---
license: mit
---
## NAST: Noise Aware Speech Tokenization for Speech Language Models
Official implementation of [NAST: Noise Aware Speech Tokenization for Speech Language Models](https://arxiv.org/abs/2406.11037), accepted at Interspeech 2024.
[](https://arxiv.org/abs/2406.11037)
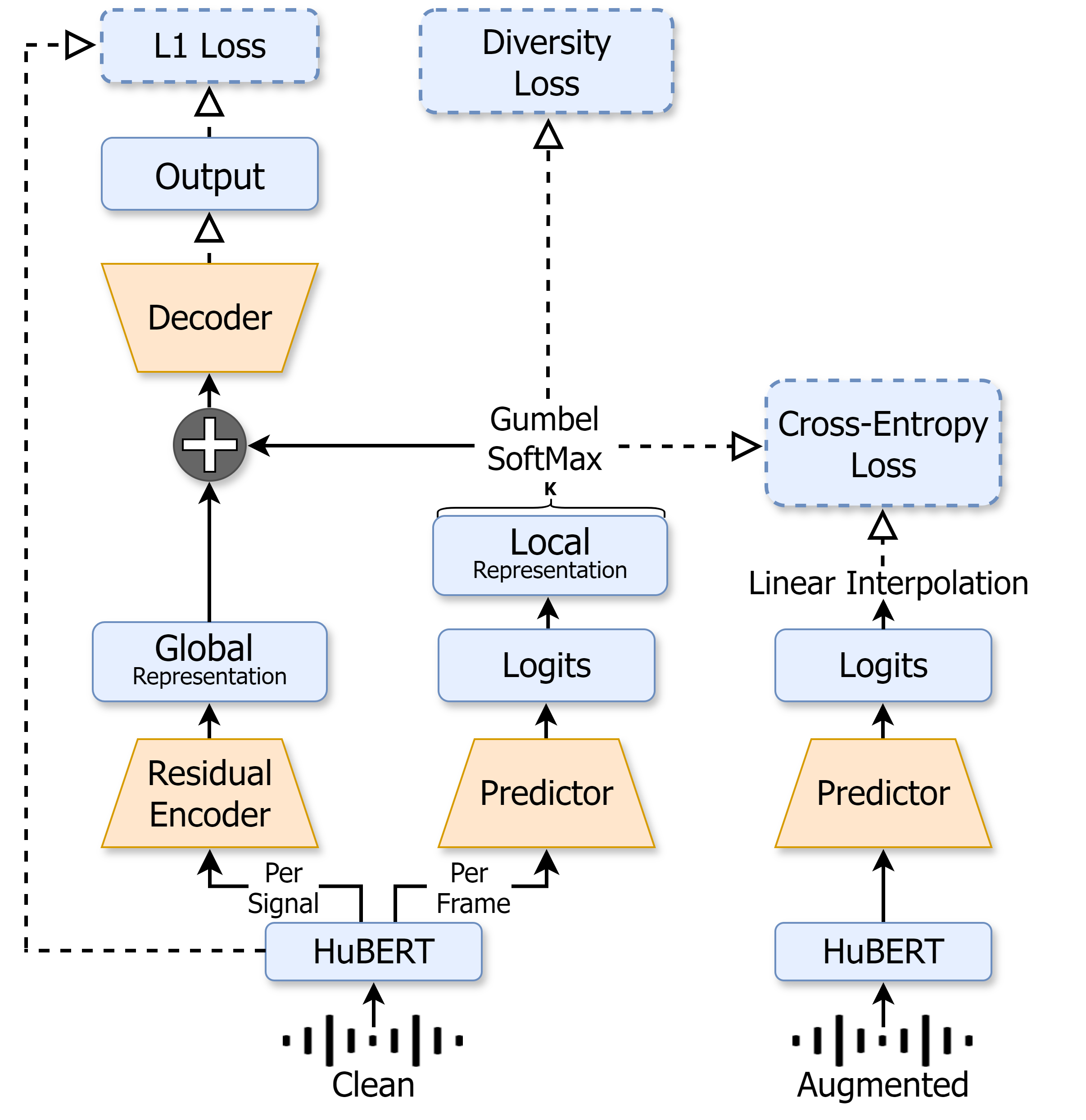
Abstract: Speech tokenization is the task of representing speech signals as a sequence of discrete units. Such representations can be later used for various downstream tasks including automatic speech recognition, text-to-speech, etc. More relevant to this study, such representation serves as the basis of Speech Language Models. In this work, we tackle the task of speech tokenization under the noisy setup and present NAST: Noise Aware Speech Tokenization for Speech Language Models. NAST is composed of three main components: (i) a predictor; (ii) a residual encoder; and (iii) a decoder. We evaluate the efficiency of NAST considering several speech language modeling tasks, and show that NAST is superior to the evaluated baselines across all setups. Lastly, we analyze NAST and show its disentanglement properties and robustness to signal variations in the form of noise, reverberation, pitch-shift, and time-stretch.
## Setup Environment
Create a conda environment and install the requirements, replace `cu118` bellow with the appropriate CUDA version on your machine:
```python
conda create -n nast python=3.9 -c conda-forge
conda activate nast
pip3 install torch torchaudio --index-url https://download.pytorch.org/whl/cu118
git clone https://github.com/ShovalMessica/NAST.git
cd NAST
conda install --file requirements.txt
pip3 install fairseq AMFM-decompy pyroomacoustics==0.7.3
```
## Usage Example
```python
import utils.override
import torch
from fairseq.examples.textless_nlp.gslm.speech2unit.pretrained.hubert_feature_reader import HubertFeatureReader
from utils.training_utils import read_audio, get_feats
from models.network import Network
from utils.checkpoint import load_checkpoint
from utils.config import load_config
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model_config_path = "path/to/model_config.yaml"
audio_path = "path/to/audio/file.wav"
num_units = 100
model_config = load_config(model_config_path)
config = {**model_config, 'num_units': num_units}
config['hubert']['checkpoint_path'] = "path/to/hubert/checkpoint.pt"
config[num_units]["discrete_local"] = True
feature_extractor = HubertFeatureReader(config['hubert']['checkpoint_path'], layer=9)
network = Network(config=config, device=device)
load_checkpoint(network, "path/to/tokenizer/checkpoint")
audio = read_audio(feature_extractor, audio_path)
features = get_feats(feature_extractor, audio)
with torch.no_grad():
units = network(features.to(device))
print("Extracted units:", units.tolist()) # [10, 11, 11, 11, 11, 9, 9, 23, 30 ... ]
```
## Acoustic Model
For quantizing speech we learn NAST clustering over [HuBERT Base](https://github.com/facebookresearch/fairseq/blob/main/examples/hubert/README.md) acoustic representation. For using the pretrained model, please download from the [link](https://dl.fbaipublicfiles.com/hubert/hubert_base_ls960.pt).
## Tokenization Model
You can download pretrained tokenization.
- **Speaker Probing Task:** For insights into speaker information evaluation using the NAST framework, follow the detaileds provided [here](eval/readme.md#speaker-probing-task).
- **UED Calculator:** To evaluate the Unit Edit Distance for models trained with NAST, use our UED calculator. Detailed instructions and tools can be found [here](eval/readme.md#unit-edit-distance-ued-calculation).
### Training
To train the tokenization model, execute the command below from the root directory:
```
python train.py --training_config_path path/to/training/config --model_config_path path/to/model/config
```
**Implementation Details:** Our training procedure is designed to ensure stability and effectiveness, utilizing three loss functions. The training is structured in two phases, each controlled by parameters set in the configuration file.
**Phase I:**
- Only *reconstruction* and *diversity* losses are active.
- Augmentations are applied with a probability of `p` (e.g 0.5), aiming to expose the model to varied and unclean speech during the initial stages of unit formation.
**Phase II:**
- All three losses, including *cross-entropy*, are active.
- A stabilization mechanism implemented in `training_utils.py` is employed to ensure smooth integration of the cross-entropy loss.
- Augmentations are applied with a probability of 1, meaning all data will undergo augmentation to enhance the model's robustness and generalization capabilities.
## Unit Language Model (ULM)
You can download pretrained unit language models, or follow the [instructions](https://github.com/facebookresearch/fairseq/tree/main/examples/textless_nlp/gslm/ulm) to train new models using fairseq. All language models were trained and evaluated on the deduplicated unit transcriptions of the respective NAST version.