# Deep Model Assembling
This repository contains the official code for [Deep Model Assembling](https://arxiv.org/abs/2212.04129).
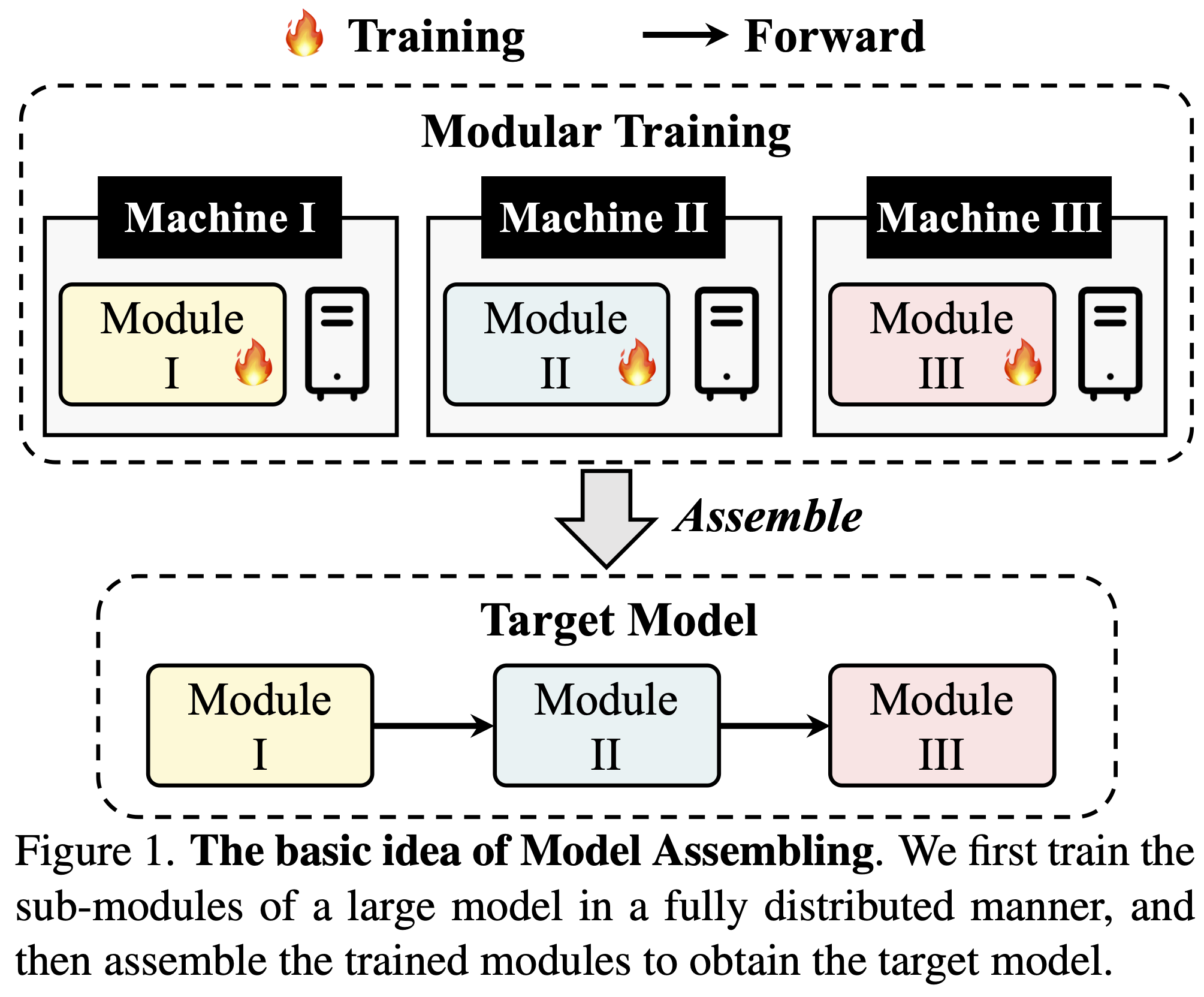
> **Title**: [**Deep Model Assembling**](https://arxiv.org/abs/2212.04129)
> **Authors**: [Zanlin Ni](https://scholar.google.com/citations?user=Yibz_asAAAAJ&hl=en&oi=ao), [Yulin Wang](https://scholar.google.com/citations?hl=en&user=gBP38gcAAAAJ), Jiangwei Yu, [Haojun Jiang](https://scholar.google.com/citations?hl=en&user=ULmStp8AAAAJ), [Yue Cao](https://scholar.google.com/citations?hl=en&user=iRUO1ckAAAAJ), [Gao Huang](https://scholar.google.com/citations?user=-P9LwcgAAAAJ&hl=en&oi=ao) (Corresponding Author)
> **Institute**: Tsinghua University and Beijing Academy of Artificial Intelligence (BAAI)
> **Publish**: *arXiv preprint ([arXiv 2212.04129](https://arxiv.org/abs/2212.04129))*
> **Contact**: nzl22 at mails dot tsinghua dot edu dot cn
## News
- `Dec 10, 2022`: release code for training ViT-B, ViT-L and ViT-H on ImageNet-1K.
## Overview
In this paper, we present a divide-and-conquer strategy for training large models. Our algorithm, Model Assembling, divides a large model into smaller modules, optimizes them independently, and then assembles them together. Though conceptually simple, our method significantly outperforms end-to-end (E2E) training in terms of both training efficiency and final accuracy. For example, on ViT-H, Model Assembling outperforms E2E training by **2.7%**, while reducing the training cost by **43%**.
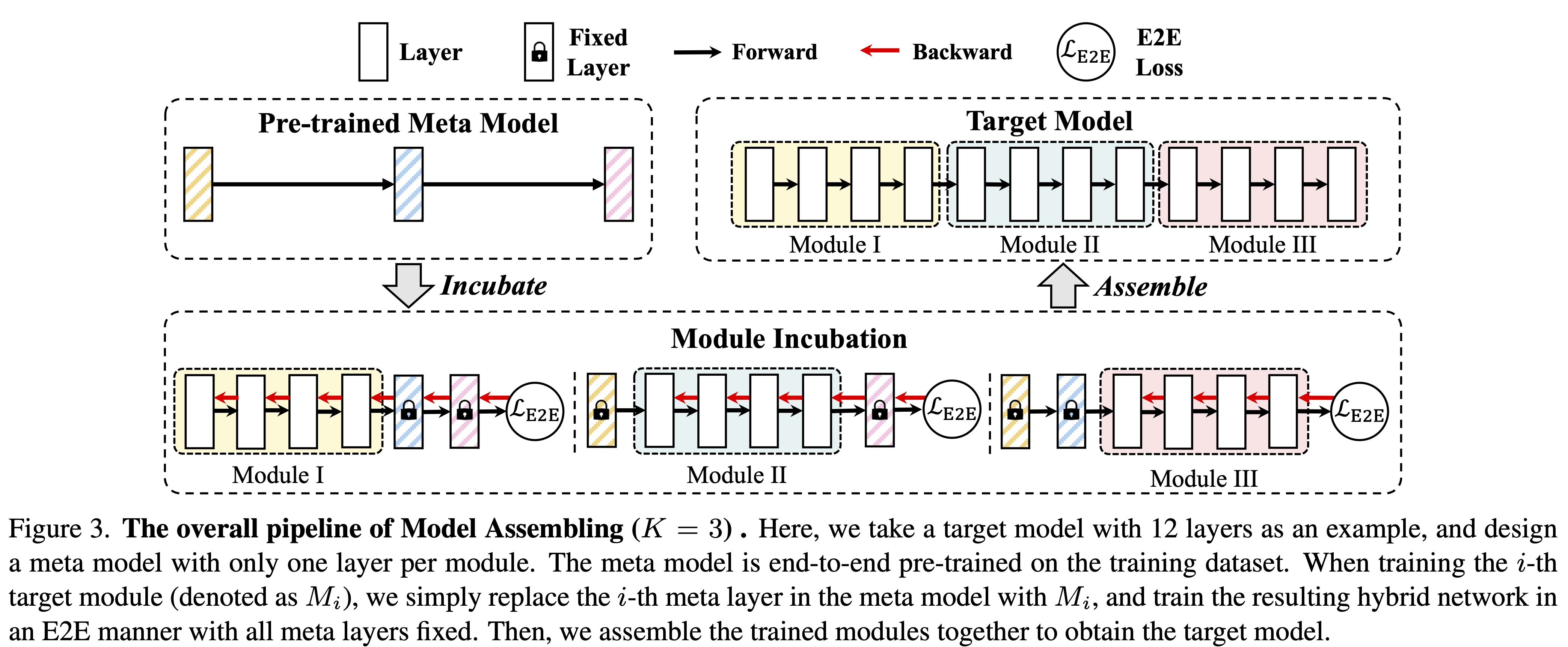
## Data Preparation
- The ImageNet dataset should be prepared as follows:
```
data
├── train
│ ├── folder 1 (class 1)
│ ├── folder 2 (class 1)
│ ├── ...
├── val
│ ├── folder 1 (class 1)
│ ├── folder 2 (class 1)
│ ├── ...
```
## Training on ImageNet-1K
- You can add `--use_amp 1` to train in PyTorch's Automatic Mixed Precision (AMP).
- Auto-resuming is enabled by default, i.e., the training script will automatically resume from the latest ckpt in output_dir.
- The effective batch size = `NGPUS` * `batch_size` * `update_freq`. We keep using an effective batch size of 2048. To avoid OOM issues, you may adjust these arguments accordingly.
- We provide single-node training scripts for simplicity. For multi-node training, simply modify the training scripts accordingly with torchrun:
```bash
python -m torch.distributed.launch --nproc_per_node=${NGPUS} --master_port=23346 --use_env main.py ...
# modify the above code to
torchrun \
--nnodes=$NODES \
--nproc_per_node=$NGPUS \
--rdzv_backend=c10d \
--rdzv_endpoint=$MASTER_ADDR:60900 \
main.py ...
```
Pre-training meta models (click to expand).
```bash
PHASE=PT # Pre-training
MODEL=base # for base
# MODEL=large # for large
# MODEL=huge # for huge
NGPUS=8
args=(
--phase ${PHASE}
--model vit_${MODEL}_patch16_224 # for base, large
# --model vit_${MODEL}_patch14_224 # for huge
--divided_depths 1 1 1 1
--output_dir ./log_dir/${PHASE}/${MODEL}
--batch_size 256
--epochs 300
--drop-path 0
)
python -m torch.distributed.launch --nproc_per_node=${NGPUS} --master_port=23346 --use_env main.py "${args[@]}"
```
Modular training (click to expand).
```bash
PHASE=MT # Modular Training
MODEL=base DEPTH=12 # for base
# MODEL=large DEPTH=24 # for large
# MODEL=huge DEPTH=32 # for huge
NGPUS=8
args=(
--phase ${PHASE}
--model vit_${MODEL}_patch16_224 # for base, large
# --model vit_${MODEL}_patch14_224 # for huge
--meta_model ./log_dir/PT_${MODEL}/finished_checkpoint.pth # loading the pre-trained meta model
--batch_size 128
--update_freq 2
--epochs 100
--drop-path 0.1
)
# Modular training each target module. Each line can be executed in parallel.
python -m torch.distributed.launch --nproc_per_node=${NGPUS} --master_port=23346 --use_env main.py "${args[@]}" --idx 0 --divided_depths $((DEPTH/4)) 1 1 1 --output_dir ./log_dir/${PHASE}_${MODEL}_0
python -m torch.distributed.launch --nproc_per_node=${NGPUS} --master_port=23346 --use_env main.py "${args[@]}" --idx 1 --divided_depths 1 $((DEPTH/4)) 1 1 --output_dir ./log_dir/${PHASE}_${MODEL}_1
python -m torch.distributed.launch --nproc_per_node=${NGPUS} --master_port=23346 --use_env main.py "${args[@]}" --idx 2 --divided_depths 1 1 $((DEPTH/4)) 1 --output_dir ./log_dir/${PHASE}_${MODEL}_2
python -m torch.distributed.launch --nproc_per_node=${NGPUS} --master_port=23346 --use_env main.py "${args[@]}" --idx 3 --divided_depths 1 1 1 $((DEPTH/4)) --output_dir ./log_dir/${PHASE}_${MODEL}_3
```
Assemble & Fine-tuning (click to expand).
```bash
PHASE=FT # Assemble & Fine-tuning
MODEL=base DEPTH=12 # for base
# MODEL=large DEPTH=24 # for large
# MODEL=huge DEPTH=32 # for huge
NGPUS=8
args=(
--phase ${PHASE}
--model vit_${MODEL}_patch16_224 # for base, large
# --model vit_${MODEL}_patch14_224 # for huge
--incubation_models ./log_dir/MT_${MODEL}_*/finished_checkpoint.pth # for assembling
--divided_depths $((DEPTH/4)) $((DEPTH/4)) $((DEPTH/4)) $((DEPTH/4)) \
--output_dir ./log_dir/${PHASE}_${MODEL}
--batch_size 64
--update_freq 4
--epochs 100
--warmup-epochs 0
--clip-grad 1
--drop-path 0.1 # for base
# --drop-path 0.5 # for large
# --drop-path 0.6 # for huge
)
python -m torch.distributed.launch --nproc_per_node=${NGPUS} --master_port=23346 --use_env main.py "${args[@]}"
```
## Results
### Results on ImageNet-1K

### Results on CIFAR-100

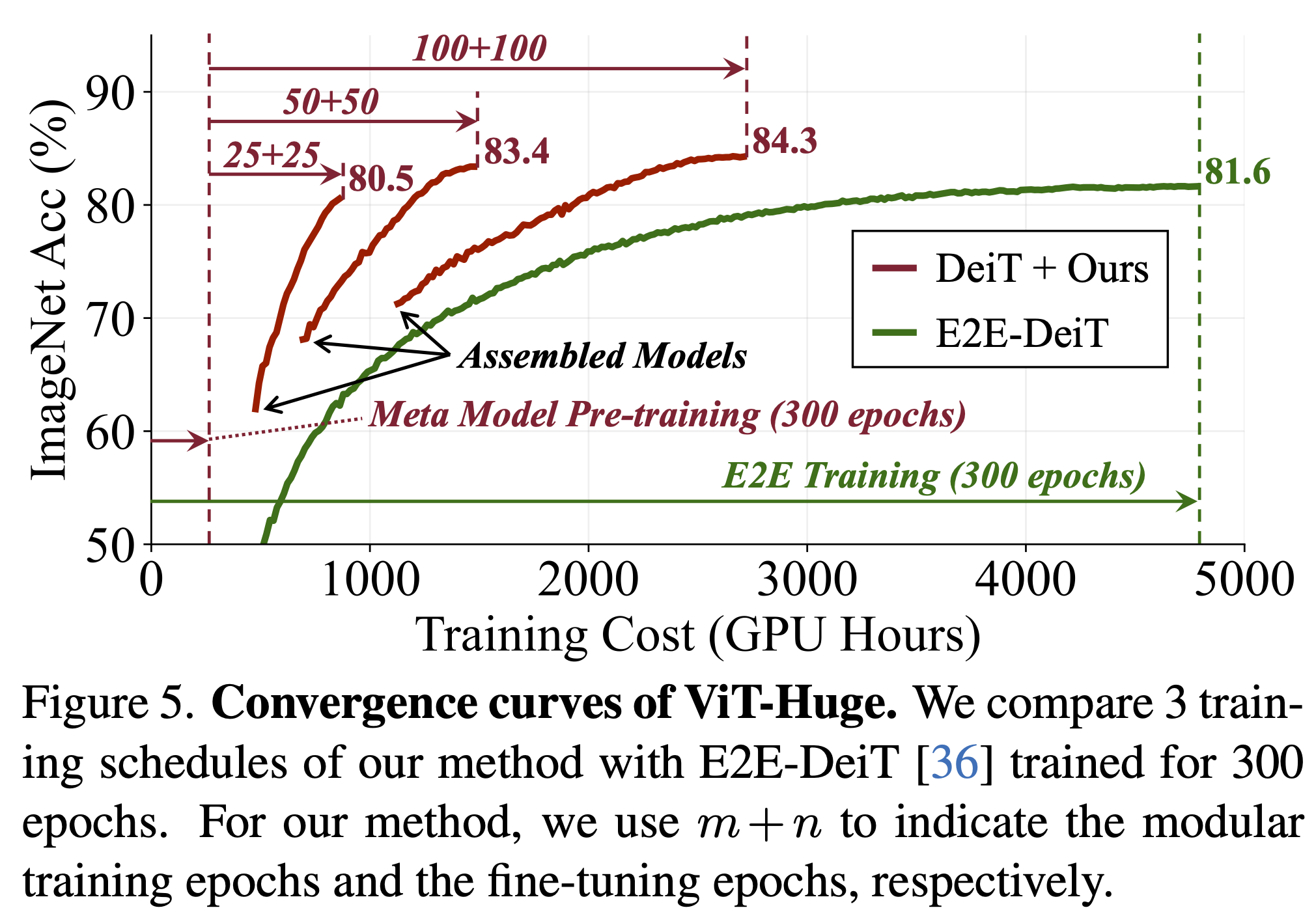
### Training Efficiency
- Comparing different training budgets

- Detailed convergence curves of ViT-Huge
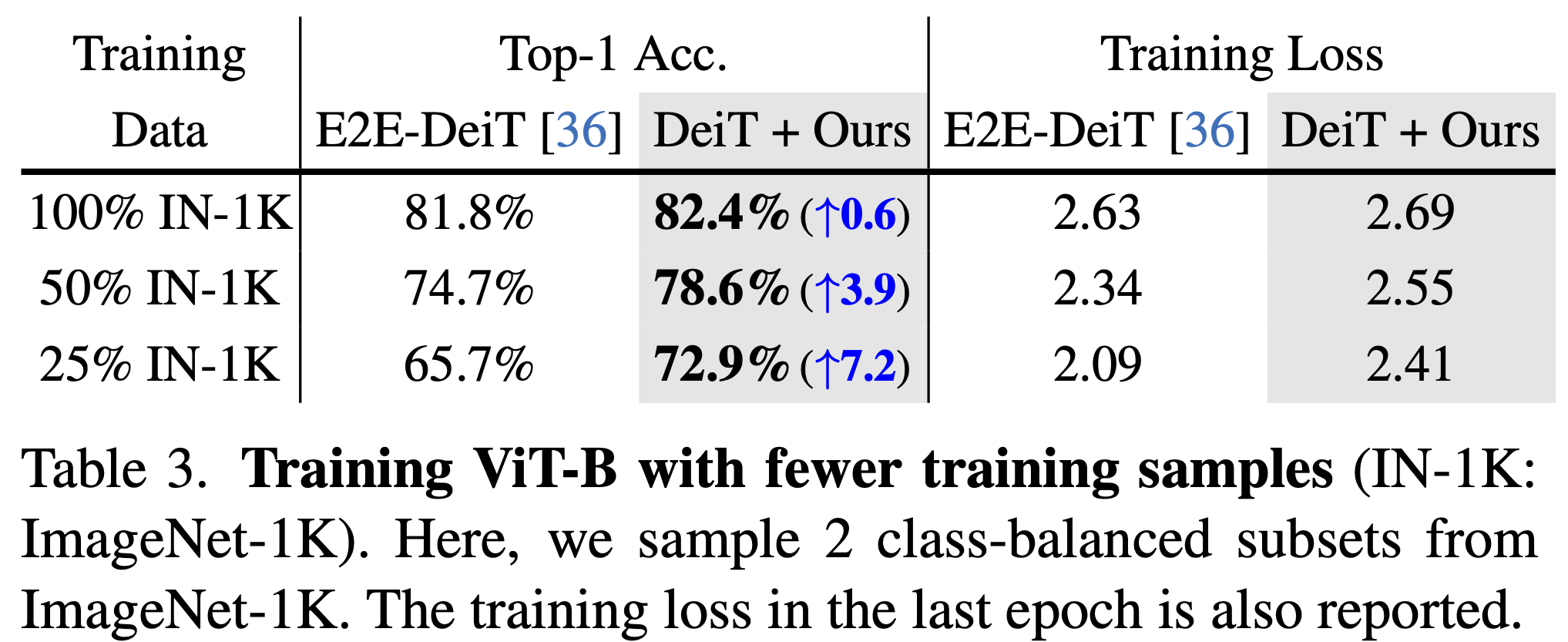
### Data Efficiency
## Citation
If you find our work helpful, please **star🌟** this repo and **cite📑** our paper. Thanks for your support!
```
@article{Ni2022Assemb,
title={Deep Model Assembling},
author={Ni, Zanlin and Wang, Yulin and Yu, Jiangwei and Jiang, Haojun and Cao, Yue and Huang, Gao},
journal={arXiv preprint arXiv:2212.04129},
year={2022}
}
```
## Acknowledgements
Our implementation is mainly based on [deit](https://github.com/facebookresearch/deit). We thank to their clean codebase.
## Contact
If you have any questions or concerns, please send mail to [nzl22@mails.tsinghua.edu.cn](mailto:nzl22@mails.tsinghua.edu.cn).