---
license: llama2
library_name: nemo
language:
- en
pipeline_tag: text-generation
inference: false
fine-tuning: true
tags:
- nvidia
- steerlm
- llama2
datasets:
- nvidia/HelpSteer
- OpenAssistant/oasst1
---
# Llama2-70B-SteerLM-Chat
## License
The use of this model is governed by the [Llama 2 Community License Agreement](https://ai.meta.com/llama/license/)
## Description:
Llama2-70B-SteerLM-Chat is a 70 billion parameter generative language model instruct-tuned using SteerLM technique. It takes input with context length up to 4,096 tokens.
The model has been aligned using the SteerLM method developed by NVIDIA to allow for user control of model outputs (in creativity, complexity and verbosity) during inference while having simplified training compared to RLHF techniques.
Llama2-70B-SteerLM-Chat reaches **7.54** on MT Bench, the highest among **commercial-use-friendly** models trained on open-source datasets based on [MT Bench Leaderboard](https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard) as of 15 Nov 2023.
Try this model instantly for free hosted by us at [NVIDIA AI Playground](https://catalog.ngc.nvidia.com/orgs/nvidia/teams/ai-foundation/models/llama2-70b-steerlm). You can use this in the provided UI or through a limited access API (up to 10, 000 requests within 30 days). If you would need more requests, we demonstrate how you can set up an inference server below.
 HelpSteer Paper : [HelpSteer: Multi-attribute Helpfulness Dataset for SteerLM](http://arxiv.org/abs/2311.09528)
SteerLM Paper: [SteerLM: Attribute Conditioned SFT as an (User-Steerable) Alternative to RLHF](https://arxiv.org/abs/2310.05344)
Llama2-70B-SteerLM-Chat is trained with NVIDIA NeMo, an end-to-end, cloud-native framework to build, customize, and deploy generative AI models anywhere. It includes training and inferencing frameworks, guardrailing toolkits, data curation tools, and pretrained models, offering enterprises an easy, cost-effective, and fast way to adopt generative AI.
You can train the model using [NeMo Aligner](https://github.com/NVIDIA/NeMo-Aligner) following [SteerLM training user guide](https://docs.nvidia.com/nemo-framework/user-guide/latest/modelalignment/steerlm.html) or run inference based on steps below.
## Model Architecture:
**Architecture Type:** Transformer
**Network Architecture:** Llama 2
The SteerLM method involves the following key steps:
1. Train an attribute prediction model on human annotated data to evaluate response quality.
2. Use this model to annotate diverse datasets and enrich training data.
3. Perform conditioned fine-tuning to align responses with specified combinations of attributes.
Llama2-70B-SteerLM-Chat applies this technique on top of the Llama 2 70B Foundational model architecture. It was pretrained on internet-scale data and then aligned using [Open Assistant](https://huggingface.co/datasets/OpenAssistant/oasst1) and [HelpSteer](https://huggingface.co/datasets/nvidia/HelpSteer).
## Software Integration:
**Runtime Engine(s):**
NVIDIA AI Enterprise
**Toolkit:**
NeMo Framework
**Supported Hardware Architecture Compatibility:**
H100, A100 80GB, A100 40GB
## Steps to run inference:
We demonstrate inference using NVIDIA NeMo Framework, which allows hassle-free model deployment based on [NVIDIA TRT-LLM](https://github.com/NVIDIA/TensorRT-LLM), a highly optimized inference solution focussing on high throughput and low latency.
Pre-requisite: You would need at least a machine with 4 40GB or 2 80GB NVIDIA GPUs, and 300GB of free disk space.
1. Please sign up to get **free and immediate** access to [NVIDIA NeMo Framework container](https://developer.nvidia.com/nemo-framework). If you don’t have an NVIDIA NGC account, you will be prompted to sign up for an account before proceeding.
2. If you don’t have an NVIDIA NGC API key, sign into [NVIDIA NGC](https://ngc.nvidia.com/setup), selecting organization/team: ea-bignlp/ga-participants and click Generate API key. Save this key for the next step. Else, skip this step.
3. On your machine, docker login to nvcr.io using
```
docker login nvcr.io
Username: $oauthtoken
Password:
```
4. Download the required container
```
docker pull nvcr.io/ea-bignlp/ga-participants/nemofw-inference:23.10
```
5. Download the checkpoint
```
git lfs install
git clone https://huggingface.co/nvidia/Llama2-70B-SteerLM-Chat
```
6. Convert checkpoint into nemo format
```
cd Llama2-70B-SteerLM-Chat/Llama2-70B-SteerLM-Chat
tar -cvf Llama2-70B-SteerLM-Chat.nemo .
mv Llama2-70B-SteerLM-Chat.nemo ../
cd ..
rm -r Llama2-70B-SteerLM-Chat
```
7. Run Docker container
```
docker run --gpus all -it --rm --shm-size=300g -p 8000:8000 -v ${PWD}/Llama2-70B-SteerLM-Chat.nemo:/opt/checkpoints/Llama2-70B-SteerLM-Chat.nemo -w /opt/NeMo nvcr.io/ea-bignlp/ga-participants/nemofw-inference:23.10
```
8. Within the container, start the server in the background. This step does both conversion of the nemo checkpoint to TRT-LLM and then deployment using TRT-LLM. For an explanation of each argument and advanced usage, please refer to [NeMo FW Deployment Guide](https://docs.nvidia.com/nemo-framework/user-guide/latest/deployingthenemoframeworkmodel.html)
```
python scripts/deploy/deploy_triton.py --nemo_checkpoint /opt/checkpoints/Llama2-70B-SteerLM-Chat.nemo --model_type="llama" --triton_model_name Llama2-70B-SteerLM-Chat --triton_http_address 0.0.0.0 --triton_port 8000 --num_gpus 2 --max_input_len 3072 --max_output_len 1024 --max_batch_size 1 &
```
9. Once the server is ready (i.e. when you see this messages below), you are ready to launch your client code
```
Started HTTPService at 0.0.0.0:8000
Started GRPCInferenceService at 0.0.0.0:8001
Started Metrics Service at 0.0.0.0:8002
```
```python
from nemo.deploy import NemoQuery
PROMPT_TEMPLATE = """System
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions.
User
{prompt}
Assistant
quality:4,toxicity:0,humor:0,creativity:0,helpfulness:4,correctness:4,coherence:4,complexity:4,verbosity:4
"""
question = "Write a poem on NVIDIA in the style of Shakespeare"
prompt = PROMPT_TEMPLATE.format(prompt=question)
print(prompt)
nq = NemoQuery(url="localhost:8000", model_name="Llama2-70B-SteerLM-Chat")
output = nq.query_llm(prompts=[prompt], max_output_token=15, top_k=1, top_p=0.0, temperature=1.0)
#this container currently does not support stop words but you do something like this as workaround
output = output[0][0].split("\n")[0]
print(output)
```
10. If you would support multi-turn conversations or adjust attribute values at inference time, here is some guidance:
Default template for Single Turn
```
System
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions.
User
{prompt 1}
Assistant
quality:4,toxicity:0,humor:0,creativity:0,helpfulness:4,correctness:4,coherence:4,complexity:4,verbosity:4
```
Default template for Multi-Turn
```
System
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions.
User
{prompt 1}
Assistant
quality:4,toxicity:0,humor:0,creativity:0,helpfulness:4,correctness:4,coherence:4,complexity:4,verbosity:4
{response 1}
User
{prompt 2}
Assistant
quality:4,toxicity:0,humor:0,creativity:0,helpfulness:4,correctness:4,coherence:4,complexity:4,verbosity:4
```
Each of the attributes (e.g. creativity, complexity and verbosity) can receive integer values in the range [0, 1, 2, 3, 4].
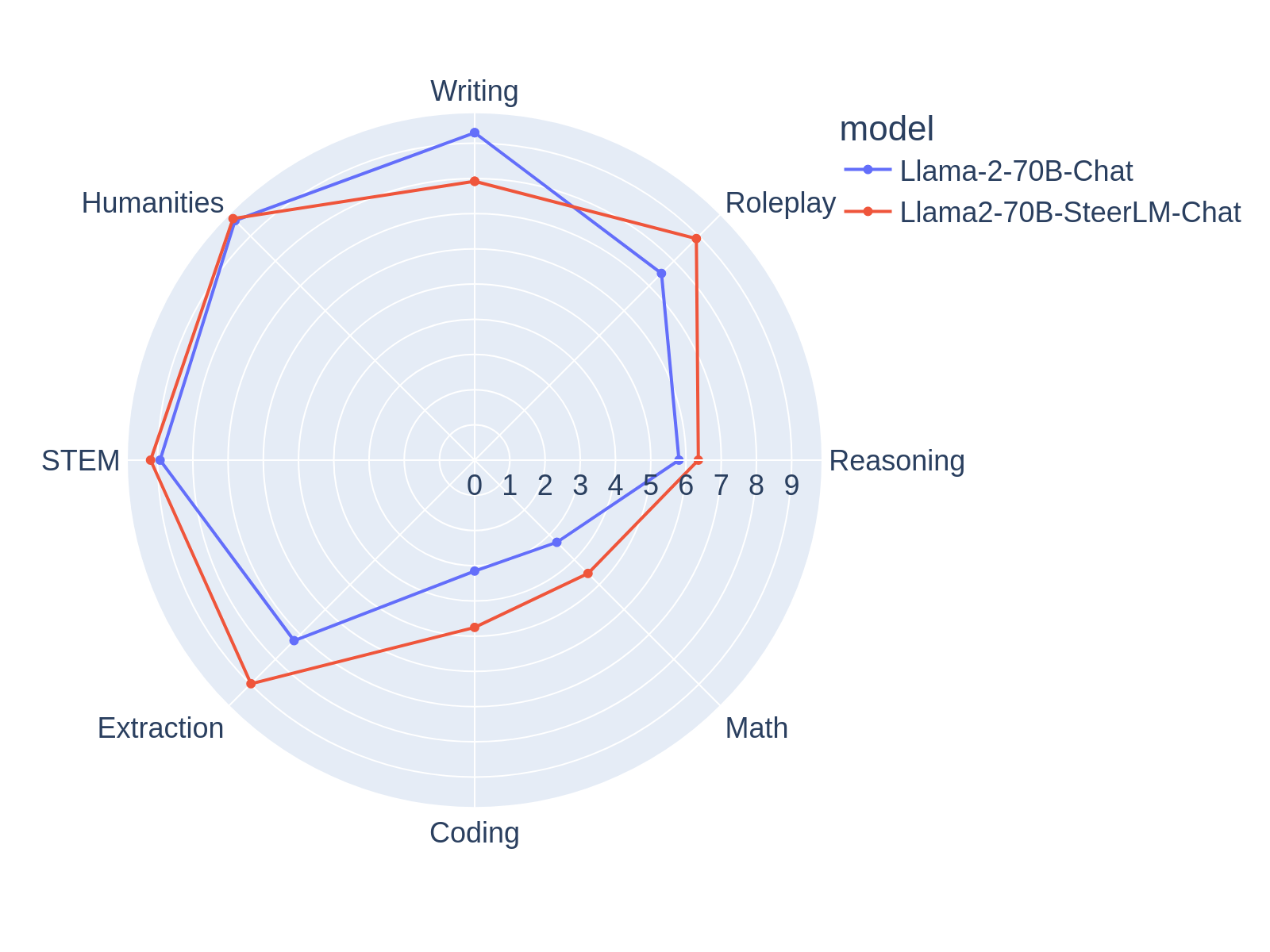
## Evaluation
MT-bench
|Category | score|
|---|---|
|total| 7.54|
|writing | 7.92|
|roleplay | 8.9|
|extraction | 8.98|
|stem | 9.2|
|humanities | 9.7|
|reasoning | 6.35|
|math | 4.55|
|coding | 4.75|
## Intended use
The SteerLM-Llama2-70B model is for users who want to customize a model’s response during inference.
Ethical use: Technology can have a profound impact on people and the world, and NVIDIA is committed to enabling trust and transparency in AI development. NVIDIA encourages users to adopt principles of AI ethics and trustworthiness to guide your business decisions by following the guidelines in the Llama 2 Community License Agreement.
## Limitations
The model was trained on the data that contains toxic language and societal biases originally crawled from the Internet. Therefore, the model may amplify those biases and return toxic responses especially when prompted with toxic prompts.
The model may generate answers that may be inaccurate, omit key information, or include irrelevant or redundant text producing socially unacceptable or undesirable text, even if the prompt itself does not include anything explicitly offensive.
We recommend deploying the model with [NeMo Guardrails](https://github.com/NVIDIA/NeMo-Guardrails) to mitigate these potential issues.
## Contact
E-Mail: [Zhilin Wang](mailto:zhilinw@nvidia.com)
## Citation
If you find this model useful, please cite the following works
```bibtex
@misc{wang2023helpsteer,
title={HelpSteer: Multi-attribute Helpfulness Dataset for SteerLM},
author={Zhilin Wang and Yi Dong and Jiaqi Zeng and Virginia Adams and Makesh Narsimhan Sreedhar and Daniel Egert and Olivier Delalleau and Jane Polak Scowcroft and Neel Kant and Aidan Swope and Oleksii Kuchaiev},
year={2023},
eprint={2311.09528},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
```bibtex
@misc{dong2023steerlm,
title={SteerLM: Attribute Conditioned SFT as an (User-Steerable) Alternative to RLHF},
author={Yi Dong and Zhilin Wang and Makesh Narsimhan Sreedhar and Xianchao Wu and Oleksii Kuchaiev},
year={2023},
eprint={2310.05344},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
HelpSteer Paper : [HelpSteer: Multi-attribute Helpfulness Dataset for SteerLM](http://arxiv.org/abs/2311.09528)
SteerLM Paper: [SteerLM: Attribute Conditioned SFT as an (User-Steerable) Alternative to RLHF](https://arxiv.org/abs/2310.05344)
Llama2-70B-SteerLM-Chat is trained with NVIDIA NeMo, an end-to-end, cloud-native framework to build, customize, and deploy generative AI models anywhere. It includes training and inferencing frameworks, guardrailing toolkits, data curation tools, and pretrained models, offering enterprises an easy, cost-effective, and fast way to adopt generative AI.
You can train the model using [NeMo Aligner](https://github.com/NVIDIA/NeMo-Aligner) following [SteerLM training user guide](https://docs.nvidia.com/nemo-framework/user-guide/latest/modelalignment/steerlm.html) or run inference based on steps below.
## Model Architecture:
**Architecture Type:** Transformer
**Network Architecture:** Llama 2
The SteerLM method involves the following key steps:
1. Train an attribute prediction model on human annotated data to evaluate response quality.
2. Use this model to annotate diverse datasets and enrich training data.
3. Perform conditioned fine-tuning to align responses with specified combinations of attributes.
Llama2-70B-SteerLM-Chat applies this technique on top of the Llama 2 70B Foundational model architecture. It was pretrained on internet-scale data and then aligned using [Open Assistant](https://huggingface.co/datasets/OpenAssistant/oasst1) and [HelpSteer](https://huggingface.co/datasets/nvidia/HelpSteer).
## Software Integration:
**Runtime Engine(s):**
NVIDIA AI Enterprise
**Toolkit:**
NeMo Framework
**Supported Hardware Architecture Compatibility:**
H100, A100 80GB, A100 40GB
## Steps to run inference:
We demonstrate inference using NVIDIA NeMo Framework, which allows hassle-free model deployment based on [NVIDIA TRT-LLM](https://github.com/NVIDIA/TensorRT-LLM), a highly optimized inference solution focussing on high throughput and low latency.
Pre-requisite: You would need at least a machine with 4 40GB or 2 80GB NVIDIA GPUs, and 300GB of free disk space.
1. Please sign up to get **free and immediate** access to [NVIDIA NeMo Framework container](https://developer.nvidia.com/nemo-framework). If you don’t have an NVIDIA NGC account, you will be prompted to sign up for an account before proceeding.
2. If you don’t have an NVIDIA NGC API key, sign into [NVIDIA NGC](https://ngc.nvidia.com/setup), selecting organization/team: ea-bignlp/ga-participants and click Generate API key. Save this key for the next step. Else, skip this step.
3. On your machine, docker login to nvcr.io using
```
docker login nvcr.io
Username: $oauthtoken
Password:
```
4. Download the required container
```
docker pull nvcr.io/ea-bignlp/ga-participants/nemofw-inference:23.10
```
5. Download the checkpoint
```
git lfs install
git clone https://huggingface.co/nvidia/Llama2-70B-SteerLM-Chat
```
6. Convert checkpoint into nemo format
```
cd Llama2-70B-SteerLM-Chat/Llama2-70B-SteerLM-Chat
tar -cvf Llama2-70B-SteerLM-Chat.nemo .
mv Llama2-70B-SteerLM-Chat.nemo ../
cd ..
rm -r Llama2-70B-SteerLM-Chat
```
7. Run Docker container
```
docker run --gpus all -it --rm --shm-size=300g -p 8000:8000 -v ${PWD}/Llama2-70B-SteerLM-Chat.nemo:/opt/checkpoints/Llama2-70B-SteerLM-Chat.nemo -w /opt/NeMo nvcr.io/ea-bignlp/ga-participants/nemofw-inference:23.10
```
8. Within the container, start the server in the background. This step does both conversion of the nemo checkpoint to TRT-LLM and then deployment using TRT-LLM. For an explanation of each argument and advanced usage, please refer to [NeMo FW Deployment Guide](https://docs.nvidia.com/nemo-framework/user-guide/latest/deployingthenemoframeworkmodel.html)
```
python scripts/deploy/deploy_triton.py --nemo_checkpoint /opt/checkpoints/Llama2-70B-SteerLM-Chat.nemo --model_type="llama" --triton_model_name Llama2-70B-SteerLM-Chat --triton_http_address 0.0.0.0 --triton_port 8000 --num_gpus 2 --max_input_len 3072 --max_output_len 1024 --max_batch_size 1 &
```
9. Once the server is ready (i.e. when you see this messages below), you are ready to launch your client code
```
Started HTTPService at 0.0.0.0:8000
Started GRPCInferenceService at 0.0.0.0:8001
Started Metrics Service at 0.0.0.0:8002
```
```python
from nemo.deploy import NemoQuery
PROMPT_TEMPLATE = """System
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions.
User
{prompt}
Assistant
quality:4,toxicity:0,humor:0,creativity:0,helpfulness:4,correctness:4,coherence:4,complexity:4,verbosity:4
"""
question = "Write a poem on NVIDIA in the style of Shakespeare"
prompt = PROMPT_TEMPLATE.format(prompt=question)
print(prompt)
nq = NemoQuery(url="localhost:8000", model_name="Llama2-70B-SteerLM-Chat")
output = nq.query_llm(prompts=[prompt], max_output_token=15, top_k=1, top_p=0.0, temperature=1.0)
#this container currently does not support stop words but you do something like this as workaround
output = output[0][0].split("\n")[0]
print(output)
```
10. If you would support multi-turn conversations or adjust attribute values at inference time, here is some guidance:
Default template for Single Turn
```
System
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions.
User
{prompt 1}
Assistant
quality:4,toxicity:0,humor:0,creativity:0,helpfulness:4,correctness:4,coherence:4,complexity:4,verbosity:4
```
Default template for Multi-Turn
```
System
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions.
User
{prompt 1}
Assistant
quality:4,toxicity:0,humor:0,creativity:0,helpfulness:4,correctness:4,coherence:4,complexity:4,verbosity:4
{response 1}
User
{prompt 2}
Assistant
quality:4,toxicity:0,humor:0,creativity:0,helpfulness:4,correctness:4,coherence:4,complexity:4,verbosity:4
```
Each of the attributes (e.g. creativity, complexity and verbosity) can receive integer values in the range [0, 1, 2, 3, 4].
## Evaluation
MT-bench
|Category | score|
|---|---|
|total| 7.54|
|writing | 7.92|
|roleplay | 8.9|
|extraction | 8.98|
|stem | 9.2|
|humanities | 9.7|
|reasoning | 6.35|
|math | 4.55|
|coding | 4.75|
## Intended use
The SteerLM-Llama2-70B model is for users who want to customize a model’s response during inference.
Ethical use: Technology can have a profound impact on people and the world, and NVIDIA is committed to enabling trust and transparency in AI development. NVIDIA encourages users to adopt principles of AI ethics and trustworthiness to guide your business decisions by following the guidelines in the Llama 2 Community License Agreement.
## Limitations
The model was trained on the data that contains toxic language and societal biases originally crawled from the Internet. Therefore, the model may amplify those biases and return toxic responses especially when prompted with toxic prompts.
The model may generate answers that may be inaccurate, omit key information, or include irrelevant or redundant text producing socially unacceptable or undesirable text, even if the prompt itself does not include anything explicitly offensive.
We recommend deploying the model with [NeMo Guardrails](https://github.com/NVIDIA/NeMo-Guardrails) to mitigate these potential issues.
## Contact
E-Mail: [Zhilin Wang](mailto:zhilinw@nvidia.com)
## Citation
If you find this model useful, please cite the following works
```bibtex
@misc{wang2023helpsteer,
title={HelpSteer: Multi-attribute Helpfulness Dataset for SteerLM},
author={Zhilin Wang and Yi Dong and Jiaqi Zeng and Virginia Adams and Makesh Narsimhan Sreedhar and Daniel Egert and Olivier Delalleau and Jane Polak Scowcroft and Neel Kant and Aidan Swope and Oleksii Kuchaiev},
year={2023},
eprint={2311.09528},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
```bibtex
@misc{dong2023steerlm,
title={SteerLM: Attribute Conditioned SFT as an (User-Steerable) Alternative to RLHF},
author={Yi Dong and Zhilin Wang and Makesh Narsimhan Sreedhar and Xianchao Wu and Oleksii Kuchaiev},
year={2023},
eprint={2310.05344},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```