plt.title(f'{osp.basename(args.config)} {param_name} curve')
+ else:
+ plt.title(args.title)
+
+
+def simulate_train(data_loader, cfg, by_epoch):
+ model = SimpleModel()
+ param_record_hook = ParamRecordHook(by_epoch=by_epoch)
+ default_hooks = dict(
+ param_scheduler=cfg.default_hooks['param_scheduler'],
+ runtime_info=None,
+ timer=None,
+ logger=None,
+ checkpoint=None,
+ sampler_seed=None,
+ param_record=param_record_hook)
+
+ runner = Runner(
+ model=model,
+ work_dir=cfg.work_dir,
+ train_dataloader=data_loader,
+ train_cfg=cfg.train_cfg,
+ log_level=cfg.log_level,
+ optim_wrapper=cfg.optim_wrapper,
+ param_scheduler=cfg.param_scheduler,
+ default_scope=cfg.default_scope,
+ default_hooks=default_hooks,
+ visualizer=MagicMock(spec=Visualizer),
+ custom_hooks=cfg.get('custom_hooks', None))
+
+ runner.train()
+
+ param_dict = dict(
+ lr=param_record_hook.lr_list,
+ momentum=param_record_hook.momentum_list,
+ wd=param_record_hook.wd_list)
+
+ return param_dict
+
+
+def build_dataset(cfg):
+ return DATASETS.build(cfg)
+
+
+def main():
+ args = parse_args()
+ cfg = Config.fromfile(args.config)
+
+ init_default_scope(cfg.get('default_scope', 'mmocr'))
+
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+ if cfg.get('work_dir', None) is None:
+ # use config filename as default work_dir if cfg.work_dir is None
+ cfg.work_dir = osp.join('./work_dirs',
+ osp.splitext(osp.basename(args.config))[0])
+
+ cfg.log_level = args.log_level
+
+ # make sure save_root exists
+ if args.save_path and not args.save_path.parent.exists():
+ raise FileNotFoundError(
+ f'The save path is {args.save_path}, and directory '
+ f"'{args.save_path.parent}' do not exist.")
+
+ # init logger
+ print('Param_scheduler :')
+ rich.print_json(json.dumps(cfg.param_scheduler))
+
+ # prepare data loader
+ batch_size = cfg.train_dataloader.batch_size * args.ngpus
+
+ if 'by_epoch' in cfg.train_cfg:
+ by_epoch = cfg.train_cfg.get('by_epoch')
+ elif 'type' in cfg.train_cfg:
+ by_epoch = cfg.train_cfg.get('type') == 'EpochBasedTrainLoop'
+ else:
+ raise ValueError('please set `train_cfg`.')
+
+ if args.dataset_size is None and by_epoch:
+ dataset_size = len(build_dataset(cfg.train_dataloader.dataset))
+ else:
+ dataset_size = args.dataset_size or batch_size
+
+ class FakeDataloader(list):
+ dataset = MagicMock(metainfo=None)
+
+ data_loader = FakeDataloader(range(dataset_size // batch_size))
+ dataset_info = (
+ f'\nDataset infos:'
+ f'\n - Dataset size: {dataset_size}'
+ f'\n - Batch size per GPU: {cfg.train_dataloader.batch_size}'
+ f'\n - Number of GPUs: {args.ngpus}'
+ f'\n - Total batch size: {batch_size}')
+ if by_epoch:
+ dataset_info += f'\n - Iterations per epoch: {len(data_loader)}'
+ rich.print(dataset_info + '\n')
+
+ # simulation training process
+ param_dict = simulate_train(data_loader, cfg, by_epoch)
+ param_list = param_dict[args.parameter]
+
+ if args.parameter == 'lr':
+ param_name = 'Learning Rate'
+ elif args.parameter == 'momentum':
+ param_name = 'Momentum'
+ else:
+ param_name = 'Weight Decay'
+ plot_curve(param_list, args, param_name, len(data_loader), by_epoch)
+
+ if args.save_path:
+ plt.savefig(args.save_path)
+ print(f'\nThe {param_name} graph is saved at {args.save_path}')
+
+ if not args.not_show:
+ plt.show()
+
+
+if __name__ == '__main__':
+ main()
 +
+ +
+ +
+ +
+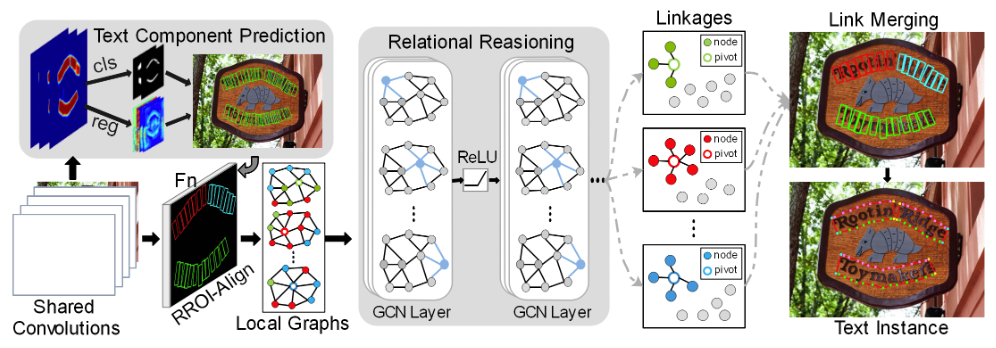 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+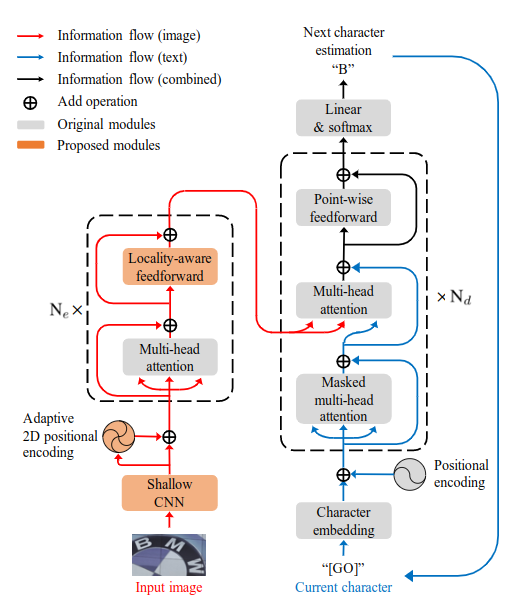 +
+ +
+