{kind=link}
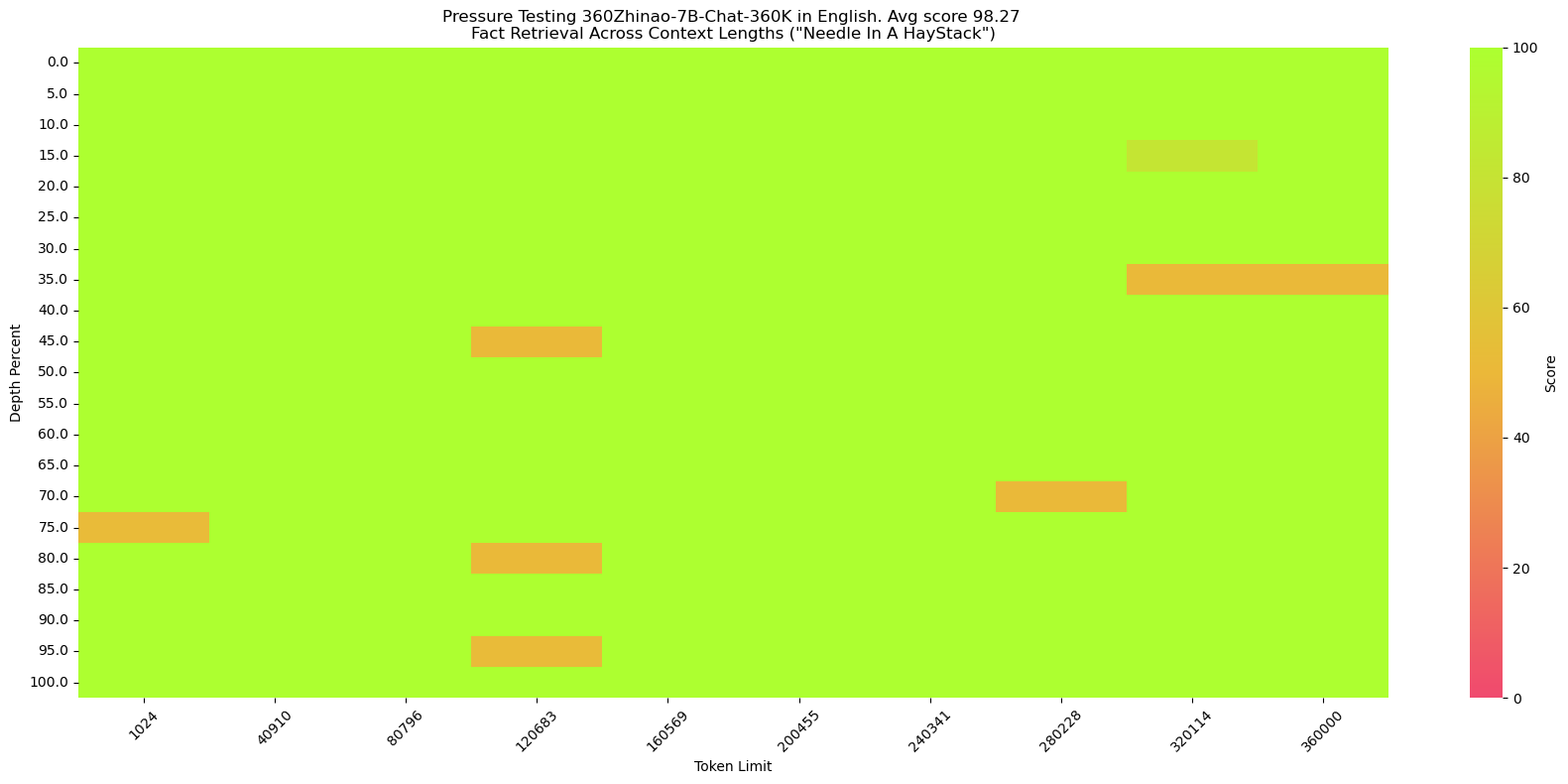
Feel free to visit 360Zhinao's official website https://ai.360.com for more experience.
**needle**:The best thing to do in San Francisco is eat a sandwich and sit in Dolores Park on a sunny day. **query**:What is the best thing to do in San Francisco? - Chinese version
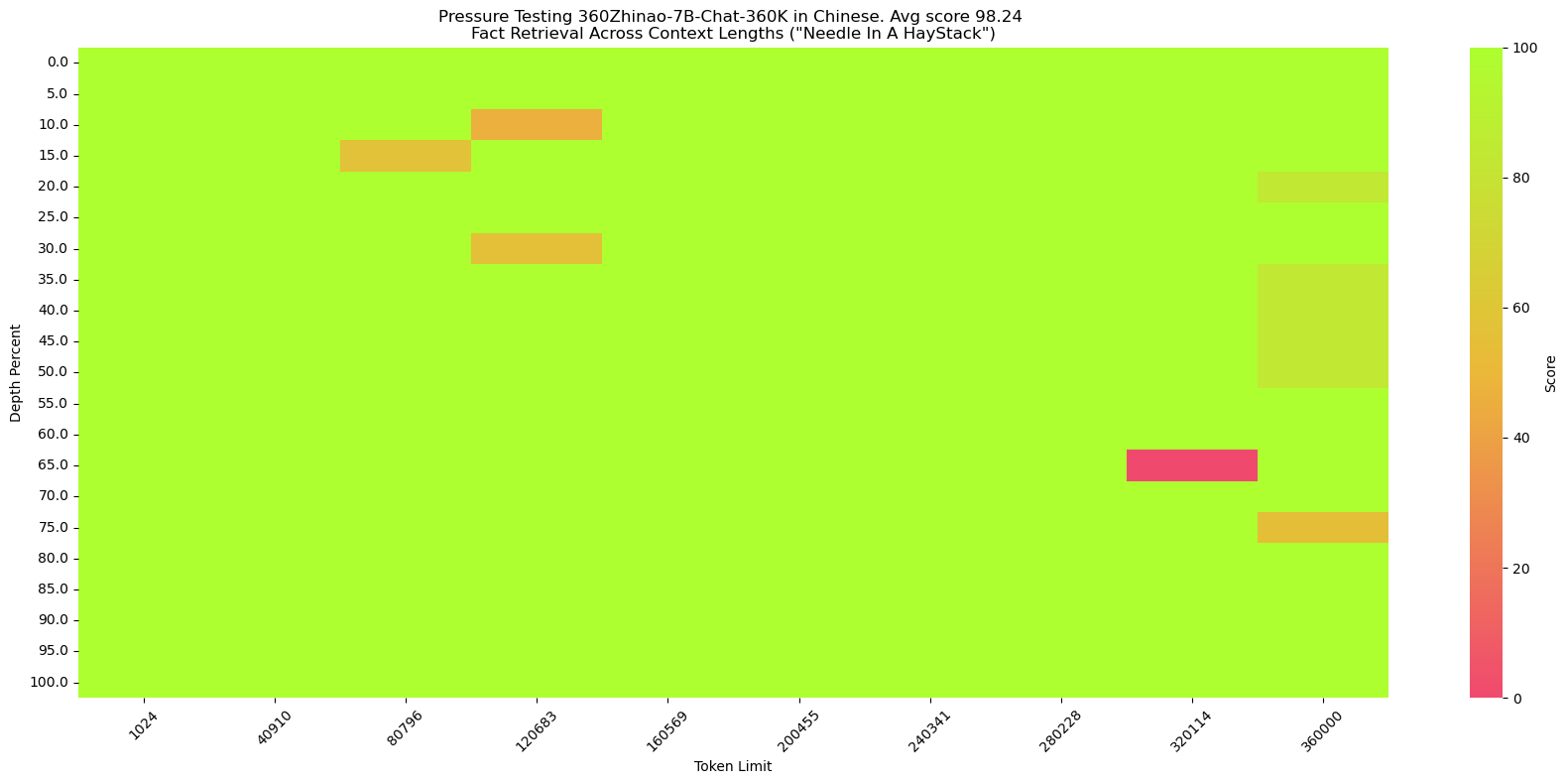
We constructed the Chinese version following the [SuperCLUE-200K benchmark](https://mp.weixin.qq.com/s/QgoRf2LB-7vc3vTFOHJkpw):
**haystack**:Chinese novels.
**needle**:(in Chinese) 王莽是一名勤奋的店员,他每天凌晨就起床,赶在第一缕阳光照亮大地之前到达店铺,为即将开始的一天做准备。他清扫店铺,整理货架,为顾客提供方便。他对五金的种类和用途了如指掌,无论顾客需要什么,他总能准确地找到。\n然而,他的老板刘秀却总是对他吹毛求疵。刘秀是个挑剔的人,他总能在王莽的工作中找出一些小错误,然后以此为由扣他的工资。他对王莽的工作要求非常严格,甚至有些过分。即使王莽做得再好,刘秀也总能找出一些小问题,让王莽感到非常沮丧。\n王莽虽然对此感到不满,但他并没有放弃。他知道,只有通过自己的努力,才能获得更好的生活。他坚持每天早起,尽管他知道那天可能会再次被刘秀扣工资。他始终保持微笑,尽管他知道刘秀可能会再次对他挑剔。
**query**:(in Chinese) 王莽在谁的手下工作?
# Quickstart
We provide simple examples illustrating the use of 360Zhinao-7B-Base and 360Zhinao-7B-Chat on 🤖ModelScope and 🤗Transformers.
## Dependency Installation
- python >= 3.8
- pytorch >= 2.0
- transformers >= 4.37.2
- CUDA >= 11.4
```shell
pip install -r requirements.txt
```
Optionally, we recommend installing Flash-Attention 2 to improve performance and reduce memory footprint.
>flash-attn >= 2.3.6
```shell
FLASH_ATTENTION_FORCE_BUILD=TRUE pip install flash-attn==2.3.6
```
## 🤗 Transformers
### Demonstration of Base Model Inference
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
from transformers.generation import GenerationConfig
MODEL_NAME_OR_PATH = "qihoo360/360Zhinao-7B-Base"
tokenizer = AutoTokenizer.from_pretrained(
MODEL_NAME_OR_PATH,
trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME_OR_PATH,
device_map="auto",
trust_remote_code=True)
generation_config = GenerationConfig.from_pretrained(
MODEL_NAME_OR_PATH,
trust_remote_code=True)
inputs = tokenizer('中国二十四节气\n1. 立春\n2. 雨水\n3. 惊蛰\n4. 春分\n5. 清明\n', return_tensors='pt')
inputs = inputs.to(model.device)
pred = model.generate(input_ids=inputs["input_ids"], generation_config=generation_config)
print("outputs:\n", tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
```
### Demonstration of Chat Model Inference
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
from transformers.generation import GenerationConfig
MODEL_NAME_OR_PATH = "qihoo360/360Zhinao-7B-Chat-4K"
tokenizer = AutoTokenizer.from_pretrained(
MODEL_NAME_OR_PATH,
trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME_OR_PATH,
device_map="auto",
trust_remote_code=True)
generation_config = GenerationConfig.from_pretrained(
MODEL_NAME_OR_PATH,
trust_remote_code=True)
messages = []
#round-1
messages.append({"role": "user", "content": "介绍一下刘德华"})
response = model.chat(tokenizer=tokenizer, messages=messages, generation_config=generation_config)
messages.append({"role": "assistant", "content": response})
print(messages)
#round-2
messages.append({"role": "user", "content": "他有什么代表作?"})
response = model.chat(tokenizer=tokenizer, messages=messages, generation_config=generation_config)
messages.append({"role": "assistant", "content": response})
print(messages)
```
## 🤖 ModelScope
### Demonstration of Base Model Inference
```python
from modelscope import AutoModelForCausalLM, AutoTokenizer
from modelscope import GenerationConfig
MODEL_NAME_OR_PATH = "qihoo360/360Zhinao-7B-Base"
tokenizer = AutoTokenizer.from_pretrained(
MODEL_NAME_OR_PATH,
trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME_OR_PATH,
device_map="auto",
trust_remote_code=True)
generation_config = GenerationConfig.from_pretrained(
MODEL_NAME_OR_PATH,
trust_remote_code=True)
inputs = tokenizer('中国二十四节气\n1. 立春\n2. 雨水\n3. 惊蛰\n4. 春分\n5. 清明\n', return_tensors='pt')
inputs = inputs.to(model.device)
pred = model.generate(input_ids=inputs["input_ids"], generation_config=generation_config)
print("outputs:\n", tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
```
### Demonstration of Chat Model Inference
```python
from modelscope import AutoModelForCausalLM, AutoTokenizer
from modelscope import GenerationConfig
MODEL_NAME_OR_PATH = "qihoo360/360Zhinao-7B-Chat-4K"
tokenizer = AutoTokenizer.from_pretrained(
MODEL_NAME_OR_PATH,
trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME_OR_PATH,
device_map="auto",
trust_remote_code=True)
generation_config = GenerationConfig.from_pretrained(
MODEL_NAME_OR_PATH,
trust_remote_code=True)
messages = []
#round-1
messages.append({"role": "user", "content": "介绍一下刘德华"})
response = model.chat(tokenizer=tokenizer, messages=messages, generation_config=generation_config)
messages.append({"role": "assistant", "content": response})
print(messages)
#round-2
messages.append({"role": "user", "content": "他有什么代表作?"})
response = model.chat(tokenizer=tokenizer, messages=messages, generation_config=generation_config)
messages.append({"role": "assistant", "content": response})
print(messages)
```
## CLI Demo
Use terminal for command-line interface:
```shell
python cli_demo.py
```

## Web Demo ```shell streamlit run web_demo.py ```

## API Demo
Launch api:
```shell
python openai_api.py
```
Then request with parameters:
```shell
curl 'http://localhost:8360/v1/chat/completions' \
-H 'Content-Type: application/json' \
-d '{
"max_new_tokens": 200,
"do_sample": true,
"top_k": 0,
"top_p": 0.8,
"temperature": 1.0,
"repetition_penalty": 1.0,
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "你好"}
]
}'
```
# Model Inference
## Quantization
We provide quantization schemes based on AutoGPTQ and release the Int4 quantization models.
## Deployment
### vLLM Installation
We recommend using `vLLM==0.3.3`.
If you are using **CUDA 12.1 and PyTorch 2.1**, you can install vLLM directly with:
```shell
pip install vllm==0.3.3
```
Otherwise, please refer to the official vLLM [Installation Instructions](https://docs.vllm.ai/en/latest/getting_started/installation.html).
After installation, perform the following steps:
1. Copy `vllm/zhinao.py` into `vllm/model_executor/models` in your vllm installation directory (in python/conda env).
2. Copy `vllm/serving_chat.py` into `vllm/entrypoints/openai` in your vllm installation directory.
3. Then add a line in `vllm/model_executor/models/__init__.py`
```shell
"ZhinaoForCausalLM": ("zhinao", "ZhinaoForCausalLM"),
```
### vLLM Service Start
Start the service:
```shell
python -m vllm.entrypoints.openai.api_server \
--served-model-name 360Zhinao-7B-Chat-4K \
--model qihoo360/360Zhinao-7B-Chat-4K \
--trust-remote-code \
--tensor-parallel-size 1 \
--max-model-len 4096 \
--host 0.0.0.0 \
--port 8360
```
Use curl to request the service:
```shell
curl http://localhost:8360/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "360Zhinao-7B-Chat-4K",
"max_tokens": 200,
"top_k": -1,
"top_p": 0.8,
"temperature": 1.0,
"presence_penalty": 0.0,
"frequency_penalty": 0.0,
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "你好"}
],
"stop": [
"
# Model Finetune
## Training data
Training Data: `data/training_data_sample.json`. This example data has 10,000 rows sampled from [multiturn_chat_0.8M](https://huggingface.co/datasets/BelleGroup/multiturn_chat_0.8M) with converted format.
Data Format:
```json
[
{
"id": 1,
"conversations": [
{
"from": "system",
"value": "You are a helpful assistant."
},
{
"from": "user",
"value": "您好啊"
},
{
"from": "assistant",
"value": "你好!我今天能为您做些什么?有什么问题或需要帮助吗? 我在这里为您提供服务。"
}
]
}
]
```
## Finetuning scripts
```shell
set -x
HOSTFILE=hostfile
DS_CONFIG=./finetune/ds_config_zero2.json
# PARAMS
LR=5e-6
EPOCHS=3
MAX_LEN=4096
BATCH_SIZE=4
NUM_NODES=1
NUM_GPUS=8
MASTER_PORT=29500
IS_CONCAT=False # Whether to concatenate to maximum length (MAX_LEN)
DATA_PATH="./data/training_data_sample.json"
MODEL_PATH="qihoo360/360Zhinao-7B-Base"
OUTPUT_DIR="./outputs/"
deepspeed --hostfile ${HOSTFILE} \
--master_port ${MASTER_PORT} \
--num_nodes ${NUM_NODES} \
--num_gpus ${NUM_GPUS} \
finetune.py \
--report_to "tensorboard" \
--data_path ${DATA_PATH} \
--model_name_or_path ${MODEL_PATH} \
--output_dir ${OUTPUT_DIR} \
--model_max_length ${MAX_LEN} \
--num_train_epochs ${EPOCHS} \
--per_device_train_batch_size ${BATCH_SIZE} \
--gradient_accumulation_steps 1 \
--save_strategy steps \
--save_steps 200 \
--learning_rate ${LR} \
--lr_scheduler_type cosine \
--adam_beta1 0.9 \
--adam_beta2 0.95 \
--adam_epsilon 1e-8 \
--max_grad_norm 1.0 \
--weight_decay 0.1 \
--warmup_ratio 0.01 \
--gradient_checkpointing True \
--bf16 True \
--tf32 True \
--deepspeed ${DS_CONFIG} \
--is_concat ${IS_CONCAT} \
--logging_steps 1 \
--log_on_each_node False
```
```shell
bash finetune/ds_finetune.sh
```
- Configuring `HOSTFILE` switches between single-machine and multi-machine training.
- configuring `ds_config` switches between zero1, zero2 and zero3.
- `fp16, bf16` could configure mixed precision training. bf16 is recommended to be consistent with the pretrained model.
- `is_concat` configures whether the training data is concatenated or not.
# License
The source code of this repository follows the open-source license Apache 2.0.
360Zhinao open-source models support commercial use. If you wish to use these models or continue training them for commercial purposes, please contact us via email (g-zhinao-opensource@360.cn) to apply. For the specific license agreement, please see [<<360 Zhinao Open-Source Model License>>](https://github.com/Qihoo360/360zhinao/blob/main/360%E6%99%BA%E8%84%91%E5%BC%80%E6%BA%90%E6%A8%A1%E5%9E%8B%E8%AE%B8%E5%8F%AF%E8%AF%81.txt).