diff --git a/.dockerignore b/.dockerignore
new file mode 100644
index 0000000000000000000000000000000000000000..d600b6c76dd93f7b2472160d42b2797cae50c8e5
--- /dev/null
+++ b/.dockerignore
@@ -0,0 +1,25 @@
+# Logs
+logs
+*.log
+npm-debug.log*
+yarn-debug.log*
+yarn-error.log*
+pnpm-debug.log*
+lerna-debug.log*
+
+node_modules
+dist
+dist-ssr
+*.local
+
+# Editor directories and files
+.vscode/*
+!.vscode/extensions.json
+.idea
+.DS_Store
+*.suo
+*.ntvs*
+*.njsproj
+*.sln
+*.sw?
+
diff --git a/.editorconfig b/.editorconfig
new file mode 100644
index 0000000000000000000000000000000000000000..a78447ebf932f1bb3a5b124b472bea8b3a86f80f
--- /dev/null
+++ b/.editorconfig
@@ -0,0 +1,7 @@
+[*]
+charset = utf-8
+insert_final_newline = true
+end_of_line = lf
+indent_style = space
+indent_size = 2
+max_line_length = 80
\ No newline at end of file
diff --git a/.env.example b/.env.example
new file mode 100644
index 0000000000000000000000000000000000000000..cfefe7af70d5c96e5a66856ebc2424ed7515ad6c
--- /dev/null
+++ b/.env.example
@@ -0,0 +1,33 @@
+# A comma-separated list of access keys. Example: `ACCESS_KEYS="ABC123,JUD71F,HUWE3"`. Leave blank for unrestricted access.
+ACCESS_KEYS=""
+
+# The timeout in hours for access key validation. Set to 0 to require validation on every page load.
+ACCESS_KEY_TIMEOUT_HOURS="24"
+
+# The default model ID for WebLLM with F16 shaders.
+WEBLLM_DEFAULT_F16_MODEL_ID="Qwen2.5-0.5B-Instruct-q4f16_1-MLC"
+
+# The default model ID for WebLLM with F32 shaders.
+WEBLLM_DEFAULT_F32_MODEL_ID="Qwen2.5-0.5B-Instruct-q4f32_1-MLC"
+
+# The default model ID for Wllama.
+WLLAMA_DEFAULT_MODEL_ID="qwen-2.5-0.5b"
+
+# The base URL for the internal OpenAI compatible API. Example: `INTERNAL_OPENAI_COMPATIBLE_API_BASE_URL="https://api.openai.com/v1"`. Leave blank to disable internal OpenAI compatible API.
+INTERNAL_OPENAI_COMPATIBLE_API_BASE_URL=""
+
+# The access key for the internal OpenAI compatible API.
+INTERNAL_OPENAI_COMPATIBLE_API_KEY=""
+
+# The model for the internal OpenAI compatible API.
+INTERNAL_OPENAI_COMPATIBLE_API_MODEL=""
+
+# The name of the internal OpenAI compatible API, displayed in the UI.
+INTERNAL_OPENAI_COMPATIBLE_API_NAME="Internal API"
+
+# The type of inference to use by default. The possible values are:
+# "browser" -> In the browser (Private)
+# "openai" -> Remote Server (API)
+# "horde" -> AI Horde (Pre-configured)
+# "internal" -> $INTERNAL_OPENAI_COMPATIBLE_API_NAME
+DEFAULT_INFERENCE_TYPE="browser"
diff --git a/.github/workflows/deploy.yml b/.github/workflows/deploy.yml
new file mode 100644
index 0000000000000000000000000000000000000000..945fa830dd3258e5313257f6ed90ca5916bd5eea
--- /dev/null
+++ b/.github/workflows/deploy.yml
@@ -0,0 +1,54 @@
+name: Deploy
+
+on:
+ workflow_dispatch:
+
+jobs:
+ build-and-push-image:
+ name: Publish Docker image to GitHub Packages
+ runs-on: ubuntu-latest
+ env:
+ REGISTRY: ghcr.io
+ IMAGE_NAME: ${{ github.repository }}
+ permissions:
+ contents: read
+ packages: write
+ steps:
+ - name: Checkout repository
+ uses: actions/checkout@v4
+ - name: Log in to the Container registry
+ uses: docker/login-action@v3
+ with:
+ registry: ${{ env.REGISTRY }}
+ username: ${{ github.actor }}
+ password: ${{ secrets.GITHUB_TOKEN }}
+ - name: Extract metadata (tags, labels) for Docker
+ id: meta
+ uses: docker/metadata-action@v5
+ with:
+ images: ${{ env.REGISTRY }}/${{ env.IMAGE_NAME }}
+ - name: Set up Docker Buildx
+ uses: docker/setup-buildx-action@v3
+ - name: Build and push Docker image
+ uses: docker/build-push-action@v6
+ with:
+ context: .
+ push: true
+ tags: ${{ steps.meta.outputs.tags }}
+ labels: ${{ steps.meta.outputs.labels }}
+ platforms: linux/amd64,linux/arm64
+
+ sync-to-hf:
+ name: Sync to HuggingFace Spaces
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/checkout@v4
+ with:
+ lfs: true
+ - uses: JacobLinCool/huggingface-sync@v1
+ with:
+ github: ${{ secrets.GITHUB_TOKEN }}
+ user: ${{ vars.HF_SPACE_OWNER }}
+ space: ${{ vars.HF_SPACE_NAME }}
+ token: ${{ secrets.HF_TOKEN }}
+ configuration: "hf-space-config.yml"
diff --git a/.github/workflows/llama-cpp.yml b/.github/workflows/llama-cpp.yml
new file mode 100644
index 0000000000000000000000000000000000000000..146aad384497a072d3415ad6a1b23a5d1ce2e4cd
--- /dev/null
+++ b/.github/workflows/llama-cpp.yml
@@ -0,0 +1,175 @@
+name: Review Pull Request with llama.cpp
+
+on:
+ pull_request:
+ types: [opened, synchronize, reopened]
+ branches: ["main"]
+
+concurrency:
+ group: ${{ github.workflow }}-${{ github.event.pull_request.number || github.ref }}
+ cancel-in-progress: true
+
+jobs:
+ llama-cpp:
+ if: ${{ !contains(github.event.pull_request.labels.*.name, 'skip-ai-review') }}
+ continue-on-error: true
+ runs-on: ubuntu-latest
+ name: llama.cpp
+ permissions:
+ pull-requests: write
+ contents: read
+ timeout-minutes: 120
+ env:
+ HF_MODEL_NAME: Qwen2.5.1-Coder-7B-Instruct-GGUF
+ steps:
+ - name: Checkout Repository
+ uses: actions/checkout@v4
+
+ - name: Create temporary directory
+ run: mkdir -p /tmp/llama_review
+
+ - name: Process PR description
+ id: process_pr
+ run: |
+ PR_BODY_ESCAPED=$(cat << 'EOF'
+ ${{ github.event.pull_request.body }}
+ EOF
+ )
+ PROCESSED_BODY=$(echo "$PR_BODY_ESCAPED" | sed -E 's/\[(.*?)\]\(.*?\)/\1/g')
+ echo "$PROCESSED_BODY" > /tmp/llama_review/processed_body.txt
+
+ - name: Fetch branches and output the diff in this step
+ run: |
+ git fetch origin main:main
+ git fetch origin pull/${{ github.event.pull_request.number }}/head:pr-branch
+ git diff main..pr-branch > /tmp/llama_review/diff.txt
+
+ - name: Write prompt to file
+ id: build_prompt
+ run: |
+ PR_TITLE=$(echo "${{ github.event.pull_request.title }}" | sed 's/[()]/\\&/g')
+ DIFF_CONTENT=$(cat /tmp/llama_review/diff.txt)
+ PROCESSED_BODY=$(cat /tmp/llama_review/processed_body.txt)
+ echo "<|im_start|>system
+ You are an experienced developer reviewing a Pull Request. You focus only on what matters and provide concise, actionable feedback.
+
+ Review Context:
+ Repository Name: \"${{ github.event.repository.name }}\"
+ Repository Description: \"${{ github.event.repository.description }}\"
+ Branch: \"${{ github.event.pull_request.head.ref }}\"
+ PR Title: \"$PR_TITLE\"
+
+ Guidelines:
+ 1. Only comment on issues that:
+ - Could cause bugs or security issues
+ - Significantly impact performance
+ - Make the code harder to maintain
+ - Violate critical best practices
+
+ 2. For each issue:
+ - Point to the specific line/file
+ - Explain why it's a problem
+ - Suggest a concrete fix
+
+ 3. Praise exceptional solutions briefly, only if truly innovative
+
+ 4. Skip commenting on:
+ - Minor style issues
+ - Obvious changes
+ - Working code that could be marginally improved
+ - Things that are just personal preference
+
+ Remember:
+ Less is more. If the code is good and working, just say so, with a short message.<|im_end|>
+ <|im_start|>user
+ This is the description of the pull request:
+ \`\`\`markdown
+ $PROCESSED_BODY
+ \`\`\`
+
+ And here is the diff of the changes, for you to review:
+ \`\`\`diff
+ $DIFF_CONTENT
+ \`\`\`
+ <|im_end|>
+ <|im_start|>assistant
+ ### Overall Summary
+ " > /tmp/llama_review/prompt.txt
+
+ - name: Show Prompt
+ run: cat /tmp/llama_review/prompt.txt
+
+ - name: Set up Homebrew
+ uses: Homebrew/actions/setup-homebrew@master
+
+ - name: Install and cache Homebrew tools
+ uses: tecolicom/actions-use-homebrew-tools@v1
+ with:
+ tools: llama.cpp
+
+ - name: Cache the LLM
+ id: cache_llama_cpp
+ uses: actions/cache@v4
+ with:
+ path: ~/.cache/llama.cpp/
+ key: llama-cpp-${{ env.HF_MODEL_NAME }}
+
+ - name: Download and cache the LLM
+ if: steps.cache_llama_cpp.outputs.cache-hit != 'true'
+ run: |
+ mkdir -p ~/.cache/llama.cpp/
+ curl -L -o ~/.cache/llama.cpp/model.gguf https://huggingface.co/bartowski/${{ env.HF_MODEL_NAME }}/resolve/main/Qwen2.5.1-Coder-7B-Instruct-IQ4_XS.gguf
+
+ - name: Run llama.cpp
+ run: |
+ llama-server \
+ --model ~/.cache/llama.cpp/model.gguf \
+ --ctx-size 32768 \
+ --threads -1 \
+ --predict -1 \
+ --temp 0.5 \
+ --top-p 0.9 \
+ --min-p 0.1 \
+ --top-k 0 \
+ --cache-type-k q8_0 \
+ --cache-type-v q8_0 \
+ --flash-attn \
+ --port 11434 &
+
+ - name: cURL llama-server to get the completion and timings
+ run: |
+ DATA=$(jq -n --arg prompt "$(cat /tmp/llama_review/prompt.txt)" '{"prompt": $prompt}')
+ echo -e '### Review\n\n' > /tmp/llama_review/response.txt
+ # Save the full response to a temporary file
+ curl \
+ --silent \
+ --request POST \
+ --url http://localhost:11434/completion \
+ --header "Content-Type: application/json" \
+ --data "$DATA" > /tmp/llama_review/full_response.json
+
+ # Extract and append content to response.txt
+ jq -r '.content' /tmp/llama_review/full_response.json >> /tmp/llama_review/response.txt
+
+ # Pretty print the timings information
+ echo "=== Performance Metrics ==="
+ jq -r '.timings | to_entries | .[] | "\(.key): \(.value)"' /tmp/llama_review/full_response.json
+
+ - name: Show Response
+ run: cat /tmp/llama_review/response.txt
+
+ - name: Find Comment
+ uses: peter-evans/find-comment@v3
+ id: find_comment
+ with:
+ issue-number: ${{ github.event.pull_request.number }}
+ comment-author: "github-actions[bot]"
+ body-includes: "### Review"
+
+ - name: Post or Update PR Review
+ uses: peter-evans/create-or-update-comment@v4
+ with:
+ comment-id: ${{ steps.find_comment.outputs.comment-id }}
+ issue-number: ${{ github.event.pull_request.number }}
+ body-path: /tmp/llama_review/response.txt
+ edit-mode: replace
diff --git a/.github/workflows/on-pull-request-to-main.yml b/.github/workflows/on-pull-request-to-main.yml
new file mode 100644
index 0000000000000000000000000000000000000000..6eae98e615c1c1f2c899a9a5f1d785dd3883ff62
--- /dev/null
+++ b/.github/workflows/on-pull-request-to-main.yml
@@ -0,0 +1,9 @@
+name: On Pull Request To Main
+on:
+ pull_request:
+ types: [opened, synchronize, reopened]
+ branches: ["main"]
+jobs:
+ test-lint-ping:
+ if: ${{ !contains(github.event.pull_request.labels.*.name, 'skip-test-lint-ping') }}
+ uses: ./.github/workflows/reusable-test-lint-ping.yml
diff --git a/.github/workflows/on-push-to-main.yml b/.github/workflows/on-push-to-main.yml
new file mode 100644
index 0000000000000000000000000000000000000000..8ce693215c4351bab8b54ccac302345e1202ba03
--- /dev/null
+++ b/.github/workflows/on-push-to-main.yml
@@ -0,0 +1,7 @@
+name: On Push To Main
+on:
+ push:
+ branches: ["main"]
+jobs:
+ test-lint-ping:
+ uses: ./.github/workflows/reusable-test-lint-ping.yml
diff --git a/.github/workflows/reusable-test-lint-ping.yml b/.github/workflows/reusable-test-lint-ping.yml
new file mode 100644
index 0000000000000000000000000000000000000000..63c8e7c09f4a8598702dd4a30cd4a920d770043d
--- /dev/null
+++ b/.github/workflows/reusable-test-lint-ping.yml
@@ -0,0 +1,25 @@
+on:
+ workflow_call:
+jobs:
+ check-code-quality:
+ name: Check Code Quality
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/checkout@v4
+ - uses: actions/setup-node@v4
+ with:
+ node-version: 20
+ cache: "npm"
+ - run: npm ci --ignore-scripts
+ - run: npm test
+ - run: npm run lint
+ check-docker-container:
+ needs: [check-code-quality]
+ name: Check Docker Container
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/checkout@v4
+ - run: docker compose -f docker-compose.production.yml up -d
+ - name: Check if main page is available
+ run: until curl -s -o /dev/null -w "%{http_code}" localhost:7860 | grep 200; do sleep 1; done
+ - run: docker compose -f docker-compose.production.yml down
diff --git a/.github/workflows/update-searxng-docker-image.yml b/.github/workflows/update-searxng-docker-image.yml
new file mode 100644
index 0000000000000000000000000000000000000000..50261a76e8453bc473fa6e487d81a45cebe7cd1a
--- /dev/null
+++ b/.github/workflows/update-searxng-docker-image.yml
@@ -0,0 +1,44 @@
+name: Update SearXNG Docker Image
+
+on:
+ schedule:
+ - cron: "0 14 * * *"
+ workflow_dispatch:
+
+permissions:
+ contents: write
+
+jobs:
+ update-searxng-image:
+ runs-on: ubuntu-latest
+ steps:
+ - name: Checkout code
+ uses: actions/checkout@v4
+ with:
+ token: ${{ secrets.GITHUB_TOKEN }}
+
+ - name: Get latest SearXNG image tag
+ id: get_latest_tag
+ run: |
+ LATEST_TAG=$(curl -s "https://hub.docker.com/v2/repositories/searxng/searxng/tags/?page_size=3&ordering=last_updated" | jq -r '.results[] | select(.name != "latest-build-cache" and .name != "latest") | .name' | head -n 1)
+ echo "LATEST_TAG=${LATEST_TAG}" >> $GITHUB_OUTPUT
+
+ - name: Update Dockerfile
+ run: |
+ sed -i 's|FROM searxng/searxng:.*|FROM searxng/searxng:${{ steps.get_latest_tag.outputs.LATEST_TAG }}|' Dockerfile
+
+ - name: Check for changes
+ id: git_status
+ run: |
+ git diff --exit-code || echo "changes=true" >> $GITHUB_OUTPUT
+
+ - name: Commit and push if changed
+ if: steps.git_status.outputs.changes == 'true'
+ run: |
+ git config --local user.email "github-actions[bot]@users.noreply.github.com"
+ git config --local user.name "github-actions[bot]"
+ git add Dockerfile
+ git commit -m "Update SearXNG Docker image to tag ${{ steps.get_latest_tag.outputs.LATEST_TAG }}"
+ git push
+ env:
+ GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
diff --git a/.gitignore b/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..f1b26f1ea73cad18af0078381a02bbc532714a0a
--- /dev/null
+++ b/.gitignore
@@ -0,0 +1,7 @@
+node_modules
+.DS_Store
+/client/dist
+/server/models
+.vscode
+/vite-build-stats.html
+.env
diff --git a/.npmrc b/.npmrc
new file mode 100644
index 0000000000000000000000000000000000000000..80bcbed90c4f2b3d895d5086dc775e1bd8b32b43
--- /dev/null
+++ b/.npmrc
@@ -0,0 +1 @@
+legacy-peer-deps = true
diff --git a/Dockerfile b/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..e9e36b3c40344a1a86cad4739e1f9da63d394f6e
--- /dev/null
+++ b/Dockerfile
@@ -0,0 +1,82 @@
+# Use the SearXNG image as the base
+FROM searxng/searxng:2024.12.16-65c970bdf
+
+# Set the default port to 7860 if not provided
+ENV PORT=7860
+
+# Expose the port specified by the PORT environment variable
+EXPOSE $PORT
+
+# Install necessary packages using Alpine's package manager
+RUN apk add --update \
+ nodejs \
+ npm \
+ git \
+ build-base \
+ cmake \
+ ccache
+
+# Set the SearXNG settings folder path
+ARG SEARXNG_SETTINGS_FOLDER=/etc/searxng
+
+# Modify SearXNG configuration:
+# 1. Change output format from HTML to JSON
+# 2. Remove user switching in the entrypoint script
+# 3. Create and set permissions for the settings folder
+RUN sed -i 's/- html/- json/' /usr/local/searxng/searx/settings.yml \
+ && sed -i 's/su-exec searxng:searxng //' /usr/local/searxng/dockerfiles/docker-entrypoint.sh \
+ && mkdir -p ${SEARXNG_SETTINGS_FOLDER} \
+ && chmod 777 ${SEARXNG_SETTINGS_FOLDER}
+
+# Set up user and directory structure
+ARG USERNAME=user
+ARG HOME_DIR=/home/${USERNAME}
+ARG APP_DIR=${HOME_DIR}/app
+
+# Create a non-root user and set up the application directory
+RUN adduser -D -u 1000 ${USERNAME} \
+ && mkdir -p ${APP_DIR} \
+ && chown -R ${USERNAME}:${USERNAME} ${HOME_DIR}
+
+# Switch to the non-root user
+USER ${USERNAME}
+
+# Set the working directory to the application directory
+WORKDIR ${APP_DIR}
+
+# Define environment variables that can be passed to the container during build.
+# This approach allows for dynamic configuration without relying on a `.env` file,
+# which might not be suitable for all deployment scenarios.
+ARG ACCESS_KEYS
+ARG ACCESS_KEY_TIMEOUT_HOURS
+ARG WEBLLM_DEFAULT_F16_MODEL_ID
+ARG WEBLLM_DEFAULT_F32_MODEL_ID
+ARG WLLAMA_DEFAULT_MODEL_ID
+ARG INTERNAL_OPENAI_COMPATIBLE_API_BASE_URL
+ARG INTERNAL_OPENAI_COMPATIBLE_API_KEY
+ARG INTERNAL_OPENAI_COMPATIBLE_API_MODEL
+ARG INTERNAL_OPENAI_COMPATIBLE_API_NAME
+ARG DEFAULT_INFERENCE_TYPE
+
+# Copy package.json, package-lock.json, and .npmrc files
+COPY --chown=${USERNAME}:${USERNAME} ./package.json ./package.json
+COPY --chown=${USERNAME}:${USERNAME} ./package-lock.json ./package-lock.json
+COPY --chown=${USERNAME}:${USERNAME} ./.npmrc ./.npmrc
+
+# Install Node.js dependencies
+RUN npm ci
+
+# Copy the rest of the application files
+COPY --chown=${USERNAME}:${USERNAME} . .
+
+# Configure Git to treat the app directory as safe
+RUN git config --global --add safe.directory ${APP_DIR}
+
+# Build the application
+RUN npm run build
+
+# Set the entrypoint to use a shell
+ENTRYPOINT [ "/bin/sh", "-c" ]
+
+# Run SearXNG in the background and start the Node.js application using PM2
+CMD [ "(/usr/local/searxng/dockerfiles/docker-entrypoint.sh -f > /dev/null 2>&1) & (npx pm2 start ecosystem.config.cjs && npx pm2 logs production-server)" ]
diff --git a/README.md b/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..be10c3348b43bb632442a3e1ed7bb0ee94ac2912
--- /dev/null
+++ b/README.md
@@ -0,0 +1,139 @@
+---
+title: MiniSearch
+emoji: 👌🔍
+colorFrom: yellow
+colorTo: yellow
+sdk: docker
+short_description: Minimalist web-searching app with browser-based AI assistant
+pinned: true
+custom_headers:
+ cross-origin-embedder-policy: require-corp
+ cross-origin-opener-policy: same-origin
+ cross-origin-resource-policy: cross-origin
+---
+
+# MiniSearch
+
+A minimalist web-searching app with an AI assistant that runs directly from your browser.
+
+Live demo: https://felladrin-minisearch.hf.space
+
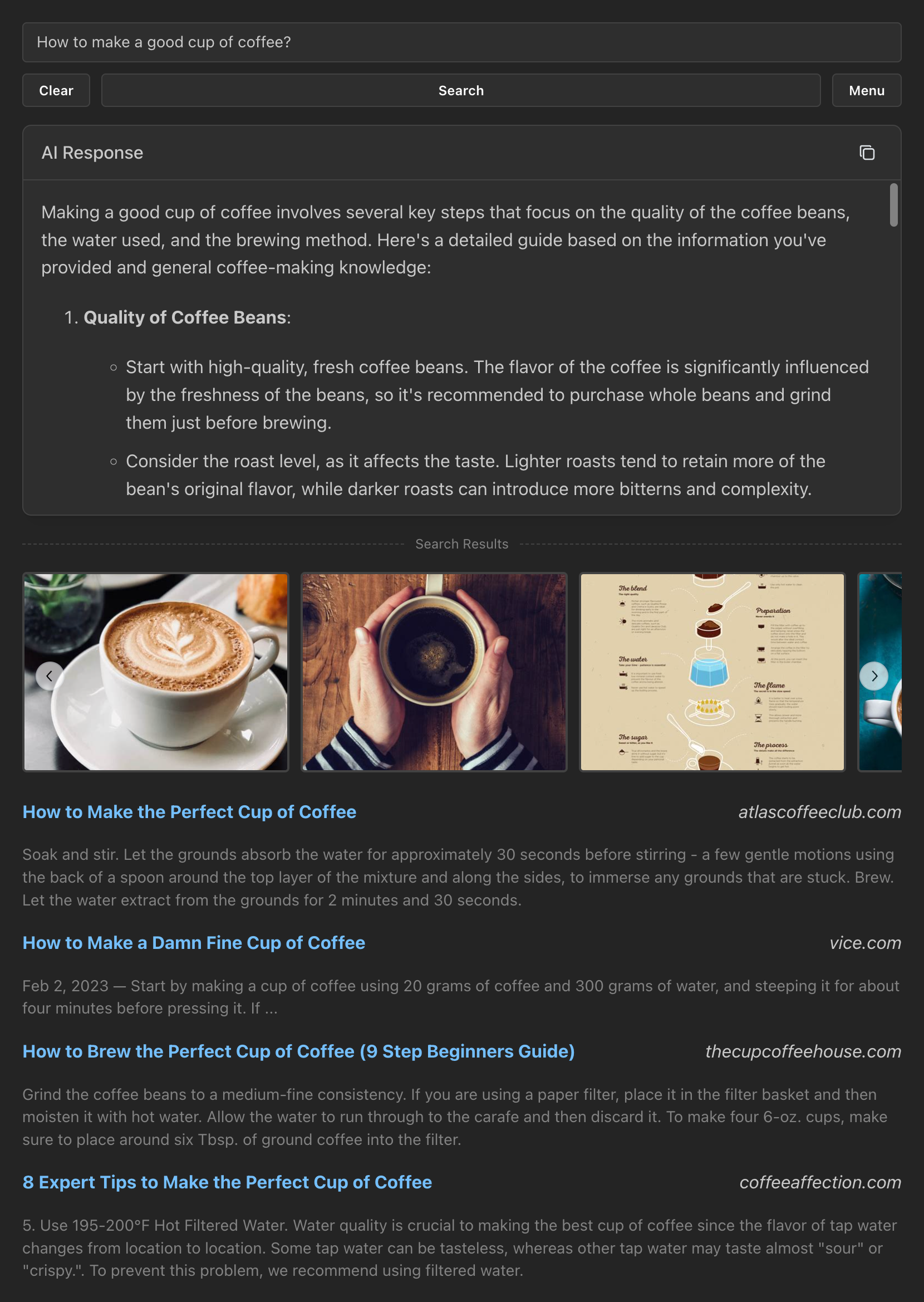
+## Screenshot
+
+
+
+## Features
+
+- **Privacy-focused**: [No tracking, no ads, no data collection](https://docs.searxng.org/own-instance.html#how-does-searxng-protect-privacy)
+- **Easy to use**: Minimalist yet intuitive interface for all users
+- **Cross-platform**: Models run inside the browser, both on desktop and mobile
+- **Integrated**: Search from the browser address bar by setting it as the default search engine
+- **Efficient**: Models are loaded and cached only when needed
+- **Customizable**: Tweakable settings for search results and text generation
+- **Open-source**: [The code is available for inspection and contribution at GitHub](https://github.com/felladrin/MiniSearch)
+
+## Prerequisites
+
+- [Docker](https://docs.docker.com/get-docker/)
+
+## Getting started
+
+Here are the easiest ways to get started with MiniSearch. Pick the one that suits you best.
+
+**Option 1** - Use [MiniSearch's Docker Image](https://github.com/felladrin/MiniSearch/pkgs/container/minisearch) by running in your terminal:
+
+```bash
+docker run -p 7860:7860 ghcr.io/felladrin/minisearch:main
+```
+
+**Option 2** - Add MiniSearch's Docker Image to your existing Docker Compose file:
+
+```yaml
+services:
+ minisearch:
+ image: ghcr.io/felladrin/minisearch:main
+ ports:
+ - "7860:7860"
+```
+
+**Option 3** - Build from source by [downloading the repository files](https://github.com/felladrin/MiniSearch/archive/refs/heads/main.zip) and running:
+
+```bash
+docker compose -f docker-compose.production.yml up --build
+```
+
+Once the container is running, open http://localhost:7860 in your browser and start searching!
+
+## Frequently asked questions
+
+
+ How do I search via the browser's address bar?
+
+ You can set MiniSearch as your browser's address-bar search engine using the pattern http://localhost:7860/?q=%s, in which your search term replaces %s.
+
+
+
+
+ How do I search via Raycast?
+
+ You can add this Quicklink to Raycast, so typying your query will open MiniSearch with the search results. You can also edit it to point to your own domain.
+
+
+
+
+
+ Can I use custom models via OpenAI-Compatible API?
+
+ Yes! For this, open the Menu and change the "AI Processing Location" to Remote server (API). Then configure the Base URL, and optionally set an API Key and a Model to use.
+
+
+
+
+ How do I restrict the access to my MiniSearch instance via password?
+
+ Create a .env file and set a value for ACCESS_KEYS. Then reset the MiniSearch docker container.
+
+
+ For example, if you to set the password to PepperoniPizza, then this is what you should add to your .env:
+ ACCESS_KEYS="PepperoniPizza"
+
+
+ You can find more examples in the .env.example file.
+
+
+
+
+ I want to serve MiniSearch to other users, allowing them to use my own OpenAI-Compatible API key, but without revealing it to them. Is it possible?
+
Yes! In MiniSearch, we call this text-generation feature "Internal OpenAI-Compatible API". To use this it:
+
+
Set up your OpenAI-Compatible API endpoint by configuring the following environment variables in your .env file:
+
+
INTERNAL_OPENAI_COMPATIBLE_API_BASE_URL: The base URL for your API
+
INTERNAL_OPENAI_COMPATIBLE_API_KEY: Your API access key
+
INTERNAL_OPENAI_COMPATIBLE_API_MODEL: The model to use
+
INTERNAL_OPENAI_COMPATIBLE_API_NAME: The name to display in the UI
+
+
+
Restart MiniSearch server.
+
In the MiniSearch menu, select the new option (named as per your INTERNAL_OPENAI_COMPATIBLE_API_NAME setting) from the "AI Processing Location" dropdown.
+
+
+
+
+ How can I contribute to the development of this tool?
+
Fork this repository and clone it. Then, start the development server by running the following command:
+
docker compose up
+
Make your changes, push them to your fork, and open a pull request! All contributions are welcome!
+
+
+
+ Why is MiniSearch built upon SearXNG's Docker Image and using a single image instead of composing it from multiple services?
+
There are a few reasons for this:
+
+
MiniSearch utilizes SearXNG as its meta-search engine.
+
Manual installation of SearXNG is not trivial, so we use the docker image they provide, which has everything set up.
+
SearXNG only provides a Docker Image based on Alpine Linux.
+
The user of the image needs to be customized in a specific way to run on HuggingFace Spaces, where MiniSearch's demo runs.
+
HuggingFace only accepts a single docker image. It doesn't run docker compose or multiple images, unfortunately.