# In Defense of Grid Features for Visual Question Answering
**Grid Feature Pre-Training Code**
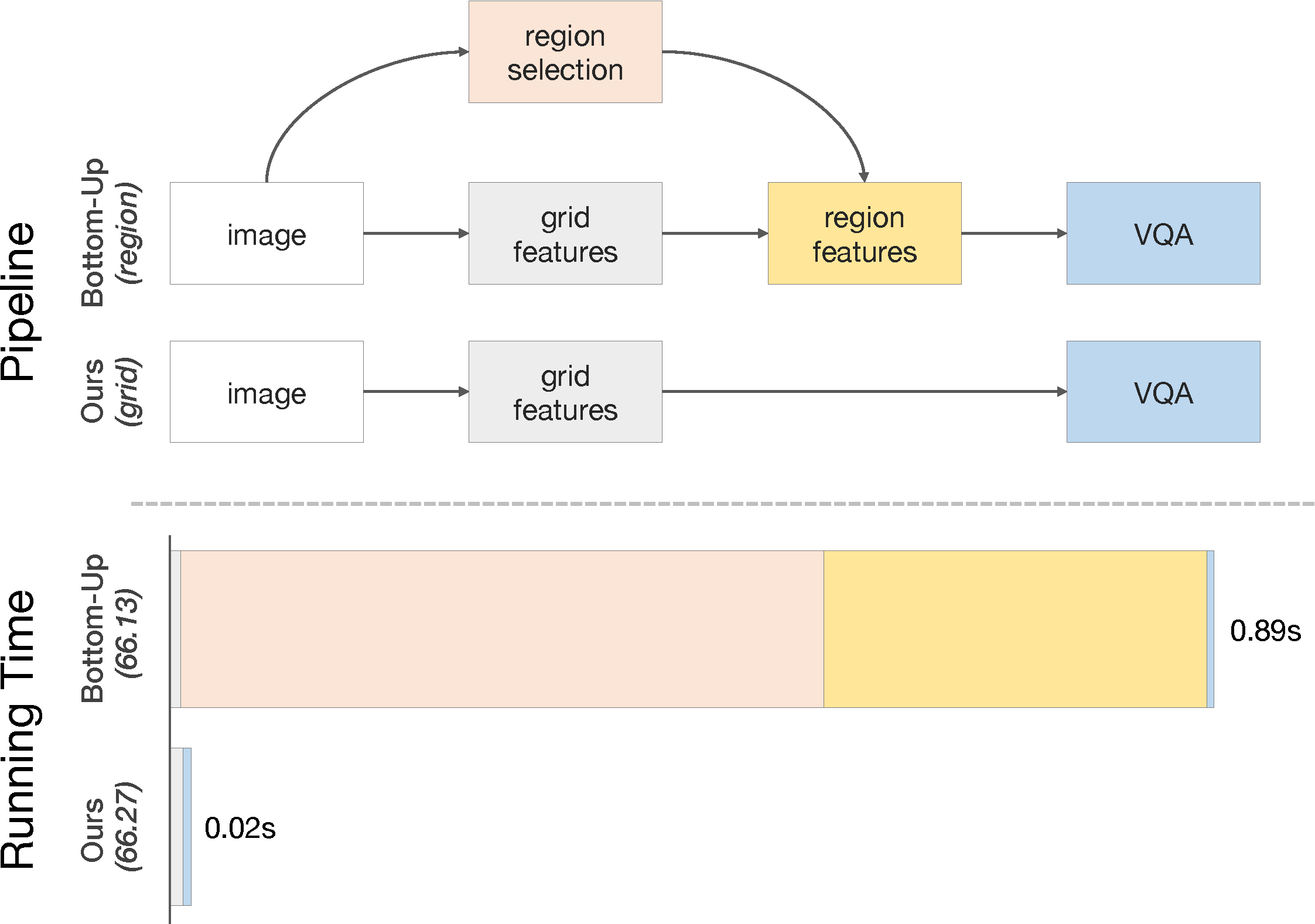
This is a feature pre-training code release of the [paper](https://arxiv.org/abs/2001.03615):
```
@InProceedings{jiang2020defense,
title={In Defense of Grid Features for Visual Question Answering},
author={Jiang, Huaizu and Misra, Ishan and Rohrbach, Marcus and Learned-Miller, Erik and Chen, Xinlei},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2020}
}
```
For more sustained maintenance, we release code using [Detectron2](https://github.com/facebookresearch/detectron2) instead of [mask-rcnn-benchmark](https://github.com/facebookresearch/maskrcnn-benchmark) which the original code is based on. The current repository should reproduce the results reported in the paper, *e.g.*, reporting **~72.5** single model VQA score for a X-101 backbone paired with [MCAN](https://github.com/MILVLG/mcan-vqa)-large.
## Installation
Install Detectron 2 following [INSTALL.md](https://github.com/facebookresearch/detectron2/blob/master/INSTALL.md). Since Detectron 2 is also being actively updated which can result in breaking behaviors, it is **highly recommended** to install via the following command:
```bash
python -m pip install 'git+https://github.com/facebookresearch/detectron2.git@ffff8ac'
```
Commits before or after `ffff8ac` might also work, but it could be risky.
Then clone this repository:
```bash
git clone git@github.com:facebookresearch/grid-feats-vqa.git
cd grid-feats-vqa
```
## Data
[Visual Genome](http://visualgenome.org/) `train+val` splits released from the bottom-up-attention [code](https://github.com/peteanderson80/bottom-up-attention) are used for pre-training, and `test` split is used for evaluating detection performance. All of them are prepared in [COCO](http://cocodataset.org/) format but include an additional field for `attribute` prediction. We provide the `.json` files [here](https://dl.fbaipublicfiles.com/grid-feats-vqa/json/visual_genome.tgz) which can be directly loaded by Detectron2. Same as in Detectron2, the expected dataset structure under the `DETECTRON2_DATASETS` (default is `./datasets` relative to your current working directory) folder should be:
```
visual_genome/
annotations/
visual_genome_{train,val,test}.json
images/
# visual genome images (~108K)
```
## Training
Once the dataset is setup, to train a model, run (by default we use 8 GPUs):
```bash
python train_net.py --num-gpus 8 --config-file
```
For example, to launch grid-feature pre-training with ResNet-50 backbone on 8 GPUs, one should execute:
```bash
python train_net.py --num-gpus 8 --config-file configs/R-50-grid.yaml
```
The final model by default should be saved under `./output` of your current working directory once it is done training. We also provide the region-feature pre-training configuration `configs/R-50-updn.yaml` for reference. Note that we use `0.2` attribute loss (`MODEL.ROI_ATTRIBUTE_HEAD.LOSS_WEIGHT = 0.2`), which is better for down-stream tasks like VQA per our analysis.
We also release the configuration (`configs/R-50-updn.yaml`) for training the region features described in **bottom-up-attention** paper, which is a faithful re-implementation of the original [one](https://github.com/peteanderson80/bottom-up-attention) in Detectron2.
## Feature Extraction
Grid feature extraction can be done by simply running once the model is trained (or you can directly download our pre-trained models, see below):
```bash
python extract_grid_feature.py -config-file configs/R-50-grid.yaml --dataset
```
and the code will load the final model from `cfg.OUTPUT_DIR` (which one can override in command line) and start extracting features for ``, we provide three options for the dataset: `coco_2014_train`, `coco_2014_val` and `coco_2015_test`, they correspond to `train`, `val` and `test` splits of the VQA dataset. The extracted features can be conveniently loaded in [Pythia](https://github.com/facebookresearch/pythia).
To extract features on your customized dataset, you may want to dump the image information into [COCO](http://cocodataset.org/) `.json` format, and add the dataset information to use `extract_grid_feature.py`, or you can hack `extract_grid_feature.py` and directly loop over images.
## Pre-Trained Models and Features
We release several pre-trained models for grid features: one with R-50 backbone, one with X-101, one with X-152, and one with additional improvements used for the 2020 VQA Challenge (see `X-152-challenge.yaml`). The models can be used directly to extract features. For your convenience, we also release the pre-extracted features for direct download.
| Backbone | AP50:95 | Download |
| -------- | ---- | -------- |
| R-50 | 3.1 | model \| metrics \| features |
| X-101 | 4.3 | model \| metrics \| features |
| X-152 | 4.7 | model \| metrics \| features |
| X-152++ | 3.7 | model \| metrics \| features |
## License
The code is released under the [Apache 2.0 license](LICENSE).