About | Intuition | QuickStart |
## About OpTrans (Re-Optimization Transformer), is an innovative framework fuses binary code optimization techniques with the transformer model for BCSD. By OpTrans employs an algorithm based on binary program analysis to determine which functions should be inlined, followed by binary rewriting techniques to effectuate re-optimization on binaries. Our goal is to provide an effective tool for researchers and practitioners in binary code similarity detection, with our models accessible on the Hugging Face Model Hub. ## Intuition This document will present how function inlining optimization improve binary code similarity detection. Function Faust_next in sc3-plugins-HOAEncLebedev501.so compiled with -O0 (sc3-plugins-HOAEncLebedev501.so-O0.i64) 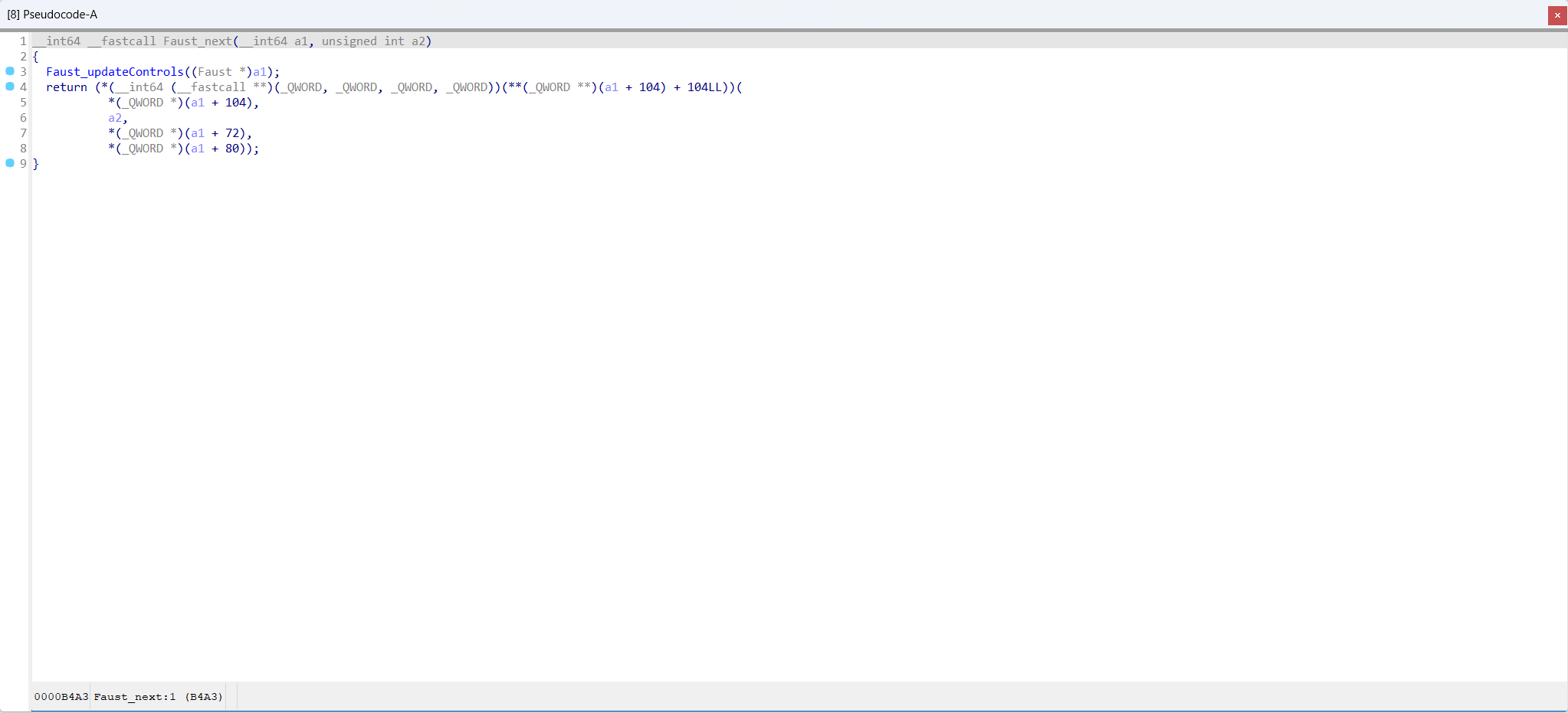 Function Faust_next in sc3-plugins-HOAEncLebedev501.so compiled with -O3 (sc3-plugins-HOAEncLebedev501.so-O3.i64) 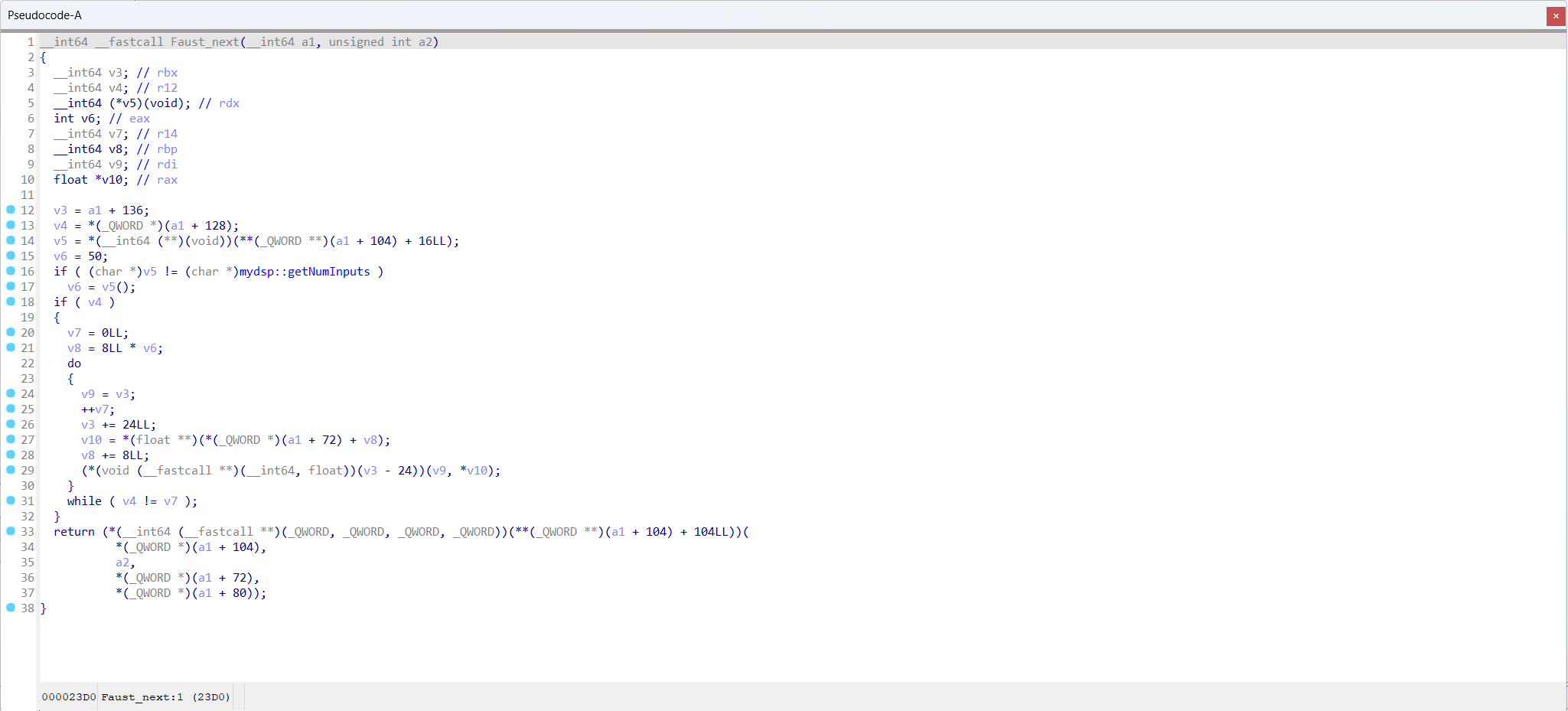 Function Faust_next in sc3-plugins-HOAEncLebedev501.so compiled with -O0 and processed by function inlining optimization (sc3-plugins-HOAEncLebedev501.so-O0-inline.i64) 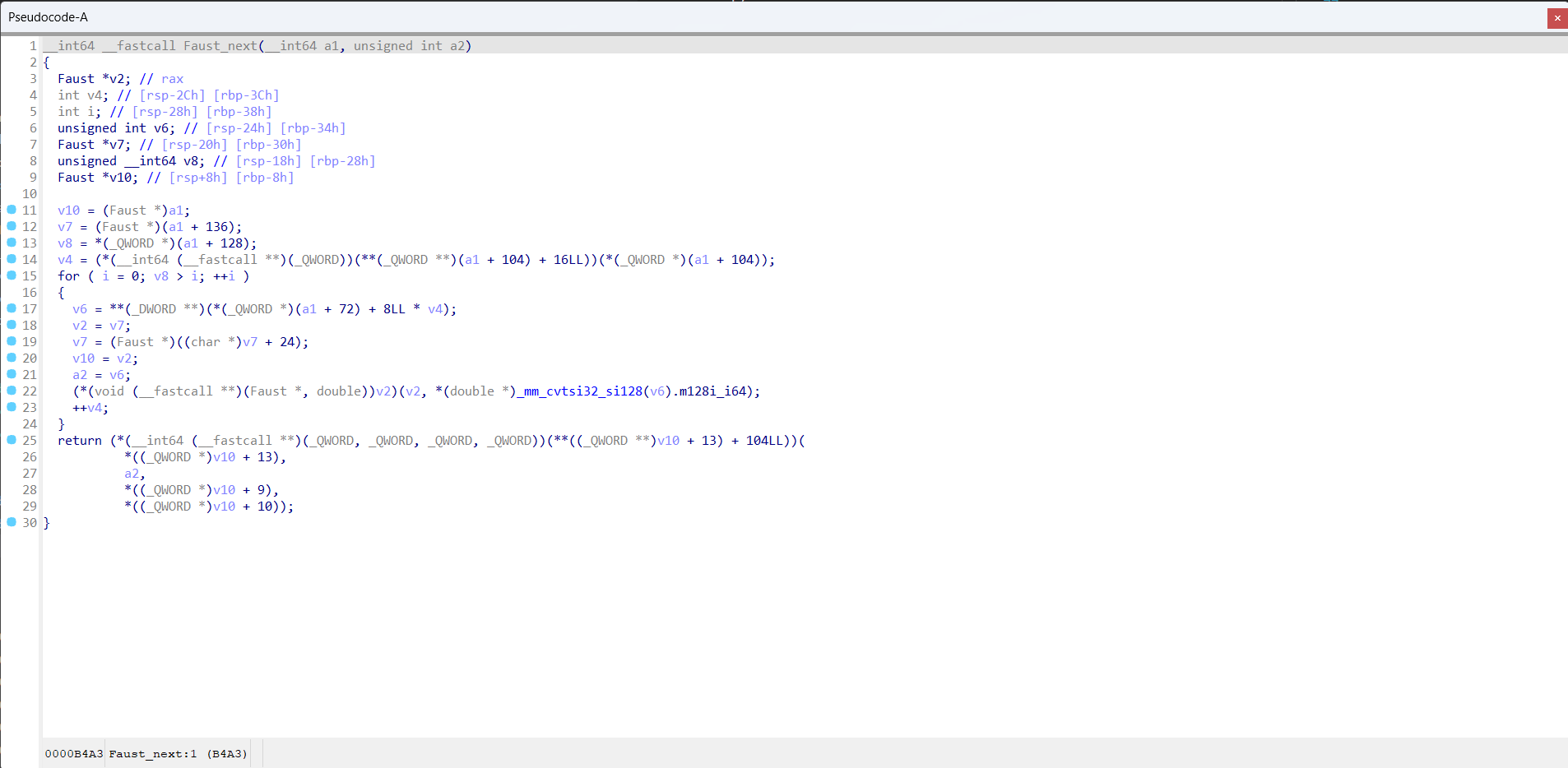 ## QuickStart This document will help you set up and start using the OpTrans model for embedding generation. ### Requirements - Python 3.6 or higher - [PyTorch](https://pytorch.org/get-started/locally/) - [Transformers library](https://huggingface.co/docs/transformers/installation) - A CUDA-enabled GPU is highly recommended for faster processing. Ensure you have Python and PyTorch installed on your system. Then, install the Transformers library using pip: ```bash pip install transformers ``` ### Preparing Tokenizers and Models Import necessary libraries and initialize the model and tokenizers: ```python import torch from transformers import AutoModel, AutoTokenizer device = torch.device("cuda" if torch.cuda.is_available() else "cpu") tokenizer = AutoTokenizer.from_pretrained("sandspeare/optrans", trust_remote_code=True) encoder = AutoModel.from_pretrained("sandspeare/optrans", trust_remote_code=True).to(device) tokenizer.pad_token = tokenizer.unk_token ``` ### Example Use Cases **Function inlining optimization for BCSD** 1. Load your binary code dataset. For demonstration, we use a pickle file containing binary code snippets for similarity compare. ```python with open("./CaseStudy/casestudy.json") as fp: data = json.load(fp) ``` 2. Encode the binary code. ```python asm_O0 = tokenizer([data["O0"]], padding=True, return_tensors="pt").to(device) asm_embedding_O0 = encoder(**asm_O0) asm_O0_inline = tokenizer([data["O0_inline"]], padding=True, return_tensors="pt").to(device) asm_embedding_O0_inline = encoder(**asm_O0_inline) asm_O3 = tokenizer([data["O3"]], padding=True, return_tensors="pt").to(device) asm_embedding_O3 = encoder(**asm_O3) ``` 3. Perform similarity comparison: ```python sim_O0vsO3 = torch.mm(asm_embedding_O0, asm_embedding_O3.T).squeeze() / 0.07 sim_O0_inlinevsO3 = torch.mm(asm_embedding_O0_inline, asm_embedding_O3.T).squeeze() / 0.07 ```